diff --git a/.github/ISSUE_TEMPLATE/custom.md b/.github/ISSUE_TEMPLATE/custom.md
new file mode 100644
index 0000000..a6d4478
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/custom.md
@@ -0,0 +1,19 @@
+---
+name: Issue template
+about: Issue template for code error.
+title: ''
+labels: ''
+assignees: ''
+
+---
+
+请提供下述完整信息以便快速定位问题/Please provide the following information to quickly locate the problem
+
+- 系统环境/System Environment:
+- 版本号/Version:Paddle: PaddleOCR: 问题相关组件/Related components:
+- 运行指令/Command Code:
+- 完整报错/Complete Error Message:
+
+我们提供了AceIssueSolver来帮助你解答问题,你是否想要它来解答(请填写yes/no)?/We provide AceIssueSolver to solve issues, do you want it? (Please write yes/no):
+
+请尽量不要包含图片在问题中/Please try to not include the image in the issue.
diff --git a/.github/pull_request_template.md b/.github/pull_request_template.md
new file mode 100644
index 0000000..ca62dac
--- /dev/null
+++ b/.github/pull_request_template.md
@@ -0,0 +1,15 @@
+### PR 类型 PR types
+
+
+### PR 变化内容类型 PR changes
+
+
+### 描述 Description
+
+
+### 提PR之前的检查 Check-list
+
+- [ ] 这个 PR 是提交到dygraph分支或者是一个cherry-pick,否则请先提交到dygarph分支。
+ This PR is pushed to the dygraph branch or cherry-picked from the dygraph branch. Otherwise, please push your changes to the dygraph branch.
+- [ ] 这个PR清楚描述了功能,帮助评审能提升效率。This PR have fully described what it does such that reviewers can speedup.
+- [ ] 这个PR已经经过本地测试。This PR can be convered by current tests or already test locally by you.
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..3a05fb7
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,34 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+.ipynb_checkpoints/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+inference/
+inference_results/
+output/
+train_data/
+log/
+*.DS_Store
+*.vs
+*.user
+*~
+*.vscode
+*.idea
+
+*.log
+.clang-format
+.clang_format.hook
+
+build/
+dist/
+paddleocr.egg-info/
+/deploy/android_demo/app/OpenCV/
+/deploy/android_demo/app/PaddleLite/
+/deploy/android_demo/app/.cxx/
+/deploy/android_demo/app/cache/
+test_tipc/web/models/
+test_tipc/web/node_modules/
\ No newline at end of file
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
new file mode 100644
index 0000000..5f7fec8
--- /dev/null
+++ b/.pre-commit-config.yaml
@@ -0,0 +1,35 @@
+- repo: https://github.com/PaddlePaddle/mirrors-yapf.git
+ sha: 0d79c0c469bab64f7229c9aca2b1186ef47f0e37
+ hooks:
+ - id: yapf
+ files: \.py$
+- repo: https://github.com/pre-commit/pre-commit-hooks
+ sha: a11d9314b22d8f8c7556443875b731ef05965464
+ hooks:
+ - id: check-merge-conflict
+ - id: check-symlinks
+ - id: detect-private-key
+ files: (?!.*paddle)^.*$
+ - id: end-of-file-fixer
+ files: \.md$
+ - id: trailing-whitespace
+ files: \.md$
+- repo: https://github.com/Lucas-C/pre-commit-hooks
+ sha: v1.0.1
+ hooks:
+ - id: forbid-crlf
+ files: \.md$
+ - id: remove-crlf
+ files: \.md$
+ - id: forbid-tabs
+ files: \.md$
+ - id: remove-tabs
+ files: \.md$
+- repo: local
+ hooks:
+ - id: clang-format
+ name: clang-format
+ description: Format files with ClangFormat
+ entry: bash .clang_format.hook -i
+ language: system
+ files: \.(c|cc|cxx|cpp|cu|h|hpp|hxx|cuh|proto)$
\ No newline at end of file
diff --git a/.style.yapf b/.style.yapf
new file mode 100644
index 0000000..4741fb4
--- /dev/null
+++ b/.style.yapf
@@ -0,0 +1,3 @@
+[style]
+based_on_style = pep8
+column_limit = 80
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000..5fe8694
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,203 @@
+Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserved
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserved.
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/MANIFEST.in b/MANIFEST.in
new file mode 100644
index 0000000..f821618
--- /dev/null
+++ b/MANIFEST.in
@@ -0,0 +1,10 @@
+include LICENSE
+include README.md
+
+recursive-include ppocr/utils *.*
+recursive-include ppocr/data *.py
+recursive-include ppocr/postprocess *.py
+recursive-include tools/infer *.py
+recursive-include tools __init__.py
+recursive-include ppocr/utils/e2e_utils *.py
+recursive-include ppstructure *.py
\ No newline at end of file
diff --git a/StyleText/README.md b/StyleText/README.md
new file mode 100644
index 0000000..eddedbd
--- /dev/null
+++ b/StyleText/README.md
@@ -0,0 +1,219 @@
+English | [简体中文](README_ch.md)
+
+## Style Text
+
+### Contents
+- [1. Introduction](#Introduction)
+- [2. Preparation](#Preparation)
+- [3. Quick Start](#Quick_Start)
+- [4. Applications](#Applications)
+- [5. Code Structure](#Code_structure)
+
+
+
+### Introduction
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+
+

+
+

+
+
+
+

+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
图1 PCB检测识别效果
+
+注:欢迎在AIStudio领取免费算力体验线上实训,项目链接: [基于PP-OCRv3实现PCB字符识别](https://aistudio.baidu.com/aistudio/projectdetail/4008973)
+
+# 2. 安装说明
+
+
+下载PaddleOCR源码,安装依赖环境。
+
+
+```python
+# 如仍需安装or安装更新,可以执行以下步骤
+git clone https://github.com/PaddlePaddle/PaddleOCR.git
+# git clone https://gitee.com/PaddlePaddle/PaddleOCR
+```
+
+
+```python
+# 安装依赖包
+pip install -r /home/aistudio/PaddleOCR/requirements.txt
+```
+
+# 3. 数据准备
+
+我们通过图片合成工具生成 **图2** 所示的PCB图片,整图只有高25、宽150左右、文字区域高9、宽45左右,包含垂直和水平2种方向的文本:
+
+
+图2 数据集示例
+
+暂时不开源生成的PCB数据集,但是通过更换背景,通过如下代码生成数据即可:
+
+```
+cd gen_data
+python3 gen.py --num_img=10
+```
+
+生成图片参数解释:
+
+```
+num_img:生成图片数量
+font_min_size、font_max_size:字体最大、最小尺寸
+bg_path:文字区域背景存放路径
+det_bg_path:整图背景存放路径
+fonts_path:字体路径
+corpus_path:语料路径
+output_dir:生成图片存储路径
+```
+
+这里生成 **100张** 相同尺寸和文本的图片,如 **图3** 所示,方便大家跑通实验。通过如下代码解压数据集:
+
+
+图3 案例提供数据集示例
+
+
+```python
+tar xf ./data/data148165/dataset.tar -C ./
+```
+
+在生成数据集的时需要生成检测和识别训练需求的格式:
+
+
+- **文本检测**
+
+标注文件格式如下,中间用'\t'分隔:
+
+```
+" 图像文件名 json.dumps编码的图像标注信息"
+ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
+```
+
+json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 `points` 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。 `transcription` 表示当前文本框的文字,***当其内容为“###”时,表示该文本框无效,在训练时会跳过。***
+
+- **文本识别**
+
+标注文件的格式如下, txt文件中默认请将图片路径和图片标签用'\t'分割,如用其他方式分割将造成训练报错。
+
+```
+" 图像文件名 图像标注信息 "
+
+train_data/rec/train/word_001.jpg 简单可依赖
+train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
+...
+```
+
+
+# 4. 文本检测
+
+选用飞桨OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)中的PP-OCRv3模型进行文本检测和识别。针对检测模型和识别模型,进行了共计9个方面的升级:
+
+- PP-OCRv3检测模型对PP-OCRv2中的CML协同互学习文本检测蒸馏策略进行了升级,分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
+
+- PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。PP-OCRv3通过轻量级文本识别网络SVTR_LCNet、Attention损失指导CTC损失训练策略、挖掘文字上下文信息的数据增广策略TextConAug、TextRotNet自监督预训练模型、UDML联合互学习策略、UIM无标注数据挖掘方案,6个方面进行模型加速和效果提升。
+
+更多细节请参考PP-OCRv3[技术报告](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md)。
+
+
+我们使用 **3种方案** 进行检测模型的训练、评估:
+- **PP-OCRv3英文超轻量检测预训练模型直接评估**
+- PP-OCRv3英文超轻量检测预训练模型 + **验证集padding**直接评估
+- PP-OCRv3英文超轻量检测预训练模型 + **fine-tune**
+
+## **4.1 预训练模型直接评估**
+
+我们首先通过PaddleOCR提供的预训练模型在验证集上进行评估,如果评估指标能满足效果,可以直接使用预训练模型,不再需要训练。
+
+使用预训练模型直接评估步骤如下:
+
+**1)下载预训练模型**
+
+
+PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示:
+
+| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
+| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar) |
+| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
+| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
+| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
+| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
+
+更多模型下载(包括多语言),可以参[考PP-OCR系列模型下载](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/models_list.md)
+
+这里我们使用PP-OCRv3英文超轻量检测模型,下载并解压预训练模型:
+
+
+
+
+```python
+# 如果更换其他模型,更新下载链接和解压指令就可以
+cd /home/aistudio/PaddleOCR
+mkdir pretrain_models
+cd pretrain_models
+# 下载英文预训练模型
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar
+tar xf en_PP-OCRv3_det_distill_train.tar && rm -rf en_PP-OCRv3_det_distill_train.tar
+%cd ..
+```
+
+**模型评估**
+
+
+首先修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml`中的以下字段:
+```
+Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset'
+Eval.dataset.label_file_list:指向验证集标注文件,'/home/aistudio/dataset/det_gt_val.txt'
+Eval.dataset.transforms.DetResizeForTest: 尺寸
+ limit_side_len: 48
+ limit_type: 'min'
+```
+
+然后在验证集上进行评估,具体代码如下:
+
+
+
+```python
+cd /home/aistudio/PaddleOCR
+python tools/eval.py \
+ -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml \
+ -o Global.checkpoints="./pretrain_models/en_PP-OCRv3_det_distill_train/best_accuracy"
+```
+
+## **4.2 预训练模型+验证集padding直接评估**
+
+考虑到PCB图片比较小,宽度只有25左右、高度只有140-170左右,我们在原图的基础上进行padding,再进行检测评估,padding前后效果对比如 **图4** 所示:
+
+
+图4 padding前后对比图
+
+将图片都padding到300*300大小,因为坐标信息发生了变化,我们同时要修改标注文件,在`/home/aistudio/dataset`目录里也提供了padding之后的图片,大家也可以尝试训练和评估:
+
+同上,我们需要修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml`中的以下字段:
+```
+Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset'
+Eval.dataset.label_file_list:指向验证集标注文件,/home/aistudio/dataset/det_gt_padding_val.txt
+Eval.dataset.transforms.DetResizeForTest: 尺寸
+ limit_side_len: 1100
+ limit_type: 'min'
+```
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+

+
图5 添加公开通用识别数据配置文件示例
+
+
+我们提取Student模型的参数,在PCB数据集上进行fine-tune,可以参考如下代码:
+
+
+```python
+import paddle
+# 加载预训练模型
+all_params = paddle.load("./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy.pdparams")
+# 查看权重参数的keys
+print(all_params.keys())
+# 学生模型的权重提取
+s_params = {key[len("student_model."):]: all_params[key] for key in all_params if "student_model." in key}
+# 查看学生模型权重参数的keys
+print(s_params.keys())
+# 保存
+paddle.save(s_params, "./pretrain_models/ch_PP-OCRv3_rec_train/student.pdparams")
+```
+
+修改参数后,**每个方案**都执行如下命令启动训练:
+
+
+
+```python
+cd /home/aistudio/PaddleOCR/
+python3 tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
+```
+
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`:
+
+
+```python
+cd /home/aistudio/PaddleOCR/
+python3 tools/eval.py \
+ -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml \
+ -o Global.checkpoints=./output/rec_ppocr_v3/latest
+```
+
+所有方案评估指标如下:
+
+| 序号 | 方案 | acc | 效果提升 | 实验分析 |
+| -------- | -------- | -------- | -------- | -------- |
+| 1 | PP-OCRv3中英文超轻量识别预训练模型直接评估 | 46.67% | - | 提供的预训练模型具有泛化能力 |
+| 2 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune | 42.02% |-4.65% | 在数据量不足的情况,反而比预训练模型效果低(也可以通过调整超参数再试试)|
+| 3 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 公开通用识别数据集 | 77.00% | +30.33% | 在数据量不足的情况下,可以考虑补充公开数据训练 |
+| 4 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 99.99% | +22.99% | 如果能获取更多数据量的情况,可以通过增加数据量提升效果 |
+
+```
+注:上述实验结果均是在1500张图片(1200张训练集,300张测试集)、2W张图片、添加公开通用识别数据集上训练、评估的得到,AIstudio只提供了100张数据,所以指标有所差异属于正常,只要策略有效、规律相同即可。
+```
+
+# 6. 模型导出
+
+inference 模型(paddle.jit.save保存的模型) 一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。 训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。 与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
+
+
+```python
+# 导出检测模型
+python3 tools/export_model.py \
+ -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml \
+ -o Global.pretrained_model="./output/ch_PP-OCR_V3_det/latest" \
+ Global.save_inference_dir="./inference_model/ch_PP-OCR_V3_det/"
+```
+
+因为上述模型只训练了1个epoch,因此我们使用训练最优的模型进行预测,存储在`/home/aistudio/best_models/`目录下,解压即可
+
+
+```python
+cd /home/aistudio/best_models/
+wget https://paddleocr.bj.bcebos.com/fanliku/PCB/det_ppocr_v3_en_infer_PCB.tar
+tar xf /home/aistudio/best_models/det_ppocr_v3_en_infer_PCB.tar -C /home/aistudio/PaddleOCR/pretrain_models/
+```
+
+
+```python
+# 检测模型inference模型预测
+cd /home/aistudio/PaddleOCR/
+python3 tools/infer/predict_det.py \
+ --image_dir="/home/aistudio/dataset/imgs/0000.jpg" \
+ --det_algorithm="DB" \
+ --det_model_dir="./pretrain_models/det_ppocr_v3_en_infer_PCB/" \
+ --det_limit_side_len=48 \
+ --det_limit_type='min' \
+ --det_db_unclip_ratio=2.5 \
+ --use_gpu=True
+```
+
+结果存储在`inference_results`目录下,检测如下图所示:
+
+图6 检测结果
+
+
+同理,导出识别模型并进行推理。
+
+```python
+# 导出识别模型
+python3 tools/export_model.py \
+ -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml \
+ -o Global.pretrained_model="./output/rec_ppocr_v3/latest" \
+ Global.save_inference_dir="./inference_model/rec_ppocr_v3/"
+
+```
+
+同检测模型,识别模型也只训练了1个epoch,因此我们使用训练最优的模型进行预测,存储在`/home/aistudio/best_models/`目录下,解压即可
+
+
+```python
+cd /home/aistudio/best_models/
+wget https://paddleocr.bj.bcebos.com/fanliku/PCB/rec_ppocr_v3_ch_infer_PCB.tar
+tar xf /home/aistudio/best_models/rec_ppocr_v3_ch_infer_PCB.tar -C /home/aistudio/PaddleOCR/pretrain_models/
+```
+
+
+```python
+# 识别模型inference模型预测
+cd /home/aistudio/PaddleOCR/
+python3 tools/infer/predict_rec.py \
+ --image_dir="../test_imgs/0000_rec.jpg" \
+ --rec_model_dir="./pretrain_models/rec_ppocr_v3_ch_infer_PCB" \
+ --rec_image_shape="3, 48, 320" \
+ --use_space_char=False \
+ --use_gpu=True
+```
+
+```python
+# 检测+识别模型inference模型预测
+cd /home/aistudio/PaddleOCR/
+python3 tools/infer/predict_system.py \
+ --image_dir="../test_imgs/0000.jpg" \
+ --det_model_dir="./pretrain_models/det_ppocr_v3_en_infer_PCB" \
+ --det_limit_side_len=48 \
+ --det_limit_type='min' \
+ --det_db_unclip_ratio=2.5 \
+ --rec_model_dir="./pretrain_models/rec_ppocr_v3_ch_infer_PCB" \
+ --rec_image_shape="3, 48, 320" \
+ --draw_img_save_dir=./det_rec_infer/ \
+ --use_space_char=False \
+ --use_angle_cls=False \
+ --use_gpu=True
+
+```
+
+端到端预测结果存储在`det_res_infer`文件夹内,结果如下图所示:
+
+图7 检测+识别结果
+
+# 7. 端对端评测
+
+接下来介绍文本检测+文本识别的端对端指标评估方式。主要分为三步:
+
+1)首先运行`tools/infer/predict_system.py`,将`image_dir`改为需要评估的数据文件家,得到保存的结果:
+
+
+```python
+# 检测+识别模型inference模型预测
+python3 tools/infer/predict_system.py \
+ --image_dir="../dataset/imgs/" \
+ --det_model_dir="./pretrain_models/det_ppocr_v3_en_infer_PCB" \
+ --det_limit_side_len=48 \
+ --det_limit_type='min' \
+ --det_db_unclip_ratio=2.5 \
+ --rec_model_dir="./pretrain_models/rec_ppocr_v3_ch_infer_PCB" \
+ --rec_image_shape="3, 48, 320" \
+ --draw_img_save_dir=./det_rec_infer/ \
+ --use_space_char=False \
+ --use_angle_cls=False \
+ --use_gpu=True
+```
+
+得到保存结果,文本检测识别可视化图保存在`det_rec_infer/`目录下,预测结果保存在`det_rec_infer/system_results.txt`中,格式如下:`0018.jpg [{"transcription": "E295", "points": [[88, 33], [137, 33], [137, 40], [88, 40]]}]`
+
+2)然后将步骤一保存的数据转换为端对端评测需要的数据格式: 修改 `tools/end2end/convert_ppocr_label.py`中的代码,convert_label函数中设置输入标签路径,Mode,保存标签路径等,对预测数据的GTlabel和预测结果的label格式进行转换。
+```
+ppocr_label_gt = "/home/aistudio/dataset/det_gt_val.txt"
+convert_label(ppocr_label_gt, "gt", "./save_gt_label/")
+
+ppocr_label_gt = "/home/aistudio/PaddleOCR/PCB_result/det_rec_infer/system_results.txt"
+convert_label(ppocr_label_gt, "pred", "./save_PPOCRV2_infer/")
+```
+
+运行`convert_ppocr_label.py`:
+
+
+```python
+ python3 tools/end2end/convert_ppocr_label.py
+```
+
+得到如下结果:
+```
+├── ./save_gt_label/
+├── ./save_PPOCRV2_infer/
+```
+
+3) 最后,执行端对端评测,运行`tools/end2end/eval_end2end.py`计算端对端指标,运行方式如下:
+
+
+```python
+pip install editdistance
+python3 tools/end2end/eval_end2end.py ./save_gt_label/ ./save_PPOCRV2_infer/
+```
+
+使用`预训练模型+fine-tune'检测模型`、`预训练模型 + 2W张PCB图片funetune`识别模型,在300张PCB图片上评估得到如下结果,fmeasure为主要关注的指标:
+
+图8 端到端评估指标
+
+```
+注: 使用上述命令不能跑出该结果,因为数据集不相同,可以更换为自己训练好的模型,按上述流程运行
+```
+
+# 8. Jetson部署
+
+我们只需要以下步骤就可以完成Jetson nano部署模型,简单易操作:
+
+**1、在Jetson nano开发版上环境准备:**
+
+* 安装PaddlePaddle
+
+* 下载PaddleOCR并安装依赖
+
+**2、执行预测**
+
+* 将推理模型下载到jetson
+
+* 执行检测、识别、串联预测即可
+
+详细[参考流程](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/deploy/Jetson/readme_ch.md)。
+
+# 9. 总结
+
+检测实验分别使用PP-OCRv3预训练模型在PCB数据集上进行了直接评估、验证集padding、 fine-tune 3种方案,识别实验分别使用PP-OCRv3预训练模型在PCB数据集上进行了直接评估、 fine-tune、添加公开通用识别数据集、增加PCB图片数量4种方案,指标对比如下:
+
+* 检测
+
+
+| 序号 | 方案 | hmean | 效果提升 | 实验分析 |
+| ---- | -------------------------------------------------------- | ------ | -------- | ------------------------------------- |
+| 1 | PP-OCRv3英文超轻量检测预训练模型直接评估 | 64.64% | - | 提供的预训练模型具有泛化能力 |
+| 2 | PP-OCRv3英文超轻量检测预训练模型 + 验证集padding直接评估 | 72.13% | +7.49% | padding可以提升尺寸较小图片的检测效果 |
+| 3 | PP-OCRv3英文超轻量检测预训练模型 + fine-tune | 100.00% | +27.87% | fine-tune会提升垂类场景效果 |
+
+* 识别
+
+| 序号 | 方案 | acc | 效果提升 | 实验分析 |
+| ---- | ------------------------------------------------------------ | ------ | -------- | ------------------------------------------------------------ |
+| 1 | PP-OCRv3中英文超轻量识别预训练模型直接评估 | 46.67% | - | 提供的预训练模型具有泛化能力 |
+| 2 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune | 42.02% | -4.65% | 在数据量不足的情况,反而比预训练模型效果低(也可以通过调整超参数再试试) |
+| 3 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 公开通用识别数据集 | 77.00% | +30.33% | 在数据量不足的情况下,可以考虑补充公开数据训练 |
+| 4 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 99.99% | +22.99% | 如果能获取更多数据量的情况,可以通过增加数据量提升效果 |
+
+* 端到端
+
+| det | rec | fmeasure |
+| --------------------------------------------- | ------------------------------------------------------------ | -------- |
+| PP-OCRv3英文超轻量检测预训练模型 + fine-tune | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 93.30% |
+
+*结论*
+
+PP-OCRv3的检测模型在未经过fine-tune的情况下,在PCB数据集上也有64.64%的精度,说明具有泛化能力。验证集padding之后,精度提升7.5%,在图片尺寸较小的情况,我们可以通过padding的方式提升检测效果。经过 fine-tune 后能够极大的提升检测效果,精度达到100%。
+
+PP-OCRv3的识别模型方案1和方案2对比可以发现,当数据量不足的情况,预训练模型精度可能比fine-tune效果还要高,所以我们可以先尝试预训练模型直接评估。如果在数据量不足的情况下想进一步提升模型效果,可以通过添加公开通用识别数据集,识别效果提升30%,非常有效。最后如果我们能够采集足够多的真实场景数据集,可以通过增加数据量提升模型效果,精度达到99.99%。
+
+# 更多资源
+
+- 更多深度学习知识、产业案例、面试宝典等,请参考:[awesome-DeepLearning](https://github.com/paddlepaddle/awesome-DeepLearning)
+
+- 更多PaddleOCR使用教程,请参考:[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph)
+
+
+- 飞桨框架相关资料,请参考:[飞桨深度学习平台](https://www.paddlepaddle.org.cn/?fr=paddleEdu_aistudio)
+
+# 参考
+
+* 数据生成代码库:https://github.com/zcswdt/Color_OCR_image_generator
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/background/bg.jpg" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/background/bg.jpg"
new file mode 100644
index 0000000..3cb6eab
Binary files /dev/null and "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/background/bg.jpg" differ
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/corpus/text.txt" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/corpus/text.txt"
new file mode 100644
index 0000000..8b8cb79
--- /dev/null
+++ "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/corpus/text.txt"
@@ -0,0 +1,30 @@
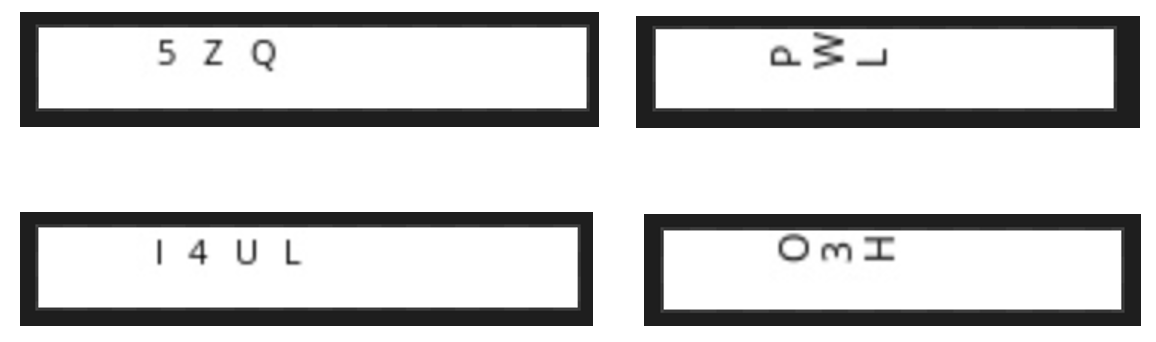
+5ZQ
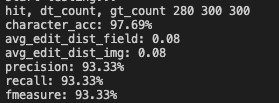
+I4UL
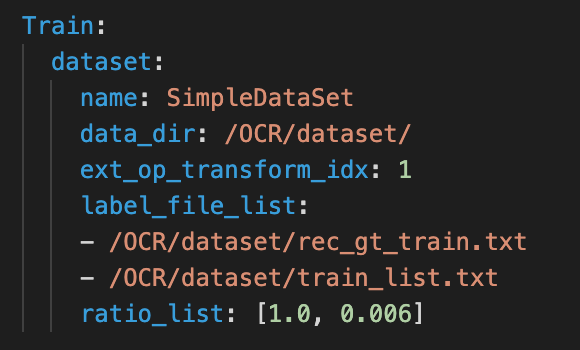
+PWL
+SNOG
+ZL02
+1C30
+O3H
+YHRS
+N03S
+1U5Y
+JTK
+EN4F
+YKJ
+DWNH
+R42W
+X0V
+4OF5
+08AM
+Y93S
+GWE2
+0KR
+9U2A
+DBQ
+Y6J
+ROZ
+K06
+KIEY
+NZQJ
+UN1B
+6X4
\ No newline at end of file
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/1.png" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/1.png"
new file mode 100644
index 0000000..8a49eaa
Binary files /dev/null and "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/1.png" differ
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/2.png" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/2.png"
new file mode 100644
index 0000000..c3fcc0c
Binary files /dev/null and "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/2.png" differ
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/gen.py" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/gen.py"
new file mode 100644
index 0000000..97024d1
--- /dev/null
+++ "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/gen.py"
@@ -0,0 +1,263 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This code is refer from:
+https://github.com/zcswdt/Color_OCR_image_generator
+"""
+import os
+import random
+from PIL import Image, ImageDraw, ImageFont
+import json
+import argparse
+
+
+def get_char_lines(txt_root_path):
+ """
+ desc:get corpus line
+ """
+ txt_files = os.listdir(txt_root_path)
+ char_lines = []
+ for txt in txt_files:
+ f = open(os.path.join(txt_root_path, txt), mode='r', encoding='utf-8')
+ lines = f.readlines()
+ f.close()
+ for line in lines:
+ char_lines.append(line.strip())
+ return char_lines
+
+
+def get_horizontal_text_picture(image_file, chars, fonts_list, cf):
+ """
+ desc:gen horizontal text picture
+ """
+ img = Image.open(image_file)
+ if img.mode != 'RGB':
+ img = img.convert('RGB')
+ img_w, img_h = img.size
+
+ # random choice font
+ font_path = random.choice(fonts_list)
+ # random choice font size
+ font_size = random.randint(cf.font_min_size, cf.font_max_size)
+ font = ImageFont.truetype(font_path, font_size)
+
+ ch_w = []
+ ch_h = []
+ for ch in chars:
+ left, top, right, bottom = font.getbbox(ch)
+ wt, ht = right - left, bottom - top
+ ch_w.append(wt)
+ ch_h.append(ht)
+ f_w = sum(ch_w)
+ f_h = max(ch_h)
+
+ # add space
+ char_space_width = max(ch_w)
+ f_w += (char_space_width * (len(chars) - 1))
+
+ x1 = random.randint(0, img_w - f_w)
+ y1 = random.randint(0, img_h - f_h)
+ x2 = x1 + f_w
+ y2 = y1 + f_h
+
+ crop_y1 = y1
+ crop_x1 = x1
+ crop_y2 = y2
+ crop_x2 = x2
+
+ best_color = (0, 0, 0)
+ draw = ImageDraw.Draw(img)
+ for i, ch in enumerate(chars):
+ draw.text((x1, y1), ch, best_color, font=font)
+ x1 += (ch_w[i] + char_space_width)
+ crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
+ return crop_img, chars
+
+
+def get_vertical_text_picture(image_file, chars, fonts_list, cf):
+ """
+ desc:gen vertical text picture
+ """
+ img = Image.open(image_file)
+ if img.mode != 'RGB':
+ img = img.convert('RGB')
+ img_w, img_h = img.size
+ # random choice font
+ font_path = random.choice(fonts_list)
+ # random choice font size
+ font_size = random.randint(cf.font_min_size, cf.font_max_size)
+ font = ImageFont.truetype(font_path, font_size)
+
+ ch_w = []
+ ch_h = []
+ for ch in chars:
+ left, top, right, bottom = font.getbbox(ch)
+ wt, ht = right - left, bottom - top
+ ch_w.append(wt)
+ ch_h.append(ht)
+ f_w = max(ch_w)
+ f_h = sum(ch_h)
+
+ x1 = random.randint(0, img_w - f_w)
+ y1 = random.randint(0, img_h - f_h)
+ x2 = x1 + f_w
+ y2 = y1 + f_h
+
+ crop_y1 = y1
+ crop_x1 = x1
+ crop_y2 = y2
+ crop_x2 = x2
+
+ best_color = (0, 0, 0)
+ draw = ImageDraw.Draw(img)
+ i = 0
+ for ch in chars:
+ draw.text((x1, y1), ch, best_color, font=font)
+ y1 = y1 + ch_h[i]
+ i = i + 1
+ crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
+ crop_img = crop_img.transpose(Image.ROTATE_90)
+ return crop_img, chars
+
+
+def get_fonts(fonts_path):
+ """
+ desc: get all fonts
+ """
+ font_files = os.listdir(fonts_path)
+ fonts_list=[]
+ for font_file in font_files:
+ font_path=os.path.join(fonts_path, font_file)
+ fonts_list.append(font_path)
+ return fonts_list
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--num_img', type=int, default=30, help="Number of images to generate")
+ parser.add_argument('--font_min_size', type=int, default=11)
+ parser.add_argument('--font_max_size', type=int, default=12,
+ help="Help adjust the size of the generated text and the size of the picture")
+ parser.add_argument('--bg_path', type=str, default='./background',
+ help='The generated text pictures will be pasted onto the pictures of this folder')
+ parser.add_argument('--det_bg_path', type=str, default='./det_background',
+ help='The generated text pictures will use the pictures of this folder as the background')
+ parser.add_argument('--fonts_path', type=str, default='../../StyleText/fonts',
+ help='The font used to generate the picture')
+ parser.add_argument('--corpus_path', type=str, default='./corpus',
+ help='The corpus used to generate the text picture')
+ parser.add_argument('--output_dir', type=str, default='./output/', help='Images save dir')
+
+
+ cf = parser.parse_args()
+ # save path
+ if not os.path.exists(cf.output_dir):
+ os.mkdir(cf.output_dir)
+
+ # get corpus
+ txt_root_path = cf.corpus_path
+ char_lines = get_char_lines(txt_root_path=txt_root_path)
+
+ # get all fonts
+ fonts_path = cf.fonts_path
+ fonts_list = get_fonts(fonts_path)
+
+ # rec bg
+ img_root_path = cf.bg_path
+ imnames=os.listdir(img_root_path)
+
+ # det bg
+ det_bg_path = cf.det_bg_path
+ bg_pics = os.listdir(det_bg_path)
+
+ # OCR det files
+ det_val_file = open(cf.output_dir + 'det_gt_val.txt', 'w', encoding='utf-8')
+ det_train_file = open(cf.output_dir + 'det_gt_train.txt', 'w', encoding='utf-8')
+ # det imgs
+ det_save_dir = 'imgs/'
+ if not os.path.exists(cf.output_dir + det_save_dir):
+ os.mkdir(cf.output_dir + det_save_dir)
+ det_val_save_dir = 'imgs_val/'
+ if not os.path.exists(cf.output_dir + det_val_save_dir):
+ os.mkdir(cf.output_dir + det_val_save_dir)
+
+ # OCR rec files
+ rec_val_file = open(cf.output_dir + 'rec_gt_val.txt', 'w', encoding='utf-8')
+ rec_train_file = open(cf.output_dir + 'rec_gt_train.txt', 'w', encoding='utf-8')
+ # rec imgs
+ rec_save_dir = 'rec_imgs/'
+ if not os.path.exists(cf.output_dir + rec_save_dir):
+ os.mkdir(cf.output_dir + rec_save_dir)
+ rec_val_save_dir = 'rec_imgs_val/'
+ if not os.path.exists(cf.output_dir + rec_val_save_dir):
+ os.mkdir(cf.output_dir + rec_val_save_dir)
+
+
+ val_ratio = cf.num_img * 0.2 # val dataset ratio
+
+ print('start generating...')
+ for i in range(0, cf.num_img):
+ imname = random.choice(imnames)
+ img_path = os.path.join(img_root_path, imname)
+
+ rnd = random.random()
+ # gen horizontal text picture
+ if rnd < 0.5:
+ gen_img, chars = get_horizontal_text_picture(img_path, char_lines[i], fonts_list, cf)
+ ori_w, ori_h = gen_img.size
+ gen_img = gen_img.crop((0, 3, ori_w, ori_h))
+ # gen vertical text picture
+ else:
+ gen_img, chars = get_vertical_text_picture(img_path, char_lines[i], fonts_list, cf)
+ ori_w, ori_h = gen_img.size
+ gen_img = gen_img.crop((3, 0, ori_w, ori_h))
+
+ ori_w, ori_h = gen_img.size
+
+ # rec imgs
+ save_img_name = str(i).zfill(4) + '.jpg'
+ if i < val_ratio:
+ save_dir = os.path.join(rec_val_save_dir, save_img_name)
+ line = save_dir + '\t' + char_lines[i] + '\n'
+ rec_val_file.write(line)
+ else:
+ save_dir = os.path.join(rec_save_dir, save_img_name)
+ line = save_dir + '\t' + char_lines[i] + '\n'
+ rec_train_file.write(line)
+ gen_img.save(cf.output_dir + save_dir, quality = 95, subsampling=0)
+
+ # det img
+ # random choice bg
+ bg_pic = random.sample(bg_pics, 1)[0]
+ det_img = Image.open(os.path.join(det_bg_path, bg_pic))
+ # the PCB position is fixed, modify it according to your own scenario
+ if bg_pic == '1.png':
+ x1 = 38
+ y1 = 3
+ else:
+ x1 = 34
+ y1 = 1
+
+ det_img.paste(gen_img, (x1, y1))
+ # text pos
+ chars_pos = [[x1, y1], [x1 + ori_w, y1], [x1 + ori_w, y1 + ori_h], [x1, y1 + ori_h]]
+ label = [{"transcription":char_lines[i], "points":chars_pos}]
+ if i < val_ratio:
+ save_dir = os.path.join(det_val_save_dir, save_img_name)
+ det_val_file.write(save_dir + '\t' + json.dumps(
+ label, ensure_ascii=False) + '\n')
+ else:
+ save_dir = os.path.join(det_save_dir, save_img_name)
+ det_train_file.write(save_dir + '\t' + json.dumps(
+ label, ensure_ascii=False) + '\n')
+ det_img.save(cf.output_dir + save_dir, quality = 95, subsampling=0)
diff --git a/applications/README.md b/applications/README.md
new file mode 100644
index 0000000..950adf7
--- /dev/null
+++ b/applications/README.md
@@ -0,0 +1,78 @@
+[English](README_en.md) | 简体中文
+
+# 场景应用
+
+PaddleOCR场景应用覆盖通用,制造、金融、交通行业的主要OCR垂类应用,在PP-OCR、PP-Structure的通用能力基础之上,以notebook的形式展示利用场景数据微调、模型优化方法、数据增广等内容,为开发者快速落地OCR应用提供示范与启发。
+
+- [教程文档](#1)
+ - [通用](#11)
+ - [制造](#12)
+ - [金融](#13)
+ - [交通](#14)
+
+- [模型下载](#2)
+
+
+
+## 教程文档
+
+
+
+### 通用
+
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| ---------------------- | ------------------------------------------------------------ | -------------- | --------------------------------------- | ------------------------------------------------------------ |
+| 高精度中文识别模型SVTR | 比PP-OCRv3识别模型精度高3%,
可用于数据挖掘或对预测效率要求不高的场景。 | [模型下载](#2) | [中文](./高精度中文识别模型.md)/English |  |
+| 手写体识别 | 新增字形支持 | [模型下载](#2) | [中文](./手写文字识别.md)/English |
|
+| 手写体识别 | 新增字形支持 | [模型下载](#2) | [中文](./手写文字识别.md)/English |  |
+
+
+
+### 制造
+
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| -------------- | ------------------------------ | -------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 数码管识别 | 数码管数据合成、漏识别调优 | [模型下载](#2) | [中文](./光功率计数码管字符识别/光功率计数码管字符识别.md)/English |
|
+
+
+
+### 制造
+
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| -------------- | ------------------------------ | -------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 数码管识别 | 数码管数据合成、漏识别调优 | [模型下载](#2) | [中文](./光功率计数码管字符识别/光功率计数码管字符识别.md)/English |  |
+| 液晶屏读数识别 | 检测模型蒸馏、Serving部署 | [模型下载](#2) | [中文](./液晶屏读数识别.md)/English |
|
+| 液晶屏读数识别 | 检测模型蒸馏、Serving部署 | [模型下载](#2) | [中文](./液晶屏读数识别.md)/English |  |
+| 包装生产日期 | 点阵字符合成、过曝过暗文字识别 | [模型下载](#2) | [中文](./包装生产日期识别.md)/English |
|
+| 包装生产日期 | 点阵字符合成、过曝过暗文字识别 | [模型下载](#2) | [中文](./包装生产日期识别.md)/English |  |
+| PCB文字识别 | 小尺寸文本检测与识别 | [模型下载](#2) | [中文](./PCB字符识别/PCB字符识别.md)/English |
|
+| PCB文字识别 | 小尺寸文本检测与识别 | [模型下载](#2) | [中文](./PCB字符识别/PCB字符识别.md)/English |  |
+| 电表识别 | 大分辨率图像检测调优 | [模型下载](#2) | | |
+| 液晶屏缺陷检测 | 非文字字符识别 | | | |
+
+
+
+### 金融
+
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| -------------- | ----------------------------- | -------------- | ----------------------------------------- | ------------------------------------------------------------ |
+| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English |
|
+| 电表识别 | 大分辨率图像检测调优 | [模型下载](#2) | | |
+| 液晶屏缺陷检测 | 非文字字符识别 | | | |
+
+
+
+### 金融
+
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| -------------- | ----------------------------- | -------------- | ----------------------------------------- | ------------------------------------------------------------ |
+| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English |  |
+| 增值税发票 | 关键信息抽取,SER、RE任务训练 | [模型下载](#2) | [中文](./发票关键信息抽取.md)/English |
|
+| 增值税发票 | 关键信息抽取,SER、RE任务训练 | [模型下载](#2) | [中文](./发票关键信息抽取.md)/English |  |
+| 印章检测与识别 | 端到端弯曲文本识别 | [模型下载](#2) | [中文](./印章弯曲文字识别.md)/English |
|
+| 印章检测与识别 | 端到端弯曲文本识别 | [模型下载](#2) | [中文](./印章弯曲文字识别.md)/English |  |
+| 通用卡证识别 | 通用结构化提取 | [模型下载](#2) | [中文](./快速构建卡证类OCR.md)/English |
|
+| 通用卡证识别 | 通用结构化提取 | [模型下载](#2) | [中文](./快速构建卡证类OCR.md)/English |  |
+| 身份证识别 | 结构化提取、图像阴影 | | | |
+| 合同比对 | 密集文本检测、NLP关键信息抽取 | [模型下载](#2) | [中文](./扫描合同关键信息提取.md)/English |
|
+| 身份证识别 | 结构化提取、图像阴影 | | | |
+| 合同比对 | 密集文本检测、NLP关键信息抽取 | [模型下载](#2) | [中文](./扫描合同关键信息提取.md)/English | 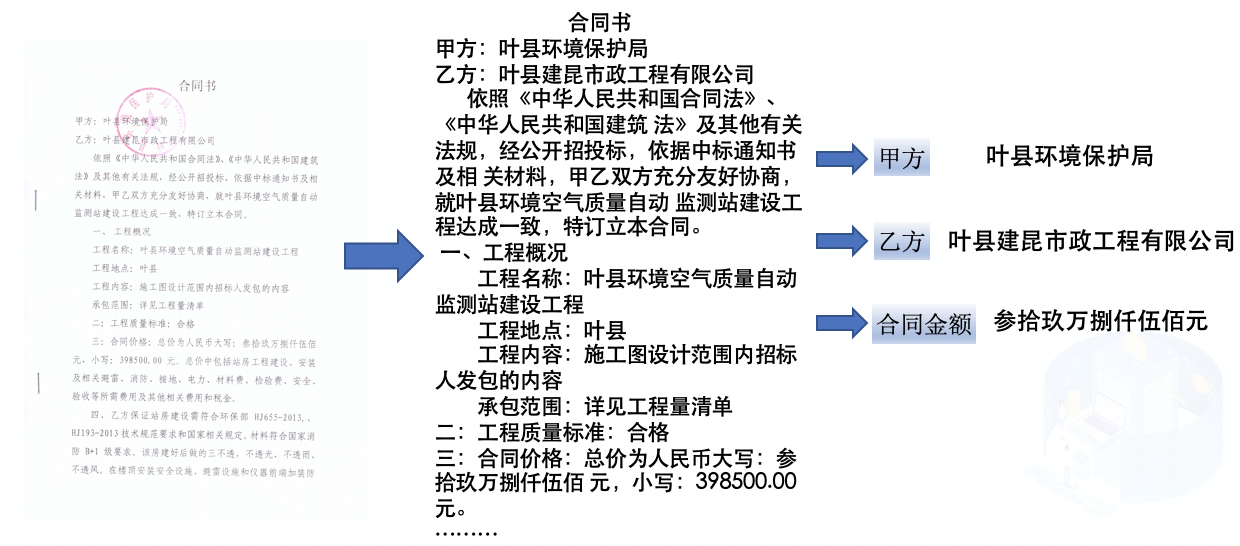 |
+
+
+
+### 交通
+
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| ----------------- | ------------------------------ | -------------- | ----------------------------------- | ------------------------------------------------------------ |
+| 车牌识别 | 多角度图像、轻量模型、端侧部署 | [模型下载](#2) | [中文](./轻量级车牌识别.md)/English |
|
+
+
+
+### 交通
+
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| ----------------- | ------------------------------ | -------------- | ----------------------------------- | ------------------------------------------------------------ |
+| 车牌识别 | 多角度图像、轻量模型、端侧部署 | [模型下载](#2) | [中文](./轻量级车牌识别.md)/English |  |
+| 驾驶证/行驶证识别 | 尽请期待 | | | |
+| 快递单识别 | 尽请期待 | | | |
+
+
+
+## 模型下载
+
+如需下载上述场景中已经训练好的垂类模型,可以扫描下方二维码,关注公众号填写问卷后,加入PaddleOCR官方交流群获取20G OCR学习大礼包(内含《动手学OCR》电子书、课程回放视频、前沿论文等重磅资料)
+
+
|
+| 驾驶证/行驶证识别 | 尽请期待 | | | |
+| 快递单识别 | 尽请期待 | | | |
+
+
+
+## 模型下载
+
+如需下载上述场景中已经训练好的垂类模型,可以扫描下方二维码,关注公众号填写问卷后,加入PaddleOCR官方交流群获取20G OCR学习大礼包(内含《动手学OCR》电子书、课程回放视频、前沿论文等重磅资料)
+
+
+
+
 +
diff --git a/applications/README_en.md b/applications/README_en.md
new file mode 100644
index 0000000..df18465
--- /dev/null
+++ b/applications/README_en.md
@@ -0,0 +1,79 @@
+English| [简体中文](README.md)
+
+# Application
+
+PaddleOCR scene application covers general, manufacturing, finance, transportation industry of the main OCR vertical applications, on the basis of the general capabilities of PP-OCR, PP-Structure, in the form of notebook to show the use of scene data fine-tuning, model optimization methods, data augmentation and other content, for developers to quickly land OCR applications to provide demonstration and inspiration.
+
+- [Tutorial](#1)
+ - [General](#11)
+ - [Manufacturing](#12)
+ - [Finance](#13)
+ - [Transportation](#14)
+
+- [Model Download](#2)
+
+
+
+## Tutorial
+
+
+
+### General
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ---------------------------------------------- | ---------------- | -------------------- | --------------------------------------- | ------------------------------------------------------------ |
+| High-precision Chineses recognition model SVTR | New model | [Model Download](#2) | [中文](./高精度中文识别模型.md)/English | |
+| Chinese handwriting recognition | New font support | [Model Download](#2) | [中文](./手写文字识别.md)/English | |
+
+
+
+### Manufacturing
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ------------------------------ | ------------------------------------------------------------ | -------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| Digital tube | Digital tube data sythesis, recognition model fine-tuning | [Model Download](#2) | [中文](./光功率计数码管字符识别/光功率计数码管字符识别.md)/English | |
+| LCD screen | Detection model distillation, serving deployment | [Model Download](#2) | [中文](./液晶屏读数识别.md)/English | |
+| Packaging production data | Dot matrix character synthesis, overexposure and overdark text recognition | [Model Download](#2) | [中文](./包装生产日期识别.md)/English | |
+| PCB text recognition | Small size text detection and recognition | [Model Download](#2) | [中文](./PCB字符识别/PCB字符识别.md)/English | |
+| Meter text recognition | High-resolution image detection fine-tuning | [Model Download](#2) | | |
+| LCD character defect detection | Non-text character recognition | | | |
+
+
+
+### Finance
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ----------------------------------- | -------------------------------------------------- | -------------------- | ----------------------------------------- | ------------------------------------------------------------ |
+| Form visual question and answer | Multimodal general form structured extraction | [Model Download](#2) | [中文](./多模态表单识别.md)/English | |
+| VAT invoice | Key information extraction, SER, RE task fine-tune | [Model Download](#2) | [中文](./发票关键信息抽取.md)/English | |
+| Seal detection and recognition | End-to-end curved text recognition | [Model Download](#2) | [中文](./印章弯曲文字识别.md)/English | |
+| Universal card recognition | Universal structured extraction | [Model Download](#2) | [中文](./快速构建卡证类OCR.md)/English | |
+| ID card recognition | Structured extraction, image shading | | | |
+| Contract key information extraction | Dense text detection, NLP concatenation | [Model Download](#2) | [中文](./扫描合同关键信息提取.md)/English | |
+
+
+
+### Transportation
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ----------------------------------------------- | ------------------------------------------------------------ | -------------------- | ----------------------------------- | ------------------------------------------------------------ |
+| License plate recognition | Multi-angle images, lightweight models, edge-side deployment | [Model Download](#2) | [中文](./轻量级车牌识别.md)/English | |
+| Driver's license/driving license identification | coming soon | | | |
+| Express text recognition | coming soon | | | |
+
+
+
+## Model Download
+
+- For international developers: We're building a way to download these trained models, and since the current tutorials are Chinese, if you are good at both Chinese and English, or willing to polish English documents, please let us know in [discussion](https://github.com/PaddlePaddle/PaddleOCR/discussions).
+- For Chinese developer: If you want to download the trained application model in the above scenarios, scan the QR code below with your WeChat, follow the PaddlePaddle official account to fill in the questionnaire, and join the PaddleOCR official group to get the 20G OCR learning materials (including "Dive into OCR" e-book, course video, application models and other materials)
+
+
+
diff --git a/applications/README_en.md b/applications/README_en.md
new file mode 100644
index 0000000..df18465
--- /dev/null
+++ b/applications/README_en.md
@@ -0,0 +1,79 @@
+English| [简体中文](README.md)
+
+# Application
+
+PaddleOCR scene application covers general, manufacturing, finance, transportation industry of the main OCR vertical applications, on the basis of the general capabilities of PP-OCR, PP-Structure, in the form of notebook to show the use of scene data fine-tuning, model optimization methods, data augmentation and other content, for developers to quickly land OCR applications to provide demonstration and inspiration.
+
+- [Tutorial](#1)
+ - [General](#11)
+ - [Manufacturing](#12)
+ - [Finance](#13)
+ - [Transportation](#14)
+
+- [Model Download](#2)
+
+
+
+## Tutorial
+
+
+
+### General
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ---------------------------------------------- | ---------------- | -------------------- | --------------------------------------- | ------------------------------------------------------------ |
+| High-precision Chineses recognition model SVTR | New model | [Model Download](#2) | [中文](./高精度中文识别模型.md)/English | |
+| Chinese handwriting recognition | New font support | [Model Download](#2) | [中文](./手写文字识别.md)/English | |
+
+
+
+### Manufacturing
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ------------------------------ | ------------------------------------------------------------ | -------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| Digital tube | Digital tube data sythesis, recognition model fine-tuning | [Model Download](#2) | [中文](./光功率计数码管字符识别/光功率计数码管字符识别.md)/English | |
+| LCD screen | Detection model distillation, serving deployment | [Model Download](#2) | [中文](./液晶屏读数识别.md)/English | |
+| Packaging production data | Dot matrix character synthesis, overexposure and overdark text recognition | [Model Download](#2) | [中文](./包装生产日期识别.md)/English | |
+| PCB text recognition | Small size text detection and recognition | [Model Download](#2) | [中文](./PCB字符识别/PCB字符识别.md)/English | |
+| Meter text recognition | High-resolution image detection fine-tuning | [Model Download](#2) | | |
+| LCD character defect detection | Non-text character recognition | | | |
+
+
+
+### Finance
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ----------------------------------- | -------------------------------------------------- | -------------------- | ----------------------------------------- | ------------------------------------------------------------ |
+| Form visual question and answer | Multimodal general form structured extraction | [Model Download](#2) | [中文](./多模态表单识别.md)/English | |
+| VAT invoice | Key information extraction, SER, RE task fine-tune | [Model Download](#2) | [中文](./发票关键信息抽取.md)/English | |
+| Seal detection and recognition | End-to-end curved text recognition | [Model Download](#2) | [中文](./印章弯曲文字识别.md)/English | |
+| Universal card recognition | Universal structured extraction | [Model Download](#2) | [中文](./快速构建卡证类OCR.md)/English | |
+| ID card recognition | Structured extraction, image shading | | | |
+| Contract key information extraction | Dense text detection, NLP concatenation | [Model Download](#2) | [中文](./扫描合同关键信息提取.md)/English | |
+
+
+
+### Transportation
+
+| Case | Feature | Model Download | Tutorial | Example |
+| ----------------------------------------------- | ------------------------------------------------------------ | -------------------- | ----------------------------------- | ------------------------------------------------------------ |
+| License plate recognition | Multi-angle images, lightweight models, edge-side deployment | [Model Download](#2) | [中文](./轻量级车牌识别.md)/English | |
+| Driver's license/driving license identification | coming soon | | | |
+| Express text recognition | coming soon | | | |
+
+
+
+## Model Download
+
+- For international developers: We're building a way to download these trained models, and since the current tutorials are Chinese, if you are good at both Chinese and English, or willing to polish English documents, please let us know in [discussion](https://github.com/PaddlePaddle/PaddleOCR/discussions).
