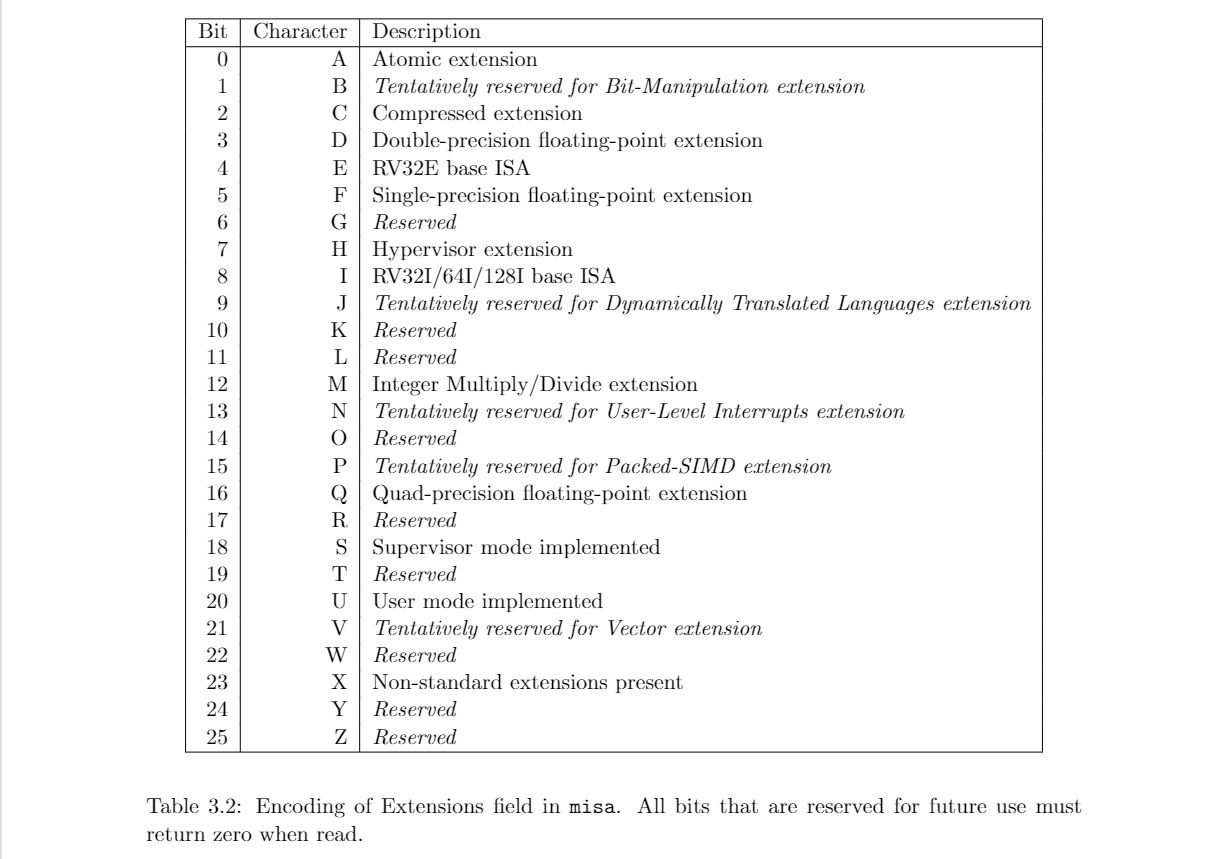
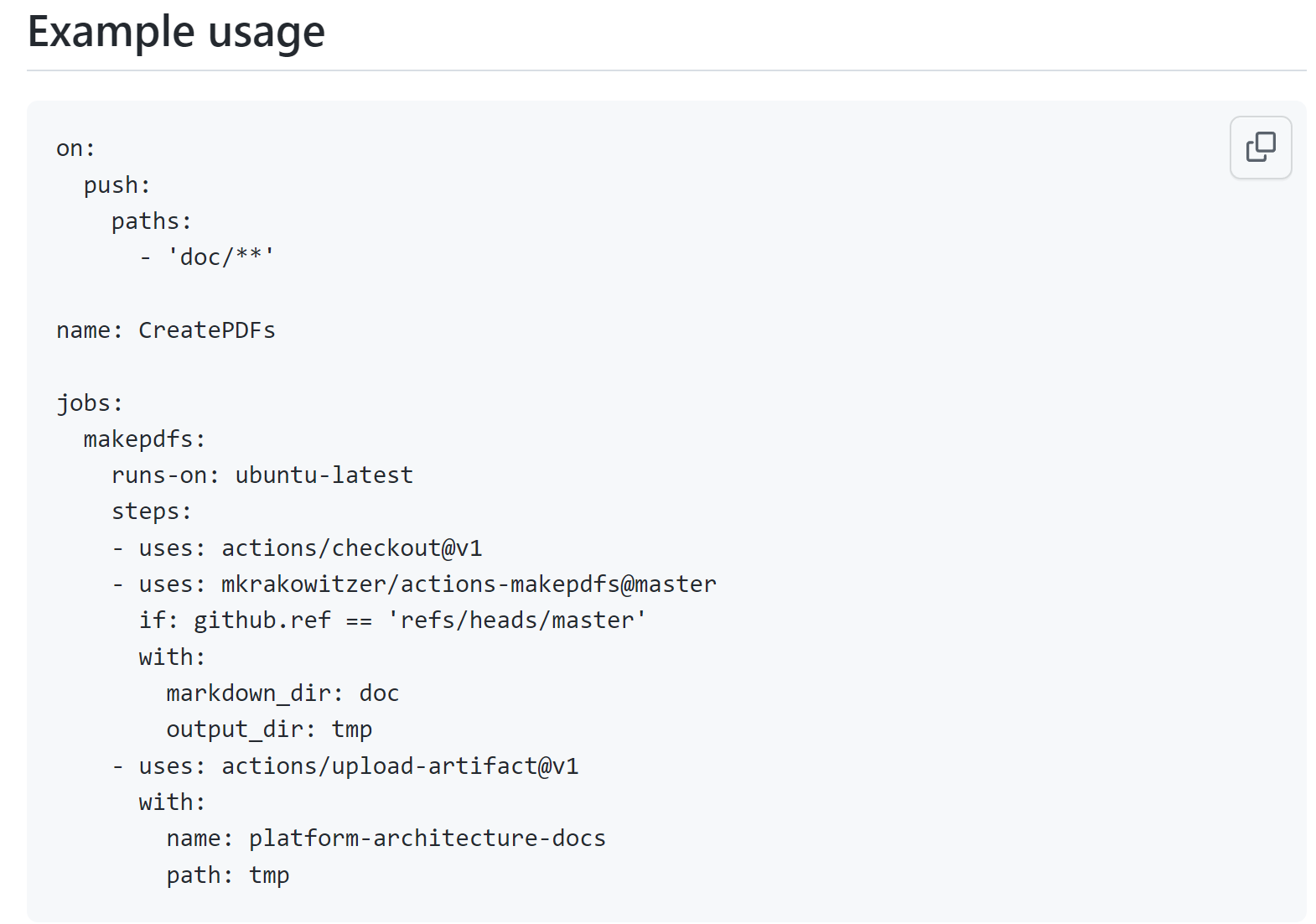
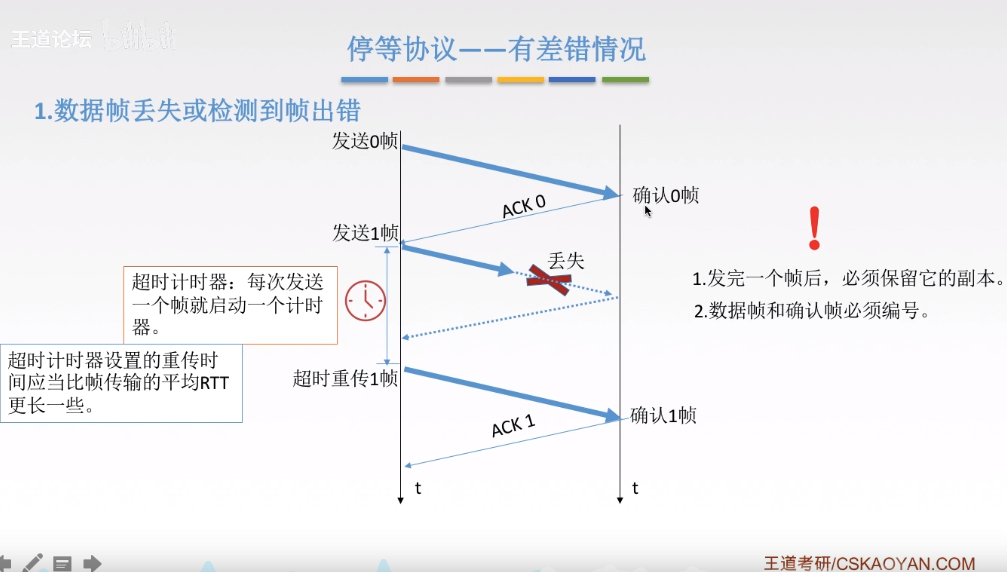
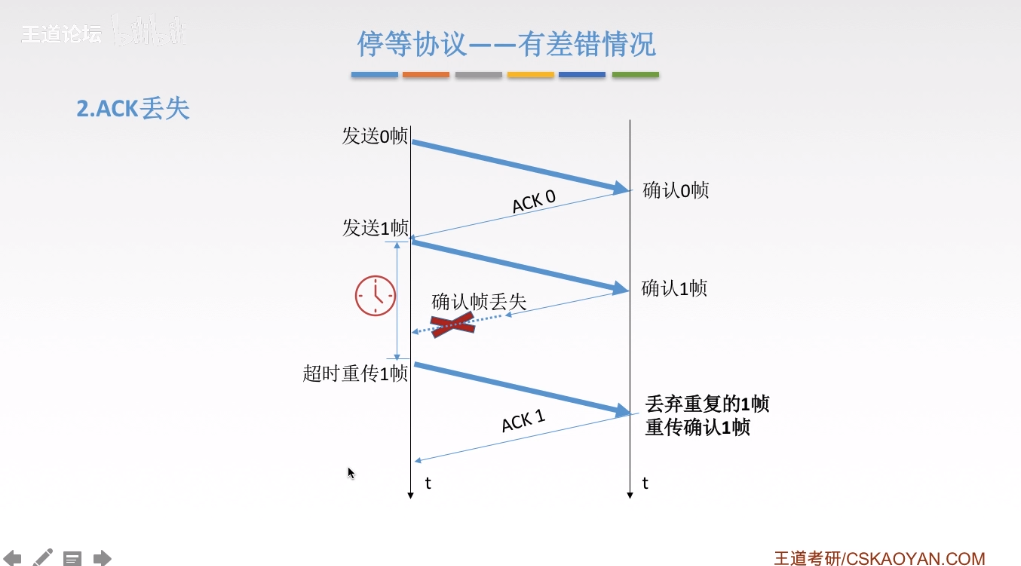
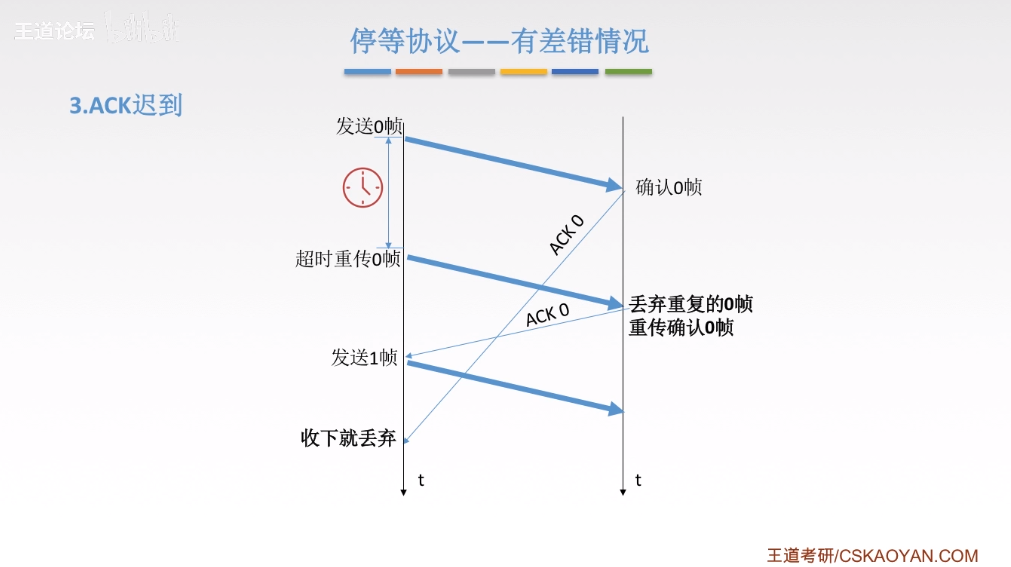
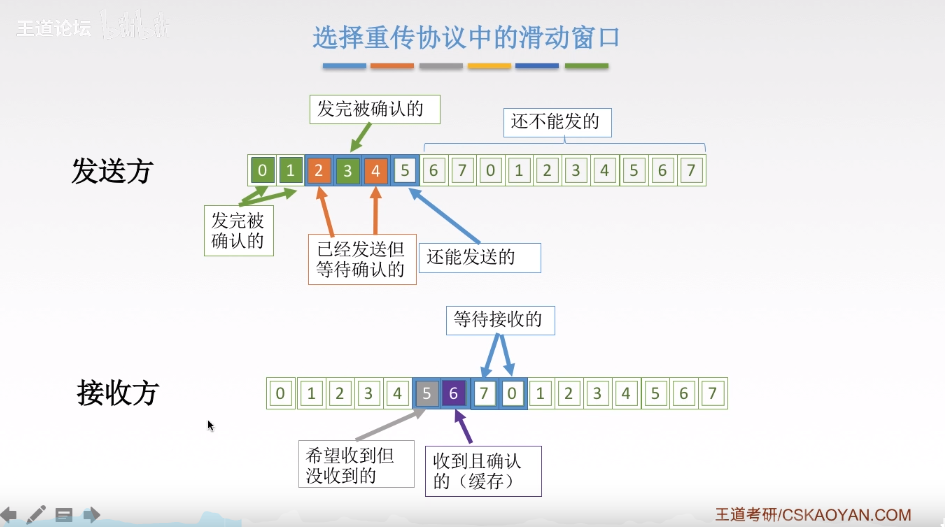
diff --git a/categories/index.html b/categories/index.html
index f693c00b92..e69de29bb2 100644
--- a/categories/index.html
+++ b/categories/index.html
@@ -1,512 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
categories | 夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- categories
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/content.json b/content.json
new file mode 100644
index 0000000000..5ce4775907
--- /dev/null
+++ b/content.json
@@ -0,0 +1 @@
+{"meta":{"title":"如云泊","subtitle":"","description":"","author":"Dominic","url":"http://example.com","root":"/"},"pages":[{"title":"about","date":"2020-08-23T01:09:13.000Z","updated":"2022-10-15T02:44:41.723Z","comments":true,"path":"about/index.html","permalink":"http://example.com/about/index.html","excerpt":"","text":"𝑯𝒊, 𝑰'𝒎 𝑫𝒐𝒎𝒊𝒏𝒊𝒄 :wave: 𝙄'𝙢 𝙘𝙪𝙧𝙧𝙚𝙣𝙩𝙡𝙮 𝙡𝙚𝙖𝙧𝙣𝙞𝙣𝙜 𝘾++ 𝙖𝙣𝙙 𝙋𝙮𝙩𝙝𝙤𝙣; ⌨️𝘿𝙖𝙗𝙗𝙡𝙚𝙧 𝙞𝙣 𝙂𝙧𝙖𝙥𝙝𝙞𝙘𝙨 𝘼𝙡𝙜𝙤𝙧𝙞𝙩𝙝𝙢 📸𝘼𝙢𝙖𝙩𝙚𝙪𝙧 𝙋𝙝𝙤𝙩𝙤𝙜𝙧𝙖𝙥𝙝𝙚𝙧 𝑰𝒍𝒍𝒖𝒎𝒊𝒏𝒂𝒕𝒊𝒐𝒏 𝒊𝒔 𝒅𝒆𝒔𝒊𝒈𝒏𝒆𝒅 𝒃𝒚 Dominic"},{"title":"categories","date":"2021-11-17T08:28:11.000Z","updated":"2022-10-15T02:44:41.724Z","comments":true,"path":"categories/index.html","permalink":"http://example.com/categories/index.html","excerpt":"","text":""},{"title":"tags","date":"2021-08-11T07:30:30.000Z","updated":"2022-10-15T02:44:42.194Z","comments":true,"path":"tags/index.html","permalink":"http://example.com/tags/index.html","excerpt":"","text":""}],"posts":[{"title":"Linux 网络配置常用命令","slug":"Linux网络配置常用命令","date":"2023-08-05T07:29:58.000Z","updated":"2023-08-05T07:30:42.502Z","comments":true,"path":"2023/08/05/Linux网络配置常用命令/","link":"","permalink":"http://example.com/2023/08/05/Linux%E7%BD%91%E7%BB%9C%E9%85%8D%E7%BD%AE%E5%B8%B8%E7%94%A8%E5%91%BD%E4%BB%A4/","excerpt":"","text":"配置网桥 brctl123456789101112131415161718192021222324# 创建一个名为 br0 的网桥sudo brctl addbr br0# 删除网桥 br0sudo brctl delbr br0# 列出所有的网桥及其接口信息sudo brctl show# 将网络接口 `eth0` 添加到网桥 `br0` 中sudo brctl addif br0 eth0# 从网桥 `br0` 中删除网络接口 `eth0`sudo brctl delif br0 eth0### 显示网桥 `br0` 的 Spanning Tree Protocol (STP)配置sudo brctl showstp br0# 禁用 Linux 内核中桥接器对数据包进行处理时调用 iptables 的功能。这种配置通常用于提高桥接速度,减少桥接过程中的 CPU 开销。sudo sysctl net.bridge.bridge-nf-call-iptables=0sudo sysctl net.bridge.bridge-nf-call-iptables=0# 为虚拟网卡设置IP并启动sudo ifconfig tap0 192.168.2.1 up 虚拟网络设备 tunctl1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162# 创建一个名为tun0的虚拟网络设备sudo tunctl -t tun0 # 将虚拟网卡设置为任何人都有权限使用:sudo chmod 0666 /dev/net/tun# 删除名为tun0的虚拟网络设备sudo tunctl -d tun0# 创建名为tun0的虚拟网络设备并指定其拥有者和组sudo tunctl -u user -g group -t tun0# 列出所有活跃的虚拟网络设备及其接口信息sudo tunctl -s # 指定虚拟网络设备的MAC地址sudo tunctl -m [mac_address] -t tun0# 列出具有给定设备名称前缀的所有已分配的虚拟网络设备sudo tunctl -g [device_name_prefix]# 分配虚拟网络设备的文件描述符,将结果输出到标准输出sudo tunctl -p -t tun0# 将虚拟网络设备关联到现有的桥接设备sudo tunctl -b -t tun0 -g br0# 从现有虚拟网络设备解除关联sudo tunctl -B -t tun0# 指定虚拟网络设备的最大传输单元(MTU)sudo ip link set tun0 mtu [value]# 启用虚拟网络设备sudo ip link set tun0 up# 禁用虚拟网络设备sudo ip link set tun0 down# 显示由Linux内核管理的虚拟网络设备的状态信息sudo ip link show tun0# 修改虚拟网络设备的MAC地址sudo ip link set dev tun0 address [mac_address]# 为虚拟网络设备分配一个IPv4地址sudo ip addr add [ip_address/cidr] dev tun0# 从虚拟网络设备中删除一个IPv4地址sudo ip addr del [ip_address/cidr] dev tun0# 检查虚拟网络设备是否已分配IPv4地址ip addr show tun0 | grep inet# 使用DLADDR命令获取虚拟网络设备的MAC地址sudo ethtool -P tun0 # 列出当前所有活动的网络接口ip a # 检查虚拟网络设备是否已分配IPv6地址ip addr show tun0 | grep inet6 网络接口管理(ifconfig)123456789101112131415161718192021222324# 显示所有网络接口信息ifconfig -a# 激活指定接口(如 eth0)ifconfig eth0 up# 关闭指定接口(如 eth0)ifconfig eth0 down# 添加 IP 地址,例如添加 IP 地址为 192.168.2.100 的网卡 eth0ifconfig eth0 192.168.2.100 netmask 255.255.255.0 up# 删除 IP 地址,例如删除网卡 eth0 上的 IP 地址ifconfig eth0 0.0.0.0# 启用或禁用广播地址ifconfig eth0 broadcast 192.168.2.255 upifconfig eth0 -broadcast# 设置网卡 mtu 大小为 9000ifconfig eth0 mtu 9000# 增加一个虚拟网络接口 eth0:1,并配置 IP 地址为 192.168.2.100ifconfig eth0:1 192.168.2.100 netmask 255.255.255.0 up 路由管理(route)1234567891011121314151617181920# 显示当前路由表route -n# 添加默认路由route add default gw 192.168.2.1# 删除默认路由route del default# 增加一个到目标网络的静态路由route add -net 192.168.100.0 netmask 255.255.255.0 gw 192.168.2.1# 删除静态路由route del -net 192.168.100.0 netmask 255.255.255.0 gw 192.168.2.1# 清除所有路由缓存项route flush cache# 查看 IP 地址对应网卡接口的 MAC 地址arping -I eth0 192.168.2.1 DNS 解析(nslookup 和 dig)1234567891011121314# 使用域名服务器解析域名nslookup www.example.com# 指定域名服务器,并解析域名nslookup www.example.com 8.8.8.8# 查询DNS地址dig example.com +nssearch# 查询所有的 NS 记录dig example.com NS# 查询某个域名的 MX 记录dig example.com MX 网络诊断工具(ping 和 traceroute)1234567891011# 测试与目标主机之间的连通性,查看网络是否可达ping 192.168.2.1# ping 命令的高级选项,控制发送的数据包数量、大小和时间间隔等参数ping -c 5 -s 100 -i 1 192.168.2.1# 显示数据包在网络上的传输路径,检测网络故障traceroute www.google.com# 显示每一跳所经过的路由器名称和 IP 地址traceroute -n www.google.com 网络流量分析工具(tcpdump 和 wireshark)1234567891011121314# 监听指定的网络接口上的数据包,显示每个数据包的详细信息tcpdump -i eth0# 监听指定端口上的数据包tcpdump port 80# 显示从指定源地址到目标地址的所有网络流量tcpdump src 192.168.2.100 and dst 192.168.2.200# 显示所有 IP 流量,并将结果保存到文件 tcp.pcap 中,以便使用 Wireshark 分析tcpdump -i eth0 -w tcp.pcap ip# 图形化的网络协议分析工具,用于分析网络流量wireshark 其他命令123456789101112131415161718# 显示网络连接状态和统计信息netstat -an# 显示 TCP/IP 配置参数sysctl net.ipv4.tcp_*# 设置 TCP/IP 参数,例如设置 SYN 攻击保护sysctl -w net.ipv4.tcp_syncookies=1# 重新加载 /etc/resolv.conf 文件systemd-resolve --flush-caches# 显示当前 DNS 服务器systemd-resolve --status | grep 'DNS Servers'# 重启网络systemctl restart NetworkManager","categories":[],"tags":[{"name":"Linux, 网络配置","slug":"Linux-网络配置","permalink":"http://example.com/tags/Linux-%E7%BD%91%E7%BB%9C%E9%85%8D%E7%BD%AE/"}]},{"title":"QEMU 虚拟机网络配置","slug":"QEMU虚拟机网络配置","date":"2023-08-05T06:47:54.000Z","updated":"2023-08-05T06:49:32.324Z","comments":true,"path":"2023/08/05/QEMU虚拟机网络配置/","link":"","permalink":"http://example.com/2023/08/05/QEMU%E8%99%9A%E6%8B%9F%E6%9C%BA%E7%BD%91%E7%BB%9C%E9%85%8D%E7%BD%AE/","excerpt":"","text":"Quick Setup宿主机查看一下网络接口信息: 123456789101112131415161718ifconfigenp3s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.12.192.173 netmask 255.255.255.0 broadcast 10.12.207.255 inet6 fe80::a00:27ff:fe32:e709 prefixlen 64 scopeid 0x20<link> ether 08:00:27:32:e7:09 txqueuelen 1000 (Ethernet) RX packets 6017 bytes 5412928 (5.4 MB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 1979 bytes 179467 (179.4 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 125 bytes 10142 (10.1 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 125 bytes 10142 (10.1 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 1234567891011121314# 安装虚拟网桥工具sudo apt install bridge-utils# UML(User-mode linux)工具 sudo apt install uml-utilities # 首先关闭宿主机网卡接口sudo ifconfig enp3s0 down# 添加名为 br0 的网桥,并在其中添加一个接口sudo brctl addbr br0sudo brctl addif br0 enp3s0# 启用 br0 接口,并从 DHCP 服务器获得 IP 地址sudo ifconfig br0 0.0.0.0 promisc upsudo dhclient br0# 启用网卡接口并关闭其 IP 地址sudo ifconfig enp3s0 0.0.0.0 promisc up 查看虚拟网桥列表 1234sudo brctl show br0bridge name bridge id STP enabled interfacesbr0 8000.000000000000 no enp3s0 查看 br0 的各接口信息 123456789101112131415161718192021222324sudo brctl showstp br0br0 bridge id 8000.000000000000 designated root 8000.000000000000 root port 0 path cost 0 max age 20.00s forward delay 15.00s hello time 2.00s ageing time 300.00s hello timer 0.00s <tbd> forward timer 0.00s <tbd> ageing timer 0.00s <tbd> enp3s0 (1) port id 8001 local state forwarding designated root 8000.000000000000 path cost 100 designated bridge 8000.000000000000 designated port 8001 forward delay 15.00s hello time 2.00s max age 20.00s ageing time 300.00s priority 128 12345678910# 创建一个 tap0 接口用于VM0使用,允许 user 用户访问tunctl -t tap0 -u user # 创建一个 tap1 接口用于VM1使用,允许 user 用户访问tunctl -t tap1 -u user # 在虚拟网桥中增加 tap0和tap1 接口 brctl addif br0 tap0brctl addif br0 tap1# 启用 tap0和tap1 接口,混杂模式,IP与enp3s0不在同一网段即可,不会冲突ifconfig tap0 10.12.193.1 promisc upifconfig tap1 10.12.193.1 promisc up 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748# 显示 br0 的各个接口sudo brctl showstp br0br0 bridge id 8000.000000000000 designated root 8000.000000000000 root port 0 path cost 0 max age 20.00s forward delay 15.00s hello time 2.00s ageing time 300.00s hello timer 0.00s <tbd> forward timer 0.00s <tbd> ageing timer 0.00s <tbd> enp3s0 (1) port id 8001 local state forwarding designated root 8000.000000000000 path cost 100 designated bridge 8000.000000000000 designated port 8001 forward delay 15.00s hello time 2.00s max age 20.00s ageing time 300.00s priority 128tap0 (2) port id 8002 local state disabled designated root 8000.000000000000 path cost 100 designated bridge 8000.000000000000 designated port 8002 forward delay 15.00s hello time 2.00s max age 20.00s ageing time 300.00s priority 128tap1 (3) port id 8003 local state disabled designated root 8000.000000000000 path cost 100 designated bridge 8000.000000000000 designated port 8003 forward delay 15.00s hello time 2.00s max age 20.00s ageing time 300.00s priority 128 将系统镜像复制一份并修改文件名,QEMU 不能同时使用一个镜像启动两个虚拟机。 1cp openEuler-22.09-riscv64-qemu.qcow2 openEuler-22.09-riscv64-qemu-vm1.qcow2 需要修改启动脚本中的镜像文件名,以及启动参数,修改了-device virtio-net-device和-netdev两个参数,需要关注: 123456789101112131415# 该脚本用于启动VM0drive="openEuler-22.09-riscv64-qemu.qcow2"....cmd="qemu-system-riscv64 \\ -nographic -machine virt \\ -smp "$vcpu" -m "$memory"G \\ -bios "$fw" \\ -drive file="$drive",format=qcow2,id=hd0 \\ -object rng-random,filename=/dev/urandom,id=rng0 \\ -device virtio-vga \\ -device virtio-rng-device,rng=rng0 \\ -device virtio-blk-device,drive=hd0 \\ -device virtio-net-device,netdev=tapnet,52:54:00:12:34:56 \\ -netdev tap,id=tapnet,ifname=tap0,script=no,downscript=no \\ -device qemu-xhci -usb -device usb-kbd -device usb-tablet" 123456789101112131415# 该脚本用于启动VM1drive="openEuler-22.09-riscv64-qemu-vm1.qcow2"....cmd="qemu-system-riscv64 \\ -nographic -machine virt \\ -smp "$vcpu" -m "$memory"G \\ -bios "$fw" \\ -drive file="$drive",format=qcow2,id=hd0 \\ -object rng-random,filename=/dev/urandom,id=rng0 \\ -device virtio-vga \\ -device virtio-rng-device,rng=rng0 \\ -device virtio-blk-device,drive=hd0 \\ -device virtio-net-device,netdev=tapnet,52:54:00:12:34:57 \\ -netdev tap,id=tapnet,ifname=tap1,script=no,downscript=no \\ -device qemu-xhci -usb -device usb-kbd -device usb-tablet" VM0启动虚拟机在虚拟机内进行网络配置 12# 查看网卡接口ifconfig 没有 IP 信息,需要手动配置,与宿主机 tap0 在同一个网段。 12# 设置IP地址sudo ifconfig eth0 10.12.193.111 up 12# 设置网关,默认网关是宿主机的tap,需要通过tap将数据转发出去sudo route add default gw 10.12.193.1 现在宿主机的 ip 就是 10.12.192.76,虚拟机的 ip 就是 10.12.193.111,可以尝试相互 ping。 VM1启动虚拟机在虚拟机内进行网络配置 12# 查看网卡接口ifconfig 没有 IP 信息,需要手动配置,与宿主机 tap1 在同一个网段。 12# 设置IP地址sudo ifconfig eth0 10.12.193.112 up 12# 设置网关,默认网关是宿主机的tap,需要通过tap将数据转发出去sudo route add default gw 10.12.193.1 现在宿主机的 ip 就是 10.12.192.76,虚拟机的 ip 就是 10.12.193.112,可以尝试相互 ping。 注意:两个虚拟机 MAC 地址不能相同,否则会出现网络冲突,导致网络不通。 原理探究 (Ongoing)QEMU 网络参数详解不同网络策略工作方式TUN/TAP 网络设备TODO Host 同网段的其他机器无法 ping 同当前 Host Host 同网段的其他机器无法 ping 通 VM0 和 VM1 Host 无法访问公网 VM 无法放问公网","categories":[],"tags":[{"name":"QEMU,虚拟机,网络配置","slug":"QEMU,虚拟机,网络配置","permalink":"http://example.com/tags/QEMU%EF%BC%8C%E8%99%9A%E6%8B%9F%E6%9C%BA%EF%BC%8C%E7%BD%91%E7%BB%9C%E9%85%8D%E7%BD%AE/"}]},{"title":"使用 Yadm 管理并同步配置文件 Dotfile","slug":"使用Yadm管理并同步配置文件Dotfile","date":"2023-07-30T05:39:04.000Z","updated":"2023-07-31T12:44:28.878Z","comments":true,"path":"2023/07/30/使用Yadm管理并同步配置文件Dotfile/","link":"","permalink":"http://example.com/2023/07/30/%E4%BD%BF%E7%94%A8Yadm%E7%AE%A1%E7%90%86%E5%B9%B6%E5%90%8C%E6%AD%A5%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6Dotfile/","excerpt":"","text":"Dotfiles 就是我们在使用软件的时候,软件为了存储我们个人偏好设置而建立的一个以 . 开头的文件。例如,vim 的配置文件就是 .vimrc,zsh 的配置文件就是 .zshrc。这些文件通常存储在用户的 home 目录中。但是,在不同的电脑上工作时,如果需要使用相同的配置,我们可以考虑使用版本控制工具来管理这些文件。或者在一台新电脑上想快速配置好环境,也可以使用版本控制工具来管理这些文件。Yadm 就可以帮助我们完成这些需求。 安装 yadm安装安装 yadm 非常简单,只需在终端输入以下命令: 1sudo apt-get install yadm 初始化 yadm 仓库创建一个新的 yadm 仓库很容易,只需在 home 目录中运行以下命令: 1yadm init 现在,yadm 已经创建了一个空白的 git 仓库。 添加 dotfile 文件要将现有的 dotfile 添加到 yadm 仓库中,请使用以下命令: 1yadm add ~/.zshrc 一旦您完成了对要添加的文件的更改并将它们添加到 yadm 仓库中,您需要提交它们。可以使用以下命令: 1yadm commit -m "Add .zshrc file to yadm repository" 建立远程仓库使用 yadm 还可以将 dotfile 文件同步到 GitHub 等 Git 托管服务中。 登录 Github,创建一个新的仓库。例如,您可以创建一个名为 dotfile 的仓库。现在,您需要将本地仓库与远程仓库连接起来。要将本地仓库连接到远程仓库,请使用以下命令: 1yadm remote add origin https://github.com/[用户名]/dotfile.git 现在 yadm 已经连接到您在 Github 上创建的仓库。要将本地代码上传到远程仓库,请使用以下命令: 1yadm push 使用多台电脑时如何同步配置假设需要在多个计算机之间共享 dotfile 文件。只需按照以下步骤即可: 在另一台计算机上安装 yadm 并初始化 yadm 仓库。 将远程仓库克隆到该计算机的 yadm 仓库中:1yadm clone https://github.com/[用户名]/dotfile.git 此时,您的 dotfile 文件应在计算机上自动更新。 执行完 clone 命令后实际上就是 yadm 会把远程仓库的文件都拷贝到本地。 如果本地有修改和远程有冲突怎么办如果本地有修改,远程也有修改,那么就会产生冲突。这时候需要先解决冲突,然后再提交。 每台电脑的配置不一样怎么办比如我们会在.zshrc中配置一些环境变量,但是每台电脑的环境变量可能不一样。这时候我们可以在.zshrc中添加一些判断,比如我们可以简单的判断一下主机名,然后根据主机名来加载不同的配置。 12345if [ $HOSTNAME = "xxx" ]; then # xxx的配置elif [ $HOSTNAME = "yyy" ]; then # yyy的配置fi 但有一些配置文件可能不支持这样的添加语句,比如.gitconfig,这时候我们可以使用 yadm 的 Alternate Files 功能解决。 Alternate Files 是一个用于管理同一文件不同版本的功能,有时在不同的主机、操作系统和用户需要不同的文件。Alternate Files 允许使用同一个文件名字,在文件名后添加一个带有条件的后缀,例如##os.Linux,hostname.host1,class.work,yadm 会根据当前系统的特定条件自动选择适当的版本,并创建符号链接。如果没有符合条件的版本,它将选择默认版本。 就以.gitconfig配置文件为例,我们通常在公司的电脑和家里的电脑配置不太一样,比如公司使用下面的配置: 123[user] email = 公司邮箱 name = 公司用户名 在家里使用下面的配置: 123[user] email = 日常使用邮箱 name = 日常使用用户名 配置文件不支持条件语句,所以无法通过直接在同一个配置文件里完成不同环境的配置。这就用到了 Alternate Files 功能,我们可以复制两个.gitconfig文件后面添加一个条件后缀,比如.gitconfig##class.work,然后在.gitconfig##class.work文件中添加公司的配置,.gitconfig文件中添加家里的配置。这样 yadm 就会根据当前的主机名自动选择合适的配置文件。并把这三个文件都加入到 yadm 仓库中。 123yadm add ~/.gitconfigyadm add ~/.gitconfig##class.workyadm add ~/.gitconfig##class.home 那么 yadm 是如何实现不同环境的切换呢?我们还需要进一步配置,有注意到我们的配置文件名中的class属性吗,这是 yadm 支持的条件属性之一。我们可以通过yadm config命令来配置当前电脑的属性。比如我们配置公司电脑的class属性为work,家里的电脑的class属性为home。 1yadm config local.class work 我们执行完此命令后,yadm 会自动为.gitconfig文件添加一个软链接,链接到.gitconfig##class.work文件。这样我们就可以在公司电脑上使用公司的配置了。如果我们在家里的电脑上执行yadm config local.class home,那么 yadm 会自动为.gitconfig文件添加一个软链接,链接到.gitconfig##class.home文件。这样我们就可以在家里的电脑上使用家里的配置了。 yadm 支持以下这些条件: 属性 意义 arch, a 如果值匹配架构则有效。通过运行 uname -m 计算架构。 class, c 如果值匹配 local.class 配置,则有效。必须使用“yadm config local.class ”手动设置 Class。 default 当没有其他备选项有效时有效。 distro, d 如果值与发行版匹配,则有效。通过运行 lsb_release -si或检查/etc/os-release来计算分布。 distro_family, f 如果值匹配发行版系列,则有效。通过检查/etc/os-release 中的 ID_LIKE 行计算发行版系列。 extension, e 一种特殊的“条件”,不影响选择过程。它的目的是允许备选文件以特定扩展名结尾,例如使编辑器正确突出显示内容。 hostname, h 如果值匹配短主机名,则有效。通过运行 uname -n,并去除任何域来计算主机名。 os,o 如果值与操作系统匹配,则有效。通过运行 uname -s 计算 OS。* template, t 当值与支持的模板处理器匹配时有效。有关更多详细信息,请参见模板部分。 user, u 如果值匹配当前用户,则有效。通过运行 id -u -n 计算当前用户。 再举个例子,上面用的 class 条件是必须通过yadm config local.class <class>手动设置的。但是有一些条件不需要手动设置 yadm 可以自动识别。比如 os 属性。我们将.zshrc文件复制两份份,命名为.zshrc##os.Linux和.zshrc##os.Darwin,然后在.zshrc##os.Linux文件中添加一些 Linux 系统的配置,.zshrc##os.Darwin文件中添加一些 Mac 系统的配置。并把这三个文件都加入到 yadm 仓库中。这样 yadm 就会根据当前的系统自动选择合适的配置文件。","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"工具推荐","slug":"工具推荐","permalink":"http://example.com/tags/%E5%B7%A5%E5%85%B7%E6%8E%A8%E8%8D%90/"}]},{"title":"QEMU启动RISC-V架构OpenEuler并配置OSC环境","slug":"QEMU启动RISC-V架构OpenEuler并配置OSC环境","date":"2023-07-23T11:28:29.000Z","updated":"2023-07-23T11:29:42.680Z","comments":true,"path":"2023/07/23/QEMU启动RISC-V架构OpenEuler并配置OSC环境/","link":"","permalink":"http://example.com/2023/07/23/QEMU%E5%90%AF%E5%8A%A8RISC-V%E6%9E%B6%E6%9E%84OpenEuler%E5%B9%B6%E9%85%8D%E7%BD%AEOSC%E7%8E%AF%E5%A2%83/","excerpt":"","text":"基于Ubuntu 18.04,QEMU 8.0.2,OpenEuler 22.09 安装QEMU安装基础编译工具12345sudo apt install build-essential autoconf automake autotools-dev pkg-config bc curl \\ gawk git bison flex texinfo gperf libtool patchutils mingw-w64 libmpc-dev \\ libmpfr-dev libgmp-dev libexpat-dev libfdt-dev zlib1g-dev libglib2.0-dev \\ libpixman-1-dev libncurses5-dev libncursesw5-dev meson libvirglrenderer-dev libsdl2-dev -y 1234sudo add-apt-repository ppa:deadsnakes/ppasudo apt install python3.8 python3-pip -ysudo apt install -fpip3 install meson 下载QEMU建立文件夹用于编译: 1cd && mkdir -p qemu-build 建立文件夹用于安装: 1cd && mkdir -p /home/user/program/riscv64-qemu 可登录官网将版本号换成最新版本即可: 1cd qemu-build && wget "https://download.qemu.org/qemu-8.0.2.tar.xz" 1tar -xf qemu-8.0.2.tar.xz --strip-components=1 安装QEMU123cd qemu-build && ./configure --target-list=riscv32-softmmu,riscv32-linux-user,riscv64-linux-user,riscv64-softmmu \\ --enable-kvm --enable-sdl \\ --prefix=/home/user/program/riscv64-qemu 1make install -j $(nproc) 配置环境变量 12echo 'export QEMU_HOME=/home/user/program/riscv64-qemu' >> ~/.bashrc && echo 'export PATH=$QEMU_HOME/bin:$PATH' >> ~/.bashrc 1source ~/.bashrc 下载 OpenEuler RISC-V 系统镜像建立目录: 1cd && mkdir -p /home/user/openeuler 根据自己的用户名修改user 下载OpenEuler 22.09版本,下载目录下所有文件/home/user/openeuler。如需下载其他版本请进入其他目录选择下载即可。 也可以根据自己的情况进入镜像站列表选择下载速度更快的镜像站下载 最新的23.03版本需要在中科院镜像站下载 文件说明: fw_payload_oe_qemuvirt.elf: 利用 openSBI 将 kernel-5.10 的 image 作为 payload 所制作的 QEMU 启动所需文件 openEuler-22.09-qemu-xfce.qcow2.tar.zst: openEuler RISC-V QEMU GUI 镜像压缩包 preview_start_vm_xfce.sh: GUI 虚拟机启动脚本 openeuler-22.09-qemu.qcow2.tar.zst: openEuler RISC-V QEMU headless 镜像压缩包 preview_start_vm.sh: headless 虚拟机启动脚本 解压: 1sudo apt-get install zstd 1tar -I 'zstdmt' -xvf openEuler-22.09-riscv64-qemu.qcow2.tar.zst 执行启动脚本 1chmod +x preview_start_vm.sh 1bash preview_start_vm.sh 登录系统 用户名: root 默认密码: openEuler12#$ 1234567891011121314151617181920212223242526openEuler 22.09Kernel 5.10.0 on an riscv644penEuler-riscv6 login: openEuler 22.09Kernel 5.10.0 on an riscv64openEuler-riscv64 login: rootPassword: Welcome to 5.10.0System information as of time: Mon Jul 3 07:52:19 PM CST 2023System load: 0.17Processes: 117Memory used: .6%Swap used: 0.0%Usage On: 6%Users online: 1[root@openEuler-riscv64 ~]# ls[root@openEuler-riscv64 ~]# pwd 远程登录系统1ssh -p 12055 root@localhost 配置系统 以下操作均在root用户下执行,如果切换了用户会有提示。因为系统初始状态没有普通用户,也没有sudo,所以需要使用root完成一些基础配置。 修改root密码原密码太复杂,修改简单密码 12passwd root# 输入两次密码 添加普通用户123# 添加用户 useruseradd -s /bin/bash -d /home/user -m user 12passwd user# 输入两次密码 12# 添加管理员权限usermod -aG wheel user 修改时间12echo "NTP=ntp.aliyun.com" >> /etc/systemd/timesyncd.conf 12systemctl restart systemd-timesyncd.service 查看timesyncd运行状态: 1systemctl status systemd-timesyncd.service date命令可查看当前系统时间。验证是否配置成功。 时间务必正确设置,错误的时间会影响诸如https的TLS认证等过程。 配置DNS12vim /etc/resolv.confnameserver 119.29.29.29 配置软件包源配置文件为 /etc/yum.repos.d/openEuler.repo 下 12345678910111213141516171819mv /etc/yum.repos.d/openEuler.repo /etc/yum.repos.d/openEuler.repo.bk && sudo bash -c "cat << EOF > /etc/yum.repos.d/openEuler.repo# just for test[mainline]name=mainlinebaseurl=https://mirror.iscas.ac.cn/openeuler-sig-riscv/openEuler-RISC-V/preview/openEuler-22.09-V1-riscv64/repo/22.09/enabled=1gpgcheck=0# just for test[epol]name=epolbaseurl=https://mirror.iscas.ac.cn/openeuler-sig-riscv/openEuler-RISC-V/preview/openEuler-22.09-V1-riscv64/repo/22.09/enabled=1gpgcheck=0[extra]name=extrabaseurl=https://mirror.iscas.ac.cn/openeuler-sig-riscv/openEuler-RISC-V/preview/openEuler-22.09-V1-riscv64/repo/extra/enabled=1gpgcheck=0EOF" 需要注意的是,因为OpenEuler还在快速发展中,镜像地址可能会发生变化,所以需确认地址是否能够正常访问,如无法访问会导致404错误 [repoid]中的repoid为软件仓库(repository)的ID号,所有.repo配置文件中的各repoid不能重复,必须唯一。示例中repoid设置为base。name为软件仓库描述的字符串。baseurl为软件仓库的地址。enabled为是否启用该软件源仓库,可选值为1和0。默认值为1,表示启用该软件源仓库。gpgcheck可设置为1或0,1表示进行gpg(GNU Private Guard)校验,0表示不进行gpg校验,gpgcheck可以确定rpm包的来源是有效和安全的。gpgkey为验证签名用的公钥。 磁盘扩容 在宿主机上安装 qemu-img 工具: 1apt install qemu-utils 在 openEuler RISC-V 虚拟机上安装 growpart 工具: 1dnf install cloud-utils-growpart 关闭QEMU虚拟机 把 qcow2 文件的容量加200GB: 123456789101112131415$ qemu-img resize *.qcow2 +200GImage resized.$ qemu-img info *.qcow2image: openEuler-preview.riscv64.qcow2file format: qcow2virtual size: 220 GiB disk size: 9.58 GiBcluster_size: 65536Format specific information: compat: 1.1 compression type: zlib lazy refcounts: false refcount bits: 16 corrupt: false extended l2: false QEMU 启动 openEuler RISC-V。 启动以后,我们先看看分区情况:可以看到根目录对应的分区只使用了 10G。 1234[root@openEuler-RISCV-rare ~]# lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTvda 254:0 0 220G 0 disk└─vda1 254:1 0 10G 0 part / 扩展分区 vda1,执行 1growpart /dev/vda1 执行 lsblk 可以看到 / 所在的 vda1 分区已经扩展到了预期大小 123456[root@openEuler-RISCV-rare ~]# growpart /dev/vda 1CHANGED: partition=1 start=2048 old: size=20969472 end=20971520 new: size=419428319 end=419430367[root@openEuler-RISCV-rare ~]# lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTvda 254:0 0 220G 0 disk└─vda1 254:1 0 220G 0 part / 扩展文件系统: 12resize2fs /dev/vda1 BUGnetwork backend ‘user‘ is not compiled into this binarygit clone https://gitlab.freedesktop.org/slirp/libslirp.git http://security.ubuntu.com/ubuntu/pool/main/libs/libslirp/libslirp-dev_4.1.0-2ubuntu2.2_amd64.deb 1sudo apt-get install libslirp-dev 重新编译QEMU: 12cd qemu-build && rm -rf build 1234cd qemu-build && ./configure --target-list=riscv32-softmmu,riscv32-linux-user,riscv64-linux-user,riscv64-softmmu \\ --enable-kvm --enable-sdl --enable-slirp\\ --prefix=/home/user/program/riscv64-qemu 1make install -j $(nproc) 参考文档RISC-V/doc/tutorials/vm-qemu-oErv.md at master · openeuler-mirror/RISC-V · GitHub openEuler 22.09技术白皮书","categories":[],"tags":[{"name":"QEMU","slug":"QEMU","permalink":"http://example.com/tags/QEMU/"},{"name":"RISC-V","slug":"RISC-V","permalink":"http://example.com/tags/RISC-V/"},{"name":"OpenEuler","slug":"OpenEuler","permalink":"http://example.com/tags/OpenEuler/"}]},{"title":"SSH 登录 OpenStack 实例","slug":"SSH-登录-OpenStack-实例","date":"2023-06-28T14:20:05.000Z","updated":"2023-06-28T14:21:29.291Z","comments":true,"path":"2023/06/28/SSH-登录-OpenStack-实例/","link":"","permalink":"http://example.com/2023/06/28/SSH-%E7%99%BB%E5%BD%95-OpenStack-%E5%AE%9E%E4%BE%8B/","excerpt":"","text":"基础配置添加安全组规则,允许 Ping 和 SSH 访问虚拟机: 1openstack security group rule create --proto icmp default 12345678910111213141516171819202122root@allone:~# openstack security group rule create --proto icmp default+-------------------+---------------------------+| Field | Value |+-------------------+-------------------------+| created_at | 2023-06-28T06:26:10Z || description | || direction | ingress || ether_type | IPv4 || id | fe9adfc3-dc42-4680-8ecd-ed5a667e1215 || location | cloud='', project.domain_id=, project.domain_name='Default', project.id='6396365541a74b6b8ea8812d1af05e70', project.name='admin', region_name='', zone= || name | None || port_range_max | None || port_range_min | None || project_id | 6396365541a74b6b8ea8812d1af05e70 || protocol | icmp || remote_group_id | None || remote_ip_prefix | 0.0.0.0/0 || revision_number | 0 || security_group_id | f10a3927-5e76-47b4-8691-4169348845ae || tags | [] || updated_at | 2023-06-28T06:26:10Z |+-------------------+--------------------------------+ 1openstack security group rule create --proto tcp --dst-port 22 default 12345678910111213141516171819202122root@allone:~# openstack security group rule create --proto tcp --dst-port 22 default+-------------------+--------------------------------------+| Field | Value |+-------------------+--------------------------------------------+| created_at | 2023-06-28T06:26:15Z || description | || direction | ingress || ether_type | IPv4 || id | af699cf9-5fc0-45e2-a009-0bb7828e2d1a || location | cloud='', project.domain_id=, project.domain_name='Default', project.id='6396365541a74b6b8ea8812d1af05e70', project.name='admin', region_name='', zone= || name | None || port_range_max | 22 || port_range_min | 22 || project_id | 6396365541a74b6b8ea8812d1af05e70 || protocol | tcp || remote_group_id | None || remote_ip_prefix | 0.0.0.0/0 || revision_number | 0 || security_group_id | f10a3927-5e76-47b4-8691-4169348845ae || tags | [] || updated_at | 2023-06-28T06:26:15Z |+-------------------+-----------------+ 命令行方式生成秘钥1ssh-keygen -q -N “” -q 选项表示静默模式,即在生成密钥对的过程中不会输出任何提示信息或警告。 -N 选项后面可以跟一个密码作为参数。该密码将用于保护生成的私钥文件。如果不指定 -N 参数,则私钥文件将不受密码保护。 该命令会在~/.ssh/目录中自动生成一对公私钥。默认私钥名称:id_rsa,默认公钥名称:id_rsa.pub 1openstack keypair create --public-key ~/.ssh/id_rsa.pub mykey 向 OpenStack 添加公钥,用于创建实例时选择: 12345678root@allone:~# openstack keypair create --public-key ~/.ssh/id_rsa.pub mykey+-------------+-------------------------------------------------+| Field | Value |+-------------+-------------------------------------------------+| fingerprint | 11:36:75:e0:c3:98:4c:97:90:30:f5:69:e1:17:a9:4b || name | mykey || user_id | 9027da91a2134825a421d78db11011d0 |+-------------+-------------------------------------------------+ 1openstack keypair list 1234567root@allone:~# openstack keypair list+---------------------+-------------------------------------------------+| Name | Fingerprint |+---------------------+-------------------------------------------------+| mykey | 11:36:75:e0:c3:98:4c:97:90:30:f5:69:e1:17:a9:4b || ubuntu cloud server | 67:b4:8a:64:83:4e:47:d0:7c:87:46:34:3b:03:e6:17 |+---------------------+-------------------------------------------------+ 1ssh ubuntu@10.0.2.111 其中,ubuntun是实例的用户名,10.0.2.111是实例的 IP 地址。 WEB 界面方式创建密钥对Project-Key Pairs-Create Keypairs 为密钥对起个名字:sshkey,并选择一个类型:SSH Key 点击创建后会弹出下载私钥的窗口,这时候需要将私钥下载到本地。并将他移动到 ssh 目录下方便管理。 123# 切换root用户,因为我们一直都是用root用户操作的OpenStacksudo sumv sshkey.pem ~/.ssh 使用公钥创建实例Project-Instances-Launch Instance 在 Key Pair 中选择刚刚创建的 sshkey。这里实际就是将创建的密钥对中的公钥放到了我们的实例中,这样我们就可以拿着本地的私钥去访问实例。 登录实例1ssh -i ~/.ssh/sshkey.pem ubuntun@10.0.2.111 其中~/.ssh/sshkey.pem是我们下载的私钥文件,ubuntun是实例的用户名,10.0.2.111是实例的 IP 地址。","categories":[{"name":"OpenStack","slug":"OpenStack","permalink":"http://example.com/categories/OpenStack/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"OpenStack","slug":"OpenStack","permalink":"http://example.com/tags/OpenStack/"}]},{"title":"VirtualBox Ubuntu 无法联网","slug":"VirtualBox-Ubuntu无法联网","date":"2023-06-26T14:38:02.000Z","updated":"2023-06-26T14:39:54.687Z","comments":true,"path":"2023/06/26/VirtualBox-Ubuntu无法联网/","link":"","permalink":"http://example.com/2023/06/26/VirtualBox-Ubuntu%E6%97%A0%E6%B3%95%E8%81%94%E7%BD%91/","excerpt":"","text":"解决方案VirtualBox Ubuntu 无法联网,重启后可以联网但是几分钟后断开网络。笔者的情况是因为 NetworkManager 自动修改了网络配置导致无法联网,具体现象是开机后网卡信息如下: 1234567891011121314151617user@allone:~$ ifconfigbrq64ff9b38-fa: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 ether ce:29:de:12:35:06 txqueuelen 1000 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0enp0s3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.0.2.15 netmask 255.255.255.0 broadcast 10.0.2.255 inet6 fe80::2e8f:2be6:3752:dec4 prefixlen 64 scopeid 0x20<link> ether 08:00:27:18:31:21 txqueuelen 1000 (Ethernet) RX packets 947 bytes 584483 (584.4 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 800 bytes 116611 (116.6 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 此时网络可以正常使用,经过一两分钟后网络信息如下: 123456789101112131415161718user@allone:~$ ifconfigbrq64ff9b38-fa: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.0.2.15 netmask 255.255.255.0 broadcast 10.0.2.255 ether ce:29:de:12:35:06 txqueuelen 1000 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0enp0s3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet6 fe80::2e8f:2be6:3752:dec4 prefixlen 64 scopeid 0x20<link> ether 08:00:27:18:31:21 txqueuelen 1000 (Ethernet) RX packets 947 bytes 584483 (584.4 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 800 bytes 116611 (116.6 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 也就是默认虚拟网卡的 IP 地址丢失,而不知名网卡 brq64ff9b38-fa 却拥有了 IP,此时网络不可用。如果有类似情况,可以使用以下方式尝试解决,如果是其他问题。请酌情参考。 关闭 NetworkManager 12sudo systemctl stop NetworkManager 1sudo systemctl disable NetworkManager 1sudo systemctl mask NetworkManager 开启 systemd-networkd 1sudo systemctl unmask systemd-networkd.service 12sudo systemctl enable systemd-networkd.service 12sudo systemctl start systemd-networkd.service 配置 Netplan 编辑/etc/netplan/01-network-manager-all.yaml 1234567891011network: version: 2 renderer: networkd ethernets: enp0s3: dhcp4: yes dhcp6: yes addresses: [10.0.2.15/23] nameservers: addresses: [8.8.8.8, 8.8.4.4] optional: true 其中 enp0s3 为网卡名称,addresses 为网卡对应的 IP,均可以通过 ifconfig 查询。 以下是一些背景知识,以及问题回溯有兴趣可以继续阅读。 背景知识NetworkManager 与 systemd-networkedNetworkManager 是一项后端服务,用于控制 Ubuntu 操作系统上的网络接口。NetworkManager 的替代方法是 systemd-networked,这两者只能使用一个。在 Ubuntu 桌面上,NetworkManager 是通过图形用户界面管理网络界面的默认服务。因此,如果要通过 GUI 配置 IP 地址,则应启用 NetworkManager。如果用的是无桌面的 Server 版,就可以使用 systemd-networked 来管理网络。 这两种方式都可以通过配置 netplan,即/etc/netplan/01-network-manager-all.yaml 来管理网络,但是在 renderer 属性中配置有所不同,使用 NetworkManager 时配置如下: 123network: version: 2 renderer: NetworkManager 而使用 systemd-networked 时,配置如下: 123network: version: 2 renderer: networkd 有时无法联网可能是因为配置与实际使用的网络管理方式不匹配导致的。","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"Virtual Box 的不同虚拟机网络模式","slug":"Virtual-Box的不同虚拟机网络模式","date":"2023-06-17T08:48:02.000Z","updated":"2023-06-17T09:03:41.765Z","comments":true,"path":"2023/06/17/Virtual-Box的不同虚拟机网络模式/","link":"","permalink":"http://example.com/2023/06/17/Virtual-Box%E7%9A%84%E4%B8%8D%E5%90%8C%E8%99%9A%E6%8B%9F%E6%9C%BA%E7%BD%91%E7%BB%9C%E6%A8%A1%E5%BC%8F/","excerpt":"","text":"💻 NAT 网络模式 NAT 网络以路由器的 NAT 功能为原理,允许虚拟机通过共享主机的 IP 地址访问互联网,但虚拟机之间不能直接通信。通过端口转发可以实现虚拟机之间的连接。 🔗 桥接网络模式 桥接网络模式通过虚拟交换机连接虚拟机和主机,使得虚拟机可以通过局域网访问互联网,并允许虚拟机之间直接通信。 🔒 内部网络模式 内部网络模式使得虚拟机可以创建一个完全隔离的网络,虚拟机之间可以直接通信,但无法访问互联网或外部网络。 🏠 仅主机网络模式 仅主机网络模式允许虚拟机之间可以通信,并且与主机之间也可以通信,但无法访问互联网或外部网络。 虚拟机 ↔ 虚拟机 虚拟机 → 宿主机 宿主机 → 虚拟机 虚拟机 → 互联网 互联网 → 虚拟机 网络地址转换 NAT × √ × √ × NAT 网络 √ √ × √ × Bridged Adapter 桥接网卡 √ √ √ √ √","categories":[],"tags":[{"name":"计算机网络","slug":"计算机网络","permalink":"http://example.com/tags/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/"}]},{"title":"计算机网络 - 数据链路层","slug":"计算机网络-数据链路层","date":"2023-06-11T02:26:10.000Z","updated":"2023-06-11T02:31:56.063Z","comments":true,"path":"2023/06/11/计算机网络-数据链路层/","link":"","permalink":"http://example.com/2023/06/11/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C-%E6%95%B0%E6%8D%AE%E9%93%BE%E8%B7%AF%E5%B1%82/","excerpt":"","text":"数据链路层基本概念结点:主机,路由器链路:网络中两个结点之间的物理通道,链路的传输介质主要有双绞线、光纤和微波。分为有线链路、无线链路。数据链路:网络中两个结点之间的逻辑通道,把实现控制数据传输协议的硬件和软件加到链路上就构成数据链路。帧:链路层的协议数据单元,封装网络层数据报。 数据链路层负责通过一条链路从一个结点向另一个物理链路直接相连的相邻结点传送数据报。 数据链路层的功能功能概述数据链路层在物理层提供服务的基础上向网络层提供服务,其最基本的服务是将源自网络层来的数据可靠地传输到相邻节点的目标机网络层。其主要作用是加强物理层传输原始比特流的功能,将物理层提供的可能出错的物理连 接改造成为逻辑上无差错的数据链路,使之对网络层表现为一条无差错的链路。 为网络层提供服务 无确认无连接服务 有确认无连接服务 有确认面向连接服务 链路管理 连接的建立,维持,释放 组帧 差错控制 封装成帧封装成帧就是在一段数据的前后部分添加首部和尾部,这样就构成了一个帧。接收端在收到物理层上交的比特流后,就能根据首部和尾部的标记(帧定界符),从收到的比特流中识别帧的开始和结束。 首部和尾部包含许多的控制信息,他们的一个重要作用:帧定界(确定帧的界限)。 帧同步:接收方应当能从接收到的二进制比特流中区分出帧的起始和终止。 透明传输 差错控制传输中的差错都是由噪声引起的。 全局性,由于线路本身电气特性所产生的随机噪声 局部性,由于外界短暂的原因造成的冲击噪声 差错又分为位错和帧错 位错,比特位出错,1 变 0,0 变 1 帧错,包括丢失,重复,失序 发现差错的帧后就将错误值丢弃,如果没有差错控制,将会浪费大量资源,因为传输过程中一直传输了错误的信息。 差错控制 检错编码 奇偶校验码 循环冗余 CRC 纠错编码 海明码 这里提到的编码和物理层的编码与调制不同,物理层的编码针对单个比特,解决传输同步问题。这里的编码针对的是一组比特,通过冗余码的技术检测传输中是否出错。 奇偶校验码奇校验码:在信息元前加上 1 位后使得 1 的个数为奇数个偶检验码:在信息元前加上 1 位后使得 1 的个数为偶数个 该检测方式只能检测出奇数个的位错,检错能力为 50% 12345如果一个字符S的ASCI编码从低到高依次为1100101,采用奇校验,在下述收到的传输后字符中,哪种错误不能检测?A.11000011B.11001010 C.11001100 D.11010011答:因为采用奇校验,所以在首位加上一个1使得所有1个数为奇数变成11100101,ABC选项中1的个数都是偶数个,明显发生了变化,所以能检测出错误,但是D选项的1也是奇数个,将无法判断是否出现差错。 CRC 循环冗余码 链路层的两种信道局域网、广域网数据链路层的设备流量控制与可靠传输单帧滑动窗口与停止等待协议 SR 选择重传协议 滑动窗口最大值","categories":[],"tags":[]},{"title":"Ubuntu 22.04 系统安装水星 wifi 驱动 Mercury MW310UH","slug":"ubuntu-22-04-系统安装水星-wifi-驱动Mercury-MW310UH","date":"2023-06-11T02:00:02.000Z","updated":"2023-06-11T02:06:56.420Z","comments":true,"path":"2023/06/11/ubuntu-22-04-系统安装水星-wifi-驱动Mercury-MW310UH/","link":"","permalink":"http://example.com/2023/06/11/ubuntu-22-04-%E7%B3%BB%E7%BB%9F%E5%AE%89%E8%A3%85%E6%B0%B4%E6%98%9F-wifi-%E9%A9%B1%E5%8A%A8Mercury-MW310UH/","excerpt":"","text":"确认网卡信息1lsusb 得到 USB 设备信息 1Bus 001 Device 013: ID 0bda:a192 Realtek Semiconductor Corp. Disk 安装网卡驱动根据设备 ID,用关键词网上搜素一下相关驱动,得到有这个驱动可用: 1234567sudo apt updatesudo apt install build-essential git dkmsgit clone https://gitee.com/BrightXu/rtl8192fu.gitcd rtl8192fumake -j$(nproc)sudo make installsudo modprobe 8192fu 查看是否安装成功 1usb-devices 如果有 Driver=rtl8192fu 字段说明安装成功。如果桌面右上角无线连接图标可用,说明可以使用无线网络了。如果不可用继续往下看。 修改设备模式如果使用lsusb命令查看设备,发现设备末尾依然是 Disk 模式,说明这个设备是磁盘设备,还不能当做网络适配器使用,需要修改其模式。 12sudo apt-get install -y usb-modeswitchsudo vim /lib/udev/rules.d/40-usb_modeswitch.rules 在最后 LABEL 之前加上 123# Realtek 8192F Wifi AC USBATTR{idVendor}=="0bda", ATTR{idProduct}=="a192", RUN+="/usr/sbin/usb_modeswitch -K -v 0bda -p a192"LABEL="modeswitch_rules_end" 1sudo usb_modeswitch -KW -v 0bda -p a192 关闭安全启动安全启动模式下无法使用第三方的驱动,所以需要在开机时进入 BIOS 将安全启动关闭,每个主板不一样,自行搜索。 参考linux 系统下 usb 网卡的驱动安装_linux usb 网卡-CSDN 博客 为 ubuntu 22.04 系统安装水星 realtek 5g wifi 驱动 - 郭华伟的博客 ubuntu 18.04 usb 无线网卡无法使用–ID 0bda:a192 Realtek Semiconductor Corp._放羊 Wa 的博客-CSDN 博客","categories":[],"tags":[]},{"title":"云计算基础技术汇总","slug":"云计算基础技术汇总","date":"2023-06-09T13:42:59.000Z","updated":"2023-06-09T13:43:13.243Z","comments":true,"path":"2023/06/09/云计算基础技术汇总/","link":"","permalink":"http://example.com/2023/06/09/%E4%BA%91%E8%AE%A1%E7%AE%97%E5%9F%BA%E7%A1%80%E6%8A%80%E6%9C%AF%E6%B1%87%E6%80%BB/","excerpt":"","text":"云计算服务类型传统架构=>Iaas=>Paas=>Saas 自己烧饭=> 叮咚买菜=> 美团外卖=> 餐厅吃饭 云计算部署形式以及应用 类型 描述 优点 缺点 私有云 利用已有设备自我构建,云端资源只给内部人员使用。 安全性高 维护成本高 社区云、行业云 为特定行业构建共享基础设施的云。 有一套用户体系 维护成本高 公有云 构建大型基础设施云出租给公众。 用户来说成本低,服务多 安全性低 混合云 两种或者两种以上的云组成的云服务 敏捷,灵活,降低成本 兼容性问题 应用存储云、医疗云、教育云、企业云、金融云、游戏云、桌面云 关键技术虚拟化 分布式存储将数据存储在不同的物理设备中。这种模式不仅摆脱了硬件设备的限制,同时扩展性更好,能够快速响应用户需求的变化(整合存储资源提供动态可伸缩资源池的分布式存储技术) 数据中心联网虚拟机之间需要实时同步大量的数据,产生大量东西流量。 并行编程在并行编程模式下,并发处理、容错、数据分布、负载均衡等细节都被抽象到一个函数库中,通过统一接口,用户大尺度的计算任务被自动并发和分布执行,即将一个任务自动分成多个子任务,并行地处理海量数据。 体系结构云计算平台体系结构由用户界面、服务目录、管理系统、部署工具、监控和服务器集群组成。 自动化部署对云资源进行自动化部署指的是基于脚本调节的基础上实现不同厂商对于设备工具的自动配置,用以减少人机交互比例、提高应变效率,避免超负荷人工操作等现象的发生,最终推进智能部署进程。 云服务提供商亚马逊云、腾讯云、阿里云、百度云、华为云 技术架构:开源(Xen,KVM),Vmware,微软 hyper-v,阿里飞天 Apsara 开源云管理平台:OpenStack 虚拟化简介虚拟化:一种计算机资源管理技术,将各种 T 实体资源抽象、转换成另一种形式的技术都是虚拟化。作用:通过该技术将一台计算机虚拟为多台逻辑计算机。在一台计算机上同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统,并且应用程序都可以在相互独立的空间内运行而互不影响,从而显著提高计算机的工作效率。 从行业数据互相关联的角度来说,云计算是极度依赖虚拟化的。但虚拟化并非云计算,云计算也并非虚拟化。虚拟化只是云计算的核心技术,但并非云计算的核心关注点。 云计算是一种服务。虚拟化是云计算的技术基础。 虚拟化相关的几个概念Guest OS:运行在虚拟机之上的 OSGuest Machine:虚拟出来的虚拟机VMM:虚拟机监控器,即虚拟化层 (Virtual Machine Monitor,VMM)Host OS:运行在物理机之上的 OSHost Machine:物理机 虚拟化类型 虚拟化类型 描述 特点 案例 寄居虚拟化(Type2) 在主机(宿主)操作系统上安装和运行虚拟化程序 - 简单、易于实现。- 安装和运行应用程序依赖于主机操作系统对设备的支持。- 有两层 OS,管理开销较大,性能损耗大。- 虚拟机对各种物理设备 (cpu、内存、硬盘等) 的调用,都通过虚拟化层和宿主机的 OS 一起协调才能完成。 - Vmware- VirturalBox 裸金属虚拟化 (Type1) 直接将 VMM 安装在硬件设备上,VMM 在这种模式下又叫做 Hypervisor,虚拟机有指令要执行时,Hypervisors 会接管该指令,模拟相应的操作。 - 不依赖于操作系统。- 支持多种操作系统,多种应用。- 依赖虚拟层内核和服务器控制台进行管理。- 需要对虚拟层的内核进行开发(难度大)。 - VMware ESX- Xen- 华为 FusionSphere 混合虚拟化 在一个现有的正常操作系统下安装一个内核模块,内核拥有虚拟化能力。(相当于寄居与裸金属的混合) - 相对于寄居虚拟化架构,性能高。- 相对于裸金属虚拟化架构,不需要开发内核。- 可支持多种操作系统。- 需底层硬件支持虚拟化扩展功能。 - KVM 寄居虚拟化(Type2) 裸金属虚拟化 (Type1) 混合虚拟化 虚拟化层架构 架构 描述 特点 典型 全虚拟化 即所抽象的 VM 具有完全的物理特性,虚拟化层负责捕获 CPU 指令,为指令访问硬件充当媒介。 - OS 无需修改。- 速度和功能都非常不错,使用非常简单。- 移植性好。 - VMware- KVM- Virtualbox- Virtual PC 半虚拟化 起初是为了解决全虚拟化效率不高的困难,它需要修改 OS,工作效率相对全虚拟化要高很多。Hypervisor 直接安装在物理机上,多个虚拟机在 Hypervisor 上运行。Hypervisor 实现方式一般是一个特殊定制的 Linux 系统。 - 架构更精简。- 在整体速度上有一定的优势。- 需要对 OS 进行修改,在用户体验方面比较麻烦。 - Xen- VMWare ESXi- 微软 Hyper-V 硬件辅助虚拟化 硬件辅助虚拟化是随着虚拟化技术的应用越来越广泛 lntl、AMD 等硬件厂商通过对硬件的改造来支持虚拟化技术。常用于优化全虚拟化和半虚拟化产品,像 VMware Workstation,它虽然属于全虚拟化,但它在 6.0 版本中引入了硬件辅助虚拟化技术,比如 Intel 的 VT-x 和 AMD 的 AMD-V。主流全虚拟化和半虚拟化产品都支持硬件辅助虚拟化。(VirtualBox,KVM,Xen 等) 辅助产品 - VT-x- AMD-V 全虚拟化 半虚拟化 全虚拟化代表 KVM 和半虚拟化代表 Xen 架构对比 架构 描述 对比 示意图 全虚拟化:KVM KVM(Kernel–Based Virtual Machines) 是一个基于 Linux 内核的虚拟化技术,可以直接将 Linux 内核转换为 Hypervisor。.从而使得 Linuxp 内核能够直接管理虚拟机,直接调用 Linux 内核中的内存管理、进程管理子系统来管理虚拟机。 - 支持全虚拟化- 内置在内核中- 便于版本安装、升级、维护,性能高总结:KVM 平台架构侧重性能 半虚拟化:Xen Xen:直接把操作系统内核改了,把 OS 改成一个轻量级 Hypervisor1 在里面运行了一个管理所有资源作资源调度的 Domain0。组成:由 Xen Hypervisor(虚拟化层)、Domin0(管理主机)、Domin U(用户虚拟机) - 支持全虚拟化、半虚拟化- 需要对内核修改- 更新版本,Xen 需要重新编译整个内核隔离性好总结:Xen 平台架构侧重安全性 容器容器:包装或装载物品的贮存器,利用一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任一 Liux 或 Windows 机器上,也可以实现虚拟化。相互之间不会有任何接口,实现 App 与操作系统的解耦。 主流容器技术定义:Docker) 属于 Liux 容器的一种封装,提供简单易用的容器使用接口,他是目前最流行的 Linux 容器解决方案。作用:将应用程序与该程序的依赖,打包在一个文件里。运行这个文件,就会生成一个虚拟容器。程序在这个虚拟容器里运行,就好像在真实的物理机上运行一样。有了 Docker,就不用担心环境问题。 组成:客户端 (Docker Client)、守护进程 (Docker Daemon)、镜像(Docker Image)、容器 (DockerContainer)、仓库(Docker Registry) 容器和虚拟化的区别 虚拟化 容器 隔离性强,有独立的 GUEST OS 共享内核和 OS,隔离性弱 虚拟化性能差 (>15%) 计算/存储无损耗,无 Guest0S 内存开销(200M) 虚拟机镜像庞大(十几 G 几十 G),且实例化时不能共享 Docker 容器镜象 200300M,且公共基础镜象实例化时可以共享 虚拟机镜象缺乏统一标准 Docker 提供了容器应用镜象事实标准,OCI 推动进一步标准化 虚拟机创建慢 (>2 分钟) 秒级创建 (<10s)相当于建立索引 虚拟机启动慢 (>30s) 读文件逐个加载 秒级 (<1s,不含应用本身启动) 资源虚拟化粒度低,单机 10~100 虚拟机 单机支持 1000+ 容器密度很高,适合大规模的部署 计算虚拟化从服务器组建角度来看,计算虚拟化可分为: CPU 虚拟化:保障 CPU 资源的合理调度以及 VM 上的指令能够正常高效的执行。 内存虚拟化:保障内存空间的合理分配、管理,隔离,以及高效可靠地使用。 I/O 虚拟化:保障 VM 的 1O 隔离与正常高效的执行。 常见的计算服务架构有: OpenStack Nova 阿里云 ECS 腾讯云 CVM NovaOpenStack 是开源的云平台,通过不同的组件提供计算、存储、网络、数据库等多种云服务。其中计算服务由 Nova 组件提供,通过 nova-API 与其他组件通信,通过 nova-computex 对接不同的虚拟层提供计算虚拟化服务。 创建实例流程:创建实例请求 nova-api,会唤醒 nova-database,请求刷新数据库。将请求给队列组件,nova-scheduler 从队列中取出请求,请求运行相对应的虚拟机。要运行不同的虚拟机,需要不同的平台支持(KVM,Xen,VMware)。虚拟机不能直接与数据库直接交互,需要通过 nova-conductor 转发。 ECS云服务器 ECS(Elastic Compute Service) 是阿里云提供的基于 KVM 虚拟化的弹性计算服务,建立在阿里云飞天 (Apsara) 分布式操作系统上。请求的主要调用流程为:OpenAPI、.业务层、控制系统、宿主机服务。 CVM云服务器 CVM(Cloud Virtual Machine)) 是腾讯提供的基于 KVM 虚拟化的弹性计算服务,建立在腾讯云分布式资源管理调度系统 VStation.上。请求的主要调用流程为:API Server、.VStation、服务器集群。 CPU 虚拟化在物理机(宿主机)中通过线程或进程这种纯软件方式模拟出假的 CPU,通过 CPU 虚拟化就可以将一个物理 CPU 发给不同的虚拟机使用。 虚拟出来的每颗 CPU 实际上就是一个线程或者进程,因此物理 CPU 核数要大于虚拟 CPU 总核数。 CPU QoS(Quality of Service) 服务质量QoS 用来控制虚拟机使用 CPU 资源量的大小。CPU 资源限额:控制虚拟机占用物理资源使用的上限。CPU 资源份额:定义了多台虚拟机在竞争物理 CPU 资源时,需按比例分配计算资源。CPU 预留资源:定义了多台虚拟机在竞争物理 CPU 时,每台虚拟机最低分配的计算资源。 NUMANUMA(Non Uniform Memory Access Architecture) 非统一内存访问体系结构,提高物理服务器性能的一种技术。 将物理服务器的 CPU 和内存资源分到多个 node 上,node 内的内存访问效率最高。 NUMA 保证了一个 VM 上的 VCPU 尽量分配到同一个 node 中的物理 CPU 上,如果一台 VM 的 VCPU 跨 node 访问内存的话,访问的延时肯定增加。 内存虚拟化 虚拟化类型 全虚拟化 半虚拟化 硬件辅助虚拟化 为每个 VM 维护一个影子页表记录虚拟化内存与物理内存的映射关系,VMM 将影子页表提交给 CPU 的内存管理单元 MMU 进行地址转换,VM 的页表无需改动。 采用页表写入法,为每个 VM 创建一个页表并向虚拟化层注册。VM运行过程中 VMM 不断管理和维护该页表,确保 VM 能直接访问到合适的地址。 EPT/NPT 是内存管理单元 MMU 的扩展,CPU 硬件一个特性,通过硬件方式实现 GuestOS 物理内存地址到主机物理内存地址的转换,系统开销更低,性能更高。 内存复用技术内存复用是指在服务器物理内存一定的情况下,通过综合运用内存复用技术对内存进行分时复用。内存复用技术有: 内存气泡:虚拟化层将较空闲 VM 内存,分配给内存使用较高的虚拟机。内存的回收和分配由虚拟化层实现,虚拟机上的应用无感知,提高物理内存利用率。(虚拟机分配的内存不超过物理机总内存) 内存交换:将外部存储虚拟成内存给 VM 使用,将 VM 上长时间未访问的数据存放到外部存储上,建立映射关系。VM 再次访问这些数据是通过映射在与内存上的数据进行交换。 内存共享:VM 只对共用的内存(共享数据内容为零的内存页)做只读操作,有写操作时运用写时复制 (VM 有写操作时,开辟另一空间,并修改映射) IO 虚拟化 全虚拟化 半虚拟化 Pass-Thorugh(直通) 硬件辅助虚拟化 通过软件模拟的形式模拟 O 设备,不需要硬件支持,对虚拟机的操作系统也不需要修改(因为模拟的都是一个常见的硬件网卡,如 IntelE1000,主流操作系统一般都自带这些驱动,因此默认情下虚拟机不需要再安装驱动。缺点就是性能差。 由 Hypervisor 提供资源调用接口。VM 通过特定的调用接口与 Hypervisor 通信,完成获取完整/O 资源控制操作。(需修改内核及驱动程序,存在移植性和适用性问题,导致其使用受限。) Hypervisor] 直接把硬件 PCI 设备分配给虚拟独占使用,性能挡当然好啦。但是浪遗硬件设备,且配置复杂,首先需要在 hypervisor 指定通过 PClid 方式分配给指定的虚拟机,然后虚拟机再识别到设备再安装驱动来使用。 通过硬件的辅助可以让虚拟机直接访问物理设备,而不需要通过 VMM。最常用的就是 SR-lOV(Single Root I/OVirtualizmion)单根 I/O 虚拟化标准,该技术可以直接虚拟出 128-512 网卡,可以让虚拟机都拿到一块独立的网卡,直接使用/O 资源。 常见集群策略集群简介集群是一种计算机系统,通过一组计算机或服务器的软硬件连接起来高度紧密地协作完成计算工作。在客户端看来为其提供服务的只有一台设备,实际上它是一群设备的集合,只不过这些设备提供的服务一样。 集群系统中单个计算机通常称为节点,通过局域网连接,利用多个计算机进行并行计算获得很高计算速度,也可以用多个计算机做备份提高可靠性。(并行计算技术) HA 策略HA(High Availability) 高可用性,一种让服务中断尽可能少的技术。将多台主机组建成一个故障转移集群,运行在集群上的服务(或 VM) 不会因为单台主机的故障而停止。 提升故障恢复速度,降低业务中断时间、保障业务连续性、实现一定的系统自维护。 DRS 策略DRS(Dynamic resource scheduling) 动态资源调度,根据对资源池资源负载的动态监控,合理触发均匀分配规侧,实现资源池中的物理服务器之间重新分配资源,达到负载均衡、消峰填谷。 当物理服务器上负载过大时,通过 DRS 将虚拟机迁移到其他负载较轻的物理服务器上。当虚拟机遇到负载增大时,DRS 将为资源池中的物理服务器重新分配虚拟机可使用资源,在多个虚拟机之间智能地分配可用资源。 DPM 策略DPM(Distributed power management) 分布式电源管理,用于业务较轻时,把虚拟机动态“集中”到集群中的少部分主机上,将其他主机待机,节省电力消耗,等业务量较大时,再重新唤醒之前待机的主机。 执行 DPM 策略的前提是开启 DRS 策略,即集群必须先设置好 DRS 策略,才能设置 DPM 策略。 存储虚拟化存储类型常用的存储类型有: 本地磁盘 DAS 简介 云计算虚拟化场景下的本地磁盘是指使用服务器本地的磁盘资源,经过 RAD(磁盘阵列) 化后提供给虚拟化平台进行使用。 DAS(Direct-Attached Storage) 直连式存储:一个存储设备与使用存储空间的服务器直接相连的架构。DAS 为服务器提供块级的存储服务。 优点 - 使用方便- 无共享框架 - 多个磁盘合并成一个逻辑磁盘,满足海量存储的需求- 可实现应用数据和操作系统的分离- 能提高存取性能- 实施简单 缺点 - 对跨服务器来说没有备份、冗余机制 - 服务器发生故障,数据不可访问- 传输距离短 NAS SAN 简介 NAS(Network Attached Storage) 网络附加存储:将分布、独立的数据进行整合,集中化管理,以便对不同主机和应用服务器进行访问的技术。NAS 将存储设备连接到现有的网络上来提供数据和文件服务。 SAN(Storage Area Networks) 存储区域网络:是一种高速的、专门用于存储操作的网络,通常独立于计算机局域网。提供在主机和存储系统之间数据传输,网络内部数据传输的速率快。常见架构有 FC SAN、IP SAN。 优点 - 支持快照等高级特性- 集中存储- 提供安全集成环境(用户认证和授权) - 存储容量利用率高- 兼容性高- 传输距离远- 高带宽- 主机、存储设备可以独立扩展 缺点 - 传输速率低- 前期安装和设备成本高 - 成本高、复杂 云存储基本概念存储资源:表示实际的物理存储设备,例如 DAS(直连存储)、NAS(网络附加存储)、SA(存储区域网络) 等。 存储设备:表示存储资源中的管理单元,例如本地磁盘、LUN(逻辑单元号)、Storage 存储池、NAS 共享目录等。 数据存储:表示虚拟化平台中可管理的存储逻辑单元,承载了虚拟机业务,创建磁盘。 创建虚拟存储的流程 在主机软件界面添加存储资源 (SAN、DAS 等),对主机的启动进行配置。 主机关联存储资源后,进行扫描存储设备(本地磁盘、LUN 等),将具体的设备扫描到主机上。 主机在选择存储设备,进行数据存储的添加,并进行虚拟化。 最后对虚拟化好的数据存储进行创建卷等操作。 存储模式 非虚拟化存储 虚拟化存储 裸设备映射 传统的存储模式,就是把磁盘进行分区,分割成不同的逻辑卷,每一个逻辑卷可以给到虚拟机进行使用。 将不同的存储设备、磁盘进行格式化,格式化的目的是屏蔽底层存储设备的能力、接口协议等差异性,将各种存储资源转化为统一管理的数据存储资源。 将磁盘直接给到虚拟机使用,让虚拟机直接处理调用存储的命令(直接访问磁盘)中间虚拟化层不再对其进行任何干预(卷都不需要创建) 特点 - 性能好 (不再有中间的虚拟化层,VM 读写直接在磁盘上)、速度快、效率高。- 支持的存储功能少(不支持快照、精简配置等) - 支持多种存储功能(快照、精简磁盘、磁盘扩容、存储热迁移等)。- 性能不高(没有非虚拟化存储好) 速度快(三种模式中最快)、性能好。支持的存储功能少(不支持快照、精简配置等),仅支持部分操作系统的虚拟机使用、数据存储只能整块当做裸设备映射的磁盘使用,不可分割。 存储虚拟化方法基于主机的存储虚拟化若仅是单个主机服务器(或单个集群)访问多个磁盘阵列,可采用基于主机的存储虚拟化:虚拟化的工作通过特定的软件在主机服务器上完成,经过虚拟化的存储空间可以跨越多个异构的磁盘阵列。 特点: 优点是稳定性,以及对异构存储系统的开放性。 软件运行于主机上。 从与主机连接的存储上创建虚拟卷。 基于存储设备的虚拟化若多个主机服务器需要访问同一个磁盘阵列时,可采用基于存储设备虚拟化。虚拟化的工作在阵列控制器上完成,将一个阵列上的存储容量划分多个存储空间 (LUN),供不同的主机系统访问。主要用在同一存储设备内部,进行数据保护和数据迁移。 优点是与主机无关,不占用主机资源,数据管理功能丰富。 软件运行于存储设备中专门的嵌入式系统上。 从与 SAN 连接的存储上创建虚拟卷。 基于网络的存储虚拟化通过在存储区域网 (SAN) 中添加虚似化引擎实现的,主要用于异构存储系统的整合和统数据管理。 特点: 优点是与主机无关,不占用主机资源; 支持异构主机、异构存储设备; 能使不同存储设备的数据管理功能统一,统一管理平台,可扩展性好。 存储虚拟化的功能存储虚拟化可以提高硬件资源的使用效率,简化系统管理的复杂度,增强云存储平台的可靠性。可以通过以下几种技术实现: 精简磁盘和空间回收精简磁盘和空间回收用于提高存储资源的使用效率、减小虚拟机未使用空间在主机上占用率过大的问题。 用户用多少分配多少空间(自动分配)空间回收可以将用户删除的数据空间释放到数据存储。 快照 指定数据集合的一个完全可用拷贝,该拷贝包括相应数据在某个时间点(拷贝开始的时间点) 的映像。 快照可以是其所表示的数据的一个副本,可以是数据的一个复制品。 快照的作用主要是能够进行在线数据备份恢复。 为用户提供了数据访问通道 特点 记录了虚拟机在某一时间点的内容和状。 恢复虚拟机快照可以使虚拟机多次快速恢复到某一时间点。 快照包含磁盘内容、虚拟机配置信息、内存数据。 多次快照之间保存差量数据,节约存储空间。 快照方式介绍创建快照时会生成一个新的差分卷,虚拟机会挂载这个差分卷作为磁盘文件。 ROW 写时重定向 COW 写时拷贝 快照链介绍对虚拟机进行多次的快照操作,这些多次的快照操作形成快照链。 虚拟机卷始终挂载在快照链的最末端。 链接克隆 将源卷和差分卷组合映射为一个链接克隆卷,给虚拟机使用。一个链接克隆需要和原始虚拟机共享同一虚拟磁盘文件。 采用共享磁盘文件缩短了创建克隆虚拟机的时间,还节省了物理磁盘空间。 通过链接克隆,可以轻松的为不同的任务创建一个独立的虚拟机。 虚拟磁盘文件迁移功能: 将虚拟机的磁盘从一个数据存储迁移到另一个数据存储。可以将虚拟机的所有磁盘整体迁移,也可以单个磁盘分别迁移。 虚拟机的快照可以一起迁移,虚拟机开启或者关闭时都可以迁移。 特点: 网络虚拟化虚拟化是对所有 T 资源的虚拟化,提高物理硬件的灵活性及利用效率。云计算中的计算和存储资源分别由计算虚拟化和存储虚拟化提供,而网络作为 T 的重要资源也有相应的虚拟化技术,网络资源由网络虚拟化提供。 网络是由各种设备组成,有传统的物理网络,还有运行在服务器上看不到的虚拟网络。如何呈现和管理它们将是网络虚拟化的首要目标。 将物理网络虚拟出多个相互隔离的虚拟网络(逻辑网络),从而使得不同用户之间使用独立的网络资源,从而提高网络资源利用率,实现弹性的网络。 VLAN 就是一种网络虚拟化,在原有网络基础上通过 VLAN Tag:划分出多个广播域。 网络虚拟化保障我们创建出来的虚拟机可以正常 通信、访问网络。 节省物理主机的网卡设备资源,并且可以提供应用的虚拟网络所需的 L2 一 L7 层网络服务。 网络虚拟化软件提供逻辑上的交换机和路由器 (L2-L3),逻辑负载均衡器,逻辑防火墙 (L4-L7) 等,且可以以任何形式进行组装,从而为虚拟机提供一个完整的 L2-L7 层的虚拟网络拓扑。 物理网络包含的设备路由器:工作在网络层,连接两个不同的网络。 二层交换机:工作在数据链路层,转发数据。 三层交换机:工作在网络层,结合了部分路由和交换机的功能。 服务器网卡:提供通信服务。 虚拟化中的网络架构网卡虚拟化方法有: 软件网卡虚拟化 主要通过软件控制各个虚拟机共享同一块物理网卡实现。软件虚拟出来的网卡可以有单独的 MAC 地址、IP 地址。 所有虚拟机的虚拟网卡通过虚拟交换机以及物理网卡连接至物理交换机。虚拟交换机负责将虚拟机上的数据报文从物理网口转发出去。 硬件网卡虚拟化 主要用到的技术是单根 I/O 虚拟化 (Single Root/O Virtulization,SR-lOV),就是 I/O 直通技术,通过硬件的辅助可以让虚拟机直接访问物理设备,而不需要通过 VMM。该技术可以直接虚拟出 128-512 网卡,可以让虚拟机都拿到一块独立的网卡,直接使用/O 资源。SR-OV 能够让网络传输绕过软件模拟层,直接分配到虚拟机,这样就降低了软件模拟层中的/○ 开销。 交换机虚拟化: OVS(Open vSwitch) 开放虚拟化软件交换机,是一款基于软件实现的开源虚拟以太网交换机,使用开源 Apache2.0 许可协议,主要用于虚拟机 VM 环境。与众多开源的虚拟化平台相整合(支持 Xen、KVM 及 VirtualBox 多种虚拟化技术),主要有两个作用:传递虚拟机之间的流量,实现虚拟机和外界网络的通信。 虚拟化中数据的转发路径 相同端口组不同服务器内的虚拟机通讯需要经过物理网络。(黑线) 相同端口组相同服务器内的虚拟机通讯不需要经过物理网络。(红线) 不同端口组相同服务器的虚拟机通讯需要经过物理网络。(黄色) 链路虚拟化VPC(Virtual Port Channel) 虚链路聚合,是最常见的二层虚拟化技术。 链路聚合将多个物理端口捆绑在一起,虚拟成为一个逻辑端口。但传统链路聚合不能跨设备,VPC 很好解决了这个问题,既可以跨设备,又可以增加链路带宽、实现链路层的高可用性。 隧道协议 (Tunneling Protocol):指通过隧道协议使多个不同协议的网络实现互联。使用隧道传递的数据可以是不同协议的数据帧或包。隧道可以将数据流强制送到特定的地址,并隐藏中间节点的网络地址,还可根据需要,提供对数据加密的功能。 GRE(Generic Routing Encapsulation) 通用路由封装。 IPsec(Internet Protocol Security)Internett 协议安全。 虚拟网络虚拟网络 (Virtual Network):是由虚拟链路组成的网络。 虚拟网络节点之间的连接并不使用物理线缆连接,而是依靠特定的虚拟化链路相连。 典型的虚拟网络包括: 层叠网络(虚拟二层延伸网络) 层叠网络 (Overlay Network):在现有网络的基础上搭建另外一种网络 层叠网络允许对没有引 P 地址标识的目的主机路由信息。 层叠网络可以充分利用现有资源,在不增加成本的前提下,提供更多的服务。(比如 ADSL Internet 接入线路就是基于已经存在的 PSTN 网络实现) 典型技术: VXLAN(Virtual eXtensible Local Area Network) 虚拟扩展局域网:很好地解决了现有 VLAN 技术无法满足大二层网络需求的问题。 VXLAN 技术是一种大二层的虚拟网络技术。 原理是引入一个 UDP 格式的外层隧道作为数据链路层,而原有数据报文内容作为隧道净荷加以传输。 VPN 网络 VPN(Virtual Private Network) 虚拟专用网:是一种常用于连接中、大型企业或团体与团体间的私人网络的通信方法。 通过公用的网络架构(比如互联网)来传送内联网的信息。 利用已加密的隧道协议来达到保密、终端认证、信息准确性等安全效果。这种技术可以 在不安全的网络上传送可靠的、安全的信息。","categories":[],"tags":[{"name":"云计算","slug":"云计算","permalink":"http://example.com/tags/%E4%BA%91%E8%AE%A1%E7%AE%97/"}]},{"title":"Devstack 部署 OpenStack","slug":"Devstack部署OpenStack","date":"2023-06-09T13:38:34.000Z","updated":"2023-06-28T14:22:15.747Z","comments":true,"path":"2023/06/09/Devstack部署OpenStack/","link":"","permalink":"http://example.com/2023/06/09/Devstack%E9%83%A8%E7%BD%B2OpenStack/","excerpt":"","text":"Devstack 部署 OpenStack试验发现在 Host 为 Ubuntu20.04 和 22.04 上无法顺利安装 VirtualBox,请在 Ubuntu18.04 上安装 VirtualBox。虚拟机镜像版本为 Ubuntu20.04,以下步骤可以稳定复现,OpenStack master(c424a7a299e37004d318107648bb18e157344985)版本。 总而言之,在 18.04 版本上安装 VirtualBox,在 20.04 版本上安装 OpenStack。 因为安装 OpenStack 容易破话系统包依赖,如果为了学习建议在虚拟机中安装。 安装过程中需要下载镜像,请确认机器可以访问外网。 安装 VirtualBox12sudo apt updatesudo apt install virtualbox virtualbox-ext-pack 确认 VirtualBox 配置请确认 VirtualBox 配置如下,VirtualBox 默认配置硬盘为 10G,远远不够用,为了避免后续的麻烦,请确认如下配置: 磁盘大于 100G 内存大于 16G CPU 大于 4 个 下载镜像并安装镜像可以去清华大学开源软件镜像站 | Tsinghua Open Source Mirror下载。 更新源123456789101112sudo mv /etc/apt/sources.list /etc/apt/sources.list.bk && sudo bash -c "cat << EOF > /etc/apt/sources.listdeb http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ jammy-security main restrcdicted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ jammy-proposed main restrcd && mkdir .pip && cd .pipicted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ jammy-proposed main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverseEOF" 备用源 (以备不时之需)123456789101112sudo mv /etc/apt/sources.list /etc/apt/sources.list.bk && sudo bash -c "cat << EOF > /etc/apt/sources.listdeb http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ jammy-security main restrcdicted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ jammy-proposed main restrcd && mkdir .pip && cd .pipicted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ jammy-proposed main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverseEOF" 123456789101112sudo mv /etc/apt/sources.list /etc/apt/sources.list.bk && sudo bash -c "cat << EOF > /etc/apt/sources.listdeb https://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiversedeb-src https://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiversedeb https://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiversedeb-src https://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiversedeb https://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiversedeb-src https://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiversedeb https://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiversedeb-src https://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverseEOF" 12345678910111213sudo mv /etc/apt/sources.list /etc/apt/sources.list.bk && sudo bash -c "cat << EOF > /etc/apt/sources.listdeb http://mirrors.aliyun.com/ubuntu/ xenial main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ xenial-security main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ xenial-updates main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ xenial-proposed main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ xenial-backports main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ xenial main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ xenial-proposed main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ xenial-backports main restricted universe multiverseEOF" 安装基础包123sudo apt updatesudo apt install gitsudo apt install aptitude aptitude 用于解决包依赖冲突。 添加用户添加 stack 用户 1sudo useradd -s /bin/bash -d /opt/stack -m stack 授予 sudo 权限 1echo "stack ALL=(ALL) NOPASSWD: ALL" | sudo tee /etc/sudoers.d/stack 切换到 stack 用户 1sudo su - stack PIP 配置123456cd && mkdir -p .pip && cd .pip && bash -c "cat << EOF > ~/.pip/pip.conf[global]timeout = 6000index-url = http://mirrors.aliyun.com/pypi/simple/trusted-host = mirrors.aliyun.comEOF" 仓库下载1git clone https://github.com/openstack/devstack --depth 1 配置 local.conf只需要修改 HOST_IP,其他的可以不用修改,HOST_IP 为本机 IP 地址,可以使用 ifconfig 查看。如果是虚拟机就是虚拟机的 IP,virtualbox 创建的虚拟机默认为 10.0.2.15。 12345678910cd devstack && touch local.conf && bash -c "cat << EOF > /opt/stack/devstack/local.conf[[local|localrc]]HOST_IP=10.0.2.15GIT_BASE=http://git.trystack.cnADMIN_PASSWORD=userDATABASE_PASSWORD=$ADMIN_PASSWORDRABBIT_PASSWORD=$ADMIN_PASSWORDSERVICE_PASSWORD=$ADMIN_PASSWORDEOF" 安装1FORCE=yes ./stack.sh BUG 解决systemd 包依赖冲突123sudo aptitude install systemd选择N再选择Y ModuleNotFoundError: No module named ‘distutils.cmd’12sudo apt-get install python3.10-distutils# 根据自己的 Python 版本决定,可以 python3.7-distutils python3.8-distutils ....都试一遍 apparmor invalid capability bpf1sudo apt install apparmor No tenant network is available for allocation123456789vim /etc/neutron/plugins/ml2/ml2_conf.ini[ml2]type_drivers = flat,vlan,vxlantenant_network_types = vxlan[ml2_type_vxlan]vni_ranges = 1:1000 unix:/var/run/openvswitch/db.sock: database connection failed (Connection refused)123456cd /opt/stack/devstack/lib/neutron_plugin vi ovn_agent 116G 跳转到116行OVS_RUNDIR=$OVS_PREFIX/var/run/openvswitch 修改为OVS_RUNDIR=$OVS_PREFIX/var/run/ovn sudo rm -rf /var/run/ovn VirtualBox 启动报错 : Failed to send host log message12Ctrl+F2进入另一个终端输入:startx进入桌面 AttributeError: module ‘collections‘ has no attribute ‘MutableMapping‘12collections.MutableMappingcollections.abc.MutableMapping ModuleNotFoundError: No module named ‘distutils.core’1sudo apt install python3-pip ERROR: Cannot uninstall ‘simplejson’. It is a distutils installed project and thus we cannot1sudo pip install --ignore-installed wrapt enum34 simplejson netaddr server certificate verification failed. CAfile: none CRLfile: none12git config --global http.sslverify falsegit config --global https.sslverify false Ubuntu:登录页面验证出错1sudo loginctl unlock-sessions Ubuntu:重装桌面1sudo apt install ubuntu-desktop Ubuntu 登录界面 Authentication Error123sudo loginctl unlock-sessionssudo echo "fs.inotify.max_user_watches=524288" >> /etc/sysctl.conf Ubuntu 无法进入桌面系统,但是可以 SSH 链接1234sudo rm -rf /var/lib/apt/lists/*sudo apt-get cleansudo apt-get updatesudo apt-get install --reinstall appstream gsettings-desktop-schemas : 破坏:mutter (< 3.31.4) 但是 3.28.4-0ubuntu18.04.2 正要被安装解决方案12sudo apt install gsettings-desktop-schemassudo apt-get install build-essential","categories":[{"name":"OpenStack","slug":"OpenStack","permalink":"http://example.com/categories/OpenStack/"}],"tags":[{"name":"OpenStack,云计算,Devstack","slug":"OpenStack,云计算,Devstack","permalink":"http://example.com/tags/OpenStack%EF%BC%8C%E4%BA%91%E8%AE%A1%E7%AE%97%EF%BC%8CDevstack/"}]},{"title":"计算机网络 - 物理层","slug":"计算机网络-物理层","date":"2023-04-10T13:14:41.000Z","updated":"2023-06-11T01:55:35.223Z","comments":true,"path":"2023/04/10/计算机网络-物理层/","link":"","permalink":"http://example.com/2023/04/10/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C-%E7%89%A9%E7%90%86%E5%B1%82/","excerpt":"","text":"物理层基本概念物理层解决如何在连接各种计算机的传输媒体上传输数据比特流,而不是指具体的传输媒体。物理层主要任务:确定与传输媒体接口有关的一些特性 机械特性:定义物理连接的特性,规定物理连接时所采用的规格、接口形状、引线数目、引脚数量和排列情况。 电气特性:规定传输二进制位时,线路上信号的电压范围、阻抗匹配、传输速率和距离限制等。 功能特性:指明某条线上出现的某一电平表示何种意义,接口部件的信号线的用途。 规程特性(过程特性):定义各条物理线路的工作规程和时序关系 数据通信基础概念典型的数据通信模型 通信的目的是传送消息。数据:传送信息的实体,通常是有意义的符号序列。信号:数据的电气/电磁的表现,是数据在传输过程中的存在形式。 数字信号:代表消息的参数取值是离散的。 - 模拟信号:代表消息的参数取值是连续的。 信源:产生和发送数据的源头。信道:信号的传输媒介。一般用来表示向某一个方向传送信息的介质,因此一条通信线路往往包含一条发送信道和一条接收信道。 通信方式从通信双方信息的交互方式看,可以有三种基本方式: 单工通信只有一个方向的通信而没有反方向的交互,仅需要一一条信道。 半双工通信通信的双方都可以发送或接收信息,但任何一方都不能同时发送和接收,需要两条信道。 全双工通信通信双方可以同时发送和接受信息,也需要两条信道。 传输方式 串行传输 速度慢,费用低,适合远距离 并行传输 速度快,费用高,适合近距离 码元码元是指用一个固定时长的信号波形(数字脉冲),代表不同离散数值的基本波形,是数字通信中数字信号的计量单位,这个时长内的信号称为k进制码元,而该时长称为码元宽度。当码元的离散状态有 M 个时(M 大于 2),此时码元为 M 进制码元。1码元可以携带多个比特的信息量。例如,在使用二进制编码时,只有两种不同的码元,一种代表 0 状态,另 - 一种代表 1 状态。在四进制码元中,一个码元就由 2 比特组成。 速率,波特,带宽速率也叫数据率,是指数据的传输速率,表示单位时间内传输的数据量。可以用码元传输速率和信息传输速率表示。传输速率是主机上发出的速率,而传播速率是在信道上的传播速率。两者是不同的概念 码元传输速率1s传输多少个码元:别名码元速率、波形速率、调制速率、符号速率等,它表示单位时间内数字通信系统所传输的码元个数(也可称为脉冲个数或信号变化的次数),单位是波特(Baud)。1 波特表示数字通信系统每秒传输一个码元。这里的码元可以是多进制的,也可以是二进制的,但码元速率与进制数无关。 信息传输速率1s传输多少个比特:别名信息速率、比特率等,表示单位时间内数字通信系统传输的二进制码元个数(即比特数),单位是比特/秒(b/s)。 关系:若一个码元携带n bit的信息量,则M Baud的码元传输速率所对应的信息传输速率为M * n bit/s。 带宽 (是个理想值):表示在单位时间内从网络中的某一点到另一 点所能通过的“最高数据率”,常用来表示网络的通信线路所能传输数据的能力。单位是 b/s。 4 进制表示码元有 4 种波形,只需要 2 位就可以表示 4 种波形,同理 16 进制需要 4 位表示。 奈氏准则失真 影响失真程度的因素: 码元传输速率 信号传输距离 噪声干扰 传输媒体质量 码间串扰 频率太低,会容易受到传输距离,噪声的干扰,从而更容易失真,所以不允许通过频率太高,不容易区分码元之间的区别 码间串扰:接收端收到的信号波形失去了码元之间清晰界限的现象。 奈氏准则奈氏准则:在理想低通(无噪声,带宽受限)条件下,为了避免码间串扰,极限码元传输速率为2W Baud,W 是信道带宽,单位是Hz。(只有在奈氏准则和香农定理中的带宽采用Hz) 理想低通信道下的极限数据传输率 =$2Wlog_2V$(b/s)W:带宽,V:码元的离散电平数目(几种码元) 1.在任何信道中,码元传输的速率是有上限的。若传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的完全正确识别成为不可能。2.信道的频带越宽(即能通过的信号高频分量越多),就可以用更高的速率进行码元的有效传输。3.奈氏准则给出了码元传输速率的限制,但并没有对信息传输速率给出限制。4.由于码元的传输速率受奈氏准则的制约,所以要提高数据的传输速率,就必须设法使每个码元能携带更多个比特的信息量,这就需要采用多元制的调制方法。 123练习:在无噪声的情况下,若某通信链路的带宽为3kHz,采用4个相位,每个相位具有4种振幅的QAM调制技术,则该通信链路的最大数据传输率是多少?答:信号有4 x 4=16种变化最大数据传输率=2 x 3k x4=24kb/s 香农定理噪声存在于所有的电子设备和通信信道中。由于噪声随机产生,它的瞬时值有时会很大,因此噪声会使接收端对码元的判决产生错误。但是噪声的影响是相对的,若信号较强,那么噪声影响相对较小。因此,信噪比就很重要。 信噪比 = 信号的平均功率 / 噪声的平均功率,常记为 S/N,并用分贝(dB)作为度量单位,即:$$dB = 10log_{10}(S/N)$$ 香农定理:在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。 信道的极限传输速率 = $Wlog_2(1+S/N)$(b/s) 1.信道的带宽或信道中的信噪比越大,则信息的极限传输速率就越高。 2.对一定的传输带宽和一 - 定的信噪比,信息传输速率的上限就确定了。 3.只要信息的传输速率低于信道的极限传输速率,就一定能找到某种方法来实现无差错的传输。 4.香农定理得出的为极限信息传输速率,实际信道能达到的传输速率要比它低不少。5.从香农定理可以看出,若信道带宽 W 或信噪比 S/N 没有上限(不可能),那么信道的极限信息传输速率也就没有上限。 1234练习:电话系统的典型参数是信道带宽为3000Hz,信噪比为30dB,则该系统最大数据传输速率是多少?答:30dB=10log1o(S/N)则S/N=1000信道的极限数据传输速率=Wlog2(1+S/N)=3000 x log2(1+1000)>30kb/s 当题目中既给出了码元信息,又给了信噪比信息,就需要用两个公式都算一下,取最小值 1234题目:二进制信号在信噪比为127:1的4kHz信道上传输,最大的数据速率可达到多少?答:Nice:2 X 4000X log2=8000b/s香浓:4000 log2(1+127)=28000b/s 编码与调制基带信号与宽带信号信道:信号的传输媒介。一般用来表示向某一个方向传送信息的介质,因此一条通信线路往往包含一条发送信道和一条接收信道。 信道上传输的信号 基带信号将数字信号 1 和 0 直接用两种不同的电压表示,再送到数字信道上去传输(基带传输)来自信源的信号,像计算机输出的代表各种文字或图像文件的数据信号都属于基带信号。基带信号就是发出的直接表达了要传输的信息的信号,比如我们说话的声波就是基带信号。 宽带信号将基带信号进行调制后形成的频分复用模拟信号,再传送到模拟信道上去传输(宽带传输)。把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道) 在传输距离较近时,计算机网络采用基带传输方式(近距离衰减小,从而信号内容不易发生变化)在传输距离较远时,计算机网络采用宽带传输方式(远距离衰减大,即使信号变化大也能最后过滤出来基带信号) 编码与调制编码:数字数据-》数字信号(数字发送器)调制:数字数据-》模拟信号(调制器) 编码:模拟数据-》数字信号(PCM 编码器)调制:模拟数据-》模拟信号(放大器调制器) 数字数据-》数字信号 非归零编码(NRZ)(高1低0)编码容易实现,但没有检错功能,且无法判断一-个码元的开始和结束,以至于收发双方难以保持同步。一个码元内电平不会跳变。 归零编码(RZ)信号电平在一一个码元之内都要恢复到零的这种编码成编码方式。 反向不归零编码(NRZI)信号电平翻转表示 0,信号电平不。变表示 1。一个码元内电平不会跳变。 曼彻斯特编码(前高后低1,前低后高为0)将一个码元分成两个相等的间隔,前一个间隔为低电平后 - 一个间隔为高电平表示码元 1;码元 0 则正好相反。也可以采用相反的规定。该编码的特点是在每–个码元的中间出现电平跳变,位中间的跳变既作时钟信号(可用于同步),又作数据信号,但它所占的频带宽度是原始的基带宽度的两倍。每一个码元都被调成两个电平,所以数据传输速率只有调制速率的1/2。 差分曼彻斯特编码(同1异0)常用于局域网传输,其规则是:若码元为 1,则前半个码元的电平与上一个码元的后半个码元的电平相同,若为 0,则相反。该编码的特点是,在每个码元的中间,都有一次电平的跳转,可以实现自同步,且抗干扰性强于曼彻斯特编码。 4B/5B编码比特流中插入额外的比特以打破连串的 0 或 1,就是用 5 个比特来编码 4 个比特的数据,之后再传给接收方,因此称为 4B/5B。编码效率为 80%。 数字数据-》模拟信号数字数据调制技术在发送端将数字信号转换为模拟信号,而在接收端将模拟信号还原为数字信号,分别对应于调制解调器的调制和解调过程。 12例:某通信链路的波特率是1200Baud,采用4个相位,每个相位有4种振幅的QAM调制技术,则该链路的信息传输速率是多少?答:4个相位4种振幅也就是说有16个码元。16个码元也就是16个状态,需要4位来表示。也就是1码元对应4bit。题目中波特率是1200,也就说明1200*4=4800bit/s。 模拟数据-》数字信号计算机内部处理的是二进制数据,处理的都是数字音频,所以需要将模拟音频通过采样、量化转换成有限个数字表示的离散序列(即实现音频数字化)。最典型的例子就是对音频信号进行编码的脉码调制(PCM),在计算机应用中,能够达到最高保真水平的就是 PCM 编码,被广泛用于素材保存及音乐欣赏,CD、DVD 以及我们常见的WAV文件中均有应用。它主要包括三步:抽样、量化、编码。 抽样对模拟信号周期性扫描,把时间上连续的信号变成时间上离散的信号。为了使所得的离散信号能无失真地代表被抽样的模拟数据,要使用采样定理采样:采样频率 >= 2*信号最高频率 量化把抽样取得的电平幅值按照一定的分级标度转化为对应的数字值,并取整数,这就把连续的电平幅值转换为离散的数字量。 编码把量化的结果转换为与之对应的二进制编码。 模拟数据-》模拟信号为了实现传输的有效性,可能需要较高的频率。这种调制方式还可以使用频分复用技术,充分利用带宽资源。在电话机和本地交换机所传输的信号是采用模拟信号传输模拟数据的方式;模拟的声音数据是加载到模拟的载波信号中传输的。 传输介质及分类传输介质也称传输媒体/传输媒介,它就是数据传输系统中在发送设备和接收设备之间的物理通路。传输媒体并不是物理层。传输媒体在物理层的下面,因为物理层是体系结构的第一层,因此有时称传输媒体为 0 层。在传输媒体中传输的是信号,但传输媒体并不知道所传输的信号代表什么意思。但物理层规定了电气特性,因此能够识别所传送的比特流。 传输介质 导向性:电磁波被导向沿着固体媒介传播 非导向性:空气,海水等 双绞线双绞线是古老、又最常用的传输介质,它由两根采用一定规则并排绞合的、相互绝缘的铜导线组成。绞合可以减少对相邻导线的电磁干扰。 双绞线价格便宜,是最常用的传输介质之一,在局域网和传统电话网中普遍使用。模拟传输和数字传输都可以使用双绞线,其通信距离一般为几公里到数十公里。距离太远时,对于模拟传输,要用放大器放大衰减的信号;对于数字传输,要用中继器将失真的信号整形。 同轴电缆同轴电缆由导体铜质芯线、绝缘层、网状编织屏蔽层和塑料外层构成。按特性阻抗数值的不同,通常将同轴电缆分为两类:50$\\Omega$同轴 电缆和 75$\\Omega$同轴电缆。其中,50$\\Omega$同轴电缆主要用于传送基带数字信号,又称为基带同轴电缆,它在局域网中得到广泛应用;75$\\Omega$同轴电缆主要用于传送宽带信号,又称为宽带同轴电缆,它主要用于有线电视系统。 由于外导体屏蔽层的作用,同轴电缆抗干扰特性比双绞线好,被厂泛用于传输较高速率的数据,其传输距离更远,但价格较双绞线贵 光纤光纤通信就是利用光导纤维(简称光纤)传递光脉冲来进行通信。有光脉冲表示 1,无光脉冲表示 0。而可见光的频率大约是 108MHz,因此光纤通信系统的带宽远远大于目前其他各种传输媒体的带宽。 光纤主要由纤芯(实心的!)和包层构成,光波通过纤芯进行传导,包层较纤芯有较低的折射率。当光线从高折射率的介质射向低折射率的介质时,其折射角将大于入射角。因此,如果入射角足够大,就会出现全反射,即光线碰到包层时候就会折射回纤芯、这个过程不断重复,光也就沿着光纤传输下去。 光纤特点: 传输损耗小,中继距离长,对远距离传输特别经济。 抗雷电和电磁干扰性能好。 无串音干扰,保密性好,也不易被窃听或截取数据。 无线电波信号所有方向都能传播 较强穿透能力,可传远距离,广泛用于通信领域(如手机通信)。 微波信号固定方向传播 微波通信频率较高、频段范围宽,因此数据率很高 优点: 通信容量大 距离远 覆盖广 广播通信和多址通信 缺点: 传播时延长(250-270ms) 受气候影响大(eg:强风太阳黑子爆发、日凌)X 信 误码率较高 成本高 红外线,激光信号固定方向传播 要把要传输的信号分别转换为各自的信号格式,即红外光信号和激光信号,再在空间中传播。 物理层设备中继器诞生原因:由于存在损耗,在线路上传输的信号功率会逐渐衰减,衰减到–定程度时将造成信号失真,因此会导致接收错误。中继器的功能(再生数字信号):对信号进行再生和还原,对衰减的信号进行放大,保持与原数据相同,以增加信号传输的距离,延长网络的长度。中继器两端:适用于完全相同的两类网络的互连,速率要相同,只做转发不做检测,可以连接不同设备,两端是同一个协议5-4-3规则:网络标准中都对信号的延迟范围作了具体的规定,因而中继器只能在规定的范围内进行,否则会网络故障。5个网段-4个中继器-3个设备 集线器(多口中继器) 功能:再生与放大信号不能分割冲突域,连接在集线器上的工作主机平分带宽","categories":[],"tags":[{"name":"计算机网络","slug":"计算机网络","permalink":"http://example.com/tags/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/"}]},{"title":"VSCode 插件 REST Client 使用文档","slug":"VSCode 插件 REST Client使用文档","date":"2023-03-24T11:59:35.000Z","updated":"2023-03-24T12:32:37.103Z","comments":true,"path":"2023/03/24/VSCode 插件 REST Client使用文档/","link":"","permalink":"http://example.com/2023/03/24/VSCode%20%E6%8F%92%E4%BB%B6%20REST%20Client%E4%BD%BF%E7%94%A8%E6%96%87%E6%A1%A3/","excerpt":"","text":"REST Client 是 VSCode 中一款非常好用的插件,能够帮助开发人员快速、方便地发送 HTTP 请求并查看响应。在本文中,我们将会详细介绍 REST Client 的使用方法。 安装 REST Client 插件在 VSCode 中,你可以通过以下步骤安装 REST Client 插件: 打开 VSCode; 点击左侧的插件图标(Ctrl+Shift+X); 搜索“REST Client”插件; 点击“安装”按钮。 发送 HTTP 请求 使用 REST Client 插件发送 HTTP 请求非常简单。你只需要创建一个新的.rest文本文件,将请求信息放入其中,然后使用快捷键Ctrl + Alt + R 或者右键菜单的 Send Request 选项发送请求。 下面是一个简单的 GET 请求的例子: 1GET https://jsonplaceholder.typicode.com/posts/1 HTTP/1.1 这个请求会获取 JSONPlaceholder API 中的一篇博客文章。 如果你想添加请求头或请求体,可以使用以下语法: 12345678GET https://jsonplaceholder.typicode.com/posts/1 HTTP/1.1Content-Type: application/json{ "title": "foo", "body": "bar", "userId": 1} 这个请求会在请求头中添加 Content-Type 头,请求体中包含 JSON 数据。 查看响应发送请求后,你可以在编辑器底部看到响应信息。如果你想查看响应头、响应体或状态码等详细信息,可以使用以下语法: 1234567891011###HTTP/1.1 200 OKContent-Type: application/json; charset=utf-8...{ "userId": 1, "id": 1, "title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit", "body": "quia et suscipit\\nsuscipit..."} 在这个例子中,###用来分隔请求和响应,这样你就可以很方便地查看请求和响应的详细信息了。 变量REST Client 插件还支持变量的使用。你可以使用${variable}语法来定义变量,然后在请求中使用它们。例如: 123@host = https://jsonplaceholder.typicode.comGET ${host}/posts/1 HTTP/1.1 在这个例子中,我们定义了一个名为 host 的变量,并在请求中使用它来指定 API 的基础 URL。 循环如果你需要发送多个请求,REST Client 插件支持循环语法。例如: 12345@host = https://jsonplaceholder.typicode.com@for(i,1,10){ GET ${host}/posts/${i} HTTP/1.1} 在这个例子中,我们使用@for 语法来发送 10 个 GET 请求,每个请求 URL 中的 i 变量从 1 到 10 依次递增。 条件语句如果你需要根据条件发送请求,REST Client 插件也支持条件语句。例如: 1234567@host = https://jsonplaceholder.typicode.com@if(isDebug){ GET ${host}/posts/1 HTTP/1.1}else{ GET ${host}/posts/2 HTTP/1.1} 在这个例子中,我们使用@if 语法来判断是否为调试模式,如果是就发送一个请求,否则发送另一个请求。 导入环境变量REST Client 插件支持从外部文件中导入环境变量。例如,你可以在.env 文件中定义变量: 12host=https://jsonplaceholder.typicode.comisDebug=true 然后在请求文件中使用@environment 语法来导入这些变量: 1234567@environment .env@if(isDebug){ GET ${host}/posts/1 HTTP/1.1}else{ GET ${host}/posts/2 HTTP/1.1} 在这个例子中,我们使用@environment 语法从.env 文件中导入环境变量,然后在请求文件中使用这些变量。 结论REST Client 插件是一个非常好用的工具,能够帮助开发人员快速、方便地发送 HTTP 请求并查看响应。在本文中,我们介绍了 REST Client 的基本使用方法,包括发送请求、查看响应、使用变量、循环、条件语句和导入环境变量等。希望这篇文章能够帮助你更好地使用 REST Client 插件。","categories":[{"name":"工欲善其事,必先利其器","slug":"工欲善其事,必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%EF%BC%8C%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"},{"name":"后端开发","slug":"后端开发","permalink":"http://example.com/tags/%E5%90%8E%E7%AB%AF%E5%BC%80%E5%8F%91/"}]},{"title":"WSL2 安装 Docker","slug":"WSL2安装Docker","date":"2023-03-16T14:19:00.000Z","updated":"2023-03-16T14:19:45.140Z","comments":true,"path":"2023/03/16/WSL2安装Docker/","link":"","permalink":"http://example.com/2023/03/16/WSL2%E5%AE%89%E8%A3%85Docker/","excerpt":"","text":"在 WSL2 中,你可能会遇到与 Docker 服务相关的问题,因为 WSL2 与传统 Linux 系统在某些方面有所不同。在这种情况下,你可以尝试以下步骤来解决问题: 首先,确保你已经安装了 WSL2 的最新版本。你可以通过运行以下命令来更新 WSL2: 1wsl --update 确保 Docker Desktop for Windows 已安装并启用 WSL2 集成。你可以在 Docker Desktop 设置中找到这个选项。确保你的 WSL2 发行版已被添加到 Docker Desktop 的 WSL 集成列表中。点击链接下载安装在 Windows 上安装 Docker 桌面。 在 WSL2 中,尝试手动停止 Docker 服务: 1sudo /etc/init.d/docker stop 如果这个命令无法停止 Docker 服务,请尝试以下命令: 1sudo killall dockerd 卸载 Docker: 1sudo apt-get purge docker-ce 删除 Docker 相关的文件和目录: 1sudo rm -rf /var/lib/docker 重新启动 WSL2: 1wsl --shutdown 然后重新打开 WSL2。 在 WSL2 中,不要直接安装 Docker CE。而是使用 Docker Desktop for Windows 提供的 Docker 服务。这意味着你不需要在 WSL2 中安装 Docker CE,因为 Docker Desktop 已经提供了 Docker 服务。 确保你的 WSL2 发行版可以访问 Docker Desktop 提供的 Docker 服务。你可以通过运行以下命令来检查: 123docker --versiondocker info","categories":[],"tags":[{"name":"WSL2","slug":"WSL2","permalink":"http://example.com/tags/WSL2/"},{"name":"Docker","slug":"Docker","permalink":"http://example.com/tags/Docker/"}]},{"title":"一生一芯笔记","slug":"一生一芯笔记","date":"2023-03-12T04:58:15.000Z","updated":"2023-04-02T09:32:19.691Z","comments":true,"path":"2023/03/12/一生一芯笔记/","link":"","permalink":"http://example.com/2023/03/12/%E4%B8%80%E7%94%9F%E4%B8%80%E8%8A%AF%E7%AC%94%E8%AE%B0/","excerpt":"","text":"一生一芯概述“一生一芯”概述 _哔哩哔哩_bilibili 程序的执行和模拟器freestanding 运行时环境程序如何结束运行在正常的环境中,写了一段代码return之后,实际上调用了一个系统调用exit。但是在 freestanding 环境中,没有操作系统支持,根据 C99 手册规定,在 freestanding 环境中结束运行是由用户实现决定的。 12345.1.2.1 Freestanding environment2 The effect of program termination in a freestanding environment isimplementation-defined. 在 qemu-system-riscv64 中的 virt 机器模型中,往一个特殊的地址写入一个特殊的“暗号”即可结束 QEMU 12345678#include <stdint.h>void _start() { volatile uint8_t *p = (uint8_t *)(uintptr_t)0x10000000; *p = 'A'; volatile uint32_t *exit = (uint32_t *)(uintptr_t)0x100000; *exit = 0x5555; // magic number _start(); // 递归调用,如果正常退出将不会再次打印A} 在自制 freestanding 运行时环境上运行 Hello 程序QEMU 虽然是个开源项目,但还挺复杂,不利于我们理解细节。让我们来设计一个面向 RISC-V 程序的简单 freestanding 运行时环境,我做以下约定。 程序从地址 0 开始执行 只支持两条指令 addi 指令 ebreak 指令 寄存器 a0=0 时,输出寄存器 a1 低 8 位的字符 寄存器 a0=1 时,结束运行 ABI Mnemonic(RISC-V 官方为每个寄存器起个名字) 12345678910111213141516171819202122232425static void ebreak(long arg0, long arg1) { asm volatile("addi a0, x0, %0;" "addi a1, x0, %1;" "ebreak" : : "i"(arg0), "i"(arg1));}static void putch(char ch) { ebreak(0, ch); }static void halt(int code) { ebreak(1, code); while (1); }void _start() { putch('A'); halt(0);}/** * 这段代码定义了三个函数:ebreak、putch 和 halt。 * ebreak 函数是一个内联汇编函数,它执行 ebreak 指令。 * 该指令是 RISC-V 架构中的一条调试指令,可以在调试器的控制下执行。 * 该函数接受两个参数 arg0 和 arg1,它们将被存储在寄存器 a0 和 a1 中。 * putch 函数调用了 ebreak 函数,并将第一个参数设为 0, * 第二个参数设为函数参数 ch。这样做的目的可能是为了在调试器的控制下输出一个字符。 * halt 函数调用了 ebreak 函数,并将第一个参数设为 1, * 第二个参数设为函数参数 code。这样做的目的可能是为了通知调试器程序已经结束, * 并使用 code 作为结束状态。然后,halt 函数进入一个死循环,等待调试器的操作。 * 最后,_start 函数调用了 putch 函数输出字符 'A',然后调用 halt 函数结束程序 */ 12riscv64-linux-gnu-gcc -march=rv64g -ffreestanding -nostdlib -static -Wl,-Ttext=0 \\ -O2 -o prog a.c riscv64-linux-gnu-gcc: 这是 GCC 的可执行文件的名称,表示使用的是 GCC 编译器。riscv64-linux-gnu 是编译器的目标平台,表示生成的代码是针对 RISC-V 架构,运行在 Linux 系统上的二进制文件。 -march=rv64g: 这个参数指定了编译器使用的指令集。rv64g 表示使用 RISC-V 架构的 64 位指令集。 -ffreestanding: 这个参数指示编译器生成的代码将在 freestanding 运行环境中运行。在 freestanding 运行环境中,程序不会自动链接标准 C 库,也不会自动调用 main 函数。 -nostdlib: 这个参数表示编译器不需要链接标准 C 库。 -static: 这个参数表示生成的代码是静态链接的。 -Wl,-Ttext=0: 这个参数是传递给链接器的,表示设置代码段的起始地址为 0。 -O2: 这个参数指示编译器使用优化级别为 2 的优化选项。 -o prog: 这个参数指定生成的可执行文件的名称为 prog。 a.c: 这是要编译的 C 源文件的名称。 1llvm-objdump -d prog 反汇编结果如下: 123456789101112prog: file format elf64-littleriscvDisassembly of section .text:0000000000000000 <_start>: 0: 13 05 00 00 li a0, 0 4: 93 05 10 04 li a1, 65 8: 73 00 10 00 ebreak c: 13 05 10 00 li a0, 1 10: 93 05 00 00 li a1, 0 14: 73 00 10 00 ebreak 18: 6f 00 00 00 j 0x18 <_start+0x18> 我们约定中没有li指令,但是汇编中却出现了,这是因为li是一条伪指令,它的实际实现依然是addi。如果不使用伪指令可以使用以下命令反汇编: 1llvm-objdump -M no-aliases -d prog 结果如下,没有伪指令,只有我们约定的几条指令。 123456789101112prog: file format elf64-littleriscvDisassembly of section .text:0000000000000000 <_start>: 0: 13 05 00 00 addi a0, zero, 0 4: 93 05 10 04 addi a1, zero, 65 8: 73 00 10 00 ebreak c: 13 05 10 00 addi a0, zero, 1 10: 93 05 00 00 addi a1, zero, 0 14: 73 00 10 00 ebreak 18: 6f 00 00 00 jal zero, 0x18 <_start+0x18> YEMU 指令如何执行ISA 手册定义了一个状态机。 状态集合 S = {<R, M>} R = {PC, x0, x1, x2, …} RISC-V 手册 -> 2.1 Programmers’Model for Base Integer ISA PC = 程序计数器 = 当前执行的指令位置 M = 内存 RISC-V 手册 -> 1.4 Memory 激励事件:执行 PC 指向的指令状态转移规则:指令的语义 (semantics)初始状态 S0 = <R0, M0> 我们只要把这个状态机实现出来,就可以用它来执行指令了! 用变量实现内存123#include <stdint.h>uint64_t R[32], PC; // according to the RISC-V manualuint8_t M[64]; // 64-Byte memory Q: 为什么不使用 int64_t 和 int8_t? A: C语言标准规定, 有符号数溢出是undefined behavior, 但无符号数不会溢出 6.5 Expressions5 If an exceptional condition occurs during the evaluation of an expression (that is,if the result is not mathematically defined or not in the range of representablevalues for its type), the behavior is undefined.6.2.5 Types9 A computation involving unsigned operands can never overflow, because a result thatcannot be represented by the resulting unsigned integer type is reduced modulo thenumber that is one greater than the largest value that can be represented by theresulting type. 用语句实现指令的语义指令周期 (instruction cycle): 执行一条指令的步骤 取指 (fetch): 从 PC 所指示的内存位置读取一条指令 译码 (decode): 按照手册解析指令的操作码 (opcode) 和操作数 (operand) 执行 (execute): 按解析出的操作码,对操作数进行处理 更新 PC: 让 PC 指向下一条指令 状态机不断执行指令,直到结束运行: 123456#include <stdbool.h>bool halt = false;while (!halt) { inst_cycle();} 1234567 31 20 19 15 14 12 11 7 6 0+---------------+-----+-----+-----+---------+| imm[11:0] | rs1 | 000 | rd | 0010011 | ADDI+---------------+-----+-----+-----+---------++---------------+-----+-----+-----+---------+| 000000000001 |00000| 000 |00000| 1110011 | EBREAK+---------------+-----+-----+-----+---------+ 一个简单的实现: 1234567891011121314void inst_cycle() { uint32_t inst = *(uint32_t *)&M[PC]; if (((inst & 0x7f) == 0x13) && ((inst >> 12) & 0x7) == 0) { // addi if (((inst >> 7) & 0x1f) != 0) { R[(inst >> 7) & 0x1f] = R[(inst >> 15) & 0x1f] + (((inst >> 20) & 0x7ff) - ((inst & 0x80000000) ? 4096 : 0)); } } else if (inst == 0x00100073) { // ebreak if (R[10] == 0) { putchar(R[11] & 0xff); } else if (R[10] == 1) { halt = true; } else { printf("Unsupported ebreak command\\n"); } } else { printf("Unsupported instuction\\n"); } PC += 4;} NEMU 代码导读make 项目构123456# 显示make踪迹strace make# 显示构建过程make -d# 显示更详细的构建构过程make --debug=v 1234567891011121314151617181920212223242526272829303132Reading makefiles...Reading makefile `Makefile'...Updating goal targets.... File `all' does not exist. File `all' does not exist. Looking for an implicit rule for `all'. Trying pattern rule with stem `all'. Trying implicit prerequisite `all.c'. Trying pattern rule with stem `all'. Trying implicit prerequisite `all.cc'. Trying pattern rule with stem `all'. Trying implicit prerequisite `all.C'. Trying pattern rule with stem `all'. Trying implicit prerequisite `all.cpp'. Trying pattern rule with stem `all'. Trying implicit prerequisite `all.CPP'. Trying pattern rule with stem `all'. Trying implicit prerequisite `all.cxx'. Trying pattern rule with stem `all'. Trying implicit prerequisite `all.CXX'. Trying pattern rule with stem `all'. Trying implicit prerequisite `all.c++'. Trying pattern rule with stem `all'. Trying implicit prerequisite `all.C++'. No implicit rule found for `all'. Finished prerequisites of target file `all'. Must remake target `all'.gcc -o all all.oFinished prerequisites of target file `all'.Must remake target `all'.gcc -o all all.oSuccessfully remade target file `all'. 1234# 只打印命令不执行make -n# 输出目标被构建的原因和执行的命令make --trace 例如,如果您有一个 makefile,其目标 all 依赖于目标 foo 和 bar,并且您运行 make --trace all,您可能会看到如下输出: 123456789make[1]: Entering directory '/path/to/project'gcc -o foo foo.cmake[1]: Leaving directory '/path/to/project'make[1]: Entering directory '/path/to/project'gcc -o bar bar.cmake[1]: Leaving directory '/path/to/project'make[1]: Entering directory '/path/to/project'gcc -o all foo.o bar.omake[1]: Leaving directory '/path/to/project' 12make -nB # -B 可以强制 make 构建所有目标,即使它们已经是最新的make -nB | vim - 在 vim 编辑器中进行二次处理,过滤不需要的信息。 1234567891011121314# 只保留 gcc 或 g++开头的行:%!grep "^\\(gcc\\|g++\\)"# 将环境变量$NEMU_HOME 所指示字符串替换为$NEMU_HOME:%!sed -e "s+$NEMU_HOME+\\$NEMU_HOME+g"# 将$NEMU_HOME/build/obj-riscv64-nemu-interpreter 替换为$OBJ_DIR:%s+\\$NEMU_HOME/build/obj-riscv64-nemu-interpreter+$OBJ_DIR+g# 将-c 之前的内容替换为$CFLAGS:%s/-O2.*=riscv64/$CFLAGS/g# 将最后一行的空格替换成换行并缩进两格:$s/ */\\r /g 调试技巧选将断言在 C 程序中使用断言(assert)不会增加额外的内存空间,也不会增加数据段空间。断言是一种在运行时检查程序假设是否为真的方法,当断言失败时,程序会终止执行并显示错误信息。 在 C 语言中,断言通常使用宏来实现。它在编译时被解释为一个简单的条件语句,因此它不会增加程序的内存空间或数据段空间。断言宏的定义通常类似于以下代码: 123#include <assert.h>#define assert(expression) ((void)0) 这里的 expression 是要检查的条件。如果 expression 为假,则 assert() 函数会发出错误消息并终止程序的执行。如果 expression 为真,则 assert() 函数不会产生任何操作,并且被解释为 ((void)0)。这个语句不会增加任何内存或数据段空间。 需要注意的是,当一个程序使用大量的断言时,它可能会对程序的性能产生一些影响,因为每个断言都需要在运行时进行检查。因此,在生产环境中,应该尽可能减少使用断言,并在测试和调试阶段使用它们来确保代码的正确性。 12345// nemu/src/isa/riscv64/local-include/reg.hstatic inline int check_reg_idx(int idx) { IFDEF(CONFIG_RT_CHECK, assert(idx >= 0 && idx < 32)); return idx;} 编译器工具 sanitizer让编译器自动插入 assert, 拦截常见的非预期行为 AddressSanitizer - 检查指针越界,use-after-free ThreadSanitizer - 检查多线程数据竞争 LeakSanitizer - 检查内存泄漏 UndefinedBehaviorSanitizer - 检查 UB 还能检查指针的比较和相减 打开后程序运行效率有所下降 但调试的时候非常值得,躺着就能让工具帮你找 bug man gcc 查看具体用法 使用方法GCC 提供了多种 Sanitizer 工具,可以帮助开发者在编译时检测和修复常见的编程错误,例如内存泄漏、缓冲区溢出、使用未初始化的变量等。以下是几个 Sanitizer 工具的示例用法: Address Sanitizer(ASAN):检测内存错误,例如使用已经释放的内存、堆栈和全局缓冲区的溢出和下溢等。 1gcc -fsanitize=address -g <source files> -o <output file> Undefined Behavior Sanitizer(UBSAN):检测未定义行为,例如除以零、使用未初始化的变量、指针溢出等。 1gcc -fsanitize=undefined -g <source files> -o <output file> Thread Sanitizer(TSAN):检测并发问题,例如竞争条件、死锁等。 1gcc -fsanitize=thread -g <source files> -o <output file> Memory Sanitizer(MSAN):检测使用未初始化的内存,例如读取未初始化的内存、使用已释放的内存等。 1gcc -fsanitize=memory -g <source files> -o <output file> 需要注意的是,Sanitizer 工具可能会增加程序的执行时间和内存消耗,并且可能会产生误报,因此在生产环境中应该禁用 Sanitizer 工具。通常情况下,开发者可以在开发和测试阶段启用 Sanitizer 工具,以帮助他们发现和修复代码中的问题。 自顶向下理解程序行为ftrace - 函数调用层次,理解程序的大体行为 itrace - 指令执行层次,理解指令级别的行为 mtrace - 访存的踪迹 dtrace - 设备访问的踪迹 sdb - 灵活细致地检查客户程序的状态 si - 细粒度的状态转移 info r/x - 检查R/M 监视点 - 捕捉某状态发生变化的时刻 sdb 与 gdb 结合使用 先用 sdb 定位到出错点附近 再用 gdb 观察 NEMU 的细节行为 程序的运行时间都花在了哪里Linux 的性能分析工具 perf 是一款功能强大的性能分析工具,它可以通过硬件计数器(Hardware counter)或者性能事件(Performance event)来对 Linux 系统的性能进行分析。以下是 perf 工具的安装和使用方法。 安装 perf 工具在大部分 Linux 发行版中,perf 工具已经预先安装,如果没有预先安装,可以通过以下命令进行安装。 Debian/Ubuntu 系统:sudo apt-get install linux-tools-common linux-tools-generic Fedora 系统:sudo dnf install perf CentOS/RHEL 系统:sudo yum install perf 安装完毕之后,可以通过 perf version 命令来检查 perf 版本信息。 编写一个简单的 C 代码这里我们编写一个简单的 C 代码,用于测试 perf 工具的使用。代码如下: 12345678910111213#include <stdio.h>int main(){ int i, sum = 0; for (i = 1; i <= 1000000; i++) sum += i; printf("sum = %d\\n", sum); return 0;} 代码的作用是计算 1 到 1000000 的和。 使用 perf 工具下面我们使用 perf 工具来对上述代码进行性能分析。假设代码保存在文件 test.c 中。 统计 CPU 周期数以下命令用于统计程序的 CPU 周期数: 1perf stat ./test 输出结果类似于: 123456789101112131415Performance counter stats for './test': 19,23 msec task-clock:u # 0.988 CPUs utilized 0 context-switches:u # 0.000 K/sec 0 cpu-migrations:u # 0.000 K/sec 575 page-faults:u # 0.030 M/sec 64,013,620,231 cycles:u # 3.324 GHz (49.80%) 40,010,335,480 instructions:u # 0.62 insn per cycle (62.34%) 9,998,469,566 branches:u # 518.693 M/sec (62.27%) 763,176 branch-misses:u # 0.01% of all branches (62.32%) 0.019438122 seconds time elapsed 0.019411000 seconds user 0.000007000 seconds sys 输出结果中的 cycles 表示 CPU 周期数,instructions 表示指令数,branches 表示分支指令数。其中,cycles 和 instructions 的比例代表了 CPU 的效率,即 IPC(Instructions Per Cycle)。 统计函数调用次数以下命令用于统计程序中函数的调用次数: 1perf record -e cycles -g ./test 这个命令将启动 perf 工具,并使用 -g 选项记录调用关系图。我们还需要使用 sudo 权限运行该命令,以便 perf 工具可以访问系统的硬件计数器。 成为专业码农 要熟悉项目了 -> STFW/RTFM/RTFSC, 尝试理解一切细节 要写代码了 仔细 RTFM, 正确理解需求 编写可读,可维护,易验证的代码 (不言自明,不言自证) 用 lint 工具检查代码 进行充分的测试 添加充分的断言 要调试了 默念“机器永远是对的/未测试代码永远是错的” sanitizer, trace, printf, gdb, … 平时 -> 用正确的工具/方法做事情 感到不爽了 -> 找正确的工具/搭基础设施 总线选讲定义广义上讲总线就是一个通信系统,以下这些都属于广义的总线概念:TCP/IP, 以太网,网线,RTL 信号,系统调用。 主动发起通信的叫 master,响应通信的叫 slave。","categories":[],"tags":[]},{"title":"JAVA 小白笔记","slug":"JAVA小白笔记","date":"2023-03-12T01:55:55.000Z","updated":"2023-03-12T04:25:57.691Z","comments":true,"path":"2023/03/12/JAVA小白笔记/","link":"","permalink":"http://example.com/2023/03/12/JAVA%E5%B0%8F%E7%99%BD%E7%AC%94%E8%AE%B0/","excerpt":"","text":"基础设施 本章记录一些配置笔记,不是 step by step 教程 安装 JAVA1234# 免登陆下载javahttps://xiandan.io/posts/jdk-download.html# 高速镜像https://github.com/LilithBristol/javajdkforwinx64 Linux 环境变量 PATH 12%JAVA_HOME%\\bin%JAVA_HOME%\\jre\\bin Windows 环境变量 1234# JAVA_HOMEC:\\Program Files\\Java\\jdk1.8.0_212# CLASSPATH.;%JAVA_HOME%\\bin;%JAVA_HOME%\\lib\\dt.jar;%JAVA_HOME%\\lib\\tools.jar VSCode 开发环境基础插件安装 Extension Pack for Java 即可,会把用到的开发插件都安装。不需要安装 Java Language Support 会和 Extension Pack for Java 中的 Language Support for Java by Red Hat 冲突。目前使用过程中也没有遇到必须使用 Java Language Support 的情况。 基本使用使用 CTRL+SHIFT+P 输入 Java: create Project,输入项目名,在 src 文件夹中,选择 Run 运行 Java 代码。 常用快捷键12# 导包 shift + alt + o IDEA 开发环境下载安装 IDEAJava 集成开发环境 IntelliJ IDEA 2022.3 Ultimate 永久激活版 - 风软资源站 配置 MAVEN,IDEA 中下载速度慢123456789101112131415161718192021222324252627282930# IDEA中编辑区右键--maven--create xml<mirrors> <mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <mirrorOf>central</mirrorOf> </mirror> <mirror> <id>uk</id> <mirrorOf>central</mirrorOf> <name>Human Readable Name for this Mirror.</name> <url>http://uk.maven.org/maven2/</url> </mirror> <mirror> <id>CN</id> <name>OSChina Central</name> <url>http://maven.oschina.net/content/groups/public/</url> <mirrorOf>central</mirrorOf> </mirror> <mirror> <id>nexus</id> <name>internal nexus repository</name> <url>http://repo.maven.apache.org/maven2</url> <mirrorOf>central</mirrorOf> </mirror></mirrors> 安装 MYSQL123sudo apt install mysqlsudo mysql -u root -psource /home/user/oa_system/VBlog/blogserver/src/main/resources/vueblog.sql 常用命令12345678910111213141516171819202122# 创建数据库CREATE DATABASE ryvue;# 切换当前数据库use ryvue;set character set utf8;# 执行sql脚本source /home/user/oa_system/RuoYi-Vue/sql/ry_20220822.sqlsource /home/user/oa_system/RuoYi-Vue/sql/quartz.sql# 删除数据库drop database 数据库名;# 显示所有数据库show databases;# 创建数据库create database 数据库名;# 显示数据库编码格式 SHOW VARIABLES LIKE 'character_set_%';# 删除 mysql 密码SET PASSWORD FOR root@localhost=PASSWORD('');# 重建数据库drop database ryvue;create database ryvue;use ryvue; 安装数据库可视化工具mysql-workbench12345678echo "deb http://security.ubuntu.com/ubuntu focal-security main" | sudo tee /etc/apt/sources.list.d/focal-security.listsudo apt-get updatesudo apt-get install libssl1.1wget https://downloads.mysql.com/archives/get/p/8/file/mysql-workbench-community_8.0.12-1ubuntu18.04_amd64.debsudo dpkg -i mysql*.deb sudo apt-get install -f sudo dpkg -i mysql*.deb VSCode 插件-MySQL by weijan Chenvscode-database-client 官方文档 安装 NPM1sudo apt install npm -y 12345678npm set progress=false npm config set registry http://registry.npmjs.org/npm install --legacy-peer-depsreify:abbrev: sill audit bulk request删除 package-lock.json 文件 安装 nvm打开终端并输入以下命令以在 Ubuntu 上下载 nvm: 1curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.38.0/install.sh | bash 该命令将从 nvm GitHub 存储库下载安装脚本,并使用 bash 在您的 Ubuntu 系统上运行它。运行此命令后,nvm 将被安装在您的家目录中。 安装完成后,在终端中运行以下命令,以使 nvm 生效: 1source ~/.bashrc 确认 nvm 是否正确安装: 1nvm --version 如果一切顺利,您将看到 nvm 的版本号。 安装 node.js 和 npm使用 nvm 安装特定版本的 Node.js: 1nvm install <node-version> 例如: 1nvm install 14.17.6 这将安装 Node.js 版本 14.17.6。 安装完成后,使用以下命令将已安装的 Node.js 版本设置为默认版本: 1nvm alias default <node-version> 例如: 1nvm alias default 14.17.6 这将设置 Node.js 版本 14.17.6 为默认版本。 确认 Node.js 和 npm 是否正确安装: 12node -vnpm -v 如果一切顺利,您将看到 Node.js 和 npm 的版本号。 使用 nvm 切换 Node.js 版本: 使用以下命令查看可用的 Node.js 版本: 1nvm ls-remote 该命令将显示可用的 Node.js 版本列表。 使用以下命令安装特定版本的 Node.js: 1nvm install <node-version> 例如: 1nvm install 12.22.6 这将安装 Node.js 版本 12.22.6。 使用以下命令切换到特定版本的 Node.js: 1nvm use <node-version> 例如: 1nvm use 12.22.6 这将切换到 Node.js 版本 12.22.6。 确认当前使用的 Node.js 版本: 1node -v 如果一切顺利,您将看到当前使用的 Node.js 版本号。 ERROR 合集JavaError: Could not find or load main class org.apache.maven.wrapper.MavenWrapperMain1maven 相关依赖还没下载完 JSON parse error: Cannot construct instance of确认请求方式是 get 还是 post,如果是 post 是不是前端发了一个空串。空串要用{}包裹 Error: JAVA_HOME is not defined correctly1234# 缺少.mavenrc 配置文件vim ~/.mavenrc# 将 JAVA 配置放进去export JAVA_HOME=/usr/lib/jvm/jdk1dot8 配置数据表中不存在的字段1@TableField(exist = false) Error creating bean with name ‘minioController’ endpoint must not be null检查配置文件是否配置了 endpoint 解决 MyBatis 报错 org.apache.ibatis.binding.BindingException: Invalid bound statement (not found)1、检查 xml 文件的 namespace 是否对应接口,要是全路径。 2、xml 中的函数 id 和接口中的函数名是否对得上,参数类型、返回值类型是否对得上 3、去看输出目录中有没有 xml 映射文件,maven 项目默认把资源文件放在 src/main/resources 下,默认只识别 src/main/resources 下的资源文件。 Unable to obtain LocalDateTime from TemporalAccessorYou can’t parse a date string into LocalDateTime without a time. LocalDateTime.parse(“2019-10-25”, DateTimeFormatter.ofPattern(“yyyy-MM-dd”)) You should parse the string into LocalDate and call LocalDate.atStartOfDay() to return LocalDateTime with time 00:00:00. LocalDate.parse(“2019-10-25”, DateTimeFormatter.ofPattern(“yyyy-MM-dd”)).atStartOfDay() 12345678910111213141516171819// 传入的时间格式要和解析的时间格式保持一致,如以下解析方式,传入参数 2023-03-08 11:11:11LocalDateTime startDateTime = LocalDateTime.parse(startTime, DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));LocalDateTime endDateTime = LocalDateTime.parse(endTime, DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")); DateTimeFormatter localDateFmt = DateTimeFormatter.ofPattern("yyyy-MM-dd"); DateTimeFormatter localDateFmt = DateTimeFormatter.ofPattern("yyyy-MM-dd"); if (!"".equals(startTime) && !"".equals(endTime)) { LocalDate startDate = LocalDate.parse(startTime, localDateFmt); LocalDate endDate = LocalDate.parse(endTime, localDateFmt); LocalDateTime startDateTime = LocalDateTime.of(startDate, LocalTime.MIN); LocalDateTime endDateTime = LocalDateTime.of(endDate, LocalTime.MAX); log.debug("startDateTime: " + startDateTime); log.debug("endDateTime: " + endDateTime); queryWrapper.between("create_time", startDateTime, endDateTime); } mybatisplus 提交数据后无法立即被查询到123提升事务隔离级别@Transactional(isolation = Isolation.READ_UNCOMMITTED) One record is expected, but the query result is multiple records12解决方案:如果想取一条并不想报错时使用 getOne(queryWrapper,false) 注意 mybatisplus 的 sql 返回值java.lang.NumberFormatException: null检查使用 Integer.parseInt 转换时,是否转换的数可能为 null Unexpected error occurred in scheduled taskjava.lang.NullPointerException: null服务类没有正确注入,每一个需要注入类都需要添加 Autowire 注解 Unhandled exception type原因:被强制异常处理的代码块,必须进行异常处理,否则编译器会提示“Unhandled exception type Exception”错误警告。 需要将代码写到 try catch 里! MySQL数据库乱码,前端乱码12345678910111213sudo vim /etc/mysql/my.cnf# 填写如下配置[client]default-character-set=utf8mb4[mysqld]character-set-server = utf8mb4collation-server = utf8mb4_unicode_ciinit_connect='SET NAMES utf8mb4'skip-character-set-client-handshake = true[mysql]default-character-set = utf8mb4 nested exception is java.lang.NullPointerException] with root cause Error attempting to get column ‘motion_id’ from result set数据库字段类型与后端类型不一致 前端digital envelope routines::unsupported1export NODE_OPTIONS=--openssl-legacy-provider 禁止跨域策略 (CORS policy)node: –openssl-legacy-provider is not allowed in NODE_OPTIONS12unset NODE_OPTIONS Unexpected character (‘}’请求的时候最后一个字段后面不要加逗号 The value of the ‘Access-Control-Allow-Origin’ header in the response must not be the wildcard ‘*’ when the request’s credentials mode is ‘include’. The credentials mode of requests initiated by the XMLHttpRequest is controlled by the withCredentials attribute这个错误通常是因为在使用 XMLHttpRequest 对象进行跨域请求时,服务器返回的响应头中的 Access-Control-Allow-Origin 的值为*,但请求的 withCredentials 属性被设置为 true,这两者之间是相互冲突的。 XMLHttpRequest 对象具有 withCredentials 属性,如果设置为 true,它将在请求中包括来自其他域的 cookie 等凭据信息。但是,如果服务器在响应头中将 Access-Control-Allow-Origin 设置为*,浏览器会禁止访问这些凭据信息。这是一项安全保护措施,防止敏感信息泄露。 解决这个问题的方法是,在服务器端,将 Access-Control-Allow-Origin 设置为请求来源的域名,而不是使用通配符*。这可以让浏览器安全地发送凭据信息。 在前端,需要将 withCredentials 属性设置为 true,以便在请求中包含凭据信息。同时,需要确保请求的来源域名与服务器端设置的 Access-Control-Allow-Origin 一致。 如果你无法更改服务器端的设置,可以考虑使用代理或者 JSONP 等跨域解决方案。 VUE 项目端口不固定Application run failed org.springframework.beans.factory.BeanCreationException: Error creating bean with name ‘communityInfoController’检查target/classes/mapper/DepartmentMapper.xml中的格式是否正确,检查引号是否多了,少了 123<select id="findIdByOrgId" resultType="resultType="java.lang.Integer">SELECT CAST(id AS UNSIGNED) AS id FROM department WHERE organization_id = #{orgId}</select> 错误码 400-前后端参数对不上 {POST/GET} there is already xx bean method NPM 启动:digital envelope routines::unsupported12export NODE_OPTIONS=--openssl-legacy-providernpm run serve The field file exceeds its maximum permitted size of 1048576 bytesspring boot 上传文件时接口报错 The field file exceeds its maximum permitted size of 1048576 bytes.经排查官方设置每个文件的配置最大为 1Mb,单次请求的文件的总数不能大于 10Mb,上传大于 1Mb 的文件需要修改配置文件(application.properties)1.Spring Boot 1.3.x 或者之前 12multipart.maxFileSize=100Mbmultipart.maxRequestSize=1000Mb 2.Spring Boot 1.4.x 以后 12spring.http.multipart.maxFileSize=100Mbspring.http.multipart.maxRequestSize=1000Mb 3.Spring Boot 2.0 之后 12spring.servlet.multipart.max-file-size=100MBspring.servlet.multipart.max-request-size=1000MB 字段不存在请求的时候字段名字和 java 中命名保持一直,而不是和数据库名字保持一样 数据库 communications link failure配置请求超时时间src/utils/request.js Request method GET not supported前端请求事件没有设置请求方式 post 还是 get Invalid cros request跨域 处理未来数据https://www.bilibili.com/video/BV1U44y1W77D?t=1655.5&p=23 TIPS前端保存代码需要等待一段时间生效获取用户 IP1String userIp = request.getRemoteAddr(); 解决方案:Java 实体类字段 不返回给前端1234@JsonIgnore@ApiModelProperty(value = "不重要")@TableField(exist = false)private String unimportant; Dateutil 包1234import java.text.SimpleDateFormat;import java.util.Calendar;import java.util.Date; 获取请求参数123456public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { //获取请求参数 String queryString = request.getQueryString(); log.info("请求参数:{}", queryString); } 后端设置 header 前端获取不到1234# 必须要加这条字段控制能够获取的 header response.addHeader("Access-Control-Expose-Headers","test"); response.addHeader("test", "sdfdsfdsf"); axios 请求1234567axios.get('http://opm.eswincomputing.com:9090/user/page') .then(function (response) { console.log(response.headers); }) .catch(function (error) { console.log(error.headers); }); 查询端口占用12lsof -ilsof -i:8080:查看 8080 端口占用 打印输出1234567891011121314# Application.ymllogging: level: com.eswincomputing.springboot: debug# 使用@Slf4j@RestController@RequestMapping("/patch-record")public class PatchRecordController { @Resource private IPatchRecordService patchRecordServic log.info(version);} 校验字符串是否为空1StrUtil.isBlank() 查询主键12SELECT id FROM department WHERE organization_id = #{orgId} 字符整型互转1Integer.parseInt(user.getDelFlag()) 解析 json 字符串123456789101112 <!-- json 解析 --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.21</version></dependency> JSONObject object = JSONObject.parseObject(patchRecord.getAttachmentList()); String fileUID = object.getString("file_uid"); String fileName = object.getString("file_name"); 逗号分割字符串1234567String string = "张三,李四,王五,马六,小气"; String substring = string.substring(0, string.length() - 1); System.out.println(substring); String[] split = substring.split(",");//以逗号分割 for (String string2 : split) { System.out.println("数据-->>>" + string2); }","categories":[{"name":"JAVA 开发","slug":"JAVA-开发","permalink":"http://example.com/categories/JAVA-%E5%BC%80%E5%8F%91/"}],"tags":[{"name":"JAVA","slug":"JAVA","permalink":"http://example.com/tags/JAVA/"}]},{"title":"如何使用 Gitlab CI Pipeline","slug":"如何使用Gitlab-CI-Pipeline","date":"2023-01-07T03:08:19.000Z","updated":"2023-03-25T04:13:10.820Z","comments":true,"path":"2023/01/07/如何使用Gitlab-CI-Pipeline/","link":"","permalink":"http://example.com/2023/01/07/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8Gitlab-CI-Pipeline/","excerpt":"","text":"GitLab CI/CD 是一个强大的工具,可以帮助开发团队实现自动化构建、测试和部署。本文将介绍如何使用 GitLab CI/CD 的 Pipeline 功能,以实现将 Markdown 文件自动编译为 PDF 并上传至 GitLab Release 界面的功能。 准备工作在开始使用 GitLab CI/CD 的 Pipeline 功能之前,需要进行一些准备工作。具体步骤如下: 创建 GitLab 项目:在 GitLab 上创建一个新项目,并将 Markdown 文件上传至项目的某个目录下。例如,我们将 Markdown 文件上传至项目的根目录下,并命名为 example.md。 安装 Pandoc:Pandoc 是一个用于文档转换的工具,我们将使用它将 Markdown 文件转换为 PDF。在安装 Pandoc 之前,需要先安装 LaTeX,因为 Pandoc 使用 LaTeX 进行 PDF 渲染。具体安装步骤请参考 Pandoc 和 LaTeX 的官方文档。 创建 Release:在 GitLab 上创建一个 Release,用于存储编译好的 PDF 文件。具体操作方法请参考 GitLab 的官方文档。 创建 CI/CD 配置文件:在项目根目录下创建一个.gitlab-ci.yml 文件,并在其中定义 Pipeline 的流程。 编写 CI/CD 配置文件下面是一个样例的.gitlab-ci.yml 文件,用于实现将 Markdown 文件编译为 PDF 并上传至 GitLab Release 界面的功能。 12345678910111213image: pandoc/core:lateststages: - buildpdf: stage: build script: - pandoc example.md -o example.pdf - curl --header "PRIVATE-TOKEN: ${CI_PRIVATE_TOKEN}" --upload-file example.pdf "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/uploads" artifacts: paths: - example.pdf 上述配置文件中,我们使用了 pandoc/core:latest 作为 Docker 镜像,该镜像已经预安装了 Pandoc 工具。 该文件中包含了一个 build 阶段,其中包含了一个 pdf 任务。在 pdf 任务中,我们使用 Pandoc 工具将 Markdown 文件转换为 PDF 文件,并使用 cURL 工具将编译好的 PDF 文件上传至 GitLab Release 界面。注意,我们使用了环境变量${CI_PRIVATE_TOKEN}和${CI_API_V4_URL},这些变量是 GitLab 自动注入的,用于进行身份验证和上传文件。 最后,我们将编译好的 PDF 文件定义为 Pipeline 的 artifacts,这样可以确保文件能够被保留并可用于后续的部署。 运行 Pipeline完成 CI/CD 配置文件的编写后,我们可以在 GitLab 上启动 Pipeline,将 Markdown 文件自动编译为 PDF 并上传至 GitLab Release 界面。具体步骤如下: 提交代码:将.gitlab-ci.yml 文件提交到 GitLab 启动 Pipeline:在 GitLab 上打开项目,并点击“CI/CD”->“Pipelines”选项卡。点击“Run Pipeline”按钮,启动 Pipeline 流程。 等待 Pipeline 完成:在 Pipeline 启动后,GitLab 会自动创建一个 Runner 并分配任务。Pipeline 的状态会在页面上实时更新,直到 Pipeline 执行完成。 查看 Release:Pipeline 执行完成后,我们可以在 GitLab Release 界面中找到编译好的 PDF 文件。点击 PDF 文件链接,即可下载并查看编译好的 PDF 文件。","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[]},{"title":"Markdown 嵌入 Draw.io","slug":"Markdown嵌入Draw-io","date":"2023-01-07T02:42:06.000Z","updated":"2023-01-07T02:42:34.820Z","comments":true,"path":"2023/01/07/Markdown嵌入Draw-io/","link":"","permalink":"http://example.com/2023/01/07/Markdown%E5%B5%8C%E5%85%A5Draw-io/","excerpt":"","text":"Markdown 是支持嵌入 HTML 的,大部分阅读器也都支持解析。Draw.io 可以导出为 HTML 格式。 文件—导出为 HTML—导出—新窗口打开—复制 HTML 代码—只保留<body>标签之间的内容,不包含<body>和</body>。","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[]},{"title":"Ubuntu 18.04 安装Clang/LLVM 11","slug":"Ubuntu-18-04-安装Clang-LLVM-11","date":"2022-12-24T07:53:22.000Z","updated":"2022-12-24T07:53:55.923Z","comments":true,"path":"2022/12/24/Ubuntu-18-04-安装Clang-LLVM-11/","link":"","permalink":"http://example.com/2022/12/24/Ubuntu-18-04-%E5%AE%89%E8%A3%85Clang-LLVM-11/","excerpt":"","text":"从 APT 安装Install the GPG Key for https://apt.llvm.org/ 1wget -O - https://apt.llvm.org/llvm-snapshot.gpg.key | sudo apt-key add - Add the repo for Clang 11 stable-old for Ubuntu 18.04 Bionic 12echo "deb http://apt.llvm.org/bionic/ llvm-toolchain-bionic-11 main" | sudo tee -a /etc/apt/sources.listsudo apt-get update Install practically everything (except python-clang-11 which for some reason doesn’t work) 123sudo apt-get install libllvm-11-ocaml-dev libllvm11 llvm-11 llvm-11-dev llvm-11-doc llvm-11-examples llvm-11-runtime \\clang-11 clang-tools-11 clang-11-doc libclang-common-11-dev libclang-11-dev libclang1-11 clang-format-11 clangd-11 \\libfuzzer-11-dev lldb-11 lld-11 libc++-11-dev libc++abi-11-dev libomp-11-dev -y Make Clang 11 and everything related to it defaults 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051sudo update-alternatives \\ --install /usr/lib/llvm llvm /usr/lib/llvm-11 50 \\ --slave /usr/bin/llvm-config llvm-config /usr/bin/llvm-config-11 \\ --slave /usr/bin/llvm-ar llvm-ar /usr/bin/llvm-ar-11 \\ --slave /usr/bin/llvm-as llvm-as /usr/bin/llvm-as-11 \\ --slave /usr/bin/llvm-bcanalyzer llvm-bcanalyzer /usr/bin/llvm-bcanalyzer-11 \\ --slave /usr/bin/llvm-cov llvm-cov /usr/bin/llvm-cov-11 \\ --slave /usr/bin/llvm-diff llvm-diff /usr/bin/llvm-diff-11 \\ --slave /usr/bin/llvm-dis llvm-dis /usr/bin/llvm-dis-11 \\ --slave /usr/bin/llvm-dwarfdump llvm-dwarfdump /usr/bin/llvm-dwarfdump-11 \\ --slave /usr/bin/llvm-extract llvm-extract /usr/bin/llvm-extract-11 \\ --slave /usr/bin/llvm-link llvm-link /usr/bin/llvm-link-11 \\ --slave /usr/bin/llvm-mc llvm-mc /usr/bin/llvm-mc-11 \\ --slave /usr/bin/llvm-mcmarkup llvm-mcmarkup /usr/bin/llvm-mcmarkup-11 \\ --slave /usr/bin/llvm-nm llvm-nm /usr/bin/llvm-nm-11 \\ --slave /usr/bin/llvm-objdump llvm-objdump /usr/bin/llvm-objdump-11 \\ --slave /usr/bin/llvm-ranlib llvm-ranlib /usr/bin/llvm-ranlib-11 \\ --slave /usr/bin/llvm-readobj llvm-readobj /usr/bin/llvm-readobj-11 \\ --slave /usr/bin/llvm-rtdyld llvm-rtdyld /usr/bin/llvm-rtdyld-11 \\ --slave /usr/bin/llvm-size llvm-size /usr/bin/llvm-size-11 \\ --slave /usr/bin/llvm-stress llvm-stress /usr/bin/llvm-stress-11 \\ --slave /usr/bin/llvm-symbolizer llvm-symbolizer /usr/bin/llvm-symbolizer-11 \\ --slave /usr/bin/llvm-tblgen llvm-tblgen /usr/bin/llvm-tblgen-11sudo update-alternatives \\ --install /usr/bin/clang clang /usr/bin/clang-11 50 \\ --slave /usr/bin/clang++ clang++ /usr/bin/clang++-11 \\ --slave /usr/bin/lld lld /usr/bin/lld-11 \\ --slave /usr/bin/clang-format clang-format /usr/bin/clang-format-11 \\ --slave /usr/bin/clang-tidy clang-tidy /usr/bin/clang-tidy-11 \\ --slave /usr/bin/clang-tidy-diff.py clang-tidy-diff.py /usr/bin/clang-tidy-diff-11.py \\ --slave /usr/bin/clang-include-fixer clang-include-fixer /usr/bin/clang-include-fixer-11 \\ --slave /usr/bin/clang-offload-bundler clang-offload-bundler /usr/bin/clang-offload-bundler-11 \\ --slave /usr/bin/clangd clangd /usr/bin/clangd-11 \\ --slave /usr/bin/clang-check clang-check /usr/bin/clang-check-11 \\ --slave /usr/bin/scan-view scan-view /usr/bin/scan-view-11 \\ --slave /usr/bin/clang-apply-replacements clang-apply-replacements /usr/bin/clang-apply-replacements-11 \\ --slave /usr/bin/clang-query clang-query /usr/bin/clang-query-11 \\ --slave /usr/bin/modularize modularize /usr/bin/modularize-11 \\ --slave /usr/bin/sancov sancov /usr/bin/sancov-11 \\ --slave /usr/bin/c-index-test c-index-test /usr/bin/c-index-test-11 \\ --slave /usr/bin/clang-reorder-fields clang-reorder-fields /usr/bin/clang-reorder-fields-11 \\ --slave /usr/bin/clang-change-namespace clang-change-namespace /usr/bin/clang-change-namespace-11 \\ --slave /usr/bin/clang-import-test clang-import-test /usr/bin/clang-import-test-11 \\ --slave /usr/bin/scan-build scan-build /usr/bin/scan-build-11 \\ --slave /usr/bin/scan-build-py scan-build-py /usr/bin/scan-build-py-11 \\ --slave /usr/bin/clang-cl clang-cl /usr/bin/clang-cl-11 \\ --slave /usr/bin/clang-rename clang-rename /usr/bin/clang-rename-11 \\ --slave /usr/bin/find-all-symbols find-all-symbols /usr/bin/find-all-symbols-11 \\ --slave /usr/bin/lldb lldb /usr/bin/lldb-11 \\ --slave /usr/bin/lldb-server lldb-server /usr/bin/lldb-server-11 Installing CMakeInstall Kitware’s GPG Key 1wget -O - https://apt.kitware.com/keys/kitware-archive-latest.asc 2>/dev/null | gpg --dearmor - | sudo tee /etc/apt/trusted.gpg.d/kitware.gpg >/dev/null Add repository 12echo "deb https://apt.kitware.com/ubuntu/ bionic main" | sudo tee -a /etc/apt/sources.listsudo apt-get update Install this optional package so you don’t have to mess with GPG keys anymore 12sudo apt-get install kitware-archive-keyringsudo rm /etc/apt/trusted.gpg.d/kitware.gpg Now upgrade cmake if you already have it installed with sudo apt-get upgrade -y or just install it using sudo apt-get install cmake -y 使用源码安装12345678910111213141516171819202122232425262728# 更新软件包列表sudo apt update# 安装必要的依赖包sudo apt install build-essential cmake python3-dev# 下载 Clang/LLVM 11 的源代码wget https://github.com/llvm/llvm-project/releases/download/llvmorg-11.0.0/llvm-11.0.0.src.tar.xz# 解压源代码文件tar xvf llvm-11.0.0.src.tar.xz# 进入解压后的目录cd llvm-11.0.0.src# 创建一个新的目录,用于存放 Clang/LLVM 编译的结果mkdir buildcd build# 使用 cmake 编译 Clang/LLVMcmake ..# 编译 Clang/LLVMmake# 安装 Clang/LLVMsudo make install","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"安装教程","slug":"安装教程","permalink":"http://example.com/tags/%E5%AE%89%E8%A3%85%E6%95%99%E7%A8%8B/"}]},{"title":"每天学命令-chown 修改文件拥有者","slug":"每天学命令-chown修改文件拥有者","date":"2022-12-04T08:32:59.000Z","updated":"2022-12-04T08:33:15.742Z","comments":true,"path":"2022/12/04/每天学命令-chown修改文件拥有者/","link":"","permalink":"http://example.com/2022/12/04/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-chown%E4%BF%AE%E6%94%B9%E6%96%87%E4%BB%B6%E6%8B%A5%E6%9C%89%E8%80%85/","excerpt":"","text":"chown 命令用来变更文件或目录的拥有者或所属群组,通过 chown 改变文件的拥有者和群组。用户可以是用户名或者用户 ID;组可以是组名或者组 ID;文件是以空格分开的文件列表,文件名也支持通配符。 命令格式12345678910chown [选项] [用户或组] [文件或目录]-c或--changes #效果类似“-v”参数,但仅回报更改的部分;-f或--quite或—-silent #不显示错误信息;-h或--no-dereference #只对符号连接的文件作修改,而不更改其他任何相关文件;-R或--recursive #递归处理,将指定目录下的所有文件及子目录一并处理;-v或--version #显示指令执行过程;--dereference #效果和“-h”参数相同;--help #在线帮助--reference=<参考文件或目录> #把指定文件或目录的拥有者与所属群组全部设成和参考文件或目录的拥有者与所属群组相同;--version #显示版本信息。 实例将文件test.md拥有者改为nic 1chown nic test.md 将目录/home/nic/develop及其下面的所有文件、子目录的文件拥有者改为nic 12chown -R nic /home/nic/develop","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"每天学命令-tree 显示目录结构","slug":"每天学命令-tree显示目录结构","date":"2022-12-04T08:31:54.000Z","updated":"2022-12-04T08:32:12.420Z","comments":true,"path":"2022/12/04/每天学命令-tree显示目录结构/","link":"","permalink":"http://example.com/2022/12/04/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-tree%E6%98%BE%E7%A4%BA%E7%9B%AE%E5%BD%95%E7%BB%93%E6%9E%84/","excerpt":"","text":"1234567891011121314151617181920-a #显示所有文件-d #只显示目录(名称)-l #显示链接文件的原始文件-f #显示所列出的文件或目录的完整目录路径-i #不以阶梯的形式显示文件或目录名称-q #将控制字符以?字符代替,显示文件和目录名称-N #直接显示文件或目录的名称-p #显示每个文件的权限信息-u #显示文件所有者或者uid-g #显示文件所属组或者gid-s #显示每个文件的大小信息-h #以可读的方式显示文件的大小信息-D #显示最后修改日期-v #按字母数字正序显示文件-r #按字母数字倒序显示文件-t #按最后时间排序显示文件-C #在文件和目录列表上加上色彩,便于区分文件类型-P pattern #只显示匹配正则表式的文件或目录名称-I pattern #与上结果相反 实例显示当前目录及其子目录下的文件及目录名称 12345678910111213141516171819$ tree .├── CODE_OF_CONDUCT.md├── CONTRIBUTING.md├── Fedora-35│ ├── Dockerfile│ └── Readme.md├── LICENSE├── README.md├── Ubuntu-20│ ├── Dockerfile│ ├── Readme.md│ ├── init_edkrepo_conf.sh│ └── ubuntu20_dev_entrypoint.sh└── Windows-2022 ├── Dockerfile └── Readme.md3 directories, 12 files 只显示一层目录结构 1234567891011$ tree -L 1 .├── CODE_OF_CONDUCT.md├── CONTRIBUTING.md├── Fedora-35├── LICENSE├── README.md├── Ubuntu-20└── Windows-20223 directories, 4 files 只显示目录不显示文件 1234567$ tree -d .├── Fedora-35├── Ubuntu-20└── Windows-20223 directories","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"CodeReview 中常见缩写","slug":"CodeReview中常见缩写","date":"2022-12-03T11:55:07.000Z","updated":"2022-12-03T12:16:19.013Z","comments":true,"path":"2022/12/03/CodeReview中常见缩写/","link":"","permalink":"http://example.com/2022/12/03/CodeReview%E4%B8%AD%E5%B8%B8%E8%A7%81%E7%BC%A9%E5%86%99/","excerpt":"","text":"ASAP: As Soon As Possible. 请尽快完成 ACK: Acknowledgement. 承认,同意。表示接受代码的改动 CR: Code Review. 请求代码审查 CCN: Code Comments Needed.需要的代码注释:在这里有一些简短的注释在高层次上描述每个主要代码块的作用(例如,“处理 HTTP 请求中的标头”)会很有帮助 DOODOO: Documentation Out Of Date Or Obsolete.文档过时或过时:此文档似乎不正确:是否过时? DNM: Do not merge. 不要合并 ditto: 多个重复的表述,下一次可以用 ditto 表示同上 IMO: In My Opinion 在我看来、依我看、依我所见 LGT1: Looks Good To 1. 如果有一个回复 LGTM 则可以添加为 LGT1,1 代表目前有 1 个赞 LGT2: Looks Good To 2. 如果有两个回复 LGTM 则可以添加为 LGT2,2 代表目前有 2 个赞 LGTM: Looks Good To Me. 代码已经过 review,可以合并 MCE: Must Check for Errors.必须检查错误:这里可能会发生错误或异常情况,但您没有任何代码来处理此类事件 MR:merge request. 合并请求 NACK/NAK: Negative acknowledgement. 不同意,不接受这次的改动 IMHO: In My Humble Opinion IMO 谦虚的说法 IMO: In My Opinion. 在我看来 IIRC: If I Recall Correctly. 如果我没有记错的话 PR:Pull Request. 拉取请求,给其他项目提交代码 PTAL: Please Take A Look. 提示项目 Owner/contributor review RFC: Request For Comment. 请求进行讨论,表示认为某个想法很好,邀请大家一起讨论一下 RCP: Repeated Code Pattern.重复代码模式:与上面几行非常相似的代码在许多不同的地方重复出现。找到一种方法来简化它(例如,定义一个隐藏细节的更高级别的 API,或者找到一个更集中的地方来执行这些操作,这样这里就不需要这段代码了)。 SGTM: Sounds Good To Me. 和上面那句意思差不多,也是已经通过了 review 的意思 TBD: To Be Done. 未完成,待续 TL;DR: Too Long; Don’t Read. PR 内容太多,没办法看 TMLI: Too Many Levels of Indentation.Too Many Levels of Indentation:缩进太深的代码很难阅读。在大多数情况下,可以重构代码以减少嵌套级别。 WIP: Work In Progress. 告诉项目维护者这个功能还未完成,方便维护者 review 已提交的代码 TBR: To Be Reviewed. 提示维护者进行 review TBD: To Be Done (or Defined/Discussed/Decided/Determined). 根据语境不同意义有所区别,但一般都是还没搞定的意思","categories":[],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"},{"name":"CodeReview","slug":"CodeReview","permalink":"http://example.com/tags/CodeReview/"}]},{"title":"OFFICE-解决 Word 编辑卡顿","slug":"OFFICE-解决Word编辑卡顿","date":"2022-12-03T11:01:27.000Z","updated":"2022-12-03T12:16:36.658Z","comments":true,"path":"2022/12/03/OFFICE-解决Word编辑卡顿/","link":"","permalink":"http://example.com/2022/12/03/OFFICE-%E8%A7%A3%E5%86%B3Word%E7%BC%96%E8%BE%91%E5%8D%A1%E9%A1%BF/","excerpt":"","text":"打开 Word 很快,但是一编辑就特别卡,尤其时拖动表格时几乎是逐帧移动。这是硬件图形加速问题。解决方式如下。 打开 Word,点击左上角—>文件—>选项—>高级,一直拉到“显示”; 勾选禁用硬件图形加速; 取消勾选子像素定位平滑屏幕上的字体。","categories":[],"tags":[{"name":"Office","slug":"Office","permalink":"http://example.com/tags/Office/"}]},{"title":"Git clone下来的分支不完整","slug":"Git-clone下来的分支不完整","date":"2022-12-03T10:52:10.000Z","updated":"2022-12-03T10:52:41.955Z","comments":true,"path":"2022/12/03/Git-clone下来的分支不完整/","link":"","permalink":"http://example.com/2022/12/03/Git-clone%E4%B8%8B%E6%9D%A5%E7%9A%84%E5%88%86%E6%94%AF%E4%B8%8D%E5%AE%8C%E6%95%B4/","excerpt":"","text":"将仓库git clone到本地后发现本地缺失了一些远程仓库的分支。一般发生在git clone —depth 1设置克隆深度时发生。因为有些大型项目一次性克隆容易出错,所以只克隆一层深度。 如远程有分支branch_a,克隆下来后使用git branch -av命令查看所有分支没有显示该分支,该如何解决? 12git remote set-branches origin 'branch_a'git fetch -v","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"手把手教你向开源社区提 Patch","slug":"手把手教你向开源社区提Patch","date":"2022-11-20T07:11:57.000Z","updated":"2022-11-20T08:16:56.657Z","comments":true,"path":"2022/11/20/手把手教你向开源社区提Patch/","link":"","permalink":"http://example.com/2022/11/20/%E6%89%8B%E6%8A%8A%E6%89%8B%E6%95%99%E4%BD%A0%E5%90%91%E5%BC%80%E6%BA%90%E7%A4%BE%E5%8C%BA%E6%8F%90Patch/","excerpt":"","text":"提交补丁的最佳实践 本文翻译自官方教程Git - MyFirstContribution,原文包含开发到提交的整个周期。但是想要提交的人应该都已经开发完代码了,所以本文用自己的实际例子重新写了一遍,省去了开发代码等流程,重点介绍如何使用 git send-email。 环境准备下载 OpenSBI 仓库12git clone https://github.com/riscv-software-src/opensbi.gitcd opensbi 安装依赖要从源代码构建 OpenSBI: 1make 注:OpenSBI 的构建是可并行的。上面的命令可以添加-j#参数,如-j12。 确认要解决的问题在本文档中,我们将模拟提交一个简单的 Patch,.gitignore文件可以过滤不必要的文件,现在使用 VSCode 的用户越来越多,使用 VSCode 开发时常常会生成.vscode目录,但是这些文件不该被推送至远程,原仓库中的.gitignore文件中没有过滤该文件,我们给他加上。 为了能够模拟一次发送多个commit的场景,我们将再添加一个.so用来过滤编译过程中生成的.so文件。 建立工作空间让我们先建立一个开发分支来进行我们的修改。 1git checkout -b update_gitignore origin/master 我们将在这里做一些提交,以演示如何将一个带有多个补丁的主题同时送审。 实现代码过滤 .vscode打开文件.gitignore,为该文件添加/.vscode/: 1234567891011121314# Object files*.o*.a*.dep#Build & install directoriesbuild/install/# Development friendly filestagscscope*/.vscode/ 为以上修改做一次提交: 1234567891011$ git statusOn branch update_gitignoreYour branch is up to date with 'origin/master'.Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: .gitignore$ git add .gitignore$ git commit -s 执行以上命令后将会弹出编辑框用来编写提交信息。主题行要少于 50 个字符,然后是一个空行(必须),然后是您的提交消息的正文。请记住要明确并提供更改的原因(理由),特别是如果无法从您的差异中轻松理解你的提交内容时。编辑提交消息时,不要删除上面 Signed-off-by 添加的 trailer。(由上面命令-s参数生成)。 其他规范请详细查阅目标社区的提交规范,如OpenSBI要求主题行需要以 lib:, platform:, firmware:, docs:, utils: 或者 top:为前缀,修改.gitignore属于top范畴,所以我们需要将其加在主题行上。 12345top: filter .vscode folderFilter the workspace's '.vscode' directory by adding '/.vscode/' to the.gitignore file.Signed-off-by: Dominic Zhang <Dominic Zhang@gmail.com> 继续用 git show 检查您的新提交。尤其不要出现不需要在本次提交的内容。通常使用不同的 IDE 都可能会无意间生成一些配置文件等,请注意将其剔除。 1234567891011121314151617181920commit 5dc340c29979d4c5d8c4d5a6e881348239714434 (HEAD -> update_gitignore)Author: Dominic Zhang <Dominic Zhang@gmail.com>Date: Fri Nov 18 16:06:21 2022 +0800 top: filter .vscode folder Filter the workspace's '.vscode' directory by adding '/.vscode/' to the.gitignore file. Signed-off-by: Dominic Zhang <Dominic Zhang@gmail.com>diff --git a/.gitignore b/.gitignoreindex 95692bb..90cf552 100644--- a/.gitignore+++ b/.gitignore@@ -10,3 +10,5 @@ install/ # Development friendly files tags cscope*++/.vscode/ 过滤 .cache与上一节步骤类似,我们在.gitignore文件中再添加一个/.cache/字段用来过滤.cache文件夹。 123456789101112131415# Object files*.o*.a*.dep#Build & install directoriesbuild/install/# Development friendly filestagscscope*/.vscode//.cache/ 添加完我们就即使保存工作进度,新生成一个commit。 12git add .gitignoregit commit -s 12345top: filter .cache folderFilter the workspace's '.cache' directory by adding '/.cache/' to the.gitignore file.Signed-off-by: Dominic Zhang <Dominic Zhang@gmail.com> 以上我们就已经准备好所有的代码了,在大部分场景下可能修改的是.c或者.h等源文件,这就需要我们能够使代码编译、运行并且测试通过后再提交。 这里为了演示提交流程,就没有涉及这些步骤。接下来我们就要准备提交的补丁文件了。 准备提交补丁OpenSBI 项目是通过电子邮件发送补丁来进行代码审查的,当补丁准备好并得到社区认可后,维护者就会应用(Apply)这些补丁。OpenSBI 项目不接受来自 Pull Request 的贡献,而且通过电子邮件发送的补丁需要以指定的方式进行审核。 在研究如何将你的提交转化为电子邮件的补丁之前,让我们先分析一下最终的结果,即补丁系列(Patch Series)是什么样子。下面是 OpenSBI 邮件列表存档的网页界面上的补丁系列的摘要视图的一个例子。 我们可以注意几点: 每次提交都是以单独的邮件形式发送,提交信息的标题为主题,前缀为[PATCH i/n],代表n个提交系列中的第 i 个提交。 每个补丁都是作为对cover letter的回复,cover letter的前缀为[PATCH 0/n],序号为 0 的标题。 补丁系列的后续迭代被标记为 PATCH v2、PATCH v3,等等,以代替 PATCH。例如,[PATCH v2 1/3]将是第二次迭代中三个补丁的第一个补丁。每次迭代都有一个新的cover letter(如上面的[PATCH v2 0/3]),本身就是对前一次迭代的cover letter的回复(下面会有更多介绍)。 注:单一补丁的主题是以[PATCH]、[PATCH v2]等发送的,没有 i/n 编号。如上图中的第四个 Patch,就是一个单一补丁。 什么是 cover letter除了给每个补丁发一封邮件外,OpenSBI 社区还希望你的补丁能附带一封 cover letter。这是修改提交的一个重要组成部分,因为它概括了你想要做什么,以及为什么要这样做,比仅仅看你的补丁更明显。 你的 cover letter 的标题应该是能简洁地涵盖你整个主题分支的目的。就像我们的提交信息标题一样。下面是我们的系列标题。 1Update gitignore --- cover letter 的正文是用来给评审员提供额外的背景。一定要解释任何你的补丁自己没有说清楚的东西,但要记住,由于 cover letter 没有记录在提交历史中,任何可能对未来版本库历史的读者有用的东西也应该在你的提交信息中出现。 下文我们将介绍如何生成 cover letter 以及如何填写 cover letter。 用 git send-email 发送补丁前提条件 - 设置 git send-email对 send-email 的配置会根据你的操作系统和电子邮件供应商而有所不同,配置可以参考文档如何使用 git-send-mail 给开源社区提交 Patch - 如云泊。 准备初始补丁集在准备邮件本身之前,你需要准备补丁。 1git format-patch --cover-letter -o update_gitignore/ --base=auto update_gitignore@{u}..update_gitignore --cover-letter 选项告诉 format-patch 为你创建一个 cover letter 模板。在你准备发送之前,你将需要填写该模板。 -o update_gitignore/ 选项告诉 format-patch 把补丁文件放到目录update_gitignore中。这样发送多个commit时就可以使用命令一次性发送,因为 git send-email 可以接收一个目录并从那里发送所有补丁。 --base=auto 选项告诉命令记录”基本提交”,接收者将在此基础上应用补丁系列。自动值将使 format-patch 自动计算基本提交,即远程跟踪分支的最新提交和指定修订范围的合并基数。 update_gitignore@{u}..update_gitignore 选项告诉 format-patch 为你在 update_gitignore 分支上创建的提交生成补丁,因为它是从上游分叉出来的。@{u}的意思就是从分叉开始到最新的提交。 执行完该命令我们看看生成了哪些内容。 123456789101112$ git statusOn branch update_gitignoreYour branch is ahead of 'origin/master' by 2 commits. (use "git push" to publish your local commits)Untracked files: (use "git add <file>..." to include in what will be committed) update_gitignore/$ ls update_gitignore 0000-cover-letter.patch 0001-top-filter-.vscode-folder.patch 0002-top-filter-.cache-folder.patch 该命令将为每次提交制作一个补丁文件。运行后,您可以用您喜欢的文本编辑器看一下每个补丁,确保一切正常。可以看到创建了一个-o参数中的update_gitignore文件夹,该文件夹下有三个文件,分别是 cover letter 和上文我们做的两次提交对应的补丁文件。 分别打开他们,结果如下: 123456789101112131415161718From 30614e5469be4a2f930cca570836627a4e91f1d1 Mon Sep 17 00:00:00 2001From: Dominic Zhang <Dominic Zhang@gmail.com>Date: Fri, 18 Nov 2022 16:41:32 +0800Subject: [PATCH 0/2] *** SUBJECT HERE ****** BLURB HERE ***Dominic Zhang (2): top: filter .vscode folder top: filter .cache folder .gitignore | 3 +++ 1 file changed, 3 insertions(+)base-commit: 880685586dcee950d209088a461443449a1693ce-- 2.17.1 12345678910111213141516171819202122232425From 5dc340c29979d4c5d8c4d5a6e881348239714434 Mon Sep 17 00:00:00 2001From: Dominic Zhang <Dominic Zhang@gmail.com>Date: Fri, 18 Nov 2022 16:06:21 +0800Subject: [PATCH 1/2] top: filter .vscode folderFilter the workspace's '.vscode' directory by adding '/.vscode/' to the.gitignore file.Signed-off-by: Dominic Zhang <Dominic Zhang@gmail.com>--- .gitignore | 2 ++ 1 file changed, 2 insertions(+)diff --git a/.gitignore b/.gitignoreindex 95692bb..90cf552 100644--- a/.gitignore+++ b/.gitignore@@ -10,3 +10,5 @@ install/ # Development friendly files tags cscope*++/.vscode/\\ No newline at end of file-- 2.17.1 123456789101112131415161718192021222324252627From 30614e5469be4a2f930cca570836627a4e91f1d1 Mon Sep 17 00:00:00 2001From: Dominic Zhang <Dominic Zhang@gmail.com>Date: Fri, 18 Nov 2022 16:20:37 +0800Subject: [PATCH 2/2] top: filter .cache folderFilter the workspace's '.cache' directory by adding '/.cache/' to the.gitignore file.Signed-off-by: Dominic Zhang <Dominic Zhang@gmail.com>--- .gitignore | 3 ++- 1 file changed, 2 insertions(+), 1 deletion(-)diff --git a/.gitignore b/.gitignoreindex 90cf552..bf9d716 100644--- a/.gitignore+++ b/.gitignore@@ -11,4 +11,5 @@ install/ tags cscope* -/.vscode/\\ No newline at end of file+/.vscode/+/.cache/\\ No newline at end of file-- 2.17.1 注:另外,你也可以使用 --rfc 参数,在你的补丁主题前加上[RFC PATCH],而不是[PATCH]。RFC 是”请求评论”的意思,表示虽然你的代码还没有准备好提交,但你想开始代码审查过程。你也可能在列表中看到标有”WIP”的补丁,这意味着他们还没有完成,但希望审查者能看看他们目前的成果。你可以用--subject-prefix=WIP来添加这个标志。 检查并确保你的补丁和 cover letter 模板存在于你指定的目录中,这就完成所有准备了。 准备邮件由于你在调用 format-patch 时使用了--cover-letter,你已经准备好了一个 cover letter 模板。在你喜欢的编辑器中打开它。 你应该看到已经有一些标题存在。检查你的From:标题是否正确。然后修改你的Subject:。 确保保留[PATCH 0/X]的部分;这是向 Git 社区表明这封邮件是一个补丁系列的开始,许多审查者会根据这种类型的标记过滤他们的邮件。 接下来,你必须填写你的 cover letter 的正文。同样,关于应包括哪些内容,见上文。 最后,信中会包括用于生成补丁的 Git 的版本。你可以不用管这个字符串。 完善后的 cover letter 如下: 123456789101112131415161718From 30614e5469be4a2f930cca570836627a4e91f1d1 Mon Sep 17 00:00:00 2001From: Dominic Zhang <Dominic Zhang@gmail.com>Date: Fri, 18 Nov 2022 16:41:32 +0800Subject: [PATCH 0/2] Update gitignorevscode is a very popular IDE, and it often needs to generate a.vscode. cache directory to hold workspace configuration files that should not be committed to a remote repository, so we made some modifications to the gitignore file to filter such directories.Dominic Zhang (2): top: filter .vscode folder top: filter .cache folder .gitignore | 3 +++ 1 file changed, 3 insertions(+)base-commit: 880685586dcee950d209088a461443449a1693ce-- 2.17.1 发送邮件到这里,你应该有一个目录 update_gitignore/,里面包含你的补丁和一封 cover letter。是时候把它发出去了!你可以像这样发送。 1git send-email --to=target@example.com update_gitignore/*.patch 注:请查看 git help send-email 中的一些其他选项,你可能会发现这些选项很有价值,比如改变回复地址或添加更多的抄送地址或密送地址。 注:当你发送一个真正的补丁时,它将被发送到 opensbi@lists.infradead.org - 但请不要把你的补丁集从教程中发送到真正的邮件列表中!现在你可以把它发送给你自己,以确保你了解它的形式。 在你运行上面的命令后,你会为每个即将发出的补丁看到一个交互提示。这给了你最后一次机会来编辑或放弃发送一些东西(但还是那句话,不要用这种方式编辑代码)。一旦你在这些提示下按下 y 或 a,你的邮件就会被发送出去!Congratulation! 发送补丁的更新版本本节将重点介绍如何发送你的补丁集的 v2 版。我们将在 v2 版中重新使用我们的 update_gitignore 分支。在我们做任何改动之前,我们先新建一个名为update_gitignore-v1的分支,这个分支是我们没有做新的改动的分支。这样在后面我们就可以方便的进行对比差异。 12git checkout update_gitignoregit branch update_gitignore-v1 在更新补丁时,我们可能会遇到两种情况,一种是社区的意见只让修改最新的一个提交,一种是修改历史记录中的 commit。我们分别来处理这两种情况。 如何修改最新的提交比如只需要修改top: filter .cache folder这个 commit。因为它在我们的修改中是最新的 commit,所以我们可以直接对代码修改。比如我们做一个简单的修改,给修改的内容/.cache加个注释。 1234567891011121314151617# Object files*.o*.a*.dep#Build & install directoriesbuild/install/# Development friendly filestagscscope*/.vscode/# Cache file/.cache/ 12git add .gitignoregit commit --amend 注意!我们不需要生成新的commit,所以使用 --amend参数修改最新的commit message即可。执行这条命令会弹出编辑窗口,因为修改内容已经很明确,我们不需要在commit message里再做额外说明,直接保存退出即可。如果修改内容比较大,需要重新编写commit message。 以上我们就完成了一次更新。 如何修改历史记录中的提交如果很不巧,社区要求修改的是top: filter .vscode folder这个提交的内容,那怎么办,因为它不是最新的提交,而是上一个提交,我们无法使用git commit --amend来直接对他修改,好在 Git 十分强大,不需要我们reset就可以完成这样的工作。 同样我们也做一个简单的修改,为/.vscode/也添加一个注释。首先我们需要使用到git rebase这个强大的命令。本文只介绍使用到的功能,其他功能需要大家自行摸索。 1git rebase -i 这条命令会弹出编辑窗口,-i参数表示以交互式方式进行变基(rebase)操作。弹出窗口内容如下: 123456789101112131415161718192021pick 7175772 top: filter .vscode folderpick 52b63f3 top: filter .cache folder# Rebase 8806855..52b63f3 onto 8806855 (2 commands)## Commands:# p, pick = use commit# r, reword = use commit, but edit the commit message# e, edit = use commit, but stop for amending# s, squash = use commit, but meld into previous commit# f, fixup = like "squash", but discard this commit's log message# x, exec = run command (the rest of the line) using shell# d, drop = remove commit## These lines can be re-ordered; they are executed from top to bottom.## If you remove a line here THAT COMMIT WILL BE LOST.## However, if you remove everything, the rebase will be aborted.## Note that empty commits are commented out 窗口会显示所有未提交到远程的 commit,下面的注释也告诉了我们该如何使用。我们找到edit的行,可以看到解释为使用当前的 commit,但是在变基过程中会停下来让我们修改。这正是我们想要的。我们编辑当前的内容如下: 12edit 7175772 top: filter .vscode folderpick 52b63f3 top: filter .cache folder 表示我们需要编辑历史记录中的top: filter .vscode folder提交,但是另一个 commit 我们不做改变。保存并退出当前窗口后,会有如下提示。 12345678Stopped at 7175772... top: filter .vscode folderYou can amend the commit now, with git commit --amend Once you are satisfied with your changes, run git rebase --continue 根据提示,我们可以进行一系列修改了,修改完使用git commit --amend保存,如果一切符合自己要求了,再使用git rebase --continue完成变基操作。 我们先修改代码,可以看到代码已经回到了没有/.cache/的状态,我们添加一行注释: 123456789101112131415# Object files*.o*.a*.dep#Build & install directoriesbuild/install/# Development friendly filestagscscope*# VSCode config file/.vscode/ 12git add .gitignoregit commit --amend 同样弹出窗口后我们直接保存退出,如果修改幅度较大,可以进一步补充说明。然后使用以下命令继续完成变基。 1git rebase --continue 此时我们可以看到我们不仅修改了历史记录中的 commit,还保证了最新的 commit 没有丢失或者更改。 准备更新版本的补丁集1234 $ git format-patch -v2 --cover-letter -o update_gitignore/ master..update_gitignore-v1update_gitignore/v2-0000-cover-letter.patchupdate_gitignore/v2-0001-top-filter-.vscode-folder.patchupdate_gitignore/v2-0002-top-filter-.cache-folder.patch --range-diff master..update_gitignore-v1 参数告诉 format-patch 在 cover letter 中包括 update_gitignore-v1 和 update_gitignore 两个分支之间的差异。这有助于告诉评审人你的 v1 和 v2 补丁之间的差异。 -v2 参数告诉 format-patch 将你的补丁输出为 v2 版本。例如,你可能注意到你的 v2 版补丁都被命名为 v2-000n-my-commit-subject.patch。-v2 也会将你的补丁格式化,在前面加上[PATCH v2],而不是[PATCH]。 运行此命令后,format-patch 会将补丁输出到 update_gitignore/ 目录,与 v1 版的补丁一起。使用一个目录可以方便在校对 v2 补丁时参考旧的 v1 补丁,但你需要注意只发送 v2 补丁。我们将使用 update_gitignore/v2-.patch这样的模式(而不是 update_gitignore/.patch,这将匹配 v1 和 v2 补丁)。 再次编辑你的 cover letter。现在是一个很好的时间来提及你的上一个版本和现在有什么不同,如果它是重要的东西。你不需要在你的第二封 cover letter 中使用完全相同的内容;重点是向审查人员解释你所做的可能不那么明显的变化。 我们就简单的写一下添加了注释。 12345678910111213141516From 30614e5469be4a2f930cca570836627a4e91f1d1 Mon Sep 17 00:00:00 2001From: Dominic Zhang <Dominic Zhang@gmail.com>Date: Fri, 18 Nov 2022 19:35:06 +0800Subject: [PATCH v2 0/2] Update gitignoreAdd a comment for the folder name.Dominic Zhang (2): top: filter .vscode folder top: filter .cache folder .gitignore | 3 +++ 1 file changed, 3 insertions(+)-- 2.17.1 发送更新版本时你需要将新版本抄送给提出建议的人,你可以在你的 cover letter 中直接添加这些抄送行,在 Subject 行上面写上这样一行。 1CC: Name <name@example.com> 例如,把更新的邮件抄送给我自己: 1234567891011121314151617From 30614e5469be4a2f930cca570836627a4e91f1d1 Mon Sep 17 00:00:00 2001From: Dominic Zhang <Dominic Zhang@gmail.com>CC: Dominic Zhang <Dominic Zhang@gmail.com>Date: Fri, 18 Nov 2022 19:35:06 +0800Subject: [PATCH v2 0/2] Update gitignoreAdd a comment for the folder name.Dominic Zhang (2): top: filter .vscode folder top: filter .cache folder .gitignore | 3 +++ 1 file changed, 3 insertions(+)-- 2.17.1 现在再次发送电子邮件,注意你传入的参数。 1git send-email --to target@example.com update_gitignore/v2-*.patch 恭喜你完成了一次补丁版本更新。 对于一些社区,要求更新的版本需要在同一个 thread 上进行。如下示例这样: 1234567[PATCH 0/2] Here is what I did... [PATCH 1/2] Clean up and tests [PATCH 2/2] Implementation [PATCH v2 0/3] Here is a reroll [PATCH v2 1/3] Clean up [PATCH v2 2/3] New tests [PATCH v2 3/3] Implementation 就是更新的版本需要关联到之前的版本,而不能作为单独的一个列表。 你还需要去找到你之前的 cover letter 的 Message-Id。你可以在发送第一个补丁系列时,从 git send-email 的输出中记下它。例如: 123456789101112131415$ git send-email --to Dominic Zhang@gmail.com update_gitignore/v2-*.patch update_gitignore/v2-0000-cover-letter.patchupdate_gitignore/v2-0001-top-filter-.vscode-folder.patchupdate_gitignore/v2-0002-top-filter-.cache-folder.patch(mbox) Adding cc: Dominic Zhang <Dominic Zhang@gmail.com> from line 'From: Dominic Zhang <Dominic Zhang@gmail.com>'(mbox) Adding cc: Dominic Zhang <254758318@qq.com> from line 'CC: Dominic Zhang <254758318@qq.com>'From: Dominic Zhang@gmail.comTo: Dominic Zhang@gmail.comCc: Dominic Zhang <254758318@qq.com>Subject: [PATCH v2 0/2] Update gitignoreDate: Fri, 18 Nov 2022 19:54:54 +0800Message-Id: <20221118115456.2242-1-Dominic Zhang@gmail.com>X-Mailer: git-send-email 2.17.1 你也可以从社区的邮箱列表中找到 Message ID,因为 OpenSBI 不要求在同一个 thread 回复,所以没有相关信息,这里以Git 社区的邮箱列表为例。随便点击一个补丁主题,在页面中找到permalink或者raw,点击打开即可找到 Message ID 信息。 它的格式一般如下: 1Message-Id: <foo.12345.author@example.com> 如果要发送更新版本,那么我们就需要找到上一版本的 Message ID。如发送的是 V3 版本,那么我们需要找到 V2 版本的 Message ID。并且在发送邮件时添加如下参数: 123$ git send-email --to Dominic Zhang@gmail.com --in-reply-to="<foo.12345.author@example.com>" update_gitignore/v2-*.patch 只有一个 Patch 的更改在某些情况下,你的非常小的变化可能只包括一个补丁。这时,你只需要发送一封邮件。你的提交信息应该已经很有意义了,你只需要生成补丁文件就可以发送了。 1git format-patch -o update_gitignore/ HEAD^ HEAD^参数表示生成与上一个提交之间的差异。","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"},{"name":"OpenSBI","slug":"OpenSBI","permalink":"http://example.com/tags/OpenSBI/"}]},{"title":"更换 Debian 软件更新源","slug":"Linux更换Debian软件更新源","date":"2022-11-05T01:27:52.000Z","updated":"2022-11-20T07:03:29.732Z","comments":true,"path":"2022/11/05/Linux更换Debian软件更新源/","link":"","permalink":"http://example.com/2022/11/05/Linux%E6%9B%B4%E6%8D%A2Debian%E8%BD%AF%E4%BB%B6%E6%9B%B4%E6%96%B0%E6%BA%90/","excerpt":"","text":"确认 Debian 版本12345678910$ cat /etc/os-release PRETTY_NAME="Debian GNU/Linux 10 (buster)"NAME="Debian GNU/Linux"VERSION_ID="10"VERSION="10 (buster)"VERSION_CODENAME=busterID=debianHOME_URL="https://www.debian.org/"SUPPORT_URL="https://www.debian.org/support"BUG_REPORT_URL="https://bugs.debian.org/" 括号里的buster就是版本信息。 获取镜像地址打开debian | 清华大学开源软件镜像站,选择buster版本,复制所有镜像地址。 1234567891011# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释deb https://mirrors.tuna.tsinghua.edu.cn/debian/ buster main contrib non-free# deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ buster main contrib non-freedeb https://mirrors.tuna.tsinghua.edu.cn/debian/ buster-updates main contrib non-free# deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ buster-updates main contrib non-freedeb https://mirrors.tuna.tsinghua.edu.cn/debian/ buster-backports main contrib non-free# deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ buster-backports main contrib non-freedeb https://mirrors.tuna.tsinghua.edu.cn/debian-security buster/updates main contrib non-free# deb-src https://mirrors.tuna.tsinghua.edu.cn/debian-security buster/updates main contrib non-free 备份原文件这也算是系统文件的一部分,还是保险一点,出错了再改回来。 1sudo cp /etc/apt/sources.list /etc/apt/sources.list.backup 打开并修改1sudo vim /etc/apt/sources.list vim用的不习惯的估计会和我一样找全选内容怎么操作。教给你了在命令模式下,就是按一下esc键,然后输入ggvG。具体什么含义看VIM 笔记吧,选择后直接delete删除,镜像地址粘贴进去。保存退出。 更新123sudo apt-get updatesudo apt-get dist-upgradesudo apt-get upgrade","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Debian","slug":"Debian","permalink":"http://example.com/tags/Debian/"}]},{"title":"QEMU's instance_init() vs. realize()","slug":"QEMU-s-instance-init-vs-realize","date":"2022-11-01T01:51:28.000Z","updated":"2022-11-20T07:03:29.699Z","comments":true,"path":"2022/11/01/QEMU-s-instance-init-vs-realize/","link":"","permalink":"http://example.com/2022/11/01/QEMU-s-instance-init-vs-realize/","excerpt":"","text":"转载自huth (Thomas Huth)的一篇文章,原文已经 404,从网页快照中找回的文章。 Note that this is a blog post for (new) QEMU developers. If you are just interested in using QEMU, you can certainly skip this text. Otherwise, in case you have ever been in touch with the QEMU device model (“qdev”), you are likely aware of the basic qdev code boilerplate already: 12345678910111213141516171819202122232425262728293031323334353637383940static void mydev_realize(DeviceState *dev, Error **errp){ }static void mydev_instance_init(Object *obj){ }static Property mydev_properties[] = { DEFINE_PROP_xxx("myprop", MyDevState, field, ...), DEFINE_PROP_END_OF_LIST(),};static void mydev_class_init(ObjectClass *oc, void *data){ DeviceClass *dc = DEVICE_CLASS(oc); dc->realize = mydev_realize; dc->desc = "My cool device"; dc->props = mydev_properties; }static const TypeInfo mydev_info = { .name = TYPE_MYDEV, .parent = TYPE_SYS_BUS_DEVICE, .instance_size = sizeof(mydev_state), .instance_init = mydev_instance_init, .class_init = mydev_class_init,};static void mydev_register_types(void){ type_register_static(&mydev_info);}type_init(mydev_register_types) There are three different initialization functions involved here, the class_init, the instance_init and the realize function. While it is quite obvious to distinguish the class_init function from the two others (it is used for initializing the class data, not the data that is used for an instance … this is similar to the object model with classes and instances in C++), I initially always wondered about the difference between the instance_init() and the realize() functions. Having fixed quite a lot of related bugs in the past months in the QEMU code base, I now know that a lot of other people are also not properly aware of the difference here, so I think it is now time to write down some information that I’m now aware of, to make sure that I don’t forget about this again, and maybe help others to avoid related bugs in the future ;-) First it is of course always a good idea to have a look at the documentation. While the documentation of TypeInfo (where instance_init() is defined) is not very helpful to understand the differences, the documentation of DeviceClass (where realize() is defined) has some more useful information: You can learn here that the object instantiation is done first, before the device is realized, i.e. the instance_init() function is called first, and the realize() function is called afterwards. The former must not fail, while the latter can return an error to its caller via a pointer to an “Error” object pointer. So the basic idea here is that device objects are first instantiated, then these objects can be inspected for their interfaces and their creators can set up their properties to configure their settings and wire them up with other devices, before the device finally becomes “active” by being realized. It is important here to notice that devices can be instantiated (and also finalized) without being realized! This happens for example if the device is introspected: If you enter for example device_add xyz,help at the HMP monitor, or if you send the device-list-properties QOM command to QEMU to retrieve the device’s properties, QEMU creates a temporary instance of the device to query the properties of the object, without realizing it. The object gets destroyed (“finalized”) immediately afterwards. Knowing this, you can avoid a set of bugs which could be found with a couple of devices in the past: If you want your device to provide properties for other parts of the QEMU code or for the users, and you want to add those properties via one of the many object_property_add*() functions of QEMU (instead of using the “props” field of the DeviceClass), then you should do this in the instance_init() and not in the realize() function. Otherwise the properties won’t show up when the user runs --device xyz,help or the device-list-properties QOM command to get some information about your device. instance_init() functions must really never fail, i.e. also not call abort() or exit(). Otherwise QEMU can terminate unexpectedly when a user simply wanted to have a look at the list of device properties with device_add xyz,help or the device-list-properties QOM command. If your device cannot work in certain circumstances, check for the error condition in the realize() function instead and return with an appropriate error there. Never assume that your device is always instantiated only with the machine that it was designed for. It’s of course a good idea to set the “user_creatable = false” flag in the DeviceClass of your device if your device cannot be plugged in arbitrary machines. But device introspection can still happen at any time, with any machine. So if you wrote a device called “mydev-a” that only works with --machine A, the user still can start QEMU with the option --machine B instead and then run device_add mydev-a,help or the device-list-properties QOM command. The instance_init() function of your device will be called to create a temporary instance of your device, even though the base machine is B and not A here. So you especially should take care to not depend on the availability of certain buses or other devices in the instance_init() function, nor use things like serial_hd() or nd_table[] in your instance_init() function, since these might (and should) have been used by the machine init function already. If your device needs to be wired up, provide properties as interfaces to the outside and let the creator of your device (e.g. the machine init code) wire your device between the device instantiation and the realize phase instead. Make sure that your device leaves a clean state after a temporary instance is destroyed again, i.e. don’t assume that there will be only one instance of your device which is created at the beginning right after QEMU has been started and is destroyed at the very end before QEMU terminates. Thus do not assume that the things that you do in your instance_init() don’t need explicit clean-up since the device instance will only be destroyed when QEMU terminates. Device instances can be created and destroyed at any time, so when the device is finalized, you must not leave any dangling pointers or references to your device behind you, e.g. in the QOM tree. When you create other objects in your instance_init() function, make sure to set proper parents of these objects or use an instance_finalize() function, so that the created objects get cleaned up correctly again when your device is destroyed. All in all, if you write code for a new QEMU device, it is likely a good idea to use the instance_init() function only for e.g. creating properties and other things that are required before device realization, and then do the main work in the realize() function instead.","categories":[{"name":"QEMU 源码分析","slug":"QEMU-源码分析","permalink":"http://example.com/categories/QEMU-%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/"}],"tags":[{"name":"QEMU","slug":"QEMU","permalink":"http://example.com/tags/QEMU/"}]},{"title":"ZH-UEFI 规范 -1-引言","slug":"ZH-UEFI规范-1-引言","date":"2022-10-18T12:07:10.000Z","updated":"2022-10-18T12:11:04.112Z","comments":true,"path":"2022/10/18/ZH-UEFI规范-1-引言/","link":"","permalink":"http://example.com/2022/10/18/ZH-UEFI%E8%A7%84%E8%8C%83-1-%E5%BC%95%E8%A8%80/","excerpt":"","text":"引言统一可扩展固件接口 (UEFI) 规范描述了操作系统和平台固件之间的接口。UEFI 之前是可扩展固件接口规范 1.10 (EFI)。因此,一些代码和某些协议名称保留了 EFI 名称。除非另有说明,本规范中的 EFI 名称可假定为 UEFI 的一部分。 该接口采用数据表的形式,其中包含与平台相关的信息,以及可供 OS 加载程序和 OS 使用的引导和运行时服务调用。它们共同提供了一个引导操作系统的标准环境。本规范是作为一个纯粹的接口规范设计的。因此,该规范定义了平台固件必须实现的接口和结构集。类似地,该规范定义了操作系统在引导时可能使用的一组接口和结构。无论是固件开发者选择如何实现所需的元素,还是操作系统开发者选择如何利用这些接口和结构,都由开发者自己决定。 该规范的目的是定义一种方法,使操作系统和平台固件仅通信支持操作系统引导过程所必需的信息。这是通过平台和固件提供给操作系统的软件可见接口的正式和完整的抽象规范来实现的。 本规范的目的是为操作系统和平台固件定义一种方式,以仅传递支持操作系统启动过程所需的信息。这是通过平台和固件呈现给操作系统的软件可见接口的抽象规范来实现的。 使用这一正式定义,旨在运行在与受支持的处理器规范兼容的平台上的收缩包装操作系统将能够在各种系统设计上启动,而无需进一步的平台或操作系统定制。该定义还允许平台创新引入新特性和功能,以增强平台的能力,而不需要按照操作系统的引导顺序编写新代码。 此外,抽象规范开辟了一条替代遗留设备和固件代码的路径。新的设备类型和相关代码可以通过相同定义的抽象接口提供同等的功能,同样不会影响 OS 引导支持代码。 该规范适用于从移动系统到服务器的所有硬件平台。该规范提供了一组核心服务以及一组协议接口。协议接口的选择可以随着时间的推移而发展,并针对不同的平台市场细分进行优化。与此同时,该规范允许 oem 提供最大限度的可扩展性和定制能力,以实现差异化。在这方面,UEFI 的目的是定义一个从传统的“PC-AT”风格的引导世界到一个没有遗留 API 的环境的进化路径。 UEFI 驱动模型扩展对启动设备的访问是通过一系列的协议接口提供的。UEFI 驱动模型的一个目的是为 “PC-AT”式的 Option ROM(TODO)提供一个替代品。需要指出的是,写在 UEFI 驱动模型上的驱动,被设计为在预启动环境中访问启动设备。它们并不是为了取代高性能的、针对操作系统的驱动程序。 UEFI 驱动模型被设计为支持执行模块化的代码,也被称为驱动,在预启动环境中运行。这些驱动程序可以管理或控制平台上的硬件总线和设备,也可以提供一些软件衍生的、平台特定的服务。 UEFI 驱动模型还包含了 UEFI 驱动编写者所需的信息,以设计和实现平台启动 UEFI 兼容的操作系统可能需要的任何总线驱动和设备驱动的组合。 UEFI 驱动模型被设计为通用的,可以适应任何类型的总线或设备。UEFI 规范描述了如何编写 PCI 总线驱动程序、PCI 设备驱动程序、USB 总线驱动程序、USB 设备驱动程序和 SCSI 驱动程序。提供了允许将 UEFI 驱动程序存储在 PCI Option ROM 中的其他详细信息,同时保持了与旧 Option ROM 镜像的兼容性。 UEFI 规范的一个设计目标是使驱动镜像尽可能的小。然而,如果一个驱动程序需要支持多个处理器架构,那么也需要为每个支持的处理器架构提供一个驱动程序对象文件。为了解决这个空间问题,本规范还定义了 EFI 字节代码虚拟机(EFI Byte Code Virtual Machine)。一个 UEFI 驱动可以被编译成一个 EFI 字节代码对象文件。UEFI Specification-complaint(TODO)的固件必须包含一个 EFI 字节代码解释器。这使得支持多种处理器架构的单一 EFI 字节代码对象文件可以被运出。另一种节省空间的技术是使用压缩。该规范定义了压缩和解压算法,可用于减少 UEFI 驱动程序的大小,从而减少 UEFI 驱动程序存储在 ROM 设备中时的开销。 OSV、IHV、OEM 和固件供应商可以使用 UEFI 规范中包含的信息来设计和实现符合本规范的固件、生成标准协议接口的驱动程序以及可用于引导 UEFI 兼容的操作系统加载程序操作系统。 章节安排本规范的章节组织如下: 章节名 内容 引言/概述 介绍 UEFI 规范,并描述 UEFI 的主要组件。 启动管理器 管理器用于加载写入此规范的驱动程序和应用程序。 EFI 系统表和分区 描述了一个 EFI 系统表,它被传递给每个兼容的驱动程序和应用程序,并定义了一个基于 GUID 的分区方案。 块转换表 用于执行块 I/O 的布局和规则集,可提供单个块的断电写入原子性。 引导服务 包含在引导操作系统之前存在于 UEFI 兼容系统中的基本服务的定义。 运行时服务 包含在操作系统启动之前和之后存在于兼容系统中的基本服务的定义。 协议 EFI 加载图像协议描述已加载到内存的 UEFI 镜像。 设备路径协议提供了在 UEFI 环境中构建和管理设备路径所需的信息。 UEFI 驱动模型描述了一组服务和协议,适用于每个总线和设备类型。 控制台支持协议定义了I/O协议,处理系统用户在启动服务环境中执行的基于文本的信息的输入和输出。 媒介访问协议定义了加载文件协议,文件系统格式和媒介格式处理可移动媒介。 PCI 总线支持协议定义 PCI 总线驱动程序,PCI 设备驱动程序和 PCI Option ROM 布局。所描述的协议包括 PCI 根桥 I/O 协议和 PCI I/O协议。 SCSI 驱动程序模型和总线支持定义了 SCSI I/O协议和扩展SCSI Pass Thru 协议,用于抽象访问由 SCSI 主机控制器产生的 SCSI 通道。 iSCSI协议定义了通过TCP/IP传输SCSI数据。 USB 支持协议定义了 USB 总线驱动程序和 USB 设备驱动程序。 调试器支持协议描述了一组可选的协议,提供所需的服务,以实现一个源级调试器的 UEFI 环境。 压缩算法规范详细描述了压缩/解压缩算法,外加一个标准的EFI解压缩接口,用于启动时使用。 ACPI 协议可用于从平台上安装或删除 ACPI 表。 字符串服务:Unicode 排序协议允许在启动服务环境中运行的代码对给定语言的 Unicode 字符串执行词法比较函数;正则表达式协议用于根据正则表达式模式匹配 Unicode 字符串。 EFI 字节码虚拟机 定义 EFI 字节码虚拟处理器及其指令集。它还定义了如何将 EBC 对象文件加载到内存中,以及从本机代码到 EBC 代码再转换到本机代码的机制。 固件更新和报告 为设备提供一个抽象,以提供固件管理支持。 网络协议 SNP、PXE、BIS 和 HTTP 启动协议定义了在 UEFI 启动服务环境中执行时提供对网络设备访问的协议。 受管网络协议定义了 EFI 受管网络协议,它提供原始 (未格式化) 异步网络数据包 I/O 服务和托管网络服务绑定协议,用于定位 MNP 驱动支持的通信设备。 VLAN、EAP、Wi-Fi 和 Supplicant 协议定义了一个协议,为 VLAN 配置提供可管理性接口。 蓝牙协议定义。 TCP、IP、PIPsec、FTP、GTLS 和 Configurations 协议定义了 EFI TCPv4 (Transmission Control Protocol version 4) 协议和 EFI IPv4 (Internet Protocol version 4) 协议。 ARP、DHCP、DNS、HTTP 和 REST 协议定义了 ARP (Address Resolution Protocol) 协议接口和 EFI DHCPv4 协议。 UDP 和 MTFTP 协议定义了 EFI UDPv4 (User Datagram Protocol version 4) 协议,该协议在 EFI IPv4 协议上接口,并定义了 EFI MTFTPv4 协议接口,该接口建立在 EFI UDPv4 协议之上。 安全引导和驱动程序签名 介绍 Secure Boot 和生成 UEFI 数字签名的方法。 人机界面基础设施 (HII) 定义实现人机接口基础设施 (HII) 所需的核心代码和服务,包括管理用户输入和相关协议的代码定义的基本机制。 描述用于管理系统配置的数据和 api:描述旋钮和设置的实际数据。 用户标识 描述描述平台当前用户的服务。 安全技术 描述用于利用安全技术的协议,包括加密散列和密钥管理。 杂项协议 Timestamp 协议提供了一个独立于平台的接口来检索高分辨率的时间戳计数器。当调用 ResetSystem 时,重置通知协议提供注册通知的服务。 附录 GUID 和时间格式。 基于基本文本的控制台要求,符合 efi 系统需要提供通信能力。 设备路径使用数据结构的例子,定义各种硬件设备的引导服务。 状态代码列出了 UEFI 接口返回的成功、错误和警告代码。 通用网络驱动程序接口定义了32/64位硬件和软件通用网络驱动程序接口(UNDIs)。 使用简单指针协议。 使用 EFI 扩展 SCISI 直通协议。 压缩源代码的一个压缩算法的实现。 一个 EFI 解压缩算法的实现的解压源代码。 EFI 字节码虚拟机操作码列表提供了相应指令集的摘要。 字母功能列表按字母顺序标识所有 UEFI 接口功能。 EFI 1.10 协议变更和折旧清单标识了协议、GUID、修订标识符名称变更以及与 EFI 1.10 规范相比已弃用的协议。 平台错误记录描述了用于表示平台硬件错误的常见平台错误记录格式。 UEFI ACPI Data Table 定义了 UEFI ACPI 表格式。 硬件错误记录持久性使用。 引用 术语表 索引 提供规范中关键术语和概念的索引。 目标“PC-AT”启动环境对行业内的创新提出了重大挑战。每一个新的平台功能或硬件创新都要求固件开发人员设计越来越复杂的解决方案,并且通常要求操作系统开发人员修改引导代码,然后客户才能从创新中受益。这可能是一个耗时的过程,需要大量的资源投资。 UEFI 规范的主要目标是定义一个替代引导环境,可以减轻这些考虑。在这个目标中,该规范类似于其他现有的引导规范。本规范的主要属性可以概括为以下属性: 一致的、可扩展的平台环境。该规范为固件定义了一个完整的解决方案,以描述所有平台特性和 OS 的 surface platform(TODO) 功能在引导过程中。这些定义非常丰富,足以涵盖一系列当代处理器设计。 从固件中抽象操作系统。该规范定义了平台功能的接口。通过使用抽象接口,该规范允许在构建 OS 加载器时,而无需了解作为这些接口基础的平台和固件。这些接口代表了底层平台和固件实现与操作系统加载程序之间定义良好的稳定边界。这样的边界允许底层固件和操作系统加载程序更改,前提是两者都将交互限制在定义的接口上。 合理的设备抽象,不需要遗留接口。“PC-AT”BIOS 接口要求操作系统加载程序对某些硬件设备的工作有特定的了解。该规范为 OS 加载器开发人员提供了一些不同的东西:抽象接口使得可以构建在一系列底层硬件设备上工作的代码,而无需明确了解该范围内每个设备的细节。 从固件中提取 Option ROM。该规范定义了平台功能的接口,包括 PCI、USB 和 SCSI 等标准总线类型。支持的总线类型可能会随着时间的推移而增加,因此包括了一种扩展到未来总线类型的机制。这些定义的接口以及扩展到未来总线类型的能力是 UEFI 驱动程序模型的组件。UEFI 驱动模型的一个目的是解决现有“PC-AT”Option ROM 中存在的广泛问题。与 OS 加载程序一样,驱动程序使用抽象接口,因此可以构建设备驱动程序和总线驱动程序,而无需了解作为这些接口基础的平台和固件。 架构上可共享的系统分区。扩展平台功能和添加新设备的计划通常需要软件支持。在许多情况下,当这些平台创新(TODO)在操作系统控制平台之前被激活时,它们必须由特定于平台而不是客户选择的操作系统的代码支持。解决这个问题的传统方法是在制造过程中将代码嵌入平台中(例如,在闪存设备中)。对这种持久存储的需求正在快速增长。该规范定义了大型海量存储媒介类型上的持久存储,以供平台支持代码扩展使用,以补充传统方法。规范中明确了其工作原理的定义,以确保固件开发商、OEM、操作系统供应商甚至第三方可以安全地共享空间,同时增加平台功能。 可以通过多种方式定义提供这些属性的引导环境。实际上,在编写本规范时,已经存在几种替代方案,从学术角度来看可能是可行的。然而,考虑到当前围绕支持的处理器平台的基础设施能力,这些替代方案通常会带来很高的门槛。本规范旨在提供上面列出的属性,同时也认识到行业的独特需求,该行业在兼容性方面进行了大量投资,并且拥有大量无法立即放弃的系统安装基础。这些需求推动了对本规范中体现的附加属性的要求: 进化性的,而不是革命性的。规范中的接口和结构旨在尽可能地减少初始实现的负担。虽然已经小注意保在接口本身中维护适当的抽象,但该设计还确保可以重用 BIOS 代码来实现接口,而只需要最少的额外编码工作。换句话说,在 PC-AT 平台上,规范最初可以作为基于现有代码的底层实现之上的薄接口(thin Interface TODO)层来实现。同时,抽象接口的引入提供了将来从遗留代码的迁移。一旦抽象被确立为固件和操作系统加载程序在引导期间交互的手段,开发人员就可以随意替换抽象接口下的遗留代码。类似的硬件遗留迁移也是可能的。由于抽象隐藏了设备的细节,因此可以移除底层硬件,并用提供改进功能、降低成本或两者兼而有之的新硬件替换它。显然,这需要编写新的平台固件来支持设备并通过抽象接口将其呈现给 OS 加载器。但是,如果没有接口抽象,则可能根本无法移除旧设备。 设计上的兼容性。系统分区结构的设计还保留了当前在“PC-AT”引导环境中使用的所有结构。因此,构建一个能够从同一磁盘引导传统操作系统或 EFI-aware 操作系统的单一系统是一件简单的事情。 简化了操作系统中立的平台增值的添加。该规范定义了一个开放的、可扩展的接口,它有助于创建平台“驱动程序”。这些可能类似于操作系统驱动程序,在引导过程中为新设备类型提供支持,或者它们可能用于实现增强的平台功能,例如容错或安全性。此外,这种扩展平台能力的能力从一开始就被设计到规范中。这旨在帮助开发人员避免在尝试将新代码挤入传统 BIOS 环境时所固有的许多挫败感。由于包含用于添加新协议的接口,OEM 或固件开发人员拥有以模块化方式向平台添加功能的基础设施。由于规范中定义的调用约定和环境,此类驱动程序可能会使用高级编码语言来实现。这反过来可能有助于降低创新的难度和成本。系统分区选项为此类扩展提供了非易失性存储器存储的替代方案。 建立在现有投入的基础上。在可能的情况下,规范避免在现有行业规范提供足够覆盖的领域重新定义接口和结构。例如,ACPI 规范为操作系统提供了发现和配置平台资源所需的所有信息。同样,规范设计的这种哲学选择旨在尽可能降低采用该规范的障碍。 目标受众本文档主要适用于以下读者: 将实现 UEFI 驱动程序的 IHV 和 OEM。 将创建支持的处理器平台的 OEM 厂商,旨在启动 shrink-wrap(TODO)的操作系统。 BIOS 开发人员,无论是创建通用 BIOS 和其他固件产品的人员,还是修改这些产品的支持人员。 操作系统开发人员将调整他们的 shrink-wrap(TODO)操作系统产品,用来在支持的基于处理器的平台上运行。 UEFI 设计概述UEFI 的设计基于以下基本要素: 重用现有的基于表格的接口。为了保持对现有基础支持代码(包括操作系统和固件)的投资,必须在希望符合 UEFI 规范的平台上,实现通常在与支持的处理器规范兼容的平台上,实现的许多现有规范。 (有关更多信息,请参阅附录 Q:参考资料。) 系统分区。系统分区定义了一个分区和文件系统,可允许多个供应商之间安全共享,并用于不同目的。包含单独的、可共享的系统分区的能力提供了增加平台附加值的机会,而不会显著增加对非易失性平台存储器的需求。 引导服务。引导服务为可在引导期间使用的设备和系统功能提供接口。设备访问是通过“句柄”(handles)和“协议”(protocols) 抽象出来的。这有利于重用现有 BIOS 代码,将基本实现要求保持在规范之外,而不会给访问设备的消费者带来负担。 运行时服务。提供了一组最小的运行时服务,以确保对基础平台的硬件资源进行适当的抽象,这些资源可能是操作系统在正常运行时需要的。 图 1-1 描述了用于完成平台和操作系统引导的符合 UEFI 规范的系统的各种组件的交互。 平台固件能够从系统分区中检索操作系统加载器镜像。该规范提供了各种大容量存储设备类型,包括磁盘、CD-ROM 和 DVD,以及通过网络的远程启动。通过可扩展的协议接口,有可能增加其他的引导媒介类型,尽管如果这些媒介需要使用本文件中定义的协议以外的协议,可能需要修改操作系统加载器。 一旦启动,操作系统加载程序将继续引导整个操作系统。为此,它可以使用本规范或其他所需规范定义的 EFI 引导服务和接口来探测、解析和初始化各种平台组件和管理它们的操作系统软件。在引导阶段,EFI 运行时服务也可供 OS 加载器使用。 UEFI 驱动模型本节描述了符合本规范的固件的驱动模型的目标。目标是让这个驱动模型为所有类型的总线和设备提供一个实现总线驱动和设备驱动的机制。在撰写本文时,支持的总线类型包括 PCI、USB 等。 随着硬件架构的不断发展,平台中存在的总线数量和类型也在不断增加。这种趋势在高端服务器中尤为明显。然而,更多样化的总线类型被设计到桌面和移动系统,甚至一些嵌入式系统中。这种日益增长的复杂性,意味着在预启动环境中,需要一种简单的方法来描述和管理平台中的所有总线和设备。UEFI 驱动模型以协议、服务和启动服务的形式提供了这种简单的方法。 UEFI 驱动程序模型目标UEFI 驱动模型有以下目标: 兼容 – 符合此规范的驱动程序必须保持与 EFI 1.10 规范和 UEFI 规范的兼容性。这意味着 UEFI 驱动程序模型利用 UEFI 2. 0 规范中的可扩展性机制来添加所需的功能。 简单 - 符合本规范的驱动程序必须易于实现,易于维护。UEFI 驱动模型必须允许驱动编写者专注于正在开发的特定设备的驱动。驱动程序不应关注平台策略或平台管理问题。这些考虑应该留给系统固件。 可扩展性 - UEFI 驱动模型必须能够适应所有类型的平台。这些平台包括嵌入式系统、移动和桌面系统,以及工作站和服务器。 灵活 - UEFI 驱动模型必须支持枚举所有设备的能力,或者只枚举启动所需操作系统的那些设备。最小的设备枚举提供了对更快速的启动能力的支持,而完整的设备媒体提供了在系统中存在的任何启动设备上执行操作系统安装、系统维护或系统诊断的能力。 可扩展性 - UEFI 驱动模型必须能够扩展到未来定义的总线类型。 可移植性 - 根据 UEFI 驱动模型编写的驱动,必须在不同平台和支持的处理器架构之间可移植。 可互操作性 - 驱动程序必须与其他驱动程序和系统固件共存,并且必须在不产生资源冲突的情况下进行操作。 描述复杂的总线层次结构 - UEFI 驱动模型必须能够描述各种总线拓扑结构,从非常简单的单总线平台到包含许多不同类型总线的非常复杂的平台。 驱动占用空间小 - 由 UEFI 驱动程序模型产生的可执行文件的大小必须最小化,以减少整体平台成本。虽然灵活性和可扩展性是目标,但支持这些所需的额外开销必须保持在最低水平,以防止固件组件的大小变得无法管理。 解决遗留 Option ROM 的问题 - UEFI 驱动模型必须直接解决遗留 Option ROM 的约束和限制。具体来说,必须能够建立同时支持 UEFI 驱动和传统 Option ROM 的插件卡,这种卡可以在传统 BIOS 系统和符合 UEFI 的平台上执行,而无需修改卡上的代码。该解决方案必须提供一个从传统 Option ROM 驱动程序迁移到 UEFI 驱动程序的进化路径。 遗留 Option ROM 问题这个支持驱动模型的想法来自于对 UEFI 规范的反馈,它提供了一个明确的、由市场驱动的对传统选项 ROM(有时也被称为扩展 ROM)的替代要求。人们认为,UEFI 规范的出现代表了一个机会,通过用一种在 UEFI 规范框架内工作的替代机制来取代传统选项 ROM 镜像的构建和操作,从而摆脱隐含的限制。 迁移要求迁移要求涵盖了从最初实施本规范到未来所有平台和操作系统都实施本规范的过渡时期。在这一时期,有两个主要的兼容性考虑是很重要的。 能够继续启动传统的操作系统; 能够在现有的平台上实现 UEFI,尽可能多地复用现有的固件代码,将开发资源和时间要求降到最低。 旧版操作系统支持UEFI 规范代表了收缩式操作系统和固件在启动过程中进行通信的首选方式。然而,选择制作一个符合该规范的平台,并不排除该平台,也支持不了解 UEFI 规范的,现有传统操作系统二进制文件。 UEFI 规范并不限制平台设计者,选择同时支持 UEFI 规范和更传统的 “PC-AT “启动基础架构。如果要实现这样的传统基础架构,应该按照现有的行业惯例来开发,这些惯例是在本规范范围之外定义的。在任何给定的平台上,支持的传统操作系统的选项是由该平台的制造商决定的。 在旧平台上支持 UEFI 规范UEFI 规范经过精心设计,允许以最少的开发工作扩展现有系统以支持它。特别是 UEFI 规范中定义的抽象结构和服务,都可以在遗留平台上得到支持 例如,要在现有且受支持的基于 32 位的平台上实现此类支持,该平台使用传统 BIOS 来支持操作系统启动,需要提供额外的固件代码层。需要这些额外的代码来将服务和设备的现有接口转换为对本规范中定义的抽象的支持。 本文档中使用的约定数据结构描述支持的处理器是“小端”机器。这种区别意味着内存中多字节数据项的低位字节位于最低地址,而高位字节位于最高地址。一些受支持的 64 位处理器可以配置为“小端”和“大端”操作。所有旨在符合本规范的实现都使用“小端”操作。 在某些内存布局描述中,某些字段被标记为保留。软件必须将这些字段初始化为零并在读取时忽略它们。在更新操作中,软件必须保留任何保留字段。 协议描述协议描述一般有以下格式: 协议名称:协议接口的正式名称。 摘要:协议接口的简要描述。 GUID:协议接口的 128 位 GUID (Globally Unique Identifier)。 协议接口结构:一种“c 风格”的数据结构定义,包含由该协议接口产生的过程和数据字段。 参数:协议接口结构中各字段的简要说明。 描述:对接口提供的功能的描述,包括调用者应该知道的任何限制和警告。 相关定义:协议接口结构或其任何过程中使用的类型声明和常量。 过程描述过程描述通常具有以下格式: 过程名称:过程的正式名称。 摘要:过程的简要说明。 原型:定义调用序列的“C 风格”过程标头。 参数:对程序原型中每个字段的简要描述。 描述:对接口所提供的功能的描述,包括调用者应该注意的任何限制和注意事项。 相关定义:仅由该过程使用的类型声明和常量。 返回的状态代码:对接口所返回的任何代码的描述。该过程需要实现本表中列出的任何状态代码。可以返回更多的错误代码,但是它们不会被标准的符合性测试所测试,而且任何使用该程序的软件,都不能依赖于实现可能提供的任何扩展错误代码。 指令描述EBC 指令的指令描述一般有以下格式: 指令名称:指令的正式名称。 语法:指令的简要描述。 描述:对指令所提供的功能的描述,并附有指令编码的详细表格。 操作:详细说明对操作数进行的操作。 行为和限制:逐项描述指令中涉及的每个操作数的行为,以及适用于操作数或指令的任何限制。 伪代码约定提出伪代码是为了以更简洁的形式描述算法。本文件中的所有算法都不打算直接进行编译。代码是在与周围文本相对应的水平上呈现的。 在描述变量时,列表是一个无序的同质对象的集合。一个队列是一个同质对象的有序列表。除非另有说明,否则假设排序为先进先出。 伪代码以类似于 C 的格式呈现,在适当的地方使用 C 约定。编码风格,特别是缩进风格,是为了可读性,不一定符合 UEFI 规范的实现。 排版约定本文件采用了以下描述的排版和说明性惯例。 纯文本:规范中的绝大部分描述性文本都使用普通文本字体。 纯文本(蓝色):任何有下划线和蓝色的纯文本都表示与交叉参考资料的活动链接。点击该词,就可以跟踪超链接。 加粗:在文本中,粗体字标识了一个处理器寄存器的名称。在其他情况下,黑体字可以作为段落中的标题。 斜体:在文本中,斜体字可以用作强调,以引入一个新的术语或表示手册或规范的名称。 加粗等宽(暗红色):计算机代码、示例代码段和所有原型代码段使用 BOLD Monospace 字体,颜色为暗红色。这些代码列表通常出现在一个或多个独立的段落中,尽管单词或片段也可以嵌入到一个正常的文本段落中。 加粗等宽(蓝色):用粗体单色字体的字,下划线和蓝色的字,表示该功能或类型定义的代码定义的活动超链接。点击该词,即可进入超链接。 注意:出于管理和文件大小的考虑,每一页上只有第一次出现的参考文献是一个主动链接。同一页上的后续参考文献不会被主动链接到定义上,而是使用标准的、无下划线的 BOLD Monospace 字体。在页面上找到该名称的第一个实例(使用下划线的 BOLD Monospace 字体),点击该词即可跳转到该功能或类型的定义。 斜体等宽:在代码或文本中,斜体字表示必须提供的变量信息的占位符名称(即参数)。 数字格式在本标准中,二进制数字是由仅由西方阿拉伯数字 0 和 1 组成的任何数字序列表示的,后面紧跟一个小写的 b(例如,0101b)。在二进制数字表示中的字符之间可以包含下划线或空格,以增加可读性或划分领域边界(例如,0 0101 1010b 或 0_0101_1010b)。 十六进制十六进制数字在本标准中用 0x 表示,前面是仅由西阿拉伯数字 0 至 9 和/或大写英文字母 A 至 F 组成的任何数字序列(例如,0xFA23)。十六进制数字表示中的字符之间可以包含下划线或空格,以增加可读性或划定字段边界(例如,0xB FD8C FA23 或 0xB_FD8C_FA23)。 十进制在本标准中,小数是由仅由阿拉伯数字 0 到 9 组成的任何数字序列来表示的,后面不紧跟小写的 b 或小写的 h(例如,25)。本标准使用以下惯例来表示小数: 小数点分隔符(即分隔数字的整数部分和小数部分)是一个句号; 千位数分隔符(即分隔数字部分的三位数组)是一个逗号; 千位数分隔符用于数字的整数部分,不用于数字的小数部分。 二进制前缀本标准使用国际单位制(SI)中定义的前缀来表示 10 的幂值。见 “SI 二进制前缀 “标题下的 “UEFI 相关文件链接”(http://uefi.org/uefi)。 本标准使用ISO/IEC 80000-13《数量和单位–第 13 部分:信息科学和技术》和 IEEE 1514《二进制倍数前缀标准》中定义的二进制前缀,用于表示 2 的幂值。 例如,4 KB 意味着 4000 个字节,4 KiB 意味着 4096 个字节。 修订号对 UEFI 规范的更新被认为是新的修订或勘误表,如下所述: 当有实质性的新内容或可能修改现有行为的变化时,就会产生一个新的修订。新的修订版由一个主要的。次要的版本号来指定(例如:xx.yy)。在变化特别小的情况下,我们可能有一个 major.minor.minor 的命名惯例(例如 xx.yy.zz)。 当批准的规范更新不包括任何重要的新材料或修改现有行为时,就会产生勘误的版本。勘误的指定方法是在版本号后面加上一个大写字母,如 xx.yy 勘误 A。","categories":[],"tags":[]},{"title":"解决 VSCode 远程登录失败 Error: WebSocket close with status code 1006","slug":"解决VSCode远程登录失败Error-WebSocket-close-with-status-code-1006","date":"2022-10-15T10:53:20.000Z","updated":"2022-10-15T10:58:17.924Z","comments":true,"path":"2022/10/15/解决VSCode远程登录失败Error-WebSocket-close-with-status-code-1006/","link":"","permalink":"http://example.com/2022/10/15/%E8%A7%A3%E5%86%B3VSCode%E8%BF%9C%E7%A8%8B%E7%99%BB%E5%BD%95%E5%A4%B1%E8%B4%A5Error-WebSocket-close-with-status-code-1006/","excerpt":"","text":"保留现场使用 VSCode 远程登录失败,报错:Failed to connect to the remote extension host server (Error: WebSocket close with status code 1006)。 解决方法1234567891011vim /etc/ssh/sshd_configAllowTcpForwarding noAllowAgentForwarding no# 替换为AllowTcpForwarding yesAllowAgentForwarding yes 保存后重启 sshd 服务: 1systemctl restart sshd","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"如何使用 GitHub Actions","slug":"如何使用GitHub-Actions","date":"2022-10-14T14:08:54.000Z","updated":"2022-12-03T12:19:56.101Z","comments":true,"path":"2022/10/14/如何使用GitHub-Actions/","link":"","permalink":"http://example.com/2022/10/14/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8GitHub-Actions/","excerpt":"","text":"简介GitHub Actions 是 GitHub 在 2018 年推出的持续集成服务。它可以自动完成一些开发周期内的任务,如 Push 代码时自动编译,Pull 代码时自动执行测试脚本等等。 我了解 GitHub Actions 的契机是,我在 GitHub 上保存了一些 Markdown 文档,我希望每次更新文档后自动使用 Pandoc 转换成 PDF 文档。接下来我们一起学习如何通过 GitHub Actions 实现这样的需求。 首先我们先直观的了解一下它在 GitHub 的位置,如果打开一个仓库,它有图中绿色对号√,或者红色叉号×,说明这个项目配置了 GitHub Actions,绿色表示自动化的流程运行成功了,红色表示失败了。 我们点开Actions按钮就可以查看具体的任务详情。下面我们先学习如何配置一个简单的 GitHub Actions。 配置 GitHub ActionsGitHub Actions 可以简单理解为一些自动化脚本,工具,目的就是为了减少重复工作,所以这些工具都可以做成普适性的工具。而 GitHub 官方就开放了一个这类工具的市场,我们可以在上面搜索自己想要的工具。因为初学 GitHub Actions 所以也不知道怎么写配置文件,我们可以直接搜索一个并应用它,看看别人是怎么写的。 我们进入一个自己的仓库,点击Actions,搜索框中搜索PDF,在搜索结果中找到Create PDF · Actions这个工具。如果搜索到点击Configure。如果显示未找到,则点击set up a workflow yourself,同样搜索PDF。 打开详情页面,拉到底,将Example usage。里的内容复制到编辑框中。点击右上角Start commit将会把我们新建的main.yml提交到仓库中。这就相当于创建了一个生成 PDF 的 GitHub Actions。当然每个 Actions 都有一些使用要求,比如这里还要根据介绍,创建几个文件夹,比如从哪个文件夹获取源文件,生成后的 PDF 又会放到哪个文件夹等。这里就不再介绍,我们先了解如何创建一个 Actions。 Workflow 配置GitHub Actions 的配置文件叫做 workflow 文件,存放在代码仓库的.github/workflows 目录。 workflow 文件采用 YAML 格式,文件名可以任意取,但是后缀名统一为.yml or .yaml,比如 foo.yml or foo.yaml。一个库可以有多个 workflow 文件。GitHub 只要发现.github/workflows 目录里面有.yml or .yaml 文件,就会自动运行该文件(并行)。 接下来我们逐个参数来解释都有哪些功能。 on触发 workflow 的 GitHub 事件的名称。比如push代码时触发,其他人fork代码仓时触发等等。 可以只有一个事件触发, 1on: push 也可有多个事件触发,使用列表列举, 1on: [push, fork] 所有支持的事件列表,请查看官方文档。 on.[push|fork].[tags|branches]注意:从这里开始就会出现一个字段下有子字段,每个点号.分割一个子字段。如push或者fork可以作为on的子字段,tags或者branches可以作为push或者fork的子字段。在yaml文件中,缩进很重要,每个缩进都表示是从属关系,表示是该字段的子字段。千万要注意缩进关系,如果缩进出错,那么将无法解析yaml文件。 指定触发事件时,可以限定分支或标签。 1234on: push: branches: - master 上面代码指定,只有 master 分支发生 push 事件时,才会触发 workflow。 name工作流程的名称。GitHub 在仓库的操作页面上显示工作流程的名称。如果省略 name,GitHub 将其设置为相对于仓库根目录的工作流程文件路径。 jobsworkflow 运行包括一项或多项 jobs。jobs 默认是并行运行。要按顺序运行作业,可以使用 [job_id].needs 关键词在其他 job 上定义依赖项。 每个作业在 runs-on 指定的运行器环境中运行。 jobs.[job_id]jobs 中的每个任务都有一个[job_id] ,且其必须为 jobs 对象中唯一的字符串键值。[job_id]必须以字母或_开头,并且只能包含字母数字字符、-或_。 12345jobs: first_job: # [job_id],任务 id name: My first job second_job: name: My second job jobs.[job_id].[runs-on]runs-on 字段指定运行所需要的虚拟机环境。它是必填字段。目前可用的虚拟机如下。 123- ubuntu-latest,ubuntu-18.04或ubuntu-16.04- windows-latest,windows-2019或windows-2016- macOS-latest或macOS-10.14 下面代码指定虚拟机环境为 ubuntu-18.04。 1runs-on: ubuntu-18.04 jobs.[job_id].nameworkflow 文件的主体是 jobs 字段,表示要执行的一项或多项任务。 job_id 里面的 name 字段是任务的说明。它可以在网页端的 UI 上显示。 12345jobs: first_job: name: My first job # [job_name],任务名称 second_job: name: My second job jobs.[job_id].needsneeds 字段指定当前任务的依赖关系,即运行顺序。 123456jobs: job1: job2: needs: job1 job3: needs: [job1, job2] 上面代码中,job1 必须先于 job2 完成,而 job3 等待 job1 和 job2 的完成才能运行。因此,这个 workflow 的运行顺序依次为:job1、job2、job3。 jobs.[job_id].stepssteps 字段指定每个 Job 的运行步骤,可以包含一个或多个步骤。每个步骤都可以指定以下三个字段。 123- jobs.[job_id].steps.name:步骤名称。- jobs.[job_id].steps.run:该步骤运行的命令或者 action。- jobs.[job_id].steps.env:该步骤所需的环境变量。 下面是一个完整的 workflow 文件的范例。 12345678910111213141516name: Greeting from Monaon: pushjobs: my-job: name: My Job runs-on: ubuntu-latest steps: - name: Print a greeting env: MY_VAR: Hi there! My name is FIRST_NAME: Mona MIDDLE_NAME: The LAST_NAME: Octocat run: | echo $MY_VAR $FIRST_NAME $MIDDLE_NAME $LAST_NAME. 上面代码中,steps 字段只包括一个步骤。该步骤先注入四个环境变量,然后执行一条 Bash 命令。 jobs.[job_id].steps[*].uses选择一个 action,可以理解为若干 steps.run,有利于代码复用。这也是 github action 最主要的功能。 比如最常用的,下载本仓库的代码到工作区,就是使用的一个 action 完成的: 123steps: - name: Check out Git repository uses: actions/checkout@v2 注:@v2 什么意思?表示 Action 的版本。我们如果不带版本号的话,就是默认使用最新版本。Github 官方强烈要求我们带上版本号。这样子的话,我们就不会出现:写好一个 Workflow,但是由于某个 Action 的作者一更新,我们的 Workflow 就崩了的问题 jobs.[job_id].steps.run在 shell 中执行的命令: 123456steps: - uses: actions/checkout@v2 - name: create dir id: dir run: | mkdir output # create output dir 以上配置是在下载完本仓库的代码后,在仓库根目录新建一个output文件夹。注意run:后的|表示可以多行命令。如果没有|表示只能执行一条命令。 jobs.[job_id].steps.working-directory用来指定在run命令在哪执行。 123- name: Create dir run: mkdir output working-directory: ./build jobs.[job_id].steps.shell用来指定 shell 类型,如 Python,bash,powershell 等。 1234steps: - name: Display the path run: echo $PATH shell: bash 所有支持的类型请查看官方文档。 如何跳过 GitHub Actions在 commit message 中只要包含了下面几个关键词就会跳过 Github Actions。 12345[skip ci][ci skip][no ci][skip actions][actions skip] 实例:自动使用 Pandoc 将 Markdown 文件转换为 PDF以Dunky-Z/uefi-spec-zh项目中使用的 GitHub Actions 为例,解释如何实现将 Markdown 文件转换为 PDF。 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253# CI 名为 MPPLname: MPPL# 在 Push 代码时触发 CIon: pushjobs: # 任务名称为 convert_via_pandoc convert_via_pandoc: # 在 ubuntu-latest 系统上运行 runs-on: ubuntu-latest steps: # 步骤一:下载最新代码 - uses: actions/checkout@v2 # 步骤二:在项目根目录建立 output 文件夹放生成的 PDF 文件 - name: create file list id: files_list run: | mkdir output # create output dir # 步骤三:更新项目的子模块 - name: Git Sumbodule Update run: | git submodule update --init --remote --recursive # 步骤四:为运行的系统中安装需要的字体,因为原系统没有需要的中文字体 # 字体来源为项目目录的MPPL/fonts - name: add fonts run: | sudo apt-get install ttf-mscorefonts-installer sudo apt-get install fontconfig fc-list :lang=zh ls -lh /usr/share/fonts/ cp -rf ./MPPL/fonts/* /usr/share/fonts/ mkfontscale mkfontdir fc-cache fc-list # 步骤五:安装 pandoc 和 texlive - name: install pandoc run: | sudo apt-get update sudo apt-get install texlive-full sudo apt-get install pandoc sudo apt-get clean # 步骤六:使用 pandoc 命令生成 pdf - name: build pdf run: | cd src pandoc -f markdown-auto_identifiers --listings --pdf-engine=xelatex --template=../MPPL/templates/mppl.tex --output=../output/UEFI规范-中文.pdf *.md # 步骤七:将生成的结果上传到 GitHub - uses: actions/upload-artifact@master with: name: output path: output 注意事项every step must define a uses or run keyevery step must define a uses or run key · Issue #2 · einaregilsson/beanstalk-deploy 参考GH actions: a step cannot have both the uses and run keys · Issue #318 · fhem/mod-Buienradar every step must define a uses or run key · Issue #2 · einaregilsson/beanstalk-deploy","categories":[],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"},{"name":"Efficiency","slug":"Efficiency","permalink":"http://example.com/tags/Efficiency/"},{"name":"Github","slug":"Github","permalink":"http://example.com/tags/Github/"},{"name":"CI","slug":"CI","permalink":"http://example.com/tags/CI/"}]},{"title":"加密算法总结","slug":"加密算法总结","date":"2022-10-10T05:44:32.000Z","updated":"2022-10-15T03:14:29.678Z","comments":true,"path":"2022/10/10/加密算法总结/","link":"","permalink":"http://example.com/2022/10/10/%E5%8A%A0%E5%AF%86%E7%AE%97%E6%B3%95%E6%80%BB%E7%BB%93/","excerpt":"","text":"基本概念明文与密文 Plaintext,明文,未经加密的消息,任何人都可以读 Ciphertext,密文,加密后的消息,不可读 Key,密钥,用于加密和解密(核心是算法) 加密与解密概念加密数据加密 的基本过程,就是对原来为 明文 的文件或数据按 某种算法 进行处理,使其成为 不可读 的一段代码,通常称为“密文”。通过这样的途径,来达到 保护数据 不被 非法人窃取、阅读的目的。 解密加密 的 逆过程 为 解密,即将该 编码信息 转化为其 原来数据 的过程。 对称加密和非对称加密加密算法分 对称加密 和 非对称加密,其中对称加密算法的加密与解密 密钥相同,非对称加密算法的加密密钥与解密 密钥不同,此外,还有一类 不需要密钥 的 散列算法。 对称加密对称加密算法 是应用较早的加密算法,又称为 共享密钥加密算法。在 对称加密算法 中,使用的密钥只有一个,发送 和 接收 双方都使用这个密钥对数据进行 加密 和 解密。这就要求加密和解密方事先都必须知道加密的密钥。 数据加密过程:在对称加密算法中,数据发送方 将 明文 (原始数据) 和 加密密钥 一起经过特殊 加密处理,生成复杂的 加密密文 进行发送。 数据解密过程:数据接收方 收到密文后,若想读取原数据,则需要使用 加密使用的密钥 及相同算法的 逆算法 对加密的密文进行解密,才能使其恢复成 可读明文。 非对称加密非对称加密算法,又称为 公开密钥加密算法。它需要两个密钥,一个称为 公开密钥 (public key),即 公钥,另一个称为 私有密钥 (private key),即 私钥。因为 加密 和 解密 使用的是两个不同的密钥,所以这种算法称为 非对称加密算法。 如果使用 公钥 对数据 进行加密,只有用对应的 私钥 才能 进行解密。 如果使用 私钥 对数据 进行加密,只有用对应的 公钥 才能 进行解密。 数字签名数字签名,顾名思义,就是用来证明自己身份的一种方式。在使用非对称加密算法通信时,如何验证发送者是真实的发送者,发送的信息没有篡改,就需要数字签名。一套 数字签名 通常定义两种 互补 的运算,一个用于 签名,另一个用于 验证。分别由 发送者 持有能够 代表自己身份 的 私钥(私钥不可泄露),由 接受者 持有与私钥对应的 公钥,能够在 接受 到来自发送者信息时用于 验证 其身份。 加密算法详解通过以上简介可以了解到,加密算法分为需要秘钥的和不需要秘钥的,需要秘钥的有可以分为对称加密与非对称加密两大类。接来来我们就详细探究一下各个加密算法。 哈希算法(不可逆)哈希算法可以将任意长度的输入数据,生成固定长度的输出(哈希值)。 常见的哈希算法有如下: 目前比较常用的是 MD5 和 SHA 系列(比如比特币用的 SHA256 算法,Git 中的 commit hash 用的 SHA1)。 MD5MD5(Message-Digest)典型应用是对一段信息产生 信息摘要,以 防止被篡改。严格来说,MD5 不是一种 加密算法 而是 摘要算法。无论是多长的输入,MD5 都会输出长度为 128bits 的一个串 (通常用 16 进制 表示为 32 个字符)。 SHA1SHA1(Secure Hash Algorithm) 是和 MD5 一样流行的 消息摘要算法,然而 SHA1 比 MD5 的 安全性更强。对于长度小于 $2 ^{64}$ 位的消息,SHA1 会产生一个 160 位的 消息摘要。 对称加密(可逆)对称加密算法是应用比较早的算法,在数据加密和解密的时用的都是同一个密钥,这就造成了密钥管理困难的问题。常见的对称加密算法有 DES、3DES、AES128、AES192、AES256。 A5/1、A5/2及RC4A5/1、A5/2及RC4他们都属于对称加密算法,并都属于流加密。先了解什么是流加密。 在密码学中,流加密(英语:Stream cipher),是一种对称加密算法,加密和解密双方使用相同伪随机加密数据流(pseudo-random stream)作为密钥,明文数据每次与密钥数据流顺次对应加密,得到密文数据流。实践中通常把信息中的每一位跟密钥流的每一位进行异或 (xor) 运算来获得密文。 DESDES(Data Encryption Standard) 是对称加密算法领域中的典型算法,是一种块加密算法(Block cipher),其密钥默认长度为 56 位。块加密或者叫分组加密,这种加密方法是把明文分成几个固定大小的 block 块,然后分别对其进行加密。 DES 加密算法是对 密钥进行保密,而 公开算法,包括加密和解密算法。这样,只有掌握了和发送方 相同密钥 的人才能解读由 DES 加密算法加密的密文数据。因此,破译 DES 加密算法实际上就是 搜索密钥的编码。对于 56 位长度的 密钥 来说,如果用 穷举法 来进行搜索的话,其运算次数为 $2 ^{56}$ 次。 AESAES 是美国国家标准技术研究所 NIST 旨在取代 DES 的 21 世纪的加密标准。AES 是块加密算法,也就是说,每次处理的数据是一块(16 字节),当数据不是 16 字节的倍数时填充,这就是所谓的分组密码(区别于基于比特位的流密码),16 字节是分组长度。AES 共有 ECB、CBC 等多种模式。 SM4SM4 算法于 2012 年被国家密码管理局确定为国家密码行业标准,最初主要用于 WAPI (WLAN Authentication and Privacy Infrastructure) 无线网络中。SM4 算法的出现为将我国商用产品上的密码算法由国际标准替换为国家标准提供了强有力的支撑。随后,SM4 算法被广泛应用于政府办公、公安、银行、税务、电力等信息系统中,其在我国密码行业中占据着极其重要的位置。类似于 DES、AES 算法,SM4 算法也是一种分组密码算法。 非对称加密(可逆)学习非对称加密之前,我们得了解如何进行安全高效地秘钥交换。我们不可能说通信双方在通信之前,先见个面协商一下秘钥 key,这样非常不方便,但是又不能直接把 key 秘钥通过一个不安全的信道发出去,这样就会被攻击者截获。 所以我们需要有一种方法,可以让双方在完全没有对方任何预先信息的条件下通过不安全信道创建起一个密钥。这个密钥可以在后续的通讯中作为对称密钥来加密通讯内容,这就是秘钥交换的概念(key exchange)。 Diffie–Hellman key exchange迪菲-赫尔曼密钥交换(英语:Diffie–Hellman key exchange,缩写为 D-H)是一种安全协议。可以完成上述秘钥交换。 通信双方 Alice 和 Bob 个准备一个大的质数,Alice 准备的质数是n=11, Bob 准备的质数是g=7,n和g是公开的,任何第三方都可以获取到这个信息。 Alice 准备一个随机自然数x=3, 除了 Alice 没有人知道x是多少,Alice 通过计算g的x次方并且对 n 取模,得到结果大 A Alice 把计算得到的结果 A=2 发送给 Bob,这个信息是公开的,任何人可以获取到 A Bob 同样准备一个随机自然数 y=6,除了 Bob 没有人知道 y 是多少,Bob 通过计算 g 的 y 次方并且对 n 取模,得到结果大 B Bob 把计算结果 B=4,发送给 Alice,,这个信息是公开的,任何人可以获取到 B Alice 拿到 B 以后,对 B 求 x 次方并对 n 取模,得到 K1=9 Bob 拿到 A 以后,对 A 对 y 次方并对 n 取模,得到 K2=9 K1 == K2,Alice 和 Bob 可以使用 K1,K2 作为 Key 进行通信加密。 在整个通信过程中,攻击者是无法知道 x,y 以及 K1,K2 的,或者说计算的困难很大,感兴趣的同学可以在网上找到具体的数学问题,离散对数问题的求解。 RSADiffie–Hellman key exchange 发明后不久出现了 RSA,另一个进行公钥交换的算法。它使用了非对称加密算法。 RSA 加密算法是目前最有影响力的 公钥加密算法,并且被普遍认为是目前 最优秀的公钥方案 之一。RSA 是第一个能同时用于 加密 和 数字签名 的算法,它能够 抵抗 到目前为止已知的 所有密码攻击,已被 ISO 推荐为公钥数据加密标准。 RSA 所用到的数学原理可以参考阮一峰老师的文章RSA 算法原理(一),文章介绍了 RSA 用到的一些数学定理,不涉及证明,这对于了解 RSA 也就足够了。 简单介绍一下秘钥是生成过程(摘自RSA 算法原理(二)): 随机选择两个不相等的质数 $p$ 和 $q$。爱丽丝选择了$61$和$53$。(实际应用中,这两个质数越大,就越难破解。) 计算$p$和$q$的乘积$n$。爱丽丝就把 $61$ 和 $53$ 相乘。 $$n = 61×53 = 3233$$ $n$ 的长度就是密钥长度。$3233$ 写成二进制是 $110010100001$,一共有 $12$ 位,所以这个密钥就是 $12$ 位。实际应用中,RSA 密钥一般是 $1024$ 位,重要场合则为 $2048$ 位。 计算 $n$ 的欧拉函数$\\varphi(n)$。根据公式: $$\\varphi(n) = (p-1)(q-1)$$ 爱丽丝算出$\\varphi(3233)$ 等于 $60×52$,即 $3120$。 随机选择一个整数 $e$,条件是 $1< e < \\varphi(n)$,且 $e$ 与$\\varphi(n)$ 互质。 爱丽丝就在 $1$ 到 $3120$ 之间,随机选择了 $17$。(实际应用中,常常选择 $65537$。) 计算 $e$ 对于$\\varphi(n)$ 的模反元素 $d$。 所谓”模反元素”就是指有一个整数 $d$,可以使得 $ed$ 被$\\varphi(n)$ 除的余数为 $1$。 $$ed ≡ 1 (mod \\varphi(n))$$ 这个式子等价于 $$ed - 1 = k\\varphi(n)$$ 于是,找到模反元素 $d$,实质上就是对下面这个二元一次方程求解。 $$ex + \\varphi(n)y = 1$$ 已知 $e=17$, $\\varphi(n)=3120$, $$17x + 3120y = 1$$ 这个方程可以用扩展欧几里得算法求解,此处省略具体过程。总之,爱丽丝算出一组整数解为 $(x,y)=(2753,-15)$,即 $d=2753$。 至此所有计算完成。 将 $n$ 和 $e$ 封装成公钥,$n$ 和 $d$ 封装成私钥。 在爱丽丝的例子中,$n=3233$,$e=17$,$d=2753$,所以公钥就是 $(3233,17)$,私钥就是$3233, 2753)$。 实际应用中,公钥和私钥的数据都采用 ASN.1 格式表达。 RSA 算法为何是可靠的呢?因为该算法基于一个十分简单的数论事实:将两个大素数相乘十分容易,但想要对其乘积进行因式分解却极其困难,因此可以将乘积公开作为加密密钥。 回顾上面的密钥生成步骤,一共出现六个数字: $$p,q,n,\\varphi(n),e,d$$ 这六个数字之中,公钥用到了两个($n$和$e$),其余四个数字都是不公开的。其中最关键的是$d$,因为$n$和$d$组成了私钥,一旦$d$泄漏,就等于私钥泄漏。 那么,有无可能在已知$n$和$e$的情况下,推导出$d$? $ed≡1 (mod φ(n))$。只有知道$e$和$φ(n)$,才能算出$d$。 $φ(n)=(p-1)(q-1)$。只有知道$p$和$q$,才能算出$φ(n)$。 $n=pq$。只有将$n$因数分解,才能算出 $p$ 和 $q$。 结论:如果 $n$ 可以被因数分解,$d$ 就可以算出,也就意味着私钥被破解。 可是,大整数的因数分解,是一件非常困难的事情。目前,除了暴力破解,还没有发现别的有效方法。 举例来说,你可以对 3233 进行因数分解(61×53),但是你没法对下面这个整数进行因数分解。 1234567891230186684530117755130494958384962720772853569595334792197322452151726400507263657518745202199786469389956474942774063845925192557326303453731548268507917026122142913461670429214311602221240479274737794080665351419597459856902143413 它等于这样两个质数的乘积: 123456789101133478071698956898786044169848212690817704794983713768568912431388982883793878002287614711652531743087737814467999489 ×36746043666799590428244633799627952632279158164343087642676032283815739666511279233373417143396810270092798736308917 事实上,这大概是人类已经分解的最大整数(232 个十进制位,768 个二进制位)。比它更大的因数分解,还没有被报道过,因此目前被破解的最长 RSA 密钥就是 768 位。 签名与证书参考 Learn Cryptography 浅谈常见的七种加密算法及实现 - 掘金 RSA 算法原理(一) - 阮一峰的网络日志 RSA 算法原理(二) - 阮一峰的网络日志 加密解密 - 面试官:说一下你常用的加密算法_个人文章 - SegmentFault 思否","categories":[],"tags":[{"name":"加密算法","slug":"加密算法","permalink":"http://example.com/tags/%E5%8A%A0%E5%AF%86%E7%AE%97%E6%B3%95/"},{"name":"Cryptography","slug":"Cryptography","permalink":"http://example.com/tags/Cryptography/"}]},{"title":"如何使用 git-send-mail 给开源社区提交 Patch","slug":"如何使用git-send-mail给开源社区提交Patch","date":"2022-09-28T13:08:29.000Z","updated":"2022-10-15T03:14:29.687Z","comments":true,"path":"2022/09/28/如何使用git-send-mail给开源社区提交Patch/","link":"","permalink":"http://example.com/2022/09/28/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8git-send-mail%E7%BB%99%E5%BC%80%E6%BA%90%E7%A4%BE%E5%8C%BA%E6%8F%90%E4%BA%A4Patch/","excerpt":"","text":"需求背景如果参与 Linux、QEMU 或者 OpenSBI 等开源项目,不能通过在 GitHub 或者 Gitlab 平台提交pull request。而是需要将修改的代码,通过 Patch 形式提交到对应的listserv供 Maintainer 审核。那么如何创建 Patch 并发送呢? 这里以向 OpenSBI 提交一个 Patch 为例。 创建 Patch首先将官方 Repository,Fork 到自己的 GitHub: 回到自己的主页,找到刚刚 Fork 的 Repository,将其 Clone 到本地: 修改代码与正常开发流程一直,修改完在git commit时需要加上Signed-off-by字段,因为 Merge 代码的人通常不是提交代码的人,有该字段才能证明是你修改了对应的代码。 -s参数会自动加上Signed-off-by字段: 12345678910111213141516171819$ git commit -sdoc:fix some typosSigned-off-by: dominic <dominic@gmail.com># Please enter the commit message for your changes. Lines starting# with '#' will be ignored, and an empty message aborts the commit.## Date: Tue Sep 27 21:11:41 2022 +0800## On branch master# Your branch is up to date with 'origin/master'.## Changes to be committed:# modified: docs/domain_support.md# modified: docs/library_usage.md# modified: docs/platform_requirements.md# modified: docs/pmu_support.md 生成.patch文件: 12$ git format-patch HEAD^0001-doc-fix-some-typos.patch 在当前目录下会生成一个0001-doc-fix-some-typos.patch文件: 123456789$ git status On branch masterYour branch is up to date with 'origin/master'.Untracked files: (use "git add <file>..." to include in what will be committed) 0001-doc-fix-some-typos.patchnothing added to commit but untracked files present (use "git add" to track) 这个文件就是我们要发送的文件,文件内容就是我们的代码修改,以及作者等信息: 123456789101112131415161718192021$ cat 0001-doc-fix-some-typos.patch From d404cb82f4c4aca15dcd35855d0bc96c5b4431d5 Mon Sep 17 00:00:00 2001From: Dunky-Z <xxxxxxxxx@qq.com>Date: Tue, 27 Sep 2022 21:11:41 +0800Subject: [PATCH] doc:fix some typosSigned-off-by: dominic <dominic@gmail.com>--- docs/domain_support.md | 6 +++--- docs/library_usage.md | 2 +- docs/platform_requirements.md | 2 +- docs/pmu_support.md | 10 +++++----- 4 files changed, 10 insertions(+), 10 deletions(-)diff --git a/docs/domain_support.md b/docs/domain_support.mdindex 73931f1..8963b57 100644--- a/docs/domain_support.md+++ b/docs/domain_support.md@@ -2,7 +2,7 @@ OpenSBI Domain Support ======================... 配置 send-email安装 git-email通过git直接发送 Patch 需要使用git-email工具,得手动安装: 1sudo apt install git-email Windows 平台在安装 Git 时默认已安装 生成 smtp 授权码登录QQ 邮箱 - 帐户: 开启 IMAP/SMTP 服务,并生成授权码: 根据提示发送短信: 记录下生成的授权码: 配置.gitconfigUbuntu 平台:~/.gitconfigWindows 平台:C:\\Users\\用户名\\.gitconfig 123456789[sendemail] smtpencryption = tls smtpserver = smtp.qq.com smtpuser = dominic_riscx@qq.com smtpserverport = 587 from = dominic_riscx@qq.com smtppass = xxxxxx cc = dominic@gmail.com #to = opensbi@lists.infradead.org 为了方便复制,单独注释: 12345678910[sendemail] smtpencryption = # 加密方式,保持默认 smtpserver = # smtp 服务器地址,保持默认 smtpuser = # 邮箱地址,改为 QQ 邮箱地址,也就是用哪个邮箱发送,就填哪个 smtpserverport = # 端口号,保持默认 from = # 同 smtpuser smtppass = # 上文生成的 smtp 授权码 cc = # 抄送的邮箱地址 #to = opensbi@lists.infradead.org # 要发送的地址,这个字段我注释了,因为怕以后发邮件默认发到这个地址,这个字段可以在发送时单独填写 发送 Patch12345#$ git send-email patch文件名$ git send-email 0001-doc-fix-some-typos.patch0001-doc-fix-some-typos.patch# 提示往哪里发送,填写要接收的邮箱即可,我这里填写的是OpenSBI接收Patch的地址To whom should the emails be sent (if anyone)? opensbi@lists.infradead.org 12Message-ID to be used as In-Reply-To for the first email (if any)? # 回车,保存默认(我还不清楚这里的作用) 123456789101112131415161718192021222324252627(mbox) Adding cc: Dunky-Z <xxxxxxxxx@qq.com> from line 'From: Dunky-Z <xxxxxxxxx@qq.com>'(body) Adding cc: dominic <dominic@gmail.com> from line 'Signed-off-by: dominic <dominic@gmail.com>' From: dominic_riscx@qq.comTo: opensbi@lists.infradead.orgCc: dominic@gmail.com, Dunky-Z <xxxxxxxxx@qq.com>Subject: [PATCH] doc:fix some typosDate: Wed, 28 Sep 2022 10:35:30 +0800Message-Id: <20220928023530.2344-1-dominic_riscx@qq.com>X-Mailer: git-send-email 2.34.1.windows.1MIME-Version: 1.0Content-Transfer-Encoding: 8bit The Cc list above has been expanded by additional addresses found in the patch commit message. By default send-email prompts before sending whenever this occurs. This behavior is controlled by the sendemail.confirm configuration setting. For additional information, run 'git send-email --help'. To retain the current behavior, but squelch this message, run 'git config --global sendemail.confirm auto'.Send this email? ([y]es|[n]o|[e]dit|[q]uit|[a]ll): y# y 确认发送 1234567891011121314151617181920OK. Log says:Server: smtp.qq.comMAIL FROM:<dominic_riscx@qq.com>RCPT TO:<opensbi@lists.infradead.org>RCPT TO:<dominic@gmail.com>RCPT TO:<xxxxxxxxx@qq.com>From: dominic_riscx@qq.comTo: opensbi@lists.infradead.orgCc: dominic@gmail.com, Dunky-Z <xxxxxxxxx@qq.com>Subject: [PATCH] doc:fix some typosDate: Wed, 28 Sep 2022 10:35:30 +0800Message-Id: <20220928023530.2344-1-dominic_riscx@qq.com>X-Mailer: git-send-email 2.34.1.windows.1MIME-Version: 1.0Content-Transfer-Encoding: 8bitResult: 250# 发送成功 前往The opensbi Archives,找到对应的月份,点击Theread,即可找到自己发送的 Patch,每个开源社区一般都会在如何提交 PR 的文档里公开 Patch Archive 网址,这里是以 OpenSBI 的网址。 前往邮箱发送记录中也可以找到对应的 Patch 信息: 以上就是完整的提交 Patch 过程。","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"Makefile 基础","slug":"Makefile基础","date":"2022-09-26T13:36:18.000Z","updated":"2022-10-15T02:59:01.566Z","comments":true,"path":"2022/09/26/Makefile基础/","link":"","permalink":"http://example.com/2022/09/26/Makefile%E5%9F%BA%E7%A1%80/","excerpt":"","text":"目标、依赖、命令 目标就是我们要去 make xxx 的那个 xxx,就是我们最终要生成的东西。 依赖是用来生成目录的原材料 命令就是加工方法,所以 make xxx 的过程其实就是使用命令将依赖加工成目标的过程。 通配符 % 和 Makefile 自动推导 % 是 Makefile 中的通配符,代表一个或几个字母。也就是说%.o就代表所有以.o为结尾的文件。 所谓自动推导其实就是 Makefile 的规则。当 Makefile 需要某一个目标时,他会把这个目标去套规则说明,一旦套上了某个规则说明,则 Makefile 会试图寻找这个规则中的依赖,如果能找到则会执行这个规则用依赖生成目标。 Makefile 中定义和使用变量 Makefile 中定义和使用变量,和 shell 脚本中非常相似。相似的是都没有变量类型,直接定义使用,引用变量时用$var。 伪目标(.PHONY) 伪目标意思是这个目标本身不代表一个文件,执行这个目标不是为了得到某个文件或东西,而是单纯为了执行这个目标下面的命令。 伪目标一般都没有依赖,因为执行伪目标就是为了执行目标下面的命令。既然一定要执行命令了那就不必加依赖,因为不加依赖意思就是无条件执行。 伪目标可以直接写,不影响使用;但是有时候为了明确声明这个目标是伪目标会在伪目标的前面用.PHONY来明确声明它是伪目标。 Makfile 中引用其他 Makefile 有时候 Makefile 总体比较复杂,因此分成好几个 Makefile 来写。然后在主 Makefile 中引用其他的,用 include 指令来引用。引用的效果也是原地展开,和 C 语言中的头文件包含非常相似。 赋值 =最简单的赋值 :=一般也是赋值 以上这两个大部分情况下效果是一样的,但是有时候不一样。用=赋值的变量,在被解析时他的值取决于最后一次赋值时的值,所以你看变量引用的值时不能只往前面看,还要往后面看。用:=来赋值的,则是就地直接解析,只用往前看即可。 ?=如果变量前面并没有赋值过则执行这条赋值,如果前面已经赋值过了则本行被忽略。(实验可以看出:所谓的没有赋值过其实就是这个变量没有被定义过) +=用来给一个已经赋值的变量接续赋值,意思就是把这次的值加到原来的值的后面,有点类似于 strcat。(注意一个细节,+=续接的内容和原来的内容之间会自动加一个空格隔开) 注意:Makefile 中并不要求赋值运算符两边一定要有空格或者无空格,这一点比 shell 的格式要求要松一些。 Makefile 的环境变量 makefile 中用 export 导出的就是环境变量。一般情况下要求环境变量名用大写,普通变量名用小写。 环境变量和普通变量不同,可以这样理解:环境变量类似于整个工程中所有 Makefile 之间可以共享的全局变量,而普通变量只是当前本 Makefile 中使用的局部变量。所以要注意:定义了一个环境变量会影响到工程中别的 Makefile 文件,因此要小心。 Makefile 中可能有一些环境变量可能是 makefile 本身自己定义的内部的环境变量或者是当前的执行环境提供的环境变量(譬如我们在 make 执行时给 makefile 传参。make CC=arm-linux-gcc,其实就是给当前 Makefile 传了一个环境变量 CC,值是 arm-linux-gcc。我们在 make 时给 makefile 传的环境变量值优先级最高的,可以覆盖 makefile 中的赋值)。这就好像 C 语言中编译器预定义的宏__LINE__ __FUNCTION__等一样。 Makefile 中使用通配符 *:若干个任意字符 ?:1 个任意字符 []:将 [] 中的字符依次去和外面的结合匹配 还有个%,也是通配符,表示任意多个字符,和*很相似,但是%一般只用于规则描述中,又叫做规则通配符。 Makefile 的自动变量 为什么使用自动变量。在有些情况下文件集合中文件非常多,描述的时候很麻烦,所以我们 Makefile 就用一些特殊的符号来替代符合某种条件的文件集,这就形成了自动变量。 自动变量的含义:预定义的特殊意义的符号。就类似于 C 语言编译器中预制的那些宏__FILE__一样。 常见自动变量: $@:规则的目标文件名 $<:规则的依赖文件名 $^:依赖的文件集合 其他 Makefile 中的注释用# 在 makefile 的命令行中前面的@表示静默执行 Makefile 中默认情况下在执行一行命令前会先把这行命令给打印出来,然后再执行这行命令 如果你不想看到命令本身,只想看到命令执行就静默执行即可","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Makefile","slug":"Makefile","permalink":"http://example.com/tags/Makefile/"}]},{"title":"嵌入式 Shell 基础","slug":"嵌入式Shell基础","date":"2022-09-25T14:35:16.000Z","updated":"2022-10-15T03:14:29.701Z","comments":true,"path":"2022/09/25/嵌入式Shell基础/","link":"","permalink":"http://example.com/2022/09/25/%E5%B5%8C%E5%85%A5%E5%BC%8FShell%E5%9F%BA%E7%A1%80/","excerpt":"","text":"脚本语言 常用的脚本语言有 sh、bash、csh、ksh、perl、python; 在 Linux 下常用的脚本语言其实就是 bash、sh; 脚本语言一般在嵌入式中应用,主要是用来做配置。(一个复杂的嵌入式程序都是可配置的,配置过程就是用脚本语言来实现的)自然不会使用过于复杂的脚本语言特性,因此只需要针对性的学习即可。 shell 脚本的运行机制 C/C++ 语言这种编写过程是:编写出源代码(源代码是不能直接运行的)然后编译链接形成可执行二进制程序,然后才能运行;而脚本程序不同,脚本程序编写好后源代码即可直接运行(没有编译链接过程); shell 程序是解释运行的,所谓解释运行就是说当我们执行一个 shell 程序时,shell 解析器会逐行的解释 shell 程序代码,然后一行一行的去运行。(顺序结构) CPU 实际只认识二进制代码,根本不认识源代码。脚本程序源代码其实也不是二进制代码,CPU 也不认识,也不能直接执行。只不过脚本程序的编译链接过程不是以脚本程序源代码为单位进行的,而是在脚本运行过程中逐行的解释执行时才去完成脚本程序源代码转成二进制的过程(不一定是编译链接,因为这行脚本程序可能早就编译连接好了,这里我们只是调用它)。 动手写第一个 shell编辑器与编译器 shell 程序是文本格式的,只要是文本编辑器都可以。但是因为我们的 shell 是要在 Linux 系统下运行的,所以换行符必须是\\n,而 Windows 下的换行符是\\r\\n,因此 Windows 中的编辑器写的 shell 不能在 Linux 下运行。 编译器不涉及,因为 shell 是解释性语言,直接编辑完就可以运行。 shell 程序运行的运行的三种方法 ./xx.sh,和运行二进制可执行程序方法一样。这样运行 shell 要求 shell 程序必须具有可执行权限。chmod a+x xx.sh 来添加可执行权限。 source xx.sh,source 是 Linux 的一个命令,这个命令就是用来执行脚本程序的。这样运行不需要脚本具有可执行权限。 bash xx.sh,bash 是一个脚本程序解释器,本质上是一个可执行程序。这样执行相当于我们执行了 bash 程序,然后把 xx.sh 作为 argv[1] 传给他运行。 hello world 程序和解释 shell 程序的第一行一般都是以#!/bin/sh开始,这行话的意思就是指定 shell 程序执行时被哪个解释器解释执行。所以我们这里写上/bin/sh意思就是这个shell将来被当前机器中/bin目录下的sh可执行程序执行。可以将第一行写为#!/bin/bash来指定使用bash执行该脚本。 脚本中的注释使用#,#开头的行是注释行。如果有多行需要注释,每行前面都要加#。(#就相当于是 C 语言中的//); shell 程序的正文,由很多行 shell 语句构成。 shell 语法shell 就是把以前命令行中键入执行的命令写成了程序。shell 其实就是为了避免反复的在命令行下手工输入而发明的一种把手工输入步骤记录下来,然后通过执行 shell 脚本程序就能再次复述原来记录的手工输入过程的一种技术。 shell 中的变量定义和引用 变量定义和初始化。shell 是弱类型语言(语言中的变量如果有明确的类型则属于强类型语言;变量没有明确类型就是弱类型语言),和 C 语言不同。在 shell 编程中定义变量不需要制定类型,也没有类型这个概念。 变量定义时可以初始化,使用=进行初始化赋值。在 shell 中赋值的=两边是不能有空格的。注意:shell 对语法非常在意,非常严格。很多地方空格都是必须没有或者必须有,而且不能随意有没有空格。 变量赋值,变量定义后可以再次赋值,新的赋值会覆盖老的赋值。shell 中并不刻意区分变量的定义和赋值,反正每个变量就是一个符号,这个符号的值就是最后一个给他赋值时的值。 变量引用。shell 中引用一个变量必须使用$符号,$符号就是变量解引用符号。 注意:$符号后面跟一个字符串,这个字符串就会被当作变量去解析。如果这个字符串本身没有定义,执行时并不会报错,而是把这个变量解析为空。也就是说在 shell 中没有被定义的变量其实就相当于是一个定义并赋值为空的变量。 注意:变量引用的时候可以$var,也可以${var}。这两种的区别是在某些情况下只能用${var}而不能简单的$var。 shell 中无引用、单引号和双引号的区别 shell 中使用字符串可以不加双引号,直接使用。而且有空格时也可以,但是缺陷是不能输出"或者其他转义字符。 shell 中也可以使用单引号来表示字符串,也是直接使用的,不能输出转义字符。 单引号中:完全字面替换(不可包含单引号本身) 双引号中: $加变量名可以取变量的值 反引号仍表示命令替换 \\$表示$的字面值(输出$符号) `表示`的字面值 \\"表示"的字面值 \\\\表示\\的字面值 除以上情况之外,在其它字符前面的\\无特殊含义,只表示字面值。 单引号会原样输出,双引号可以调用命令: 123456PATH_A="`pwd`/include"PATH_B='`pwd`/include'echo $PATH_A# /home/a/b/includeecho $PATH_B# `pwd`/include shell 中调用 Linux 命令 直接执行 反引号括起来执行。有时候我们在 shell 中调用 Linux 命令是为了得到这个命令的返回值(结果值),这时候就适合用一对反引号 (键盘上 ESC 按键下面的那个按键,和~在一个按键上) 来调用执行命令。 shell 中的选择分支结构 shell 的 if 语言用法很多,在此只介绍常用的,其他感兴趣可以自己去学 典型if语言格式: 123456789if [ 表达式 ]; then xxx yyy zzzelse xxx ddd uuufi if 的典型应用 -f判断文件是否存在,注意[]里面前后都有空格,不能省略 -d判断目录是否存在 "str1" = "str2"判断字符串是否相等,注意用一个等号而不是两个 判断数字是否相等 -eq等于 -gt大于 -lt小于 -ge大于等于 -le小于等于 -z判断字符串是否为空,注意-z判断时如果变量本身没定义也是不成立(也就是说-z 认为没定义不等于为空) -o表示逻辑或,连接两个表达式 if [ 10 -eq 10 -o ]; then && ||表示逻辑与和逻辑或 shell 中的循环结构for 循环,要求能看懂、能改即可。不要求能够完全不参考写出来。因为毕竟嵌入式并不需要完全重新手写。 while 循环,和 C 语言的循环在逻辑上无差别,要注意很多格式要求,譬如:while 后面的 [] 两边都有空格,[] 后面有分号(如果 do 放在一行的话),i++的写法中有两层括号。 echo 的创建和追加输入文件 在 shell 中可以直接使用 echo 指令新建一个文件,并且将一些内容传入这个文件中。创建文件并输入内容的关键就是>。 还可以使用 echo 指令配合追加符号>> 向一个已经存在的文件末尾追加输入内容。 shell 中其他值得关注的知识点case 语句 shell 中的 case 语句和 C 语言中的 switch case 语句作用一样,格式有差异 shell 中的 case 语句天生没有 break,也不需要break,和 C 语言中的 switch case 不同。shell 中的 case 默认就是匹配上哪个执行哪个,不会说执行完了还去执行后面的其他 case 调用 shell 程序的传参 C 语言中可以通过 main 函数的 argc 和 argv 给程序传参 shell 程序本身也可以在调用时传参给他。在 shell 程序内部使用传参也是使用的一些特定符号来表示的,包括: $#表示调用该 shell 时传参的个数。($#计数时只考虑真正的参数个数) $0、$1、$2·····则依次表示传参的各个参数 12345./a.out aa bb cc # argc = 4# argv[0] = ./a.out# argv[1] 是第一个有效参数···· 12345source a.sh aa bb cc # $# = 3# $0是执行这个 shell 程序的解析程序的名字# $1是第一个有效参数的值# $2是第 2 个有效参数的值····· while 循环和 case 语言和传参结合 shell 中的 break 关键字和 C 语言中意义相同(都是跳出)但是用法不同。因为 shell 中 case 语句默认不用 break 的,因此在 shell 中 break 只用于循环跳出。所以当 while 中内嵌 case 语句时,case 中的 break 是跳出外层的 while 循环的,不是用来跳出 case 语句的。 shell 中的$# $1等内置变量的值是可以被改变,被 shift 指令改变。shift 指令有点像左移运算符,把我们给 shell 程序的传参左移了一个移出去了,原来的$2变成了新的$1,原来的$#少了 1 个。","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Shell","slug":"Shell","permalink":"http://example.com/tags/Shell/"},{"name":"嵌入式开发","slug":"嵌入式开发","permalink":"http://example.com/tags/%E5%B5%8C%E5%85%A5%E5%BC%8F%E5%BC%80%E5%8F%91/"}]},{"title":"每天学命令-chattr 修改文件与目录属性防止误删除","slug":"每天学命令-chattr修改文件与目录属性防止误删除","date":"2022-09-25T03:20:35.000Z","updated":"2022-10-15T03:03:19.401Z","comments":true,"path":"2022/09/25/每天学命令-chattr修改文件与目录属性防止误删除/","link":"","permalink":"http://example.com/2022/09/25/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-chattr%E4%BF%AE%E6%94%B9%E6%96%87%E4%BB%B6%E4%B8%8E%E7%9B%AE%E5%BD%95%E5%B1%9E%E6%80%A7%E9%98%B2%E6%AD%A2%E8%AF%AF%E5%88%A0%E9%99%A4/","excerpt":"","text":"使用背景chattr命令可以修改 Linux 的文件属性,在类 Unix 等发行版中,该命令能够有效防止文件和目录被意外的删除或修改。文件在 Linux 中被描述为一个数据结构,chattr 命令在大多数现代 Linux 操作系统中是可用的,可以修改文件属性,一旦定义文件的隐藏属性,那么该文件的拥有者和 root 用户也无权操作该文件,只能解除文件的隐藏属性。这就可以有效的避免被误删除。 命令格式一个完整的命令一般由命令 (chattr),可选项 (option),操作符 (operator) 与属性 (attribute) 组成: 1chattr [option] [operator] [attribute] file [option] 可选项: 123-R, 递归更改目录及其内容的属性。-V, 详细说明chattr的输出并打印程序版本。-f, 隐藏大多数错误消息。 [operator] 操作符: 123+,追加指定属性到文件已存在属性中-, 删除指定属性=,直接设置文件属性为指定属性 [attribute] 属性如下: 123a, 只能向文件中添加数据A,不更新文件或目录的最后访问时间i, 文件或目录不可改变 使用实例lsattr 命令检查文件已有属性12-d:如果目标是目录,只会列出目录本身的隐藏属性,而不会列出所含文件或子目录的隐藏属性信息-R:作用于目录时,会显示所有的子目录和文件的隐藏信息 12345678910111213141516171819202122232425262728293031$ lsattr clash--------------e------- clash/glados.yaml--------------e------- clash/clash-linux-386-v1.10.0--------------e------- clash/Country.mmdb--------------e------- clash/cache.db--------------e------- clash/clash-linux-amd64-v1.10.0--------------e------- clash/dashboard$ lsattr -d clash--------------e------- clash$ lsattr -R clash--------------e------- clash/glados.yaml--------------e------- clash/clash-linux-386-v1.10.0--------------e------- clash/Country.mmdb--------------e------- clash/cache.db--------------e------- clash/clash-linux-amd64-v1.10.0--------------e------- clash/dashboardclash/dashboard:--------------e------- clash/dashboard/manifest.webmanifest--------------e------- clash/dashboard/assetsclash/dashboard/assets:--------------e------- clash/dashboard/assets/logo.b453e72f.png--------------e------- clash/dashboard/assets/index.408383.js--------------e------- clash/dashboard/assets/index.966f8a.css--------------e------- clash/dashboard/assets/vendor.ca5569.js--------------e------- clash/dashboard/sw.js--------------e------- clash/dashboard/workbox-7ce28d.js--------------e------- clash/dashboard/index.html 禁止对文件test.md重命名,移动或删除,也不能修改其内容1sudo chattr +i test.md 尝试修改该文件,将会被拒绝: 12345678$ rm -f ./test.mdrm: cannot remove './test.md': Operation not permitted$ echo 'Hello World!' > test.mdbash: ./test.md: Operation not permitted$ mv ./test.md ./fileDirmv: cannot move './test.md' to './fileDir/test.md': Operation not permitted 禁止修改文件夹fileDir及文件夹中的数据12mkdir ./fileDir && touch ./fileDir/test.mdsudo chattr +i -R ./fileDir 尝试修改文件夹中的内容: 12$ rm -rf ./fileDirrm: cannot remove './fileDir/test.md': Operation not permitted 允许向文件添加内容,禁止修改或删除内容,禁止移动文件1234567$ sudo chattr +a ./test.md$ lsattr ./test.md-----a--------e--- ./test.md$ echo "Hello World!" >> ./test.md # 追加内容 OK$ echo "hello"> ./test.md # 修改内容 NObash: ./test.md: Operation not permitted 只允许在目录fileDir中建立和修改文件,但是禁止删除、移动文件1sudo chattr +a ./fileDir 取消某个属性使用-操作符即可: 123456789# 先给文件添加属性a$ sudo chattr +a ./test.md$ lsattr ./test.md-----a--------e--- ./test.md# 取消属性a$ sudo chattr -a ./test.md$ lsattr ./test.md--------------e--- ./test.md","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"解决 Pandoc 将 MD 转换为 PDF 时报错 (error)\\tightlist","slug":"解决Pandoc将MD转换为PDF时报错-error-tightlist","date":"2022-09-24T09:27:00.000Z","updated":"2022-10-15T02:59:01.840Z","comments":true,"path":"2022/09/24/解决Pandoc将MD转换为PDF时报错-error-tightlist/","link":"","permalink":"http://example.com/2022/09/24/%E8%A7%A3%E5%86%B3Pandoc%E5%B0%86MD%E8%BD%AC%E6%8D%A2%E4%B8%BAPDF%E6%97%B6%E6%8A%A5%E9%94%99-error-tightlist/","excerpt":"","text":"使用 Pandoc 将test.md转换位 PDF 时,出现如下错误: 1234567! Undefined control sequence.