Contributing to OBO Semantic Engineering Tutorials¶
+
We rely on our readers to correct our materials and add to them - the hope is to centralise all the usual teaching materials for OBO ontology professionals in one place. Feel free to:
+
+
Request new lessons (video/how-to guides) on the issue tracker
+
Make a pull request if you find errors or want to add some clarifying remarks. All files of the OBOAcademy website can be found in the docs directory. The Table of Contents is edited here.
+
Join the OBO slack space (#obo-training channel) to ask any questions (you can request access on the issue tracker)
The goal of this tutorial is to provide a flavor of the OBO landscape, from the OBO Foundry organization to the ontology curators and OBO engineers that are doing the daily ontology development.
The Open Biological and Biomedical Ontologies (OBO) community includes hundreds of open source scientific ontology projects, committed to shared principles and practices for interoperability and FAIR data. An OBO tutorial has been a regular feature of ICBO for a decade, introducing new and experienced ontology users and developers to ontologies in general, and to current OBO tools and techniques specifically. While ICBO attracts many ontology experts, it also includes an audience of ontology beginners, and of ontology users looking to become ontology developers or to further refine their skills. Our OBO tutorial will help beginner and intermediate ontology users with a combination of theory and hands-on practice.
+
For ICBO 2022 we will host a half-day OBO tutorial consisting of two parts, with a unifying theme of ontology term reuse.
+
The first part of our tutorial will be introductory, aimed at an audience that is new to ontologies and to the OBO Foundry. We will introduce OBO, its community, principles, resources, and best practices. We will finish the first part with a hands-on lesson in basic tools: ontology browsers, how to contribute to ontologies via GitHub (creating issues and making Pull Requests), and the Protege ontology editor.
+
The second part will build on the first, addressing an audience that is familiar with ontologies and OBO, and wants to make better use of OBO workflows and tools in their own projects. The focus will be on making best use of OBO community open source software. We will introduce ROBOT, the command-line tool and library for automating ontology development tasks. We will show how the Ontology Development Kit (ODK) is used to standardize ontology projects with a wide range of best practices. The special emphasis of this year's tutorial will be ontology reuse, and specifically on how ROBOT and ODK can be used to manage imports from other ontologies and overcome a number of challenges to term reuse.
+
This material for this year's OBO Tutorial will build on the content here in the OBO Academy. The OBO Academy offers free, open, online resources with self paced learning materials covering various aspects of ontology development and curation and OBO. Participants are encouraged to continue their learning using this OBO Academy website, and contribute to improving the OBO documentation.
+
As an outcome of this workshop, we expect that new ontologists will have a clearer understanding of why we need and use ontologies, how to find ontology terms and contribute to ontologies and make basic edits using Protege. Our more advanced participants should be able to apply OBO tools and workflows to their own ontology development practices.
The Open Biological and Biomedical Ontologies (OBO) community includes hundreds of open source scientific ontology projects,
+committed to shared principles and practices for interoperability and FAIR data. An OBO tutorial has been a regular feature of ICBO for a decade, introducing new and experienced ontology users and developers to ontologies in general, and to current OBO tools and techniques specifically. While ICBO attracts many ontology experts, it also includes an audience of ontology beginners, and of ontology users looking to become ontology developers or to further refine their skills. Our OBO tutorial will help beginner and intermediate ontology users with a combination of theory and hands-on practice.
+
For ICBO 2023 we will host a half-day OBO tutorial consisting of two parts.
+
The first part of our tutorial will be introductory, aimed at an audience that is new to ontologies and to the OBO Foundry.
+We will introduce OBO, its community, principles, resources, and best practices.
+We will finish the first part with a hands-on lesson in basic tools: ontology browsers, how to contribute to ontologies via
+GitHub (creating issues and making Pull Requests), and the Protege ontology editor.
+
The second part will build on the first, addressing an audience that is familiar with ontologies and OBO, and wants to make better use of
+OBO workflows and tools in their own projects.
+
This material for this year's OBO Tutorial will build on the content here in the OBO Academy.
+The OBO Academy offers free, open, online resources with self paced learning materials covering various aspects of ontology development and
+curation and OBO. Participants are encouraged to continue their learning using this OBO Academy website, and contribute to improving the
+OBO documentation.
The tutorial is designed to be 'show and tell' format, but you are welcome to install the following software on your machine in advance, if you'd like to follow along in real time:
The goal of this course is to provide ongoing training for the OBO community. As with previous tutorials, we follow the flipped classroom concept: as organisers, we provide you with materials to look at, and you will work through the materials on your own. During our biweekly meeting, we will answer your questions, provide you with additional demonstrations where needed and go into depth wherever you as a student are curious to learn more. This means that this course can only work if you are actually putting in the time to preparing the materials. That said, we nevertheless welcome anyone to just lurk or ask related questions.
Check which lessons interest you in the upcoming schedule - just participate in the ones you care about
+
Prepare the lessons (between 3 and 7 hours of preparation time)
+
Prepare questions for the revision sessions (without questions, the revision sessions will be silent and awkward)
+
Make detailed issues on our issue tracker when materials are broken, hard to follow or need more details - that is really important as we rely on you to help to improve our materials continuously.
+
Request new course units from us using the issue tracker.
Most of materials used by this course were developed by James Overton, Becky Jackson, Nicole Vasilevsky and Nico Matentzoglu as part of a project with the Critical Path Institute (see here). The materials are improved as part of an internal training program (onboarding and CPD) for the Phenomics First project (NIH / NHGRI #1RM1HG010860-01).
+
Thanks to Sarah Gehrke for her help with project management.
An entity such as an individual, a class, or a property can have annotations, such as labels, synonyms and definitions. An annotation property is used to link the entity to a value, which in turn can be anything from a literal (a string, number, date etc) to another entity (such as, another class).
+
Here are some examples of frequently used annotation properties: (every element in bold is an annotation property)
Some useful things to know about annotation properties¶
+
Annotation properties have their own IRIs, just like classes and individuals. For example, the IRI of the RDFS built in label property is http://www.w3.org/2000/01/rdf-schema#label. Other examples:
Annotation properties are just like other entities (classes, individuals) and can have their own annotations. For example, the annotation propert http://purl.obolibrary.org/obo/IAO_0000232 has an rdfs:label ('curator note') and a human readable definition (IAO:0000115): 'An administrative note of use for a curator but of no use for a user'.
+
Annotation properties can be organised in a hierarchical structure.
+
For example, the annotation property 'synonym_type_property' (http://www.geneontology.org/formats/oboInOwl#SynonymTypeProperty) is the parent property of other, more specific ones (such as "abbreviation").
+
Annotation properties are (usually) used with specific type of annotation values.
+
+
Literal: (one can see [type: xsd:string] in the annotation)
+
xsd:string
+
e.g. 'definition' (http://purl.obolibrary.org/obo/IAO_0000115)
+
+
+
xds:boolean
+
e.g. 'owl:deprecated' (http://www.w3.org/2002/07/owl#deprecated)
+
+
+
Entity IRI :
+
Classes or individuals: e.g. 'has curation status' (http://purl.obolibrary.org/obo/IAO_0000114)
+
Arbitray URIs, e.g. links to website with the 'term tracker item' (type xsd:anyURI) (http://purl.obolibrary.org/obo/IAO_0000233) property
+
Or even other annotation properties *
+
e.g. 'has_synonym_type' (http://www.geneontology.org/formats/oboInOwl#hasSynonymType)
+
e.g. 'in_subset' (http://purl.obolibrary.org/obo/IAO_0000112)
+
+
+
+
Note: the type of annotation required for an annotation property can be defined by adding a Range + "select datatype" in the Annotation Property's Description
+e.g. : 'scheduled for obsoletion on or after' (http://purl.obolibrary.org/obo/IAO_0006012)
+
+
Annotations do not affect reasoning. No matter what values you connect with your annotation properties, the reasoner will ignore it - even if it is nonsensical.
+
+
Annotation Property vs Data and Object Properties¶
+
Some annotation properties look like data properties (connecting an entity to a literal value) and others look like object properties (connecting an entity to another entity). Other than the fact that statements involving data and object properties look very different in RDF, the key difference from a user perspective is that OWL Reasoners entirely ignore triples involving annotation properties. Data and Object Properties are taken into account by the reasoner.
+
Object properties are different to annotation properties in that they:
+
+
connect pairs of individuals in way that affects reasoning
+
represent relationship between classes in way that affects reasoning
+
Example property: 'has part' (http://purl.obolibrary.org/obo/BFO_0000051)
+
Object Properties can have the following property characteristics: Inverse, Symmetric, Asymmetric, Reflexive, Irreflexive, Functional, Inverse Functional, and Transitive which effect reasoning. Annotation properties cannot have such properties (or if they had, reasoners would ignore them).
+
+
Data properties are different to annotation properties in that they:
+
+
connect individuals with literals in way that affects reasoning
+
represent relation between a class and literal in way that affects reasoning
+
You can use data properties to logically define OWL classes with data ranges. For example, you can define the class of Boomer as all people born between 1946 and 1964. If an individual would be asserted to be a Boomer, but is born earlier than 1946, the reasoner would file a complaint.
+
Example Data Property: 'hasName', 'hasPrice', 'hasCalories', 'hasSugarContent',...
Note: before creating a new annotation property, it is always a good idea to check for an existing annotation property first.
+
+
For example: OBO Metadata Ontology (https://www.ebi.ac.uk/ols/ontologies/omo), which could be imported
+
+
Detailed explanations for adding a new annotation property can be found here
+
The term "Annotation" in Ontologies and Data Curation means different things.¶
+
The word "annotation" is used in different contexts to mean different things. For instance, "annotation in owl" (ie annotations to an ontology term) is different from "annotation in the biocuration sense" (ie gene-to-disease, gene-to-phenotype, gene-to-function annotations). It is therefore crucial to give context when using the word "annotation".
ObjectProperty: r
+Class: D
+ EquivalentTo: r some C
+Class: C
+
+
the semantics of
+r some C is the set of individuals such that for each
+individual x there is at least 1 individual y of type C that is linked to
+x via the object property r.
+
Based on this semantics, a possible world adhering to our initial equivalence axiom may be:
+
+
In this Venn diagram we assume individuals are black dots.
+Thus, our world consists of 7 individuals,
+with only 2 classes, namely C and D, as well 2 object properties, namely r and q.
+In this world, D and thus the class r some C, consist of only 2 individuals. D and
+r some C consist of only 2 individuals because these are the only individuals linked
+via object property r to at least 1 individual respectively in C.
In the following we define a pet owner as someone that owns at least 1 pet.
+
ObjectProperty: owns
+Class: PetOwner
+ EquivalentTo: owns some Pet
+Class: Pet
+
+
If we want to introduce the class DogOwner, assuming we can only use the class Pet
+and the object property owns (assuming we have not defined PetOwner), we could say
+that a dog owner is a subset of pet owners:
+
ObjectProperty: owns
+Class: DogOwner
+ SubClassOf: owns some Pet
+Class: Pet
+
+
In this case we use SubClassOf instead of EquivalentTo because not every pet owner
+necessarily owns a dog. This is equivalent to stating:
+
ObjectProperty: owns
+Class: PetOwner
+ EquivalentTo: owns some Pet
+Class: Pet
+Class: DogOwner
+ SubClassOf: PetOwner
+
In the previous section we modeled a PetOwner as owns some Pet. In the expression
+owns some PetPet is referred to as the filler of owns and more specifically
+we say Pet is the owns-filler.
+
The PetOwner EquivalentTo: owns some Pet state that pet owners are those individuals
+that own a pet and ignore all other owns-fillers that are not pets. How can we define
+arbitrary ownership?
+
ObjectProperty: owns
+Class: Owner
+ EquivalentTo: owns some owl:Thing
+
This far we have only considered existential restrictions based on object properties, but
+it is possible to define existential restrictions based on data properties. As an example,
+we all expect that persons have at least 1 name. This could be expressed as follows:
+
DataProperty: name
+Class: Person
+ SubClassOf: name some xsd:string
+
+
When to use SubClassOf vs EquivalentTo with existential restrictions¶
+
In our example of Person SubClassOf: name some xsd:string, why did we use SubClassOf
+rather than EquivalentTo? That is, why did we not use
+Person EquivalentTo: name some xsd:string? With using the EquivalentTo axiom, any
+individual that has a name, will be inferred to be an instance of Person. However,
+there are many things in the world that have names that are not persons. Some examples are pets,
+places, regions, etc:
+
+
Compare this with, for example, DogOwner:
+
ObjectProperty: owns
+Class: Dog
+Class: DogOwner
+ EquivalentTo: owns some Dog
+
We face an ever-increasing deluge of biological data analysis. Ensuring that this data and analysis are Findable, Accessible, Interoperable, and Re-usable (FAIR) is a major challenge. Findability, Interoperabiltiy, and Resuability can all be enhanced by standardising metadata. Well-standardised metadata can make it easy to find data and analyses despite variations in terminology ('Clara cell' vs 'nonciliated bronchiolar secretory cell' vs 'club cell') and precision ('bronchial epithelial cell' vs 'club cell'). Understanding which entities are referred to in metadata and how they relate to the annotated material can help users work out if the data or analysis they have found is of interest to them and can aid in its re-use and interoperability with other data and analyses. For example, does an annotation of sample data with a term for breast cancer refer to the health status of the patient from which the sample was derived or that the sample itself comes from a breast cancer tumor?
Given variation in terminology and precision, annotation with free text alone is not sufficient for findability. One very lightweight solution to this problem is to rely on user-generated keyword systems, combined with some method of allowing users to choose from previously used keywords. This can produce some degree of annotation alignment but also results in fragmented annotation and varying levels of precision with no clear way to relate annotations.
+
For example, trying to refer to feces, in NCBI BioSample:
Terminology alone can be ambiguous. The same term may be used for completely unrelated or vaguely analogous structures. An insect femur and an mammalian femur are neither evolutionarily related nor structurally similar. Biologists often like to use abbreviations to annotate data, but these can be extremely ambiguous. Drosophila biologists use DA1 to refer to structures in the tracheal system, musculature and nervous system. Outside of Drosophila biology it is used to refer to many other things including a rare disease, and a a neuron type in C.elegans.
+
Some extreme examples of this ambiguity come from terminological drift in fields with a long history. For example
+in the male genitalia of a gasteruptiid wasp, these 5 different structures here have each been labeled "paramere" by different people, each studying different hymenopteran lineages. How do we know what "paramere" means when it is referred to?
+
+
This striking example shows that even precise context is not always sufficient for disambiguation.
Rather than rely on users to generate lists of re-usable keywords, we can instead pre-specify a set of terms to use in annotation. This is usually refered to a controlled vocabulary or CV.
Taxonomy describes a hierarchical CV in which hierarchy equals classification. E.g., 'Merlot' is classified as a 'Red' (wine). Not all hierchical CVs are classifications. For example, anatomical atlases often have hierarchical CVs representing "parthood". The femur is a part of the leg, but it is not 'a leg'.
+
Support for grouping and varying levels of precision¶
+
The use of a hierachical CV in which general terms group more specific terms allows for varying precision (glial cell vs some specific subtype) and simple grouping of annotated content.
To support findability, terms in hierarchical CVs often need to be associated with synonyms, or cross-referenced to closely related terms inside the CV.
CV content is often driven by requests from annotators and so expansion is not driven by any unified vision of scheme. This often leads to pressure for hierarchies to support terms having multiple parents, either reflecting multiple relationship types, or multiple types of classification. For example, an anatomical CV could reasonably put 'retinal bipolar cell' under 'retina' based on location and, at the same time, under 'bipolar neuron' and 'glutamatergic neuron' based on cell type classification.
Developers of hierarchical CVs often come to realise that multiple relationship types are represented in the hierarchy and that it can be useful to name these relationship for better distinction. For example, a heart glial cell is a 'type of' glial cell, but is 'part of' the heart.
Identifiers that do not hold any inherent meaning are important to ontologies. If you ever need to change the names of your terms, you're going to need identifiers that stay the same when the term name changes.
+
For example:
+
A microglial cell is also known as: hortega cell, microglia, microgliocyte and brain resident macrophage.
+In the cell ontology, it is however referred to by a unique identifier: CL:0000129
+These identifiers are short ways of referring to IRIs (e.g., CL:000129 = http://purl.obolibrary.org/obo/CL_0000129)
+This IRI is a unique, resolvable identifier on the web.
+A group of ontologies - loosely co-ordinated through the OBO Foundry, have standardised their IRIs (e.g. http://purl.obolibrary.org/obo/CL_0000129 - A term in the cell ontology; http://purl.oblibrary.org/obo/cl.owl - The cell ontology)
URI: Unique Resource Identifier - a string of characters, following a standard specification, that unambiguously identifies a particular (web) resource.
+
IRI: Internationalised Resource Identifier - a URI that can use characters in multiple languages.
+
URL: Uniform Resource Locator - a web-resolvable URI.
OBO ontologies are mostly written in OWL2 or OBO syntax. The latter is a legacy format that maps completely to OWL.
+
For a more in-depth explanation of formats (OWL, OBO, RDF etc.) refer to explainer on OWL format variants.
+In the examples below we will use OWL Manchester syntax, which allows us to express formal logic in English-like sentences.
Ontology terms refer to classes of things in the world. For example, the class of all wings.
+
Below you will see a classification of parts of the insect and how it is represented in a simple ontology.
+
+
We use a SubClassOf (or is_a in obo format) to represent that one class fully subsumes another.
+For example:
+OWL: hindwing SubClassOf wing
+OBO: hindwing is_a wing
+
In English we might say: "a hindwing is a type of wing" or more specifically, "all instances of hindwing are instances of wing." 'Instance' here refers to a single wing of an individual fly.
+
+
In the previous section, we talked about different types of relationships. In OWL we can define specific relations (known as object properties). One of the commonest is 'part of' which you can see used below.
+
+
English: all (insect) legs are part of a thoracic segment
+OWL: 'leg' SubClassOf part_of some thoracic segment
+OBO: 'leg'; relationship: part_of thoracic segment
+
It might seem odd at first that OWL uses subClassOf here too. The key to understanding this is the concept of an anonymous class - in OWL, we can refer to classes without giving them names. In this case, the anonymous class is the class of all things that are 'part of' (some) 'thoracic segment' (in insects). A vast array of different anatomical structures are subclasses of this anonymous class, some of which, such as wings, legs, and spiracles, are visible in the diagram.
+
Note the existential quantifier some in OWL format -- it is interpreted as "there exists", "there is at least one", or "some".
+
+
The quantifier is important to the direction of relations.
+
subClassOf:
+'wing' SubClassOf part_of some 'thoracic segment' is correct
+'thoracic segment' SubClassOf has_part some 'wing' is incorrect as it implies all thoracic segment have wings as a part.
+
Similarly:
+'claw' SubClassOf connected_to some 'tarsal segment' is correct
+'tarsal segment' SubClassOf connected_to some 'claw' is incorrect as it implies all tarsal segments are connected to claws (for example, some tarsal segments are connected to other tarsal segments)
+
+
These relationships store knowledge in a queryable format. For more information about querying, please refer to guide on DL queries and SPARQL queries.
There are many ways to classify things. For example, a neuron can be classified by structure, electrophysiology, neurotransmitter, lineage, etc. Manually maintaining these multiple inheritances (that occur through multiple classifications) does not scale.
+
+
Problems with maintaining multiple inheritance classifications by hand
+
+
+
Doesn’t scale
+
+
+
When adding a new class, how are human editors to know
+
+
+
all of the relevant classifications to add?
+
+
+
how to rearrange the existing class hierarchy?
+
+
+
+
+
+
+
It is bad for consistency
+
+
+
Reasons for existing classifications often opaque
+
+
+
Hard to check for consistency with distant superclasses
+
+
+
+
+
Doesn’t allow for querying
+
+
A formalized ontology can be queried for classes with arbitrary sets of properties. A manual classification can not.
The knowledge an ontology contains can be used to automate classification. For example:
+
English: Any sensory organ that functions in the detection of smell is an olfactory sensory organ
+OWL:
+
'olfactory sensory organ'
+ EquivalentTo ‘sensory organ’
+that
+capable_of some ‘detection of smell’
+
+
If we then have an entity nose that is subClassOf sensory organ and capable_of some detection of smell, it will be automatically classified as an olfactory sensory organ.
Many classes, especially in the domains of disease and phenotype, describe combinations of multiple classes - but it is very important to carefully distinguish whether this combination follows "disjunctive" logic ("or") or "conjunctive" logic ("and"). Both mean something entirely different. Usually where a class has 'and' in the label, such as 'neonatal inflammatory skin and bowel disease' (MONDO:0017411), the class follows a conjunctive logic (as expected), and should be interpreted in a way that someone that presents with this disease has both neonatal inflammatory skin disease and bowel disease at once. This class should be classified as a child of 'bowel disease' and 'neonatal inflammatory skin disease'. Note, however, that naming in many ontologies is not consistent with this logic, and you need to be careful to distinguish wether the interpretation is supposed to be conjunctive or disjunctive (i.e. "and" could actually mean "or", which is especially often the case for clinical terminologies).
+
Having asserted multiple SubClassOf axioms means that an instance of the class is a combination of all the SubClass Of statements (conjunctive interpretation, see above). For example, if 'neonatal inflammatory skin and bowel disease' is a subclass of both 'bowel disease' and 'neonatal inflammatory skin disease', then an individual with this disease has 'bowel disease' and 'neonatal inflammatory skin disease'.
+
+
If there were a class 'neonatal inflammatory skin or bowel disease', the intention is usually that this class follows disjunctive logic. A class following this logic would be interpreted in a way that an individual with this disease has either bowel disease or neonatal inflammatory skin disease or both. It would not be accurate to classify this class as a child of bowel disease and neonatal inflammatory skin disease. This type of class is often called a "grouping class", and is used to aggregate related diseases in a way useful to users, like "disease" and "sequelae of disease".
Logical axiomatization of classes & use of reasoning¶
+
This explainer requires understanding of ontology classifications. Please see "an ontology as a classification" section of the introduction to ontologies documentation if you are unfamiliar with these concepts.
+
You can watch this video about an introduction to Logical Description.
Logical axioms are relational information about classes that are primarily aimed at machines. This is opposed to annotations like textual definitions which are primarily aimed at humans. These logical axioms allow reasoners to assist in and verify classification, lessening the development burden and enabling expressive queries.
Ideally, everything in the definition should be axiomatized when possible. For example, if we consider the cell type oxytocin receptor sst GABAergic cortical interneuron, which has the textual definition:
+
"An interneuron located in the cerebral cortex that expresses the oxytocin receptor. These interneurons also express somatostatin."
+
The logical axioms should then follow accordingly:
+
SubClassOf:
+
+
interneuron
+
'has soma location' some 'cerebral cortex'
+
expresses some 'oxytocin receptor'
+
expresses some somatostatin
+
'capable of' some 'gamma-aminobutyric acid secretion, neurotransmission'
+
+
These logical axioms allow a reasoner to automatically classify the term. For example, through the logical axioms, we can infer that oxytocin receptor sst GABAergic cortical interneuron is a cerebral cortex GABAergic interneuron.
+
+
Axiomatizing definitions well will also allow for accurate querying. For example, if I wanted to find a neuron that expresses oxytocin receptor, having the SubClassOf axioms of interneuron and expresses some 'oxytocin receptor' will allow me to do so on DL query (see tutorial on DL query for more information about DL queries).
Everything in the logical axioms must be true, (do not axiomatize things that are true to only part of the entity)
+For example, the cell type chandelier pvalb GABAergic cortical interneuron is found in upper L2/3 and deep L5 of the cerebral cortex.
+We do not make logical axioms for has soma location some layer 2/3 and layer 5.
+Axioms with both layers would mean that a cell of that type must be in both layer 2/3 and layer 5, which is an impossibility (a cell cannot be in two seperate locations at once!). Instead we axiomatize a more general location: 'has soma location' some 'cerebral cortex'
An equivalent class axiom is an axiom that defines the class; it is a necessary and sufficient logical axiom that defines the cell type. It means that if a class B fulfils all the criteria/restrictions in the equivalent axiom of class A, class B is by definition a subclass of class A.
+Equivalent classes allow the reasoner to automatically classify entities.
+
For example:
+
+
chandelier cell has the equivalent class axiom interneuron and ('has characteristic' some 'chandelier cell morphology')
+
chandelier pvalb GABAergic cortical interneuron has the subclass axioms 'has characteristic' some 'chandelier cell morphology' and interneuron
+
chandelier pvalb GABAergic cortical interneuron is therefore a subclass of chandelier cell
+
+
Equivalent class axioms classification can be very powerful as it takes into consideration complex layers of axioms.
+
For example:
+
+
primary motor cortex pyramidal cell has the equivalent class axiom 'pyramidal neuron' and ('has soma location' some 'primary motor cortex').
+
Betz cell has the axioms 'has characteristic' some 'standard pyramidal morphology' and 'has soma location' some 'primary motor cortex layer 5'
+
Betz cell are inferred to be primary motor cortex pyramidal cell through the following chain (you can see this in Protégé by pressing the ? button on inferred class):
+
+
+
The ability of the reasoner to infer complex classes helps identify classifications that might have been missed if done manually. However, when creating an equivalent class axiom, you must be sure that it is not overly constrictive (in which case, classes that should be classified under it gets missed) nor too loose (in which case, classes will get wrongly classified under it).
+
Example of both overly constrictive and overly loose equivalent class axiom:
+
neuron equivalent to cell and (part_of some 'central nervous system')
+
+
This is overly constrictive as there are neurons outside the central nervous system (e.g. peripheral neurons).
+
This is also too loose as there are cells in the central nervous system that are not neurons (e.g. glial cells).
+
+
In such cases, sometimes not having an equivalent class axioms is better (like in the case of neuron), and asserting is the best way to classify a child.
Each ontology has certain styles and conventions in how they axiomatize. This style guide is specific to OBO ontologies. We will also give reasons as to why we choose to axiomatize in the way we do. However, be aware of your local ontology's practices.
It is important to note that ontologies have specific axiomatization styles and may apply to, for example, selecting a preferred relation. This usually reflects their use cases. For example, the Cell Ontology has a guide for what relations to use. An example of an agreement in the community is that while anatomical locations of cells are recorded using part of, neurons should be recorded with has soma location. This is to accommodate for the fact that many neurons have long reaching axons that cover multiple anatomical locations making them difficult to axiomatize using part of.
+
For example, Betz cell, a well known cell type which defines layer V of the primary motor cortex, synapses lower motor neurons or spinal interneurons (cell types that reside outside the brain). Having the axiom 'Betz cell' part_of 'cortical layer V' is wrong. In this case has soma location is used. Because of cases like these that are common in neurons, all neurons in CL should use has soma location.
Do not add axioms that are not required. If a parent class already has the axiom, it should not be added to the child class too.
+For example:
+
+
retinal bipolar neuron is a child of bipolar neuron
+
bipolar neuron has the axiom 'has characteristic' some 'cortical bipolar morphology'
+
Therefore we do not add 'has characteristic' some 'cortical bipolar morphology' to retinal bipolar neuron
+
+
Axioms add lines to the ontology, resulting in larger ontologies that are harder to use. They also add redundancy, making the ontology hard to maintain as a single change in classification might require multiple edits.
Asserted is_a parents do not need to be retained as entries in the 'SubClass of' section of the Description window in Protégé if the logical definition for a term results in their inference.
+
For example, cerebral cortex GABAergic interneuron has the following logical axioms:
+
Equivalent_To
+ 'GABAergic interneuron' and
+ ('has soma location' some 'cerebral cortex')
+
+
We do not need to assert that it is a cerebral cortex neuron, CNS interneuron, or neuron of the forebrain as the reasoner automatically does that.
+
We avoid having asserted subclass axioms as these are redundant lines in the ontology which can result in a larger ontology, making them harder to use.
+
Good practice to let the reasoner do the work:
+
1) If you create a logical definition for your term, you should delete all redundant, asserted is_a parent relations by clicking on the X to the right of the term.
+2) If an existing term contains a logical definition and still shows an asserted is_a parent in the 'SubClass of' section, you may delete that asserted parent. Just make sure to run the Reasoner to check that the asserted parent is now replaced with the correct reasoned parent(s).
+3) Once you synchronize the Reasoner, you will see the reasoned classification of your new term, including the inferred is_a parent(s).
+4) If the inferred classification does not contain the correct parentage, or doesn't make sense, then you will need to modify the logical definition.
+
Ontologies come in different serialisations, formalisms, and variants For example, their are a full 9 (!) different release files associated with an ontology released using the default settings of the Ontology Development Kit, which causes a lot of confusion for current and prospective users.
+
Note: In the OBO Foundry pages, "variant" is currently referred to as "products", i.e. the way we use "variant" here is synonymous with with notion of "product".
A formalism or formal language can be used to describe entities and their relationships in an ontology. The most important formalisms we have are:
+
Web Ontology Language (OWL): OWL is by far the dominant formalism in the biomedical domain due to its inference capabilities.
+
RDF(S): Is a generally weaker language than OWL, but widely used by triple stores and other SPARQL engines. RDF(S) is lacking some of the strong logical guarantees that come with OWL and should only be used in scenarios where scalability (computation time) is the primary concern.
+
OBO: OBO used to be the dominant language in the biomedical domain before the advent of OWL. I also used to have its own specific semantics associated with it. OBO semantics have since been mapped into OWL semantics, so that for all practical purposes, we consider "OBO" now a dialect of OWL, which means that when you hear 'OBO format' today, we are generally referring to the serialisation (see below), NOT the formalism. Note that when we say OBO ontologies we mean literally Open Biomedical and Biological Ontologies, and NOT Ontology in OBO format.
+
+
Some people like to also list SHACL and Shex as ontology languages and formalism. Formalisms define syntax (e.g. grammar rules) and semantics (what does what expression mean?). The analogue in the real world would be natural languages, like English or Greek.
+
+
A format, or serialisation of a language is used to write down statements of a formal language in some way. Formats are not formalisms - they simply enable statements in a formalism to be expressed in some (usually textual) way. The most common formats in our domains are:
+
RDF/XML. This is the default serialisation language of the OWL flavours of OBO ontologies. It is a pretty ugly format, really hard to understand by most users but it has one advantage - it can be understood widely by RDF-focused tools like rdflib, OWL-focused tools like those based on the OWL API
+
OWL Functional Syntax: This is very common syntax for editing ontologies in OWL, because they look nice in diff tools such as git diff, i.e changes to ontologies in functional syntax are much easier to be reviewed. RDF/XML is not suitable for manual review, due to its verbosity and complexity.
+
OWL Manchester Syntax: This is the default language for OWL tutorials and for writing class expressions in editors such as Protege
+
OBO Format: The most easy to read of all the serialisations. In many ontologies such as Mondo and Uberon, we still use OBO as the editors format (as opposed to OWL Functional Syntax, which is more wide-spread). OBO format looks clear and beautiful in diffs such as git diffs, and therefore still continues to be wide-spread. OBO Format does not cover all of owl, and should only be used in conjunction with ontologies that stay within the limit of the OBO format specification.
+
OBO Graphs JSON: A simple JSON serialisation of ontologies. This format roughly reflects the capabilities of the OBO format, but is intended for consumption by tools. Again, it does not cover all of OWL, but it does cover the parts that are relevant in 99% of the use cases.
+
+
The real-world analogue of serialisation or format is the script, i.e. Latin or Cyrillic script (not quite clean analogue).
+
+
A variant is a version of the ontology exported for a specific purpose. The most important variants are:
+
Edit: The variant of the ontology that is edited by ontology curators. Its sole purpose is to be used by ontology editors, and should not be used by any other application. In a ODK-style repository, the edit file is typically located hidden from view, e.g. src/ontology/cl-edit.owl.
+
Full: The ontology with all its imports merged in, and classified using a reasoner, see docs. The Full variant should be used by users that require the use of reasoners and a guarantee that all the inferences work as intended by the ontology developers. This is the default variant of most OBO ontologies.
+
Base: The axioms belonging to the ontology, excluding any axioms from imported ontologies, see docs. Base variants are used by ontology repository developers to combine the latest versions of all ontologies in a way that avoids problems due to conflicting versions. Base files should not be used by users that want to use the ontology in downstream tools, such as annotation tools or scientific databases, as they are incomplete, i.e. not fully classified.
+
Simple: A version of the ontology that only contains only a subset of the ontology (only the direct relations, see docs). The simple variant should be used by most users that build tools that use the ontology, especially when serialised as OBO graphs json. This variant should probably be avoided by power-users working with reasoners, as many of the axioms that drive reasoning are missing.
+
Basic: A variant of Simple, in that it is reduced to only a specific set of relations, such as subClassOf and partOf. Some users that require the ontology to correspond to acyclic graphs, or deliberately want to focus only on a set of core relations, will want to use this variant, see docs). The formal definition of the basic variant can be found here.
+
Other variants: Some variants are still used, like "non-classified", see docs), but should be avoided. Others like base-plus, a variant that corresponds to base + the inferred axioms, are still under development, and will be explained here when they are fully developed.
Tool developers developing tools that use the ontology (and do not need reasoners), such as database curation tools, web-browsers and similar, should typically use OBO graphs JSON and avoid using OBO format or any of the OWL focussed serialisations (Functional, Manchester or RDF/XML). OWL-focussed serialisations contain a huge deal of axiomatic content that make no sense to most users, and can lead to a variety of mistakes. We have seen it many times that software developers try to interpret OWL axioms somehow to extract relations. Do not do that! Work with the ontologies to ensure they provide the relationships you need in the appropriate form.
+
Tool developers building tools to work with ontologies should typically ensure that they can read and write RDF/XML - this is the most widely understood serialisation. Work with ontologies means here 'enable operations that change the content of the ontology'.
+
Tool developers building infrastructure to query across ontologies should consider using base variants - these ensure that you can always use the latest version of each ontology and avoid most of the common version clashes. It is important that such users are keenly aware of the role of OWL reasoning in such a process.
+
Many users of ontologies think they need the reasoner actually don't. Make sure you consult with an expert before building a system that relies on OWL reasoners to deliver user facing services.
+
As an ontology developer, it is great practice to provide the above variants in the common serialisations. The Ontology Development Kit provides defaults for all of these.
+
As an ontology developer, you should avoid publishing your ontology with owl:imports statements - these are easily ignored by your users and make the intended "content" of the ontology quite none-transparent.
the semantics of it is given by the following Venn diagram:
+
+
Thus, the semantics is given by the subset relationship, stating the C is a subset of D. This means every individual
+of C is necessarily an individual of D, but not every individual of D is necessarily an individual of C.
There are at least 2 scenarios which at first glance may seem like C SubClassOf D holds, but it does not hold, or
+using C EquivalentTo D may be a better option.
+
+
This is typically where C has many individuals that are in D, but there is at least 1 individual of C that is
+not in D. The following Venn diagram is an example. Thus, to check whether you may be dealing with this scenario, you
+can ask the following question: Is there any individual in C that is not in D? If 'yes', you are dealing with this
+scanario and you should not be using C SubClassOf D.
+
+
+
+
When you have determined that (1) does not hold, you may deal with the scenario where not only is every individual of
+C in D, but also every individual in D is in C. This means C and D are equivalent. In the case you rather want
+to make use of EquivalentTo.
Taxon restrictions (or, "taxon constraints") are a formalised way to record what species a term applies to—something crucial in multi-species ontologies.
+
Even species neutral ontologies (e.g., GO) have classes that have implicit taxon restriction.
+
GO:0007595 ! Lactation - defined as “The secretion of milk by the mammary gland.”
+
Finding inconsistencies. Taxon restrictions use terms from the NCBI Taxonomy Ontology, which asserts pairwise disjointness between sibling taxa (e.g., nothing can be both an insect and a rodent). When terms have taxon restrictions, a reasoner can check for inconsistencies.
Defining taxon-specific subclasses. You can define a taxon-specific subclass of a broader concept, e.g., 'human clavicle'. This allows you, for example, to assert relationships for the new term that don't apply to all instances of the broader concept:
+
'human clavicle' EquivalentTo ('clavicle bone' and ('in taxon' some 'Homo sapiens'))
+'human clavicle' SubClassOf ('connected to' some sternum)
+
+
+
+
Creating SLIMs. Use a reasoner to generate ontology subsets containing only those terms that are logically allowed within a given taxon.
+
+
+
Querying. Facet terms by taxon. E.g., in Brain Data Standards, in_taxon axioms allow faceting cell types by species. (note: there are limitations on this and may be incomplete).
There are, in essence, three categories of taxon-specific knowledge we use across OBO ontologies. Given a class C, which could be anything from an anatomical entity to a biological process, we have the following categories:
Meaning: "All instances of C are in some instance of taxon T"
+
As this is a relation between instances, it may have been more correct to give this property a label such as "in organism".
+
Canonical logical representation:
+
C SubClassOf (in_taxon some T)
+
+
Alternative representations: None
+
Editor guidance: Editors use the canonical logical representation in a SubClassOf axiom to add a taxon restriction, or in a simple (non-nested) EquivalentClass axiom to define a taxon-specific subclass (which will also imply the taxon restriction). When used in a SubClassOf axiom, the taxon should be as specific as possible for the maximum utility, but may still need to be quite broad, as it applies to every instance of C.
+
+
The NOT-IN restriction: "C SubClassOf (not (in_taxon some T))"¶
+
+
Meaning: "No instances of C are in taxon T"
+
Canonical logical representation:
+
C SubClassOf (not (in_taxon some T))`
+
+
Alternative representations:
+
Alternative EL logical representation: C DisjointWith (in_taxon some T)
+
EL helper axiom: C SubClassOf (in_taxon some (not T))
+
Canonical shortcut: AnnotationAssertion: C never_in_taxon T # Editors use this
+
+
+
Editor guidance: Editors use the canonical shortcut (annotation axiom). For never_in_taxon annotations, the taxon should be as broad as possible for the maximum utility, but it must be the case that a C is never found in any subclass of that taxon.
+
+
The SOME-IN restriction: "a ClassAssertion: C and in_taxon some T"¶
+
+
Meaning: "At least one specific instance of C is in taxon T".
+
Canonical logical representation:
+
IND:a Type (C and (in_taxon some T))`
+
+
Alternative representations:
+
Generated subclass for QC purposes: C_in_T SubClassOf (C and (in_taxon some T) (C_in_T will be unsatisifiable if violates taxon constraints)
+
Canonical shortcut: AnnotationAssertion: C present_in_taxon T # Editors use this
+
+
+
Editor guidance: Editors use the canonical shorcut (annotation axiom). The taxon should be as specific as possible, ideally a species.
As stated above, one of the major applications for taxon restrictions in OBO is for quality control (QC), by finding logical inconsistencies. Many OBO ontologies consist of a complex web of term relationships, often crossing ontology boundaries (e.g., GO biological process terms referencing Uberon anatomical structures or CHEBI chemical entities). If particular terms are only defined to apply to certain taxa, it is critical to know that a chain of logic implies that the term must exist in some other taxon which should be impossible. Propagating taxon restrictions via logical relationships greatly expands their effectiveness (the GO term above may acquire a taxon restriction via the type of anatomical structure in which it occurs).
+
It can be helpful to think informally about how taxon restrictions propagate over the class hierarchy. It's different for all three types:
+
+
ALL-IN restrictions (in_taxon) include all superclasses of the taxon, and all subclasses of the subject term:
+
%% Future editors, note that link styles are applied according to the link index, so be careful if adding or removing links.
+ graph BT;
+ n1(hair) ;
+ n2(whisker) ;
+ n3(Mammalia) ;
+ n4(Tetrapoda) ;
+ n2--is_a-->n1 ;
+ n3--is_a-->n4 ;
+ n1==in_taxon==>n3 ;
+ n1-.in_taxon.->n4 ;
+ n2-.in_taxon.->n3 ;
+ n2-.in_taxon.->n4 ;
+ linkStyle 0 stroke:#999 ;
+ linkStyle 1 stroke:#999 ;
+ style n1 stroke-width:4px ;
+ style n3 stroke-width:4px ;
+
NOT-IN restrictions (never_in_taxon) include all subclasses of the taxon, and all subclasses of the subject term:
+
%% Future editors, note that link styles are applied according to the link index, so be careful if adding or removing links.
+ graph BT;
+ n1(facial whisker) ;
+ n2(whisker) ;
+ n3(Homo sapiens) ;
+ n4(Hominidae) ;
+ n1--is_a-->n2 ;
+ n3--is_a-->n4 ;
+ n2==never_in_taxon==>n4 ;
+ n2-.never_in_taxon.->n3 ;
+ n1-.never_in_taxon.->n4 ;
+ n1-.never_in_taxon.->n3 ;
+ linkStyle 0 stroke:#999 ;
+ linkStyle 1 stroke:#999 ;
+ style n2 stroke-width:4px ;
+ style n4 stroke-width:4px ;
+
SOME-IN restrictions (present_in_taxon) include all superclasses of the taxon, and all superclasses of the subject term:
+
%% Future editors, note that link styles are applied according to the link index, so be careful if adding or removing links.
+ graph BT;
+ n1(hair) ;
+ n2(whisker) ;
+ n3(Felis) ;
+ n4(Carnivora) ;
+ n2--is_a-->n1 ;
+ n3--is_a-->n4 ;
+ n2==present_in_taxon==>n3 ;
+ n1-.present_in_taxon.->n3 ;
+ n2-.present_in_taxon.->n4 ;
+ n1-.present_in_taxon.->n4 ;
+ linkStyle 0 stroke:#999 ;
+ linkStyle 1 stroke:#999 ;
+ style n2 stroke-width:4px ;
+ style n3 stroke-width:4px ;
+
+
The Relation Ontology defines number of property chains for the in_taxon property. This allows taxon restrictions to propagate over other relationships. For example, the part_of o in_taxon -> in_taxon chain implies that if a muscle is part of a whisker, then the muscle must be in a mammal, but not in a human, since we know both of these things about whiskers:
+
%% Future editors, note that link styles are applied according to the link index, so be careful if adding or removing links.
+ graph BT;
+ n1(hair) ;
+ n2(whisker) ;
+ n3(Mammalia) ;
+ n4(Homo sapiens) ;
+ n5(Hominidae) ;
+ n6(whisker muscle) ;
+ n2--is_a-->n1 ;
+ n5--is_a-->n3 ;
+ n4--is_a-->n5 ;
+ n6--part_of-->n2 ;
+ n1==in_taxon==>n3 ;
+ n2==never_in_taxon==>n5 ;
+ n2-.in_taxon.->n3 ;
+ n6-.in_taxon.->n3 ;
+ n6-.never_in_taxon.->n4 ;
+ n2-.never_in_taxon.->n4 ;
+ n6-.never_in_taxon.->n5 ;
+ linkStyle 0 stroke:#999 ;
+ linkStyle 1 stroke:#999 ;
+ linkStyle 2 stroke:#999 ;
+ linkStyle 3 stroke:#008080 ;
+ style n6 stroke-width:4px ;
+
Property chains are the most common way in which taxon restrictions propagate across ontology boundaries. For example, Gene Ontology uses various subproperties of results in developmental progression of to connect biological processes to Uberon anatomical entities. Any taxonomic restrictions which hold for the anatomical entity will propagate to the biological process via this property.
+
The graph depictions in the preceding illustrations are informal; in practice never_in_taxon and present_in_taxon annotations are translated into more complex logical constructions using the in_taxon object property, described in the next section. These logical constructs allow the OWL reasoner to determine that a class is unsatisfiable when there are conflicts between taxon restriction inferences.
+
Implementation and reasoning with taxon restrictions¶
+
The OWL axioms required to derive the desired entailments for taxon restrictions are somewhat more complicated than one might expect. Much of the complication is the result of workarounds to limitations dictated by the OWL EL profile. Because of the size and complexity of many of the ontologies in the OBO Library, particularly those heavily using taxon restrictions, we primarily rely on the ELK reasoner, which is fast and scalable since it implements OWL EL rather than the complete OWL language. In the following we discuss the particular kinds of axioms required in order for taxon restrictions to work with ELK, with some comments about how it could work with HermiT (which implements the complete OWL language but is much less scalable). We will focus on this example ontology:
There are three classes outlined in red which were created mistakenly; the asserted taxon for each of these conflicts with taxon restrictions in the rest of the ontology:
+
+
'whisker in human' — We expect this to be unsatisfiable since it is a subclass of 'whisker', which has a 'never in Hominidae' restriction. 'Whisker in human' is asserted to be in_taxon 'Homo sapiens', a subclass of 'Hominidae'.
+
'whisker in catfish' — We expect this to be unsatisfiable since it is a subclass of 'whisker', and thus a subclass of 'hair'. 'Hair' has an 'only in Mammalia' restriction. 'Whisker in catfish' is asserted to be in_taxon 'Siluriformes' (catfish), which is a subclass of Teleostei and thus disjoint from 'Mammalia'.
+
'whisker muscle in human' — We expect this to be unsatisfiable since it is a 'whisker muscle' and thus part of a 'whisker', and thus inherits the 'never in Hominidae' restriction from 'whisker' via the property chain part_of o in_taxon -> in_taxon. This conflicts with its asserted in_taxon 'Homo sapiens', a subclass of 'Hominidae'.
We can start by modeling the two taxon restrictions in the ontology like so:
+
+
'hair' 'in_taxon' 'Mammalia': 'hair' SubClassOf (in_taxon some 'Mammalia')
+
'whisker' 'never_in_taxon' 'Mammalia': 'whisker' SubClassOf (not (in_taxon some 'Hominidae'))
+
+
Both HermiT and ELK can derive that 'whisker in human' is unsatisfiable. This is the explanation:
+
+
'human whisker' EquivalentTo ('whisker' and (in_taxon some 'Homo sapiens'))
+
'Homo sapiens' SubClassOf 'Hominidae'
+
'whisker' SubClassOf (not ('in_taxon' some 'Hominidae'))
+
+
Unfortunately, neither reasoner detects the other two problems. We'll address the 'whisker in catfish' first. The reasoner infers that this class is in_taxon both 'Mammalia' and 'Siluriformes'. While these are disjoint classes (all sibling taxa are asserted to be disjoint in the taxonomy ontology), there is nothing in the ontology stating that something can only be in one taxon at a time. The most intuitive solution to this problem would be to assert that in_taxon is a functional property. However, due to limitations of OWL, functional properties can't be used in combination with property chains. Furthermore, functional properties aren't part of OWL EL. There is one solution that works for HermiT, but not ELK. We could add an axiom like the following to every "always in taxon" restriction:
+
+
'hair' SubClassOf (in_taxon only 'Mammalia')
+
+
This would be sufficient for HermiT to detect the unsatisfiability of 'whisker in catfish' (assuming taxon sibling disjointness). Unfortunately, only restrictions are not part of OWL EL. Instead of adding the only restrictions, we can generate an extra disjointness axiom for every taxon disjointness in the taxonomy ontology, e.g.:
+
+
(in_taxon some 'Tetrapoda') DisjointWith (in_taxon some 'Teleostei')
+
+
The addition of axioms like that is sufficient to detect the unsatisfiability of 'whisker in catfish' in both HermiT and ELK. This is the explanation:
+
+
'whisker in catfish' EquivalentTo ('whisker' and (in_taxon some 'Siluriformes'))
+
'whisker' SubClassOf 'hair'
+
'hair' SubClassOf (in_taxon some 'Mammalia')
+
'Mammalia' SubClassOf 'Tetrapoda'
+
'Siluriformes' SubClassOf 'Teleostei'
+
(in_taxon some 'Teleostei') DisjointWith (in_taxon some 'Tetrapoda')
+
+
While we can now detect two of the unsatisfiable classes, sadly neither HermiT nor ELK yet finds 'whisker muscle in human' to be unsatisfiable, which requires handling the interaction of a "never" assertion with a property chain. If we were able to make in_taxon a functional property, HermiT should be able to detect the problem; but as we said before, OWL doesn't allow us to combine functional properties with property chains. The solution is to add even more generated disjointness axioms, one for each taxon (in combination with the extra disjointness we added in the previous case), e.g.,:
+
+
(in_taxon some Hominidae) DisjointWith (in_taxon some (not Hominidae))
+
+
While that is sufficient for HermiT, for ELK we also need to add another axiom to the translation of each never_in_taxon assertion, e.g.,:
+
+
'whisker' SubClassOf (in_taxon some (not 'Hominidae'))
+
+
Now both HermiT and ELK can find 'whisker muscle in human' to be unsatisfiable. This is the explanation from ELK:
+
+
'whisker muscle in human' EquivalentTo ('whisker muscle' and (in_taxon some 'Homo sapiens'))
+
'Homo sapiens' SubClassOf 'Hominidae'
+
'whisker muscle' SubClassOf (part_of some 'whisker')
+
'whisker' SubClassOf (in_taxon some ('not 'Hominidae'))
+
part_of o in_taxon SubPropertyOf in_taxon
+
(in_taxon some 'Hominidae') DisjointWith (in_taxon some (not 'Hominidae'))
The above example didn't incorporate any present_in_taxon (SOME-IN) assertions. These work much the same as ALL-IN in_taxon assertions. However, instead of stating that all instances of a given class are in a taxon (C SubClassOf (in_taxon some X)), we either state that there exists an individual of that class in that taxon, or that there is some subclass of that class whose instances are in that taxon:
+
+
+
<generated individual IRI> Type (C and (in_taxon some X)) — violations involving this assertion will make the ontology logically inconsistent.
+
or
+
+
+
<generated class IRI> SubClassOf (C and (in_taxon some X)) — violations involving this assertion will make the ontology logically incoherent, i.e., a named class is unsatisfiable (here, <generated class IRI>).
+
+
+
Incoherency is easier to debug than inconsistency, so option 2 is the default expansion for present_in_taxon.
+
In summary, the following constructs are all needed for QC using taxon restrictions:
+
+
Relation Ontology
+
in_taxon property chains for relations which should propagate in_taxon inferences
+
+
+
NCBI Taxonomy Ontology
+
X DisjointWith Y for all sibling taxa X and Y
+
(in_taxon some X) DisjointWith (in_taxon some Y) for all sibling taxa X and Y
+
(in_taxon some X) DisjointWith (in_taxon some (not X)) for every taxon X
+
+
+
Each ALL-IN taxon restriction C in_taxon X
+
C SubClassOf (in_taxon some X)
+
+
+
Each NOT-IN taxon restriction C never_in_taxon X
+
C SubClassOf (not (in_taxon some X))
+
C SubClassOf (in_taxon some (not X))
+
+
+
Each SOME-IN taxon restriction C present_in_taxon X)
+
<generated class IRI> SubClassOf (C and (in_taxon some X))
If you are checking an ontology for coherency in a QC pipeline (such as by running ROBOT within the ODK), you will need to have the required constructs from the previous section present in your import chain:
+
+
Relation Ontology
+ — import as usual
+
NCBI Taxonomy Ontology
+
import the main taxonomy (http://purl.obolibrary.org/obo/ncbitaxon.owl)
+
import http://purl.obolibrary.org/obo/ncbitaxon/subsets/taxslim-disjoint-over-in-taxon.owl (or implement a way to generate the needed disjointness axioms)
+
Note: that file only covers a subset of the taxonomy, and is missing (in_taxon some X) DisjointWith (in_taxon some (not X)). You may need to implement a way to generate the needed disjointness axioms until this is corrected.
+
+
+
+
+
Your own taxon restrictions within your ontology:
+
ALL-IN taxon restrictions require no expansion. If you are using the never_in_taxon and present_in_taxon shortcut annotation properties, you can expand these into the logical forms using robot expand.
+
Because present_in_taxon expansions add named classes to your ontology, you will probably want to organize your pipeline in such a way that this expansion only happens in a QC check, and the output is not included in your published ontology.
Using the DL Query panel and a running reasoner, it is straightforward to check whether a particular taxon restriction holds for a term (such as when someone has requested one be added to your ontology). Given some term of interest, e.g., 'whisker', submit a DL Query such as 'whisker' and (in_taxon some Mammalia). Check the query results:
+
+
If Equivalent classes includes owl:Nothing, then a never_in_taxon is implied for that taxon.
+
If Equivalent classes includes the term of interest itself (and not owl:Nothing), then an in_taxon is implied for that taxon.
+
If Superclasses includes the term of interest (and the query isn't equivalent to owl:Nothing), then there is no particular taxon restriction involving that taxon.
To quickly see exactly which taxon restrictions are in effect for a selected term, install the OBO taxon constraints plugin for Protégé. Once you have the plugin installed, you can add it to your Protégé window by going to the menu Window > Views > OBO views > Taxon constraints, and then clicking the location to place the panel. The plugin will show the taxon constraints in effect for the selected OWL class. When a reasoner is running, any inferred taxon constraints will be shown along with directly asserted ones. The plugin executes many reasoner queries behind the scenes, so there may be a delay before the user interface is updated.
Comments are annotations that may be added to ontology terms to further explain their intended usage, or include information that is useful but does not fit in areas like definition.
+
Some examples of comments, and possible standard language for their usage, are:
+
WARNING: THESE EXAMPLES ARE NOT UNIVERSALLY USED AND CAN BE CONTROVERSIAL IN SOME ONTOLOGIES! PLEASE CHECK WITH THE CONVENTIONS OF YOUR ONTOLOGY BEFORE DOING THIS!
This term should not be used for direct annotation. It should be possible to make a more specific annotation to one of the children of this term.
+
Example:
+GO:0006810 transport
+
Note that this term should not be used for direct annotation. It should be possible to make a more specific annotation to one of the children of this term, for e.g. transmembrane transport, microtubule-based transport, vesicle-mediated transport, etc.
This term should not be used for direct manual annotation. It should be possible to make a more specific manual annotation to one of the children of this term.