+- For Chinese developer: If you want to download the trained application model in the above scenarios, scan the QR code below with your WeChat, follow the PaddlePaddle official account to fill in the questionnaire, and join the PaddleOCR official group to get the 20G OCR learning materials (including "Dive into OCR" e-book, course video, application models and other materials)
+
+
+
+
 +
diff --git "a/applications/\344\270\255\346\226\207\350\241\250\346\240\274\350\257\206\345\210\253.md" "b/applications/\344\270\255\346\226\207\350\241\250\346\240\274\350\257\206\345\210\253.md"
new file mode 100644
index 0000000..d61514f
--- /dev/null
+++ "b/applications/\344\270\255\346\226\207\350\241\250\346\240\274\350\257\206\345\210\253.md"
@@ -0,0 +1,472 @@
+# 智能运营:通用中文表格识别
+
+- [1. 背景介绍](#1-背景介绍)
+- [2. 中文表格识别](#2-中文表格识别)
+- [2.1 环境准备](#21-环境准备)
+- [2.2 准备数据集](#22-准备数据集)
+ - [2.2.1 划分训练测试集](#221-划分训练测试集)
+ - [2.2.2 查看数据集](#222-查看数据集)
+- [2.3 训练](#23-训练)
+- [2.4 验证](#24-验证)
+- [2.5 训练引擎推理](#25-训练引擎推理)
+- [2.6 模型导出](#26-模型导出)
+- [2.7 预测引擎推理](#27-预测引擎推理)
+- [2.8 表格识别](#28-表格识别)
+- [3. 表格属性识别](#3-表格属性识别)
+- [3.1 代码、环境、数据准备](#31-代码环境数据准备)
+ - [3.1.1 代码准备](#311-代码准备)
+ - [3.1.2 环境准备](#312-环境准备)
+ - [3.1.3 数据准备](#313-数据准备)
+- [3.2 表格属性识别训练](#32-表格属性识别训练)
+- [3.3 表格属性识别推理和部署](#33-表格属性识别推理和部署)
+ - [3.3.1 模型转换](#331-模型转换)
+ - [3.3.2 模型推理](#332-模型推理)
+
+## 1. 背景介绍
+
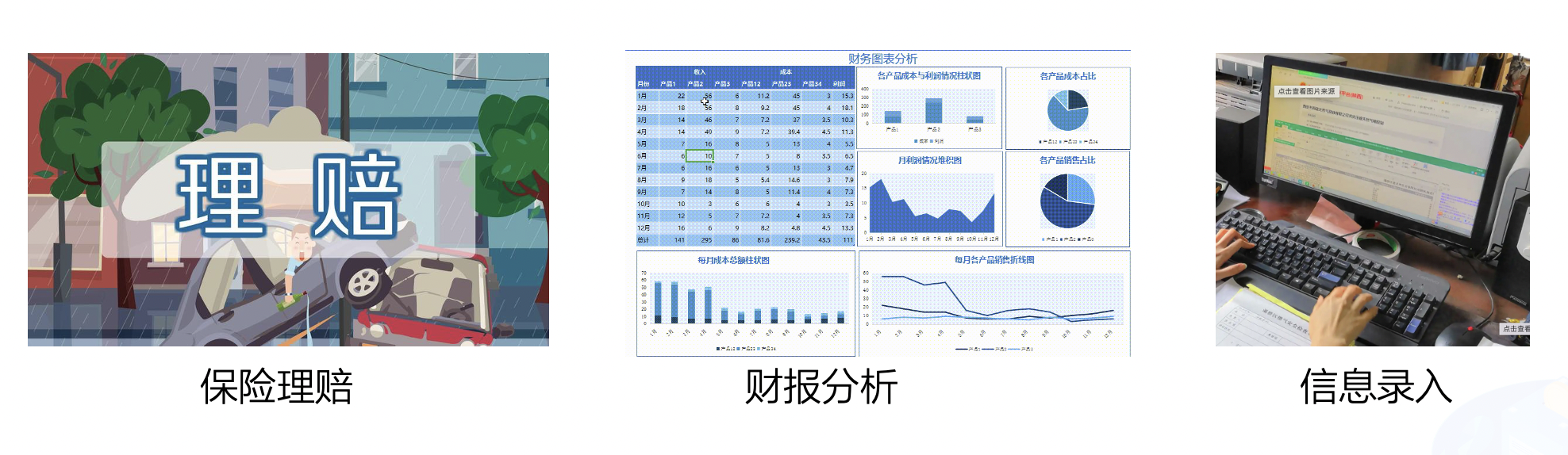
+中文表格识别在金融行业有着广泛的应用,如保险理赔、财报分析和信息录入等领域。当前,金融行业的表格识别主要以手动录入为主,开发一种自动表格识别成为丞待解决的问题。
+
+
+
+在金融行业中,表格图像主要有清单类的单元格密集型表格,申请表类的大单元格表格,拍照表格和倾斜表格四种主要形式。
+
+
+
+
+
+当前的表格识别算法不能很好的处理这些场景下的表格图像。在本例中,我们使用PP-StructureV2最新发布的表格识别模型SLANet来演示如何进行中文表格是识别。同时,为了方便作业流程,我们使用表格属性识别模型对表格图像的属性进行识别,对表格的难易程度进行判断,加快人工进行校对速度。
+
+本项目AI Studio链接:https://aistudio.baidu.com/aistudio/projectdetail/4588067
+
+## 2. 中文表格识别
+### 2.1 环境准备
+
+
+```python
+# 下载PaddleOCR代码
+! git clone -b dygraph https://gitee.com/paddlepaddle/PaddleOCR
+```
+
+
+```python
+# 安装PaddleOCR环境
+! pip install -r PaddleOCR/requirements.txt --force-reinstall
+! pip install protobuf==3.19
+```
+
+### 2.2 准备数据集
+
+本例中使用的数据集采用表格[生成工具](https://github.com/WenmuZhou/TableGeneration)制作。
+
+使用如下命令对数据集进行解压,并查看数据集大小
+
+
+```python
+! cd data/data165849 && tar -xf table_gen_dataset.tar && cd -
+! wc -l data/data165849/table_gen_dataset/gt.txt
+```
+
+#### 2.2.1 划分训练测试集
+
+使用下述命令将数据集划分为训练集和测试集, 这里将90%划分为训练集,10%划分为测试集
+
+
+```python
+import random
+with open('/home/aistudio/data/data165849/table_gen_dataset/gt.txt') as f:
+ lines = f.readlines()
+random.shuffle(lines)
+train_len = int(len(lines)*0.9)
+train_list = lines[:train_len]
+val_list = lines[train_len:]
+
+# 保存结果
+with open('/home/aistudio/train.txt','w',encoding='utf-8') as f:
+ f.writelines(train_list)
+with open('/home/aistudio/val.txt','w',encoding='utf-8') as f:
+ f.writelines(val_list)
+```
+
+划分完成后,数据集信息如下
+
+|类型|数量|图片地址|标注文件路径|
+|---|---|---|---|
+|训练集|18000|/home/aistudio/data/data165849/table_gen_dataset|/home/aistudio/train.txt|
+|测试集|2000|/home/aistudio/data/data165849/table_gen_dataset|/home/aistudio/val.txt|
+
+#### 2.2.2 查看数据集
+
+
+```python
+import cv2
+import os, json
+import numpy as np
+from matplotlib import pyplot as plt
+%matplotlib inline
+
+def parse_line(data_dir, line):
+ data_line = line.strip("\n")
+ info = json.loads(data_line)
+ file_name = info['filename']
+ cells = info['html']['cells'].copy()
+ structure = info['html']['structure']['tokens'].copy()
+
+ img_path = os.path.join(data_dir, file_name)
+ if not os.path.exists(img_path):
+ print(img_path)
+ return None
+ data = {
+ 'img_path': img_path,
+ 'cells': cells,
+ 'structure': structure,
+ 'file_name': file_name
+ }
+ return data
+
+def draw_bbox(img_path, points, color=(255, 0, 0), thickness=2):
+ if isinstance(img_path, str):
+ img_path = cv2.imread(img_path)
+ img_path = img_path.copy()
+ for point in points:
+ cv2.polylines(img_path, [point.astype(int)], True, color, thickness)
+ return img_path
+
+
+def rebuild_html(data):
+ html_code = data['structure']
+ cells = data['cells']
+ to_insert = [i for i, tag in enumerate(html_code) if tag in ('
+
diff --git "a/applications/\344\270\255\346\226\207\350\241\250\346\240\274\350\257\206\345\210\253.md" "b/applications/\344\270\255\346\226\207\350\241\250\346\240\274\350\257\206\345\210\253.md"
new file mode 100644
index 0000000..d61514f
--- /dev/null
+++ "b/applications/\344\270\255\346\226\207\350\241\250\346\240\274\350\257\206\345\210\253.md"
@@ -0,0 +1,472 @@
+# 智能运营:通用中文表格识别
+
+- [1. 背景介绍](#1-背景介绍)
+- [2. 中文表格识别](#2-中文表格识别)
+- [2.1 环境准备](#21-环境准备)
+- [2.2 准备数据集](#22-准备数据集)
+ - [2.2.1 划分训练测试集](#221-划分训练测试集)
+ - [2.2.2 查看数据集](#222-查看数据集)
+- [2.3 训练](#23-训练)
+- [2.4 验证](#24-验证)
+- [2.5 训练引擎推理](#25-训练引擎推理)
+- [2.6 模型导出](#26-模型导出)
+- [2.7 预测引擎推理](#27-预测引擎推理)
+- [2.8 表格识别](#28-表格识别)
+- [3. 表格属性识别](#3-表格属性识别)
+- [3.1 代码、环境、数据准备](#31-代码环境数据准备)
+ - [3.1.1 代码准备](#311-代码准备)
+ - [3.1.2 环境准备](#312-环境准备)
+ - [3.1.3 数据准备](#313-数据准备)
+- [3.2 表格属性识别训练](#32-表格属性识别训练)
+- [3.3 表格属性识别推理和部署](#33-表格属性识别推理和部署)
+ - [3.3.1 模型转换](#331-模型转换)
+ - [3.3.2 模型推理](#332-模型推理)
+
+## 1. 背景介绍
+
+中文表格识别在金融行业有着广泛的应用,如保险理赔、财报分析和信息录入等领域。当前,金融行业的表格识别主要以手动录入为主,开发一种自动表格识别成为丞待解决的问题。
+
+
+
+在金融行业中,表格图像主要有清单类的单元格密集型表格,申请表类的大单元格表格,拍照表格和倾斜表格四种主要形式。
+
+
+
+
+
+当前的表格识别算法不能很好的处理这些场景下的表格图像。在本例中,我们使用PP-StructureV2最新发布的表格识别模型SLANet来演示如何进行中文表格是识别。同时,为了方便作业流程,我们使用表格属性识别模型对表格图像的属性进行识别,对表格的难易程度进行判断,加快人工进行校对速度。
+
+本项目AI Studio链接:https://aistudio.baidu.com/aistudio/projectdetail/4588067
+
+## 2. 中文表格识别
+### 2.1 环境准备
+
+
+```python
+# 下载PaddleOCR代码
+! git clone -b dygraph https://gitee.com/paddlepaddle/PaddleOCR
+```
+
+
+```python
+# 安装PaddleOCR环境
+! pip install -r PaddleOCR/requirements.txt --force-reinstall
+! pip install protobuf==3.19
+```
+
+### 2.2 准备数据集
+
+本例中使用的数据集采用表格[生成工具](https://github.com/WenmuZhou/TableGeneration)制作。
+
+使用如下命令对数据集进行解压,并查看数据集大小
+
+
+```python
+! cd data/data165849 && tar -xf table_gen_dataset.tar && cd -
+! wc -l data/data165849/table_gen_dataset/gt.txt
+```
+
+#### 2.2.1 划分训练测试集
+
+使用下述命令将数据集划分为训练集和测试集, 这里将90%划分为训练集,10%划分为测试集
+
+
+```python
+import random
+with open('/home/aistudio/data/data165849/table_gen_dataset/gt.txt') as f:
+ lines = f.readlines()
+random.shuffle(lines)
+train_len = int(len(lines)*0.9)
+train_list = lines[:train_len]
+val_list = lines[train_len:]
+
+# 保存结果
+with open('/home/aistudio/train.txt','w',encoding='utf-8') as f:
+ f.writelines(train_list)
+with open('/home/aistudio/val.txt','w',encoding='utf-8') as f:
+ f.writelines(val_list)
+```
+
+划分完成后,数据集信息如下
+
+|类型|数量|图片地址|标注文件路径|
+|---|---|---|---|
+|训练集|18000|/home/aistudio/data/data165849/table_gen_dataset|/home/aistudio/train.txt|
+|测试集|2000|/home/aistudio/data/data165849/table_gen_dataset|/home/aistudio/val.txt|
+
+#### 2.2.2 查看数据集
+
+
+```python
+import cv2
+import os, json
+import numpy as np
+from matplotlib import pyplot as plt
+%matplotlib inline
+
+def parse_line(data_dir, line):
+ data_line = line.strip("\n")
+ info = json.loads(data_line)
+ file_name = info['filename']
+ cells = info['html']['cells'].copy()
+ structure = info['html']['structure']['tokens'].copy()
+
+ img_path = os.path.join(data_dir, file_name)
+ if not os.path.exists(img_path):
+ print(img_path)
+ return None
+ data = {
+ 'img_path': img_path,
+ 'cells': cells,
+ 'structure': structure,
+ 'file_name': file_name
+ }
+ return data
+
+def draw_bbox(img_path, points, color=(255, 0, 0), thickness=2):
+ if isinstance(img_path, str):
+ img_path = cv2.imread(img_path)
+ img_path = img_path.copy()
+ for point in points:
+ cv2.polylines(img_path, [point.astype(int)], True, color, thickness)
+ return img_path
+
+
+def rebuild_html(data):
+ html_code = data['structure']
+ cells = data['cells']
+ to_insert = [i for i, tag in enumerate(html_code) if tag in ('', '>')]
+
+ for i, cell in zip(to_insert[::-1], cells[::-1]):
+ if cell['tokens']:
+ text = ''.join(cell['tokens'])
+ # skip empty text
+ sp_char_list = ['', '', '\u2028', ' ', '', '']
+ text_remove_style = skip_char(text, sp_char_list)
+ if len(text_remove_style) == 0:
+ continue
+ html_code.insert(i + 1, text)
+
+ html_code = ''.join(html_code)
+ return html_code
+
+
+def skip_char(text, sp_char_list):
+ """
+ skip empty cell
+ @param text: text in cell
+ @param sp_char_list: style char and special code
+ @return:
+ """
+ for sp_char in sp_char_list:
+ text = text.replace(sp_char, '')
+ return text
+
+save_dir = '/home/aistudio/vis'
+os.makedirs(save_dir, exist_ok=True)
+image_dir = '/home/aistudio/data/data165849/'
+html_str = ''
+
+# 解析标注信息并还原html表格
+data = parse_line(image_dir, val_list[0])
+
+img = cv2.imread(data['img_path'])
+img_name = ''.join(os.path.basename(data['file_name']).split('.')[:-1])
+img_save_name = os.path.join(save_dir, img_name)
+boxes = [np.array(x['bbox']) for x in data['cells']]
+show_img = draw_bbox(data['img_path'], boxes)
+cv2.imwrite(img_save_name + '_show.jpg', show_img)
+
+html = rebuild_html(data)
+html_str += html
+html_str += ' '
+
+# 显示标注的html字符串
+from IPython.core.display import display, HTML
+display(HTML(html_str))
+# 显示单元格坐标
+plt.figure(figsize=(15,15))
+plt.imshow(show_img)
+plt.show()
+```
+
+### 2.3 训练
+
+这里选用PP-StructureV2中的表格识别模型[SLANet](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/configs/table/SLANet.yml)
+
+SLANet是PP-StructureV2全新推出的表格识别模型,相比PP-StructureV1中TableRec-RARE,在速度不变的情况下精度提升4.7%。TEDS提升2%
+
+
+|算法|Acc|[TEDS(Tree-Edit-Distance-based Similarity)](https://github.com/ibm-aur-nlp/PubTabNet/tree/master/src)|Speed|
+| --- | --- | --- | ---|
+| EDD[2] |x| 88.30% |x|
+| TableRec-RARE(ours) | 71.73%| 93.88% |779ms|
+| SLANet(ours) | 76.31%| 95.89%|766ms|
+
+进行训练之前先使用如下命令下载预训练模型
+
+
+```python
+# 进入PaddleOCR工作目录
+os.chdir('/home/aistudio/PaddleOCR')
+# 下载英文预训练模型
+! wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/ppstructure/models/slanet/en_ppstructure_mobile_v2.0_SLANet_train.tar --no-check-certificate
+! cd ./pretrain_models/ && tar xf en_ppstructure_mobile_v2.0_SLANet_train.tar && cd ../
+```
+
+使用如下命令即可启动训练,需要修改的配置有
+
+|字段|修改值|含义|
+|---|---|---|
+|Global.pretrained_model|./pretrain_models/en_ppstructure_mobile_v2.0_SLANet_train/best_accuracy.pdparams|指向英文表格预训练模型地址|
+|Global.eval_batch_step|562|模型多少step评估一次,一般设置为一个epoch总的step数|
+|Optimizer.lr.name|Const|学习率衰减器 |
+|Optimizer.lr.learning_rate|0.0005|学习率设为之前的0.05倍 |
+|Train.dataset.data_dir|/home/aistudio/data/data165849|指向训练集图片存放目录 |
+|Train.dataset.label_file_list|/home/aistudio/data/data165849/table_gen_dataset/train.txt|指向训练集标注文件 |
+|Train.loader.batch_size_per_card|32|训练时每张卡的batch_size |
+|Train.loader.num_workers|1|训练集多进程数据读取的进程数,在aistudio中需要设为1 |
+|Eval.dataset.data_dir|/home/aistudio/data/data165849|指向测试集图片存放目录 |
+|Eval.dataset.label_file_list|/home/aistudio/data/data165849/table_gen_dataset/val.txt|指向测试集标注文件 |
+|Eval.loader.batch_size_per_card|32|测试时每张卡的batch_size |
+|Eval.loader.num_workers|1|测试集多进程数据读取的进程数,在aistudio中需要设为1 |
+
+
+已经修改好的配置存储在 `/home/aistudio/SLANet_ch.yml`
+
+
+```python
+import os
+os.chdir('/home/aistudio/PaddleOCR')
+! python3 tools/train.py -c /home/aistudio/SLANet_ch.yml
+```
+
+大约在7个epoch后达到最高精度 97.49%
+
+### 2.4 验证
+
+训练完成后,可使用如下命令在测试集上评估最优模型的精度
+
+
+```python
+! python3 tools/eval.py -c /home/aistudio/SLANet_ch.yml -o Global.checkpoints=/home/aistudio/PaddleOCR/output/SLANet_ch/best_accuracy.pdparams
+```
+
+### 2.5 训练引擎推理
+使用如下命令可使用训练引擎对单张图片进行推理
+
+
+```python
+import os;os.chdir('/home/aistudio/PaddleOCR')
+! python3 tools/infer_table.py -c /home/aistudio/SLANet_ch.yml -o Global.checkpoints=/home/aistudio/PaddleOCR/output/SLANet_ch/best_accuracy.pdparams Global.infer_img=/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg
+```
+
+
+```python
+import cv2
+from matplotlib import pyplot as plt
+%matplotlib inline
+
+# 显示原图
+show_img = cv2.imread('/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg')
+plt.figure(figsize=(15,15))
+plt.imshow(show_img)
+plt.show()
+
+# 显示预测的单元格
+show_img = cv2.imread('/home/aistudio/PaddleOCR/output/infer/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg')
+plt.figure(figsize=(15,15))
+plt.imshow(show_img)
+plt.show()
+```
+
+### 2.6 模型导出
+
+使用如下命令可将模型导出为inference模型
+
+
+```python
+! python3 tools/export_model.py -c /home/aistudio/SLANet_ch.yml -o Global.checkpoints=/home/aistudio/PaddleOCR/output/SLANet_ch/best_accuracy.pdparams Global.save_inference_dir=/home/aistudio/SLANet_ch/infer
+```
+
+### 2.7 预测引擎推理
+使用如下命令可使用预测引擎对单张图片进行推理
+
+
+
+```python
+os.chdir('/home/aistudio/PaddleOCR/ppstructure')
+! python3 table/predict_structure.py \
+ --table_model_dir=/home/aistudio/SLANet_ch/infer \
+ --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
+ --image_dir=/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg \
+ --output=../output/inference
+```
+
+
+```python
+# 显示原图
+show_img = cv2.imread('/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg')
+plt.figure(figsize=(15,15))
+plt.imshow(show_img)
+plt.show()
+
+# 显示预测的单元格
+show_img = cv2.imread('/home/aistudio/PaddleOCR/output/inference/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg')
+plt.figure(figsize=(15,15))
+plt.imshow(show_img)
+plt.show()
+```
+
+### 2.8 表格识别
+
+在表格结构模型训练完成后,可结合OCR检测识别模型,对表格内容进行识别。
+
+首先下载PP-OCRv3文字检测识别模型
+
+
+```python
+# 下载PP-OCRv3文本检测识别模型并解压
+! wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_slim_infer.tar --no-check-certificate
+! wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_slim_infer.tar --no-check-certificate
+! cd ./inference/ && tar xf ch_PP-OCRv3_det_slim_infer.tar && tar xf ch_PP-OCRv3_rec_slim_infer.tar && cd ../
+```
+
+模型下载完成后,使用如下命令进行表格识别
+
+
+```python
+import os;os.chdir('/home/aistudio/PaddleOCR/ppstructure')
+! python3 table/predict_table.py \
+ --det_model_dir=inference/ch_PP-OCRv3_det_slim_infer \
+ --rec_model_dir=inference/ch_PP-OCRv3_rec_slim_infer \
+ --table_model_dir=/home/aistudio/SLANet_ch/infer \
+ --rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt \
+ --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
+ --image_dir=/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg \
+ --output=../output/table
+```
+
+
+```python
+# 显示原图
+show_img = cv2.imread('/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg')
+plt.figure(figsize=(15,15))
+plt.imshow(show_img)
+plt.show()
+
+# 显示预测结果
+from IPython.core.display import display, HTML
+display(HTML('| alleadersh | 不贰过,推 | 从自己参与浙江数 | 。另一方 | | AnSha | 自己越 | 共商共建工作协商 | w.east | 抓好改革试点任务 | | Edime | ImisesElec | 怀天下”。 | | 22.26 | 31.61 | 4.30 | 794.94 | | ip | Profundi | :2019年12月1 | Horspro | 444.48 | 2.41 | 87 | 679.98 | | iehaiTrain | 组长蒋蕊 | Toafterdec | 203.43 | 23.54 | 4 | 4266.62 | | Tyint | roudlyRol | 谢您的好意,我知道 | ErChows | | 48.90 | 1031 | 6 | | NaFlint | | 一辈的 | aterreclam | 7823.86 | 9829.23 | 7.96 | 3068 | | 家上下游企业,5 | Tr | 景象。当地球上的我们 | Urelaw | 799.62 | 354.96 | 12.98 | 33 | | 赛事( | uestCh | 复制的业务模式并 | Listicjust | 9.23 | | 92 | 53.22 | | Ca | Iskole | 扶贫"之名引导 | Papua | 7191.90 | 1.65 | 3.62 | 48 | | 避讳 | ir | 但由于 | Fficeof | 0.22 | 6.37 | 7.17 | 3397.75 | | ndaTurk | 百处遗址 | gMa | 1288.34 | 2053.66 | 2.29 | 885.45 |
'))
+```
+
+## 3. 表格属性识别
+### 3.1 代码、环境、数据准备
+#### 3.1.1 代码准备
+首先,我们需要准备训练表格属性的代码,PaddleClas集成了PULC方案,该方案可以快速获得一个在CPU上用时2ms的属性识别模型。PaddleClas代码可以clone下载得到。获取方式如下:
+
+
+
+```python
+! git clone -b develop https://gitee.com/paddlepaddle/PaddleClas
+```
+
+#### 3.1.2 环境准备
+其次,我们需要安装训练PaddleClas相关的依赖包
+
+
+```python
+! pip install -r PaddleClas/requirements.txt --force-reinstall
+! pip install protobuf==3.20.0
+```
+
+
+#### 3.1.3 数据准备
+
+最后,准备训练数据。在这里,我们一共定义了表格的6个属性,分别是表格来源、表格数量、表格颜色、表格清晰度、表格有无干扰、表格角度。其可视化如下:
+
+
+
+这里,我们提供了一个表格属性的demo子集,可以快速迭代体验。下载方式如下:
+
+
+```python
+%cd PaddleClas/dataset
+!wget https://paddleclas.bj.bcebos.com/data/PULC/table_attribute.tar
+!tar -xf table_attribute.tar
+%cd ../PaddleClas/dataset
+%cd ../
+```
+
+### 3.2 表格属性识别训练
+表格属性训练整体pipelinie如下:
+
+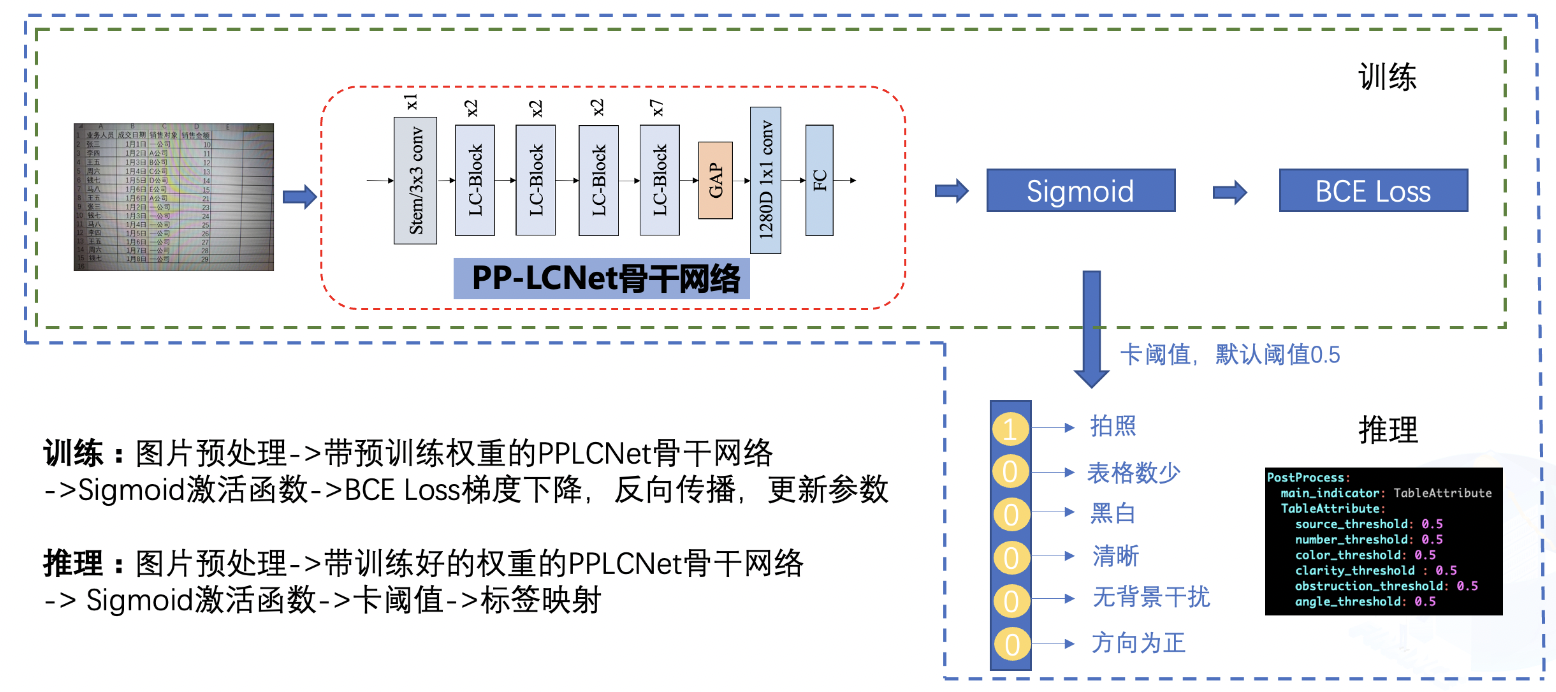
+
+1.训练过程中,图片经过预处理之后,送入到骨干网络之中,骨干网络将抽取表格图片的特征,最终该特征连接输出的FC层,FC层经过Sigmoid激活函数后和真实标签做交叉熵损失函数,优化器通过对该损失函数做梯度下降来更新骨干网络的参数,经过多轮训练后,骨干网络的参数可以对为止图片做很好的预测;
+
+2.推理过程中,图片经过预处理之后,送入到骨干网络之中,骨干网络加载学习好的权重后对该表格图片做出预测,预测的结果为一个6维向量,该向量中的每个元素反映了每个属性对应的概率值,通过对该值进一步卡阈值之后,得到最终的输出,最终的输出描述了该表格的6个属性。
+
+当准备好相关的数据之后,可以一键启动表格属性的训练,训练代码如下:
+
+
+```python
+
+!python tools/train.py -c ./ppcls/configs/PULC/table_attribute/PPLCNet_x1_0.yaml -o Global.device=cpu -o Global.epochs=10
+```
+
+### 3.3 表格属性识别推理和部署
+#### 3.3.1 模型转换
+当训练好模型之后,需要将模型转换为推理模型进行部署。转换脚本如下:
+
+
+```python
+!python tools/export_model.py -c ppcls/configs/PULC/table_attribute/PPLCNet_x1_0.yaml -o Global.pretrained_model=output/PPLCNet_x1_0/best_model
+```
+
+执行以上命令之后,会在当前目录上生成`inference`文件夹,该文件夹中保存了当前精度最高的推理模型。
+
+#### 3.3.2 模型推理
+安装推理需要的paddleclas包, 此时需要通过下载安装paddleclas的develop的whl包
+
+
+
+```python
+!pip install https://paddleclas.bj.bcebos.com/whl/paddleclas-0.0.0-py3-none-any.whl
+```
+
+进入`deploy`目录下即可对模型进行推理
+
+
+```python
+%cd deploy/
+```
+
+推理命令如下:
+
+
+```python
+!python python/predict_cls.py -c configs/PULC/table_attribute/inference_table_attribute.yaml -o Global.inference_model_dir="../inference" -o Global.infer_imgs="../dataset/table_attribute/Table_val/val_9.jpg"
+!python python/predict_cls.py -c configs/PULC/table_attribute/inference_table_attribute.yaml -o Global.inference_model_dir="../inference" -o Global.infer_imgs="../dataset/table_attribute/Table_val/val_3253.jpg"
+```
+
+推理的表格图片:
+
+
+
+预测结果如下:
+```
+val_9.jpg: {'attributes': ['Scanned', 'Little', 'Black-and-White', 'Clear', 'Without-Obstacles', 'Horizontal'], 'output': [1, 1, 1, 1, 1, 1]}
+```
+
+
+推理的表格图片:
+
+
+
+预测结果如下:
+```
+val_3253.jpg: {'attributes': ['Photo', 'Little', 'Black-and-White', 'Blurry', 'Without-Obstacles', 'Tilted'], 'output': [0, 1, 1, 0, 1, 0]}
+```
+
+对比两张图片可以发现,第一张图片比较清晰,表格属性的结果也偏向于比较容易识别,我们可以更相信表格识别的结果,第二张图片比较模糊,且存在倾斜现象,表格识别可能存在错误,需要我们人工进一步校验。通过表格的属性识别能力,可以进一步将“人工”和“智能”很好的结合起来,为表格识别能力的落地的精度提供保障。
diff --git "a/applications/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253/corpus/digital.txt" "b/applications/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253/corpus/digital.txt"
new file mode 100644
index 0000000..26b06e7
--- /dev/null
+++ "b/applications/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253/corpus/digital.txt"
@@ -0,0 +1,43 @@
+46.39
+40.08
+89.52
+-71.93
+23.19
+-81.02
+-34.09
+05.87
+-67.80
+-51.56
+-34.58
+37.91
+56.98
+29.01
+-90.13
+35.55
+66.07
+-90.35
+-50.93
+42.42
+21.40
+-30.99
+-71.78
+25.60
+-48.69
+-72.28
+-17.55
+-99.93
+-47.35
+-64.89
+-31.28
+-90.01
+05.17
+30.91
+30.56
+-06.90
+79.05
+67.74
+-32.31
+94.22
+28.75
+51.03
+-58.96
diff --git "a/applications/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253/fonts/DS-DIGI.TTF" "b/applications/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253/fonts/DS-DIGI.TTF"
new file mode 100644
index 0000000..0925877
Binary files /dev/null and "b/applications/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253/fonts/DS-DIGI.TTF" differ
diff --git "a/applications/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253/fonts/DS-DIGIB.TTF" "b/applications/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253/fonts/DS-DIGIB.TTF"
new file mode 100644
index 0000000..064ad47
Binary files /dev/null and "b/applications/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253/fonts/DS-DIGIB.TTF" differ
diff --git "a/applications/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253.md" "b/applications/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253.md"
new file mode 100644
index 0000000..25e32cf
--- /dev/null
+++ "b/applications/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253/\345\205\211\345\212\237\347\216\207\350\256\241\346\225\260\347\240\201\347\256\241\345\255\227\347\254\246\350\257\206\345\210\253.md"
@@ -0,0 +1,467 @@
+# 光功率计数码管字符识别
+
+本案例将使用OCR技术自动识别光功率计显示屏文字,通过本章您可以掌握:
+
+- PaddleOCR快速使用
+- 数据合成方法
+- 数据挖掘方法
+- 基于现有数据微调
+
+## 1. 背景介绍
+
+光功率计(optical power meter )是指用于测量绝对光功率或通过一段光纤的光功率相对损耗的仪器。在光纤系统中,测量光功率是最基本的,非常像电子学中的万用表;在光纤测量中,光功率计是重负荷常用表。
+
+ +
+目前光功率计缺少将数据直接输出的功能,需要人工读数。这一项工作单调重复,如果可以使用机器替代人工,将节约大量成本。针对上述问题,希望通过摄像头拍照->智能读数的方式高效地完成此任务。
+
+为实现智能读数,通常会采取文本检测+文本识别的方案:
+
+第一步,使用文本检测模型定位出光功率计中的数字部分;
+
+第二步,使用文本识别模型获得准确的数字和单位信息。
+
+本项目主要介绍如何完成第二步文本识别部分,包括:真实评估集的建立、训练数据的合成、基于 PP-OCRv3 和 SVTR_Tiny 两个模型进行训练,以及评估和推理。
+
+本项目难点如下:
+
+- 光功率计数码管字符数据较少,难以获取。
+- 数码管中小数点占像素较少,容易漏识别。
+
+针对以上问题, 本例选用 PP-OCRv3 和 SVTR_Tiny 两个高精度模型训练,同时提供了真实数据挖掘案例和数据合成案例。基于 PP-OCRv3 模型,在构建的真实评估集上精度从 52% 提升至 72%,SVTR_Tiny 模型精度可达到 78.9%。
+
+aistudio项目链接: [光功率计数码管字符识别](https://aistudio.baidu.com/aistudio/projectdetail/4049044?contributionType=1)
+
+## 2. PaddleOCR 快速使用
+
+PaddleOCR 旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
+
+
+
+
+官方提供了适用于通用场景的高精轻量模型,首先使用官方提供的 PP-OCRv3 模型预测图片,验证下当前模型在光功率计场景上的效果。
+
+- 准备环境
+
+```
+python3 -m pip install -U pip
+python3 -m pip install paddleocr
+```
+
+
+- 测试效果
+
+测试图:
+
+
+
+
+```
+paddleocr --lang=ch --det=Fase --image_dir=data
+```
+
+得到如下测试结果:
+
+```
+('.7000', 0.6885431408882141)
+```
+
+发现数字识别较准,然而对负号和小数点识别不准确。 由于PP-OCRv3的训练数据大多为通用场景数据,在特定的场景上效果可能不够好。因此需要基于场景数据进行微调。
+
+下面就主要介绍如何在光功率计(数码管)场景上微调训练。
+
+
+## 3. 开始训练
+
+### 3.1 数据准备
+
+特定的工业场景往往很难获取开源的真实数据集,光功率计也是如此。在实际工业场景中,可以通过摄像头采集的方法收集大量真实数据,本例中重点介绍数据合成方法和真实数据挖掘方法,如何利用有限的数据优化模型精度。
+
+数据集分为两个部分:合成数据,真实数据, 其中合成数据由 text_renderer 工具批量生成得到, 真实数据通过爬虫等方式在百度图片中搜索并使用 PPOCRLabel 标注得到。
+
+
+- 合成数据
+
+本例中数据合成工具使用的是 [text_renderer](https://github.com/Sanster/text_renderer), 该工具可以合成用于文本识别训练的文本行数据:
+
+
+
+
+
+
+```
+export https_proxy=http://172.19.57.45:3128
+git clone https://github.com/oh-my-ocr/text_renderer
+```
+
+```
+import os
+python3 setup.py develop
+python3 -m pip install -r docker/requirements.txt
+python3 main.py \
+ --config example_data/example.py \
+ --dataset img \
+ --num_processes 2 \
+ --log_period 10
+```
+
+给定字体和语料,就可以合成较为丰富样式的文本行数据。 光功率计识别场景,目标是正确识别数码管文本,因此需要收集部分数码管字体,训练语料,用于合成文本识别数据。
+
+将收集好的语料存放在 example_data 路径下:
+
+```
+ln -s ./fonts/DS* text_renderer/example_data/font/
+ln -s ./corpus/digital.txt text_renderer/example_data/text/
+```
+
+修改 text_renderer/example_data/font_list/font_list.txt ,选择需要的字体开始合成:
+
+```
+python3 main.py \
+ --config example_data/digital_example.py \
+ --dataset img \
+ --num_processes 2 \
+ --log_period 10
+```
+
+合成图片会被存在目录 text_renderer/example_data/digital/chn_data 下
+
+查看合成的数据样例:
+
+
+
+
+- 真实数据挖掘
+
+模型训练需要使用真实数据作为评价指标,否则很容易过拟合到简单的合成数据中。没有开源数据的情况下,可以利用部分无标注数据+标注工具获得真实数据。
+
+
+1. 数据搜集
+
+使用[爬虫工具](https://github.com/Joeclinton1/google-images-download.git)获得无标注数据
+
+2. [PPOCRLabel](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.5/PPOCRLabel) 完成半自动标注
+
+PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注、表格标注、不规则文本标注、关键信息标注模式,导出格式可直接用于PaddleOCR检测和识别模型的训练。
+
+
+
+
+收集完数据后就可以进行分配了,验证集中一般都是真实数据,训练集中包含合成数据+真实数据。本例中标注了155张图片,其中训练集和验证集的数目为100和55。
+
+
+最终 `data` 文件夹应包含以下几部分:
+
+```
+|-data
+ |- synth_train.txt
+ |- real_train.txt
+ |- real_eval.txt
+ |- synthetic_data
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+ |- real_data
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+ ...
+```
+
+### 3.2 模型选择
+
+本案例提供了2种文本识别模型:PP-OCRv3 识别模型 和 SVTR_Tiny:
+
+[PP-OCRv3 识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md):PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。并进行了一系列结构改进加速模型预测。
+
+[SVTR_Tiny](https://arxiv.org/abs/2205.00159):SVTR提出了一种用于场景文本识别的单视觉模型,该模型在patch-wise image tokenization框架内,完全摒弃了序列建模,在精度具有竞争力的前提下,模型参数量更少,速度更快。
+
+以上两个策略在自建中文数据集上的精度和速度对比如下:
+
+| ID | 策略 | 模型大小 | 精度 | 预测耗时(CPU + MKLDNN)|
+|-----|-----|--------|----| --- |
+| 01 | PP-OCRv2 | 8M | 74.80% | 8.54ms |
+| 02 | SVTR_Tiny | 21M | 80.10% | 97.00ms |
+| 03 | SVTR_LCNet(h32) | 12M | 71.90% | 6.60ms |
+| 04 | SVTR_LCNet(h48) | 12M | 73.98% | 7.60ms |
+| 05 | + GTC | 12M | 75.80% | 7.60ms |
+| 06 | + TextConAug | 12M | 76.30% | 7.60ms |
+| 07 | + TextRotNet | 12M | 76.90% | 7.60ms |
+| 08 | + UDML | 12M | 78.40% | 7.60ms |
+| 09 | + UIM | 12M | 79.40% | 7.60ms |
+
+
+### 3.3 开始训练
+
+首先下载 PaddleOCR 代码库
+
+```
+git clone -b release/2.5 https://github.com/PaddlePaddle/PaddleOCR.git
+```
+
+PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以 PP-OCRv3 中文识别模型为例:
+
+**Step1:下载预训练模型**
+
+首先下载 pretrain model,您可以下载训练好的模型在自定义数据上进行finetune
+
+```
+cd PaddleOCR/
+# 下载PP-OCRv3 中文预训练模型
+wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
+# 解压模型参数
+cd pretrain_models
+tar -xf ch_PP-OCRv3_rec_train.tar && rm -rf ch_PP-OCRv3_rec_train.tar
+```
+
+**Step2:自定义字典文件**
+
+接下来需要提供一个字典({word_dict_name}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。
+
+因此字典需要包含所有希望被正确识别的字符,{word_dict_name}.txt需要写成如下格式,并以 `utf-8` 编码格式保存:
+
+```
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+-
+.
+```
+
+word_dict.txt 每行有一个单字,将字符与数字索引映射在一起,“3.14” 将被映射成 [3, 11, 1, 4]
+
+* 内置字典
+
+PaddleOCR内置了一部分字典,可以按需使用。
+
+`ppocr/utils/ppocr_keys_v1.txt` 是一个包含6623个字符的中文字典
+
+`ppocr/utils/ic15_dict.txt` 是一个包含36个字符的英文字典
+
+* 自定义字典
+
+内置字典面向通用场景,具体的工业场景中,可能需要识别特殊字符,或者只需识别某几个字符,此时自定义字典会更提升模型精度。例如在光功率计场景中,需要识别数字和单位。
+
+遍历真实数据标签中的字符,制作字典`digital_dict.txt`如下所示:
+
+```
+-
+.
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+B
+E
+F
+H
+L
+N
+T
+W
+d
+k
+m
+n
+o
+z
+```
+
+
+
+
+**Step3:修改配置文件**
+
+为了更好的使用预训练模型,训练推荐使用[ch_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml)配置文件,并参考下列说明修改配置文件:
+
+以 `ch_PP-OCRv3_rec_distillation.yml` 为例:
+```
+Global:
+ ...
+ # 添加自定义字典,如修改字典请将路径指向新字典
+ character_dict_path: ppocr/utils/dict/digital_dict.txt
+ ...
+ # 识别空格
+ use_space_char: True
+
+
+Optimizer:
+ ...
+ # 添加学习率衰减策略
+ lr:
+ name: Cosine
+ learning_rate: 0.001
+ ...
+
+...
+
+Train:
+ dataset:
+ # 数据集格式,支持LMDBDataSet以及SimpleDataSet
+ name: SimpleDataSet
+ # 数据集路径
+ data_dir: ./data/
+ # 训练集标签文件
+ label_file_list:
+ - ./train_data/digital_img/digital_train.txt #11w
+ - ./train_data/digital_img/real_train.txt #100
+ - ./train_data/digital_img/dbm_img/dbm.txt #3w
+ ratio_list:
+ - 0.3
+ - 1.0
+ - 1.0
+ transforms:
+ ...
+ - RecResizeImg:
+ # 修改 image_shape 以适应长文本
+ image_shape: [3, 48, 320]
+ ...
+ loader:
+ ...
+ # 单卡训练的batch_size
+ batch_size_per_card: 256
+ ...
+
+Eval:
+ dataset:
+ # 数据集格式,支持LMDBDataSet以及SimpleDataSet
+ name: SimpleDataSet
+ # 数据集路径
+ data_dir: ./data
+ # 验证集标签文件
+ label_file_list:
+ - ./train_data/digital_img/real_val.txt
+ transforms:
+ ...
+ - RecResizeImg:
+ # 修改 image_shape 以适应长文本
+ image_shape: [3, 48, 320]
+ ...
+ loader:
+ # 单卡验证的batch_size
+ batch_size_per_card: 256
+ ...
+```
+**注意,训练/预测/评估时的配置文件请务必与训练一致。**
+
+**Step4:启动训练**
+
+*如果您安装的是cpu版本,请将配置文件中的 `use_gpu` 字段修改为false*
+
+```
+# GPU训练 支持单卡,多卡训练
+# 训练数码管数据 训练日志会自动保存为 "{save_model_dir}" 下的train.log
+
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
+```
+
+
+PaddleOCR支持训练和评估交替进行, 可以在 `configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml` 中修改 `eval_batch_step` 设置评估频率,默认每500个iter评估一次。评估过程中默认将最佳acc模型,保存为 `output/ch_PP-OCRv3_rec_distill/best_accuracy` 。
+
+如果验证集很大,测试将会比较耗时,建议减少评估次数,或训练完再进行评估。
+
+### SVTR_Tiny 训练
+
+SVTR_Tiny 训练步骤与上面一致,SVTR支持的配置和模型训练权重可以参考[算法介绍文档](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/algorithm_rec_svtr.md)
+
+**Step1:下载预训练模型**
+
+```
+# 下载 SVTR_Tiny 中文识别预训练模型和配置文件
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/rec_svtr_tiny_none_ctc_ch_train.tar
+# 解压模型参数
+tar -xf rec_svtr_tiny_none_ctc_ch_train.tar && rm -rf rec_svtr_tiny_none_ctc_ch_train.tar
+```
+**Step2:自定义字典文件**
+
+字典依然使用自定义的 digital_dict.txt
+
+**Step3:修改配置文件**
+
+配置文件中对应修改字典路径和数据路径
+
+**Step4:启动训练**
+
+```
+## 单卡训练
+python tools/train.py -c rec_svtr_tiny_none_ctc_ch_train/rec_svtr_tiny_6local_6global_stn_ch.yml \
+ -o Global.pretrained_model=./rec_svtr_tiny_none_ctc_ch_train/best_accuracy
+```
+
+### 3.4 验证效果
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+目前光功率计缺少将数据直接输出的功能,需要人工读数。这一项工作单调重复,如果可以使用机器替代人工,将节约大量成本。针对上述问题,希望通过摄像头拍照->智能读数的方式高效地完成此任务。
+
+为实现智能读数,通常会采取文本检测+文本识别的方案:
+
+第一步,使用文本检测模型定位出光功率计中的数字部分;
+
+第二步,使用文本识别模型获得准确的数字和单位信息。
+
+本项目主要介绍如何完成第二步文本识别部分,包括:真实评估集的建立、训练数据的合成、基于 PP-OCRv3 和 SVTR_Tiny 两个模型进行训练,以及评估和推理。
+
+本项目难点如下:
+
+- 光功率计数码管字符数据较少,难以获取。
+- 数码管中小数点占像素较少,容易漏识别。
+
+针对以上问题, 本例选用 PP-OCRv3 和 SVTR_Tiny 两个高精度模型训练,同时提供了真实数据挖掘案例和数据合成案例。基于 PP-OCRv3 模型,在构建的真实评估集上精度从 52% 提升至 72%,SVTR_Tiny 模型精度可达到 78.9%。
+
+aistudio项目链接: [光功率计数码管字符识别](https://aistudio.baidu.com/aistudio/projectdetail/4049044?contributionType=1)
+
+## 2. PaddleOCR 快速使用
+
+PaddleOCR 旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
+
+
+
+
+官方提供了适用于通用场景的高精轻量模型,首先使用官方提供的 PP-OCRv3 模型预测图片,验证下当前模型在光功率计场景上的效果。
+
+- 准备环境
+
+```
+python3 -m pip install -U pip
+python3 -m pip install paddleocr
+```
+
+
+- 测试效果
+
+测试图:
+
+
+
+
+```
+paddleocr --lang=ch --det=Fase --image_dir=data
+```
+
+得到如下测试结果:
+
+```
+('.7000', 0.6885431408882141)
+```
+
+发现数字识别较准,然而对负号和小数点识别不准确。 由于PP-OCRv3的训练数据大多为通用场景数据,在特定的场景上效果可能不够好。因此需要基于场景数据进行微调。
+
+下面就主要介绍如何在光功率计(数码管)场景上微调训练。
+
+
+## 3. 开始训练
+
+### 3.1 数据准备
+
+特定的工业场景往往很难获取开源的真实数据集,光功率计也是如此。在实际工业场景中,可以通过摄像头采集的方法收集大量真实数据,本例中重点介绍数据合成方法和真实数据挖掘方法,如何利用有限的数据优化模型精度。
+
+数据集分为两个部分:合成数据,真实数据, 其中合成数据由 text_renderer 工具批量生成得到, 真实数据通过爬虫等方式在百度图片中搜索并使用 PPOCRLabel 标注得到。
+
+
+- 合成数据
+
+本例中数据合成工具使用的是 [text_renderer](https://github.com/Sanster/text_renderer), 该工具可以合成用于文本识别训练的文本行数据:
+
+
+
+
+
+
+```
+export https_proxy=http://172.19.57.45:3128
+git clone https://github.com/oh-my-ocr/text_renderer
+```
+
+```
+import os
+python3 setup.py develop
+python3 -m pip install -r docker/requirements.txt
+python3 main.py \
+ --config example_data/example.py \
+ --dataset img \
+ --num_processes 2 \
+ --log_period 10
+```
+
+给定字体和语料,就可以合成较为丰富样式的文本行数据。 光功率计识别场景,目标是正确识别数码管文本,因此需要收集部分数码管字体,训练语料,用于合成文本识别数据。
+
+将收集好的语料存放在 example_data 路径下:
+
+```
+ln -s ./fonts/DS* text_renderer/example_data/font/
+ln -s ./corpus/digital.txt text_renderer/example_data/text/
+```
+
+修改 text_renderer/example_data/font_list/font_list.txt ,选择需要的字体开始合成:
+
+```
+python3 main.py \
+ --config example_data/digital_example.py \
+ --dataset img \
+ --num_processes 2 \
+ --log_period 10
+```
+
+合成图片会被存在目录 text_renderer/example_data/digital/chn_data 下
+
+查看合成的数据样例:
+
+
+
+
+- 真实数据挖掘
+
+模型训练需要使用真实数据作为评价指标,否则很容易过拟合到简单的合成数据中。没有开源数据的情况下,可以利用部分无标注数据+标注工具获得真实数据。
+
+
+1. 数据搜集
+
+使用[爬虫工具](https://github.com/Joeclinton1/google-images-download.git)获得无标注数据
+
+2. [PPOCRLabel](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.5/PPOCRLabel) 完成半自动标注
+
+PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注、表格标注、不规则文本标注、关键信息标注模式,导出格式可直接用于PaddleOCR检测和识别模型的训练。
+
+
+
+
+收集完数据后就可以进行分配了,验证集中一般都是真实数据,训练集中包含合成数据+真实数据。本例中标注了155张图片,其中训练集和验证集的数目为100和55。
+
+
+最终 `data` 文件夹应包含以下几部分:
+
+```
+|-data
+ |- synth_train.txt
+ |- real_train.txt
+ |- real_eval.txt
+ |- synthetic_data
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+ |- real_data
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+ ...
+```
+
+### 3.2 模型选择
+
+本案例提供了2种文本识别模型:PP-OCRv3 识别模型 和 SVTR_Tiny:
+
+[PP-OCRv3 识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md):PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。并进行了一系列结构改进加速模型预测。
+
+[SVTR_Tiny](https://arxiv.org/abs/2205.00159):SVTR提出了一种用于场景文本识别的单视觉模型,该模型在patch-wise image tokenization框架内,完全摒弃了序列建模,在精度具有竞争力的前提下,模型参数量更少,速度更快。
+
+以上两个策略在自建中文数据集上的精度和速度对比如下:
+
+| ID | 策略 | 模型大小 | 精度 | 预测耗时(CPU + MKLDNN)|
+|-----|-----|--------|----| --- |
+| 01 | PP-OCRv2 | 8M | 74.80% | 8.54ms |
+| 02 | SVTR_Tiny | 21M | 80.10% | 97.00ms |
+| 03 | SVTR_LCNet(h32) | 12M | 71.90% | 6.60ms |
+| 04 | SVTR_LCNet(h48) | 12M | 73.98% | 7.60ms |
+| 05 | + GTC | 12M | 75.80% | 7.60ms |
+| 06 | + TextConAug | 12M | 76.30% | 7.60ms |
+| 07 | + TextRotNet | 12M | 76.90% | 7.60ms |
+| 08 | + UDML | 12M | 78.40% | 7.60ms |
+| 09 | + UIM | 12M | 79.40% | 7.60ms |
+
+
+### 3.3 开始训练
+
+首先下载 PaddleOCR 代码库
+
+```
+git clone -b release/2.5 https://github.com/PaddlePaddle/PaddleOCR.git
+```
+
+PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以 PP-OCRv3 中文识别模型为例:
+
+**Step1:下载预训练模型**
+
+首先下载 pretrain model,您可以下载训练好的模型在自定义数据上进行finetune
+
+```
+cd PaddleOCR/
+# 下载PP-OCRv3 中文预训练模型
+wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
+# 解压模型参数
+cd pretrain_models
+tar -xf ch_PP-OCRv3_rec_train.tar && rm -rf ch_PP-OCRv3_rec_train.tar
+```
+
+**Step2:自定义字典文件**
+
+接下来需要提供一个字典({word_dict_name}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。
+
+因此字典需要包含所有希望被正确识别的字符,{word_dict_name}.txt需要写成如下格式,并以 `utf-8` 编码格式保存:
+
+```
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+-
+.
+```
+
+word_dict.txt 每行有一个单字,将字符与数字索引映射在一起,“3.14” 将被映射成 [3, 11, 1, 4]
+
+* 内置字典
+
+PaddleOCR内置了一部分字典,可以按需使用。
+
+`ppocr/utils/ppocr_keys_v1.txt` 是一个包含6623个字符的中文字典
+
+`ppocr/utils/ic15_dict.txt` 是一个包含36个字符的英文字典
+
+* 自定义字典
+
+内置字典面向通用场景,具体的工业场景中,可能需要识别特殊字符,或者只需识别某几个字符,此时自定义字典会更提升模型精度。例如在光功率计场景中,需要识别数字和单位。
+
+遍历真实数据标签中的字符,制作字典`digital_dict.txt`如下所示:
+
+```
+-
+.
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+B
+E
+F
+H
+L
+N
+T
+W
+d
+k
+m
+n
+o
+z
+```
+
+
+
+
+**Step3:修改配置文件**
+
+为了更好的使用预训练模型,训练推荐使用[ch_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml)配置文件,并参考下列说明修改配置文件:
+
+以 `ch_PP-OCRv3_rec_distillation.yml` 为例:
+```
+Global:
+ ...
+ # 添加自定义字典,如修改字典请将路径指向新字典
+ character_dict_path: ppocr/utils/dict/digital_dict.txt
+ ...
+ # 识别空格
+ use_space_char: True
+
+
+Optimizer:
+ ...
+ # 添加学习率衰减策略
+ lr:
+ name: Cosine
+ learning_rate: 0.001
+ ...
+
+...
+
+Train:
+ dataset:
+ # 数据集格式,支持LMDBDataSet以及SimpleDataSet
+ name: SimpleDataSet
+ # 数据集路径
+ data_dir: ./data/
+ # 训练集标签文件
+ label_file_list:
+ - ./train_data/digital_img/digital_train.txt #11w
+ - ./train_data/digital_img/real_train.txt #100
+ - ./train_data/digital_img/dbm_img/dbm.txt #3w
+ ratio_list:
+ - 0.3
+ - 1.0
+ - 1.0
+ transforms:
+ ...
+ - RecResizeImg:
+ # 修改 image_shape 以适应长文本
+ image_shape: [3, 48, 320]
+ ...
+ loader:
+ ...
+ # 单卡训练的batch_size
+ batch_size_per_card: 256
+ ...
+
+Eval:
+ dataset:
+ # 数据集格式,支持LMDBDataSet以及SimpleDataSet
+ name: SimpleDataSet
+ # 数据集路径
+ data_dir: ./data
+ # 验证集标签文件
+ label_file_list:
+ - ./train_data/digital_img/real_val.txt
+ transforms:
+ ...
+ - RecResizeImg:
+ # 修改 image_shape 以适应长文本
+ image_shape: [3, 48, 320]
+ ...
+ loader:
+ # 单卡验证的batch_size
+ batch_size_per_card: 256
+ ...
+```
+**注意,训练/预测/评估时的配置文件请务必与训练一致。**
+
+**Step4:启动训练**
+
+*如果您安装的是cpu版本,请将配置文件中的 `use_gpu` 字段修改为false*
+
+```
+# GPU训练 支持单卡,多卡训练
+# 训练数码管数据 训练日志会自动保存为 "{save_model_dir}" 下的train.log
+
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
+```
+
+
+PaddleOCR支持训练和评估交替进行, 可以在 `configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml` 中修改 `eval_batch_step` 设置评估频率,默认每500个iter评估一次。评估过程中默认将最佳acc模型,保存为 `output/ch_PP-OCRv3_rec_distill/best_accuracy` 。
+
+如果验证集很大,测试将会比较耗时,建议减少评估次数,或训练完再进行评估。
+
+### SVTR_Tiny 训练
+
+SVTR_Tiny 训练步骤与上面一致,SVTR支持的配置和模型训练权重可以参考[算法介绍文档](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/algorithm_rec_svtr.md)
+
+**Step1:下载预训练模型**
+
+```
+# 下载 SVTR_Tiny 中文识别预训练模型和配置文件
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/rec_svtr_tiny_none_ctc_ch_train.tar
+# 解压模型参数
+tar -xf rec_svtr_tiny_none_ctc_ch_train.tar && rm -rf rec_svtr_tiny_none_ctc_ch_train.tar
+```
+**Step2:自定义字典文件**
+
+字典依然使用自定义的 digital_dict.txt
+
+**Step3:修改配置文件**
+
+配置文件中对应修改字典路径和数据路径
+
+**Step4:启动训练**
+
+```
+## 单卡训练
+python tools/train.py -c rec_svtr_tiny_none_ctc_ch_train/rec_svtr_tiny_6local_6global_stn_ch.yml \
+ -o Global.pretrained_model=./rec_svtr_tiny_none_ctc_ch_train/best_accuracy
+```
+
+### 3.4 验证效果
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+
+
+ \n')
+ html.write("")
+
+ html.write("\n")
+ html.write(f'| \n GT')
+
+ for i, filename in enumerate(sorted(images_dir)):
+ if filename.endswith("txt"): continue
+ print(filename)
+
+ base = "{}".format(filename)
+ if True:
+ html.write(" | \n")
+ html.write(f'| {filename}\n GT')
+ html.write(' | GT 310\n | ' % (base))
+ html.write(" \n")
+
+ html.write('\n')
+ html.write(' \n')
+ html.write('\n\n')
+ print("ok")
+
+
+def crop_seal_from_img(label_file, data_dir, save_dir, save_gt_path):
+
+ if not os.path.exists(save_dir):
+ os.makedirs(save_dir)
+
+ datas = open(label_file, 'r').readlines()
+ all_gts = []
+ count = 0
+ for idx, line in enumerate(datas):
+ img_path, label = line.strip().split('\t')
+ img_path = os.path.join(data_dir, img_path)
+
+ label = json.loads(label)
+ src_im = cv2.imread(img_path)
+ if src_im is None:
+ continue
+
+ for c, anno in enumerate(label):
+ seal_poly = anno['seal_box']
+ txt_boxes = anno['polys']
+ txts = anno['texts']
+ ignore_tags = anno['ignore_tags']
+
+ box = poly2box(seal_poly)
+ img_crop = src_im[box[0][1]:box[2][1], box[0][0]:box[2][0], :]
+
+ save_path = os.path.join(save_dir, f"{idx}_{c}.jpg")
+ cv2.imwrite(save_path, np.array(img_crop))
+
+ img_gt = []
+ for i in range(len(txts)):
+ txt_boxes_crop = np.array(txt_boxes[i])
+ txt_boxes_crop[:, 1] -= box[0, 1]
+ txt_boxes_crop[:, 0] -= box[0, 0]
+ img_gt.append({'transcription': txts[i], "points": txt_boxes_crop.tolist(), "ignore_tag": ignore_tags[i]})
+
+ if len(img_gt) >= 1:
+ count += 1
+ save_gt = f"{os.path.basename(save_path)}\t{json.dumps(img_gt)}\n"
+
+ all_gts.append(save_gt)
+
+ print(f"The num of all image: {len(all_gts)}, and the number of useful image: {count}")
+ if not os.path.exists(os.path.dirname(save_gt_path)):
+ os.makedirs(os.path.dirname(save_gt_path))
+
+ with open(save_gt_path, "w") as f:
+ f.writelines(all_gts)
+ f.close()
+ print("Done")
+
+
+
+if __name__ == "__main__":
+
+ # 数据处理
+ gen_extract_label("./seal_labeled_datas", "./seal_labeled_datas/Label.txt", "./seal_ppocr_gt/seal_det_img.txt", "./seal_ppocr_gt/seal_ppocr_img.txt")
+ vis_seal_ppocr("./seal_labeled_datas", "./seal_ppocr_gt/seal_ppocr_img.txt", "./seal_ppocr_gt/seal_ppocr_vis/")
+ draw_html("./seal_ppocr_gt/seal_ppocr_vis/", "./vis_seal_ppocr.html")
+ seal_ppocr_img_label = "./seal_ppocr_gt/seal_ppocr_img.txt"
+ crop_seal_from_img(seal_ppocr_img_label, "./seal_labeled_datas/", "./seal_img_crop", "./seal_img_crop/label.txt")
+
+```
+
+处理完成后,生成的文件如下:
+```
+├── seal_img_crop/
+│ ├── 0_0.jpg
+│ ├── ...
+│ └── label.txt
+├── seal_ppocr_gt/
+│ ├── seal_det_img.txt
+│ ├── seal_ppocr_img.txt
+│ └── seal_ppocr_vis/
+│ ├── test1.png
+│ ├── ...
+└── vis_seal_ppocr.html
+
+```
+其中`seal_img_crop/label.txt`文件为印章识别标签文件,其内容格式为:
+```
+0_0.jpg [{"transcription": "\u7535\u5b50\u56de\u5355", "points": [[29, 73], [96, 73], [96, 90], [29, 90]], "ignore_tag": false}, {"transcription": "\u4e91\u5357\u7701\u519c\u6751\u4fe1\u7528\u793e", "points": [[9, 58], [26, 63], [30, 49], [38, 35], [47, 29], [64, 26], [81, 32], [90, 45], [94, 63], [118, 57], [110, 35], [95, 17], [67, 0], [38, 7], [21, 23], [10, 43]], "ignore_tag": false}, {"transcription": "\u4e13\u7528\u7ae0", "points": [[29, 87], [95, 87], [95, 106], [29, 106]], "ignore_tag": false}]
+```
+可以直接用于PaddleOCR的PGNet算法的训练。
+
+`seal_ppocr_gt/seal_det_img.txt`为印章检测标签文件,其内容格式为:
+```
+img/test1.png [{"polys": [[408, 232], [537, 232], [537, 352], [408, 352]], "cls": 1}]
+```
+为了使用PaddleDetection工具完成印章检测模型的训练,需要将`seal_det_img.txt`转换为COCO或者VOC的数据标注格式。
+
+可以直接使用下述代码将印章检测标注转换成VOC格式。
+
+
+```
+import numpy as np
+import json
+import cv2
+import os
+from shapely.geometry import Polygon
+
+seal_train_gt = "./seal_ppocr_gt/seal_det_img.txt"
+# 注:仅用于示例,实际使用中需要分别转换训练集和测试集的标签
+seal_valid_gt = "./seal_ppocr_gt/seal_det_img.txt"
+
+def gen_main_train_txt(mode='train'):
+ if mode == "train":
+ file_path = seal_train_gt
+ if mode in ['valid', 'test']:
+ file_path = seal_valid_gt
+
+ save_path = f"./seal_VOC/ImageSets/Main/{mode}.txt"
+ save_train_path = f"./seal_VOC/{mode}.txt"
+ if not os.path.exists(os.path.dirname(save_path)):
+ os.makedirs(os.path.dirname(save_path))
+
+ datas = open(file_path, 'r').readlines()
+ img_names = []
+ train_names = []
+ for line in datas:
+ img_name = line.strip().split('\t')[0]
+ img_name = os.path.basename(img_name)
+ (i_name, extension) = os.path.splitext(img_name)
+ t_name = 'JPEGImages/'+str(img_name)+' '+'Annotations/'+str(i_name)+'.xml\n'
+ train_names.append(t_name)
+ img_names.append(i_name + "\n")
+
+ with open(save_train_path, "w") as f:
+ f.writelines(train_names)
+ f.close()
+
+ with open(save_path, "w") as f:
+ f.writelines(img_names)
+ f.close()
+
+ print(f"{mode} save done")
+
+
+def gen_xml_label(mode='train'):
+ if mode == "train":
+ file_path = seal_train_gt
+ if mode in ['valid', 'test']:
+ file_path = seal_valid_gt
+
+ datas = open(file_path, 'r').readlines()
+ img_names = []
+ train_names = []
+ anno_path = "./seal_VOC/Annotations"
+ img_path = "./seal_VOC/JPEGImages"
+
+ if not os.path.exists(anno_path):
+ os.makedirs(anno_path)
+ if not os.path.exists(img_path):
+ os.makedirs(img_path)
+
+ for idx, line in enumerate(datas):
+ img_name, label = line.strip().split('\t')
+ img = cv2.imread(os.path.join("./seal_labeled_datas", img_name))
+ cv2.imwrite(os.path.join(img_path, os.path.basename(img_name)), img)
+ height, width, c = img.shape
+ img_name = os.path.basename(img_name)
+ (i_name, extension) = os.path.splitext(img_name)
+ label = json.loads(label)
+
+ xml_file = open(("./seal_VOC/Annotations" + '/' + i_name + '.xml'), 'w')
+ xml_file.write('\n')
+ xml_file.write(' seal_VOC\n')
+ xml_file.write(' ' + str(img_name) + '\n')
+ xml_file.write(' ' + 'Annotations/' + str(img_name) + '\n')
+ xml_file.write(' \n')
+ xml_file.write(' ' + str(width) + '\n')
+ xml_file.write(' ' + str(height) + '\n')
+ xml_file.write(' 3\n')
+ xml_file.write(' \n')
+ xml_file.write(' 0\n')
+
+ for anno in label:
+ poly = anno['polys']
+ if anno['cls'] == 1:
+ gt_cls = 'redseal'
+ xmin = np.min(np.array(poly)[:, 0])
+ ymin = np.min(np.array(poly)[:, 1])
+ xmax = np.max(np.array(poly)[:, 0])
+ ymax = np.max(np.array(poly)[:, 1])
+ xmin,ymin,xmax,ymax= int(xmin),int(ymin),int(xmax),int(ymax)
+ xml_file.write(' \n')
+ xml_file.write('')
+ xml_file.close()
+ print(f'{mode} xml save done!')