<recently read> \\tightlist l.213 \\end{frame}pandoc: Error producing PDF from TeX sourcemake: *** [test.pdf] Error 43 这是因为在 Markdown 文件中使用-表示无序列表,被转化成了\\tightlist但是 Pandoc 版本太老,不支持这个命令。(严格来说是 Pandoc 没有处理这个 LaTeX 命令,不是不支持,因为这是 LaTeX 命令和 Pandoc 没关系)。 有两种方式解决,一是升级 Pandoc 版本,二是将处理\\tightlist的命令加到自己使用的模板中。 12\\providecommand{\\tightlist}{% \\setlength{\\itemsep}{0pt}\\setlength{\\parskip}{0pt}} 或者 1\\def\\tightlist{}","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"LaTeX","slug":"LaTeX","permalink":"http://example.com/tags/LaTeX/"},{"name":"Markdown","slug":"Markdown","permalink":"http://example.com/tags/Markdown/"},{"name":"Pandoc","slug":"Pandoc","permalink":"http://example.com/tags/Pandoc/"}]},{"title":"Markdown 语法简明教程","slug":"Markdown语法简明教程","date":"2022-09-24T07:05:12.000Z","updated":"2022-10-15T03:14:29.363Z","comments":true,"path":"2022/09/24/Markdown语法简明教程/","link":"","permalink":"http://example.com/2022/09/24/Markdown%E8%AF%AD%E6%B3%95%E7%AE%80%E6%98%8E%E6%95%99%E7%A8%8B/","excerpt":"","text":"Markdown 简介Markdown 是什么?Markdown是一种轻量级标记语言,它以纯文本形式 (易读、易写、易更改) 编写文档,并最终以 HTML 格式发布。 Markdown也可以理解为将以 Markdown 语法编写的语言转换成 HTML 内容的工具。 谁创造了它?它由Aaron Swartz和John共同设计,Aaron Swartz就是那位于去年(2013 年 1 月 11 日)自杀,有着开挂一般人生经历的程序员。维基百科对他的介绍是:软件工程师、作家、政治组织者、互联网活动家、维基百科人。 14 岁参与 RSS 1.0 规格标准的制订。 2004年入读斯坦福,之后退学。 2005年创建Infogami,之后与Reddit合并成为其合伙人。 2010年创立求进会(Demand Progress),积极参与禁止网络盗版法案(SOPA)活动,最终该提案被撤回。 2011年 7 月 19 日,因被控从 MIT 和 JSTOR 下载 480 万篇学术论文并以免费形式上传于网络被捕。 2013年 1 月自杀身亡。 为什么要使用它? 它是易读(看起来舒服)、易写(语法简单)、易更改纯文本。处处体现着极简主义的影子。 兼容 HTML,可以转换为 HTML 格式发布。 跨平台使用。 越来越多的网站支持 Markdown。 更方便清晰地组织你的电子邮件。(Markdown-here, Airmail) 摆脱 Word 怎么使用?如果不算扩展,Markdown 的语法绝对简单到让你爱不释手。 Markdown 语法主要分为如下几大部分: 标题,段落,区块引用,代码区块,强调,列表,分割线,链接,图片,**反斜杠 \\,符号’`’**。 谁在用?Markdown 的使用者: GitHub 简书 Stack Overflow Apollo Moodle Reddit 等等 语法介绍标题两种形式: 使用=和-标记一级和二级标题。 一级标题=========二级标题--------- 使用#,可表示 1-6 级标题。 # 一级标题## 二级标题### 三级标题#### 四级标题##### 五级标题###### 六级标题 段落段落的前后要有空行,所谓的空行是指没有文字内容。若想在段内强制换行的方式是使用两个以上空格加上回车(引用中换行省略回车)。 区块引用区块引用需要在被引用的文本前加上 > 符号。 123> 这是一个区块引用实例,> Markdown. 这是一个区块引用实例, Markdown. Markdown 也允许你偷懒只在整个段落的第一行最前面加上 > : 123456> 平生不会相思,才会相思,便害相思。> 空一缕余香在此,盼千金游子何之。 平生不会相思,才会相思,便害相思。 空一缕余香在此,盼千金游子何之。 引用的多层嵌套区块引用可以嵌套(例如:引用内的引用), 只要根据层次加上不同数量的 > : 12345>>> 锄禾日当午,汗滴禾下土。 - 李绅>> 山有木兮木有枝,心悦君兮君不知。 - 越人歌> 去年今日此门中,人面桃花相映红。 - 崔护 锄禾日当午,汗滴禾下土。 - 李绅 山有木兮木有枝,心悦君兮君不知。 - 越人歌 去年今日此门中,人面桃花相映红。 - 题都城南庄 锚点网页中,锚点其实就是页内超链接,也就是链接本文档内部的某些元素,实现当前页面中的跳转。比如我这里写下一个锚点,点击跳转到指定章节。 1[点击跳转至区块引用](#区块引用) 点击跳转至区块引用 代码区块代码区块的建立是在每行加上 4 个空格或者一个制表符(如同写代码一样)。如普通段落: void main(){ printf(“Hello, Markdown.”);} 代码区块: void main() { printf("Hello, Markdown."); } 注意:需要和普通段落之间存在空行。 强调Markdown 使用星号*和底线_作为标记强调字词的符号。 斜体1*花自飘零水自流* 花自飘零水自流 粗体1**花自飘零水自流** 花自飘零水自流 删除线1~~花自飘零水自流~~ 花自飘零水自流 列表使用·、+、或-标记无序列表,如: -(+*)第一项-(+*)第二项- (+*)第三项 注意:标记后面最少有一个_空格_或_制表符_。若不在引用区块中,必须和前方段落之间存在空行。 效果: 第一项 第二项 第三项 有序列表的标记方式是将上述的符号换成数字,并辅以.,如: 1 . 第一项2 . 第二项3 . 第三项 效果: 第一项 第二项 第三项 分割线分割线最常使用就是三个或以上*,还可以使用-和_。 链接Markdown 支持两种形式的链接语法:行内式和参考式两种形式,行内式一般使用较多。 行内式[]里写链接文字,()里写链接地址,()中的 "" 中可以为链接指定 title 属性,title 属性可加可不加。title 属性的效果是鼠标悬停在链接上会出现指定的 title 文字。[链接文字](链接地址 "链接标题") 这样的形式。链接地址与链接标题前有一个空格。 12[MPPL: Markdown to PDF with Pandoc via Latex](https://github.com/Dunky-Z/MPPL)[MPPL: Markdown to PDF with Pandoc via Latex](https://github.com/Dunky-Z/MPPL "MPPL") MPPL: Markdown to PDF with Pandoc via Latex MPPL: Markdown to PDF with Pandoc via Latex 参考式参考式超链接一般用在学术论文上面,或者另一种情况,如果某一个链接在文章中多处使用,那么使用引用的方式创建链接将非常好,它可以让你对链接进行统一的管理。 参考式链接分为两部分,文中的写法 [链接文字][链接标记],在文本的任意位置添加 [链接标记]:链接地址 "链接标题", 链接地址与链接标题前有一个空格。 123全球最大的搜索引擎网站是 [Google][1]。[1]:http://www.google.com "Google" 全球最大的搜索引擎网站是 Google。 图片图片的创建方式与超链接相似,而且和超链接一样也有两种写法,行内式和参考式写法。 语法中图片 Alt 的意思是如果图片因为某些原因不能显示,就用定义的图片 Alt 文字来代替图片。图片 Title 则和链接中的 Title 一样,表示鼠标悬停与图片上时出现的文字。Alt 和 Title 都不是必须的,可以省略,但建议写上。 图片行内式 1 图片参考式在文档要插入图片的地方写 ![图片 Alt][标记]。 在文档的最后写上 [标记]:图片地址 "Title"。 123![MarkdownLogo][MarkdownLogo][MarkdownLogo]:../img/Markdown-mark.png "MarkdownLogo" 反斜杠\\相当于反转义作用。使符号成为普通符号。 代码对于程序员来说这个功能是必不可少的,插入程序代码的方式有两种,一种是利用缩进 (Tab), 另一种是利用 “`” 符号 (一般在 ESC 键下方) 包裹代码。 插入行内代码,即插入一个单词或者一句代码的情况,使用 `code` 这样的形式插入。 插入多行代码,可以使用缩进或者 ``` code ```, 具体看示例。 代码行内式1PHP 打印堆栈信息 `debug_backtrace()`。 PHP 打印堆栈信息 debug_backtrace()。 缩进式多行代码缩进 4 个空格或是 1 个制表符。 一个代码区块会一直持续到没有缩进的那一行 (或是文件结尾)。 123$closure = function () use($name) { return $name;} $closure = function () use($name) { return $name; } 用六个 ` 包裹多行代码1234567> ```c # 为了能够在 Markdown 里演示,所以加了>符号#include <stdio.h>int main(){ printf("Hello, World!\\n"); return 0;} 12345678```c#include <stdio.h>int main(){ printf("Hello, World!\\n"); return 0;} 内容目录在段落中填写 [TOC] 以显示全文内容的目录结构。 表格 不管是哪种方式, 第一行为表头, 第二行分隔表头和主体部分, 第三行开始每一行为一个表格行。 列于列之间用管道符|隔开。原生方式的表格每一行的两边也要有管道符。 第二行还可以为不同的列指定对齐方向。默认为左对齐, 在-右边加上:就右对齐。 简单方式: 12345诗名|作者|朝代-|-|-白头吟|卓文君|两汉锦瑟|李商隐|唐代登科后|孟郊|唐代 诗名 作者 朝代 白头吟 卓文君 两汉 锦瑟 李商隐 唐代 登科后 孟郊 唐代 原生方式: 12345|诗名|作者|朝代||-|-|-||白头吟|卓文君|两汉||锦瑟|李商隐|唐代||登科后|孟郊|唐代| 诗名 作者 朝代 白头吟 卓文君 两汉 锦瑟 李商隐 唐代 登科后 孟郊 唐代 为表格第二列指定方向: 1234诗名|名句-|-:梦微之|君埋泉下泥销骨。上邪|上邪,我欲与君相知,长命无绝衰。 诗名 名句 梦微之 君埋泉下泥销骨。 上邪 上邪,我欲与君相知,长命无绝衰。 注脚在需要添加注脚的文字后加上脚注名字[^注脚名字], 称为加注。 然后在文本的任意位置(一般在最后)添加脚注, 脚注前必须有对应的脚注名字。 12345使用 Markdown[^1] 可以效率的书写文档,直接转换成 HTML[^2]。[^1]: Markdown 是一种纯文本标记语言[^2]: HyperText Markup Language 超文本标记语言 LaTeX 公式$ 表示行内公式1质能守恒方程可以用一个很简洁的方程式 $E=mc^2$ 来表达。 质能守恒方程可以用一个很简洁的方程式$E=mc^2$来表达。 $$ 表示整行公式123$$\\sum_{i=1}^n a_i=0$$$$f(x_1,x_x,\\ldots,x_n) = x_1^2 + x_2^2 + \\cdots + x_n^2 $$$$\\sum^{j-1}_{k=0}{\\widehat{\\gamma}_{kj} z_k}$$ $$\\sum_{i=1}^n a_i=0$$ 尝试一下 Chrome下的插件诸如stackedit与markdown-here等非常方便,也不用担心平台受限。 在线的Cmd Markdown 编辑阅读器 - 作业部落出品。 Windowns下的Typora — a markdown editor, markdown reader。 Mac下的 Mou 是国人贡献的,口碑很好。 Linux下的 ReText 不错。 当然,最终境界永远都是笔下是语法,心中格式化。 注意:不同的 Markdown 解释器或工具对相应语法(扩展语法)的解释效果不尽相同,具体可参见工具的使用说明。虽然有人想出面搞一个所谓的标准化的 Markdown,没想到还惹怒了健在的创始人 John Gruber。 以上基本是所有 traditonal Markdown 的语法。 关于其它扩展语法可参见具体工具的使用说明。 参考资料 Markdown 基本语法。 cdoco/markdown-syntax: Markdown 语法详解。","categories":[],"tags":[{"name":"Markdown","slug":"Markdown","permalink":"http://example.com/tags/Markdown/"}]},{"title":"Markdown 表格竖线自动对齐","slug":"Markdown表格竖线自动对齐","date":"2022-09-24T07:01:41.000Z","updated":"2022-10-15T03:08:33.812Z","comments":true,"path":"2022/09/24/Markdown表格竖线自动对齐/","link":"","permalink":"http://example.com/2022/09/24/Markdown%E8%A1%A8%E6%A0%BC%E7%AB%96%E7%BA%BF%E8%87%AA%E5%8A%A8%E5%AF%B9%E9%BD%90/","excerpt":"","text":"需求背景Markdown 中的表格,只要符合语法就能够正常渲染显示,但是符合语法但是 Markdown 源码却不一定易读。就如以下的这个表格,可以正常显示,但是源码在源文件中竖线不对齐,就阅读困难。 源码: 12345|诗名|作者|朝代||-|-|-||白头吟|卓文君|两汉||锦瑟|李商隐|唐代||登科后|孟郊|唐代| 显示效果: 诗名 作者 朝代 白头吟 卓文君 两汉 锦瑟 李商隐 唐代 登科后 孟郊 唐代 我们可以手动将其竖线对齐,如下这样就易读许多: 12345| 诗名 | 作者 | 朝代 || ------ | ------ | ---- || 白头吟 | 卓文君 | 两汉 || 锦瑟 | 李商隐 | 唐代 || 登科后 | 孟郊 | 唐代 | 显示效果保持一致。但是如果一个字符一个字符去手动对齐效率太低,也不符合 Markdown 设计初衷。这就用到了额外的插件,能够辅助我们完成这个工作。 Markdown All in OneVSCode 插件中心搜索Markdown All in One安装。 安装完成后,使用时右击窗口选择Format Document with: 选择Markdown All in One即可自动对齐所有表格竖线: 常见问题格式化文档后仍未对齐这是由于表格中同时有中英文,而中英文字体不等宽导致的。如果对阅读要求不高,可以不用管,实际上已经格式化完成了。如果需要对齐,那么可以查看编码字体与阅读字体推荐这篇文章的中文等宽字体下载并安装,即可正常对齐。","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"},{"name":"Efficiency","slug":"Efficiency","permalink":"http://example.com/tags/Efficiency/"},{"name":"Markdown","slug":"Markdown","permalink":"http://example.com/tags/Markdown/"}]},{"title":"ZH-The RISC-V Instruction Set Manual Volume 2-特权级架构","slug":"ZH-The-RISC-V-Instruction-Set-Manual-Volume-2-特权级架构","date":"2022-09-22T01:37:54.000Z","updated":"2022-10-15T03:14:29.627Z","comments":true,"path":"2022/09/22/ZH-The-RISC-V-Instruction-Set-Manual-Volume-2-特权级架构/","link":"","permalink":"http://example.com/2022/09/22/ZH-The-RISC-V-Instruction-Set-Manual-Volume-2-%E7%89%B9%E6%9D%83%E7%BA%A7%E6%9E%B6%E6%9E%84/","excerpt":"","text":"Introduction Document Version 20211203 Control and Status Registers (CSRs)Machine-Level ISA, Version 1.12本章介绍了机器模式(M-mode)中可用的机器级操作,这是 RISC-V 系统中最高权限的模式。M 模式用于对硬件平台的低级访问,是复位时进入的第一个模式。M 模式也可以用来实现那些在硬件中直接实现过于困难或成本高昂的功能。RISC-V 的机器级 ISA 包含一个共同的核心,根据支持的其他权限级别和硬件实现的其他细节来扩展。 Machine-Level CSRs除了本节中描述的机器级 CSRs 外,M-mode 代码还可以访问较低特权级别的所有 CSRs。 Machine ISA Register misamisa CSR 是 WARL 读写寄存器,报告硬件 (hart) 支持的 ISA。该寄存器在任何实现中都必须是可读的,但是可以返回零值以指示未实现 misa 寄存器,这就需要通过一个单独的非标准机制确定 CPU 功能。 MXL(机器 XLEN)字段编码本机基本整数 ISA 宽度,如表 3.1 所示。MXL 字段在支持多个基本 ISA 宽度的实现中可能是可写的。M-mode 下的有效 XLEN, MXLEN,由 MXL 的设置给出,如果 misa 为零,则有一个固定的值。重置时,MXL 字段始终设置为最广泛支持的 ISA 变种。 misa CSR 为 MXLEN 位宽。如果从 misa 读取的值不为零,该值的 MXL 字段总是表示当前的 MXLEN。如果对 misa 的写操作导致 MXLEN 发生更改,则 MXL 的位置将以新的宽度移动到 misa 的最高有效两位。 可以使用返回的 misa 值的符号上的分支,以及可能在符号上左移一个分支和第二个分支,来快速确定基本宽度。这些检查可以用汇编代码编写,而无需知道机器的寄存器宽度(XLEN)。基本宽度由 XLEN = 2^(MXL + 4) 给出。如果 misa 为零,则可以通过将立即数 4 放置在一个寄存器中,然后一次将寄存器左移 31 位来找到基本宽度。如果在一次移位后为零,则该机器为 RV32。如果两次移位后为零,则机器为 RV64,否则为 RV128。 Extensions 字段编码了目前存有的标准扩展,其每个 bit 都对应了字母表中的一个字母(bit 0 编码扩展“A”是否存在,bit 1 编码扩展“B”是否存在… 直至 bit 25 编码“Z”)。如果基础 ISA 是 RV32I、RV64I 或 RV128I,则置位“I”bit,否则如果基础 ISA 是 RV32E,则置位“E”bit。 Extensions 字段是一个能包含可写位的 WARL 字段(如果实现允许修改所支持的 ISA)。 复位(reset)时,Extensions 应包含所支持扩展的最大集,如果 E 和 I 都可用,则优先选择 I。 在通过清除 misa 中相应 bit 来禁止一个标准扩展时,由该扩展所定义或修改的指令和 CSR 将恢复为该扩展未实现时的定义,或者保留行为(revert to their defined or reserved behaviors as if the extension is not implemented)。 RV128 base ISA 的设计尚未完工,尽管预计本 specification 中大部分的剩余部分都将适用于 RV128,但本版本的文档仅关注 RV32 和 RV64。 如果支持用户模式(user mode),则将“U”bit 置位;如果支持主管模式(supervisor mode),则将“S”bit 置位。 如果存在任何非标准扩展(non-standard extensions),则将“X”bit 置位。 “E”位是只读的。除非将 misa 硬连线为零,否则“E”位始终读取为“I”位的补码(补集?)。同时支持 RV32E 和 RV32I 的实现可以通过清除“I”位来选择 RV32E。 如果 ISA 功能 x 依赖 ISA 功能 y,则尝试启用功能 x 但禁用功能 y 会导致两个功能都被禁用。例如,设置“F” = 0 和“D” = 1 会导致同时清除“F”和“D”。 具体实现可能会在 2 或多个 misa 字段的集体设置上施加额外约束,此时将它们的集体看作是一个 WARL 字段。试图向其中写入一个不支持的组合会导致这些 bits 被置为某个支持的组合。 写 misa 可能会增加 IALIGN,例如,通过禁用 C 扩展。如果要写入 misa 的指令增加了 IALIGN,而后一条指令的地址未按 IALIGN 位对齐,则将抑制对 misa 的写入,从而使 misa 保持不变。 在软件启用一个之前被禁用的扩展时,除该扩展另有规定(specified),否则所有单独与该扩展有关的状态都将是未指定的(unspecified)。 Machine Vendor ID Register mvendoridmvendorid CSR 是一个 32 位只读寄存器,提供内核供应商的 JEDEC 制造商 ID。此寄存器在任何实现中都必须是可读的,但可以返回 0,表示该字段未实现或这是非商业实现。 JEDEC 制造商 ID 通常编码为单字节连续的 0x7f 代码的序列,以不等于 0x7f 的单字节 ID 终止,并且在每个字节的最高有效位中带有奇校验位。mvendorid 在 Bank 字段中编码单字节的连续代码,并在 Offset 字段中编码最后一个字节,丢弃奇偶校验位。例如,JEDEC 制造商 ID 0x7f 0x7f 0x7f 0x7f 0x7f 0x7f 0x7f 0x7f 0x7f 0x7f 0x7f 0x7f 0x8a(十二个连续代码,后跟 0x8a)将在 mvendorid 字段中编码为 0x60a。 译者注:JEDEC 固态技术协会(JEDEC Solid State Technology Association)是固态及半导体工业界的一个标准化组织,它由约 300 家公司成员组成,约 3300 名技术人员通过 50 个不同的委员会运作,制定固态电子方面的工业标准。JEDEC 曾经是电子工业联盟(EIA)的一部分:联合电子设备工程委员会(Joint Electron Device Engineering Council,JEDEC)。该协会制定了一个制造商标识码的标准:Standard Manufacturer’s Identification Code,通过读取mvendorid寄存器值,查阅该标准即可确定制造商。 注:用 JEDEC 的话来说,Bank 编号比 Continuation 的数量大 1;因此,mvendorid Bank 字段编码的值比 JEDEC Bank 编号小一。 注:以前,供应商 ID 是 RISC-V 基金会分配的编号,但这与 JEDEC 在维护制造商 ID 标准方面的工作重复。在撰写本文时,向 JEDEC 注册制造商 ID 的一次性费用为 500 美元。 Machine-Mode Privileged InstructionsEnvironment Call and BreakpointTrap-Return InstructionsWait for Interrupt等待中断指令 (WFI) 为实现提供了一个提示,即当前的 hart 可以停止,直到需要服务中断。WFI 指令的执行也可以用来通知硬件平台合适的中断应该优先路由到这个 hart。WFI 在所有特权模式下都可用,并且可用于 U 模式 (可选地)。当 mstatus 中的 TW = 1 时,该指令可能会引发非法指令异常,如第 3.1.6.5 节所述。 如果在 hart 停止时存在或稍后出现启用的中断,则中断 trap 将在以下指令上执行,即在 trap 处理程序中恢复执行并且 mepc = pc + 4。","categories":[{"name":"RISC-V 入门","slug":"RISC-V-入门","permalink":"http://example.com/categories/RISC-V-%E5%85%A5%E9%97%A8/"}],"tags":[{"name":"RISC-V","slug":"RISC-V","permalink":"http://example.com/tags/RISC-V/"},{"name":"Translation","slug":"Translation","permalink":"http://example.com/tags/Translation/"}]},{"title":"使用 Markdownlint 对 Markdown 文本格式检查","slug":"使用Markdownlint对Markdown文本格式检查","date":"2022-09-17T03:07:10.000Z","updated":"2022-10-15T03:04:19.451Z","comments":true,"path":"2022/09/17/使用Markdownlint对Markdown文本格式检查/","link":"","permalink":"http://example.com/2022/09/17/%E4%BD%BF%E7%94%A8Markdownlint%E5%AF%B9Markdown%E6%96%87%E6%9C%AC%E6%A0%BC%E5%BC%8F%E6%A3%80%E6%9F%A5/","excerpt":"","text":"Markdownlint 简介Markdown 标记语言旨在易于阅读、编写和理解。它的灵活性既是优点也是缺点。语法众多,因此格式可能不一致。某些构造在所有解析器中都不能很好地工作,应该避免。CommonMark 规范标准化解析器。 Markdownlint 是一个用于 Node.js 的静态分析工具,有一个标准规范,用于强制执行 Markdown 文件的标准和一致性。 Markdownlint 插件使用markdownlint提供了多种使用场景下的解决方案,如命令行,编辑器甚至 GitHub Action。因为我平时写 Markdown 文档都是使用 VSCode,所以介绍一下 VSCode 下的使用。其他编辑器包括 VIM,Sublime 也都支持,可以前往官网查阅方法。 VSCode 需要下载插件,Ctrl+Shift+X打开插件中心,搜索Markdownlint安装即可。 安装插件后打开 Markdown 文档,如果有不符合规范的语法将会警告标识。如,标题前后没有空行,将会标识: 提示违反了第 22 条规范,第 22 条规范的就是标题前后需要有空行隔开。 目前有 53 条规范,可以在markdownlint/Rules.md查看所有规范的内容。 当然这些规范也都可以自定义是否检查,比如第 24 条规定,文档内不可以有重复的标题,但是我就有重复标题的需求,那该如何关闭这个检查呢,Markdownlint 提供了配置的方式。 Ctrl+Shift+P打开运行窗口,输入 Markdownlint,找到Creat or open the markdownlint configuration file。 创建一个配置文件,并输入以下内容,表示关闭第 24 条规范的检查: 123{ "MD024": false,} 这样文档中将不会有第 24 条规范的检查警告,其他检查同理。 Markdownlint 自定义规则MD001 - Heading levels should only increment by one level at a time标题等级一次只能增加一级,不能跨级。 原理:标题代表文档的结构,跳过时可能会造成混淆 - 特别是对于可访问性场景。 MD002 - First heading should be a top-level heading文档的第一个标题必须是最高级的标题(标题等级 1 级到 6 级逐渐降低) MD003 - Heading style整篇文档需要采用一致的标题格式。 MD004 - Unordered list style无序列表格式需要一致。 MD005 - Inconsistent indentation for list items at the same level 同一级的列表缩进必须一致 在有序列表中,前面的数字序号可以左对齐,也可以右对齐 MD006 - Consider starting bulleted lists at the beginning of the line一级列表不能缩进。 如下为报错: 1234Some text * List item * List item MD007 - Unordered list indentation无序列表嵌套缩进时默认采用两个空格。 MD009 - Trailing spaces行尾最多可以添加两个空格,超过会给出警告,两个空格正好可以用于换行。 MD010 - Hard tabs不能使用 tab 键缩进,要使用空格。 原理:硬制表符通常由不同的编辑器以不一致的方式呈现,并且比空格更难处理。 MD011 - Reversed link syntax当遇到看似链接的文本,但语法似乎已反转([] 和 () 反转)时,将触发此规则。 MD012 - Multiple consecutive blank lines文档中不能有连续的空行,在代码块中此规则不会生效。 MD013 - Line length默认行的最大长度是 80,此规则对代码块、表格、标题也生效。 MD014 - Dollar signs used before commands without showing output在代码块中,终端命令前不需要有美元符号 ($)如果代码块中既有终端命令,也有命令的输出,则终端命令前可以有美元符号 ($)。 MD018 - No space after hash on atx style heading在”atx”格式的标题中,#号和文字间需用一个空格隔开。 MD019 - Multiple spaces after hash on atx style heading在”atx”格式的标题中,#号和文字间只能用一个空格隔开,不能有多余的空格。 MD020 - No space inside hashes on closed atx style heading在”closed_atx”格式的标题中,文字和前后的#号之间需用一个空格隔开。 MD021 - Multiple spaces inside hashes on closed atx style heading在”closed_atx”格式的标题中,文字和前后的#号之间只能用一个空格隔开,不能有多余的空格。 MD022 - Headings should be surrounded by blank lines标题行的上下行必须都是空行。 MD023 - Headings must start at the beginning of the line标题行不能缩进。 MD024 - Multiple headings with the same content文档不能有内容重复的标题。 MD025 - Multiple top-level headings in the same document同一文档只能有一个最高级的标题,默认是只能有一个 1 级标题。 MD026 - Trailing punctuation in heading标题行末尾不能有以下标点符号。 MD027 - Multiple spaces after blockquote symbol创建引用区块时,右尖括号 ( > ) 和文字之间有且只能有一个空格。 MD028 - Blank line inside blockquote两个引用区块间不能仅用一个空行隔开或者同一引用区块中不能有空行,如果一行中没有内容,则这一行要用>开头。 MD029 - Ordered list item prefix有序列表的前缀序号格式必须只用 1 或者从 1 开始的加 1 递增数字。 MD030 - Spaces after list markers列表(有序、无序)的前缀符号和文字之间用 1 个空格隔开在列表嵌套或者同一列表项中有多个段落时,无序列表缩进两个空格,有序列表缩进 3 个空格。 MD031 - Fenced code blocks should be surrounded by blank lines单独的代码块前后需要用空行隔开(除非是在文档开头或末尾),否则有些解释器不会解释为代码块 MD032 - Lists should be surrounded by blank lines列表(有序、无序)前后需要用空行隔开,否则有些解释器不会解释为列表。 列表的缩进必须一致。 MD033 - Inline HTML文档中不允许使用 HTML 语句。 MD034 - Bare URL used单纯的链接地址需要用尖括号 (<>) 包裹,否则有些解释器不会解释为链接。 MD035 - Horizontal rule style创建水平线时整篇文档要统一 (consistent),要和文档中第一次创建水平线使用的符号一致。 MD036 - Emphasis used instead of a heading不能用加粗代替标题。 MD037 - Spaces inside emphasis markers用于创建强调的符号和强调的的文字之间不能有空格。 MD038 - Spaces inside code span elements当用单反引号创建代码段的时候,单反引号和它们之间的代码不能有空格如果要把单反引号嵌入到代码段的首尾,创建代码段的单反引号和嵌入的单反引号间要有一个空格隔开。 MD039 - Spaces inside link text链接名和包围它的中括号之间不能有空格,但链接名中间可以有空格。 MD040 - Fenced code blocks should have a language specified单独的代码块(此处是指上下用三个反引号包围的代码块)应该指定代码块的编程语言,这一点有助于解释器对代码进行代码高亮。 MD041 - First line in a file should be a top-level heading文档的第一个非空行应该是文档最高级的标题,默认是 1 级标题。 MD042 - No empty links链接的地址不能为空。 MD043 - Required heading structure要求标题遵循一定的结构,默认是没有规定的结构。 MD044 - Proper names should have the correct capitalization指定一些名称,会检查它是否有正确的大写。 MD045 - Images should have alternate text (alt text)图片链接必须包含描述文本(alt text)。 MD046 - Code block style整篇文档采用一致的代码格式。 MD047 - Files should end with a single newline character文档需用一个空行结尾。 MD048 - Code fence style表示代码块的标记需要一直,可以是波浪号,也可以是点号。但是需要保持一致。 MD049 - Emphasis style should be consistent强调符号需要一直,如斜体。 MD050 - Strong style should be consistent加粗符号需要保持一致。 MD051 - Link fragments should be valid锚点需要表示正确。","categories":[{"name":"万能 VSCode","slug":"万能-VSCode","permalink":"http://example.com/categories/%E4%B8%87%E8%83%BD-VSCode/"}],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"},{"name":"Efficiency","slug":"Efficiency","permalink":"http://example.com/tags/Efficiency/"},{"name":"Markdown","slug":"Markdown","permalink":"http://example.com/tags/Markdown/"},{"name":"插件","slug":"插件","permalink":"http://example.com/tags/%E6%8F%92%E4%BB%B6/"},{"name":"推荐","slug":"推荐","permalink":"http://example.com/tags/%E6%8E%A8%E8%8D%90/"}]},{"title":"VSCode 字体快速切换","slug":"VSCode字体快速切换","date":"2022-09-12T07:05:16.000Z","updated":"2022-10-15T03:10:27.075Z","comments":true,"path":"2022/09/12/VSCode字体快速切换/","link":"","permalink":"http://example.com/2022/09/12/VSCode%E5%AD%97%E4%BD%93%E5%BF%AB%E9%80%9F%E5%88%87%E6%8D%A2/","excerpt":"","text":"需求背景在写 MD 文档时为了追求美观,表格通常都是对齐的,这就需要字体必须等宽,但是写代码时等宽字体的因为很瘦小,不容易阅读,所以想要一个插件能够在多个字体直接快速切换。万能 VSCode 啥都有,插件中心就有一款专门切换字体的插件Font Switcher。直接搜索安装。 配置与使用打开配置脚本settings.json,如果以前修改过字体,找到"editor.fontFamily"配置项,如果没有就直接添加。 这是我的字体,添加你们机器上安装的字体,每个逗号间隔都是不同的字体,可以使用Font Switcher切换,需要注意的是,字体名没有空格不需要加单引号,加了也无妨,如果有空格,一定要加引号。 1"editor.fontFamily": "'Sarasa Mono SC', 微软雅黑,'Noto Sans Mono CJK SC', 'JetBrains Mono', Consolas, monospace", Ctrl+Shift+P打开运行窗口,输入Switch Font,选择切换的字体。如图: ","categories":[{"name":"万能 VSCode","slug":"万能-VSCode","permalink":"http://example.com/categories/%E4%B8%87%E8%83%BD-VSCode/"}],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"},{"name":"Efficiency","slug":"Efficiency","permalink":"http://example.com/tags/Efficiency/"}]},{"title":"解决 Linux 终端回车键变成字符 M","slug":"解决Linux终端回车键变成字符M","date":"2022-09-12T06:52:12.000Z","updated":"2022-10-15T03:14:29.817Z","comments":true,"path":"2022/09/12/解决Linux终端回车键变成字符M/","link":"","permalink":"http://example.com/2022/09/12/%E8%A7%A3%E5%86%B3Linux%E7%BB%88%E7%AB%AF%E5%9B%9E%E8%BD%A6%E9%94%AE%E5%8F%98%E6%88%90%E5%AD%97%E7%AC%A6M/","excerpt":"","text":"保留现场 解决方法命令行执行 1stty sane","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"Linux 下切换 Python 版本","slug":"解决Linux下切换Python版本","date":"2022-09-12T06:05:17.000Z","updated":"2022-10-15T03:14:29.813Z","comments":true,"path":"2022/09/12/解决Linux下切换Python版本/","link":"","permalink":"http://example.com/2022/09/12/%E8%A7%A3%E5%86%B3Linux%E4%B8%8B%E5%88%87%E6%8D%A2Python%E7%89%88%E6%9C%AC/","excerpt":"","text":"需求背景用过 Python 的都知道,Python 是不向后兼容的,也就是 Python3.X 开发的程序,使用 Python2.X 环境就无法正常运行。因为很多语法都改变了。现在接触到的大部分 Python 程序都是 Python3.X 开发的,但是偶尔也会遇到使用 Python2.X 的时候。这就需要灵活切换版本。 一般 Linux 的各个发行版都预装了 Python2.X。我使用的 Debian 就预装了 Python2.7。 12$ python -VPython 2.7.16 但是我同时也安装了 Python3.7 123456789$ ls /usr/bin | grep "python*"dh_python2pythonpython2python2.7python3python3.7python3.7mpython3m alias 修改别名123$ alias python=/usr/bin/python3$ python -VPython 3.7.3 上面的别名修改只对当前终端有效。如果要使每个窗口都使用这个别名,将别名加入~/.bashrc,如 zsh 是则是~/.zshrc。 软链接和修改别名类似 1ln -s python /usr/bin/python3 update-alternativesupdate-alternatives是 Debian 系统提供的一个工具,Ubuntu 是基于 Debian 的,所以 Ubuntu 也可以使用,其他发行版没有该工具。它可以用来方便快捷地切换应用版本,不仅仅用来切换 Python,其他应用程序有多个版本的也可以使用该工具。 update-alternatives本质也是建立软链接,只不过有了统一的管理,首先我们需要使用--install参数,添加一些候选项,也就是执行python这个命令时,它可以有哪些选择,在这里就是python3.7.3和python2.7.16两个选择。 123# --install <链接> <名称> <路径> <优先级>sudo update-alternatives --install /usr/bin/python python /usr/bin/python2.7 2sudo update-alternatives --install /usr/bin/python python /usr/bin/python3.7 1 注意,这里的/usr/bin/python链接文件,两个可选项必须是一样的,这样这个链接文件才可以选择两个不同的可选项去链接。 python是在命令行执行的命令。/usr/bin/python2.7是执行python命令后调用具体哪个版本。最后的数字2是优先级,也就是python2.7比python3.7优先级高,如果不指定版本,那么默认就是使用python2。 我们再查看一下版本信息,发现是python2.7.16。说明是默认版本。并且python已被链接到我们管理的软链接上。 12345$ python -VPython 2.7.16$ ll /usr/bin | grep "python"lrwxrwxrwx 1 root python -> /etc/alternatives/python 查看python的可选配置,可以看到有两个可选配置,默认是python2,第一列是序号,如果我们想切换到python3,对应的数字2即可。 123456789101112root at RISCX in ~$ update-alternatives --config pythonThere are 2 choices for the alternative python (providing /usr/bin/python). Selection Path Priority Status------------------------------------------------------------* 0 /usr/bin/python2.7 2 auto mode 1 /usr/bin/python2.7 2 manual mode 2 /usr/bin/python3.7 1 manual modePress <enter> to keep the current choice[*], or type selection number:2update-alternatives: using /usr/bin/python3.7 to provide /usr/bin/python (python) in manual mode 再次查看版本信息,发现已经切换成功。 12$ python -VPython 3.7.3 执行update-alternatives经常会导致我的终端回车失效,可以参考解决 Linux 终端回车键变成字符 M --remove,删除可选项: 1sudo update-alternatives --remove python /usr/bin/python2.7","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Python","slug":"Python","permalink":"http://example.com/tags/Python/"},{"name":"效率","slug":"效率","permalink":"http://example.com/tags/%E6%95%88%E7%8E%87/"}]},{"title":"解决 Python No module named 'ConfigParser'","slug":"解决Python-No-module-named-ConfigParser","date":"2022-09-11T15:20:05.000Z","updated":"2022-10-15T03:14:29.825Z","comments":true,"path":"2022/09/11/解决Python-No-module-named-ConfigParser/","link":"","permalink":"http://example.com/2022/09/11/%E8%A7%A3%E5%86%B3Python-No-module-named-ConfigParser/","excerpt":"","text":"保留现场123ImportError: No module named 'ConfigParser'Command "python setup.py egg_info" failed with error code 1 in 解决方法在 Python 3.x 版本后,ConfigParser.py 已经更名为 configparser.py 所以出错! 可以切换 Python2 执行。 也可以尝试将文件重命名为ConfigParser.py。 以下为参考,每个人安装路径可能不一样,可以全局搜索configparser.py。 1cp /usr/lib/python3.7/configparser.py /usr/lib/python3.7/ConfigParser.py","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Python","slug":"Python","permalink":"http://example.com/tags/Python/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"解决 LaTeX 编译 Missing character There is no (U+00A0) in font","slug":"解决LaTex编译Missing-character-There-is-no-U-00A0-U-00A0-in-font","date":"2022-09-11T14:20:02.000Z","updated":"2022-10-15T03:14:29.811Z","comments":true,"path":"2022/09/11/解决LaTex编译Missing-character-There-is-no-U-00A0-U-00A0-in-font/","link":"","permalink":"http://example.com/2022/09/11/%E8%A7%A3%E5%86%B3LaTex%E7%BC%96%E8%AF%91Missing-character-There-is-no-U-00A0-U-00A0-in-font/","excerpt":"","text":"保留现场在 LaTeX 编译中报错:Missing character: There is no (U+00A0) (U+00A0) in font JetBrains Mono。 探究原因如果要搞清楚具体原因,就得从字符与字符编码说起了。解决办法直接跳到下一节吧。 字符,就是“a”,“A”,“你”等书写符号。 字符集,通常就是某种语言字符集合,比如英语就是ASCII 字符集,中文有GBK 字符集等 注意,不是每种语言只对应一种字符集(比如 GB2312,GBK,GB18030 都包含了常用汉字,后者是前者的超集),而且字符集也不是只对应一种语言,例如 Unicode 字符集就包含所有语言字符,字符集只是设计者为了给字符编码(Code Point/Numbering)设计编码时,为了收录到命名的字符集合,但是通常设计者都为字符集设计了对应的编码规范。 字符编码,给字符集里的字符编号。 编码页,在 unicode 发明之前,各个地区都用 2 字节编码自己的字符集,相同的编码对应不同的字符,为了本地化,Windows 发明了编码页,来对应不同的字符集。 字符编码,对给定的字符编码编码成字节表示。 早期,字符被编号后,存储时就按照编号的方式存储,没有 encoding 的过程,后来发明 Unicode 后,发现如果按照 Unicode 的编号直接存储的话,对于英文字符就有很大存储浪费,因为任意字符都需要 2 字节存储,后来人们发明 UTF-8 这种编码方式,这样 UTF-8 就可以一个字节表示英文字符,2 个以上字节表示汉字字符。 字体,定义了字符的图形表示,现在的软件展示字符时用 Unicode 表示,字体是 Unicode 编码和字符图形的映射,而以往比如 WindowsCMD 控制台,没有对应 Unicode,则用编码页来区分,所以字体就是字符编码金和代码页到字符图形的映射。 文本文件存储在磁盘上,都是一系列的字节流,如果不告诉文本编辑器该文件的编码方式,编辑器会尝试用默认的编码(依赖于操作系统设置)又或者自己探测(detect,比如文件开头有 FFEF 或者 EFFF 字节就表明 UTF-16 编码,有很多 10,110 开头的字节,很可能是 UTF-8 编码)并尝试解码,如果没有猜对,那就会显示乱码。 回到出错的问题,提示我们在字体 JetBrains Mono中没有U+00A0,我们搜索一下就知道这是一个 Unicode 字符NO-BREAK SPACE。我们通过上面的了解也知道了,字体就是字符编码到字符图像的映射,但是一个字体尤其是一些有专门用途的字体(比如 JetBrains Mono 设计初衷是为软件工程显示代码用的),它不会映射所有的字符,JetBrains Mono 这个字体里就没有映射 U+00A0。这就导致在 LaTeX 编译时无法在字体中找到对应的字符图像显示。 所有解决办法就是要不替换掉这个字符,要不换个字体。 解决方法VSCode 正则搜索\\U00A0即可搜索到相关字符,将其替换成空格。 参考字符,字符集,字符编码,编码页,字体 - 简书","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"},{"name":"字体","slug":"字体","permalink":"http://example.com/tags/%E5%AD%97%E4%BD%93/"},{"name":"LaTex","slug":"LaTex","permalink":"http://example.com/tags/LaTex/"}]},{"title":"每天学命令-nohup 后台运行","slug":"每天学命令-nohup后台运行","date":"2022-09-10T09:14:58.000Z","updated":"2022-10-15T03:03:19.398Z","comments":true,"path":"2022/09/10/每天学命令-nohup后台运行/","link":"","permalink":"http://example.com/2022/09/10/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-nohup%E5%90%8E%E5%8F%B0%E8%BF%90%E8%A1%8C/","excerpt":"","text":"使用 MobaXertm 连接服务器后,想要在运行一个下载任务,使用&挂在后台后,退出 MobaXterm,后台的任务也随之中断,于是搜到这个nohup命令,可以完成我的需求。 nohup意思是 No Hang Up,不要挂起的意思,即使退出终端也不会中断任务。 为了方便以后查阅,这里总结一下关于后台运行相关的命令。首先是最常用的&符号。 & 后台运行比如执行编译任务时通常会占用终端前台,这时候无法再执行其他命令,除非再开一个终端,对于有 GUI 界面时,再开一个终端很方便,但是如果是服务器就只能再想办法了。 &可以将命令执行过程放在后台运行,如: 12$ make > make.log 2>&1 & [1] 16586 2>&1 是将标准出错重定向到标准输出,这里的标准输出已经重定向到了make.log文件,即将标准出错也输出到make.log文件中。最后一个&,是让该命令在后台执行。试想2>1代表什么,2与>结合代表错误重定向,而1则代表错误重定向到一个文件1,而不代表标准输出;换成2>&1,&与1结合就代表标准输出了,就变成错误重定向到标准输出。 在后台运行make进行编译,并将输出结果(错误和正常输出)都保存到make.log文件中,提交任务成功后,会显示进程 ID,编译的进程 ID 为 16586。 有了进程 ID 我们可以监控,也可以中断进程: 1234# 查看进程状态ps -ef | grep 16586# 中断进程kill -9 16586 但是使用 &时关闭终端后,进程也会随之关闭。如果想要在后台持续运行程序,就需要nohup命令。 nohup 使用12$ nohup make > make.log 2>&1 & [1] 112233 命令功能同上,但是终端关闭,后台程序也会继续执行。 NOTE:终端关闭,是指带 GUI 的界面里终端,如果使用 SSH 等登陆,比如使用 MobaXterm,一个 session 相当于一个登陆账户,如果异常退出了这个账户,那么后台执行的程序也会中断。如果需要继续执行,需要正常退出账户,执行exit命令。 汇总12345678910fg # 将后台中的命令调至前台继续运行bg # 将一个在后台暂停的命令,变成继续执行 (在后台执行)jobs # 查看当前有多少在后台运行的命令kill %num # 终止进程num& # 加在命令后可以将其置于后台运行ctrl + z # 置于后台,并且暂停不可执行ctrl + c # 终止前台进程ctrl + \\ # 退出ctrl + d # 结束当前输入(即用户不再给当前程序发出指令),那么Linux通常将结束当前程序","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"从零开始搭建一台 NAS 存储服务器","slug":"从零开始搭建一台NAS存储服务器","date":"2022-09-10T03:37:47.000Z","updated":"2022-10-22T12:12:18.960Z","comments":true,"path":"2022/09/10/从零开始搭建一台NAS存储服务器/","link":"","permalink":"http://example.com/2022/09/10/%E4%BB%8E%E9%9B%B6%E5%BC%80%E5%A7%8B%E6%90%AD%E5%BB%BA%E4%B8%80%E5%8F%B0NAS%E5%AD%98%E5%82%A8%E6%9C%8D%E5%8A%A1%E5%99%A8/","excerpt":"","text":"技术没学多少,教程下满了硬盘,一直想专门部署 NAS 来存文件,但是一来要花钱,二来搭建 NAS 没有经验怕部署不好,没有现在硬盘直连舒适,所以将就用吧。 自从有天忘了忘了休眠电脑,一个自动备份任务开启,在 40 度的高温天,满速跑了一天,下班回来硬盘直接报废。这就加速我折腾部署 NAS 的进程。 准备阶段威联通的几款中意的 NAS 放购物车很久了,如果硬盘没有这么早坏掉,可能在双十一就买整机了,现在离双十一还早,硬件价格都不便宜,想来想去还是买二手硬件攒一台更划算。如果买整机,硬盘加 NAS 主机就得五千大洋,只是用来存文件,部署个 Jellyfin 看电影用,属实奢侈了。 ¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥ 买二手就得从零开始学。生命不休,折腾不止。经过一次完整的 NAS 攒机过程发现,其实 NAS 就是安装了专用系统的一台电脑而已。这个专用系统就是面向网络存储开发的,如群晖,威联通,开源的 OMV,FreeNAS 等等。 既然是一台电脑,其实攒 NAS 就和攒电脑一样,选配好以下几大件即可。 CPU 主板 散热器 机箱 内存 电源 机箱风扇 下面分别介绍在攒机过程中遇到的一些概念,参数到底是什么意思。 CPUCPU 型号字母数字都是什么意思 Intel 是英特尔的英文名称,也是目前热门的 CPU 品牌; “酷睿”代表英特尔品牌下面向普通消费者的一个 CPU 系列,一般划分为 Core(酷睿)、Pentium(奔腾)、Celeron(赛扬)、Xeon(至强)、Atom(凌动)等; i5 代表这款 CPU 定位中端,在其下面还有 i3,在其上面还有 i7 和 i9,同一代中,数字越大,性能越强;但是不同代 - 数之间,性能不能直接相比,比如 12 代的 i5 在理论性能上是强于 10 代 i7 的。 12 代表这款 CPU 的代数,说明其已经发展到第十二代了,数字越大越新; 600 这三位数字代表 Intel SKU 型号划分,一般来说 Core i7 有固定几个 SKU,比方说 700;Core i5有600/500/400;Core i3有300/100等等,一般来说数字越大说明隶属的Core系列越高级,同级别下比较,数字越大频率越高,换句话说性能就越强,比方说Core i5-8600 默认 3.1GHz,睿频 4.3GHz,比 Core i5-8500 默认 3.0GHz,睿频 4.1GHz 要强。 K 带 K 的表示不锁频,可以配合 Z 系列主板进行超频操作,适合会超频玩家使用,比方说 i7-12700K,i5-12600K 等 F 带 F 的表示不带集成显卡,你必须配合独立显卡使用; 当然,除了例子中的这种情况,我们还会遇到其它 CPU 型号的后缀: K:表示支持超频且内置核显的 CPU 型号,例如型号:i5-12600K、i7-12700K; F:表示无内置核显,例如型号:i5-12400F、i7-12700F; KF:表示支持超频且无内置核显的 CPU 型号,例如型号:i5-12600KF,i7-12700KF。 T:表示低功耗版,相同型号下功耗更低,性能也差一些,例如型号:i7-10700T; X/XE:表示至尊旗舰级,例如型号:i9-10980XE。 KS:可以理解为官方超频版,提升了主频的版本,例如 i9-9900K 和 i9-9900KS,i9-9900KS 出厂的主频要高于 K,例如型号:i9-9900KS。 U:低电压,性能弱些但功耗低,通常出现在轻薄本中,举例型号:i7 10510U; H:标压,性能强,通常出现在游戏本中,举例型号:i5-11300H Y:超低电压,性能很弱功耗非常低,通常出现在轻薄本中,举例型号:i3-10110Y; HK:一般使用在 Intel 高端发烧级 CPU 上,可超频,举例型号:i9-11980HK; G:G1、G4 以及 G7 等,G 后面的数字表示核显性能强弱,数字越大代表核显性能越强,通常数字小于 4 的是集成的普通超高清 (UHD) 核显,大于等于 4 的是集成的高性能锐炬 (Iris) 核显。Intel 移动版 CPU 后缀,举例型号:i5-1155G7、i3-1115G4、i3-1005G1; HQ:标准电压,Q 板载四核,早期的老后缀,举例型号:i7-7700HQ; MQ:标准电压,Q 插拔四核,早期的老后缀,举例型号:i7-4810MQ; M:早期后缀 M 就是移动端 CPU,只是为了与台式机区别开,举例型号:i7-2620M。 主板ATX,Micro-ATX,Mini-ITX 区别在了解买啥主板时,不免会看到各种 TX,比如我买的这块七彩虹 B460iTX 主板,简称就是七彩虹 B460i,还有不带最后字母i的。他们有啥区别呢?其实这就是表示了主板的尺寸。主板尺寸常见的有三种尺寸: 标准-ATX:30.5 厘米 x 24.4 厘米 Micro-ATX:24.4 cm x 24.4 cm Mini-ITX:17 厘米 x 17 厘米 一般攒机会用标准 ATX,或者 MATX 也很常用,而 ITX 就常被用来搭建低功耗的服务器,如我们要搭建的 NAS。因为它是 7*24 小时不间断工作的,功耗是需要多考虑的。 散热器风冷与水冷 风冷就是散热鳍片加风扇。散热鳍片会穿入铜管,铜管与下方底座相连,底座与 CPU 直接接触。CPU 热量铜管底座传导给铜管,铜管传导给散热鳍片,散热鳍片铜管风扇散热。 水冷就是水冷头加风扇。简单理解就是风冷的铜管换成了液体。液体流动传导比铜管更快。 各有优缺点,风冷更安全,比较简单,性能上限比较低,而水冷在外观、性能方面有很大的优势,缺点就是相对比较贵,还有漏液风险,不过现在的水冷漏液概率很小。细分的话风冷还有下压式,下压式比较适合 itx 小机箱,而塔式就适合普通机箱,水冷也分一体式水冷和分体式水冷,常见的都是一体式水冷。 机箱塔式,机架与刀片区别塔式服务器外形和普通家用服务器相差不多,塔式主机在主板扩展上有优势,一般预留接口较多,方便扩展。适用于入门和工作站。 机架服务器的外观安装工业标准统一设计,需要配合机柜统一使用,主要用于企业服务器密集部署。机架服务器因为需要密集紧凑,所以在设计时会非常紧凑,充分利用有限的空间。机架服务器宽度 19 英寸,高度以 U 为单位 (1U=1.75 英寸 =44.45 毫米). 刀片服务器的主体结构是主体机箱中可以有许多热拔插的主板,每一块主板都可以独立运行自己的系统,这些主板可以集合成一个服务器集群,在集群模式下可以连接起来提供更好的网络以及共享资源。 全塔,中塔与小塔区别形容的是机箱的大小。 普通机箱,只能放 mATX 主板和一个标准电源,仅有 1-2 个光驱位; 中塔机箱 AT,X 主板甚至是 EATX 主板和一个标准电源,拥有 3-4 个光驱位; 全塔机箱,可以在主板上下的位置都安放一个电源,一共放两个电源拥有 4 个以上的光驱位。 内存电源全模组,半模组与非模组区别总结一句话就是能不能拔掉不需要的供电线,能拔多少。 非模组一个都不能拔,电源线直接从电源内部引出,输出线缆固定,无法进行扩展。 半模组 能拔一部分,输出设计上既有非模组电源的直出线,又有全模组电源的扩展接口。 全模组能全拔,所有线缆都能按需插上。因为一般一块主板不会把所有电源线都用上,这样只需要插上自己需要的线缆即可,可以保证走线清楚,机箱清爽。 金牌,银牌和铜牌啥区别金牌,银牌,铜牌指的是电源的转换效率。有钛金、白金、金牌、银牌、铜牌、白牌等档次,档次越高,转换效率也越高,但成本也越高,功率越小,相对成本也越高。每个“牌”对应的攻略转换或者参数也是不同的。 白牌:最低要求是 20-100% 负载下,转换效率必须达到 80%; 铜牌:与上同条件大于等于 82%,85%@50% 负载; 银牌:大于等于 85%,88%@50% 负载; 金牌:大于等于 87%,90%@50% 负载; 白金牌:90%@20% 负载、92%@50% 负载、89%@100% 负载。 钛金牌:要求 10%、20%、50%、100% 负载下的效率分别为 90%、94%、96%、92%。 举个例子:500w 金牌和 500w 铜牌,都能带动 500w 功耗的电脑。金牌电源在 100% 负载时,转换率超过 87%,可以算一下,500/0.87=575w 耗电。铜牌 100% 负载转换率超过 82% 500/0.82=610w耗电,简单说就是好电源省电。 硬盘固态硬盘机械硬盘垂直盘 PMR 与叠瓦盘 SMR 区别 作者:一起学点什么链接:https://www.zhihu.com/question/369882964/answer/2227127605 垂直磁记录(Perpendicular magnetic recording,PMR),也称为传统磁性记录 (conventional magnetic recording,CMR),由于 SMR 其实也是垂直式磁记录的一种,只是相较于垂直磁记录方式磁盘优化了写入密度,因此为了避免被认为所有垂直磁记录的硬盘都是 SMR 硬盘,大家也习惯把非 SMR 的垂直机械盘称为 CMR。 最开始由于硬盘容量提升的需求,磁性记录颗粒的尺寸需要不断下降,导致出现了电磁学上的超顺磁效应(超顺磁性:当某些具有磁性的颗粒小于某个尺寸时,外场产生的磁取向力太小而无法抵抗热扰动的干扰,而导致其磁化性质与顺磁体(通俗来说就是指材料对磁场响应很弱的磁)相似。),这就限制了硬盘容量提升的潜力。 之前硬盘厂商使用纵向(平行,Longitudinal Magnetic Recording,LMR)读写技术,磁性记录颗粒的易磁化方向相对于碟片是平行的,颗粒沿着碟片圆周以端对端排列,所以便有机会出现 SS(南)和 NN(北)的互斥排列。当颗粒的尺寸不断下降而密度不断提升,在室温的情况下颗粒便会对随机的热运动异常敏感,失去稳定性,导致出现比特(0 和 1)翻转的现象,记录的数据因此被破坏。 而为了解决以上问题,后来就开发出了垂直磁记录技术(Perpendicular Recording)的硬盘,这种硬盘中的磁性记录颗粒的易磁化方向相对于碟片是垂直的,允许使用单极磁头配合磁记录介质下的软磁层将信息写入磁记录介质中,这样采用具有相同饱和磁化强度的材料所制备的垂直写入磁头,能产生远多于传统写入磁头所能产生的磁场。更大的写入磁场允许我们使用具有更高磁各向异性的材料来制备磁记录介质,而磁各向异性越强,出现超顺磁性效应的临界体积就越小,因此,碟片中的存储密度可以在一定程度内得到进一步的提高。 但是这样虽然提高了硬盘的存储密度,但是很快也就达到了瓶颈,工程师又开始想新的方法来提高硬盘的存储密度,这就诞生了大家都知道的 SMR 叠瓦盘。 叠瓦式机械硬盘(Shingled magnetic recording,SMR,直译为分层磁记录):也是一种用于硬盘驱动器的磁存储数据记录技术,可提高存储密度和每个驱动器的整体存储容量。常规的硬盘驱动器通过写入彼此平行而不重叠的磁道来记录数据,例如 PMR。而叠瓦磁记录技术的硬盘写入的新磁道则与先前写入的磁道部分重叠,从而使先前的磁道更窄,因此能拥有更高的磁道密度,进而提高磁盘容量。使用叠瓦磁技术的磁道相互重叠,与用作屋顶的瓦片堆叠方式类似。之所以能这样做是因为磁盘写入磁头由于物理上的原因比读取磁头宽上许多,因而由正常方式写入的磁道宽度远比读取磁头所需的磁道宽度来得宽,此外为了避免磁道间相互干扰,磁道和磁道之间其实还有一部分空隙,因此读取信息的磁道仅占所有磁道的很小一部分,很大的磁盘空间都被浪费了,只是因为技术原因我们不能将写入磁头制作的和读取磁头一样小。 由于磁道存在重叠,叠瓦式磁盘的写入过程较为复杂。如果我们随机写入一个磁道,由于写入磁头的宽度比磁道宽,因此写入会影响到临近磁道,如果这个临近磁道有数据,这些数据就也需要依次重写以免数据被破坏,依此类推。因此,SMR 磁盘一般分成很多块只能追加数据(顺序写入)的区域(Zone),这和固态硬盘的闪存页管理类似。使用“设备管理”(device-managed)方式的 SMR 磁盘通过内部固件处理了 SMR 磁盘复杂的写入问题,从而对用户封装了 SMR 磁盘的复杂性,令用户可以像使用 PMR 硬盘一样随机写入 SMR 硬盘。其他 SMR 磁盘则使用“主机管理”(host-managed)方式,需要操作系统识别 SMR 磁盘并拥有能对 SMR 磁盘进行正确顺序写入的驱动程序才能被正常使用。 叠瓦盘相较于垂直盘性能也有一定下降,因为传统的 CMR 硬盘磁道之间不会互相干扰,写入数据时可以任意进行写入,而叠瓦盘由于在一个磁道写入数据时不可避免会影响相邻的磁道,需要将下一磁道的数据先拿出(暂时放入硬盘 CMR 缓冲区)再进行写入,而恢复下一磁道的数据则又会对下下磁道的数据进行影响,则又需要先取出下下磁道的数据,因此完成传统垂直硬盘一次的写入操作,叠瓦式硬盘则需要多次的写入,同样的数据量需要更多的写入操作,也会增大损坏的概率。 配件选购 配件 型号 价格 主板 七彩虹 B460-ITX 300^1^ CPU I3-10100 600^1^ 机箱 Invasion X5 330^1^ 电源 振华冰山金蝶 550W 300^1^ 硬盘 西数 HC550 1390 SSD xxxxx 旧电脑拆的 散热器 利民 AX120 RSE 74 内存条 酷兽 DDR4 16G 245 合计 3239 1.表示二手价格 主板刚入门其实最头疼的就是到底买什么型号,因为各个配件之间又有兼容问题,比如相中了一款 ITX 的机箱,但是主板却是 ATX 的,主板都放不进机箱里,这就很麻烦。所以我们首先要确定一个配件,其余配件都安装这个配件的规格去买,并且都要适配这个配件。那么这个配件最好的选择就是主板。 我们先确定自己要买一个什么样的主板,让所有其他的配件都适配这个主板。选择主板的好处是,主板上各个接口就能体现出这台 NAS 的性能。不至于配件买的太离谱。 机箱微型机箱买 ITX 板,MINI 机箱买 M-ATX 板和 ITX 板,中塔机箱买 ATX 板。因为 NAS 是个服务器,可能会永远被放在墙角,所以颜值不重要,实用才是王道,买一个盘位多实用性强的就行。 在前期准备时看到很多推荐迎广的机箱,本来决定要买它,但是了解到 NAS 的本质就是一台电脑主机时,意识到为何不买个电脑机箱?为何要选择成品的机箱?虽然成品的 NAS 机箱有硬盘位,可热插拔。但是我为啥要去插拔服务器上的硬盘? 当我有这个意识后,我的选择一下子多了起来,我最终选了逛淘宝偶然看的 Invasion 机箱。十分简约的外形,甚至还有玻璃侧罩,四格金属硬盘架专为 NAS 打造。只要不到三百块。于是立马转头打开小黄鱼,一搜还真有转卖的,升级版的 8 格硬盘架只要 330。收到货后也很满意,几乎是全新的,玻璃膜都没有撕,还送了俩风扇。 CPU选择 CPU 对于小白来说最重要的就是要选择带核显的 CPU,因为 NAS 上显卡其实没必要,CPU 的核显就绰绰有余了,如果既没有显卡也没有核显就会无法亮机。所以选择 CPU 时要选择带核显的,也就是 Intel 的 CPU 型号不带F的,比如我最终选择的 I3-10100。AMD 的 CPU 型号标识我也没弄清楚,可以自己搜索一下自己想要的 CPU 是否有核显。 其次就是功耗,因为 NAS 要 7*24 小时运行,所以选择性能低一点的 CPU 就好了,另外就是需要关注 CPU 是否有音视频解码的能力。因为平时爱折腾,想着以后指不定在 NAS 上折腾些啥,所以选择了性能不算低的 I3-10100。两个月体验下来,性能还是过剩了,日常基本上都处于待机状态,只有周末看电影会用一下,CPU 利用率很低,好在日常功耗只有 30W。- 安装 OVM (OpenMediaVaultt)参考视频:蜗牛星际安装开源 NAS 系统 Openmediavault 及初始化配置(司波图)——OMV 系列教程 01 为什么选择它OpenMediaVault(以下均简称 OMV)是除 FreeNAS 外目前使用最广泛的开源 NAS 系统。 预备软件下载下载 OpenMediaVaultt 系统,我选择的是 ISO 格式 Old Stable 版本,虽然想用最新的版本,但是第一次安装没有成功,选择了旧版本安装成功了。 下载 微 PE 工具箱,用来格式化系统盘,如果是新买的系统盘就不需要下载。 下载 Rufus 轻松创建 USB 启动盘,这个必须要用的。 制作启动盘需要一个容量大于 4G 的 U 盘,用 Rufus 将 OMV 写入 U 盘即可。安装时会从 U 盘启动,然后将系统安装到插在主板上的系统盘内。 启动盘制作就不详细说了,都是一键式操作。 制作完后进入 U 盘内查看是否写入成功,U 盘内是否有文件,或者查看一下 U 盘使用大小,如果比系统 ISO 大小还小,那肯定没有写成功。我就制作了三遍才发现没有写成功,虽然能看到启动选项,但是进入安装就黑屏,因为根本没有可以安装的文件。 如果没有制作成功,尝试格式化U 盘后重新制作。 安装过程参考视频即可,很详细。 踩坑记录123456# gitsudo apt install git# pythonsudo apt install python# vimsudo apt install vim Docker 配置安装 Portainer 管理容器更换国内镜像源 网易 http://hub-mirror.c.163.com ustc http://docker.mirrors.ustc.edu.cn 阿里云 http://<你的 ID>.mirror.aliyuncs.com 或者使用一位网友提供的 http://1nj0zren.mirror.aliyuncs.com 因为可能有朋友看了比较老的教程(比如我,:( ),可能会用到一些停止服务的进行,如: https://dockerhub.azk8s.cn https://reg-mirror.qiniu.com https://registry.docker-cn.com 如果无法拉取镜像,检查是否用了这几个,如果用了请换镜像源。 安装 Jellyfin 部署影音服务器安装 Transmission 下载安装 qBittorrent 下载 添加 tracker listngosang/trackerslist: Updated list of public BitTorrent trackers 安装 Jackett 搜索种子Docker 中安装,选择网易的镜像,阿里的镜像太旧了。 配置端口号9117,映射两个路径即可。 安装过程参考How to configure Jackett plugin。 点击这里下载源码,复制全文并保存为jackett.py文件。 如果按照以上安装 qBittorrent 那么保存路径为共享文件夹下appdata/qBittorrent/nova3/engines/。 如果没找到,找找是否有以下路径。 123~/.local/share/data/qBittorrent/nova3/engines/# 或者~/.local/share/qBittorrent/nova3/engines/ 再在相同路径下,新建一个配置文件jackett.json,写入以下配置: 123456{ "api_key": "YOUR_API_KEY_HERE", "tracker_first": false, // 如果你登录 OMV 的地址是 192.168.0.1 "url": "http://192.168.0.1:9117"} 安装 Hlink 硬链接持续做种下载的文件名太过杂乱,可以用 TMM 等刮削工具刮削,重命名,建立影音库。但是重命名后就无法做种。想起了 Linux 有硬链接功能,在每天学命令-ln 软硬链接这篇文章中有详细说明。简言之就是创建的硬链接可以任意修改文件名,看上去是一份拷贝,但是实际不占用硬盘空间。 下载的文件太多,又是文件夹嵌套,手动创建比较麻烦,有人专门为这个需求开源了一个项目hlink,可以批量创建硬链接。这里还是以使用 Docker 为例。 配置 Docker镜像名:likun7981/hlink端口号:9090目录映射:/media : /root/sharedfolder环境变量:HLINK_HOME:/root/sharedfolder/appdata/hlink 选择自己放配置文件的目录即可 /root/sharedfolder 是我挂载的硬盘的根目录,建议映射根目录,不要创建多个目录,比如映射/root/sharedfolder/movie 和/root/sharedfolder/music。因为硬链接不支持跨盘符创建,虽然我们本地 music 和 movie 是在一个盘符,但是这样映射在容器中就是两个盘,就会无法创建硬链接,所以只映射一个根目录。 配置 Hlink浏览器输入 IP:9090,打开配置界面。 添加一个新配置,注释十分详细,就不赘述了,但是路径一定要写对,可以新建两个测试目录,测试一下是否能够创建成功。 两个重要配置解释: 1234567891011121314151617/** * /media 是容器里的目录,因为我只映射了一个目录,所以这就是容器的根目录 * 对应到我主机,就是/root/sharedfolder 这个目录 * 所以/media/downloads/qbittorrent/qbcomplete/movie * 就是/root/sharedfolder/downloads/qbittorrent/qbcomplete/movie * 后一个路径/media/media/movie同理 * 等价于/root/sharedfolder/media/movie */ /** * 前一个路径是下载的路径,这里的文件都是不能重命名整理的 * 后一个路径是影音库的路径,hlink 执行完会在这里创建相同的文件链接 * 这个链接可以任意修改,移动,删除 */ pathsMapping: { '/media/downloads/qbittorrent/qbcomplete/movie': '/media/media/movie', }, 12345/** * 设置 true 打开缓存,这样即使影音库里的文件被删除,移动 * 也不会创建新的硬链接 */openCache: true, 缓存的文件信息在右上角编辑缓存可以查看,如果已经执行过创建硬链接但是没有显示,Shfit+F5刷新界面重试。 踩坑记录主板无法识别固态硬盘因为想利用上三年前从笔记本上拆下来的固态,但没注意接口的协议。主板现在大多默认支持 NEVe 协议,但是我的硬盘是很久之前的 SATA 协议。这块 B460i 主板默认支持 NVMe 协议的,但是也支持 SATA 协议,需要更改跳帽。 找了半天图片没有找到一样的,官网的图片是和说明书上的一样是拨动开关形式的,但是我买的二手的是跳帽(哭),不会是买到假的了吧。开关全部拨到左边才支持 SATA 协议。用跳帽也是一样,必须都连接的是左边两个引脚。 无法识别 U 盘启动盘引导模式有两种 UEFI 和 Legacy,这个在做启动盘时就确定了。如果主板使用的 UEFI 模式,而启动盘制作的是 Legacy 模式,就无法识别,需要在 Bios 里找到启动模式选择的相关选项,配置可以使用 Legacy 模式或者 UEFI。(记录这些时已经不想再进 Bios 了所以也没有图片,总之要配置引导方式,避免过滤了一些引导方式导致 U 盘无法识别) 不同网段设备无法互通OVM 无法挂载移动硬盘报错:The filesystem label contains blanks. Please remove them by renaming the filesystem to be able to mount it. 移动硬盘名里有空格,插到 Windows 上重命名一下即可。 ifconfig not found12# ifconfigsudo apt install net-tools ll not found123vim ~/.bashrc# 找到 #alias ll=’ls -l’,去掉前面的#就可以了。source ~/.bashrc 参考 CPU 型号解读:教你 CPU 型号后缀怎么看?CPU 型号后面的字母和数字区别是什么? - 知乎 从零开始搭建 NAS: 硬件篇 | Verne in GitHub 从零搭建一台 NAS:软件篇 | Verne in GitHub Intel CPU 型号解读以及如何粗略判断 Intel CPU 的性能 (i3、i5、i7 以及 CPU 的代数)_吮指原味张的博客-CSDN 博客_cpu 代数 NAS | 群晖安装 qBittorrent 套件并优化设置、替换 UI(非 docker 安装) | 醉渔小站 Docker 中国源 - 简书 金牌 铜牌 什么区别呀? - 电源 - Antec 网站 机·科普贴:电脑电源金、银、铜牌到底是什么意思?_铜牌电源和金牌电源的区别 - 调色盘网络 【非模组电源,半模组电源,全模组电源有什么区别?】 - 知乎 电源全模组和非模组究竟有什么区别?_电脑电源_什么值得买 浅谈组装机机箱的选择(篇一:大小) - 知乎 哪種 PC 機箱尺寸最適合您的下一個版本? - HowThere 199 元风冷/水冷散热器简单对比:谁才是你的爱 - 超能网 【教程】蜗牛星际安装开源 NAS 系统 Openmediavault 及初始化配置(司波图)——OMV 系列教程 01_哔哩哔哩_bilibili How to configure Jackett plugin · qbittorrent/search-plugins Wiki 安装 NAS Tools,打造自动化观影、追剧系统,NAS 媒体库整理工具,威联通 Docker 版 NAS Tools 安装教程~feat.威联通 HS 264_哔哩哔哩_bilibili Home | hlink","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"NAS","slug":"NAS","permalink":"http://example.com/tags/NAS/"},{"name":"Linux,攒机","slug":"Linux,攒机","permalink":"http://example.com/tags/Linux%EF%BC%8C%E6%94%92%E6%9C%BA/"}]},{"title":"Linux 下使用 Clash 作代理并配置开机启动","slug":"Linux下使用Clash作代理并配置开机启动","date":"2022-09-10T02:03:25.000Z","updated":"2022-10-15T03:08:16.455Z","comments":true,"path":"2022/09/10/Linux下使用Clash作代理并配置开机启动/","link":"","permalink":"http://example.com/2022/09/10/Linux%E4%B8%8B%E4%BD%BF%E7%94%A8Clash%E4%BD%9C%E4%BB%A3%E7%90%86%E5%B9%B6%E9%85%8D%E7%BD%AE%E5%BC%80%E6%9C%BA%E5%90%AF%E5%8A%A8/","excerpt":"","text":"下载安装前往下载页面,选择合适的版本下载,Linux 一般下载linux-amd64版本。 123gunzip clash-linux-amd64-v1.11.8.gzsudo mv clash-linux-amd64-v1.11.8 /usr/local/bin/clashsudo chmod +x /usr/local/bin/clash 初步使用123clash-linux-amd64-v1.11.8 -f 从订阅商那获取的配置文件.ymal -d .git clone https://github.com/twbs/bootstrap.git --config "http.proxy=127.0.0.1:7890" # 即可正常下载 开机启动123cd ~sudo cp /usr/local/bin/clash /etc/sudo vim /etc/systemd/system/clash.service 添加如下内容,并保存: 123456789[Unit]Description=Clash Daemon[Service]ExecStart=/usr/local/bin/clash -f /etc/clash/订阅的配置文件.yaml -d /etc/clash/Restart=on-failure[Install]WantedBy=multi-user.target 启用 clash 服务 12sudo systemctl enable clash.service 启动 clash 服务 12sudo systemctl start clash.service 此外也可以停止或者禁用 clash 服务 123sudo systemctl stop clash.servicesudo systemctl disable clash.service 查看运行状态: 1sudo systemctl status clash 查看 clash 服务日志 1journalctl -e -u clash.service","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"Clash","slug":"Clash","permalink":"http://example.com/tags/Clash/"}]},{"title":"解决 No module named 'ConfigParser'","slug":"解决No-module-named-ConfigParser","date":"2022-09-05T07:43:20.000Z","updated":"2022-10-15T02:59:01.841Z","comments":true,"path":"2022/09/05/解决No-module-named-ConfigParser/","link":"","permalink":"http://example.com/2022/09/05/%E8%A7%A3%E5%86%B3No-module-named-ConfigParser/","excerpt":"","text":"","categories":[],"tags":[{"name":"Python","slug":"Python","permalink":"http://example.com/tags/Python/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"Linux 终端回车变成^M","slug":"Linux终端回车变成-M","date":"2022-09-05T07:37:58.000Z","updated":"2022-10-15T03:14:29.335Z","comments":true,"path":"2022/09/05/Linux终端回车变成-M/","link":"","permalink":"http://example.com/2022/09/05/Linux%E7%BB%88%E7%AB%AF%E5%9B%9E%E8%BD%A6%E5%8F%98%E6%88%90-M/","excerpt":"","text":"解决方法终端执行: 1stty sane 参考command line - Pressing enter produces ^M instead of a newline - Ask Ubuntu","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"Linux 切换不同 Python 版本","slug":"Linux切换不同Python版本","date":"2022-09-05T07:31:27.000Z","updated":"2022-10-15T02:59:01.461Z","comments":true,"path":"2022/09/05/Linux切换不同Python版本/","link":"","permalink":"http://example.com/2022/09/05/Linux%E5%88%87%E6%8D%A2%E4%B8%8D%E5%90%8CPython%E7%89%88%E6%9C%AC/","excerpt":"","text":"","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Python","slug":"Python","permalink":"http://example.com/tags/Python/"}]},{"title":"HEXO 博客嵌入 PDF","slug":"HEXO博客嵌入PDF","date":"2022-09-03T09:01:48.000Z","updated":"2022-10-15T03:14:29.247Z","comments":true,"path":"2022/09/03/HEXO博客嵌入PDF/","link":"","permalink":"http://example.com/2022/09/03/HEXO%E5%8D%9A%E5%AE%A2%E5%B5%8C%E5%85%A5PDF/","excerpt":"","text":"效果 下载 pdf.js前往官网下载pdf.js。 为了保证兼容性,建议下载旧版: 添加 pdfjs 到主题中将下载文件夹命名为 pdfjs,拷贝到 themes/fluid/source/myjs 中。myjs目录为自己新建目录。并将该目录skip_render。 打开 HEXO 的配置文件(不是主题的配置文件)_config.yml,搜索skip_render,配置如下: 1skip_render: [myjs/**] 如果不配置该选项,嵌入的 PDF 将会带有博客主题边框。如图: 修改 viewer.js直接使用下载的文件会报错: 1Error: file origin does not match viewer's 注释web/viewer.js文件中的相应内容: 使用方法在 Markdown 文档中使用 <iframe> 控件配合pdf.js 库完成 pdf 显示 1<iframe src='/myjs/pdfjs/web/viewer.html?file=<src-to-pdf>' style='width:100%;height:100%'></iframe> <src-to-pdf>:需要显示的 pdf 文件的链接 /myjs/pdfjs/web/viewer.html:改为自己的 pdfjs 目录 参考 Fluid -3- pdf.js PC,移动端查看 PDF - 又见苍岚","categories":[],"tags":[{"name":"HEXO","slug":"HEXO","permalink":"http://example.com/tags/HEXO/"}]},{"title":"RISC-V 入门 - 系统调用","slug":"RISC-V入门-系统调用","date":"2022-08-29T05:16:03.000Z","updated":"2022-10-15T03:14:29.567Z","comments":true,"path":"2022/08/29/RISC-V入门-系统调用/","link":"","permalink":"http://example.com/2022/08/29/RISC-V%E5%85%A5%E9%97%A8-%E7%B3%BB%E7%BB%9F%E8%B0%83%E7%94%A8/","excerpt":"","text":"用户态与内核态目前为止的学习过程中,所有的程序都是运行在 Machine 模式下,但是在哪决定程序运行在什么模式下的呢? 在学习抢占式多任务时,我们有了创建任务的概念,在汇编代码中有这么一段,使用到了mstatus寄存器: 123456789# Notice: default mstatus is 0# Set mstatus.MPP to 3, so we still run in Machine mode after MRET.# Set mstatus.MPIE to 1, so MRET will enable the interrupt.li t0, 3 << 11 | 1 << 7csrr a1, mstatus # a1 = mstatusor t0, t0, a1 # t0 = t0 | a1csrw mstatus, t0 # mstatus = t0j start_kernel # hart 0 jump to c mret返回后,是根据寄存器mstatus的MPP来决定接来来是处于什么模式,我们在上面将MPP配置为3, MPP的功能是 记录 Machine 模式下,前一个,特权级。这里解实现了在mret之后将模式设置为 Machine 模式(3)。 因为mstatus上电后默认为全 0,所以如果不对其设置,那么在mret之后,就是运行在用户态(0)。 如果想让程序跑在用户态,只要不对齐设置,保持默认即可: 123456789# Notice: default mstatus is 0# Set mstatus.MPP to 3, so we still run in Machine mode after MRET.# Set mstatus.MPIE to 1, so MRET will enable the interrupt.li t0, 1 << 7csrr a1, mstatus # a1 = mstatusor t0, t0, a1 # t0 = t0 | a1csrw mstatus, t0 # mstatus = t0j start_kernel # hart 0 jump to c 为什么需要系统调用?因为在用户态一些资源(寄存器)的访问是受限的,所以需要封装一些函数,这些函数里会进行模式切换,然后访问需要的资源。 那么如何进行模式的切换呢?这就需要ecall指令。它本质上是触发了异常,就会进入到 Machine 模式处理异常,在 Machine 模式下就相当于在内核态了,就没有访问资源的限制了。 系统模式的切换 ECALL指令实际就是主动触发异常,根据ECALL的权限级别产生不同的异常码,如下图: 从 User 模式调用ECALL异常码等于 8,从 Supervisor 模式调用异常码等于 9,从 Machine 模式调用异常码等于 11。 异常产生时epc寄存器的值存放的是ECALL指令本身的地址。 如果想触发完异常接着往下执行,需要在异常处理逻辑里把 epc 寄存器值改为下一条指令地址,否则会进入死循环。 系统调用的执行流程 系统调用的传参系统调用作为操作系统的对外接口,由操作系统的实现负责定义。参考 Linux 的系统调用,RVOS 定义系统调用的传参规则如下: 系统调用号放在a7中 系统调用参数使用a0-a5 返回值使用a0 系统调用的封装","categories":[{"name":"RISC-V 入门","slug":"RISC-V-入门","permalink":"http://example.com/categories/RISC-V-%E5%85%A5%E9%97%A8/"}],"tags":[{"name":"RISCV","slug":"RISCV","permalink":"http://example.com/tags/RISCV/"}]},{"title":"浏览器任务栏多窗口命名","slug":"浏览器任务栏多窗口命名","date":"2022-08-28T00:56:28.000Z","updated":"2022-10-15T03:14:29.752Z","comments":true,"path":"2022/08/28/浏览器任务栏多窗口命名/","link":"","permalink":"http://example.com/2022/08/28/%E6%B5%8F%E8%A7%88%E5%99%A8%E4%BB%BB%E5%8A%A1%E6%A0%8F%E5%A4%9A%E7%AA%97%E5%8F%A3%E5%91%BD%E5%90%8D/","excerpt":"","text":"需求工作时需要开启多个标签页,在同一个窗口里打开又查找不变,于是分为多个窗口,每个窗口里的标签页工作内容一致。如所有文档放在一个窗口,需要百度,Google 搜索时用单独的一个问题搜索窗口。这样就避免每次打开窗口都要挨个点一遍。 Edge 设置打开设置-更多工具 - 为窗口命名。即可重命名窗口 Chrome 设置同上,路径基本一致都是在设置-更多工具中。 升级 在使用过程中发现窗口太多任务栏太挤了,Chrome 自身有标签分组的功能,其实完全可以替代窗口。也可以满足我的需求。少数派有介绍,就不造轮子了。体验一段时间确实很好用。","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"效率","slug":"效率","permalink":"http://example.com/tags/%E6%95%88%E7%8E%87/"},{"name":"推荐","slug":"推荐","permalink":"http://example.com/tags/%E6%8E%A8%E8%8D%90/"}]},{"title":"VSCode 任务栏多窗口命名","slug":"VSCode任务栏多窗口命名","date":"2022-08-28T00:55:55.000Z","updated":"2022-10-15T03:14:29.579Z","comments":true,"path":"2022/08/28/VSCode任务栏多窗口命名/","link":"","permalink":"http://example.com/2022/08/28/VSCode%E4%BB%BB%E5%8A%A1%E6%A0%8F%E5%A4%9A%E7%AA%97%E5%8F%A3%E5%91%BD%E5%90%8D/","excerpt":"","text":"调教背景当有多个项目同时打开时,VSCode 窗口开得太多就找不到自己想要打开的窗口,因为窗口命名默认按照当前打开的文件命名的,不是很清楚。就需要挨个打开才能确定自己想要打开的窗口。 如果能按照项目名命名窗口就会便捷许多,好在 VSCode 提供重命名的方式。同样的需求可能在浏览器中也会遇到,可以参考浏览器任务栏多窗口命名 - 如云泊。 修改方式File -> Preferences -> Setting 搜索 Window: Title 改成: 1${dirty}${rootName}${separator}${activeEditorMedium}${separator}${appName} 其他可用配置说明: 1234567891011121314"${activeEditorShort}": 文件名 (例如 myFile.txt)。"${activeEditorMedium}": 相对于工作区文件夹的文件路径 (例如, myFolder/myFileFolder/myFile.txt)。"${activeEditorLong}": 文件的完整路径 (例如 /Users/Development/myFolder/myFileFolder/myFile.txt)。"${activeFolderShort}": 文件所在的文件夹名称 (例如, myFileFolder)。"${activeFolderMedium}": 相对于工作区文件夹的、包含文件的文件夹的路径, (例如 myFolder/myFileFolder)。"${activeFolderLong}": 文件所在文件夹的完整路径 (例如 /Users/Development/myFolder/myFileFolder)。"${folderName}": 文件所在工作区文件夹的名称 (例如 myFolder)。"${folderpath}": 文件所在工作区文件夹的路径 (例如 /Users/Development/myFolder)。"${rootName}": 打开的工作区或文件夹的名称 (例如 myFolder 或 myWorkspace)。"${rootPath}": 打开的工作区或文件夹的文件路径 (例如 /Users/Development/myWorkspace)。"${appName}": 例如 VS Code。“${remoteName}”: 例如 SSH${dirty}: 表明活动编辑器具有未保存更改的时间的指示器。"${separator}": 一种条件分隔符 ("-"), 仅在被包含值或静态文本的变量包围时显示","categories":[{"name":"万能 VSCode","slug":"万能-VSCode","permalink":"http://example.com/categories/%E4%B8%87%E8%83%BD-VSCode/"}],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"}]},{"title":"解决 ERROR Could not install packages due to an EnvironmentError 拒绝访问","slug":"解决ERROR-Could-not-install-packages-due-to-an-EnvironmentError-拒绝访问","date":"2022-08-27T13:55:26.000Z","updated":"2022-10-15T03:00:30.004Z","comments":true,"path":"2022/08/27/解决ERROR-Could-not-install-packages-due-to-an-EnvironmentError-拒绝访问/","link":"","permalink":"http://example.com/2022/08/27/%E8%A7%A3%E5%86%B3ERROR-Could-not-install-packages-due-to-an-EnvironmentError-%E6%8B%92%E7%BB%9D%E8%AE%BF%E9%97%AE/","excerpt":"","text":"保留现场升级pip时出现报错: 解决方法加上--user 1python -m pip install --upgrade pip --user","categories":[],"tags":[{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"编码字体与阅读字体推荐","slug":"编码字体与阅读字体推荐","date":"2022-08-27T11:59:58.000Z","updated":"2022-10-15T03:14:29.783Z","comments":true,"path":"2022/08/27/编码字体与阅读字体推荐/","link":"","permalink":"http://example.com/2022/08/27/%E7%BC%96%E7%A0%81%E5%AD%97%E4%BD%93%E4%B8%8E%E9%98%85%E8%AF%BB%E5%AD%97%E4%BD%93%E6%8E%A8%E8%8D%90/","excerpt":"","text":"编码字体编码字体首要原则:等宽,等宽,还是 TMD 等宽! JetBrains Mono Hack Source Code Pro Fira Mono Consolas保底字体,基本上 Windows 电脑都有预装。 阅读字体看多了黑体,其实有衬线的宋体才能体现中文文字之美。 思源宋体 华文中宋 中文等宽字体对于既想要满足编程字体又想要中文书写的,有几款等宽中文字体也不错。 Sarasa Gothic / 更纱黑体 思源黑体/Source Han Sans","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"推荐","slug":"推荐","permalink":"http://example.com/tags/%E6%8E%A8%E8%8D%90/"},{"name":"字体","slug":"字体","permalink":"http://example.com/tags/%E5%AD%97%E4%BD%93/"}]},{"title":"多版本 Python 使用 pip 安装 package 问题","slug":"多版本Python使用pip安装package问题","date":"2022-08-27T07:30:58.000Z","updated":"2022-10-15T03:14:29.680Z","comments":true,"path":"2022/08/27/多版本Python使用pip安装package问题/","link":"","permalink":"http://example.com/2022/08/27/%E5%A4%9A%E7%89%88%E6%9C%ACPython%E4%BD%BF%E7%94%A8pip%E5%AE%89%E8%A3%85package%E9%97%AE%E9%A2%98/","excerpt":"","text":"最简单的方式使用参数指定安装路径: 1pip install -t D:\\python3.5(32bit)\\Lib\\site-packages numpy 叨叨叨如果电脑上安装了多个版本的Python的话,在需要使用pip安装新package时,就会遇到这个问题:我把package安装到哪了? 因为每个版本的 Python 是有自己独立的pip,也有独立的lib目录的,管理的包也各不同。一般来说,使用默认的pip命令安装的位置,就是默认的python位置。 比如我在终端敲下python,使用的是python3.6那么安装的package就会在C:\\Python36\\Lib\\site-packages(根据自己安装 Python 的路径稍有区别)。 情景一:安装的都是 Python3.x 版本有时候会遇到这样的需求,我准备跑的项目只能用python3.8,我得把package安装到python38里,怎么办? 方法 1把其中一个python环境变量删掉,留下(如果没有需要添加)python38的路径和script添加到环境变量。 使用以下命令安装: 1python -m pip install xxxxx 因为默认Python已经被修改为python38。 方法 2使用文章开头的方式,最方便,直接指定 python 全局路径 1pip install -t D:\\python3.5(32bit)\\Lib\\site-packages numpy 情景二:安装 Python2.x 与 Python3.xPython3.x 使用: 1py -3 -m pip install numpy Python2.x 使用: 1py -2 -m pip install numpy","categories":[],"tags":[{"name":"Python","slug":"Python","permalink":"http://example.com/tags/Python/"},{"name":"pip","slug":"pip","permalink":"http://example.com/tags/pip/"}]},{"title":"解决 Unable to 加载 picture or PDF file","slug":"解决Unable-to-load-picture-or-PDF-file","date":"2022-08-26T11:22:24.000Z","updated":"2022-10-15T03:14:29.844Z","comments":true,"path":"2022/08/26/解决Unable-to-load-picture-or-PDF-file/","link":"","permalink":"http://example.com/2022/08/26/%E8%A7%A3%E5%86%B3Unable-to-load-picture-or-PDF-file/","excerpt":"","text":"保留现场 1Unable to load picture or PDF file 'xxxxxx' <to be read again> xxxx 探究原因图片链接错误,转换 PDF 过程中会先下载所有图片到AppData/Local/Temp/tex2pdf.****文件夹里,因为无法正常下载图片,所有报错。检查图片链接是否有效。 解决方法检查图片链接是否有效。","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"},{"name":"Markdown","slug":"Markdown","permalink":"http://example.com/tags/Markdown/"},{"name":"Pandoc","slug":"Pandoc","permalink":"http://example.com/tags/Pandoc/"},{"name":"PDF","slug":"PDF","permalink":"http://example.com/tags/PDF/"}]},{"title":"VSCode搜索结果/匹配高亮","slug":"VSCode搜索结果-匹配高亮","date":"2022-08-26T08:42:50.000Z","updated":"2022-10-15T03:14:29.597Z","comments":true,"path":"2022/08/26/VSCode搜索结果-匹配高亮/","link":"","permalink":"http://example.com/2022/08/26/VSCode%E6%90%9C%E7%B4%A2%E7%BB%93%E6%9E%9C-%E5%8C%B9%E9%85%8D%E9%AB%98%E4%BA%AE/","excerpt":"","text":"调教背景在VSCode使用搜索/替换时,匹配的字符会“高亮”(高亮个屁),知道自己当前搜到到什么位置,如果匹配字符较少还好,如果匹配太多,默认的高亮就很难发现当前已经搜索到什么位置了。比如我当前在搜索“搜索”这两个字: 大家还能看到我当前搜索到哪了吗? 但是如果设置成这样呢? 配置搜索匹配时高亮颜色 添加如下配置: 123"workbench.colorCustomizations": { "editor.findMatchBackground": "#ff0000",} 表示搜索匹配时高亮,高亮颜色为红色。自己可以选择合适的颜色。 搜索结果高亮与上面不同的是,搜索时会高亮所有的结果,但是点击箭头匹配到当前结果时就是上面的高亮,其余未匹配的状态就是下面的高亮: 123"workbench.colorCustomizations": { "editor.findMatchHighlightBackground": "#ff00ff",} 选择时颜色 123"workbench.colorCustomizations": { "editor.selectionBackground": "#2f00ff",} 范围搜索时背景颜色有时候搜索不是全局搜索,是在自己选中的范围内搜索,那这个范围也是可以高亮的,开启范围搜索需要点击搜索框的按钮,如图所示: 1234"workbench.colorCustomizations": { "editor.findMatchHighlightBackground": "#ff00ff", "editor.findRangeHighlightBackground": "#ff9900"}","categories":[{"name":"万能 VSCode","slug":"万能-VSCode","permalink":"http://example.com/categories/%E4%B8%87%E8%83%BD-VSCode/"}],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"}]},{"title":"RISC-V 入门 - 任务切换与锁","slug":"RISC-V入门-任务切换与锁","date":"2022-08-26T07:15:34.000Z","updated":"2022-10-15T03:14:29.560Z","comments":true,"path":"2022/08/26/RISC-V入门-任务切换与锁/","link":"","permalink":"http://example.com/2022/08/26/RISC-V%E5%85%A5%E9%97%A8-%E4%BB%BB%E5%8A%A1%E5%88%87%E6%8D%A2%E4%B8%8E%E9%94%81/","excerpt":"","text":"任务切换任务简介多任务与上下文任务就是一个指令执行流。 如果有多个 HART,那就可以同时执行多个指令执行流。 协作式多任务 协作式环境下,下一个任务被调度的前提是当前任务主动放弃处理器。 抢占式多任务 抢占式环境下,操作系统完全决定任务调度方案,操作系统可以剥夺当前任务对处理器的使用,将处理器提供给其它任务。 协作式多任务上下文切换 切换过程需要完成: 保存上文(保存上一个任务的寄存器信息) 恢复下文(恢复下一个任务的寄存器信息) CPU 中有 32 个寄存器,保存各种状态,在切换过程中我们主要关注两个寄存器:ra(x1) 存放返回地址,mscratch 一个特权寄存器,指向当前处理的任务。 切换过程初始化寄存器,ra都初始化为任务的第一条指令地址。mscratch开始指向 Task A。 Task A 稳定执行,当他想要放弃 CPU 时,就会执行 call swithc_to指令。执行call的过程中,就会把当前指令的下一条指令的地址放到 CPU 的ra寄存器。 接下里跳转到swithc_to函数执行,该函数是切换上下文的核心函数。首先保存上文,将 CPU 中的寄存器信息全部保存: 切换mscratch指针到下一个任务 Task B: 恢复下文: 当swithc_to函数执行到return时,接下来执行的指令就是 CPU 中ra保存的那条指令,也就是地址为j指令,这就是 Task B 的第一条指令,这样就完成了任务的切换。 源码分析切换核心函数 switch_to1234567891011121314151617181920212223switch_to: csrrw t6, mscratch, t6 # swap t6 and mscratch beqz t6, 1f # Notice: previous task may be NULL reg_save t6 # save context of prev task # 把CPU的信息保存到内存 # Save the actual t6 register, which we swapped into # mscratch mv t5, t6 # t5 points to the context of current task csrr t6, mscratch # read t6 back from mscratch sw t6, 120(t5) # save t6 with t5 as base1: # switch mscratch to point to the context of the next task csrw mscratch, a0 # Restore all GP registers # Use t6 to point to the context of the new task mv t6, a0 reg_restore t6 # 把内存里的信息恢复到CPU # Do actual context switching. ret 创建和初始化第一号任务使用结构体context保存上下文中寄存器的信息: 1234567891011121314151617181920212223242526272829303132333435363738struct context { /* ignore x0 */ reg_t ra; reg_t sp; reg_t gp; reg_t tp; reg_t t0; reg_t t1; reg_t t2; reg_t s0; reg_t s1; reg_t a0; reg_t a1; reg_t a2; reg_t a3; reg_t a4; reg_t a5; reg_t a6; reg_t a7; reg_t s2; reg_t s3; reg_t s4; reg_t s5; reg_t s6; reg_t s7; reg_t s8; reg_t s9; reg_t s10; reg_t s11; reg_t t3; reg_t t4; reg_t t5; reg_t t6;};#define STACK_SIZE 1024uint8_t task_stack[STACK_SIZE];struct context ctx_task; 写一个任务函数,功能就是每隔1000 滴答打印一句话。 12345678void user_task0(void){ uart_puts("Task 0: Created!\\n"); while (1) { uart_puts("Task 0: Running...\\n"); task_delay(1000); }} 初始化任务,需要初始化栈,并把任务的首地址保存到context的ra寄存器。 1234567void sched_init(){ w_mscratch(0); ctx_task.sp = (reg_t) &task_stack[STACK_SIZE - 1]; ctx_task.ra = (reg_t) user_task0;} 切换到第一个用户任务switch_to函数的参数就是上下文,当执行到ret时也就切换到了user_task0。 12345void schedule(){ struct context *next = &ctx_task; switch_to(next);} 以上是单任务的情况,如果是多任务时,就用数组保存多个context,最大支持 10 个任务。 1234#define MAX_TASKS 10#define STACK_SIZE 1024uint8_t task_stack[MAX_TASKS][STACK_SIZE];struct context ctx_tasks[MAX_TASKS]; 使用简单的求模取余的方式确定下一个任务是哪一个: 123456789101112131415161718192021/* * _top is used to mark the max available position of ctx_tasks * _current is used to point to the context of current task */static int _top = 0;static int _current = -1;/* * implment a simple cycle FIFO schedular */void schedule(){ if (_top <= 0) { panic("Num of task should be greater than zero!"); return; } _current = (_current + 1) % _top; struct context *next = &(ctx_tasks[_current]); switch_to(next);} 因为多个任务协作,需要一个函数来表示主动放弃 CPU: 123456789/* * DESCRIPTION * task_yield() causes the calling task to relinquish the CPU and a new * task gets to run. */void task_yield(){ schedule();} 调用关系 抢占式多任务抢占式多任务:抢占式环境下,操作系统完全决定任务调度方案,操作系统可以剥夺当前任务对处理器的使用,将处理器提供给其他任务。 寄存器 对 MSIP 写入 1 时触发 软中断,写入 0 时表示对中断进行应答,也就是处理完了软中断。 任务同步与锁并发与同步并发:多个控制流同时执行 多处理器多任务 单处理器多任务 单处理器任务 + 中断 同步:为了保证在并发执行的环境中各个控制流可以有效执行而采用的一种编程技术 临界区、锁与死锁临界区:在并发的程序执行环境中,所谓临界区指的是一个会访问共享资源的指令片段,而且当这样的多个指令片段同时访问某个共享资源时可能会引发问题。 在并发环境下为了有效控制临界区的执行(同步),我们要做的是当有一个控制流进入临界区时,其他相关控制流必须等待。 锁:一种常见的用来实现同步的技术 不可睡眠锁 可睡眠锁 当发生中断时,右边的任务获取 CPU 资源,开始执行,但是获取锁时发现当前已经处于锁定状态,所以就处于等待状态。 当下一个中断发生,左侧任务回去 CPU 后会继续执行,实际上左侧任务也不必等待,他可以一直执行,因为右侧任务一直无法获取锁。 当然,右侧任务也可以一直触发中断,让左侧任务让出 CPU。也就是左侧任务逻辑上可以一直运行,但是实际还是会被打断。 当左侧任务执行完释放锁,右侧任务就可以获取锁,并正常执行下去。 死锁:当控制流执行路径中会涉及多个锁,并且这些控制流执行路径获取的顺序不同时就可能发送死锁。 解决死锁: 调整获取锁的顺序,比如保持一致 尽可能防止任务在持有一把锁同时申请其他锁 自旋锁 不能从 C 语言的层面去理解锁,应该要从指令级别去理解。上面的这种上锁方式是有问题的。 如果两个控制流同时加锁,就可能同时获取了锁,因为在汇编指令级别,每条指令执行也是需要时间的: AMOSWAP loop: lw a4, -20(s0) # 参数1 li a5, 1 # 参数 2 amoswap.w.aq a5, a5, (a4) # 将a5与a4指向的内存的值进行交换 # 将 1 与 a4 交换,表示如果原来上锁(1)那就什么都没做 # 如果原来没上锁(0)那就立即上锁 mv a3, a5 bnez a3,loop 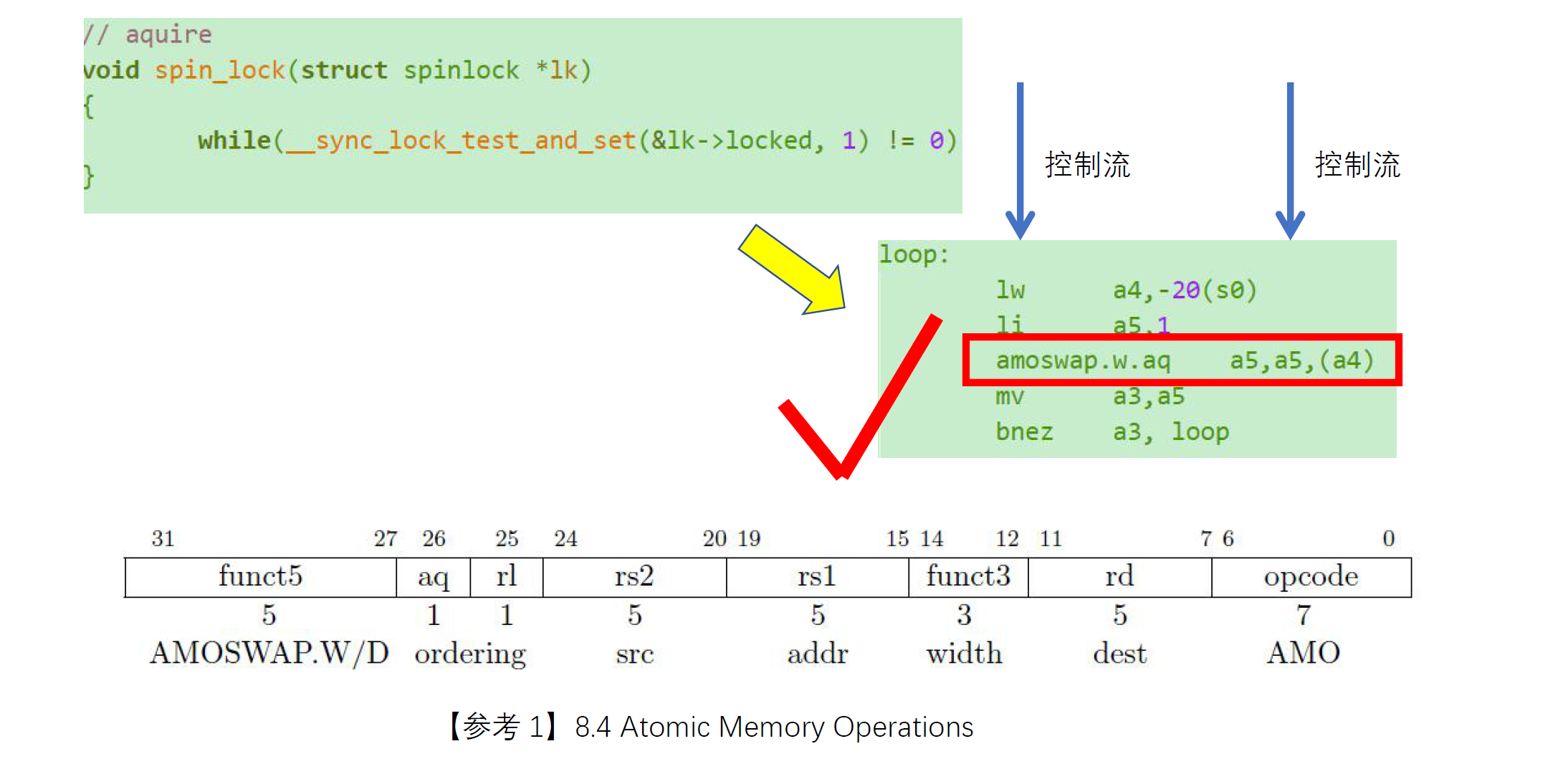","categories":[{"name":"RISC-V 入门","slug":"RISC-V-入门","permalink":"http://example.com/categories/RISC-V-%E5%85%A5%E9%97%A8/"}],"tags":[{"name":"RISCV","slug":"RISCV","permalink":"http://example.com/tags/RISCV/"}]},{"title":"RISC-V 入门 - 内存管理","slug":"RISC-V入门-内存管理","date":"2022-08-23T14:33:11.000Z","updated":"2022-10-15T03:14:29.564Z","comments":true,"path":"2022/08/23/RISC-V入门-内存管理/","link":"","permalink":"http://example.com/2022/08/23/RISC-V%E5%85%A5%E9%97%A8-%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86/","excerpt":"","text":"如何计算堆的大小,只有算出可用空间才能对其管理。 ENTRY 功能:用于设置入口点,即程序中执行的第一条指令symbol 参数是一个符号的名称 OUTPUT_ARCH 功能:指定输出文件所适用的计算机体系架构 为什么用 riscv64-unknown-elf-gcc,但是编译出来的文件是 32 位程序?riscv64 是 host 是 64 位系统,编译 target 是由 gcc 的参数决定 MEMORY 功能:用于描述目标机器上内存区域的位置,大小和相关 1234567MEMORY{ /* 内存类型为ROM,起始地址0,长度256K */ rom(rx):ORIGIN = 0, LENGTH = 256K /* 内存类型为RAM,起始地址0x40000000,长度4M */ ram(!rx):org = 0x40000000, l = 4M} TODO:括号里的 rx 含义是? SECTION 功能:告诉链接器如何将 input sections 映射到 output sections,以及如何将 output sections 放置到内存中。 12345678SECTION{ .=0x0000; .text:{*(.text)} .=0x8000000; .data:{*(.data)} .bss:{*(.bss)}}>ram PROVIDE 功能: 可以在 Linker Script 中定义符号(Symbols) 每个符号包括一个名字(name) 和一个对应的地址值(address) 在代码中可以访问这些符号,等同于访问一个地址。 123456789101112.bss :{ PROVIDE(_bss_start = .); /* 当前地址赋值给符号_bss_start */ *(.sbss .sbss.*) *(.bss .bss.*) *(COMMON) PROVIDE(_bss_end = .);} >ram PROVIDE(_memory_start = ORIGIN(ram));PROVIDE(_memory_end = ORIGIN(ram) + LENGTH(ram));PROVIDE(_heap_start = _bss_end); /* 堆空间就是接在了bss段之后,所以堆开始地址就是bss结束地址 */ PROVIDE(_heap_size = _memory_end - _heap_start); /* 计算堆大小 */ .global表示全局变量,.word表示定义变量,下面的代码就是定义一些全局变量,方便在 C 代码中使用。 12345678910111213141516171819202122232425262728293031/* mem.S */ .section .rodata.global HEAP_STARTHEAP_START: .word _heap_start.global HEAP_SIZEHEAP_SIZE: .word _heap_size.global TEXT_STARTTEXT_START: .word _text_start.global TEXT_ENDTEXT_END: .word _text_end.global DATA_STARTDATA_START: .word _data_start.global DATA_ENDDATA_END: .word _data_end.global RODATA_STARTRODATA_START: .word _rodata_start.global RODATA_ENDRODATA_END: .word _rodata_end.global BSS_STARTBSS_START: .word _bss_start.global BSS_ENDBSS_END: .word _bss_end 12345678910111213141516/* * Following global vars are defined in mem.S */extern uint32_t TEXT_START;extern uint32_t TEXT_END;extern uint32_t DATA_START;extern uint32_t DATA_END;extern uint32_t RODATA_START;extern uint32_t RODATA_END;extern uint32_t BSS_START;extern uint32_t BSS_END;extern uint32_t HEAP_START;extern uint32_t HEAP_SIZE;#define PAGE_SIZE 4096static uint32_t _num_pages = _num_pages = (HEAP_SIZE / PAGE_SIZE) - 8; 实现 Page 级别的内存分配与释放 日常使用的操作系统,都是以字节为单位分配空间,但是为了教学方便,RVOS 是以 Page 为单位分配内存。 数据结构设计 数组方式管理将内存模拟为一个连续的数组,数组的前部预留 8 个 Page 来管理其余的内存。目前考虑管理的状态有: 这 Page 是否被使用了 这个 Page 是不是最后一块分配的内存,方便我们释放内存时找到最后一块分配的内存 我们可以使用一个 8 bit 的flag来记录这些信息,flag bit[0]表示是否已使用,flag bit[1]表示是否是最后一个分配的页面。 123456789/* * Page Descriptor * flags: * - bit 0: flag if this page is taken(allocated) * - bit 1: flag if this page is the last page of the memory block allocated */struct Page { uint8_t flags;}; 也就是每一个 Page 都由一个 8 bit 的结构体struct Page管理,我们总共分配了 8 个 Page 用来管理,一个 Page 占 4K,那么我们可以一个管理$8 \\times 4096 = 32768$个 Page。那就刚好可以管理$32768 \\times 4096 = 134217728 \\text{bit}$内存=128M。 Page 分配与释放接口设计 123456789101112131415161718192021222324252627282930313233343536373839404142/* * 分配连续n个可用物理页 * - npages: 需要分配的页的个数 */void *page_alloc(int npages){ /* Note we are searching the page descriptor bitmaps. */ int found = 0; struct Page *page_i = (struct Page *)HEAP_START; for (int i = 0; i < (_num_pages - npages); i++) { if (_is_free(page_i)) { found = 1; /* * 找到第一个可用Page,继续判断是否有N个连续可用page */ struct Page *page_j = page_i; for (int j = i; j < (i + npages); j++) { if (!_is_free(page_j)) { found = 0; break; } page_j++; } /* * 找到了连续的N个可用page,将N个page设置为已分配状态 */ if (found) { struct Page *page_k = page_i; for (int k = i; k < (i + npages); k++) { _set_flag(page_k, PAGE_TAKEN); page_k++; } page_k--; _set_flag(page_k, PAGE_LAST); // 返回可用page首地址 return (void *)(_alloc_start + i * PAGE_SIZE); } } page_i++; } return NULL;} 1234567891011121314151617181920212223242526/* * 释放已分配的物理页 * - p: 待释放的首地址 */void page_free(void *p){ /* * 判断非法输入,p不能为空或者超出最大可分配大小 */ if (!p || (uint32_t)p >= _alloc_end) { return; } /* 计算出这个首地址p所在的page的描述符,也就是找到第几个描述符在管理这块内存 */ struct Page *page = (struct Page *)HEAP_START; page += ((uint32_t)p - _alloc_start)/ PAGE_SIZE; /* 循环清空标识 */ while (!_is_free(page)) { if (_is_last(page)) { _clear(page); break; } else { _clear(page); page++;; } }}","categories":[{"name":"RISC-V 入门","slug":"RISC-V-入门","permalink":"http://example.com/categories/RISC-V-%E5%85%A5%E9%97%A8/"}],"tags":[{"name":"RISCV","slug":"RISCV","permalink":"http://example.com/tags/RISCV/"}]},{"title":"LaTex-listing 环境设置","slug":"LaTex-listing环境设置","date":"2022-08-21T06:28:42.000Z","updated":"2022-10-15T03:14:29.266Z","comments":true,"path":"2022/08/21/LaTex-listing环境设置/","link":"","permalink":"http://example.com/2022/08/21/LaTex-listing%E7%8E%AF%E5%A2%83%E8%AE%BE%E7%BD%AE/","excerpt":"","text":"总览1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950% 代码块listing设置\\lstdefinestyle{mppl-listing-style}{ language = java, % 语言类型 backgroundcolor = \\color{{HTML}{F7F7F7}}, % 背景色 numbers = left, % 行号显示位置 xleftmargin = 5em, % 左边距 xrightmargin = 0em, % 右边距 aboveskip = 2em, % 上方留白 belowskip = 0em, % 下方留白 frame = single, % 代码块边框是单线条 rulecolor = \\color{black}, % 边框颜色 frameround = tttt, % 边框圆角 framesep = 0.19em, % 边框与代码间距 rulesepcolor = \\color{black}, % 阴影颜色 framexleftmargin = -2em, % 左边框与代码距离 framexrightmargin = -5em, % 右边框与代码距离 framexbottommargin = 2em, % 下边框与代码距离 framextopmargin = 2em, % 上边框与代码距离 breaklines = true, % 代码超出边界换行 tabsize = 4, % tab缩进 numberstyle = \\color{red}, % 行号颜色 keywordstyle = \\color{red}, % 关键字颜色 identifierstyle = \\color{listing-identifier}, % 变量颜色 commentstyle = \\color{listing-comment}, % 注释颜色 basicstyle = \\color{listing-text-color}\\small\\ttfamily{}\\linespread{1.15}, % print whole listing small abovecaptionskip = 0em, % 上标题边距 belowcaptionskip = 1.0em, % 下标颜边距 classoffset = 0, % 类名偏移量 sensitive = true, % 是否区分大小写 morecomment = [s][\\color{listing-javadoc-comment}]{/**}{*/}, stringstyle = \\color{listing-string}, showstringspaces = false, % 是否显示字符串空格 escapeinside = {/*@}{@*/}, % Allow LaTeX inside these special comments literate = {á}{{\\'a}}1 {é}{{\\'e}}1 {í}{{\\'i}}1 {ó}{{\\'o}}1 {ú}{{\\'u}}1 {Á}{{\\'A}}1 {É}{{\\'E}}1 {Í}{{\\'I}}1 {Ó}{{\\'O}}1 {Ú}{{\\'U}}1 {à}{{\\`a}}1 {è}{{\\'e}}1 {ì}{{\\`i}}1 {ò}{{\\`o}}1 {ù}{{\\`u}}1 {À}{{\\`A}}1 {È}{{\\'E}}1 {Ì}{{\\`I}}1 {Ò}{{\\`O}}1 {Ù}{{\\`U}}1 {ä}{{\\"a}}1 {ë}{{\\"e}}1 {ï}{{\\"i}}1 {ö}{{\\"o}}1 {ü}{{\\"u}}1 {Ä}{{\\"A}}1 {Ë}{{\\"E}}1 {Ï}{{\\"I}}1 {Ö}{{\\"O}}1 {Ü}{{\\"U}}1 {â}{{\\^a}}1 {ê}{{\\^e}}1 {î}{{\\^i}}1 {ô}{{\\^o}}1 {û}{{\\^u}}1 {Â}{{\\^A}}1 {Ê}{{\\^E}}1 {Î}{{\\^I}}1 {Ô}{{\\^O}}1 {Û}{{\\^U}}1 {œ}{{\\oe}}1 {Œ}{{\\OE}}1 {æ}{{\\ae}}1 {Æ}{{\\AE}}1 {ß}{{\\ss}}1 {ç}{{\\c c}}1 {Ç}{{\\c C}}1 {ø}{{\\o}}1 {å}{{\\r a}}1 {Å}{{\\r A}}1 {€}{{\\EUR}}1 {£}{{\\pounds}}1 {«}{{\\guillemotleft}}1 {»}{{\\guillemotright}}1 {ñ}{{\\~n}}1 {Ñ}{{\\~N}}1 {¿}{{?`}}1 {…}{{\\ldots}}1 {≥}{{>=}}1 {≤}{{<=}}1 {„}{{\\glqq}}1 {“}{{\\grqq}}1 {”}{{''}}1 } backgroundcolor 背景颜色numbers 代码行号123456789101112\\lstset{ numbers = left, % 行号靠左 basicstyle = \\ttfamily, % 基本代码风格 keywordstyle = \\bfseries, % 关键字风格 commentstyle = \\ttfamily, % 注释的风格 frame = single, % 阴影效果 escapeinside=``, % 英文分号中可写入中文 xleftmargin=2em,xrightmargin=2em, aboveskip=1em, breaklines = true, language = C, % 语言选C} 123456789101112\\lstset{ numbers = right, % 行号靠左 basicstyle = \\ttfamily, % 基本代码风格 keywordstyle = \\bfseries, % 关键字风格 commentstyle = \\ttfamily, % 注释的风格 frame = single, % 阴影效果 escapeinside=``, % 英文分号中可写入中文 xleftmargin=2em,xrightmargin=2em, aboveskip=1em, breaklines = true, language = C, % 语言选C} stepnumber 间隔显示行号1234\\lstset{ numbers = right, % 行号靠左 stepnumber = 2, % 每两行显示一次行号} firstnumber 开始行号 firstnumber = 10 开始行号为 10 firstnumber = last 开始行号为上一段 listing 的结束行号 xleftmargin/xrightmargin/aboveskip/below 距离外部元素距离设置代码块上下左右的距离,与外部元素的距离,而不是代码与边框的距离。 1234567891011\\lstset{ basicstyle = \\ttfamily, % 基本代码风格 numbers = left, % 行号靠左 keywordstyle = \\bfseries, % 关键字风格 commentstyle = \\ttfamily, % 注释的风格 frame = single, % 阴影效果 escapeinside=``, % 英文分号中可写入中文 xleftmargin=0em,xrightmargin=0em, aboveskip=0em,belowskip=0em, breaklines = true, language = C, % 语言选C} 1234567891011121314\\lstset{ basicstyle = \\ttfamily, % 基本代码风格 numbers = left, % 行号靠左 keywordstyle = \\bfseries, % 关键字风格 commentstyle = \\ttfamily, % 注释的风格 frame = single, % 线框 escapeinside =``, % 英文分号中可写入中文 xleftmargin =5em, xrightmargin =0em, aboveskip =2em, belowskip =0em, breaklines = true, language = C, % 语言选C} frame 边框样式设置边框样式: none:无框 single:单线框 leftline,topline,rightline,bottomline:上下左右的线 ltrb:上面参数的缩写,frame=lr 表示左右有线 LTRB:大写表示双线 123\\lstset{ frame = single, % 线框} 123\\lstset{ frame = shadowbox, % 阴影} 123\\lstset{ frame = LR, % 左右边框双线} rulesepcolor 阴影颜色1234\\lstset{ frame = shadowbox, % 阴影 rulesepcolor= \\color{ red!20!green!20!blue!20} , % 阴影颜色} rulecolor 边框颜色123\\lstset{ rulecolor = \\color{red}, % 边框颜色} frameround 边框倒角123\\lstset{ frameround = fftt, % 边框倒角,f表示尖角,t表示倒角,顺序是第一个字母表示右上角,顺时针} framesep 边框与代码的距离代码不会移动,动的是边框。 123\\lstset{ framesep = 6em, % 边框与代码的距离} 123\\lstset{ framesep = 6em, % 边框与代码的距离} framexleftmargin/framexrightmargin/frameytopmargin/frameybottommargin 边框与代码距离123456\\lstset{ framexleftmargin = -2em, % 左边框与代码距离 framexrightmargin = -5em, % 右边框与代码距离 framexbottommargin = 2em, % 下边框与代码距离 framextopmargin = 2em, % 上边框与代码距离} 123456\\lstset{ framexleftmargin = 1em, % 左边框与代码距离 framexrightmargin = 1em, % 右边框与代码距离 framexbottommargin = 0em, % 下边框与代码距离 framextopmargin = 0em, % 上边框与代码距离} breaklines 强制换行设置代码超长时自动换行: 123\\lstset{ breaklines = false, % 不换行} 123\\lstset{ breaklines = true, % 不换行} numberstyle/keywordstyle/identifierstyle/commentstyle/commentstyle 行号、关键字、标识符、注释的样式12345678910111213141516\\definecolor{listing-background}{HTML}{F7F7F7}\\definecolor{listing-rule}{HTML}{B3B2B3}\\definecolor{listing-numbers}{HTML}{B3B2B3}\\definecolor{listing-text-color}{HTML}{000000}\\definecolor{listing-keyword}{HTML}{435489}\\definecolor{listing-identifier}{HTML}{435489}\\definecolor{listing-string}{HTML}{00999A}\\definecolor{listing-comment}{HTML}{8E8E8E}\\definecolor{listing-javadoc-comment}{HTML}{006CA9}\\lstset{ numberstyle = \\color{listing-numbers}, % 行号颜色 keywordstyle = \\color{listing-keyword}, % 关键字颜色 identifierstyle = \\color{listing-identifier}, % 变量颜色 commentstyle = \\color{listing-comment}, % 注释颜色}","categories":[{"name":"LaTeX","slug":"LaTeX","permalink":"http://example.com/categories/LaTeX/"}],"tags":[{"name":"LaTeX","slug":"LaTeX","permalink":"http://example.com/tags/LaTeX/"},{"name":"listing","slug":"listing","permalink":"http://example.com/tags/listing/"}]},{"title":"Markdown 书写 PDF 输出优雅的解决方案","slug":"Markdown书写PDF输出优雅的解决方案","date":"2022-08-20T00:28:03.000Z","updated":"2022-10-15T03:14:29.347Z","comments":true,"path":"2022/08/20/Markdown书写PDF输出优雅的解决方案/","link":"","permalink":"http://example.com/2022/08/20/Markdown%E4%B9%A6%E5%86%99PDF%E8%BE%93%E5%87%BA%E4%BC%98%E9%9B%85%E7%9A%84%E8%A7%A3%E5%86%B3%E6%96%B9%E6%A1%88/","excerpt":"","text":"折腾背景Markdown 的简便性是 LaTeX 无法替代的,LaTeX 对排版的精准控制能力又是 Markdown 无法比拟的。一直在寻找一种能够将 Markdown 优雅地转换成 PDF 的解决方案,虽然早就听说也使用过 Pandoc 这把瑞士军刀,但是它太过强大,以致于一直都没用明白。只会简单的转换命令,但是实际效果并不好,最近学会了使用 LaTeX 模板的功能,这才让我眼前一亮,这才是我想要的结果。 效果演示 基础环境配置Markdown 生成 PDF 主要需要使用 Pandoc 和 LaTeX 两个工具,具体安装方式如下: Pandoc 的安装Pandoc 是由 John MacFarlane 开发的标记语言转换工具,可实现不同标记语言间的格式转换。 Windows 下的安装: 下载安装包直接安装即可 如果安装了 Chocolate:choco install pandoc 如果安装了 winget:winget install pandoc Linux/FreeBSD下的安装: Pandoc 已经包含在大部分 Linux 发行版的官方仓库中,直接使用诸如apt/dnf/yum/pacman之类的安装工具直接安装即可 macOS 下的安装: brew install pandoc 详细的安装说明参见:官方安装文档 LaTeX 的安装LaTeX 工具,建议安装 texlive。 Windows 下的安装: 参考该文章下载完整 texlive,注意安装后需要再安装 cjk,cjk-fonts 等相关 package Linux/FreeBSD下的安装: 使用 apt/dnf/yum/pacman/pkg 等安装工具安装 texlive、texlive-latex 等相关软件包 macOS 下的安装: 使用 HomeBrew 安装 texlive 即可 模板配置配置 Pandoc 模板为保证生成的 pdf 格式(自动插入封面、目录页、页眉页脚等信息),在本地环境中安装模板,具体步骤是: 下载MPPL: Markdown to PDF with Pandoc via Latex仓库 将template/mppl.latex拷贝到*/pandoc/templates目录下 Window 下:C:/Users/USERNAME/AppData/Roaming/pandoc/templates,如果Roaming没有pandoc目录,请手动创建! Linux/FreeBSD/MacOS:~/.pandoc/templates/ 配置 LaTeX 模板模板定制主要修改模板最前面的模板基础配置相关内容,主要可修改的包括: 公司和组织,目前默认是”MPPL” 正文缩进,目前默认是 2em(2 个中文字符,4 个英文字符) 主要中文字体和英文字体:目前都是微软雅黑 页眉、页脚展示内容,目前是: 左页眉:title 右页眉:”企业机密 - 禁止外传” 左页脚:company 右页脚:页码 字体设置目前页面默认的字体是微软雅黑,对于非 Windows 系统,可能不存在该字体,则有以下两种解决方案: 手工安装微软雅黑字体(需要 msyh,msyhbd 两个文件) 修改为其他字体,如苹方、文泉驿等 若需要多个团队共同使用,建议采用方案一。 如何生成 PDFPDF 文件指定 metadata 信息在每个 Markdown 最前面增加以下主要 metadata 信息,metadata 内容开始行内容为三个“-”,结束行为三个“.”,示例如下: 1234567891011121314title: "MPPL"version: "0.1"subtitle: "Markdown to PDF with Pandoc via LaTeX"date: "2022-08"author: "Dominic"company: COMPANYNAMEfile-code: COMPANY-DEPARTMENT-00000000logo: truelogo-url: ./img/logo.pnghistory: - version: V0.1 author: Dominic date: 2022-08-19 desc: 创建文档 其他可选配置项目如下: header-left: 左页眉 header-right: 右页眉 footer-left: 左页脚 footer-right: 右页脚 CJKmainfont: 主要中文字体 mainfont: 主要字体 lot: 是否创建表格目录 lof: 是否创建图片目录 可选配置项中,建议除了 subtitle 外,全部在模板中定制,不在 Markdown 文件中定制 Markdown 其他编写要求Pandoc 默认使用的 pandoc_markdown 格式,为避免 Markdown 转 pdf 格式异常,在编写 Markdown 的时候有几个原则要求: 每个标题前后都必须有空行 每个表格前后都必须有空行 每个代码块前后收必须有空行 每个列表前后必须有空行 总之,不同文本类型之间都要有空行。 生成 PDF 文件1pandoc --listings --pdf-engine=xelatex --template=mppl.latex README.md -o README.pdf 摆脱命令行,优雅的 VSCode 书写转换方案VSCode 与插件安装打开 VSCode 编辑器,在插件页搜索 markdown-preview-enhanced,接着点击 Install 按钮。详情参考VS Code 安装 MPE。 Markdown Preview Enhanced 以下简称 MPE 使用 VSCode 书写 Markdown新建文件以.md为后缀即可开始编辑 Markdown 文件,使用 MPE 实时预览与导出。 配置 MPE 使用 Pandoc 导出右击 MPE 的预览区域,可以看到 MPE 提供多种导出 PDF 的方案,如使用 Chrome 的 Puppeteer 导出,Prince 导出,Pandoc 导出等等。 在未使用 Pandoc 前,我也一直使用 MPE 提供的 Chrome 方式导出,但是导出的 PDF 排版总是不尽如意。现在介绍如何使用 Pandoc 方式导出。 创建 PDF 文档,你需要在 markdown 文件中的 front-matter 里声明 pdf_document 的输出类型: 123456---output: pdf_document: latex_engine: xelatex pandoc_args: [--template=mppl.latex,--listings]--- front-matter:文章的最开头,也就是上文元数据放的地方。和元数据放在一起即可,如图所示: latex_engine:默认情况下 PDF 文档由 pdflatex 生成。你可以用 latex_engine 选项来定义你想用的引擎。支持的引擎有 pdflatex,xelatex,以及 lualatex。这里需要使用xelatex。 pandoc_args:配置 Pandoc 接受的一些参数,这里我们使用 --template=mppl.latex 和 --listings 来指定模板和使用 listings。这里配置的参数就是执行 Pandoc 时使用的参数,以后就不需要命令行输入了。这里使用上文的mppl.latex模板。 配置完之后,右击预览界面,选择 Pandoc 导出,稍等片刻,即可生成 PDF 文件。 常见问题解决LaTeX 相关错误VSCode 导出出错时报错信息较短,并且常常不知道具体报错原因及位置,因为是 LaTeX 转换成 PDF 的过程中出现的错误。报错位置是 LaTeX 中间源码的位置,而不是 VSCode 中的位置。这时候我常用的方法是先将 Markdown 转为 LaTeX,然后再转为 PDF,在 LaTeX 编辑器里就可以看到错误位置了。 比如下面这个错误,我们能看到一些报错信息cant use \\spacefactor in math mode,但是并不知道具体哪里的错误。从信息里可以看出和\\LaTex有关,大概能推测出是使用了这个命令,因为文章里使用了这个命令的地方只有一处。但是如果有其他的错误,就很难确定了。 Markdown 转换 LaTeX这里还是以模板仓库的README.md为例,当然这个文件是可以正常转换 PDF 的,不会报错。这里只是拿README.md做一个如何使用命令的演示。 1pandoc --listings --template=mppl.latex -s README.md -o README.tex LaTeX 编辑器打开,以 TexStudio 为例打开README.tex文件,编译: 我们可以快速的定位到问题出现的位置,只要搜索相关问题即可。 \\LaTeX{} 这个宏不能用在数学模式下。但是因为我在 Markdown 里必须使用美元符号$$才能表示 LaTeX 环境,才能正确输出 LaTeX 符号,而 Markdown 转换成 LaTeX 源码时,这个宏就会被包裹在数学环境里,就会报错。如果我想在 PDF 里显示这个符号,那就在 Markdown 里不使用美元符号$$,而是直接输入\\LaTeX{}即可,再导出 PDF 时就不会报错。","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"LaTeX","slug":"LaTeX","permalink":"http://example.com/tags/LaTeX/"},{"name":"Markdown","slug":"Markdown","permalink":"http://example.com/tags/Markdown/"},{"name":"Pandoc","slug":"Pandoc","permalink":"http://example.com/tags/Pandoc/"},{"name":"PDF","slug":"PDF","permalink":"http://example.com/tags/PDF/"},{"name":"效率","slug":"效率","permalink":"http://example.com/tags/%E6%95%88%E7%8E%87/"}]},{"title":"编译错误以英文输出","slug":"编译错误以英文输出","date":"2022-08-16T14:31:43.000Z","updated":"2022-08-16T14:35:43.000Z","comments":true,"path":"2022/08/16/编译错误以英文输出/","link":"","permalink":"http://example.com/2022/08/16/%E7%BC%96%E8%AF%91%E9%94%99%E8%AF%AF%E4%BB%A5%E8%8B%B1%E6%96%87%E8%BE%93%E5%87%BA/","excerpt":"","text":"因为终端配置的原因,编译的结果输出是中文,这样搜索问题不如英文的表述精确。配置终端的语言为英文,就可以输出英文。 1export LANG=en_US","categories":[{"name":"万能 VSCode","slug":"万能-VSCode","permalink":"http://example.com/categories/%E4%B8%87%E8%83%BD-VSCode/"}],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"}]},{"title":"解决 cast from pointer to integer of different size","slug":"解决cast-from-pointer-to-integer-of-different-size","date":"2022-08-16T03:42:24.000Z","updated":"2022-10-15T02:59:01.809Z","comments":true,"path":"2022/08/16/解决cast-from-pointer-to-integer-of-different-size/","link":"","permalink":"http://example.com/2022/08/16/%E8%A7%A3%E5%86%B3cast-from-pointer-to-integer-of-different-size/","excerpt":"","text":"保留现场12345void* foo(void *dst, ...) { // some code unsigned int offset = (unsigned int) dst % 8; // warning here! // some code continue...} 写驱动程序时经常会直接对地址进行修改,配置寄存器的值,也会将地址的值作为数据进行传递,这就会遇到一个问题,指针强转成整型,类型不匹配数据丢失的问题。 探究原因出现这个警告的原因是,将void*类型强转成unsigned int是不可移植的。什么叫不可移植呢? 我们知道指针类型,在 32 位系统下是 4 字节,在 64 位系统下是 8 字节,而unsigned int不管在什么系统下都是是 4 字节,所以,如果将void*类型强转成unsigned int,在 64 位系统下就没有足够的空间保存真正的数据。 解决方法粗暴地用double来接收先接收,再截断: 12345void* foo(void *dst, ...) { // some code unsigned int offset = (unsigned int)(unsigned double) dst % 8; // warning here! // some code continue...} uintptr_tuintptr_t 保证足够宽,以便将 void* 转换为 uintptr_t 并再次返回将产生原始指针值。还有一个类型 intptr_t,它是有符号的; 1234567#include <stdint.h>// 或者 <inttypes.h>void* foo(void *dst, ...) { // some code unsigned int offset = (uintptr_t) dst % 8; // warning here! // some code continue...}","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"DEBUG 原理","slug":"DEBUG原理","date":"2022-08-14T06:17:26.000Z","updated":"2022-10-15T03:14:29.194Z","comments":true,"path":"2022/08/14/DEBUG原理/","link":"","permalink":"http://example.com/2022/08/14/DEBUG%E5%8E%9F%E7%90%86/","excerpt":"","text":"了解调试原理时看到了一个质量比较高的视频,【蛋饼嵌入式】一起探究调试原理。UP 通俗,形象地讲解了 DEBUG 的一些原理,值得反复观看,但是视频不如文字查阅效率高,遂记录了以下文稿内容。 什么是 JTAG1985 年,几家半导体厂商为了解决板级测试的问题,成立了 Joint Test Action Group(JTAG)联合测试行动小组,他们希望将测试点和测试电路集成在芯片内部引脚处。同时,留出一个统一协议的接口,大家都能通过这个接口来访问芯片的输入与输出状态。这样就省去了板级测试是的物理接触,同时还能进行逻辑性调试。后来 IEEE 组织,将这个方案制定成了标准 IEEE 1149.1,这就是现在我们常听到的 JTAG 调试。 边界扫描技术实现 JTAG 调试最重要的一个技术就是边界扫描技术,核心思想是给芯片的每一个输入输出引脚,添加一个移位寄存器单元,也称为边界扫描单元(Boundary Scan Cell,BSC)。通过它一边可以实现对芯片输出数据的截取,另一边可以完成对输入数据的替代。正常运行状态下,这些寄存器又是透明般的存在。 这些位于引脚边界的移位寄存器,还可以串在一起,形成一条边界扫描链,以串行的方式从外部更新扫描单元上的数据,以及对外输出边界扫描单元捕获的数据。如果板上有多个这样的芯片,他们还能以菊花链的形式串联在一起,这样就大大方便了测试的过程。 要实现对内部移位寄存器单元或者说对整个扫描链的访问和操作,便依赖于 JTAG 调试协议和相应的物理接口。JTAG 标准接口包括以下几个部分: TDI(Test Data In) TDO(Test Data Out) TCLK(Test Clock) TMS(Test Mode Select) TRST(Test Reset):可选,用于复位 调试逻辑的实现,是通过芯片内部的 TAP(Test Access Port)来完成的。模式状态信号 TMS 配合测试时钟信号 TCLK,以一定的时序进入到 TAP 控制器后,由 TAP 控制器内部的状态机转化为相应的控制动作。从而完成数据的移位,引脚状态的捕获和更新。 设备 ID 寄存器构成的扫描链,板卡一连上调试器,通过对这条扫描链的访问,就能够识别到被调试芯片的信号。存放调试机制相关配置的数据寄存器,所构成的扫描链,后面断点和单步调试时就会用到。以及移位的 BYPASS 寄存器,当调试链路上有多个芯片连接时,来减少总调试链路的长度。 以上都属于数据寄存器构成扫描链,因为想要在他们之间进行切换,需要引入另外的指令寄存器,以及对应的扫描链,这样调试主机将不同的调试命令写到指令寄存器中,就可以选通需要调试的数据链路。数据与指令寄存器两种链路的切换,就通过 TAP 控制器完成。 补充:如果芯片支持 JTAG 调试,那么芯片上就必须有上述的四个接口,TDI,TDO,TCLK,TMS。芯片外有个 Adapter 与之 Pin to Pin 连接,负责协议转换,把 USB 的 JTAG 控制信息按 JTAG 协议转换输出,满足协议定义的电气特性。Adapter 与 Host 连接,Host 可以是我们的 PC,也可以是另一个嵌入式调试器。Host 上通常需要运行一些软件,如 OpenOCD,负责把 GDB 的高级别命令转换成 JTAG 命令,并通过特定 Adapter 的要求进行打包,调用 OS 提供的 USB/ETH/PCI 驱动发送出去。GDB 与 OpenOCD 通过一些远程协议,如 TCP/IP,进行通信。这样就能够调试 Chip。 断点是如何实现的?通过以上 JTAG 调试接口,我们已经能够测试引脚的输入输出了,同时也获得了观察和改变芯片内部数据的机会,那么接下来我们如何进行调试呢?比如打个断点? 断点作为一种干预性调试,根据调试行为的不同,分为监控模式和中止模式。 监控模式(软件断点):会触发异常,交由相应的软件程序来处理,处理器仍然处于运行状态。 中止模式(硬件断点),使处理器进入非正常运行的调试状态。 以 ARM 架构来说,最初工程师想到的办法是插入一条指令集中没有定义的无效指令,来替换掉希望打断指令处的源指令。这样内核运行到这条指令时,就会进入到无效指令的服务程序,在这个异常的服务程序中,我们再去做想要的调试操作,操作完成后,还原当时被替换的指令。并继续执行。 后来 ARMv5 开始引入专门用于调试的BKPT指令,类似与 X86 指令集的INT3指令,但不管是不是专用指令,他们都属于软件中断。这意味着我想要实时地添加这种断点,就要求能够随时地更改程序,插入断点指令,而一般只有程序运行在 RAM 上,才方便这样操作。那如果直接从 FLASH 上取址运行的程序,因为 FLASH 先擦后写的物理特性,是无法通过随意插入指令来实现断点的。更不要说从只读存储器上运行的程序,比如说固化在 BIOS 中上电自检 POST 程序,面对这种情况,需要的就是硬件断点。 硬件断点顾名思义,需要额外的硬件逻辑支持,主要起的作用就是暂存和比较,我们把这种实现特定逻辑的组合电路,称为宏单元(Macro Cell)。 还记得我们前面说过 JTAG 协议,支持自定义扩展扫描链吗?硬件断点宏单元的控制和比较两种数据寄存器,就可以作为两条拓展扫描链,加入到 JTAG 调试框架中。 你在调试软件中按下一个按钮,对应的那行代码地址,就会通过上述扫描链,被记录到断点宏单元相应的寄存器中,当然,调试器能够知道某行代码的地址,是依赖于编译时生成的 ELF 文件中的符号表信息。而当程序正常运行取址时,如果宏单元的寄存器,发现了总线上出现了记录过的地址,比较器就会发出调试状态信号,CPU 接收到这个信号后暂停运行,进入调试模式或者异常。 因为每打一个断点,都需要宏单元相应的寄存器来保存地址信息。而寄存器数量是有限的,所以调试软件一旦和芯片建立起了连接,就会通过上述的另外一条控制寄存器获得该硬件断点宏单元所支持的最大断点数,这样你在调试过程中如果断点打多了,调试器就会报错。 为什么调试器能够烧录程序呢?正常情况下,CPU 内核通过内部的系统总线,从 FLASH 或者 RAM 中获取运行的指令,交换数据,并在一定的驱动程序下,实现对 FLASH 的擦除和写入操作。为了把指令和数据直接给 CPU 内核,我们还需要定义一条扫描链,这条扫描链直接在系统总线上开了一个口子,通过上位机的调试信号,把相关的操作指令直接传到总线上,供 CPU 内核取用。 那么整个调试器的下载过程是这样的: 第一,通过调试器使得 CPU 进入调试模式; 第二,通过总线扫描链将 FLASH 编程算法与即将被下载的用户程序放到 RAM 中; 第三,将 CPU 的 PC 指针指向刚刚搬运完成的 RAM 地址起始处,并退出调试状态; 第四,CPU 将在正常状态下运行 RAM 中的 FLASH 编程算法。将用户代码烧录到确定位置上,执行完成后回到调试状态。 如果 RAM 空间不够大,以上操作还需要重复多次执行。 需要注意的是,在第二步操作 RAM 时,是处于调试状态下,而调试时钟的速率是无法满足 RAM 或者 FLASH 的访问速率要求的,所以在这一过程中,CPU 会频繁的在系统时钟与调试时钟之间切换 调试时钟下,总线扫描链先传递来要写入的数据和 RAM 地址,CPU 先分别暂存在内部通用寄存器中,接着扫描链传递写入指令,并切换为系统时钟。CPU 在正常状态下执行搬运指令,往 RAM 里写入数据,执行完成后回到调试状态,继续通过扫描链传递后面要写入的值, OpenOCD (Open On-Chip Debugger)OpenOCD(Open On-Chip Debugger)开源片上调试器,是一款开源软件,最初是由 Dominic Rath 同学还在大学期间发起的(2005 年)项目。OpenOCD 旨在提供针对嵌入式设备的调试、系统编程和边界扫描功能。 参考资料【蛋饼嵌入式】饮茶先?DEBUG 先!一起探究调试原理_哔哩哔哩_bilibili浅谈 RISC-V 的 DEBUG 系统及其仿真 - 知乎ESP32 JTAG Debug 01: JTAG 接口简介_哔哩哔哩_bilibili+","categories":[],"tags":[{"name":"GDB","slug":"GDB","permalink":"http://example.com/tags/GDB/"},{"name":"嵌入式","slug":"嵌入式","permalink":"http://example.com/tags/%E5%B5%8C%E5%85%A5%E5%BC%8F/"},{"name":"芯片开发","slug":"芯片开发","permalink":"http://example.com/tags/%E8%8A%AF%E7%89%87%E5%BC%80%E5%8F%91/"},{"name":"硬件","slug":"硬件","permalink":"http://example.com/tags/%E7%A1%AC%E4%BB%B6/"},{"name":"JTAG","slug":"JTAG","permalink":"http://example.com/tags/JTAG/"},{"name":"OpenOCD","slug":"OpenOCD","permalink":"http://example.com/tags/OpenOCD/"}]},{"title":"保持 SSH 连接","slug":"保持SSH连接","date":"2022-08-13T12:28:57.000Z","updated":"2022-10-15T03:14:29.673Z","comments":true,"path":"2022/08/13/保持SSH连接/","link":"","permalink":"http://example.com/2022/08/13/%E4%BF%9D%E6%8C%81SSH%E8%BF%9E%E6%8E%A5/","excerpt":"","text":"SSH 总是被强行中断,尤其是用 VSCode 代码写的好好的,突然刷新窗口,不仅效率低,更惹人恼火。 可以通过配置服务端或客户端的 SSH 来保持 SSH 链接: 方法一:配置服务端可以在服务端配置,让 server 每隔 30 秒向 client 发送一个 keep-alive 包来保持连接: 1vim /etc/ssh/sshd_config 12ClientAliveInterval 30ClientAliveCountMax 60 第二行配置表示如果发送 keep-alive 包数量达到 60 次,客户端依然没有反应,则服务端 sshd 断开连接。如果什么都不操作,该配置可以让连接保持 30s*60,30 min 重启本地 ssh 1sudo service ssh restart 如果找不到 ssh,”Failed to restart ssh.service: Unit ssh.service not found.” ,需要安装 1sudo apt-get install openssh-server 方法二:配置客户端如果服务端没有权限配置,或者无法配置,可以配置客户端 ssh,使客户端发起的所有会话都保持连接: 1vim /etc/ssh/ssh_config 12ServerAliveInterval 30ServerAliveCountMax 60 本地 ssh 每隔 30s 向 server 端 sshd 发送 keep-alive 包,如果发送 60 次,server 无回应断开连接。 在 VSCode 里可以直接添加配置,效果一样: 123456Host 11.22.33.44 HostName 11.22.33.44 User user Port 112343 ServerAliveInterval 30 ServerAliveCountMax 60","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"},{"name":"Efficiency","slug":"Efficiency","permalink":"http://example.com/tags/Efficiency/"},{"name":"SSH","slug":"SSH","permalink":"http://example.com/tags/SSH/"}]},{"title":"VSCode 隐藏编辑页面右上角的按钮","slug":"VSCode隐藏编辑页面右上角的按钮","date":"2022-08-02T14:10:55.000Z","updated":"2022-10-15T03:14:29.609Z","comments":true,"path":"2022/08/02/VSCode隐藏编辑页面右上角的按钮/","link":"","permalink":"http://example.com/2022/08/02/VSCode%E9%9A%90%E8%97%8F%E7%BC%96%E8%BE%91%E9%A1%B5%E9%9D%A2%E5%8F%B3%E4%B8%8A%E8%A7%92%E7%9A%84%E6%8C%89%E9%92%AE/","excerpt":"","text":"随着插件越装越多,标签栏右侧的按钮也越来越多,严重缩小了标题栏显示范围。这片按钮区域又有最大长度的限制,当按钮太多,就会隐藏到下拉菜单里(最右侧的三个点)。这样就会导致一些常用的按钮被隐藏,而不常用的按钮又占地方。那么怎样才能隐藏不需要的按钮呢? 123456"gitlens.menus": { "editorGroup": { "blame": false, "compare": true },},","categories":[{"name":"万能 VSCode","slug":"万能-VSCode","permalink":"http://example.com/categories/%E4%B8%87%E8%83%BD-VSCode/"}],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"}]},{"title":"Jellyfin 打造本地影音库","slug":"Jellyfin打造本地影音库","date":"2022-08-01T15:05:52.000Z","updated":"2022-10-15T03:14:29.261Z","comments":true,"path":"2022/08/01/Jellyfin打造本地影音库/","link":"","permalink":"http://example.com/2022/08/01/Jellyfin%E6%89%93%E9%80%A0%E6%9C%AC%E5%9C%B0%E5%BD%B1%E9%9F%B3%E5%BA%93/","excerpt":"","text":"周末花了一整天,是在没精力了。占坑。得空慢慢补!","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"NAS","slug":"NAS","permalink":"http://example.com/tags/NAS/"},{"name":"Jellyfin","slug":"Jellyfin","permalink":"http://example.com/tags/Jellyfin/"}]},{"title":"使用 Syncthing 多端丝滑同步与备份","slug":"使用Syncthing多端丝滑同步与备份","date":"2022-08-01T14:48:21.000Z","updated":"2022-10-15T03:14:29.670Z","comments":true,"path":"2022/08/01/使用Syncthing多端丝滑同步与备份/","link":"","permalink":"http://example.com/2022/08/01/%E4%BD%BF%E7%94%A8Syncthing%E5%A4%9A%E7%AB%AF%E4%B8%9D%E6%BB%91%E5%90%8C%E6%AD%A5%E4%B8%8E%E5%A4%87%E4%BB%BD/","excerpt":"","text":"折腾背景一直想找一个能够快速同步手机与电脑数据的工具,因为手机云服务的空间少的可怜,所以习惯隔一段时间将手机里的照片、视频还有一些文件导出到电脑上。但是每次备份文件都得连接数据线,并且没法增量备份,得手动挑选,也还挺麻烦的。 逛 GitHub 时,无意间发现了 Syncthing,几乎符合了我所有的预期。 开源,免费,自己电脑就可以当服务器,以后入了 NAS,可以自己搭建本地服务器。 同步速度快,取决 WIFI 的速度,目前使用 30M/s,基本满速。 多端支持,除了 IOS(反正我也没有 iOS 设备,嘿嘿),几乎全平台支持,包括 NAS 及路由器。 增量同步,再也不用挑文件备份了。 话不多说,开整。 下载安装直接进入Syncthing官网,下载安装。在 Ubuntu 下安装参考这里。Android 版本下载Syncthing。 接下来以 Windows 与 Android 手机同步为例,下载安装后,打开syncthing.exe,即可打开管理界面,或者浏览器输入http://127.0.0.1:8384也可进入管理界面。 Windows 界面: Android 界面: 设备配对Windows 管理页面->操作->显示 ID,会显示本机的二维码: Android 手机打开应用,切换到设备界面,点击右上角加号,点击二维码标识,即可扫描二维码,完成设备添加。 如果正确添加,Windows 管理界面会显示 Android 设备: Android 同步至 Windows打开 Android 应用,切换到文件夹界面,点击右上角加号,配置同步的文件夹: 根据下图提示,配置应用,记得保存:目录列表显示刚刚的配置: 点击打开,开启与远程设备 Windows 同步: 当返回时,Windows 端将会弹出通知,提示有 Android 设备的文件要分享到电脑,点击添加: 至此,Android 同步至 Windows 完成。此时在 Android 设备的文件夹中添加任意文件,都会同步到 Windows。 Windows 同步至 AndroidWindows 管理界面,添加文件夹: 点击保存后,与之前类似,Android 会提示有 Windows 设备的文件要分享到 Android,点击添加: 如果 Android 设备没有弹出提示添加共享文件夹,那么打开应用侧边栏->网页管理页面,将会有弹窗,如下图 点击添加,配置文件夹目录等与之前类似。 至此,Windows 同步至 Android 完成。此时在 Windows 设备的文件夹中添加任意文件,都会同步到 Android。 使用技巧Syncthing 支持三种工作模式 发送和接收,Send & Receive Folder,这是文件夹的默认模式,对文件夹的修改会发送,其他设备的修改也会同步回来。 仅发送 Send Only,这种模式表示仅仅将当前设备上的文件夹的改动发送到其他设备,用来隐式地表示其他同步设备上的文件不会被修改,或者其他设备上的修改可以被忽略。这种模式非常适合,将当前设备设定为工作设备,然后设定一台设备作为此设备的备份。 在 Send Only 模式下,集群中其他设备的修改都会被忽略,修改依然会接收,文件夹可能会出现 「out of sync」,但是没有修改会被应用到本地。 当 Send Only 文件夹出现 out of sync,那么一个红色的 Override Changes 会出现在文件夹详情中,点击该按钮会强制将当前主机的状态同步到其他剩余节点。任何对文件的修改,都会被当前主机上的版本所覆盖,任何不存在于当前主机节点的文件都会被删除,其他类似。 仅接收 Receive Only,这种模式下所有的修改都会被接收并应用,然后重新分发给其他使用 send-receive 模式的设备。但是本地的修改不会被分发给其他设备。这种模式适合于建立备份镜像(replication mirrors),或者备份目的主机的场景,这些情况下不期望有本地修改或者本地的修改是不允许的 当本地文件被删除时,Syncthing 会显示一个 Revert Local Changes 按钮。使用这个按钮会将本地的修改回撤,所有添加的文件会被删除,修改或删除的文件会重新从其他节点同步,比较容易理解,但是假如 A 设备设置仅发送,B 设备设置发送和接收,A 是不会同步 B 的更改的! 忽略特定文件、目录忽略列表,和 gitignore 类似。每一台设备上的 .stignore 都是分别设置的,不会进行同步。 如果 A 的.stignore忽略了 test ,而 B 没有这样做,实际上会发生这样的事情: A 不会扫描和通知 B(广播)关于 test 的变动; B 对关于 test 的变动持开放的姿态,但不会收到任何关于 A 上面 test 的变动信息(可能接收到其它同步设备的); B 会扫描 test 以及推送其关于 test 变动的信息,但会被 A 忽略,A 也会忽略其它同步设备关于 test 的信息; B 会接收来自其它同步设备推送的关于 test 的信息; 参考资料Syncthing 又一款同步工具 | Verne in GitHub Folder Types — Syncthing documentation","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"Efficiency","slug":"Efficiency","permalink":"http://example.com/tags/Efficiency/"},{"name":"工具","slug":"工具","permalink":"http://example.com/tags/%E5%B7%A5%E5%85%B7/"},{"name":"同步","slug":"同步","permalink":"http://example.com/tags/%E5%90%8C%E6%AD%A5/"},{"name":"备份","slug":"备份","permalink":"http://example.com/tags/%E5%A4%87%E4%BB%BD/"}]},{"title":"解决提交 gerrit missing Change-Id","slug":"解决提交gerrit-missing-Change-Id","date":"2022-07-30T07:05:48.000Z","updated":"2022-10-15T03:14:29.858Z","comments":true,"path":"2022/07/30/解决提交gerrit-missing-Change-Id/","link":"","permalink":"http://example.com/2022/07/30/%E8%A7%A3%E5%86%B3%E6%8F%90%E4%BA%A4gerrit-missing-Change-Id/","excerpt":"","text":"保留现场12345678remote: Resolving deltas: 100% (114/114)remote: Processing changes: refs: 1,done remote: ERROR: missing Change-Idincommit message footerremote:remote: Hint: To automatically insert Change-Id,installthe hook:remote: gitdir=$(git rev-parse --git-dir);scp-p -P XX XX@gerrit.xxxxx.com:hooks/commit-msg${gitdir}/hooks/remote: And then amend the commit:remote: git commit --amend 探究原因理解 change-id代码审核是要对一个完整的变更进行审核,比如一次 Bug 修复,有多次提交 Commit,每次的 Commit Id 都不同,那么如何将多个不同的 Commit ID 关联到同一个 Chanege-Id 呢?我们需要将 Change-Id 添加到 Commit 的 footer(最后一行)中,这样就可以将多个 Commit 关联到同一个 Change-Id 了。 Change-Id 为避免与提交 Id 冲突,通常以大写字母 I 为前缀。此外,我们需要明确,Change-Id 是 Gerrit 的概念,不是 Git 的概念。你只有用 Gerrit 才会有 Change-Id,而 Git 只有提交 Id。 那么这个 Change-Id 是怎么生成的呢? 理解 git hooks我在Git hooks 钩子的使用中有详细解释。在这里简单的介绍一下,钩子 (hooks) 是一些在.git/hooks目录的脚本,在被特定的事件触发后被调用。比如执行git commit,git push,git pull等命令时,脚本会被调用。 Gerrit 也提供了一个标准的commit-msg钩子,当我们在执行git commit时,会被调用。会自动生成Change-Id,并将其添加到commit的 footer 中。 通常我们从远程下载代码后,会自动下载commit-msg钩子,并将其添加到.git/hooks目录中。正常来说hooks是不会加入代码仓库的,这应该取决于 Gerrit 的配置。 这次错误应该是我在测试钩子的时候,将 Gerrit 标准钩子删除了,导致无法正确生成 Change-Id。 解决方法报错时其实已经提供了解决方式: 12345678# 提示让我们安装远程的钩子remote: Hint: To automatically insert Change-Id,installthe hook:# 在命令行输入以下两条命令:# 这条命令将找到该项目的 git 目录,并将其赋值给 gitdir 这个变量gitdir=$(git rev-parse --git-dir)# 执行 scp 命令,从 gerrit 代码服务器将钩子脚本文件 commit-msg 下载到项目的钩子目录下 (一般是 .git/hooks/)scp-p -P XX XX@gerrit.xxxxx.com:hooks/commit-msg${gitdir}/hooks/ 安装完之后重新git commit --amend,就可以正常生成 Change-Id 了。","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"Gerrit 批量添加抄送提醒","slug":"Gerrit批量添加抄送提醒","date":"2022-07-29T05:58:27.000Z","updated":"2022-10-15T03:14:29.204Z","comments":true,"path":"2022/07/29/Gerrit批量添加抄送提醒/","link":"","permalink":"http://example.com/2022/07/29/Gerrit%E6%89%B9%E9%87%8F%E6%B7%BB%E5%8A%A0%E6%8A%84%E9%80%81%E6%8F%90%E9%86%92/","excerpt":"","text":"背景公司使用 Gerrit 作为 Review 平台,但是每次提交代码都需要手动添加 Reviewer,还要抄送组内成员,这种重复性劳动,程序员是绝不能容忍的。gerrit 提供了发送邮件的功能。 解决方法官方示例: 1git push ssh://john.doe@git.example.com:29418/kernel/common HEAD:refs/for/experimental%r=a@a.com,cc=b@o.com 最后的%是个分隔符,r='a@a.com表示 Reviewer 是a@a.com,cc=b@o.com表示抄送组内成员是b@o.com。 注意!邮箱之间不能有空格! 以一个仓库为例: 1git push origin HEAD:refs/for/branch_dev_name%cc=zhangsan@qq.com,cc=lisi@qq.com,cc=wangerma@qq.com,cc=chenwu@qq.com 但是要这么写,岂不是把操作搞更复杂了。 终极办法,打开项目路径下的.git目录。编辑config文件: 原文件里有如下字段: 123456789[core] repositoryformatversion = 0 filemode = false bare = false logallrefupdates = true ignorecase = true[remote "origin"] url = git@github.com:Dunky-Z/Dunky-Z.github.io.git fetch = +refs/heads/*:refs/remotes/origin/* 我们可以将远程仓库名换成容易区分的名字,自己随意: 1234567891011121314151617[core] repositoryformatversion = 0 filemode = false bare = false logallrefupdates = true ignorecase = true[remote "origin"] url = git@github.com:Dunky-Z/Dunky-Z.github.io.git fetch = +refs/heads/*:refs/remotes/origin/*# 以下为新增内容[remote "review"] url = git@github.com:Dunky-Z/Dunky-Z.github.io.git fetch = +refs/heads/*:refs/remotes/origin/* push = HEAD:refs/for/%cc=zhangsan@qq.com, cc=lisi@qq.com, cc=wangerma@qq.com, cc=chenwu@qq.com 下次想要推送需要 review 的代码,就直接执行git push review,其中push就相当于: 1push HEAD:refs/for/%cc=zhangsan@qq.com,cc=lisi@qq.com,cc=wangerma@qq.com,cc=chenwu@qq.com 参考资料Gerrit Code Review - Uploading Changes","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"Efficiency","slug":"Efficiency","permalink":"http://example.com/tags/Efficiency/"},{"name":"Gerrit","slug":"Gerrit","permalink":"http://example.com/tags/Gerrit/"}]},{"title":"Makefile 确定宏定义","slug":"Makefile确定宏定义","date":"2022-07-27T00:28:03.000Z","updated":"2022-10-15T03:14:29.341Z","comments":true,"path":"2022/07/27/Makefile确定宏定义/","link":"","permalink":"http://example.com/2022/07/27/Makefile%E7%A1%AE%E5%AE%9A%E5%AE%8F%E5%AE%9A%E4%B9%89/","excerpt":"","text":"有时需要通过make编译命令时确定代码中的宏定义,如编译不同的版本只需要使用不同的编译命令即可,而不需要修改内部代码。 当前的需求是代码中有一部分代码通过宏定义来确定编译的是 DIE0 版本还是 DIE1 版本,如果定义了DIE_ORDINAL_0 就使用 DIE0 的基地址,如果未定义就使用 DIE1 的基地址。 123456#define DIE_ORDINAL_0#ifdef DIE_ORDINAL_0#define PERIPH_BASE (SYS_BASE_ADDR_DIE0)#else#define PERIPH_BASE (SYS_BASE_ADDR_DIE1)#endif gcc 命令支持-D宏定义,相当于 C 中的全局#define,在 Makefile 中我们可以通过宏定义来控制源程序的编译。只要在 Makefile 中的 CFLAGS 中通过选项-D 来指定你于定义的宏即可。 123CFLAGS += -D DIE_ORDINAL_0# 在编译的时候加上此选项就可以了$(CC) $(CFLAGS) $^ -o $@ 这样的话,相当于设置了DIE_ORDINAL_0这个宏定义。但是我们想通过命令行的参数来决定是否使用这个宏定义,可以通过一些简单的方法获取: 123456ifeq ($(DIE0), y) CFLAGS +=-DDIE_ORDINAL_0else CFLAGS +=-DDIE_ORDINAL_1endif$(CC) $(CFLAGS) $^ -o $@ 从命令行找到DIE0这个参数,如果它等于y表示使用DIE_ORDINAL_0。如果不等于y则使用DIE_ORDINAL_1,因为我们代码里没有DIE_ORDINAL_1,所以就相当于没有定义DIE_ORDINAL_0。 命令行示例: 1234# 编译DIE0make DIE0="y"# 编译DIE1make DIE0="n"","categories":[],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"Makefile","slug":"Makefile","permalink":"http://example.com/tags/Makefile/"}]},{"title":"每天学命令-生成指定大小文件","slug":"每天学命令-生成指定大小文件","date":"2022-07-23T08:14:38.000Z","updated":"2022-10-15T02:59:01.821Z","comments":true,"path":"2022/07/23/每天学命令-生成指定大小文件/","link":"","permalink":"http://example.com/2022/07/23/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-%E7%94%9F%E6%88%90%E6%8C%87%E5%AE%9A%E5%A4%A7%E5%B0%8F%E6%96%87%E4%BB%B6/","excerpt":"","text":"使用背景在测试下载速度,或者测试加解密文件,亦或者制作文件系统时都需要一些指定大小的文件。Linux 有一些命令可以快速完成这样的任务。接下来介绍几个好用的命令。 空洞文件在 Unix 文件操作中,操作文件的位移量可以大于文件的当前长度,在下一次写操作时,就会把文件撑大(Extend),在文件里创建空洞(Hole),没有被实际写入的部分都是 0。空洞文件是否占用实际磁盘空间由文件系统觉得,Linux 中空洞文件不占用实际磁盘空间。 fallocatefallocate用于将块预分配给文件。对于支持fallocate系统调用的文件系统,这可以通过分配块并将其标记为未初始化来快速完成,因此不需要对数据块进行 I/O 操作。这是创建文件而不是用零填充的更快的方法。大文件几乎可以立即创建,而不必等待任何 I/O 操作完成。 语法: 1fallocate [-n] [-o offset] -l length filename d: 检测零并替换为空洞。 -n:指定文件的大小,单位为字节。 -o:指定文件的偏移量,可以跟二进制$2^{N}$后缀KiB,MiB,GiB,TiB,PiB和EiB(iB为可选,例如,K的含义与KiB的含义相同或后缀KB,MB,GB,PB和EB的十进制($10^{N}$)。 -l:指定文件的大小,单位同上。 -p, --punch-hole: 将某个范围替换为空洞 (连带打开 -n)。 filename:指定文件名。 示例:分配一个大小为512MB的文件,文件名为efi.img: 1fallocate -l 512M efi.img 将efi.img文件中的0替换为空洞: 1fallocate -d efi.img 从偏移 128M 的位置挖一个 10M 大小的洞 1fallocate -p -o 128M -l 10M efi.img ddLinux dd 命令用于读取、转换并输出数据。dd 可从标准输入或文件中读取数据,根据指定的格式来转换数据,再输出到文件、设备或标准输出 dd 的原意为 data duplicator,但由于 dd 属于较低阶的资料处理工具,通常都会以管理者(root)权限来执行,如果稍有不慎,也很容易造成严重的后果(例如整颗硬碟的资料不见等等),所以有些人也把 dd 取名为 data destroyer。dd 指令教学与实用范例,备份与回复资料的小工具 - GT Wang if=FILE : 指定输入文件,若不指定则从标注输入读取。这里指定为/dev/zero 是 Linux 的一个伪文件,它可以产生连续不断的 null 流(二进制的 0)。 of=FILE : 指定输出文件,若不指定则输出到标准输出。 bs=BYTES : 每次读写的字节数,可以使用单位 K、M、G 等等。另外输入输出可以分别用 ibs、obs 指定,若使用 bs,则表示是 ibs 和 obs 都是用该参数。 count=BLOCKS : 读取的 block 数,block 的大小由 ibs 指定。 示例:生成一个1g大小的文件,内容全为0,块大小为1M,文件名为efi.img: 1dd if=/dev/zero of=efi.img bs=1M count=1024 生成一个1g大小的文件,内容为随机数,块大小为10M,文件名为efi.img: 1dd if=/dev/urandom of=efi.img bs=10M count=1024 truncate -s:指定文件的大小,可以跟二进制$2^{N}$后缀KiB,MiB,GiB,TiB,PiB和EiB(iB为可选,例如,K的含义与KiB的含义相同或后缀KB,MB,GB,PB和EB的十进制($10^{N}$)。 示例:生成一个 100M 大小的文件,文件名为efi.img: 1truncate -s 100M efi.img 参考Linux 文件空洞与稀疏文件","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux,每天学命令","slug":"Linux,每天学命令","permalink":"http://example.com/tags/Linux%EF%BC%8C%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"理解虚拟内存","slug":"理解虚拟内存","date":"2022-07-17T13:45:20.000Z","updated":"2022-10-15T03:14:29.759Z","comments":true,"path":"2022/07/17/理解虚拟内存/","link":"","permalink":"http://example.com/2022/07/17/%E7%90%86%E8%A7%A3%E8%99%9A%E6%8B%9F%E5%86%85%E5%AD%98/","excerpt":"","text":"为什么需要虚拟内存?CPU 访问内存的最自然的方式就是使用物理地址,这种方式称为物理寻址。1,计算机中并不是只有一个程序在运行,如果它们都是用物理寻址的方式,那么所有程序必须在链接之前确定好自己所用到的内存范围,否则两个程序就可能会发生冲突。2,程序大于内存的问题早在上世纪六十年代就出现,后来出现了覆盖技术(Overlay),把程序分割成许多片段。程序开始执行时,将覆盖管理模块装入内存,该管理模块立即装入并运行覆盖 0。执行完成后,覆盖 0 通知管理模块装入覆盖 1,或者占用覆盖 0 的上方位置(如果有空间),或者占用覆盖 0(如果没有空间)。把一个大程序分割成小的、模块化的片段是非常费时和枯燥的,并且易于出错。很少程序员擅长使用覆盖技术。 为了更加有效地管理内存并且少出错,现代系统提供了一种对主存的抽象概念,叫做虚拟内存(VM)。主要有三个功能: 它将主存看成是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据,通过这种方式,它高效地使用了主存。 它为每个进程提供了一致的地址空间,从而简化了内存管理。 它保护了每个进程的地址空间不被其他进程破坏。 什么是虚拟寻址?如果主存被分为长度为$M$的单字节大小的数组,每个字节都对应一个物理地址,CPU 通过这个唯一的地址访问主存,这样的方式就是物理寻址。现代处理器使用虚拟寻址的方式。CPU 通过生成的虚拟地址来访问内存,这个地址在送到内存之前会被转换成物理地址。这个过程称为地址翻译。CPU 芯片上叫做内存管理单元(Memory Management Unit, MMU)的专用硬件,利用存放在主存中的查询表来动态翻译虚拟地址,该表的内容由操作系统管理。 虚拟内存作为缓存的工具概念上而言,虚拟内存被组织成为一个由存放在磁盘上的 N 个连续的字节大小的单元组成的数组,也就是字节数组。每个字节都有一个唯一的虚拟地址作为数组的索引。磁盘上活动的数组内容被缓存在主存中。在存储器结构中,较低层次上的磁盘的数据被分割成块,这些块作为和较高层次的主存之间的传输单元。主存作为虚拟内存的缓存。 虚拟内存被分割为大小固定的块,这些块叫虚拟页(Virtual Page,VP),类似的物理内存也有物理页(Physical Page, PP)。虚拟页有三种不同的状态: 未分配:VM 系统还未分配 (或者创建)的页。未分配的块没有任何数据和它们相关联,因此也就不占用任何磁盘空间。 已缓存:当前已缓存在物理内存中的已分配页。 未缓存:未缓存在物理内存中的已分配页。 为了有助于清晰理解存储层次结构中不同的缓存概念,我们将使用术语SRAM缓存来表示位于 CPU 和主存之间的 Ll、L2 和 L3 高速缓存,并且用术语 DRAM 缓存来表示虚拟内存系统的缓存,它在主存中缓存虚拟页。 在存储层次结构中,DRAM 缓存的位置对它的组织结构有很大的影响。回想一下,DRAM 比 SRAM 要慢大约 10 倍,而磁盘要比 DRAM 慢大约 100000 多倍。因此,DRAM 缓存中的不命中比起 SRAM 缓存中的不命中要昂贵得多。因此,与硬件对 SRAM 缓存相比,操作系统对 DRAM 缓存使用了更复杂精密的替换算法。(这些替换算法超出了我们的讨论范围)。最后,因为对磁盘的访问时间很长,DRAM 缓存总是使用写回,而不是直写。 页表虚拟内存系统可以完成以下这些功能, 判定一个虚拟页是否缓存在 DRAM 中的某个地方; 可以确定这个虚拟页存放在哪个物理页中; 如果不命中,系统必须判断这个虚拟页存放在磁盘的哪个位置,在物理内存中选择一个牺牲页,并将虚拟页从磁盘复制到 DRAM 中,替换这个牺牲页。 这些功能是由软硬件联合提供的,包括操作系统软件、MMU(内存管理单元)中的地址翻译硬件和一个存放在物理内存中叫做页表(page table)的数据结构。页表将虚拟页映射到物理页。每次地址翻译硬件将一个虚拟地址转换为物理地址时,都会读取页表。操作系统负责维护页表的内容,以及在磁盘与 DRAM 之间来回传送页。 图 9-4 展示了一个页表的基本组织结构。页表就是一个页表条目(Page Table Entry,PTE)的数组。虚拟地址空间中的每个页在页表中一个固定偏移量处都有一个 PTE。 PTE 由两部分组成: 有效位:表明了该虚拟页当前是否被缓存在 DRAM 中; 地址:表示 DRAM 中相应的物理页的起始位置,这个物理页中缓存了该虚拟页。 页命中与缺页l 当 CPU 访问已被缓存的地址时,就叫做页命中。如访问上图 VP2,虚拟地址索引到 PTE2,此时有效位为 1,地址翻译硬件就知道该地址被缓存了。 当 CPU 访问未被缓存的地址时,会导致缺页。如访问上图的 VP3,虚拟地址索引到 PTE3,此时有效位为 0,地址翻译硬件就知道该地址未被缓存,需要从磁盘中读取。 这时会触发一个缺页异常。缺页异常调用内核中的缺页异常处理程序,该程序会选择一个牺牲页,在此例中就是存放在 PP 3 中的 VP 4。如果 VP 4 已经被修改了,那么内核就会将它复制回磁盘。无论哪种情况,内核都会修改 VP 4 的页表条目,反映出 VP 4 不再缓存在主存中这一事实。 接下来,内核从磁盘复制 VP 3 到内存中的 PP 3,更新 PTE 3,随后返回。当异常处理程序返回时,它会重新启动导致缺页的指令,该指令会把导致缺页的虚拟地址重发送到地址翻译硬件。但是现在,VP 3 已经缓存在主存中了,那么页命中也能由地址翻译硬件正常处理了。图 9-7 展示了在缺页之后我们的示例页表的状态。 在虚拟内存的习惯说法中,块被称为页。在磁盘和内存之间传送页的活动叫做交换(swapping)或者页面调度(paging)。页从磁盘换入(或者页面调入)DRAM 和从 DRAM 换出(或者页面调出)磁盘。一直等待,直到最后时刻,也就是当有不命中发生时,才换入页面的这种策略称为按需页面调度(demand paging)。 虚拟内存作为内存管理的工具之前我们只讨论了一个页表的情况,但是实际上操作系统为每个进程都分配了一个独立的页表。多个虚拟页面可以映射到同一个共享物理页面上。 按需页面调度和独立的虚拟地址空间的结合,对系统中内存的使用和管理造成了深远的影响。特别地,VM 简化了链接和加载、代码和数据共享,以及应用程序的内存分配。 简化链接。独立的地址空间允许每个进程的内存映像使用相同的基本格式,而不管代码和数据实际存放在物理内存的何处。例如,一个给定的 Linux 系统上的每个进程都使用类似的内存格式。对于 64 位地址空间,代码段总是从虚拟地址 0x400000 开始。数据段跟在代码段之后,中间有一段符合要求的对齐空白。栈占据用户进程地址空间最高的部分,并向下生长。这样的一致性极大地简化了链接器的设计和实现,允许链接器生成完全链接的可执行文件,这些可执行文件是独立于物理内存中代码和数据的最终位置的。 简化加载。虚拟内存还使得容易向内存中加载可执行文件和共享对象文件。要把目标文件中 .text 和 .data 节加载到一个新创建的进程中,Linux 加载器为代码和数据段分配虚拟页,把它们标记为无效的(即未被缓存的),将页表条目指向目标文件中适当的位置。有趣的是,加载器从不从磁盘到内存实际复制任何数据。在每个页初次被引用时,要么是 CPU 取指令时引用的,要么是一条正在执行的指令引用一个内存位置时引用的,虚拟内存系统会按照需要自动地调入数据页。将一组连续的虚拟页映射到任意一个文件中的任意位置的表示法称作内存映射(memory mapping)。Linux 提供一个称为 mmap 的系统调用,允许应用程序自己做内存映射。 简化共享。独立地址空间为操作系统提供了一个管理用户进程和操作系统自身之间共享的一致机制。一般而言,每个进程都有自己私有的代码、数据、堆以及栈区域,是不和其他进程共享的。在这种情况中,操作系统创建页表,将相应的虚拟页映射到不连续的物理页面。 简化内存分配。虚拟内存为向用户进程提供一个简单的分配额外内存的机制。当一个运行在用户进程中的程序要求额外的堆空间时(如调用 malloc 的结果),操作系统分配一个适当数字(例如 k)个连续的虚拟内存页面,并且将它们映射到物理内存中任意位置的 k 个任意的物理页面。由于页表工作的方式,操作系统没有必要分配 k 个连续的物理内存页面。页面可以随机地分散在物理内存中。 虚拟内存作为内存保护的工具操作系统中的用户程序不应该修改只读的代码段,也不应该读取或者修改内核中的代码和数据结构或者访问私有的以及其他的进程的内存,如果无法对用户进程的内存访问进行限制,攻击者就可以访问和修改其他进程的内存影响系统的安全。 通过在页表中添加页面的保护属性,可以让操作系统在页面被访问时进行检查,如果页面被保护为只读,则操作系统会报错。 在图 9-10 这个示例中,每个 PTE 中已经添加了三个许可位。SUP 位表示进程是否必须运行在内核(超级用户)模式下才能访问该页。运行在内核模式中的进程可以访问任何页面,但是运行在用户模式中的进程只允许访问那些 SUP 为 0 的页面。READ 位和 WRITE 位控制对页面的读和写访问。例如,如果进程 i 运行在用户模式下,那么它有读 VP 0 和读写 VP 1 的权限。然而,不允许它访问 VP 2。 如果一条指令违反了这些许可条件,那么 CPU 就触发一个一般保护故障,将控制传递给一个内核中的异常处理程序。Linux shell 一般将这种异常报告为段错误(segmentation fault)。 地址翻译基本参数 符号 描述 $$\\small N=2^n$$ 虚拟地址空间中的地址数量 $$\\small M=2^m$$ 物理地址空间中的地址数量 $$\\small P=2^p$$ 页的大小(字节) 虚拟地址(VA)的组成部分 符号 描述 VPO 虚拟页面偏移量(字节) VPN 虚拟页号 TLBI TLB 索引 TLBT TLB 标记 物理地址(PA)的组成部分 符号 描述 PPO 物理页面偏移量(字节) PPN 物理页号 CO 缓冲块内的字节偏移量 CI 高速缓存索引 CT 高速缓存标记 图 9-12 展示了 MMU 如何利用页表来实现地址翻译。CPU 中的一个控制寄存器,页表基址寄存器(Page Table Base Register,PTBR)指向当前页表。$n$ 位的虚拟地址包含两个部分:一个 $p$ 位的虚拟页面偏移(Virtual Page Offset,VPO)和一个$\\small (n-p)$位的虚拟页号(Virtual Page Number,VPN)。MMU 利用 VPN 来选择适当的 PTE。例如,VPN 0 选择 PTE 0,VPN 1 选择 PTE 1,以此类推。将页表条目中物理页号(Physical Page Number,PPN)和虚拟地址中的 VP。串联起来,就得到相应的物理地址。注意,因为物理和虚拟页面都是 P 字节的,所以物理页面偏移(Physical Page Offset,PPO)和 VPO 是相同的。 图 9-13a 展示了当页面命中时,CPU 硬件执行的步骤。 第 1 步:处理器生成一个虚拟地址,并把它传送给 MMU。 第 2 步:MMU 生成 PTE 地址,并从高速缓存/主存请求得到它。 第 3 步:高速缓存/主存向 MMU 返回 PTE。 第 4 步:MMU 构造物理地址,并把它传送给高速缓存/主存。 第 5 步:高速缓存/主存返回所请求的数据字给处理器。 页面命中完全是由硬件来处理的,与之不同的是,处理缺页要求硬件和操作系统内核协作完成,如图 9-13b 所示。 第 1 - 3 步:和图 9-13a 中的第 1 步到第 3 步相同。 第 4 步:PTE 中的有效位是零,所以 MMU 触发了一次异常,传递 CPU 中的控制到操作系统内核中的缺页异常处理程序。 第 5 步:缺页处理程序确定出物理内存中的牺牲页,如果这个页面已经被修改了,则把它换出到磁盘。 第 6 步:缺页处理程序页面调入新的页面,并更新内存中的 PTE。 第 7 步:缺页处理程序返回到原来的进程,再次执行导致缺页的指令。CPU 将引起缺页的虚拟地址重新发送给 MMU。因为虚拟页面现在缓存在物理内存中,所以就会命中,在 MMU 执行了图 9-13b 中的步骤之后,主存就会将所请求字返回给处理器。 利用 TLB 加速地址翻译每次 CPU 访问一个虚拟地址,MMU 就必须查找 PTE,以便将虚拟地址翻译为物理地址。在最糟糕的情况下,这会要求从内存多取一次数据,代价是几十到几百个周期。如果 PTE 碰巧缓存在 L1 中,那么开销就下降到 1 个或 2 个周期。为了消除这样的开销,在 MMU 中包括了一个关于 PTE 的小的缓存,称为翻译后备缓冲器(Translation Lookaside Buffer,TLB)。 TLB 是一个小的、虚拟寻址的缓存,其中每一行都保存着一个由单个 PTE 组成的块。TLB 通常有高度的相联度。如图 9-15 所示,用于组选择和行匹配的索引和标记字段是从虚拟地址中的虚拟页号中提取出来的。如果 TLB 有$\\small T = 2^t$个组,那么 TLB 索引(TLBI)是由 VPN 的 $t$ 个最低位组成的,而 TLB 标记(TLBT)是由 VPN 中剩余的位组成的。 图 9-16a 展示了当 TLB 命中时(通常情况)所包括的步骤。这里的关键点是,所有的地址翻译步骤都是在芯片上的 MMU 中执行的,因此非常快。 第 1 步:CPU 产生一个虚拟地址。 第 2 - 3 步:MMU 从 TLB 中取出相应的 PTE。 第 4 步:MMU 将这个虚拟地址翻译成一个物理地址,并且将它发送到高速缓存/主存。 第 5 步:高速缓存/主存将所请求的数据字返回给 CPU。 当 TLB 不命中时,MMU 必须从 L1 缓存中取出相应的 PTE,如图 9-16b 所示。新取出的 PTE 存放在 TLB 中,可能会覆盖一个已经存在的条目。 多级页表32 位环境下,虚拟地址空间共 4GB。如果分成 4KB 一个页,那就是 1M 个页。每个页表项需要 4 个字节来存储,那么整个 4GB 空间的映射就需要 4MB 的内存来存储映射表。如果每个进程都有自己的映射表,100 个进程就需要 400MB 的内存。对于内核来讲,有点大了。 页表中所有页表项必须提前建好,并且要求是连续的。如果不连续,就没有办法通过虚拟地址里面的页号找到对应的页表项了。 那怎么办呢?我们可以试着将页表再分页,4G 的空间需要 4M 的页表来存储映射。我们把这 4M 分成 1K(1024)个 4K,每个 4K 又能放在一页里面,这样 1K 个 4K 就是 1K 个页,这 1K 个页也需要一个表进行管理,我们称为页目录表,这个页目录表里面有 1K 项,每项 4 个字节,页目录表大小也是 4K。 页目录有 1K 项,用 10 位就可以表示访问页目录的哪一项。这一项其实对应的是一整页的页表项,也即 4K 的页表项。每个页表项也是 4 个字节,因而一整页的页表项是 1K 个。再用 10 位就可以表示访问页表项的哪一项,页表项中的一项对应的就是一个页,是存放数据的页,这个页的大小是 4K,用 12 位可以定位这个页内的任何一个位置。 这样加起来正好 32 位,也就是用前 10 位定位到页目录表中的一项。将这一项对应的页表取出来共 1k 项,再用中间 10 位定位到页表中的一项,将这一项对应的存放数据的页取出来,再用最后 12 位定位到页中的具体位置访问数据。 你可能会问,如果这样的话,映射 4GB 地址空间就需要 4MB+4KB 的内存,这样不是更大 了吗?当然如果页是满的,当时是更大了,但是,我们往往不会为一个进程分配那么多内 存。比如说,上面图中,我们假设只给这个进程分配了一个数据页。如果只使用页表,也需要完 整的 1M 个页表项共 4M 的内存,但是如果使用了页目录,页目录需要 1K 个全部分配,占用内存 4K,但是里面只有一项使用了。到了页表项,只需要分配能够管理那个数据页的页表项页就可以了,也就是说,最多 4K,这样内存就节省多了 当然对于 64 位的系统,两级肯定不够了,就变成了四级目录,分别是全局页目录项 PGD(Page Global Directory)、上层页目录项 PUD(Page Upper Directory)、中间页目录项 PMD(Page Middle Directory)和页表项 PTE(Page Table Entry)。也就是一级页表,二级页表,三级页表,四级页表。","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Virtual Memory","slug":"Virtual-Memory","permalink":"http://example.com/tags/Virtual-Memory/"},{"name":"TLB","slug":"TLB","permalink":"http://example.com/tags/TLB/"},{"name":"内存管理","slug":"内存管理","permalink":"http://example.com/tags/%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86/"},{"name":"页表","slug":"页表","permalink":"http://example.com/tags/%E9%A1%B5%E8%A1%A8/"},{"name":"多级页表","slug":"多级页表","permalink":"http://example.com/tags/%E5%A4%9A%E7%BA%A7%E9%A1%B5%E8%A1%A8/"},{"name":"MMU","slug":"MMU","permalink":"http://example.com/tags/MMU/"}]},{"title":"C 语言 getopt() 函数的用法","slug":"C语言getopt-函数的用法","date":"2022-07-16T14:42:03.000Z","updated":"2022-10-15T03:14:29.130Z","comments":true,"path":"2022/07/16/C语言getopt-函数的用法/","link":"","permalink":"http://example.com/2022/07/16/C%E8%AF%AD%E8%A8%80getopt-%E5%87%BD%E6%95%B0%E7%9A%84%E7%94%A8%E6%B3%95/","excerpt":"","text":"在做CSAPP_LAB-Cache Lab时,实验要求对输入参数进行处理,如程序csim执行需要 4 个参数: 1./csim -s 4 -E 6 -b 4 -t <tracefile> 原先想通过字符串解析,一个个处理,但是看到了其他参考代码后发现了一个更简单的方法,可以通过getopt()函数来解析参数。 函数的功能:解析命令行参数。头文件 #include <unistd.h> 在学习函数前需要了解与该函数相关的四个变量: int opterr:控制是否输出错误;如果此变量的值非零,则 getopt 在遇到未知选项字符或缺少必需参数的选项时将错误消息打印到标准错误流 (终端)。该值默认为非零。如果将此变量设置为零,getopt 不会打印任何消息,但仍会返回问号?提示错误。 int optopt:保存未知的选项;当 getopt 遇到未知选项字符或缺少必需参数的选项时,它将该选项字符存储在此变量中。 int optind:指向下一个要处理的参数;此变量由 getopt 设置为要处理的 argv 数组的下一个元素的索引。一旦 getopt 找到所有选项参数,就可以使用此变量来确定其余非选项参数的开始位置。该变量的初始值为 1。 char * optarg:保存选项参数;对于那些接受参数的选项,此变量由 getopt 设置为指向选项参数的值。 函数原型: 1int getopt(int argc, char * const argv[], const char * options); 参数解析: 参数argc 和argv 是由main()传递的参数个数和内容。 options 参数是一个字符串,它指定对该程序有效的选项字符。此字符串中的选项字符后面可以跟一个冒号(:),表示它需要一个必需的参数,这个参数可以与选项连写也可以空格分开,如-a13 or -a 13。如果选项字符后跟两个冒号(::),则其参数是可选的,如果有参数,那么参数不能与选项分割,如只能写成-a13而不能写成-a 13;这是一个 GNU 扩展。 实例: 下面是一个示例,展示了通常如何使用 getopt。需要注意的关键点是: 通常,getopt 在循环中被调用。当 getopt 返回 -1 表示没有更多选项存在时,循环终止。 switch 语句用于调度 getopt 的返回值。在典型使用中,每种情况只设置一个稍后在程序中使用的变量。 第二个循环用于处理剩余的非选项参数。 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849#include <ctype.h>#include <stdio.h>#include <stdlib.h>#include <unistd.h>intmain (int argc, char **argv){ int aflag = 0; int bflag = 0; char *cvalue = NULL; int index; int c; opterr = 0; while ((c = getopt (argc, argv, "abc:")) != -1) switch (c) { case 'a': aflag = 1; break; case 'b': bflag = 1; break; case 'c': cvalue = optarg; break; case '?': if (optopt == 'c') fprintf (stderr, "Option -%c requires an argument.\\n", optopt); else if (isprint (optopt)) fprintf (stderr, "Unknown option `-%c'.\\n", optopt); else fprintf (stderr, "Unknown option character `\\\\x%x'.\\n", optopt); return 1; default: abort (); } printf ("aflag = %d, bflag = %d, cvalue = %s\\n", aflag, bflag, cvalue); for (index = optind; index < argc; index++) printf ("Non-option argument %s\\n", argv[index]); return 0;} 以下是一些示例,展示了该程序使用不同的参数组合打印的内容: 12345678910111213141516171819202122232425262728293031323334353637383940% testoptaflag = 0, bflag = 0, cvalue = (null)// 选项可以用空格分割% testopt -a -baflag = 1, bflag = 1, cvalue = (null)// 也可以连写% testopt -abaflag = 1, bflag = 1, cvalue = (null)// 必选参数,可以用空格分割% testopt -c fooaflag = 0, bflag = 0, cvalue = foo// 必选参数,可以连写% testopt -cfooaflag = 0, bflag = 0, cvalue = foo// 没有对应的选项% testopt arg1aflag = 0, bflag = 0, cvalue = (null)Non-option argument arg1// -a选项没有需要处理的参数,所以arg1无法处理% testopt -a arg1aflag = 1, bflag = 0, cvalue = (null)Non-option argument arg1% testopt -c foo arg1aflag = 0, bflag = 0, cvalue = fooNon-option argument arg1% testopt -a -- -baflag = 1, bflag = 0, cvalue = (null)Non-option argument -b% testopt -a -aflag = 1, bflag = 0, cvalue = (null)Non-option argument - 参考资料原来命令行参数处理可以这么写-getopt?_huangxiaohu_coder 的博客-CSDN 博客Linux 下 getopt() 函数的简单使用 - 青儿哥哥 - 博客园Using Getopt (The GNU C Library)","categories":[],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"}]},{"title":"解决 VS Code 终端使用 git bash 时中文乱码","slug":"解决VS-Code终端使用git-bash时中文乱码","date":"2022-07-16T13:59:50.000Z","updated":"2022-10-15T03:14:29.850Z","comments":true,"path":"2022/07/16/解决VS-Code终端使用git-bash时中文乱码/","link":"","permalink":"http://example.com/2022/07/16/%E8%A7%A3%E5%86%B3VS-Code%E7%BB%88%E7%AB%AF%E4%BD%BF%E7%94%A8git-bash%E6%97%B6%E4%B8%AD%E6%96%87%E4%B9%B1%E7%A0%81/","excerpt":"","text":"保留现场Windows 环境下,使用 VSCode 的终端时,中文显示为乱码,如使用git status命令查看修改文件时,中文文件名就无法正常显示: 探究原因因为终端被替换成了 git bash,它对所有非英文的字符进行了转义。 官方文档提到: 输出路径的命令(例如ls-files、diff)将通过将路径名括在双引号中并以与 C 转义控制字符相同的方式用反斜杠转义这些字符来引用路径名中的异常字符(例如\\t用于 TAB, \\n 表示LF,\\\\表示反斜杠)或值大于 0x80 的字节(例如,八进制 \\302\\265 表示 UTF-8 中的“micro”)。如果此变量设置为 false,则高于 0x80 的字节不再被视为异常。无论此变量的设置如何,双引号、反斜杠和控制字符总是被转义。一个简单的空格字符不被认为是异常的。许多命令可以使用 -z 选项完全逐字输出路径名。默认值是 true。 解决方法命令行输入,取消转义: 1git config --global core.quotepath false","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"NOC(net-on-chip) 总线互联构架","slug":"NOC-net-on-chip-总线互联构架","date":"2022-07-12T15:13:51.000Z","updated":"2022-10-15T03:14:29.367Z","comments":true,"path":"2022/07/12/NOC-net-on-chip-总线互联构架/","link":"","permalink":"http://example.com/2022/07/12/NOC-net-on-chip-%E6%80%BB%E7%BA%BF%E4%BA%92%E8%81%94%E6%9E%84%E6%9E%B6/","excerpt":"","text":"技术背景 转载自^[片上网络(NoC)技术的背景、意义以及发展_碎碎思的博客-CSDN 博客] 在过去的几十年里,集成电路制造工艺技术、封装与测试技术、设计方法学和 EDA 工具等微电子相关技术始终保持着快速的发展。根据国际半导体技术发展路线图(International Technology Roadmap for Semiconductors, ITRS)预测,到 2024 年 IC 制造技术将达到 2 nm。但是,全局互连线的性能提升程度明显低于晶体管性能提升程度。受到亚阈值漏电流功耗、动态功耗、器件可靠性以及全局互连线等影响,通过提升单个处理器核的性能来提升系统整体性能已变得非常难以实现,同时芯片设计的难度和复杂度也在进一步增加。片上系统(System on Chip, SoC)具有集成度高、功耗低、成本低、体积小等优点,已经成为超大规模集成电路系统设计的主流方向。随着片上系统 SoC 的应用需求越来越丰富、越来越复杂,片上多核 MPSoC (MultiprocessorSystem on Chip, MPSoC) 已经成为发展的必然趋势,同时 MPSoC 上集成的 IP 核数量也将会按照摩尔定律继续发展。目前,MPSoC 已经逐渐应用于网络通信、多媒体等嵌入式电子设备中。半导体工艺技术的快速发展为集成电路设计提供了很大的发展空间,同时也带来了一系列新的问题和挑战,如芯片的性能、功耗、可靠性、可扩展性等等。 随着系统性能需求越来越高,处理器核之间的互连架构必须能够提供具有较低延迟和高吞吐率的服务,并且具有良好的可扩展性。传统的基于总线的集中式互连架构已经难以满足现今系统的性能需求,而基于报文交换的片上网络(Network on Chip, NoC)逐渐成为片上多核间通讯的首选互连架构。在 NoC 中,路由节点之间通过局部互连线相连接,每一个路由节点通过网络接口 NI 与一个本地 IP 核相连接,源路由节点和目的路由节点之间的数据通讯需要经过多个跳步来实现。因此,NoC 技术的出现使得片上系统 SoC 的设计也将从以计算为中心逐渐过渡到以通讯为中心。 传统的 SoC 系统采用总线互连结构,如 所示。虽然人们已经提出了很多改进的总线结构,例如将共享总线改进为桥接多总线结构、层次化总线结构等更复杂的结构。但是当进入 MPSoC 时代,单芯片上集成的处理器核数越来越多时,总线结构在通讯性能、功耗、全局时钟同步、信号完整性以及信号可靠性等方面面临着巨大的挑战,这些复杂的改进型总线结构仍无法解决片上多核间通信所面临的问题。因此,MPSoC 上多核间的通讯问题已经成为制约系统性能提升的主要瓶颈。 NoC 的概念是由 Agarwal(1999 年)、Guerrier 和 Greiner(2000 年)、Dally 和 Towles(2001 年)、Benini 和 Micheli(2002 年)、Jantsch 和 Tenhunen(2003 年)等人逐步提出的。目前,对于 NoC 还没有一个统一的定义,大多数 NoC 研究者认为 NoC 是 SoC 系统的通讯子集,并且应该引入互联网络技术来解决片上多核的通讯问题。 NoC 的意义 转载自^[片上网络(NoC)技术的背景、意义以及发展_碎碎思的博客-CSDN 博客] 随着单芯片上集成的处理器核数越来越多,片上互连架构经历了从专用互连线,Bus,Crossbar 到 NoC。NoC 借鉴了分布式计算系统的通讯方式,采用数据路由和分组交换技术替代传统的总线结构,从体系结构上解决了 SoC 总线结构由于地址空间有限导致的可扩展性差,分时通讯引起的通讯效率低下,以及全局时钟同步引起的功耗和面积等问题。与传统的总线互连技术相比,片上网络具有如下优点: 第一,网络带宽。总线结构互连多个 IP 核,共享一条数据总线,其缺点是同一时间只能有一对 IP 进行通信。随着系统规模的逐渐增大,总线结构的通信效率必然成为限制系统性能提升的瓶颈。片上网络具有非常丰富的信道资源,为系统提供了一个网络化的通信平台。网络中的多个节点可以同时利用网络中的不同物理链路进行信息交换,支持多个 IP 核并发地进行数据通信。随着网络规模的增大,网络上的信道资源也相应增多。因此,NoC 技术相对于 Bus 互连技术具有较高的带宽,以及更高的通信效率。当并发进行数据通信时网络会产生竞争,即会存在请求同一条物理链路的节点对。NoC 的路由节点通过分时复用物理链路来解决竞争,与 Bus 结构相比,NoC 能够降低竞争发生的概率。 第二,可扩展性和设计成本。总线结构需要针对不同的系统需求单独进行设计,当系统功能扩展时,需要对现有的设计方案重新设计,从而严重影响设计的周期和资本投入。NoC 中每个路由节点和本地 IP 核通过网络接口(NetworkInterface, NI)相连,当系统需要升级扩展新功能时,只需要将新增加的处理器核通过网络接口 NI 接入到网络中的路由节点即可,无需重新设计网络。因此,片上网络具有良好的可扩展性。片上网络作为一个独立的片上互连结构,能够满足不同系统的应用需求,当网络中节点数量增加时,仅需要按照相应的拓扑结构规则继续增大网络的规模即可,缩短了产品的设计周期,节约了设计成本。 第三,功耗。随着 SoC 规模的不断增大,总线上每次信息交互都需要驱动全局互连线,因此总线结构所消耗的功耗将显著增加,并且随着集成电路工艺的不断发展,想要保证全局时钟同步也将变得难以实现。而在 NoC 中,信息交互消耗的功耗与进行通讯的路由节点之间的距离密切相关,距离较近的两个节点进行通讯时消耗的功耗就比较低。 第四,信号完整性和信号延迟。随着集成电路特征尺寸的不断减小,电路规模的不断增大,互连线的宽度和间距也在不断地减小,线间耦合电容相应增大,长的全局并行总线会引起较大的串扰噪声,从而影响信号的完整性以及信号传输的正确性。同时,互连线上的延迟将成为影响信号延迟的主要因素,总线结构全局互连线上的延迟将大于一个时钟周期,从而使得时钟的偏移很难管理。 第五,全局同步。总线结构采用全局同步时钟,随着芯片集成度的提高,芯片的工作频率也在不断提高,在芯片内会形成很庞大的时钟树,因此很难实现片上各个模块的全局同步时钟。采用时钟树(Clock Tree)优化的方法可以改善由时钟翻转引起的时钟偏差和时钟抖动,但同步时钟网络所产生的动态功耗甚至可达总功耗的 40% 以上。为了提高系统的时钟频率,只能对全局互连线采用分布式流水线结构,或者采用全局异步局部同步(Global Asynchronous Local Synchronous,GALS)的时钟策略。","categories":[],"tags":[{"name":"NOC","slug":"NOC","permalink":"http://example.com/tags/NOC/"},{"name":"SoC","slug":"SoC","permalink":"http://example.com/tags/SoC/"}]},{"title":"构建和测试 RISC-V 架构下启用 ACPI 的内核","slug":"构建和测试RISC-V架构下启用ACPI的内核","date":"2022-07-12T07:06:51.000Z","updated":"2022-10-15T03:14:29.708Z","comments":true,"path":"2022/07/12/构建和测试RISC-V架构下启用ACPI的内核/","link":"","permalink":"http://example.com/2022/07/12/%E6%9E%84%E5%BB%BA%E5%92%8C%E6%B5%8B%E8%AF%95RISC-V%E6%9E%B6%E6%9E%84%E4%B8%8B%E5%90%AF%E7%94%A8ACPI%E7%9A%84%E5%86%85%E6%A0%B8/","excerpt":"","text":"参考自PoC : How to build and test ACPI enabled kernel · riscv-non-isa/riscv-acpi Wiki 准备环境及工具链 安装 RISC-V 工具链,需下载原发行版。好在 apt 可以安装。 如果报错:riscv64-linux-gnu-gcc: error: unrecognized command line option ‘-mno-relax’; did you mean ‘-Wno-vla’?,多半是工具链原因,请按照以下方法安装!!! 12sudo apt remove gcc-riscv64-linux-gnusudo apt install gcc-8-riscv64-linux-gnu 安装必要的三方库,以下为Ubuntu下的命令,其他平台可以参考这个文档。 123sudo apt install autoconf automake autotools-dev curl libmpc-dev libmpfr-dev libgmp-dev \\ gawk build-essential bison flex texinfo gperf libtool patchutils bc \\ zlib1g-dev libexpat-dev git 下载源码可能无法一次搭建成功,一些环境变量会经常用到,所以干脆把所有环境变量放到.bashrc。 12345678vim ~/.bashrc# 添加以下内容export WORK_DIR=~/riscv64-acpiexport GCC5_RISCV64_PREFIX=riscv64-unknown-elf-export MAINSPACE=~/riscv64-acpi/tianocoreexport PACKAGES_PATH=$MAINSPACE/edk2:$MAINSPACE/edk2-platformsexport EDK_TOOLS_PATH=$MAINSPACE/edk2/BaseTools 首先,创建一个工作目录,我们将在其中下载并构建所有源代码。 1234source ~/.bashrcWORK_DIR=$PWD/riscv64-acpimkdir -p $WORK_DIRcd $WORK_DIR 然后下载所有需要的源,它们是:qemu、opensbi、edk2、edk2-platforms、linux。 下载地址更换成了加速镜像源,原来地址下载太慢,容易中断。下载地址更换成了加速镜像源,原来地址下载太慢,容易中断。有两个项目包含子模块,下载容易出错,所以--depth=1舍弃了多余的提交记录。 12345git clone --branch dev-upstream https://hub.fastgit.xyz/ventanamicro/qemu.git qemugit clone --branch dev-upstream https://hub.fastgit.xyz/ventanamicro/opensbi.git opensbigit clone --branch dev-upstream --recurse-submodules --depth=1 https://hub.fastgit.xyz/ventanamicro/edk2.git tianocore/edk2git clone --branch dev-upstream --recurse-submodules --depth=1 https://hub.fastgit.xyz/ventanamicro/edk2-platforms.git tianocore/edk2-platformsgit clone --branch dev-upstream https://hub.fastgit.xyz/ventanamicro/linux.git linux 编译构建QEMU123cd $WORK_DIR/qemu./configure --target-list=riscv64-softmmumake -j $(nproc) OPENSBI 此处我们使用以riscv64-unknown-elf-为前缀的版本,则表示该版本GCC工具链会使用newlib作为C运行库。原文使用riscv64-linux-gnu-,表示GCC工具链会使用Linux的Glibc作为C运行库。但是本人未编译成功。故后面编译工具均使用riscv64-unknown-elf-,与原文不同。 12cd $WORK_DIR/opensbimake ARCH=riscv CROSS_COMPILE=riscv64-unknown-elf- make PLATFORM=generic EDK2 固件 此处原文里设置了一些环境变量在开头我们设置了,请不要重新设置,尤其不能export WORKSPACE=pwd,因为与源码脚本的WORKSPACE冲突。 12345678cd $WORK_DIR/tianocoresource edk2/edksetup.shmake -C edk2/BaseTools cleanmake -C edk2/BaseToolsmake -C edk2/BaseTools/Source/Csource edk2/edksetup.sh BaseTools# 原文使用 -buildtarget RELEASE。但是提示 Not supported target RELEASEbuild -a RISCV64 -b DEBUG -D FW_BASE_ADDRESS=0x80200000 -D EDK2_PAYLOAD_OFFSET -p Platform/Qemu/RiscvVirt/RiscvVirt.dsc -t GCC5 ERROR StoreCurrentConfiguration:7: no such file or directory: /home/user/riscv64-acpi/tianocore/Conf/BuildEnv.sh 不要设置export WORKSPACE=pwd!!!如果所有方法都不可行,直接把路径写死export CONF_PATH=$WORK_DIR/tianocore/edk2/Conf uuid/uuid.h: No such file or directory 1sudo apt install uuid-dev Not supported target RELEASE 12# 将build命令改为如下,使用DEBUG版本。build -a RISCV64 -b DEBUG -D FW_BASE_ADDRESS=0x80200000 -D EDK2_PAYLOAD_OFFSET -p Platform/Qemu/RiscvVirt/RiscvVirt.dsc -t GCC5 Linux123cd $WORK_DIR/linuxmake ARCH=riscv CROSS_COMPILE=riscv64-unknown-elf- defconfigmake ARCH=riscv CROSS_COMPILE=riscv64-unknown-elf- -j $(nproc) Rootfs您可以使用您选择的任何 rootfs。此示例使用 buildroot。 此步耗时较久,与网络环境有关,如果网络不好可能按小时算。容易中断,需要重新下载。 12345cd $WORK_DIR/git clone https://hub.fastgit.xyz/buildroot/buildroot.gitcd $WORK_DIR/buildrootmake qemu_riscv64_virt_defconfigmake rootfs-cpio 创建 EFI 分区并复制文件1234567891011fallocate -l 512M efi.imgsgdisk -n 1:34: -t 1:EF00 $WORK_DIR/efi.imgsudo losetup -fP $WORK_DIR/efi.imgloopdev=`losetup -j $WORK_DIR/efi.img | awk -F: '{print $1}'`efi_part="$loopdev"p1sudo mkfs.msdos $efi_partmkdir -p /tmp/mntsudo mount $efi_part /tmp/mnt/sudo cp $WORK_DIR/linux/arch/riscv/boot/Image /tmp/mnt/sudo umount /tmp/mntsudo losetup -D $loopdev 运行使用 virtio-blk 磁盘 原文参数-drive file=$WORK_DIR/buildroot/output/images/rootfs.ext2,format=raw,id=hd0需要更改如下。因为在编译 Rootfs 时的命令是make rootfs-cpio所以生成的是rootfs.cpio。无法找到rootfs.ext2 12345678910$WORK_DIR/qemu/build/qemu-system-riscv64 -nographic \\-machine virt,aclint=on,aia=aplic-imsic,acpi=on -cpu rv64,sscofpmf=true -smp 8 -m 2G \\-bios $WORK_DIR/opensbi/build/platform/generic/firmware/fw_jump.elf \\-kernel $WORK_DIR/tianocore/Build/RiscvVirt/DEBUG_GCC5/FV/RISCVVIRT.fd \\-drive file=$WORK_DIR/buildroot/output/images/rootfs.cpio,format=raw,id=hd0 \\-device virtio-blk-device,drive=hd0 \\-drive file=$WORK_DIR/efi.img,format=raw,id=hd1 \\-device virtio-blk-device,drive=hd1 \\-device virtio-net-device,netdev=usernet \\-netdev user,id=usernet,hostfwd=tcp::9990-:22 ERROR 无法找到rootfs.ext2 12345# 因为在编译 Rootfs 时的命令是 make rootfs-cpio 所以生成的是 rootfs.cpio# 原文参数-drive file=$WORK_DIR/buildroot/output/images/rootfs.ext2,format=raw,id=hd0 \\# 修改为-drive file=$WORK_DIR/buildroot/output/images/rootfs.cpio,format=raw,id=hd0 \\ 无法找到RISCVVIRT.fd 12345# 因为编译 EDK2 固件时,参数是-b DEBUG 版本,原文是 RELEASE 版本,这两个版本路径不一样,所以找不到# 原文参数-kernel $WORK_DIR/tianocore/Build/RiscvVirt/RELEASE_GCC5/FV/RISCVVIRT.fd \\# 修改为-kernel $WORK_DIR/tianocore/Build/RiscvVirt/DEBUG_GCC5/FV/RISCVVIRT.fd \\ At EFI Shell: 1Shell> fs0:\\Image root=/dev/vdb console=ttyS0 rootwait earlycon 使用 virtio-scsi 磁盘123456789101112$WORK_DIR/qemu/build/qemu-system-riscv64 -nographic \\-machine virt,aclint=on,aia=aplic-imsic,acpi=on -cpu rv64,ssofpmf=true -smp 8 -m 2G \\-bios $WORK_DIR/opensbi/build/platform/generic/firmware/fw_jump.elf \\-kernel $WORK_DIR/tianocore/Build/RiscvVirt/DEBUG_GCC5/FV/RISCVVIRT.fd \\-device virtio-scsi-pci,id=scsi0,num_queues=4 \\-device scsi-hd,drive=drive0,bus=scsi0.0,channel=0,scsi-id=0,lun=0 \\-drive file=$WORK_DIR/buildroot/output/images/rootfs.cpio,format=raw,if=none,id=drive0 \\-device virtio-scsi-pci,id=scsi1,num_queues=4 \\-device scsi-hd,drive=drive1,bus=scsi0.0,channel=0,scsi-id=1,lun=0 \\-drive file=$WORK_DIR/efi.img,format=raw,if=none,id=drive1 \\-device virtio-net-device,netdev=usernet \\-netdev user,id=usernet,hostfwd=tcp::9990-:22 At EFI Shell: 1Shell> fs0:\\Image root=/dev/sda console=ttyS0 rootwait earlycon","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"RISC-V","slug":"RISC-V","permalink":"http://example.com/tags/RISC-V/"},{"name":"ACPI","slug":"ACPI","permalink":"http://example.com/tags/ACPI/"},{"name":"Kernel","slug":"Kernel","permalink":"http://example.com/tags/Kernel/"},{"name":"内核","slug":"内核","permalink":"http://example.com/tags/%E5%86%85%E6%A0%B8/"}]},{"title":"CSAPP-LAB-Cache Lab","slug":"CSAPP-LAB-Cache-Lab","date":"2022-07-11T01:55:39.000Z","updated":"2022-10-15T03:14:29.117Z","comments":true,"path":"2022/07/11/CSAPP-LAB-Cache-Lab/","link":"","permalink":"http://example.com/2022/07/11/CSAPP-LAB-Cache-Lab/","excerpt":"","text":"预备知识开始这个实验前,需要学习《CSAPP 第六章-存储器层次结构》的相关内容,与缓存相关的内容,我也做了相关的CPU Cache 高速缓存学习记录可以参考。 实验相关的文件可以从CS:APP3e, Bryant and O’Hallaron下载。 其中, README:介绍实验目的和实验要求,以及实验的相关文件。需要注意的是,必须在 64-bit x86-64 system 上运行实验。需要安装 Valgrind 工具。 Writeup:实验指导。 Release Notes:版本发布信息。 Self-Study Handout:需要下载的压缩包,里面包含了待修改的源码文件等。 下载 Self-Study Handout 并解压,得到如下文件: 1234567891011121314151617├── cachelab.c # 一些辅助函数,如打印输出等,不需要修改├── cachelab.h # 同上├── csim.c # 需要完善的主文件,需要在这里模拟Cache├── csim-ref # 已经编译好的程序,我们模拟的Cache需要与这个程序运行的结果保持一致├── driver.py # 驱动程序,运行 test-csim 和 test-trans├── Makefile # 用来编译csim程序├── README # ├── test-csim # 测试缓存模拟器├── test-trans.c # 测试转置功能├── tracegen.c # test-trans 辅助程序├── traces # test-csim.c 使用的跟踪文件│ ├── dave.trace│ ├── long.trace│ ├── trans.trace│ ├── yi2.trace│ └── yi.trace└── trans.c Part A —— Writing A Cache Simulator在 Part A,我们将在 csim.c 中编写一个缓存模拟器,它将 valgrind 内存跟踪作为输入,在此跟踪上模拟高速缓存的命中/未命中行为,并输出命中、未命中和驱逐的总数。 这里的输入由valgrind通过以下命令生成的: 1valgrind --log-fd=1 --tool=lackey -v --trace-mem=yes ls -l --log-fd=1表示将输出输出到标准输出;--tool=lackey:Lackey 是一个简单的 Valgrind 工具,可进行各种基本程序测量;--trace-mem=yes:Lackey 的一个参数,启用后,Lackey 会打印程序几乎所有内存访问的大小和地址;ls -l:是一个简单的程序,可以查看当前目录下的文件列表。也就是检测ls -l程序在运行时访问内存的情况。 执行结果像下面的形式: 1234567891011# [space]operation address,sizeI 0400639c,4 L 1ffeffec00,8I 040063a0,2 S 1ffeffea50,8I 040063a2,4 L 1ffeffebf0,8I 040063a6,3I 040063a9,3 L 1ffeffebf8,4I 040063ac,7 操作字段表示内存访问的类型:I表示指令加载,L表示数据加载,S表示数据存储,M表示数据修改(即,数据加载后跟数据存储) )。每个I之前都没有空格。每个M、L和S之前总是有一个空格。地址字段指定一个 64 位的十六进制内存地址。 size 字段指定操作访问的字节数。 了解这些基础后,我们最主要的是要明确,我们需要实现一个什么样的程序,这个程序具体有哪些参数,怎么执行的。csim-ref是已经完成的可执行文件,它的用法是 1./csim-ref [-hv] -s <s> -E <E> -b <b> -t <tracefile> -h:打印帮助信息; -v:显示详细信息,如是 I,L 还是 M; -s <s>:组索引位数($S=2^{s}$组个数); -E <E>:关联性(每组的行数); -b <b>:块位数($B=2^{b}$ 是块大小); -t <tracefile>:valgrind 生成的文件; 如: 12./csim-ref -s 4 -E 1 -b 4 -t traces/yi.tracehits:4 misses:5 evictions:3 如果显示详细信息可以执行: 123456789./csim-ref -v -s 4 -E 1 -b 4 -t traces/yi.traceL 10,1 missM 20,1 miss hitL 22,1 hitS 18,1 hitL 110,1 miss evictionL 210,1 miss evictionM 12,1 miss eviction hithits:4 misses:5 evictions:3 我们的目的就是要完善csim.c,使其能够使用上面相同的参数,得到与csim-ref相同的结果。Cache Lab Implementa/on and Blocking这份 PPT 里有一些实验指导,可以参考。首先需要解决的就是如何处理输入的参数,我们可以使用 PPT 里提到的getopt库来解决。 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161#include <stdbool.h>#include <string.h>#include "cachelab.h"#include "getopt.h"static int S; // 组个数static int s; // 组占的位数static int E;static int B;static int hits = 0;static int misses = 0;static int evictions = 0;typedef struct _CacheLine { unsigned tag; struct _CacheLine *next; struct _CacheLine *prev;} CacheLine;typedef struct _Cache { CacheLine *head; CacheLine *tail; int *size;} Cache;static Cache *cache;void parse_option(int argc, char **argv, char **fileName){ int option; while ((option = getopt(argc, argv, "s:E:b:t:")) != -1) { switch (option) { case 's': s = atoi(optarg); // 传入的参数为占用的bit,需要转换为10进制 S = 1 << s; case 'E': E = atoi(optarg); case 'b': B = atoi(optarg); case 't': strcpy(*fileName, optarg); } }}void initialize_cache(){ cache = malloc(S * sizeof(*cache)); for (int i = 0; i < S; i++) { cache[i].head = malloc(sizeof(CacheLine)); cache[i].tail = malloc(sizeof(CacheLine)); cache[i].head->next = cache[i].tail; cache[i].tail->prev = cache[i].head; (cache[i].size) = (int *)malloc(sizeof(int)); *(cache[i].size) = 0; }}/*! * @breif Add a new CacheLine to the Cache first line * @param nodeToDel CacheLine to be deleted * @param curLru Current Cache */void insert_first_line(CacheLine *node, Cache *curLru){ node->next = curLru->head->next; node->prev = curLru->head; curLru->head->next->prev = node; curLru->head->next = node; *(curLru->size) = *(curLru->size) + 1;}void evict(CacheLine *nodeToDel, Cache *curLru){ nodeToDel->next->prev = nodeToDel->prev; nodeToDel->prev->next = nodeToDel->next; *(curLru->size) = *(curLru->size) - 1;}void update(unsigned address){ unsigned int mask = 0xFFFFFFFF; unsigned int maskSet = mask >> (32 - s); // 取出组索引 unsigned int targetSet = ((maskSet) & (address >> B)); // 取出标记 unsigned int targetTag = address >> (s + B); Cache curLru = cache[targetSet]; // 查找是否存与当前标记位相同的缓存行 CacheLine *cur = curLru.head->next; bool found = 0; while (cur != curLru.tail) { if (cur->tag == targetTag) { found = true; break; } cur = cur->next; } if (found) { hits++; evict(cur, &curLru); insert_first_line(cur, &curLru); printf("> hit!, set: %d \\n", targetSet); } else { CacheLine *newNode = malloc(sizeof(CacheLine)); newNode->tag = targetTag; if (*(curLru.size) == E) { // 如果缓存已满,则删除最后一个缓存行 evict(curLru.tail->prev, &curLru); insert_first_line(newNode, &curLru); evictions++; misses++; printf("> evic && miss set:%d\\n", targetSet); } else { misses++; insert_first_line(newNode, &curLru); printf("> miss %d\\n", targetSet); } }}void cache_simulate(char *fileName){ // 分配并初始化S组缓存 initialize_cache(); FILE *file = fopen(fileName, "r"); char op; unsigned int address; int size; while (fscanf(file, " %c %x,%d", &op, &address, &size) > 0) { printf("%c, %x %d\\n", op, address, size); switch (op) { case 'L': update(address); break; case 'M': update(address); case 'S': update(address); break; } }}int main(int argc, char **argv){ char *fileName = malloc(100 * sizeof(char)); parse_option(argc, argv, &fileName); cache_simulate(fileName); printSummary(hits, misses, evictions); return 0;}","categories":[{"name":"CSAPP-Lab","slug":"CSAPP-Lab","permalink":"http://example.com/categories/CSAPP-Lab/"}],"tags":[{"name":"Cache","slug":"Cache","permalink":"http://example.com/tags/Cache/"},{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"CSAPP","slug":"CSAPP","permalink":"http://example.com/tags/CSAPP/"}]},{"title":"CPU Cache 高速缓存","slug":"CPU-Cache高速缓存","date":"2022-07-10T02:43:17.000Z","updated":"2022-10-15T03:14:29.078Z","comments":true,"path":"2022/07/10/CPU-Cache高速缓存/","link":"","permalink":"http://example.com/2022/07/10/CPU-Cache%E9%AB%98%E9%80%9F%E7%BC%93%E5%AD%98/","excerpt":"","text":"存储器的层次结构 从 Cache、内存,到 SSD 和 HDD 硬盘,一台现代计算机中,就用上了所有这些存储器设备。其中,容量越小的设备速度越快,而且,CPU 并不是直接和每一种存储器设备打交道,而是每一种存储器设备,只和它相邻的存储设备打交道。比如,CPUCache 是从内存里加载而来的,或者需要写回内存,并不会直接写回数据到硬盘,也不会直接从硬盘加载数据到 CPUCache 中,而是先加载到内存,再从内存加载到 Cache 中。 这样,各个存储器只和相邻的一层存储器打交道,并且随着一层层向下,存储器的容量逐层增大,访问速度逐层变慢,而单位存储成本也逐层下降,也就构成了我们日常所说的存储器层次结构。 高速缓存缓存不是 CPU 的专属功能,可以把它当成一种策略,任何时候想要增加数据传输性能,都可以通过加一层缓存试试。 存储器层次结构的中心思想是,对于每个$k$,位于$k$层的更快更小的存储设备作为位于$k+1$层的更大更慢的存储设备的缓存。下图展示了存储器层次结构中缓存的一般性概念。 数据总是以块block为单位,在层与层之间来回复制。 说回高速缓存,按照摩尔定律,CPU 的访问速度每 18 个月便会翻一翻,相当于每年增长 60%。内存的访问速度虽然不断增长,却远没有那么快,每年只增长 7% 左右。这样就导致 CPU 性能和内存访问的差距不断拉大。为了弥补两者之间差异,现代 CPU 引入了高速缓存。 CPU 的读(load)实质上就是从缓存中读取数据到寄存器(register)里,在多级缓存的架构中,如果缓存中找不到数据(Cache miss),就会层层读取二级缓存三级缓存,一旦所有的缓存里都找不到对应的数据,就要去内存里寻址了。寻址到的数据首先放到寄存器里,其副本会驻留到 CPU 的缓存中。 CPU 的写(store)也是针对缓存作写入。并不会直接和内存打交道,而是通过某种机制实现数据从缓存到内存的写回(write back)。 缓存到底如何与 CPU 和主存数据交换的?CPU 如何从缓存中读写数据的?缓存中没有读的数据,或者缓存写满了怎么办?我们先从 CPU 如何读取数据说起。 缓存读取CPU 发起一个读取请求后,返回的结果会有如下几种情况: 缓存命中 (cache hit)要读取的数据刚好在缓存中,叫做缓存命中。 缓存不命中 (cache miss)发送缓存不命中,缓存就得执行一直放置策略(placement policy),比如 LRU。来决定从主存中取出的数据放到哪里。 强制性不命中(compulsory miss)/冷不命中(cold miss):缓存中没有要读取的数据,需要从主存读取数据,并将数据放入缓存。 冲突不命中(conflict miss):缓存中有要读的数据,在采取放置策略时,从主存中取数据放到缓存时发生了冲突,这叫做冲突不命中。 高速缓存存储器组织结构整个 Cache 被划分为 1 个或多个组 (Set),$S$ 表示组的个数。每个组包含 1 个或多个缓存行(Cache line),$E$ 表示一个组中缓存行的行数。每个缓存行由三部分组成:有效位(valid),标记位(tag),数据块(cache block)。 有效位:该位等于 1,表示这个行数据有效。 标记位:唯一的标识了存储在高速缓存中的块,标识目标数据是否存在当前的缓存行中。 数据块:一部分内存数据的副本。 Cache 的结构可以由元组$(S,E,B,m)$表示。不包括有效位和标记位。Cache 的大小为 $C=S \\times E \\times B$. 接下来看看 Cache 是如何工作的,当 CPU 执行数据加载指令,从内存地址 A 读取数据时,根据存储器层次原理,如果 Cache 中保存着目标数据的副本,那么就立即将数据返回给 CPU。那么 Cache 如何知道自己保存了目标数据的副本呢? 假设目标地址的数据长度为$m$位,这个地址被参数 $S$ 和 $B$ 分成了三个字段: 首先通过长度为$s$的组索引,确定目标数据保存在哪一个组 (Set) 中,其次通过长度为$t$的标记,确定在哪一行,需要注意的是此时有效位必须等于 1,最后根据长度为$b$的块偏移,来确定目标数据在数据块中的确切位置。 Q:既然读取 Cache 第一步是组选择,为什么不用高位作为组索引,而使用中间的为作为组索引?A:如果使用了高位作索引,那么一些连续的内存块就会映射到相同的高速缓存块。如图前四个块映射到第一个缓存组,第二个四个块映射到第二个组,依次类推。如果一个程序有良好的空间局部性,顺序扫描一个数组的元素,那么在任何时候,缓存中都只保存在一个块大小的数组内容。这样对缓存的使用率很低。相比而言,如果使用中间的位作为组索引,那么相邻的块总是映射到不同的组,图中的情况能够存放整个大小的数组片。 直接映射高速缓存 Direct Mapped Cache根据每个组的缓存行数 $E$ 的不同,Cache 被分为不同的类。每个组只有一行$E=1$的高速缓存被称为直接映射高速缓存(direct-mapped cache)。 当一条加载指令指示 CPU 从主存地址 A 中读取一个字 w 时,会将该主存地址 A 发送到高速缓存中,则高速缓存会根据组选择,行匹配和字抽取三步来判断地址 A 是否命中。 组选择(set selection):根据组索引值来确定属于哪一个组,如图中索引长度为 5 位,可以检索 32 个组 ($2^5=32$)。当$s=0$时,此时组选择的结果为set 0,当$s=1$时,此时组选择的结果为set 1。 **行匹配 (line match)**:首先看缓存行的有效位,此时有效位为 1,表示当前数据有效。然后对比缓存行的标记0110与地址中的标记0110是否相等,如果相等,则表示目标数据在当前的缓存行中(缓存命中)。如果不一致或者有效位为 0,则表示目标数据不在当前的缓存行中(缓存不命中)。如果命中,就可以进行下一步字抽取。 **字抽取 (word extraction)**:根据偏移量$b$确定目标数据的确切位置,通俗来说就是从数据块的什么位置开始抽取位置。如当偏移块等于100时,表示目标数据起始地址位于字节 4 处。 下面通过一个例子来解释清除这个过程。假设我们有一个直接映射高速缓存,描述为$(S,E,B,m) = (4,1,2,4)$。换句话说,高速缓存有 4 个组,每个组 1 行,每个数据块 2 个字节,地址长度为 4 位。 从图中可以看出,8 个内存块,但只有 4 个高速缓存组,所以会有多个块映射到同一个高速缓存组中。例如,块 0 和块 4 都会被映射到组 0。 下面我们来模拟当 CPU 执行一系列读的时候,高速缓存的执行情况,我们假设每次 CPU 读 1 个字节的字。 读地址 0(0000) 的字: 读地址 1(0001) 的字: 读地址 13(1101) 的字: 读地址 8(1000) 的字: 读地址 0(0000) 的字: 组相联高速缓存 Set Associative Cache由于直接映射高速缓存的组中只有一行,所以容易发生冲突不命中。组相联高速缓存 (Set associative cache) 运行有多行缓存行。但是缓存行最大不能超过 $C/B$。 如图一个组中包含了两行缓存行,这种我们称为 2 路相联高速缓存。 组选择:与直接映射高速缓存的组选择过程一样。 行匹配:因为一个组有多行,所以需要遍历所有行,找到一个有效位为 1,并且标记为与地址中的标记位相匹配的一行。如果找到了,表示缓存命中。 字抽取:根据偏移量$b$确定目标数据的确切位置,通俗来说就是从数据块的什么位置开始抽取位置。如当偏移块等于100时,表示目标数据起始地址位于字节 4 处。 如果不命中,那么就需要从主存中取出需要的数据块,但是将数据块放在哪一行缓存行呢?如果存在空行 ($valid=0$),那就放到空行里。如果没有空行,就得选择一个非空行来替换,同时希望 CPU 不会很快引用这个被替换的行。这里介绍几个替换策略。 最简单的方式就是随机选择一行来替换,其他复杂的方式就是利用局部性原理,使得接下来 CPU 引用替换的行概率最小。如 最不常使用 (LFU, Least Frequently Used),选择使用次数最少的行。 最近最少使用 (LRU, Least Recently Used),选择最近使用最少的行。 全相联高速缓存 Fully Associative Cache整个 Cache 只有一个组,这个组包含了所有的缓存行。 组选择:因为只有一个组,所有默认总是选择 set 0。实际上这不就直接可以忽略了,访问的地址也就只需要划分为标记和偏移。 行匹配:同组相联高速缓存。 字抽取:同组相联高速缓存。 由于硬件实现及成本等原因,全相联高速缓存只适合做小规模的缓存。例如虚拟内存中的 TLB(翻译备用缓存器,Translation Lookaside Buffer)。 缓存写入写入 Cache 的性能比写入主内存要快,那么写入数据到底是写入 Cache 还是写入主内存呢?如果直接写入主内存里,Cache 里面的数据是否会失效呢? 写直达写直达策略(Write-Through):当数据要写入主内存里面,写入前,会先去判断数据是否已经在 Cache 里面了。如果数据已经在 Cache 里了,先把数据写入更新到 Cache 里面,再写入到主内存里面;如果数据不在 Cache 里,就只更新主内存。 写回写回策略(Write-Back):如果发现要写入的数据,就在 CPU Cache 里面,那么就只是更新 CPU Cache 里面的数据。同时,会标记 CPU Cache 里的这个 Block 是脏(Dirty)的,表示 CPU Cache 里面的这个 Block 的数据,和主内存是不一致的。如果发现,要写入的数据所对应的 Cache Block 里,放的是别的内存地址的数据,那么就要看一看,那个 Cache Block 里面的数据有没有标记成脏的。如果是脏的话,要先把这个 Cache Block 里面的数据,写入到主内存里面。然后,再把当前要写入的数据,写入到 Cache 里,同时把 Cache Block 标记成脏的。如果 Block 里面的数据没有被标记成脏的话,那么直接把数据写入到 Cache 里面,然后再把 Cache Block 标记成脏的就好了。 在用了写回这个策略之后,在加载内存数据到 Cache 里面的时候,也要多出一步同步脏 Cache 的动作。如果加载内存里面的数据到 Cache 的时候,发现 Cache Block 里面有脏标记,也要先把 Cache Block 里的数据写回到主内存,才能加载数据覆盖掉 Cache。 缓存一致性CPU 缓存一致性 MESI 协议 - 如云泊 参考资料C/C++中 volatile 关键字详解 - chao_yu - 博客园volatile 能解决 cache 的数据一致性吗?答案是不能_天才 2012 的博客-CSDN 博客_volatilewritecachecpu 缓存和 volatile - XuMinzhe - 博客园【CSAPP-深入理解计算机系统】6-5. 直接映射高速缓存_哔哩哔哩_bilibili24 张图 7000 字详解计算机中的高速缓存 - 腾讯云开发者社区 - 腾讯云","categories":[],"tags":[{"name":"缓存一致性","slug":"缓存一致性","permalink":"http://example.com/tags/%E7%BC%93%E5%AD%98%E4%B8%80%E8%87%B4%E6%80%A7/"},{"name":"Cache","slug":"Cache","permalink":"http://example.com/tags/Cache/"},{"name":"组成原理","slug":"组成原理","permalink":"http://example.com/tags/%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86/"}]},{"title":"密码管理器-KeePass","slug":"密码管理器-KeePass","date":"2022-07-09T11:11:40.000Z","updated":"2022-10-15T03:14:29.697Z","comments":true,"path":"2022/07/09/密码管理器-KeePass/","link":"","permalink":"http://example.com/2022/07/09/%E5%AF%86%E7%A0%81%E7%AE%A1%E7%90%86%E5%99%A8-KeePass/","excerpt":"","text":"KeePass 安装下载与安装 官网: https://keepass.info/download.html 下载完成后进行安装,默认安装位置是:C:\\Program Files (x86)\\KeePass Password Safe 2文件夹下,可以根据自己需要选择安装路径。 更改中文语言 中文语言包: KeePass-Chinese_Simplified 将语言包下载后复制到安装路径下的Languages文件夹下,默认为:C:\\Program Files (x86)\\KeePass Password Safe 2\\Languages。重启软件。 点击 View->Change Language. 选择中文简体(Chinese-Simplified)。重启软件,即可完成语言更改。 中文界面: 基本使用1.创建一个数据库 点击 文件-》新建。弹出对话框为数据库创建管理密码。这个密码是唯一需要记忆的密码。当然如果追求更高的安全性,可以点击显示高级选项,提供更多的密码选项。 2.添加记录 点击添加记录,在弹出的窗口填入相关信息。即可完成密码添加。 如果是第一次使用的网站,第一次注册密码。可以通过密码生成器,生成一个高强度的密码来添加记录。 3.创建一个密码生成模板 正常国内的网站可以使用的密码长度 6-16 位,可以使用大小写,数字,下划线。我们把这些选项勾选,密码长度设置 16 位。 点击保存并给模板设置个名字方便下次使用 如果保存后想更改一下,比如再加个可以使用空格,可以重新勾选刚刚的选项,保存时点击小三角,选择刚刚保存的方案就可以覆盖。 导入 Chrome 已保存的密码 很多小伙伴在使用 KeePass 之前肯定在 Chrome 等浏览器里也保存了很多密码。想将其导入 KeePass 方便管理。Chrome 是可以导出密码的,KeePass 也可以导入密码。 点击浏览器右上角,打开设置界面。找到密码 找到已保存的密码-》导出密码。选择方便找到的路径,保存密码记录。 打开 KeePass,点击文件-》导入,选择 Chrome 浏览器的格式。点击文件夹图标找到刚刚导出的密码文件。 高级配置KeePass 搭配坚果云实现云同步登录坚果云创建个人同步文件夹,若没有先注册。 最好单独建一个专门的文件夹 将已经生成的数据库上传到这个文件夹下 点击右上角进入账户信息,点击安全选项: 点击添加应用 输入应用名称,应用名称只是方便区分作用,所以和要同步的应用名称一致就好: 点击生成密码: 此时云盘端配置完成,切回到 KeePass 进行客户端配置。点击文件-》同步-》与网址(URL)同步 网址: https://dav.jianguoyun.com/dav/KeePass/keepassData.kdbx 注意:红色部分是个人同步文件夹的名称,绿色部分是上传的数据库全称,一定别忘了后缀 用户名:你的坚果云登录名(邮箱或者手机号) 密码:生成应用的密码,(不是登录坚果云的密码) 点击确定,此时已经可以完成同步,但是每次同步仍然需要手动确定。参考了什么值得买上小乐 CSN的方法,通过触发器实现自动同步。 触发器代码: 12345678910111213141516171819202122232425262728293031323334353637383940414243<?xml version="1.0" encoding="utf-8"?><TriggerCollection xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <Triggers> <Trigger> <Guid>L2euC7Mr/EKh7nPjueuZvQ==</Guid> <Name>SaveSync</Name> <Events> <Event> <TypeGuid>s6j9/ngTSmqcXdW6hDqbjg==</TypeGuid> <Parameters> <Parameter>1</Parameter> <Parameter>kdbx</Parameter> </Parameters> </Event> </Events> <Conditions /> <Actions> <Action> <TypeGuid>tkamn96US7mbrjykfswQ6g==</TypeGuid> <Parameters> <Parameter>SaveSync</Parameter> <Parameter>0</Parameter> </Parameters> </Action> <Action> <TypeGuid>Iq135Bd4Tu2ZtFcdArOtTQ==</TypeGuid> <Parameters> <Parameter>https://dav.jianguoyun.com/dav/keePass/passwordSync.kdbx</Parameter> <Parameter>123456</Parameter> <Parameter>123456</Parameter> </Parameters> </Action> <Action> <TypeGuid>tkamn96US7mbrjykfswQ6g==</TypeGuid> <Parameters> <Parameter>SaveSync</Parameter> <Parameter>1</Parameter> </Parameters> </Action> </Actions> </Trigger> </Triggers></TriggerCollection> 复制触发器代码,点击工具-》触发器,点击工具-》从剪切板粘贴触发器: 导入成功后,在触发器页面会多一个触发器: 双击打开SaveSync,打开最后一个动作窗口: 双击中间的条目: 将信息换成同步云盘的信息: 文件/网址: https://dav.jianguoyun.com/dav/KeePass/keepassData.kdbx 注意:红色部分是个人同步文件夹的名称,绿色部分是上传的数据库全称,一定别忘了后缀 IO 连接 - 用户名:你的坚果云登录名(邮箱或者手机号) IO 连接 - 密码:生成应用的密码,(不是登录坚果云的密码) 点击确定,回到主页面,点击工具-》选项 找到 高级,向下翻,在文件输入/输出连接 栏目里找到 写入数据库时使用文件交换 此项不勾选 点击确定,返回主页面。此时点击保存按钮或者 Ctrl+S。即可与云盘进行同步。 Chrome 上使用插件实现密码自动填充与同步在 KeePass 客户端安装KeePassRPC 插件: 将其放入安装目录(.\\KeePass\\Plugins)文件夹下,退出软件,重启即可自动安装。 在浏览器客户端安装浏览器插件Kee,若无法科学上网,可能需要自行百度搜索 Kee 插件 安装完成后会跳出窗口提示授权,将 KeePass 客户端跳出的窗口中的红色授权码填入即可连接浏览器: 使用 Kee 再次使用浏览器填写密码是可以看到文本框会有 logo,Kee 会自动填写已保存的密码。如果第一次登陆,在登录后可以点击浏览器插件图标,找到 Save latest login,保存刚刚输入的密码。 密码管理器的重要作用之一就是生成高强度密码,可以用 KeePass 客户端来生成,也可以是 Kee 这个插件的一个生成密码功能生成。英文版的是Generate new password","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"Efficiency","slug":"Efficiency","permalink":"http://example.com/tags/Efficiency/"},{"name":"推荐","slug":"推荐","permalink":"http://example.com/tags/%E6%8E%A8%E8%8D%90/"},{"name":"KeePass","slug":"KeePass","permalink":"http://example.com/tags/KeePass/"},{"name":"工具","slug":"工具","permalink":"http://example.com/tags/%E5%B7%A5%E5%85%B7/"},{"name":"密码管理","slug":"密码管理","permalink":"http://example.com/tags/%E5%AF%86%E7%A0%81%E7%AE%A1%E7%90%86/"}]},{"title":"volatile 能否解决缓存一致性问题","slug":"volatile能否解决缓存一致性问题","date":"2022-07-08T01:10:27.000Z","updated":"2022-10-15T03:14:29.576Z","comments":true,"path":"2022/07/08/volatile能否解决缓存一致性问题/","link":"","permalink":"http://example.com/2022/07/08/volatile%E8%83%BD%E5%90%A6%E8%A7%A3%E5%86%B3%E7%BC%93%E5%AD%98%E4%B8%80%E8%87%B4%E6%80%A7%E9%97%AE%E9%A2%98/","excerpt":"","text":"volatile 能否解决缓存一致性问题为何会产生这样的疑问,还得从一个工作中的 Bug 说起。在使用 PMP(Physical Memory Protect)对物理内存进行保护时,无法成功保护,简单来说 PMP 可以对一段物理内存设置保护,如保护这段内存不可写。测试时,先对这段内存写入0x1234,再读取这段内存。如果读取的值为0x0表示保护成功,但实际总能成功读取0x1234。 1234567volatile int test;test = read(0xFF740000);print("Before = %x\\n", test); // 保护之前数据 Before = 0x1111 PMP(0xFF740000, 0x400); // 保护这段内存不可写write(0xFF740000, 0x1234); // 写入数据test = read(0xFF740000);print("After = %x\\n", test); // 预期读取为0x0,实际总能成功读取0x1234 因为读取的变量test设置为volatile,所以按照以往的理解,系统总是重新从它所在的内存读取数据,这里应该能正确读取出数据。 但是忽略了一点,当使用volatile变量时,CPU 只是不再使用寄存器中的值,直接去内存中读取数据,这里的内存实际上是包括 Cache 的。 所以当数据被 Cached 之后,当再次读取时,CPU 可能会直接读取 Cached 的数据,而不是去读取真正内存中的数据。因此,volatile 不能解决缓存一致性问题。 关于 Cache 的详细信息,请参考CPU Cache 高速缓存 - 如云泊。","categories":[],"tags":[{"name":"缓存一致性","slug":"缓存一致性","permalink":"http://example.com/tags/%E7%BC%93%E5%AD%98%E4%B8%80%E8%87%B4%E6%80%A7/"},{"name":"Cache","slug":"Cache","permalink":"http://example.com/tags/Cache/"}]},{"title":"ZH-CS 可视化 - 常用的 Git 命令","slug":"ZH-CS可视化-常用的Git命令","date":"2022-07-07T08:20:48.000Z","updated":"2022-10-15T03:14:29.623Z","comments":true,"path":"2022/07/07/ZH-CS可视化-常用的Git命令/","link":"","permalink":"http://example.com/2022/07/07/ZH-CS%E5%8F%AF%E8%A7%86%E5%8C%96-%E5%B8%B8%E7%94%A8%E7%9A%84Git%E5%91%BD%E4%BB%A4/","excerpt":"","text":"CS 可视化 - 常用的 Git 命令 Author:Lydia Hallie译:🌳🚀 CS Visualized: Useful Git Commands - DEV Community 尽管 Git 是一个非常强大的工具,但我想大多数人都会同意,当我说它也可能是……一场彻头彻尾的噩梦当我执行某个命令时分支交互,它将如何影响历史记录?当我在master分支执行hard reset、force push到 origin、在.git文件夹执行rimraf的时候,为什么我的同事都哭了? 我认为这将是创建一些最常见和最有用命令的可视化示例的完美用例!我介绍的许多命令都有可选参数,您可以使用这些参数来更改它们的行为。在我的示例中,我将介绍命令的默认行为,而不添加(太多)配置选项! Merging拥有多个分支非常方便,可以将新更改彼此分开,并确保您不会意外地将未经批准或损坏的更改推送到生产环境。一旦更改获得批准,我们希望在我们的生产分支中获得这些更改! 将更改从一个分支转移到另一个分支的一种方法是执行 git merge!Git 可以执行两种类型的合并:fast-forward 或 no-fast-forward。 现在这可能没有多大意义,所以让我们看看差异! Fast-forward (--ff)如果当前分支与即将合并过来的分支相比,没有额外的提交,这种就是fast-forward合并。Git 很会偷懒,它会首先尝试最简单的方案,即fast-forward。这种合并方式不会创建新的提交,只是把另一个分支的提交记录直接合并到当前分支。 完美的!我们现在可以在 master 分支上使用在 dev 分支上所做的所有更改。那么,no-fast-forward 到底是什么? No-fast-foward (--no-ff)如果与您要合并的分支相比,您当前的分支没有任何额外的提交,那就太好了,但不幸的是,这种情况很少见!如果我们在当前分支上提交了我们想要合并的分支没有的更改,Git 将执行 no-fast-forward 合并。 使用 no-fast-forward 合并,Git 在活动分支上创建一个新的合并提交。提交的父提交指向活动分支和我们要合并的分支! 没什么大不了的,完美的合并! master 分支现在包含我们在 dev 分支上所做的所有更改。 Merge Conflicts尽管 Git 擅长决定如何合并分支和向文件添加更改,但它不能总是自己做出这个决定。当我们尝试合并的两个分支在同一个文件的同一行上发生更改时,可能会发生这种情况,或者如果一个分支删除了另一个分支修改的文件,等等。 在这种情况下,Git 会要求您帮助决定我们要保留两个选项中的哪一个!假设在两个分支上,我们编辑了 README.md 中的第一行。 如果我们想将 dev 合并到 master 中,这将导致合并冲突:您希望标题是 Hello! 还是 Hey!? 当试图合并分支时,Git 会告诉你冲突发生在哪里。我们可以手动删除不想保留的更改,保存更改,再次添加更改的文件,然后提交更改 耶!尽管合并冲突通常很烦人,但它完全有道理:Git 不应该自己决定选择哪一个更改。 Rebasing我们刚刚看到了如何通过执行 git merge 将更改从一个分支应用到另一个分支。另一种将更改从一个分支添加到另一个的方法是执行git rebase。 git rebase 复制当前分支的提交,并将这些复制的提交放在指定分支的顶部。 完美,我们现在可以在 dev 分支上使用在 master 分支上所做的所有更改! 与合并相比,一个很大的区别是 Git 不会尝试找出要保留和不保留的文件。我们正在变基的分支总是有我们想要保留的最新更改!通过这种方式,您不会遇到任何合并冲突,并保持良好的线性 Git 历史记录。 这个例子展示了基于 master 分支的变基。然而,在更大的项目中,您通常不想这样做。 git rebase 改变了项目的历史,因为为复制的提交创建了新的哈希! 每当您在功能分支上工作并且主分支已更新时,重新定基都很棒。您可以获得分支上的所有更新,这将防止未来的合并冲突! Interactive Rebase在重新提交提交之前,我们可以修改它们!我们可以使用 interactive rebase 来做到这一点。交互式变基对于您当前正在处理的分支也很有用,并且想要修改一些提交。 我们可以对我们正在变基的提交执行 6 项操作: reword: Change the commit message edit: Amend this commit squash: Meld commit into the previous commit fixup: Meld commit into the previous commit, without keeping the commit’s log message exec: Run a command on each commit we want to rebase drop: Remove the commit 惊人的!这样,我们可以完全控制我们的提交。如果我们想删除一个提交,我们可以直接 drop 它。 或者,如果我们想将多个提交压缩在一起以获得更清晰的历史记录,没问题! 交互式变基使您可以对尝试变基的提交进行大量控制,即使在当前活动分支上也是如此! Resetting我们可能会提交我们以后不想要的更改。也许它是一个WIP提交,或者是一个引入错误的提交!在这种情况下,我们可以执行 git reset。 git reset 会删除所有当前暂存的文件,并让我们控制 HEAD 应该指向的位置。 Soft reset软重置将 HEAD 移动到指定的提交(或提交的索引与 HEAD 相比),而不会消除随后在提交中引入的更改! 假设我们不想保留添加了style.css文件的提交9e78i,也不想保留添加了index.js文件的提交035cc。但是,我们确实希望保留新添加的 style.css 和 index.js 文件!软重置的完美用例。 输入 git status 时,您会看到我们仍然可以访问对先前提交所做的所有更改。这很棒,因为这意味着我们可以修复这些文件的内容并在以后再次提交它们! Hard reset有时,我们不想保留某些提交引入的更改。与软重置不同,我们不再需要访问它们。Git 应该简单地将其状态重置回指定提交时的状态:这甚至包括工作目录和暂存文件中的更改! Git 丢弃了在 9e78i 和 035cc 上引入的更改,并将其状态重置为提交 ec5be 时的状态。 Reverting撤消更改的另一种方法是执行git revert。通过恢复某个提交,我们创建了一个包含恢复的更改的新提交! 假设 ec5be 添加了一个 index.js 文件。后来,我们实际上意识到我们不再希望这次提交引入的这种变化!让我们恢复 ec5be 提交。 完美的!提交9e78i恢复了由ec5be提交引入的更改。执行 git revert 非常有用,可以撤消某个提交,而无需修改分支的历史记录。 Cherry-picking当某个分支包含在活动分支上引入了我们需要的更改的提交时,我们可以 cherry-pick 该命令!通过 cherry-pick 提交,我们在活动分支上创建了一个新提交,其中包含由 cherry-pick 提交所引入的更改。 假设 dev 分支上的提交 76d12 添加了我们想要在 master 分支中的 index.js 文件的更改。我们不想要整个,我们只关心这一次提交! 很酷,master 分支现在包含了 76d12 引入的更改! Fetching如果我们有一个远程 Git 分支,例如 GitHub 上的一个分支,则可能会发生远程分支具有当前分支没有的提交!也许另一个分支被合并了,你的同事推送了一个快速修复,等等。 我们可以通过在远程分支上执行 git fetch 在本地获取这些更改!它不会以任何方式影响您的本地分支:fetch 只是下载新数据。 我们现在可以看到自上次推送以来所做的所有更改!既然我们在本地拥有新数据,我们就可以决定要如何处理这些数据。 Pulling虽然 git fetch 对于获取分支的远程信息非常有用,但我们也可以执行 git pull。 git pull 实际上是两个命令合二为一:git fetch 和 git merge。当我们从源中提取更改时,我们首先像使用 git fetch 一样获取所有数据,之后最新的更改会自动合并到本地分支中。 太棒了,我们现在与远程分支完美同步,并拥有所有最新更改! Reflog每个人都会犯错,这完全没关系!有时你可能会觉得你把你的 git repo 搞砸了,以至于你只想完全删除它。 git reflog 是一个非常有用的命令,用于显示所有已采取的操作的日志!这包括合并、重置、恢复:基本上是对分支的任何更改。 如果您犯了错误,您可以根据 reflog 提供给我们的信息通过重置 HEAD 轻松地重做此操作! 假设我们实际上并不想合并 origin 分支。当我们执行 git reflog 命令时,我们看到合并前 repo 的状态是在 HEAD@{1}。让我们执行 git reset 将 HEAD 指向它在 HEAD@{1} 上的位置! 我们可以看到最新的 action 已经推送到reflog了!","categories":[],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"},{"name":"Translation","slug":"Translation","permalink":"http://example.com/tags/Translation/"}]},{"title":"C语言数组/结构体/结构体数组/联合体初始化","slug":"C语言数组-结构体-结构体数组-联合体初始化","date":"2022-06-30T07:30:41.000Z","updated":"2022-10-15T03:14:29.176Z","comments":true,"path":"2022/06/30/C语言数组-结构体-结构体数组-联合体初始化/","link":"","permalink":"http://example.com/2022/06/30/C%E8%AF%AD%E8%A8%80%E6%95%B0%E7%BB%84-%E7%BB%93%E6%9E%84%E4%BD%93-%E7%BB%93%E6%9E%84%E4%BD%93%E6%95%B0%E7%BB%84-%E8%81%94%E5%90%88%E4%BD%93%E5%88%9D%E5%A7%8B%E5%8C%96/","excerpt":"","text":"数组初始化1234int arr[6] = { [0]=5, [1]=6, [3] =10, [4]=11 }; 或int arr[6] = { [0]=5, 6, [3] =10, 11 }; 或int arr[6] = { [3] =10, 11, [0]=5, 6 }; (指定顺序可变)均等效于:int arr[6] = {5, 6, 0, 10, 11, 0}; Note: 若在某个指定初始化项目后跟有不至一个值,如[3]=10,11。则多出的数值用于对后续的数组元素进行初始化,即数值 11 用来初始化 arr[4]。 C 数组初始化一个或多个元素后,未初始化的元素将被自动地初始化为 0 或 NULL(针对指针变量)。未经过任何初始化的数组,所有元素的值都是不确定的。 GNU C 还支持[first … last]=value(…两侧有空格) 的形式,将该范围内的若干元素初始化为相同值。如: 123int arr[]={ [0 ... 3]=1, [4 ... 5]=2, [6 ... 9] =3}; 或int arr[]={ [0 ... 3]=1, [4 ... 5]=2, [6 ... 8] =3, [9] =3};均等效于:int arr[10] = {1, 1, 1, 1, 2, 2, 3, 3, 3, 3}; 结构体初始化对于结构体 12struct Structure{ int a; int b; }; 或struct Structure{ int a, b; }; 有以下几种初始化方式:用.fieldname=指定待初始化成员名(成员初始化顺序可变),推荐使用的方式,该方式初始化时不必严格按照定义时的顺序,灵活性很高。 1234struct Structure tStct = { .a = 1, .b = 2}; 用fieldname:指定待初始化成员名(成员初始化顺序可变),GCC 2.5 已废除,但仍接受 1234struct Structure tStct = { a : 1, b : 2}; 用初始化列表初始化 1struct Structure tStct = { 1, 2 }; 结构体数组初始化方法一: 123struct Structure ptStct[10] = { [2].b = 0x2B, [2].a = 0x2A, [0].a = 0x0A }; 方法二:该方法可以用于清除结构体。 1memset(ptStct, 0, sizeof(struct Structure) * 10); 联合体初始化可用.fieldname(或已废弃的fieldname:) 指示符来指定使用联合体的哪个元素,如: 12union UnionT { int i; double d; };union UnionT tUnion = { .d = 4 };","categories":[],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"}]},{"title":"每天学命令-watch 周期执行命令","slug":"每天学命令-watch周期执行命令","date":"2022-06-09T14:50:54.000Z","updated":"2022-10-15T03:03:19.398Z","comments":true,"path":"2022/06/09/每天学命令-watch周期执行命令/","link":"","permalink":"http://example.com/2022/06/09/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-watch%E5%91%A8%E6%9C%9F%E6%89%A7%E8%A1%8C%E5%91%BD%E4%BB%A4/","excerpt":"","text":"功能watch 命令的功能如其名,可以监视命令的执行结果。它实现的原理就是每隔一段时间执行一次命令,然后显示结果。他的用途很广,具体怎么用就靠想象力了。 命令参数1234-n # 或--interval watch默认每2秒运行一下程序,可以用-n或-interval来指定间隔的时间。-d # 或--differences 用-d或--differences 选项watch 会高亮显示变化的区域。 而-d=cumulative选项会把变动过的地方(不管最近的那次有没有变动)都高亮显示出来。-t # 或-no-title 会关闭watch命令在顶部的时间间隔,命令,当前时间的输出。-h # 或--help # 查看帮助文档 实例1watch -d 'ls -l | grep tmp' # 监测当前目录中 scf' 的文件的变化","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"Git hooks 钩子的使用","slug":"Git-hooks钩子的使用","date":"2022-05-30T04:16:11.000Z","updated":"2022-10-15T03:14:29.215Z","comments":true,"path":"2022/05/30/Git-hooks钩子的使用/","link":"","permalink":"http://example.com/2022/05/30/Git-hooks%E9%92%A9%E5%AD%90%E7%9A%84%E4%BD%BF%E7%94%A8/","excerpt":"","text":"Git hooks 简介 Git 能在特定的重要动作发生时触发自定义脚本。比如,commit之前检查commit message是否符合约定的格式,push之前检查代码格式是否正确,是否编译通过等等。Git 就提供了hooks这样的机制。 我们在哪能找到hooks呢?在初始化代码仓库git init时,Git 会自动为我们创建一个.git/hooks目录,里面存放了所有的钩子。因为.git是隐藏目录,显示隐藏目录后就可以找到hooks这个目录。 在 VSCode 里一般默认把.git目录排除显示,所以打开项目目录时不会显示该目录,我们可以收到在 VSCode 显示.git目录:打开设置界面,搜索exclude找到图中的设置,将.git目录从排除列表中移除,即可在 VSCode 中显示.git目录。 现在我们找到了hooks,该如何使用呢?所有默认的hooks都是以.sample为后缀,只需要移除.sample即可激活hooks。 随便打开一个hooks文件,我们可以发现,实际是hooks就是一个个shell脚本。这些脚本会在特定的动作发生时被执行。示范的这些hooks都是shell脚本,实际上只要是文件名正确的可执行脚本都可以使用,如将pre-push内容改为python, Ruby等等脚本都可以。 如何使用一个 hooks以pre-commit这个hooks为例,来示范一下如何使用 Git hooks。 打开.git/hooks/pre-commit.sample,这个hooks的大体功能是检查文件名是否包含非ASCII字符,如果包含,则无法执行commit操作,并提示用户修改文件名。 删除pre-commit.sample的后缀 1➜ mv .git/hooks/pre-commit.sample .git/hooks/pre-commit 添加一个有汉字的文件名,如测试.md 1➜ touch 测试.md 将新文件提交 1234567891011➜ git add 测试.md➜ git commit -m "测试"Error: Attempt to add a non-ASCII file name.This can cause problems if you want to work with people on other platforms.To be portable it is advisable to rename the file.If you know what you are doing you can disable this check using:git config hooks.allownonascii true 如果无法执行pre-commit可能未被赋予执行权限,修改一下权限即可:chmod +x .git/hooks/pre-commit 我们可以发现,在进行commit操作时被中断了,会提示用户修改文件名。其他的hooks用法类似,我们可以自定义在什么时候可以push,什么时候可以rebase等等。 hooks通常会被用来做提交代码前的一个检查,比如风格是否统一,编译是否通过等等。如果团队合作时,这样的检查最好能够与成员保持一致,但是hooks所在的.git目录是不会被Git自己版本管理的,换句话说,它不能推送到远端与成员共享。那么如何解决这个问题呢? 如何同步hooks文件方案一:与源码放在一起代码仓库中新建一个hooks目录,将该目录同步到远程。其他成员下载代码时也会下载hooks目录,通过脚本的方式将hooks目录覆盖本地的.git/hooks目录。 12345#!/bin/bashcp -r ./hooks/ .git/hooks/chmod +x -R .git/hooksecho 'Hooks sync to remote success!'exit 0 方案二:使用pre-commit框架pre_commit 是 pre-commit 同名的开源应用,使用pre-commit,代码仓库里只需要有一个配置文件,所有成员都可以根据配置文件,使用pre_commit生成统一的hooks。 pre-commit随着发展,已经不单单只能用于git hooks的pre-commit阶段,而是能作用于所有git hooks的所有阶段,如上面说的prepare-commit-msg, commit-msg, post-commi等。 安装pre-commit 1pip install pre-commit 在项目目录下,添加配置文件 .pre-commit-config.yaml 1touch .pre-commit-config.yaml 首先了解配置的格式 顶层有一个参数名为 repos repos 中每个元素为 repo ,代表一个代码库,一般是github或gitlab链接。在使用时会从对应地址下载,如果出现下载慢的情况,可以在gitee搜索是否有相关镜像。 每个 repo 中有一个或多个 hook ,每个 hook 代表一个任务。 每个任务里可理解为一个命令行指令,例如flake8/yapf/black。 pre_commit官方提供了各种配置,我们可以根据需要选择一个合适的。比如我需要一个格式化C语言代码的配置,选择了mirrors-clang-format,还选了一个用来删除行尾空格的。 1234567891011repos:- repo: https://github.com/pre-commit/pre-commit-hooks rev: v4.3.0 hooks: - id: trailing-whitespace- repo: https://github.com/pre-commit/mirrors-clang-format rev: v14.0.6 hooks: - id: clang-format types_or: [c] 参数的含义可以参考pre-commit的文档。每个id对应的其实都是一个程序,为了保证都能正常运行,还需要安装这些程序。一般在仓库的README中都会有提示如何安装。 根据配置文件安装hooks 在项目根目录下运行: 1pre-commit install 在执行git commit命令时将会自动检查。这个过程中,pre-commit会从仓库里下载代码,然后根据里面的配置执行相应的脚本。完成各种检查。 常用命令12345678# 手动对所有的文件执行 hooks,新增 hook 的时候可以执行,使得代码均符合规范。直接执行该指令则无需等到 pre-commit 阶段再触发 hookspre-commit run --all-files# 执行特定 hookspre-commit run <hook_id># 将所有的hook更新到最新的版本/tagpre-commit autoupdate# 指定更新 repopre-commit autoupdate --repo https://github.com/pre-commit/mirrors-clang-format 参考资料 C++ 项目中使用 Pre-commit 协助实现代码规范检查_清欢守护者的博客-CSDN 博客 git push 之前自动编译验证 - 简书 使用 pre-commit 实现代码检查_清欢守护者的博客-CSDN 博客 pre-commit Git 基本原理介绍 (32)——git hook 和 python_哔哩哔哩_bilibili","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"CPU 缓存一致性 MESI 协议","slug":"CPU缓存一致性MESI协议","date":"2022-05-29T07:04:59.000Z","updated":"2022-10-15T03:14:29.096Z","comments":true,"path":"2022/05/29/CPU缓存一致性MESI协议/","link":"","permalink":"http://example.com/2022/05/29/CPU%E7%BC%93%E5%AD%98%E4%B8%80%E8%87%B4%E6%80%A7MESI%E5%8D%8F%E8%AE%AE/","excerpt":"","text":"为什么需要缓存一致目前主流电脑的 CPU 都是多核心的,多核心的有点就是在不能提升 CPU 主频后,通过增加核心来提升 CPU 吞吐量。每个核心都有自己的 L1 Cache 和 L2 Cache,只是共用 L3 Cache 和主内存。每个核心操作是独立的,每个核心的 Cache 就不是同步更新的,这样就会带来缓存一致性(Cache Coherence)的问题。 举个例子,如图: 有 2 个 CPU,主内存里有个变量x=0。CPU A 中有个需要将变量x加1。CPU A 就将变量x加载到自己的缓存中,然后将变量x加1。因为此时 CPU A 还未将缓存数据写回主内存,CPU B 再读取变量x时,变量x的值依然是0。 这里的问题就是所谓的缓存一致性问题,因为 CPU A 的缓存与 CPU B 的缓存是不一致的。 如何解决缓存一致性问题通过在总线加 LOCK 锁的方式在锁住总线上加一个 LOCK 标识,CPU A 进行读写操作时,锁住总线,其他 CPU 此时无法进行内存读写操作,只有等解锁了才能进行操作。 该方式因为锁住了整个总线,所以效率低。 缓存一致性协议 MESI该方式对单个缓存行的数据进行加锁,不会影响到内存其他数据的读写。 在学习 MESI 协议之前,简单了解一下总线嗅探机制(Bus Snooping)。要对自己的缓存加锁,需要通知其他 CPU,多个 CPU 核心之间的数据传播问题。最常见的一种解决方案就是总线嗅探。 这个策略,本质上就是把所有的读写请求都通过总线广播给所有的 CPU 核心,然后让各个核心去“嗅探”这些请求,再根据本地的情况进行响应。MESI 就是基于总线嗅探机制的缓存一致性协议。 MESI 协议的由来是对 Cache Line 的四个不同的标记,分别是: 状态 状态 描述 监听任务 Modified 已修改 该 Cache Line 有效,数据被修改了,和内存中的数据不一致,数据只存在于本 Cache 中 Cache Line 必须时刻监听所有试图读该 Cache Line 相对于主存的操作,这种操作必须在缓存将该 Cache Line 写回主存并将状态改为 S 状态之前,被延迟执行 Exclusive 独享,互斥 该 Cache Line 有效,数据和内存中的数据一直,数据只存在于本 Cache Cache Line 必须监听其他缓存读主存中该 Cache Line 的操作,一旦有这种操作,该 Cache Line 需要改为 S 状态 Shared 共享的 该 Cache Line 有效,数据和内存中的数据一直,数据存在于很多个 Cache 中 Cache Line 必须监听其他 Cache Line 使该 Cache Line 无效或者独享该 Cache Line 的请求,并将 Cache Line 改为 I 状态 Invalid 无效的 该 Cache Line 无效 无 整个 MESI 的状态,可以用一个有限状态机来表示它的状态流转。需要注意的是,对于不同状态触发的事件操作,可能来自于当前 CPU 核心,也可能来自总线里其他 CPU 核心广播出来的信号。我把各个状态之间的流转用表格总结了一下: 当前状态 事件 行为 下个状态 M Local Read 从 Cache 中读,状态不变 M M Local Write 修改 cache 数据,状态不变 M M Remote Read 这行数据被写到内存中,使其他核能使用到最新数据,状态变为 S S M Remote Write 这行数据被写入内存中,其他核可以获取到最新数据,由于其他 CPU 修改该条数据,则本地 Cache 变为 I I 当前状态 事件 行为 下个状态 E Local Read 从 Cache 中读,状态不变 E E Local Write 修改数据,状态改为 M M E Remote Read 数据和其他 CPU 共享,变为 S S E Remote Write 数据被修改,本地缓存失效,变为 I I 当前状态 事件 行为 下个状态 S Local Read 从 Cache 中读,状态不变 S S Local Write 修改数据,状态改为 M,其他 CPU 的 Cache Line 状态改为 I M S Remote Read 数据和其他 CPU 共享,状态不变 S S Remote Write 数据被修改,本地缓存失效,变为 I I 当前状态 事件 行为 下个状态 I Local Read 1. 如果其他 CPU 没有这份数据,直接从内存中加载数据,状态变为 E; 2. 如果其他 CPU 有这个数据,且 Cache Line 状态为 M,则先把 Cache Line 中的内容写回到主存。本地 Cache 再从内存中读取数据,这时两个 Cache Line 的状态都变为 S;3. 如果其他 Cache Line 有这份数据,并且状态为 S 或者 E,则本地 Cache Line 从主存读取数据,并将这些 Cache Line 状态改为 S E 或者 S I Local Write 1. 先从内存中读取数据,如果其他 Cache Line 中有这份数据,且状态为 M,则现将数据更新到主存再读取,将 Cache Line 状态改为 M; 2. 如果其他 Cache Line 有这份数据,且状态为 E 或者 S,则其他 Cache Line 状态改为 I M I Remote Read 数据和其他 CPU 共享,状态不变 S I Remote Write 数据被修改,本地缓存失效,变为 I I","categories":[],"tags":[{"name":"通信协议","slug":"通信协议","permalink":"http://example.com/tags/%E9%80%9A%E4%BF%A1%E5%8D%8F%E8%AE%AE/"},{"name":"计算机组成原理","slug":"计算机组成原理","permalink":"http://example.com/tags/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86/"},{"name":"CPU","slug":"CPU","permalink":"http://example.com/tags/CPU/"},{"name":"MESI","slug":"MESI","permalink":"http://example.com/tags/MESI/"}]},{"title":"VSCode 设置终端为 Gitbash","slug":"VSCode设置终端为Gitbash","date":"2022-05-24T06:42:48.000Z","updated":"2022-10-15T03:14:29.601Z","comments":true,"path":"2022/05/24/VSCode设置终端为Gitbash/","link":"","permalink":"http://example.com/2022/05/24/VSCode%E8%AE%BE%E7%BD%AE%E7%BB%88%E7%AB%AF%E4%B8%BAGitbash/","excerpt":"","text":"设置终端为 Gitbash用惯了 Linux 终端的命令,Windows 的 shell 真的太不顺手了,但是 Gitbash 很多命令相似,可以将默认的 shell 换成 Gitbash。 打开settings.json配置文件,添加如下 12345678910111213"terminal.integrated.profiles.windows": { "PowerShell -NoProfile": { "source": "PowerShell", "args": [ "-NoProfile" ] }, "Git-Bash": { "path": "D:\\\\Software\\\\Git\\\\bin\\\\bash.exe", //bin路径下的bash,不是git-bash.exe。否则会打开外部窗口 "args": [] } },"terminal.integrated.defaultProfile.windows": "Git-Bash", 修改终端配色打开Base16 Terminal Colors for Visual Studio Code,选择一款配置复制 打开 VScodesettings.json,替换如下 12345678910111213141516171819202122"workbench.colorCustomizations": { "terminal.background":"#1C2023", "terminal.foreground":"#C7CCD1", "terminalCursor.background":"#C7CCD1", "terminalCursor.foreground":"#C7CCD1", "terminal.ansiBlack":"#1C2023", "terminal.ansiBlue":"#AE95C7", "terminal.ansiBrightBlack":"#747C84", "terminal.ansiBrightBlue":"#AE95C7", "terminal.ansiBrightCyan":"#95AEC7", "terminal.ansiBrightGreen":"#95C7AE", "terminal.ansiBrightMagenta":"#C795AE", "terminal.ansiBrightRed":"#C7AE95", "terminal.ansiBrightWhite":"#F3F4F5", "terminal.ansiBrightYellow":"#AEC795", "terminal.ansiCyan":"#95AEC7", "terminal.ansiGreen":"#95C7AE", "terminal.ansiMagenta":"#C795AE", "terminal.ansiRed":"#C7AE95", "terminal.ansiWhite":"#C7CCD1", "terminal.ansiYellow":"#AEC795" }, 修改后效果 修改终端字体方法一:打开 VScodesettings.json,加上下面这个配置,字体改成自己电脑上的字体 12"terminal.integrated.fontFamily": "JetBrains Mono", 方法二:打开设置页面,搜索terminal font 修改后的效果 解决中文乱码1git config --global core.quotepath false","categories":[{"name":"万能 VSCode","slug":"万能-VSCode","permalink":"http://example.com/categories/%E4%B8%87%E8%83%BD-VSCode/"}],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"},{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"},{"name":"Gitbash","slug":"Gitbash","permalink":"http://example.com/tags/Gitbash/"}]},{"title":"CPU 亲和性与中断亲和性","slug":"CPU亲和性与中断亲和性","date":"2022-05-23T14:38:14.000Z","updated":"2022-10-15T03:14:29.087Z","comments":true,"path":"2022/05/23/CPU亲和性与中断亲和性/","link":"","permalink":"http://example.com/2022/05/23/CPU%E4%BA%B2%E5%92%8C%E6%80%A7%E4%B8%8E%E4%B8%AD%E6%96%AD%E4%BA%B2%E5%92%8C%E6%80%A7/","excerpt":"","text":"预备知识超线程技术 (Hyper-Threading):就是利用特殊的硬件指令,把两个逻辑内核 (CPU core) 模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了 CPU 的闲置时间,提高的 CPU 的运行效率。 我们常听到的双核四线程/四核八线程指的就是支持超线程技术的CPU. 物理 CPU:机器上安装的实际 CPU, 比如说你的主板上安装了一个 8 核 CPU,那么物理 CPU 个数就是 1 个,所以物理 CPU 个数就是主板上安装的 CPU 个数。 逻辑 CPU:一般情况,我们认为一颗 CPU 可以有多核,加上 Intel 的超线程技术 (HT), 可以在逻辑上再分一倍数量的 CPU core 出来; 12逻辑CPU数量 = 物理CPU数量 x CPU cores x 2(如果支持并开启HT) //前提是CPU的型号一致,如果不一致只能一个一个的加起来,不用直接乘以物理CPU数量//比如你的电脑安装了一块4核CPU,并且支持且开启了超线程(HT)技术,那么逻辑CPU数量 = 1 × 4 × 2 = 8 Linux 下查看 CPU 相关信息, CPU 的信息主要都在/proc/cupinfo中。 123456789101112131415161718# 查看物理CPU个数➜ ~ cat /proc/cpuinfo|grep "physical id"|sort -u|wc -l32# 查看每个物理CPU中core的个数(即核数)➜ ~ cat /proc/cpuinfo|grep "cpu cores"|uniq1# 或者➜ cat /proc/cpuinfo | grep 'process' | sort | uniq | wc -l1# 查看逻辑CPU的个数➜ ~ cat /proc/cpuinfo|grep "processor"|wc -l32# 查看CPU的名称型号➜ ~ cat /proc/cpuinfo|grep "name"|cut -f2 -d:|uniqIntel Xeon Processor (Skylake, IBRS) Linux 查看某个进程运行在哪个逻辑 CPU 上 1ps -eo pid,args,psr pid:进程 ID args:该进程执行时传入的命令行参数 psr:分配给进程的逻辑 CPU 例子: 12345678910111213➜ ps -eo pid,args,psr | grep firefox20118 /usr/lib/firefox/firefox -n 1320208 /usr/lib/firefox/firefox -c 920266 /usr/lib/firefox/firefox -c 2920329 /usr/lib/firefox/firefox -c 2420499 /usr/lib/firefox/firefox -c 720565 /usr/lib/firefox/firefox -c 1520596 /usr/lib/firefox/firefox -c 2420760 /usr/lib/firefox/firefox -c 1822110 /usr/lib/firefox/firefox -c 2725857 /usr/lib/firefox/firefox -c 2826347 /usr/lib/firefox/firefox -c 1926899 /usr/lib/firefox/firefox -c 29 Linux 查看线程的 TID TID 就是 Thread ID,他和 POSIX 中pthread_t表示的线程 ID 完全不是同一个东西。 Linux 中的 POSIX 线程库实现的线程其实也是一个轻量级进程 (LWP),这个 TID 就是这个线程的真实 PID. 但是又不能通过getpid()函数获取,Linux 中定义了gettid()这个接口,但是通常都是未实现的,所以需要使用下面的方式获取 TID。 使用 API 获取: 123#include <sys/syscall.h> pid_t tid;tid = syscall(__NR_gettid); // or syscall(SYS_gettid) 命令行方式获取: 1234# 3种方法(推荐第三种方法)➜ ps -efL | grep prog_name➜ ls /proc/pid/task //文件夹名即TID➜ ps -To 'pid,lwp,psr,cmd' -p PID 什么是 CPU 亲和性CPU 的亲和性 (Affinity),属于一种调度属性,可以绑定进程到指定 CPU 上。 换句话说,就是进程要在指定的 CPU 上尽量长时间地运行而不被迁移到其他处理器。 为何会出现这种技术?在 SMP(Symmetric Multi-Processing 对称多处理) 架构下,调度器会试图保持进程在相同的 CPU 上运行,这意味着进程通常不会在处理器之间频繁迁移,进程迁移的频率小就意味着产生的负载小。 又如,每个 CPU 本身自己会有缓存,缓存着进程使用的信息,而进程可能会被操作系统调度到其他 CPU 上,如此,CPU 缓存命中率就低了,当绑定 CPU 后,程序就会一直在指定的 CPU 跑,不会由操作系统调度到其他 CPU 上,性能有一定的提高。 软亲和性: 就是进程要在指定的 CPU 上尽量长时间地运行而不被迁移到其他处理器,Linux 内核进程调度器天生就具有被称为 软 CPU 亲和性(affinity)的特性,这意味着进程通常不会在处理器之间频繁迁移。这种状态正是我们希望的,因为进程迁移的频率小就意味着产生的负载小。 硬亲和性:简单来说就是利用 Linux 内核提供给用户的 API,强行将进程或者线程绑定到某一个指定的 CPU 核运行。 CPU affinity 使用位掩码 (bitmask) 表示,每一位都表示一个 CPU, 置 1 表示”绑定”。最低位表示第一个逻辑 CPU, 最高位表示最后一个逻辑 CPU。 CPU affinity 典型的表示方法是使用 16 进制,具体如下。 12345678910110b00000000000000000000000000000001= 0x00000001表示 processor #00b00000000000000000000000001010101= 0x00000055表示 processors #0, #2, #4, #60b11111111111111111111111111111111= 0xFFFFFFFF表示所有 processors (#0 through #31) 使用taskset命令设置 CPU 亲和性命令行形式 12taskset [options] mask command [arg]...taskset [options] -p [mask] pid 参数解析[OPTIONS]taskset 的可选参数 -a, --all-tasks (旧版本中没有这个选项) 这个选项涉及到了linux中TID的概念,他会将一个进程中所有的TID都执行一次CPU亲和性设置. TID 就是 Thread ID,他和 POSIX 中 pthread_t 表示的线程 ID 完全不是同一个东西。 Linux中的POSIX线程库实现的线程其实也是一个进程(LWP),这个TID就是这个线程的真实PID. -p, --pid 操作已存在的PID,而不是加载一个新的程序 -c, --cpu-list 声明CPU的亲和力使用数字表示而不是用位掩码表示. 例如 0,5,7,9-11. -h, --help 显示帮助信息 -V, --version 显示版本信息 mask : cpu 亲和性,当没有-c选项时,其值前无论有没有0x标记都是 16 进制的,当有-c选项时,其值是十进制的。 command : 命令或者可执行程序 pid : 进程 ID,可以通过ps/top/pidof等命令获取 [arg] command 的参数 实例使用指定的 CPU 亲和性运行一个新程序123taskset [-c] mask command [arg]...# 举例: 使用CPU0运行ls命令显示/etc/init.d下的所有内容taskset -c 0 ls -al /etc/init.d/ 显示已经运行的进程的 CPU 亲和性123taskset -p pid# 举例:查看init进程(PID=1)的CPU亲和性taskset -p 1 改变已经运行进程的 CPU 亲和性12345taskset -p[c] mask pid举例:打开2个终端,在第一个终端运行top命令,第二个终端中 首先运行:[~]# ps -eo pid,args,psr | grep top #获取top命令的pid和其所运行的CPU号 其次运行:[~]# taskset -cp 新的CPU号 pid #更改top命令运行的CPU号 最后运行:[~]# ps -eo pid,args,psr | grep top #查看是否更改成功 12345678910111213➜ ~ ps -eo pid,args,psr | grep top2501 nautilus-desktop 242634 /usr/libexec/xdg-desktop-po 182658 /usr/libexec/xdg-desktop-po 1123848 top 6➜ ~ taskset -cp 10 23848pid 23848's current affinity list: 0-31pid 23848's new affinity list: 10➜ ~ ps -eo pid,args,psr | grep top 2501 nautilus-desktop 24 2634 /usr/libexec/xdg-desktop-po 18 2658 /usr/libexec/xdg-desktop-po 1123848 top 10 一个用户要设定一个进程的 CPU 亲和性,如果目标进程是该用户的,则可以设置,如果是其他用户的,则会设置失败,提示 Operation not permitted.当然 root 用户没有任何限制。任何用户都可以获取任意一个进程的 CPU 亲和性。 程序 API 实现硬亲和性以下实验使用的源码可以从这个仓库获取。 以下是一些设置亲和性时会用到的宏定义及函数: 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576#define _GNU_SOURCE#include <sched.h>#include <pthread.h> //注意<pthread.h>包含<sched.h>/* MACRO */ // 对 CPU 集初始化,将其设置为空集 void CPU_ZERO(cpu_set_t *set); void CPU_ZERO_S(size_t setsize, cpu_set_t *set); // 将 CPU 加入到 CPU 集中 void CPU_SET(int cpu, cpu_set_t *set); void CPU_SET_S(int cpu, size_t setsize, cpu_set_t *set); // 将 CPU 从 CPU 集中移除 void CPU_CLR(int cpu, cpu_set_t *set); void CPU_CLR_S(int cpu, size_t setsize, cpu_set_t *set); // 判断 CPU 是否在 CPU 集中 int CPU_ISSET(int cpu, cpu_set_t *set); int CPU_ISSET_S(int cpu, size_t setsize, cpu_set_t *set); // 计算 CPU 集的大小 void CPU_COUNT(cpu_set_t *set); void CPU_COUNT_S(size_t setsize, cpu_set_t *set); // The following macros perform logical operations on CPU sets /* Store the logical AND of the sets srcset1 and srcset2 in destset (which may be one of the source sets). */ void CPU_AND(cpu_set_t *destset, cpu_set_t *srcset1, cpu_set_t *srcset2); void CPU_AND_S(size_t setsize, cpu_set_t *destset, cpu_set_t *srcset1, cpu_set_t *srcset2); /* Store the logical OR of the sets srcset1 and srcset2 in destset (which may be one of the source sets). */ void CPU_OR(cpu_set_t *destset, cpu_set_t *srcset1, cpu_set_t *srcset2); void CPU_OR_S(size_t setsize, cpu_set_t *destset, cpu_set_t *srcset1, cpu_set_t *srcset2); /* Store the logical XOR of the sets srcset1 and srcset2 in destset (which may be one of the source sets). */ void CPU_XOR(cpu_set_t *destset, cpu_set_t *srcset1, cpu_set_t *srcset2); void CPU_XOR_S(size_t setsize, cpu_set_t *destset, cpu_set_t *srcset1, cpu_set_t *srcset2); /* Test whether two CPU set contain exactly the same CPUs. */ int CPU_EQUAL(cpu_set_t *set1, cpu_set_t *set2); int CPU_EQUAL_S(size_t setsize, cpu_set_t *set1, cpu_set_t *set2); /* The following macros are used to allocate and deallocate CPU sets: */ /* Allocate a CPU set large enough to hold CPUs in the range 0 to num_cpus-1 */ cpu_set_t *CPU_ALLOC(int num_cpus); /* Return the size in bytes of the CPU set that would be needed to hold CPUs in the range 0 to num_cpus-1. This macro provides the value that can be used for the setsize argument in the CPU_*_S() macros */ size_t CPU_ALLOC_SIZE(int num_cpus); /* Free a CPU set previously allocated by CPU_ALLOC(). */ void CPU_FREE(cpu_set_t *set);/* API */ /*该函数设置进程为 pid 的这个进程,让它运行在 mask 所设定的 CPU 上。如果 pid 的值为 0, *则表示指定的是当前进程,使当前进程运行在 mask 所设定的那些 CPU 上. *第二个参数 cpusetsize 是 mask 所指定的数的长度。通常设定为 sizeof(cpu_set_t). *如果当前 pid 所指定的进程此时没有运行在 mask 所指定的任意一个 CPU 上, *则该指定的进程会从其它 CPU 上迁移到 mask 的指定的一个 CPU 上运行. */ int sched_setaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask); /*该函数获得 pid 所指示的进程的 CPU 位掩码,并将该掩码返回到 mask 所指向的结构中. *即获得指定 pid 当前可以运行在哪些 CPU 上. *同样,如果 pid 的值为 0.也表示的是当前进程 */ int sched_getaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask); /* set CPU affinity attribute in thread attributes object */ int pthread_attr_setaffinity_np(pthread_attr_t *attr, size_t cpusetsize, const cpu_set_t *cpuset); /* get CPU affinity attribute in thread attributes object */ int pthread_attr_getaffinity_np(const pthread_attr_t *attr, size_t cpusetsize, cpu_set_t *cpuset); /* set CPU affinity of a thread */ int pthread_setaffinity_np(pthread_t thread, size_t cpusetsize, const cpu_set_t *cpuset); /* get CPU affinity of a thread */ int pthread_getaffinity_np(pthread_t thread, size_t cpusetsize, cpu_set_t *cpuset); 程序中会使用syscall来获取一些内核数据,syscall是执行一个系统调用,根据指定的参数number和所有系统调用的接口来确定调用哪个系统调用,用于用户空间跟内核之间的数据交换,下面是syscall函数原型及一些常用的number: 12345678910111213141516171819202122232425262728//syscall - indirect system call#define _GNU_SOURCE /* See feature_test_macros(7) */#include <unistd.h>#include <sys/syscall.h> /* For SYS_xxx definitions */int syscall(int number, ...);// 查看缓存内存页面的大小;打印用%ld 长整型。sysconf(_SC_PAGESIZE); // 查看内存的总页数;打印用%ld 长整型。sysconf(_SC_PHYS_PAGES) // 查看可以利用的总页数;打印用%ld 长整型。sysconf(_SC_AVPHYS_PAGES) // 查看 CPU 的个数;打印用%ld 长整。sysconf(_SC_NPROCESSORS_CONF) // 查看在使用的 CPU 个数;打印用%ld 长整。sysconf(_SC_NPROCESSORS_ONLN) // 计算内存大小。(long long)sysconf(_SC_PAGESIZE) * (long long)sysconf(_SC_PHYS_PAGES) // 查看最大登录名长度;打印用%ld 长整。sysconf(_SC_LOGIN_NAME_MAX) // 查看最大主机长度;打印用%ld 长整。sysconf(_SC_HOST_NAME_MAX) // 每个进程运行时打开的文件数目;打印用%ld 长整。sysconf(_SC_OPEN_MAX) // 查看每秒中跑过的运算速率;打印用%ld 长整。sysconf(_SC_CLK_TCK) 使用 2 种方式 (带和不带_S 后缀的宏) 获取当前进程的 CPU 亲和性相关的宏通常都分为 2 种,一种是带_S后缀的,一种不是不带_S后缀的,从声明上看带_S后缀的宏都多出一个参数 setsize。 从功能上看他们的区别是带_S后缀的宏是用于操作动态申请的CPU set(s),所谓的动态申请其实就是使用宏 CPU_ALLOC 申请, 参数 setsize 可以是通过宏 CPU_ALLOC_SIZE 获得,两者的用法详见下面的例子。 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970#define _GNU_SOURCE#include <sched.h>#include <unistd.h>#include <stdlib.h>#include <stdio.h>#undef WITH_S#ifdef WITH_Sint main(void){ int i, nrcpus; cpu_set_t *pmask; size_t cpusize; unsigned long bitmask = 0; /* 获取逻辑 CPU 个数 */ nrcpus = sysconf(_SC_NPROCESSORS_CONF); pmask = CPU_ALLOC(nrcpus); cpusize = CPU_ALLOC_SIZE(nrcpus); CPU_ZERO_S(cpusize, pmask); /* 获取 CPU 亲和性 */ if (sched_getaffinity(0, cpusize, pmask) == -1) { perror("sched_getaffinity"); CPU_FREE(pmask); exit(EXIT_FAILURE); } for (i = 0; i < nrcpus; i++) { if (CPU_ISSET_S(i, cpusize, pmask)) { bitmask |= (unsigned long)0x01 << i; printf("processor #%d is set\\n", i); } } printf("bitmask = %#lx\\n", bitmask); CPU_FREE(pmask); exit(EXIT_SUCCESS);}#elseint main(void){ int i, nrcpus; cpu_set_t mask; unsigned long bitmask = 0; CPU_ZERO(&mask); /* 获取 CPU 亲和性 */ if (sched_getaffinity(0, sizeof(cpu_set_t), &mask) == -1) { perror("sched_getaffinity"); exit(EXIT_FAILURE); } /* 获取逻辑 CPU 个数 */ nrcpus = sysconf(_SC_NPROCESSORS_CONF); for (i = 0; i < nrcpus; i++) { if (CPU_ISSET(i, &mask)) { bitmask |= (unsigned long)0x01 << i; printf("processor #%d is set\\n", i); } } printf("bitmask = %#lx\\n", bitmask); exit(EXIT_SUCCESS);}#endif 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556# 直接运行,不设置亲和性,获取CPU亲和性为所有CPU都会被设置➜ Affinity git:(main) ./bin/main processor #0 is setprocessor #1 is setprocessor #2 is setprocessor #3 is setprocessor #4 is setprocessor #5 is setprocessor #6 is setprocessor #7 is setprocessor #8 is setprocessor #9 is setprocessor #10 is setprocessor #11 is setprocessor #12 is setprocessor #13 is setprocessor #14 is setprocessor #15 is setprocessor #16 is setprocessor #17 is setprocessor #18 is setprocessor #19 is setprocessor #20 is setprocessor #21 is setprocessor #22 is setprocessor #23 is setprocessor #24 is setprocessor #25 is setprocessor #26 is setprocessor #27 is setprocessor #28 is setprocessor #29 is setprocessor #30 is setprocessor #31 is setbitmask = 0xffffffff# 使用taskset设置亲和性,将main程序绑定到第1个CPU上,mask转化为16进制为0x1➜ Affinity git:(main) taskset 1 ./bin/mainprocessor #0 is setbitmask = 0x1# 使用taskset设置亲和性,将main程序绑定到第1,3,5,7个CPU上,mask转化为16进制为0x55➜ Affinity git:(main) taskset 55 ./bin/mainprocessor #0 is setprocessor #2 is setprocessor #4 is setprocessor #6 is setbitmask = 0x55# 使用taskset设置亲和性,将main程序绑定到第1,2,3,4个CPU上,mask转化为16进制为0xf➜ Affinity git:(main) taskset F ./bin/mainprocessor #0 is setprocessor #1 is setprocessor #2 is setprocessor #3 is setbitmask = 0xf 设置进程的 CPU 亲和性后再获取显示 CPU 亲和性123456789101112131415161718192021222324252627282930313233343536373839404142434445464748#define _GNU_SOURCE#include <sched.h>#include <unistd.h> /* sysconf */#include <stdlib.h> /* exit */#include <stdio.h>int main(void){ int i, nrcpus; cpu_set_t mask; unsigned long bitmask = 0; CPU_ZERO(&mask); CPU_SET(0, &mask); /* add CPU0 to cpu set */ CPU_SET(2, &mask); /* add CPU2 to cpu set */ CPU_SET(3, &mask); /* add CPU3 to cpu set */ /* 设置 CPU 亲和性 */ if (sched_setaffinity(0, sizeof(cpu_set_t), &mask) == -1) { perror("sched_setaffinity"); exit(EXIT_FAILURE); } CPU_ZERO(&mask); if (sched_getaffinity(0, sizeof(cpu_set_t), &mask) == -1) { perror("sched_getaffinity"); exit(EXIT_FAILURE); } /* get logical cpu number */ nrcpus = sysconf(_SC_NPROCESSORS_CONF); for (i = 0; i < nrcpus; i++) { if (CPU_ISSET(i, &mask)) { bitmask |= (unsigned long)0x01 << i; printf("processor #%d is set\\n", i); } } printf("bitmask = %#lx\\n", bitmask); exit(EXIT_SUCCESS);} 12345➜ Affinity git:(main) ✗ ./bin/main processor #0 is setprocessor #2 is setprocessor #3 is setbitmask = 0xd 设置线程的 CPU 属性后再获取显示 CPU 亲和性12345678910111213141516171819202122232425262728293031323334353637383940414243444546#define _GNU_SOURCE#include <pthread.h> //不用再包含<sched.h>#include <stdio.h>#include <stdlib.h>#include <errno.h>#define handle_error_en(en, msg) \\ do { errno = en; perror(msg); exit(EXIT_FAILURE); } while (0)intmain(int argc, char *argv[]){ int s, j; cpu_set_t cpuset; pthread_t thread; thread = pthread_self(); /* Set affinity mask to include CPUs 0 to 7 */ CPU_ZERO(&cpuset); for (j = 0; j < 8; j++) CPU_SET(j, &cpuset); s = pthread_setaffinity_np(thread, sizeof(cpu_set_t), &cpuset); if (s != 0) { handle_error_en(s, "pthread_setaffinity_np"); } /* Check the actual affinity mask assigned to the thread */ s = pthread_getaffinity_np(thread, sizeof(cpu_set_t), &cpuset); if (s != 0) { handle_error_en(s, "pthread_getaffinity_np"); } printf("Set returned by pthread_getaffinity_np() contained:\\n"); for (j = 0; j < CPU_SETSIZE; j++) //CPU_SETSIZE 是定义在<sched.h>中的宏,通常是 1024 { if (CPU_ISSET(j, &cpuset)) { printf(" CPU %d\\n", j); } } exit(EXIT_SUCCESS);} 12345678910➜ Affinity git:(main) ./bin/mainSet returned by pthread_getaffinity_np() contained: CPU 0 CPU 1 CPU 2 CPU 3 CPU 4 CPU 5 CPU 6 CPU 7 使用 seched_setaffinity 设置线程的 CPU 亲和性123456789101112131415161718192021222324252627282930313233343536#define _GNU_SOURCE#include <sched.h>#include <stdlib.h>#include <sys/syscall.h> // syscallint main(void){ pid_t tid; int i, nrcpus; cpu_set_t mask; unsigned long bitmask = 0; CPU_ZERO(&mask); CPU_SET(0, &mask); /* add CPU0 to cpu set */ CPU_SET(2, &mask); /* add CPU2 to cpu set */ // 获取线程 id tid = syscall(__NR_gettid); // or syscall(SYS_gettid); // 对指定线程 id 设置 CPU 亲和性 if (sched_setaffinity(tid, sizeof(cpu_set_t), &mask) == -1) { perror("sched_setaffinity"); exit(EXIT_FAILURE); } nrcpus = sysconf(_SC_NPROCESSORS_CONF); for (i = 0; i < nrcpus; i++) { if (CPU_ISSET(i, &mask)) { bitmask |= (unsigned long)0x01 << i; printf("processor #%d is set\\n", i); } } exit(EXIT_SUCCESS);} 123➜ Affinity git:(main) ./bin/mainprocessor #0 is setprocessor #2 is set 什么是中断亲和性计算机中,中断是一种电信号,由硬件产生并直接送到中断控制器上,再由中断控制器向 CPU 发送中断信号,CPU 检测到信号后,中断当前工作转而处理中断信号。CPU 会通知操作系统已经产生中断,操作系统就会对中断进行处理。这里有篇推文:CPU 明明 8 个核,网卡为啥拼命折腾一号核?生动的解释了中断亲和性。 默认情况下,Linux 中断响应会被平均分配到所有 CPU 核心上,势必会发生写新的数据和指令缓存,并与 CPU 核心上原有进程产生冲突,造成中断响应延迟,影响进程处理时间。为了解决这个问题,可以将中断(或进程)绑定到指定 CPU 核心上,中断(或进程)所需要指令代码和数据有更大概率位于指定 CPU 本地数据和指令缓存内,而不必进行新的写缓存,从而提高中断响应(或进程)的处理速度。 中断亲和性的使用场景对于文件服务器、Web 服务器,把不同的网卡 IRQ 均衡绑定到不同的 CPU 上将会减轻某 CP 的负载,提高多个 CPU 整体处理中断的能力; 对于数据库服务器,把磁盘控制器绑到一个 CPU、把网卡绑定到另一个 CPU 将会提高数据库的响应时间、优化性能。合理的根据自己的生产环境和应用的特点来平衡 IRQ 中断有助于提高系统的整体吞吐能力和性能。 中断绑定流程 关闭中断平衡守护进程中断平衡守护进程(irqbalance daemon)会周期性地将中断平均地公平地分配给各个 CPU 核心,默认开启。为了实现中断绑定,首先需要将中断平衡守护进程关闭。 systemctl status irqbalance查看守护进程的运行状态 1234567891011➜ ~ systemctl status irqbalance● irqbalance.service - irqbalance daemonLoaded: loaded (/lib/systemd/system/irqbalance.service; enabled; vendor preset: enableActive: active (running) since Thu 2022-05-19 14:46:20 CST; 1 weeks 1 days agoMain PID: 1062 (irqbalance) Tasks: 2 (limit: 4915)CGroup: /system.slice/irqbalance.service └─1062 /usr/sbin/irqbalance --foreground5月 19 14:46:20 zdd systemd[1]: Started irqbalance daemon. systemctl stop irqbalance关闭中断平衡守护进程,中断响应默认都会由 CPU0 核心处理。或者systemctl disable irqbalance取消中断平衡守护进程开机重启。因为关闭中断平衡守护进程过于强硬,可以在不关闭中断平衡守护进程条件下,让某些 CPU 核心脱离中断平衡守护进程的管理。 绑定中断中断绑定时,需要关闭系统中断平衡守护进程systemctl stop irqbalance计算机当前各种中断响应情况在 /proc/interrupts 文件中。 第一列是中断 ID 号,CPU N 列是中断在第 n 个 CPU 核心上的响应次数,倒数第二列是中断类型,最后一列是描述。 利用 echo 命令将 CPU 掩码写入 /proc/irq/中断 ID/smp_affinity 文件中,即可实现修改某一中断的 CPU 亲和性。例如 1echo 0x0004 > /proc/irq /50/smp_affinity 参考资料Linux 中 CPU 亲和性 (affinity) - LubinLew - 博客园操作系统底层技术——CPU 亲和性_mb60ed33cfc44fa 的技术博客_51CTO 博客linux 进程、线程与 CPU 的亲和性(affinity)_wx61d68abba262d 的技术博客_51CTO 博客CPU 明明 8 个核,网卡为啥拼命折腾一号核?Processor affinity - Wikipedia什么?一个核同时执行两个线程?linux 进程、线程与 CPU 的亲和性(affinity) - zhangwju - 博客园","categories":[],"tags":[{"name":"CPU","slug":"CPU","permalink":"http://example.com/tags/CPU/"},{"name":"亲和性","slug":"亲和性","permalink":"http://example.com/tags/%E4%BA%B2%E5%92%8C%E6%80%A7/"},{"name":"Affinity","slug":"Affinity","permalink":"http://example.com/tags/Affinity/"},{"name":"操作系统","slug":"操作系统","permalink":"http://example.com/tags/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/"},{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"}]},{"title":"SoC 存储器比较","slug":"SoC存储器比较","date":"2022-05-21T09:13:33.000Z","updated":"2022-10-15T03:14:29.573Z","comments":true,"path":"2022/05/21/SoC存储器比较/","link":"","permalink":"http://example.com/2022/05/21/SoC%E5%AD%98%E5%82%A8%E5%99%A8%E6%AF%94%E8%BE%83/","excerpt":"","text":"内存也就是内部存储器,主要用来运行程序的,典型的就是 RAM 随机存储器(Random Access Memory),那么随机是什么意思?所谓随机,指的是当存储器中的数据被读取或写入时,所需要的时间与这段信息所在的位置无关(任何位置读写速度一样)。 DRAM(Dynamic Random Access Memory,动态随机存储器)是最为常见的系统内存。我们使用的电脑和手机的运行内存都是 DRAM。DRAM 使用电容存储,DRAM 只能将数据保持很短的时间。为了保持数据,所以必须隔一段时间刷新(refresh)一次,如果存储单元没有被刷新,存储的信息就会丢失。数据的存储,请参考数据存储模型。我们知道,电容中的电荷很容易变化,所以随着时间推移,电容中的电荷数会增加或减少,为了确保数据不会丢失,DRAM 每隔一段时间会给电容刷新(充电或放电)。动态:定时刷新数据 SRAM(Static Random Access Memory,静态随机存储器),它是一种具有静止存取功能的内存,其内部机构比 DRAM 复杂,可以做到不刷新电路即能保存它内部存储的数据。静态:不需要刷新 DDR SDRAM(Double Data Rate SDRAM):为双信道同步动态随机存取内存,是新一代的 SDRAM 技术。DDR 内存芯片的数据预取宽度(Prefetch)为 2 bit(SDRAM 的两倍)。 DDR2 SDRAM(Double Data Rate Two SDRAM):为双信道两次同步动态随机存取内存。DDR2 内存 Prefetch 又再度提升至 4 bit(DDR 的两倍) DDR3 SDRAM(Double Data Rate Three SDRAM):为双信道三次同步动态随机存取内存。DDR3 内存 Prefetch 提升至 8 bit,即每次会存取 8 bits 为一组的数据。运算频率介于 800MHz -1600MHz 之间。 外存外部存储器,通常用来存储文件的,一般也叫 ROM(Read-only memory)只读存储器。 CPU 连接内存和外存的连接方式不同。内存需要直接地址访问,所以是通过地址总线&数据总线的总线式访问方式连接的(好处是直接访问,随机访问;坏处是占用 CPU 的地址空间,大小受限);外存是通过 CPU 的外存接口来连接的(好处是不占用 CPU 的地址空间,坏处是访问速度没有总线式快,访问时序较复杂) 我们平时用的硬盘,SD 卡都属于 ROM,但是他们却可以写入?ROM 严格意义来讲确实是只读的,但是随着储存器的发展,出现了可擦可编程只读存储器(EPROM)、电可擦可编程只读存储器(EEPROM)形式的半导体存储器,以及 flash。他们都是可写的。ROM 就不再单单只表示只读存储器了,一般来说与 RAM 相对,掉电不易失的存储器都被当做 ROM。 