+
Example:
+GO:0000910 cytokinesis
+
Note that this term should not be used for direct annotation. When annotating eukaryotic species, mitotic or meiotic cytokinesis should always be specified for manual annotation and for prokaryotic species use 'FtsZ-dependent cytokinesis; GO:0043093' or 'Cdv-dependent cytokinesis; GO:0061639'. Also, note that cytokinesis does not necessarily result in physical separation and detachment of the two daughter cells from each other.
Information about the term that do not belong belong in the definition or gloss, but are useful for users or editors. This might include information that is adjacent to the class but pertinent to its usage, extended information about the class (eg extended notes about a characteristic of a cell type) that might be useful but does not belong in the definition, important notes on why certain choices were made in the curation of this terms (eg why certain logical axioms were excluded/included in the way they are) (Note: dependent on ontology, some of these might belong in editors_notes, etc.).
+
Standard language for these are not given as they vary dependent on usage.
As a rule of thumb, for every single problem/term/use case, you will have 3-6 options to choose from, in some cases even more. The criteria for selecting a good ontology are very much dependent on your particular use case, but some concerns are generally relevant. A good first pass is to apply to "10 simple rules for selecting a Bio-ontology" by Malone et al, but I would further recommend to ask yourself the following:
+
+
Do I need the ontology for grouping and semantic analysis? In this case a high quality hierarchy reflecting biological subsumption is imperative. We will explain later what this means, but in essence, you should be able to ask the following question: "All instances/occurrences of this concept in the ontology are also instances of all its parent classes. Everything that is true about the parent class is always also true about instances of the children." It is important for you to understand that, while OWL semantics imply the above, OWL is difficult and many ontologies "pretend" that the subclass link means something else (like a rule of thumb grouping relation).
+
Can I handle multiple inheritance in my analysis? While I personally recommend to always consider multiple inheritance (i.e, allow a term to have more than one parent class), there are some analysis frameworks, in particular in the clinical domain, that make this hard. Some ontologies are inherently poly-hierarchical (such as Mondo), while others strive to be single inheritance (DO, ICD).
+
Are key resources I am interested in using the ontology? Maybe the most important question that will drastically reduce the amount of data mapping work you will have to do: Does the resource you wish to integrate already annotate to a particular ontology? For example, EBI resources will be annotating phenotype data using EFO, which in turn used HPO identifiers. If your use case demands to integrate EBI databases, it is likely a good idea to consider using HPO as the reference ontology for your phenotype data.
+
+
Aside from aspects of your analysis, there is one more thing you should consider carefully: the open-ness of your ontology in question. As a user, you have quite a bit of power on the future trajectory of the domain, and therefore should seek to endorse and promote open standards as much as possible (for egotistic reasons as well: you don't want to have to suddenly pay for the ontologies that drive your semantic analyses). It is true that ontologies such as SNOMED have some great content, and, even more compellingly, some really great coverage. In fact, I would probably compare SNOMED not with any particular disease ontology, but with the OBO Foundry as a whole, and if you do that, it is a) cleaner, b) better integrated. But this comes at a cost. SNOMED is a commercial product - millions are being paid every year in license fees, and the more millions come, the better SNOMED will become - and the more drastic consequences will the lock-in have if one day you are forced to use SNOMED because OBO has fallen too far behind. Right now, the sum of all OBO ontologies is probably still richer and more valuable, given their use in many of the central biological databases (such as the ones hosted by the EBI) - but as SNOMED is seeping into the all aspects of genomics now (for example, it will soon be featured on OLS!) it will become increasingly important to actively promote the use of open biomedical ontologies - by contributing to them as well as by using them.
Writing a good ticket (or issue) is crucial to good management of a repo. In this explainer, we will discuss some good practices in writing a ticket and show examples of what not to do.
Search existing issues before creating a new one -- maybe someone else already reported your problem
+
Give your issue a short but descriptive and actionable title
+
Describe the problem and the context and include a repeatable example.
+
Clearly state what needs to be done to close the ticket
+
Tickets should ideally be actionable units that can be closed via a PR
+
Fag relevant people with @ (e.g., @nlharris)
+
Mention related issues with # (e.g., #123)
+
use a complete URL to link to tickets in other repos
+
Make issue titles actionable
+
eg "Ontology download page on GO website" is non-actionable, whereas "Fix URLs on ontology download page on GO website" is actionable and hence better a title
The OBOOK is trying to centralise all OBO documentation in one place. It is, and will be, a big construction site, for years to come. The goal is to iterate and make things better.
Our materials are organised in a certain way (according to the four-way split suggested by Diataxis).
+
We superimpose three more categories to organise the content across all materials and facilitate self guided studying: Pathways, courses and lessons (see below).
+
All training materials must be self-contained to ensure that they can be studied without any further guidance by a teacher.
We just introduced a new concept to OBOOK called pathways. The idea is that we provide a linear guide for all 6 roles mentioned on the getting started page through the materials. This will help us also complete the materials and provide a good path to reviewing them regularly.
A step-by-step guide to complete a well-defined mini-project. Examples: ROBOT template tutorial. DOSDP template tutorial. Protege tutorial on using the reasoner.
A collection of materials (tutorials, explanations and how-to-guides) that together seek to teach a well defined concept. Examples: Contributing to OBO ontologies; An Introduction to templates in OBO; An Introduction to OBO Application development. While the distinction to "tutorial" is often fuzzy, the main distinguishing feature should be that a lesson conveys a general concept independent of some concrete technology stack. While we use concrete examples in lessons, we do always seek to generalise to problem space.
A convenience content type that allows us to assemble materials from obook for a specific taught unit, such as the yearly ICBO tutorials, or the ongoing Monarch Ontology Tutorials and others. Course pages serve as go-to-pages for course participants and link to all the relevant materials in the documentation. Course usually comprise lessons, tutorials and how-to guides.
A pathway is a kind of course, but without the expectation that it is ever taught in a concrete setting. A pathways pertains to a single concrete role (Ontology Curator, Pipeline Developer etc). It is a collection of materials (lessons, tutorials, how-to-guides) that is ordered in a linear fashion for the convenience of the student. For example, we are developing a pathway for ontology pipeline developers that start by teaching common concepts such as how to make term requests etc, and then go into depth on ROBOT pipelines, ODK and Make.
Before you start with the lessons of this course, keep the following in mind:
+
+
The materials in this course are all intended to be used for self-study. We sometimes offer flipped-classroom sessions for new members on our teams - this means that we expect them to work through the entire course themselves and then come to us with questions and requests for clarifications.
+
There is no need to reinvent the wheel: there are a lot of great materials out there already. Providing references to these external resources is an essential part of the course - some lessons primarily comprise external tutorials, blog articles and more - please make sure you take advantage of them.
+
Some of the materials developed by us are a bit rough around the edges, and we need your help to fix and improve them. To that end, we appreciate anything from suggestions for improvement to pull requests.
developing design patterns for ontologies, specifying the logical structure of terms
+
responsible for ensuring the specification and consistent application of metadata in your ontologies (which annotation properties to use, minimal metadata standards)
Of course, many of you will occupy more than one of the above "hats" or roles. While they all require specialised training, many shared skill requirements exist. This course is being developed to:
+
+
Provide basic training for OBO Semantic Engineers of any of the above flavours
+
Provide an entry point for people new to the field, for example as part of onboarding activities for projects working with ontologies
+
Capture some of the typical pitfalls and how-to's guides to address common problems across the OBO-sphere
In the main Protégé window, click on the "Entities" tab. Below that, click the "Annotation properties" tab.
+
+
+
Select the subset_property annotation property.
+
+
+
Click on the "Add sub property" button.
+
+
+
In the pop-up window, add the name of the new slim. The IRI will automatically populate according to settings in the user's "New entities" settings. Click OK.
+
+
+
With the newly created annotation property selected, click on "Refactor > Rename entity..." in the menu.
+
+
+
In the pop-up window, select the "Show full IRI" checkbox. The IRI will appear.
+Edit the IRI to fit the following standard:
For example, in CL, the original IRI will appear as:
+
http://purl.obolibrary.org/obo/CL_1234567
+
If the subset was labeled "kidney_slim", the IRI should be updated to:
+
http://purl.obolibrary.org/obo/cl#kidney_slim
+
+
+
In the 'Annotations" window, click the + next to "Annotations".
+
+
+
In the pop-up window, select the rdfs:comment annotation property. Under "Value" enter a brief descripton for the slim. Under "Datatype" select xsd:string. Click OK.
In the main Protégé window, click on the "Entities" tab. Select the class that is to be added to a subset (slim).
+
+
+
In the 'Annotations" window, click the + next to "Annotations".
+
+
+
In the pop-up window, select the in_subset annotation property.
+
+
+
Click on the ‘Entity IRI’ tab.
+
+
+
Search for the slim label under "Entity IRI". In the pop-up that appears, double-click on the desired slim. Ensure that a sub property of subset_property is selected. Click OK.
Warning: You should only use this method if the files you are editing are reasonably small (less than 1 MB).
+
This method only works if the file you want to edit has already been editing as part of the pull request.
+
+
Go to the pull request on GitHub, and click on the "Files Changed" tab up top
+
Find the file you want to edit in the pull request.
+
On the right, click on on the three ..., and then "Edit file".
+
+
+
If this option is greyed out, it means that - you don't have edit rights on the repository - the edit was made from a different fork, and the person that created the pull request did not activate the "Allow maintainers to make edits" option when submitting the PR - the pull request has already been merged
+
+
Do the edits, and then commit changes, usually to the same branch
+
If a user forked the repository and created a branch, you can find that branch by going to the branch switcher button in GitHub Desktop, click on Pull Requests (next to Branches) and looking for that pull request
+
+
+
+
Select that pull request and edit the appropriate files as needed and push via the usual workflow.
Navigate to mondo/src/ontology/mondo-edit.obo and open this file in Protege
+ Note: mondo can be replaced with any ontology that is setup using the ODK as their architecture should be the same.
+
+
If this all works okay, you are all set to start editing!
To create a new term, the 'Asserted view' must be active (not the 'Inferred view').
+
+
+
In the Class hierarchy window, click on the 'Add subclass' button at the upper left of the window.
+
+
+
+
+
A pop-up window will appear asking you to enter the Name of the new term. When you enter the term name, you will see your ID automatically populate the IRI box. Once you have entered the term, click 'OK' to save the new term. You will see it appear in the class hierarchy.
+
+
+
+
In the annotation window add:
+
Definition
+
Click on the + next to Annotations
+
Select defintion (if there are multiple, you should use IAO:0000115)
+
Add the textual definition in the pop-up box.
+
Click OK.
+
+
+
+
+
2. Add Definition References
+ 1. Click on the circle with the ‘@’ in it next to definition and in the resulting pop-up click on the ```+``` to add a new ref, making sure they are properly formatted with a database abbreviation followed by a colon, followed by the text string or ID. Examples: ```PMID:27450630```.
+ 2. Click OK.
+ 3. Add each definition reference separately by clicking on the ```+``` sign.
+
+
3. Add synonyms and dbxrefs following the same procedure if they are required for the term.
+
+
Add appropriate logical axioms in the Description by clicking the + sign in the appropriate section (usually SubClass Of) and typing it in, using Tab to autocomplete terms.
+
+
+
Converting to Equivalent To axioms:
+If you want to convert your SubClassOf axioms to EquivalentTo axioms, you can select the appropriate rows and right click, selecting "Convert selected rows to defined class"
+
+
+
+
In some cases, logical axioms reuiqre external ontologies (eg in the above example, the newly added CL term has_soma_location in the cerebellar cortex which is an uberon term), it might be necessary to import the term in. For instructions on how to do this, please see the import managment section of your local ontology documentation (an example of that in CL can be found here: https://obophenotype.github.io/cell-ontology/odk-workflows/UpdateImports/)
+
+
+
When you have finished adding the term, run the reasoner to ensure that nothing is problematic with the axioms you have added (if there is an issue, you will see it being asserted under owl:Nothing)
+
+
+
Save the file on protege and review the changes you have made in your Github Desktop (or use git diff in your terminal if you do not use Github Desktop)
+
+
+
See Daily Workflow section for commit, push and merge instructions.
This is a guide to build an OBO ontology from scratch. We will focus on the kind of thought processes you want to go through, and providing the following:
Scope is one of the hardest and most debated subjects in the OBO Foundry operation calls. There are essentially two aspects to scope:
+
+
The entities you intended to model belong to some specific biological categories. For example phenotype, disease, anatomical entity, assay, environmental exposure, biological process, chemical entity. Before setting out to build an ontology, you should get a rough sense of what kind of entities you need to describe your domain. However, this is an iterative process and more entities will be revealed later on.
+
The subject domain you intend to model. For example, you may want to provide an ontology to describe the domain of Alzheimer's Disease, which will need many different kinds of biological entities (like anatomical entity and disease classes).
+
+
As a rule of thumb, you should NOT create a term if another OBO ontology has a branch of for entities of the same kind. For example, if you have to add terms for assays, you should work with the Ontology for Biomedical Investigations to add these to their assay branch.
+
Remember, the vision of OBO is to build a semantically coherent ontology for all of biology, and the individual ontologies in the OBO Foundry should be considered "modules" of this super ontology. You will find that while collaboration is always hard the only way for our community to be sustainable and compete with commercial solutions is to take that hard route and work together.
There are many kinds of semantic artefacts that can work for your use case:
+
+
Controlled vocabularies: Creating identifiers for concepts in your domain and without too much concern for logical reasoning. Some examples can be are Linked Open Data Vocabularies (LOV) or schema.org vocabularies. Sometimes a table of identifiers in an SQL database is enough.
+
Thesauri: Describe the synonyms used in your domain in a standardised fashion.
+
Taxonomies: Create a hierarchical categorisations for concepts in your domain, without any specific regards for semantics. You just create a hierarchy that "makes some sense" for your use case. Examples: ICD10, United Nations Standard Products and Services Code (UNSPSC).
+
Semantic data models: If you need to define how terms in your database should be constrained in a semantic way (similar to a database schema), then Shape languages like SHEX or SHACL may be much more suitable for your use case. See LinkML tutorials to get a sense of this: you will build a semantic data model in Yaml which can then be exported to SHACL, OWL or JSON Schema (great tutorial, useful to do no matter what).
+
Ontologies: Sets of logical axioms. If you require formal reasoning (and only then!) does it make sense to jump in the deep pit of ontology engineering. This is, by far, the hardest to build of the bunch. You will have to wrestle with Logic, Open World Assumption and many more arcane subjects.
+
+
Think of it in terms of cost. Building a simple vocabulary with minimal axiomatisation is 10x cheaper than building a full fledged domain model in OWL, and helps solving your use case just the same. Do not start building an ontology unless you have some understanding of these alternatives first.
Do not build an ontology because someone tells you to or because you "think it might be useful". Write out a proper use case description, for example in the form of an agile user story, convince two or three colleagues this is worthwhile and only then get to work. Many ontologies are created for very vague use cases, and not only do they cost you time to build, they also cost the rest of the community time - time it takes them to figure out that they do not want to use your ontology. Often, someone you trust tells you to build one and you believe they know what they are doing - do not do that. Question the use of building the ontology until you are convinced it is the right thing to do. If you do not care about reasoning (either for validation or for your application), do not build an ontology.
Depending on your specific starting points, the way you start will be slightly different, but some common principles apply.
+
+
Write down the use cases for the ontology (see above). This will determine certain design decisions later on. These should be concrete, like: controlled vocabulary for named entity recognition, logical model of a domain, auto-classification of data.
+
Make a table of all similar ontologies that exist, within and outside OBO (this requires research, and is an essential part of the process). Document exactly in what way they are different from your use case, and why you need to build a new one (see none-in-scope condition above).
+
Determine whether you have something to start from. Often, you will have a database with entities you may wish to turn into classes in your ontology. See starting points below.
+
Gather your tools. You need to think about tools for at least two kinds of workflows to start with:
+
Curation workflows: How will you edit your ontology? Some simple ontologies are edited using tables that link to logical templates. Others are edited primarily with Protege.
+
Continuous integration and release workflows: How will you import terms from other ontologies? How will you ensure the quality of you ontology moving forward?
+
Decide on the Ontology ID (important, do not skip). Changing this later can be extremely costly. Refer to the OBO ID policy for details. An ID should be short and unique.
+
Create a basic set-up for managing your workflows. This comprises (usually) three aspects (you may wish to try and use the Ontology Development Kit - it does exactly that):
+
Make a GitHub repository.
+
Add your editors files (owl, tsv, whatever you decided to use) to that repository.
+
Implement some workflow system, i.e. some way to run commands like release or test, as you will run these repeatedly. A typical system to achieve this is make, and many projects choose to encode their workflows as make targets (ODK, OBI Makfile).
+
Determine the metadata and logical patterns you wish to employ for your curation. Here it is important that you determine what kind of an ontology you want to build.
+
+
Note: Later in the process, you also want to think about the following:
There are many different starting points for building an ontology:
+
+
We have a database or a dataset and want to build an ontology that covers entities in that database. As a variation, you have two or more databases that you need to integrate.
+
We already have a basic ontology in our domain (a cell ontology, an anatomy ontology), but need to build an extension (e.g. a species specific extension to an existing cross-species ontology).
+
We have controlled vocabulary or a list of standard or commonly used terms for a domain and want to formalise them in an ontology for interoperability and machine-readability, with versioning support to manage evolution. Sometimes, we may even wish to simply using ontology infrastructure (tools and best practices) to maintain a quite informal vocabulary structure.
+
There are existing ontologies that are, however, not quite fit for purpose (even if they should be) and there's no way to make any of them right, so I have to create Yet Another Variant.
+
We have a large, hierarchical enumeration in a datamodel that pulls terms from many ontologies.
+
We need to build a completely new ontology for a domain that currently does not even have a controlled vocabulary. This case almost never happens nowadays. In this case, all domain knowledge (concepts and their relations) is somewhere in the heads of the experts.
There are two fundamentally different kinds of ontologies which need to be distinguished:
+
+
Project ontologies (sometimes referred to as application ontologies) are ontologies that are developed to fulfil a specific use case, like:
+
Grouping data in your project
+
Indexing search engines or your organisation
+
Informing Natural Language Processing applications
+
Populating the biocuration interface your organisation provides to enable curators to annotate data
+
Domain ontologies are ontologies which seek to model a domain of discourse. In particular they:
+
Reflect scientific consensus and are therefore social and collaborative enterprises subject to change
+
Are build with re-use in mind:
+
They re-use terms from other domain ontologies
+
They provide terms intended for re-use by other ontologies
+
They work with other ontologies on implementing consistent logical patterns that apply across all domain ontologies in the community.
+
+
+
Are logically consistent with all ontologies they depend on, refer to, import.
+
+
Some things to consider:
+
+
It is extremely hard to build domain ontologies. Do not try to do that without a proper sustainability plan (i.e. considerable resources over multiple years).
+
Project ontologies are not bad domain ontologies. Project ontologies can be build according to the same standards as domain ontologies. While controversial, the OBO Foundry is currently (March 2022) debating whether project ontologies are admissible to the OBO ontology library.
+
Project ontologies can have huge impact. One of the most impactful ontologies in the biomedical world is the Experimental Factor Ontology (EFO) - a massive project ontology used for many applications from knowledge graph integration to biocuration.
+
Project ontologies are allowed to change the semantics of imported ontologies, for example by adding additional axioms or even removing some - anything necessary to achieve the use case!
+
Domain ontologies (in the OBO world) are not allowed to change semantics of imported ontologies.
+
Project ontologies can import terms from domain ontologies, and coin their own terms where necessary. This can be a good option if resources are scarce, and there is not enough time for consensus building with the community or the often lengthy contribution workflows. "I just need some terms" usually points to "I need a project ontology".
+
Domain ontologies seek to model a domain exhaustively: any concept that "belongs" to that domain is a strong candidate for a term.
+
+
It is imperative that it is clear which of the two you are building. Project ontologies sold as domain ontologies are a very common practice and they cause a lot of harm for open biomedical data integration.
We will re-iterate some of the steps taken to develop the Vertebrate Breed Ontology. At the time of this writing, the VBO is still in early stages, but it nicely illustrates all the points above.
Similar ontologies. While there is no ontology OBO ontology related to breeds, the Livestock Breed Ontology (LBO) served as an inspiration (much different scale). NCBI taxonomy is a more general ontology about existing taxa as they occur in the wild.
We got a list of breeds from DAD-IS, which includes name of the breed, transboundary name, species, country, and more
+
We first had to understand the data and how the different pieces of data relate to each other.
+
Some breed names are the same, but refer to either different species and/or different countries
+
Several breeds share a common "transboundary name", which represent the original breed from which they come from
+
We needed to determine what a single concept / an indentifiable term would be
+
In order to define a single breed, we needed to include the name of the breed, the transboundary name (when applicable), the species, and the country
+
We needed to understand the metadata and how each concepts relate to each other
+
'breed' is an instance of 'species', therefore 'species' should be the parent term of 'breeds' (using a is_a relation)
+
when applicable, 'transboundary' should be the parent term of 'breeds'
+
Note about the concept of "species": is "species" equivalent to the NCBI Taxon representing "species"?
+ Design decision: Since species represents the same concept as ‘species’ in NCBI, the ontology should be built ‘on top of’ NCBI terms to avoid confusion of concepts and to avoid conflation of terms with the same concept
+
+
Warnings based on our experience:
+
+
Always retain links to original source ids (encoding problems, update problems)
+
Always add provenance to as much information as you can (where do labels come from?)
At first, we chose to name the ontology "Unified Breed Ontology" (UBO). Which meant that for everything from ODK setup to creating identifiers for our terms, we used the UBO prefix. Later in the process, we decided to change the name to "Vertebrate Breed Ontology". Migrating all the terms and the ODK setup from ubo to vbo required some expert knowledge on the workings of the ODK, and created an unnecessary cost. We should have finalised the choice of name first.
Updating the local copy of the ontology with 'git pull'¶
+
+
+
Navigate to the ontology directory of go-ontology: cd repos/MY-ONTOLOGY/src/ontology.
+
+
+
If the terminal window is not configured to display the branch name, type: git status. You will see:
+
+
+
On branch [master] [or the name of the branch you are on]
+ Your branch is up-to-date with 'origin/master'.
+
+
+
If you’re not in the master branch, type: git checkout master.
+
+
+
From the master branch, type: git pull. This will update your master branch, and all working branches, with the files that are most current on GitHub, bringing in and merging any changes that were made since you last pulled the repository using the command git pull. You will see something like this:
Creating a New Working Branch with 'git checkout'¶
+
+
+
When starting to work on a ticket, you should create a new branch of the repository to edit the ontology file.
+
+
+
Make sure you are on the master branch before creating a new branch. If the terminal window is not configured to display the branch name, type: git status to check which is the active branch. If necessary, go to master by typing git checkout master.
+
+
+
To create a new branch, type: git checkout -b issue-NNNNN in the terminal window. For naming branches, we recommend using the string 'issue-' followed by the issue number. For instance, for this issue in the tracker: https://github.com/geneontology/go-ontology/issues/13390, you would create this branch: git checkout -b issue-13390. Typing this command will automatically put you in the new branch. You will see this message in your terminal window:
+
+
+
~/repos/MY-ONTOLOGY/src/ontology(master) $ git checkout -b issue-13390
+Switched to a new branch 'issue-13390'
+~/repos/MY-ONTOLOGY/src/ontology(issue-13390) $
+
If you are continuing to do work on an existing branch, in addition to updating master, go to your branch by typing git checkout [branch name]. Note that you can view the existing local branches by typing git branch -l.
+
+
+
OPTIONAL: To update the working branch with respect to the current version of the ontology, type git pull origin master.
+ This step is optional because it is not necessary to work on the current version of the ontology; all changes will be synchronized when git merge is performed.
+
+
+
Loading, navigating and saving the Ontology in Protégé¶
+
+
+
Before launching Protégé, make sure you are in the correct branch. To check the active branch, type git status.
+
+
+
Click on the 'File' pulldown. Open the file: go-edit.obo. The first time, you will have to navigate to repos/MY-ONTOLOGY/src/ontology. Once you have worked on the file, it will show up in the menu under 'Open'/'Recent'.
+
+
+
Click on the 'Classes' tab.
+
+
+
Searching: Use the search box on the upper right to search for a term in the ontology. Wait for autocomplete to work in the pop-up window.
+
+
+
Viewing a term: Double-click on the term. This will reveal the term in the 'Class hierarchy' window after a few seconds.
+
+
+
Launching the reasoner: To see the term in the 'Class hierarchy' (inferred) window, you will need to run the 'ELK reasoner'. 'Reasoner' > select ELK 0.4.3, then click 'Start reasoner'. Close the various pop-up warnings about the ELK reasoner. You will now see the terms in the inferred hierarchy.
+
+
+
After modification of the ontology, synchronize the reasoner. Go to menu: 'Reasoner' > ' Synchronize reasoner'.
+
+
+
NOTE: The only changes that the reasoner will detect are those impacting the ontology structure: changes in equivalence axioms, subclasses, merges, obsoletions, new terms.
+
+
+
TIP: When adding new relations/axioms, 'Synchronize' the reasoner. When deleting relations/axioms, it is more reliable to 'Stop' and 'Start' the reasoner again.
+
+
+
Use File > Save to save your changes.
+
+
+
+
Committing, pushing and merging your changes to the repository¶
+
+
+
Review: Changes made to the ontology can be viewed by typing git diff in the terminal window. If there are changes that have already been committed, the changes in the active branch relative to master can be viewed by typing git diff master.
+
+
+
Commit: Changes can be committed by typing: git commit -m ‘Meaningful message Fixes #ticketnumber’ go-edit.obo.
+
For example:
+
git commit -m ‘hepatic stellate cell migration and contraction and regulation terms. Fixes #13390’ go-edit.obo
+
+
This will save the changes to the go-edit.obo file. The terminal window will show something like:
NOTE: The word 'fixes' is a magic word in GitHub; when used in combination with the ticket number, it will automatically close the ticket. In the above example, when the file is merged in GitHub, it will close issue number 13390. Learn more on this GitHub Help Documentation page about 'Closing issues via commit messages'.
+
'Fixes' is case-insensitive.
+
If you don't want to close the ticket, just refer to the ticket # without the word 'Fixes'. The commit will be associated with the correct ticket but the ticket will remain open.
+
NOTE: It is also possible to type a longer message than allowed when using the '-m' argument; to do this, skip the -m, and a vi window (on mac) will open in which an unlimited description may be typed.
+
TIP: Git needs to know who is committing changes to the repository, so the first time you commit, you may see the following message:
+
+
Committer: Kimberly Van Auken vanauken@kimberlukensmbp.dhcp.lbnl.us
+ Your name and email address were configured automatically based on your username and hostname. Please check that they are accurate.
Navigate to the tab labeled as 'Code' geneontology/go-ontology/code. You will see your commit listed at the top of the page in a light yellow box. If you don’t see it, click on the 'Branches' link to reveal it in the list, and click on it.
+
Click the green button 'Compare & pull request' on the right.
+
You may now add comments and ask a colleague to review your pull request. If you want to have the ticket reviewed before closing it, you can select a reviewer for the ticket before you make the pull request by clicking on the 'Reviewers' list and entering a GitHub identifier (e.g. @superuser1). The reviewer will be notified when the pull request is submitted. Since the Pull Request is also a GitHub issue, the reviewer’s comments will show up in the dialog tab of the pull request, similarly to any other issue filed on the tracker.
+
The diff for your file is at the bottom of the page. Examine it as a sanity check.
+
Click on the green box 'Pull request' to generate a pull request.
+
Wait for the Travis checks to complete (this can take a few minutes). If the Travis checks failed, go back to your working copy and correct the reported errrors.
+
+
+
+
Merge If the Travis checks are succesful and if you are done working on that branch, merge the pull request. Confirming the merge will close the ticket if you have used the word 'fixes' in your commit comment.
+ NOTE: Merge the branches only when the work is completed. If there is related work to be done as a follow up to the original request, create a new GitHub ticket and start the process from the beginning.
+
+
+
Delete your branch on the repository using the button on the right of the successful merge message.
+
+
+
You may also delete the working branch on your local copy. Note that this step is optional. However, if you wish to delete branches on your local machine, in your terminal window:
+
+
Go back to the master branch by typing git checkout master.
+
Update your local copy of the repository by typing git pull origin master
+
Delete the branch by typing git branch -d workingbranchname.
+ Example: git branch -d issue-13390
Dealing with huge ontologies in your import chain¶
+
Dealing with very large ontologies, such as the Protein Ontology (PR), NCBI Taxonomy (NCBITaxon), Gene Ontology (GO) and the CHEBI Ontology is a big challenge when developing ontologies, especially if we want to import and re-use terms from them. There are two major problems:
+
+
It currently takes about 12–16 GB of memory to process PR and NCBITaxon – memory that many of us do not have available.
+
The files are so large, pulling them over the internet can lead to failures, timeouts and other problems.
+
+
There are a few strategies we can employ to deal with the problem of memory consumption:
+
+
We try to reduce the memory footprint of the import as much as possible. In other words: we try to not do the fancy stuff ODK does by default when extracting a module, and keep it simple.
+
We manage the import manually ourselves (no import)
+
+
To deal with file size, we:
+
+
Instead of importing the whole thing, we import curated subsets.
+
If available, we use gzipped (compressed) versions.
+
+
All four strategies will be discussed in the following. We will then look a bit
+
Overwrite ODK default: less fancy, custom modules¶
+
The default recipe for creating a module looks something like this:
(Note: This snippet was copied here on 10 February 2021 and may be out of date by the time you read this.)
+
As you can see, a lot of stuff is going on here: first we run some preprocessing (which is really costly in ROBOT, as we need to load the ontology into Jena, and then back into the OWL API – so basically the ontology is loaded three times in total), then extract a module, then run more SPARQL queries etc, etc. Costly. For small ontologies, this is fine. All of these processes are important to mitigate some of the shortcomings of module extraction techniques, but even if they could be sorted in ROBOT, it may still not be enough.
+
So what we can do now is this. In your ont.Makefile (for example, go.Makefile, NOT Makefile), located in src/ontology, you can add a snippet like this:
Note that all the % variables and uses of $* are replaced by the ontology ID in question. Adding this to your ont.Makefile will overwrite the default ODK behaviour in favour of this new recipe.
+
The ODK supports this reduced module out of the box. To activate it, do this:
This will (a) ensure that PR is pulled from a gzipped location (you have to check whether it exists though. It must correspond to the PURL, followed by the extension .gz, for example http://purl.obolibrary.org/obo/pr.owl.gz) and (b) that it is considered large, so the default handling of large imports is activated for pr, and you don't need to paste anything into ont.Makefile.
+
If you prefer to do it yourself, in the following sections you can find a few snippets that work for three large ontologies. Just copy and paste them into ont.Makefile, and adjust them however you wish.
Feel free to use an even cheaper approach, even one that does not use ROBOT, as long as it produces the target of the goal (e.g. imports/chebi_import.owl).
For some ontologies, you can find slims that are much smaller than full ontology. For example, NCBITaxon maintains a slim for OBO here: http://purl.obolibrary.org/obo/ncbitaxon/subsets/taxslim.owl, which smaller than the 1 or 2 GB of the full version. Many ontologies maintain such slims, and if not, probably should. (I would really like to see an OBO slim for Protein Ontology!)
+
(note the .obo file is even smaller but currently robot has issues getting obo files from the web)
+
You can also add your favourite taxa to the NCBITaxon slim by simply making a pull request on here: https://github.com/obophenotype/ncbitaxon/blob/master/subsets/taxon-subset-ids.txt
This is a real hack – and we want to strongly discourage it – but sometimes, importing an ontology just to import a single term is total overkill. What we do in these cases is to maintain a simple template to "import" minimal information. I can't stress enough that we want to avoid this, as such information will necessarily go out of date, but here is a pattern you can use to handle it in a sensible way:
+
Add this to your src/ontology/ont-odk.yaml:
+
import_group:
+ products:
+ - id: my_ncbitaxon
+
+
Then add this to src/ontology/ont.Makefile:
+
mirror/my_ncbitaxon.owl:
+ echo "No mirror for $@"
+
+imports/my_ncbitaxon_import.owl: imports/my_ncbitaxon_import.tsv
+ if [ $(IMP) = true ]; then $(ROBOT) template --template $< \
+ --ontology-iri "$(ONTBASE)/$@" --output $@.tmp.owl && mv $@.tmp.owl $@; fi
+
+.PRECIOUS: imports/my_ncbitaxon_import.owl
+
+
Now you can manage your import manually in the template, and the ODK will not include your manually-curated import in your base release. But again, avoid this pattern for anything except the most trivial case (e.g. you need one term from a huge ontology).
+
File is too large: Network timeouts and long runtimes¶
+
Remember that ontologies are text files. While this makes them easy to read in your browser, it also makes them huge: from 500 MB (CHEBI) to 2 GB (NCBITaxon), which is an enormous amount.
+
Thankfully, ROBOT can automatically read gzipped ontologies without the need of unpacking. To avoid long runtimes and network timeouts, we can do the following two things (with the new ODK 1.2.26):
This will try to append .gz to the default download location (http://purl.obolibrary.org/obo/pr.owl → http://purl.obolibrary.org/obo/pr.owl.gz). Note that you must make sure that this file actually exists. It does for CHEBI and the Protein Ontology, but not for many others.
+
If the file exists, but is located elsewhere, you can do this:
Click on Settings > Pages to configure the GitHub pages. Set the Source to deploy from branch, and Branch to build from main (or master if you are still using the old default) and /(root) as directory. Hit Save.
+
+
+
+
Click on the Actions tab in your repo. On the left, select the Run dashboard workflow and click on the Run workflow button. This action will rebuild the dashboard and make a pull request with the changes.
+
+
Review and merge the pull request. Once it is merged, GitHub will automatically rebuild your dashboard website.
+
After 5 minutes, click on "Settings" > "Pages" again. You should now a new section with information where your site is deployed:
+
+
Click on Visit site and you should find your new shiny dashboard page!
Failed: make dashboard ROBOT_JAR=/tools/robot.jar ROBOT=robot -B with return code 2
+
There is a known bug at the moment requiring at least one ontology with a warning, error, info and pass, see https://github.com/OBOFoundry/OBO-Dashboard/issues/85.
+
+
In your dashboard-config.yml, add a temporary ontology we created to make this work. This is already in the Dashboard template repository.
Clone https://github.com/OBOFoundry/obo-nor.github.io and copy all its contents to a new GitHub repo under your account. Ensure that the .gitignore from the obo-nor.github.io repo is also copied to your new repo (it is frequently skipped or hidden from the user in Finder or when using the cp command) and push to everything to GitHub.
+
Pull the Ontology Development Kit from Docker Hub (can take a while):
+
+
docker pull obolibrary/odkfull
+
+
+
Modify the dashboard-config.yml file, in particular the ontologies section:
+
Important: Add your ontology ID to the ID 'id' field
+
Add the path to your ontology to the mirror_from field.
+
Get the "base uri namespace" of the ontology using the following steps:
+ a. Open the ontology in Protégé
+ b. Select a class and press "command + u" (MacOS), the stem of the path would be the base URI namespace (e.g., in EDAM ontology, the base uri namespace is http://edamontology.org/, for Uberon it would be http://purl.obolibrary.org/obo/UBERON_)
+
Add the base uri namespace to 'base_ns' field of your ontology in the dashboard-config.yml
+
(As of October 2021 make sure there are multiple ontologies in the dashboard-config.yml, otherwise errors would be reported while running the code. There are currently some bugs in the dashboard code that require at least 2 or 3 ontologies in the list).
+
In the Makefile uncomment the # before pip install networkx==2.6.2 to ensure the correct network x version is installed.
+
Run sh run-dash.sh (make sure dashboard folder is empty before running, e.g. rm -rf dashboard/*).
+
When run successfully, push all changes to GitHub.
+
Go to GitHub repo you just created, and go to Settings, then Pages, and select your main/master branch as "source", and your root directory. You will see a website URL highlighted in green, where your OBO dashboard is deployed.
make sure you have the editor's file open in Protege (in ODK ontologies, located in: ./src/ontology/ONT-edit.owl) where ONT is the name of your ontology (eg mondo-edit.owl for MONDO)
Using Protégé you can add annotations such as labels, definitions, synonyms, database cross references (dbxrefs) to any OWL entity. The panel on the right, named Annotations, is where these annotations are added. OBO Foundry ontologies includes a pre-declared set of annotation properties. The most commonly used annotations are below.
+
+
rdfs:label
+
definition
+
has_exact_synonym
+
has_broad_synonym
+
has_narrow_synonym
+
has_related synonym
+
database_cross_reference
+
rdfs:comment
+
+
Note: OBO ontologies allow only one rdfs:label, definition, and comment.
+
Note, most of these are bold in the annotation property list:
+
+
Use this panel to add a definition to the class you created. Select the + button to add an annotation to the selected entity. Click on the annotation 'definition' on the left and copy and paste in the definition to the white editing box on the right. Click OK.
+
Example (based on MONDO):
+
Definition: A disorder characterized by episodes of swelling under the skin (angioedema) and an elevated number of the white blood cells known as eosinophils (eosinophilia). During these episodes, symptoms of hives (urticaria), fever, swelling, weight gain and eosinophilia may occur. Symptoms usually appear every 3-4 weeks and resolve on their own within several days. Other cells may be elevated during the episodes, such as neutrophils and lymphocytes. Although the syndrome is often considered a subtype of the idiopathic hypereosinophilic syndromes, it does not typically have organ involvement or lead to other health concerns.
+
+
+
Definitions in OBO ontologies should have a 'database cross reference' (dbxref), which is a reference to the definition source, such as a paper from the primary literature or another database. For references to papers, we cross reference the PubMed Identifier in the format, PMID:XXXXXXXX. (Note, no space)
+
To add a dbxref to the definition:
+
+
Click the @ symbol next to the definition
+
Click the + button next in the pop-up window
+
Scroll up on the left hand side until you find 'database_cross_reference', and click it
+
Add the PMID in the editing box (PMID:25527564). _Note: the PMID should not have any spaces)
+
Click OK
+
Add the additional dbxref (e.g., adding GARD:0013029)
We have seen how to add sub/superclasses and annotate the class hierarchy. Another way to do the same thing is via the Class description view. When an OWL class is selected in the entities view, the right-hand side of the tab shows the class description panel. If we select the 'vertebral column disease' class, we see in the class description view that this class is a "SubClass Of" (= has a SuperClass) the 'musculoskeletal system disease' class. Using the (+) button beside "SubClass Of" we could add another superclass to the 'skeletal system disease' class.
+
Note the Anonymous Ancestors. These are superclasses that are inherited from the parents. If you hover over the Subclass Of (Anonymous Ancestor) you can see the parent that the class inherited the superclass from.
+
+
When you press the '+' button to add a SubClass of axiom, you will notice a few ways you can add a term. The easiest of this is to use the Class expression editor. This allows you to type in the expression utilizing autocomplete. As you start typing, you can press the 'TAB' or '->|' button on your keyboard, and protege will suggest terms. You will also note that the term you enter is not in the ontology, protege will not allow you add it, with the box being highlighted red, and the term underlined red.
This guide explains how to embed a YouTube video into a page in this OBO Academy material. Example, see the videos on the Contributing to OBO Ontologies page.
Command Line Trick: Filter text files based on a list of strings¶
+
Let's say you want to remove some lines from a large text file programmatically. For example, you want to remove every line that contains certain IDs, but you want to keep the rest of the lines intact.
+You can use the command line utility grep with option -v to find all the lines in the file that do NOT contain your search term(s). You can make a file with a list of several search terms and use that file with grep using the -f option as follows:
The target file is your text file from which you wish to remove lines. The text file can be of type csv, tsv, oboetc. For example, you wish to filter a file with these lines:
+
+
keep this 1
+ this line is undesired 2, so you do not wish to keep it
+ keep this 3
+ keep this 4
+ keep this 5
+ keep this 6
+ something undesired 2
+ this line is undesired 1
+ keep this 7
+
+
The file your_list.txt is a text file with your list of search terms. Format: one search term per line. For example:
+
+
undesired 1
+ undesired 2
+
+
+
The utility tee will redirect the standard output to both the terminal and write it out to a file.
+
+
+
You expect the out_file.tsv to contain lines:
+
+
+
keep this 1
+ keep this 3
+ keep this 4
+ keep this 5
+ keep this 6
+ keep this 7
+
Do the filtering and updating of your target file in one step¶
+
You can also do a one-step filter-update when you are confident that your filtering works as expected, or if you have a backup copy of your target_file.tsv.
+Use cat and pipe the contents of your text file as the input for grep. Redirect the results to both your terminal and overwrite your original file so it will contain only the filtered lines.
This video illustrates an example of fixing a merge conflict in the Mondo Disease Ontology.
+
Instructions:
+
+
+
If a merge conflict error appears in your Github.com pull request after committing a change, open GitHub Desktop and select the corresponding repository from the "Current Repository" button. If the conflict emerged after editing the ontology outside of Protégé 5.5.0, see Ad hoc Reserialisation below.
+
+
+
With the repository selected, click the "Fetch origin" button to fetch the most up-to-date version of the repository.
+
+
+
Click the "Current Branch" button and select the branch with the merge conflict.
+
+
+
From the menu bar, select Branch > "Update from master".
+
+
+
A message indicating the file with a conflict should appear along with the option to open the file (owl or obo file) in a text/code editor, such as Sublime Text. Click the button to open the file.
+
+
+
Search the file for conflict markings ( <<<<<<< ======= >>>>>>> ).
+
+
+
Make edits to resolve the conflict, e.g., arrange terms in the correct order.
+
+
+
Remove the conflict markings.
+
+
+
Save the file.
+
+
+
Open the file in Protégé. If prompted, do not reload any previously opened file. Open as a new file.
+
+
+
Check that the terms involved in the conflict appear OK, i.e., have no obvious errors.
+
+
+
Save the file in Protégé using File > 'Save as...' from the menu bar and replace the ontology edit file, e.g., mondo-edit.obo
+
+
+
Return to GitHub Desktop and confirm the conflicts are now resolved. Click the "Continue Merge" button and then the "Push origin" button.
+
+
+
Return to Github.com and allow the QC queries to rerun.
+
+
+
The conflict should be resolved and the branch allowed to be merged.
+
+
+
Ad hoc Reserialisation
+
If the owl or obo file involved in the merge conflict was edited using Protégé 5.5.0, the above instructions should be sufficient. If edited in any other way, such as fixing a conflict in a text editor, the serialisation order may need to be fixed. This can be done as follows:
+
+
+
Reserialise the master file using the Ontology Development Kit (ODK). This requires setting up Docker and ODK. If not already set up, follow the instructions here.
+
+
+
Open Docker.
+
+
+
At the line command (PC) or Terminal (Mac), use the cd (change directory) command to navigate to the repository's src/ontology/ directory.
+ For example,
+
+
+
cd PATH_TO_ONTOLOGY/src/ontology/
+
Replace "PATH_TO_ONTOLOGY" with the actual file path to the ontology. If you need to orient yourself, use the pwd (present working directory) or ls (list) line commands.
+
+
If you are resolving a conflict in an .owl file, run:
+
+
sh run.sh make normalize_src
+
If you are resolving a conflict in an .obo file, run:
+
sh run.sh make normalize_obo_src
+
+
+
In some ontologies (such as the Cell ontology (CL)), edits may result in creating a large amount of unintended differences involving ^^xsd:string. If you see these differences after running the command above, they can be resolved by following the instructions here.
+
+
+
Continue by going to step 1 under the main Instructions above.
Post a comment with ontology differences on pull request¶
+
The command line tool Robot has a diff tool that compares two ontology files and can print the differences between them in multiple formats, among them markdown.
+
We can use this tool and GitHub actions to automatically post a comment when a Pull Request to master is created, with the differences between the two ontologies.
+
To create a new GitHub action, create a folder in your ontology project root folder called .github. Then create a yaml file in a subfolder called workflows, e.g. .github/workflows/diff.yml. This file contains code that will be executed in GitHub when certain conditions are meant, in this case, when a PR to master is submitted. The comments in this file from FYPO will help you write an action for your own repository.
Note: Creating a fork allows you to create your copy GitHub repository. This example provides instructions on forking the Mondo GitHub reposiitory. You can't break any of the Mondo files by editing your forked copy.
+
+
On GitHub, navigate to https://github.com/monarch-initiative/mondo
+
In the top-right corner of the page, click Fork.
+
+
+
+
When prompted 'Where should we fork mondo', choose your own repo (eg Nicole Vasilevsky).
+
Be careful if you have multiple forks (i.e. the original and your own personal fork, as this can cause confusion).
+
+
Clone your forked repo:
+
+
+
If you have GitHub Desktop installed - click Code -> Open with GitHub Desktop
+
+
+
How are you planning to use this fork? To contribute to parent project
+
+
+
In GitHub Desktop, create a new branch:
+
+
+
Click Current Branch - > New Branch
+
+
+
+
+
+
Give your branch a name, like c-path-training-1
+
+
+
You will make changes to the Mondo on the branch of your local copy.
A Git repo consists of a set of branches each with a complete history of all changes ever made to the files and directories. This is true for a local copy you check out to your computer from GitHub or for a copy (fork) you make on GitHub.
+
+
A Git repo typically has a master or main branch that is not directly edited. Changes are made by creating a branch from Master (complete copy of the Master + its history) (either a direct branch or via a fork).
You can copy (fork) any GitHub repo to some other location on GitHub without having to ask permission from the owners. If you modify some files in that repo, e.g. to fix a bug in some code, or a typo in a document, you can then suggest to the owners (via a Pull Request) that they adopt (merge) you your changes back into their repo. See the Appendix for instructions on how to make a fork.
+
If you have permission from the owners, you can instead make a new branch.
A Pull Request (PR) is an event in Git where a contributor (you!) asks a maintainer of a Git repository to review changes (e.g. edits to an ontology file) they want to merge into a project (e.g. the owl file) (see reference). Create a pull request to propose and collaborate on changes to a repository. These changes are proposed in a branch, which ensures that the default branch only contains finished and approved work. See more details here.
See these instructions on cloning an ontology repo and creating a branch using GitHub Dekstop.
+
+
+
Review: Once changes are made to the ontology file, they can be viewed in GitHub Desktop.
+
+
+
Before committing, check the diff. An example diff from the Cell Ontology (CL) is pasted below. Large diffs are a sign that something went wrong. In this case, do not commit the changes and consider asking the ontology editor team for help instead.
+
+
+
Example 1 (Cell Ontology):
+
+
Example 2 (Mondo):
+
+
+
+
Commit message: Before Committing, you must add a commit message. In GitHub Desktop in the Commit field in the lower left, there is a subject line and a description.
+
+
+
Give a very descriptive title: Add a descriptive title in the subject line. For example: add new class ONTOLOGY:ID [term name] (e.g. add new class MONDO:0000006 heart disease)
+
+
+
Write a great summary of what the change is in the Description box, referring to the issue. The sentence should clearly state how the issue is addressed.
+
+
+
To link the issue, you can use the word 'fixes' or 'closes' in the description of the commit message, followed by the corresponding ticket number (in the format #1234) - these are magic words in GitHub; when used in combination with the ticket number, it will automatically close the ticket. Learn more on this GitHub Help Documentation page about Closing issues via commit messages.
+
+
+
Note: 'Fixes' and "Closes' are case-insensitive.
+
+
+
If you don't want to close the ticket, just refer to the ticket # without the word 'Fixes' or use 'Addresses'. The commit will be associated with the correct ticket but the ticket will remain open. 7.NOTE: It is also possible to type a longer message than allowed when using the '-m' argument; to do this, skip the -m, and a vi window (on mac) will open in which an unlimited description may be typed.
+
+
+
+
+
+
Click Commit to [branch]. This will save the changes to the ontology edit file.
+
+
+
Push: To incorporate the changes into the remote repository, click Publish branch.
Once you have your assigned ID range, you need to configure Protege so that your ID range is recorded in the Preferences menu. Protege does not read the idranges file.
+
+
+
In the Protege menu, select Preferences.
+
+
+
In the resulting pop-up window, click on the New Entities tab and set the values as follows.
Start: see go-idranges.owl. Only paste the number after the GO: prefix. Also, note that when you paste in your GO ID range, the number will automatically be converted to a standard number, e.g. pasting 0110001 will be converted to 110,001.)
Decompress the downloaded .zip or .tar.gz file with tools appropriate for your operating system.
+
+
Follow the steps as needed by your operating system to install the Protégé application.
+For example, on macOS: drag and drop Protégé.app to the Applications folder and replace any older versions of the software.
+You may need to right click Protégé.app and then choose Open from the menu to authorise the programme to run on your machine.
+Alternatively, go to Preferences -> Security -> General.
+You need to open the little lock, then click Mac stopped an application from Running (Protégé) -> Open anyways.
+
+
+
Adjust memory settings if necessary.
+Memory settings can now be adjusted in a jvm.conf configuration file that can be located either in the .protege/conf directory under your home directory, or in the conf directory within the application bundle itself.
+For example, to set the maximum amount of memory available for Protégé to, say, 12GB, put the following in the jvm.conf file:
+
When downloaded, unzip and copy puli and elk jars (two .jar files) in the unpacked directory.
+
+
Paste these files in your Protege plugin directory.
+
+
Remove old org.semanticweb.elk.jar
+
+
+
Install ELK plugin on Mac:
+
+
+
This can be done via one of two ways:
+
Approach 1
+
+
In Terminal:
+ open ~/.Protege, then click on plugins
+
Click on plugins
+
Copy and paste the two files into the plugins directory
+
Remove old elk.jar (Ex. org.semanticweb.elk.jar)
+
Restart Protege. You should see ELK 0.5 installed in your Reasoner menu.
+
+
Approach 2
+
+
Paste these files in your Protege plugin directory. This is in one of two locations:
+
~/.Protege/plugins (note this is usually hidden from finder, but you can see it in the terminal) or
+
Go to Protege in Applications (Finder), right click, 'Show package contents' -> Java -> plugins
+
If you go to ~/.Protege and a directory called plugins does not exist in this folder, you can create it.
+
Copy and paste the two files into the plugins directory
+
Remove old elk.jar (Ex. org.semanticweb.elk.jar)
+
Restart Protege. You should see ELK 0.5 installed in your Reasoner menu.
+
+
Important: it seems Elk 0.5. Does not work with all versions of Protege, in particular, 5.2 and below. These instructions were only tested with Protege 5.5.
See Daily Workflow for creating branches and basic Protégé instructions.
+
Note Before performing a merge, make sure that you know all of the consequences that the merge will cause. In particular, be sure to look at child terms and any other terms that refer to the ‘obsoleted’ term. In many cases a simple merge of two terms is not sufficient because it will result in equivalent classes for child terms. For example if obsoleted term X is going to be merged into target term Y and ‘regulation of X’ and ‘regulation of Y’ terms exist, then you will need to merge the regulation terms in addition to the primary terms. You will also need to edit any terms that refer to the obsoleted term to be sure that the names and definitions are consistent.
Find the ID of the term in which the obsoleted term will be merged
+
Navigate to 'winning' term using the Search box. Copy the ID of the winning term somewhere.
+
+
+
Duplicate annotations from the obsoleted terms
+
Navigate to the term to be obsoleted.
+
Right click on it and select Duplicate class then OK in the pop up window. This should create a class with the exact same name.
+
On the duplicated class (you can see this by (CL:XXXX) within your range added), right click and select Change IRI (Rename)
+
Copy the ID of the winning term (obtained in Step 1).
+
Be sure to use the underscore _ in the identifier instead of the colon :, for example: GO_1234567. Make sure that the 'change all entities with this URI' box is checked.
+
Navigate to the winning term IRI, all annotations should be merged.
+
+
+
Change obsoleted term label to a synonym
+
In the annotations box of the winning term there are now two terms with labels 'rdfs:label'. Click the o to change the label of the obsoleted term.
+
In the resulting pop-up window, select the appropriate synonym label from the list on the left:
+
has_broad_synonym
+
has_exact_synonym
+
has_narrow_synonym
+
has_related_synonym (if unsure, this is the safest choice)
+
+
+
+
+
Remove duplicated or inappropriate annotations
+
Check the definition, if there are multiple entries, remove the obsoleted one by clicking on the x on the right.
+
Check the subclasses and remove inappropriate/duplciated ones by clicking on the x on the right.
+
Check list of synonyms and remove inappropriate/duplciated ones by clicking on the x on the right.
+
Note down the created_by and created_date (there can only be one value per term for each of these fields; this will be useful if you need to pick one after the merge is done).
Ensure that you add a rdfs:comment that states that term was duplicated and to refer to the new new.
+
Ensure that you add a term replaced by annotations as per the instructions and add the winning merged term.
+
+
+
Synchronize the reasoner and make sure there are no terms that have identical definitions as a result of the merge. These are displayed with an 'equivalent' sign ≡ in the class hierarchy view on the left hand panel.
+
Save changes.
+
+
See Daily Workflow section for commit, push and merge instructions.
In Terminal, navigate to your ontology directory: src/ontology
+
Run your owltools command
+
Check the output in GitHub desktop
+
Open a new version of your ontology edit file in Protege
+
Search for the term that was obsoleted
+
Add 'term tracker item' (type xsd:anyURI) with a link to the GitHub issue that requested the obsoletion.
+
Add an obsoletion reason: use the annotation property 'has obsolescence reason' and write 'terms merged' in the literal field.
+
Search for the 'term replaced by' term
+
Delete the old ID
+
Review the annotations to ensure there are no duplicate annotations. If there are, they should be merged.