+
+
+gen_main_train_txt()
+gen_main_train_txt('valid')
+gen_xml_label('train')
+gen_xml_label('valid')
+
+```
+
+数据处理完成后,转换为VOC格式的印章检测数据存储在~/data/seal_VOC目录下,目录组织结构为:
+
+```
+├── Annotations/
+├── ImageSets/
+│ └── Main/
+│ ├── train.txt
+│ └── valid.txt
+├── JPEGImages/
+├── train.txt
+└── valid.txt
+└── label_list.txt
+```
+
+Annotations下为数据的标签,JPEGImages目录下为图像文件,label_list.txt为标注检测框类别标签文件。
+
+在接下来一节中,将介绍如何使用PaddleDetection工具库完成印章检测模型的训练。
+
+# 4. 印章检测实践
+
+在实际应用中,印章多是出现在合同,发票,公告等场景中,印章文字识别的任务需要排除图像中背景文字的影响,因此需要先检测出图像中的印章区域。
+
+
+借助PaddleDetection目标检测库可以很容易的实现印章检测任务,使用PaddleDetection训练印章检测任务流程如下:
+
+- 选择算法
+- 修改数据集配置路径
+- 启动训练
+
+
+**算法选择**
+
+PaddleDetection中有许多检测算法可以选择,考虑到每条数据中印章区域较为清晰,且考虑到性能需求。在本项目中,我们采用mobilenetv3为backbone的ppyolo算法完成印章检测任务,对应的配置文件是:configs/ppyolo/ppyolo_mbv3_large.yml
+
+
+
+**修改配置文件**
+
+配置文件中的默认数据路径是COCO,
+需要修改为印章检测的数据路径,主要修改如下:
+在配置文件'configs/ppyolo/ppyolo_mbv3_large.yml'末尾增加如下内容:
+```
+metric: VOC
+map_type: 11point
+num_classes: 2
+
+TrainDataset:
+ !VOCDataSet
+ dataset_dir: dataset/seal_VOC
+ anno_path: train.txt
+ label_list: label_list.txt
+ data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
+
+EvalDataset:
+ !VOCDataSet
+ dataset_dir: dataset/seal_VOC
+ anno_path: test.txt
+ label_list: label_list.txt
+ data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
+
+TestDataset:
+ !ImageFolder
+ anno_path: dataset/seal_VOC/label_list.txt
+```
+
+配置文件中设置的数据路径在PaddleDetection/dataset目录下,我们可以将处理后的印章检测训练数据移动到PaddleDetection/dataset目录下或者创建一个软连接。
+
+```
+!ln -s seal_VOC ./PaddleDetection/dataset/
+```
+
+另外图象中印章数量比较少,可以调整NMS后处理的检测框数量,即keep_top_k,nms_top_k 从100,1000,调整为10,100。在配置文件'configs/ppyolo/ppyolo_mbv3_large.yml'末尾增加如下内容完成后处理参数的调整
+```
+BBoxPostProcess:
+ decode:
+ name: YOLOBox
+ conf_thresh: 0.005
+ downsample_ratio: 32
+ clip_bbox: true
+ scale_x_y: 1.05
+ nms:
+ name: MultiClassNMS
+ keep_top_k: 10 # 修改前100
+ nms_threshold: 0.45
+ nms_top_k: 100 # 修改前1000
+ score_threshold: 0.005
+```
+
+
+修改完成后,需要在PaddleDetection中增加印章数据的处理代码,即在PaddleDetection/ppdet/data/source/目录下创建seal.py文件,文件中填充如下代码:
+```
+import os
+import numpy as np
+from ppdet.core.workspace import register, serializable
+from .dataset import DetDataset
+import cv2
+import json
+
+from ppdet.utils.logger import setup_logger
+logger = setup_logger(__name__)
+
+
+@register
+@serializable
+class SealDataSet(DetDataset):
+ """
+ Load dataset with COCO format.
+
+ Args:
+ dataset_dir (str): root directory for dataset.
+ image_dir (str): directory for images.
+ anno_path (str): coco annotation file path.
+ data_fields (list): key name of data dictionary, at least have 'image'.
+ sample_num (int): number of samples to load, -1 means all.
+ load_crowd (bool): whether to load crowded ground-truth.
+ False as default
+ allow_empty (bool): whether to load empty entry. False as default
+ empty_ratio (float): the ratio of empty record number to total
+ record's, if empty_ratio is out of [0. ,1.), do not sample the
+ records and use all the empty entries. 1. as default
+ """
+
+ def __init__(self,
+ dataset_dir=None,
+ image_dir=None,
+ anno_path=None,
+ data_fields=['image'],
+ sample_num=-1,
+ load_crowd=False,
+ allow_empty=False,
+ empty_ratio=1.):
+ super(SealDataSet, self).__init__(dataset_dir, image_dir, anno_path,
+ data_fields, sample_num)
+ self.load_image_only = False
+ self.load_semantic = False
+ self.load_crowd = load_crowd
+ self.allow_empty = allow_empty
+ self.empty_ratio = empty_ratio
+
+ def _sample_empty(self, records, num):
+ # if empty_ratio is out of [0. ,1.), do not sample the records
+ if self.empty_ratio < 0. or self.empty_ratio >= 1.:
+ return records
+ import random
+ sample_num = min(
+ int(num * self.empty_ratio / (1 - self.empty_ratio)), len(records))
+ records = random.sample(records, sample_num)
+ return records
+
+ def parse_dataset(self):
+ anno_path = os.path.join(self.dataset_dir, self.anno_path)
+ image_dir = os.path.join(self.dataset_dir, self.image_dir)
+
+ records = []
+ empty_records = []
+ ct = 0
+
+ assert anno_path.endswith('.txt'), \
+ 'invalid seal_gt file: ' + anno_path
+
+ all_datas = open(anno_path, 'r').readlines()
+
+ for idx, line in enumerate(all_datas):
+ im_path, label = line.strip().split('\t')
+ img_path = os.path.join(image_dir, im_path)
+ label = json.loads(label)
+ im_h, im_w, im_c = cv2.imread(img_path).shape
+
+ coco_rec = {
+ 'im_file': img_path,
+ 'im_id': np.array([idx]),
+ 'h': im_h,
+ 'w': im_w,
+ } if 'image' in self.data_fields else {}
+
+ if not self.load_image_only:
+ bboxes = []
+ for anno in label:
+ poly = anno['polys']
+ # poly to box
+ x1 = np.min(np.array(poly)[:, 0])
+ y1 = np.min(np.array(poly)[:, 1])
+ x2 = np.max(np.array(poly)[:, 0])
+ y2 = np.max(np.array(poly)[:, 1])
+ eps = 1e-5
+ if x2 - x1 > eps and y2 - y1 > eps:
+ clean_box = [
+ round(float(x), 3) for x in [x1, y1, x2, y2]
+ ]
+ anno = {'clean_box': clean_box, 'gt_cls':int(anno['cls'])}
+ bboxes.append(anno)
+ else:
+ logger.info("invalid box")
+
+ num_bbox = len(bboxes)
+ if num_bbox <= 0:
+ continue
+
+ gt_bbox = np.zeros((num_bbox, 4), dtype=np.float32)
+ gt_class = np.zeros((num_bbox, 1), dtype=np.int32)
+ is_crowd = np.zeros((num_bbox, 1), dtype=np.int32)
+ # gt_poly = [None] * num_bbox
+
+ for i, box in enumerate(bboxes):
+ gt_class[i][0] = box['gt_cls']
+ gt_bbox[i, :] = box['clean_box']
+ is_crowd[i][0] = 0
+
+ gt_rec = {
+ 'is_crowd': is_crowd,
+ 'gt_class': gt_class,
+ 'gt_bbox': gt_bbox,
+ # 'gt_poly': gt_poly,
+ }
+
+ for k, v in gt_rec.items():
+ if k in self.data_fields:
+ coco_rec[k] = v
+
+ records.append(coco_rec)
+ ct += 1
+ if self.sample_num > 0 and ct >= self.sample_num:
+ break
+ self.roidbs = records
+```
+
+**启动训练**
+
+启动单卡训练的命令为:
+```
+!python3 tools/train.py -c configs/ppyolo/ppyolo_mbv3_large.yml --eval
+
+# 分布式训练命令为:
+!python3 -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 tools/train.py -c configs/ppyolo/ppyolo_mbv3_large.yml --eval
+```
+
+训练完成后,日志中会打印模型的精度:
+
+```
+[07/05 11:42:09] ppdet.engine INFO: Eval iter: 0
+[07/05 11:42:14] ppdet.metrics.metrics INFO: Accumulating evaluatation results...
+[07/05 11:42:14] ppdet.metrics.metrics INFO: mAP(0.50, 11point) = 99.31%
+[07/05 11:42:14] ppdet.engine INFO: Total sample number: 112, averge FPS: 26.45840794253432
+[07/05 11:42:14] ppdet.engine INFO: Best test bbox ap is 0.996.
+```
+
+
+我们可以使用训练好的模型观察预测结果:
+```
+!python3 tools/infer.py -c configs/ppyolo/ppyolo_mbv3_large.yml -o weights=./output/ppyolo_mbv3_large/model_final.pdparams --img_dir=./test.jpg
+```
+预测结果如下:
+
+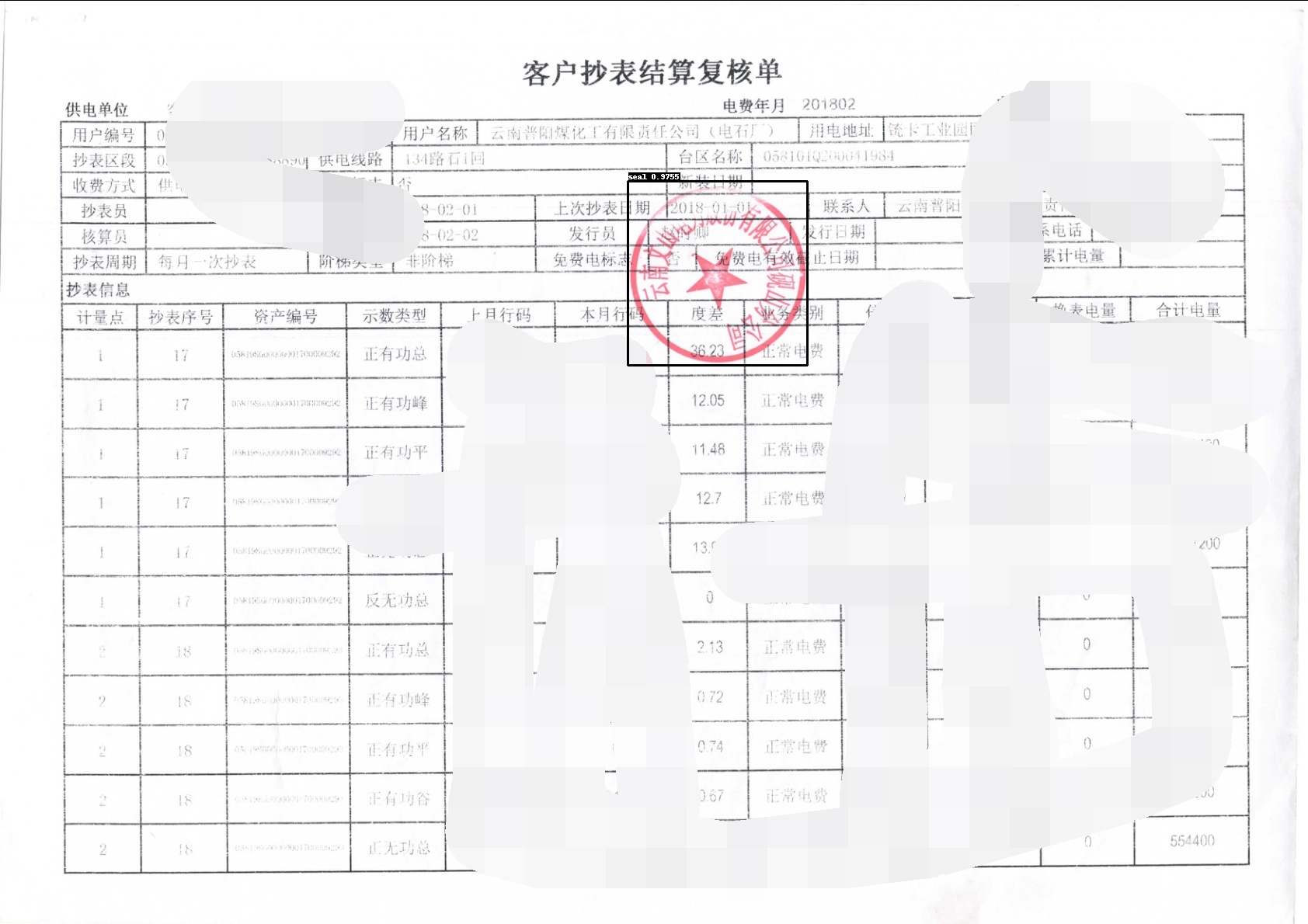
+
+# 5. 印章文字识别实践
+
+在使用ppyolo检测到印章区域后,接下来借助PaddleOCR里的文字识别能力,完成印章中文字的识别。
+
+PaddleOCR中的OCR算法包含文字检测算法,文字识别算法以及OCR端对端算法。
+
+文字检测算法负责检测到图像中的文字,再由文字识别模型识别出检测到的文字,进而实现OCR的任务。文字检测+文字识别串联完成OCR任务的架构称为两阶段的OCR算法。相对应的端对端的OCR方法可以用一个算法同时完成文字检测和识别的任务。
+
+
+| 文字检测 | 文字识别 | 端对端算法 |
+| -------- | -------- | -------- |
+| DB\DB++\EAST\SAST\PSENet | SVTR\CRNN\NRTN\Abinet\SAR\... | PGNet |
+
+
+本节中将分别介绍端对端的文字检测识别算法以及两阶段的文字检测识别算法在印章检测识别任务上的实践。
+
+
+## 5.1 端对端印章文字识别实践
+
+本节介绍使用PaddleOCR里的PGNet算法完成印章文字识别。
+
+PGNet属于端对端的文字检测识别算法,在PaddleOCR中的配置文件为:
+[PaddleOCR/configs/e2e/e2e_r50_vd_pg.yml](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/configs/e2e/e2e_r50_vd_pg.yml)
+
+使用PGNet完成文字检测识别任务的步骤为:
+- 修改配置文件
+- 启动训练
+
+PGNet默认配置文件的数据路径为totaltext数据集路径,本次训练中,需要修改为上一节数据处理后得到的标签文件和数据目录:
+
+训练数据配置修改后如下:
+```
+Train:
+ dataset:
+ name: PGDataSet
+ data_dir: ./train_data/seal_ppocr
+ label_file_list: [./train_data/seal_ppocr/seal_ppocr_img.txt]
+ ratio_list: [1.0]
+```
+测试数据集配置修改后如下:
+```
+Eval:
+ dataset:
+ name: PGDataSet
+ data_dir: ./train_data/seal_ppocr_test
+ label_file_list: [./train_data/seal_ppocr_test/seal_ppocr_img.txt]
+```
+
+启动训练的命令为:
+```
+!python3 tools/train.py -c configs/e2e/e2e_r50_vd_pg.yml
+```
+模型训练完成后,可以得到最终的精度为47.4%。数据量较少,以及数据质量较差会影响模型的训练精度,如果有更多的数据参与训练,精度将进一步提升。
+
+如需获取已训练模型,请扫文末的二维码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+## 5.2 两阶段印章文字识别实践
+
+上一节介绍了使用PGNet实现印章识别任务的训练流程。本小节将介绍使用PaddleOCR里的文字检测和文字识别算法分别完成印章文字的检测和识别。
+
+### 5.2.1 印章文字检测
+
+PaddleOCR中包含丰富的文字检测算法,包含DB,DB++,EAST,SAST,PSENet等等。其中DB,DB++,PSENet均支持弯曲文字检测,本项目中,使用DB++作为印章弯曲文字检测算法。
+
+PaddleOCR中发布的db++文字检测算法模型是英文文本检测模型,因此需要重新训练模型。
+
+
+修改[DB++配置文件](DB++的默认配置文件位于[configs/det/det_r50_db++_icdar15.yml](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/configs/det/det_r50_db%2B%2B_icdar15.yml)
+中的数据路径:
+
+
+```
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/seal_ppocr
+ label_file_list: [./train_data/seal_ppocr/seal_ppocr_img.txt]
+ ratio_list: [1.0]
+```
+测试数据集配置修改后如下:
+```
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/seal_ppocr_test
+ label_file_list: [./train_data/seal_ppocr_test/seal_ppocr_img.txt]
+```
+
+
+启动训练:
+```
+!python3 tools/train.py -c configs/det/det_r50_db++_icdar15.yml -o Global.epoch_num=100
+```
+
+考虑到数据较少,通过Global.epoch_num设置仅训练100个epoch。
+模型训练完成后,在测试集上预测的可视化效果如下:
+
+
+
+
+如需获取已训练模型,请扫文末的二维码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+### 5.2.2 印章文字识别
+
+上一节中完成了印章文字的检测模型训练,本节介绍印章文字识别模型的训练。识别模型采用SVTR算法,SVTR算法是IJCAI收录的文字识别算法,SVTR模型具备超轻量高精度的特点。
+
+在启动训练之前,需要准备印章文字识别需要的数据集,需要使用如下代码,将印章中的文字区域剪切出来构建训练集。
+
+```
+import cv2
+import numpy as np
+
+def get_rotate_crop_image(img, points):
+ '''
+ img_height, img_width = img.shape[0:2]
+ left = int(np.min(points[:, 0]))
+ right = int(np.max(points[:, 0]))
+ top = int(np.min(points[:, 1]))
+ bottom = int(np.max(points[:, 1]))
+ img_crop = img[top:bottom, left:right, :].copy()
+ points[:, 0] = points[:, 0] - left
+ points[:, 1] = points[:, 1] - top
+ '''
+ assert len(points) == 4, "shape of points must be 4*2"
+ img_crop_width = int(
+ max(
+ np.linalg.norm(points[0] - points[1]),
+ np.linalg.norm(points[2] - points[3])))
+ img_crop_height = int(
+ max(
+ np.linalg.norm(points[0] - points[3]),
+ np.linalg.norm(points[1] - points[2])))
+ pts_std = np.float32([[0, 0], [img_crop_width, 0],
+ [img_crop_width, img_crop_height],
+ [0, img_crop_height]])
+ M = cv2.getPerspectiveTransform(points, pts_std)
+ dst_img = cv2.warpPerspective(
+ img,
+ M, (img_crop_width, img_crop_height),
+ borderMode=cv2.BORDER_REPLICATE,
+ flags=cv2.INTER_CUBIC)
+ dst_img_height, dst_img_width = dst_img.shape[0:2]
+ if dst_img_height * 1.0 / dst_img_width >= 1.5:
+ dst_img = np.rot90(dst_img)
+ return dst_img
+
+
+def run(data_dir, label_file, save_dir):
+ datas = open(label_file, 'r').readlines()
+ for idx, line in enumerate(datas):
+ img_path, label = line.strip().split('\t')
+ img_path = os.path.join(data_dir, img_path)
+
+ label = json.loads(label)
+ src_im = cv2.imread(img_path)
+ if src_im is None:
+ continue
+
+ for anno in label:
+ seal_box = anno['seal_box']
+ txt_boxes = anno['polys']
+ crop_im = get_rotate_crop_image(src_im, text_boxes)
+
+ save_path = os.path.join(save_dir, f'{idx}.png')
+ if not os.path.exists(save_dir):
+ os.makedirs(save_dir)
+ # print(src_im.shape)
+ cv2.imwrite(save_path, crop_im)
+
+```
+
+
+数据处理完成后,即可配置训练的配置文件。SVTR配置文件选择[configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml)
+修改SVTR配置文件中的训练数据部分如下:
+
+```
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/seal_ppocr_crop/
+ label_file_list:
+ - ./train_data/seal_ppocr_crop/train_list.txt
+```
+
+修改预测部分配置文件:
+```
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/seal_ppocr_crop/
+ label_file_list:
+ - ./train_data/seal_ppocr_crop_test/train_list.txt
+```
+
+启动训练:
+
+```
+!python3 tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
+
+```
+
+训练完成后可以发现测试集指标达到了61%。
+由于数据较少,训练时会发现在训练集上的acc指标远大于测试集上的acc指标,即出现过拟合现象。通过补充数据和一些数据增强可以缓解这个问题。
+
+
+
+如需获取已训练模型,请扫下图二维码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+ 
+
+ 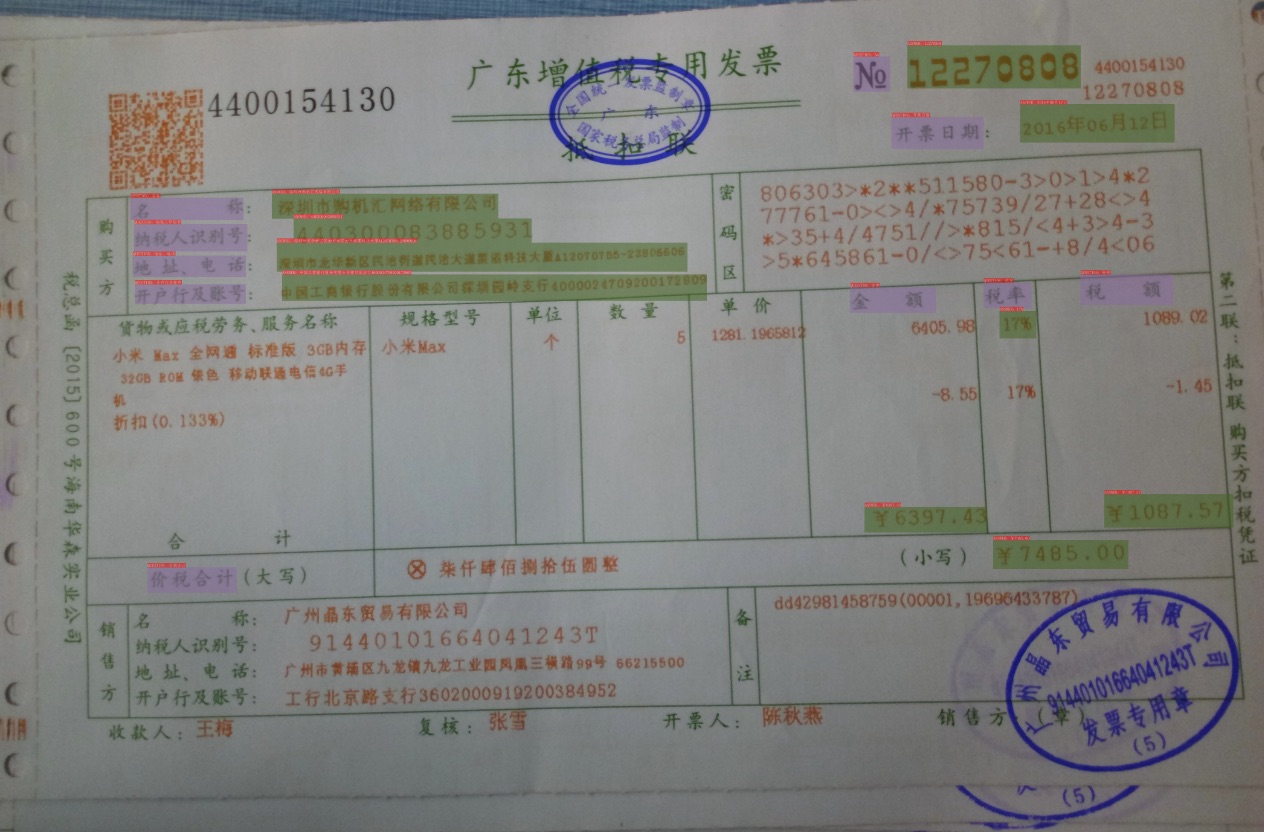
+
+ 
+
+ 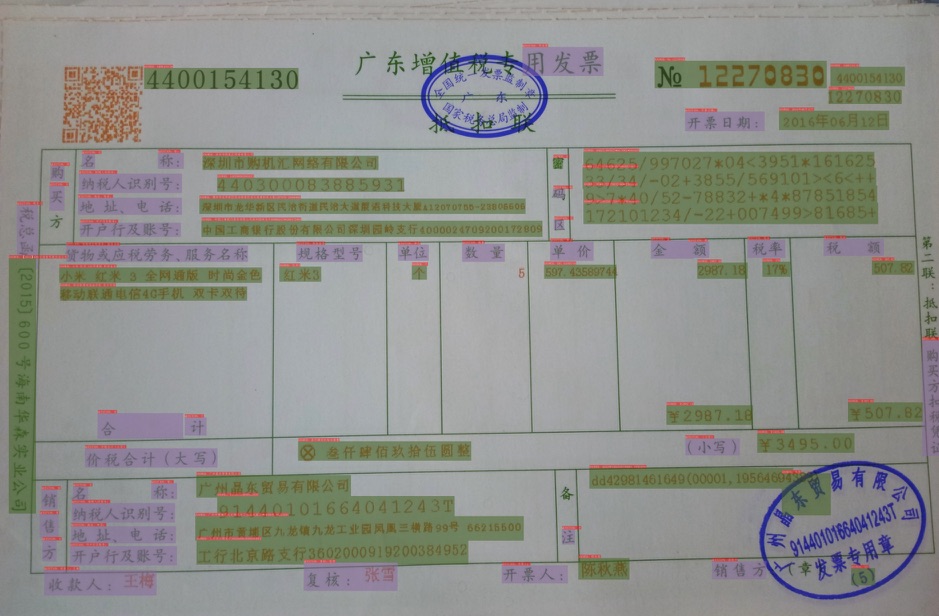
+
+ 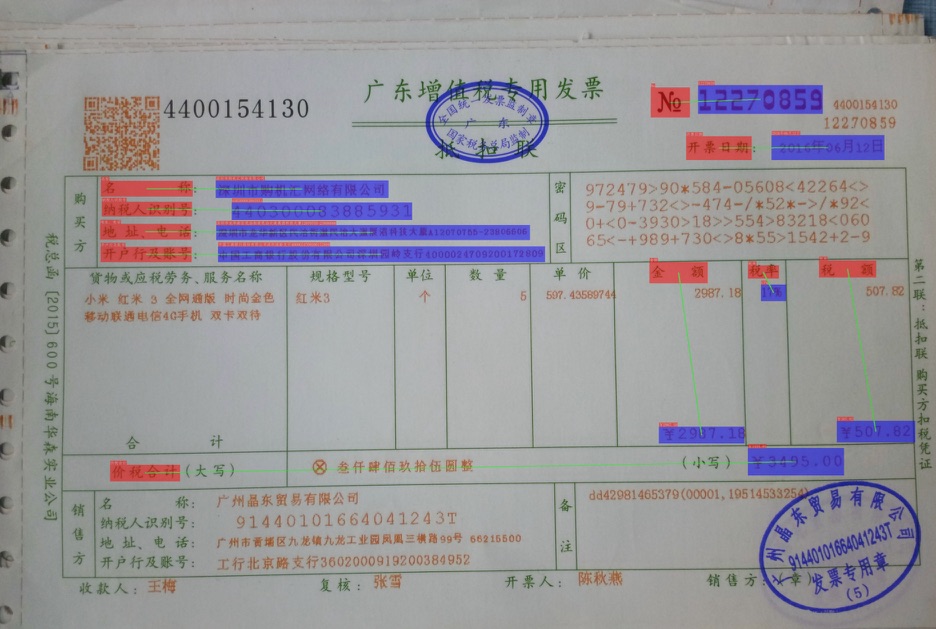
+
+
+
+
+ 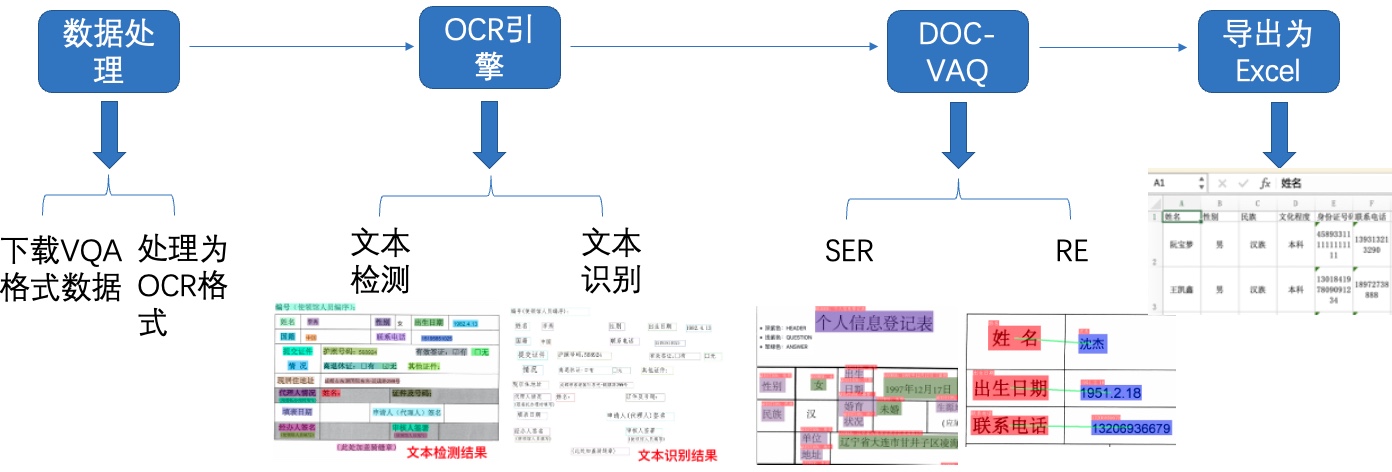 +图1 多模态表单识别流程图
+
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375?contributionType=1)
+
+## 2 安装说明
+
+
+下载PaddleOCR源码,上述AIStudio项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
+
+
+```python
+unzip -q PaddleOCR.zip
+```
+
+
+```python
+# 如仍需安装or安装更新,可以执行以下步骤
+# git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
+# git clone https://gitee.com/PaddlePaddle/PaddleOCR
+```
+
+
+```python
+# 安装依赖包
+pip install -U pip
+pip install -r /home/aistudio/PaddleOCR/requirements.txt
+pip install paddleocr
+
+pip install yacs gnureadline paddlenlp==2.2.1
+pip install xlsxwriter
+```
+
+## 3 数据准备
+
+这里使用[XFUN数据集](https://github.com/doc-analysis/XFUND)做为实验数据集。 XFUN数据集是微软提出的一个用于KIE任务的多语言数据集,共包含七个数据集,每个数据集包含149张训练集和50张验证集
+
+分别为:ZH(中文)、JA(日语)、ES(西班牙)、FR(法语)、IT(意大利)、DE(德语)、PT(葡萄牙)
+
+本次实验选取中文数据集作为我们的演示数据集。法语数据集作为实践课程的数据集,数据集样例图如 **图2** 所示。
+
+
+图1 多模态表单识别流程图
+
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375?contributionType=1)
+
+## 2 安装说明
+
+
+下载PaddleOCR源码,上述AIStudio项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
+
+
+```python
+unzip -q PaddleOCR.zip
+```
+
+
+```python
+# 如仍需安装or安装更新,可以执行以下步骤
+# git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
+# git clone https://gitee.com/PaddlePaddle/PaddleOCR
+```
+
+
+```python
+# 安装依赖包
+pip install -U pip
+pip install -r /home/aistudio/PaddleOCR/requirements.txt
+pip install paddleocr
+
+pip install yacs gnureadline paddlenlp==2.2.1
+pip install xlsxwriter
+```
+
+## 3 数据准备
+
+这里使用[XFUN数据集](https://github.com/doc-analysis/XFUND)做为实验数据集。 XFUN数据集是微软提出的一个用于KIE任务的多语言数据集,共包含七个数据集,每个数据集包含149张训练集和50张验证集
+
+分别为:ZH(中文)、JA(日语)、ES(西班牙)、FR(法语)、IT(意大利)、DE(德语)、PT(葡萄牙)
+
+本次实验选取中文数据集作为我们的演示数据集。法语数据集作为实践课程的数据集,数据集样例图如 **图2** 所示。
+
+ +图2 数据集样例,左中文,右法语
+
+### 3.1 下载处理好的数据集
+
+
+处理好的XFUND中文数据集下载地址:[https://paddleocr.bj.bcebos.com/dataset/XFUND.tar](https://paddleocr.bj.bcebos.com/dataset/XFUND.tar) ,可以运行如下指令完成中文数据集下载和解压。
+
+
+图2 数据集样例,左中文,右法语
+
+### 3.1 下载处理好的数据集
+
+
+处理好的XFUND中文数据集下载地址:[https://paddleocr.bj.bcebos.com/dataset/XFUND.tar](https://paddleocr.bj.bcebos.com/dataset/XFUND.tar) ,可以运行如下指令完成中文数据集下载和解压。
+
+ +图3 下载数据集
+
+
+```python
+wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
+tar -xf XFUND.tar
+
+# XFUN其他数据集使用下面的代码进行转换
+# 代码链接:https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.4/ppstructure/vqa/helper/trans_xfun_data.py
+# %cd PaddleOCR
+# python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
+# %cd ../
+```
+
+运行上述指令后在 /home/aistudio/PaddleOCR/ppstructure/vqa/XFUND 目录下有2个文件夹,目录结构如下所示:
+
+```bash
+/home/aistudio/PaddleOCR/ppstructure/vqa/XFUND
+ └─ zh_train/ 训练集
+ ├── image/ 图片存放文件夹
+ ├── xfun_normalize_train.json 标注信息
+ └─ zh_val/ 验证集
+ ├── image/ 图片存放文件夹
+ ├── xfun_normalize_val.json 标注信息
+
+```
+
+该数据集的标注格式为
+
+```bash
+{
+ "height": 3508, # 图像高度
+ "width": 2480, # 图像宽度
+ "ocr_info": [
+ {
+ "text": "邮政地址:", # 单个文本内容
+ "label": "question", # 文本所属类别
+ "bbox": [261, 802, 483, 859], # 单个文本框
+ "id": 54, # 文本索引
+ "linking": [[54, 60]], # 当前文本和其他文本的关系 [question, answer]
+ "words": []
+ },
+ {
+ "text": "湖南省怀化市市辖区",
+ "label": "answer",
+ "bbox": [487, 810, 862, 859],
+ "id": 60,
+ "linking": [[54, 60]],
+ "words": []
+ }
+ ]
+}
+```
+
+### 3.2 转换为PaddleOCR检测和识别格式
+
+使用XFUND训练PaddleOCR检测和识别模型,需要将数据集格式改为训练需求的格式。
+
+
+图3 下载数据集
+
+
+```python
+wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
+tar -xf XFUND.tar
+
+# XFUN其他数据集使用下面的代码进行转换
+# 代码链接:https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.4/ppstructure/vqa/helper/trans_xfun_data.py
+# %cd PaddleOCR
+# python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
+# %cd ../
+```
+
+运行上述指令后在 /home/aistudio/PaddleOCR/ppstructure/vqa/XFUND 目录下有2个文件夹,目录结构如下所示:
+
+```bash
+/home/aistudio/PaddleOCR/ppstructure/vqa/XFUND
+ └─ zh_train/ 训练集
+ ├── image/ 图片存放文件夹
+ ├── xfun_normalize_train.json 标注信息
+ └─ zh_val/ 验证集
+ ├── image/ 图片存放文件夹
+ ├── xfun_normalize_val.json 标注信息
+
+```
+
+该数据集的标注格式为
+
+```bash
+{
+ "height": 3508, # 图像高度
+ "width": 2480, # 图像宽度
+ "ocr_info": [
+ {
+ "text": "邮政地址:", # 单个文本内容
+ "label": "question", # 文本所属类别
+ "bbox": [261, 802, 483, 859], # 单个文本框
+ "id": 54, # 文本索引
+ "linking": [[54, 60]], # 当前文本和其他文本的关系 [question, answer]
+ "words": []
+ },
+ {
+ "text": "湖南省怀化市市辖区",
+ "label": "answer",
+ "bbox": [487, 810, 862, 859],
+ "id": 60,
+ "linking": [[54, 60]],
+ "words": []
+ }
+ ]
+}
+```
+
+### 3.2 转换为PaddleOCR检测和识别格式
+
+使用XFUND训练PaddleOCR检测和识别模型,需要将数据集格式改为训练需求的格式。
+
+ +图4 转换为OCR格式
+
+- **文本检测** 标注文件格式如下,中间用'\t'分隔:
+
+" 图像文件名 json.dumps编码的图像标注信息"
+ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
+
+json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 `points` 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。 `transcription` 表示当前文本框的文字,***当其内容为“###”时,表示该文本框无效,在训练时会跳过。***
+
+- **文本识别** 标注文件的格式如下, txt文件中默认请将图片路径和图片标签用'\t'分割,如用其他方式分割将造成训练报错。
+
+```
+" 图像文件名 图像标注信息 "
+
+train_data/rec/train/word_001.jpg 简单可依赖
+train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
+...
+```
+
+
+
+
+```python
+unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
+```
+
+已经提供转换脚本,执行如下代码即可转换成功:
+
+
+```python
+%cd /home/aistudio/
+python trans_xfund_data.py
+```
+
+## 4 OCR
+
+选用飞桨OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/README_ch.md)中的PP-OCRv2模型进行文本检测和识别。PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和[Enhanced CTC loss](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_ch/enhanced_ctc_loss.md)损失函数改进,进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCRv2[技术报告](https://arxiv.org/abs/2109.03144)。
+
+### 4.1 文本检测
+
+我们使用2种方案进行训练、评估:
+- **PP-OCRv2中英文超轻量检测预训练模型**
+- **XFUND数据集+fine-tune**
+
+#### 4.1.1 方案1:预训练模型
+
+**1)下载预训练模型**
+
+
+图4 转换为OCR格式
+
+- **文本检测** 标注文件格式如下,中间用'\t'分隔:
+
+" 图像文件名 json.dumps编码的图像标注信息"
+ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
+
+json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 `points` 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。 `transcription` 表示当前文本框的文字,***当其内容为“###”时,表示该文本框无效,在训练时会跳过。***
+
+- **文本识别** 标注文件的格式如下, txt文件中默认请将图片路径和图片标签用'\t'分割,如用其他方式分割将造成训练报错。
+
+```
+" 图像文件名 图像标注信息 "
+
+train_data/rec/train/word_001.jpg 简单可依赖
+train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
+...
+```
+
+
+
+
+```python
+unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
+```
+
+已经提供转换脚本,执行如下代码即可转换成功:
+
+
+```python
+%cd /home/aistudio/
+python trans_xfund_data.py
+```
+
+## 4 OCR
+
+选用飞桨OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/README_ch.md)中的PP-OCRv2模型进行文本检测和识别。PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和[Enhanced CTC loss](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_ch/enhanced_ctc_loss.md)损失函数改进,进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCRv2[技术报告](https://arxiv.org/abs/2109.03144)。
+
+### 4.1 文本检测
+
+我们使用2种方案进行训练、评估:
+- **PP-OCRv2中英文超轻量检测预训练模型**
+- **XFUND数据集+fine-tune**
+
+#### 4.1.1 方案1:预训练模型
+
+**1)下载预训练模型**
+
+ +图5 文本检测方案1-下载预训练模型
+
+
+PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示:
+
+| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
+| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
+| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
+| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
+
+更多模型下载(包括多语言),可以参考[PP-OCR 系列模型下载](./doc/doc_ch/models_list.md)
+
+
+这里我们使用PP-OCRv2中英文超轻量检测模型,下载并解压预训练模型:
+
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/pretrain/
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
+tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
+% cd ..
+```
+
+**2)模型评估**
+
+
+图5 文本检测方案1-下载预训练模型
+
+
+PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示:
+
+| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
+| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
+| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
+| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
+
+更多模型下载(包括多语言),可以参考[PP-OCR 系列模型下载](./doc/doc_ch/models_list.md)
+
+
+这里我们使用PP-OCRv2中英文超轻量检测模型,下载并解压预训练模型:
+
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/pretrain/
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
+tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
+% cd ..
+```
+
+**2)模型评估**
+
+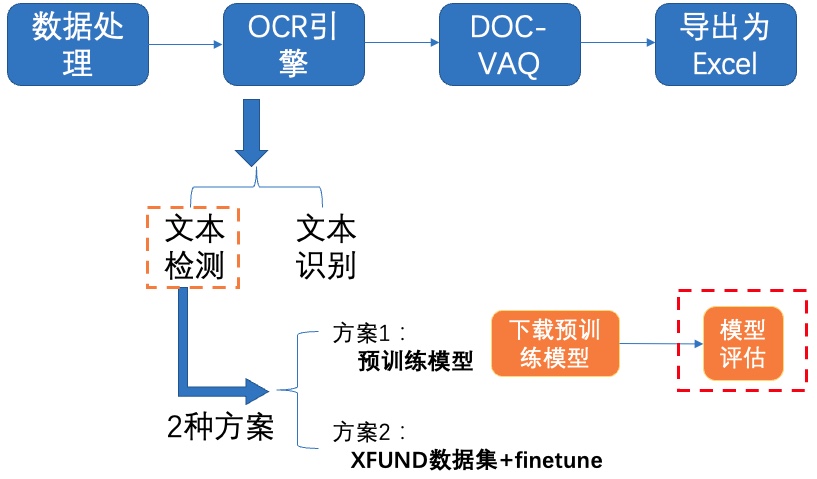 +图6 文本检测方案1-模型评估
+
+接着使用下载的超轻量检测模型在XFUND验证集上进行评估,由于蒸馏需要包含多个网络,甚至多个Student网络,在计算指标的时候只需要计算一个Student网络的指标即可,key字段设置为Student则表示只计算Student网络的精度。
+
+```
+Metric:
+ name: DistillationMetric
+ base_metric_name: DetMetric
+ main_indicator: hmean
+ key: "Student"
+```
+首先修改配置文件`configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_distill.yml`中的以下字段:
+```
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+
+
+然后在XFUND验证集上进行评估,具体代码如下:
+
+
+```python
+%cd /home/aistudio/PaddleOCR
+python tools/eval.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_distill.yml \
+ -o Global.checkpoints="./pretrain_models/ch_PP-OCRv2_det_distill_train/best_accuracy"
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | hmeans |
+| -------- | -------- |
+| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% |
+
+使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型具有泛化能力。
+
+#### 4.1.2 方案2:XFUND数据集+fine-tune
+
+PaddleOCR提供的蒸馏预训练模型包含了多个模型的参数,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
+
+```python
+import paddle
+# 加载预训练模型
+all_params = paddle.load("pretrain/ch_PP-OCRv2_det_distill_train/best_accuracy.pdparams")
+# 查看权重参数的keys
+# print(all_params.keys())
+# 学生模型的权重提取
+s_params = {key[len("student_model."):]: all_params[key] for key in all_params if "student_model." in key}
+# 查看学生模型权重参数的keys
+print(s_params.keys())
+# 保存
+paddle.save(s_params, "pretrain/ch_PP-OCRv2_det_distill_train/student.pdparams")
+```
+
+**1)模型训练**
+
+
+图6 文本检测方案1-模型评估
+
+接着使用下载的超轻量检测模型在XFUND验证集上进行评估,由于蒸馏需要包含多个网络,甚至多个Student网络,在计算指标的时候只需要计算一个Student网络的指标即可,key字段设置为Student则表示只计算Student网络的精度。
+
+```
+Metric:
+ name: DistillationMetric
+ base_metric_name: DetMetric
+ main_indicator: hmean
+ key: "Student"
+```
+首先修改配置文件`configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_distill.yml`中的以下字段:
+```
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+
+
+然后在XFUND验证集上进行评估,具体代码如下:
+
+
+```python
+%cd /home/aistudio/PaddleOCR
+python tools/eval.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_distill.yml \
+ -o Global.checkpoints="./pretrain_models/ch_PP-OCRv2_det_distill_train/best_accuracy"
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | hmeans |
+| -------- | -------- |
+| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% |
+
+使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型具有泛化能力。
+
+#### 4.1.2 方案2:XFUND数据集+fine-tune
+
+PaddleOCR提供的蒸馏预训练模型包含了多个模型的参数,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
+
+```python
+import paddle
+# 加载预训练模型
+all_params = paddle.load("pretrain/ch_PP-OCRv2_det_distill_train/best_accuracy.pdparams")
+# 查看权重参数的keys
+# print(all_params.keys())
+# 学生模型的权重提取
+s_params = {key[len("student_model."):]: all_params[key] for key in all_params if "student_model." in key}
+# 查看学生模型权重参数的keys
+print(s_params.keys())
+# 保存
+paddle.save(s_params, "pretrain/ch_PP-OCRv2_det_distill_train/student.pdparams")
+```
+
+**1)模型训练**
+
+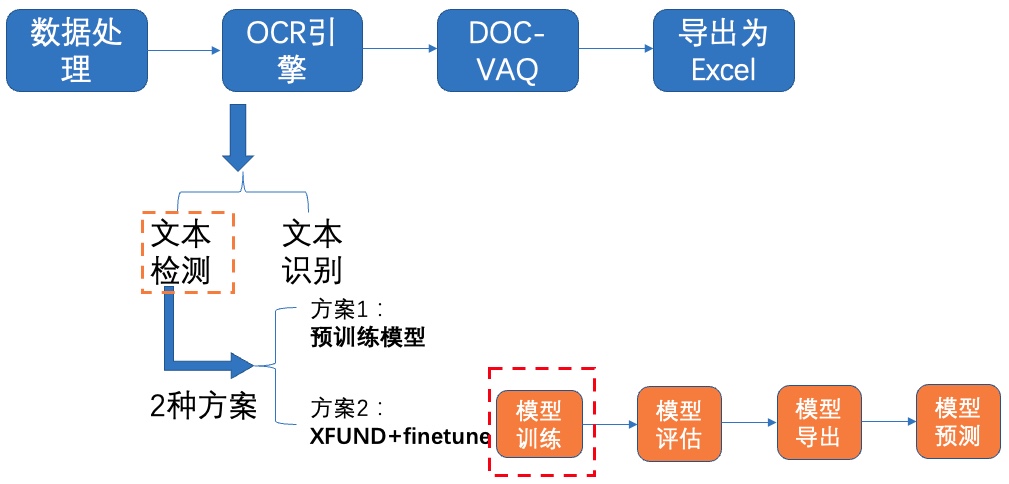 +图7 文本检测方案2-模型训练
+
+
+修改配置文件`configs/det/ch_PP-OCRv2_det_student.yml`中的以下字段:
+```
+Global.pretrained_model:指向预训练模型路径
+Train.dataset.data_dir:指向训练集图片存放目录
+Train.dataset.label_file_list:指向训练集标注文件
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+Optimizer.lr.learning_rate:调整学习率,本实验设置为0.005
+Train.dataset.transforms.EastRandomCropData.size:训练尺寸改为[1600, 1600]
+Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
+ limit_side_len: 1600
+ limit_type: 'min'
+
+```
+执行下面命令启动训练:
+
+
+```python
+CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml
+```
+
+**2)模型评估**
+
+
+图7 文本检测方案2-模型训练
+
+
+修改配置文件`configs/det/ch_PP-OCRv2_det_student.yml`中的以下字段:
+```
+Global.pretrained_model:指向预训练模型路径
+Train.dataset.data_dir:指向训练集图片存放目录
+Train.dataset.label_file_list:指向训练集标注文件
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+Optimizer.lr.learning_rate:调整学习率,本实验设置为0.005
+Train.dataset.transforms.EastRandomCropData.size:训练尺寸改为[1600, 1600]
+Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
+ limit_side_len: 1600
+ limit_type: 'min'
+
+```
+执行下面命令启动训练:
+
+
+```python
+CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml
+```
+
+**2)模型评估**
+
+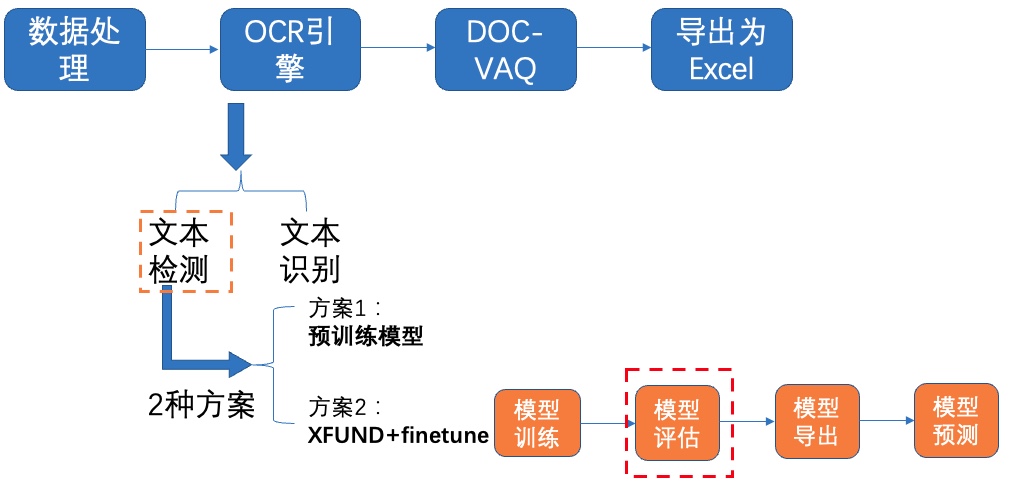 +图8 文本检测方案2-模型评估
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+图8 文本检测方案2-模型评估
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+
+ 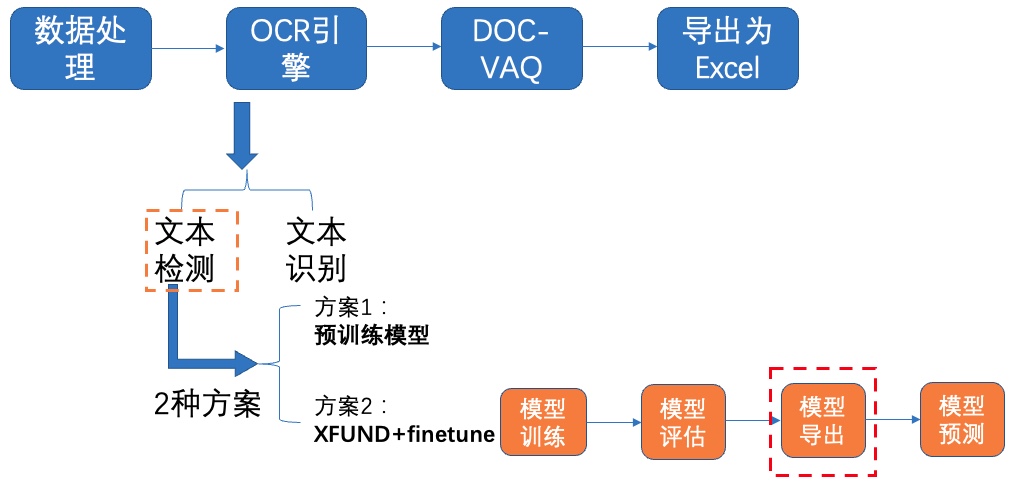 +图9 文本检测方案2-模型导出
+
+在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。 执行下面命令,即可导出模型。
+
+
+```python
+# 加载配置文件`ch_PP-OCRv2_det_student.yml`,从`pretrain/ch_db_mv3-student1600-finetune`目录下加载`best_accuracy`模型
+# inference模型保存在`./output/det_db_inference`目录下
+%cd /home/aistudio/PaddleOCR/
+python tools/export_model.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml \
+ -o Global.pretrained_model="pretrain/ch_db_mv3-student1600-finetune/best_accuracy" \
+ Global.save_inference_dir="./output/det_db_inference/"
+```
+
+转换成功后,在目录下有三个文件:
+```
+/inference/rec_crnn/
+ ├── inference.pdiparams # 识别inference模型的参数文件
+ ├── inference.pdiparams.info # 识别inference模型的参数信息,可忽略
+ └── inference.pdmodel # 识别inference模型的program文件
+```
+
+**4)模型预测**
+
+
+图9 文本检测方案2-模型导出
+
+在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。 执行下面命令,即可导出模型。
+
+
+```python
+# 加载配置文件`ch_PP-OCRv2_det_student.yml`,从`pretrain/ch_db_mv3-student1600-finetune`目录下加载`best_accuracy`模型
+# inference模型保存在`./output/det_db_inference`目录下
+%cd /home/aistudio/PaddleOCR/
+python tools/export_model.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml \
+ -o Global.pretrained_model="pretrain/ch_db_mv3-student1600-finetune/best_accuracy" \
+ Global.save_inference_dir="./output/det_db_inference/"
+```
+
+转换成功后,在目录下有三个文件:
+```
+/inference/rec_crnn/
+ ├── inference.pdiparams # 识别inference模型的参数文件
+ ├── inference.pdiparams.info # 识别inference模型的参数信息,可忽略
+ └── inference.pdmodel # 识别inference模型的program文件
+```
+
+**4)模型预测**
+
+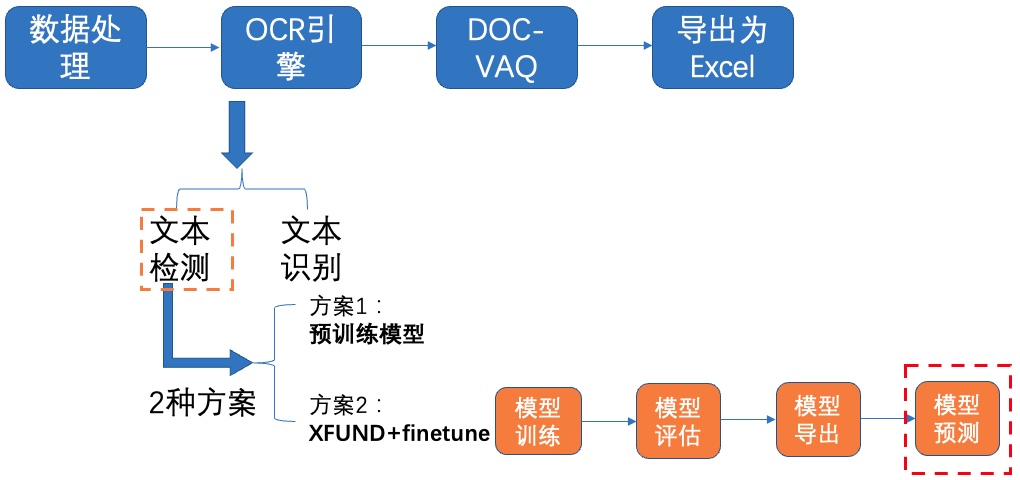 +图10 文本检测方案2-模型预测
+
+加载上面导出的模型,执行如下命令对验证集或测试集图片进行预测:
+
+```
+det_model_dir:预测模型
+image_dir:测试图片路径
+use_gpu:是否使用GPU
+```
+
+检测可视化结果保存在`/home/aistudio/inference_results/`目录下,查看检测效果。
+
+
+```python
+%pwd
+!python tools/infer/predict_det.py \
+ --det_algorithm="DB" \
+ --det_model_dir="./output/det_db_inference/" \
+ --image_dir="./doc/vqa/input/zh_val_21.jpg" \
+ --use_gpu=True
+```
+
+总结,我们分别使用PP-OCRv2中英文超轻量检测预训练模型、XFUND数据集+finetune2种方案进行评估、训练等,指标对比如下:
+
+| 方案 | hmeans | 结果分析 |
+| -------- | -------- | -------- |
+| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% | ppocr提供的预训练模型有泛化能力 |
+| XFUND数据集 | 79.27% | |
+| XFUND数据集+finetune | 85.24% | finetune会提升垂类场景效果 |
+
+### 4.2 文本识别
+
+我们分别使用如下3种方案进行训练、评估:
+
+- PP-OCRv2中英文超轻量识别预训练模型
+- XFUND数据集+fine-tune
+- XFUND数据集+fine-tune+真实通用识别数据
+
+#### 4.2.1 方案1:预训练模型
+
+**1)下载预训练模型**
+
+
+图10 文本检测方案2-模型预测
+
+加载上面导出的模型,执行如下命令对验证集或测试集图片进行预测:
+
+```
+det_model_dir:预测模型
+image_dir:测试图片路径
+use_gpu:是否使用GPU
+```
+
+检测可视化结果保存在`/home/aistudio/inference_results/`目录下,查看检测效果。
+
+
+```python
+%pwd
+!python tools/infer/predict_det.py \
+ --det_algorithm="DB" \
+ --det_model_dir="./output/det_db_inference/" \
+ --image_dir="./doc/vqa/input/zh_val_21.jpg" \
+ --use_gpu=True
+```
+
+总结,我们分别使用PP-OCRv2中英文超轻量检测预训练模型、XFUND数据集+finetune2种方案进行评估、训练等,指标对比如下:
+
+| 方案 | hmeans | 结果分析 |
+| -------- | -------- | -------- |
+| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% | ppocr提供的预训练模型有泛化能力 |
+| XFUND数据集 | 79.27% | |
+| XFUND数据集+finetune | 85.24% | finetune会提升垂类场景效果 |
+
+### 4.2 文本识别
+
+我们分别使用如下3种方案进行训练、评估:
+
+- PP-OCRv2中英文超轻量识别预训练模型
+- XFUND数据集+fine-tune
+- XFUND数据集+fine-tune+真实通用识别数据
+
+#### 4.2.1 方案1:预训练模型
+
+**1)下载预训练模型**
+
+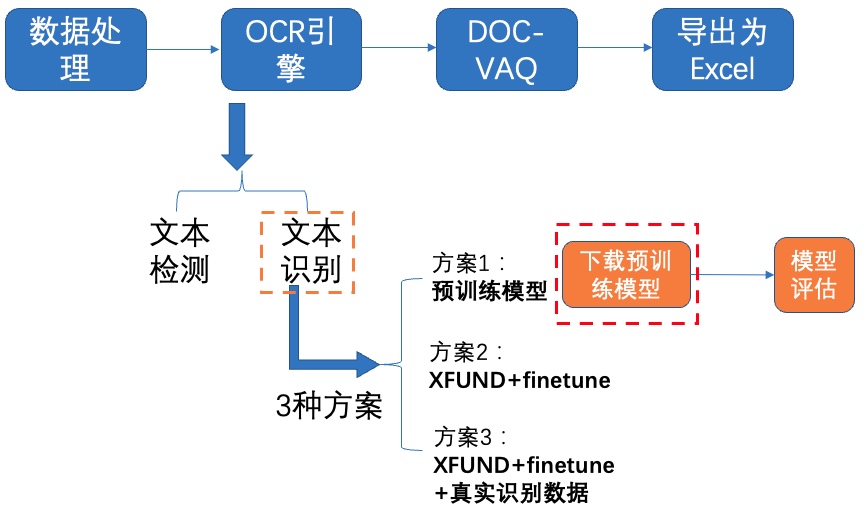 +
+图11 文本识别方案1-下载预训练模型
+
+我们使用PP-OCRv2中英文超轻量文本识别模型,下载并解压预训练模型:
+
+
+```python
+%cd /home/aistudio/PaddleOCR/pretrain/
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar
+tar -xf ch_PP-OCRv2_rec_train.tar && rm -rf ch_PP-OCRv2_rec_train.tar
+% cd ..