ROMROM(Read Only Memory)只读存储器,这种存储器(Memory)的内容任何情况下都不会改变,电脑与用户只能读取保存在这里的指令,和使用存储在 ROM 的资料,但不能变更或存入资料。ROM 被存储在一个非易失性芯片上,也就是说,即使在关机之后记忆的内容仍可以被保存,所以这种存储器多用来存储特定功能的程序,如固件。ROM 存储用来启动电脑的程序(如BIOS),电脑引导的时候 BIOS 提供一连串的指令对中央处理器(CPU)等组件进行初始化,在初始化过程中,BIOS 程序初始化并检查RAM。 NorFlash总线式访问,接到 SROM bank,优点是可以直接总线访问,一般用来启动。 NandFlashSLC:容量小,价格高,稳定性高 MLC:容量大,价格低,稳定性差,易出坏块 iNandSanDisk 公司出产的 eMMC moviNand三星公司出产的 eMMC oneNAND三星公司出的一种 Nand,价格贵,用的少 SD 卡(Secure Digital Memory Card) TF 卡(TransFLash Card, MicroSD) MMC 卡 eMMC 卡(embeded MMC)嵌入式的 MMC,可以当成一种芯片,内部做了坏块处理 SATA 硬盘 特点:机械式访问、磁存储原理、SATA 是接口。","categories":[],"tags":[{"name":"芯片开发","slug":"芯片开发","permalink":"http://example.com/tags/%E8%8A%AF%E7%89%87%E5%BC%80%E5%8F%91/"},{"name":"SoC","slug":"SoC","permalink":"http://example.com/tags/SoC/"},{"name":"固件开发","slug":"固件开发","permalink":"http://example.com/tags/%E5%9B%BA%E4%BB%B6%E5%BC%80%E5%8F%91/"},{"name":"存储器","slug":"存储器","permalink":"http://example.com/tags/%E5%AD%98%E5%82%A8%E5%99%A8/"}]},{"title":"Interlaken 协议","slug":"Interlaken协议","date":"2022-05-18T14:40:47.000Z","updated":"2022-10-15T03:14:29.259Z","comments":true,"path":"2022/05/18/Interlaken协议/","link":"","permalink":"http://example.com/2022/05/18/Interlaken%E5%8D%8F%E8%AE%AE/","excerpt":"","text":"对 Interlaken 协议文档的翻译加了一些自己的理解; 8b/10b编码:在串行通道上传输时,将 8bits 数据编码为 10bits 数据,做一个转换,使各位数据之间有更多的 1 到 0 和 0 到 1 的跳变,以便接收设备检测这些跳变,能更容易地恢复时钟。64B/67B 编码编码的原因也是类似的。这样,在串行通道上传输 10 位数据,实际上只传输了 8 位。 协议层(Protocol Layer)传输格式数据通过可配置数量的 SerDes 通道(Lane),再由 Interlaken 接口传输。在本文档中,通道被定义为两个 IC 之间的单工串行链路(simplex serial link)。该协议旨在与任意数量的通道一起运行(1 个或多个,没有上限)。实际实现时会固定一个数值,不会设计为可变值。 接口发送数据的基本单位是一个 8 字节的字(Word)。用 8 字节是为了符合64B/67B 编码,用于描述突发(Burst)的控制字的大小也是 8 字节。通过使基本传输单元与控制字大小相等,可以很容易地调整接口的宽度。 数据和控制字按顺序在通道上传输,从通道 0 开始,到通道 M 结束,并在下一个数据块中重复。图 4 说明了该过程 64B/67B编码在每个通道上独立进行。传输通过两种基本数据类型实现:数据字和控制字,他们通过64B/67B 帧位(framing bits)进行区分。这两种数据字类型的格式如下图所示: 数据和控制信息都是以位 66~0 的顺序传输的,框架层引入了 4 个附加控制字,详细信息后面将描述。 Burst 结构(Burst Structure)数据传输流程Interlaken 接口的带宽在支持的通道上被划分为 Bursts。数据包通过一个或多个 Burst 在接口上传输。Burst 通过一个或多个控制字来描述。为了将任意大小的数据包分割成 Burst,定义以下两个参数: BurstMax:Burst 的最大大小(64Bytes 的倍数) BurstShort:Burst 的最小大小(最小 32Bytes,增量为 8Bytes) 该接口通常通过发送一个 BurstMax 长度的数据突发来运行,然后是一个控制字。发送设备中的调度逻辑可以自由选择信道服务的顺序,受流控状态的约束。Burst 在每个通道上传输,直到数据包完全传输,此时该通道上的新数据包传输才开始。 因为接口是信道化的,数据包的结束可能会在几个信道上连续地出现,每个信道上的剩余数据量非常小。由于发射器和接收器的存储器可能被理想地设计成宽数据通路,它们需要以非常高的速率来处理这种情况。为了减少接收器和发射器的负担,BurstShort 参数保证了连续的 Burst 控制字之间的最小间隔。最小的 BurstShort 间隔是 32 字节,更大的值可以以 8 字节为增量。 如果没有最小 Burst 的限制,那么数据包太小的话,发送器或者接收器就会频繁收到 end-of-packet,这就增加了处理负担。 控制字格式突发通过一个 8 字节的控制字来描述。控制字在数据流中通过使用位 [66:64] 的“0x10”控制代码和位 [63] = ‘1’ 来标识突发和空闲控制字格式如第 16 页的图 7 所示: 流控(Flow Control)Interlaken 的一个关键特性是能够传达每个通道背压(backpressure)。为了提供此功能,指定了两个选项:带外流控接口和带内通道。从语义上讲,流控制信息使用简单的开关机制来表示允许在特定通道上传输。 开关流控制状态与每个通道的单个状态位进行通信。按照惯例,“1”标识“XON”状态,表示允许发送器在该通道上发送数据。 “0”标识“XOFF”状态,表示发送器不允许在该通道上发送数据。 该协议没有 Credits 的概念;一旦通道被指示为 XON,发送器可以在该通道上发送尽可能多的数据,直到流控制状态更改为 XOFF。接收器选择在 XON 和 XOFF 状态之间切换的阈值是留给用户的可编程选项,取决于支持的通道数量、接收缓冲区的深度和给定环境的流控制延迟。 流控制通道可以选择映射到 calendar,从而流控制可以映射到任何一组 calendar entry。例如,这些可以包括通道到 calendar entry 的一对一映射、一对多映射或插入空字段以匹配具有不同通道定义的设备。 Channel Calendar 将通道映射到流控状态槽 这个 Calendar 结构也可以用来提供链路级的流控制,Calendar 中的一个 bit 代表了在整个接口上传输数据的权限。链路状态的极性将与通道状态的极性相同:“1”表示允许传输,“0”表示立即停止传输。要启用此功能,可以为每个 Calendar entry 配置通道信息或链接信息。为了促进低延迟链路状态,接口需要提供足够的 Calendar entry,以便在每个突发/空闲控制字的相同位位置编程链路状态。例如,使用超过 16 个通道,这可以通过以下设置执行: 使用此方法,link status将始终出现在突发/空闲控制字的位[55]中。 带外流控为了支持需要单工操作的系统,定义了带外流量控制选项。这是作为一个源同步接口实现的,并由以下信号指定: 型号名称 功能 FC_CLK 与流控数据同步的时钟 FC_DATA 流量控制状态信息 (单比特) FC_SYNC 一种同步信号,用于标识流控制 calendar 的开头 每个信号的 pad 技术可以是 LVDS 或 LVCMOS。这些信号的逻辑时序关系如下图所示: 带外流控制通道由 4 位 CRC 计算保护,该 CRC 计算覆盖了多达 64 位的流控制数据。根据^[P. Koopman and T. Chakravarty, Cyclic Redundancy Code (CRC) Polynomial Selectionfor Embedded Networks, The International Conference on Dependable Networks andSystems, DSN-2004.] 中的建议,CRC4 多项式为: $$x^4+x+1$$ 带内流控当使用此选项时,接收器利用通过接口发送的控制字中的流控制状态,作为正常数据传输的一部分。提供此选项的目的是,需要最少数量的外部信号引脚的全双工实现。 如 Figure 7 所示,控制字的流控制字段为 16 位,位于 bit[55:40]。控制字的位 [31:24] 也可以用于流控制的另外 8 位,总共 24 位。这些状态位表示每个 Interlaken Calendar 通道的 ON-OFF 流控制状态,当前 Calendar Entry X 在位 [55],Calendar Entry X + 1 在位 [54],依此类推。为了同步 calendar 的开始,在空闲/突发控制字中提供了“reset calendar”位。当该位为“1”时,calendar entry 0 的状态将出现在位 [55] 中。当“reset calendar”为“0”时,calendar 将从上一个控制字中保留的位置开始继续。当所有通道的流控状态被传输完,发送器将重置复位 calendar,然后重复上一轮顺序操作。Calendar 最后一个控制字中不需要的 bit(即,当通道数目不是状态数目的倍数时)被发送端置 0,接收端忽略。 参考资料","categories":[{"name":"通信协议","slug":"通信协议","permalink":"http://example.com/categories/%E9%80%9A%E4%BF%A1%E5%8D%8F%E8%AE%AE/"}],"tags":[{"name":"Interlaken","slug":"Interlaken","permalink":"http://example.com/tags/Interlaken/"}]},{"title":"AMBA 总线协议-AXI 协议","slug":"AMBA总线协议-AXI协议","date":"2022-05-17T13:16:45.000Z","updated":"2022-10-15T03:14:29.046Z","comments":true,"path":"2022/05/17/AMBA总线协议-AXI协议/","link":"","permalink":"http://example.com/2022/05/17/AMBA%E6%80%BB%E7%BA%BF%E5%8D%8F%E8%AE%AE-AXI%E5%8D%8F%E8%AE%AE/","excerpt":"","text":"AXI组成部分: AXI4 协议中包含五种信道,通道之间相互独立且存在差别,通过通道进行通信之前需要使用 VALID/READY 进行握手,Read 和 Write 根据 Master 定义: 读地址信道(Read Address Channel) 写地址信道(Write Address Channel) 读数据信道(Read Data Channel) 写数据信道(Write Data Channel) 写响应信道(Write Response Channel) 还有两种 Component Master component Slave component 通信由 Master 发起,Master 可以对 Slave 进行读数据(read)或写(write)数据。每次读写操作都需要一个地址,读地址信道(Read Address Channel)和写地址信道(Write Address Channel)用于传输地址。在写完数据后,Master 需要确认 Slave 有没有收完数据,Slave 收到完整数据后,会通过写响应信道(Write Response Channel)给 Master 一个反馈(completion),表示写操作已经完成。 VALID/READY 握手机制AXI 五个信道相互独立,但是使用同一个握手机制来实现信息传递。 在握手机制中,通信双方分别扮演发送方(Source) 和接收方(Destination),两者的操作(技能)并不相同。 发送方置高 VALID 信号表示发送方已经将数据,地址或者控制信息已经就绪,并保持于消息总线上。 接收方置高 READY 信号表示接收方已经做好接收的准备。 当双方的 VALID/READY 信号同时为高,在时钟 ACLK 上升沿,完成一次数据传输。所有数据传输完毕后,双方同时置低自己的信号。 每个通道都有自己的 VALID /READY 握手信号对: 在握手过程中,还会用到 LAST 信号。LAST 信号存在 Write Data Channel 和 Read Data Channel 中,分别表示为 WLAST 和 RLAST,用于标记 burst 的最后一次数据传输,当 slave 接收到 LAST 信号后,说明本次数据传输完成。 双向流控所谓的双向流控机制,指的是发送方通过置起 VALID 信号控制发送的时机与速度,接收方也可以通过 READY 信号的置起与否控制接收速度。 发送方拥有传输的主动权,但接收方在不具备接收能力时,也能够置低信号停止传输,反压发送方。 握手过程分析 图中 INFORMATION 信号无底色区域表示此时数据已经准备好,已经有新的数据到达。 VALID 信号先到 发送方 VALID 信号早早就到了,但是接收方的 READY 信号在 T2 之前都没有发送。可能接收方在接收其他数据,或者被堵在数据通路上。 过了 T2 后,READY 信号到来,此时开始传输,直到 T3 结束,传输完成。 这里也体现了双向流控机制,发送方的 VALID 信号只要置高,再握手完成之前都不能置低,必须等到接收方 READY 信号置高。 READY 信号先到 READY 信号很自由,可以等待 VALID 信号到来再做响应,但也完全可以在 VALID 信号到来前就置高,表示接收端已经做好准备了。 而且,READY 信号与 VALID 不同,接收方可以置起 READY 之后在 VALID 置高之前都可以随时再置低 READY 信号。 信号同时同时到达 这个最简单,两个信号都等着一个时钟上升沿就完成传输了。 握手信号之间的依赖关系为了防止死锁发生,信号之间要遵循一些规矩,举例来说,如上面提到的 READY 信号依赖 VALID 信号,但是 VALID 信号不能根据 READY 信号来判断是否数据已准备好,否则将会造成死锁。下面详细解释读写过程中需要遵循的依赖关系。 单箭头指向的两个信号,信号的置高,低没有顺序要求。 双箭头表示箭头所指对象应迟于箭头出发信号发送。 Read transaction dependencies Master 不得等待 Slave 置高 ARREADY Slave 可以在置高 ARREADY 之前等待 ARVALID 置高 Slave 能够在 ARVALID 置高之前先置高 ARREADY Slave 必须等待 ARVALID 和 ARREADY 都被置高,然后才置高 RVALID 以表示有效数据可用 在置高 RVALID 之前,Slave 不得等待 Master 置高 RREADY Master 可以在置高 RREADY 之前等待 RVALID 被置高 Master 可以在 RVALID 被置高之前置高 RREADY Write transaction dependencies 在置高 AWVALID 或 WVALID 之前,Master 不得等待 Slave 置高 AWREADY 或 WREADY Slave 可以在置高 AWREADY 之前等待 AWVALID 或 WVALID,或两者都等待 Slave 可以在 AWVALID 或 WVALID 或两者都被置高之前置高 AWREADY 在置高 WREADY 之前,Slave 可以等待 AWVALID 或 WVALID,或两者都等待 Slave 可以在 AWVALID 或 WVALID 或两者都被置高之前置高 WREADY 在置高 BVALID 之前,Slave 必须等待 WVALID 和 WREADY 都被置高 Slave还必须在置高 BVALID 之前等待 WLAST 被置高,因为写入响应 BRESP 必须在写入事务的最后一次数据传输之后才发出信号 在置高 BVALID 之前,Slave 不得等待 Master 置高 BREADY Master 可以在置高 BREADY 之前等待 BVALID Master 可以在 BVALID 被置高之前置高 BREADY 地址结构(Address structure)AXI 协议是基于 Burst 的,地址结构里声明了一些传输过程中需要的信号,如起始地址,burst 传输长度,传输模式等等。 Burst在介绍 Burst transfer 之前,需要解释一下什么是 Burst。在手册的术语表中,与 AXI 传输相关的有三个概念,分别是 transfer(beat)、burst、transaction。 AXI Transaction:the complete set of required operations on the AXI bus form the AXI Transaction.表示传输一段数据 (AXI burst) 所需的一整套操作; AXI Burst:any required payload data is transferred as an AXI Burst.表示 AXI 待传数据; AXI Beats:a burst can comprise multiple data transfers, or AXI Beats.表示 AXI burst 的组成,一个 Beat 就是一个 transfer。 三者的关系:在 AXI 传输事务(Transaction)中,数据以突发传输(Burst)的形式组织。一次突发传输中可以包含一至多个数据(Transfer)。每个 transfer 因为使用一个周期,又被称为一拍数据(Beat)。 $$\\text{Transaction} = M \\text{Burst} ,M \\geq 1 \\\\text{Burst} = N \\text{Transfer( or Beat)} ,N \\geq 1$$ 在地址通道中有三个信号控制进行控制,包括: ARLEN(Burst Length) 指一次突发传输中包含的数据传输 (transfer) 数量,在协议中使用 AxLen 信号控制。在 AXI4 中,INCR 类型最大支持长度为 256,其他类型最大长度为 16。而 AXI3 中这一数字无论何种模式均为 16。因此 AXI4 中 AxLen 信号位宽为 8bit,AXI3 中的 AxLen 则仅需要 4bit。 ARSIZE(Burst Size) 指传输中的数据位宽,具体地,是每周期传输数据的字节数量,在协议中使用 AXSIZE 信号控制。突发传输数据宽度不能超过数据总线本身的位宽。而当数据总线位宽大于突发传输宽度时,将根据协议的相关规定,将数据在部分数据线上传输。 ARBURST(Burst Type) Burst Type:AXI 协议中支持不同的 Burst 传输类型,主要分 FIXED、INCR、WRAP。 FIXED 传输为地址固定传输,所有传输都会写在同一个地址中。主要应用在 FIFO 的传输中,因为 FIFO 为先入先出,只需要往同一个地址写数据即可。 INCR 传输为地址递增传输,可根据具体的配置有固定长度递增和非定长递增。大部分的数据传输都是使用这种方式,尤其是在内存访问中,可以大大提高效率。 WRAP 传输为地址回环传输,在一定长度后会回环到起始地址。主要应用在 Cache 操作中,因为 cache 是按照 cache line 进行操作,采用 wrap 传输可以方便的实现从内存中取回整个 cache line。 AXI burst 读操作:master 只需要发送 burst 的起始地址,slave 会根据 burst 的起始地址与 burst 场地自动进行地址计算,将对应的数据与响应发送到 master 侧。 AXI burst 写操作中,也只需要发送 burst 写的起始地址,slave 只需要接受起始地址,然后根据传输的长度将数据传输到对应的地址缓存中。只需要进行一次握手就可以实现地址通道的请求传输,避免系统总线的占用。 数据结构(Data read and write structure)读写数据结构中声明了几种数据传输方式。 在介绍这些传输方式之前,需要了解WSTRB(Write strobes) 写选通信号。写选通信号 WSTRB 允许在写数据总线上进行 稀疏数据 传输。每个写选通信号对应写数据总线上的一个字节。当写选通断言时,表示写数据总线上对应的字节通道中包含将被更新到 memory 的有效信息。 写数据总线上每 8 位具有一个写选通位,因此 WSTRB[n] 对应 WDATA[(8 x n) + 7 : (8 x n)]。默认情况下 WSTRB = 0xFFFF。也就是所有通路都是通的。 Narrow Transfer当本次传输中数据位宽小于通道本身的数据位宽时,称为窄位宽数据传输,或者直接翻译成窄传输。如下图,传输总线为 32bit,但是每次只传了 8 bit。 窄传输就是通过 STRB 信号指定有效传输数据的位宽来实现。针对一些特定的寄存器读写,或者在不同数据位宽的总线传输中会使用窄传输操作。如图,第一次传输时,WSTRB 信号为 0x01,WSTRB = b’001,表示 WDATA[7:0] 数据有效。 需要注意在多笔连续的窄传输操作中,STRB 会随着地址递增进行响应的变化,这样方便在系统设计使用中可以方便的将窄传输合并,从而提升系统传输效率。 Unaligned TransferAXI 协议规定单次 burst 传输中的数据,其地址不能跨越 4KB 边界。也就是在传输过程中会进行 4K 对齐。但是在某些时候,会期望在非对齐的地址开始一个突发,即非对齐传输。 协议中之所以规定一个 burst 不能跨越 4K 边界是为了避免一次 burst 访问两个 slave(每个 slave 的地址空间是 4K/1K 对齐的)。4K 对齐最大原因是系统中定义一个 page 大小是 4K,而所谓的 4K 边界是指低 12bit 为 0 的地址。 非对齐传输是指有些传输指令不是按照 word 对齐,而是按照 Byte 对齐进行传输。起始地址可能是任意的地址。如下图中,起始地址为 0x1,则在系统上需要按照非对齐的方式进行传输。第一次传输采用 strb 信号指定对应的 Byte 有效,后面的传输可以按照正常的传输进行。 下图是一些传输示例,有阴影的格子表示当前字节不会被传输。 图一为正常的对齐传输,传输起始地址为 0x00。 图二为非对齐传输,起始地址为 0x01,第一个格子对应的 WSTRB = b’1110。 图三同上,只是 Burst length 为 5。 图四也为非对齐传输,起始地址为 0x07。对应的 WSTRB = b’1000。","categories":[{"name":"通信协议","slug":"通信协议","permalink":"http://example.com/categories/%E9%80%9A%E4%BF%A1%E5%8D%8F%E8%AE%AE/"}],"tags":[{"name":"AMBA","slug":"AMBA","permalink":"http://example.com/tags/AMBA/"},{"name":"AXI","slug":"AXI","permalink":"http://example.com/tags/AXI/"},{"name":"总线协议","slug":"总线协议","permalink":"http://example.com/tags/%E6%80%BB%E7%BA%BF%E5%8D%8F%E8%AE%AE/"},{"name":"协议","slug":"协议","permalink":"http://example.com/tags/%E5%8D%8F%E8%AE%AE/"},{"name":"通信协议","slug":"通信协议","permalink":"http://example.com/tags/%E9%80%9A%E4%BF%A1%E5%8D%8F%E8%AE%AE/"}]},{"title":"C 语言实现简单有限状态机","slug":"C语言实现简单有限状态机","date":"2022-05-15T04:41:30.000Z","updated":"2022-10-15T03:14:29.173Z","comments":true,"path":"2022/05/15/C语言实现简单有限状态机/","link":"","permalink":"http://example.com/2022/05/15/C%E8%AF%AD%E8%A8%80%E5%AE%9E%E7%8E%B0%E7%AE%80%E5%8D%95%E6%9C%89%E9%99%90%E7%8A%B6%E6%80%81%E6%9C%BA/","excerpt":"","text":"简介常说的状态机是有限状态机 FSM,是表示有限个状态以及在这些状态之间的转移和动作等行为的数学计算模型。三个特征: 状态总数(state)是有限的。 任一时刻,只处在一种状态之中。 某种条件下,会从一种状态转变(transition)到另一种状态。 设计状态机的关键点:当前状态、外部输入、下一个状态。 状态机分类Moore 型状态机Moore 型状态机特点是:输出只与当前状态有关(与输入信号无关)。相对简单,考虑状态机的下一个状态时只需要考虑它的当前状态就行了。 Mealy 型状态机Mealy 型状态机的特点是:输出不只和当前状态有关,还与输入信号有关。状态机接收到一个输入信号需要跳转到下一个状态时,状态机综合考虑 2 个条件(当前状态、输入值)后才决定跳转到哪个状态。 实现一个简单的状态机代码参考AstarLight/FSM-framework。 以小明的一天设计出一个状态机,下图为状态转移图: 首先,有限状态机的状态是有限的,我们可以定义一天中的状态: 12345678enum{ GET_UP, GO_TO_SCHOOL, HAVE_LUNCH, DO_HOMEWORK, SLEEP,}; 状态机在没有事件的驱动下就是一潭死水,所以我们还需要定义出一些会发生的事件,去驱动状态机的运转: 123456enum{ EVENT1 = 1, EVENT2, EVENT3,}; 再定义一些在某个状态下需要处理的动作,也就是函数: 12345678910111213141516171819202122232425262728293031void GetUp(){ // do something printf("xiao ming gets up!\\n");}void Go2School(){ // do something printf("xiao ming goes to school!\\n");}void HaveLunch(){ // do something printf("xiao ming has lunch!\\n");}void DoHomework(){ // do something printf("xiao ming does homework!\\n");}void Go2Bed(){ // do something printf("xiao ming goes to bed!\\n");} 定义一个状态表结构,用来表示一个状态机的状态: 1234567typedef struct FsmTable_s{ int event; //事件 int CurState; //当前状态 void (*eventActFun)(); //函数指针 int NextState; //下一个状态}FsmTable_t; 接下来,我们就可以这个结构定义一个状态表,状态机根据这个表进行状态的流转: 123456789FsmTable_t XiaoMingTable[] ={ //{到来的事件,当前的状态,将要要执行的函数,下一个状态} { EVENT1, SLEEP, GetUp, GET_UP }, { EVENT2, GET_UP, Go2School, GO_TO_SCHOOL }, { EVENT3, GO_TO_SCHOOL, HaveLunch, HAVE_LUNCH }, { EVENT1, HAVE_LUNCH, DoHomework, DO_HOMEWORK }, { EVENT2, DO_HOMEWORK, Go2Bed, SLEEP },}; 定义一个状态机结构,表示一个状态机: 123456typedef struct FSM_s{ FsmTable_t* FsmTable; //指向的状态表 int curState; //FSM当前所处的状态}FSM_t; 有了这些基本的结构,就可以写主函数了: 12345678910111213141516171819202122232425262728293031323334int main(){ FSM_t fsm; // 实例化一个状态机 InitFsm(&fsm); // 初始化状态机 int event = EVENT1; // 初始化事件,为了启动状态机流转, // 因为状态机只有在有时间发生时才会改变状态 //小明的一天,周而复始的一天又一天,进行着相同的活动 while (1) { printf("event %d is coming...\\n", event); FSM_EventHandle(&fsm, event); // 有了初始事件,我们就需要处理这个事件, // 再写一个处理事件的函数 printf("fsm current state %d\\n", fsm.curState); test(&event); Sleep(1); //休眠1秒,方便观察 } return 0;}// 测试用的,模拟事件的发生void test(int *event){ if (*event == 3) { *event = 1; } else { (*event)++; } } 编写初始化状态机的函数: 12345678int g_state_max_num = 0; // 状态机的状态最大数量,根据状态表的大小来计算// 初始化FSMvoid InitFsm(FSM_t* pFsm){ g_state_max_num = sizeof(XiaoMingTable) / sizeof(FsmTable_t); pFsm->curState = SLEEP; // 初始状态为睡觉 pFsm->FsmTable = XiaoMingTable;} 编写事件处理函数: 123456789101112131415161718192021222324/* 事件处理 */void FSM_EventHandle(FSM_t* pFsm, int event){ FsmTable_t* pActTable = pFsm->FsmTable; void (*eventActFun)() = NULL; //函数指针初始化为空 int NextState; int CurState = pFsm->curState; /* 获取当前动作函数 */ for (int i = 0; i<g_max_num; i++) { //当且仅当当前状态下来个指定的事件,我才执行它 if (event == pActTable[i].event && CurState == pActTable[i].CurState) { pActTable[i].eventActFun(); // 执行动作函数 FSM_StateTransfer(pFsm, pActTable[i].NextState); // 执行状态转移 break; } else { // do nothing } }} 12345/* 状态迁移 */void FSM_StateTransfer(FSM_t* pFsm, int state){ pFsm->curState = state;} 参考资料Linux 编程之有限状态机 FSM 的理解与实现 - Madcola - 博客园JavaScript 与有限状态机 - 阮一峰的网络日志有限状态机 - 维基百科,自由的百科全书","categories":[],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"FSM","slug":"FSM","permalink":"http://example.com/tags/FSM/"},{"name":"有限状态机","slug":"有限状态机","permalink":"http://example.com/tags/%E6%9C%89%E9%99%90%E7%8A%B6%E6%80%81%E6%9C%BA/"}]},{"title":"链接脚本入门","slug":"链接脚本入门","date":"2022-05-08T13:32:23.000Z","updated":"2022-10-15T03:14:29.898Z","comments":true,"path":"2022/05/08/链接脚本入门/","link":"","permalink":"http://example.com/2022/05/08/%E9%93%BE%E6%8E%A5%E8%84%9A%E6%9C%AC%E5%85%A5%E9%97%A8/","excerpt":"","text":"重定位位置无关编码 (PIC,position independent code):汇编源文件被编码成二进制可执行程序时编码方式与位置(内存地址)无关。 位置有关编码:汇编源码编码成二进制可执行程序后和内存地址是有关的。 我们在设计一个程序时,会给这个程序指定一个运行地址(链接地址)。就是说我们在编译程序时其实心里是知道我们程序将来被运行时的地址(运行地址)的,而且必须给编译器链接器指定这个地址(链接地址)才行。 最后得到的二进制程序理论上是和你指定的运行地址有关的,将来这个程序被执行时必须放在当时编译链接时给定的那个地址(链接地址)下才行,否则不能运行(就叫位置有关代码)。但是有个别特别的指令他可以跟指定的地址(链接地址)没有关系,也就是说这些代码实际运行时不管放在哪里都能正常运行。 运行地址:由运行时决定的(编译链接时是无法绝对确定运行时地址的)。 链接地址:由程序员在编译链接的过程中,通过Makefile中-Ttext xxx或者在链接脚本中指定的。程序员事先会预知自己的程序的执行要求,并且有一个期望的执行地址,并且会用这个地址来做链接地址。 举例:Linux 中的应用程序。gcc hello.c -o hello,这时使用默认的链接地址就是0x0,所以应用程序都是链接在0x0地址的。因为应用程序运行在操作系统的一个进程中,在这个进程中这个应用程序独享 4G 的虚拟地址空间。所以应用程序都可以链接到 0 地址,因为每个进程都是从 0 地址开始的。(编译时可以不给定链接地址而都使用0x0) 编译链接过程每个过程的作用 预编译:预编译器执行。替换宏定义,删除注释等工作。 编译:编译器来执行。把源码.c .S编程机器码.o文件。 链接:链接器来执行。把.o文件中的各函数(段)按照一定规则(链接脚本来指定)累积在一起,形成可执行文件。 strip:strip 是把可执行程序中的符号信息给拿掉,以节省空间。(Debug 版本和 Release 版本) objcopy:由可执行程序生成可烧录的镜像bin文件。 编译后生成的段段就是程序的一部分,我们把整个程序的所有东西分成了一个一个的段,给每个段起个名字,然后在链接时就可以用这个名字来指示这些段。也就是说给段命名就是为了在链接脚本中用段名来让段放在合适的位置。 段名分为 2 种:一种是编译器链接器内部定好的,一种是程序员自己指定的、自定义的段名。已有段名: 代码段:(.text),又叫文本段,代码段其实就是函数编译后生成的东西 数据段:(.data),数据段就是 C 语言中有显式初始化为非 0 的全局变量 bss 段:(.bss),又叫 ZI(zero initial)段,就是零初始化段,对应 C 语言中初始化为 0 的全局变量。 自定义段名:段名由程序员自己定义,段的属性和特征也由程序员自己定义。 C 语言中全局变量如果未显式初始化,值是 0。本质就是 C 语言把这类全局变量放在了 bss 段,从而保证了为 0。C 运行时环境如何保证显式初始化为非 0 的全局变量的值在 main 之前就被赋值了?就是因为它把这类变量放在了.data 段中,而.data 段会在 main 执行之前被处理(初始化)。 链接脚本链接脚本做什么事?链接脚本其实是个规则文件,他是程序员用来指挥链接器工作的。链接器会参考链接脚本,并且使用其中规定的规则来处理.o文件中那些段,将其链接成一个可执行程序。 链接脚本的关键内容有 2 部分:段名 + 地址(作为链接地址的内存地址)。把段,放到一个地址的意思。 链接脚本就像是一个从上到下顺序执行的一个代码 . 表示当前位置 = 表示赋值 * 表示通配符 链接脚本里的符号,可以在汇编源码里引用。 一个简易示例: 1234567891011121314151617181920SECTIONS{ . = 0xd0024000; # 当前地址为0xd0024000 .text : { start.o * (.text) # 所有的text段 } .data : { * (.data) } bss_start = .; # bss_start的值为当前地址,是执行到这里的地址,不是最上面. = 0xd0024000的地址 .bss : { * (.bss) } bss_end = .; } 怎么做?任务:在 SRAM 中将代码从 0xd0020010 重定位到 0xd0024000。 第一点:通过链接脚本将代码链接到 0xd0024000 重定位代码的作用就是:在PIC执行完之前(在代码中第一句位置有关码执行之前)必须将整个代码搬移到0xd0024000位置去执行,这就是重定位。 第二点:dnw 下载时将 bin 文件下载到 0xd0020010 这样就能完成,下载代码与运行代码位置不同。 第三点:代码执行时通过代码前段的少量位置无关码将整个代码搬移到 0xd0024000。 第四点:使用一个长跳转跳转到 0xd0024000 处的代码继续执行,重定位完成。 长跳转:一种跳转指令,类似于分支指令 B,BL 等作用的指令,跳转指令通过给 PC(r15)赋一个新值来完成代码跳转。当我们执行完重定位后,实际上 SRAM 中有两份代码的镜像(一份是我们下载到 0xd0020010 处的,一份是重定位到 0xd0024000 处的),这两份代码内容完全相同。 短跳转:短跳转指令可以实现向前或向后 32MB 的地址空间跳转。 当链接地址和运行地址相同是,短跳转和长跳转实际效果一样。但是当链接地址和运行地址不同时,短跳转和长跳转就有差异了,这时候段跳转执行的是运行地址处的那一份,而长跳转执行的是链接地址的那一份。 重定位实际就是在运行地址处执行一段位置无关码 PIC,让这段 PIC(也就是重定位代码)从运行地址处把整个程序镜像拷贝一份到链接地址处,完了之后使用一句长跳转指令从运行地址处直接跳转到链接地址处去执行同一个函数(led_blink),这样就实现了重定位之后的无缝连接。 汇编代码: 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475/* * 文件名: led.s * 作者: 朱老师(朱友鹏) * 描述: 演示重定位(在SRAM内部重定位) */#define WTCON 0xE2700000#define SVC_STACK 0xd0037d80.global _start // 把_start链接属性改为外部,这样其他文件就可以看见_start了_start: // 第1步:关看门狗(向WTCON的bit5写入0即可) ldr r0, =WTCON ldr r1, =0x0 str r1, [r0] // 第2步:设置SVC栈 ldr sp, =SVC_STACK // 第3步:开/关icache mrc p15,0,r0,c1,c0,0; // 读出cp15的c1到r0中 //bic r0, r0, #(1<<12) // bit12 置0 关icache orr r0, r0, #(1<<12) // bit12 置1 开icache mcr p15,0,r0,c1,c0,0; // 第4步:重定位 adr r0, _start // adr加载时就叫短加载,此处adr指令用于加载_start当前运行地址,详解见正文 ldr r1, =_start // ldr加载时如果目标寄存器是pc就叫长跳转,如果目标寄存器是r1等就叫长加载 // 此处ldr指令用于加载_start的链接地址:0xd0024000 // bss段的起始地址 ldr r2, =bss_start // 就是我们重定位代码的结束地址,重定位只需重定位代码段和数据段即可 // 该符号在链接脚本里定义 cmp r0, r1 // 比较_start的运行时地址和链接地址是否相等 beq clean_bss // 如果相等说明不需要重定位,所以跳过copy_loop,直接到clean_bss // 如果不相等说明需要重定位,那么会顺序执行下面的copy_loop进行重定位 // 重定位完成后继续执行clean_bss。// 用汇编来实现的一个while循环copy_loop: ldr r3, [r0], #4 // 源 r0内容写入r3,然后r0自增4 str r3, [r1], #4 // 目的 r3内容写入r1,然后r1自增4 // 这两句代码就完成了4个字节内容的拷贝 cmp r1, r2 // r1和r2都是用ldr加载的,都是链接地址,所以r1不断+4总能等于r2 bne copy_loop// 清bss段,其实就是在链接地址处把bss段全部清零clean_bss: ldr r0, =bss_start ldr r1, =bss_end cmp r0, r1 // 如果r0等于r1,说明bss段为空,直接继续执行下面的代码 beq run_on_dram // 清除bss完之后的地址 mov r2, #0clear_loop: str r2, [r0], #4 // 先将r2中的值放入r0所指向的内存地址(r0中的值作为内存地址), cmp r0, r1 // 然后r0 = r0 + 4 bne clear_loop// 清理完bss段后重定位就结束了。然后当前的状况是:// 1、当前运行地址还在0xd0020010开头的(重定位前的)那一份代码中运行着。// 2、此时SRAM中已经有了2份代码,1份在d0020010开头,另一份在d0024000开头的位置。// 然后就要长跳转了。run_on_dram: // 长跳转到led_blink开始第二阶段 ldr pc, =led_blink // ldr指令实现长跳转,把led_blink的值,写入pc寄存器 // 从这里之后就可以开始调用C程序了 //bl led_blink // bl指令实现短跳转 // 汇编最后的这个死循环不能丢 b . adr与 ldr 伪指令的区别:ldr和adr都是伪指令 adr短加载,指令加载符号地址,加载的是运行时地址; ldr长加载,指令在加载符号地址时,加载的是链接地址; 重定位就是汇编代码中的copy_loop函数,代码的作用是使用循环结构来逐句复制代码到链接地址。复制的源地址是 SRAM 的0xd0020010,复制目标地址是 SRAM 的0xd0024000,复制长度是bss_start减去_start,所以复制的长度就是整个重定位需要重定位的长度,也就是整个程序中代码段 + 数据段的长度。bss段(bss 段中就是 0 初始化的全局变量)不需要重定位。 清除bss段是为了满足 C 语言的运行时要求(C 语言要求显式初始化为 0 的全局变量,或者未显式初始化的全局变量的值为 0,实际上 C 语言编译器就是通过清bss段来实现 C 语言的这个特性的)。一般情况下我们的程序是不需要负责清零bss段的(C 语言编译器和链接器会帮我们的程序自动添加一段头程序,这段程序会在我们的 main 函数之前运行,这段代码就负责清除bss)。但是在我们代码重定位了之后,因为编译器帮我们附加的代码只是帮我们清除了运行地址那一份代码中的bss,而未清除重定位地址处开头的那一份代码的bss,所以重定位之后需要自己去清除bss。","categories":[],"tags":[{"name":"链接","slug":"链接","permalink":"http://example.com/tags/%E9%93%BE%E6%8E%A5/"},{"name":"编译","slug":"编译","permalink":"http://example.com/tags/%E7%BC%96%E8%AF%91/"},{"name":"动态链接","slug":"动态链接","permalink":"http://example.com/tags/%E5%8A%A8%E6%80%81%E9%93%BE%E6%8E%A5/"}]},{"title":"计算机组成原理-存储与 IO 系统","slug":"计算机组成原理-存储与IO系统","date":"2022-05-08T02:48:23.000Z","updated":"2022-10-15T03:14:29.872Z","comments":true,"path":"2022/05/08/计算机组成原理-存储与IO系统/","link":"","permalink":"http://example.com/2022/05/08/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86-%E5%AD%98%E5%82%A8%E4%B8%8EIO%E7%B3%BB%E7%BB%9F/","excerpt":"","text":"存储器存储器的层次结构SRAM(Static Random-Access Memory,静态随机存取存储器)CPU 如果形容成人的大脑的话,那么 CPU Cache (高速缓存) 就好比人的记忆。它用的是 SRAM 芯片。 SRAM 的“静态”的意思是,只要处于通电状态,里面的数据就保持存在,一旦断电,数据就会丢失。SRAM 里 1bit 数据需要 6-8 个晶体管,所以 SRAM 的存储密度不高,同样的物理空间,能够存的数据有限。因为其电路简单,访问速度非常快。 在 CPU 里,通常会有 L1、L2、L3 这样三层高速缓存。每个 CPU 核心都有一块属于自己的 L1 高速缓存,通常分成指令缓存和数据缓存,分开存放 CPU 使用的指令和数据。 L2 的 Cache 同样是每个 CPU 核心都有的,不过它往往不在 CPU 核心的内部。所以,L2 Cache 的访问速度会比 L1 稍微慢一些。而 L3Cache,则通常是多个 CPU 核心共用的,尺寸会更大一些,访问速度自然也就更慢一些。 你可以把 CPU 中的 L1Cache 理解为我们的短期记忆,把 L2/L3Cache 理解成长期记忆,把内存当成我们拥有的书架或者书桌。当我们自己记忆中没有资料的时候,可以从书桌或者书架上拿书来翻阅。这个过程中就相当于,数据从内存中加载到 CPU 的寄存器和 Cache 中,然后通过“大脑”,也就是 CPU,进行处理和运算。 DRAM(Dynamic Random Access Memory,动态随机存取存储器)内存用的芯片和 Cache 有所不同,它用的是一种叫作 DRAM 的芯片,比起 SRAM 来说,它的密度更高,有更大的容量,而且它也比 SRAM 芯片便宜不少。 DRAM 被称为“动态”存储器,是因为 DRAM 需要靠不断地“刷新”,才能保持数据被存储起来。DRAM 的一个比特,只需要一个晶体管和一个电容就能存储。所以,DRAM 在同样的物理空间下,能够存储的数据也就更多,也就是存储的“密度”更大。但是,因为数据是存储在电容里的,电容会不断漏电,所以需要定时刷新充电,才能保持数据不丢失。DRAM 的数据访问电路和刷新电路都比 SRAM 更复杂,所以访问延时也就更长。 从 Cache、内存,到 SSD 和 HDD 硬盘,一台现代计算机中,就用上了所有这些存储器设备。其中,容量越小的设备速度越快,而且,CPU 并不是直接和每一种存储器设备打交道,而是每一种存储器设备,只和它相邻的存储设备打交道。比如,CPUCache 是从内存里加载而来的,或者需要写回内存,并不会直接写回数据到硬盘,也不会直接从硬盘加载数据到 CPUCache 中,而是先加载到内存,再从内存加载到 Cache 中。 这样,各个存储器只和相邻的一层存储器打交道,并且随着一层层向下,存储器的容量逐层增大,访问速度逐层变慢,而单位存储成本也逐层下降,也就构成了我们日常所说的存储器层次结构。 缓存CPU cache高速缓存缓存不是 CPU 的专属功能,可以把它当成一种策略,任何时候想要增加数据传输性能,都可以通过加一层缓存试试。 存储器层次结构的中心思想是,对于每个$k$,位于$k$层的更快更小的存储设备作为位于$k+1$层的更大更慢的存储设备的缓存。下图展示了存储器层次结构中缓存的一般性概念。 数据总是以块block为单位,在层与层之间来回复制。 说回高速缓存,按照摩尔定律,CPU 的访问速度每 18 个月便会翻一翻,相当于每年增长 60%。内存的访问速度虽然不断增长,却远没有那么快,每年只增长 7% 左右。这样就导致 CPU 性能和内存访问的差距不断拉大。为了弥补两者之间差异,现代 CPU 引入了高速缓存。 CPU 的读(load)实质上就是从缓存中读取数据到寄存器(register)里,在多级缓存的架构中,如果缓存中找不到数据(Cache miss),就会层层读取二级缓存三级缓存,一旦所有的缓存里都找不到对应的数据,就要去内存里寻址了。寻址到的数据首先放到寄存器里,其副本会驻留到 CPU 的缓存中。 CPU 的写(store)也是针对缓存作写入。并不会直接和内存打交道,而是通过某种机制实现数据从缓存到内存的写回(write back)。 缓存到底如何与 CPU 和主存数据交换的?CPU 如何从缓存中读写数据的?缓存中没有读的数据,或者缓存写满了怎么办?我们先从 CPU 如何读取数据说起。 缓存读取CPU 发起一个读取请求后,返回的结果会有如下几种情况: 缓存命中 (cache hit)要读取的数据刚好在缓存中,叫做缓存命中。 缓存不命中 (cache miss)发送缓存不命中,缓存就得执行一直放置策略(placement policy),比如 LRU。来决定从主存中取出的数据放到哪里。 强制性不命中(compulsory miss)/冷不命中(cold miss):缓存中没有要读取的数据,需要从主存读取数据,并将数据放入缓存。 冲突不命中(conflict miss):缓存中有要读的数据,在采取放置策略时,从主存中取数据放到缓存时发生了冲突,这叫做冲突不命中。 高速缓存存储器组织结构整个 Cache 被划分为 1 个或多个组 (Set),$S$ 表示组的个数。每个组包含 1 个或多个缓存行(Cache line),$E$ 表示一个组中缓存行的行数。每个缓存行由三部分组成:有效位(valid),标记位(tag),数据块(cache block)。 有效位:该位等于 1,表示这个行数据有效。 标记位:唯一的标识了存储在高速缓存中的块,标识目标数据是否存在当前的缓存行中。 数据块:一部分内存数据的副本。 Cache 的结构可以由元组$(S,E,B,m)$表示。不包括有效位和标记位。Cache 的大小为 $C=S \\times E \\times B$. 接下来看看 Cache 是如何工作的,当 CPU 执行数据加载指令,从内存地址 A 读取数据时,根据存储器层次原理,如果 Cache 中保存着目标数据的副本,那么就立即将数据返回给 CPU。那么 Cache 如何知道自己保存了目标数据的副本呢? 假设目标地址的数据长度为$m$位,这个地址被参数 $S$ 和 $B$ 分成了三个字段: 首先通过长度为$s$的组索引,确定目标数据保存在哪一个组 (Set) 中,其次通过长度为$t$的标记,确定在哪一行,需要注意的是此时有效位必须等于 1,最后根据长度为$b$的块偏移,来确定目标数据在数据块中的确切位置。 Q:既然读取 Cache 第一步是组选择,为什么不用高位作为组索引,而使用中间的为作为组索引?A:如果使用了高位作索引,那么一些连续的内存块就会映射到相同的高速缓存块。如图前四个块映射到第一个缓存组,第二个四个块映射到第二个组,依次类推。如果一个程序有良好的空间局部性,顺序扫描一个数组的元素,那么在任何时候,缓存中都只保存在一个块大小的数组内容。这样对缓存的使用率很低。相比而言,如果使用中间的位作为组索引,那么相邻的块总是映射到不同的组,图中的情况能够存放整个大小的数组片。 直接映射高速缓存 Direct Mapped Cache根据每个组的缓存行数 $E$ 的不同,Cache 被分为不同的类。每个组只有一行$E=1$的高速缓存被称为直接映射高速缓存(direct-mapped cache)。 当一条加载指令指示 CPU 从主存地址 A 中读取一个字 w 时,会将该主存地址 A 发送到高速缓存中,则高速缓存会根据组选择,行匹配和字抽取三步来判断地址 A 是否命中。 组选择(set selection):根据组索引值来确定属于哪一个组,如图中索引长度为 5 位,可以检索 32 个组 ($2^5=32$)。当$s=0$时,此时组选择的结果为set 0,当$s=1$时,此时组选择的结果为set 1。 **行匹配 (line match)**:首先看缓存行的有效位,此时有效位为 1,表示当前数据有效。然后对比缓存行的标记0110与地址中的标记0110是否相等,如果相等,则表示目标数据在当前的缓存行中(缓存命中)。如果不一致或者有效位为 0,则表示目标数据不在当前的缓存行中(缓存不命中)。如果命中,就可以进行下一步字抽取。 **字抽取 (word extraction)**:根据偏移量$b$确定目标数据的确切位置,通俗来说就是从数据块的什么位置开始抽取位置。如当偏移块等于100时,表示目标数据起始地址位于字节 4 处。 下面通过一个例子来解释清除这个过程。假设我们有一个直接映射高速缓存,描述为$(S,E,B,m) = (4,1,2,4)$。换句话说,高速缓存有 4 个组,每个组 1 行,每个数据块 2 个字节,地址长度为 4 位。 从图中可以看出,8 个内存块,但只有 4 个高速缓存组,所以会有多个块映射到同一个高速缓存组中。例如,块 0 和块 4 都会被映射到组 0。 下面我们来模拟当 CPU 执行一系列读的时候,高速缓存的执行情况,我们假设每次 CPU 读 1 个字节的字。 读地址 0(0000) 的字: 读地址 1(0001) 的字: 读地址 13(1101) 的字: 读地址 8(1000) 的字: 读地址 0(0000) 的字: 组相联高速缓存 Set Associative Cache由于直接映射高速缓存的组中只有一行,所以容易发生冲突不命中。组相联高速缓存 (Set associative cache) 运行有多行缓存行。但是缓存行最大不能超过 $C/B$。 如图一个组中包含了两行缓存行,这种我们称为 2 路相联高速缓存。 组选择:与直接映射高速缓存的组选择过程一样。 行匹配:因为一个组有多行,所以需要遍历所有行,找到一个有效位为 1,并且标记为与地址中的标记位相匹配的一行。如果找到了,表示缓存命中。 字抽取:根据偏移量$b$确定目标数据的确切位置,通俗来说就是从数据块的什么位置开始抽取位置。如当偏移块等于100时,表示目标数据起始地址位于字节 4 处。 如果不命中,那么就需要从主存中取出需要的数据块,但是将数据块放在哪一行缓存行呢?如果存在空行 ($valid=0$),那就放到空行里。如果没有空行,就得选择一个非空行来替换,同时希望 CPU 不会很快引用这个被替换的行。这里介绍几个替换策略。 最简单的方式就是随机选择一行来替换,其他复杂的方式就是利用局部性原理,使得接下来 CPU 引用替换的行概率最小。如 缓存一致性协议 MESI为什么需要缓存一致目前主流电脑的 CPU 都是多核心的,多核心的有点就是在不能提升 CPU 主频后,通过增加核心来提升 CPU 吞吐量。每个核心都有自己的 L1 Cache 和 L2 Cache,只是共用 L3 Cache 和主内存。每个核心操作是独立的,每个核心的 Cache 就不是同步更新的,这样就会带来缓存一致性(Cache Coherence)的问题。 举个例子,如图: 有 2 个 CPU,主内存里有个变量x=0。CPU A 中有个需要将变量x加1。CPU A 就将变量x加载到自己的缓存中,然后将变量x加1。因为此时 CPU A 还未将缓存数据写回主内存,CPU B 再读取变量x时,变量x的值依然是0。 这里的问题就是所谓的缓存一致性问题,因为 CPU A 的缓存与 CPU B 的缓存是不一致的。 如何解决缓存一致性问题通过在总线加 LOCK 锁的方式在锁住总线上加一个 LOCK 标识,CPU A 进行读写操作时,锁住总线,其他 CPU 此时无法进行内存读写操作,只有等解锁了才能进行操作。 该方式因为锁住了整个总线,所以效率低。 缓存一致性协议 MESI该方式对单个缓存行的数据进行加锁,不会影响到内存其他数据的读写。 在学习 MESI 协议之前,简单了解一下总线嗅探机制(Bus Snooping)。要对自己的缓存加锁,需要通知其他 CPU,多个 CPU 核心之间的数据传播问题。最常见的一种解决方案就是总线嗅探。 这个策略,本质上就是把所有的读写请求都通过总线广播给所有的 CPU 核心,然后让各个核心去“嗅探”这些请求,再根据本地的情况进行响应。MESI 就是基于总线嗅探机制的缓存一致性协议。 MESI 协议的由来是对 Cache Line 的四个不同的标记,分别是: 状态 状态 描述 监听任务 Modified 已修改 该 Cache Line 有效,数据被修改了,和内存中的数据不一致,数据只存在于本 Cache 中 Cache Line 必须时刻监听所有试图读该 Cache Line 相对于主存的操作,这种操作必须在缓存将该 Cache Line 写回主存并将状态改为 S 状态之前,被延迟执行 Exclusive 独享,互斥 该 Cache Line 有效,数据和内存中的数据一直,数据只存在于本 Cache Cache Line 必须监听其他缓存读主存中该 Cache Line 的操作,一旦有这种操作,该 Cache Line 需要改为 S 状态 Shared 共享的 该 Cache Line 有效,数据和内存中的数据一直,数据存在于很多个 Cache 中 Cache Line 必须监听其他 Cache Line 使该 Cache Line 无效或者独享该 Cache Line 的请求,并将 Cache Line 改为 I 状态 Invalid 无效的 该 Cache Line 无效 无 整个 MESI 的状态,可以用一个有限状态机来表示它的状态流转。需要注意的是,对于不同状态触发的事件操作,可能来自于当前 CPU 核心,也可能来自总线里其他 CPU 核心广播出来的信号。我把各个状态之间的流转用表格总结了一下: 当前状态 事件 行为 下个状态 M Local Read 从 Cache 中读,状态不变 M M Local Write 修改 cache 数据,状态不变 M M Remote Read 这行数据被写到内存中,使其他核能使用到最新数据,状态变为 S S M Remote Write 这行数据被写入内存中,其他核可以获取到最新数据,由于其他 CPU 修改该条数据,则本地 Cache 变为 I I 当前状态 事件 行为 下个状态 E Local Read 从 Cache 中读,状态不变 E E Local Write 修改数据,状态改为 M M E Remote Read 数据和其他 CPU 共享,变为 S S E Remote Write 数据被修改,本地缓存失效,变为 I I 当前状态 事件 行为 下个状态 S Local Read 从 Cache 中读,状态不变 S S Local Write 修改数据,状态改为 M,其他 CPU 的 Cache Line 状态改为 I M S Remote Read 数据和其他 CPU 共享,状态不变 S S Remote Write 数据被修改,本地缓存失效,变为 I I 当前状态 事件 行为 下个状态 I Local Read 1. 如果其他 CPU 没有这份数据,直接从内存中加载数据,状态变为 E; 2. 如果其他 CPU 有这个数据,且 Cache Line 状态为 M,则先把 Cache Line 中的内容写回到主存。本地 Cache 再从内存中读取数据,这时两个 Cache Line 的状态都变为 S;3. 如果其他 Cache Line 有这份数据,并且状态为 S 或者 E,则本地 Cache Line 从主存读取数据,并将这些 Cache Line 状态改为 S E 或者 S I Local Write 1. 先从内存中读取数据,如果其他 Cache Line 中有这份数据,且状态为 M,则现将数据更新到主存再读取,将 Cache Line 状态改为 M; 2. 如果其他 Cache Line 有这份数据,且状态为 E 或者 S,则其他 Cache Line 状态改为 I M I Remote Read 数据和其他 CPU 共享,状态不变 S I Remote Write 数据被修改,本地缓存失效,变为 I I 内存计算机有五大组成部分,分别是:运算器、控制器、存储器、输入设备和输出设备。而内存就是其中的存储器。我们的数据和指令都需要先放到内存中,然后再被 CPU 执行。 操作系统中程序并不能直接访问物理内存,我们的内存需要被分成固定大小的页(Page),然后再通过虚拟内存地址(Virtual Address)到物理内存地址(Physical Address)的地址转换(Address Translation),才能到达实际存放数据的物理内存位置。而我们的程序看到的内存地址,都是虚拟内存地址。那么如何进行转换的呢? 简单页表最简单的方式,就是建立一张虚拟内存到物理内存的映射表,在计算机里叫做页表(Page Table)。页表这个地址转换的办法,会把一个内存地址分成页号(Directory)和偏移量(Offset)两个部分,是不是似曾相识,因为在前面的高速缓存里,缓存的结构也是这样的。 以一个 32 位地址举例,高 20 位是虚拟页号,可以从虚拟页表中找到物理页号的信息,低 12 位是偏移量,可以准确获得物理地址。 总结一下,对于一个内存地址转换,其实就是这样三个步骤: 把虚拟内存地址,切分成页号和偏移量的组合; 从页表里面,查询出虚拟页号,对应的物理页号; 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。 但是这样的页表有个问题,它需要记录$2^{20}$个物理页表,这个存储关系,就好比一个 $2^{20}$大小的数组。一个页号是完整的 32 位的 4 字节(Byte),这样一个页表就需要 4MB 的空间。并且每个进程都会有这样一个页表,现代电脑正常都有成百上千个进程,如果用这样的页表肯定行不通的。 多级页表所以,在一个实际的程序进程里面,虚拟内存占用的地址空间,通常是两段连续的空间。而不是完全散落的随机的内存地址。而多级页表,就特别适合这样的内存地址分布。 谈一谈内存管理,虚拟内存,多级页表 - 知乎 TLB内存保护 - 可执行空间保护内存保护 - 地址空间布局随机化Address Space Layout Randomization 总线:计算机内部的高速公路计算机由控制器、运算器、存储器、输入设备以及输出设备五大部分组成。CPU 所代表的控制器和运算器,要和存储器,也就是我们的主内存,以及输入和输出设备进行通信。那么计算机是用什么样的方式来完成,CPU 和内存、以及外部输入输出设备的通信呢?答案就是通过总线来通信。 计算机里有不同的硬件设备,如果设备与设备之间都单独连接,那么就需要 N*N 的连线。那么怎么降低复杂度呢?与其让各个设备之间互相单独通信,不如我们去设计一个公用的线路。CPU 想要和什么设备通信,通信的指令是什么,对应的数据是什么,都发送到这个线路上;设备要向 CPU 发送什么信息呢,也发送到这个线路上。这个线路就好像一个高速公路,各个设备和其他设备之间,不需要单独建公路,只建一条小路通向这条高速公路就好了。 三种线路和多总线架构首先,CPU 和内存以及高速缓存通信的总线,这里面通常有两种总线。这种方式,我们称之为双独立总线(Dual Independent Bus,缩写为 DIB)。CPU 里,有一个快速的本地总线(Local Bus),以及一个速度相对较慢的前端总线(Front-side Bus)。 现代的 CPU 里,通常有专门的高速缓存芯片。这里的高速本地总线,就是用来和高速缓存通信的。而前端总线,则是用来和主内存以及输入输出设备通信的。有时候,我们会把本地总线也叫作后端总线(Back-sideBus),和前面的前端总线对应起来。 除了前端总线呢,我们常常还会听到 PCI 总线、I/O 总线或者系统总线(System Bus)。看到这么多总线的名字,你是不是已经有点晕了。这些名词确实容易混为一谈。其实各种总线的命名一直都很混乱,我们不如直接来看一看 CPU 的硬件架构图。对照图来看,一切问题就都清楚了。 CPU 里面的北桥芯片,把我们上面说的前端总线,一分为二,变成了三个总线。我们的前端总线,其实就是系统总线。CPU 里面的内存接口,直接和系统总线通信,然后系统总线再接入一个 I/O 桥接器(I/OBridge)。这个 I/O 桥接器,一边接入了我们的内存总线,使得我们的 CPU 和内存通信;另一边呢,又接入了一个 I/O 总线,用来连接 I/O 设备。 事实上,真实的计算机里,这个总线层面拆分得更细。根据不同的设备,还会分成独立的 PCI 总线、ISA 总线等等。 在物理层面,其实我们完全可以把总线看作一组“电线”。不过呢,这些电线之间也是有分工的,我们通常有三类线路。 数据线(Data Bus),用来传输实际的数据信息,也就是实际上了公交车的“人”。 地址线(Address Bus),用来确定到底把数据传输到哪里去,是内存的某个位置,还是某一个 I/O 设备。这个其实就相当于拿了个纸条,写下了上面的人要下车的站点。 控制线(ControlBus),用来控制对于总线的访问。虽然我们把总线比喻成了一辆公交车。那么有人想要做公交车的时候,需要告诉公交车司机,这个就是我们的控制信号。 尽管总线减少了设备之间的耦合,也降低了系统设计的复杂度,但同时也带来了一个新问题,那就是总线不能同时给多个设备提供通信功能。 我们的总线是很多个设备公用的,那多个设备都想要用总线,我们就需要有一个机制,去决定这种情况下,到底把总线给哪一个设备用。这个机制,就叫作总线裁决(Bus Arbitraction) 硬盘DMA过去几年,计算机产业一直在为提升 I/O 设备的速度而努力,从机械硬盘 HDD 到固态硬盘 SSD,从 SATA 协议到 PCIE 协议,虽然速度都几十上百倍的增加,但是仍然不够快。因为相比于 CPU 基本都是 2GHz 的频率(每秒会有 20 亿次的操作),SSD 硬盘的 IOPS 的 2 万次操作就显得微不足道。 如果我们对于 I/O 的操作,都是由 CPU 发出对应的指令,然后等待 I/O 设备完成操作之后返回,那 CPU 有大量的时间其实都是在等待 I/O 设备完成操作。特别是当传输的数据量比较大的时候,比如进行大文件复制,如果所有数据都要经过 CPU,实在是有点儿太浪费时间了。 因此,计算机工程师们,就发明了DMA 技术,也就是直接内存访问(Direct Memory Access)技术,来减少 CPU 等待的时间。 什么是 DMA本质上,DMA 技术就是我们在主板上放一块独立的芯片。在进行内存和 I/O 设备的数据传输的时候,我们不再通过 CPU 来控制数据传输,而直接通过 DMA 控制器(DMA Controller,简称 DMAC)。这块芯片,我们可以认为它其实就是一个协处理器(Co-Processor)。 DMAC 最有价值的地方体现在,当我们要传输的数据特别大、速度特别快,或者传输的数据特别小、速度特别慢的时候。 比如说,我们用千兆网卡或者硬盘传输大量数据的时候,如果都用 CPU 来搬运的话,肯定忙不过来,所以可以选择 DMAC。而当数据传输很慢的时候,DMAC 可以等数据到齐了,再向 CPU 发起中断,让 CPU 去处理,而不是让 CPU 在那里忙等待。 首先,CPU 还是作为一个主设备,向 DMAC 设备发起请求。这个请求,其实就是在 DMAC 里面修改配置寄存器。 CPU 修改 DMAC 的配置的时候,会告诉 DMAC 这样几个信息: 源地址的初始值:数据要从哪里传输过来。如果我们要从内存里面写入数据到硬盘上,那么就是要读取的数据在内存里面的地址 传输时候的地址增减方式:数据是从大的地址向小的地址传输,还是从小的地址往大的地址传输 传输的数据长度:也就是我们一共要传输多少数据 设置完这些信息之后,DMAC 就会变成一个空闲的状态(Idle)。 如果我们要从硬盘上往内存里面加载数据,这个时候,硬盘就会向 DMAC 发起一个数据传输请求。这个请求并不是通过总线,而是通过一个额外的连线。 然后,我们的 DMAC 需要再通过一个额外的连线响应这个申请。 DMAC 这个芯片,就向硬盘的接口发起要总线读的传输请求。数据就从硬盘里面,读到了 DMAC 的控制器里面。 DMAC 再向我们的内存发起总线写的数据传输请求,把数据写入到内存里面。 DMAC 会反复进行上面第 6、7 步的操作,直到 DMAC 的寄存器里面设置的数据长度传输完成。 数据传输完成之后,DMAC 重新回到第 3 步的空闲状态。 所以,整个数据传输的过程中,我们不是通过 CPU 来搬运数据,而是由 DMAC 这个芯片来搬运数据。但是 CPU 在这个过程中也是必不可少的。因为传输什么数据,从哪里传输到哪里,其实还是由 CPU 来设置的。这也是为什么,DMAC 被叫作 协处理器。 参考资料【硬件科普】电脑主板右下角的散热片下面究竟隐藏着什么?详解主板南桥芯片组的功能和作用_哔哩哔哩_bilibili","categories":[{"name":"计算机组成原理","slug":"计算机组成原理","permalink":"http://example.com/categories/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86/"}],"tags":[{"name":"Cache","slug":"Cache","permalink":"http://example.com/tags/Cache/"},{"name":"计算机组成原理","slug":"计算机组成原理","permalink":"http://example.com/tags/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86/"},{"name":"页表","slug":"页表","permalink":"http://example.com/tags/%E9%A1%B5%E8%A1%A8/"},{"name":"DMA","slug":"DMA","permalink":"http://example.com/tags/DMA/"},{"name":"虚拟内存","slug":"虚拟内存","permalink":"http://example.com/tags/%E8%99%9A%E6%8B%9F%E5%86%85%E5%AD%98/"},{"name":"缓存","slug":"缓存","permalink":"http://example.com/tags/%E7%BC%93%E5%AD%98/"},{"name":"总线","slug":"总线","permalink":"http://example.com/tags/%E6%80%BB%E7%BA%BF/"}]},{"title":"计算机组成原理-处理器","slug":"计算机组成原理-处理器","date":"2022-05-01T07:42:11.000Z","updated":"2022-05-08T04:42:11.000Z","comments":true,"path":"2022/05/01/计算机组成原理-处理器/","link":"","permalink":"http://example.com/2022/05/01/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86-%E5%A4%84%E7%90%86%E5%99%A8/","excerpt":"","text":"建立数据通路:指令 + 运算=CPU指令周期 Fetch(取得指令):从内存里把指令加载到指令寄存器中。 Decode(指令译码) Execute(执行指令)重复操作这三步,这个循环称为指令周期。 不同的步骤在不同组件内完成 机器周期/CPU周期:从内存里读取一条指令的最短时间。时钟周期:就是机器的主频,一个 CPU 周期由多个时钟周期组成。 操作元件:组合逻辑元件,ALU,功能是在特定的输入下,生成特定的输出。存储元件:状态元件,寄存器。 将操作元件,操作原件通过数据总线的方式连接起来,就建立了数据通路了。 控制器:循环执行取址-译码,产生控制信号交给 ALU 处理。电路特别复杂,CPU 如果支持 2000 个指令,意味着控制器输出的信号有 2000 个不同的组合。 CPU 需要的电路 根据输入计算出结果的一个电路,ALU 能够进行状态读写的电路元件,寄存器 按照固定周期,不停实现 PC 寄存器自增的电路 译码电路,能够对于拿到的内存地址获取对应的数据或者指令 Q : CPU 好像一个永不停歇的机器,一直在不停地读取下一条指令去运行。那 为什么 CPU 还会有满载运行和 Idle 闲置的状态呢?A:CPU 还会有满载运行和 Idle 闲置的状态,指的系统层面的状态。即使是 Idle 空闲状态,CPU 也在执行循环指令。操作系统内核有 idle 进程,优先级最低,仅当其他进程都阻塞时被调度器选中。idle 进程循环执行 HLT 指令,关闭 CPU 大部分功能以降低功耗,收到中断信号时 CPU 恢复正常状态。CPU 在空闲状态就会停止执行,即切断时钟信号,CPU 主频会瞬间降低为 0,功耗也会瞬间降为 0。由于这个空闲状态是十分短暂的,所以你在任务管理器也只会看到 CPU 频率下降,不会看到降为 0。当 CPU 从空闲状态中恢复时,就会接通时钟信号,CPU 频率就会上升。所以你会在任务管理器里面看到 CPU 的频率起伏变化。 实现一个完整的 CPU,除了组合逻辑电路,还需要时序逻辑电路。因为组合逻辑电路只是处理固定输入,得到固定输出,这种电路只能协助我们完成一些计算工作,干不了太复杂的工作。 时序逻辑电路可以解决这几个问题: 自动运行问题 时序电路接通之后可以不停地开启和关闭开关,进入一个自动运行的状态。这个使得我们上一讲说的,控制器不停地让 PC 寄存器自增读取下一条指令成为可能。 存储问题 通过时序电路实现的触发器,能把计算结果存储在特定的电路里面, 而不是像组合逻辑电路那样,一旦输入有任何改变,对应的输出也会改变。 时序协调问题 无论是程序实现的软件指令,还是到硬件层面,各种指令的操作都有先后的顺序要求。时序电路使得不同的事件按照时间顺序发生。 解决自动运行问题实现时序逻辑电路的第一步就需要一个时钟。CPU 的主频是一个晶振来实现的,晶振生成的电路信号就是我们的时钟信号。 实现如图所示,我们在原先一般只放一个开关的信号输入端,放上了两个开 关。一个开关 A,一开始是断开的,由我们手工控制;另外一个开关 B,一开始是合上的,磁性线圈对准一开始就合上的开关 B。 于是,一旦我们合上开关 A,磁性线圈就会通电,产生磁性,开关 B 就会从合上变成断 开。一旦这个开关断开了,电路就中断了,磁性线圈就失去了磁性。于是,开关 B 又会弹 回到合上的状态。这样一来,电路接通,线圈又有了磁性。我们的电路就会来回不断地在开启、关闭这两个状态中切换。 这个不断切换的过程,对于下游电路来说,就是不断地产生新的 0 和 1 这样的信号。如果 你在下游的电路上接上一个灯泡,就会发现这个灯泡在亮和暗之间不停切换。这个按照固定的周期不断在 0 和 1 之间切换的信号,就是我们的时钟信号。 一般这样产生的时钟信号,就像你在各种教科书图例中看到的一样,是一个振荡产生的 0、1 信号。 这种电路,其实就相当于把电路的输出信号作为输入信号,再回到当前电路。这样的电路构 造方式呢,我们叫作反馈电路(Feedback Circuit)。 上面这个反馈电路一般可以用下面这个示意图来表 示,其实就是一个输出结果接回输入的反相器(Inverter),也就是我们之前讲过的非门。 解决存储问题 有了时钟信号,我们的系统里就有了一个像“自动门”一样的开关。利用这个开关和相同的 反馈电路,我们就可以构造出一个有“记忆”功能的电路。 我们先来看下面这个 RS 触发器电路。这个电路由两个或非门电路组成。我在图里面,把它 标成了 A 和 B。 或非门真值表:|NOR|0| 1|| —- | —- | —- ||0|1|0||1|0|0| 在这个电路一开始,输入开关都是关闭的,所以或非门(NOR)A 的输入是 0 和 0。对 应到我列的这个真值表,输出就是 1。而或非门 B 的输入是 0 和 A 的输出 1,对应输出 就是 0。B 的输出 0 反馈到 A,和之前的输入没有变化,A 的输出仍然是 1。而整个电 路的输出 Q,也就是 0。 当我们把 A 前面的开关 R 合上的时候,A 的输入变成了 1 和 0,输出就变成了 0,对应 B 的输入变成 0 和 0,输出就变成了 1。B 的输出 1 反馈给到了 A,A 的输入变成了 1 和 1,输出仍然是 0。所以把 A 的开关合上之后,电路仍然是稳定的,不会像晶振那样 振荡,但是整个电路的输出 Q 变成了 1。 这个时候,如果我们再把 A 前面的开关 R 打开,A 的输入变成和 1 和 0,输出还是 0,对应的 B 的输入没有变化,输出也还是 1。B 的输出 1 反馈给到了 A,A 的输入变成了 1 和 0,输出仍然是 0。这个时候,电路仍然稳定。开关 R 和 S 的状态和上面的第一步是一样的,但是最终的输出 Q 仍然是 1,和第 1 步里 Q 状态是相反的。我们的输入和刚才第二步的开关状态不一样,但是输出结果仍然保留在了第 2 步时的输出没有发生变 化。 这个时候,只有我们再去关闭下面的开关 S,才可以看到,这个时候,B 有一个输入必然是 1,所以 B 的输出必然是 0,也就是电路的最终输出 Q 必然是 0。 这样一个电路,我们称之为触发器(Flip-Flop)。接通开关 R,输出变为 1,即使断开开 关,输出还是 1 不变。接通开关 S,输出变为 0,即使断开开关,输出也还是 0。也就是, 当两个开关都断开的时候,最终的输出结果,取决于之前动作的输出结果,这个也就是我们说的记忆功能。 面向流水线的指令设计单指令周期处理器一条 CPU 指令的执行,有三步:取得指令,译码,执行。需要一个时钟周期。自然设计指令时,我们也希望一整条指令能在一个时钟周期内完成。这就是单指令周期处理器。 不过,时钟周期是固定的,但是指令的电路复杂程度是不同的,所以实际一条指令执行的时间是不同的。从前面的学习中也知道,随着门电路层数的增加,门延迟的存在,计算复杂的指令需要的时间更长。 不同指令的执行时间不同,但是我们需要让所有指令都在一个时钟周期内完成,那就只好把执行时间最长的那个指令和时钟周期设成一样。 所以,在单指令周期处理器里面,无论是执行一条用不到 ALU 的无条件跳转指令,还是一条计算起来电路特别复杂的浮点数乘法运算,我们都等要等满一个时钟周期。这样时钟频率就无法提高,因为太高了,有些复杂指令无法在一个时钟周期内运行完。 到这可能就有人发问了,之前不是说一个 CPU 时钟周期,可以认为是完成一条简单指令的时间。为什么单指令周期处理器上,却成了执行一条最复杂的指令的时间? 这是因为,无论是 PC 上使用的 Intel CPU,还是手机上使用的 ARM CPU,都不是单指令周期处理器,而是采用了一种叫作指令流水线(Instruction Pipeline)的技术。 流水线设计CPU 执行指令的过程和我们做饭一样,我们不会等米饭蒸好再洗菜,不会等肉腌好再切菜,而是蒸饭时,可以洗菜,腌肉时可以切菜。 CPU 的指令执行过程,其实也是由各个电路模块组成的。我们在取指令的时候,需要一个译码器把数据从内存里面取出来,写入到寄存器中;在指令译码的时候,我们需要另外一个译码器,把指令解析成对应的控制信号、内存地址和数据;到了指令执行的时候,我们需要的则是一个完成计算工作的 ALU。 这样一来,我们就不用把时钟周期设置成整条指令执行的时间,而是拆分成完成这样的一个一个小步骤需要的时间。同时,每一个阶段的电路在完成对应的任务之后,也不需要等待整个指令执行完成,而是可以直接执行下一条指令的对应阶段。 如果我们把一个指令拆分成“取指令 - 指令译码 - 执行指令”这样三个部分,那这就是一个三级的流水线。如果我们进一步把“执行指令”拆分成“ALU 计算(指令执行)- 内存访问 - 数据写回”,那么它就会变成一个五级的流水线。 五级的流水线,就表示我们在同一个时钟周期里面,同时运行五条指令的不同阶段。这个时候,虽然执行一条指令的时钟周期变成了 5,但是我们可以把 CPU 的主频提得更高了。我们不需要确保最复杂的那条指令在时钟周期里面执行完成,而只要保障一个最复杂的流水线级的操作,在一个时钟周期内完成就好了。 如果某一个操作步骤的时间太长,我们就可以考虑把这个步骤,拆分成更多的步骤,让所有步骤需要执行的时间尽量都差不多长。 既然流水线可以增加我们的吞吐率,你可能要问了,为什么我们不把流水线级数做得更深 呢?为什么不做成 20 级,乃至 40 级呢?这个其实有很多原因,我在之后几讲里面会详细讲解。这里,我先讲一个最基本的原因,就是增加流水线深度,其实是有性能成本的。 我们用来同步时钟周期的,不再是指令级别的,而是流水线阶段级别的。每一级流水线对应 的输出,都要放到流水线寄存器(Pipeline Register)里面,然后在下一个时钟周期,交给下一个流水线级去处理。所以,每增加一级的流水线,就要多一级写入到流水线寄存器的操作。虽然流水线寄存器非常快,比如只有 20 皮秒(ps,10−12 秒)。 但是,如果我们不断加深流水线,这些操作占整个指令的执行时间的比例就会不断增加。最后,我们的性能瓶颈就会出现在这些 overhead 上。如果我们指令的执行有 3 纳秒,也就 是 3000 皮秒。我们需要 20 级的流水线,那流水线寄存器的写入就需要花费 400 皮秒,占了超过 10%。如果我们需要 50 级流水线,就要多花费 1 纳秒在流水线寄存器上,占到 25%。这也就意味着,单纯地增加流水线级数,不仅不能提升性能,反而会有更多的 overhead 的开销。所以,设计合理的流水线级数也是现代 CPU 中非常重要的一点。 FPGA/ASIC/TPUFPGACPU 是由简单的门电路搭积木一样搭建出来的,那一个 CPU 里有多少个晶体管这样的电路开关呢?一个四核 i7 的 Intel CPU,有 20 亿个晶体管。那么问题来了,我们要设计一个 CPU,就要想办法连接这 20 亿个晶体管。 连接一次已经很难了,我们还要根据问题重新调整连接。设计更简单的特定功能的芯片,少说要几个月。而设计一个 CPU 往往以年计。在这个过程中,硬件工程师要设计、验证各种各样的方案,可能会遇到各种 BUG。如果每验证一个方案都要生产一块芯片,这代价太高了。 我们有没有什么办法,不用单独制造一块专门的芯片来验证 硬件设计呢?能不能设计一个硬件,通过不同的程序代码,来操作这个硬件之前的电路连线,通过“编程”让这个硬件 变成我们设计的电路连线的芯片呢? 这个,就是我们接下来要说的 FPGA,也就是现场可编程门阵列(Field-Programmable Gate Array)。 P 代表 Programmable,也就是说这 是一个可以通过编程来控制的硬件。 G 代表 Gate,它就代表芯片里面的门电路。我们能够去进行编程组合的就是这样一个一个门电路。 A 代表的 Array,叫作阵列,说的是在一块 FPGA 上,密密麻麻列了大量 Gate 这样的门电路。 F,不太容易理解。它其实是说,一块 FPGA 这样的板子,可以进行在“现场”多次地进行编程。它不像 PAL(Programmable Array Logic,可编程阵列逻辑)这样更古老的硬件设备,只能“编程”一次,把预先写好的程序一次性烧录到硬件里面,之后就不能再修改了。 我们之前说过,CPU 其实就是通过晶体管,来实现各 种组合逻辑或者时序逻辑。那么,我们怎么去“编程”连接这些线路呢? FPGA 的解决方案分三步: 第一,用存储换功能实现组合逻辑。在实现 CPU 的功能的时候,我们需要完成各种各样的电路逻辑。在 FPGA 里,这 些基本的电路逻辑,不是采用布线连接的方式进行的,而是 预先根据我们在软件里面设计的逻辑电路,算出对应的真值表,然后直接存到一个叫作 LUT(Look-Up Table,查找 表)的电路里面。这个 LUT 呢,其实就是一块存储空间,里面存储了“特定的输入信号下,对应输出 0 还是 1”。 第二,对于需要实现的时序逻辑电路,我们可以在 FPGA 里面直接放上 D 触发器,作为寄存器。这个和 CPU 里的触发器没有什么本质不同。不过,我们会把很多个 LUT 的电路和寄存器组合在一起,变成一个叫作逻辑簇(Logic Cluster)的东西。在 FPGA 里,这样组合了多个 LUT 和寄 存器的设备,也被叫做 CLB Configurable Logic Block,可配置逻辑块)。 可以把 CLB 想象成函数或者 API,设计更复杂的功能,不用重新造轮子,只需要调用函数或者 API 即可。设计芯片也是一样,不用再从门电路开始搭建,可以通过 CLB 组合搭建。 第三,FPGA 是通过可编程逻辑布线,来连接各个不同的 CLB,最终实现我们想要实现的芯片功能。这个可编程逻辑布线,你可以把它当成我们的铁路网。整个铁路系统已经铺 好了,但是整个铁路网里面,设计了很多个道岔。我们可以 通过控制道岔,来确定不同的列车线路。在可编程逻辑布线 里面,“编程”在做的,就是拨动像道岔一样的各个电路开 关,最终实现不同 CLB 之间的连接,完成我们想要的芯片功能。 ASIC除了 CPU,GPU 以及 FPGA,我们还需要用到很多其他芯片,比如除了音视频的芯片,或者专门用来挖矿的芯片。尽管 CPU 也能实现这些功能,但是有点大炮打蚊子的感觉。 于是针对一些特殊场景,单独设计一个芯片,我们称这些芯片为 ASIC(Application-Specific Integrated Circuit),专用集成电路。设计精简,制造成本低。 其实我们的 FPGA 也能做 ASIC 的事情,每次对 FPGA 进行编程,就是把 FPGA 电路编程了一个 ASIC。但是如果全用 FPGA,同样会浪费。因为每一个 LUT 电路,都可以实现与门以及或门,这比单纯连死的与门或者或门,用到的晶体管数量要多的多。自然功耗也要大得多,单片 FPGA 的生产制造成本也比 ASIC 要高。 FPAG ASIC 一次性成本 极低,约等于 0 高 量产成本 高 低 延迟 低 低 开发周期 短 长 市场风险 低 高 开发环境 设置 FPGA 需要硬件知识,编程和配置门槛很高 需要底层硬件变成,开发难度很高 TPUTPU(Tensor Processing Unit)张量处理器;","categories":[{"name":"计算机组成原理","slug":"计算机组成原理","permalink":"http://example.com/categories/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86/"}],"tags":[{"name":"计算机组成原理","slug":"计算机组成原理","permalink":"http://example.com/tags/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86/"}]},{"title":"替换 Gitee 图床为腾讯云 COS","slug":"替换Gitee图床为腾讯云COS","date":"2022-04-09T08:43:08.000Z","updated":"2022-10-15T03:14:29.704Z","comments":true,"path":"2022/04/09/替换Gitee图床为腾讯云COS/","link":"","permalink":"http://example.com/2022/04/09/%E6%9B%BF%E6%8D%A2Gitee%E5%9B%BE%E5%BA%8A%E4%B8%BA%E8%85%BE%E8%AE%AF%E4%BA%91COS/","excerpt":"","text":"Gitee 图床挂了,但是各大云服务厂商提供的对象存储服务免费额度,对于个人小博客来说也够用了。下面介绍如何将图床更换为腾讯云 COS。 下载原有图片从gitee下载整个仓库。保持原有目录结构。 配置腾讯云 COS注册腾讯云账号,创建 COS 存储桶,选择公有读私有写。创建 COS 存储桶地址:https://console.cloud.tencent.com/cos,创建存储桶后可以在存储桶里打开防盗链设置。 创建桶–选择地域–填写名称–选择公有读私有写–点击创建。 如果忘了设置读写权限可以按一下方法设置; 选择菜单–文件列表。上传下载好的文件夹(整个仓库的文件夹)。鼠标放到选择文件出现上传文件夹选项,或者将文件夹拖入浏览器。 配置 Picgo COS 版本:V5设定 Secreid,设定 Secrekey,设定 APPID: APPID、SecretID 与 SecretKey 点此直达获取。选择继续使用–创建秘钥。 设定存储空间名,设定存储区域: 点此获取存储空间名以及存储区域。桶名称即存储空间名,所属区域:ap-shanghai即确认存储区域。 指定存储区域:指定上传到 COS 的目录,比如我原先从gitee下载来的图床的仓库名是markdown_picbed,图片又保存在markdown_picbed/img目录下,那么就指定markdown_picbed/img目录。 替换旧图床 URLVSCode 全局替换:","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"Markdown","slug":"Markdown","permalink":"http://example.com/tags/Markdown/"},{"name":"图床","slug":"图床","permalink":"http://example.com/tags/%E5%9B%BE%E5%BA%8A/"},{"name":"腾讯云","slug":"腾讯云","permalink":"http://example.com/tags/%E8%85%BE%E8%AE%AF%E4%BA%91/"}]},{"title":"程序员的自我修养笔记","slug":"程序员的自我修养读书笔记","date":"2022-03-30T03:12:31.000Z","updated":"2022-04-30T03:12:31.000Z","comments":true,"path":"2022/03/30/程序员的自我修养读书笔记/","link":"","permalink":"http://example.com/2022/03/30/%E7%A8%8B%E5%BA%8F%E5%91%98%E7%9A%84%E8%87%AA%E6%88%91%E4%BF%AE%E5%85%BB%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0/","excerpt":"","text":"静态链接库是一组目标文件的包,就是一些常用的代码编译成目标文件后打包存放。 第三章 目标文件里有什么目标文件的格式目标文件从结构上讲,它是已经编译后的可执行文件格式,只是还没有经过链接的过程,其中可能有些符号或者有些地址还没有被调整。 现在 PC 平台流形的可执行文件格式,主要是 Windows 下的 PE(Portable Executable)和 Linux 下的 ELF(Executable Linkable Format),它们都是 COFF(Common file format)格式的变种。 指令和数据分开存放的好处: 一方面当程序被装载后,数据和指令分别被映射到两个虚存区域。由于数据区域对于进程来说是可读写的,而指令区域对于进程来说是只读的,所以这两个虚存区域的权限可以被设置成可读写和只读,这样可以防止程序的指令被有意或无意地改写。 另一方面是现代 CPU 有强大的缓存体系,由于缓存很重要,所以程序必须尽量提高缓存命中率。指令区和数据区分离有利于提高程序的局部性。现代 CPU 的缓存一般都被设计成数据缓存和指令缓存,所以程序的指令和数据分开存放对于 CPU 的缓存命中率提高有好处。 第三个原因,也是最重要的原因,就是当系统中运行着多个该进程副本时,他们的指令都是一样的,所以内存中只需要保存一份程序的指令部分。 真正了牛逼的程序员对自己的程序每一个字节都了如指掌。 123objdump -h SimpleSsection.o # 打印elf文件各个段的信息size SimpleSsection.o # 查看elf文件各个段的长度objdump -s -d SimpleSsection.o # -s将所有段内容以十六进制打印,-d将所有包含指令的段反汇编 段名称 内容 .data - 初始化的全局变量 - 局部静态变量 .rodata 只读数据段,对这个段的任何修改都是非法的,保证了程序的安全性。 有时候编译器会把字符串放到 data 段 - 只读变量 const 修饰 - 字符串常量 .bss 不占磁盘空间, - 未初始化的全局变量 - 未初始化的局部静态变量 - 初始化为 0 的静态变量 .comment 存放编译器版本信息,比如字符串“GCC:(GNU)4.2.0” .line 调试时的行号表,即源代码行号与编译后指令的对应表 .note 额外的编译器信息,如程序公司名,版本号 .symtab Symbol Table 符号表 .plt 动态链接的跳转表 .got 动态链接的全局入口表 段名称都是.前缀,表示这些表名字是系统保留的,应用程序也可以使用一些非系统保留的名字作为段名称。比如可以加入一个music段,里面存一首 mp3 音乐,运行起来后就会播放音乐,打算自定义段不能使用.作为前缀,以免与系统保留段名冲突。 Q: 如何将一个二进制文件,如图片,MP3 文件作为目标文件的一个段?A: 可以使用 objcopy 工具,比如有一个图片 image..jpg,大小为 0x2100 字节:$ objcopy -I binary -O elf32-i388 -B i38 image.jpg image.o 正常情况下编译出来的目标文件,代码会放到.text段,但是有时候你希望变量或者某些代码能放到你指定的段中去,以实现某些特定的功能。比如为了满足某些硬件的内存和 IO 地址布局。GCC 提供了扩展机制,使得程序员可以指定变量所处的段: 12__attribute__((section("FOO"))) int global = 42;__attribute__((section("BAR"))) void foo; ELF 文件结构使用readelf命令查看 elf 文件详细信息。 ELF 魔数,确认文件类型。 文件类型 常量 值 含义 ET_REL 1 可重定位文件,一般问.o文件 ET_EXEC 2 可执行文件 ET_DYN 3 共享目标文件,一般为.so文件 机器类型 常量 值 含义 EM_M32 1 AT&T WE 32100 EM_SPARC 2 SPARC EM_M386 3 Intel x86 EM_68K 4 Motorola 68000 EM_88K 5 Motorola 88000 EM_860 6 Intel 80860 段表是保存各个段的基本属性的结构。段表是除文件头外最重要的结构。编译器,链接器和装载器都是依靠段表来定位和访问各个段的属性。 链接的接口 - 符号符号表结构链接过程的本质就是要把多个不同的目标文件之间相互粘到一起。 目标文件 B 要用到目标文件 A 的函数foo,我们称目标文件 A定义了函数foo,目标文件 B引用了目标文件 A 的函数foo。 链接中,我们将函数和变量统称为符号,函数名或变量名就是符号名。、 每一个目标文件都会有一个相应的符号表,表里记录了目标文件中所用到的所有符号。每个符号都有一个对应值,叫符号值,对于变量和函数来说,符号值就是他们的地址。 符号类型: 定义在本目标文件的全局符号,可以被其他目标引用。 在本目标文件中应用的全局符号,却没有定义在本目标文件。 段名称,也就是段起始地址。 局部符号,一些静态变量等。 行号信息。 最重要的就是第一类和第二类。链接只关心全局符号的相互粘合,其他都是次要的。 可以使用 readelf objdump nm等命令查看符号信息。 特殊符号一些特殊符号,没有在程序中定义,但是可以直接声明并引用它: __executable_start,程序起始地址,不是入口地址,是程序最开始的地址。 __etext __etext etext 代码段结束地址,代码段最末尾的地址。 _edata edata 数据段结束地址,数据段最末尾地址。 __end end 程序结束地址。 符号修饰符号应与对应的函数或者变量同名,但是在 C 语言发明时,已经存在了很多库和目标文件,如果再用一样的函数或变量就会冲突为了避免冲突,C 语言编译后符号名前会加上下划线_,如foo变成_foo,Fortran 语言编译后会在符号前后加上下划线_foo_。 C++具有类,继承,重载等复杂机制,为了支持这些复杂特性,人们发明了符号修饰和符号改编。 函数签名包含了一个函数的信息,包括函数名,参数类型,所在类和名称空间等信息。它用于识别不同的函数。在编译器和链接器处理符号时,使用某种名称修饰的方法,是的每个函数签名对应一个修饰后名称。 由于不同的编译器采用不同的名字修饰方式,必然导致由不同编译器编译产生的目标文件无法正常互相链接,这是导致不同编译器之间不能互操作的主要原因之一。 extern CC++为了兼容 C,C++编译器会将在extern C 的大括号内部的代码当做 C 语言代码处理,这样就不会使用 C++的名称修饰机制。(也就不会在编译的时候加上下划线) 但是 C 语言并不支持extern C关键字,又不能为同一个库函数写两套头文件,这时候就可以用 C++的宏,__cplusplus。C++编译器会在编译 C++的程序时默认定义这个宏,我们可以用条件宏来判断当前编译单元是不是 C++代码。 123456789#ifdef __cplusplusextern "C" {#endifvoid *memset(void *, int , size_t);#ifdef __cplusplus}#endif 弱符号与强符号我们经常碰到符号重定义,多个目标文件中含有相同名字全局符号的定义,那么这些目标文件链接的时候就会出现符号重定义的错误。比如在两个文件中定义了相同的全局变量。 对于C/C++来说,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号。 也可以使用 GCC 的__attribute__((weak))来定义任何一个强符号为弱符号。 不允许强符号被多次定义,如果多次定义,则链接器报重复定义错误; 如果一个符号在某文件中是强符号,在其他文件中都是弱符号,那么选择强符号。 如果一个符号在所有目标文件中都是弱符号,那么选择其中占用空间最大的一个。 第四章 静态链接空间地址分配可执行文件中的代码段和数据段就是多个文件合并而来的,对于多个文件链接器如何将它们合并到输出文件? 按序叠加:最简单的方式,按照输入文件顺序依次合并。这会导致大量碎片,比如 x86 的硬件,段的装载地址和空间的对齐单位是页,也就是 4096 字节,那么如果一个段的长度只有 1 字节,它在内存里也要占用 4096 字节。 相似段合并:将所有相同性质的段合并在一起。 现在的链接器基本上采用第二种。使用这种方法的链接器都采用一种叫两步链接的方法。 第一步,空间与地址分配。扫描所有的输入目标文件,并且获得各个段的长度,属性和位置,并将输入目标文件中的符号表所有的符号定义和符号引用收集起来,统一放到一个全局符号表。这一步,链接器将能够获得所有输入目标文件的段长度,并且将他们合并,计算出输出文件中各个段合并后的长度和位置,并建立映射关系。 第二部,符号解析与重定位。使用上面收集到的信息,读取输入文件中段的数据,重定位信息。并且进行符号解析与重定位,调整代码中的地址。 VMA(Virtual Memory Address)虚拟地址,LMA(Load Memory Address)加载地址。正常情况这两个值是一样的。 链接之前目标文件的所有短 VMA 都是 0,因为虚拟空间还没有被分配,默认为 0,链接之后各个段就会被分配相应的虚拟地址。 Linux 下,ELF 可执行文件默认从地址0x8048000开始分配。 符号解析与重定位1objdump -d 查看代码段反汇编结果 源代码在编译成目标文件时并不知道函数的调用地址。需要通过链接时重定位。 链接器如何知道哪些指令需要被调整?这就用到了重定位表。 重定位表就是 ELF 文件的一个段,所以其实重定位表也可以叫重定位段。 1objdump -r 查看重定位表 每个要被重定位的地方叫一个重定位入口(Relocation Entry)。 重定位过程也伴随着符号的解析过程,每个目标文件都可能定义一些符号,或引用到定义在其他文件的符号。重定位过程中,每个重定位的入口都是对一个符号的引用,那么当链接器需要对某个符号的引用进行重定位时,他就要确定这个符号的目标地址。这时候链接器就会取查找由所有输入目标文件的符号表组成的全局符号表,找到对应的符号进行重定位。 1readelf -s 查看符号表 对于 32 位 x86 平台下的 ELF 文件的重定位入口所修正的指令寻址方式只有两种: 绝对近址 32 位寻址 相对近址 32 位寻址 x86 基本重定位类型 宏定义 值 重定位修正方法 R_386_32 1 绝对寻址修正 S+A R_386_PC32 2 相对寻址修正 S+A-P A = 保存在被修正位置的值P = 被修正的位置 (相对于段开始的偏移量或者虚拟地址),注意,该值可通过 r_offset 计算得到S = 符号的实际地址,即由 r_info的高 24 位指定的符号的实际地址 第六章 可执行文件的装载与进程程序运行时是有局部性原理的,所以我们可以将程序最常用的部分驻留在内存中,将不常用的数据存放在磁盘里,这就是动态载入的基本原理。 COMMON 块 Q:在目标文件中,编译器为什么不直接把未初始化的全局变量也当做未初始化的局部静态变量一样处理,为它在 BSS 段分配空间,而是将其标记为一个 COMMON 类型的变量?A:当编译器将一个编译单元编译成目标文件时,如果该编译单元包含了弱符号(未初始化的全局变量就是典型),那么该弱符号最终所占大小未知,因为有可能其他编译单元中该符号所占空间比当前的大所以编译器此时无法为该符号在 BSS 段分配空间。但链接器在链接过程中可以确定弱符号大小,因为当链接器读取所有输入目标文件后,任何一个弱符号大小都可以确定,所以它可以在最终输出文件的 BSS 段为其分配空间。总体来看,未初始化全局变量最终还是被放在 BSS 段。 GCC 的-fno-common吧所有未初始化的全局变量不以 COMMON 块形式处理。 __attribute__扩展也可以实现,int global __attribute__((nocommon))。这样未初始化的全局变量就是强符号。 Q: 为什么静态运行库里面一个目标文件只包含一个函数?比如 libc.o 里面 printf.o 只包含 printf() 函数,strlen.o 只有 strlen 函数?A:因为链接器在链接静态库时是以目标文件为单位的,比如我们引用了静态库中的 printf 函数,那么链接器就会把库中包含 printf 函数的那个目标文件链接进来,如果很多函数写在一个目标文件中,就将没用到的函数一起链接进了输出结果中。 链接的过程控制第 6 章 可执行文件的装载与进程程序运行时是有局部性原理的,所以我们可以将程序最常用的部分驻留在内存中,将不常用的数据存放在磁盘里,这就是动态载入的基本原理。 可执行文件在装载时实际上是被映射的虚拟空间,所以可执行文件又被叫做映像文件 (Image)。 Segment 和 Section 很难从中文翻译上区分,ELF 文件按 Section 存储的,从装载的角度 ELF 文件又可以按照 Segment 划分。 段地址对齐可执行文件需要被装载,装载一般通过虚拟内存页映射机制完成,页是映射的最小单位,对于 x86 处理器来说,默认页大小为 4096 字节,所以内存空间的长度必须是 4096 的整数倍,并且这段空间在物理内存和进程虚拟地址空间的起始地址必须是 4096 的整数倍。 第 7 章 动态链接第七章 动态链接为什么要动态链接? 内存和磁盘空间:如果两个程序都用到一个静态库,链接时就会有静态库的两个副本,运行时就会占用两份内存。 程序的开发与发布:一个程序用到的静态库如果有更新,那么程序就需要重新链接,发布给用户。 要解决以上问题,最简单的方法就是把程序的模块相互分割开来,形成独立的文件,而不再将它们静态链接。就是不对目标文件进行链接,而等到程序运行时再链接。这就是动态链接的基本思想。 动态链接模块的装载地址是从0x00000000开始的。 共享对象的最终装载地址在编译时是不确定的。 地址无关代码静态共享库:将程序的各个模块交给操作系统管理,操作系统在某个特定的地址划分出一些地址块,为那些已知的模块预留足够的空间。 装载时重定位:程序在编译时被装载的目标地址为0x1000,但是在装载时操作系统发现0x1000这个地址已经被别的程序使用了,从0x4000开始有一块足够大的空间可以容纳,那么该程序就可以被装载至0x4000,程序指令和数据所有引用都只需要加上0x3000偏移量即可。因为他们在程序中的相对位置是不会改变的。 地址无关代码为了解决共享对象指令中对绝对地址的重定位问题,基本想法是把指令中那些需要被修改的部分分离出来,跟数据部分放在一起,这样指令部分就可以保持不变,而数据部分可以在每个进程中拥有一个副本。 模块中四类地址引用: 模块内部调用或者跳转不需要重定位,本身就是地址无关的。 模块内部数据访问指令中不能包含数据的绝对地址,所以使用相对寻址的方式。 模块间数据访问把跟地址相关的部分放到数据段里面。ELF 的做法是在数据段里面建立一个指向这些数据的指针数据,称为全局偏移表(GOT)。当代码需要引用全局变量时,可以通过 GOT 间接引用。 链接器在装载时会查找每个变量的地址,填充 GOT 每个项,当指令中需要访问变量时,程序会先找到 GOT,根据 GOT 中对应的地址,找到对应的变量。GOT 本身放在数据段,所以他可以在模块装载时被修改,并且每个进程有独立副本,相互不影响。 以访问变量 b 为例,程序首先计算出变量 b 的地址在 GOT 中的位置,即 0x10000000 + 0x454 + 0x118c + 0xfffffff8 = 0x100015d8 0xfffffff8为-8的补码表示,然后使用寄存器间接寻址方式给变量 b 赋值 2。 模块间调用跳转类似于模块机数据访问,不同的是 GOT 中相应项保存的是目标函数的地址。 各种地址引用方式 指令跳转,调用 数据访问 模块内部 相对跳转和调用 相对地址访问 模块外部 间接跳转和调用(GOT) 间接访问(GOT) Q : -fpic 和-fPIC 的区别?A: 都是 GCC 产生地址无关代码的参数。-fpic产生的代码较小,-fPIC产生的代码较大。因为地址无关代码和硬件平台相关,在一些平台上-fpic会受到限制,比如全局符号的数量或者代码长度等,而后者没有这样的限制。 Q: 如果一个共享对象 lib.so 中定义了一个全局变量 G,进程 A 和进程 B 都是用了 lib.so。那么当进程 A 改变这个全局变量时,进程 B 的 G 是否受到影响?A: 不会,应当 lib.so 被加载时,它的数据段部分在每个进程都有独立的副本。如果是同一个进程里的线程 A 和线程 B,那么他们是共享数据 G 的。 如果代码不是地址无关的,它就不能被多个进程共享,就失去了节省内存的优点。但是装载是重定位的共享对象的运行速度要比使用地址无关代码的共享对象快,因为它省去了地址无关代码中每次访问全局数据和函数是需要做一次计算当前地址以及间接地址寻址的过程。 延迟绑定 PLT动态链接要比静态链接慢,一是因为动态链接下,对全局和静态数据的访问都要进行复杂的 GOT 定位,然后间接寻址。另外,程序开始执行时,动态链接器都要进行一次链接工作。 而在一个程序运行过程中,可能很多函数在程序执行完时都不会用到,如果一开始就把所有函数链接好实际就是一种浪费,所有 ELF 采用了一种叫做延迟绑定的做法,基本思想就是当函数第一次使用时才进行绑定(符号查找,重定位等)。 ELF 使用 PLT(Procedure Linkage Table)来实现延迟绑定。以调用bar()函数为例,之前的做法是通过 GOT 中的相应项进行跳转,而延迟绑定下,在这过程中间加了一层 PLT 间接跳转。每个外部函数在 PLT 中都有一个对应项,比如bar()在 PLT 中项的地址为bar@plt。 12345bar@plt: jmp *(bar@GOT) push n push moduleID jump _dl_runtime_resolve 第一条是指令通过 GOT 间接跳转的指令,如果链接器在初始化阶段已经初始化该项,并将bar()地址填入该项,那么就能正确跳转到bar()。但是为了延迟绑定,链接器初始化时并没有将bar()地址填入,而是将第二条指令push n的地址填入了bar@GOT中,这一步不需要查找符号,代价很低。 第一条指令的效果就是跳转到第二条指令,第二条指令将数字n压入堆栈,这个数字是bar这个符号引用在重定位表.rel.plt中的下标。第三条指令将模块 ID 压入堆栈,最后跳转到_dl_runtime_resolve。 _dl_runtime_resolve进行一系列工作后将bar()真正地址填入到bar@GOT。 一旦bar()这个函数被解析完,当面再次调用bar@plt时,第一条jump指令就能跳转到bar()的真正地址。bar()函数返回时根据堆栈里保存的EIP直接返回到调用者,而不会执行bar@plt中第二条指令。那段代码只会在符号未被解析时执行一次。 PLT 在 ELF 文件中以独立段存在,段名通常叫做.plt,因为它本身是一些地址无关的代码,所以可以跟代码段合并成同一个可读可执行的 Segment 被装载入内存。 动态链接相关结构.interp 段 1234objdump -s a.outContents of section .interp:804811 2f6c6962 2f6c696d 6c696e78 782e736f /lib/ld-linux.so.2 里面保存的就是可执行文件所需要的动态链接器的路径,在 Linux 下,可执行文件动态链接器几乎都是/lib/ld-linux.so.2。 这是个软链接,会他会指向系统中安装的动态链接器。当系统中的 Glibc 库更新时,软链接也会指向新的动态链接器,所以.interp段不需要修改。 可以通过以下命令查看可执行文件需要的动态链接器的路径: 12$ readelf -l a.out | grep interpreter [Requesting program interpreter: /lib/ld-linux.so.2] .dynamic 段 动态链接 ELF 中最重要的结构,这里保存了动态链接器所需要的基本信息,如依赖哪些共享对象,动态链接符号表的位置,动态链接重定位表的位置,共享对象初始化代码的地址等。 动态符号表 Program1程序一来Lib.so,引用到了里面的foobar()函数,那么对于Program1来说,称Program1导入(Import)了foobar函数,foobar是Program1的导入函数。 而站在Lib.so角度来说,它定义了foobar函数,我们称Lib.so导出(Export)了foobar函数,foobar是Lib.so的导出函数。 为了表示动态链接这些模块之间的符号导入导出关系,ELF 专门有一个叫做动态符号表的段来保存这些信息,段名通常叫.dynsym。 .dynsym只保存与动态链接相关的符号,对于那些模块内部的符号,比如模块私有变量则不保存。 动态链接重定位表 PIC 模式的共享对象也需要重定位。 对于使用 PIC 技术的可执行文件或共享对象来说,虽然代码段不需要重定位,但是数据段还包含了绝对地址的引用,因为代码段中绝对地址相关的部分被分离出来,变成了 GOT,而 GOT 实际上是数据段的一部分。 目标文件的重定位在静态链接时完成,共享对象的重定位在装载时完成。 目标文件里包含专门用于重定位信息的重定位表,比如.rel.text表示是代码段重定位表,.rel.data表示数据段重定位表。 共享对象里类似的重定位表叫做.rel.dyn和.rel.plt。.rel.dyn实际上是对数据引用的修正,它所修正的位置位于.got以及数据段;.rel.plt实际上是对代码引用的修正,它所修正的位置位于.got.plt。 用以下命令可以查看重定位表; printf这个重定位入口,它的类型为R_386_JUMP_SLOT,它的偏移为0x000015d8。它实际位于.got.plt中,前三项是被系统占用的,第四项开始才是真正存放导入函数地址的地方,刚好是0x000015c8 + 4 * 3 = 0x000015d4,即__gmon_start__。 当动态链接器要进行重定位时,先查找printf的地址,假设链接器在全局符号表中找到printf的地址为0x08801234,那么链接器就会将这个地址填入.got.plt中偏移为0x000015d8的位置。从而实现了地址重定位,即动态链接最关键的一步。 动态链接时进程堆栈初始化信息动态链接的步骤和实现动态链接分为三步:启动动态链接本身,装载所有的共享对象,重定位和初始化。 Q:动态链接器本身是动态链接还是静态链接?A:动态链接器本身应该是静态链接的,它不能依赖于其他共享对象,动态链接器本身使用来帮助其他 ELF 文件解决共享对象依赖问题的,如果它也依赖其他共享对象,那就陷入矛盾了。 Q:动态链接器本身必须是 PIC 的吗?A:动态链接器可以是 PIC 的也可以不是,但是往往用 PIC 会简单一些。 Q:动态链接器可以被当做可执行文件运行,那么它的装载地址是多少?A:ld.so 的装载地址跟一般的共享对象一样,即0x00000000。这个装载地址是一个无效的装载地址,作为一个共享库,内核在装载它时会为其选择一个合适的装载地址。 显示运行时链接第 10 章 内存程序的内存布局在 32 位操作系统里,有 4GB 的寻址能力,大部分操作系统会将一部分挪给内核使用,应用程序无法直接访问这段内存。这部分称为内核空间。Windows 默认将高地址的 2GB 分给内核,Linux 默认分 1GB 给内核。 剩下的称为用户空间,在用户空间里也有一些特殊的地址区间: 栈:维护函数调用上下文,通常在用户空间的最高地址处分配。 堆:用来容纳程序动态分配的内存区域,当使用 malloc 或者 new 分配内存时,得到的内存来自于堆。通常在栈下方。 可执行文件映像:存储可执行文件再内存里的映像,由装载器在装载时将可执行文件的内存读取活映射到这里。 保留区:保留区并不是一个单一的内存区域,而是对内存中受到保护而禁止访问的内存区域的总称。比如NULL。 栈与调用惯例栈保存了一个函数调用所需要的维护信息,通常这被称为栈帧。一般包括如下几个方面: 函数的返回地址和参数 临时变量 保存的上下文 一个函数的调用流程: I386 标准函数进入和退出指令序列,基本形式: 123456789101112131415push ebpmov ebp, espsub esp, x[push reg1]...[push regn]函数实际内存[pop regn]...[pop reg1]mov esp, ebppop ebpret Hot Patch Prologue 热补丁在 Windows 函数里,有些函数尽管使用了标准的进入指令序列,但是在这些指令之前却插入了一些特殊内容: 1mov edi,edi 这条指令没有任何用,在汇编之后会成为一个占用 2 字节的机器码,纯粹为了占位符而存在,使用这条指令开头的函数整体看起来是这样的: 123456789nopnopnopnopnopFUNCTION:mov edi,edipush ebpmov ebp, esp 其中 nop 占 1 个字节,也是占位符,FUNCTION 为一个标号,表示函数入口,本身不占空间。 设计成这样的函数在运行时可以很容易被其他函数替换掉,在上面的指令序列中调用的函数是 FUNCTION,但是我们可以做一些修改,可以在运行时刻意改成调用函数 REPLACEMENT_FUNCTION。首先在进程内存空间任意处写入 REPLACEMENT_FUNCTION 的定义: 1234567REPLACEMENT_FUNCTION:push ebpmov ebp, esp...mov esp, ebppop ebpret 然后修改原函数的内容: 1234567LABEL: # 标号不占字节jmp REPLACEMENT_FUNCTION # 占5字节,刚好五个nopFUNCTION: # 函数入口标号,不占字节jmp LABEL # 近跳指令,占2字节,跳跃到上方,即使截获失败也不影响原函数执行push ebpmov ebp, esp... 将 5 个nop换成一个jmp指令,然后将占用两个字节的mov edi,edi换成另一个jmp指令。因为这个jmp指令跳转的距离非常近,因此被汇编器翻译成了一个“近跳”指令,这种指令只占用两个字节。但只能跳跃到当前地址前后 127 个字节范围的目标位置。 这里的替换机制,可以实现一种叫做钩子(HOOK)的技术,允许用户在某时刻截获特定函数的调用。 函数传递参数时压栈顺序,传递参数是寄存器传参还是栈传参等等都需要遵守一定的约定,否则函数将无法正确执行,这样的约定称为调用惯例。 一个调用惯例一般会规定如下几个方面: 函数参数的传递顺序和方式 调用方压栈,函数自己从栈用取参数 调用方压栈顺序:从左至右,还是从右至左? 栈的维护方式 参数出栈,可以由调用方完成还是由函数自己完成? 名字修饰的策略 为了链接的时候对调用惯例进行区分,调用惯例要对函数本身的名字进行修饰,不同调用惯例有不同的名字修饰策略 没有显示指定调用惯例的函数默认是cdecl惯例 1int _cdecl foo(int n, float m) _cdel 是非标准关键字,在不同编译器中写法不同,在 gcc 中使用的是__attribute__((cdecl)) 附录文件名 英文名 Linux 扩展名 英文名 Windows 扩展名 功能 DSO-Dynamic Shared Objects ELF 动态链接文件,动态共享对象,共享对象 .so DLL-Dynamic Linking Library 动态链接库 .dll 1111 Static Shared Library 静态共享库 2222 2222 2222 2222 2222 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111","categories":[{"name":"读书笔记","slug":"读书笔记","permalink":"http://example.com/categories/%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0/"}],"tags":[{"name":"读书笔记","slug":"读书笔记","permalink":"http://example.com/tags/%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0/"}]},{"title":"ZH-什么是 Die-to-Die 接口","slug":"ZH-什么是Die-to-Die接口","date":"2022-03-28T11:06:56.000Z","updated":"2022-10-15T03:14:29.633Z","comments":true,"path":"2022/03/28/ZH-什么是Die-to-Die接口/","link":"","permalink":"http://example.com/2022/03/28/ZH-%E4%BB%80%E4%B9%88%E6%98%AFDie-to-Die%E6%8E%A5%E5%8F%A3/","excerpt":"","text":"什么是 Die-to-Die 接口 Author:Synopsys译:What is a Die-to-Die Interface? – How it Works | Synopsys 定义裸片到裸片(Die2Die)接口是一个功能块,它提供组装在同一封装中的两个硅管芯之间的数据接口。芯片到芯片接口利用非常短的通道连接封装内的两个芯片,以实现功率效率和非常高的带宽效率,这超出了传统芯片到芯片接口所能达到的效果。 Die2Die 接口通常由 PHY 和控制器块组成,控制器块在两个 die 上的内部互连结构之间提供无缝连接。Die2Die 的 PHY 使用高速 SerDes 架构或高密度并行架构实现,经过优化以支持多种先进的 2D、2.5D 和 3D 封装技术。 Die2Die 接口是推动行业趋势从单片 SoC 设计转向同一封装中的多 Die SoC 组件的关键推动力。这种方法减轻了人们对小型工艺节点的高成本/低产量日益增长的担忧,并提供了额外的产品模块化和灵活性。 Die-to-Die 接口如何工作?Die2Die 的接口,就像任何其他芯片到芯片的接口一样,在两个芯片之间建立了可靠的数据链路。 接口在逻辑上分为物理层、链路层和事务层。它在芯片运行期间建立和维护链路,同时向应用程序提供连接到内部互连结构的标准化并行接口。 通过添加诸如前向纠错 (FEC) 和/或循环冗余码 (CRC) 和重试等错误检测和纠正机制来保证链路可靠性。 物理层架构可以是基于 SerDes 或基于并行的。 基于 SerDes 的架构包括并行到串行(串行到并行)数据转换、阻抗匹配电路和时钟数据恢复或时钟转发功能。它可以支持更高带宽的 NRZ 信令或 PAM-4 信令,最高可达 112 Gbps。SerDes 架构的主要作用是尽量减少简单 2D 类型封装(如有机基板)中的 I/O 互连数量。 基于并行的架构包括许多并行的低速简单收发器,每个收发器都由驱动器和具有转发时钟技术的接收器组成,以进一步简化架构。它支持 DDR 类型的信令。并行架构的主要作用是最大限度地降低密集 2.5D 型封装(如硅中介层)的功耗。 Die2Die 的优势现代芯片实现趋向于基于在封装中组装多个裸片以提高模块化和灵活性的解决方案。当(单片)芯片尺寸接近全光罩尺寸时,这种多管芯方法还通过将功能分成几个管芯来提高产量,从而促进更具成本效益的解决方案。 Die 之间的接口必须满足此类系统的所有关键要求: 电源效率。多芯片系统实现应该与等效的单片实现一样节能。Die2Die 链接使用短距离、低损耗的信道,没有明显的不连续性。PHY 架构利用良好的通道特性来降低 PHY 复杂性并节省功耗。 低延迟。将服务器或加速器 SoC 划分为多个 Die 不应导致内存架构不统一,因为访问不同 Die 中的内存具有显着不同的延迟。Die2Die 接口实现了简化的协议,并直接连接到芯片互连结构,以最大限度地减少延迟。 高带宽效率。高级服务器、加速器和网络交换机需要在 Die 之间传输大量数据。Die2Die 接口必须能够支持所有需要的带宽,同时减少 Die 边缘的占用。通常使用两种替代方案来实现此目标:通过以非常高的每通道数据速率(高达 112 Gbps)部署 PHY 来最小化所需通道的数量,或者通过使用更精细的凸块间距(微凸块)来增加 PHY 的密度) 在大量并行化以实现所需带宽的低数据速率通道(高达 8 Gbps/通道)上。 健壮的链接。Die2Die 链接必须没有错误。该接口必须实现足够强大的低延迟错误检测和纠正机制,以检测所有错误并以低延迟纠正它们。这些机制通常包括 FEC 和重试协议。 Die-to-Die 接口用例通过将多个 Die 组合到一个封装中,小芯片提供了另一种扩展摩尔定律的方法,同时实现了产品模块化和工艺节点优化。小芯片用于计算密集型、工作负载繁重的应用程序,如高性能计算 (HPC)。 针对 HPC、网络、超大规模数据中心和人工智能 (AI) 等应用程序的 die-to-die 接口有四个主要用例: Scale SoC目标是通过虚拟(裸片到裸片)连接来连接裸片,从而提高计算能力并为服务器和 AI 加速器创建多个 SKU,从而实现裸片之间的紧密耦合性能。 Split SoC目标是启用非常大的 SoC。大型计算和网络交换机芯片正在接近光罩限制。将它们分成几个裸片会带来技术可行性、提高产量、降低成本并扩展摩尔定律。 Aggregate其目的是聚合在不同模具中实现的多种不同的功能,以利用每个功能的最佳工艺节点,降低功率,并改善 FPGA、汽车和 5G 基站等应用的外形尺寸。 Disaggregate目标是将中央芯片与 I/O 芯片分离,以便将中央芯片轻松迁移到高级工艺,同时将 I/O 芯片保持在保守节点中,以降低产品演进的风险/成本,实现重用并缩短时间在服务器、FPGA、网络交换机和其他应用程序中投放市场。 Die-to-Die 接口和 SynopsysSynopsys 结合了广泛的 Die2Die 112G USR/XSR 和 HBI PHY IP、控制器 IP 和中介层专业知识产品组合,提供全面的 die-to-die IP 解决方案,以支持芯片拆分、芯片分解、计算扩展和聚合的功能。基于 SerDes 的 112G USR/XSR PHY 和基于并行的 8G OpenHBI PHY 可用于高级 FinFET 工艺。可配置控制器使用具有重放和可选 (FEC) 功能的纠错机制,以最大限度地降低可靠芯片到芯片链接的误码率。它支持用于连贯和非连贯数据通信的 Arm® 特定接口。 Q&A PHY 架构 SerDes 架构 reticleLCD 厂掩膜版叫 Mask,Fab 里掩膜版叫 reticle,两者有什么区别? - 知乎 原文参考What is a Die-to-Die Interface? – How it Works | Synopsys","categories":[],"tags":[{"name":"Translation","slug":"Translation","permalink":"http://example.com/tags/Translation/"},{"name":"Die2Die","slug":"Die2Die","permalink":"http://example.com/tags/Die2Die/"}]},{"title":"Qt 编译后的程序放到指定目录,屏蔽 qDebug 输出","slug":"Qt编译后的程序放到指定目录,屏蔽qDebug输出","date":"2022-03-18T05:50:35.000Z","updated":"2022-10-15T03:14:29.509Z","comments":true,"path":"2022/03/18/Qt编译后的程序放到指定目录,屏蔽qDebug输出/","link":"","permalink":"http://example.com/2022/03/18/Qt%E7%BC%96%E8%AF%91%E5%90%8E%E7%9A%84%E7%A8%8B%E5%BA%8F%E6%94%BE%E5%88%B0%E6%8C%87%E5%AE%9A%E7%9B%AE%E5%BD%95%EF%BC%8C%E5%B1%8F%E8%94%BDqDebug%E8%BE%93%E5%87%BA/","excerpt":"","text":"可执行程序放到指定目录默认情况下 QtCreator 会将编译链接后的可执行程序与中间生成的文件防盗build-***-文件中,如何能将可执行文件生成在指定目录? 修改.pro: 12345CONFIG(debug ,debug|release){ DESTDIR = ../debug}else{ DESTDIR = ../release} debug版本放在../debug目录中,release版本放在../release目录中。 屏蔽 qDebug 输出12345CONFIG(debug ,debug|release){ DEFINES -= QT_NO_DEBUG_OUTPUT}else{ DEFINES += QT_NO_DEBUG_OUTPUT} QT_NO_DEBUG_OUTPUT即为屏蔽 qDebug 输出的宏定义,可以在debug版本中不屏蔽 qDebug 输出,release版本中屏蔽 qDebug 输出。 参考QT 屏蔽 qDebug()、qWarning() 打印信息_qq_35173114 的博客-CSDN 博客_qwarningQT 的 QDebug 无法输出日志_amwha 的专栏 - 程序员宅基地_qdebug 打印不出来 - 程序员宅基地Qt Creator 中的.pro 文件的详解_hebbely 的博客-CSDN 博客_qt 的 pro 文件","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"}]},{"title":"QEMU 源码分析-QOM","slug":"QEMU源码分析-QOM","date":"2022-03-09T08:02:19.000Z","updated":"2022-11-20T07:03:29.699Z","comments":true,"path":"2022/03/09/QEMU源码分析-QOM/","link":"","permalink":"http://example.com/2022/03/09/QEMU%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90-QOM/","excerpt":"","text":"QOM 简介QOM(QEMU Object Model) 是 QEMU 的一个模块,用于描述虚拟机的结构,包括虚拟机的 CPU、内存、硬盘、网络、输入输出设备等。QEMU 为了方便整个系统的构建,实现了自己的一套的面向对象机制,也就是 QOM(QEMU Object Model)。它能够方便的表示各个设备(Device)与总线(Bus)之间的关系。 这个模型主要包含四个结构体: Object: 是所有对象的 基类 Base Object ObjectClass: 是所有类对象的基类 TypeInfo:是用户用来定义一个 Type 的工具型的数据结构 TypeImpl:TypeInfo 抽象数据结构,TypeInfo 的属性与 TypeImpl 的属性对应 在 QEMU 里要初始化一个对象需要完成四步: 将 TypeInfo 注册 TypeImpl 实例化 Class(ObjectClass) 实例化 Object 添加 Property QOM 中的面向对象继承在 QEMU 中通过 TypeInfo 来定义一个类。 例如 x86_base_cpu_type_info 就是一个 class, 12345static const TypeInfo x86_base_cpu_type_info = { .name = X86_CPU_TYPE_NAME("base"), .parent = TYPE_X86_CPU, .class_init = x86_cpu_base_class_init,}; 利用结构体包含来实现继承。这应该是所有的语言实现继承的方法,在 C++ 中,结构体包含的操作被语言内部实现了,而 C 语言需要自己实现。 例如 x86_cpu_type_info 的 parent 是 cpu_type_info, 他们的结构体分别是 X86CPU 和 CPUState。 12345678910111213static const TypeInfo x86_cpu_type_info = { .name = TYPE_X86_CPU, .parent = TYPE_CPU, // ... .instance_size = sizeof(X86CPU),};static const TypeInfo cpu_type_info = { .name = TYPE_CPU, .parent = TYPE_DEVICE, // ... .instance_size = sizeof(CPUState),}; 在 X86CPU 中包含一个 CPUState。 123456struct X86CPU { /*< private >*/ CPUState parent_obj; /*< public >*/ CPUNegativeOffsetState neg; 静态成员静态成员变量可以在类的多个对象中访问,但是要在类外声明。不同对象访问的其实是同一个实体,静态成员变量被多个对象共享。 1234567891011static const TypeInfo x86_cpu_type_info = { .name = TYPE_X86_CPU, .parent = TYPE_CPU, .instance_size = sizeof(X86CPU), .instance_init = x86_cpu_initfn, .instance_post_init = x86_cpu_post_initfn, .abstract = true, .class_size = sizeof(X86CPUClass), .class_init = x86_cpu_common_class_init,}; 其中 X86CPU 描述的是非静态成员,而 X86CPUClass 描述的是静态的成员。也就是说class_init初始化静态成员,instance_init初始化非静态成员。 那么何时初始化静态成员呢?首先得告诉系统,咱有class_init这个初始化函数,等需要的时候随时可以调用它初始化,所有先解决如何将这个初始化函数注册到系统中? 在target/i386/cpu.c最后使用了type_init。在qemu/include/qemu/module.h中有一个type_init宏定义,除了type_init还有其他宏,比如block_init,opts_init等。每个宏都表示一类module,通过module_init构造出来。我们展开这个宏, 1234static void __attribute__((constructor))do_qemu_init_x86_cpu_register_types(void) { register_module_init(x86_cpu_register_types, MODULE_INIT_QOM);} 通过 gcc 扩展属性__attribute__((constructor))可以让 do_qemu_init_x86_cpu_register_types 在运行 main 函数之前运行。 register_module_init 会让 x86_cpu_register_types 这个函数挂载到 init_type_list[MODULE_INIT_QOM] 这个链表上。 到底,所有的 TypeInfo 通过 type_init 都被放到 type_table 上了,之后通过 Typeinfo 的名称调用 type_table_lookup 获取到 TypeImpl 了。 到这里,将TYPE_X86_CPU注册进类系统,包括其初始化函数,这部分也就是 QEMU 中类型的构造。那么何时调用静态成员初始化函数呢?也就是类型的初始化。 静态成员是所有的对象公用的,其初始化显然要发生在所有的对象初始化之前。 12345678910main qemu_init select_machine object_class_get_list object_class_foreach g_hash_table_foreach object_class_foreach_tramp type_initialize type_initialize x86_cpu_common_class_init select_machine 需要获取所有的 TYPE_MACHINE 的 class, 其首先会调用所有的class_list,其会遍历 type_table,遍历的过程中会顺带 type_initialize 所有的 TypeImpl 进而调用的 class_init。 说完类型的初始化,再讲一下对象的初始化,也就是初始化非静态成员,也就是instance_init在何时被调用? 对象初始化,通过调用 object_new 来实现初始化。 object_initialize_with_type 初始化一个空的 :Object::properties object_init_with_type 如果 object 有 parent,那么调用 object_init_with_type 首先初始化 parent 的 调用TypeImpl::instance_init 1234567891011121314main qemu_init qmp_x_exit_preconfig qemu_init_board machine_run_board_init pc_init_v6_1 pc_init1 x86_cpus_init x86_cpu_new object_new object_new_with_type object_initialize_with_type object_init_with_type x86_cpu_initfn 多态多态是指同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。为了实现多态,QOM 实现了一个非常重要的功能,就是动态类型转换。我们可以使用相关的函数,将一个Object的指针在运行时转换为子类对象的指针,可以将一个ObjectClass的指针在运行时转换为子类的指针。这样就可以调用子类中定义的函数指针来完成相应的功能。 QEMU 定义了一些列的宏封来进行动态类型转换: 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145//include/qom/object.h/** * DECLARE_INSTANCE_CHECKER: * @InstanceType: instance struct name * @OBJ_NAME: the object name in uppercase with underscore separators * @TYPENAME: type name * * Direct usage of this macro should be avoided, and the complete * OBJECT_DECLARE_TYPE macro is recommended instead. * * This macro will provide the instance type cast functions for a * QOM type. */#define DECLARE_INSTANCE_CHECKER(InstanceType, OBJ_NAME, TYPENAME) \\ static inline G_GNUC_UNUSED InstanceType * \\ OBJ_NAME(const void *obj) \\ { return OBJECT_CHECK(InstanceType, obj, TYPENAME); }/** * DECLARE_CLASS_CHECKERS: * @ClassType: class struct name * @OBJ_NAME: the object name in uppercase with underscore separators * @TYPENAME: type name * * Direct usage of this macro should be avoided, and the complete * OBJECT_DECLARE_TYPE macro is recommended instead. * * This macro will provide the class type cast functions for a * QOM type. */#define DECLARE_CLASS_CHECKERS(ClassType, OBJ_NAME, TYPENAME) \\ static inline G_GNUC_UNUSED ClassType * \\ OBJ_NAME##_GET_CLASS(const void *obj) \\ { return OBJECT_GET_CLASS(ClassType, obj, TYPENAME); } \\ \\ static inline G_GNUC_UNUSED ClassType * \\ OBJ_NAME##_CLASS(const void *klass) \\ { return OBJECT_CLASS_CHECK(ClassType, klass, TYPENAME); }/** * DECLARE_OBJ_CHECKERS: * @InstanceType: instance struct name * @ClassType: class struct name * @OBJ_NAME: the object name in uppercase with underscore separators * @TYPENAME: type name * * Direct usage of this macro should be avoided, and the complete * OBJECT_DECLARE_TYPE macro is recommended instead. * * This macro will provide the three standard type cast functions for a * QOM type. */#define DECLARE_OBJ_CHECKERS(InstanceType, ClassType, OBJ_NAME, TYPENAME) \\ DECLARE_INSTANCE_CHECKER(InstanceType, OBJ_NAME, TYPENAME) \\ \\ DECLARE_CLASS_CHECKERS(ClassType, OBJ_NAME, TYPENAME)/** * OBJECT_DECLARE_TYPE: * @InstanceType: instance struct name * @ClassType: class struct name * @MODULE_OBJ_NAME: the object name in uppercase with underscore separators * * This macro is typically used in a header file, and will: * * - create the typedefs for the object and class structs * - register the type for use with g_autoptr * - provide three standard type cast functions * * The object struct and class struct need to be declared manually. */#define OBJECT_DECLARE_TYPE(InstanceType, ClassType, MODULE_OBJ_NAME) \\ typedef struct InstanceType InstanceType; \\ typedef struct ClassType ClassType; \\ \\ G_DEFINE_AUTOPTR_CLEANUP_FUNC(InstanceType, object_unref) \\ \\ DECLARE_OBJ_CHECKERS(InstanceType, ClassType, \\ MODULE_OBJ_NAME, TYPE_##MODULE_OBJ_NAME)/** * OBJECT: * @obj: A derivative of #Object * * Converts an object to a #Object. Since all objects are #Objects, * this function will always succeed. */#define OBJECT(obj) \\ ((Object *)(obj))/** * OBJECT_CLASS: * @class: A derivative of #ObjectClass. * * Converts a class to an #ObjectClass. Since all objects are #Objects, * this function will always succeed. */#define OBJECT_CLASS(class) \\ ((ObjectClass *)(class))/** * OBJECT_CHECK: * @type: The C type to use for the return value. * @obj: A derivative of @type to cast. * @name: The QOM typename of @type * * A type safe version of @object_dynamic_cast_assert. Typically each class * will define a macro based on this type to perform type safe dynamic_casts to * this object type. * * If an invalid object is passed to this function, a run time assert will be * generated. */#define OBJECT_CHECK(type, obj, name) \\ ((type *)object_dynamic_cast_assert(OBJECT(obj), (name), \\ __FILE__, __LINE__, __func__))/** * OBJECT_CLASS_CHECK: * @class_type: The C type to use for the return value. * @class: A derivative class of @class_type to cast. * @name: the QOM typename of @class_type. * * A type safe version of @object_class_dynamic_cast_assert. This macro is * typically wrapped by each type to perform type safe casts of a class to a * specific class type. */#define OBJECT_CLASS_CHECK(class_type, class, name) \\ ((class_type *)object_class_dynamic_cast_assert(OBJECT_CLASS(class), (name), \\ __FILE__, __LINE__, __func__))/** * OBJECT_GET_CLASS: * @class: The C type to use for the return value. * @obj: The object to obtain the class for. * @name: The QOM typename of @obj. * * This function will return a specific class for a given object. Its generally * used by each type to provide a type safe macro to get a specific class type * from an object. */#define OBJECT_GET_CLASS(class, obj, name) \\ OBJECT_CLASS_CHECK(class, object_get_class(OBJECT(obj)), name) 以OBJECT_DECLARE_TYPE(X86CPU, X86CPUClass, X86_CPU)为例,宏展开如下: 123456789101112131415161718typedef struct X86CPU X86CPU;typedef struct X86CPUClass X86CPUClass;G_DEFINE_AUTOPTR_CLEANUP_FUNC(X86CPU, object_unref)static inline G_GNUC_UNUSED X86CPU *X86_CPU(const void *obj) { return ((X86CPU *)object_dynamic_cast_assert( ((Object *)(obj)), (TYPE_X86_CPU), "~/core/vn/docs/qemu/res/qom-macros.c", 64, __func__));}static inline G_GNUC_UNUSED X86CPUClass *X86_CPU_GET_CLASS(const void *obj) { return ((X86CPUClass *)object_class_dynamic_cast_assert( ((ObjectClass *)(object_get_class(((Object *)(obj))))), (TYPE_X86_CPU), "~/core/vn/docs/qemu/res/qom-macros.c", 64, __func__));}static inline G_GNUC_UNUSED X86CPUClass *X86_CPU_CLASS(const void *klass) { return ((X86CPUClass *)object_class_dynamic_cast_assert( ((ObjectClass *)(klass)), (TYPE_X86_CPU), "~/core/vn/docs/qemu/res/qom-macros.c", 64, __func__));} OBJECT_DECLARE_TYPE通常在头文件中使用,效果是: 创建了X86CPU和X86CPUClass的typedef 用G_DEFINE_AUTOPTR_CLEANUP_FUNC注册类型 创建了三个类型转换函数 X86_CPU : 将任何一个 object 指针 转换为 X86CPU(Object 转子对象) X86_CPU_GET_CLASS : 根据 object 指针获取到 X86CPUClass X86_CPU_CLASS : 根据 ObjectClass 指针转换到 X86CPUClass(基类转子类) 这里的转换依赖内存布局,子类型的第一个成员总是基类型。子类转基类就很容易,只需要强制类型转换就可以实现。 参考QEMU 中的面向对象 : QOM | Deep Dark Fantasy浅谈 QEMU 的对象系统 - 简书","categories":[{"name":"QEMU 源码分析","slug":"QEMU-源码分析","permalink":"http://example.com/categories/QEMU-%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"QEMU","slug":"QEMU","permalink":"http://example.com/tags/QEMU/"}]},{"title":"RGB 与 YUV 颜色空间","slug":"RGB与YUV颜色空间","date":"2022-03-01T08:00:03.000Z","updated":"2022-10-15T03:14:29.519Z","comments":true,"path":"2022/03/01/RGB与YUV颜色空间/","link":"","permalink":"http://example.com/2022/03/01/RGB%E4%B8%8EYUV%E9%A2%9C%E8%89%B2%E7%A9%BA%E9%97%B4/","excerpt":"","text":"基础概念RGB 和 YUV 都属于一种颜色编码方式,或者说颜色空间。 RGB 色彩模式是工业界的一种颜色标准,是通过对红、绿、蓝三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,RGB 即是代表红、绿、蓝三个通道的颜色,这个标准几乎包括了人类视力所能感知的所有颜色,是目前运用最广的颜色系统之一。 在 YUV 空间中,Y 代表亮度,其实 Y 就是图像的灰度值;UV 代表色差,U 和 V 是构成彩色的两个分量。在现代彩色电视系统中,通常采用三管彩色摄影机或彩色 CCD 摄影机进行取像,然后把取得的彩色图像信号经分色、分别放大校正后得到 RGB,再经过矩阵变换电路得到亮度信号 Y 和两个色差信号 B–Y(即 U)、R–Y(即 V),最后发送端将亮度和色差三个信号分别进行编码,用同一信道发送出去。这种色彩的表示方法就是所谓的 YUV 色彩空间表示。 解析RGB 格式RGB16RGB16 数据格式主要有二种:RGB565 和 RGB555。 RGB565,每个像素用 16 比特位表示,占 2 个字节,RGB 分量分别使用 5 位、6 位、5 位。 123456//获取高字节的5个bitR = color & 0xF800;//获取中间6个bitG = color & 0x07E0;//获取低字节5个bitB = color & 0x001F; RGB555,每个像素用 16 比特位表示,占 2 个字节,RGB 分量都使用 5 位 (最高位不用)。 123456//获取高字节的5个bitR = color & 0x7C00;//获取中间5个bitG = color & 0x03E0;//获取低字节5个bitB = color & 0x001F; RGB24RGB24 图像每个像素用 24 比特位表示,占 3 个字节,注意:在内存中 RGB 各分量的排列顺序为:BGR BGR BGR。 RGB32RGB32 图像每个像素用 32 比特位表示,占 4 个字节,R,G,B 分量分别用 8 个 bit 表示,存储顺序为 B,G,R,最后 8 个字节保留。注意:在内存中 RGB 各分量的排列顺序为:BGRA BGRA BGRA ……。 本质就是带 alpha 通道的 RGB24,与 RGB32 的区别在与,保留的 8 个 bit 用来表示透明,也就是 alpha 的值。 1234R = color & 0x0000FF00;G = color & 0x00FF0000;B = color & 0xFF000000;A = color & 0x000000FF; YUV 采样 YUV444:一个像素就有 YUV 三个值,和 RGB 类似;一个 YUV 占 8+8+8 = 24bits 3 个字节。 YUV422:第一个像素有 YUV 三个值,第二个像素只有 Y,与前一个像素共用 UV;一个 YUV 占 8+4+4 = 16bits 2 个字节。 YUV420:上下四个像素共用一个 UV。一个 YUV 占 8+2+2 = 12bits 1.5 个字节。 转换YUV2RGB$$R = Y + 1.403 \\times (V-128)\\G=Y-0.343 \\times (U-128) - 0.714 \\times (V-128)\\B=Y + 1.770 \\times (U-128)$$ RGB2YUV$$Y = 0.299 \\times R + 0.587 \\times G + 0.114 \\times B\\U = -0.169 \\times R - 0.331 \\times G + 0.500 \\times B + 128\\V = 0.500 \\times R - 0.419 \\times G - 0.081 \\times B + 128\\$$ 浮点型运算比较耗时,将所有运算换成位运算,提高效率。具体推倒过程见色彩转换系列之 RGB 格式与 YUV 格式互转原理及实现_小武的博客-CSDN 博客_rgb yuv 123Y= ((R << 6) + (R << 3) + (R << 2) + R + (G << 7) + (G << 4) + (G << 2) + (G << 1) + (B << 4) + (B << 3) + (B << 2) + B) >> 8U= (-((R << 5) + (R << 3) + (R << 1)+ R) - ((G << 6) + (G << 4) + (G << 2)+G) + (B << 7) + 32768) >> 8V= ((R << 7) - ((G << 6) + (G << 5) + (G << 3) + (G << 3) + G) - ((B << 4) + (B << 2) + B) + 32768 )>> 8 参考RGB 和 YUV - 简书颜色空间 YUV 简介_网络资源是无限的-CSDN 博客_yuv 颜色空间图解 RGB565、RGB555、RGB16、RGB24、RGB32、ARGB32 等格式的区别_handy 周-CSDN 博客_rgb565图解 YU12、I420、YV12、NV12、NV21、YUV420P、YUV420SP、YUV422P、YUV444P 的区别_handy 周-CSDN 博客_yv12","categories":[],"tags":[]},{"title":"计算机组成原理-指令和运算","slug":"计算机组成原理-指令和运算","date":"2022-02-28T13:28:56.000Z","updated":"2022-10-15T03:14:29.878Z","comments":true,"path":"2022/02/28/计算机组成原理-指令和运算/","link":"","permalink":"http://example.com/2022/02/28/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86-%E6%8C%87%E4%BB%A4%E5%92%8C%E8%BF%90%E7%AE%97/","excerpt":"","text":"计算机指令上世纪 60 年代晚期或 70 年代初期,程序需要先写在纸上,然后转成二进制机器码,再打到打孔卡上(0 表示不打孔,1 表示打孔),送入特殊的计算机中执行。 从硬件的角度来看,CPU 就是一个超大规模集成电路,通过电路实现了加法、乘法乃至各种各样的处理逻辑。 从软件的角度来看,CPU 就是一个执行各种计算机指令(Instruction Code)的逻辑机器。这里的计算机指令,就好比一门 CPU 能够听得懂的语言,我们也可以把它叫作机器语言(Machine Language)。 不同的 CPU 能够听懂的语言不太一样。也就是 CPU 支持的语言不一样,这里的语言叫指令集(Instruction Set)。 一个计算机程序由成千上万条指令组成的。但是 CPU 里不能一直放着所有指令,所以计算机程序平时是存储在存储器中的。这种程序指令存储在存储器里面的计算机,我们就叫作存储程序型计算机(Stored-program Computer)。 了解了计算机指令和计算机指令集,接下来我们来看看,平时编写的代码,到底是怎么变成一条条计算机指令,最后被 CPU 执行的呢?我们拿一小段真实的 C 语言程序来看看。 1234567// test.cint main(){ int a = 1; int b = 2; a = a + b;} 通过编译器,可以将上述代码编译成汇编代码,再通过汇编器,将汇编代码编译成机器码,最后通过 CPU 执行。 在一个 Linux 操作系统上,我们可以简单地使用 gcc 和 objdump 这样两条命令,把对应的汇编代码和机器码都打印出来。 1234567891011121314151617181920$ gcc -g -c test.c$ objdump -d -M intel -S test.otest.o: file format elf64-x86-64Disassembly of section .text:0000000000000000 <main>:int main(){ 0: 55 push rbp 1: 48 89 e5 mov rbp,rsp int a = 1; 4: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1 int b = 2; b: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2 a = a + b; 12: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8] 15: 01 45 fc add DWORD PTR [rbp-0x4],eax} 18: 5d pop rbp 19: c3 ret 左侧有一堆数字,这些就是一条条机器码;右边有一系列的push、mov、add、pop 等,这些就是对应的汇编代码。 了解了这个过程,下面我们放大局部,来看看这一行行的汇编代码和机器指令,到底是什么意思。 常见的指令可以分成五大类。 第一类是算术类指令。我们的加减乘除,在 CPU 层面,都会变成一条条算术类指令。 第二类是数据传输类指令。给变量赋值、在内存里读写数据,用的都是数据传输类指令。 第三类是逻辑类指令。逻辑上的与或非,都是这一类指令。 第四类是条件分支类指令。日常我们写的“if/else”,其实都是条件分支类指令。 最后一类是无条件跳转指令。写一些大一点的程序,我们常常需要写一些函数或者方法。在调用函数的时候,其实就是发起了一个无条件跳转指令。 指令跳转CPU 如何执行指令的代码经过软件层面的编译后就是一条条二进制指令,指令交由 CPU 中几百亿个晶体管去执行。我们先不管几百亿的晶体管的背后是怎么通过电路运转起来的,逻辑上,我们可以认为,CPU 其实就是由一堆寄存器组成的。而寄存器就是 CPU 内部,由多个触发器(Flip-Flop)或者锁存器(Latches)组成的简单电路。触发器和锁存器,其实就是两种不同原理的数字电路组成的逻辑门。 N 个触发器或者锁存器,就可以组成一个N位(Bit)的寄存器,能够保存 N位的数据。比方说,我们用的64位 Intel服务器,寄存器就是64 位的。 一个 CPU 里面会有很多种不同功能的寄存器。这里介绍三种比较特殊的。 PC 寄存器(Program Counter Register),我们也叫指令地址寄存器(Instruction Address Register)。顾名思义,它就是用来存放下一条需要执行的计算机指令的内存地址。 指令寄存器(Instruction Register),用来存放当前正在执行的指令。 条件码寄存器(Status Register),用里面的一个一个标记位(Flag),存放 CPU 进行算术或者逻辑计算的结果。 除此之外还有整数寄存器、浮点数寄存器、向量寄存器和地址寄存器等等。有些寄存器既可以存放数据,又能存放地址,我们就叫它通用寄存器。 实际上,一个程序执行的时候,CPU 会根据 PC 寄存器里的地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。可以看到,一个程序的一条条指令,在内存里面是连续保存的,也会一条条顺序加载。 而有些特殊指令,比如上一讲我们讲到 J 类指令,也就是跳转指令,会修改 PC 寄存器里面的地址值。 从 if…else 来看程序的执行和跳转首先看如下的例程, 123456789101112131415// test.c#include <time.h>#include <stdlib.h> int main(){ srand(time(NULL)); int r = rand() % 2; int a = 10; if (r == 0) { a = 1; } else { a = 2; } 12gcc -g -c test.cobjdump -d -M intel -S test.o 编译后打印出汇编代码如下: 1234567891011121314if (r == 0) 3b: 83 7d fc 00 cmp DWORD PTR [rbp-0x4],0x0 3f: 75 09 jne 4a <main+0x4a> { a = 1; 41: c7 45 f8 01 00 00 00 mov DWORD PTR [rbp-0x8],0x1 48: eb 07 jmp 51 <main+0x51> } else { a = 2; 4a: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2 51: b8 00 00 00 00 mov eax,0x0 } 可以看到,这里对于 r == 0的条件判断,被编译成了 cmp 和 jne 这两条指令。 cmp 指令比较了前后两个操作数的值,这里的DWORD PTR 代表操作的数据类型是 32位的整数,而 [rbp-0x4] 则是一个寄存器的地址。所以,第一个操作数就是从寄存器里拿到的变量 r 的值。第二个操作数 0x0 就是我们设定的常量0的 16 进制表示。cmp 指令的比较结果,会存入到条件码寄存器当中去。 在这里,如果比较的结果是 True,也就是 r == 0,就把零标志条件码(对应的条件码是 ZF,Zero Flag)设置为 1。除了零标志之外,Intel 的 CPU 下还有进位标志(CF,Carry Flag)、符号标志(SF,Sign Flag)以及溢出标志(OF,Overflow Flag),用在不同的判断条件下。 cmp 指令执行完成之后,PC 寄存器会自动自增,开始执行下一条 jne 的指令。 跟着的 jne 指令,是 jump if not equal 的意思,它会查看对应的零标志位。如果为0,会跳转到后面跟着的操作数 4a 的位置。这个 4a,对应这里汇编代码的行号,也就是上面设置的 else 条件里的第一条指令。当跳转发生的时候,PC 寄存器就不再是自增变成下一条指令的地址,而是被直接设置成这里的 4a 这个地址。这个时候,CPU 再把 4a 地址里的指令加载到指令寄存器中来执行。 跳转到执行地址为 4a 的指令,实际是一条 mov 指令,第一个操作数和前面的 cmp 指令一样,是另一个 32 位整型的寄存器地址,以及对应的 2 的16 进制值 0x2。mov 指令把 2 设置到对应的寄存器里去,相当于一个赋值操作。然后,PC寄存器里的值继续自增,执行下一条 mov 指令。 这条 mov 指令的第一个操作数eax,代表累加寄存器,第二个操作数0x0则是 16 进制的0的表示。这条指令其实没有实际的作用,它的作用是一个占位符。我们回过头去看前面的 if 条件,如果满足的话,在赋值的 mov 指令执行完成之后,有一个 jmp 的无条件跳转指令。跳转的地址就是这一行的地址51。我们的 main 函数没有设定返回值,而mov eax, 0x0 其实就是给 main 函数生成了一个默认的为 0 的返回值到累加器里面。if 条件里面的内容执行完成之后也会跳转到这里,和 else 里的内容结束之后的位置是一样的。 函数调用:为什么会发生 Stack Overflow静态链接既然我们的程序最终都被变成了一条条机器码去执行,那为什么同一个程序,在同一台计算机上,在 Linux 下可以运行,而在 Windows 下却不行呢?反过来,Windows 上的程序在 Linux 上也是一样不能执行的。可是我们的 CPU 并没有换掉,它应该可以识别同样的指令呀? 将以下两个例程编译,然后通过 objdump 命令看看它们的汇编代码。 123456789101112131415// add_lib.cint add(int a, int b){ return a+b;}// link_example.c#include <stdio.h>int main(){ int a = 10; int b = 5; int c = add(a, b); printf("c = %d\\n", c);} 123gcc -g -c add_lib.c link_example.cobjdump -d -M intel -S add_lib.oobjdump -d -M intel -S link_example.o 123456789101112add_lib.o: file format elf64-x86-64Disassembly of section .text:0000000000000000 <add>: 0: 55 push rbp 1: 48 89 e5 mov rbp,rsp 4: 89 7d fc mov DWORD PTR [rbp-0x4],edi 7: 89 75 f8 mov DWORD PTR [rbp-0x8],esi a: 8b 55 fc mov edx,DWORD PTR [rbp-0x4] d: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8] 10: 01 d0 add eax,edx 12: 5d pop rbp 13: c3 ret 1234567891011121314151617181920212223link_example.o: file format elf64-x86-64Disassembly of section .text:0000000000000000 <main>: 0: 55 push rbp 1: 48 89 e5 mov rbp,rsp 4: 48 83 ec 10 sub rsp,0x10 8: c7 45 fc 0a 00 00 00 mov DWORD PTR [rbp-0x4],0xa f: c7 45 f8 05 00 00 00 mov DWORD PTR [rbp-0x8],0x5 16: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8] 19: 8b 45 fc mov eax,DWORD PTR [rbp-0x4] 1c: 89 d6 mov esi,edx 1e: 89 c7 mov edi,eax 20: b8 00 00 00 00 mov eax,0x0 25: e8 00 00 00 00 call 2a <main+0x2a> 2a: 89 45 f4 mov DWORD PTR [rbp-0xc],eax 2d: 8b 45 f4 mov eax,DWORD PTR [rbp-0xc] 30: 89 c6 mov esi,eax 32: 48 8d 3d 00 00 00 00 lea rdi,[rip+0x0] # 39 <main+0x39> 39: b8 00 00 00 00 mov eax,0x0 3e: e8 00 00 00 00 call 43 <main+0x43> 43: b8 00 00 00 00 mov eax,0x0 48: c9 leave 49: c3 ret 既然代码已经被我们“编译”成了指令,我们不妨尝试运行一下 ./link_example.o。 然而我们并不能成功运行,会得到一条cannot execute binary file: Exec format error 的错误。 我们再仔细看一下 objdump 出来的两个文件的代码,会发现两个程序的地址都是从 0 开始的。如果地址是一样的,程序如果需要通过 call 指令调用函数的话,它怎么知道应该跳转到哪一个文件里呢? 无论是这里的运行报错,还是 objdump 出来的汇编代码里面的重复地址,都是因为add_lib.o以及 link_example.o 并不是一个可执行文件(Executable Program),而是目标文件(Object File)。只有通过链接器(Linker)把多个目标文件以及调用的各种函数库链接起来,我们才能得到一个可执行文件。 通过 gcc 的-o参数,可以生成对应的可执行文件。 123$ gcc -o link-example add_lib.o link_example.o$ ./link_examplec = 15 ELF(Execuatable and Linkable File Format)的文件格式,中文名字叫可执行与可链接文件格式,这里面不仅存放了编译成的汇编指令,还保留了很多别的数据。 链接器会扫描所有输入的目标文件,然后把所有符号表里的信息收集起来,构成一个全局的符号表。然后再根据重定位表,把所有不确定要跳转地址的代码,根据符号表里面存储的地址,进行一次修正。最后,把所有的目标文件的对应段进行一次合并,变成了最终的可执行代码。这也是为什么,可执行文件里面的函数调用的地址都是正确的。 在链接器把程序变成可执行文件之后,要装载器去执行程序就容易多了。装载器不再需要考虑地址跳转的问题,只需要解析 ELF 文件,把对应的指令和数据,加载到内存里面供 CPU 执行就可以了。 为什么同样一个程序,在 Linux 下可以执行而在 Windows 下不能执行了。其中一个非常重要的原因就是,两个操作系统下可执行文件的格式不一样。 我们今天讲的是 Linux 下的 ELF 文件格式,而 Windows 的可执行文件格式是一种叫作 PE(Portable Executable Format)的文件格式。Linux 下的装载器只能解析 ELF 格式而不能解析 PE 格式。 如果我们有一个可以能够解析 PE 格式的装载器,我们就有可能在 Linux 下运行 Windows 程序了。这样的程序真的存在吗?没错,Linux 下著名的开源项目 Wine,就是通过兼容 PE 格式的装载器,使得我们能直接在 Linux 下运行 Windows 程序的。而现在微软的 Windows 里面也提供了 WSL,也就是 Windows Subsystem for Linux,可以解析和加载 ELF 格式的文件。 程序装载程序装载面临的挑战 可执行程序加载后占用的内存空间应该是连续的。 这点很好理解,指令正常都是顺序执行的。 我们需要同时加载很多个程序,并且不能让程序自己规定在内存中加载的位置。 计算机通常会同时运行很多个程序,可能你想要的内存地址已经被其他加载了的程序占用了。 我们把指令里用到的内存地址叫作虚拟内存地址(Virtual Memory Address),实际在内存硬件里面的空间地址,我们叫物理内存地址(Physical Memory Address)。 程序里有指令和各种内存地址,我们只需要关心虚拟内存地址就行了。对于任何一个程序来说,它看到的都是同样的内存地址。我们维护一个虚拟内存到物理内存的映射表,这样实际程序指令执行的时候,会通过虚拟内存地址,找到对应的物理内存地址,然后执行。 内存分段这种找出一段连续的物理内存和虚拟内存地址进行映射的方法,我们叫分段(Segmentation)。这里的段,就是指系统分配出来的那个连续的内存空间。 分段的办法很好,解决了程序本身不需要关心具体的物理内存地址的问题,但它也有一些不足之处,第一个就是内存碎片(Memory Fragmentation)的问题。 我们可以通过内存交换(Memory Swapping)技术解决。 我们可以把 Python 程序占用的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存里面。不过读回来的时候,我们不再把它加载到原来的位置,而是紧紧跟在那已经被占用了的 512MB 内存后面。这样,我们就有了连续的 256MB 内存空间,就可以去加载一个新的 200MB 的程序。 如果你自己安装过 Linux 操作系统,你应该遇到过分配一个 swap 硬盘分区的问题。这块分出来的磁盘空间,其实就是专门给 Linux 操作系统进行内存交换用的。 硬盘的访问速度要比内存慢很多,而每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。所以,如果内存交换的时候,交换的是一个很占内存空间的程序,这样整个机器都会显得卡顿。 内存分页既然问题出在内存碎片和内存交换的空间太大上,那么解决问题的办法就是,少出现一些内存碎片,并且让需要交换写入或者从磁盘装载的数据更少一点。于是就有了内存分页(Paging)。 和分段这样分配一整段连续的空间给到程序相比,分页是把整个物理内存空间切成一段段固定尺寸的大小。而对应的程序所需要占用的虚拟内存空间,也会同样切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。 从虚拟内存到物理内存的映射,不再是拿整段连续的内存的物理地址,而是按照一个一个页来的。页的尺寸一般远远小于整个程序的大小。在 Linux 下,我们通常只设置成 4KB。 由于内存空间都是预先划分好的,也就没有了不能使用的碎片,而只有被释放出来的很多 4KB 的页。即使内存空间不够,需要让现有的、正在运行的其他程序,通过内存交换释放出一些内存的页出来,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,让整个机器被内存交换的过程给卡住。 分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。 实际上,我们的操作系统,的确是这么做的。当要读取特定的页,却发现数据并没有加载到物理内存里的时候,就会触发一个来自于 CPU 的缺页错误(Page Fault)。我们的操作系统会捕捉到这个错误,然后将对应的页,从存放在硬盘上的虚拟内存里读取出来,加载到物理内存里。 动态链接如果我们有很多个程序都要通过装载器装载到内存里面,那里面链接好的同样的功能代码,也都需要再装载一遍,再占一遍内存空间。在一个运行上百个进程的系统中,这将会造成极大的资源浪费。 共享库(shared library)是致力于解决静态库缺陷的一个现代创新产物。共享库是一个目标模块,在运行或加载时,可以加载到任意的内存地址,并和一个在内存中的程序链接起来。这个过程称为动态链接(dynamic linking)是由一个叫做动态链接器(dynamic linker)的程序来执行的。Linux 中为.so文件,Windows 中为.dll文件。 PIC (Position-Independent Code)要想要在程序运行的时候共享代码,也有一定的要求,就是这些机器码必须是“地址无关”的。也就是说,我们编译出来的共享库文件的指令代码,放在哪个内存地址都能正常运行。 对于所有动态链接共享库的程序来讲,虽然我们的共享库用的都是同一段物理内存地址,但是在不同的应用程序里,它所在的虚拟内存地址是不同的。我们没办法、也不应该要求动态链接同一个共享库的不同程序,必须把这个共享库所使用的虚拟内存地址变成一致。如果这样的话,我们写的程序就必须明确地知道内部的内存地址分配。 如何才能实现地址无关? 动态代码库内部的变量和函数调用都很容易解决,我们只需要使用相对地址(Relative Address)就好了。各种指令中使用到的内存地址,给出的不是一个绝对的地址空间,而是一个相对于当前指令偏移量的内存地址。因为整个共享库是放在一段连续的虚拟内存地址中的,无论装载到哪一段地址,不同指令之间的相对地址都是不变的。 PLT 和 GOT1234567891011121314// lib.h#ifndef LIB_H#define LIB_H void show_me_the_money(int money);#endif// lib.c#include <stdio.h> void show_me_the_money(int money){ printf("Show me USD %d from lib.c \\n", money);} 1234567// show_me_poor.c#include "lib.h"int main(){ int money = 5; show_me_the_money(money);} 12gcc lib.c -fPIC -shared -o lib.sogcc -o show_me_poor show_me_poor.c ./lib.so -fpic 选项指示编译器生成与位置无关的代码。-shared选项指示链接器创建一个共享的目标文件。 然后,我们再通过 gcc 编译 show_me_poor 动态链接了 lib.so 的可执行文件。在这些操作都完成了之后,我们把 show_me_poor 这个文件通过 objdump 出来看一下。 123456789101112131415161718192021222324252627$ objdump -d -M intel -S show_me_poor……0000000000400540 <show_me_the_money@plt-0x10>: 400540: ff 35 12 05 20 00 push QWORD PTR [rip+0x200512] # 600a58 <_GLOBAL_OFFSET_TABLE_+0x8> 400546: ff 25 14 05 20 00 jmp QWORD PTR [rip+0x200514] # 600a60 <_GLOBAL_OFFSET_TABLE_+0x10> 40054c: 0f 1f 40 00 nop DWORD PTR [rax+0x0] 0000000000400550 <show_me_the_money@plt>: 400550: ff 25 12 05 20 00 jmp QWORD PTR [rip+0x200512] # 600a68 <_GLOBAL_OFFSET_TABLE_+0x18> 400556: 68 00 00 00 00 push 0x0 40055b: e9 e0 ff ff ff jmp 400540 <_init+0x28>……0000000000400676 <main>: 400676: 55 push rbp 400677: 48 89 e5 mov rbp,rsp 40067a: 48 83 ec 10 sub rsp,0x10 40067e: c7 45 fc 05 00 00 00 mov DWORD PTR [rbp-0x4],0x5 400685: 8b 45 fc mov eax,DWORD PTR [rbp-0x4] 400688: 89 c7 mov edi,eax 40068a: e8 c1 fe ff ff call 400550 <show_me_the_money@plt> 40068f: c9 leave 400690: c3 ret 400691: 66 2e 0f 1f 84 00 00 nop WORD PTR cs:[rax+rax*1+0x0] 400698: 00 00 00 40069b: 0f 1f 44 00 00 nop DWORD PTR [rax+rax*1+0x0]…… 在 main 函数调用 show_me_the_money 的函数的时候,对应的代码是这样的: 1call 400550 <show_me_the_money@plt> 这里后面有一个@plt 的关键字,代表了我们需要从PLT,也就是过程链接表(Procedure Link Table)里面找要调用的函数。对应的地址呢,则是 400550 这个地址。 那当我们把目光挪到上面的 400550 这个地址,你又会看到里面进行了一次跳转,这个跳转指定的跳转地址,你可以在后面的注释里面可以看到,GLOBAL_OFFSET_TABLE+0x18。这里的 GLOBAL_OFFSET_TABLE,就是我接下来要说的全局偏移表。 1400550: ff 25 12 05 20 00 jmp QWORD PTR [rip+0x200512] # 600a68 <_GLOBAL_OFFSET_TABLE_+0x18> 在动态链接对应的共享库,我们在共享库的 data section 里面,保存了一张全局偏移表(GOT,Global Offset Table)。虽然共享库的代码部分的物理内存是共享的,但是数据部分是各个动态链接它的应用程序里面各加载一份的。所有需要引用当前共享库外部的地址的指令,都会查询 GOT,来找到当前运行程序的虚拟内存里的对应位置。而 GOT 表里的数据,则是在我们加载一个个共享库的时候写进去的。 虽然不同的程序调用的同样的动态库,各自的内存地址是独立的,调用的又都是同一个动态库,但是不需要去修改动态库里面的代码所使用的地址,而是各个程序各自维护好自己的 GOT,能够找到对应的动态库就好了。 二进制编码原码表示法,左侧第一位是符号位,符号位为 1 时表示负数,为 0 时表示正数。补码表示法,我们不再把这一位当成单独的符号位,在剩下几位计算出的十进制前加上正负号,而是在计算整个二进制值的时候,在左侧最高位前面加个负号。 比如,一个 4 位的二进制补码数值 1011,转换成十进制,就是$-1 \\times 2^3 + 0 \\times 2^2 + 1 \\times 2^1 + 1 \\times 2^0 = -5$ 一个 4 位的二进制数,可以表示从 -8 到 7 这 16 个整数,不会白白浪费一位。 字符集:表示的可以是字符的一个集合。比如说“第一版《新华字典》里面出现的所有汉字”,这是一个中文字符集。比如,我们日常说的Unicode,其实就是一个字符集,包含了 150 种语言的 14 万个不同的字符。 字符编码:对于字符集里的这些字符,怎么一一用二进制表示出来的一个字典。我们上面说的 Unicode,就可以用UTF-8、UTF-16,乃至 UTF-32 来进行编码,存储成二进制。 同样的文本,采用不同的编码存储下来。如果另外一个程序,用一种不同的编码方式来进行解码和展示,就会出现乱码。 锟斤拷 烫烫烫Unicode 编码一直持续在收录各种字元,这就可能会出现各种作业系统支援的 Unicode 字元不一样。这也就会导致 A 上的一个用 Unicode 编码的字元,在 B 上就会出现无法显示的情况。为了避免这种情况,在 Unicode 中定义了一个特殊字元�,它的 Unicode 编码为 0xFFFD。 假如 A 支援特殊字元⬆,但是 B 并不支援这个⬆,那么在 B 中将会用�来代替。 这个字元用 UTF-8 编码后,十六进位表示为0xEF 0XBF 0XBD。如果连续出现两个⬆符号,那么用 UTF-8 编码后的十六进位则表示为0xEF 0XBF 0XBD 0xEF 0XBF 0XBD,这时候再转码成 GBK,因为 GBK 中用两个位元组表示一个字元,那么上述的字元就成了锟(0xEFBF),斤(0xBDEF),拷(0xBFBD)。出现锟斤拷的原因就是 UTF-8 转码 GBK 的过程中出现了问题。当然如果想要出现锟斤拷,则至少需要两个字元出现乱码。 而“烫烫烫”,则是因为如果你用了 Visual Studio 的调试器,默认使用 MBCS 字符集。“烫”在里面是由 0xCCCC 来表示的,而 0xCC 又恰好是未初始化的内存的赋值。于是,在读到没有赋值的内存地址或者变量的时候,电脑就开始大叫“烫烫烫”了。 理解电路从以上的学习可以知道,最终执行的程序都是二进制的指令。那为何计算机最终选择了二进制呢?接下来看看计算机在硬件层面究竟是怎么表示二进制的,以此你就会明白,为什么计算机会选择二进制。 加法器乘法器浮点数和定点数","categories":[{"name":"计算机组成原理","slug":"计算机组成原理","permalink":"http://example.com/categories/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86/"}],"tags":[{"name":"计算机组成原理","slug":"计算机组成原理","permalink":"http://example.com/tags/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86/"}]},{"title":"解决 OpenSSL SSL_read: Connection was reset, errno 10054","slug":"解决OpenSSL-SSL-read-Connection-was-reset-errno-10054","date":"2022-02-16T03:12:31.000Z","updated":"2022-10-15T03:14:29.821Z","comments":true,"path":"2022/02/16/解决OpenSSL-SSL-read-Connection-was-reset-errno-10054/","link":"","permalink":"http://example.com/2022/02/16/%E8%A7%A3%E5%86%B3OpenSSL-SSL-read-Connection-was-reset-errno-10054/","excerpt":"","text":"解决方法方法一: 1git config --global http.sslVerify "false" 方法二: 1git config --global https.sslVerify "false" 方法三:这可能是因为版本库的大小和 git 的默认缓冲区大小,所以通过下述操作(在 git bash 上),git 的缓冲区大小会增加。 1234//在仓库init后,添加以下配置git config http.postBuffer 524288000//如果仓库不是自己的,可以添加以下配置git config --global http.postBuffer 524288000 方法四:网速太慢,换个网速快的环境。 Referencewindows - git clone error: RPC failed; curl 56 OpenSSL SSL_read: SSL_ERROR_SYSCALL, errno 10054 - Stack Overflow解决 OpenSSL SSL_read: Connection was reset, errno 10054 問題","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"C 语言中的变长数组与零长数组","slug":"C语言中的变长数组与零长数组","date":"2022-02-11T13:09:35.000Z","updated":"2022-10-15T03:14:29.150Z","comments":true,"path":"2022/02/11/C语言中的变长数组与零长数组/","link":"","permalink":"http://example.com/2022/02/11/C%E8%AF%AD%E8%A8%80%E4%B8%AD%E7%9A%84%E5%8F%98%E9%95%BF%E6%95%B0%E7%BB%84%E4%B8%8E%E9%9B%B6%E9%95%BF%E6%95%B0%E7%BB%84/","excerpt":"","text":"变长数组想必很多学习 C 语言的人都会在书上看到,数组在初始化时必须要确定长度(维度),也就是说定义数组时,维度一定要用常量。但是在编程中很多人肯定发现了,及时像下面这样写,编译器也不会报错。 12int n; int array[n]; 这是怎么回事?难道以前我学的是错的吗?当然不是。最官方的解释应该是 C 语言的规范和编译器的规范说明了。 在 ISO/IEC9899 标准的 6.7.5.2 Array declarators 中明确说明了数组的长度可以为变量的,称为变长数组(VLA,variable length array)。(注:这里的变长指的是数组的长度是在运行时才能决定,但一旦决定在数组的生命周期内就不会再变。) 在 GCC 标准规范的 6.19 Arrays of Variable Length 中指出,作为编译器扩展,GCC 在 C90 模式和 C++ 编译器下遵守 ISO C99 关于变长数组的规范。 原来这种语法确实是 C 语言规范,GCC 非常完美的支持了 ISO C99。但是在 C99 之前的 C 语言中,变长数组的语法是不存在的。 这种变长数组有什么好处呢?它可以实现与alloca函数一样的效果,在栈上进行动态的空间分配,并且在函数返回时自动释放内存,无需手动释放。 alloca 函数用来在栈上分配空间,当函数返回时自动释放,无需手动再去释放; 可变数组示例:所有可变修改 (VM) 类型的声明必须在块范围或函数原型范围内。使用 static 或 extern 存储类说明符声明的数组对象不能具有可变长度数组 (VLA) 类型。但是,使用静态存储类说明符声明的对象可以具有 VM 类型(即,指向 VLA 类型的指针)。最后,使用 VM 类型声明的所有标识符都必须是普通标识符,因此不能是结构或联合的成员。 12345678910111213141516171819202122extern int n;int A[n]; // Error - file scope VLA.extern int (*p2)[n]; // Error - file scope VM.int B[100]; // OK - file scope but not VM.void fvla(int m, int C[m][m]) // OK - VLA with prototype scope.{ typedef int VLA[m][m] // OK - block scope typedef VLA. struct tag { int (*y)[n]; // Error - y not ordinary identifier. int z[n]; // Error - z not ordinary identifier. }; int D[m]; // OK - auto VLA. static int E[m]; // Error - static block scope VLA. extern int F[m]; // Error - F has linkage and is VLA. int (*s)[m]; // OK - auto pointer to VLA. extern int (*r)[m]; // Error - r had linkage and is // a pointer to VLA. static int (*q)[m] = &B; // OK - q is a static block // pointer to VLA.} 零长数组GNU/GCC 在标准的 C/C++ 基础上做了有实用性的扩展,零长度数组(Arrays of Length Zero)就是其中一个知名的扩展。使用零长数组,把它作为结构体的最后一个元素非常有用: 1234567struct line { int length; char contents[0];};struct line *thisline = (struct line *) malloc (sizeof (struct line) + this_length);thisline->length = this_length; 从上例就可以看出,零长数组在有固定头部的可变对象上非常适用,我们可以根据对象的大小动态地去分配结构体的大小。 在 Linux 内核中也有这种应用,例如由于 PID 命名空间的存在,每个进程 PID 需要映射到所有能看到其的命名空间上,但该进程所在的命名空间在开始并不确定(但至少为 init 命名空间),需要在运行是根据 level 的值来确定,所以在该结构体后面增加了一个长度为 1 的数组(因为至少在一个init命名空间上),使得该结构体 pid 是个可变长的结构体,在运行时根据进程所处的命名空间的 level 来决定 numbers 分配多大。(注:虽然不是零长度的数组,但用法是一样的) 123456789struct pid{ atomic_t count; unsigned int level; /* lists of tasks that use this pid */ struct hlist_head tasks[PIDTYPE_MAX]; struct rcu_head rcu; struct upid numbers[1];}; 什么 0 长度数组不占用存储空间0 长度数组与指针实现有什么区别呢,为什么 0 长度数组不占用存储空间呢? 其实本质上涉及到的是一个 C 语言里面的数组和指针的区别问题。char a[1] 里面的 a 和 char *b 的 b 相同吗? 《Programming Abstractions in C》(Roberts, E. S.,机械工业出版社,2004.6)82 页里面说。 “arr is defined to be identical to &arr[0]”. 也就是说,char a[1]里面的a实际是一个常量,等于&a[0]。而char *b是有一个实实在在的指针变量b存在。所以,a=b是不允许的,而b=a是允许的。 本质上因为数组名它只是一个偏移量,数组名这个符号本身代 表了一个不可修改的地址常量 (注意:数组名永远都不会是指针! ),但对于这个数组的大小,我们可以进行动态分配,对于编译器而言,数组名仅仅是一个符号,它不会占用任何空间,它在结构体中,只是代表了一个偏移量,代表一个不可修改的地址常量! Referencesalloca 函数用来在栈上分配空间,当函数返回时自动释放,无需手动再去释放 C 语言 0 长度数组 (可变数组/柔性数组) 详解_OSKernelLAB(gatieme)-CSDN 博客_柔性数组 零长数组(柔性数组、可变数组)的使用_禾仔仔的博客-CSDN 博客 Zero Length - Using the GNU Compiler Collection (GCC)","categories":[],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"}]},{"title":"SSH 原理","slug":"SSH原理","date":"2022-01-27T13:30:29.000Z","updated":"2022-10-15T02:59:01.676Z","comments":true,"path":"2022/01/27/SSH原理/","link":"","permalink":"http://example.com/2022/01/27/SSH%E5%8E%9F%E7%90%86/","excerpt":"","text":"","categories":[],"tags":[]},{"title":"QEMU 源码分析-内存虚拟化","slug":"QEMU源码分析-内存虚拟化","date":"2022-01-25T05:42:11.000Z","updated":"2022-10-15T03:14:29.433Z","comments":true,"path":"2022/01/25/QEMU源码分析-内存虚拟化/","link":"","permalink":"http://example.com/2022/01/25/QEMU%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90-%E5%86%85%E5%AD%98%E8%99%9A%E6%8B%9F%E5%8C%96/","excerpt":"","text":"1.大部分转载自QEMU 内存虚拟化源码分析 | Keep Coding | 苏易北2.原文源码为 QEMU1.2.0,版本较旧,部分源码内容根据 QEMU6.2 版本修改3.部分内容根据自己理解补充添加 概述我们知道操作系统给每个进程分配虚拟内存,通过页表映射,变成物理内存进行访问。当有了虚拟机之后,情况会变得更加复杂。因为虚拟机对于物理机来讲是一个进程,但是虚拟机里面也有内核,也有虚拟机里面跑的进程。所以有了虚拟机,内存就变成了四类: 虚拟机里面的虚拟内存(Guest OS Virtual Memory,GVA),这是虚拟机里面的进程看到的内存空间; 虚拟机里面的物理内存(Guest OS Physical Memory,GPA),这是虚拟机里面的操作系统看到的内存,它认为这是物理内存; 物理机的虚拟内存(Host Virtual Memory,HVA),这是物理机上的 qemu 进程看到的内存空间; 物理机的物理内存(Host Physical Memory,HPA),这是物理机上的操作系统看到的内存。 内存虚拟化的关键在于维护 GPA 到 HVA 的映射关系。 页面分配和映射的两种方式要搞清楚 QEMU system emulation 的仿真架构,首先对于 Host OS,将 QEMU 作为进程启动,然后对于 QEMU 进程,会仿真各种硬件和运行 Guest OS,在这层 OS 上运行要全系统模拟的应用程序,因此对于 Guest OS 管理的内存要实现到 QEMU 进程的虚拟空间的转换需要 softMMU(即需要对 GPA 到 HVA 进行转换)。从 GVA 到 GPA 到 HVA 到 HPA,性能很差,为了解决这个问题,有两种主要的思路。 影子页表 Shadow Page Table,SPT第一种方式就是软件的方式,影子页表(Shadow Page Table)。 KVM 通过维护记录 GVA->HPA 的影子页表 SPT,减少了地址转换带来的开销,可以直接将 GVA 转换为 HPA。 内存映射要通过页表来管理,页表地址应该放在 CR3 寄存器里面。在软件虚拟化的内存转换中,GVA 到 GPA 的转换通过查询 CR3 寄存器来完成,CR3 中保存了 Guest 的页表基地址,然后载入 MMU 中进行地址转换。 在加入了 SPT 技术后,当 Guest 访问 CR3 时,KVM 会捕获到这个操作 EXIT_REASON_CR_ACCESS,之后 KVM 会载入特殊的 CR3 和影子页表,欺骗 Guest 这就是真实的 CR3。之后就和传统的访问内存方式一致,当需要访问物理内存的时候,只会经过一层影子页表的转换。 本来的过程是,客户机要通过 cr3 找到客户机的页表,实现从 GVA 到 GPA 的转换,然后在宿主机上,要通过 cr3 找到宿主机的页表,实现从 HVA 到 HPA 的转换。为了实现客户机虚拟地址空间到宿主机物理地址空间的直接映射。客户机中每个进程都有自己的虚拟地址空间,所以 KVM 需要为客户机中的每个进程页表都要维护一套相应的影子页表。在客户机访问内存时,使用的不是客户机的原来的页表,而是这个页表对应的影子页表,从而实现了从客户机虚拟地址到宿主机物理地址的直接转换。而且,在 TLB 和 CPU 缓存上缓存的是来自影子页表中客户机虚拟地址和宿主机物理地址之间的映射,也因此提高了缓存的效率。 为了快速检索 Guest 页表对应的影子页表,KVM 为每个客户机维护了一个 hash 表来进行客户机页表到影子页表之间的映射。对于每一个 Guest 来说,其页目录和页表都有唯一的 GPA,通过页目录/页表的 GPA 就可以在哈希链表中快速地找到对应的影子页目录/页表。 当 Guest 切换进程时,Guest 会把待切换进程的页表基址载入 CR3,而 KVM 将会截获这一特权指令。KVM 在哈希表中找到与此页表基址对应的影子页表基址,载入 Guest CR3,使 Guest 在恢复运行时 CR3 实际指向的是新切换进程对应的影子页表。 影子页表的引入,减少了 GVA->HPA 的转换开销,但是缺点在于需要为 Guest 的每个进程都维护一个影子页表,这将带来很大的内存开销。同时影子页表的建立是很耗时的,如果 Guest 的进程过多,将导致影子页表频繁切换。 因此 Intel 和 AMD 在此基础上提供了基于硬件的虚拟化技术 EPT。 扩展页表 Extent Page Table,EPTIntel 的 EPT(Extent Page Table)技术和 AMD 的 NPT(Nest Page Table)技术都对内存虚拟化提供了硬件支持。这两种技术原理类似,都是在硬件层面上实现 GVA 到 HPA 之间的转换。下面就以 EPT 为例分析一下 KVM 基于硬件辅助的内存虚拟化实现。 EPT 在原有客户机页表对客户机虚拟地址 GVA 到客户机物理地址 GPA 映射的基础上,又引入了 EPT 页表来实现客户机物理地址 GPA 到宿主机物理地址 HPA 的另一次映射。客户机运行时,客户机页表被载入 CR3,而 EPT 页表被载入专门的 EPT 页表指针寄存器 EPTP。 即 EPT 技术采用了在两级页表结构,即原有 Guest OS 页表对 GVA->GPA 映射的基础上,又引入了 EPT 页表来实现 GPA->HPA 的另一次映射,这两次地址映射都是由硬件自动完成。 有了 EPT,在GPA->HPA转换的过程中,缺页会产生 EPT 缺页异常。KVM 首先根据引起异常的客户机物理地址,映射到对应的宿主机虚拟地址,然后为此虚拟地址分配新的物理页,最后 KVM 再更新 EPT 页表,建立起引起异常的客户机物理地址到宿主机物理地址之间的映射。 KVM 只需为每个客户机维护一套 EPT 页表,也大大减少了内存的开销。 这里,我们重点看第二种方式。因为使用了 EPT 之后,客户机里面的页表映射,也即从 GVA 到 GPA 的转换,还是用传统的方式,和在内存管理那一章讲的没有什么区别。而 EPT 重点帮我们解决的就是从 GPA 到 HPA 的转换问题。因为要经过两次页表,所以 EPT 又 tdp(two dimentional paging)。 EPT 的页表结构也是分为四层,EPT Pointer(EPTP)指向 PML4 的首地址。 QEMU 的主要工作内存虚拟化的目的就是让虚拟机能够无缝的访问内存。有了 Intel EPT 的支持后,CPU 在 VMX non-root 状态时进行内存访问会再做一次 EPT 转换。在这个过程中,QEMU 会负责以下内容: 首先需要从自己的进程地址空间中申请内存用于 Guest需要将上一步中申请到的内存的虚拟地址(HVA)和 Guest 的物理地址之间的映射关系传递给 KVM(kernel),即 GPA->HVA需要组织一系列的数据结构来管理虚拟内存空间,并在内存拓扑结构更改时将最新的内存信息同步至 KVM 中 QEMU 和 KVM 的工作分界QEMU 和 KVM 之间是通过 KVM 提供的 ioctl() 接口进行交互的。在内核的 kvm_vm_ioctl() 中,设置虚拟机内存的系统调用【kernel 就是一系列系统调用函数接口和处理逻辑,其中有个处理”创建/设置虚拟机内存“的系统调用接口】为 VM_SET_USER_MEMORY_REGION: 1234567891011121314151617181920static long kvm_vm_ioctl(struct file *filp, unsigned int ioctl, unsigned long arg){ /* ... */ case KVM_SET_USER_MEMORY_REGION: { // 在 KVM 中注册用户空间传入的内存信息 struct kvm_userspace_memory_region kvm_userspace_mem; r = -EFAULT; // 将传入的数据结构复制到内核空间 if (copy_from_user(&kvm_userspace_mem, argp, sizeof kvm_userspace_mem)) goto out; // 实际进行处理的函数 r = kvm_vm_ioctl_set_memory_region(kvm, &kvm_userspace_mem, 1); if (r) goto out; break; } /* ... */} 可以看到这里需要传递的参数类型为 kvm_userspace_memory_region: 12345678/* for KVM_SET_USER_MEMORY_REGION */struct kvm_userspace_memory_region { __u32 slot; // slot 编号 [参考:https://www.cnblogs.com/LoyenWang/p/11922887.html] __u32 flags; // 标志位,例如是否追踪脏页、是否可用等 __u64 guest_phys_addr; // Guest 物理地址,即 GPA __u64 memory_size; // 内存大小,单位 bytes __u64 userspace_addr; // 从 QEMU 进程地址空间中分配内存的起始地址,即 HVA}; KVM_SET_USER_MEMORY_REGION这个 ioctl 主要目的就是设置GPA->HVA的映射关系,KVM 会继续调用kvm_vm_ioctl_set_memory_region(),在内核空间维护并管理 Guest 的内存。 相关数据结构AddressSpace结构体定义QEMU 用 AddressSpace 结构体表示 Guest 中 CPU/设备看到的内存【也就是Guest OS 可以在 QEMU 进程虚存中用到的所有内存,是 MemoryRegion 的集合,即 GPA 的整体】,类似于物理机中地址空间的概念,但在这里表示的是 Guest 的一段地址空间,如内存地址空间 address_space_memory 、I/O 地址空间address_space_io,它在 QEMU 源码memory.c中定义: 1234567891011121314151617/** * struct AddressSpace: describes a mapping of addresses to #MemoryRegion objects */struct AddressSpace { /* private: */ struct rcu_head rcu; char *name; MemoryRegion *root; /* Accessed via RCU. */ struct FlatView *current_map; int ioeventfd_nb; struct MemoryRegionIoeventfd *ioeventfds; QTAILQ_HEAD(, MemoryListener) listeners; QTAILQ_ENTRY(AddressSpace) address_spaces_link;}; 每个 AddressSpace 一般包含一系列的 MemoryRegion:root指针指向根级 MemoryRegion,而 root 可能有自己的若干个 sub-regions(子节点),于是形成树状结构。这些 MemoryRegion 通过树连接起来,树的根即为 AddressSpace 的 root 域。 全局变量另外,QEMU 中有两个全局的静态 AddressSpace,在 memory.c 中定义: 12static AddressSpace address_space_memory; // 内存地址空间static AddressSpace address_space_io; // I/O 地址空间 其 root 域分别指向之后会提到的两个 MemoryRegion 类型变量:system_memory、system_io。 MemoryRegion结构体定义MemoryRegion 表示在 Guest Memory Layout 中的一段内存区域【也就是单元级 GPA 的概念,Guest OS 可以管理到的那些 Guest 物理内存单元】,它是联系 GPA 和 RAMBlocks(描述真实内存)之间的桥梁,在memory.h中定义: 123456789101112131415161718192021222324252627282930struct MemoryRegion { /* All fields are private - violators will be prosecuted */ const MemoryRegionOps *ops; // 回调函数集合 void *opaque; MemoryRegion *parent; // 父 MemoryRegion 指针 Int128 size; // 该区域内存的大小 target_phys_addr_t addr; // 在 Address Space 中的地址,即 HVA void (*destructor)(MemoryRegion *mr); ram_addr_t ram_addr; // MemoryRegion 的起始地址,即 GPA bool subpage; bool terminates; bool readable; bool ram; // 是否表示 RAM bool readonly; /* For RAM regions */ bool enabled; // 是否已经通知 KVM 使用这段内存 bool rom_device; bool warning_printed; /* For reservations */ MemoryRegion *alias; // 是否为 MemoryRegion alias target_phys_addr_t alias_offset; // 若为 alias,在原 MemoryRegion 中的 offset unsigned priority; bool may_overlap; QTAILQ_HEAD(subregions, MemoryRegion) subregions; // 子区域链表头 QTAILQ_ENTRY(MemoryRegion) subregions_link; // 子区域链表节点 QTAILQ_HEAD(coalesced_ranges, CoalescedMemoryRange) coalesced; const char *name; // MemoryRegion 的名字,调试时使用 uint8_t dirty_log_mask; // 表示哪一种 dirty map 被使用,共分三种 unsigned ioeventfd_nb; MemoryRegionIoeventfd *ioeventfds;}; 全局变量在 QEMU 的 exec.c 中也定义了两个静态的 MemoryRegion 指针变量: 12static MemoryRegion *system_memory; // 内存 MemoryRegion,对应 address_space_memorystatic MemoryRegion *system_io; // I/O MemoryRegion,对应 address_space_io 与两个全局 AddressSpace 对应,即 AddressSpace 的 root 域指向这两个 MemoryRegion。 MemoryRegion 的类型MemoryRegion 有多种类型,可以表示一段 RAM、ROM、MMIO、alias(别名)。 若为 alias 则表示一个 MemoryRegion 的部分区域,例如,QEMU 会为 pc.ram 这个表示 RAM 的 MemoryRegion 添加两个 alias:ram-below-4g 和 ram-above-4g,之后会看到具体的代码实例。 另外,MemoryRegion 也可以表示一个 container,这就表示它只是其他若干个 MemoryRegion 的容器。 那么要如何创建不同类型的 MemoryRegion 呢? 在 QEMU 中实际上是通过调用不同的初始化函数区分的。根据不同的初始化函数及其功能,可以将 MemoryRegion 划分为以下三种类型: 根级 MemoryRegion:直接通过 memory_region_init 初始化,没有自己的内存,用于管理 subregion,例如 system_memory: 123456789101112131415161718192021222324252627282930void memory_region_init(MemoryRegion *mr, const char *name, uint64_t size){ mr->ops = NULL; mr->parent = NULL; mr->size = int128_make64(size); if (size == UINT64_MAX) { mr->size = int128_2_64(); } mr->addr = 0; mr->subpage = false; mr->enabled = true; mr->terminates = false; // 非实体 MemoryRegion,搜索时会继续前往其 subregions mr->ram = false; // 根级 MemoryRegion 不分配内存 mr->readable = true; mr->readonly = false; mr->rom_device = false; mr->destructor = memory_region_destructor_none; mr->priority = 0; mr->may_overlap = false; mr->alias = NULL; QTAILQ_INIT(&mr->subregions); memset(&mr->subregions_link, 0, sizeof mr->subregions_link); QTAILQ_INIT(&mr->coalesced); mr->name = g_strdup(name); mr->dirty_log_mask = 0; mr->ioeventfd_nb = 0; mr->ioeventfds = NULL;} 可以看到 mr->addr 被设置为 0,而 mr->ram_addr 则并没有初始化。 实体 MemoryRegion:通过memory_region_init_ram()初始化,有自己的内存(从 QEMU 进程地址空间中分配),大小为size,例如ram_memory、 pci_memory: 123456789101112131415161718192021222324void *pc_memory_init(MemoryRegion *system_memory, const char *kernel_filename, const char *kernel_cmdline, const char *initrd_filename, ram_addr_t below_4g_mem_size, ram_addr_t above_4g_mem_size, MemoryRegion *rom_memory, MemoryRegion **ram_memory){ MemoryRegion *ram, *option_rom_mr; /* ...*/ /* Allocate RAM. We allocate it as a single memory region and use * aliases to address portions of it, mostly for backwards compatibility * with older qemus that used qemu_ram_alloc(). */ ram = g_malloc(sizeof(*ram)); // 调用 memory_region_init_ram 对 ram_memory 进行初始化 memory_region_init_ram(ram, "pc.ram", below_4g_mem_size + above_4g_mem_size); vmstate_register_ram_global(ram); *ram_memory = ram; /* ... */} 12345678910void memory_region_init_ram(MemoryRegion *mr, const char *name, uint64_t size){ memory_region_init(mr, name, size); mr->ram = true; mr->terminates = true; mr->destructor = memory_region_destructor_ram; mr->ram_addr = qemu_ram_alloc(size, mr);} 可以看到这里是先调用了memory_region_init(),之后设置 RAM 属性,并继续调用qemu_ram_alloc()分配内存。 别名 MemoryRegion:通过memory_region_init_alias() 初始化,没有自己的内存,表示实体 MemoryRegion 的一部分。通过 alias 成员指向实体 MemoryRegion,alias_offset为在实体 MemoryRegion 中的偏移量,例如ram_below_4g、ram_above_4g: 123456789101112131415void *pc_memory_init(MemoryRegion *system_memory, const char *kernel_filename, const char *kernel_cmdline, const char *initrd_filename, ram_addr_t below_4g_mem_size, ram_addr_t above_4g_mem_size, MemoryRegion *rom_memory, MemoryRegion **ram_memory){ MemoryRegion *ram_below_4g, *ram_above_4g; /* ... */ ram_below_4g = g_malloc(sizeof(*ram_below_4g)); // 调用 memory_region_init_alias 对 ram_below_4g 进行初始化 memory_region_init_alias(ram_below_4g, "ram-below-4g", ram, 0, below_4g_mem_size); /* .. 12345678910void memory_region_init_alias(MemoryRegion *mr, const char *name, MemoryRegion *orig, target_phys_addr_t offset, uint64_t size){ memory_region_init(mr, name, size); mr->alias = orig; // 指向实体 MemoryRegion mr->alias_offset = offset; //通过 offset 得到实体的某一个部分} RAMBlock结构体定义MemoryRegion 用来描述一段逻辑层面上的内存区域,而记录实际分配的内存地址信息的结构体则是 RAMBlock,在ramblock.h中定义: 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950struct RAMBlock { struct rcu_head rcu; struct MemoryRegion *mr; uint8_t *host; uint8_t *colo_cache; /* For colo, VM's ram cache */ ram_addr_t offset; ram_addr_t used_length; ram_addr_t max_length; void (*resized)(const char*, uint64_t length, void *host); uint32_t flags; /* Protected by iothread lock. */ char idstr[256]; /* RCU-enabled, writes protected by the ramlist lock */ QLIST_ENTRY(RAMBlock) next; QLIST_HEAD(, RAMBlockNotifier) ramblock_notifiers; int fd; size_t page_size; /* dirty bitmap used during migration */ unsigned long *bmap; /* bitmap of already received pages in postcopy */ unsigned long *receivedmap; /* * bitmap to track already cleared dirty bitmap. When the bit is * set, it means the corresponding memory chunk needs a log-clear. * Set this up to non-NULL to enable the capability to postpone * and split clearing of dirty bitmap on the remote node (e.g., * KVM). The bitmap will be set only when doing global sync. * * NOTE: this bitmap is different comparing to the other bitmaps * in that one bit can represent multiple guest pages (which is * decided by the `clear_bmap_shift' variable below). On * destination side, this should always be NULL, and the variable * `clear_bmap_shift' is meaningless. */ unsigned long *clear_bmap; uint8_t clear_bmap_shift; /* * RAM block length that corresponds to the used_length on the migration * source (after RAM block sizes were synchronized). Especially, after * starting to run the guest, used_length and postcopy_length can differ. * Used to register/unregister uffd handlers and as the size of the received * bitmap. Receiving any page beyond this length will bail out, as it * could not have been valid on the source. */ ram_addr_t postcopy_length;}; 可以看到在 RAMBlock 中 host 和 offset 域分别对应了 HVA 和GPA,因此也可以说 RAMBlock 中存储了GPA->HVA的映射关系,另外每一个 RAMBlock 都会指向其所属的 MemoryRegion。 全局变量 ram_listQEMU 在ramlist.h中定义了一个全局变量ram_list,以链表的形式维护了所有的 RAMBlock: 12345678910typedef struct RAMList { QemuMutex mutex; RAMBlock *mru_block; /* RCU-enabled, writes protected by the ramlist lock. */ QLIST_HEAD(, RAMBlock) blocks; DirtyMemoryBlocks *dirty_memory[DIRTY_MEMORY_NUM]; uint32_t version; QLIST_HEAD(, RAMBlockNotifier) ramblock_notifiers;} RAMList;extern RAMList ram_list; 每一个新分配的 RAMBlock 都会被插入到ram_list的头部。如需查找地址所对应的 RAMBlock,则需要遍历ram_list,当目标地址落在当前RAMBlock的地址区间时,该 RAMBlock 即为查找目标。 AS、MR、RAMBlock 之间的关系 FlatViewAddressSpace 的 root 域及其子树共同构成了 Guest 的物理地址空间,但这些都是在 QEMU 侧定义的。要传入 KVM 进行设置时,复杂的树状结构是不利于内核进行处理的,因此需要将其转换为一个“平坦”的地址模型,也就是一个从零开始、只包含地址信息的数据结构,这在 QEMU 中通过 FlatView 来表示。每个 AddressSpace 都有一个与之对应的 FlatView 指针 current_map,表示其对应的平面展开视图。 结构体定义FlatView 在memory.c中定义: 12345678910111213/* Flattened global view of current active memory hierarchy. Kept in sorted * order. */struct FlatView { struct rcu_head rcu; unsigned ref; FlatRange *ranges; // 对应的 FlatRange 数组 unsigned nr; // FlatRange 的数目 unsigned nr_allocated; // 当前数组的项数 struct AddressSpaceDispatch *dispatch; MemoryRegion *root;}; 其中,ranges是一个数组,记录了 FlatView 下所有的 FlatRange。 FlatRange在 FlatView 中,FlatRange 表示在 FlatView 中的一段内存范围,同样在memory.c中定义: 12345678910/* Range of memory in the global map. Addresses are absolute. */struct FlatRange { MemoryRegion *mr; // 指向所属的 MemoryRegion hwaddr offset_in_region; // 在全局 MemoryRegion 中的 offset,对应 GPA AddrRange addr; // 代表的地址区间,对应 HVA uint8_t dirty_log_mask; bool romd_mode; bool readonly; bool nonvolatile;}; 每个 FlatRange 对应一段虚拟机物理地址区间,各个 FlatRange 不会重叠,按照地址的顺序保存在数组中,具体的地址范围由一个 AddrRange 结构来描述: 1234567/* * AddrRange 用于表示 FlatRange 的起始地址及大小 */struct AddrRange { Int128 start; Int128 size;}; MemoryRegionSection结构体定义在 QEMU 中,还有几个起到中介作用的结构体,MemoryRegionSection 就是其中之一。 之前介绍的 FlatRange 代表一个物理地址空间的片段,偏向于描述在 Host 侧即 AddressSpace 中的分布【Guest 的物理空间】,而 MemoryRegionSection 则代表在 Guest 侧即 MemoryRegion 中的片段。MemoryRegionSection 在memory.h中定义: 123456789101112131415161718192021/** * MemoryRegionSection: describes a fragment of a #MemoryRegion * * @mr: the region, or %NULL if empty * @address_space: the address space the region is mapped in * @offset_within_region: the beginning of the section, relative to @mr's start * @size: the size of the section; will not exceed @mr's boundaries * @offset_within_address_space: the address of the first byte of the section * relative to the region's address space * @readonly: writes to this section are ignored */ //只是起到描述的作用,描述了是哪个 AddressSpace 的 MemoryRegion, //并且在 MemoryRegion 中的 offset,和在 AddressSpace 展开为平坦内存的 offsetstruct MemoryRegionSection { MemoryRegion *mr; // 所属的 MemoryRegion MemoryRegion *address_space; // 关联的 AddressSpace target_phys_addr_t offset_within_region; // 在 MemoryRegion 内部的 offset uint64_t size; // Section 的大小 target_phys_addr_t offset_within_address_space; // 在 AddressSpace 内部的 offset bool readonly; // 是否为只读}; offset_within_region:在所属 MemoryRegion 中的offset。一个AddressSpace 可能由多个 MemoryRegion 组成,因此该 offset 是局部的 offset_within_address_space:在所属 AddressSpace 中的 offset,它是全局的 和其他数据结构之间的关系 AddressSpace 的root指向对应的根级MemoryRegion,current_map指向AddressSpace 的root通过generate_memory_topology()生成的 FlatView FlatView 中的ranges数组表示该MemoryRegion 所表示的Guest地址区间【GPA 的整个平坦物理空间】,并按照地址的顺序进行排列 MemoryRegionSection 由ranges数组中的 FlatRange 对应生成,作为注册到 KVM中的基本单位 QEMU 在用户空间申请内存后,需要将内存信息通过一系列系统调用传入内核空间的 KVM,由 KVM 侧进行管理,因此 QEMU 侧也定义了一些用于向 KVM 传递参数的结构体。 以下为KVM相关的数据结构。 KVMSlot在 kvm_init.h中定义,是 KVM 中内存管理的基本单位: 123456789101112131415typedef struct KVMSlot{ hwaddr start_addr; // Guest 物理地址,GPA ram_addr_t memory_size; // 内存大小 void *ram; // QEMU 用户空间地址,HVA int slot; // Slot 编号 int flags; // 标志位,例如是否追踪脏页、是否可用等 /* Dirty bitmap cache for the slot */ unsigned long *dirty_bmap; unsigned long dirty_bmap_size; /* Cache of the address space ID */ int as_id; /* Cache of the offset in ram address space */ ram_addr_t ram_start_offset;} KVMSlot; KVMSlot 类似于内存插槽的概念。 kvm_userspace_memory_region调用ioctl(KVM_SET_USER_MEMORY_REGION)时需要向 KVM 传递的参数,在kvm.h中定义 12345678/* for KVM_SET_USER_MEMORY_REGION */struct kvm_userspace_memory_region { __u32 slot; // slot 编号 __u32 flags; // 标志位,例如是否追踪脏页、是否可用等 __u64 guest_phys_addr; // Guest 物理地址,GPA __u64 memory_size; // 内存大小,bytes __u64 userspace_addr; // 从 QEMU 进程空间分配的起始地址,HVA}; MemoryListener结构体定义为了监控虚拟机的物理地址访问,对于每一个 AddressSpace,都会有一个 MemoryListener 与之对应。每当物理映射GPA->HVA发生改变时,就会回调这些函数。MemoryListener 是对一些事件的回调函数合集,在memory.h中定义: 1234567891011121314151617181920212223242526/** * MemoryListener: callbacks structure for updates to the physical memory map * * Allows a component to adjust to changes in the guest-visible memory map. * Use with memory_listener_register() and memory_listener_unregister(). */struct MemoryListener { void (*begin)(MemoryListener *listener); void (*commit)(MemoryListener *listener); void (*region_add)(MemoryListener *listener, MemoryRegionSection *section); void (*region_del)(MemoryListener *listener, MemoryRegionSection *section); void (*region_nop)(MemoryListener *listener, MemoryRegionSection *section); void (*log_start)(MemoryListener *listener, MemoryRegionSection *section); void (*log_stop)(MemoryListener *listener, MemoryRegionSection *section); void (*log_sync)(MemoryListener *listener, MemoryRegionSection *section); void (*log_global_start)(MemoryListener *listener); void (*log_global_stop)(MemoryListener *listener); void (*eventfd_add)(MemoryListener *listener, MemoryRegionSection *section, bool match_data, uint64_t data, EventNotifier *e); void (*eventfd_del)(MemoryListener *listener, MemoryRegionSection *section, bool match_data, uint64_t data, EventNotifier *e); /* Lower = earlier (during add), later (during del) */ unsigned priority; MemoryRegion *address_space_filter; QTAILQ_ENTRY(MemoryListener) link;}; 全局变量 memory_listeners所有的 MemoryListener 都会挂在全局变量memory_listeners链表上,在memory.c中定义: 12static QTAILQ_HEAD(, MemoryListener) memory_listeners = QTAILQ_HEAD_INITIALIZER(memory_listeners); 在memory.c中枚举了ListenerDirection: 1enum ListenerDirection { Forward, Reverse }; 重要数据结构总览 结构体名 说明 AddressSpace VM 能看到的一段地址空间,偏向 Host 侧【注意指的是偏向】 MemoryRegion 地址空间中一段逻辑层面的内存区域,偏向 Guest 侧 RAMBlock 记录实际分配的内存地址信息,存储了 GPA->HVA 的映射关系 FlatView MemoryRegion 对应的平面展开视图,包含一个 FlatRange 类型的 ranges 数组 FlatRange 对应一段虚拟机物理地址区间,各个 FlatRange 不会重叠,按照地址的顺序保存在数组中 MemoryRegionSection 表示 MemoryRegion 中的片段 MemoryListener 回调函数集合 KVMSlot KVM 中内存管理的基本单位,表示一个内存插槽 kvm_userspace_memory_region 调用 ioctl(KVM_SET_USER_MEMORY_REGION) 时需要向 KVM 传递的参数 具体实现机制QEMU 的内存申请流程大致可分为三个部分:回调函数的注册、AddressSpace 的初始化、实际内存的分配。下面将根据在 vl.c 的 main() 函数中的调用顺序分别介绍。 回调函数的注册 1234567891011int main() └─ static int configure_accelerator() └─ int kvm_init() // 初始化 KVM ├─ int kvm_ioctl(KVM_CREATE_VM) // 创建 VM ├─ int kvm_arch_init() // 针对不同的架构进行初始化 └─ void memory_listener_register() // 注册 kvm_memory_listener └─ static void listener_add_address_space() // 调用 region_add 回调 └─ static void kvm_region_add() // region_add 对应的回调实现 └─ static void kvm_set_phys_mem() // 根据传入的 section 填充 KVMSlot └─ static int kvm_set_user_memory_region() └─ int ioctl(KVM_SET_USER_MEMORY_REGION) 进入configure_accelerator()后,QEMU会先调用configure_accelerator()设置 KVM 的加速支持,之后进入kvm_init()。该函数主要完成对 KVM 的初始化,包括一些常规检查如 CPU 个数、KVM 版本等,之后通过kvm_ioctl(KVM_CREATE_VM)与内核交互,创建 KVM 虚拟机。在kvm_init()的最后,会调用memory_listener_register()注册kvm_memory_listener: 12345678910111213141516171819static int kvm_init(MachineState *ms){ MachineClass *mc = MACHINE_GET_CLASS(ms); // 打开/dev/kvm s->fd = qemu_open_old("/dev/kvm", O_RDWR); // 创建 VM do { ret = kvm_ioctl(s, KVM_CREATE_VM, type); } while (ret == -EINTR);/* ... */ ret = kvm_arch_init(s); // 针对不同的架构进行初始化 // 对于以下 AddressSpace,设置其对应的 listener kvm_memory_listener_register(s, &s->memory_listener, &address_space_memory, 0, "kvm-memory"); memory_listener_register(&kvm_coalesced_pio_listener, &address_space_io);/* ... */} 12345678910111213141516171819202122232425262728293031323334void memory_listener_register(MemoryListener *listener, AddressSpace *as){ MemoryListener *other = NULL; /* Only one of them can be defined for a listener */ assert(!(listener->log_sync && listener->log_sync_global)); listener->address_space = as; if (QTAILQ_EMPTY(&memory_listeners) || listener->priority >= QTAILQ_LAST(&memory_listeners)->priority) { QTAILQ_INSERT_TAIL(&memory_listeners, listener, link); } else { QTAILQ_FOREACH(other, &memory_listeners, link) { if (listener->priority < other->priority) { break; } } QTAILQ_INSERT_BEFORE(other, listener, link); } if (QTAILQ_EMPTY(&as->listeners) || listener->priority >= QTAILQ_LAST(&as->listeners)->priority) { QTAILQ_INSERT_TAIL(&as->listeners, listener, link_as); } else { QTAILQ_FOREACH(other, &as->listeners, link_as) { if (listener->priority < other->priority) { break; } } QTAILQ_INSERT_BEFORE(other, listener, link_as); } listener_add_address_space(listener, as);} 最后的listener_add_address_space()主要是将 listener 注册到其对应的 AddressSpace 上,并根据 AddressSpace 对应的 FlatRange 数组,生成 MemoryRegionSection【MemoryRegionSection就像是为FlatRange数组设置的一种中介表示,便于传入KVM,因为传入KVM应该是对平坦内存的一种表示】,并注册到 KVM 中: 12345678910111213141516171819202122232425262728293031323334static void listener_add_address_space(MemoryListener *listener, AddressSpace *as){ FlatView *view; FlatRange *fr; if (listener->begin) { listener->begin(listener); } /* 开启内存脏页记录 */ if (global_dirty_tracking) { if (listener->log_global_start) { listener->log_global_start(listener); } } /* 遍历 AddressSpace 对应的 FlatRange 数组,并将其转换成 MemoryRegionSection */ view = address_space_get_flatview(as); FOR_EACH_FLAT_RANGE(fr, view) { MemoryRegionSection section = section_from_flat_range(fr, view); /* 将 section 所代表的内存区域注册到 KVM 中 */ if (listener->region_add) { listener->region_add(listener, §ion); } if (fr->dirty_log_mask && listener->log_start) { listener->log_start(listener, §ion, 0, fr->dirty_log_mask); } } if (listener->commit) { listener->commit(listener); } flatview_unref(view);} 由于此时 AddressSapce 尚未初始化,所以此处的循环为空,仅是在全局注册了kvm_memory_listener。最后调用了kvm_memory_listener->region_add(),对应的实现是kvm_region_add(),该函数最终会通过ioctl(KVM_SET_USER_MEMORY_REGION),将 QEMU 侧申请的内存信息传入 KVM 进行注册,这里的流程会在下一部分进行分析。 AddressSpace 的初始化 12345678910111213141516171819int main() └─ void cpu_exec_init_all() ├─ static void memory_map_init() | ├─ void memory_region_init() // 初始化 system_memory/io 这两个全局 MemoryRegion | ├─ void set_system_memory_map() // address_space_memory->root = system_memory | | └─ static void memory_region_update_topology() // 为 MemoryRegion 生成 FlatView | | └─ static void address_space_update_topology() // as->current_map = new_view | | └─ static void address_space_update_topology_pass() | | └─ static void kvm_region_add() // region_add 对应的回调实现 | | └─ static void kvm_set_phys_mem() // 根据传入的 section 填充 KVMSlot | | └─ static int kvm_set_user_memory_region() | | └─ int ioctl(KVM_SET_USER_MEMORY_REGION) | | | └─ void memory_listener_register() // 注册对应的 MemoryListener | └─ static void listener_add_address_space() | └─ static void io_mem_init() └─ void memory_region_init_io() // ram/rom/unassigned/notdirty/subpage-ram/watch └─ void memory_region_init() 第一部分在全局注册了kvm_memory_listener,但由于AddressSpace 尚未初始化,实际上并未向 KVM 中注册任何实际的内存信息。QEMU 在main()函数中会继续调用cpu_exec_init_all()对AddressSpace进行初始化,该函数实际上是对两个 init 函数的封装调用: 12345678910111213141516void cpu_exec_init_all(void){ qemu_mutex_init(&ram_list.mutex); /* The data structures we set up here depend on knowing the page size, * so no more changes can be made after this point. * In an ideal world, nothing we did before we had finished the * machine setup would care about the target page size, and we could * do this much later, rather than requiring board models to state * up front what their requirements are. */ finalize_target_page_bits(); io_mem_init(); // 初始化六个I/O MemoryRegion memory_map_init(); // 初始化两个全局 AddressSpace,以及对应的 MemoryRegion、FlatView qemu_mutex_init(&map_client_list_lock);} 先来看memory_map_init(),主要用来初始化两个全局的系统地址空间system_memory、system_io 123456789101112131415161718static void memory_map_init(void){ system_memory = g_malloc(sizeof(*system_memory)); // 1. 初始化 system_memory memory_region_init(system_memory, NULL, "system", UINT64_MAX); // 2. 设置 address_space_memory 关联 system_memory // 这两个都是全局变量,也就是把内存地址空间和 IO 地址空间于对应的 MemoryRegion 联系起来 //及其对应的 FlatView address_space_init(&address_space_memory, system_memory, "memory"); system_io = g_malloc(sizeof(*system_io)); // 1. 初始化 system_io memory_region_init_io(system_io, NULL, &unassigned_io_ops, NULL, "io", 65536); // 2. 设置 address_space_io 关联 system_io // 及其对应的 FlatView address_space_init(&address_space_io, system_io, "I/O");} 这里比较重要的是address_space_init(),先设置 AddressSpace 对应的 MemoryRegion,之后根据system_memory更新address_space_memory对应的 FlatView: 123456789101112131415void address_space_init(AddressSpace *as, MemoryRegion *root, const char *name){ memory_region_ref(root); // 将 address_space_memory 的 root 域指向 system_memory as->root = root; as->current_map = NULL; as->ioeventfd_nb = 0; as->ioeventfds = NULL; QTAILQ_INIT(&as->listeners); QTAILQ_INSERT_TAIL(&address_spaces, as, address_spaces_link); as->name = g_strdup(name ? name : "anonymous"); // 根据 system_memory 更新 address_space_memory 对应的 FlatView address_space_update_topology(as); address_space_update_ioeventfds(as);} address_space_update_topology()会继续调用generate_memory_topology()生成 AddressSpace 对应的 FlatView视图: 12345678910static void address_space_update_topology(AddressSpace *as){ MemoryRegion *physmr = memory_region_get_flatview_root(as->root); flatviews_init(); if (!g_hash_table_lookup(flat_views, physmr)) { generate_memory_topology(physmr); } address_space_set_flatview(as);} address_space_update_topology()会先调用generate_memory_topology()生成system_memory更新后的视图new_view,再将address_space_memory的current_map指向这个new_view,最后销毁old_view: 1234567891011121314151617181920212223242526272829303132333435363738394041424344static void address_space_set_flatview(AddressSpace *as){ FlatView *old_view = address_space_to_flatview(as); MemoryRegion *physmr = memory_region_get_flatview_root(as->root); FlatView *new_view = g_hash_table_lookup(flat_views, physmr); assert(new_view); if (old_view == new_view) { return; } if (old_view) { flatview_ref(old_view); } flatview_ref(new_view); if (!QTAILQ_EMPTY(&as->listeners)) { FlatView tmpview = { .nr = 0 }, *old_view2 = old_view; if (!old_view2) { old_view2 = &tmpview; } address_space_update_topology_pass(as, old_view2, new_view, false); address_space_update_topology_pass(as, old_view2, new_view, true); } /* Writes are protected by the BQL. */ qatomic_rcu_set(&as->current_map, new_view); if (old_view) { flatview_unref(old_view); } /* Note that all the old MemoryRegions are still alive up to this * point. This relieves most MemoryListeners from the need to * ref/unref the MemoryRegions they get---unless they use them * outside the iothread mutex, in which case precise reference * counting is necessary. */ if (old_view) { flatview_unref(old_view); }} 在address_space_update_topology_pass()的最后,会调用MEMORY_LISTENER_UPDATE_REGION这个宏,触发region_add对应的回调函数kvm_region_add()。 这个宏在memory.c中定义,会将 FlatView 中的 FlatRange 转换为 MemoryRegionSection,作为入参传递给kvm_region_add(): 1234567/* No need to ref/unref .mr, the FlatRange keeps it alive. */#define MEMORY_LISTENER_UPDATE_REGION(fr, as, dir, callback, _args...) \\ do { \\ MemoryRegionSection mrs = section_from_flat_range(fr, \\ address_space_to_flatview(as)); \\ MEMORY_LISTENER_CALL(as, callback, dir, &mrs, ##_args); \\ } while(0) 而kvm_region_add()实际上是对kvm_set_phys_mem()的封装调用。该函数比较复杂,会根据传入的section填充 KVMSlot,再传递给kvm_set_user_memory_region(): 123456789101112131415161718192021222324252627static int kvm_set_user_memory_region(KVMMemoryListener *kml, KVMSlot *slot, bool new){ KVMState *s = kvm_state; struct kvm_userspace_memory_region mem; int ret; // 根据 KVMSlot 填充 kvm_userspace_memory_region mem.slot = slot->slot | (kml->as_id << 16); mem.guest_phys_addr = slot->start_addr; mem.userspace_addr = (unsigned long)slot->ram; mem.flags = slot->flags; if (slot->memory_size && !new && (mem.flags ^ slot->old_flags) & KVM_MEM_READONLY) { /* Set the slot size to 0 before setting the slot to the desired * value. This is needed based on KVM commit 75d61fbc. */ mem.memory_size = 0; ret = kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem); if (ret < 0) { goto err; } } mem.memory_size = slot->memory_size; ret = kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem); slot->old_flags = mem.flags; return ret;} 可以看到这里又将 KVMSlot 转换为 kvm_userspace_memory_region,作为ioctl()的参数,交给内核中的 KVM 进行内存的注册【设置GPA->HVA的映射关系,在内核空间维护并管理 Guest 的内存】。 至此 QEMU 侧负责管理内存的数据结构均已完成初始化,可以参考下面的图片了解各数据结构之间的对应关系 实际内存的分配 12345678910111213141516171819202122232425int main() └─ void machine->init(ram_size, ...) └─ static void pc_init_pci(ram_size, ...) // 初始化虚拟机 └─ static void pc_init1(system_memory, system_io, ram_size, ...) ├─ void memory_region_init(pci_memory, "pci", ...) // pci_memory, rom_memory └─ void pc_memory_init() // 初始化内存,分配实际的物理内存地址 ├─ void memory_region_init_ram() // 创建 pc.ram, pc.rom 并分配内存 | ├─ void memory_region_init() | └─ ram_addr_t qemu_ram_alloc() | └─ ram_addr_t qemu_ram_alloc_from_ptr() | ├─ void vmstate_register_ram_global() // 将 MR 的 name 写入 RAMBlock 的 idstr | └─ void vmstate_register_ram() | └─ void qemu_ram_set_idstr() | ├─ void memory_region_init_alias() // 初始化 ram_below_4g, ram_above_4g └─ void memory_region_add_subregion() // 在 system_memory 中添加 subregions └─ static void memory_region_add_subregion_common() └─ static void memory_region_update_topology() // 为 MemoryRegion 生成 FlatView └─ static void address_space_update_topology() // as->current_map = new_view └─ static void address_space_update_topology_pass() └─ static void kvm_region_add() // region_add 对应的回调实现 └─ static void kvm_set_phys_mem() // 根据传入的 section 填充 KVMSlot └─ static int kvm_set_user_memory_region() └─ int ioctl(KVM_SET_USER_MEMORY_REGION) 之前的回调函数注册、AddressSpace 的初始化,实际上均没有对应的物理内存。【实际的内存是在 RAMBlock 中】 我们再回到 qemu 启动的 main 函数中。接下来的初始化过程会调用 pc_init1。在这里面,对于 CPU 虚拟化,我们会调用 pc_cpus_init。另外,pc_init1 还会调用pc_memory_init,进行内存的虚拟化。 123456789101112131415161718192021222324252627282930313233343536void *pc_memory_init(MemoryRegion *system_memory, const char *kernel_filename, const char *kernel_cmdline, const char *initrd_filename, ram_addr_t below_4g_mem_size, ram_addr_t above_4g_mem_size, MemoryRegion *rom_memory, MemoryRegion **ram_memory){ MemoryRegion *ram, *option_rom_mr; // 两个实体 MR: pc.ram, pc.rom MemoryRegion *ram_below_4g, *ram_above_4g; // 两个别名 MR: ram_below_4g, ram_above_4g /* Allocate RAM. We allocate it as a single memory region and use * aliases to address portions of it, mostly for backwards compatibility * with older qemus that used qemu_ram_alloc(). */ ram = g_malloc(sizeof(*ram)); // 创建 ram // 分配具体的内存(实际上会创建一个 RAMBlock 并将其 offset 值写入 ram.ram_addr,对应 GPA) memory_region_init_ram(ram, "pc.ram", below_4g_mem_size + above_4g_mem_size); // 将 MR 的 name 写入 RAMBlock 的 idstr vmstate_register_ram_global(ram); *ram_memory = ram; // 创建 ram_below_4g 表示 4G 以下的内存 ram_below_4g = g_malloc(sizeof(*ram_below_4g)); memory_region_init_alias(ram_below_4g, "ram-below-4g", ram, 0, below_4g_mem_size); // 将 ram_below_4g 挂在 system_memory 下 memory_region_add_subregion(system_memory, 0, ram_below_4g); if (above_4g_mem_size > 0) { ram_above_4g = g_malloc(sizeof(*ram_above_4g)); memory_region_init_alias(ram_above_4g, "ram-above-4g", ram, below_4g_mem_size, above_4g_mem_size); memory_region_add_subregion(system_memory, 0x100000000ULL, ram_above_4g); } /* ... */} 这里的重点在于memory_region_init_ram(),它通过qemu_ram_alloc()获取 ram 这个 MemoryRegion 对应的 RAMBlock 的offset,并存入ram.ram_addr,这样就可以在ram_list中根据该字段查找 MR 对应的 RAMBlock: 12345678void memory_region_init_ram(MemoryRegion *mr, const char *name, uint64_t size){ memory_region_init(mr, name, size); // 填充字段,初始化默认值 mr->ram = true; // 表示为 RAM mr->terminates = true; // 表示为实体 MemoryRegion mr->destructor = memory_region_destructor_ram; mr->ram_addr = qemu_ram_alloc(size, mr); // 这里保存 RAMBlock 的 offset,即 GPA} 而 qemu_ram_alloc() 最终会调用 qemu_ram_alloc_from_ptr(),创建一个对应大小 RAMBlock 并分配内存,返回对应的 GPA 地址存入 mr->ram_addr 中: 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354ram_addr_t qemu_ram_alloc_from_ptr(ram_addr_t size, void *host, MemoryRegion *mr){ RAMBlock *new_block; // 创建一个 RAMBlock size = TARGET_PAGE_ALIGN(size); // 页对齐 new_block = g_malloc0(sizeof(*new_block)); // 初始化 new_block new_block->mr = mr; // 将 new_block-> 指向入参的 MemoryRegion new_block->offset = find_ram_offset(size); // 从 ram_list 中的 RAMBlock 之间找到一段可以满足 size 需求的 gap,并返回起始地址的 offset,对应 GPA if (host) { // 新建的 RAMBlock host 字段为空,跳过 new_block->host = host; new_block->flags |= RAM_PREALLOC_MASK; } else { if (mem_path) { // 未指定 mem_path#if defined (__linux__) && !defined(TARGET_S390X) new_block->host = file_ram_alloc(new_block, size, mem_path); if (!new_block->host) { new_block->host = qemu_vmalloc(size); qemu_madvise(new_block->host, size, QEMU_MADV_MERGEABLE); }#else fprintf(stderr, "-mem-path option unsupported\\n"); exit(1);#endif } else { if (xen_enabled()) { xen_ram_alloc(new_block->offset, size, mr); } else if (kvm_enabled()) { // 从这里继续 /* some s390/kvm configurations have special constraints */ new_block->host = kvm_vmalloc(size); // 实际上还是调用 qemu_vmalloc(size) } else { new_block->host = qemu_vmalloc(size); // 从 QEMU 的线性空间中分配 size 大小的内存,返回 HVA } qemu_madvise(new_block->host, size, QEMU_MADV_MERGEABLE); } } new_block->length = size; // 将 length 设置为 size QLIST_INSERT_HEAD(&ram_list.blocks, new_block, next); // 将该 RAMBlock 插入 ram_list 头部 ram_list.phys_dirty = g_realloc(ram_list.phys_dirty, // 重新分配 ram_list.phys_dirty 的内存空间 last_ram_offset() >> TARGET_PAGE_BITS); memset(ram_list.phys_dirty + (new_block->offset >> TARGET_PAGE_BITS), 0, size >> TARGET_PAGE_BITS); cpu_physical_memory_set_dirty_range(new_block->offset, size, 0xff); // 对该 RAMBlock 对应的内存标记为 dirty qemu_ram_setup_dump(new_block->host, size); if (kvm_enabled()) kvm_setup_guest_memory(new_block->host, size); return new_block->offset;} 这样一来ram【其实就是system memory,整个Guest物理空间的大小】对应的 RAMBlock 中就分配好了 GPA 和 HVA,就可以将内存信息同步至 KVM 侧了。 最后回到pc_memory_init()中,在分配完实际内存后,会先调用memory_region_init_alias()初始化ram_below_4g、ram_above_4g这两个alias,之后调用memory_region_add_subregion()将这两个 alias 指向ram这个实体 MemoryRegion。如下图,该函数最终会触发kvm_region_add()回调,将实际的内存信息传入 KVM 注册。该过程如下图所示,与之前分析的流程相同,此处不再赘述。 总结虚拟机的内存管理也是需要用户态的 qemu 和内核态的 KVM 共同完成。为了加速内存映射,需要借助硬件的 EPT 技术。 QEMU 侧 创建一系列 MemoryRegion,分别表示 Guest 中的 RAM、ROM 等区域。MemoryRegion之间通过 alias 或 subregions 的方式维护相互之间的关系,从而进一步细化区域的定义 对于一个实体 MemoryRegion(非 alias),在初始化内存的过程中 QEMU 会创建它所对应的 RAMBlock。该 RAMBlock 通过调用qemu_ram_alloc_from_ptr()从 QEMU 的进程地址空间中以 mmap 的方式分配内存,并负责维护该 MemoryRegion 对应内存的起始 GPA/HVA/size 等相关信息【在qemu_ram_alloc_from_ptr中创建的新RAMBlock有offset、host的赋值,即GPA->HVA的对应关系】 AddressSpace 表示 Guest 的物理地址空间。如果 AddressSpace 中的 MemoryRegion 发生变化,则注册的 listener 会被触发,将所属的 MemoryRegion 树展开生成一维的 FlatView,比较 FlatRange 是否发生了变化。如果是,则调用相应的方法对 MemoryRegionSection 进行检查,更新 QEMU 中的 KVMSlot,同时填充kvm_userspace_memory_region结构体,作为ioctl()的参数更新 KVM 中的kvm_memory_slot KVM 侧 当 QEMU 通过ioctl()创建 vcpu 时,调用kvm_mmu_create()初始化 MMU 相关信息。当 KVM 要进入 Guest 前,vcpu_enter_guest()=>kvm_mmu_reload()会将根级页表地址加载到 VMCS,让 Guest 使用该页表 当发生EPT Violation 时,VM-EXIT到 KVM 中。如果是缺页,则根据 GPA 算出 gfn,再根据 gfn 找到对应的 KVMSlot,从中得到对应的 HVA。然后根据 HVA 算出对应的 pfn,确保该 Page 位于内存中。填好缺失的页之后,需要更新 EPT,完善其中缺少的页表项,逐层补全页表 虚拟机的物理内存空间里面的页面当然不是一开始就映射到物理页面的,只有当虚拟机的内存被访问的时候,也即 mmap 分配的虚拟内存空间被访问的时候,先查看 EPT 页表,是否已经映射过,如果已经映射过,则经过四级页表映射,就能访问到物理页面。如果没有映射过,则虚拟机会通过VM-Exit指令回到宿主机模式,通过 handle_ept_violation 补充页表映射。先是通过 handle_mm_fault为虚拟机的物理内存空间分配真正的物理页面,然后通过 __direct_map 添加 EPT 页表映射。 Reference“QEMU 内存空间虚拟化及内存管理” - B10g | FΓom 许大仙【原创】Linux 虚拟化 KVM-Qemu 分析(五)之内存虚拟化 - LoyenWang - 博客园KVM/Qemu 工作原理系列目录_xiongwenwu 的专栏-CSDN 博客_qemu 目录结构QEMU 内存虚拟化源码分析 | Keep Coding | 苏易北","categories":[{"name":"QEMU 源码分析","slug":"QEMU-源码分析","permalink":"http://example.com/categories/QEMU-%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"QEMU","slug":"QEMU","permalink":"http://example.com/tags/QEMU/"}]},{"title":"解决 VSCode 配置远程连接,过程试图写入的管道不存在","slug":"解决VSCode配置远程连接,过程试图写入的管道不存在","date":"2022-01-19T15:07:49.000Z","updated":"2022-10-15T03:14:29.853Z","comments":true,"path":"2022/01/19/解决VSCode配置远程连接,过程试图写入的管道不存在/","link":"","permalink":"http://example.com/2022/01/19/%E8%A7%A3%E5%86%B3VSCode%E9%85%8D%E7%BD%AE%E8%BF%9C%E7%A8%8B%E8%BF%9E%E6%8E%A5%EF%BC%8C%E8%BF%87%E7%A8%8B%E8%AF%95%E5%9B%BE%E5%86%99%E5%85%A5%E7%9A%84%E7%AE%A1%E9%81%93%E4%B8%8D%E5%AD%98%E5%9C%A8/","excerpt":"","text":"保留现场 探究原因本地记录的服务器信息和现有的产生了冲突 解决方法方法一将known_hosts文件的内容全部删除。 C:\\Users\\user name\\.ssh\\known_hosts 方法二搜遍全网几乎都是上述方法,应该绝大部分人通过上述方法都能解决。如果你也跟我一样不走运,不管是重新生成公私钥,还是删除hnow_hosts都不行,那么可以尝试修改 VSCode 使用的ssh.exe。Windows 下默认使用的是环境变量里配置的OpenSSH提供的ssh.exe。你可以将环境变量里的OpenSSH删除。然后在VSCode设置里搜索remote,也就是设置插件remote ssh。 将 Path 强制设置成Git安装包内的ssh.exe 或者mobaxterm安装包内的ssh.exe 参考Debug | VSCode | 过程试图写入的管道不存在 - CodeAntenna VScode 通过 remote ssh 连接虚拟机 & 报错 过程试图写入的管道不存在(已解决)_Tasdily 的博客-CSDN 博客_vscode 过程试图写入的管道不存在","categories":[],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"Linux 帧缓冲","slug":"Linux帧缓冲","date":"2022-01-17T09:38:04.000Z","updated":"2022-10-15T03:14:29.293Z","comments":true,"path":"2022/01/17/Linux帧缓冲/","link":"","permalink":"http://example.com/2022/01/17/Linux%E5%B8%A7%E7%BC%93%E5%86%B2/","excerpt":"","text":"简介FrameBuffer 是内核当中的一种驱动程序接口。Linux 是工作在保护模式下,所以用户态进程是无法象 DOS 那样使用显卡 BIOS 里提供的中断调用来实现直接写屏,Linux 抽象出 FrameBuffer 这个设备来供用户态进程实现直接写屏。 帧缓冲主要结构 fb_info 该结构体记录当前帧缓冲设备的状态信息,如果系统中有多个帧缓冲设备,就需要两个fb_info结构,这个结构只在内核中可以看到,对用户空间不可见。 fb_var_screeninfo 该结构体记录指定的帧缓冲设备和显示模式中可以被修改的信息,其中包括显示器分辨率等信息。 fb_fix_screeninfo 该结构体表示帧缓冲设备中一些不能修改的参数,包括特定的显示模式,屏幕缓冲区的物理地址,显示缓冲区的长度信息。 fb_ops LCD底层硬件操作接口集。比如fb_open、fb_release、fb_read、fb_write、fb_ioctl、fb_mmap等: fb_cmap fb_cmap指定颜色映射,用于以内核可以理解的方式存储用户的颜色定义。 帧缓冲显示原理帧缓冲设备是一种显示抽象的设备,也可以被理解为它是一个内存区域,上面的应用程序可以直接对显示缓冲区进行读和写操作,就像访问文件的通用接口一样,用户可以认为帧缓冲是一块内存,能读取数据的内存块也可以向这个内存写入数据,因此显示器显示图形界面实际上根据根据的是指定的内存数据块内的数据。 帧缓冲的显示缓冲区位于 Linux 内核地址空间,应用程序不能直接访问内核地址空间,在 Linux 中,只有一个内存的内核地址空间映射到用户地址空间才可以由用户访问,内存的映射是通过MMAP函数实现的在 Linux 中。对于帧缓冲,虚拟地址是通过内存映射的方法将显示缓冲区内核地址映射到用户空间的,然后用户可以通过读和写这部分的虚拟地址来访问显示缓冲区,在屏幕上绘图。 使用流程使用帧缓冲之前应该首先确定 Linux 系统上已安装了帧缓冲驱动,可以在目录/dev/下查找fb*如,/dev/fb0, /dev/fb1等设备来确定是否安装。如果没有需要安装一个帧缓冲驱动的模块到内核,或者重新编译内核生成一个带帧缓冲模块的镜像。 使用帧缓冲需要进入控制台模式,即纯命令行的模式进行编程。一般可以通过快捷键CTRL+ALT+F1进入控制台模式,CTRL+ALT+F7切回图形窗口。如果控制台模式没有登录,可以CTRL+ALT+F6尝试登录。 因硬件显示设备的物理显示区是通过帧缓存区操作,而帧缓存区是处于内核空间,应用程序不能随意操作,此时可以通过系统调用mmap把帧缓存映射到用户空间,在用户空间中创建出帧缓存映射区(用户图像数据缓存区),以后只需把用户图像数据写入到帧缓存映射区就可在硬件设备上显示图像。 具体实现流程如下: 打开帧缓冲设备/dev/f0在Linux的/dev目录的寻找b*设备文件然后使用读写模式打开它,Linux 系统将使用通用的open系统调用来完成功能, open的功能原型如下: 1int open(const char *path, int oflags); Path是准备打开的文件或设备的路径参数; oflags指定打开文件时使用的参数; flags参数的指定,是通过组合文件访问模式和其他的可选模式一起的,可以支持多个模式或,参数必须是指定下列文件的访问模式。 只读:O_RDONLLY 只写:O_WRONLY 读写:O_RDWR 简而言之, open函数建立设备文件的访问路径。如果操作成功,它返回一个文件描述符,只是一个文件描述符,它将不使用其他任何正在运行的进程共享。如果两个程序同时打开相同的文件,将得到两个不同的文件描述符。如果他们执行文件写入操作,他们将操作每个文件描述符,不会发生冲突,写完之后退出。他们的数据不会互相交织在一起的,但会互相的彼此覆盖 (后写完的内容覆盖前面写的内容),两个程序来读取和写入的文件位置看似一样但是有各自不同拷贝所以不会发生交织。如果open调用未能返回1,则将全局变量errno设置为指示失败的原因。 通过系统调用ioctl函数获得帧设备相关信息通过顿缓冲文件描述符,屏幕的分辨率、颜色深度等信息可以被获得,帧缓冲驱动中存放了这些对应的信息,必须使用 Linux 系统调用ioctl首先将帧缓冲的文件描述符和fb_var_screeninfo 结构体对应起来。 结构体fb_var_screeninfo包含以下三个重要数据结构: 屏幕的 x 方向分辨率,像素作为单位。 屏幕的 Y 方向分辨率,像素作为单位。 屏幕的像素颜色深度,每个像素用多少比特数表示。 ioctl函数原型如下: 1extern int ioctl (int __fd, unsigned long int __request, ...) __THROW; ioctl调用实现访问设备驱动各种各样的配置信息功能,它提供了一个控制设备的行为和配置底层服务接口的驱动函数,各种设备驱动程序,例如套接字和系统终端,还有磁带机都有ioctl命令可以支持。 __fd:ioctl命令中是该帧缓冲的文件描述符; __request:ioctl函数将要执行的命令,实现参数给定的对象描述符中指定的函数操作,各种设备支持的功能是有差异的 FBIOGET_VSCREENINFO命令字返回与Framebuffer有关的固定的信息; FBIOGET_VSCREENINFO命令字返回与 Framebuffer 有关的可变的信息; 第三个参数是一个指针用来指向结构体fb_var_screeninfo。 最后使用者可以通过结构体fb_var_screeninfo来获得屏幕的分辨率和颜色位深和其他重要的屏幕信息。根据这些信息可以计算屏幕缓冲区的大小:屏幕缓冲区大小 (以字节为单位) = 屏幕宽度x高度x屏幕颜色深度/8 帧缓冲映射在进行帧缓冲的MMAP映射之前,要先得到帧缓冲文件描述符,才能像屏幕上面显示,必须首先将缓冲区的内核地址映射映射到用户地址空间。Linux 系统将使用MMAP系统调用完成功能,MMAP函数原型如下: 12extern void *mmap (void *__addr, size_t __len, int __prot, int __flags, int __fd, __off_t __offset) __THROW; __addr:返回一个指向mmap函数的内存区域的指针,与内容相关的文件指针,通过指针可以访问帧缓冲区的内存区域。 __len:可以请求使用特定内存地址,通过设置地址参数,如果值为0,将自动分配指针,这是推荐的做法,否则会降低程序的可移植性,因为不同的系统可用的地址范围是不一样的。 __prot:设置内存访问的权限设定,通过端口相关的参数定义,位的定义值如下: PORT_EXEC:允许内存段的执行。 PORT_NONE:无法访问内存段。 PORT_READ:允许读取内存段。 PORT_WRITE:允许编写内存段。 __flags:改变控制参数标志,能够影响该内存段的作用域,如下所示: MAP_FIXED:内存段必须位于addr中指定的地址。 MAP_SHARED:内存的修改保存到一个文件中。 MAP_PRIVATE:内存段是私人的,变化仅在本地范围内有效。 __fd:是通过一个open调用得到的访问文件的描述符。 offset:用于指定访问数据的开始偏移量在内存段中,和访问普通文件使用方式是相同的,再指定文件描述符参数,以及访问的数据长度参数即可。 读写帧缓冲MMAP返回的指针,可以访问到帧缓冲内存区,可以定位到屏幕缓冲区具体为每个显示像素的位置,通过读函数调用读取对应的位置数据在帧缓冲内存中,相反写操作对应于内存的写入数据可以显示内容写到屏幕上。 解除帧缓冲映射在绘图完成后,帧缓冲文件描述符必须被释放之前,解除帧缓冲区的地址映射,使用 Linux 系统调用完成mmap函数的逆函数实现,即是munmap,函数的原型如下: 1extern int munmap (void *__addr, size_t __len) __THROW; addr参数应该与调用MMAP时指定的参数值一致, len参数也应该与之前调用MMAP时指定的len参数保持一致。 mmap调用返回0成功,失败则返回1,同时将全局变量erno设置为指示失败的原因。 调用close关闭设备使用帧缓冲设备后,应关闭相应的文件描述符,使用 Linux 系统标准的函数完成关闭功能,close函数的原型如下: 1extern int close (int __fd); close的参数和在开始调用open时指定的参数一致,文件描述符释放后可以重用,结束调用成功返回0,失败返回1。 帧缓冲实例以下代码摘自xianjimli/linux-framebuffer-tools: linux framebuffer tool,演示了帧缓冲设备的使用流程。 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667fb_info_t *linux_fb_open(const char *filename){ uint32_t size = 0; fb_info_t *fb = NULL; struct fb_fix_screeninfo fix; struct fb_var_screeninfo var; return_value_if_fail(filename != NULL, NULL); fb = (fb_info_t *)calloc(1, sizeof(fb_info_t)); return_value_if_fail(fb != NULL, NULL); // 打开帧缓冲设备,O_RDWR 读写模式 fb->fd = open(filename, O_RDWR); if (fb->fd < 0) { log_debug("open %s failed(%d)\\n", filename, errno); free(fb); return NULL; } // 通过系统调用 ioctl 函数获得帧设备相关信息 // FBIOGET_FSCREENINFO 命令字返回与 Framebuffer 有关的固定的信息 if (ioctl(fb->fd, FBIOGET_FSCREENINFO, &fix) < 0) goto fail; //命令字返回与 Framebuffer 有关的可变的信息 if (ioctl(fb->fd, FBIOGET_VSCREENINFO, &var) < 0) goto fail; var.xoffset = 0; var.yoffset = 0; // 显示 ioctl(fb->fd, FBIOPAN_DISPLAY, &(var)); log_debug("fb_info_t: %s\\n", filename); log_debug("fb_info_t: xres=%d yres=%d bits_per_pixel=%d mem_size=%d\\n", var.xres, var.yres, var.bits_per_pixel, fb_size(fb)); log_debug("fb_info_t: red(%d %d) green(%d %d) blue(%d %d)\\n", var.red.offset, var.red.length, var.green.offset, var.green.length, var.blue.offset, var.blue.length); fb->w = var.xres; fb->h = var.yres; fb->bpp = var.bits_per_pixel / 8; fb->line_length = fix.line_length; size = fb_size(fb); // 帧缓冲映射 // PROT_READ | PROT_WRITE:可读写 // MAP_SHARED:内存的修改保存到一个文件 fb->data = (uint8_t *)mmap(0, size, PROT_READ | PROT_WRITE, MAP_SHARED, fb->fd, 0); if (fb->data == MAP_FAILED) { log_debug("map framebuffer failed.\\n"); goto fail; } log_debug("line_length=%d mem_size=%d\\n", fix.line_length, fb_size(fb)); log_debug("xres_virtual =%d yres_virtual=%d xpanstep=%d ywrapstep=%d\\n", var.xres_virtual, var.yres_virtual, fix.xpanstep, fix.ywrapstep); return fb;fail: log_debug("%s is not a framebuffer.\\n", filename); close(fb->fd); free(fb); return NULL;} 感兴趣可以下载源码编译运行,其中/bin/fbshow可以使用帧缓冲设备显示图片。图形界面下直接运行可能提示无法运行,需要Chrtl+Alt+F1切换到控制台模式。 LCD 与 Framebuffer 的关系 LCD 控制器首先通过 VDEN 信号,使能。接下来根据 VCLK 时钟信号,在像素点上“喷涂”不同的颜色(打个比方),控制器有 VD(video data)信号,传送不同颜色信息。每来一个时钟信号,就向右移动一个像素,根据行同步信号 HSYNC,就从最右边移动到最左边。当移动到右下角时根据垂直同步信号 VSYNC。 那么问题来了,不同颜色的信息从哪里来?就是从上文介绍的 Framebuffer 中来的。 很多人都会说操纵 LCD 显示就是操纵 FrameBuffer,表面上来看是这样的。实际上是 FrameBuffer 就是 Linux 内核驱动申请的一片内存空间,然后 LCD 内有一片 sram,CPU 内部有个 LCD 控制器,它有个单独的 dma 用来将 FrameBuffer 中的数据拷贝到 LCD 的 sram 中去 拷贝到 LCD 的 sram 中的数据就会显示在 LCD 上,LCD 驱动和 FrameBuffer 驱动没有必然的联系,它只是驱动 LCD 正常工作的,比如有信号传过来,那么 LCD 驱动负责把信号转成显示屏上的内容,至于什么内容这就是应用层要处理的。 静态随机存取存储器(Static Random-Access Memory,SRAM)是随机存取存储器的一种。所谓的“静态”,是指这种存储器只要保持通电,里面储存的数据就可以恒常保持。DMA(Direct Memory Access),直接内存访问。使用 DMA 的好处就是它不需要 CPU 的干预而直接服务外设,这样 CPU 就可以去处理别的事务,从而提高系统的效率。 ReferenceLinux 驱动之 Framebuffer 子系统 | 量子范式Linux 驱动开发(9)——- framebuffer 驱动详解 | 码农家园嵌入式系统中帧缓冲显示模块的设计与实现 - 中国知网research/framebuffer/fivechess/fivechess-0.1 at master · tsuibin/research五子棋 framebuffer 版 - 尚码园FrameBuffer 驱动程序分析_深入剖析 Android 系统-CSDN 博客_framebufferxianjimli/linux-framebuffer-tools: linux framebuffer tool韦东山_嵌入式 Linux_第 2 期_Linux 高级驱动视频教程_免费试看版_哔哩哔哩_bilibiliLinux LCD Frambuffer 基础介绍和使用(1) - 知乎","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"FrameBuffer","slug":"FrameBuffer","permalink":"http://example.com/tags/FrameBuffer/"},{"name":"LCD","slug":"LCD","permalink":"http://example.com/tags/LCD/"}]},{"title":"解决 ssh permission denied(publickey)","slug":"解决Git ssh permission denied(publickey)","date":"2022-01-13T14:43:02.000Z","updated":"2022-10-15T03:14:29.809Z","comments":true,"path":"2022/01/13/解决Git ssh permission denied(publickey)/","link":"","permalink":"http://example.com/2022/01/13/%E8%A7%A3%E5%86%B3Git%20ssh%20permission%20denied(publickey)/","excerpt":"","text":"保留现场12linux> ssh -p 2221 xxx@gerrit.comxxx@gerrit.com: Permission denied(publickey) 探究原因本次出错是在测试是否能连接 gerrit 时。连接 GitHub 也可能会出现。只要用到 ssh 功能的都有可能。 出错的原因: 网页(如 gerrit,github)没有设置公钥,一般为id_rsa.pub内容; 本地生成了多个公私钥,配对配错了; 本地没有配置好git,比如git config时用户名或者邮箱填错; 需要开启 ssh 代理; 解决方法 生成密钥cd ~/.ssh && ssh-keygen 复制公钥内容,添加到网页中github或者gerrit的设置里。cat id_rsa.pub | xclip 配置git账户 git config --global user.name "bob" git config --global user.email bob@... 以上检查无误,仍然报错 开启ssh代理 eval $(ssh-agent -s) 将私钥加入代理 ssh-add ~/.ssh/id_rsa 登陆用户时启动 ssh-agent如果不幸你的问题就是需要开启ssh-agent,那么每次重启电脑都需要开启一次。这也是相当麻烦的,可以通过将以下配置添加到~/.bashrc中,让 Linux 启动时自动开启ssh-agent。 12345678910111213141516171819202122# Add following code at the end of ~/.bashrc# Check if ~/.pid_ssh_agent exists.if [ -f ~/.pid_ssh_agent ]; then source ~/.pid_ssh_agent # Check process of ssh-agent still exists. TEST=$(ssh-add -l) if [ -z "$TEST" ]; then # Reinit if not. NEED_INIT=1 fielse NEED_INIT=1 # PID file doesm't exist, reinit it.fi# Try start ssh-agent.if [ ! -z "$NEED_INIT" ]; then echo $(ssh-agent -s) | sed -e 's/echo[ A-Za-z0-9]*;//g' > ~/.pid_ssh_agent # save the PID to file. source ~/.pid_ssh_agentfi 参考ssh - Git: How to solve Permission denied (publickey) error when using Git? - Stack Overflow Linux 登陆用户时启动 ssh-agent 并复用 - Fenying","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"Linux 安装 Node.js 以及 hexo","slug":"Linux安装nodejs","date":"2022-01-10T03:51:50.000Z","updated":"2022-10-15T03:14:29.286Z","comments":true,"path":"2022/01/10/Linux安装nodejs/","link":"","permalink":"http://example.com/2022/01/10/Linux%E5%AE%89%E8%A3%85nodejs/","excerpt":"","text":"安装 Node.js 过程进入该网站下载 | Node.js也可以进入该网站下载历史版本,Previous Releases | Node.js 进入 download 目录, 12cd downloadwget https://nodejs.org/dist/v10.16.3/node-v10.16.3-linux-x64.tar.xz -O nodejs.tar.xz 解压 1tar -xvf node-v10.16.3-linux-x64.tar.xz 改名 Node.js 1mv node-v10.16.3-linux-x64 nodejs 将 npm,node 两个程序建立软连接,能够全局可用 123ln -s /download/nodejs/bin/npm /usr/local/bin/ ln -s /download/nodejs/bin/node /usr/local/bin/ 检查是否安装 123node -vnpm -v 安装 hexo 过程12npm i hexo-cli -ghexo -v 如果出现命令未找到到错误,说明 hexo 还未加入全局变量。将下面命令加入 12vim ~/.bashrcexport PATH=/usr/local/nodejs/lib/node_modules/hexo-cli/bin/:$PATH ReferencePrevious Releases | Node.jsLinux 安装 Node.js | F2E 前端技术论坛Linux 下安装 node 及 npm - SegmentFault 思否超详细 Hexo+Github 博客搭建小白教程 - 知乎","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"}]},{"title":"C 语言__attribute__使用","slug":"C语言-attribute-使用","date":"2022-01-08T07:40:51.000Z","updated":"2022-10-15T03:14:29.124Z","comments":true,"path":"2022/01/08/C语言-attribute-使用/","link":"","permalink":"http://example.com/2022/01/08/C%E8%AF%AD%E8%A8%80-attribute-%E4%BD%BF%E7%94%A8/","excerpt":"","text":"简介__attribute__ 其实是个编译器指令,告诉编译器声明的特性,或者让编译器进行更多的错误检查和高级优化。 __attribute__ 可以设置函数属性(Function Attribute)、变量属性(Variable Attribute)和类型属性(Type Attribute)。每一类都包含数十种属性,本文不会逐一解释,只抛砖引玉,完整属性可以查看链接中的官方文档。 一个属性说明符的形式是__attribute__ ((attribute-list))。一个属性列表是一个可能为空的逗号分隔的属性序列,其中每个属性都是以下的一个。 属性为空。空属性会被忽略。 一个单词(可能是未使用的标识符,也可能是 const 等保留字)。 一个单词,后面跟着括号中的属性参数。这些参数采用以下形式之一: 一个标识符。例如,mode属性使用这种形式。 一个标识符,后跟一个逗号和一个以逗号分隔的非空表达式列表。例如,format属性使用这种形式。 一个可能是空的逗号分隔的表达式列表。例如,format_arg属性使用这种形式,该列表是一个单一的整数常量表达式,而alias属性也使用这种形式,该列表是一个单一的字符串常量。 使用方法函数属性alias该属性可以设置函数的别名。 12345678910void __f() { printf("__attribute__ test\\n"); };void f() __attribute__((weak, alias("__f")));int main() { f(); return 0;}/*--- 输出 ---*/ //__attribute__ test 函数f()的别名为__f(),调用f()即调用__f()。 alloc_sizealloc_size属性用来告诉编译器,函数的返回值指向内存,其中的大小由一个或两个函数参数给出。GCC 使用这些信息来提高__builtin_object_size的正确性。 alloc_size后面可以跟一到二个参数,alloc_size 后面跟的参数是指定使用函数的第几个参数。 函数的参数的个数只有一个,那么 alloc_size 的参数只能是 1。通过__builtin_object_size 获取的值 就是传入的参数值。如图,我们给函数my_malloc 传入的值是100 ,那么我们通过__builtin_object_size 获取的值就是100。 函数的参数的个数多余两个,那么alloc_size 的最多可以指定两个参数。传入两个参数,__builtin_object_size的值是这两个参数的乘积。传入一个参数,__builtin_object_size的值就是这个参数的值。如图,my_callocd函数指定的参数是alloc_size(2,3),通过__builtin_object_size获取的值就是my_callocd传入的第二和三个参数的乘积(2*3=6)。 1234567891011121314151617void *my_calloc(int a) __attribute__((alloc_size(1)));void *my_realloc(int a, int b, int c) __attribute__((alloc_size(2, 3)));void *my_calloc(int a) { return NULL; }void *my_realloc(int a, int b, int c) { return NULL; }int main() { void *const p = my_calloc(100); printf("size : %ld\\n", __builtin_object_size(p, 0)); void *const a = my_realloc(1, 2, 3); printf("size : %ld\\n", __builtin_object_size(a, 1)); return 0;}/*--- 输出 ---*/ //100//6 constructor (priority) / destructor (priority)constructor属性使该函数在执行进入main()之前被自动调用。同样地,destructor属性使函数在main()完成后或exit()被调用后被自动调用。具有这些属性的函数对于初始化将在程序执行过程中隐含使用的数据非常有用。 constructor 和 +load 都是在 main 函数执行前调用,但 +load 比 constructor 更加早一丢丢,因为 dyld(动态链接器,程序的最初起点)在加载 image(可以理解成 Mach-O 文件)时会先通知 objc runtime 去加载其中所有的类,每加载一个类时,它的 +load 随之调用,全部加载完成后,dyld 才会调用这个 image 中所有的 constructor 方法。 若有多个 constructor 且想控制优先级的话,可以写成 attribute((constructor(101))),里面的数字越小优先级越高,1 ~ 100 为系统保留。 变量属性cleanup该属性在变量作用域结束时,调用指定的一个函数。这个属性只能应用于自动函数范围的变量;它不能应用于参数或具有静态存储期限的变量。该函数必须接受一个参数,一个指向与变量兼容的类型的指针。函数的返回值(如果有的话)被忽略。 12345678910111213141516171819#include <stdlib.h>#include <string.h>void test_cleanup(char **str) { printf("after cleanup: %s\\n", *str); free(*str);}int main(int argc, char **argv) { char *str __attribute__((__cleanup__(test_cleanup))) = NULL; str = (char *)malloc((sizeof(char)) * 100); strcpy(str, "test"); printf("before cleanup : %s\\n", str); return 0;}/*--- 输出 ---*/ //before cleanup : test//after cleanup: test 作用域结束包括大括号结束、return、goto、break、exception等各种情况。在上面的实验中,main函数返回标志变量str作用域结束,所以最后才打印after cleanup: test。 类型属性aligned (alignment)这个属性指定了函数的最小对齐方式,以字节为单位。对齐的大小只能增加,不能减小。 1234567891011121314151617181920212223242526#include <stdio.h>struct stu { char sex; int length; char name[2]; char value[15];} __attribute__((aligned(1)));struct stu my_stu;int main() { printf("%d \\n", sizeof(my_stu)); printf("%p %p,%p,%p \\n", &my_stu, &my_stu.length, &my_stu.name, &my_stu.value); return 0;}/*--- __attribute__((aligned(1)));输出 ---*/ //28 //0x55af2ba25020 0x55af2ba25024,0x55af2ba25028,0x55af2ba2502a/*--- __attribute__((aligned(4)));输出 ---*/ //28 //0x556fbce54020 0x556fbce54024,0x556fbce54028,0x556fbce5402a /*--- __attribute__((aligned(8)));输出 ---*/ //32 //0x5646e130e040 0x5646e130e044,0x5646e130e048,0x5646e130e04a 由以上代码实验结果发现,默认对齐代下为 4 字节,小于这个值就被忽略,大于 4 字节才生效。 Referneceattribute 机制使用 - 简书C 语言复杂声明解析_wangweixaut061 的专栏-CSDN 博客_c 语言复杂声明attribute 你知多少?","categories":[],"tags":[]},{"title":"C 语言 typedef 用法","slug":"C语言typedef用法","date":"2022-01-07T03:51:50.000Z","updated":"2022-10-15T03:14:29.145Z","comments":true,"path":"2022/01/07/C语言typedef用法/","link":"","permalink":"http://example.com/2022/01/07/C%E8%AF%AD%E8%A8%80typedef%E7%94%A8%E6%B3%95/","excerpt":"","text":"简介typedef为 C 语言的关键字,作用是为一种数据类型定义一个新名字。这里的数据类型包括内部数据类型(int,char 等)和自定义的数据类型(struct 等)。在使用语法上类似与static,extern等。typedef 行为有点像 #define 宏,用其实际类型替代同义字。不同点是 typedef在编译时被解释,因此让编译器来应付超越预处理器能力的文本替换。 基本使用方法示例 1: 123int a; ———— 传统变量声明表达式int myint_t; ———— 使用新的类型名myint_t替换变量名atypedef int myint_t; ———— 在语句开头加上typedef关键字,myint_t就是我们定义的新类型 示例 2: 123void (*pfunA)(int a); ———— 传统变量(函数)声明表达式void (*PFUNA)(int a); ———— 使用新的类型名PFUNA替换变量名pfunAtypedef void (*PFUNA)(int a); ———— 在语句开头加上typedef关键字,PFUNA就是我们定义的新类型 促使我写这篇文章的原因不是如何去用typedef,而是在代码中看不懂如何简化了一个复杂声明。比如上文的 1typedef void (*PFUNA)(int a); 本以为是将void类型替换成了(*PFUNA)(int a),但是语法上这明显讲不通啊。现在明白了,这就是将void (*pfunA)(int a);类型名换成了PFUNA。以后就可以用PFUNA来声明变量。比如 1PFUNA arr[10] 表示声明了一个大小为10的数组,数组的元素是PFUNA类型。将PFUNA类型展开就是,这是一个函数指针,函数参数为int类型,返回值为void类型。完整的含义就是,声明了一个大小为10的数组,数组元素是函数指针,函数参数为int类型,返回值为void类型。 代码简化typedef可以为复杂的声明定义一个新的简单的别名。关于复杂声明,可以阅读这篇C 语言复杂声明。方法是:在原来的声明里逐步用别名替换一部分复杂声明,递归操作,把带变量名的部分留到最后替换,得到的就是原声明的最简化版。举例: 12//复杂声明void (*b[10]) (void (*)()); 变量名为b,先替换右边部分括号里的,pFunParam为别名 1typedef void (*pFunParam)(); 再替换左边的变量b,pFunx为别名二: 1typedef void (*pFunx)(pFunParam); 简化后的声明: 1pFunx b[10]; 减少错误定义一种类型的别名,而不只是简单的宏替换。可以用作同时声明指针型的多个对象。比如: 123// 这多数不符合我们的意图,它只声明了一个指向字符变量的指针,// 和一个字符变量;char* pa, pb; 以下则可行: 12typedef char* PCHAR;PCHAR pa, pb; 这种用法很有用,特别是char* pa, pb的定义,初学者往往认为是定义了两个字符型指针,其实不是,而用typedef char* PCHAR就不会出现这样的问题,减少了错误的发生。 直观简洁声明struct新对象时,必须要带上struct 123456struct tagPOINT1 { int x; int y; };struct tagPOINT1 p1; 在经常使用这个结构体时,就显得麻烦,可以用typedef简化 12345typedef struct tagPOINT{ int x; int y;}POINT; 定义平台无关的类型当跨平台时,只要改下 typedef 本身就行,不用对其他源码做任何修改。 1typedef unsigned int u_32t; 掩饰复合类型typedef 还可以掩饰复合类型,如指针和数组。 例如,你不用像下面这样重复定义有 81 个字符元素的数组: 1char line[81]; 定义一个 typedef,每当要用到相同类型和大小的数组时,可以这样: 1typedef char Line[81]; 此时 Line 类型即代表了具有 81 个元素的字符数组,使用方法如下: 1Line text, secondline; 同样,可以象下面这样隐藏指针语法: 1typedef char * pstr; 这里将带我们到达第一个 typedef 陷阱。标准函数 strcmp()有两个const char *类型的参数。因此,它可能会误导人们象下面这样声明 mystrcmp(): 1int mystrcmp(const pstr, const pstr); 用 GNU 的 gcc 和 g++编译器,是会出现警告的,按照顺序,const pstr被解释为char* const(一个指向 char 的指针常量),两者表达的并非同一意思。为了得到正确的类型,应当如下声明: 1typedef const char* pstr; typedef 和存储类关键字typedef 就像 auto,extern,mutable,static,和 register 一样,是一个存储类关键字。这并不是说 typedef 会真正影响对象的存储特性;它只是说在语句构成上,typedef 声明看起来象 static,extern 等类型的变量声明。下面将带到第二个陷阱: 1typedef register int FAST_COUNTER; // 错误 编译通不过。问题出在你不能在声明中有多个存储类关键字。因为符号 typedef 已经占据了存储类关键字的位置,在 typedef 声明中不能用 register(或任何其它存储类关键字)。 Referencetypedef 介绍_liitdar 的博客-CSDN 博客_typedef 关于 typedef 的用法总结_IT 民工-CSDN 博客_typedef","categories":[],"tags":[]},{"title":"Windows 批处理定时任务","slug":"Windows批处理定时任务","date":"2022-01-05T14:39:03.000Z","updated":"2022-10-15T03:14:29.613Z","comments":true,"path":"2022/01/05/Windows批处理定时任务/","link":"","permalink":"http://example.com/2022/01/05/Windows%E6%89%B9%E5%A4%84%E7%90%86%E5%AE%9A%E6%97%B6%E4%BB%BB%E5%8A%A1/","excerpt":"","text":"折腾背景一些常用的离线软件在重新安装,重装电脑或者更好环境时,调教好的配置总需要重新设置一遍,甚是麻烦。但是这些设置通常都保存在配置文件里,只要能备份好这些配置文件,下次重装后覆盖就可以恢复所需设置。 现在的问题就是如何备份这些配置文件,可以选择各类网盘,硬盘等等。但是这些多少都有点炮打蚊子,小题大做。而且定时备份也不是很方便。既然配置文件都很小,其实就是个文本文件,那有个万能免费存储地 GitHub 就派上用场了。我们只要把配置文件定时 push 到 GitHub 即可,以后随时可以 clone 下来。 首先建立一个私密仓库,用来专门存放配置文件。其次通过批处理命令,将配置文件复制到本地仓库的文件夹下。最后设置定时任务。 折腾过程新建仓库这一步不用赘述了,主要就是要勾选私密仓库,保护隐私,一些配置文件可能会包含个人信息。 批处理将仓库克隆到本地后就是个文件夹,这一步主要就是如何能把安装在不同位置的软件的配置文件,都汇集到这个仓库下。通过批处理命令可以快速,方便的完成。 123456789101112131415echo Start backup config files! # 打印这句话copy D:\\Tools\\MouseInc\\MouseInc.json D:\\Develop\\fxxk-config\\mouseinc # 将前者复制到后者copy D:\\Tools\\JD\\Config.ini D:\\Develop\\fxxk-config\\jdcd /d D:\\Develop\\fxxk-config # 切换目录# git推送的一些命令git add . git commit -m "update"git push# 防止窗口闪退pause 一些常用命令参考WindowDos 批处理指导。 定时任务控制面板-管理工具 - 任务计划程序","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"DOS","slug":"DOS","permalink":"http://example.com/tags/DOS/"}]},{"title":"解决 unable to install libpng12.so.0","slug":"解决unable-to-install-libpng12-so-0","date":"2022-01-05T05:01:47.000Z","updated":"2022-10-15T03:14:29.841Z","comments":true,"path":"2022/01/05/解决unable-to-install-libpng12-so-0/","link":"","permalink":"http://example.com/2022/01/05/%E8%A7%A3%E5%86%B3unable-to-install-libpng12-so-0/","excerpt":"","text":"保留现场apt工具损坏了,在修复时使用了sudo apt-get install -f命令,中途会提示需要安装libpng12-0,但是始终无法安装,会提示如下错误。 1234567Unpacking libpng12-0:amd64 (1.2.50-2+deb8u3) ... dpkg: error processing archive libpng12-0_1.2.50-2+deb8u3_amd64.deb (--install): unable to install new version of '/usr/lib/x86_64-linux-gnu/libpng12.so.0': No such file or directory Errors were encountered while processing: libpng12-0_1.2.50-2+deb8u3_amd64.deb 探究原因具体原因未知,网上答案众说纷纭。 解决方法这个问题遇到的人还挺多的,解决方法也各不相同,我先说我自己最终解决的方法。 方法一 将软件源更换成中科院的源,使用 Linux 自带的软件和更新工具,具体方法参考这篇文章。更换完之后可以重新尝试安装,有人换源后即可成功安装。 如果未能安装成功,可能曾经手动添加过软件源,将其删除。 12# 将所有内容注释vim /etc/apt/sources.list 方法二 下载已安装的库文件libpng12.so.0,可以从该链接下载。 将该文件复制到它本该安装的位置。 1sudo cp libpng12.so.0 /usr/lib/x86_64-linux-gnu/ 方法三123sudo add-apt-repository ppa:linuxuprising/libpng12sudo apt updatesudo apt install libpng12-0","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"RISC-V 入门-Trap","slug":"RISC-V入门-Trap和Exception","date":"2021-12-30T05:42:34.000Z","updated":"2022-10-15T03:14:29.553Z","comments":true,"path":"2021/12/30/RISC-V入门-Trap和Exception/","link":"","permalink":"http://example.com/2021/12/30/RISC-V%E5%85%A5%E9%97%A8-Trap%E5%92%8CException/","excerpt":"","text":"Trap 简介控制流(Control Flow)和 Trap 控制流(Control Flow)从给处理器加电开始,直到你断电为止,程序计数器假设一个值的序列$$a_0,a_1,\\dotsb,a_{n-1}$$每个$a_k$都是指令的地址,每次从$a_{k}$到$a_{k+1}$的过渡称为控制转移,而这样的控制转移序列叫做处理器的控制流。 异常控制流(Exceptional Control Flow, ECF)系统也必须能够对系统状态的变化做出反应,这些系统状态不是被内部程序变量捕获的,而且也不一定要和程序的执行相关。比如,一个硬件定时器定期产生信号,这个事件必须得到处理。包到达网络适配器后,必须存放在内存中。程序向磁盘请求数据,然后休眠,直到被通知说数据已就绪。现代系统通过使控制流发生突变来对这些情况做出反应。我们把这些突变称为异常控制流。 exception interrupt RISC-V 把 ECF 统称为 Trap。 RISC-V Trap 处理中涉及的寄存器 寄存器 全称 用途说明 mtvec Machine Trap-Vector Base-Address 它保存发生异常时处理器需要跳转到的地址。 mepc Machine Exception Program Counter 当 trap 发生时,hart 会将发生 trap 所对应的指令的地址值(pc)保存在 mepc 中。 mcause Machine Cause 当 trap 发生时,hart 会设置该寄存器通知我们 trap 发生的原因。 mtval Machine Trap Value 它保存了 exception 发生时的附加信息:譬如访问地址出错时的地址信息、或者执行非法指令时的指令本身,对于其他异常,它的值为 0。 mstatus Machine Status 用于跟踪和控制 hart 的当前操作状态(特别地,包括关闭和打开全局中断)。 mscratch Machine Scratch Machine 模式下专用寄存器,我们可以自己定义其用法,譬如用该寄存器保存当前在 hart 上运行的 task 的上下文(context)的地址。 mtvec(Machine Trap-Vector Base-Address) WARL: Write Any Values, Read Legal Values BASE:trap 入口函数的基地址,必须保证四字节对齐; MODE:进一步用于控制入口函数的地址配置方式: Direct,所有异常和中断发生后,PC都跳转到BASE指定的地址处; 通常中断处理函数内部会有switch case条件语句,通过不同的中断采用不同的处理方式。 123456789101112131415161718192021222324252627282930reg_t trap_handler(reg_t epc, reg_t cause){ reg_t return_pc = epc; reg_t cause_code = cause & 0xfff; if (cause & 0x80000000) { /* Asynchronous trap - interrupt */ switch (cause_code) { case 3: uart_puts("software interruption!\\n"); break; case 7: uart_puts("timer interruption!\\n"); break; case 11: uart_puts("external interruption!\\n"); break; default: uart_puts("unknown async exception!\\n"); break; } } else { /* Synchronous trap - exception */ printf("Sync exceptions!, code = %d\\n", cause_code); panic("OOPS! What can I do!"); //return_pc += 4; } return return_pc;} Vectored,异常的处理方式同上,但是中断的入口地址以数组方式排列; 12345678910111213141516171819202122232425262728trap_vector: # save context(registers). csrrw t6, mscratch, t6 # swap t6 and mscratch reg_save t6 # Save the actual t6 register, which we swapped into # mscratch mv t5, t6 # t5 points to the context of current task csrr t6, mscratch # read t6 back from mscratch sw t6, 120(t5) # save t6 with t5 as base # Restore the context pointer into mscratch csrw mscratch, t5 # call the C trap handler in trap.c csrr a0, mepc csrr a1, mcause call trap_handler # trap_handler will return the return address via a0. csrw mepc, a0 # restore context(registers). csrr t6, mscratch reg_restore t6 # return to whatever we were doing before trap. mret MODE可取值如下: 采用Vectored方式效率更高。 mepc(Machine Exception Program Counter) 当trap发生时,pc会被替换为 mtvec设定的地址,同时hart 会设置mepc为当前指令或者下一条指令的地址(处理异常时,mepc 为当前指令的地址,处理中断时,mepc 为下一条指令的地址)。 当我们需要退出trap 时可以调用特殊的 mret 指令,该指令会将mepc中的值恢复到pc中(实现返回的效果); 在处理 trap 的程序中我们可以修改 mepc 的值达到改变mret 返回地址的目的。 mcause(Machine Cause) 当 trap 发生时,hart 会设置该寄存器通知我们 trap 发生的原因。 最高位 Interrupt 为 1 时标识了当前 trap 为interrupt,否则是exception。 剩余的 Exception Code 用于标识具体的interrupt或者exception 的种类。 mtval(Machine Trap Value) 当 trap 发生时,除了通过mcause 可以获取exception的种类 code 值外,hart 还提供了 mtval 来提供exception 的其他信息来辅助我们执行更进一步的操作。 具体的辅助信息由特定的硬件实现定义,RISC-V 规范没有定义具体的值。但规范定义了一些行为,譬如访问地址出错时的地址信息、或者执行非法指令时的指令本身等。 mstatus(Machine Status) 寄存器各个位可以大致分为以下三类,其中x可以为U,S,M。表示用户模式以及两种特权模式。 xIE(x=M/S/U): 分别用于打开(1)或者关闭(0)M/S/U 模式下的全局中断。当 trap 发生时,hart会自动将 xIE 设置为 0。 xPIE(x=M/S/U):当 trap 发生时用于保存 trap 发生之前的 xIE 值。 xPP(x=M/S):当 trap 发生时用于保存 trap 发生之前的权限级别值。注意没有 UPP。因为异常只会从低权限向高权限跳转,通常低权限如user模式,会被置于上方,高权限如内核一般都会画在下方,这也解释了异常,中断处理为什么叫trap,因为是向下陷入的过程。 其他标志位涉及内存访问权限、虚拟内存控制等,暂不考虑。 Trap 处理流程 主要为 Exception,下一章详解 Interrupt。 初始化将trap的基地址写入寄存器, Top Half 把 mstatus 的 MIE 值复制到 MPIE 中,清除 mstatus中的 MIE 标志位,效果是中断被禁止。 设置mepc,同时PC被设置为 mtvec。(需要注意的是,对于exception, mepc指向导致异常的指令;对于 interrupt,它指向被中断的指令的下一条指令的位置。) 根据 trap 的种类设置 mcause,并根据需要为mtval设置附加信息。 将 trap 发生之前的权限模式保存在 mstatus 的 MPP 域中,再把hart 权限模式更改为 M(也就是说无论在任何 Level 下触发trap,hart 首先切换到 Machine 模式)。 Bottom Half 保存(save)当前控制流的上下文信息(利用 mscratch); 调用 C 语言的 trap handler; 从 trap handler 函数返回,mepc的值有可能需要调整; 恢复(restore)上下文的信息; 执行MRET指令返回到 trap之前的状态。 12345678910111213141516171819202122232425262728trap_vector: # save context(registers). csrrw t6, mscratch, t6 # swap t6 and mscratch reg_save t6 # Save the actual t6 register, which we swapped into # mscratch mv t5, t6 # t5 points to the context of current task csrr t6, mscratch # read t6 back from mscratch sw t6, 120(t5) # save t6 with t5 as base # Restore the context pointer into mscratch csrw mscratch, t5 # call the C trap handler in trap.c csrr a0, mepc csrr a1, mcause call trap_handler # trap_handler will return the return address via a0. csrw mepc, a0 # restore context(registers). csrr t6, mscratch reg_restore t6 # return to whatever we were doing before trap. mret 退出 trap:编程调用 MRET 指令针对不同权限级别下如何退出 trap 有各自的返回指令xRET(x = M/S/U)。以在 M 模式下执行mret 指令为例,会执行如下操作: 当前 Hart 的权限级别 = mstatus.MPP;mstatus.MPP = U(如果 hart 不支持 U 则为 M) mstatus.MIE = mstatus.MPIE; mstatus.MPIE = 1 pc = mepc 中断中断分类 本地(Local)中断 软中断software interrupt 定时器中断 timer interrupt 全局(Global)中断 外部中断 externel interrupt RISC-V 中断编程中涉及的寄存器 寄存器 全称 用途说明 mie Machine Interrupt Enable 用于进一步控制(打开和关闭)software interrupt/timer interrupt/external interrupt mip Machine Interrupt Pending 它列出目前已发生等待处理的中断。 mie(Machine Interrupt Enable) 打开(1)或者关闭(0)M/S/U 模式下对应的 External/Timer/Software 中断。 mip(Machine Interrupt Pending) 获取当前 M/S/U 模式下对应的 External/Timer/Software 中断是否发生。 中断处理流程中断处理 把 mstatus 的 MIE 值复制到 MPIE 中,清除 mstatus 中的 MIE 标志位,效果是中断被禁止。 当前的 PC 的下一条指令地址被复制到 mepc 中,同时 PC 被设置为mtvec。注意如果我们设置 mtvec.MODE = vetcored,PC =mtvec.BASE + 4 × exception-code。 根据 interrupt 的种类设置 mcause,并根据需要为 mtval 设置附加信息。 将 trap 发生之前的权限模式保存在 mstatus 的 MPP 域中,再把hart 权限模式更改为 M。 退出中断以在 M 模式下执行 mret 指令为例,会执行如下操作: 当前 Hart 的权限级别 = mstatus.MPP; mstatus.MPP= U(如果 hart 不支持 U 则为 M) mstatus.MIE = mstatus.MPIE; mstatus.MPIE = 1 pc = mepc PLIC(Platform-Level Interrupt Controller)PLIC 简介HART 只能处理一个中断,PLIC 相当于一个控制中心,它通过中断类型,优先级等等来选出一个需要处理的中断。协调多个中断,服务一个 HART。 12345678enum { UART0_IRQ = 10, //Interrupt Source ID RTC_IRQ = 11, VIRTIO_IRQ = 1, /* 1 to 8 */ VIRTIO_COUNT = 8, PCIE_IRQ = 0x20, /* 32 to 35 */ VIRTIO_NDEV = 0x35 /* Arbitrary maximum number of interrupts */}; Interrupt Source ID 范围:1 ~ 53(0x35) 0 预留不用 PLIC本身也是一个外设,RISC-V 规范规定,PLIC 的寄存器编址采用内存映射(memory map)方式。每个寄存器的宽度为 32-bit。 具体寄存器编址采用 base + offset 的格式,且 base 由各个特定platform 自己定义。针对 QEMU-virt,其 PLIC 的设计参考了FU540-C000,base 为 0x0c000000。 1234567891011121314151617static const MemMapEntry virt_memmap[] = { [VIRT_DEBUG] = { 0x0, 0x100 }, [VIRT_MROM] = { 0x1000, 0xf000 }, [VIRT_TEST] = { 0x100000, 0x1000 }, [VIRT_RTC] = { 0x101000, 0x1000 }, [VIRT_CLINT] = { 0x2000000, 0x10000 }, [VIRT_ACLINT_SSWI] = { 0x2F00000, 0x4000 }, [VIRT_PCIE_PIO] = { 0x3000000, 0x10000 }, [VIRT_PLIC] = { 0xc000000, VIRT_PLIC_SIZE(VIRT_CPUS_MAX * 2) }, [VIRT_UART0] = { 0x10000000, 0x100 }, [VIRT_VIRTIO] = { 0x10001000, 0x1000 }, [VIRT_FW_CFG] = { 0x10100000, 0x18 }, [VIRT_FLASH] = { 0x20000000, 0x4000000 }, [VIRT_PCIE_ECAM] = { 0x30000000, 0x10000000 }, [VIRT_PCIE_MMIO] = { 0x40000000, 0x40000000 }, [VIRT_DRAM] = { 0x80000000, 0x0 },}; PLIC 编程接口 - 寄存器Priority功能:设置某一路中断源的优先级内存映射地址:BASE + (interrupt-id) * 4 每个 PLIC 中断源对应一个寄存器,用于配置该中断源的优先级。 QEMU-virt 支持 7 个优先级。0 表示对该中断源禁用中断。其余优先级,1 最低,7 最高。 如果两个中断源优先级相同,则根据中断源的 ID 值进一步区分优先级,ID 值越小的优先级越高。 Pending功能:用于指示某一路中断源是否发生内存映射地址:BASE + 0x1000 + ((interrupt-id) / 32) * 4 每个 PLIC 包含 2 个 32 位的 Pending 寄存器,因为总共有 54 个中断源,每一个 bit 对应一个中断源,如果为 1 表示该中断源上发生了中断(进入Pending 状态),有待 hart 处理,否则表示该中断源上当前无中断发生。 Pending 寄存器中断的 Pending 状态可以通过claim 方式清除。 第一个 Pending 寄存器的第 0 位对应不存在的 0 号中断源,其值永远为 0。 Enable功能:针对某个 hart 开启或者关闭某一路中断源内存映射地址:BASE + 0x2000 + (hart) * 0x80 每个 Hart 有 2 个 Enable 寄存器(Enable1 和 Enable2)用于针对该Hart 启动或者关闭某路中断源。 每个中断源对应 Enable 寄存器的一个 bit,其中Enable1 负责控制 1 ~ 31 号中断源;Enable2 负责控制 32 ~ 53 号中断源。将对应的 bit 位设置为 1 表示使能该中断源,否则表示关闭该中断源。 Threshold功能:针对某个 hart 设置中断源优先级的阈值内存映射地址:BASE + 0x200000 + (hart) * 0x1000 每个 Hart 有 1 个 Threshold 寄存器用于设置中断优先级的阈值。 所有小于或者等于(<=)该阈值的中断源即使发生了也会被 PLIC 丢弃。特别地,当阈值为 0 时允许所有中断源上发生的中断;当阈值为 7 时丢弃所有中断源上发生的中断。 Claim/Complete功能:如下内存映射地址:BASE + 0x200004 + (hart) * 0x1000 Claim 和 Complete 是同一个寄存器,每个 Hart 一个。 对该寄存器执行读操作称之为 Claim,即获取当前发生的最高优先级的中断源ID。Claim 成功后会清除对应的 Pending 位。 对该寄存器执行写操作称之为 Complete。所谓 Complete指的是通知PLIC 对该路中断的处理已经结束。 1234567891011121314void external_interrupt_handler(){ int irq = plic_claim(); // if (irq == UART0_IRQ){ uart_isr(); } else if (irq) { printf("unexpected interrupt irq = %d\\n", irq); } if (irq) { plic_complete(irq); // }} CLINT (Core Local INTerruptor)定时器中断,属于本地中断的一种,由芯片内部CLINT设备产生的中断。 RISC-V 规范规定,CLINT 的寄存器编址采用内存映射(memory map)方式。 具体寄存器编址采用base + offset的格式,且 base 由各个特定 platform 自己定义。针对 QEMU-virt,其 CLINT 的设计参考了 SFIVE,base 为 0x2000000。 CLINT 编程接口 - 寄存器 (Timer 部分)mtime功能:real-time 计数器(counter)内存映射地址:BASE + 0xbff8 由晶振产生,系统全局唯一,在 RV32 和 RV64 上都是 64-bit。系统必须保证该计数器的值始终按照一个固定的频率递增。 上电复位时,硬件负责将 mtime 的值恢复为 0。 mtimecmp功能:定时器比较寄存器内存映射地址:BASE + 0x4000 + (hart) * 8) 每个 hart 一个 mtimecmp 寄存器,64-bit。 上电复位时,系统不负责设置 mt`imecmp 的初值。 当mtime >= mtimecmp 时,CLINT 会产生一个 timer 中断。如果要使能该中断需要保证全局中断打开并且mie.MTIE 标志位置 1。 当 timer 中断发生时,hart 会设置 mip.MTIP,程序可以在 mtimecmp 中写入新的值清除mip.MTIP。 时钟节拍 tick 操作系统中最小的时间单位; Tick 的单位(周期)由硬件定时器的周期决定(通常为 1 ~ 100ms); Tick 周期越小,也就是1s内产生的中断越多,系统的精度越高,但开销越大。","categories":[{"name":"RISC-V 入门","slug":"RISC-V-入门","permalink":"http://example.com/categories/RISC-V-%E5%85%A5%E9%97%A8/"}],"tags":[{"name":"RISCV","slug":"RISCV","permalink":"http://example.com/tags/RISCV/"}]},{"title":"VSCode 使用 sftp 插件上传本地文件至局域网服务器","slug":"VSCode使用sftp插件上传本地文件至局域网服务器","date":"2021-12-24T03:39:03.000Z","updated":"2022-02-24T03:39:03.000Z","comments":true,"path":"2021/12/24/VSCode使用sftp插件上传本地文件至局域网服务器/","link":"","permalink":"http://example.com/2021/12/24/VSCode%E4%BD%BF%E7%94%A8sftp%E6%8F%92%E4%BB%B6%E4%B8%8A%E4%BC%A0%E6%9C%AC%E5%9C%B0%E6%96%87%E4%BB%B6%E8%87%B3%E5%B1%80%E5%9F%9F%E7%BD%91%E6%9C%8D%E5%8A%A1%E5%99%A8/","excerpt":"","text":"测试代码时经常需要上传文件至服务器端运行,每次上传都需要通过第三方传输工具如 FileZilla,有了SFTP插件,可以直接在 VSCode 上编译成功后,一键上传本地文件。 安装插件打开插件中心,搜索sftp,安装量最高的就是我们需要的插件,点击安装。 配置插件插件安装完成后,输入快捷键Control + Shift + P 弹出命令面板,然后输入sftp:config,回车,当前工程的.vscode文件夹下就会自动生成一个sftp.json文件,我们需要在这个文件里配置的内容可以是: 123456789101112131415161718192021222324252627282930{ "host": "192.168.xxx.xxx", //服务器 ip "port": 22, //端口,sftp 模式是 22 "username": "", //用户名 "password": "", //密码 "protocol": "ftp", //模式,sfpt 或者 ftp "agent": null, "privateKeyPath": null, //存放在本地的已配置好的用于登录工作站的密钥文件(也可以是 ppk 文件) "passphrase": null, "passive": false, "interactiveAuth": false, "remotePath": "/root/node/build/", //服务器上的文件地址 "context": "./server/build", //本地的文件地址 "uploadOnSave": true, //监听保存并上传 "syncMode": "update", "watcher": { //监听外部文件 "files": false, //外部文件的绝对路径 "autoUpload": false, "autoDelete": false }, "ignore": [ //指定在使用 sftp: sync to remote 的时候忽略的文件及文件夹 //注意每一行后面有逗号,最后一行没有逗号 //忽略项 "**/.vscode/**", "**/.git/**", "**/.DS_Store" ]} 插件使用 可以直接右击文件,选择Upload,会将文件上传至配置好的remotePath。 可以Control + Shift + P输入sftp,选择想要执行的命令,命令都是字面意思,不多做解释。 如果有多个 IP 需要配置,可以在sftp.json文件中,通过方括号[]添加。比如 1234567891011121314151617181920212223242526[ { "host": "192.168.xxx.01", //服务器 ip "port": 22, //端口,sftp模式是22 "username": "", //用户名 "password": "", //密码 "protocol": "sftp", //模式,sfpt 或者 ftp "agent": null, }, { "host": "192.168.xxx.02", //服务器 ip "port": 22, //端口,sftp模式是22 "username": "", //用户名 "password": "", //密码 "protocol": "sftp", //模式,sfpt 或者 ftp "agent": null, }, { "host": "192.168.xxx.03", //服务器 ip "port": 22, //端口,sftp模式是22 "username": "", //用户名 "password": "", //密码 "protocol": "sftp", //模式,sfpt 或者 ftp "agent": null, }]","categories":[{"name":"万能 VSCode","slug":"万能-VSCode","permalink":"http://example.com/categories/%E4%B8%87%E8%83%BD-VSCode/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"}]},{"title":"C 程序内存区域分配","slug":"C程序内存区域分配","date":"2021-12-22T01:16:25.000Z","updated":"2022-10-15T02:59:00.971Z","comments":true,"path":"2021/12/22/C程序内存区域分配/","link":"","permalink":"http://example.com/2021/12/22/C%E7%A8%8B%E5%BA%8F%E5%86%85%E5%AD%98%E5%8C%BA%E5%9F%9F%E5%88%86%E9%85%8D/","excerpt":"","text":"","categories":[],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"ELF","slug":"ELF","permalink":"http://example.com/tags/ELF/"}]},{"title":"芯片启动过程全解析","slug":"芯片启动过程全解析","date":"2021-12-18T14:32:27.000Z","updated":"2022-10-15T03:14:29.789Z","comments":true,"path":"2021/12/18/芯片启动过程全解析/","link":"","permalink":"http://example.com/2021/12/18/%E8%8A%AF%E7%89%87%E5%90%AF%E5%8A%A8%E8%BF%87%E7%A8%8B%E5%85%A8%E8%A7%A3%E6%9E%90/","excerpt":"","text":"内容总结自 B 站 Up【蛋饼嵌入式】我提着鞋带拎自己?嵌入式芯片启动过程全解析,彻底理解 bootloader 当你按下电源开关的那一瞬间,第一行代码如何在芯片上运行起来的呢?嵌入式软件代码需要一定的方式烧录到芯片中才能运行,除了物理刻蚀,无论是通讯端口的传输或者调试端口的烧录,都需要驱动程序的支持。所以说是程序烧录了程序,软件启动了软件。 这就像自己提着自己的鞋带,把自己拎起来。靴子(Boot),鞋带(Strap),提鞋带(Loader)。这就是Boot Strap Loader的命名来源。通常称BootLoader,中文翻译为自举。 BootLoader是芯片最初运行的代码吗?当然不是,其实每一块芯片在出厂时都在其内部的ROM中,烧录了它最基础的软件。CPU 搬运并运行的第一条代码的默认位置,就在ROM的地址空间。所以一切的起始都在硬件上。 以 X86 架构的鼻祖 8086 芯片为例,按下开关的一瞬间,芯片 Reset 引脚接收到了电平跳变,在一连串电路的作用下,代码段寄存器CS恢复成0XFFFF,指令指针寄存器IP恢复成0X0000,他们组合成 20 位的地址正好等于 ROM 中存放第一条代码的位置。之后取出这里的指令在跳转到别处。 ARM 架构的芯片也是类似的过程,对于 32 位的芯片,通电后,PC指针寄存器复位至零地址,随后从中断向量表表头的 reset 向量处获取下一个跳转的地址。这时候的代码已经以二进制形式存储,处理器可以直接搬到自身缓存中运行。有了这部分代码,就能跳转到存放有更多更复杂的代码的地址。执行硬件自检,基本的初始化操作,提供基础的输入输出支持。之后可以将操作系统从外部的存储空间加载到内部。代码就这样接力式的流转起来。 所以我们把出厂就写在ROM里,负责启动后续用户软件的软件,称为Boot ROM或者ROM Code。现在不一定是用只读存储器(Read Only Memory),但是至少是一块掉电不易失的存储器,现在主要用EEPROM,NOR Flash。我们一般没有权限修改它,但是它也不完全是黑盒,大部分芯片都会有外部启动配置引脚,通常是以拨码快关的形式。对于 PC 机来说,Boot ROM就是我们常说的BIOS,它也有启动配置途径。而且提供了交互界面,用于配置部分功能和选择后续的引导设备。 除了芯片自带的Boot ROM,还需要再给自己实际的应用程序,写一个二次引导代码或者 N 次引导代码,用作操作系统,文件系统加载等等。我们所说的Bootloader时,其实大多数就是这样的二次引导代码。 这些事其实Boot ROM它也能做,但是Boot ROM实现的功能和配置方法不灵活,但是Bootloader是开发人员可以而完全控制的引导代码。 在设计Bootloader时,MCU的引导步骤就开始和嵌入式 Linux 或者 PC 有所不同。这一定程度与芯片架构所采用的的存储方案有关。 先来说MCU,与SOC相比MCU的主要特征是单核和或多核同构的微处理器,单核或多核同构,主频 < 1GHz,没有MMU内存管理单元,只能运行实时操作系统。常见MCU内核: 程序的主要运行介质为NOR Flash,因为和RAM一样有分离的地址线和数据线。并且可以以字节长度精确寻址,所以程序不需要拷贝到RAM中运行的。 以英飞凌家的 TC27x 系列 MCU 为例,上电后的默认取址位置是0x8FFF 8000,这就是他的Boot ROM在NorFlash中的地址。并且这块Boot Rom分为SSW,BSL,TF。 SSW 每次上电必须运行,他会根据写在program flash,PFO地址的前 32byte 中的配置字,来决定SSW执行完的跳转地址。我们可以选择一个合适的跳转地址,比如0x80000020,放上自己写的Bootloader。也可以选择不跳转,运行厂家提供的Bootloader(BSL)。 MCU下的Bootloader主要完成的事情有以下: 关闭看门狗,初始化中断和 trap 向量表,进行时钟和外设初始化,让芯片正常运行起来。 提供CAN,UART, ETH等用于通讯功能的驱动,能够接收外部数据传输请求。 提供FLASH的读写与擦除驱动,设计服务来对通讯端口接收到的更新代码进行校验、存储,以及跳转操作系统或后续应用程序代码。 如有必要,还会开发一些基础诊断服务,串口交互程序等等。 那么运行 Linux 的SOC和 PC 的这一过程有何不同呢。还是先看存储方案,运行嵌入式 Linux 的 SoC。一般将它的操作系统,文件系统和他的应用程序放在nand flash中。运行代码前,现将代码搬运到SRAM中,相比MCU多了一道步骤。 对于SOC的Boot ROM 和 PC 的BIOS而言,他们结束运行前的最终任务,是将某些代码从nand flash搬运到SRAM中,其中最重要的内容就是Boot Loader。 而一般SOC的Bootloader,又分为SPL(Secondary Program Loader)和uBOOT两个阶段。SPL的 Secondary 就是相对于BootROM而言,他就像是接力赛中的第二棒选手。SPL会初始化更大空间的外部DRAM,再把uBoot搬运到外部DRAM中去运行。uBoot作为第三棒选手,开始运行它的初始化程序。之后再根据系统环境变量,将 OS 内核搬运到外部DRAM中去运行。OS 再完成根文件系统的加载等等等等。","categories":[{"name":"嵌入式开发","slug":"嵌入式开发","permalink":"http://example.com/categories/%E5%B5%8C%E5%85%A5%E5%BC%8F%E5%BC%80%E5%8F%91/"}],"tags":[{"name":"Bootloader","slug":"Bootloader","permalink":"http://example.com/tags/Bootloader/"},{"name":"Boot Rom","slug":"Boot-Rom","permalink":"http://example.com/tags/Boot-Rom/"}]},{"title":"定时器 Timer 基础","slug":"定时器Timer基础","date":"2021-12-15T04:22:18.000Z","updated":"2022-10-15T03:15:53.139Z","comments":true,"path":"2021/12/15/定时器Timer基础/","link":"","permalink":"http://example.com/2021/12/15/%E5%AE%9A%E6%97%B6%E5%99%A8Timer%E5%9F%BA%E7%A1%80/","excerpt":"","text":"概念定时器(Timer),又叫计时器,顾名思义,它的主要功能就是计时。因为 CPU 计时会占用大量资源,而定时器独立于 CPU,专门用来计时。单核 CPU 好比人的大脑,一心不可二用,它只能知道自己当前要干什么。人可以用闹钟来提醒自己某个时间需要做某件事,而 CPU 就需要定时器来完成这样的工作。 当定时器被开启后,里面的计数器就以计数器时钟的频率开始运行,内部的计数值不断增加。例如一个时钟为1MHz的定时器,被开启后每隔1us计数值就会加 1。但计数值不可能无限增加,最大值比如65535。将这个十进制数转为二进制数后应该是一个 16 位的二进制数1111 1111 1111 1111。所以我们需要有一个 16 位大小的存储空间来存储它。那这就是一个 16 位定时器。 功能定时器可以让 SoC 在执行主程序的同时,可以 (通过定时器) 具有计时功能,到了一定时间 (计时结束) 后,定时器会产生中断提醒 CPU,CPU 会去处理中断并执行定时器中断的 ISR,从而去执行预先设定好的事件。打个比方,定时器就像一个秘书,CPU 就是老板。老板每天都有很多事要做,具体时间安排不想操心,就安排给秘书。秘书每天就是盯着表,到点就提醒老板要做某事。 原理外设的工作频率是与它所挂载在的外设总线的时钟频率相同的。但工作频率不是时钟频率,工作频率到时钟频率需要进行一次分频。这个可调节的分频值使得定时器的计时更加灵活。这个分频值就是需要设置的第一个参数预分频系数。 $$计数器时钟频率 = 工作频率/(预分频系数+1)$$ $$定时频率 = 计时器时钟频率/(自动重载值+1)$$ 假设定时器时钟频率为1MHz,那定时1ms该如何做?计数 1000 次即可。最大的计数值就是自动重载值,是我们需要设置的第二个参数。定时器被打开后,计数值就增加,一旦达到自动重载值就会出发定时器溢出中断,就实现了定时1ms。 计数模式 中心计数:计数器从 0 开始计数到自动装入的值 -1,产生一个计数器溢出事件,0 然后向下计数到 1 并且产生一个计数器溢出事件,然后再从 0 开始重新计数。 向上计数:计数器从 0 计数到自动加载值 (TIMx_ARR) ,然后重新从 0 开始计数并且产生一个计数器溢出事件。 向下计数:计数器从自动装入的值 (TIMx_ARR) 开始向下计数到 0,然后从自动装入的值重新开始,并产生一个计数器向下溢出事件。","categories":[{"name":"嵌入式开发","slug":"嵌入式开发","permalink":"http://example.com/categories/%E5%B5%8C%E5%85%A5%E5%BC%8F%E5%BC%80%E5%8F%91/"}],"tags":[{"name":"嵌入式","slug":"嵌入式","permalink":"http://example.com/tags/%E5%B5%8C%E5%85%A5%E5%BC%8F/"},{"name":"Timer","slug":"Timer","permalink":"http://example.com/tags/Timer/"},{"name":"外设","slug":"外设","permalink":"http://example.com/tags/%E5%A4%96%E8%AE%BE/"}]},{"title":"解决 Qt-QObject::connect: Cannot queue arguments of type‘QTextCursor’错误","slug":"解决Qt-QObject-connect-Cannot-queue-arguments-of-type-‘QTextCursor’错误","date":"2021-12-04T03:41:46.000Z","updated":"2022-10-15T03:14:29.827Z","comments":true,"path":"2021/12/04/解决Qt-QObject-connect-Cannot-queue-arguments-of-type-‘QTextCursor’错误/","link":"","permalink":"http://example.com/2021/12/04/%E8%A7%A3%E5%86%B3Qt-QObject-connect-Cannot-queue-arguments-of-type-%E2%80%98QTextCursor%E2%80%99%E9%94%99%E8%AF%AF/","excerpt":"","text":"保留现场我在线程中直接调用了 QTextEdit 的 append 函数时,候就会出现下面的错误: 123QObject::connect: Cannot queue arguments of type 'QTextCursor' (Make sure 'QTextCursor' is registered using qRegisterMetaType().) 探究原因原因是**我们不能通过线程来修改 UI,较为安全的修改用户界面的方式是向 UI 窗口发送信号 (signal)**,较为简单的方式是使用 Qt threading 类。 解决方法在窗口类中定义信号和槽,并声明和实现一个接口函数,这个接口函数由线程调用,在接口函数中 emit 一个信号,示例代码如下: 12345678910111213141516171819//mainwindow.hsignals: void AppendText(const QString &text);private slots: void SlotAppendText(const QString &text);public: void Append(const QString &text);//mainwindow.cppconnect(this,SIGNAL(AppendText(QString)),this,SLOT(SlotAppendText(QString)));void ClassName::Append(const QString &text){ emit AppendText("ok: string1");}//thread.cppvoid ThreadClassName::SlotAppendText(const QString &text){ mText.append(text);}","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"解决 Linux 启动出现 fsck exited with status code 4","slug":"解决Linux启动出现fsck-exited-with-status-code-4","date":"2021-12-04T02:18:09.000Z","updated":"2022-10-15T03:14:29.815Z","comments":true,"path":"2021/12/04/解决Linux启动出现fsck-exited-with-status-code-4/","link":"","permalink":"http://example.com/2021/12/04/%E8%A7%A3%E5%86%B3Linux%E5%90%AF%E5%8A%A8%E5%87%BA%E7%8E%B0fsck-exited-with-status-code-4/","excerpt":"","text":"保留现场 探究原因磁盘检测不能通过,可能是因为系统突然断电或其它未正常关闭系统导致。 