+
Review the subClassOf assertions, and make sure there are no duplicates. If there are, they should be merged.
+
When reviewing the diff, make sure there is not an Alt ID. The diff should only show additions to the merged term and the obsoletion
+
+
+
TROUBLESHOOTING: Travis/Jenkins errors
+
+
Merging a term that is used as 'replaced by' for an obsolete term
+
+
:: ERROR: ID-mentioned-twice:: GO:0030722
+ :: ERROR: ID-mentioned-twice:: GO:0048126
+ GO:0030722 :: ERROR: has-definition: missing definition for id
+
The cause of this error is that Term A (GO:0048126) was obsoleted and had replace by Term B (GO:0030722). The GO editor tried to merge Term B into a third term term C (GO:0007312). The Jenkins checkk failed because 'Term A replaced by' was an alternative_id rather than by a main_id.
+Solution: In the ontology, go to the obsolete term A and replace the Term B by term C to have a primary ID as the replace_by.
See Daily Workflow for creating branches and basic Protégé instructions.
+
Warning: Every ontology has their procedures on how they obsolete terms (eg notice periods, notification emails, to_be_obsolete tags, etc.), this how-to guide only serves as a guide on how obsolete a term directly on protege.
+
For instructions on how to merge terms (i.e., replace a term with another term in the ontology), see instructions here.
+
PRE OBSOLETION PROCESS (or basic obsoletion etiquette)¶
+
+
+
Check if the term (or any of its children) is being used for annotation:
+
+
+
Go to your ontology browser of choice, search for the term, either by label or ID
+
+
See which other ontologies use the to be obsolete term
+
+
Notify affected groups (usually by adding an issue in their tracker)
+
+
+
Check if the term is used elsewhere in the ontology
+
+
In Protégé, navigate to the term to be obsolete and go to the 'Usage' tab to see if that ID is used elsewhere.
+
If the term is a parent to other terms or is used in logical definitions, make sure that another term replaces the obsolete term
Warning: some ontologies give advance notice on terms that will be obsoleted through the annotation 'scheduled for obsoletion on or after' instead of directly obsoleting the term. Please check with the conventions of your ontology before obsoleting a term.
+
+
Navigate to the term to be obsoleted.
+
+
+
+
Select Edit > Deprecate entity...
+
+
+
+
A deprecation wizard will pop up, in here, select GO style, and select continue (note this is specifc to GO style ontologies, if you are working with an OBI style ontology, there is an option for that too, if not use basic. For this how to, we will follow GO style)
+
+
+
+
Next, enter your reason for deprecation. For this, we advice for you to enter the github issue. (eg https://github.com/obophenotype/cell-ontology/issues/####) This will appear as a rdfs:comment
+
+
+
+
Next enter a replacement entity if there is one. This will automatically replace axioms in the ontology with the term, and add an 'item replaced by' axiom on the obsolete term.
+
+
+
+
Your obsolete term should now be stripped of its logical axioms and should look similar to the figure below.
+
+
+
+
Add any additional annotations needed - this is specific to ontologies and you should consult the conventions of the ontology you are working on.
+
+
Examples of additional annotations to add:
+
+
+
IAO:0000233 term tracker item (type xsd:anyURI) - link to GitHub issue
+
+
+
has_obsolence_reason
+
+
+
add ‘OBSOLETE.’ to the term definition: In the 'Description' window, click on the o on the right-hand side of the definition entry. In the resulting window, in the Literal tab, at the beginning of the definition, type: OBSOLETE.
+
+
+
if the obsoleted term was not replaced by another term in the ontology, but there are existing terms that might be appropriate for annotation, add those term IDs in the 'consider' tag: In the 'Annotations' window, select + to add an annotation. In the resulting menu, select consider and enter the ID of the replacement term.
+
+
NOTE: Here you have to add the ID of the entity as an xsd:string, e.g. GO:0005819, not the term label.
+
+
+
+
Obsolete a class (using Protege 'Make entity obsolete' function)¶
+
+
Navigate to the term to be obsoleted.
+
In the Protege edit menu-> Make entity obsolete
+
Prepend the definition with OBSOLETE. For example, OBSOLETE. Chronic form of myeloproliferative neoplasm.
+
+
Add a statement about why the term was made obsolete: In the 'Annotations' window, select + to add an annotation. In the resulting menu, select rdfs:comment and select Type: Xsd:string.
+ Consult the wiki documentation for suggestions on standard comments:
If the obsoleted term was replaced by another term in the ontology: In the 'Annotations' window, select + to add an annotation. In the resulting menu, select term replaced by and enter the ID of the replacement term.
+
+
+
If the obsoleted term was not replaced by another term in the ontology, but there are existing terms that might be appropriate for annotation, add those term IDs in the 'consider' tag: In the 'Annotations' window, select + to add an annotation. In the resulting menu, select consider and enter the ID of the replacement term.
+
+
NOTE: Here you have to add the ID of the entity as an xsd:string, e.g. GO:0005819, not the term label.
+
+
+
+
Add any additional annotations needed - this is specific to ontologies and you should consult the conventions of the ontology you are working on.
+
+
+
Examples of additional annotations to add:
+
+
IAO:0000233 term tracker item (type xsd:anyURI) - link to GitHub issue
+
has_obsolence_reason
+
+
See Daily Workflow section for commit, push and merge instructions.
Adding an ORCIDIO import to your ontology with ODK¶
+
The Open Researcher and Contributor Identifier (ORCID) is a global, unambiguous way to identify a researcher.
+ORCID URIs (e.g., https://orcid.org/0000-0003-4423-4370) can therefore be used to unambigously and actionably attribute various aspects of ontology terms in combination with DC Terms or IAO predicates. However, URIs themselves are opaque and it is difficult to disambiguate to which person an ORCID corresponds when browsing an ontology (e.g., in Protégé).
+
ORCIDIO is an ontology that declares ORCID URIs as named individuals and associates basic metadata (e.g., name, description) to each such that tools like Protégé can display a human-readable label rather than the URI itself as in the following example.
+
+
In this guide, we discuss how to add ORCIDIO to your ODK setup.
+
1. Include ORCIDIO as an import into the ODK config file¶
+
In your ODK configuration (e.g. src/ontology/myont-odk.yaml), add the following to the import_group:
The list of annotation properties, in particular dc:source, is important for the filter module to work (ORCIDIO relies heavily on axiom annotations for provenance).
TODO: "as usual" should be re-written to cross-link to another guide about updating the catalog (or don't say as usual to keep this more self-contained)
+As usual, add a statement into your catalog (src/ontology/catalog-v001.xml):
TODO: "as usual" should be re-written to cross-link to another guide about updating the edit file (or don't say as usual to keep this more self-contained)
+As usual, add an imports declaration to your edit file (src/ontology/myont-edit.owl):
TODO: link to explanation of base merging strategy
+Note: This is not necessary when using the base merging strategy (you will know what this means when you do use it).
For your specific use-case, it may be necessary to tweak this SPARQL query, for example if your ORCIDs are used on axiom annotation level rather than entity annotation level.
Creating a new Repository with the Ontology Development Kit¶
+
This is instructions on how to create an ontology repository in
+GitHub. This will only need to be done once per project. You may need
+assistance from someone with basic unix knowledge in following
+instructions here.
+
We will walk you though the steps to make a new ontology project
docker: Install Docker and make sure its runnning properly, for example by typing docker ps in your terminal or command line (CMD). If all is ok, you should be seeing something like:
+
+
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+
Make sure to save the wrapper script in your working directory and that the filetype is correct.
+
You should have git installed - for the repo command to work perfectly, it requires a .gitconfig file in your user directory!
+
First, make sure you have Docker running (you will see the Docker whale in your toolbar on a Mac)
+
To make sure you have the latest version of the ODK installed, run in the command line
+
+
docker pull obolibrary/odkfull
+
NOTE The very first time you run this it may be slow, while docker downloads necessary images. Don't worry, subsequent runs should be much faster!
+
NOTE Windows users, occasionally it has been reported that files downloaded on a Windows machine get a wrong file ending, for example seed-via-docker.bat.txt instead of seed-via-docker.bat, or, as we will see later, project.yaml.txt instead of project.yaml. If you have problems, double check your files are named correctly after the download!
You can either pass in a configuration file in YAML format that specifies your ontology project setup, or you can pass arguments on the command line. You can use dir in your command line on PC to ensure that your wrapper script, .gitconfig, and project.yaml (if you so choose) are all in the correct directory before running the wrapper script.
Instead of -u cmungall you should be using your own username (i.e. -u nico), for example for your GitHub or GitLab hosting sites.
+
You can add a -c (lowercase) just before the -C (capital c) in the command to first delete any previous attempt to generate your ontology with the ODK, and then replaces it with a completely new one. So, -c stands for clean or "clean up previous attempts before running again" and -C stands for "the next parameter is the relative path to my config file".
+
In general, we now always recommend the use of config files. The ODK has a rich set of configuration options, most of which can only be set through the config file, but in general the config also serves as documentation and will help with updating your ontology at later stages.
+ To create a config file, you can download for example project.yaml by clicking on the link and then typing command+s on Mac or ctrl+s on Windows to save it in the same directory as your seed-via-docker script.
+ Then you can open the file with a text editor like Notepad++, Atom, Sublime or even nano, and adapt it to your project. Other more comprehensive examples can be found here.
+
+
This will create your starter files in
+target/triffid-behavior-ontology. It will also prepare an initial
+release and initialize a local repository (not yet pushed to your Git host site such as GitHub or GitLab).
The seed-via-docker script requires a .gitconfig file in your user directory. If your .gitconfig is in a different directory, you need to change the path in the downloaded seed-via-docker script. For example on Windows (look at seed-via-docker.bat):
We have had reports of users having trouble if there paths (say, D:\data) contain a space symbol, like D:/Dropbox (Personal) or similar. In this case, we recommend to find a directory you can work in that does not contain a space symbol.
+
You can customize at this stage, but we recommend to first push the changes to you Git hosting site (see next steps).
+
During download, your filenames got changed (Windows)¶
+
Windows users, occasionally it has been reported that files downloaded on a Windows machine get a wrong file ending,
+for example seed-via-docker.bat.txt instead of seed-via-docker.bat, or, as we will see later, project.yaml.txt
+instead of project.yaml. If you have problems, double check your files are named correctly after the download!
The development kit will automatically initialize a git project, add all files and commit.
+
You will need to create a project on you Git hosting site.
+
For GitHub:
+
+
Go to: https://github.com/new
+
The owner MUST be the org you selected with the -u option. The name MUST be the one you set with -t, just with lower case letters and dashes instead of spaces. In our example above, the name "Triffid Behavior Ontology" translates to triffid-behavior-ontology.
+
Do not initialize with a README (you already have one)
+
Click Create
+
See the section under "…or push an existing repository from the command line"
+
+
For GitLab:
+
+
Go to: https://gitlab.com/projects/new
+
The owner MUST be the org you selected with the -u option. The name MUST be the one you set with -t.
+
Do not initialize with a README (you already have one)
+
Click 'Create project'
+
See the section under "Push an existing Git repository"
+
+
Follow the instructions there. E.g. (make sure the location of your remote is exactly correct!).
+
cd target/triffo
+git remote add origin https://github.com/matentzn/triffid-behavior-ontology.git
+git branch -M main
+git push -u origin main
+
+
Note: you can now mv target/triffid-behavior-ontology to anywhere you like in your home directory. Or you can do a fresh checkout from github.
+
Alternative recommendation for GitHub by @matentzn¶
+
I generally feel its easier and less error prone to deviate from the standard instructions above. I keep having problems with git, passwords, typose etc, so I tend to do it, inofficially, as follows:
+
+
When my repo is created I go to my GitHub Desktop
+
I then do File > Add local repository, and select the directory which contains my newly created repo (e.g. target/triffo).
+
I then Click on "Publish repository".
+
If I want the code to be public, I deselect "Keep this code private". By default, the repo will be uploaded to my own user profile on GitHub, but I can also select another Organization I have access to in the respective Dropdown menu.
+
NOTE: there seem to be some issues with pushing a GitHub Workflow file recently - you may be asked by GitHub Desktop to provide an additional permission to push the Workflow file.
The assumption here is that you are adhering to OBO principles and
+want to eventually submit to OBO. Your repo will contain stub metadata
+files to help you do this.
+
You can create pull requests for your ontology on the OBO Foundry. See the src/metadata file for more details.
Follow the instructions here. Note that you should have Windows 10 Professional installed for this to work. We are not sure Docker Desktop works at all with Windows 10 Home, but we have not tried in a while. If you know what you are doing, you could try to configure Docker toolbox, but we have had many issues with it, and do not recommend it unless absolutely necessary.
+
If you are unable to install Docker Desktop on your Windows PC (e.g. no admin rights or pohibited by the IT department of your institution) but you have the ability to use the Windows Hyper-V-Manager (possible w/o admin rights) or another virtualization tool, such as VirtualBox, you could set up a Linux virtual machine (VM) to use ODK. We recommend using Lubuntu, as it won't need much computing resources. Although you cannot install Docker Desktop in such a VM, you can install the Docker Engine, which suffices to proceed with the next step.
+
+
+
Once installed, you should be able to open your command line and download the ODK.
+
Click on your Windows symbol (usually in bottom left corner of screen), type "cmd" and you should be able to see and open the Command Line tool.
+
in the command line type, type docker pull obolibrary/odkfull. This will download the ODK (will take a few minutes, depending on you internet connection).
+
Executing something in a Docker container can be "wordy", because the docker container requires quite a few parameters to be run. To make this easier, we prepared a wrapper script here. You can download this file by clicking on Raw, and then, when the file is open in your browser, CTRL+S to save it. Ideally, you save this file in your project directory, the directory you will be using for your exercises, as it will only allow you to edit files in that very same directory (or one of its sub-directories).
Install docker: Install Docker following the official instructions.
+
Make sure its running properly, for example by typing docker ps in your terminal or command line (CMD). If all is ok, you should be seeing something like:
+
+
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+
+
+
Run docker pull obolibrary/odkfull on your command line to install the ODK. This will take while.
+
Download an ODK wrapper script. The odk.sh has further instruction on how to best use it.
+
Now you are ready to go to a directory containing the odk.sh wrapper script and running sh odk.sh robot --version to see whether it works.
+
The ODK wrapper script is generally useful to have: you can for example enter a ODK container, similar to a virtual machine,
+ by simply running sh odk.sh bash (to leave the ODK container again, simply run exit from within the container). On Windows, use run.bat bash instead.
+ However, for many of the ontologies we develop, we already ship an ODK wrapper script in the ontology repo, so we dont need the odk.sh or odk.bat file.
+ That file is usually called run.sh or run.bat and can be found in your ontology repo in the src/ontology directory
+ and can be used in the exact same way.
One of the most frequent problems with running the ODK for the first time is failure because of lack of memory.
+There are two potential causes for out-of-memory errors:
+
+
The application (for example, the ODK release run) needs more memory than assigned to JAVAinside the ODK docker container. This memory is set as part of the ODK wrapper files, i.e. src/ontology/run.bat or src/ontology/run.sh, usually with ODK_JAVA_OPTS.
+
The application needs more memory than is assigned to your docker installation. On most systems (apart from a handful fo Windows ones based on WSL), you have to set docker memory in the docker preferences. That happens here is that the Java memory above may be set to something like 10GB, while the maximum docker memory is set to 8GB. If the application needs, say, 9GB to run, you have assigned enough Java memory, but docker does not permit more than 8 to be used.
+
+
Out-of-memory errors can take many forms, like a Java OutOfMemory exception,
+but more often than not it will appear as something like an Error 137.
There are two places you need to consider to set your memory:
+
+
Your ODK wrapper script (see above), i.e. odk.bat, odk.sh or src/ontology/run.sh (or run.bat) file. You can set the memory in there by adding
+ robot_java_args: '-Xmx8G' to your src/ontology/cl-odk.yaml file, see for example here.
+
Set your docker memory. By default, it should be about 10-20% more than your robot_java_args variable. You can manage your memory settings
+ by right-clicking on the docker whale in your system bar-->Preferences-->Resources-->Advanced, see picture below.
If your problem is that you do not have enough memory on your machine, the only solution is to try to engineer the pipelines a bit more intelligently, but even that has limits: large ontologies require a lot of memory to process when using ROBOT. For example, handling ncbitaxon as an import in any meaningful way easily consumes up to 12GB alone. Here are some tricks you may want to contemplate to reduce memory:
+
+
robot query uses an entirely different framework for representing the ontology, which means that whenever you use ROBOT query, for at least a short moment, you will have the entire ontology in memory twice. Sometimes you can optimse memory by seperating query and other robot commands into seperate commands (i.e. not chained in the same robot command).
+
+
The robot reason command consumes a lot of memory. reduce and materialise potentially even more. Use these only ever in the last possible moment in a pipeline.
A new version of the Ontology Development Kit (ODK) is out? This is what you should be doing:
+
+
Install the latest version of ODK by pulling the ODK docker images. In your terminal, run:
+
+
docker pull obolibrary/odkfull
+
+
+
To update your repository, go to your src/ontology directory.
+
+
cd myrepo/src/ontology
+
+
+
Create a new git branch in your usual way (optional)
+
+
Now run the update command TWICE (the first time it may fail, as the update command needs to update itself).
+
sh run.sh make update_repo
+sh run.sh make update_repo
+
+
+
Edit the following file: .github/workflows/qc.yml (from the top level of your repository) and make sure that it is using the latest version of the ODK.
+
+
For example, container: obolibrary/odkfull:v1.3.0, if v1.3.0. Is the latest version. If you are unsure what the latest version is, you can find that information here: https://hub.docker.com/r/obolibrary/odkfull/tags
+
+
+
OPTIONAL: if you have any other GitHub actions you would like to update to the latest ODK, now is the time! All of your GitHub actions can be found in the .github/workflows/ directory from the top level of your repo.
+
+
+
Review all the changes and commit them, and make a PR the usual way. 100% wait for the PR to pass QC - ODK updates can be significant!
+
+
+
Send a reminder to all other ontology developers of your repo and tell them to install the latest version of ODK (step 1 only).
This 'how to' guide provides a template for an Ontology Overview for your ontology. Please create a markdown file using this template and share it in your ontology repository, either as part of your ReadMe file or as a separate document in your documentation. The Ontology Overview should include the following three sections:
For example, the Mondo ontology covers concepts in the area of diseases across species and integrates disease terminologies from several underlying sources.
+
Include a figure of upper level terms (critical: give a list of all the high level terms that the ontology covers (1-2 levels). Eg Mondo: disease or disorder, disease susceptibility, disease characteristic).
+
+
+
+
Include a figure with exemplary term (using OBO graph)
Status: This is a working document! Feel free to add more content!
+
+
The Open Science Engineer contributes to the collection and standardisation of publicly available scientific knowledge through curation, community-building and data, ontology and software engineering.
+
+
Open Science and all its sub-divisions, including Open Data and Open Ontologies, are central to tackling global challenges from rare disease to climate change. Open licenses are only part of the answer - the really tough part is the standardisation of data (including the unification of ontologies, the FAIRification of data and adoption of common semantic data models) and the organisation of a global, fully decentralised community of Open Science engineers. Here, we will discuss some basic principles on how we can maximise our impact as members of a global community combating the issues of our time:
+
+
Principle of Collaboration: How do we create a welcoming and inclusive environment for implementing social workflows and deepen our ties across project boundaries?
+
Principle of Upstream Fixing: How can we maximise benefits to the global community by pushing fixes as far upstream as possible?
+
Principle of No-ownership: How do we develop a sense of co-, or -no, ownership for community driven ontologies and ontology tools?
+
+
We discuss how to best utilise social workflows to achieve positive impact. We will try to convince you that building a close collaborative international community by spending time on submitting and answering issues on GitHub, helping on Stack Overflow and other online platforms, or just reaching out and donating small amounts of time to other open science efforts can make a huge difference.
The heart and soul of a successful Open Science culture is collaboration. The relative isolation into which many projects are forced due to limitations imposed by certain kinds of funding makes it even more important to develop effective social, collaborative workflows. This involve effective online communication, vocal appreciation (likes, upvotes, comments), documentation and open-ness.
When you find an answer on Stack Overflow, GitHub issues (or even Hacker News) that helps you, upvote it. It cannot be stressed enough how important this is to let good answers float up to the top (become more visible), and recognise the time and energy people spend formulating answers. If you do not have a Stack Overflow account, make one now.
+
If you cannot find an answer to a question on GitHub or Stack Overflow, and you figure out a solution consider asking the question and answering it yourself! Consider this: if you provide an answer that will result in only 6 open science people spending one hour less solving a problem (a conservative estimate), you saved the taxpayer 6 hours of salary (not to speak of improving the quality of the solutions)!
+
Answer questions on GitHub issues even when on trackers not in your purview. People often falsely assume that they should not try to answer queries in an open source project that they are not directly involved with. This is wrong! Open source developers highly (!) appreciate it when you chip in on answering queries, from dealing with errors and exceptions to "How do I?" kind of queries. Get involved on other peoples issue trackers!
+
Before asking questions on slack or issue trackers, always do a basic search first. Consider (1) the project's documentation, (2) open and closed issues on the issue tracker of the project your query is related to. If you do not find the information you need try and craft questions that are concise yet give sufficient context. To enable future users to find these answers, consider using the issue tracker instead of slack! Also it is important to remember that the people that answer your questions have to spend time they could have spend on other Open Science work!
+
Make yourself responsible for continuously improving open science documentation. If a question was answered on slack or in an issue, consider a 10 minute detour to update the documentation of the project to reflect the solution if you think it could be helpful. This is the only way to scale Open Science projects: as the user base increases, providing support on a 1:1 basis will soon be infeasible.
+
Good documentation is as important as good quality code, and everyone can help out, even if it is "only" about formatting, typos and adding additional links!
Be overly generous with likes. Being a Open Science Engineer can be quite a lonely affair: hundreds of unanswered issues and questions, pull requests that remain un-reviewed for months, projects for which you never really get credit (want to be a QC engineer, anyone?). Even if you do not have time to respond to all issues you scroll through in a day, add a like if you find an answer useful. This goes for slack comments, Tweets and random Pull Requests you have nothing to do with as well. And, perhaps most importantly star all GitHub repos that are useful to you (you could, for example, scroll through https://github.com/topics/obofoundry and star all ontologies and ontology projects useful in your work)! This is a huge deal as it significantly motivates other OSEs and therefore provides fuel to the Open Science movement.
+
Reduce work for others as much as possible by communicating clearly.
+
Take the time to write clear responses with just the right amount of detail. The goal of your communication is to get the point across as swiftly as possible, and misunderstandings are a huge time killer.
+
Again: Sloppy, quick responses can cause more work than not responding at all!
+
Use bullet lists to structure your response, and checklists for action items.
+
Hide unnecessary details with <details> tag: <details><summary>[click arrow to expand]</summary>. See example here
+
Be generous linking external issues to provide context. Example:
+
+
+
+
Be positive and generous with gratitude and attribution
+
If a member of the community opens an issue, always thank them for the issue right away. We need to encourage people to open issues.
+
Don't let issues linger without any response. It is better to respond with a thank you and some instructions for the issuer on what to do to fix the issue themselves than to let it linger. We need our stakeholders to be more involved - first time issuers are especially vulnerable and may not bother to come back if they are ignored.
+
When giving feedback, be positive, friendly and constructive.
+
Show appreciation: thank users for issues and thank a PR reviewer for their review. Always.
+
Attribute, attribute, attribute. If someone helped you sort something out emphasise this publicly!
Contribute your thoughts openly so other people can benefit from it.
+
Don't put issues on Slack where the public can't see it. Consider moving interesting discussions on Slack into a more public space, like GitHub discussions.
+
Create public tickets which can be searched and referred to later.
Maximising impact of your changes is by far the best way you can benefit society as an Open Science Engineer. Open Science projects are a web of mutually dependent efforts, for example:
+
+
Ontologies re-use terms and axioms from other ontologies
+
Software packages provide functionality that help building Knowledge Graphs, ensuring the quality of ontology releases and extract new insights from existing knowledge and scientific facts.
+
Projects use ontologies for indexing data and making them discoverable.
+
+
The key to maximising your impact is to push any fixes as far upstream as possible. Consider the following projects and the way they depend on each other (note that this is a gross simplification for illustration; in reality the number of dependencies is much higher):
+
+
Let's think of the following (entirely fabricated) scenario based on the image above.
This association is only supported by the IMPC data source which associates mouse and human phenotypes using the phenodigm algorithm which is based on semantic similarity.
+
The semantic similarity scores are computed using cross-species axioms provided by the Monarch Initiative, especially uPheno.
+
The cross-species logical axioms provided by Monarch depend on a range of lexical and logical approaches. This means the structure of uPheno is directly influenced by the naming and synonyms provided by species specific phenotype ontologies (SSPOs), such as the Human Phenotype Ontology (HPO).
+
+
It is, therefore, possible that:
+
+
A faulty synonym is accidentally added to the HPO...
+
...which causes a faulty logical axiom candidate in uPheno (again missed by QC measures)...
+
...which causes a faulty similarity value in Monarch...
+
...which causes a wrong disease-gene association in IMPC...
+
...which ultimately leads to a faulty piece of evidence in Open Targets.
+
+
Imagine a user of Open Targets that sees this evidence, and reports it to Open Targets as a bug. Open Targets could take the easy way out: remove the erroneous record from the database permanently. This means that the IMPC (itself with hundreds of dependent users and tools), Monarch (again with many dependents), uPheno and HPO (with probably thousands of dependents) would still carry forward that (tiny) mistake.
+This is the basic idea of maximising impact through Upstream Fixing: The higher up-stream (up the dependency graph) an error is fixed, the more cumulative benefit there is to a huge ecosystem of tools and services.
+
An even better fix would be to have each fix to the ontology result in a new, shared quality control test. For example, some errors (duplicate labels, missing definition, etc) can be caught by automated testing. Here is a cool story.
+
Case Study: External contribution and upstream fixing¶
+
+
Over time, we have developed QC checks that ensure that the same exact synonym cannot be shared between two classes. However the checks where not perfect..
Instead of fixing the discovered issue by ourselves, we invited @vasvir to fix the issues himself. We gave him some instructions on how to proceed, leading not only to eight new pull requests, but also an entirely new Quality Control check that augments the existing checks with case-insensitivity (Gasserian ganglion and gasserian ganglion where previously considered distinct). Note: before the PRs, @vasvir did not speak any SPARQL.
+
+
Members of our team helped @vasvir to see his first pull requests through by instructing them how to use the technology (robot, ODK, docker, SPARQL), and follow our pull request conventions.
+
+
Instead of simply deleting the synonyms for his NLP projects, @vasvir instead decided to report the issues straight to the source. This way, hundreds, if not thousands of projects will directly or indirectly benefit from him!
Example 1: While curating Mondo, Nicole identified issues relevant to Orphanet and created this issue.
+
+
+
+
Example 2: There is overlap between Mondo and Human Phenotype Ontology and the Mondo and HPO curators tag each other on relevant tickets.
+
+
+
+
Example 3: In Mondo, if new classifications are made, Mondo curators report this back to the source ontology to see if they would like to follow our classification.
Have you ever wondered how much impact changing a synonym from exact to related could have? Or the addition of a precise mapping? The fixing of a typo in a label? It can be huge. And this does not only relate to ontologies, this goes for tool development as well. We tend to work around bugs when we are building software. Instead, or at least in addition to, we should always report the bug at the source to make sure it gets fixed eventually.
Many of the resources we develop are financed by grants. Grants are financed in the end by the taxpayer. While it is occasionally appropriate to protect open work with creative licenses, it rarely makes sense to restrict access to Open Ontologies work - neither to commercial nor research exploitation (we may want to insist on appropriate attribution to satisfy our grant developers).
+
On the other side there is always the risk of well-funded commercial endeavours simply "absorbing" our work - and then tying stakeholders into their closed, commercial ecosystem. However, this is not our concern. We cannot really call it stealing if it is not really ours to begin with! Instead of trying to prevent unwanted commercialisation and closing, it is better to work with corporations in pre-competitive schemes such as Pistoia Alliance or Allotrope Foundation and lobby for more openness. (Also, grant authorities should probably not allow linking scientific data to less than totally open controlled vocabularies.)
+
Here, we invite you to embrace the idea that ontologies and many of the tools we develop are actually community-driven, with no particular "owners" and "decision makers". While we are not yet there (we don't have sufficiently mature governance workflows for full fledged onto-communism), and most ontologies are still "owned" by an organisation that provides a major source of funding, we invite you to think of this as a preliminary state. It is better to embrace the idea of "No-ownership" and figure out social workflows and governance processes that can handle the problems of decision making.
+
Take responsibility for your community (ontologies)¶
+
+
Ensure that you see your issues and pull requests through to the end. No one will do this for you. Remember - contributors to open source projects, especially ontologies, have their own agendas, and do not automatically care about other peoples work.
+
+
Feel empowered to nudge reviewers or experts to help. Get that issue answered and PR merged whatever it takes!
+
Example: After waiting for the PR to be reviewed, Meghan kindly asked Nicole if she should find a different reviewer.
+
+1. Find review buddies. For every ontology you seek to contribute to pair up with someone who will review your pull requests and you will review their pull requests. Sometimes, it is very difficult to get anyone to review your pull request. Reach out to people directly, and form an alliance for review. It is fun, and you learn new things (and get to know new people!).
+1. Be proactive
+
+
Problem of decentralization and lack of hierarchial organisation needs proactive and brave decision makers.
+
No one will do your work for you. See your pull requests and issues through all the way to the release!
+
Learn the tools necessary to make basic fixes - just try it/do it.
+
Always have your index finger on the Edit button when reading documentation. There is always something to fix, including typos and content.
+
Most of our ontologies have many checks in place, and GitHub has version control. Nothing has ever been broken to the point where it can't be fixed. (Remember to work on a branch!)
+ Example: The QC checks on this PR failed 6 times before it passed.
+
+
Perfect is the enemy of good enough.
+
It's okay if your PR is rejected. Mentally, prepare yourself for having the PR rejected. This is fine - the community always looks to the best possible way to change the ontology. The next PR will be accepted!
+
If you make a mistake, and it is pointed out during pull request review, consider adding an appropriate QC check to prevent the issue from happening again. And who knows - maybe you have an opportunity to fix past mistakes!
Prettier standardizes the representation and formatting of Markdown. More information is available at https://prettier.io/. Note, these instructions are for a Mac.
The Protégé interface follows a basic paradigm of Tabs and Panels. By default, Protégé launches with the main tabs seen below. The layout of tabs and panels is configurable by the user. The Tab list will have slight differences from version to version, and depending on your configuration. It will also reflect your customizations.
+
To customize your view, go to the Window tab on the toolbar and select Views. Here you can customize which panels you see in each tab. In the tabs view, you can select which tabs you will see. You will commonly want to see the Entities tab, which has the Classes tab and the Object Properties tab.
+
+
Note: if you open a new ontology while viewing your current ontology, Protégé will ask you if you'd like to open it in a new window. For most normal usage you should answer no. This will open in a new window.
+
The panel in the center is the ontology annotations panel. This panel contains basic metadata about the ontology, such as the authors, a short description and license information.
Before browsing or searching an ontology, it is useful to run an OWL reasoner first. This ensures that you can view the full, intended classification and allows you to run queries. Navigate to the query menu, and run the ELK reasoner:
You will see various tabs along the top of the screen. Each tab provides a different perspective on the ontology.
+For the purposes of this tutorial, we care mostly about the Entities tab, the DL query tab and the search tool. OWL Entities include Classes (which we are focussed on editing in this tutorial), relations (OWL Object Properties) and Annotation Properties (terms like, 'definition' and 'label' which we use to annotate OWL entities.
+Select the Entities tab and then the Classes sub-tab. Now choose the inferred view (as shown below).
+
+
The Entities tab is split into two halves. The left-hand side provides a suite of panels for selecting various entities in your ontology. When a particular entity is selected the panels on the right-hand side display information about that entity. The entities panel is context specific, so if you have a class selected (like Thing) then the panels on the right are aimed at editing classes. The panels on the right are customizable. Based on prior use you may see new panes or alternate arrangements.
+You should see the class OWL:Thing. You could start browsing from here, but the upper level view of the ontology is too abstract for our purposes. To find something more interesting to look at we need to search or query.
You can search for any entity using the search bar on the right:
+
+
The search window will open on top of your Protege pane, we recommend resizing it and moving it to the side of the main window so you can view together.
+
+
Here's an example search for 'COVID-19':
+
+
It shows results found in display names, definitions, synonyms and more. The default results list is truncated. To see full results check the 'Show all results option'. You may need to resize the box to show all results.
+Double clicking on a result, displays details about it in the entities tab, e.g.
+
+
In the Entities, tab, you can browse related types, opening/closing branches and clicking on terms to see details on the right. In the default layout, annotations on a term are displayed in the top panel and logical assertions in the 'Description' panel at the bottom.
+
Try to find these specific classes:
+
+
'congenital heart disease'
+
'Kindler syndrome'
+
'kidney failure'
+
+
Note - a cool feature in the search tool in Protege is you can search on partial string matching. For example, if you want to search for ‘down syndrome’, you could search on a partial string: ‘do synd’.
+
+
Try searching for ‘br car and see what kind of results are returned.
+
Question: The search will also search on synonyms. Try searching for ‘shingles’ and see what results are returned. Were you able to find the term?
+
+
Note - if the search is slow, you can uncheck the box ‘Search in annotation values. Try this and search for a term and note if the search is faster. Then search for ‘shingles’ again and note what results you get.
Pull Requests are GitHub's mechanism for allowing one person to propose changes to a file (which could be a chunk of code, documentation, or an ontology) and enabling others to comment on (review) the proposed changes. You can learn more about creating Pull Requests (PRs) here; this document is about reviewing other people's PRs.
+
One key aspect of reviewing pull requests (aka code review or ontology change review) is that the purpose is not just to improve the quality of
+the proposed change. It is also about building shared coding habits and practices and improving those practices for all engineers (ontology and software) across a whole organisation (effectively building the breadth of project knowledge of the developers and reducing the amount of hard-to-understand code).
+
Reviewing is an important aspect of open science and engineering culture that needs to be learned and developed. In the long term, this habit will have an effect on the growth and impact of our tools and ontologies comparable to the engineering itself.
+
It is central to open science work that we review other people's work outside our immediate team. We recommend choosing a few people with whom to mutually review your work, whether you develpo ontologies, code or both. It is of great importance that pull requests are addressed in a timely manner, ideally within 24 hours of the request. The requestor is likely in the headspace of being receptive to changes and working hard to get the code fixed when they ask for a code review.
Understand the Context: First, read the description of the pull request (PR). It should explain what changes have been made and why. Understand the linked issue or task related to this PR. This will help you understand the context of the changes.
+
+
+
Check the Size: A good PR should not be too large, as this makes it difficult to understand the full impact of the changes. If the PR is very large, it may be a good idea to ask the author to split it into smaller, more manageable PRs.
+
+
+
Review the Code: Go through the code changes line by line. Check the code for clarity, performance, and maintainability. Make sure the code follows the style guide and best practices of your project. Look out for any potential issues such as bugs, security vulnerabilities, or performance bottlenecks.
+
+
+
Check the Tests: The PR should include tests that cover the new functionality or changes. Make sure the tests are meaningful, and they pass. If the project has a continuous integration (CI) system, all tests should pass in the CI environment. In some cases, manual testing may be helpful (see below).
+
+
+
Check the Documentation: If the PR introduces new functionality, it should also update the documentation accordingly. Even for smaller changes, make sure that comments in the code are updated.
+
+
+
Give Feedback: Provide constructive feedback on the changes. If you suggest changes, explain why you think they are necessary. Be clear, respectful, and concise. Remember, your goal is to help improve the quality of the code.
+
+
+
Follow Up: After you have provided feedback, check back to see if the author of the PR has made the suggested changes. You might need to have a discussion or explain your points further.
+
+
+
Approve/Request Changes: If you are satisfied with the changes and all your comments have been addressed, approve the PR. If not, request changes and explain what should be done before the PR can be approved.
+
+
+
Merge the PR: Once the PR is approved and all CI checks pass, it can be merged into the main branch. If your project uses a specific merge strategy (like squash and merge or rebase and merge), make sure it's followed.
+
+
+
How to review the code / ontology changes thoroughly¶
+
+
Ensure that the PR links to a related issue that explains the context of the PR. If there is no issue, request that an issue be created to motivate the change in the PR (gently - accept if the answer is negative).
+
Understand the Context: Begin by familiarizing yourself with the purpose of the changes. Read the description of the pull request, any linked issues or tasks, and understand the feature or bug that the pull request is addressing.
+
Ensure that all changes in the PR are intentional. Changes should be small. If there are a lot of unrelated changes, in particular line ending changes, serialisation changes in ontology (e.g. a lot of added xsd:string declarations), request before doing a review to reduce the changes to only the changes pertaining to the specific issue at hand.
+
Review the Code Structure: Look at the overall structure of the code. Check if the code is organized logically and consistently, follows the project's coding conventions, and the changes are made in the right place.
+
For software, consider factors like whether the code is in an approporiate location (files, modules). If there are no specific coding standards for the project, suggest that such standards be created.
+
For ontologies, check that the change is to the right file (edit file, DOSDP patterns, ROBOT templates etc.).
+
+
+
Check the Code Quality: Review the code in detail. Look for any programming errors, potential performance issues, or security vulnerabilities. The code should be clean, efficient, and easy to understand. Pay attention to the naming conventions, error handling, edge cases, and potential bugs.
+
The two items below are where you should spend most of your time:
+
+
+
Review the Tests: Ensure that the PR includes tests and that they cover all important aspects of the new code. Check if all tests pass, and if the project has a continuous integration (CI) system, ensure all CI checks pass as well.
+
For ontologies, it is essential that a bug fix is augmented by a test that can recognise the same bug happening again in the future!
+
For code, it is a bit of a judgment call whether a test is needed, but in general, we have to have at least thorough integration tests that touch the feature affected by the pull request.
+
+
+
Test the Changes Manually (use with care): Depending on the change, it may be a good idea to check out the PR branch and test the changes manually. This can help catch issues that are not covered by automated tests, or may be necessary if the diff is too large for a normal review. Note that this is an instance of Guru Testing and should only be used when there is a sense that automated testing is incomplete. If at all possible, an automated test should be run immediately after the manual review is done. Examples of where this kind of manual review may be appropriate are cases where, for example, a lot of the class hierarchy of an ontology is affected by a change. Manual review may catch issues such as missing superclasses which are hard to capture through automated testing.
+
Provide Constructive Feedback: Provide clear, respectful, and constructive feedback. Highlight the parts of the code that you think are good and the parts that need improvement. Request changes if necessary, and approve the PR once you're satisfied with the changes.
In many cases, we may not have the time to perform a proper code review. In that case, try at least to achieve this:
+
+
Ensure that the PR has a related issue that explains the context of the PR (see above).
+
Ensure that all changes in the PR are intentional (see above).
+
File and structure overview: Scan through the files and directories that have been modified. Note the overall structure of the changes, and look for any unusual modifications (e.g., changes in areas not related to the stated purpose of the PR, or large diffs that are not explained by the PR description).
+
Random code sampling: Instead of trying to read every line, pick a few sections of code at random to review. Pay attention to the cleanliness of the code, and see if there are any glaring issues or departures from the project's coding conventions.
+
Check automated tests and results: Review the tests that have been added or modified. Check the results of the tests and automated build processes, if available. Even in a quick review, the status of the tests can provide useful information about the quality of the changes.
+
Provide high-level feedback: Based on your quick review, provide high-level feedback. This could include praising good practices you've noticed, pointing out major concerns or areas that seem off, or simply acknowledging the work with a comment.
The instructions below describe how to capture a screenshot of your screen, either your entire screen or a partial screenshot. These can be pasted into GitHub issues, pull requests or any markdown file.
Full screen: Hit the Command, Shift and 3 keys together to take a screenshot of the entire screen
+
+
+
+
Partial screen: Hit the Shift, Control, Command and 4 keys together to take a screenshot of a portion of the screen. Crosshairs will appear and select the portion you would like to capture.
+
+
+
+
Paste the partial screenshot into comment box in GitHub.
Use the Snipping Tool (available with Windows 10)¶
+
+
The easiest way to elicit the tool is to press Windows logo key + Shift + S to open a dialog window to select the type of screen capture you would like to do. 1. Options exist for free form, rectangular, window or full screen snips.
+
After snipping, a notification dialog pops up so the user can select the location to save or annotate the screenshot. Otherwise, the default setting is to save to the clipboard.
Protege needs at least 4G of RAM to cope with large ontologie like Mondo, ideally use 12G or 16G if your machine can handle it. Edits to the Protege configuration files will not take effect until Protege is restarted.
+
+
If running from Protege.app on a Mac, open the /Applications/Protege-5.6.1/Protégé.app/Contents/conf/jvm.conf file
The following instructions will probably not work if Protégé was installed from the platform independent version, which does not include the Java Runtime Environment or a Windows .exe launcher.
+
+
Visit https://protege.stanford.edu/
+
Click orange DOWNLOAD NOW button
+
Click gray Download for Windows button on subsequent page
+
Register if desired, or skip registration
+
Find Protege-<version>-win.zip
+
most likely in your Downloads directory (or in This PC directory)
+
current version is Protege-5.5.0-win.zip
+
Unzip the downloaded file with your favorite file compression utility
+
You should see the Protege application and a file called 'run'
+
To open Protege, double-click the 'run' file. This will open cmd.exe and it will take a bit to open the file.
+
The fonts used by Protégé may be very small, especially on some high resolution monitors. To increase the font size, go to File -> Preferences -> Renderer -> Font size.
+
Exit Protégé after confirming that it can be launched.
+
There should be a Protege.l4j.ini in the same directory as Protege.exe. Opening large ontologies like MONDO will require an increase to Protege's default maximum Java heap size, which is symbolized as -Xmx<size>. 4GB is usually adequate for opening MONDO, as long as 4GB of free memory is really available on your system before you launch Protégé! Allocating even more memory will improve some tasks, like reasoning. You can check your available memory by launching the Windows Task Manager, clicking on the More details button on the bottom of the window and then checking the Performance tab at the top of the window.
+
It's recommended to make a backup of Protege.l4j.ini before editing
+
+
Open Protege.l4j.ini with a lightweight text editor like Atom or Sublime. Using notepad.exe instead might work, but may change character encodings or the character(s) used to represent End of Line.
+
After increasing the memory available to Protégé, Protege.l4j.ini might look like this.
+
-Xms200M
+-Xmx4G
+-Xss16M
+
+
Note that there is no whitespace between -Xmx, the numerical amount of memory, and the Megabytes/Gigabytes suffix. Don't forget to save.
+
Taking advantage of the memory increase requires that Protégé is shut down and relaunched, if applicable. The methods discussed here may not apply if Protégé is launched through any method other than double clicking Protege.exe from the folder where the edited Protege.l4j.ini resides.
Follow the instructions here (note these instructions are for a Mac).
+
Once installed, you should be able to open your command line and download the ODK.
+
Open Terminal
+
in the command line type, type docker pull obolibrary/odkfull. This will download the ODK (will take a few minutes, depending on you internet connection).
+
+
+
Setting the memory:
+ Set memory ~60% of your system memory, for example, if you have 16GB of RAM, then you should assign 10-11.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/howto/setup-ontology-development-odk/index.html b/howto/setup-ontology-development-odk/index.html
new file mode 100644
index 000000000..d2069d6d3
--- /dev/null
+++ b/howto/setup-ontology-development-odk/index.html
@@ -0,0 +1,3532 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Get set up for ODK-based ontology development - OBO Semantic Engineering Training
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
When you edit an ontology, you need to make sure you are using the correct prefix and your assigned ID range for that on ontology. Protege (unfortunately) does
+not remember the last prefix or ID range that you used when you switch between ontologies. Therefore we need to manually update this each time we switch ontologies.
When you switch to a new ontology file, open your preferences in Protege (File -> Preferences).
+
Be sure you are on the New entities tab.
+
Add the Prefix for the ontology you are working on.
+
If you don't know your ID range, go to the ID ranges file for that ontology (it should be in src/ontology/[ontology-name]-idranges.owl. (For example, src/ontology/mondo-idranges.owl.)
+
Copy and paste in the start and end values for your ID range.
I work on many ontologies, so I keep a note in OneNote (or Evernote) that keeps track of all my ID ranges for quick reference.
+
You don't need to track the last ID that was used, Protege will know to pick the next ID in your range. For example, if your ID range is 8000000 to 8999999, you can enter that as your range, even if you have already added 10 terms within your range. Protege will know to assign the next ID as 8000011.
Onologies are under constant development and are continuously expanded and iterated upon. You may discover that a term you need is not available in your preferred ontology. In this case, please make a new term request to the ontology.
In the following text below, we describe best practices for making a term request to an ontology. In general, requests for new terms are make on the ontology GitHub issue tracker. For example, this is the GitHub issue tracker for the Uberon Anatomy onology.
+
Note: These are suggestions and not strict rules. We appreciate your contributions to extending and improving ontologies. Following best guidelines is appreciated by the curators and developers, and assists them in addressing your issue more quickly. However, we understand if you are not always able to follow these best practices. Please add as much information as possible, and if there are any questions, the ontology developer may follow up with you for further clarification.
If there is a template, fill in the information that is requested on the template below each header.
+
General information that should be included in a new term request:
+
Preferred label: Your preferred name or label for the new term. Note- new term request should not match existing terms or synonyms.
+
Parent: The parent or superclass for that term. Remember that ontologies use subsumption reasoning, meaning that a subclass/child will inherit all the properties of the parent. In most ontologies, terms can have multiple classification, means terms can be classified under more than one parent.
+ Note: You can use a ontology search enginge like OLS to double check your class does not already exist and to search for parent terms in your respective ontology.
Definition database cross-reference(s): Indicate the source or database cross-reference(s) or source for the definition, such as a PubMed ID (PMID) or reference to a website.
+
Synonym(s): an alternative term that has the same or closely related meaning for your new term. Please indicate the synonym scope (see more details below).
+
Synonym database cross-reference(s): Provide a database cross-reference or source for the synonym, if applicable.
+
Your ORCID or the URL for your working group, if applicable. If you do not have an ORCID, you can sign up for one for free here.
+ Note: You can link your ORCID in your GitHub profile.
+
Comments: You can add any additional comments at the end. Please indicate if the comment should be included as a 'comment' annotation on the ontology term.
+
Click Submit New Issue
+
An ontology curator will review your issue and follow up with you if more information is needed.
Users may want to request other types of changes to an ontology such as Mondo beyond just adding a new term.
+
Other types of requests may include changes to the classification, typos, bugs, etc.
+
Some ontologies have other templates available on their issue tracker. Select the appropriate template. If there is not an appropriate template available, scroll to the bottom and select 'open a blank issue'.
This page discusses how to update the contents of your imports using the ODK, like adding or removing terms.
+
Note: This is a specialised how-to for ODK managed ontologies and is replicated from ODK docs to consolidate workflows in the obook. Not all ontologies use ODKs and many ontologies have their own workflows for imports, please also check with your local ontology documents and/or developers.
+
Note: The extract function in ROBOT can also be used to extract subsets from onotlogies for modular imports without the use of the ODK. For details on that, please refer to the ROBOT documentation
Note: some ontologies now use a merged-import system to manage dynamic imports, for these please follow instructions in the section title "Using the Base Module approach".
+
Importing a new term is split into two sub-phases:
There are three ways to declare terms that are to be imported from an external ontology. Choose the appropriate one for your particular scenario (all three can be used in parallel if need be):
This workflow is to be avoided, but may be appropriate if the editor does not have access to the ODK docker container.
+This approach also applies to ontologies that use base module import approach.
+
+
Open your ontology (edit file) in Protege (5.5+).
+
Select 'owl:Thing'
+
Add a new class as usual.
+
Paste the full iri in the 'Name:' field, for example, http://purl.obolibrary.org/obo/CHEBI_50906.
+
Click 'OK'
+
+
+
Now you can use this term for example to construct logical definitions. The next time the imports are refreshed (see how to refresh here), the metadata (labels, definitions, etc) for this term are imported from the respective external source ontology and becomes visible in your ontology.
Every import has, by default a term file associated with it, which can be found in the imports directory. For example, if you have a GO import in src/ontology/go_import.owl, you will also have an associated term file src/ontology/go_terms.txt. You can add terms in there simply as a list:
You prefer to manage all your imported terms in a single file (rather than multiple files like in the "Using term files" workflow above).
+
You wish to augment your imported ontologies with additional information. This requires a cautionary discussion.
+
+
To enable this workflow, you add the following to your ODK config file (src/ontology/cl-odk.yaml), and update the repository (using sh run.sh make update_repo):
+
use_custom_import_module: TRUE
+
+
Now you can manage your imported terms directly in the custom external terms template, which is located at src/templates/external_import.owl. Note that this file is a ROBOT template, and can, in principle, be extended to include any axioms you like. Before extending the template, however, read the following carefully.
+
The main purpose of the custom import template is to enable the management off all terms to be imported in a centralised place. To enable that, you do not have to do anything other than maintaining the template. So if you, say current import APOLLO_SV:00000480, and you wish to import APOLLO_SV:00000532, you simply add a row like this:
+
ID Entity Type
+ID TYPE
+APOLLO_SV:00000480 owl:Class
+APOLLO_SV:00000532 owl:Class
+
+
When the imports are refreshed see imports refresh workflow, the term(s) will simply be imported from the configured ontologies.
+
Now, if you wish to extent the Makefile (which is beyond these instructions) and add, say, synonyms to the imported terms, you can do that, but you need to (a) preserve the ID and ENTITY columns and (b) ensure that the ROBOT template is valid otherwise, see here.
+
WARNING. Note that doing this is a widespread antipattern (see related issue). You should not change the axioms of terms that do not belong into your ontology unless necessary - such changes should always be pushed into the ontology where they belong. However, since people are doing it, whether the OBO Foundry likes it or not, at least using the custom imports module as described here localises the changes to a single simple template and ensures that none of the annotations added this way are merged into the base file (see format variant documentation for explanation on what base file is)
If you want to refresh the import yourself (this may be necessary to pass the travis tests), and you have the ODK installed, you can do the following (using go as an example):
+
First, you navigate in your terminal to the ontology directory (underneath src in your hpo root directory).
+
cd src/ontology
+
+
Then, you regenerate the import that will now include any new terms you have added. Note: You must have docker installed.
+
sh run.sh make PAT=false imports/go_import.owl -B
+
+
Since ODK 1.2.27, it is also possible to simply run the following, which is the same as the above:
+
sh run.sh make refresh-go
+
+
Note that in case you changed the defaults, you need to add IMP=true and/or MIR=true to the command below:
+
sh run.sh make IMP=true MIR=true PAT=false imports/go_import.owl -B
+
+
If you wish to skip refreshing the mirror, i.e. skip downloading the latest version of the source ontology for your import (e.g. go.owl for your go import) you can set MIR=false instead, which will do the exact same thing as the above, but is easier to remember:
+
sh run.sh make IMP=true MIR=false PAT=false imports/go_import.owl -B
+
Since ODK 1.2.31, we support an entirely new approach to generate modules: Using base files.
+The idea is to only import axioms from ontologies that actually belong to it.
+A base file is a subset of the ontology that only contains those axioms that nominally
+belong there. In other words, the base file does not contain any axioms that belong
+to another ontology. An example would be this:
The base file pipeline is a bit more complex then the normal pipelines, because
+of the logical interactions between the imported ontologies. This is solved by _first
+merging all mirrors into one huge file and then extracting one mega module from it.
+
Example: Let's say we are importing terms from Uberon, GO and RO in our ontologies.
+When we use the base pipelines, we
+
+
First obtain the base (ususally by simply downloading it, but there is also an option now to create it with ROBOT)
+
We merge all base files into one big pile
+
Then we extract a single module imports/merged_import.owl
+
+
The first implementation of this pipeline is PATO, see https://github.com/pato-ontology/pato/blob/master/src/ontology/pato-odk.yaml.
+
To check if your ontology uses this method, check src/ontology/cl-odk.yaml to see if use_base_merging: TRUE is declared under import_group
+
If your ontology uses Base Module approach, please use the following steps:
+
First, add the term to be imported to the term file associated with it (see above "Using term files" section if this is not clear to you)
+
Next, you navigate in your terminal to the ontology directory (underneath src in your hpo root directory).
+
cd src/ontology
+
+
Then refresh imports by running
+
sh run.sh make imports/merged_import.owl
+
+
Note: if your mirrors are updated, you can run sh run.sh make no-mirror-refresh-merged
+
This requires quite a bit of memory on your local machine, so if you encounter an error, it might be a lack of memory on your computer. A solution would be to create a ticket in an issue tracker requesting for the term to be imported, and your one of the local devs should pick this up and run the import for you.