+```
+
+**2)模型评估**
+
+
+
+图11 文本识别方案1-下载预训练模型
+
+我们使用PP-OCRv2中英文超轻量文本识别模型,下载并解压预训练模型:
+
+
+```python
+%cd /home/aistudio/PaddleOCR/pretrain/
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar
+tar -xf ch_PP-OCRv2_rec_train.tar && rm -rf ch_PP-OCRv2_rec_train.tar
+% cd ..
+```
+
+**2)模型评估**
+
+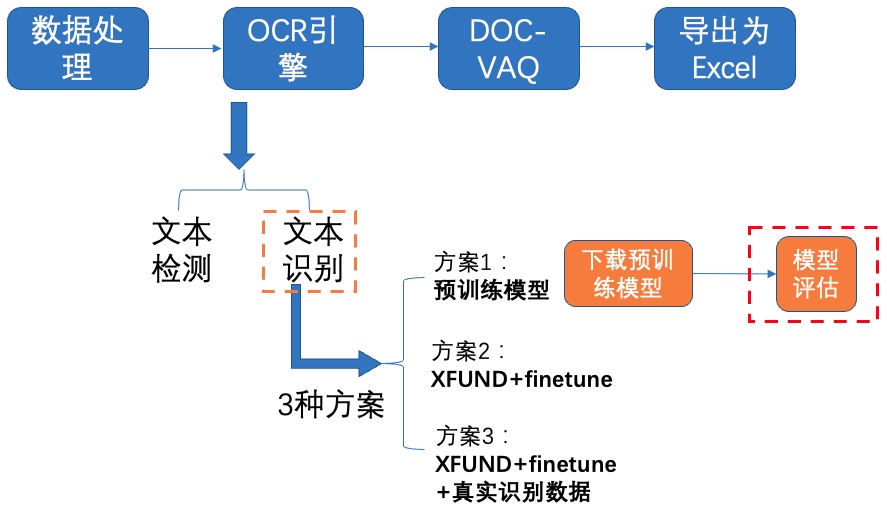 +
+图12 文本识别方案1-模型评估
+
+首先修改配置文件`configs/det/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml`中的以下字段:
+
+```
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+
+我们使用下载的预训练模型进行评估:
+
+
+```python
+%cd /home/aistudio/PaddleOCR
+CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml \
+ -o Global.checkpoints=./pretrain/ch_PP-OCRv2_rec_train/best_accuracy
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | acc |
+| -------- | -------- |
+| PP-OCRv2中英文超轻量识别预训练模型 | 67.48% |
+
+使用文本预训练模型在XFUND验证集上评估,acc达到67%左右,充分说明ppocr提供的预训练模型具有泛化能力。
+
+#### 4.2.2 方案2:XFUND数据集+finetune
+
+同检测模型,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
+
+
+```python
+import paddle
+# 加载预训练模型
+all_params = paddle.load("pretrain/ch_PP-OCRv2_rec_train/best_accuracy.pdparams")
+# 查看权重参数的keys
+print(all_params.keys())
+# 学生模型的权重提取
+s_params = {key[len("Student."):]: all_params[key] for key in all_params if "Student." in key}
+# 查看学生模型权重参数的keys
+print(s_params.keys())
+# 保存
+paddle.save(s_params, "pretrain/ch_PP-OCRv2_rec_train/student.pdparams")
+```
+
+**1)模型训练**
+
+
+
+图12 文本识别方案1-模型评估
+
+首先修改配置文件`configs/det/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml`中的以下字段:
+
+```
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+
+我们使用下载的预训练模型进行评估:
+
+
+```python
+%cd /home/aistudio/PaddleOCR
+CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml \
+ -o Global.checkpoints=./pretrain/ch_PP-OCRv2_rec_train/best_accuracy
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | acc |
+| -------- | -------- |
+| PP-OCRv2中英文超轻量识别预训练模型 | 67.48% |
+
+使用文本预训练模型在XFUND验证集上评估,acc达到67%左右,充分说明ppocr提供的预训练模型具有泛化能力。
+
+#### 4.2.2 方案2:XFUND数据集+finetune
+
+同检测模型,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
+
+
+```python
+import paddle
+# 加载预训练模型
+all_params = paddle.load("pretrain/ch_PP-OCRv2_rec_train/best_accuracy.pdparams")
+# 查看权重参数的keys
+print(all_params.keys())
+# 学生模型的权重提取
+s_params = {key[len("Student."):]: all_params[key] for key in all_params if "Student." in key}
+# 查看学生模型权重参数的keys
+print(s_params.keys())
+# 保存
+paddle.save(s_params, "pretrain/ch_PP-OCRv2_rec_train/student.pdparams")
+```
+
+**1)模型训练**
+
+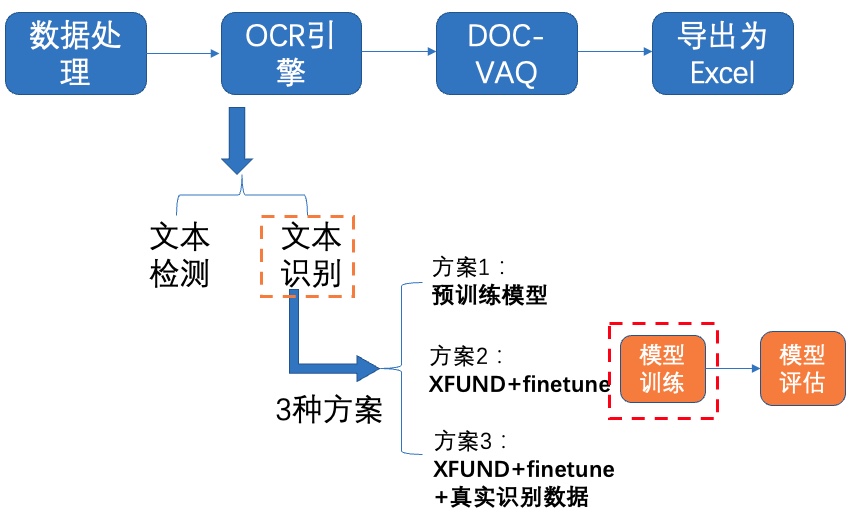 +图13 文本识别方案2-模型训练
+
+修改配置文件`configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml`中的以下字段:
+
+```
+Global.pretrained_model:指向预训练模型路径
+Global.character_dict_path: 字典路径
+Optimizer.lr.values:学习率
+Train.dataset.data_dir:指向训练集图片存放目录
+Train.dataset.label_file_list:指向训练集标注文件
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+执行如下命令启动训练:
+
+```python
+%cd /home/aistudio/PaddleOCR/
+CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml
+```
+
+**2)模型评估**
+
+
+图13 文本识别方案2-模型训练
+
+修改配置文件`configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml`中的以下字段:
+
+```
+Global.pretrained_model:指向预训练模型路径
+Global.character_dict_path: 字典路径
+Optimizer.lr.values:学习率
+Train.dataset.data_dir:指向训练集图片存放目录
+Train.dataset.label_file_list:指向训练集标注文件
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+执行如下命令启动训练:
+
+```python
+%cd /home/aistudio/PaddleOCR/
+CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml
+```
+
+**2)模型评估**
+
+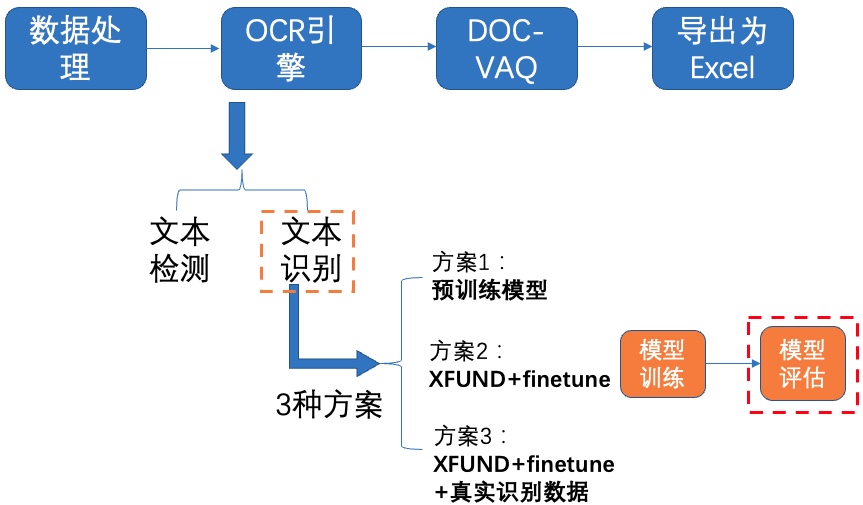 +
+图14 文本识别方案2-模型评估
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-finetune/best_accuracy`
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
+ -o Global.checkpoints=./pretrain/rec_mobile_pp-OCRv2-student-finetune/best_accuracy
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | acc |
+| -------- | -------- |
+| XFUND数据集+finetune | 72.33% |
+
+使用XFUND数据集+finetune训练,在验证集上评估达到72%左右,说明 finetune会提升垂类场景效果。
+
+#### 4.2.3 方案3:XFUND数据集+finetune+真实通用识别数据
+
+接着我们在上述`XFUND数据集+finetune`实验的基础上,添加真实通用识别数据,进一步提升识别效果。首先准备真实通用识别数据,并上传到AIStudio:
+
+**1)模型训练**
+
+
+
+图14 文本识别方案2-模型评估
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-finetune/best_accuracy`
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
+ -o Global.checkpoints=./pretrain/rec_mobile_pp-OCRv2-student-finetune/best_accuracy
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | acc |
+| -------- | -------- |
+| XFUND数据集+finetune | 72.33% |
+
+使用XFUND数据集+finetune训练,在验证集上评估达到72%左右,说明 finetune会提升垂类场景效果。
+
+#### 4.2.3 方案3:XFUND数据集+finetune+真实通用识别数据
+
+接着我们在上述`XFUND数据集+finetune`实验的基础上,添加真实通用识别数据,进一步提升识别效果。首先准备真实通用识别数据,并上传到AIStudio:
+
+**1)模型训练**
+
+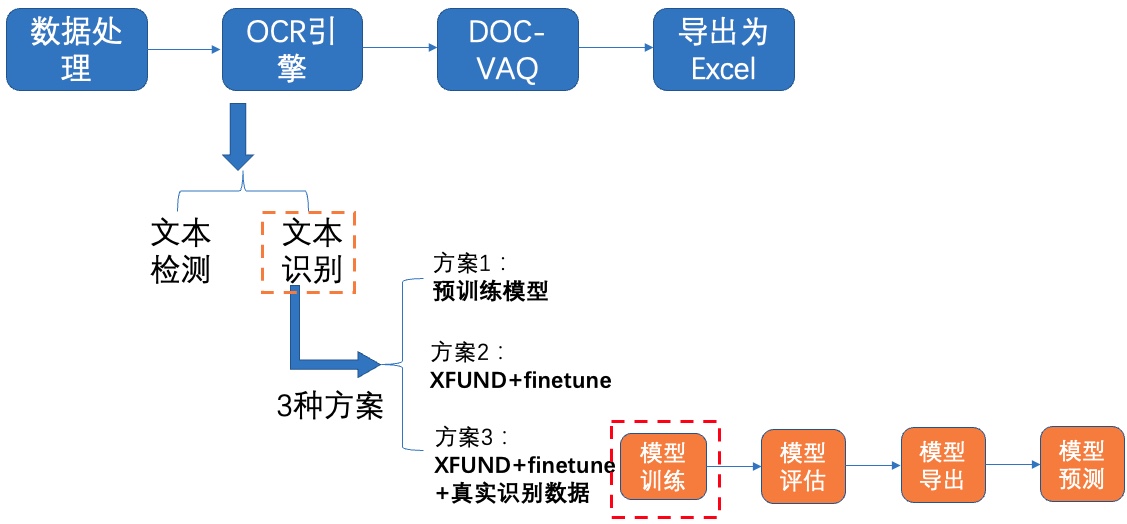 +
+图15 文本识别方案3-模型训练
+
+在上述`XFUND数据集+finetune`实验中修改配置文件`configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml`的基础上,继续修改以下字段:
+
+```
+Train.dataset.label_file_list:指向真实识别训练集图片存放目录
+Train.dataset.ratio_list:动态采样
+```
+执行如下命令启动训练:
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml
+```
+
+**2)模型评估**
+
+
+
+图15 文本识别方案3-模型训练
+
+在上述`XFUND数据集+finetune`实验中修改配置文件`configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml`的基础上,继续修改以下字段:
+
+```
+Train.dataset.label_file_list:指向真实识别训练集图片存放目录
+Train.dataset.ratio_list:动态采样
+```
+执行如下命令启动训练:
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml
+```
+
+**2)模型评估**
+
+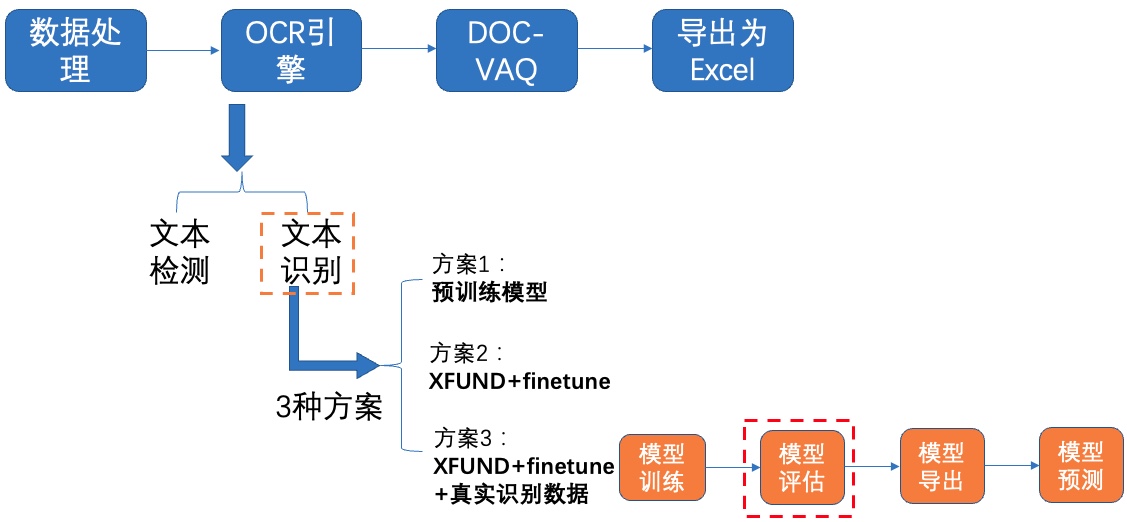 +
+图16 文本识别方案3-模型评估
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。
+
+
+```python
+CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
+ -o Global.checkpoints=./pretrain/rec_mobile_pp-OCRv2-student-realdata/best_accuracy
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | acc |
+| -------- | -------- |
+| XFUND数据集+fine-tune+真实通用识别数据 | 85.29% |
+
+使用XFUND数据集+finetune训练,在验证集上评估达到85%左右,说明真实通用识别数据对于性能提升很有帮助。
+
+**3)导出模型**
+
+
+
+图16 文本识别方案3-模型评估
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。
+
+
+```python
+CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
+ -o Global.checkpoints=./pretrain/rec_mobile_pp-OCRv2-student-realdata/best_accuracy
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | acc |
+| -------- | -------- |
+| XFUND数据集+fine-tune+真实通用识别数据 | 85.29% |
+
+使用XFUND数据集+finetune训练,在验证集上评估达到85%左右,说明真实通用识别数据对于性能提升很有帮助。
+
+**3)导出模型**
+
+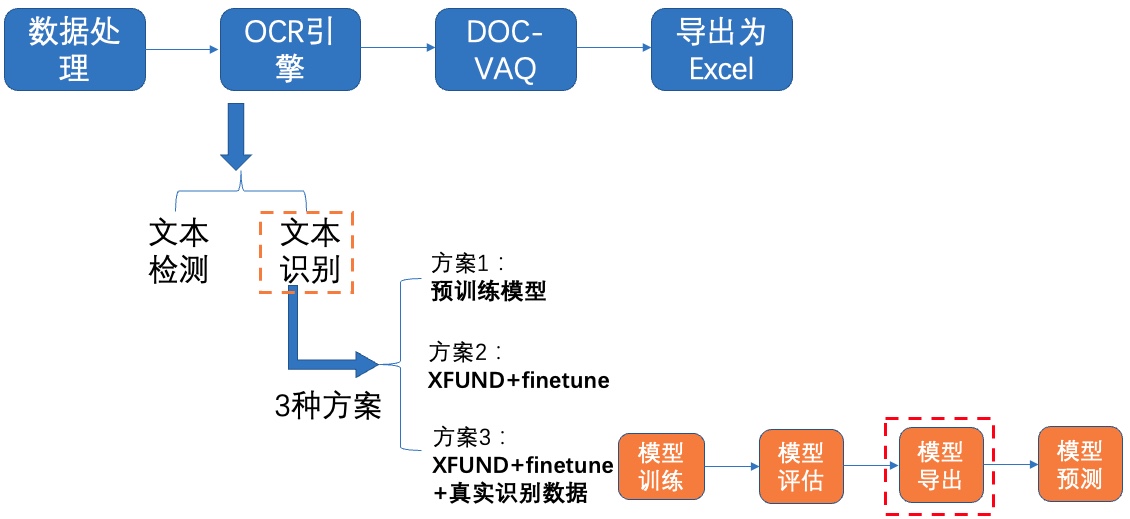 +图17 文本识别方案3-导出模型
+
+导出模型只保留前向预测的过程:
+
+
+```python
+!python tools/export_model.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
+ -o Global.pretrained_model=pretrain/rec_mobile_pp-OCRv2-student-realdata/best_accuracy \
+ Global.save_inference_dir=./output/rec_crnn_inference/
+```
+
+**4)模型预测**
+
+
+图17 文本识别方案3-导出模型
+
+导出模型只保留前向预测的过程:
+
+
+```python
+!python tools/export_model.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
+ -o Global.pretrained_model=pretrain/rec_mobile_pp-OCRv2-student-realdata/best_accuracy \
+ Global.save_inference_dir=./output/rec_crnn_inference/
+```
+
+**4)模型预测**
+
+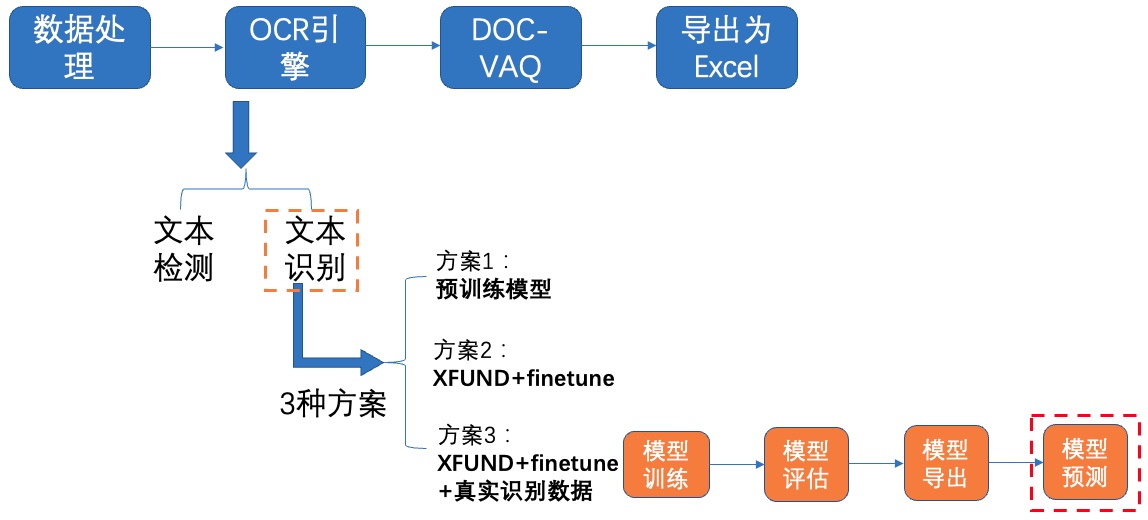 +
+图18 文本识别方案3-模型预测
+
+加载上面导出的模型,执行如下命令对验证集或测试集图片进行预测,检测可视化结果保存在`/home/aistudio/inference_results/`目录下,查看检测、识别效果。需要通过`--rec_char_dict_path`指定使用的字典路径
+
+
+```python
+python tools/infer/predict_system.py \
+ --image_dir="./doc/vqa/input/zh_val_21.jpg" \
+ --det_model_dir="./output/det_db_inference/" \
+ --rec_model_dir="./output/rec_crnn_inference/" \
+ --rec_image_shape="3, 32, 320" \
+ --rec_char_dict_path="/home/aistudio/XFUND/word_dict.txt"
+```
+
+总结,我们分别使用PP-OCRv2中英文超轻量检测预训练模型、XFUND数据集+finetune2种方案进行评估、训练等,指标对比如下:
+
+| 方案 | acc | 结果分析 |
+| -------- | -------- | -------- |
+| PP-OCRv2中英文超轻量识别预训练模型 | 67.48% | ppocr提供的预训练模型具有泛化能力 |
+| XFUND数据集+fine-tune |72.33% | finetune会提升垂类场景效果 |
+| XFUND数据集+fine-tune+真实通用识别数据 | 85.29% | 真实通用识别数据对于性能提升很有帮助 |
+
+## 5 文档视觉问答(DOC-VQA)
+
+VQA指视觉问答,主要针对图像内容进行提问和回答,DOC-VQA是VQA任务中的一种,DOC-VQA主要针对文本图像的文字内容提出问题。
+
+PaddleOCR中DOC-VQA系列算法基于PaddleNLP自然语言处理算法库实现LayoutXLM论文,支持基于多模态方法的 **语义实体识别 (Semantic Entity Recognition, SER)** 以及 **关系抽取 (Relation Extraction, RE)** 任务。
+
+如果希望直接体验预测过程,可以下载我们提供的预训练模型,跳过训练过程,直接预测即可。
+
+
+```python
+%cd pretrain
+#下载SER模型
+wget https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar && tar -xvf ser_LayoutXLM_xfun_zh.tar
+#下载RE模型
+wget https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar && tar -xvf re_LayoutXLM_xfun_zh.tar
+%cd ../
+```
+
+### 5.1 SER
+
+SER: 语义实体识别 (Semantic Entity Recognition), 可以完成对图像中的文本识别与分类。
+
+
+图19 SER测试效果图
+
+**图19** 中不同颜色的框表示不同的类别,对于XFUND数据集,有QUESTION, ANSWER, HEADER 3种类别
+
+- 深紫色:HEADER
+- 浅紫色:QUESTION
+- 军绿色:ANSWER
+
+在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
+
+#### 5.1.1 模型训练
+
+
+
+图18 文本识别方案3-模型预测
+
+加载上面导出的模型,执行如下命令对验证集或测试集图片进行预测,检测可视化结果保存在`/home/aistudio/inference_results/`目录下,查看检测、识别效果。需要通过`--rec_char_dict_path`指定使用的字典路径
+
+
+```python
+python tools/infer/predict_system.py \
+ --image_dir="./doc/vqa/input/zh_val_21.jpg" \
+ --det_model_dir="./output/det_db_inference/" \
+ --rec_model_dir="./output/rec_crnn_inference/" \
+ --rec_image_shape="3, 32, 320" \
+ --rec_char_dict_path="/home/aistudio/XFUND/word_dict.txt"
+```
+
+总结,我们分别使用PP-OCRv2中英文超轻量检测预训练模型、XFUND数据集+finetune2种方案进行评估、训练等,指标对比如下:
+
+| 方案 | acc | 结果分析 |
+| -------- | -------- | -------- |
+| PP-OCRv2中英文超轻量识别预训练模型 | 67.48% | ppocr提供的预训练模型具有泛化能力 |
+| XFUND数据集+fine-tune |72.33% | finetune会提升垂类场景效果 |
+| XFUND数据集+fine-tune+真实通用识别数据 | 85.29% | 真实通用识别数据对于性能提升很有帮助 |
+
+## 5 文档视觉问答(DOC-VQA)
+
+VQA指视觉问答,主要针对图像内容进行提问和回答,DOC-VQA是VQA任务中的一种,DOC-VQA主要针对文本图像的文字内容提出问题。
+
+PaddleOCR中DOC-VQA系列算法基于PaddleNLP自然语言处理算法库实现LayoutXLM论文,支持基于多模态方法的 **语义实体识别 (Semantic Entity Recognition, SER)** 以及 **关系抽取 (Relation Extraction, RE)** 任务。
+
+如果希望直接体验预测过程,可以下载我们提供的预训练模型,跳过训练过程,直接预测即可。
+
+
+```python
+%cd pretrain
+#下载SER模型
+wget https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar && tar -xvf ser_LayoutXLM_xfun_zh.tar
+#下载RE模型
+wget https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar && tar -xvf re_LayoutXLM_xfun_zh.tar
+%cd ../
+```
+
+### 5.1 SER
+
+SER: 语义实体识别 (Semantic Entity Recognition), 可以完成对图像中的文本识别与分类。
+
+
+图19 SER测试效果图
+
+**图19** 中不同颜色的框表示不同的类别,对于XFUND数据集,有QUESTION, ANSWER, HEADER 3种类别
+
+- 深紫色:HEADER
+- 浅紫色:QUESTION
+- 军绿色:ANSWER
+
+在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
+
+#### 5.1.1 模型训练
+
+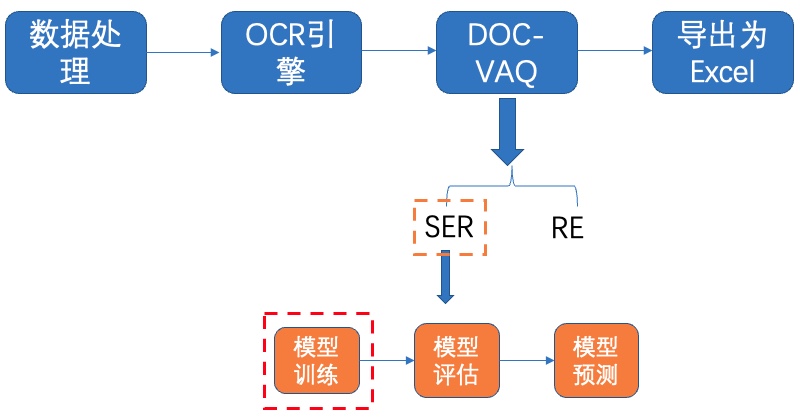 +
+图20 SER-模型训练
+
+启动训练之前,需要修改配置文件 `configs/vqa/ser/layoutxlm.yml` 以下四个字段:
+
+ 1. Train.dataset.data_dir:指向训练集图片存放目录
+ 2. Train.dataset.label_file_list:指向训练集标注文件
+ 3. Eval.dataset.data_dir:指指向验证集图片存放目录
+ 4. Eval.dataset.label_file_list:指向验证集标注文件
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+CUDA_VISIBLE_DEVICES=0 python tools/train.py -c configs/vqa/ser/layoutxlm.yml
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标。 在`./output/ser_layoutxlm/`文件夹中会保存训练日志,最优的模型和最新epoch的模型。
+
+#### 5.1.2 模型评估
+
+
+
+图20 SER-模型训练
+
+启动训练之前,需要修改配置文件 `configs/vqa/ser/layoutxlm.yml` 以下四个字段:
+
+ 1. Train.dataset.data_dir:指向训练集图片存放目录
+ 2. Train.dataset.label_file_list:指向训练集标注文件
+ 3. Eval.dataset.data_dir:指指向验证集图片存放目录
+ 4. Eval.dataset.label_file_list:指向验证集标注文件
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+CUDA_VISIBLE_DEVICES=0 python tools/train.py -c configs/vqa/ser/layoutxlm.yml
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标。 在`./output/ser_layoutxlm/`文件夹中会保存训练日志,最优的模型和最新epoch的模型。
+
+#### 5.1.2 模型评估
+
+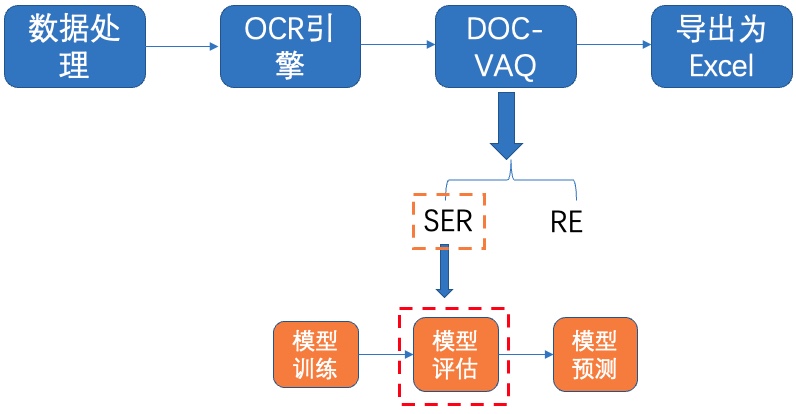 +
+图21 SER-模型评估
+
+我们使用下载的预训练模型进行评估,如果使用自己训练好的模型进行评估,将待评估的模型所在文件夹路径赋值给 `Architecture.Backbone.checkpoints` 字段即可。
+
+
+
+
+```python
+CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/vqa/ser/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标,预训练模型评估指标如下:
+
+
+
+图21 SER-模型评估
+
+我们使用下载的预训练模型进行评估,如果使用自己训练好的模型进行评估,将待评估的模型所在文件夹路径赋值给 `Architecture.Backbone.checkpoints` 字段即可。
+
+
+
+
+```python
+CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/vqa/ser/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标,预训练模型评估指标如下:
+
+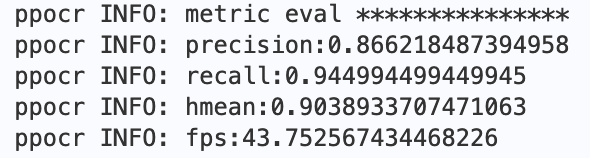 +图 SER预训练模型评估指标
+
+#### 5.1.3 模型预测
+
+
+图 SER预训练模型评估指标
+
+#### 5.1.3 模型预测
+
+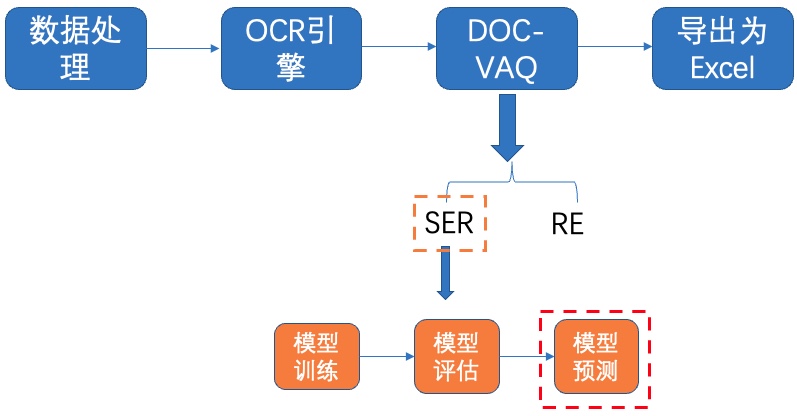 +
+图22 SER-模型预测
+
+使用如下命令即可完成`OCR引擎 + SER`的串联预测, 以SER预训练模型为例:
+
+
+```python
+CUDA_VISIBLE_DEVICES=0 python tools/infer_vqa_token_ser.py \
+ -c configs/vqa/ser/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/ \
+ Global.infer_img=doc/vqa/input/zh_val_42.jpg
+```
+
+最终会在`config.Global.save_res_path`字段所配置的目录下保存预测结果可视化图像以及预测结果文本文件,预测结果文本文件名为`infer_results.txt`。通过如下命令查看预测图片:
+
+
+```python
+import cv2
+from matplotlib import pyplot as plt
+# 在notebook中使用matplotlib.pyplot绘图时,需要添加该命令进行显示
+%matplotlib inline
+
+img = cv2.imread('output/ser/zh_val_42_ser.jpg')
+plt.figure(figsize=(48,24))
+plt.imshow(img)
+```
+
+### 5.2 RE
+
+基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair)。
+
+
+
+图22 SER-模型预测
+
+使用如下命令即可完成`OCR引擎 + SER`的串联预测, 以SER预训练模型为例:
+
+
+```python
+CUDA_VISIBLE_DEVICES=0 python tools/infer_vqa_token_ser.py \
+ -c configs/vqa/ser/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/ \
+ Global.infer_img=doc/vqa/input/zh_val_42.jpg
+```
+
+最终会在`config.Global.save_res_path`字段所配置的目录下保存预测结果可视化图像以及预测结果文本文件,预测结果文本文件名为`infer_results.txt`。通过如下命令查看预测图片:
+
+
+```python
+import cv2
+from matplotlib import pyplot as plt
+# 在notebook中使用matplotlib.pyplot绘图时,需要添加该命令进行显示
+%matplotlib inline
+
+img = cv2.imread('output/ser/zh_val_42_ser.jpg')
+plt.figure(figsize=(48,24))
+plt.imshow(img)
+```
+
+### 5.2 RE
+
+基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair)。
+
+ +图23 RE预测效果图
+
+图中红色框表示问题,蓝色框表示答案,问题和答案之间使用绿色线连接。在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
+
+#### 5.2.1 模型训练
+
+
+图23 RE预测效果图
+
+图中红色框表示问题,蓝色框表示答案,问题和答案之间使用绿色线连接。在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
+
+#### 5.2.1 模型训练
+
+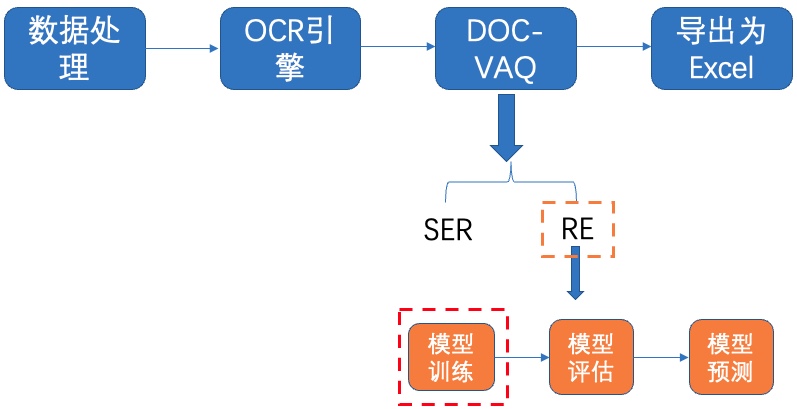 +
+图24 RE-模型训练
+
+启动训练之前,需要修改配置文件`configs/vqa/re/layoutxlm.yml`中的以下四个字段
+
+ Train.dataset.data_dir:指向训练集图片存放目录
+ Train.dataset.label_file_list:指向训练集标注文件
+ Eval.dataset.data_dir:指指向验证集图片存放目录
+ Eval.dataset.label_file_list:指向验证集标注文件
+
+
+
+```python
+CUDA_VISIBLE_DEVICES=0 python3 tools/train.py -c configs/vqa/re/layoutxlm.yml
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标。 在`./output/re_layoutxlm/`文件夹中会保存训练日志,最优的模型和最新epoch的模型
+
+#### 5.2.2 模型评估
+
+
+
+图24 RE-模型训练
+
+启动训练之前,需要修改配置文件`configs/vqa/re/layoutxlm.yml`中的以下四个字段
+
+ Train.dataset.data_dir:指向训练集图片存放目录
+ Train.dataset.label_file_list:指向训练集标注文件
+ Eval.dataset.data_dir:指指向验证集图片存放目录
+ Eval.dataset.label_file_list:指向验证集标注文件
+
+
+
+```python
+CUDA_VISIBLE_DEVICES=0 python3 tools/train.py -c configs/vqa/re/layoutxlm.yml
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标。 在`./output/re_layoutxlm/`文件夹中会保存训练日志,最优的模型和最新epoch的模型
+
+#### 5.2.2 模型评估
+
+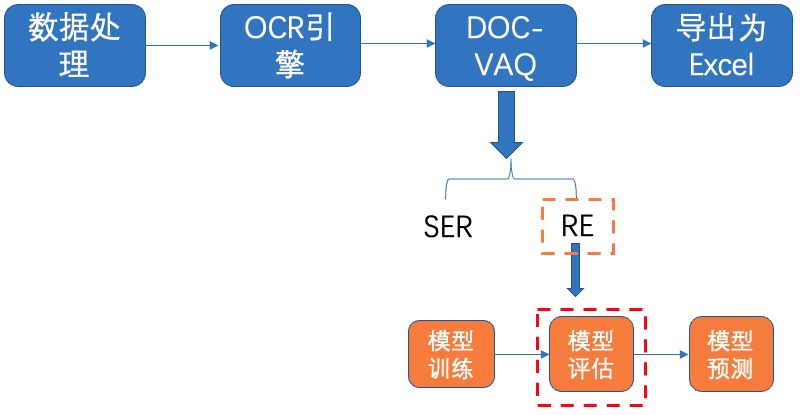 +图25 RE-模型评估
+
+
+我们使用下载的预训练模型进行评估,如果使用自己训练好的模型进行评估,将待评估的模型所在文件夹路径赋值给 `Architecture.Backbone.checkpoints` 字段即可。
+
+
+```python
+CUDA_VISIBLE_DEVICES=0 python3 tools/eval.py \
+ -c configs/vqa/re/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标,预训练模型评估指标如下:
+
+
+图25 RE-模型评估
+
+
+我们使用下载的预训练模型进行评估,如果使用自己训练好的模型进行评估,将待评估的模型所在文件夹路径赋值给 `Architecture.Backbone.checkpoints` 字段即可。
+
+
+```python
+CUDA_VISIBLE_DEVICES=0 python3 tools/eval.py \
+ -c configs/vqa/re/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标,预训练模型评估指标如下:
+
+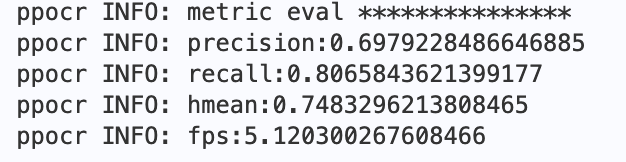 +图 RE预训练模型评估指标
+
+#### 5.2.3 模型预测
+
+
+图 RE预训练模型评估指标
+
+#### 5.2.3 模型预测
+
+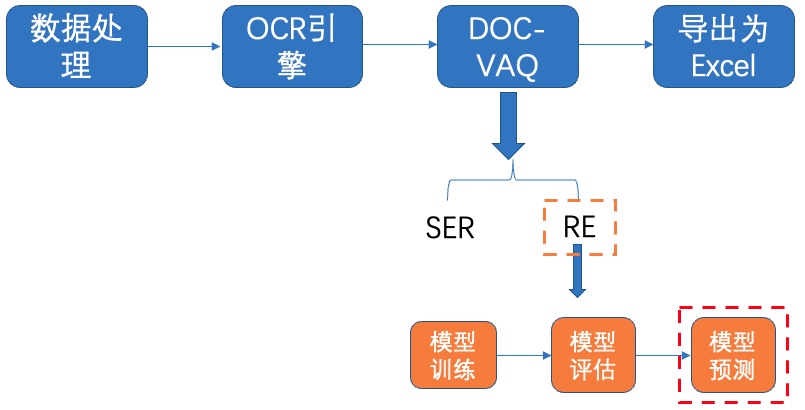 +
+图26 RE-模型预测
+
+使用如下命令即可完成OCR引擎 + SER + RE的串联预测, 以预训练SER和RE模型为例,
+
+最终会在config.Global.save_res_path字段所配置的目录下保存预测结果可视化图像以及预测结果文本文件,预测结果文本文件名为infer_results.txt。
+
+
+```python
+cd /home/aistudio/PaddleOCR
+CUDA_VISIBLE_DEVICES=0 python3 tools/infer_vqa_token_ser_re.py \
+ -c configs/vqa/re/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/ \
+ Global.infer_img=test_imgs/ \
+ -c_ser configs/vqa/ser/layoutxlm.yml \
+ -o_ser Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/
+```
+
+最终会在config.Global.save_res_path字段所配置的目录下保存预测结果可视化图像以及预测结果文本文件,预测结果文本文件名为infer_results.txt, 每一行表示一张图片的结果,每张图片的结果如下所示,前面表示测试图片路径,后面为测试结果:key字段及对应的value字段。
+
+```
+test_imgs/t131.jpg {"政治面税": "群众", "性别": "男", "籍贯": "河北省邯郸市", "婚姻状况": "亏末婚口已婚口已娇", "通讯地址": "邯郸市阳光苑7号楼003", "民族": "汉族", "毕业院校": "河南工业大学", "户口性质": "口农村城镇", "户口地址": "河北省邯郸市", "联系电话": "13288888888", "健康状况": "健康", "姓名": "小六", "好高cm": "180", "出生年月": "1996年8月9日", "文化程度": "本科", "身份证号码": "458933777777777777"}
+````
+
+展示预测结果
+
+```python
+import cv2
+from matplotlib import pyplot as plt
+%matplotlib inline
+
+img = cv2.imread('./output/re/t131_ser.jpg')
+plt.figure(figsize=(48,24))
+plt.imshow(img)
+```
+
+## 6 导出Excel
+
+
+
+图26 RE-模型预测
+
+使用如下命令即可完成OCR引擎 + SER + RE的串联预测, 以预训练SER和RE模型为例,
+
+最终会在config.Global.save_res_path字段所配置的目录下保存预测结果可视化图像以及预测结果文本文件,预测结果文本文件名为infer_results.txt。
+
+
+```python
+cd /home/aistudio/PaddleOCR
+CUDA_VISIBLE_DEVICES=0 python3 tools/infer_vqa_token_ser_re.py \
+ -c configs/vqa/re/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/ \
+ Global.infer_img=test_imgs/ \
+ -c_ser configs/vqa/ser/layoutxlm.yml \
+ -o_ser Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/
+```
+
+最终会在config.Global.save_res_path字段所配置的目录下保存预测结果可视化图像以及预测结果文本文件,预测结果文本文件名为infer_results.txt, 每一行表示一张图片的结果,每张图片的结果如下所示,前面表示测试图片路径,后面为测试结果:key字段及对应的value字段。
+
+```
+test_imgs/t131.jpg {"政治面税": "群众", "性别": "男", "籍贯": "河北省邯郸市", "婚姻状况": "亏末婚口已婚口已娇", "通讯地址": "邯郸市阳光苑7号楼003", "民族": "汉族", "毕业院校": "河南工业大学", "户口性质": "口农村城镇", "户口地址": "河北省邯郸市", "联系电话": "13288888888", "健康状况": "健康", "姓名": "小六", "好高cm": "180", "出生年月": "1996年8月9日", "文化程度": "本科", "身份证号码": "458933777777777777"}
+````
+
+展示预测结果
+
+```python
+import cv2
+from matplotlib import pyplot as plt
+%matplotlib inline
+
+img = cv2.imread('./output/re/t131_ser.jpg')
+plt.figure(figsize=(48,24))
+plt.imshow(img)
+```
+
+## 6 导出Excel
+
+ +图27 导出Excel
+
+为了输出信息匹配对,我们修改`tools/infer_vqa_token_ser_re.py`文件中的`line 194-197`。
+```
+ fout.write(img_path + "\t" + json.dumps(
+ {
+ "ser_result": result,
+ }, ensure_ascii=False) + "\n")
+
+```
+更改为
+```
+result_key = {}
+for ocr_info_head, ocr_info_tail in result:
+ result_key[ocr_info_head['text']] = ocr_info_tail['text']
+
+fout.write(img_path + "\t" + json.dumps(
+ result_key, ensure_ascii=False) + "\n")
+```
+
+同时将输出结果导出到Excel中,效果如 图28 所示:
+
+
+图27 导出Excel
+
+为了输出信息匹配对,我们修改`tools/infer_vqa_token_ser_re.py`文件中的`line 194-197`。
+```
+ fout.write(img_path + "\t" + json.dumps(
+ {
+ "ser_result": result,
+ }, ensure_ascii=False) + "\n")
+
+```
+更改为
+```
+result_key = {}
+for ocr_info_head, ocr_info_tail in result:
+ result_key[ocr_info_head['text']] = ocr_info_tail['text']
+
+fout.write(img_path + "\t" + json.dumps(
+ result_key, ensure_ascii=False) + "\n")
+```
+
+同时将输出结果导出到Excel中,效果如 图28 所示:
+
+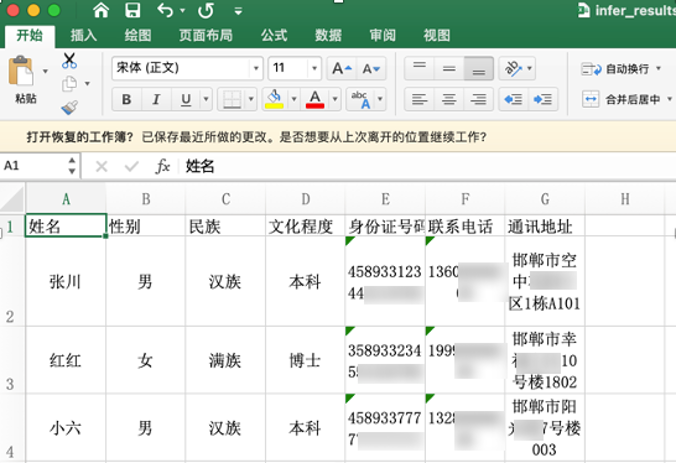 +图28 Excel效果图
+
+
+```python
+import json
+import xlsxwriter as xw
+
+workbook = xw.Workbook('output/re/infer_results.xlsx')
+format1 = workbook.add_format({
+ 'align': 'center',
+ 'valign': 'vcenter',
+ 'text_wrap': True,
+})
+worksheet1 = workbook.add_worksheet('sheet1')
+worksheet1.activate()
+title = ['姓名', '性别', '民族', '文化程度', '身份证号码', '联系电话', '通讯地址']
+worksheet1.write_row('A1', title)
+i = 2
+
+with open('output/re/infer_results.txt', 'r', encoding='utf-8') as fin:
+ lines = fin.readlines()
+ for line in lines:
+ img_path, result = line.strip().split('\t')
+ result_key = json.loads(result)
+ # 写入Excel
+ row_data = [result_key['姓名'], result_key['性别'], result_key['民族'], result_key['文化程度'], result_key['身份证号码'],
+ result_key['联系电话'], result_key['通讯地址']]
+ row = 'A' + str(i)
+ worksheet1.write_row(row, row_data, format1)
+ i+=1
+workbook.close()
+```
+
+## 更多资源
+
+- 更多深度学习知识、产业案例、面试宝典等,请参考:[awesome-DeepLearning](https://github.com/paddlepaddle/awesome-DeepLearning)
+
+- 更多PaddleOCR使用教程,请参考:[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph)
+
+- 更多PaddleNLP使用教程,请参考:[PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP)
+
+- 飞桨框架相关资料,请参考:[飞桨深度学习平台](https://www.paddlepaddle.org.cn/?fr=paddleEdu_aistudio)
+
+## 参考链接
+
+- LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding, https://arxiv.org/pdf/2104.08836.pdf
+
+- microsoft/unilm/layoutxlm, https://github.com/microsoft/unilm/tree/master/layoutxlm
+
+- XFUND dataset, https://github.com/doc-analysis/XFUND
+
diff --git "a/applications/\345\277\253\351\200\237\346\236\204\345\273\272\345\215\241\350\257\201\347\261\273OCR.md" "b/applications/\345\277\253\351\200\237\346\236\204\345\273\272\345\215\241\350\257\201\347\261\273OCR.md"
new file mode 100644
index 0000000..50b70ff
--- /dev/null
+++ "b/applications/\345\277\253\351\200\237\346\236\204\345\273\272\345\215\241\350\257\201\347\261\273OCR.md"
@@ -0,0 +1,775 @@
+# 快速构建卡证类OCR
+
+
+- [快速构建卡证类OCR](#快速构建卡证类ocr)
+ - [1. 金融行业卡证识别应用](#1-金融行业卡证识别应用)
+ - [1.1 金融行业中的OCR相关技术](#11-金融行业中的ocr相关技术)
+ - [1.2 金融行业中的卡证识别场景介绍](#12-金融行业中的卡证识别场景介绍)
+ - [1.3 OCR落地挑战](#13-ocr落地挑战)
+ - [2. 卡证识别技术解析](#2-卡证识别技术解析)
+ - [2.1 卡证分类模型](#21-卡证分类模型)
+ - [2.2 卡证识别模型](#22-卡证识别模型)
+ - [3. OCR技术拆解](#3-ocr技术拆解)
+ - [3.1技术流程](#31技术流程)
+ - [3.2 OCR技术拆解---卡证分类](#32-ocr技术拆解---卡证分类)
+ - [卡证分类:数据、模型准备](#卡证分类数据模型准备)
+ - [卡证分类---修改配置文件](#卡证分类---修改配置文件)
+ - [卡证分类---训练](#卡证分类---训练)
+ - [3.2 OCR技术拆解---卡证识别](#32-ocr技术拆解---卡证识别)
+ - [身份证识别:检测+分类](#身份证识别检测分类)
+ - [数据标注](#数据标注)
+ - [4 . 项目实践](#4--项目实践)
+ - [4.1 环境准备](#41-环境准备)
+ - [4.2 配置文件修改](#42-配置文件修改)
+ - [4.3 代码修改](#43-代码修改)
+ - [4.3.1 数据读取](#431-数据读取)
+ - [4.3.2 head修改](#432--head修改)
+ - [4.3.3 修改loss](#433-修改loss)
+ - [4.3.4 后处理](#434-后处理)
+ - [4.4. 模型启动](#44-模型启动)
+ - [5 总结](#5-总结)
+ - [References](#references)
+
+## 1. 金融行业卡证识别应用
+
+### 1.1 金融行业中的OCR相关技术
+
+* 《“十四五”数字经济发展规划》指出,2020年我国数字经济核心产业增加值占GDP比重达7.8%,随着数字经济迈向全面扩展,到2025年该比例将提升至10%。
+
+* 在过去数年的跨越发展与积累沉淀中,数字金融、金融科技已在对金融业的重塑与再造中充分印证了其自身价值。
+
+* 以智能为目标,提升金融数字化水平,实现业务流程自动化,降低人力成本。
+
+
+
+
+
+
+### 1.2 金融行业中的卡证识别场景介绍
+
+应用场景:身份证、银行卡、营业执照、驾驶证等。
+
+应用难点:由于数据的采集来源多样,以及实际采集数据各种噪声:反光、褶皱、模糊、倾斜等各种问题干扰。
+
+
+
+
+
+### 1.3 OCR落地挑战
+
+
+
+
+
+
+
+
+## 2. 卡证识别技术解析
+
+
+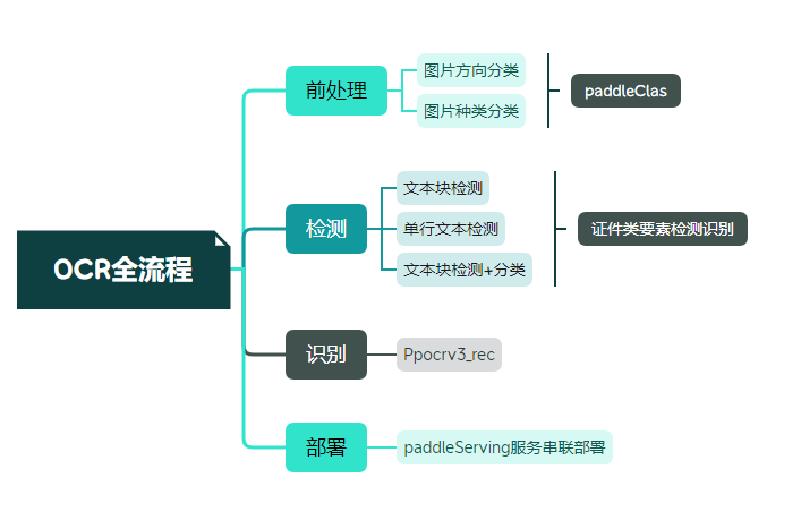
+
+
+### 2.1 卡证分类模型
+
+卡证分类:基于PPLCNet
+
+与其他轻量级模型相比在CPU环境下ImageNet数据集上的表现
+
+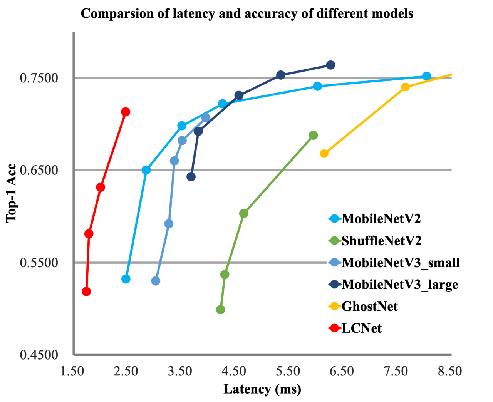
+
+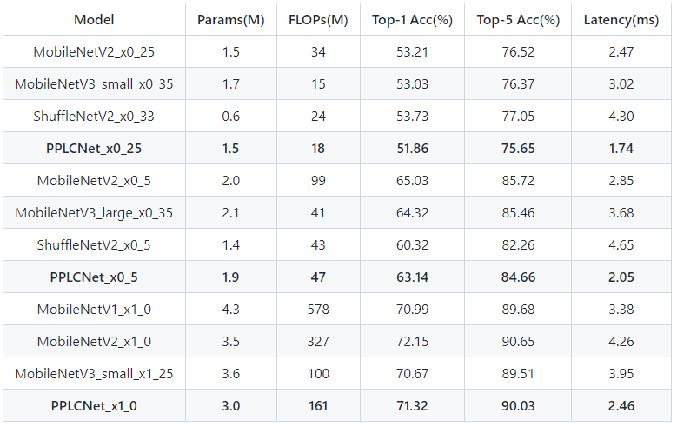
+
+
+
+* 模型来自模型库PaddleClas,它是一个图像识别和图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。
+
+### 2.2 卡证识别模型
+
+* 检测:DBNet 识别:SVRT
+
+
+
+
+* PPOCRv3在文本检测、识别进行了一系列改进优化,在保证精度的同时提升预测效率
+
+
+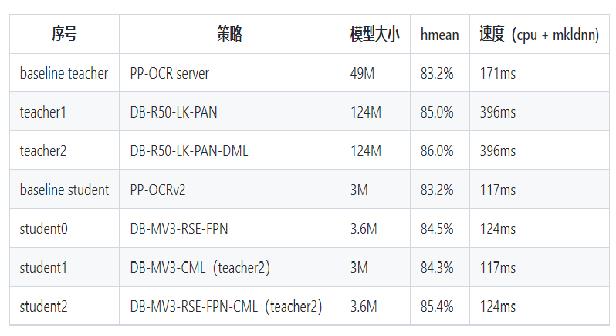
+
+
+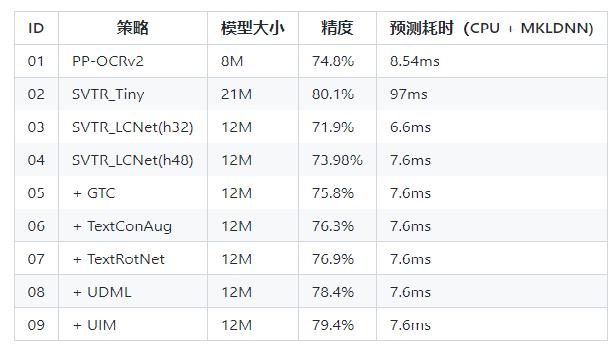
+
+
+## 3. OCR技术拆解
+
+### 3.1技术流程
+
+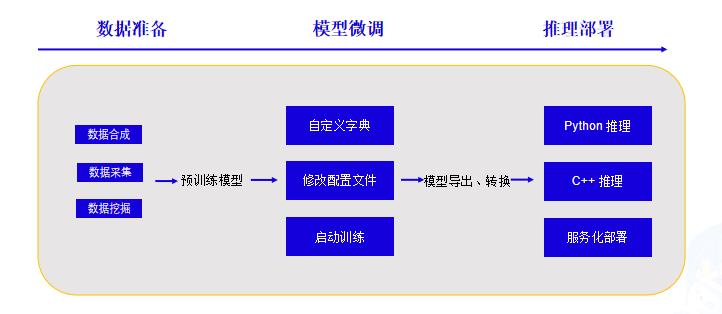
+
+
+### 3.2 OCR技术拆解---卡证分类
+
+#### 卡证分类:数据、模型准备
+
+
+A 使用爬虫获取无标注数据,将相同类别的放在同一文件夹下,文件名从0开始命名。具体格式如下图所示。
+
+ 注:卡证类数据,建议每个类别数据量在500张以上
+
+
+
+B 一行命令生成标签文件
+
+```
+tree -r -i -f | grep -E "jpg|JPG|jpeg|JPEG|png|PNG|webp" | awk -F "/" '{print $0" "$2}' > train_list.txt
+```
+
+C [下载预训练模型 ](https://github.com/PaddlePaddle/PaddleClas/blob/release/2.4/docs/zh_CN/models/PP-LCNet.md)
+
+
+
+#### 卡证分类---修改配置文件
+
+
+配置文件主要修改三个部分:
+
+ 全局参数:预训练模型路径/训练轮次/图像尺寸
+
+ 模型结构:分类数
+
+ 数据处理:训练/评估数据路径
+
+
+ 
+
+#### 卡证分类---训练
+
+
+指定配置文件启动训练:
+
+```
+!python /home/aistudio/work/PaddleClas/tools/train.py -c /home/aistudio/work/PaddleClas/ppcls/configs/PULC/text_image_orientation/PPLCNet_x1_0.yaml
+```
+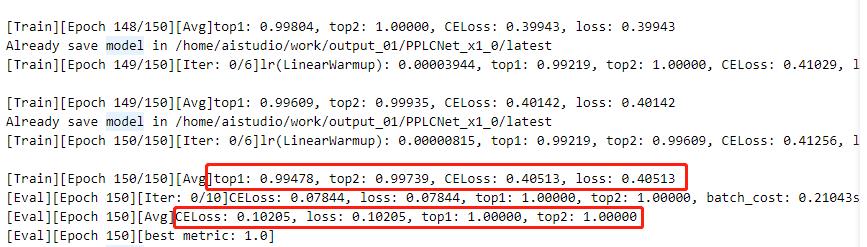
+
+ 注:日志中显示了训练结果和评估结果(训练时可以设置固定轮数评估一次)
+
+
+### 3.2 OCR技术拆解---卡证识别
+
+卡证识别(以身份证检测为例)
+存在的困难及问题:
+
+ * 在自然场景下,由于各种拍摄设备以及光线、角度不同等影响导致实际得到的证件影像千差万别。
+
+ * 如何快速提取需要的关键信息
+
+ * 多行的文本信息,检测结果如何正确拼接
+
+ 
+
+
+
+* OCR技术拆解---OCR工具库
+
+ PaddleOCR是一个丰富、领先且实用的OCR工具库,助力开发者训练出更好的模型并应用落地
+
+
+身份证识别:用现有的方法识别
+
+
+
+
+
+
+#### 身份证识别:检测+分类
+
+> 方法:基于现有的dbnet检测模型,加入分类方法。检测同时进行分类,从一定程度上优化识别流程
+
+
+
+
+
+
+#### 数据标注
+
+使用PaddleOCRLable进行快速标注
+
+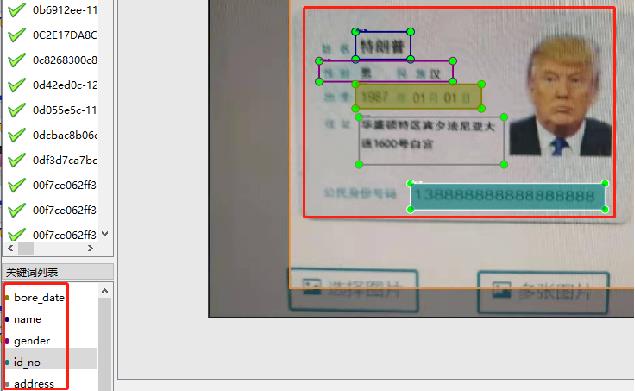
+
+
+* 修改PPOCRLabel.py,将下图中的kie参数设置为True
+
+
+
+
+
+* 数据标注踩坑分享
+
+
+
+ 注:两者只有标注有差别,训练参数数据集都相同
+
+## 4 . 项目实践
+
+AIStudio项目链接:[快速构建卡证类OCR](https://aistudio.baidu.com/aistudio/projectdetail/4459116)
+
+### 4.1 环境准备
+
+1)拉取[paddleocr](https://github.com/PaddlePaddle/PaddleOCR)项目,如果从github上拉取速度慢可以选择从gitee上获取。
+```
+!git clone https://github.com/PaddlePaddle/PaddleOCR.git -b release/2.6 /home/aistudio/work/
+```
+
+2)获取并解压预训练模型,如果要使用其他模型可以从模型库里自主选择合适模型。
+```
+!wget -P work/pre_trained/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
+!tar -vxf /home/aistudio/work/pre_trained/ch_PP-OCRv3_det_distill_train.tar -C /home/aistudio/work/pre_trained
+```
+3) 安装必要依赖
+```
+!pip install -r /home/aistudio/work/requirements.txt
+```
+
+### 4.2 配置文件修改
+
+修改配置文件 *work/configs/det/detmv3db.yml*
+
+具体修改说明如下:
+
+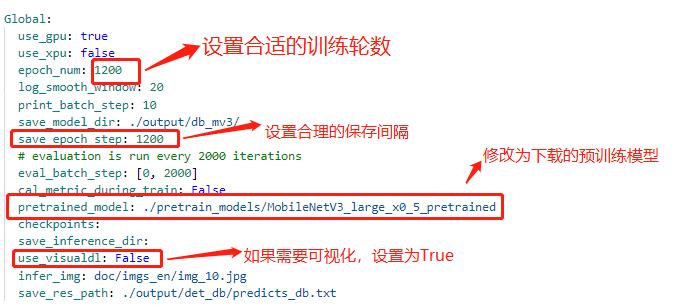
+
+ 注:在上述的配置文件的Global变量中需要添加以下两个参数:
+
+ label_list 为标签表
+ num_classes 为分类数
+ 上述两个参数根据实际的情况配置即可
+
+
+
+
+其中lable_list内容如下例所示,***建议第一个参数设置为 background,不要设置为实际要提取的关键信息种类***:
+
+
+
+配置文件中的其他设置说明
+
+
+
+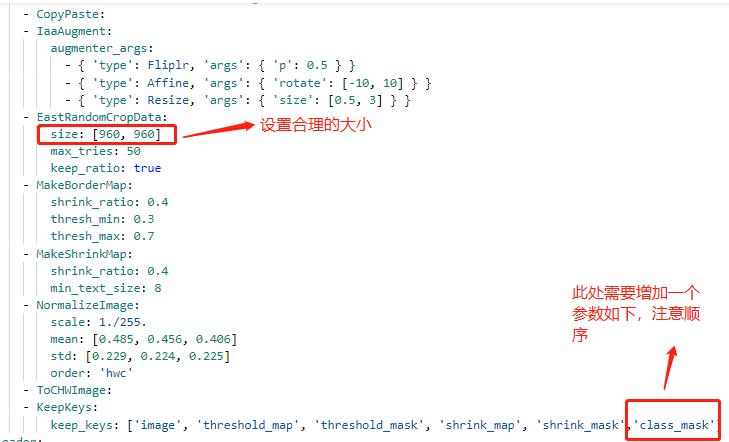
+
+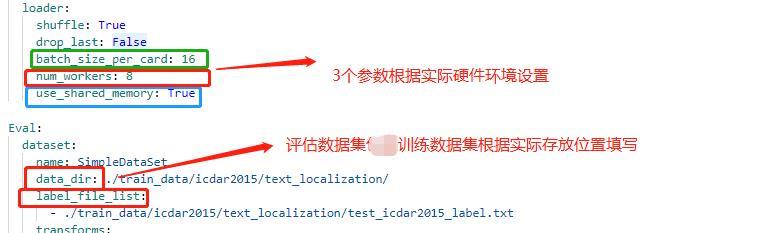
+
+
+
+
+### 4.3 代码修改
+
+
+#### 4.3.1 数据读取
+
+
+
+* 修改 PaddleOCR/ppocr/data/imaug/label_ops.py中的DetLabelEncode
+
+
+```python
+class DetLabelEncode(object):
+
+ # 修改检测标签的编码处,新增了参数分类数:num_classes,重写初始化方法,以及分类标签的读取
+
+ def __init__(self, label_list, num_classes=8, **kwargs):
+ self.num_classes = num_classes
+ self.label_list = []
+ if label_list:
+ if isinstance(label_list, str):
+ with open(label_list, 'r+', encoding='utf-8') as f:
+ for line in f.readlines():
+ self.label_list.append(line.replace("\n", ""))
+ else:
+ self.label_list = label_list
+ else:
+ assert ' please check label_list whether it is none or config is right'
+
+ if num_classes != len(self.label_list): # 校验分类数和标签的一致性
+ assert 'label_list length is not equal to the num_classes'
+
+ def __call__(self, data):
+ label = data['label']
+ label = json.loads(label)
+ nBox = len(label)
+ boxes, txts, txt_tags, classes = [], [], [], []
+ for bno in range(0, nBox):
+ box = label[bno]['points']
+ txt = label[bno]['key_cls'] # 此处将kie中的参数作为分类读取
+ boxes.append(box)
+ txts.append(txt)
+
+ if txt in ['*', '###']:
+ txt_tags.append(True)
+ if self.num_classes > 1:
+ classes.append(-2)
+ else:
+ txt_tags.append(False)
+ if self.num_classes > 1: # 将KIE内容的key标签作为分类标签使用
+ classes.append(int(self.label_list.index(txt)))
+
+ if len(boxes) == 0:
+
+ return None
+ boxes = self.expand_points_num(boxes)
+ boxes = np.array(boxes, dtype=np.float32)
+ txt_tags = np.array(txt_tags, dtype=np.bool_)
+ classes = classes
+ data['polys'] = boxes
+ data['texts'] = txts
+ data['ignore_tags'] = txt_tags
+ if self.num_classes > 1:
+ data['classes'] = classes
+ return data
+```
+
+* 修改 PaddleOCR/ppocr/data/imaug/make_shrink_map.py中的MakeShrinkMap类。这里需要注意的是,如果我们设置的label_list中的第一个参数为要检测的信息那么会得到如下的mask,
+
+举例说明:
+这是检测的mask图,图中有四个mask那么实际对应的分类应该是4类
+
+
+
+
+
+label_list中第一个为关键分类,则得到的分类Mask实际如下,与上图相比,少了一个box:
+
+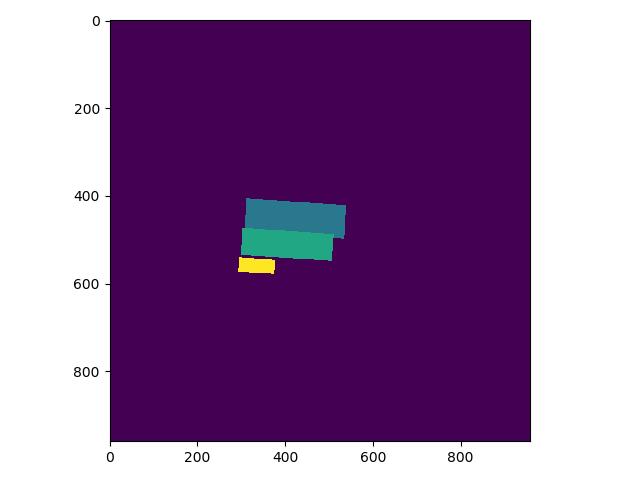
+
+
+
+```python
+class MakeShrinkMap(object):
+ r'''
+ Making binary mask from detection data with ICDAR format.