解决方法根据提示可以看到是dev/sda5这个扇区出现了异常,所以通过fsck命令修复文件系统。详细命令解释。 将sda5改为自己损坏的扇区即可,等待一段时间修复完成后,输入exit即可重启。 1fsck -y /dev/sda5","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"Qt 跨窗口,控件类传递数据","slug":"Qt跨窗口,控件类传递数据","date":"2021-12-02T02:35:14.000Z","updated":"2022-10-15T03:14:29.514Z","comments":true,"path":"2021/12/02/Qt跨窗口,控件类传递数据/","link":"","permalink":"http://example.com/2021/12/02/Qt%E8%B7%A8%E7%AA%97%E5%8F%A3%EF%BC%8C%E6%8E%A7%E4%BB%B6%E7%B1%BB%E4%BC%A0%E9%80%92%E6%95%B0%E6%8D%AE/","excerpt":"","text":"问题简介本文基于【Qt】窗体间传递数据(跨控件跨类),三种情况与处理方法 已知三个窗体,A 为 B C 的父控件,B 与 C 互为兄弟控件那么参数传递分三种情况: B 向 A(C 向 A)传递参数 B 向 C(C 向 B)传递参数 A 向 B(A 向 C)传递参数 三个空间关系模型参考如下, B 向 A(C 向 A)传递参数123456789101112//B.hclass B{signals: void toA([ParamList]);}//B.cppB::B(){ emit toA([ParamList]);} 1234567891011121314151617181920//A.hclass A{private: B *b;private slots: void fromB([ParamList]);}//A.cppA::A(){ b = new B; connect(b, SIGNAL(toA([ParamList])), this, SLOT(fromB([ParamList])));}void A::fromB([ParamList]){//get[ParamList]} B 向 C(C 向 B)传递参数12345678910111213141516171819202122232425262728293031323334353637383940//A.h{private: B *b; C *c;}//A.cppA::A(){ b = new B; c = new C; connect(b, SIGNAL(toC([ParamList]), c, SLOT(fromB([ParamList])));}//B.hclass B{signals: void toC([ParamList]);}//B.cppB::B(){ emit toC([ParamList]);}//C.hclass C{private slots: void fromB([ParamList]);}//C.cppvoid C::fromB([ParamList]){//get[ParamList]} A 向 B(A 向 C)传递参数1234567891011121314151617181920212223242526//B.hclass B{public: void fromA([ParamList]);} //B.cppvoid B::fromA([ParamList]){//get[ParamList]}//A.hclass A{private: B *b;}//A.cppA:A(){ b = new B; b->fromA([ParamList]);}","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"}]},{"title":"Clang-Format 格式化代码","slug":"Clang-Format格式化代码","date":"2021-12-01T09:42:45.000Z","updated":"2022-10-15T03:14:29.062Z","comments":true,"path":"2021/12/01/Clang-Format格式化代码/","link":"","permalink":"http://example.com/2021/12/01/Clang-Format%E6%A0%BC%E5%BC%8F%E5%8C%96%E4%BB%A3%E7%A0%81/","excerpt":"","text":"安装Linux1sudo apt-get install clang-format windows每每到这时候就越能感受到用 Linux 作为开发环境的优势,Windows 安装就稍显复杂了。 你可以选择安装完整的 LLVM,在bin目录可以看到clang-format.exe。安装完后,将 bin 目录添加到环境变量中。 你也可以只下载clang-format.exe,从LLVM Snapshot Builds下载安装包。在下载页面的底部。同样你需要将单独下载的文件加入到环境变量中。 使用入门使用Linux 可以直接命令行,使用以 LLVM 代码风格格式化main.cpp, 结果直接写到main.cpp 1clang g-format -i main.cpp -style=LLVM 进阶配置如果每次编码都命令行执行一遍那也太麻烦了,而且每次修改也不止一个文件。最好的方式就是每次保存文件时自动格式化。比如 VSCode 已经内置了Clang-Format稍作配置即可实现,接下来介绍几种常见 IDE 如何配置Clang-Format。 VSCodeVSCode 最常用,因为内置了Clang-Format也最容易配置。 安装C/C++插件,Ctrl+Shift+X打开应用商店,搜索C/C++找到下图插件,安装后会自动安装Clang-Format程序,无需单独下载。默认安装路径为:C:\\Users\\(你的用户名)\\.vscode\\extensions\\ms-vscode.cpptools-1.7.1\\LLVM\\bin\\clang-format.exe。 打开设置页面(左下角齿轮 - 设置),搜索format,勾选Format On Save,每次保存文件时自动格式化文档。下方的设置是决定每次格式化是整个文档,还是做过修改的内容。默认是file,对整个文档进行格式化。 仍在设置页面搜索Clang,配置如下。.clang-format文件最后详解。 效果图 QtCreator 安装Beautifier插件:帮助(Help)-关于插件(About Plugins)- Beautifier勾选,重启 QtCreator。 工具(Tool)- Beautifier,配置如图。该配置,保存文档时自动格式化,并选择Clang-Format作为格式化工具。配置Clang-Format程序路径,如果开头已经apt install安装过,这里会自动补全。 Use predefined style可以选择内置的一些代码风格,如LLVM,Google等。 Use customized style使用自定义的一些代码风格。点击添加(Add)将配置文件粘贴进去即可,具体配置文件见最后。 别忘了点击OK保存。 Eclipse 安装cppstyle插件:Help - Eclipse Marketplace - 搜索cppstyle。 下载cpplint。 可以去github上下载cpplint的源码,下载完之后解压放到某个目录下。 在Window - Preferences - C/C++ - CppStyle页面把clang-format的路径添加进去,然后把cpplint的目录指向刚才下载的styleguide目录下的cpplint/cpplint.py就可以了。勾选下面的Enable cpplint,Run clang-format on file save,然后点击Apply and Close保存修改并退出。如下图所示。 此时再保存代码,将会出现如下错误,因为我们还未给当前项目编写配置文件.clang-format。将最后一章提到的配置文件放到当前项目的下即可,程序会自动搜索。 12Cannot find .clang-format or _clang-format configuration file under any level parent directories of path.Clang-format will default to Google style. 配置简介上文多次提到了.clang-format配置文件,该文件决定了代码如何格式化,现在来介绍如何使用该文件。 导出.clang-format文件如果重新编写一份配置文件,需要考虑的东西太多,clang-format内置了一些常见风格,我们可以根据已有的配置文件稍作修改,形成自己的代码风格。所以我们先导出一份内置的配置文件。 12clang-format -style=可选格式名 -dump-config > .clang-format# 可选格式最好写预设那那几个写最接近你想要的格式。比如我想要接近 Google C++ style 的。我就写-style=google 各个选项的含义这里给出了配置的含义,感兴趣也可以查看官方文档,还提供了一些有案例,描述更清晰。 一些比较明显的代码分格区别 1234567891011121314151617181920212223242526272829303132# 括号是分行,还是不分行,只有当 BreakBeforeBraces 设置为 Custom 时才有效BraceWrapping: AfterCaseLabel: true # class 定义后面 AfterClass: true # 控制语句后面 AfterControlStatement: true AfterEnum: true AfterFunction: true AfterNamespace: true AfterObjCDeclaration: true AfterStruct: true AfterUnion: true AfterExternBlock: true BeforeCatch: true BeforeElse: true # 缩进大括号,if else 语句后面的括号缩进 IndentBraces: false SplitEmptyFunction: true SplitEmptyRecord: true SplitEmptyNamespace: trueBreakBeforeBinaryOperators: NoneBreakBeforeBraces: Custom# tab 宽度TabWidth: 4# 换行缩进字符数IndentWidth: 4# 宏定义对齐AlignConsecutiveMacros: AcrossEmptyLinesAndComments 基于LLVM代码风格修改的个人使用版本: 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145---Language: Cpp# BasedOnStyle: LLVMAccessModifierOffset: -2AlignAfterOpenBracket: Align# 宏定义对齐AlignConsecutiveMacros: AcrossEmptyLinesAndCommentsAlignConsecutiveAssignments: trueAlignConsecutiveDeclarations: trueAlignConsecutiveBitFields: trueAlignEscapedNewlines: RightAlignOperands: trueAlignTrailingComments: trueAllowAllArgumentsOnNextLine: trueAllowAllConstructorInitializersOnNextLine: trueAllowAllParametersOfDeclarationOnNextLine: trueAllowShortBlocksOnASingleLine: NeverAllowShortCaseLabelsOnASingleLine: false# 是否允许短方法单行,只有一行的函数将不会分行,直接写在函数名后AllowShortFunctionsOnASingleLine: falseAllowShortLambdasOnASingleLine: AllAllowShortIfStatementsOnASingleLine: NeverAllowShortLoopsOnASingleLine: falseAlwaysBreakAfterDefinitionReturnType: NoneAlwaysBreakAfterReturnType: NoneAlwaysBreakBeforeMultilineStrings: falseAlwaysBreakTemplateDeclarations: MultiLineBinPackArguments: trueBinPackParameters: true# 括号是分行,还是不分行,只有当 BreakBeforeBraces 设置为 Custom 时才有效BraceWrapping: AfterCaseLabel: true # class 定义后面 AfterClass: true # 控制语句后面 AfterControlStatement: true AfterEnum: true AfterFunction: true AfterNamespace: true AfterObjCDeclaration: true AfterStruct: true AfterUnion: true AfterExternBlock: false BeforeCatch: true BeforeElse: true # 缩进大括号 IndentBraces: false SplitEmptyFunction: true SplitEmptyRecord: true SplitEmptyNamespace: trueBreakBeforeBinaryOperators: NoneBreakBeforeBraces: CustomBreakBeforeInheritanceComma: falseBreakInheritanceList: BeforeColonBreakBeforeTernaryOperators: trueBreakConstructorInitializersBeforeComma: falseBreakConstructorInitializers: BeforeColonBreakAfterJavaFieldAnnotations: falseBreakStringLiterals: trueColumnLimit: 100CommentPragmas: '^ IWYU pragma:'CompactNamespaces: falseConstructorInitializerAllOnOneLineOrOnePerLine: falseConstructorInitializerIndentWidth: 4ContinuationIndentWidth: 4Cpp11BracedListStyle: trueDeriveLineEnding: trueDerivePointerAlignment: falseDisableFormat: falseExperimentalAutoDetectBinPacking: falseFixNamespaceComments: trueForEachMacros: - foreach - Q_FOREACH - BOOST_FOREACHIncludeBlocks: PreserveIncludeCategories: - Regex: '^"(llvm|llvm-c|clang|clang-c)/' Priority: 2 SortPriority: 0 - Regex: '^(<|"(gtest|gmock|isl|json)/)' Priority: 3 SortPriority: 0 - Regex: '.*' Priority: 1 SortPriority: 0IncludeIsMainRegex: '(Test)?$'IncludeIsMainSourceRegex: ''IndentCaseLabels: falseIndentGotoLabels: trueIndentPPDirectives: None# 换行缩进字符数IndentWidth: 4IndentWrappedFunctionNames: falseJavaScriptQuotes: LeaveJavaScriptWrapImports: trueKeepEmptyLinesAtTheStartOfBlocks: trueMacroBlockBegin: ''MacroBlockEnd: ''MaxEmptyLinesToKeep: 1NamespaceIndentation: NoneObjCBinPackProtocolList: AutoObjCBlockIndentWidth: 0ObjCSpaceAfterProperty: falseObjCSpaceBeforeProtocolList: truePenaltyBreakAssignment: 2PenaltyBreakBeforeFirstCallParameter: 19PenaltyBreakComment: 300PenaltyBreakFirstLessLess: 120PenaltyBreakString: 1000PenaltyBreakTemplateDeclaration: 10PenaltyExcessCharacter: 1000000PenaltyReturnTypeOnItsOwnLine: 60PointerAlignment: RightReflowComments: trueSortIncludes: trueSortUsingDeclarations: trueSpaceAfterCStyleCast: falseSpaceAfterLogicalNot: falseSpaceAfterTemplateKeyword: trueSpaceBeforeAssignmentOperators: trueSpaceBeforeCpp11BracedList: falseSpaceBeforeCtorInitializerColon: trueSpaceBeforeInheritanceColon: trueSpaceBeforeParens: ControlStatementsSpaceBeforeRangeBasedForLoopColon: trueSpaceInEmptyBlock: falseSpaceInEmptyParentheses: falseSpacesBeforeTrailingComments: 1SpacesInAngles: falseSpacesInConditionalStatement: falseSpacesInContainerLiterals: trueSpacesInCStyleCastParentheses: falseSpacesInParentheses: falseSpacesInSquareBrackets: falseSpaceBeforeSquareBrackets: falseStandard: LatestStatementMacros: - Q_UNUSED - QT_REQUIRE_VERSIONTabWidth: 8UseCRLF: falseUseTab: Never... 格式化最新的commit代码clang-format还提供一个clang-format-diff.py脚本,用来格式化patch,code review提交代码前,跑一遍下面的代码。 12// 格式化最新的 commit,并直接在原文件上修改git diff -U0 HEAD^ | clang-format-diff.py -i -p1 常见问题如何看懂官方文档并编写配置文件官方文档里有各种设置的示例代码,即使不知道想要的格式化是哪个配置参数,翻一翻官方文档是示例大概率能找到。那么找到了想要的配置参数,如何在文件里配置呢? 以宏定义对齐为例。我们想要宏定义的值保持对齐的状态,如下一节图片所示。可以翻一遍官方文档,可以发现这个示例代码对应的参数可能是我们想要的,AlignConsecutiveMacros翻译为对齐连续的宏定义。那应该八九不离十了。 找到了参数如何编写配置文件呢?可以继续看这个参数下面的更多示例,每一个示例都对应一个配置可能值Possible values。 ACS_None (in configuration: None)Do not align macro definitions on consecutive lines.ACS_None为这个配置的缩写,None表示在配置文件里的值。该配置表示不对宏定义进行对齐操作,在配置文件里可以添加如下: 1AlignConsecutiveMacros: None ACS_Consecutive (in configuration: Consecutive)Align macro definitions on consecutive lines. This will result in formattings like: 1234567#define SHORT_NAME 42#define LONGER_NAME 0x007f#define EVEN_LONGER_NAME (2)#define foo(x) (x * x)/* some comment */#define bar(y, z) (y + z) ACS_Consecutive为这个配置的缩写,Consecutive表示在配置文件里的值。该配置表示对连续的宏定义进行对齐,在配置文件里可以添加如下: 1AlignConsecutiveMacros: Consecutive 宏定义对齐失效12# 宏定义对齐AlignConsecutiveMacros: AcrossEmptyLinesAndComments 使用宏定义对齐更详细的配置,可以参考官方文档。使用该配置一定要使用等宽的字体,否则配置生效但是显示不正确。比如我是用微软雅黑字体作为编码字体,因为该字体每个字符不等宽,导致格式化正确,但是显示不正确。 如果将字体换位等宽字体如常用的Consolas,就可以正常显示。","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"},{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"}]},{"title":"《代码整洁之道》读书笔记","slug":"《代码整洁之道》读书笔记","date":"2021-11-29T15:20:18.000Z","updated":"2022-10-15T02:59:01.401Z","comments":true,"path":"2021/11/29/《代码整洁之道》读书笔记/","link":"","permalink":"http://example.com/2021/11/29/%E3%80%8A%E4%BB%A3%E7%A0%81%E6%95%B4%E6%B4%81%E4%B9%8B%E9%81%93%E3%80%8B%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0/","excerpt":"","text":"代码整洁之道整洁代码整洁之道 代码是我们最终用来表达需求的那种语言,代码永存; 时时保持代码整洁,稍后等于永不(Later equals never); 整洁代码力求集中,每个函数、每个类和每个模块都全神贯注于一件事; 整洁代码简单直接,从不隐藏设计者的意图; 整洁代码应当有单元测试和验收测试。它使用有意义的命名,代码通过其字面表达含义; 消除重复代码,提高代码表达力。 有意义的命名避免误导 “一组账号”别用accountList表示,List对程序员有特殊含义,可以用 accountGroup、bunchOfAccounts、甚至是accounts; 不使用区别较小的名称,ZYXControllerForEfficientHandlingOfStrings和 ZYXControllerForEfficientStorageOfStrings难以辨别; 不使用小写 l、大写 O 作变量名,看起来像常量 1、0。 做有意义的区分 不以数字系列命名(a1、a2、a3),按照真实含义命名; Product/ProductInfo/ProductData 意思无区别,只统一用一个; 别写冗余的名字,变量名别带variable、表名别带table。 使用读得出来的名称 genymdhms(生成日期,年、月、日、时、分、秒)肯定不如generation timestamp(生成时间戳)方便交流。 使用可搜索的名称 单字母名称和数字常量很难在上下文中找出。名称长短应与其作用域大小相对应,越是频繁出现的变量名称得越容易搜索 (越长)。 命名时避免使用编码 把类型和作用域编码进名称里增加了解码负担。意味着新人除了了解代码逻辑之外,还需要学习这种编码语言; 别使用匈牙利语标记法(格式:**[Prefix]-BaseTag-Name** 其中 BaseTag 是数据类型的缩写,Name 是变量名字),纯属多余。例如,szCmdLine的前缀sz表示“以零结束的字符串”; 不必用m_前缀来表明成员变量; 接口和实现别在名称中编码。接口名IShapeFactory的前导”I”是废话。如果接口和实现必须选一个编码,宁可选实现,ShapeFactoryImp都比对接口名称编码来的好。 避免思维映射 不应当让读者在脑中把你的名称翻译为他们熟知的名称。例如,循环计数器自然有可能被命名为i或j或k,但千万别用字母l; 专业程序员了解,明确是王道,编写能方便他人理解的代码。 类名、方法名 类名应当是名词或名词短语,方法名应当是动词或动词短语。 命名不要耍宝幽默 言到意到,意到言到,不要在命名上展示幽默感。 每个概念用一个词 fetch、retrieve、get约定一个一直用即可。 尽管使用计算机科学术语 只有程序员才会读你的代码,不需要按照问题所在邻域取名称。 别用双关语 add方法一般语义是:根据两个值获得一个新的值。如果要把单个值加入到某个集合,用insert或append命名更好,这里用add就是双关语了。 添加有意义的语境 很少有名称能自我说明,需要用良好命名的类、函数、或者命名空间来放置名称,给读者提供语境,如果做不到的话,给名称添加前缀就是最后一招了。 函数越短越好 短小,20 行封顶; if/else/while语句的代码块应该只有一行,该行应该是一个函数调用语句; 函数的缩进层级不应该多于一层或两层。 一个函数只做一件事 如果函数只是做了该函数名下同一抽象层上的步骤,则函数只做了一件事; 要判断函数是否不止做了一件事,就是要看是否能再拆出一个函数; 每个函数一个抽象层级 向下规则:让代码拥有自顶向下的阅读顺序。每个函数后面都跟着位于下一抽象层级的函数,这样一来,在查看函数列表时,就能循抽象层级向下阅读了。 switch 语句 把 switch 埋在较低的抽象层级,一般可以放在抽象工厂底下,用于创建多态对象。 使用描述性的名称 函数越短小、功能越集中,就越便于取个好名字; 别害怕长名称,长而具有描述性的名称,要比短而令人费解的名称好,要比描述性的长注释好; 别害怕花时间取名字。 函数参数 参数越少越好,0 参数最好,尽量避免用三个以上参数; 参数越多,编写组合参数的测试用例就越困难; 别用标识参数,向函数传入bool值是不好的,这意味着函数不止做一件事。可以将此函数拆成两个; 如果函数需要两个、三个或者三个以上参数,就说明其中一些参数应该封装成类了; 将参数的顺序编码进函数名,减轻记忆参数顺序的负担,例如 assertExpectedEqualsActual(expected, actual)。 副作用 (函数在正常工作任务之外对外部环境所施加的影响) 检查密码并且初始化session的方法命名为checkPasswordAndInitializeSession而非 checkPassword,即使违反单一职责原则也不要有副作用; 避免使用”输出参数”,如果函数必须修改某种状态,就修改所属对象的状态吧。 设置 (写) 和查询 (读) 分离- 1234if(set("username", "unclebob")) { ... } 含义模糊不清。应该改为: 1234if (attributeExists("username")) { setAttribute("username", "unclebob");} 使用异常代替返回错误码 返回错误码会要求调用者立刻处理错误,从而引起深层次的嵌套结构; 12345678910111213141516171819202122if (deletePate(page) == E_OK) { if (xxx() == E_OK) { if (yyy() == E_OK) { log(); } else { log(); } } else { log(); }} else { log();} 所以需要用try catch异常机制; 12345678910try { deletePage(); xxx(); yyy(); zzz();} catch (Exception e) { log(e->getMessage());} try/catch代码块丑陋不堪,所以最好把try和 catch代码块的主体抽离出来,单独形成函数。 1234567try { do();} catch (Exception e) { handle();} 不要写重复代码 重复是软件中一切邪恶的根源。当算法改变时需要修改多处地方。 结构化编程 只要函数保持短小,偶尔出现的return、break、continue语句没有坏处,甚至还比单入单出原则更具有表达力。goto只有在大函数里才有道理,应该尽量避免使用。 并不需要一开始就按照这些规则写函数,没人做得到。想些什么就写什么,然后再打磨这些代码,按照这些规则组装函数。 注释 若编程语言足够有表现力,我们就不需要注释; 注释总是一种失败,因为我们无法找到不用注释就能表达自我的方法; 代码在演化,注释却不总是随之变动,会变得越来越不准确。 用代码来阐述 创建一个与注释所言同一事物的函数即可, 12// check to see if the employee is eligible for full benefits if ((employee.falgs & HOURLY_FLAG) && (employee.age > 65)) 应替换为 1if (employee.isEligibleForFullBenefits()) 好注释 法律信息,并且只要有可能就指向标准许可或者外部文档,而不是放全文; 提供基本信息,如解释某个抽象方法的返回值; 对意图的解释,反应了作者某个决定后面的意图; 阐释。把某些晦涩的参数或者返回值的意义翻译成可读的形式(更好的方法是让它们自身变得足够清晰,但是类似标准库的代码我们无法修改); 1if (b.compareTo(a) == 1) //b > a 警示。// don't run unless you have some time to kill; TODO注释; 放大 一些看似不合理之物的重要性。 坏注释 自言自语; 多余的注释。把逻辑在注释里写一遍不能比代码提供更多信息,读它不比读代码简单。一目了然的成员变量别加注释,显得很多余; 误导性注释; 遵循规矩的注释。每个函数都加注释、每个变量都加注释是愚蠢的; 日志式注释。有了代码版本控制工具,不必在文件开头维护修改时间、修改人这类日志式的注释; 能用函数或者变量表示就别用注释; 1234// does the module from the global list <mod> // depend on the subsystem we are part of?if (smodule.getDependSubsystems().contains(subSysMod.getSubSystem()) 可以改为: 123ArrayList moduleDependees = smodule.getDependSubsystems();String ourSubSystem = subSysMod.getSubSystem();if (moduleDependees.contains(ourSubSystem)) 位置标记。标记多了会被我们忽略掉; ///////////////////// Actions ////////////////////////// 右括号注释; 123456789101112try { while () { if () { ... } // if ... } // while ...} // try 如果你想标记右括号,其实应该做的是缩短函数 署名 /* add by rick */ 源代码控制工具会记住你,署名注释跟不上代码的演变; 注释掉的代码。会导致看到这段代码其他人不敢删除,使用版本控制系统,可以大胆删除需要注释的代码; 信息过多。别在注释中添加有趣的历史话题或者无关的细节; 没解释清楚的注释。注释的作用是解释未能自行解释的代码,如果注释本身还需要解释就太遗憾了; 短函数的函数头注释。为短函数选个好名字比函数头注释要好; 非公共API函数的javadoc/phpdoc注释。 格式垂直格式 短文件比长文件更易于理解。平均200行,最多不超过500行的单个文件可以构造出色的系统; 像报纸一样排版,由略及详,层层递进; 区隔: 封包声明、导入声明、每个函数之间,都用空白行分隔开,空白行下面标识着新的独立概念,表示一个思路的开始 靠近: 紧密相关的代码应该互相靠近,例如一个类里的属性之间别用空白行隔开; 123456789101112131415161718192021public class ReporterConfig { //The class name of the reporter listener private String m_className; //The properties of the reporter listener private List<Property> m_properties = new ArrayList<Property>(); public void addProperty(Property property) { m_properties.add(property); }}///////////////////////对比////////////////////////////////////public class ReporterConfig { private String m_className; private List<Property> m_properties = new ArrayList<Property>(); public void addProperty(Property property) { m_properties.add(property); }} 变量声明应尽可能靠近其使用位置:循环中的控制变量应该总是在循环语句中声明; 成员变量应该放在类的顶部声明,不要四处放置; 如果某个函数调用了另外一个,就应该把它们放在一起。我们希望底层细节最后展现出来,不用沉溺于细节,所以调用者尽可能放在被调用者之上; 执行同一基础任务的几个函数应该放在一起。 水平格式 一行代码不必死守80字符的上限,偶尔到达100字符不超过120字符即可; 区隔与靠近: 空格强调左右两边的分割。*赋值运算符两边加空格,函数名与左圆括号之间不加空格,乘法运算符在与加减法运算符组合时不用加空格(ab - c)**; 不必水平对齐。例如声明一堆成员变量时,各行不用每一个单词都对齐,代码自动格式化工具通常会把这类对齐消除掉; 1234567public class FitNesseExpediter implements ResponseSender{ private Socket socket; private InputStream input; private OutputStream output; private Request request;} 短小的if、while、函数里最好也不要违反缩进规则,不要这样:if (xx == yy) z = 1; while语句为空,最好分行写分号; 12while(1); 团队规则 团队绝对不要用各种不同的风格来编写源代码,这样会增加其复杂度。 对象和数据结构数据抽象 对象:暴露行为 (接口),隐藏数据 (私有变量) ; 数据结构:没有明显的行为 (接口),暴露数据。如DTO(Data Transfer Objects)、Entity; 数据,对象的反对称性 使用数据结构便于在不改动现在数据结构的前提下添加新函数;使用对象便于在不改动既有函数的前提下添加新类; 使用数据结构难以添加新数据结构,因为必须修改所有函数;使用对象难以添加新函数,因为必须修改所有类; 万物皆对象只是个传说,有时候我们也会在简单数据结构上做一些过程式的操作。 Law of Demeter 模块不应该了解它所操作对象的内部情形; class C的方法f只应该调用以下对象的方法: C 在方法f里创建的对象 作为参数传递给方法f的对象 C持有的对象 方法不应调用 由任何函数返回的对象 的方法。下面的代码违反了 demeter 定律: 1final String outputDir = ctxt.getOptions().getScratchDir().getAbsolutePath(); 一个简单例子是,人可以命令一条狗行走(walk),但是不应该直接指挥狗的腿行走,应该由狗去指挥控制它的腿如何行走。 错误处理 错误处理很重要,但是不能凌乱到打乱代码逻辑。 使用异常而不是返回错误码 如果使用错误码,调用者必须在函数返回时立刻处理错误,但这很容易被我们忘记; 错误码通常会导致嵌套if else。 先写 try-catch 语句 当编写可能会抛异常的代码时,先写好try-catch再往里堆逻辑。 在 catch 里尽可能的记录 在catch里尽可能的记录错误信息,记录失败的操作以及失败的类型 依调用者定义异常类 对错误分类有很多方式。可以依其来源分类:是来自组件还是其他地方?或依其类型分类:是设备错误、网络错误还是编程错误? 别返回 null 值 返回null值只要一处没检查null,应用程序就会失败; 当想返回null值的时候,可以试试抛出异常,或者返回特例模式的对象。 别传递 null 值 在方法中传递null值是一种糟糕的做法,应该尽量避免; 在方法里用if或assert过滤null值参数,但是还是会出现运行时错误,没有良好的办法对付调动者意外传入的null值,恰当的做法就是禁止传入null值。 边界将第三方代码干净利落地整合进自己的代码中 避免公共 API 返回边界接口,或者将边界接口作为参数传递给 API。将边界保留在近亲类中; 不要在生产代码中试验新东西,而是编写测试来理解第三方代码; 避免我们的代码过多地了解第三方代码中的特定信息。 学习性测试是一种精确试验,帮助我们增进对 API 的理解。 单元测试TDD(Test-driven development) 三定律 First Law: You may not write production code until you have written a failing unit test. Second Law: You may not write more of a unit test than is sufficient to fail, and not compiling is failing. Third Law: You may not write more production code than is sufficient to pass the currently failing test. 保持测试整洁 脏测试等同于没测试,测试代码越脏生产代码越难修改; 测试代码和生产代码一样重要; 整洁的测试代码最应具有的要素是:整洁性。测试代码中不要有大量重复代码的调用。 每个测试一个断言 每个测试函数有且仅有一个断言语句; 每个测试函数中只测试一个概念。 整洁的测试依赖于 FIRST 规则 fast: 测试代码应该能够快速运行,因为我们需要频繁运行它; independent: 测试应该相互独立,某个测试不应该依赖上一个测试的结果,测试可以以任何顺序进行; repeatable: 测试应可以在任何环境中通过; self-validating: 测试应该有bool值输出,不应通过查看日志来确认测试结果,不应手工对比两个文本文件确认测试结果; timely: 及时编写测试代码。单元测试应该在生产代码之前编写,否则生产代码会变得难以测试。 类类的组织以下针对 JAVA 语言,其他语言类似,变量在前,方法在后,公有在前,私有在后。 公共静态常量 私有静态变量 私有实体变量 公共函数 私有工具函数 如果测试需要调用一个函数或变量,可以设为保护类型。 类应该短小 对于函数我们计算代码行数衡量大小,对于类我们使用权责来衡量; 类的名称应当描述其权责。类的命名是判断类长度的第一个手段,如果无法为某个类命以准确的名称,这个类就太长了。类名包含模糊的词汇,如Processor、Manager、Super,这种现象就说明有不恰当的权责聚集情况; 单一权责原则(Single Responsibility Principle,SRP): 类或者模块应该有一个权责——只有一条修改的理由 (A class should have only one reason to change.); 系统应该由许多短小的类而不是少量巨大的类组成; 类应该只有少量的实体变量,如果一个类中每个实体变量都被每个方法所使用,则说明该类具有最大的内聚性。创建最大化的内聚类不太现实,但是应该以高内聚为目标,内聚性越高说明类中的方法和变量互相依赖、互相结合形成一个逻辑整体; 保持内聚性就会得到许多短小的类。如果你想把一个大函数的某一小部分拆解成单独的函数,拆解出的函数使用了大函数中的 4 个变量,不必将 4 个变量作为参数传递到新函数里,仅需将这 4 个变量提升为大函数所在类的实体变量,但是这么做却因为实体变量的增多而丧失了类的内聚性,更好多做法是让这 4 个变量拆出来,拥有自己的类。将大函数拆解成小函数往往是将类拆分为小类的时机。 为了修改而组织 类应当对扩展开放,对修改封闭 (开放闭合原则); 在理想系统中,我们通过扩展系统而非修改现有代码来添加新特性。 系统将系统的构造与使用分开 软件系统应将起始过程和之后的运行逻辑分开。 分解 main 将全部构造过程搬迁到 main或者被称之为main的模块中,涉及系统其余部分时,假设所有对象都已经正确构造; 依赖注入 (DI),控制反转 (IoC) 是分离构造与使用的强大机制。 迭代表达力 作者把代码写的越清晰,其他人理解代码就越快; 太多时候我们深入于要解决的问题中,写出能工作的代码之后,就转移到下一个问题上,没有下足功夫调整代码让后来者易于阅读。多少尊重一下我们的手艺,花一点点时间在每个函数和类上。 尽可能少的类和方法 为了保持类和函数的短小,我们可能会早出太多细小的类和方法; 类和方法数量太多,有时是由毫无意义的教条主义导致的。 以上 4 条规则优先级依次递减。重要的是测试、消除重复、表达意图并发编程为什么要并发编程 并发总能改进性能; 编写并发程序无需修改设计; 在采用Web或EJB容器的时候,理解并发问题并不重要。 防御并发代码问题的原则与技巧 遵循单一职责原则。分离并发代码与非并发代码; 限制临界区数量、限制对共享数据的访问; 避免使用共享数据,使用对象的副本; 线程尽可能地独立,不与其他线程共享数据。","categories":[{"name":"读书笔记","slug":"读书笔记","permalink":"http://example.com/categories/%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0/"}],"tags":[]},{"title":"Git-git pull 与 git pull --rebase 的区别","slug":"Git-git-pull与git-pull-rebase的区别","date":"2021-11-29T08:09:12.000Z","updated":"2022-10-15T03:14:29.209Z","comments":true,"path":"2021/11/29/Git-git-pull与git-pull-rebase的区别/","link":"","permalink":"http://example.com/2021/11/29/Git-git-pull%E4%B8%8Egit-pull-rebase%E7%9A%84%E5%8C%BA%E5%88%AB/","excerpt":"","text":"12git pull == git fetch + git mergegit pull --rebase == git fetch + git rebase 拆解来看这两个命令就是在拉取远端代码后,是合并还是进行变基操作。 假设当前有三个提交A,B,C,并且分支feature都与远程代码同步。 我们在feature上做了一些修改,并产生了E提交,远程也有用户进行了更新到了D提交。 此时我们需要git fetch获取最新的代码,然后git merge解决冲突后重新git add git commit,得到F提交。最后git push即可成功推送,得到如下的关系 而使用git rebase将会创建一个新的提交F,F的文件内容和上面F的一样,但我们将 E 提交废除,当它不存在(图中用虚线表示)。由于这种删除,避免了菱形的产生,保持提交曲线为直线。 在rebase的过程中,有时也会有冲突,这时 Git 会停止rebase并让用户去解决冲突,解决完冲突后,用git add添加修改的文件,然后不用执行git commit,直接执行git rebase --continue,这样 git 会继续 apply 余下的补丁。","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[]},{"title":"Git 同一文件被多人修改了文件名该如何处理","slug":"Git同一文件被多人修改了文件名该如何处理","date":"2021-11-28T13:55:24.000Z","updated":"2022-10-15T02:59:01.420Z","comments":true,"path":"2021/11/28/Git同一文件被多人修改了文件名该如何处理/","link":"","permalink":"http://example.com/2021/11/28/Git%E5%90%8C%E4%B8%80%E6%96%87%E4%BB%B6%E8%A2%AB%E5%A4%9A%E4%BA%BA%E4%BF%AE%E6%94%B9%E4%BA%86%E6%96%87%E4%BB%B6%E5%90%8D%E8%AF%A5%E5%A6%82%E4%BD%95%E5%A4%84%E7%90%86/","excerpt":"","text":"用户一修改了文件名,并推送到了远端。用户二也修改了文件名,在进行推送时,就会被拒绝。 拉取最新代码后发现有相同的文件,只是文件名不同。index1.htm和index2.htm两个文件内容是完全相同的。 查看当前状态,可知有其他想把文件名修改为index2.htm。此时只需要根据提示,删除index.htm。协商后决定保留哪一个文件,比如我们决定保留index1.htm。那么删除index2.htm。 最后在commit一次,即可顺利推送。","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"Git 他人同时修改了文件名和文件内容该如何处理","slug":"Git他人同时修改了文件名和文件内容该如何处理","date":"2021-11-27T15:07:37.000Z","updated":"2022-10-15T03:14:29.227Z","comments":true,"path":"2021/11/27/Git他人同时修改了文件名和文件内容该如何处理/","link":"","permalink":"http://example.com/2021/11/27/Git%E4%BB%96%E4%BA%BA%E5%90%8C%E6%97%B6%E4%BF%AE%E6%94%B9%E4%BA%86%E6%96%87%E4%BB%B6%E5%90%8D%E5%92%8C%E6%96%87%E4%BB%B6%E5%86%85%E5%AE%B9%E8%AF%A5%E5%A6%82%E4%BD%95%E5%A4%84%E7%90%86/","excerpt":"","text":"用户一修改了文件名,并提交远端。 用户二修改了文件内容,也进行了推送, 当然会被无情拒绝, 解决这个问题也十分简单,Git 可以智能的感知到只是文件名被修改,只需要一个git pull命令就可以解决。弹出弹窗可以直接保存退出,默认不变就行。","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"Git 不同人修改了相同文件的相同区域","slug":"Git不同人修改了相同文件的相同区域","date":"2021-11-27T14:13:28.000Z","updated":"2022-10-15T03:14:29.222Z","comments":true,"path":"2021/11/27/Git不同人修改了相同文件的相同区域/","link":"","permalink":"http://example.com/2021/11/27/Git%E4%B8%8D%E5%90%8C%E4%BA%BA%E4%BF%AE%E6%94%B9%E4%BA%86%E7%9B%B8%E5%90%8C%E6%96%87%E4%BB%B6%E7%9A%84%E7%9B%B8%E5%90%8C%E5%8C%BA%E5%9F%9F/","excerpt":"","text":"不同人修改了文件的相同区域,如果向远端推送,肯定会被拒绝。这时候就需要解决冲突, 首先拉取远端最新的代码,会提示有冲突的文件, 打开冲突的文件,git 会对冲突区域进行标记,<<<<<<到======区域表示远端的代码。======到>>>>>>>表示本地的代码。这时候就需要自己来判断需要哪些代码,也可以增删一些内容,修改完成后将这些标识符号删除,然后保存退出。 git status查看当前状态,提示还有未合并的路径,需要进行commit操作。 及时git push当前代码。","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"Linux 文件删除仍然在 Trash 目录下占用空间,该如何删除 Trash 下的文件","slug":"Linux文件删除仍然在Trash目录下占用空间,该如何删除Trash下的文件","date":"2021-11-25T02:31:27.000Z","updated":"2022-10-15T03:14:29.326Z","comments":true,"path":"2021/11/25/Linux文件删除仍然在Trash目录下占用空间,该如何删除Trash下的文件/","link":"","permalink":"http://example.com/2021/11/25/Linux%E6%96%87%E4%BB%B6%E5%88%A0%E9%99%A4%E4%BB%8D%E7%84%B6%E5%9C%A8Trash%E7%9B%AE%E5%BD%95%E4%B8%8B%E5%8D%A0%E7%94%A8%E7%A9%BA%E9%97%B4%EF%BC%8C%E8%AF%A5%E5%A6%82%E4%BD%95%E5%88%A0%E9%99%A4Trash%E4%B8%8B%E7%9A%84%E6%96%87%E4%BB%B6/","excerpt":"","text":"保留现场探究原因查阅了一个网上的答案,大意就是,你删除了属于你的文件夹,但其中包含属于另一个用户的文件时,文件可能会卡住,就会在 Trash 目录里不会被彻底删除。 解决方法1sudo rm -rv /home/<your_username>/.local/share/Trash/expunged/* PS:发现一个好用的磁盘分析工具,Linux 内置应用Disk Usage Analyzer。按Win键后搜索框搜索即可打开。 图形化的方式快速找到占用空间较大的目录,文件。可以右击直接删除。","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"}]},{"title":"Git 如何合并连续的多个 commit","slug":"Git如何合并连续的多个commit","date":"2021-11-24T15:18:49.000Z","updated":"2022-10-15T03:14:29.235Z","comments":true,"path":"2021/11/24/Git如何合并连续的多个commit/","link":"","permalink":"http://example.com/2021/11/24/Git%E5%A6%82%E4%BD%95%E5%90%88%E5%B9%B6%E8%BF%9E%E7%BB%AD%E7%9A%84%E5%A4%9A%E4%B8%AAcommit/","excerpt":"","text":"确定需要合并的commit 变基操作,以需要合并的commit下方的结点为基准。 交互式变基,squash表示合并到上方commit 编写合并commit的message,保留原先的不变","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"Git 不同人修改了同一文件的不同区域该如何处理","slug":"Git不同人修改了同一文件的不同区域该如何处理","date":"2021-11-23T14:49:46.000Z","updated":"2022-10-15T03:14:29.220Z","comments":true,"path":"2021/11/23/Git不同人修改了同一文件的不同区域该如何处理/","link":"","permalink":"http://example.com/2021/11/23/Git%E4%B8%8D%E5%90%8C%E4%BA%BA%E4%BF%AE%E6%94%B9%E4%BA%86%E5%90%8C%E4%B8%80%E6%96%87%E4%BB%B6%E7%9A%84%E4%B8%8D%E5%90%8C%E5%8C%BA%E5%9F%9F%E8%AF%A5%E5%A6%82%E4%BD%95%E5%A4%84%E7%90%86/","excerpt":"","text":"git fetch git merge或者 git pull","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"Git 修改老旧 commit 的 message","slug":"Git修改老旧commit的message","date":"2021-11-22T14:50:25.000Z","updated":"2022-10-15T03:14:29.231Z","comments":true,"path":"2021/11/22/Git修改老旧commit的message/","link":"","permalink":"http://example.com/2021/11/22/Git%E4%BF%AE%E6%94%B9%E8%80%81%E6%97%A7commit%E7%9A%84message/","excerpt":"","text":"以下操作仅限于维护自己的分支,不建议对团队共享的代码进行修改。 以最近三次提交为例,假设想要修改第二个提交的message。可以使用git rebase命令 1git rebase -i 27d2f -i交互式变基 27d2f需要改变message的提交的父节点 弹出页面可以使用提供的命令进行操作,比如pick意思就是挑选需要的commit。本次任务需要修改message,从下方帮助文档里可以找到reword命令,可以保留commit,只修改message。 保存退出后,会弹出另外一个界面。 在这里就可以真正修改需要更新的message。保存退出即可。","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"Git 修改最新 commit 的 message","slug":"Git修改最新commit的message","date":"2021-11-22T14:44:45.000Z","updated":"2022-10-15T03:14:29.228Z","comments":true,"path":"2021/11/22/Git修改最新commit的message/","link":"","permalink":"http://example.com/2021/11/22/Git%E4%BF%AE%E6%94%B9%E6%9C%80%E6%96%B0commit%E7%9A%84message/","excerpt":"","text":"commit提交后觉得描述信息不准确,想重新修改message内容,该如何操作? 1git commit --amend 弹出页面就和git commit操作时的一样,将其改为新内容即可。","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"解决 C 语言 undefined reference to pthread_join","slug":"解决C语言undefined-reference-to-pthread-join","date":"2021-11-17T11:30:20.000Z","updated":"2022-10-15T03:14:29.796Z","comments":true,"path":"2021/11/17/解决C语言undefined-reference-to-pthread-join/","link":"","permalink":"http://example.com/2021/11/17/%E8%A7%A3%E5%86%B3C%E8%AF%AD%E8%A8%80undefined-reference-to-pthread-join/","excerpt":"","text":"保留现场undefined reference to sleep同样的问题。在使用 C 语言线程函数时,需要包含#include <pthread>,编译时就会报这种错误。 探究原因pthread 库不是 Linux 系统默认的库,连接时需要使用静态库 libpthread.a,所以在使用pthread_create()创建线程,以及调用pthread_atfork()函数建立fork处理程序时,需要链接该库。 解决方法1gcc thread.c -o thread -lpthread 如果是Makefile配置的编译条件,在Makefile文件中加上如下: 1CFLAGS += -lpthread","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"解决 QT 点击按钮无响应","slug":"解决QT点击按钮无响应","date":"2021-11-16T09:42:47.000Z","updated":"2022-10-15T03:14:29.830Z","comments":true,"path":"2021/11/16/解决QT点击按钮无响应/","link":"","permalink":"http://example.com/2021/11/16/%E8%A7%A3%E5%86%B3QT%E7%82%B9%E5%87%BB%E6%8C%89%E9%92%AE%E6%97%A0%E5%93%8D%E5%BA%94/","excerpt":"","text":"保留现场在运行中的界面上点击按钮没有效果,像是按钮上层有其他遮盖层。 探究原因widget的父控件上又添加了其他Widget,覆盖在了按钮上,因此无法点击。通过new得到的控件,默认显示在比它new的早的控件上面。 解决方法123// 将有按钮的那一层widget置于上层widget->raise();","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"解决 QT 在构造函数中写的控件不显示的问题","slug":"解决QT在构造函数中写的控件不显示的问题","date":"2021-11-16T08:15:26.000Z","updated":"2022-10-15T03:14:29.829Z","comments":true,"path":"2021/11/16/解决QT在构造函数中写的控件不显示的问题/","link":"","permalink":"http://example.com/2021/11/16/%E8%A7%A3%E5%86%B3QT%E5%9C%A8%E6%9E%84%E9%80%A0%E5%87%BD%E6%95%B0%E4%B8%AD%E5%86%99%E7%9A%84%E6%8E%A7%E4%BB%B6%E4%B8%8D%E6%98%BE%E7%A4%BA%E7%9A%84%E9%97%AE%E9%A2%98/","excerpt":"","text":"保留现场在新窗口中的构造函数中添加控件运行后却没有显示 探究原因 新建的工程师 MainWindow 子类工程,没有设置父窗口。 没有将控件的父窗口设置成自己定义的 widget。 12345678910#include<QMainWindow> QMainWindow::QMainWindow(QMainWindow*parent) : QMainWindow(parent), ui(new Ui::QMainWindow){ ui->setupUi(this); QPushButton* button_1 = new QPushButton("add"); QPushButton* button_1 = new QPushButton("del");} 解决方法方法 1:给按钮控件设置父窗口:QWidget,并且把按钮添加到父窗口中。 123456789101112131415161718#include<QMainWindow>#include<QPushButton>#include<QHBoxLayout> QMainWindow::QMainWindow(QMainWindow*parent) : QMainWindow(parent), ui(new Ui::QMainWindow){ ui->setupUi(this); QWidget* w = new QWidget(); this->setCentralWidget(w); QHBoxLayout* hLayout = new QHBoxLayout(); QPushButton* button_1 = new QPushButton("add"); QPushButton* button_1 = new QPushButton("del"); hLayout->addWidget(button_1); hLayout->addWidget(button_2); w->setLayout(hLayout);} 方法 2:手动指定父窗口 123456789101112131415161718#include<QMainWindow>#include<QPushButton>#include<QHBoxLayout> QMainWindow::QMainWindow(QMainWindow*parent) : QMainWindow(parent), ui(new Ui::QMainWindow){ ui->setupUi(this); QPushButton* button_1 = new QPushButton("add"); QPushButton* button_1 = new QPushButton("del"); button_1->setParent(this); button_2->setParent(this); button_2->move(300,100); }","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"QWidget 中 update 不执行 paintEvent","slug":"解决QWidget中update不执行paintEvent","date":"2021-11-15T10:04:50.000Z","updated":"2022-10-15T03:14:29.832Z","comments":true,"path":"2021/11/15/解决QWidget中update不执行paintEvent/","link":"","permalink":"http://example.com/2021/11/15/%E8%A7%A3%E5%86%B3QWidget%E4%B8%ADupdate%E4%B8%8D%E6%89%A7%E8%A1%8CpaintEvent/","excerpt":"","text":"保留现场手动执行update()或者repaint()都不能执行paintEvent函数。 探究原因如果是代码new出来的控件,检查是否正确显示,比如有没有加入到layout中。或者有没有设置父窗口(可能被其他空间遮挡)。 检查控件width或者height大小是否不为 0。如果为 0,也不会出出发paintEvent。 解决方法参考 QT 在构造函数中写的控件不显示","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"解决 C++中 vector 声明错误 expected parameter declarator","slug":"解决C-中vector声明错误expected-parameter-declarator","date":"2021-11-13T11:00:29.000Z","updated":"2022-10-15T03:14:29.794Z","comments":true,"path":"2021/11/13/解决C-中vector声明错误expected-parameter-declarator/","link":"","permalink":"http://example.com/2021/11/13/%E8%A7%A3%E5%86%B3C-%E4%B8%ADvector%E5%A3%B0%E6%98%8E%E9%94%99%E8%AF%AFexpected-parameter-declarator/","excerpt":"","text":"保留现场12QVector<uint32_t> buttonPins(3); 声明了一个长度为 3 的vector数组,编译是会报这个错误。 探究原因编译器可能无法区分这是一个成员函数声明还是一个成员变量声明,也就是产生歧义。 解决方法方法 1: 12QVector<uint32_t> buttonPins = QVector<uint32_t>(3);//明确这是一个成员变量 方法 2:默认构造函数里面进行成员变量的初始化 12MainWindow::MainWindow(QWidget *parent) : QMainWindow(parent), ui(new Ui::MainWindow),buttonPins(3){} 方法 3:列表初始化 1QVector<uint32_t> buttonPins{0, 0, 0};","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"C++","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"解决 expected identifier before‘(’token","slug":"解决expected-identifier-before-‘-’-token","date":"2021-11-12T11:34:54.000Z","updated":"2022-10-15T03:14:29.801Z","comments":true,"path":"2021/11/12/解决expected-identifier-before-‘-’-token/","link":"","permalink":"http://example.com/2021/11/12/%E8%A7%A3%E5%86%B3expected-identifier-before-%E2%80%98-%E2%80%99-token/","excerpt":"","text":"保留现场比如在一个枚举类型中,会告诉你某行有这种错误。又或者,在一个宏定义语句中出现这种错误。 探究原因一般来说,出现这种情况,是语句中有些定义的名字发生了冲突。 解决方法定位错误位置,搜索是否有同名的函数,变量等等。改个名字。","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"QEMU 源码分析-外设模拟(以 GPIO 为例)","slug":"QEMU源码分析-外设模拟(以GPIO为例)","date":"2021-11-11T02:11:32.000Z","updated":"2022-10-15T03:14:29.437Z","comments":true,"path":"2021/11/11/QEMU源码分析-外设模拟(以GPIO为例)/","link":"","permalink":"http://example.com/2021/11/11/QEMU%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90-%E5%A4%96%E8%AE%BE%E6%A8%A1%E6%8B%9F%EF%BC%88%E4%BB%A5GPIO%E4%B8%BA%E4%BE%8B%EF%BC%89/","excerpt":"","text":"QEMU 模拟外设的原理QEMU 主要是实现了 CPU 核的模拟,可以读写某个地址。QEMU 的模拟外设的原理很简单:硬件即内存。要在 QEMU 上模拟某个外设,思路就是: CPU 读某个地址时,QEMU 模拟外设的行为,把数据返回给 CPU CPU 写某个地址时,QEMU 获得数据,用来模拟外设的行为。即:要模拟外设备,我们只需要针对外设的地址提供对应的读写函数即可。 以 GPIO 为例: QEMU 为GPIO内存地址提供读写回调函数, 123static void sifive_gpio_write(void *opaque, hwaddr offset, uint64_t value, unsigned int size)static uint64_t sifive_gpio_read(void *opaque, hwaddr offset, unsigned int size) 给外设地址提供读写函数怎么描述某段地址:基地址、大小?如何给这段地址提供读写函数呢?这段地址设置好后,如何添加进system_memory去?有 2 种方法。 法 1:memory_region_init_io/memory_region_add_subregion以SIFIVE_UART为例, 123memory_region_init_io(&s->mmio, NULL, &uart_ops, s, TYPE_SIFIVE_UART, 0x2000);memory_region_add_subregion(address_space, base, &s->mmio); memory_region_init_io函数初始化iomem,读写函数,大小。memory_region_add_subregion函数s->iomem指定了基地址,并添加进system_memory中。以后,客户机上的程序读写这块地址时,就会导致对应的读写函数被调用。 法 2:memory_region_init_io/sysbus_init_mmio/sysbus_mmio_map以SIFIVE_GPIO为例, 123memory_region_init_io(&s->mmio, OBJECT(dev), &gpio_ops, s, TYPE_SIFIVE_GPIO, SIFIVE_GPIO_SIZE);sysbus_init_mmio(SYS_BUS_DEVICE(dev), &s->mmio); memory_region_init_io函数初始化iomem,读写函数,大小。sysbus_init_mmio将mmin传给设备; 1sysbus_mmio_map(SYS_BUS_DEVICE(&s->gpio), 0, memmap[SIFIVE_E_DEV_GPIO0].base); sysbus_mmio_map从设备中吧mmio添加进system_memory并指定基地址。","categories":[{"name":"QEMU 源码分析","slug":"QEMU-源码分析","permalink":"http://example.com/categories/QEMU-%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/"}],"tags":[{"name":"QEMU","slug":"QEMU","permalink":"http://example.com/tags/QEMU/"},{"name":"GPIO","slug":"GPIO","permalink":"http://example.com/tags/GPIO/"}]},{"title":"QEMU 源码分析 - 虚拟外设创建","slug":"QEMU源码分析-虚拟外设创建","date":"2021-11-09T09:39:38.000Z","updated":"2022-11-20T07:07:38.480Z","comments":true,"path":"2021/11/09/QEMU源码分析-虚拟外设创建/","link":"","permalink":"http://example.com/2021/11/09/QEMU%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90-%E8%99%9A%E6%8B%9F%E5%A4%96%E8%AE%BE%E5%88%9B%E5%BB%BA/","excerpt":"","text":"QOM 简介QOM(QEMU Object Model) 是 QEMU 的一个模块,用于描述虚拟机的结构,包括虚拟机的 CPU、内存、硬盘、网络、输入输出设备等。QEMU 为了方便整个系统的构建,实现了自己的一套的面向对象机制,也就是 QOM(QEMU Object Model)。它能够方便的表示各个设备(Device)与总线(Bus)之间的关系。 这个模型主要包含四个结构体: Object: 是所有对象的 基类 Base Object ObjectClass: 是所有类对象的基类 TypeInfo:是用户用来定义一个 Type 的工具型的数据结构 TypeImpl:TypeInfo 抽象数据结构,TypeInfo 的属性与 TypeImpl 的属性对应 在 QEMU 里要初始化一个对象需要完成四步: 将 TypeInfo 注册 TypeImpl 实例化 Class(ObjectClass) 实例化 Object 添加 Property 如何描述硬件一个板子上有很多硬件:芯片,LED、按键、LCD、触摸屏、网卡等等。芯片里面也有很多部件,比如 CPU、GPIO、SD 控制器、中断控制器等等。 这些硬件,或是部件,各有不同。怎么描述它们? 每一个都使用一个 TypeInfo 结构体来描述,TypeInfo 是用户用来定义一个 Type 的工具型的数据结构。它包含了很多成员变量,这些成员合在一起描述了一个设备类型。 123456789101112131415// include/qom/object.hstruct TypeInfo{ const char *name; const char *parent; size_t instance_size; size_t instance_align; void (*instance_init)(Object *obj); void (*instance_post_init)(Object *obj); void (*instance_finalize)(Object *obj); bool abstract; size_t class_size; void (*class_init)(ObjectClass *klass, void *data); void (*class_base_init)(ObjectClass *klass, void *data); void *class_data; InterfaceInfo *interfaces;}; 这个结构体我们在刚刚也提到,他在图里是独立的,在注册的时候会将它的信息都传给 Typeimpl 结构体。 我们以 Timer 为例,我们要添加一个 Timer 外设,首先就要定义一个 Typeinfo 结构体。他在代码中像这样。我们只看 name,这里用一个宏赋值,这个宏是个我们定义的字符串,它唯一标识了这个硬件。这些结构体在运行时会被注册进程序里,保存在一个链表中备用,为什么是备用,因为不是每一个硬件都会被用到。 12345678// hw/timer/dw_timer.cstatic const TypeInfo dw_timer_info = { .name = TYPE_DW_TIMER, .parent = TYPE_SYS_BUS_DEVICE, .instance_size = sizeof(DWTimerState), .instance_init = dw_timer_init, .class_init = dw_timer_class_init,}; 这些结构体在运行时会被注册进程序里,保存在一个链表中备用,为什么是备用,因为不是每一个硬件都会被用到。 如何注册硬件什么是注册,说白了就是将一些可能需要的信息添加到系统中,在系统运行时能够随时调用到。就拿 Timer 来说,现在将一些信息添加到了列表,系统运行起来时我可以随时从链表中取出 Timer 这个设备的信息,用来实例化一个 Timer,但是我没有注册 Timer,也就是没有将其加入到链表,那我后期就无法找到它。 怎么注册这些TypeInfo结构体呢?在实现的源码中有这个函数 dw_timer_register_types(),他是用来注册 Timer 这个设备的。 我们追根溯源,调用过程如下, 分配一个 TypeImpl 结构体,使用 Typeinfo 来设置它 把 TypeImpl 加入链表:type_table 在 QEMU 里面,有一个全局的哈希表 type_table,用来存放所有定义的类。在 type_new 里面,我们先从全局表里面根据名字 type_table_lookup 查找找这个类。 如果找到,说明这个类曾经被注册过,就报错; 如果没有找到,说明这是一个新的类,则将 Typeinfo 里面信息填到 TypeImpl 里面。type_table_add 会将这个类注册到全局的表里面。 以上的过程可以用上图来表示。Typeinfo 通过 type_new() 生成一个对应的 TypeImpl 类型,并以 name 为关键字添加到名为 type_table 的一个 hash table 中。 什么时候注册这些设备呢?不需要我们去调用注册函数,以 Timer 为例,在 hw/timer/dw_timer.c 中有如下代码,一般在最后一行: 1type_init(dw_timer_register_types) F12找到这个宏定义,我们追根溯源,调用过程如下 123456789101112131415161718192021222324252627type_init() -> module_init() -> register_module_init()type_init(dw_timer_register_types)#define type_init(function) module_init(function, MODULE_INIT_QOM)#define module_init(function, type) \\static void __attribute__((constructor)) do_qemu_init_ ## function(void) \\{ \\ register_module_init(function, type); \\}void register_module_init(void (*fn)(void), module_init_type type){ ModuleEntry *e; //构造 ModuleEntry ModuleTypeList *l; //构造链表 e = g_malloc0(sizeof(*e)); e->init = fn; //设置初始化函数,fn 即 sifive_gpio_register_types e->type = type; l = find_type(type); QTAILQ_INSERT_TAIL(l, e, node);//将 ModuleEntry 插入链表尾} type_init是个宏定义,调用了__attribute__((constructor))函数,我们知道这个 C 语言中位数不多的在main函数执行前,执行的函数。函数中调用了register_module_init注册函数,说明在main函数执行前,已经注册好硬件了。该函数将一个新的ModuleEntry加到链表里。 注意,注册的只是个函数,并不是注册了设备。也就是已上过程,只是把一个 ModuleEntry 放到了一个链表里,这个 ModuleEntry 带了两个信息,一个是函数,一个是类型。这个函数就是我们真正的注册注册函数。 已上过程大概是如下所示: 那什么时候还真正注册设备呢,我们就得回到主函数,它有以下调用流程,在 module_call_init 中,我们会找到 MODULE_INIT_QOM 这种类型对应的 ModuleTypeList找出列表中所有的 ModuleEntry,然后调用每个 ModuleEntry 的 init 函数。 12// softmmu/runstate.cmodule_call_init(MODULE_INIT_QOM); 1234567891011// utils/module.csoftmmu/runstate.cvoid module_call_init(module_init_type type){ ModuleTypeList *l; ModuleEntry *e; // 找到 MODULE_INIT_QOM 这种类型对应的 ModuleTypeList l = find_type(type); QTAILQ_FOREACH(e, l, node) { e->init(); }} 初始化设备到这里我们需要注意,我们在注册设备的时候虽然将设备从 Typeinfo 变成了 TypeImpl,把 Typeinfo 里的信息都复制到了 TypeImpl,但是 class_init 还没有被调用,也即这个类现在还处于纸面的状态。 什么时候才真正初始化这个类呢,这得等在用到它的时候。我们在一块板子上才会用到一个设备。我们使用的是 Sifive-e 这个板子,准确来说我们用的不是这个板子,我们只是在原先的代码上做了修改。 为了方便描述,就当是用的 sifive-e 这个板子。在实现的源码里,有 object_initialize_child函数,跟踪一下调用流程可以看到最后在 type_initialize 函数中初始化了类。同时我们也看到在 object_init_with_type 函数中实例化了类。这个稍后再讲。 123456789// hw/riscv/sifive_e.c static void sifive_e_soc_init(Object *obj){ MachineState *ms = MACHINE(qdev_get_machine()); SiFiveESoCState *s = RISCV_E_SOC(obj); . . . object_initialize_child(obj, "timer", &s->timer, TYPE_DW_TIMER);} 123456789101112131415161718object_initialize_child(obj, name, &s->timer, TYPE_DW_TIMER); object_initialize_child_internal() object_initialize_child_with_props() object_initialize_child_with_propsv() object_initialize() object_initialize_with_type() type_initialize() { if (ti->class_init) { ti->class_init(ti->class, ti->class_data); } } object_init_with_type() { if (ti->instance_init) { ti->instance_init(obj); } } 在调用 class_init 函数时,其实就是调用的设备模块下的 dw_timer_class_init,这个函数中又是一些配置,尤其是 realize 函数的配置。还有一些属性的配置,如 Timer 的频率。 到这里,我们才有有了一个真正意义上的设备类。 1234567891011hw/timer/dw_timer.c static void dw_timer_class_init(ObjectClass *klass, void *data){ // 这里又是一些配置,尤其是回调函数的配置 DeviceClass *dc = DEVICE_CLASS(klass); dc->reset = dw_timer_reset; // 设置 Timer 基本属性如频率等 device_class_set_props(dc, dw_timer_properties); dc->vmsd = &vmstate_dw_timer; dc->realize = dw_timer_realize;} 实例化设备说白了初始化过程就是在配置各种结构体成员的过程,比如刚刚的初始化过程就是在配置 DeviceClass 这个类的各个成员。实际上我们还没有真正实例化 Timer,我们还不能使用它。 我们只有在实例化后才能使用它,也就是之前提到的 instance_init()。但是在 QEMU 中要实例化一个设备,不仅仅需要调用 instance_init,还需要调用刚刚初始化时设置的 realize 函数。 12345678910111213141516static const TypeInfo dw_timer_info = { .name = TYPE_DW_TIMER, .parent = TYPE_SYS_BUS_DEVICE, .instance_size = sizeof(DWTimerState), .instance_init = dw_timer_init, .class_init = dw_timer_class_init,};// hw/timer/dw_timer.cstatic void dw_timer_init(Object *obj){ DWTimerState *s = DWTIMER(obj); // 为这段内存注册回调函数 memory_region_init_io(&s->iomem, obj, &dw_timer_ops, s, "dw_timer", 0x2000); sysbus_init_mmio(SYS_BUS_DEVICE(obj), &s->iomem);} 这两个函数的功能很像,具体细节差异我也还没弄明白,但是需要注意的是 instance_init 一定要在 realize 之前完成,并且没有错误。否则将无法完成实例化。 123456789// hw/timer/dw_timer.cstatic void dw_timer_realize(DeviceState *dev, Error **errp){ DWTimerState *s = DWTIMER(dev); sysbus_init_irq(SYS_BUS_DEVICE(dev), &s->irq); for (int i = 0; i < n; i++) { s->timer[i] = timer_new_ns(QEMU_CLOCK_VIRTUAL, dw_timer_interrupt, s); }} instance_init 这个函数主要完成的工作就是为一段内存绑定了读写函数,为什么要这么做,我们再往下看。 如何操作设备设备创建完成了,那 QEMU 是如何模拟设备的行为的?这也是 QEMU 驱动开发最重要的一步,因为以上的部分是实现设备所必须的,我们只需要参考其他已经实现的模块,修改成我们的信息即可。 但是每个 IP 的寄存器不同,他们的功能也就不同,这是我们真正需要实现的内容。我们知道写驱动其实就是操作各个 IP 的寄存器,以实现想要的功能。对应到 QEMU 中,就成了在操作各个寄存器时,我们要在 QEMU 中将驱动寄存器的功能先模拟出来,再返回给驱动程序。 以 Timer 为例我想要获取 TimerNLoadCount 的值,真实硬件有这个寄存器保存了值,但是 QEMU 上我们就得维护一个变量去保存这个值。在需要的时候能读取到。比如代码里比较重要的参数是 offset,这个参数是基于外设基地址的偏移,其实就是寄存器的偏移量。比如我们查看 Timer 的手册,TimerNLoadCount 偏移量为 0,所以当我们在驱动中读取地址为 0x2000000 时,代码就会走到这里,因为我们维护了一个 timer_n_load_count 变量,所以我直接将这个变量当前值返回即可,这就是这个寄存器的值。我们要写这个寄存器也同理,我们需要更新 timer_n_load_count 这个变量。 1234567891011121314151617181920212223242526272829303132333435// hw/timer/dw_timer.cstatic uint64_t dw_timer_read(void *opaque, hwaddr offset, unsigned size){ DWTimerState *s = opaque; int index = 0; switch (offset) { case TimerNLoadCount: case 1*0x14: case 2*0x14: index = offset / 0x14; return s->timer_n_load_count[index];...}static void dw_timer_write(void *opaque, hwaddr offset, uint64_t val64, unsigned size){ DWTimerState *s = opaque; uint32_t value = val64; int index = 0; int change = 0; switch (offset) { case TimerNLoadCount: case 1*0x14: case 2*0x14: index = (offset) / 0x14; s->timer_n_load_count[index] = value; set_alarm_time(s,index); return;...} 读写函数写好了,需要给谁调用呢。我们刚刚提到了,这是个回调函数,我们需要给一段内存注册这个回调函数。如代码所示。我们给 Timer iomem 绑定了读写函数。具体哪一段地址还没定,但是我们定了 0x2000 这么长一段。我觉得这里应该是最高位的一个寄存器偏移量。因为再高就没啥用了,或者就是 SoC 里定的寄存器空间大小 0x1000。这里应该是为了图省事写的一个值。 12345678910111213141516// hw/timer/dw_timer.cstatic const MemoryRegionOps dw_timer_ops = { .read = dw_timer_read, .write = dw_timer_write, .endianness = DEVICE_NATIVE_ENDIAN,};static void dw_timer_init(Object *obj){ DWTimerState *s = DWTIMER(obj); // 为这段内存注册回调函数 memory_region_init_io(&s->iomem, obj, &dw_timer_ops, s, "dw_timer", 0x2000); sysbus_init_mmio(SYS_BUS_DEVICE(obj), &s->iomem);} 下面在hw/riscv/sifive_e.c里会映射寄存器空间到 QEMU 的内存空间。 12// hw/riscv/sifive_e.csysbus_mmio_map(SYS_BUS_DEVICE(&s->timer), 0, memmap[SIFIVE_E_DEV_TIMER].base); 参考 QEMU 中基于 QOM 的 VFIO 类的定义 - EwanHai - 博客园","categories":[{"name":"QEMU 源码分析","slug":"QEMU-源码分析","permalink":"http://example.com/categories/QEMU-%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/"}],"tags":[{"name":"QEMU","slug":"QEMU","permalink":"http://example.com/tags/QEMU/"}]},{"title":"解决一台电脑配置两个 GIT 账户","slug":"解决一台电脑配置两个GIT账户","date":"2021-10-30T03:14:27.000Z","updated":"2022-10-15T03:14:29.856Z","comments":true,"path":"2021/10/30/解决一台电脑配置两个GIT账户/","link":"","permalink":"http://example.com/2021/10/30/%E8%A7%A3%E5%86%B3%E4%B8%80%E5%8F%B0%E7%94%B5%E8%84%91%E9%85%8D%E7%BD%AE%E4%B8%A4%E4%B8%AAGIT%E8%B4%A6%E6%88%B7/","excerpt":"","text":"公司的也在用 git,但是账号和地址肯定都不同,需要配置两个不同的提交环境。 生成两个 Key生成第一个 Key如果电脑上已经在用 Git 了就无需重新生成 key,用当前的就可以。key 保存在~/.ssh文件夹内。 如果第一次使用,就使用以下命令重新生成: 1234➜ .ssh ssh-keygen -t rsa -C home_pcGenerating public/private rsa key pair.Enter file in which to save the key (/home/dominic/.ssh/id_rsa): id_rsa_pc home_pc就是个备注名,假设我们这个 key 是平时捣腾 GitHub 玩,用来和 GitHub 同步用的,id_rsa_pc是生成的文件名,打开id_rsa_pc.pub可以看到生成的 key 最后就是备注名(如下)。 1ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABR/Fyj7Pz+e+/////////////////ZbdPGtHB86fLQYh/uR+TKcCERedrDKzGPdVt8= home_pc 配置 GitHub SSH路径为: 1Github-头像-settings-SSH and GPG keys-New SSH key 测试连通1ssh -T git@github.com 生成第二 Key这个 key 就打算用来和公司代码同步用,所以备注名换成了work_ubuntu,文件名也换成了id_rsa_work。 1234➜ .ssh ssh-keygen -t rsa -C work_ubuntuGenerating public/private rsa key pair.Enter file in which to save the key (/home/dominic/.ssh/id_rsa): id_rsa_work 配置公司 SSH和 GitHub 类似,根据自己公司使用的平台设置。 配置本地账户因为本地的代码仓库可能是从 GitHub 下载的,也有从公司仓库下载的。那么提交代码时就需要为仓库配置指定的用户名和邮箱。以前只有一个 GitHub,所以配置时使用的是-global参数,任何一个仓库都是配置的相同的用户名与邮箱,而现在需要区分。 取消全局配置12345 # 取消全局 用户名/邮箱 配置git config --global --unset user.namegit config --global --unset user.email 单独配置代码仓进入项目目录,有.git目录的那一级。 123# 单独设置每个repo 用户名/邮箱git config user.email “xxxx@xx.com”git config user.name “xxxx”","categories":[],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"C 语言复杂声明","slug":"C语言复杂声明","date":"2021-10-22T03:02:58.000Z","updated":"2022-10-15T03:14:29.167Z","comments":true,"path":"2021/10/22/C语言复杂声明/","link":"","permalink":"http://example.com/2021/10/22/C%E8%AF%AD%E8%A8%80%E5%A4%8D%E6%9D%82%E5%A3%B0%E6%98%8E/","excerpt":"","text":"C 语言常常因为声明的语法问题而受到人们的批评,特别是涉及到函数指针的语法。C 语言的语法力图使声明和使用相一致。对于简单的情况,C 语言的做法是很有效的,但是,如果情况比较复杂,则容易让人混淆,原因在于,C 语言的声明不能从左至右阅读,而且使用了太多的圆括号。在 C 中,声明的形式为(dcl 是 declaration 的简写): 12345dcl: optional *'s direct-dcl(含有可选"*"的direct-dcl)direct-dcl name (dcl) direct-dcl() direct-dcl[optional size] 简而言之,声明符dc1(可以理解成间接声明) 就是前面可能带有多个*的direcr-dclo。direct-dcl可以是name、由一对圆括号括起来的dcl、后面跟有一对圆括号的direct-dcl、后面跟有用方括号括起来的表示可选长度的direc-dcl。 根据该规则进行逆向解析,就可以得到正确的声明。简化一下:TypeName Declarator;其中,Declarator就是声明中的那个name。当你遇到任何你不能理解的声明时,这个法则就是救命稻草。最简单的例子: 1int aInt; 这里,int是TypeName,aInt是Declarator。 再说明一下结合紧密度。在声或定义变量时,可以使用一些修饰比如*,[],()等。()(非函数声明中的())具有最高的紧密度,其次才是函数和数组的()和[]。 没有*的声明称为直接声明(direct-dcl),而有*称为声明(dcl)。直接声明要比声明结合的紧。分解声明时,先读出结合紧的。在这里,我把direct-dcl称为更紧的结合,它比dcl结合得紧。 最后,需要你用英语来读出这个声明。对于[],应该读成array of。 对于复杂的定义,可以将其分解。比如T (*p)()可以分解成T D1(),D1读作:*function returning T。其中D1是*p。那么该声明应该读成:p is a poniter to*。二者合在一起,就变成了 *p is a pointer to function returning T*,即:p是指向返回T类对象的函数的指针。 再看一个稍微复杂的示例: 1T (*pfa[])(); 根据dcl和direct-dcl,可以分解成T1 D1(因为结合紧密度),T1也就是T (),那么应该读作:*D1 is function returning T*。 D1又可以写成T2 D2,其中T2是T1 [],可以分解成T1 D2[],读作:*array of D2 function returning T*。 D2是指针,读作:*pointers to。那么整个 T (*pfa[])() 应该读作:pfa is an array of pointers to function returning T*,即:pfa是个存放指向返回 T 类对象函数的指针的数组。 换种方式看,在这个例子中,pfa是名字,T(*[])()是类型。将(*pfa[])视为一体(direct-dcl),称为D1,那么可以写成T D1(),*function returning object of T*。在D1中,将*pfa视为一体(dcl),称为D2,那么*pfa[]应该是D2[](direct-dcl),array of D2。合起来就是 *array of D2 function returning object of T*。D2是*pfa(dcl),替换到前面这句话,结果就是 *array of pointers to function returning object of T*。 有了这些说明,可以试着做一下下面的题,看看自己是否真的理解了: 12345678910111213141516171819202122char **argv // argv: pointer to pointer to char // 指向 char 型指针的指针int (*daytab)[13] // daytab: pointer to array[13] of int // 指向 int 型数组的指针int *daytab[13] // daytab: array[13] of pointer to int // 存放 int 型指针的数组void *comp() // comp: function returning pointer to void // 返回值为指向 void 型指针的函数void (*comp)() // comp: pointer to function returning void // 指向返回值为 void 型函数的指针char (*(*x())[])() // x: function returning pointer to array[] of // pointer to function returning char // 返回值为 char 型的函数char (*(*x[3])())[5] // x: array[3] of pointer to function returning // pointer to array[5] of char 理解复杂声明可用的“右左法则”:从变量名看起,先往右,再往左,碰到一个圆括号就调转阅读的方向;括号内分析完就跳出括号,还是按先右后左的顺序,如此循环,直到整个声明分析完。举例: 1int (*func)(int *p); 首先找到变量名func,外面有一对圆括号,而且左边是一个*号,这说明func是一个指针;然后跳出这个圆括号,先看右边,又遇到圆括号,这说明(*func)是一个函数,所以func是一个指向这类函数的指针,即函数指针,这类函数具有int*类型的形参,返回值类型是int。 1int (*func[5])(int *); func右边是一个[]运算符,说明func是具有5个元素的数组;func的左边有一个*,说明func的元素是指针(注意这里的*不是修饰func,而是修饰func[5]的,原因是[]运算符优先级比*高,func先跟[]结合)。跳出这个括号,看右边,又遇到圆括号,说明func数组的元素是函数类型的指针,它指向的函数具有int*类型的形参,返回值类型为int。 在 C++中,规则比 C 要复杂一些。不过,基本思想保持不变,按照 C 的原则来理解复杂的声明,基本上就能满足要求了。没有在这里列出 C++的规则一方面是因为太广,不能覆盖全;另一个原因就是,按照 C 的规则来就足够了,毕竟 C++要与 C 兼容。","categories":[],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"}]},{"title":"C 语言共享内存实现 CyclicBuffer 循环缓冲区","slug":"C语言共享内存实现CyclicBuffer循环缓冲区","date":"2021-10-21T09:12:06.000Z","updated":"2022-10-15T03:14:29.156Z","comments":true,"path":"2021/10/21/C语言共享内存实现CyclicBuffer循环缓冲区/","link":"","permalink":"http://example.com/2021/10/21/C%E8%AF%AD%E8%A8%80%E5%85%B1%E4%BA%AB%E5%86%85%E5%AD%98%E5%AE%9E%E7%8E%B0CyclicBuffer%E5%BE%AA%E7%8E%AF%E7%BC%93%E5%86%B2%E5%8C%BA/","excerpt":"","text":"完整代码详见GitHub CyclicBuffer。 什么是循环缓冲区 循环缓冲区通常应用在模块与模块之间的通信,可以减少程序挂起的时间,节省内存空间。 如图所示,蓝色箭头表示读取指针,红色表示写入指针。写入指针可以在缓冲区有剩余空间时不中断地写入数据,读取指针可以在循环缓冲区有数据时不停读取。 如何设计循环缓冲区为了方便两个进程之间的通信,我们在共享内存中创建循环缓冲区。基本原理如图: 结构体定义1234567typedef struct CyclicBuffer{ uint8_t buf[CYCBUFFSIZ]; //缓冲区 uint8_t read; //读指针 uint8_t write; //写指针 uint32_t valid_size; //已写入数据数} CyCBuf; 写入数据123456789void cycbuff_write(CyCBuf *cycbuff, uint8_t ch){ while (cycbuff_isfull(cycbuff)) ; cycbuff->buf[cycbuff->write] = ch; cycbuff->write++; cycbuff->write %= CYCBUFFSIZ; cycbuff->valid_size++;} 写入数据前,要检查缓冲区是否已满,如果已满就得挂起等待。直到缓冲区有空间再进行写入。 写入指针每次写完向后偏移一位,valid_size记录当前缓冲区中有效数据个数。 读取数据1234567891011uint8_t cycbuff_read(CyCBuf *cycbuff){ uint8_t ch; while (cycbuff_isempty(cycbuff)) ; ch = cycbuff->buf[cycbuff->read]; cycbuff->read++; cycbuff->read %= CYCBUFFSIZ; cycbuff->valid_size--; return ch;} 读取数据前,要检查缓冲区是否为空,如果为空就要挂起等待。 判断空123456bool cycbuff_isempty(CyCBuf *cycbuff){ if (cycbuff->valid_size == 0) return true; return false;} 判断满123456bool cycbuff_isfull(CyCBuf *cycbuff){ if (cycbuff->valid_size == CYCBUFFSIZ) return true; return false;} 本次实验中,为了方便期间,用valid_size保存有效数据个数,没有用读写指针是否重合来判断,这就无需再考虑读写指针重合时,是空还是满。 数据收发流程服务端 - 写入12345678910111213141516void server(CyCBuf *cycbuff, SHMS *shms){ cycbuff_init(cycbuff); while (1) { puts("Enter Message: "); uint8_t ch[BUFFERSIZE]; fgets(ch, BUFFERSIZE, stdin); for (size_t i = 0; ch[i] != '\\n' && i < BUFFERSIZE; i++) { cycbuff_write(cycbuff, ch[i]); } cycbuff_write(cycbuff, '\\n'); } exit(0);} SHMS *shms为共享内存相关数据,有关共享内存的使用可以参考进程间通信(IPC)之共享内存(SharedMemory)。 客户端 - 读取1234567891011121314151617181920void client(CyCBuf *cycbuff, SHMS *shms){ printf("Server operational: shm id is %d\\n", shms->shmid); while (1) { uint8_t ch; puts("Recv Message: "); while (1) { ch = cycbuff_read(cycbuff); if (ch == '\\n') { printf("\\n"); break; } fflush(stdout); printf("%c", ch); } }} 读取数据以回车符为分界,当读到回车符时进行换行处理,并等待接收下一波数据。 实验结果 ReferenceCircular buffer","categories":[],"tags":[]},{"title":"解决 gcc 编译后 fflush 失效","slug":"解决gcc编译后fflush失效","date":"2021-10-21T01:56:51.000Z","updated":"2022-10-15T03:14:29.806Z","comments":true,"path":"2021/10/21/解决gcc编译后fflush失效/","link":"","permalink":"http://example.com/2021/10/21/%E8%A7%A3%E5%86%B3gcc%E7%BC%96%E8%AF%91%E5%90%8Efflush%E5%A4%B1%E6%95%88/","excerpt":"","text":"保留现场使用scanf()获取输入时,因为涉及键盘缓冲区的问题,每次输入后想要把缓冲清空,但是在 gcc 编译后,使用fflush无法清空缓冲区。 探究原因C 标准 (ISO/IEC 9899:1999 standard) 规定fflush(stdin)操作是未定义的<参看《ISO/IEC 9899:1999 standard》p270>;。也就是说不一定能实现刷新功能,但有的编译器可能不遵循标准,对fflush(stdin)操作不予警告,并且有时可能产生正确的结果,但最好不要这样使用。 解决方法通过 while 循环把输入流中的余留数据“吃”掉: 123int c;while ((c=getchar()) != ‘\\n’ && c != EOF);","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"RISC-V 入门-RVOS 系统引导","slug":"RISC-V入门-RVOS系统引导","date":"2021-10-20T15:13:40.000Z","updated":"2022-10-15T03:14:29.542Z","comments":true,"path":"2021/10/20/RISC-V入门-RVOS系统引导/","link":"","permalink":"http://example.com/2021/10/20/RISC-V%E5%85%A5%E9%97%A8-RVOS%E7%B3%BB%E7%BB%9F%E5%BC%95%E5%AF%BC/","excerpt":"","text":"操作系统定义与分类操作系统(英语:Operating System,缩写:OS)是一组系统软件程序,狭义上就是内核如 Linux,广义上就是内核加一组软件组成的发行包,如 Ubuntu,Debian: • 主管并控制计算机操作、运用和运行硬件、软件资源 • 提供公共服务来组织用户交互。 硬件的基本概念 Hart Platform不能说是个板子,应该理解为芯片。早期的板子就是一块芯片加上各种外设,但是随着技术发展,板子越来越小,外设却并没有变少,是因为外设都被集成到了芯片中。当所有外设都被集成,那么芯片就是 platform。 SoC(System on Chip)片上系统 QEMU 模拟 virt 这个平台,这个平台有八个 Hart。 地址映射 为了方便访问外设,现在主流的 platform 会对外设的内存地址做一个映射。映射到 platform 的真实物理地址。对真实物理地址进行操作时,就是对外设的地址进行操作。 物理地址从最低位到最高位都被分配给了各种外设。 引导过程介绍 通电后,会先到箭头所指的地址,这个地址就是对应的 ROM 外设首地址。ROM 相当于一个小硬盘,断电后不会丢失数据。这里面固化了一些指令。 主要就是跳转指令,运行到 kernel 段继续执行。 八核同时会执行这个过程。 以上是硬件的部分过程,软件该如何写? 为了简化学习流程和降低调试难度,目前只支持单核,其余七个核处于空转状态。 如何判断当前 Hart 是不是第一个? 这些寄存器必须使用以下的指令读写: 以上指令就是将寄存器值进行一次交换,只不过这个过程是原子性的,不能被打断。 CSRRW经常会用在伪指令CSRW中,完整指令中,第一步向x0写入数据,就是空操作,第二步将rs写入csr。这个伪指令就是完成了一个写入csr的操作。 mhartid就是machine hart id。 学习以上几个指令,就可以完成判断 hart 是否为第一个的工作了, 123csrr t0, mhartid #读寄存器值mv tp, t0 #bnez t0, park # 跳转指令,不等于 0 就跳转到 park 标签 Assembly12wfi休眠指令 如何初始化栈空间如何跳转到 C 语言环境Assembly123456789101112131415161718192021222324252627282930313233343536373839# start.S#include "platform.h" # size of each hart's stack is 1024 bytes .equ STACK_SIZE, 1024 .global _start .text_start: # park harts with id != 0 csrr t0, mhartid # read current hart id mv tp, t0 # keep CPU's hartid in its tp for later usage. bnez t0, park # if we're not on the hart 0 # we park the hart # Setup stacks, the stack grows from bottom to top, so we put the # stack pointer to the very end of the stack range. slli t0, t0, 10 # shift left the hart id by 1024 ###### 初始化栈空间 ###### # set the initial stack pointer to the end of the first stack space la sp, stacks + STACK_SIZE # move the current hart stack pointer to its place in the stack space add sp, sp, t0 ###### 初始化栈空间 ###### ###### 跳转到C语言环境 ###### j start_kernel # hart 0 jump to c, start_kernel is the entry point of the kernel ###### 跳转到C语言环境 ######park: wfi j parkstacks: # allocate space for all the harts stacks .skip STACK_SIZE * MAXNUM_CPU .end # End of file 123456// kernel.cvoid start_kernel(void){ while (1) {}; // stop here!} 通过 UART 打印信息连接方式 真实的硬件开发是有一个快开发板,但是这个课程里使用的是 QEMU 来模拟开发板的硬件环境。如果要在程序里打印一段信息,正常的情况是在开发板上连接显示器,但是这里是通过将信息用串口传到主机上,然后用主机的屏幕显示信息。 串口线里是有两根线,负责收信息和发信息。 UART 特点 并行就是需要多根线,比如有两根线,那么就可以一次发送两位。但是串行节省材料。 数据通信就会涉及同步的问题,同步的话需要一根时钟线来协商好发送时间和接收时间。而 UART 使用异步,发送的数据不仅仅是真实的数据,还会带有一些标识信息。这些标识可以判断出是收还是发。 物理接口 UART 通讯协议 图示中横轴可以表示时间,纵轴表示高低电平。 在需要发送数据时,会进行“下拉”1bit,1bit 持续的时间就是波特率分之一秒。 数据在发送过程中可能会受到干扰,会产生畸变,所以需要检验位来判断是否发生畸变。 初始化 在软件中,配置 UART 就是配置寄存器的信息。 在板子上有个元器件叫晶振(crystal),他会产生固定频率的时钟。一种是 1.8432MHZ,一种是 7.3728MHZ。想要获得指定的输出频率就需要对寄存器进行配置。查表可以得到配置信息。比如获得 38.4K 频率的输出,就要配置寄存器值为 3。 LCR 寄存器功能比较多,将第 7 位设置为 1 就是用来设置波特率。 图中DLL和DLM寄存器就是需要配置的寄存器。因为 UART 寄存器都是 8 位的,将值0x0003高位0x00存在DLM中,将低位0x03存入DLL。","categories":[{"name":"RISC-V 入门","slug":"RISC-V-入门","permalink":"http://example.com/categories/RISC-V-%E5%85%A5%E9%97%A8/"}],"tags":[{"name":"RISCV","slug":"RISCV","permalink":"http://example.com/tags/RISCV/"}]},{"title":"解决 Segmentation fault (core dumped)","slug":"解决Segmentation-fault-core-dumped","date":"2021-10-20T06:23:02.000Z","updated":"2022-10-15T03:14:29.836Z","comments":true,"path":"2021/10/20/解决Segmentation-fault-core-dumped/","link":"","permalink":"http://example.com/2021/10/20/%E8%A7%A3%E5%86%B3Segmentation-fault-core-dumped/","excerpt":"","text":"相关概念Core在使用半导体作为内存的材料前,人类是利用线圈当作内存的材料(发明者为王安),线圈就叫作 core ,用线圈做的内存就叫作 core memory。如今,半导体工业澎勃发展,已经没有人用core memory 了,不过,在许多情况下,人们还是把记忆体叫作 core 。 Core dump我们在开发(或使用)一个程序时,最怕的就是程序莫明其妙地宕掉。虽然系统没事,但我们下次仍可能遇到相同的问题。于是这时操作系统就会把程序宕掉时的内存内容 dump 出来(现在通常是写在一个叫 core 的 file 里面),让我们做为参考。这个动作就叫作 core dump。 如何获取 Core 文件1、在一些 Linux 版本下,默认是不产生core文件的,首先可以查看一下系统core文件的大小限制: 12$:~/segfault$ ulimit -c0 2、可以看到默认设置情况下,本机 Linux 环境下发生段错误时不会自动生成core文件,下面设置下core文件的大小限制(单位为 KB): 123$:~/segfault$ ulimit -c 1024$:~/segfault$ ulimit -c1024 3、重新运行程序,如果发生段错误,就会生成core文件。 出现段错误的可能原因访问不存在的内存地址1234567#include<stdio.h>#include<stdlib.h>void main(){ int *ptr = NULL; *ptr = 0;} 访问系统保护的内存地址1234567#include<stdio.h>#include<stdlib.h>void main(){ int *ptr = (int *)0; *ptr = 100;} 访问只读的内存地址12345678#include<stdio.h>#include<stdlib.h>#include<string.h>void main(){ char *ptr = "test"; strcpy(ptr, "TEST");} 栈溢出123456#include<stdio.h>#include<stdlib.h>void main(){ main();} 段错误信息获取程序发生段错误时,提示信息很少,下面有几种查看段错误的发生信息的途径。 dmesgdmesg 可以在应用程序 crash 掉时,显示内核中保存的相关信息。如下所示,通过dmesg命令可以查看发生段错误的程序名称、引起段错误发生的内存地址、指令指针地址、堆栈指针地址、错误代码、错误原因等。 12$:~/segfault$ dmesg[ 2329.479037] segfault3[2700]: segfault at 80484e0 ip 00d2906a sp bfbbec3c error 7 in libc-2.10.1.so[cb4000+13e000] -g使用 gcc 编译程序的源码时,加上-g参数,这样可以使得生成的二进制文件中加入可以用于 gdb 调试的有用信息。 12$:~/segfault$ gcc -g -o segfault3 segfault3.c nm使用 nm 命令列出二进制文件中的符号表,包括符号地址、符号类型、符号名等,这样可以帮助定位在哪里发生了段错误。 123456789101112131415161718192021222324252627282930313233343536panfeng@ubuntu:~/segfault$ nm segfault308049f20 d _DYNAMIC08049ff4 d _GLOBAL_OFFSET_TABLE_080484dc R _IO_stdin_used w _Jv_RegisterClasses08049f10 d __CTOR_END__08049f0c d __CTOR_LIST__08049f18 D __DTOR_END__08049f14 d __DTOR_LIST__080484ec r __FRAME_END__08049f1c d __JCR_END__08049f1c d __JCR_LIST__0804a014 A __bss_start0804a00c D __data_start08048490 t __do_global_ctors_aux08048360 t __do_global_dtors_aux0804a010 D __dso_handle w __gmon_start__0804848a T __i686.get_pc_thunk.bx08049f0c d __init_array_end08049f0c d __init_array_start08048420 T __libc_csu_fini08048430 T __libc_csu_init U __libc_start_main@@GLIBC_2.00804a014 A _edata0804a01c A _end080484bc T _fini080484d8 R _fp_hw080482bc T _init08048330 T _start0804a014 b completed.69900804a00c W data_start0804a018 b dtor_idx.6992080483c0 t frame_dummy080483e4 T main U memcpy@@GLIBC_2.0 ldd使用 ldd 命令查看二进制程序的共享链接库依赖,包括库的名称、起始地址,这样可以确定段错误到底是发生在了自己的程序中还是依赖的共享库中。 1234$:~/segfault$ ldd ./segfault3 linux-gate.so.1 => (0x00e08000) libc.so.6 => /lib/tls/i686/cmov/libc.so.6 (0x00675000) /lib/ld-linux.so.2 (0x00482000) 调试方法和技巧使用 gcc 和 gdb调试流程 为了能够使用 gdb 调试程序,在编译阶段加上-g 参数, 1$:~/segfault$ gcc -g -o segfault3 segfault3.c 使用 gdb 命令调试程序: 123$:~/segfault$ gdb -q ./segfault3 Reading symbols from ./segfault3...done.(gdb) 进入 gdb 后,运行程序: 123456(gdb) runStarting program: ./segfault3 Program received signal SIGSEGV, Segmentation fault.0x001a306a in memcpy () from /lib/tls/i686/cmov/libc.so.6(gdb) 从输出看出,程序收到SIGSEGV信号,触发段错误,并提示地址0x001a306a、调用 memcpy 报的错,位于/lib/tls/i686/cmov/libc.so.6库中。 完成调试后,输入quit命令退出 gdb: 适用场景 仅当能确定程序一定会发生段错误的情况下使用。 当程序的源码可以获得的情况下,使用-g参数编译程序。 一般用于测试阶段,生产环境下 gdb 会有副作用:使程序运行减慢,运行不够稳定,等等。 即使在测试阶段,如果程序过于复杂,gdb 也不能处理。 使用 core 文件和 gdb在上节中提到段错误会触发SIGSEGV信号,通过man 7 signal,可以看到SIGSEGV默认的handler会打印段错误出错信息,并产生core文件,由此我们可以借助于程序异常退出时生成的core文件中的调试信息,使用 gdb 工具来调试程序中的段错误。 调试流程 运行有段错误的程序,生成 core 文件。 gdb 加载 core 文件 1234567891011$:~/segfault$ gdb ./segfault3 ./core Reading symbols from /home/panfeng/segfault/segfault3...done.warning: Can't read pathname for load map: 输入/输出错误.Reading symbols from /lib/tls/i686/cmov/libc.so.6...(no debugging symbols found)...done.Loaded symbols for /lib/tls/i686/cmov/libc.so.6Reading symbols from /lib/ld-linux.so.2...(no debugging symbols found)...done.Loaded symbols for /lib/ld-linux.so.2Core was generated by `./segfault3'.Program terminated with signal 11, Segmentation fault.#0 0x0018506a in memcpy () from /lib/tls/i686/cmov/libc.6 从输出看出,同上节中一样的段错误信息。 适用场景 适合于在实际生成环境下调试程序的段错误(即在不用重新发生段错误的情况下重现段错误)。 当程序很复杂,core 文件相当大时,该方法不可用。 使用 objdump调试流程 使用 dmesg 命令,找到最近发生的段错误输出信息: 123$:~/segfault$ dmesg... ...[17257.502808] segfault3[3320]: segfault at 80484e0 ip 0018506a sp bfc1cd6c error 7 in libc-2.10.1.so[110000+13e000] 其中,对我们接下来的调试过程有用的是发生段错误的地址:80484e0和指令指针地址:0018506a。 使用objdump生成二进制的相关信息,重定向到文件中: 1$:~/segfault$ objdump -d ./segfault3 > segfault3Dump 其中,生成的segfault3Dump文件中包含了二进制文件的segfault3的汇编代码。 在segfault3Dump文件中查找发生段错误的地址: 12345678910111213141516171819202122panfeng@ubuntu:~/segfault$ grep -n -A 10 -B 10 "80484e0" ./segfault3Dump 121- 80483df: ff d0 call *%eax122- 80483e1: c9 leave 123- 80483e2: c3 ret 124- 80483e3: 90 nop125-126-080483e4 <main>:127- 80483e4: 55 push %ebp128- 80483e5: 89 e5 mov %esp,%ebp129- 80483e7: 83 e4 f0 and $0xfffffff0,%esp130- 80483ea: 83 ec 20 sub $0x20,%esp131: 80483ed: c7 44 24 1c e0 84 04 movl $0x80484e0,0x1c(%esp)132- 80483f4: 08 133- 80483f5: b8 e5 84 04 08 mov $0x80484e5,%eax134- 80483fa: c7 44 24 08 05 00 00 movl $0x5,0x8(%esp)135- 8048401: 00 136- 8048402: 89 44 24 04 mov %eax,0x4(%esp)137- 8048406: 8b 44 24 1c mov 0x1c(%esp),%eax138- 804840a: 89 04 24 mov %eax,(%esp)139- 804840d: e8 0a ff ff ff call 804831c <memcpy@plt>140- 8048412: c9 leave 141- 8048413: c3 ret 通过对以上汇编代码分析,得知段错误发生main函数,对应的汇编指令是movl $0x80484e0,0x1c(%esp),接下来打开程序的源码,找到汇编指令对应的源码,也就定位到段错误了。 适用场景 不需要-g参数编译,不需要借助于core文件,但需要有一定的汇编语言基础。 2、如果使用了 gcc 编译优化参数(-O1,-O2,-O3)的话,生成的汇编指令将会被优化,使得调试过程有些难度。 使用 catchsegvcatchsegv命令专门用来扑获段错误,它通过动态加载器(ld-linux.so)的预加载机制(PRELOAD)把一个事先写好的库(/lib/libSegFault.so)加载上,用于捕捉断错误的出错信息。 123456789101112131415161718192021222324252627282930313233343536373839404142434445$:~/segfault$ catchsegv ./segfault3Segmentation fault (core dumped)*** Segmentation faultRegister dump: EAX: 00000000 EBX: 00fb3ff4 ECX: 00000002 EDX: 00000000 ESI: 080484e5 EDI: 080484e0 EBP: bfb7ad38 ESP: bfb7ad0c EIP: 00ee806a EFLAGS: 00010203 CS: 0073 DS: 007b ES: 007b FS: 0000 GS: 0033 SS: 007b Trap: 0000000e Error: 00000007 OldMask: 00000000 ESP/signal: bfb7ad0c CR2: 080484e0Backtrace:/lib/libSegFault.so[0x3b606f]??:0(??)[0xc76400]/lib/tls/i686/cmov/libc.so.6(__libc_start_main+0xe6)[0xe89b56]/build/buildd/eglibc-2.10.1/csu/../sysdeps/i386/elf/start.S:122(_start)[0x8048351]Memory map:00258000-00273000 r-xp 00000000 08:01 157 /lib/ld-2.10.1.so00273000-00274000 r--p 0001a000 08:01 157 /lib/ld-2.10.1.so00274000-00275000 rw-p 0001b000 08:01 157 /lib/ld-2.10.1.so003b4000-003b7000 r-xp 00000000 08:01 13105 /lib/libSegFault.so003b7000-003b8000 r--p 00002000 08:01 13105 /lib/libSegFault.so003b8000-003b9000 rw-p 00003000 08:01 13105 /lib/libSegFault.so00c76000-00c77000 r-xp 00000000 00:00 0 [vdso]00e0d000-00e29000 r-xp 00000000 08:01 4817 /lib/libgcc_s.so.100e29000-00e2a000 r--p 0001b000 08:01 4817 /lib/libgcc_s.so.100e2a000-00e2b000 rw-p 0001c000 08:01 4817 /lib/libgcc_s.so.100e73000-00fb1000 r-xp 00000000 08:01 1800 /lib/tls/i686/cmov/libc-2.10.1.so00fb1000-00fb2000 ---p 0013e000 08:01 1800 /lib/tls/i686/cmov/libc-2.10.1.so00fb2000-00fb4000 r--p 0013e000 08:01 1800 /lib/tls/i686/cmov/libc-2.10.1.so00fb4000-00fb5000 rw-p 00140000 08:01 1800 /lib/tls/i686/cmov/libc-2.10.1.so00fb5000-00fb8000 rw-p 00000000 00:00 008048000-08049000 r-xp 00000000 08:01 303895 /home/segfault/segfault308049000-0804a000 r--p 00000000 08:01 303895 /home/segfault/segfault30804a000-0804b000 rw-p 00001000 08:01 303895 /home/segfault/segfault309432000-09457000 rw-p 00000000 00:00 0 [heap]b78cf000-b78d1000 rw-p 00000000 00:00 0b78df000-b78e1000 rw-p 00000000 00:00 0bfb67000-bfb7c000 rw-p 00000000 00:00 0 [stack] 如何避免段错误 出现段错误时,首先应该想到段错误的定义,从它出发考虑引发错误的原因。 在使用指针时,定义了指针后记得初始化指针,在使用的时候记得判断是否为 NULL。 在使用数组时,注意数组是否被初始化,数组下标是否越界,数组元素是否存在等。 在访问变量时,注意变量所占地址空间是否已经被程序释放掉。 在处理变量时,注意变量的格式控制是否合理等。 Reference","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"RISC-V 入门-RISC-V 汇编语言编程","slug":"RISC-V入门-RISC-V汇编语言编程","date":"2021-10-16T15:26:42.000Z","updated":"2022-10-15T03:14:29.532Z","comments":true,"path":"2021/10/16/RISC-V入门-RISC-V汇编语言编程/","link":"","permalink":"http://example.com/2021/10/16/RISC-V%E5%85%A5%E9%97%A8-RISC-V%E6%B1%87%E7%BC%96%E8%AF%AD%E8%A8%80%E7%BC%96%E7%A8%8B/","excerpt":"","text":"汇编语法介绍一条典型的 RISC-V 汇编语句由三个部分组成[label:][operation][comment]。后缀.s和.S区别:后者纯汇编。 label(标号) operation 可以有以下多种类型: instruction (指令) :直接对应二进制机器指令的宇符串 pseudo-instruction (伪指令) :为了提高编写代码的效率,可以用一条伪指令指示汇编器产生多条实际的指令 (instructions)。 directive (指示/伪操作) :通过类似指令的形式(以”.”开头),通知汇编器如何控制代码的产生等,不对应具体的指令。 macro:采用.macro/.endm 自定义的宏例子 123456789101112131415.macro do_nothing # directive nop # pseudo-instruction nop # pseudo-instruction.endm # directive .text # directive .global _start # directive_start: # Label li x6, 5 # pseudo-instruction li x7, 4 # pseudo-instruction add x5, x6, x7 # instruction do_nothing # Calling macrostop: j stop # statement in one line .end # End of file comment(注释)以#开头到行尾 RISC-V 汇编指令总览操作对象 寄存器 32个通用寄存器,x0 ~ x31(注意:本章节课程仅涉及RV32I的通用寄存器组); 在 RISC-V 中,Hart 在执行算术逻辑运算时所操作的数据必须直接来自寄存器。 内存 Hart可以执行在寄存器和内存之间的数据读写操作; 读写操作使用字节 (Byte) 为基本单位进行寻址; RV32可以访问最多2^32个字节的内存空间。 编码格式 指令长度:32bit,本文讨论的都是 RV32 指令集 指令对齐:指令加载到内存是以 32bit 对齐 funct3、funct7和opcode一起决定指令类型,funct3表示占 3bit,funct7占 7bit。 opcode映射关系: [1:0] 永远为 11 [4:2] 为下图横轴 [6:5] 为下图纵轴,三部分决定指令的类型。 以BEQ指令为例opcode=1100011。[4:2]=000,[6:5]=11查表可得BEQ指令类型为BRANCH。 小端序 主机字节序 (HBO-Host Byte Order) 一个多字节整数在计算机内存中存储的字节顺序称主机字节序 (HBO- Host Byte Order,或者叫本地字节序) 不同类型 CPU 的 HBO 不同,这与 CPU 的设计有关。分为大端序 (Big-Endian) 和小端序 (Little-Endian) 指令分类 rd(register destination)目标寄存器,rs(register source)源寄存器,大小都是 5bit,因为可以表示2^5=32寄存器。 指令详解算术运算指令ADD算数指令只包含加减,不包含乘除,乘除运算有专门的扩展。 数据传送顺序是由后向前,和正常的编码习惯类似。 SUB Substract练习 现知道某条 RISC-V 的机器指令在内存中的值为b3 05 95 00,从左往右为从低地址到高地址,单位为字节,请将其翻译为对应的汇编指令。 确定字节序在 RISC-V 中存放是小端序,根据题意真正指令应该是00 95 05 b3 转换二进制机器码是二进制,所以需要将上述指令值转换为二进制,可得0000000 01001 01010 000 01011 0110011 查阅手册查阅The RISC-V Instruction Set Manual Volume I: Unprivileged ISA找到RV32/64G Instruction Set Listings指令表格,低 7 位是opcode,查表可得0110011对应操作码有多个SLLI SRAI SUB等等,此时再看最高位00000000,可以确定是ADD指令 将分割的二进制转成十进制0000000 9 10 000 11 010011->ADD x11 x10 x9 ADDI ADD Immediate LUI Load Upper Immediate LI AUIPC 经常用于构造一个相对地址。 LA 基于算术运算指令实现的其他伪指令x0寄存器具有特殊含义,往里写数据没有意义NOP指令主要为了占位,空转 逻辑运算指令 NOTAssembly12341010101011111111(-1)-------- XOR01010101 移位运算指令 算数移位只有右移,没有左移。左移会把最高位覆盖。 Assembly1210001000 >> 2= 11100001 内存读写指令加载,内存读,将数据从内存读入寄存器 Store,内存写,将数据从寄存器写出到内存 为何对 word 的 加载 不区分无符号和有符号方式 (RV32)?RV32 下寄存器是 4 字节,加载 word 也是 4 字节,自然不需要扩展。 为何 store 不区分有符号还是无符号?因为从目的地址只有 1 字节,不管是写 1 字节,2 字节,还是 4 字节,都只用到最低的 1 字节。不需要考虑符号 立即数分两个地方存,为了解码效率 条件分支指令 指令格式中的立即数 (imm) 存放有些奇怪,第 [1-4] 位和第 [11] 位放在一起,第 [5-10] 位和第 [12] 位放在一起。这是为了迎合硬件处理效率,编程时不需要考虑立即数存储方式。 无条件跳转指令 1234567891011121314int a = 1;int b = 1;void sum(){ a = a+b; return; // jalr x0 0(x5) 当前指令的下一条指令存到x0中,并跳转到(0 + x5),也就是sum的下一条指令}void _start(){ sum(); // jal x5 sum 把sum的下一条指令存到x5,然后跳转到sum ...} 如何解决长距离跳转?使用 AUIPC 来构建一个大数,配合 JALR 使用。如 auipc x6,imm-20 jalr x1,x6,imm-12 RISC-V 指令寻址模式总结 汇编函数调用约定函数调用过程概述栈(stack)数据结构,在函数调用过程中会用来保存变量,函数地址等等。 栈帧里保存的变量是自动变量,会被内存自动释放。 为何要有调用者与被调用者保存的概念 函数调用过程中就会有参数和返回值的传递,自己写的函数可能由别人来调用,如果没有约定好某个参数存放位置,就不能够顺利执行函数。 因为寄存器需要经常在编程中使用,所以 ABI 名就是寄存器的别名。 这些寄存器其实都可以设置成被调用者保存,也就是在被调用函数中保存一遍为啥还要分这么多答:因为保存一遍效率低 尾调用实例Assembly12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061# Calling Convention# Demo to create a leaf routine## void _start()# {# // calling leaf routine# square(3);# }## int square(int num)# {# return num * num;# } .text # Define beginning of text section .global _start # Define entry _start_start: la sp, stack_end # prepare stack for calling functions li a0, 3 # pass 3 to square call square # call square # the time return here, a0 should stores the resultstop: j stop # Infinite loop to stop execution# int square(int num)square: # prologue addi sp, sp, -8 # reserve space for local variables sw s0, 0(sp) # save s0 sw s1, 4(sp) # save s1 # `mul a0, a0, a0` should be fine, # programing as below just to demo we can contine use the stack mv s0, a0 # s0 = a0 mul s1, s0, s0 # s1 = s0 * s0 mv a0, s1 # a0 = s1 # epilogue lw s0, 0(sp) # restore s0 lw s1, 4(sp) # restore s1 addi sp, sp, 8 # release space for local variables ret # return from function # add nop here just for demo in gdb nop # allocate stack spacestack_start: .rept 10 # reserve 10 words for stack .word 0 # fill with 0 .endr # end of repeatstack_end: .end # End of file 非尾调用实例Assembly123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899# Calling Convention# Demo how to write nested routines## void _start()# {# // calling nested routine# aa_bb(3, 4);# }## int aa_bb(int a, int b)# {# return square(a) + square(b);# }## int square(int num)# {# return num * num;# } .text # Define beginning of text section .global _start # Define entry _start_start: la sp, stack_end # prepare stack for calling functions # aa_bb(3, 4); li a0, 3 # load argument a li a1, 4 # load argument b call aa_bb # call aa_bbstop: j stop # Infinite loop to stop execution# int aa_bb(int a, int b)# return a^2 + b^2aa_bb: # prologue addi sp, sp, -16 # decrement stack pointer by 16 bytes sw s0, 0(sp) # save s0 sw s1, 4(sp) # save s1 sw s2, 8(sp) # save s2 sw ra, 12(sp) # save ra # cp and store the input params mv s0, a0 # copy a to s0 mv s1, a1 # copy b to s1 # sum will be stored in s2 and is initialized as zero li s2, 0 # initialize s2 to zero mv a0, s0 # copy s0 to a0 jal square # call square add s2, s2, a0 # add a0 to s2 mv a0, s1 # copy s1 to a0 jal square # call square add s2, s2, a0 # add a0 to s2 mv a0, s2 # copy s2 to a0 # epilogue lw s0, 0(sp) # restore s0 lw s1, 4(sp) # restore s1 lw s2, 8(sp) # restore s2 lw ra, 12(sp) # restore ra addi sp, sp, 16 # increment stack pointer by 16 bytes ret # return from aa_bb# int square(int num)square: # prologue addi sp, sp, -8 # decrement stack pointer by 8 bytes sw s0, 0(sp) # save s0 sw s1, 4(sp) # save s1 # `mul a0, a0, a0` should be fine, # programing as below just to demo we can contine use the stack mv s0, a0 # copy a to s0 mul s1, s0, s0 # s1 = a * a mv a0, s1 # copy s1 to a0 # epilogue lw s0, 0(sp) # restore s0 lw s1, 4(sp) # restore s1 addi sp, sp, 8 # increment stack pointer by 8 bytes ret # return from square # add nop here just for demo in gdb nop # allocate stack spacestack_start: .rept 10 # allocate 10 words of stack space .word 0 # initialize stack space to 0 .endr # end of stack allocationstack_end: .end # End of file 汇编与 C 混合编程前提遵守 ABI(Abstract Binary Interface)的规定 数据类型大小,布局,对齐 函数调用约定 系统调用约定等等 RISC-V 函数调用约定规定 函数参数采用寄存器a0-a7 函数返回值采用寄存器a0,a1 汇编嵌入 C 语言Assembly1234567891011121314151617181920212223242526272829# ASM call C .text # Define beginning of text section .global _start # Define entry _start .global foo # foo is a C function defined in test.c_start: la sp, stack_end # prepare stack for calling functions # RISC-V uses a0 ~ a7 to transfer parameters li a0, 1 li a1, 2 call foo #调用了C语言函数 # RISC-V uses a0 & a1 to transfer return value # check value of a0stop: j stop # Infinite loop to stop execution nop # just for demo effectstack_start: .rept 10 .word 0 .endrstack_end: .end # End of file call foo就是在调用 C 语言函数,foo。.global foo告诉编译器foo函数定义在外面。 C 语言嵌入汇编下图中为简化写法","categories":[{"name":"RISC-V 入门","slug":"RISC-V-入门","permalink":"http://example.com/categories/RISC-V-%E5%85%A5%E9%97%A8/"}],"tags":[{"name":"RISCV","slug":"RISCV","permalink":"http://example.com/tags/RISCV/"}]},{"title":"C 语言可变参数","slug":"C语言可变参数","date":"2021-10-12T03:21:49.000Z","updated":"2022-10-15T03:14:29.161Z","comments":true,"path":"2021/10/12/C语言可变参数/","link":"","permalink":"http://example.com/2021/10/12/C%E8%AF%AD%E8%A8%80%E5%8F%AF%E5%8F%98%E5%8F%82%E6%95%B0/","excerpt":"","text":"学习过程中查看了printf()源码,遇到了这样的函数定义, 1234567891011void printf(char *fmt, ...){ char buf[256]; va_list args; memset(buf, 0, sizeof(buf)); va_start(args, fmt); vsprint(buf, fmt, args); va_end(args); puts(buf);} 参数中的三个点号,就是 C 语言中可变参数的标识。这样的函数称为可变参数函数。这种函数需要固定数量的强制参数(mandatory argument),后面是数量可变的可选参数(optional argument)。 这种函数必须至少有一个强制参数。可选参数的类型可以变化。可选参数的数量由强制参数的值决定,或由用来定义可选参数列表的特殊值决定。 C 语言中最常用的可变参数函数例子是printf()和 scanf()。这两个函数都有一个强制参数,即格式化字符串。格式化字符串中的转换修饰符决定了可选参数的数量和类型。 可变参数函数要获取可选参数时,必须通过一个类型为 va_list 的对象,它包含了参数信息。这种类型的对象也称为参数指针(argument pointer),它包含了栈中至少一个参数的位置。可以使用这个参数指针从一个可选参数移动到下一个可选参数,由此,函数就可以获取所有的可选参数。va_list 类型被定义在头文件 stdarg.h 中。 当编写支持参数数量可变的函数时,必须用 va_list 类型定义参数指针,以获取可选参数。在下面的讨论中,va_list 对象被命名为 argptr。可以用 4个宏来处理该参数指针,这些宏都定义在头文件 stdarg.h 中: 宏 va_start 使用第一个可选参数的位置来初始化 argptr 参数指针。该宏的第二个参数必须是该函数最后一个有名称参数的名称。必须先调用该宏,才可以开始使用可选参数。 1void va_start(va_list argptr, lastparam); 展开宏 va_arg 会得到当前 argptr 所引用的可选参数,也会将 argptr 移动到列表中的下一个参数。宏 va_arg 的第二个参数是刚刚被读入的参数的类型。 1type va_arg(va_list argptr, type); 当不再需要使用参数指针时,必须调用宏 va_end。如果想使用宏 va_start 或者宏 va_copy 来重新初始化一个之前用过的参数指针,也必须先调用宏 va_end。va_end被定义为空。它只是为实现与 va_start 配对 (实现代码对称和”代码自注释”(根据代码就能知道功能,不需要额外注释) 功能) 1void va_end(va_list argptr); 宏 va_copy 使用当前的src值来初始化参数指针 dest。然后就可以使用 dest中的备份获取可选参数列表,从src 所引用的位置开始。 1void va_copy(va_list dest, va_list src); 1234567891011121314// 函数 add() 计算可选参数之和// 参数:第一个强制参数指定了可选参数的数量,可选参数为 double 类型// 返回值:和值,double 类型double add( int n, ... ){ int i = 0; double sum = 0.0; va_list argptr; va_start( argptr, n ); // 初始化 argptr for ( i = 0; i < n; ++i ) // 对每个可选参数,读取类型为 double 的参数, sum += va_arg( argptr, double ); // 然后累加到 sum 中 va_end( argptr ); return sum;} 简易printf函数 12345678910111213141516171819202122232425262728293031323334353637#include <stdarg.h>/* minprintf: minimal printf with variable arqument list */void minprintf(char *fmt, ...){ GPIO va_list ap; /* points to each unnamed arq in turn */ char *p, *sval; int ival; double dval; va_start(ap, fmt); /* make ap point to 1st unnamed arg */ for (p = fmt; *p; p++) { if (*p != '%') { putchar(*p); continue; } } switch (*++p) { case 'd': ival = va_arg(ap, int); printf("%d", ival); break; case 'f': dval = va_arg(ap, double); printf("%f", dval); break; case 's': for (sval = va_arq(ap, char *); *sval; sval++) putchar(*sval); break; default: putchar(*p); break; } va_end(ap); /* clean up when done */}","categories":[],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"C++","slug":"C","permalink":"http://example.com/tags/C/"}]},{"title":"Linux 下将编译结果输出到文件","slug":"Linux下将编译结果输出到文件","date":"2021-09-30T07:18:32.000Z","updated":"2022-10-15T03:14:29.281Z","comments":true,"path":"2021/09/30/Linux下将编译结果输出到文件/","link":"","permalink":"http://example.com/2021/09/30/Linux%E4%B8%8B%E5%B0%86%E7%BC%96%E8%AF%91%E7%BB%93%E6%9E%9C%E8%BE%93%E5%87%BA%E5%88%B0%E6%96%87%E4%BB%B6/","excerpt":"","text":"在命令行编译项目时,经常遇到编译结果太长,覆盖了最先输出的结果,此时就需要将结果输出到文件再查看。命令如下: 123456make > make.log 2>&1# make 编译命令# make.log 输出文件名# 2 文件描述符,标准错误# > 重定向符,输出# &1 文件描述符&,文件描述符1 标准输入 该命令功能即将make编译时输出,标准错误重定向为标准输入,写入到make.log文件中。符号的含义可以参考Linux 文件描述符","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"}]},{"title":"Linux 文件描述符","slug":"Linux文件描述符","date":"2021-09-30T03:13:02.000Z","updated":"2022-10-15T03:14:29.331Z","comments":true,"path":"2021/09/30/Linux文件描述符/","link":"","permalink":"http://example.com/2021/09/30/Linux%E6%96%87%E4%BB%B6%E6%8F%8F%E8%BF%B0%E7%AC%A6/","excerpt":"","text":"前言Linux 中一切皆文件,比如 C++ 源文件、视频文件、Shell 脚本、可执行文件等,就连键盘、显示器、鼠标等硬件设备也都是文件。 一个 Linux 进程可以打开成百上千个文件,为了表示和区分已经打开的文件,Linux 会给每个文件分配一个编号(一个 ID),这个编号就是一个整数,被称为文件描述符(File Descriptor)。 文件描述符是什么?一个 Linux 进程启动后,会在内核空间中创建一个 PCB 控制块,PCB 内部有一个文件描述符表(File descriptor table),记录着当前进程所有可用的文件描述符,也即当前进程所有打开的文件。 除了文件描述符表,系统还需要维护另外两张表: 打开文件表(Open file table) i-node 表(i-node table) 文件描述符表每个进程都有一个,打开文件表和 i-node 表整个系统只有一个,它们三者之间的关系如下图所示。 对上图的说明: 在进程A 中,文件描述符 1 和20 都指向了同一个打开文件表项,标号为 23(指向了打开文件表中下标为 23 的数组元素),这可能是通过调用 dup()、dup2()、fcntl() 或者对同一个文件多次调用了 open() 函数形成的。 进程 A 的文件描述符 2和进程B 的文件描述符2 都指向了同一个文件,这可能是在调用 fork() 后出现的(即进程 A、B是父子进程关系),或者是不同的进程独自去调用open() 函数打开了同一个文件,此时进程内部的描述符正好分配到与其他进程打开该文件的描述符一样。 进程 A 的描述符0和进程B的描述符3分别指向不同的打开文件表项,但这些表项均指向 i-node 表的同一个条目(标号为 1976);换言之,它们指向了同一个文件。发生这种情况是因为每个进程各自对同一个文件发起了 open() 调用。同一个进程两次打开同一个文件,也会发生类似情况。 通过文件描述符,可以找到文件指针,从而进入打开文件表。该表存储了以下信息: 文件偏移量,也就是文件内部指针偏移量。调用read()或者write() 函数时,文件偏移量会自动更新,当然也可以使用 lseek() 直接修改。 状态标志,比如只读模式、读写模式、追加模式、覆盖模式等。 i-node 表指针。 然而,要想真正读写文件,还得通过打开文件表的 i-node 指针进入 i-node 表,该表包含了诸如以下的信息: 文件类型,例如常规文件、套接字或 FIFO。 文件大小。 时间戳,比如创建时间、更新时间。 文件锁。 标准文件描述符 文件描述符 用途 POSIX 名称 stdio 流 0 标准输入 STDIN FILENO stdin 1 标准输出 STDOUT FILENO stdout 2 标准错误 STDERR FILENO stderr 标准文件描述符通常会和重定向符<,>,<<,>>结合使用。箭头向左表示输入重定向,向右表示输出重定向。文件描述符中的0通常省略。如0< ~ <,0<< ~ <<。 标准输入使用wc命令统计文档中有多少行字,命令格式如下,详细介绍参考这篇文章。 1wc [选项] [文件名] 123456$ cat test.txtThis is a test file.Hello world!$ wc -l <test.txt2 这里的重定向符号<作用就是将test.txt的内容作为标准输入,传递给wc命令。 标准输出与标准错误这个我们每天都在接触,但是可能没有留意。假设我当前目录下只有一个test.txt文件,执行如下命令 1234567891011121314$ cat text.txtThis is a test file.Hello world! #标准输出1$ cat text.mdcat: test.md: No such file or directory #标准错误2$ ls text.txt text.md 1>file.out 2>file.err # 执行后,没有任何返回值. 原因是, 返回值都重定向到相应的文件中了,而不再前端显示 $ cat file.out text.txt $ cat file.err cat: test.md: No such file or directory &描述符& 是一个描述符,如果1或2前不加&,会被当成一个普通文件。 1>&2 意思是把标准输出重定向到标准错误。2>&1 意思是把标准错误输出重定向到标准输出。&>filename 意思是把标准输出和标准错误输出都重定向到文件 filename 中 参考Linux Shell 重定向(输入输出重定向)精讲","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"}]},{"title":"VScode 快速添加注释模板","slug":"VScode快速添加注释模板","date":"2021-09-29T09:03:13.000Z","updated":"2022-10-15T03:18:34.344Z","comments":true,"path":"2021/09/29/VScode快速添加注释模板/","link":"","permalink":"http://example.com/2021/09/29/VScode%E5%BF%AB%E9%80%9F%E6%B7%BB%E5%8A%A0%E6%B3%A8%E9%87%8A%E6%A8%A1%E6%9D%BF/","excerpt":"","text":"需求通常函数的注释一般都比较长,而且每个函数注释都格式一致,例如下面的函数注释模板。如果每次写注释都要复制一遍比较麻烦,复制完还要删除多余的字符。但是现有的编辑器一般都支持快捷输入。下面介绍在 VSCode 中如何快捷输入注释模板。 方法 Ctrl+Shift+P打开编辑器命令窗口 - 输入snippets-选择Preferences:Configure User Snippets-选择·c.json· 更改如下: 123456789101112131415161718192021222324252627 {// Place your snippets for c here. Each snippet is defined under a snippet name and has a prefix, body and// description. The prefix is what is used to trigger the snippet and the body will be expanded and inserted. Possible variables are:// $1, $2 for tab stops, $0 for the final cursor position, and ${1:label}, ${2:another} for placeholders. Placeholders with the// same ids are connected.// Example:// "Print to console": {// "prefix": "log",// "body": [// "console.log('$1');",// "$2"// ],// "description": "Log output to console"// } "Function comment": { "prefix": "funcom", "body": [ "/*" "* Description: " "*Input Parameter: " "* Output Parameter: " "*Return: " "*/ " ], "description": "function comment" } prefix:输入时的缩写,触发器 body:内容 description:描述 参考资料VSCode 利用 Snippets 设置超实用的代码块 - 掘金","categories":[{"name":"万能 VSCode","slug":"万能-VSCode","permalink":"http://example.com/categories/%E4%B8%87%E8%83%BD-VSCode/"}],"tags":[{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"}]},{"title":"QtCreator 快速添加注释模板","slug":"QtCreator快速添加注释模板","date":"2021-09-28T11:26:03.000Z","updated":"2022-10-15T03:14:29.458Z","comments":true,"path":"2021/09/28/QtCreator快速添加注释模板/","link":"","permalink":"http://example.com/2021/09/28/QtCreator%E5%BF%AB%E9%80%9F%E6%B7%BB%E5%8A%A0%E6%B3%A8%E9%87%8A%E6%A8%A1%E6%9D%BF/","excerpt":"","text":"需求通常函数的注释一般都比较长,而且每个函数注释都格式一致,例如下面的函数注释模板。如果每次写注释都要复制一遍比较麻烦,复制完还要删除多余的字符。但是现有的编辑器一般都支持快捷输入。下面介绍在 QtCreator 中如何快捷输入注释模板。 123456/* * Description: // 函数功能、性能等的描述 * Input Parameter: // 输入参数说明,包括每个参数的作 * Output Parameter: // 对输出参数的说明。 * Return: // 函数返回值的说明 */ 方法 QtCreator-菜单栏工具(Tool)- 选项(Options)- 文本编辑器(Text Editor)- 片段(Snippets) 组(Group)选择C++-添加(Add) 现在要为我们的触发(Trigger)起个名字,因为是函数注释,我起了个funcom,然后在下方空白框里填入注释模板。Apply 保存。如图 在需要添加注释模板的地方输入funcom即可提示快捷输入,回车即可添加注释模板。 我们可以看到片段里有很多熟悉的内容,比如if else,我们在写代码时输入if else自动补全花括号其实就是在这里设置的。同理,我们还可以设置一些其他需要的快捷输入内容。比如行注释,文件注释,经常使用的代码框架等等。","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"},{"name":"QtCreator","slug":"QtCreator","permalink":"http://example.com/tags/QtCreator/"}]},{"title":"Qt 修改 UI 文件不生效","slug":"Qt修改UI文件不生效","date":"2021-09-26T01:19:18.000Z","updated":"2022-10-15T03:14:29.466Z","comments":true,"path":"2021/09/26/Qt修改UI文件不生效/","link":"","permalink":"http://example.com/2021/09/26/Qt%E4%BF%AE%E6%94%B9UI%E6%96%87%E4%BB%B6%E4%B8%8D%E7%94%9F%E6%95%88/","excerpt":"","text":"保留现场修改了 UI 文件后,在代码中无法调用新增的内容。 探究原因导致ui_*.h文件没有更新的原因是源代码中#include ui_*.h的位置和实际生成的位置不同,引用的是老的ui_*.h 解决方法方法一: 项目设置文件.pro内增加 UI_DIR=./UI,同时删除掉源代码目录中ui_*.h,clear all,->qmake->rebuilt all方法二:","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"QtCreator 修改项目构建目录","slug":"QtCreator修改项目构建目录","date":"2021-09-25T11:17:46.000Z","updated":"2022-10-15T03:14:29.455Z","comments":true,"path":"2021/09/25/QtCreator修改项目构建目录/","link":"","permalink":"http://example.com/2021/09/25/QtCreator%E4%BF%AE%E6%94%B9%E9%A1%B9%E7%9B%AE%E6%9E%84%E5%BB%BA%E7%9B%AE%E5%BD%95/","excerpt":"","text":"保留现场QtCreator 构建项目时,会在统计目录新建一个build-xxx-debug的目录,如果想要自己修改这个目录的位置,名称,该怎么办。 解决方法仅修改工具(Tool)–>选项 (Options)–>构建和运行 (Build&Run) 中Default build directory:./%{CurrentBuild:Name}是不会生效的。 将工具–>选项–>构建和运行中Default build directory修改为./%{CurrentBuild:Name}(改为你想要的目标目录都行); 把 QtCreator 关闭,把工程目录下后缀名为.pro.user的文件删掉; 用 QtCreator 打开工程,会提示你创建构建目录,此时提示的就是你修改后的Default build directory中填写的目录; 其中.pro.user文件记录了编译器、构建工具链、构建目录、版本…..等工程编译相关信息,想要更换项目的编译环境,得删除这个文件,由 QtCreator 自动重新创建。","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"Git-把本地仓库同步到 GitHub","slug":"Git把本地仓库同步到GitHub","date":"2021-09-23T15:06:28.000Z","updated":"2022-10-15T03:14:29.239Z","comments":true,"path":"2021/09/23/Git把本地仓库同步到GitHub/","link":"","permalink":"http://example.com/2021/09/23/Git%E6%8A%8A%E6%9C%AC%E5%9C%B0%E4%BB%93%E5%BA%93%E5%90%8C%E6%AD%A5%E5%88%B0GitHub/","excerpt":"","text":"需求因为现在大部分情况下是先从远程 Clone 下来代码,所以这一功能用的不多。但是如果自己想把本地已有的代码同步到远程,本文就可以解决这一的需求。 方法 GitHub 新建一个仓库,并复制 SSH 地址 1git@github.com:git201901/git_learning.git git remote add 名称 1pc:git-learning suling$ git remote add github git@github.com:git201901/git_learning.git 这里的github就是自定义的一个名称,用于替换后面的远程地址。方便后续git push github以及git fetch github。","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"解决 Undefined reference to 问题","slug":"解决Undefined-reference-to问题","date":"2021-09-17T03:14:30.000Z","updated":"2022-10-15T03:14:29.846Z","comments":true,"path":"2021/09/17/解决Undefined-reference-to问题/","link":"","permalink":"http://example.com/2021/09/17/%E8%A7%A3%E5%86%B3Undefined-reference-to%E9%97%AE%E9%A2%98/","excerpt":"","text":"链接时缺失了相关目标文件这是最典型最常见的情况。比如新添加了一个模块fun.h fun.c两个文件,其他文件中使用了这个模块里的函数,如果编译时忘记加上这两个文件,调用fun模块函数的地方,就会报undefined reference错误。 这个问题在编辑器中一般不容易发现,因为头文件包含是正确的,编辑器能够找到相关的函数及其实现,所以在编写代码时不会报错。 链接时缺少相关的库文件这个原因和上一条类似,我们在调用静态库中的函数时,编译时如果没有将静态库一起编译,就会报同样的错误。 链接的库文件中又使用了另一个库文件在使用第三方库时,一定要在编译中加入第三方库的路径。 多个库文件链接顺序问题在链接命令中给出所依赖的库时,需要注意库之间的依赖顺序,依赖其他库的库一定要放到被依赖库的前面,这样才能真正避免 undefined reference 的错误,完成编译链接。 声明与实现不一致这个原因也比较典型,注意排查声明与实现的参数是否一致,返回值是否一致。 在 c++代码中链接 c 语言的库在C++代码中,调用了C语言库的函数,因此链接的时候找不到,解决方法是在相关文件添加一个extern "C"的声明即可。 总结顾名思义,这个错误就是未定义你使用的内容导致的。所以要排查使用的内容是否能够被正确“找到”。使用的时候有没有声明,有没有定义,声明与定义是否一致,编译时能否正确链接等等。 相关参考“undefined reference to” 问题汇总及解决方法","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"C++","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"C/C++如何避免过多使用全局变量","slug":"C-C-如何避免过多使用全局变量","date":"2021-09-17T02:49:15.000Z","updated":"2022-10-15T03:14:29.050Z","comments":true,"path":"2021/09/17/C-C-如何避免过多使用全局变量/","link":"","permalink":"http://example.com/2021/09/17/C-C-%E5%A6%82%E4%BD%95%E9%81%BF%E5%85%8D%E8%BF%87%E5%A4%9A%E4%BD%BF%E7%94%A8%E5%85%A8%E5%B1%80%E5%8F%98%E9%87%8F/","excerpt":"","text":"‘ 具体实例可以参考Marc Pony 指针传参C 语言中,全局变量用结构体封装,设计函数时,将参数以结构体指针形式传入。 定义获取变量的方法/函数定义一个函数以get/set全局变量,利用static变量,将全局变量作用域限定于该函数,将全局变量隐藏起来。 善用static把全局变量定义在某一个 .c 文件中,并定义为 static 类型,然后定义一系列操作这个变量的函数,头文件里面只有操作函数,没有变量的声明","categories":[],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"C++","slug":"C","permalink":"http://example.com/tags/C/"}]},{"title":"C 语言 sizeof(结构体) 到底有多大","slug":"C语言sizeof-结构体-到底有多大","date":"2021-09-15T10:38:07.000Z","updated":"2022-10-15T03:14:29.138Z","comments":true,"path":"2021/09/15/C语言sizeof-结构体-到底有多大/","link":"","permalink":"http://example.com/2021/09/15/C%E8%AF%AD%E8%A8%80sizeof-%E7%BB%93%E6%9E%84%E4%BD%93-%E5%88%B0%E5%BA%95%E6%9C%89%E5%A4%9A%E5%A4%A7/","excerpt":"","text":"C 语言中各个数据类型的大小 类型 大小 范围 char 1 字节 -128 到 127 或 0 到 255 unsigned char 1 字节 0 到 255 signed char 1 字节 -128 到 127 int 2 或 4 字节 -32,768 到 32,767 或 -2,147,483,648 到 2,147,483,647 unsigned int 2 或 4 字节 0 到 65,535 或 0 到 4,294,967,295 short 2 字节 -32,768 到 32,767 unsigned short 2 字节 0 到 65,535 long 4 字节 -2,147,483,648 到 2,147,483,647 unsigned long 4 字节 0 到 4,294,967,295 结构体 (struct) 待分析,需要考虑字节对齐 联合 (union) 所有成员中最长的 枚举 (enum) 根据数据类型 单层结构体大小如果结构体中的成员数据类型相同,这样的情况最简单,结构体大小=数据类型*数据个数。 123456789101112131415161718192021222324#include <stdio.h>typedef struct Test1{ int a; int b;} T1;typedef struct Test2{ char a; char b;} T2;int main(){ T1 t1; int siz01 = sizeof(t1); printf("%d\\n", siz01); //8 T2 t2; int siz02 = sizeof(t2); printf("%d\\n", siz02); //2 return 0;} 但是结构体中通常数据类型都各不相同,成员按照定义时的顺序依次存储在连续的内存空间。和数组不一样的是,结构体的大小不是所有成员大小简单的相加,需要考虑到地址对齐问题。看下面这样的一个结构体: 123456789101112131415#include <stdio.h>typedef struct Test3{ int a; char b; int c;} T3;int main(){ T3 t3; int siz03 = sizeof(t3); printf("t3: %d\\n", siz03); //t3: 12 return 0;} 用sizeof求该结构体的大小,发现值为12。int占4个字节,char占1个字节,结果应该是9个字节才对啊,为什么呢? 先介绍一个相关的概念——偏移量。偏移量指的是结构体变量中成员的地址和结构体变量地址的差。结构体大小等于最后一个成员的偏移量加上最后一个成员的大小。显然,结构体变量中第一个成员的地址就是结构体变量的首地址。因此,第一个成员int a的偏移量为0。第二个成员char b的偏移量是第一个成员的偏移量加上第一个成员的大小0+4,其值为4;第三个成员int c的偏移量是第二个成员的偏移量加上第二个成员的大小4+1,其值为5。 即结构体的大小等于最后一个成员变量的地址与第一个成员变量的地址之差,再加上最后一个成员变量的大小。 如果不考虑对齐的情况,变量在内存中的存放如下, 12345//t3 ________0 |aaaabccc| 78 |c | 15 ‾‾‾‾‾‾‾‾ 当我们凭直觉去用4+1+4=9来计算结构体大小时并不会觉得有什么错,但是通过内存的排放可以直观的看到,第三个变量的存放有点奇怪。CPU 从内存中读取肯定也是极为不便的。实际存储变量时,地址要求对齐的。编译器在编译程序时会遵循两条原则: 结构体变量中成员的偏移量必须是成员大小的整数倍(0被认为是任何数的整数倍) 结构体大小必须是所有成员大小的整数倍,也即所有成员大小的公倍数。 我们在回头分析上述的例子,前两个成员的偏移量0 4都满足要求,但第三个成员的偏移量为5,并不是自身int大小的整数倍。编译器在处理时会在第二个成员后面补上3个空字节,使得第三个成员的偏移量变成8。结构体大小等于最后一个成员的偏移量加上其大小,上面的例子中计算出来的大小为12,满足公倍数要求。 直观描述这个结构体在内存中的存储如下,星号*表示该段内存因为内存对齐被占用,也就是其实际大小。字母个数表示其单独拿出来的大小 12345//t3 ________0 |aaaab***| 78 |cccc | 15 ‾‾‾‾‾‾‾‾ 再看一例, 12345678910111213#include <stdio.h>typedef struct Test4{ int a; short b;} T4;int main(){ T4 t4; int siz04 = sizeof(t4); printf("t4: %d\\n", siz04); //t4: 8 return 0;} 成员int a的偏移量为 0;成员short b的偏移量为 4,都不需要调整。但计算出来的大小为6,显然不是成员int a大小的整数倍。因此,编译器会在成员int b后面补上2个字节,使得结构体的大小变成8从而满足第二个公倍数要求。 由此可见,结构体类型需要考虑到字节对齐的情况,不同的顺序会影响结构体的大小。 123456789101112131415161718192021222324#include <stdio.h>typedef struct Test5{ char a; int b; char c;} T5;typedef struct Test6{ char a; char b; int c;} T6;int main(){ T5 t5; int siz05 = sizeof(t5); printf("t5: %d\\n", siz05); //t5: 12 T4 t6; int siz06 = sizeof(t6); printf("t6: %d\\n", siz06); //t6: 8 return 0;} 两个结构体成员都一样,但是一个大小为12一个大小为8。我们将其在内存的存储画出来就可以明白, 123456789//t5 ________0 |a***bbbb| 78 |c*** | 15 ‾‾‾‾‾‾‾‾//t6 ________0 |ab**cccc| 7 ‾‾‾‾‾‾‾‾ 总结: 结构体大小等于最后一个成员的偏移量加上最后一个成员的大小 结构体变量中成员的偏移量必须是成员大小的整数倍(0被认为是任何数的整数倍) 结构体大小必须是所有成员大小的整数倍,也即所有成员大小的公倍数 不同的顺序会影响结构体的大小 嵌套结构体大小对于嵌套的结构体,需要将其展开。对结构体求sizeof时,上述两种原则变为: 展开后的结构体的第一个成员的偏移量应当是被展开的结构体中最大的成员的整数倍。 结构体大小必须是所有成员大小的整数倍,这里所有成员计算的是展开后的成员,而不是将嵌套的结构体当做一个整体。 123456789101112131415161718#include <stdio.h>typedef struct Test7{ short a; struct { char b; int c; } tt; int d;} T7;int main(){ T7 t7; int siz07 = sizeof(t7); printf("t7: %d\\n", siz07); //t7: 16 return 0;} 根据原则一,tt的偏移量应该是4,而不是2。 在内存中的存储, 12345//t7 ________0 |aa**b***| 78 |ccccdddd| 15 ‾‾‾‾‾‾‾‾ 1234567891011121314151617181920212223#include <stdio.h>typedef struct Test8{ char a; struct { char b; int c; } tt; char d; char e; char f; char g; char h;} T8;int main(){ T8 t8; int siz08 = sizeof(t8); printf("t8: %d\\n", siz08); //t8: 20 return 0;} 结构体tt单独计算占用空间为8,而t8则是20,不是8的整数倍,这说明在计算sizeof(t8)时,将嵌套的结构体tt展开了,这样t8中最大的成员为tt.c,占用 4 个字节,20为 4 的整数倍。如果将tt当做一个整体,结果应该是24了。 在内存中的存储, 123456//t8 ________0 |a***b***| 78 |ccccdefg| 1516 |h*** | 31 ‾‾‾‾‾‾‾‾ 另一个特殊的例子是结构体中包含数组,其大小计算应当和处理嵌套结构体一样,将其展开,如下例子: 1234567891011121314#include <stdio.h>typedef struct Test9{ char a; float b; int c[2];} T9;int main(){ T9 t9; int siz09 = sizeof(t9); printf("t9: %d\\n", siz09); //t9: 16 return 0;} char a占一个字节,偏移量为0,short b占四字节,偏移量为2,不是最大成员的整数倍,这里取最大成员是int或者short的大小的倍数。而不是整个数组int c[2]的倍数。所以short b偏移量扩展为4。 内存中存储, 12345//t9 ________0 |a***bbbb| 78 |cccccccc| 15 ‾‾‾‾‾‾‾‾ 总结: 展开后的结构体的第一个成员的偏移量应当是被展开的结构体中最大的成员的整数倍。 结构体大小必须是所有成员大小的整数倍,这里所有成员计算的是展开后的成员,而不是将嵌套的结构体当做一个整体。 想象在内存中的存储,保证对齐要求,基本上可以比较准确的算出来","categories":[],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"}]},{"title":"Qt 命令行带参数启动 Qt 程序","slug":"Qt命令行带参数启动Qt程序","date":"2021-09-13T04:03:44.000Z","updated":"2022-10-15T03:14:29.468Z","comments":true,"path":"2021/09/13/Qt命令行带参数启动Qt程序/","link":"","permalink":"http://example.com/2021/09/13/Qt%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%B8%A6%E5%8F%82%E6%95%B0%E5%90%AF%E5%8A%A8Qt%E7%A8%8B%E5%BA%8F/","excerpt":"","text":"简介我们经常用到命令行参数,比如最常见的 Linux 命令,显示所有文件ls -a,ls其实就是一个程序,-a就是该程序需要解析的一个参数。那么如何能让 Qt 程序也能解析命令行参数,从命令行启动呢? Qt 从 5.2 版开始提供了两个类QCommandLineOption和QCommandLineParser来解析应用的命令行参数。 添加程序属性信息,帮助,版本一个程序启动后,我们会在命令行看到程序的一些简要信息,以及可以使用-v命令显示其版本信息,这些通用的参数以及被 Qt 分装好,可以直接使用。 123456789101112131415161718#include "mainwindow.h"#include <QApplication>#include <QCommandLineParser>int main(int argc, char *argv[]){ QApplication a(argc, argv); QCommandLineParser parser; // 定义解析实例 parser.setApplicationDescription("TestCommandLine"); // 描述可执行程序的属性 parser.addHelpOption(); // 添加帮助命令 parser.addVersionOption(); // 添加版本选择命令 parser.process(a); // 把用户的命令行的放入解析实例 MainWindow w; w.show(); return a.exec();} 运行结果: 12345678➜ ./CommandLine -hUsage: ./CommandLine [options]TestCommandLineOptions: -h, --help Displays help on commandline options. --help-all Displays help including Qt specific options. -v, --version Displays version information. 自定义参数12345678910111213141516171819202122232425#include "mainwindow.h"#include <QApplication>#include <QCommandLineParser>#include <QCommandLineOption>int main(int argc, char *argv[]){ QApplication a(argc, argv); QCommandLineParser parser; // 定义解析实例 parser.setApplicationDescription("TestCommandLine"); // 描述可执行程序的属性 parser.addHelpOption(); // 添加帮助命令 parser.addVersionOption(); // 添加版本选择命令 QCommandLineOption CommandExe("c", QGuiApplication::translate("main","Take the first argument as a command to execute, " "rather than reading commands from a script or standard input. " "If any fur‐\\ther arguments are given, " "the first one is assigned to $0," " rather than being used as a positional parameter.")); parser.addOption(CommandExe); parser.process(a); // 把用户的命令行的放入解析实例 MainWindow w; w.show(); return a.exec();} 运行结果: 123456789101112➜ ./CommandLine -hUsage: ./CommandLine [options]TestCommandLineOptions: -h, --help Displays help on commandline options. --help-all Displays help including Qt specific options. -v, --version Displays version information. -c Take the first argument as a command to execute, rather than reading commands from a script or standard input. If any fur‐ her arguments are given, the first one is assigned to $0, rather than being used as a positional parameter. 获取参数值如果需要从命令行获取参数值,那么必须要给参数值,指定一个名字。如,参数接收的是路径,可以setValueName("path"),如,参数接收的是个数值,可以setValueName("value")。 如果不设置参数值名称,那么将无法获取其值。","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"}]},{"title":"Git 不同人修改了不同的文件该如何处理","slug":"Git不同人修改了不同的文件该如何处理","date":"2021-09-12T15:19:28.000Z","updated":"2022-10-15T03:14:29.218Z","comments":true,"path":"2021/09/12/Git不同人修改了不同的文件该如何处理/","link":"","permalink":"http://example.com/2021/09/12/Git%E4%B8%8D%E5%90%8C%E4%BA%BA%E4%BF%AE%E6%94%B9%E4%BA%86%E4%B8%8D%E5%90%8C%E7%9A%84%E6%96%87%E4%BB%B6%E8%AF%A5%E5%A6%82%E4%BD%95%E5%A4%84%E7%90%86/","excerpt":"","text":"需求同一个项目,不同的开发者修改了不同的文件,如何解决同步冲突。 模拟用户一修改第一个用户新建一个分支, 以上命令就是新建一个分支feature/add_git_commands 将其与远端分支origin/feature/add_git_commands相关联,并切换到该分支。 修改 readme 文件,并推送到远端。因为新建分支时已经做了与远端关联,所以可以直接git push。 用户二修改第二个用户,首先拉取远端分支。 git branch -v查看本地分支,保持不变,但是git branch -av查看所有分支,可以发现多了两个远端分支。 新建本地分支,保持与远端分支名相同。 此时再对与 readme 不同的文件进行修改,提交,推送都会比较顺利。因为当前分支保持fast forward。 用户二继续做开发,但是没再往远端推送代码。在此期间,用户一对远端代码进行了更新。用户二想再次推送代码,将会报错,提示当前提交不再fast forward。 解决方法 git fetch远端分支 git merge合并远端分支 因为两个用户修改的不同文件,所以合并不会产生冲突。","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"解决 TypeError [ERR_INVALID_ARG_TYPE]: The data argument must be of type string or an instance of Buffe","slug":"解决TypeError-ERR-INVALID-ARG-TYPE-The-data-argument-must-be-of-type-string-or-an-instance-of-Buffe","date":"2021-09-10T07:59:34.000Z","updated":"2022-10-15T03:14:29.839Z","comments":true,"path":"2021/09/10/解决TypeError-ERR-INVALID-ARG-TYPE-The-data-argument-must-be-of-type-string-or-an-instance-of-Buffe/","link":"","permalink":"http://example.com/2021/09/10/%E8%A7%A3%E5%86%B3TypeError-ERR-INVALID-ARG-TYPE-The-data-argument-must-be-of-type-string-or-an-instance-of-Buffe/","excerpt":"","text":"安装 GitBook 时出现这个错误,将node版本降级即可 12345678MINGW64 ~/Desktop/dir1/dir11$ gitbook initwarn: no summary file in this bookinfo: create SUMMARY.mdTypeError [ERR_INVALID_ARG_TYPE]: The "data" argument must be of type string or an instance of Buffer, TypedArray, or DataView. Received an instance ofPromise","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"C 语言预处理","slug":"C语言预处理","date":"2021-09-09T06:10:40.000Z","updated":"2022-10-15T03:18:34.051Z","comments":true,"path":"2021/09/09/C语言预处理/","link":"","permalink":"http://example.com/2021/09/09/C%E8%AF%AD%E8%A8%80%E9%A2%84%E5%A4%84%E7%90%86/","excerpt":"","text":"什么是预处理C 语言通过预处理器提供了一些语言功能。从概念上讲,预处理器是编译过程中单独执行的第一个步骤。两个最常用的预处理器指令是:#include 指令 (用于在编译期间把指定文件的内容包含进当前文件中) 和 #define 指令 (用任意字符序列替代一个标记)。 为啥要进行预先处理呢?如果要深入的了解的话可以参考《程序员的自我修养:链接、装载与库》这本书。这里举一个非常常见的例子,假如我们编写跨平台的程序时,我们就需要考虑不同平台的系统库是不同的,如果只包含了一个平台下的库文件,换个平台编译就可能出错。这时候就需要在编译前进行预处理。 有重要的预处理器指令:| 指令 | 描述||:———-:|:—–:|| #define | 定义宏|| #include | 包含一个源代码文件|| #undef | 取消已定义的宏|| #ifdef | 如果宏已经定义,则返回真|| #ifndef | 如果宏没有定义,则返回真|| #if | 如果给定条件为真,则编译下面代码|| #else | #if 的替代方案|| #elif | 如果前面的 #if 给定条件不为真,当前条件为真,则编译下面代码 || #endif | 结束一个 #if……#else 条件编译块|| #error | 当遇到标准错误时,输出错误消息|| #pragma | 使用标准化方法,向编译器发布特殊的命令到编译器中| 条件编译#if123456789#if 整型常量表达式1 程序段1#elif 整型常量表达式2 程序段2#elif 整型常量表达式3 程序段3#else 程序段4#endif 它的意思是:如常“表达式 1”的值为真(非 0),就对“程序段 1”进行编译,否则就计算“表达式 2”,结果为真的话就对“程序段 2”进行编译,为假的话就继续往下匹配,直到遇到值为真的表达式,或者遇到 #else 。这一点和 if else 非常类似。 需要注意的是, #if 命令要求判断条件为整型常量表达式,也就是说,表达式中不能包含变量,而且结果必须是整数;而 if 后面的表达式没有限制,只要符合语法就行。这是 #if 和 if 的一个重要区别。 1234567891011121314151617#include <stdio.h>//不同的平台下引入不同的头文件#if _WIN32 //识别 Windows 平台#include <windows.h>#elif __linux__ //识别 Linux 平台#include <unistd.h>#endifint main() { //不同的平台下调用不同的函数 #if _WIN32 //识别 Windows 平台 Sleep(5000); #elif __linux__ //识别 Linux 平台 sleep(5); #endif puts("http://c.biancheng.net/"); return 0;} #ifedf12345#ifdef 宏名 程序段1#else 程序段2#endif #ifndef12345#ifndef 宏名 程序段1 #else 程序段2 #endif 与#ifdef相比,仅仅是将 #ifdef 改为了 #ifndef。它的意思是,如果当前的宏未被定义,则对“程序段 1”进行编译,否则对“程序段 2”进行编译,这与#ifdef 的功能正好相反。 文件包含#include#include 叫做文件包含命令,用来引入对应的头文件(.h 文件)。 #include 的处理过程很简单,就是将头文件的内容插入到该命令所在的位置,从而把头文件和当前源文件连接成一个源文件,这与复制粘贴的效果相同。 #include 的用法有两种,如下所示: 12#include <stdHeader.h>#include "myHeader.h" 使用尖括号 < > 和双引号 " " 的区别在于头文件的搜索路径不同: 使用尖括号< >,编译器会到环境变量下查找头文件; 使用双引号" ",编译器首先在当前目录下查找头文件,如果没有找到,再到环境变量下查找。 注意事项: 在头文件中尽量不要进行函数的定义,只对其进行声明。否则如果有多个源文件链接时会报错 某一个头文件的内容发生变化,所有包含该文件的源文件都需要重新编译 一个#include命令指定一个头文件,多个头文件需要多个#include 包含可以嵌套 文件 1 包含文件 2,文件 2 用到文件 3,则文件 3 的包含命令#include 应放在文件 1 的头部第一行; 被包含文件中的静态全局变量不用在包含文件中声明 宏定义what#define 叫做宏定义命令,它也是 C 语言预处理命令的一种。所谓宏定义,就是用一个标识符来表示一个字符串,如果在后面的代码中出现了该标识符,那么就全部替换成指定的字符串。 123456#define 宏名 字符串 //基本格式#define N 100 //将所有N都替换成整数100#define forever for (;;) //该语句为无限循环定义了一个新名字forever#define max(A, B) ((A)> (B) ? (A) : (B) ) why对于函数,其调用必须要将程序执行的顺序跳转到函数所在内存的某个地址,在将函数程序执行完成后,再跳转回去执行函数调用前的地方。这种跳转操作要求在函数执行前保存现场并记录当前执行地址,函数调用返回后要恢复现场,并按原来保存地址继续执行。因此,函数调用会有一定的时间和空间方面的开销,必将影响程序的运行效率。 对于宏,它只是在预处理的地方把代码展开,而不需要额外的空间和时间方面的开销,因此调用宏比调用函数更有效率。 但是,宏也有很多的问题和缺陷: 在 C 语言中,宏容易出现一些边界性的问题,容易产生歧义。(优先级的问题,能加括号都加括号) 在 C++语言中,宏不可以调用 C++类中的私有或受保护的成员。 Tips 能用括号的地方都用括号,不要偷懒省略,以免歧义,特别是于带参宏定义不仅要在参数两侧加括号,还应该在整个字符串外加括号 宏定义不是说明或语句,在行末不必加分号,如加上分号则连分号也一起替换 宏定义必须写在函数之外,其作用域为宏定义命令起到源程序结束。如要终止其作用域可使用#undef命令 代码中的宏名如果被引号包围,那么预处理程序不对其作宏代替 宏定义允许嵌套,在宏定义的字符串中可以使用已经定义的宏名,在宏展开时由预处理程序层层代换 习惯上宏名用大写字母表示,以便于与变量区别 可用宏定义表示数据类型,使书写方便 带参数的宏和函数很相似,但有本质上的区别:宏展开仅仅是字符串的替换,不会对表达式进行计算;宏在编译之前就被处理掉了,它没有机会参与编译,也不会占用内存。而函数是一段可以重复使用的代码,会被编译,会给它分配内存,每次调用函数,就是执行这块内存中的代码。 内联函数从上文可知,可以看到宏有一些难以避免的问题,对于不能访问 C++类中私有或者受保护的成员,我们应该如何解决呢? what关键字 inline 告诉编译器,任何地方只要调用内联函数,就直接把该函数的机器码插入到调用它的地方。这样程序执行更有效率,就好像将内联函数中的语句直接插入到了源代码文件中需要调用该函数的地方一样。 why内联函数是代码被插入到调用者代码处的函数。如同 #define 宏,内联函数通过避免被调用的开销来提高执行效率,尤其是它能够通过调用(过程化集成)被编译器优化。 内联函数和宏很类似,而区别在于,宏是由预处理器对宏进行替代,而内联函数是通过编译器控制来实现的。而且内联函数是真正的函数,只是在需要用到的时候,内联函数像宏一样的展开,所以取消了函数的参数压栈,减少了调用的开销。你可以像调用函数一样来调用内联函数,而不必担心会产生于处理宏的一些问题。 How对于内联函数,其工作原理是: 对于任何内联函数,编译器在符号表里放入函数的声明(包括名字、参数类型、返回值类型)。如果编译器没有发现内联函数存在错误,那么该函数的代码也被放入符号表里。在调用一个内联函数时,编译器首先检查调用是否正确(进行类型安全检查,或者进行自动类型转换,当然对所有的函数都一样)。如果正确,内联函数的代码就会直接替换函数调用,于是省去了函数调用的开销。 这个过程与预处理有显著的不同,因为预处理器不能进行类型安全检查,或者进行自动类型转换。假如内联函数是成员函数,对象的地址(this)会被放在合适的地方,这也是预处理器办不到的。 Tips 当你定义一个内联函数时,在函数定义前加上 inline 关键字,并且将定义放入头文件。 内联函数必须是和函数体声明在一起才有效 内联函数不宜过大,比如循环体,递归体就不适合内联。如果过大,编译器会放弃内联,采用普通方式调用函数。 相关参考C 预处理器C 语言预处理命令是什么?C 语言中宏与内联函数解析C 语言内联函数内联函数","categories":[],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"}]},{"title":"解决 expected 'char * const*' but argument is of type 'char **'","slug":"解决expected-char-const-but-argument-is-of-type-char","date":"2021-09-08T11:07:27.000Z","updated":"2022-10-15T03:14:29.799Z","comments":true,"path":"2021/09/08/解决expected-char-const-but-argument-is-of-type-char/","link":"","permalink":"http://example.com/2021/09/08/%E8%A7%A3%E5%86%B3expected-char-const-but-argument-is-of-type-char/","excerpt":"","text":"在使用exec系列函数时,execle,execv,execvp三个函数,都可以使用char *arg[]传入启动参数。以下面的程序为例, 12345678910111213#include <stdio.h>#include <stdlib.h>#include <unistd.h>int main(void){ int ret; char *argv[] = {"ls","-l",NULL}; ret = execvp("ls",argv); if(ret == -1) perror("execl error"); return 0;} 编译时就会出现一下,警告, 1expected 'char * const*' but argument is of type 'const char **' 因为项目中不允许警告产生,所以编译选项是-Werror,所有警告都会被升级成错误。编译时就会产生如下提示, 1ccl : all warnings being treated as errors 如果是平时练习,改一下编译选项,把这个警告忽略就行,但是现在只能解决。 出现这个问题就是因为定义数组时char *argv[]类型是char **。但是execvp()函数签名是execvp(const char *file, char *const argv[]);第二个参数的类型是char * const *。 本以为直接将变量定义更改成char * const argv[]就行了,但是它等价于const char **,所以仍然不能和函数签名匹配。 实在没办法只能改成如下: 1234567891011121314151617#include <stdio.h>#include <stdlib.h>#include <unistd.h>int main(void){ printf("entering main process---\\n"); int ret; char str1[] = "ls"; char str2[] = "-l"; char * const argv[] = {str1, str2, NULL}; ret = execvp("ls",argv); if(ret == -1) perror("execl error"); printf("exiting main process ----\\n"); return 0;} 或者在将形参argv进行强制转换。 123456789101112131415#include <stdio.h>#include <stdlib.h>#include <unistd.h>int main(void){ printf("entering main process---\\n"); int ret; char const *argv[] = {"ls", "-l", NULL}; ret = execvp("ls",(char * const *)argv); if(ret == -1) perror("execl error"); printf("exiting main process ----\\n"); return 0;}","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"VSCode 中调试带 Makefile 文件的项目","slug":"VSCode中调试带Makefile文件的项目","date":"2021-09-06T07:41:56.000Z","updated":"2022-10-15T02:59:01.683Z","comments":true,"path":"2021/09/06/VSCode中调试带Makefile文件的项目/","link":"","permalink":"http://example.com/2021/09/06/VSCode%E4%B8%AD%E8%B0%83%E8%AF%95%E5%B8%A6Makefile%E6%96%87%E4%BB%B6%E7%9A%84%E9%A1%B9%E7%9B%AE/","excerpt":"","text":"在调试 QEMU 时,自己需要修改源文件,但是每次修改都需要在命令行重新make编译一遍,比较麻烦,想到之前刚刚配置过tasks.json文件,可以把命令行任务配置到文件里,make命令不也一样可以加入吗?修改tasks.json文件如下: 1234567891011121314151617181920212223242526272829303132{ "version": "2.0.0", "tasks": [ { //任务的名字方便执行 "label": "make qemu", "type": "shell", "command": "make", "args":[ //8 线程编译 "-j8", ], "options": { //切换到 build 文件夹下 "cwd": "${workspaceFolder}/build" }, }, { // 启动 qemu 供调试器连接 "type": "shell", "label": "Run Qemu Server(RISCV)", //在执行这个任务前,先执行 make qemu 任务、 //这样就可以在执行调试时,自动先编译一遍 "dependsOn": "make qemu", "command": "qemu-system-riscv64", "args": [ "-g", "${workspaceFolder}/debug/${fileBasenameNoExtension}" ], }, ]}","categories":[{"name":"万能 VSCode","slug":"万能-VSCode","permalink":"http://example.com/categories/%E4%B8%87%E8%83%BD-VSCode/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"}]},{"title":"解决 gcc-multilib : 依赖:gcc-4.8-multilib (>= 4.8.2-5~) 但是它将不会被安装","slug":"解决gcc-multilib-依赖-gcc-4-8-multilib-4-8-2-5-但是它将不会被安装","date":"2021-09-03T02:44:44.000Z","updated":"2022-10-15T03:14:29.804Z","comments":true,"path":"2021/09/03/解决gcc-multilib-依赖-gcc-4-8-multilib-4-8-2-5-但是它将不会被安装/","link":"","permalink":"http://example.com/2021/09/03/%E8%A7%A3%E5%86%B3gcc-multilib-%E4%BE%9D%E8%B5%96-gcc-4-8-multilib-4-8-2-5-%E4%BD%86%E6%98%AF%E5%AE%83%E5%B0%86%E4%B8%8D%E4%BC%9A%E8%A2%AB%E5%AE%89%E8%A3%85/","excerpt":"","text":"问题这是一类问题,不仅限于安装 gcc,这类问题的根本原因在于,Ubuntu 已安装的软件包版本高,而所安装软件的依赖包版本低,这样在安装高版软件时,已有的软件包依赖你要安装的软件包,你把软件包升级了,可能就会破坏这个依赖关系,所以apt-get不让你安装。 这时就要请到大杀器-aptitude,它与 apt-get一样,是 Debian 及其衍生系统中功能极其强大的包管理工具。与 apt-get 不同的是,aptitude在处理依赖问题上更佳一些。举例来说,aptitude在删除一个包时,会同时删除本身所依赖的包。这样,系统中不会残留无用的包,整个系统更为干净。 方法12$sudo apt-get install aptitude //安装aptitude包管理器$sudo aptitude install gcc-multilib //用新的包管理器安装你要安装的软件 安装gcc-multilib时会把所有依赖包一并安装,此时会让你同意,选择n就行。 接下来就会解决已经安装的包之间的依赖关系,他会降级或升级一些软件包来匹配当前安装的软件版本,此时选择y。 完成以上操作,再次正常安装需要的软件包即可成功安装。 如果无法正常安装,重复以上操作,每次都选择n。","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"解决 fatal error: bits/libc-header-start.h:no such file","slug":"解决fatal-error-bits-libc-header-start-h:no-such-file","date":"2021-09-03T01:26:34.000Z","updated":"2022-10-15T03:14:29.803Z","comments":true,"path":"2021/09/03/解决fatal-error-bits-libc-header-start-h:no-such-file/","link":"","permalink":"http://example.com/2021/09/03/%E8%A7%A3%E5%86%B3fatal-error-bits-libc-header-start-h%EF%BC%9Ano-such-file/","excerpt":"","text":"保留现场想要分别编译 32 位和 64 位的程序时,gcc 出现了错误, 12345In file included from func_call.c:1:/usr/include/stdio.h:27:10: fatal error: bits/libc-header-start.h: 没有那个文件或目录 27 | #include <bits/libc-header-start.h> | ^~~~~~~~~~~~~~~~~~~~~~~~~~compilation terminated. 问题解决问题原因猜测是默认 gcc 只提供当前机器的版本,解决如下 1apt install gcc-multilib","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"},{"name":"汇编语言","slug":"汇编语言","permalink":"http://example.com/tags/%E6%B1%87%E7%BC%96%E8%AF%AD%E8%A8%80/"},{"name":"GCC","slug":"GCC","permalink":"http://example.com/tags/GCC/"}]},{"title":"QEMU 源码分析-虚拟 CPU 创建","slug":"QEMU源码分析-虚拟CPU创建","date":"2021-09-01T10:22:14.000Z","updated":"2022-10-15T03:14:29.445Z","comments":true,"path":"2021/09/01/QEMU源码分析-虚拟CPU创建/","link":"","permalink":"http://example.com/2021/09/01/QEMU%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90-%E8%99%9A%E6%8B%9FCPU%E5%88%9B%E5%BB%BA/","excerpt":"","text":"流程图先开个头吧,把创建流程稍微捋一下,找到创建虚拟 CPU 的模块。至于中间的流程还没有详细分析,万事开头难,先上手再说吧。 qemu_add_opts解析 qemu 的命令行qemu_init函数中下面这一长串内容,就是在解析命令行的参数。 1234567891011121314151617qemu add opts (&qemu drive opts);qemu add drive opts(&qemu Legacy drive opts);qemu add drive opts (&qemu common drive opts);qemu add drive opts (&qemu drive opts);qemu add drive opts (sbdry runtime opts);qemu add opts (qemu chardev opts);qemu add opts (&qemu device opts);qemu add opts (&qemu netdev opts);qemu add opts (&qemu nic opts);qemu add opts (sqemu net optsqemu add opts (&qemu rtc opts)qemu add opts (&qemu global_opts);qemu add opts (&qemu mon opts);qemu add opts (sqemu trace opts);... 为什么有这么多的 opts呢?这是因为,实际运行中创建的kvm参数会复杂N倍。这里我们贴一个开源云平台软件 OpenStack 创建出来的KVM的参数,如下所示。 12345678910111213141516qemu-system-x86_64-enable-kvm-name instance-00000024-machine pc-i440fx-trusty,accel=kvm,usb=off-cpu SandyBridge,+erms,+smep,+fsgsbase,+pdpe1gb,+rdrand,+f16c,+osxsave,+dca,+pcid,+pdcm,+xtpr,+tm2,+est,+smx,+vmx,+ds_cpl,+monitor,+dtes64,+pbe,+tm,+ht,+ss,+acpi,+ds,+vme-m 2048-smp 1,sockets=1,cores=1,threads=1......-rtc base=utc,driftfix=slew-drive file=/var/lib/nova/instances/1f8e6f7e-5a70-4780-89c1-464dc0e7f308/disk,if=none,id=drive-virtio-disk0,format=qcow2,cache=none-device virtio-blk-pci,scsi=off,bus=pci.0,addr=0x4,drive=drive-virtio-disk0,id=virtio-disk0,bootindex=1-netdev tap,fd=32,id=hostnet0,vhost=on,vhostfd=37-device virtio-net-pci,netdev=hostnet0,id=net0,mac=fa:16:3e:d1:2d:99,bus=pci.0,addr=0x3-chardev file,id=charserial0,path=/var/lib/nova/instances/1f8e6f7e-5a70-4780-89c1-464dc0e7f308/console.log-vnc 0.0.0.0:12-device cirrus-vga,id=video0,bus=pci.0,addr=0x2 -enable-kvm:表示启用硬件辅助虚拟化。 -name instance-00000024:表示虚拟机的名称。 -machine pc-i440fx-trusty,accel=kvm,usb=off:machine 是什么呢?其实就是计算机体系结构。不知道什么是体系结构的话,可以订阅极客时间的另一个专栏《深入浅出计算机组成原理》。qemu 会模拟多种体系结构,常用的有普通 PC 机,也即 x86 的 32 位或者 64 位的体系结构、Mac 电脑 PowerPC 的体系结构、Sun 的体系结构、MIPS 的体系结构,精简指令集。如果使用 KVM hardware-assisted virtualization,也即 BIOS 中 VD-T 是打开的,则参数中 accel=kvm。如果不使用 hardware-assisted virtualization,用的是纯模拟,则有参数 accel = tcg,-no-kvm。 -cpu SandyBridge,+erms,+smep,+fsgsbase,+pdpe1gb,+rdrand,+f16c,+osxsave,+dca,+pcid,+pdcm,+xtpr,+tm2,+est,+smx,+vmx,+ds_cpl,+monitor,+dtes64,+pbe,+tm,+ht,+ss,+acpi,+ds,+vme:表示设置 CPU,SandyBridge 是 Intel 处理器,后面的加号都是添加的 CPU 的参数,这些参数会显示在 /proc/cpuinfo 里面。 -m 2048:表示内存。 -smp 1,sockets=1,cores=1,threads=1:SMP 我们解析过,叫对称多处理器,和NUMA 对应。qemu 仿真了一个具有 1 个 vcpu,一个 socket,一个 core,一个 threads 的处理器。socket、core、threads 是什么概念呢?socket 就是主板上插 CPU 的槽的数目,也即常说的“路”,core 就是我们平时说的“核”,即双核、4 核等。thread 就是每个 core 的硬件线程数,即超线程。举个具体的例子,某个服务器是:2 路 4 核超线程(一般默认为 2 个线程),通过 cat /proc/cpuinfo,我们看到的是 242=16 个processor,很多人也习惯成为 16 核了。 -rtc base=utc,driftfix=slew:表示系统时间由参数 -rtc 指定。 -device cirrus-vga,id=video0,bus=pci.0,addr=0x2:表示显示器用参数 -vga 设置,默认为 cirrus,它模拟了 CL-GD5446PCI VGA card。 有关网卡,使用 -net 参数和 -device。 从 HOST 角度:-netdev tap,fd=32,id=hostnet0,vhost=on,vhostfd=37。 从 GUEST 角度:-device virtio-net-pci,netdev=hostnet0,id=net0,mac=fa:16:3e:d1:2d:99,bus=pci.0,addr=0x3。 有关硬盘,使用 -hda -hdb,或者使用 -drive 和 -device。 从 HOST 角度:-drive file=/var/lib/nova/instances/1f8e6f7e-5a70-4780-89c1-464dc0e7f308/disk,if=none,id=drive-virtio-disk0,format=qcow2,cache=none 从 GUEST 角度:-device virtio-blk-pci,scsi=off,bus=pci.0,addr=0x4,drive=drive-virtio-disk0,id=virtio-disk0,bootindex=1 -vnc 0.0.0.0:12:设置 VNC。 module_call_init初始化所有模块1234int main()--> qemu_init()--> qemu_init_subsystems()--> module_call_init() 当虚拟机真的要使用物理资源的时候,对下面的物理机上的资源要进行请求,所以它的工作模式有点儿类似操作系统对接驱动。驱动要符合一定的格式,才能算操作系统的一个模块。同理,qemu 为了模拟各种各样的设备,也需要管理各种各样的模块,这些模块也需要符合一定的格式。 定义一个 qemu 模块会调用 type_init。例如,kvm 的模块要在 accel/kvm/kvm-all.c 文件里面实现。在这个文件里面,有一行下面的代码: 1234567891011121314static const TypeInfo kvm_accel_type = { .name = TYPE_KVM_ACCEL, .parent = TYPE_ACCEL, .instance_init = kvm_accel_instance_init, .class_init = kvm_accel_class_init, .instance_size = sizeof(KVMState),};static void kvm_type_init(void){ type_register_static(&kvm_accel_type);}type_init(kvm_type_init); 找到type_init的定义 1#define type_init(function) module_init(function, MODULE_INIT_QOM) 从代码里面的定义我们可以看出来,type_init 后面的参数是一个函数,调用 type_init 就相当于调用 module_init,在这里函数就是 kvm_type_init,类型就是 MODULE_INIT_QOM。 再查看一下module_init的定义 123456//include/qemu/module.h#define module_init(function, type) \\static void __attribute__((constructor)) do_qemu_init_ ## function(void) \\{ \\ register_module_init(function, type); \\} module_init 最终要调用 register_module_init。属于 MODULE_INIT_QOM 这种类型的,有一个 Module 列表 ModuleTypeList,列表里面是一项一项的 ModuleEntry。KVM 就是其中一项,并且会初始化每一项的 init 函数为参数表示的函数 fn,也即 KVM 这个 module 的 init 函数就是 kvm_type_init。 当然,MODULE_INIT_QOM 这种类型会有很多很多的 module,从后面的代码我们可以看到,所有调用 type_init 的地方都注册了一个 MODULE_INIT_QOM 类型的 Module。 了解了 Module 的注册机制,我们继续回到 qemu_init_subsystems 函数中 module_call_init 的调用。 123456789101112131415void qemu_init_subsystems(void){ Error *err; os_set_line_buffering(); module_call_init(MODULE_INIT_TRACE); qemu_init_cpu_list(); qemu_init_cpu_loop(); qemu_mutex_lock_iothread(); atexit(qemu_run_exit_notifiers); module_call_init(MODULE_INIT_QOM); module_call_init(MODULE_INIT_MIGRATION);...} 12345678910// utils/module.cvoid module_call_init(module_init_type type){ ModuleTypeList *l; ModuleEntry *e; l = find_type(type); QTAILQ_FOREACH(e, l, node) { e->init(); }} 在 module_call_init 中,我们会找到 MODULE_INIT_QOM 这种类型对应的 ModuleTypeList,找出列表中所有的 ModuleEntry,然后调用每个 ModuleEntry 的 init 函数。这里需要注意的是,在 module_call_init 调用的这一步,所有 Module 的 init 函数都已经被调用过了。 后面我们会看到很多的 Module,当我们后面再次遇到时,需要意识到,它的 init 函数在这里也被调用过了。这里我们还是以对于 kvm 这个 module 为例子,看看它的 init 函数都做了哪些事情。我们会发现,其实它调用的是 kvm_type_init。 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566static void kvm_type_init(void){ type_register_static(&kvm_accel_type);}TypeImpl *type_register_static(const TypeInfo *info){ return type_register(info);}TypeImpl *type_register(const TypeInfo *info){ assert(info->parent); return type_register_internal(info);}static TypeImpl *type_register_internal(const TypeInfo *info){ TypeImpl *ti; ti = type_new(info); type_table_add(ti); return ti;}static TypeImpl *type_new(const TypeInfo *info){ TypeImpl *ti = g_malloc0(sizeof(*ti)); int i; if (type_table_lookup(info->name) != NULL) { } ti->name = g_strdup(info->name); ti->parent = g_strdup(info->parent); ti->class_size = info->class_size; ti->instance_size = info->instance_size; ti->class_init = info->class_init; ti->class_base_init = info->class_base_init; ti->class_data = info->class_data; ti->instance_init = info->instance_init; ti->instance_post_init = info->instance_post_init; ti->instance_finalize = info->instance_finalize; ti->abstract = info->abstract; for (i = 0; info->interfaces && info->interfaces[i].type; i++) { ti->interfaces[i].typename = g_strdup(info->interfaces[i].type); } ti->num_interfaces = i; return ti;}static void type_table_add(TypeImpl *ti){ assert(!enumerating_types); g_hash_table_insert(type_table_get(), (void *)ti->name, ti);}static GHashTable *type_table_get(void){ static GHashTable *type_table; if (type_table == NULL) { type_table = g_hash_table_new(g_str_hash, g_str_equal); } return type_table;}static const TypeInfo kvm_accel_type = { .name = TYPE_KVM_ACCEL, .parent = TYPE_ACCEL, .class_init = kvm_accel_class_init, .instance_size = sizeof(KVMState),}; 调用流程如下:虚线表示返回 每一个 Module 既然要模拟某种设备,那应该定义一种类型 TypeImpl 来表示这些设备,这其实是一种面向对象编程的思路,只不过这里用的是纯 C 语言的实现,所以需要变相实现一下类和对象。 kvm_type_init 会注册 kvm_accel_type,定义上面的代码,我们可以认为这样动态定义了一个类。这个类的名字是 TYPE_KVM_ACCEL,这个类有父类 TYPE_ACCEL,这个类的初始化应该调用函数 kvm_accel_class_init。如果用这个类声明一个对象,对象的大小应该是 instance_size。 在 type_register_internal 中,我们会根据 kvm_accel_type 这个 TypeInfo,创建一个TypeImpl 来表示这个新注册的类,也就是说,TypeImpl 才是我们想要声明的那个 class。在 qemu 里面,有一个全局的哈希表 type_table,用来存放所有定义的类。在 type_new 里面,我们先从全局表里面根据名字type_table_lookup查找找这个类。如果找到,说明这个类曾经被注册过,就报错;如果没有找到,说明这是一个新的类,则将 TypeInfo 里面信息填到 TypeImpl 里面。type_table_add 会将这个类注册到全局的表里面。到这里,我们注意,class_init 还没有被调用,也即这个类现在还处于纸面的状态。 这点更加像 Java 的反射机制了。在 Java 里面,对于一个类,首先我们写代码的时候要写一个 class xxx 的定义,编译好就放在.class 文件中,这也是出于纸面的状态。然后,Java 会有一个 Class 对象,用于读取和表示这个纸面上的 class xxx,可以生成真正的对象。 相同的过程在后面的代码中我们也可以看到,class_init 会生成XXXClass,就相当于 Java 里面的 Class对象,TypeImpl 还会有一个 instance_init 函数,相当于构造函数,用于根据 XXXClass 生成 Object,这就相当于 Java 反射里面最终创建的对象。和构造函数对应的还有 instance_finalize,相当于析构函数。 这一套反射机制放在 qom 文件夹下面,全称 QEMU Object Model,也即用 C 实现了一套面向对象的反射机制。 初始化 machine 12//vl.cqemu_create_machine (select_machine()); 在创建 machine 之前,先要通过select_machine确定一个machine。select_machine又是怎么确定的呢,这就和我们命令行的输入有关,比如我们-m spike,那么这里就会选择spike作为machine。它的定义在hw/riscv/spike.c中。 在源码最后有这么一句,会和我们上面解析的type_init 是一样的,在全局的表里面注册了一个全局的名字是spike的纸面上的 class,也即 TypeImpl。 1type_init(spike_machine_init_reqister_types) 现在全局表中有这个纸面上的 class 了。我们回到 select_machine。 在 select_machine 中,有两种方式可以生成 MachineClass。一种方式是 find_default_machine,找一个默认的;另一种方式是 machine_parse,通过解析参数生成 MachineClass。无论哪种方式,都会调用 object_class_get_list 获得一个 MachineClass 的列表,然后在里面找。 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566static MachineClass *select_machine(void){ GSList *machines = object_class_get_list(TYPE_MACHINE, false); MachineClass *machine_class = find_default_machine(machines); const char *optarg; QemuOpts *opts; Location loc; loc_push_none(&loc); opts = qemu_get_machine_opts(); qemu_opts_loc_restore(opts); optarg = qemu_opt_get(opts, "type"); if (optarg) { machine_class = machine_parse(optarg, machines); } if (!machine_class) { error_report("No machine specified, and there is no default"); error_printf("Use -machine help to list supported machines\\n"); exit(1); } loc_pop(&loc); g_slist_free(machines); return machine_class;}static MachineClass *find_default_machine(GSList *machines){ GSList *el; MachineClass *default_machineclass = NULL; for (el = machines; el; el = el->next) { MachineClass *mc = el->data; if (mc->is_default) { assert(default_machineclass == NULL && "Multiple default machines"); default_machineclass = mc; } } return default_machineclass;}static MachineClass *machine_parse(const char *name, GSList *machines){ MachineClass *mc; GSList *el; if (is_help_option(name)) { printf("Supported machines are:\\n"); machines = g_slist_sort(machines, machine_class_cmp); for (el = machines; el; el = el->next) { MachineClass *mc = el->data; if (mc->alias) { printf("%-20s %s (alias of %s)\\n", mc->alias, mc->desc, mc->name); } printf("%-20s %s%s%s\\n", mc->name, mc->desc, mc->is_default ? " (default)" : "", mc->deprecation_reason ? " (deprecated)" : ""); } exit(0); } mc = find_machine(name, machines); if (!mc) { error_report("unsupported machine type"); error_printf("Use -machine help to list supported machines\\n"); exit(1); } return mc;} object_class_get_list 定义如下: 123456789101112131415161718GSList *object_class_get_list(const char *implements_type,bool include_abstract){ GSList *list = NULL; object_class_foreach(object_class_get_list_tramp, implements_type, include_abstract, &list); return list;}void object_class_foreach(void (*fn)(ObjectClass *klass, void *opaque), const char *implements_type, bool include_abstract, void *opaque){ OCFData data = { fn, implements_type, include_abstract, opaque }; enumerating_types = true; g_hash_table_foreach(type_table_get(), object_class_foreach_tramp, &data); enumerating_types = false;} 在全局表 type_table_get() 中,对于每一项 TypeImpl,我们都执行 object_class_foreach_tramp。 1234567891011121314151617static void object_class_foreach_tramp(gpointer key, gpointer value, gpointer opaque){ OCFData *data = opaque; TypeImpl *type = value; ObjectClass *k; type_initialize(type); k = type->class; if (!data->include_abstract && type->abstract) { return; } if (data->implements_type && !object_class_dynamic_cast(k, data->implements_type)) { return; } data->fn(k, data->opaque);} 在 object_class_foreach_tramp 中,会调用将 type_initialize,这里面会调用 class_init 将纸面上的 class 也即 TypeImpl 变为 ObjectClass,ObjectClass 是所有Class 类的祖先,MachineClass 是它的子类。 因为在 machine 的命令行里面,我们指定了名字为spike,就肯定能够找到我们注册过了的 TypeImpl,并调用它的 class_init 函数。 所以,当 select_machine 执行完毕后,就有一个 MachineClass 了。 接着,我们回到 qemu_create_machine 中的object_new_with_class。这就很好理解了,MachineClass 是一个 Class 类,接下来应该通过它生成一个 Instance,也即对象,这就是 object_new_with_class 的作用。 object_new_with_class 中,TypeImpl 的 instance_init 会被调用,创建一个对象。current_machine 就是这个对象,它的类型是MachineState。 1234567891011121314Object *object_new_with_class(ObjectClass *klass){ return object_new_with_type(klass->type);}static Object *object_new_with_type(Type type){ Object *obj; type_initialize(type); obj = g_malloc(type->instance_size); object_initialize_with_type(obj, type->instance_size, type); obj->free = g_free; return obj;} 至此,绕了这么大一圈,有关体系结构的对象才创建完毕,接下来很多的设备的初始化,包括 CPU 和内存的初始化,都是围绕着体系结构的对象来的,后面我们会常常看到current_machine。 参考Qemu CPU 虚拟化 - 人生一世,草木一秋。 - 博客园【原创】Linux 虚拟化 KVM-Qemu 分析(四)之 CPU 虚拟化(2) - LoyenWang - 博客园","categories":[{"name":"QEMU 源码分析","slug":"QEMU-源码分析","permalink":"http://example.com/categories/QEMU-%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"QEMU","slug":"QEMU","permalink":"http://example.com/tags/QEMU/"}]},{"title":"Qt 文件系统","slug":"Qt文件系统","date":"2021-08-31T12:00:06.000Z","updated":"2022-10-15T03:14:29.476Z","comments":true,"path":"2021/08/31/Qt文件系统/","link":"","permalink":"http://example.com/2021/08/31/Qt%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F/","excerpt":"","text":"Qt 通过QIODevice提供了对 I/O 设备的抽象,这些设备具有读写字节块的能力。下面是 I/O 设备的类图: 图中所涉及的类及其用途简要说明如下: QIODevice:所有I/O设备类的父类,提供了字节块读写的通用操作以及基本接口;QFlie:访问本地文件或者嵌入资源;QTemporaryFile:创建和访问本地文件系统的临时文件;QBuffer:读写QByteArray;QProcess:运行外部程序,处理进程间通讯;QAbstractSocket:所有套接字类的父类;QTcpSocket:TCP协议网络数据传输;QUdpSocket:传输 UDP 报文;QSslSocket:使用 SSL/TLS 传输数据;QFileDevice:Qt5 新增加的类,提供了有关文件操作的通用实现。 QFile 及其相关类我们通常会将文件路径作为参数传给QFile的构造函数。不过也可以在创建好对象最后,使用setFileName()来修改。QFile需要使用/作为文件分隔符,不过,它会自动将其转换成操作系统所需要的形式。例如C:/windows这样的路径在 Windows 平台下同样是可以的。 QFile主要提供了有关文件的各种操作,比如打开文件、关闭文件、刷新文件等。我们可以使用QDataStream或QTextStream类来读写文件,也可以使用QIODevice类提供的read()、readLine()、readAll()以及write()这样的函数。值得注意的是,有关文件本身的信息,比如文件名、文件所在目录的名字等,则是通过QFileInfo获取,而不是自己分析文件路径字符串。 在这段代码中,我们首先使用QFile创建了一个文件对象。这个文件名字是 test.txt。只要将这个文件放在同执行路径一致的目录下即可。可以使用QDir::currentPath()来获得应用程序执行时的当前路径。只要将这个文件放在与当前路径一致的目录下即可。然后,我们使用open()函数打开这个文件,打开形式是只读方式,文本格式。这个类似于fopen()的 r 这样的参数。open()函数返回一个 bool 类型,如果打开失败,我们在控制台输出一段提示然后程序退出。否则,我们利用 while 循环,将每一行读到的内容输出。 123456789101112131415161718192021222324252627282930313233343536373839#include <QWidget>#include <QApplication>#include <QDebug>#include <QFile>#include <QFileInfo>#include <QMainWindow>int main(int argc, char *argv[]){ QApplication app(argc, argv); QFile file("test.txt"); if (!file.open(QIODevice::ReadOnly | QIODevice::Text)) { qDebug() << "Open file failed."; return -1; } else { while (!file.atEnd()) { qDebug() << file.readLine(); } } QFileInfo info(file); qDebug() << info.isDir(); //false qDebug() << info.isExecutable(); //false qDebug() << info.baseName(); //test qDebug() << info.completeBaseName(); //test.txt qDebug() << info.suffix(); //txt qDebug() << info.completeSuffix(); //txt QFileInfo fi("/tmp/archive.tar.gz"); QString base = fi.baseName(); // base = "archive" QString cbase = fi.completeBaseName(); // base = "archive.tar" QString ext = fi.suffix(); // ext = "gz" QString ext = fi.completeSuffix(); // ext = "tar.gz" return app.exec();} 二进制文件读写本节,我们将学习QDataStream的使用以及一些技巧。 QDataStream提供了基于QIODevice的二进制数据的序列化。数据流是一种二进制流,这种流完全不依赖于底层操作系统、CPU 或者字节顺序(大端或小端)。例如,在安装了 Windows 平台的 PC 上面写入的一个数据流,可以不经过任何处理,直接拿到运行了 Solaris 的 SPARC 机器上读取。由于数据流就是二进制流,因此我们也可以直接读写没有编码的二进制数据,例如图像、视频、音频等。 QDataStream既能够存取 C++ 基本类型,如 int、char、short 等,也可以存取复杂的数据类型,例如自定义的类。实际上,QDataStream对于类的存储,是将复杂的类分割为很多基本单元实现的。 结合QIODevice,QDataStream可以很方便地对文件、网络套接字等进行读写操作。 12345QFile file("file.dat");file.open(QIODevice::WriteOnly);QDataStream out(&file);out << QString("the answer is");out << (qint32)42; 在这段代码中,我们首先打开一个名为 file.dat 的文件(注意,我们为简单起见,并没有检查文件打开是否成功,这在正式程序中是不允许的)。然后,我们将刚刚创建的file对象的指针传递给一个QDataStream实例out。类似于std::cout标准输出流,QDataStream也重载了输出重定向<<运算符。后面的代码就很简单了:将“the answer is”和数字42输出到数据流(如果你不明白这句话的意思,这可是宇宙终极问题的答案,请自行搜索《银河系漫游指南》)。由于我们的 out 对象建立在file之上,因此相当于将宇宙终极问题的答案写入file。 需要指出一点:最好使用Qt整型来进行读写,比如程序中的qint32。这保证了在任意平台和任意编译器都能够有相同的行为。 我们通过一个例子来看看 Qt 是如何存储数据的。例如char *字符串,在存储时,会首先存储该字符串包括\\0结束符的长度(32位整型),然后是字符串的内容以及结束符\\0。在读取时,先以32位整型读出整个的长度,然后按照这个长度取出整个字符串的内容。 但是,如果你直接运行这段代码,你会得到一个空白的 file.dat,并没有写入任何数据。这是因为我们的file没有正常关闭。为性能起见,数据只有在文件关闭时才会真正写入。因此,我们必须在最后添加一行代码: 1file.close(); // 如果不想关闭文件,可以使用 file.flush(); 重新运行一下程序,你就得到宇宙终极问题的答案了。 我们已经获得宇宙终极问题的答案了,下面,我们要将这个答案读取出来: 123456QFile file("file.dat");file.open(QIODevice::ReadOnly);QDataStream in(&file);QString str;qint32 a;in >> str >> a; 这段代码没什么好说的。唯一需要注意的是,你必须按照写入的顺序,将数据读取出来。也就是说,程序数据写入的顺序必须预先定义好。在这个例子中,我们首先写入字符串,然后写入数字,那么就首先读出来的就是字符串,然后才是数字。顺序颠倒的话,程序行为是不确定的,严重时会直接造成程序崩溃。 由于二进制流是纯粹的字节数据,带来的问题是,如果程序不同版本之间按照不同的方式读取(前面说过,Qt 保证读写内容的一致,但是并不能保证不同 Qt 版本之间的一致),数据就会出现错误。因此,我们必须提供一种机制来确保不同版本之间的一致性。通常,我们会使用如下的代码写入: 123456789101112QFile file("file.dat");file.open(QIODevice::WriteOnly);QDataStream out(&file);// 写入魔术数字和版本out << (quint32)0xA0B0C0D0;out << (qint32)123;out.setVersion(QDataStream::Qt_4_0);// 写入数据out << lots_of_interesting_data; 所谓魔术数字,是二进制输出中经常使用的一种技术。二进制格式是人不可读的,并且通常具有相同的后缀名(比如 dat 之类),因此我们没有办法区分两个二进制文件哪个是合法的。所以,我们定义的二进制格式通常具有一个魔术数字,用于标识文件的合法性。在本例中,我们在文件最开始写入 0xA0B0C0D0,在读取的时候首先检查这个数字是不是 0xA0B0C0D0。如果不是的话,说明这个文件不是可识别格式,因此根本不需要去继续读取。一般二进制文件都会有这么一个魔术数字,例如 Java 的 class 文件的魔术数字就是 0xCAFEBABE,使用二进制查看器就可以查看。魔术数字是一个 32 位的无符号整型,因此我们使用quint32来得到一个平台无关的 32 位无符号整型。 out << (qint32)123是标识文件的版本。我们用魔术数字标识文件的类型,从而判断文件是不是合法的。但是,文件的不同版本之间也可能存在差异:我们可能在第一版保存整型,第二版可能保存字符串。为了标识不同的版本,我们只能将版本写入文件。比如,现在我们的版本是 123。 out.setVersion(QDataStream::Qt_4_0)上面一句是文件的版本号,但是,Qt不同版本之间的读取方式可能也不一样。这样,我们就得指定Qt 按照哪个版本去读。这里,我们指定以Qt 4.0 格式去读取内容。 当我们这样写入文件之后,我们在读取的时候就需要增加一系列的判断: 12345678910111213141516171819202122232425262728293031323334QFile file("file.dat");file.open(QIODevice::ReadOnly);QDataStream in(&file);// 检查魔术数字quint32 magic;in >> magic;if (magic != 0xA0B0C0D0) { return BAD_FILE_FORMAT;}// 检查版本qint32 version;in >> version;if (version < 100) { return BAD_FILE_TOO_OLD;}if (version > 123) { return BAD_FILE_TOO_NEW;}if (version <= 110) { in.setVersion(QDataStream::Qt_3_2);} else { in.setVersion(QDataStream::Qt_4_0);}// 读取数据in >> lots_of_interesting_data;if (version >= 120) { in >> data_new_in_version_1_2;}in >> other_interesting_data; 我们通过下面一段代码看看什么是流的形式: 12345678910QFile file("file.dat");file.open(QIODevice::ReadWrite);QDataStream stream(&file);QString str = "the answer is 42";QString strout;stream << str;file.flush();stream >> strout; 在这段代码中,我们首先向文件中写入数据,紧接着把数据读出来。有什么问题吗?运行之后你会发现,strout实际是空的。为什么没有读取出来?我们不是已经添加了file.flush();语句吗?原因并不在于文件有没有写入,而是在于我们使用的是“流”。所谓流,就像水流一样,它的游标会随着输出向后移动。当使用<<操作符输出之后,流的游标已经到了最后,此时你再去读,当然什么也读不到了。所以你需要在输出之后重新把游标设置为0的位置才能够继续读取。具体代码片段如下: 123stream << str;stream.device()->seek(0);stream >> strout; 文本文件读写","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"}]},{"title":"Linux 操作系统-虚拟化","slug":"Linux操作系统-虚拟化","date":"2021-08-31T01:44:40.000Z","updated":"2022-10-15T03:14:29.309Z","comments":true,"path":"2021/08/31/Linux操作系统-虚拟化/","link":"","permalink":"http://example.com/2021/08/31/Linux%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F-%E8%99%9A%E6%8B%9F%E5%8C%96/","excerpt":"","text":"虚拟化虚拟机QEMU 工作原理 单纯使用 qemu,采用的是完全虚拟化的模式。qemu 向 Guest OS 模拟 CPU,也模拟其他的硬件,GuestOS 认为自己和硬件直接打交道,其实是同 qemu 模拟出来的硬件打交道,qemu 会将这些指令转译给真正的硬件。由于所有的指令都要从 qemu 里面过一手,因而性能就会比较差。 完全虚拟化是非常慢的,所以要使用硬件辅助虚拟化技术 Intel-VT,AMD-V,所以需要 CPU 硬件开启这个标志位,一般在 BIOS 里面设置。当确认开始了标志位之后,通过 KVM,GuestOS 的 CPU 指令不用经过 Qemu 转译,直接运行,大大提高了速度。所以,KVM 在内核里面需要有一个模块,来设置当前 CPU 是 Guest OS 在用,还是 Host OS 在用。 可以通过如下命令查看内核模块中是否有 KVM 1lsmod | grep kvm KVM 内核模块通过 /dev/kvm 暴露接口,用户态程序可以通过 ioctl来访问这个接口。Qemu 将 KVM 整合进来,将有关 CPU 指令的部分交由内核模块来做,就是 qemu-kvm (qemu-system-XXX)。 qemu 和 kvm 整合之后,CPU 的性能问题解决了。另外 Qemu 还会模拟其他的硬件,如网络和硬盘。同样,全虚拟化的方式也会影响这些设备的性能。 于是,qemu 采取半虚拟化的方式,让 Guest OS 加载特殊的驱动来做这件事情。 例如,网络需要加载 virtio_net,存储需要加载 virtio_blk,Guest 需要安装这些半虚拟化驱动,GuestOS 知道自己是虚拟机,所以数据会直接发送给半虚拟化设备,经过特殊处理(例如排队、缓存、批量处理等性能优化方式),最终发送给真正的硬件。这在一定程度上提高了性能。 计算虚拟化之 CPU计算虚拟化之内存","categories":[{"name":"Linux 操作系统","slug":"Linux-操作系统","permalink":"http://example.com/categories/Linux-%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/"}],"tags":[]},{"title":"Linux 操作系统-进程管理","slug":"Linux操作系统-进程管理","date":"2021-08-30T01:41:50.000Z","updated":"2022-07-04T00:41:50.000Z","comments":true,"path":"2021/08/30/Linux操作系统-进程管理/","link":"","permalink":"http://example.com/2021/08/30/Linux%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F-%E8%BF%9B%E7%A8%8B%E7%AE%A1%E7%90%86/","excerpt":"","text":"进程源码1234567891011121314151617181920//process.c#include <stdio.h>#include <stdlib.h>#include <sys/types.h>#include <unistd.h>extern int create_process (char* program, char** arg_list);int create_process (char* program, char** arg_list){ pid_t child_pid; child_pid = fork (); if (child_pid != 0) { return child_pid; } else { execvp (program, arg_list); abort (); }} 在这里,我们创建的子程序运行了一个最最简单的命令 ls。 1234567891011121314151617//createprocess.c#include <stdio.h>#include <stdlib.h>#include <sys/types.h>#include <unistd.h>extern int create_process (char* program, char** arg_list);int main (){ char* arg_list[] = { "ls", "-l", "/etc/yum.repos.d/", NULL }; create_process ("ls", arg_list); return 0;} 编译CPU 看不懂源码里的函数,命令,CPU 只认二进制数据,所以源码需要翻译成01二进制数据,这个过程就是编译(Compile)的过程。 编译出的文件好比一个公司的项目执行计划书,你要把一个项目执行好,计划书得有章法,有一定格式。在 Linux 下,二进制程序也有这样的格式,叫ELF(Executeable and Linkable Format,可执行与可链接格式),这个格式可以根据编译的结果不同,分为不同的格式。 ELF-可重定位文件下图展示了如何从源码到二进制文件的转化 12gcc -c -fPIC process.cgcc -c -fPIC createprocess.c -fPIC作用于编译阶段,告诉编译器产生与位置无关代码 (Position-Independent Code)。产生的代码中,没有绝对地址,全部使用相对地址,故而代码可以被加载器加载到内存的任意位置,都可以正确的执行。 在编译的时候,先做预处理工作,例如将头文件嵌入到正文中,将定义的宏展开,然后就是真正的编译过程,最终编译成为.o文件,这就是ELF的第一种类型,可重定位文件(Relocatable File)。文件格式如下, ELF 文件的头是用于描述整个文件的。这个文件格式在内核中有定义,分别为 struct elf32_hdr 和 struct elf64_hdr。 section 内容 .text 放编译好的二进制可执行代码 .data 已经初始化好的全局变量(临时变量放在栈里) .rodata 只读数据,例如字符串常量、const 的变量 .bss 未初始化全局变量,运行时会置 0 .symtab 符号表,记录的则是函数和变量 .strtab 字符串表、字符串常量和变量名 第一种 ELF 文件叫可重定位文件,为啥可重定位?我们可以想象一下,这个编译好的代码和变量,将来加载到内存里面的时候,都是要加载到一定位置的。比如说,调用一个函数,其实就是跳到这个函数所在的代码位置执行;再比如修改一个全局变量,也是要到变量的位置那里去修改。但是现在这个时候,还是.o文件,不是一个可以直接运行的程序,这里面只是部分代码片段。 例如这里的 create_process函数,将来被谁调用,在哪里调用都不清楚,就更别提确定位置了。所以,.o里面的位置是不确定的,但是必须是可重新定位的,因为它将来是要做函数库的嘛,就是一块砖,哪里需要哪里搬,搬到哪里就重新定位这些代码、变量的位置。 ELF-可执行文件要让create_process这个函数作为库文件重用,需要将其形成库文件,最简单的类型是静态链接库.a文件,它将一系列.o文件归档为一个文件。使用ar命令创建.a文件。使用方法看这里。 1ar cr libstaticprocess.a process.o 虽然这里 libstaticprocess.a 里面只有一个.o,但是实际情况可以有多个.o。当有程序要使用这个静态连接库的时候,会将.o 文件提取出来,链接到程序中。 1gcc -o staticcreateprocess createprocess.o -L. -lstaticprocess -L表示在当前目录下找.a文件,-lstaticprocess 会自动补全文件名,比如加前缀 lib,后缀.a,变成 libstaticprocess.a,找到这个.a文件后,将里面的 process.o 取出来,和 createprocess.o 做一个链接,形成二进制执行文件 staticcreateprocess。 在链接过程中,重定位就起作用了,在createprocess.o里调用了create_process函数,但是不能确定位置,现在将process.o合并进来,就知道位置了。 这个格式和.o 文件大致相似,还是分成一个个的 section,并且被节头表描述。只不过这些section 是多个.o 文件合并过的。但是这个时候,这个文件已经是马上就可以加载到内存里面执行的文件了,因而这些 section 被分成了需要加载到内存里面的代码段、数据段和不需要加载到内存里面的部分,将小的 section 合成了大的段 segment,并且在最前面加一个段头表(Segment Header Table)。 在代码里面的定义为 struct elf32_phdr和 struct elf64_phdr,这里面除了有对于段的描述之外,最重要的是 p_vaddr,这个是这个段加载到内存的虚拟地址。 在 ELF 头里面,有一项 e_entry,也是个虚拟地址,是这个程序运行的入口。 ELF-共享对象文件静态库一旦被链接,代码和变量的section会被合并,所以运行时不依赖静态库文件,但是缺点就是,相同代码段被多个程序使用,在内存里会有多份,而且静态库更新需要重新编译。 因而就出现了另一种,动态链接库(Shared Libraries),不仅仅是一组对象文件的简单归档,而是多个对象文件的重新组合,可被多个程序共享。 1gcc -shared -fPIC -o libdynamicprocess.so process.o 当一个动态链接库被链接到一个程序文件中的时候,最后的程序文件并不包括动态链接库中的代码,而仅仅包括对动态链接库的引用,并且不保存动态链接库的全路径,仅仅保存动态链接库的名称。 1gcc -o dynamiccreateprocess createprocess.o -L. -ldynamicprocess 当运行这个程序的时候,首先寻找动态链接库,然后加载它。默认情况下,系统在 /lib 和/usr/lib 文件夹下寻找动态链接库。如果找不到就会报错,我们可以设定 LD_LIBRARY_PATH环境变量,程序运行时会在此环境变量指定的文件夹下寻找动态链接库。 12345# export LD_LIBRARY_PATH=.# ./dynamiccreateprocess# total 40-rw-r--r--. 1 root root 1572 Oct 24 18:38 CentOS-Base.repo...... 动态链接库,就是ELF的第三种类型,共享对象文件(Shared Object)。 文件格式和上两种文件稍有不同,首先,多了一个.interp的 Segment,这里面是 ld-linux.so,这是动态链接器,也就是说,运行时的链接动作都是它做的。 另外,ELF文件中还多了两个section,一个是.plt,过程链接表(Procedure Linkage Table,PLT),一个是。got.plt,全局偏移量表(Global Offset Table,GOT)。 运行在内核中,有linux_binfmt elf_format数据结构定义了加载 ELF 的方法,使用load_elf_binary加载二进制文件,该函数由do_execve调用,学过系统调用知道exec调用了do_execve函数。所以流程为 1exec->do_execve->load_elf_binary 进程树所有进程都是从父进程 fork 来的,祖宗进程就是init 进程。 系统启动之后,init 进程会启动很多的daemon 进程,为系统运行提供服务,然后就是启动 getty,让用户登录,登录后运行 shell,用户启动的进程都是通过 shell运行的,从而形成了一棵进程树。 我们可以通过 ps -ef命令查看当前系统启动的进程,我们会发现有三类进程。PID 1 的进程就是我们的init进程 systemd,PID 2 的进程是内核线程 kthreadd。 内核态进程的PPID祖先进程都是 2 号进程,用户态进程祖先进程都是 1 号进程,tty列是问号的,说明是后台服务进程。 进程数据结构在 Linux 里面,无论是进程还是线程,到了内核里面,我们统一都叫任务(Task),由一个统一的结构task_struct进行管理。 每个任务应该包含的字段: 任务 ID123pid_t pid; #process idpid_t tgid; #thread group IDstruct task_struct *group_leader; 为何要有这么多 ID,一个不够吗? 可以方便任务展示,比如在命令行中 ps 显示所有进程,只显示pid_t pid,而不会把所有内部线程摊开展示,这样太碍眼。 方便下达命令,当我 kill 一个进程时,我们是对整个进程发送信号,但是有时候一些命令只需要对某个线程发送信号。 信号处理12345678910/* Signal handlers: */struct signal_struct *signal;struct sighand_struct *sighand;sigset_t blocked;sigset_t real_blocked;sigset_t saved_sigmask;struct sigpending pending;unsigned long sas_ss_sp;size_t sas_ss_size;unsigned int sas_ss_flags; 这里定义了哪些信号被阻塞暂不处理(blocked),哪些信号尚等待处理(pending),哪些信号正在通过信号处理函数进行处理(sighand)。处理的结果可以是忽略,可以是结束进程等等。 任务状态1234567volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */int exit_state;unsigned int flags; state可取值定义如下 123456789101112131415161718/* Used in tsk->state: */#define TASK_RUNNING 0#define TASK_INTERRUPTIBLE 1#define TASK_UNINTERRUPTIBLE 2#define __TASK_STOPPED 4#define __TASK_TRACED 8/* Used in tsk->exit_state: */#define EXIT_DEAD 16#define EXIT_ZOMBIE 32#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)/* Used in tsk->state again: */#define TASK_DEAD 64#define TASK_WAKEKILL 128#define TASK_WAKING 256#define TASK_PARKED 512#define TASK_NOLOAD 1024#define TASK_NEW 2048#define TASK_STATE_MAX 4096 可以发现 Linux 通过 bitset 方式设置状态,当前什么状态,哪一位就置 1。 进程调度进程的状态切换往往涉及调度,下面这些字段都是用于调度的。 12345678910111213141516171819// 是否在运行队列上int on_rq;// 优先级int prio;int static_prio;int normal_prio;unsigned int rt_priority;// 调度器类const struct sched_class *sched_class;// 调度实体struct sched_entity se;struct sched_rt_entity rt;struct sched_dl_entity dl;// 调度策略unsigned int policy;// 可以使用哪些 CPUint nr_cpus_allowed;cpumask_t cpus_allowed;struct sched_info sched_info; 运行统计信息123456u64 utime;// 用户态消耗的 CPU 时间u64 stime;// 内核态消耗的 CPU 时间unsigned long nvcsw;// 自愿 (voluntary) 上下文切换计数unsigned long nivcsw;// 非自愿 (involuntary) 上下文切换计数u64 start_time;// 进程启动时间,不包含睡眠时间u64 real_start_time;// 进程启动时间,包含睡眠时间 进程亲缘关系进程有棵进程树,所以有亲缘关系。 1234struct task_struct __rcu *real_parent; /* real parent process */struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */struct list_head children; /* list of my children */struct list_head sibling; /* linkage in my parent's children list */ 通常情况下,real_parent 和 parent 是一样的,但是也会有另外的情况存在。例如,bash 创建一个进程,那进程的 parent 和 real_parent 就都是 bash。如果在 bash 上使用 GDB 来 debug 一个进程,这个时候 GDB 是 real_parent,bash 是这个进程的 parent。 进程权限1234/* Objective and real subjective task credentials (COW): */const struct cred __rcu *real_cred;/* Effective (overridable) subjective task credentials (COW): */const struct cred __rcu real_cred 就是说明谁能操作我这个进程,而 cred 就是说明我这个进程能够操作谁。 总结到一起,task_struct结构图如下,","categories":[{"name":"Linux 操作系统","slug":"Linux-操作系统","permalink":"http://example.com/categories/Linux-%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"}]},{"title":"CSAPPLAB-Bomb Lab","slug":"CSAPP-LAB-Bomb Lab","date":"2021-08-29T10:40:16.000Z","updated":"2022-10-15T03:14:29.112Z","comments":true,"path":"2021/08/29/CSAPP-LAB-Bomb Lab/","link":"","permalink":"http://example.com/2021/08/29/CSAPP-LAB-Bomb%20Lab/","excerpt":"","text":"Tips缩写注释CSAPP:Computer Systems A Programmer’s Perspective(深入理解计算机操作系统)。CSAPP(C:P166,O:P278)表示书本的中文版第 166 页,英文原版第 278 页。 寄存器信息了解寄存器的基本用途,看到一个汇编代码,可以大概了解这个寄存器是在栈中使用的,还是保存参数的,是调用者保存,还是被调用者保存。 GDB调试过程用到的 GDB 命令可以先参考GDB 调试入门这篇文章。文中所用例子也是摘自与 BombLab 的源码,更容易理解如何使用。还有一定比较重要的是,如何使用 gdb 带参数调试。为了不用每次运行bomb程序都需要重新输入答案,bomb程序可以读取文本信息,在文本文件中写入答案即可免去手动输入。 phase_1拆弹专家已上线,开干!!!!!!!!!!!!! 1234567891011121314(gdb) b phase_1(gdb) b explode_bomb(gdb) disas phase_1Dump of assembler code for function phase_1:' 0x0000000000400ee0 <+0>: sub $0x8,%rsp 0x0000000000400ee4 <+4>: mov $0x402400,%esi 0x0000000000400ee9 <+9>: callq 0x401338 <strings_not_equal> 0x0000000000400eee <+14>: test %eax,%eax 0x0000000000400ef0 <+16>: je 0x400ef7 <phase_1+23> 0x0000000000400ef2 <+18>: callq 0x40143a <explode_bomb> 0x0000000000400ef7 <+23>: add $0x8,%rsp 0x0000000000400efb <+27>: retq End of assembler dump. 3:将栈指针rsp减去 8 个字节,也就是申请 8 个字节的栈空间 4:将一个立即数存到寄存器esi中 5:调用函数strings_not_equal,该函数第一条语句的地址为0x401338。callq指令的执行过程可参考书本 CSAPP(C:P166,O:P278) 6:使用test命令(同and命令,不修改目标对象的值)来测试eax中的值是否为0,如果为0则跳过引爆炸弹的函数 7:这一句和上一句是一个整体,如果eax==0,就跳转到0x400ef7,这个地址也就是第 9 行的地址,成功跳过了引爆炸弹函数。意思就是我们输入的某个字符串成功匹配,也就是strings_not_equal函数返回值为 0。 8:调用函数explode_bomb,引爆炸弹 9:将栈指针rsp加上 8 个字节,也就是恢复 8 个字节的栈空间 123456789101112131415161718192021222324252627282930313233343536373839404142(gdb) disas strings_not_equal Dump of assembler code for function strings_not_equal:=> 0x0000000000401338 <+0>: push %r12 0x000000000040133a <+2>: push %rbp 0x000000000040133b <+3>: push %rbx 0x000000000040133c <+4>: mov %rdi,%rbx 0x000000000040133f <+7>: mov %rsi,%rbp 0x0000000000401342 <+10>: callq 0x40131b <string_length> 0x0000000000401347 <+15>: mov %eax,%r12d 0x000000000040134a <+18>: mov %rbp,%rdi 0x000000000040134d <+21>: callq 0x40131b <string_length> 0x0000000000401352 <+26>: mov $0x1,%edx 0x0000000000401357 <+31>: cmp %eax,%r12d 0x000000000040135a <+34>: jne 0x40139b <strings_not_equal+99> 0x000000000040135c <+36>: movzbl (%rbx),%eax 0x000000000040135f <+39>: test %al,%al 0x0000000000401361 <+41>: je 0x401388 <strings_not_equal+80> 0x0000000000401363 <+43>: cmp 0x0(%rbp),%al 0x0000000000401366 <+46>: je 0x401372 <strings_not_equal+58> 0x0000000000401368 <+48>: jmp 0x40138f <strings_not_equal+87> 0x000000000040136a <+50>: cmp 0x0(%rbp),%al 0x000000000040136d <+53>: nopl (%rax) 0x0000000000401370 <+56>: jne 0x401396 <strings_not_equal+94> 0x0000000000401372 <+58>: add $0x1,%rbx 0x0000000000401376 <+62>: add $0x1,%rbp 0x000000000040137a <+66>: movzbl (%rbx),%eax 0x000000000040137d <+69>: test %al,%al 0x000000000040137f <+71>: jne 0x40136a <strings_not_equal+50> 0x0000000000401381 <+73>: mov $0x0,%edx 0x0000000000401386 <+78>: jmp 0x40139b <strings_not_equal+99> 0x0000000000401388 <+80>: mov $0x0,%edx 0x000000000040138d <+85>: jmp 0x40139b <strings_not_equal+99> 0x000000000040138f <+87>: mov $0x1,%edx 0x0000000000401394 <+92>: jmp 0x40139b <strings_not_equal+99> 0x0000000000401396 <+94>: mov $0x1,%edx 0x000000000040139b <+99>: mov %edx,%eax 0x000000000040139d <+101>: pop %rbx 0x000000000040139e <+102>: pop %rbp 0x000000000040139f <+103>: pop %r12 0x00000000004013a1 <+105>: retq End of assembler dump. 3-5:在函数调用时先保存相关寄存器值,rbp和rbx就是用来保存两个参数的寄存器 6:将寄存器rdi的值复制到寄存器rbp 7:将寄存器rsi的值复制到寄存器rbx 其实看到这里就一直能够猜到答案是什么了。我们通过之前的phase_1函数能够大概知道需要输入一个值进行比较,如果比较正确就能解除炸弹。现在我们又进入到了这个比较函数,比较函数有两个参数,分别保存在两个寄存器里。我们正常的思维如果写一个比较函数,肯定一个参数是我们输入的值,一个参数是正确的值。 这里看到了rsi寄存器,我们还记得在phase_1函数中第 4 行的esi寄存器吗?这两个寄存器是同一个寄存器,只不过esi是寄存器的低 32 位,既然esi已经赋值了,那剩下的一个参数保存我们输入的内容。所以esi内存的内容就是我们需要的正确答案。我们只要把寄存器esi中的值打印出来,或者内存地址为0x402400的内容打印出来即可。可以通过以下三条命令查看。 123456(gdb) p (char*)($esi)$5 = 0x402400 "Border relations with Canada have never been better."(gdb) x/s 0x4024000x402400: "Border relations with Canada have never been better."(gdb) x/s $esi0x402400: "Border relations with Canada have never been better." 将答案复制,然后继续运行 123456789101112131415The program being debugged has been started already.Start it from the beginning? (y or n) yStarting program: /home/dominic/learning-linux/bomb/bomb Welcome to my fiendish little bomb. You have 6 phases withwhich to blow yourself up. Have a nice day!Border relations with Canada have never been better.Breakpoint 2, 0x0000000000400ee0 in phase_1 ()(gdb) sSingle stepping until exit from function phase_1,which has no line number information.main (argc=<optimized out>, argv=<optimized out>) at bomb.c:7575 phase_defused(); /* Drat! They figured it out!(gdb) s77 printf("Phase 1 defused. How about the next one?\\n"); 从 13 行phase_defused()可以知道我们已经解除了炸弹,从 15 行printf函数也可以看到,需要进行下一个炸弹的拆除。过来人的建议,在这里就开始分析phase_2,寻找答案,因为继续执行就要开始输入内容了,将无法调试。 phase_2继续分析第二个炸弹, 12345678910111213141516171819202122232425262728(gdb) disas phase_2Dump of assembler code for function phase_2: 0x0000000000400efc <+0>: push %rbp 0x0000000000400efd <+1>: push %rbx 0x0000000000400efe <+2>: sub $0x28,%rsp 0x0000000000400f02 <+6>: mov %rsp,%rsi 0x0000000000400f05 <+9>: callq 0x40145c <read_six_numbers> 0x0000000000400f0a <+14>: cmpl $0x1,(%rsp) 0x0000000000400f0e <+18>: je 0x400f30 <phase_2+52> 0x0000000000400f10 <+20>: callq 0x40143a <explode_bomb> 0x0000000000400f15 <+25>: jmp 0x400f30 <phase_2+52> 0x0000000000400f17 <+27>: mov -0x4(%rbx),%eax 0x0000000000400f1a <+30>: add %eax,%eax 0x0000000000400f1c <+32>: cmp %eax,(%rbx) 0x0000000000400f1e <+34>: je 0x400f25 <phase_2+41> 0x0000000000400f20 <+36>: callq 0x40143a <explode_bomb> 0x0000000000400f25 <+41>: add $0x4,%rbx 0x0000000000400f29 <+45>: cmp %rbp,%rbx 0x0000000000400f2c <+48>: jne 0x400f17 <phase_2+27> 0x0000000000400f2e <+50>: jmp 0x400f3c <phase_2+64> 0x0000000000400f30 <+52>: lea 0x4(%rsp),%rbx 0x0000000000400f35 <+57>: lea 0x18(%rsp),%rbp 0x0000000000400f3a <+62>: jmp 0x400f17 <phase_2+27> 0x0000000000400f3c <+64>: add $0x28,%rsp 0x0000000000400f40 <+68>: pop %rbx 0x0000000000400f41 <+69>: pop %rbp 0x0000000000400f42 <+70>: retq End of assembler dump. 3-6:保存程序入口地址,变量等内容,就不再赘述了 7: 调用read_six_numbers函数,根据函数名我们可以猜测这个函数需要读入六个数字 8-9:比较寄存器rsp存的第一个数字是否等于0x1,如果等于就跳转到phase_2+52处继续执行,如果不等于就执行explode_bomb。栈中保存了六个输入的数字,保存顺序是从右往左,假如输入1,2,3,4,5,6。那么入栈的顺序就是6,5,4,3,2,1,寄存器rsp指向栈顶,也就是数字1的地址。 21:假设第一个数字正确,我们跳转到<+52>位置,也就是第 21 行,将rsp+0x4写入寄存器rbx,栈指针向上移动四个字节,也就是取第二个输入的参数,将它赋给寄存器rbx 22:将rsp+0x18写入寄存器rbp,十六进制0x18=24,4 个字节一个数,刚好 6 个数,就是将输入参数的最后一个位置赋给寄存器rbp 23:跳到phase_2+27继续执行 12:rbx-0x4赋给寄存器eax。第 21 行我们知道,rbx此时已经到第二个参数了,这一句就是说把第一个参数的值写入寄存器eax 13:将eax翻一倍,第 8 行知道第一个参数值为1,所以此时eax值为2 14-15:比较eax是否等于rbx。rbx此时保存的是第二个参数,这里也就是比较第二个参数是否等于2。如果等于跳转到phase_2+41位置,如果不等于就调用爆炸函数 17-18:假设第二个参数就是 2,我们跳过了炸弹来到第 17 行,将rbx继续上移,然后比较rbp是否等于rbx,我们知道rbp保存了最后一个参数的地址,所以这里的意思就是看看参数有没有到最后一个参数。 19:如果rbx<rbp,意思就是还没到最后一个参数,就跳转到phase_2+27 12:再次回到第 12 行,这里就是相当于一个循环了,让rbx一直向上移动,分别存入第 2,3,4,5,6 个参数,在移动到下一个参数时先保存当前参数到寄存器eax让其翻一倍,然后rbx再移动到下一个参数,比较eax==rbx。直到rbx越过了rbp。程序跳转到phase_2+64,将栈空间恢复。 以上分析也可以得出答案了,我们只要输入一个以1为初值,公比为2,个数为6的等比数列就是答案,也就是1 2 4 8 16 32。 123456789101112(gdb) cContinuing.Phase 1 defused. How about the next one?1 2 4 8 16 32Breakpoint 6, 0x00000000004015c4 in phase_defused ()(gdb) sSingle stepping until exit from function phase_defused,which has no line number information.main (argc=<optimized out>, argv=<optimized out>) at bomb.c:8484 printf("That's number 2. Keep going!\\n");(gdb) s 这个炸弹的作者应该再心狠手辣一点,把函数名换成read_some_numbers,这样我们就不得不看这个函数的内容了,因为这个函数里还有一个坑,这个坑在函数名字上一句被填了。那就是这个函数会对参数个数做判断,如果小于 5 就爆炸。 1234567891011121314151617181920(gdb) disas read_six_numbersDump of assembler code for function read_six_numbers: 0x000000000040145c <+0>: sub $0x18,%rsp 0x0000000000401460 <+4>: mov %rsi,%rdx 0x0000000000401463 <+7>: lea 0x4(%rsi),%rcx 0x0000000000401467 <+11>: lea 0x14(%rsi),%rax 0x000000000040146b <+15>: mov %rax,0x8(%rsp) 0x0000000000401470 <+20>: lea 0x10(%rsi),%rax 0x0000000000401474 <+24>: mov %rax,(%rsp) 0x0000000000401478 <+28>: lea 0xc(%rsi),%r9 0x000000000040147c <+32>: lea 0x8(%rsi),%r8 0x0000000000401480 <+36>: mov $0x4025c3,%esi 0x0000000000401485 <+41>: mov $0x0,%eax 0x000000000040148a <+46>: callq 0x400bf0 <__isoc99_sscanf@plt> 0x000000000040148f <+51>: cmp $0x5,%eax 0x0000000000401492 <+54>: jg 0x401499 <read_six_numbers+61> 0x0000000000401494 <+56>: callq 0x40143a <explode_bomb> 0x0000000000401499 <+61>: add $0x18,%rsp 0x000000000040149d <+65>: retq End of assembler dump. 3:申请 24 个字节栈空间 4:rdx=rsi,将输入参数的第一个参数放到寄存器rdx中,为啥是第一个参数,因为rsi现在保存的地址是栈顶位置,栈顶目前保存就是第一个参数。 5:rcx = rsi + 4,把第二个参数的地址传给寄存器rcx 6:rax = rsi + 20,把第六个参数的地址传给寄存器rax 7:rsp + 8 = rax第八个参数 8:rax = rsi + 16,把第五个参数传给 9:rsp = rax第七个参数 10:r9 = rsi + 12把第四个参数传给寄存器r9 11:r8 = rsi + 8把第三个参数传给寄存器r8 12: 13:eax = 0 14:调用输入函数sscanf 15-17:函数返回值个数与 5 比较,如果小于 5 就爆炸,否则返回 phase_3123456789101112131415161718192021222324252627282930313233343536370x0000000000400f43 <+0>: sub $0x18,%rsp0x0000000000400f47 <+4>: lea 0xc(%rsp),%rcx0x0000000000400f4c <+9>: lea 0x8(%rsp),%rdx0x0000000000400f51 <+14>: mov $0x4025cf,%esi0x0000000000400f56 <+19>: mov $0x0,%eax0x0000000000400f5b <+24>: callq 0x400bf0 <__isoc99_sscanf@plt>0x0000000000400f60 <+29>: cmp $0x1,%eax0x0000000000400f63 <+32>: jg 0x400f6a <phase_3+39>0x0000000000400f65 <+34>: callq 0x40143a <explode_bomb>0x0000000000400f6a <+39>: cmpl $0x7,0x8(%rsp)0x0000000000400f6f <+44>: ja 0x400fad <phase_3+106>0x0000000000400f71 <+46>: mov 0x8(%rsp),%eax0x0000000000400f75 <+50>: jmpq *0x402470(,%rax,8)0x0000000000400f7c <+57>: mov $0xcf,%eax0x0000000000400f81 <+62>: jmp 0x400fbe <phase_3+123>0x0000000000400f83 <+64>: mov $0x2c3,%eax0x0000000000400f88 <+69>: jmp 0x400fbe <phase_3+123>0x0000000000400f8a <+71>: mov $0x100,%eax0x0000000000400f8f <+76>: jmp 0x400fbe <phase_3+123>0x0000000000400f91 <+78>: mov $0x185,%eax0x0000000000400f96 <+83>: jmp 0x400fbe <phase_3+123>0x0000000000400f98 <+85>: mov $0xce,%eax0x0000000000400f9d <+90>: jmp 0x400fbe <phase_3+123>0x0000000000400f9f <+92>: mov $0x2aa,%eax0x0000000000400fa4 <+97>: jmp 0x400fbe <phase_3+123>0x0000000000400fa6 <+99>: mov $0x147,%eax0x0000000000400fab <+104>: jmp 0x400fbe <phase_3+123>0x0000000000400fad <+106>: callq 0x40143a <explode_bomb>0x0000000000400fb2 <+111>: mov $0x0,%eax0x0000000000400fb7 <+116>: jmp 0x400fbe <phase_3+123>0x0000000000400fb9 <+118>: mov $0x137,%eax0x0000000000400fbe <+123>: cmp 0xc(%rsp),%eax0x0000000000400fc2 <+127>: je 0x400fc9 <phase_3+134>0x0000000000400fc4 <+129>: callq 0x40143a <explode_bomb>0x0000000000400fc9 <+134>: add $0x18,%rsp0x0000000000400fcd <+138>: retq 1:开辟 24 字节的栈空间 2:rcx = rsp + 12第二个参数 3:rdx = rsp + 8第一个参数 4-8:和phase_2里read_six_numbers函数中的第 13 行开始一样,输入数据,判断一下输入参数的个数,只不过这里是返回值个数大于 1,如果参数个数正确就跳到phase_3+39也就是第 10 行,否则引爆炸弹。 10-11:如果7 < rsp + 8 等价于 7 < rdx 等价于 7 < 第一个参数就跳转到phase_3+106,爆炸。这里确定第一个数必须小于 7 12:eax = rsp + 8 等价于 eax = 第一个参数 13:跳转至0x402470 + 8 * rax处,具体跳转到哪里根据第一个值做判断 14:eax = 207 15:跳转至phase_3+123,即 32 行 16:eax = 707 17:跳转到 32 行 18:eax = 256 19:跳转到 32 行 20:eax = 389 21-27:以此类推 29:eax = 0 30: 31:eax = 311 32-34:比较eax和rsp + 12 等价于 比较 第二个参数和eax。如果相等就返回,如果不等就引爆。 分析至此,我们也就知道了程序的大概流程,输入两个值,第一个值必须小于等于 7,第二个值根据第一个值来确定,具体等于多少,根据跳转表确定,因为第一个值有八个数,也就对应着汇编中八段寄存器eax赋值的过程,我们只要输入第一个合法的数值,然后再打印出寄存器eax的值,即可确定答案。 比如我们先测试一下第一个值为 0 时,对应的第二个值为多少,我们输入0 10,因为只是测试,第二个值任意。 12345678910111213That's number 2. Keep going! //接上个炸弹后面88 input = read_line();(gdb) n0 10 //输入测试答案89 phase_3(input);(gdb) nBreakpoint 4, 0x0000000000400f43 in phase_3 ()(gdb) nSingle stepping until exit from function phase_3,which has no line number information.Breakpoint 2, 0x000000000040143a in explode_bomb ()(gdb) p $eax$14 = 207 //207即是答案 输入真正答案测试, 123456789101112(gdb) n0 207 //输入答案89 phase_3(input);(gdb) nBreakpoint 4, 0x0000000000400f43 in phase_3 ()(gdb) nSingle stepping until exit from function phase_3,which has no line number information.main (argc=<optimized out>, argv=<optimized out>) at bomb.c:9090 phase_defused(); //炸弹拆除(gdb) 91 printf("Halfway there!\\n"); 我们上面说过,第一个值有八种可能,所以这题答案也有八个,我们只要挨个测试0-7,分别打印出寄存器eax的值就可以得到所有答案。他们分别是 123456780 2071 3112 7073 2564 3895 2066 6827 327 phase_4行百里者半九十,NO 123456789101112131415161718192021222324(gdb) disas phase_4Dump of assembler code for function phase_4: 0x000000000040100c <+0>: sub $0x18,%rsp 0x0000000000401010 <+4>: lea 0xc(%rsp),%rcx 0x0000000000401015 <+9>: lea 0x8(%rsp),%rdx 0x000000000040101a <+14>: mov $0x4025cf,%esi 0x000000000040101f <+19>: mov $0x0,%eax 0x0000000000401024 <+24>: callq 0x400bf0 <__isoc99_sscanf@plt> 0x0000000000401029 <+29>: cmp $0x2,%eax 0x000000000040102c <+32>: jne 0x401035 <phase_4+41> 0x000000000040102e <+34>: cmpl $0xe,0x8(%rsp) 0x0000000000401033 <+39>: jbe 0x40103a <phase_4+46> 0x0000000000401035 <+41>: callq 0x40143a <explode_bomb> 0x000000000040103a <+46>: mov $0xe,%edx 0x000000000040103f <+51>: mov $0x0,%esi 0x0000000000401044 <+56>: mov 0x8(%rsp),%edi 0x0000000000401048 <+60>: callq 0x400fce <func4> 0x000000000040104d <+65>: test %eax,%eax 0x000000000040104f <+67>: jne 0x401058 <phase_4+76> 0x0000000000401051 <+69>: cmpl $0x0,0xc(%rsp) 0x0000000000401056 <+74>: je 0x40105d <phase_4+81> 0x0000000000401058 <+76>: callq 0x40143a <explode_bomb> 0x000000000040105d <+81>: add $0x18,%rsp 0x0000000000401061 <+85>: retq 1-8:开辟空间,保存参数信息,调用输入函数,和上面的分析重复,不再赘述。注意的是第 6 行,x/s 0x4025cf可知两个参数是整型数值。 9-10:参数个数必须等于 2,否则引爆 11-12:14与rsp + 8比较,等价于14与第一个参数比较。表示第一个参数必须小于等于 14,否则引爆。 14:edx = 14 15:esi = 0 16:edi = rsp + 8即edi = 第一个参数 17:调用函数fun4,参数分别为edi 0 14 18:测试返回值是否为 0,如果不为 0,引爆 20-22:比较0和rsp + 12,如果不等,引爆,否则返回 123456789101112131415161718192021222324(gdb) disas func4Dump of assembler code for function func4: 0x0000000000400fce <+0>: sub $0x8,%rsp 0x0000000000400fd2 <+4>: mov %edx,%eax 0x0000000000400fd4 <+6>: sub %esi,%eax 0x0000000000400fd6 <+8>: mov %eax,%ecx 0x0000000000400fd8 <+10>: shr $0x1f,%ecx 0x0000000000400fdb <+13>: add %ecx,%eax 0x0000000000400fdd <+15>: sar %eax 0x0000000000400fdf <+17>: lea (%rax,%rsi,1),%ecx 0x0000000000400fe2 <+20>: cmp %edi,%ecx 0x0000000000400fe4 <+22>: jle 0x400ff2 <func4+36> 0x0000000000400fe6 <+24>: lea -0x1(%rcx),%edx 0x0000000000400fe9 <+27>: callq 0x400fce <func4> 0x0000000000400fee <+32>: add %eax,%eax 0x0000000000400ff0 <+34>: jmp 0x401007 <func4+57> 0x0000000000400ff2 <+36>: mov $0x0,%eax 0x0000000000400ff7 <+41>: cmp %edi,%ecx 0x0000000000400ff9 <+43>: jge 0x401007 <func4+57> 0x0000000000400ffb <+45>: lea 0x1(%rcx),%esi 0x0000000000400ffe <+48>: callq 0x400fce <func4> 0x0000000000401003 <+53>: lea 0x1(%rax,%rax,1),%eax 0x0000000000401007 <+57>: add $0x8,%rsp 0x000000000040100b <+61>: retq 12345678910111213141516171819202122232425262728293031323334func (edi, esi, edx){ // edi = 第一个参数, esi = 0, edx = 14 eax = edx // 4:mov %edx, %eax eax = eax -esi // 5:sub esi, %eax eax = edx -esi ecx = eax // 6:mov %eax, %ecx ecx = edx - esi eсx = ecx >> 31 // 7:shr $0x1f, %ecx ecx = (edx - esi) >> 31 eax = eax + ecx // 8:add %ecx, %eax eax = (edx - esi) + ((edx - esi) >> 31)//替换eax和ecx eax = eax > 1; // 9:sar %eax eax = ((edx - esi) +((edx -esi) >> 31)) / 2 ecx = eax + esi * 1 // 10:lea (rax,ersi,1), %ecx ecx = ((edx - esi) +((edx -esi) >> 31)) / 2 + esi * 1 ecx = ((14 - 0) + ((14 - 0) >> 31)) / 2 + 0 ecx = 7 // 11:cmp %edi, %ecx if (ecx <= edi) { // 12:jle 400ff2 eax = 0 // mov $0x0,%eax // 18:cmp %edi, %ecx if(ecx >= edi) { // 19:jge 0x401007 <func4+57> return; //由此可以得知道 edx == edi } }} phase_51234567891011121314151617181920212223242526272829303132333435363738390x0000000000401062 <+0>: push %rbx0x0000000000401063 <+1>: sub $0x20,%rsp0x0000000000401067 <+5>: mov %rdi,%rbx0x000000000040106a <+8>: mov %fs:0x28,%rax0x0000000000401073 <+17>: mov %rax,0x18(%rsp)0x0000000000401078 <+22>: xor %eax,%eax0x000000000040107a <+24>: callq 0x40131b <string_length>0x000000000040107f <+29>: cmp $0x6,%eax0x0000000000401082 <+32>: je 0x4010d2 <phase_5+112>0x0000000000401084 <+34>: callq 0x40143a <explode_bomb>0x0000000000401089 <+39>: jmp 0x4010d2 <phase_5+112>0x000000000040108b <+41>: movzbl (%rbx,%rax,1),%ecx0x000000000040108f <+45>: mov %cl,(%rsp)0x0000000000401092 <+48>: mov (%rsp),%rdx0x0000000000401096 <+52>: and $0xf,%edx0x0000000000401099 <+55>: movzbl 0x4024b0(%rdx),%edx0x00000000004010a0 <+62>: mov %dl,0x10(%rsp,%rax,1)0x00000000004010a4 <+66>: add $0x1,%rax0x00000000004010a8 <+70>: cmp $0x6,%rax0x00000000004010ac <+74>: jne 0x40108b <phase_5+41>0x00000000004010ae <+76>: movb $0x0,0x16(%rsp)0x00000000004010b3 <+81>: mov $0x40245e,%esi 0x00000000004010b8 <+86>: lea 0x10(%rsp),%rdi0x00000000004010bd <+91>: callq 0x401338 <strings_not_equal>0x00000000004010c2 <+96>: test %eax,%eax0x00000000004010c4 <+98>: je 0x4010d9 <phase_5+119>0x00000000004010c6 <+100>: callq 0x40143a <explode_bomb>0x00000000004010cb <+105>: nopl 0x0(%rax,%rax,1)0x00000000004010d0 <+110>: jmp 0x4010d9 <phase_5+119>0x00000000004010d2 <+112>: mov $0x0,%eax0x00000000004010d7 <+117>: jmp 0x40108b <phase_5+41>0x00000000004010d9 <+119>: mov 0x18(%rsp),%rax0x00000000004010de <+124>: xor %fs:0x28,%rax0x00000000004010e7 <+133>: je 0x4010ee <phase_5+140>0x00000000004010e9 <+135>: callq 0x400b30 <__stack_chk_fail@plt>0x00000000004010ee <+140>: add $0x20,%rsp0x00000000004010f2 <+144>: pop %rbx0x00000000004010f3 <+145>: retq","categories":[{"name":"CSAPP-Lab","slug":"CSAPP-Lab","permalink":"http://example.com/categories/CSAPP-Lab/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"GDB","slug":"GDB","permalink":"http://example.com/tags/GDB/"},{"name":"CSAPP","slug":"CSAPP","permalink":"http://example.com/tags/CSAPP/"}]},{"title":"GDB 调试入门","slug":"GDB调试入门","date":"2021-08-29T10:40:16.000Z","updated":"2022-10-15T03:14:29.201Z","comments":true,"path":"2021/08/29/GDB调试入门/","link":"","permalink":"http://example.com/2021/08/29/GDB%E8%B0%83%E8%AF%95%E5%85%A5%E9%97%A8/","excerpt":"","text":"file 加载程序12(gdb) file bombReading symbols from bomb... set args 带参数调试有时候程序不是直接可以运行的,需要加上一些必要的参数。带上参数运行很容易,只要在程序名后加上相应参数即可,但是如何带上参数进行调试呢?这就需要set args命令。 比如在BombLab实验中,我们不可能一次解决所有phase,但是每次重新调试,已经解决的phase还要重新输入一次答案,这就很麻烦,好在这个实验的作者也考虑到了,他支持读取文本。我们可以把答案预先写入一个文本文件中,程序读取已经保存的答案即可跳过相应的phase。 假设我们把答案写入了solutions.txt文件中,首先,我们加载程序,然后通过set args solutions.txt设置运行参数。 123456789(gdb) file bombReading symbols from bomb...(gdb) set args solutions.txt (gdb) rStarting program: /home/dominic/learning-linux/bomb/bomb solutions.txt Welcome to my fiendish little bomb. You have 6 phases withwhich to blow yourself up. Have a nice day!Phase 1 defused. How about the next one?That's number 2. Keep going! list 查看源码查看 10 行源码每条命令显示 10 行代码 12345678910111213141516171819202122(gdb) l23 #include <stdio.h>24 #include <stdlib.h>25 #include "support.h"26 #include "phases.h"27 28 /* 29 * Note to self: Remember to erase this file so my victims will have no30 * idea what is going on, and so they will all blow up in a31 * spectaculary fiendish explosion. -- Dr. Evil 32 */(gdb) l33 34 FILE *infile;35 36 int main(int argc, char *argv[])37 {38 char *input;39 40 /* Note to self: remember to port this bomb to Windows and put a 41 * fantastic GUI on it. */42 set list num 设置默认显示代码行数1(gdb) set list 20 //默认显示20行代码 list linenumber 查看指定行代码12(gdb) l 10 (gdb) l main.h : 10 //指定main.c文件中的第十行 list function 查看指定函数的代码break 打断点break linenum 对指定行打断点123(gdb) b 36Note: breakpoint 1 also set at pc 0x400da0.Breakpoint 2 at 0x400da0: file bomb.c, line 37. break function 对指定函数打断点1234(gdb) b mainBreakpoint 3 at 0x400da0: file bomb.c, line 37.(gdb) b phase_1Breakpoint 4 at 0x400ee0 删除断点包括禁用断点delete 删除所有断点12(gdb) delete Delete all breakpoints? (y or n) y disable breakpoint 禁用断点12345678(gdb) info b #先看有哪些断点Num Type Disp Enb Address What3 breakpoint keep y 0x0000000000400da0 in main at bomb.c:374 breakpoint keep y 0x0000000000400ee0 <phase_1>(gdb) d 3 #禁用第三号断点(gdb) info b #再次查看断点信息发现已经没有第三号断点Num Type Disp Enb Address What4 breakpoint keep y 0x0000000000400ee0 <phase_1> clear function 删除一个函数中所有的断点123456(gdb) info bNum Type Disp Enb Address What4 breakpoint keep y 0x0000000000400ee0 <phase_1>(gdb) clear phase_1(gdb) info bDeleted breakpoint 4 No breakpoints or watchpoints. 启动与退出run 启动程序直到遇到断点1(gdb) run start 启动程序并在第一条代码处停下1(gdb) start x 配置 gdb 常用命令1gdb -q -x gdbinit 1234567//gdbinitdisplay/z $xsdisplay/z $x6display/z $x7set disassemble-next-line onb _starttarget remote: 34 有了配置文件,就不用每次启动 gdb 时都要重新输入一遍调试命令。 quit 退出调试1(gdb) quit 调试命令print 打印变量值 格式化字符 (/fmt) 说明 /x 以十六进制的形式打印出整数。 /d 以有符号、十进制的形式打印出整数。 /u 以无符号、十进制的形式打印出整数。 /o 以八进制的形式打印出整数。 /t 以二进制的形式打印出整数。 /f 以浮点数的形式打印变量或表达式的值。 /c 以字符形式打印变量或表达式的值。 1234567(gdb) p i # 10进制$5 = 3(gdb) p/x i # 16进制$6 = 0x3(gdb) p/o i # 8进制$7 = 03 打印地址值表示从内存地址 0x54320 读取内容,h 表示以双字节为单位,3 表示输出 3 个单位,u 表示按照十六进制显示。 1(gdb) x/3uh 0x54320 查看当前程序栈的内容:x/10x $sp–>打印 stack 的前 10 个元素查看当前程序栈的信息:info frame—-list general info about the frame查看当前程序栈的参数:info args—lists arguments to the function查看当前程序栈的局部变量:info locals—list variables stored in the frame查看当前寄存器的值:info registers(不包括浮点寄存器) ptype 打印变量类型123456(gdb) ptype itype = int(gdb) ptype array[i]type = int(gdb) ptype arraytype = int [12] display 跟踪显示变量print命令可以打印出变量的值,但是只是一次性的。如果我们想要跟踪某个变量的变化,可以使用display命令,每当程序在断点处停下,都会打印出跟踪的变量值。 1(gdb) display info display查看已跟踪的变量,delete display取消跟踪显示变量。 step 执行一行代码执行一行代码,如果改行代码是函数,将进入函数内部。 1(gdb) s finish 跳出函数如果通过s单步调试进入到函数内部,想要跳出这个函数体,可以执行 finish命令。如果想要跳出函数体必须要保证函数体内不能有有效断点,否则无法跳出。 next 执行一行代码next 命令和 step 命令功能是相似的,只是在使用 next 调试程序的时候不会进入到函数体内部,next 可以缩写为 n。 until 跳出循环体通过 until 命令可以直接跳出某个循环体,这样就能提高调试效率了。如果想直接从循环体中跳出,必须要保证,要跳出的循环体内部不能有有效的断点,必须要在循环体的开始 / 结束行执行该命令。 layout 分割窗口,边调试边看源码layout src layout asm layout split 远程调试-s -S-s启动gdb server,默认端口号为 1234-S让程序在_start处停下。","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"GDB","slug":"GDB","permalink":"http://example.com/tags/GDB/"},{"name":"CSAPP","slug":"CSAPP","permalink":"http://example.com/tags/CSAPP/"}]},{"title":"oh-my-zsh 让你的终端更加顺手(眼)","slug":"oh-my-zsh让你的终端更加顺手(眼)","date":"2021-08-29T01:56:21.000Z","updated":"2022-10-15T03:14:29.371Z","comments":true,"path":"2021/08/29/oh-my-zsh让你的终端更加顺手(眼)/","link":"","permalink":"http://example.com/2021/08/29/oh-my-zsh%E8%AE%A9%E4%BD%A0%E7%9A%84%E7%BB%88%E7%AB%AF%E6%9B%B4%E5%8A%A0%E9%A1%BA%E6%89%8B%EF%BC%88%E7%9C%BC%EF%BC%89/","excerpt":"","text":"效果主题:evan 主题:dallas 主题:robbyrussell 如果原先其他电脑安装过把.oh-my-zsh整个文件夹,.zshrc,.zsh_history复制到/home/user/目录; 安装zsh 12sudo apt install zsh 切换shell 1chsh -s /bin/zsh 1source ~/.zshrc 即可使用。所有配置都会和原先一样。 如果是新安装官方方法,curl和wget二选一即可 12curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.shwget -O- https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh 应该也有人和我一样,可能会遇到连接 GitHub 失败的问题,要不就是 SSL 验证失败,要不就是连接无响应。可以更换下面的方法。 1234# 先下载git clone git://github.com/robbyrussell/oh-my-zsh.git ~/.oh-my-zsh## 再替换cp ~/.oh-my-zsh/templates/zshrc.zsh-template ~/.zshrc 重启终端即可成功。 如果无法访问 GitHub,其实oh-my-zsh并不需要安装,完整的工程就是oh-my-zsh本体,只要想办法把整个工程下载下来,并重命名为oh-my-zsh即可。所以找找 gitee 有没有相关工程。这也是为什么从旧电脑里直接复制.oh-my-zsh就能用的原因。 问题oh-my-zsh.sh parse error near `<<<’一般是在更新oh-my-zsh时出现,因为更新相当于就是从远程拉取了内容,可能本地的oh-my-zsh.sh脚本自己做了修改与远程冲突了。只要退回上个版本,重新拉取就可以了。 123cd $ZSHgit reset --hard HEAD^git pull --rebase 如果本地修改了一些内容需要保留,可以打开oh-my-zsh.sh看看冲突在哪,自己做个备份,保存一下。","categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Plugins","slug":"Plugins","permalink":"http://example.com/tags/Plugins/"},{"name":"zsh","slug":"zsh","permalink":"http://example.com/tags/zsh/"}]},{"title":"Qt 绘制系统","slug":"Qt绘制系统","date":"2021-08-27T06:39:12.000Z","updated":"2022-10-15T03:14:29.507Z","comments":true,"path":"2021/08/27/Qt绘制系统/","link":"","permalink":"http://example.com/2021/08/27/Qt%E7%BB%98%E5%88%B6%E7%B3%BB%E7%BB%9F/","excerpt":"","text":"本篇文章所涉及代码可在此处查看。 绘制系统简介Qt 的绘图系统允许使用相同的 API 在屏幕和其它打印设备上进行绘制。整个绘图系统基于QPainter,QPainterDevice和QPaintEngine三个类。 QPainter用来执行绘制的操作;QPaintDevice是一个二维空间的抽象,这个二维空间允许QPainter在其上面进行绘制,也就是QPainter工作的空间;QPaintEngine提供了画笔(QPainter)在不同的设备上进行绘制的统一的接口。QPaintEngine类应用于QPainter和QPaintDevice之间,通常对开发人员是透明的。 三个类的关系:QPainter->QPaintEngine->QPaintDevice。通过这个关系我们也可以知道,QPainter通过QPaintEngine翻译指令在QPaintDevice上绘制。 通过一个实例来了解一下绘制系统的, 12345678910111213141516//main.h#include <QPainter>#include <QWidget>#include <QPaintEvent>#include <QApplication>#include <QMainWindow>class PaintedWidget : public QWidget{ Q_OBJECTpublic: PaintedWidget(QWidget *parent = 0);protected: void paintEvent(QPaintEvent *);}; 1234567891011121314151617181920212223242526272829//main.cpp#include "paintwidget.h"PaintedWidget::PaintedWidget(QWidget *parent) : QWidget(parent){ resize(800, 600); setWindowTitle(tr("Paint Demo"));}void PaintedWidget::paintEvent(QPaintEvent *){ QPainter painter(this); painter.drawLine(20, 20, 700, 20); painter.setPen(Qt::red); painter.drawRect(10, 10, 100, 400); painter.setPen(QPen(Qt::green, 5)); painter.setBrush(Qt::blue); painter.drawEllipse(0, 0, 300, 40); // painter.drawRect(120, 50, 50, 400);}int main(int argc, char *argv[]){ QApplication app(argc, argv); PaintedWidget paintMap; paintMap.show(); return app.exec();} 在构造函数中,我们仅仅设置了窗口的大小和标题。而paintEvent()函数则是绘制的代码。 首先,我们在栈上创建了一个QPainter对象,也就是说,每次运行paintEvent()函数的时候,都会重建这个QPainter对象。注意,这一点可能会引发某些细节问题:由于我们每次重建QPainter,因此第一次运行时所设置的画笔颜色、状态等,第二次再进入这个函数时就会全部丢失。有时候我们希望保存画笔状态,就必须自己保存数据,否则的话则需要将QPainter作为类的成员变量。 paintEvent()作为重绘函数,会在需要重绘时由 Qt 自动调用。“需要重绘”可能发生在很多地方,比如组件刚刚创建出来的时候就需要重绘;组件最大化、最小化的时候也需要重新绘制;组件由遮挡变成完全显示的时候也需要等等。 QPainter接收一个QPaintDevice指针作为参数。QPaintDevice有很多子类,比如QImage,以及QWidget。注意回忆一下,QPaintDevice可以理解成要在哪里去绘制,而现在我们希望画在这个组件,因此传入的是 this 指针。 我们还需要注意绘制的顺序,直线-矩形 - 椭圆,所以直线位于最下方,以此类推。 如果了解 OpenGL,肯定听说过这么一句话:OpenGL 是一个状态机。所谓状态机,就是说,OpenGL 保存的只是各种状态。比如,将画笔颜色设置成红色,那么,除非你重新设置另外的颜色,它的颜色会一直是红色。QPainter也是这样,它的状态不会自己恢复,除非你使用了各种设置函数。因此,如果在上面的代码中,我们在椭圆绘制之后再画一个矩形,它的样式还会是绿色5像素的轮廓线以及蓝色的填充,除非你显式地调用了设置函数进行状态的更新。 这是大多数绘图系统的实现方式,包括 OpenGL、QPainter以及 Java2D。正因为QPainter是一个状态机,才会引出我们前面曾经介绍过的一个细节问题:由于paintEvent()是需要重复进入的,因此,需要注意第二次进入时,QPainter的状态是不是和第一次一致,否则的话可能会造成闪烁的现象。这个闪烁并不是由于双缓冲的问题,而是由于绘制状态的快速切换。 画刷和画笔画刷和画笔。前者使用QBrush描述,大多用于填充;后者使用QPen描述,大多用于绘制轮廓线。 123456789101112131415161718192021222324//main.cppvoid PaintedWidget::paintEvent(QPaintEvent *){ QPainter painter(this); painter.drawLine(20, 20, 700, 20); painter.setPen(Qt::red); painter.drawRect(10, 10, 100, 400); painter.setPen(QPen(Qt::green, 5)); painter.setBrush(Qt::blue); painter.drawEllipse(0, 0, 300, 40); painter.drawRect(120, 50, 50, 400); ///////////////////画笔与笔刷 QLinearGradient gradient(QPointF(180, 50), QPointF(230, 400)); gradient.setColorAt(0, Qt::black); gradient.setColorAt(1, Qt::red); gradient.setSpread(QGradient::PadSpread); QBrush brush(gradient); QPen pen(Qt::green, 3, Qt::DashDotLine, Qt::RoundCap, Qt::RoundJoin); // painter.setPen(pen); painter.setBrush(brush); painter.drawRect(180, 50, 50, 400);} 画刷的style()定义了填充的样式,使用Qt::BrushStyle枚举,默认值是Qt::NoBrush,也就是不进行任何填充。我们可以从下面的图示中看到各种填充样式的区别: 画刷的gradient()定义了渐变填充。这个属性只有在样式是Qt::LinearGradientPattern、Qt::RadialGradientPattern或者Qt::ConicalGradientPattern之一时才有效。渐变可以由QGradient对象表示。Qt 提供了三种渐变:QLinearGradient、QConicalGradient和QRadialGradient,它们都是QGradient的子类。 本文以QLinearGradient为例,两个坐标分别为起点与重点坐标。setColorAt设置渐变颜色,0表示开始,1表示结束。意思就是从黑色渐变到红色。setSpread设置显示方式为平铺。 1234QLinearGradient gradient(QPointF(180, 50), QPointF(230, 400));gradient.setColorAt(0, Qt::black);gradient.setColorAt(1, Qt::red);gradient.setSpread(QGradient::PadSpread); 默认的画笔属性是纯黑色,0 像素,方形笔帽(Qt::SquareCap),斜面型连接(Qt::BevelJoin)。 画笔样式有一下几种, 你也可以使用setDashPattern()函数自定义样式,例如如下代码片段: 123456789QVector<qreal> dashes;qreal space = 4;dashes << 1 << space << 3 << space << 9 << space << 27 << space << 9 << space;pen.setColor(Qt::black);pen.setDashPattern(dashes);painter.setPen(pen);painter.drawLine(30, 300, 600, 30); pen.setCapStyle(Qt::RoundCap)笔帽定义了画笔末端的样式,例如: pen.setJoinStyle(Qt::RoundJoin)连接样式定义了两条线连接时的样式,例如: 反走样我们在光栅图形显示器上绘制非水平、非垂直的直线或多边形边界时,或多或少会呈现锯齿状外观。这是因为直线和多边形的边界是连续的,而光栅则是由离散的点组成。在光栅显示设备上表现直线、多边形等,必须在离散位置采样。由于采样不充分重建后造成的信息失真,就叫走样;用于减少或消除这种效果的技术,就称为反走样。也就是常说的防锯齿现象。因为性能方面的考虑,Qt 默认关闭反走样。 12345678910111213void paintEvent(QPaintEvent *){ ///////////////////对比反走样效果 QPainter painter(this); painter.setPen(QPen(Qt::black, 5, Qt::DashDotLine, Qt::RoundCap)); painter.setBrush(Qt::yellow); painter.drawEllipse(550, 150, 200, 150); painter.setRenderHint(QPainter::Antialiasing, true); painter.setPen(QPen(Qt::black, 5, Qt::DashDotLine, Qt::RoundCap)); painter.setBrush(Qt::yellow); painter.drawEllipse(300, 150, 200, 150);} 我们可以明显观察到右边的椭圆轮廓是有锯齿现象的,这两个椭圆除了位置位置不同,唯一的区别就是右边的开启了反锯齿。 1painter.setRenderHint(QPainter::Antialiasing, true); 虽然反走样比不反走样的图像质量高很多,但是,没有反走样的图形绘制还是有很大用处的。首先,就像前面说的一样,在一些对图像质量要求不高的环境下,或者说性能受限的环境下,比如嵌入式和手机环境,一般是不进行反走样的。另外,在一些必须精确操作像素的应用中,也是不能进行反走样的。 坐标系统在 Qt 的坐标系统中,每个像素占据 1x1 的空间。你可以把它想象成一张方格纸,每个小格都是 1 个像素。方格的焦点定义了坐标,也就是说,像素 (x, y) 的中心位置其实是在(x + 0.5, y + 0.5)的位置上。这个坐标系统实际上是一个“半像素坐标系”。我们可以通过下面的示意图来理解这种坐标系: 我们使用一个像素的画笔进行绘制,可以看到,每一个绘制像素都是以坐标点为中心的矩形。注意,这是坐标的逻辑表示,实际绘制则与此不同。因为在实际设备上,像素是最小单位,我们不能像上面一样,在两个像素之间进行绘制。所以在实际绘制时,Qt 的定义是,绘制点所在像素是逻辑定义点的右下方的像素。 接下来,我们探究 Qt 绘制图像的坐标情况,对于画笔大小为一个像素的情况比较容易理解,当我们绘制矩形左上角 (1, 2) 时,实际绘制的像素是在右下方。 当画笔大小超过 1 个像素时,就略显复杂了。如果绘制像素是偶数,则实际绘制会包裹住逻辑坐标值;如果是奇数,则是包裹住逻辑坐标值,再加上右下角一个像素的偏移。具体请看下面的图示: 从上图可以看出,如果实际绘制是偶数像素,则会将逻辑坐标值夹在相等的两部分像素之间;如果是奇数,则会在右下方多出一个像素。 Qt 的这种处理,带来的一个问题是,我们可能获取不到真实的坐标值。由于历史原因,QRect::right()和QRect::bottom()的返回值并不是矩形右下角点的真实坐标值:QRect::right()返回的是left() + width() - 1;QRect::bottom()则返回 top() + height() - 1,上图的绿色点指出了这两个函数的返回点的坐标。 为避免这个问题,我们建议是使用QRectF。QRectF使用浮点值,而不是整数值,来描述坐标。这个类的两个函数QRectF::right()和QRectF::bottom()是正确的。如果你不得不使用QRect,那么可以利用 x() + width() 和 y() + height()来替代 right()和bottom()函数。 对于反走样,实际绘制会包裹住逻辑坐标值: 前面说过,QPainter是一个状态机。那么,有时我想保存下当前的状态:当我临时绘制某些图像时,就可能想这么做。当然,我们有最原始的办法:将可能改变的状态,比如画笔颜色、粗细等,在临时绘制结束之后再全部恢复。对此,QPainter提供了内置的函数:save()和restore()。save()就是保存下当前状态;restore()则恢复上一次保存的结果。这两个函数必须成对出现:QPainter使用栈来保存数据,每一次save(),将当前状态压入栈顶,restore()则弹出栈顶进行恢复。 在了解了这两个函数之后,我们就可以进行示例代码了: 12345678910111213141516171819202122232425262728293031323334353637383940//绘制一个网格背景void CoordinateWidget::paintGrid(){ size_t win_width = this->geometry().width(); size_t win_height = this->geometry().height(); QPainter painter(this); for (size_t x = 0; x < win_width; x += 25) { painter.drawLine(QPoint(x, 1), QPoint(x, win_height)); } for (size_t y = 0; y < win_height; y += 25) { painter.drawLine(QPoint(1, y), QPoint(win_width, y)); }}void CoordinateWidget::paintEvent(QPaintEvent *){ paintGrid(); QPainter painter(this); painter.fillRect(10, 10, 50, 100, Qt::red); painter.save(); painter.translate(100, 0); // 向右平移 100px painter.fillRect(10, 10, 50, 100, Qt::yellow); painter.restore(); painter.save(); painter.translate(300, 0); // 向右平移 300px painter.rotate(30); // 顺时针旋转 30 度 painter.fillRect(10, 10, 50, 100, Qt::green); painter.restore(); painter.save(); painter.translate(400, 0); // 向右平移 400px painter.scale(2, 3); // 横坐标单位放大 2 倍,纵坐标放大 3 倍 painter.fillRect(10, 10, 50, 100, Qt::blue); painter.restore(); painter.save(); painter.translate(600, 0); // 向右平移 600px painter.shear(0, 1); // 横向不变,纵向扭曲 1 倍 painter.fillRect(10, 10, 50, 100, Qt::cyan); painter.restore();} Qt 提供了四种坐标变换:平移 translate,旋转 rotate,缩放 scale 和扭曲 shear。在这段代码中,我们首先在 (10, 10) 点绘制一个红色的 50x100 矩形。保存当前状态,将坐标系平移到 (100, 0),绘制一个黄色的矩形。注意,translate()操作平移的是坐标系,不是矩形。因此,我们还是在(10, 10) 点绘制一个 50x100 矩形,现在,它跑到了右侧的位置。然后恢复先前状态,也就是把坐标系重新设为默认坐标系(相当于进行translate(-100, 0)),再进行下面的操作。之后也是类似的。由于我们只是保存了默认坐标系的状态,因此我们之后的translate()横坐标值必须增加,否则就会覆盖掉前面的图形。所有这些操作都是针对坐标系的,因此在绘制时,我们提供的矩形的坐标参数都是不变的。 为了更直观的查看绘制坐标,先在背景画了一个网格。 运行结果如下:","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"}]},{"title":"RISC-V 入门 - 计算机基础","slug":"RISC-V入门-计算机基础","date":"2021-08-26T05:42:34.000Z","updated":"2022-10-15T03:14:29.570Z","comments":true,"path":"2021/08/26/RISC-V入门-计算机基础/","link":"","permalink":"http://example.com/2021/08/26/RISC-V%E5%85%A5%E9%97%A8-%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9F%BA%E7%A1%80/","excerpt":"","text":"计算机基础计算机硬件基础两大硬件架构 冯诺依曼架构 一根总线,开销小,控制逻辑实现简单 执行效率低 哈佛架构 与上一架构相反 程序的存储与执行.c文件经过编译链接,生成.out文件。加载到内存中,到控制单元运行。进行取值,译码,执行。 晶振发出脉冲。 语言的设计与进化上图是冯诺依曼架构,特点就是指令与数据放在一起。黄色部分表示指令,绿色部分表示数据。我们来看看指令是如何执行的。ProgramCounter指到右图内存的第一条指令,程序开始执行。将第一条 指令读入指令寄存器。然后将指令解码,根据之前的规定,我们可以知道这条指令是将0100(二进制即 5)位置的数据,00(load)到00(Register 0)中。下面的指令一次类推,每次取指,Program Counter移动一次。","categories":[{"name":"RISC-V 入门","slug":"RISC-V-入门","permalink":"http://example.com/categories/RISC-V-%E5%85%A5%E9%97%A8/"}],"tags":[{"name":"RISCV","slug":"RISCV","permalink":"http://example.com/tags/RISCV/"}]},{"title":"VSCode 单步调试 QEMU","slug":"VSCode单步调试QEMU","date":"2021-08-24T11:24:08.000Z","updated":"2022-10-15T02:59:01.689Z","comments":true,"path":"2021/08/24/VSCode单步调试QEMU/","link":"","permalink":"http://example.com/2021/08/24/VSCode%E5%8D%95%E6%AD%A5%E8%B0%83%E8%AF%95QEMU/","excerpt":"","text":"了解了如何在VSCode 中调试程序,接下来我们在 VSCode 中搭建调试 QEMU 的环境。 配置首先我们需要下载和编译 QEMU 源码 1./configure --enable-debug --target-list=riscv32-softmmu,riscv32-linux-user --enable-kvm 一定要加上--enable-debug,编译出的程序才带有调试信息,不用设置安装路径,编译时会自动在 qemu 文件夹下自动创建一个build文件夹,编译后的程序也在build文件夹下。 用 VSCode 打开qemu-6.X.X文件夹,Ctrl+Shift+D打开调试配置。如果参考过VSCode 中调试程序这篇文章,接下来就很容易。我们只需要将launch.jason文件中的program属性改为${workspaceFolder}/build/qemu-system-riscv32即可。 调试打开qemu-6.X.X/softmmu/main.c文件,在main函数入口处打上断点,即可开始调试。 现在只需要点击屏幕上的图标,就可以快速的进行单步调试。 如果需要进行命令行操作,在屏幕下方打开DEBUG CONSOLE,输入-exec+正常命令行下的命令即可在命令行中进行更多的调试。如查看断点信息-exec info breakpoints","categories":[{"name":"万能 VSCode","slug":"万能-VSCode","permalink":"http://example.com/categories/%E4%B8%87%E8%83%BD-VSCode/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"},{"name":"QEMU","slug":"QEMU","permalink":"http://example.com/tags/QEMU/"}]},{"title":"Qt 模仿登录界面-页面反转效果","slug":"Qt模仿登录界面-页面反转效果","date":"2021-08-24T05:55:37.000Z","updated":"2022-10-15T03:14:29.492Z","comments":true,"path":"2021/08/24/Qt模仿登录界面-页面反转效果/","link":"","permalink":"http://example.com/2021/08/24/Qt%E6%A8%A1%E4%BB%BF%E7%99%BB%E5%BD%95%E7%95%8C%E9%9D%A2-%E9%A1%B5%E9%9D%A2%E5%8F%8D%E8%BD%AC%E6%95%88%E6%9E%9C/","excerpt":"","text":"设置一个旋转效果,将登录界面旋转翻个面,设置一些网络参数。 效果 网络参数设置界面布局 网络参数设置界面123456789101112131415161718192021222324252627282930313233343536373839404142434445464748//loginnetsetwindow.cpp//初始化标题void LoginNetSetWindow::initMyTitle(){ m_titleBar->move(0, 0); m_titleBar->raise(); m_titleBar->setBackgroundColor(0, 0, 0, true); m_titleBar->setButtonType(MIN_BUTTON); m_titleBar->setTitleWidth(this->width()); m_titleBar->setMoveParentWindowFlag(false);}void LoginNetSetWindow::initWindow(){ QLabel* pBack = new QLabel(this); QMovie *movie = new QMovie(); movie->setFileName(":/Resources/NetSetWindow/headBack.gif"); pBack->setMovie(movie); movie->start(); pBack->move(0, 0); connect(ui.pButtonOk, SIGNAL(clicked()), this, SIGNAL(rotateWindow())); connect(ui.pButtonCancel, SIGNAL(clicked()), this, SIGNAL(rotateWindow())); ui.comboBoxNetType->addItem(QStringLiteral("不使用代理")); ui.comboBoxServerType->addItem(QStringLiteral("不使用高级选项"));}void LoginNetSetWindow::paintEvent(QPaintEvent *event){ // 绘制背景图; QPainter painter(this); QPainterPath pathBack; pathBack.setFillRule(Qt::WindingFill); pathBack.addRoundedRect(QRect(0, 0, this->width(), this->height()), 3, 3); painter.setRenderHint(QPainter::Antialiasing, true); painter.fillPath(pathBack, QBrush(QColor(235, 242, 249))); QPainterPath pathBottom; pathBottom.setFillRule(Qt::WindingFill); pathBottom.addRoundedRect(QRect(0, 300, this->width(), this->height() - 300), 3, 3); painter.setRenderHint(QPainter::Antialiasing, true); painter.fillPath(pathBottom, QBrush(QColor(205, 226, 242))); painter.setPen(QPen(QColor(160 , 175 , 189))); painter.drawRoundedRect(QRect(0, 0, this->width(), this->height()), 3, 3);} initMyTitle()就不多说了,和正面登录界面差不多。 QPainterPath类它是由一些图形如曲线、矩形、椭圆组成的对象。主要的用途是,能保存已经绘制好的图形。实现图形元素的构造和复用;图形状只需创建一次,然后调用QPainter::drawPath() 函数多次绘制。painterpath可以加入闭合或不闭合的图形 ( 如:矩形、椭圆和曲线) 。QPainterPath 可用于填充,描边,clipping。 