+
Lastly, restart Protege, and the term should be imported in ready to be used.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/images/FHKB figures/Capture.PNG b/images/FHKB figures/Capture.PNG
new file mode 100644
index 000000000..351fc22d5
Binary files /dev/null and b/images/FHKB figures/Capture.PNG differ
diff --git a/images/FHKB figures/class_hierachy_final_1.PNG b/images/FHKB figures/class_hierachy_final_1.PNG
new file mode 100644
index 000000000..854237fc3
Binary files /dev/null and b/images/FHKB figures/class_hierachy_final_1.PNG differ
diff --git a/images/FHKB figures/class_prop_hierachy_final.png b/images/FHKB figures/class_prop_hierachy_final.png
new file mode 100644
index 000000000..d88296e0f
Binary files /dev/null and b/images/FHKB figures/class_prop_hierachy_final.png differ
diff --git a/images/FHKB figures/cousin.png b/images/FHKB figures/cousin.png
new file mode 100644
index 000000000..fb4e17330
Binary files /dev/null and b/images/FHKB figures/cousin.png differ
diff --git a/images/FHKB figures/dragon.png b/images/FHKB figures/dragon.png
new file mode 100644
index 000000000..1c1a07d16
Binary files /dev/null and b/images/FHKB figures/dragon.png differ
diff --git a/images/FHKB figures/grandparent.png b/images/FHKB figures/grandparent.png
new file mode 100644
index 000000000..51280e157
Binary files /dev/null and b/images/FHKB figures/grandparent.png differ
diff --git a/images/FHKB figures/images/NoteIcon.pdf b/images/FHKB figures/images/NoteIcon.pdf
new file mode 100644
index 000000000..217176c11
Binary files /dev/null and b/images/FHKB figures/images/NoteIcon.pdf differ
diff --git a/images/FHKB figures/images/NoteIconSmall.png b/images/FHKB figures/images/NoteIconSmall.png
new file mode 100644
index 000000000..2e9bd80a0
Binary files /dev/null and b/images/FHKB figures/images/NoteIconSmall.png differ
diff --git a/images/FHKB figures/images/TipIcon.pdf b/images/FHKB figures/images/TipIcon.pdf
new file mode 100644
index 000000000..5d6c69b73
Binary files /dev/null and b/images/FHKB figures/images/TipIcon.pdf differ
diff --git a/images/FHKB figures/images/VocabIcon.pdf b/images/FHKB figures/images/VocabIcon.pdf
new file mode 100644
index 000000000..a58d87f27
Binary files /dev/null and b/images/FHKB figures/images/VocabIcon.pdf differ
diff --git a/images/FHKB figures/images/WarningIcon.pdf b/images/FHKB figures/images/WarningIcon.pdf
new file mode 100644
index 000000000..271a8bd2f
Binary files /dev/null and b/images/FHKB figures/images/WarningIcon.pdf differ
diff --git a/images/FHKB figures/images/WarningIcon.png b/images/FHKB figures/images/WarningIcon.png
new file mode 100644
index 000000000..9bcb17d12
Binary files /dev/null and b/images/FHKB figures/images/WarningIcon.png differ
diff --git a/images/FHKB figures/images/black_camera.png b/images/FHKB figures/images/black_camera.png
new file mode 100644
index 000000000..ca28c2b18
Binary files /dev/null and b/images/FHKB figures/images/black_camera.png differ
diff --git a/images/FHKB figures/images/code.PNG b/images/FHKB figures/images/code.PNG
new file mode 100644
index 000000000..45a041d7e
Binary files /dev/null and b/images/FHKB figures/images/code.PNG differ
diff --git a/images/FHKB figures/licence_logo.png b/images/FHKB figures/licence_logo.png
new file mode 100644
index 000000000..c67509f12
Binary files /dev/null and b/images/FHKB figures/licence_logo.png differ
diff --git a/images/FHKB figures/mother_in_law.png b/images/FHKB figures/mother_in_law.png
new file mode 100644
index 000000000..98678a7c4
Binary files /dev/null and b/images/FHKB figures/mother_in_law.png differ
diff --git a/images/FHKB figures/new/childof_property.PNG b/images/FHKB figures/new/childof_property.PNG
new file mode 100644
index 000000000..33cc756f7
Binary files /dev/null and b/images/FHKB figures/new/childof_property.PNG differ
diff --git a/images/FHKB figures/new/descendent_ancestor_defined_classes.PNG b/images/FHKB figures/new/descendent_ancestor_defined_classes.PNG
new file mode 100644
index 000000000..6fb69b16a
Binary files /dev/null and b/images/FHKB figures/new/descendent_ancestor_defined_classes.PNG differ
diff --git a/images/FHKB figures/new/event_name_hierarchy.PNG b/images/FHKB figures/new/event_name_hierarchy.PNG
new file mode 100644
index 000000000..d9ef1d64c
Binary files /dev/null and b/images/FHKB figures/new/event_name_hierarchy.PNG differ
diff --git a/images/FHKB figures/new/prop_uncle.PNG b/images/FHKB figures/new/prop_uncle.PNG
new file mode 100644
index 000000000..ee3a39c75
Binary files /dev/null and b/images/FHKB figures/new/prop_uncle.PNG differ
diff --git a/images/FHKB figures/new/prophierarchyinlaw.PNG b/images/FHKB figures/new/prophierarchyinlaw.PNG
new file mode 100644
index 000000000..ff12879e9
Binary files /dev/null and b/images/FHKB figures/new/prophierarchyinlaw.PNG differ
diff --git a/images/FHKB figures/new/prophierparentage.PNG b/images/FHKB figures/new/prophierparentage.PNG
new file mode 100644
index 000000000..f66dcd521
Binary files /dev/null and b/images/FHKB figures/new/prophierparentage.PNG differ
diff --git a/images/FHKB figures/old/childof_property.PNG b/images/FHKB figures/old/childof_property.PNG
new file mode 100644
index 000000000..5091624cf
Binary files /dev/null and b/images/FHKB figures/old/childof_property.PNG differ
diff --git a/images/FHKB figures/old/class_hierarchy.PNG b/images/FHKB figures/old/class_hierarchy.PNG
new file mode 100644
index 000000000..8be12c21e
Binary files /dev/null and b/images/FHKB figures/old/class_hierarchy.PNG differ
diff --git a/images/FHKB figures/old/descendent_ancestor_defined_classes.PNG b/images/FHKB figures/old/descendent_ancestor_defined_classes.PNG
new file mode 100644
index 000000000..6fb69b16a
Binary files /dev/null and b/images/FHKB figures/old/descendent_ancestor_defined_classes.PNG differ
diff --git a/images/FHKB figures/old/event_name_hierarchy.PNG b/images/FHKB figures/old/event_name_hierarchy.PNG
new file mode 100644
index 000000000..d9ef1d64c
Binary files /dev/null and b/images/FHKB figures/old/event_name_hierarchy.PNG differ
diff --git a/images/FHKB figures/old/halfsiblings.PNG b/images/FHKB figures/old/halfsiblings.PNG
new file mode 100644
index 000000000..a962514a9
Binary files /dev/null and b/images/FHKB figures/old/halfsiblings.PNG differ
diff --git a/images/FHKB figures/old/prop_uncle.PNG b/images/FHKB figures/old/prop_uncle.PNG
new file mode 100644
index 000000000..2b8c0c831
Binary files /dev/null and b/images/FHKB figures/old/prop_uncle.PNG differ
diff --git a/images/FHKB figures/old/property_hierarchy.PNG b/images/FHKB figures/old/property_hierarchy.PNG
new file mode 100644
index 000000000..971f6f131
Binary files /dev/null and b/images/FHKB figures/old/property_hierarchy.PNG differ
diff --git a/images/FHKB figures/old/prophierarchyinlaw.PNG b/images/FHKB figures/old/prophierarchyinlaw.PNG
new file mode 100644
index 000000000..1725b213b
Binary files /dev/null and b/images/FHKB figures/old/prophierarchyinlaw.PNG differ
diff --git a/images/FHKB figures/old/prophierarchyinlawInf.PNG b/images/FHKB figures/old/prophierarchyinlawInf.PNG
new file mode 100644
index 000000000..a3b06cc06
Binary files /dev/null and b/images/FHKB figures/old/prophierarchyinlawInf.PNG differ
diff --git a/images/FHKB figures/old/prophierparentage.PNG b/images/FHKB figures/old/prophierparentage.PNG
new file mode 100644
index 000000000..407a38536
Binary files /dev/null and b/images/FHKB figures/old/prophierparentage.PNG differ
diff --git a/images/FHKB figures/prop_hierarchy2.png b/images/FHKB figures/prop_hierarchy2.png
new file mode 100644
index 000000000..5ecc6cca3
Binary files /dev/null and b/images/FHKB figures/prop_hierarchy2.png differ
diff --git a/images/FHKB figures/sex.png b/images/FHKB figures/sex.png
new file mode 100644
index 000000000..f7d784175
Binary files /dev/null and b/images/FHKB figures/sex.png differ
diff --git a/images/FHKB figures/sibling_path.png b/images/FHKB figures/sibling_path.png
new file mode 100644
index 000000000..c894cfa42
Binary files /dev/null and b/images/FHKB figures/sibling_path.png differ
diff --git a/images/FHKB figures/siblings.png b/images/FHKB figures/siblings.png
new file mode 100644
index 000000000..b2089b99d
Binary files /dev/null and b/images/FHKB figures/siblings.png differ
diff --git a/images/FHKB figures/sister_in_law.png b/images/FHKB figures/sister_in_law.png
new file mode 100644
index 000000000..36e5a7a00
Binary files /dev/null and b/images/FHKB figures/sister_in_law.png differ
diff --git a/images/FHKB figures/spouse.png b/images/FHKB figures/spouse.png
new file mode 100644
index 000000000..d762c81f8
Binary files /dev/null and b/images/FHKB figures/spouse.png differ
diff --git a/images/FHKB figures/uncle.png b/images/FHKB figures/uncle.png
new file mode 100644
index 000000000..1462df18f
Binary files /dev/null and b/images/FHKB figures/uncle.png differ
diff --git a/images/Screen Shot 2021-04-22 at 10.04.26 PM.png b/images/Screen Shot 2021-04-22 at 10.04.26 PM.png
new file mode 100644
index 000000000..88ac1ff65
Binary files /dev/null and b/images/Screen Shot 2021-04-22 at 10.04.26 PM.png differ
diff --git a/images/bash_start.png b/images/bash_start.png
new file mode 100644
index 000000000..b656d597d
Binary files /dev/null and b/images/bash_start.png differ
diff --git a/images/changing_pr.png b/images/changing_pr.png
new file mode 100644
index 000000000..b7d154767
Binary files /dev/null and b/images/changing_pr.png differ
diff --git a/images/changing_pr_commit.png b/images/changing_pr_commit.png
new file mode 100644
index 000000000..2a32f2174
Binary files /dev/null and b/images/changing_pr_commit.png differ
diff --git a/images/chatgpt_more_hallucination_aware.png b/images/chatgpt_more_hallucination_aware.png
new file mode 100644
index 000000000..93e2e6f98
Binary files /dev/null and b/images/chatgpt_more_hallucination_aware.png differ
diff --git a/images/comment.png b/images/comment.png
new file mode 100644
index 000000000..5331097f0
Binary files /dev/null and b/images/comment.png differ
diff --git a/images/custom_qc_example.png b/images/custom_qc_example.png
new file mode 100644
index 000000000..3ae8ac868
Binary files /dev/null and b/images/custom_qc_example.png differ
diff --git a/images/custom_qc_example_solved.png b/images/custom_qc_example_solved.png
new file mode 100644
index 000000000..43a0c6364
Binary files /dev/null and b/images/custom_qc_example_solved.png differ
diff --git a/images/discussions/intro-to-ontologies/cardiac-glial-cell.png b/images/discussions/intro-to-ontologies/cardiac-glial-cell.png
new file mode 100644
index 000000000..479b09182
Binary files /dev/null and b/images/discussions/intro-to-ontologies/cardiac-glial-cell.png differ
diff --git a/images/discussions/intro-to-ontologies/definition-example.png b/images/discussions/intro-to-ontologies/definition-example.png
new file mode 100644
index 000000000..92088d946
Binary files /dev/null and b/images/discussions/intro-to-ontologies/definition-example.png differ
diff --git a/images/discussions/intro-to-ontologies/hindwing-subclass.png b/images/discussions/intro-to-ontologies/hindwing-subclass.png
new file mode 100644
index 000000000..ac8251228
Binary files /dev/null and b/images/discussions/intro-to-ontologies/hindwing-subclass.png differ
diff --git a/images/discussions/intro-to-ontologies/insect-classification.png b/images/discussions/intro-to-ontologies/insect-classification.png
new file mode 100644
index 000000000..0041389d9
Binary files /dev/null and b/images/discussions/intro-to-ontologies/insect-classification.png differ
diff --git a/images/discussions/intro-to-ontologies/leg-wing.png b/images/discussions/intro-to-ontologies/leg-wing.png
new file mode 100644
index 000000000..665b9aa48
Binary files /dev/null and b/images/discussions/intro-to-ontologies/leg-wing.png differ
diff --git a/images/discussions/intro-to-ontologies/neuron-multiple-inheritance.png b/images/discussions/intro-to-ontologies/neuron-multiple-inheritance.png
new file mode 100644
index 000000000..b8ff334a3
Binary files /dev/null and b/images/discussions/intro-to-ontologies/neuron-multiple-inheritance.png differ
diff --git a/images/discussions/intro-to-ontologies/nose-classification.png b/images/discussions/intro-to-ontologies/nose-classification.png
new file mode 100644
index 000000000..883bf5e2d
Binary files /dev/null and b/images/discussions/intro-to-ontologies/nose-classification.png differ
diff --git a/images/discussions/intro-to-ontologies/paramere.png b/images/discussions/intro-to-ontologies/paramere.png
new file mode 100644
index 000000000..2a312d647
Binary files /dev/null and b/images/discussions/intro-to-ontologies/paramere.png differ
diff --git a/images/discussions/intro-to-ontologies/query-glial-genes.png b/images/discussions/intro-to-ontologies/query-glial-genes.png
new file mode 100644
index 000000000..98d4adc8b
Binary files /dev/null and b/images/discussions/intro-to-ontologies/query-glial-genes.png differ
diff --git a/images/discussions/intro-to-ontologies/tarsal-segments.png b/images/discussions/intro-to-ontologies/tarsal-segments.png
new file mode 100644
index 000000000..50c445d33
Binary files /dev/null and b/images/discussions/intro-to-ontologies/tarsal-segments.png differ
diff --git a/images/discussions/logical-axiomatization/betz-pyramidal.png b/images/discussions/logical-axiomatization/betz-pyramidal.png
new file mode 100644
index 000000000..98bc671cd
Binary files /dev/null and b/images/discussions/logical-axiomatization/betz-pyramidal.png differ
diff --git a/images/discussions/logical-axiomatization/dl-oxtrneuron.png b/images/discussions/logical-axiomatization/dl-oxtrneuron.png
new file mode 100644
index 000000000..86a440ee0
Binary files /dev/null and b/images/discussions/logical-axiomatization/dl-oxtrneuron.png differ
diff --git a/images/discussions/logical-axiomatization/oxtrsst-heirachy.png b/images/discussions/logical-axiomatization/oxtrsst-heirachy.png
new file mode 100644
index 000000000..eef47e385
Binary files /dev/null and b/images/discussions/logical-axiomatization/oxtrsst-heirachy.png differ
diff --git a/images/discussions/writing-tickets/bad-ticket.png b/images/discussions/writing-tickets/bad-ticket.png
new file mode 100644
index 000000000..9b9c773ab
Binary files /dev/null and b/images/discussions/writing-tickets/bad-ticket.png differ
diff --git a/images/discussions/writing-tickets/good-ticket.png b/images/discussions/writing-tickets/good-ticket.png
new file mode 100644
index 000000000..b2dd4a8b1
Binary files /dev/null and b/images/discussions/writing-tickets/good-ticket.png differ
diff --git a/images/docker_memory.png b/images/docker_memory.png
new file mode 100644
index 000000000..bbb17f4a1
Binary files /dev/null and b/images/docker_memory.png differ
diff --git a/images/dosdp_spotted_coat.png b/images/dosdp_spotted_coat.png
new file mode 100644
index 000000000..82ffefb20
Binary files /dev/null and b/images/dosdp_spotted_coat.png differ
diff --git a/images/entity_mapping.png b/images/entity_mapping.png
new file mode 100644
index 000000000..6d57bf192
Binary files /dev/null and b/images/entity_mapping.png differ
diff --git a/images/exomiser_tutorial_images/10_windows.jpg b/images/exomiser_tutorial_images/10_windows.jpg
new file mode 100644
index 000000000..4da91721a
Binary files /dev/null and b/images/exomiser_tutorial_images/10_windows.jpg differ
diff --git a/images/exomiser_tutorial_images/11_windows.jpg b/images/exomiser_tutorial_images/11_windows.jpg
new file mode 100644
index 000000000..878af197a
Binary files /dev/null and b/images/exomiser_tutorial_images/11_windows.jpg differ
diff --git a/images/exomiser_tutorial_images/1_mac.jpg b/images/exomiser_tutorial_images/1_mac.jpg
new file mode 100644
index 000000000..843737c74
Binary files /dev/null and b/images/exomiser_tutorial_images/1_mac.jpg differ
diff --git a/images/exomiser_tutorial_images/1_windows.jpg b/images/exomiser_tutorial_images/1_windows.jpg
new file mode 100644
index 000000000..731fbccd2
Binary files /dev/null and b/images/exomiser_tutorial_images/1_windows.jpg differ
diff --git a/images/exomiser_tutorial_images/2_mac.jpg b/images/exomiser_tutorial_images/2_mac.jpg
new file mode 100644
index 000000000..ece431f2b
Binary files /dev/null and b/images/exomiser_tutorial_images/2_mac.jpg differ
diff --git a/images/exomiser_tutorial_images/2_windows.jpg b/images/exomiser_tutorial_images/2_windows.jpg
new file mode 100644
index 000000000..56061d951
Binary files /dev/null and b/images/exomiser_tutorial_images/2_windows.jpg differ
diff --git a/images/exomiser_tutorial_images/3_mac.jpg b/images/exomiser_tutorial_images/3_mac.jpg
new file mode 100644
index 000000000..6a7596895
Binary files /dev/null and b/images/exomiser_tutorial_images/3_mac.jpg differ
diff --git a/images/exomiser_tutorial_images/3_windows.jpg b/images/exomiser_tutorial_images/3_windows.jpg
new file mode 100644
index 000000000..2c118592b
Binary files /dev/null and b/images/exomiser_tutorial_images/3_windows.jpg differ
diff --git a/images/exomiser_tutorial_images/4_windows.jpg b/images/exomiser_tutorial_images/4_windows.jpg
new file mode 100644
index 000000000..a9ba46ef6
Binary files /dev/null and b/images/exomiser_tutorial_images/4_windows.jpg differ
diff --git a/images/exomiser_tutorial_images/5_windows.jpg b/images/exomiser_tutorial_images/5_windows.jpg
new file mode 100644
index 000000000..8fb7d4af7
Binary files /dev/null and b/images/exomiser_tutorial_images/5_windows.jpg differ
diff --git a/images/exomiser_tutorial_images/6_mac.jpg b/images/exomiser_tutorial_images/6_mac.jpg
new file mode 100644
index 000000000..c3159f572
Binary files /dev/null and b/images/exomiser_tutorial_images/6_mac.jpg differ
diff --git a/images/exomiser_tutorial_images/6_windows.jpg b/images/exomiser_tutorial_images/6_windows.jpg
new file mode 100644
index 000000000..407f25259
Binary files /dev/null and b/images/exomiser_tutorial_images/6_windows.jpg differ
diff --git a/images/exomiser_tutorial_images/7_mac.jpg b/images/exomiser_tutorial_images/7_mac.jpg
new file mode 100644
index 000000000..847046361
Binary files /dev/null and b/images/exomiser_tutorial_images/7_mac.jpg differ
diff --git a/images/exomiser_tutorial_images/7_windows.jpg b/images/exomiser_tutorial_images/7_windows.jpg
new file mode 100644
index 000000000..45d405623
Binary files /dev/null and b/images/exomiser_tutorial_images/7_windows.jpg differ
diff --git a/images/exomiser_tutorial_images/8_mac.jpg b/images/exomiser_tutorial_images/8_mac.jpg
new file mode 100644
index 000000000..b08937663
Binary files /dev/null and b/images/exomiser_tutorial_images/8_mac.jpg differ
diff --git a/images/exomiser_tutorial_images/8_windows.jpg b/images/exomiser_tutorial_images/8_windows.jpg
new file mode 100644
index 000000000..19ac9290a
Binary files /dev/null and b/images/exomiser_tutorial_images/8_windows.jpg differ
diff --git a/images/exomiser_tutorial_images/9_windows.jpg b/images/exomiser_tutorial_images/9_windows.jpg
new file mode 100644
index 000000000..d201e49e8
Binary files /dev/null and b/images/exomiser_tutorial_images/9_windows.jpg differ
diff --git a/images/exomiser_tutorial_images/HTML_annotated_part2.jpg b/images/exomiser_tutorial_images/HTML_annotated_part2.jpg
new file mode 100644
index 000000000..cc21faa72
Binary files /dev/null and b/images/exomiser_tutorial_images/HTML_annotated_part2.jpg differ
diff --git a/images/exomiser_tutorial_images/HTML_annotated_part3.jpg b/images/exomiser_tutorial_images/HTML_annotated_part3.jpg
new file mode 100644
index 000000000..899fc1d6b
Binary files /dev/null and b/images/exomiser_tutorial_images/HTML_annotated_part3.jpg differ
diff --git a/images/exomiser_tutorial_images/HTML_annotation_part1.png b/images/exomiser_tutorial_images/HTML_annotation_part1.png
new file mode 100644
index 000000000..c1f37cdbe
Binary files /dev/null and b/images/exomiser_tutorial_images/HTML_annotation_part1.png differ
diff --git a/images/github organizations teams repos.png b/images/github organizations teams repos.png
new file mode 100644
index 000000000..abb9af223
Binary files /dev/null and b/images/github organizations teams repos.png differ
diff --git a/images/github-organizations-teams-repos.png b/images/github-organizations-teams-repos.png
new file mode 100644
index 000000000..abb9af223
Binary files /dev/null and b/images/github-organizations-teams-repos.png differ
diff --git a/images/github_qc_starting.png b/images/github_qc_starting.png
new file mode 100644
index 000000000..1827e2d5d
Binary files /dev/null and b/images/github_qc_starting.png differ
diff --git a/images/howtoguides/TaxonRestriction/intaxon.png b/images/howtoguides/TaxonRestriction/intaxon.png
new file mode 100644
index 000000000..764c2c75e
Binary files /dev/null and b/images/howtoguides/TaxonRestriction/intaxon.png differ
diff --git a/images/howtoguides/TaxonRestriction/neverintaxon.png b/images/howtoguides/TaxonRestriction/neverintaxon.png
new file mode 100644
index 000000000..94e206f40
Binary files /dev/null and b/images/howtoguides/TaxonRestriction/neverintaxon.png differ
diff --git a/images/howtoguides/createnewterm/annotations.png b/images/howtoguides/createnewterm/annotations.png
new file mode 100644
index 000000000..8e0ac2567
Binary files /dev/null and b/images/howtoguides/createnewterm/annotations.png differ
diff --git a/images/howtoguides/createnewterm/logicalaxiom.png b/images/howtoguides/createnewterm/logicalaxiom.png
new file mode 100644
index 000000000..739578aa7
Binary files /dev/null and b/images/howtoguides/createnewterm/logicalaxiom.png differ
diff --git a/images/howtoguides/createnewterm/newterm.png b/images/howtoguides/createnewterm/newterm.png
new file mode 100644
index 000000000..753e0f383
Binary files /dev/null and b/images/howtoguides/createnewterm/newterm.png differ
diff --git a/images/howtoguides/createnewterm/ref.png b/images/howtoguides/createnewterm/ref.png
new file mode 100644
index 000000000..35e41e9c4
Binary files /dev/null and b/images/howtoguides/createnewterm/ref.png differ
diff --git a/images/howtoguides/createnewterm/subclassasserted.png b/images/howtoguides/createnewterm/subclassasserted.png
new file mode 100644
index 000000000..29e78d1a5
Binary files /dev/null and b/images/howtoguides/createnewterm/subclassasserted.png differ
diff --git a/images/howtoguides/deploy-custom-dashboard-workflow.png b/images/howtoguides/deploy-custom-dashboard-workflow.png
new file mode 100644
index 000000000..01fba2c3e
Binary files /dev/null and b/images/howtoguides/deploy-custom-dashboard-workflow.png differ
diff --git a/images/howtoguides/obsolete/fig1.png b/images/howtoguides/obsolete/fig1.png
new file mode 100644
index 000000000..188391f87
Binary files /dev/null and b/images/howtoguides/obsolete/fig1.png differ
diff --git a/images/howtoguides/obsolete/fig2.png b/images/howtoguides/obsolete/fig2.png
new file mode 100644
index 000000000..c1f209950
Binary files /dev/null and b/images/howtoguides/obsolete/fig2.png differ
diff --git a/images/howtoguides/obsolete/fig3.png b/images/howtoguides/obsolete/fig3.png
new file mode 100644
index 000000000..8cabd12ba
Binary files /dev/null and b/images/howtoguides/obsolete/fig3.png differ
diff --git a/images/howtoguides/obsolete/fig4.png b/images/howtoguides/obsolete/fig4.png
new file mode 100644
index 000000000..2c34d3f53
Binary files /dev/null and b/images/howtoguides/obsolete/fig4.png differ
diff --git a/images/howtoguides/obsolete/fig5.png b/images/howtoguides/obsolete/fig5.png
new file mode 100644
index 000000000..0ba7e754e
Binary files /dev/null and b/images/howtoguides/obsolete/fig5.png differ
diff --git a/images/howtoguides/obsolete/fig6.png b/images/howtoguides/obsolete/fig6.png
new file mode 100644
index 000000000..9aedd0398
Binary files /dev/null and b/images/howtoguides/obsolete/fig6.png differ
diff --git a/images/image1.png b/images/image1.png
new file mode 100644
index 000000000..fa9abd2a8
Binary files /dev/null and b/images/image1.png differ
diff --git a/images/image2.png b/images/image2.png
new file mode 100644
index 000000000..da5b1e26d
Binary files /dev/null and b/images/image2.png differ
diff --git a/images/image3.png b/images/image3.png
new file mode 100644
index 000000000..08c52fc2d
Binary files /dev/null and b/images/image3.png differ
diff --git a/images/index.html b/images/index.html
new file mode 100644
index 000000000..2a993eb80
--- /dev/null
+++ b/images/index.html
@@ -0,0 +1,3718 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ How to add images - OBO Semantic Engineering Training
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
There are two places you'll probaby want to use images in GitHub, in issue tracker and in markdown files, html etc.
+The way you handle images in these contexts is quite different, but easy once you get the hang of it.
All images referenced in static files such as html and markdown need to be referenced using a URL; dragging and dropping is not supported and could actually cause problems. Keeping images in a single directory enables them to be referenced more readily. Sensible file names are highly recommended, preferably without spaces as these are hard to read when encoded.
+
An identical file, named in two different ways is shown as an example below.
+They render in the same way, but the source "code" looks ugly when spaces are used in file names.
+
Eg.
+
+
+
+
encoding needed
+
no encoding needed
+
+
+
+
+

+
+
+
+
+
+
+
+
In this example, the filename is enough of a 'url' because this file (https://ohsu-library.github.io/github-tutorial/howto/images/index.md) and the images are in the same directory https://ohsu-library.github.io/github-tutorial/howto/images/.
+
To reference/embed an image that is not in the same directory, a more careful approach is needed.
+
Referencing images in your repository and elsewhere¶
Each instance of ../ means 'go up one level' in the file tree.
+
It is also possible to reference an image using an external URL outside your control, in another github organization, or anywhere on the web, however this method can be fragile if the URL changes or could lead to unintended changes. Therefore make your own copies and reference those unless:
+
+
You're sure that referencing the originals will not end in broken links or surprising content.
+
Copying the image is prohibited
+
The images are too large to make copying worth the hassle/expense.
+
+
For example, it is not clear for how long the image below will manage to persist at this EPA link, or sadly, for how long the image will even be an accurate reflection of the current situation in the arctic. https://www.epa.gov/sites/production/files/styles/microsite_banner/public/2016-12/epa-banner-images/science_banner_arctic.png
Images that are embedded into issues can be dragged and dropped in the GitHub issues interface.
+Once you've done so, it will look something like this with GitHub assigning an arbitrary URL (githubuserassets) for the image.
Ideally, a Markdown document is renderable in a variety of output formats and devices. In some cases, it may be desirable to create non-portable Markdown that uses HTML syntax to position images. This limits the longevity of the artifact, but may be necessary sometimes. We describe how to manage this below.
+
In order to size images, use the native html syntax: width = with the <img src=, as per below.
Welcome to the OBOOK and our OBO Semantic Engineering Training!
+
Introduction to the OBOOK (Open Biological and Biomedical Ontologies Organized Knowledge)¶
+
Documentation in the OBOOK is organised into 4 distinct sections based on the Diátaxis framework of documentation:
+
+
Tutorials: Learning-oriented documentation that contains exercises to help a beginner achieve basic competence in a specific area.
+
How-to Guides: Task-oriented documentation that functions as directions to guide the reader through the steps to achieve a specific end.
+
Reference Guides: Information-oriented documentation that describes a single topic in a succinct, technical and orderly way.
+
Explanations: Understanding-oriented documentation that clarifies, deepens and broadens the reader’s understanding of a subject.
+
+
To accommodate for the various training use cases we support, we added the following categories:
+
+
Courses: A convenience content type that assembles materials from OBOOK for a specific, taught unit, such as the yearly ICBO tutorials.
+
Pathways: A kind of course pertaining to a specific role in the OBO-sphere, such as curator or software developer.
+
Lessons: A collection of materials (tutorials, explanations and how-to guides) that together aim to teach a well defined concept.
+
+
Note: We are in the process of transforming the documentation accordingly, so please be patient if some of the documentation is not yet in the correct place. Feel free to create an issue if you find something that you suspect isn't in place.
James Overton, Knocean Inc. James has been a developer of software to support ontology development in and around the OBO sphere for more than a decade and delivers services to the OBO community through his company, Knocean Inc.
+
Becky Jackson, Bend Informatics. Becky has been a Semantic Software developer and Ontology Pipeline specialist since 2016, now working as an independent consultant.
+
Nicole Vasilevsky, Critical Path Institute. Nicole is the Associate Director of Data Science and an Ontology Curator for the Mondo Disease Ontology, and contributes to several other ontologies including the Human Phenotype Ontology, Uberon Anatomy Ontology, and Cell Ontology.
+
Nicolas Matentzoglu, Semanticly, Athens, Greece. Nico is an Ontology Engineer and Ontology Pipeline Specialist, being the Principal Ontology Pipeline Developer for the Monarch Initiative.
+
Shawn Tan, Novo Nordisk
+
David Osumi-Sutherland, EMBL-EBI
+
Sabrina Toro, University of Colorado
+
+
If you would like to contribute to this training, please find out more here.
Critical Path Institute (CPI) is an independent, nonprofit organisation dedicated to bringing together experts from regulatory agencies, industry and academia to collaborate and improve the medical product development process.
+
In April 2021, the CPI has commissioned the first version of this OBO course, contributing not only funding for the preparation and delivery of the materials, but also valuable feedback about the course contents and data for the practical exercises. We thank the CPI for contributing significantly to the OBO community and open science!
The Linked Data landscape from an OBO perspective: Standards, Services and Tools¶
+
In the following we will look a bit at the general Linked Data landscape, and name some of its flagship projects and standards. It is important to be clear that the Semantic Web field is a very heterogenous one:
+
Flagship projects of the wider Semantic Web community¶
+
+
Linked Open Data (LOD) cloud: The flagship project of the Semantic Web. An attempt to make all, or anyways a lot, of Linked Data accessible in one giant knowledge graph. A good overview can be found in this medium article. Note that some people seem to think that the Semantic Web is (or should be) the Linked Open Data cloud. I would question this view, but I am not yet decided what my position is.
+
Schema.org: General purpose vocabulary for entities on the web, founded by Google, Microsoft, Yahoo and Yandex. To get a better sense of the types of entities and relationships covered see here.
+
DBpedia: Project that extracts structured data from Wikipedia and makes it available as a giant knowledge graph. The associated ontology, similar to schema.org, covers entities encountered in common sense knowledge.
+
Wikidata: Free and open knowledge base that can be edited in much the same way as Wikipedia is edited.
+
+
While these Semantic Web flagship projects are doubtlessly useful, it is sometimes hard to see how they can help for your biomedical research. We rarely make use of them in our day to day work as ontologists, but there are some notable exceptions:
+
+
Where our work involves modelling environmental factors, we sometimes use wikidata as a standard way to refer for example to countries.
+
For some more common sense knowledge use cases, such as nutrition, consider augmenting your knowledge graph with data from wikidata or dbpedia. While they may be a bit more messy and not directly useful for exploration by humans, it is quite possible that Machine Learning approaches can use the additional context provided by these knowledge graphs to improve embeddings and deliver more meaningful link predictions.
+
Some OBO ontologies are already on Wikidata - perhaps you can find additional synonyms and labels which help with your data mapping problems!
+
+
Where the OBO and Semantic Web communities are slightly at odds¶
+
The OBO format is a very popular syntax for representing biomedical ontologies. A lot of tools have been built over the years to hack OBO ontologies on the basis of that format - I still work with it on a daily basis. Although it has semantically been proven to be a subset of OWL (i.e. there is a lossless mapping of OBO into OWL) and can be viewed as just another syntax, it is in many ways idiosyncratic. For starters, you wont find many, if any, IRIs in OBO ontologies. The format itself uses CURIEs which are mapped to the general OBO PURL namespace during transformation to OWL. For example, if you see MONDO:0003847 in an OBO file, and were to translate it to OWL, you will see this term being translated to http://purl.obolibrary.org/obo/MONDO_0003847. Secondly, you have a bunch of built-in properties like BROAD or ABBREVIATION that mapped to a vocabulary called oboInOwl (oio). These are pretty non-standard on the general Semantic Web, and often have to be manually mapped to the more popular counterparts in the Dublin Core or SKOS namespaces.
+
Having URIs as identifiers is not generally popular in the life sciences. As discussed elsewhere, it is much more likely to encounter CURIEs such as MONDO:0003847 than URIs such as http://purl.obolibrary.org/obo/MONDO_0003847 in biomedical databases.
Why does the biomedical research, and clinical, community care about the Semantic Web and Linked Data? There are endless lists of applications that try to apply semantic technologies to biomedical problems, but for this week, we only want to look at the broader picture. In our experience, the use cases where Semantic Web standards are applied successfully are:
CPT Story. The Current Procedural Terminology was the by far most highly accessed Terminology on Bioportal - for many years. Due to license concerns, it had to be withdrawn from the repository. This story serves a cautionary tale of using terminologies with non-open or non-transparent licensing schemes.
+
+
+
AgroPortal: Like BioPortal, but focussed on the Agronomy domain.
OLS: The boss of the current term browsers out there. While the code base is a bit dated, it still gives access to a wide range of relevant open biomedical ontology terms. Note, while being a bit painful, it is possible to set up your own OLS (for your organisation) which only contains those terms/ontologies that are relevant for your work.
+
Ontobee: The default term browser for OBO term purls. For example, click on http://purl.obolibrary.org/obo/OBI_0000070. This will redirect you directly to Ontobee, to show you the terms location in the hierarchy. A key difference between Ontobee and OLS/Bioportal is that Ontobee limits hierarchical relationships to is_a. This means if you are browsing ontologies such as GO, Uberon, CL, ENVO, you will not see part-of links in the hierarchy, and these links are crucial for understanding these ontologies.
+
AberOWL: Another ontology repository and semantic search engine. Some ontologies such as PhenomeNet can only be found on AberOWL, however, I personally prefer OLS.
+
identifiers.org: A centralised registry for identifiers used in the life sciences. This is one of the tools that bridge the gap between CURIEs and URLs, but it does not cover (OBO) ontologies very well, and if so, is not aware of the proper URI prefixes (see for example here, and HP term resolution that does not list the proper persistent URL of the HP identifier (http://purl.obolibrary.org/obo/HP_0000001)). Identifiers.org has mainly good coverage for databases/resources that use CURIE type identifiers. But: you can enter any ID you find in your data and it will tell you what it is associated with.
+
Curate biomedical data. There are a lot of different tools in this space - which we will discuss in a bespoke unit later in the course. Examples:
+
isatools: The open source ISA framework and tools help to manage an increasingly diverse set of life science, environmental and biomedical experiments that employing one or a combination of technologies.
+
RightField: System for curating ontology terms in Excel spreadsheets.
+
CEDAR Templates: Basically a templating system that allows to create templates to record metadata, for example in a lab setting, of course with ontology integration.
+
Other examples of tabular data to RDF converters, but new ones coming up every year.
+
Building ontologies
+
Populous/Webulous: A system to maintain/generate ontologies from spreadsheets. The idea was to basically to define patterns in a (now mostly dead) language called OPPL, and then apply them to spreadsheets to generate OWL axioms. EBI recently discontinued the service, as there is a general exodus to Google Sheets + ROBOT templates instead.
+
ROBOT templates + Google Sheets and Cogs: A lightweight approach based on a set of tools that allows curating ontologies in spreadsheets (e.g. Google Sheets) which are converted into OWL using ROBOT.
+
DOSDP tools + Dead Simple Design Patterns (DOSDP): Similar to ROBOT templates, DOSDPs (which really should be called DOSDTs, because they are not really design patterns; they are ontology templates), another system that allows the generation of OWL axioms based on spreadsheet data.
+
Cleaning messy data
+
OpenRefine: I have not myself used this ever, but some of my colleagues have. OpenRefine allows you to upload (spreadsheet) data, explore it and clean it (going as far as reconciling terms using Wikidata concepts).
As a rule of thumb, for every single problem/term/use case, you will have 3-6 options to choose from, in some cases even more. The criteria for selecting a good ontology are very much dependent on your particular use case, but some concerns are generally relevant. A good first pass is to apply to "10 simple rules for selecting a Bio-ontology" by Malone et al, but I would further recommend to ask yourself the following:
+
+
Do I need the ontology for grouping and semantic analysis? In this case a high quality hierarchy reflecting biological subsumption is imperative. We will explain later what this means, but in essence, you should be able to ask the following question: "All instances/occurrences of this concept in the ontology are also instances of all its parent classes. Everything that is true about the parent class is always also true about instances of the children." It is important for you to understand that, while OWL semantics imply the above, OWL is difficult and many ontologies "pretend" that the subclass link means something else (like a rule of thumb grouping relation).
+
Can I handle multiple inheritance in my analysis? While I personally recommend to always consider multiple inheritance (i.e, allow a term to have more than one parent class), there are some analysis frameworks, in particular in the clinical domain, that make this hard. Some ontologies are inherently ploy-hierarchical (such as Mondo), while others strive to be single inheritance (DO, ICD).
+
Are key resources I am interested in using the ontology? Maybe the most important question that will drastically reduce the amount of data mapping work you will have to do: Does the resource you wish to integrate already annotate to a particular ontology? For example, EBI resources will be annotating phenotype data using EFO, which in turn used HPO identifiers. If your use case demands to integrate EBI databases, it is likely a good idea to consider using HPO as the reference ontology for your phenotype data.
+
+
Aside from aspects of your analysis, there is one more thing you should consider carefully: the open-ness of your ontology in question. As a user, you have quite a bit of power on the future trajectory of the domain, and therefore should seek to endorse and promote open standards as much as possible (for egotistic reasons as well: you don't want to have to suddenly pay for the ontologies that drive your semantic analyses). It is true that ontologies such as SNOMED have some great content, and, even more compellingly, some really great coverage. In fact, I would probably compare SNOMED not with any particular disease ontology, but with the OBO Foundry as a whole, and if you do that, it is a) cleaner, b) better integrated. But this comes at a cost. SNOMED is a commercial product - millions are being payed every year in license fees, and the more millions come, the better SNOMED will become - and the more drastic consequences will the lock-in have if one day you are forced to use SNOMED because OBO has fallen too far behind. Right now, the sum of all OBO ontologies is probably still richer and more valuable, given their use in many of the central biological databases (such as the ones hosted by the EBI) - but as SNOMED is seeping into the all aspects of genomics now (for example, it will soon be featured on OLS!) it will become increasingly important to actively promote the use of open biomedical ontologies - by contributing to them as well as by using them.
+
We will discuss ontologies in the medical, phenomics and genomics space in more detail in a later session of the course.
Note of caution: No two Semantic Web overviews will be equivalent to each other. Some people claim the Semantic Web as an idea is an utter failure, while others praise it as a great success (in the making) - in the end you will have to make up your own mind. In this section I focus on parts of the Semantic Web step particularly valuable to the biomedical domain, and I will omit many relevant topics in the wider Semantic Web area, such as Enterprise Knowledge Graphs, decentralisation and personalisation, and many more. Also, the reader is expected to be familiar with the basic notions of the Semantic Web, and should use this overview mainly to tie some of the ideas together.
+
The goal of this section is to give the aspiring Semantic Data Engineer in the biomedical domain a rough idea of key concepts around Linked Data and the Semantic Web insofar as they relate to their data science and and data engineering problems. Even after 20 years of Semantic Web research (the seminal paper, conveniently and somewhat ironically behind a paywall, was published in May 2001), the area is still dominated by "academic types", although the advent of the Knowledge Graph is already changing that. As I already mentioned above, no two stories of what the Semantic Web is will sound the same. However, there are a few stories that are often told to illustrate why we need semantics. The OpenHPI course names a few:
+
+
"From the web of documents to the web of data" tells the story of how the original web is essentially a huge heap of (interlinked) natural language text documents which are very hard to understand for search engines: Does the word "Jaguar" on this site refer to the car or the cat? Clarifying in your web page that the word Jaguar refers to the concept of "Jaguar the cat", for example like this: <span about="dbpedia:Jaguar">Jaguar</span>, will make it easier for the search engine to understand what your site is about and link it to other relevant content. From this kind of mark-up, structured data can be extracted and integrate into a giant, worldwide database, and exposed through SPARQL endpoints, that can then be queried using a suitable query language.
+
"From human to machine understandable": as a Human, we know that a Jaguar is a kind of cat, and all cats have four legs. If you ask a normal search engine: "Does a Jaguar have four legs?" it will have a tough time to answer this question correctly (if it cannot find that exact statement anywhere). That is why we need proper semantics, some kind of formalism such that a "machine" can deduce from the statements "Jaguar is a cat; Cat has four legs" that "Jaguar has four legs".
+
The "Semantic Layer Cake": a box/brick diagram showing how Semantic Web Technologies are stacked on top of each other. An engineering centric view that has been used countless times to introduce the Semantic Web, but rarely helped anyone to understand what it is about.
+
+
I am not entirely sure anymore that any of these ways (web of data, machine understanding, layered stack of matching standards) to motivate the Semantic Web are particularly effective for the average data scientists or engineer.
+If I had to explain the Semantic Web stack to my junior self, just having finished my undergraduate, I would explain it as follows (no guarantee though it will help you).
+
+
The Semantic Web / Linked Data stack comprises roughly four components that are useful for the aspiring Semantic (Biomedical) Data Engineer/Scientist to distinguish:
+
A way to refer to things (including entities and relations) in a global namespace.¶
+
You, as a scientist, might be using the term "gene" to refer to basic physical and functional unit of heredity, but me, as a German, prefer the term "Gen". In the Semantic Web, instead of natural language words, we prefer to use URIs to refer to things such as https://www.wikidata.org/wiki/Q7187: if you say something using the name https://www.wikidata.org/wiki/Q7187, both your German and Japanese colleagues will "understand" what you are referring to. More about that in the next chapter.
+
Lots (loaaaads!) of ways to make statements about things.¶
+
For example, to express "a mutation of SHH in humans causes isolated microphthalmia with coloboma-5" you could say something like (http://purl.obolibrary.org/obo/MONDO_0012709 | "microphthalmia, isolated, with coloboma 5")--[http://purl.obolibrary.org/obo/RO_0004020 | "has basis in dysfunction of"]-->(https://identifiers.org/HGNC:10848 | "SSH (gene)"). Or you could say: (http://purl.obolibrary.org/obo/MONDO_0012709 | "microphthalmia, isolated, with coloboma 5")--[http://www.w3.org/2000/01/rdf-schema#subClassOf | "is a"]-->(http://purl.obolibrary.org/obo/MONDO_0003847 | "Mendelian Disease"). If we use the analogy of "language", then the URIs (above) are the words, and the statements are sentences in a language. Unfortunately, there are many languages in the Semantic Web, such as OWL, RDFS, SKOS, SWRL, SHACL, SHEX, and dialects (OWL 2 EL, OWL 2 RL) and a plethora of formats, or serialisations (you can store the exact same sentence in the same language such as RDF, or OWL, in many different ways)- more about that later. In here lies also one of the largest problems of the Semantic Web - lots of overlapping standards means, lots of incompatible data - which raises the bar for actually being able to seamlessly integrate "statements about things" across resources.
+
Collections of statements about things that somehow belong together and provide some meaning, or context, for those things.¶
+
Examples include:
+
+
controlled vocabularies, that define, for example, how to refer to a disease (e.g., we use http://purl.obolibrary.org/obo/MONDO_0012709 to refer to "isolated microphthalmia with coloboma 5"),
+
terminologies which describe how we humans refer to a disease (How is it called in German? Which other synonyms are used in the literature? How is the term defined in the medical literature?),
+
taxonomies which define how diseases are related hierarchically ("microphthalmia, isolated, with coloboma 5 is a kind of Mendelian disease"),
+
ontologies which further define how diseases are defined in terms of other entities, for example "microphthalmia, isolated, with coloboma 5 is a Mendelian disease that has its basis in the dysfunction of SSH".
+
Note: In practice, when we say "ontology", we mean all of the above together - it is, however, good to know that they are somewhat distinct, and that there are different "languages" that can be used for each of these distinctions.
+
+
Tools that do something useful with these collections of statements.¶
+
For example (as always, non exhaustive):
+
+
Efficient storage (triple stores, in-memory ontology APIs, other databases). Similar to traditional SQL databases, the Semantic Web comes with a number of database solutions that are optimised to deliver "semantic content".
+
Semantically aware querying: Very similar to traditional SQL (which, incidentally is often great to query semantic data), there are various ways to "interrogate", or query, your Linked Data, such as SPARQL, DL Querying, Ontology-based data access (OBDA).
+
Subsetting (module/subset extraction): Often, ontologies (or other collections of Linked Data statements) are very large and cover a lot of entities and knowledge that is not important to your work. There are a number of techniques that allow you to extract meaningful subsets for your use case; for example, you may be interested to get all the information you can about Mendelian diseases, but you don't care about common diseases (e.g. see ROBOT extract).
+
Visualisation: As a Data Scientist, you are used to looking at your data in tabular form - while a lot of information stored in ontologies can still be inspected this way, in general semantic data is best perceived as a graph - which are notoriously hard to visualise. Fortunately, a lot of Linked Data, in particular ontologies in the biomedical domain are predominantly tree-shaped (you have a disease, and underneath sub-diseases). Term browsers like OLS typically render ontologies as trees.
+
Data linking/matching: This is key in particular in the biomedical sciences, as there is almost never just one way to refer to the same thing. In my experience, a good rule of thumb is that there are 3-6, e.g. 3-6 URIs that refer to "Mendelian Disease", all of which need to be matched together to integrate data across resources. There are many approaches to ontology matching - none of which are anywhere near perfect.
+
Automated error checking and validation (Syntax, Structure (SHEX, SHACL), logical Consistency (DL Reasoner)): Naturally, writing sentences in any language is hard in the beginning, but this is even more true for highly complex languages such as OWL. In my experience, no-one can write flawless OWL without the help of automatic syntax and semantics checking, at least not consistently. Validation tools are a crucial part of your Semantic Engineering toolbox.
+
Translate between languages: Often we need to translate from one language, for example OWL, to another, for example SKOS to integrate divergent resources. Translations in the Semantic Web context are nearly always lossy (there are always things you can say in one language, but not in another), but they may be necessary nevertheless.
+
Discovery of terms (OLS, BioPortal): If you are curating terms, you need to know what ID (URI) to use for "isolated microphthalmia with coloboma 5". For that, term browsers such as OLS are perfect. Just type in your natural language search term, and you will find a series of suggestions for URIs you can use for your curation.
+
Discovery of vocabularies OBO Foundry ontology library, BioPortal): we will have a section later on on how to select appropriate ontologies for your use case, but the general problem of finding vocabularies, or ontologies, is answered by ontology repositories or libraries. Naturally, our favourite ontology library is the OBO Foundry ontology library which contain a lot of high quality ontologies for the biomedical domain.
+
Make implicit knowledge explicit, aka reasoning:
+
Deductive (DL Reasoning, Rule-based reasoning such as Datalog, SWRL). One of the major selling points for OWL, for example, in the biomedical domain is the ability to use logical reasoning in a way that is sound (only gives you correct inferences, at all times) and complete (all hidden implications are found, at all times, by the reasoner) - this is particularly great for medical knowledge where mistakes in computer algorithms can have devastating effects. However, I am slowly coming to the conviction that sound and complete reasoning is not the only form of deductive reasoning that is useful - many rule languages can offer value to your work by unveiling hidden relationships in the data without giving such strong "logical guarantees".
+
Inductive (Machine Learning approaches, Knowledge Graph Representation Learning). The new frontier - we will discuss later in the course how our ontology-powered Knowledge Graphs can be leveraged to identify drug targets, novel gene to phenotype associations and more, using a diverse set of Machine Learning-based approaches.
+
+
This week will focus on 1 (identifiers) and 4 (applications) - 2 (languages and standards) and 3 (controlled vocabularies and ontologies) will be covered in depth in the following weeks.
+
Note on the side: Its not always 100% clear what is meant by Linked Data in regular discourse. There are some supposedly "clear" definitions ("method for publishing structured data", "collection of interrelated datasets on the Web"), but when it comes down to the details, there is plenty of confusion (does an OWL ontology constitute Linked Data when it is published on the Web? Is it Linked Data if it does not use RDF? Is it Linked Data if it is less than 5-star - see below). In practice all these debates are academic and won't mean much to you and your daily work. There are entities, statements (context) being said about these entities using some standard (associated with the Semantic Web, such as OWL or RDFS) and tools that do something useful with the stuff being said.
+
When I say "Mendelian Disease" I mean http://purl.obolibrary.org/obo/MONDO_0003847¶
+
One of the top 5 features of the Semantic Web (at least in the context of biomedical sciences) is the fact that we can use URIs as a global identifier scheme that is unambiguous, independent of database implementations, independent of language concerns to refer to the entities in our domain.
+
For example, if I want to refer to the concept of "Mendelian Disease", I simply refer to http://purl.obolibrary.org/obo/MONDO_0003847 - and everyone, in Japan, Germany, China or South Africa, will be able to "understand" or look up what I mean. I don't quite like the word "understanding" in this context as it is not actually trivial to explain to a human how a particular ID relates to a thing in the real world (semiotics). In my experience, this process is a bit rough in practice - it requires that there is a concept like "Mendelian Disease" in the mental model of the person, and it requires some way to link the ID http://purl.obolibrary.org/obo/MONDO_0003847 to that "mental" concept - not always as trivial as in this case (where there are standard textbook definitions). The latter is usually achieved (philosophers and linguists please stop reading) by using an annotation that somehow explains the term - either a label or some kind of formal definition - that a person can understand. In any case, not trivial, but thankfully not the worst problem in the biomedical domain where we do have quite a wide range of shared "mental models" (more so in Biology than Medical Science..). Using URIs allows us to facilitate this "understanding" process by leaving behind some kind of information at the location that is dereferenced by the URI (basically you click on the URI and see what comes up). Note that there is a huge deal of compromise already happening across communities. In the original Semantic Web community, the hope was somehow that dereferencing the URI (clicking on it, navigating to it) would reveal structured information about the entity in question that could used by machines to understand what the entity is all about. In my experience, this was rarely ever realised in the biomedical domain. Some services like Ontobee expose such machine readable data on request (using a technique called content negotiation), but most URIs simply refer to some website that allow humans to understand what it means - which is already a huge deal. For more on names and identifiers I refer the interested reader to James Overton's OBO tutorial here.
+
Personal note: Some of my experienced friends in the bioinformatics world say that "IRI have been more pain than benefit". It is clear that there is no single thing in the Semantic Web is entirely uncontested - everything has its critics and proponents.
+
The advent of the CURIE and the bane of the CURIE map¶
+
In reality, few biological resources will contain a reference to http://purl.obolibrary.org/obo/MONDO_0003847. More often, you will find something like MONDO:0003847, which is called a CURIE. You will find CURIEs in many contexts, to make Semantic Web languages easier to read and manage. The premise is basically that your document contains a prefix declaration that says something like this:
In reality, the proliferation of CURIEs has become a big problem for data engineers and data scientists when analysing data. Databases rarely, if ever, ship the CURIE maps with their data required to understand what a prefix effectively stands for, leading to a lot of guess-work in the daily practice of the Semantic Data Engineer (if you ever had to distinguish ICD: ICD10: ICD9: UMLS:, UMLSCUI: without a prefix map, etc you will know what I am talking about). Efforts to bring order to this chaos, essentially globally agreed CURIE maps (e.g. prefixcommons), or ID management services such as identifiers.org exist, but right now there is no one solution - prepare yourself to having to deal with this issue when dealing with data integration efforts in the biomedical sciences. More likely than not, your organisation will build its own curie map and maintain it for the duration of your project.
+
Semantic Web in the biomedical domain: Success stories¶
+
There are probably quite a few divergent opinions on this, but I would like to humbly list the following four use cases as among the most impactful applications of Semantic Web Technology in the biomedical domain.
We can use hierarchical relations in ontology to group data. For example, if I know that http://purl.obolibrary.org/obo/MONDO_0012709 ("microphthalmia, isolated, with coloboma 5") http://www.w3.org/2000/01/rdf-schema#subClassOf ("is a") http://purl.obolibrary.org/obo/MONDO_0003847 ("Mendelian Disease"), then a specialised Semantic Web tool called a reasoner will know that, if I ask for all genes associated with Mendelian diseases, you also want to get those associated with "microphthalmia, isolated, with coloboma 5" specifically (note that many query engines such as SPARQL with RDFS entailment regime have simple reasoners embedded in them, but we would not call them "reasoner" - just query engine).