+ Typically following the process of class `MakeICDARData`.
+ '''
+
+ def __init__(self, min_text_size=8, shrink_ratio=0.4, num_classes=8, **kwargs):
+ self.min_text_size = min_text_size
+ self.shrink_ratio = shrink_ratio
+ self.num_classes = num_classes # 添加了分类
+
+ def __call__(self, data):
+ image = data['image']
+ text_polys = data['polys']
+ ignore_tags = data['ignore_tags']
+ if self.num_classes > 1:
+ classes = data['classes']
+
+ h, w = image.shape[:2]
+ text_polys, ignore_tags = self.validate_polygons(text_polys,
+ ignore_tags, h, w)
+ gt = np.zeros((h, w), dtype=np.float32)
+ mask = np.ones((h, w), dtype=np.float32)
+ gt_class = np.zeros((h, w), dtype=np.float32) # 新增分类
+ for i in range(len(text_polys)):
+ polygon = text_polys[i]
+ height = max(polygon[:, 1]) - min(polygon[:, 1])
+ width = max(polygon[:, 0]) - min(polygon[:, 0])
+ if ignore_tags[i] or min(height, width) < self.min_text_size:
+ cv2.fillPoly(mask,
+ polygon.astype(np.int32)[np.newaxis, :, :], 0)
+ ignore_tags[i] = True
+ else:
+ polygon_shape = Polygon(polygon)
+ subject = [tuple(l) for l in polygon]
+ padding = pyclipper.PyclipperOffset()
+ padding.AddPath(subject, pyclipper.JT_ROUND,
+ pyclipper.ET_CLOSEDPOLYGON)
+ shrinked = []
+
+ # Increase the shrink ratio every time we get multiple polygon returned back
+ possible_ratios = np.arange(self.shrink_ratio, 1,
+ self.shrink_ratio)
+ np.append(possible_ratios, 1)
+ for ratio in possible_ratios:
+ distance = polygon_shape.area * (
+ 1 - np.power(ratio, 2)) / polygon_shape.length
+ shrinked = padding.Execute(-distance)
+ if len(shrinked) == 1:
+ break
+
+ if shrinked == []:
+ cv2.fillPoly(mask,
+ polygon.astype(np.int32)[np.newaxis, :, :], 0)
+ ignore_tags[i] = True
+ continue
+
+ for each_shirnk in shrinked:
+ shirnk = np.array(each_shirnk).reshape(-1, 2)
+ cv2.fillPoly(gt, [shirnk.astype(np.int32)], 1)
+ if self.num_classes > 1: # 绘制分类的mask
+ cv2.fillPoly(gt_class, polygon.astype(np.int32)[np.newaxis, :, :], classes[i])
+
+
+ data['shrink_map'] = gt
+
+ if self.num_classes > 1:
+ data['class_mask'] = gt_class
+
+ data['shrink_mask'] = mask
+ return data
+```
+
+由于在训练数据中会对数据进行resize设置,yml中的操作为:EastRandomCropData,所以需要修改PaddleOCR/ppocr/data/imaug/random_crop_data.py中的EastRandomCropData
+
+
+```python
+class EastRandomCropData(object):
+ def __init__(self,
+ size=(640, 640),
+ max_tries=10,
+ min_crop_side_ratio=0.1,
+ keep_ratio=True,
+ num_classes=8,
+ **kwargs):
+ self.size = size
+ self.max_tries = max_tries
+ self.min_crop_side_ratio = min_crop_side_ratio
+ self.keep_ratio = keep_ratio
+ self.num_classes = num_classes
+
+ def __call__(self, data):
+ img = data['image']
+ text_polys = data['polys']
+ ignore_tags = data['ignore_tags']
+ texts = data['texts']
+ if self.num_classes > 1:
+ classes = data['classes']
+ all_care_polys = [
+ text_polys[i] for i, tag in enumerate(ignore_tags) if not tag
+ ]
+ # 计算crop区域
+ crop_x, crop_y, crop_w, crop_h = crop_area(
+ img, all_care_polys, self.min_crop_side_ratio, self.max_tries)
+ # crop 图片 保持比例填充
+ scale_w = self.size[0] / crop_w
+ scale_h = self.size[1] / crop_h
+ scale = min(scale_w, scale_h)
+ h = int(crop_h * scale)
+ w = int(crop_w * scale)
+ if self.keep_ratio:
+ padimg = np.zeros((self.size[1], self.size[0], img.shape[2]),
+ img.dtype)
+ padimg[:h, :w] = cv2.resize(
+ img[crop_y:crop_y + crop_h, crop_x:crop_x + crop_w], (w, h))
+ img = padimg
+ else:
+ img = cv2.resize(
+ img[crop_y:crop_y + crop_h, crop_x:crop_x + crop_w],
+ tuple(self.size))
+ # crop 文本框
+ text_polys_crop = []
+ ignore_tags_crop = []
+ texts_crop = []
+ classes_crop = []
+ for poly, text, tag,class_index in zip(text_polys, texts, ignore_tags,classes):
+ poly = ((poly - (crop_x, crop_y)) * scale).tolist()
+ if not is_poly_outside_rect(poly, 0, 0, w, h):
+ text_polys_crop.append(poly)
+ ignore_tags_crop.append(tag)
+ texts_crop.append(text)
+ if self.num_classes > 1:
+ classes_crop.append(class_index)
+ data['image'] = img
+ data['polys'] = np.array(text_polys_crop)
+ data['ignore_tags'] = ignore_tags_crop
+ data['texts'] = texts_crop
+ if self.num_classes > 1:
+ data['classes'] = classes_crop
+ return data
+```
+
+#### 4.3.2 head修改
+
+
+
+主要修改 ppocr/modeling/heads/det_db_head.py,将Head类中的最后一层的输出修改为实际的分类数,同时在DBHead中新增分类的head。
+
+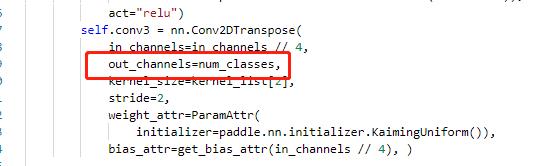
+
+
+
+#### 4.3.3 修改loss
+
+
+修改PaddleOCR/ppocr/losses/det_db_loss.py中的DBLoss类,分类采用交叉熵损失函数进行计算。
+
+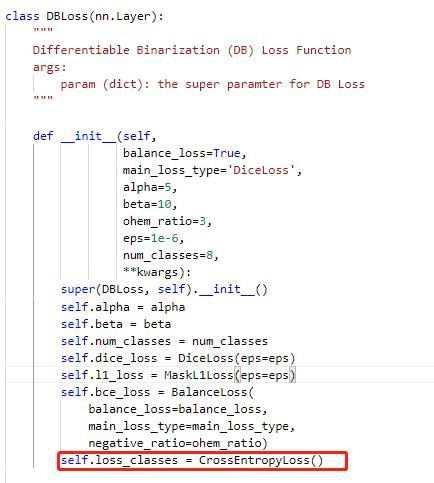
+
+
+#### 4.3.4 后处理
+
+
+
+由于涉及到eval以及后续推理能否正常使用,我们需要修改后处理的相关代码,修改位置 PaddleOCR/ppocr/postprocess/db_postprocess.py中的DBPostProcess类
+
+
+```python
+class DBPostProcess(object):
+ """
+ The post process for Differentiable Binarization (DB).
+ """
+
+ def __init__(self,
+ thresh=0.3,
+ box_thresh=0.7,
+ max_candidates=1000,
+ unclip_ratio=2.0,
+ use_dilation=False,
+ score_mode="fast",
+ **kwargs):
+ self.thresh = thresh
+ self.box_thresh = box_thresh
+ self.max_candidates = max_candidates
+ self.unclip_ratio = unclip_ratio
+ self.min_size = 3
+ self.score_mode = score_mode
+ assert score_mode in [
+ "slow", "fast"
+ ], "Score mode must be in [slow, fast] but got: {}".format(score_mode)
+
+ self.dilation_kernel = None if not use_dilation else np.array(
+ [[1, 1], [1, 1]])
+
+ def boxes_from_bitmap(self, pred, _bitmap, classes, dest_width, dest_height):
+ """
+ _bitmap: single map with shape (1, H, W),
+ whose values are binarized as {0, 1}
+ """
+
+ bitmap = _bitmap
+ height, width = bitmap.shape
+
+ outs = cv2.findContours((bitmap * 255).astype(np.uint8), cv2.RETR_LIST,
+ cv2.CHAIN_APPROX_SIMPLE)
+ if len(outs) == 3:
+ img, contours, _ = outs[0], outs[1], outs[2]
+ elif len(outs) == 2:
+ contours, _ = outs[0], outs[1]
+
+ num_contours = min(len(contours), self.max_candidates)
+
+ boxes = []
+ scores = []
+ class_indexes = []
+ class_scores = []
+ for index in range(num_contours):
+ contour = contours[index]
+ points, sside = self.get_mini_boxes(contour)
+ if sside < self.min_size:
+ continue
+ points = np.array(points)
+ if self.score_mode == "fast":
+ score, class_index, class_score = self.box_score_fast(pred, points.reshape(-1, 2), classes)
+ else:
+ score, class_index, class_score = self.box_score_slow(pred, contour, classes)
+ if self.box_thresh > score:
+ continue
+
+ box = self.unclip(points).reshape(-1, 1, 2)
+ box, sside = self.get_mini_boxes(box)
+ if sside < self.min_size + 2:
+ continue
+ box = np.array(box)
+
+ box[:, 0] = np.clip(
+ np.round(box[:, 0] / width * dest_width), 0, dest_width)
+ box[:, 1] = np.clip(
+ np.round(box[:, 1] / height * dest_height), 0, dest_height)
+
+ boxes.append(box.astype(np.int16))
+ scores.append(score)
+
+ class_indexes.append(class_index)
+ class_scores.append(class_score)
+
+ if classes is None:
+ return np.array(boxes, dtype=np.int16), scores
+ else:
+ return np.array(boxes, dtype=np.int16), scores, class_indexes, class_scores
+
+ def unclip(self, box):
+ unclip_ratio = self.unclip_ratio
+ poly = Polygon(box)
+ distance = poly.area * unclip_ratio / poly.length
+ offset = pyclipper.PyclipperOffset()
+ offset.AddPath(box, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
+ expanded = np.array(offset.Execute(distance))
+ return expanded
+
+ def get_mini_boxes(self, contour):
+ bounding_box = cv2.minAreaRect(contour)
+ points = sorted(list(cv2.boxPoints(bounding_box)), key=lambda x: x[0])
+
+ index_1, index_2, index_3, index_4 = 0, 1, 2, 3
+ if points[1][1] > points[0][1]:
+ index_1 = 0
+ index_4 = 1
+ else:
+ index_1 = 1
+ index_4 = 0
+ if points[3][1] > points[2][1]:
+ index_2 = 2
+ index_3 = 3
+ else:
+ index_2 = 3
+ index_3 = 2
+
+ box = [
+ points[index_1], points[index_2], points[index_3], points[index_4]
+ ]
+ return box, min(bounding_box[1])
+
+ def box_score_fast(self, bitmap, _box, classes):
+ '''
+ box_score_fast: use bbox mean score as the mean score
+ '''
+ h, w = bitmap.shape[:2]
+ box = _box.copy()
+ xmin = np.clip(np.floor(box[:, 0].min()).astype(np.int32), 0, w - 1)
+ xmax = np.clip(np.ceil(box[:, 0].max()).astype(np.int32), 0, w - 1)
+ ymin = np.clip(np.floor(box[:, 1].min()).astype(np.int32), 0, h - 1)
+ ymax = np.clip(np.ceil(box[:, 1].max()).astype(np.int32), 0, h - 1)
+
+ mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
+ box[:, 0] = box[:, 0] - xmin
+ box[:, 1] = box[:, 1] - ymin
+ cv2.fillPoly(mask, box.reshape(1, -1, 2).astype(np.int32), 1)
+
+ if classes is None:
+ return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], None, None
+ else:
+ k = 999
+ class_mask = np.full((ymax - ymin + 1, xmax - xmin + 1), k, dtype=np.int32)
+
+ cv2.fillPoly(class_mask, box.reshape(1, -1, 2).astype(np.int32), 0)
+ classes = classes[ymin:ymax + 1, xmin:xmax + 1]
+
+ new_classes = classes + class_mask
+ a = new_classes.reshape(-1)
+ b = np.where(a >= k)
+ classes = np.delete(a, b[0].tolist())
+
+ class_index = np.argmax(np.bincount(classes))
+ class_score = np.sum(classes == class_index) / len(classes)
+
+ return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], class_index, class_score
+
+ def box_score_slow(self, bitmap, contour, classes):
+ """
+ box_score_slow: use polyon mean score as the mean score
+ """
+ h, w = bitmap.shape[:2]
+ contour = contour.copy()
+ contour = np.reshape(contour, (-1, 2))
+
+ xmin = np.clip(np.min(contour[:, 0]), 0, w - 1)
+ xmax = np.clip(np.max(contour[:, 0]), 0, w - 1)
+ ymin = np.clip(np.min(contour[:, 1]), 0, h - 1)
+ ymax = np.clip(np.max(contour[:, 1]), 0, h - 1)
+
+ mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
+
+ contour[:, 0] = contour[:, 0] - xmin
+ contour[:, 1] = contour[:, 1] - ymin
+
+ cv2.fillPoly(mask, contour.reshape(1, -1, 2).astype(np.int32), 1)
+
+ if classes is None:
+ return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], None, None
+ else:
+ k = 999
+ class_mask = np.full((ymax - ymin + 1, xmax - xmin + 1), k, dtype=np.int32)
+
+ cv2.fillPoly(class_mask, contour.reshape(1, -1, 2).astype(np.int32), 0)
+ classes = classes[ymin:ymax + 1, xmin:xmax + 1]
+
+ new_classes = classes + class_mask
+ a = new_classes.reshape(-1)
+ b = np.where(a >= k)
+ classes = np.delete(a, b[0].tolist())
+
+ class_index = np.argmax(np.bincount(classes))
+ class_score = np.sum(classes == class_index) / len(classes)
+
+ return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], class_index, class_score
+
+ def __call__(self, outs_dict, shape_list):
+ pred = outs_dict['maps']
+ if isinstance(pred, paddle.Tensor):
+ pred = pred.numpy()
+ pred = pred[:, 0, :, :]
+ segmentation = pred > self.thresh
+
+ if "classes" in outs_dict:
+ classes = outs_dict['classes']
+ if isinstance(classes, paddle.Tensor):
+ classes = classes.numpy()
+ classes = classes[:, 0, :, :]
+
+ else:
+ classes = None
+
+ boxes_batch = []
+ for batch_index in range(pred.shape[0]):
+ src_h, src_w, ratio_h, ratio_w = shape_list[batch_index]
+ if self.dilation_kernel is not None:
+ mask = cv2.dilate(
+ np.array(segmentation[batch_index]).astype(np.uint8),
+ self.dilation_kernel)
+ else:
+ mask = segmentation[batch_index]
+
+ if classes is None:
+ boxes, scores = self.boxes_from_bitmap(pred[batch_index], mask, None,
+ src_w, src_h)
+ boxes_batch.append({'points': boxes})
+ else:
+ boxes, scores, class_indexes, class_scores = self.boxes_from_bitmap(pred[batch_index], mask,
+ classes[batch_index],
+ src_w, src_h)
+ boxes_batch.append({'points': boxes, "classes": class_indexes, "class_scores": class_scores})
+
+ return boxes_batch
+```
+
+### 4.4. 模型启动
+
+在完成上述步骤后我们就可以正常启动训练
+
+```
+!python /home/aistudio/work/PaddleOCR/tools/train.py -c /home/aistudio/work/PaddleOCR/configs/det/det_mv3_db.yml
+```
+
+其他命令:
+```
+!python /home/aistudio/work/PaddleOCR/tools/eval.py -c /home/aistudio/work/PaddleOCR/configs/det/det_mv3_db.yml
+!python /home/aistudio/work/PaddleOCR/tools/infer_det.py -c /home/aistudio/work/PaddleOCR/configs/det/det_mv3_db.yml
+```
+模型推理
+```
+!python /home/aistudio/work/PaddleOCR/tools/infer/predict_det.py --image_dir="/home/aistudio/work/test_img/" --det_model_dir="/home/aistudio/work/PaddleOCR/output/infer"
+```
+
+## 5 总结
+
+1. 分类+检测在一定程度上能够缩短用时,具体的模型选取要根据业务场景恰当选择。
+2. 数据标注需要多次进行测试调整标注方法,一般进行检测模型微调,需要标注至少上百张。
+3. 设置合理的batch_size以及resize大小,同时注意lr设置。
+
+
+## References
+
+1 https://github.com/PaddlePaddle/PaddleOCR
+
+2 https://github.com/PaddlePaddle/PaddleClas
+
+3 https://blog.csdn.net/YY007H/article/details/124491217
diff --git "a/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md" "b/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md"
new file mode 100644
index 0000000..09d1bba
--- /dev/null
+++ "b/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md"
@@ -0,0 +1,251 @@
+# 基于PP-OCRv3的手写文字识别
+
+- [1. 项目背景及意义](#1-项目背景及意义)
+- [2. 项目内容](#2-项目内容)
+- [3. PP-OCRv3识别算法介绍](#3-PP-OCRv3识别算法介绍)
+- [4. 安装环境](#4-安装环境)
+- [5. 数据准备](#5-数据准备)
+- [6. 模型训练](#6-模型训练)
+ - [6.1 下载预训练模型](#61-下载预训练模型)
+ - [6.2 修改配置文件](#62-修改配置文件)
+ - [6.3 开始训练](#63-开始训练)
+- [7. 模型评估](#7-模型评估)
+- [8. 模型导出推理](#8-模型导出推理)
+ - [8.1 模型导出](#81-模型导出)
+ - [8.2 模型推理](#82-模型推理)
+
+
+## 1. 项目背景及意义
+目前光学字符识别(OCR)技术在我们的生活当中被广泛使用,但是大多数模型在通用场景下的准确性还有待提高。针对于此我们借助飞桨提供的PaddleOCR套件较容易的实现了在垂类场景下的应用。手写体在日常生活中较为常见,然而手写体的识别却存在着很大的挑战,因为每个人的手写字体风格不一样,这对于视觉模型来说还是相当有挑战的。因此训练一个手写体识别模型具有很好的现实意义。下面给出一些手写体的示例图:
+
+
+
+## 2. 项目内容
+本项目基于PaddleOCR套件,以PP-OCRv3识别模型为基础,针对手写文字识别场景进行优化。
+
+Aistudio项目链接:[OCR手写文字识别](https://aistudio.baidu.com/aistudio/projectdetail/4330587)
+
+## 3. PP-OCRv3识别算法介绍
+PP-OCRv3的识别模块是基于文本识别算法[SVTR](https://arxiv.org/abs/2205.00159)优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。如下图所示,PP-OCRv3采用了6个优化策略。
+
+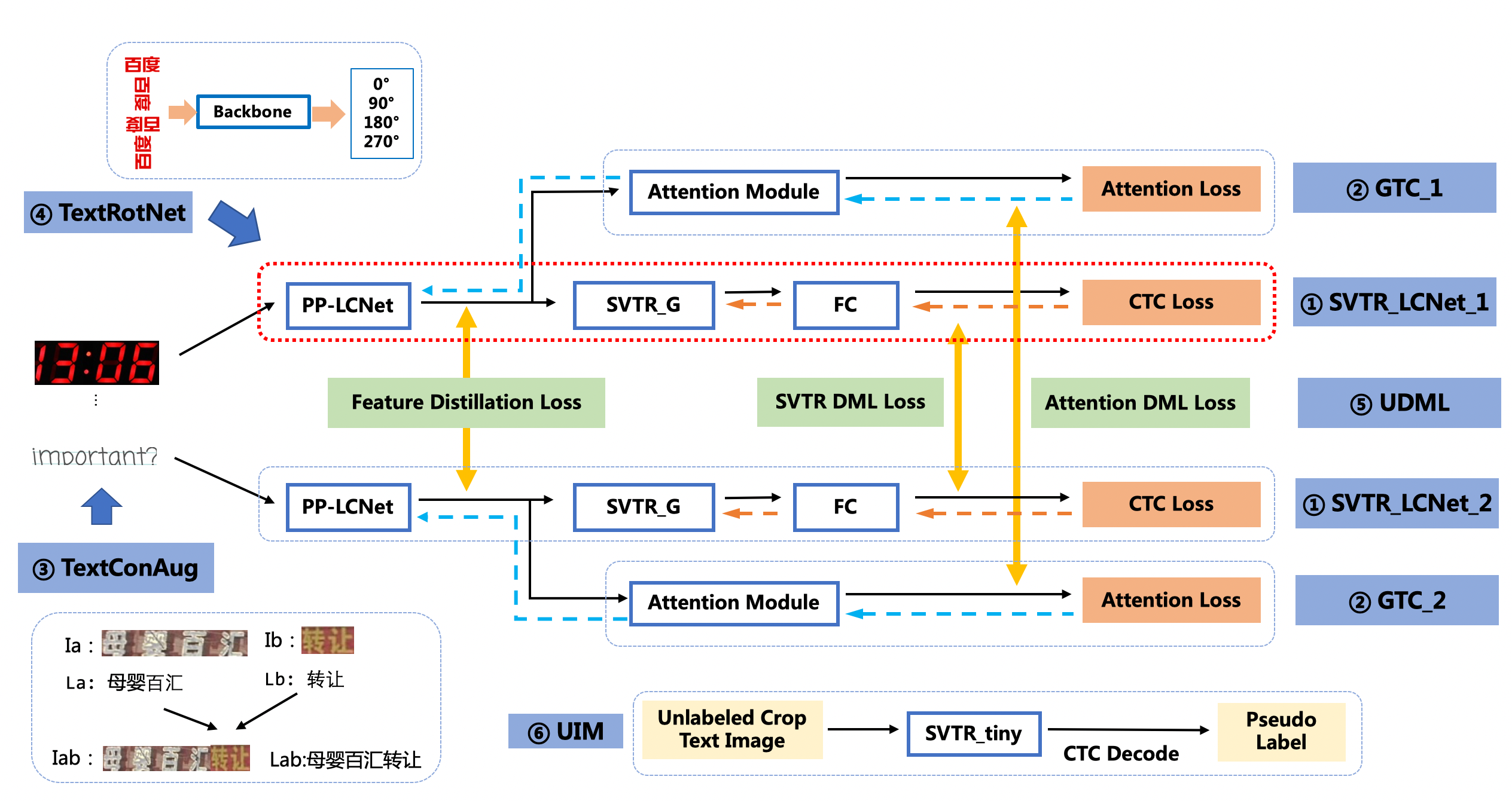
+
+优化策略汇总如下:
+
+* SVTR_LCNet:轻量级文本识别网络
+* GTC:Attention指导CTC训练策略
+* TextConAug:挖掘文字上下文信息的数据增广策略
+* TextRotNet:自监督的预训练模型
+* UDML:联合互学习策略
+* UIM:无标注数据挖掘方案
+
+详细优化策略描述请参考[PP-OCRv3优化策略](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md#3-%E8%AF%86%E5%88%AB%E4%BC%98%E5%8C%96)
+
+## 4. 安装环境
+
+
+```python
+# 首先git官方的PaddleOCR项目,安装需要的依赖
+git clone https://github.com/PaddlePaddle/PaddleOCR.git
+cd PaddleOCR
+pip install -r requirements.txt
+```
+
+## 5. 数据准备
+本项目使用公开的手写文本识别数据集,包含Chinese OCR, 中科院自动化研究所-手写中文数据集[CASIA-HWDB2.x](http://www.nlpr.ia.ac.cn/databases/handwriting/Download.html),以及由中科院手写数据和网上开源数据合并组合的[数据集](https://aistudio.baidu.com/aistudio/datasetdetail/102884/0)等,该项目已经挂载处理好的数据集,可直接下载使用进行训练。
+
+
+```python
+下载并解压数据
+tar -xf hw_data.tar
+```
+
+## 6. 模型训练
+### 6.1 下载预训练模型
+首先需要下载我们需要的PP-OCRv3识别预训练模型,更多选择请自行选择其他的[文字识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/models_list.md#2-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E6%A8%A1%E5%9E%8B)
+
+
+```python
+# 使用该指令下载需要的预训练模型
+wget -P ./pretrained_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
+# 解压预训练模型文件
+tar -xf ./pretrained_models/ch_PP-OCRv3_rec_train.tar -C pretrained_models
+```
+
+### 6.2 修改配置文件
+我们使用`configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml`,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+
+```
+ epoch_num: 100 # 训练epoch数
+ save_model_dir: ./output/ch_PP-OCR_v3_rec
+ save_epoch_step: 10
+ eval_batch_step: [0, 100] # 评估间隔,每隔100step评估一次
+ pretrained_model: ./pretrained_models/ch_PP-OCRv3_rec_train/best_accuracy # 预训练模型路径
+
+
+ lr:
+ name: Cosine # 修改学习率衰减策略为Cosine
+ learning_rate: 0.0001 # 修改fine-tune的学习率
+ warmup_epoch: 2 # 修改warmup轮数
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data # 训练集图片路径
+ ext_op_transform_idx: 1
+ label_file_list:
+ - ./train_data/chineseocr-data/rec_hand_line_all_label_train.txt # 训练集标签
+ - ./train_data/handwrite/HWDB2.0Train_label.txt
+ - ./train_data/handwrite/HWDB2.1Train_label.txt
+ - ./train_data/handwrite/HWDB2.2Train_label.txt
+ - ./train_data/handwrite/hwdb_ic13/handwriting_hwdb_train_labels.txt
+ - ./train_data/handwrite/HW_Chinese/train_hw.txt
+ ratio_list:
+ - 0.1
+ - 1.0
+ - 1.0
+ - 1.0
+ - 0.02
+ - 1.0
+ loader:
+ shuffle: true
+ batch_size_per_card: 64
+ drop_last: true
+ num_workers: 4
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data # 测试集图片路径
+ label_file_list:
+ - ./train_data/chineseocr-data/rec_hand_line_all_label_val.txt # 测试集标签
+ - ./train_data/handwrite/HWDB2.0Test_label.txt
+ - ./train_data/handwrite/HWDB2.1Test_label.txt
+ - ./train_data/handwrite/HWDB2.2Test_label.txt
+ - ./train_data/handwrite/hwdb_ic13/handwriting_hwdb_val_labels.txt
+ - ./train_data/handwrite/HW_Chinese/test_hw.txt
+ loader:
+ shuffle: false
+ drop_last: false
+ batch_size_per_card: 64
+ num_workers: 4
+```
+由于数据集大多是长文本,因此需要**注释**掉下面的数据增广策略,以便训练出更好的模型。
+```
+- RecConAug:
+ prob: 0.5
+ ext_data_num: 2
+ image_shape: [48, 320, 3]
+```
+
+
+### 6.3 开始训练
+我们使用上面修改好的配置文件`configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml`,预训练模型,数据集路径,学习率,训练轮数等都已经设置完毕后,可以使用下面命令开始训练。
+
+
+```python
+# 开始训练识别模型
+python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
+
+```
+
+## 7. 模型评估
+在训练之前,我们可以直接使用下面命令来评估预训练模型的效果:
+
+
+
+```python
+# 评估预训练模型
+python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model="./pretrained_models/ch_PP-OCRv3_rec_train/best_accuracy"
+```
+```
+[2022/07/14 10:46:22] ppocr INFO: load pretrain successful from ./pretrained_models/ch_PP-OCRv3_rec_train/best_accuracy
+eval model:: 100%|████████████████████████████| 687/687 [03:29<00:00, 3.27it/s]
+[2022/07/14 10:49:52] ppocr INFO: metric eval ***************
+[2022/07/14 10:49:52] ppocr INFO: acc:0.03724954461811258
+[2022/07/14 10:49:52] ppocr INFO: norm_edit_dis:0.4859541065843199
+[2022/07/14 10:49:52] ppocr INFO: Teacher_acc:0.0371584699368947
+[2022/07/14 10:49:52] ppocr INFO: Teacher_norm_edit_dis:0.48718814890536477
+[2022/07/14 10:49:52] ppocr INFO: fps:947.8562684823883
+```
+
+可以看出,直接加载预训练模型进行评估,效果较差,因为预训练模型并不是基于手写文字进行单独训练的,所以我们需要基于预训练模型进行finetune。
+训练完成后,可以进行测试评估,评估命令如下:
+
+
+
+```python
+# 评估finetune效果
+python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_rec/best_accuracy"
+
+```
+
+评估结果如下,可以看出识别准确率为54.3%。
+```
+[2022/07/14 10:54:06] ppocr INFO: metric eval ***************
+[2022/07/14 10:54:06] ppocr INFO: acc:0.5430100180913
+[2022/07/14 10:54:06] ppocr INFO: norm_edit_dis:0.9203322593158589
+[2022/07/14 10:54:06] ppocr INFO: Teacher_acc:0.5401183969626324
+[2022/07/14 10:54:06] ppocr INFO: Teacher_norm_edit_dis:0.919827504507755
+[2022/07/14 10:54:06] ppocr INFO: fps:928.948733797251
+```
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+图28 Excel效果图
+
+
+```python
+import json
+import xlsxwriter as xw
+
+workbook = xw.Workbook('output/re/infer_results.xlsx')
+format1 = workbook.add_format({
+ 'align': 'center',
+ 'valign': 'vcenter',
+ 'text_wrap': True,
+})
+worksheet1 = workbook.add_worksheet('sheet1')
+worksheet1.activate()
+title = ['姓名', '性别', '民族', '文化程度', '身份证号码', '联系电话', '通讯地址']
+worksheet1.write_row('A1', title)
+i = 2
+
+with open('output/re/infer_results.txt', 'r', encoding='utf-8') as fin:
+ lines = fin.readlines()
+ for line in lines:
+ img_path, result = line.strip().split('\t')
+ result_key = json.loads(result)
+ # 写入Excel
+ row_data = [result_key['姓名'], result_key['性别'], result_key['民族'], result_key['文化程度'], result_key['身份证号码'],
+ result_key['联系电话'], result_key['通讯地址']]
+ row = 'A' + str(i)
+ worksheet1.write_row(row, row_data, format1)
+ i+=1
+workbook.close()
+```
+
+## 更多资源
+
+- 更多深度学习知识、产业案例、面试宝典等,请参考:[awesome-DeepLearning](https://github.com/paddlepaddle/awesome-DeepLearning)
+
+- 更多PaddleOCR使用教程,请参考:[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph)
+
+- 更多PaddleNLP使用教程,请参考:[PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP)
+
+- 飞桨框架相关资料,请参考:[飞桨深度学习平台](https://www.paddlepaddle.org.cn/?fr=paddleEdu_aistudio)
+
+## 参考链接
+
+- LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding, https://arxiv.org/pdf/2104.08836.pdf
+
+- microsoft/unilm/layoutxlm, https://github.com/microsoft/unilm/tree/master/layoutxlm
+
+- XFUND dataset, https://github.com/doc-analysis/XFUND
+
diff --git "a/applications/\345\277\253\351\200\237\346\236\204\345\273\272\345\215\241\350\257\201\347\261\273OCR.md" "b/applications/\345\277\253\351\200\237\346\236\204\345\273\272\345\215\241\350\257\201\347\261\273OCR.md"
new file mode 100644
index 0000000..50b70ff
--- /dev/null
+++ "b/applications/\345\277\253\351\200\237\346\236\204\345\273\272\345\215\241\350\257\201\347\261\273OCR.md"
@@ -0,0 +1,775 @@
+# 快速构建卡证类OCR
+
+
+- [快速构建卡证类OCR](#快速构建卡证类ocr)
+ - [1. 金融行业卡证识别应用](#1-金融行业卡证识别应用)
+ - [1.1 金融行业中的OCR相关技术](#11-金融行业中的ocr相关技术)
+ - [1.2 金融行业中的卡证识别场景介绍](#12-金融行业中的卡证识别场景介绍)
+ - [1.3 OCR落地挑战](#13-ocr落地挑战)
+ - [2. 卡证识别技术解析](#2-卡证识别技术解析)
+ - [2.1 卡证分类模型](#21-卡证分类模型)
+ - [2.2 卡证识别模型](#22-卡证识别模型)
+ - [3. OCR技术拆解](#3-ocr技术拆解)
+ - [3.1技术流程](#31技术流程)
+ - [3.2 OCR技术拆解---卡证分类](#32-ocr技术拆解---卡证分类)
+ - [卡证分类:数据、模型准备](#卡证分类数据模型准备)
+ - [卡证分类---修改配置文件](#卡证分类---修改配置文件)
+ - [卡证分类---训练](#卡证分类---训练)
+ - [3.2 OCR技术拆解---卡证识别](#32-ocr技术拆解---卡证识别)
+ - [身份证识别:检测+分类](#身份证识别检测分类)
+ - [数据标注](#数据标注)
+ - [4 . 项目实践](#4--项目实践)
+ - [4.1 环境准备](#41-环境准备)
+ - [4.2 配置文件修改](#42-配置文件修改)
+ - [4.3 代码修改](#43-代码修改)
+ - [4.3.1 数据读取](#431-数据读取)
+ - [4.3.2 head修改](#432--head修改)
+ - [4.3.3 修改loss](#433-修改loss)
+ - [4.3.4 后处理](#434-后处理)
+ - [4.4. 模型启动](#44-模型启动)
+ - [5 总结](#5-总结)
+ - [References](#references)
+
+## 1. 金融行业卡证识别应用
+
+### 1.1 金融行业中的OCR相关技术
+
+* 《“十四五”数字经济发展规划》指出,2020年我国数字经济核心产业增加值占GDP比重达7.8%,随着数字经济迈向全面扩展,到2025年该比例将提升至10%。
+
+* 在过去数年的跨越发展与积累沉淀中,数字金融、金融科技已在对金融业的重塑与再造中充分印证了其自身价值。
+
+* 以智能为目标,提升金融数字化水平,实现业务流程自动化,降低人力成本。
+
+
+
+
+
+
+### 1.2 金融行业中的卡证识别场景介绍
+
+应用场景:身份证、银行卡、营业执照、驾驶证等。
+
+应用难点:由于数据的采集来源多样,以及实际采集数据各种噪声:反光、褶皱、模糊、倾斜等各种问题干扰。
+
+
+
+
+
+### 1.3 OCR落地挑战
+
+
+
+
+
+
+
+
+## 2. 卡证识别技术解析
+
+
+
+
+
+### 2.1 卡证分类模型
+
+卡证分类:基于PPLCNet
+
+与其他轻量级模型相比在CPU环境下ImageNet数据集上的表现
+
+
+
+
+
+
+
+* 模型来自模型库PaddleClas,它是一个图像识别和图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。
+
+### 2.2 卡证识别模型
+
+* 检测:DBNet 识别:SVRT
+
+
+
+
+* PPOCRv3在文本检测、识别进行了一系列改进优化,在保证精度的同时提升预测效率
+
+
+
+
+
+
+
+
+## 3. OCR技术拆解
+
+### 3.1技术流程
+
+
+
+
+### 3.2 OCR技术拆解---卡证分类
+
+#### 卡证分类:数据、模型准备
+
+
+A 使用爬虫获取无标注数据,将相同类别的放在同一文件夹下,文件名从0开始命名。具体格式如下图所示。
+
+ 注:卡证类数据,建议每个类别数据量在500张以上
+
+
+
+B 一行命令生成标签文件
+
+```
+tree -r -i -f | grep -E "jpg|JPG|jpeg|JPEG|png|PNG|webp" | awk -F "/" '{print $0" "$2}' > train_list.txt
+```
+
+C [下载预训练模型 ](https://github.com/PaddlePaddle/PaddleClas/blob/release/2.4/docs/zh_CN/models/PP-LCNet.md)
+
+
+
+#### 卡证分类---修改配置文件
+
+
+配置文件主要修改三个部分:
+
+ 全局参数:预训练模型路径/训练轮次/图像尺寸
+
+ 模型结构:分类数
+
+ 数据处理:训练/评估数据路径
+
+
+ 
+
+#### 卡证分类---训练
+
+
+指定配置文件启动训练:
+
+```
+!python /home/aistudio/work/PaddleClas/tools/train.py -c /home/aistudio/work/PaddleClas/ppcls/configs/PULC/text_image_orientation/PPLCNet_x1_0.yaml
+```
+
+
+ 注:日志中显示了训练结果和评估结果(训练时可以设置固定轮数评估一次)
+
+
+### 3.2 OCR技术拆解---卡证识别
+
+卡证识别(以身份证检测为例)
+存在的困难及问题:
+
+ * 在自然场景下,由于各种拍摄设备以及光线、角度不同等影响导致实际得到的证件影像千差万别。
+
+ * 如何快速提取需要的关键信息
+
+ * 多行的文本信息,检测结果如何正确拼接
+
+ 
+
+
+
+* OCR技术拆解---OCR工具库
+
+ PaddleOCR是一个丰富、领先且实用的OCR工具库,助力开发者训练出更好的模型并应用落地
+
+
+身份证识别:用现有的方法识别
+
+
+
+
+
+
+#### 身份证识别:检测+分类
+
+> 方法:基于现有的dbnet检测模型,加入分类方法。检测同时进行分类,从一定程度上优化识别流程
+
+
+
+
+
+
+#### 数据标注
+
+使用PaddleOCRLable进行快速标注
+
+
+
+
+* 修改PPOCRLabel.py,将下图中的kie参数设置为True
+
+
+
+
+
+* 数据标注踩坑分享
+
+
+
+ 注:两者只有标注有差别,训练参数数据集都相同
+
+## 4 . 项目实践
+
+AIStudio项目链接:[快速构建卡证类OCR](https://aistudio.baidu.com/aistudio/projectdetail/4459116)
+
+### 4.1 环境准备
+
+1)拉取[paddleocr](https://github.com/PaddlePaddle/PaddleOCR)项目,如果从github上拉取速度慢可以选择从gitee上获取。
+```
+!git clone https://github.com/PaddlePaddle/PaddleOCR.git -b release/2.6 /home/aistudio/work/
+```
+
+2)获取并解压预训练模型,如果要使用其他模型可以从模型库里自主选择合适模型。
+```
+!wget -P work/pre_trained/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
+!tar -vxf /home/aistudio/work/pre_trained/ch_PP-OCRv3_det_distill_train.tar -C /home/aistudio/work/pre_trained
+```
+3) 安装必要依赖
+```
+!pip install -r /home/aistudio/work/requirements.txt
+```
+
+### 4.2 配置文件修改
+
+修改配置文件 *work/configs/det/detmv3db.yml*
+
+具体修改说明如下:
+
+
+
+ 注:在上述的配置文件的Global变量中需要添加以下两个参数:
+
+ label_list 为标签表
+ num_classes 为分类数
+ 上述两个参数根据实际的情况配置即可
+
+
+
+
+其中lable_list内容如下例所示,***建议第一个参数设置为 background,不要设置为实际要提取的关键信息种类***:
+
+
+
+配置文件中的其他设置说明
+
+
+
+
+
+
+
+
+
+
+### 4.3 代码修改
+
+
+#### 4.3.1 数据读取
+
+
+
+* 修改 PaddleOCR/ppocr/data/imaug/label_ops.py中的DetLabelEncode
+
+
+```python
+class DetLabelEncode(object):
+
+ # 修改检测标签的编码处,新增了参数分类数:num_classes,重写初始化方法,以及分类标签的读取
+
+ def __init__(self, label_list, num_classes=8, **kwargs):
+ self.num_classes = num_classes
+ self.label_list = []
+ if label_list:
+ if isinstance(label_list, str):
+ with open(label_list, 'r+', encoding='utf-8') as f:
+ for line in f.readlines():
+ self.label_list.append(line.replace("\n", ""))
+ else:
+ self.label_list = label_list
+ else:
+ assert ' please check label_list whether it is none or config is right'
+
+ if num_classes != len(self.label_list): # 校验分类数和标签的一致性
+ assert 'label_list length is not equal to the num_classes'
+
+ def __call__(self, data):
+ label = data['label']
+ label = json.loads(label)
+ nBox = len(label)
+ boxes, txts, txt_tags, classes = [], [], [], []
+ for bno in range(0, nBox):
+ box = label[bno]['points']
+ txt = label[bno]['key_cls'] # 此处将kie中的参数作为分类读取
+ boxes.append(box)
+ txts.append(txt)
+
+ if txt in ['*', '###']:
+ txt_tags.append(True)
+ if self.num_classes > 1:
+ classes.append(-2)
+ else:
+ txt_tags.append(False)
+ if self.num_classes > 1: # 将KIE内容的key标签作为分类标签使用
+ classes.append(int(self.label_list.index(txt)))
+
+ if len(boxes) == 0:
+
+ return None
+ boxes = self.expand_points_num(boxes)
+ boxes = np.array(boxes, dtype=np.float32)
+ txt_tags = np.array(txt_tags, dtype=np.bool_)
+ classes = classes
+ data['polys'] = boxes
+ data['texts'] = txts
+ data['ignore_tags'] = txt_tags
+ if self.num_classes > 1:
+ data['classes'] = classes
+ return data
+```
+
+* 修改 PaddleOCR/ppocr/data/imaug/make_shrink_map.py中的MakeShrinkMap类。这里需要注意的是,如果我们设置的label_list中的第一个参数为要检测的信息那么会得到如下的mask,
+
+举例说明:
+这是检测的mask图,图中有四个mask那么实际对应的分类应该是4类
+
+
+
+
+
+label_list中第一个为关键分类,则得到的分类Mask实际如下,与上图相比,少了一个box:
+
+
+
+
+
+```python
+class MakeShrinkMap(object):
+ r'''
+ Making binary mask from detection data with ICDAR format.
+ Typically following the process of class `MakeICDARData`.
+ '''
+
+ def __init__(self, min_text_size=8, shrink_ratio=0.4, num_classes=8, **kwargs):
+ self.min_text_size = min_text_size
+ self.shrink_ratio = shrink_ratio
+ self.num_classes = num_classes # 添加了分类
+
+ def __call__(self, data):
+ image = data['image']
+ text_polys = data['polys']
+ ignore_tags = data['ignore_tags']
+ if self.num_classes > 1:
+ classes = data['classes']
+
+ h, w = image.shape[:2]
+ text_polys, ignore_tags = self.validate_polygons(text_polys,
+ ignore_tags, h, w)
+ gt = np.zeros((h, w), dtype=np.float32)
+ mask = np.ones((h, w), dtype=np.float32)
+ gt_class = np.zeros((h, w), dtype=np.float32) # 新增分类
+ for i in range(len(text_polys)):
+ polygon = text_polys[i]
+ height = max(polygon[:, 1]) - min(polygon[:, 1])
+ width = max(polygon[:, 0]) - min(polygon[:, 0])
+ if ignore_tags[i] or min(height, width) < self.min_text_size:
+ cv2.fillPoly(mask,
+ polygon.astype(np.int32)[np.newaxis, :, :], 0)
+ ignore_tags[i] = True
+ else:
+ polygon_shape = Polygon(polygon)
+ subject = [tuple(l) for l in polygon]
+ padding = pyclipper.PyclipperOffset()
+ padding.AddPath(subject, pyclipper.JT_ROUND,
+ pyclipper.ET_CLOSEDPOLYGON)
+ shrinked = []
+
+ # Increase the shrink ratio every time we get multiple polygon returned back
+ possible_ratios = np.arange(self.shrink_ratio, 1,
+ self.shrink_ratio)
+ np.append(possible_ratios, 1)
+ for ratio in possible_ratios:
+ distance = polygon_shape.area * (
+ 1 - np.power(ratio, 2)) / polygon_shape.length
+ shrinked = padding.Execute(-distance)
+ if len(shrinked) == 1:
+ break
+
+ if shrinked == []:
+ cv2.fillPoly(mask,
+ polygon.astype(np.int32)[np.newaxis, :, :], 0)
+ ignore_tags[i] = True
+ continue
+
+ for each_shirnk in shrinked:
+ shirnk = np.array(each_shirnk).reshape(-1, 2)
+ cv2.fillPoly(gt, [shirnk.astype(np.int32)], 1)
+ if self.num_classes > 1: # 绘制分类的mask
+ cv2.fillPoly(gt_class, polygon.astype(np.int32)[np.newaxis, :, :], classes[i])
+
+
+ data['shrink_map'] = gt
+
+ if self.num_classes > 1:
+ data['class_mask'] = gt_class
+
+ data['shrink_mask'] = mask
+ return data
+```
+
+由于在训练数据中会对数据进行resize设置,yml中的操作为:EastRandomCropData,所以需要修改PaddleOCR/ppocr/data/imaug/random_crop_data.py中的EastRandomCropData
+
+
+```python
+class EastRandomCropData(object):
+ def __init__(self,
+ size=(640, 640),
+ max_tries=10,
+ min_crop_side_ratio=0.1,
+ keep_ratio=True,
+ num_classes=8,
+ **kwargs):
+ self.size = size
+ self.max_tries = max_tries
+ self.min_crop_side_ratio = min_crop_side_ratio
+ self.keep_ratio = keep_ratio
+ self.num_classes = num_classes
+
+ def __call__(self, data):
+ img = data['image']
+ text_polys = data['polys']
+ ignore_tags = data['ignore_tags']
+ texts = data['texts']
+ if self.num_classes > 1:
+ classes = data['classes']
+ all_care_polys = [
+ text_polys[i] for i, tag in enumerate(ignore_tags) if not tag
+ ]
+ # 计算crop区域
+ crop_x, crop_y, crop_w, crop_h = crop_area(
+ img, all_care_polys, self.min_crop_side_ratio, self.max_tries)
+ # crop 图片 保持比例填充
+ scale_w = self.size[0] / crop_w
+ scale_h = self.size[1] / crop_h
+ scale = min(scale_w, scale_h)
+ h = int(crop_h * scale)
+ w = int(crop_w * scale)
+ if self.keep_ratio:
+ padimg = np.zeros((self.size[1], self.size[0], img.shape[2]),
+ img.dtype)
+ padimg[:h, :w] = cv2.resize(
+ img[crop_y:crop_y + crop_h, crop_x:crop_x + crop_w], (w, h))
+ img = padimg
+ else:
+ img = cv2.resize(
+ img[crop_y:crop_y + crop_h, crop_x:crop_x + crop_w],
+ tuple(self.size))
+ # crop 文本框
+ text_polys_crop = []
+ ignore_tags_crop = []
+ texts_crop = []
+ classes_crop = []
+ for poly, text, tag,class_index in zip(text_polys, texts, ignore_tags,classes):
+ poly = ((poly - (crop_x, crop_y)) * scale).tolist()
+ if not is_poly_outside_rect(poly, 0, 0, w, h):
+ text_polys_crop.append(poly)
+ ignore_tags_crop.append(tag)
+ texts_crop.append(text)
+ if self.num_classes > 1:
+ classes_crop.append(class_index)
+ data['image'] = img
+ data['polys'] = np.array(text_polys_crop)
+ data['ignore_tags'] = ignore_tags_crop
+ data['texts'] = texts_crop
+ if self.num_classes > 1:
+ data['classes'] = classes_crop
+ return data
+```
+
+#### 4.3.2 head修改
+
+
+
+主要修改 ppocr/modeling/heads/det_db_head.py,将Head类中的最后一层的输出修改为实际的分类数,同时在DBHead中新增分类的head。
+
+
+
+
+
+#### 4.3.3 修改loss
+
+
+修改PaddleOCR/ppocr/losses/det_db_loss.py中的DBLoss类,分类采用交叉熵损失函数进行计算。
+
+
+
+
+#### 4.3.4 后处理
+
+
+
+由于涉及到eval以及后续推理能否正常使用,我们需要修改后处理的相关代码,修改位置 PaddleOCR/ppocr/postprocess/db_postprocess.py中的DBPostProcess类
+
+
+```python
+class DBPostProcess(object):
+ """
+ The post process for Differentiable Binarization (DB).