setFillRule()设置填充模式不是很理解 https://doc.qt.io/qt-5/qt.html#FillRule-enum addRoundedRect(QRect(0, 0, this->width(), this->height()), 3, 3)圆角矩形 QRect(0, 300, this->width(), this->height() - 300)设置了矩形的位置及大小 (3,3)表示倒圆角的大小 setRenderHint()开启反走样 QPainter::Antialiasing 告诉绘图引擎应该在可能的情况下进行边的反锯齿绘制 QPainter::TextAntialiasing 尽可能的情况下文字的反锯齿绘制 QPainter::SmoothPixmapTransform 使用平滑的 pixmap 变换算法 (双线性插值算法),而不是近邻插值算 初始化旋转窗口1234567891011121314151617181920// 初始化旋转的窗口;void RotateWidget::initRotateWindow(){ m_loginWindow = new LoginWindow(this); // 这里定义了两个信号,需要自己去发送信号; connect(m_loginWindow, SIGNAL(rotateWindow()), this, SLOT(onRotateWindow())); connect(m_loginWindow, SIGNAL(closeWindow()), this, SLOT(close())); connect(m_loginWindow, SIGNAL(hideWindow()), this, SLOT(onHideWindow())); m_loginNetSetWindow = new LoginNetSetWindow(this); connect(m_loginNetSetWindow, SIGNAL(rotateWindow()), this, SLOT(onRotateWindow())); connect(m_loginNetSetWindow, SIGNAL(closeWindow()), this, SLOT(close())); connect(m_loginNetSetWindow, SIGNAL(hideWindow()), this, SLOT(onHideWindow())); this->addWidget(m_loginWindow); this->addWidget(m_loginNetSetWindow); // 这里宽和高都增加,是因为在旋转过程中窗口宽和高都会变化; this->setFixedSize(QSize(m_loginWindow->width() + 20, m_loginWindow->height() + 100));} 对正面和反面分别定义了信号槽,当对应的面接收到信号时,执行对应的动作。因为是旋转一百八十度,所以选择函数可以公用。 旋转窗口 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071// 开始旋转窗口;void RotateWidget::onRotateWindow(){ // 如果窗口正在旋转,直接返回; if (m_isRoratingWindow) { return; } m_isRoratingWindow = true; m_nextPageIndex = (currentIndex() + 1) >= count() ? 0 : (currentIndex() + 1); QPropertyAnimation *rotateAnimation = new QPropertyAnimation(this, "rotateValue"); // 设置旋转持续时间; rotateAnimation->setDuration(1500); // 设置旋转角度变化趋势; rotateAnimation->setEasingCurve(QEasingCurve::InCubic); // 设置旋转角度范围; rotateAnimation->setStartValue(0); rotateAnimation->setEndValue(180); connect(rotateAnimation, SIGNAL(valueChanged(QVariant)), this, SLOT(repaint())); connect(rotateAnimation, SIGNAL(finished()), this, SLOT(onRotateFinished())); // 隐藏当前窗口,通过不同角度的绘制来达到旋转的效果; currentWidget()->hide(); rotateAnimation->start();}// 旋转结束;void RotateWidget::onRotateFinished(){ m_isRoratingWindow = false; setCurrentWidget(widget(m_nextPageIndex)); repaint();}/ 绘制旋转效果;void RotateWidget::paintEvent(QPaintEvent *event){ if (m_isRoratingWindow) { // 小于 90 度时; int rotateValue = this->property("rotateValue").toInt(); if (rotateValue <= 90) { QPixmap rotatePixmap(currentWidget()->size()); currentWidget()->render(&rotatePixmap); QPainter painter(this); painter.setRenderHint(QPainter::Antialiasing); QTransform transform; transform.translate(width() / 2, 0); transform.rotate(rotateValue, Qt::YAxis); painter.setTransform(transform); painter.drawPixmap(-1 * width() / 2, 0, rotatePixmap); } // 大于 90 度时 else { QPixmap rotatePixmap(widget(m_nextPageIndex)->size()); widget(m_nextPageIndex)->render(&rotatePixmap); QPainter painter(this); painter.setRenderHint(QPainter::Antialiasing); QTransform transform; transform.translate(width() / 2, 0); transform.rotate(rotateValue + 180, Qt::YAxis); painter.setTransform(transform); painter.drawPixmap(-1 * width() / 2, 0, rotatePixmap); } } else { return QStackedWidget::paintEvent(event); }} QPropertyAnimation动画类QPropertyAnimation *rotateAnimation = new QPropertyAnimation(this, "rotateValue") rotateValue就是这个动画的属性,我们这个动画中变化的就是旋转值,也就是旋转角度。这个属性名完全自己起,也可以改成rotateAngle等等,或者说想做一个平移的动画,也可以取一个moveDist等名字。 下面这一串就是标准的一套动画流程 123456789// 设置旋转持续时间;rotateAnimation->setDuration(1000);// 设置旋转角度变化趋势;rotateAnimation->setEasingCurve(QEasingCurve::InCubic);// 设置旋转角度范围;rotateAnimation->setStartValue(0);rotateAnimation->setEndValue(180);//开始动画rotateAnimation->start(); paintEvent绘图事件12345678910#include <QtWidgets/QApplication>#include "rotatewidget.h"int main(int argc, char *argv[]){ QApplication a(argc, argv); RotateWidget w; w.show(); return a.exec();} 我们main函数得知,最开始显示的窗口就是RotateWidget。在实例化一个RotateWidget类后,进行了标题栏的初始化工作,然后开始执行w.show()显示,但是此时窗口是不显示的。这是因为我们在RotateWidget的构造函数中进行了设置不显示窗口。 123this->setWindowFlags(Qt::FramelessWindowHint | Qt::WindowStaysOnTopHint | Qt::WindowMinimizeButtonHint); 当运行到return a.exec()时,Qt 会自动调用void RotateWidget::paintEvent()。此时开始正式绘制窗口,但是因为我们还没哟点击登录页面的网络设置按钮,所以m_isRoratingWindow=0。会调用父类的绘图事件,QStackedWidget::paintEvent(),最后也就是BaseWindow::paintEvent()。会将登录页面先绘制出来。 当我们点击网络设置按钮时,m_isRoratingWindow=1开始绘制旋转画面。","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"}]},{"title":"Linux 操作系统-系统初始化","slug":"Linux操作系统-系统初始化","date":"2021-08-24T01:45:57.000Z","updated":"2022-10-15T03:14:29.307Z","comments":true,"path":"2021/08/24/Linux操作系统-系统初始化/","link":"","permalink":"http://example.com/2021/08/24/Linux%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F-%E7%B3%BB%E7%BB%9F%E5%88%9D%E5%A7%8B%E5%8C%96/","excerpt":"","text":"系统初始化x86 架构概述CPU(Central Processing Unit):中央处理器,计算机所有设备都围绕它展开工作。 运算单元:只管算,例如做加法、做位移等等。但是,它不知道应该算哪些数据,运算结果应该放在哪里。 数据单元:运算单元计算的数据如果每次都要经过总线,到内存里面现拿,这样就太慢了,所以就有了数据单元。数据单元包括 CPU 内部的缓存和寄存器组,空间很小,但是速度飞快,可以暂时存放数据和运算结果。 控制单元:有了放数据的地方,也有了算的地方,还需要有个指挥到底做什么运算的地方,这就是控制单元。控制单元是一个统一的指挥中心,它可以获得下一条指令,然后执行这条指令。这个指令会指导运算单元取出数据单元中的某几个数据,计算出个结果,然后放在数据单元的某个地方。 内存(Memory):CPU 本身不能保存大量数据,许多复杂的计算需要将中间结果保存下来就必须用到内存。 总线(Bus):CPU 和其他设备连接,就靠总线,其实就是主板上密密麻麻的集成电路,这些东西组成了 CPU 和其他设备的高速通道。 地址总线:传输地址数据(我想拿内存中哪个位置的数据) 数据总线:传输真正的数据 总线就像 CPU 和内存之间的高速公路,总线多少位就类似高速公路多少个车道,但两种总线的位数意义不同。 地址总线的位数决定了访问地址范围有多广,数据总线位数决定了一次能拿多少数据进来。那么 CPU 中总线的位数有没有标准呢?如果没有标准,那操作系统作为软件就很难办了,因为软件层没办法实现通用的运算逻辑。早期每家公司的 CPU 架构都不同,后来历史将 x86 平台推到了开放,统一,兼容的位置。 8086 架构图 数据单元: 8086 处理器内部共有 8 个 16 位的通用寄存器,分别是 数据寄存器(AX、BX、CX、DX)、指针寄存器(SP、BP)、变址寄存器(SI、DI)。其中 AX、BX、CX、DX 可以分成两个 8 位的寄存器来使用,分别是 AH、AL、BH、BL、CH、CL、DH、DL,其中 H 就是 High(高位),L 就是 Low(低位)的意思。 控制单元: IP 寄存器(Instruction Pointer Register)就是指令指针寄存器,它指向代码段中下一条指令的位置。CPU 会根据它来不断地将指令从内存的代码段中,加载到 CPU 的指令队列中,然后交给运算单元去执行。 如果需要切换进程呢?每个进程都分代码段和数据段,为了指向不同进程的地址空间,有四个 16 位的段寄存器,分别是 CS、DS、SS、ES。 其中,CS 就是代码段寄存器(Code Segment Register),通过它可以找到代码在内存中的位置;DS 是数据段的寄存器(Data Segment Register),通过它可以找到数据在内存中的位置。SS 是栈寄存器(Stack Register)。栈是程序运行中一个特殊的数据结构,数据的存取只能从一端进行,秉承后进先出的原则。ES是扩展段寄存器(Extra Segment Register)顾名思义。 如果 CPU 运算中需要加载内存中的数据,需要通过 DS 找到内存中的数据,加载到通用寄存器中,应该如何加载呢?对于一个段,有一个起始的地址,而段内的具体位置,我们称为偏移量(Offset)。在 CS 和 DS 中都存放着一个段的起始地址。代码段的偏移量在 IP 寄存器中,数据段的偏移量会放在通用寄存器中。因为段寄存器都是 16 位的,而地址总线是 20 位的,所以通过 *起始地址 16+ 偏移量 的方式,将寻址位数都变成 20 位,也就是将 CS 和 DS 的值左移 4 位。 对于只有 20 位地址总线的 8086 来说,寻址空间最大也就是$2^{20}=1\\text{M}$,超过这个位置就访问不到了,一个段因为偏移量只有 16 位,所以一个段最大是$2^{16}=64\\text{k}$。 32 位处理器随着计算机发展,内存越来越大,总线也越来越宽。在 32 位处理器中,有 32 根地址总线,可以访问 $2^{32}=4\\text{G}$ 的内存。使用原来的模式肯定不行了,但是又不能完全抛弃原来的模式,因为这个架构是开放的。那么在开发架构的基础上如何保持兼容呢? 首先,通用寄存器有扩展,可以将 8 个 16 位的扩展到 8 个 32 位的,但是依然可以保留 16 位的和 8 位的使用方式。其中,指向下一条指令的指令指针寄存器 IP,就会扩展成 32 位的,同样也兼容 16 位的。 段寄存器改动较大,新的段寄存器都改成了 32 位的,每个寄存器又分为段描述符缓存器(Segment Descriptor),和段选择子寄存器(Selector) ,现在的段寄存器不在是段的起始地址,段的起始地址保存在表格一样的段描述符缓冲器中,段选择子寄存器保存地址在段描述符缓存器中的哪一项。这样,将一个从段寄存器直接拿到的段起始地址,就变成了先间接地从段寄存器找到表格中的一项,再从表格中的一项中拿到段起始地址。 虽然现在的这种模式和之前的模式不兼容,但是后面这种模式灵活的非常高,可以保持一直兼容下去。在 32 位的系统架构下,将前一种模式称为实模式(Real Pattern),后一种模式称为保护模式(Protected Pattern) 。当系统刚刚启动的时候,CPU 是处于实模式的,这个时候和原来的模式是兼容的。也就是说,哪怕你买了 32 位的 CPU,也支持在原来的模式下运行。 汇编命令学习mov,call, jmp, int, ret, add, or, xor, shl, shr, push, pop, inc, dec, sub, cmp。 BIOS 与 BootLoaderBIOS:基本输入输出系统 ROM:只读存储器 RAM:随机存取存储器 在我们按下电脑电源键的那一刻,主板就加电了,CPU 就要开始执行指令了,但是刚开始操作系统都没,CPU 执行什么指令呢?这就有了BIOS,它相当于一个指导手册,告诉 CPU 接下来要干啥。 刚开机时,系统初始化代码从 ROM 读取,将 CS 设置为 0xFFFF,将 IP 设置为 0x0000,所以第一条指令就会指向 0xFFFF0,初始化完成后确定访问指令位置。 接下来 BIOS 会检查各个硬件是否正常,检测内容显卡等关键部件的存在于工作状态,设备初始化,执行系统 BIOS 进行系统检测,更新 CMOS 中的扩展系统配置数据 ESCD。这期间也会建立中断向量表和中断服务程序,因为要使用键盘鼠标都需要中断进行。 下一步 BIOS 就得要找操作系统了,操作系统一般安装在硬盘上,但是 BIOS 得先找到启动盘,启动盘一般安装在第一个扇区,占 512 字节,会包含启动的相关代码。在 Linux 中,可以通过Grub2配置这些代码。 1grub2-mkconfig -o /boot/grub2/grub.cfg grub2第一个要安装的就是boot.img。它由 boot.S编译而成,一共 512 字节,正式安装到启动盘的第一个扇区。这个扇区通常称为MBR(Master Boot Record,主引导记录 / 扇区)。 BIOS 完成任务后,会将 boot.img 从硬盘加载到内存中的 0x7c00来运行。 由于 512 个字节实在有限,boot.img 做不了太多的事情。它能做的最重要的一个事情就是加载grub2 的另一个镜像 core.img。 core.img 由lzma_decompress.img、diskboot.img、kernel.img 和一系列的模块组成,功能比较丰富,能做很多事情。 boot.img 先加载的是 core.img 的第一个扇区。如果从硬盘启动的话,这个扇区里面是diskboot.img,对应的代码是 diskboot.S。 boot.img 将控制权交给 diskboot.img 后,diskboot.img 的任务就是将core.img 的其他部分加载进来,先是解压缩程序 lzma_decompress.img,再往下是 kernel.img,最后是各个模块module对应的映像。这里需要注意,它不是 Linux 的内核,而是grub 的内核。 在这之前,我们所有遇到过的程序都非常非常小,完全可以在实模式下运行,但是随着我们加载的东西越来越大,实模式这1M 的地址空间实在放不下了,所以在真正的解压缩之前,lzma_decompress.img 做了一个重要的决定,就是调用 real_to_prot,切换到保护模式,这样就能在更大的寻址空间里面,加载更多的东西。 BIOS将加载程序从硬盘的引导扇区加载到指定位置,再跳转到指定位置,将控制权转交给加载程序。加载程序将操作系统代码读取到内存,并将控制权转到操作系统。 Q:BIOS-操作系统,中间经过加载程序。为何不直接读取?A:磁盘文件系统多种多样,硬盘出厂时不能限制只能用一种文件系统,而 BIOS 也不能加上识别所有文件系统的代码。所有为了灵活性只读取磁盘的一块,由加载程序来识别磁盘的文件系统。 切换到保护模式后,将会做以下这些事,大多数都与内存访问方式有关。 首先启动分段,就是在内存里面建立段描述符表,将寄存器里面的段寄存器变成段选择子,指向某个段描述符,这样就能实现不同进程的切换了。 接着是启动分页。能够管理的内存变大了,就需要将内存分成相等大小的块。 打开 Gate20,也就是第 21 根地址线的控制线。因为在实模式 8086 下,一共就 20 根地址线,最大访问1M的地址空间。切换保护模式的函数DATA32 call real_to_prot会打开Gate A20。 现在好了,有的是空间了。接下来我们要对压缩过的 kernel.img 进行解压缩,然后跳转到 kernel.img 开始运行。 内核初始化 start_kernel() INIT_TASK(init_task) trap_init() mm_init() sched_init() rest_init() kernel_thread(kernel_init, NULL,CLONE_FS) kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES) 内核的启动从入口函数start_kernel() 开始。在 init/main.c 文件中,start_kernel 相当于内核的 main 函数。打开这个函数,我们会发现,里面是各种各样初始化函数 XXXX_init。 在操作系统里面,先要有个创始进程,有一行指令 set_task_stack_end_magic(&init_task)。这里面有一个参数 init_task,它的定义是 struct task_struct init_task = INIT_TASK(init_task)。它是系统创建的第一个进程,我们称为0号进程。这是唯一一个没有通过fork 或者kernel_thread 产生的进程,是进程列表的第一个。 trap_init()里设置了很多**中断门 (Interrupt Gate)**处理各种中断。 mm_init()初始化内存管理模块,sched_init()初始化调度模块。 vfs_caches_init() 会用来初始化基于内存的文件系统 rootfs。在这个函数里面,会调用 mnt_init()->init_rootfs()。这里面有一行代码,register_filesystem(&rootfs_fs_type)。在 VFS 虚拟文件系统里面注册了一种类型,我们定义为 struct file_system_type rootfs_fs_type。为了兼容各种各样的文件系统,我们需要将文件的相关数据结构和操作抽象出来,形成一个抽象层对上提供统一的接口,这个抽象层就是 VFS(Virtual File System),虚拟文件系统。 最后start_kernel()调用rest_init()来做其他方面的初始化,如初始化 1 号进程,内核态与用户态转化等。 rest_init 的第一大工作是,用 kernel_thread(kernel_init, NULL, CLONE_FS)创建第二个进程,这个是1 号进程。这对操作系统意义非凡,因为他将运行第一个用户进程,一旦有了用户进程,运行模式也将发生改变,之前所有资源都是给一个进程用,现在有了用户进程,就会出现抢夺资源的现象。资源也分核心和非核心资源,具有不同权限的进程可以获取不同的资源。x86提供了分层的权限机制,分成四个Ring,越往里权限越高。 操作系统很好地利用了这个机制,将能够访问关键资源的代码放在 Ring0,我们称为内核态(Kernel Mode);将普通的程序代码放在 Ring3,我们称为用户态(User Mode)。 继续探究kernel_thread()这个函数,它的一个参数有一个函数kernel_init,在这个函数里会调用kernel_init_freeable(),里面有这样一段代码 12if (!ramdisk_execute_command) ramdisk_execute_command = "/init"; 先不管ramdisk 是啥,我们回到 kernel_init 里面。这里面有这样的代码块: 12345678910if (ramdisk_execute_command) { ret = run_init_process(ramdisk_execute_command);....}....if (!try_to_run_init_process("/sbin/init") || !try_to_run_init_process("/etc/init") || !try_to_run_init_process("/bin/init") || !try_to_run_init_process("/bin/sh")) return 0; 我们可以发现,1 号进程运行的是一个文件,如果我们打开run_init_process函数,会发现它调用的是do_execve。 前面讲系统调用的时候,execve 是一个系统调用,它的作用是运行一个执行文件。加一个 do_ 的往往是内核系统调用的实现。没错,这就是一个系统调用,它会尝试运行 ramdisk 的“/init”,或者普通文件系统上的“/sbin/init”“/etc/init”“/bin/init”“/bin/sh”。不同版本的 Linux 会选择不同的文件启动,但是只要有一个起来了就可以。 1234567static int run_init_process(const char *init_filename){ argv_init[0] = init_filename; return do_execve(getname_kernel(init_filename), (const char __user *const __user *)argv_init, (const char __user *const __user *)envp_init);} 如何利用执行 init 文件的机会,从内核态回到用户态呢? 我们从系统调用的过程可以得到启发,“用户态 - 系统调用 - 保存寄存器 - 内核态执行系统调用 - 恢复寄存器 - 返回用户态”,然后接着运行。而咱们刚才运行init,是调用 do_execve,正是上面的过程的后半部分,从内核态执行系统调用开始。 do_execve->do_execveat_common->exec_binprm->search_binary_handler,这里面会调用这段内容: 12345678int search_binary_handler(struct linux_binprm *bprm){ ...... struct linux_binfmt *fmt; ...... retval = fmt->load_binary(bprm); ......} 也就是说,我要运行一个程序,需要加载这个二进制文件,这就是我们常说的项目执行计划书。它是有一定格式的。Linux 下一个常用的格式是 ELF(Executable and Linkable Format,可执行与可链接格式)。于是我们就有了下面这个定义: 1234567static struct linux_binfmt elf_format = {.module = THIS_MODULE,.load_binary = load_elf_binary,.load_shlib = load_elf_library,.core_dump = elf_core_dump,.min_coredump = ELF_EXEC_PAGESIZE,}; 这其实就是先调用 load_elf_binary,最后调用 start_thread。 123456789101112131415voidstart_thread(struct pt_regs *regs, unsigned long new_ip, unsigned long new_sp){set_user_gs(regs, 0);regs->fs = 0;regs->ds = __USER_DS;regs->es = __USER_DS;regs->ss = __USER_DS;regs->cs = __USER_CS;regs->ip = new_ip;regs->sp = new_sp;regs->flags = X86_EFLAGS_IF;force_iret();}EXPORT_SYMBOL_GPL(start_thread); struct pt_regs,看名字里的 register,就是寄存器啊!这个结构就是在系统调用的时候,内核中保存用户态运行上下文的,里面将用户态的代码段 CS设置为 __USER_CS,将用户态的数据段 DS 设置为 __USER_DS,以及指令指针寄存器 IP、栈指针寄存器 SP。这里相当于补上了原来系统调用里,保存寄存器的一个步骤。 最后的 iret 是干什么的呢?它是用于从系统调用中返回。这个时候会恢复寄存器。从哪里恢复呢?按说是从进入系统调用的时候,保存的寄存器里面拿出。好在上面的函数补上了寄存器。CS 和指令指针寄存器 IP 恢复了,指向用户态下一个要执行的语句。DS 和函数栈指针 SP 也被恢复了,指向用户态函数栈的栈顶。所以,下一条指令,就从用户态开始运行了。 init 终于从内核到用户态了。一开始到用户态的是 ramdisk 的 init,后来会启动真正根文件系统上的 init,成为所有用户态进程的祖先。 为什么会有 ramdisk 这个东西呢?还记得上一节咱们内核启动的时候,配置过这个参数: 1initrd16 /boot/initramfs-3.10.0-862.el7.x86_64.img 就是这个东西,这是一个基于内存的文件系统。为啥会有这个呢? 是因为刚才那个 init 程序是在文件系统上的,文件系统一定是在一个存储设备上的,例如硬盘。Linux 访问存储设备,要有驱动才能访问。如果存储系统数目很有限,那驱动可以直接放到内核里面,反正前面我们加载过内核到内存里了,现在可以直接对存储系统进行访问。 但是存储系统越来越多了,如果所有市面上的存储系统的驱动都默认放进内核,内核就太大了。这该怎么办呢? 我们只好先弄一个基于内存的文件系统。内存访问是不需要驱动的,这个就是 ramdisk。这个时候,ramdisk 是根文件系统。 然后,我们开始运行 ramdisk 上的 /init。等它运行完了就已经在用户态了。/init 这个程序会先根据存储系统的类型加载驱动,有了驱动就可以设置真正的根文件系统了。有了真正的根文件系统,ramdisk上的 /init 会启动文件系统上的 init。 接下来就是各种系统的初始化。启动系统的服务,启动控制台,用户就可以登录进来了。 至此,用户态进程有了一个祖宗,那内核态的进程呢?这就是rest_init接下来要做的是,创建 2 号线程。 kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES)又一次使用 kernel_thread 函数创建进程。这里的函数 kthreadd,负责所有内核态的线程的调度和管理,是内核态所有线程运行的祖先。 系统调用Linux 提供了glibc这个库封装了系统调用,方便用户使用。那么在打开一个文件时,glibc是如何调用内核的open的呢? 在 glibc 的源代码中,有个文件syscalls.list,里面列着所有 glibc 的函数对应的系统调用,就像下面这个样子: 12# File name Caller Syscall name Args Strong name Weak namesopen - open Ci:siv __libc_open __open open 另外,glibc 还有一个脚本 make-syscall.sh,可以根据上面的配置文件,对于每一个封装好的系统调用,生成一个文件。这个文件里面定义了一些宏,例如 #define SYSCALL_NAME open。 glibc 还有一个文件 syscall-template.S,使用上面这个宏,定义了这个系统调用的调用方式。 对于任何一个系统调用,会调用DO_CALL。这也是一个宏,这个宏 32 位和 64 位的定义是不一样的。 32 位系统调用过程i386 目录下的sysdep.h 文件 12345678910111213141516/* Linux takes system call arguments in registers: syscall number %eax call-clobbered arg 1 %ebx call-saved arg 2 %ecx call-clobbered arg 3 %edx call-clobbered arg 4 %esi call-saved arg 5 %edi call-saved arg 6 %ebp call-saved......*/#define DO_CALL(syscall_name, args) PUSHARGS_##args DOARGS_##args movl $SYS_ify (syscall_name), %eax; ENTER_KERNEL POPARGS_##args 这里,我们将请求参数放在寄存器里面,根据系统调用的名称,得到系统调用号,放在寄存器 eax 里面,然后执行 ENTER_KERNEL。 1# define ENTER_KERNEL int $0x80 ENTER_KERNEL就是一个软中断,通过它可以陷入 (trap) 内核。 在内核启动的时候,还记得有一个 trap_init(),这是一个软中断的陷入门。当接到一个系统调用时,trap_init()就会调用entry_INT80_32。 通过 push 和 SAVE_ALL 将当前用户态的寄存器,保存在 pt_regs 结构里面,然后调用 do_syscall_32_irqs_on。 64 位系统调用过程","categories":[{"name":"Linux 操作系统","slug":"Linux-操作系统","permalink":"http://example.com/categories/Linux-%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"}]},{"title":"VSCode 调试 RISC-V 程序","slug":"VSCode调试程序","date":"2021-08-23T07:51:51.000Z","updated":"2022-10-15T03:14:29.607Z","comments":true,"path":"2021/08/23/VSCode调试程序/","link":"","permalink":"http://example.com/2021/08/23/VSCode%E8%B0%83%E8%AF%95%E7%A8%8B%E5%BA%8F/","excerpt":"","text":"前提本文主要涉及 VSCode 的相关配置,编译及调试工具需要提前安装好。 已经安装好riscv-toolchain,包括riscv64-unknown-elf-gcc,riscv64-unknown-elf-gdb 已经安装好qemu,包括riscv32-softmmu,riscv32-linux-user,riscv64-softmmu,riscv64-linux-user 已经安装好g++,gdb 调试流程简介对于我这样的新手,要调试一个项目源码最怕的就是开始,也就是怎么能把项目跑起来。 我们以一个简单的test项目,看看在 VSCode 里怎么跑起来。 拿到源码后,将其以文件夹形式,加入到 VSCode 中,文件 - 打开文件夹 - 选择 test 项目文件夹。项目就会在 VSCode 中打开,但是此时我们还无法编译运行,我们需要在 VSCode 上构建出一个 C 语言的编译与调试环境。 首先得安装一个插件C/C++,打开插件中心Ctrl+Shit+X,搜索,安装。 然后输入F5,会弹出对话框,选择C++(GDB),继续选择g++。VSCode 会自动创建.vscode文件夹,已经两个文件launch.json和tasks.json。 launch.json用来配置调试环境,tasks.json主要用来配置编译环境,当然也可以配置其他任务。task.json里配置的每个任务其实就相当于多开一个控制台。 配置tasks.json因为我们先要编译源码,生成.out或者.exe文件,才能调试,所以先进行编译任务配置。 自动生成的文件是个配置模板,我们可以根据自己的实际情况进行配置,也有一部分可以保持默认。 12345678910111213141516171819202122232425// tasks.json{ // https://code.visualstudio.com/docs/editor/tasks "version": "2.0.0", "tasks": [ { // 任务的名字,注意是大小写区分的 //会在launch中调用这个名字 "label": "C/C++: g++ build active file", // 任务执行的是shell "type": "shell", // 命令是g++ "command": "g++", //g++ 后面带的参数 "args": [ "'-Wall'", "-g", // 生成调试信息,否则无法进入断点 "'-std=c++17'", //使用c++17标准编译 "'${file}'", //当前文件名 "-o", //对象名,不进行编译优化 "'${fileBasenameNoExtension}.exe'", //当前文件名(去掉扩展名) ], } ]} 如果项目是通过 Makefile 编译的,那就更加简单,只需要配置一个任务即可。 123456789101112131415{ "version": "2.0.0", "tasks": [ { //任务的名字方便执行 "label": "Make Project", "type": "shell", "command": "make", "args":[ //8线程编译 "-j8", ], }, ]} 运行该任务时就会执行make命令进行编译。 配置launch.json123456789101112131415161718192021222324252627282930313233// launch.json{ "version": "0.2.0", "configurations": [ { //调试任务的名字 "name": "g++ - Build and debug active file", //在launch之前运行的任务名,这个名字一定要跟tasks.json中的任务名字大小写一致 "preLaunchTask": "C/C++: g++ build active file", "type": "cppdbg", "request": "launch", //需要运行的是当前打开文件的目录中, //名字和当前文件相同,但扩展名为exe的程序 "program": "${fileDirname}/${fileBasenameNoExtension}.exe", "args": [], // 选为true则会在打开控制台后停滞,暂时不执行程序 "stopAtEntry": false, // 当前工作路径:当前文件所在的工作空间 "cwd": "${workspaceFolder}", "environment": [], // 是否使用外部控制台 "externalConsole": false, "MIMode": "gdb", "setupCommands": [ { "description": "Enable pretty-printing for gdb", "text": "-enable-pretty-printing", "ignoreFailures": true } ] }]} 运行经过以上配置后,我们打开main.cpp文件,在cout处打一个断点,按F5,即可编译,运行,调试。一定要打开main.cpp文件,不能随便打开文件就开始哦。因为我们在配置时使用了一些预定义,比如${file}表示当前文件,所以只有打开需要调试的文件才能开始。 程序将会在cout语句停下来。 我们可以注意一下界面下方的控制台,可以更直观了解launch.jason和tasks.jason。 右边的框,就是我们在tasks.jason中配置的任务,左边的框就是我们在tasks.jason中command以及args的内容,他就是帮我们提前写好编译的选项。然后在 shell 中运行。 编译调试 RISC-V 程序了解以上这些,就可以按需配置所需的环境了。我们还是从tasks.jason开始。因为开发用的电脑是x86的,所以先要编译出riscv的程序,再用模拟器模拟出rsicv的环境,然后在模拟的环境中运行程序,最后才能开始调试。 假设已经安装好开头所提到的工具。首先配置tasks.jason: 1234567891011121314151617181920212223242526272829303132333435363738394041424344{ "version": "2.0.0", "tasks": [ { // 编译当前代码 "type": "shell", "label": "C/C++(RISCV): Build active file", // 编译器的位置 "command": "/opt/riscv/bin/riscv64-unknown-elf-g++", "args": [ "-Wall", // 开启所有警告 "-g", // 生成调试信息s "${file}", "-o", "${workspaceFolder}/debug/${fileBasenameNoExtension}" // 我选择将可执行文件放在debug目录下 ], // 当前工作路径:执行当前命令时所在的路径 "options": { "cwd": "${workspaceFolder}" }, "problemMatcher": [ "$gcc" ] }, { // 启动qemu供调试器连接 "type": "shell", "label": "Run Qemu Server(RISCV)", "dependsOn": "C/C++(RISCV): Build active file", "command": "qemu-system-riscv64", "args": [ "-g", "65500", // gdb端口,自己定义 "${workspaceFolder}/debug/${fileBasenameNoExtension}" ], }, { // 有时候qemu有可能没法退出,故编写一个任务用于强行结束qemu进程 "type": "shell", "label": "Kill Qemu Server(RISCV)", "command": "ps -C qemu-riscv64 --no-headers | cut -d \\\\ -f 1 | xargs kill -9", } ]} tasks.jason是可以配置多个任务的,第一个任务用来编译成riscv架构下的程序,第二个任务用来启动 qemu,让程序在 qemu 上运行起来。 第一个任务中,command就是配置编译器riscv64-unkonown-elf-gcc的属性,第二个任务中,command是配置 qemu 模拟器qemu-system-riscv32的属性。第三个任务中,用来配置结束 qemu 模拟器的命令。 接下来配置launch.jason: 12345678910111213141516171819202122232425262728{ "version": "0.2.0", "configurations": [ { "name": "C/C++(RISCV) - Debug Active File", "type": "cppdbg", "request": "launch", "program": "${workspaceFolder}/debug/${fileBasenameNoExtension}", "args": [], "stopAtEntry": false, "cwd": "${workspaceFolder}", "environment": [], "externalConsole": false, "MIMode": "gdb", "setupCommands": [ { "description": "为 gdb 启用整齐打印", "text": "-enable-pretty-printing", "ignoreFailures": true } ], // RISC-V工具链中的gdb "miDebuggerPath": "/opt/riscv/bin/riscv64-unknown-elf-gdb", // 这里需要与task.json中定义的端口一致 "miDebuggerServerAddress": "localhost:65500" } ]} 我们在配置x86下的调试环境时,launch.jason中有个"preLaunchTask": "C/C++: g++ build active file",属性,这个属性的目的是在启动调试之前,先执行任务名字为"C/C++: g++ build active file"任务,也是就编译的任务。 因为启动 qemu 会导致阻塞,所以这里没有加preLaunchTask,在启动调试之前,先把 qemu 运行起来。输入Ctrl+Shift+P,打开 VSCode 命令行。输入Run Task, 点击第一个,选择任务,我们可以看到出现的三个任务就是我们在tasks.jason中配置的三个任务。选择第一个 Build,编译出程序,再重复操作,选择第三个执行 QEMU 任务。 预定义变量官网","categories":[{"name":"万能 VSCode","slug":"万能-VSCode","permalink":"http://example.com/categories/%E4%B8%87%E8%83%BD-VSCode/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"GDB","slug":"GDB","permalink":"http://example.com/tags/GDB/"},{"name":"RISCV","slug":"RISCV","permalink":"http://example.com/tags/RISCV/"}]},{"title":"进程间通信(IPC)之信号量(Semaphore)","slug":"进程间通信(IPC)之信号量(Semaphore)","date":"2021-08-19T07:36:02.000Z","updated":"2022-10-15T03:14:29.884Z","comments":true,"path":"2021/08/19/进程间通信(IPC)之信号量(Semaphore)/","link":"","permalink":"http://example.com/2021/08/19/%E8%BF%9B%E7%A8%8B%E9%97%B4%E9%80%9A%E4%BF%A1%EF%BC%88IPC%EF%BC%89%E4%B9%8B%E4%BF%A1%E5%8F%B7%E9%87%8F%EF%BC%88Semaphore%EF%BC%89/","excerpt":"","text":"简介为了防止出现因多个程序同时访问一个共享资源而引发的一系列问题,我们需要一种方法,它可以通过生成并使用令牌来授权,在任一时刻只能有一个执行线程访问代码的临界区域。临界区域是指执行数据更新的代码需要独占式地执行。而信号量就可以提供这样的一种访问机制,让一个临界区同一时间只有一个线程在访问它,也就是说信号量是用来调协进程对共享资源的访问的。 信号量是一个特殊的变量,程序对其访问都是原子操作,且只允许对它进行等待(即P) 和发送(即V) 信息操作。最简单的信号量是只能取 0 和 1 的变量,这也是信号量最常见的一种形式,叫做二进制信号量。而可以取多个正整数的信号量被称为通用信号量。这里主要讨论二进制信号量。 由于信号量只能进行两种操作等待和发送信号,即 P(sv) 和 V(sv),他们的行为是这样的: P(sv):如果sv的值大于零,就给它减 1;如果它的值为零,就挂起该进程的执行 V(sv):如果有其他进程因等待sv而被挂起,就让它恢复运行,如果没有进程因等待sv而挂起,就给它加 1. 举个例子,就是两个进程共享信号量sv,一旦其中一个进程执行了P(sv)操作,它将得到信号量,并可以进入临界区,使sv减 1。而第二个进程将被阻止进入临界区,因为当它试图执行P(sv)时,sv为 0,它会被挂起以等待第一个进程离开临界区域并执行V(sv)释放信号量,这时第二个进程就可以恢复执行。 本文代码同步在这里。 相关函数Linux 提供了一组精心设计的信号量接口来对信号进行操作,它们不只是针对二进制信号量,下面将会对这些函数进行介绍,但请注意,这些函数都是用来对成组的信号量值进行操作的。它们声明在头文件 sys/sem.h 中。 semget()它的作用是创建一个新信号量或取得一个已有信号量,原型为: 1int semget(key_t key, int num_sems, int sem_flags); key是整数值(唯一非零),不相关的进程可以通过它访问一个信号量,它代表程序可能要使用的某个资源,程序对所有信号量的访问都是间接的,程序先通过调用semget()函数并提供一个键,再由系统生成一个相应的信号标识符(semget()函数的返回值),只有semget()函数才直接使用信号量键,所有其他的信号量函数使用由semget()函数返回的信号量标识符。如果多个程序使用相同的key值,key将负责协调工作。 num_sems指定需要的信号量数目,它的值几乎总是 1。 sem_flags是一组标志,当想要当信号量不存在时创建一个新的信号量,可以和值IPC_CREAT做按位或操作。设置了IPC_CREAT标志后,即使给出的键是一个已有信号量的键,也不会产生错误。而IPC_CREAT | IPC_EXCL则可以创建一个新的,唯一的信号量,如果信号量已存在,返回一个错误。 semget()函数成功返回一个相应信号标识符(非零),失败返回-1. semop()它的作用是改变信号量的值,原型为: 1int semop(int sem_id, struct sembuf *sem_opa, size_t num_sem_ops); sem_id是由semget()返回的信号量标识符,sembuf结构的定义如下: 1234567struct sembuf{ short sem_num; // 除非使用一组信号量,否则它为0 short sem_op; // 信号量在一次操作中需要改变的数据,通常是两个数,一个是-1,即 P(等待)操作, // 一个是+1,即V(发送信号)操作。 short sem_flg; // 通常为 SEM_UNDO,使操作系统跟踪信号, // 并在进程没有释放该信号量而终止时,操作系统释放信号量}; num_sem_ops:操作sops中的操作个数,通常取值为 1 semctl()该函数用来直接控制信号量信息,它的原型为: 1int semctl(int sem_id, int sem_num, int command, ...); 如果有第四个参数,它通常是一个union semum结构,定义如下: 12345union semun { int val; struct semid_ds *buf; unsigned short *arry;}; 前两个参数与前面一个函数中的一样,command通常是下面两个值中的其中一个 SETVAL:用来把信号量初始化为一个已知的值。p 这个值通过 union semun 中的 val 成员设置,其作用是在信号量第一次使用前对它进行设置。 IPC_RMID:用于删除一个已经无需继续使用的信号量标识符。","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"IPC","slug":"IPC","permalink":"http://example.com/tags/IPC/"}]},{"title":"进程间通信(IPC)之消息队列(MessageQueue)","slug":"进程间通信(IPC)之消息队列(MessageQueue)","date":"2021-08-19T02:53:09.000Z","updated":"2022-10-15T03:14:29.894Z","comments":true,"path":"2021/08/19/进程间通信(IPC)之消息队列(MessageQueue)/","link":"","permalink":"http://example.com/2021/08/19/%E8%BF%9B%E7%A8%8B%E9%97%B4%E9%80%9A%E4%BF%A1%EF%BC%88IPC%EF%BC%89%E4%B9%8B%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97%EF%BC%88MessageQueue%EF%BC%89/","excerpt":"","text":"简介消息队列提供了一种从一个进程向另一个进程发送一个数据块的方法。 每个数据块都被认为含有一个类型,接收进程可以独立地接收含有不同类型的数据结构。我们可以通过发送消息来避免命名管道的同步和阻塞问题。但是消息队列与命名管道一样,每个数据块都有一个最大长度的限制。 本文代码同步在这里。 相关函数msgget()该函数用来创建和访问一个消息队列。它的原型为: 1int msgget(key_t, key, int msgflg); key:与其他的 IPC 机制一样,程序必须提供一个键来命名某个特定的消息队列。 msgflg是一个权限标志,表示消息队列的访问权限,它与文件的访问权限一样。msgflg可以与IPC_CREAT做或操作,表示当 key 所命名的消息队列不存在时创建一个消息队列,如果 key 所命名的消息队列存在时,IPC_CREAT标志会被忽略,而只返回一个标识符。 它返回一个以key命名的消息队列的标识符(非零整数),失败时返回-1. msgsnd()该函数用来把消息添加到消息队列中。它的原型为: 1int msgsend(int msgid, const void *msg_ptr, size_t msg_sz, int msgflg); msgid是由msgget函数返回的消息队列标识符。 msg_ptr是一个指向准备发送消息的指针,但是消息的数据结构却有一定的要求,指针msg_ptr所指向的消息结构一定要是以一个长整型成员变量开始的结构体,接收函数将用这个成员来确定消息的类型。所以消息结构要定义成这样: 1234struct my_message { long int message_type; /* The data you wish to transfer */}; msg_sz 是msg_ptr指向的消息的长度 msgflg 用于控制当前消息队列满或队列消息到达系统范围的限制时将要发生的事情 如果调用成功,消息数据的副本将被放到消息队列中,并返回0,失败时返回-1. msgrcv()该函数用来从一个消息队列获取消息,它的原型为 1int msgrcv(int msgid, void *msg_ptr, size_t msg_st, long int msgtype, int msgflg); 前三个参数参照前面的解释 msgtype 可以实现一种简单的接收优先级。如果msgtype为0,就获取队列中的第一个消息。如果它的值大于零,将获取具有相同消息类型的第一个信息。如果它小于零,就获取类型等于或小于msgtype的绝对值的第一个消息。 msgflg 用于控制当队列中没有相应类型的消息可以接收时将发生的事情。 调用成功时,该函数返回放到接收缓存区中的字节数,消息被复制到由msg_ptr指向的用户分配的缓存区中,然后删除消息队列中的对应消息。失败时返回-1。 msgctl()该函数用来控制消息队列,它与共享内存的shmctl函数相似,它的原型为: 1int msgctl(int msgid, int command, struct msgid_ds *buf); msgid同上 command是将要采取的动作,它可以取3个值: IPC_STAT:把msgid_ds结构中的数据设置为消息队列的当前关联值,即用消息队列的当前关联值覆盖msgid_ds的值。 IPC_SET:如果进程有足够的权限,就把消息列队的当前关联值设置为msgid_ds结构中给出的值 IPC_RMID:删除消息队列 buf是指向msgid_ds结构的指针,它指向消息队列模式和访问权限的结构。msgid_ds结构至少包括以下成员: 123456struct msgid_ds{ uid_t shm_perm.uid; uid_t shm_perm.gid; mode_t shm_perm.mode;}; 成功时返回 0,失败时返回 -1. Demo123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354//msgsnd#include <stdio.h>#include <errno.h>#include <string.h>#include <unistd.h>#include <stdlib.h>#include <sys/msg.h>#define MAX_TXT 512struct msg_st{ long int msg_type; char msg[MAX_TXT];};int main(){ struct msg_st message; int msgid = 1; char buffer[BUFSIZ]; key_t msgKey = ftok("./msgsnd.c", 0); msgid = msgget(msgKey, 0666 | IPC_CREAT); if (msgid == -1) { fprintf(stderr, "masget failed error: %d\\n", errno); exit(EXIT_FAILURE); } while (1) { printf("Enter some text: \\n"); fgets(buffer, BUFSIZ, stdin); message.msg_type = 1; // 注意 2 strcpy(message.msg, buffer); // 向队列里发送数据 if (msgsnd(msgid, (void *)&message, MAX_TXT, 0) == -1) { fprintf(stderr, "msgsnd failed\\n"); exit(EXIT_FAILURE); } // 输入 end 结束输入 if (strncmp(buffer, "end", 3) == 0) { break; } sleep(1); } exit(EXIT_SUCCESS);} 12345678910111213141516171819202122232425262728293031323334353637383940414243444546//msgrcv#include <stdio.h>#include <errno.h>#include <string.h>#include <stdlib.h>#include <sys/msg.h>#define MAX_TXT 512struct msg_st{ long int msg_type; char msg[MAX_TXT];};int main(){ struct msg_st message; int msgid = 1; long int msgtype = 0; key_t msgKey = ftok("./msgsnd.c", 0); msgid = msgget(msgKey, 0666 | IPC_CREAT); if (msgid == -1) { fprintf(stderr, "masget failed error: %d\\n", errno); exit(EXIT_FAILURE); } while (1) { if (msgrcv(msgid, (void *)&message, BUFSIZ, msgtype, 0) == -1) { fprintf(stderr, "msgsnd failed\\n"); exit(EXIT_FAILURE); } printf("You wrote: %s\\n", message.msg); if (strncmp(message.msg, "end", 3) == 0) { break; } } exit(EXIT_SUCCESS);} 运行结果","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"IPC","slug":"IPC","permalink":"http://example.com/tags/IPC/"}]},{"title":"Linux(Ubuntu) 环境下安装 VSCode","slug":"Linux-Ubuntu-环境下安装VSCode","date":"2021-08-19T01:38:22.000Z","updated":"2022-10-15T03:14:29.276Z","comments":true,"path":"2021/08/19/Linux-Ubuntu-环境下安装VSCode/","link":"","permalink":"http://example.com/2021/08/19/Linux-Ubuntu-%E7%8E%AF%E5%A2%83%E4%B8%8B%E5%AE%89%E8%A3%85VSCode/","excerpt":"","text":"本来不想写这一篇的,安装 VSCode 时随便搜一下就 OK 了,但是因为 APT 源中没有 VSCode,所以需要找下载网址,几次的安装经历下来,找下载网址也经历了一番折腾。今天又要安装一遍,就顺手记录一下吧。以后翻自己记录总比翻全网记录方便。 官方文档其实最完备安装教程在官方文档里。本文也算是对官方文档的一个翻译版吧。 基于 Debian 和 Ubuntu 的发行版如果下载了.deb 安装包,那么只需要一个命令就可以完成安装了。 1sudo apt install ./<file>.deb 无奈的是,我需要在开发机安装,无法下载安装包,但是我又不想用ftp传来传去,要是apt能完成,绝不单独下载安装包。 可以使用以下脚本手动安装存储库和密钥 1wget -qO- https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor > packages.microsoft.gpg 1sudo install -o root -g root -m 644 packages.microsoft.gpg /etc/apt/trusted.gpg.d/ 1sudo sh -c 'echo "deb [arch=amd64,arm64,armhf signed-by=/etc/apt/trusted.gpg.d/packages.microsoft.gpg] https://packages.microsoft.com/repos/code stable main" > /etc/apt/sources.list.d/vscode.list' 1rm -f packages.microsoft.gpg 更新与安装 123sudo apt install apt-transport-httpssudo apt updatesudo apt install code # or code-insiders","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"}]},{"title":"Linux 操作系统-内存管理","slug":"Linux操作系统-内存管理","date":"2021-08-19T01:37:04.000Z","updated":"2022-10-15T03:14:29.298Z","comments":true,"path":"2021/08/19/Linux操作系统-内存管理/","link":"","permalink":"http://example.com/2021/08/19/Linux%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F-%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86/","excerpt":"","text":"内存管理概述计算机所谓的“计算”指的是: 进程和线程对于 CPU 的使用 对内存的管理 独享内存空间的原理每个进程都独享一段内存空间,并且真实物理内存地址对进程不可见,操作系统会给进程分配一个虚拟地址,每个进程看到的内存地址都是从 0 开始。操作系统会将不同进程的虚拟地址和不同内存的物理地址做映射。当程序访问虚拟地址时,由内核的数据结构进行转换,转换成不同的物理地址,这样不同的进程运行的时候,写入的是不同的物理地址。 规划虚拟地址空间通过以上的原理,我们可以看出,操作系统的内存管理,主要分为三个方面。 物理内存的管理; 虚拟地址的管理; 虚拟地址和物理地址如何映射; 进程获取了一段独立的虚拟内存空间后,可以不用管其他进程,“任意”使用这片内存,但是也有一点规则。这篇内存需要存放内核态和用户态的内容。高地址存放内核态的内容,低地址存放用户态的内容。具体分界线 64 位与 32 位不同,暂不深究。 我们从最低位开始排起,先是Text Segment、Data Segment 和 BSS Segment。Text Segment 是存放二进制可执行代码的位置,Data Segment 存放静态常量,BSS Segment 存放未初始化的静态变量。是不是觉得这几个名字很熟悉?没错,咱们前面讲 ELF 格式的时候提到过,在二进制执行文件里面,就有这三个部分。这里就是把二进制执行文件的三个部分加载到内存里面。 接下来是堆(Heap)段。堆是往高地址增长的,是用来动态分配内存的区域,malloc 就是在这里面分配的。接下来的区域是Memory Mapping Segment。这块地址可以用来把文件映射进内存用的,如果二进制的执行文件依赖于某个动态链接库,就是在这个区域里面将 so 文件映射到了内存中。再下面就是栈(Stack)地址段。主线程的函数调用的函数栈就是用这里的。 普通进程不能访问内核空间,如果需要进行更高权限的工作,就需要系统调用进入内核。每一段进程的内存空间存放的内容各不相同,但是进入内核后看到的都是同一个内核空间,同一个进程列表。 内核的代码访问内核的数据结构,大部分的情况下都是使用虚拟地址的,虽然内核代码权限很大,但是能够使用的虚拟地址范围也只能在内核空间,也即内核代码访问内核数据结构。 接下来,我们需要知道,如何将其映射成为物理地址呢? 咱们前面讲 x86 CPU 的时候,讲过分段机制,咱们规划虚拟空间的时候,也是将空间分成多个段进行保存。我们来看看分段机制的原理。 分段机制下的虚拟地址由两部分组成,段选择子和段内偏移量。段选择子就保存在咱们前面讲过的段寄存器里面。段选择子里面最重要的是段号,用作段表的索引。段表里面保存的是这个段的基地址、段的界限和特权等级等。虚拟地址中的段内偏移量应该位于 0 和段界限之间。如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。 例如,我们将上面的虚拟空间分成以下 4 个段,用 0~3 来编号。每个段在段表中有一个项,在物理空间中,段的排列如下图的右边所示。如果要访问段 2 中偏移量 600 的虚拟地址,我们可以计算出物理地址为,段 2 基地址 2000 + 偏移量 600 = 2600。 在 Linux 里面,段表全称段描述符表(segment descriptors),放在全局描述符表 GDT(Global Descriptor Table)里面,会有下面的宏来初始化段描述符表里面的表项。 12345#define GDT_ENTRY_INIT(flags, base, limit) { { { \\ .a = ((limit) & 0xffff) | (((base) & 0xffff) << 16), \\ .b = (((base) & 0xff0000) >> 16) | (((flags) & 0xf0ff) << 8) | \\ ((limit) & 0xf0000) | ((base) & 0xff000000), \\ } } } 一个段表项由段基地址 base、段界限 limit,还有一些标识符组成。 1234567891011121314151617DEFINE_PER_CPU_PAGE_ALIGNED(struct gdt_page, gdt_page) = { .gdt = {#ifdef CONFIG_X86_64 [GDT_ENTRY_KERNEL32_CS] = GDT_ENTRY_INIT(0xc09b, 0, 0xfffff), [GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xa09b, 0, 0xfffff), [GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc093, 0, 0xfffff), [GDT_ENTRY_DEFAULT_USER32_CS] = GDT_ENTRY_INIT(0xc0fb, 0, 0xfffff), [GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f3, 0, 0xfffff), [GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xa0fb, 0, 0xfffff),#else [GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xc09a, 0, 0xfffff), [GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff), [GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xc0fa, 0, 0xfffff), [GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f2, 0, 0xfffff),......#endif} };EXPORT_PER_CPU_SYMBOL_GPL(gdt_page); 这里面对于 64 位的和 32 位的,都定义了内核代码段、内核数据段、用户代码段和用户数据段。另外,还会定义下面四个段选择子,指向上面的段描述符表项。 1234#define __KERNEL_CS (GDT_ENTRY_KERNEL_CS*8)#define __KERNEL_DS (GDT_ENTRY_KERNEL_DS*8)#define __USER_DS (GDT_ENTRY_DEFAULT_USER_DS*8 + 3)#define __USER_CS (GDT_ENTRY_DEFAULT_USER_CS*8 + 3) 通过分析,我们发现,所有的段的起始地址都是一样的,都是 0。所以,在 Linux 操作系统中,并没有使用到全部的分段功能。那分段是不是完全没有用处呢?分段可以做权限审核,例如用户态 DPL 是 3,内核态 DPL 是 0。当用户态试图访问内核态的时候,会因为权限不足而报错。其实 Linux 倾向于另外一种从虚拟地址到物理地址的转换方式,称为分页(Paging)。对于物理内存,操作系统把它分成一块一块大小相同的页,这样更方便管理,例如有的内存页面长时间不用了,可以暂时写到硬盘上,称为换出。一旦需要的时候,再加载进来,叫作换入。这样可以扩大可用物理内存的大小,提高物理内存的利用率。 这个换入和换出都是以页为单位的。页面的大小一般为 4KB。为了能够定位和访问每个页,需要有个页表,保存每个页的起始地址,再加上在页内的偏移量,组成线性地址,就能对于内存中的每个位置进行访问了。 虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址。这个基地址与页内偏移的组合就形成了物理内存地址。 32 位环境下,虚拟地址空间共 4GB。如果分成 4KB 一个页,那就是 1M 个页。每个页表项需要 4 个字节来存储,那么整个 4GB 空间的映射就需要 4MB 的内存来存储映射表。如果每个进程都有自己的映射表,100 个进程就需要 400MB 的内存。对于内核来讲,有点大了。 页表中所有页表项必须提前建好,并且要求是连续的。如果不连续,就没有办法通过虚拟地址里面的页号找到对应的页表项了。 那怎么办呢?我们可以试着将页表再分页,4G 的空间需要 4M 的页表来存储映射。我们把这 4M 分成 1K(1024)个 4K,每个 4K 又能放在一页里面,这样 1K 个 4K 就是 1K 个页,这 1K 个页也需要一个表进行管理,我们称为页目录表,这个页目录表里面有 1K 项,每项 4 个字节,页目录表大小也是 4K。 页目录有 1K 项,用 10 位就可以表示访问页目录的哪一项。这一项其实对应的是一整页的页表项,也即 4K 的页表项。每个页表项也是 4 个字节,因而一整页的页表项是 1K 个。再用 10 位就可以表示访问页表项的哪一项,页表项中的一项对应的就是一个页,是存放数据的页,这个页的大小是 4K,用 12 位可以定位这个页内的任何一个位置。 这样加起来正好 32 位,也就是用前 10 位定位到页目录表中的一项。将这一项对应的页表取出来共 1k 项,再用中间 10 位定位到页表中的一项,将这一项对应的存放数据的页取出来,再用最后 12 位定位到页中的具体位置访问数据。 你可能会问,如果这样的话,映射 4GB 地址空间就需要 4MB+4KB 的内存,这样不是更大了吗?当然如果页是满的,当时是更大了,但是,我们往往不会为一个进程分配那么多内存。 比如说,上面图中,我们假设只给这个进程分配了一个数据页。如果只使用页表,也需要完整的 1M 个页表项共 4M 的内存,但是如果使用了页目录,页目录需要 1K 个全部分配,占用内存 4K,但是里面只有一项使用了。到了页表项,只需要分配能够管理那个数据页的页表项页就可以了,也就是说,最多 4K,这样内存就节省多了。 当然对于 64 位的系统,两级肯定不够了,就变成了四级目录,分别是全局页目录项 PGD(Page Global Directory)、上层页目录项 PUD(Page Upper Directory)、中间页目录项 PMD(Page Middle Directory)和页表项 PTE(Page Table Entry)。 进程空间管理物理内存管理用户态内存映射12345#define GDT_ENTRY_INIT(flags, base, limit) { { { \\ .a = ((limit) & 0xffff) | (((base) & 0xffff) << 16), \\ .b = (((base) & 0xff0000) >> 16) | (((flags) & 0xf0ff) << 8) | \\ ((limit) & 0xf0000) | ((base) & 0xff000000), \\ } } } 通过分析,我们发现,所有的段的起始地址都是一样的,都是 0。这算哪门子分段嘛!所以,在 Linux 操作系统中,并没有使用到全部的分段功能。那分段是不是完全没有用处呢?分段可以做权限审核,例如用户态 DPL 是 3,内核态 DPL 是 0。当用户态试图访问内核态的时候,会因为权限不足而报错。 其实 Linux 倾向于另外一种从虚拟地址到物理地址的转换方式,称为分页(Paging)。 对于物理内存,操作系统把它分成一块一块大小相同的页,这样更方便管理,例如有的内存页面长时间不用了,可以暂时写到硬盘上,称为换出。一旦需要的时候,再加载进来,叫作换入。这样可以扩大可用物理内存的大小,提高物理内存的利用率。","categories":[{"name":"Linux 操作系统","slug":"Linux-操作系统","permalink":"http://example.com/categories/Linux-%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"}]},{"title":"Qt 模仿登录界面-交互响应","slug":"Qt模仿登录界面-交互响应","date":"2021-08-18T05:07:01.000Z","updated":"2022-10-15T03:14:29.482Z","comments":true,"path":"2021/08/18/Qt模仿登录界面-交互响应/","link":"","permalink":"http://example.com/2021/08/18/Qt%E6%A8%A1%E4%BB%BF%E7%99%BB%E5%BD%95%E7%95%8C%E9%9D%A2-%E4%BA%A4%E4%BA%92%E5%93%8D%E5%BA%94/","excerpt":"","text":"效果预览 设置窗口拖动因为这个项目中没有将登录界面直接继承MainWindow,而是继承的Dialog类,所以它是不能直接移动的,需要我们自己添加相应的方法。这里实现了三种方法,点击,拖动,释放。 123456789101112131415161718192021222324252627282930313233343536373839//mytitlebar.cpp// 以下通过 mousePressEvent、mouseMoveEvent、mouseReleaseEvent 三个事件实现了鼠标拖动标题栏移动窗口的效果;void MyTitleBar::mousePressEvent(QMouseEvent *event){ if (m_buttonType == MIN_MAX_BUTTON) { // 在窗口最大化时禁止拖动窗口; if (m_pButtonMax->isVisible()) { m_isPressed = true; m_startMovePos = event->globalPos(); } } else { m_isPressed = true; m_startMovePos = event->globalPos(); } return QWidget::mousePressEvent(event);}void MyTitleBar::mouseMoveEvent(QMouseEvent *event){ if (m_isPressed && m_isMoveParentWindow) { QPoint movePoint = event->globalPos() - m_startMovePos; QPoint widgetPos = this->parentWidget()->pos() + movePoint; m_startMovePos = event->globalPos(); this->parentWidget()->move(widgetPos.x(), widgetPos.y()); } return QWidget::mouseMoveEvent(event);}void MyTitleBar::mouseReleaseEvent(QMouseEvent *event){ m_isPressed = false; return QWidget::mouseReleaseEvent(event);} globalPos()获取全局的坐标event->globalPos()是获取全局的坐标,全局是相对于整个屏幕而言的。还有一个函数pos()获取的是局部坐标,相对于一个widget窗口而言。 move()移动窗口12void move(int x, int y);void move(const QPoint &); 其中move的原点是父窗口的左上角,如果没有父窗口,则桌面即为父窗口。x 往右递增,y 往下递增 mouseMoveEvent()这个函数里有一点需要注意的是,m_startMovePos = event->globalPos()这条语句。每次移动窗口之前,先把鼠标移动后的位置记录下来,作为下一次移动的起点。 设置最小化,关闭1234567891011121314151617//mytitlebar.cpp// 信号槽的绑定;void MyTitleBar::initConnections(){ connect(m_pButtonMin, SIGNAL(clicked()), this, SLOT(onButtonMinClicked())); connect(m_pButtonClose, SIGNAL(clicked()), this, SLOT(onButtonCloseClicked()));}void MyTitleBar::onButtonMinClicked(){ emit signalButtonMinClicked();}void MyTitleBar::onButtonCloseClicked(){ emit signalButtonCloseClicked();} 标题栏是在basewindow中 new 出来的,mytitlebar类只负责发送信号,真正处理信号的是在basewindow类中。 123456789101112131415161718192021222324252627//basewindow.cppvoid BaseWindow::initTitleBar(){ createMyTitle(this); m_titleBar->move(0, 0); connect(m_titleBar, SIGNAL(signalButtonMinClicked()), this, SLOT(onButtonMinClicked())); connect(m_titleBar, SIGNAL(signalButtonCloseClicked()), this, SLOT(onButtonCloseClicked()));}void BaseWindow::onButtonMinClicked(){ if (Qt::Tool == (windowFlags() & Qt::Tool)) { hide(); } else { showMinimized(); }}void BaseWindow::onButtonCloseClicked(){ close();} 在初始化标题栏时,就把点击信号与相关的槽函数绑定。当有最小化点击信号发生时,就会调用最小化操作。 和窗口相关的几个函数12345678showMinimized() //最小化showNormal() //从最小化或者最大化窗口恢复到正常窗口showMaximized() //最大化show() //显示窗口,可以显示模态窗口也可以显示非模态hide() //隐藏窗口isVisible() //判断是否可见isMinimized() //判断是否处于最小化状态close() //关闭窗口 切换用户及删除用户12345678910111213141516171819202122232425262728293031323334353637383940414243//loginwindow.cpp// 初始化用户登录信息;void LoginWindow::initAccountList(){ // 设置代理; m_Accountlist = new QListWidget(this); ui->accountComboBox->setModel(m_Accountlist->model()); ui->accountComboBox->setView(m_Accountlist); for (int i = 0; i < 3; i++) { AccountItem *account_item = new AccountItem(); account_item->setAccountInfo(i, QStringLiteral("Dominic%1号").arg(i), QString(":/Resources/LoginWindow/headImage/head_%1.png").arg(i)); connect(account_item, SIGNAL(signalShowAccountInfo(int, QString)), this, SLOT(onShowAccountInfo(int, QString))); connect(account_item, SIGNAL(signalRemoveAccount(int)), this, SLOT(onRemoveAccount(int))); QListWidgetItem *list_item = new QListWidgetItem(m_Accountlist); m_Accountlist->setItemWidget(list_item, account_item); }}//将选项文本显示在 QComboBox 当中void LoginWindow::onShowAccountInfo(int index, QString accountName){ ui->accountComboBox->setEditText(accountName); ui->accountComboBox->hidePopup(); // 更换用户头像; QString fileName = QString(":/Resources/LoginWindow/headImage/head_%1.png").arg(index); ui->userHead->setPixmap(QPixmap(fileName).scaled(ui->userHead->width(), ui->userHead->height()));}// 移除当前登录列表中某一项;void LoginWindow::onRemoveAccount(int index){ for (int row = 0; row < m_Accountlist->count(); row++) { AccountItem* itemWidget = (AccountItem*)m_Accountlist->itemWidget(m_Accountlist->item(row)); if (itemWidget != NULL && itemWidget->getItemWidgetIndex() == index) { m_Accountlist->takeItem(row); itemWidget->deleteLater(); } }} 在initAccountList()中,初始化好了三个账户信息,当接收到显示用户信息的信号signalShowAccountInfo后,就会调用onShowAccountInfo槽函数显示用户信息。在这个函数中,将下拉框的内容设置成切换后的用户名,然后隐藏下拉框hidPopup。更改头像。 当接收到删除信号时,调用onRemoveAccount槽函数,删除指定的用户信息。 hidPopup()隐藏下拉框文章开头的效果图是隐藏下拉框的效果,每次切换用户下拉框隐藏,我们再来看一下不隐藏什么效果就容易理解了。 takeItem()删除部件1QListWidgetItem *QListWidget::takeItem(int row) 从下拉菜单中选择一行部件删除。 deleteLater()稍后删除对象deletelater的原理是 QObject::deleteLater()并没有将对象立即销毁,而是向主消息循环发送了一个event,下一次主消息循环收到这个event之后才会销毁对象。 切换登录状态123456789101112131415161718192021222324252627282930313233343536//loginwindow.cpp// 选择了新的用户登录状态;void LoginWindow::onLoginStateClicked(){ m_loginStateMemu = new QMenu(); QAction *pActionOnline = m_loginStateMemu->addAction(QIcon(":/Resources/LoginWindow/LoginState/state_online.png"), QStringLiteral("我在线上")); QAction *pActionActive = m_loginStateMemu->addAction(QIcon(":/Resources/LoginWindow/LoginState/state_Qme.png"), QStringLiteral("Q 我吧")); m_loginStateMemu->addSeparator(); QAction *pActionAway = m_loginStateMemu->addAction(QIcon(":/Resources/LoginWindow/LoginState/state_away.png"), QStringLiteral("离开")); QAction *pActionBusy = m_loginStateMemu->addAction(QIcon(":/Resources/LoginWindow/LoginState/state_busy.png"), QStringLiteral("忙碌")); QAction *pActionNoDisturb = m_loginStateMemu->addAction(QIcon(":/Resources/LoginWindow/LoginState/state_notdisturb.png"), QStringLiteral("请勿打扰")); m_loginStateMemu->addSeparator(); QAction *pActionHide = m_loginStateMemu->addAction(QIcon(":/Resources/LoginWindow/LoginState/state_hide.png"), QStringLiteral("隐身")); // 设置状态值; pActionOnline->setData(ONLINE); pActionActive->setData(ACTIVE); pActionAway->setData(AWAY); pActionBusy->setData(BUSY); pActionNoDisturb->setData(NOT_DISTURB); pActionHide->setData(HIDE); connect(m_loginStateMemu, SIGNAL(triggered(QAction *)), this, SLOT(onMenuClicked(QAction*))); QPoint pos = ui->loginState->mapToGlobal(QPoint(0, 0)) + QPoint(0, 20); m_loginStateMemu->exec(pos);}// 用户状态菜单点击;void LoginWindow::onMenuClicked(QAction * action){ ui->loginState->setIcon(action->icon()); // 获取状态值; m_loginState = (LoginState)action->data().toInt(); qDebug() << "onMenuClicked" << m_loginState;} 在接收到点击状态按钮信号时,调用onLoginStateClicked槽函数,改变用户登录状态。切换的下拉菜单用的是QMenu。 addSeparator()添加分割线Q 我吧和离开状态之间的分割线。 mapToGlobal()映射成全局坐标弹出登录状态菜单m_loginStateMemu是我们自己 new 出来的,默认显示是从左上角开始显示,这样当然不行。 mapToGlobal()的作用就是将控件的坐标映射成全局坐标。代码里的意思就是将loginState控件里面的坐标用全局坐标表示。然后再向下偏移20个单位。再把得到的全局坐标作为m_loginStateMemu显示起始坐标。 下图是未偏移的结果, 向下偏移20个单位的效果,因为我们mapToGlobal(QPoint(0, 0))的参数是(0,0)为起点。如果我们mapToGlobal(QPoint(0, 20))的参数是(0,20),就不用再加上偏移了。","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"}]},{"title":"Qt 模仿登录界面-窗口布局及样式","slug":"Qt模仿登录界面-窗口布局及样式","date":"2021-08-17T03:30:06.000Z","updated":"2022-10-15T03:14:29.487Z","comments":true,"path":"2021/08/17/Qt模仿登录界面-窗口布局及样式/","link":"","permalink":"http://example.com/2021/08/17/Qt%E6%A8%A1%E4%BB%BF%E7%99%BB%E5%BD%95%E7%95%8C%E9%9D%A2-%E7%AA%97%E5%8F%A3%E5%B8%83%E5%B1%80%E5%8F%8A%E6%A0%B7%E5%BC%8F/","excerpt":"","text":"框架类图 效果预览完整项目及资源文件请在Github查看。 页面布局 初始化标题栏12345678910111213// 初始化标题栏;void LoginWindow::initMyTitle(){ // 因为这里有控件层叠了,所以要注意控件 raise() 方法的调用顺序; m_titleBar->move(0, 0); m_titleBar->raise(); m_titleBar->setBackgroundColor(100, 0, 0, true); m_titleBar->setButtonType(MIN_BUTTON); m_titleBar->setTitleWidth(this->width()); // 这里需要设置成 false,不允许通过标题栏拖动来移动窗口位置,否则会造成窗口位置错误; m_titleBar->setMoveParentWindowFlag(false); ui->pButtonArrow->raise();} raise()将控件置于顶层程序在打开后一般都在所有窗体的顶层,打开其他程序后之前的程序就会被放到下一层,在这里,当设置完my_titleBar后对其他控件操作就会把my_titleBar控件覆盖。所有要用raise()方法将其置于顶层。 初始化窗口12345678910111213141516171819202122232425262728293031323334353637383940// 初始化窗口;void LoginWindow::initWindow(){ //背景 GIG 图; QLabel* pBack = new QLabel(this); QMovie *movie = new QMovie(); movie->setFileName(":/Resources/LoginWindow/back.gif"); pBack->setMovie(movie); movie->start(); pBack->move(0, 0); //文本框内提示 ui->accountComboBox->setEditable(true); QLineEdit* lineEdit = ui->accountComboBox->lineEdit(); lineEdit->setPlaceholderText(QStringLiteral("QQ 号码/手机/邮箱")); QRegExp regExp("[A-Za-z0-9_]{6,30}"); //正则表达式限制用户名输入不能输入汉字 lineEdit->setValidator(new QRegExpValidator(regExp,this)); ui->passwordEdit->setPlaceholderText(QStringLiteral("密码")); //密码框中的小键盘按钮; m_keyboardButton = new QPushButton(); m_keyboardButton->setObjectName("pButtonKeyboard"); m_keyboardButton->setFixedSize(QSize(16, 16)); m_keyboardButton->setCursor(QCursor(Qt::PointingHandCursor));//鼠标放上去变成手形 QHBoxLayout* passwordEditLayout = new QHBoxLayout(); passwordEditLayout->addStretch(); passwordEditLayout->addWidget(m_keyboardButton); passwordEditLayout->setSpacing(0); passwordEditLayout->setContentsMargins(0, 0, 8, 0); ui->passwordEdit->setLayout(passwordEditLayout); //设置密码达到最长时最后一个字符离小键盘图标的距离(12) ui->passwordEdit->setTextMargins(0, 0, m_keyboardButton->width() + 12, 0); //设置头像以及状态图标 ui->userHead->setPixmap(QPixmap(":/Resources/LoginWindow/HeadImage.png")); ui->loginState->setIcon(QIcon(":/Resources/LoginWindow/LoginState/state_online.png")); ui->loginState->setIconSize(QSize(13, 13));} lineEdit->setPlaceholderTextQStringLiteral:如果该 QString 不会修改的话,那使用 QStringLiteral setPlaceholderText()设置文本提示该方法可以设置文本框中的默认文字提示,如图片中的 QQ 号码/手机/邮箱。 setCursor()设置鼠标形态共有以下 19 种鼠标形态: 图片来自这里 addStretch()布局加入弹簧123QHBoxLayout* passwordEditLayout = new QHBoxLayout();passwordEditLayout->addStretch();passwordEditLayout->addWidget(m_keyboardButton); addStretch()用来在布局中平分布局,他就是个弹簧的作用。如果不加参数,就是等于加个弹簧,会把小键盘图标挤到边上。如图: 如果将代码改一下: 1234QHBoxLayout* passwordEditLayout = new QHBoxLayout();passwordEditLayout->addStretch(1);passwordEditLayout->addWidget(m_keyboardButton);passwordEditLayout->addStretch(1); 意思就是将除了小键盘图标以外的空间分成两份,那么刚好小键盘图标就是在中间位置,就像两遍各防止了一个弹簧。效果如下: setSpacing()设置空间之间上下距离,还有一个容易混淆的设置setMargin()表示设置空间与窗口边缘的左右距离。 setContentsMargins设置左侧、顶部、右侧和底部边距,以便在布局周围使用。 现在我们设置的是setContentsMargins(0, 0, 8, 0),现在我们设置大一点看看效果。 QLineEdit.setTextMargins(left=,top=,right=,bottom=)设置文本边距,这里主要为了设置密码输入过长时,最后一个字符距离小键盘图标有一定间隙。 初始化用户登录信息1234567891011//accountitem.cppvoid LoginWindow::initAccountList(){ for (int i = 0; i < 3; i++) { AccountItem *account_item = new AccountItem(); account_item->setAccountInfo(i, QStringLiteral("Dominic_%1号").arg(i), QString(":/Resources/LoginWindow/headImage/head_%1.png").arg(i)); QListWidgetItem *list_item = new QListWidgetItem(m_Accountlist); m_Accountlist->setItemWidget(list_item, account_item); }}","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"}]},{"title":"Linux 操作系统-进程间通信","slug":"Linux操作系统-进程间通信","date":"2021-08-14T01:46:39.000Z","updated":"2022-10-15T03:14:29.324Z","comments":true,"path":"2021/08/14/Linux操作系统-进程间通信/","link":"","permalink":"http://example.com/2021/08/14/Linux%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F-%E8%BF%9B%E7%A8%8B%E9%97%B4%E9%80%9A%E4%BF%A1/","excerpt":"","text":"Linux 环境下,进程地址空间相互独立,每个进程各自有不同的用户地址空间。任何一个进程的全局变量在另一个进程中都看不到,所以进程和进程之间不能相互访问,要交换数据必须通过内核,在内核中开辟一块缓冲区,进程 1 把数据从用户空间拷到内核缓冲区,进程 2 再从内核缓冲区把数据读走,内核提供的这种机制称为进程间通信(IPC,InterProcess Communication)。 进程间通信概述管道在学 Linux 命令时就有管道在这个概念,比如下面这个命令 1ps -ef | -grep root | xargs kill -9 将上一个命令的输出作为下一个命令的输入,数据只能向一个方向流动;双方需要互相通信时,需要建立起两个管道。 管道有两种类型:匿名管道和命名管道。上面提到的命令中|表示的管道即匿名管道 pipe。用完即销毁,自动创建,自动销毁。 使用mkfifo显示创建的是命名管道 fifo, 1mkfifo hello hello即是管道名称,类型为p,就是pipe,接下来就可以在管道里写入东西, 1# echo "hello world" > hello 光写入还不行,只有有另一个进程读取了内容才完成一次信息交换,才完成一次通信, 12# cat < hello hello world 这种方式通信效率低,无法频繁通信。 消息队列类似于日常沟通使用的邮件,有一定格式,有个收件列表,列表上的用户都可以反复在原邮件基础上回复,达到频繁交流的目的。这种模型就是消息队列模型。 共享内存共享内存允许两个或多个进程共享一个给定的存储区,这一段存储区可以被两个或两个以上的进程映射至自身的地址空间中,一个进程写入共享内存的信息,可以被其他使用这个共享内存的进程,通过一个简单的内存读取错做读出,从而实现了进程间的通信。 每个进程都有自己独立的虚拟内存空间,不同进程的虚拟内存空间映射到不同的物理内存中去。这个进程访问 A 地址和另一个进程访问 A 地址,其实访问的是不同的物理内存地址,对于数据的增删查改互不影响。 但是,咱们是不是可以变通一下,拿出一块虚拟地址空间来,映射到相同的物理内存中。这样这个进程写入的东西,另外一个进程马上就能看到了,都不需要拷贝来拷贝去,传来传去。 使用shmget函数创建一个共享内存, 1234//key_t key: 唯一定位一个共享内存对象//size_t size: 共享内存大小//int flag: 如果是 IPC_CREAT 表示创建新的共享内存空间int shmget(key_t key, size_t size, int flag); 创建完毕之后,我们可以通过 ipcs 命令查看这个共享内存。 12345#ipcs --shmems ------ Shared Memory Segments ------ key shmid owner perms bytes nattch status0x00000000 19398656 marc 600 1048576 2 dest 进程通过shmat,就是attach的意思,将内存加载到自己虚拟地址空间某个位置。 1234//int shm_id://const void *addr: 加载的地址,通常设为 NULL,让内核选一个合适地址//int flag:void *shmat(int shm_id, const void *addr, int flag); 如果共享内存使用完毕,可以通过 shmdt 解除绑定,然后通过 shmctl,将 cmd 设置为 IPC_RMID,从而删除这个共享内存对象。 12int shmdt(void *addr); int shmctl(int shm_id, int cmd, struct shmid_ds *buf); 共享内存的最大不足之处在于,由于多个进程对同一块内存区具有访问的权限,各个进程之间的同步问题显得尤为突出。必须控制同一时刻只有一个进程对共享内存区域写入数据,否则将造成数据的混乱。 信号量如果两个进程同时向一个共享内存读写数据,很可能就会导致冲突。所以需要有一种保护机制,使得同一个共享资源同时只能被一个进程访问。在进程间通信机制中,信号量(Semaphore)就是用来实现进程间互斥与同步的。它其实是个计数器,只不过不是用来记录进程间通信数据的。 我们可以将信号量初始化为一个数值,来代表某种资源的总体数量。对于信号量来讲,会定义两种原子操作,一个是P 操作,我们称为申请资源操作。这个操作会申请将信号量的数值减去 N,表示这些数量被他申请使用了,其他人不能用了。另一个是V操作,我们称为归还资源操作,这个操作会申请将信号量加上 M,表示这些数量已经还给信号量了,其他人可以使用了。 所谓原子操作(Atom Operation)就是不可被中断的一个或一系列操作。 使用semget创建信号量,第一个参数表示唯一标识,第二个参数表示可以创建多少个信号量。 1int semget(key_t key, int num_sems, int sem_flags); 接下来,我们需要初始化信号量的总的资源数量。通过semctl 函数,第一个参数 semid是这个信号量组的id,第二个参数 semnum 才是在这个信号量组中某个信号量的id,第三个参数是命令,如果是初始化,则用 SETVAL,第四个参数是一个 union。如果初始化,应该用里面的val设置资源总量。 12345678910int semctl(int semid, int semnum, int cmd, union semun args); union semun{ int val; struct semid_ds *buf; unsigned short int *array; struct seminfo *__buf;}; 无论是 P 操作还是 V 操作,我们统一用 semop 函数。第一个参数还是信号量组的 id,一次可以操作多个信号量。第三个参数 numops 就是有多少个操作,第二个参数将这些操作放在一个数组中。 数组的每一项是一个 struct sembuf,里面的第一个成员是这个操作的对象是哪个信号量。第二个成员就是要对这个信号量做多少改变。如果 sem_op < 0,就请求 sem_op 的绝对值的资源。如果相应的资源数可以满足请求,则将该信号量的值减去 sem_op 的绝对值,函数成功返回。 当相应的资源数不能满足请求时,就要看sem_flg 了。如果把 sem_flg 设置为IPC_NOWAIT,也就是没有资源也不等待,则 semop 函数出错返回 EAGAIN。如果 sem_flg 没有指定IPC_NOWAIT,则进程挂起,直到当相应的资源数可以满足请求。若 sem_op > 0,表示进程归还相应的资源数,将 sem_op 的值加到信号量的值上。如果有进程正在休眠等待此信号量,则唤醒它们。 1234567int semop(int semid, struct sembuf semoparray[], size_t numops);struct sembuf { short sem_num; // 信号量组中对应的序号,0~sem_nums-1 short sem_op; // 信号量值在一次操作中的改变量 short sem_flg; // IPC_NOWAIT, SEM_UNDO} 信号以上提到的通信方式,都是常规状态下的工作模式,而信号一般是由错误产生的。 信号没有特别复杂的数据结构,就是用一个代号一样的数字。Linux 提供了几十种信号,分别代表不同的意义。信号之间依靠它们的值来区分。","categories":[{"name":"Linux 操作系统","slug":"Linux-操作系统","permalink":"http://example.com/categories/Linux-%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"}]},{"title":"每天学命令-rename 批量重命名","slug":"每天学命令-rename批量重命名","date":"2021-08-13T10:40:16.000Z","updated":"2022-10-15T03:03:19.398Z","comments":true,"path":"2021/08/13/每天学命令-rename批量重命名/","link":"","permalink":"http://example.com/2021/08/13/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-rename%E6%89%B9%E9%87%8F%E9%87%8D%E5%91%BD%E5%90%8D/","excerpt":"","text":"Commands1rename [options] "s/oldname/newname/" file 格式就很容易看出来怎么用的,就是/不能丢。 12345-v 将重命名的内容都打印到标准输出,v 可以看成 verbose-n 测试会重命名的内容,将结果都打印,但是并不真正执行重命名的过程-f force 会覆盖本地已经存在的文件-h -m -V 分别为帮助,帮助,版本-e 比较复杂,可以通过该选项,写一些脚本来做一些复杂的事情 Examples替换文件名中的特定字段1rename "s/AA/aa/" * # 把文件名中的AA替换成aa 修改文件后缀12rename "s/.html/.php/" * # 把.html 后缀的改成 .php后缀rename "s/.png/.jpg/" * # 将 png 改为 jpg 添加后缀1rename "s/$/.txt/" * # 把所有的文件名都以txt结尾 $正则表达式中表示结尾。 保留部分文件名假如需要在批量修改的时候保留部分文件名,可以使用引用\\1 ,比如有下面格式的文件,只想保留日期部分。 12Screenshot from 2019-01-02 15-56-49.jpgrename -n "s/Screenshot from ([0-9\\\\- ]+).jpg/\\1.jpg/" * 将() 匹配的内容取出来放到替换部分。","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"每天学命令-apt 安装卸载软件","slug":"每天学命令-apt安装卸载软件","date":"2021-08-12T10:42:39.000Z","updated":"2022-10-15T03:14:29.710Z","comments":true,"path":"2021/08/12/每天学命令-apt安装卸载软件/","link":"","permalink":"http://example.com/2021/08/12/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-apt%E5%AE%89%E8%A3%85%E5%8D%B8%E8%BD%BD%E8%BD%AF%E4%BB%B6/","excerpt":"","text":"这个命令应该是我们平时用的最多的命令之一了,应该早就拿出来讲一下的。但是平时用的太多,总感觉自己都会用了,但是仔细看了所有命令,还是有一些比较实用但是没记住的命令。 apt的全称是Advanced Packaging Tool是 Linux 系统下的一款安装包管理工具。APT 可以自动下载、配置和安装二进制或源代码格式软件包,简化了 Unix 系统上管理软件的过程。 APT 主要由以下几个命令组成: 123apt-getapt-cacheapt-file Commands搜索软件包1apt search python3 安装软件包1apt install python3 更新源1sudo apt install update 更新软件执行完 update 命令后,就可以使用 apt upgrade 来升级软件包了。执行命令后系统会提示有几个软件需要升级。在得到你的同意后,系统即开始自动下载安装软件包。 1sudo apt install upgrade 卸载软件123apt remove python3 # 移除软件包,但是保留配置文件apt purge python3 #移除软件包并移除配置apt autoremove # 移除孤立的并不被依赖的软件包 列出软件清单1apt list","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"Qt 添加资源文件(QtCreator)","slug":"Qt添加资源文件(QtCreator)","date":"2021-08-12T02:23:58.000Z","updated":"2022-10-15T03:14:29.496Z","comments":true,"path":"2021/08/12/Qt添加资源文件(QtCreator)/","link":"","permalink":"http://example.com/2021/08/12/Qt%E6%B7%BB%E5%8A%A0%E8%B5%84%E6%BA%90%E6%96%87%E4%BB%B6%EF%BC%88QtCreator%EF%BC%89/","excerpt":"","text":"QtCreator➜新建文件或项目➜Qt➜Qt Resource File 点击Choose,设置资源文件名和路径。资源文件是一系列文件的集合,比如我要建立一个图片的资源文件,我可以设置img为资源文件名,将来所有图片类资源,都放到这个资源文件里,加入还有音频类的文件,我可以新建一个audio的资源文件,以后所有音频类的文件都放到这个资源文件下。 而不是我想要添加的文件名。 右侧编辑器下方有个Add Prefix(添加前缀),我们首先要添加文件前缀,前缀就是存放文件的文件夹名,然后添加需要的文件。添加完以后看效果就知道啥意思了。 这么做带来的一个问题是,如果以后我们要更改文件名,比如将 xbl.png 改成 xiabanle.png,那么,所有使用了这个名字的路径都需要修改。所以,更好的办法是,我们给这个文件去一个“别名”,以后就以这个别名来引用这个文件。具体做法是,选中这个文件,添加别名信息: 这样,我们可以直接使用:/images/avatar用到这个资源,无需关心图片的真实文件名。","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"}]},{"title":"每天学命令-kill 这个进程","slug":"每天学命令-kill这个进程","date":"2021-08-11T07:22:40.000Z","updated":"2022-10-15T03:03:19.398Z","comments":true,"path":"2021/08/11/每天学命令-kill这个进程/","link":"","permalink":"http://example.com/2021/08/11/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-kill%E8%BF%99%E4%B8%AA%E8%BF%9B%E7%A8%8B/","excerpt":"","text":"对于在前台运行的程序,我们可以用Ctrl+C来终止运行,但是在后台的程序就必须用kill命令来终止了。 Command12345-l 信号,若果不加信号的编号参数,则使用“-l”参数会列出全部的信号名称-a 当处理当前进程时,不限制命令名和进程号的对应关系-p 指定 kill 命令只打印相关进程的进程号,而不发送任何信号-s 指定发送信号-u 指定用户 Examples查看所有信号1234➜ kill -lHUP INT QUIT ILL TRAP ABRT BUS FPE KILL USR1 SEGV USR2 PIPE ALRM TERM STKFLT CHLD CONT STOP TSTP TTIN TTOU URG XCPU XFSZ VTALRM PROF WINCH POLL PWR SYS 常用信号 1234567HUP 1 终端断线INT 2 中断(同 Ctrl + C)QUIT 3 退出(同 Ctrl + \\)TERM 15 终止KILL 9 强制终止CONT 18 继续(与 STOP 相反, fg/bg 命令)STOP 19 暂停(同 Ctrl + Z) 用 ps 查找进程,然后用 kill 杀掉12ps -ef | grep 'program'kill PID 无条件彻底杀死进程1kill –9 PID 杀死指定用户所有进程12kill -9 $(ps -ef | grep username)kill -u username","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"进程间通信(IPC)之信号(Signal)","slug":"进程间通信(IPC)之信号(Signal)","date":"2021-08-11T02:59:22.000Z","updated":"2022-10-15T03:14:29.881Z","comments":true,"path":"2021/08/11/进程间通信(IPC)之信号(Signal)/","link":"","permalink":"http://example.com/2021/08/11/%E8%BF%9B%E7%A8%8B%E9%97%B4%E9%80%9A%E4%BF%A1%EF%BC%88IPC%EF%BC%89%E4%B9%8B%E4%BF%A1%E5%8F%B7%EF%BC%88Signal%EF%BC%89/","excerpt":"","text":"关于进程间通信的概述可以查看Linux 操作系统 - 进程间通信,代码同步在这里。 本文通过实例介绍通过共享内存实现进程间通信。 简介信号就像实际生产过程中的应急预案,发生了某个异常就会启动特定的应急预案,为了响应各类异常情况,所以就定义了很多个信号,信号的名称是在头文件signal.h中定义的,信号都以SIG开头,常用的信号并不多,常用的信号如下: 1234567SIGALRM #时钟定时信号, 计算的是实际的时间或时钟时间SIGHUP #终端的挂断或进程死亡SIGINT #来自键盘的中断信号SIGKILL #用来立即结束程序的运行. 本信号不能被阻塞、处理和忽略。SIGPIPE #管道破裂SIGTERM #程序结束(terminate)信号, 与SIGKILL不同的是该信号可以被阻塞和处理SIGUSR1,SIGUSR2 #留给用户使用 实例12345678910111213141516171819202122232425#include <signal.h>#include <stdio.h>#include <unistd.h>void signalHandler(int sig){ printf("\\nOps! - I got signal %d\\n", sig); // 恢复终端中断信号 SIGINT 的默认行为 (void)signal(SIGINT, SIG_DFL);}int main(){ // 改变终端中断信号 SIGINT 的默认行为,使之执行 ouch 函数 // 而不是终止程序的执行 (void)signal(SIGINT, signalHandler); while (1) { printf("Hello World!\\n"); sleep(1); } return 0;} 我们可以用signal()函数处理指定的信号,主要通过忽略和恢复其默认行为来工作。signal() 函数的原型如下: 1void (*signal(int sig, void (*func)(int)))(int); 这是一个相当复杂的声明,耐心点看可以知道 signal 是一个带有sig和func两个参数的函数,func是一个类型为void (*)(int)的函数指针。该函数返回一个与func相同类型的指针,指向先前指定信号处理函数的函数指针。准备捕获的信号的参数由sig给出,接收到的指定信号后要调用的函数由参数func给出。其实这个函数的使用是相当简单的,通过下面的例子就可以知道。注意信号处理函数的原型必须为void func(int),或者是下面的特殊值: 12SIG_IGN : 忽略信号SIG_DFL : 恢复信号的默认行为 我们程序的目的是想要捕获键盘输入Ctrl+C,这个中断。通过表里可以查到,我们使用SIGINT这个信号,当我们的程序出现SIGINT信号时,让程序接下来干啥呢?正常情况下,我们的Ctrl+C会中断当前运行的程序,但是现在我们做了一些更改,更改的内容在我们自己编写的signalHandler中。我们让程序输出一行字符串加上信号值。然后再把信号的行为恢复原样。此时我们运行程序可以得到如下 在我们第一输入Ctrl+C时,程序没有中断,而是调用了signalHanlder函数,因为我们更改了信号的行为。但是第二次输入Ctrl+C时,程序中断了。","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"IPC","slug":"IPC","permalink":"http://example.com/tags/IPC/"}]},{"title":"进程间通信(IPC)之共享内存 (SharedMemory)","slug":"进程间通信(IPC)之共享内存(SharedMemory)","date":"2021-08-10T09:41:26.000Z","updated":"2022-10-15T03:14:29.888Z","comments":true,"path":"2021/08/10/进程间通信(IPC)之共享内存(SharedMemory)/","link":"","permalink":"http://example.com/2021/08/10/%E8%BF%9B%E7%A8%8B%E9%97%B4%E9%80%9A%E4%BF%A1%EF%BC%88IPC%EF%BC%89%E4%B9%8B%E5%85%B1%E4%BA%AB%E5%86%85%E5%AD%98%EF%BC%88SharedMemory%EF%BC%89/","excerpt":"","text":"关于进程间通信的概述可以查看Linux 操作系统 - 进程间通信,代码同步在这里。 本文通过实例介绍通过共享内存实现进程间通信。 shmget(得到一个共享内存标识符或创建一个共享内存对象)我们可以通过shmget函数创建或打开共享内存,通过函数签名 1234//key_t key: 唯一定位一个共享内存对象//size_t size: 共享内存大小//int flag: 如果是 IPC_CREAT 表示创建新的共享内存空间int shmget(key_t key, size_t size, int flag); 第一个参数是共享内存的唯一标识,是需要我们指定的。那么如何指定key呢?如何保证唯一性呢?我们可以指定一个文件,ftok会根据这个文件的 inode,生成一个近乎唯一的 key。只要在这个消息队列的生命周期内,这个文件不要被删除就可以了。只要不删除,无论什么时刻,再调用 ftok,也会得到同样的key。 第二个参数是申请的空间大小,我们就申请 1024B。 第三个参数是权限标识,IPC_CREAT表示创建共享内存,0644表示允许一个进程创建的共享内存被内存创建者所拥有的进程向共享内存读取和写入数据,同时其他用户创建的进程只能读取共享内存。 shmat(把共享内存区对象映射到调用进程的地址空间)第一次创建完共享内存时,它还不能被任何进程访问,shmat()函数的作用就是用来启动对该共享内存的访问,并把共享内存连接到当前进程的地址空间。它的签名如下: 1void *shmat(int shm_id, const void *shm_addr, int shmflg); 第一个参数就是上文产生的唯一标识。 第二个参数,shm_addr指定共享内存连接到当前进程中的地址位置,通常为空,表示让系统来选择共享内存的地址。 第三个参数,shm_flg是一组标志位,通常为 0。调用成功时返回一个指向共享内存第一个字节的指针,如果调用失败返回-1. (void *) - 1把-1转换为指针0xFFFFFFFF,有时也会用到(void*)0,表示一个空指针。 shmdt(断开共享内存连接)与 shmat 函数相反,是用来断开与共享内存附加点的地址,禁止本进程访问此片共享内存 函数签名如下: 1int shmdt(const void *shmaddr) 参数一shmaddr为连接共享内存的起始地址。 需要注意的是,本函数调用并不删除所指定的共享内存区,而只是将先前用 shmat 函数连接(attach)好的共享内存脱离(detach)目前的进程。删除共享内存就需要下面的这个函数。 shmctl(共享内存管理)完成对共享内存的控制,包括改变状态,删除共享内存等。 函数签名如下: 1int shmctl(int shmid, int cmd, struct shmid_ds *buf) shmid共享内存唯一标识符 cmd执行的操作,包括如下 IPC_STAT:得到共享内存的状态,把共享内存的shmid_ds结构复制到buf中 IPC_SET:改变共享内存的状态,把buf所指的shmid_ds结构中的uid、gid、mode复制到共享内存的shmid_ds结构内 IPC_RMID:删除这片共享内存 buf共享内存管理结构体。具体说明参见共享内存内核结构定义部分 1234567891011121314151617181920212223242526272829303132333435363738//server.c#include <sys/types.h>#include <sys/ipc.h>#include <sys/shm.h>#include <stdio.h>#include <stdlib.h>int main(void){ int shmid; key_t shmkey; char *shmptr; shmkey = ftok("./client.c", 0); // 创建或打开内存共享区域 shmid = shmget(shmkey, 1024, 0666 | IPC_CREAT); if (shmid == -1) { printf("shmget error!\\n"); exit(1); } //将共享内存映射到当前进程的地址中, //之后直接对进程中的地址 addr 操作就是对共享内存操作 shmptr = (char *)shmat(shmid, NULL, 0); if (shmptr == (void *)-1) { printf("shmat error!\\n"); exit(1); } while (1) { // 把用户的输入存到共享内存区域中 printf("input:"); scanf("%s", shmptr); } exit(0);} 123456789101112131415161718192021222324252627282930313233343536373839//client.c#include <sys/types.h>#include <sys/ipc.h>#include <sys/shm.h>#include <stdio.h>#include <stdlib.h>#include <unistd.h>int main(void){ int shmid; char *shmptr; key_t shmkey; shmkey = ftok("./client.c", 0); // 创建或打开内存共享区域 shmid = shmget(shmkey, 1024, 0666 | IPC_CREAT); if (shmid == -1) { printf("shmget error!\\n"); exit(1); } //将共享内存映射到当前进程的地址中, //之后直接对进程中的地址 addr 操作就是对共享内存操作 shmptr = (char *)shmat(shmid, NULL, 0); if (shmptr == (void *)-1) { fprintf(stderr, "shmat error!\\n"); exit(1); } while (1) { // 每隔 3 秒从共享内存中取一次数据并打印到控制台 printf("string:%s\\n", shmptr); sleep(3); } exit(0);} 在两个终端分别运行client和server,client会每三秒在终端打印出server输入的内容。 如何手动删除共享内存?列出所有的共享内存段: 123456789101112ipcs -m------------ 共享内存段 --------------键 shmid 拥有者 权限 字节 连接数 状态 0x00000000 2 dominic 600 16384 1 目标 0x00000000 753668 dominic 606 10089696 2 目标 0x00000000 622597 dominic 600 4194304 2 目标 0x00000000 753670 dominic 606 10089696 2 目标 0x00000000 688135 dominic 600 899976 2 目标 0x00000000 8 dominic 600 524288 2 目标 0x00000000 9 dominic 600 524288 2 目标 0x00000000 753674 dominic 600 7127040 2 目标 0x0000006f 720918 dominic 666 1024 0 我们发现最后一个键值为0x0000006f = 111的共享内存段,就是我们创建的共享内存段。删除指定共享内存段: 123ipcrm -m 720918 或者 ipcrm -M 0x0000006f 信号量和消息队列的操作,命令类似,只是参数不同。查看命令: 1ipcs [-m|-q|-s] -m 输出有关共享内存 (shared memory) 的信息 -q 输出有关信息队列 (message queue) 的信息 -s 输出有关“信号量”(semaphore) 的信息 删除命令 1ipcrm [ -M key | -m id | -Q key | -q id | -S key | -s id ] -M用 shmkey 删除共享内存 -m用 shmid 删除共享内存 -Q用 msgkey 删除消息队列 -q用 msgid 删除消息队列 -S用 semkey 删除信号量 -s用 semid 删除信号量 超过共享内存的大小限制共享内存的总体大小是有限制的,这个大小通过 SHMMAX 参数来定义(以字节为单位),您可以通过执行以下命令来确定 SHMMAX 的值: 1cat /proc/sys/kernel/shmmax 如果机器上创建的共享内存的总共大小超出了这个限制,在程序中使用标准错误perror可能会出现以下的信息: 1unable to attach to shared memory 1、设置 SHMMAX SHMMAX 的默认值是 32MB 。一般使用下列方法之一种将 SHMMAX 参数设为 2GB :通过直接更改 /proc 文件系统,你不需重新启动机器就可以改变 SHMMAX 的默认设置。我使用的方法是将以下命令放入 />etc/rc.local 启动文件中: 1echo "2147483648" > /proc/sys/kernel/shmmax 您还可以使用 sysctl 命令来更改 SHMMAX 的值: 1sysctl -w kernel.shmmax=2147483648 最后,通过将该内核参数插入到/etc/sysctl.conf 启动文件中,您可以使这种更改永久有效: 1echo "kernel.shmmax=2147483648" >> /etc/sysctl.conf 2、设置 SHMMNI 我们现在来看 SHMMNI 参数。这个内核参数用于设置系统范围内共享内存段的最大数量。该参数的默认值是 4096 。这一数值已经足够,通常不需要更改。您可以通过执行以下命令来确定 SHMMNI 的值: 1cat /proc/sys/kernel/shmmni 3、设置 SHMALL 最后,我们来看 SHMALL 共享内存内核参数。该参数控制着系统一次可以使用的共享内存总量(以页为单位)。简言之,该参数的值始终应该至少为:ceil(SHMMAX/PAGE_SIZE) SHMALL 的默认大小为 2097152 ,可以使用以下命令进行查询: 1cat /proc/sys/kernel/shmall SHMALL 的默认设置对于我们来说应该足够使用。注意:在 i386 平台上 Red Hat Linux 的 页面大小 为 4096 字节。但是,您可以使用 bigpages ,它支持配置更大的内存页面尺寸。 多次进行 shmat 操作会出现什么问题一个进程是可以对同一个共享内存多次 shmat 进行挂载的,物理内存是指向同一块,如果 shmaddr 为 NULL,则每次返回的线性地址空间都不同。而且指向这块共享内存的引用计数会增加。也就是进程多块线性空间会指向同一块物理地址。这样,如果之前挂载过这块共享内存的进程的线性地址没有被shmdt掉,即申请的线性地址都没有释放,就会一直消耗进程的虚拟内存空间,很有可能会最后导致进程线性空间被使用完而导致下次 shmat 或者其他操作失败。 shmget 创建共享内存,当 key 相同时,什么情况下会出错?当创建一个新的共享内存区时,size 的值必须大于 0;如果是访问一个已经存在的内存共享区,则置 size 为 0。 已经创建的共享内存的大小是可以调整的,但是已经创建的共享内存的大小只能调小,不能调大 当多个进程都能创建共享内存的时候,如果 key 出现相同的情况,并且一个进程需要创建的共享内存的大小要比另外一个进程要创建的共享内存小,共享内存大的进程先创建共享内存,共享内存小的进程后创建共享内存,小共享内存的进程就会获取到大的共享内存进程的共享内存,并修改其共享内存的大小和内容,从而可能导致大的共享内存进程崩溃。 ftok 是否一定会产生唯一的 key 值?ftok 原型如下: 1key_t ftok(char * pathname, int proj_id) pathname就时你指定的文件名,proj_id是子序号。在一般的 UNIX 实现中,是将文件的索引节点号取出,前面加上子序号得到key_t的返回值。如指定文件的索引节点号为 65538,换算成 16 进制为0×010002,而你指定的proj_id值为38,换算成 16 进制为0×26,则最后的key_t返回值为0×26010002。","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"IPC","slug":"IPC","permalink":"http://example.com/tags/IPC/"}]},{"title":"每天学命令-ar 多文件归档为一个文件","slug":"每天学命令-ar多文件归档为一个文件","date":"2021-08-10T03:33:49.000Z","updated":"2022-10-15T03:14:29.712Z","comments":true,"path":"2021/08/10/每天学命令-ar多文件归档为一个文件/","link":"","permalink":"http://example.com/2021/08/10/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-ar%E5%A4%9A%E6%96%87%E4%BB%B6%E5%BD%92%E6%A1%A3%E4%B8%BA%E4%B8%80%E4%B8%AA%E6%96%87%E4%BB%B6/","excerpt":"","text":"现在我们有solution.c,solution.h两个文件,他们实现了某一个功能,自成一个模块。在其他项目中也可复用。我们就可以把它做成库文件。ar命令就可以将锁哥文件整合成一个库文件,也可以从一个库中单独提取出某一个文件。 Commands1234567-d 删除备存文件中的成员文件。-m 变更成员文件在备存文件中的次序。-p 显示备存文件中的成员文件内容。-q 将文件附加在备存文件末端。-r 将文件插入备存文件中。-t 显示备存文件中所包含的文件。-x 自备存文件中取出成员文件。 Examples打包文件将solution.c solution.h两个文件打包成solution.bak,并显示详细信息 1234➜ ar rv solution.bak solution.c solution.har: 正在创建 solution.baka - solution.ca - solution.h 显示打包文件内容123➜ ar t solution.bak solution.csolution.h","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"每日学命令-ps 显示进程状态","slug":"每日学命令-ps显示进程状态","date":"2021-08-09T11:37:38.000Z","updated":"2022-10-15T03:02:55.820Z","comments":true,"path":"2021/08/09/每日学命令-ps显示进程状态/","link":"","permalink":"http://example.com/2021/08/09/%E6%AF%8F%E6%97%A5%E5%AD%A6%E5%91%BD%E4%BB%A4-ps%E6%98%BE%E7%A4%BA%E8%BF%9B%E7%A8%8B%E7%8A%B6%E6%80%81/","excerpt":"","text":"ps命令显示的信息类似于 Windows 的任务管理器。也是参数超级多的一个命令,所以就不列参数了,需要查看时直接搜索,这里列举一下实例。 使用实例显示当前执行的所有程序 1234567➜ ~ ps -a PID TTY TIME CMD 879 tty2 00:03:43 Xorg 990 tty2 00:00:00 gnome-session-b 2653 pts/0 00:00:00 zsh 12365 pts/0 00:00:00 ps 显示所有程序 1234567891011121314151617➜ ~ ps -A PID TTY TIME CMD 1 ? 00:00:01 systemd 2 ? 00:00:00 kthreadd 3 ? 00:00:00 rcu_gp 4 ? 00:00:00 rcu_par_gp 6 ? 00:00:00 kworker/0:0H-kblockd 9 ? 00:00:00 mm_percpu_wq 10 ? 00:00:00 ksoftirqd/0 11 ? 00:00:02 rcu_sched 12 ? 00:00:00 migration/0 13 ? 00:00:00 idle_inject/0 14 ? 00:00:00 cpuhp/0 15 ? 00:00:00 kdevtmpfs... 显示指定用户的信息 1➜ ~ ps -u root a显示现行终端机下的所有程序,包括其他用户的程序,u以用户为主的格式来显示程序状况,x显示所有程序,不以终端机来区分USER-运行该流程的用户。 %CPU-进程 CPU 利用率。 %MEM-进程驻留集大小占计算机物理内存的百分比。 VSZ-KiB 中进程的虚拟内存大小。 RSS-进程正在使用的物理内存的大小。 STAT-进程状态代码,可以是 Z(zombie),S(休眠),R(运行)..等等。 START-命令启动的时间。 12345➜ ~ ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 1 0.0 0.2 102084 11540 ? Ss 09:09 0:01 /sbin/init splashroot 2 0.0 0.0 0 0 ? S 09:09 0:00 [kthreadd]root 3 0.0 0.0 0 0 ? I< 09:09 0:00 [rcu_gp] 按 CPU 资源的使用量对进程进行排序: 1234567891011➜ ~ ps aux | sort -nk 3avahi 492 0.0 0.0 8536 3260 ? Ss 09:09 0:00 avahi-daemon: running [hanhan.local]avahi 552 0.0 0.0 8352 332 ? S 09:09 0:00 avahi-daemon: chroot helpercolord 1442 0.0 0.3 255144 14408 ? Ssl 09:09 0:00 /usr/libexec/colorddominic 1068 0.0 0.0 31244 364 ? S 09:09 0:00 /usr/bin/VBoxClient --clipboarddominic 1069 0.0 0.9 163512 39088 ? Sl 09:09 0:00 /usr/bin/VBoxClient --clipboarddominic 1080 0.0 0.0 31244 364 ? S 09:09 0:00 /usr/bin/VBoxClient --seamless# 其中`sort`命令中`-n`为按数值进行排序,`-k 3` 表示以输出结果的第三列来进行排序,# 从上一个实例中看到,第三列为CPU使用率`%CPU`。# 同理ps aux | sort -rnk 4 即按内存使用降序排序 显示前 5 名最耗 CPU 的进程 12345➜ ~ ps aux --sort=-pcpu | head -5USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 1 2.6 0.7 51396 7644 ? Ss 02:02 0:03 /usr/lib/systemd/systemd --switched-root --system --deserialize 23root 1249 2.6 3.0 355800 30896 tty1 Rsl+ 02:02 0:02 /usr/bin/X -background none :0 vt01 -nolisten tcproot 508 2.4 1.6 248488 16776 ? Ss 02:02 0:03 /usr/bin/python /usr/sbin/firewalld --nofor 下面的命令会显示进程 id 为 3150 的进程的所有线程 1➜ ~ ps -p 3150 -L","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"解决 OpenSSL SSL_connect: Connection was reset in connection to github.com:443","slug":"解决OpenSSL-SSL-connect-Connection-was-reset-in-connection-to-github-com-443","date":"2021-08-09T10:20:51.000Z","updated":"2022-10-15T03:14:29.819Z","comments":true,"path":"2021/08/09/解决OpenSSL-SSL-connect-Connection-was-reset-in-connection-to-github-com-443/","link":"","permalink":"http://example.com/2021/08/09/%E8%A7%A3%E5%86%B3OpenSSL-SSL-connect-Connection-was-reset-in-connection-to-github-com-443/","excerpt":"","text":"在向 GitHub 推送博客时,推送失败报了这个错。也不知道是改了什么设置突然报错。SSL 的错之前遇到一次,就是刚开始配置 Git 时用的https协议,每次push都需要重新输入一次密码。改成ssl协议就 OK 了。当时把 Linux 环境的 Git 改了,但是现在的 Windows 下没改,猜测可能和这也有关,于是就把 URL 改了一下,结果还真好了。在本地仓库的.git文件里找到config文件,打开后将url改为ssl协议,git@github.com:XXX格式的。 将 Hexo 的配置也改了,找到仓库下的_config.yml 1234deploy: type: git repository: 改成ssl协议地址 branch: master","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"},{"name":"Hexo","slug":"Hexo","permalink":"http://example.com/tags/Hexo/"}]},{"title":"Qt 事件","slug":"Qt事件","date":"2021-08-09T01:55:07.000Z","updated":"2022-10-15T03:14:29.464Z","comments":true,"path":"2021/08/09/Qt事件/","link":"","permalink":"http://example.com/2021/08/09/Qt%E4%BA%8B%E4%BB%B6/","excerpt":"","text":"本篇文章所涉及代码可在此处查看 事件以及与信号的区别事件(event)是由系统或者 Qt 本身在不同的时刻发出的。当用户按下鼠标、敲下键盘,或者是窗口需要重新绘制的时候,都会发出一个相应的事件。一些事件在对用户操作做出响应时发出,如键盘事件等;另一些事件则是由系统自动发出,如计时器事件。 事件和信号槽的区别 信号是由具体对象发出,然后马上交给connect函数连接的槽进行处理,如果处理过程中产生了新的信号,将会继续执行新的信号,一直这样递归进行下去。而事件使用一个事件队列对发出的所有事件进行维护,当新的事件产生时会被加到事件队列的尾部。 在运行过程中发现,刚启动时并不会显示任何内容,只有在点击一次后,平面才会显示信息。这是因为QWidget中有一个mouseTracking属性,该属性用于设置是否追踪鼠标。只有鼠标被追踪时,mouseMoveEvent()才会发出。如果mouseTracking是 false(默认即是),组件在至少一次鼠标点击之后,才能够被追踪,也就是能够发出mouseMoveEvent()事件。如果mouseTracking为 true,则mouseMoveEvent()直接可以被发出。知道了这一点,我们就可以在main()函数中直接设置下: 12345EventLabel *label = new EventLabel;label->setWindowTitle("MouseEvent Demo");label->resize(300, 200);label->setMouseTracking(true);label->show(); 显示效果 事件的接受与忽略12345678910111213141516//custombutton.h#include <QDebug>#include <QMouseEvent>#include <QApplication>#include <QPushButton>class CustomButton : public QPushButton{ Q_OBJECTprivate: void onButtonClicked();public: CustomButton(QWidget *parent = 0);}; 123456789101112//custombutton.cpp#include "custombutton.h"CustomButton::CustomButton(QWidget *parent) : QPushButton(parent){ connect(this, &CustomButton::clicked, this, &CustomButton::onButtonClicked);}void CustomButton::onButtonClicked(){ qDebug() << "You clicked this!";} 123456789101112//main02.cpp#include "custombutton.h"int main(int argc, char *argv[]){ QApplication a(argc, argv); CustomButton btn; btn.setText("This is a Button!"); btn.show(); return a.exec();} 以上代码运行结果就是点击按钮会在控制台输出:”You clicked this!”。 现在,我们在CustomButton类中再添加一个事件函数: 123//custombutton.hprotected: void mousePressEvent(QMouseEvent *event); 123456789101112//custombutton.cppvoid CustomButton::mousePressEvent(QMouseEvent *event){ if (event->button() == Qt::LeftButton) { qDebug() << "Left"; } else { QPushButton::mousePressEvent(event); }} 这时运行结果为点击按键输出”Left”。而没有再输出”You clicked this!”。说明我们把父类的实现覆盖了。当重写事件回调函数时,时刻注意是否需要通过调用父类的同名函数来确保原有实现仍能进行!。这一定程度上说,我们的组件忽略了父类的事件。 通过调用父类的同名函数,我们可以把 Qt 的事件传递看成链状:如果子类没有处理这个事件,就会继续向其父类传递。Qt 的事件对象有两个函数:accept()和ignore()。正如它们的名字一样,前者用来告诉 Qt,这个类的事件处理函数想要处理这个事件;后者则告诉 Qt,这个类的事件处理函数不想要处理这个事件。在事件处理函数中,可以使用isAccepted()来查询这个事件是不是已经被接收了。具体来说:如果一个事件处理函数调用了一个事件对象的accept()函数,这个事件就不会被继续传播给其父组件;如果它调用了事件的ignore()函数,Qt 会从其父组件中寻找另外的接受者。 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677//custombutton01.h#include <QDebug>#include <QVBoxLayout>#include <QMainWindow>#include <QMouseEvent>#include <QPushButton>#include <QApplication>class CustomButton : public QPushButton{ Q_OBJECTpublic: CustomButton(QWidget *parent) : QPushButton(parent) { }protected: void mousePressEvent(QMouseEvent *event) { qDebug() << "CustomButton"; }};class CustomButtonEx : public CustomButton{ Q_OBJECTpublic: CustomButtonEx(QWidget *parent) : CustomButton(parent) { }protected: void mousePressEvent(QMouseEvent *event) { qDebug() << "CustomButtonEx"; }};class CustomWidget : public QWidget{ Q_OBJECTpublic: CustomWidget(QWidget *parent) : QWidget(parent) { }protected: void mousePressEvent(QMouseEvent *event) { qDebug() << "CustomWidget"; }};class MainWindow : public QMainWindow{ Q_OBJECTpublic: MainWindow(QWidget *parent = 0) : QMainWindow(parent) { CustomWidget *widget = new CustomWidget(this); CustomButton *cbex = new CustomButton(widget); cbex->setText(tr("CustomButton")); CustomButtonEx *cb = new CustomButtonEx(widget); cb->setText(tr("CustomButtonEx")); QVBoxLayout *widgetLayout = new QVBoxLayout(widget); widgetLayout->addWidget(cbex); widgetLayout->addWidget(cb); this->setCentralWidget(widget); }protected: void mousePressEvent(QMouseEvent *event) { qDebug() << "MainWindow"; }}; 12345678910//mai03.cpp#include "custombutton01.h"int main(int argc, char *argv[]){ QApplication app(argc, argv); MainWindow win; win.show(); return app.exec();} 这段代码在一个MainWindow中添加了一个CustomWidget,里面有两个按钮对象:CustomButton和CustomButtonEx。每一个类都重写了mousePressEvent()函数。 运行程序点击 CustomButtonEx,结果是 1CustomButtonEx 因为我们重写了mousePressEvent(),所以调用子类自己的函数,如果在CustomButtonEx的mousePressEvent()第一行增加一句event->accept(),重新运行,发现结果不变。正如我们前面所说,QEvent 默认是accept的,调用这个函数并没有什么区别。然后我们将CustomButtonEx的event->accept()改成event->ignore()。这次运行结果是 12CustomButtonExCustomWidget ignore()说明我们想让事件继续传播,于是CustomButtonEx的父组件CustomWidget也收到了这个事件,所以输出了自己的结果。 同理,CustomWidget又没有调用父类函数或者显式设置accept()或ignore(),所以事件传播就此打住。 这里值得注意的是,CustomButtonEx的事件传播给了父组件CustomWidget,而不是它的父类CustomButton。事件的传播是在组件层次上面的,而不是依靠类继承机制。 在一个特殊的情形下,我们必须使用accept()和ignore()函数,那就是窗口关闭的事件。对于窗口关闭QCloseEvent事件,调用accept()意味着 Qt 会停止事件的传播,窗口关闭;调用ignore()则意味着事件继续传播,即阻止窗口关闭。回到我们前面写的简单的文本编辑器。 event() 函数事件对象创建完毕后,Qt 将这个事件对象传递给QObject的event()函数。event()函数并不直接处理事件,而是将这些事件对象按照它们不同的类型,分发给不同的事件处理器(event handler)。 如上所述,event()函数主要用于事件的分发。所以,如果你希望在事件分发之前做一些操作,就可以重写这个event()函数了。例如,我们希望在一个 QWidget 组件中监听 tab 键的按下,那么就可以继承 QWidget,并重写它的event()函数,来达到这个目的: 12345678910111213bool CustomWidget::event(QEvent *e){ if (e->type() == QEvent::KeyPress) { QKeyEvent *keyEvent = static_cast<QKeyEvent *>(e); if (keyEvent->key() == Qt::Key_Tab) { qDebug() << "You press tab."; return true; } } return QWidget::event(e);} CustomWidget是一个普通的QWidget子类。我们重写了它的event()函数,这个函数有一个QEvent对象作为参数,也就是需要转发的事件对象。函数返回值是 bool 类型。如果传入的事件已被识别并且处理,则需要返回 true,否则返回 false。如果返回值是 true,并且,该事件对象设置了accept(),那么 Qt 会认为这个事件已经处理完毕,不会再将这个事件发送给其它对象,而是会继续处理事件队列中的下一事件。注意,在event()函数中,调用事件对象的accept()和ignore()函数是没有作用的,不会影响到事件的传播。 我们可以通过使用QEvent::type()函数可以检查事件的实际类型,其返回值是QEvent::Type类型的枚举。我们处理过自己感兴趣的事件之后,可以直接返回 true,表示我们已经对此事件进行了处理;对于其它我们不关心的事件,则需要调用父类的event()函数继续转发,否则这个组件就只能处理我们定义的事件了。为了测试这一种情况,我们可以尝试下面的代码: 1234567891011bool CustomTextEdit::event(QEvent *e){ if (e->type() == QEvent::KeyPress) { QKeyEvent *keyEvent = static_cast<QKeyEvent *>(e); if (keyEvent->key() == Qt::Key_Tab) { qDebug() << "You press tab."; return true; } } return false;} CustomTextEdit是QTextEdit的一个子类。我们重写了其event()函数,却没有调用父类的同名函数。这样,我们的组件就只能处理 Tab 键,再也无法输入任何文本,也不能响应其它事件,比如鼠标点击之后也不会有光标出现。这是因为我们只处理的KeyPress类型的事件,并且如果不是KeyPress事件,则直接返回 false,鼠标事件根本不会被转发,也就没有了鼠标事件。 事件过滤器有时候,对象需要查看、甚至要拦截发送到另外对象的事件。例如,对话框可能想要拦截按键事件,不让别的组件接收到;或者要修改回车键的默认处理。 通过前面的章节,我们已经知道,Qt 创建了QEvent事件对象之后,会调用QObject的event()函数处理事件的分发。显然,我们可以在event()函数中实现拦截的操作。由于event()函数是 protected 的,因此,需要继承已有类。如果组件很多,就需要重写很多个event()函数。这当然相当麻烦,更不用说重写event()函数还得小心一堆问题。好在 Qt 提供了另外一种机制来达到这一目的:事件过滤器。 QObject有一个eventFilter()函数,用于建立事件过滤器。这个函数的签名如下: 这个函数正如其名字显示的那样,是一个“事件过滤器”。所谓事件过滤器,可以理解成一种过滤代码。想想做化学实验时用到的过滤器,可以将杂质留到滤纸上,让过滤后的液体溜走。事件过滤器也是如此:它会检查接收到的事件。如果这个事件是我们感兴趣的类型,就进行我们自己的处理;如果不是,就继续转发。这个函数返回一个 bool 类型,如果你想将参数 event 过滤出来,比如,不想让它继续转发,就返回 true,否则返回 false。事件过滤器的调用时间是目标对象(也就是参数里面的watched对象)接收到事件对象之前。也就是说,如果你在事件过滤器中停止了某个事件,那么,watched对象以及以后所有的事件过滤器根本不会知道这么一个事件。 1234567891011121314151617181920212223242526272829303132class MainWindow : public QMainWindow { public: MainWindow(); protected: bool eventFilter(QObject *obj, QEvent *event); private: QTextEdit *textEdit; }; MainWindow::MainWindow() { textEdit = new QTextEdit; setCentralWidget(textEdit); textEdit->installEventFilter(this); } bool MainWindow::eventFilter(QObject *obj, QEvent *event) { if (obj == textEdit) { if (event->type() == QEvent::KeyPress) { QKeyEvent *keyEvent = static_cast<QKeyEvent *>(event); qDebug() << "Ate key press" << keyEvent->key(); return true; } else { return false; } } else { // pass the event on to the parent class return QMainWindow::eventFilter(obj, event); } } MainWindow是我们定义的一个类。我们重写了它的eventFilter()函数。为了过滤特定组件上的事件,首先需要判断这个对象是不是我们感兴趣的组件,然后判断这个事件的类型。在上面的代码中,我们不想让textEdit组件处理键盘按下的事件。所以,首先我们找到这个组件,如果这个事件是键盘事件,则直接返回 true,也就是过滤掉了这个事件,其他事件还是要继续处理,所以返回 false。对于其它的组件,我们并不保证是不是还有过滤器,于是最保险的办法是调用父类的函数。 eventFilter()函数相当于创建了过滤器,然后我们需要安装这个过滤器。安装过滤器需要调用QObject::installEventFilter()函数。这个函数的签名如下: 1void QObject::installEventFilter ( QObject * filterObj ) 这个函数接受一个QObject *类型的参数。记得刚刚我们说的,eventFilter()函数是QObject的一个成员函数,因此,任意QObject都可以作为事件过滤器(问题在于,如果你没有重写eventFilter()函数,这个事件过滤器是没有任何作用的,因为默认什么都不会过滤)。已经存在的过滤器则可以通过QObject::removeEventFilter()函数移除。 我们可以向一个对象上面安装多个事件处理器,只要调用多次installEventFilter()函数。如果一个对象存在多个事件过滤器,那么,最后一个安装的会第一个执行,也就是后进先执行的顺序。 还记得我们前面的那个例子吗?我们使用event()函数处理了 Tab 键: 1234567891011bool CustomWidget::event(QEvent *e){ if (e->type() == QEvent::KeyPress) { QKeyEvent *keyEvent = static_cast<QKeyEvent *>(e); if (keyEvent->key() == Qt::Key_Tab) { qDebug() << "You press tab."; return true; } } return QWidget::event(e);} 12345678910111213bool FilterObject::eventFilter(QObject *object, QEvent *event){ if (object == target && event->type() == QEvent::KeyPress) { QKeyEvent *keyEvent = static_cast<QKeyEvent *>(event); if (keyEvent->key() == Qt::Key_Tab) { qDebug() << "You press tab."; return true; } else { return false; } } return false;} 事件过滤器的强大之处在于,我们可以为整个应用程序添加一个事件过滤器。记得,installEventFilter()函数是QObject的函数,QApplication或者QCoreApplication对象都是QObject的子类,因此,我们可以向QApplication或者QCoreApplication添加事件过滤器。这种全局的事件过滤器将会在所有其它特性对象的事件过滤器之前调用。尽管很强大,但这种行为会严重降低整个应用程序的事件分发效率。因此,除非是不得不使用的情况,否则的话我们不应该这么做。 注意,如果你在事件过滤器中 delete 了某个接收组件,务必将函数返回值设为 true。否则,Qt 还是会将事件分发给这个接收组件,从而导致程序崩溃。 事件过滤器和被安装过滤器的组件必须在同一线程,否则,过滤器将不起作用。另外,如果在安装过滤器之后,这两个组件到了不同的线程,那么,只有等到二者重新回到同一线程的时候过滤器才会有效。 事件过滤器和安装过滤器的组件必须在同一线程。Qt 里面,对象创建之后,可以使用 moveToThread() 函数将一个对象移动到另外的线程。在这种情形下(当然,事件过滤器必须在同一线程时才能被正确安装,这是第一句话说明的),在它们分属在不同线程时,事件过滤器也是不起作用的,只用当它们重新回到同一线程(使用 moveToThread() 或者是线程自然结束)时,过滤器才能重新工作","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"}]},{"title":"每天学命令-scp 远程拷贝文件","slug":"每天学命令-scp远程拷贝文件","date":"2021-08-06T12:05:56.000Z","updated":"2022-10-15T03:03:19.398Z","comments":true,"path":"2021/08/06/每天学命令-scp远程拷贝文件/","link":"","permalink":"http://example.com/2021/08/06/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-scp%E8%BF%9C%E7%A8%8B%E6%8B%B7%E8%B4%9D%E6%96%87%E4%BB%B6/","excerpt":"","text":"看到同事要安装自己编译一天的库,本想传授一下“踩坑经验”,结果他用scp命令直接从已经安装好的电脑里复制了一份。心里一万只 XXX 在奔腾。 早知道先学学这个命令了。 可选参数 参数 功能 -1 强制 scp 命令使用协议 ssh1 -2 强制 scp 命令使用协议 ssh2 -4 强制 scp 命令使用协议 ssh2 -6 强制 scp 命令只使用 IPv6 寻址 -B 使用批处理模式(传输过程中不询问传输口令或短语) -C 允许压缩 -p 保留原文件的修改时间,访问时间和访问权限。 -q 不显示传输进度条 -r 递归复制整个目录 -v 详细方式显示输出 -P 注意是大写的 P, port 是指定数据传输用到的端口号 使用实例复制文件 12scp local_file rmot_usr@rmot_ip:rmot_folderscp /opt/soft/ root@192.168.120.204:/opt/soft/nginx-0.5.38.tar.gz","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"每天学命令-grep 文本搜索","slug":"每天学命令-grep文本搜索","date":"2021-08-05T11:27:48.000Z","updated":"2022-10-15T03:03:19.398Z","comments":true,"path":"2021/08/05/每天学命令-grep文本搜索/","link":"","permalink":"http://example.com/2021/08/05/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-grep%E6%96%87%E6%9C%AC%E6%90%9C%E7%B4%A2/","excerpt":"","text":"grep全称global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来。这名字就怪吓人,如果熟练掌握正则表达式,配上这命令 Linux 里可以横着走了。 这个命令参数实在太多,加上正则表达式估计一张纸不够。那就直接上实例吧。 使用实例在当前目录中,查找后缀带有cpp字样的文中包含test字符串的文件,并打印所在行 12grep test *cppgrep --colorauto test *cpp # 用颜色标记 通过”-v”参数可以打印出不符合条件行的内容。 1grep -v test *cpp 系统报警显示了时间,但是日志文件太大无法直接 cat 查看。(查询含有特定文本的文件,并拿到这些文本所在的行)。-n 或 --line-number 可以显示符合样式的那一行之前,标示出该行的列数编号。 1grep -n '2019-10-24 00:01:11' *.log grep 静默输出,不会输出任何信息,如果命令运行成功返回 0,失败则返回非 0 值。一般用于条件测试。 1grep -q "test" filename 在多级目录中对文本进行递归搜索 1grep "text" . -r -n 配合管道,查找指定的进程信息 1ps -ef | grep svn 查找指定的进程个数,-c计数 1ps -ef | grep svn -c 常用正则表达式通配符| 通配符 | 功能 || :—-: | :—-: || c* | 将匹配 0 个(即空白)或多个字符 c(c 为任一字符) || . | 将匹配任何一个字符,且只能是一个字符 || [xyz] | 匹配方括号中的任意一个字符 || [^xyz] | 匹配除方括号中字符外的所有字符 || ^ | 锁定行的开头 || $ | 锁定行的结尾 | 在id.txt中找到所有以 3207 开头的数据 1grep ^3207 id.txt","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"Qt 对话框","slug":"Qt对话框","date":"2021-08-05T02:11:33.000Z","updated":"2022-10-15T03:14:29.472Z","comments":true,"path":"2021/08/05/Qt对话框/","link":"","permalink":"http://example.com/2021/08/05/Qt%E5%AF%B9%E8%AF%9D%E6%A1%86/","excerpt":"","text":"本篇文章所涉及代码,可在此处查看 Qt 中使用 QDialog 类实现对话框。就像主窗口一样,我们通常会设计一个类继承 QDialog。QDialog(及其子类,以及所有 Qt::Dialog 类型的类)的对于其 parent 指针都有额外的解释: 如果 parent 为 NULL,则该对话框会作为一个顶层窗口,否则则作为其父组件的子对话框(此时,其默认出现的位置是 parent 的中心)。 顶层窗口与非顶层窗口的区别在于,顶层窗口在任务栏会有自己的位置,而非顶层窗口则会共享其父组件的位置。 对话框分为模态对话框和非模态对话框。所谓模态对话框,就是会阻塞同一应用程序中其它窗口的输入。模态对话框很常见,比如“打开文件”功能。你可以尝试一下记事本的打开文件,当打开文件对话框出现时,我们是不能对除此对话框之外的窗口部分进行操作的。 与此相反的是非模态对话框,例如查找对话框,我们可以在显示着查找对话框的同时,继续对记事本的内容进行编辑。 Qt 支持模态对话框和非模态对话框。其中,Qt 有两种级别的模态对话框:应用程序级别的模态和窗口级别的模态,默认是应用程序级别的模态。应用程序级别的模态是指,当该种模态的对话框出现时,用户必须首先对对话框进行交互,直到关闭对话框,然后才能访问程序中其他的窗口。窗口级别的模态是指,该模态仅仅阻塞与对话框关联的窗口,但是依然允许用户与程序中其它窗口交互。 消息对话框 QMessageBox文件对话框 QFileDialog‘QTextEdit’ Does not name a type需要包含头文件 1#include <QTextEdit> Qt 需要包含的头文件实在太多了。 可能添加了头文件仍然报同样的错,没有搜索到相关的解答。 我的做法是: 确保在.pro文件中加入QT += widgets和CONFIG += c++11 将包含库文件语句都放到头文件.h中","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"}]},{"title":"Git 中添加 gitignore 并更新远程仓库","slug":"Git中添加gitignore并更新远程仓库","date":"2021-08-04T06:09:20.000Z","updated":"2022-10-15T03:14:29.225Z","comments":true,"path":"2021/08/04/Git中添加gitignore并更新远程仓库/","link":"","permalink":"http://example.com/2021/08/04/Git%E4%B8%AD%E6%B7%BB%E5%8A%A0gitignore%E5%B9%B6%E6%9B%B4%E6%96%B0%E8%BF%9C%E7%A8%8B%E4%BB%93%E5%BA%93/","excerpt":"","text":"gitignore 的作用在使用Git版本控制时,必须要用.gitignore这个文件来告诉Git那些文件或目录不需要添加到版本控制中。通俗点说,就是不需要git push到远程仓库。 在平时开发过程中,开发目录下会有各种格式的文件,比如 C 语言除了.c源码,还会有.o目标文件,没有后缀的可执行程序等等,假如你要进行深度学习类的开发,如图像识别,需要训练大量数据,如果这些训练数据也到跟踪管理,那push一次就可以下班回家了。 但是我们怎么让Git知道哪些文件需要跟踪,哪些文件不需要呢,这时候.gitignore文件就起作用了。 常用规则简单介绍一下常用的规则,虽然后面有现成的模板,但是我们还是了解一下常用规则,能看得懂.gitignore里写了啥。也方便自己编写一些规则适应自己的工作。 12345/test/ # 过滤整个test文件夹*.o # 过滤所有.o文件/test/hello.o # 过滤test文件夹下hello.o这个文件!src/ # 不过滤src这个文件夹!*.c # 不过滤.c文件 通过 gitignore 文件更新远程仓库上面说到我们在不同环境下需要制定不同的规则,但是每次都要重新写一遍,又或者不知道制定什么样的规则,还是挺麻烦的。 首先推荐一个.gitignore模板仓库,在平时工作学习中遇到的各种语言环境下的模板都能找到。这是广大开发人员总结的一些规则。 最近在学习Qt,在所有模板中搜索关键字,找到了Qt.gitignore这个模板打开并复制,在自己本地仓库里新建一个.gitignore文件,将复制的内容粘贴进去。 现在就要解决如何更新远程仓库的内容,因为我在使用.gitignore文件之前已经向远程push过了,现在需要删除不需要的文件。 1git rm -r --cached . rm就是Linux下常用的删除命令,-r表示递归删除,--cached表示需要在本地端(工作区)保留文件,.表示所有文件。 123git add . # 重新添加所有文件到暂存区,然后提交,推送git commit -m "update"git push","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"},{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"Qt 添加资源文件","slug":"Qt添加资源文件","date":"2021-08-04T03:34:10.000Z","updated":"2022-10-15T03:14:29.500Z","comments":true,"path":"2021/08/04/Qt添加资源文件/","link":"","permalink":"http://example.com/2021/08/04/Qt%E6%B7%BB%E5%8A%A0%E8%B5%84%E6%BA%90%E6%96%87%E4%BB%B6/","excerpt":"","text":"本文是学习【Qt 学习之路】的学习笔记,源码非原创。Github同步本文更改的代码。 在建立 Qt 学习代码仓时,推送到远程的代码比较乱,所以用gitignore文件屏蔽了一些。相关方法在这里。 资源文件Qt 资源系统是一个跨平台的资源机制,用于将程序运行时所需要的资源以二进制的形式存储于可执行文件内部。如果你的程序需要加载特定的资源(图标、文本翻译等),那么,将其放置在资源文件中,就再也不需要担心这些文件的丢失。也就是说,如果你将资源以资源文件形式存储,它是会编译到可执行文件内部。 使用 QtCreator 的相关方法,讲得也很清楚了,就不赘述了。 不使用 QtCreator 添加资源文件在使用命令行编译运行时,并不能像在 QtCreator 中一样,可以自动的生成一个.qrc文件,这就需要我们自己去编写。从原文的讲解中我们也知道,它就是一个XML描述文件,里面定义了文件位置等信息。如原文中的.qrc文件: 12345<RCC> <qresource prefix="/images"> <file alias="doc-open">document-open.png</file> </qresource></RCC> 其中 12345<RCC> <qresource> </qresource></RCC> 是固定的标记,再往中间加东西。如果学过html语言就很容易理解。其中prefix="/images"就是自动加上前缀/images,因为图片在images目录下,每次都加这个路径太麻烦,太长。 alias="doc-open"意思是将document-open.png这个文件起个别名,原来的太长了。下次再用document-open.png就只需要用doc-open就行了。 我们知道了这些,就可以编写一个自己的.qrc文件了。我也自己下载了一个打开文件的图标open.png,文件比较少,就和代码放在同一个目录下了。我们将其命名为ico.qrc,这个文件中以后都存放有关图标的资源,我们开始编写: 12345<RCC> <qresource> <file>open.png</file> </qresource></RCC> 因为添加资源后需要更新.pro文件才能正常编译,所以需要在.pro中加入RESOURCES 信息,就在.pro文件最后一行加入: 1RESOURCES += ico.qrc 然后输入命令 1234qmake MainWindow.promake clean #因为之前可能make过,先清理一遍make./MainWindow 如果一切顺利,将会得到下面的窗口: Reference https://www.devbean.net/2012/08/qt-study-road-2-action/","categories":[],"tags":[{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"}]},{"title":"每天学命令-cat 可以查看文件的小猫咪","slug":"每天学命令-cat可以查看文件的小猫咪","date":"2021-08-04T01:57:51.000Z","updated":"2022-10-15T03:14:29.714Z","comments":true,"path":"2021/08/04/每天学命令-cat可以查看文件的小猫咪/","link":"","permalink":"http://example.com/2021/08/04/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-cat%E5%8F%AF%E4%BB%A5%E6%9F%A5%E7%9C%8B%E6%96%87%E4%BB%B6%E7%9A%84%E5%B0%8F%E7%8C%AB%E5%92%AA/","excerpt":"","text":"cat 可以将文件的内容方便地输出到屏幕上。但是它的全称concatenate意为“连接”,连接文件也是它的重要功能之一,很多人可能都不常用。只记得输出文件内容了。 可选参数123456789-n 或 --number #由 1 开始对所有输出的行数编号。-b 或 --number-nonblank #和 -n 相似,只不过对于空白行不编号。-s 或 --squeeze-blank #当遇到有连续两行以上的空白行,就代换为一行的空白行。-v 或 --show-nonprinting #使用 ^ 和 M- 符号,除了 LFD 和 TAB 之外。-E 或 --show-ends # 在每行结束处显示 $。-T 或 --show-tabs: #将 TAB 字符显示为 ^I。-A, --show-all #等价于 -vET。-e #等价于"-vE"选项;-t #等价于"-vT"选项; 使用实例将文件内容输出到屏幕 12345➜ ~ cat test.txt This is firt line!This is second line!This is third line!This is fourth line! 将test.txt的内容输入到test01.txt中 123456➜ ~ cat test.txt > test01.txt➜ ~ cat test01.txt This is firt line!This is second line!This is third line!This is fourth line! 带行号输出 12345➜ ~ cat -n test.txt 1 This is firt line! 2 This is second line! 3 This is third line! 4 This is fourth line! 将两个文件内容合并,再写入到第三个文件中 12345678910➜ ~ cat test.txt test01.txt >> test02.txt➜ ~ cat test02.txt This is firt line!This is second line!This is third line!This is fourth line!This is firt line!This is second line!This is third line!This is fourth line! 清空文件中的内容 123➜ ~ cat /dev/null > test.txt ➜ ~ cat test.txt ➜ ~ 在类 Unix 系统中,/dev/null 称空设备,是一个特殊的设备文件,它丢弃一切写入其中的数据(但报告写入操作成功),读取它则会立即得到一个 EOF。 Reference https://www.runoob.com/linux/linux-comm-cat.html","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"解决/usr/bin/env:python:No such file or directory","slug":"解决-usr-bin-env-python-No-such-file-or-directory","date":"2021-08-03T07:58:44.000Z","updated":"2022-10-15T03:14:29.848Z","comments":true,"path":"2021/08/03/解决-usr-bin-env-python-No-such-file-or-directory/","link":"","permalink":"http://example.com/2021/08/03/%E8%A7%A3%E5%86%B3-usr-bin-env-python-No-such-file-or-directory/","excerpt":"","text":"在执行的程序源码开头有这么一句!#/usr/bin/env python,!#这玩意叫shebang也叫hashbang。他用来指定脚本的解释器,也就是说这个程序指定python解释器。 再看这个错误提示,罪魁祸首就是这句命令,就是说在环境变量找不到python,通俗点说,假如我要能直接用python来跑这个程序,我在命令行直接输入python应该是可以进入python环境的,但是此时肯定不能。我们可以试试 12dominic@hanhan:~$ pythonCommond not found xxxxxxxxxxx 解决方案一系统里没有python还跑个锤子,先装上再说 1apt-get install python3 这时候可能就解决问题了 解决方案二有的人可能python早就装了,但是仍然有这个问题,但是我们在命令输入python仍然没法用,但是输入python3就可以 那python3可以,我直接将python改成python3不就完了。没错! 打开文件将!#/usr/bin/env python改成!#/usr/bin/env python3 解决方案三如果了解软链接,那我们就可以不用去改源码了,源码最好还是保持原样。 既然找不到python这玩意,那我们给他建一个不就完了。 他要python就是用来解释程序的,我们本地装的python3就是他需要的东西 先找找我们的python3在哪 12dominic@hanhan:~$ whereis python3python3: /usr/bin/python3.8 /usr/bin/python3.8-config /usr/bin/python3 一般在/usr/bin目录下,然后我们在这个目录下给他创建一个软链接“快捷方式”,具体咋用的啥意思,可以参考这篇文章。 1sudo ln -s /usr/bin/python3 /usr/bin/python 这样程序再找python时就会链接到python3,然后用python3去当解释器。 解决方案四可能在root目录下使用过repo,将其删除","categories":[{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"}]},{"title":"每天学命令-ln 软硬链接","slug":"每天学命令-ln软硬链接","date":"2021-08-03T03:57:02.000Z","updated":"2022-10-15T03:03:19.398Z","comments":true,"path":"2021/08/03/每天学命令-ln软硬链接/","link":"","permalink":"http://example.com/2021/08/03/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-ln%E8%BD%AF%E7%A1%AC%E9%93%BE%E6%8E%A5/","excerpt":"","text":"Linux ln(英文全拼:link files)命令是一个非常重要命令,它的功能是为某一个文件在另外一个位置建立一个同步的链接。这有点像 Windows 环境下的快捷方式。介绍命令前了解一下软链接,硬链接具体是什么。 硬链接 Hard Link在 Linux 系统中,每个文件对应一个 inode,文件的内容在存储在 inode 指向的 data block 中。要读取该文件的内容,需要通过文件所在的目录中记录的文件名找到文件的 inode 号,然后通过 inode 找到存储文件内容的 data block。当然多个文件名可以指向同一个inode。 使用ll命令显示文件的详细信息,-i参数显示其结点信息,其中最前面的一串数字就是inode信息。我们以/opt/test.txt文件为例,查看其结点信息。 12dominic@hanhan:/opt$ ll -i test.txt 2498138 -rw-r--r-- 1 root root 4 8月 3 12:16 test.txt 使用 ln 命令在/opt/temp目录下创建一个 test.txt 文件的硬链接,然后观察其文件属性: 1234dominic@hanhan:/opt/temp$ sudo ln ../test.txt .dominic@hanhan:/opt/temp$ ll -i ../test.txt test.txt 2498138 -rw-r--r-- 2 root root 4 8月 3 12:16 ../test.txt2498138 -rw-r--r-- 2 root root 4 8月 3 12:16 test.txt 我们再用ll -i命令查看结点信息,发现这两个文件名的结点信息是一样的。说明这两个文件名指向的是同一个文件。其中第三个字段是链接数,数字2,表示有两个文件名链接到同一个inode。 硬链接的特点 硬链接,以文件副本的形式存在。但不占用实际空间。由于硬链接只是在目录中添加了一条包含文件名和 对应 inode 的记录,所以它几乎不会消耗额外的磁盘容量。 不允许给目录创建硬链接 硬链接只有在同一个文件系统中才能创建 只要还有一个文件名引用着文件,文件就不会被真正删除删除硬链接所关联的文件时,其实只是删除了一条目录中的记录,真正的文件并不受影响。只有在删除最后一个硬链接时才会真正删除文件的内容数据。 软链接 Symbolic Link软链接的实现方式与硬链接有本质上的不同。创建软链接时会创建一个新的文件 (分配一个inode 和对应的 data block),新文件的 data block 中存储了目标文件的路径。 我们以/opt/test.txt为例,在/opt/temp目录中,为其创建一个软链接,然后查看其inode结点信息。 1234dominic@hanhan:/opt/temp$ sudo ln -s ../test.txt test2.txtdominic@hanhan:/opt/temp$ ll -i ../test.txt test2.txt 2498139 lrwxrwxrwx 1 root root 11 8月 3 14:01 test2.txt -> ../test.txt2498138 -rw-r--r-- 2 root root 4 8月 3 12:16 ../test.txt 第一个字段不同,说明是两个文件了 第二个字段表示权限,第一个字母表示文件类型,l说明书软链接文件 第三个字段表示链接数,仍然是2,说明软链接不增加源文件链接数 第六个字段是文件大小,新建的软链接文件时 11 字节,这就是/opt/test.txt的长度。 软链接特点 软链接,以路径的形式存在。类似于 Windows 操作系统中的快捷方式 软链接可以 跨文件系统,硬链接不可以 软链接可以对一个不存在的文件名进行链接 软链接可以对目录进行链接 使用实例ln [参数][源文件或目录][目标文件或目录]为文件test.txt创建一个硬链接 1sudo ln test.txt /etc/ 删除test.txt的硬链接,因为是以副本形式存在的,所以直接用rm命令将其删除即可。 1sudo rm /etc/test.txt 为文件test.txt创建一个软链接 1sudo ln -s test.txt /etc/test2.txt 删除软链接也一样,直接用rm命令删除软链接的名称即可。 Reference https://www.runoob.com/linux/linux-comm-ln.html https://www.cnblogs.com/lixuze/p/14248559.html","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"每天学命令-ed 行编辑器","slug":"每天学命令-ed行编辑器","date":"2021-08-02T01:57:10.000Z","updated":"2022-10-15T03:14:29.722Z","comments":true,"path":"2021/08/02/每天学命令-ed行编辑器/","link":"","permalink":"http://example.com/2021/08/02/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-ed%E8%A1%8C%E7%BC%96%E8%BE%91%E5%99%A8/","excerpt":"","text":"ed命令是文本编辑器,用于文本编辑。 ed是 Linux 中功能最简单的文本编辑程序,一次仅能编辑一行而非全屏幕方式的操作。很多命令和vim相似,平时开发中并不常用,但是在编辑大文本时还是会用到。 学学无妨毕竟这是 Unix 系统三大要件(编辑器,汇编器和 shell)之一。 ed编辑器有两种模式:命令模式和输入模式。命令模式下输入a,i,c,d可以进入对应的编辑模式,接下来可以输入任何想要输入的内容,输入完毕或者要切换命令时,可以输入.退出输入模式。 Commands1234a #添加到行i #添加到行首c #改变行d #删除行 Line Address12345678910. #buffer 中 当前行$ #最后一行n #第 n 行,行的范围是 [0,$]- or ^ #前一行-n or ^n #前 n 行+ or +n #后一行及后n行, or % #全部行,等同于 1,$; #当前行到最后一行 .,$/re/ #下一个包含正则 re 的行?re? #上一个包含正则 re 的行 使用实例12345678910111213141516171819202122232425262728293031dominic@hanhan:~$ ed # 进入编辑模式This is a test text! # 输入文本. # 结束输入命令This is a test text! # 回显当前行n # 显示行号命令1 This is a test text! # 回显当前行并显示行号c # 改变行命令This is changed text! # 输入更改后的内容. # 结束输入命令n # 显示行号命令1 This is changed text! # 回显当前行并显示行号i # 在首行插入命令This is first line! # 输入插入内容. # 结束输入命令+ # 后一行命令This is changed text! # 回显后一行d # 删除当前行 . # 回显当前行命令This is firt line! # 回显当前行aThis is second line!This is third line!This is fourth line!w test.txt # 写入并保存文件q # 退出编辑器dominic@hanhan:~$ cat test.txt # 查看内容This is first line!sThis is second line!This is third line!This is fourth line!","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"每天学命令-wc 统计文件有多少字多少行","slug":"每天学命令-wc统计文件有多少字多少行","date":"2021-07-30T09:26:39.000Z","updated":"2022-10-15T03:03:19.398Z","comments":true,"path":"2021/07/30/每天学命令-wc统计文件有多少字多少行/","link":"","permalink":"http://example.com/2021/07/30/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-wc%E7%BB%9F%E8%AE%A1%E6%96%87%E4%BB%B6%E6%9C%89%E5%A4%9A%E5%B0%91%E5%AD%97%E5%A4%9A%E5%B0%91%E8%A1%8C/","excerpt":"","text":"想知道自己代码写了多少行,可以一个wc命令搞定。 可选参数123-l:仅列出行;-w:仅列出多少字 (英文单字);-m:多少字符 使用实例统计hello.c文件夹下文件总共多少行 12$ wc -l hello.c14 hello.c 统计文件夹下文件的个数 12ls -l | grep "^-" | wc -l 统计当前目录下文件的个数(包括子目录) 12ls -lR| grep "^-" | wc -l 查看目录下文件夹 (目录) 的个数(包括子目录) 1ls -lR | grep "^d" | wc -l 过滤ls的输出信息,只保留一般文件,只保留目录是grep "^d"。","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"更换 Ubuntu 软件更新源","slug":"Linux更换Ubuntu软件更新源","date":"2021-07-30T03:14:41.000Z","updated":"2022-11-20T07:03:29.733Z","comments":true,"path":"2021/07/30/Linux更换Ubuntu软件更新源/","link":"","permalink":"http://example.com/2021/07/30/Linux%E6%9B%B4%E6%8D%A2Ubuntu%E8%BD%AF%E4%BB%B6%E6%9B%B4%E6%96%B0%E6%BA%90/","excerpt":"","text":"Ubuntu 默认是国外的源,软件下载和更新都比较慢。两种方法将下载源换成国内的源。 用”软件和更新”工具从 Ubuntu 菜单中找到软件和更新这个应用并打开。 找到下载自,选择其他 - 国内-aliyun,然后勾选前四个选项。关闭时会弹出对话框,点击更新。然后就能愉快的下载软件了。 修改sourcelist备份原文件这也算是系统文件的一部分,还是保险一点,出错了再改回来。 1sudo cp /etc/apt/sources.list /etc/apt/sources.list.backup 打开并修改1sudo vi /etc/apt/sources.list vim用的不习惯的估计会和我一样找全选内容怎么操作。教给你了在命令模式下,就是按一下esc键,然后输入ggvG。具体什么含义看VIM 笔记吧,选择后直接delete删除,再把阿里云源粘贴进去。保存退出。 1234567891011#阿里云deb http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ trusty-proposed main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ trusty-proposed main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverse 更新123sudo apt-get updatesudo apt-get dist-upgradesudo apt-get upgrade","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"}]},{"title":"每天学命令-find 查找文件","slug":"每天学命令-find查找文件","date":"2021-07-29T03:05:43.000Z","updated":"2022-10-15T03:03:19.398Z","comments":true,"path":"2021/07/29/每天学命令-find查找文件/","link":"","permalink":"http://example.com/2021/07/29/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-find%E6%9F%A5%E6%89%BE%E6%96%87%E4%BB%B6/","excerpt":"","text":"命令格式1find [path] [expression] 在path下查找expression表示的文件 常用命令一般常见就是自己不知道写的某个文件或者文件夹放哪里了,又或者只记住部分文件名。以下几个命令就能帮到你。 按文件名查找12345find -name filename(查找结果显示路径)或者 find filename(查找结果不显示路径)find hello.cpp #当前目录下精确查找hello.cpp文件find hello #当前目录下精确查找hello文件find hello* #当前目录下模糊查找以hello为前缀的文件 按类型查找这就是为查找文件夹用的。 1find -type [fdlcb] name [fdlcb]都是类型,d就是目录,文件夹类型。 1find / -type d -name "helloworld" #查找名为helloworld的文件夹 按文件名查找以下就详细介绍一些参数 12find -name "hello.cpp" # 搜索文件名,大小写敏感find -iname "hello.cpp" #大小写不敏感 按文件大小查找12345find [path] -size 50Mfind / -size 10M # 查找系统中大小等于10M的文件find / -size +50M # 查找系统中大小大于50M的文件find / -size -30M # 查找系统中大小小于30M的文件 按时间来查找文件Linux 会存储下面的时间: Access time 上一次文件读或者写的时间 Modifica time 上一次文件被修改的时间 Change time 上一次文件 inode meta 信息被修改的时间 在按照时间查找时,可以使用 -atime, -mtime 或者 -ctime,和之前 size参数一样可以使用 + 或者 -时间范围,下图表示find的时间轴。+表示超过多少天,-表示多少天以内。 此外,也可以换成-amin, -mmin 或者 -cmin参数,单位是分钟。 123find / -mtime 1 # 寻找修改时间超过一天的文件find / -atime -1 # 寻找在一天时间内被访问的文件find / -ctime +3 # 寻找 meta 信息被修改的时间超过 3 天的文件 Reference http://c.biancheng.net/view/779.html https://einverne.github.io/post/2018/02/find-command.html#%E6%89%B9%E9%87%8F%E5%88%A0%E9%99%A4%E6%97%B6%E9%97%B4%E8%B6%85%E8%BF%87-1-%E5%A4%A9%E7%9A%84%E6%96%87%E4%BB%B6","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"git clone 快速下载子模块","slug":"git-clone快速下载子模块","date":"2021-07-28T07:28:58.000Z","updated":"2022-10-15T03:14:29.206Z","comments":true,"path":"2021/07/28/git-clone快速下载子模块/","link":"","permalink":"http://example.com/2021/07/28/git-clone%E5%BF%AB%E9%80%9F%E4%B8%8B%E8%BD%BD%E5%AD%90%E6%A8%A1%E5%9D%97/","excerpt":"","text":"在git clone时候,如果遇到项目里有子模块通常会在下载时加上--recursive参数,一起下载。但是子模块较多,体积较大时大概率都会下载失败。 好在可以通过一些小技巧,下载国内镜像,进行加速。但是下载项目时,只是主体是国内的镜像,子模块仍然下载很慢。首先解决获取国内镜像的问题。有三个方法: 在码云 Gitee 上搜索下载 在码云上搜索同样的项目,然后用码云git 的地址下载。 加上.cnpmjs.org后缀 在地址后面加上后缀,如git clone https://github.com.cnpmjs.org/riscv/riscv-binutils-gdb.git。 使用油猴脚本获取镜像地址 如果你有油猴插件可以去greasyfork搜索安装GitHub镜像访问,加速下载这个脚本,刷新GitHub仓库界面就会多出几个镜像地址,一般下载都会快好几倍。 再来解决子模块下载速度慢的问题,下载项目时,先不加--recursive参数,只下载项目的本题。 下载完后找到.gitmodules文件,这是一个隐藏文件,需要显示隐藏文件,Linux 下使用快捷键Ctrl+H。用vim打开后可以得到: 这个文件里写入了子模块的下载信息,url就是下载地址。我们把所有子模块中的 URL 地址同样加上.cnpmjs.org后缀。或者使用上述三种方式得到的镜像地址。 然后利用git submodule sync更新子项目对应的url 最后再git submodule update --init --recursive,即可快速下载所有子项目。","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"在 QEMU 上运行 64 位和 32 位 RISC-V-Linux","slug":"QEMU上运行64位和32位RISC-V-Linux","date":"2021-07-28T05:47:56.000Z","updated":"2022-10-15T03:14:29.375Z","comments":true,"path":"2021/07/28/QEMU上运行64位和32位RISC-V-Linux/","link":"","permalink":"http://example.com/2021/07/28/QEMU%E4%B8%8A%E8%BF%90%E8%A1%8C64%E4%BD%8D%E5%92%8C32%E4%BD%8DRISC-V-Linux/","excerpt":"","text":"制作交叉工具链 riscv-gnu-toolchain下载源码这个仓库是我遇到的最难下载的一个仓库了,公司网慢和虚拟机性能差都脱不了干系。估计下载了五小时都不止,刚开始还指望一个命令所有子模块都下载完的,结果愣是等了半天中断了。试了两次后放弃了。如果各位看官能一次完成,那您是福大。 国内的码云平台有个Gitee 极速下载项目,上面有 GitHub 的一些常用开源项目的镜像,可供加速下载。 12# riscv-gnu-toolchainhttps://gitee.com/mirrors/riscv-gnu-toolchain.git 下载时问题出现了,如果下载子模块仍然会卡住,如果不加--recursive就只能下载主体内容,子模块都没有。(以下内容为第一安装时的方法,后续又找到了git clone 快速下载子模块的方法) 开始下载时不加--recursive参数,只下载riscv-gnu-toolchain的主体内容,然后进入到riscv-gnu-toolchain文件夹下,手动下载子模块的内容。 当下完riscv-binutils继续下载riscv-gdb时发现这两个项目是同一个项目,只是不同的分支。但是码云上并没有区分,但是我也没找到在码云上的对应分支。只能用油猴脚本了。 如果你有油猴插件可以去greasyfork搜索安装GitHub 镜像访问,加速下载这个脚本,刷新 GitHub 仓库界面就会多出几个镜像地址,一般下载都会快好几倍。如果不用油猴插件的可以用我复制好的链接。 123456789101112# riscv-binutilsgit clone https://gitee.com/mirrors/riscv-binutils-gdb.git# riscv-gccgit clone https://gitee.com/mirrors/riscv-gcc.git# riscv-dejagnugit clone https://gitee.com/mirrors/riscv-dejagnu.git# riscv-glibcgit clone https://gitee.com/mirrors/riscv-glibc.git# riscv-newlibgit clone https://gitee.com/mirrors/riscv-newlib.git# riscv-gdbgit clone --depth=1 https://hub.fastgit.org/riscv/riscv-binutils-gdb.git 编译 riscv-gnu-toolchain提前安装如下软件: 1sudo apt-get install autoconf automake autotools-dev curl python3 libmpc-dev libmpfr-dev libgmp-dev gawk build-essential bison flex texinfo gperf libtool patchutils bc zlib1g-dev libexpat-dev 不听老人言,吃亏在眼前呀,本以为这是可选项,很多库都安装了,就没有操作这一步,结果就是编译半天结果还错了。如果报make 错误 127,那就老老实实把前置的这些库都装上。 建立riscv-gnu-toolchain安装目录/opt/riscv64。 12./configure --prefix=/opt/riscv64 sudo make linux -j8 导出安装路径1export PATH="$PATH:/opt/riscv64/bin" 出现一下信息表示安装成功。 12345678Using built-in specs.COLLECT_GCC=riscv64-unknown-linux-gnu-gccCOLLECT_LTO_WRAPPER=/opt/riscv64/libexec/gcc/riscv64-unknown-linux-gnu/10.2.0/lto-wrapperTarget: riscv64-unknown-linux-gnuConfigured with: /home/dominic/riscv64-linux/riscv-gnu-toolchain/riscv-gcc/configure --target=riscv64-unknown-linux-gnu --prefix=/opt/riscv64 --with-sysroot=/opt/riscv64/sysroot --with-system-zlib --enable-shared --enable-tls --enable-languages=c,c++,fortran --disable-libmudflap --disable-libssp --disable-libquadmath --disable-libsanitizer --disable-nls --disable-bootstrap --src=.././riscv-gcc --disable-multilib --with-abi=lp64d --with-arch=rv64imafdc --with-tune=rocket 'CFLAGS_FOR_TARGET=-O2 -mcmodel=medlow' 'CXXFLAGS_FOR_TARGET=-O2 -mcmodel=medlow'Thread model: posixSupported LTO compression algorithms: zlibgcc version 10.2.0 (GCC) 制作内核下载 Linux 内核makefile","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"QEMU","slug":"QEMU","permalink":"http://example.com/tags/QEMU/"},{"name":"RISC-V","slug":"RISC-V","permalink":"http://example.com/tags/RISC-V/"}]},{"title":"每天学命令-df/du查看磁盘剩余空间","slug":"每天学命令-df-du查看磁盘剩余空间","date":"2021-07-28T02:13:58.000Z","updated":"2022-10-15T03:14:29.720Z","comments":true,"path":"2021/07/28/每天学命令-df-du查看磁盘剩余空间/","link":"","permalink":"http://example.com/2021/07/28/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4-df-du%E6%9F%A5%E7%9C%8B%E7%A3%81%E7%9B%98%E5%89%A9%E4%BD%99%E7%A9%BA%E9%97%B4/","excerpt":"","text":"df全称disk filesystem ,以磁盘分区为单位查看文件系统,可以查看磁盘文件占用空间,磁盘剩余空间等信息。 命令格式1df [] [] 可选参数1234567891011-a 全部文件系统列表-h 方便阅读方式显示-H 等于“-h”,但是计算式,1K=1000,而不是 1K=1024-i 显示 inode 信息-k 区块为 1024 字节-l 只显示本地文件系统-m 区块为 1048576 字节--no-sync 忽略 sync 命令-P 输出格式为 POSIX--sync 在取得磁盘信息前,先执行 sync 命令-T 文件系统类型 使用实例df -T显示包含文件系统,类型,可用大小,已用大小,挂载点等信息。 12345678910dominic@hanhan:~$ df -T文件系统 类型 1K-块 已用 可用 已用% 挂载点udev devtmpfs 1985056 0 1985056 0% /devtmpfs tmpfs 403036 1304 401732 1% /run/dev/sda5 ext4 50824704 20826256 27386992 44% /tmpfs tmpfs 2015172 0 2015172 0% /dev/shmtmpfs tmpfs 5120 4 5116 1% /run/locktmpfs tmpfs 2015172 0 2015172 0% /sys/fs/cgroup/dev/loop0 squashfs 56832 56832 0 100% /snap/core18/1988/dev/loop1 squashfs 56832 56832 0 100% /snap/core18/2074 du全称disk usage可以查看文件,文件夹占用情况。 命令格式1du [opt] [filename] 可选参数12345678910111213141516171819-a或-all #显示目录中个别文件的大小。-b或-bytes #显示目录或文件大小时,以byte为单位。-c或--total #除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。-D或--dereference-args #显示指定符号连接的源文件大小。-h或--human-readable #以K,M,G为单位,提高信息的可读性。-H或--si #与-h参数相同,但是K,M,G是以1000为换算单位。-k或--kilobytes #以1024 bytes为单位。-l或--count-links #重复计算硬件连接的文件。-L<符号连接>或--dereference<符号连接> #显示选项中所指定符号连接的源文件大小。-m或--megabytes #以1MB为单位。-s或--summarize #仅显示总计。-S或--separate-dirs #显示个别目录的大小时,并不含其子目录的大小。-x或--one-file-xystem #以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。-X<文件>或--exclude-from=<文件> #在<文件>指定目录或文件。--exclude=<目录或文件> #略过指定的目录或文件。--max-depth=<目录层数> #超过指定层数的目录后,予以忽略。--help #显示帮助。--version #显示版本信息 使用实例查看当前目录使用情况 12345678dominic@hanhan:~/learning-linux$ du56 ./.git/hooks8 ./.git/logs/refs/heads8 ./.git/logs/refs/remotes/origin12 ./.git/logs/refs/remotes24 ./.git/logs/refs32 ./.git/logs8 ./.git/info 以易读的方式查看使用情况 12345678dominic@hanhan:~/learning-linux$ du -h56K ./.git/hooks8.0K ./.git/logs/refs/heads8.0K ./.git/logs/refs/remotes/origin12K ./.git/logs/refs/remotes24K ./.git/logs/refs32K ./.git/logs8.0K ./.git/info 只输出当前目录占用总空间,同上-h命令就是以人读的方式(加上了数据单位) 12dominic@hanhan:~/learning-linux$ du -hs264K . 查看当前目录及其指定深度目录的大小 123不深入子目录,就是当前文件夹所占用大小dominic@hanhan:~/learning-linux$ du -h --max-depth=0264K . 12345678910111213深入一层dominic@hanhan:~/learning-linux$ du -h --max-depth=256K ./.git/hooks32K ./.git/logs8.0K ./.git/info28K ./.git/objects4.0K ./.git/branches28K ./.git/refs180K ./.git24K ./helloworld/c44K ./helloworld/shell72K ./helloworld264K . 忽略helloworld这个文件夹 12345678910111213141516171819dominic@hanhan:~/learning-linux$ du --exclude=helloworld56 ./.git/hooks8 ./.git/logs/refs/heads8 ./.git/logs/refs/remotes/origin12 ./.git/logs/refs/remotes24 ./.git/logs/refs32 ./.git/logs8 ./.git/info4 ./.git/objects/info20 ./.git/objects/pack28 ./.git/objects4 ./.git/branches8 ./.git/refs/heads4 ./.git/refs/tags8 ./.git/refs/remotes/origin12 ./.git/refs/remotes28 ./.git/refs180 ./.git192 . Refernece https://einverne.github.io/post/2018/03/du-find-out-which-fold-take-space.html https://www.runoob.com/linux/linux-comm-du.html","categories":[{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"}]},{"title":"Linux(Ubuntu) 环境下安装 Qt","slug":"Linux-Ubuntu-环境下安装Qt","date":"2021-07-27T08:34:50.000Z","updated":"2022-10-15T03:14:29.271Z","comments":true,"path":"2021/07/27/Linux-Ubuntu-环境下安装Qt/","link":"","permalink":"http://example.com/2021/07/27/Linux-Ubuntu-%E7%8E%AF%E5%A2%83%E4%B8%8B%E5%AE%89%E8%A3%85Qt/","excerpt":"","text":"真蠢,之前费那么大劲,只要一句命令就完事了 下载安装1sudo apt install qtcreator 但是在用命令行构建 project 时可能会报错 12qmake -projectcould not find a Qt installation of '' 这时候需要 1sudo apt-get install qt5-default 好了可以愉快玩耍了。 瞎折腾 下载 Qt从 Qt5.15.0 起,对于开源用户,Qt 官方不再提供独立安装文件,且不再有 bug 修复版本(比如 Qt5.15.1),如果从官网下载,需要自己编译。虽然想试试编译,但是虚拟机刚开始开的空间太小了,还是另寻他法吧。以后有机会再来编译试试新功能。若读者有兴趣可以从官网下载源码并编译。或者参考官方的编译教程,从 GitHub 上下载。 国内有一些镜像站,提供 qt 镜像下载:清华大学:https://mirrors.tuna.tsinghua.edu.cn/qt/archive/qt/中国科学技术大学:http://mirrors.ustc.edu.cn/qtproject/北京理工大学:https://mirrors.cnnic.cn/qt/ 以清华大学的镜像为例,找到archive/qt/5.14/5.14.0/qt-opensource-linux-x64-5.14.0.run,点击即可开始下载。 qt 5.15 已经不提供安装包,想要最新版本,只能下 5.14,但是 5.14.2 下载没资源,下不动,如果遇到下不动的情况换一个版本吧 安装 Qt下载的.run文件双击是无法安装的,因为它还没有可执行的权限,需要我们赋给它执行权限,打开终端进入安装包的目录。 1chmod +x filename.run chmod命令是控制用户对文件的权限修改的命令,x是可执行权限的参数。执行以上命令后就可以直接双击安装了。 网上一些教程可以跳过登录,我没找到跳过按钮,需要注册一个账号才能继续安装。 安装目录一般选择在/opt目录下 安装的附加组件最好都选择,以免后期使用再安装麻烦。Qt Creator 肯定要装的。 安装依赖库12345apt-get install g++apt-get install libgl1-mesa-devapt-get install libqt4-devapt-get install build-essential # Build Essential,它是一个元软件包,可让您在Ubuntu中安装和使用c ++工具。sudo apt install qt5-default # 如果要将Qt 5用作默认的Qt Creator版本需要安装,否则会报 qmake: could not find a Qt installation of ''的错误 使用 Qt Creator 创建第一个程序使用 Qt Creator 创建首先我们先创建一个不带窗口的 HelloWorld 程序,测试安装是否成功,打开 Qt Creator-文件 - 新建文件或项目,选择 Non-Qt Project-Plain C++ Application。接下来就设置项目名等,一直下一步。完成后就可以在编辑器看到如下 点击左下角运行按钮就可以得到如下: 再创建一个带窗口的 HelloWorld,在选择模板时选择 Application-Qt Widgets Application。一路点下一步就可以完成创建,运行后就可得到一个灰白的 HelloWorld 窗口。 命令行编译第一个 Qt 程序首先创建工作目录HelloWorldQt 1mkdir HelloWorld 进入项目目录下,新建一个main.cpp文件 12cd HelloWorldQtvim main.cpp 编辑以下内容: 12345678910111213#include <QApplication>#include <QLabel>#include <QWidget>int main(int argc, char *argv[ ]){ QApplication app(argc, argv); QLabel hello("<center>Welcome to my first Qt program</center>"); hello.setWindowTitle("My First Qt Program"); hello.resize(400, 400); hello.show(); return app.exec();} 建立 QtProject 文件 1qmake -project 用vim打开HelloWorldQt.pro文件,添加以下内容 1QT += gui widgets 运行qmake,使项目 platform-specific,会得到一个Makefile文件 1qmake HelloWorldQt.pro 使用make命令将Makefile编译为可执行程序 123456789101112131415➜ HelloWorldQt makeg++ -c -pipe -O2 -Wall -W -D_REENTRANT -fPIC -DQT_DEPRECATED_WARNINGS / -DQT_NO_DEBUG -DQT_WIDGETS_LIB /-DQT_GUI_LIB -DQT_CORE_LIB -I. / -I. -isystem / /usr/include/x86_64-linux-gnu/qt5 -isystem / /usr/include/x86_64-linux-gnu/qt5/QtWidgets /-isystem /usr/include/x86_64-linux-gnu/qt5/QtGui /-isystem /usr/include/x86_64-linux-gnu/qt5/QtCore -I. /-I/usr/lib/x86_64-linux-gnu/qt5/mkspecs/linux-g++ -o main.o main.cppg++ -Wl,-O1 -o HelloWorldQt main.o //usr/lib/x86_64-linux-gnu/libQt5Widgets.so //usr/lib/x86_64-linux-gnu/libQt5Gui.so / /usr/lib/x86_64-linux-gnu/libQt5Core.so //usr/lib/x86_64-linux-gnu/libGL.so -lpthread 如果一切顺利,执行可以得到如下 1./HelloWorldQt","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"}]},{"title":"QEMU 文档","slug":"QEMU文档","date":"2021-07-27T03:12:01.000Z","updated":"2022-10-15T03:14:29.406Z","comments":true,"path":"2021/07/27/QEMU文档/","link":"","permalink":"http://example.com/2021/07/27/QEMU%E6%96%87%E6%A1%A3/","excerpt":"","text":"调用文档qemu-system-x86_64 [options] [disk_image] disk_image是 IDE 硬盘 0 的原始硬盘映像。某些目标不需要磁盘映像。 标准参数 Standard options-h 功能显示帮助信息并退出 子参数 调用实例 1qemu-system-riscv32 -h -version 功能显示 qemu 版本信息并退出 子参数 调用实例 1qemu-system-riscv32 -version -machine [type=]name[,prop=value[,...]] 功能通过名称选择模拟器。使用 -machine help 可以查看可用的模拟器。对于支持跨版本实时迁移兼容性的架构,每个版本都会引入一个新的版本化模拟器类型。例如,2.8.0 版本为 x86_64/i686 架构引入了“pc-i440fx-2.8”和“pc-q35-2.8”。 子参数为了允许用户从 QEMU 2.8.0 版实时迁移到 QEMU 2.9.0 版,2.9.0 版也必须支持“pc-i440fx-2.8”和“pc-q35-2.8”机器。为了允许用户在升级时实时迁移 VMs 跳过多个中间版本,QEMU 的新版本将支持多个以前版本的机器类型。支持的机器属性有: accel=accels1[:accels2[:...]]This is used to enable an accelerator. Depending on the target architecture, kvm, xen, hax, hvf, nvmm, whpx or tcg can be available. By default, tcg is used. If there is more than one accelerator specified, the next one is used if the previous one fails to initialize. vmport=on|off|autoEnables emulation of VMWare IO port, for vmmouse etc. auto says to select the value based on accel. For accel=xen the default is off otherwise the default is on. dump-guest-core=on|offInclude guest memory in a core dump. The default is on. mem-merge=on|offEnables or disables memory merge support. This feature, when supported by the host, de-duplicates identical memory pages among VMs instances (enabled by default). aes-key-wrap=on|offEnables or disables AES key wrapping support on s390-ccw hosts. This feature controls whether AES wrapping keys will be created to allow execution of AES cryptographic functions. The default is on. dea-key-wrap=on|offEnables or disables DEA key wrapping support on s390-ccw hosts. This feature controls whether DEA wrapping keys will be created to allow execution of DEA cryptographic functions. The default is on. nvdimm=on|offEnables or disables NVDIMM support. The default is off. memory-encryption=Memory encryption object to use. The default is none. hmat=on|offEnables or disables ACPI Heterogeneous Memory Attribute Table (HMAT) support. The default is off. memory-backend='id'An alternative to legacy -mem-path and mem-prealloc options. Allows to use a memory backend as main RAM.For example: :: -object memory-backend-file,id=pc.ram,size=512M,mem-path=/hugetlbfs,prealloc=on,share=on -machine memory-backend=pc.ram -m 512MMigration compatibility note: a) as backend id one shall use value of ‘default-ram-id’, advertised by machine type (available via query-machines QMP command), if migration to/from old QEMU (<5.0) is expected. b) for machine types 4.0 and older, user shall use x-use-canonical-path-for-ramblock-id=off backend option if migration to/from old QEMU (<5.0) is expected. For example: :: -object memory-backend-ram,id=pc.ram,size=512M,x-use-canonical-path-for-ramblock-id=off -machine memory-backend=pc.ram -m 512M 调用实例: 1qemu-system-riscv32 -machine virt,mem-merge=on -cpu model 功能选择 CPU 型号(-cpu help显示帮助列表和附加功能的选项) 默认情况会给客户机提供 qemu64 或 qemu32 的基本 CPU 模型。这样做可以对 CPU 特性提供一些高级的过滤功能,让客户机在同一组硬件平台上的动态迁移会更加平滑和安全。在客户机中查看 CPU 信息 (cat /proc/cpuinfo),model name 就是当前 CPU 模型的名称。 调用实例 1qemu-system-riscv32 -cpu rv32 accel name[,prop=value[,...]] 功能This is used to enable an accelerator. Depending on the target architecture, kvm, xen, hax, hvf, nvmm, whpx or tcg can be available. By default, tcg is used. If there is more than one accelerator specified, the next one is used if the previous one fails to initialize. 子参数 igd-passthru=on|offWhen Xen is in use, this option controls whether Intel integrated graphics devices can be passed through to the guest (default=off) kernel-irqchip=on|off|splitControls KVM in-kernel irqchip support. The default is full acceleration of the interrupt controllers. On x86, split irqchip reduces the kernel attack surface, at a performance cost for non-MSI interrupts. Disabling the in-kernel irqchip completely is not recommended except for debugging purposes. kvm-shadow-mem=sizeDefines the size of the KVM shadow MMU. split-wx=on|offControls the use of split w^x mapping for the TCG code generation buffer. Some operating systems require this to be enabled, and in such a case this will default on. On other operating systems, this will default off, but one may enable this for testing or debugging. tb-size=nControls the size (in MiB) of the TCG translation block cache. thread=single|multiControls number of TCG threads. When the TCG is multi-threaded there will be one thread per vCPU therefore taking advantage of additional host cores. The default is to enable multi-threading where both the back-end and front-ends support it and no incompatible TCG features have been enabled (e.g. icount/replay). dirty-ring-size=nWhen the KVM accelerator is used, it controls the size of the per-vCPU dirty page ring buffer (number of entries for each vCPU). It should be a value that is power of two, and it should be 1024 or bigger (but still less than the maximum value that the kernel supports). 4096 could be a good initial value if you have no idea which is the best. Set this value to 0 to disable the feature. By default, this feature is disabled (dirty-ring-size=0). When enabled, KVM will instead record dirty pages in a bitmap. smp [[cpus=]n][,maxcpus=maxcpus][,sockets=sockets][,dies=dies][,cores=cores][,threads=threads] 功能配置客户机的 SMP(Symmetric Multi-Processing),对称多处理机 子参数 [cpus=]n设置客户机中使用逻辑的 CPU 数量(默认值是 1)。 [,maxcpus=cpus]设置客户机最大可能被使用的 CPU 数量(可以用热插拔 hot-plug 添加 CPU,不能超过 maxcpus 上限)。 [,cores=cores]设置每个 CPU socket 上的 core 数量(默认值是 1)。 [,threads=threads]设置每个 CPU core 上的线程数(默认值是 1)。 [,sockets=sockets]设置客户机中总的 CPU socket 数量。 调用实例 1qemu-system-x86_64 -smp 1,sockets=1,cores=2,threads=2 -numa node[,mem=size][,cpus=firstcpu[-lastcpu]][,nodeid=node][,initiator=initiator]-numa node[,memdev=id][,cpus=firstcpu[-lastcpu]][,nodeid=node][,initiator=initiator]-numa dist,src=source,dst=destination,val=distance-numa cpu,node-id=node[,socket-id=x][,core-id=y][,thread-id=z]-numa hmat-lb,initiator=node,target=node,hierarchy=hierarchy,data-type=tpye[,latency=lat][,bandwidth=bw]-numa hmat-cache,node-id=node,size=size,level=level[,associativity=str][,policy=str][,line=size] 功能 子参数 调用实例 -add-fd fd=fd,set=set[,opaque=opaque] 功能 子参数 调用实例 -set group.id.arg=value 功能 子参数 调用实例 -global driver.prop=value 功能 子参数 调用实例 -global driver=driver,property=property,value=value 功能 子参数 调用实例 -boot [order=drives][,once=drives][,menu=on|off][,splash=sp_name][,splash-time=sp_time][,reboot-timeout=rb_timeout][,strict=on|off] 功能设置客户机启动顺序 在 qemu 模拟的 x86 平台中,用”a”、”b”分别表示第一和第二软驱,用”c”表示第一个硬盘,用”d”表示 CD-ROM 光驱,用”n”表示从网络启动。默认从硬盘启动。 子参数 [order=drives]设置启动顺序。 [,once=drives]只设置下一次启动的顺序,再重启后无效。 [,menu=on|off]只要固件/BIOS 支持,就可以启用交互式引导菜单/提示。默认为非交互式引导。 [,splash=sp_name]如果固件/BIOS 支持选项 splash=sp_name 和 menu=on,则可以将启动画面传递给 bios,使用户能够将其显示为徽标。目前 Seabios for X86 系统支持它。限制:启动文件可以是 24 BPP 格式(真彩色)的 jpeg 文件或 BMP 文件。分辨率应该是 SVGA 模式支持的,推荐 320x240、640x480、800x640。 [,splash-time=sp_time] [,reboot-timeout=rb_timeout]引导失败时,客户机将暂停 rb_timeout 毫秒,然后重新启动。如果 rb_timeout 为 ‘-1’,客户机不会重启,qemu 默认将 ‘-1’ 传递给 bios。目前 Seabios for X86 系统支持它。 [,strict=on|off]只要固件/BIOS 支持,就通过严格启动。这仅在 bootindex 选项更改引导优先级时有效。默认为非严格引导。 调用实例 123456# 尝试先从网络启动,然后从硬盘启动qemu-system-x86_64 -boot order=nc# 先从光驱启动,重启后切换回默认顺序qemu-system-x86_64 -boot once=d# 5 秒钟的启动画面。qemu-system-x86_64 -boot menu=on,splash=/root/boot.bmp,splash-time=5000 -m [size=]megs[,slots=n,maxmem=size] 功能将客户机内存设置为 megs M字节。默认值为 128 MiB。或者,也可以使用“M”或“G”的后缀。齐。 子参数 [size=]megs将客户机内存设置为 megs M字节 [,slots=n,maxmem=size]可用于设置可热插拔内存插槽的数量和最大内存数量。maxmem 必须与页面大小对 调用实例以下命令行将客户机启动 RAM 大小设置为 1GB,创建 3 个插槽以热插拔额外内存,并将客户机可以达到的最大内存设置为 4GB: 1qemu-system-x86_64 -m 1G,slots=3,maxmem=4G 如果未指定 slot 和 maxmem,则不会启用内存热插拔,并且客户机内存永远不会增加。 -mem-path path 功能使用huge page。对于内存访问密集型的应用,使用huge page是可以比较明显地提高客户机性能。 使用huge page的内存不能被换出(swap out),也不能使用ballooning方式自动增长。 子参数 调用实例 -mem-prealloc 功能使宿主机在客户机启动时就全部分配好客户机的内存 子参数 调用实例 -k language 功能设置键盘布局语言,默认为en-us 子参数可用布局: 123ar de-ch es fo fr-ca hu ja mk no pt-br svda en-gb et fr fr-ch is lt nl pl ru thde en-us fi fr-be hr it lv nl-be pt sl tr 调用实例 块设备参数 Block device optionsfda file 功能为客户机指定软盘设备,指定客户机的第一个软盘设备,在客户机中显示为/dev/fd0 子参数 调用实例 fdb file 功能为客户机指定软盘设备,指定客户机的第一个软盘设备,在客户机中显示为/dev/fd1 子参数 调用实例 hda filehdb filehdc filehdd file 功能为客户机指定块存储设备,指定客户机种的第一个 IDE 设备 子参数若客户机使用PIIX_IDE驱动,显示为/dev/hda设备;若客户机使用ata_piix驱动,显示为/dev/sda设备。若没有使用-hdx的参数,则默认使用-hda参数;可以将宿主机的一块硬盘作为-hda的参数使用;若文件名包含逗号,应使用两个连续的逗号进行转义。 调用实例 -cdrom file 功能为客户机指定光盘 CD-ROM。可以将宿主机的光驱/dev/cdrom设备作为-cdrom参数使用。-cdrom参数不能与-hdc参数同时使用,因为-cdrom就是客户机里的第三个 IDE 设备 子参数 调用实例 -blockdev option[,option[,option[,...]]] 功能 子参数 调用实例 -drive option[,option[,option[,...]]] 功能定义一个存储驱动器 子参数 [file=file]加载file镜像文件到客户机的驱动器中。 [,if=type]指定驱动器使用的接口类型:可用的类类型有:ide、scsi、virtio、sd、floopy、pflash等。 [,bus=n]设置驱动器在客户机中的总线编号。 [,unit=m]设置驱动器在客户机中的单元编号。 [,media=d]设置驱动器中媒介的类型,值为 disk 或 cdrom。 [,index=i]设置在通一种接口的驱动器中的索引编号。 [,snapshot=on|off]当值为 on 时,qemu 不会将磁盘数据的更改写回到镜像文件中,而是写到临时文件中,可以在 qemu moinitor 中使用 commit 命令强制将磁盘数据保存回镜像文件中。 [,cache=writethrough|writeback|none|directsync|unsafe]设置宿主机对块设备数据访问的 cache 模式。,writethrough(直写模式):调用 write 写入数据的同时将数据写入磁盘缓存和后端块设备中。writeback(回写模式):调用 write 写入数据时只将数据写入到磁盘缓存中,当数据被换出缓存时才写入到后端存储中。优点写入数据块,缺点系统掉电数据无法恢复。 [,aio=threads|native]选择异步 IO 的方式 threads为 aio 参数的默认值,让一个线程池去处理异步 IO; native只适用于 cache=none 的情况,使用的是 Linux 原生的 AIO。 [,format=f]指定使用的磁盘格式,默认是 QEMU 自动检测磁盘格式的。 [,serial=s]指定分配给设备的序列号。 [,addr=A]分配给驱动器控制器的 PCI 地址,只在使用 virtio 接口时适用。 [,id=name]设置驱动器的 ID,可以在 QEMU monitor 中用 info block 看到。[,readonly=on|off]设置驱动器是否只读。 调用实例 USB 参数 USB convenience options显示参数 Display options仅限 i386 架构的参数 i386 target only网络参数 Network options字符设备参数 Character device optionsTPM 设备 TPM device options指定启动指引 Linux/Multiboot boot specific当使用该调用参数时,你可以使用给定的 Linux 或者多重引导内核,而不需要安装内核到一个光盘中。这样可以更方便地测试不同内核。 -kernel bzImage 功能用 bzImage 作为内核镜像,也可以使用其他启动格式。 -append cmdline 功能用cmd命令行,作为内核的命令行 -initrd file 功能用文件作为初始化 ram -initrd "file1 arg=foo,file2" 功能此语法仅适用于多重引导使用 file1 和 file2 作为模块并将 arg=foo 作为参数传递给第一个模块 -dtb file 功能将文件用作设备树二进制 (dtb) 映像并在启动时将其传递给内核","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"QEMU","slug":"QEMU","permalink":"http://example.com/tags/QEMU/"}]},{"title":"Git 踩坑记录","slug":"git踩坑记录","date":"2021-07-23T03:55:57.000Z","updated":"2022-10-15T03:14:29.241Z","comments":true,"path":"2021/07/23/git踩坑记录/","link":"","permalink":"http://example.com/2021/07/23/git%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/","excerpt":"","text":"创建仓库时没有加入 gitignore 文件,上传了不需要的文件,后添加了 gitignore 文件如何同步远程与本地的文件(自动删除不需要的文件)1234567# 注意有个点“.”取消版本控制git rm -r --cached .重新添加git add -A重新提交git commit -m "update .gitignore" Git rm 和 rm –cached 区别rm :当需要删除暂存区或分支上的文件,同时工作区不需要这个文件 rm --cached:当需要删除暂存区或分支上的文件,同时工作区需要这个文件,但是不需要被版本控制。就是本地需要保留,但是远程不保留 推送空文件夹到远程仓库在需要推送的空文件下创建”.gitkeep”文件在”.gitignore”文件中编写规则!.gitkeep 克隆指定分支代码1git clone -b master https://github.com/Dunky-Z/Dunky-Z.github.io.git master就是分支名","categories":[{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"}],"tags":[{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"}]},{"title":"QEMU 初识","slug":"QEMU初识","date":"2021-07-23T03:54:49.000Z","updated":"2022-10-15T03:14:29.378Z","comments":true,"path":"2021/07/23/QEMU初识/","link":"","permalink":"http://example.com/2021/07/23/QEMU%E5%88%9D%E8%AF%86/","excerpt":"","text":"简介QEMU 是一款开源的模拟器及虚拟机监管器 (Virtual Machine Monitor, VMM)。QEMU 主要提供两种功能给用户使用。一是作为用户态模拟器,利用动态代码翻译机制来执行不同于主机架构的代码。二是作为虚拟机监管器,模拟全系统,利用其他 VMM(Xen, KVM, etc) 来使用硬件提供的虚拟化支持,创建接近于主机性能的虚拟机。 安装使用包管理安装1sudo apt-get install qemu 使用源码安装123wget wget https://download.qemu.org/qemu-6.1.0-rc3.tar.xztar xvJf qemu-6.1.0-rc3.tar.xzcd qemu-6.1.0-rc3 安装相关库12345apt-get install libglib2.0-devapt-get install ninja-buildapt install g++apt install libpixman-1-devapt install libsdl2-dev -y 配置通过./configure --help 的查看编译时的选项,--target-list选项为可选的模拟器,默认全选。--target-list 中的 xxx-soft 和 xxx-linux-user 分别指系统模拟器和应用程序模拟器,生成的二进制文件名字为qemu-system-xxx和 qemu-xxx本文使用如下配置: 1234./configure --prefix=XXX --enable-debug --target-list=riscv32-softmmu,riscv32-linux-user,riscv64-linux-user,riscv64-softmmu --enable-kvm# --prefix 选项设置qemu的安装位置绝对路径,之后若要卸载删除qemu只要删除该文件夹即可,--enable-kvm开启kvm# config完,可以在指定的qemu安装文件夹下面找到config-host.mak文件,# 该文件记录着qemu配置的选项,可以和自己设置的进行对比,确保配置和自己已知 接着进行编译 1make -j8 直接make会很慢,第一次编译时默认安装说有模拟器,编译了三四个小时。加上-j8可以进行多线程编译 创建与使用创建虚拟镜像使用虚拟镜像来模拟虚拟机的硬盘,在启动虚拟机之前需要创建一个镜像文件 1234root@hanhan:/home/dominic/qemu/# qemu-img create -f qcow2 qmtest.img 10GFormatting 'qmtest.img', fmt=qcow2 size=10737418240 encryption=off cluster_size=65536 lazy_refcounts=off root@hanhan:/home/dominic/qemu/# lsqmtest.img -f选项用于指定镜像的格式,qcow2格式是 QEMU 最常用的镜像格式,采用写时复制技术来优化性能。qmtest.img是镜像文件的名字,10G是镜像文件大小。 镜像文件创建完成后,可使用qemu-system-x86来启动x86架构的虚拟机: 1qemu-system-x86_64 qmtest.img qmtest.img 中还未安装操作系统,所以会提示“No bootable device”的错误。 准备操作系统镜像下载需要的 Linux 发行版镜像文件,https://launchpad.net/ubuntu/+cdmirrors,找到想要下载的镜像,这里以交通大学的镜像为例右击链接复制地址:https://ftp.sjtu.edu.cn/ubuntu-cd/20.10/ubuntu-20.10-live-server-amd64.iso 1root@hanhan:/home/dominic/qemu/# wget https://ftp.sjtu.edu.cn/ubuntu-cd/20.10/ubuntu-20.10-live-server-amd64.iso 检查 KVM 是否可用QEMU 使用 KVM 来提升虚拟机性能,如果不启用 KVM 会导致性能损失。要使用 KVM,首先要检查硬件是否有虚拟化支持: 1root@hanhan:/home/dominic/qemu/# grep -E 'vmx|svm' /proc/cpuinfo 如果有输出则表示硬件有虚拟化支持。其次要检查 kvm 模块是否已经加载: 123root@hanhan:/home/dominic/qemu/# lsmod | grep kvmkvm_intel 142999 0 kvm 444314 1 kvm_intel 如果kvm_intel/kvm_amd、kvm模块被显示出来,则kvm模块已经加载。最后要确保 qemu 在编译的时候使能了KVM,即在执行configure脚本的时候加入了–enable-kvm选项。 启动虚拟机安装操作系统1root@hanhan:/home/dominic/qemu/# qemu-system-x86_64 -m 2048 -enable-kvm qmtest.img -cdrom ./Fedora-Live-Desktop-x86_64-20-1.iso -m指定虚拟机内存大小,默认单位是 MB,-enable-kvm使用 KVM 进行加速,-cdrom添加 fedora 的安装镜像。可在弹出的窗口中操作虚拟机,安装操作系统,安装完成后重起虚拟机便会从硬盘 (qmtest.img) 启动。之后再启动虚拟机只需要执行: 1root@hanhan:/home/dominic/qemu/# qemu-system-x86_64 -m 2048 -enable-kvm qmtest.img 退出 qemu在运行 qemu 后,关闭图形界面但是终端仍然是处于 qemu 环境中,可以直接关闭终端退出。如果不想关闭终端,可以另外打开一个终端 kill 进程 1killall qemu-system-riscv32 如果记不清全称,可以输入大概名称回车后会列出相关的进程","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"QEMU","slug":"QEMU","permalink":"http://example.com/tags/QEMU/"}]},{"title":"什么是驱动,驱动的作用又是什么?","slug":"什么是驱动,驱动的作用又是什么?","date":"2021-07-21T07:02:58.000Z","updated":"2022-10-15T02:59:01.706Z","comments":true,"path":"2021/07/21/什么是驱动,驱动的作用又是什么?/","link":"","permalink":"http://example.com/2021/07/21/%E4%BB%80%E4%B9%88%E6%98%AF%E9%A9%B1%E5%8A%A8%EF%BC%8C%E9%A9%B1%E5%8A%A8%E7%9A%84%E4%BD%9C%E7%94%A8%E5%8F%88%E6%98%AF%E4%BB%80%E4%B9%88%EF%BC%9F/","excerpt":"","text":"任何一个计算机系统的运行都是系统中软硬件协作的结果,没有硬件的软件是空中楼阁,而没有软件的硬件则只是一堆废铁。–天朗 - 星空 硬件是底层基础,所有软件代码的运行平台,相对固定不易改变,而软件是具体的应用,它灵活多变,可以应对用户的不同需求。 为尽可能快速地完成设计,应用软件工程师不想也不必关心硬件,而硬件工程师也难有足够的闲暇和能力来顾忌软件。譬如,应用软件工程师在调用套接字发送和接收数据包的时候,不必关心网卡上的寄存器、存储空间、I/O 端口、片选以及其他任何硬件层面的操作调度;在使用printf()函数输出信息的时候,他不用知道底层究竟是怎样把相应的信息输出到屏幕或者串口的具体硬件过程,需要的只是出现相应的显示效果。 也就是说,应用软件工程师需要看到一个没有硬件的纯粹的软件世界,硬件必须被透明地呈现给他们。谁来实现硬件对应用软件工程师的隐形?这个艰巨的任务就落在了驱动工程师的头上。 对设备驱动最通俗的解释就是“驱使硬件设备行动” 。设备驱动与底层硬件直接打交道,按照硬件设备的具体工作方式读写设备寄存器,完成设备的轮询、中断处理、DMA 通信,进行物理内存向虚拟内存的映射,最终使通信设备能够收发数据,使显示设备能够显示文字和画面,使存储设备能够记录文件和数据。","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Driver","slug":"Driver","permalink":"http://example.com/tags/Driver/"}]},{"title":"Hexo 搭建 GitHub 博客如何添加 README 文件","slug":"Hexo搭建GitHub博客如何添加README文件","date":"2021-07-21T04:14:46.000Z","updated":"2022-10-15T03:14:29.254Z","comments":true,"path":"2021/07/21/Hexo搭建GitHub博客如何添加README文件/","link":"","permalink":"http://example.com/2021/07/21/Hexo%E6%90%AD%E5%BB%BAGitHub%E5%8D%9A%E5%AE%A2%E5%A6%82%E4%BD%95%E6%B7%BB%E5%8A%A0README%E6%96%87%E4%BB%B6/","excerpt":"","text":"刚开始搭建的时候并没有为仓库添加 Readme 文件,但是后期添加也不能直接在仓库里直接添加,因为每次部署都会被自动删除。添加方法: 在博客根目录的source文件夹下新建README.md文件 在根目录的_config.yml文件中搜索skip_render,并做如下更改 1skip_render: README.md 因为在每次hexo g时候,README 文件都会被自动渲染为 HTML 文件,所以在配置文件中告诉渲染器跳过这个文件不要渲染它。","categories":[],"tags":[{"name":"HEXO","slug":"HEXO","permalink":"http://example.com/tags/HEXO/"}]},{"title":"QEMU 学习记录","slug":"QEMU学习记录","date":"2021-07-20T08:51:34.000Z","updated":"2022-10-15T03:14:29.386Z","comments":true,"path":"2021/07/20/QEMU学习记录/","link":"","permalink":"http://example.com/2021/07/20/QEMU%E5%AD%A6%E4%B9%A0%E8%AE%B0%E5%BD%95/","excerpt":"","text":"QEMU 学习记录什么是 KVM?基于内核的虚拟机 Kernel-based Virtual Machine(KVM)是一种内建于 Linux 中的开源虚拟化技术。具体而言,KVM 可帮助用户将 Linux 转变为虚拟机监控程序,使主机计算机能够运行多个隔离的虚拟环境,即虚拟客户机或虚拟机(VM)。 什么是 QEMU?Qemu 是一个完整的可以单独运行的软件,它可以用来模拟不同架构的机器,非常灵活和可移植。它主要通过一个特殊的’重编译器’将为特定处理器编写二进制代码转换为另一种。 KVM 与 QEMU 的关系KVM 是 Linux 的一个模块。可以用modprobe去加载 KVM 模块。加载了模块后,才能进一步通过其他工具创建虚拟机。但仅有 KVM 模块是 远远不够的,因为用户无法直接控制内核模块去作事情:还必须有一个用户空间的工具才行。这个用户空间的工具,开发者选择了已经成型的开源虚拟化软件 QEMU。KVM 使用了 QEMU 的一部分,并稍加改造,就成了可控制 KVM 的用户空间工具了。所以你会看到,官方提供的 KVM 下载有两 大部分三个文件,分别是 KVM 模块、QEMU 工具以及二者的合集。也就是说,你可以只升级 KVM 模块,也可以只升级 QEMU 工具。 QEMU 用户模式与系统模式QEMU 属于应用层的仿真程序,它支持两种操作模式:用户模式模拟和系统模式模拟。 用户模式仿真 利用动态代码翻译机制,可以在当前 CPU 上执行被编译为支持其他 CPU 的程序,如可以在 x86 机器上执行一个 ARM 二进制可执行程序。(执行主机 CPU 指令的动态翻译并相应地转换 Linux 系统调用)。 系统模式仿真 利用其它 VMM(Xen, KVM) 来使用硬件提供的虚拟化支持,创建接近于主机性能的全功能虚拟机,包括处理器和配套的外围设备(磁盘,以太网等)。 用户模式支持的 CPU:x86 (32 and 64 bit), PowerPC (32 and 64 bit), ARM, MIPS (32 bit only), Sparc (32 and 64 bit), Alpha, ColdFire(m68k), CRISv32 和 MicroBlaze下列操作系统支持 QEMU 的用户模式模拟: Linux (referred as qemu-linux-user) BSD (referred as qemu-bsd-user) 调用(具体参数含义) 1qemu-i386 [-h] [-d] [-L path] [-s size] [-cpu model] [-g port] [-B offset] [-R size] program [arguments...] 用户模式模拟环境下运行速度要比系统模式模拟环境下快,但并不是完美模拟,比如程序读取/proc/cpuinfo内容时,由主机内核返回,因此返回的信息是描述主机 CPU 的,而不是模拟的 CPU。 系统模式首先创建虚拟镜像,模拟硬盘空间: 1234root@hanhan:/home/dominic/qemu/# qemu-img create -f qcow2 qmtest.img 10GFormatting 'qmtest.img', fmt=qcow2 size=10737418240 encryption=off cluster_size=65536 lazy_refcounts=off root@hanhan:/home/dominic/qemu/# lsqmtest.img -f选项用于指定镜像的格式,qcow2格式是 QEMU 最常用的镜像格式,采用写时复制技术来优化性能。qmtest.img是镜像文件的名字,10G是镜像文件大小。 镜像文件创建完成后,可使用qemu-system-x86来启动x86架构的虚拟机: 1qemu-system-x86_64 qmtest.img qmtest.img 中还未安装操作系统,所以会提示“No bootable device”的错误。 其次,准备操作系统镜像下载需要的 Linux 发行版镜像文件,https://launchpad.net/ubuntu/+cdmirrors,找到想要下载的镜像,这里以交通大学的镜像为例右击链接复制地址:https://ftp.sjtu.edu.cn/ubuntu-cd/20.10/ubuntu-20.10-live-server-amd64.iso 1root@hanhan:/home/dominic/qemu/# wget https://ftp.sjtu.edu.cn/ubuntu-cd/20.10/ubuntu-20.10-live-server-amd64.iso 最后,启动虚拟机安装操作系统 1root@hanhan:/home/dominic/qemu/# qemu-system-x86_64 -m 2048 -enable-kvm qmtest.img -cdrom ./Fedora-Live-Desktop-x86_64-20-1.iso -m指定虚拟机内存大小,默认单位是 MB,-enable-kvm使用 KVM 进行加速,-cdrom添加 fedora 的安装镜像。 该模式下,要比用户模式模拟慢得多,因为模拟了目标内核,以及设备输入/输出、中断等。 QEMU 工作原理单纯使用 qemu,采用的是完全虚拟化的模式。qemu 向 Guest OS 模拟 CPU,也模拟其他的硬件,GuestOS 认为自己和硬件直接打交道,其实是同 qemu 模拟出来的硬件打交道,qemu 会将这些指令转译给真正的硬件。由于所有的指令都要从 qemu 里面过一手,因而性能就会比较差。 完全虚拟化是非常慢的,所以要使用硬件辅助虚拟化技术 Intel-VT,AMD-V,所以需要 CPU 硬件开启这个标志位,一般在 BIOS 里面设置。当确认开始了标志位之后,通过KVM,GuestOS 的 CPU 指令不用经过 Qemu 转译,直接运行,大大提高了速度。所以,KVM 在内核里面需要有一个模块,来设置当前 CPU 是 Guest OS 在用,还是 Host OS 在用。 可以通过如下命令查看内核模块中是否有 KVM 1lsmod | grep kvm KVM 内核模块通过 /dev/kvm 暴露接口,用户态程序可以通过 ioctl来访问这个接口。Qemu 将 KVM 整合进来,将有关 CPU 指令的部分交由内核模块来做,就是 qemu-kvm (qemu-system-XXX)。 qemu 和 kvm 整合之后,CPU 的性能问题解决了。另外 Qemu 还会模拟其他的硬件,如网络和硬盘。同样,全虚拟化的方式也会影响这些设备的性能。 于是,qemu 采取半虚拟化的方式,让 Guest OS 加载特殊的驱动来做这件事情。 例如,网络需要加载 virtio_net,存储需要加载 virtio_blk,Guest 需要安装这些半虚拟化驱动,GuestOS 知道自己是虚拟机,所以数据会直接发送给半虚拟化设备,经过特殊处理(例如排队、缓存、批量处理等性能优化方式),最终发送给真正的硬件。这在一定程度上提高了性能。 Q : 系统模式和用户模式的区别?系统模式 是 qemu 虚拟出一套完整的硬件环境,包含 CPU,内存,网卡,硬盘,对于虚拟机上运行的 OS 看到的和硬件和真实的是一样的。用户模式是直接将可执行的文件进行指令翻译,只虚拟出 CPU。假设有 KVM:host 是 x86,QEMU 虚拟出 x86 的系统模式 运行 Windows 系统。QEMU 会将 Windows 指令直接交给 host CPU 直接运行(这个功能是由 KVM 实现的,相当于直接调用 host CPU),性能损失小。内存,硬盘,网络等外设是由 qemu 虚拟出来的。假设无 KVM:host 是 x86,QEMU 虚拟出 x86 的系统模式运行 Windows 系统。QEMU 会将 Windows 指令翻译成中间码,中间码再转成 host CPU 指令(这个功能是由 qemu TCG 实现的),性能损失大。内存,硬盘,网洛等外设是由 qemu 虚拟出来的。假设有 KVM:host 是 x86,QEMU 虚拟出 RISC-V 的系统模式 运行 Linux 系统。QEMU 会将 Linux 指令翻译成中间码,中间码再转成 host CPU 指令(这个功能是由 qemu TCG 实现的),性能损失大。内存,硬盘,网洛等外设是由 qemu 虚拟出来的。KVM 需要在虚拟机与宿主机架构相同时才生效。此外,用户模式下调用 IO 硬件会报错。qemu 系统模式下会模拟出所有设备,但是模拟的 IO 设备效率低,所以后来有了半虚拟化。","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"QEMU","slug":"QEMU","permalink":"http://example.com/tags/QEMU/"}]},{"title":"ZH-Unix 是什么,为什么重要?","slug":"ZH-Unix是什么,为什么重要?","date":"2021-07-20T07:44:05.000Z","updated":"2022-10-15T03:14:29.629Z","comments":true,"path":"2021/07/20/ZH-Unix是什么,为什么重要?/","link":"","permalink":"http://example.com/2021/07/20/ZH-Unix%E6%98%AF%E4%BB%80%E4%B9%88%EF%BC%8C%E4%B8%BA%E4%BB%80%E4%B9%88%E9%87%8D%E8%A6%81%EF%BC%9F/","excerpt":"","text":"Unix 是什么,为什么重要? Author:CHRIS HOFFMAN译:What Is Unix, and Why Does It Matter? 大多数操作系统都可以分为两大类。除了微软基于 Windows NT 的操作系统之外,几乎所有其他系统的祖宗都是 Unix。 Linux、Mac OS X、Android、iOS、Chrome OS、PlayStation 4 上使用的 Orbis 操作系统,无论路由器上运行的是什么固件——所有这些操作系统通常都被称为“类 Unix”操作系统。 Unix 的设计延续至今19 世纪中后期 Unix 在贝尔实验室中被开发出来。最初版的 Unix 有许多重要的设计特性至今仍然在使用。 “Unix 哲学”之一就是,创建小型、模块化的程序,一个程序只做一件事并把它做好。如果你经常使用 Linux 终端,那么你应该对此很熟悉——系统提供了许多实用程序,这些程序可以通过管道和其他功能以不同方式组合以执行更复杂的任务。甚至图形程序也可能在后台调用更简单的实用程序来完成复杂的工作。这也使得创建 shell 脚本变得容易,将简单的工具串在一起来完成复杂的事情。 Unix 有一个程序之间通信用的单一文件系统。这就是为什么在 Linux 上“一切都是文件” ——包括硬件设备和提供系统信息或其他数据的特殊文件。这也是为什么只有 Windows 有驱动器号(C、D、E 盘)的原因,它是从 DOS 继承的——在其他操作系统上,系统上的每个文件都是单个目录层次结构的一部分。 追寻 Unix 的后代Unix 及其后代的历史错综复杂,简化起见,我们大致将 Unix 的后代分为两类。 一类 Unix 后代是在学术界发展起来的。第一个是 BSD(BerkeleySoftwareDistribution),一个开源、类 Unix 操作系统。BSD 通过 FreeBSD、NetBSD 和 OpenBSD 延续至今。NeXTStep 也是基于最初的 BSD 开发的,Apple 的 Mac OS X 是基于 NeXTStep 开发出来的,而 iOS 则基于 Mac OS X。还有一些操作系统,包括 PlayStation 4 上使用的 Orbis OS,都是从 BSD 操作系统衍生而来的。 Richard Stallman 的 GNU 项目也是为了应对 AT&T 日益严格的 Unix 软件许可条款而启动的。MINIX 是一个为教育目的而创建的类 Unix 操作系统,Linux 的灵感来自于 MINIX。我们今天所知道的 Linux 实际上是 GNU/Linux,因为它由 Linux 内核和许多 GNU 实用程序组成。GNU/Linux 并非直接继承自 BSD,但它继承了 Unix 的设计并植根于学术界。当今的许多操作系统,包括 Android、ChromeOS、SteamOS 以及大量设备的嵌入式操作系统,都基于 Linux。 另一类就是商业 Unix 操作系统。AT&T UNIX、SCO UnixWare、Sun Microsystems Solaris、HP-UX、IBM AIX、SGI IRIX——许多大公司想要创建他们自己的 Unix 版本。这些在今天并不常见,但其中一些仍然存在。 DOS 和 Windows NT 的崛起许多人期望 Unix 成为行业标准操作系统,但 DOS 系统和“IBM PC 兼容”的计算机最终流行起来。Microsoft 的 DOS 成为其中最成功的 DOS 系统。DOS 系统完全不同于 Unix,这就是为什么 Windows 使用反斜杠作为文件路径,而其他一切都使用正斜杠。这个决定是在 DOS 系统早期做出的,后来的 Windows 版本继承了它,就像 BSD、Linux、Mac OS X 和其他类 Unix 操作系统继承了许多 Unix 的设计一样。 Windows 3.1、Windows 95、Windows 98 和 Windows ME 都基于底层的 DOS。当时,微软正在开发一种更现代、更稳定的操作系统,他们将其命名为 Windows NT——即“Windows New Technology”。Windows NT 最终以 Windows XP 的形式出现在普通用户的计算机中,但在此之前,它以 Windows 2000 和 Windows NT 的形式供公司使用。 今天,微软的所有操作系统都基于 Windows NT 内核。Windows 7、Windows 8、Windows RT、Windows Phone 8、Windows Server 和 Xbox One 的操作系统都使用 Windows NT 内核。与大多数其他操作系统不同,Windows NT 并不是作为类 Unix 操作系统开发的。 当然,微软并不是完全重新开始。为了保持与 DOS 和旧的 Windows 软件的兼容性,Windows NT 继承了许多 DOS 约定,如驱动器号、文件路径的反斜杠和命令行的正斜杠。 “在绝大多数地方,用的都是/(slash),包括 Mac/Linux,也包括 URL。你唯一需要记住的是,Microsoft 这个怪鸡在自己的操作系统里面偏要用\\(backslash),使得自己与众不同。在 Windows 中,正斜杠/表示除法,用来进行整除运算;反斜杠\\用来表示目录。在 Unix 系统中,/表示目录;\\表示跳脱字符将特殊字符变成一般字符Windows由于使用斜杠/作为DOS命令提示符的参数标志了,为了不混淆,所以采用反斜杠\\作为路径分隔符。所以目前windows系统上的文件浏览器都是用反斜杠\\作为路径分隔符。 为什么重要?你是否曾经看过 Mac OS X 终端或文件系统,并注意到它与 Linux 的相似之处,以及它们与 Windows 的不同之处?嗯,这就是为什么——Mac OSX 和 Linux 都是类 Unix 操作系统。 了解这段历史有助于您了解什么是“类 Unix”操作系统,以及为什么这么多操作系统看起来彼此如此相似而 Windows 似乎如此不同。这解释了为什么 Linux 极客会觉得 Mac OS X 上的终端如此熟悉,而 Windows 上的命令提示符和 PowerShell 与其他命令行环境如此不同。 这只是一个简短的历史,它将帮助您了解我们如何到达今天的位置,而不会陷入细节中。如果您想了解更多信息,可以找到有关 Unix 历史的整本书。","categories":[],"tags":[{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"Translation","slug":"Translation","permalink":"http://example.com/tags/Translation/"},{"name":"Unix","slug":"Unix","permalink":"http://example.com/tags/Unix/"}]},{"title":"Hexo 实时更新预览","slug":"Hexo实时更新预览","date":"2021-07-20T06:32:12.000Z","updated":"2022-10-15T03:14:29.252Z","comments":true,"path":"2021/07/20/Hexo实时更新预览/","link":"","permalink":"http://example.com/2021/07/20/Hexo%E5%AE%9E%E6%97%B6%E6%9B%B4%E6%96%B0%E9%A2%84%E8%A7%88/","excerpt":"","text":"在项目目录下安装 hexo-browsersync 插件 1npm install hexo-browsersync --save hexo s启动服务后,每次保存 Markdown 文件都会实时更新页面。","categories":[],"tags":[{"name":"HEXO","slug":"HEXO","permalink":"http://example.com/tags/HEXO/"}]},{"title":"Hexo 和 GitHub 搭建博客以及更换电脑同步博客","slug":"Hexo和GitHub搭建博客以及更换电脑同步博客","date":"2021-07-20T04:04:37.000Z","updated":"2022-10-15T03:16:50.608Z","comments":true,"path":"2021/07/20/Hexo和GitHub搭建博客以及更换电脑同步博客/","link":"","permalink":"http://example.com/2021/07/20/Hexo%E5%92%8CGitHub%E6%90%AD%E5%BB%BA%E5%8D%9A%E5%AE%A2%E4%BB%A5%E5%8F%8A%E6%9B%B4%E6%8D%A2%E7%94%B5%E8%84%91%E5%90%8C%E6%AD%A5%E5%8D%9A%E5%AE%A2/","excerpt":"","text":"只要有source文件夹下所有源文件就可以重新部署,按照正常的搭建 Hexo 环境开始搭建,搭建好以后将source文件夹替换即可,需要应用主题就下载主题然后替换。 注意: 主题更换需要更改_config_yml文件 _config_yml文件中的部署配置,branch:master就是每次hexo d操作推送的分支。而在命令行每次git push推送的分支是设置的默认分支hexo 1234deploy: type: git repository: https://github.com/Dunky-Z/Dunky-Z.github.io.git branch: master 利用 Hexo 在多台电脑上提交和更新 GitHub pages 博客","categories":[],"tags":[{"name":"HEXO","slug":"HEXO","permalink":"http://example.com/tags/HEXO/"}]},{"title":"HelloWorld","slug":"HelloWorld","date":"2020-08-23T01:09:13.000Z","updated":"2022-10-15T03:14:29.243Z","comments":true,"path":"2020/08/23/HelloWorld/","link":"","permalink":"http://example.com/2020/08/23/HelloWorld/","excerpt":"","text":"这是博客的第一篇文章","categories":[],"tags":[]}],"categories":[{"name":"工欲善其事必先利其器","slug":"工欲善其事必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"},{"name":"OpenStack","slug":"OpenStack","permalink":"http://example.com/categories/OpenStack/"},{"name":"Bug 踩坑记录","slug":"Bug-踩坑记录","permalink":"http://example.com/categories/Bug-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/"},{"name":"工欲善其事,必先利其器","slug":"工欲善其事,必先利其器","permalink":"http://example.com/categories/%E5%B7%A5%E6%AC%B2%E5%96%84%E5%85%B6%E4%BA%8B%EF%BC%8C%E5%BF%85%E5%85%88%E5%88%A9%E5%85%B6%E5%99%A8/"},{"name":"JAVA 开发","slug":"JAVA-开发","permalink":"http://example.com/categories/JAVA-%E5%BC%80%E5%8F%91/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/categories/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"},{"name":"Git 实战","slug":"Git-实战","permalink":"http://example.com/categories/Git-%E5%AE%9E%E6%88%98/"},{"name":"QEMU 源码分析","slug":"QEMU-源码分析","permalink":"http://example.com/categories/QEMU-%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/"},{"name":"RISC-V 入门","slug":"RISC-V-入门","permalink":"http://example.com/categories/RISC-V-%E5%85%A5%E9%97%A8/"},{"name":"万能 VSCode","slug":"万能-VSCode","permalink":"http://example.com/categories/%E4%B8%87%E8%83%BD-VSCode/"},{"name":"LaTeX","slug":"LaTeX","permalink":"http://example.com/categories/LaTeX/"},{"name":"CSAPP-Lab","slug":"CSAPP-Lab","permalink":"http://example.com/categories/CSAPP-Lab/"},{"name":"通信协议","slug":"通信协议","permalink":"http://example.com/categories/%E9%80%9A%E4%BF%A1%E5%8D%8F%E8%AE%AE/"},{"name":"计算机组成原理","slug":"计算机组成原理","permalink":"http://example.com/categories/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86/"},{"name":"读书笔记","slug":"读书笔记","permalink":"http://example.com/categories/%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0/"},{"name":"嵌入式开发","slug":"嵌入式开发","permalink":"http://example.com/categories/%E5%B5%8C%E5%85%A5%E5%BC%8F%E5%BC%80%E5%8F%91/"},{"name":"Linux 操作系统","slug":"Linux-操作系统","permalink":"http://example.com/categories/Linux-%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/"}],"tags":[{"name":"Linux, 网络配置","slug":"Linux-网络配置","permalink":"http://example.com/tags/Linux-%E7%BD%91%E7%BB%9C%E9%85%8D%E7%BD%AE/"},{"name":"QEMU,虚拟机,网络配置","slug":"QEMU,虚拟机,网络配置","permalink":"http://example.com/tags/QEMU%EF%BC%8C%E8%99%9A%E6%8B%9F%E6%9C%BA%EF%BC%8C%E7%BD%91%E7%BB%9C%E9%85%8D%E7%BD%AE/"},{"name":"工具推荐","slug":"工具推荐","permalink":"http://example.com/tags/%E5%B7%A5%E5%85%B7%E6%8E%A8%E8%8D%90/"},{"name":"QEMU","slug":"QEMU","permalink":"http://example.com/tags/QEMU/"},{"name":"RISC-V","slug":"RISC-V","permalink":"http://example.com/tags/RISC-V/"},{"name":"OpenEuler","slug":"OpenEuler","permalink":"http://example.com/tags/OpenEuler/"},{"name":"Linux","slug":"Linux","permalink":"http://example.com/tags/Linux/"},{"name":"OpenStack","slug":"OpenStack","permalink":"http://example.com/tags/OpenStack/"},{"name":"Bug","slug":"Bug","permalink":"http://example.com/tags/Bug/"},{"name":"计算机网络","slug":"计算机网络","permalink":"http://example.com/tags/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/"},{"name":"云计算","slug":"云计算","permalink":"http://example.com/tags/%E4%BA%91%E8%AE%A1%E7%AE%97/"},{"name":"OpenStack,云计算,Devstack","slug":"OpenStack,云计算,Devstack","permalink":"http://example.com/tags/OpenStack%EF%BC%8C%E4%BA%91%E8%AE%A1%E7%AE%97%EF%BC%8CDevstack/"},{"name":"VSCode","slug":"VSCode","permalink":"http://example.com/tags/VSCode/"},{"name":"后端开发","slug":"后端开发","permalink":"http://example.com/tags/%E5%90%8E%E7%AB%AF%E5%BC%80%E5%8F%91/"},{"name":"WSL2","slug":"WSL2","permalink":"http://example.com/tags/WSL2/"},{"name":"Docker","slug":"Docker","permalink":"http://example.com/tags/Docker/"},{"name":"JAVA","slug":"JAVA","permalink":"http://example.com/tags/JAVA/"},{"name":"安装教程","slug":"安装教程","permalink":"http://example.com/tags/%E5%AE%89%E8%A3%85%E6%95%99%E7%A8%8B/"},{"name":"每天学命令","slug":"每天学命令","permalink":"http://example.com/tags/%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"},{"name":"Git","slug":"Git","permalink":"http://example.com/tags/Git/"},{"name":"CodeReview","slug":"CodeReview","permalink":"http://example.com/tags/CodeReview/"},{"name":"Office","slug":"Office","permalink":"http://example.com/tags/Office/"},{"name":"OpenSBI","slug":"OpenSBI","permalink":"http://example.com/tags/OpenSBI/"},{"name":"Debian","slug":"Debian","permalink":"http://example.com/tags/Debian/"},{"name":"Efficiency","slug":"Efficiency","permalink":"http://example.com/tags/Efficiency/"},{"name":"Github","slug":"Github","permalink":"http://example.com/tags/Github/"},{"name":"CI","slug":"CI","permalink":"http://example.com/tags/CI/"},{"name":"加密算法","slug":"加密算法","permalink":"http://example.com/tags/%E5%8A%A0%E5%AF%86%E7%AE%97%E6%B3%95/"},{"name":"Cryptography","slug":"Cryptography","permalink":"http://example.com/tags/Cryptography/"},{"name":"Makefile","slug":"Makefile","permalink":"http://example.com/tags/Makefile/"},{"name":"Shell","slug":"Shell","permalink":"http://example.com/tags/Shell/"},{"name":"嵌入式开发","slug":"嵌入式开发","permalink":"http://example.com/tags/%E5%B5%8C%E5%85%A5%E5%BC%8F%E5%BC%80%E5%8F%91/"},{"name":"LaTeX","slug":"LaTeX","permalink":"http://example.com/tags/LaTeX/"},{"name":"Markdown","slug":"Markdown","permalink":"http://example.com/tags/Markdown/"},{"name":"Pandoc","slug":"Pandoc","permalink":"http://example.com/tags/Pandoc/"},{"name":"Translation","slug":"Translation","permalink":"http://example.com/tags/Translation/"},{"name":"插件","slug":"插件","permalink":"http://example.com/tags/%E6%8F%92%E4%BB%B6/"},{"name":"推荐","slug":"推荐","permalink":"http://example.com/tags/%E6%8E%A8%E8%8D%90/"},{"name":"Python","slug":"Python","permalink":"http://example.com/tags/Python/"},{"name":"效率","slug":"效率","permalink":"http://example.com/tags/%E6%95%88%E7%8E%87/"},{"name":"字体","slug":"字体","permalink":"http://example.com/tags/%E5%AD%97%E4%BD%93/"},{"name":"LaTex","slug":"LaTex","permalink":"http://example.com/tags/LaTex/"},{"name":"NAS","slug":"NAS","permalink":"http://example.com/tags/NAS/"},{"name":"Linux,攒机","slug":"Linux,攒机","permalink":"http://example.com/tags/Linux%EF%BC%8C%E6%94%92%E6%9C%BA/"},{"name":"Clash","slug":"Clash","permalink":"http://example.com/tags/Clash/"},{"name":"HEXO","slug":"HEXO","permalink":"http://example.com/tags/HEXO/"},{"name":"RISCV","slug":"RISCV","permalink":"http://example.com/tags/RISCV/"},{"name":"pip","slug":"pip","permalink":"http://example.com/tags/pip/"},{"name":"PDF","slug":"PDF","permalink":"http://example.com/tags/PDF/"},{"name":"listing","slug":"listing","permalink":"http://example.com/tags/listing/"},{"name":"C","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"GDB","slug":"GDB","permalink":"http://example.com/tags/GDB/"},{"name":"嵌入式","slug":"嵌入式","permalink":"http://example.com/tags/%E5%B5%8C%E5%85%A5%E5%BC%8F/"},{"name":"芯片开发","slug":"芯片开发","permalink":"http://example.com/tags/%E8%8A%AF%E7%89%87%E5%BC%80%E5%8F%91/"},{"name":"硬件","slug":"硬件","permalink":"http://example.com/tags/%E7%A1%AC%E4%BB%B6/"},{"name":"JTAG","slug":"JTAG","permalink":"http://example.com/tags/JTAG/"},{"name":"OpenOCD","slug":"OpenOCD","permalink":"http://example.com/tags/OpenOCD/"},{"name":"SSH","slug":"SSH","permalink":"http://example.com/tags/SSH/"},{"name":"Jellyfin","slug":"Jellyfin","permalink":"http://example.com/tags/Jellyfin/"},{"name":"工具","slug":"工具","permalink":"http://example.com/tags/%E5%B7%A5%E5%85%B7/"},{"name":"同步","slug":"同步","permalink":"http://example.com/tags/%E5%90%8C%E6%AD%A5/"},{"name":"备份","slug":"备份","permalink":"http://example.com/tags/%E5%A4%87%E4%BB%BD/"},{"name":"Gerrit","slug":"Gerrit","permalink":"http://example.com/tags/Gerrit/"},{"name":"Linux,每天学命令","slug":"Linux,每天学命令","permalink":"http://example.com/tags/Linux%EF%BC%8C%E6%AF%8F%E5%A4%A9%E5%AD%A6%E5%91%BD%E4%BB%A4/"},{"name":"Virtual Memory","slug":"Virtual-Memory","permalink":"http://example.com/tags/Virtual-Memory/"},{"name":"TLB","slug":"TLB","permalink":"http://example.com/tags/TLB/"},{"name":"内存管理","slug":"内存管理","permalink":"http://example.com/tags/%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86/"},{"name":"页表","slug":"页表","permalink":"http://example.com/tags/%E9%A1%B5%E8%A1%A8/"},{"name":"多级页表","slug":"多级页表","permalink":"http://example.com/tags/%E5%A4%9A%E7%BA%A7%E9%A1%B5%E8%A1%A8/"},{"name":"MMU","slug":"MMU","permalink":"http://example.com/tags/MMU/"},{"name":"NOC","slug":"NOC","permalink":"http://example.com/tags/NOC/"},{"name":"SoC","slug":"SoC","permalink":"http://example.com/tags/SoC/"},{"name":"ACPI","slug":"ACPI","permalink":"http://example.com/tags/ACPI/"},{"name":"Kernel","slug":"Kernel","permalink":"http://example.com/tags/Kernel/"},{"name":"内核","slug":"内核","permalink":"http://example.com/tags/%E5%86%85%E6%A0%B8/"},{"name":"Cache","slug":"Cache","permalink":"http://example.com/tags/Cache/"},{"name":"CSAPP","slug":"CSAPP","permalink":"http://example.com/tags/CSAPP/"},{"name":"缓存一致性","slug":"缓存一致性","permalink":"http://example.com/tags/%E7%BC%93%E5%AD%98%E4%B8%80%E8%87%B4%E6%80%A7/"},{"name":"组成原理","slug":"组成原理","permalink":"http://example.com/tags/%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86/"},{"name":"KeePass","slug":"KeePass","permalink":"http://example.com/tags/KeePass/"},{"name":"密码管理","slug":"密码管理","permalink":"http://example.com/tags/%E5%AF%86%E7%A0%81%E7%AE%A1%E7%90%86/"},{"name":"通信协议","slug":"通信协议","permalink":"http://example.com/tags/%E9%80%9A%E4%BF%A1%E5%8D%8F%E8%AE%AE/"},{"name":"计算机组成原理","slug":"计算机组成原理","permalink":"http://example.com/tags/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86/"},{"name":"CPU","slug":"CPU","permalink":"http://example.com/tags/CPU/"},{"name":"MESI","slug":"MESI","permalink":"http://example.com/tags/MESI/"},{"name":"Gitbash","slug":"Gitbash","permalink":"http://example.com/tags/Gitbash/"},{"name":"亲和性","slug":"亲和性","permalink":"http://example.com/tags/%E4%BA%B2%E5%92%8C%E6%80%A7/"},{"name":"Affinity","slug":"Affinity","permalink":"http://example.com/tags/Affinity/"},{"name":"操作系统","slug":"操作系统","permalink":"http://example.com/tags/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/"},{"name":"固件开发","slug":"固件开发","permalink":"http://example.com/tags/%E5%9B%BA%E4%BB%B6%E5%BC%80%E5%8F%91/"},{"name":"存储器","slug":"存储器","permalink":"http://example.com/tags/%E5%AD%98%E5%82%A8%E5%99%A8/"},{"name":"Interlaken","slug":"Interlaken","permalink":"http://example.com/tags/Interlaken/"},{"name":"AMBA","slug":"AMBA","permalink":"http://example.com/tags/AMBA/"},{"name":"AXI","slug":"AXI","permalink":"http://example.com/tags/AXI/"},{"name":"总线协议","slug":"总线协议","permalink":"http://example.com/tags/%E6%80%BB%E7%BA%BF%E5%8D%8F%E8%AE%AE/"},{"name":"协议","slug":"协议","permalink":"http://example.com/tags/%E5%8D%8F%E8%AE%AE/"},{"name":"FSM","slug":"FSM","permalink":"http://example.com/tags/FSM/"},{"name":"有限状态机","slug":"有限状态机","permalink":"http://example.com/tags/%E6%9C%89%E9%99%90%E7%8A%B6%E6%80%81%E6%9C%BA/"},{"name":"链接","slug":"链接","permalink":"http://example.com/tags/%E9%93%BE%E6%8E%A5/"},{"name":"编译","slug":"编译","permalink":"http://example.com/tags/%E7%BC%96%E8%AF%91/"},{"name":"动态链接","slug":"动态链接","permalink":"http://example.com/tags/%E5%8A%A8%E6%80%81%E9%93%BE%E6%8E%A5/"},{"name":"DMA","slug":"DMA","permalink":"http://example.com/tags/DMA/"},{"name":"虚拟内存","slug":"虚拟内存","permalink":"http://example.com/tags/%E8%99%9A%E6%8B%9F%E5%86%85%E5%AD%98/"},{"name":"缓存","slug":"缓存","permalink":"http://example.com/tags/%E7%BC%93%E5%AD%98/"},{"name":"总线","slug":"总线","permalink":"http://example.com/tags/%E6%80%BB%E7%BA%BF/"},{"name":"图床","slug":"图床","permalink":"http://example.com/tags/%E5%9B%BE%E5%BA%8A/"},{"name":"腾讯云","slug":"腾讯云","permalink":"http://example.com/tags/%E8%85%BE%E8%AE%AF%E4%BA%91/"},{"name":"读书笔记","slug":"读书笔记","permalink":"http://example.com/tags/%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0/"},{"name":"Die2Die","slug":"Die2Die","permalink":"http://example.com/tags/Die2Die/"},{"name":"Qt","slug":"Qt","permalink":"http://example.com/tags/Qt/"},{"name":"FrameBuffer","slug":"FrameBuffer","permalink":"http://example.com/tags/FrameBuffer/"},{"name":"LCD","slug":"LCD","permalink":"http://example.com/tags/LCD/"},{"name":"DOS","slug":"DOS","permalink":"http://example.com/tags/DOS/"},{"name":"ELF","slug":"ELF","permalink":"http://example.com/tags/ELF/"},{"name":"Bootloader","slug":"Bootloader","permalink":"http://example.com/tags/Bootloader/"},{"name":"Boot Rom","slug":"Boot-Rom","permalink":"http://example.com/tags/Boot-Rom/"},{"name":"Timer","slug":"Timer","permalink":"http://example.com/tags/Timer/"},{"name":"外设","slug":"外设","permalink":"http://example.com/tags/%E5%A4%96%E8%AE%BE/"},{"name":"C++","slug":"C","permalink":"http://example.com/tags/C/"},{"name":"GPIO","slug":"GPIO","permalink":"http://example.com/tags/GPIO/"},{"name":"QtCreator","slug":"QtCreator","permalink":"http://example.com/tags/QtCreator/"},{"name":"汇编语言","slug":"汇编语言","permalink":"http://example.com/tags/%E6%B1%87%E7%BC%96%E8%AF%AD%E8%A8%80/"},{"name":"GCC","slug":"GCC","permalink":"http://example.com/tags/GCC/"},{"name":"Plugins","slug":"Plugins","permalink":"http://example.com/tags/Plugins/"},{"name":"zsh","slug":"zsh","permalink":"http://example.com/tags/zsh/"},{"name":"IPC","slug":"IPC","permalink":"http://example.com/tags/IPC/"},{"name":"Hexo","slug":"Hexo","permalink":"http://example.com/tags/Hexo/"},{"name":"Driver","slug":"Driver","permalink":"http://example.com/tags/Driver/"},{"name":"Unix","slug":"Unix","permalink":"http://example.com/tags/Unix/"}]}
\ No newline at end of file
diff --git a/index.html b/index.html
index 65d10e4411..e69de29bb2 100644
--- a/index.html
+++ b/index.html
@@ -1,747 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 5
-
-
-
-
-
- Linux, 网络配置
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 5
-
-
-
-
-
- QEMU,虚拟机,网络配置
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 30
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- 工具推荐
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 23
-
-
-
-
-
- OpenEuler , QEMU , RISC-V
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 6月 28
-
-
-
-
- OpenStack
-
-
-
-
- Linux , OpenStack
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 6月 26
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 6月 17
-
-
-
-
-
- 计算机网络
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 6月 11
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 6月 11
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 6月 9
-
-
-
-
-
- 云计算
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/10/index.html b/page/10/index.html
index dc79b6d4d2..e69de29bb2 100644
--- a/page/10/index.html
+++ b/page/10/index.html
@@ -1,772 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 5月 23
-
-
-
-
-
- Affinity , CPU , Linux , 亲和性 , 操作系统
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 5月 21
-
-
-
-
-
- SoC , 固件开发 , 存储器 , 芯片开发
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 5月 18
-
-
-
-
- 通信协议
-
-
-
-
- Interlaken
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 5月 17
-
-
-
-
- 通信协议
-
-
-
-
- AMBA , AXI , 协议 , 总线协议 , 通信协议
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 5月 15
-
-
-
-
-
- C , FSM , 有限状态机
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 5月 8
-
-
-
-
-
- 动态链接 , 编译 , 链接
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 5月 8
-
-
-
-
- 计算机组成原理
-
-
-
-
- Cache , DMA , 总线 , 缓存 , 虚拟内存 , 计算机组成原理 , 页表
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 5月 1
-
-
-
-
- 计算机组成原理
-
-
-
-
- 计算机组成原理
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 4月 9
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- Markdown , 图床 , 腾讯云
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 3月 30
-
-
-
-
- 读书笔记
-
-
-
-
- 读书笔记
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/11/index.html b/page/11/index.html
index 65ea7b002c..e69de29bb2 100644
--- a/page/11/index.html
+++ b/page/11/index.html
@@ -1,752 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 3月 28
-
-
-
-
-
- Die2Die , Translation
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 3月 18
-
-
-
-
-
- Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 3月 9
-
-
-
-
- QEMU 源码分析
-
-
-
-
- Linux , QEMU
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 3月 1
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 2月 28
-
-
-
-
- 计算机组成原理
-
-
-
-
- 计算机组成原理
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 2月 16
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 2月 11
-
-
-
-
-
- C
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 1月 27
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 1月 25
-
-
-
-
- QEMU 源码分析
-
-
-
-
- Linux , QEMU
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 1月 19
-
-
-
-
-
- Bug , VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/12/index.html b/page/12/index.html
index 1b9ca60a8f..e69de29bb2 100644
--- a/page/12/index.html
+++ b/page/12/index.html
@@ -1,757 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 1月 17
-
-
-
-
-
- FrameBuffer , LCD , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 1月 13
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 1月 10
-
-
-
-
-
- Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 1月 8
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 1月 7
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 1月 5
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- DOS
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 1月 5
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 30
-
-
-
-
- RISC-V 入门
-
-
-
-
- RISCV
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 24
-
-
-
-
- 万能 VSCode
-
-
-
-
- Linux , VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 22
-
-
-
-
-
- C , ELF
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/13/index.html b/page/13/index.html
index a1f1b739b5..e69de29bb2 100644
--- a/page/13/index.html
+++ b/page/13/index.html
@@ -1,777 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 18
-
-
-
-
- 嵌入式开发
-
-
-
-
- Boot Rom , Bootloader
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 15
-
-
-
-
- 嵌入式开发
-
-
-
-
- Timer , 外设 , 嵌入式
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 4
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 4
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 2
-
-
-
-
-
- Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 1
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- Linux , Qt , VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 29
-
-
-
-
- 读书笔记
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 29
-
-
-
-
- Git 实战
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 28
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 27
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/14/index.html b/page/14/index.html
index 7d85f58449..e69de29bb2 100644
--- a/page/14/index.html
+++ b/page/14/index.html
@@ -1,787 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 27
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 25
-
-
-
-
-
- Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 24
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 23
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 22
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 22
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 17
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , C
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 16
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 16
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 15
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/15/index.html b/page/15/index.html
index 0230a6e647..e69de29bb2 100644
--- a/page/15/index.html
+++ b/page/15/index.html
@@ -1,772 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 13
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , C++
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 12
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , C
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 11
-
-
-
-
- QEMU 源码分析
-
-
-
-
- GPIO , QEMU
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 9
-
-
-
-
- QEMU 源码分析
-
-
-
-
- QEMU
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 10月 30
-
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 10月 22
-
-
-
-
-
- C
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 10月 21
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 10月 21
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , C
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 10月 20
-
-
-
-
- RISC-V 入门
-
-
-
-
- RISCV
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 10月 20
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , C
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/16/index.html b/page/16/index.html
index cfed6bff03..e69de29bb2 100644
--- a/page/16/index.html
+++ b/page/16/index.html
@@ -1,762 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 10月 16
-
-
-
-
- RISC-V 入门
-
-
-
-
- RISCV
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 10月 12
-
-
-
-
-
- C , C++
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 30
-
-
-
-
-
- Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 30
-
-
-
-
-
- Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 29
-
-
-
-
- 万能 VSCode
-
-
-
-
- VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 28
-
-
-
-
-
- Qt , QtCreator
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 26
-
-
-
-
-
- Bug , Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 25
-
-
-
-
-
- Bug , Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 23
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 17
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , C , C++
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/17/index.html b/page/17/index.html
index b50a343ee9..e69de29bb2 100644
--- a/page/17/index.html
+++ b/page/17/index.html
@@ -1,772 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 17
-
-
-
-
-
- C , C++
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 15
-
-
-
-
-
- C
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 13
-
-
-
-
-
- Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 12
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 10
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 9
-
-
-
-
-
- C
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 8
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , C
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 6
-
-
-
-
- 万能 VSCode
-
-
-
-
- Linux , VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 3
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 3
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , GCC , Linux , 汇编语言
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/18/index.html b/page/18/index.html
index cb24188215..e69de29bb2 100644
--- a/page/18/index.html
+++ b/page/18/index.html
@@ -1,772 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 1
-
-
-
-
- QEMU 源码分析
-
-
-
-
- Linux , QEMU
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 31
-
-
-
-
-
- Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 31
-
-
-
-
- Linux 操作系统
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 30
-
-
-
-
- Linux 操作系统
-
-
-
-
- Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 29
-
-
-
-
- CSAPP-Lab
-
-
-
-
- CSAPP , GDB , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 29
-
-
-
-
-
- CSAPP , GDB , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 29
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- Linux , Plugins , zsh
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 27
-
-
-
-
-
- Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 26
-
-
-
-
- RISC-V 入门
-
-
-
-
- RISCV
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 24
-
-
-
-
- 万能 VSCode
-
-
-
-
- Linux , QEMU , VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/19/index.html b/page/19/index.html
index 2c37c05392..e69de29bb2 100644
--- a/page/19/index.html
+++ b/page/19/index.html
@@ -1,762 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 24
-
-
-
-
-
- Linux , Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 24
-
-
-
-
- Linux 操作系统
-
-
-
-
- Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 23
-
-
-
-
- 万能 VSCode
-
-
-
-
- GDB , Linux , RISCV
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 19
-
-
-
-
-
- IPC , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 19
-
-
-
-
-
- IPC , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 19
-
-
-
-
-
- Linux , VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 19
-
-
-
-
- Linux 操作系统
-
-
-
-
- Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 18
-
-
-
-
-
- Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 17
-
-
-
-
-
- Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 14
-
-
-
-
- Linux 操作系统
-
-
-
-
- Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/2/index.html b/page/2/index.html
index 1a17bf6e85..e69de29bb2 100644
--- a/page/2/index.html
+++ b/page/2/index.html
@@ -1,757 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 6月 9
-
-
-
-
- OpenStack
-
-
-
-
- OpenStack,云计算,Devstack
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 4月 10
-
-
-
-
-
- 计算机网络
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 3月 24
-
-
-
-
- 工欲善其事,必先利其器
-
-
-
-
- VSCode , 后端开发
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 3月 16
-
-
-
-
-
- Docker , WSL2
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 3月 12
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 3月 12
-
-
-
-
- JAVA 开发
-
-
-
-
- JAVA
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 1月 7
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 1月 7
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 24
-
-
-
-
-
- Linux , 安装教程
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 4
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/20/index.html b/page/20/index.html
index f2d629e040..e69de29bb2 100644
--- a/page/20/index.html
+++ b/page/20/index.html
@@ -1,772 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 13
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 12
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 12
-
-
-
-
-
- Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 11
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 11
-
-
-
-
-
- IPC , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 10
-
-
-
-
-
- IPC , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 10
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 9
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 9
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Git , Hexo
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 9
-
-
-
-
-
- Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/21/index.html b/page/21/index.html
index 691783f838..e69de29bb2 100644
--- a/page/21/index.html
+++ b/page/21/index.html
@@ -1,782 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 6
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 5
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 5
-
-
-
-
-
- Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 4
-
-
-
-
- Git 实战
-
-
-
-
- Git , Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 4
-
-
-
-
-
- Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 4
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 3
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 3
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 2
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 30
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/22/index.html b/page/22/index.html
index f6d930348c..e69de29bb2 100644
--- a/page/22/index.html
+++ b/page/22/index.html
@@ -1,762 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 30
-
-
-
-
-
- Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 29
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 28
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 28
-
-
-
-
-
- Linux , QEMU , RISC-V
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 28
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 27
-
-
-
-
-
- Linux , Qt
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 27
-
-
-
-
-
- Linux , QEMU
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 23
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 23
-
-
-
-
-
- Linux , QEMU
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 21
-
-
-
-
-
- Driver , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/23/index.html b/page/23/index.html
index b53d5fc256..e69de29bb2 100644
--- a/page/23/index.html
+++ b/page/23/index.html
@@ -1,609 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 21
-
-
-
-
-
- HEXO
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 20
-
-
-
-
-
- Linux , QEMU
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 20
-
-
-
-
-
- Linux , Translation , Unix
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 20
-
-
-
-
-
- HEXO
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 20
-
-
-
-
-
- HEXO
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 23
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/3/index.html b/page/3/index.html
index dc7820489f..e69de29bb2 100644
--- a/page/3/index.html
+++ b/page/3/index.html
@@ -1,762 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 4
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 3
-
-
-
-
-
- CodeReview , Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 3
-
-
-
-
-
- Office
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 12月 3
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 20
-
-
-
-
- Git 实战
-
-
-
-
- Git , OpenSBI
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 5
-
-
-
-
-
- Debian , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11月 1
-
-
-
-
- QEMU 源码分析
-
-
-
-
- QEMU
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 10月 18
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 10月 15
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 10月 14
-
-
-
-
-
- CI , Efficiency , Git , Github
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/4/index.html b/page/4/index.html
index a4634c3559..e69de29bb2 100644
--- a/page/4/index.html
+++ b/page/4/index.html
@@ -1,772 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 10月 10
-
-
-
-
-
- Cryptography , 加密算法
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 28
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 26
-
-
-
-
-
- Linux , Makefile
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 25
-
-
-
-
-
- Linux , Shell , 嵌入式开发
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 25
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 24
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- LaTeX , Markdown , Pandoc
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 24
-
-
-
-
-
- Markdown
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 24
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- Efficiency , Markdown , VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 22
-
-
-
-
- RISC-V 入门
-
-
-
-
- RISC-V , Translation
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 17
-
-
-
-
- 万能 VSCode
-
-
-
-
- Efficiency , Markdown , VSCode , 推荐 , 插件
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/5/index.html b/page/5/index.html
index 9030de3fb1..e69de29bb2 100644
--- a/page/5/index.html
+++ b/page/5/index.html
@@ -1,777 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 12
-
-
-
-
- 万能 VSCode
-
-
-
-
- Efficiency , VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 12
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 12
-
-
-
-
-
- Linux , Python , 效率
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 11
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Python
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 11
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , LaTex , 字体
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 10
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 10
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- Linux,攒机 , NAS
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 10
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- Clash
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 5
-
-
-
-
-
- Bug , Python
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 5
-
-
-
-
-
- Bug , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/6/index.html b/page/6/index.html
index ffc1f80168..e69de29bb2 100644
--- a/page/6/index.html
+++ b/page/6/index.html
@@ -1,772 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 5
-
-
-
-
-
- Linux , Python
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 9月 3
-
-
-
-
-
- HEXO
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 29
-
-
-
-
- RISC-V 入门
-
-
-
-
- RISCV
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 28
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- 推荐 , 效率
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 28
-
-
-
-
- 万能 VSCode
-
-
-
-
- VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 27
-
-
-
-
-
- Bug
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 27
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- 字体 , 推荐
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 27
-
-
-
-
-
- Python , pip
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 26
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , Markdown , PDF , Pandoc
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 26
-
-
-
-
- 万能 VSCode
-
-
-
-
- VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/7/index.html b/page/7/index.html
index ad04e31788..e69de29bb2 100644
--- a/page/7/index.html
+++ b/page/7/index.html
@@ -1,787 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 26
-
-
-
-
- RISC-V 入门
-
-
-
-
- RISCV
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 23
-
-
-
-
- RISC-V 入门
-
-
-
-
- RISCV
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 21
-
-
-
-
- LaTeX
-
-
-
-
- LaTeX , listing
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 20
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- LaTeX , Markdown , PDF , Pandoc , 效率
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 16
-
-
-
-
- 万能 VSCode
-
-
-
-
- VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 16
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , C
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 14
-
-
-
-
-
- GDB , JTAG , OpenOCD , 嵌入式 , 硬件 , 芯片开发
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 13
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- Efficiency , SSH , VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 2
-
-
-
-
- 万能 VSCode
-
-
-
-
- VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 1
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- Jellyfin , NAS
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/8/index.html b/page/8/index.html
index 4b16e760d0..e69de29bb2 100644
--- a/page/8/index.html
+++ b/page/8/index.html
@@ -1,767 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 8月 1
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- Efficiency , 同步 , 备份 , 工具
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 30
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 29
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- Efficiency , Gerrit
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 27
-
-
-
-
-
- C , Makefile
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 23
-
-
-
-
- 每天学命令
-
-
-
-
- Linux,每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 17
-
-
-
-
-
- Linux , MMU , TLB , Virtual Memory , 内存管理 , 多级页表 , 页表
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 16
-
-
-
-
-
- C , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 16
-
-
-
-
- Bug 踩坑记录
-
-
-
-
- Bug , VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 12
-
-
-
-
-
- NOC , SoC
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 12
-
-
-
-
-
- ACPI , Kernel , Linux , RISC-V , 内核
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/page/9/index.html b/page/9/index.html
index 8a3d2f5b6c..e69de29bb2 100644
--- a/page/9/index.html
+++ b/page/9/index.html
@@ -1,767 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
夜云泊个人博客
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 11
-
-
-
-
- CSAPP-Lab
-
-
-
-
- CSAPP , Cache , Linux
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 10
-
-
-
-
-
- Cache , 组成原理 , 缓存一致性
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 9
-
-
-
-
- 工欲善其事必先利其器
-
-
-
-
- Efficiency , KeePass , 密码管理 , 工具 , 推荐
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 8
-
-
-
-
-
- Cache , 缓存一致性
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 7月 7
-
-
-
-
-
- Git , Translation
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 6月 30
-
-
-
-
-
- C
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 6月 9
-
-
-
-
- 每天学命令
-
-
-
-
- Linux , 每天学命令
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 5月 30
-
-
-
-
- Git 实战
-
-
-
-
- Git
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 5月 29
-
-
-
-
-
- CPU , MESI , 计算机组成原理 , 通信协议
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 5月 24
-
-
-
-
- 万能 VSCode
-
-
-
-
- Git , Gitbash , VSCode
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
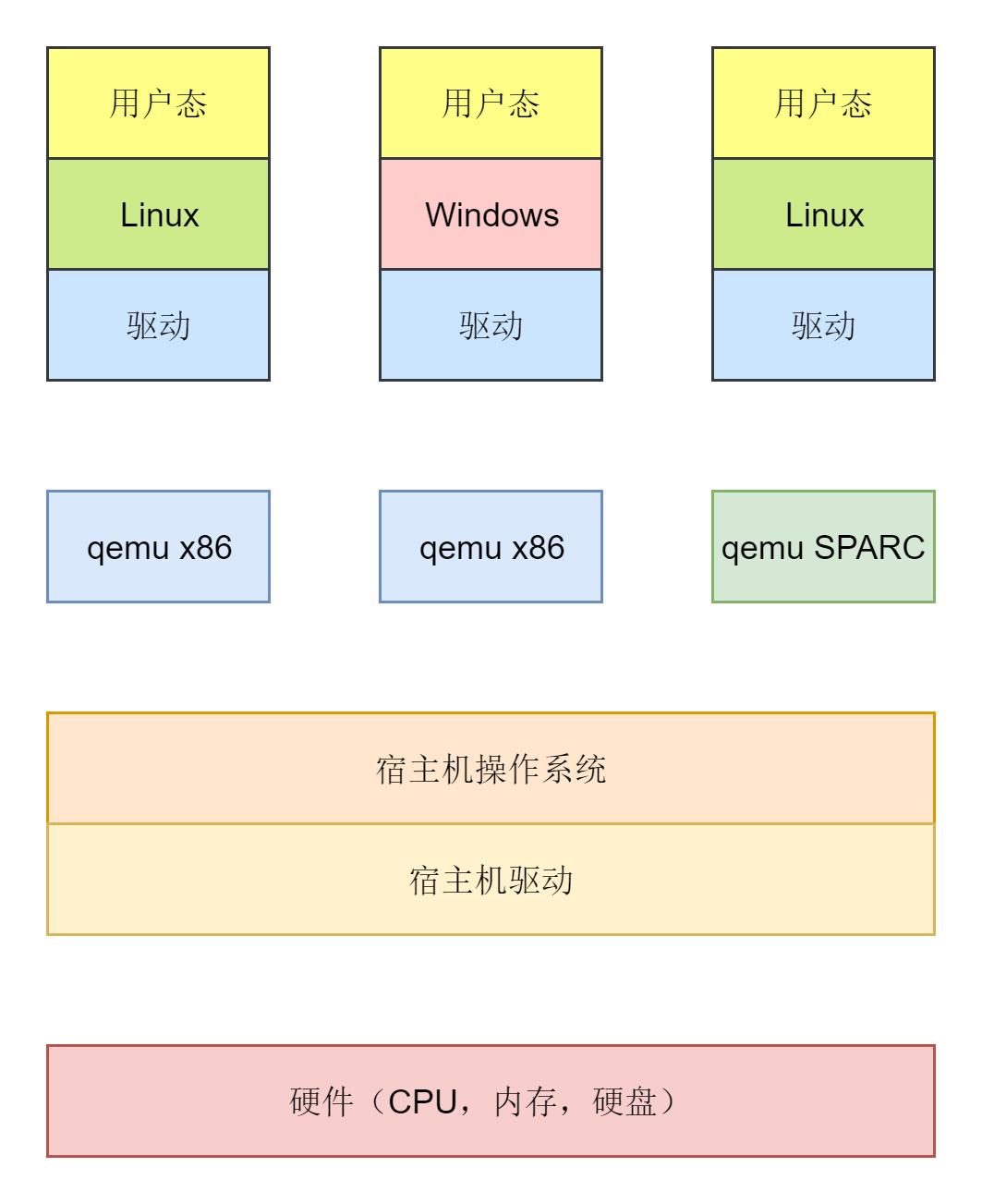
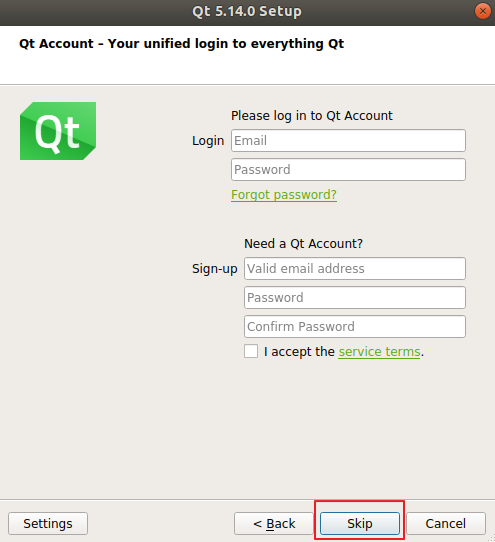
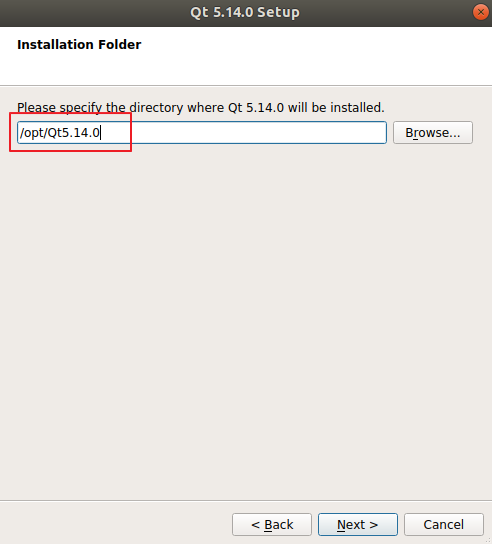
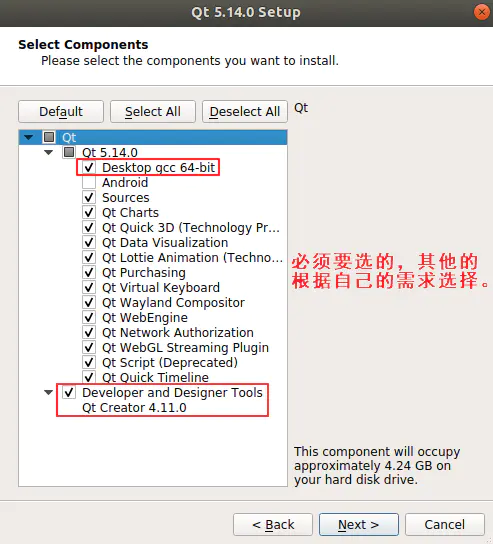
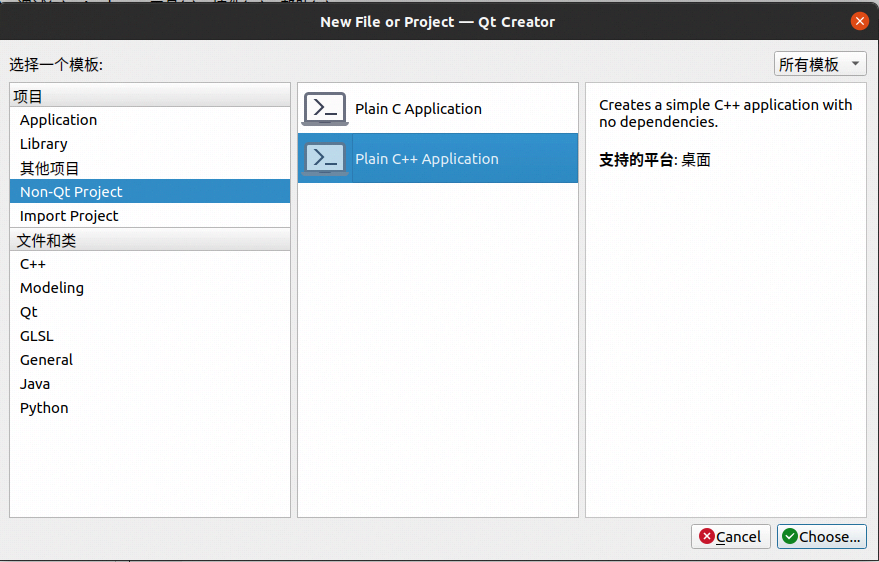
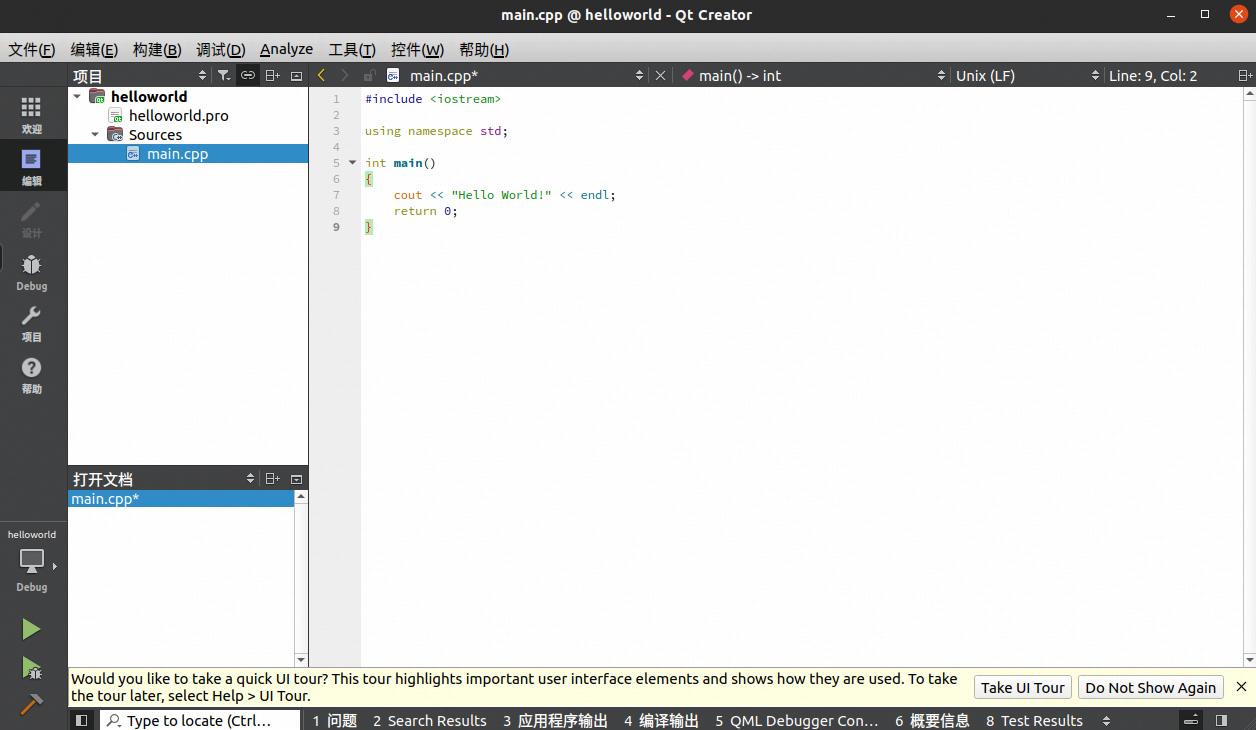
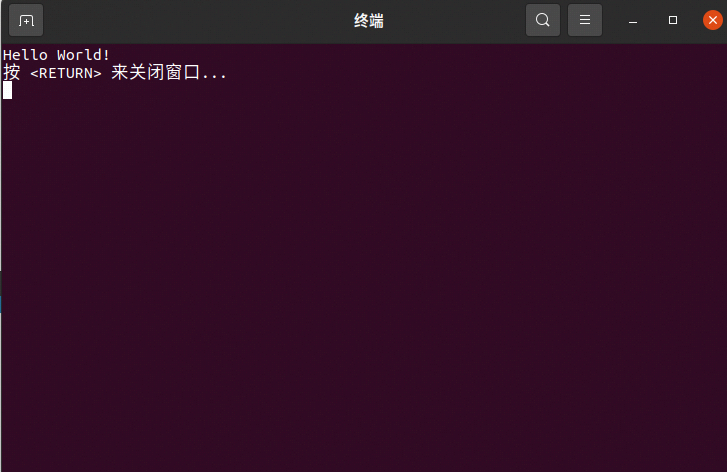
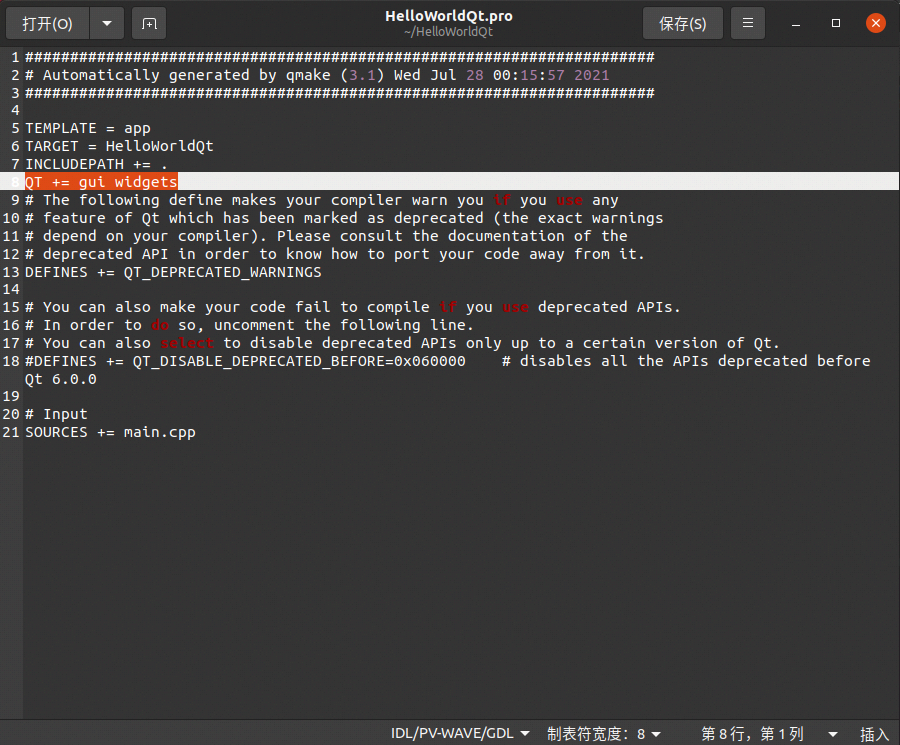
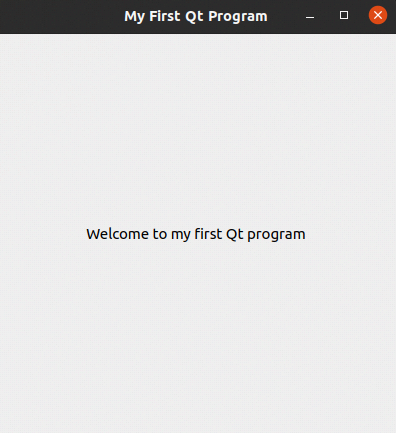
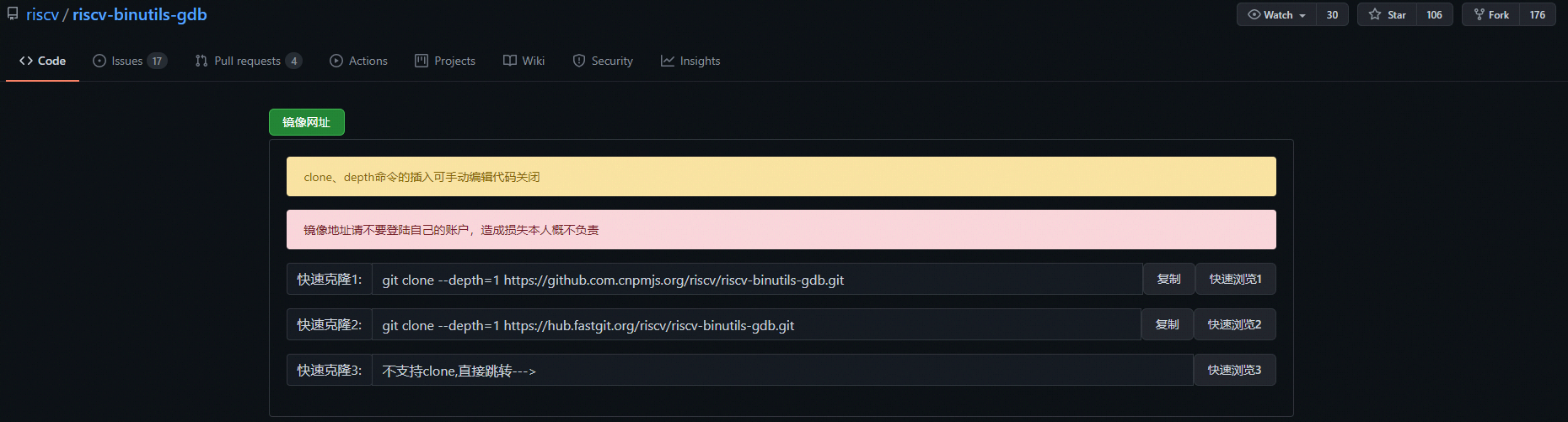
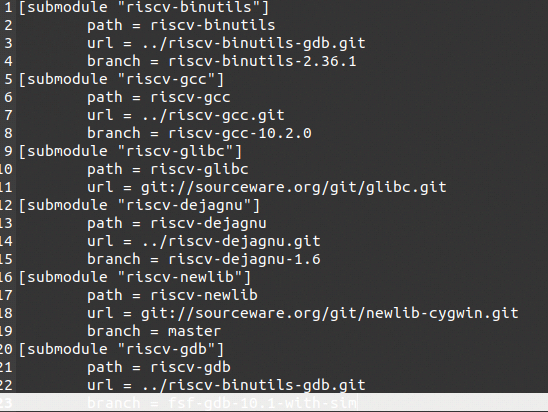
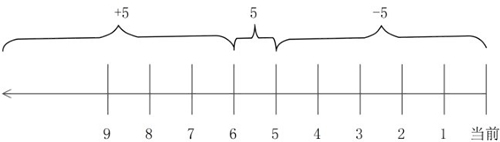