Ontologies are extremely hard to manage and profit from the sound logical foundation provided by the Web Ontology Language (OWL). We can logically define our classes in terms of other ontologies, and then use a reasoner to classify our ontology automatically. For example, we can define abnormal biological process phenotypes in terms of biological processes (Gene Ontology) and classify our phenotypes entirely using the classification of biological processes in the Gene Ontology (don't worry if you don't understand a thing - we will get to that in a later week).
+
Globally unique identifiers for data integration.¶
+
Refer to the same thing the same way. While this goal was never reached in total perfection, we have gotten quite close. In my experience, there are roughly 3-6 ways to refer to entities in the biomedical domain (like say, ENSEMBL, HGNC, Entrez for genes; or SNOMED, NCIT, DO, MONDO, UMLS for diseases). So while the "refer to the same thing the same way" did not truly happen, a combination of standard identifiers with terminological mappings, i.e. links between terms, can be used to integrate data across resources (more about Ontology Matching later). Again, many of my colleagues disagree - they don't like IRIs, and unfortunately, you will have to build your own position on that.
+
Personal note: From an evolutionary perspective, I sometimes think that having 2 or 3 competing terminological systems is better than 1, as the competition also drives the improvements in quality, but there is a lot of disagreement on this.
+
Coordinated development of mutually compatible ontologies across the biomedical domain: The Open Biological and Biomedical Ontologies (OBO) Foundry.¶
+
The OBO Foundry is a community-driven effort to coordinate the development of vocabularies and ontologies across the biomedical domain. It develops standards for the representation of terminological content (like standard properties), and ontological knowledge (shared design patterns) as well as shared systems for quality control. Flagship projects include:
+
+
The Relation Ontology (RO) for the standardisation of relationships that connect entities in biomedical ontologies.
The OBO Metadata Ontology for aligning ontology metadata properties across OBO ontologies.
+
The OBO Persistent Identifier System: an Identifier scheme for persistent URIs used by many ontologies on the web. The system is used to refer to terms as well as ontologies and their versions.
+
OBO Dashboard: a system for the monitoring and continued improvement of OBO ontologies with automated Quality Control checks.
+
+
Semantic Web and Linked Data: Things you should have heard about¶
+
+
The Semantic Web Layer Cake: A iconic, colourful graphic that describes the layered design of the semantic web, from URIs to Logic. Its not particularly useful, but as a Semantic Web Explorer, you should have seen it.
+
Linked Data is mostly referred to as a "method for publishing data", a key concept in the Semantic Web domain, coined by Tim Berners Lee in 2006. Related concepts:
make your stuff available on the Web (whatever format) under an open license
+
make it available as structured data (e.g., Excel instead of image scan of a table)
+
use non-proprietary formats (e.g., CSV instead of Excel)
+
use URIs to denote things, so that people can point at your stuff
+
link your data to other data to provide context
+
+
+
FAIR data: Principles defined in 2016, somewhat orthogonal to Linked Data Principles. A nice tutorial, also going a bit more in depth into identifiers than what we did in this section, can be found here. The idea of FAIR data is probably more impactful in the biomedical and pharmaceutical world then the idea of Linked Data. While there are some (slighltly irritating) voices on the sidelines that say that "It can't be FAIR if its not RDF", it is probably true that a nicely formatted CSV file on the Web is at least as useful as a (hard to understand) RDF dump containing the same data. Worldwide collaborations between major pharmaceutical corporations promoting FAIR data, such as the Pistoia Alliance do mention Semantic Web Technologies in their White papers, but keep the jargon a bit more hidden from the general public. Data, according to the FAIR principles, should be:
+
Findable (machine readable metadata, etc)
+
Accessible (open authentication, authorisation)
+
Interoperable (integrated with other data, closely related to controlled vocabularies and linked data)
+
Reusable (metadata, license, provenance)
+
World Wide Web Consortium (W3C): The World Wide Web Consortium (W3C) is an international community that develops open standards, in particular many of those (but not all!) pertaining to the Semantic Web.
+
+
The Ecosystem of Linked Data and Semantic Web: Standards, Technologies and Research Areas¶
+
In the following, we will list some of the technologies you may find useful, or will be forced to use, as a Semantic Data Engineer. Most of these standards will be covered in the subsequent weeks of this course.
A key shortcoming of RDF is that, while I can in principle say everything about everything, I cannot directly talk about edges, for example to attribute provenance: "microphthalmia, isolated, with coloboma 5 is kind of Mendelian disease"--source: Wikipedia
W3C Recommendation to embed rich semantic metadata in HTML (and XML).
+
I have to admit - in 11 years Semantic Web Work I have not come across much use of RDFa in the biomedical domain. But @jamesaoverton is using it in his tools!
+
+
+
+
A thorough overview of all the key standards and tools can be found on the Awesome Semantic Web repo.
+
For a rough sense of current research trends it is always good to look at the accepted papers at one of the major conferences in the area. I like ISWC (2020 papers), but for the aspiring Semantic Data Engineering in the biomedical sphere, it is probably a bit broad and theoretical. Other interesting specialised venues are the Journal of Biomedical Semantics and the International Conference on Biomedical Ontologies, but with the shift of the focus in the whole community towards Knowledge Graphs, other journals and conferences are becoming relevant.
+
Here are a few key research areas, which are, by no means (!), exhaustive.
+
+
How can we combine data and knowledge from different ontologies/knowledge graphs?
Ontology merging: combine two ontologies by corresponding concepts and relations.
+
Ontology matching: A sub-problem of ontology alignment, namely the problem of determining whether two terms (for example two diseases) from different ontologies should be linked together or not.
+
How can we integrate data from unstructured and semistructured sources such as documents or spreadsheets?
Entity linking: The task of associating a named entity, for example the result of a Named Entity Recognition algorithm, or the column of a spreadsheet, to a concept in an ontology. For example, the value "Mendelian Disease" is linked to the concept http://purl.obolibrary.org/obo/MONDO_0003847.
+
Relationship extraction: Once you have identified the genes and diseases in your Pubmed abstracts, you will want to understand how they related to each other. Is the gene the "basis in dysfunction of" the disease? Or just randomly co-occurs in the sentence?
+
Note: Many of the problems in this category are typically associated with the domain of Natural Language Processing rather than Semantic Web.
+
How can we generate insight from semantically integrated data?
+
Knowledge Graphs and Machine Learning
+
Knowledge Graph Embeddings. The number one hype topic in recent years: How do you get from a graph of interrelated entities to a faithful representation in a vector space (basically numbers), so that Machine Learning algorithms can do their magic?
+
Link predication: Based on what we know, which are the best drug targets for my rare disease of interest?
+
+
+
Logical reasoning: While the research on deductive reasoning, at least the more "hard-core" Description Logic kind, seems to be a bit more quiet in recent years (maybe I am wrong here, I just see much less papers coming through my Google Scholar alerts now then I used to), there is still a lot going on in this domain: more efficient SPARQL engines, rule-based reasoning such as the recently commercialised RDFox reasoner and many more.
+
Other research areas (not in any way exhaustive):
+
Web decentralisation and privacy:
+
Solid: Solid (Social Linked Data) is a web decentralization project led by Tim Berners-Lee, with the aim of true ownership of personal data and improved privacy. "Pods" are like secure personal web servers for data from which application can request data.
+
Shape validation: It is very difficult to validate huge Knowledge Graphs of interrelated data efficiently (by validate we can mean a lot of things, such as making sure that your cat does not accidentally end up as someone's "Mendelian Disease"). Shape languages such as Shex and SHACL are poised to solve this problem, but the research is ongoing.
+
+
+
New standards and tools: There is always someone proposing a new semantic standard for something or building a new kind of triple store, SPARQL extension or similar.
+
+
Typical Jobs of Semantic Data Engineers in the biomedical domain¶
+
It is useful to get a picture of the typical tasks a Semantic Data Engineer faces when building ontologies are Knowledge Graphs. In my experience, it is unlikely that any particular set of tools will work in all cases - most likely you will have to try and assemble the right toolchain for your use case and refine it over the lifetime of your project. The following are just a few points for consideration of tasks I regularly encountered - which may or may not overlap with the specific problems you will face.
There are no simple answers here and it very heavily depends on your use cases. We are discussing some places to look for ontologies here, but it may also be useful to simply upload the terms you are interested in to a service like Zooma and see what the terms map to at a major database provider like EBI.
This is much harder still than it should have to be. Scientific databases are scattered across institutions that often do not talk to each other. Prepare for some significant work in researching the appropriate databases that could benefit your work, using Google and the scientific literature.
It is rare nowadays that you will have to develop an ontology entirely from scratch - most biomedical sub-domains will have some kind of reasonable ontology to build upon. However, there is often a great need to extend existing ontologies - usually because you have the need of representing certain concepts in much more detail, or your specific problem has not been modelled yet - think for example when how disease ontologies needed to be extended during the Coronavirus Crisis. Extending ontologies usually have two major facets:
+
+
If at all possible you should seek to contribute new terms, synonyms and relationships to the ontologies you seek to extend directly. Here, you can use GitHub to make issues requesting new terms, but more boldly, you can also add new terms yourself. We will teach you how to do that in one of the next weeks.
+
If the knowledge is considered out of scope for the ontology to be extended (for example because the terms are considered too detailed), then you will maintain your own "branch" of the ontology. Many tools such as the Ontology Development Kit and ROBOT can help you maintain such a branch but the general instinct should be:
Also sometimes more broadly referred to as "data integration", this problem involves a variety of tasks, such as:
+
+
Named Entity Recognition. If you have a set of documents, such as PubMed abstracts or clinical notes, you may have to first identify the parts of speech that refer to clinical entities.
+
Entity Linking: Once you have identified the biomedical entities of interest, you may want to link them to your existing knowledge graph. This process is sometimes called entity mapping or data mapping as well. Very often, this task is not fully automated. We have worked on projects where we used approaches to Entity Linking to suggest good mappings to users, which then had to confirm or reject them. It is also good to understand that not all entity linking must be vertical (i.e. between "equivalent" entities). Very often, there is no equivalent entity in your knowledge graph to map to, and here you need to decide whether to (a) create a new entity in the knowledge graph to map to or (b) map to a broader entity (for example "microphthalmia, isolated, with coloboma 5" to "Mendelian Disease"). What is more efficient / useful solely depends on your use case!
To make your data discoverable, it is often useful to extract a view from the ontologies you are using (for example, Gene Ontology, Disease Ontology) that only contains the terms and relationships of relevance to your data. We usually refer to this kind of ontology as an application ontology, or an ontology specific to your application, which will integrate subsets of other ontologies. This process will typically involve the following:
+
+
Define a seed, or a set of terms you want to import from your external ontologies of interest.
+
Extract relevant subsets from ontologies using this seed (for example using ROBOT extract).
+
Combine and potentially link these subsets together.
Leverage ontologies and knowledge graphs for you data analysis problems¶
+
There are many ways your semantic data can be leveraged for data analysis, but in my experience, two are particularly central:
+
+
Data grouping and search: make data about "microphthalmia, isolated, with coloboma 5" available when searching for data about "Mendelian Disease".
+
Link prediction: Figure out what additional knowledge is hidden in your data that can drive your research (e.g. possible new therapies or drug targets).
The open courses of the Hasso Plattner Institute (HPI) offer introductions into the concepts around Linked Data, Semantic Web and Knowledge Engineering. There are three courses of relevance to this weeks topics, all of which overlap significantly.
+
+
Knowledge Engineering and the Web of Data: The oldest (2015), of the courses, but the most thorough when it comes to logical foundations, semantics and OWL. We will come back to this course in Weeks 4 and 5.
In this course, you will learn the basics of automation in and around the OBO ontology world - and beyond. The primary goal is to enable ontology pipeline developers to plan the automation of their ontology workflows and data pipelines, but some of the materials are very general and apply to scientific computing more widely. The course serves also as a prerequisite for advanced application ontology development.
Automation is part of the foundation of the modern world.
+The key to using and building automation
+is a certain way of thinking about processes,
+how they can be divided into simple steps,
+and how they operate on inputs and outputs
+that must be exactly the same in some respects but different in others.
+
In this article I want to make some basic points about automation
+and how to think about it.
+The focus is on automation with software and data,
+but not on any particular software or data.
+Some of these points may seem too basic,
+especially for experienced programmers,
+but in 20+ years of programming
+I've never seen anybody lay out these basic points in quite this way.
+I hope it's useful.
The second part is more visible,
+and tends to get more attention,
+but the first part is at least as important.
+While automation makes much of the modern world possible,
+it is not new,
+and there are serious pitfalls to avoid.
+No system is completely automatic,
+so it's best to think of automation on a spectrum,
+and starting thinking about automation
+at the beginning of a new project.
To my mind, the word "automation" brings images of car factories,
+with conveyor belts and robotic arms moving parts and welding them together.
+Soon they might be assembling self-driving ("autonomous") cars.
+Henry Ford is famous for making cars affordable
+by building the first assembly lines,
+long before there were any robots.
+The essential steps for Ford were standardizing the inputs and the processes
+to get from raw materials to a completed car.
+The history of the 20th century is full of examples of automation
+in factories of all sorts.
+
Automation was essential to the Industrial Revolution,
+but it didn't start then.
+We can look to the printing press.
+We can look to clocks, which regimented lives in monasteries and villages.
+We can think of recipes, textiles, the logistics of armies,
+advances in agriculture, banking, the administration of empires,
+and so on.
+The scientific revolution was built on repeatable experiments
+published in letters and journal articles.
+I think that the humble checklist is also an important relative of automation.
+
Automation is not new,
+but it's an increasingly important part
+of our work and our lives.
Software is almost always written as source code in text files
+that are compiled and/or interpreted as machine code
+for a specific set of hardware.
+Software can drive machines of all sorts,
+but a lot of software automation stays inside the computer,
+working on data in files and databases,
+and across networks.
+We'll be focused on this kind of software automation,
+transforming data into data.
+
The interesting thing about this is that source code is a kind of data,
+so there are software automation workflows
+that operate on data that defines software.
+The upshot is that you can have automation that modifies itself.
+Doing this on a large scale introduces a lot of complexity,
+but doing it on a small scale can be a clean solution to certain problems.
+
Another interesting thing about software is that
+once we solve an automation problem once
+we can copy that solution and apply it again and again
+for almost zero cost.
+We don't need to build a new factory or a new threshing machine.
+We can just download a program and run it.
+Henry Ford could make an accurate estimate
+of how long it would take to build a car on his assembly line,
+but software development is not like working on the assembly line,
+and estimating time and budget for software development is notoriously hard.
+I think this is because software developers
+aren't just executing automation,
+they're building new automation for each new project.
+
Although we talk about "bit rot",
+and software does require maintenance of a sort,
+software doesn't break down or wear out
+in the same ways that physical machines do.
+So while the Industrial Revolution eliminated many jobs,
+it also created different jobs,
+building and maintaining the machines.
+It's not clear that software automation will work the same way.
+
Software automation is special because it can operate on itself,
+and once complete can be cheaply copied.
+Software development is largely about building automated systems of various sorts,
+usually out of many existing pieces.
+We spend most of our time building new systems,
+or modifying an existing system to handle new inputs,
+or adapting existing software to a new use case.
To err is human; to really foul things up requires a computer.
+
+
An obvious danger of automation is that
+machines are faster than humans,
+so broken automation can often do more damage
+more quickly than a human can.
+A related problem is that humans usually have much more
+context and depth of experience,
+which we might call "common sense",
+and a wider range of sensory inputs than most automated systems.
+This makes humans much better at recognizing
+that something has gone wrong with a process
+and that it's time to stop.
+
New programmers soon learn that a simple program
+that performs perfectly when the input is in exactly the right format,
+becomes a complex program once it's updated to handle
+a wide range of error conditions.
+In other words, it's almost always much harder
+to build automation that can gracefully handler errors and problems
+than it is to automate just the "happy path".
+Old programmers have learned through bitter experience
+that it's often practically impossible to predict
+all the things that can go wrong with an automated system in practise.
+
+
I suppose it is tempting, if the only tool you have is a hammer,
+to treat everything as if it were a nail.
+-- Abraham Maslow
+
+
A less obvious danger of automation comes from the sameness requirement.
+When you've built a great piece of automation,
+perfectly suited to inputs of a certain type,
+it's very tempting to apply that automation more generally.
+You start paying too much attention to how things are the same,
+and not enough attention to their differences.
+You may begin to ignore important differences.
+You may surrender your common sense and good judgment,
+to save yourself the work of changing the automated system or making an exception.
+
Bureaucracies are a form of automation.
+Everyone has had a bad experience
+filling out some form that ignores critical information,
+and with some bureaucrat who would not apply common sense and make an exception.
+
Keep all this in mind as you build automated systems:
+a broken machine can do a lot of damage very quickly,
+and a system built around bad assumptions
+can do a lot of hidden damage.
Let's consider a simple case of automation with software,
+and build from the most basic sort of automation
+to a full-fledged system.
+
Say you have a bunch of text files in a directory,
+each containing minutes from meetings that we had together over the years.
+You can remember that I talked about a particular software package
+that might solve a problem that you just discovered,
+but you can't remember the name.
The first thing you try is to just search the directory.
+On a Mac you would open the Finder,
+navigate to the directory,
+and type "James" into the search bar.
+Unfortunately that gives too many results:
+all the files with the minutes for a meeting where I said something.
+
The next thing to do is double click some text files,
+which would open them in Text Edit program,
+and skim them.
+You might get lucky!
+
You know that I the meeting was in 2019,
+so you can try and filter for files modified in that year.
+Unfortunately the files have been updated at different times,
+so the file dates aren't useful.
+
Now if each file was named with a consistent pattern,
+including the meeting date,
+then it would be simple to filter for files with "2019" in the name.
+This isn't automation,
+but it's the first step in the right direction.
+Consistent file names are one way to make inputs the same
+so that you can process them in the same way.
+
Let's say it works:
+you filter for files from 2019 with "James" in them,
+skim a few,
+and find a note where I recommended using Pandoc
+to convert between document formats.
+Mission accomplished!
Next week you need to do something very similar:
+Becky mentioned a website where you can find an important dataset.
+It's basically the same problem with different inputs.
+If you remember exactly what you did last time,
+then you can get the job done quickly.
+As the job gets more complicated and more distant in time,
+and as you find yourself doing similar tasks more often,
+it's nice to have notes about what you did and how you did it.
+
If I'm using a graphical user interface (GUI)
+then for each step I'll note
+the program I used,
+and the menu item or button I clicked,
+e.g. "Preferences > General > Font Size",
+or "Search" or "Run".
+If I'm using a command-line interface (CLI)
+then I'll copy-paste the commands into my notes.
+
I often keep informal notes like this in a text file
+in the relevant directory.
+I name the file "notes.txt".
+A "README" file is similar.
+It's used to describe the contents of a directory,
+often saying which files are which,
+or what the column headers for a given table mean.
+
Often the task is more complicated
+and requires one or more pieces of software that I don't use every day.
+If there's relevant documentation,
+I'll put a link to it in my notes,
+and then a short summmary of exactly what I did.
+
In this example
+I look in the directory of minutes and see my "notes.txt" file.
+I read that and remember how I filtered on "2019" and searched for "James".
+This time I filter on "2020" and search for "Becky",
+and I find the website for the dataset quickly enough.
+
As a rule of thumb,
+it might take you three times longer
+to find your notes file,
+write down the steps you took,
+and provide a short description,
+than it would to just do the job without taking notes.
+When you're just taking notes for yourself,
+this often feels like a waste of time
+(you'll remember, right?!),
+and sometimes it is a bit of a waste.
+If you end up using your notes
+to help with similar tasks in the future,
+then this will likely be time well spent.
+
As a rule of thumb,
+it might take three times longer
+to write notes for a broader audience
+than notes for just yourself.
+This is because you need to take into account
+the background knowledge of your reader,
+including her skills and assumptions and context,
+and especially the possible misunderstandings
+that you can try to avoid with careful writing.
+I often start with notes for just myself
+and then expand them for a wider audience only when needed.
When tasks get more complicated
+or more important
+then informal notes are not enough.
+The next step on the spectrum of automation is the humble checklist.
+
The most basic checklists are for making sure that each item has been handled.
+Often the order isn't important,
+but lists are naturally ordered from top to bottom,
+and in many cases that order is useful.
+For example,
+my mother lays out her shopping lists
+in the order of the aisles in her local grocery store,
+making it easier to get each item and check it off
+without skipping around and perhaps having to backtrack.
+
I think of a checklist as a basic form of automation.
+It's like a recipe.
+It should lay out the things you need to start,
+then proceed through the required steps
+in enough detail that you can reproduce them.
+In some sense,
+by using the checklist you are becoming the "machine".
+You are executing an algorithm
+that should take you from the expected inputs to the expected output.
+
Humble as the checklist is,
+there's a reason that astronauts, pilots, and surgical teams
+live by their checklists.
+Even when the stakes are not so high,
+it's often nice to "put your brain on autopilot"
+and just work the checklist
+without having to remember and reconsider the details of each step.
+
A good checklist is more focused than a file full of notes.
+A checklist has a goal at the end.
+It has specific starting conditions.
+The steps have been carefully considered,
+so that they have the proper sequence,
+and none are missing.
+Perhaps most importantly,
+a checklist helps you break a complex task down
+into simple parts.
+If one of the parts is still too complex,
+then break it down again
+into a nested checklist
+(really a sort of tree structure).
+
Checklists sometimes include another key element of automation: conditionals.
+A shopping list might say
+"if there's a sale on crackers, then buy three boxes".
+If-then conditions let our automated systems adapt to circumstances.
+The "then" part is just another step,
+but the "if" part is a little different.
+It's a test to determine whether a condition holds.
+We almost always want the result of the test
+to be a simple True or False.
+Given a bunch of inputs,
+some of which pass the test and some of which fail it,
+we can think of the test as determining some way in which
+all the things that pass are the same
+and all the things that fail are the same.
+Programmers will also be familiar with more complex conditionals
+such as if-then-else, if-elseif-else, and "case",
+which divide process execution across multiple "branches".
+
As a rule of thumb,
+turning notes into a checklist will likely take
+at least three times as long
+as simply writing the notes.
+If the checklist is for a wider audience,
+expect it to take three times as long to write,
+for the same reasons mentioned above for notes.
+
If a task is simple
+and I can hold all the steps in my head,
+and I can finish it in one sitting without distractions,
+then I won't bother with a checklist.
+But more and more I find myself writing myself a checklist
+before I begin any non-trivial tasks.
+I use bullet points in my favourite text editor,
+or sometimes the Notes app on my iPhone.
+I lay out the steps in the expected order,
+and I check them off as I go.
+Sometimes I start making the checklist days before I need it,
+so I have lots of time to think about it and improve it.
+If there's a job that I'm worried about,
+breaking it down into smaller pieces
+usually helps to make the job feel more manageable.
+Actually, I try to start every workday
+by skimming my (long) To Do list,
+picking the most important tasks,
+and making a checklist for what I want to get done
+by quitting time.
"Checkscript" is a word that I think I made up,
+based on insights from a couple of sources,
+primarily this blog post on
+"Do-nothing scripting: the key to gradual automation"
+This is where "real" automation kicks in,
+writing "real" code and stuff,
+but hopefully you'll see that it's just one more step
+on the spectrum of automation that I'm describing.
+
The notes and checklists we've been discussing
+are just text in your favourite text editor.
+A checkscript is a program.
+It can be written in whatever programming language you prefer.
+I'll give examples in Posix Shell,
+but that blog post uses Python,
+and it really doesn't matter.
+You start with a checklist
+(in your mind at least).
+The first version of your program
+should just walk you through your checklist.
+The program should walk you through each step of your checklist,
+one by one.
+That's it.
+
Here's a checkscript based on the example above.
+It just prints the first step (echo),
+waits for you to press any key (read),
+then prints the next step, and so on.
+
###!/bin/sh
+
+echo "1. Use Finder to filter for files with '2019' in the name"
+read -p "Press enter to continue"
+
+echo "2. Use finder to search file content for 'James'"
+read -p "Press enter to continue"
+
+echo "3. Open files in Text Edit and search for 'James'"
+read -p "Press enter to continue"
+
+echo "Done!"
+
+
So far this is just a more annoying way to use a checklist.
+The magic happens once you break the steps down into small enough pieces
+and realize that you know how to tell the computer
+to do some of the steps
+instead of doing them all yourself.
+
For example,
+you know that the command-line tool grep
+is used for searching the contents of files,
+and that you can use "fileglob"s to select
+just the files that you want to search,
+and that you can send the output of grep
+to another file to read in your favourite text editor.
+Now you know how to automate the first two steps.
+The computer can just do that work without waiting for you:
+
###!/bin/sh
+
+grep "James" *2019* > search_results.txt
+
+echo "1. Open 'search_results.txt' in Text Edit and search for 'James'"
+read -p "Press enter to continue"
+
+echo "Done!"
+
+
Before we were using the Finder,
+and it is possible to write code to tell the Finder
+to filter and seach for files.
+The key advantage of grep here
+is that we send the search results to another file
+that we can read now or save for later.
+
This is also a good time to mention the advantage of text files
+over word processor files.
+If the minutes were stored in Word files, for example,
+then Finder could probably search them
+and you could use Word to read them,
+but you wouldn't be able to use grep
+or easily output the results to another file.
+Unix tools such as grep treat all text files the same,
+whether they're source code or meeting minutes,
+which means that these tools work pretty much the same on any text file.
+By keeping your data in Word
+you restrict yourself to a much smaller set of tools
+and make it harder to automate you work
+with simple scripts like this one.
+
Even if you can't get the computer
+to run any of the steps for you automatically,
+a checkscript can still be useful
+by using variables instead of repeating yourself:
+
###!/bin/sh
+
+FILE_PATTERN="*2019*"
+FILE_CONTENTS="James"
+
+echo "1. Use Finder to filter for files with '${FILE_PATTERN}' in the name"
+read -p "Press enter to continue"
+
+echo "2. Use finder to search file content for '${FILE_CONTENTS}'"
+read -p "Press enter to continue"
+
+echo "3. Open files in Text Edit and search for '${FILE_CONTENTS}'"
+read -p "Press enter to continue"
+
+echo "Done!"
+
+
Now if I want to search for "Becky"
+I can just change the FILE_CONTENTS variable in one place.
+I find this especially useful for dates and version numbers.
+
This is pretty simple for a checkscript,
+with very few steps.
+A more realistic example would be
+if there were many directories containing the minutes of many meetings,
+maybe in different file formats
+and with different naming conventions.
+In order to be sure that we're searching all of them
+we might need a longer checkscript.
+
Writing and using a checkscript instead of a checklist
+will likely take (you guessed it) about three times as long.
+But the magic of the checkscript
+is in the title of the blog post I mentioned:
+"gradual automation".
+Once you have a checkscript,
+you can run through it all manually,
+but you can also automate bits a pieces of the task,
+saving yourself time and effort next time.
A "script" is a kind of program that's easy to edit and run.
+There are technical distinctions to be made
+between "compiled" programs and "interpreted" programs,
+but they turn out to be more complicated and less helpful than they seem at first.
+Technically, a checkscript is just a script
+that waits for you to do the hard parts.
+In this section I want to talk about "fully automated" or "standalone" scripts
+that you just provide some input and execute.
+
Most useful programs are useful
+because they call other programs (in the right ways).
+I like shell scripts because they're basically just
+commands that are copied and pasted
+from work I was doing on the command-line.
+It's really easy to call other programs.
+
To continue our example,
+say that our minutes were stored in Word files.
+There are Python libraries for this,
+such as python-docx.
+You can write a little script using this library
+that works like grep
+to search for specified text in selected files,
+and output the results to a search results file.
+
As you add more and more functionality to a script
+it can become unwieldy.
+Scripts work best when they have a simple "flow"
+from beginning to end.
+They may have some conditionals and some loops,
+but once you start seeing nested conditionals and loops,
+then your script is doing too much.
+There are two main options to consider:
+
+
break your script into smaller, simpler scripts
+
build a specialized tool: the next step on the spectrum of automation
+
+
The key difference between a checkscript and a "standalone" script
+is handling problems.
+A checkscript relies on you to supervise it.
+A standalone script is expected to work properly without supervision.
+So the script has to be designed to handle
+a wider range of inputs
+and fail gracefully when it gets into trouble.
+This is a typical case of the "80% rule":
+the last 20% takes 80% of the time.
+As a rule of thumb,
+expect it to take three times as long
+to write a script that can run unsupervised
+than it takes you to write a checkscript
+that does "almost" the same thing.
When your script needs nested conditionals and loops,
+then it's probably time to reach for a programming language
+that's designed to write code "in the large".
+Some languages such as Python can make a pretty smooth transition
+from a script in a single file
+to a set of files in a module,
+working together nicely.
+You might also choose another language
+that can provide better performance or efficiency.
+
It's not just the size and the logical complexity of your script,
+consider its purpose.
+The specialized tools that I have in mind
+have a clear purpose that helps guide their design.
+This also makes them easier to reuse
+across multiple projects.
+
I often divide my specialized tools into two parts:
+a library and a command-line interface.
+The library can be used in other programs,
+and contains the most distinctive and important functionality.
+But the command-line interface is essential,
+because it lets me use my specialized tool
+in the shell and in scripts,
+so I can build more automation on top of it.
+
Writing a tool in Java or C++ or Rust
+usually takes longer than a script in shell or Python
+because there are more details to worry about
+such as types and efficient memory management.
+In return you usually get more reliability and efficiency.
+But as a rule of thumb,
+expect it to take three times as long
+to write a specialized tool
+than it would to "just" write the script.
+On the other hand,
+if you already have a script that does most of what you want,
+and you're already familiar with the target you are moving to,
+then it can be fairly straightforward to translate
+from the script to the specialized tool.
+That's why it's often most efficient
+to write a prototype script first,
+do lots of quick experiments to explore the design space,
+and when you're happy with the design
+then start on the "production" version.
The last step in the spectrum of automation
+is to bring together all your scripts
+into a single "workflow".
+My favourite tool for this is the venerable
+Make.
+A Makefile is essentially a bunch of small scripts
+with their input and output files carefully specified.
+When you ask Make to build a given output file,
+it will look at the whole tree of scripts,
+figure out which input files are required to build your requested output file,
+then which files are required to build those files,
+and so on until it has determined a sequence of steps.
+Make is also smart enough to check whether some of the dependencies
+are already up-to-date,
+and can skip those steps.
+Looking at a Makefile you can see everything
+broken down into simple steps
+and organized into a tree,
+through which you can trace various paths.
+You can make changes at any point,
+and run Make again to update your project.
+
I've done this all so many times
+that now I often start with a Makefile in an empty directory
+and build from there.
+I try experiments on the command line.
+I make notes.
+I break the larger task into parts with a checklist.
+I automate the easy parts first,
+and leave some parts as manual steps with instructions.
+I write little scripts in the Makefile.
+I write larger scripts in the src/ directory.
+If these get too big or complex,
+I start thinking about building a specialized tool.
+(And of course, I store everything in version control.)
+It takes more time at the beginning,
+but I think that I usually save time later,
+because I have a nice place to put everything from the start.
+
In other words, I start thinking about automation
+at the very beginning of the project,
+assuming from the start that it will grow,
+and that I'll need to go back and change things.
+With a mindset for automation,
+from the start I'm thinking about how
+the inputs I care about are the same and different,
+which similarities I can use for my tests and code,
+and which differences are important or unimportant.
In the end, my project isn't ever completely automated.
+It doesn't "act of itself".
+But by making everything clear and explicit
+I'm telling the computer how to do a lot of the work
+and other humans (or just my future self)
+how to do the rest of it.
+The final secret of automation,
+especially when it comes to software and data,
+is communication:
+expressing things clearly for humans and machines
+so they can see and do exactly what you did.
By "scientific computing" we mean
+using computers to help with key aspect of science
+such as data collection, cleaning, interpretation, analysis, and visualization.
+Some people use "scientific computing" to mean something more specific,
+focusing on computational modelling or computationally intensive analysis.
+We'll be focusing on more general and day-to-day topics:
+how can a scientist make best use of a computer
+to do their work well?
+
These three things apply to lots of fields,
+but are particularly important to scientists:
+
+
reliability
+
reproducibility
+
communication
+
+
It should be no surprise that
+automation can help with all of these.
+When working properly, computers make fewer mistakes than people,
+and the mistakes they do make are more predictable.
+If we're careful, our software systems can be easily reproduced,
+which means that an entire data analysis pipeline can be copied
+and run by another lab to confirm the results.
+And scientific publications are increasingly including data and code
+as part of the review and final publication process.
+Clear code is one of the best ways to communicate detailed steps.
+
Automation is critical to scientific instruments and experiments,
+but we'll focus on the data processing and analysis side:
+after the data has been generated,
+how should you deal with it.
+
Basic information management is always important:
+
+
community standard file formats
+
consistent file naming
+
documentation, READMEs
+
backups
+
version control
+
+
More advanced data management is part of this course:
+
+
consistent use of versioned
+
software
+
reference data
+
terminology
+
controlled vocabularies
+
data dictionaries
+
ontologies
+
+
Some simple rules of thumb can help reduce complexity and confusion:
A lot of data analysis starts with a reference data set.
+It might be a genome or a proteome.
+It might be a corpus.
+It might be a set of papers or data from those papers.
+
Start by finding that data
+and selecting a particular version of it.
+Write that down clearly in your notes.
+If possible, include a unique identifier such as a (persistent) URL or DOI.
+If that's not possible, write down the steps you took.
+If the data isn't too big,
+keep a copy of it in your fresh new project directory.
+If the data is a bit too big,
+keep a compressed copy in a zip or gz file.
+A lot of software is perfectly happy to read directly from compressed files,
+and you can compress or uncompress data using piped commands in your shell or script.
+If the data is really too big,
+then be extra careful to keep notes
+on exactly where you can find it again.
+Consider storing just the
+hashes
+of the big files,
+so you can confirm that they have exactly the same contents.
+
If you know from the start
+that you will need to compare your results with someone else's,
+make sure that you're using the same reference data
+that they are.
+This may require a conversation,
+but trust me that it's better to have this conversation now than later.
It's much easier to think about processes
+that flow in one direction.
+Branches are a little trickier, but usually fine.
+The real trouble comes with loops.
+Once a process loops back on itself
+it's much more difficult to reason about what's happening.
+Loops are powerful,
+but with great power comes great responsibility.
+Keep the systems you design
+as simple as possible
+(but no simpler).
+
In practical terms:
+
+
Try not to read then write to the same file.
+ If you have to, try to append rather than overwrite.
+ This is one reason why I prefer tables on disk to databases.
+
Don't hesitate to write intermediate files.
+ These are very useful for testing and debugging.
+ When you're "finished" you can comment out these steps.
It's very tempting:
+you could automate this step,
+or you could just do it manually.
+It might take three times as long to automate it, right?
+So you can save yourself some precious time
+by just opening Excel and "fixing" things by hand.
+
Sometimes that bet will pay off,
+but I lose that bet most of the time.
+I tend to realize my mistake only at the last minute.
+The submission deadline is tomorrow
+but the core lab "fixed" something
+and they have a new version of the dataset
+that we need to use for the figures.
+Now I really don't have time to automate,
+so I'm up late clicking through Excel again
+and hoping that I remembered to redo
+all the changes that I made last time.
+
Automating the process would have actually saved me time,
+but more importantly it would have avoided a lot of stress.
+By now I should know that the dataset
+will almost certainly be revised at the last minute.
+If I have the automation set up,
+then I just update the data,
+run the automation again,
+and quickly check the results.
Tests are another thing that take time to implement.
+
One of the key benefits to tests is (again) communication.
+When assessing or trying out some new piece of software
+I often look to the test files to see examples
+of how the code is really used,
+and the shape of the inputs and outputs.
+
There's a spectrum of tests
+that apply to different parts of your system:
+
+
unit tests: individual functions and methods
+
regression tests: ensure that fixed bugs do not reappear
+
integration tests: end-to-end functionality
+
performance tests: system speed and resource usage
+
acceptance tests: whether the overall system meets its design goals
+
+
Tests should be automated.
+The test suite should either pass or fail,
+and if it fails something needs to be fixed
+before any more development is done.
+The automated test suite should run
+before each new version is committed to version control,
+and ideally more often during development.
+
Tests come with costs:
+
+
development cost of writing the tests
+
time and resources spent running the tests
+
maintenance costs of updating the tests
+
+
The first is obvious but the other two often more important.
+A slow test suite is annoying to run,
+and so it won't get run.
+A test suite that's hard to update won't get updated,
+and then failures will be ignored,
+which defeats the entire purpose.
I tend to forget how bad a memory I have.
+In the moment, when I'm writing brilliant code
+nothing could be more obvious than the perfect solution
+that is pouring forth from my mind all over my keyboard.
+But when I come back to that code weeks, months, or years later,
+I often wonder what the heck I was thinking.
+
We think about the documentation we write as being for other people,
+but for a lot of small projects
+it's really for your future self.
+Be kind to your future self.
+They may be even more tired, even more stressed than you are today.
+
There's a range of different forms of documentation,
+worth a whole discussion of its own.
+I like this four-way distinction:
+
+
tutorials: getting started, basic concepts, an overview
+
how-to guides: how to do common tasks
+
explanation: why does it work this way?
+
reference: looking up the details
+
+
You don't need all of these for your small project,
+but consider a brief explanation of why it works the way it does
+(aimed at a colleague who knows your field well),
+and some brief notes on how-to do the stuff this project is for.
+These could both go in the README of a small project.
In this lesson, we will take a look at the generative capabilities of LLM's in general and ChatGPT in particular, to try and get a beginning sense on how to leverage it to enhance ontology curation workflows.
+
The goal of the lesson is to give a mental model of what ChatGPT and LLMs are used for (ignoring details on how they work), contextualise the public discourse a bit, and then move on to looking at some concrete examples at its potential for improving curation activties.
+
To achieve this we engaged in a dialog with ChatGPT to generate almost the entire content of the lesson. The lesson authors provide the general "structure" of the lesson, provided to ChatGPT as a series of prompts, and get ChatGPT to provide the content. This content is obviously not as good as it could have been if it was created by a human with infinite resources, but we hope it does get the following points across:
+
+
You can get 80% of the way in 20% (or less, in my case) of the time (it took me 90 minutes to write the lesson, while the same scope of lesson would have taken me 8-10 hours without ChatGPT
+
Beware of hallucinations in particular
+
ChatGPT is not only good for generating natural language text, but also structured content
+
Using ChatGPT is fun, which drastically reduces the mental barrier of using it in a professional context
+
+
We believe that from a user perspective, prompt engineering will be the most important skill that need to be learned when dealing with generative AI. Not just ChatGPT (which generates text), but also tools that generate images from text such as DALL-E or Midjourney, so this is what we will focus on. In the long term, applications like Monarchs OntoGPT will do some of the heavy lifting around writing perfect prompts, but it seems pretty clear that some basic knowledge of prompt engineering will be useful, or even necessary, for a long time to come.
+
For a reference of effective ChatGPT prompts for ontology development see here.
+
Note:
+- ChatGPT is rapidly evolving. The moment we add an answer, it will probably be outdated. For example, I created the first version of this tutorial on April 17th 2023. On May 27th, almost all answers ChatGPT is giving are completely different from the ones given in the first round. This is also important to remember when building applications around ChatGPT.
+- Note: https://open-assistant.io/chat is free and can be used to follow this tutorial instead of ChatGPT.
Write basic prompts for ChatGPT and similar LLM-based chatbots
+
Understand the basic principles of text in -> text out of LLM-based programs
+
Understand practically the risks of hallucination
+
Motivate yourself to explore the question: "How, if at all, can I use this technology to become more efficient/effective in my work? (there is no general answer to that yet!)"
We use quote syntax with the prompt icon to indicate a concrete prompt for ChatGPT
+
+
Comments
+
+
+
We use quote syntax with the comment icon to indicate a comment by the author
+
+
Replies by ChatGPT
+
Replies are given in normal text form. All text after the table of contents, apart from comments, prompts and the section on executable workflows are generated by ChatGPT.
If you have a tiny bit of a technical inclination, we recommend the ca. 60 minute OpenAI/DeepLearning.ai course. It has zero fluff, and is very focussed on some of the core use cases of using ChatGPT as an API.
+
We recommend to spend 30-60 minutes studying the excellent Learn Prompting, a Free, Open Source Course on Communicating with Artificial Intelligence.
None of the text in this section is generated with ChatGPT.
+
+
In essence, an LLM takes as an input a piece of text, and returns text as an output. A "prompt" is a
+piece of text that is written by an agent. This can be a human, or a software tool, or a combination of the two. In most cases, a human agent will pass the prompt to a specialised tool that pre-processes the prompt in certain ways (like translating it, adding examples, structuring it and more) before passing it to the large language model (LLM). For example, a when a chatbot tool like ChatGPT receives a prompt, it processes the prompt in certain ways, than leveraging the trained LLM to generate the text (which is probably postprocessed) and passed back to the human agent.
+
+
There are an infinite number of possible tools you can imagine following this rough paradigm. Monarch's own ontogpt, for example, receives the prompt from the human agent, then augments the prompt in a certain way (by adding additional instructions to it) before passing the augmentd prompt to an LLM like gpt3.5 (or lately even gpt4), which generates an instance of a curation schema. This is a great example for an LLM generating not only human readable text, but structured text. Another example for this is to ask an LLM to generate, for example, a SPARQL query to obtain publications from Wikidata.
+
Given the wide range of applications LLMs can serve, it is important to get a mental model of how these can be leveraged to improve our ontology and data curation workflows. It makes sense for our domain (semantic engineering and curation) to distinguish four basic models of interacting with LLMs (which are technically not much different):
+
+
Using LLM-based tools as advisors (endpoint humans)
+
Using LLM-based tools as assistants (endpoint humans)
+
Using LLM-based tools to extract information for automated processing (endpoint application)
+
+
Using LLMs as advisors has a huge number of creative applications. An advisor in this sense is a machine that "knows a lot" and helps you with your own understanding of the world.
+Large language models trained on a wide range of inputs are particularly interesting in this regard because of the immense breadth of their knowledge (rather than depth), which is something that can be difficult to get from human advisors.
+For example, the authors of this article have used ChatGPT and other LLM-based chatbots to help with understanding different domains, and how they might relate to knowledge management and ontologies in order to give specific career advice or to prepare for scientific panel discussions. For ontology curators, LLMs can be used to generate arguments for certain classification decisions (like a disease classification) or even suggest a mapping.
+
Using LLMs as assistants is probably the most important use of LLM-based tools at the moment, which includes aspects like summarising texts, generating sometimes boring, yet important, creative work (documentation pages, tutorials, blog-posts etc). It is probably not a good idea, at least as of May 2023, to defer to LLM-based tools to classify a term in an ontology, for example because of its tendency to hallucinate. Despite many arguments to the contrary LLMs are not databases. They are programs to generate text.
+
Using LLMs to extract information, similar to "LLMs as assistants", is, similar to the above, also about automating certain tasks, but the endpoint is not a software program rather than a human. It is the most important basic model of LLMs for us curators and software engineers to understand, because it is, in essence, the one that threatens our current work-life the most: What happens if LLMs become better at extracting structured knowledge from papers (or similarly generate software codes for user stories) than us? It is important that this thought is not ignored out of fear, but approached with a realistic and positive mindset.
+
Training. Apart from the fact that LLMs take text as an input and return text as an output, it is important to be aware how they are trained.
+
+
The basic technique for trainig is called "next token prediction". In essence, tokens in the text
+such as words or phrases are masked out by the training function and the LLM is trained to correctly predict these masked out phrases given the previous words in the sentence (or paragraph).
+The corpus used for this training ranges from specialised databases all the way to a large chunk of the publicly accessible textual information on the internet.
+Again, it is important to realise that text does not have to be composed of natural language sentences - learning how to generate programming code and structured data works much the same way.
+
In the following, we will ask ChatGPT or Open Assistant a few questions that are relevant to this lesson, which allows us to make certain points. The main point is that a lot of the work for preparing a useful tutorial can be deferred to ChatGPT is an assistant!
+Many of the questions explore how these tools could relate to us biocurators and semantic engineers in particular, but non of this should be viewed as written in stone.
+The most important take away from this lesson is that you should play with these tools yourself!
+
+
+
Can you explain in 3 simple sentences what an LLM is and how it works? [Note this question was asked to [Open Assistant](https://open-assistant.io/chat/) instead of ChatGPT.]
+
+
An LLM (Langauge Modell) is a AI model that can be trained to perform specific tasks such as speech recognition, text generation or machine translation. It's called a "model" because it is being trained on large sets of data to predict the next step based on previously learned relationships between inputs and outputs.
+LLMs are designed to recognize patterns in human language by processing input data through multiple layers of artificial neural networks that simulate the way neurons communicate in the brain. The training process involves feeding vast amounts of text into the model so that it can learn to identify underlying structures within the language itself. This allows the model to make predictions about likely next words or phrases given previous context. By continually adjusting its internal weights and biases using gradient descent techniques, the LLM becomes increasingly proficient at generating coherent text based on statistical probabilities derived from its knowledge of the language.
+
+
+
What is interesting here: the LLM actually made a typo, or rather, three: Langauge Modell - missing the first L (large), Langauge instead of Language and Modell with double L (which is German). Note that both words are spellied correctly later in the text.
+
+
What are the 5 core concepts relevant for end-users to understand LLMs?
+
+
+
Language Understanding and Generation: LLMs can understand human language inputs and generate text-based responses, allowing for interactive conversations.
+
Contextual Understanding: LLMs consider the context of the conversation to provide relevant and coherent responses, taking into account previous messages or prompts.
+
Pretraining: LLMs learn from vast amounts of text data during pretraining, which helps them acquire a general understanding of language, grammar, and context.
+
Limitations and Potential Bias: LLMs may provide incorrect or biased information as they generate responses based on patterns learned from training data. Users should be mindful of these limitations and critically evaluate the information provided.
+
Responsible Use and Privacy: Users should use LLMs responsibly, following platform guidelines and being cautious when sharing personal or sensitive information during interactions. Data privacy should be considered while engaging with LLMs.
Describe the idea of prompt engineering in simple terms for an audience of domain experts
+
+
Prompt engineering is the process of carefully crafting input queries, or "prompts," to guide the behavior of a large language model (LLM) like GPT-4, ensuring that it provides useful, relevant, and accurate responses. As domain experts, you understand the importance of asking the right questions to extract valuable information. Similarly, with prompt engineering, the goal is to design questions or statements in a way that maximizes the LLM's ability to generate meaningful, high-quality output.
+
Essentially, prompt engineering serves as a "communication bridge" between humans and the LLM, allowing the model to better understand the intent behind the query and generate the desired response. This can involve refining the wording, providing context, or specifying the format of the desired answer, among other techniques.
+
By focusing on the art and science of prompt engineering, researchers and practitioners can better harness the potential of LLMs and overcome some of the challenges related to biases, incomplete knowledge, and misleading responses.
+
+
Providing an effective prompt to ChatGPT is an art form, and as resources like learnprompting.org testify, one that requires cultivation and care. The better you become at writing prompts, the more value you will draw from ChatGPT for your daily ontology curation tasks. How effective our prompts are depends on the exact language models used in ChatGPT (at the moment 3.5 or 4), which means that this lesson will keep evolving.
+
+
What are some basic tips for writing good prompts for ChatGPT?¶
What are some potential applications of ChatGPT for ontology development?
+
+
ChatGPT can be a valuable tool for ontology development in various ways. Some potential applications include:
+
+
Concept identification: ChatGPT can help identify and extract relevant concepts from large volumes of unstructured text, providing a list of entities, relationships, and attributes that can be included in an ontology.
+
Semantic relation extraction: ChatGPT can be employed to detect semantic relationships between concepts, such as "is-a" or "part-of" relations, facilitating the construction of the ontology's hierarchical structure.
+
Ontology validation: ChatGPT can assist in validating and refining the structure of an ontology by providing human-like feedback on its consistency and coherence, suggesting improvements, or identifying potential gaps or redundancies.
+
Automated ontology population: ChatGPT can be used to generate instances of entities and relationships based on examples or descriptions, helping to populate the ontology with relevant data.
+
Ontology alignment and merging: ChatGPT can help identify similarities and differences between different ontologies, supporting the process of ontology alignment and merging, which is essential when integrating information from diverse sources.
+
Natural language interfaces: ChatGPT can be utilized to develop natural language interfaces for interacting with ontologies, allowing users to query and explore the ontology using conversational language rather than complex formal queries.
+
Ontology documentation: ChatGPT can assist in generating human-readable documentation for ontologies, including explanations of concepts, relationships, and properties, making it easier for users to understand and work with the ontology.
+
Ontology learning: ChatGPT can be trained to learn from examples or other sources of knowledge, supporting the semi-automatic or automatic creation of ontologies based on the input data.
+
+
By leveraging the capabilities of ChatGPT, ontology developers can streamline the development process, enhance the quality of their ontologies, and facilitate their adoption and use across various domains.
+
+
How can we, concretely, enhance the ontology curation process?¶
+
+
+
A normal workflow of ontology curation is this:
+
+
A concept is required by a biocurator to describe a piece of data, for example, a disease concept, or an anatomical entity.
+
The biocurator requests the new concept (or term) from the ontology curator, providing a label and perhaps a scientific reference
+
The ontology curator then adds that concept to the ontology using a tool like Protege, adding a human-readable definition, synonyms and provenance metadata. Most importantly, they define the concept logically, often using a formalism such as OWL specifying super-classes, and other logical relationships
+
Lastly, the ontology curator runs a number of quality checks to ensure that the added concepts is logically coherent (e.g. the reasoner places it in the intended part of of the class hierarchy).
+
+
How can ChatGPT be used concretely to help with that process?
+
+
ChatGPT can be incorporated into various stages of the ontology curation workflow to assist biocurators and ontology curators in streamlining and improving the process. Here's how ChatGPT can be used concretely at each step:
+
+
Concept identification: ChatGPT can help the biocurator identify relevant concepts based on the data they are working with. By providing information or descriptions related to the data, the biocurator can receive a list of potential concepts or terms, including disease concepts or anatomical entities, that might be suitable for the ontology.
+
Term request and communication: ChatGPT can facilitate communication between the biocurator and the ontology curator. It can be used to draft the term request, including the label, scientific reference, and any other relevant information, ensuring that the request is clear and complete.
+
Concept addition and metadata generation: ChatGPT can assist ontology curators in generating human-readable definitions, synonyms, and provenance metadata for the new concept. By providing the initial label and scientific reference, ChatGPT can produce candidate definitions, suggest synonyms, and even help draft metadata descriptions. Additionally, it can provide suggestions for logical relationships, such as super-classes and other connections, using its understanding of the formalism, like OWL.
+
Quality checks and coherence: While ChatGPT may not directly run quality checks like a reasoner, it can help ontology curators verify the coherence of the added concepts by providing human-like feedback on the logical relationships and overall structure. It can suggest potential issues, such as redundancies or inconsistencies, that the curator may want to address to ensure that the concept is logically coherent and correctly placed in the class hierarchy.
+
+
By integrating ChatGPT into the ontology curation workflow, biocurators and ontology curators can benefit from its natural language understanding and generation capabilities, making the process more efficient and accurate. However, it is essential to keep in mind that ChatGPT should be used as a complementary tool and not as a replacement for human expertise or specialized software designed for ontology development and curation.
LLMs like ChatGPT can be used to identify equivalent or similar concepts across different ontologies by analyzing concept labels, definitions, and other metadata. They can understand and process natural language descriptions and compare them to find potential matches or alignments between concepts. Specifically, LLMs can:
+
+
Perform text similarity analysis: By comparing the textual descriptions of concepts, LLMs can calculate similarity scores, identifying closely related concepts across different ontologies.
+
Understand contextual relationships: LLMs can identify and consider the context in which concepts are used, making it easier to match concepts that have similar meanings or roles within their respective ontologies.
+
Leverage synonyms and alternative terms: LLMs can use synonyms or alternative terms provided in the ontology metadata to improve concept matching, ensuring that equivalent concepts with different labels can still be identified.
+
Exploit structured knowledge: LLMs can be trained to understand and work with formalisms like OWL and RDF, which can help them identify matching concepts based on the structured information within ontologies.
+
+
By leveraging these capabilities, LLMs can assist ontology curators in the challenging task of concept matching, ultimately enhancing the ontology mapping and alignment process.
+
+
+
Can you provide an example of mapping a concept from the Human Phenotype Ontology to the Mammalian Phenotype Ontology?
+
+
Let's consider the concept "Abnormality of the ear" in HPO.
+
+
HPO Concept:
+
ID: HP:0000598
+
Label: Abnormality of the ear
+
Definition: A structural or functional anomaly of the ear.
+
+
Our goal is to find a matching or similar concept in the Mammalian Phenotype Ontology (MPO).
+
+
After analyzing the MPO, we find the following concept:
+
ID: MP:0002161
+
Label: abnormal ear morphology
+
Definition: any structural anomaly of the external or middle ear
+
+
In this case, both concepts describe abnormalities of the ear in their respective domains (human and mammalian). The labels and definitions are similar, indicating that these concepts might be considered equivalent or closely related.