+ """
+
+ def __init__(self,
+ thresh=0.3,
+ box_thresh=0.7,
+ max_candidates=1000,
+ unclip_ratio=2.0,
+ use_dilation=False,
+ score_mode="fast",
+ **kwargs):
+ self.thresh = thresh
+ self.box_thresh = box_thresh
+ self.max_candidates = max_candidates
+ self.unclip_ratio = unclip_ratio
+ self.min_size = 3
+ self.score_mode = score_mode
+ assert score_mode in [
+ "slow", "fast"
+ ], "Score mode must be in [slow, fast] but got: {}".format(score_mode)
+
+ self.dilation_kernel = None if not use_dilation else np.array(
+ [[1, 1], [1, 1]])
+
+ def boxes_from_bitmap(self, pred, _bitmap, classes, dest_width, dest_height):
+ """
+ _bitmap: single map with shape (1, H, W),
+ whose values are binarized as {0, 1}
+ """
+
+ bitmap = _bitmap
+ height, width = bitmap.shape
+
+ outs = cv2.findContours((bitmap * 255).astype(np.uint8), cv2.RETR_LIST,
+ cv2.CHAIN_APPROX_SIMPLE)
+ if len(outs) == 3:
+ img, contours, _ = outs[0], outs[1], outs[2]
+ elif len(outs) == 2:
+ contours, _ = outs[0], outs[1]
+
+ num_contours = min(len(contours), self.max_candidates)
+
+ boxes = []
+ scores = []
+ class_indexes = []
+ class_scores = []
+ for index in range(num_contours):
+ contour = contours[index]
+ points, sside = self.get_mini_boxes(contour)
+ if sside < self.min_size:
+ continue
+ points = np.array(points)
+ if self.score_mode == "fast":
+ score, class_index, class_score = self.box_score_fast(pred, points.reshape(-1, 2), classes)
+ else:
+ score, class_index, class_score = self.box_score_slow(pred, contour, classes)
+ if self.box_thresh > score:
+ continue
+
+ box = self.unclip(points).reshape(-1, 1, 2)
+ box, sside = self.get_mini_boxes(box)
+ if sside < self.min_size + 2:
+ continue
+ box = np.array(box)
+
+ box[:, 0] = np.clip(
+ np.round(box[:, 0] / width * dest_width), 0, dest_width)
+ box[:, 1] = np.clip(
+ np.round(box[:, 1] / height * dest_height), 0, dest_height)
+
+ boxes.append(box.astype(np.int16))
+ scores.append(score)
+
+ class_indexes.append(class_index)
+ class_scores.append(class_score)
+
+ if classes is None:
+ return np.array(boxes, dtype=np.int16), scores
+ else:
+ return np.array(boxes, dtype=np.int16), scores, class_indexes, class_scores
+
+ def unclip(self, box):
+ unclip_ratio = self.unclip_ratio
+ poly = Polygon(box)
+ distance = poly.area * unclip_ratio / poly.length
+ offset = pyclipper.PyclipperOffset()
+ offset.AddPath(box, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
+ expanded = np.array(offset.Execute(distance))
+ return expanded
+
+ def get_mini_boxes(self, contour):
+ bounding_box = cv2.minAreaRect(contour)
+ points = sorted(list(cv2.boxPoints(bounding_box)), key=lambda x: x[0])
+
+ index_1, index_2, index_3, index_4 = 0, 1, 2, 3
+ if points[1][1] > points[0][1]:
+ index_1 = 0
+ index_4 = 1
+ else:
+ index_1 = 1
+ index_4 = 0
+ if points[3][1] > points[2][1]:
+ index_2 = 2
+ index_3 = 3
+ else:
+ index_2 = 3
+ index_3 = 2
+
+ box = [
+ points[index_1], points[index_2], points[index_3], points[index_4]
+ ]
+ return box, min(bounding_box[1])
+
+ def box_score_fast(self, bitmap, _box, classes):
+ '''
+ box_score_fast: use bbox mean score as the mean score
+ '''
+ h, w = bitmap.shape[:2]
+ box = _box.copy()
+ xmin = np.clip(np.floor(box[:, 0].min()).astype(np.int32), 0, w - 1)
+ xmax = np.clip(np.ceil(box[:, 0].max()).astype(np.int32), 0, w - 1)
+ ymin = np.clip(np.floor(box[:, 1].min()).astype(np.int32), 0, h - 1)
+ ymax = np.clip(np.ceil(box[:, 1].max()).astype(np.int32), 0, h - 1)
+
+ mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
+ box[:, 0] = box[:, 0] - xmin
+ box[:, 1] = box[:, 1] - ymin
+ cv2.fillPoly(mask, box.reshape(1, -1, 2).astype(np.int32), 1)
+
+ if classes is None:
+ return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], None, None
+ else:
+ k = 999
+ class_mask = np.full((ymax - ymin + 1, xmax - xmin + 1), k, dtype=np.int32)
+
+ cv2.fillPoly(class_mask, box.reshape(1, -1, 2).astype(np.int32), 0)
+ classes = classes[ymin:ymax + 1, xmin:xmax + 1]
+
+ new_classes = classes + class_mask
+ a = new_classes.reshape(-1)
+ b = np.where(a >= k)
+ classes = np.delete(a, b[0].tolist())
+
+ class_index = np.argmax(np.bincount(classes))
+ class_score = np.sum(classes == class_index) / len(classes)
+
+ return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], class_index, class_score
+
+ def box_score_slow(self, bitmap, contour, classes):
+ """
+ box_score_slow: use polyon mean score as the mean score
+ """
+ h, w = bitmap.shape[:2]
+ contour = contour.copy()
+ contour = np.reshape(contour, (-1, 2))
+
+ xmin = np.clip(np.min(contour[:, 0]), 0, w - 1)
+ xmax = np.clip(np.max(contour[:, 0]), 0, w - 1)
+ ymin = np.clip(np.min(contour[:, 1]), 0, h - 1)
+ ymax = np.clip(np.max(contour[:, 1]), 0, h - 1)
+
+ mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
+
+ contour[:, 0] = contour[:, 0] - xmin
+ contour[:, 1] = contour[:, 1] - ymin
+
+ cv2.fillPoly(mask, contour.reshape(1, -1, 2).astype(np.int32), 1)
+
+ if classes is None:
+ return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], None, None
+ else:
+ k = 999
+ class_mask = np.full((ymax - ymin + 1, xmax - xmin + 1), k, dtype=np.int32)
+
+ cv2.fillPoly(class_mask, contour.reshape(1, -1, 2).astype(np.int32), 0)
+ classes = classes[ymin:ymax + 1, xmin:xmax + 1]
+
+ new_classes = classes + class_mask
+ a = new_classes.reshape(-1)
+ b = np.where(a >= k)
+ classes = np.delete(a, b[0].tolist())
+
+ class_index = np.argmax(np.bincount(classes))
+ class_score = np.sum(classes == class_index) / len(classes)
+
+ return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], class_index, class_score
+
+ def __call__(self, outs_dict, shape_list):
+ pred = outs_dict['maps']
+ if isinstance(pred, paddle.Tensor):
+ pred = pred.numpy()
+ pred = pred[:, 0, :, :]
+ segmentation = pred > self.thresh
+
+ if "classes" in outs_dict:
+ classes = outs_dict['classes']
+ if isinstance(classes, paddle.Tensor):
+ classes = classes.numpy()
+ classes = classes[:, 0, :, :]
+
+ else:
+ classes = None
+
+ boxes_batch = []
+ for batch_index in range(pred.shape[0]):
+ src_h, src_w, ratio_h, ratio_w = shape_list[batch_index]
+ if self.dilation_kernel is not None:
+ mask = cv2.dilate(
+ np.array(segmentation[batch_index]).astype(np.uint8),
+ self.dilation_kernel)
+ else:
+ mask = segmentation[batch_index]
+
+ if classes is None:
+ boxes, scores = self.boxes_from_bitmap(pred[batch_index], mask, None,
+ src_w, src_h)
+ boxes_batch.append({'points': boxes})
+ else:
+ boxes, scores, class_indexes, class_scores = self.boxes_from_bitmap(pred[batch_index], mask,
+ classes[batch_index],
+ src_w, src_h)
+ boxes_batch.append({'points': boxes, "classes": class_indexes, "class_scores": class_scores})
+
+ return boxes_batch
+```
+
+### 4.4. 模型启动
+
+在完成上述步骤后我们就可以正常启动训练
+
+```
+!python /home/aistudio/work/PaddleOCR/tools/train.py -c /home/aistudio/work/PaddleOCR/configs/det/det_mv3_db.yml
+```
+
+其他命令:
+```
+!python /home/aistudio/work/PaddleOCR/tools/eval.py -c /home/aistudio/work/PaddleOCR/configs/det/det_mv3_db.yml
+!python /home/aistudio/work/PaddleOCR/tools/infer_det.py -c /home/aistudio/work/PaddleOCR/configs/det/det_mv3_db.yml
+```
+模型推理
+```
+!python /home/aistudio/work/PaddleOCR/tools/infer/predict_det.py --image_dir="/home/aistudio/work/test_img/" --det_model_dir="/home/aistudio/work/PaddleOCR/output/infer"
+```
+
+## 5 总结
+
+1. 分类+检测在一定程度上能够缩短用时,具体的模型选取要根据业务场景恰当选择。
+2. 数据标注需要多次进行测试调整标注方法,一般进行检测模型微调,需要标注至少上百张。
+3. 设置合理的batch_size以及resize大小,同时注意lr设置。
+
+
+## References
+
+1 https://github.com/PaddlePaddle/PaddleOCR
+
+2 https://github.com/PaddlePaddle/PaddleClas
+
+3 https://blog.csdn.net/YY007H/article/details/124491217
diff --git "a/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md" "b/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md"
new file mode 100644
index 0000000..09d1bba
--- /dev/null
+++ "b/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md"
@@ -0,0 +1,251 @@
+# 基于PP-OCRv3的手写文字识别
+
+- [1. 项目背景及意义](#1-项目背景及意义)
+- [2. 项目内容](#2-项目内容)
+- [3. PP-OCRv3识别算法介绍](#3-PP-OCRv3识别算法介绍)
+- [4. 安装环境](#4-安装环境)
+- [5. 数据准备](#5-数据准备)
+- [6. 模型训练](#6-模型训练)
+ - [6.1 下载预训练模型](#61-下载预训练模型)
+ - [6.2 修改配置文件](#62-修改配置文件)
+ - [6.3 开始训练](#63-开始训练)
+- [7. 模型评估](#7-模型评估)
+- [8. 模型导出推理](#8-模型导出推理)
+ - [8.1 模型导出](#81-模型导出)
+ - [8.2 模型推理](#82-模型推理)
+
+
+## 1. 项目背景及意义
+目前光学字符识别(OCR)技术在我们的生活当中被广泛使用,但是大多数模型在通用场景下的准确性还有待提高。针对于此我们借助飞桨提供的PaddleOCR套件较容易的实现了在垂类场景下的应用。手写体在日常生活中较为常见,然而手写体的识别却存在着很大的挑战,因为每个人的手写字体风格不一样,这对于视觉模型来说还是相当有挑战的。因此训练一个手写体识别模型具有很好的现实意义。下面给出一些手写体的示例图:
+
+
+
+## 2. 项目内容
+本项目基于PaddleOCR套件,以PP-OCRv3识别模型为基础,针对手写文字识别场景进行优化。
+
+Aistudio项目链接:[OCR手写文字识别](https://aistudio.baidu.com/aistudio/projectdetail/4330587)
+
+## 3. PP-OCRv3识别算法介绍
+PP-OCRv3的识别模块是基于文本识别算法[SVTR](https://arxiv.org/abs/2205.00159)优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。如下图所示,PP-OCRv3采用了6个优化策略。
+
+
+
+优化策略汇总如下:
+
+* SVTR_LCNet:轻量级文本识别网络
+* GTC:Attention指导CTC训练策略
+* TextConAug:挖掘文字上下文信息的数据增广策略
+* TextRotNet:自监督的预训练模型
+* UDML:联合互学习策略
+* UIM:无标注数据挖掘方案
+
+详细优化策略描述请参考[PP-OCRv3优化策略](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md#3-%E8%AF%86%E5%88%AB%E4%BC%98%E5%8C%96)
+
+## 4. 安装环境
+
+
+```python
+# 首先git官方的PaddleOCR项目,安装需要的依赖
+git clone https://github.com/PaddlePaddle/PaddleOCR.git
+cd PaddleOCR
+pip install -r requirements.txt
+```
+
+## 5. 数据准备
+本项目使用公开的手写文本识别数据集,包含Chinese OCR, 中科院自动化研究所-手写中文数据集[CASIA-HWDB2.x](http://www.nlpr.ia.ac.cn/databases/handwriting/Download.html),以及由中科院手写数据和网上开源数据合并组合的[数据集](https://aistudio.baidu.com/aistudio/datasetdetail/102884/0)等,该项目已经挂载处理好的数据集,可直接下载使用进行训练。
+
+
+```python
+下载并解压数据
+tar -xf hw_data.tar
+```
+
+## 6. 模型训练
+### 6.1 下载预训练模型
+首先需要下载我们需要的PP-OCRv3识别预训练模型,更多选择请自行选择其他的[文字识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/models_list.md#2-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E6%A8%A1%E5%9E%8B)
+
+
+```python
+# 使用该指令下载需要的预训练模型
+wget -P ./pretrained_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
+# 解压预训练模型文件
+tar -xf ./pretrained_models/ch_PP-OCRv3_rec_train.tar -C pretrained_models
+```
+
+### 6.2 修改配置文件
+我们使用`configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml`,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+
+```
+ epoch_num: 100 # 训练epoch数
+ save_model_dir: ./output/ch_PP-OCR_v3_rec
+ save_epoch_step: 10
+ eval_batch_step: [0, 100] # 评估间隔,每隔100step评估一次
+ pretrained_model: ./pretrained_models/ch_PP-OCRv3_rec_train/best_accuracy # 预训练模型路径
+
+
+ lr:
+ name: Cosine # 修改学习率衰减策略为Cosine
+ learning_rate: 0.0001 # 修改fine-tune的学习率
+ warmup_epoch: 2 # 修改warmup轮数
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data # 训练集图片路径
+ ext_op_transform_idx: 1
+ label_file_list:
+ - ./train_data/chineseocr-data/rec_hand_line_all_label_train.txt # 训练集标签
+ - ./train_data/handwrite/HWDB2.0Train_label.txt
+ - ./train_data/handwrite/HWDB2.1Train_label.txt
+ - ./train_data/handwrite/HWDB2.2Train_label.txt
+ - ./train_data/handwrite/hwdb_ic13/handwriting_hwdb_train_labels.txt
+ - ./train_data/handwrite/HW_Chinese/train_hw.txt
+ ratio_list:
+ - 0.1
+ - 1.0
+ - 1.0
+ - 1.0
+ - 0.02
+ - 1.0
+ loader:
+ shuffle: true
+ batch_size_per_card: 64
+ drop_last: true
+ num_workers: 4
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data # 测试集图片路径
+ label_file_list:
+ - ./train_data/chineseocr-data/rec_hand_line_all_label_val.txt # 测试集标签
+ - ./train_data/handwrite/HWDB2.0Test_label.txt
+ - ./train_data/handwrite/HWDB2.1Test_label.txt
+ - ./train_data/handwrite/HWDB2.2Test_label.txt
+ - ./train_data/handwrite/hwdb_ic13/handwriting_hwdb_val_labels.txt
+ - ./train_data/handwrite/HW_Chinese/test_hw.txt
+ loader:
+ shuffle: false
+ drop_last: false
+ batch_size_per_card: 64
+ num_workers: 4
+```
+由于数据集大多是长文本,因此需要**注释**掉下面的数据增广策略,以便训练出更好的模型。
+```
+- RecConAug:
+ prob: 0.5
+ ext_data_num: 2
+ image_shape: [48, 320, 3]
+```
+
+
+### 6.3 开始训练
+我们使用上面修改好的配置文件`configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml`,预训练模型,数据集路径,学习率,训练轮数等都已经设置完毕后,可以使用下面命令开始训练。
+
+
+```python
+# 开始训练识别模型
+python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
+
+```
+
+## 7. 模型评估
+在训练之前,我们可以直接使用下面命令来评估预训练模型的效果:
+
+
+
+```python
+# 评估预训练模型
+python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model="./pretrained_models/ch_PP-OCRv3_rec_train/best_accuracy"
+```
+```
+[2022/07/14 10:46:22] ppocr INFO: load pretrain successful from ./pretrained_models/ch_PP-OCRv3_rec_train/best_accuracy
+eval model:: 100%|████████████████████████████| 687/687 [03:29<00:00, 3.27it/s]
+[2022/07/14 10:49:52] ppocr INFO: metric eval ***************
+[2022/07/14 10:49:52] ppocr INFO: acc:0.03724954461811258
+[2022/07/14 10:49:52] ppocr INFO: norm_edit_dis:0.4859541065843199
+[2022/07/14 10:49:52] ppocr INFO: Teacher_acc:0.0371584699368947
+[2022/07/14 10:49:52] ppocr INFO: Teacher_norm_edit_dis:0.48718814890536477
+[2022/07/14 10:49:52] ppocr INFO: fps:947.8562684823883
+```
+
+可以看出,直接加载预训练模型进行评估,效果较差,因为预训练模型并不是基于手写文字进行单独训练的,所以我们需要基于预训练模型进行finetune。
+训练完成后,可以进行测试评估,评估命令如下:
+
+
+
+```python
+# 评估finetune效果
+python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_rec/best_accuracy"
+
+```
+
+评估结果如下,可以看出识别准确率为54.3%。
+```
+[2022/07/14 10:54:06] ppocr INFO: metric eval ***************
+[2022/07/14 10:54:06] ppocr INFO: acc:0.5430100180913
+[2022/07/14 10:54:06] ppocr INFO: norm_edit_dis:0.9203322593158589
+[2022/07/14 10:54:06] ppocr INFO: Teacher_acc:0.5401183969626324
+[2022/07/14 10:54:06] ppocr INFO: Teacher_norm_edit_dis:0.919827504507755
+[2022/07/14 10:54:06] ppocr INFO: fps:928.948733797251
+```
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+  +
+使用中文检测+识别模型提取文本,实例化PaddleOCR类:
+
+```
+from paddleocr import PaddleOCR, draw_ocr
+
+# paddleocr目前支持中英文、英文、法语、德语、韩语、日语等80个语种,可以通过修改lang参数进行切换
+ocr = PaddleOCR(use_angle_cls=False, lang="ch") # need to run only once to download and load model into memory
+```
+
+一行命令启动预测,预测结果包括`检测框`和`文本识别内容`:
+
+```
+img_path = "./test_img/hetong2.jpg"
+result = ocr.ocr(img_path, cls=False)
+for line in result:
+ print(line)
+
+# 可视化结果
+from PIL import Image
+
+image = Image.open(img_path).convert('RGB')
+boxes = [line[0] for line in result]
+txts = [line[1][0] for line in result]
+scores = [line[1][1] for line in result]
+im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
+im_show = Image.fromarray(im_show)
+im_show.show()
+```
+
+#### 2.1.3 图片预处理
+
+通过上图可视化结果可以看到,印章部分造成的文本遮盖,影响了文本识别结果,因此可以考虑通道提取,去除图片中的红色印章:
+
+```
+import cv2
+import numpy as np
+import matplotlib.pyplot as plt
+
+#读入图像,三通道
+image=cv2.imread("./test_img/hetong2.jpg",cv2.IMREAD_COLOR) #timg.jpeg
+
+#获得三个通道
+Bch,Gch,Rch=cv2.split(image)
+
+#保存三通道图片
+cv2.imwrite('blue_channel.jpg',Bch)
+cv2.imwrite('green_channel.jpg',Gch)
+cv2.imwrite('red_channel.jpg',Rch)
+```
+#### 2.1.4 合同文本信息提取
+
+经过2.1.3的预处理后,合同照片的红色通道被分离,获得了一张相对更干净的图片,此时可以再次使用ppocr模型提取文本内容:
+
+```
+import numpy as np
+import cv2
+
+
+img_path = './red_channel.jpg'
+result = ocr.ocr(img_path, cls=False)
+
+# 可视化结果
+from PIL import Image
+
+image = Image.open(img_path).convert('RGB')
+boxes = [line[0] for line in result]
+txts = [line[1][0] for line in result]
+scores = [line[1][1] for line in result]
+im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
+im_show = Image.fromarray(im_show)
+vis = np.array(im_show)
+im_show.show()
+```
+
+忽略检测框内容,提取完整的合同文本:
+
+```
+txts = [line[1][0] for line in result]
+all_context = "\n".join(txts)
+print(all_context)
+```
+
+通过以上环节就完成了扫描合同关键信息抽取的第一步:文本内容提取,接下来可以基于识别出的文本内容抽取关键信息
+
+### 2.2 合同关键信息抽取
+
+#### 2.2.1 环境准备
+
+安装PaddleNLP
+
+
+```
+pip install --upgrade pip
+pip install --upgrade paddlenlp
+```
+
+#### 2.2.2 合同关键信息抽取
+
+PaddleNLP 使用 Taskflow 统一管理多场景任务的预测功能,其中`information_extraction` 通过大量的有标签样本进行训练,在通用的场景中一般可以直接使用,只需更换关键字即可。例如在合同信息抽取中,我们重新定义抽取关键字:
+
+甲方、乙方、币种、金额、付款方式
+
+
+将使用OCR提取好的文本作为输入,使用三行命令可以对上文中提取到的合同文本进行关键信息抽取:
+
+```
+from paddlenlp import Taskflow
+schema = ["甲方","乙方","总价"]
+ie = Taskflow('information_extraction', schema=schema)
+ie.set_schema(schema)
+ie(all_context)
+```
+
+可以看到UIE模型可以准确的提取出关键信息,用于后续的信息比对或审核。
+
+## 3.效果优化
+
+### 3.1 文本识别后处理调优
+
+实际图片采集过程中,可能出现部分图片弯曲等问题,导致使用默认参数识别文本时存在漏检,影响关键信息获取。
+
+例如下图:
+
+
+
+使用中文检测+识别模型提取文本,实例化PaddleOCR类:
+
+```
+from paddleocr import PaddleOCR, draw_ocr
+
+# paddleocr目前支持中英文、英文、法语、德语、韩语、日语等80个语种,可以通过修改lang参数进行切换
+ocr = PaddleOCR(use_angle_cls=False, lang="ch") # need to run only once to download and load model into memory
+```
+
+一行命令启动预测,预测结果包括`检测框`和`文本识别内容`:
+
+```
+img_path = "./test_img/hetong2.jpg"
+result = ocr.ocr(img_path, cls=False)
+for line in result:
+ print(line)
+
+# 可视化结果
+from PIL import Image
+
+image = Image.open(img_path).convert('RGB')
+boxes = [line[0] for line in result]
+txts = [line[1][0] for line in result]
+scores = [line[1][1] for line in result]
+im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
+im_show = Image.fromarray(im_show)
+im_show.show()
+```
+
+#### 2.1.3 图片预处理
+
+通过上图可视化结果可以看到,印章部分造成的文本遮盖,影响了文本识别结果,因此可以考虑通道提取,去除图片中的红色印章:
+
+```
+import cv2
+import numpy as np
+import matplotlib.pyplot as plt
+
+#读入图像,三通道
+image=cv2.imread("./test_img/hetong2.jpg",cv2.IMREAD_COLOR) #timg.jpeg
+
+#获得三个通道
+Bch,Gch,Rch=cv2.split(image)
+
+#保存三通道图片
+cv2.imwrite('blue_channel.jpg',Bch)
+cv2.imwrite('green_channel.jpg',Gch)
+cv2.imwrite('red_channel.jpg',Rch)
+```
+#### 2.1.4 合同文本信息提取
+
+经过2.1.3的预处理后,合同照片的红色通道被分离,获得了一张相对更干净的图片,此时可以再次使用ppocr模型提取文本内容:
+
+```
+import numpy as np
+import cv2
+
+
+img_path = './red_channel.jpg'
+result = ocr.ocr(img_path, cls=False)
+
+# 可视化结果
+from PIL import Image
+
+image = Image.open(img_path).convert('RGB')
+boxes = [line[0] for line in result]
+txts = [line[1][0] for line in result]
+scores = [line[1][1] for line in result]
+im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
+im_show = Image.fromarray(im_show)
+vis = np.array(im_show)
+im_show.show()
+```
+
+忽略检测框内容,提取完整的合同文本:
+
+```
+txts = [line[1][0] for line in result]
+all_context = "\n".join(txts)
+print(all_context)
+```
+
+通过以上环节就完成了扫描合同关键信息抽取的第一步:文本内容提取,接下来可以基于识别出的文本内容抽取关键信息
+
+### 2.2 合同关键信息抽取
+
+#### 2.2.1 环境准备
+
+安装PaddleNLP
+
+
+```
+pip install --upgrade pip
+pip install --upgrade paddlenlp
+```
+
+#### 2.2.2 合同关键信息抽取
+
+PaddleNLP 使用 Taskflow 统一管理多场景任务的预测功能,其中`information_extraction` 通过大量的有标签样本进行训练,在通用的场景中一般可以直接使用,只需更换关键字即可。例如在合同信息抽取中,我们重新定义抽取关键字:
+
+甲方、乙方、币种、金额、付款方式
+
+
+将使用OCR提取好的文本作为输入,使用三行命令可以对上文中提取到的合同文本进行关键信息抽取:
+
+```
+from paddlenlp import Taskflow
+schema = ["甲方","乙方","总价"]
+ie = Taskflow('information_extraction', schema=schema)
+ie.set_schema(schema)
+ie(all_context)
+```
+
+可以看到UIE模型可以准确的提取出关键信息,用于后续的信息比对或审核。
+
+## 3.效果优化
+
+### 3.1 文本识别后处理调优
+
+实际图片采集过程中,可能出现部分图片弯曲等问题,导致使用默认参数识别文本时存在漏检,影响关键信息获取。
+
+例如下图:
+
+ +
+
+直接进行预测:
+
+```
+img_path = "./test_img/hetong3.jpg"
+# 预测结果
+result = ocr.ocr(img_path, cls=False)
+# 可视化结果
+from PIL import Image
+
+image = Image.open(img_path).convert('RGB')
+boxes = [line[0] for line in result]
+txts = [line[1][0] for line in result]
+scores = [line[1][1] for line in result]
+im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
+im_show = Image.fromarray(im_show)
+im_show.show()
+```
+
+可视化结果可以看到,弯曲图片存在漏检,一般来说可以通过调整后处理参数解决,无需重新训练模型。漏检问题往往是因为检测模型获得的分割图太小,生成框的得分过低被过滤掉了,通常有两种方式调整参数:
+- 开启`use_dilatiion=True` 膨胀分割区域
+- 调小`det_db_box_thresh`阈值
+
+```
+# 重新实例化 PaddleOCR
+ocr = PaddleOCR(use_angle_cls=False, lang="ch", det_db_box_thresh=0.3, use_dilation=True)
+
+# 预测并可视化
+img_path = "./test_img/hetong3.jpg"
+# 预测结果
+result = ocr.ocr(img_path, cls=False)
+# 可视化结果
+image = Image.open(img_path).convert('RGB')
+boxes = [line[0] for line in result]
+txts = [line[1][0] for line in result]
+scores = [line[1][1] for line in result]
+im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
+im_show = Image.fromarray(im_show)
+im_show.show()
+```
+
+可以看到漏检问题被很好的解决,提取完整的文本内容:
+
+```
+txts = [line[1][0] for line in result]
+context = "\n".join(txts)
+print(context)
+```
+
+### 3.2 关键信息提取调优
+
+UIE通过大量有标签样本进行训练,得到了一个开箱即用的高精模型。 然而针对不同场景,可能会出现部分实体无法被抽取的情况。通常来说有以下几个方法进行效果调优:
+
+
+- 修改 schema
+- 添加正则方法
+- 标注小样本微调模型
+
+**修改schema**
+
+Prompt和原文描述越像,抽取效果越好,例如
+```
+三:合同价格:总价为人民币大写:参拾玖万捌仟伍佰
+元,小写:398500.00元。总价中包括站房工程建设、安装
+及相关避雷、消防、接地、电力、材料费、检验费、安全、
+验收等所需费用及其他相关费用和税金。
+```
+schema = ["总金额"] 时无法准确抽取,与原文描述差异较大。 修改 schema = ["总价"] 再次尝试:
+
+```
+from paddlenlp import Taskflow
+# schema = ["总金额"]
+schema = ["总价"]
+ie = Taskflow('information_extraction', schema=schema)
+ie.set_schema(schema)
+ie(all_context)
+```
+
+
+**模型微调**
+
+UIE的建模方式主要是通过 `Prompt` 方式来建模, `Prompt` 在小样本上进行微调效果非常有效。详细的数据标注+模型微调步骤可以参考项目:
+
+[PaddleNLP信息抽取技术重磅升级!](https://aistudio.baidu.com/aistudio/projectdetail/3914778?channelType=0&channel=0)
+
+[工单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/3914778?contributionType=1)
+
+[快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/4038499?contributionType=1)
+
+
+## 总结
+
+扫描合同的关键信息提取可以使用 PaddleOCR + PaddleNLP 组合实现,两个工具均有以下优势:
+
+* 使用简单:whl包一键安装,3行命令调用
+* 效果领先:优秀的模型效果可覆盖几乎全部的应用场景
+* 调优成本低:OCR模型可通过后处理参数的调整适配略有偏差的扫描文本, UIE模型可以通过极少的标注样本微调,成本很低。
+
+## 作业
+
+尝试自己解析出 `test_img/homework.png` 扫描合同中的 [甲方、乙方] 关键词:
+
+
+
+
+
+
+直接进行预测:
+
+```
+img_path = "./test_img/hetong3.jpg"
+# 预测结果
+result = ocr.ocr(img_path, cls=False)
+# 可视化结果
+from PIL import Image
+
+image = Image.open(img_path).convert('RGB')
+boxes = [line[0] for line in result]
+txts = [line[1][0] for line in result]
+scores = [line[1][1] for line in result]
+im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
+im_show = Image.fromarray(im_show)
+im_show.show()
+```
+
+可视化结果可以看到,弯曲图片存在漏检,一般来说可以通过调整后处理参数解决,无需重新训练模型。漏检问题往往是因为检测模型获得的分割图太小,生成框的得分过低被过滤掉了,通常有两种方式调整参数:
+- 开启`use_dilatiion=True` 膨胀分割区域
+- 调小`det_db_box_thresh`阈值
+
+```
+# 重新实例化 PaddleOCR
+ocr = PaddleOCR(use_angle_cls=False, lang="ch", det_db_box_thresh=0.3, use_dilation=True)
+
+# 预测并可视化
+img_path = "./test_img/hetong3.jpg"
+# 预测结果
+result = ocr.ocr(img_path, cls=False)
+# 可视化结果
+image = Image.open(img_path).convert('RGB')
+boxes = [line[0] for line in result]
+txts = [line[1][0] for line in result]
+scores = [line[1][1] for line in result]
+im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
+im_show = Image.fromarray(im_show)
+im_show.show()
+```
+
+可以看到漏检问题被很好的解决,提取完整的文本内容:
+
+```
+txts = [line[1][0] for line in result]
+context = "\n".join(txts)
+print(context)
+```
+
+### 3.2 关键信息提取调优
+
+UIE通过大量有标签样本进行训练,得到了一个开箱即用的高精模型。 然而针对不同场景,可能会出现部分实体无法被抽取的情况。通常来说有以下几个方法进行效果调优:
+
+
+- 修改 schema
+- 添加正则方法
+- 标注小样本微调模型
+
+**修改schema**
+
+Prompt和原文描述越像,抽取效果越好,例如
+```
+三:合同价格:总价为人民币大写:参拾玖万捌仟伍佰
+元,小写:398500.00元。总价中包括站房工程建设、安装
+及相关避雷、消防、接地、电力、材料费、检验费、安全、
+验收等所需费用及其他相关费用和税金。
+```
+schema = ["总金额"] 时无法准确抽取,与原文描述差异较大。 修改 schema = ["总价"] 再次尝试:
+
+```
+from paddlenlp import Taskflow
+# schema = ["总金额"]
+schema = ["总价"]
+ie = Taskflow('information_extraction', schema=schema)
+ie.set_schema(schema)
+ie(all_context)
+```
+
+
+**模型微调**
+
+UIE的建模方式主要是通过 `Prompt` 方式来建模, `Prompt` 在小样本上进行微调效果非常有效。详细的数据标注+模型微调步骤可以参考项目:
+
+[PaddleNLP信息抽取技术重磅升级!](https://aistudio.baidu.com/aistudio/projectdetail/3914778?channelType=0&channel=0)
+
+[工单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/3914778?contributionType=1)
+
+[快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/4038499?contributionType=1)
+
+
+## 总结
+
+扫描合同的关键信息提取可以使用 PaddleOCR + PaddleNLP 组合实现,两个工具均有以下优势:
+
+* 使用简单:whl包一键安装,3行命令调用
+* 效果领先:优秀的模型效果可覆盖几乎全部的应用场景
+* 调优成本低:OCR模型可通过后处理参数的调整适配略有偏差的扫描文本, UIE模型可以通过极少的标注样本微调,成本很低。
+
+## 作业
+
+尝试自己解析出 `test_img/homework.png` 扫描合同中的 [甲方、乙方] 关键词:
+
+
+
+ +
+
+
+更多场景下的垂类模型获取,请扫下图二维码填写问卷,加入PaddleOCR官方交流群获取模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+
+
+
+更多场景下的垂类模型获取,请扫下图二维码填写问卷,加入PaddleOCR官方交流群获取模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+ diff --git "a/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md" "b/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md"
new file mode 100644
index 0000000..f70fa06
--- /dev/null
+++ "b/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md"
@@ -0,0 +1,616 @@
+# 基于PP-OCRv3的液晶屏读数识别
+
+- [1. 项目背景及意义](#1-项目背景及意义)
+- [2. 项目内容](#2-项目内容)
+- [3. 安装环境](#3-安装环境)
+- [4. 文字检测](#4-文字检测)
+ - [4.1 PP-OCRv3检测算法介绍](#41-PP-OCRv3检测算法介绍)
+ - [4.2 数据准备](#42-数据准备)
+ - [4.3 模型训练](#43-模型训练)
+ - [4.3.1 预训练模型直接评估](#431-预训练模型直接评估)
+ - [4.3.2 预训练模型直接finetune](#432-预训练模型直接finetune)
+ - [4.3.3 基于预训练模型Finetune_student模型](#433-基于预训练模型Finetune_student模型)
+ - [4.3.4 基于预训练模型Finetune_teacher模型](#434-基于预训练模型Finetune_teacher模型)
+ - [4.3.5 采用CML蒸馏进一步提升student模型精度](#435-采用CML蒸馏进一步提升student模型精度)
+ - [4.3.6 模型导出推理](#436-4.3.6-模型导出推理)
+- [5. 文字识别](#5-文字识别)
+ - [5.1 PP-OCRv3识别算法介绍](#51-PP-OCRv3识别算法介绍)
+ - [5.2 数据准备](#52-数据准备)
+ - [5.3 模型训练](#53-模型训练)
+ - [5.4 模型导出推理](#54-模型导出推理)
+- [6. 系统串联](#6-系统串联)
+ - [6.1 后处理](#61-后处理)
+- [7. PaddleServing部署](#7-PaddleServing部署)
+
+
+## 1. 项目背景及意义
+目前光学字符识别(OCR)技术在我们的生活当中被广泛使用,但是大多数模型在通用场景下的准确性还有待提高,针对于此我们借助飞桨提供的PaddleOCR套件较容易的实现了在垂类场景下的应用。
+
+该项目以国家质量基础(NQI)为准绳,充分利用大数据、云计算、物联网等高新技术,构建覆盖计量端、实验室端、数据端和硬件端的完整计量解决方案,解决传统计量校准中存在的难题,拓宽计量检测服务体系和服务领域;解决无数传接口或数传接口不统一、不公开的计量设备,以及计量设备所处的环境比较恶劣,不适合人工读取数据。通过OCR技术实现远程计量,引领计量行业向智慧计量转型和发展。
+
+## 2. 项目内容
+本项目基于PaddleOCR开源套件,以PP-OCRv3检测和识别模型为基础,针对液晶屏读数识别场景进行优化。
+
+Aistudio项目链接:[OCR液晶屏读数识别](https://aistudio.baidu.com/aistudio/projectdetail/4080130)
+
+## 3. 安装环境
+
+```python
+# 首先git官方的PaddleOCR项目,安装需要的依赖
+# 第一次运行打开该注释
+# git clone https://gitee.com/PaddlePaddle/PaddleOCR.git
+cd PaddleOCR
+pip install -r requirements.txt
+```
+
+## 4. 文字检测
+文本检测的任务是定位出输入图像中的文字区域。近年来学术界关于文本检测的研究非常丰富,一类方法将文本检测视为目标检测中的一个特定场景,基于通用目标检测算法进行改进适配,如TextBoxes[1]基于一阶段目标检测器SSD[2]算法,调整目标框使之适合极端长宽比的文本行,CTPN[3]则是基于Faster RCNN[4]架构改进而来。但是文本检测与目标检测在目标信息以及任务本身上仍存在一些区别,如文本一般长宽比较大,往往呈“条状”,文本行之间可能比较密集,弯曲文本等,因此又衍生了很多专用于文本检测的算法。本项目基于PP-OCRv3算法进行优化。
+
+### 4.1 PP-OCRv3检测算法介绍
+PP-OCRv3检测模型是对PP-OCRv2中的CML(Collaborative Mutual Learning) 协同互学习文本检测蒸馏策略进行了升级。如下图所示,CML的核心思想结合了①传统的Teacher指导Student的标准蒸馏与 ②Students网络之间的DML互学习,可以让Students网络互学习的同时,Teacher网络予以指导。PP-OCRv3分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML(Deep Mutual Learning)蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
+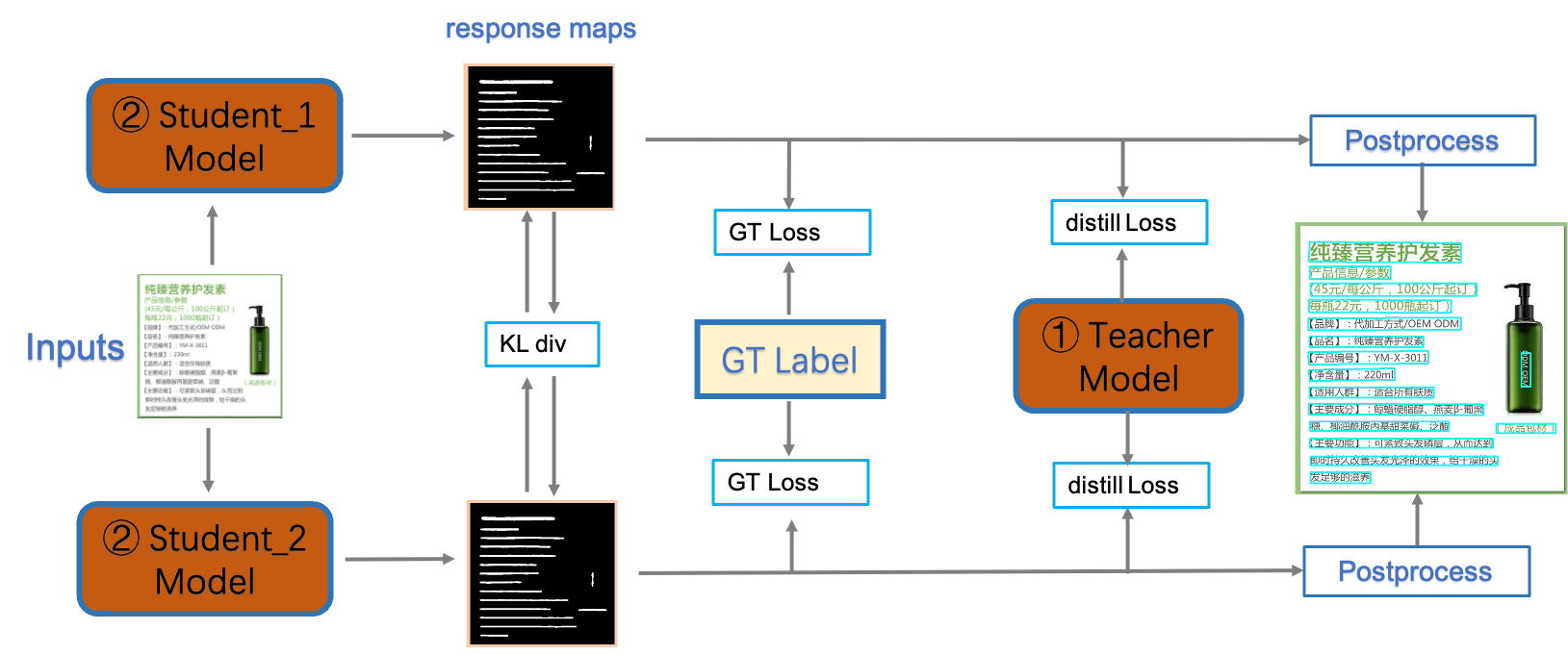
+
+详细优化策略描述请参考[PP-OCRv3优化策略](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md#2)
+
+### 4.2 数据准备
+[计量设备屏幕字符检测数据集](https://aistudio.baidu.com/aistudio/datasetdetail/127845)数据来源于实际项目中各种计量设备的数显屏,以及在网上搜集的一些其他数显屏,包含训练集755张,测试集355张。
+
+```python
+# 在PaddleOCR下创建新的文件夹train_data
+mkdir train_data
+# 下载数据集并解压到指定路径下
+unzip icdar2015.zip -d train_data
+```
+
+```python
+# 随机查看文字检测数据集图片
+from PIL import Image
+import matplotlib.pyplot as plt
+import numpy as np
+import os
+
+
+train = './train_data/icdar2015/text_localization/test'
+# 从指定目录中选取一张图片
+def get_one_image(train):
+ plt.figure()
+ files = os.listdir(train)
+ n = len(files)
+ ind = np.random.randint(0,n)
+ img_dir = os.path.join(train,files[ind])
+ image = Image.open(img_dir)
+ plt.imshow(image)
+ plt.show()
+ image = image.resize([208, 208])
+
+get_one_image(train)
+```
+
+
+### 4.3 模型训练
+
+#### 4.3.1 预训练模型直接评估
+下载我们需要的PP-OCRv3检测预训练模型,更多选择请自行选择其他的[文字检测模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/models_list.md#1-%E6%96%87%E6%9C%AC%E6%A3%80%E6%B5%8B%E6%A8%A1%E5%9E%8B)
+
+```python
+#使用该指令下载需要的预训练模型
+wget -P ./pretrained_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
+# 解压预训练模型文件
+tar -xf ./pretrained_models/ch_PP-OCRv3_det_distill_train.tar -C pretrained_models
+```
+
+在训练之前,我们可以直接使用下面命令来评估预训练模型的效果:
+
+```python
+# 评估预训练模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model="./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy"
+```
+
+结果如下:
+
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.50%|
+
+#### 4.3.2 预训练模型直接finetune
+##### 修改配置文件
+我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+```
+epoch:100
+save_epoch_step:10
+eval_batch_step:[0, 50]
+save_model_dir: ./output/ch_PP-OCR_v3_det/
+pretrained_model: ./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy
+learning_rate: 0.00025
+num_workers: 0 # 如果单卡训练,建议将Train和Eval的loader部分的num_workers设置为0,否则会出现`/dev/shm insufficient`的报错
+```
+
+##### 开始训练
+使用我们上面修改的配置文件configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml,训练命令如下:
+
+```python
+# 开始训练模型
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.50%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.20%|
+
+#### 4.3.3 基于预训练模型Finetune_student模型
+
+我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+```
+epoch:100
+save_epoch_step:10
+eval_batch_step:[0, 50]
+save_model_dir: ./output/ch_PP-OCR_v3_det_student/
+pretrained_model: ./pretrained_models/ch_PP-OCRv3_det_distill_train/student
+learning_rate: 0.00025
+num_workers: 0 # 如果单卡训练,建议将Train和Eval的loader部分的num_workers设置为0,否则会出现`/dev/shm insufficient`的报错
+```
+
+训练命令如下:
+
+```python
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/student
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det_student/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.50%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.20%|
+| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.00%|
+
+#### 4.3.4 基于预训练模型Finetune_teacher模型
+
+首先需要从提供的预训练模型best_accuracy.pdparams中提取teacher参数,组合成适合dml训练的初始化模型,提取代码如下:
+
+```python
+cd ./pretrained_models/
+# transform teacher params in best_accuracy.pdparams into teacher_dml.paramers
+import paddle
+
+# load pretrained model
+all_params = paddle.load("ch_PP-OCRv3_det_distill_train/best_accuracy.pdparams")
+# print(all_params.keys())
+
+# keep teacher params
+t_params = {key[len("Teacher."):]: all_params[key] for key in all_params if "Teacher." in key}
+
+# print(t_params.keys())
+
+s_params = {"Student." + key: t_params[key] for key in t_params}
+s2_params = {"Student2." + key: t_params[key] for key in t_params}
+s_params = {**s_params, **s2_params}
+# print(s_params.keys())
+
+paddle.save(s_params, "ch_PP-OCRv3_det_distill_train/teacher_dml.pdparams")
+
+```
+
+我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+```
+epoch:100
+save_epoch_step:10
+eval_batch_step:[0, 50]
+save_model_dir: ./output/ch_PP-OCR_v3_det_teacher/
+pretrained_model: ./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_dml
+learning_rate: 0.00025
+num_workers: 0 # 如果单卡训练,建议将Train和Eval的loader部分的num_workers设置为0,否则会出现`/dev/shm insufficient`的报错
+```
+
+训练命令如下:
+
+```python
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_dml
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det_teacher/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.50%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.20%|
+| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.00%|
+| 3 | PP-OCRv3中英文超轻量检测预训练模型fintune教师模型 |84.80%|
+
+#### 4.3.5 采用CML蒸馏进一步提升student模型精度
+
+需要从4.3.3和4.3.4训练得到的best_accuracy.pdparams中提取各自代表student和teacher的参数,组合成适合cml训练的初始化模型,提取代码如下:
+
+```python
+# transform teacher params and student parameters into cml model
+import paddle
+
+all_params = paddle.load("./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy.pdparams")
+# print(all_params.keys())
+
+t_params = paddle.load("./output/ch_PP-OCR_v3_det_teacher/best_accuracy.pdparams")
+# print(t_params.keys())
+
+s_params = paddle.load("./output/ch_PP-OCR_v3_det_student/best_accuracy.pdparams")
+# print(s_params.keys())
+
+for key in all_params:
+ # teacher is OK
+ if "Teacher." in key:
+ new_key = key.replace("Teacher", "Student")
+ #print("{} >> {}\n".format(key, new_key))
+ assert all_params[key].shape == t_params[new_key].shape
+ all_params[key] = t_params[new_key]
+
+ if "Student." in key:
+ new_key = key.replace("Student.", "")
+ #print("{} >> {}\n".format(key, new_key))
+ assert all_params[key].shape == s_params[new_key].shape
+ all_params[key] = s_params[new_key]
+
+ if "Student2." in key:
+ new_key = key.replace("Student2.", "")
+ print("{} >> {}\n".format(key, new_key))
+ assert all_params[key].shape == s_params[new_key].shape
+ all_params[key] = s_params[new_key]
+
+paddle.save(all_params, "./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_cml_student.pdparams")
+```
+
+训练命令如下:
+
+```python
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_cml_student Global.save_model_dir=./output/ch_PP-OCR_v3_det_finetune/
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det_finetune/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.50%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.20%|
+| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.00%|
+| 3 | PP-OCRv3中英文超轻量检测预训练模型fintune教师模型 |84.80%|
+| 4 | 基于2和3训练好的模型fintune |82.70%|
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
diff --git "a/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md" "b/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md"
new file mode 100644
index 0000000..f70fa06
--- /dev/null
+++ "b/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md"
@@ -0,0 +1,616 @@
+# 基于PP-OCRv3的液晶屏读数识别
+
+- [1. 项目背景及意义](#1-项目背景及意义)
+- [2. 项目内容](#2-项目内容)
+- [3. 安装环境](#3-安装环境)
+- [4. 文字检测](#4-文字检测)
+ - [4.1 PP-OCRv3检测算法介绍](#41-PP-OCRv3检测算法介绍)
+ - [4.2 数据准备](#42-数据准备)
+ - [4.3 模型训练](#43-模型训练)
+ - [4.3.1 预训练模型直接评估](#431-预训练模型直接评估)
+ - [4.3.2 预训练模型直接finetune](#432-预训练模型直接finetune)
+ - [4.3.3 基于预训练模型Finetune_student模型](#433-基于预训练模型Finetune_student模型)
+ - [4.3.4 基于预训练模型Finetune_teacher模型](#434-基于预训练模型Finetune_teacher模型)
+ - [4.3.5 采用CML蒸馏进一步提升student模型精度](#435-采用CML蒸馏进一步提升student模型精度)
+ - [4.3.6 模型导出推理](#436-4.3.6-模型导出推理)
+- [5. 文字识别](#5-文字识别)
+ - [5.1 PP-OCRv3识别算法介绍](#51-PP-OCRv3识别算法介绍)
+ - [5.2 数据准备](#52-数据准备)
+ - [5.3 模型训练](#53-模型训练)
+ - [5.4 模型导出推理](#54-模型导出推理)
+- [6. 系统串联](#6-系统串联)
+ - [6.1 后处理](#61-后处理)
+- [7. PaddleServing部署](#7-PaddleServing部署)
+
+
+## 1. 项目背景及意义
+目前光学字符识别(OCR)技术在我们的生活当中被广泛使用,但是大多数模型在通用场景下的准确性还有待提高,针对于此我们借助飞桨提供的PaddleOCR套件较容易的实现了在垂类场景下的应用。
+
+该项目以国家质量基础(NQI)为准绳,充分利用大数据、云计算、物联网等高新技术,构建覆盖计量端、实验室端、数据端和硬件端的完整计量解决方案,解决传统计量校准中存在的难题,拓宽计量检测服务体系和服务领域;解决无数传接口或数传接口不统一、不公开的计量设备,以及计量设备所处的环境比较恶劣,不适合人工读取数据。通过OCR技术实现远程计量,引领计量行业向智慧计量转型和发展。
+
+## 2. 项目内容
+本项目基于PaddleOCR开源套件,以PP-OCRv3检测和识别模型为基础,针对液晶屏读数识别场景进行优化。
+
+Aistudio项目链接:[OCR液晶屏读数识别](https://aistudio.baidu.com/aistudio/projectdetail/4080130)
+
+## 3. 安装环境
+
+```python
+# 首先git官方的PaddleOCR项目,安装需要的依赖
+# 第一次运行打开该注释
+# git clone https://gitee.com/PaddlePaddle/PaddleOCR.git
+cd PaddleOCR
+pip install -r requirements.txt
+```
+
+## 4. 文字检测
+文本检测的任务是定位出输入图像中的文字区域。近年来学术界关于文本检测的研究非常丰富,一类方法将文本检测视为目标检测中的一个特定场景,基于通用目标检测算法进行改进适配,如TextBoxes[1]基于一阶段目标检测器SSD[2]算法,调整目标框使之适合极端长宽比的文本行,CTPN[3]则是基于Faster RCNN[4]架构改进而来。但是文本检测与目标检测在目标信息以及任务本身上仍存在一些区别,如文本一般长宽比较大,往往呈“条状”,文本行之间可能比较密集,弯曲文本等,因此又衍生了很多专用于文本检测的算法。本项目基于PP-OCRv3算法进行优化。
+
+### 4.1 PP-OCRv3检测算法介绍
+PP-OCRv3检测模型是对PP-OCRv2中的CML(Collaborative Mutual Learning) 协同互学习文本检测蒸馏策略进行了升级。如下图所示,CML的核心思想结合了①传统的Teacher指导Student的标准蒸馏与 ②Students网络之间的DML互学习,可以让Students网络互学习的同时,Teacher网络予以指导。PP-OCRv3分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML(Deep Mutual Learning)蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
+
+
+详细优化策略描述请参考[PP-OCRv3优化策略](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md#2)
+
+### 4.2 数据准备
+[计量设备屏幕字符检测数据集](https://aistudio.baidu.com/aistudio/datasetdetail/127845)数据来源于实际项目中各种计量设备的数显屏,以及在网上搜集的一些其他数显屏,包含训练集755张,测试集355张。
+
+```python
+# 在PaddleOCR下创建新的文件夹train_data
+mkdir train_data
+# 下载数据集并解压到指定路径下
+unzip icdar2015.zip -d train_data
+```
+
+```python
+# 随机查看文字检测数据集图片
+from PIL import Image
+import matplotlib.pyplot as plt
+import numpy as np
+import os
+
+
+train = './train_data/icdar2015/text_localization/test'
+# 从指定目录中选取一张图片
+def get_one_image(train):
+ plt.figure()
+ files = os.listdir(train)
+ n = len(files)
+ ind = np.random.randint(0,n)
+ img_dir = os.path.join(train,files[ind])
+ image = Image.open(img_dir)
+ plt.imshow(image)
+ plt.show()
+ image = image.resize([208, 208])
+
+get_one_image(train)
+```
+
+
+### 4.3 模型训练
+
+#### 4.3.1 预训练模型直接评估
+下载我们需要的PP-OCRv3检测预训练模型,更多选择请自行选择其他的[文字检测模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/models_list.md#1-%E6%96%87%E6%9C%AC%E6%A3%80%E6%B5%8B%E6%A8%A1%E5%9E%8B)
+
+```python
+#使用该指令下载需要的预训练模型
+wget -P ./pretrained_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
+# 解压预训练模型文件
+tar -xf ./pretrained_models/ch_PP-OCRv3_det_distill_train.tar -C pretrained_models
+```
+
+在训练之前,我们可以直接使用下面命令来评估预训练模型的效果:
+
+```python
+# 评估预训练模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model="./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy"
+```
+
+结果如下:
+
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.50%|
+
+#### 4.3.2 预训练模型直接finetune
+##### 修改配置文件
+我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+```
+epoch:100
+save_epoch_step:10
+eval_batch_step:[0, 50]
+save_model_dir: ./output/ch_PP-OCR_v3_det/
+pretrained_model: ./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy
+learning_rate: 0.00025
+num_workers: 0 # 如果单卡训练,建议将Train和Eval的loader部分的num_workers设置为0,否则会出现`/dev/shm insufficient`的报错
+```
+
+##### 开始训练
+使用我们上面修改的配置文件configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml,训练命令如下:
+
+```python
+# 开始训练模型
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.50%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.20%|
+
+#### 4.3.3 基于预训练模型Finetune_student模型
+
+我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+```
+epoch:100
+save_epoch_step:10
+eval_batch_step:[0, 50]
+save_model_dir: ./output/ch_PP-OCR_v3_det_student/
+pretrained_model: ./pretrained_models/ch_PP-OCRv3_det_distill_train/student
+learning_rate: 0.00025
+num_workers: 0 # 如果单卡训练,建议将Train和Eval的loader部分的num_workers设置为0,否则会出现`/dev/shm insufficient`的报错
+```
+
+训练命令如下:
+
+```python
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/student
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det_student/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.50%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.20%|
+| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.00%|
+
+#### 4.3.4 基于预训练模型Finetune_teacher模型
+
+首先需要从提供的预训练模型best_accuracy.pdparams中提取teacher参数,组合成适合dml训练的初始化模型,提取代码如下:
+
+```python
+cd ./pretrained_models/
+# transform teacher params in best_accuracy.pdparams into teacher_dml.paramers
+import paddle
+
+# load pretrained model
+all_params = paddle.load("ch_PP-OCRv3_det_distill_train/best_accuracy.pdparams")
+# print(all_params.keys())
+
+# keep teacher params
+t_params = {key[len("Teacher."):]: all_params[key] for key in all_params if "Teacher." in key}
+
+# print(t_params.keys())
+
+s_params = {"Student." + key: t_params[key] for key in t_params}
+s2_params = {"Student2." + key: t_params[key] for key in t_params}
+s_params = {**s_params, **s2_params}
+# print(s_params.keys())
+
+paddle.save(s_params, "ch_PP-OCRv3_det_distill_train/teacher_dml.pdparams")
+
+```
+
+我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+```
+epoch:100
+save_epoch_step:10
+eval_batch_step:[0, 50]
+save_model_dir: ./output/ch_PP-OCR_v3_det_teacher/
+pretrained_model: ./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_dml
+learning_rate: 0.00025
+num_workers: 0 # 如果单卡训练,建议将Train和Eval的loader部分的num_workers设置为0,否则会出现`/dev/shm insufficient`的报错
+```
+
+训练命令如下:
+
+```python
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_dml
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det_teacher/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.50%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.20%|
+| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.00%|
+| 3 | PP-OCRv3中英文超轻量检测预训练模型fintune教师模型 |84.80%|
+
+#### 4.3.5 采用CML蒸馏进一步提升student模型精度
+
+需要从4.3.3和4.3.4训练得到的best_accuracy.pdparams中提取各自代表student和teacher的参数,组合成适合cml训练的初始化模型,提取代码如下:
+
+```python
+# transform teacher params and student parameters into cml model
+import paddle
+
+all_params = paddle.load("./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy.pdparams")
+# print(all_params.keys())
+
+t_params = paddle.load("./output/ch_PP-OCR_v3_det_teacher/best_accuracy.pdparams")
+# print(t_params.keys())
+
+s_params = paddle.load("./output/ch_PP-OCR_v3_det_student/best_accuracy.pdparams")
+# print(s_params.keys())
+
+for key in all_params:
+ # teacher is OK
+ if "Teacher." in key:
+ new_key = key.replace("Teacher", "Student")
+ #print("{} >> {}\n".format(key, new_key))
+ assert all_params[key].shape == t_params[new_key].shape
+ all_params[key] = t_params[new_key]
+
+ if "Student." in key:
+ new_key = key.replace("Student.", "")
+ #print("{} >> {}\n".format(key, new_key))
+ assert all_params[key].shape == s_params[new_key].shape
+ all_params[key] = s_params[new_key]
+
+ if "Student2." in key:
+ new_key = key.replace("Student2.", "")
+ print("{} >> {}\n".format(key, new_key))
+ assert all_params[key].shape == s_params[new_key].shape
+ all_params[key] = s_params[new_key]
+
+paddle.save(all_params, "./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_cml_student.pdparams")
+```
+
+训练命令如下:
+
+```python
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_cml_student Global.save_model_dir=./output/ch_PP-OCR_v3_det_finetune/
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det_finetune/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.50%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.20%|
+| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.00%|
+| 3 | PP-OCRv3中英文超轻量检测预训练模型fintune教师模型 |84.80%|
+| 4 | 基于2和3训练好的模型fintune |82.70%|
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+
+
+
+
+
PP-OCRv3中英文超轻量识别预训练模型| 0.04% |
+|PP-OCRv3中英文超轻量检测预训练模型
PP-OCRv3中英文超轻量识别预训练模型 + 后处理去掉多识别的`·`| 78.27% |
+|PP-OCRv3中英文超轻量检测预训练模型+fine-tune
PP-OCRv3中英文超轻量识别预训练模型+fine-tune| 87.14% |
+|PP-OCRv3中英文超轻量检测预训练模型+fine-tune+量化
PP-OCRv3中英文超轻量识别预训练模型+fine-tune+量化| 88.00% |
+
+从结果中可以看到对预训练模型不做修改,只根据场景下的具体情况进行后处理的修改就能大幅提升端到端指标到78.27%,在CCPD数据集上进行 fine-tune 后指标进一步提升到87.14%, 在经过量化训练之后,由于检测模型的recall变高,指标进一步提升到88%。但是这个结果仍旧不符合检测模型+识别模型的真实性能(99%*94%=93%),因此我们需要对 base case 进行具体分析。
+
+在之前的端到端预测结果中,可以看到很多不符合车牌标注的文字被识别出来, 因此可以进行简单的过滤来提升precision
+
+为了快速评估,我们在 ` tools/end2end/convert_ppocr_label.py` 脚本的 58 行加入如下代码,对非8个字符的结果进行过滤
+```python
+if len(txt) != 8: # 车牌字符串长度为8
+ continue
+```
+
+此外,通过可视化box可以发现有很多框都是竖直翻转之后的框,并且没有完全框住车牌边界,因此需要进行框的竖直翻转以及轻微扩大,示意图如下:
+
+
+
+修改前后个方案指标对比如下:
+
+
+各个方案端到端指标如下:
+
+|模型|base|A:识别结果过滤|B:use_dilation|C:flip_box|best|
+|---|---|---|---|---|---|
+|PP-OCRv3中英文超轻量检测预训练模型
PP-OCRv3中英文超轻量识别预训练模型|0.04%|0.08%|0.02%|0.05%|0.00%(A)|
+|PP-OCRv3中英文超轻量检测预训练模型
PP-OCRv3中英文超轻量识别预训练模型 + 后处理去掉多识别的`·`|78.27%|90.84%|78.61%|79.43%|91.66%(A+B+C)|
+|PP-OCRv3中英文超轻量检测预训练模型+fine-tune
PP-OCRv3中英文超轻量识别预训练模型+fine-tune|87.14%|90.40%|87.66%|89.98%|92.50%(A+B+C)|
+|PP-OCRv3中英文超轻量检测预训练模型+fine-tune+量化
PP-OCRv3中英文超轻量识别预训练模型+fine-tune+量化|88.00%|90.54%|88.50%|89.46%|92.02%(A+B+C)|
+
+
+从结果中可以看到对预训练模型不做修改,只根据场景下的具体情况进行后处理的修改就能大幅提升端到端指标到91.66%,在CCPD数据集上进行 fine-tune 后指标进一步提升到92.5%, 在经过量化训练之后,指标变为92.02%。
+
+### 4.4 部署
+
+- 基于 Paddle Inference 的python推理
+
+检测模型和识别模型分别 fine-tune 并导出为inference模型之后,可以使用如下命令基于 Paddle Inference 进行端到端推理并对结果进行可视化。
+
+```bash
+python tools/infer/predict_system.py \
+ --det_model_dir=output/CCPD/det/infer/ \
+ --rec_model_dir=output/CCPD/rec/infer/ \
+ --image_dir="/home/aistudio/data/CCPD2020/ccpd_green/test/04131106321839081-92_258-159&509_530&611-527&611_172&599_159&509_530&525-0_0_3_32_30_31_30_30-109-106.jpg" \
+ --rec_image_shape=3,48,320
+```
+推理结果如下
+
+
+
+- 端侧部署
+
+端侧部署我们采用基于 PaddleLite 的 cpp 推理。Paddle Lite是飞桨轻量化推理引擎,为手机、IOT端提供高效推理能力,并广泛整合跨平台硬件,为端侧部署及应用落地问题提供轻量化的部署方案。具体可参考 [PaddleOCR lite教程](../deploy/lite/readme_ch.md)
+
+
+### 4.5 实验总结
+
+我们分别使用PP-OCRv3中英文超轻量预训练模型在车牌数据集上进行了直接评估和 fine-tune 和 fine-tune +量化3种方案的实验,并基于[PaddleOCR lite教程](../deploy/lite/readme_ch.md)进行了速度测试,指标对比如下:
+
+- 检测
+
+|方案|hmeans| 模型大小 | 预测速度(lite) |
+|---|---|------|------------|
+|PP-OCRv3中英文超轻量检测预训练模型直接预测|76.12%|2.5M| 233ms |
+|PP-OCRv3中英文超轻量检测预训练模型 fine-tune|99.00%| 2.5M | 233ms |
+|PP-OCRv3中英文超轻量检测预训练模型 fine-tune + 量化|98.91%| 1.0M | 189ms |fine-tune
+
+- 识别
+
+|方案| acc | 模型大小 | 预测速度(lite) |
+|---|--------|-------|------------|
+|PP-OCRv3中英文超轻量识别预训练模型直接预测| 0.00% |10.3M| 4.2ms |
+|PP-OCRv3中英文超轻量识别预训练模型直接预测+后处理去掉多识别的`·`| 90.97% |10.3M| 4.2ms |
+|PP-OCRv3中英文超轻量识别预训练模型 fine-tune| 94.54% | 10.3M | 4.2ms |
+|PP-OCRv3中英文超轻量识别预训练模型 fine-tune + 量化| 93.40% | 4.8M | 1.8ms |
+
+
+- 端到端指标如下:
+
+|方案|fmeasure|模型大小|预测速度(lite) |
+|---|---|---|---|
+|PP-OCRv3中英文超轻量检测预训练模型
PP-OCRv3中英文超轻量识别预训练模型|0.08%|12.8M|298ms|
+|PP-OCRv3中英文超轻量检测预训练模型
PP-OCRv3中英文超轻量识别预训练模型 + 后处理去掉多识别的`·`|91.66%|12.8M|298ms|
+|PP-OCRv3中英文超轻量检测预训练模型+fine-tune
PP-OCRv3中英文超轻量识别预训练模型+fine-tune|92.50%|12.8M|298ms|
+|PP-OCRv3中英文超轻量检测预训练模型+fine-tune+量化
PP-OCRv3中英文超轻量识别预训练模型+fine-tune+量化|92.02%|5.80M|224ms|
+
+
+**结论**
+
+PP-OCRv3的检测模型在未经过fine-tune的情况下,在车牌数据集上也有一定的精度,经过 fine-tune 后能够极大的提升检测效果,精度达到99%。在使用量化训练后检测模型的精度几乎无损,并且模型大小压缩60%。
+
+PP-OCRv3的识别模型在未经过fine-tune的情况下,在车牌数据集上精度为0,但是经过分析可以知道,模型大部分字符都预测正确,但是会多预测一个特殊字符,去掉这个特殊字符后,精度达到90%。PP-OCRv3识别模型在经过 fine-tune 后识别精度进一步提升,达到94.4%。在使用量化训练后识别模型大小压缩53%,但是由于数据量多少,带来了1%的精度损失。
+
+从端到端结果中可以看到对预训练模型不做修改,只根据场景下的具体情况进行后处理的修改就能大幅提升端到端指标到91.66%,在CCPD数据集上进行 fine-tune 后指标进一步提升到92.5%, 在经过量化训练之后,指标轻微下降到92.02%但模型大小降低54%。
diff --git "a/applications/\351\253\230\347\262\276\345\272\246\344\270\255\346\226\207\350\257\206\345\210\253\346\250\241\345\236\213.md" "b/applications/\351\253\230\347\262\276\345\272\246\344\270\255\346\226\207\350\257\206\345\210\253\346\250\241\345\236\213.md"
new file mode 100644
index 0000000..b233855
--- /dev/null
+++ "b/applications/\351\253\230\347\262\276\345\272\246\344\270\255\346\226\207\350\257\206\345\210\253\346\250\241\345\236\213.md"
@@ -0,0 +1,107 @@
+# 高精度中文场景文本识别模型SVTR
+
+## 1. 简介
+
+PP-OCRv3是百度开源的超轻量级场景文本检测识别模型库,其中超轻量的场景中文识别模型SVTR_LCNet使用了SVTR算法结构。为了保证速度,SVTR_LCNet将SVTR模型的Local Blocks替换为LCNet,使用两层Global Blocks。在中文场景中,PP-OCRv3识别主要使用如下优化策略([详细技术报告](../doc/doc_ch/PP-OCRv3_introduction.md)):
+- GTC:Attention指导CTC训练策略;
+- TextConAug:挖掘文字上下文信息的数据增广策略;
+- TextRotNet:自监督的预训练模型;
+- UDML:联合互学习策略;
+- UIM:无标注数据挖掘方案。
+
+其中 *UIM:无标注数据挖掘方案* 使用了高精度的SVTR中文模型进行无标注文件的刷库,该模型在PP-OCRv3识别的数据集上训练,精度对比如下表。
+
+|中文识别算法|模型|UIM|精度|
+| --- | --- | --- |--- |
+|PP-OCRv3|SVTR_LCNet| w/o |78.40%|
+|PP-OCRv3|SVTR_LCNet| w |79.40%|
+|SVTR|SVTR-Tiny|-|82.50%|
+
+aistudio项目链接: [高精度中文场景文本识别模型SVTR](https://aistudio.baidu.com/aistudio/projectdetail/4263032)
+
+## 2. SVTR中文模型使用
+
+### 环境准备
+
+
+本任务基于Aistudio完成, 具体环境如下:
+
+- 操作系统: Linux
+- PaddlePaddle: 2.3
+- PaddleOCR: dygraph
+
+下载 PaddleOCR代码
+
+```bash
+git clone -b dygraph https://github.com/PaddlePaddle/PaddleOCR
+```
+
+安装依赖库
+
+```bash
+pip install -r PaddleOCR/requirements.txt -i https://mirror.baidu.com/pypi/simple
+```
+
+### 快速使用
+
+获取SVTR中文模型文件,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+
+ 
+
+ 
+
+ 
+
+ 
+  +
+模型运行完成后,模型和运行状态显示区`STATUS`字段显示了当前模型的运行状态,这里显示为`run model successed`表明模型运行成功。
+
+模型的运行结果显示在运行结果显示区,显示格式为
+```text
+序号:Det:(x1,y1)(x2,y2)(x3,y3)(x4,y4) Rec: 识别文本,识别置信度 Cls:分类类别,分类分时
+```
+
+### 3.4 运行模式
+
+PaddleOCR demo共提供了6种运行模式,如下图
+
+
+模型运行完成后,模型和运行状态显示区`STATUS`字段显示了当前模型的运行状态,这里显示为`run model successed`表明模型运行成功。
+
+模型的运行结果显示在运行结果显示区,显示格式为
+```text
+序号:Det:(x1,y1)(x2,y2)(x3,y3)(x4,y4) Rec: 识别文本,识别置信度 Cls:分类类别,分类分时
+```
+
+### 3.4 运行模式
+
+PaddleOCR demo共提供了6种运行模式,如下图
+
+ 
+  | |  |
+
+
+| 检测 | 识别 | 分类 |
+|----------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------|
+| |
+
+
+| 检测 | 识别 | 分类 |
+|----------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------|
+|  | |  | |  |
+
+### 3.5 设置
+
+设置界面如下
+
+ |
+
+### 3.5 设置
+
+设置界面如下
+
+
+ 
+
+#include
+#include
+#include
+#include
+#include
+
+namespace ClipperLib {
+
+enum ClipType { ctIntersection, ctUnion, ctDifference, ctXor };
+enum PolyType { ptSubject, ptClip };
+// By far the most widely used winding rules for polygon filling are
+// EvenOdd & NonZero (GDI, GDI+, XLib, OpenGL, Cairo, AGG, Quartz, SVG, Gr32)
+// Others rules include Positive, Negative and ABS_GTR_EQ_TWO (only in OpenGL)
+// see http://glprogramming.com/red/chapter11.html
+enum PolyFillType { pftEvenOdd, pftNonZero, pftPositive, pftNegative };
+
+#ifdef use_int32
+typedef int cInt;
+static cInt const loRange = 0x7FFF;
+static cInt const hiRange = 0x7FFF;
+#else
+typedef signed long long cInt;
+static cInt const loRange = 0x3FFFFFFF;
+static cInt const hiRange = 0x3FFFFFFFFFFFFFFFLL;
+typedef signed long long long64; // used by Int128 class
+typedef unsigned long long ulong64;
+
+#endif
+
+struct IntPoint {
+ cInt X;
+ cInt Y;
+#ifdef use_xyz
+ cInt Z;
+ IntPoint(cInt x = 0, cInt y = 0, cInt z = 0) : X(x), Y(y), Z(z){};
+#else
+
+ IntPoint(cInt x = 0, cInt y = 0) : X(x), Y(y){};
+#endif
+
+ friend inline bool operator==(const IntPoint &a, const IntPoint &b) {
+ return a.X == b.X && a.Y == b.Y;
+ }
+
+ friend inline bool operator!=(const IntPoint &a, const IntPoint &b) {
+ return a.X != b.X || a.Y != b.Y;
+ }
+};
+//------------------------------------------------------------------------------
+
+typedef std::vector Path;
+typedef std::vector Paths;
+
+inline Path &operator<<(Path &poly, const IntPoint &p) {
+ poly.push_back(p);
+ return poly;
+}
+
+inline Paths &operator<<(Paths &polys, const Path &p) {
+ polys.push_back(p);
+ return polys;
+}
+
+std::ostream &operator<<(std::ostream &s, const IntPoint &p);
+
+std::ostream &operator<<(std::ostream &s, const Path &p);
+
+std::ostream &operator<<(std::ostream &s, const Paths &p);
+
+struct DoublePoint {
+ double X;
+ double Y;
+
+ DoublePoint(double x = 0, double y = 0) : X(x), Y(y) {}
+
+ DoublePoint(IntPoint ip) : X((double)ip.X), Y((double)ip.Y) {}
+};
+//------------------------------------------------------------------------------
+
+#ifdef use_xyz
+typedef void (*ZFillCallback)(IntPoint &e1bot, IntPoint &e1top, IntPoint &e2bot,
+ IntPoint &e2top, IntPoint &pt);
+#endif
+
+enum InitOptions {
+ ioReverseSolution = 1,
+ ioStrictlySimple = 2,
+ ioPreserveCollinear = 4
+};
+enum JoinType { jtSquare, jtRound, jtMiter };
+enum EndType {
+ etClosedPolygon,
+ etClosedLine,
+ etOpenButt,
+ etOpenSquare,
+ etOpenRound
+};
+
+class PolyNode;
+
+typedef std::vector PolyNodes;
+
+class PolyNode {
+public:
+ PolyNode();
+
+ virtual ~PolyNode(){};
+ Path Contour;
+ PolyNodes Childs;
+ PolyNode *Parent;
+
+ PolyNode *GetNext() const;
+
+ bool IsHole() const;
+
+ bool IsOpen() const;
+
+ int ChildCount() const;
+
+private:
+ // PolyNode& operator =(PolyNode& other);
+ unsigned Index; // node index in Parent.Childs
+ bool m_IsOpen;
+ JoinType m_jointype;
+ EndType m_endtype;
+
+ PolyNode *GetNextSiblingUp() const;
+
+ void AddChild(PolyNode &child);
+
+ friend class Clipper; // to access Index
+ friend class ClipperOffset;
+};
+
+class PolyTree : public PolyNode {
+public:
+ ~PolyTree() { Clear(); };
+
+ PolyNode *GetFirst() const;
+
+ void Clear();
+
+ int Total() const;
+
+private:
+ // PolyTree& operator =(PolyTree& other);
+ PolyNodes AllNodes;
+
+ friend class Clipper; // to access AllNodes
+};
+
+bool Orientation(const Path &poly);
+
+double Area(const Path &poly);
+
+int PointInPolygon(const IntPoint &pt, const Path &path);
+
+void SimplifyPolygon(const Path &in_poly, Paths &out_polys,
+ PolyFillType fillType = pftEvenOdd);
+
+void SimplifyPolygons(const Paths &in_polys, Paths &out_polys,
+ PolyFillType fillType = pftEvenOdd);
+
+void SimplifyPolygons(Paths &polys, PolyFillType fillType = pftEvenOdd);
+
+void CleanPolygon(const Path &in_poly, Path &out_poly, double distance = 1.415);
+
+void CleanPolygon(Path &poly, double distance = 1.415);
+
+void CleanPolygons(const Paths &in_polys, Paths &out_polys,
+ double distance = 1.415);
+
+void CleanPolygons(Paths &polys, double distance = 1.415);
+
+void MinkowskiSum(const Path &pattern, const Path &path, Paths &solution,
+ bool pathIsClosed);
+
+void MinkowskiSum(const Path &pattern, const Paths &paths, Paths &solution,
+ bool pathIsClosed);
+
+void MinkowskiDiff(const Path &poly1, const Path &poly2, Paths &solution);
+
+void PolyTreeToPaths(const PolyTree &polytree, Paths &paths);
+
+void ClosedPathsFromPolyTree(const PolyTree &polytree, Paths &paths);
+
+void OpenPathsFromPolyTree(PolyTree &polytree, Paths &paths);
+
+void ReversePath(Path &p);
+
+void ReversePaths(Paths &p);
+
+struct IntRect {
+ cInt left;
+ cInt top;
+ cInt right;
+ cInt bottom;
+};
+
+// enums that are used internally ...