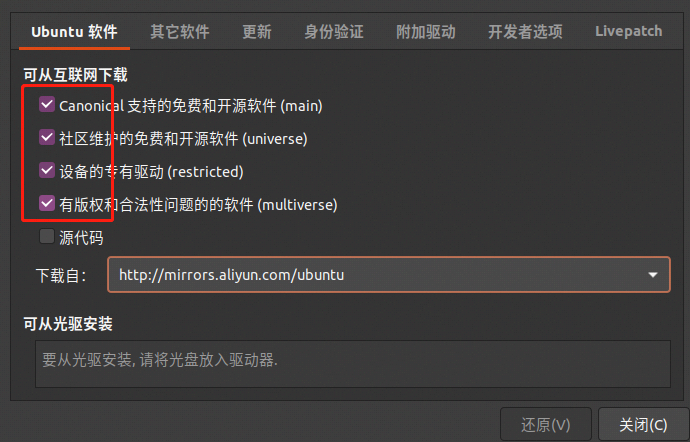



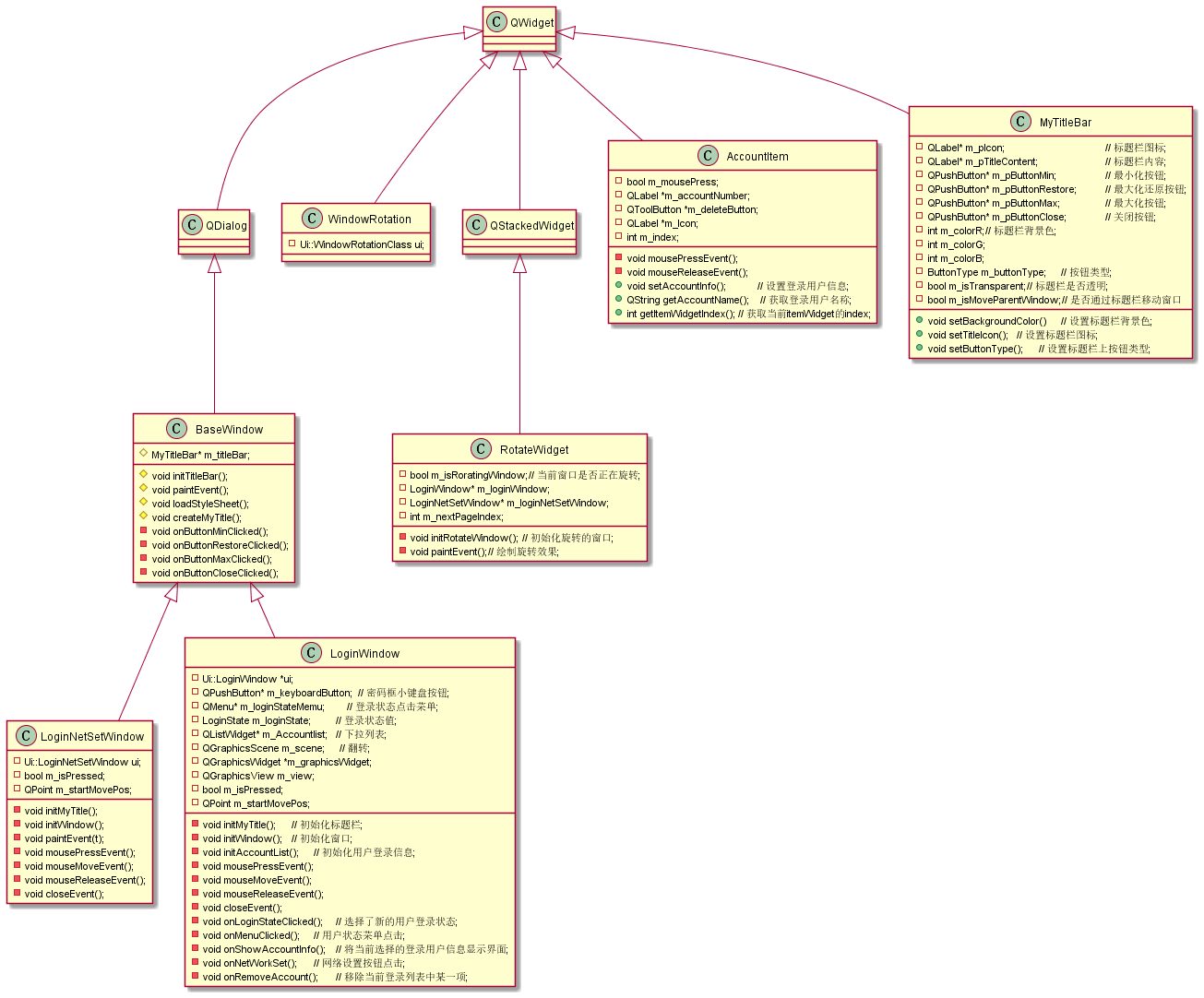




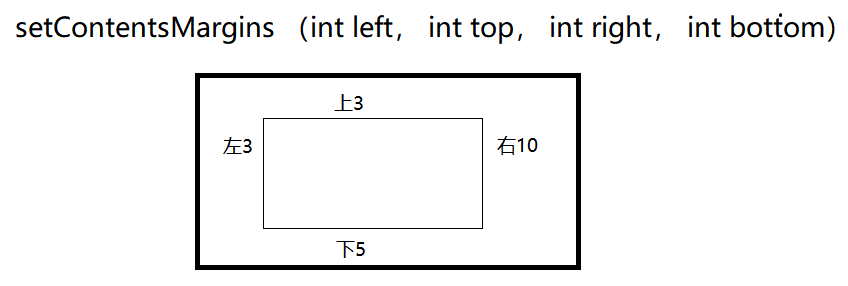


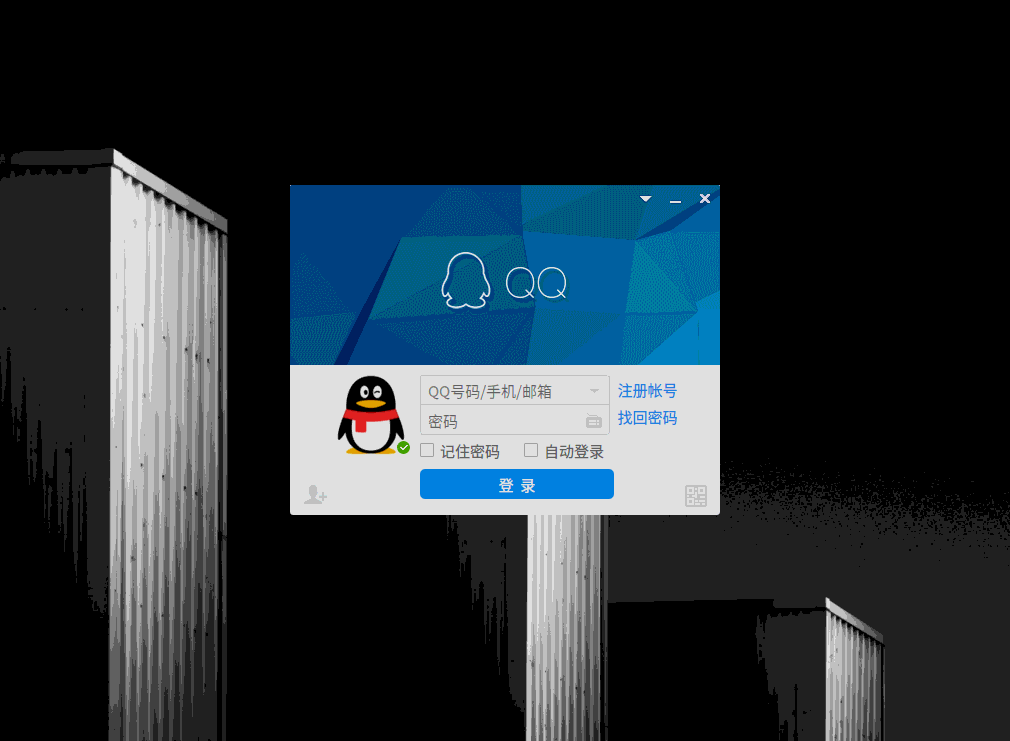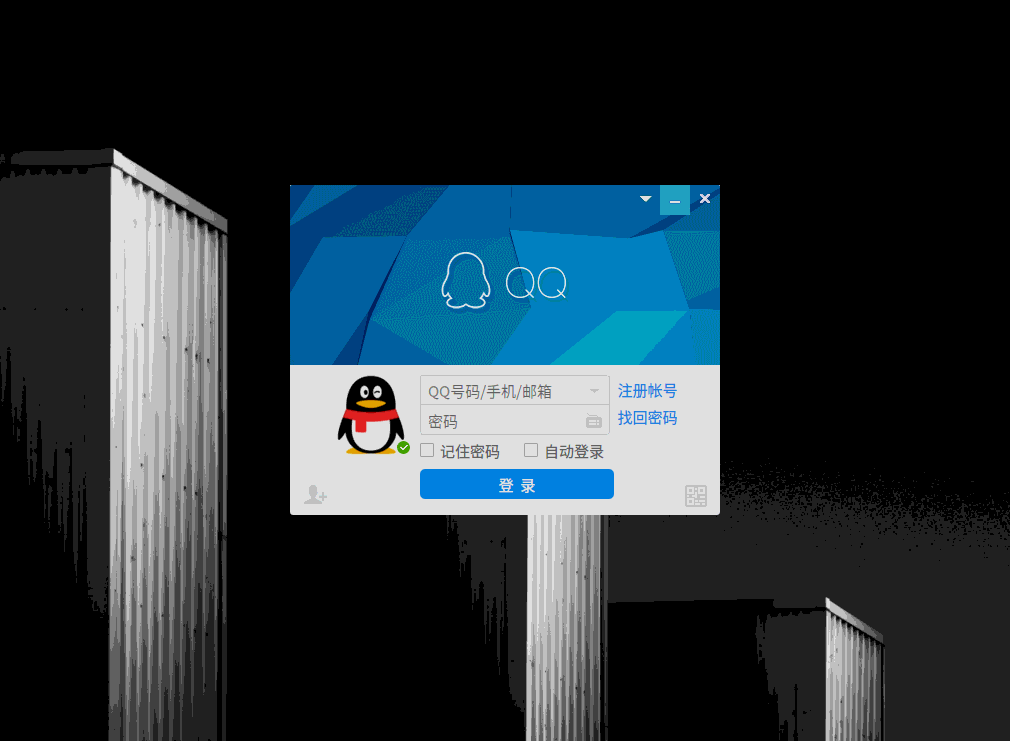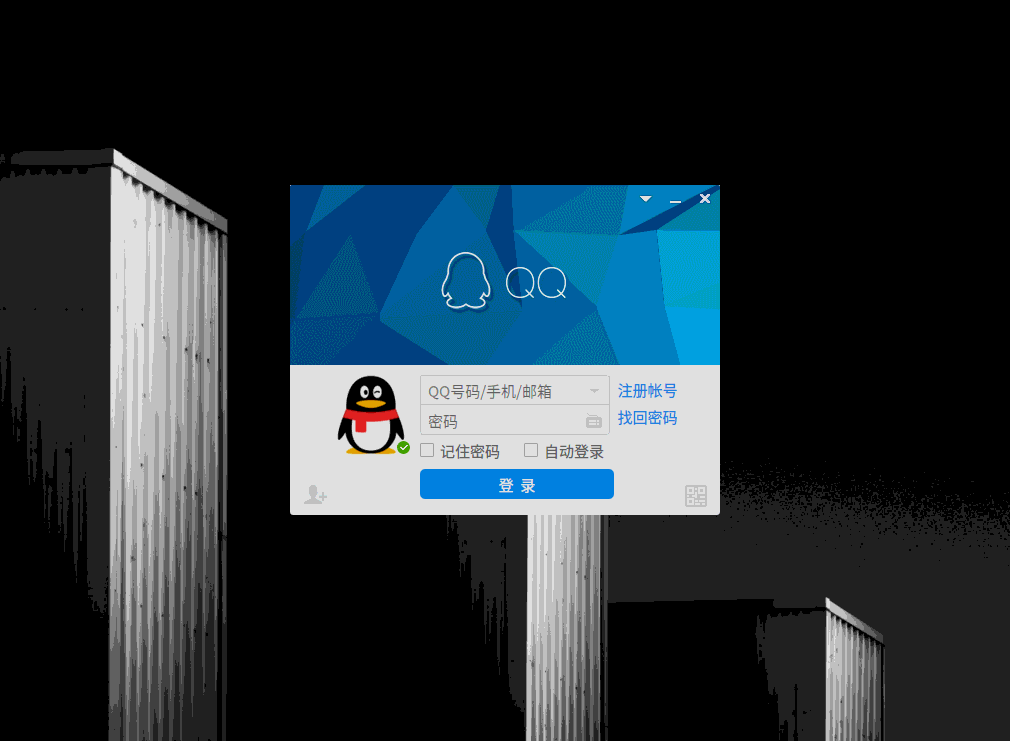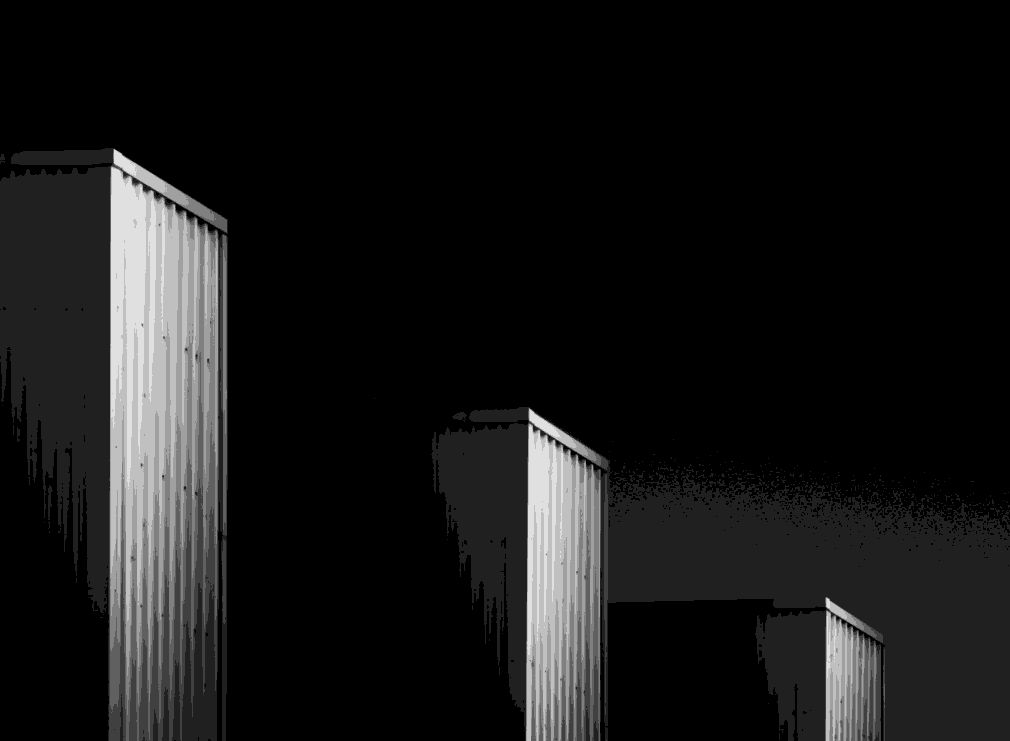


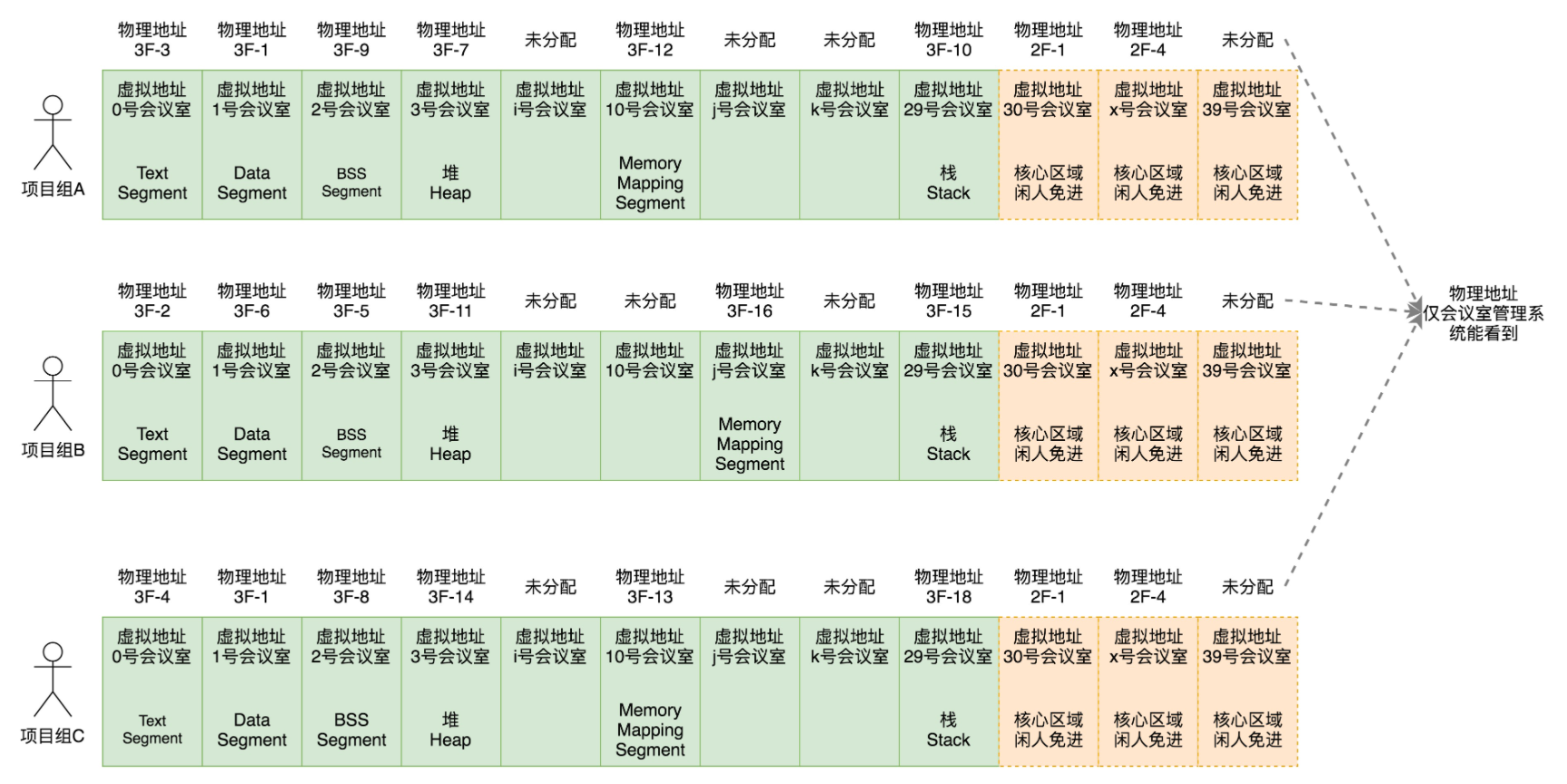
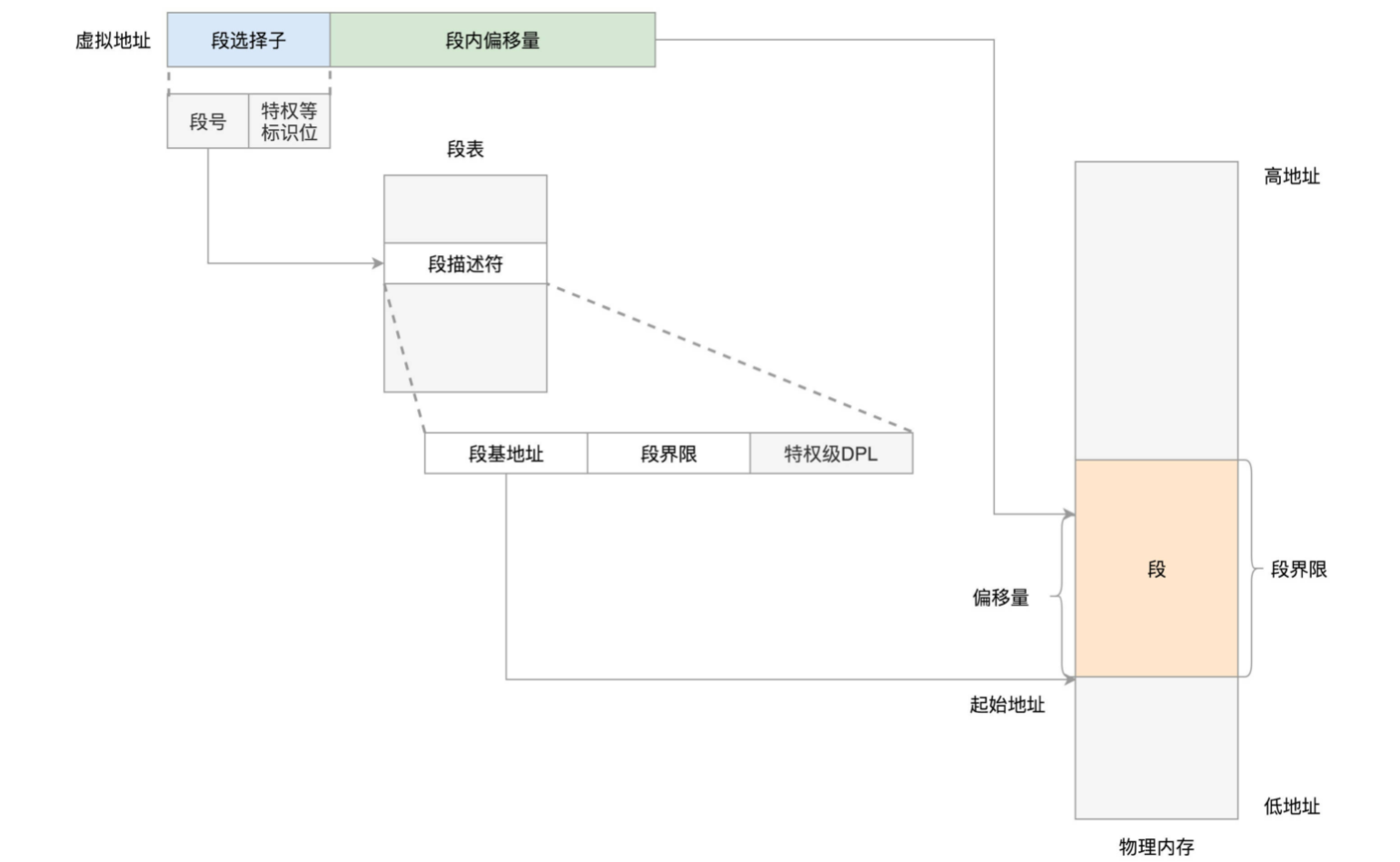
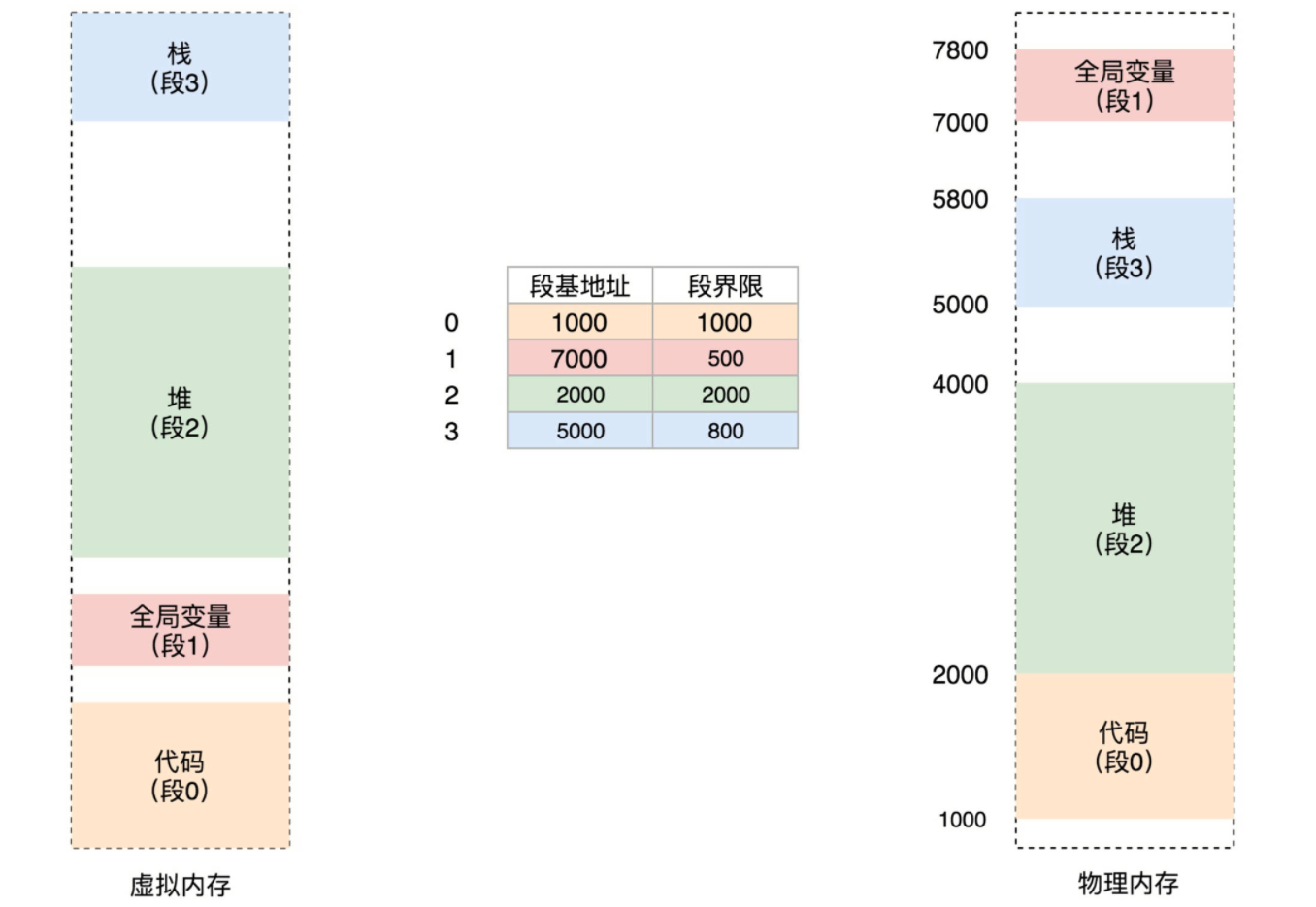
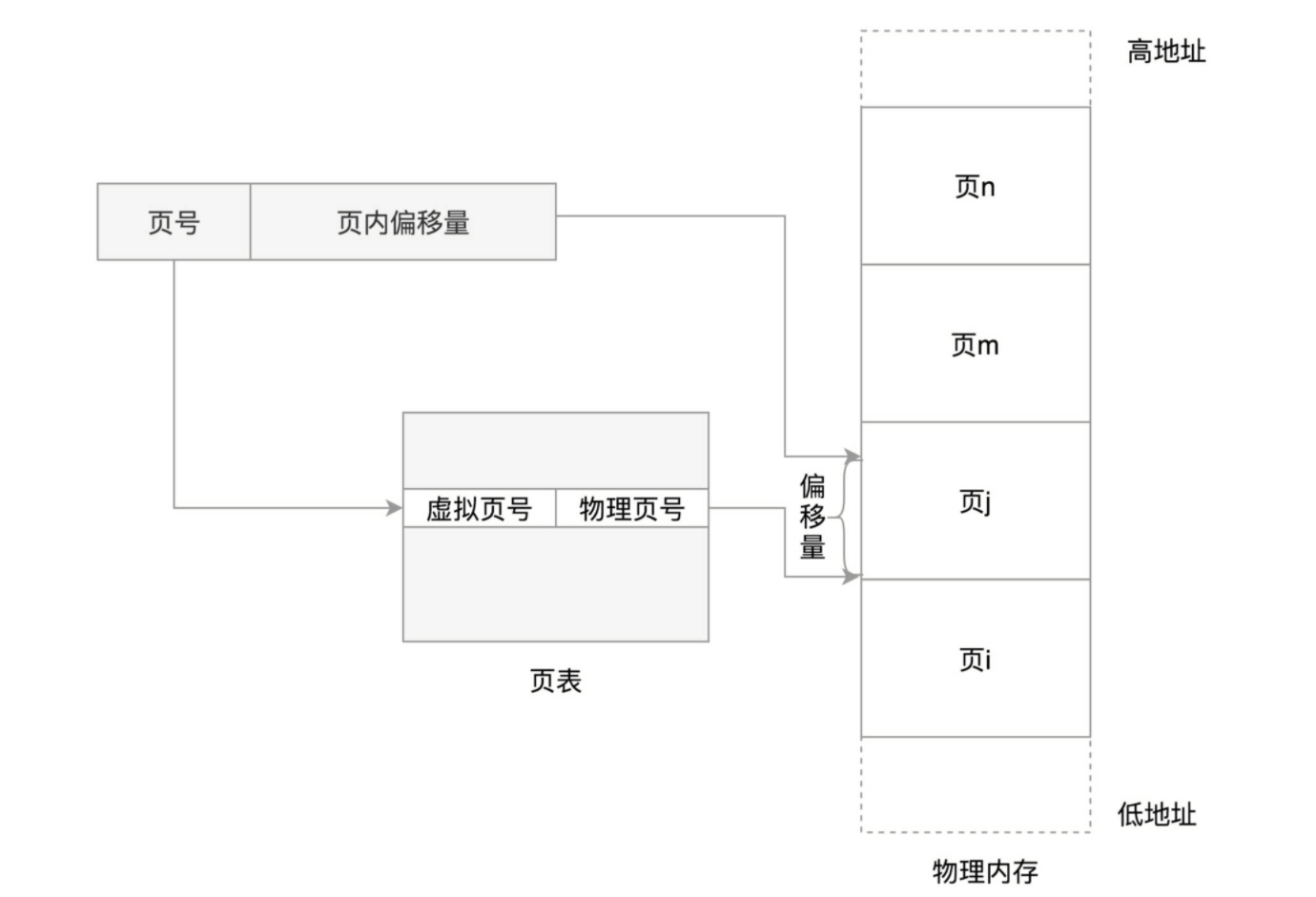

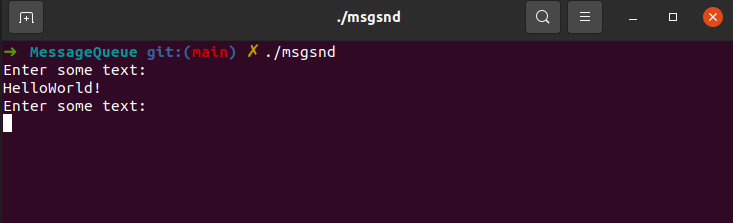
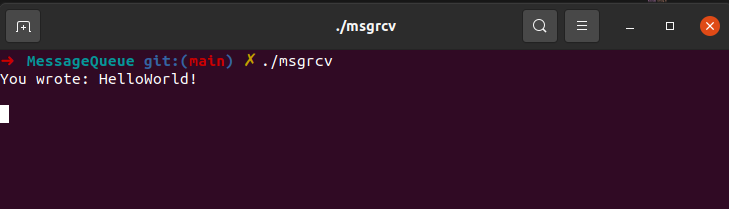

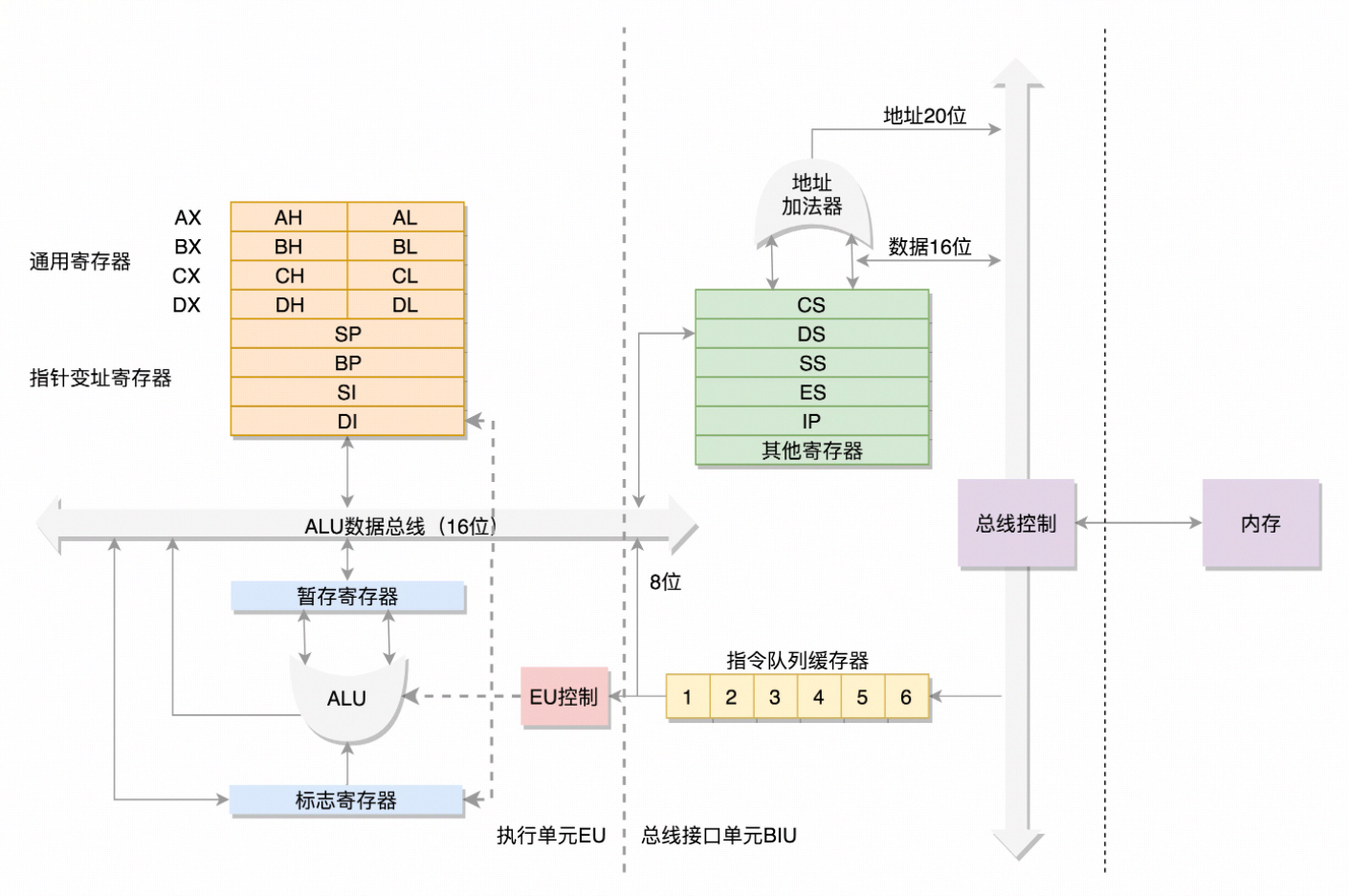

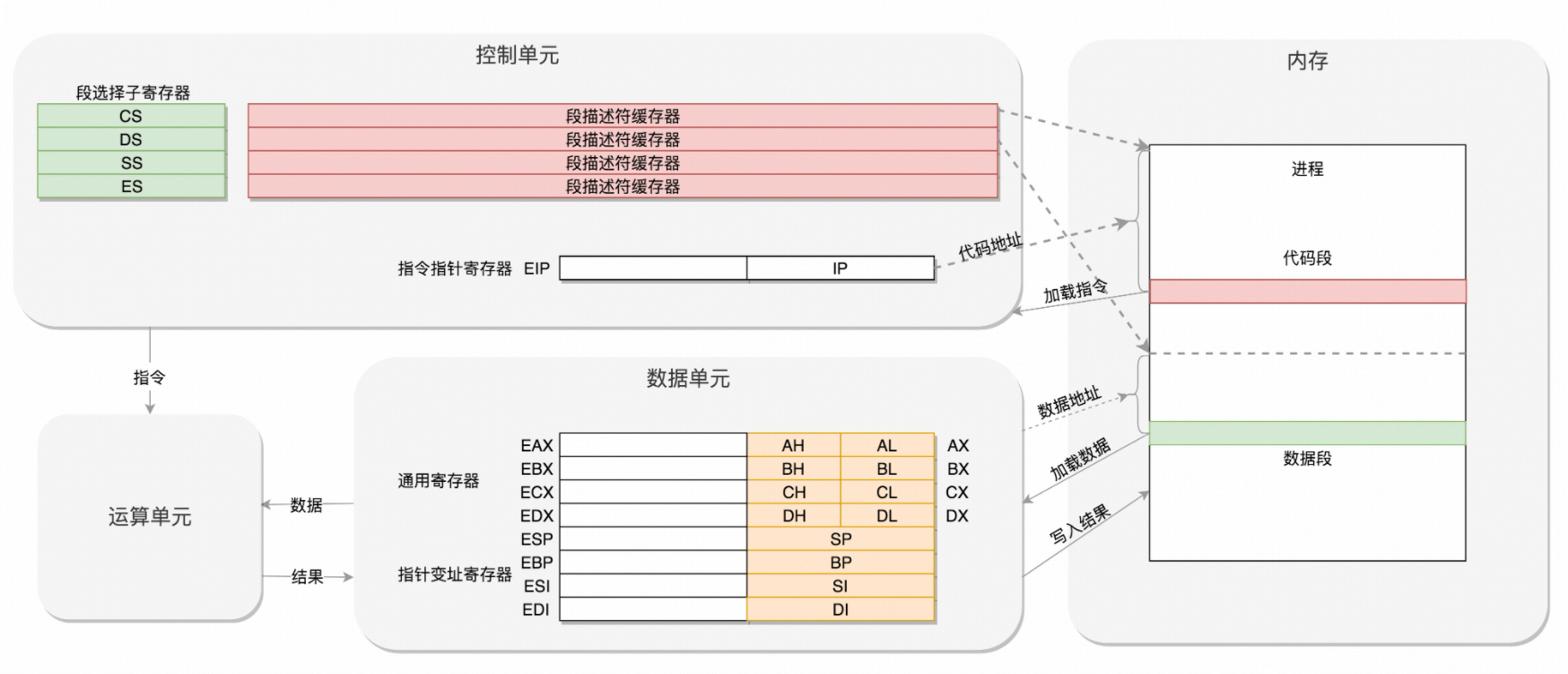
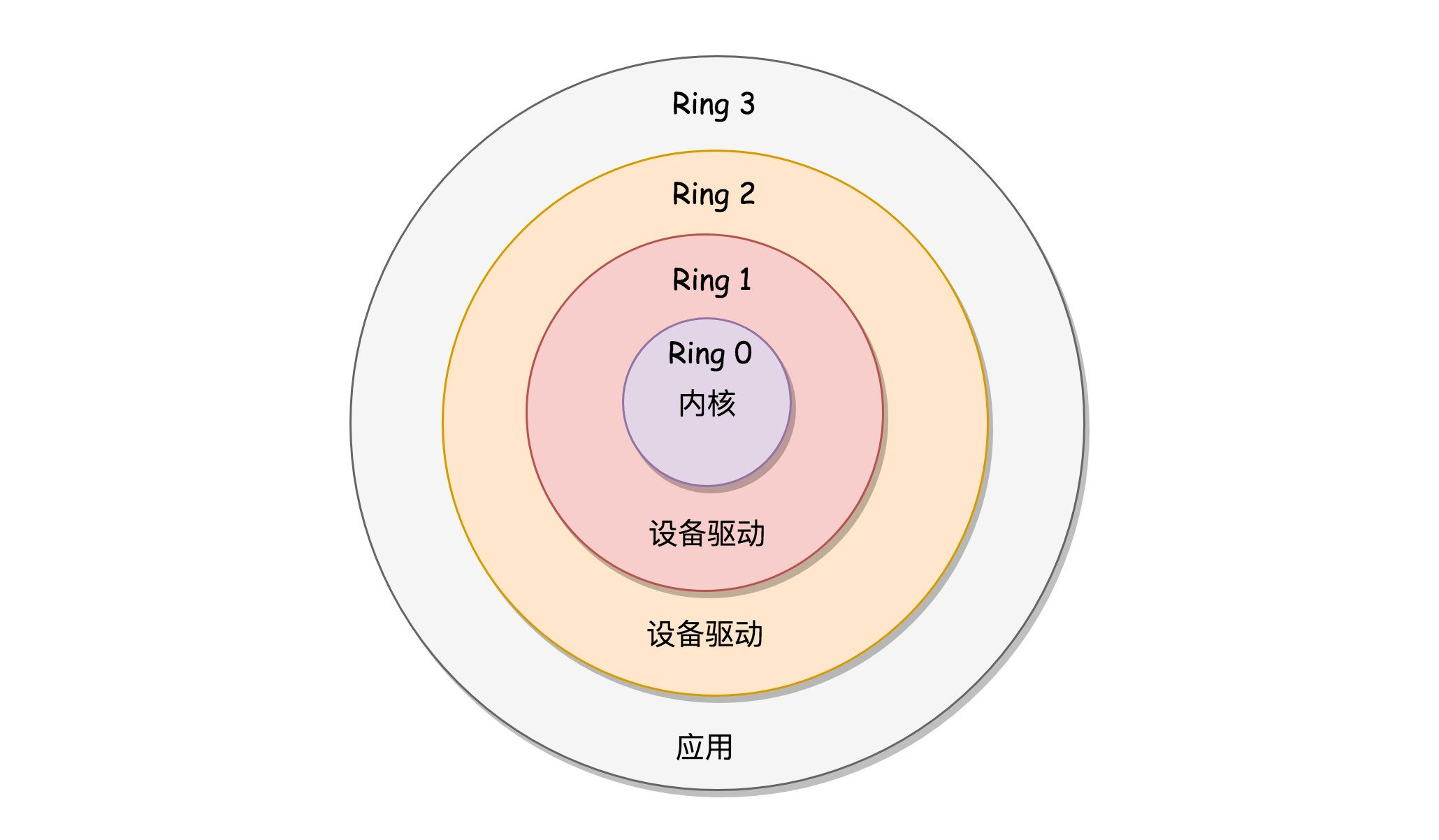

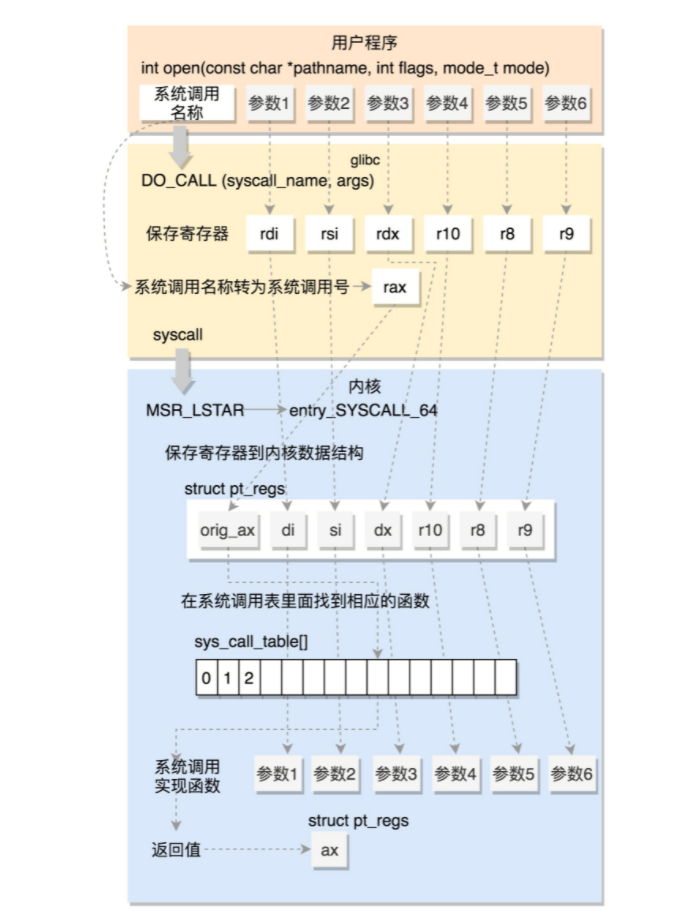
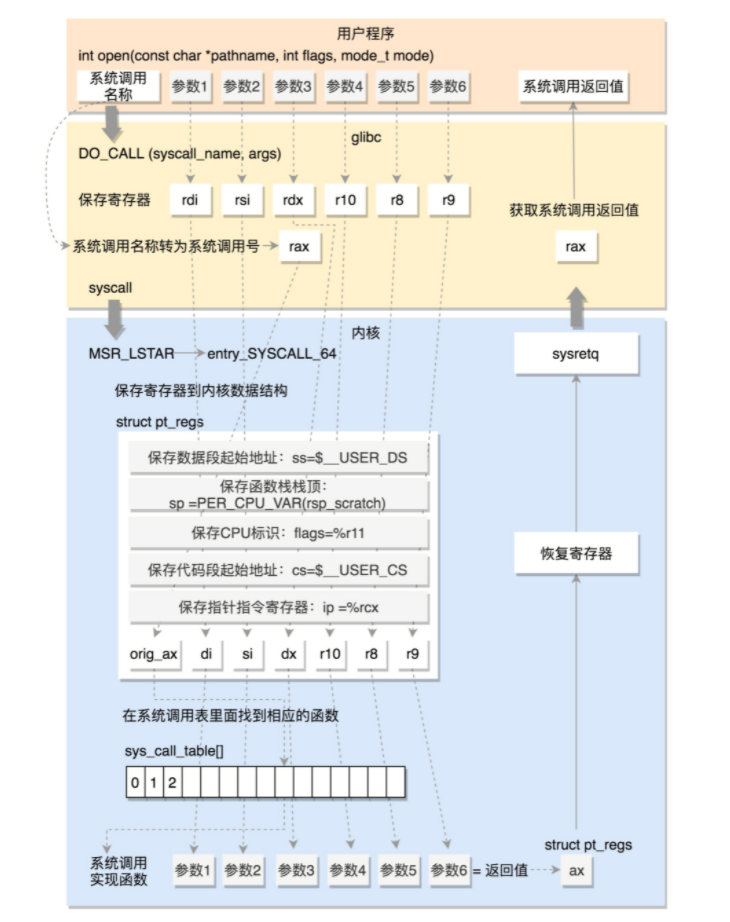


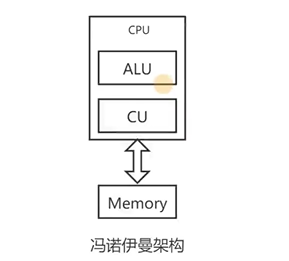










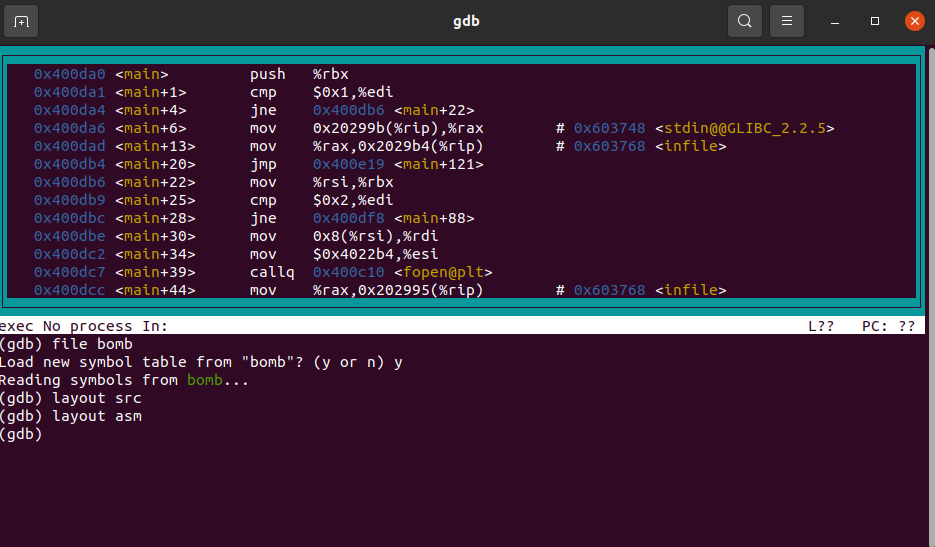
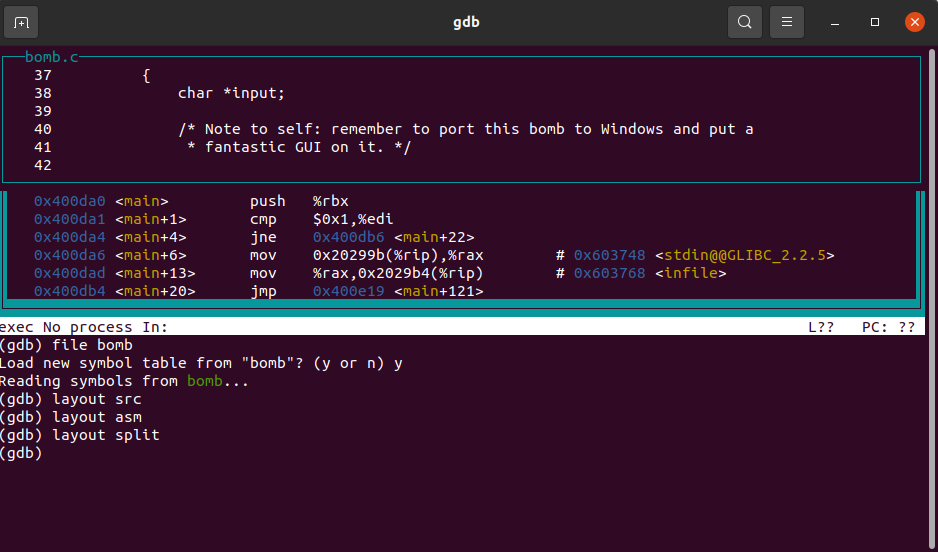


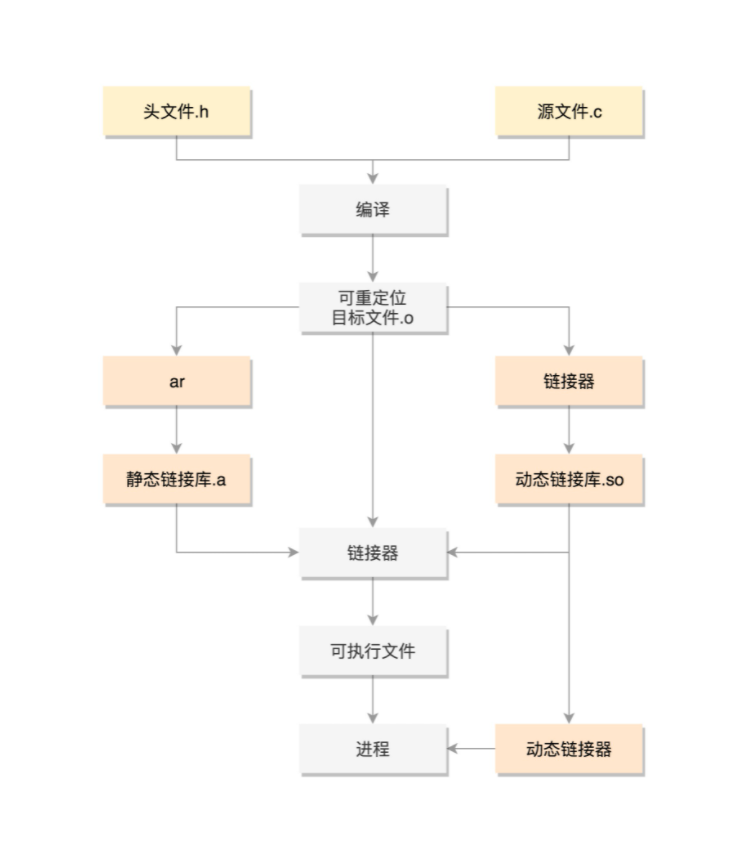
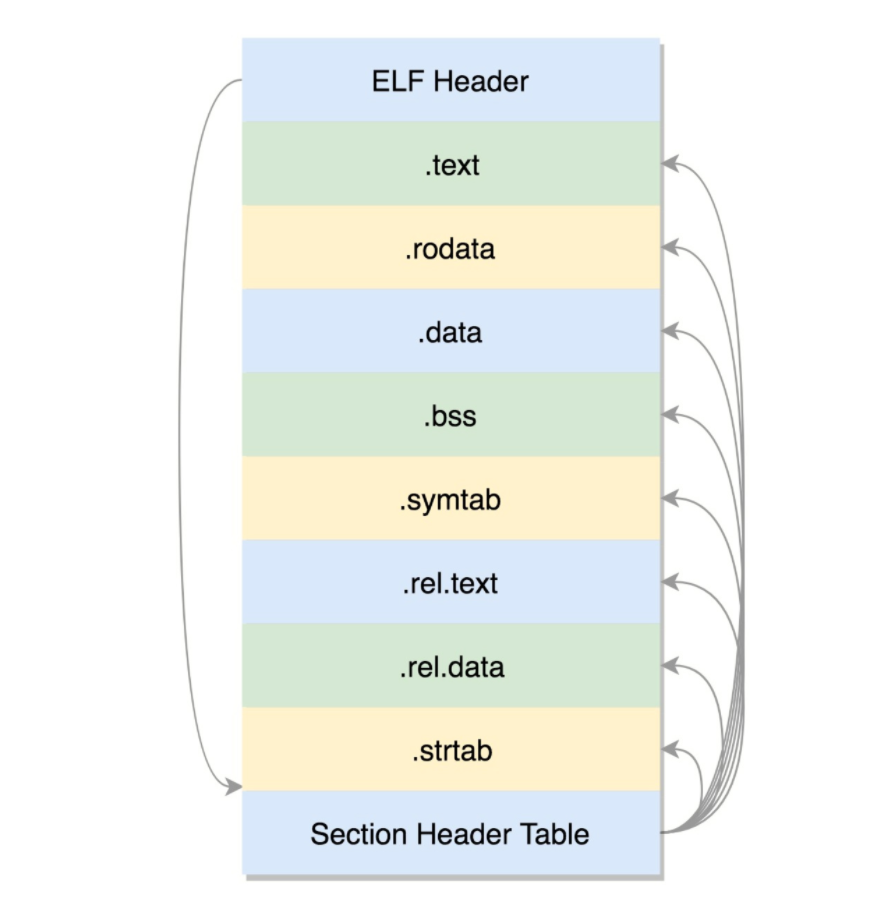

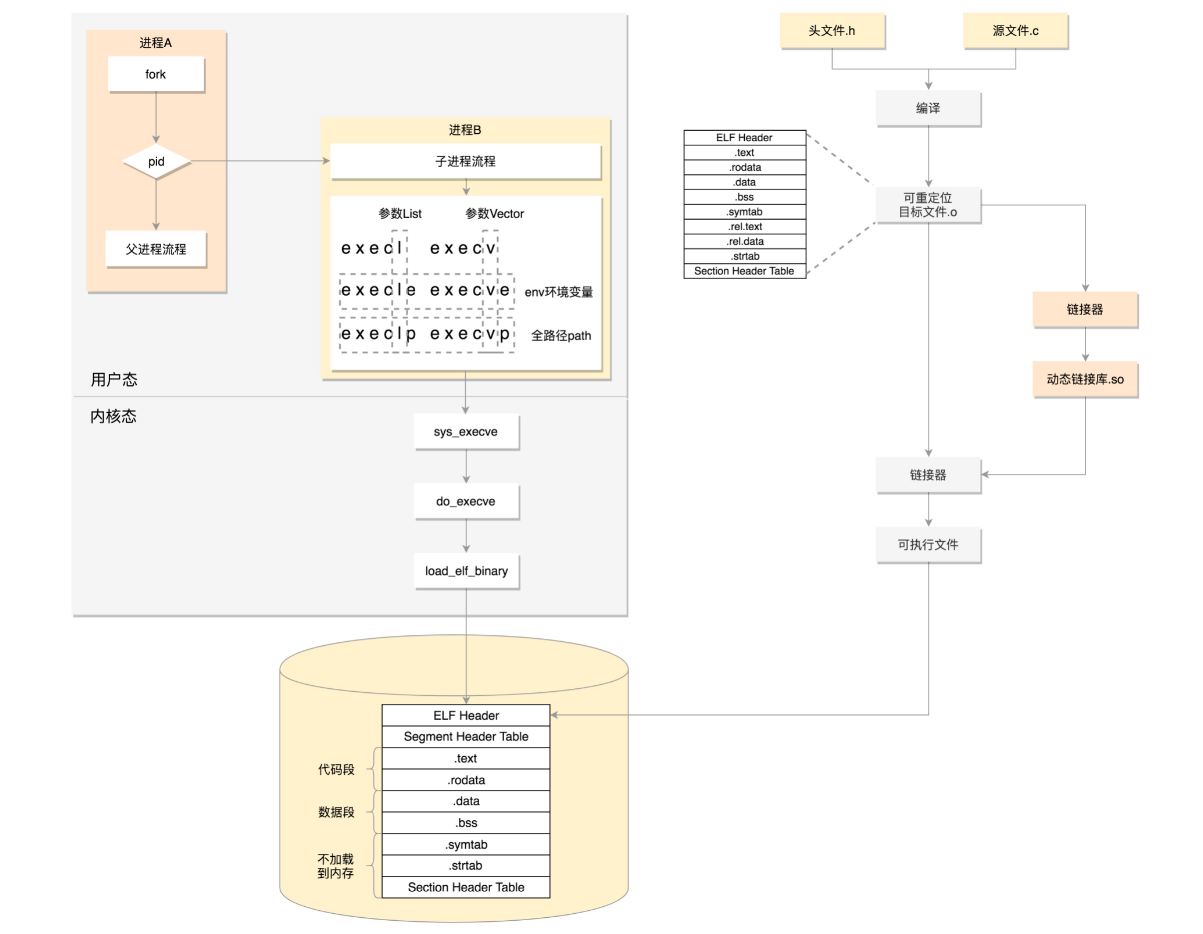

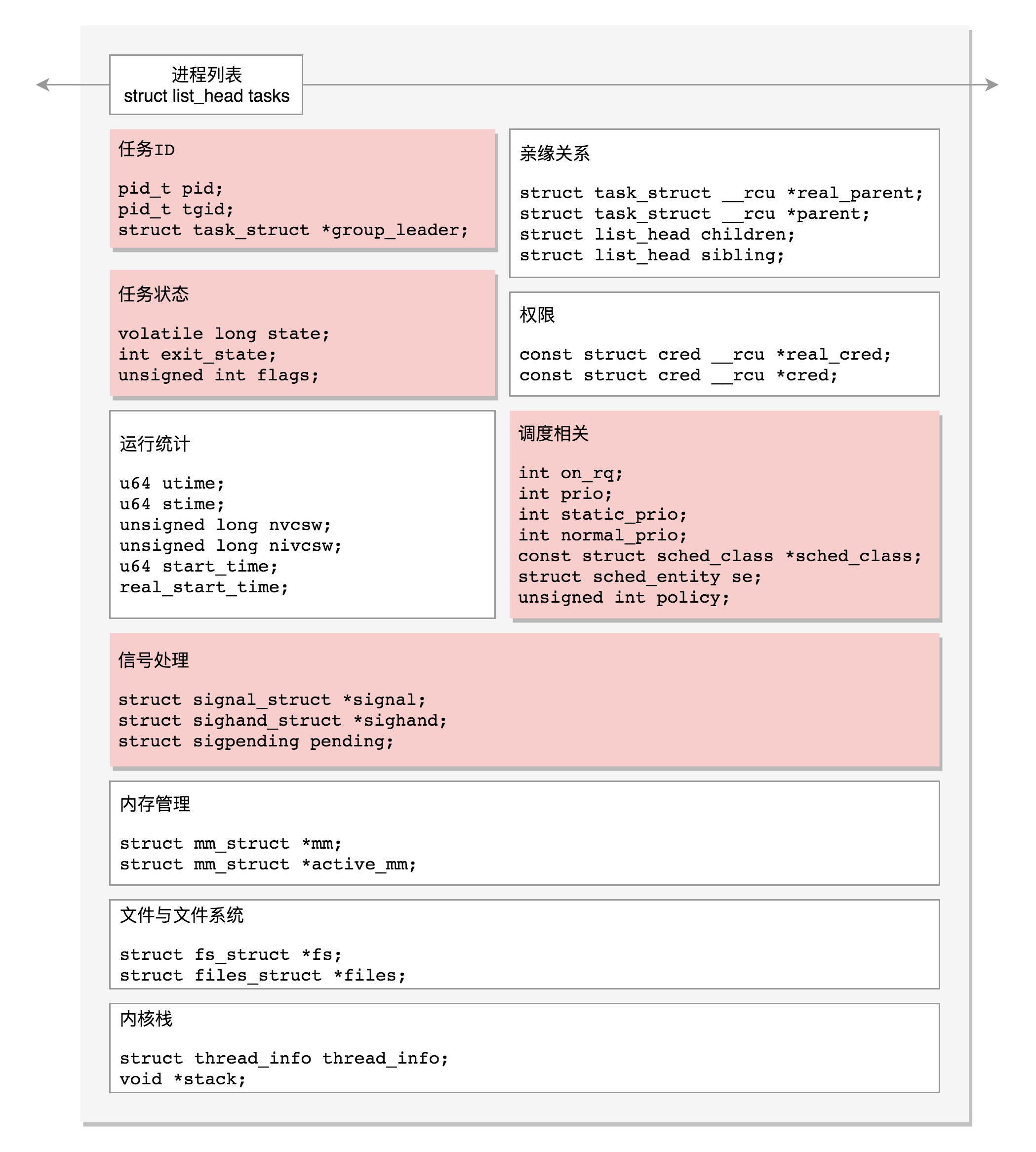
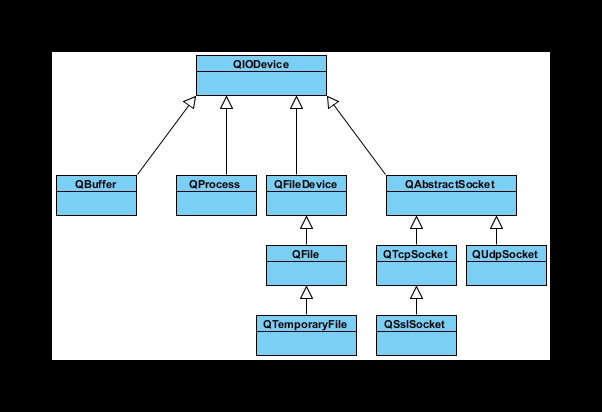





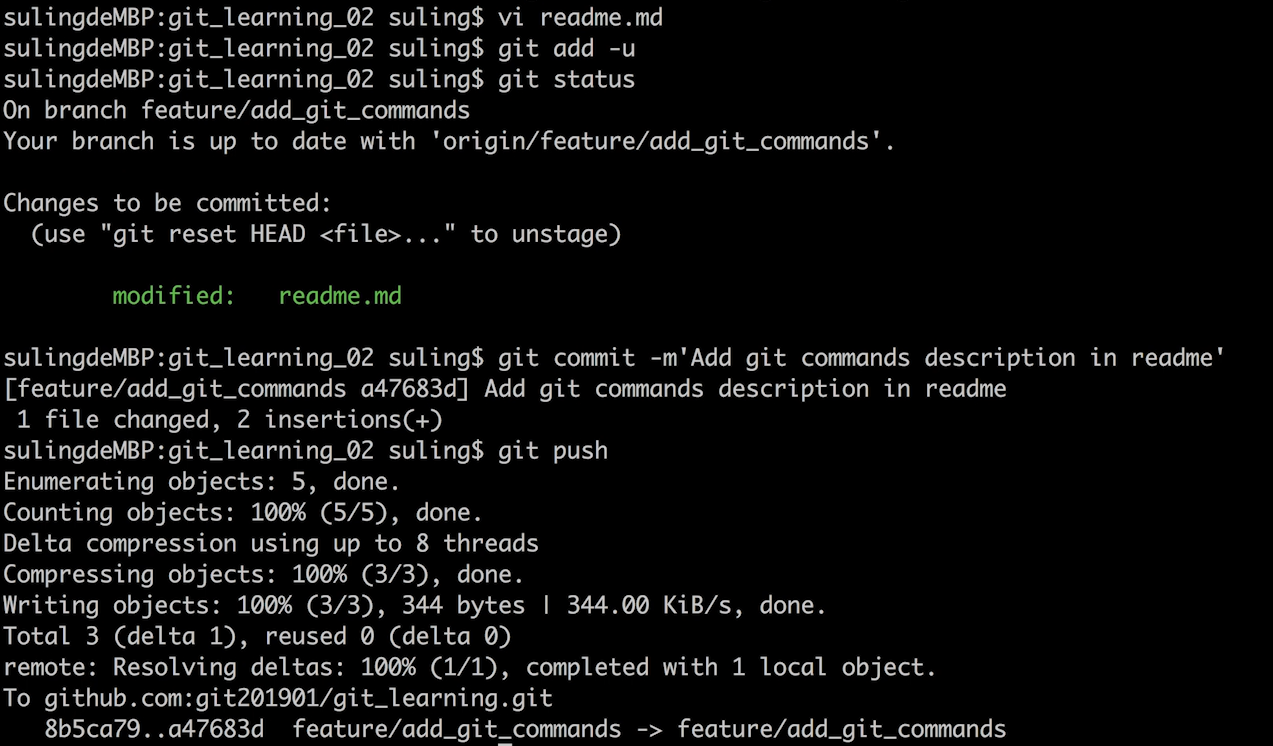
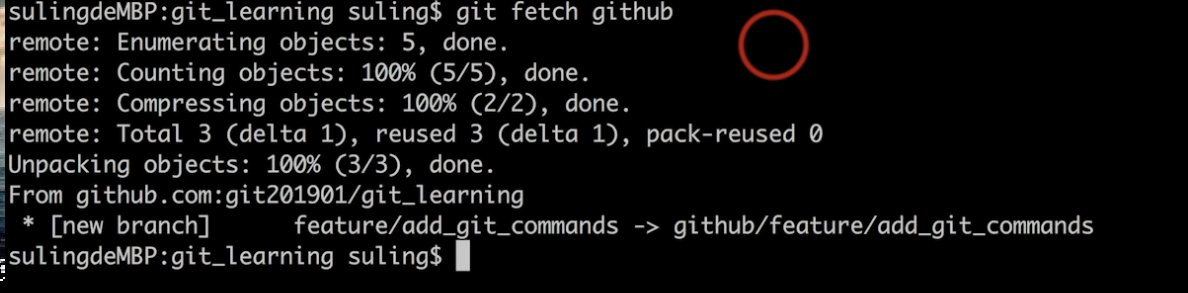
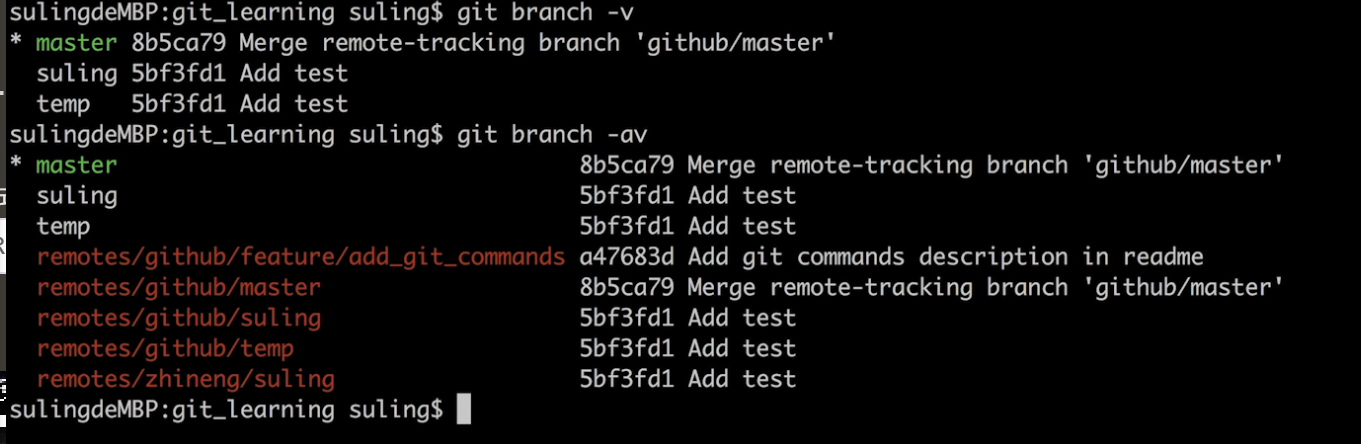




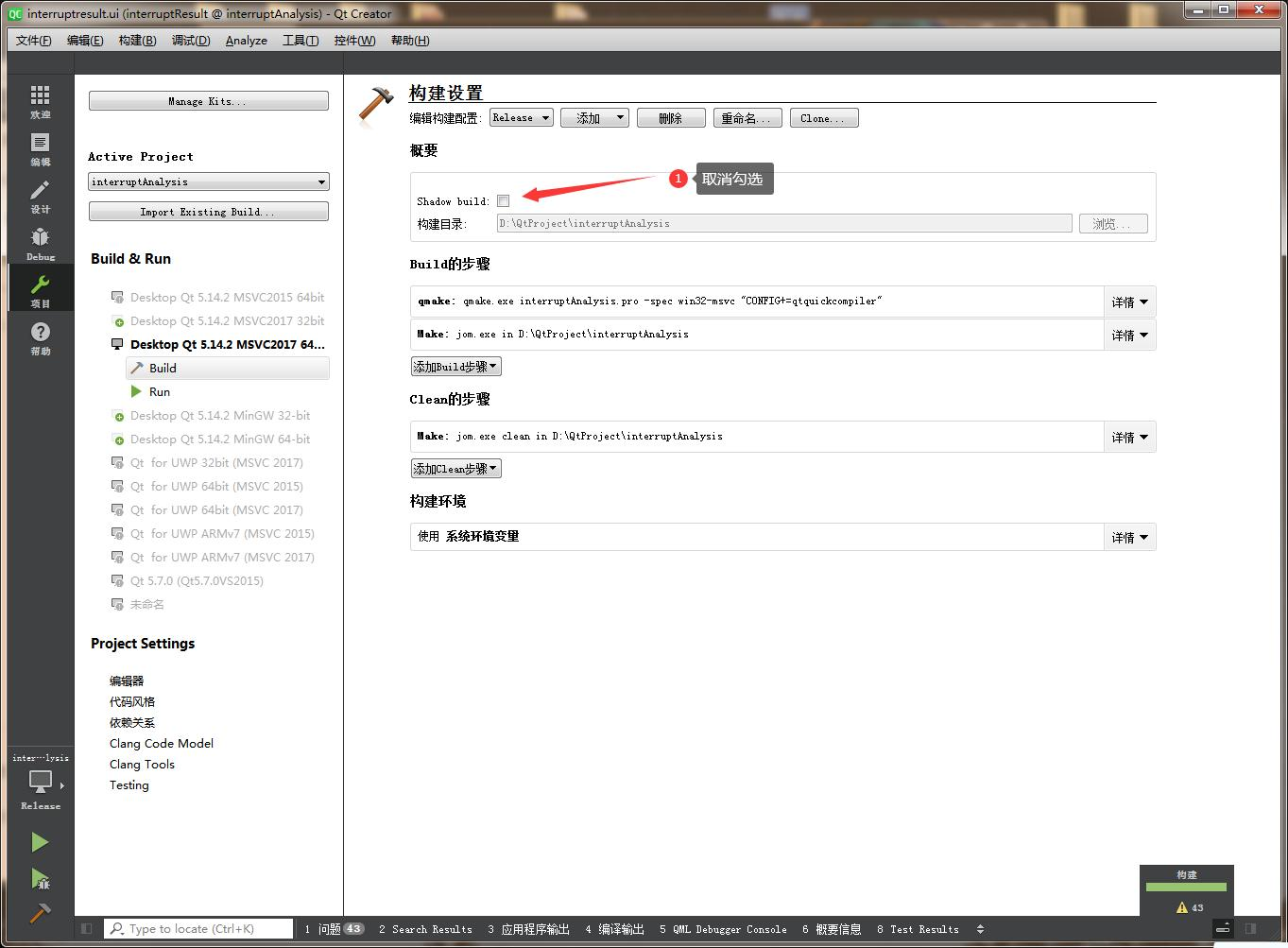


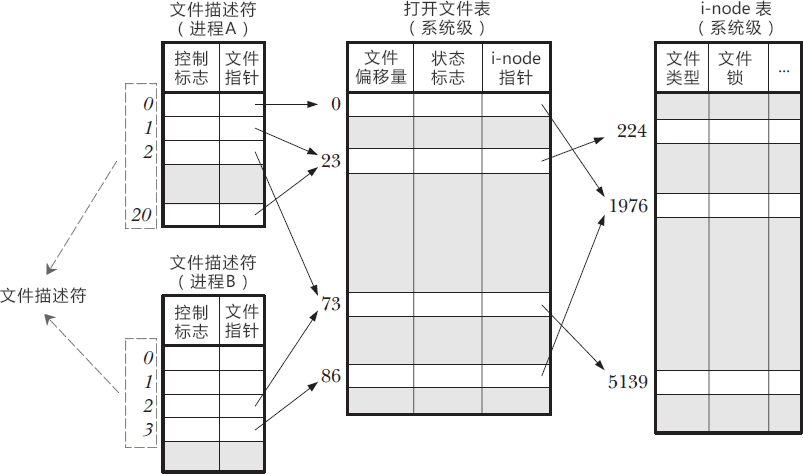


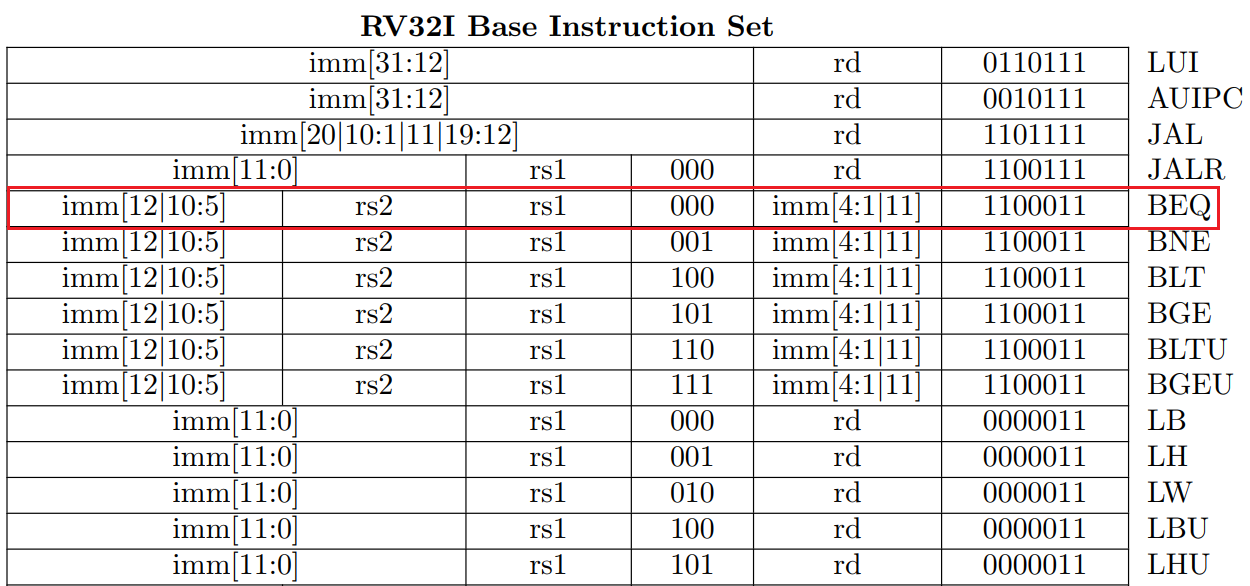
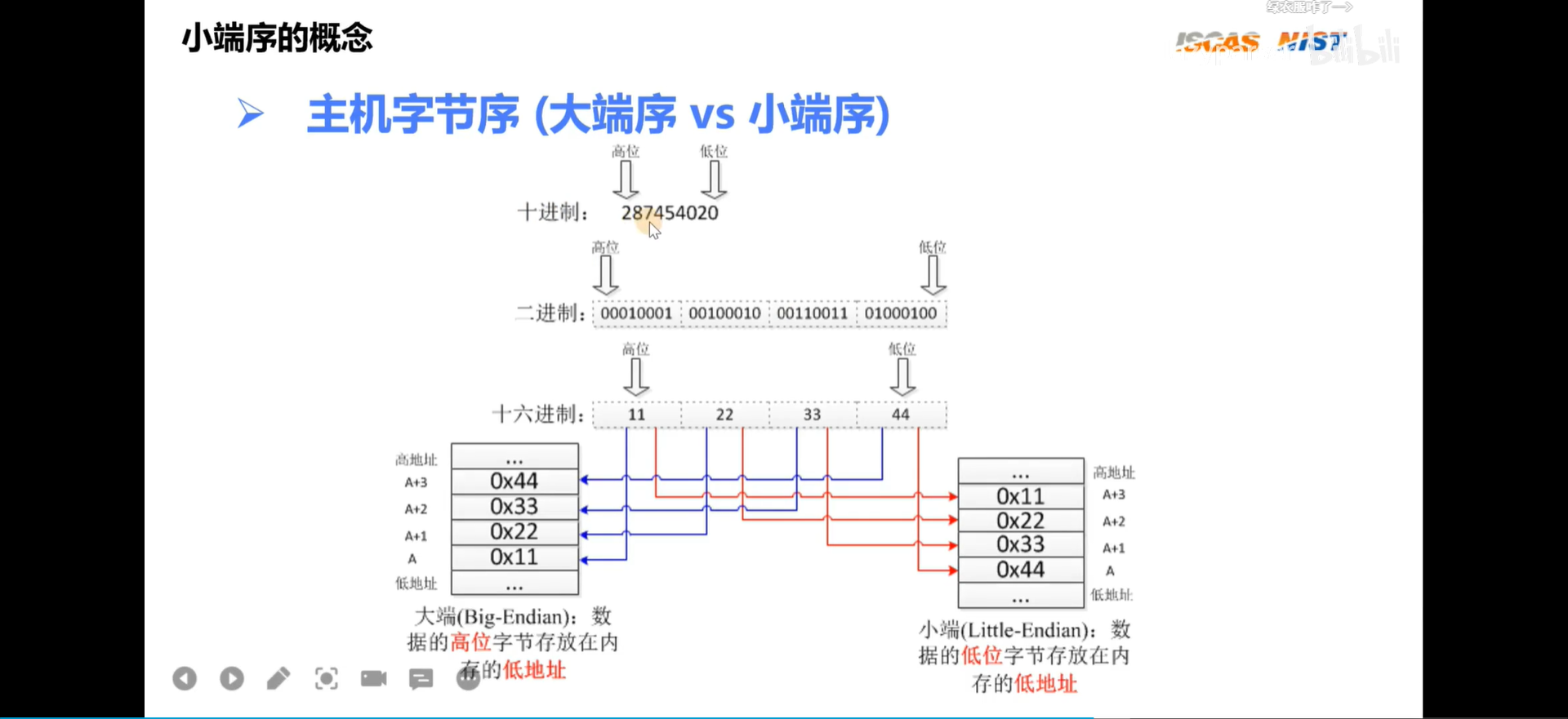

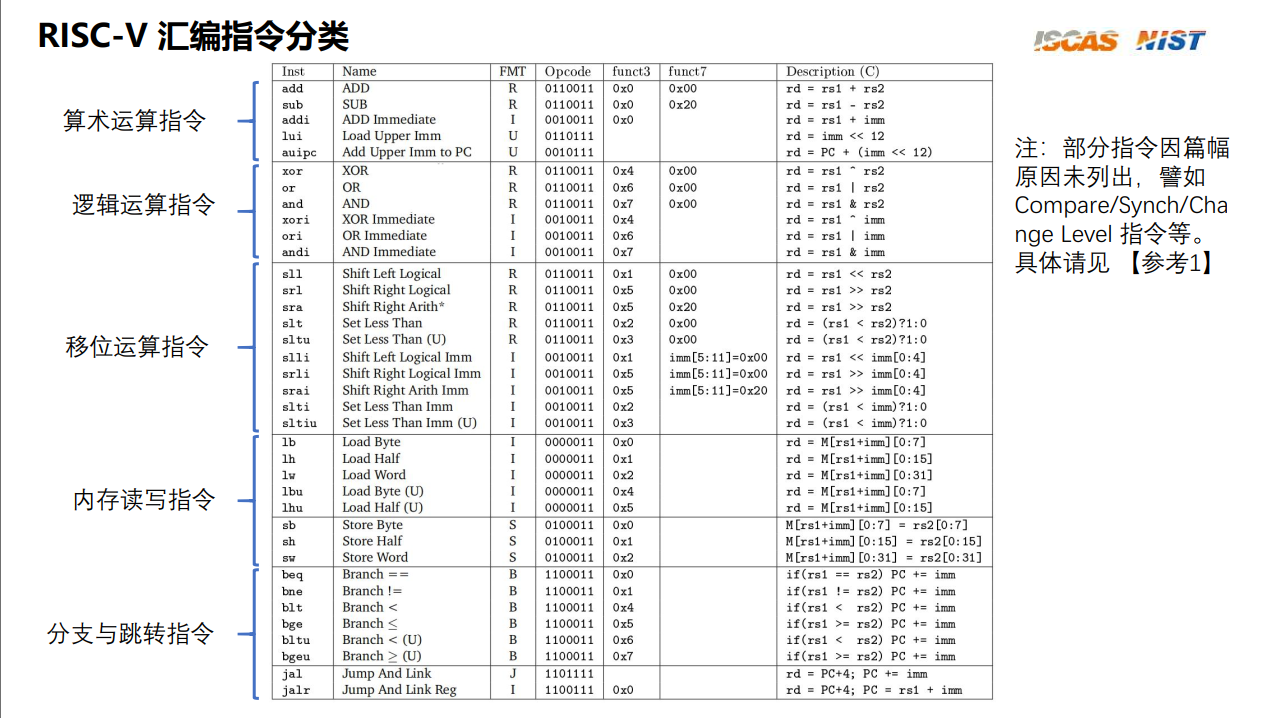







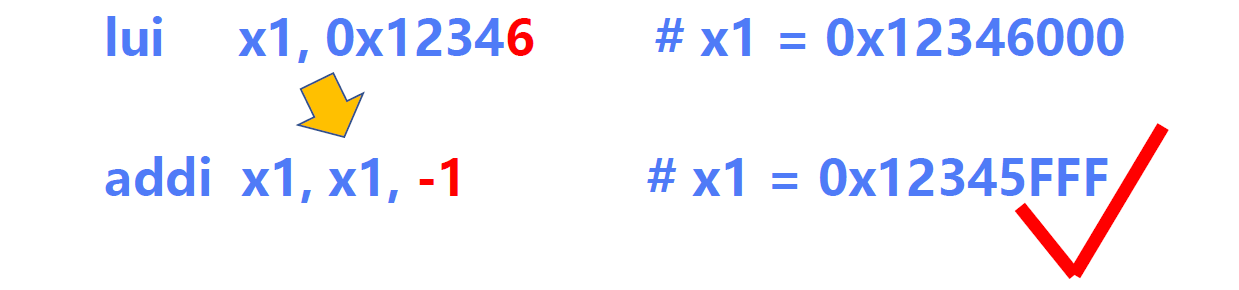



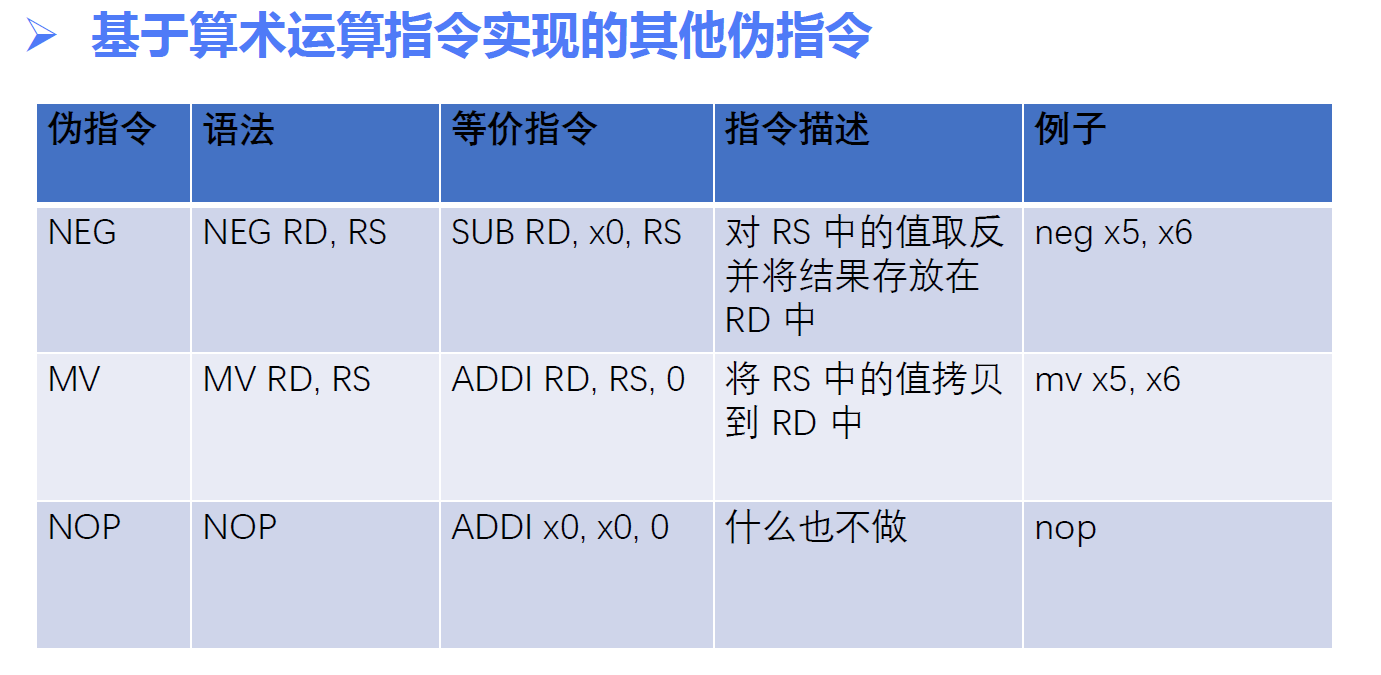
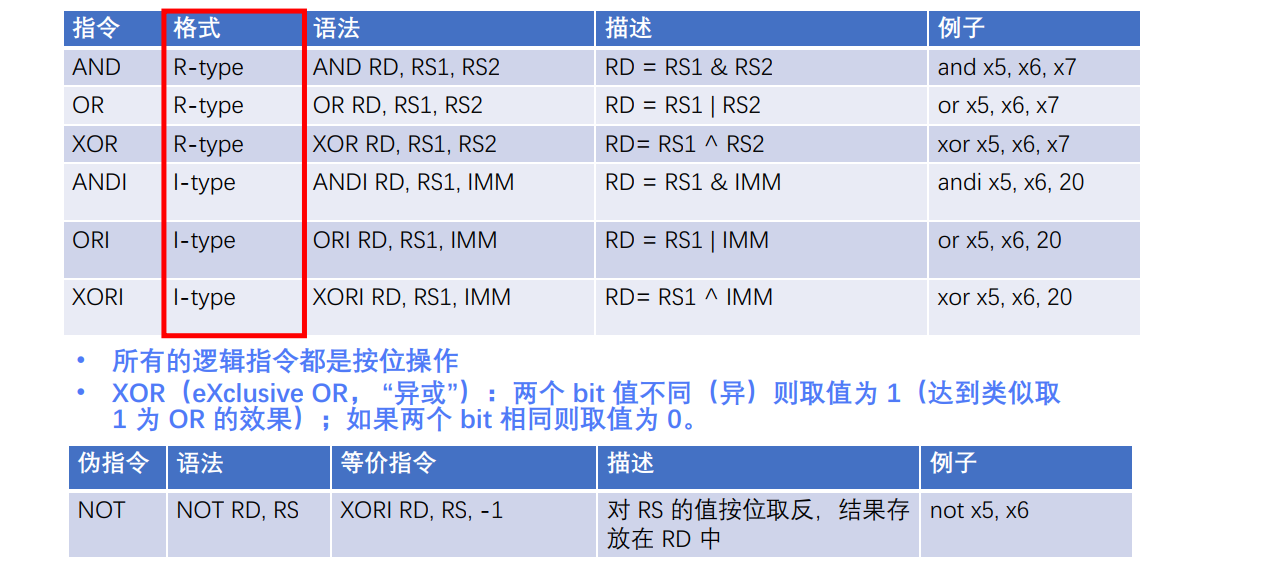
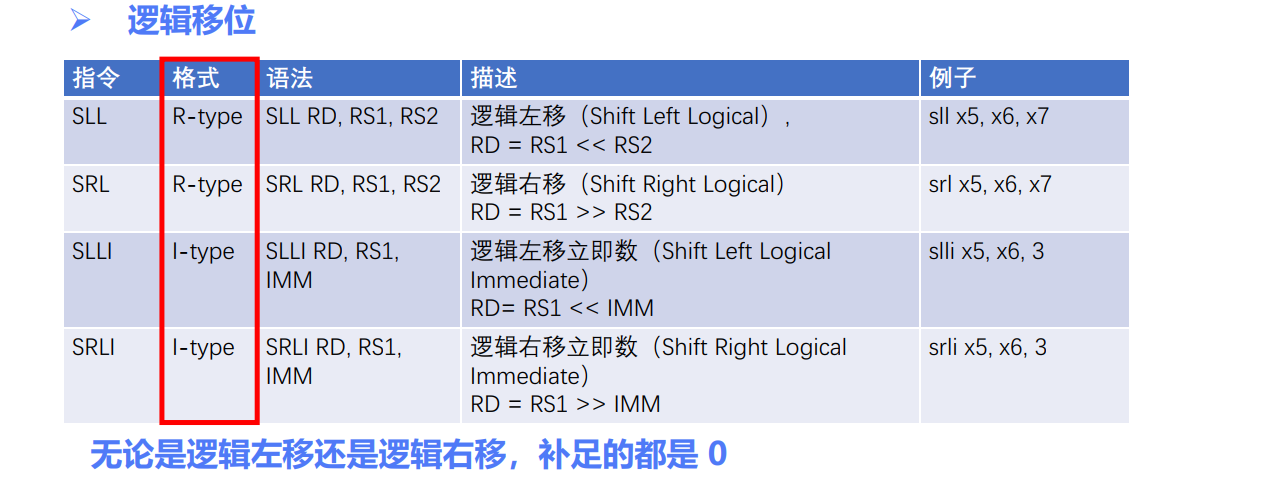
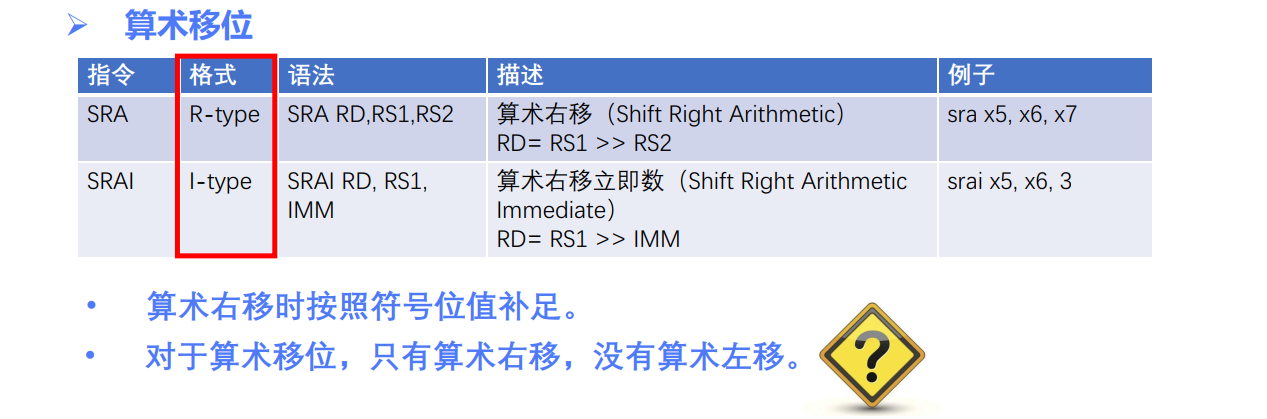

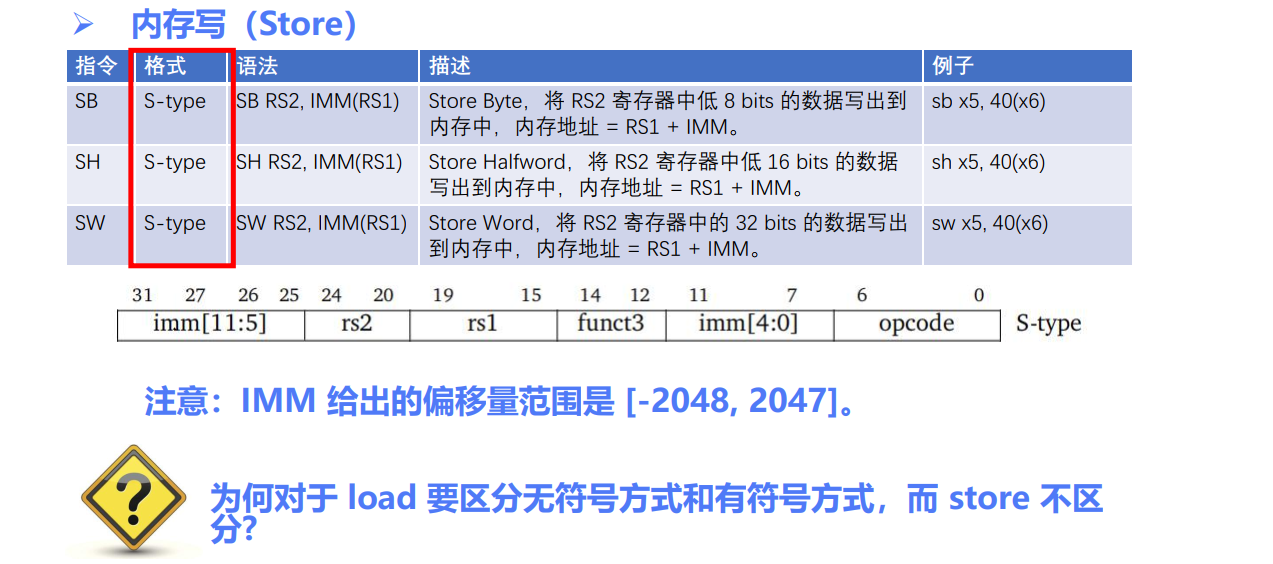
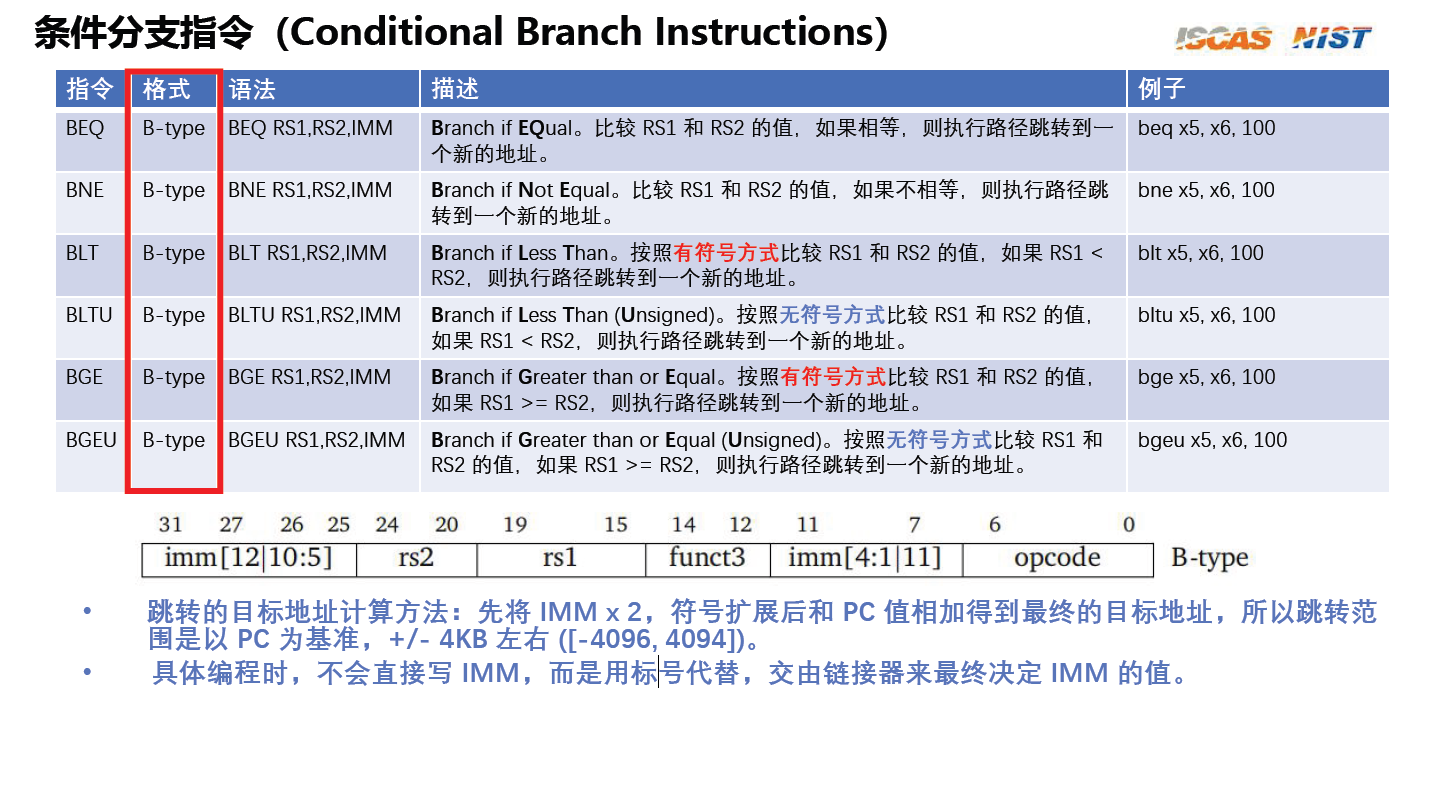
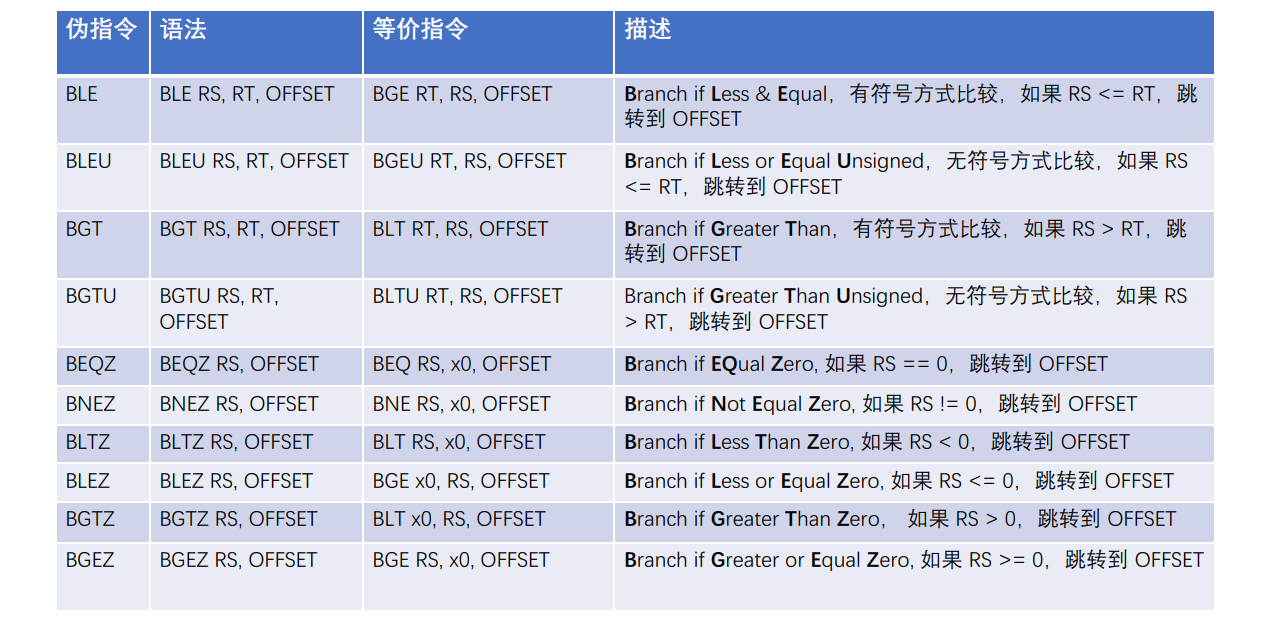


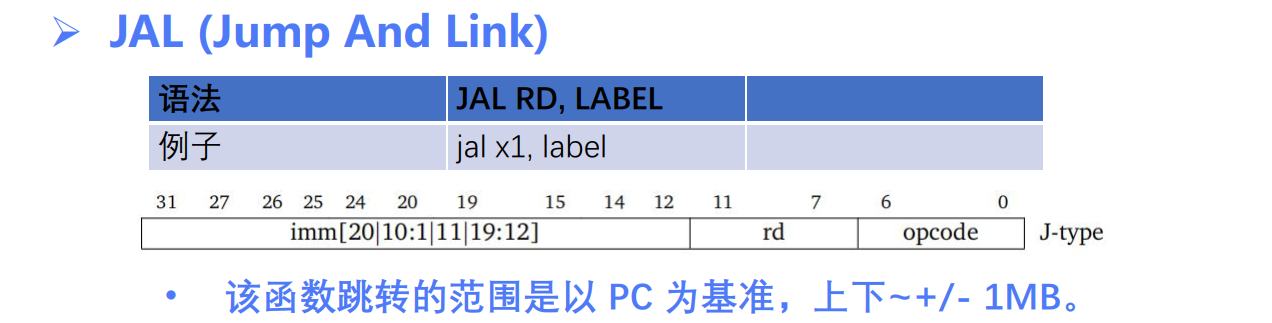
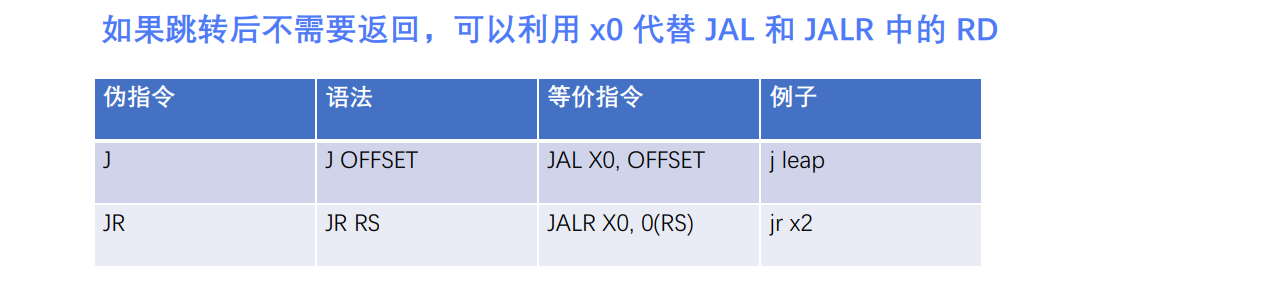
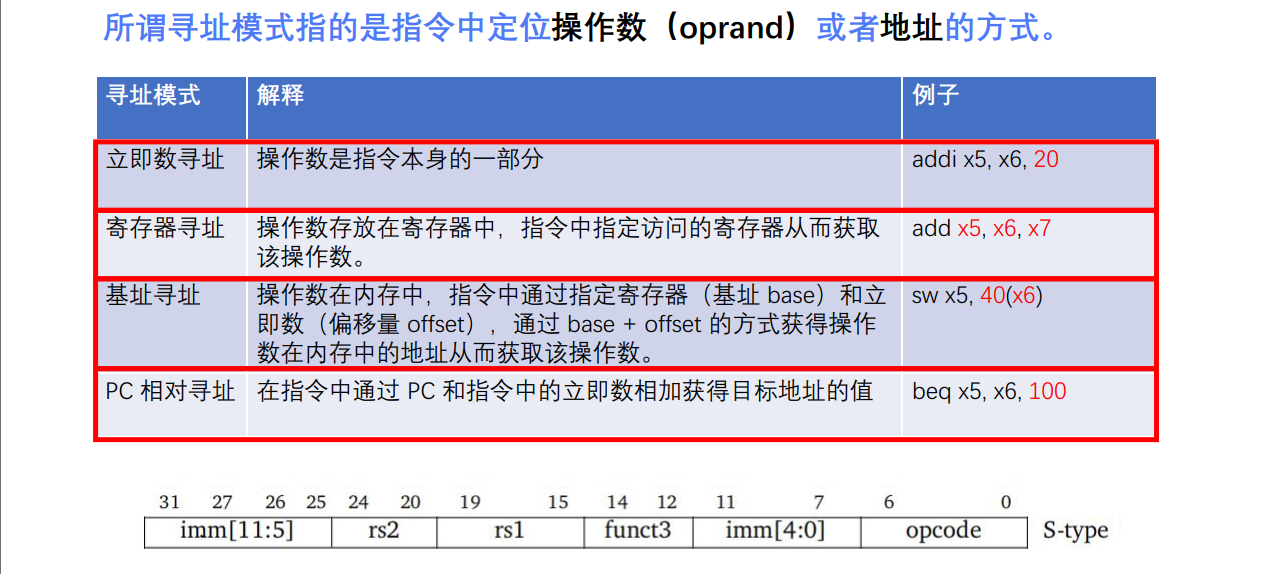

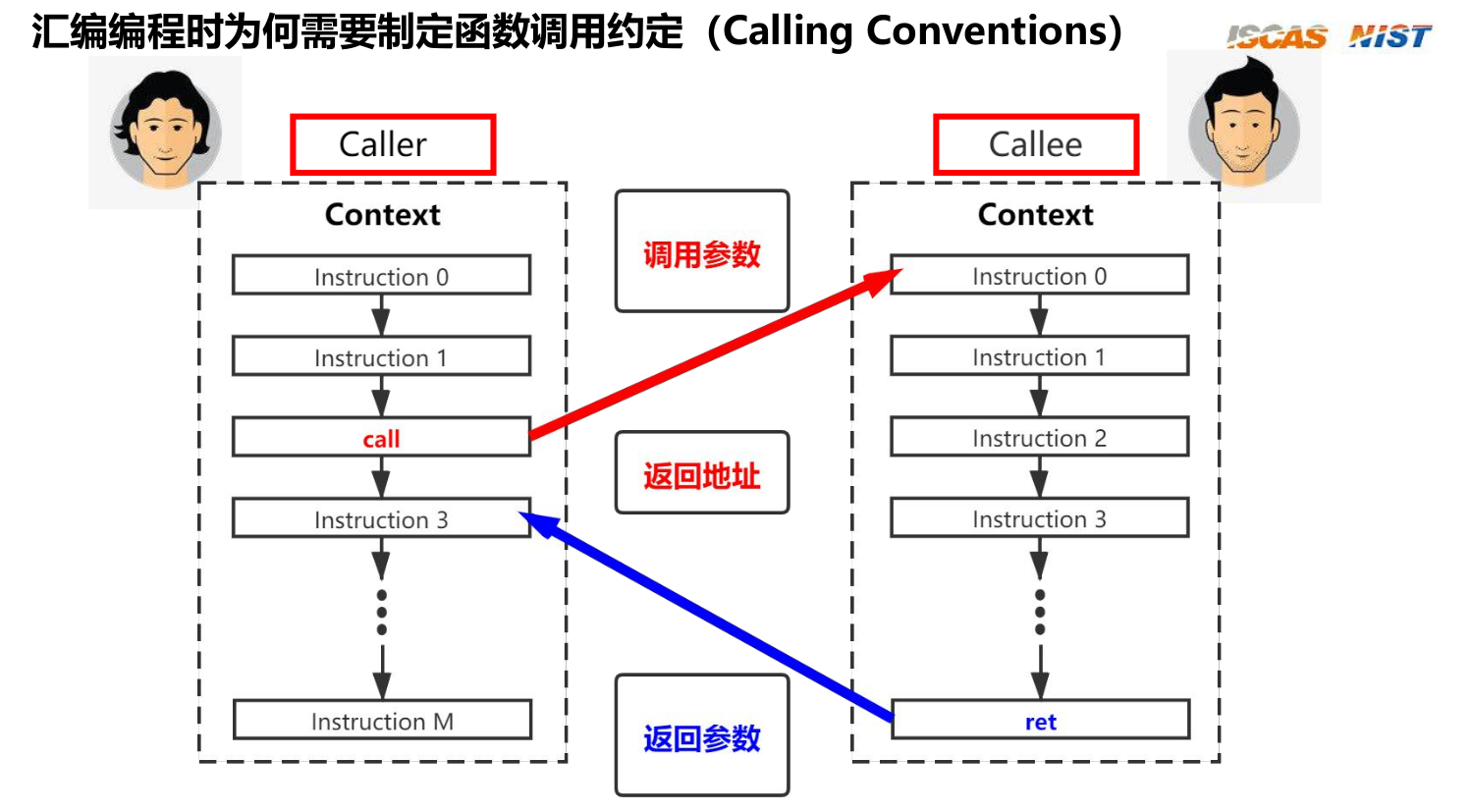
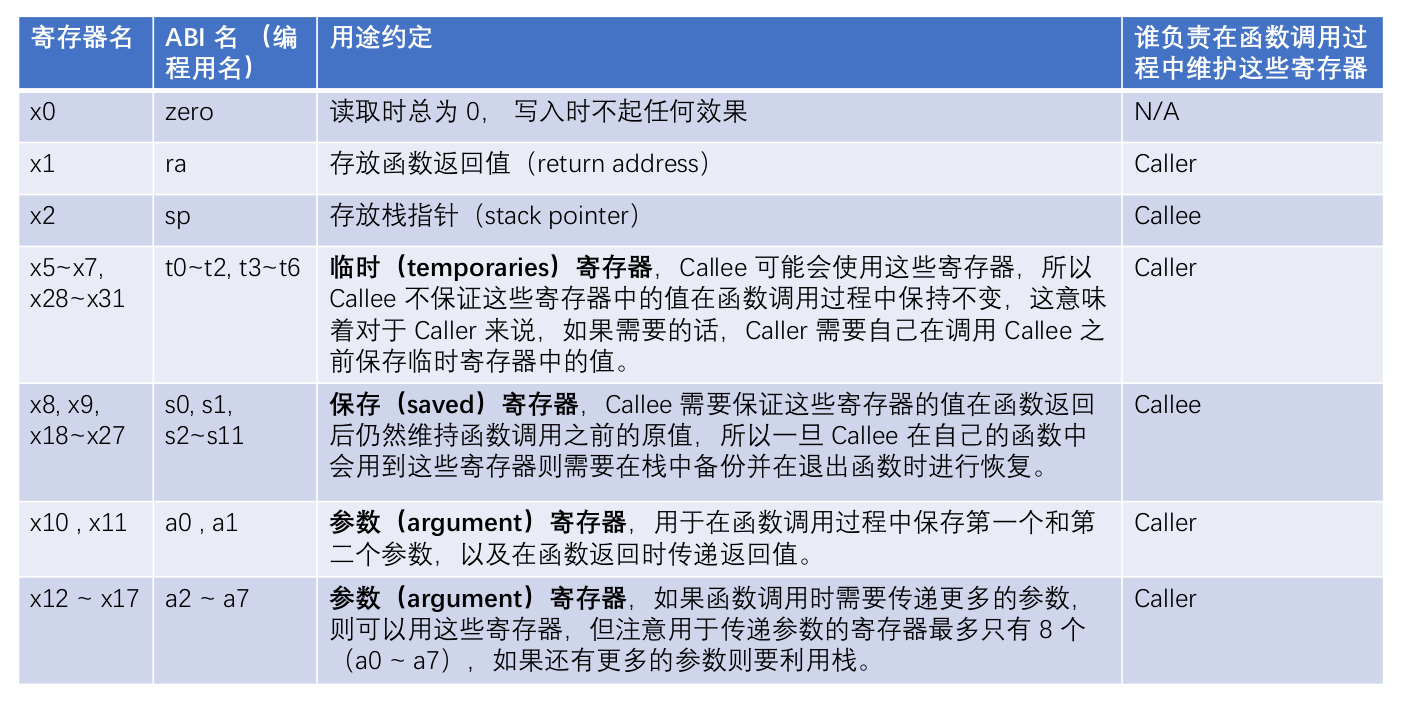
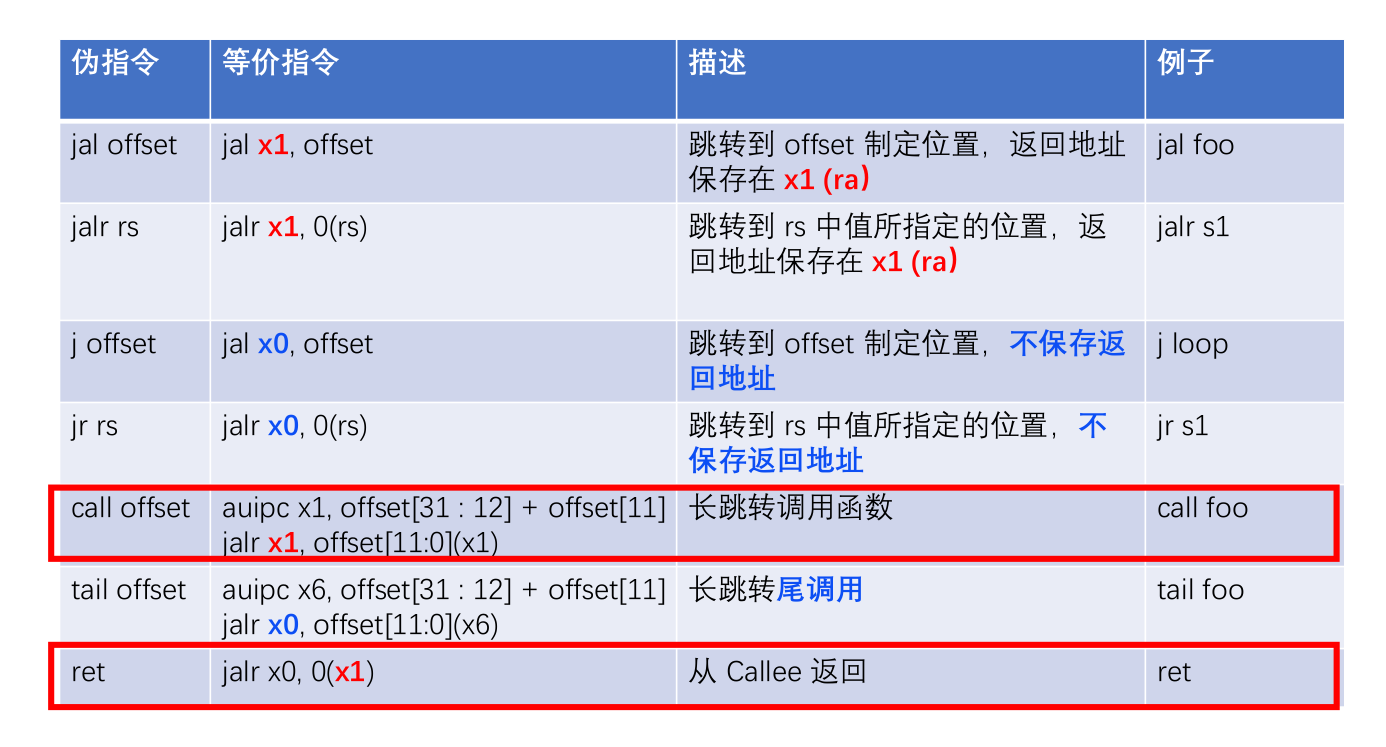
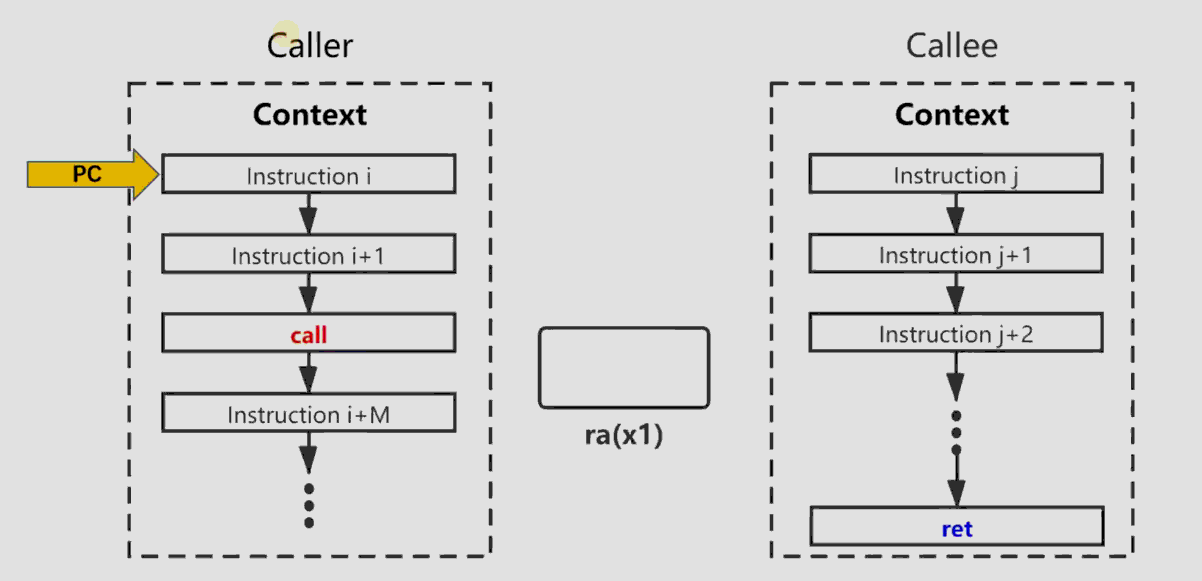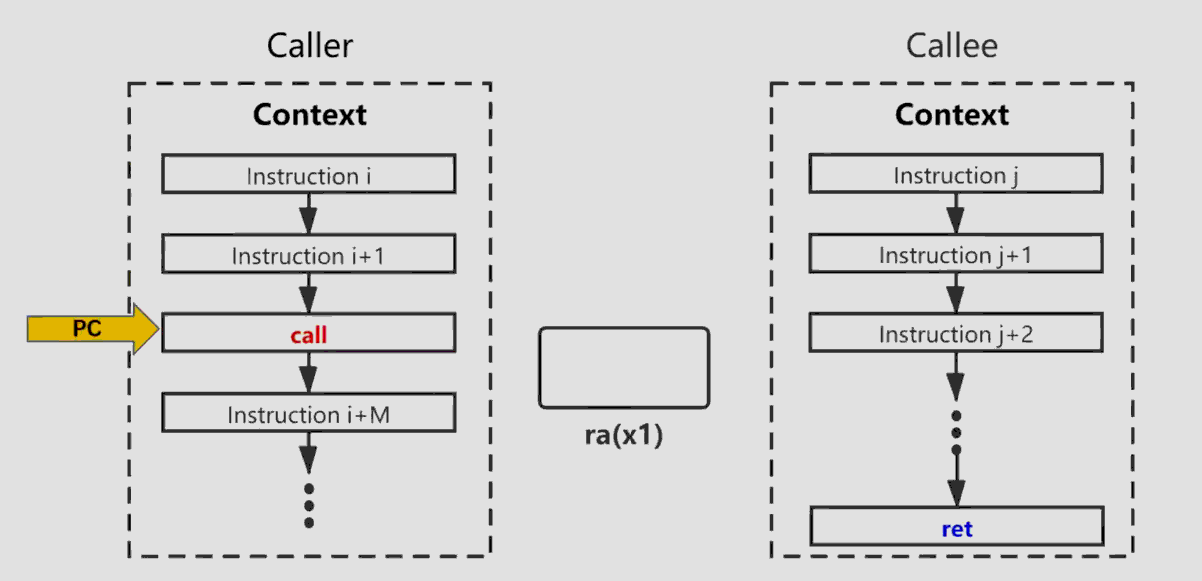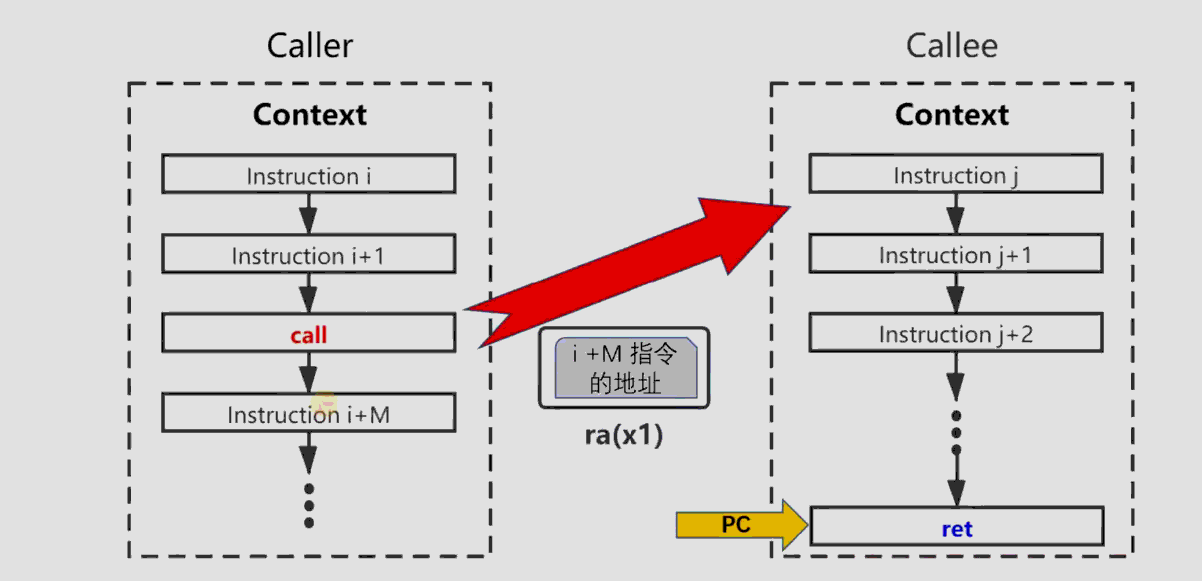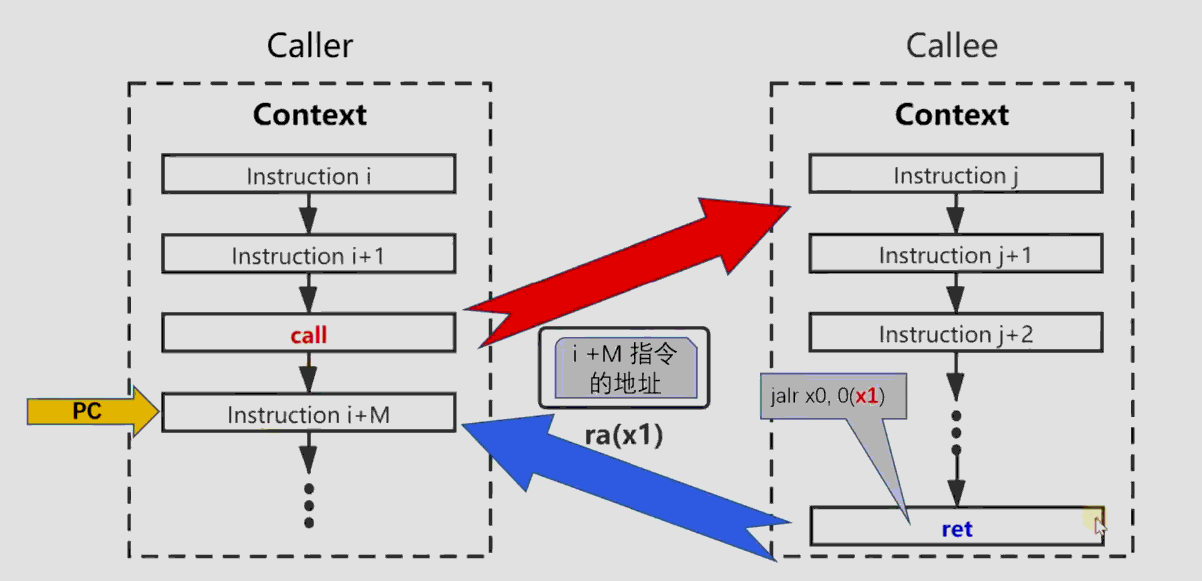



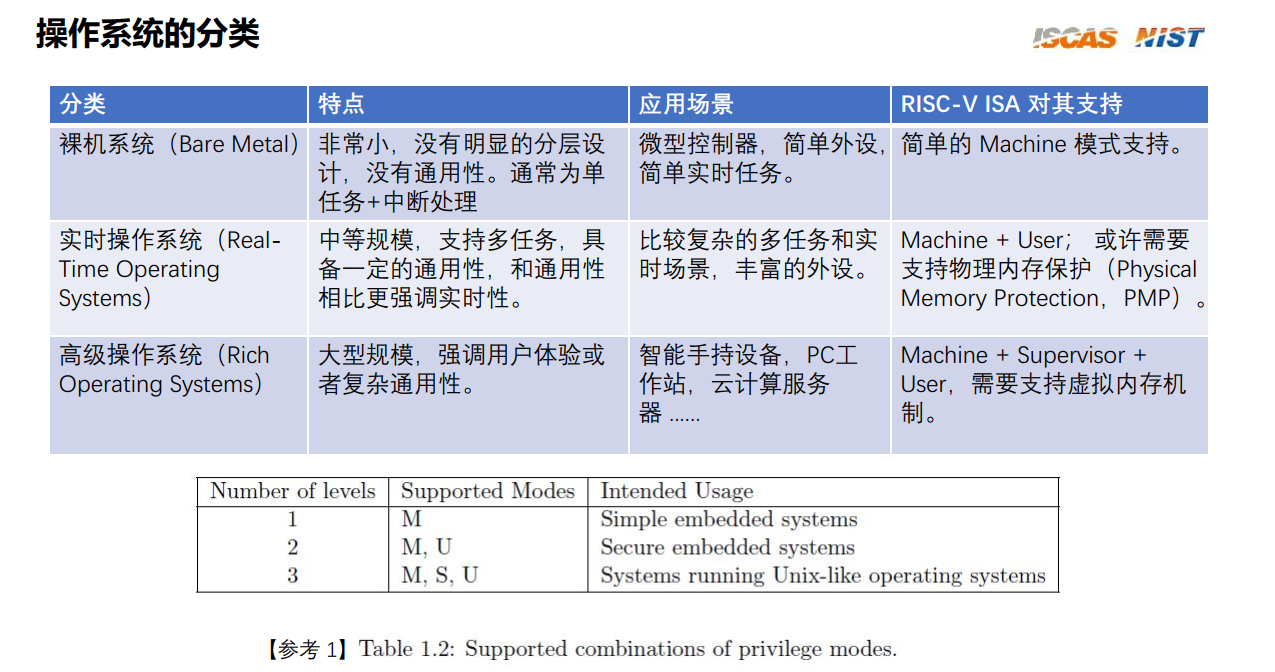

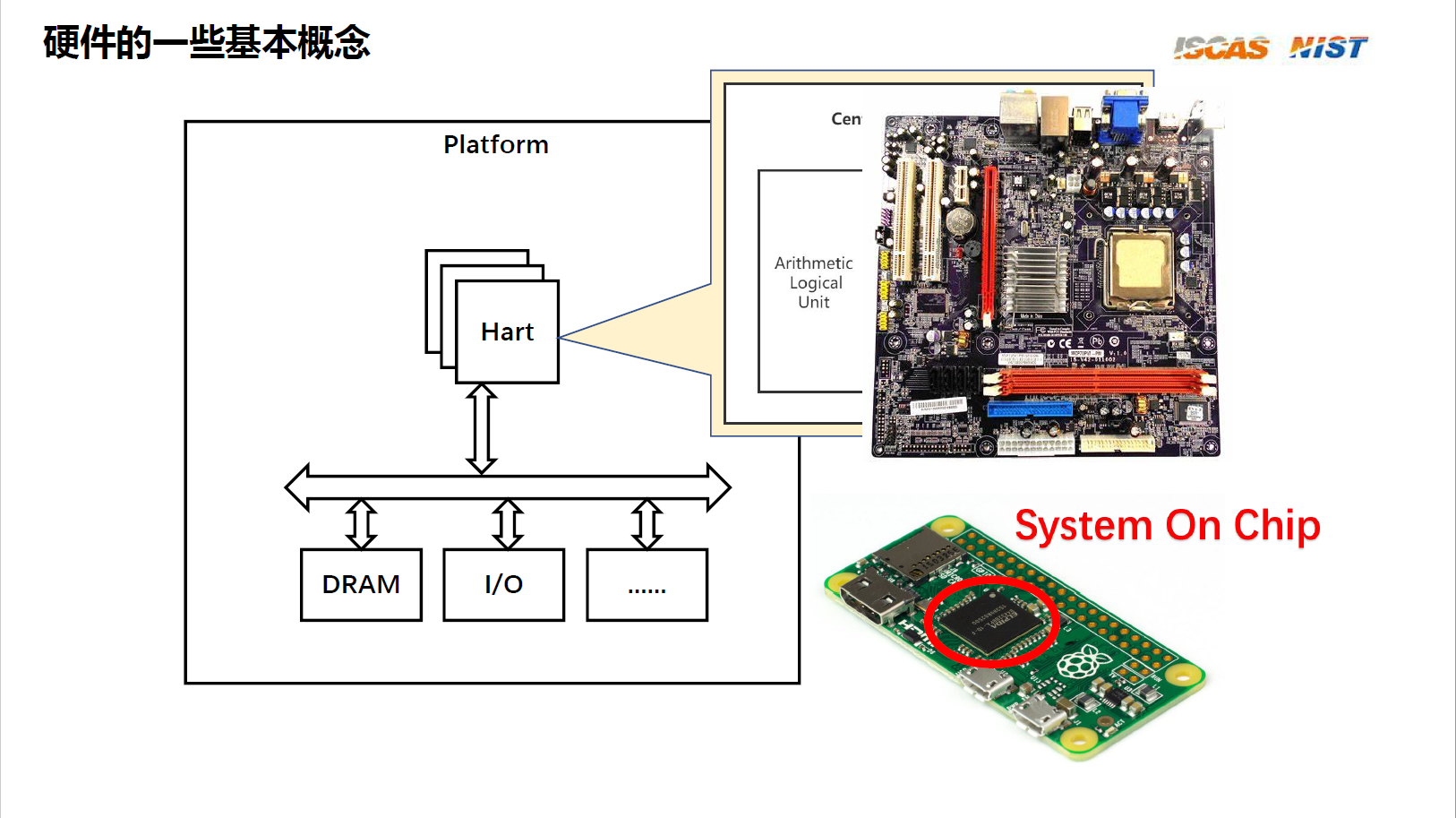



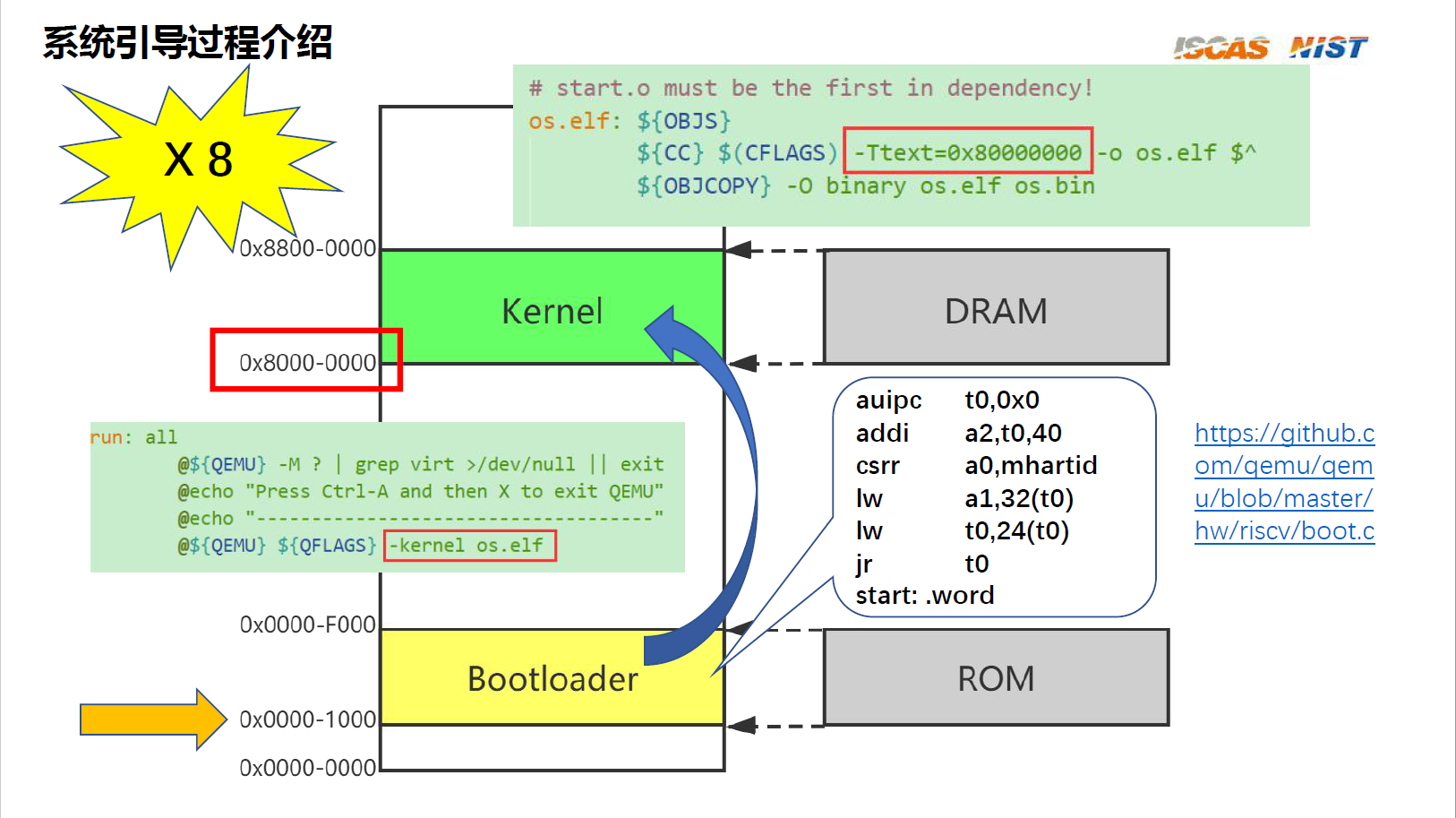

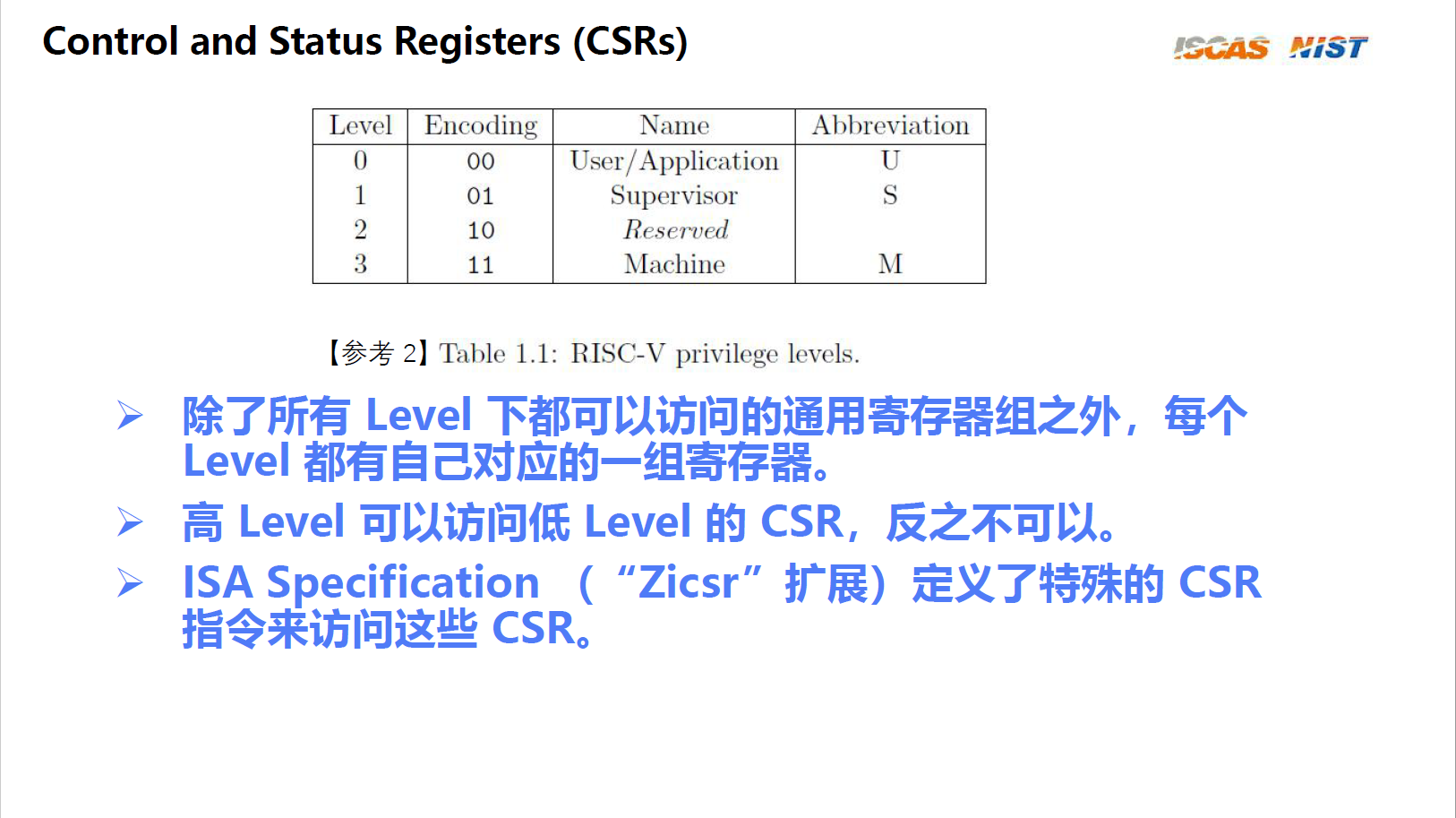



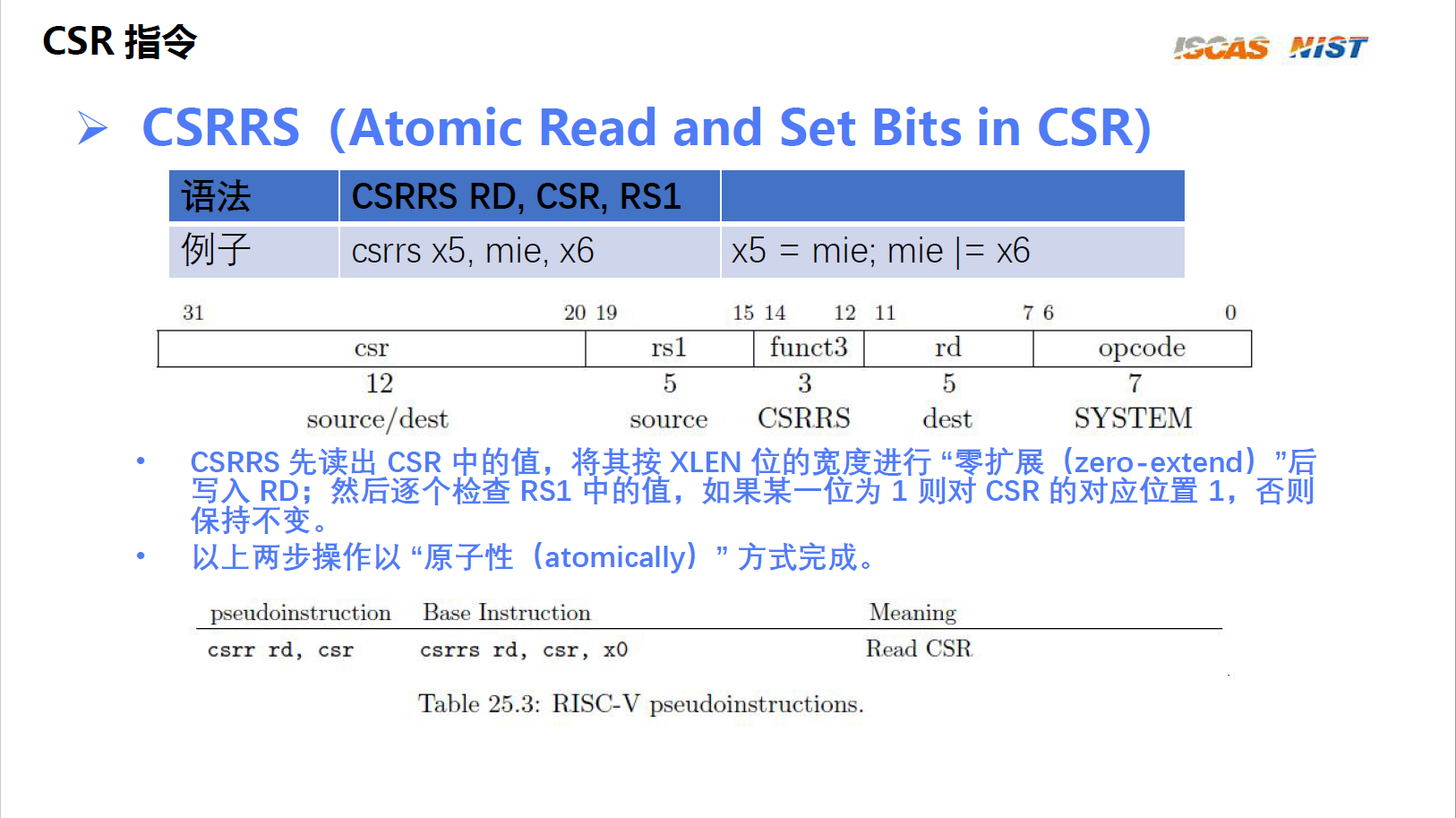


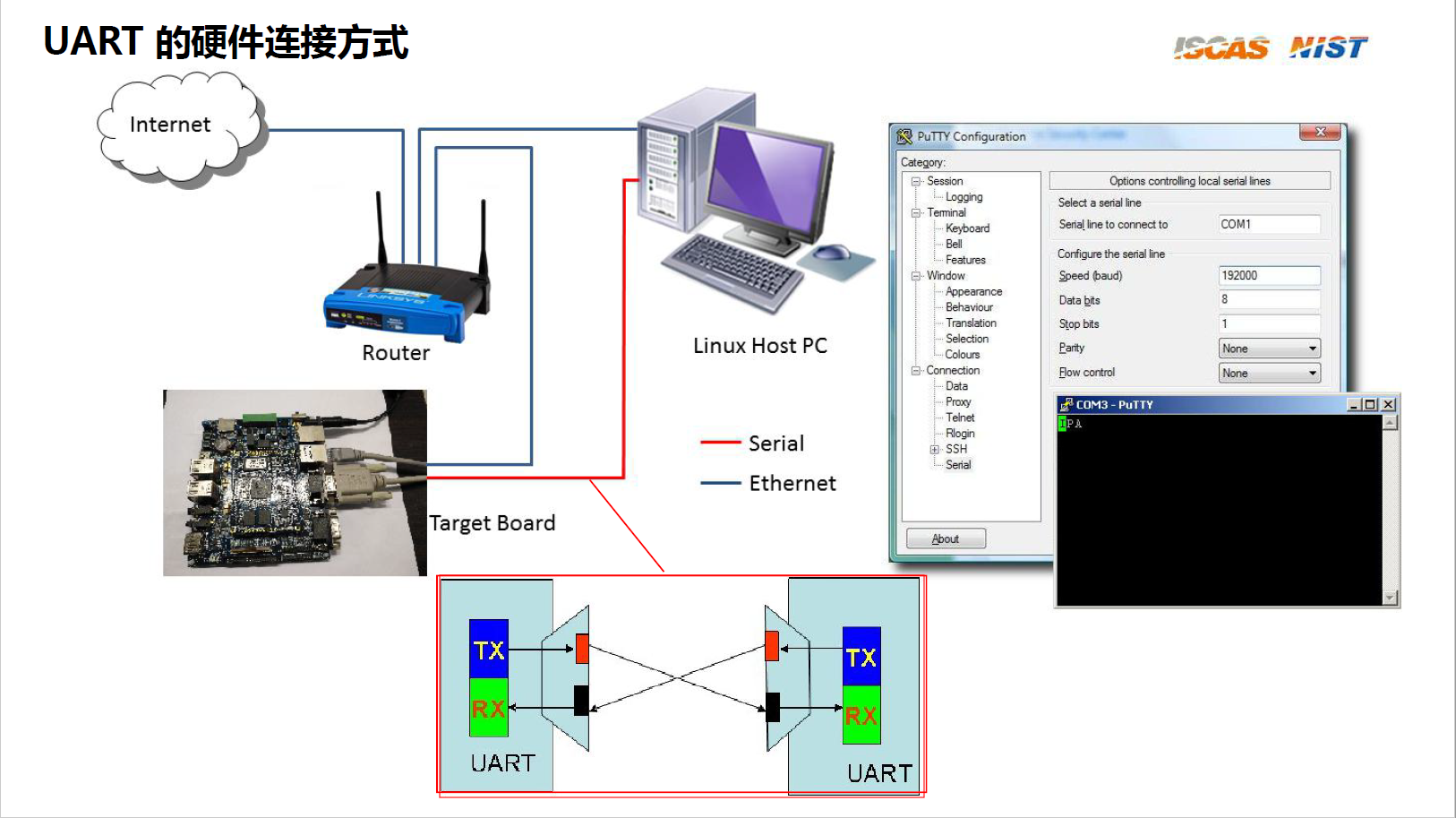

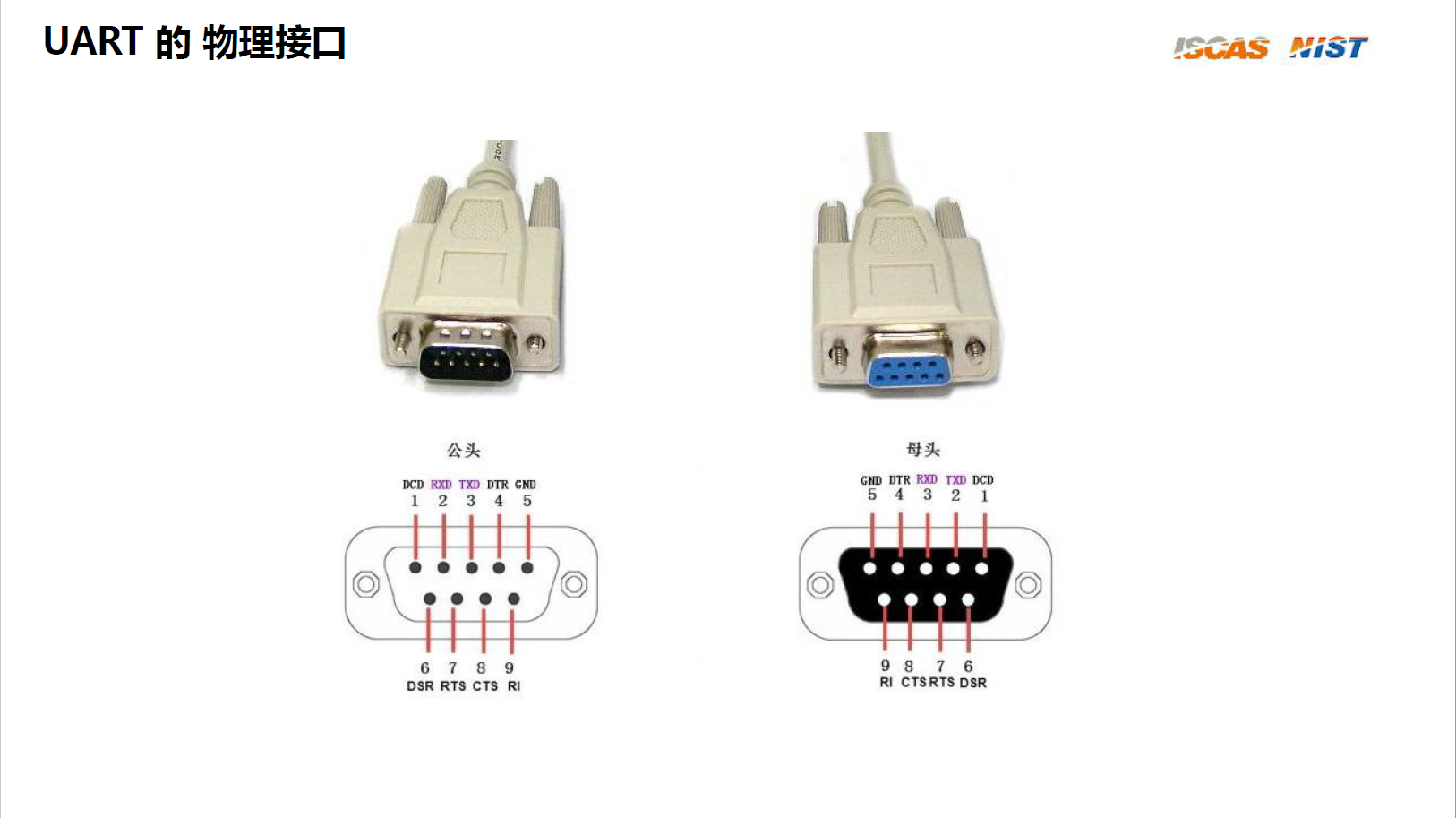

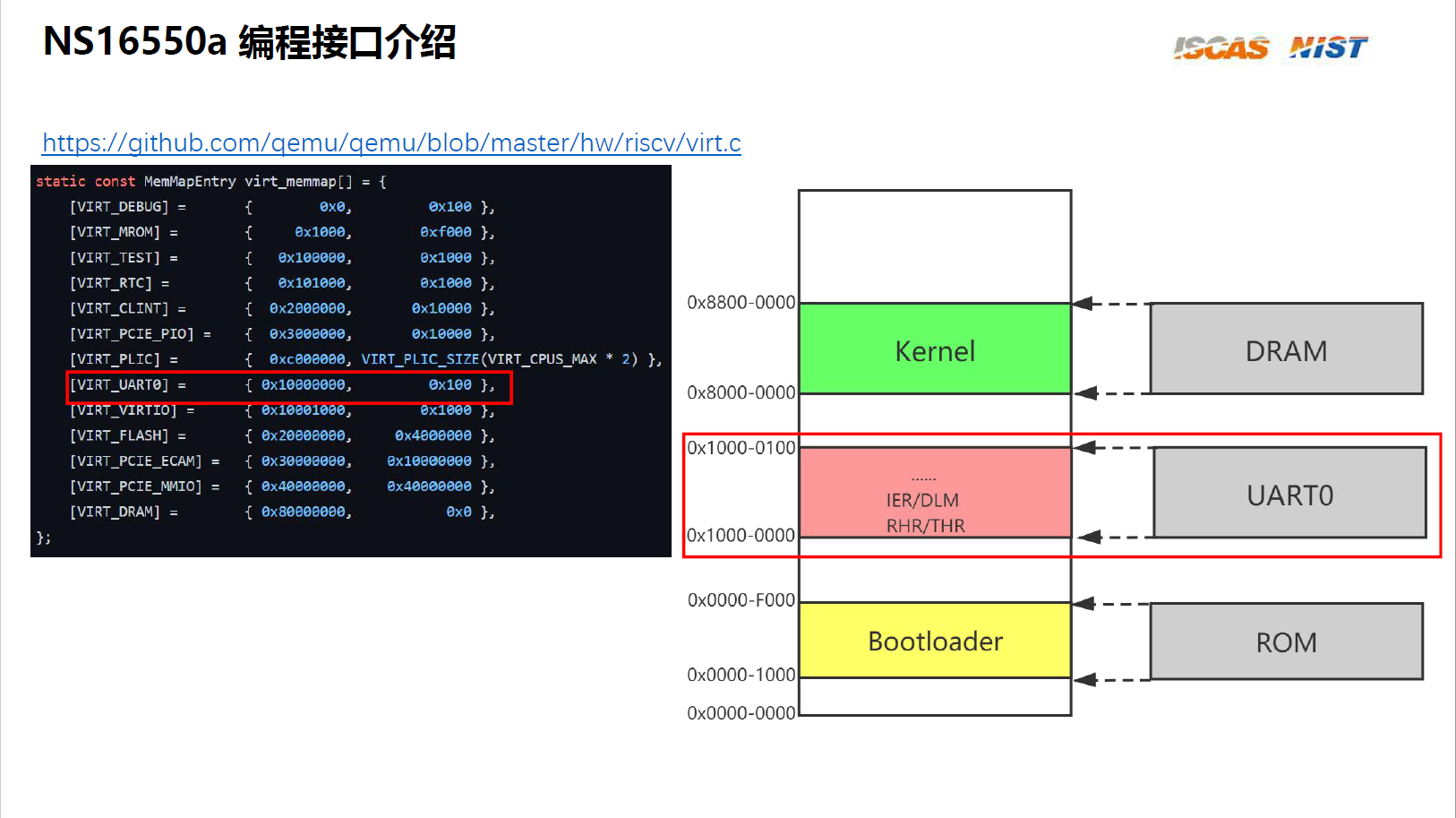








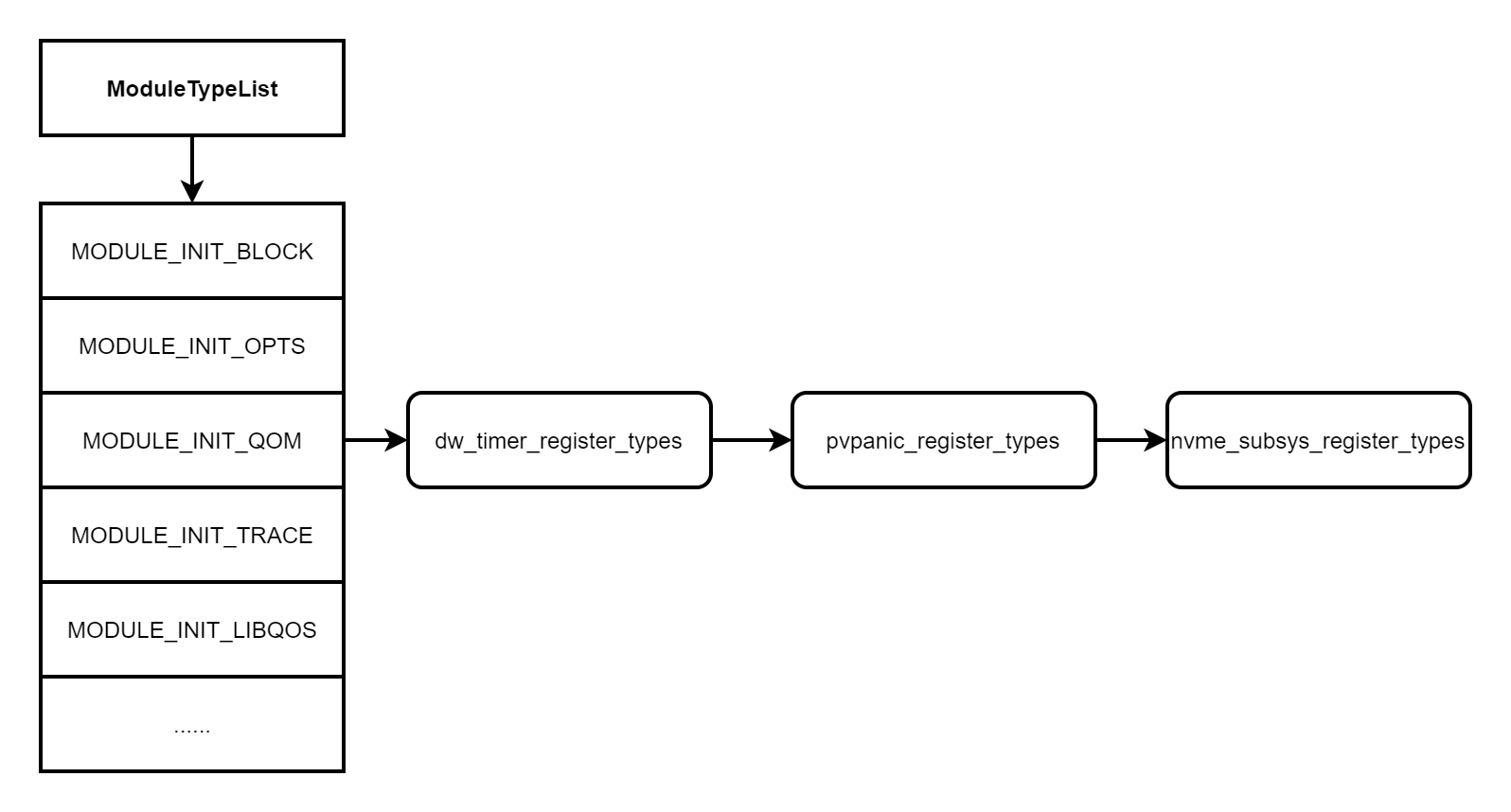

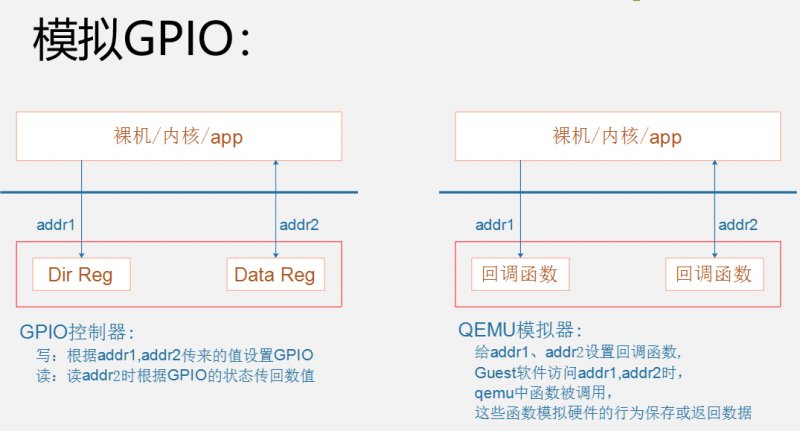

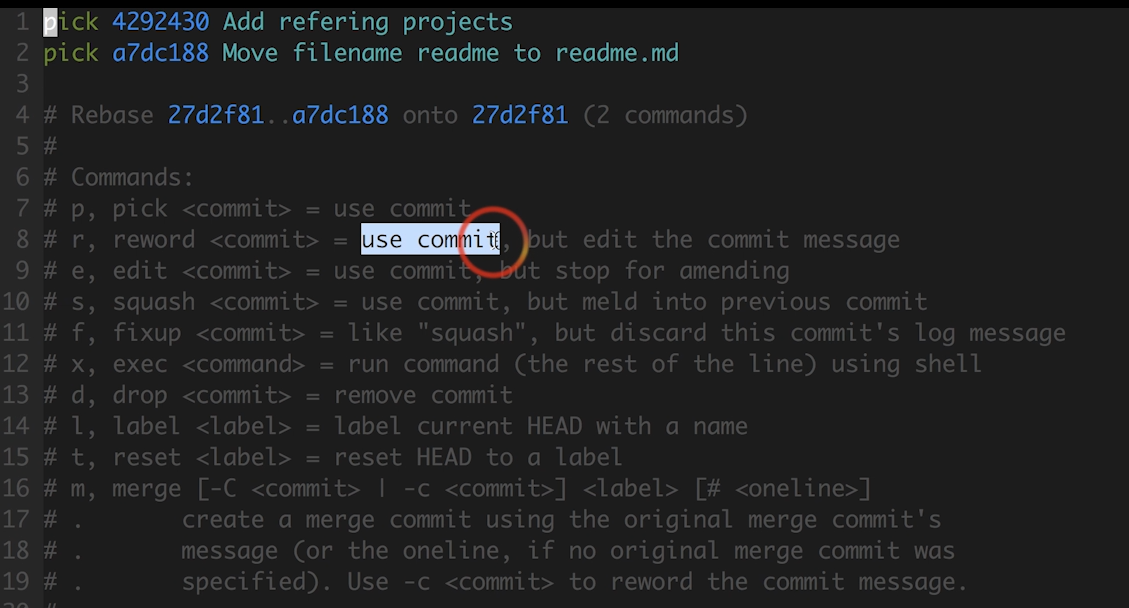





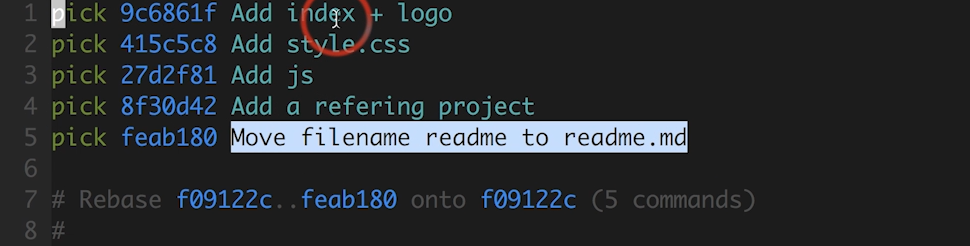
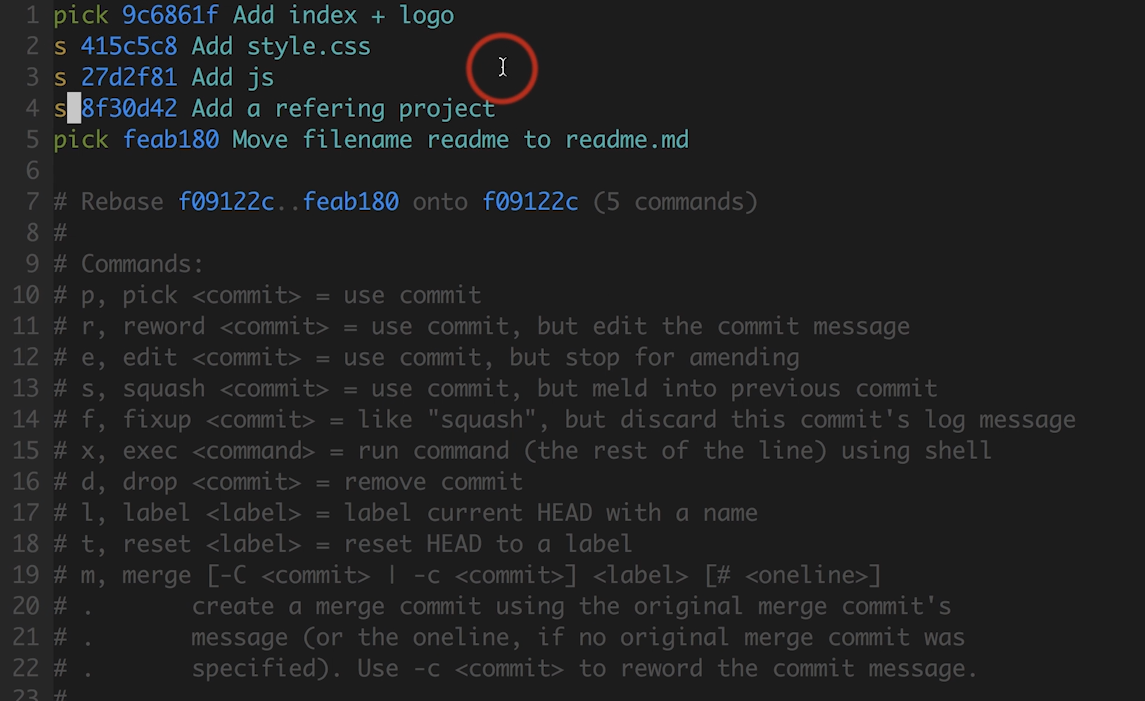
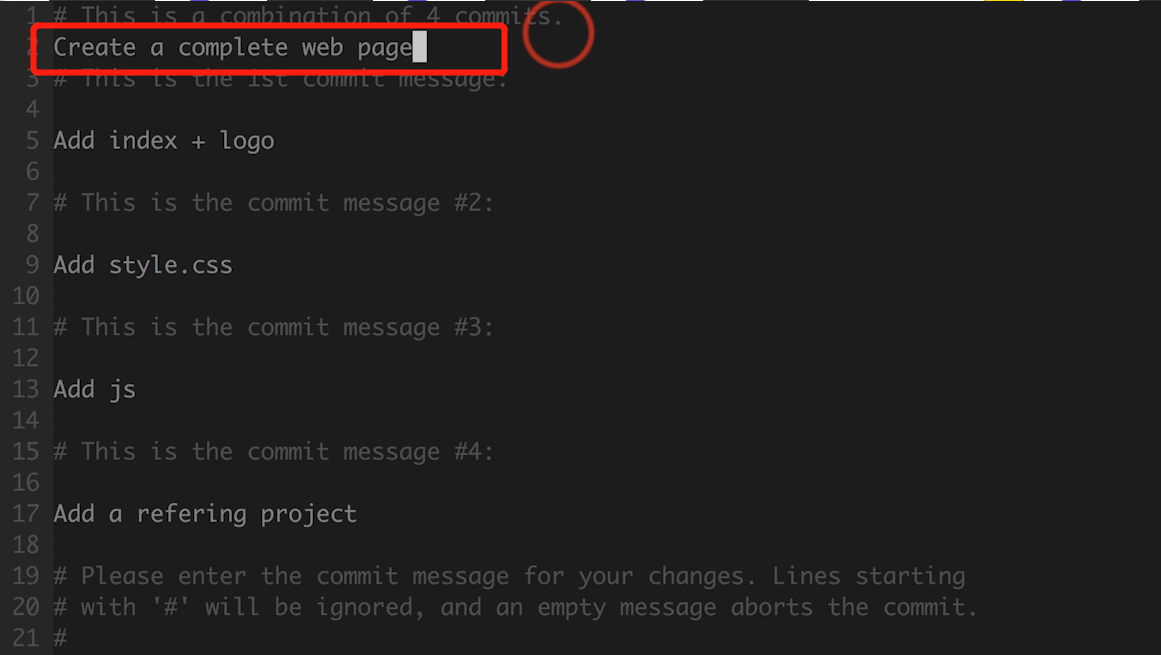
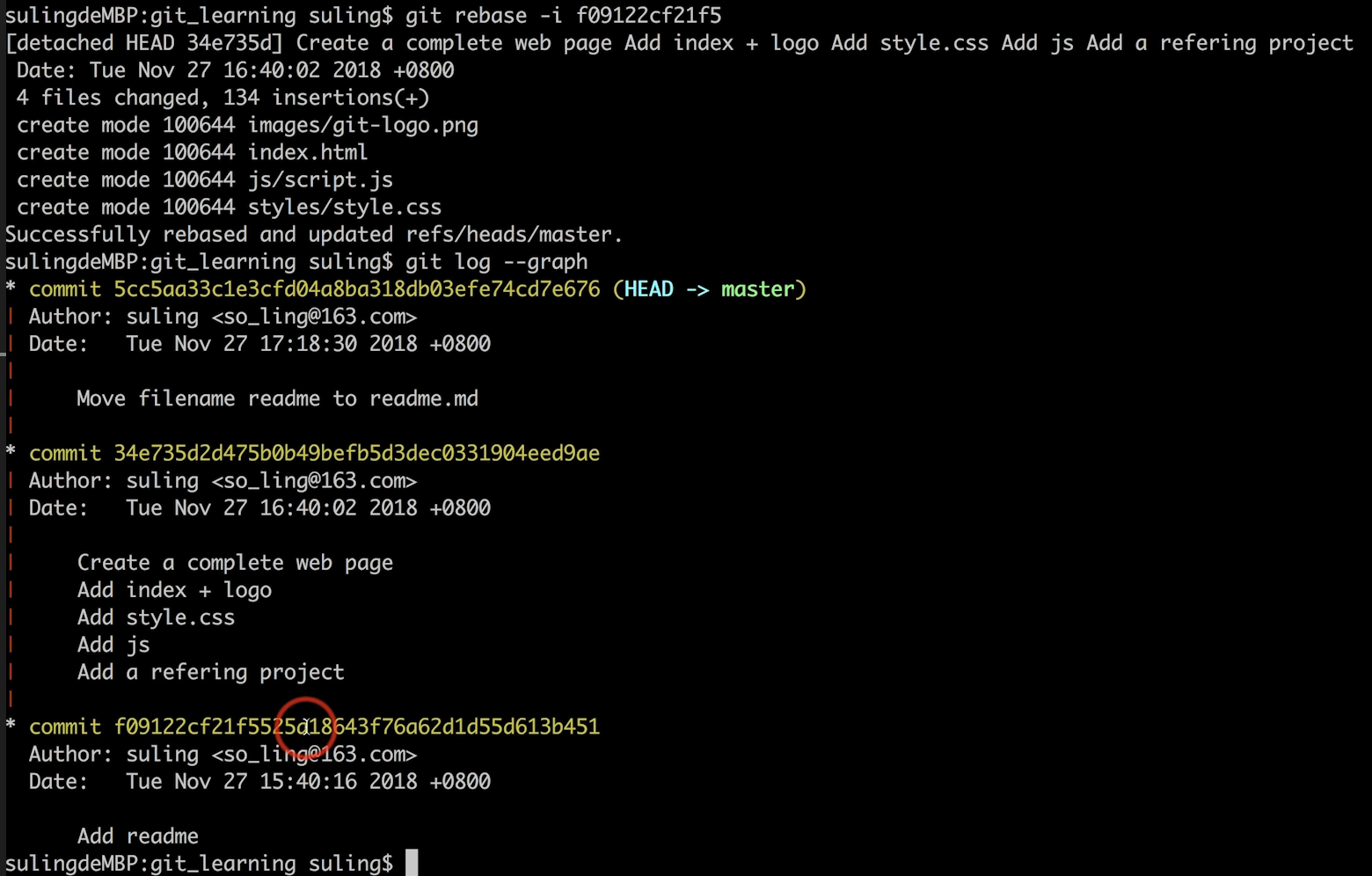
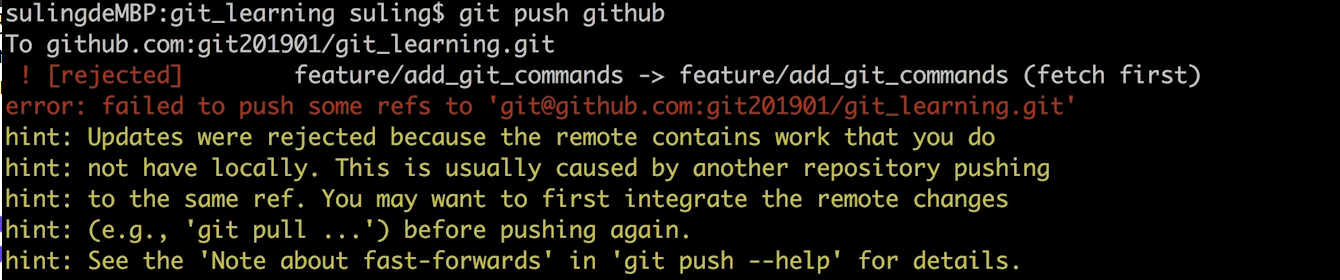