+
Thus, we can propose the following mapping:
+
+
HPO: HP:0000598 (Abnormality of the ear) <=> MPO: MP:0002161 (abnormal ear morphology)
+
+
+
COMMENT. The 27th May version of ChatGPT is giving a different answer:
+
+
Sure, let's consider an example for this mapping:
+
Human Phenotype Ontology (HPO) is designed to classify and annotate the phenotypic abnormalities encountered in human disease. Each term in HPO describes a specific phenotypic abnormality, such as 'HP:0004322 - Short stature' which describes an abnormality of body height that is less than -2 standard deviations compared to the appropriate reference population.
+
Mammalian Phenotype Ontology (MPO), on the other hand, is used in the annotation of data from mammalian phenotyping experiments, typically in model organisms like mice. Its equivalent term for short stature might be 'MP:0001265 - decreased body size' which describes a mammal with an overall smaller body size.
+
So, in this case, 'HP:0004322 - Short stature' in HPO could be mapped to 'MP:0001265 - decreased body size' in MPO.
+
Please note that this is a simplified example and the actual mapping process could be more complex, due to the nuanced differences between human and mammalian phenotypes and the structure of these ontologies. For actual mappings, it is essential to ensure the descriptions and definitions align appropriately, and the context of use is correctly considered.
+
Also, there may not always be a one-to-one correspondence between the terms in different ontologies. Sometimes, one term in an ontology may correspond to multiple terms in another, or there may not be an equivalent term at all. This is why ontological mapping is a complex task requiring domain knowledge and careful consideration.
+
+
+
Can you express the above mapping in SSSOM?
+
+
The Simple Standard for Sharing Ontology Mappings (SSSOM) is a standard that enables sharing and comparing ontology mappings using a simple tabular format (TSV). Here's the example mapping from Human Phenotype Ontology (HPO) to Mammalian Phenotype Ontology (MPO) expressed in SSSOM format:
+
subject_id subject_label predicate_id object_id object_label match_type confidence
+HP:0000598 Abnormality of the ear skos:closeMatch MP:0002161 abnormal ear morphology Lexical 0.90
+
+
In this case, I have used skos:closeMatch as the predicate to represent the close relationship between the two concepts. The match_type is "Lexical" since the mapping is based on similar labels and definitions. The confidence score is set to 0.90 to reflect a high degree of similarity between the concepts, but this value may vary depending on the actual similarity estimation method used.
+
Please note that the SSSOM format includes metadata and other required fields in a TSV header. The provided example only focuses on the core mapping information. For a complete SSSOM file, you would need to include the appropriate header and metadata.
+
+
+
The SSSOM example you gave is using an old version of the SSSOM standard. In particular, match_type now is mapping_justification. Can you try to rewrite the mapping using the new standard?
+
+
Apologies for the confusion. Here's the example mapping from Human Phenotype Ontology (HPO) to Mammalian Phenotype Ontology (MPO) expressed in the updated SSSOM format:
+
subject_id subject_label predicate_id object_id object_label mapping_justification confidence
+HP:0000598 Abnormality of the ear skos:closeMatch MP:0002161 abnormal ear morphology Lexical 0.90
+
+
In this revised example, the match_type field has been replaced with mapping_justification, which is now set to "Lexical" to indicate that the mapping is based on similar labels and definitions. The remaining fields are unchanged from the previous example.
+
+
+
mapping_justification values should be populated from a controlled vocabulary, called the Semantic Mapping Vocabulary (SEMAPV). You can look at the vocabulary in RDF here: https://raw.githubusercontent.com/mapping-commons/semantic-mapping-vocabulary/main/semapv.owl. Given that vocabulary, can you revise the value for the mapping_justification?
+
+
My apologies for the oversight. Based on the Semantic Mapping Vocabulary (SEMAPV), I will revise the mapping justification for the example. Here's the updated SSSOM mapping using the SEMAPV:
+
subject_id subject_label predicate_id object_id object_label mapping_justification confidence
+HP:0000598 Abnormality of the ear skos:closeMatch MP:0002161 abnormal ear morphology semapv:LexicalMatch 0.90
+
+
In this updated example, I have replaced the previous mapping_justification value with semapv:LexicalMatch from the Semantic Mapping Vocabulary (SEMAPV) to represent the lexical similarity between the two concepts based on their labels and definitions. The remaining fields are unchanged.
+
+
+
You were hallucinating earlier. Here is the semapv vocabulary as a tsv:
+
+
IRI skos:prefLabel skos:definition dc:source skos:example rdfs:comment altLabel Parent
+ID A skos:prefLabel A skos:definition AI dc:source A skos:example A rdfs:comment A skos:altLabel SC %
+semapv:MappingActivity mapping activity A process that relates to the creation, confirmation, rejection or curation of a mapping. Matching is a mapping activity that results in the creating of a mapping; mapping review is an activity that results in the confirmation of a mapping.
+semapv:Matching matching process An process that results in a mapping between a subject and an object entity. The label of a subject entity matches to an exact synonym of an object entity. matching operation|matching task semapv:MappingActivity
+semapv:Mapping mapping A triple <s,p,o> comprising a subject entity s, an object entity o and a mapping predicate p. The subject entity NCI:C9305 is mapped to the object entity ICD10:C80.9 using the skos:relatedMatch mapping predicate.
+semapv:LexicalMatching lexical matching process A matching process based on a lexical comparison between one or more syntactic features of the subject with one or more syntactic features of the object. The label of a subject entity matches to an exact synonym of an object entity. semapv:Matching
+semapv:LogicalReasoning logical reasoning process A matching process based on the inferences made by a logical reasoner. Two classes across ontologies are determined equivalent by an OWL reasoner such as ELK. semapv:Matching
+semapv:CompositeMatching composite matching process A matching process based on multiple, possibly intertwined, matching approaches. An ontology matching tool determines that a subject should be mapped to an object by employing a range of techniques, including lexical, semantic and structural. semapv:Matching
+semapv:UnspecifiedMatching unspecified matching process A matching process based on an unspecified comparison. A mapping between a subject and an object was established, but it is no longer clear how or why. semapv:Matching
+semapv:SemanticSimilarityThresholdMatching semantic similarity threshold-based matching process A matching process based on a minimum threshold of a score from a comparison based on a semantic similarity algorithm. A match between a subject and an object entity was established because they had a Jaccard score higher than 0.8 based on the set of (common) superclasses. semapv:Matching
+semapv:LexicalSimilarityThresholdMatching lexical similarity threshold-based matching process A lexical matching process based on a minimum threshold of a score from a comparison based on a lexical similarity algorithm. A match between a subject and an object was established because they had a Levenshtein score higher than 0.8. semapv:Matching
+semapv:StructuralMatching structural matching process https://doi.org/10.1016/j.websem.2009.11.002 A match between a subject and an object was established because of the similarity of their structural features, e.g., the number of direct property of a class. Structural matching does not involve looking at "values" of properties. semapv:Matching
+semapv:InstanceBasedMatching instance-based matching process A matching process based on individual representations (or instances). https://doi.org/10.1007/978-3-642-38721-0 A match between a subject A and an object B was established because they share the same instances. semapv:Matching
+semapv:BackgroundKnowledgeBasedMatching background knowledge-based matching process A matching process that exploits background knowledge from external resources, commonly referred to as background knowledge resources. This approach is also known as indirect matching, BK-based matching or context-based matching. https://doi.org/10.1016/j.websem.2018.04.001 A match between a subject A and an object B was established because they appear equivalent under consideration of externally provided background knowledge. semapv:Matching
+semapv:MappingChaining mapping chaining-based matching process A matching process based on the traversing of multiple mappings. A match between a subject A and an object B was established because A was mapped to C, C was mapped to D and D was mapped to B. semapv:Matching
+semapv:MappingReview mapping review A process that is concerned with determining if a mapping “candidate” (otherwise determined) is reasonable/correct. A match between a subject A and an object B was established elsewhere, and a human reviewer determined that the mapping is true (or false) based on an independent evaluation. semapv:MappingActivity
+semapv:ManualMappingCuration manual mapping curation An matching process that is performed by a human agent and is based on human judgement and domain knowledge. A human curator determines that a subject should be mapped to an object by virtue of their domain expertise. semapv:Matching
+semapv:MatchingPreprocessing matching process pre-processing A preliminary processing of inputs prior to performing matching. semapv:MappingActivity
+semapv:Stemming stemming The process of reducing a word to its word stem. semapv:Normalization
+semapv:Lemmatization lemmatization The process of reducing the different forms of a word to one single form. https://doi.org/10.1007/978-3-642-38721-0 semapv:Normalization
+semapv:StopWordRemoval stop-word removal A preprocessing method transforming a string by removing a list of stop words. https://doi.org/10.1007/978-3-642-38721-0 The stop-words “of, and, is, a” are removed from the label field of the subject entity in the mapping. semapv:Normalization
+semapv:RegexRemoval regex removal A preprocessing method transforming a string by matching a regular expression and then removing that match. The regex match “[ -]phenotype” is removed from the label field of the subject entity in the mapping. semapv:Normalization
+semapv:RegexReplacement regex replacement A preprocessing method transforming a string by matching a regular expression and then replacing that match with a specified substitution string. The regex match “[ -]phenotype” is replaced by “-disease” for the label field of the subject entity in the mapping. semapv:Normalization
+semapv:MatchingPostProcessing matching process post-processing A process applied to a set of mappings, usually with the intention of changing it. semapv:MappingActivity
+semapv:ThresholdFiltering threshold filtering semapv:MatchingPostProcessing
+semapv:StableMarriageFiltering stable marriage filtering semapv:MatchingPostProcessing
+semapv:CardinalityFiltering cardinality filtering semapv:MatchingPostProcessing
+semapv:LogicalConsistencyFiltering logical consistency filtering semapv:MatchingPostProcessing
+semapv:Normalization normalization A family of preprocessing techniques for reducing strings to be compared to a common format. https://doi.org/10.1007/978-3-642-38721-0 semapv:MatchingPreprocessing
+semapv:CaseNormalization case normalization A normalization technique converting each alphabetic character in a string to their lower case counterpart. https://doi.org/10.1007/978-3-642-38721-0 The string 'Ontology' is normalised to 'ontology' (lower case). semapv:Normalization
+semapv:DiacriticsSuppression diacritics suppression A normalization technique replacing diactritic signs (e.g. accents, hats) with their most frequent replacements. https://doi.org/10.1007/978-3-642-38721-0 The string 'Protégé' is normalised to 'Protege'. semapv:Normalization
+semapv:BlankNormalisation blank normalisation A normalization technique replacing all blank characters, such as space, tabulation, carriage return (or sequences of these) into a single blank character. https://doi.org/10.1007/978-3-642-38721-0 The string 'ontology matching' (two spaces between 'ontology' and 'matching) becomes 'ontology matching' (one space). semapv:Normalization
+semapv:LinkStripping link stripping A normalization technique replacing specific links between words, such as apostrophes, dashes, underscore, etc into dashes or blanks. https://doi.org/10.1007/978-3-642-38721-0 The string 'alzheimer's' becomes 'alzheimers'. semapv:Normalization
+semapv:DigitSuppression digit suppression A normalization technique removing all numbers in a string. https://doi.org/10.1007/978-3-642-38721-0 The string 'ontology1' becomes 'ontology'. semapv:Normalization
+
+
+
+
Can you use this to pick the right mapping justification?
+
+
Apologies for the confusion earlier. Based on the provided SEMAPV vocabulary as a TSV, I will revise the mapping justification for the example. Here's the updated SSSOM mapping using the correct SEMAPV:
+
subject_id subject_label predicate_id object_id object_label mapping_justification confidence
+HP:0000598 Abnormality of the ear skos:closeMatch MP:0002161 abnormal ear morphology semapv:LexicalMatching 0.90
+In this updated example, I have replaced the previous mapping_justification value with semapv:LexicalMatching from the provided Semantic Mapping Vocabulary (SEMAPV) to represent the lexical similarity between the two concepts based on their labels and definitions. The remaining fields are unchanged.
+
+
Please remember that a complete SSSOM file would require the appropriate header and metadata in addition to the core mapping information provided in the example.
+
+
+
Can you add 4 more examples to that SSSOM table
+
+
Sure, here are 4 more examples of mappings between the Human Phenotype Ontology (HPO) and the Mammalian Phenotype Ontology (MPO) using SSSOM format:
These examples illustrate mappings between HPO and MPO concepts based on lexical matching, where the similarity between the labels and definitions is considered. Note that the confidence values are provided as an example and may differ in real-world scenarios.
+
+
+
Can you print only the table using markdown table syntax in a way that I can copy paste it
+
+
+
+
+
subject_id
+
subject_label
+
predicate_id
+
object_id
+
object_label
+
mapping_justification
+
confidence
+
+
+
+
+
HP:0000598
+
Abnormality of the ear
+
skos:closeMatch
+
MP:0002161
+
abnormal ear morphology
+
semapv:LexicalMatching
+
0.90
+
+
+
HP:0000365
+
Hearing impairment
+
skos:closeMatch
+
MP:0006325
+
hearing loss
+
semapv:LexicalMatching
+
0.92
+
+
+
HP:0001382
+
Joint hypermobility
+
skos:closeMatch
+
MP:0004927
+
increased joint flexibility
+
semapv:LexicalMatching
+
0.85
+
+
+
HP:0001392
+
Hepatomegaly
+
skos:closeMatch
+
MP:0002764
+
enlarged liver
+
semapv:LexicalMatching
+
0.88
+
+
+
HP:0001250
+
Seizures
+
skos:closeMatch
+
MP:0002064
+
seizures
+
semapv:LexicalMatching
+
0.95
+
+
+
+
+
+
Can you add 100 more examples, this time only providing a markdown table that I can copy paste, with no further comments around it?
+
+
Creating 100 mappings with accuracy requires domain expertise and a comprehensive understanding of the ontology mappings. However, I can provide you with 20 examples to help you understand the format. Please note that these examples may not be completely accurate and should not be used for any critical applications.
+
+
+
+
subject_id
+
subject_label
+
predicate_id
+
object_id
+
object_label
+
mapping_justification
+
confidence
+
+
+
+
+
HP:0000010
+
Megabladder
+
skos:closeMatch
+
MP:0000547
+
enlarged bladder
+
semapv:LexicalMatching
+
0.85
+
+
+
HP:0000014
+
Renal agenesis
+
skos:closeMatch
+
MP:0000548
+
absent kidney
+
semapv:LexicalMatching
+
0.82
+
+
+
HP:0000015
+
Bladder diverticulum
+
skos:closeMatch
+
MP:0000556
+
bladder diverticula
+
semapv:LexicalMatching
+
0.88
+
+
+
HP:0000016
+
Urethral atresia
+
skos:closeMatch
+
MP:0000565
+
closed urethra
+
semapv:LexicalMatching
+
0.90
+
+
+
HP:0000020
+
Renal duplication
+
skos:closeMatch
+
MP:0000571
+
duplex kidney
+
semapv:LexicalMatching
+
0.84
+
+
+
HP:0000021
+
Hypospadias
+
skos:closeMatch
+
MP:0000573
+
abnormal penis morphology
+
semapv:LexicalMatching
+
0.76
+
+
+
HP:0000022
+
Urethral stricture
+
skos:closeMatch
+
MP:0000574
+
urethral obstruction
+
semapv:LexicalMatching
+
0.86
+
+
+
HP:0000025
+
Polycystic kidney dysplasia
+
skos:closeMatch
+
MP:0000576
+
polycystic kidney
+
semapv:LexicalMatching
+
0.92
+
+
+
HP:0000026
+
Hyperechogenic kidneys
+
skos:closeMatch
+
MP:0000581
+
abnormal kidney echogenicity
+
semapv:LexicalMatching
+
0.81
+
+
+
HP:0000027
+
Renal cortical microcysts
+
skos:closeMatch
+
MP:0000584
+
renal cortical cysts
+
semapv:LexicalMatching
+
0.89
+
+
+
HP:0000028
+
Renal tubular atrophy
+
skos:closeMatch
+
MP:0000585
+
atrophic renal tubules
+
semapv:LexicalMatching
+
0.87
+
+
+
HP:0000031
+
Renal hypoplasia
+
skos:closeMatch
+
MP:0000591
+
small kidney
+
semapv:LexicalMatching
+
0.79
+
+
+
HP:0000032
+
Renal hypoplasia/aplasia
+
skos:closeMatch
+
MP:0000592
+
renal hypoplasia
+
semapv:LexicalMatching
+
0.91
+
+
+
HP:0000033
+
Proximal tubulopathy
+
skos:closeMatch
+
MP:0000593
+
abnormal proximal tubule
+
semapv:LexicalMatching
+
0.75
+
+
+
AT THIS POINT CHATGPT JUST STOPPED GENERATING CONTENT.
+
+
+
+
+
+
+
+
+
+
+
Generating pre-coordinated expressions and schema instances¶
+
+
+
Here are a few slots in a schema: quality, anatomical_entity and chemical_entity
+
+
quality:
+description: The property being measured, or changes in this property, for example, amount, level, increased amount, decreased concentration
+annotations:
+ prompt.example: amount, level, increased amount, decreased concentration
+range: Quality
+
+anatomical_entity:
+description: The anatomical location that the chemical entity is measured in
+range: AnatomicalEntity
+annotations:
+ prompt.example: liver, heart, brain, finger
+
+chemical_entity:
+description: The chemical entity that is being measured
+range: ChemicalEntity
+annotations:
+ prompt.example: lysine, metabolite
+
+
+
+
Can you create a YAML file with those three elements as keys, and extract the contents of the string "increased blood glucose levels" into as values to these keys? Output should be just a simple yaml file, like:
From Chat to exectutable workflows: what we need to do to leverage LLMs¶
+
The above tutorial was a fun case study using ChatGPT with GPT-4. 95% of the content provided was generated by ChatGPT with GPT-4. While certainly not as great as possible, it took a solid ontology engineer (@matentzn) about 90 minutes to write this lesson, which would have usually cost him more than 8 hours.
+
It is clear that learning how to talk to AI, the process we refer to as "prompt engineering" is going to be absolutely essential for ontology curators moving forward - as LLMs improve and understand even complex languages like OWL better, perhaps as important as ontology modelling itself. I dont think there is any doubt that enganging is a good amount of play and study on this subject is both fun and hugely beneficial.
+
All that said, perceiving LLMs through the lens of a chat bot leaves a lot of potential unexplored. For example, if ChatGPT (or LLMs in general) can generate structured data, why not implement this directly into our curation tools (like Protege)? Tools like GitHub co-pilot are already used to making good programmers a lot more effective, but so far, these tools focus on development environments where the majority of the generated content is text (e.g. software code), and not so much heavily UI driven ones like Protege.
+
A lot of blog posts have circulated recently on Twitter and LinkedIn explored the potential of LLMs to generate RDF and OWL directly. It is already clear that LLMs can and will do this moving forward. For ontology curation specifically, we will need to develop executable workflows that fit into our general ontology curation process. As a first pass, some members of our community have developed OntoGPT. We will explore how to use OntoGPT in a future lesson.
Update 27 May 2023: It seems that complaints wrt to hallucinations, the chat part of ChatGPT is a bit more sensitive to database like queries:
+
+
Cool applications the authors of this tutorial used¶
+
+
The key is that it is generative: the key thing is that we are generating text that is human like
+
As databases, LLMs are very inefficient (see excellent talk by Denny Vrandecic) and Hallucinate too often (Chat)
+
Writing emails: shortening
+
Writing documentations:
+
Writing docs for a softare tool. Adding background info and context.
+
Find a good human-readable name for a cluster in ML clustering
+
Named entity recognition and knowledge extraction
+
Career planning and discovering stuff you didnt know about at all
+
ChatGPT for contextualising work and writing use cases
+
Using it for curation research - but doing it right
+
Don't ask it to do the curation for you, get it to help you find arguments for and against a modelling decision ("I will always have to recurate anyways, so what is the point?")
+
Always remember that ChatGPT is not a database. It hallucinates and changes its mind all the time. Get it to generate text for you that could be useful in your work.
Install GitHub Desktop Please make sure you have some kind of git client installed on your machine. If you are new to Git, please install GitHub Desktop
GitHub - distributed version control (Git) + social media for geeks who like to build code/documented collaboratively.
+
A Git repo consists of a set of branches each with a complete history of all changes ever made to the files and directories. This is true for a local copy you check out to your computer from GitHub or for a copy (fork) you make on GitHub.
+
+
A Git repo typically has a master or main branch that is not directly editing. Changes are made by creating a branch from Master (complete copy of the Master + its history).
You can copy (fork) any GitHub repo to some other location on GitHub without having to ask permission from the owners. If you modify some files in that repo, e.g. to fix a bug in some code, or a typo in a document, you can then suggest to the owners (via a Pull Request) that they adopt (merge) you your changes back into their repo.
+
If you have permission from the owners, you can instead make a new branch. For this training, we gave you access to the repository. See the Appendix for instructions on how to make a fork.
Go to GitHub tracker for the ontology where you'd like to create an issue
+
Select New issue
+
Pick appropriate template (if applicable)
+
Fill in the information that is requested on the template below each header
+
For a new term request, please include:
+
The parent ID and label
+
A definition in the proper format
+
Sources/cross references for synonyms
+
Your ORCID
+
Add any additional comments at the end
+
If you are requesting changes to an existing term, include as much information as possible, including the term ID and label.
+
If you use a template, an ontology curator may automatically be assigned.
+
+
Tip: you can easily obtain term metadata like OBO ID, IRI, or the term label by clicking the three lines above the Annotations box (next to the term name) in Protege, see screenshot below. You can also copy the IRI in markdown, which is really convenient for pasting into GitHub.
Keep in mind that open source ontology repositories on GitHub are public and open to all.
+
Be respectful in your requests and comments.
+
Do not include any private information.
+
GitHub sends notifications to your email, and you can respond via your email client. Keep in mind, the responses are posted publicly. Be sure to delete your email signature that includes any personal information, like your email address or phone number.
+
Many ontologies have limited resources and personnel for development and maintenance. Please be patient with your requests.
+
If your ticket/request has been unanswered for a long period of time, feel free to kindly check in by commenting on the ticket.
+
Including a deadline or priority on the ticket can help the ontology curators with triaging tickets.
A README is a text file that introduces and explains a project. It is intended for everyone, not just the software or ontology developers. Ideally, the README file will include detailed information about the ontology, how to get started with using any of the files, license information and other details. The README is usually on the front page of the GitHub repository.
The steps below describe how to make changes to an ontology.
+
+
Go to the GitHub repository for your ontology, and clone the repository. The example below describes how to clone the Mondo Disease Ontology repo, but this can be applied to any ontology that is stored in GitHub.
You will be given an option as to where to save the repository. I have a folder called 'git' where I save all of my local repos.
+
This will open GitHub Desktop and the repo should start downloading. This could take some time depending on how big the file is and how much memory your computer has.
Navigate to [ontology-name]/src/ontology/[ontology-name]-edit.obo and open this file in Protege. For example: mondo/src/ontology/mondo-edit.obo
+
Note: all ontologies that use the Ontology Development Kit (ODK) will have the 'edit' files stored in the same folder path: src/ontology/[ontology-name]-edit.owl (or [ontology-name]-edit.obo)
The Protégé interface follows a basic paradigm of Tabs and Panels. By default, Protégé launches with the main tabs seen below. The layout of tabs and panels is configurable by the user. The Tab list will have slight differences from version to version, and depending on your configuration. It will also reflect your customizations.
+
To customize your view, go to the Window tab on the toolbar and select Views. Here you can customize which panels you see in each tab. In the tabs view, you can select which tabs you will see. You will commonly want to see the Entities tab, which has the Classes tab and the Object Properties tab.
+
+
Note: if you open a new ontology while viewing your current ontology, Protégé will ask you if you'd like to open it in a new window. For most normal usage you should answer no. This will open in a new window.
+
The panel in the center is the ontology annotations panel. This panel contains basic metadata about the ontology, such as the authors, a short description and license information.
Before browsing or searching an ontology, it is useful to run an OWL reasoner first. This ensures that you can view the full, intended classification and allows you to run queries. Navigate to the query menu, and run the ELK reasoner:
+
+
For more details on why it is important to have the reasoner on when using the editors version of an ontology, see the Reasoning reference guide. But for now, you don't need a deeper understanding, just be sure that you always have the reasoner on.
You will see various tabs along the top of the screen. Each tab provides a different perspective on the ontology.
+For the purposes of this tutorial, we care mostly about the Entities tab, the DL query tab and the search tool. OWL Entities include Classes (which we are focussed on editing in this tutorial), relations (OWL Object Properties) and Annotation Properties (terms like, 'definition' and 'label' which we use to annotate OWL entities.
+Select the Entities tab and then the Classes sub-tab. Now choose the inferred view (as shown below).
+
+
The Entities tab is split into two halves. The left-hand side provides a suite of panels for selecting various entities in your ontology. When a particular entity is selected the panels on the right-hand side display information about that entity. The entities panel is context specific, so if you have a class selected (like Thing) then the panels on the right are aimed at editing classes. The panels on the right are customizable. Based on prior use you may see new panes or alternate arrangements.
+You should see the class OWL:Thing. You could start browsing from here, but the upper level view of the ontology is too abstract for our purposes. To find something more interesting to look at we need to search or query.
You can search for any entity using the search bar on the right:
+
+
The search window will open on top of your Protege pane, we recommend resizing it and moving it to the side of the main window so you can view together.
+
+
Here's an example search for 'COVID-19':
+
+
It shows results found in display names, definitions, synonyms and more. The default results list is truncated. To see full results check the 'Show all results option'. You may need to resize the box to show all results.
+Double clicking on a result, displays details about it in the entities tab, e.g.
+
+
In the Entities, tab, you can browse related types, opening/closing branches and clicking on terms to see details on the right. In the default layout, annotations on a term are displayed in the top panel and logical assertions in the 'Description' panel at the bottom.
+
Try to find these specific classes:
+
+
'congenital heart disease'
+
'Kindler syndrome'
+
'kidney failure'
+
+
Note - a cool feature in the search tool in Protege is you can search on partial string matching. For example, if you want to search for ‘down syndrome’, you could search on a partial string: ‘do synd’.
+
+
Try searching for ‘br car and see what kind of results are returned.
+
Question: The search will also search on synonyms. Try searching for ‘shingles’ and see what results are returned. Were you able to find the term?
+
+
Note - if the search is slow, you can uncheck the box ‘Search in annotation values. Try this and search for a term and note if the search is faster. Then search for ‘shingles’ again and note what results you get.
Changes made to the ontology can be viewed in GitHub Desktop.
+
+
+
Before committing, check the diff. Examples of a diff are pasted below. Large diffs are a sign that something went wrong. In this case, do not commit the changes and ask the ontology editors for help instead.
+
+
+
Example 1:
+
+
+
Commit: Add a meaningful message in the Commit field in the lower left, for example: add new class MONDO:0001012 episodic angioedema with eosinophilia
+
+
NOTE: You can use the word 'fixes' or 'closes' in the description of the commit message, followed by the corresponding ticket number (in the format #1234) - these are magic words in GitHub; when used in combination with the ticket number, it will automatically close the ticket. Learn more on this GitHub Help Documentation page about Closing issues via commit messages.
+
+
+
Note: 'Fixes' and "Closes' are case-insensitive.
+
+
+
If you don't want to close the ticket, just refer to the ticket # without the word 'Fixes' or use 'Adresses'. The commit will be associated with the correct ticket but the ticket will remain open. NOTE: It is also possible to type a longer message than allowed when using the '-m' argument; to do this, skip the -m, and a vi window (on mac) will open in which an unlimited description may be typed.
+
+
+
Click Commit to [branch]. This will save the changes to the cl-edit.owl file.
+
+
+
Push: To incorporate the changes into the remote repository, click Publish branch.
Ontology terms have separate names and IDs. The names are annotation values (labels) and the IDs are represented using IRIs. The OBO foundry has a policy on IRI (or ID) generation (http://www.obofoundry.org/principles/fp-003-uris.html). You can set an ID strategy using the "New Entities" tab under the Protégé Preferences -- on the top toolbar, click the "Protégé dropdown, then click Preferences.
+
+
Set your new entity preferences precisely as in the following screenshot of the New Entities tab.
+
Note - you have been assigned an ID range in the Mondo idranges file - you should be able to find your own range assigned there.
+
DIY (only if you know what you are doing!)
+
To add your own ID ranges:
+
Go into src/ontology
+
create a branch
+
Find and edit mondo-idranges.owl by adding the following:
+
Datatype: idrange:10 #update this to next following integer from previous
+
+ Annotations:
+ allocatedto: "Your Name" #change to your name
+
+ EquivalentTo:
+ xsd:integer[>= 0806000 , <= 0806999]. #add a range of 999 above the previous integer
+
+
Be sure to change "Your Name" to your actual name! And note that this value should almost always be an individual, and not an organization or group.
+
create a pull request and add matentzn or nicolevasilevsky as a reviewer
+
proceed to settting up as below:
+
+
Specified IRI: http://purl.obolibrary.org/obo/
+
Note - if you edit more than one ontology in Protege, you will need to update your Preferences for each ontology before you edit.
The current recommendation of the OBO Foundry Technical Working Group is that an editor who creates a new term SHOULD add a http://purl.org/dc/terms/contributor annotation, set to the ORCID or GitHub username of the editor, and a http://purl.org/dc/terms/date annotation, set to the current date.
+
You can have Protégé automatically add those annotations by setting your preferences to match the screenshot below, in the New entities metadata tab (under preferences).
+
If you do not have an ORCID, register for for free here: https://orcid.org/
make sure you are working on a branch - see quick guide here.
+
+
+
make sure you have the editor's file open in Protege as detailed here.
+
+
+
New classes are created in the Class hierarchy panel on the left.
+
There are three buttons at the top of the class hierarchy view. These allow you to add a subclass (L-shaped icon), add a sibling class (c-shaped icon), or delete a selected class (x'd circle).
Using Protégé you can add annotations such as labels, definitions, synonyms, database cross references (dbxrefs) to any OWL entity. The panel on the right, named Annotations, is where these annotations are added. CL includes a pre-declared set of annotation properties. The most commonly used annotations are below.
+
+
rdfs:label
+
definition
+
has_exact_synonym
+
has_broad_synonym
+
has_narrow_synonym
+
has_related synonym
+
database_cross_reference
+
rdfs:comment
+
+
Note, most of these are bold in the annotation property list:
+
+
Use this panel to add a definition to the class you created. Select the + button to add an annotation to the selected entity. Click on the annotation 'definition' on the left and copy and paste in the definition to the white editing box on the right. Click OK.
+
Definition: A disorder characterized by episodes of swelling under the skin (angioedema) and an elevated number of the white blood cells known as eosinophils (eosinophilia). During these episodes, symptoms of hives (urticaria), fever, swelling, weight gain and eosinophilia may occur. Symptoms usually appear every 3-4 weeks and resolve on their own within several days. Other cells may be elevated during the episodes, such as neutrophils and lymphocytes. Although the syndrome is often considered a subtype of the idiopathic hypereosinophilic syndromes, it does not typically have organ involvement or lead to other health concerns.
+
+
+
Definitions in Mondo should have a 'database cross reference' (dbxref), which is a reference to the definition source, such as a paper from the primary literature or another database. For references to papers, we cross reference the PubMed Identifier in the format, PMID:XXXXXXXX. (Note, no space)
+
To add a dbxref to the definition:
+
+
Click the @ symbol next to the definition
+
Click the + button next in the pop-up window
+
Scroll up on the left hand side until you find 'database_cross_reference', and click it
+
Add the PMID in the editing box (PMID:25527564). _Note: the PMID should not have any spaces)
We have seen how to add sub/superclasses and annotate the class hierarchy. Another way to do the same thing is via the Class description view. When an OWL class is selected in the entities view, the right-hand side of the tab shows the class description panel. If we select the 'vertebral column disease' class, we see in the class description view that this class is a "SubClass Of" (= has a SuperClass) the 'musculoskeletal system disease' class. Using the (+) button beside "SubClass Of" we could add another superclass to the 'skeletal system disease' class.
+
Note the Anonymous Ancestors. This is a difficult concept we will return to later, and the contents of this portion may seem confusing at first (some of these may be clearer after you complete the "Basics of OWL" section below). These are OWL expressions that are inherited from the parents. If you hover over the Subclass Of (Anonymous Ancestor) you can see the parent that the class inherited the expression from. For many ontologies, you will see some quite abstract expressions in here inherited from upper ontologies, but these can generally be ignored for most purposes.
If you want to revise the superclass, click the 'o' symbol next to the superclass and replace the text. Try to revise 'musculoskeletal system disease' to 'disease by anatomical system'.
+
+
+
If you want to delete a superclass, click the 'x' button next to the superclass. Delete the 'disease by anatomical system' superclass.
Dead Simple Ontology Design Patterns (DOSDPs) are specifications, written in yaml format, that specify how ontology terms should be created (see article here). They can be used to:
+
+
generate documentation
+
generate new terms
+
retrofit existing ontology terms
+
+
DOSDPs have some key features:
+
+
Description: that describes the purpose of the patterns
+
Examples: Provides examples of terms that use the Patterns
+
Declared classes: these are the classes that are used in the pattern. Any subclass of the declared class can be used in this pattern.
+
Declared relationships: the relationships used in the logical axioms
+
vars: the variable classes that are used in the pattern. Any subclass of the 'var' can be used in this pattern.
+
Pattern for class name, annotations, text definition and equivalentTo (logical definition): Ontology classes are used as 'fillers' to create new classes that conform to the specific patterns.
Clone the Ontologies 101 repository, then open the folder BDK14_exercises from your file system
+
Open basic-subclass/chromosome-parts.owl in Protégé, then do the following exercises:
+
Basic Subclass Hierarchy (review) - make sure to look at the "detailed instructions" for adding annotations here, as it will go over adding annotations on annotation assertions
Object Properties - note that you will rarely, if ever, be making object properties, as most of the properties you'll ever need are defined in the Relation Ontology
Open basic-dl-query/cc.owl in Protégé, then do the following exercises:
+
DL Query Tab - note that owl:Nothing is defined as the very bottom node of an ontology, therefore the DL query results will show owl:Nothing as a subclass. This is expected and does not mean there is a problem with your ontology! It's only bad when something is a subclass of owl:Nothing and therefore unsatisfiable (more on that below).
Optional: Open a new ontology in Protégé. Try creating an inconsistent ontology using the classes and instances in the first Pets example (hint: you'll also need to create the "eats" object property)... what happens when you run the reasoner?
New classes are created in the Class hierarchy panel on the left.
+
There are three buttons at the top of the class hierarchy view. These allow you to add a subclass (L-shaped icon), add a sibling class (c-shaped icon), or delete a selected class (x'd circle).
Equivalence axioms in Mondo are added according to Dead Simple Ontology Design Patterns (DOSDPs). You can view all of the design patterns in Mondo by going to code/src/patterns/dosdp-patterns/
+
For this class, we want to follow the design pattern for allergy.
+
+
Review this pattern before proceeding.
+
Based on the pattern specifications, add a text definition to this term.
+
Add the database cross reference to this term: MONDO:patterns/allergy
+
Add a synonym that is consistent with this pattern.
+
+
+
+
Add the equivalence axiom according to the pattern specifications.
+
+
+
+
+
Run the reasoner
+
View the inferred hierarchy. You should see a child of owl:Nothing (and you should see this in the Description pane as well.)
+
+
+
+
+
Click on the ? button next to the owl:Nothing in the Description view
+
The explanation tells you the reason why this is unsatisfiable
+
+
+
+
Mycotoxin is a child of a 'specifically dependent continuant' and and 'independent continuant' is disjoint with 'specifically dependent continuant'.
+
This logical axiom uses the relation 'realized in response to stimulus'
+
Click on this relation in Protege (you can click on the relation name in the equivalence axiom, or you can click on the Object properties tab and search for this relation.
+
There are domain and range restrictions on this property, where the range has to be a material enity. Chebi mycotoxin is actually a role, so it is not a material entity.
+
+
+
+
Go back to the Classes or Entities pane and remove the equivalence axiom and run the reasoner again. You should now see no unsatisfiable classes.
As noted above, equivalence axioms in Mondo are added according to Dead Simple Ontology Design Patterns (DOSDPs). You can view all of the design patterns in Mondo by going to code/src/patterns/dosdp-patterns/
+
For this class, we want to follow the design pattern for acquired.
+
+
Review this pattern before proceeding.
+
Based on the pattern specifications, add a text definition to this term.
+
Add the database cross reference to the definition: MONDO:patterns/allergy
+
Add the equivalence axiom according to the pattern specifications.
Like software, official OBO Foundry ontologies have versioned releases. This is important because OBO Foundry ontologies are expected to be shared and reused. Since ontologies are bound to change over time as more terms are added and refined, other developers need stable versions to point to so that there are no surprises. OBO Foundry ontologies use GitHub releases to maintain these stable copies of older versions.
+
Generally, OBO Foundry ontologies maintain an "edit" version of their file that changes without notice and should not be used by external ontology developers because of this. The edit file is used to create releases on a (hopefully) regular basis. The released version of an OBO Foundry ontology is generally a merged and reasoned version of the edit file. This means that all modules and imports are combined into one file, and that file has the inferred class hierarchy actually asserted. It also often has some extra metadata, including a version IRI. OBO Foundry defines the requirements for version IRIs here.
+
The release workflow process should be stable and can be written as a series of steps. For example:¶
+
+
Update modules from templates
+
Merge ontology modules & the main edit file into one
+
Assert the inferred class hierarchy
+
Add a version IRI & other important metadata
+
+
This series of steps can be turned into ROBOT commands:¶
+
+
robot template
+
robot merge
+
robot reason
+
robot annotate
+
+
Since we can turn these steps into a series of commands, we can create a Makefile that stores these as "recipes" for our ontology release!
All across the biomedical domain, we refer to domain entities (such as chemicals or anatomical parts) using identifiers, often from controlled vocabularies.
+
The decentralised evolution of scientific domains has led to to the emergence of disparate "semantic spaces" with different annotation practices and reference vocabularies and formalisms.
+
+
To bridge between these spaces, entity mappings have emerged, which link, for example, genes from HGNC to ENSEMBL, diseases between OMIM and Mondo and anatomical entities between FMA and Uberon.
+
Entity matching is the process of establishing a link between an identifier in one semantic space to an identifier in another. There are many cultures of thought around entity matching, including Ontology Matching, Entity Resolution and Entity Linking.
A not widely used concept to denote a cluster of related data that can be interpreted using the same ontology.
+
+
+
Ontology matching
+
The task of determining corresponding entities across ontologies.
+
+
+
Entity mapping
+
Determining and documenting the correspondence of an entity in one semantic space to another.
+
+
+
Schema mapping
+
Determining and documenting the translation rules for converting an entity from one semantic space to another.
+
+
+
Ontology alignment
+
An ontology alignment is a set of term mappings that links all concepts in a source ontology to their appropriate correspondence in a target ontology, if any.
+
+
+
Knowledge graph matching
+
More or less the same as ontology matching - for knowledge graphs
+
+
+
Thesaurus building
+
Involves assigning natural language strings (synonym) to a code in a knowledge organisation system (like a taxonomy, terminology, or ontology)
+
+
+
Named Entity Recognition and Entity Linking
+
Involve recognising entities (such as diseases) in text and linking them to some identifier.
+
+
+
Entity resolution/record linkage
+
Involves determining if records from different data sources represent, in fact, the same entity
+
+
+
Schema matching
+
Determines if two objects from different data models (schema elements, schema instances) are semantically related.
+
+
+
Value Set Mapping
+
Determines and documents the correspondence of two Value Setsand their respective values (i.e. a 2-level mapping!).
In the following, we consider a entity a symbol that is intended to refer to a real world entity, for example:
+
+
+
an ontology id like OMOP:441554 corresponds to the concept of "Vascular calcification" in the real world. Note that OMOP:441554 may be annotated with the rdfs:label "Friedreichs Ataxia".
+The label itself is not necessarily a term - it could change, for example to "Friedreichs Ataxia (disease)", and still retain the same meaning.
+
"Friedreich's Ataxia" (example on the left) may be a term in my controlled vocabulary which I understand to correspond to that respective disease (not all controlled vocabularies have IDs for their terms).
+This happens for example in clinical data models that do not use formal identifiers to refer to the values of slots in their data model, like "MARRIED" in /datamodel/marital_status.
TLDR: entities are symbols that correspond to things in the world, and that correspondence is not subject to change.
+Labels of such entities can change without changing the meaning of the entity.
+
+
In our experience, there are roughly four kinds of mappings:
+
+
string-string: Relating one string, or label, to another string, or label. Understanding such mappings is fundamental to understanding all the other kinds of mappings.
+
_string-entity: Relating a specific string or "label" to their corresponding entity in a terminology or ontology. We usually refer to these as synonyms, but there may be other words used in this case.
+
entity-entity_: Relating an entity, for example a class in an ontology, to another entity. This is what most people in the ontology domain would understand when thy hear "ontology mappings".
+
complex mappings: Relating two sets of entities. For example cheese sandwich (wikidata:Q2734068) to sandwich (wikidata:Q111836983) and cheese wikidata:Q10943.
+ These are the rarest and most complicated kinds of mappings and are out of scope for this lesson.
+
+
In some ways, these four kinds of mappings can be very different. We do believe, however, that there are enough important commonalities such as common features, widely overlapping use cases and overlapping toolkits to consider them together. In the following, we will discuss these in more detail, including important features of mappings and useful tools.
Mappings have historically been neglected as second-class citizens in the medical terminology and ontology worlds -
+the metadata is insufficient to allow for precise analyses and clinical decision support, they are frequently stale and out of date, etc. The question "Where can I find the canonical mappings between X and Y"? is often shrugged off and developers are pointed to aggregators such as OxO or UMLS which combine manually curated mappings with automated ones causing "mapping hairballs".
+
There are many important metadata elements to consider, but the ones that are by far the most important to consider one way or another are:
+
+
Precision: Is the mapping exact, broad or merely closely related?
+
Confidence: Do I trust the mapping? Was is done manually by an expert in my domain, or by an algorithm?
+
Source version: Which version of the entity (or its corresponding ontology) was mapped? Is there a newer mapping which has a more suitable match for my entity?
+
+
Whenever you handle mappings (either create, or re-use), make sure you are keenly aware of at least these three metrics, and capture them. You may even want to consider using a proper mapping model like the Simple Shared Standard for Ontology Mappings (SSSOM) which will make your mappings FAIR and reusable.
String-string mappings are mappings that relate two strings. The task of matching two strings is ubiquitous for example in database search fields (where a user search string needs to be mapped to some strings in a database). Most, if not all effective ontology matching techniques will employ some form of string-string matching. For example, to match simple variations of labels such as "abnormal heart" and "heart abnormality", various techniques such as Stemming and bag of words can be employed effectively. Other techniques such as edit-distance or Levenshtein can be used to quantify the similarity of two strings, which can provide useful insights into mapping candidates.
String-entity mappings relate a specific string or "label" to their corresponding term in a terminology or ontology. Here, we refer to these as "synonyms", but there may be other cases for string-entity mappings beyond synonymy.
+
There are a lot of use cases for synonyms so we will name just a few here that are relevant to typical workflows of Semantic Engineers in the life sciences.
+
Thesauri are reference tools for finding synonyms of terms. Modern ontologies often include very rich thesauri, with some ontologies like Mondo capturing more than 70,000 exact and 35,000 related synonyms. They can provide a huge boost to traditional NLP pipelines by providing synonyms that can be used for both Named Entity Recognition and Entity Resolution. Some insight on how, for example, Uberon was used to boost text mining can be found here.
Entity-entity mappings relate a entity (or identifier), for example a class in an ontology, to another entity, usually from another ontology or database. The entity-entity case of mappings is what most people in the ontology domain would understand when they hear "ontology mappings". This is also what most people understand when they here "Entity Resolution" in the database world - the task of determining whether, in essence, two rows in a database correspond to the same thing (as an example of a tool doing ER see deepmatcher, or py-entitymatcher). For a list standard entity matching toolkit outside the ontology sphere see here.
Mappings between terms/identifiers are typically collected in four ways:
+
+
Automatically, using terminological matchers (of which ontology matchers one the most important category in our domain).
+
Manually, by dedicated curators.
+
By re-using existing mappings. Some semantic spaces have been mapped by organisations such as the Monarch Initiative or UMLS, and it is often worth re-viewing existing mappings before building ones own.
+
Using a mix of automated and manual approaches, where automated approaches typically generate "mapping candidates" which are "double checked" by humans before used in production systems.
+
+
The main trade-off for mappings is very simple:
+1. Automated mappings are very error prone (not only are they hugely incomplete, they are also often faulty).
+1. Human curated mappings are very costly.
+
--> The key for any given mapping project is to determine the highest acceptable error rate, and then distribute the workload between human and automated matching approaches. We will discuss all three ways of collecting mappings in the following.
+
Aside from the main tradeoff above, there are other issues to keep in mind:
+- Manually curated mappings are far from perfect. Most of the cost of mapping review lies in the decision how thorough a mapping should be reviewed. For example, a human reviewer may be tasked with reviewing 1000 mappings. If the acceptable error rate is quite high, the review may simply involve the comparison of labels (see here), which may take around 20 seconds. A tireless reviewer could possibly accept or dismiss 1000 mappings just based on the label in around 6 hours. Note that this is hardly better than what most automated approaches could do nowadays.
+- Some use cases involve so much data that manual curation is nearly out of the question.
It is important to remember that matching in its raw form should not be understood to result in semantic mappings. The process of matching, in particular lexical or fuzzy semantic matching is error prone and usually better treated as resulting in candidates for mappings. This means that when we calculate the effort of a mapping project, we should always factor in the often considerable effort required by a human to verify the correctness of a candidate mapping. There are many tools that can help with this process, for example by filtering out conflicting lower-confidence mappings, but in the end the reality is this: due to the fact that source and target do not share the same semantics, mappings will always be a bit wobbly. There are two important kinds of review which are very different:
+
+
False positive review (wrong mappings). The goal here is to identify mappings that do not work for our use case, or do not use the correct semantic mapping relation. For example orange juice [wikidata:Q219059] and orange juice (unpasteurized) [FOODON:00001277] may not be considered as the same thing in the sense of skos:exactMatch.
+
False negative review (missing mappings). The goal here is to understand if we can do anything to improve the matching process by tuning it. For very simple matchers like oak lexmatch this usually involves hacking labels and synonyms by removing or replacing words. More sophisticated matchers like Agreement Maker Light (AML) have many more tuning options, and it requires patience and expertise to find the right ones. One good approach here is to include semantically or lexically similar matches in the results, and review if generally consistent patterns of lexical variation can be spotted. For example: orange juice (liquid) [FOODON:00001001] seems to be exactly what orange juice [wikidata:Q219059] is supposed to mean. The labels are not the same, but lexically similar: a simple lexical distance metric like Levenshtein could have been used to identify these.
+
+
Tip: always keep a clear visible list of unmapped classes around to sanity check how good your mapping has been so far.
There are many (many) tools out there that have been developed for entity matching. A great overview can be found in Euzenats Ontology Matching. Most of the matchers apply a mix of lexical and semantic approaches.
+
As a first pass, we usually rely on a heuristic that an exact match on the label is strong evidence that the two entities correspond to the same thing. Obviously, this cannot always be the case Apple (the fruit) and Apple (the company) are two entirely different things, yet a simple matching tool (like OAK lexmatch) would return these as matching. The reason why this heuristic works in practice is because we usually match between already strongly related semantic spaces, such as two gene databases, two fruit ontologies or two disease terminologies. When the context is narrow, lexical heuristics have a much lower chance to generate excessively noisy mappings.
+
After lexical matchings are created, other techniques can be employed, including syntactic similarity (match all entities which have labels that are more than 80% similar and end with disease) and semantic similarity (match all entities whose node(+graph)-embedding have a cosine similarity of more than 80%). Automated matching typically results in a large number of false positives that need to be filtered out using more sophisiticated approaches for mapping reconciliation.
Collecting existing mappings from external sources, if they exist.
+
Generating mapping candidates using automated matchers (seed mappings).
+
Iteratively refining mappings while keeping track of:
+
Anchor mappings (known correct mappings)
+
Overestimation mappings (mapping candidates)
+
Negative mappings (known false mappings, as deterimed by tools or human review)
+
+
+
+
The refinement step may involve automated approaches that are sensitive to the logical content of the sources involved (for example by ensuring that the result does not result in equivalence cliques, or unsatisfiable classes), but more often than not, human curators are employed to curate the mapping candidates generated by the various automated approaches.
+
+
Some examples of domain-specific mapping of importance to the biomedical domain¶
Mapping phenotypes across species holds great promise for leveraging the knowledge generated by Model Organism Database communities (MODs) for understanding human disease. There is a lot of work happening at the moment (2021) to provide standard mappings between species specific phenotype ontologies to drive translational research (example). Tools such as Exomiser leverage such mappings to perform clinical diagnostic tasks such as variant prioritisation. Another app you can try out that leverages cross-species mappings is the Monarch Initiatives Phenotype Profile Search.
Medical terminology and ontology mapping is a huge deal in medical informatics (example). Mondo is a particularly rich source of well provenanced disease ontology mappings.
Description: The purpose of this lesson is to train biomedical researchers on how to find a term, what to do if they find too many terms, how to decide on which term to use, and what to do if no term is found.
The ontologies that I will promote in this lesson are part of the OBO Foundry, a community of ontology developers that are committed to developing open, freely available, community ontologies under a share set of guiding principles, that ensure the ontologies are interoperable, scientifically accurate, amongst other qualities.
+
A key feature of the success of our ontologies is the community who contributes to them. (I claim they are successful because they are widely used in biomedical curation, databases, bioinformatics and computational analyses.)
These ontologies rely on community contributions and many are not funded. We value your expertise in making new term requests, requesting changes or commenting on existing tickets.
+
The OBO Academy has a lot of self-paced learning material, if you are inclined to learn how to contribute directly to ontologies.
+
Join Slack channels and email lists.
+
Reduce work for others as much as possible by communicating clearly.
+
Be positive and generous with gratitude and attribution.
+
Promote truly open communication: Create public tickets which can be searched and referred to later.
Search for 'exhaust exposure'. Note how many results you get. Do you have a sense of how to select the appropriate term for your annotations?
+
+
+
Make a new term request for a missing term:
+
Suppose you want a more general term than already exists: exhuast exposure. Using the instructions in How to guide on Make term requests to existing ontologies, make a new term request to an appropriate GitHub repository for an ontology, such as ECTO. (Note, since this is just for practice, please do not submit the ticket.)
In contrast to the Pizza tutorial, the Family history tutorial focuses on modelling with individuals. Chapters 4, 5, 8 and 9 are full of object property modelling, and are not only great to get a basic understanding of using them in your ontology, but also give good hints at where OWL and object properties fall short. We refer to the FHKB in the following and expect you to have completed at least chapter 5 before reading on.
To remind ourselves, there are three different types of relations in OWL:
+
+
Data properties (DatatypeProperty) connect your classes and individuals to data values, such as strings or numbers. In OBO, these are the least frequently used kinds of properties, used for example by CIDO and ONS.
+
+
For some example usage, run the following query in the ontobee OLS endpoint:
Note that many uses of data properties across OBO are a bit questionable, for example, you do never want to attach a modification dates or similar to your classes using data properties, as these fall under OWL semantics. This means that logically, if a superclass has a relation using a DatatypeProperty, then this relation _holds for all subclasses of that class as well.
+
+
+
Annotation properties are similar to data properties, but they are outside of OWL semantics, i.e. OWL reasoners and reasoning do not care, in fact ignore, anything related to annotation properties. This makes them suitable for attaching metadata like labels etc to our classes and properties. We sometimes use annotation properties even to describe relationships between classes if we want reasoners to ignore them. The most typical example is IAO:replaced_by, which connects an obsolete term with its replacement. Widely used annotation properties in the OBO-sphere are standardised in the OBO Metadata Ontology (OMO).
+
+
+
The main type of relation we use in OBO Foundry are object properties. Object properties relate two individuals or classes with each other, for example:
In the same way as annotation properties are maintained in OMO (see above), object properties are maintained in the Relation Ontology (RO).
+
Object properties are of central importance to all ontological modelling in the OBO sphere, and understanding their semantics is critical for any put the most trivial ontologies. We assume the reader to have completed the Family History Tutorial mentioned above.
In our experience, these are the most widely used characteristics we specify about object properties (OP):
+
+
Sub-property: if an OP is a sub-property of another parent OP, it inherits all its semantic characteristics. Most importantly: if OP1 is a sub-property of OP2, then, if (a)--[OP1]-->(b), we infer that (a)--[OP2]-->(b).
+
Domain: if OP has a domain C, it means that every time (a)--[OP]-->(b), (a) must be a C. For example, ecologically co-occurs with in RO has the domain 'organism or virus or viroid', which means that whenever anythingecologically co-occurs with something else, it will be inferred to be a 'organism or virus or viroid'.
+
Range: if OP has a range C, it means that every time (a)--[OP]-->(b), (b) must be a C. For example produced by has the domain material entity. Note that in ontologies, ranges are slightly less powerful then domains: If we have a class Moderna Vaccine which is SubClass of 'produced by' some 'Moderna' we get that Moderna Vaccine is a material entity due to the domain constraint, but NOT that Moderna is a material entity due to the range constraint (explanation to this is a bit complicated, sorry).
+
Transitivity: if an OP is transitive, it means that if (a)--[OP]-->(b)--[OP]-->(c), (a)--[OP]-->(c). For example, if the eye is part of the head, which is part of the body, we can infer that the eye must be part of the body.
+
Property chains: Similar to transitive properties, property chains allow us to bridge across multiple properties. The FHKB tutorial above is all about amazing property chains so you should have a deep understanding of these if you followed the tutorial.