+enum EdgeSide { esLeft = 1, esRight = 2 };
+
+// forward declarations (for stuff used internally) ...
+struct TEdge;
+struct IntersectNode;
+struct LocalMinimum;
+struct OutPt;
+struct OutRec;
+struct Join;
+
+typedef std::vector PolyOutList;
+typedef std::vector EdgeList;
+typedef std::vector JoinList;
+typedef std::vector IntersectList;
+
+//------------------------------------------------------------------------------
+
+// ClipperBase is the ancestor to the Clipper class. It should not be
+// instantiated directly. This class simply abstracts the conversion of sets of
+// polygon coordinates into edge objects that are stored in a LocalMinima list.
+class ClipperBase {
+public:
+ ClipperBase();
+
+ virtual ~ClipperBase();
+
+ virtual bool AddPath(const Path &pg, PolyType PolyTyp, bool Closed);
+
+ bool AddPaths(const Paths &ppg, PolyType PolyTyp, bool Closed);
+
+ virtual void Clear();
+
+ IntRect GetBounds();
+
+ bool PreserveCollinear() { return m_PreserveCollinear; };
+
+ void PreserveCollinear(bool value) { m_PreserveCollinear = value; };
+
+protected:
+ void DisposeLocalMinimaList();
+
+ TEdge *AddBoundsToLML(TEdge *e, bool IsClosed);
+
+ virtual void Reset();
+
+ TEdge *ProcessBound(TEdge *E, bool IsClockwise);
+
+ void InsertScanbeam(const cInt Y);
+
+ bool PopScanbeam(cInt &Y);
+
+ bool LocalMinimaPending();
+
+ bool PopLocalMinima(cInt Y, const LocalMinimum *&locMin);
+
+ OutRec *CreateOutRec();
+
+ void DisposeAllOutRecs();
+
+ void DisposeOutRec(PolyOutList::size_type index);
+
+ void SwapPositionsInAEL(TEdge *edge1, TEdge *edge2);
+
+ void DeleteFromAEL(TEdge *e);
+
+ void UpdateEdgeIntoAEL(TEdge *&e);
+
+ typedef std::vector MinimaList;
+ MinimaList::iterator m_CurrentLM;
+ MinimaList m_MinimaList;
+
+ bool m_UseFullRange;
+ EdgeList m_edges;
+ bool m_PreserveCollinear;
+ bool m_HasOpenPaths;
+ PolyOutList m_PolyOuts;
+ TEdge *m_ActiveEdges;
+
+ typedef std::priority_queue ScanbeamList;
+ ScanbeamList m_Scanbeam;
+};
+//------------------------------------------------------------------------------
+
+class Clipper : public virtual ClipperBase {
+public:
+ Clipper(int initOptions = 0);
+
+ bool Execute(ClipType clipType, Paths &solution,
+ PolyFillType fillType = pftEvenOdd);
+
+ bool Execute(ClipType clipType, Paths &solution, PolyFillType subjFillType,
+ PolyFillType clipFillType);
+
+ bool Execute(ClipType clipType, PolyTree &polytree,
+ PolyFillType fillType = pftEvenOdd);
+
+ bool Execute(ClipType clipType, PolyTree &polytree, PolyFillType subjFillType,
+ PolyFillType clipFillType);
+
+ bool ReverseSolution() { return m_ReverseOutput; };
+
+ void ReverseSolution(bool value) { m_ReverseOutput = value; };
+
+ bool StrictlySimple() { return m_StrictSimple; };
+
+ void StrictlySimple(bool value) { m_StrictSimple = value; };
+// set the callback function for z value filling on intersections (otherwise Z
+// is 0)
+#ifdef use_xyz
+ void ZFillFunction(ZFillCallback zFillFunc);
+#endif
+protected:
+ virtual bool ExecuteInternal();
+
+private:
+ JoinList m_Joins;
+ JoinList m_GhostJoins;
+ IntersectList m_IntersectList;
+ ClipType m_ClipType;
+ typedef std::list MaximaList;
+ MaximaList m_Maxima;
+ TEdge *m_SortedEdges;
+ bool m_ExecuteLocked;
+ PolyFillType m_ClipFillType;
+ PolyFillType m_SubjFillType;
+ bool m_ReverseOutput;
+ bool m_UsingPolyTree;
+ bool m_StrictSimple;
+#ifdef use_xyz
+ ZFillCallback m_ZFill; // custom callback
+#endif
+
+ void SetWindingCount(TEdge &edge);
+
+ bool IsEvenOddFillType(const TEdge &edge) const;
+
+ bool IsEvenOddAltFillType(const TEdge &edge) const;
+
+ void InsertLocalMinimaIntoAEL(const cInt botY);
+
+ void InsertEdgeIntoAEL(TEdge *edge, TEdge *startEdge);
+
+ void AddEdgeToSEL(TEdge *edge);
+
+ bool PopEdgeFromSEL(TEdge *&edge);
+
+ void CopyAELToSEL();
+
+ void DeleteFromSEL(TEdge *e);
+
+ void SwapPositionsInSEL(TEdge *edge1, TEdge *edge2);
+
+ bool IsContributing(const TEdge &edge) const;
+
+ bool IsTopHorz(const cInt XPos);
+
+ void DoMaxima(TEdge *e);
+
+ void ProcessHorizontals();
+
+ void ProcessHorizontal(TEdge *horzEdge);
+
+ void AddLocalMaxPoly(TEdge *e1, TEdge *e2, const IntPoint &pt);
+
+ OutPt *AddLocalMinPoly(TEdge *e1, TEdge *e2, const IntPoint &pt);
+
+ OutRec *GetOutRec(int idx);
+
+ void AppendPolygon(TEdge *e1, TEdge *e2);
+
+ void IntersectEdges(TEdge *e1, TEdge *e2, IntPoint &pt);
+
+ OutPt *AddOutPt(TEdge *e, const IntPoint &pt);
+
+ OutPt *GetLastOutPt(TEdge *e);
+
+ bool ProcessIntersections(const cInt topY);
+
+ void BuildIntersectList(const cInt topY);
+
+ void ProcessIntersectList();
+
+ void ProcessEdgesAtTopOfScanbeam(const cInt topY);
+
+ void BuildResult(Paths &polys);
+
+ void BuildResult2(PolyTree &polytree);
+
+ void SetHoleState(TEdge *e, OutRec *outrec);
+
+ void DisposeIntersectNodes();
+
+ bool FixupIntersectionOrder();
+
+ void FixupOutPolygon(OutRec &outrec);
+
+ void FixupOutPolyline(OutRec &outrec);
+
+ bool IsHole(TEdge *e);
+
+ bool FindOwnerFromSplitRecs(OutRec &outRec, OutRec *&currOrfl);
+
+ void FixHoleLinkage(OutRec &outrec);
+
+ void AddJoin(OutPt *op1, OutPt *op2, const IntPoint offPt);
+
+ void ClearJoins();
+
+ void ClearGhostJoins();
+
+ void AddGhostJoin(OutPt *op, const IntPoint offPt);
+
+ bool JoinPoints(Join *j, OutRec *outRec1, OutRec *outRec2);
+
+ void JoinCommonEdges();
+
+ void DoSimplePolygons();
+
+ void FixupFirstLefts1(OutRec *OldOutRec, OutRec *NewOutRec);
+
+ void FixupFirstLefts2(OutRec *InnerOutRec, OutRec *OuterOutRec);
+
+ void FixupFirstLefts3(OutRec *OldOutRec, OutRec *NewOutRec);
+
+#ifdef use_xyz
+ void SetZ(IntPoint &pt, TEdge &e1, TEdge &e2);
+#endif
+};
+//------------------------------------------------------------------------------
+
+class ClipperOffset {
+public:
+ ClipperOffset(double miterLimit = 2.0, double roundPrecision = 0.25);
+
+ ~ClipperOffset();
+
+ void AddPath(const Path &path, JoinType joinType, EndType endType);
+
+ void AddPaths(const Paths &paths, JoinType joinType, EndType endType);
+
+ void Execute(Paths &solution, double delta);
+
+ void Execute(PolyTree &solution, double delta);
+
+ void Clear();
+
+ double MiterLimit;
+ double ArcTolerance;
+
+private:
+ Paths m_destPolys;
+ Path m_srcPoly;
+ Path m_destPoly;
+ std::vector m_normals;
+ double m_delta, m_sinA, m_sin, m_cos;
+ double m_miterLim, m_StepsPerRad;
+ IntPoint m_lowest;
+ PolyNode m_polyNodes;
+
+ void FixOrientations();
+
+ void DoOffset(double delta);
+
+ void OffsetPoint(int j, int &k, JoinType jointype);
+
+ void DoSquare(int j, int k);
+
+ void DoMiter(int j, int k, double r);
+
+ void DoRound(int j, int k);
+};
+//------------------------------------------------------------------------------
+
+class clipperException : public std::exception {
+public:
+ clipperException(const char *description) : m_descr(description) {}
+
+ virtual ~clipperException() throw() {}
+
+ virtual const char *what() const throw() { return m_descr.c_str(); }
+
+private:
+ std::string m_descr;
+};
+//------------------------------------------------------------------------------
+
+} // ClipperLib namespace
+
+#endif // clipper_hpp
diff --git a/deploy/android_demo/app/src/main/cpp/ocr_cls_process.cpp b/deploy/android_demo/app/src/main/cpp/ocr_cls_process.cpp
new file mode 100644
index 0000000..e7de9b0
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/ocr_cls_process.cpp
@@ -0,0 +1,46 @@
+// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include "ocr_cls_process.h"
+#include
+#include
+#include
+#include
+#include
+#include
+
+const std::vector CLS_IMAGE_SHAPE = {3, 48, 192};
+
+cv::Mat cls_resize_img(const cv::Mat &img) {
+ int imgC = CLS_IMAGE_SHAPE[0];
+ int imgW = CLS_IMAGE_SHAPE[2];
+ int imgH = CLS_IMAGE_SHAPE[1];
+
+ float ratio = float(img.cols) / float(img.rows);
+ int resize_w = 0;
+ if (ceilf(imgH * ratio) > imgW)
+ resize_w = imgW;
+ else
+ resize_w = int(ceilf(imgH * ratio));
+
+ cv::Mat resize_img;
+ cv::resize(img, resize_img, cv::Size(resize_w, imgH), 0.f, 0.f,
+ cv::INTER_CUBIC);
+
+ if (resize_w < imgW) {
+ cv::copyMakeBorder(resize_img, resize_img, 0, 0, 0, int(imgW - resize_w),
+ cv::BORDER_CONSTANT, {0, 0, 0});
+ }
+ return resize_img;
+}
\ No newline at end of file
diff --git a/deploy/android_demo/app/src/main/cpp/ocr_cls_process.h b/deploy/android_demo/app/src/main/cpp/ocr_cls_process.h
new file mode 100644
index 0000000..1c30ee1
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/ocr_cls_process.h
@@ -0,0 +1,23 @@
+// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#pragma once
+
+#include "common.h"
+#include
+#include
+
+extern const std::vector CLS_IMAGE_SHAPE;
+
+cv::Mat cls_resize_img(const cv::Mat &img);
\ No newline at end of file
diff --git a/deploy/android_demo/app/src/main/cpp/ocr_crnn_process.cpp b/deploy/android_demo/app/src/main/cpp/ocr_crnn_process.cpp
new file mode 100644
index 0000000..44c34a2
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/ocr_crnn_process.cpp
@@ -0,0 +1,142 @@
+// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include "ocr_crnn_process.h"
+#include
+#include
+#include
+#include
+#include
+#include
+
+const std::string CHARACTER_TYPE = "ch";
+const int MAX_DICT_LENGTH = 6624;
+const std::vector REC_IMAGE_SHAPE = {3, 32, 320};
+
+static cv::Mat crnn_resize_norm_img(cv::Mat img, float wh_ratio) {
+ int imgC = REC_IMAGE_SHAPE[0];
+ int imgW = REC_IMAGE_SHAPE[2];
+ int imgH = REC_IMAGE_SHAPE[1];
+
+ if (CHARACTER_TYPE == "ch")
+ imgW = int(32 * wh_ratio);
+
+ float ratio = float(img.cols) / float(img.rows);
+ int resize_w = 0;
+ if (ceilf(imgH * ratio) > imgW)
+ resize_w = imgW;
+ else
+ resize_w = int(ceilf(imgH * ratio));
+ cv::Mat resize_img;
+ cv::resize(img, resize_img, cv::Size(resize_w, imgH), 0.f, 0.f,
+ cv::INTER_CUBIC);
+
+ resize_img.convertTo(resize_img, CV_32FC3, 1 / 255.f);
+
+ for (int h = 0; h < resize_img.rows; h++) {
+ for (int w = 0; w < resize_img.cols; w++) {
+ resize_img.at(h, w)[0] =
+ (resize_img.at(h, w)[0] - 0.5) * 2;
+ resize_img.at(h, w)[1] =
+ (resize_img.at(h, w)[1] - 0.5) * 2;
+ resize_img.at(h, w)[2] =
+ (resize_img.at(h, w)[2] - 0.5) * 2;
+ }
+ }
+
+ cv::Mat dist;
+ cv::copyMakeBorder(resize_img, dist, 0, 0, 0, int(imgW - resize_w),
+ cv::BORDER_CONSTANT, {0, 0, 0});
+
+ return dist;
+}
+
+cv::Mat crnn_resize_img(const cv::Mat &img, float wh_ratio) {
+ int imgC = REC_IMAGE_SHAPE[0];
+ int imgW = REC_IMAGE_SHAPE[2];
+ int imgH = REC_IMAGE_SHAPE[1];
+
+ if (CHARACTER_TYPE == "ch") {
+ imgW = int(32 * wh_ratio);
+ }
+
+ float ratio = float(img.cols) / float(img.rows);
+ int resize_w = 0;
+ if (ceilf(imgH * ratio) > imgW)
+ resize_w = imgW;
+ else
+ resize_w = int(ceilf(imgH * ratio));
+ cv::Mat resize_img;
+ cv::resize(img, resize_img, cv::Size(resize_w, imgH));
+ return resize_img;
+}
+
+cv::Mat get_rotate_crop_image(const cv::Mat &srcimage,
+ const std::vector> &box) {
+
+ std::vector> points = box;
+
+ int x_collect[4] = {box[0][0], box[1][0], box[2][0], box[3][0]};
+ int y_collect[4] = {box[0][1], box[1][1], box[2][1], box[3][1]};
+ int left = int(*std::min_element(x_collect, x_collect + 4));
+ int right = int(*std::max_element(x_collect, x_collect + 4));
+ int top = int(*std::min_element(y_collect, y_collect + 4));
+ int bottom = int(*std::max_element(y_collect, y_collect + 4));
+
+ cv::Mat img_crop;
+ srcimage(cv::Rect(left, top, right - left, bottom - top)).copyTo(img_crop);
+
+ for (int i = 0; i < points.size(); i++) {
+ points[i][0] -= left;
+ points[i][1] -= top;
+ }
+
+ int img_crop_width = int(sqrt(pow(points[0][0] - points[1][0], 2) +
+ pow(points[0][1] - points[1][1], 2)));
+ int img_crop_height = int(sqrt(pow(points[0][0] - points[3][0], 2) +
+ pow(points[0][1] - points[3][1], 2)));
+
+ cv::Point2f pts_std[4];
+ pts_std[0] = cv::Point2f(0., 0.);
+ pts_std[1] = cv::Point2f(img_crop_width, 0.);
+ pts_std[2] = cv::Point2f(img_crop_width, img_crop_height);
+ pts_std[3] = cv::Point2f(0.f, img_crop_height);
+
+ cv::Point2f pointsf[4];
+ pointsf[0] = cv::Point2f(points[0][0], points[0][1]);
+ pointsf[1] = cv::Point2f(points[1][0], points[1][1]);
+ pointsf[2] = cv::Point2f(points[2][0], points[2][1]);
+ pointsf[3] = cv::Point2f(points[3][0], points[3][1]);
+
+ cv::Mat M = cv::getPerspectiveTransform(pointsf, pts_std);
+
+ cv::Mat dst_img;
+ cv::warpPerspective(img_crop, dst_img, M,
+ cv::Size(img_crop_width, img_crop_height),
+ cv::BORDER_REPLICATE);
+
+ if (float(dst_img.rows) >= float(dst_img.cols) * 1.5) {
+ /*
+ cv::Mat srcCopy = cv::Mat(dst_img.rows, dst_img.cols, dst_img.depth());
+ cv::transpose(dst_img, srcCopy);
+ cv::flip(srcCopy, srcCopy, 0);
+ return srcCopy;
+ */
+ cv::transpose(dst_img, dst_img);
+ cv::flip(dst_img, dst_img, 0);
+ return dst_img;
+ } else {
+ return dst_img;
+ }
+}
diff --git a/deploy/android_demo/app/src/main/cpp/ocr_crnn_process.h b/deploy/android_demo/app/src/main/cpp/ocr_crnn_process.h
new file mode 100644
index 0000000..0346afe
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/ocr_crnn_process.h
@@ -0,0 +1,20 @@
+//
+// Created by fujiayi on 2020/7/3.
+//
+#pragma once
+
+#include "common.h"
+#include
+#include
+
+extern const std::vector REC_IMAGE_SHAPE;
+
+cv::Mat get_rotate_crop_image(const cv::Mat &srcimage,
+ const std::vector> &box);
+
+cv::Mat crnn_resize_img(const cv::Mat &img, float wh_ratio);
+
+template
+inline size_t argmax(ForwardIterator first, ForwardIterator last) {
+ return std::distance(first, std::max_element(first, last));
+}
\ No newline at end of file
diff --git a/deploy/android_demo/app/src/main/cpp/ocr_db_post_process.cpp b/deploy/android_demo/app/src/main/cpp/ocr_db_post_process.cpp
new file mode 100644
index 0000000..9816ea4
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/ocr_db_post_process.cpp
@@ -0,0 +1,342 @@
+// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include "ocr_clipper.hpp"
+#include "opencv2/core.hpp"
+#include "opencv2/imgcodecs.hpp"
+#include "opencv2/imgproc.hpp"
+#include
+#include
+#include
+
+static void getcontourarea(float **box, float unclip_ratio, float &distance) {
+ int pts_num = 4;
+ float area = 0.0f;
+ float dist = 0.0f;
+ for (int i = 0; i < pts_num; i++) {
+ area += box[i][0] * box[(i + 1) % pts_num][1] -
+ box[i][1] * box[(i + 1) % pts_num][0];
+ dist += sqrtf((box[i][0] - box[(i + 1) % pts_num][0]) *
+ (box[i][0] - box[(i + 1) % pts_num][0]) +
+ (box[i][1] - box[(i + 1) % pts_num][1]) *
+ (box[i][1] - box[(i + 1) % pts_num][1]));
+ }
+ area = fabs(float(area / 2.0));
+
+ distance = area * unclip_ratio / dist;
+}
+
+static cv::RotatedRect unclip(float **box) {
+ float unclip_ratio = 2.0;
+ float distance = 1.0;
+
+ getcontourarea(box, unclip_ratio, distance);
+
+ ClipperLib::ClipperOffset offset;
+ ClipperLib::Path p;
+ p << ClipperLib::IntPoint(int(box[0][0]), int(box[0][1]))
+ << ClipperLib::IntPoint(int(box[1][0]), int(box[1][1]))
+ << ClipperLib::IntPoint(int(box[2][0]), int(box[2][1]))
+ << ClipperLib::IntPoint(int(box[3][0]), int(box[3][1]));
+ offset.AddPath(p, ClipperLib::jtRound, ClipperLib::etClosedPolygon);
+
+ ClipperLib::Paths soln;
+ offset.Execute(soln, distance);
+ std::vector points;
+
+ for (int j = 0; j < soln.size(); j++) {
+ for (int i = 0; i < soln[soln.size() - 1].size(); i++) {
+ points.emplace_back(soln[j][i].X, soln[j][i].Y);
+ }
+ }
+ cv::RotatedRect res = cv::minAreaRect(points);
+
+ return res;
+}
+
+static float **Mat2Vec(cv::Mat mat) {
+ auto **array = new float *[mat.rows];
+ for (int i = 0; i < mat.rows; ++i) {
+ array[i] = new float[mat.cols];
+ }
+ for (int i = 0; i < mat.rows; ++i) {
+ for (int j = 0; j < mat.cols; ++j) {
+ array[i][j] = mat.at(i, j);
+ }
+ }
+
+ return array;
+}
+
+static void quickSort(float **s, int l, int r) {
+ if (l < r) {
+ int i = l, j = r;
+ float x = s[l][0];
+ float *xp = s[l];
+ while (i < j) {
+ while (i < j && s[j][0] >= x) {
+ j--;
+ }
+ if (i < j) {
+ std::swap(s[i++], s[j]);
+ }
+ while (i < j && s[i][0] < x) {
+ i++;
+ }
+ if (i < j) {
+ std::swap(s[j--], s[i]);
+ }
+ }
+ s[i] = xp;
+ quickSort(s, l, i - 1);
+ quickSort(s, i + 1, r);
+ }
+}
+
+static void quickSort_vector(std::vector> &box, int l, int r,
+ int axis) {
+ if (l < r) {
+ int i = l, j = r;
+ int x = box[l][axis];
+ std::vector xp(box[l]);
+ while (i < j) {
+ while (i < j && box[j][axis] >= x) {
+ j--;
+ }
+ if (i < j) {
+ std::swap(box[i++], box[j]);
+ }
+ while (i < j && box[i][axis] < x) {
+ i++;
+ }
+ if (i < j) {
+ std::swap(box[j--], box[i]);
+ }
+ }
+ box[i] = xp;
+ quickSort_vector(box, l, i - 1, axis);
+ quickSort_vector(box, i + 1, r, axis);
+ }
+}
+
+static std::vector>
+order_points_clockwise(std::vector> pts) {
+ std::vector> box = pts;
+ quickSort_vector(box, 0, int(box.size() - 1), 0);
+ std::vector> leftmost = {box[0], box[1]};
+ std::vector> rightmost = {box[2], box[3]};
+
+ if (leftmost[0][1] > leftmost[1][1]) {
+ std::swap(leftmost[0], leftmost[1]);
+ }
+
+ if (rightmost[0][1] > rightmost[1][1]) {
+ std::swap(rightmost[0], rightmost[1]);
+ }
+
+ std::vector> rect = {leftmost[0], rightmost[0], rightmost[1],
+ leftmost[1]};
+ return rect;
+}
+
+static float **get_mini_boxes(cv::RotatedRect box, float &ssid) {
+ ssid = box.size.width >= box.size.height ? box.size.height : box.size.width;
+
+ cv::Mat points;
+ cv::boxPoints(box, points);
+ // sorted box points
+ auto array = Mat2Vec(points);
+ quickSort(array, 0, 3);
+
+ float *idx1 = array[0], *idx2 = array[1], *idx3 = array[2], *idx4 = array[3];
+ if (array[3][1] <= array[2][1]) {
+ idx2 = array[3];
+ idx3 = array[2];
+ } else {
+ idx2 = array[2];
+ idx3 = array[3];
+ }
+ if (array[1][1] <= array[0][1]) {
+ idx1 = array[1];
+ idx4 = array[0];
+ } else {
+ idx1 = array[0];
+ idx4 = array[1];
+ }
+
+ array[0] = idx1;
+ array[1] = idx2;
+ array[2] = idx3;
+ array[3] = idx4;
+
+ return array;
+}
+
+template T clamp(T x, T min, T max) {
+ if (x > max) {
+ return max;
+ }
+ if (x < min) {
+ return min;
+ }
+ return x;
+}
+
+static float clampf(float x, float min, float max) {
+ if (x > max)
+ return max;
+ if (x < min)
+ return min;
+ return x;
+}
+
+float box_score_fast(float **box_array, cv::Mat pred) {
+ auto array = box_array;
+ int width = pred.cols;
+ int height = pred.rows;
+
+ float box_x[4] = {array[0][0], array[1][0], array[2][0], array[3][0]};
+ float box_y[4] = {array[0][1], array[1][1], array[2][1], array[3][1]};
+
+ int xmin = clamp(int(std::floorf(*(std::min_element(box_x, box_x + 4)))), 0,
+ width - 1);
+ int xmax = clamp(int(std::ceilf(*(std::max_element(box_x, box_x + 4)))), 0,
+ width - 1);
+ int ymin = clamp(int(std::floorf(*(std::min_element(box_y, box_y + 4)))), 0,
+ height - 1);
+ int ymax = clamp(int(std::ceilf(*(std::max_element(box_y, box_y + 4)))), 0,
+ height - 1);
+
+ cv::Mat mask;
+ mask = cv::Mat::zeros(ymax - ymin + 1, xmax - xmin + 1, CV_8UC1);
+
+ cv::Point root_point[4];
+ root_point[0] = cv::Point(int(array[0][0]) - xmin, int(array[0][1]) - ymin);
+ root_point[1] = cv::Point(int(array[1][0]) - xmin, int(array[1][1]) - ymin);
+ root_point[2] = cv::Point(int(array[2][0]) - xmin, int(array[2][1]) - ymin);
+ root_point[3] = cv::Point(int(array[3][0]) - xmin, int(array[3][1]) - ymin);
+ const cv::Point *ppt[1] = {root_point};
+ int npt[] = {4};
+ cv::fillPoly(mask, ppt, npt, 1, cv::Scalar(1));
+
+ cv::Mat croppedImg;
+ pred(cv::Rect(xmin, ymin, xmax - xmin + 1, ymax - ymin + 1))
+ .copyTo(croppedImg);
+
+ auto score = cv::mean(croppedImg, mask)[0];
+ return score;
+}
+
+std::vector>>
+boxes_from_bitmap(const cv::Mat &pred, const cv::Mat &bitmap) {
+ const int min_size = 3;
+ const int max_candidates = 1000;
+ const float box_thresh = 0.5;
+
+ int width = bitmap.cols;
+ int height = bitmap.rows;
+
+ std::vector> contours;
+ std::vector hierarchy;
+
+ cv::findContours(bitmap, contours, hierarchy, cv::RETR_LIST,
+ cv::CHAIN_APPROX_SIMPLE);
+
+ int num_contours =
+ contours.size() >= max_candidates ? max_candidates : contours.size();
+
+ std::vector>> boxes;
+
+ for (int _i = 0; _i < num_contours; _i++) {
+ float ssid;
+ cv::RotatedRect box = cv::minAreaRect(contours[_i]);
+ auto array = get_mini_boxes(box, ssid);
+
+ auto box_for_unclip = array;
+ // end get_mini_box
+
+ if (ssid < min_size) {
+ continue;
+ }
+
+ float score;
+ score = box_score_fast(array, pred);
+ // end box_score_fast
+ if (score < box_thresh) {
+ continue;
+ }
+
+ // start for unclip
+ cv::RotatedRect points = unclip(box_for_unclip);
+ // end for unclip
+
+ cv::RotatedRect clipbox = points;
+ auto cliparray = get_mini_boxes(clipbox, ssid);
+
+ if (ssid < min_size + 2)
+ continue;
+
+ int dest_width = pred.cols;
+ int dest_height = pred.rows;
+ std::vector> intcliparray;
+
+ for (int num_pt = 0; num_pt < 4; num_pt++) {
+ std::vector a{int(clampf(roundf(cliparray[num_pt][0] / float(width) *
+ float(dest_width)),
+ 0, float(dest_width))),
+ int(clampf(roundf(cliparray[num_pt][1] /
+ float(height) * float(dest_height)),
+ 0, float(dest_height)))};
+ intcliparray.emplace_back(std::move(a));
+ }
+ boxes.emplace_back(std::move(intcliparray));
+
+ } // end for
+ return boxes;
+}
+
+int _max(int a, int b) { return a >= b ? a : b; }
+
+int _min(int a, int b) { return a >= b ? b : a; }
+
+std::vector>>
+filter_tag_det_res(const std::vector>> &o_boxes,
+ float ratio_h, float ratio_w, const cv::Mat &srcimg) {
+ int oriimg_h = srcimg.rows;
+ int oriimg_w = srcimg.cols;
+ std::vector>> boxes{o_boxes};
+ std::vector>> root_points;
+ for (int n = 0; n < boxes.size(); n++) {
+ boxes[n] = order_points_clockwise(boxes[n]);
+ for (int m = 0; m < boxes[0].size(); m++) {
+ boxes[n][m][0] /= ratio_w;
+ boxes[n][m][1] /= ratio_h;
+
+ boxes[n][m][0] = int(_min(_max(boxes[n][m][0], 0), oriimg_w - 1));
+ boxes[n][m][1] = int(_min(_max(boxes[n][m][1], 0), oriimg_h - 1));
+ }
+ }
+
+ for (int n = 0; n < boxes.size(); n++) {
+ int rect_width, rect_height;
+ rect_width = int(sqrt(pow(boxes[n][0][0] - boxes[n][1][0], 2) +
+ pow(boxes[n][0][1] - boxes[n][1][1], 2)));
+ rect_height = int(sqrt(pow(boxes[n][0][0] - boxes[n][3][0], 2) +
+ pow(boxes[n][0][1] - boxes[n][3][1], 2)));
+ if (rect_width <= 10 || rect_height <= 10)
+ continue;
+ root_points.push_back(boxes[n]);
+ }
+ return root_points;
+}
\ No newline at end of file
diff --git a/deploy/android_demo/app/src/main/cpp/ocr_db_post_process.h b/deploy/android_demo/app/src/main/cpp/ocr_db_post_process.h
new file mode 100644
index 0000000..327da36
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/ocr_db_post_process.h
@@ -0,0 +1,13 @@
+//
+// Created by fujiayi on 2020/7/2.
+//
+#pragma once
+#include
+#include
+
+std::vector>>
+boxes_from_bitmap(const cv::Mat &pred, const cv::Mat &bitmap);
+
+std::vector>>
+filter_tag_det_res(const std::vector>> &o_boxes,
+ float ratio_h, float ratio_w, const cv::Mat &srcimg);
\ No newline at end of file
diff --git a/deploy/android_demo/app/src/main/cpp/ocr_ppredictor.cpp b/deploy/android_demo/app/src/main/cpp/ocr_ppredictor.cpp
new file mode 100644
index 0000000..1bd989c
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/ocr_ppredictor.cpp
@@ -0,0 +1,350 @@
+//
+// Created by fujiayi on 2020/7/1.
+//
+
+#include "ocr_ppredictor.h"
+#include "common.h"
+#include "ocr_cls_process.h"
+#include "ocr_crnn_process.h"
+#include "ocr_db_post_process.h"
+#include "preprocess.h"
+
+namespace ppredictor {
+
+OCR_PPredictor::OCR_PPredictor(const OCR_Config &config) : _config(config) {}
+
+int OCR_PPredictor::init(const std::string &det_model_content,
+ const std::string &rec_model_content,
+ const std::string &cls_model_content) {
+ _det_predictor = std::unique_ptr(
+ new PPredictor{_config.use_opencl,_config.thread_num, NET_OCR, _config.mode});
+ _det_predictor->init_nb(det_model_content);
+
+ _rec_predictor = std::unique_ptr(
+ new PPredictor{_config.use_opencl,_config.thread_num, NET_OCR_INTERNAL, _config.mode});
+ _rec_predictor->init_nb(rec_model_content);
+
+ _cls_predictor = std::unique_ptr(
+ new PPredictor{_config.use_opencl,_config.thread_num, NET_OCR_INTERNAL, _config.mode});
+ _cls_predictor->init_nb(cls_model_content);
+ return RETURN_OK;
+}
+
+int OCR_PPredictor::init_from_file(const std::string &det_model_path,
+ const std::string &rec_model_path,
+ const std::string &cls_model_path) {
+ _det_predictor = std::unique_ptr(
+ new PPredictor{_config.use_opencl, _config.thread_num, NET_OCR, _config.mode});
+ _det_predictor->init_from_file(det_model_path);
+
+
+ _rec_predictor = std::unique_ptr(
+ new PPredictor{_config.use_opencl,_config.thread_num, NET_OCR_INTERNAL, _config.mode});
+ _rec_predictor->init_from_file(rec_model_path);
+
+ _cls_predictor = std::unique_ptr(
+ new PPredictor{_config.use_opencl,_config.thread_num, NET_OCR_INTERNAL, _config.mode});
+ _cls_predictor->init_from_file(cls_model_path);
+ return RETURN_OK;
+}
+/**
+ * for debug use, show result of First Step
+ * @param filter_boxes
+ * @param boxes
+ * @param srcimg
+ */
+static void
+visual_img(const std::vector>> &filter_boxes,
+ const std::vector>> &boxes,
+ const cv::Mat &srcimg) {
+ // visualization
+ cv::Point rook_points[filter_boxes.size()][4];
+ for (int n = 0; n < filter_boxes.size(); n++) {
+ for (int m = 0; m < filter_boxes[0].size(); m++) {
+ rook_points[n][m] =
+ cv::Point(int(filter_boxes[n][m][0]), int(filter_boxes[n][m][1]));
+ }
+ }
+
+ cv::Mat img_vis;
+ srcimg.copyTo(img_vis);
+ for (int n = 0; n < boxes.size(); n++) {
+ const cv::Point *ppt[1] = {rook_points[n]};
+ int npt[] = {4};
+ cv::polylines(img_vis, ppt, npt, 1, 1, CV_RGB(0, 255, 0), 2, 8, 0);
+ }
+ // 调试用,自行替换需要修改的路径
+ cv::imwrite("/sdcard/1/vis.png", img_vis);
+}
+
+std::vector
+OCR_PPredictor::infer_ocr(cv::Mat &origin,int max_size_len, int run_det, int run_cls, int run_rec) {
+ LOGI("ocr cpp start *****************");
+ LOGI("ocr cpp det: %d, cls: %d, rec: %d", run_det, run_cls, run_rec);
+ std::vector ocr_results;
+ if(run_det){
+ infer_det(origin, max_size_len, ocr_results);
+ }
+ if(run_rec){
+ if(ocr_results.size()==0){
+ OCRPredictResult res;
+ ocr_results.emplace_back(std::move(res));
+ }
+ for(int i = 0; i < ocr_results.size();i++) {
+ infer_rec(origin, run_cls, ocr_results[i]);
+ }
+ }else if(run_cls){
+ ClsPredictResult cls_res = infer_cls(origin);
+ OCRPredictResult res;
+ res.cls_score = cls_res.cls_score;
+ res.cls_label = cls_res.cls_label;
+ ocr_results.push_back(res);
+ }
+
+ LOGI("ocr cpp end *****************");
+ return ocr_results;
+}
+
+cv::Mat DetResizeImg(const cv::Mat img, int max_size_len,
+ std::vector &ratio_hw) {
+ int w = img.cols;
+ int h = img.rows;
+
+ float ratio = 1.f;
+ int max_wh = w >= h ? w : h;
+ if (max_wh > max_size_len) {
+ if (h > w) {
+ ratio = static_cast(max_size_len) / static_cast(h);
+ } else {
+ ratio = static_cast(max_size_len) / static_cast(w);
+ }
+ }
+
+ int resize_h = static_cast(float(h) * ratio);
+ int resize_w = static_cast(float(w) * ratio);
+ if (resize_h % 32 == 0)
+ resize_h = resize_h;
+ else if (resize_h / 32 < 1 + 1e-5)
+ resize_h = 32;
+ else
+ resize_h = (resize_h / 32 - 1) * 32;
+
+ if (resize_w % 32 == 0)
+ resize_w = resize_w;
+ else if (resize_w / 32 < 1 + 1e-5)
+ resize_w = 32;
+ else
+ resize_w = (resize_w / 32 - 1) * 32;
+
+ cv::Mat resize_img;
+ cv::resize(img, resize_img, cv::Size(resize_w, resize_h));
+
+ ratio_hw.push_back(static_cast(resize_h) / static_cast(h));
+ ratio_hw.push_back(static_cast(resize_w) / static_cast(w));
+ return resize_img;
+}
+
+void OCR_PPredictor::infer_det(cv::Mat &origin, int max_size_len, std::vector &ocr_results) {
+ std::vector mean = {0.485f, 0.456f, 0.406f};
+ std::vector scale = {1 / 0.229f, 1 / 0.224f, 1 / 0.225f};
+
+ PredictorInput input = _det_predictor->get_first_input();
+
+ std::vector ratio_hw;
+ cv::Mat input_image = DetResizeImg(origin, max_size_len, ratio_hw);
+ input_image.convertTo(input_image, CV_32FC3, 1 / 255.0f);
+ const float *dimg = reinterpret_cast(input_image.data);
+ int input_size = input_image.rows * input_image.cols;
+
+ input.set_dims({1, 3, input_image.rows, input_image.cols});
+
+ neon_mean_scale(dimg, input.get_mutable_float_data(), input_size, mean,
+ scale);
+ LOGI("ocr cpp det shape %d,%d", input_image.rows,input_image.cols);
+ std::vector results = _det_predictor->infer();
+ PredictorOutput &res = results.at(0);
+ std::vector>> filtered_box = calc_filtered_boxes(
+ res.get_float_data(), res.get_size(), input_image.rows, input_image.cols, origin);
+ LOGI("ocr cpp det Filter_box size %ld", filtered_box.size());
+
+ for(int i = 0;i mean = {0.5f, 0.5f, 0.5f};
+ std::vector scale = {1 / 0.5f, 1 / 0.5f, 1 / 0.5f};
+ std::vector dims = {1, 3, 0, 0};
+
+ PredictorInput input = _rec_predictor->get_first_input();
+
+ const std::vector> &box = ocr_result.points;
+ cv::Mat crop_img;
+ if(box.size()>0){
+ crop_img = get_rotate_crop_image(origin_img, box);
+ }
+ else{
+ crop_img = origin_img;
+ }
+
+ if(run_cls){
+ ClsPredictResult cls_res = infer_cls(crop_img);
+ crop_img = cls_res.img;
+ ocr_result.cls_score = cls_res.cls_score;
+ ocr_result.cls_label = cls_res.cls_label;
+ }
+
+
+ float wh_ratio = float(crop_img.cols) / float(crop_img.rows);
+ cv::Mat input_image = crnn_resize_img(crop_img, wh_ratio);
+ input_image.convertTo(input_image, CV_32FC3, 1 / 255.0f);
+ const float *dimg = reinterpret_cast(input_image.data);
+ int input_size = input_image.rows * input_image.cols;
+
+ dims[2] = input_image.rows;
+ dims[3] = input_image.cols;
+ input.set_dims(dims);
+
+ neon_mean_scale(dimg, input.get_mutable_float_data(), input_size, mean,
+ scale);
+
+ std::vector results = _rec_predictor->infer();
+ const float *predict_batch = results.at(0).get_float_data();
+ const std::vector predict_shape = results.at(0).get_shape();
+
+ // ctc decode
+ int argmax_idx;
+ int last_index = 0;
+ float score = 0.f;
+ int count = 0;
+ float max_value = 0.0f;
+
+ for (int n = 0; n < predict_shape[1]; n++) {
+ argmax_idx = int(argmax(&predict_batch[n * predict_shape[2]],
+ &predict_batch[(n + 1) * predict_shape[2]]));
+ max_value =
+ float(*std::max_element(&predict_batch[n * predict_shape[2]],
+ &predict_batch[(n + 1) * predict_shape[2]]));
+ if (argmax_idx > 0 && (!(n > 0 && argmax_idx == last_index))) {
+ score += max_value;
+ count += 1;
+ ocr_result.word_index.push_back(argmax_idx);
+ }
+ last_index = argmax_idx;
+ }
+ score /= count;
+ ocr_result.score = score;
+ LOGI("ocr cpp rec word size %ld", count);
+}
+
+ClsPredictResult OCR_PPredictor::infer_cls(const cv::Mat &img, float thresh) {
+ std::vector mean = {0.5f, 0.5f, 0.5f};
+ std::vector scale = {1 / 0.5f, 1 / 0.5f, 1 / 0.5f};
+ std::vector dims = {1, 3, 0, 0};
+
+ PredictorInput input = _cls_predictor->get_first_input();
+
+ cv::Mat input_image = cls_resize_img(img);
+ input_image.convertTo(input_image, CV_32FC3, 1 / 255.0f);
+ const float *dimg = reinterpret_cast(input_image.data);
+ int input_size = input_image.rows * input_image.cols;
+
+ dims[2] = input_image.rows;
+ dims[3] = input_image.cols;
+ input.set_dims(dims);
+
+ neon_mean_scale(dimg, input.get_mutable_float_data(), input_size, mean,
+ scale);
+
+ std::vector results = _cls_predictor->infer();
+
+ const float *scores = results.at(0).get_float_data();
+ float score = 0;
+ int label = 0;
+ for (int64_t i = 0; i < results.at(0).get_size(); i++) {
+ LOGI("ocr cpp cls output scores [%f]", scores[i]);
+ if (scores[i] > score) {
+ score = scores[i];
+ label = i;
+ }
+ }
+ cv::Mat srcimg;
+ img.copyTo(srcimg);
+ if (label % 2 == 1 && score > thresh) {
+ cv::rotate(srcimg, srcimg, 1);
+ }
+ ClsPredictResult res;
+ res.cls_label = label;
+ res.cls_score = score;
+ res.img = srcimg;
+ LOGI("ocr cpp cls word cls %ld, %f", label, score);
+ return res;
+}
+
+std::vector>>
+OCR_PPredictor::calc_filtered_boxes(const float *pred, int pred_size,
+ int output_height, int output_width,
+ const cv::Mat &origin) {
+ const double threshold = 0.3;
+ const double maxvalue = 1;
+
+ cv::Mat pred_map = cv::Mat::zeros(output_height, output_width, CV_32F);
+ memcpy(pred_map.data, pred, pred_size * sizeof(float));
+ cv::Mat cbuf_map;
+ pred_map.convertTo(cbuf_map, CV_8UC1);
+
+ cv::Mat bit_map;
+ cv::threshold(cbuf_map, bit_map, threshold, maxvalue, cv::THRESH_BINARY);
+
+ std::vector>> boxes =
+ boxes_from_bitmap(pred_map, bit_map);
+ float ratio_h = output_height * 1.0f / origin.rows;
+ float ratio_w = output_width * 1.0f / origin.cols;
+ std::vector>> filter_boxes =
+ filter_tag_det_res(boxes, ratio_h, ratio_w, origin);
+ return filter_boxes;
+}
+
+std::vector
+OCR_PPredictor::postprocess_rec_word_index(const PredictorOutput &res) {
+ const int *rec_idx = res.get_int_data();
+ const std::vector> rec_idx_lod = res.get_lod();
+
+ std::vector pred_idx;
+ for (int n = int(rec_idx_lod[0][0]); n < int(rec_idx_lod[0][1] * 2); n += 2) {
+ pred_idx.emplace_back(rec_idx[n]);
+ }
+ return pred_idx;
+}
+
+float OCR_PPredictor::postprocess_rec_score(const PredictorOutput &res) {
+ const float *predict_batch = res.get_float_data();
+ const std::vector predict_shape = res.get_shape();
+ const std::vector> predict_lod = res.get_lod();
+ int blank = predict_shape[1];
+ float score = 0.f;
+ int count = 0;
+ for (int n = predict_lod[0][0]; n < predict_lod[0][1] - 1; n++) {
+ int argmax_idx = argmax(predict_batch + n * predict_shape[1],
+ predict_batch + (n + 1) * predict_shape[1]);
+ float max_value = predict_batch[n * predict_shape[1] + argmax_idx];
+ if (blank - 1 - argmax_idx > 1e-5) {
+ score += max_value;
+ count += 1;
+ }
+ }
+ if (count == 0) {
+ LOGE("calc score count 0");
+ } else {
+ score /= count;
+ }
+ LOGI("calc score: %f", score);
+ return score;
+}
+
+NET_TYPE OCR_PPredictor::get_net_flag() const { return NET_OCR; }
+}
\ No newline at end of file
diff --git a/deploy/android_demo/app/src/main/cpp/ocr_ppredictor.h b/deploy/android_demo/app/src/main/cpp/ocr_ppredictor.h
new file mode 100644
index 0000000..f0bff93
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/ocr_ppredictor.h
@@ -0,0 +1,130 @@
+//
+// Created by fujiayi on 2020/7/1.