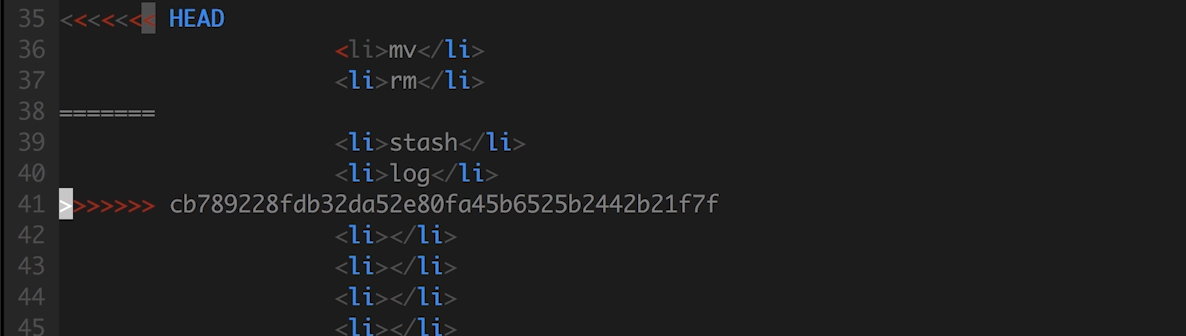


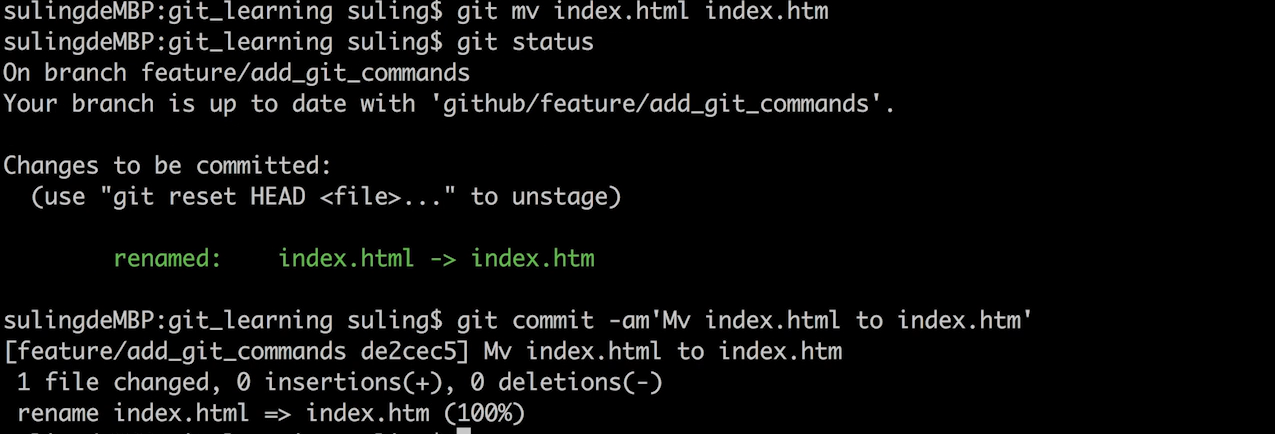

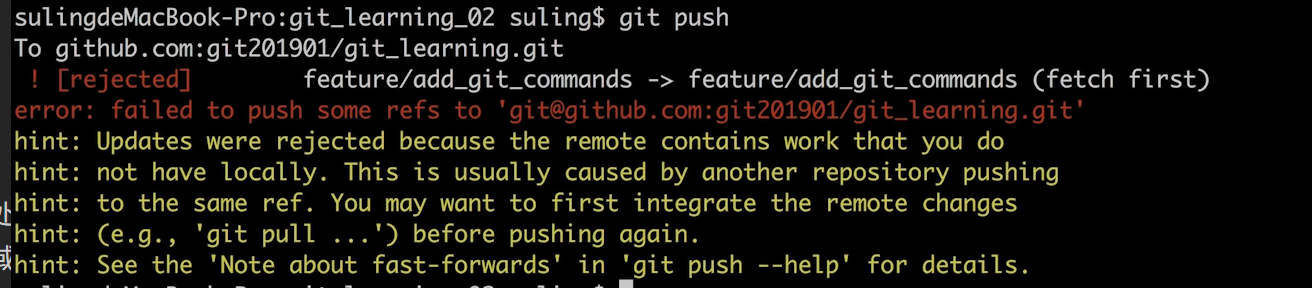
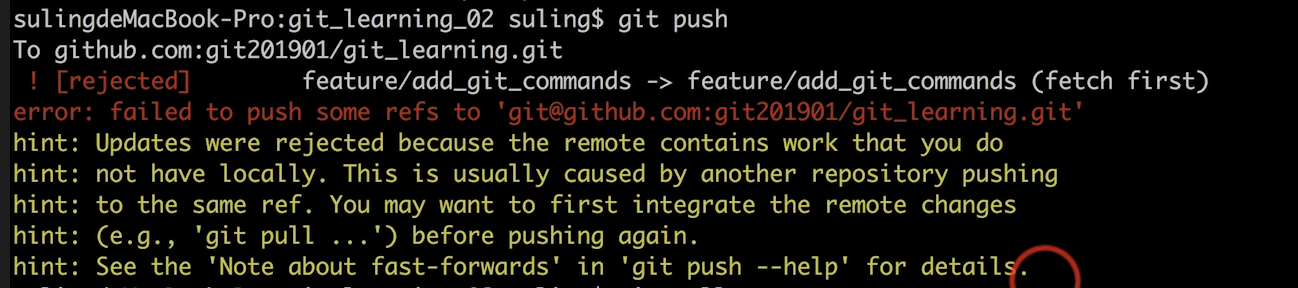

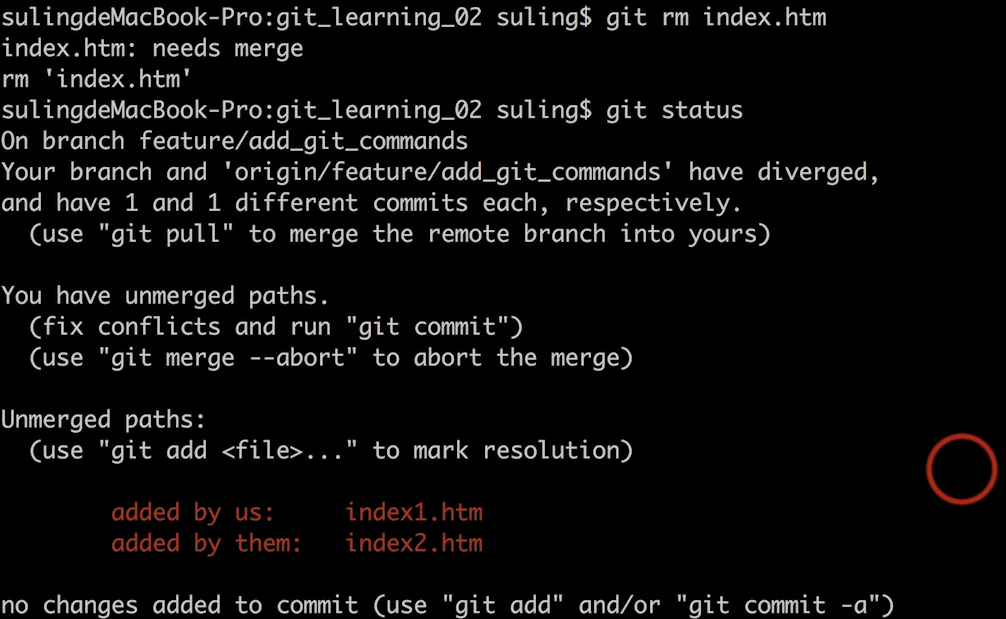




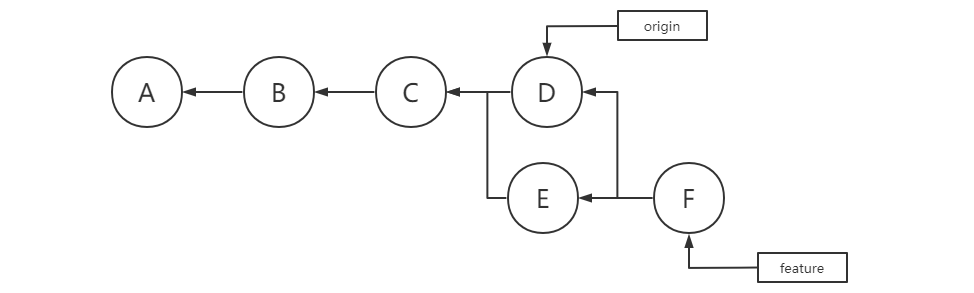
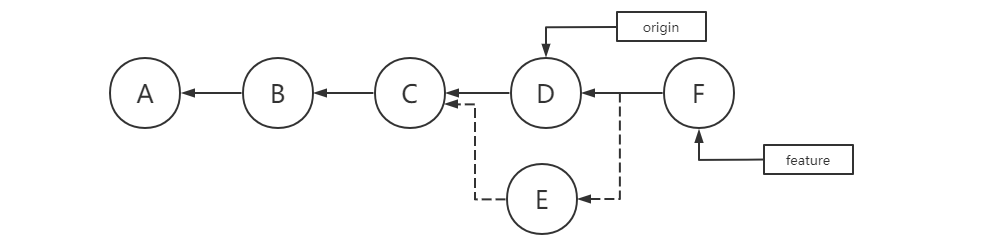
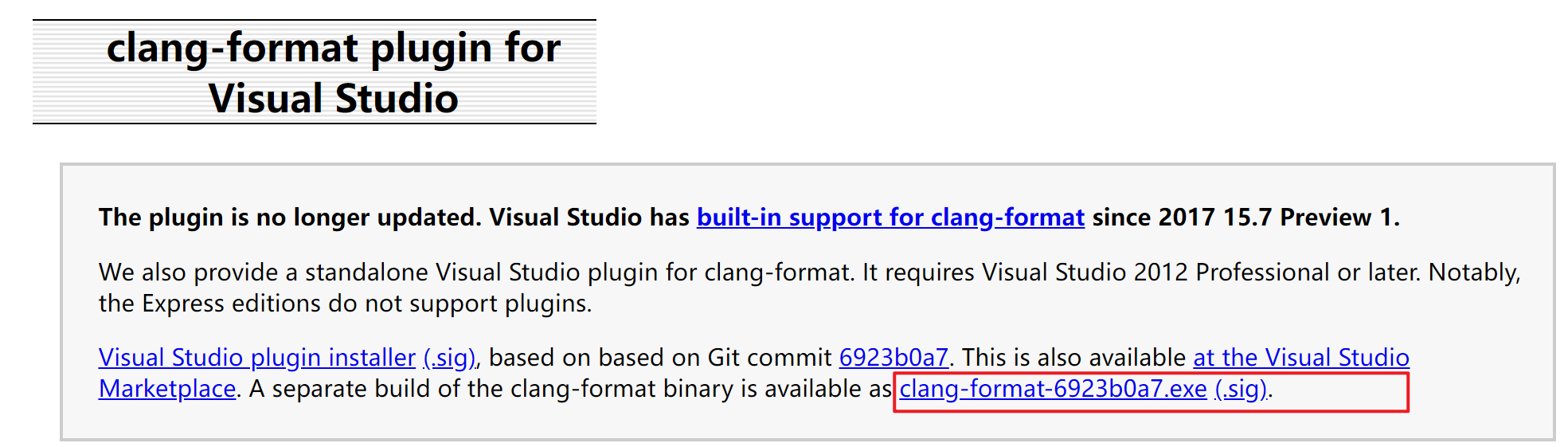
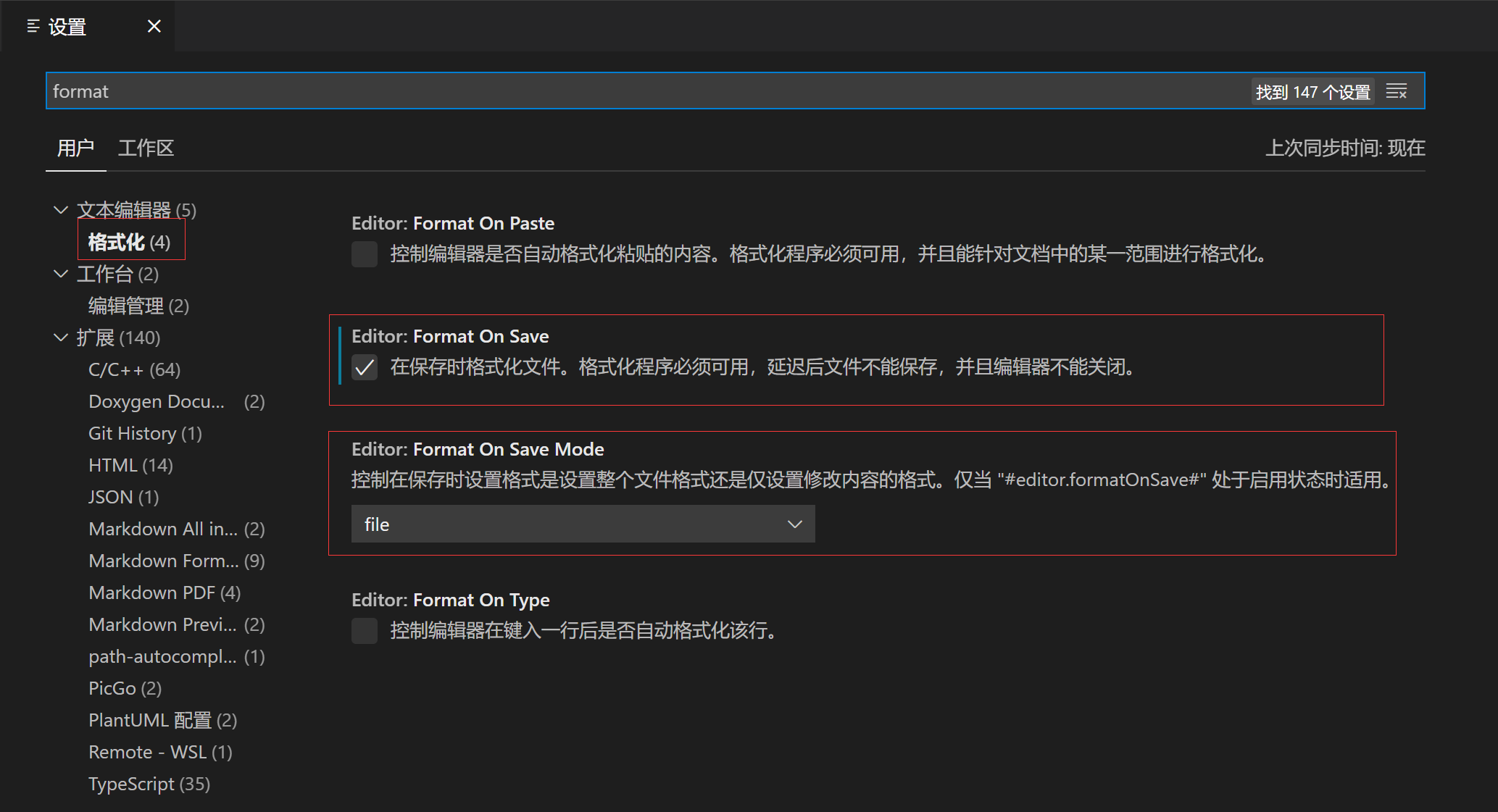
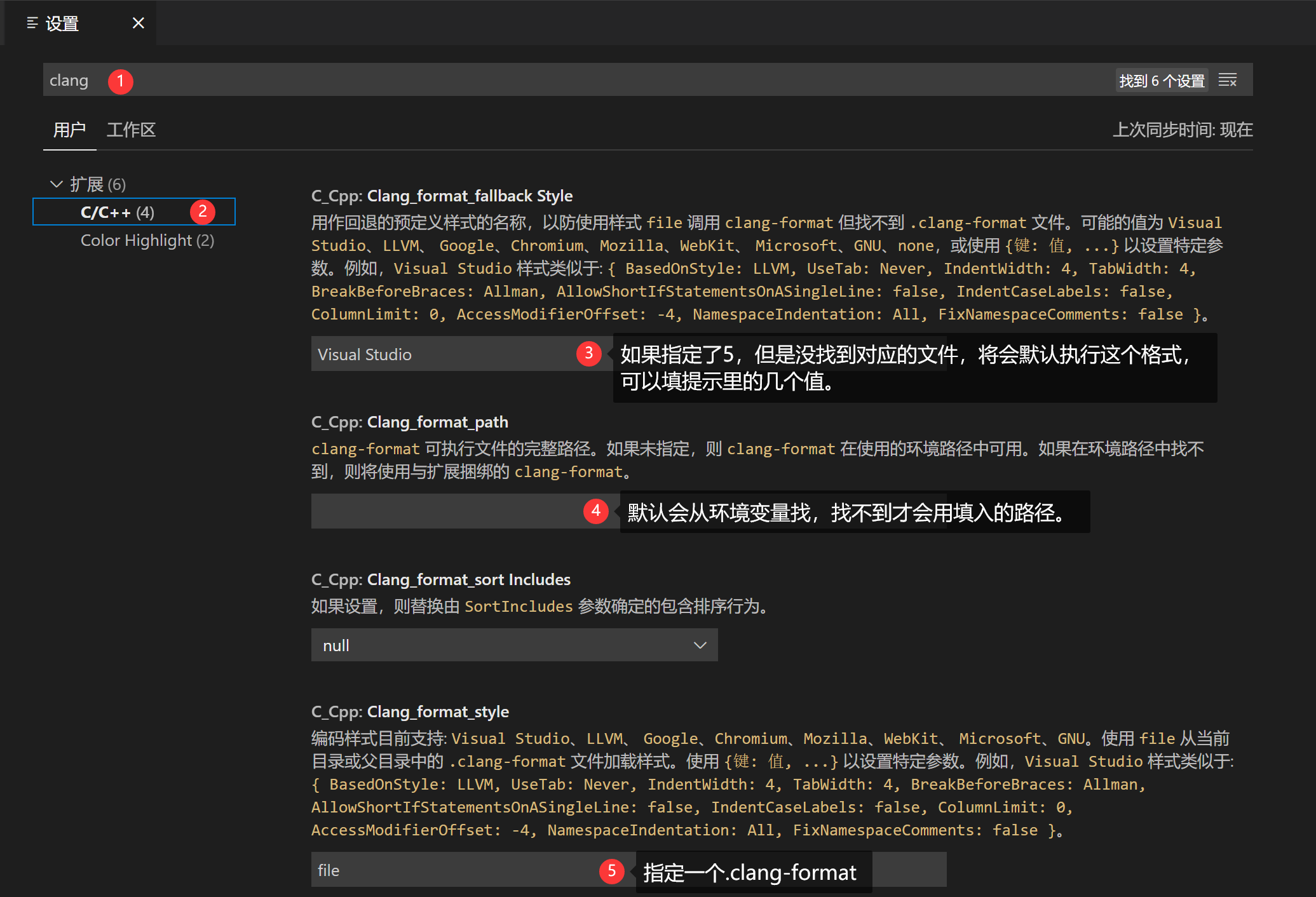

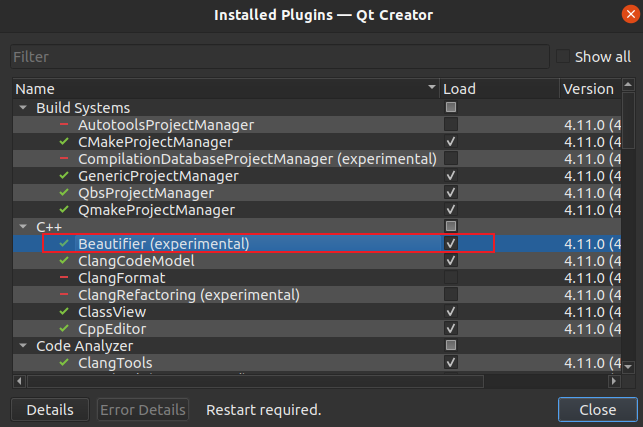
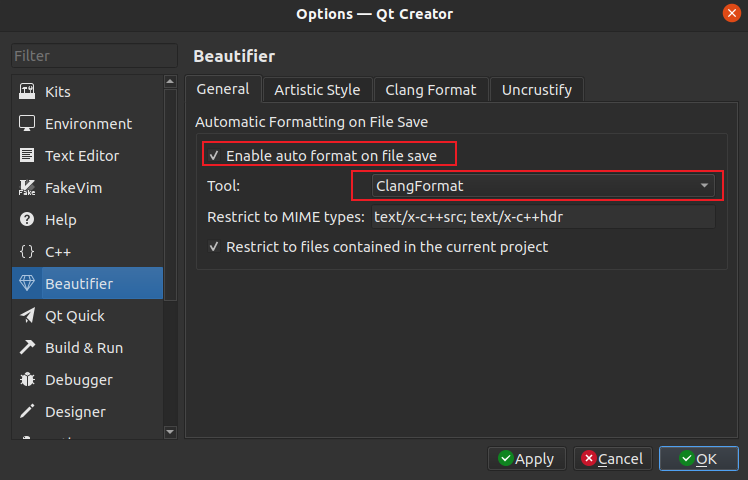
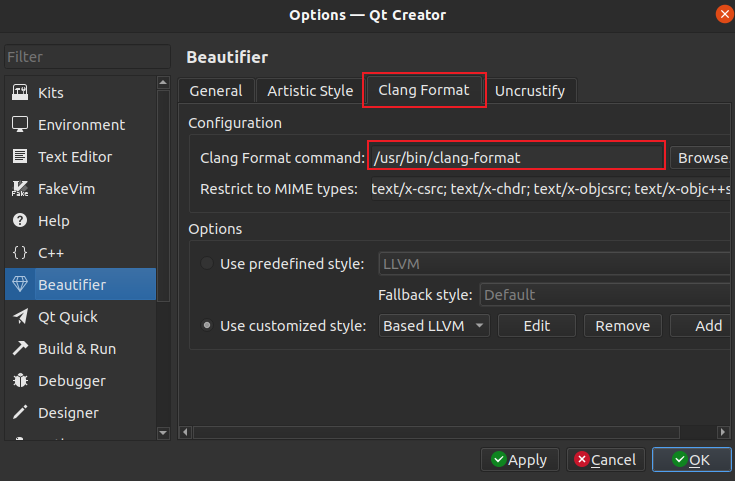



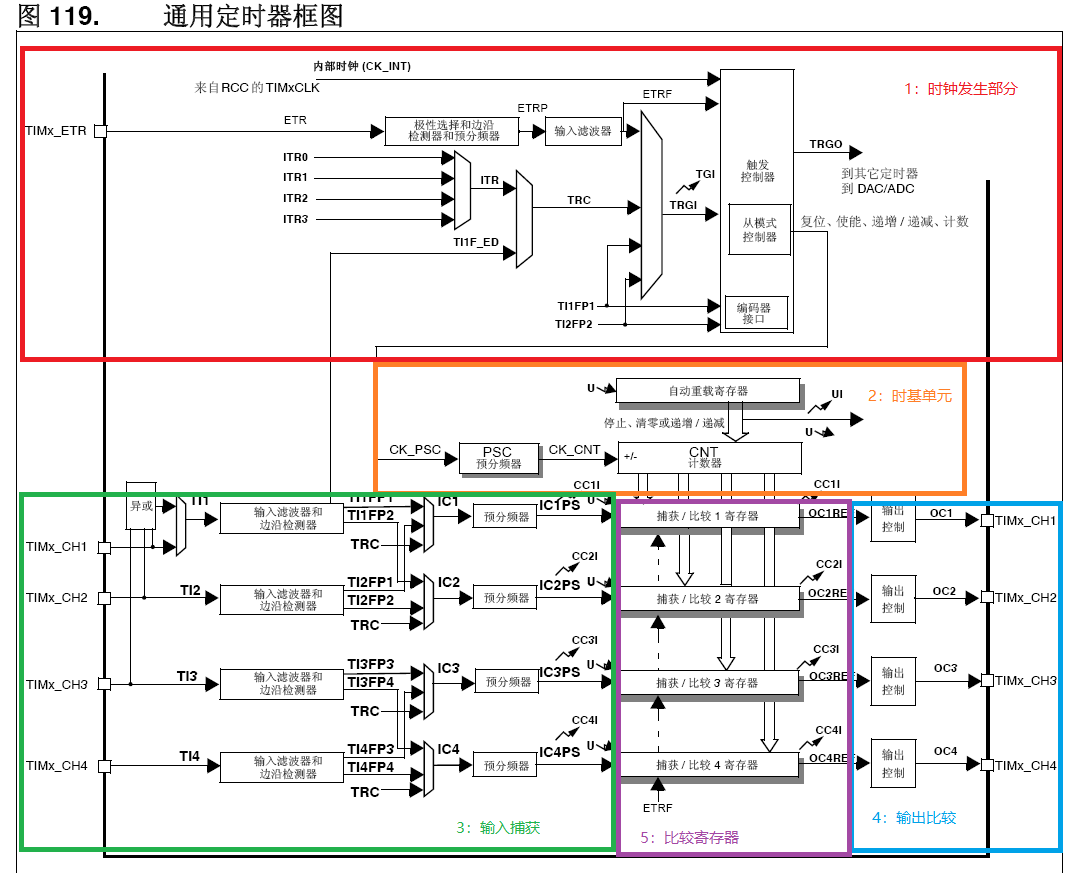
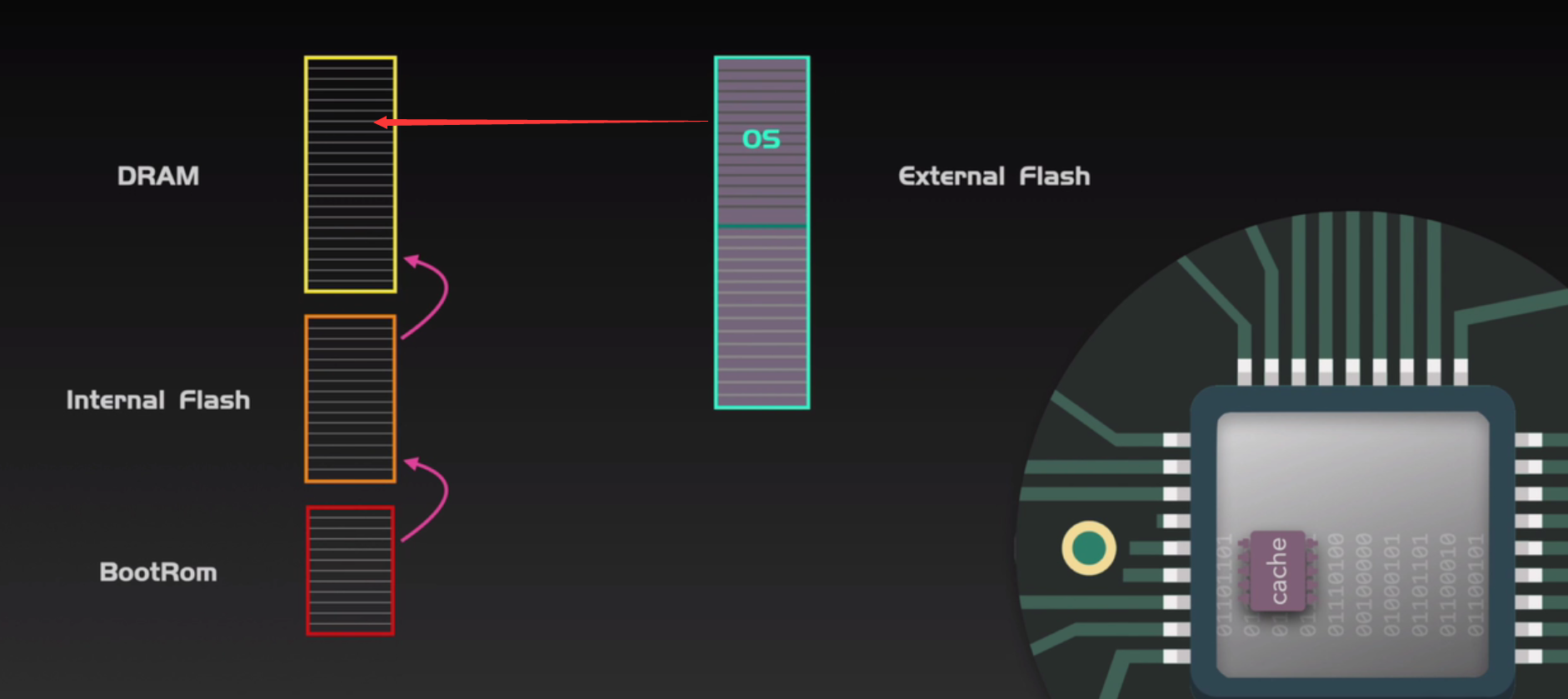
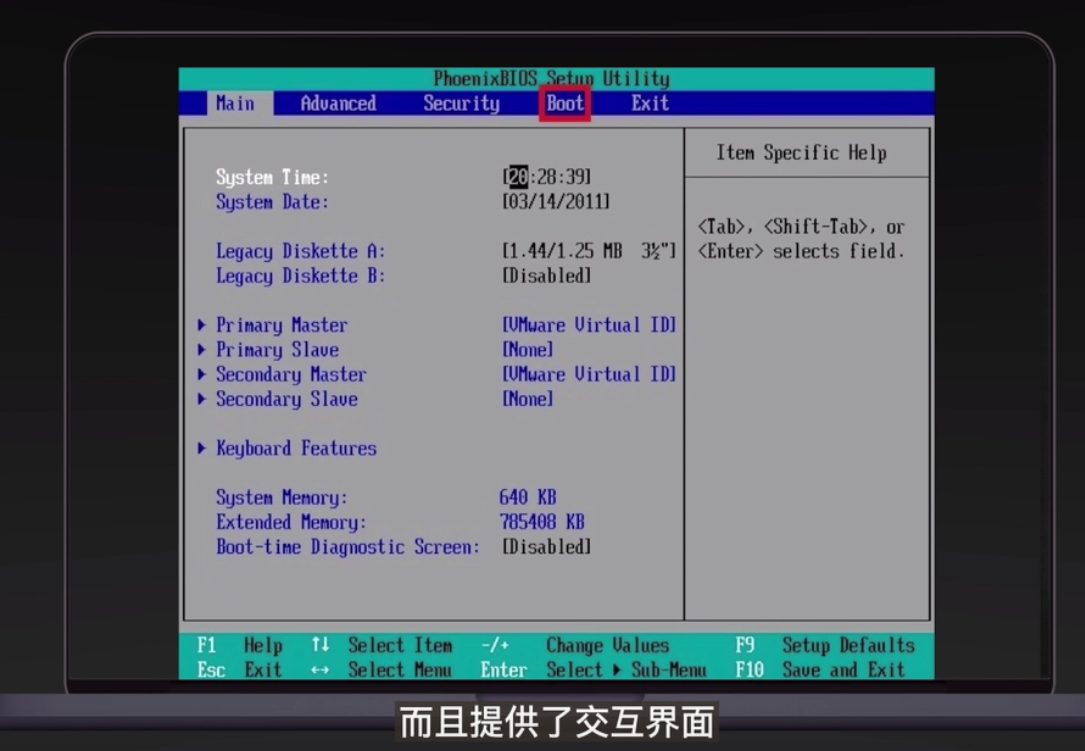

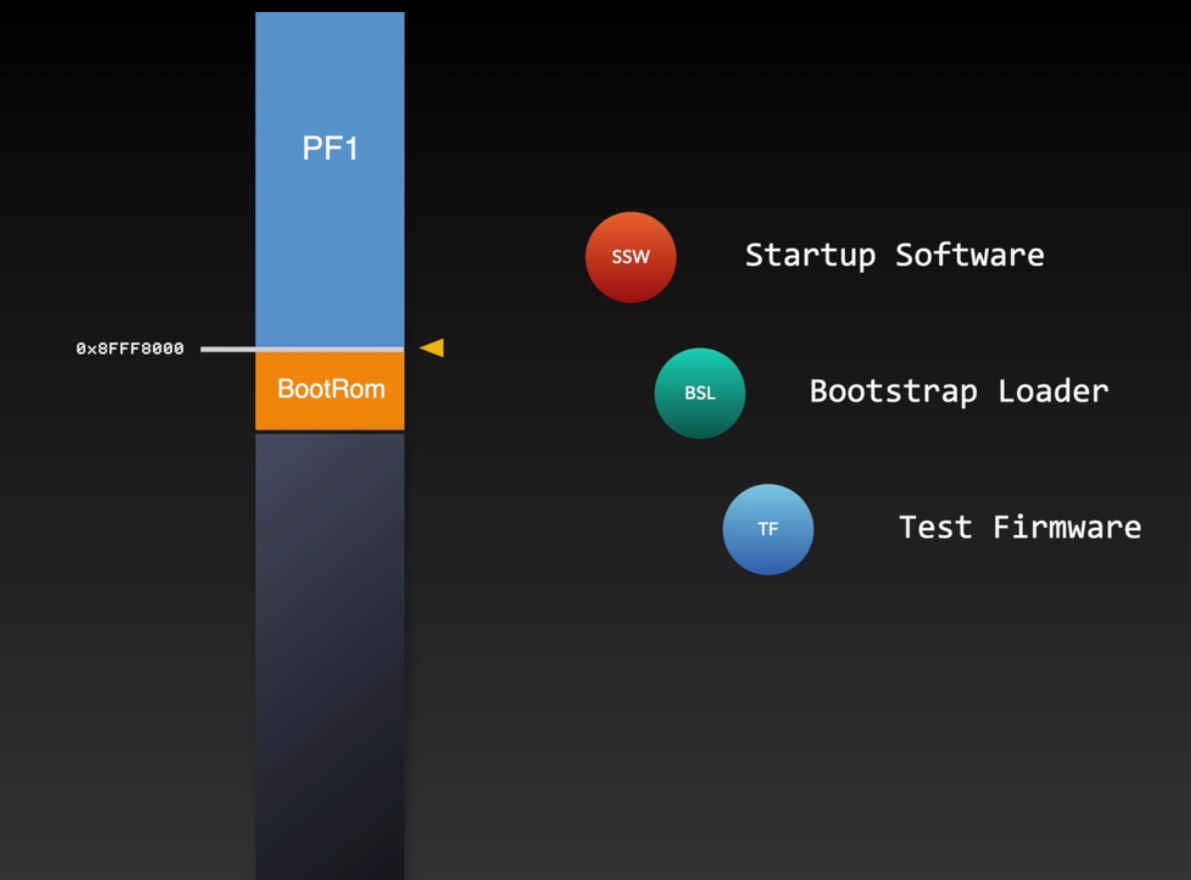

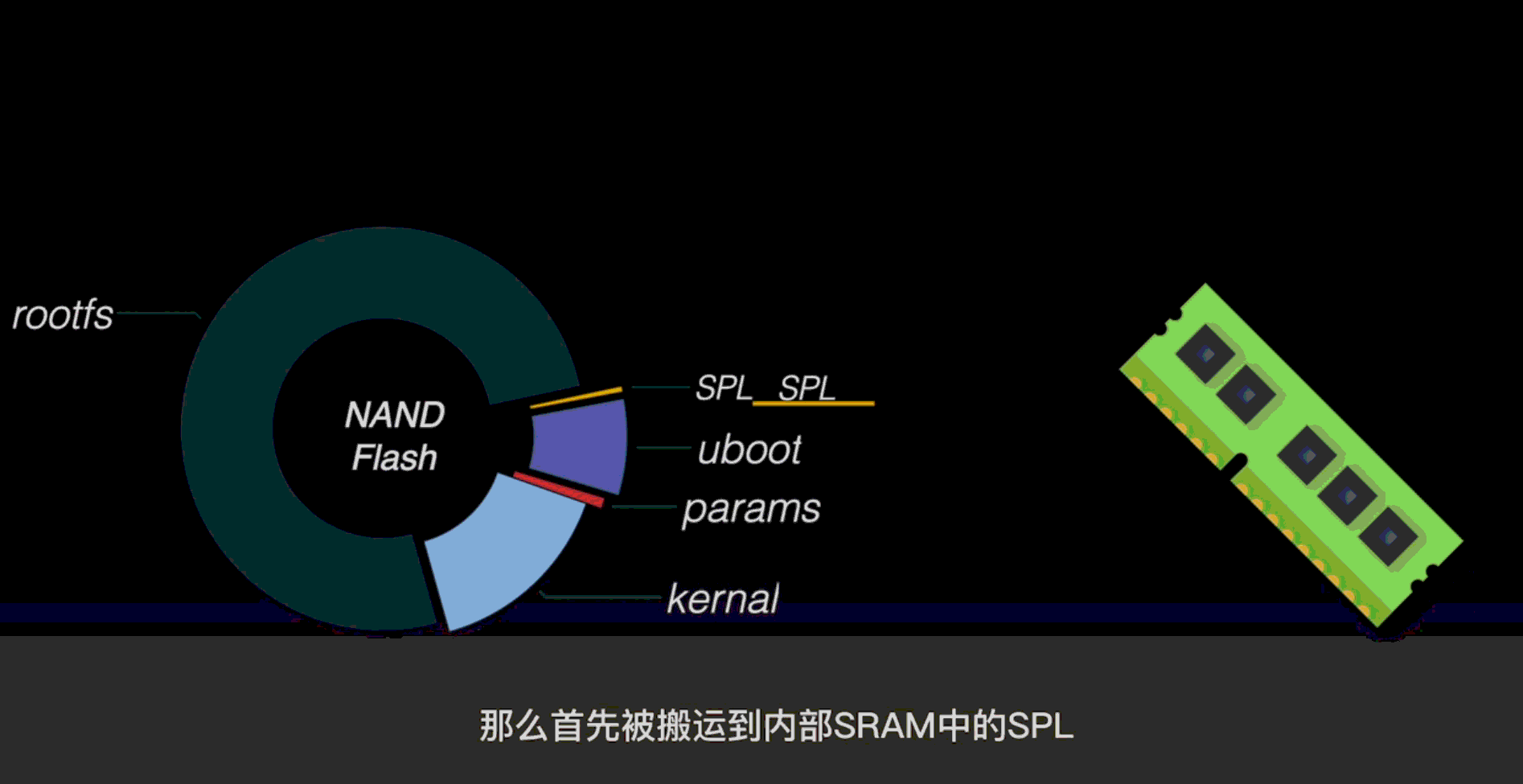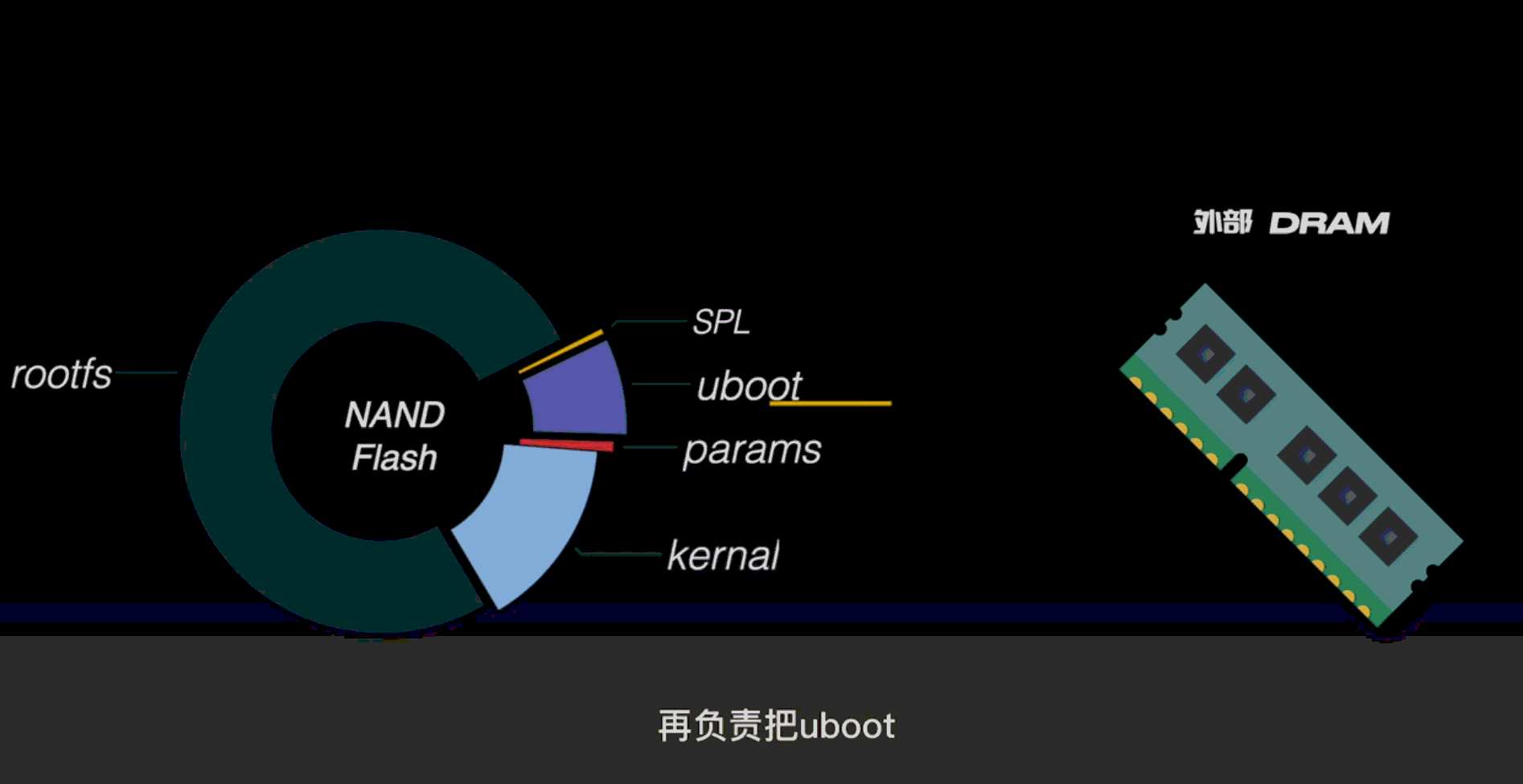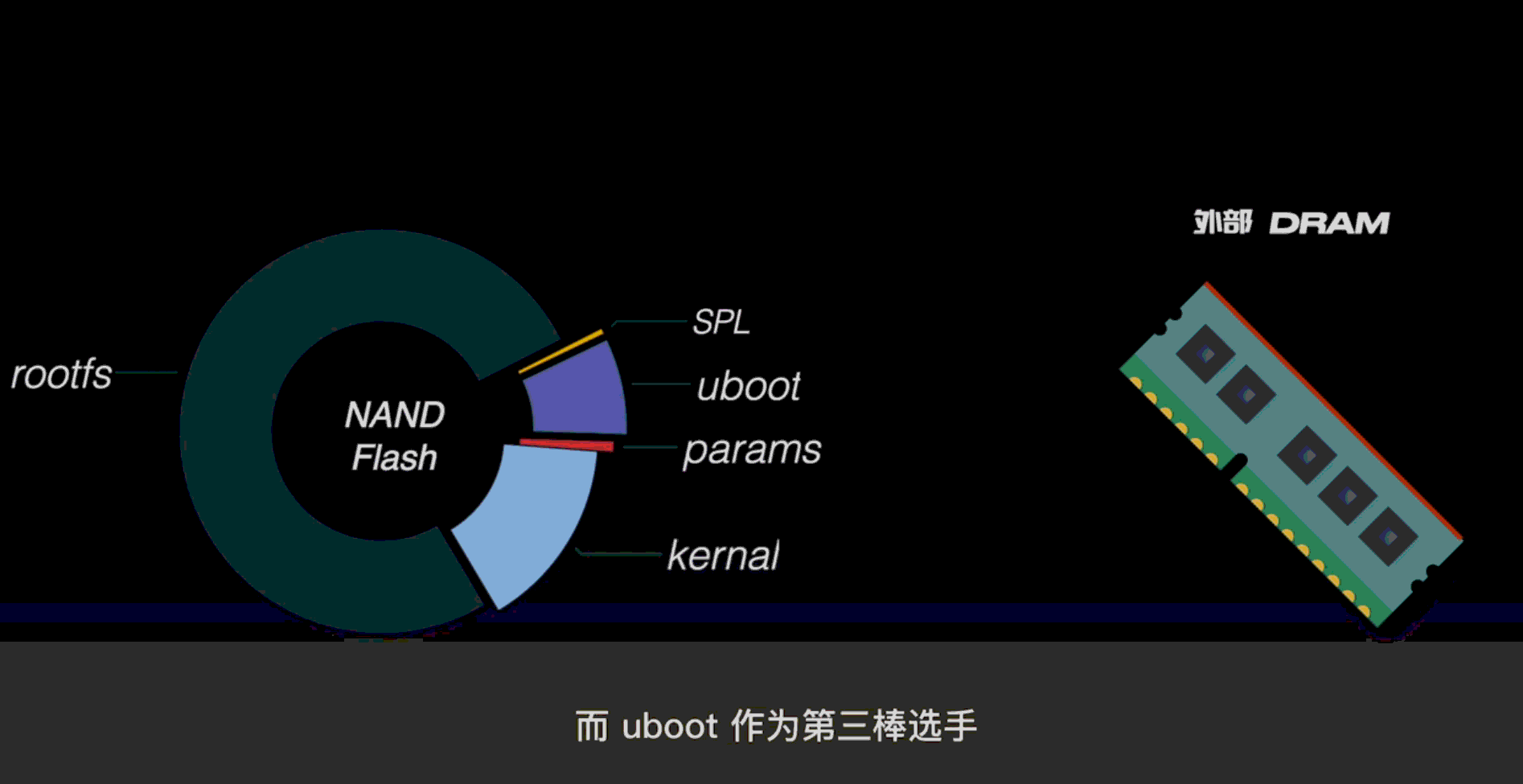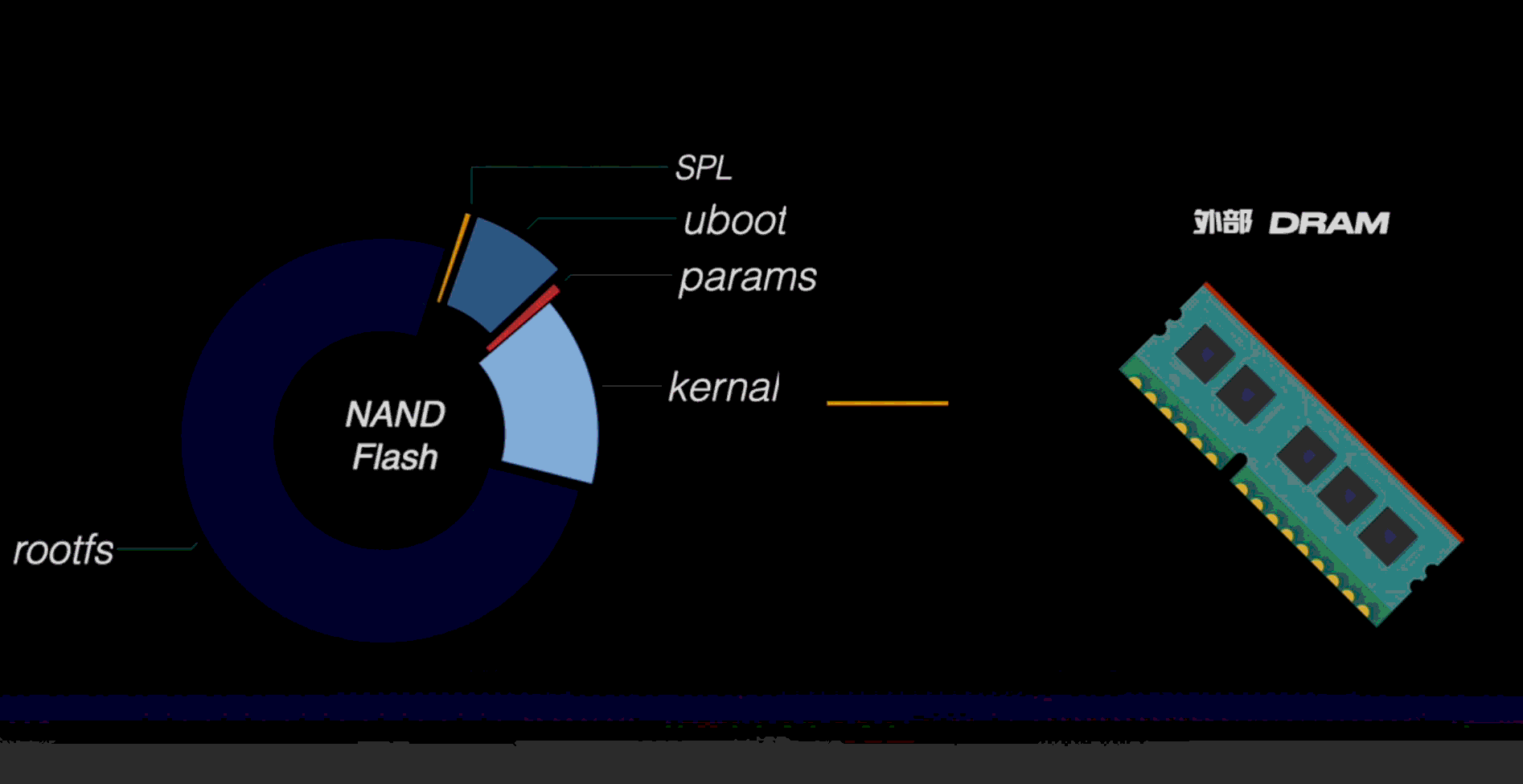




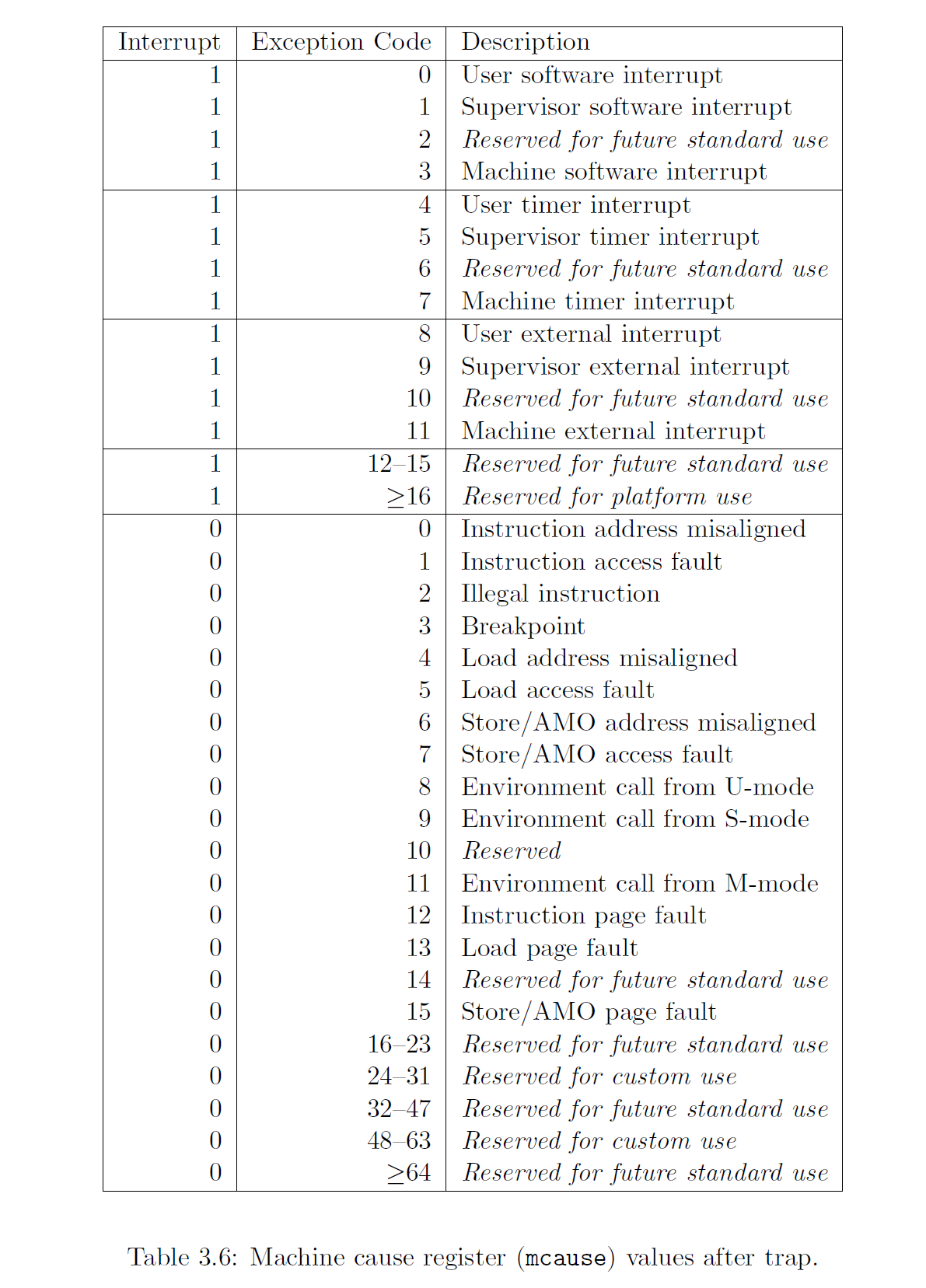


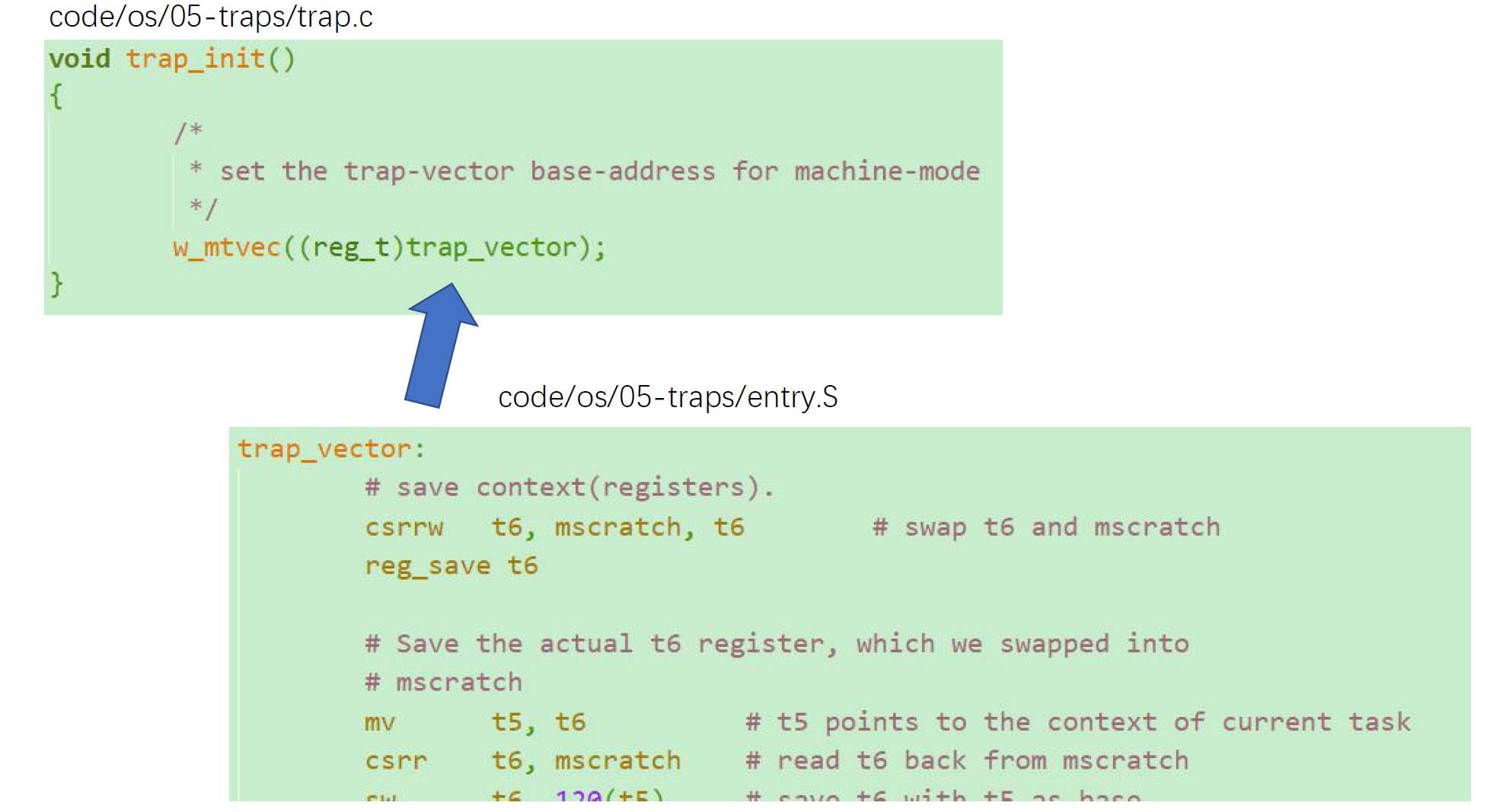


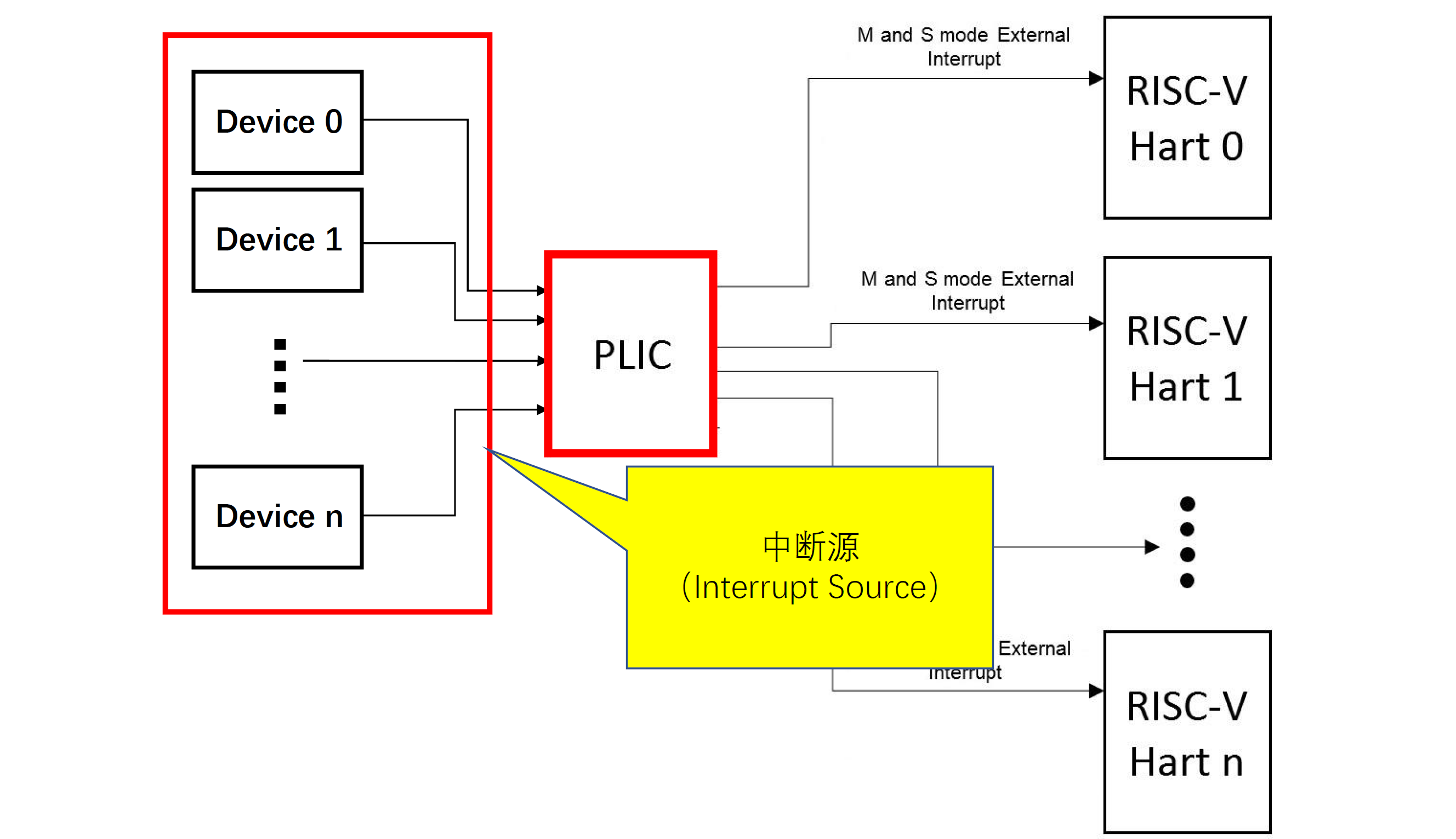
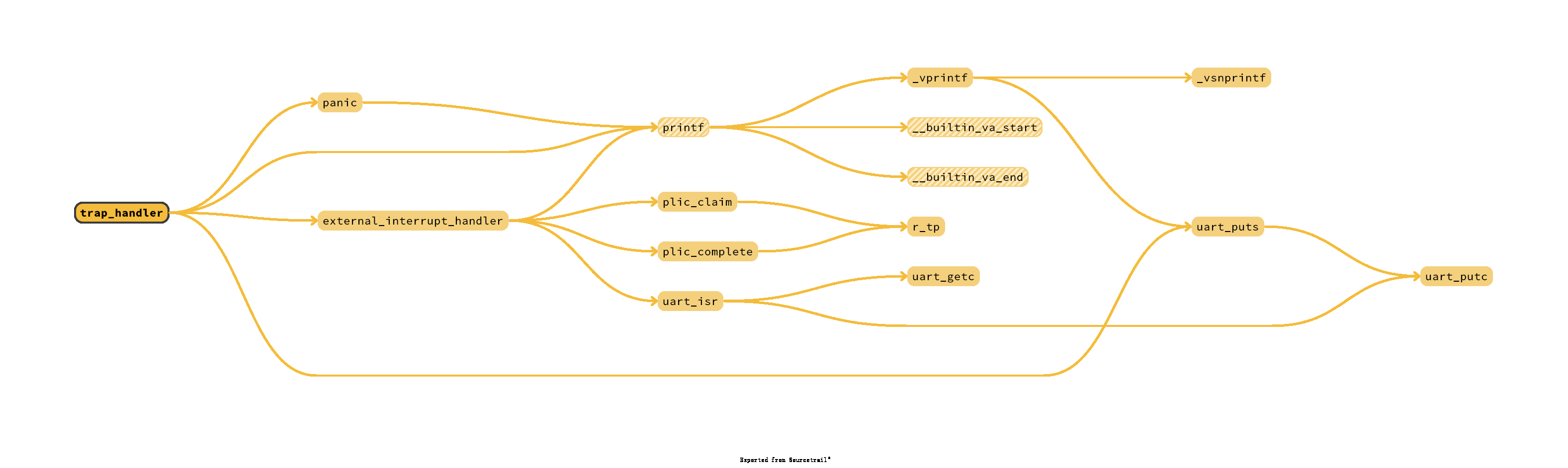
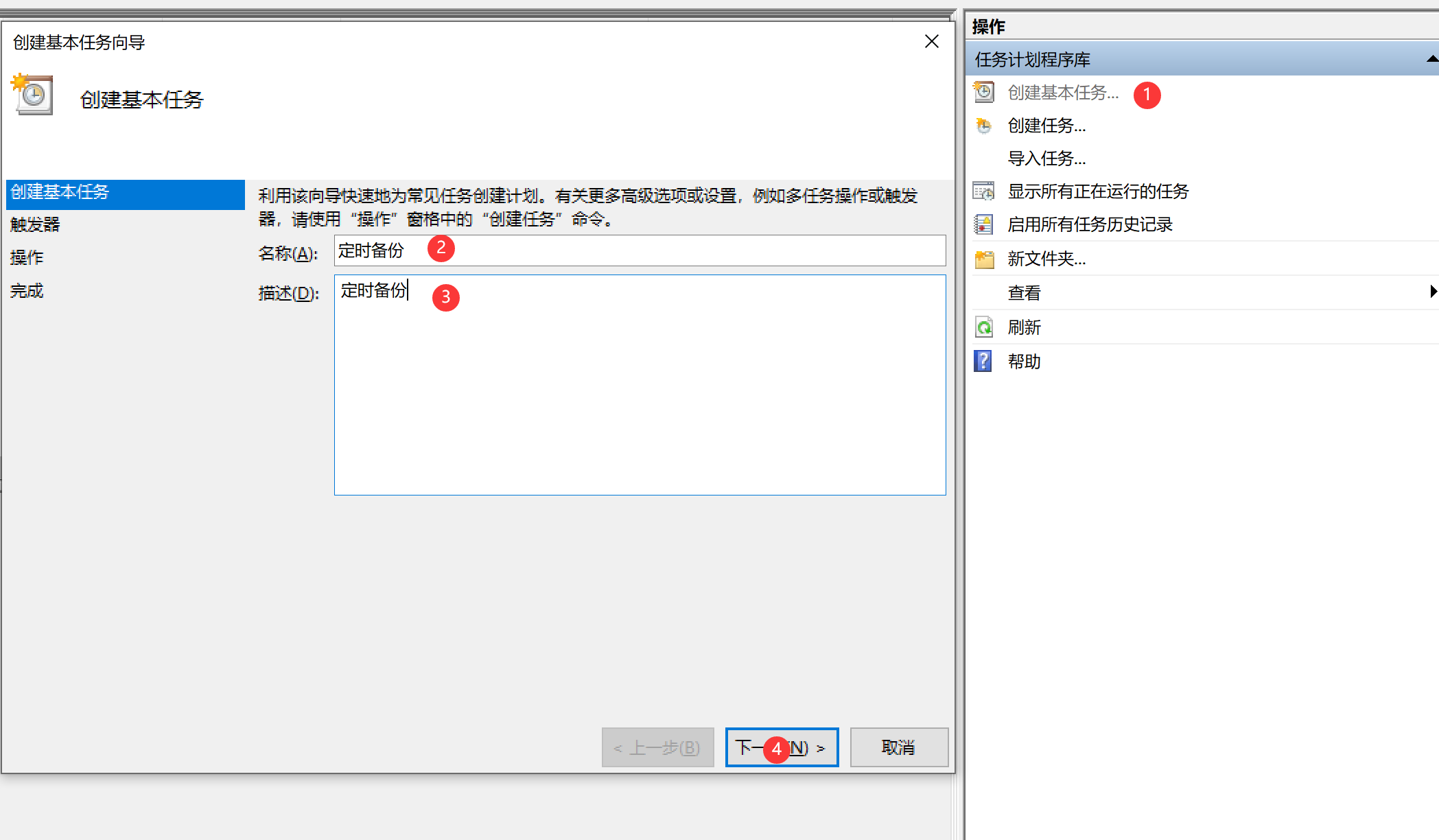
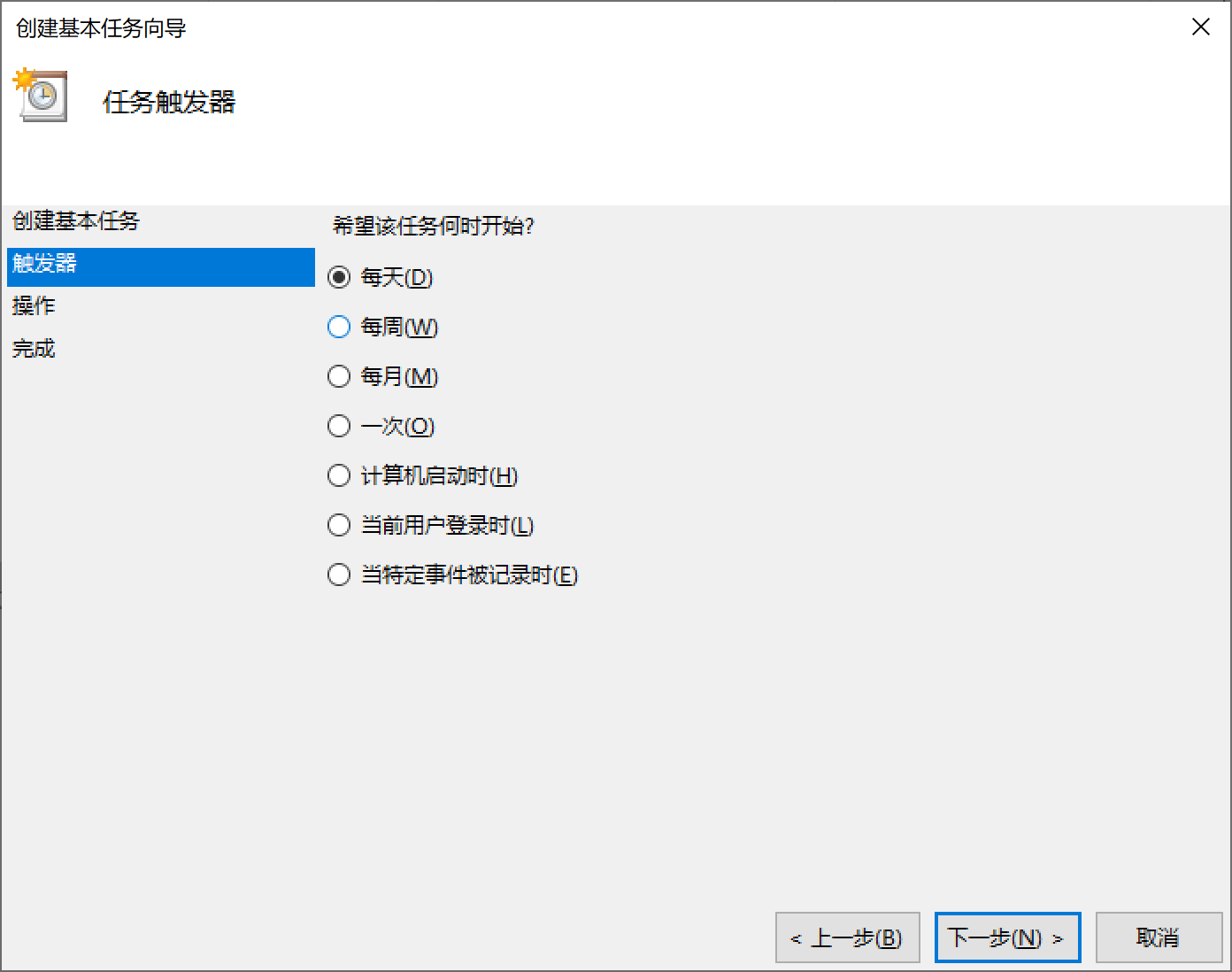
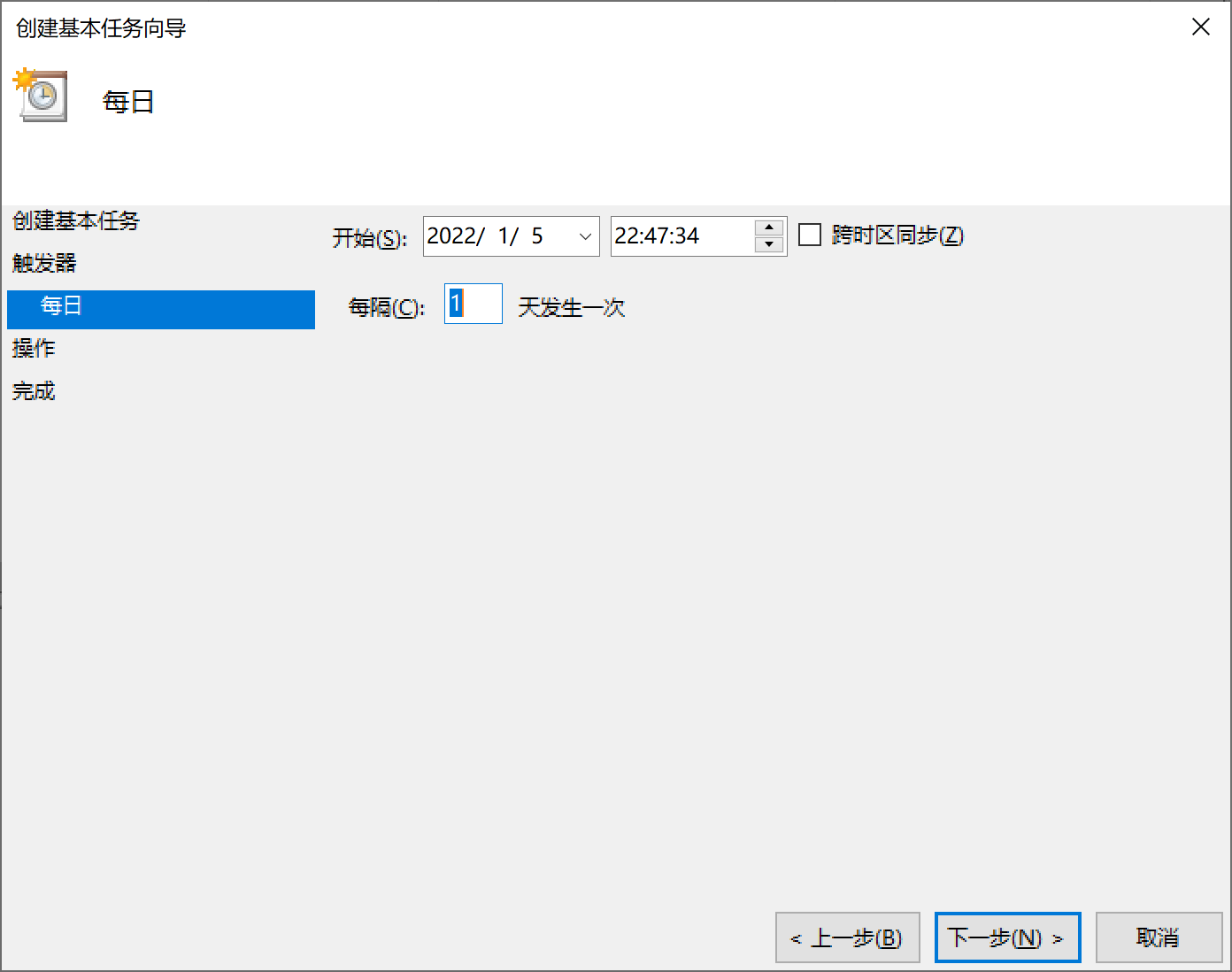
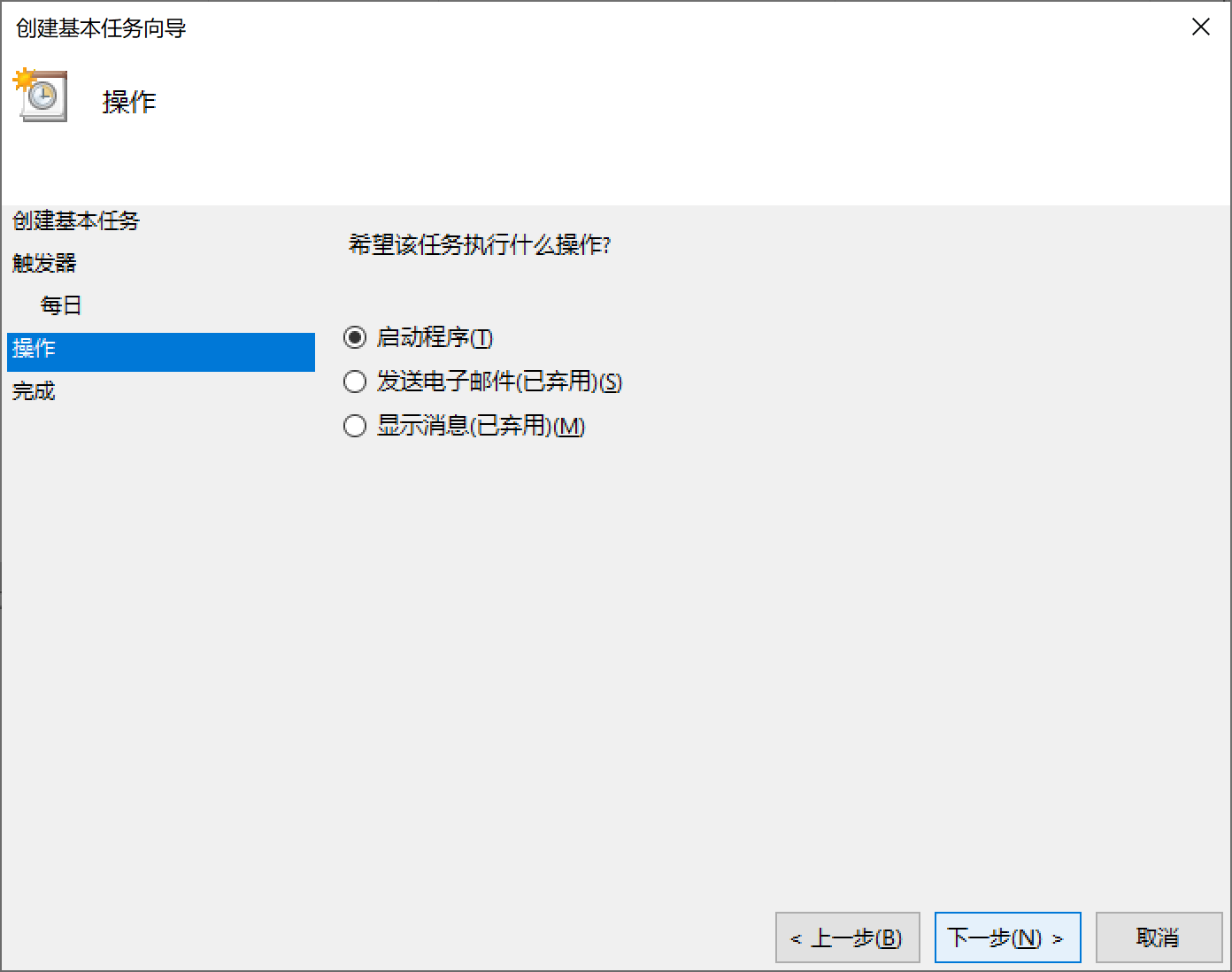
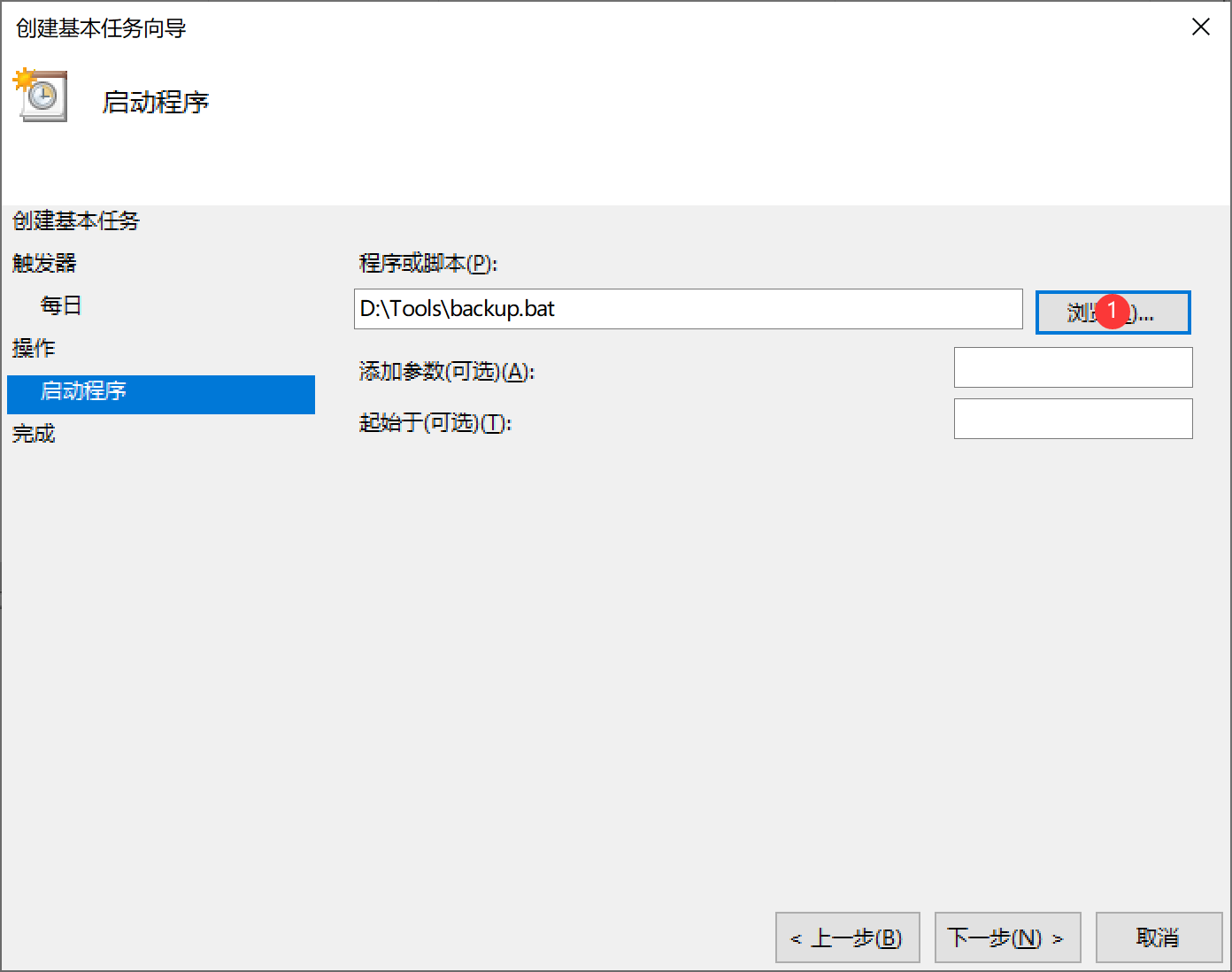


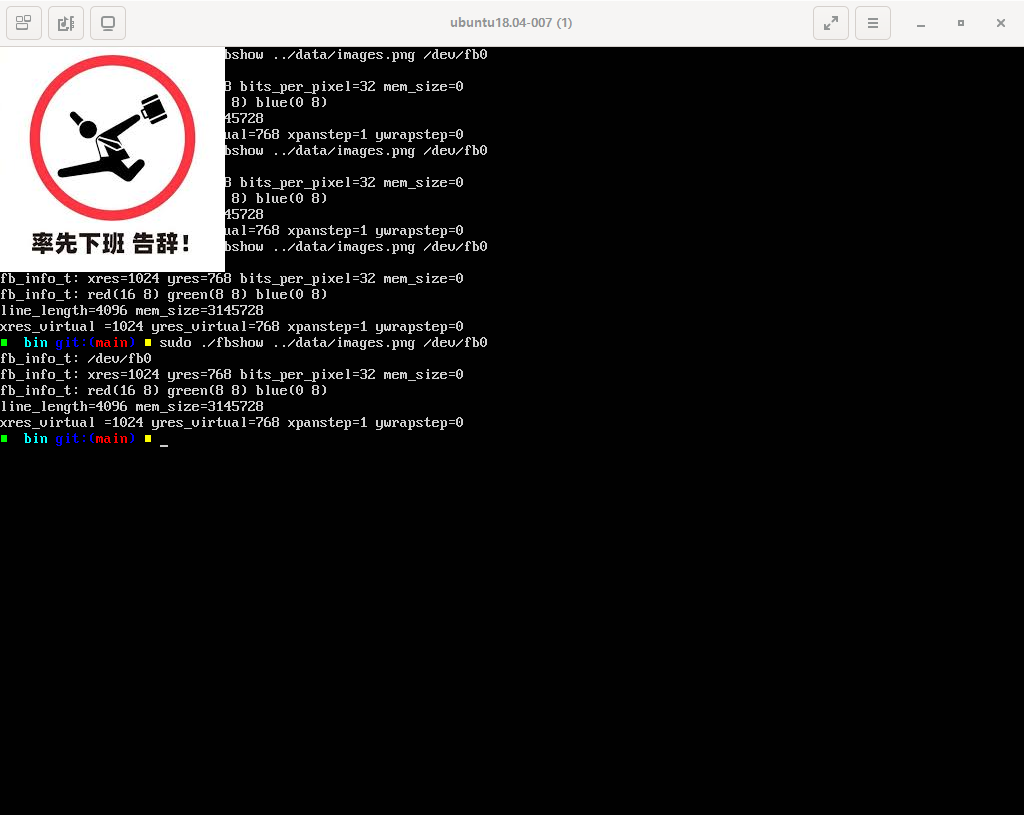
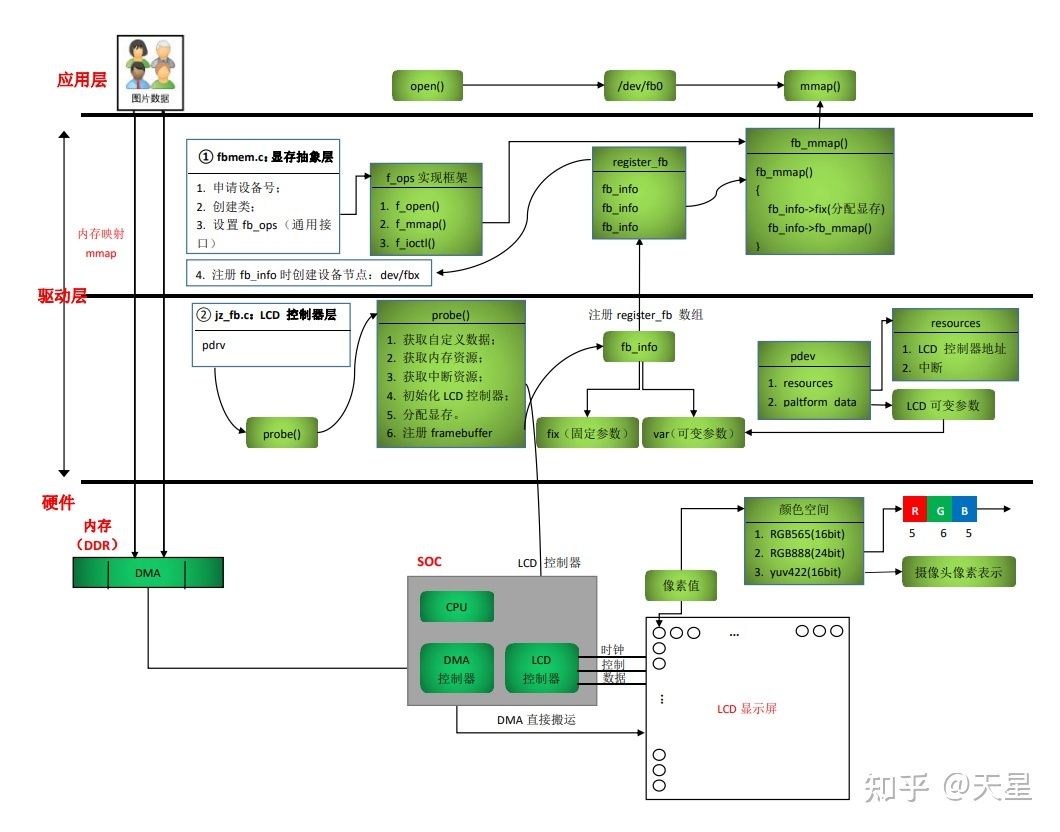
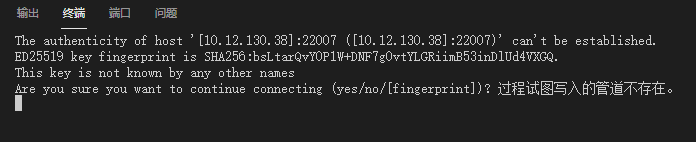

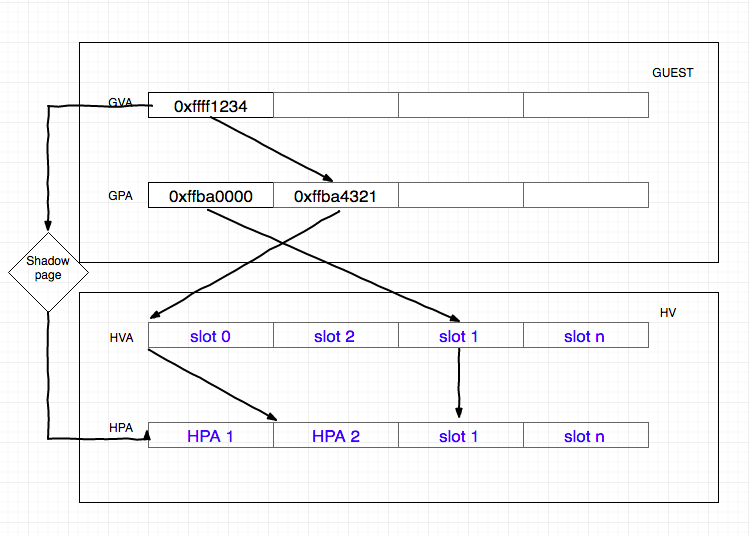
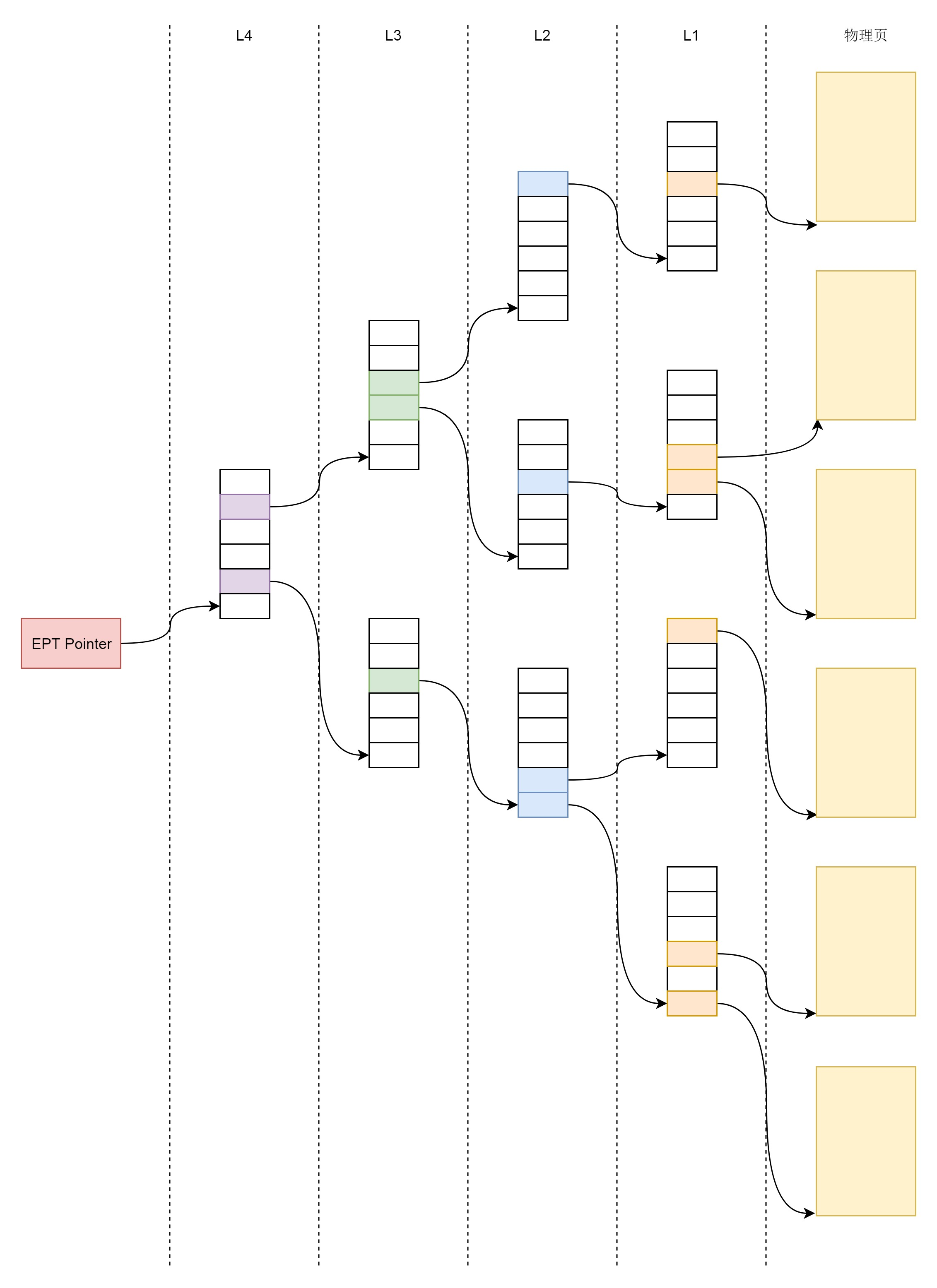
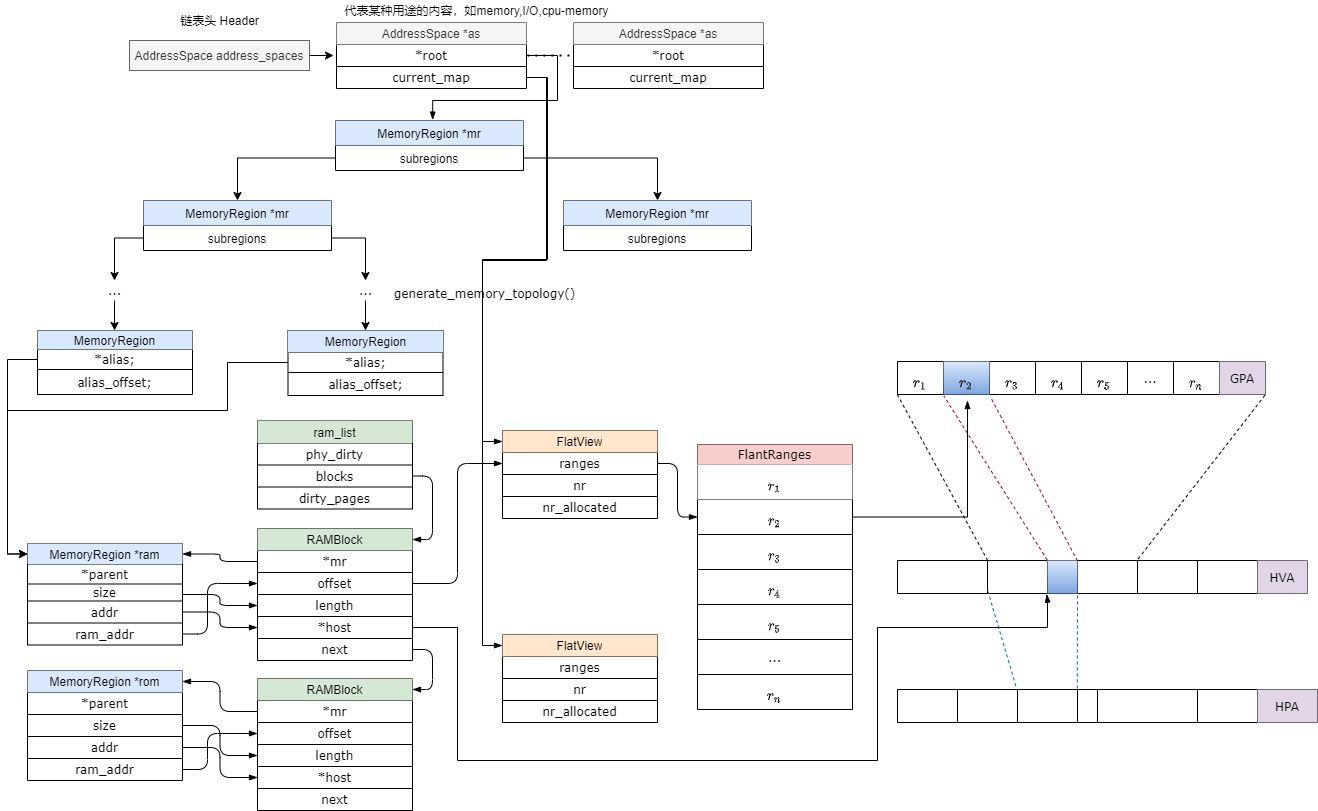
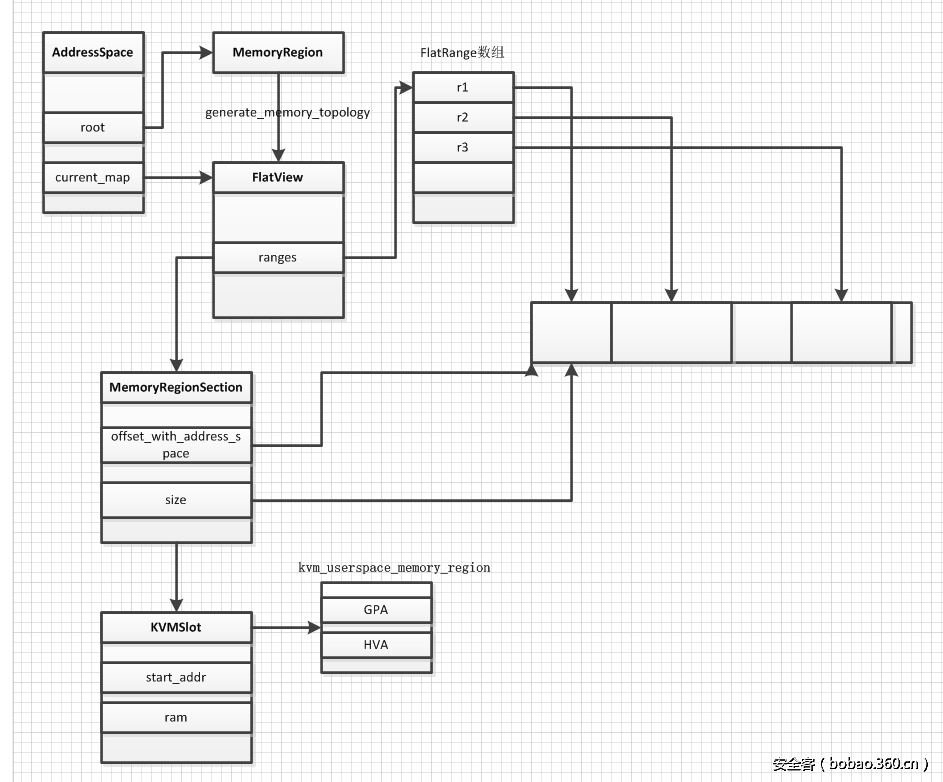

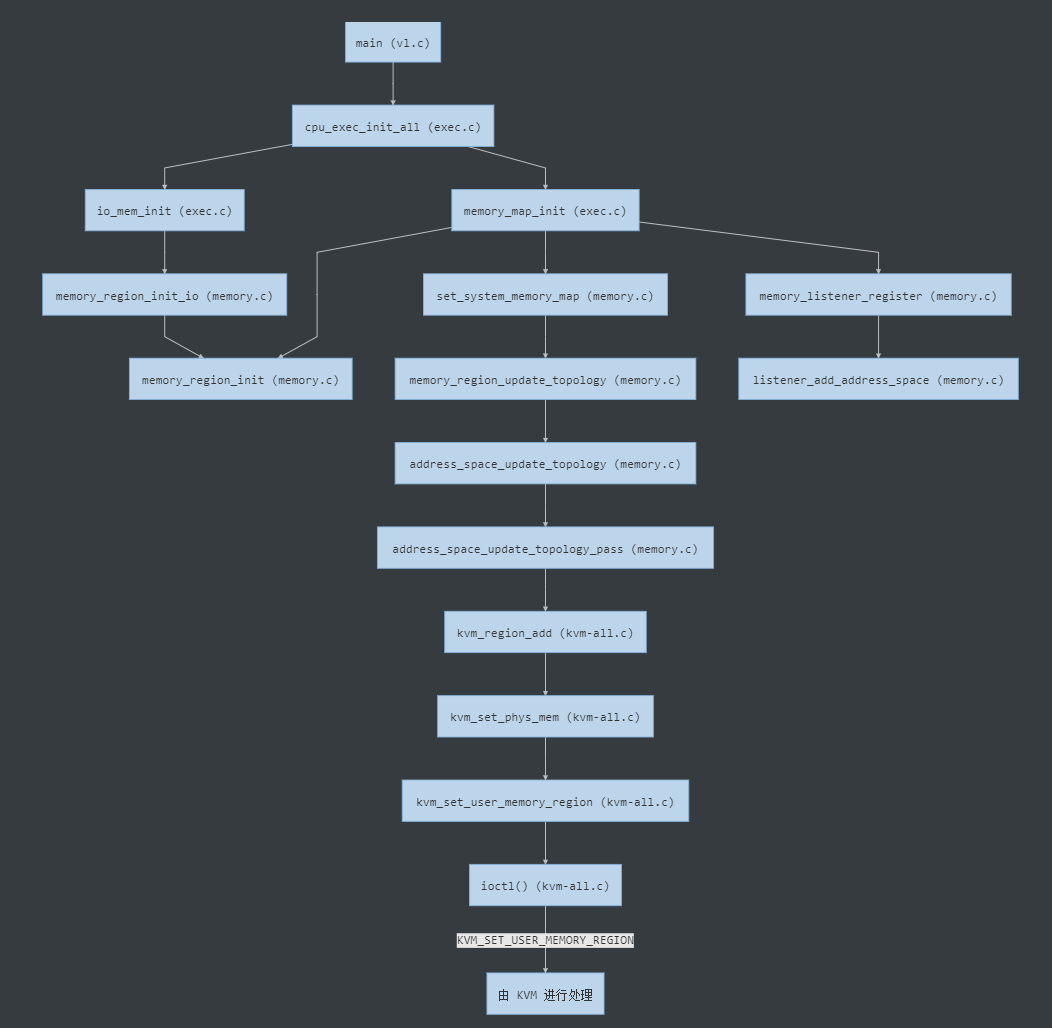

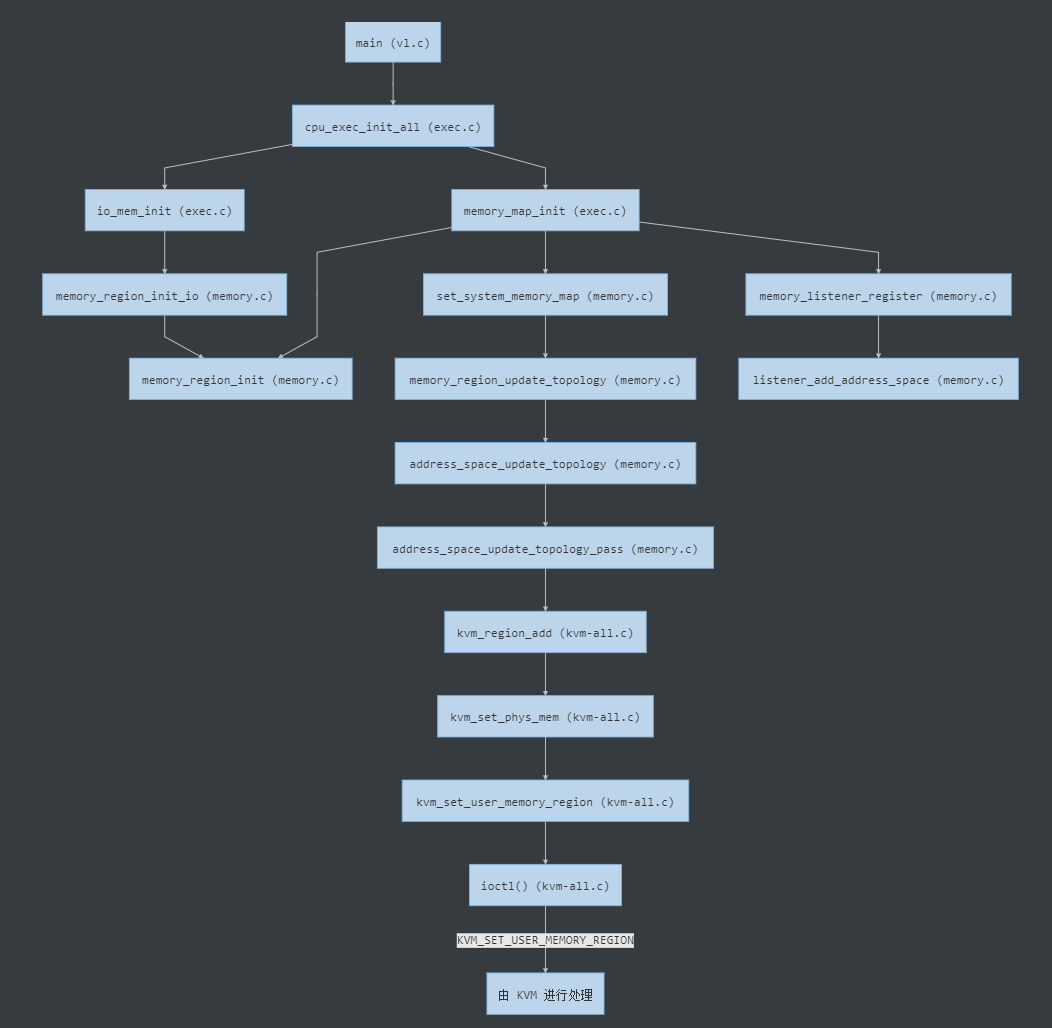
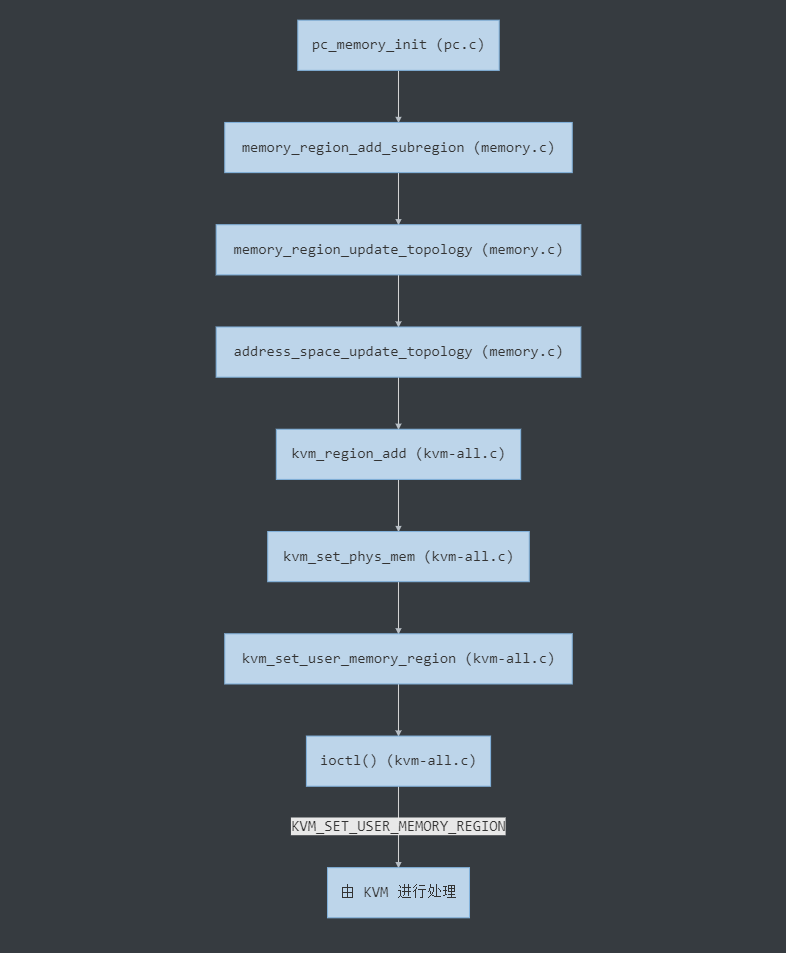
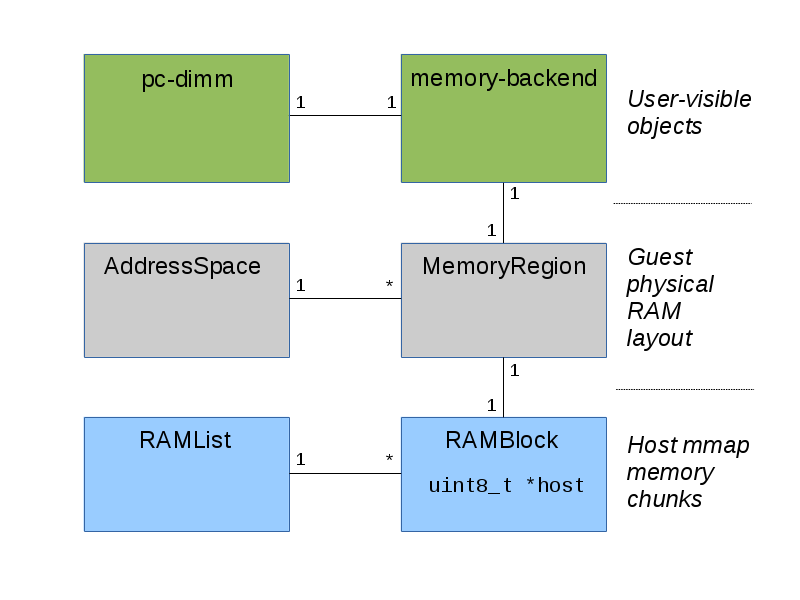
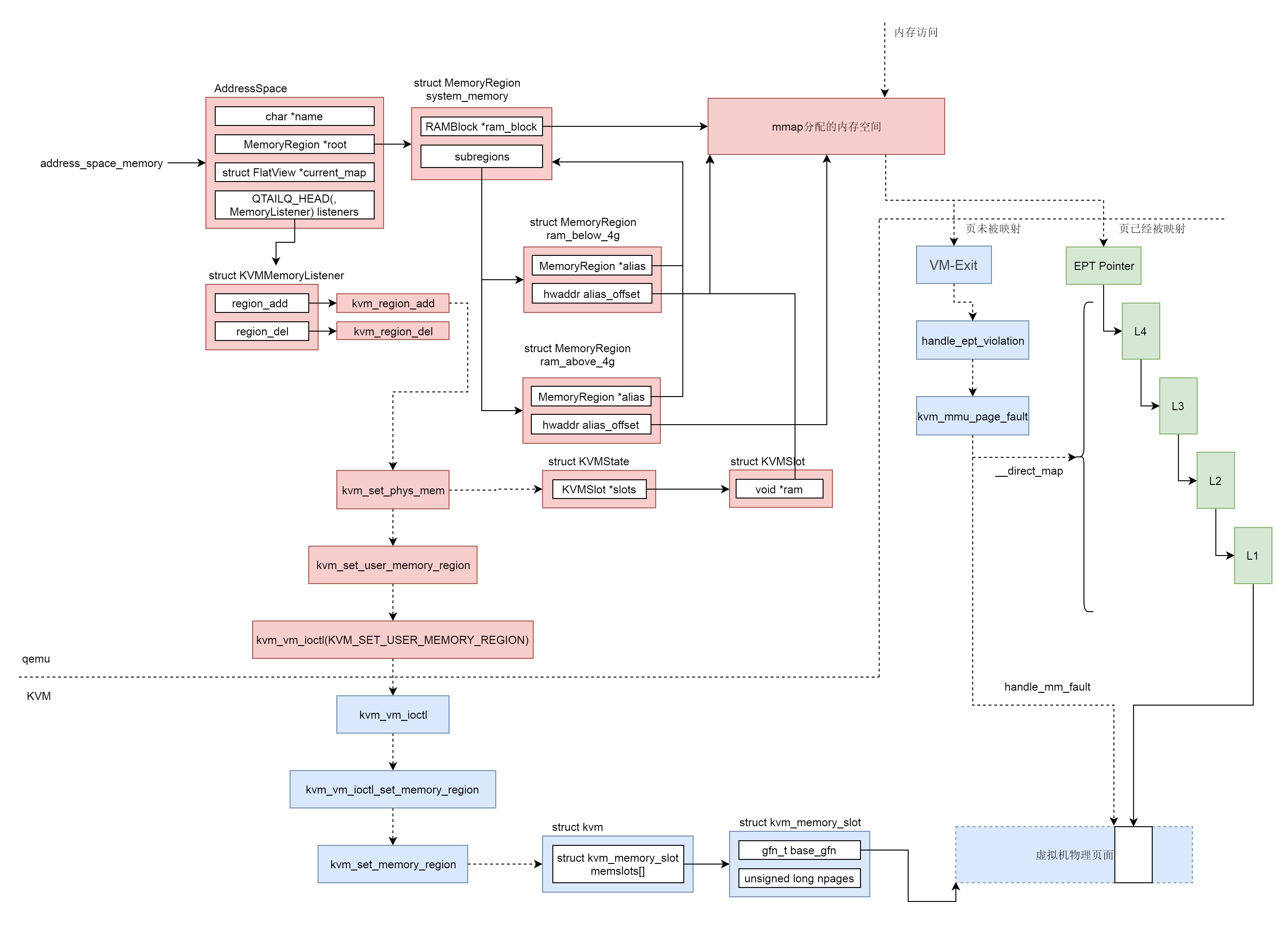
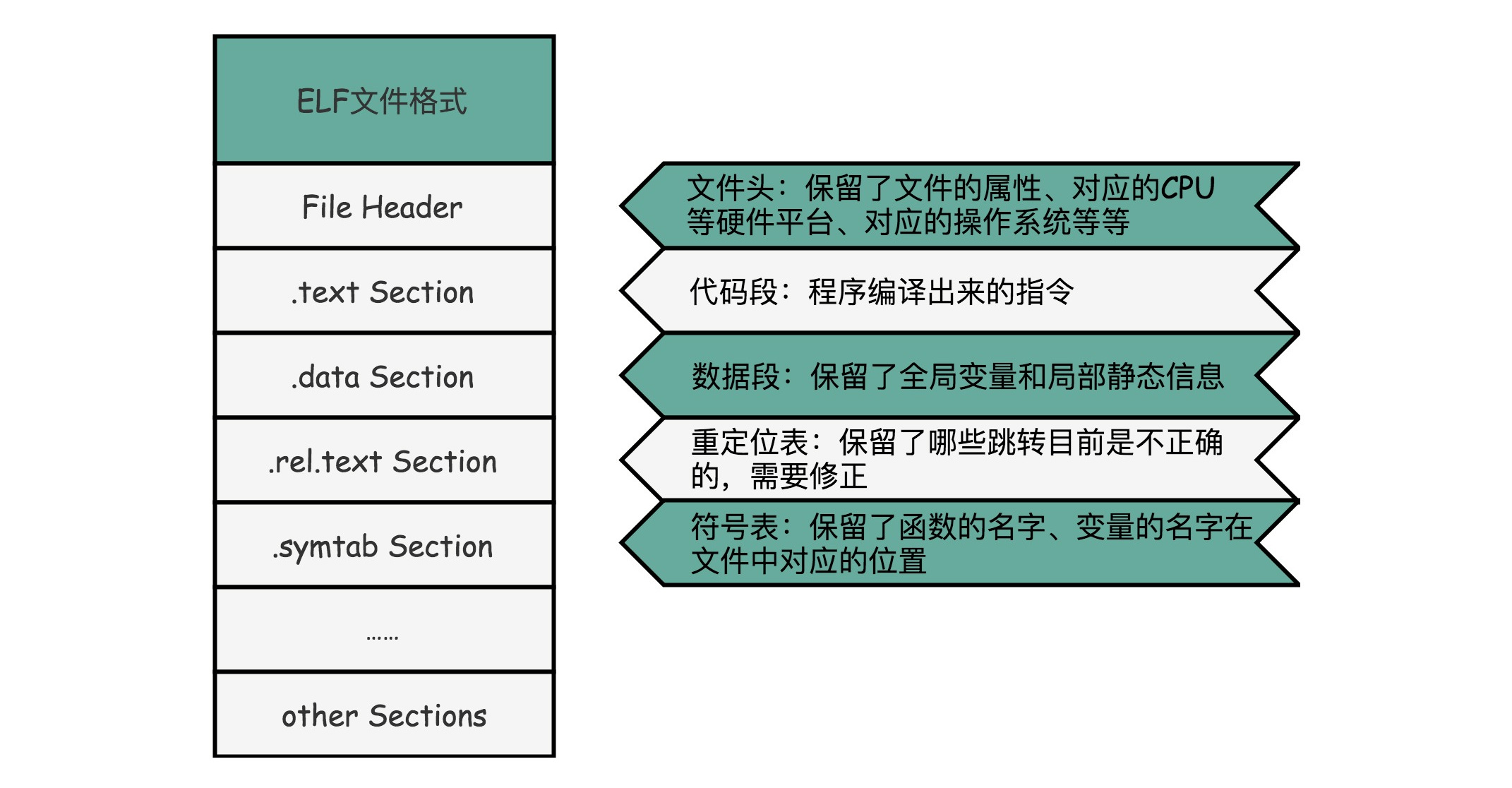
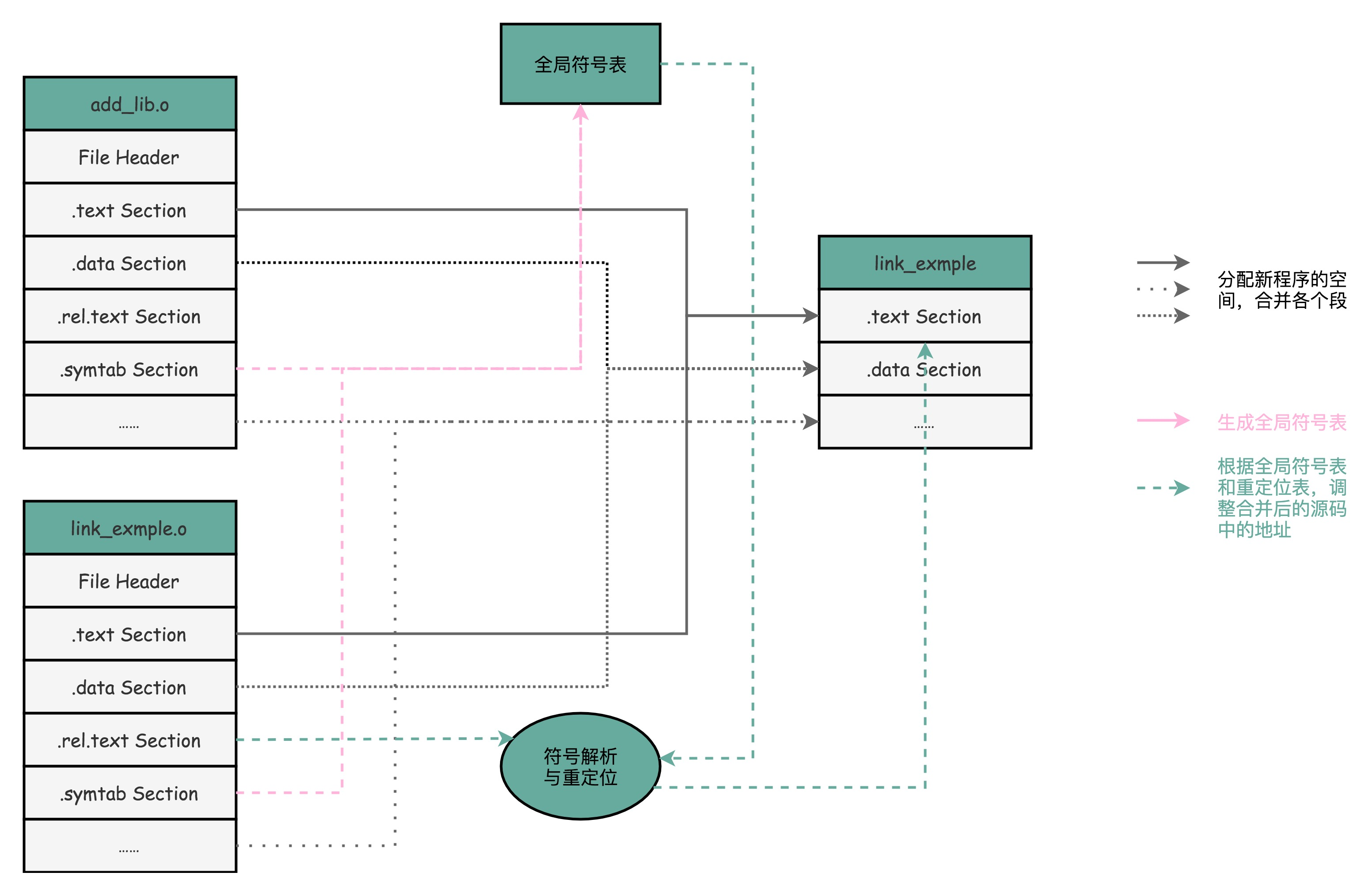
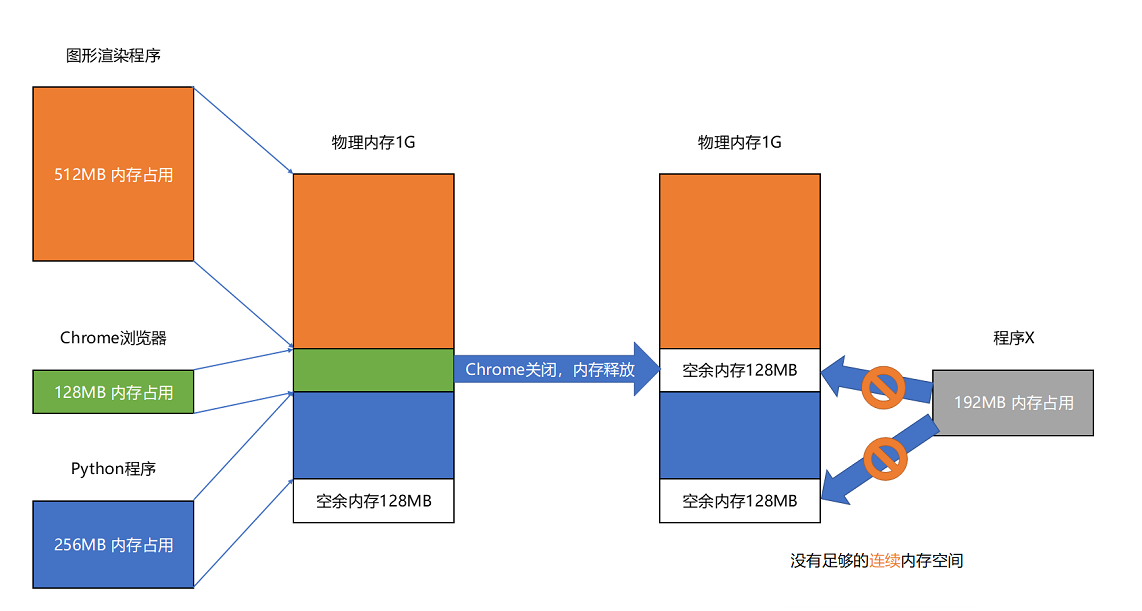
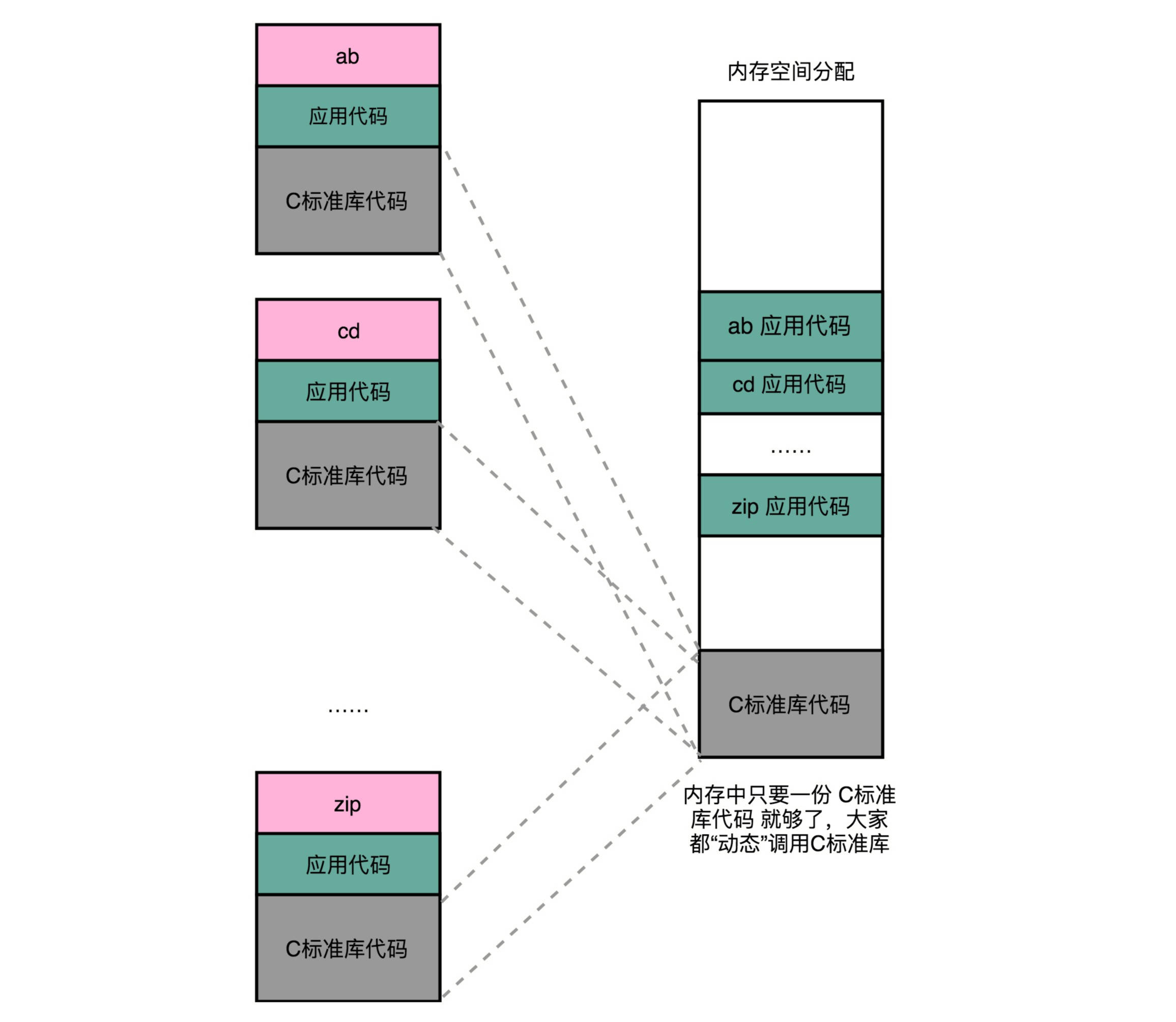
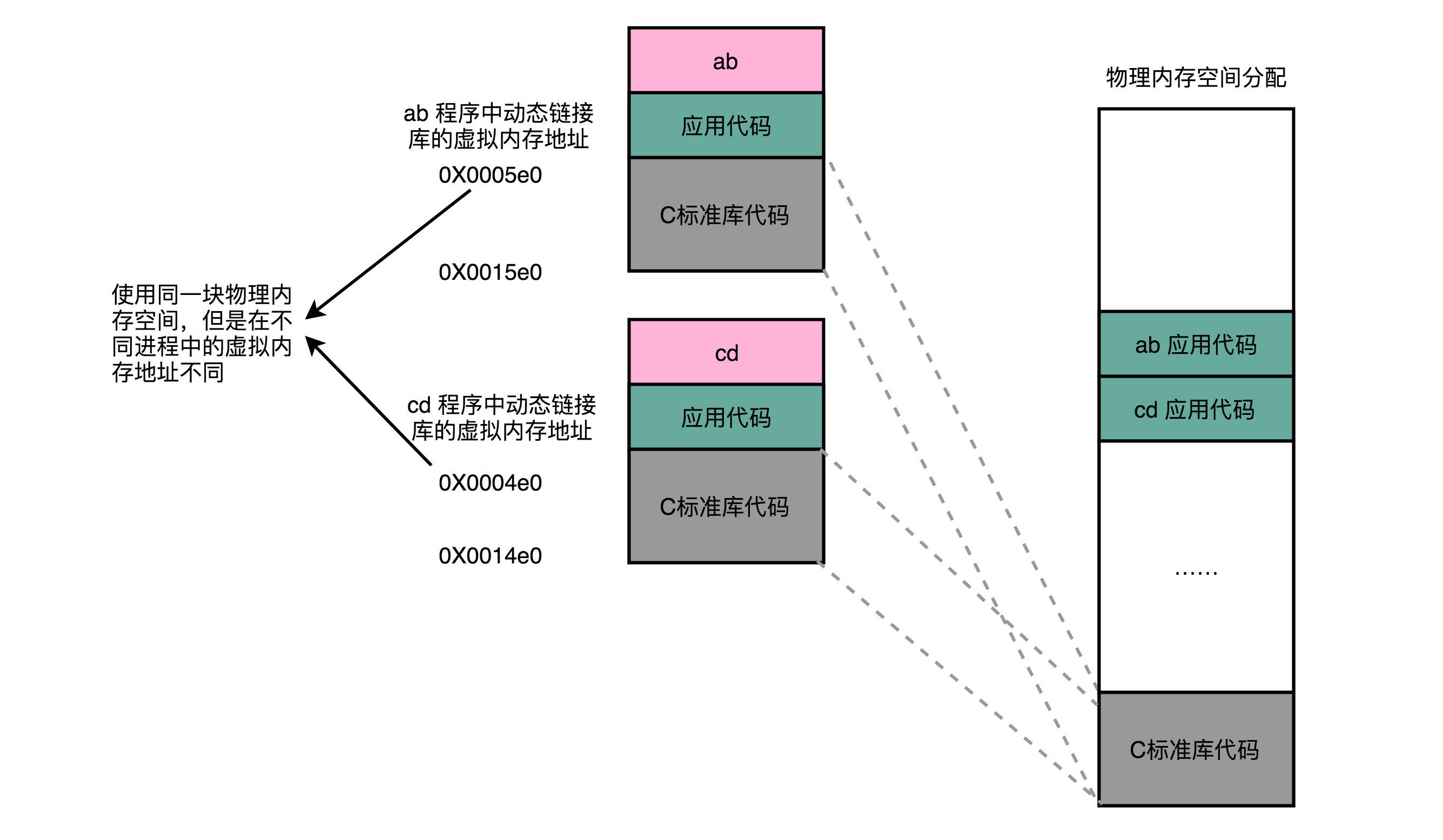
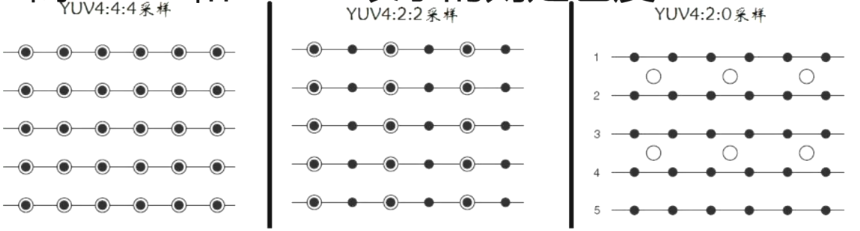



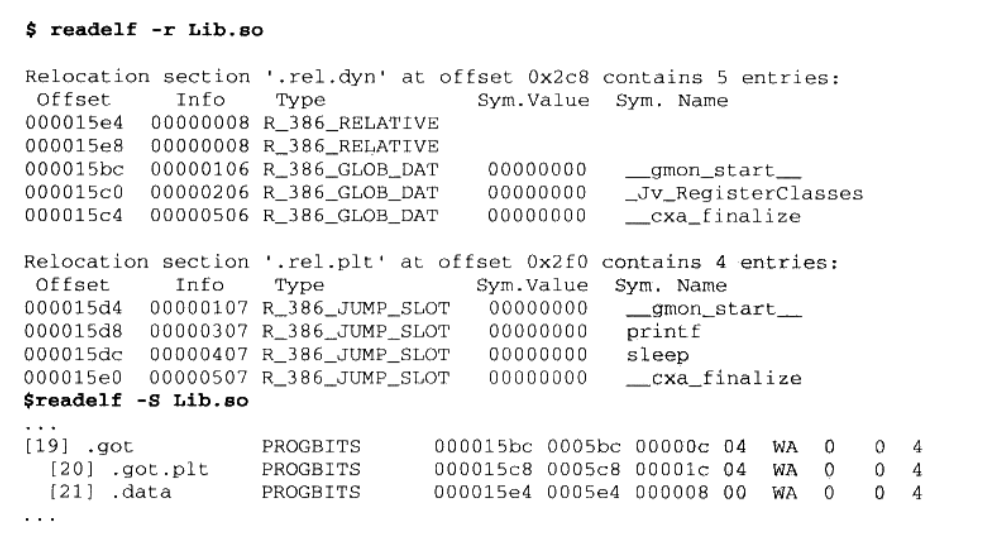
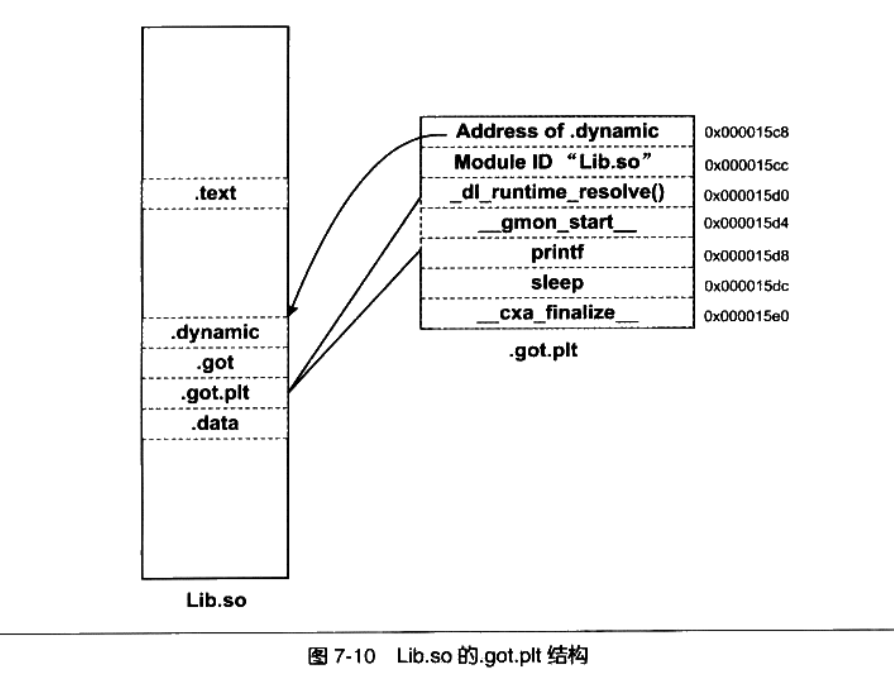
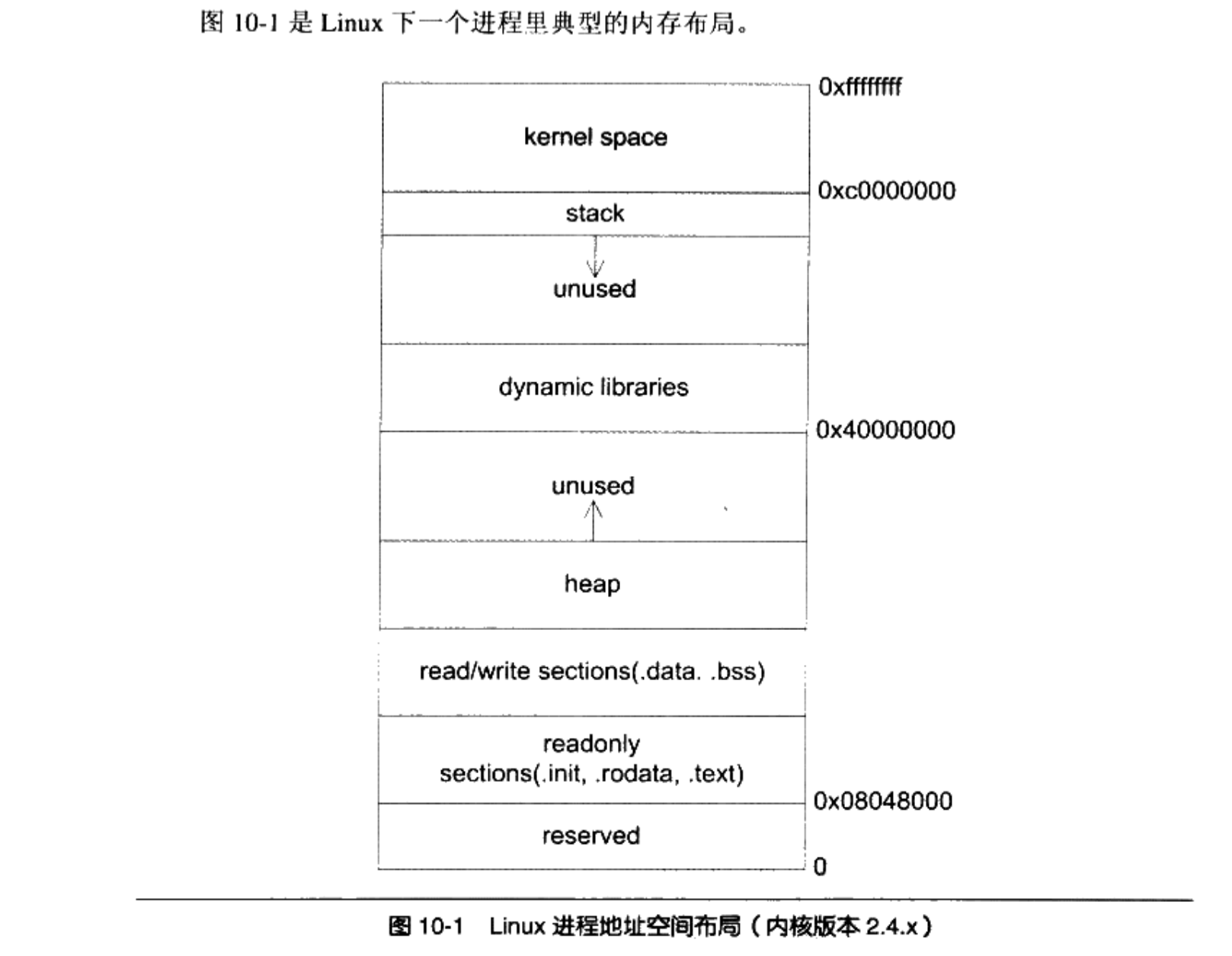



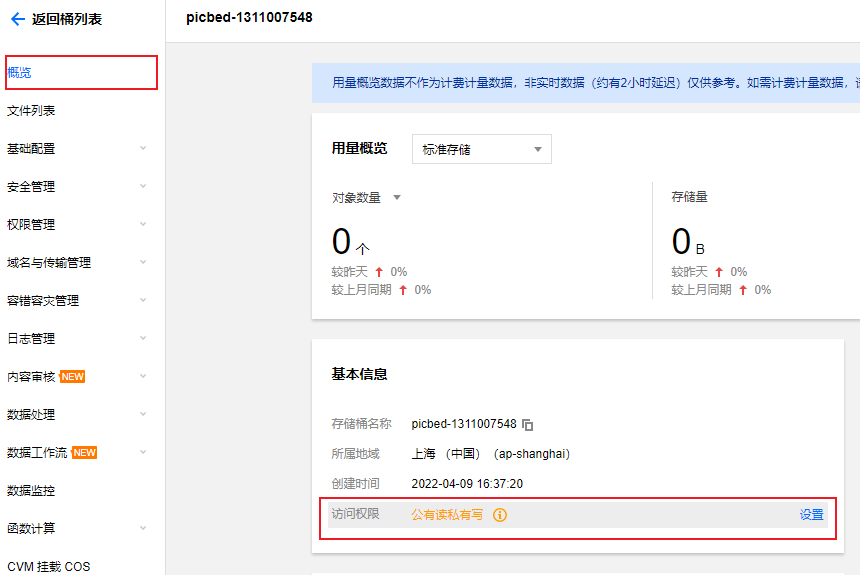
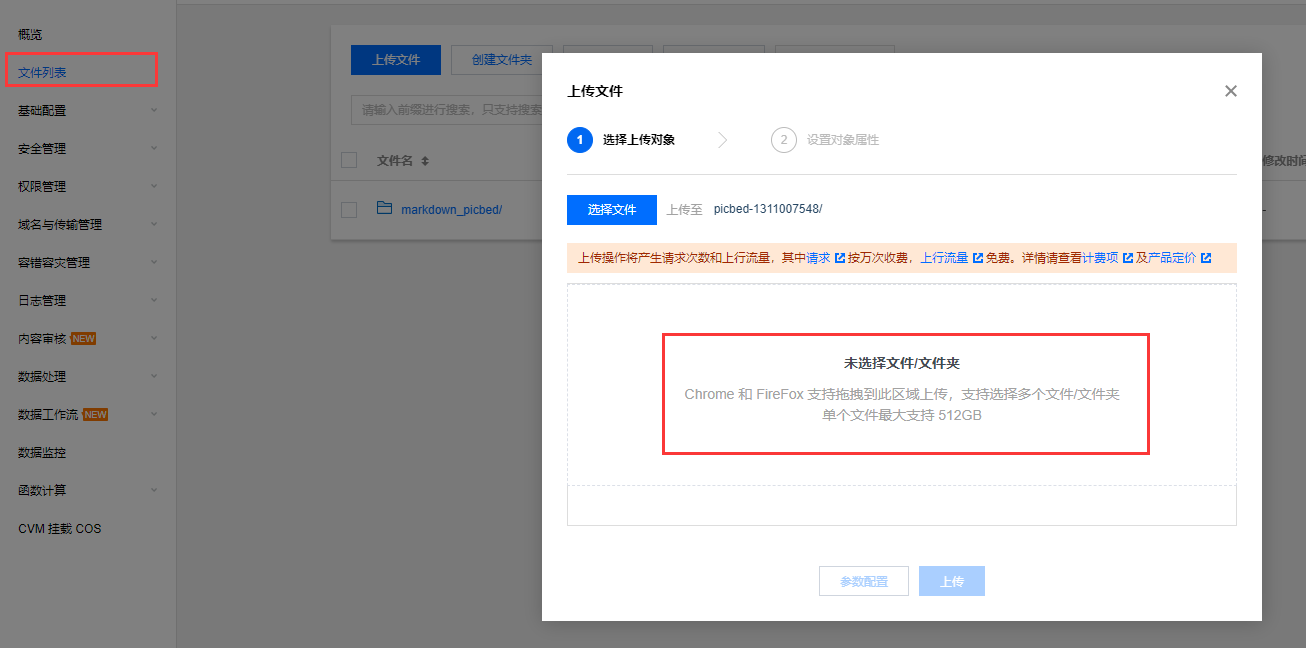
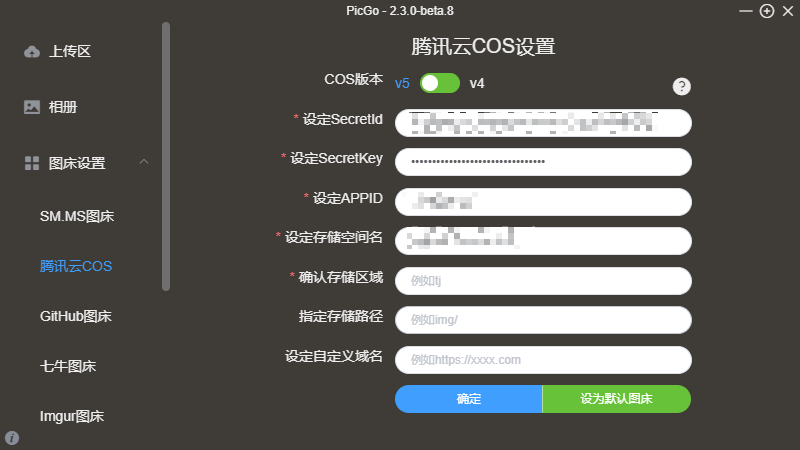




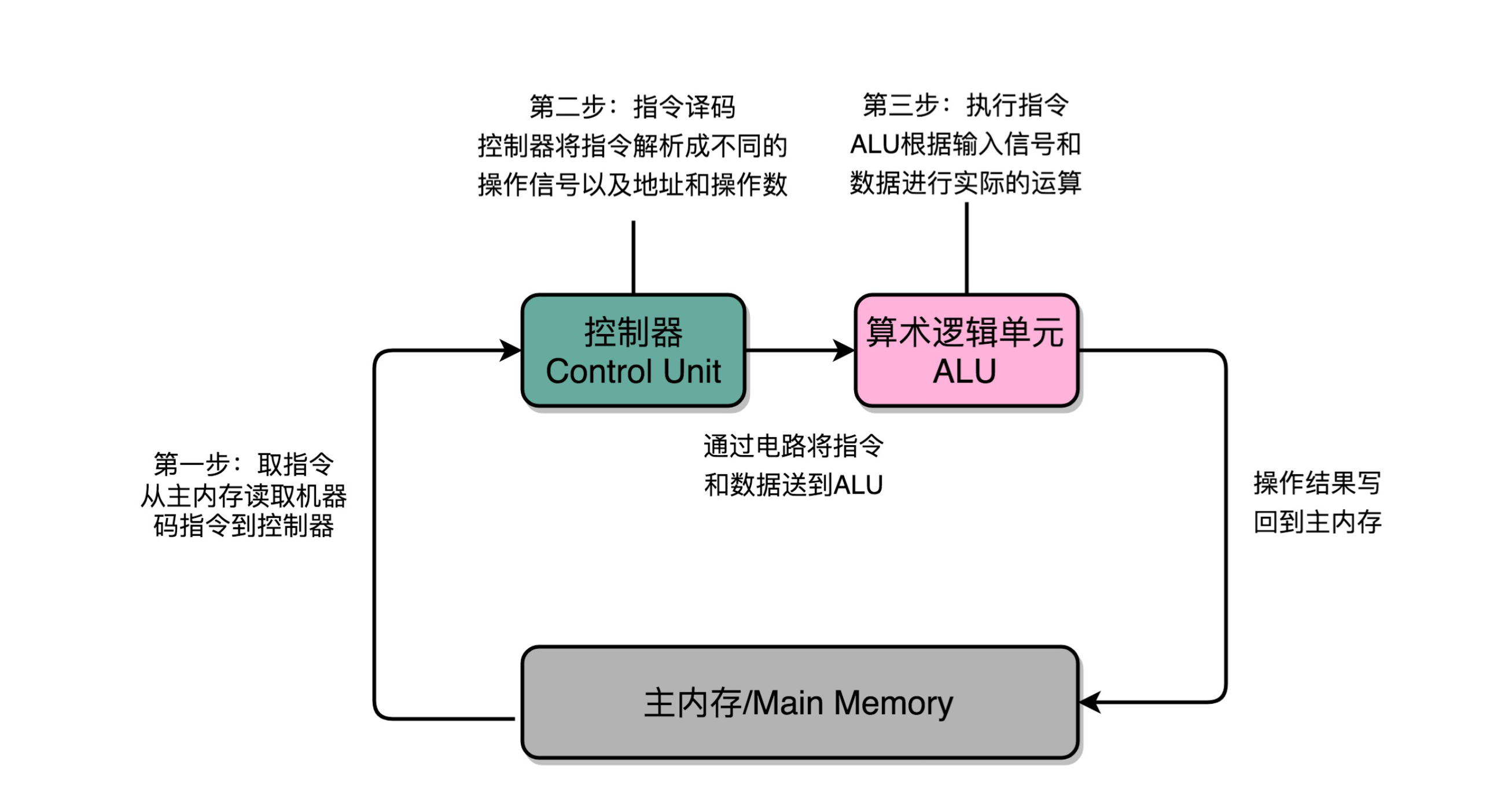
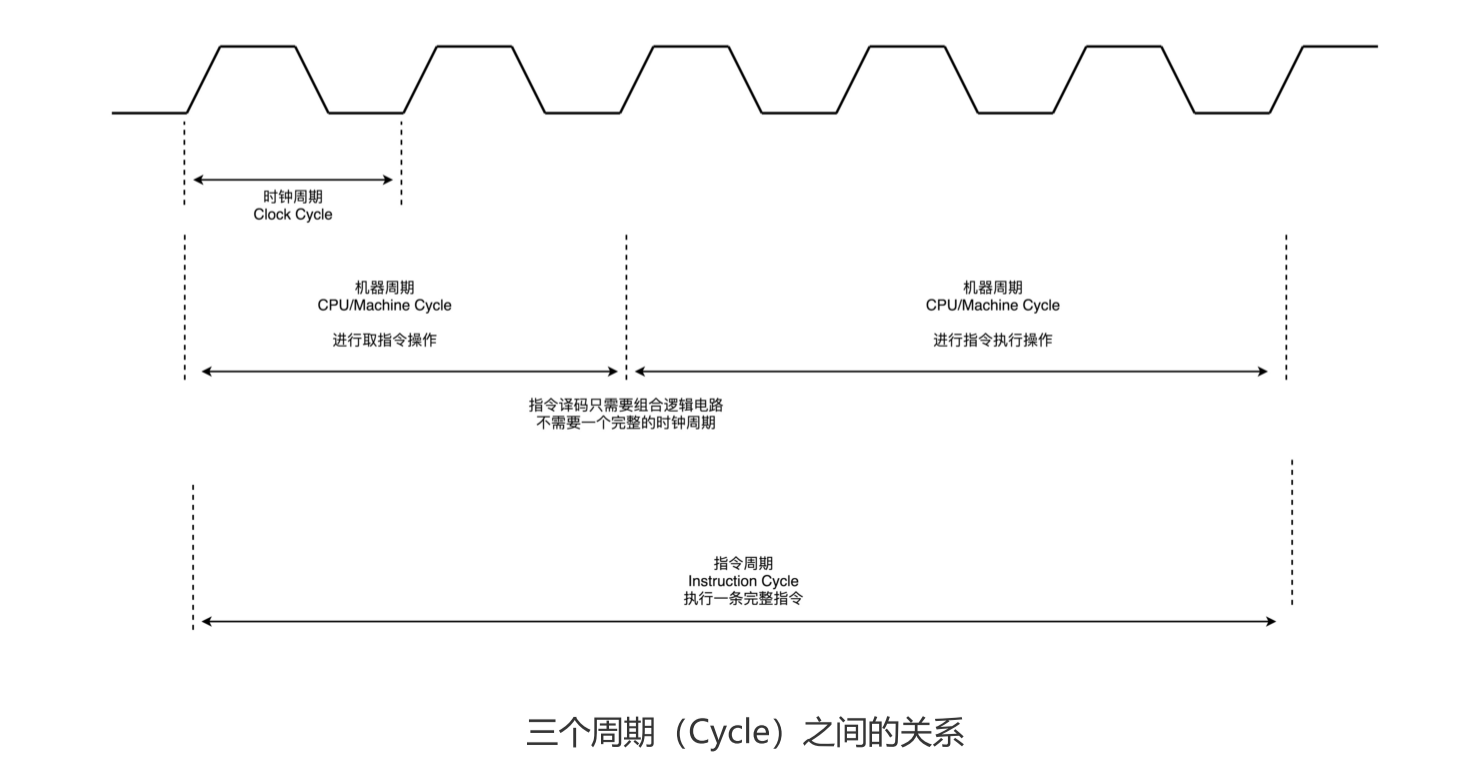
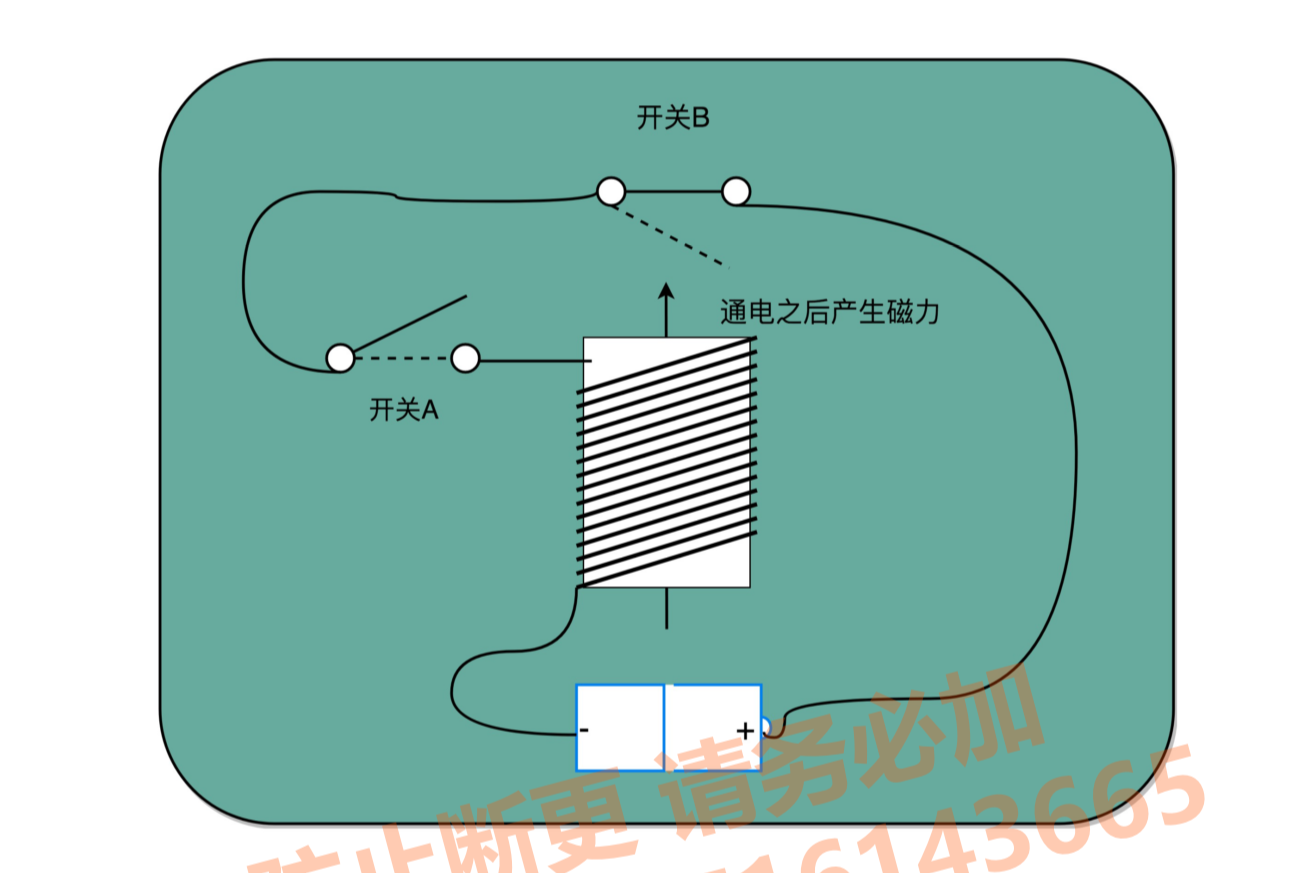
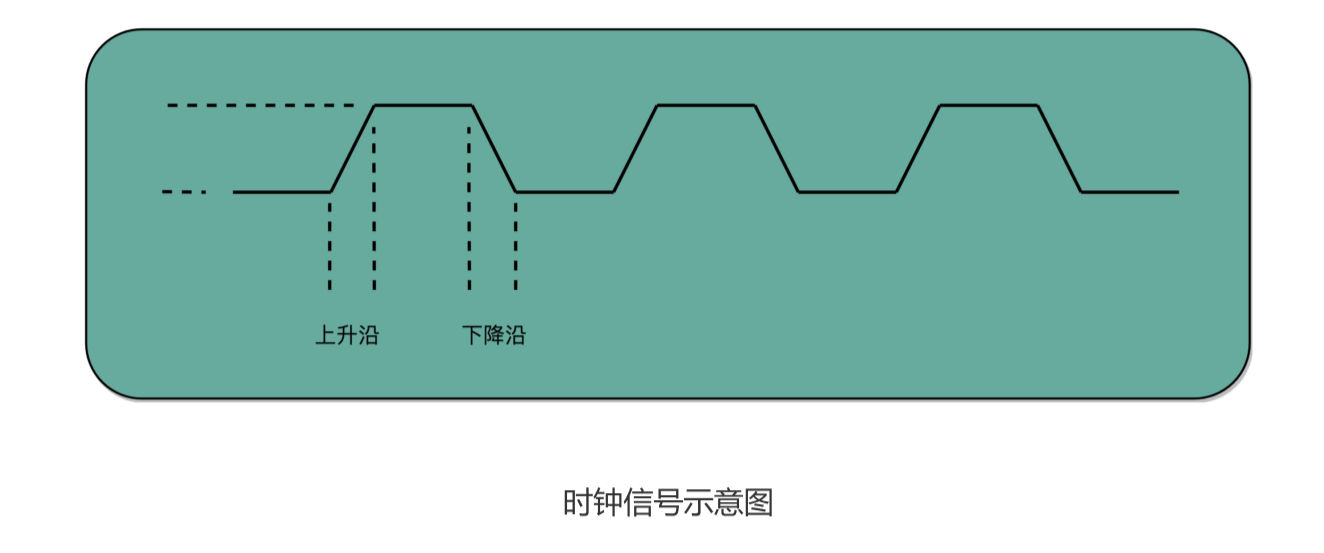
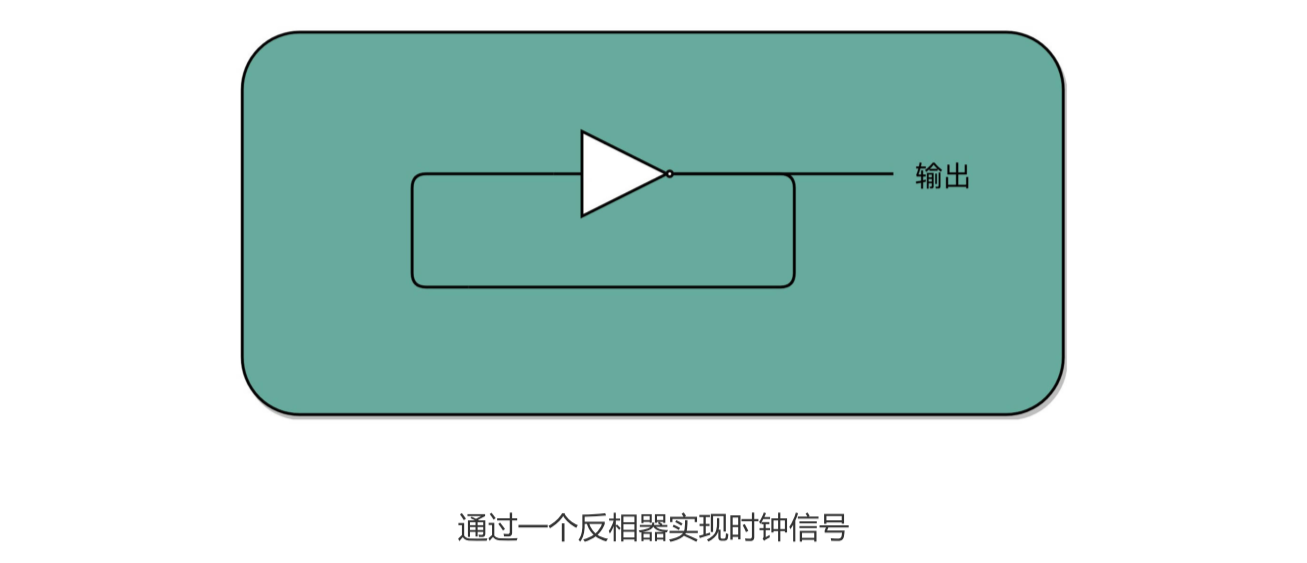

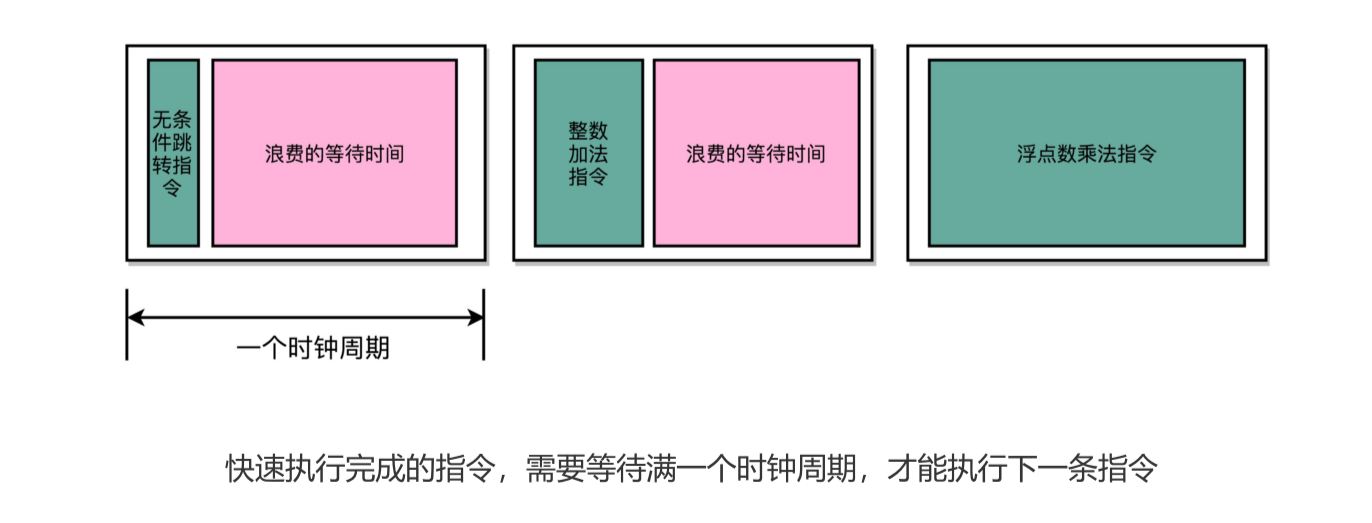
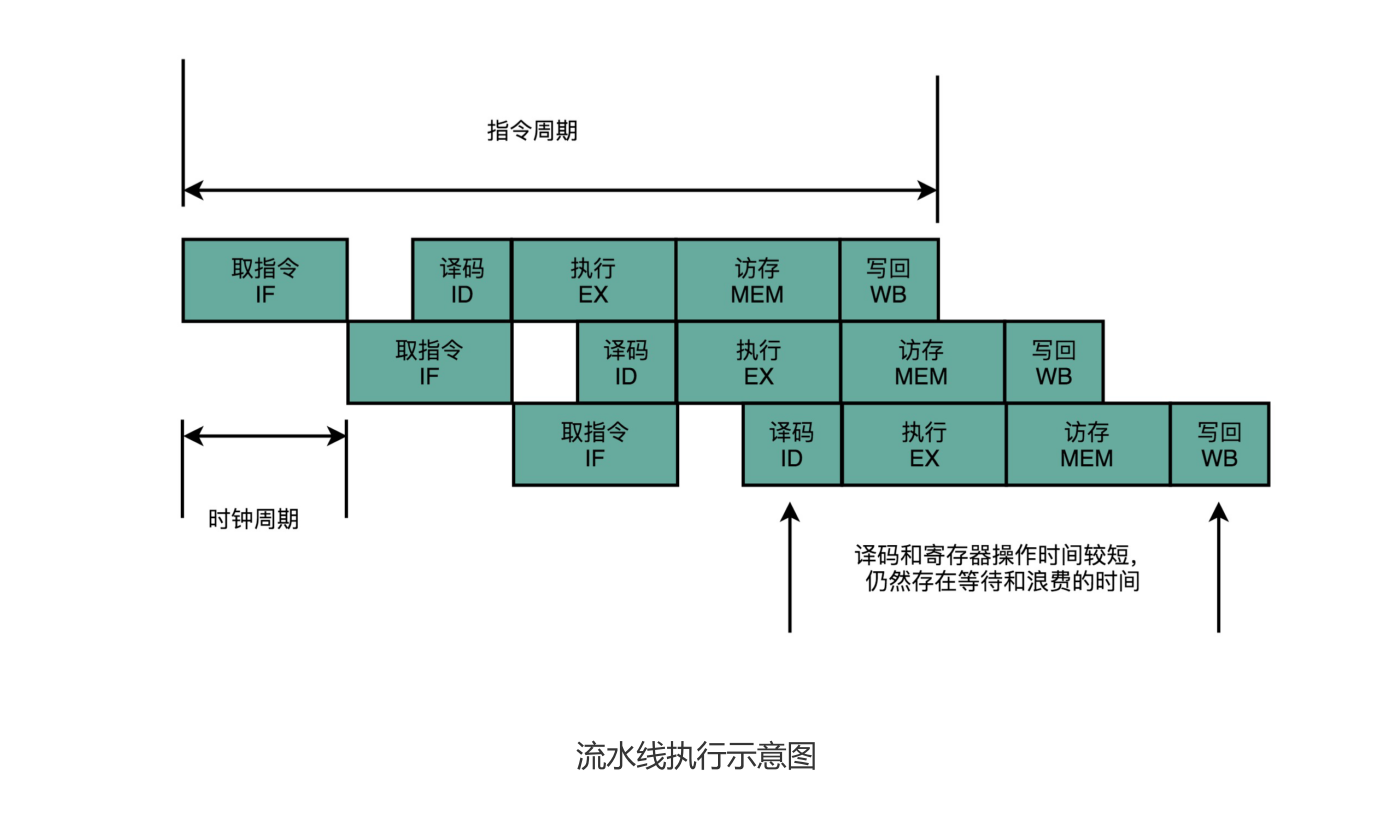
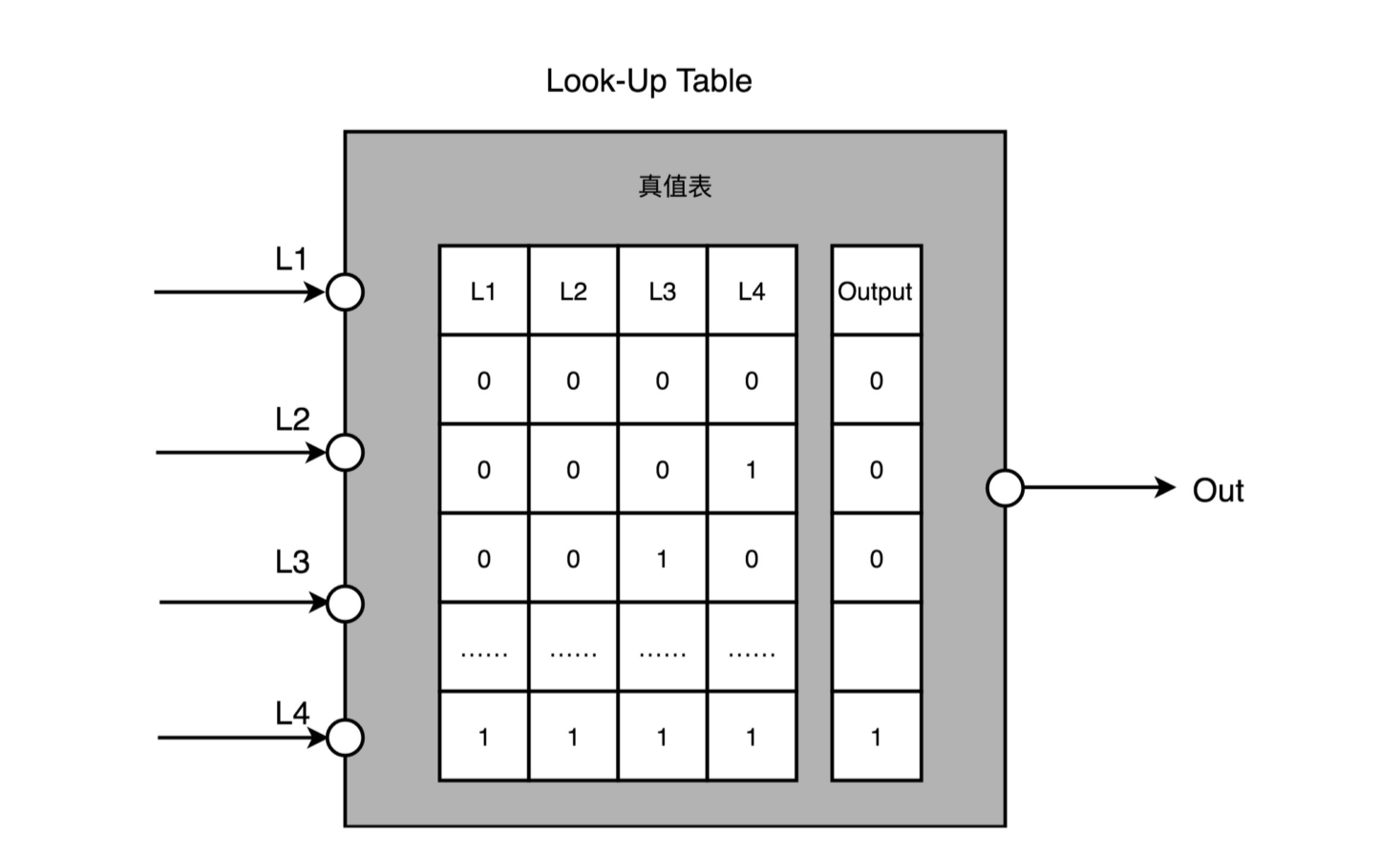
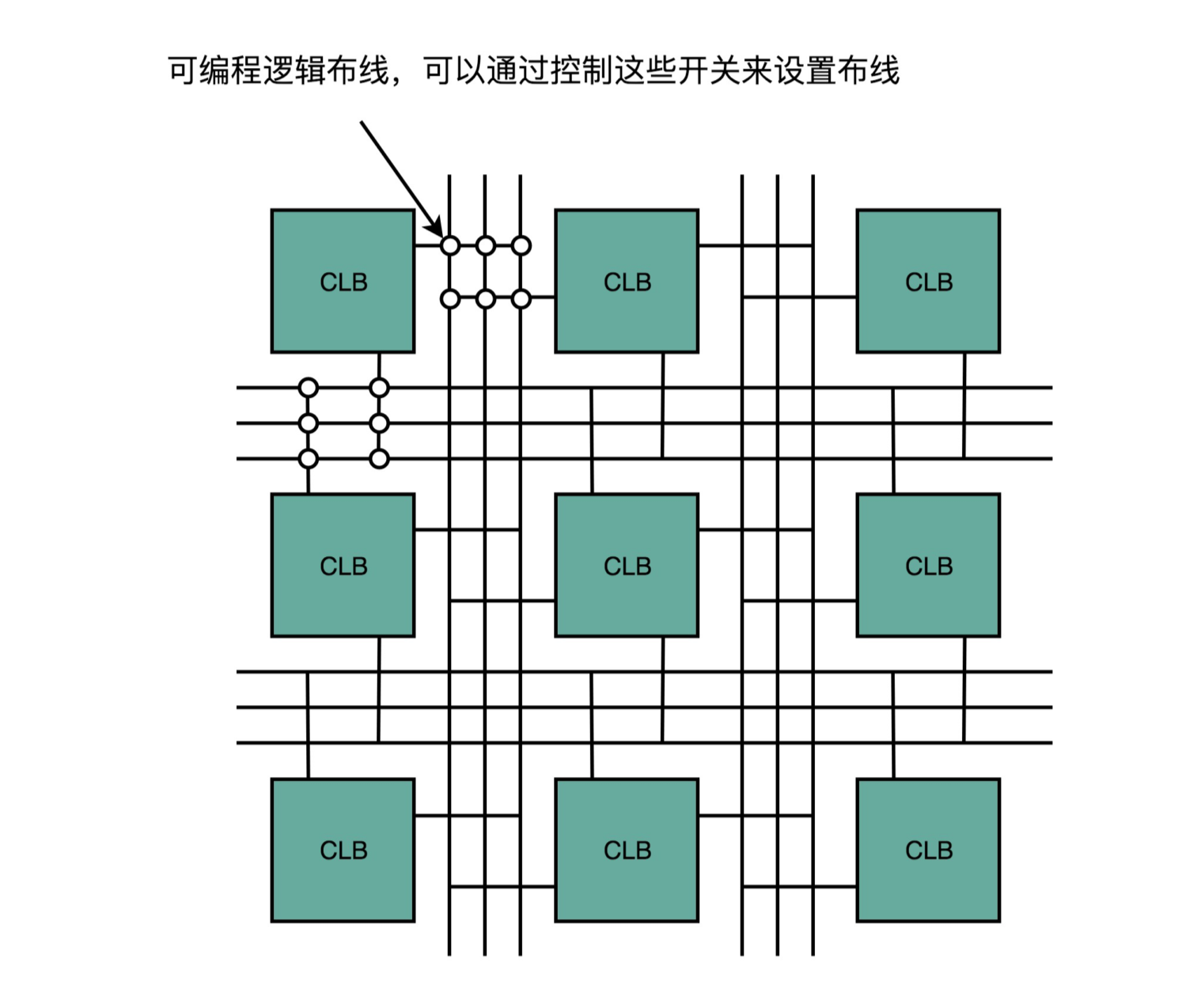
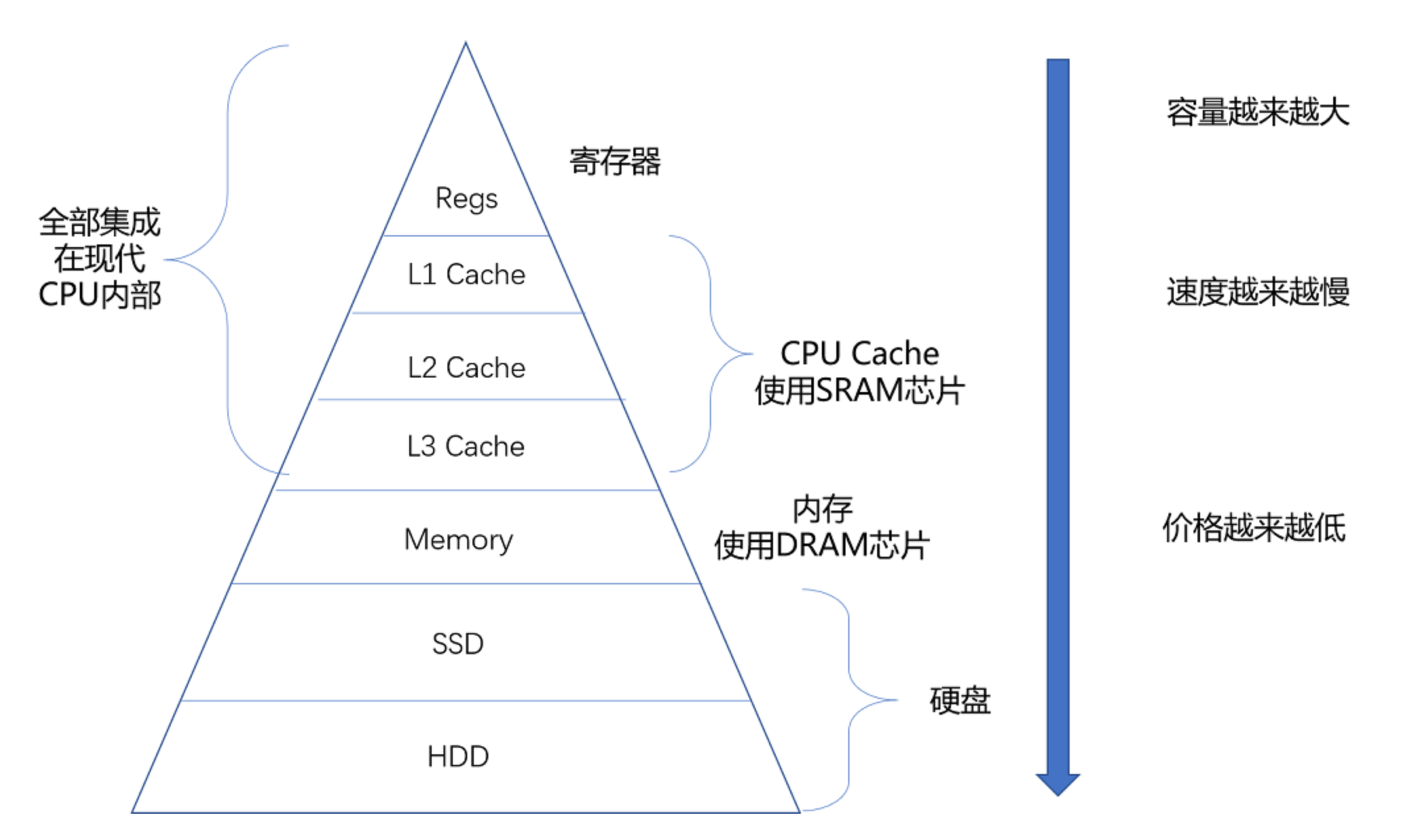
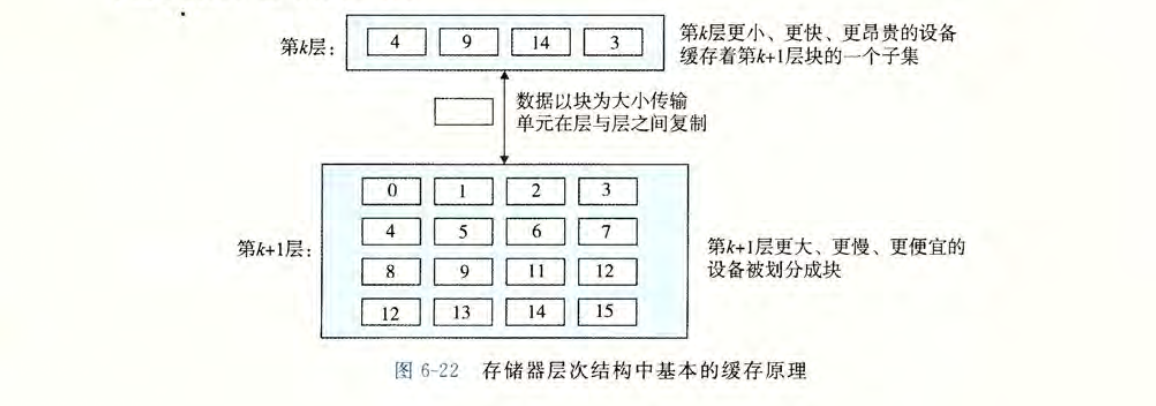
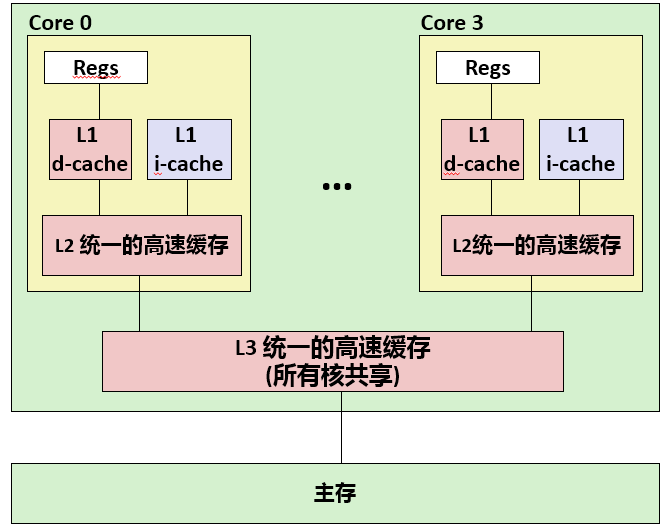



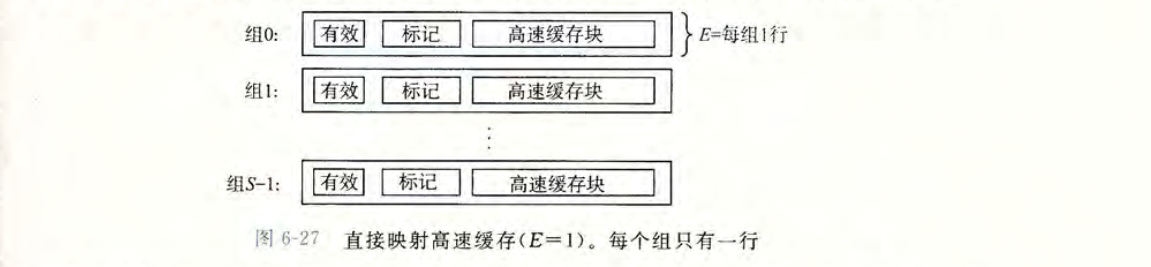


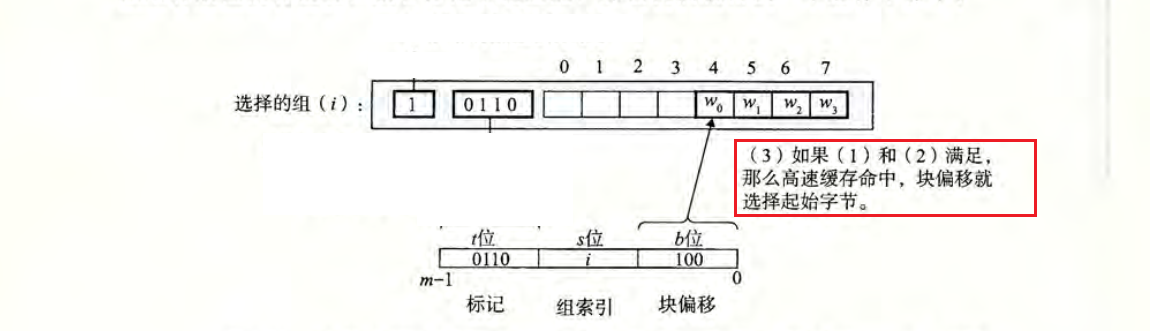
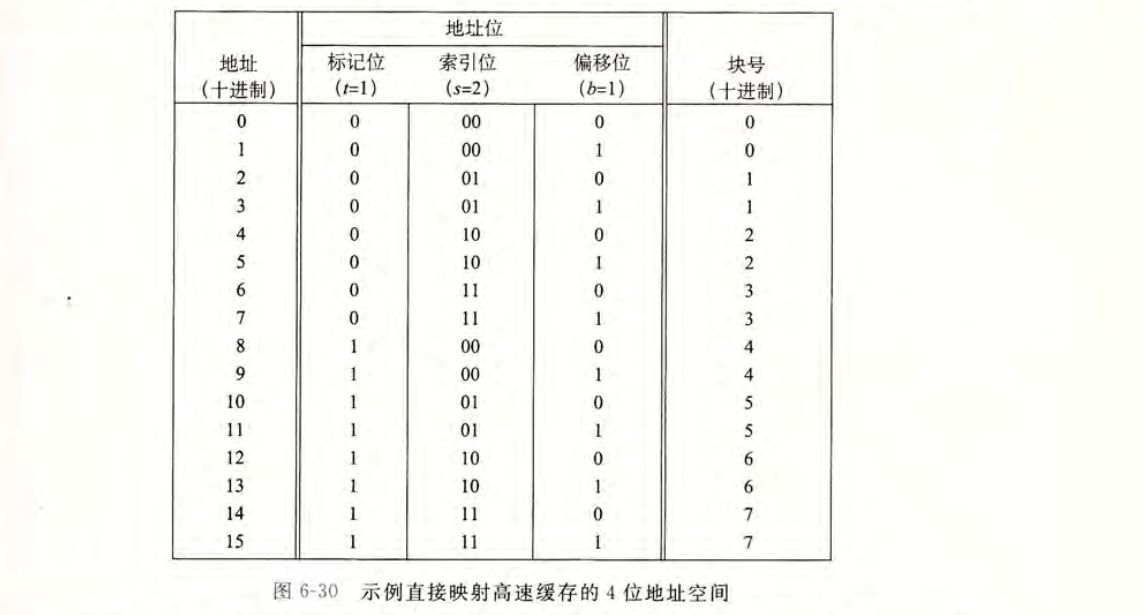
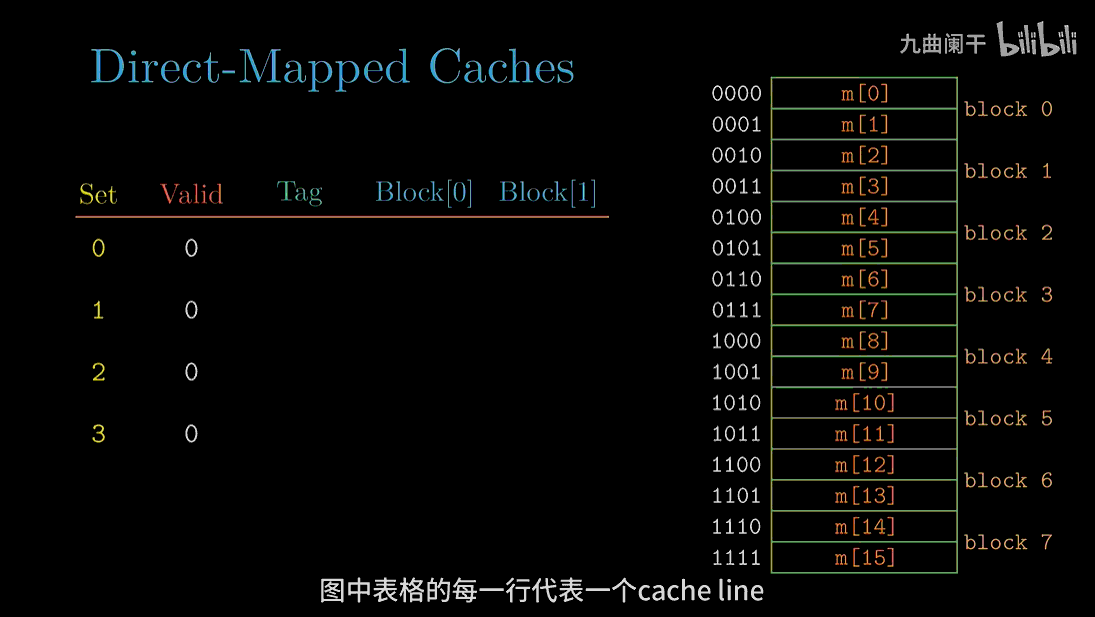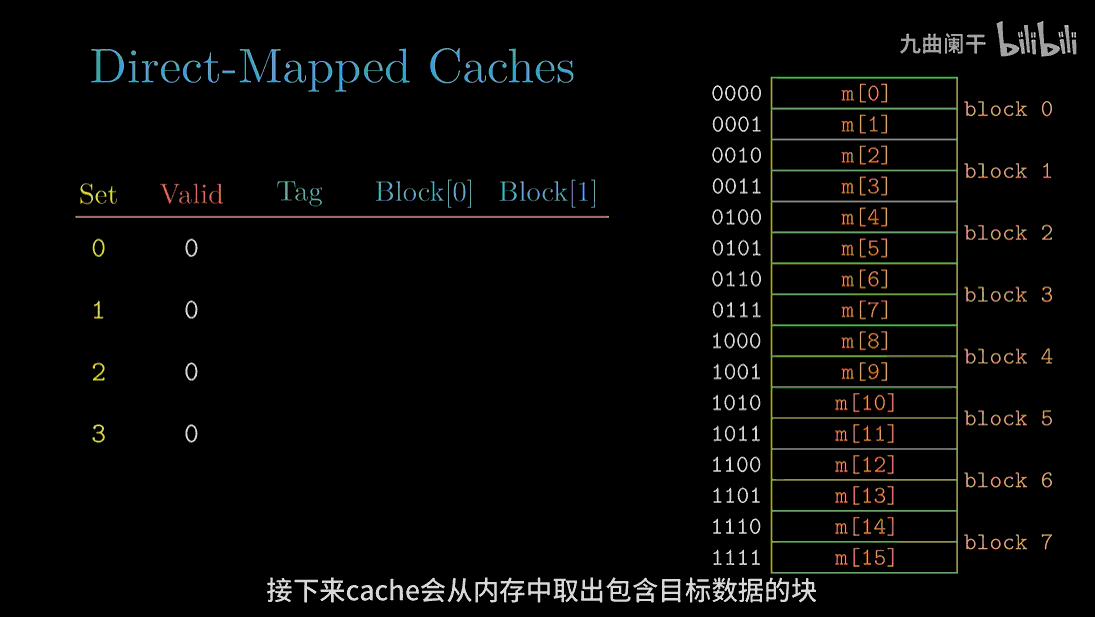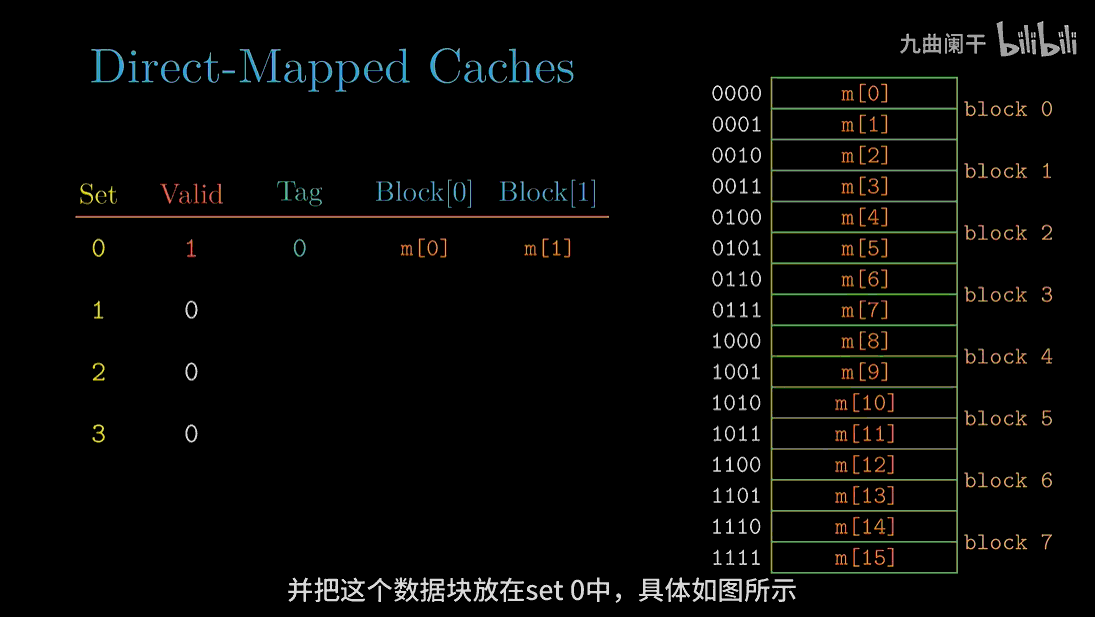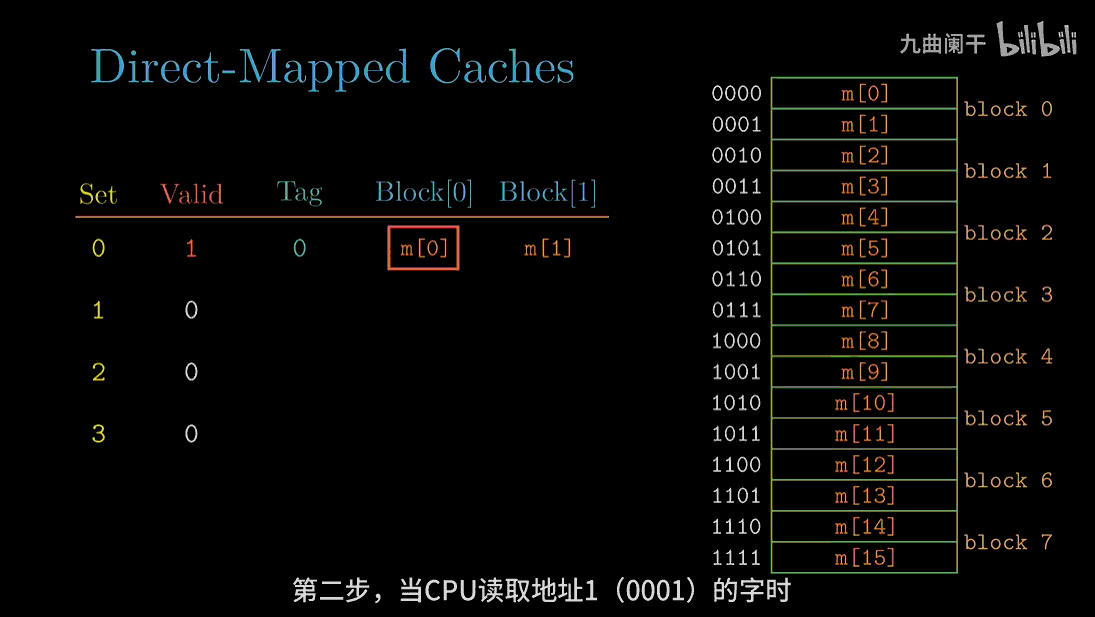

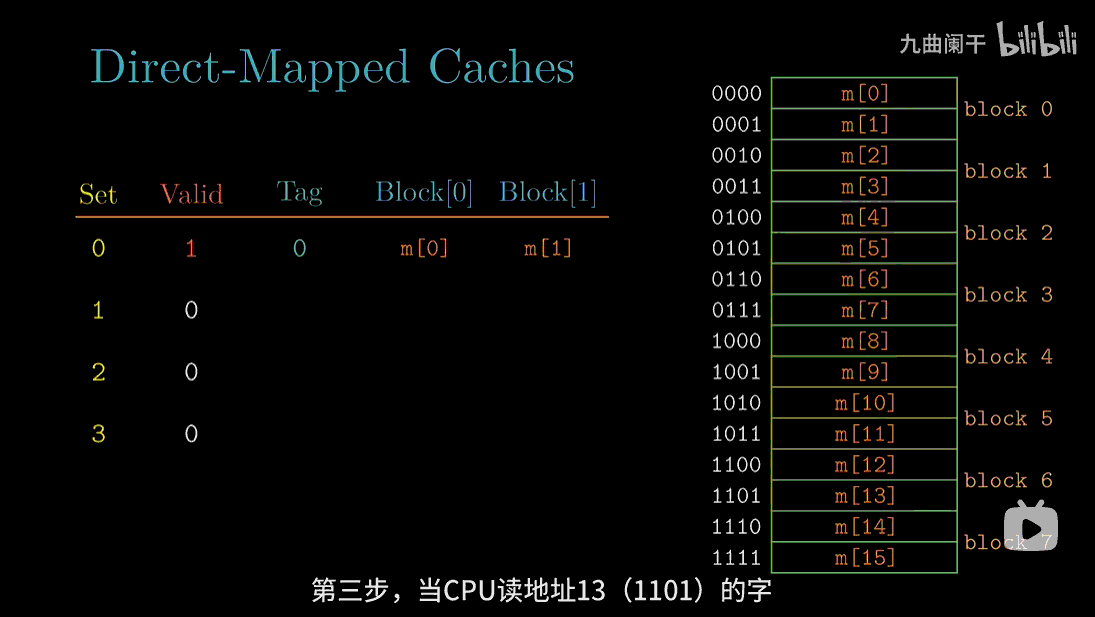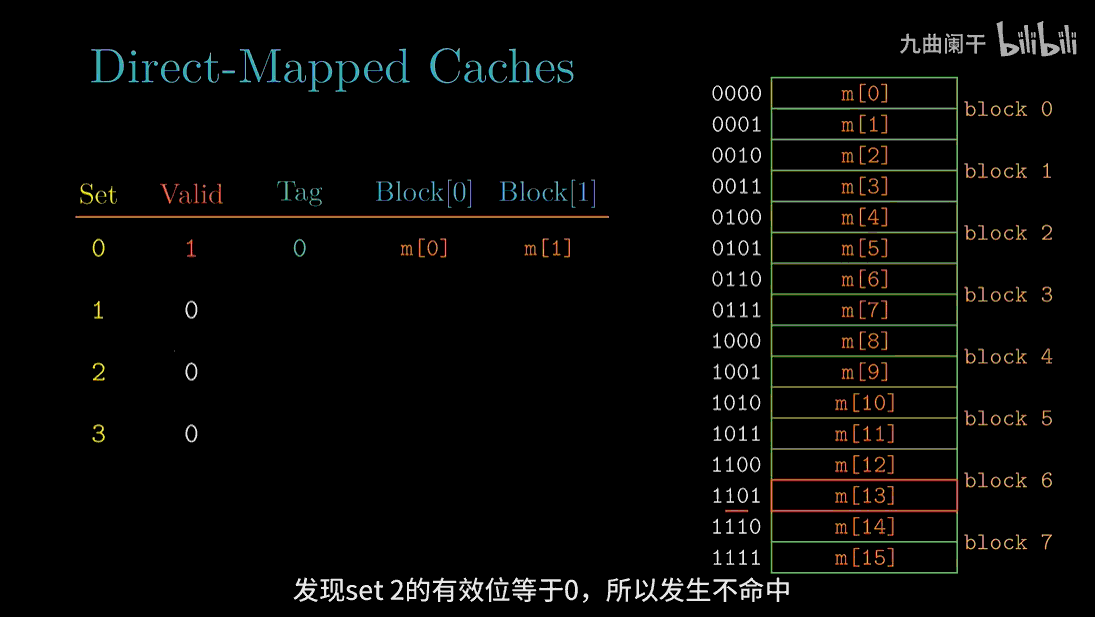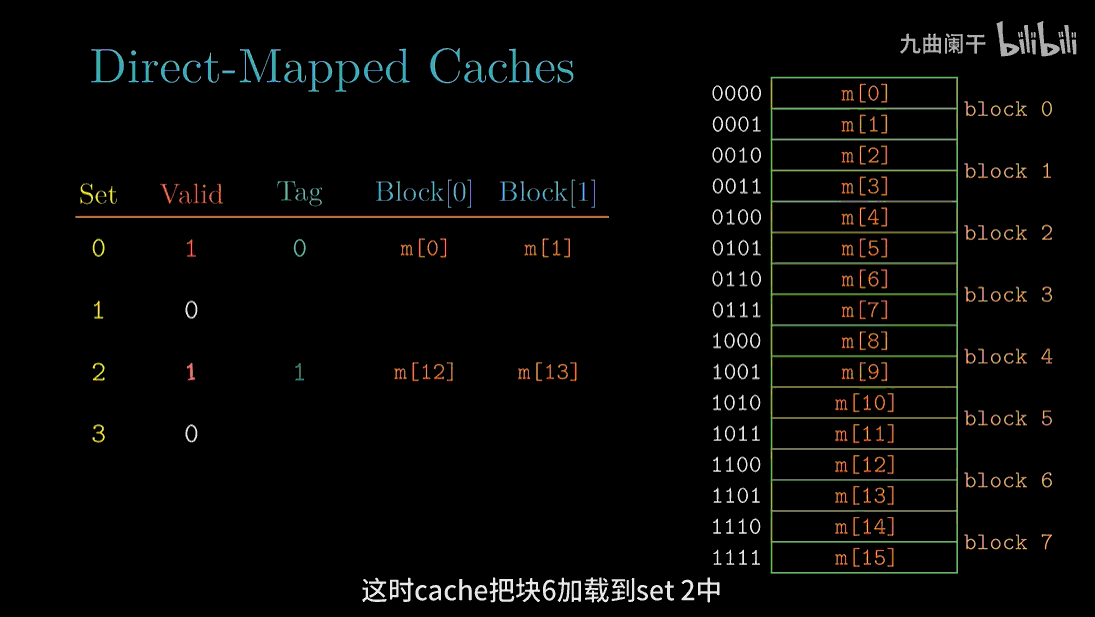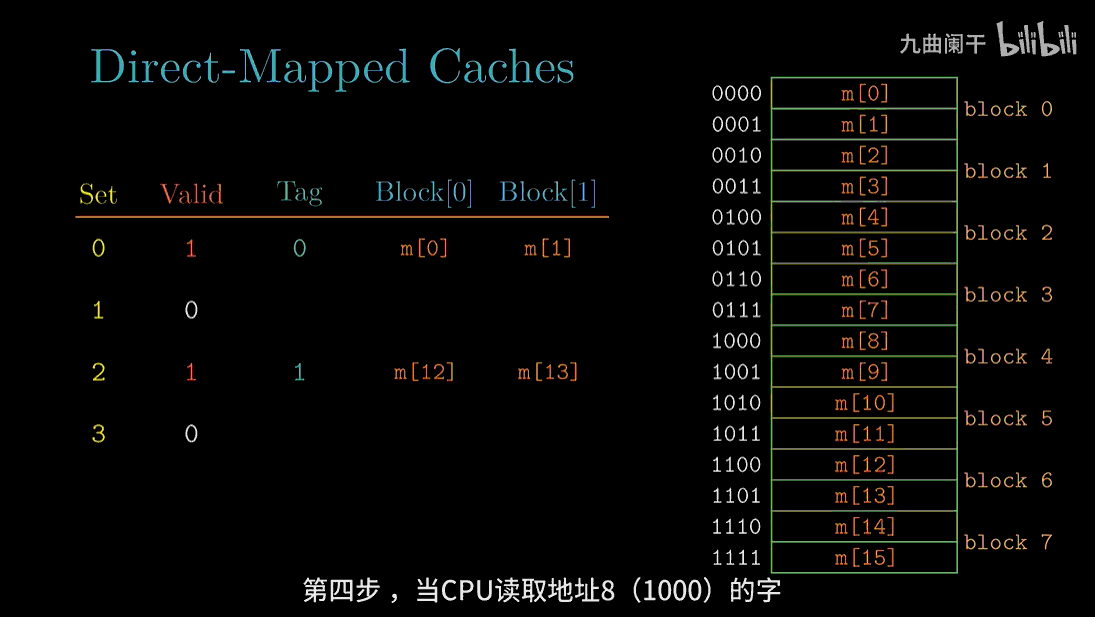
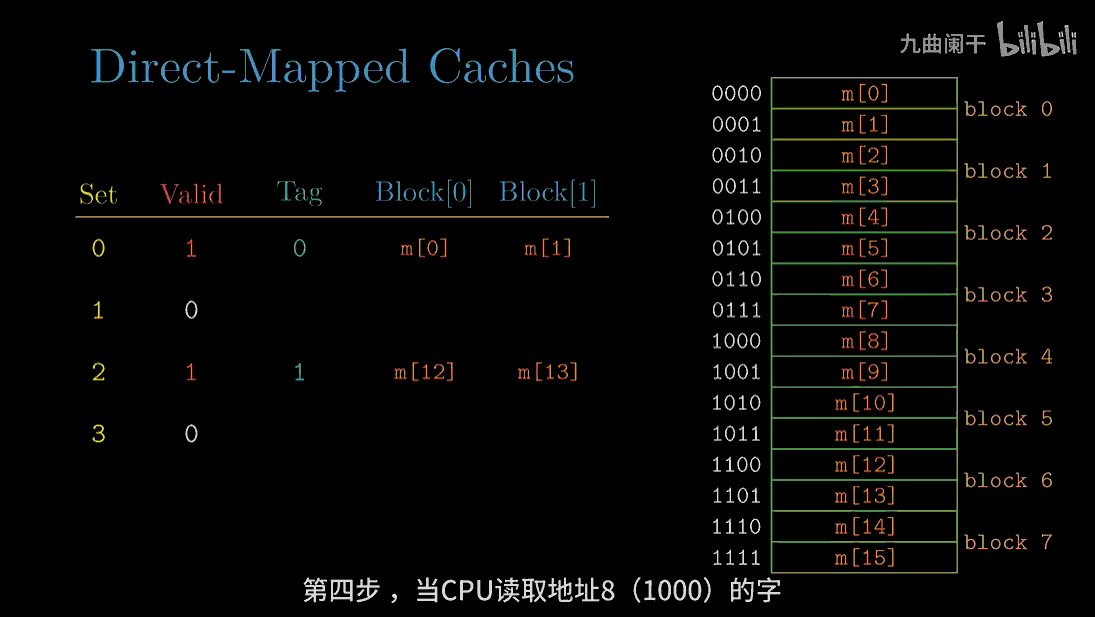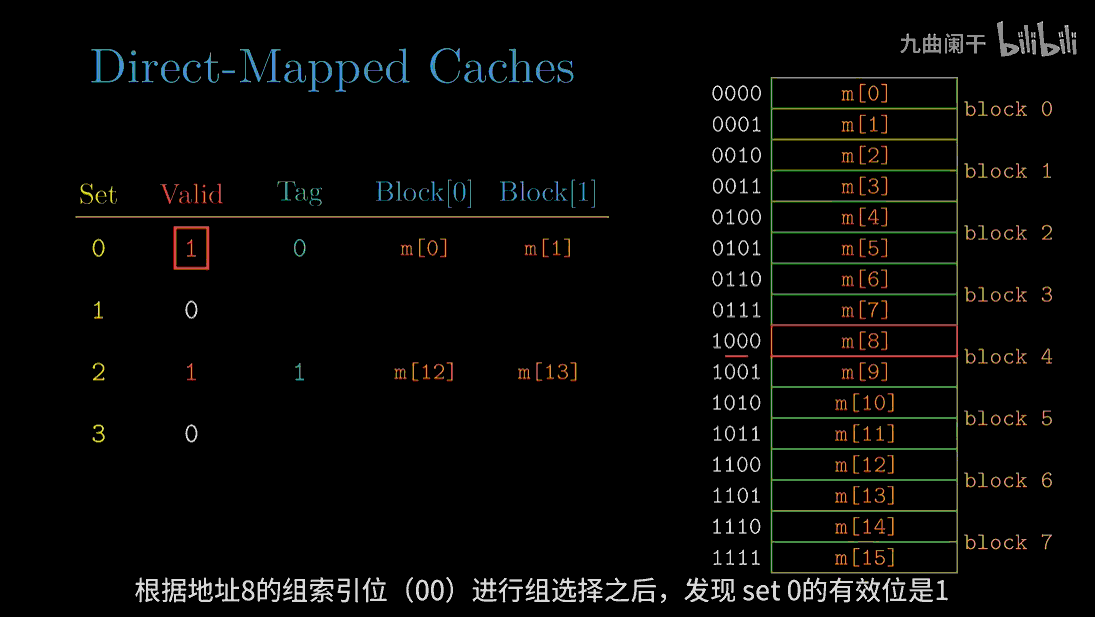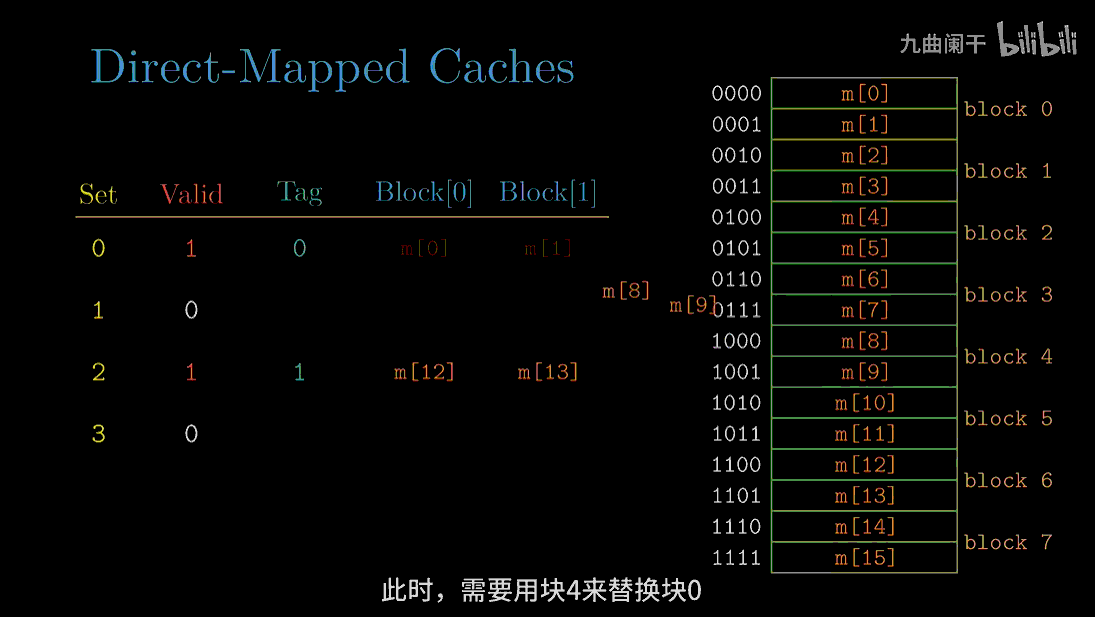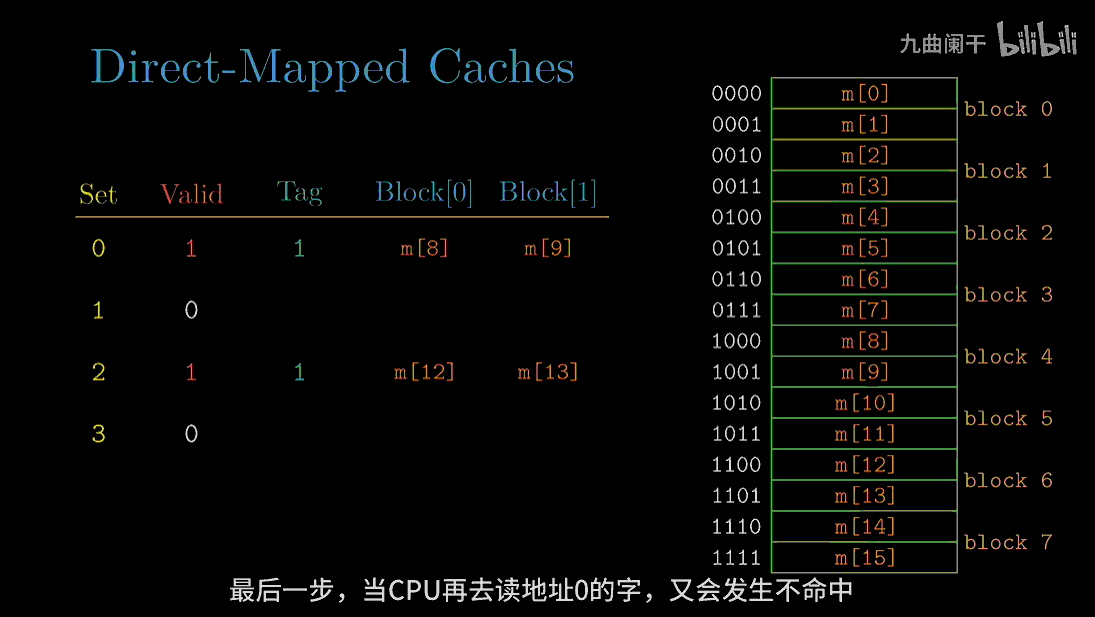

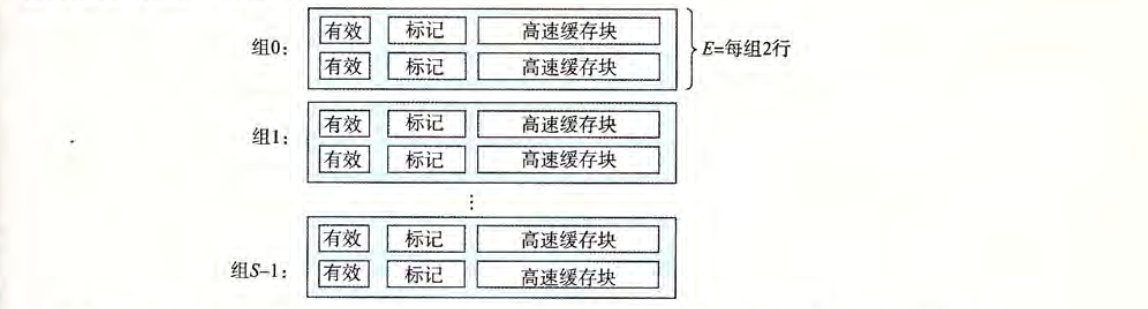
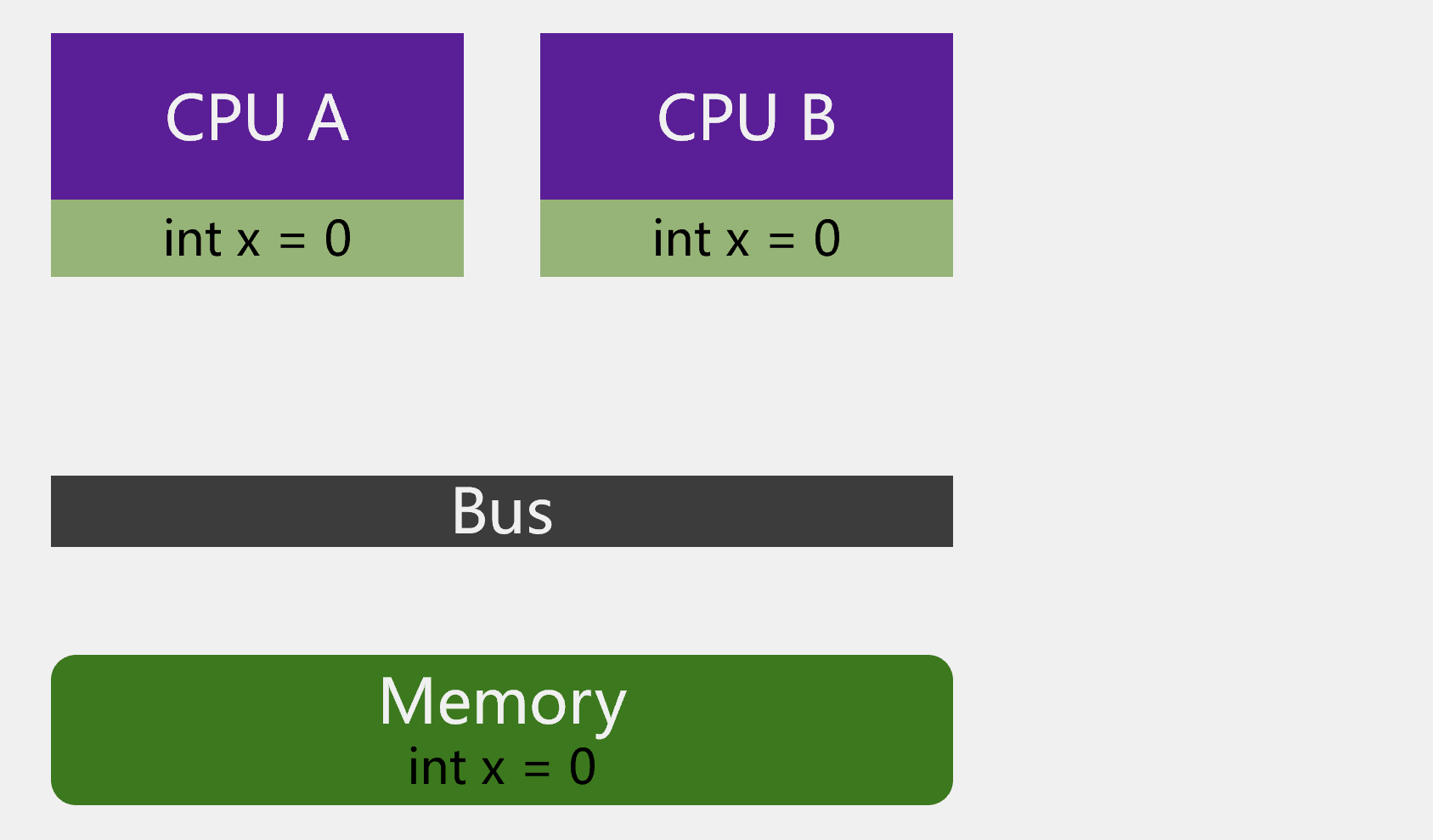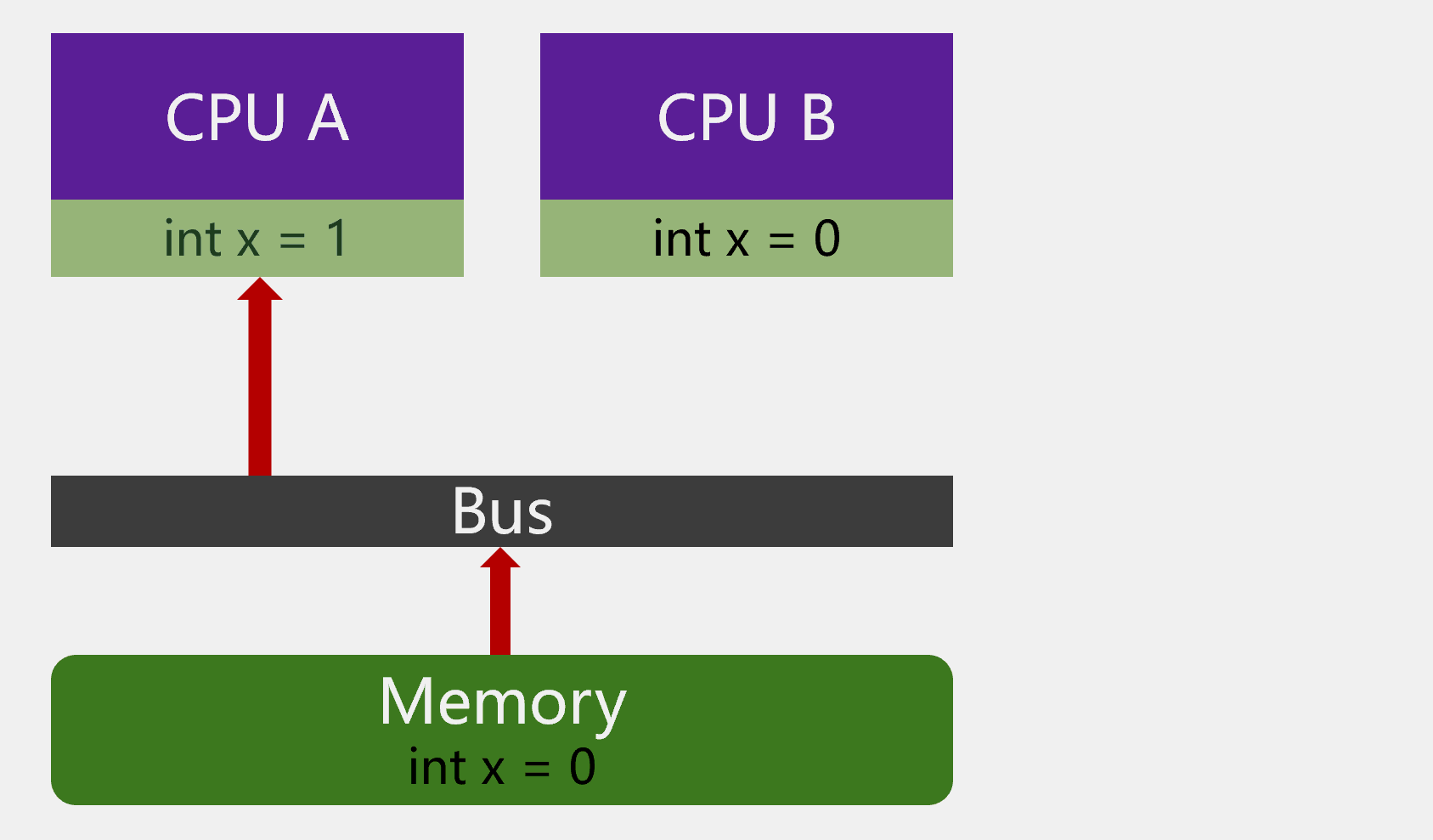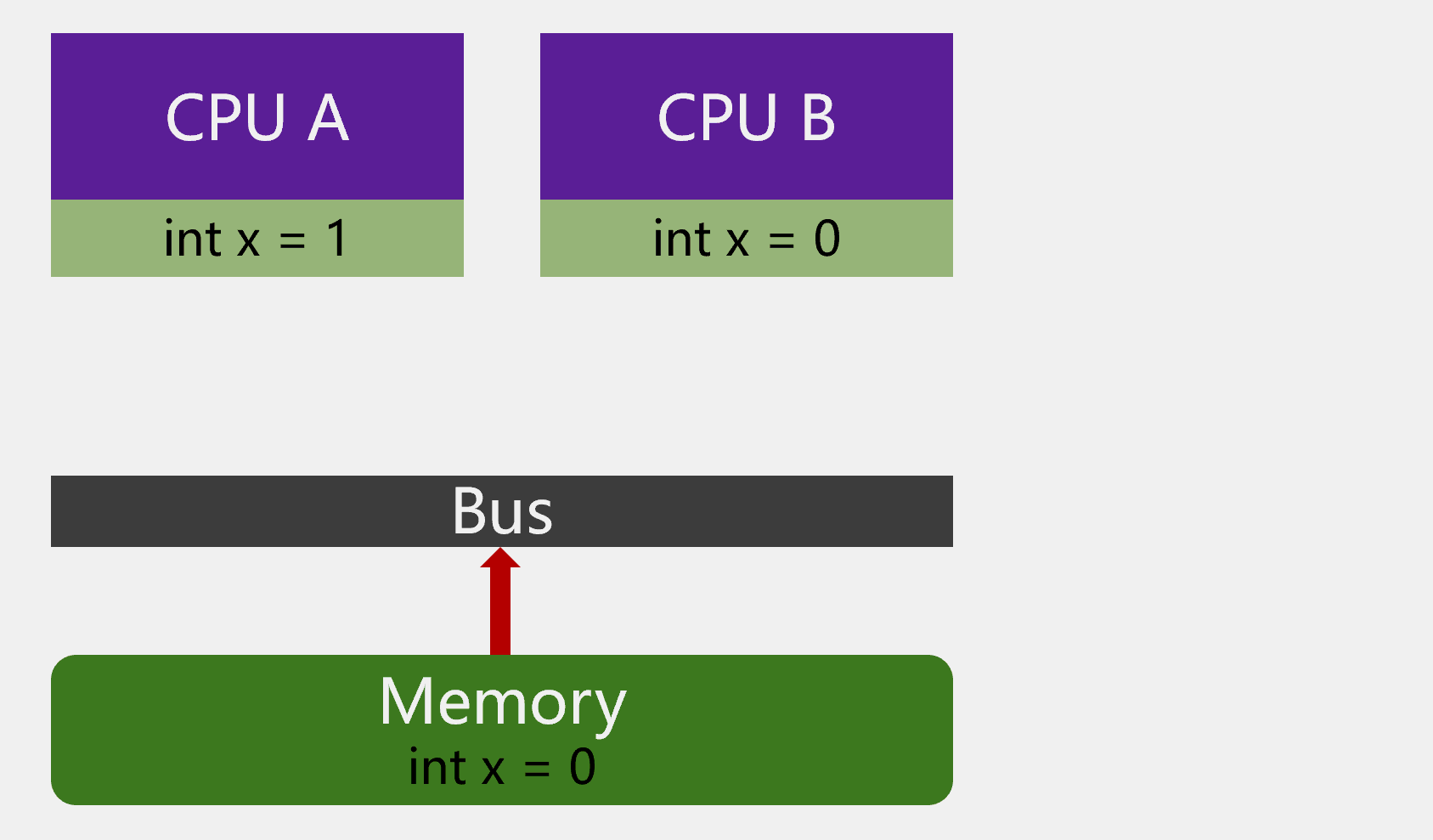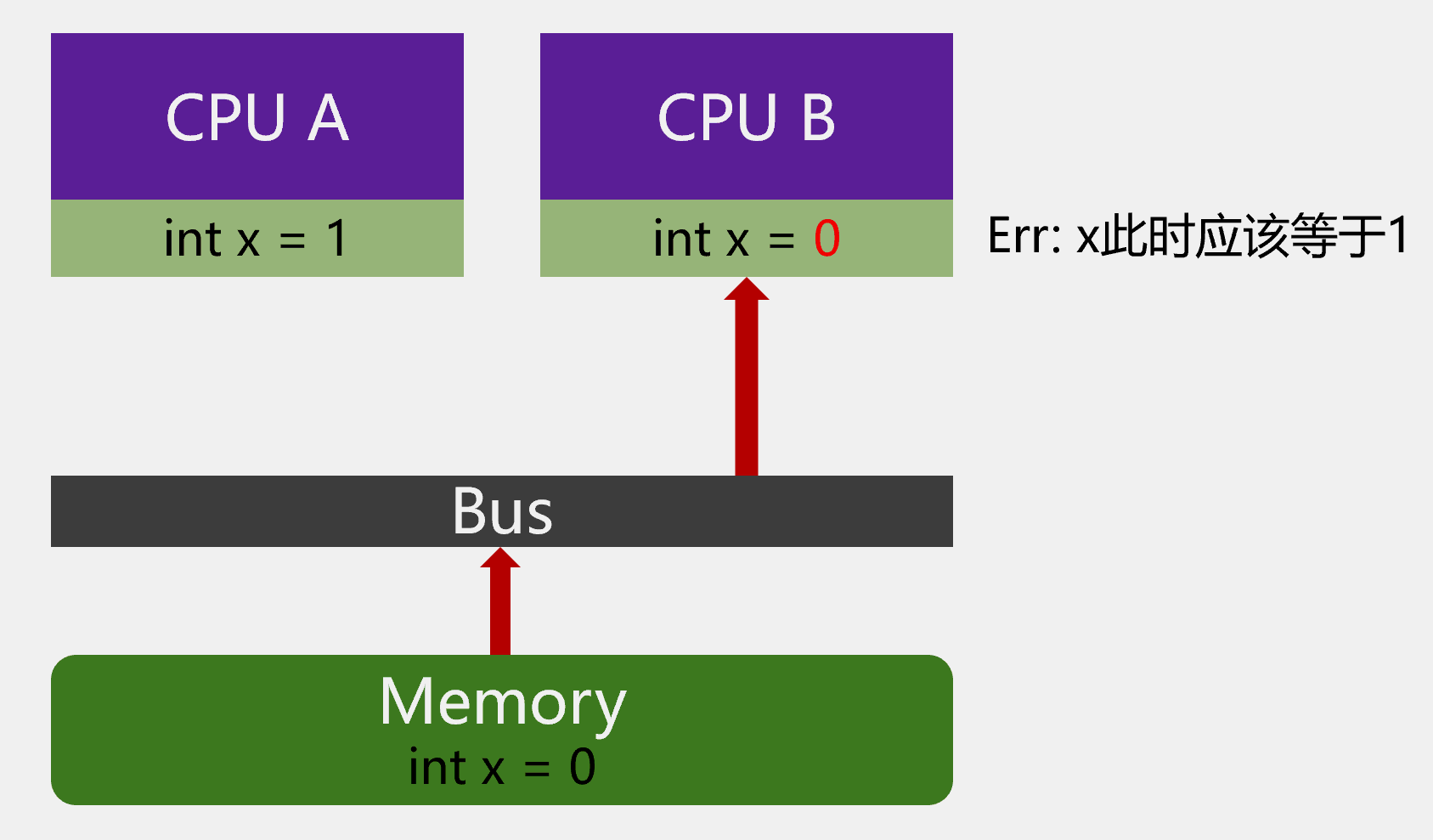
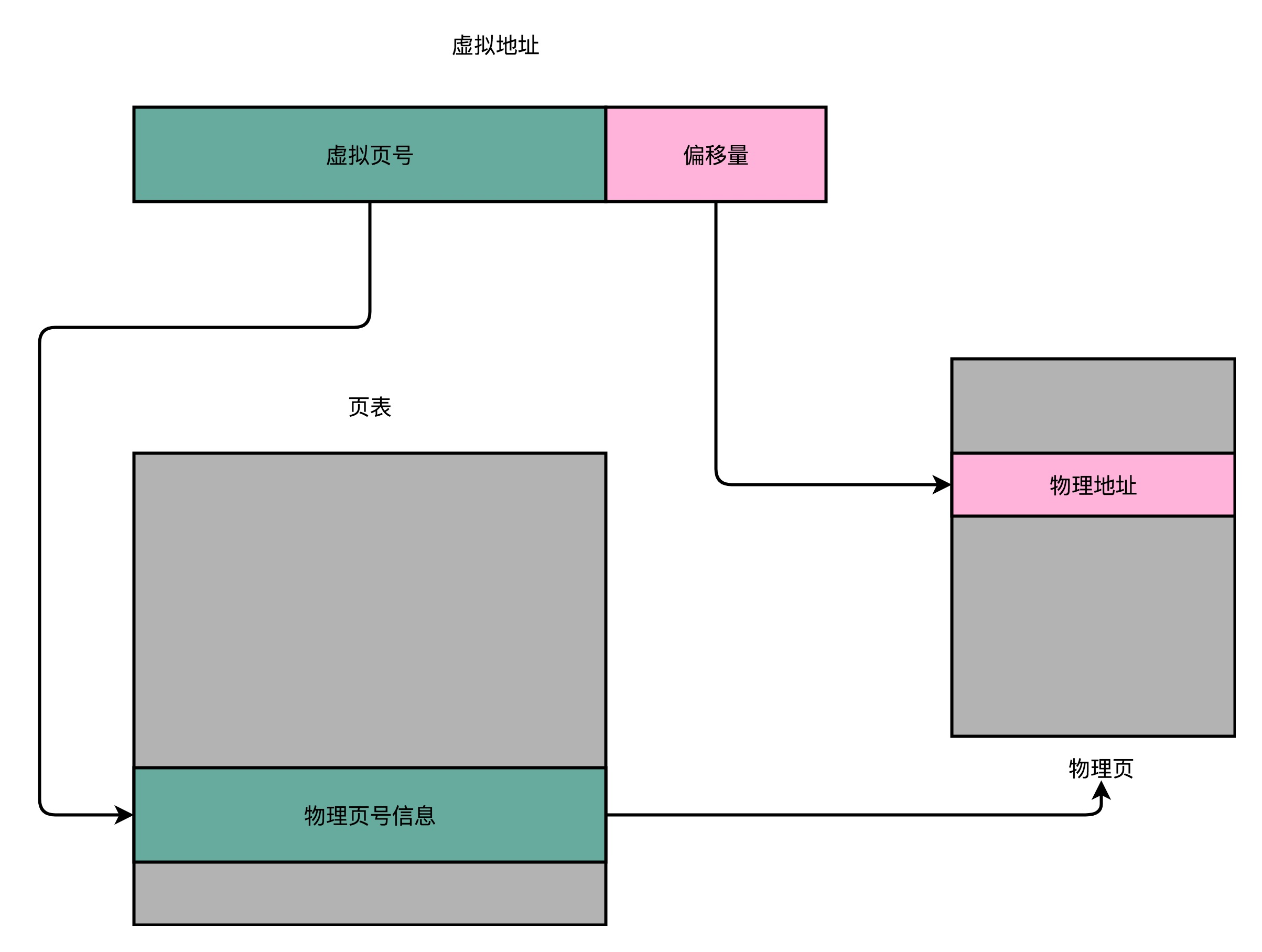
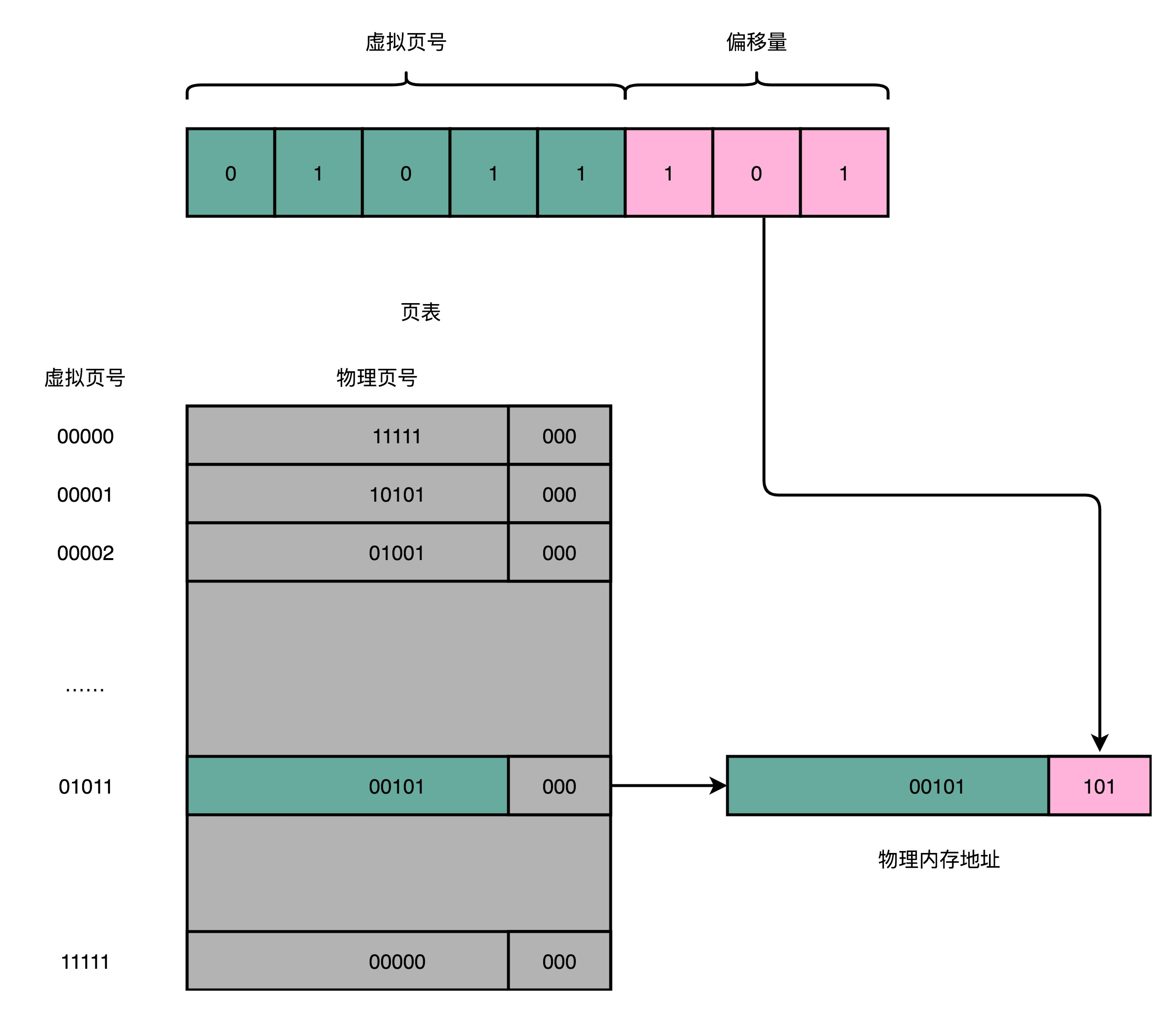
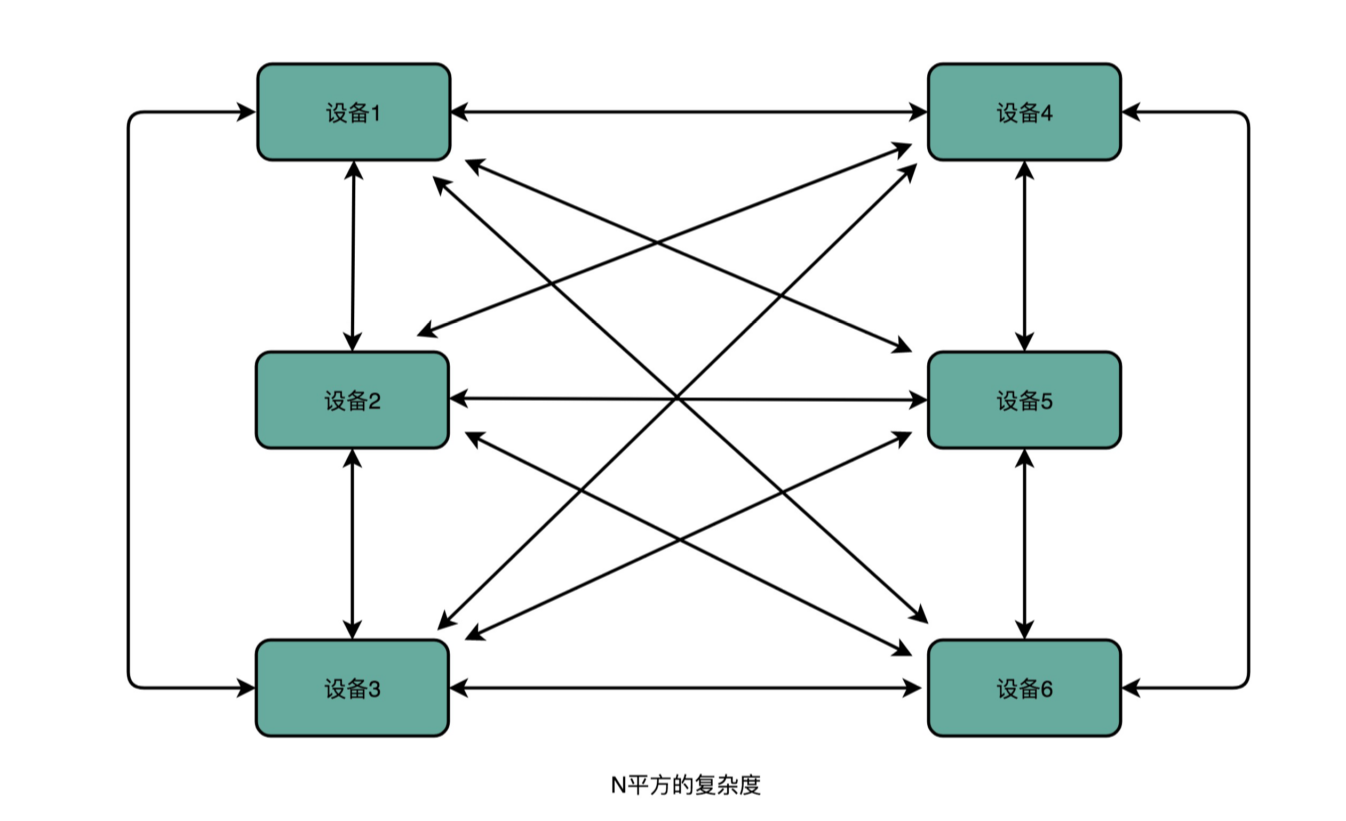
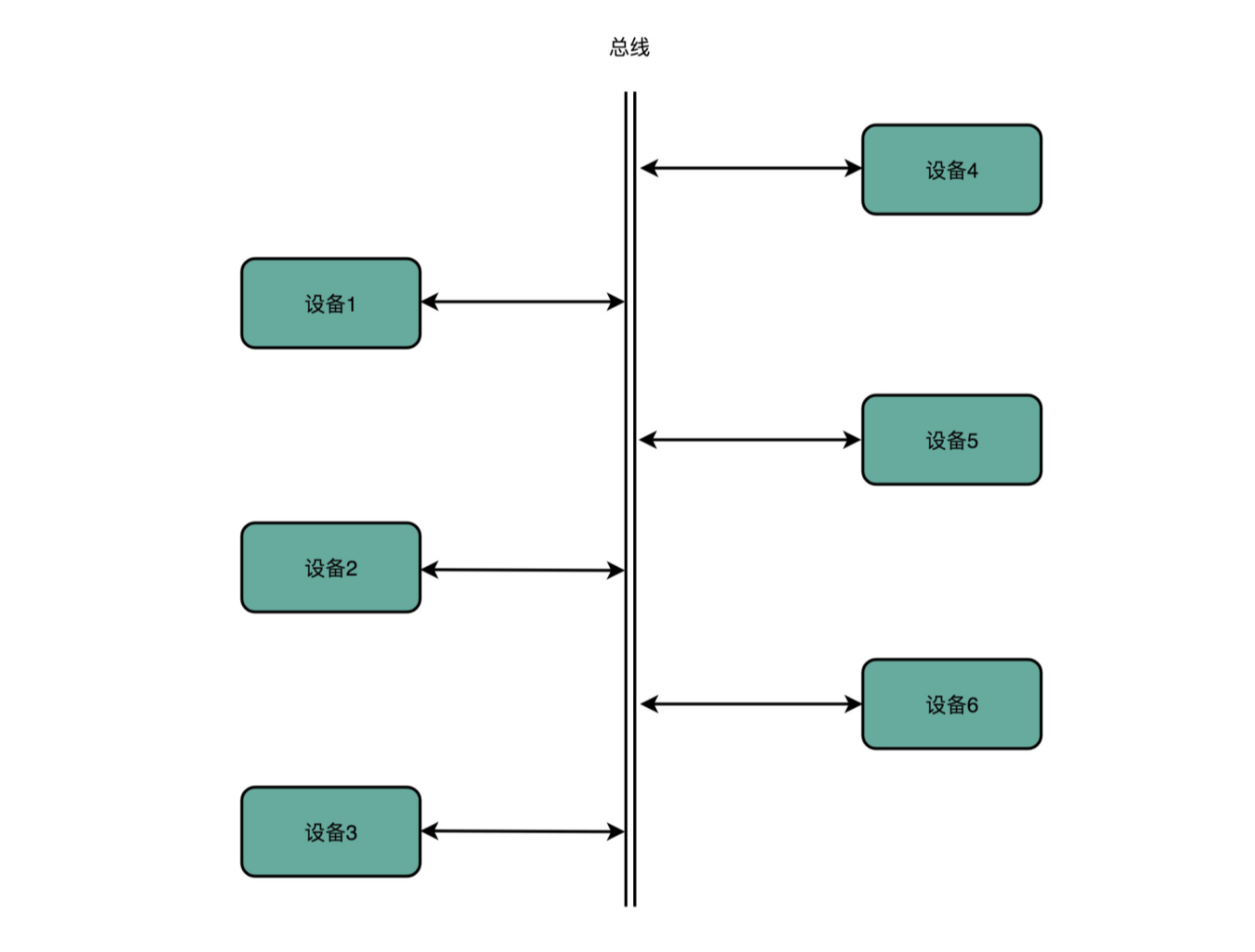

