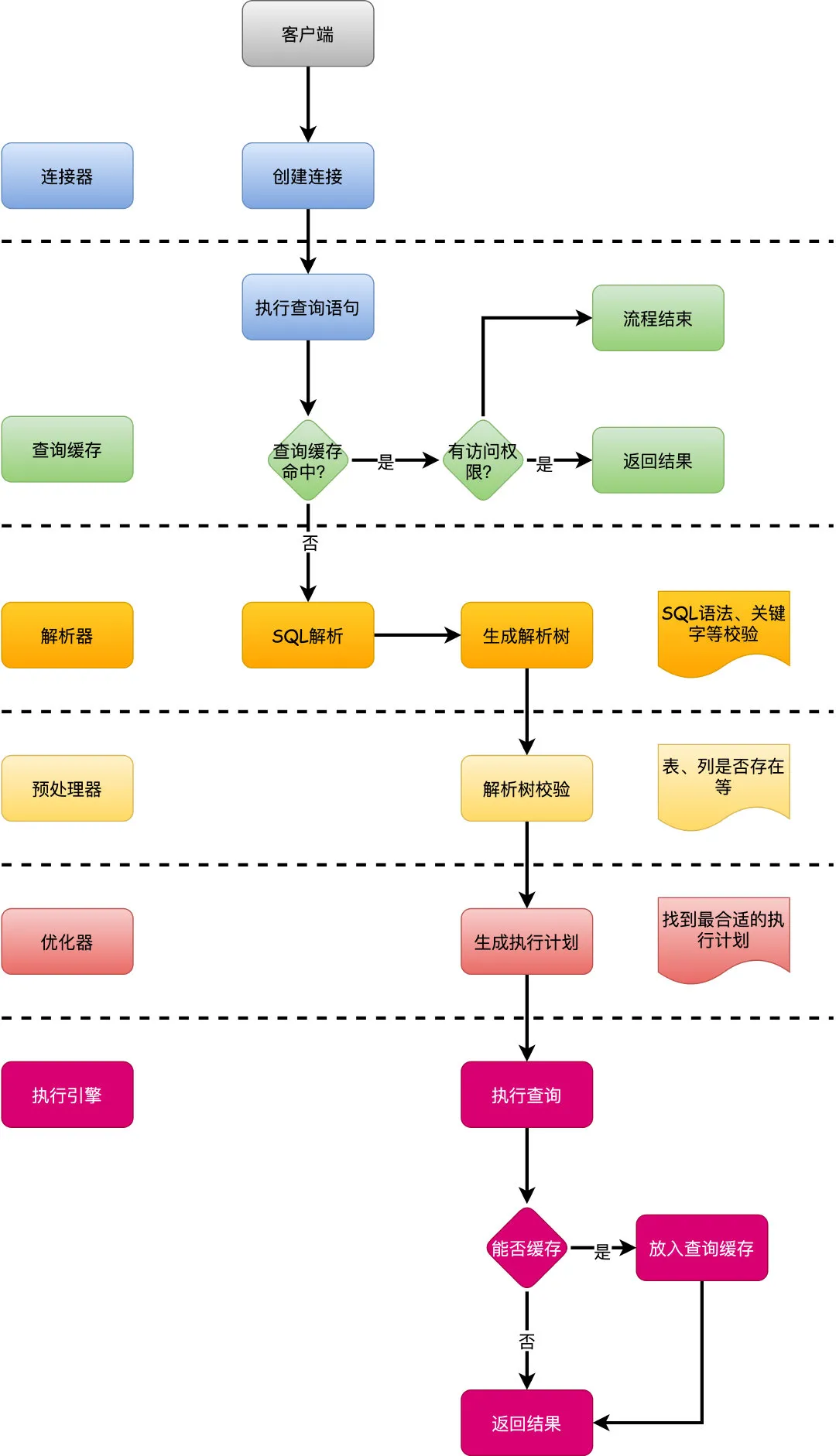
- 客户端发送请求到服务端,建立连接
- 服务端先看查询缓存是否命中,命中就直接返回,否则继续执行
- 通过解析器进行语法分析,包括系统关键字校验,检查语法是否合规
- 通过优化器进行SQL优化,比如怎么选择索引之类,然后生成执行计划
- 最后执行引擎调用存储引擎API查询数据,返回结果
- 查询缓存在5.7.20版本已经被弃用,并且8.0的版本已经删除
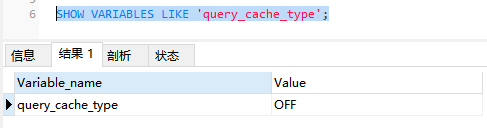
- 使用如下命令查看查询缓存是否可用:
SHOW VARIABLES LIKE 'have_query_cache';
SHOW VARIABLES LIKE 'query_cache_type';
- SQL没有命中缓存,进入正常SQL执行环节
- 解析器会进行词法语法分析,基于语法规则对SQL进行校验
- 比如关键字是否使用正确啊,或者说关键字顺序是不是正确
- 预处理器就是进一步依据合法规则生成的解析树进行校验,比如表名、列名是否存在等等
- 一条查询SQL可以有N种执行方式,优化器的最终目标是找到最好的执行计划,交给执行引擎去执行
- Mysql的优化器是基于成本模型的优化器,他只是基于已有的成本计算公式来选择一个成本最低的执行方式,这个执行方式不一定会是最快的
- 执行引擎只需要根据执行计划的指令调用存储引擎的API就可以了,如果可以缓存查询结果,返回客户端