+//
+
+#pragma once
+
+#include "ppredictor.h"
+#include
+#include
+#include
+
+namespace ppredictor {
+
+/**
+ * Config
+ */
+struct OCR_Config {
+ int use_opencl = 0;
+ int thread_num = 4; // Thread num
+ paddle::lite_api::PowerMode mode =
+ paddle::lite_api::LITE_POWER_HIGH; // PaddleLite Mode
+};
+
+/**
+ * PolyGone Result
+ */
+struct OCRPredictResult {
+ std::vector word_index;
+ std::vector> points;
+ float score;
+ float cls_score;
+ int cls_label=-1;
+};
+
+struct ClsPredictResult {
+ float cls_score;
+ int cls_label=-1;
+ cv::Mat img;
+};
+/**
+ * OCR there are 2 models
+ * 1. First model(det),select polygones to show where are the texts
+ * 2. crop from the origin images, use these polygones to infer
+ */
+class OCR_PPredictor : public PPredictor_Interface {
+public:
+ OCR_PPredictor(const OCR_Config &config);
+
+ virtual ~OCR_PPredictor() {}
+
+ /**
+ * 初始化二个模型的Predictor
+ * @param det_model_content
+ * @param rec_model_content
+ * @return
+ */
+ int init(const std::string &det_model_content,
+ const std::string &rec_model_content,
+ const std::string &cls_model_content);
+ int init_from_file(const std::string &det_model_path,
+ const std::string &rec_model_path,
+ const std::string &cls_model_path);
+ /**
+ * Return OCR result
+ * @param dims
+ * @param input_data
+ * @param input_len
+ * @param net_flag
+ * @param origin
+ * @return
+ */
+ virtual std::vector
+ infer_ocr(cv::Mat &origin, int max_size_len, int run_det, int run_cls, int run_rec);
+
+ virtual NET_TYPE get_net_flag() const;
+
+private:
+ /**
+ * calcul Polygone from the result image of first model
+ * @param pred
+ * @param output_height
+ * @param output_width
+ * @param origin
+ * @return
+ */
+ std::vector>>
+ calc_filtered_boxes(const float *pred, int pred_size, int output_height,
+ int output_width, const cv::Mat &origin);
+
+ void
+ infer_det(cv::Mat &origin, int max_side_len, std::vector& ocr_results);
+ /**
+ * infer for rec model
+ *
+ * @param boxes
+ * @param origin
+ * @return
+ */
+ void
+ infer_rec(const cv::Mat &origin, int run_cls, OCRPredictResult& ocr_result);
+
+ /**
+ * infer for cls model
+ *
+ * @param boxes
+ * @param origin
+ * @return
+ */
+ ClsPredictResult infer_cls(const cv::Mat &origin, float thresh = 0.9);
+
+ /**
+ * Postprocess or sencod model to extract text
+ * @param res
+ * @return
+ */
+ std::vector postprocess_rec_word_index(const PredictorOutput &res);
+
+ /**
+ * calculate confidence of second model text result
+ * @param res
+ * @return
+ */
+ float postprocess_rec_score(const PredictorOutput &res);
+
+ std::unique_ptr _det_predictor;
+ std::unique_ptr _rec_predictor;
+ std::unique_ptr _cls_predictor;
+ OCR_Config _config;
+};
+}
diff --git a/deploy/android_demo/app/src/main/cpp/ppredictor.cpp b/deploy/android_demo/app/src/main/cpp/ppredictor.cpp
new file mode 100644
index 0000000..a40fe5e
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/ppredictor.cpp
@@ -0,0 +1,95 @@
+#include "ppredictor.h"
+#include "common.h"
+
+namespace ppredictor {
+PPredictor::PPredictor(int use_opencl, int thread_num, int net_flag,
+ paddle::lite_api::PowerMode mode)
+ : _use_opencl(use_opencl), _thread_num(thread_num), _net_flag(net_flag), _mode(mode) {}
+
+int PPredictor::init_nb(const std::string &model_content) {
+ paddle::lite_api::MobileConfig config;
+ config.set_model_from_buffer(model_content);
+ return _init(config);
+}
+
+int PPredictor::init_from_file(const std::string &model_content) {
+ paddle::lite_api::MobileConfig config;
+ config.set_model_from_file(model_content);
+ return _init(config);
+}
+
+template int PPredictor::_init(ConfigT &config) {
+ bool is_opencl_backend_valid = paddle::lite_api::IsOpenCLBackendValid(/*check_fp16_valid = false*/);
+ if (is_opencl_backend_valid) {
+ if (_use_opencl != 0) {
+ // Make sure you have write permission of the binary path.
+ // We strongly recommend each model has a unique binary name.
+ const std::string bin_path = "/data/local/tmp/";
+ const std::string bin_name = "lite_opencl_kernel.bin";
+ config.set_opencl_binary_path_name(bin_path, bin_name);
+
+ // opencl tune option
+ // CL_TUNE_NONE: 0
+ // CL_TUNE_RAPID: 1
+ // CL_TUNE_NORMAL: 2
+ // CL_TUNE_EXHAUSTIVE: 3
+ const std::string tuned_path = "/data/local/tmp/";
+ const std::string tuned_name = "lite_opencl_tuned.bin";
+ config.set_opencl_tune(paddle::lite_api::CL_TUNE_NORMAL, tuned_path, tuned_name);
+
+ // opencl precision option
+ // CL_PRECISION_AUTO: 0, first fp16 if valid, default
+ // CL_PRECISION_FP32: 1, force fp32
+ // CL_PRECISION_FP16: 2, force fp16
+ config.set_opencl_precision(paddle::lite_api::CL_PRECISION_FP32);
+ LOGI("ocr cpp device: running on gpu.");
+ }
+ } else {
+ LOGI("ocr cpp device: running on cpu.");
+ // you can give backup cpu nb model instead
+ // config.set_model_from_file(cpu_nb_model_dir);
+ }
+ config.set_threads(_thread_num);
+ config.set_power_mode(_mode);
+ _predictor = paddle::lite_api::CreatePaddlePredictor(config);
+ LOGI("ocr cpp paddle instance created");
+ return RETURN_OK;
+}
+
+PredictorInput PPredictor::get_input(int index) {
+ PredictorInput input{_predictor->GetInput(index), index, _net_flag};
+ _is_input_get = true;
+ return input;
+}
+
+std::vector PPredictor::get_inputs(int num) {
+ std::vector results;
+ for (int i = 0; i < num; i++) {
+ results.emplace_back(get_input(i));
+ }
+ return results;
+}
+
+PredictorInput PPredictor::get_first_input() { return get_input(0); }
+
+std::vector PPredictor::infer() {
+ LOGI("ocr cpp infer Run start %d", _net_flag);
+ std::vector results;
+ if (!_is_input_get) {
+ return results;
+ }
+ _predictor->Run();
+ LOGI("ocr cpp infer Run end");
+
+ for (int i = 0; i < _predictor->GetOutputNames().size(); i++) {
+ std::unique_ptr output_tensor =
+ _predictor->GetOutput(i);
+ LOGI("ocr cpp output tensor[%d] size %ld", i, product(output_tensor->shape()));
+ PredictorOutput result{std::move(output_tensor), i, _net_flag};
+ results.emplace_back(std::move(result));
+ }
+ return results;
+}
+
+NET_TYPE PPredictor::get_net_flag() const { return (NET_TYPE)_net_flag; }
+}
\ No newline at end of file
diff --git a/deploy/android_demo/app/src/main/cpp/ppredictor.h b/deploy/android_demo/app/src/main/cpp/ppredictor.h
new file mode 100644
index 0000000..4025076
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/ppredictor.h
@@ -0,0 +1,64 @@
+#pragma once
+
+#include "paddle_api.h"
+#include "predictor_input.h"
+#include "predictor_output.h"
+
+namespace ppredictor {
+
+/**
+ * PaddleLite Preditor Common Interface
+ */
+class PPredictor_Interface {
+public:
+ virtual ~PPredictor_Interface() {}
+
+ virtual NET_TYPE get_net_flag() const = 0;
+};
+
+/**
+ * Common Predictor
+ */
+class PPredictor : public PPredictor_Interface {
+public:
+ PPredictor(
+ int use_opencl, int thread_num, int net_flag = 0,
+ paddle::lite_api::PowerMode mode = paddle::lite_api::LITE_POWER_HIGH);
+
+ virtual ~PPredictor() {}
+
+ /**
+ * init paddlitelite opt model,nb format ,or use ini_paddle
+ * @param model_content
+ * @return 0
+ */
+ virtual int init_nb(const std::string &model_content);
+
+ virtual int init_from_file(const std::string &model_content);
+
+ std::vector infer();
+
+ std::shared_ptr get_predictor() {
+ return _predictor;
+ }
+
+ virtual std::vector get_inputs(int num);
+
+ virtual PredictorInput get_input(int index);
+
+ virtual PredictorInput get_first_input();
+
+ virtual NET_TYPE get_net_flag() const;
+
+protected:
+ template int _init(ConfigT &config);
+
+private:
+ int _use_opencl;
+ int _thread_num;
+ paddle::lite_api::PowerMode _mode;
+ std::shared_ptr _predictor;
+ bool _is_input_get = false;
+ int _net_flag;
+};
+}
diff --git a/deploy/android_demo/app/src/main/cpp/predictor_input.cpp b/deploy/android_demo/app/src/main/cpp/predictor_input.cpp
new file mode 100644
index 0000000..f0b4bf8
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/predictor_input.cpp
@@ -0,0 +1,28 @@
+#include "predictor_input.h"
+
+namespace ppredictor {
+
+void PredictorInput::set_dims(std::vector dims) {
+ // yolov3
+ if (_net_flag == 101 && _index == 1) {
+ _tensor->Resize({1, 2});
+ _tensor->mutable_data()[0] = (int)dims.at(2);
+ _tensor->mutable_data()[1] = (int)dims.at(3);
+ } else {
+ _tensor->Resize(dims);
+ }
+ _is_dims_set = true;
+}
+
+float *PredictorInput::get_mutable_float_data() {
+ if (!_is_dims_set) {
+ LOGE("PredictorInput::set_dims is not called");
+ }
+ return _tensor->mutable_data();
+}
+
+void PredictorInput::set_data(const float *input_data, int input_float_len) {
+ float *input_raw_data = get_mutable_float_data();
+ memcpy(input_raw_data, input_data, input_float_len * sizeof(float));
+}
+}
\ No newline at end of file
diff --git a/deploy/android_demo/app/src/main/cpp/predictor_input.h b/deploy/android_demo/app/src/main/cpp/predictor_input.h
new file mode 100644
index 0000000..f3fd6cf
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/predictor_input.h
@@ -0,0 +1,26 @@
+#pragma once
+
+#include "common.h"
+#include
+#include
+
+namespace ppredictor {
+class PredictorInput {
+public:
+ PredictorInput(std::unique_ptr &&tensor, int index,
+ int net_flag)
+ : _tensor(std::move(tensor)), _index(index), _net_flag(net_flag) {}
+
+ void set_dims(std::vector dims);
+
+ float *get_mutable_float_data();
+
+ void set_data(const float *input_data, int input_float_len);
+
+private:
+ std::unique_ptr _tensor;
+ bool _is_dims_set = false;
+ int _index;
+ int _net_flag;
+};
+}
diff --git a/deploy/android_demo/app/src/main/cpp/predictor_output.cpp b/deploy/android_demo/app/src/main/cpp/predictor_output.cpp
new file mode 100644
index 0000000..e9cfdbc
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/predictor_output.cpp
@@ -0,0 +1,26 @@
+#include "predictor_output.h"
+namespace ppredictor {
+const float *PredictorOutput::get_float_data() const {
+ return _tensor->data();
+}
+
+const int *PredictorOutput::get_int_data() const {
+ return _tensor->data();
+}
+
+const std::vector> PredictorOutput::get_lod() const {
+ return _tensor->lod();
+}
+
+int64_t PredictorOutput::get_size() const {
+ if (_net_flag == NET_OCR) {
+ return _tensor->shape().at(2) * _tensor->shape().at(3);
+ } else {
+ return product(_tensor->shape());
+ }
+}
+
+const std::vector PredictorOutput::get_shape() const {
+ return _tensor->shape();
+}
+}
\ No newline at end of file
diff --git a/deploy/android_demo/app/src/main/cpp/predictor_output.h b/deploy/android_demo/app/src/main/cpp/predictor_output.h
new file mode 100644
index 0000000..8e8c9ba
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/predictor_output.h
@@ -0,0 +1,31 @@
+#pragma once
+
+#include "common.h"
+#include
+#include
+
+namespace ppredictor {
+class PredictorOutput {
+public:
+ PredictorOutput() {}
+ PredictorOutput(std::unique_ptr &&tensor,
+ int index, int net_flag)
+ : _tensor(std::move(tensor)), _index(index), _net_flag(net_flag) {}
+
+ const float *get_float_data() const;
+ const int *get_int_data() const;
+ int64_t get_size() const;
+ const std::vector> get_lod() const;
+ const std::vector get_shape() const;
+
+ std::vector data; // return float, or use data_int
+ std::vector data_int; // several layers return int ,or use data
+ std::vector shape; // PaddleLite output shape
+ std::vector> lod; // PaddleLite output lod
+
+private:
+ std::unique_ptr _tensor;
+ int _index;
+ int _net_flag;
+};
+}
diff --git a/deploy/android_demo/app/src/main/cpp/preprocess.cpp b/deploy/android_demo/app/src/main/cpp/preprocess.cpp
new file mode 100644
index 0000000..e99b2cd
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/preprocess.cpp
@@ -0,0 +1,82 @@
+#include "preprocess.h"
+#include
+
+cv::Mat bitmap_to_cv_mat(JNIEnv *env, jobject bitmap) {
+ AndroidBitmapInfo info;
+ int result = AndroidBitmap_getInfo(env, bitmap, &info);
+ if (result != ANDROID_BITMAP_RESULT_SUCCESS) {
+ LOGE("AndroidBitmap_getInfo failed, result: %d", result);
+ return cv::Mat{};
+ }
+ if (info.format != ANDROID_BITMAP_FORMAT_RGBA_8888) {
+ LOGE("Bitmap format is not RGBA_8888 !");
+ return cv::Mat{};
+ }
+ unsigned char *srcData = NULL;
+ AndroidBitmap_lockPixels(env, bitmap, (void **)&srcData);
+ cv::Mat mat = cv::Mat::zeros(info.height, info.width, CV_8UC4);
+ memcpy(mat.data, srcData, info.height * info.width * 4);
+ AndroidBitmap_unlockPixels(env, bitmap);
+ cv::cvtColor(mat, mat, cv::COLOR_RGBA2BGR);
+ /**
+ if (!cv::imwrite("/sdcard/1/copy.jpg", mat)){
+ LOGE("Write image failed " );
+ }
+ */
+
+ return mat;
+}
+
+cv::Mat resize_img(const cv::Mat &img, int height, int width) {
+ if (img.rows == height && img.cols == width) {
+ return img;
+ }
+ cv::Mat new_img;
+ cv::resize(img, new_img, cv::Size(height, width));
+ return new_img;
+}
+
+// fill tensor with mean and scale and trans layout: nhwc -> nchw, neon speed up
+void neon_mean_scale(const float *din, float *dout, int size,
+ const std::vector &mean,
+ const std::vector &scale) {
+ if (mean.size() != 3 || scale.size() != 3) {
+ LOGE("[ERROR] mean or scale size must equal to 3");
+ return;
+ }
+
+ float32x4_t vmean0 = vdupq_n_f32(mean[0]);
+ float32x4_t vmean1 = vdupq_n_f32(mean[1]);
+ float32x4_t vmean2 = vdupq_n_f32(mean[2]);
+ float32x4_t vscale0 = vdupq_n_f32(scale[0]);
+ float32x4_t vscale1 = vdupq_n_f32(scale[1]);
+ float32x4_t vscale2 = vdupq_n_f32(scale[2]);
+
+ float *dout_c0 = dout;
+ float *dout_c1 = dout + size;
+ float *dout_c2 = dout + size * 2;
+
+ int i = 0;
+ for (; i < size - 3; i += 4) {
+ float32x4x3_t vin3 = vld3q_f32(din);
+ float32x4_t vsub0 = vsubq_f32(vin3.val[0], vmean0);
+ float32x4_t vsub1 = vsubq_f32(vin3.val[1], vmean1);
+ float32x4_t vsub2 = vsubq_f32(vin3.val[2], vmean2);
+ float32x4_t vs0 = vmulq_f32(vsub0, vscale0);
+ float32x4_t vs1 = vmulq_f32(vsub1, vscale1);
+ float32x4_t vs2 = vmulq_f32(vsub2, vscale2);
+ vst1q_f32(dout_c0, vs0);
+ vst1q_f32(dout_c1, vs1);
+ vst1q_f32(dout_c2, vs2);
+
+ din += 12;
+ dout_c0 += 4;
+ dout_c1 += 4;
+ dout_c2 += 4;
+ }
+ for (; i < size; i++) {
+ *(dout_c0++) = (*(din++) - mean[0]) * scale[0];
+ *(dout_c1++) = (*(din++) - mean[1]) * scale[1];
+ *(dout_c2++) = (*(din++) - mean[2]) * scale[2];
+ }
+}
\ No newline at end of file
diff --git a/deploy/android_demo/app/src/main/cpp/preprocess.h b/deploy/android_demo/app/src/main/cpp/preprocess.h
new file mode 100644
index 0000000..7909152
--- /dev/null
+++ b/deploy/android_demo/app/src/main/cpp/preprocess.h
@@ -0,0 +1,12 @@
+#pragma once
+
+#include "common.h"
+#include
+#include
+cv::Mat bitmap_to_cv_mat(JNIEnv *env, jobject bitmap);
+
+cv::Mat resize_img(const cv::Mat &img, int height, int width);
+
+void neon_mean_scale(const float *din, float *dout, int size,
+ const std::vector &mean,
+ const std::vector &scale);
diff --git a/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/AppCompatPreferenceActivity.java b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/AppCompatPreferenceActivity.java
new file mode 100644
index 0000000..49af0af
--- /dev/null
+++ b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/AppCompatPreferenceActivity.java
@@ -0,0 +1,128 @@
+/*
+ * Copyright (C) 2014 The Android Open Source Project
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License");
+ * you may not use this file except in compliance with the License.
+ * You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package com.baidu.paddle.lite.demo.ocr;
+
+import android.content.res.Configuration;
+import android.os.Bundle;
+import android.preference.PreferenceActivity;
+import android.view.MenuInflater;
+import android.view.View;
+import android.view.ViewGroup;
+
+import androidx.annotation.LayoutRes;
+import androidx.annotation.Nullable;
+import androidx.appcompat.app.ActionBar;
+import androidx.appcompat.app.AppCompatDelegate;
+import androidx.appcompat.widget.Toolbar;
+
+/**
+ * A {@link PreferenceActivity} which implements and proxies the necessary calls
+ * to be used with AppCompat.
+ *
+ * This technique can be used with an {@link android.app.Activity} class, not just
+ * {@link PreferenceActivity}.
+ */
+public abstract class AppCompatPreferenceActivity extends PreferenceActivity {
+ private AppCompatDelegate mDelegate;
+
+ @Override
+ protected void onCreate(Bundle savedInstanceState) {
+ getDelegate().installViewFactory();
+ getDelegate().onCreate(savedInstanceState);
+ super.onCreate(savedInstanceState);
+ }
+
+ @Override
+ protected void onPostCreate(Bundle savedInstanceState) {
+ super.onPostCreate(savedInstanceState);
+ getDelegate().onPostCreate(savedInstanceState);
+ }
+
+ public ActionBar getSupportActionBar() {
+ return getDelegate().getSupportActionBar();
+ }
+
+ public void setSupportActionBar(@Nullable Toolbar toolbar) {
+ getDelegate().setSupportActionBar(toolbar);
+ }
+
+ @Override
+ public MenuInflater getMenuInflater() {
+ return getDelegate().getMenuInflater();
+ }
+
+ @Override
+ public void setContentView(@LayoutRes int layoutResID) {
+ getDelegate().setContentView(layoutResID);
+ }
+
+ @Override
+ public void setContentView(View view) {
+ getDelegate().setContentView(view);
+ }
+
+ @Override
+ public void setContentView(View view, ViewGroup.LayoutParams params) {
+ getDelegate().setContentView(view, params);
+ }
+
+ @Override
+ public void addContentView(View view, ViewGroup.LayoutParams params) {
+ getDelegate().addContentView(view, params);
+ }
+
+ @Override
+ protected void onPostResume() {
+ super.onPostResume();
+ getDelegate().onPostResume();
+ }
+
+ @Override
+ protected void onTitleChanged(CharSequence title, int color) {
+ super.onTitleChanged(title, color);
+ getDelegate().setTitle(title);
+ }
+
+ @Override
+ public void onConfigurationChanged(Configuration newConfig) {
+ super.onConfigurationChanged(newConfig);
+ getDelegate().onConfigurationChanged(newConfig);
+ }
+
+ @Override
+ protected void onStop() {
+ super.onStop();
+ getDelegate().onStop();
+ }
+
+ @Override
+ protected void onDestroy() {
+ super.onDestroy();
+ getDelegate().onDestroy();
+ }
+
+ public void invalidateOptionsMenu() {
+ getDelegate().invalidateOptionsMenu();
+ }
+
+ private AppCompatDelegate getDelegate() {
+ if (mDelegate == null) {
+ mDelegate = AppCompatDelegate.create(this, null);
+ }
+ return mDelegate;
+ }
+}
diff --git a/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/MainActivity.java b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/MainActivity.java
new file mode 100644
index 0000000..f932718
--- /dev/null
+++ b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/MainActivity.java
@@ -0,0 +1,520 @@
+package com.baidu.paddle.lite.demo.ocr;
+
+import android.Manifest;
+import android.app.ProgressDialog;
+import android.content.ContentResolver;
+import android.content.Context;
+import android.content.Intent;
+import android.content.SharedPreferences;
+import android.content.pm.PackageManager;
+import android.database.Cursor;
+import android.graphics.Bitmap;
+import android.graphics.BitmapFactory;
+import android.graphics.drawable.BitmapDrawable;
+import android.media.ExifInterface;
+import android.content.res.AssetManager;
+import android.media.FaceDetector;
+import android.net.Uri;
+import android.os.Bundle;
+import android.os.Environment;
+import android.os.Handler;
+import android.os.HandlerThread;
+import android.os.Message;
+import android.preference.PreferenceManager;
+import android.provider.MediaStore;
+import android.text.method.ScrollingMovementMethod;
+import android.util.Log;
+import android.view.Menu;
+import android.view.MenuInflater;
+import android.view.MenuItem;
+import android.view.View;
+import android.widget.CheckBox;
+import android.widget.ImageView;
+import android.widget.Spinner;
+import android.widget.TextView;
+import android.widget.Toast;
+
+import androidx.annotation.NonNull;
+import androidx.appcompat.app.AppCompatActivity;
+import androidx.core.app.ActivityCompat;
+import androidx.core.content.ContextCompat;
+import androidx.core.content.FileProvider;
+
+import java.io.File;
+import java.io.IOException;
+import java.io.InputStream;
+import java.text.SimpleDateFormat;
+import java.util.Date;
+
+public class MainActivity extends AppCompatActivity {
+ private static final String TAG = MainActivity.class.getSimpleName();
+ public static final int OPEN_GALLERY_REQUEST_CODE = 0;
+ public static final int TAKE_PHOTO_REQUEST_CODE = 1;
+
+ public static final int REQUEST_LOAD_MODEL = 0;
+ public static final int REQUEST_RUN_MODEL = 1;
+ public static final int RESPONSE_LOAD_MODEL_SUCCESSED = 0;
+ public static final int RESPONSE_LOAD_MODEL_FAILED = 1;
+ public static final int RESPONSE_RUN_MODEL_SUCCESSED = 2;
+ public static final int RESPONSE_RUN_MODEL_FAILED = 3;
+
+ protected ProgressDialog pbLoadModel = null;
+ protected ProgressDialog pbRunModel = null;
+
+ protected Handler receiver = null; // Receive messages from worker thread
+ protected Handler sender = null; // Send command to worker thread
+ protected HandlerThread worker = null; // Worker thread to load&run model
+
+ // UI components of object detection
+ protected TextView tvInputSetting;
+ protected TextView tvStatus;
+ protected ImageView ivInputImage;
+ protected TextView tvOutputResult;
+ protected TextView tvInferenceTime;
+ protected CheckBox cbOpencl;
+ protected Spinner spRunMode;
+
+ // Model settings of ocr
+ protected String modelPath = "";
+ protected String labelPath = "";
+ protected String imagePath = "";
+ protected int cpuThreadNum = 1;
+ protected String cpuPowerMode = "";
+ protected int detLongSize = 960;
+ protected float scoreThreshold = 0.1f;
+ private String currentPhotoPath;
+ private AssetManager assetManager = null;
+
+ protected Predictor predictor = new Predictor();
+
+ private Bitmap cur_predict_image = null;
+
+ @Override
+ protected void onCreate(Bundle savedInstanceState) {
+ super.onCreate(savedInstanceState);
+ setContentView(R.layout.activity_main);
+
+ // Clear all setting items to avoid app crashing due to the incorrect settings
+ SharedPreferences sharedPreferences = PreferenceManager.getDefaultSharedPreferences(this);
+ SharedPreferences.Editor editor = sharedPreferences.edit();
+ editor.clear();
+ editor.apply();
+
+ // Setup the UI components
+ tvInputSetting = findViewById(R.id.tv_input_setting);
+ cbOpencl = findViewById(R.id.cb_opencl);
+ tvStatus = findViewById(R.id.tv_model_img_status);
+ ivInputImage = findViewById(R.id.iv_input_image);
+ tvInferenceTime = findViewById(R.id.tv_inference_time);
+ tvOutputResult = findViewById(R.id.tv_output_result);
+ spRunMode = findViewById(R.id.sp_run_mode);
+ tvInputSetting.setMovementMethod(ScrollingMovementMethod.getInstance());
+ tvOutputResult.setMovementMethod(ScrollingMovementMethod.getInstance());
+
+ // Prepare the worker thread for mode loading and inference
+ receiver = new Handler() {
+ @Override
+ public void handleMessage(Message msg) {
+ switch (msg.what) {
+ case RESPONSE_LOAD_MODEL_SUCCESSED:
+ if (pbLoadModel != null && pbLoadModel.isShowing()) {
+ pbLoadModel.dismiss();
+ }
+ onLoadModelSuccessed();
+ break;
+ case RESPONSE_LOAD_MODEL_FAILED:
+ if (pbLoadModel != null && pbLoadModel.isShowing()) {
+ pbLoadModel.dismiss();
+ }
+ Toast.makeText(MainActivity.this, "Load model failed!", Toast.LENGTH_SHORT).show();
+ onLoadModelFailed();
+ break;
+ case RESPONSE_RUN_MODEL_SUCCESSED:
+ if (pbRunModel != null && pbRunModel.isShowing()) {
+ pbRunModel.dismiss();
+ }
+ onRunModelSuccessed();
+ break;
+ case RESPONSE_RUN_MODEL_FAILED:
+ if (pbRunModel != null && pbRunModel.isShowing()) {
+ pbRunModel.dismiss();
+ }
+ Toast.makeText(MainActivity.this, "Run model failed!", Toast.LENGTH_SHORT).show();
+ onRunModelFailed();
+ break;
+ default:
+ break;
+ }
+ }
+ };
+
+ worker = new HandlerThread("Predictor Worker");
+ worker.start();
+ sender = new Handler(worker.getLooper()) {
+ public void handleMessage(Message msg) {
+ switch (msg.what) {
+ case REQUEST_LOAD_MODEL:
+ // Load model and reload test image
+ if (onLoadModel()) {
+ receiver.sendEmptyMessage(RESPONSE_LOAD_MODEL_SUCCESSED);
+ } else {
+ receiver.sendEmptyMessage(RESPONSE_LOAD_MODEL_FAILED);
+ }
+ break;
+ case REQUEST_RUN_MODEL:
+ // Run model if model is loaded
+ if (onRunModel()) {
+ receiver.sendEmptyMessage(RESPONSE_RUN_MODEL_SUCCESSED);
+ } else {
+ receiver.sendEmptyMessage(RESPONSE_RUN_MODEL_FAILED);
+ }
+ break;
+ default:
+ break;
+ }
+ }
+ };
+ }
+
+ @Override
+ protected void onResume() {
+ super.onResume();
+ SharedPreferences sharedPreferences = PreferenceManager.getDefaultSharedPreferences(this);
+ boolean settingsChanged = false;
+ boolean model_settingsChanged = false;
+ String model_path = sharedPreferences.getString(getString(R.string.MODEL_PATH_KEY),
+ getString(R.string.MODEL_PATH_DEFAULT));
+ String label_path = sharedPreferences.getString(getString(R.string.LABEL_PATH_KEY),
+ getString(R.string.LABEL_PATH_DEFAULT));
+ String image_path = sharedPreferences.getString(getString(R.string.IMAGE_PATH_KEY),
+ getString(R.string.IMAGE_PATH_DEFAULT));
+ model_settingsChanged |= !model_path.equalsIgnoreCase(modelPath);
+ settingsChanged |= !label_path.equalsIgnoreCase(labelPath);
+ settingsChanged |= !image_path.equalsIgnoreCase(imagePath);
+ int cpu_thread_num = Integer.parseInt(sharedPreferences.getString(getString(R.string.CPU_THREAD_NUM_KEY),
+ getString(R.string.CPU_THREAD_NUM_DEFAULT)));
+ model_settingsChanged |= cpu_thread_num != cpuThreadNum;
+ String cpu_power_mode =
+ sharedPreferences.getString(getString(R.string.CPU_POWER_MODE_KEY),
+ getString(R.string.CPU_POWER_MODE_DEFAULT));
+ model_settingsChanged |= !cpu_power_mode.equalsIgnoreCase(cpuPowerMode);
+
+ int det_long_size = Integer.parseInt(sharedPreferences.getString(getString(R.string.DET_LONG_SIZE_KEY),
+ getString(R.string.DET_LONG_SIZE_DEFAULT)));
+ settingsChanged |= det_long_size != detLongSize;
+ float score_threshold =
+ Float.parseFloat(sharedPreferences.getString(getString(R.string.SCORE_THRESHOLD_KEY),
+ getString(R.string.SCORE_THRESHOLD_DEFAULT)));
+ settingsChanged |= scoreThreshold != score_threshold;
+ if (settingsChanged) {
+ labelPath = label_path;
+ imagePath = image_path;
+ detLongSize = det_long_size;
+ scoreThreshold = score_threshold;
+ set_img();
+ }
+ if (model_settingsChanged) {
+ modelPath = model_path;
+ cpuThreadNum = cpu_thread_num;
+ cpuPowerMode = cpu_power_mode;
+ // Update UI
+ tvInputSetting.setText("Model: " + modelPath.substring(modelPath.lastIndexOf("/") + 1) + "\nOPENCL: " + cbOpencl.isChecked() + "\nCPU Thread Num: " + cpuThreadNum + "\nCPU Power Mode: " + cpuPowerMode);
+ tvInputSetting.scrollTo(0, 0);
+ // Reload model if configure has been changed
+ loadModel();
+ }
+ }
+
+ public void loadModel() {
+ pbLoadModel = ProgressDialog.show(this, "", "loading model...", false, false);
+ sender.sendEmptyMessage(REQUEST_LOAD_MODEL);
+ }
+
+ public void runModel() {
+ pbRunModel = ProgressDialog.show(this, "", "running model...", false, false);
+ sender.sendEmptyMessage(REQUEST_RUN_MODEL);
+ }
+
+ public boolean onLoadModel() {
+ if (predictor.isLoaded()) {
+ predictor.releaseModel();
+ }
+ return predictor.init(MainActivity.this, modelPath, labelPath, cbOpencl.isChecked() ? 1 : 0, cpuThreadNum,
+ cpuPowerMode,
+ detLongSize, scoreThreshold);
+ }
+
+ public boolean onRunModel() {
+ String run_mode = spRunMode.getSelectedItem().toString();
+ int run_det = run_mode.contains("检测") ? 1 : 0;
+ int run_cls = run_mode.contains("分类") ? 1 : 0;
+ int run_rec = run_mode.contains("识别") ? 1 : 0;
+ return predictor.isLoaded() && predictor.runModel(run_det, run_cls, run_rec);
+ }
+
+ public void onLoadModelSuccessed() {
+ // Load test image from path and run model
+ tvInputSetting.setText("Model: " + modelPath.substring(modelPath.lastIndexOf("/") + 1) + "\nOPENCL: " + cbOpencl.isChecked() + "\nCPU Thread Num: " + cpuThreadNum + "\nCPU Power Mode: " + cpuPowerMode);
+ tvInputSetting.scrollTo(0, 0);
+ tvStatus.setText("STATUS: load model successed");
+
+ }
+
+ public void onLoadModelFailed() {
+ tvStatus.setText("STATUS: load model failed");
+ }
+
+ public void onRunModelSuccessed() {
+ tvStatus.setText("STATUS: run model successed");
+ // Obtain results and update UI
+ tvInferenceTime.setText("Inference time: " + predictor.inferenceTime() + " ms");
+ Bitmap outputImage = predictor.outputImage();
+ if (outputImage != null) {
+ ivInputImage.setImageBitmap(outputImage);
+ }
+ tvOutputResult.setText(predictor.outputResult());
+ tvOutputResult.scrollTo(0, 0);
+ }
+
+ public void onRunModelFailed() {
+ tvStatus.setText("STATUS: run model failed");
+ }
+
+ public void set_img() {
+ // Load test image from path and run model
+ try {
+ assetManager = getAssets();
+ InputStream in = assetManager.open(imagePath);
+ Bitmap bmp = BitmapFactory.decodeStream(in);
+ cur_predict_image = bmp;
+ ivInputImage.setImageBitmap(bmp);
+ } catch (IOException e) {
+ Toast.makeText(MainActivity.this, "Load image failed!", Toast.LENGTH_SHORT).show();
+ e.printStackTrace();
+ }
+ }
+
+ public void onSettingsClicked() {
+ startActivity(new Intent(MainActivity.this, SettingsActivity.class));
+ }
+
+ @Override
+ public boolean onCreateOptionsMenu(Menu menu) {
+ MenuInflater inflater = getMenuInflater();
+ inflater.inflate(R.menu.menu_action_options, menu);
+ return true;
+ }
+
+ public boolean onPrepareOptionsMenu(Menu menu) {
+ boolean isLoaded = predictor.isLoaded();
+ return super.onPrepareOptionsMenu(menu);
+ }
+
+ @Override
+ public boolean onOptionsItemSelected(MenuItem item) {
+ switch (item.getItemId()) {
+ case android.R.id.home:
+ finish();
+ break;
+ case R.id.settings:
+ if (requestAllPermissions()) {
+ // Make sure we have SDCard r&w permissions to load model from SDCard
+ onSettingsClicked();
+ }
+ break;
+ }
+ return super.onOptionsItemSelected(item);
+ }
+
+ @Override
+ public void onRequestPermissionsResult(int requestCode, @NonNull String[] permissions,
+ @NonNull int[] grantResults) {
+ super.onRequestPermissionsResult(requestCode, permissions, grantResults);
+ if (grantResults[0] != PackageManager.PERMISSION_GRANTED || grantResults[1] != PackageManager.PERMISSION_GRANTED) {
+ Toast.makeText(this, "Permission Denied", Toast.LENGTH_SHORT).show();
+ }
+ }
+
+ private boolean requestAllPermissions() {
+ if (ContextCompat.checkSelfPermission(this, Manifest.permission.WRITE_EXTERNAL_STORAGE)
+ != PackageManager.PERMISSION_GRANTED || ContextCompat.checkSelfPermission(this,
+ Manifest.permission.CAMERA)
+ != PackageManager.PERMISSION_GRANTED) {
+ ActivityCompat.requestPermissions(this, new String[]{Manifest.permission.WRITE_EXTERNAL_STORAGE,
+ Manifest.permission.CAMERA},
+ 0);
+ return false;
+ }
+ return true;
+ }
+
+ private void openGallery() {
+ Intent intent = new Intent(Intent.ACTION_PICK, null);
+ intent.setDataAndType(MediaStore.Images.Media.EXTERNAL_CONTENT_URI, "image/*");
+ startActivityForResult(intent, OPEN_GALLERY_REQUEST_CODE);
+ }
+
+ private void takePhoto() {
+ Intent takePictureIntent = new Intent(MediaStore.ACTION_IMAGE_CAPTURE);
+ // Ensure that there's a camera activity to handle the intent
+ if (takePictureIntent.resolveActivity(getPackageManager()) != null) {
+ // Create the File where the photo should go
+ File photoFile = null;
+ try {
+ photoFile = createImageFile();
+ } catch (IOException ex) {
+ Log.e("MainActitity", ex.getMessage(), ex);
+ Toast.makeText(MainActivity.this,
+ "Create Camera temp file failed: " + ex.getMessage(), Toast.LENGTH_SHORT).show();
+ }
+ // Continue only if the File was successfully created
+ if (photoFile != null) {
+ Log.i(TAG, "FILEPATH " + getExternalFilesDir("Pictures").getAbsolutePath());
+ Uri photoURI = FileProvider.getUriForFile(this,
+ "com.baidu.paddle.lite.demo.ocr.fileprovider",
+ photoFile);
+ currentPhotoPath = photoFile.getAbsolutePath();
+ takePictureIntent.putExtra(MediaStore.EXTRA_OUTPUT, photoURI);
+ startActivityForResult(takePictureIntent, TAKE_PHOTO_REQUEST_CODE);
+ Log.i(TAG, "startActivityForResult finished");
+ }
+ }
+
+ }
+
+ private File createImageFile() throws IOException {
+ // Create an image file name
+ String timeStamp = new SimpleDateFormat("yyyyMMdd_HHmmss").format(new Date());
+ String imageFileName = "JPEG_" + timeStamp + "_";
+ File storageDir = getExternalFilesDir(Environment.DIRECTORY_PICTURES);
+ File image = File.createTempFile(
+ imageFileName, /* prefix */
+ ".bmp", /* suffix */
+ storageDir /* directory */
+ );
+
+ return image;
+ }
+
+ @Override
+ protected void onActivityResult(int requestCode, int resultCode, Intent data) {
+ super.onActivityResult(requestCode, resultCode, data);
+ if (resultCode == RESULT_OK) {
+ switch (requestCode) {
+ case OPEN_GALLERY_REQUEST_CODE:
+ if (data == null) {
+ break;
+ }
+ try {
+ ContentResolver resolver = getContentResolver();
+ Uri uri = data.getData();
+ Bitmap image = MediaStore.Images.Media.getBitmap(resolver, uri);
+ String[] proj = {MediaStore.Images.Media.DATA};
+ Cursor cursor = managedQuery(uri, proj, null, null, null);
+ cursor.moveToFirst();
+ if (image != null) {
+ cur_predict_image = image;
+ ivInputImage.setImageBitmap(image);
+ }
+ } catch (IOException e) {
+ Log.e(TAG, e.toString());
+ }
+ break;
+ case TAKE_PHOTO_REQUEST_CODE:
+ if (currentPhotoPath != null) {
+ ExifInterface exif = null;
+ try {
+ exif = new ExifInterface(currentPhotoPath);
+ } catch (IOException e) {
+ e.printStackTrace();
+ }
+ int orientation = exif.getAttributeInt(ExifInterface.TAG_ORIENTATION,
+ ExifInterface.ORIENTATION_UNDEFINED);
+ Log.i(TAG, "rotation " + orientation);
+ Bitmap image = BitmapFactory.decodeFile(currentPhotoPath);
+ image = Utils.rotateBitmap(image, orientation);
+ if (image != null) {
+ cur_predict_image = image;
+ ivInputImage.setImageBitmap(image);
+ }
+ } else {
+ Log.e(TAG, "currentPhotoPath is null");
+ }
+ break;
+ default:
+ break;
+ }
+ }
+ }
+
+ public void btn_reset_img_click(View view) {
+ ivInputImage.setImageBitmap(cur_predict_image);
+ }
+
+ public void cb_opencl_click(View view) {
+ tvStatus.setText("STATUS: load model ......");
+ loadModel();
+ }
+
+ public void btn_run_model_click(View view) {
+ Bitmap image = ((BitmapDrawable) ivInputImage.getDrawable()).getBitmap();
+ if (image == null) {
+ tvStatus.setText("STATUS: image is not exists");
+ } else if (!predictor.isLoaded()) {
+ tvStatus.setText("STATUS: model is not loaded");
+ } else {
+ tvStatus.setText("STATUS: run model ...... ");
+ predictor.setInputImage(image);
+ runModel();
+ }
+ }
+
+ public void btn_choice_img_click(View view) {
+ if (requestAllPermissions()) {
+ openGallery();
+ }
+ }
+
+ public void btn_take_photo_click(View view) {
+ if (requestAllPermissions()) {
+ takePhoto();
+ }
+ }
+
+ @Override
+ protected void onDestroy() {
+ if (predictor != null) {
+ predictor.releaseModel();
+ }
+ worker.quit();
+ super.onDestroy();
+ }
+
+ public int get_run_mode() {
+ String run_mode = spRunMode.getSelectedItem().toString();
+ int mode;
+ switch (run_mode) {
+ case "检测+分类+识别":
+ mode = 1;
+ break;
+ case "检测+识别":
+ mode = 2;
+ break;
+ case "识别+分类":
+ mode = 3;
+ break;
+ case "检测":
+ mode = 4;
+ break;
+ case "识别":
+ mode = 5;
+ break;
+ case "分类":
+ mode = 6;
+ break;
+ default:
+ mode = 1;
+ }
+ return mode;
+ }
+}
diff --git a/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/OCRPredictorNative.java b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/OCRPredictorNative.java
new file mode 100644
index 0000000..41fa183
--- /dev/null
+++ b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/OCRPredictorNative.java
@@ -0,0 +1,105 @@
+package com.baidu.paddle.lite.demo.ocr;
+
+import android.graphics.Bitmap;
+import android.util.Log;
+
+import java.util.ArrayList;
+import java.util.concurrent.atomic.AtomicBoolean;
+
+public class OCRPredictorNative {
+
+ private static final AtomicBoolean isSOLoaded = new AtomicBoolean();
+
+ public static void loadLibrary() throws RuntimeException {
+ if (!isSOLoaded.get() && isSOLoaded.compareAndSet(false, true)) {
+ try {
+ System.loadLibrary("Native");
+ } catch (Throwable e) {
+ RuntimeException exception = new RuntimeException(
+ "Load libNative.so failed, please check it exists in apk file.", e);
+ throw exception;
+ }
+ }
+ }
+
+ private Config config;
+
+ private long nativePointer = 0;
+
+ public OCRPredictorNative(Config config) {
+ this.config = config;
+ loadLibrary();
+ nativePointer = init(config.detModelFilename, config.recModelFilename, config.clsModelFilename, config.useOpencl,
+ config.cpuThreadNum, config.cpuPower);
+ Log.i("OCRPredictorNative", "load success " + nativePointer);
+
+ }
+
+
+ public ArrayList runImage(Bitmap originalImage, int max_size_len, int run_det, int run_cls, int run_rec) {
+ Log.i("OCRPredictorNative", "begin to run image ");
+ float[] rawResults = forward(nativePointer, originalImage, max_size_len, run_det, run_cls, run_rec);
+ ArrayList results = postprocess(rawResults);
+ return results;
+ }
+
+ public static class Config {
+ public int useOpencl;
+ public int cpuThreadNum;
+ public String cpuPower;
+ public String detModelFilename;
+ public String recModelFilename;
+ public String clsModelFilename;
+
+ }
+
+ public void destory() {
+ if (nativePointer != 0) {
+ release(nativePointer);
+ nativePointer = 0;
+ }
+ }
+
+ protected native long init(String detModelPath, String recModelPath, String clsModelPath, int useOpencl, int threadNum, String cpuMode);
+
+ protected native float[] forward(long pointer, Bitmap originalImage,int max_size_len, int run_det, int run_cls, int run_rec);
+
+ protected native void release(long pointer);
+
+ private ArrayList postprocess(float[] raw) {
+ ArrayList results = new ArrayList();
+ int begin = 0;
+
+ while (begin < raw.length) {
+ int point_num = Math.round(raw[begin]);
+ int word_num = Math.round(raw[begin + 1]);
+ OcrResultModel res = parse(raw, begin + 2, point_num, word_num);
+ begin += 2 + 1 + point_num * 2 + word_num + 2;
+ results.add(res);
+ }
+
+ return results;
+ }
+
+ private OcrResultModel parse(float[] raw, int begin, int pointNum, int wordNum) {
+ int current = begin;
+ OcrResultModel res = new OcrResultModel();
+ res.setConfidence(raw[current]);
+ current++;
+ for (int i = 0; i < pointNum; i++) {
+ res.addPoints(Math.round(raw[current + i * 2]), Math.round(raw[current + i * 2 + 1]));
+ }
+ current += (pointNum * 2);
+ for (int i = 0; i < wordNum; i++) {
+ int index = Math.round(raw[current + i]);
+ res.addWordIndex(index);
+ }
+ current += wordNum;
+ res.setClsIdx(raw[current]);
+ res.setClsConfidence(raw[current + 1]);
+ Log.i("OCRPredictorNative", "word finished " + wordNum);
+ return res;
+ }
+
+
+}
diff --git a/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/OcrResultModel.java b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/OcrResultModel.java
new file mode 100644
index 0000000..1bccbc7
--- /dev/null
+++ b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/OcrResultModel.java
@@ -0,0 +1,79 @@
+package com.baidu.paddle.lite.demo.ocr;
+
+import android.graphics.Point;
+
+import java.util.ArrayList;
+import java.util.List;
+
+public class OcrResultModel {
+ private List points;
+ private List wordIndex;
+ private String label;
+ private float confidence;
+ private float cls_idx;
+ private String cls_label;
+ private float cls_confidence;
+
+ public OcrResultModel() {
+ super();
+ points = new ArrayList<>();
+ wordIndex = new ArrayList<>();
+ }
+
+ public void addPoints(int x, int y) {
+ Point point = new Point(x, y);
+ points.add(point);
+ }
+
+ public void addWordIndex(int index) {
+ wordIndex.add(index);
+ }
+
+ public List getPoints() {
+ return points;
+ }
+
+ public List getWordIndex() {
+ return wordIndex;
+ }
+
+ public String getLabel() {
+ return label;
+ }
+
+ public void setLabel(String label) {
+ this.label = label;
+ }
+
+ public float getConfidence() {
+ return confidence;
+ }
+
+ public void setConfidence(float confidence) {
+ this.confidence = confidence;
+ }
+
+ public float getClsIdx() {
+ return cls_idx;
+ }
+
+ public void setClsIdx(float idx) {
+ this.cls_idx = idx;
+ }
+
+ public String getClsLabel() {
+ return cls_label;
+ }
+
+ public void setClsLabel(String label) {
+ this.cls_label = label;
+ }
+
+ public float getClsConfidence() {
+ return cls_confidence;
+ }
+
+ public void setClsConfidence(float confidence) {
+ this.cls_confidence = confidence;
+ }
+}
diff --git a/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/Predictor.java b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/Predictor.java
new file mode 100644
index 0000000..ab31216
--- /dev/null
+++ b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/Predictor.java
@@ -0,0 +1,278 @@
+package com.baidu.paddle.lite.demo.ocr;
+
+import android.content.Context;
+import android.graphics.Bitmap;
+import android.graphics.Canvas;
+import android.graphics.Color;
+import android.graphics.Paint;
+import android.graphics.Path;
+import android.graphics.Point;
+import android.util.Log;
+
+import java.io.File;
+import java.io.InputStream;
+import java.util.ArrayList;
+import java.util.Date;
+import java.util.List;
+import java.util.Vector;
+
+import static android.graphics.Color.*;
+
+public class Predictor {
+ private static final String TAG = Predictor.class.getSimpleName();
+ public boolean isLoaded = false;
+ public int warmupIterNum = 1;
+ public int inferIterNum = 1;
+ public int cpuThreadNum = 4;
+ public String cpuPowerMode = "LITE_POWER_HIGH";
+ public String modelPath = "";
+ public String modelName = "";
+ protected OCRPredictorNative paddlePredictor = null;
+ protected float inferenceTime = 0;
+ // Only for object detection
+ protected Vector wordLabels = new Vector();
+ protected int detLongSize = 960;
+ protected float scoreThreshold = 0.1f;
+ protected Bitmap inputImage = null;
+ protected Bitmap outputImage = null;
+ protected volatile String outputResult = "";
+ protected float postprocessTime = 0;
+
+
+ public Predictor() {
+ }
+
+ public boolean init(Context appCtx, String modelPath, String labelPath, int useOpencl, int cpuThreadNum, String cpuPowerMode) {
+ isLoaded = loadModel(appCtx, modelPath, useOpencl, cpuThreadNum, cpuPowerMode);
+ if (!isLoaded) {
+ return false;
+ }
+ isLoaded = loadLabel(appCtx, labelPath);
+ return isLoaded;
+ }
+
+
+ public boolean init(Context appCtx, String modelPath, String labelPath, int useOpencl, int cpuThreadNum, String cpuPowerMode,
+ int detLongSize, float scoreThreshold) {
+ boolean isLoaded = init(appCtx, modelPath, labelPath, useOpencl, cpuThreadNum, cpuPowerMode);
+ if (!isLoaded) {
+ return false;
+ }
+ this.detLongSize = detLongSize;
+ this.scoreThreshold = scoreThreshold;
+ return true;
+ }
+
+ protected boolean loadModel(Context appCtx, String modelPath, int useOpencl, int cpuThreadNum, String cpuPowerMode) {
+ // Release model if exists
+ releaseModel();
+
+ // Load model
+ if (modelPath.isEmpty()) {
+ return false;
+ }
+ String realPath = modelPath;
+ if (!modelPath.substring(0, 1).equals("/")) {
+ // Read model files from custom path if the first character of mode path is '/'
+ // otherwise copy model to cache from assets
+ realPath = appCtx.getCacheDir() + "/" + modelPath;
+ Utils.copyDirectoryFromAssets(appCtx, modelPath, realPath);
+ }
+ if (realPath.isEmpty()) {
+ return false;
+ }
+
+ OCRPredictorNative.Config config = new OCRPredictorNative.Config();
+ config.useOpencl = useOpencl;
+ config.cpuThreadNum = cpuThreadNum;
+ config.cpuPower = cpuPowerMode;
+ config.detModelFilename = realPath + File.separator + "det_db.nb";
+ config.recModelFilename = realPath + File.separator + "rec_crnn.nb";
+ config.clsModelFilename = realPath + File.separator + "cls.nb";
+ Log.i("Predictor", "model path" + config.detModelFilename + " ; " + config.recModelFilename + ";" + config.clsModelFilename);
+ paddlePredictor = new OCRPredictorNative(config);
+
+ this.cpuThreadNum = cpuThreadNum;
+ this.cpuPowerMode = cpuPowerMode;
+ this.modelPath = realPath;
+ this.modelName = realPath.substring(realPath.lastIndexOf("/") + 1);
+ return true;
+ }
+
+ public void releaseModel() {
+ if (paddlePredictor != null) {
+ paddlePredictor.destory();
+ paddlePredictor = null;
+ }
+ isLoaded = false;
+ cpuThreadNum = 1;
+ cpuPowerMode = "LITE_POWER_HIGH";
+ modelPath = "";
+ modelName = "";
+ }
+
+ protected boolean loadLabel(Context appCtx, String labelPath) {
+ wordLabels.clear();
+ wordLabels.add("black");
+ // Load word labels from file
+ try {
+ InputStream assetsInputStream = appCtx.getAssets().open(labelPath);
+ int available = assetsInputStream.available();
+ byte[] lines = new byte[available];
+ assetsInputStream.read(lines);
+ assetsInputStream.close();
+ String words = new String(lines);
+ String[] contents = words.split("\n");
+ for (String content : contents) {
+ wordLabels.add(content);
+ }
+ wordLabels.add(" ");
+ Log.i(TAG, "Word label size: " + wordLabels.size());
+ } catch (Exception e) {
+ Log.e(TAG, e.getMessage());
+ return false;
+ }
+ return true;
+ }
+
+
+ public boolean runModel(int run_det, int run_cls, int run_rec) {
+ if (inputImage == null || !isLoaded()) {
+ return false;
+ }
+
+ // Warm up
+ for (int i = 0; i < warmupIterNum; i++) {
+ paddlePredictor.runImage(inputImage, detLongSize, run_det, run_cls, run_rec);
+ }
+ warmupIterNum = 0; // do not need warm
+ // Run inference
+ Date start = new Date();
+ ArrayList results = paddlePredictor.runImage(inputImage, detLongSize, run_det, run_cls, run_rec);
+ Date end = new Date();
+ inferenceTime = (end.getTime() - start.getTime()) / (float) inferIterNum;
+
+ results = postprocess(results);
+ Log.i(TAG, "[stat] Inference Time: " + inferenceTime + " ;Box Size " + results.size());
+ drawResults(results);
+
+ return true;
+ }
+
+ public boolean isLoaded() {
+ return paddlePredictor != null && isLoaded;
+ }
+
+ public String modelPath() {
+ return modelPath;
+ }
+
+ public String modelName() {
+ return modelName;
+ }
+
+ public int cpuThreadNum() {
+ return cpuThreadNum;
+ }
+
+ public String cpuPowerMode() {
+ return cpuPowerMode;
+ }
+
+ public float inferenceTime() {
+ return inferenceTime;
+ }
+
+ public Bitmap inputImage() {
+ return inputImage;
+ }
+
+ public Bitmap outputImage() {
+ return outputImage;
+ }
+
+ public String outputResult() {
+ return outputResult;
+ }
+
+ public float postprocessTime() {
+ return postprocessTime;
+ }
+
+
+ public void setInputImage(Bitmap image) {
+ if (image == null) {
+ return;
+ }
+ this.inputImage = image.copy(Bitmap.Config.ARGB_8888, true);
+ }
+
+ private ArrayList postprocess(ArrayList results) {
+ for (OcrResultModel r : results) {
+ StringBuffer word = new StringBuffer();
+ for (int index : r.getWordIndex()) {
+ if (index >= 0 && index < wordLabels.size()) {
+ word.append(wordLabels.get(index));
+ } else {
+ Log.e(TAG, "Word index is not in label list:" + index);
+ word.append("×");
+ }
+ }
+ r.setLabel(word.toString());
+ r.setClsLabel(r.getClsIdx() == 1 ? "180" : "0");
+ }
+ return results;
+ }
+
+ private void drawResults(ArrayList results) {
+ StringBuffer outputResultSb = new StringBuffer("");
+ for (int i = 0; i < results.size(); i++) {
+ OcrResultModel result = results.get(i);
+ StringBuilder sb = new StringBuilder("");
+ if(result.getPoints().size()>0){
+ sb.append("Det: ");
+ for (Point p : result.getPoints()) {
+ sb.append("(").append(p.x).append(",").append(p.y).append(") ");
+ }
+ }
+ if(result.getLabel().length() > 0){
+ sb.append("\n Rec: ").append(result.getLabel());
+ sb.append(",").append(result.getConfidence());
+ }
+ if(result.getClsIdx()!=-1){
+ sb.append(" Cls: ").append(result.getClsLabel());
+ sb.append(",").append(result.getClsConfidence());
+ }
+ Log.i(TAG, sb.toString()); // show LOG in Logcat panel
+ outputResultSb.append(i + 1).append(": ").append(sb.toString()).append("\n");
+ }
+ outputResult = outputResultSb.toString();
+ outputImage = inputImage;
+ Canvas canvas = new Canvas(outputImage);
+ Paint paintFillAlpha = new Paint();
+ paintFillAlpha.setStyle(Paint.Style.FILL);
+ paintFillAlpha.setColor(Color.parseColor("#3B85F5"));
+ paintFillAlpha.setAlpha(50);
+
+ Paint paint = new Paint();
+ paint.setColor(Color.parseColor("#3B85F5"));
+ paint.setStrokeWidth(5);
+ paint.setStyle(Paint.Style.STROKE);
+
+ for (OcrResultModel result : results) {
+ Path path = new Path();
+ List points = result.getPoints();
+ if(points.size()==0){
+ continue;
+ }
+ path.moveTo(points.get(0).x, points.get(0).y);
+ for (int i = points.size() - 1; i >= 0; i--) {
+ Point p = points.get(i);
+ path.lineTo(p.x, p.y);
+ }
+ canvas.drawPath(path, paint);
+ canvas.drawPath(path, paintFillAlpha);
+ }
+ }
+
+}
diff --git a/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/SettingsActivity.java b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/SettingsActivity.java
new file mode 100644
index 0000000..477cd5d
--- /dev/null
+++ b/deploy/android_demo/app/src/main/java/com/baidu/paddle/lite/demo/ocr/SettingsActivity.java
@@ -0,0 +1,172 @@
+package com.baidu.paddle.lite.demo.ocr;
+
+import android.content.SharedPreferences;
+import android.os.Bundle;
+import android.preference.CheckBoxPreference;
+import android.preference.EditTextPreference;
+import android.preference.ListPreference;
+
+import androidx.appcompat.app.ActionBar;
+
+import java.util.ArrayList;
+import java.util.List;
+
+
+public class SettingsActivity extends AppCompatPreferenceActivity implements SharedPreferences.OnSharedPreferenceChangeListener {
+ ListPreference lpChoosePreInstalledModel = null;
+ CheckBoxPreference cbEnableCustomSettings = null;
+ EditTextPreference etModelPath = null;
+ EditTextPreference etLabelPath = null;
+ ListPreference etImagePath = null;
+ ListPreference lpCPUThreadNum = null;
+ ListPreference lpCPUPowerMode = null;
+ EditTextPreference etDetLongSize = null;
+ EditTextPreference etScoreThreshold = null;
+
+ List preInstalledModelPaths = null;
+ List preInstalledLabelPaths = null;
+ List preInstalledImagePaths = null;
+ List preInstalledDetLongSizes = null;
+ List preInstalledCPUThreadNums = null;
+ List preInstalledCPUPowerModes = null;
+ List preInstalledInputColorFormats = null;
+ List preInstalledInputMeans = null;
+ List preInstalledInputStds = null;
+ List preInstalledScoreThresholds = null;
+
+ @Override
+ public void onCreate(Bundle savedInstanceState) {
+ super.onCreate(savedInstanceState);
+ addPreferencesFromResource(R.xml.settings);
+ ActionBar supportActionBar = getSupportActionBar();
+ if (supportActionBar != null) {
+ supportActionBar.setDisplayHomeAsUpEnabled(true);
+ }
+
+ // Initialized pre-installed models
+ preInstalledModelPaths = new ArrayList |