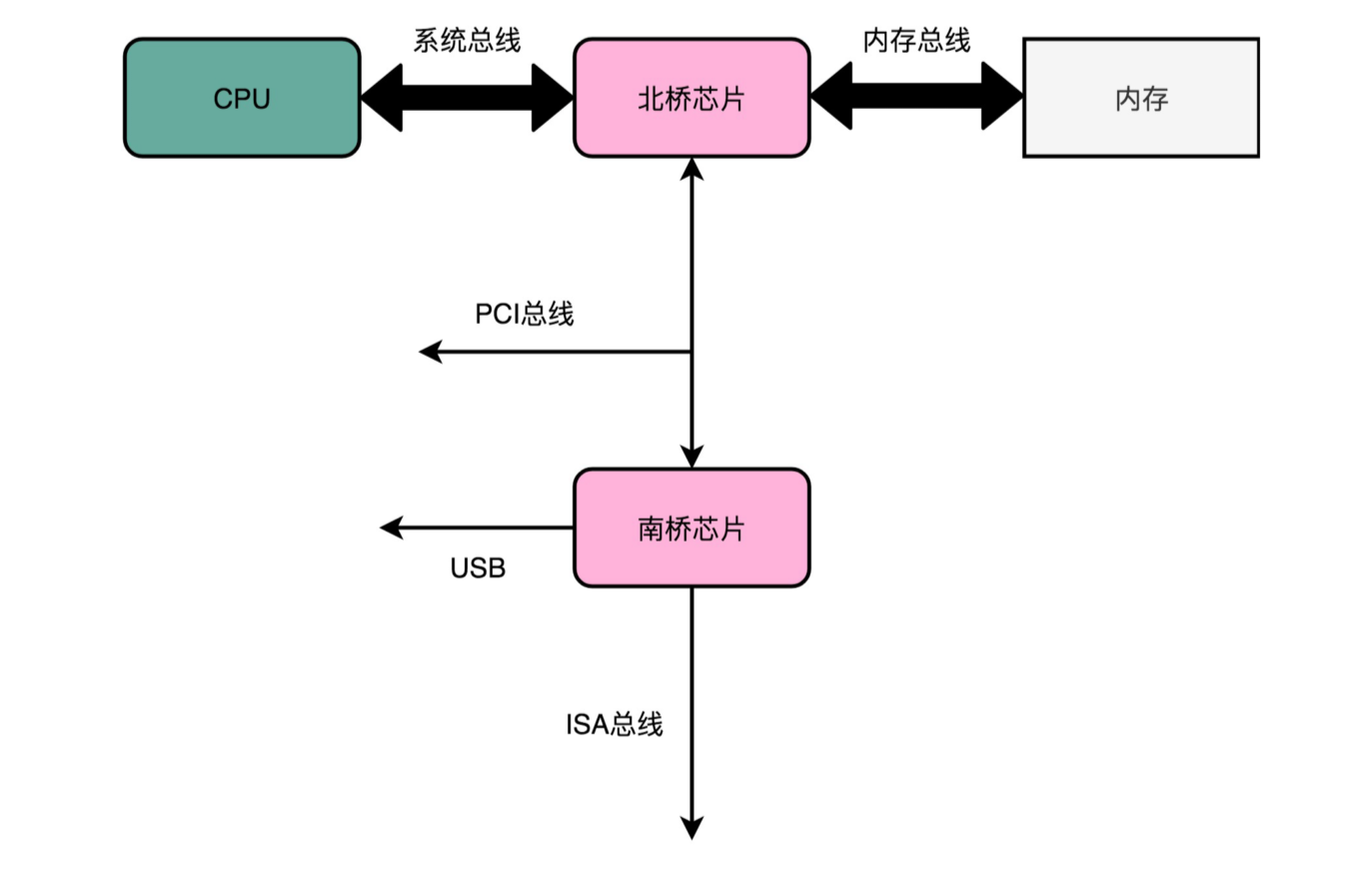


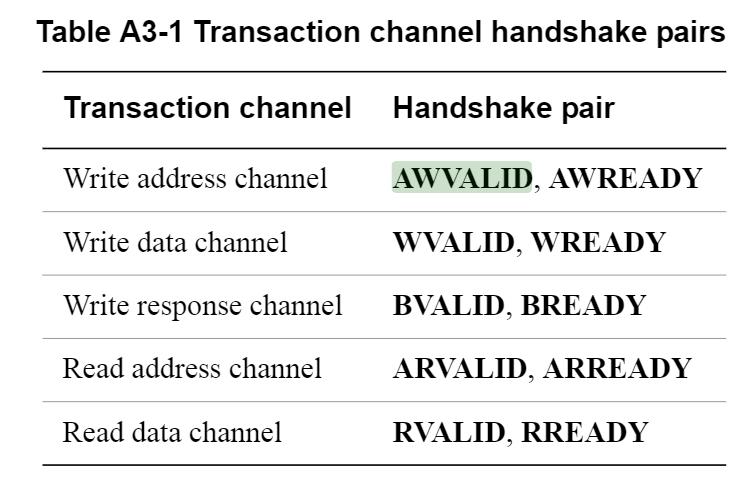
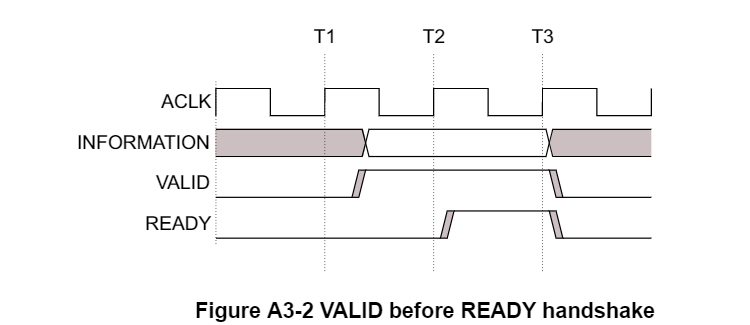
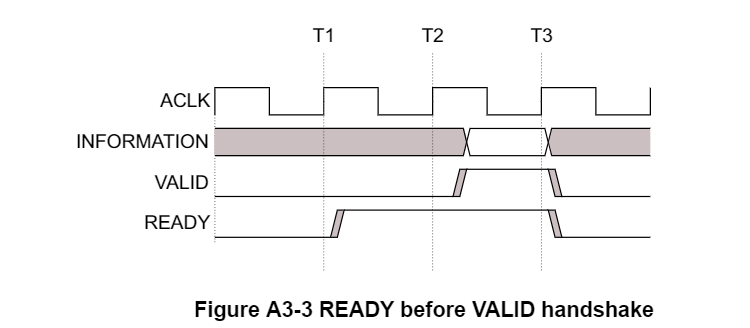
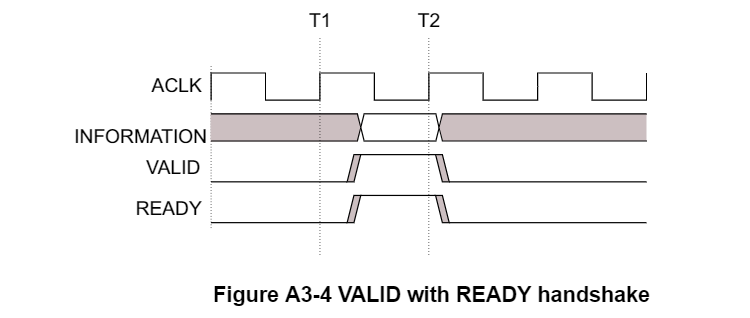
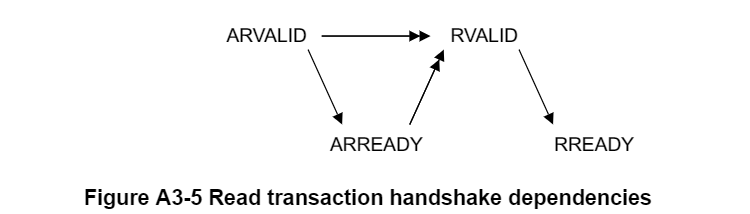
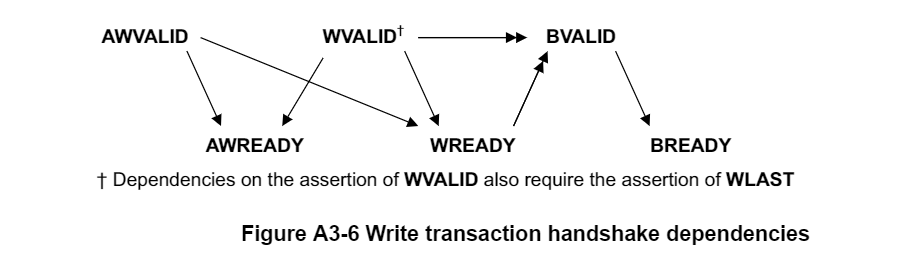

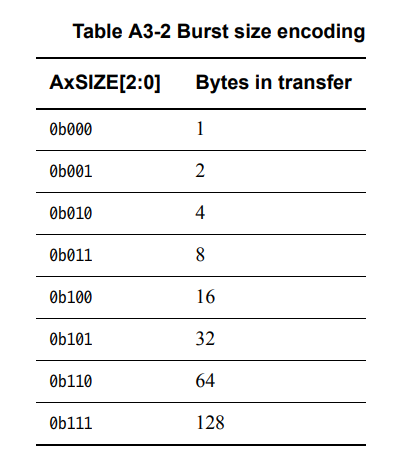
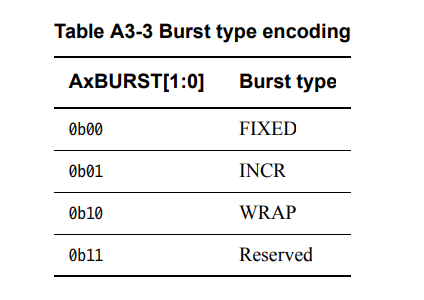

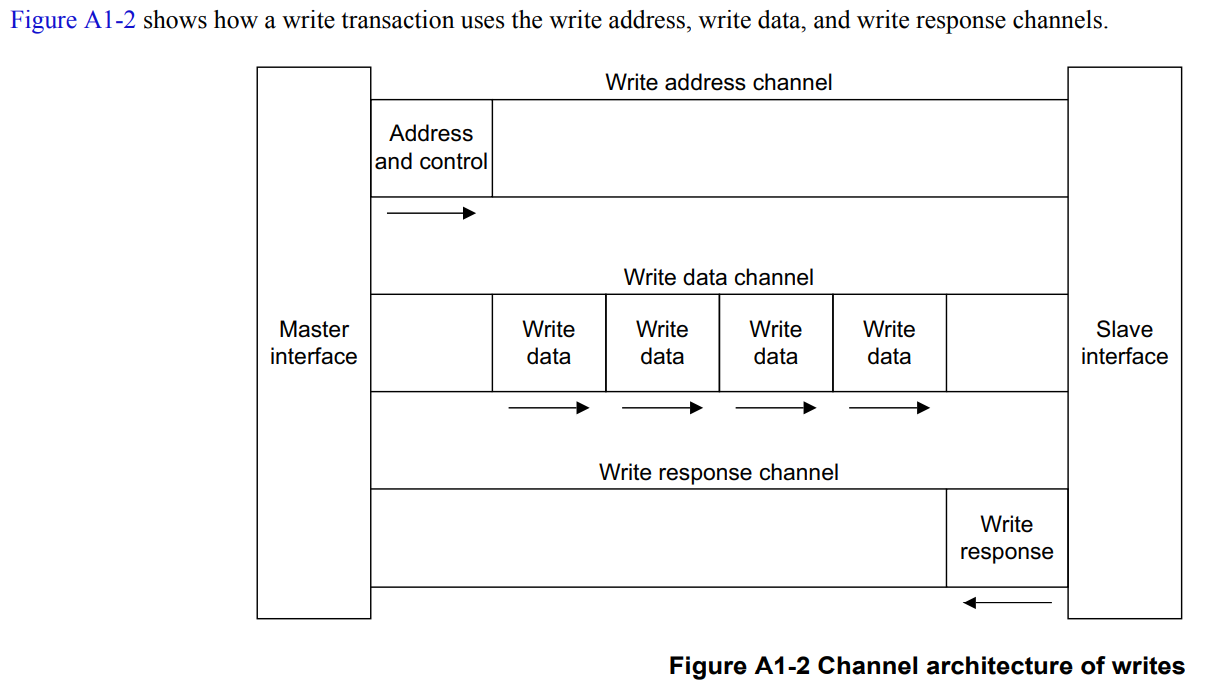
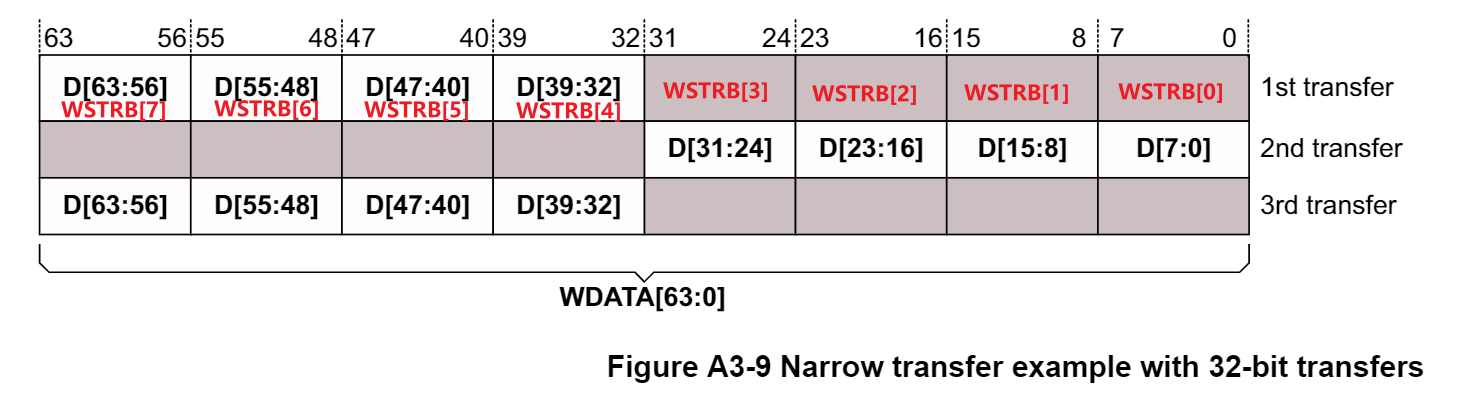
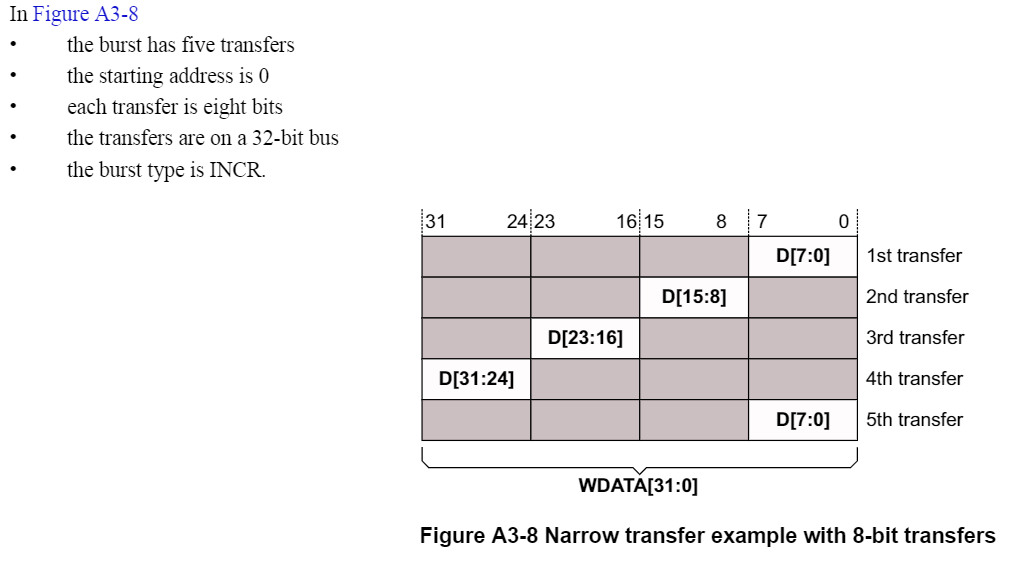

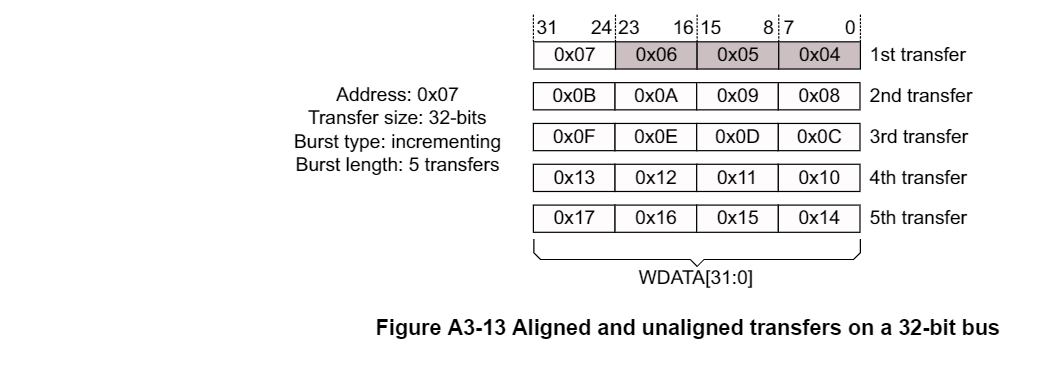
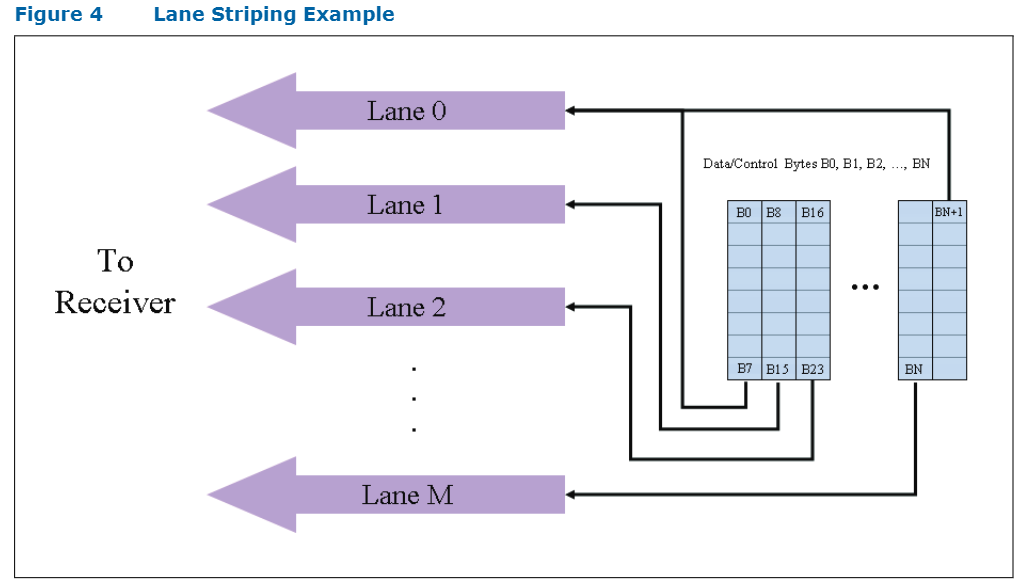

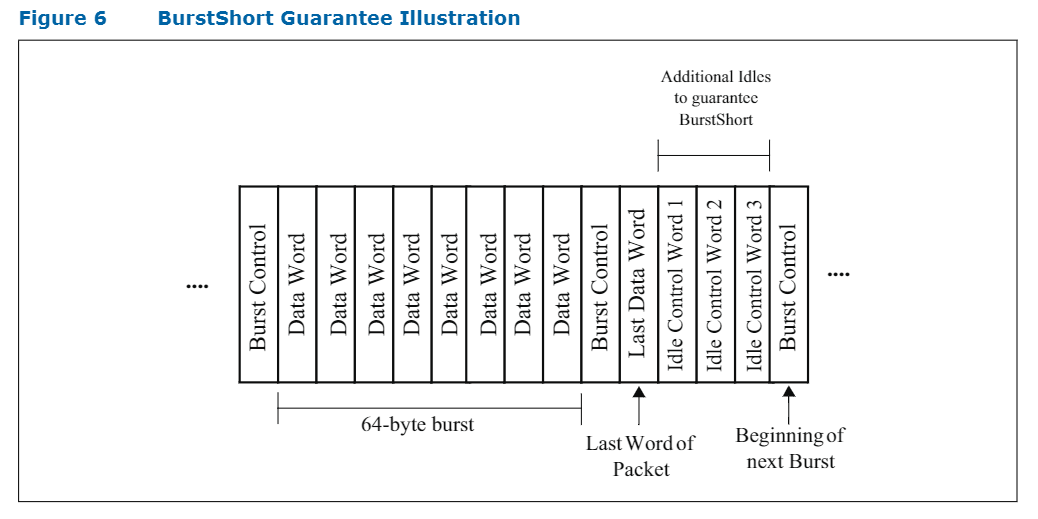


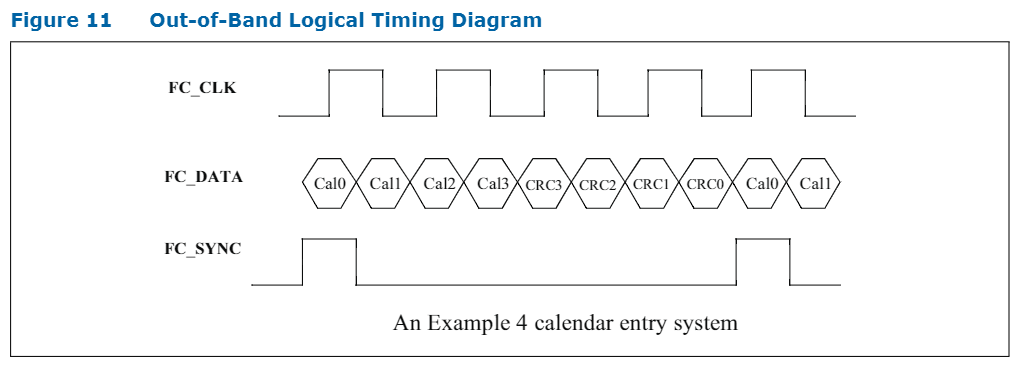








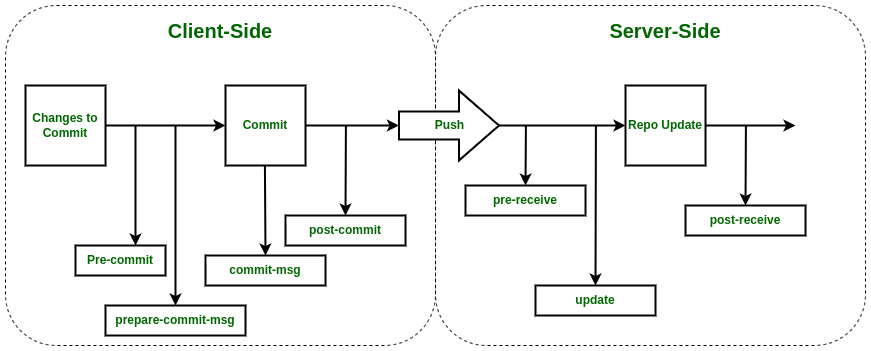
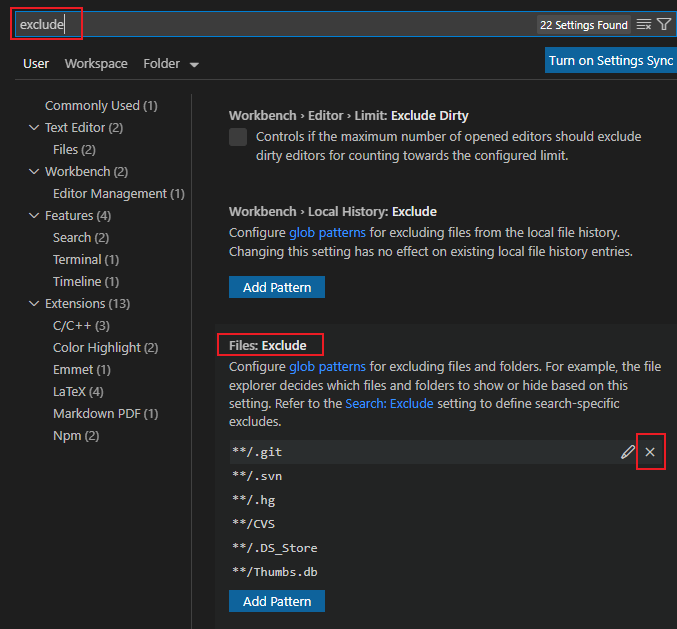
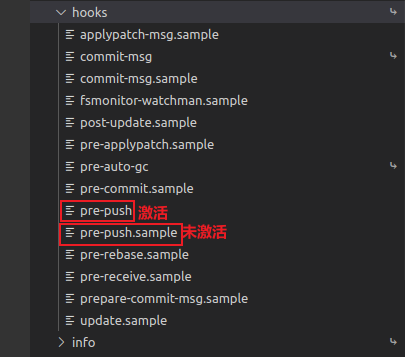
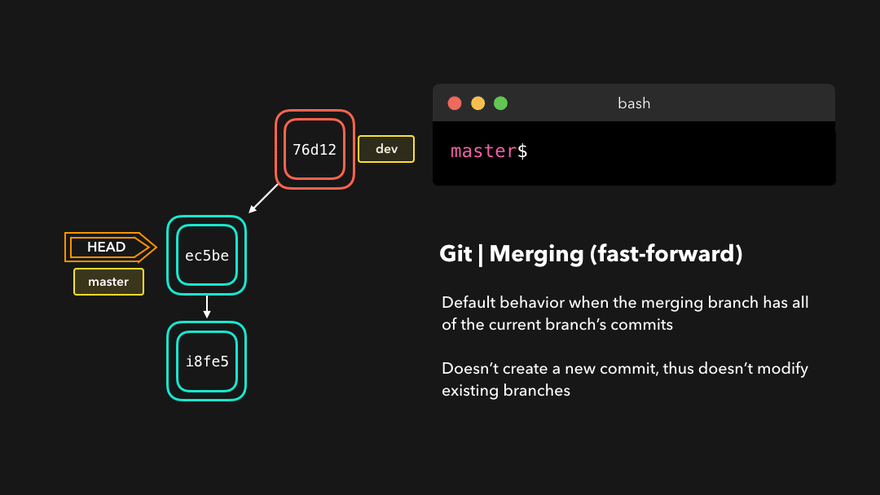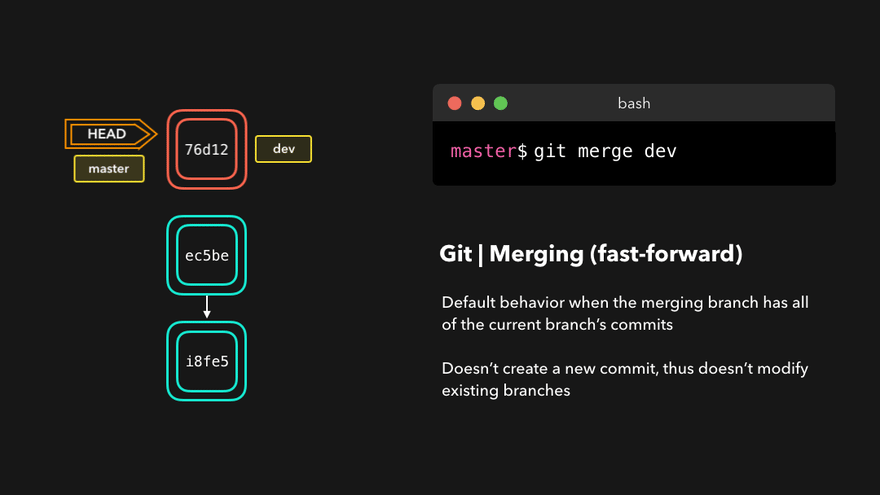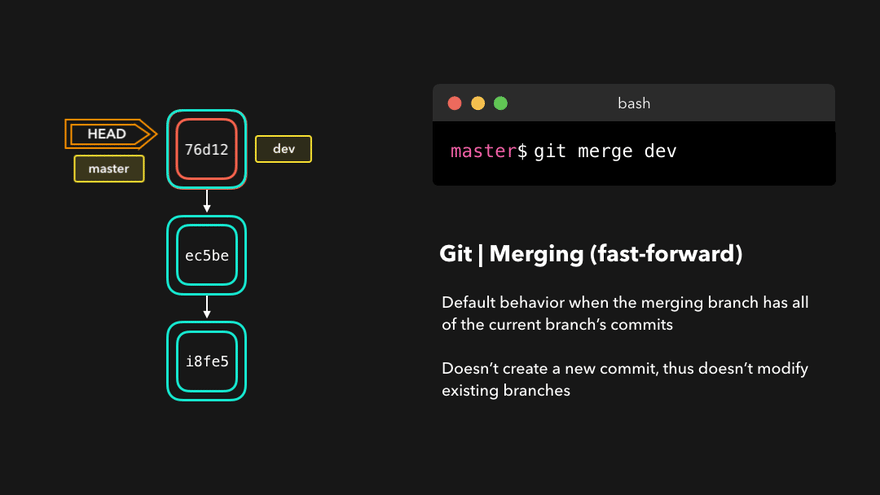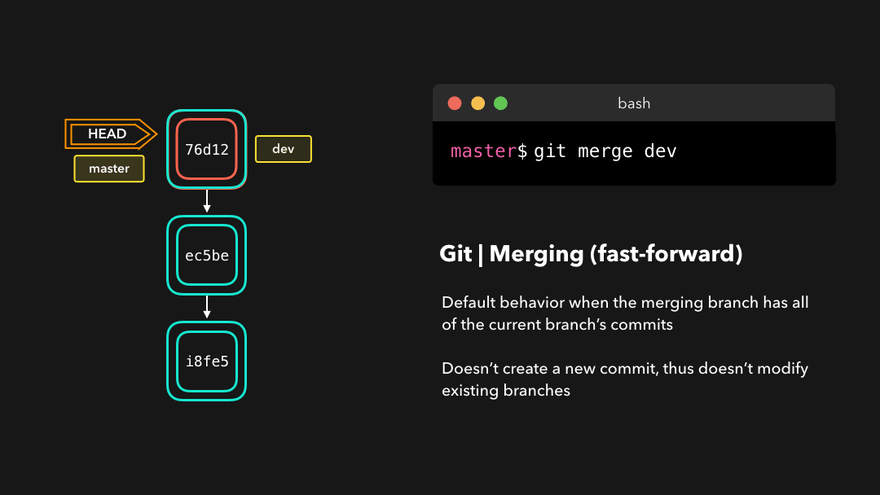
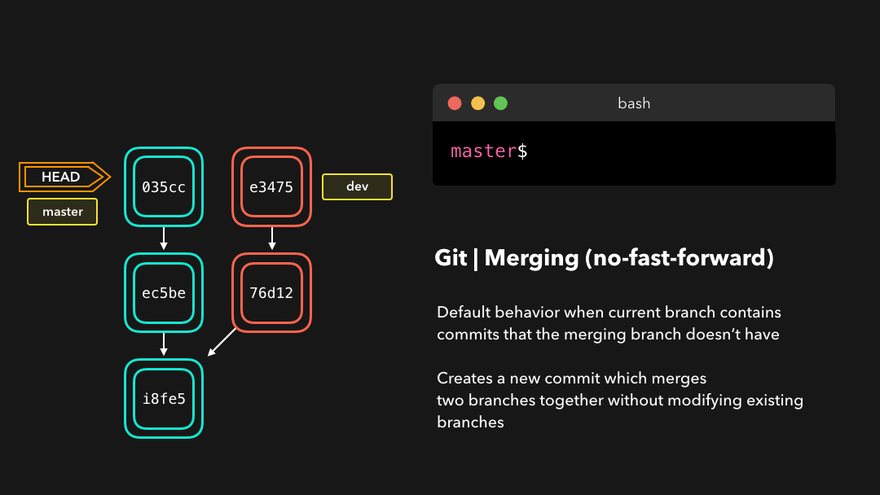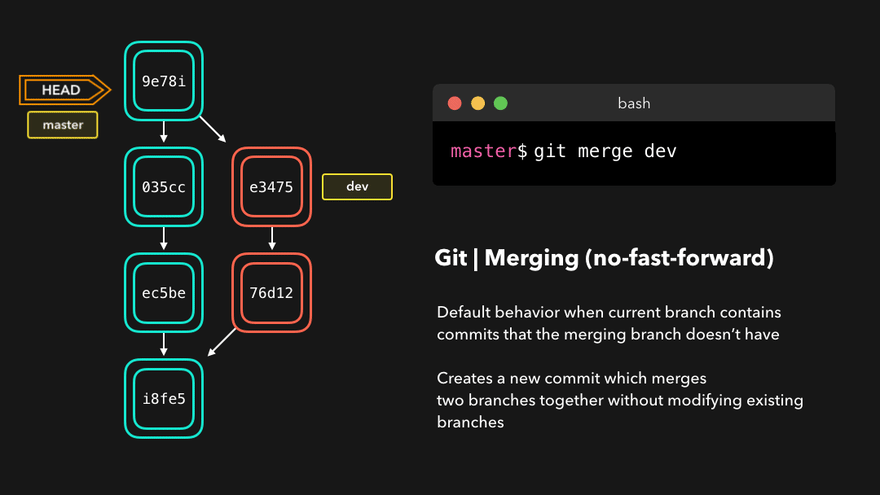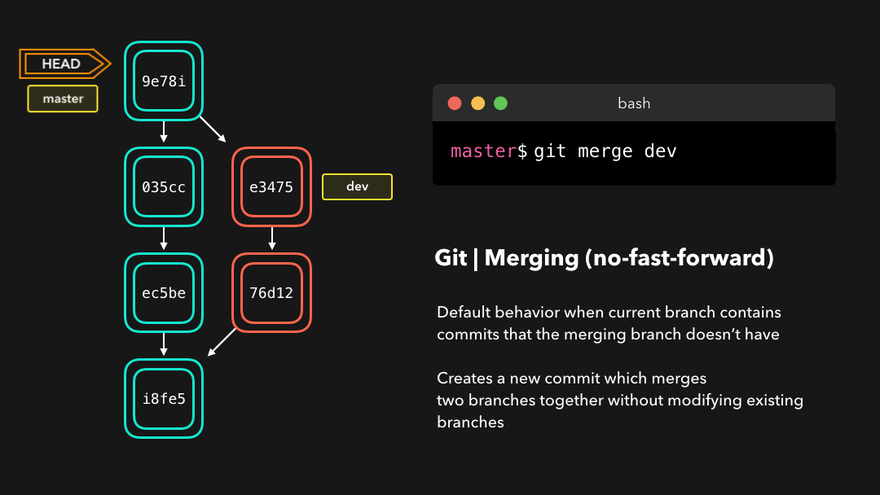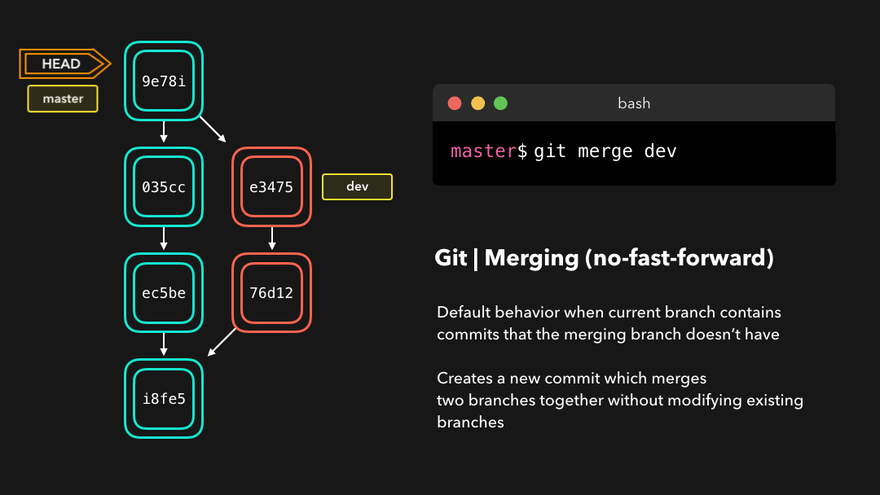
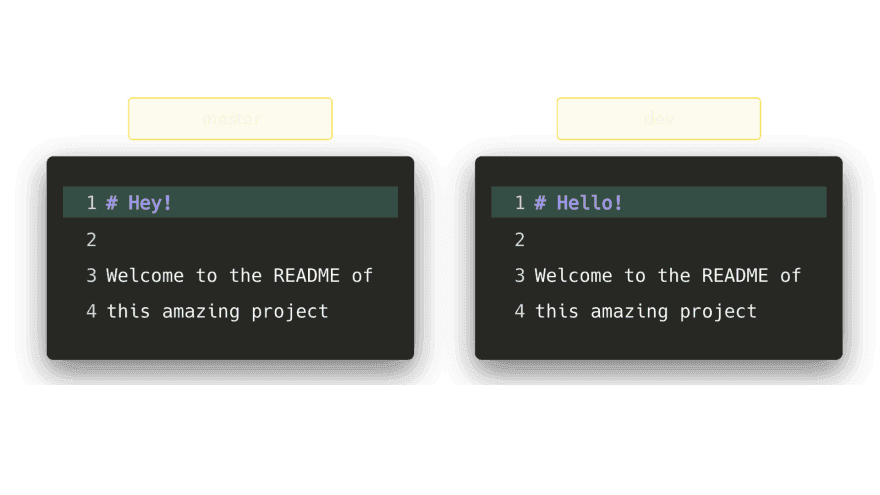
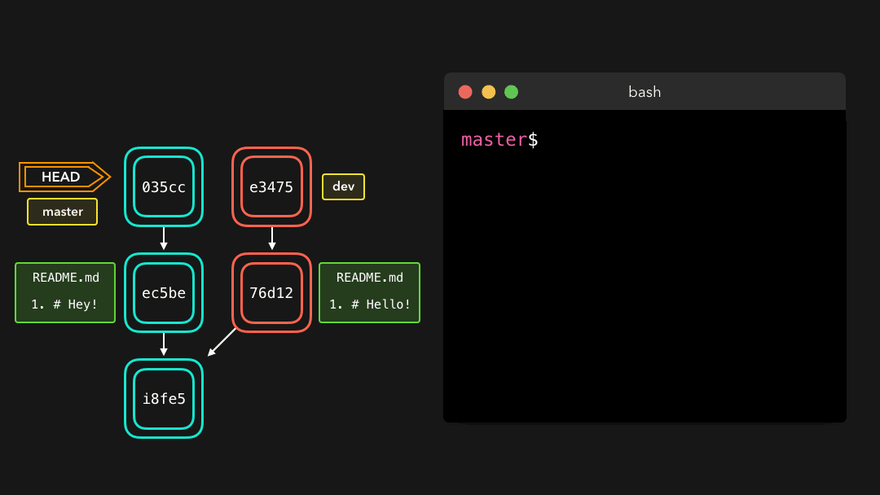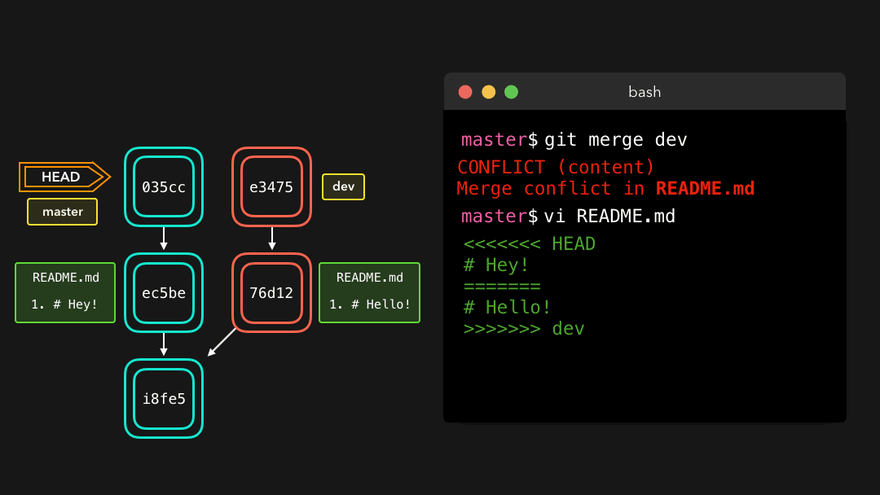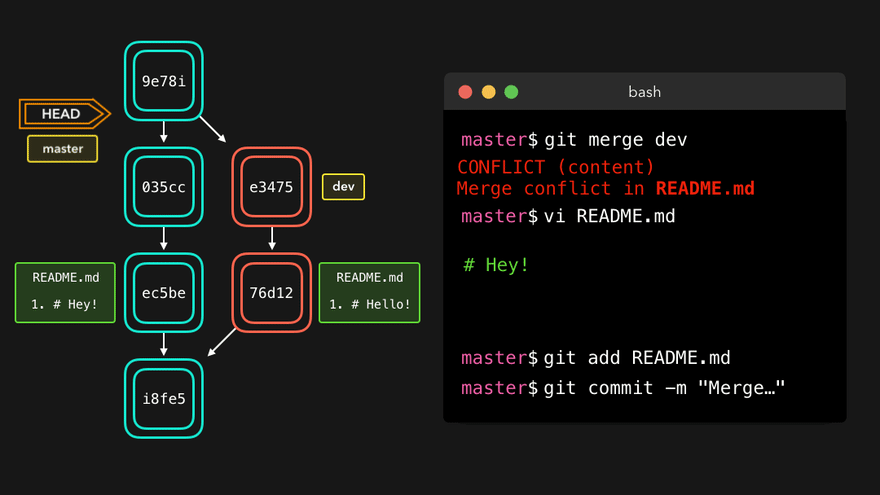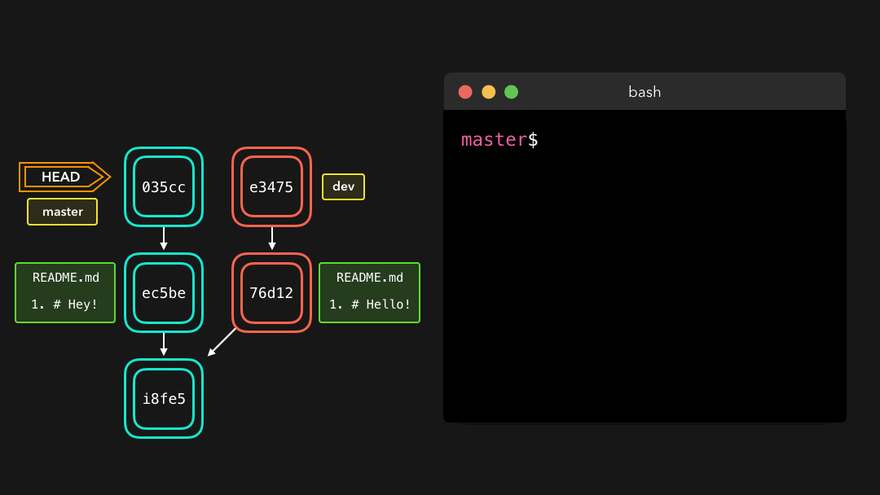
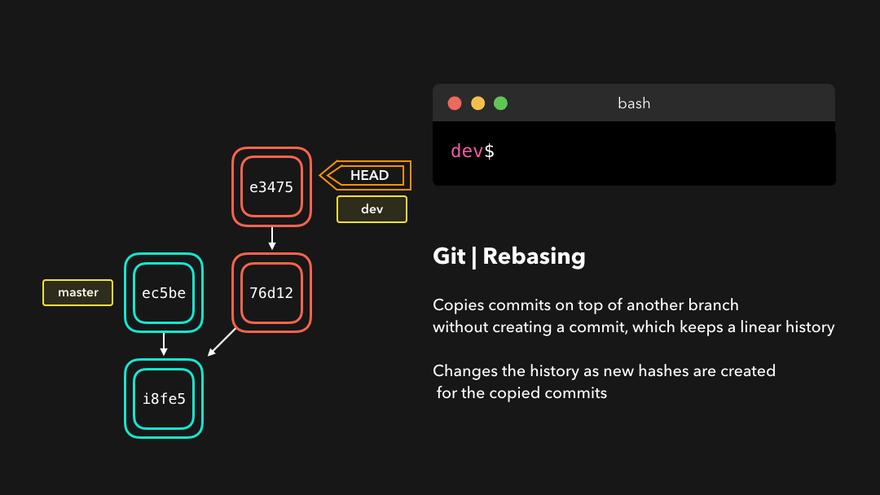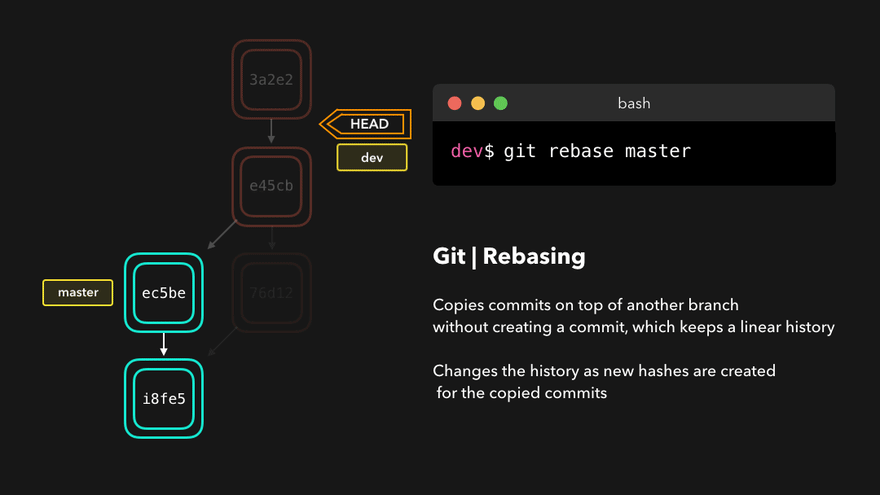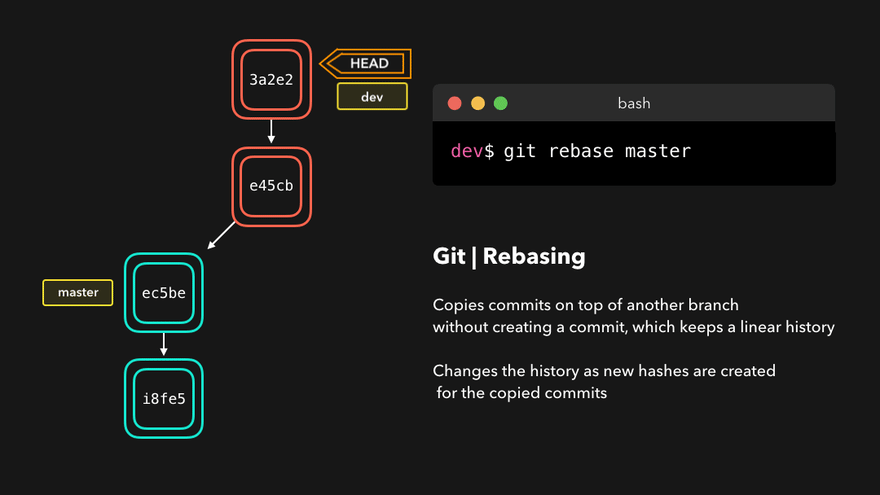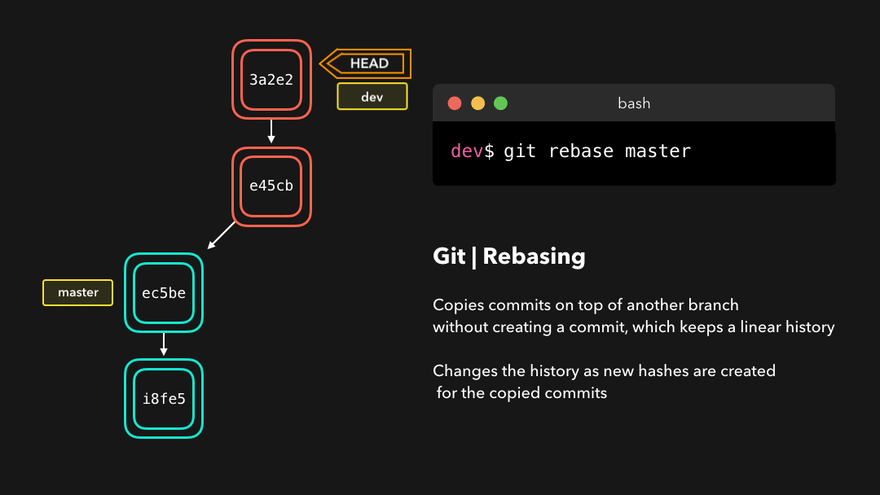




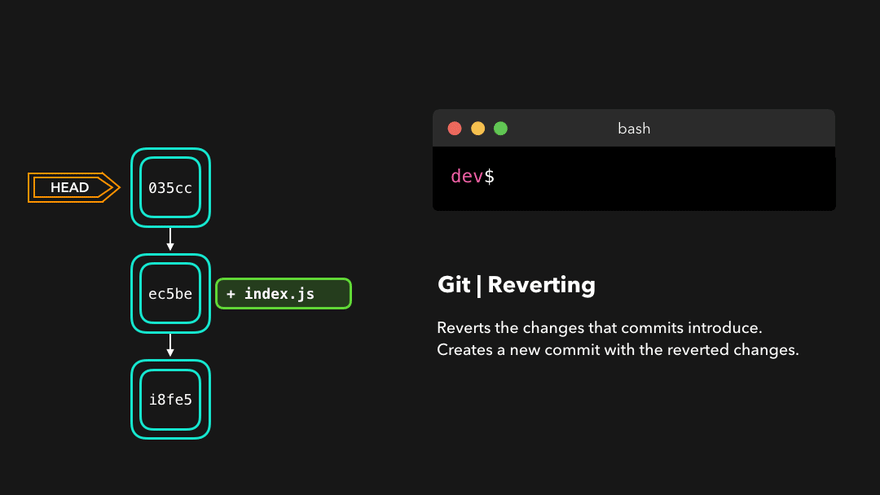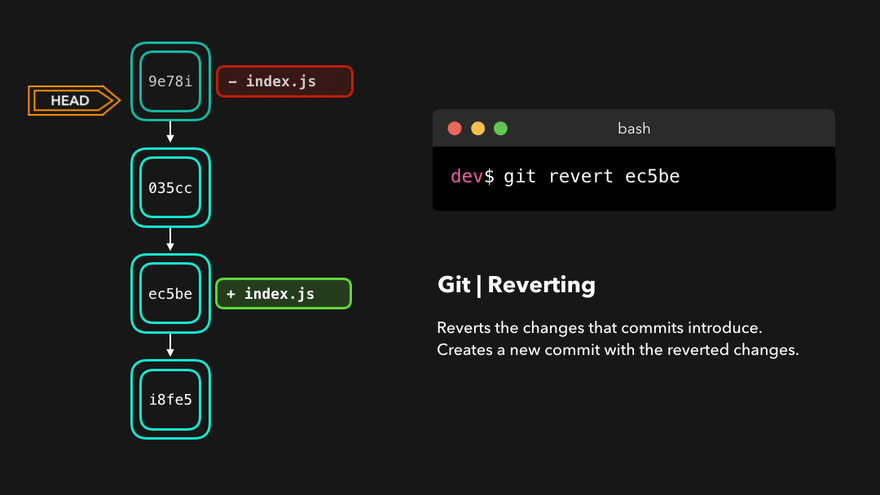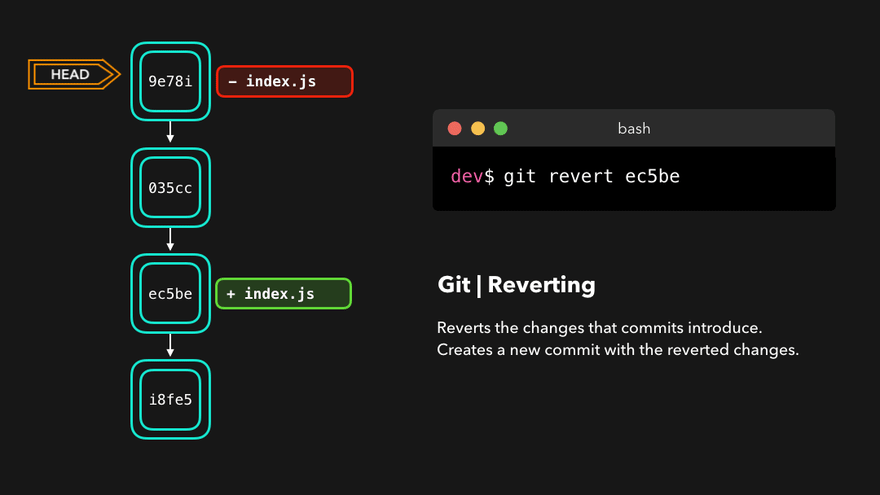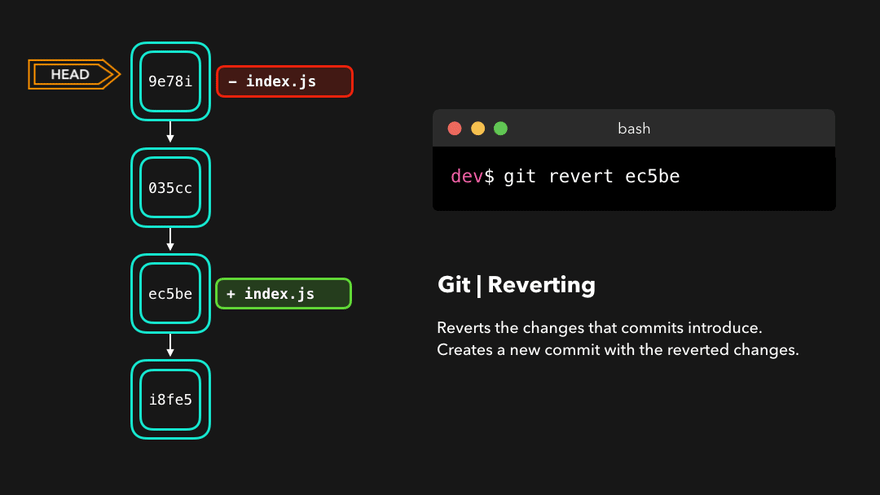
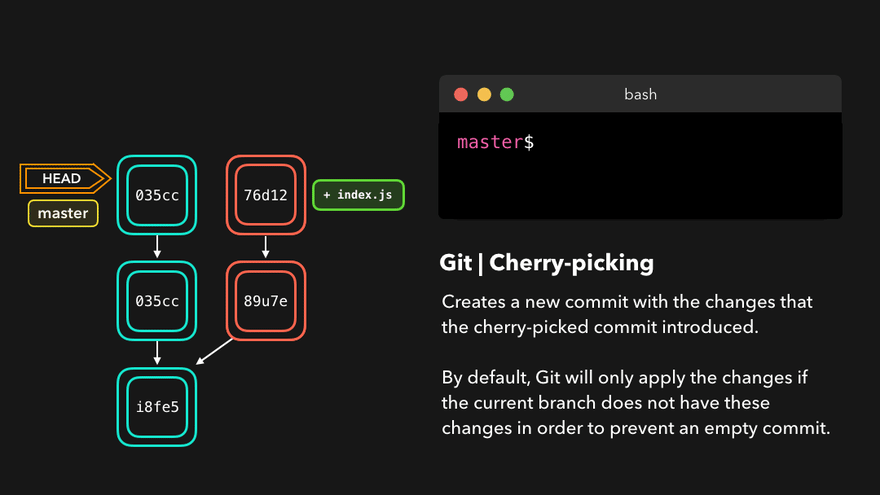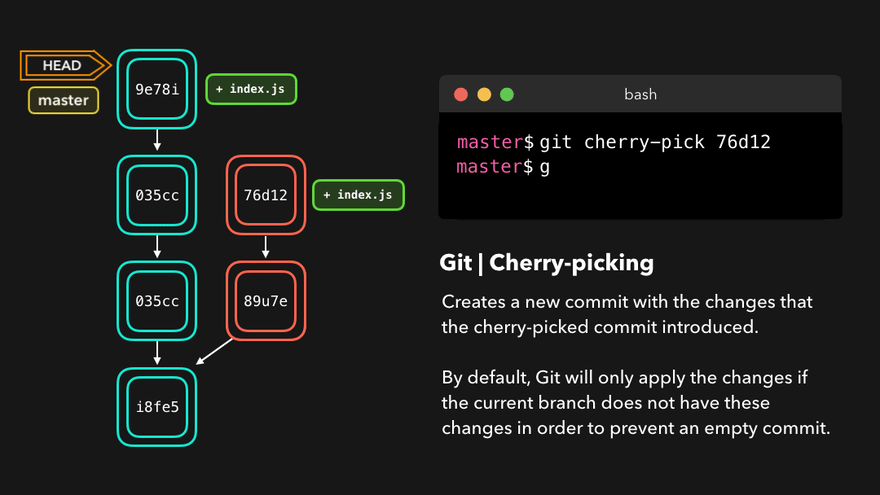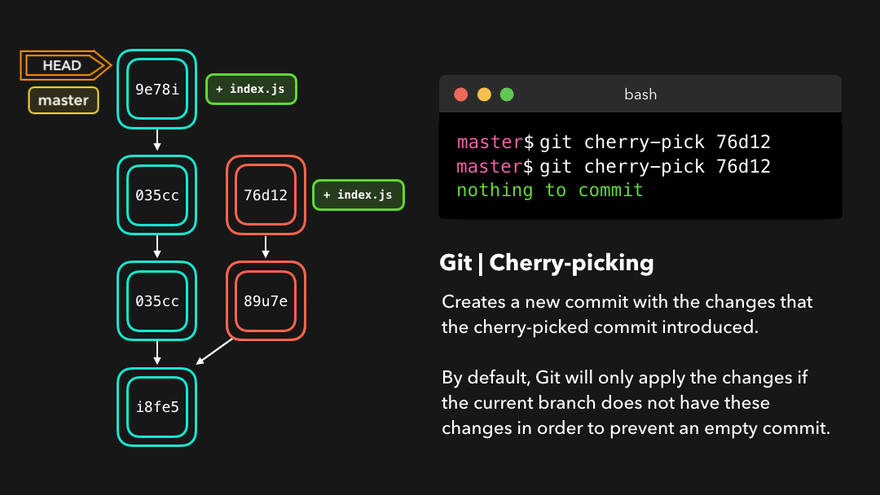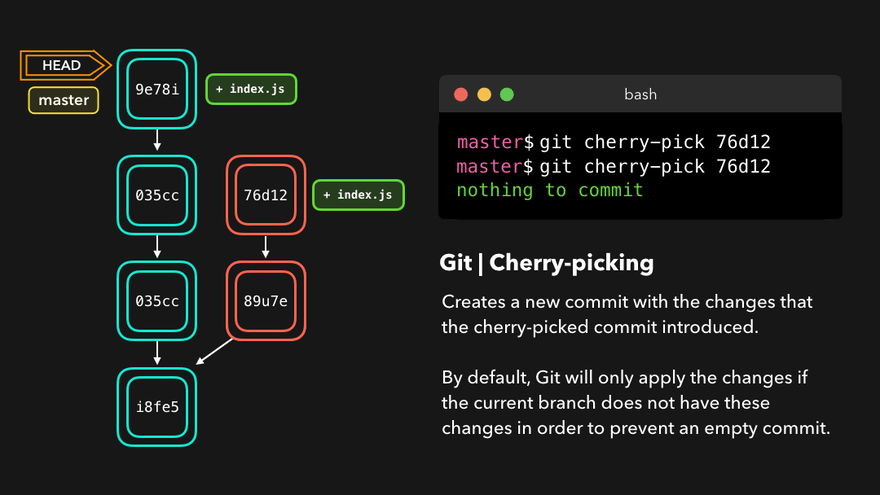
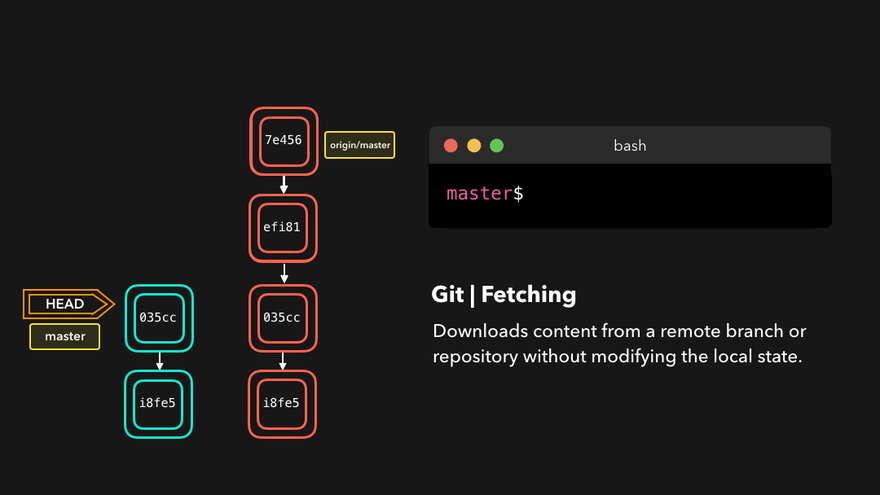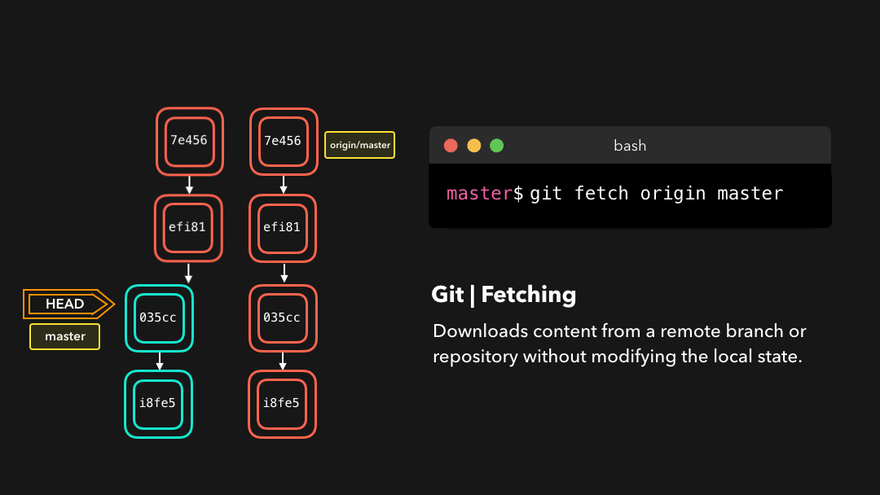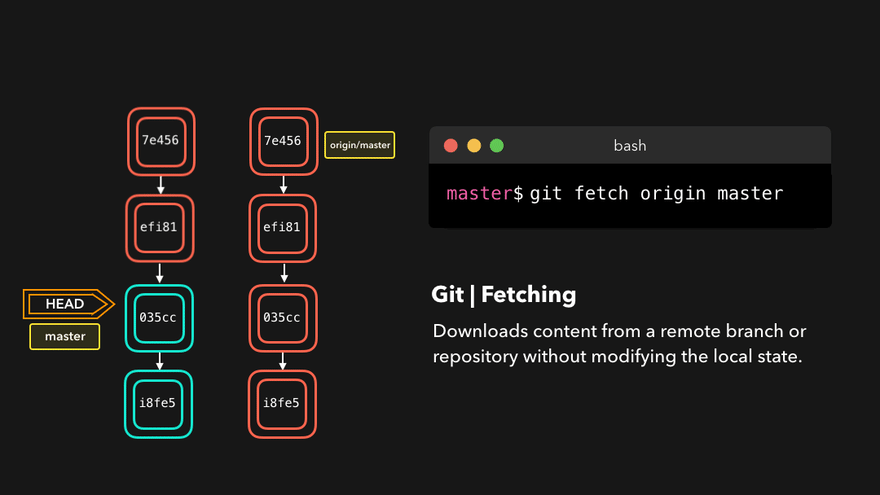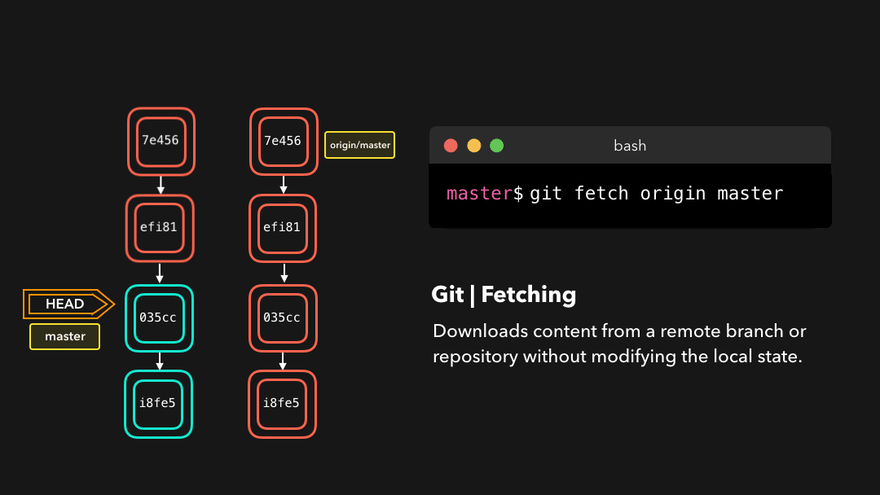
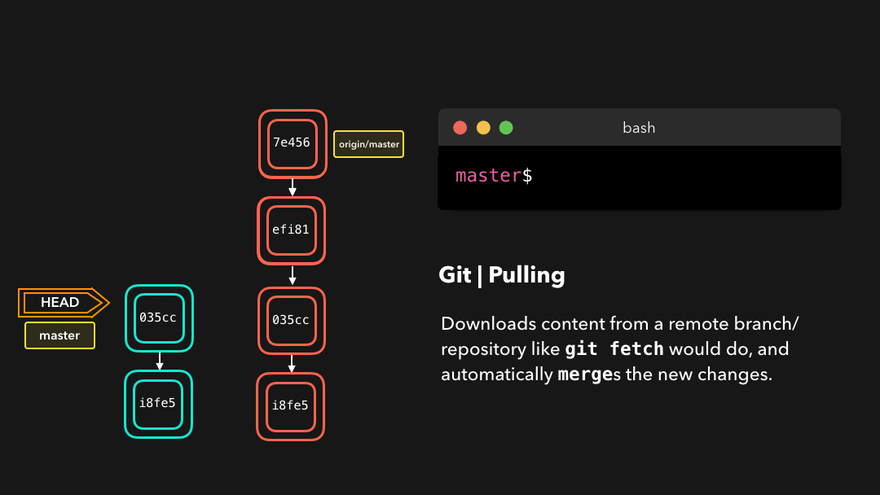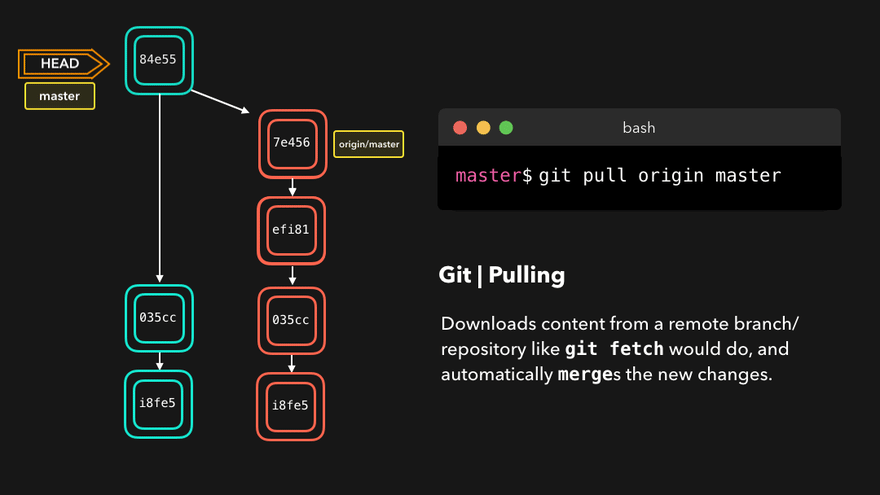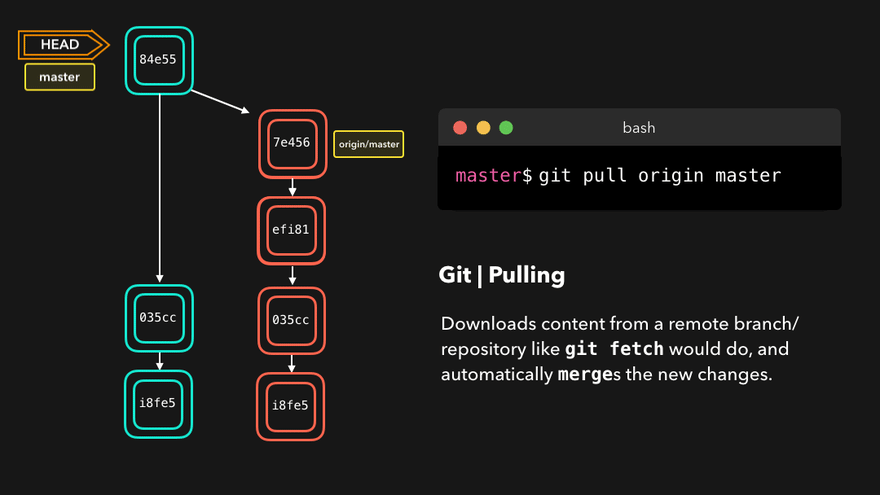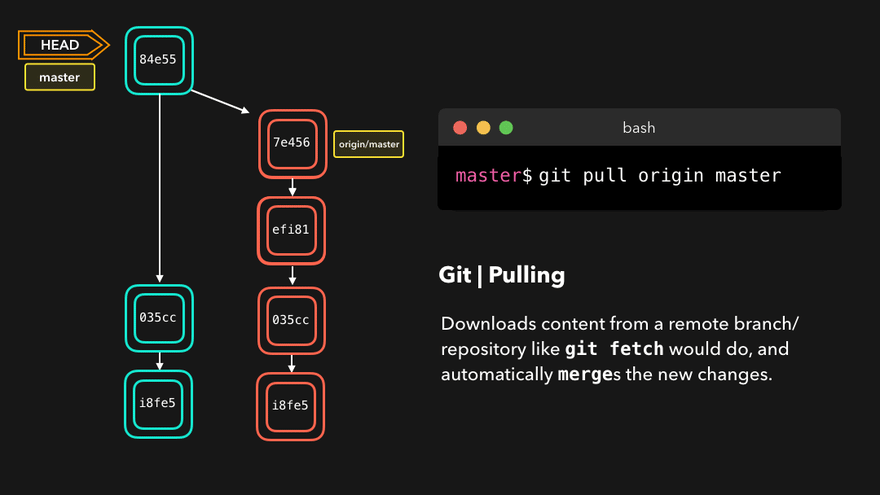
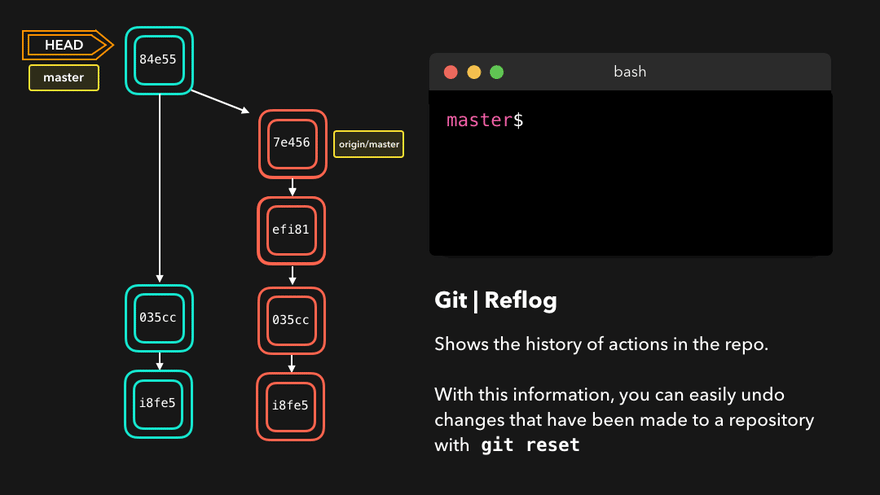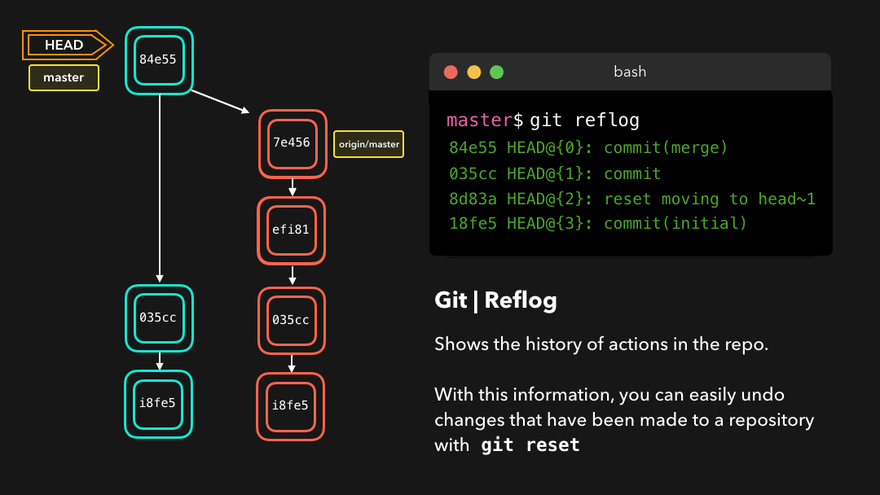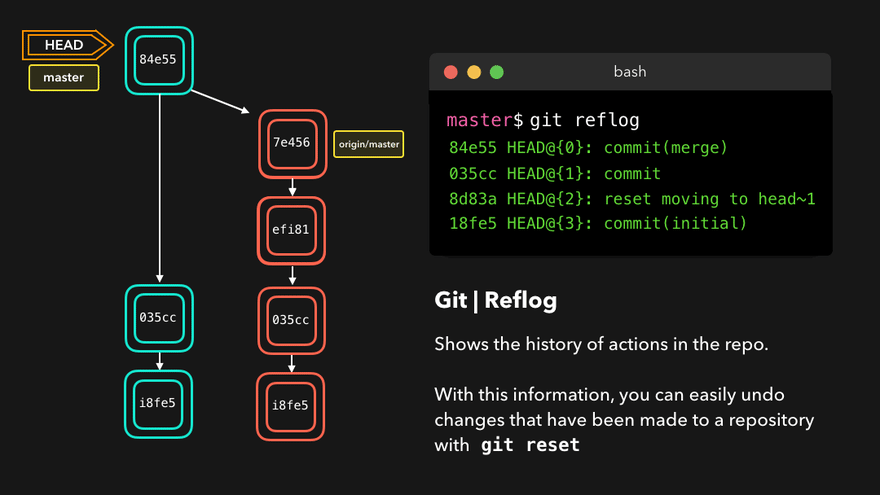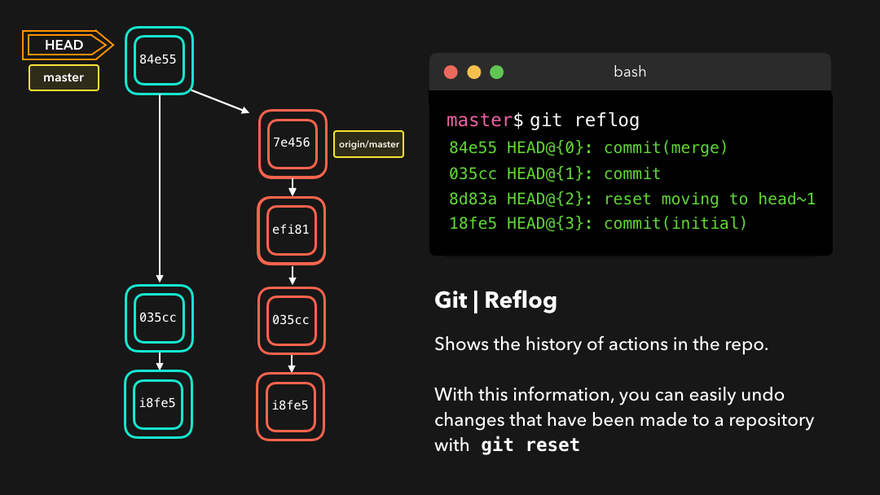

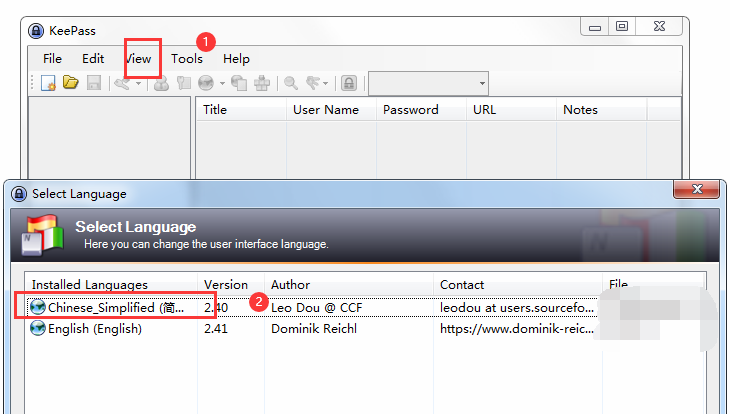

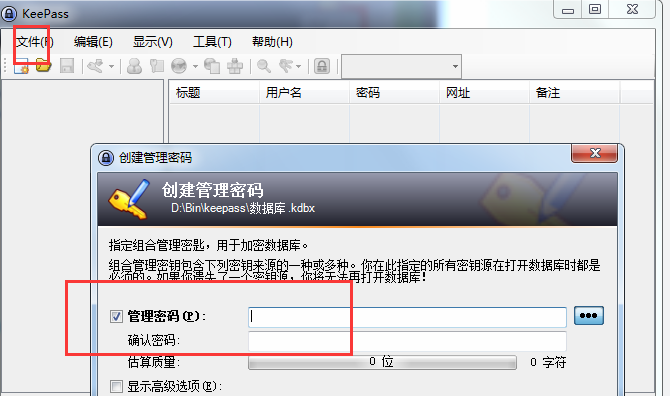

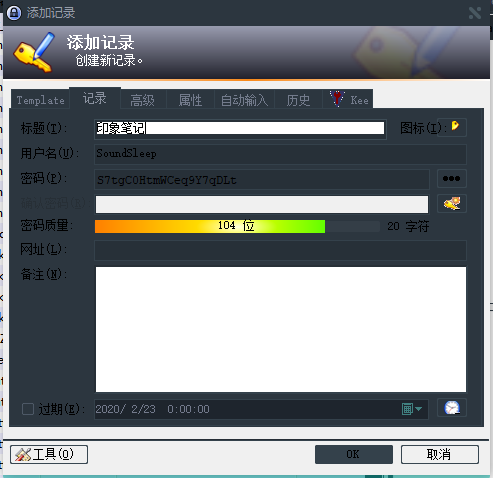
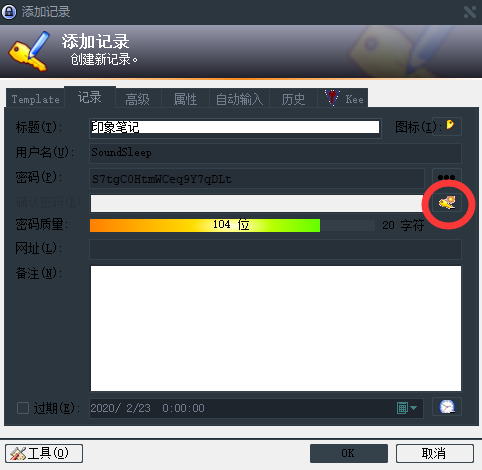
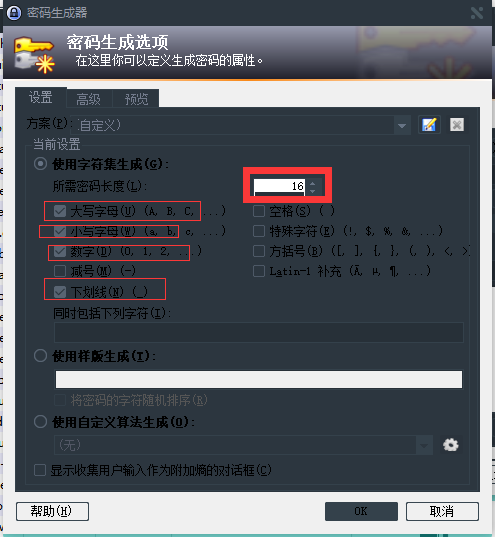

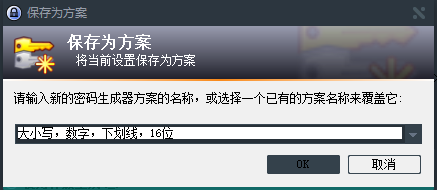
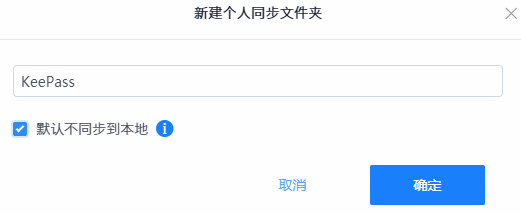
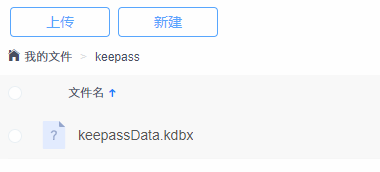








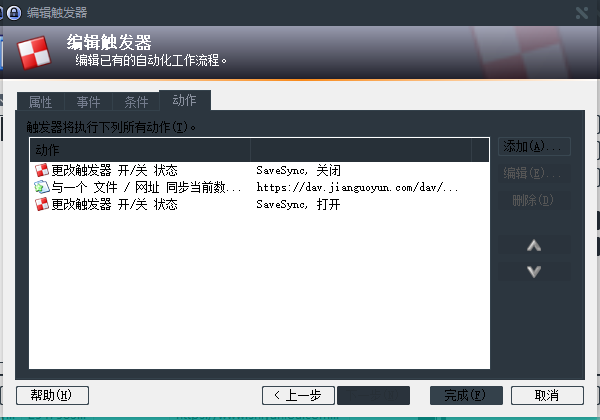
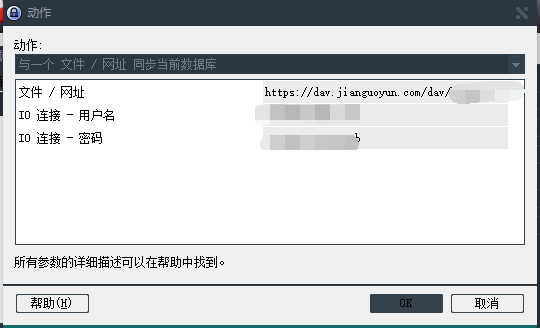

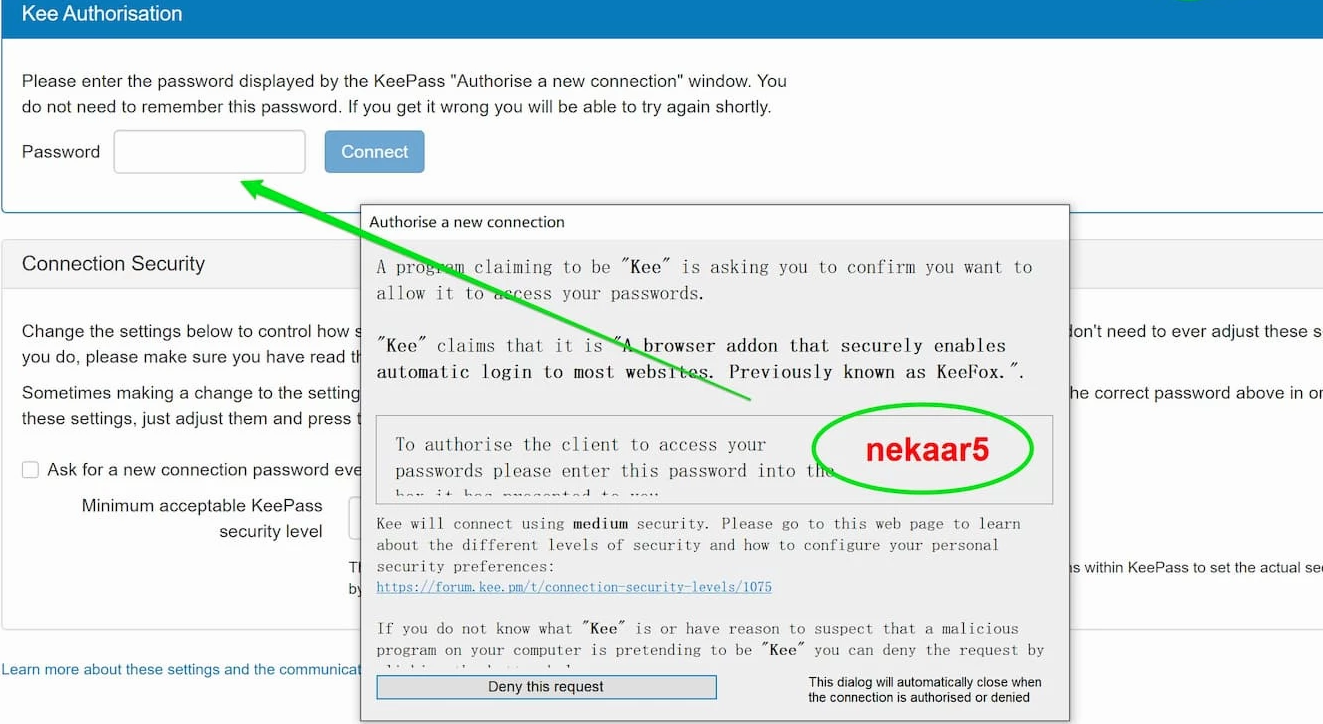

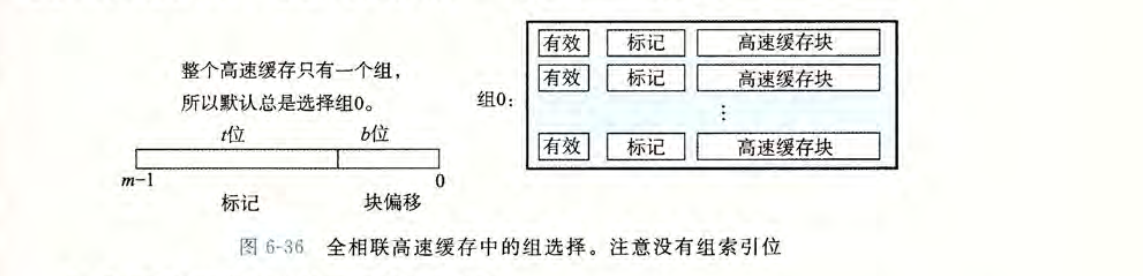

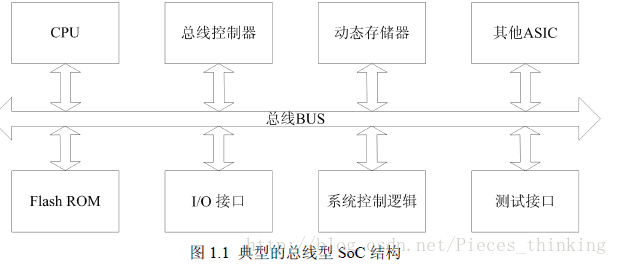

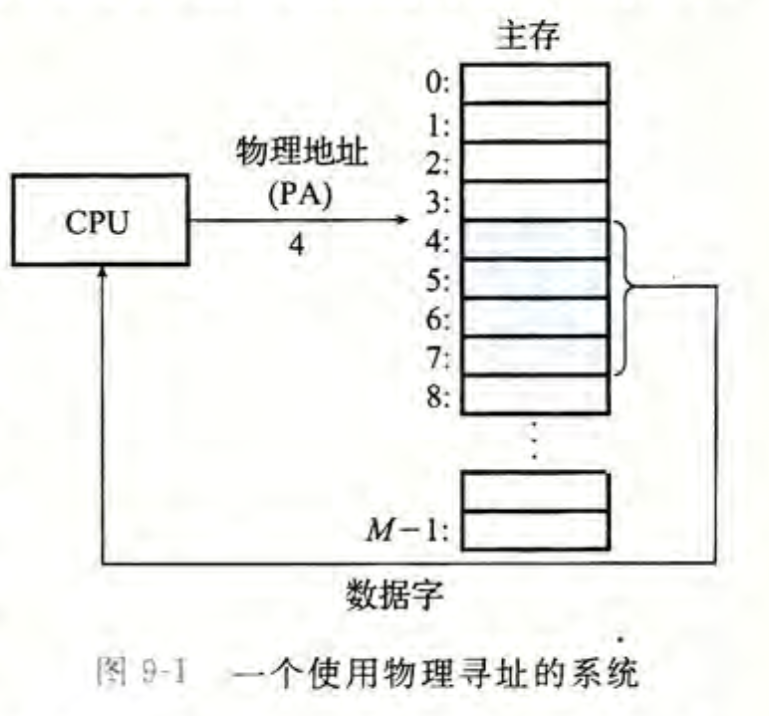
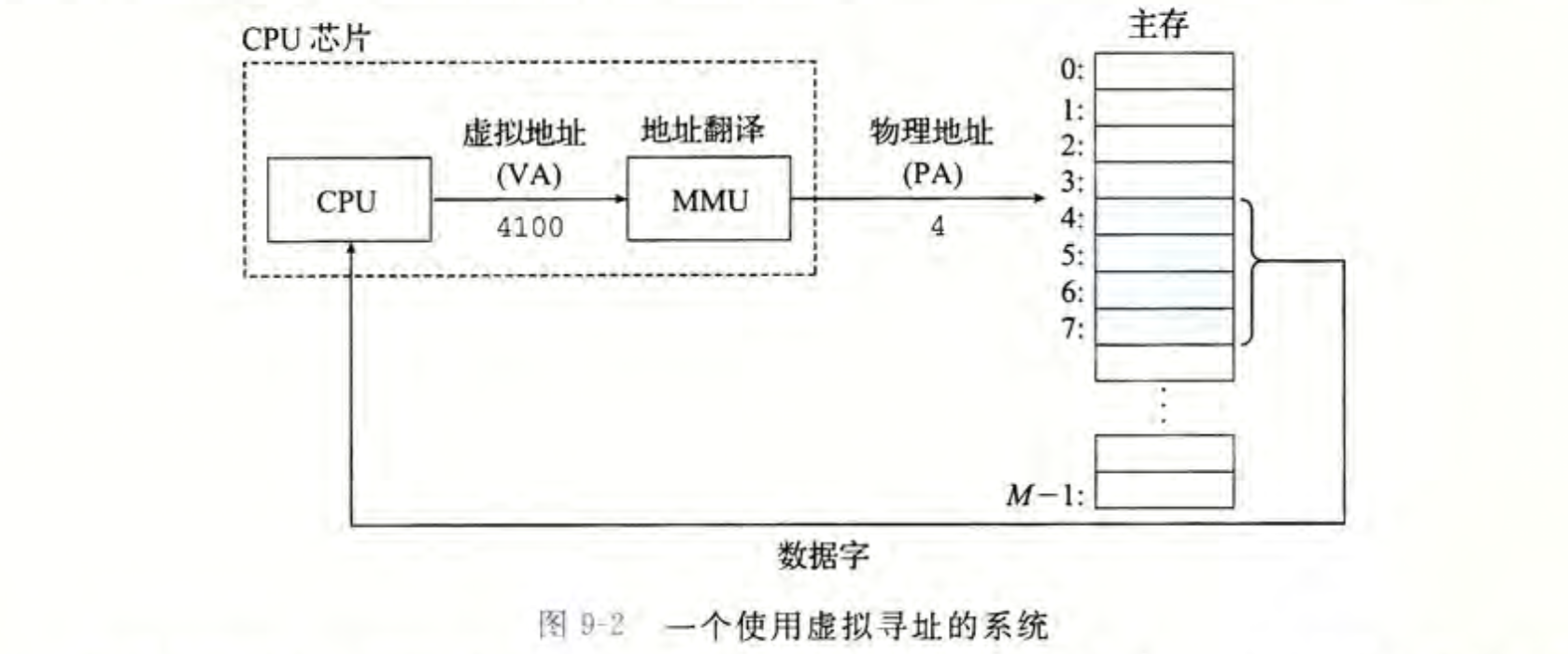
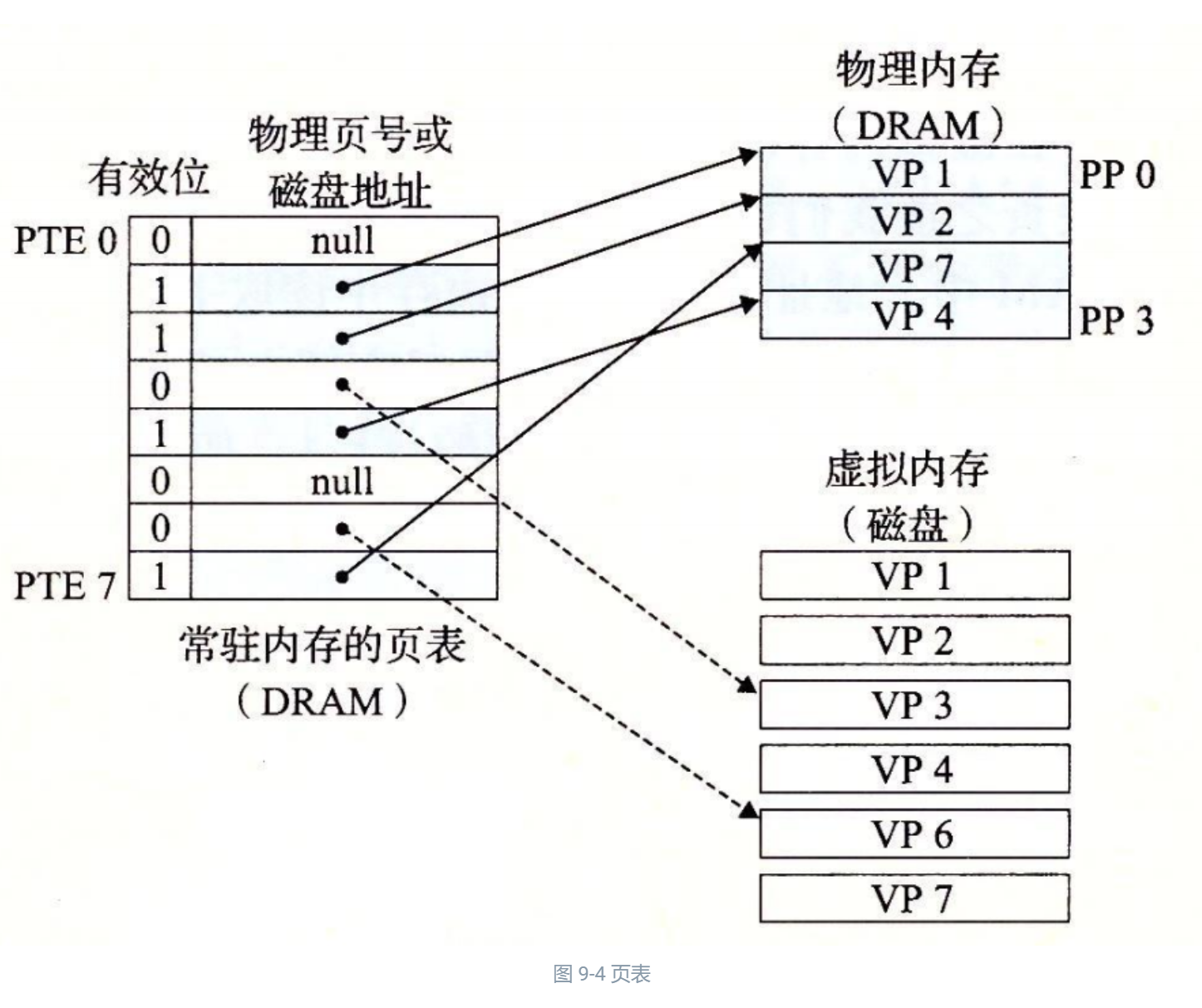
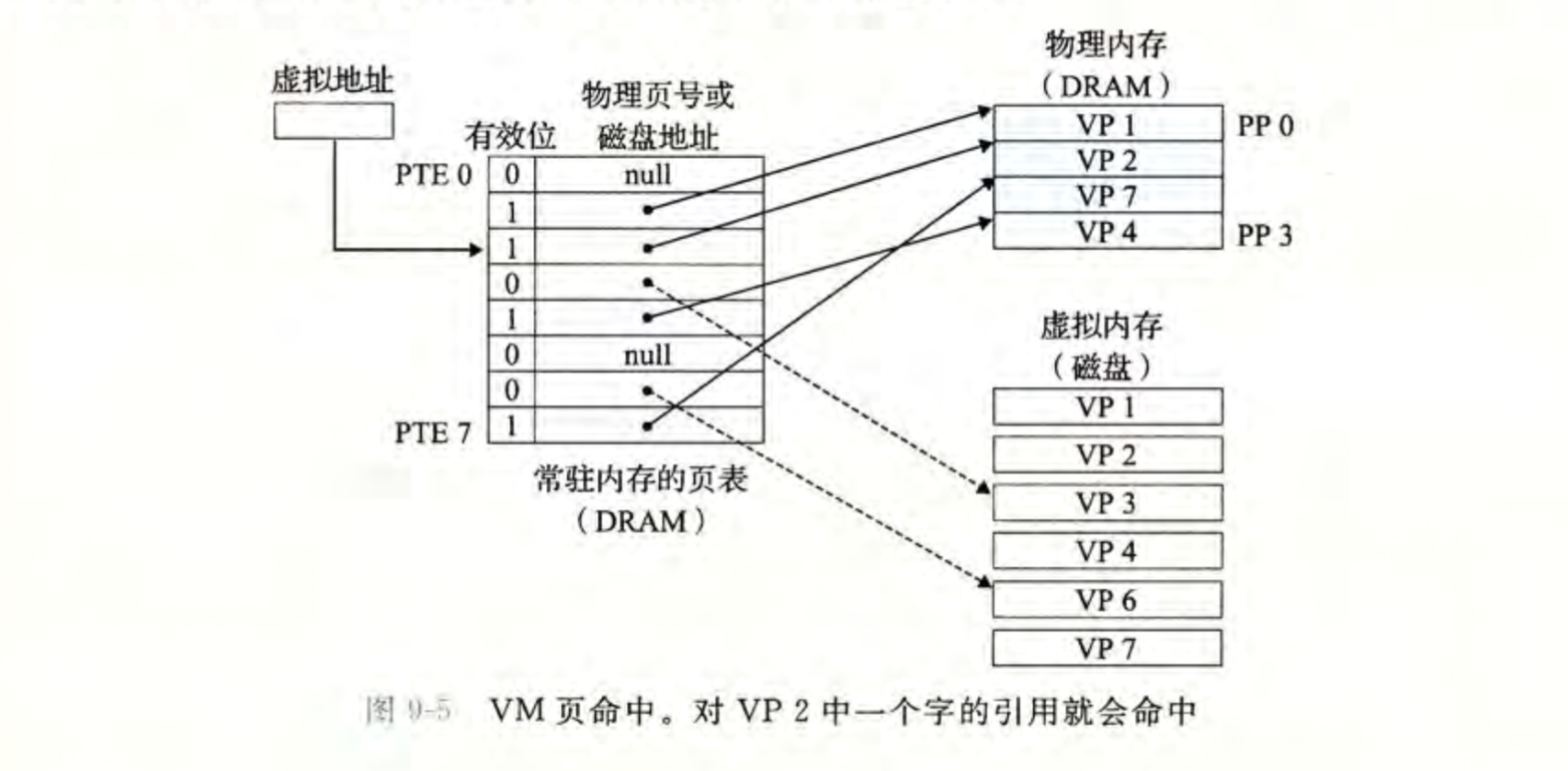 l
l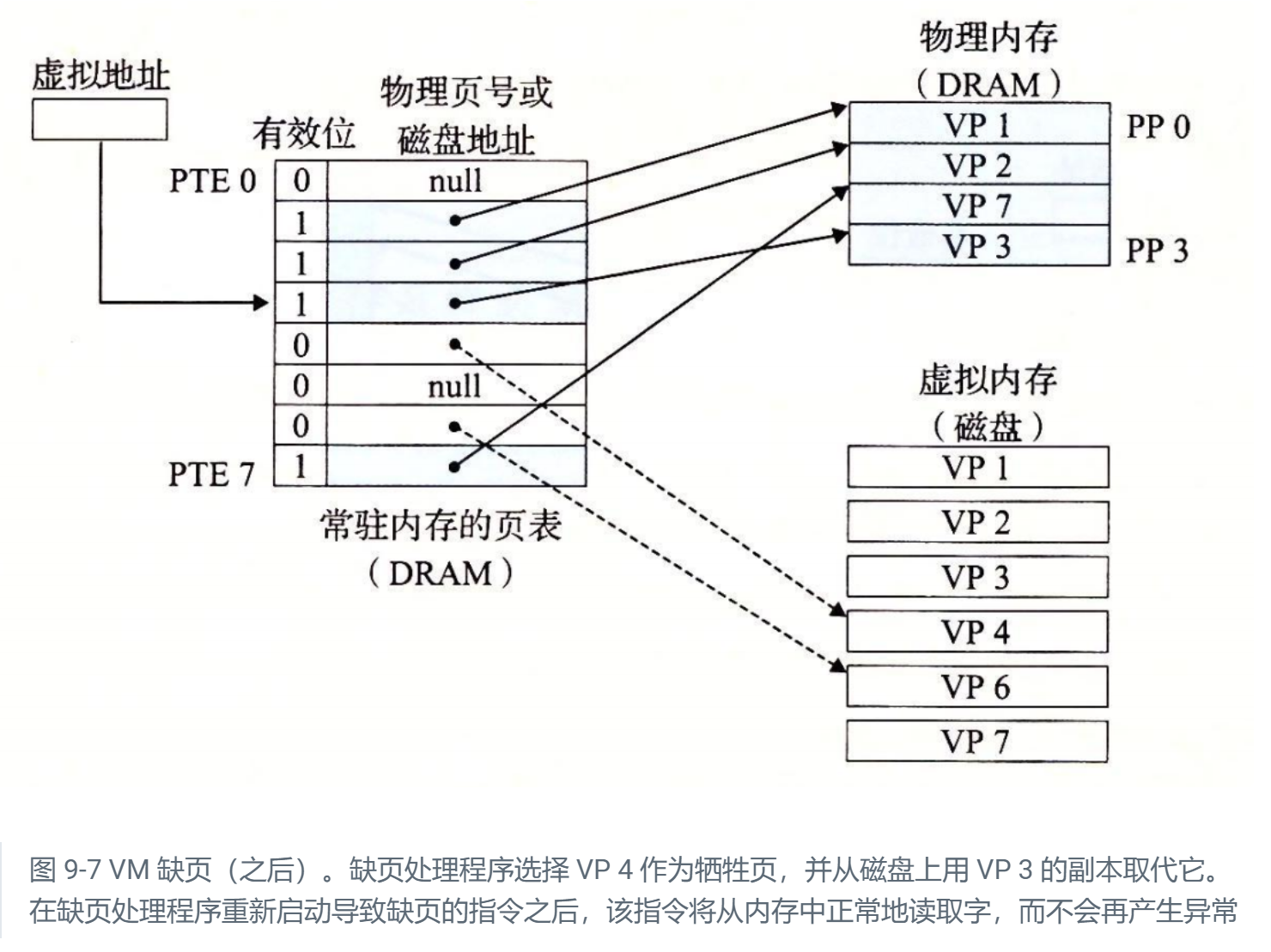
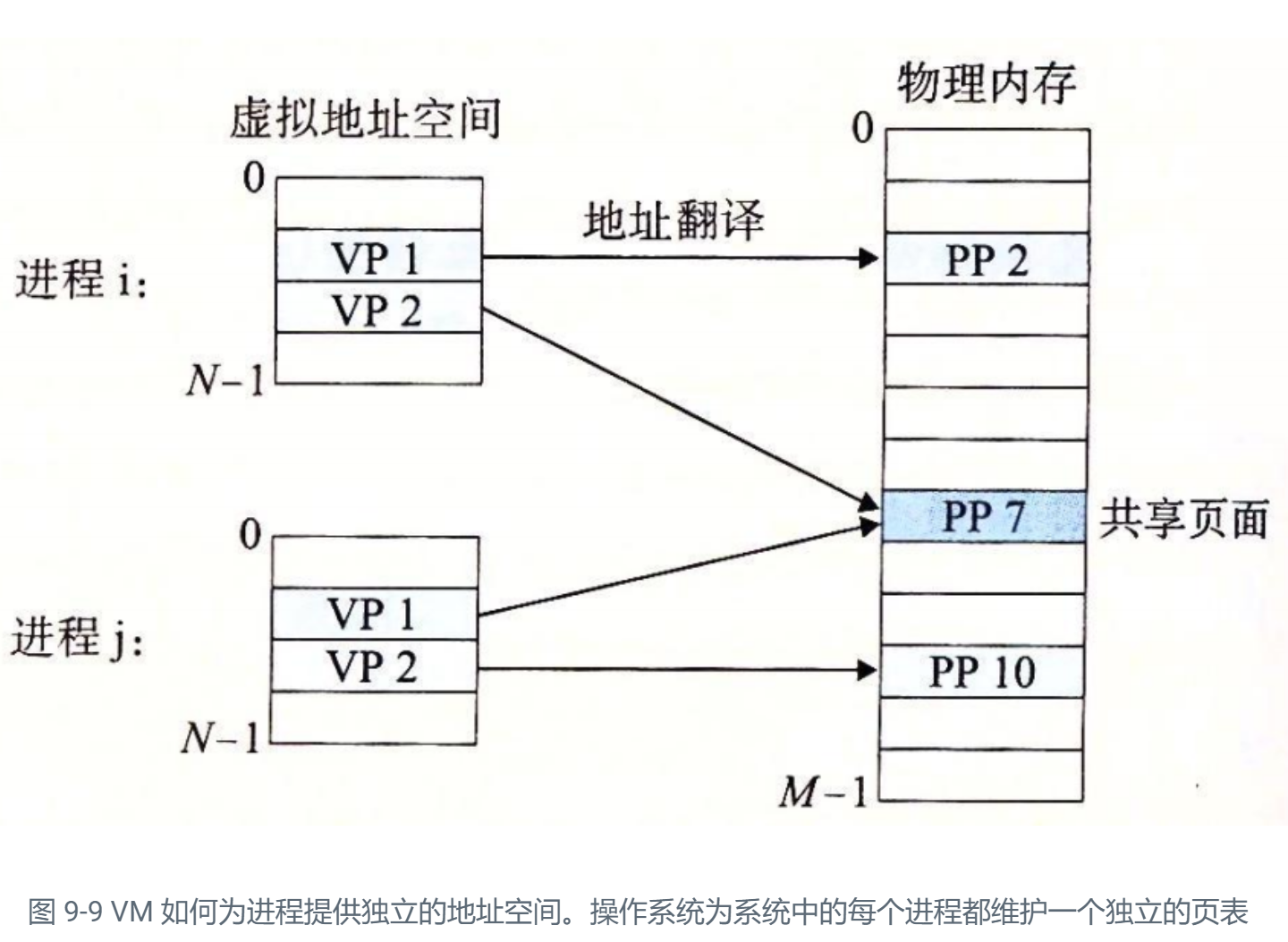
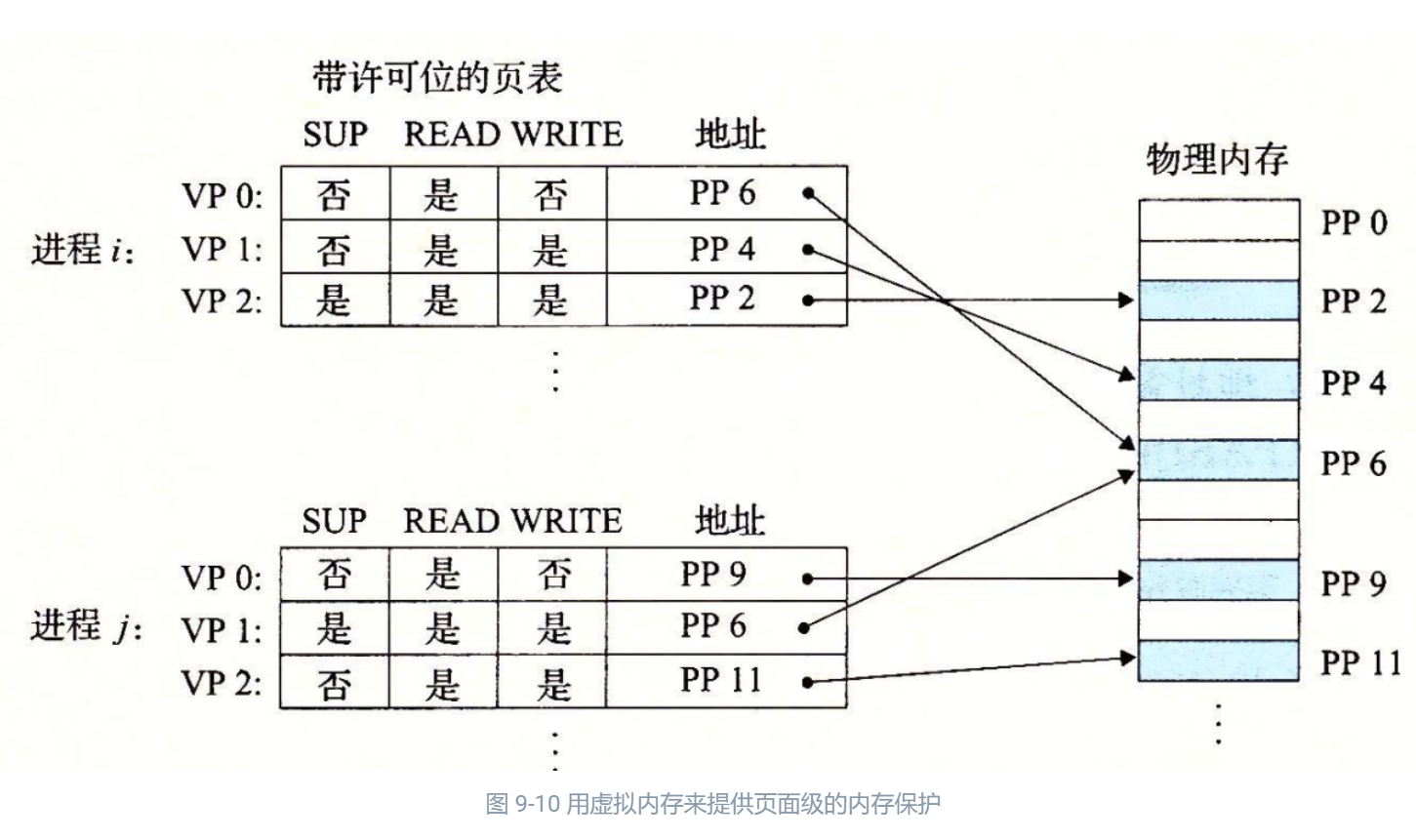

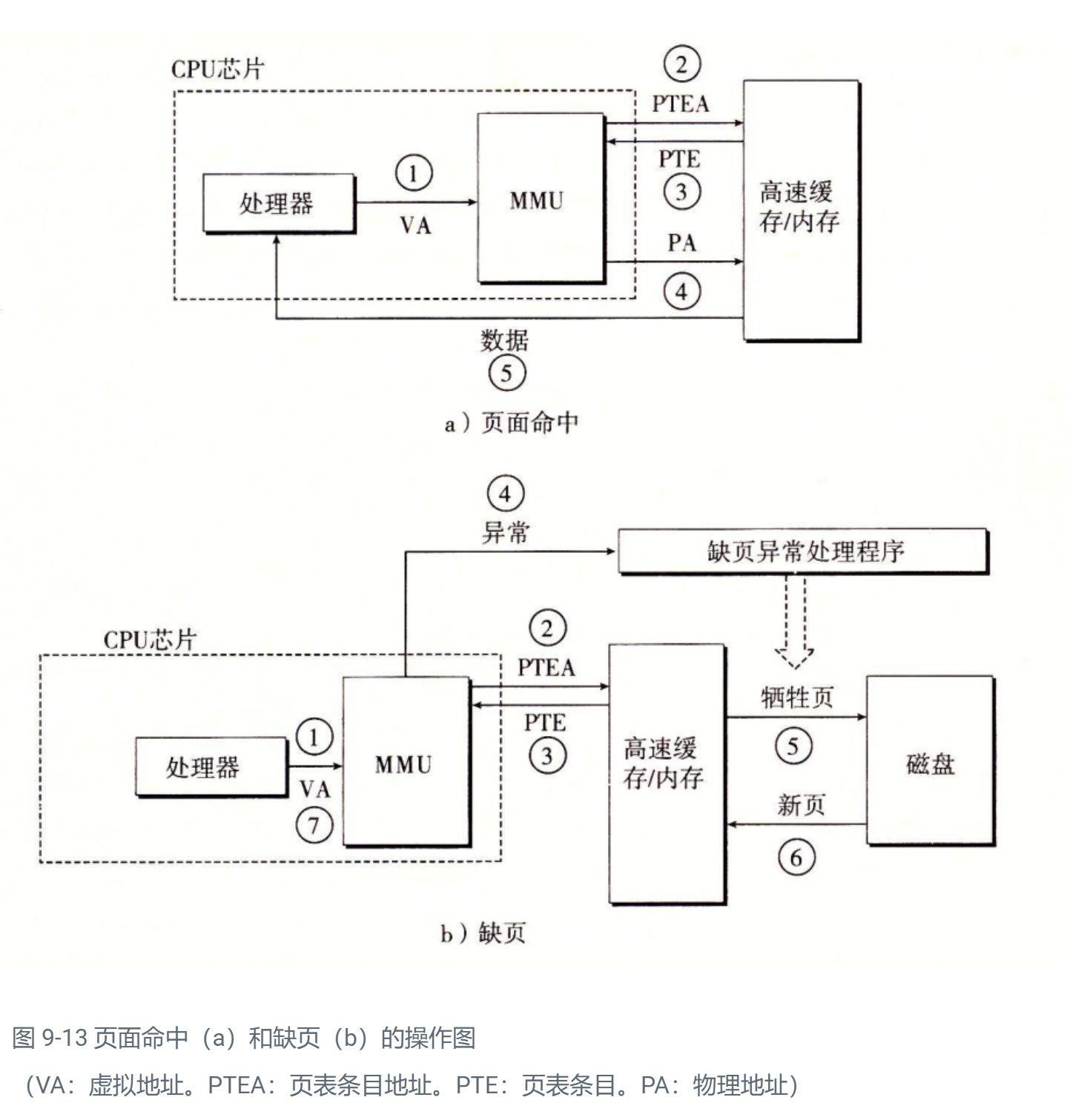
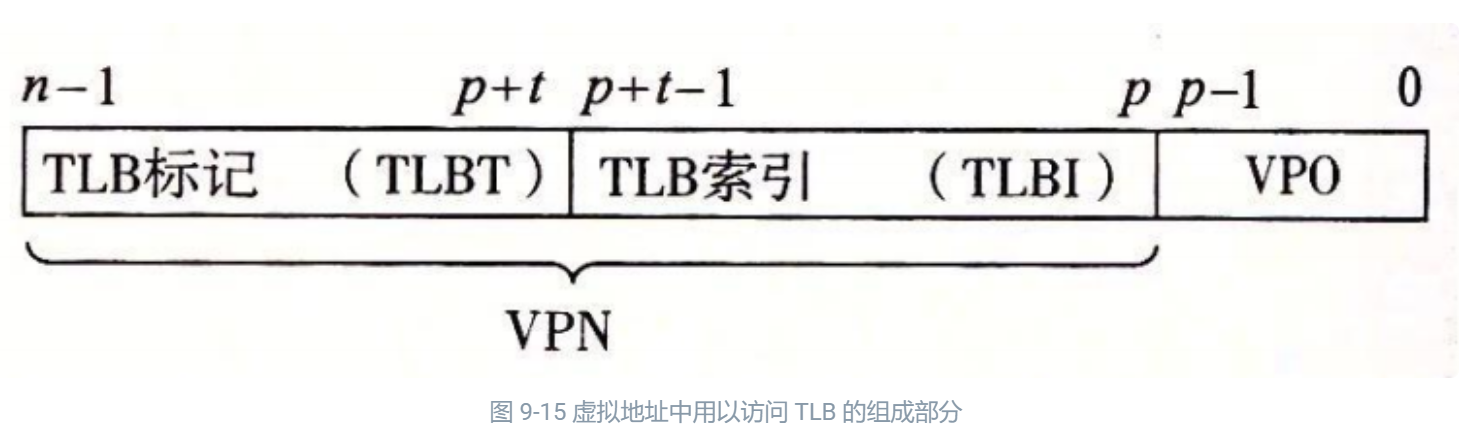
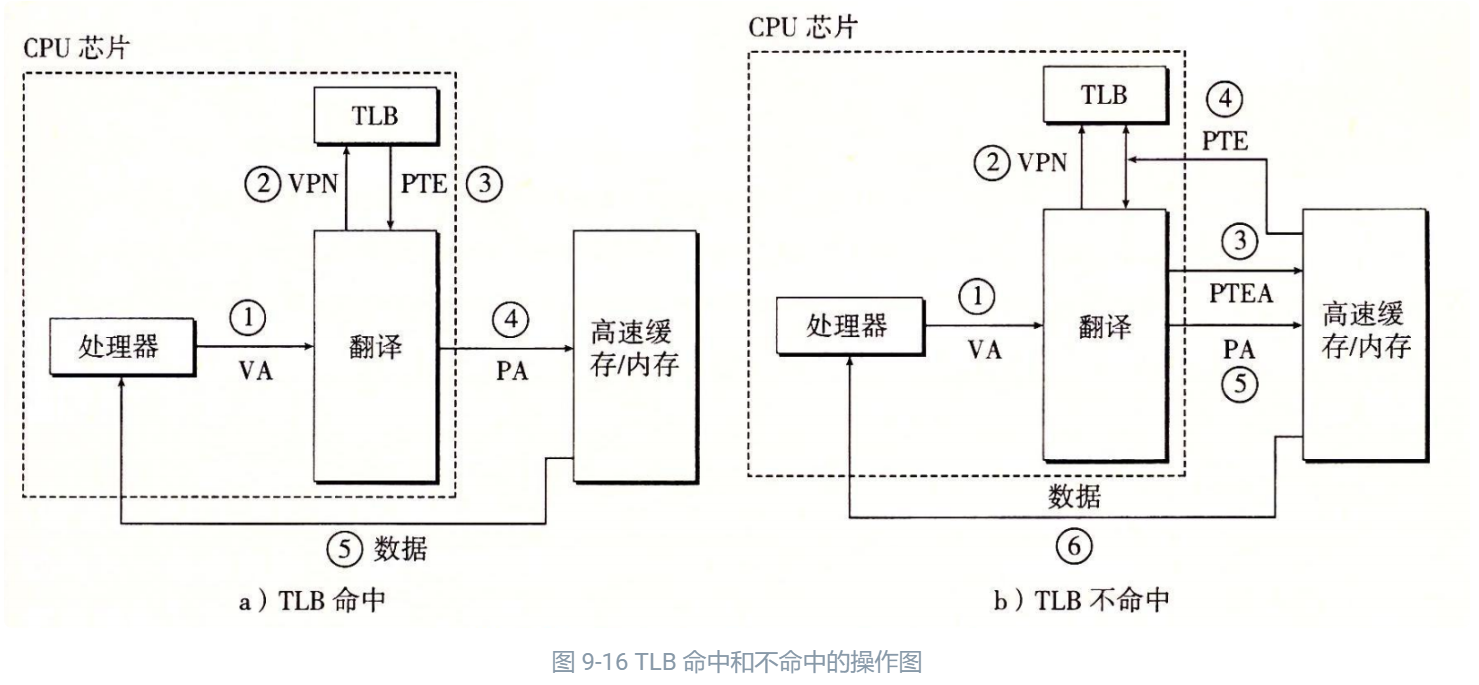
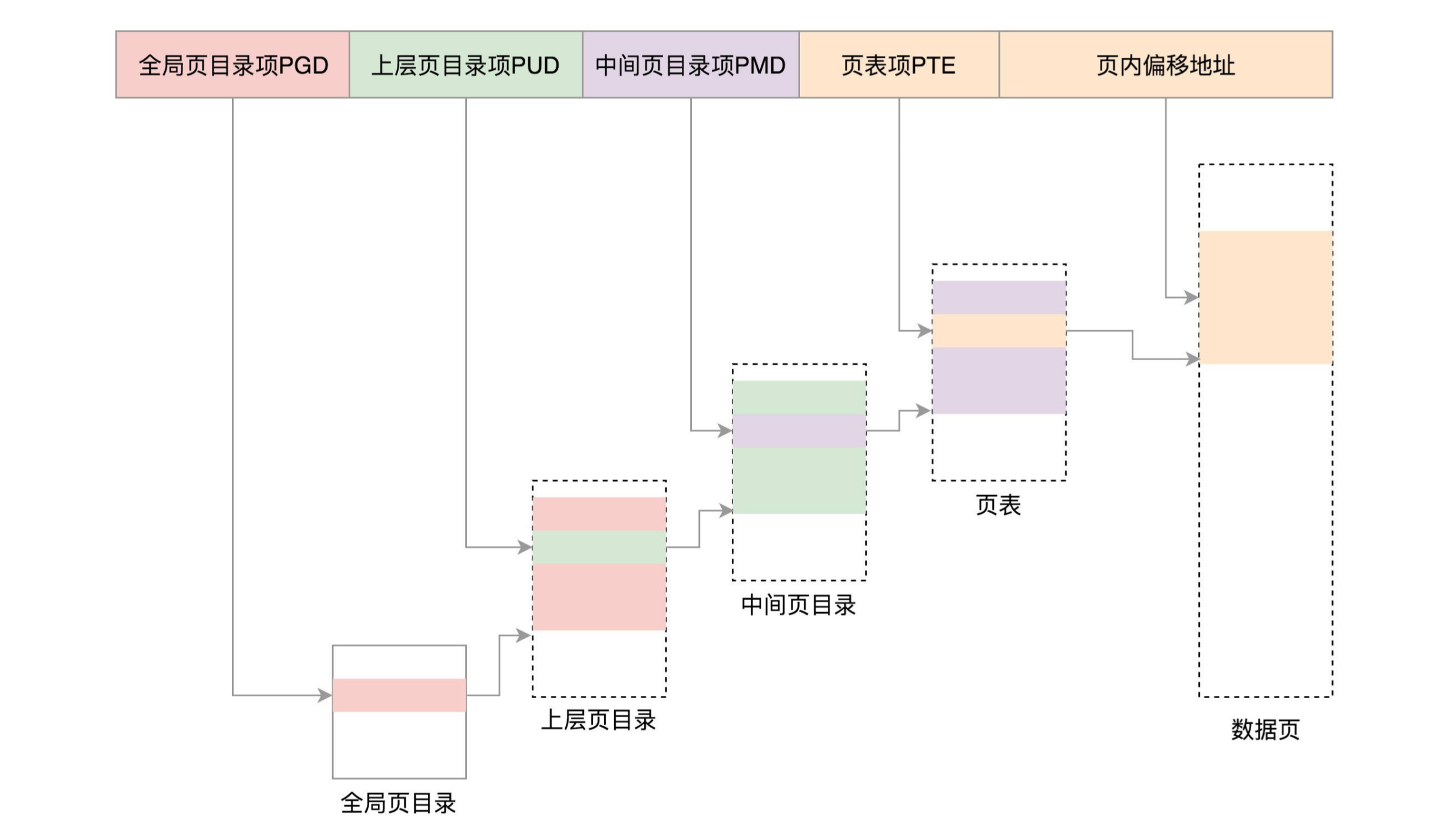
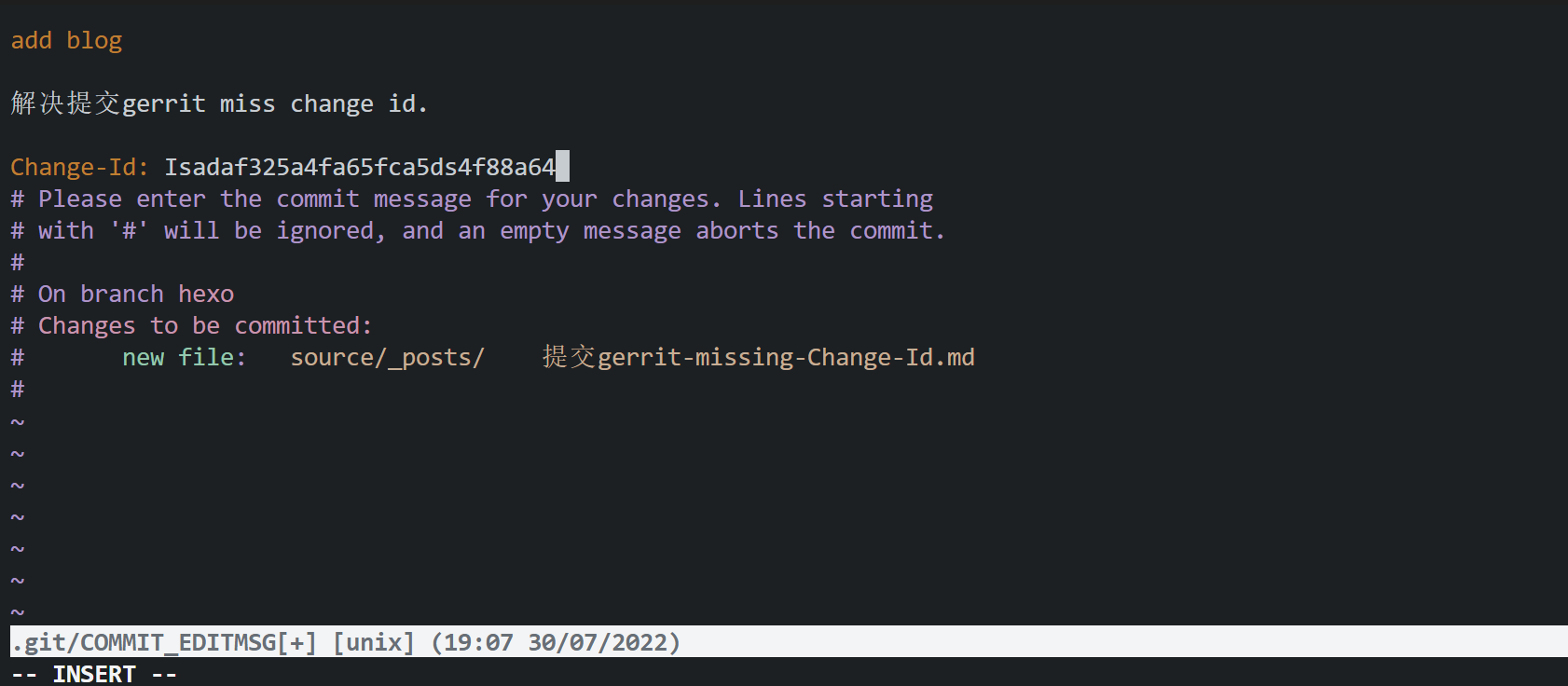



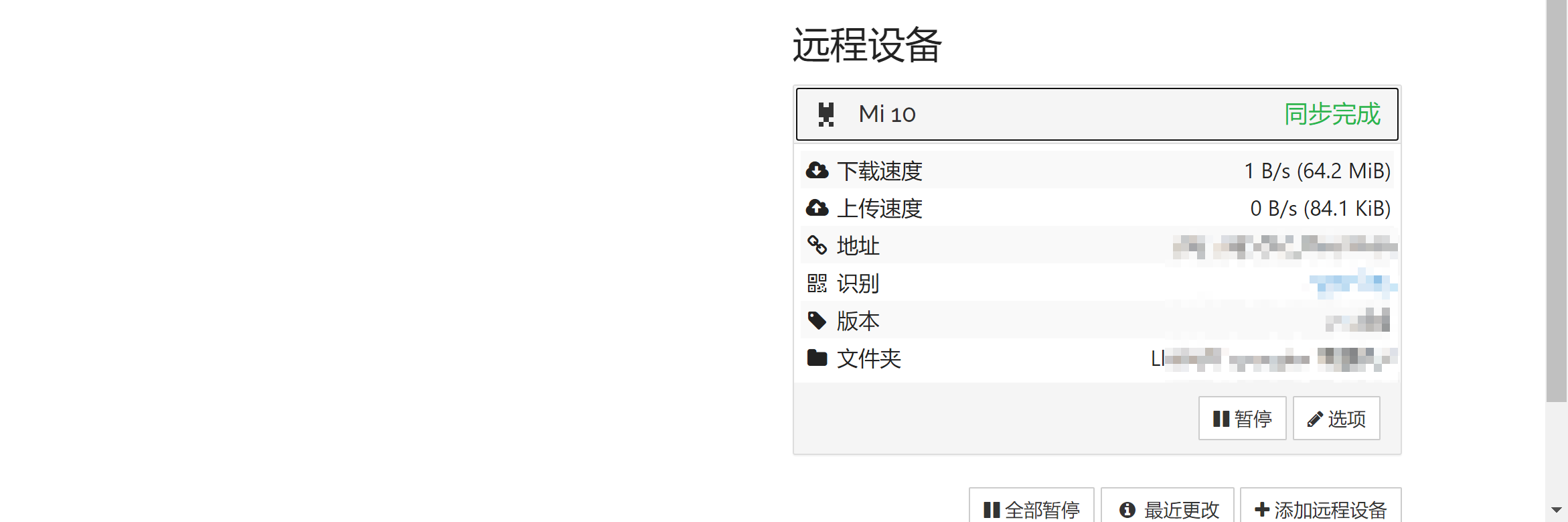


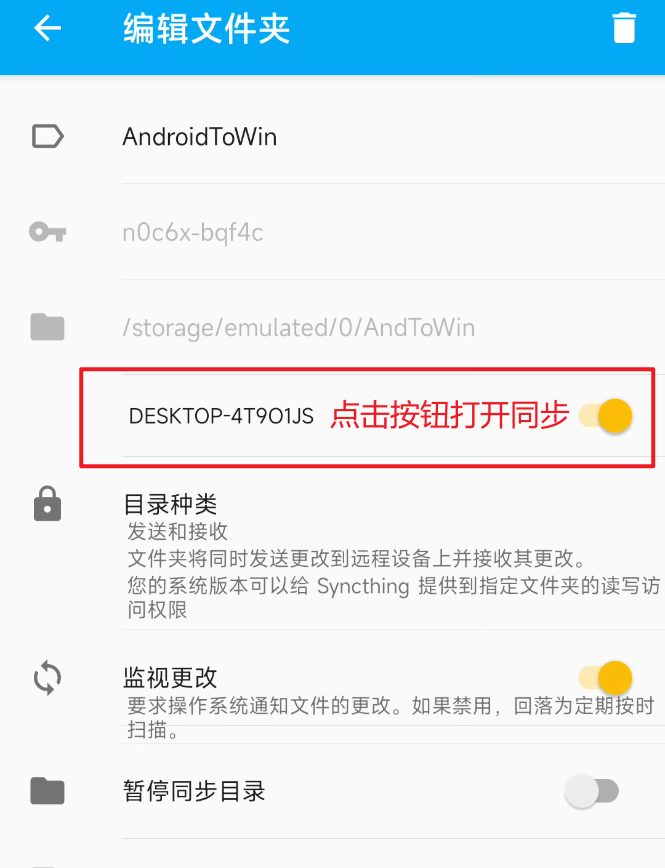
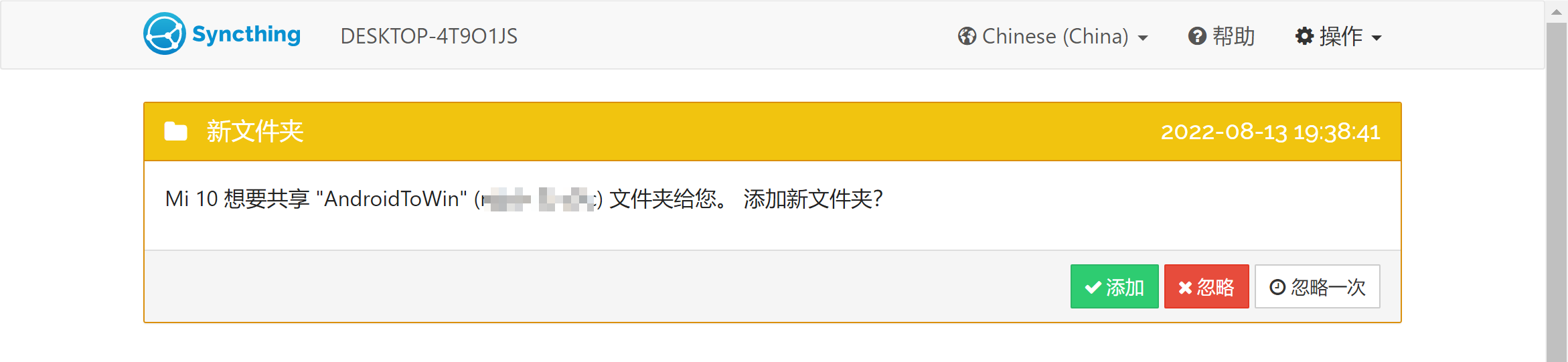
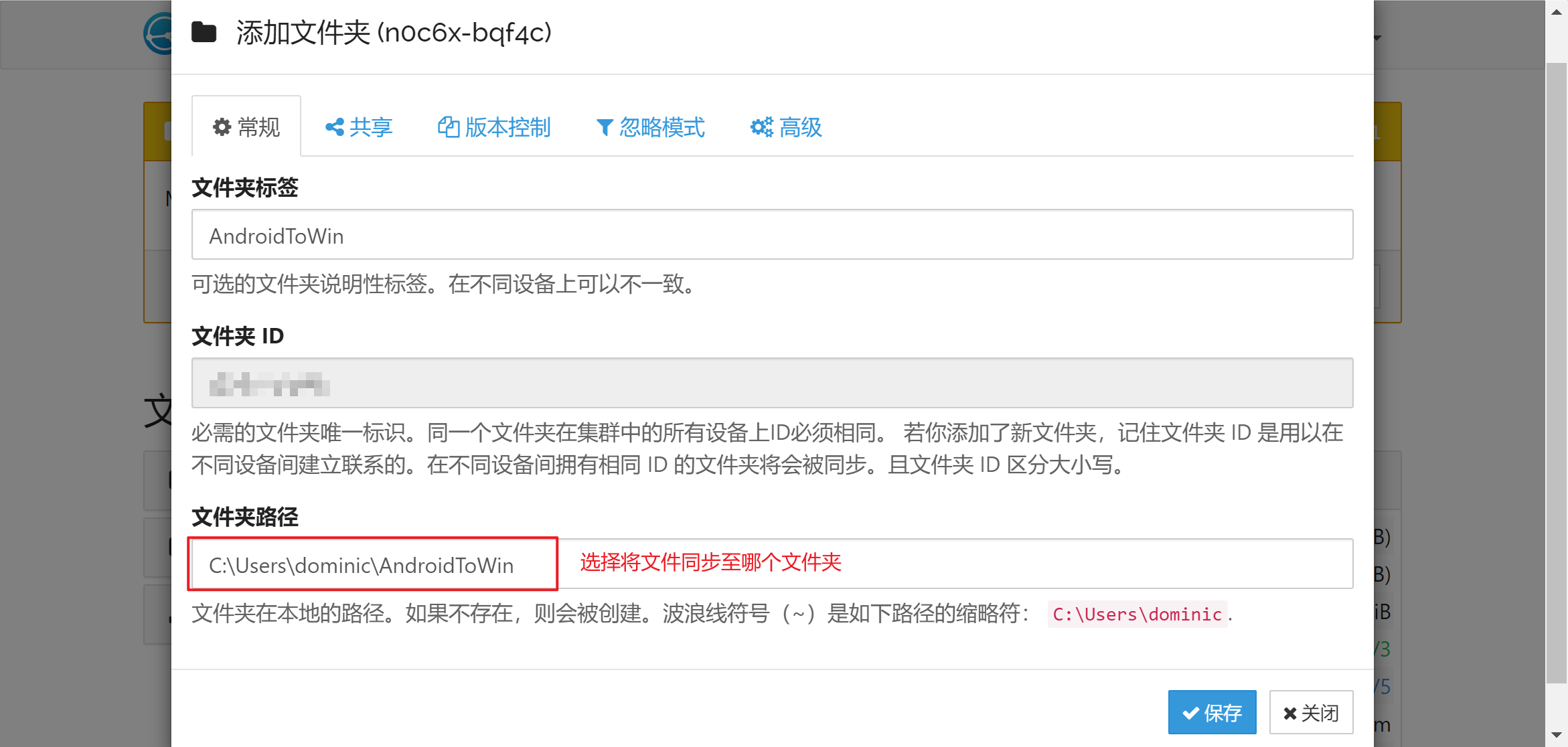
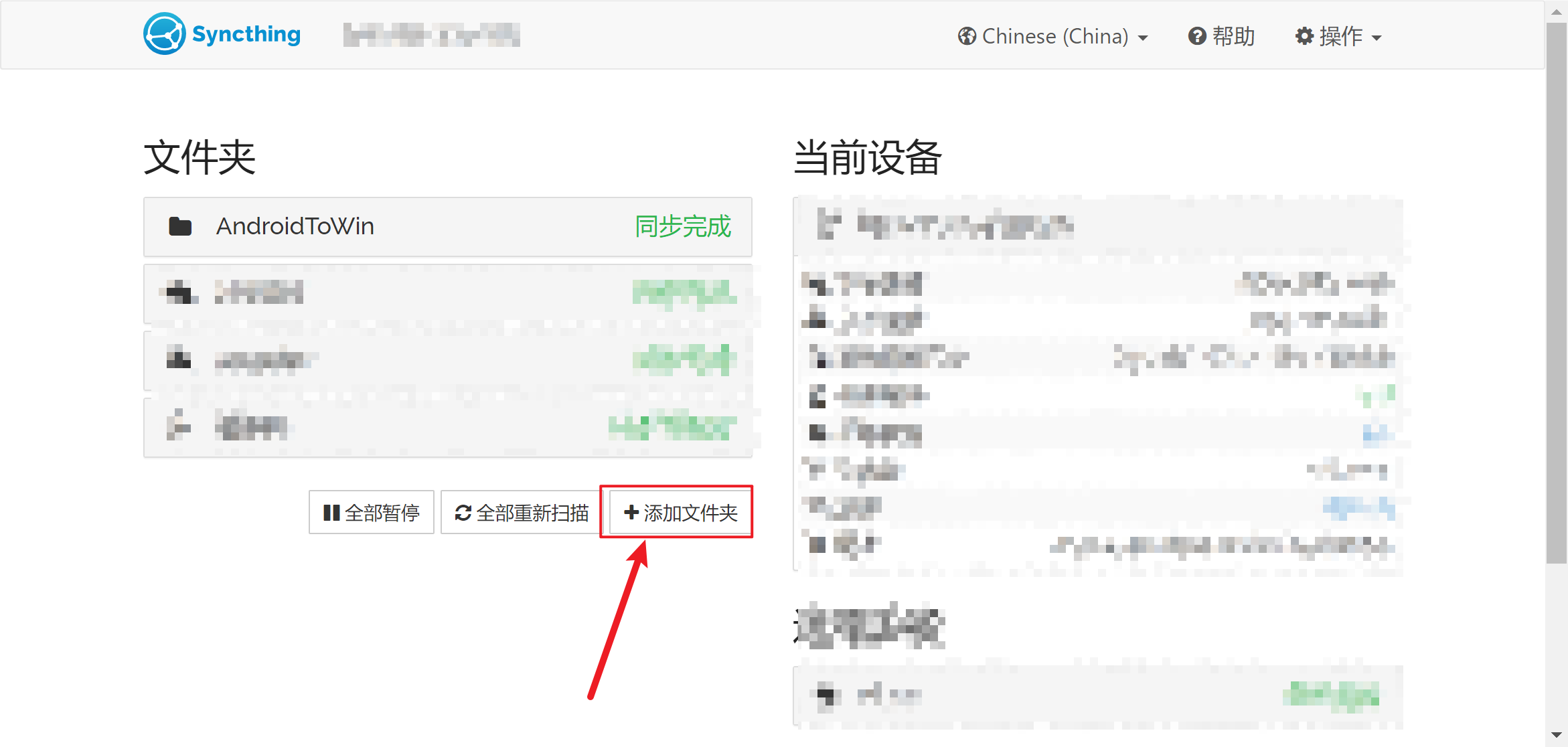
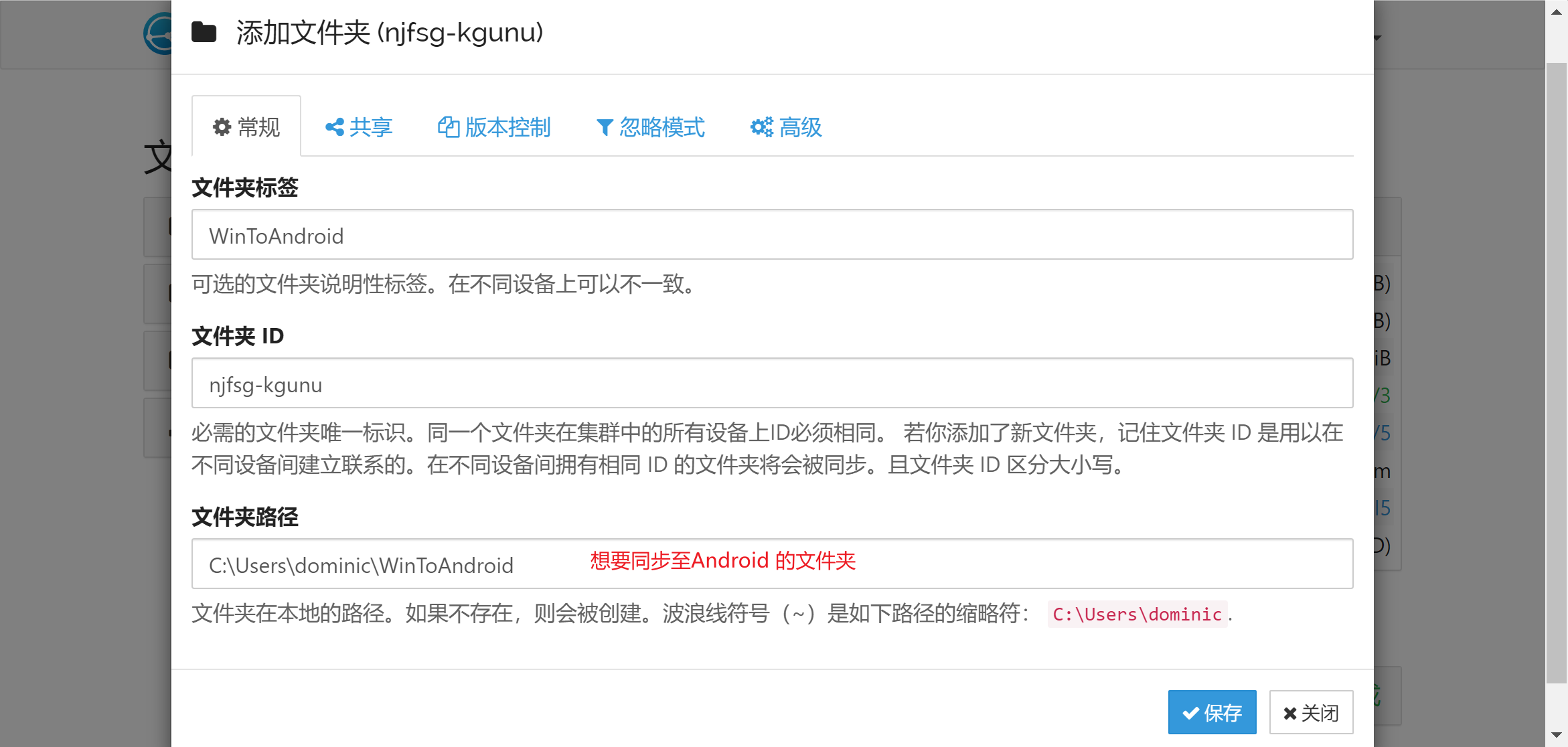
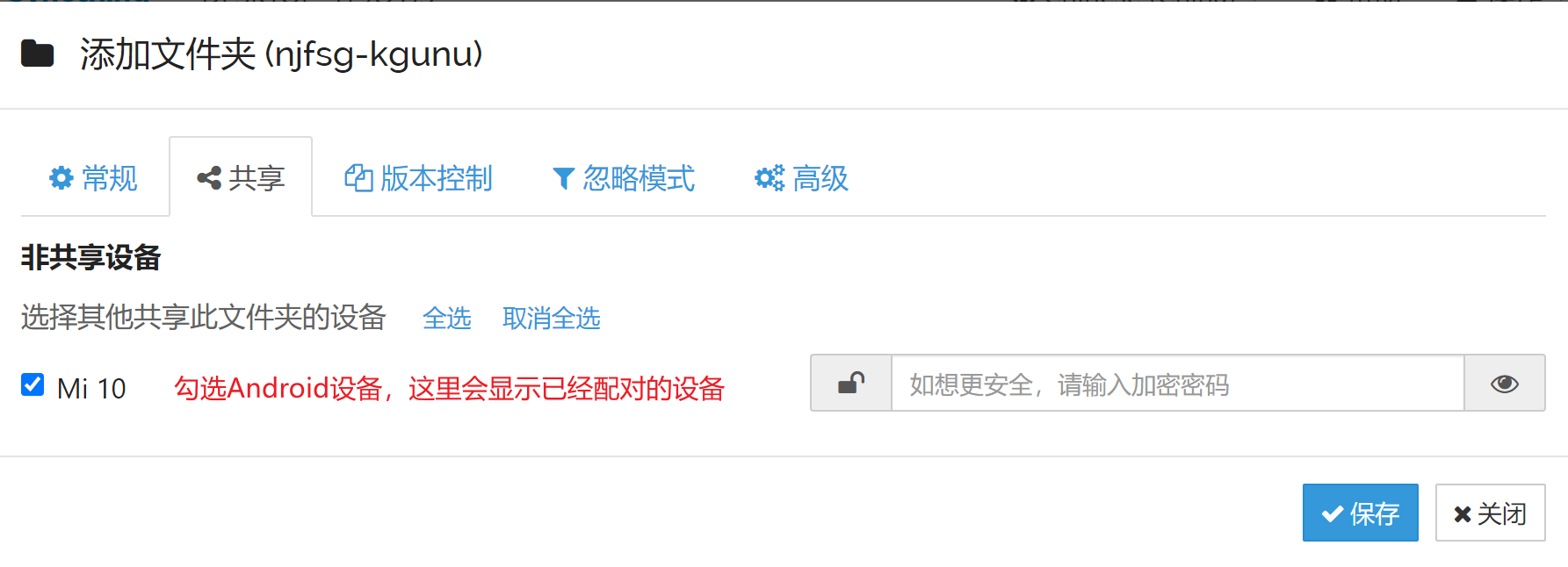



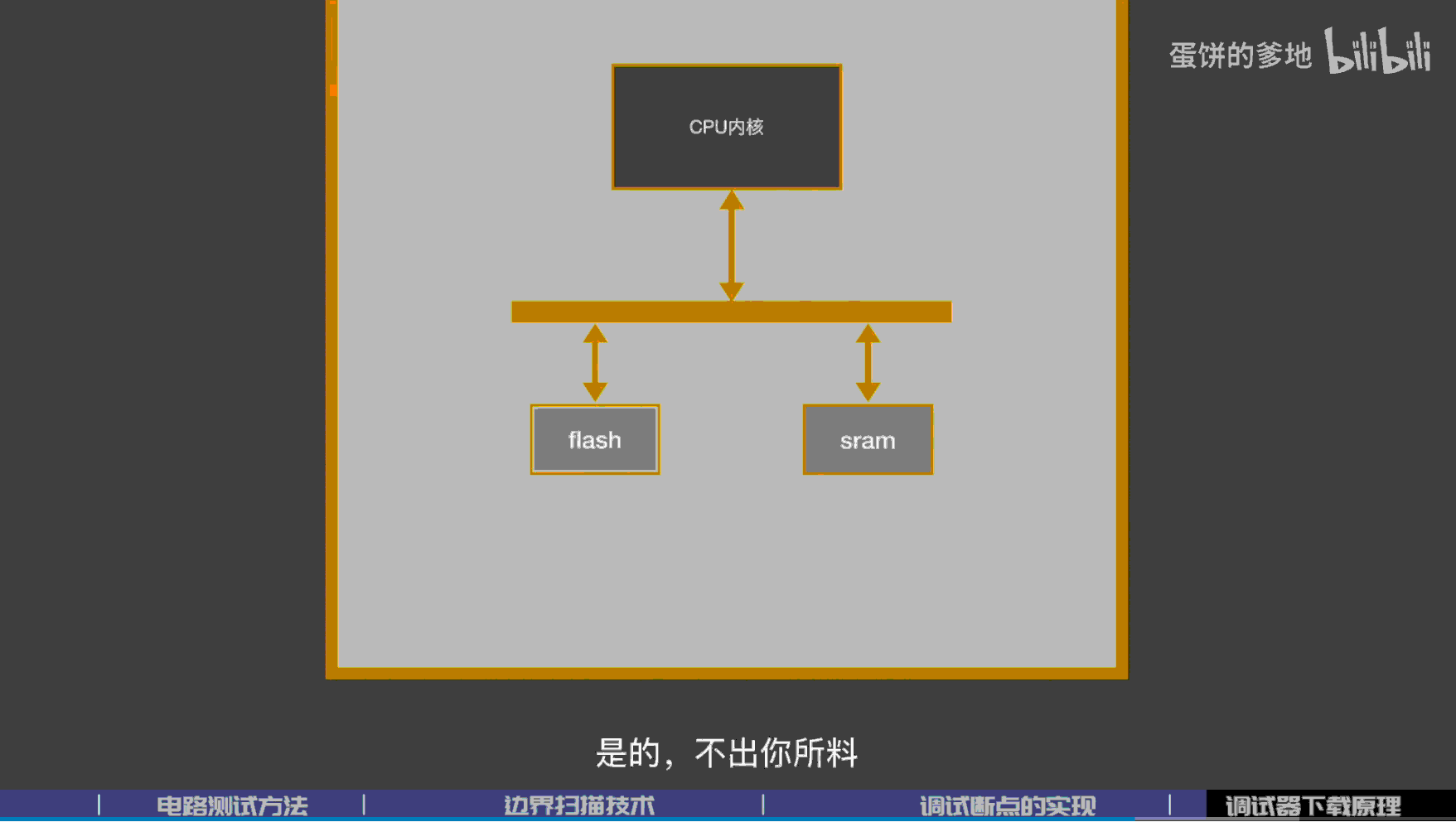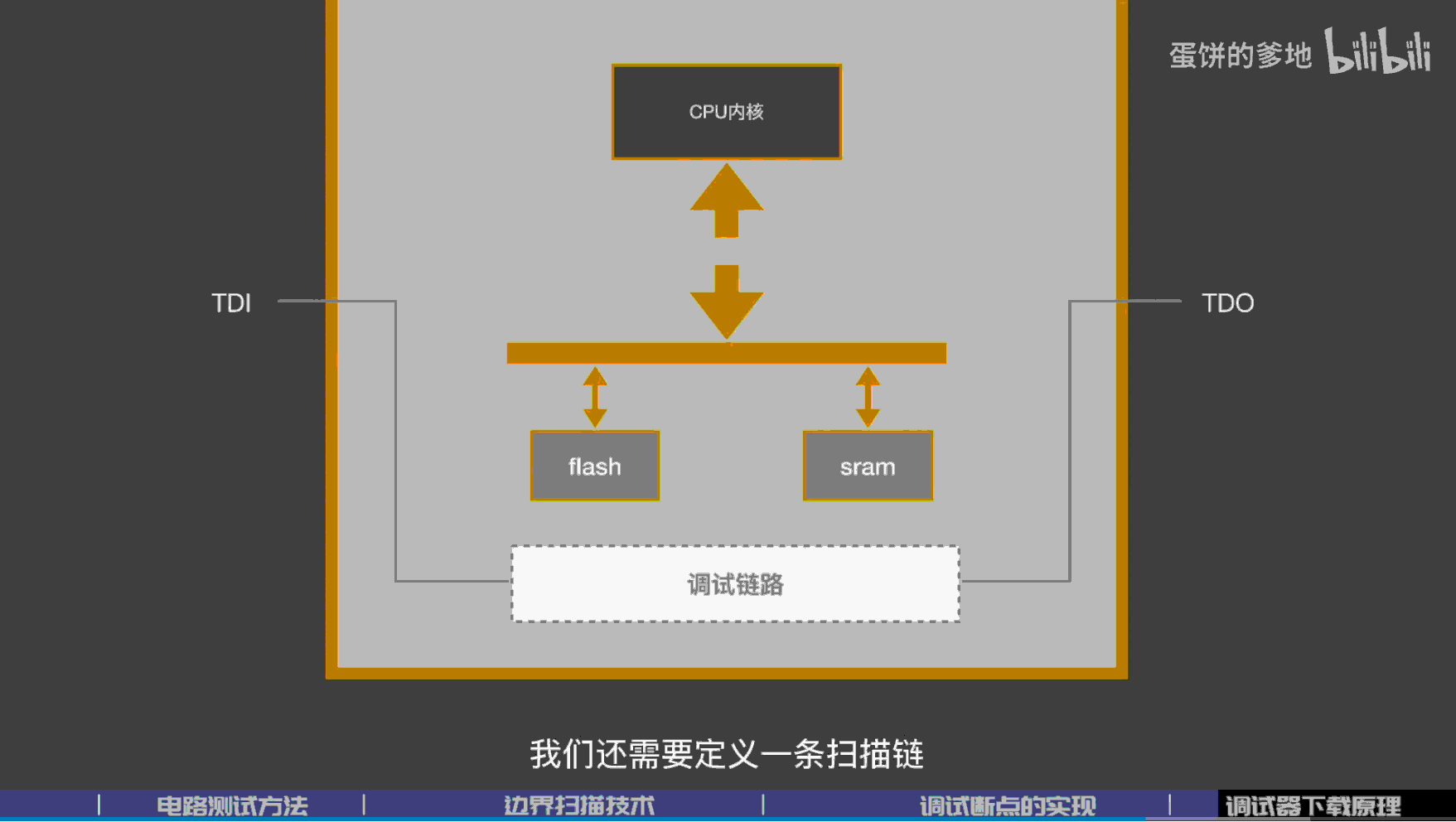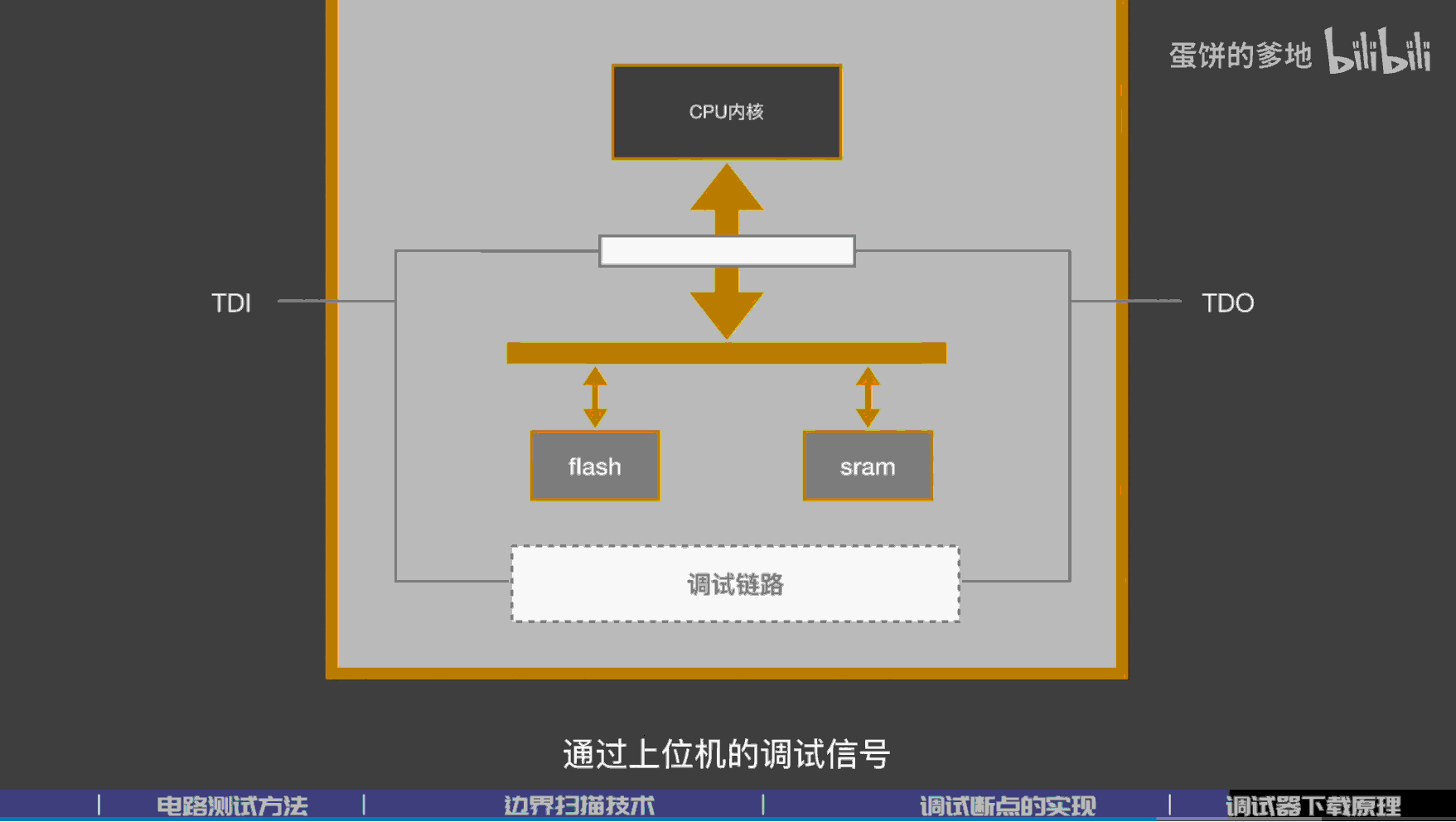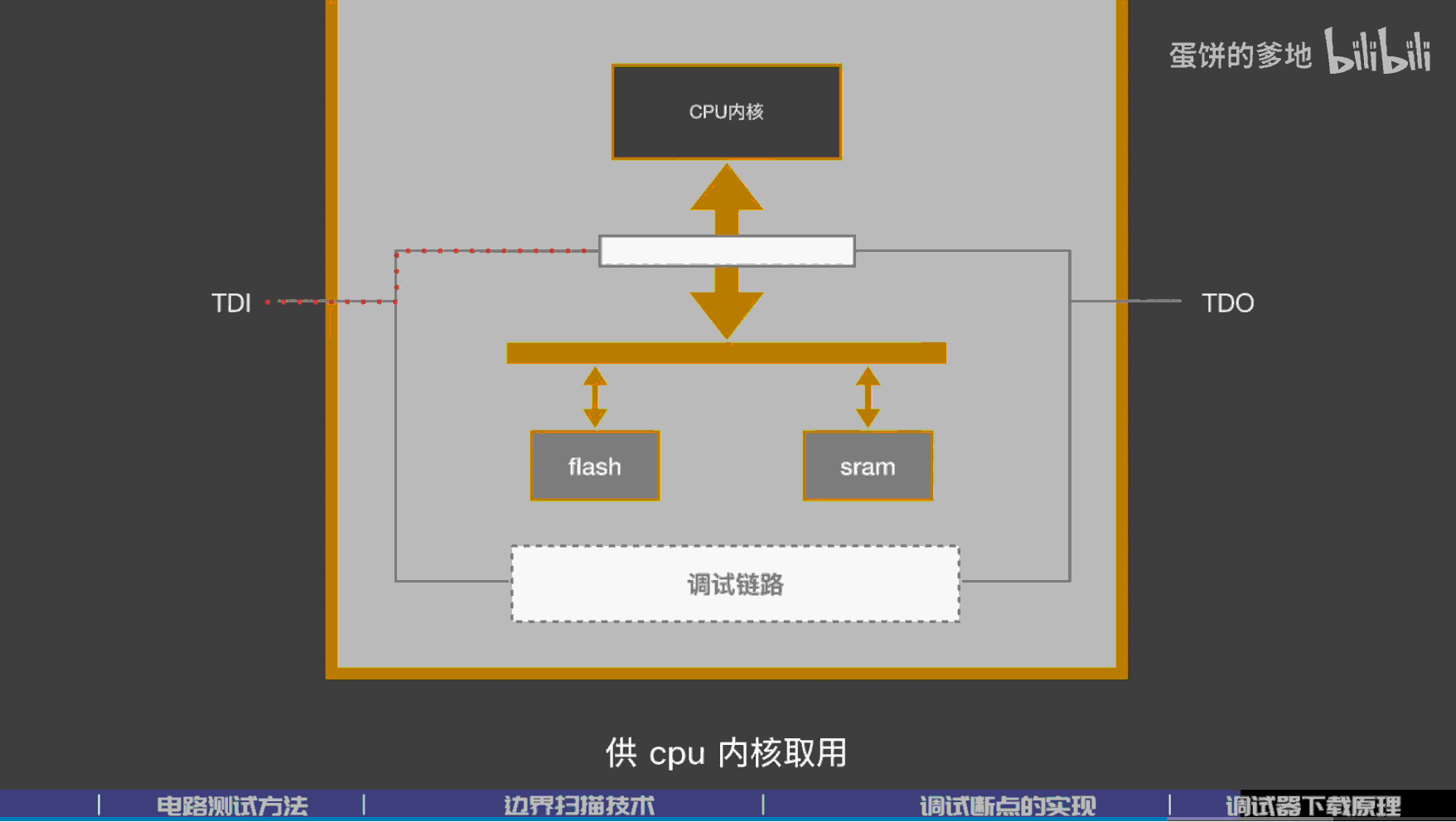
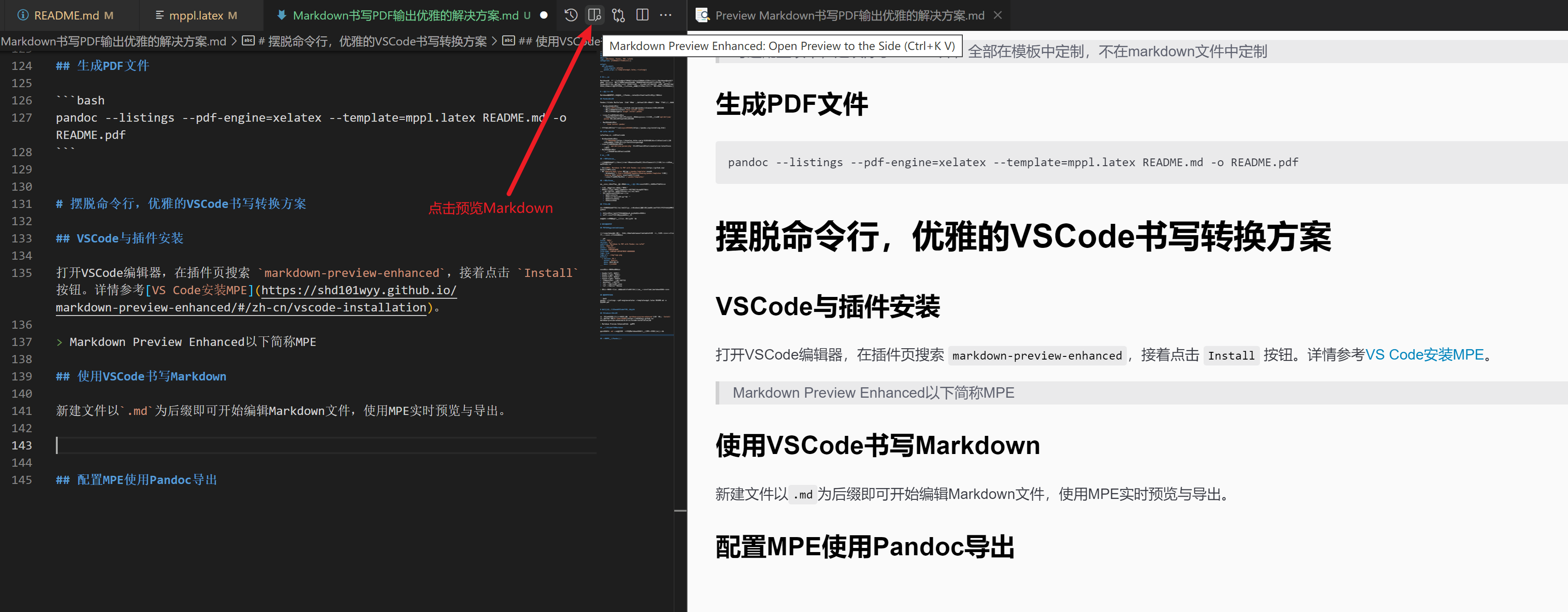
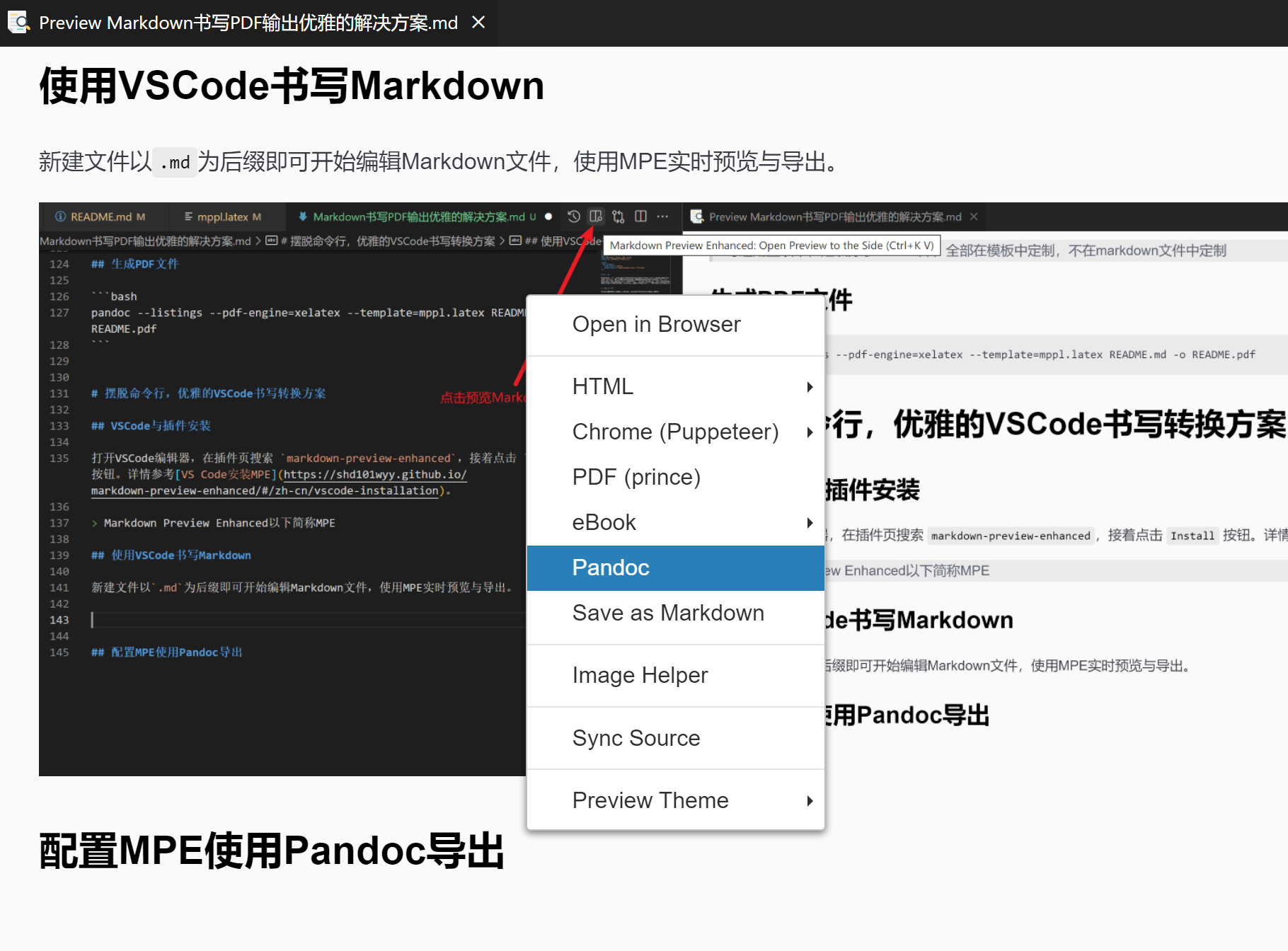
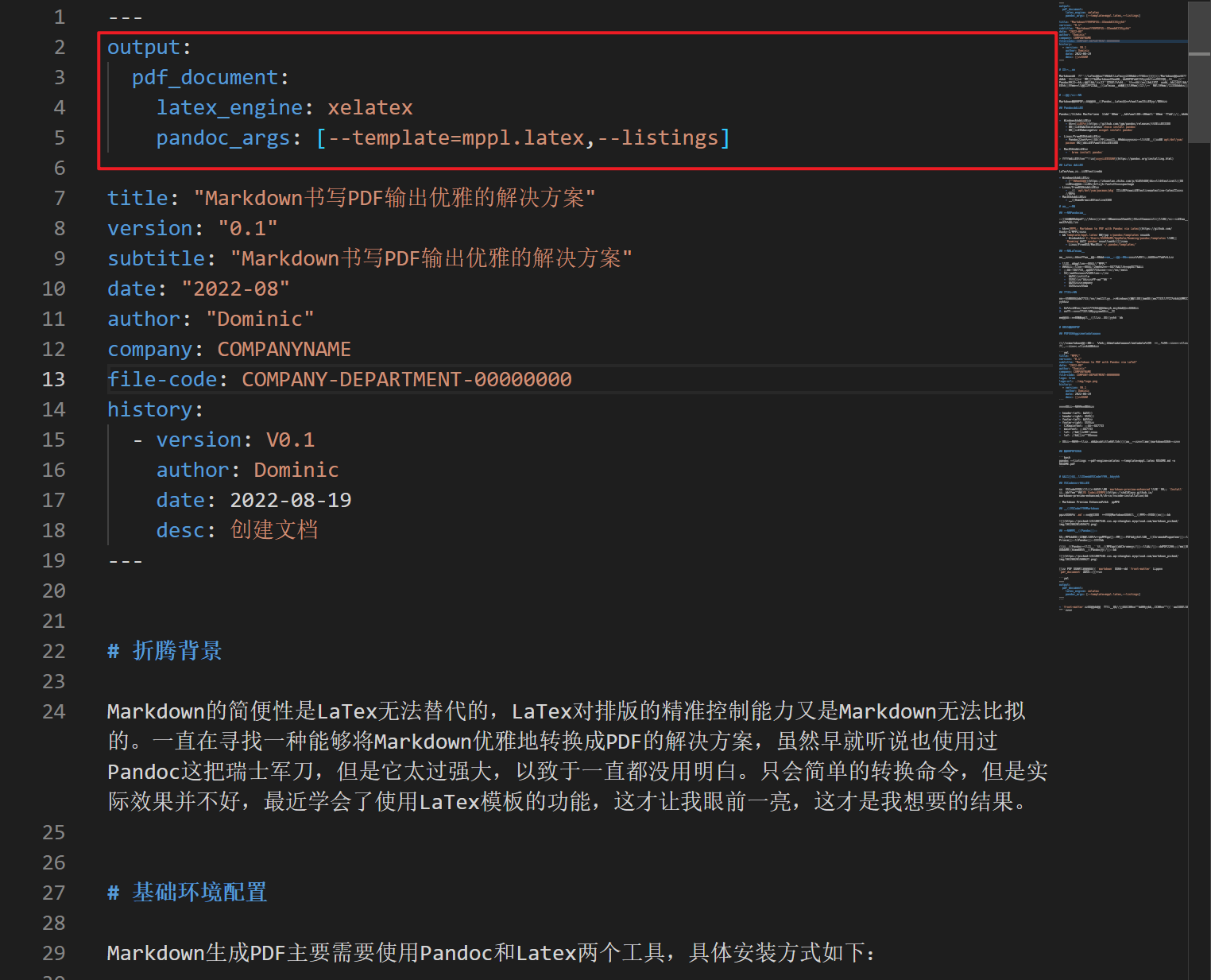

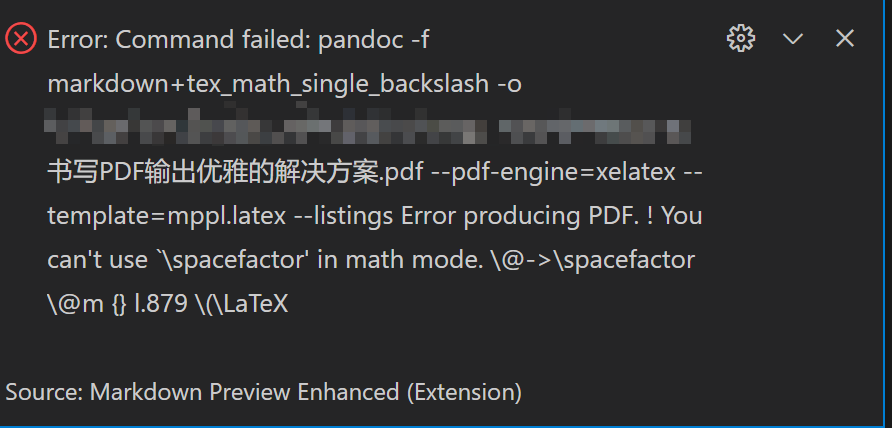
















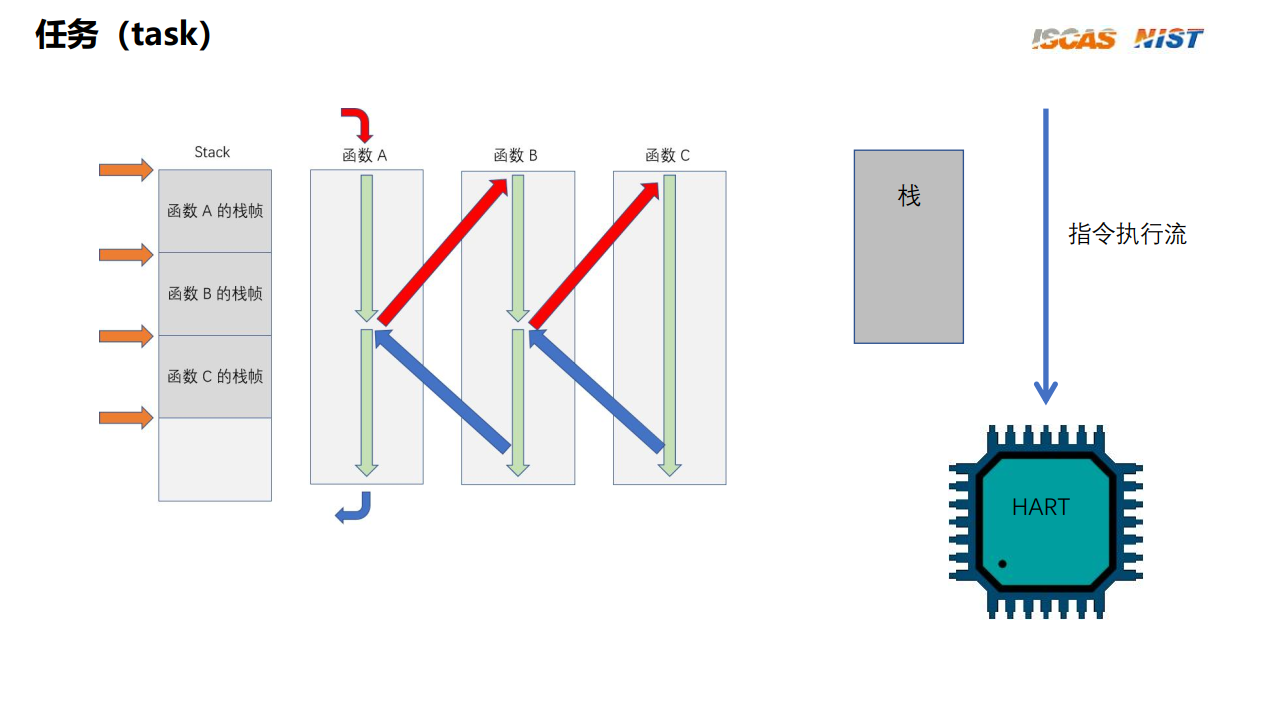
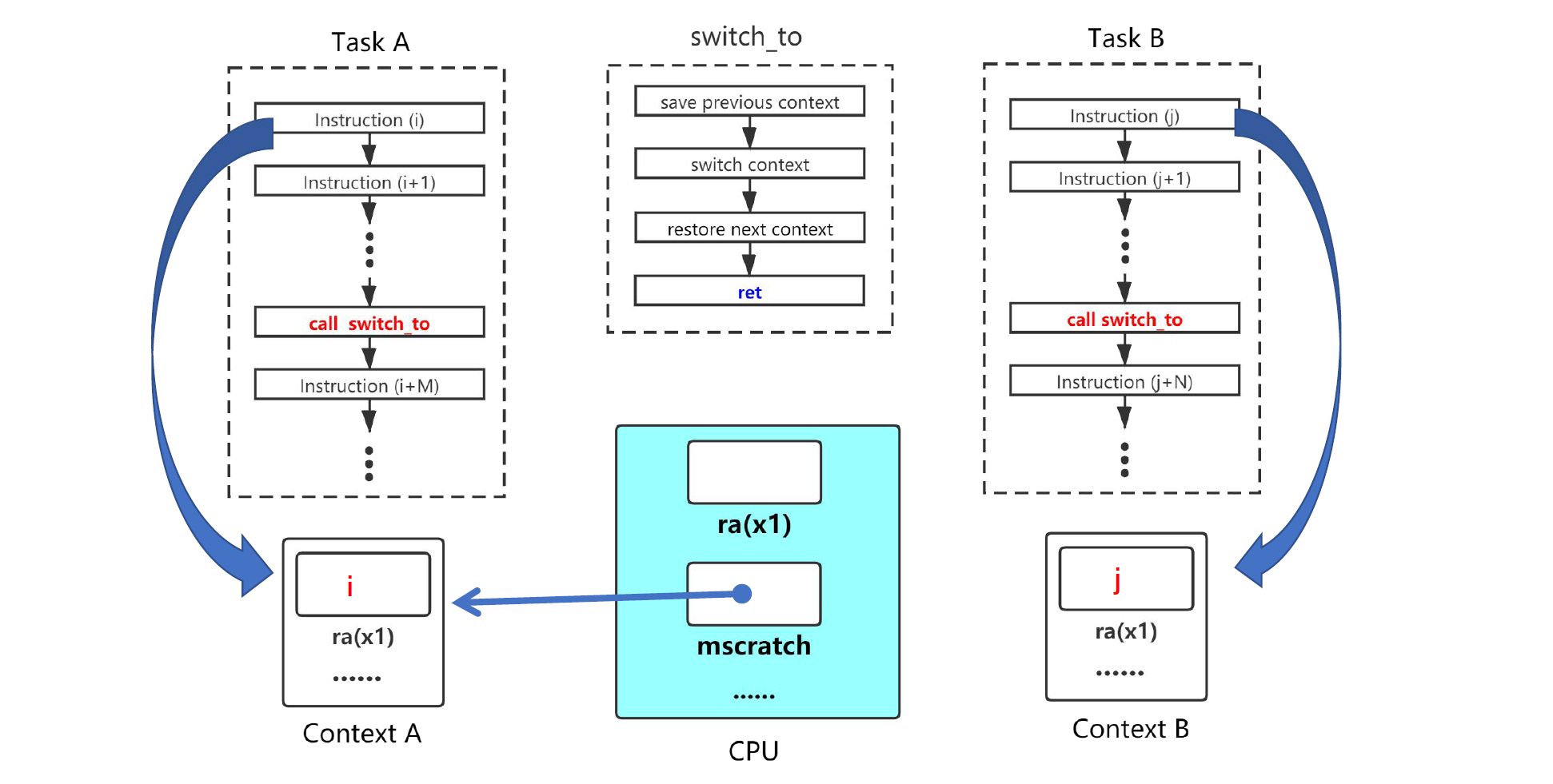
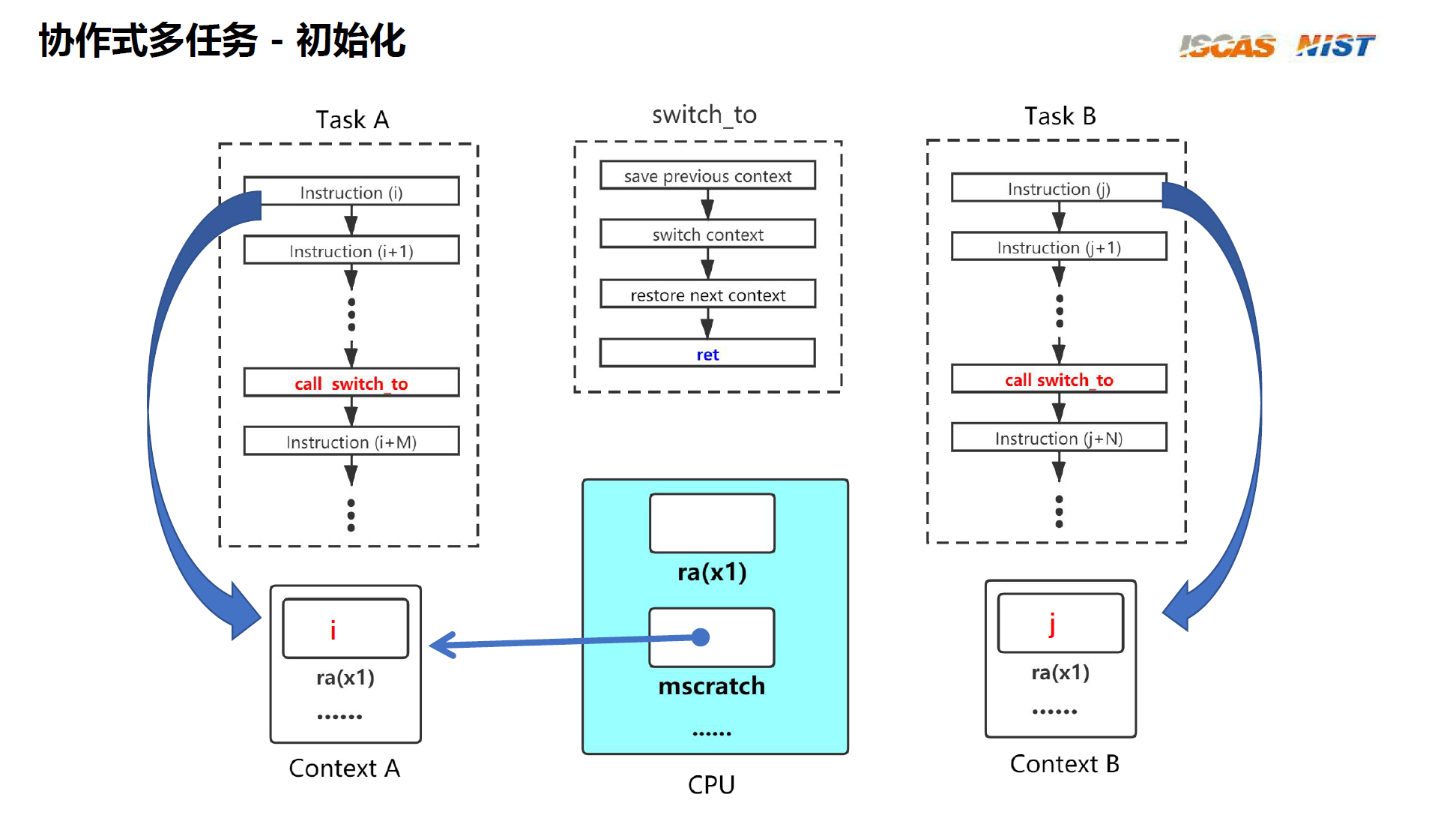
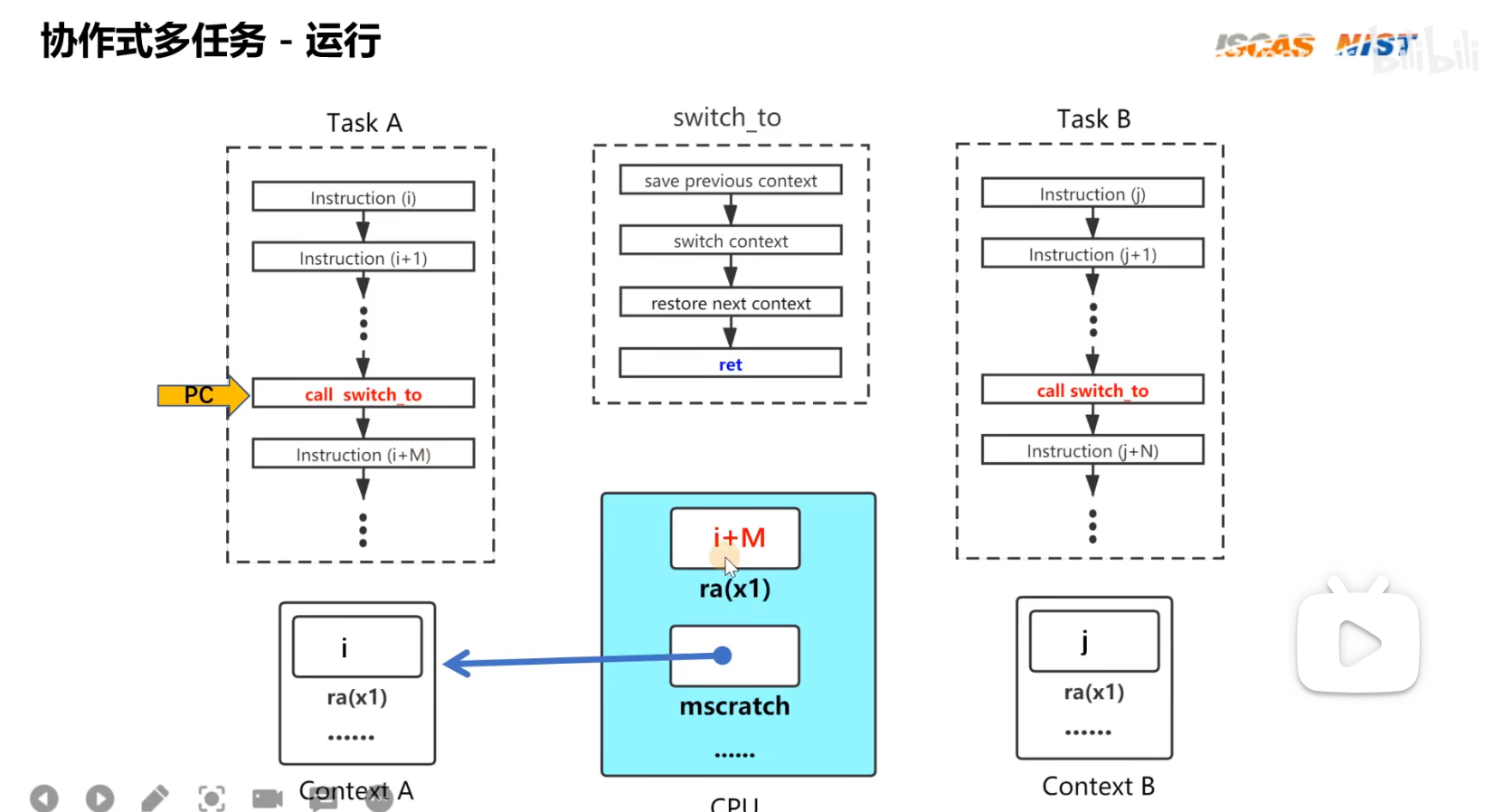
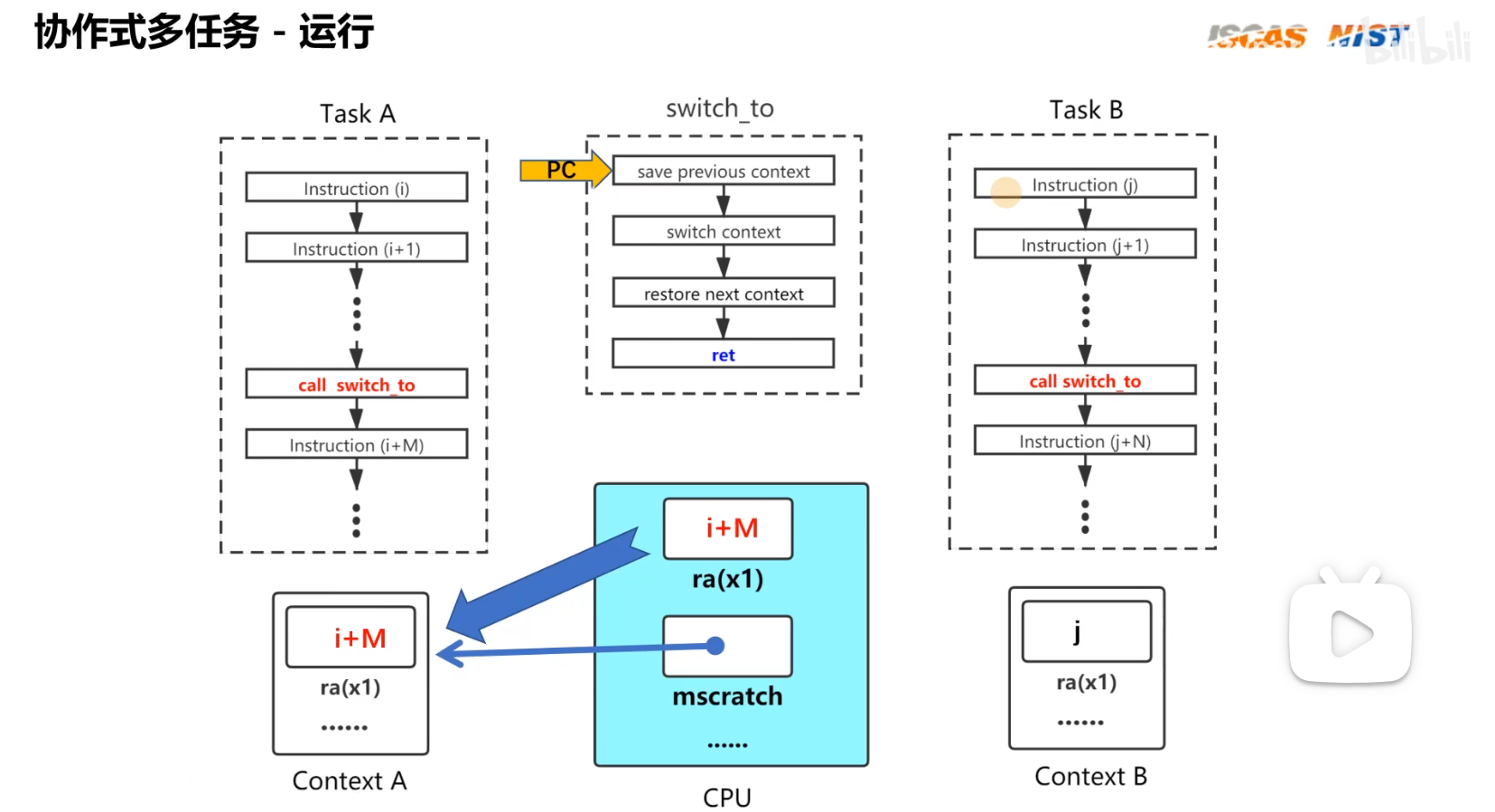


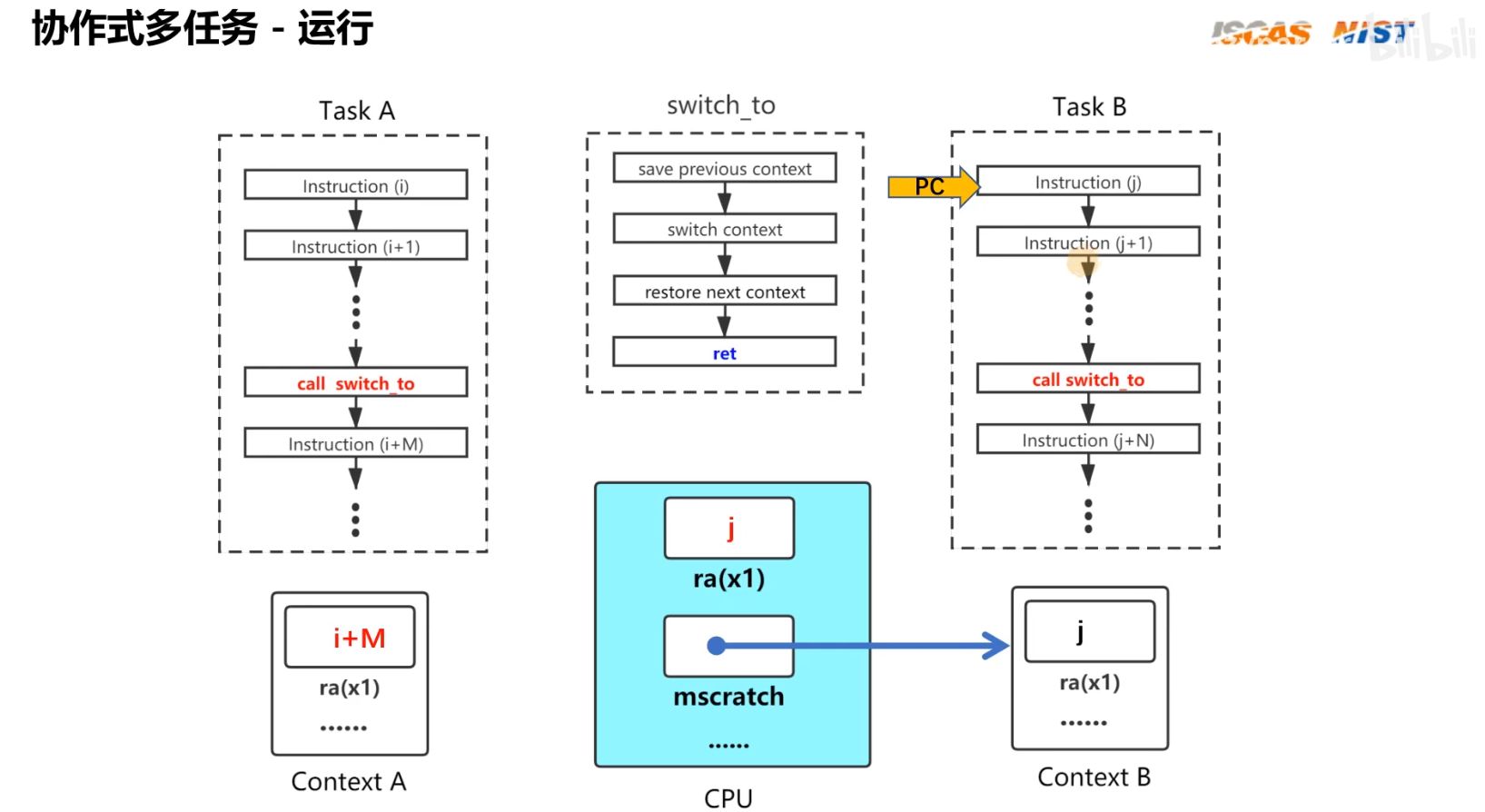
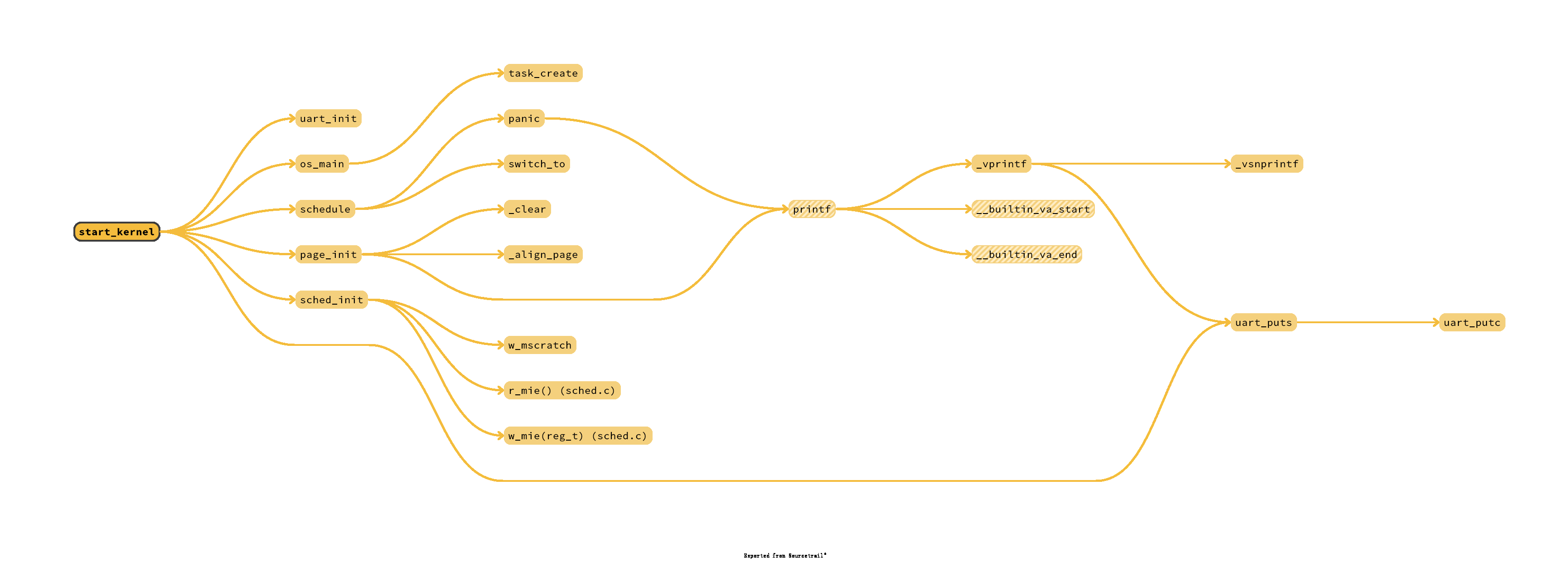


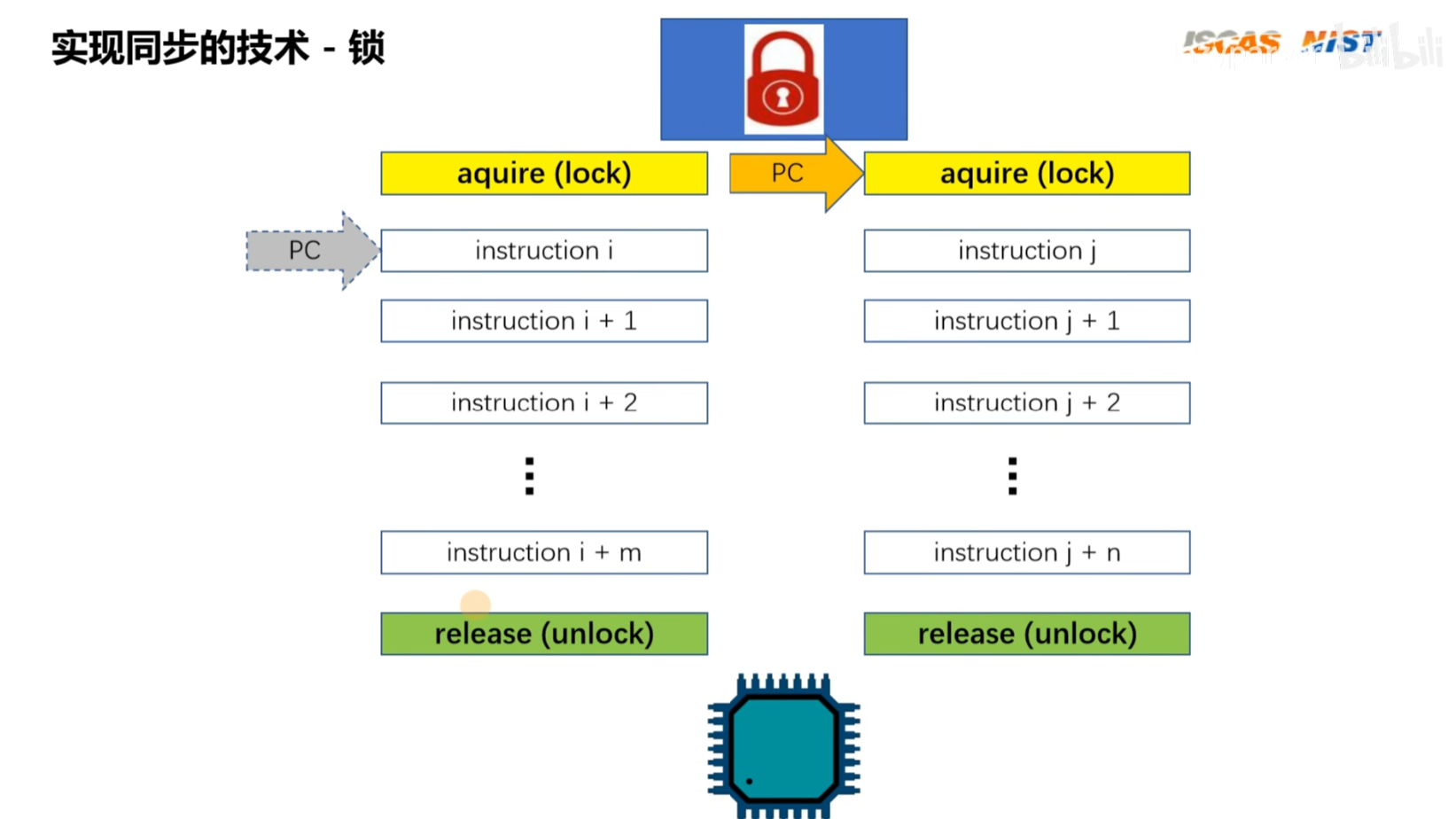
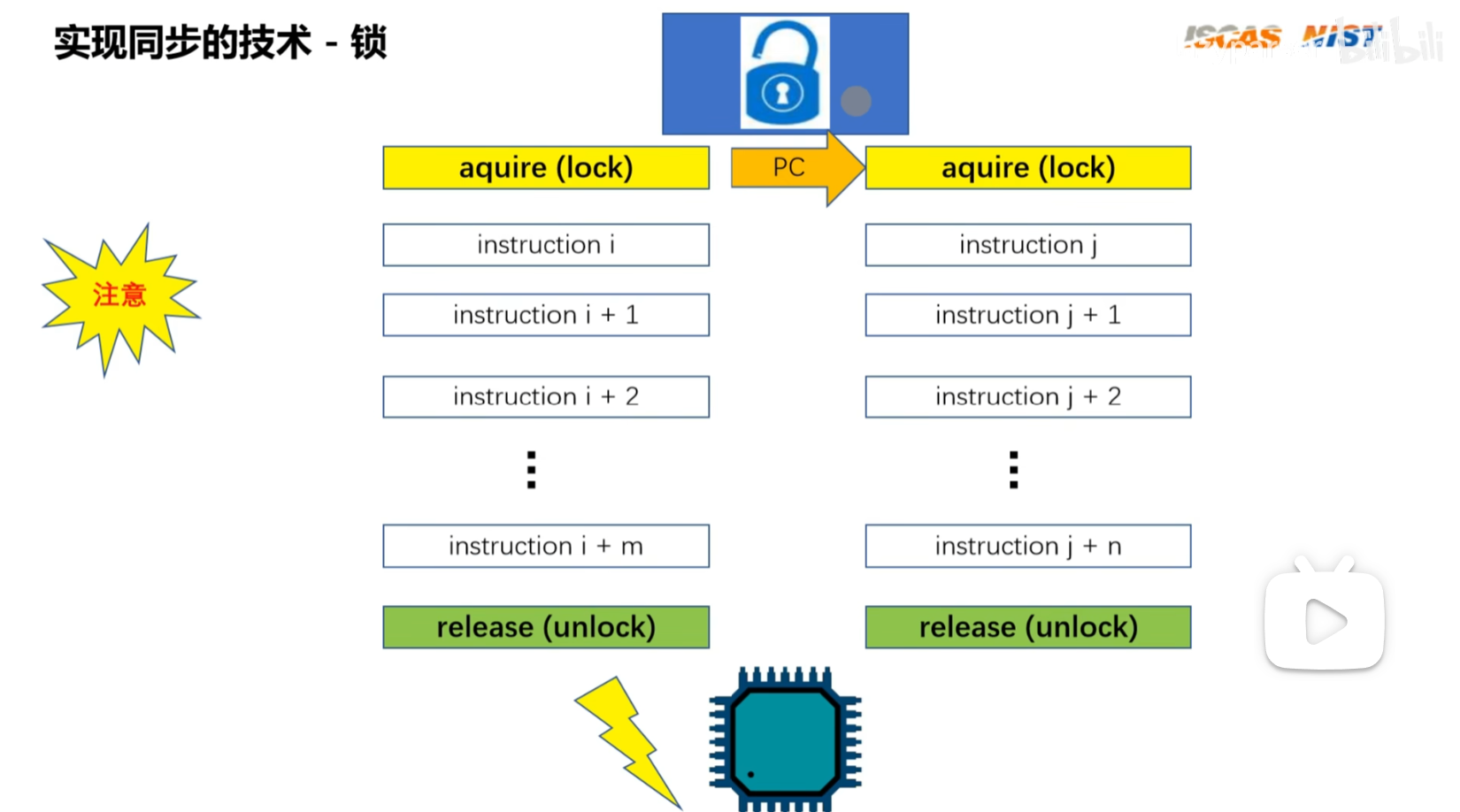
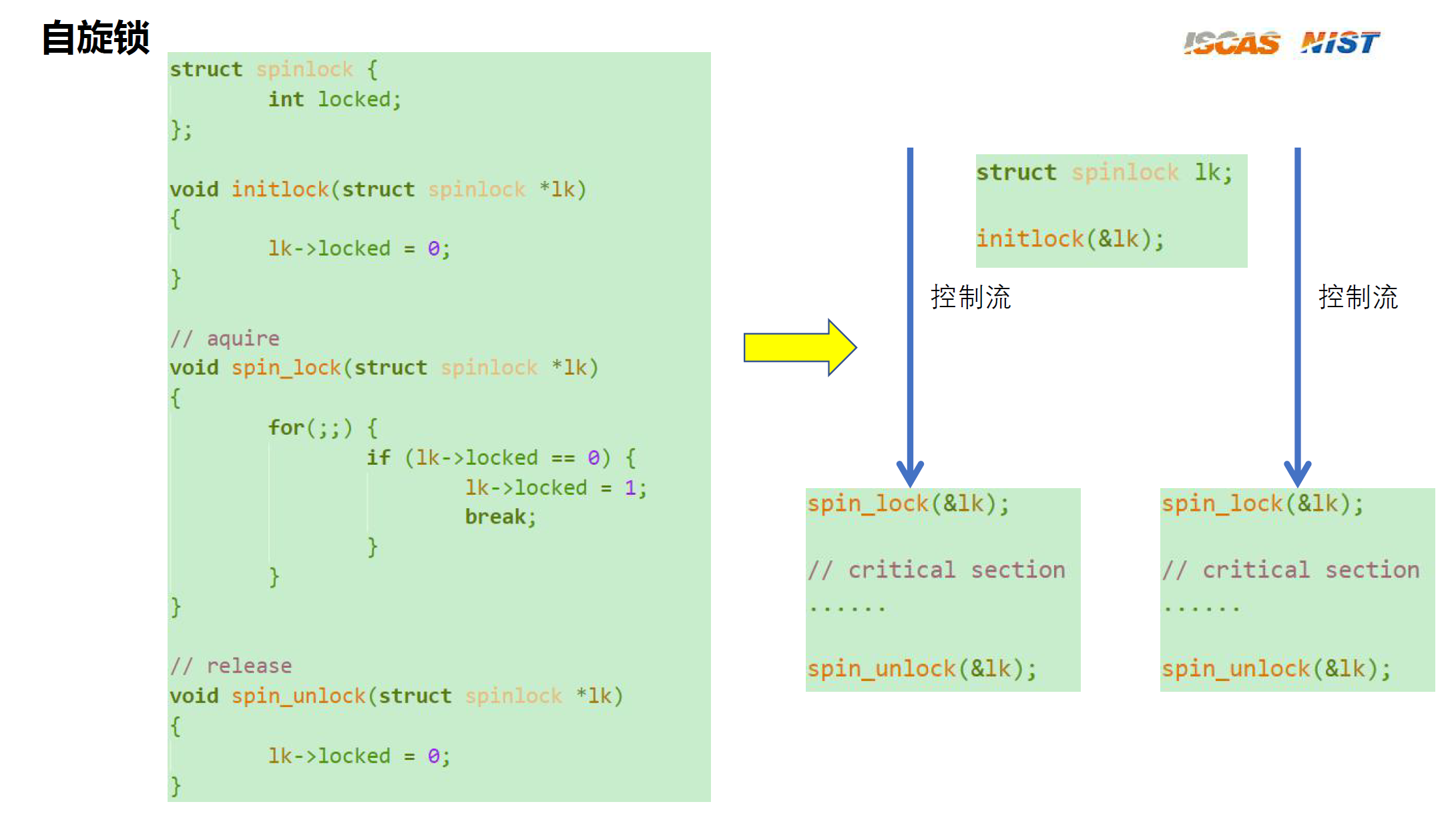
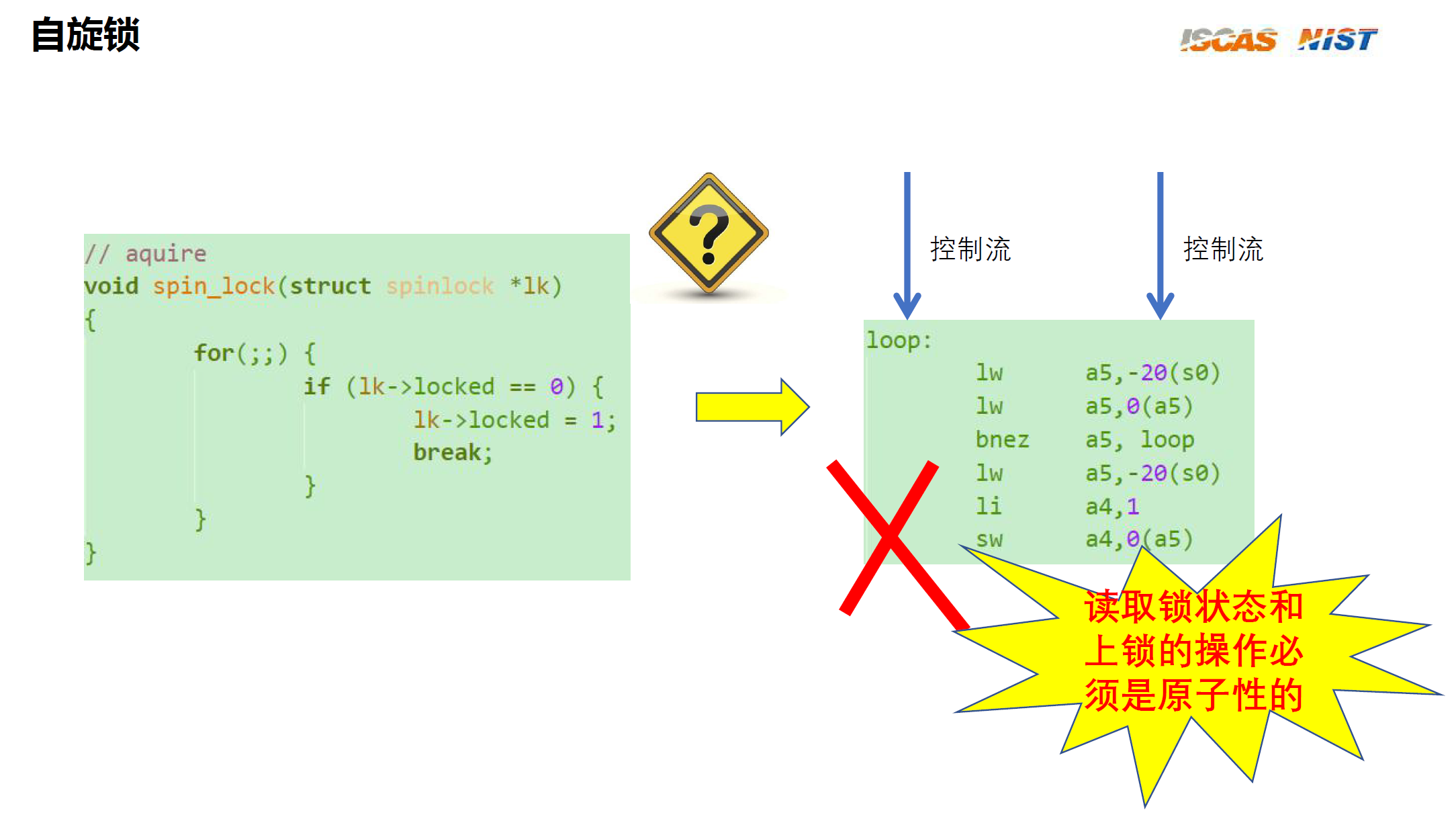




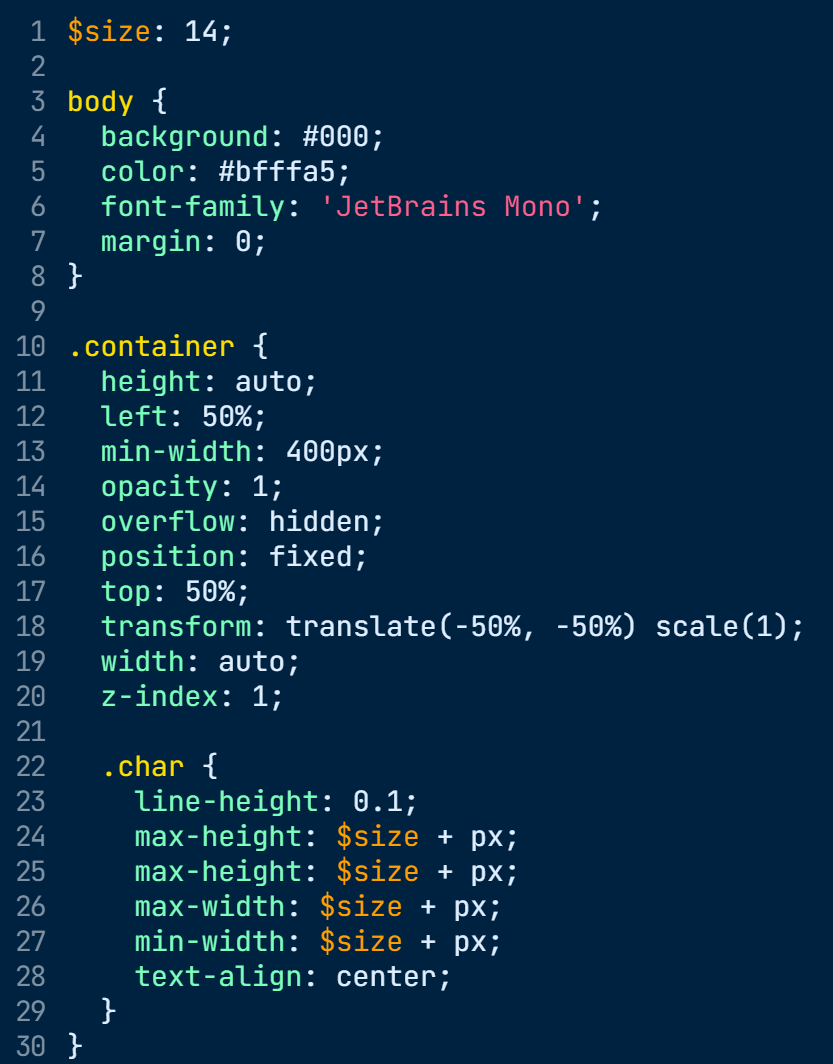
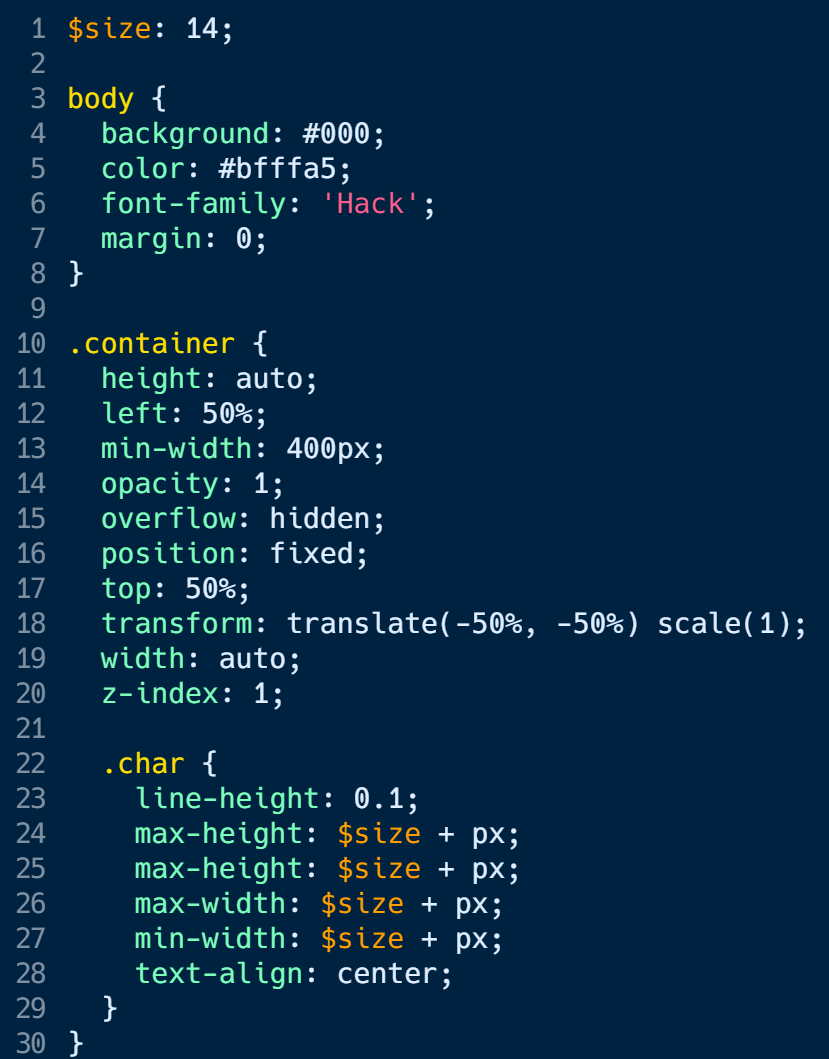
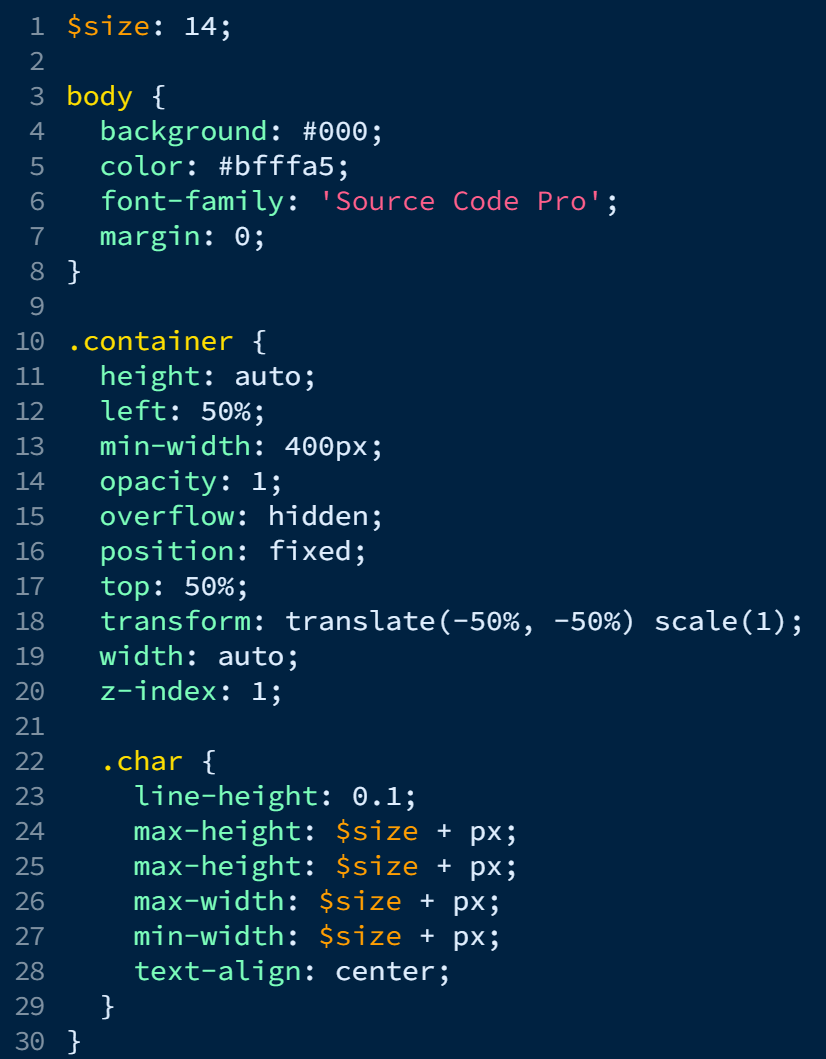
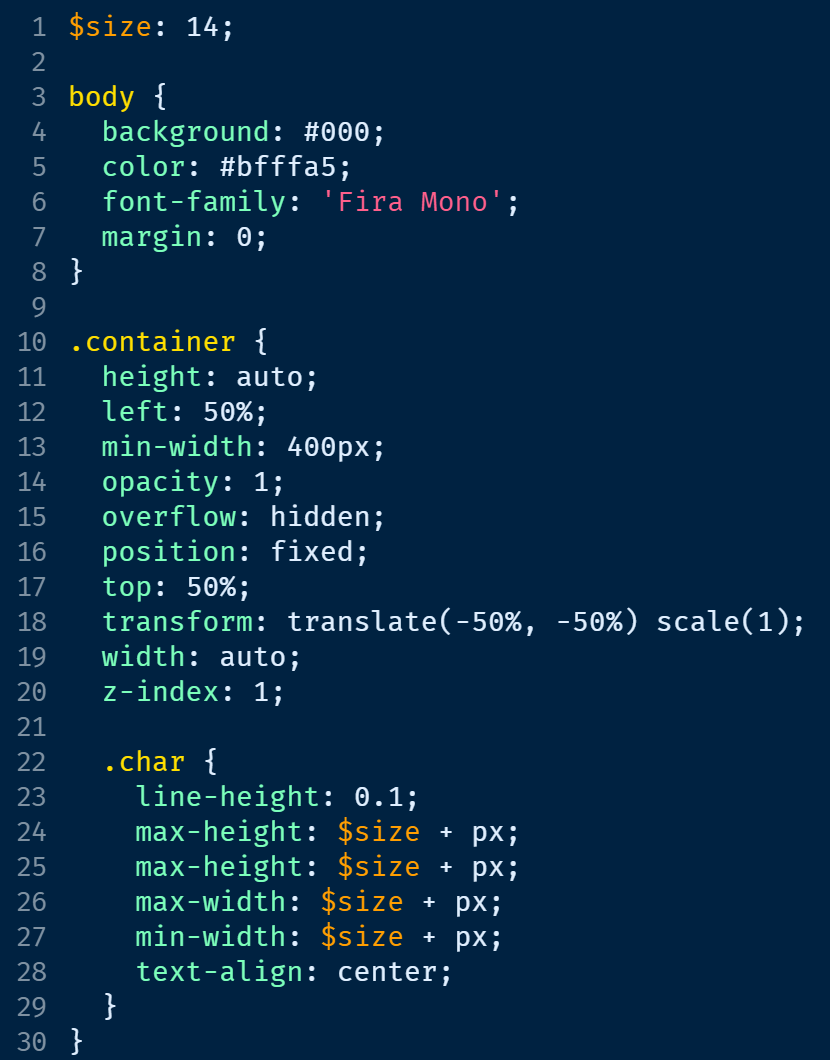




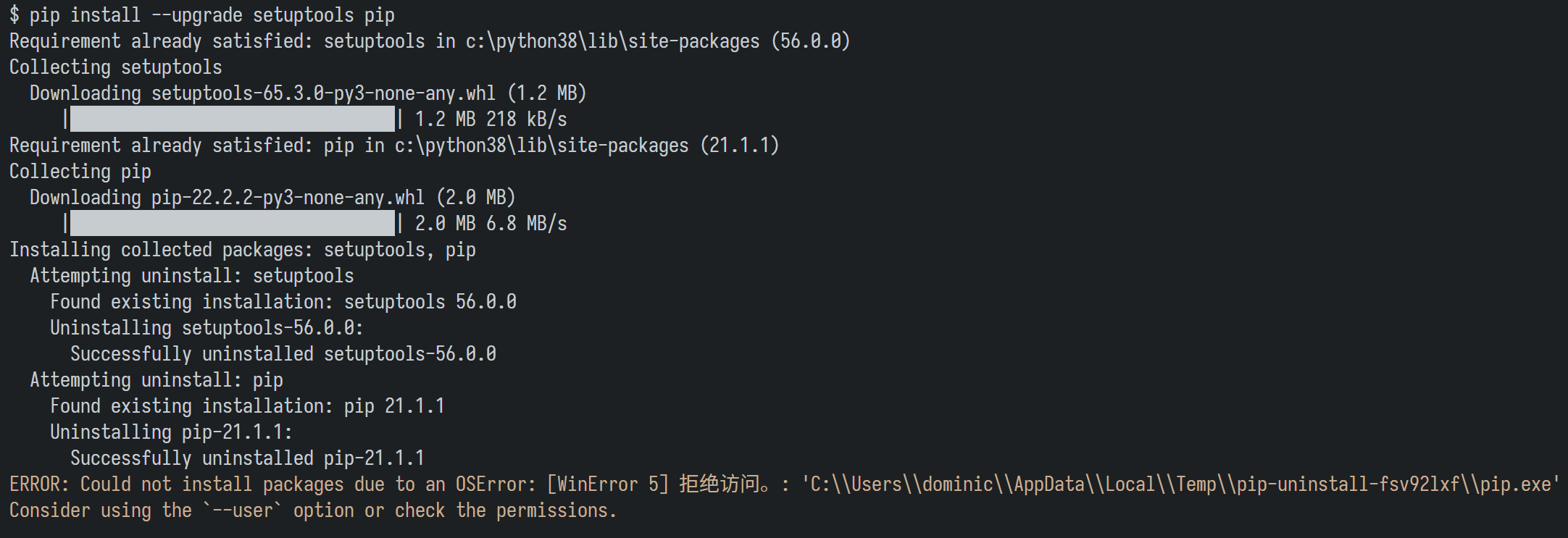
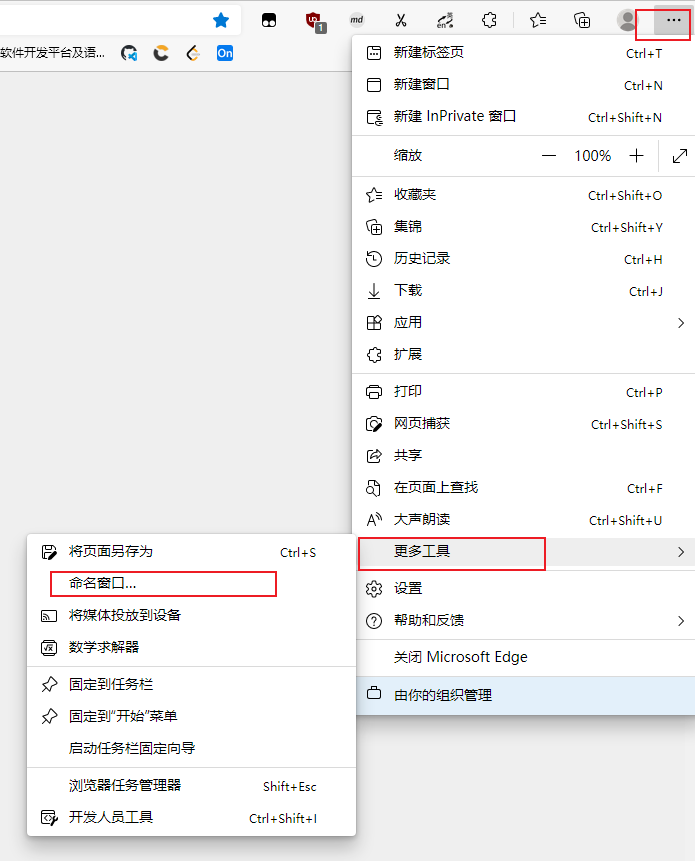


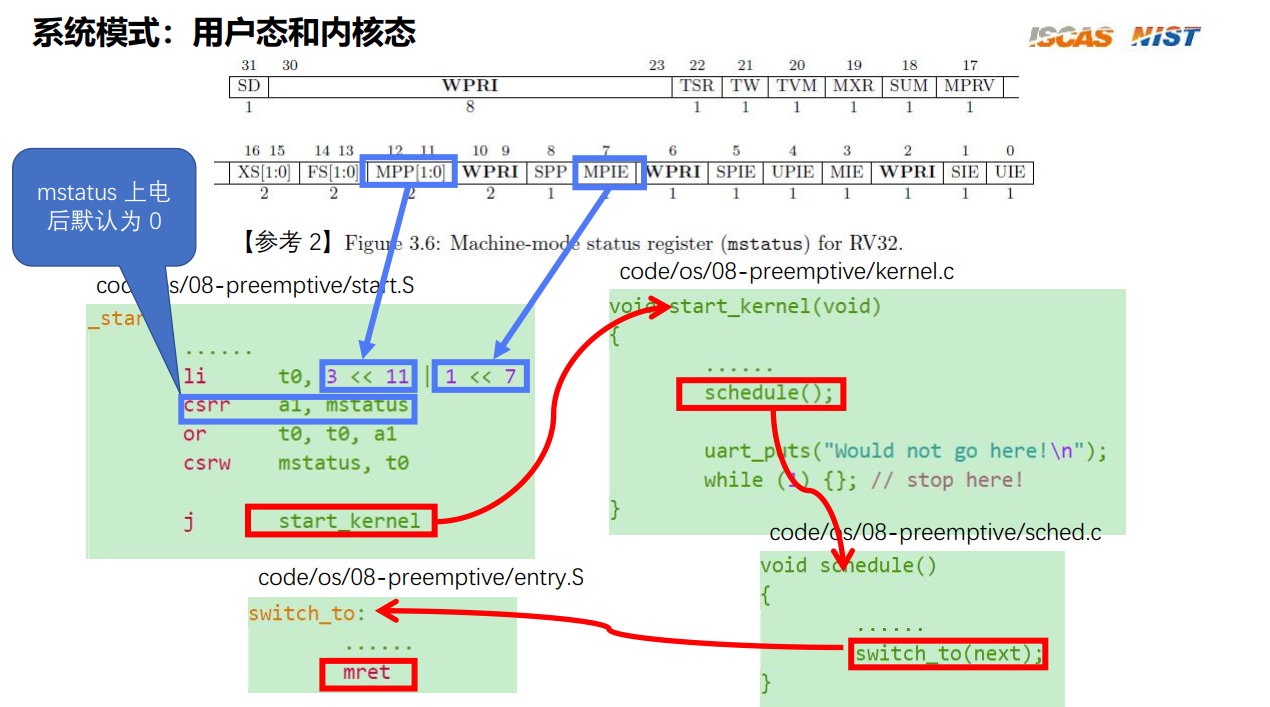
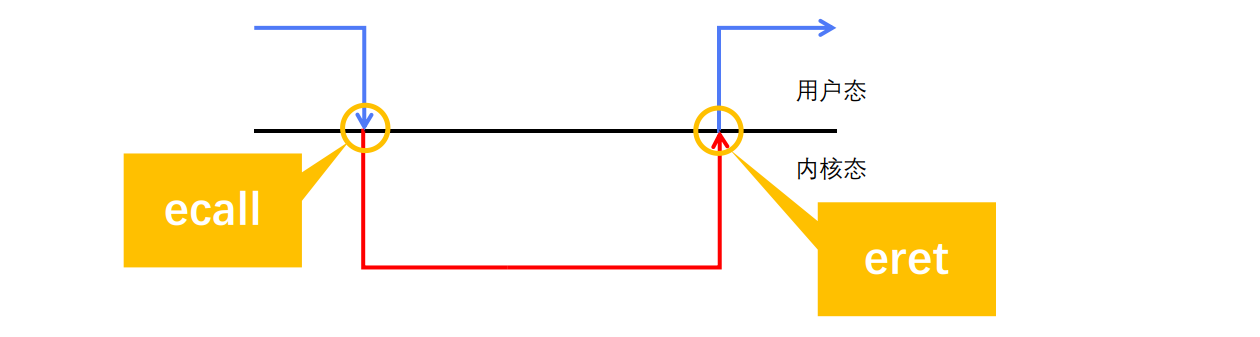
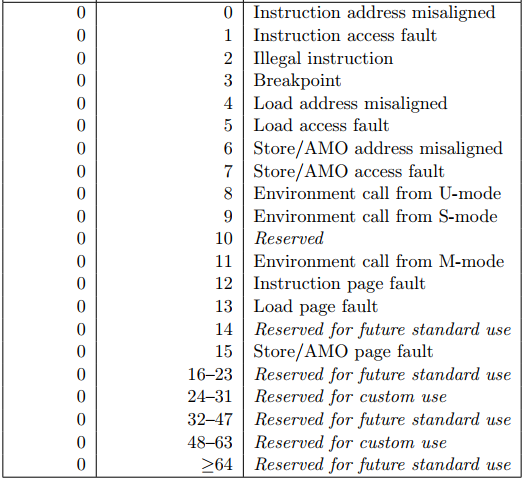
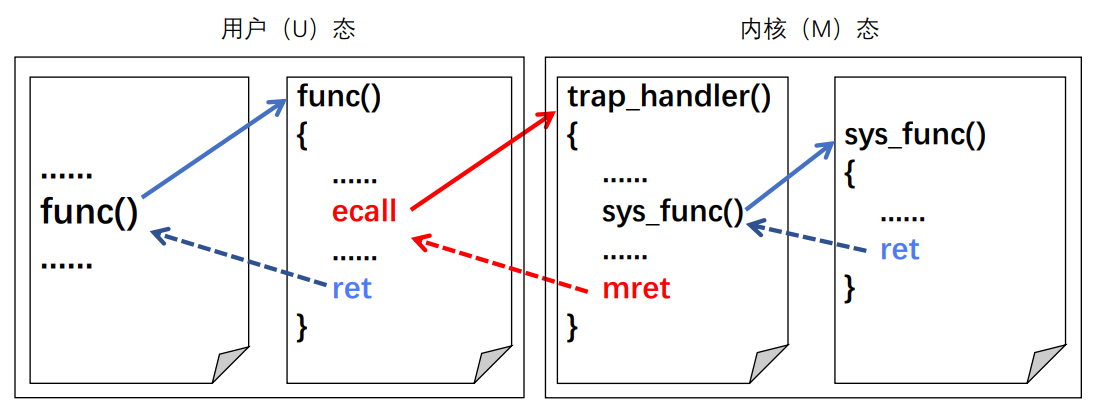
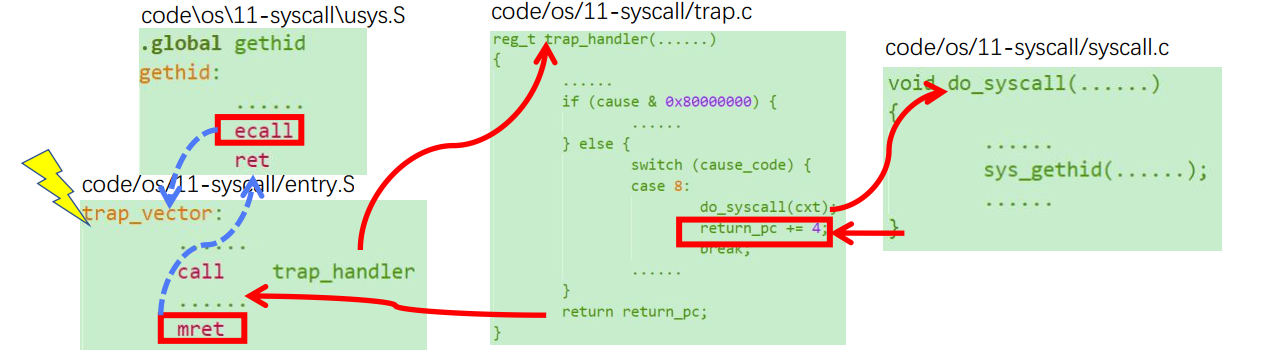

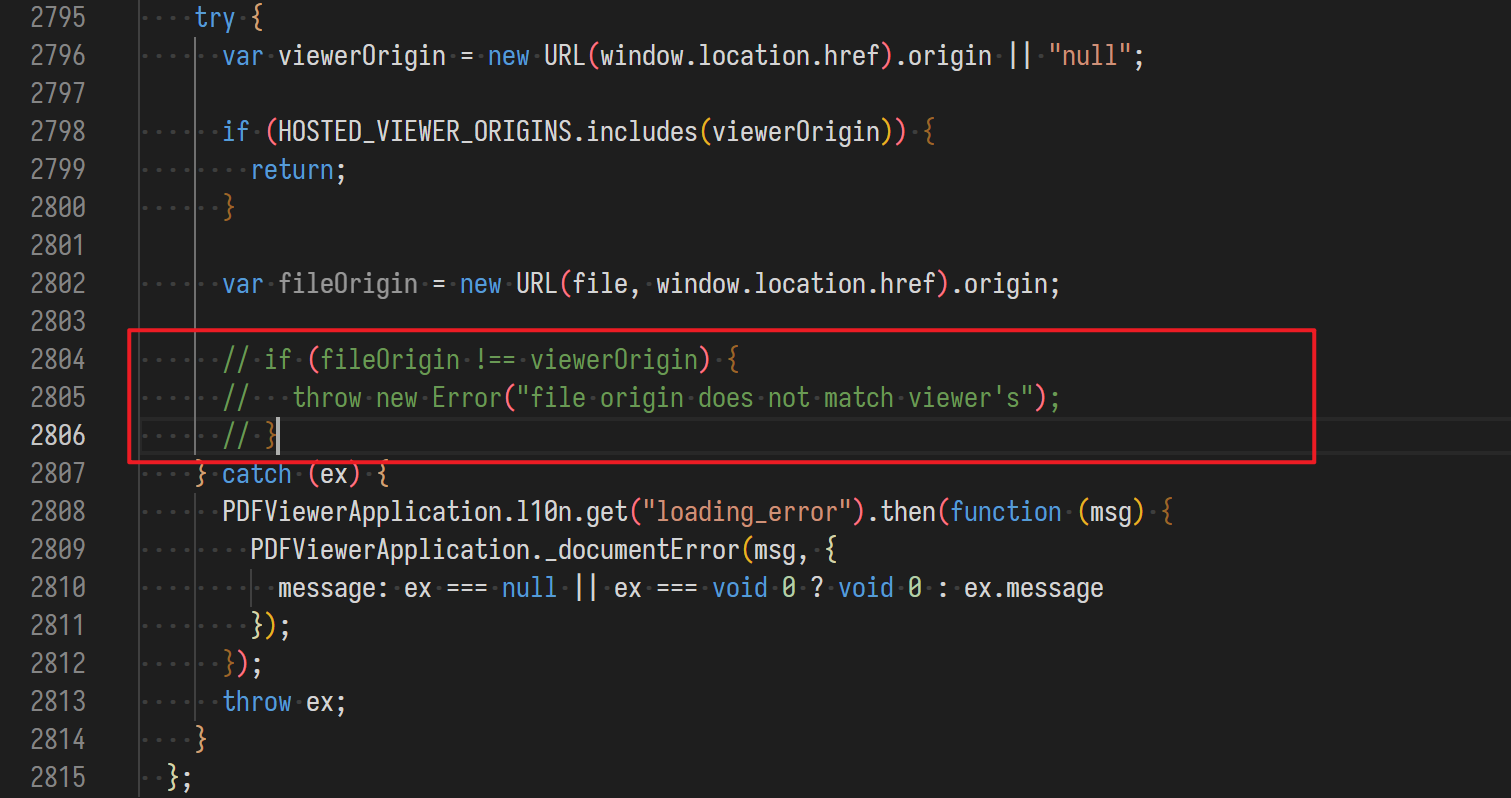














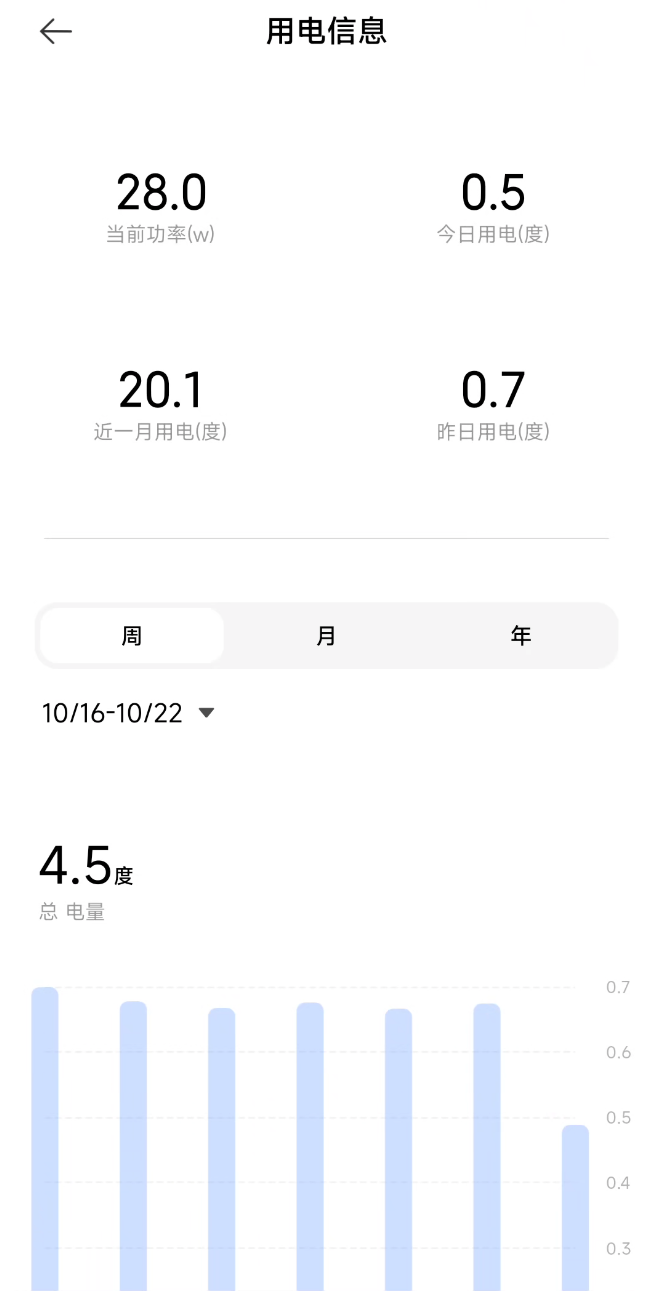
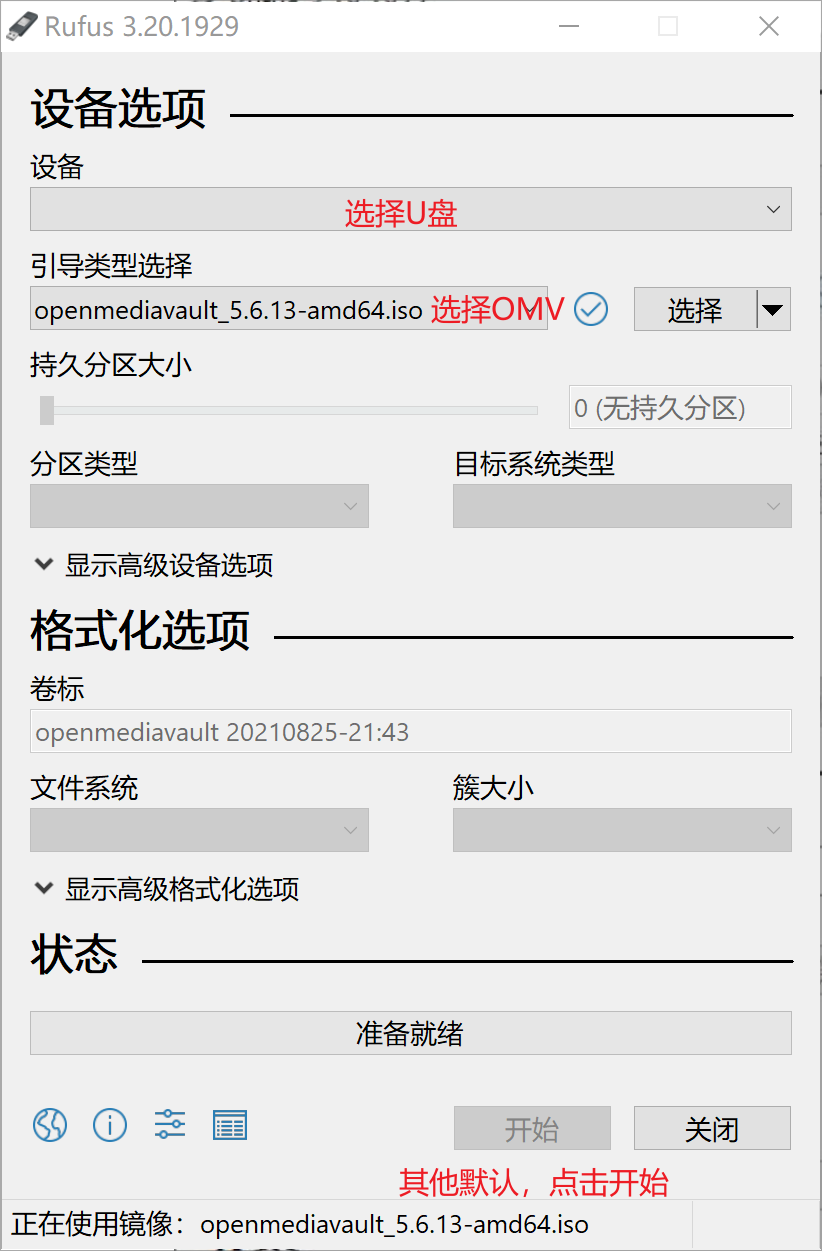






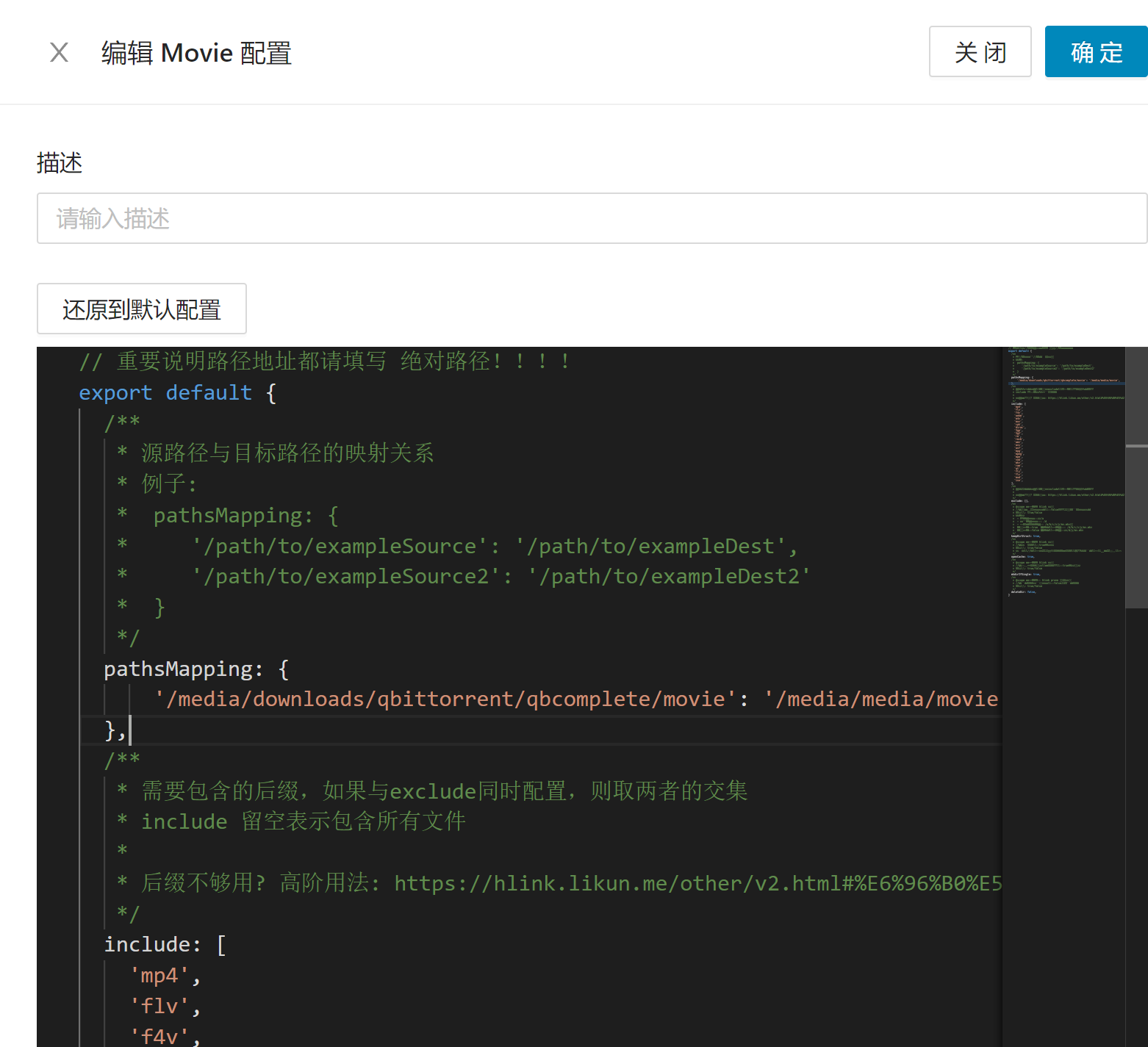

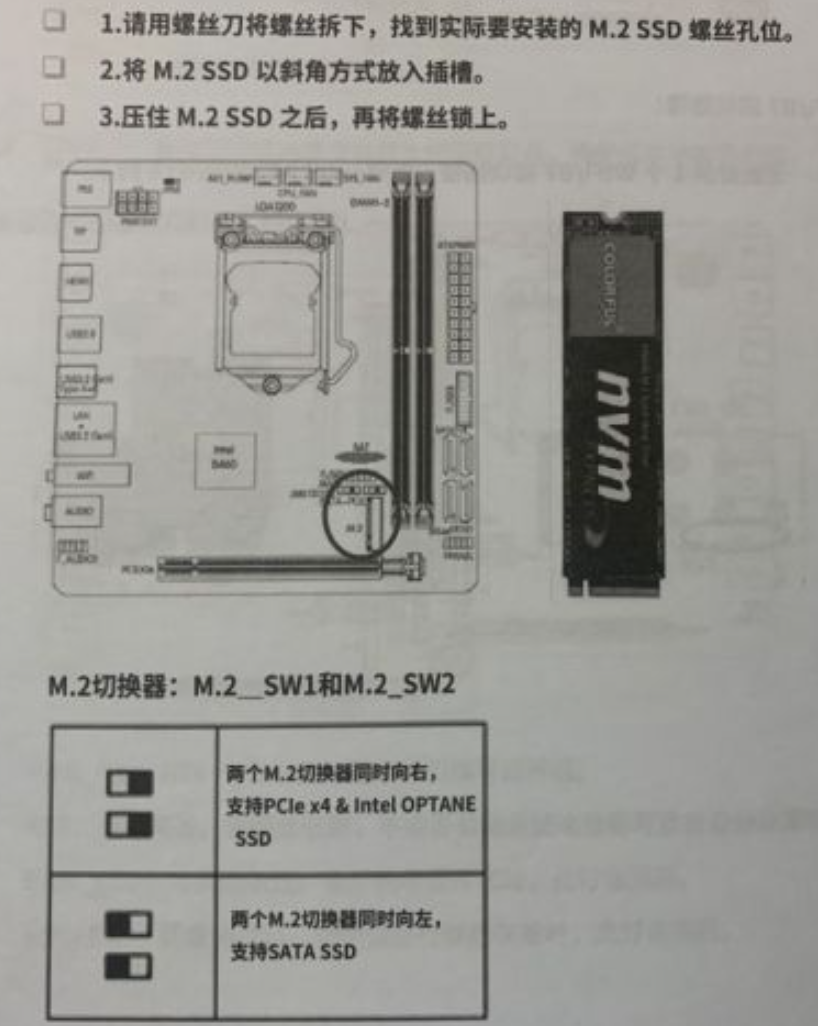

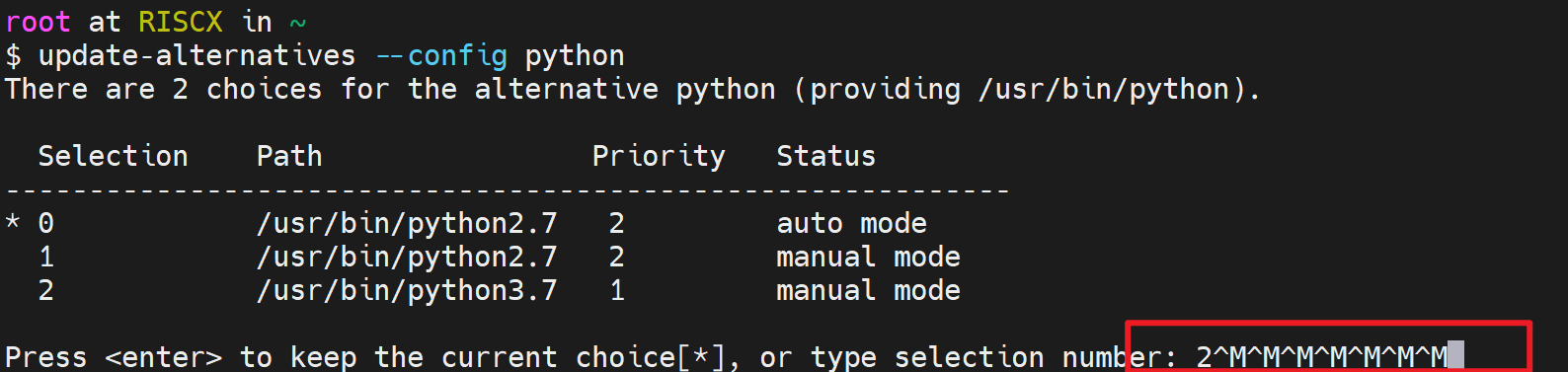

")