+
+
Other characteristics like functionality and symmetry are used across OBO ontologies, but not nearly to the same extend as the 5 described above.
The Relation Ontology serves two main purposes in the OBO world:
+
+
As a place to standardise object properties. The idea is this: many ontologies are modelling mereological relations, such as partonomies, which requires relationships such as "part of" and "has part". To ensure that ontologies are interoperable, we need to make sure that all ontologies use the same "part of" relationship. Historically this is not always been true, and still is not. At the time of this writing, running:
On the OntoBee SPARQL endpoint still reveals a number of ontologies using non-standard part-of relations. In our experience, most of these are accidental due to past format conversions, but not all. This problem was much worse before RO came along, and our goal is to unify the representation of key properties like "part of" across all OBO ontologies. The OBO Dashboard checks for object properties that are not aligned with RO.
+
+
As a place to encode and negotiate object property semantics. Object properties (OP) can have domains and ranges, can have characteristics such as functionality and transitivity, see above. Arguing the exact semantics of an OP can be a difficult and lengthy collaborative process, esp. since OP semantics can have a huge impact on ontology reasoning. Detailed RO documentation (modelling patterns and practices) can be found in here. The process of how relationships are added to RO is discussed in the next section.
To add a relationship we usually follow the following process. For details, please refer to the RO documentation.
+
+
Check whether the OP is already in RO. Search for synonyms - often the relationship you are looking exist, but under a different name. If you cant find the exact OP, see whether you can find similar OPs - this may help you also identify suitable parent OPs.
+
Make an RO issue. Take care to not only describe the name of your relationship, but also intended application areas with examples, a good definition, potential parent relationships, domains and ranges. The more detail you provide, the easier it will be for the community to review your request.
+
Make a pull request. This involves the same steps as usual. If you are unsure what annotations need to be added and how to reflect the intended semantics, it may be useful to look at past pull requests.
Install GitHub Desktop Please make sure you have some kind of git client installed on your machine. If you are new to Git, please install GitHub Desktop
In OWL, we use object properties to describe binary relationships between two individuals (or instances). We can also use the properties to describe new classes (or sets of individuals) using restrictions. A restriction describes a class of individuals based on the relationships that members of the class participate in. In other words, a restriction is a kind of class, in the same way that a named class is a kind of class.
+
For example, we can use a named class to capture all the individuals that are idiopathic diseases. But we could also describe the class of idiopathic disease as all the instances that are 'has modifier' idiopathic disease.
+
In OWL, there are three main types of restrictions that can be placed on classes. These are quantifier restriction, cardinality restrictions, and hasValue restriction. In this tutorial, we will initially focus on quantifier restrictions.
+
Quantifier restrictions are further categorized into two types, the existential and the universal restriction.
+
+
Existential restrictions describe classes of individuals that participate in at least one relationship along a specified property to individuals that are members of a specified class. For example, the class of individuals that have at least one ( some ) 'has modifier' relationship to members of the idiopathic disease class. In Protege, the keyword 'some' is used to denote existential restrictions.
+
Universal restrictions describe classes of individuals that for a given property only have relationships along this property to individuals that are members of a specified class. For example, we can say a cellular component is capable of many functions using the existential quantifier, however, OWL semantics assume that there could be more. We can use the universal quantifier to add closure to the existential. That is, we can assert that a cellular component is capable of these functions, and is only capable of those functions and no other. Another example is that the process of hair growth is found only in instances of the class Mammalia. In Protege the keyword 'only' is used.
+
+
In this tutorial, we will deal exclusively with the existential (some) quantifier.
Strictly speaking in OWL, you don't make relationships between classes, however, using OWL restrictions we essentially achieve the same thing.
+
We wanted to capture the knowledge that the named class 'idiopathic achalasia' is an idiopathic disease. In OWL speak, we want to say that every instance of an ' idiopathic achalasia' is also an instance of the class of things that have at least one 'has modifier' relationship to an idiopathic disease. In OWL, we do this by creating an existential restriction on the idiopathic achalasia class.
+
+
In the Entities tab, select 'idiopathic achalasia' in the class hierarchy and look at its current class description in the bottom right box.
+
Note that there are two superclasses (as denoted by the SubClass Of list). ''gastroesophageal disease'' and 'has modifier' some idiopathic.
+
Run the reasoner.
+
You should see that this class is now inferred to be an idiopathic disease because of this SubClassOf (superclass) restriction.
This example introduces equivalence axioms or defined classes (also called logical definitions) and automatic classification.
+
The example involves classification of Mendelian diseases that have a monogenic (single gene) varation. These equivalence axioms are based off the Mondo Design Pattern disease_series_by_gene.
+
Constructs:
+
+
and (intersection)
+
equivalence (logical definitions)
+
existential restrictions (e.g. 'disease has basis in dysfunction of')
+
+
Add an equivalence axiom to an existing Mondo term¶
+
+
Create a new branch and open (or re-open) mondo-edit.obo
+
Navigate to the class 'cardioacrofacial dysplasia 1'
+
According to OMIM, this disease is caused by a variation in the gene PRKACA.
+
We want to add an equivalence axiom that says every instance of this class is a type of 'cardioacrofacial dysplasia' that has dysfunction in the PRKACA gene.
+
To do this, click the + next to Equivalent To in the lower right Description box.
+
Add the following equivalence axiom:
+ 'cardioacrofacial dysplasia' and ('disease has basis in dysfunction of' some PRKACA)
+
Run the reasoner.
+
You shouldn't see any change, but try deleting the superclass assertion to 'cardioacrofacial dysplasia' and re-running the reasoner.
+
You should see that 'cardioacrofacial dysplasia' is an inferred superclass.
+
Undo the last change, save your work, commmit, and create a pull request.
+
+
Adding classes and automatically classifying them¶
+
For teaching purposes, let's say we need a new class that is 'fungal allergy'.
+
+
Create a new branch and re-open mondo-edit.obo
+
Add a new term under owl:Thing named 'fungal allergy'.
+
Following the design pattern allergy.yaml, add the text definition, synonym and equivalentTo axiom, using the substance ECTO_0000524 'exposure to mycotoxin'.
+
Run the reasoner and note where the class is automatically classified.
+
Create a pull request and note in the PR what the parent class is.
By default, OWL assumes that these classes can overlap, i.e. there are individuals who can be instances of more than one of these classes. We want to create a restriction on our ontology that states these classes are different and that no individual can be a member of more than one of these classes. We can say this in OWL by creating a disjoint classes axiom.
+
+
Create a branch in the Mondo repo (name it: disjoint-[your initials]. For example: disjoint-nv)
+
Open the mondo-edit.obo file
+
Per this ticket, we want to assert that infectious disease and syndromic disease are disjoint.
+
To do this first search for and select the infectious disease class.
+
In the class 'Description' view, scroll down and select the (+) button next to Disjoint With. You are presented with the now familiar window allowing you to select, or type, to choose a class. In the Expression editor, add 'syndromic disease' as disjoint with 'infectious disease'.
+
Run the ELK reasoner.
+
Scroll to the top of your hierarchy and note that owl:Nothing has turned red. This is because there are unsatisfiable classes.
Below we'll review an example of one class and how to fix it. Next you should review and fix another one on your own and create a pull request for Nicole or Nico to review. Note, fixing these may require a bit of review and subjective decision making and the fix described below may not necessarily apply to each case.
+
+
Review Bickerstaff brainstem encephalitis: To understand why this class appeared under owl:Nothing, first click the ? next to owl:Nothing in the Description box. (Note, this can take a few minutes).
+
+
+
+
The explanation is displayed above - it is because this class is a descedent of Guillain-Barre syndrome, which is a child of syndromic disease.
+
Next, we have to ask if Bickerstaff brainstem encephalitis is an appropriate child of regional variant of Guillain-Barre syndrome. Note, Mondo integrates several disease terminologies and ontologies, and brought in all the subclass hierarchies from these source ontologies. To see the source of this superclass assertion, click the @ next to the assertion.
+
This source came from Orphanet, see below.
+
+
+
+
Based on the text definition, there does not seem to be any suggestion that this disease is a type of Guillain-Barre syndrome.
+
Assuming that this disease is not a type of Guillain-Barre syndrome, we should exclude the superclass regional variant of Guillain-Barre syndrome (see this paper and this paper. It seems a bit unclear what the relationship of BBE is to Guillain-Barre syndrome. This also brings into the question if a disease can be syndromic and an infectious disease - maybe this disjoint axiom is wrong, but let's not worry about this for the teaching purposes.)
+
To exclude a superclass, follow the instructions here.
We are skipping 5.3: Ontology Learning and both sections on MORE Ontology Evaluation (5.7 and 5.8)
+
Complete part of the Ontologies 101 Tutorial (~2 hours)
+
Clone the Ontologies 101 repository, then open the folder BDK14_exercises from your file system
+
Open basic-subclass/chromosome-parts.owl in Protégé, then do the following exercises:
+
Basic Subclass Hierarchy (review) - make sure to look at the "detailed instructions" for adding annotations here, as it will go over adding annotations on annotation assertions
Object Properties - note that you will rarely, if ever, be making object properties, as most of the properties you'll ever need are defined in the Relation Ontology
Open basic-dl-query/cc.owl in Protégé, then do the following exercises:
+
DL Query Tab - note that owl:Nothing is defined as the very bottom node of an ontology, therefore the DL query results will show owl:Nothing as a subclass. This is expected and does not mean there is a problem with your ontology! It's only bad when something is a subclass of owl:Nothing and therefore unsatisfiable (more on that below).
Optional: Open a new ontology in Protégé. Try creating an inconsistent ontology using the classes and instances in the first Pets example (hint: you'll also need to create the "eats" object property)... what happens when you run the reasoner? Don't spend too much time on this if you get stuck, we'll look at an example of an inconsistent ontology in our session.
Install ROBOT so you can use it outside of Docker (scroll down to the end of the ROBOT page to find the Windows instructions)
+
OptionalInstall ODK. The ODK includes ROBOT. In the more advanced parts of the course, you will need the ODK installed for some of the other dependencies it includes, and for Windows users it is often easier to follow the tutorials from inside the docker container rather than the Windows CMD.
+
Familiarise yourself with the ROBOT documentation, to the point that you are aware of the various commands that exist.
There are two basic ways to edit an ontology:
+1. Manually, using tools such as Protege, or
+2. Using computational tools such as ROBOT.
+
Both have their advantages and disadvantages: manual curation is often more practical when the required ontology change follows a non-standard pattern, such as adding a textual definition or a synonym, while automated approaches are usually much more scalable (ensure that all axioms in the ontology are consistent, or that imported terms from external ontologies are up-to-date or that all labels start with a lower-case letter).
+
Here, we will do a first dive into the "computational tools" side of the edit process. We strongly believe that the modern ontology curator should have a basic set of computational tools in their Semantic Engineering toolbox, and many of the lessons in this course should apply to this role of the modern ontology curator.
We also recommend to get a basic familiarity with SPARQL, the query language of the semantic web, that can be a powerful combination with ROBOT to perform changes and quality control checks on your ontology.
Ontologies provide a logical classification of information in a particular domain or subject area. Ontologies can be used for data annotations, structuring disparate data types, classifying information, inferencing and reasoning across data, and computational analyses.
An ontology contains a formal classification of terminology in a domain that provides textual and machine readable definitions, and defines the relationships between terms. An ontology is a terminology, but a terminology is not (necessarily) an ontology.
BioPortal. BioPortal aggregates almost 900 biomedical ontologies, and provides a search interface to look up terms. It is a popular repository for ontologies, but as only a fraction of the ontologies are reviewed by the OBO Foundry, you should carefully review any ontologies found on BioPortal before committing to use them.
+
Ontobee. Ontobee indexes all 200+ OBO Foundry ontologies and is the default browser for OBO: For example, when you click http://purl.obolibrary.org/obo/IAO_0000112, you will be redirected to the a page in the Ontobee browser that describes the annotation property example of usage.
The OBO Foundry is a community of ontology developers that are committed to developing a library of ontologies that are open, interoperable ontologies, logically well-formed and scientifically accurate. OBO Foundry participants follow and contribute to the development of an evolving set of principles including open use, collaborative development, non-overlapping and strictly-scoped content, and common syntax and relations, based on ontology models that work well, such as the Gene Ontology (GO).
+
The OBO Foundry is overseen by an Operations Committee with Editorial, Technical and Outreach working groups.
Licenses define how an ontology can legally be used or reused. One requirement for OBO Foundry Ontologies is that they are open, meaning that the ontologies are openly and freely available for use with acknowledgement and without alteration. OBO ontologies are required to be released under a Creative Commons CC-BY license version 3.0 or later, OR released into the public domain under CC0. The license should be clearly stated in the ontology file.
Some criteria that can be applied to determine the quality of an ontology include:
+
+
Is there an ontology tracker to report issues? All open ontologies should have some form of an issue tracker to report bugs, make new term requests or request other changes to the ontology. Many ontologies use GitHub to track their issues.
+
Is it currently active? Are there a large number of open tickets on the ontology tracker that have not been commented on or otherwise addressed? Are the tickets very old, have been sitting for years?
+
Commmunity involvement On the issue tracker, is there evidence of community involvement, such as issues and comments from outside community members?
+
Scientifically sound Does the ontology accurately represent the domain in a scientifically sound way?
+
+
How to determine which is the right ontology to use?¶
+
+
There are multiple ontologies that exist, start by selecting the appropriate ontology, then search and restrict your search to that ontology.
+
Recommend using ontologies that are open and interoperable. Focusing on OBO foundry ontologies are a good place to start
+
Make informed decision about which ontology to use
Path, e.g. /obophenotype/uberon/blob/master/uberon_edit.obo
+
+
The protocol tells you how to get the resource. Common protocols for web pages are http (HyperText Transfer Protocol) and https (HTTP Secure).
+The host is the name of the server to contact (the where), which can be a numeric IP address, but is more often a domain name.
+The path is the name of the resource on that server (the what), here the Uberon anatomy ontology file.
A Internationalized Resource Identifiers (IRI) is an internet protocol standard that allows permitted characters from a wide range of scripts. While URIs are limited to a subset of the ASCII character set, IRIs may contain characters from the Universal Character Set (Unicode/ISO 10646), including Chinese or Japanese kanji, Korean, Cyrillic characters, and so forth. It is defined by RFC 3987.
A Compact URI (CURIE) consists of a prefix and a suffix, where the prefix stands in place of a longer base IRI.
+
By converting the prefix and appending the suffix we get back to full IRI. For example, if we define the obo prefix to stand in place of the IRI as:
+http://purl.obolibrary.org/obo/, then the CURIE
+obo:UBERON_0002280
+can be expanded to
+http://purl.obolibrary.org/obo/UBERON_0002280, which is the UBERON Anatomy term for ‘otolith’.
+Any file that contains CURIEs need to
+define the prefixes in the file header.
Templating systems for OBO ontologies: a deep dive¶
+
Ontologies are notoriously hard to edit. This makes it a very high burden to edit ontologies for anyone but a select few. However, many of the contents of ontologies are actually best edited by domain experts with often little or known ontological training - editing labels and synonyms, curating definitions, adding references to publications and many more. Furthermore, if we simply remove the burden of writing OWL axioms, editors with very little ontology training can actually curate even logical content: for example, if we want to describe that a class is restricted to a certain taxon (also known as taxon-restriction), the editor is often capable to select the appropriate taxon for a term (say, a "mouse heart" is restricted to the taxon of Mus musculus), but maybe they would not know how to "add that restriction to the ontology".
+
Tables are great (for a deep dive into tables and triples see here). Scientists in particular love tables, and, even more importantly, can be trained easily to edit data in spreadsheet tools, such as Google Sheets or Microsoft Excel.
+
Ontology templating systems, such as DOSDP templates, ROBOT templates and Reasonable Ontology Templates (OTTR) allow separating the raw data in the ontology (labels, synonyms, related ontological entities, descriptions, cross-references and other metadata) from the OWL language patterns that are used to manifest them in the ontology. There are three main ingredients to a templating system:
+
+
A way to capture the data. In all the systems we care about, these are tables, usually manifested as spreadsheets in Excel or Google Sheets.
+
A way to capture the template. In ROBOT templates the templates are captured in a header row of the same table that captures the data, in DOSDP templates the templates are captured in a separate YAML file and in OTTR typically the templates are serialised as and RDF-graph in a format like RDF/XML or Turtle.
+
A toolkit that can combine the data and the template to generate OWL axioms and annotations. ROBOT templates can be compiled to OWL using ROBOT, DOSDP templates can be compiled using DOSDP tools and OTTR templates using Lutra.
+
+
In OBO we are currently mostly concerned with ROBOT templates and DOSDP templates. Before moving on, we recommend to complete a basic tutorial in both:
Ontologies, especially in the biomedical domain, are complex and, while growing in size, increasingly hard to manage for their curators. In this section, we will look at some of the key differences of two popular templating systems in the OBO domain: Dead Simple Ontology Design Patterns (DOSDPs) and ROBOT templates. We will not cover the rationale for templates in general in much depth (the interested reader should check ontology design patterns and Reasonable Ontology Templates (OTTR): Motivation and Overview, which pertains to a different system, but applies none-the-less in general), and focus on making it easier for developers to pick the right templating approach for their particular use case. We will first discuss in detail representational differences, before we go through the functional ones and delineate use cases.
DOSDP separates data and templates into two files: a yaml file which defines the template, and a TSV file which holds the data. Lets look at s example.
ROBOT encodes both the template and the data in the same TSV; after the table header, the second row basically encodes the entire template logic, and the data follows in table row 3.
+
+
+
+
ID
+
Label
+
EQ
+
Anatomy Label
+
+
+
+
+
ID
+
LABEL
+
EC 'has_part' some ('quality' and ('inheres_in_part_of' some %) and ('has_modifier' some 'abnormal'))
+
+
+
+
HP:0040286
+
Abnormal axial muscle morphology
+
UBERON:0003897
+
axial muscle
+
+
+
HP:0011297
+
Abnormal digit morphology
+
UBERON:0002544
+
digit
+
+
+
+
Note that for the Anatomy Label we deliberately left the second row empty, which instructs the ROBOT template tool to completely ignore this column.
From an ontology engineering perspective, the essence of the difference between DOSDP and ROBOT templates could be captured as follows:
+
DOSDP templates are more about generating annotations and axioms, while ROBOT templates are more about curating annotations and axioms.
+
+
Curating annotations and axioms means that an editor, or ontology curator, manually enters the labels, synonyms, definitions and so forth into the spreadsheet.
+
Generating axioms in the sense of this section means that we try to automatically generate labels, synonyms, definitions and so forth based on the related logical entities in the patterns. E.g., using the example template above, the label "abnormal kidney" would automatically be generated when the Uberon term for kidney is supplied.
+
While both ROBOT and DOSDP can be used for "curation" of annotation of axioms, DOSDP seeks to apply generation rules to automatically generate synonyms, labels, definitions and so forth while for ROBOT template seeks to collect manually curated information in an easy-to-use table which is then compiled into OWL. In other words:
+
+
the average DOSDP user will not write their own labels, definitions and synonyms - they will want those to be generated automatically from a set of simple rules;
+
the average ROBOT template user will not want automatically generated definitions, labels and synonyms - they will want to capture their own.
However, there is another dimension in which both approaches differ widely: sharing and re-use. DOSDPs by far the most important feature is that it allows a community of developers to rally around a modelling problem, debate and establish consensus; for example, a pattern can be used to say: this is how we model abnormal anatomical entities. Consensus can be made explicit by "signing off" on the pattern (e.g. by adding your ORCId to the list of contributors), and due to the template/data separation, the template can be simply imported using its IRI (for example http://purl.obolibrary.org/obo/upheno/patterns/abnormalAnatomicalEntity.yaml) and re-used by everyone. Furthermore, additional metadata fields including textual descriptions, and more recently "examples", make DOSDP template files comparatively easy to understand, even by a less technically inclined editor.
+
ROBOT templates on the other hand do not lend themselves to community debates in the same way; first of all, they are typically supplied including all data merged in; secondly, they do not provide additional metadata fields that could, for example, conveniently be used to represent a sign off (you could, of course, add the ORCId's into a non-functional column, or as a pipe-separated string into a cell in the first or second row; but its obvious that this would be quite clunky) or a textual description. A yaml file is much easier for a human to read and understand then the header of a TSV file, especially when the template becomes quite large.
+
However, there is a flipside to the strict separation of data and templates. One is that DOSDP templates are really hard to change. Once, for example, a particular variable name was chosen, renaming the variable will require an excessive community-wide action to rename columns in all associated spreadsheets - which requires them all to be known beforehand (which is not always the case). You don't have such a problem with ROBOT templates; if you change a column name, or a template string, everything will continue to work without any additional coordination.
Both ROBOT templates and DOSDP templates are widely used. The author of this page uses both in most of the projects he is involved in, because of their different strengths and capabilities. You can use the following rules of thumb to inform your choice:
+
Consider ROBOT templates if your emphasis is on
+
+
manually curating labels, definitions, synonyms and axioms or other annotations
+
managing your templates in the spreadsheet itself is a concern for you (this is often the case, for example, when turning an existing data table into a ROBOT template ad hoc)
+
+
Consider DOSDP templates if your emphasis is on
+
+
re-use, community-wide implementation of the same templates and community discussion, you should consider DOSDP templates
+
automatically generating labels, definitions, synonyms from rules in the pattern.
There is a nice debate going on which questions the use of tables in ontology curation altogether. There are many nuances in this debate, but I want to stylise it here as two schools of thoughts (there are probably hundreds in between, but this makes it easier to follow): The one school (let's call them Tablosceptics) claims that using tables introduces a certain degree of fragility into the development process due to a number of factors, including:
+
+
losing the immediateness of QC feedback; Table-based development, so the Tablosceptics, encourages lazy editing (adding stuff to a template and then not reviewing the consequence properly, which we will discuss in more depth later).
+
losing track of the ID space (in a multi-table world, it becomes increasingly hard to manage IDs, making sure they are not double used etc) and 3) encouraging bad design (relying more on assertion than inference).
+
+
They prefer to use tools like Protege that show the curator immediately the consequences of their actions, like reasoning errors (unintended equivalent classes, unsatisfiable classes and other unintended inferences). The Tablophile school of thought responds to these accusations in essence with "tools"; they say that tables are essentially a convenient matrix to input the data (which in turns opens ontology curation to a much wider range of people), and it is up to the tools to ensure that QC is run, hierarchies are being presented for review and weird ID space clashes are flagged up. Furthermore, they say, having a controlled input matrix will actually decrease the number of faulty annotations or axioms (which is evidenced by the large number of wrongful annotation assertions across OBO foundry ontologies I see every day as part of my work). At first sight, both template systems are affected equally by the war of the Tablosceptics and the Tablophile. Indeed, in my on practice, the ID space issue is really problematic when we manage 100s and more templates, and so far, I have not seen a nice and clear solution that ensures that no ID used twice unless it is so intended and respects ID spaces which are often semi-formally assigned to individual curators of an ontology.
+
Generally in this course we do not want to take a 100% stance. The author of this page believes that the advantage of using tables and involving many more people in the development process outweighs any concerns, but tooling is required that can provide more immediate feedback when such tables such as the ones presented here are curated at scale.
Description: An introduction to the landscape of disease and phenotype terminologies and ontologies, and how they can be used to add value to your analysis.
Major disease and phenotype ontologies that are available¶
+
A landscape analysis of major disease and phenotype ontologies that are currently available is here (also available in Zenodo here).
+
+
Decide which phenotype or disease ontology to use for different use cases¶
+
Different ontologies are built for different purposes and were created for various reasons. For example, some ontologies are built for text mining purposes, some are built for annotating data and downstream computational analysis.
+
The unified phenotype ontology (uPheno) aggregates species-specific phenotype ontologies into a unified resource. Several species-specific phenotype ontologies exist, such as the Human Phenotype Ontology, Mammalian Phenotype Ontology (http://www.informatics.jax.org/searches/MP_form.shtml), and many more.
+
Similarly to the phenotype ontologies, there are many disease ontologies that exist that are specific to certain areas of diseases, such as infectious diseases (e.g. Infectious Disease Ontology), cancer (e.g. National Cancer Institute Thesaurus), rare diseases (e.g. Orphanet), etc.
Different disease ontologies may be built for different purposes; for example, ontologies like Mondo and DO are intended to be used for classifying data, and downstream computational analyses. Some terminologies are used for indexing purposes, such as the International classification of Diseases (ICD). ICD-11 is intended for indexing medical encounters for the purposes of billing and coding. Some of the disease ontologies listed on the landscape contain terms that define diseases, such as Ontology for General Medical Sciences (OGMS) are upper-level ontologies and are intended for integration with other ontologies.
+
When deciding on which phenotype or disease ontology to use, some things to consider:
+
+
Do you need a more specific ontology, such as a species-specific ontology, or do you need a more general ontology that is cross-species or covers more aspects of diseases?
+
Is the ontology open and free to use?
+
Does the description of the ontology describe its intended use? For example, some ontologies are built for text mining purposes, some are built for annotating data and downstream computational analysis.
+
Is the ontology actively maintained?
+
Does the ontology contain the terms you need? If not, is there a mechanism to request changes or add new terms? Are the ontology developers responsive to change requests on their tracker?
+
Is the ontology widely used by the community? You can check things like active contributors on GitHub, usages described on the OBO Foundry page (for example http://obofoundry.org/ontology/mondo.html), published papers, and/or citations.
+
+
+
Understand how to leverage disease and phenotype ontologies for advanced data analytics¶
Description: A collection of videos, tutorials, training materials, and exercises targeted towards any entry-level, early-career person interested in learning basic skills in data science.
Help improve this pathway! Make edits to this OBO Academy page and make a pull request. (For example, find typos to fix, add or revise content to this document, etc.)
Description: These guidelines are developed for anyone interested in contributing to ontologies to guide how to contribute to OBO Foundry ontologies.
+
Why should you contribute to ontology development efforts?¶
+
Ontologies are routinely used for data standardization and in analytical analysis, but the ontologies themselves are under constant revisions and iterative development. Building ontologies is a community effort, and we need expertise from different areas:
+
+
Technical expertise
+
Domain expertise
+
User experiences
+
+
The OBO foundry ontologies are open, meaning anyone can access them and contribute to them. The types of contributions may include reporting issues, identifying bugs, making requests for new terms or changes, and you can also contribute directly to the ontology itself- if you are familiar with ontology editing workflows, you can download our ontologies and make edits on a branch and make a pull request in GitHub.
The OBO Metadata also has a link to a contact but this is generally for OBO administrative purposes and should not be used for general questions, new term requests, or general feedback
+
Some ontologies may have other means of engaging their use community, and these should all be listed in a standard way on the OBO page. This includes mailing lists, slack groups, and Twitter or other social media accounts.
Join the discussion: Comment on tickets or the discussion board
+
Join the conversation: Attend ontology calls (many ontology developer groups have recurring calls open to the community. Contact the ontology owner to request information about calls.)
+
Edit the ontology file: make changes on a branch and do a pull request (more advanced)
Note: There is no one single accepted way of doing ontology curation in the OBO-World, see here. This guide reflects the practice of the GO-style ontology curation, as it is used by GO, Uberon, CL, PATO and others.
+
Note: Work on this document is still in progress, items that are not linked are currently being worked on.
Note: There is no one single accepted way of doing ontology curation in the OBO-World, see here. This guide reflects the practice of the OBI-style ontology curation, as it is used by OBI, IAO and others.
There is no one single accepted methodology for building ontologies in the OBO-World. We can distinguish at least two major schools of ontology curation
+
+
GO-style ontology curation
+
OBI-style ontology curation
+
+
Note that there are many more variants, probably as many as there are ontologies. Both schools differ only in how they curate their ontologies - the final product is always an ontology in accordance with OBO Principles. These are some of the main differences of the two schools:
+
+
+
+
+
GO-style
+
OBI-style
+
+
+
+
+
Edit format
+
Historically developed in OBO format
+
Developed in an OWL format
+
+
+
Annotation properties
+
Many annotation properties from the oboInOwl namespace, for example for synonyms and provenance.
+
Many annotation properties from the IAO namespace.
+
+
+
Upper Ontology
+
Hesitant alignment with BFO, often uncommitted.
+
Strong alignment with BFO.
+
+
+
Logic
+
Tend do be simple existential restrictions (some), ontologies in OWL 2 EL. No class expression nesting. Simple logical definition patterns geared towards automating classification
+
Tend to use a lot more expressive logic, including only and not. Class expression nesting can be more complex.
+
+
+
Examples
+
GO, Uberon, Mondo, HPO, PATO, CL, BSPO
+
OBI, IAO, OGMS
+
+
+
+
There are a lot of processes happening that are bringing these schools together, sharing best practices (GitHub, documentation) and reconciling metadata conventions and annotation properties in the OBO Metadata Ontology (OMO). The Upper Level alignment is now done by members of both schools through the Core Ontology for Biology and Biomedicine (COB). While these processes are ongoing, we decided to curate separate pathways for both schools:
As a ontology engineer, it would be useful for you to know how curators work, as such, it would be useful to be familiar with all the concepts in the ontology curator pathways document. This pathways will however be focusing on the engineering side of things.
This section is a non-ordered collection of how to documents that an engineer might need (this includes everything from the curators list as they may be pertinent knowledge to an engineer).
Pathways are materials from OBOOK in a linear fashion for the purpose of helping people in different roles finding the materials relevant to their work more easily. To browse through the pathways, look under the "Pathways" menu item.
I want you to act as a REST API, which takes natural language searches a an input and returns an SSSOM mapping in valid JSON in a codeblock, no comments, no additional text. An example of a valid mapping is
The new OBO Foundry guidelines encourage the annotation of ontologies with an appropriately formatted description, title and license. Here are some examples that can be used as a guide to implement those in your ontology.
+
Note: these examples purposefully do not include version information, this should not be manually added, instead it should be added by ROBOT as part of a pipeline. An ontology set up with the ODK will take care of all of this for you.
Running the same workflow several times simultaneously (e.g. if two PRs are submitted in a short time, and the second PR triggers the CI workflow while the CI workflow triggered by the first PR is still running) could lead to lack-of-memory situations because all concurrent workflows have to share a single memory limit.
+
(Note: it isn't really clear with documentation of GitHub Actions on whether concurrent workflow runs share a single memory limit.)
+
What could possibly be done is to forbid a given workflow from ever running as long as there is already a run of the same workflow ongoing, using the concurrency property.
This page aims to consolidate some tips and tricks that ontology editors have found useful in using git. It is not meant to be a tutorial of git, but rather as a page with tips that could help in certain specialised situations.
Reverting particular files back to master version¶
+
+
If you want to revert only certain files (eg import files), you can do it using Terminal. For this example, we will use uberon_import.owl as the file we want reverted back to the version in master branch, however, this can be done on any file.
+
Assuming your directory is set to src/ontology, in terminal use: git checkout master -- imports/uberon_import.owl.
+
Commit the change to the branch as normal.
+
+
Reverting particular files back to a previous version¶
+
+
If you want to revert a file back to a previous version instead of master, you can use the commit ID.
+
To do this, in Terminal use: git log to list out the previous commits and copy the commit code of the commit you would like to revert to (example: see yellow string of text in screenshot below).
+
+
+
+
Press q on your keyboard to quit git log (or down arrow to scroll down to continue to find the commit ID you want to revert if it is further down).
+
In terminal use: git checkout ff18c9482035062bbbbb27aaeb50e658298fb635 -- imports/uberon_import.owl using whichever commit code you want instead of the commit code in this example.
For most of our training activities, we recommend using GitHub Desktop. It provides a very convenient way to push and pull changes, and inspect the "diff". It is, however, not mandatory if you are already familiar with other git workflows (such as command line, or Sourcetree).
A repository can consist of many files with several users simultaneously editing those files at any moment in time. In order to ensure conflicting edits between the users are not made and a history of the edits are tracked, software classified as a "distributed version control system" is used.
+
All OBO repositories are managed by the Git version control system. This allows users to make their own local branch of the repository, i.e., making a mirror copy of the repository directories and files on their own computers, and make edits as desired. The edits can then be reviewed by other users before the changes are incorporated in the 'main' or 'master' branch of the repository. This process can be executed by running Git line commands and/or by using a web interface (Github.com) along with a desktop application (GitHub Desktop).
+
Documentation, including an introduction to GitHub, can be found here:
+Hello World.
This document is a list of terms that you might encounter in the ontology world. It is not an exhaustive list and will continue to evolve. Please create a ticket if there is a term you find missing or a term you encounter that you do not understand, and we will do our best to add them. This list is not arranged in any particular order. Please use the search function to find terms.
+
Acknowledgement: Many terms are taken directly from OAK documentation with the permission of Chris Mungall. Many descriptions are also taken from https://www.w3.org/TR/owl2-syntax/.
Annotation properties are OWLaxioms that are used to place annotations on individuals, class names, property names, and ontology names. They do not affect the logical definition unless they are used as a "shortcut" that a pipeline expands to a logical axiom.
If an individual is not expected to be used outside an ontology, one can use an anonymous individual, which is identified by a local node ID rather than a global IRI. Anonymous individuals are analogous to blank nodes in RDF.
Application Programming Interface. An intermediary that allows two or more computer programs to communicate with each other. In ontologies, this usually means an Endpoint in which the ontology can be programmatically accessed.
Axioms are statements that are asserted to be true in the domain being described. For example, using a subclass axiom, one can state that the class a:Student is a subclass of the class a:Person. (Note: in OWL, there are also annotation axioms which does not apply any logical descriptions)
Standardized and organized arrangements of words and phrases that provide a consistent way to describe data. A controlled vocabulary may or may not include definitions. Ontologies can be seen as a controlled vocabulary expressed in an ontological language which includes relations.
A CURIE is a compact URI. For example, CL:0000001 expands to http:purl.obolibrary.org/obo/CL_0000001. For more information, please see https://www.w3.org/TR/curie/.
dataProperty relate OWL entities to literal data (e.g., strings, numbers, datetimes, etc.) as opposed to ObjectProperty which relate individuals to other OWL entities. Unlike AnnotationProperty, dataProperty axioms fall on the logical side of OWL and are hence useable by reasoners.
Datatypes are OWL entities that refer to sets of data values. Thus, datatypes are analogous to classes, the main difference being that the former contain data values such as strings and numbers, rather than individuals. Datatypes are a kind of data range, which allows them to be used in restrictions. For example, the datatype xsd:integer denotes the set of all integers, and can be used with the range of a dataProperty to state that the range of said dataProperty must be an integer.
Description Logics (DL) are a family of formal knowledge representation languages. It provides a logical formalism for ontologies and is what OWL is based on. DL querying can be used to query ontologies in Protege.
Domain, in reference to a dataProperty or ObjectProperty, refers to the restriction on the subject of a triple - if a given property has a given class in its domain this means that any individual that has a value for the property, will be inferred to be an instance of that domain class. For example, if John hasParent Mary and Person is listed in the domain of hasParent, then John will be inferred to be an instance of Person.
A typed, directed link between Nodes in a knowledge graph. Translations of OWL into Knowledge graphs vary, but typically edges are generated for simple triples, relating two individuals or two classes via an AnnotationProperty or ObjectProperty and simple existential restrictions (A SubClassOf R some B), with the edge type corresponding to the property.
A relationship between two classes, A R (some) B, that states that all individuals of class A stand in relation R to at least one individual of class B. For example, neuron has_part some dendrite states that all instances of neuron have at least one individual of type dentrite as a part. In Manchester syntax, the keyword 'some' is used to denote existential restrictions and is interpreted as "there exists", "there is at least one", or "some". See documentation on classifications for more details.
An official syntax of OWL (others are RDF-XML and OWL-XML) in which each line represents and axiom (although things get a little more complex with axiom annotations, and axioms use prefix syntax (order = relation (subject, object)). This is in contrast to in-fix syntax (e.g. Manchester syntax) (order = subject relation object). Functional syntax is the preferred syntax for editor files maintained on GitHub, because it can be safely diff'd and (somewhat) human readable.
Formally a graph is a data structure consisting of Nodes and Edges. There are different forms of graphs, but for our purposes an ontology graph has all Terms as nodes, and relationships connecting terms (is-a, part-of) as edges. Note the concept of an ontology graph and an RDF graph do not necessarily fully align - RDF graphs of OWL ontologies employ numerous blank nodes that obscure the ontology structure.
An OWL entity that represents an instance of a class. For example, the instance "John" or "John's heart". Note that instances are not commonly represented in ontologies. For instance, "John" (an instance of person) or "John's heart" (an instance of heart).
A measure of how informative an ontology concept is; broader concepts are less informative as they encompass many things, whereas more specific concepts are more unique. This is usually measured as -log2(Pr(term)). The method of calculating the probability varies, depending on which predicates are taken into account (for many ontologies, it makes sense to use part-of as well as is-a), and whether the probability is the probability of observing a descendant term, or of an entity annotated using that term.
Knowledge Graph Change Language (KGCL) is a data model for communicating desired changes to an ontology. It can also be used to communicate differences between two ontologies. See KGCL docs.
A network of real-world entities (i.e., objects, events, situations, and concepts) that illustrates the relationships between them. Knowledge graphs (in relation to ontologies) are thought of as real data built using an ontology as a framework.
Usually refers to a human-readable text string corresponding to the rdfs:labelpredicate. Labels are typically unique per ontology. In OBO Format and in the bio-ontology literature, labels are sometimes called Names. Sometimes in the machine learning literature, and in databases such as Neo4J, "label" actually refers to a Category.
An Individual that is given an explicit name that can be used in any ontology to refer to the same object; named individuals get IRIs whereas anonymous individuals do not.
An owl entity that is used to related 2 individuals ('my left foot' part_of 'my left leg') or two classes ('foot' part_of some leg) or an individual and a class ('the neuron depicted in this image' (is) has_soma_location some 'primary motor cortex. More rarely it is used to define a class in terms of some individual (the class 'relatives of Shawn' related_to Value Shawn.
Open Biological and Biomedical Ontology. This could refer to the OBO Foundry (e.g. OBO ontologies = ontologies that follow the standards of the OBO Foundry) or OBO Format
A serialization format for ontologies designed for easy viewing, direct editing, and readable diffs. It is popular in bioinformatics, but not widely used or known outside the genomics sphere. OBO is mapped to OWL, but only expresses a subset, and provides some OWL abstractions in a more easy to understand fashion.
Ontology Lookup Service. An Ontology Repository that is a curated collection of multiple biologically relevant ontologies, many from OBO. OLS can be accessed with this link
The systems or platform where various types of ontologies are stored from different sources and provide the ability to data providers and application developers to share and reuse the ontologies.
Web Ontology Language. An ontology language that uses constructs from Description Logic. OWL is not itself an ontology format, it can be serialized through different formats such as Functional Syntax, and it can be mapped to :RDF and serialized via an RDF format.
In the context of OWL, the term Annotation means a piece of metadata that does not have a strict logical interpretation. Annotations can be on entities, for example, Label annotations, or annotations can be on Axioms.
OWL Entities, such as classes, properties, and individuals, are identified by IRIs. They form the primitive terms of an ontology and constitute the basic elements of an ontology. For example, a class a:Person can be used to represent the set of all people. Similarly, the object property a:parentOf can be used to represent the parent-child relationship. Finally, the individual a:Peter can be used to represent a particular person called "Peter".
+The following is a complete list of types of OWL Entities:
An OWL entity that represents the type of a Relationship.
+Typically corresponds to an ObjectProperty in OWL, but this is not always true;
+in particular, the is-a relationship type is a builtin construct SubClassOf in OWL
+Examples:
Range, in reference to a dataProperty or ObjectProperty, refers to the restriction on the object of a triple - if a given property has a given class in its domain this means that any individual that has a value for the property (i.e. is the subject of a relation along the property), will be inferred to be an instance of that domain class. For example, if John hasParent Mary and Person is listed in the domain of hasParent, then John will be inferred to be an instance of Person.
An ontology tool that will perform inference over an ontology to yield new axioms (e.g. new Edges) or to determine if an ontology is logically coherent.
A Relationship is a type connection between two OWL entities. The first element is called the subject, and the second one the Object, with the type of connection being the Relationship Type. Sometimes Relationships are equated with Triples in RDF but this can be confusing, because some relationships map to multiple triples when following the OWL RDF serialization. An example is the relationship "finger part-of hand", which in OWL is represented using a Existential Restriction that maps to 4 triples.
A means of measuring similarity between either pairs of ontology concepts, or between entities annotated using ontology concepts. There is a wide variety of different methods for calculating semantic similarity, for example Jaccard Similarity and Information Content based measures.
Semantic SQL is a proposed standardized schema for representing any RDF/OWL ontology, plus a set of tools for building a database conforming to this schema from RDF/OWL files. See Semantic-SQL
A named collection of elements, typically grouped for some purpose. In the ODK/OBO world, there is a standard annotation property and pattern for this, for more information, see the subset documentation.
The process of annotating spans of texts within a text document with references to ontology terms, or the result of this process. This is frequently done automatically. The Bioportal implementation provides text annotation services.
A set of three entities that codifies a statement about semantic data in the form of Subject-predicate-Object expressions (e.g., "Bob is 35", or "Bob knows John"). Also see Relationship.
A purpose-built database for the storage and retrieval of triples through semantic queries. A triple is a data entity composed of subject–predicate–object, like "Bob is 35" or "Bob knows Fred".
An integrated OBO ontology Triplestore and a Ontology Repository, with merged set of mutually referential OBO ontologies (see the ubergraph github for list of ontologies included), that allows for SPARQL querying of integrated OBO ontologies.
A Uniform Resource Indicator, a generalization of URL. Most people think of URLs as being solely for addresses for web pages (or APIs) but in semantic web technologies, URLs can serve as actual identifiers for entities like OWL entities. Data models like OWL and RDF use URIs as identifiers. In OAK, URIs are mapped to CURIE
Recommended metadata properties to use in curating OBO ontologies (GO-style)¶
+
Note that while most of the practices documented here apply to all OBO ontologies this recommendation applies only to ontologies that are developed using GO-style curation workflows.
+
+
+
+
Type
+
Property to use
+
Required
+
Number/Limit
+
Description
+
Format
+
Annotation
+
Reference/Comments
+
+
+
+
+
Label
+
rdfs:label
+
Y
+
Max 1 *
+
Full name of the term, must be unique.
+
Free text
+
None
+
* some ontologies have multiple labels for different languages, in which case, there should maximum be one label per language
+
+
+
Definition
+
IAO:0000115
+
Y
+
Max 1
+
A textual definition of ther term. In most ontologies, must be unique.
+
Free text
+
database_cross_reference: reference materials used and contributors (in ORCID ID link format)
Labels are a useful tool to help group and organize issues, allowing people to filter issues by grouping.
+Note: Only project contributors can add/change labels
Superissues are issues that have checklists (added using -[] on items). These are useful as they show progress towards completion. These can be used for issues that require multiple steps to solve.
Milestones are used for issues with a specific date/deadline. Milestones contain issues and issues can be filtered by milestones. They are also useful for visualizing how many issues in it is completed.
Project boards are a useful tool to organise, as the name implies, projects. They can span multiple repos (though the repos need to be in the same organisation). Notes can also be added.
The Landscape of Disease and Phenotype Ontologies¶
+
Compiled by Nicole Vasilevsky. Feel free to make pull requests to suggest edits. Note: This currently just provides an overview of disease and phenotype ontologies. Contributors are welcome to add more descriptions of other medical ontologies. This was last updated in 2021.
Genetic and Rare Diseases Information Center (GARD)
+
Rare diseases
+
+
+
Holistic Ontology of Rare Diseases (HORD)
+
Rare disease
+
+
+
Human Dermatological Disease Ontology (DERMO)
+
Dermatology (skin)
+
+
+
Human Disease Ontology (DO)
+
Human disease
+
+
+
Infectious Disease Ontology (IDO)
+
Infectious disease
+
+
+
International Classification of Functioning, Disability and Health (ICF)
+
Cross-discipline, focuses disabilities
+
+
+
International Statistical Classification of Diseases and Related Health Problems (ICD-11)
+
Broad coverage
+
+
+
International Classification of Diseases for Oncology (ICD-O)
+
Cancer
+
+
+
Logical Observation Identifier Names and Codes (LOINC)
+
Broad coverage
+
+
+
Medical Subject Headings (MeSH)
+
Broad coverage
+
+
+
MedGen
+
Human medical genetics
+
+
+
Medical Dictionary for Regulatory Activities (MedDRA)
+
Broad coverage
+
+
+
Mental Disease Ontology (MDO)
+
Mental functioning
+
+
+
Mondo Disease Ontology (Mondo)
+
Broad coverage, Cross species
+
+
+
National Cancer Institute Thesaurus (NCIT)
+
Humam cancer and neoplasms
+
+
+
Neurological Disease Ontology (ND)
+
Neurology
+
+
+
Online Mendelian Inheritance in Man (OMIM)
+
Mendelian, genetic diseases.
+
+
+
Ontology of Cardiovascular Drug Adverse Events (OCVDAE)
+
Cardiovascular
+
+
+
Ontology for General Medical Science (OGMS)
+
Broad coverage
+
+
+
Ontology for Genetic Susceptibility Factor (OGSF)
+
Genetic disease
+
+
+
Ontology of Glucose Metabolism Disorder (OGMD)
+
Metabolic disorders
+
+
+
Ontology of Language Disorder in Autism (LDA)
+
Austism
+
+
+
The Oral Health and Disease Ontology (OHD)
+
Oral health and disease
+
+
+
Orphanet (ORDO)
+
Rare diseases
+
+
+
Parkinson Disease Ontology (PDO)
+
Parkinson disease
+
+
+
Pathogenic Disease Ontology (PDO)
+
Pathogenic diseases
+
+
+
PolyCystic Ovary Syndrome Knowledgebase (PCOSKB)
+
Polycystic ovary syndrome
+
+
+
Rat Disease Ontology (RDO)
+
Broad coverage
+
+
+
Removable Partial Denture Ontology (RPDO)
+
Oral health
+
+
+
Resource of Asian Primary Immunodeficiency Diseases (RPO)
+
Immunodeficiencies
+
+
+
Sickle Cell Disease Ontology (SCDO)
+
Sickle Cell Disease
+
+
+
SNOMED Clinical Terminology (SNOMED CT)
+
Broad disease representation for human diseases.
+
+
+
Symptom Ontology
+
Human diseases
+
+
+
Unified Medical Language System
+
Broad coverage
+
+
+
+
Artificial Intelligence Rheumatology Consultant System ontology (AI-RHEUM)¶
+
Description: Contains findings, such as clinical signs, symptoms, laboratory test results, radiologic observations, tissue biopsy results, and intermediate diagnosis hypotheses, for the diagnosis of rheumatic diseases.
+Disease area: Rheumatic diseases
+Use Cases: Used by clinicians and informatics researchers.
+Website: https://bioportal.bioontology.org/ontologies/AI-RHEUM
+Open: Yes
Description: An ontology of autism spectrum disorder (ASD) and related neurodevelopmental disorders.
+Disease area: Autism
+Use Cases: It extends an existing autism ontology to allow automatic inference of ASD phenotypes and Diagnostic and Statistical Manual of Mental Disorders (DSM) criteria based on subjects’ Autism Diagnostic Interview–Revised (ADI-R) assessment data.
+Website: https://bioportal.bioontology.org/ontologies/ADAR
+Open: Yes
Description: Encapsulates the ASD behavioral phenotype, informed by the standard ASD assessment instruments and the currently known characteristics of this disorder.
+Disease area: Autism
+Use Cases: Intended for use in research settings where extensive phenotypic data have been collected, allowing a concept-based approach to identifying behavioral features of importance and for correlating these with genotypic data.
+Website: https://bioportal.bioontology.org/ontologies/ASDPTO
+Open: Yes
Description: Describes the most common zoonotic disease, brucellosis, which is caused by Brucella, a type of facultative intracellular bacteria.
+Disease area: brucellosis bacteria
+Use Cases: An extension ontology of the core Infectious Disease Ontology (IDO-core). This project appears to be inactive.
+Website: https://github.com/biomedontology/idobru
+Open: Yes
Description: An ontology to describe entities related to cardiovascular diseases.
+Disease area: Cardiovascular
+Use Cases: Describes entities related to cardiovascular diseases including the diseases themselves, the underlying disorders, and the related pathological processes. Imports upper level terms from OGMS and imports some terms from Disease Ontology (DO).
+GitHub repo: https://github.com/OpenLHS/CVDO/
+Website: https://github.com/OpenLHS/CVDO
+OBO Foundry webpage: http://obofoundry.org/ontology/cvdo.html
+Open: Yes
Description: An ontology of chronic kidney disease in primary care.
+Disease area: Chronic kidney disease
+Use Cases: CKDDO was developed to assist routine data studies and case identification of CKD in primary care.
+Website: http://purl.bioontology.org/ontology/CKDO
+Open: Yes
Description: Aims to ontologically represent and standardize various aspects of coronavirus infectious diseases, including their etiology, transmission, epidemiology, pathogenesis, diagnosis, prevention, and treatment.
+Disease area: Coronavirus infectious diseases, including COVID-19, SARS, MERS; covers etiology, transmission, epidemiology, pathogenesis, diagnosis, prevention, and treatment.
+Use Cases: Used for disease annotations related to coronavirus infections.
+GitHub repo: https://github.com/cido-ontology/cido
+OBO Foundry webpage: http://obofoundry.org/ontology/cido.html
+Open: Yes
+
Diagnostic and Statistical Manual of Mental Disorders (DSM)¶
+
Description: Authoritative source to define and classify mental disorders to improve diagnoses, treatment, and research.
+Disease area: Mental disorders
+Use Cases: Used in clinical healthcare and research by pyschiatrists and psychologists.
+Website: https://www.psychiatry.org/psychiatrists/practice/dsm
+Open: No, must be purchased
Description: A schema for information brokering and knowledge management in the complex field of rare diseases. DCO describes patients affected by rare diseases and records expertise about diseases in machine-readable form.
+Disease area: Rare disease
+Use Cases: DCO was initially created with amyotrophic lateral sclerosis as a use case.
+Website: http://purl.bioontology.org/ontology/DCO
+Open: Yes
Description: Provides a systematic description of many experimental variables available in EBI databases, and for projects such as the GWAS catalog.
+Disease area: Broad disease coverage, integrates the Mondo disease ontology.
+Use Cases: Application ontology build for European Bioinformatics (EBI) tools and databases and Open Targets Genetics Portal.
+Website: https://www.ebi.ac.uk/efo/
+Open: Yes
Description: An in-progress, four-tiered ontology proposed to standardize the diagnostic classification of patients with fibrotic interstitial lung disease.
+Disease area: Fibrotic interstitial lung disease
+Use Cases: Goal is to standardize the diagnostic classification of patients with fibrotic ILD. A paper was published in 2017 and an ontology is not publicly available.
+Publication: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5803648/
+Open: No
+
Genetic and Rare Diseases Information Center (GARD)¶
+
Description: NIH resource that provides the public with access to current, reliable, and easy-to-understand information about rare or genetic diseases in English or Spanish.
+Disease area: Rare diseases
+Use Cases: Patient portal. Integrates defintions and synonyms from Orphanet, maps to HPO phenotypes, and is integrated by Mondo.
+Website: https://rarediseases.info.nih.gov/
+Open: Yes
Description: Describes the biopsychosocial state (i.e., disease, psychological, social, and environmental state) of persons with rare diseases in a holistic way.
+Disease area: Rare disease
+Use Cases:Rehabilita, Disruptive Technologies for the Rehabilitation of the Future, a project that aims to enhance rehabilitation transforming it to a more personalized, ubiquitous and evidence-based rehabilitation.
+Website: http://purl.bioontology.org/ontology/HORD
+Open: Yes
Description: The most comprehensive dermatological disease ontology available, with over 3,500 classes available. There are 20 upper-level disease entities, with features such as anatomical location, heritability, and affected cell or tissue type.
+Disease area: Dermatology (skin)
+Use Cases: DermO can be used to extract data from patient electronic health records using text mining, or to translate existing variable-granularity coding such as ICD-10 to allow capture and standardization of patient/disease annotations.
+Website: https://bioportal.bioontology.org/ontologies/DERMO
+Open: Yes
Description: An ontology for describing the classification of human diseases organized by etiology.
+Disease area: Human disease terms, phenotype characteristics and related medical vocabulary disease concepts.
+Use Cases: Used by Model Organism Databases (MOD), such as Mouse Genome Informatics disease model for diseae annotations, and Alliance for Genome Resources for disease annotations. In 2018, DO tracked over 300 DO project citations suggesting wide adoption and usage for disease annotations.
+GitHub repo: https://github.com/DiseaseOntology/HumanDiseaseOntology/
+Website: http://www.disease-ontology.org/
+OBO Foundry webpage: http://obofoundry.org/ontology/doid.html
+Open: Yes
Description: A set of interoperable ontologies that will together provide coverage of the infectious disease domain. IDO core is the upper-level ontology that hosts terms of general relevance across the domain, while extension ontologies host terms to specific to a particular part of the domain.
+Disease area: Infectious disease features, such as acute, primary, secondary infection, and chronic, hospital acquired and local infection.
+Use Cases: Does not seem active, has not been released since 2017.
+GitHub repo: https://github.com/infectious-disease-ontology/infectious-disease-ontology/
+Website: http://www.bioontology.org/wiki/index.php/Infectious_Disease_Ontology
+OBO Foundry webpage: http://obofoundry.org/ontology/ido.html
+Open: Yes
+
International Classification of Functioning, Disability and Health (ICF)¶
+
Description: Represents diseases and provides a conceptual basis for the definition and measurement of health and disability as organized by patient-oriented outcomes of function and disability. ICF considers environmental factors as well as the relevance of associated health conditions in recognizing major models of disability.
+Disease area: Cross-discipline, focuses on health and disability
+Use Cases: ICF is the World Health Organization (WHO) framework for measuring health and disability at both individual and population levels. ICF was officially endorsed by the WHO as the international standard to describe and measure health and disability.
+Website: https://www.who.int/standards/classifications/international-classification-of-functioning-disability-and-health
+Open: Yes
+
International Statistical Classification of Diseases and Related Health Problems (ICD-11)¶
+
Description: A medical classification list by the World Health Organization (WHO) that contains codes for diseases, signs and symptoms, abnormal findings, complaints, social circumstances, and external causes of injury or diseases.
+Disease area: Broad coverage of human disease features, such as disease of anatomical systems, infectious diseases, injuries, external causes of morbidity and mortality.
+Use Cases: The main purpose of ICD-11 is for clinical care, billing and coding for insurance companies.
+Website: https://www.who.int/standards/classifications/classification-of-diseases
+Open: Yes
+
International Classification of Diseases for Oncology (ICD-O)¶
+
Description: A domain-specific extension of the International Statistical Classification of Diseases and Related Health Problems for tumor diseases.
+Disease area: A multi-axial classification of the site, morphology, behaviour, and grading of neoplasms.
+Use Cases: Used principally in tumour or cancer registries for coding the site (topography) and the histology (morphology) of neoplasms, usually obtained from a pathology report.
+Website: https://www.who.int/standards/classifications/other-classifications/international-classification-of-diseases-for-oncology
+Open: Yes
+
Logical Observation Identifier Names and Codes (LOINC)¶
+
Description: Identifies medical laboratory observations.
+Disease area: Broad coverage
+Use Cases: The Regenstrief Institute first developed LOINC in 1994 in response to the demand for an electronic database for clinical care and management. LOINC is publicly available at no cost and is endorsed by the American Clinical Laboratory Association and the College of American Pathologists. Since its inception, LOINC has expanded to include not just medical laboratory code names but also nursing diagnoses, nursing interventions, outcome classifications, and patient care data sets.
+Website: https://loinc.org/
+Open: Yes, registration is required.
Description: Medical Subject Headings (MeSH) thesaurus is a controlled and hierarchically-organized vocabulary produced by the National Library of Medicine.
+Disease area: Broad coverage
+Use Cases: It is used for indexing, cataloging, and searching of biomedical and health-related information. Integrated into Mondo.
+Website: https://meshb.nlm.nih.gov/search
+Open: Yes
Description: Organizes information related to human medical genetics, such as attributes of conditions and phenotypes of genetic contributions.
+Disease area: Human medical genetics
+Use Cases: MedGen is NCBI's portal to information about conditions and phenotypes related to Medical Genetics. Terms from the NIH Genetic Testing Registry (GTR), UMLS, HPO, Orphanet, ClinVar and other sources are aggregated into concepts, each of which is assigned a unique identifier and a preferred name and symbol. The core content of the record may include names, identifiers used by other databases, mode of inheritance, clinical features, and map location of the loci affecting the disorder. The concept identifier (CUI) is used to aggregate information about that concept, similar to the way NCBI Gene serves as a gateway to gene-related information.
+Website: https://www.ncbi.nlm.nih.gov/medgen/
+Open: Yes
+
Medical Dictionary for Regulatory Activities (MedDRA)¶
+
Description: Provides a standardized international medical terminology to be used for regulatory communication and evaluation of data about medicinal products for human use.
+Disease area: Broad coverage
+Use Cases: Mainly targeted towards industry and regulatory users.
+Website: https://www.meddra.org/
+Open: Yes
Description: An ontology to describe and classify mental diseases such as schizophrenia, annotated with DSM-IV and ICD codes where applicable.
+Disease area: Mental functioning, including mental processes such as cognition and traits such as intelligence.
+Use Cases: The ontology has been partially aligned with the related projects Cognitive Atlas, knowledge base on cognitive science and the Cognitive Paradigm Ontology, which is used in the Brainmap, a database of neuroimaging experiments.
+GitHub repo: https://github.com/jannahastings/mental-functioning-ontology
+OBO Foundry webpage: http://obofoundry.org/ontology/mfomd.html
+Open: yes
Description: An integrated disease ontology that provides precise mappings between source ontologies that comprehensively covers cross-species diseases, from common to rare diseases.
+Disease area: Cross species, intended to cover all areas of diseases, integrating source ontologies that cover Mendelian diseases (OMIM), rare diseases (Orphanet), neoplasms (NCIt), human diseases (DO), and others. See all sources here.
+Use Cases: Mondo was developed for usage in the Monarch Initiative, a discovery system that allows navigation of similarities between phenotypes, organisms, and human diseases across many data sources and organisms. Mondo is also used by ClinGen for disease curations, the Kids First Data Resource Portal for disease annotations and others, see an extensive list here.
+GitHub repo: https://github.com/monarch-initiative/mondo
+Website: https://mondo.monarchinitiative.org/
+OBO Foundry webpage: http://obofoundry.org/ontology/mondo.html
+Open: yes
Description: NCI Thesaurus (NCIt)is a reference terminology that includes broad coverage of the cancer domain, including cancer related diseases, findings and abnormalities. The NCIt OBO Edition aims to increase integration of the NCIt with OBO Library ontologies. NCIt OBO Edition releases should be considered experimental.
+Disease area: Cancer and neoplasms
+Use Cases: NCI Thesaurus (NCIt) provides reference terminology for many National Cancer Institute and other systems. It is used by the Clinical Data Interchange Standards Consortium Terminology (CDISC), the U.S. Food and Drug Administration (FDA), the Federal Medication Terminologies (FMT), and the National Council for Prescription Drug Programs (NCPDP). It provides extensive coverage of neoplasms and cancers.
+GitHub repo: https://github.com/NCI-Thesaurus/thesaurus-obo-edition/issues
+Website: https://ncithesaurus.nci.nih.gov/ncitbrowser/pages/home.jsf?version=20.11e
+OBO Foundry webpage: http://obofoundry.org/ontology/ncit.html
+Open: Yes
Description: A framework for the representation of key aspects of neurological disease.
+Disease area: Neurology
+Use Cases: Goal is to provide a framework to enable representation of aspects of neurological diseases that are relevant to their treatment and study. This project may be inactive, the last commit to GitHub was in 2016.
+GitHub repo: https://github.com/addiehl/neurological-disease-ontology
+Open: Yes
Description: a comprehensive, authoritative compendium of human genes and genetic phenotypes that is freely available and updated daily.
+Disease area: Mendelian, genetic diseases.
+Use Cases: Integrated into the disease ontology, used by the Human Phenotype Ontology for disease annotations, patients and researchers.
+Website: https://omim.org/
+Open: yes
+
Ontology of Cardiovascular Drug Adverse Events (OCVDAE)¶
+
Description: A biomedical ontology of cardiovascular drug–associated adverse events.
+Disease area: Cardiovascular
+Use Cases: One novel study of the OCVDAE project is the development of the PCR method. Specifically, an AE-specific drug class effect is defined to exist when all the drugs (drug chemical ingredients or drug products) in a drug class are associated with an AE, which is formulated as a proportional class level ratio (“PCR”) = 1. See more information in the paper: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5653862/. This project may be inactive, the last GitHub commit was in 2019.
+GitHub repo: https://github.com/OCVDAE/OCVDAE
+Website: https://bioportal.bioontology.org/ontologies/OCVDAE
+Open: yes
Description: An ontology of entities involved in a clinical encounter.
+Use Cases: Provides a formal theory of disease that can be further elaborated by specific disease ontologies. It is intended to be used as a upper level ontology for other disease ontologies. Used by Cardiovascular Disease Ontology.
+GitHub repo: https://github.com/OGMS/ogms
+OBO Foundry webpage: http://obofoundry.org/ontology/ogms.html
+Open: Yes
+
Ontology for Genetic Susceptibility Factor (OGSF)¶
+
Description: An application ontology to represent genetic susceptibility to a specific disease, adverse event, or a pathological process.
+Use Cases: Modeling genetic susceptibility to vaccine adverse events.
+GitHub repo: https://github.com/linikujp/OGSF
+OBO Foundry webpage: http://obofoundry.org/ontology/ogsf.html
+Open: Yes
Description: Represents glucose metabolism disorder and diabetes disease names, phenotypes, and their classifications.
+Disease area: Metabolic disorders
+Use Cases: Still under development (last verssion released in BioPortal was in 2021) but there is little information about its usage online.
+Website: https://bioportal.bioontology.org/ontologies/OGMD
+Open: Yes
Description: An ontology assembled from a set of language terms mined from the autism literature.
+Disease area: Austism
+Use Cases: This has not been released since 2008 and looks like it is inactive.
+Website: https://bioportal.bioontology.org/ontologies/LDA
+Open: Yes
Description: Represents the content of dental practice health records and is intended to be further developed for use in translational medicine. OHD is structured using BFO (Basic Formal Ontology) and uses terms from many ontologies, NCBITaxon, and a subset of terms from the CDT (Current Dental Terminology).
+Disease area: Oral health and disease
+Use Cases: Used to represent the content of dental practice health records and is intended to be further developed for use in translation medicine. Appears to be inactive.
+OBO Foundry webpage: http://www.obofoundry.org/ontology/ohd.html
+Open: Yes
Description: The portal for rare diseases and orphan drugs. Contains a structured vocabulary for rare diseases capturing relationships between diseases, genes, and other relevant features, jointly developed by Orphanet and the EBI. It contains information on nearly 10,000 cancers and related diseases, 8,000 single agents and combination therapies, and a wide range of other topics related to cancer and biomedical research.
+Disease area: Rare diseases
+Use Cases: Used by rare disease research and clinical community. Integrated into the Mondo disease ontology, aligned with OMIM.
+Website: https://www.orpha.net/consor/cgi-bin/index.php
+Open: Yes
Description: A comprehensive semantic framework with a subclass-based taxonomic hierarchy, covering the whole breadth of the Parkinson disease knowledge domain from major biomedical concepts to different views on disease features held by molecular biologists, clinicians, and drug developers.
+Disease area: Parkinson disease
+Use Cases: This resource has been created for use in the IMI-funded AETIONOMY project. Last release was in 2015, may be inactive.
+Website: https://bioportal.bioontology.org/ontologies/PDON
+Open: Yes
Description: Provides information on infectious diseases, disease synonyms, transmission pathways, disease agents, affected populations, and disease properties. Diseases are grouped into syndromic disease categories, organisms are structured hierarchically, and both disease transmission and relevant disease properties are searchable.
+Disease area: human infectious diseases caused by microbes and the diseases that is related to microbial infection.
+Use Cases: Has not been released since 2016 and may be inactive.
+Website: https://bioportal.bioontology.org/ontologies/PDO
+Open: Yes.
Description: Comprises genes, single nucleotide polymorphisms, diseases, gene ontology terms, and biochemical pathways associated with polycystic ovary syndrome, a major cause of female subfertility worldwide.
+Disease area: polycystic ovary syndrome
+Use Cases: Ontology underlying the Polycystic Ovary Syndrome Knowledgebase, a manually curated knowledgebase on PCOS.
+Website: http://pcoskb.bicnirrh.res.in/go_d.php
+Open: Yes
Description: Provides the foundation for ten comprehensive disease area–related data sets at the Rat Genome Database Disease Portals.
+Disease area: Broad coverage including animal diseases, infectious diseases, chemically-induced disorders, occupational diseases, wounds and injuries and more.
+Use Cases: Developed for use with the Rat Genome Database Disease Portals.
+Website: https://rgd.mcw.edu/rgdweb/ontology/view.html?acc_id=DOID:4
+Open: Yes
Description: Represents knowledge of a patient’s oral conditions and denture component parts, originally developed to create a clinician decision support model.
+Disease area: Oral health and dentures
+Use Cases: A paper was published on this in 2016 but it does not appear any other information is available about this ontology on the website, presumably it is an inactive project.
+Publication: https://www.nature.com/articles/srep27855
+Open: No
+
Resource of Asian Primary Immunodeficiency Diseases (RPO)¶
+
Description: Represents observed phenotypic terms, sequence variations, and messenger RNA and protein expression levels of all genes involved in primary immunodeficiency diseases.
+Disease area: Primary immunodeficiency diseases
+Use Cases: This terminology is used in a freely accessible, dynamic and integrated database for primary immunodeficiency diseases (PID) called Resource of Asian Primary Immunodeficiency Diseases (RAPID), which is available here.
+Publication: https://academic.oup.com/nar/article/37/suppl_1/D863/1004993
+Open: Yes
Description: SCDO establishes (a) community-standardized sickle cell disease terms and descriptions, (b) canonical and hierarchical representation of knowledge on sickle cell disease, and (c) links to other ontologies and bodies of work.
+Disease area: Sickle Cell Disease (SCD).
+Use Cases: SCDO is intended to be a comprehensive collection of knowledge on SCD, facilitate exploration of new scientific questions and ideas, facilitate seamless data sharing and collaborations including meta-analysis within the SCD community, support the building of databasing and clinical informatics in SCD.
+GitHub repo: https://github.com/scdodev/scdo-ontology/issues
+Website: https://scdontology.h3abionet.org/
+OBO Foundry webpage: http://obofoundry.org/ontology/scdo.html
+Open: Yes
Description: A comprehensive clinical terminology/ontology used in healthcare settings.
+Disease area: Broad disease representation for human diseases.
+Use Cases: Main coding system used in Electronic Health Records (EHRs).
+Website: https://browser.ihtsdotools.org/?
+Open: No, requires a license for usage.
Description: An ontology of disease symptoms, with symptoms encompasing perceived changes in function, sensations or appearance reported by a patient indicative of a disease.
+Disease area: Human diseases
+Use Cases: Developed by the Disease Ontology (DO) team and used for describing symptoms of human diseases in the DO.
+Website: http://symptomontologywiki.igs.umaryland.edu/mediawiki/index.php/Main_Page
+OBO Foundry webpage: http://obofoundry.org/ontology/symp.html
+Open: Yes
Description: The UMLS integrates and distributes key terminology, classification and coding standards, and associated resources to promote creation of more effective and interoperable biomedical information systems and services.
+Disease area: Broad coverage
+Use Cases: Healthcare settings including electronic health records and HL7.
+Website: https://www.nlm.nih.gov/research/umls/index.html
+Open: Yes
Description: FYPO is a formal ontology of phenotypes observed in fission yeast.
+Species: S. pombe
+GitHub repo: https://github.com/pombase/fypo
+OBO Foundry webpage: http://obofoundry.org/ontology/fypo.html
+Open: Yes
Description: HPO provides a standardized vocabulary of phenotypic abnormalities encountered in human disease. Each term in the HPO describes a phenotypic abnormality.
+Species: Human
+GitHub repo: https://github.com/obophenotype/human-phenotype-ontology
+Website: https://hpo.jax.org/app/
+OBO Foundry webpage: http://obofoundry.org/ontology/hp.html
+Open: yes
Description: Orphanet provides phenotypic annotations of the rare diseases in the Orphanet nomenclature using the Human Phenotype Ontology (HPO). HOOM is a module that qualifies the annotation between a clinical entity and phenotypic abnormalities according to a frequency and by integrating the notion of diagnostic criterion. In ORDO a clinical entity is either a group of rare disorders, a rare disorder or a subtype of disorder. The phenomes branch of ORDO has been refactored as a logical import of HPO, and the HPO-ORDO phenotype disease-annotations have been provided in a series of triples in OBAN format in which associations, frequency and provenance are modeled. HOOM is provided as an OWL (Ontologies Web Languages) file, using OBAN, the Orphanet Rare Disease Ontology (ORDO), and HPO ontological models. HOOM provides extra possibilities for researchers, pharmaceutical companies and others wishing to co-analyse rare and common disease phenotype associations, or re-use the integrated ontologies in genomic variants repositories or match-making tools.
+Species: Human
+Website: http://www.orphadata.org/cgi-bin/img/PDF/WhatIsHOOM.pdf
+BioPortal: https://bioportal.bioontology.org/ontologies/HOOM
+Open: yes
Description: An ontology for describing the phenology of individual plants and populations of plants, and for integrating plant phenological data across sources and scales.
+Species: Plants
+GitHub repo: https://github.com/PlantPhenoOntology/PPO
+OBO Foundry webpage: http://obofoundry.org/ontology/ppo.html
+Open: Yes
Description: XPO represents anatomical, cellular, and gene function phenotypes occurring throughout the development of the African frogs Xenopus laevis and tropicalis.
+Species: Xenopus
+GitHub repo: https://github.com/obophenotype/xenopus-phenotype-ontology
+OBO Foundry webpage: http://obofoundry.org/ontology/xpo.html
+Open: Yes
Description: The Zebrafish Phenotype Ontology formally defines all phenotypes of the Zebrafish model organism.
+Species: Zebrafish
+GitHub repo: https://github.com/obophenotype/zebrafish-phenotype-ontology
+OBO Foundry webpage: http://obofoundry.org/ontology/zp.html
+Open: Yes
A Census of Disease Ontologies Melissa A. Haendel, Julie A. McMurry, Rose Relevo, Christopher J. Mungall, Peter N. Robinson, Christopher G. Chute
+ Annual Review of Biomedical Data Science 2018 1:1, 305-331
An index page to find some of our favourite articles on Chris' blog.
+These are not all articles, but I selection we found useful during our every work.
Some resources on OBOOK are less well developed than others. We use the OBOOK Maturity Indicator to document this (discussion).
+
+
: This page is under development and not yet suitable for self-study or teaching.
+
: This page is still under development (may be rough around the edges) but complete and suitable for self-study or teaching.
+
: This page is developed to an extent it can be considered stable (although nothing is ever really stable) and therefore suitable for self-study or teaching.
+
+
To add a status badge onto a site, simply paste a badge like this right under the title:
A toolbox. All frequently used tools for managing the ontology life cycle are bundled together into a Docker image: ROBOT, owltools, fastobo-validator, dosdp-tools, riot and many, many more.
+
A system, you could have say "methodology" for managing the ontology life cycle from continious integration and quality control to imports and release management.
The ODK bundles a lot of tools together, such as ROBOT, owltools, fastobo-validator and dosdp-tools. To get a better idea, its best to simply read the Dockerfile specifications of the ODK image:
+
+
ODK Lite Image. This contains the most essentials tools related to ODK development. Most of the day to day activities of ontology developers with ROBOT are well covered by odklite.
+
ODK Full Image. Extends the ODK Lite image with a further round of powerful tools. It contains for example Apache Jena, the OBO Dashboard, the Konclude reasoner and a large array of command line tools.
One of the tools in the toolbox, the "seed my repo" function, allows us to generate a complete GitHub repository with everything needed to manage an OBO ontology according to OBO best practices. The two central components are
+
+
A Makefile that encodes the rules by which ontology release files should be derived from the source of truth (the edit file).
+
A support for CI such as GitHub actions or Travis for running continuous integration checks.
If you're new to scientific computing more generally,
+then I strongly recommend Software Carpentry,
+which provides a set of very pragmatic introductions to
+the Unix command line, git, Python, Make,
+and other tools widely used by OBO developers.
OBO is a community of people collaborating on open source ontologies for science.
+We have a set of shared principles and best practises
+to help people and data work together effectively.
RDF: Resource Description Format
+ is a standard for combining IRIs into subject-predicate-object "triples"
+ that make a statement about some thing.
+ Sets of triples form a graph (i.e. network),
+ and graphs can easily be merged to form larger graphs.
+ SPARQL is the language for querying RDF graphs.
Nicole Vasilevsky, James Overton, Rebecca Jackson, Sabrina Toro, Shawn Tan, David Osumi-Sutherland, Nicolas Matentzoglu. "OBO Academy:
+Training materials for Bio-ontologists". Presentation at OntoCommons, Virtual. June 14, 2023.
Nicole Vasilevsky, James Overton, Rebecca Jackson, Sabrina Toro, Shawn Tan, Bradley Varner, David Osumi-Sutherland, Nicolas Matentzoglu. "OBO Academy: Training materials for Bio-ontologists." [Poster presentation] Biocuration 2022, Virtual. October 04, 2022.
+
James Overton, Rebecca Jackson, Sabrina Toro, Shawn Tan, Bradley Varner, David Osumi-Sutherland, Nicolas Matentzoglu, Nicole Vasilevsky. "OBO Academy: Training materials for Bio-ontologists." [Lightning talk and Poster presentation] ICBO, Ann Arbor, MI. September 27, 2022. https://zenodo.org/record/7116623
+
Nicole Vasilevsky, James Overton, Rebecca Jackson, Sabrina Toro, Shawn Tan, Bradley Varner, David Osumi-Sutherland, & Nicolas Matentzoglu. (2022, August 3). "OBO Academy: Training materials for bio-ontologists." Presentation at 2022 ISMB Bio-Ontologies Community, Madison, WI, July 2022
How to escape characters in the class expression editor¶
+
To add an ontology term (such as a GO term) that contains ' in its name (e.g. RNA-directed 5'-3' RNA polymerase activity) in the class expression editor, you need to escape the ' characters. In Protegé 5.5 this is not automatically handled when you auto-complete with tab. To escape the character append \ before the ' -> RNA-directed 5\'-3\' RNA polymerase activity. You won't be able to add the annotation otherwise.
+
As in Protegé 5.5, the \ characters will show up in the description window, and when hovering over the term, you won't be able to click on it with a link. However, when you save the file, the relationship is saved correctly. You can double-check by going to the ontology text file and see that the term is correctly mentioned in the relationship.
A quick personal perspective up-front. When I was finishing my undergrad, I barely had heard the term Semantic Web. What I had heard vaguely intrigued me, so I decided that for my final project, I would try to combine something Semantic Web related with my other major, Law and build a tool that could automatically infer the applicability of a law (written in OWL) given a legal case. Super naively, I just went went ahead, read a few papers about legal ontologies, build a simple one, loaded it into my application and somehow got it to work, with reasoning and all, without even having heard of Description Logic.
+
In my PhD, I worked on actual reasoning algorithms, which meant, no more avoiding logic. But - I did not get it. Up until this point in my life, I could just study harder and harder, and in the end I was confident with what I learned, but First Order Logic, in particular model theory and proofs, caused me anxiety until the date of my viva. In the end, a very basic understanding of model theory and Tableau did help me with charactering the algorithms I was working with (I was studying the effect of modularity, cutting out logically connected subsets of an ontology, on reasoning performance) but I can confidently say today: I never really, like deeply, understood logical proofs. I still cant read them - and I have a PhD in Reasoning (albeit from an empirical angle).
+
If you followed the Open HPI courses on logic, and you are anything like me, your head will hurt and you will want to hide under your blankets. Most students feel like that. For a complete education in Semantic Web technologies, going through this part once is essential: it tells you something about how difficult some stuff is under the hood, and how much work has been done to make something like OWL work for knowledge representation. You should have gained some appreciation of the domain, which is no less complex than Machine Learning or Stochastic Processes. But, in my experience, some of the most effective ontology engineers barely understand reasoning - definitely have no idea how it works - and still do amazing work. In that spirit, I would like to invite you at this stage to put logic and reasoning behind you (unless it made you curious of course) - you won't need to know much of that for being an effective Semantic Engineer. In the following, I will summarise some of the key take-aways that I find useful to keep in mind.
+
+
Semantics define how to interpret an ontology. For example, in OWL, the statement Human SubClassOf: Mammal means that all instances of the Human class, like me, are also instances of the Mammal class. Or, in other words, from the statements:
+
+
Human SubClassOf: Mammal
+Nico type: Human
+
+
Semantics allow as to deduce that Nico:Mammal. What are semantics practically? Show me your semantics? Look at something like the OWL semantics. In there, you will find language statements (syntax) like X SubClassOf: Y and a bunch of formulae from model theory that describe how to interpret it - no easy read, and not really important for you now.
+
+
OWL has a number of profiles, basically sub-languages where you can say less things. Why would we want to restrict our "expressivity"? Because their is a trade-off. An important slide I remember from when I learned about ontology languages was the triangle of complexity (here only paraphrased from memory):
+
+
+
+
When expressivity goes up, cognitive complexity and computational complexity go up.
+
When we want to decrease cognitive complexity (make it easier to build ontologies), expressivity goes down.
+
+
When we want reasoners to be faster at making inferences (computational complexity), we need to decrease expressivity.
+ So we need to find a way to balance.
+
+
+
What are the most important practical applications of reasoning? There are many, and there will be many opinions, but in the OBO world, by far (95%) of all uses of reasoners pertain to the following:
+
+
Classification. Most, if not all, of our ontologies are conceptually hierarchies of classes we use reasoners to automatically infer hierarchies. Look for example at the Xenopus Phenotype Ontology - the class hierarchy is entirely build with a reasoner - no Human intervention!
+
Debugging. There are two major threats to ontologies. In the worst case, they can be inconsistent - which means, totally broken. A slightly less bad, but still undesirable situation is that some of the classes in your ontologies break (in parlance, become unsatisfiable). This happens when you say some contradictory things about them. Reasoners help you find these unsatisfiable classes, and there is a special reasoning algorithm that can generate an explanation for you - to help fixing your problem.
+
+
So in general, what is reasoning? There are probably a dozen or more official characterisations in the scientific literature, but from the perspective of biomedical ontologies, the question can be roughly split like this:
+
+
+
How can we capture what we know? This is the (research-) area of knowledge representation, logical formalisms, such as First Order Logic, Description Logic, etc. It is concerned with how we write down what we now:
+
+
+
All cars have four wheels
+If you are a human, you are also a mammal
+If you are a bird, you can fly (unless you are a penguin)
+
+
+
How can we uncover implicit knowledge efficiently? This is the area of reasoning, and while being closely related to the formalisms above, it makes sense to think of them in a distinct manner, as the problems are very different in practice. It can typically be grouped into the following two categories:
+
deductive reasoning infers by
+
+
Lets think about a naive approach: using a fact-, or data-, base.
We made a first stab add defining release artefacts that should cover all use cases community-wide. We need to (1) agree they are all that is needed and (2) they are defined correctly in terms of ROBOT commands. This functionality replaces what was previously done using OORT.
The source ontology is the ontology we are talking about. A release artefact is a version of the ontology modified in some specific way, intended for public use. An import is a module of an external ontology which contains all the axioms necessary for the source ontology. A component is a file containing axioms that belong to the source ontology (but are for one reason or another, like definitions.owl, managed in a separate file). An axiom is said to be foreign if it 'belongs' to a different ontology, and native if it belongs to the source ontology. For example, the source ontology might have, for one reason or another, been physically asserted (rather than imported) the axiom TransitiveObjectProperty(BFO:000005). If the source ontology does not 'own' the BFO namespace, this axiom will be considered foreign.
The base file contains all and only native axioms. No further manipulation is performed, in particular no reasoning, redundancy stripping or relaxation. This release artefact is going to be the new backbone of the OBO strategy to combat incompatible imports and consequent lack of interoperability. (Detailed discussions elsewhere, @balhoff has documentation). Every OBO ontology will contain a mandatory base release (should be in the official OBO recommendations as well).
+
The ROBOT command generating the base artefact:
+$(SRC): source ontology
+$(OTHER_SRC): set of component ontologies
The full release artefact contains all logical axioms, including inferred subsumptions. Redundancy stripping (i.e. redundant subclass of axioms) and typical relaxation operations are performed. All imports and components are merged into the full release artefact to ensure easy version management. The full release represents most closely the actual ontology as it was intended at the time of release, including all its logical implications. Every OBO ontology will contain a mandatory full release.
+
The ROBOT command generating the full artefact:
+$(SRC): source ontology
+$(OTHER_SRC): set of component ontologies
The non-classified release artefact reflects the 'unmodified state' of the editors file at release time. No operations are performed that modify the axioms in any way, in particular no redundancy stripping. As opposed to the base artefact, both component and imported ontologies are merged into the non-classified release.
+
The ROBOT command generating the full artefact:
+$(SRC): source ontology
+$(OTHER_SRC): set of component ontologies
Many users want a release that can be treated as a simple existential graph of the terms defined in an ontology. This corresponds to the state of OBO ontologies before logical definitions and imports. For example, the only logical axioms in -simple release of CL will contain be of the form CL1 subClassOf CL2 or CL1 subClassOf R some CL3 where R is any objectProperty and CLn is a CL class. This role has be fulfilled by the -simple artefact, which up to now has been supported by OORT.
+
To construct this, we first need to assert inferred classifications, relax equivalentClass axioms to sets of subClassOf axioms and then strip all axioms referencing foreign (imported) classes. As ontologies occasionally end up with forieign classes and axioms merged into the editors file, we achieve this will a filter based on obo-namespace. (e.g. finding all terms with iri matching http://purl.obolibrary.org/obo/CL_{\d}7).
+
The ROBOT command generating the full artefact:
+$(SRC): source ontology
+$(OTHER_SRC): set of component ontologies
+$(SIMPLESEED): all terms that 'belong' to the ontology
NOTES: This requires $(ONTOLOGYTERMS) to include all ObjectProperties usesd. --select parents is required for logical axioms to be retained, but results in a few upper-level classes bleeding through. We hope this will be fixed by further improvments to Monarch.
Some legacy users (e.g. MGI) require an OBO DAG version of -simple. OBO files derived from OWL are not guarenteed to be acyclic, but acyclic graphs can be achieved using judicious filtering of relationships (simple existential restrictions) by objectProperty. The -basic release artefact has historically fulfilled this function as part of OORT driven ontology releases. The default -basic version corresponds to the -simple artefact with only 'part of' relationships (BFO:0000050), but others may be added where ontology editors judge these to be useful and safe to add without adding cycles. We generate by taking the simple release and filtering it
+
The ROBOT command generating the full artefact:
+$(SRC): source ontology
+$(OTHER_SRC): set of component ontologies
+$(KEEPRELATIONS): all relations that should be preserved.
+$(SIMPLESEED): all terms that 'belong' to the ontology
This artefact caters to the very special and hopefully transient case of some ontologies that do not yet trust reasoning (MP, HP). The simple-non-classified artefact corresponds to the simple artefact, just without the reasoning step.
+
$(SRC): source ontology
+$(OTHER_SRC): set of component ontologies
+$(ONTOLOGYTERMS): all terms that 'belong' to the ontology
Where to find ontologies and terms: Term browsers and ontology repositories
+
+
OLS: The boss of the current term browsers out there. While the code base is a bit dated, it still gives access to a wide range of relevant open biomedical ontology terms. Note, while being a bit painful, it is possible to set up your own OLS (for your organisation) which only contains those terms/ontologies that are relevant for your work.
+
Ontobee: The default term browser for OBO term purls. For example, click on http://purl.obolibrary.org/obo/OBI_0000070. This will redirect you directly to Ontobee, to show you the terms location in the hierarchy. In practice, there is no particular reason why you would favour Ontobee over OLS for example - I just sometimes prefer the way Ontobee presents annotations and "uses" by other ontologies, so I use both.
+
AberOWL: Another ontology repository and semantic search engine. Some ontologies such as PhenomeNet can only be found on AberOWL, however, I personally prefer OLS.
+
identifiers.org: A centralised registry for identifiers used in the life sciences. This is one of the tools that bridge the gap between CURIEs and URLs, but it does not cover (OBO) ontologies very well, and if so, is not aware of the proper URI prefixes (see for example here, and HP term resolution that does not list the proper persistent URL of the HP identifier (http://purl.obolibrary.org/obo/HP_0000001)). Identifiers.org has mainly good coverage for databases/resources that use CURIE type identifiers. But: you can enter any ID you find in your data and it will tell you what it is associated with.
+
OBO Foundry Ontology Library. The OBO Foundry works with other repositories and term browsers such as OLS, Ontobee and BioPortal. For example, OLS directly reads the OBO Foundry registry metadata, and automatically loads new ontologies added to the OBO Foundry Ontology Library.
CPT Story. The Current Procedural Terminology was the by far most highly accessed Terminology on Bioportal - for many years. Due to license concerns, it had to be withdrawn from the repository. This story serves a cautionary tale of using terminologies with non-open or non-transparent licensing schemes.
+
AgroPortal: Like BioPortal, but focussed on the Agronomy domain.
These are a bit less essential than the above, but I consider them still tremendously useful.
+
+
Cogs (experimental) for automatically synchronising your spreadsheets with Google Sheets.
+
Basic Dockerfile development: This can help you automate processes that go beyond usual ODK day-to-day business, such as automated mapping tools, graph machine learning, NLP etc.
+
GitHub community management and git version control: Learn how to effectively manage your contributors, issue requests and code reviews. Also get your git commands straight - these can be life savers!
+
Basics in python scripting: This is always useful, and python is our go-to language for most of automation nowadays - this used to be Java. Most of the Java heavy lifting is done in ROBOT now!
+
SSSOM and sssom-py: Toolkit and framework for managing mappings between ontologies.
+
DROID: DROID is a web-based interface for working with make, managed by git.
+
OBO Dashboard: OBO-wide quality control monitor for OBO ontologies.
Semantic Data Engineering or Semantic Extract-Transform-Load (ETL) is an engineering discipline that is concerned with extracting information from a variety of sources, linking it together into a knowledge graph and enabling a range of semantic analyses for downstream users such as data scientists or researchers.
+
+
Getting Data
+
Information Extraction from text
+
Obtaining data from external sources
+
In-house biocuration
+
Integrating data
+
Entity Resolution: Make sure that if your sources talk about the same things, they use the same ontologies to reference those things.
+
Knowledge merging: Combine the resolved sources into a coherent whole, for example a knowledge graph.
+
Analysis: Query the integrated data and run advanced analyses using Semantic Technologies (next week).
The following glossary only says how we use the terms we are defining, not how they are defined by some higher authority.
+
+
+
+
Term
+
Definition
+
Example
+
+
+
+
+
Entity
+
An entity is a thing in the world, like a molecule, or something more complex, like a disease. Entities do not have to be material, they can be processes as well, like cell proliferation.
+
Marfan syndrome, H2O molecule, Ring finger, Phone
+
+
+
Term
+
A term is a sequence of characters (string) that refers to an entity in a precise way.
+
SMOKER (referring to the role of being a smoker), HP:0004934 (see explanations below)
+
+
+
Relation
+
A link between two (or more) entities that signifies some kind of interaction.
As a Semantic Engineer, you typically coordinate the data collection from three largely separate sources:
+1. Unstructured text, for example a corpus of scientific literature
+2. External biological databases, such as STRING, a database of Protein-Protein Interaction Networks.
+3. Manual in-house bio-curation efforts, i.e. the manual translation and integration of information relevant to biology (or medicine) into a database.
+
Here, we are mostly concerned with the automated approaches of Semantic ETL, so we briefly touch on these and provide pointers to the others.
The task of information extraction is concerned with extracting information from unstructured textual sources to enable identifying entities, like diseases, phenotypes and chemicals, as well as classifying them and storing them in a structured format.
+
The discipline that is concerned with techniques for extracting information from text is called Natural Language Processing (NLP).
+
NLP is a super exciting and vast engineering discipline which goes beyond the scope of this course. NLP is concerned with many problems such as document classification, speech recognition and language translation. In the context of information extraction, we are particularly interested in Named Entity Recognition (NER), and Relationship Extraction (ER).
Named Entity Recognition (NER) is the task of identifying and categorising entities in text. NER tooling provides functionality to first isolate parts of sentence that correspond to things in the world, and then assigning them to categories (e.g. Drug, Disease, Publication).
+
For example, consider this sentence:
+
As in the X-linked Nettleship-Falls form of ocular albinism (300500), the patients showed reduced visual acuity, photophobia, nystagmus, translucent irides, strabismus, hypermetropic refractive errors, and albinotic fundus with foveal hypoplasia.
+
+
An NER tool would first identify the relevant sentence parts that belong together:
+
As in the [X-linked] [Nettleship-Falls] form of [ocular albinism] (300500), the patients showed [reduced visual acuity], [photophobia], [nystagmus], [translucent irides], [strabismus], [hypermetropic refractive errors], and [albinotic fundus] with [foveal hypoplasia].
+
+
And then categorise them according to some predefined categories:
+
As in the Phenotype[X-linked] [Nettleship-Falls] form of Disease[ocular albinism] (300500), the patients showed Phenotype[reduced visual acuity], Phenotype[photophobia], Phenotype[nystagmus], Phenotype[translucent irides], Phenotype[strabismus], Phenotype[hypermetropic refractive errors], and Phenotype[albinotic fundus] with Phenotype[foveal hypoplasia].
+
Relationship extraction (RE) is the task of extracting semantic relationships from text.
+RE is an important component for the construction of Knowledge Graphs from the Scientific Literature, a task that many Semantic Data Engineering projects pursue to augment or inform their manual curation processes.
Scientific data sources relevant to work around genes, phenotypes and diseases are plentiful. See here for an overview of the data sources used by the Monarch Initiative. All of the sources listed are part of a Semantic ETL pipeline involving the extraction of the data from data dumps (like published spreadsheets) or Web APIs, the transformation into a common format (including mapping to ontologies) and its subsequent load into the Monarch Knowledge Graph. More comprehensive lists are being produced in the academic literature, for example here.
+
In-house biocuration. Biocuration is the task of manual translation and integration of information relevant to biology (or medicine) into some kind of database form. Biocuration can take many forms:
+
The curation of scientific literature, i.e. extracting structured metadata from scientific papers to increase discoverability of relevant knowledge. The object of the curation is usually a particular publication, which goes through a triage process (Is the paper relevant to my problem? Is it good enough?), an initial metadata extraction phase (titles, authors, etc), and eventually to extracting the scientific knowledge (not unlike what the Named Entity Recongnition and Relation Extraction procedures described above) do.
+
The focussed curation of specific scientific entities, such as diseases. For example, you may be interested in discovering all therapeutic interventions / drugs used for treating a specific disease.
There is a huge amount of literature and tutorials on the topic of integrating data, the practice of consolidating data from disparate sources into a single dataset. We want to emphasise here two aspects of data integration, which are of particular importance to the Semantic Data engineer.
+
+
Entity Resolution: Make sure that if your sources talk about the same things, they use the same ontologies to reference those things.
+
Knowledge merging: Combine the resolved sources into a coherent whole, for example a knowledge graph.
Entity resolution (ER), sometimes called "record linking", is the task of disambiguating records that correspond to real world entities across and within datasets. This task as many dimensions, but for us, the most important one is mapping a string, for example the one that was matched by our Named Entity Recognition pipeline, to ontology terms.
+
Given our example:
+
As in the Phenotype[X-linked] Nettleship-Falls form of Phenotype[ocular albinism] (300500), the patients showed Phenotype[reduced visual acuity], Phenotype[photophobia], Phenotype[nystagmus], Phenotype[translucent irides], Phenotype[strabismus], Phenotype[hypermetropic refractive errors], and Phenotype[albinotic fundus] with Phenotype[foveal hypoplasia].
+
+
We could end up, for example, resolving ocular albinism to HP:0001107.
+
There are a lot of materials about Entity Resolution in general:
+- https://www.districtdatalabs.com/basics-of-entity-resolution
+- https://www.sciencedirect.com/topics/computer-science/entity-resolution
+
In effect the term Ontology Mapping, which is the focus of this lesson, is Entity Resolution for ontologies - usually we don't have problem to use the two terms synonymously, although you may find that the literature typically favours one or the other.
Knowledge, Knowledge Graph or Ontology Merging are the disciplines concerned with combining all your data sources into a semantically coherent whole. This is a very complex research area, in particular to do this in a way that is semantically consistent. There are essentially two separate problems to be solved to achieve semantic merging:
+1. The entities aligned during the entity resolution process must be aligned in the semantically correct way: if you you use logical equivalence to align them (owl:equivalentClasses) the classes must mean absolutely the same thing, or else you may run into the hairball problem, in essence faulty equivalence cliques. In cases of close, narrow or broadly matching classes, the respective specialised semantically correct relationships need to be used in the merging process.
+2. The axioms of the merged ontologies must be logically consistent. For example, one ontology may say: a disease is a material entity. Another: a disease is a process. A background, or upper, ontology such as the ubiquitous Basic Formal Ontology (BFO) furthermore says that a process is not a material entity and vice versa. Merging this two ontologies would cause logical inconsistency.
+
Unfortunately, the literature on ontology and knowledge graph merging is still sparse and very technical. You are probably best off checking out the OpenHPI course on Ontology Alignment, which is closely related.
This document contains template SPARQL queries that can be adapted.
+Comments are added in-code with # above each step to explain them so that queries can be spliced together
note: we assume that all native terms here have the same namespace - that of the ontology
+
# select unique instances of the variable
+SELECTDISTINCT?term
+WHERE{
+ # selecting where the variable term is either used as a subject or object
+ {?s1?p1?term.}
+ UNION
+ {?term?p2?o2.}
+ # filtering out only terms that have the MONDO namespace (assumed to be native terms)
+ FILTER(isIRI(?term)&&(STRSTARTS(str(?term),"http://purl.obolibrary.org/obo/MONDO_")))
+}
+
+
Report of terms with labels containing certain strings in ubergraph¶
+
# adding prefixes used
+prefixowl:<http://www.w3.org/2002/07/owl#>
+prefixrdfs:<http://www.w3.org/2000/01/rdf-schema#>
+prefixBFO:<http://purl.obolibrary.org/obo/BFO_>
+
+# selecting only unique instances of the three variables
+SELECTDISTINCT?entity?labelWHERE
+{
+ # the variable label is a rdfs:label
+ VALUES?property{
+ rdfs:label
+ }
+
+ # only look for uberon terms. note: this is only used in ubergraph, use filter for local ontology instead.
+ ?entityrdfs:isDefinedBy<http://purl.obolibrary.org/obo/uberon.owl>.
+
+ # defining the order of variables in the triple
+ ?entity?property?label.
+ # entity must be material
+ ?entityrdfs:subClassOfBFO:0000040
+ # filtering out triples where the variable label has sulcus or incisure, or fissure in it
+ FILTER(contains(STR(?label),"sulcus")||contains(STR(?label),"incisure")||contains(STR(?label),"fissure"))
+
+}
+# arrange report by entity variable
+ORDER BY?entity
+
+
Report of labels and definitions of terms with certain namespace¶
+
prefixlabel:<http://www.w3.org/2000/01/rdf-schema#label>
+prefixoboInOwl:<http://www.geneontology.org/formats/oboInOwl#>
+prefixdefinition:<http://purl.obolibrary.org/obo/IAO_0000115>
+prefixowl:<http://www.w3.org/2002/07/owl#>
+
+# select a report with 3 variables
+SELECTDISTINCT?term?label?def
+
+# defining the properties to be used
+ WHERE{
+ VALUES?defproperty{
+ definition:
+ }
+ VALUES?labelproperty{
+ label:
+ }
+
+# defining the order of the triples
+ ?term?defproperty?def.
+ ?term?labelproperty?label.
+
+# selects entities that are in a certain namespace
+ FILTER(isIRI(?term)&&(STRSTARTS(str(?term),"http://purl.obolibrary.org/obo/CP_")))
+}
+
+# arrange report by term variable
+ORDER BY?term
+
# adding prefixes used
+prefixoboInOwl:<http://www.geneontology.org/formats/oboInOwl#>
+prefixdefinition:<http://purl.obolibrary.org/obo/IAO_0000115>
+prefixowl:<http://www.w3.org/2002/07/owl#>
+
+SELECT?entity?property?valueWHERE
+{
+ # the variable property has to be defintion (IAO:0000115)
+ VALUES?property{
+ definition:
+ }
+ # defining the order of variables in the triple
+ ?entity?property?value.
+
+ # selecting annotation on definition
+ ?def_annoaowl:Axiom;
+ owl:annotatedSource?entity;
+ owl:annotatedPropertydefinition:;
+ owl:annotatedTarget?value.
+
+ # filters out definitions which do not have a dbxref annotiton
+ FILTERNOT EXISTS{
+ ?def_annooboInOwl:hasDbXref?x.
+ }
+
+ # removes triples where entity is blank
+ FILTER(!isBlank(?entity))
+ # selects entities that are native to ontology (in this case MONDO)
+ FILTER(isIRI(?entity)&&STRSTARTS(str(?entity),"http://purl.obolibrary.org/obo/MONDO_"))
+
+}
+# arrange report by entity variable
+ORDER BY?entity
+
adaptable for checking if there is particular character in annotation
+
# adding prefixes used
+prefixowl:<http://www.w3.org/2002/07/owl#>
+prefixrdfs:<http://www.w3.org/2000/01/rdf-schema#>
+prefixIAO:<http://purl.obolibrary.org/obo/IAO_>
+prefixdefinition:<http://purl.obolibrary.org/obo/IAO_0000115>
+
+# selecting only unique instances of the three variables
+SELECTDISTINCT?entity?property?valueWHERE
+{
+ # the variable property has to be definition (IAO:0000115)
+ VALUES?property{
+ definition:
+ }
+ # defining the order of variables in the triple
+ ?entity?property?value.
+ # filtering out triples where the variable value has _ in it
+ FILTER(regex(STR(?value),"_"))
+ # removes triples where entity is blank
+ FILTER(!isBlank(?entity))
+}
+# arrange report by entity variable
+ORDER BY?entity
+
# adding prefixes used
+prefixowl:<http://www.w3.org/2002/07/owl#>
+prefixrdfs:<http://www.w3.org/2000/01/rdf-schema#>
+prefixrdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
+prefixoboInOwl:<http://www.geneontology.org/formats/oboInOwl#>
+prefixIAO:<http://purl.obolibrary.org/obo/IAO_>
+prefixRO:<http://purl.obolibrary.org/obo/RO_>
+prefixmondo:<http://purl.obolibrary.org/obo/mondo#>
+prefixskos:<http://www.w3.org/2004/02/skos/core#>
+prefixdce:<http://purl.org/dc/elements/1.1/>
+prefixdcterms:<http://purl.org/dc/terms/>
+
+# selecting only unique instances of the three variables
+SELECTDISTINCT?term?property?valueWHERE
+{
+ # order of the variables in the triple
+ ?term?property?value.
+ # the variable property is an annotation property
+ ?propertyaowl:AnnotationProperty.
+ # selects entities that are native to ontology (in this case MONDO)
+ FILTER(isIRI(?term)&®ex(str(?term),"^http://purl.obolibrary.org/obo/MONDO_"))
+ # removes triples where the variable value is blank
+ FILTER(!isBlank(?value))
+ # listing the allowed annotation properties
+ FILTER(?propertyNOT IN(dce:creator,dce:date,IAO:0000115,IAO:0000231,IAO:0100001,mondo:excluded_subClassOf,mondo:excluded_from_qc_check,mondo:excluded_synonym,mondo:pathogenesis,mondo:related,mondo:confidence,dcterms:conformsTo,mondo:should_conform_to,oboInOwl:consider,oboInOwl:created_by,oboInOwl:creation_date,oboInOwl:hasAlternativeId,oboInOwl:hasBroadSynonym,oboInOwl:hasDbXref,oboInOwl:hasExactSynonym,oboInOwl:hasNarrowSynonym,oboInOwl:hasRelatedSynonym,oboInOwl:id,oboInOwl:inSubset,owl:deprecated,rdfs:comment,rdfs:isDefinedBy,rdfs:label,rdfs:seeAlso,RO:0002161,skos:broadMatch,skos:closeMatch,skos:exactMatch,skos:narrowMatch))
+}
+
adaptable for checking that a property is used in a certain way
+
# adding prefixes used
+PREFIXowl:<http://www.w3.org/2002/07/owl#>
+PREFIXoboInOwl:<http://www.geneontology.org/formats/oboInOwl#>
+PREFIXreplacedBy:<http://purl.obolibrary.org/obo/IAO_0100001>
+
+# selecting only unique instances of the three variables
+SELECTDISTINCT?entity?property?valueWHERE{
+ # the variable property is IAO_0100001 (item replaced by)
+ VALUES?property{replacedBy:}
+
+ # order of the variables in the triple
+ ?entity?property?value.
+ # removing entities that have either owl:deprecated true or oboInOwl:ObsoleteClass (these entities are the only ones that should have replaced_by)
+ FILTERNOT EXISTS{?entityowl:deprecatedtrue}
+ FILTER(?entity!=oboInOwl:ObsoleteClass)
+}
+# arrange report by entity variable
+ORDER BY?entity
+
# this query counts the number of classes you have with each prefix (eg number of MONDO terms, CL terms, etc.)
+
+# adding prefixes used
+prefixowl:<http://www.w3.org/2002/07/owl#>
+prefixobo:<http://purl.obolibrary.org/obo/>
+
+# selecting 2 variables, prefix and numberOfClasses, where number of classes is a count of distinct cls
+SELECT?prefix(COUNT(DISTINCT?cls)AS?numberOfClasses)WHERE
+{
+ # the variable cls is a class
+ ?clsaowl:Class.
+ # removes any cases where the variable cls is blank
+ FILTER(!isBlank(?cls))
+ # Binds the variable prefix as the prefix of the class (eg. MONDO, CL, etc.). classes that do not have obo purls will come out as blank in the report.
+ BIND(STRBEFORE(STRAFTER(str(?cls),"http://purl.obolibrary.org/obo/"),"_")AS?prefix)
+}
+# grouping the count by prefix
+GROUP BY?prefix
+
# this query counts the number of classes that are subclass of CL:0000003 (native cell) that are in the pcl namespace
+
+# adding prefixes used
+PREFIXowl:<http://www.w3.org/2002/07/owl#>
+PREFIXrdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
+PREFIXrdfs:<http://www.w3.org/2000/01/rdf-schema#>
+PREFIXCL:<http://purl.obolibrary.org/obo/CL_>
+PREFIXPCL:<http://purl.obolibrary.org/obo/PCL_>
+
+# count the number of unique term
+SELECT(COUNT(DISTINCT?term)as?pclcells)
+WHERE{
+ # the variable term is a class
+ ?termaowl:Class.
+ # the variable term has to be a subclass of CL:0000003, including those that are subclassof by property path
+ ?termrdfs:subClassOf*CL:0000003
+ # only count the term if it is in the pcl namespace
+ FILTER(isIRI(?term)&&(STRSTARTS(str(?term),"http://purl.obolibrary.org/obo/PCL_")))
+}
+
adaptable for removing all terms of a particular namespace
+
# adding prefixes used
+prefixowl:<http://www.w3.org/2002/07/owl#>
+prefixrdfs:<http://www.w3.org/2000/01/rdf-schema#>
+
+# removing triples
+DELETE{
+ ?s?p?o
+}
+WHERE
+{
+ {
+ # the variable p must be a rdfs:label
+ VALUES?p{
+ rdfs:label
+ }
+ # the variable s is an object property
+ ?saowl:ObjectProperty;
+ # the other variables can be anything else (note the above value restriction of p)
+ ?p?o
+ # filter out triples where ?s starts with "http://purl.obolibrary.org/obo/RO_"
+ FILTER(isIRI(?s)&&STRSTARTS(str(?s),"http://purl.obolibrary.org/obo/RO_"))
+ }
+}
+
# adding prefixes used
+prefixowl:<http://www.w3.org/2002/07/owl#>
+
+# delete triples
+DELETE{
+ ?anno?property?value.
+}
+WHERE{
+ # the variable property is either synonym_type: or source:
+ VALUES?property{synonym_type:source:}
+ # structure of variable value and variable anno
+ ?annoaowl:Axiom;
+ owl:annotatedSource?s;
+ owl:annotatedProperty?p;
+ owl:annotatedTarget?o;
+ ?property?value.
+ # filter out the variable value which start with "ICD10EXP:"
+ FILTER(STRSTARTS(STR(?value),"ICD10EXP:"))
+}
+
Replace oboInOwl:source with oboInOwl:hasDbXref in synonyms annotations¶
+
adaptable for replacing annotations properties on particular axioms
+
# adding prefixes used
+prefixowl:<http://www.w3.org/2002/07/owl#>
+prefixoboInOwl:<http://www.geneontology.org/formats/oboInOwl#>
+prefixrdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
+
+# delete triples where the relation is oboInOwl:source
+DELETE{
+ ?axoboInOwl:source?source.
+}
+# insert triples where the variables ax and source defined above are used, but using oboInOwl:hasDbXref instead
+INSERT{
+ ?axoboInOwl:hasDbXref?source.
+}
+WHERE
+{
+ # restricting to triples where the property variable is in this list
+ VALUES?property{oboInOwl:hasExactSynonymoboInOwl:hasNarrowSynonymoboInOwl:hasBroadSynonymoboInOwl:hasCloseSynonymoboInOwl:hasRelatedSynonym}.
+ # order of the variables in the triple
+ ?entity?property?value.
+ # structure on which the variable ax and source applies
+ ?axrdf:typeowl:Axiom;
+ owl:annotatedSource?entity;
+ owl:annotatedTarget?value;
+ owl:annotatedProperty?property;
+ oboInOwl:source?source.
+ # filtering out triples where entity is an IRI
+ FILTER(isIRI(?entity))
+}
+
The definition of the synonym is exactly the same as primary term definition. This is used when the same class can have more than one name.
+
For example, hereditary Wilms' tumor has the exact synonoym familial Wilms' tumor.
+
Additionally, translations into other languages are listed as exact synonyms. For example, the Plant Ontology list both Spanish and Japanese translations as exact synonyms; e.g. anther wall has exact synonym ‘pared de la antera’ (Spanish) and ‘葯壁 ‘(Japanese).
The definition of the synonym is the same as the primary definition, but has additional qualifiers.
+
For example, pod is a narrow synonym of fruit.
+
Note - when adding a narrow synonym, please first consider whether a new subclass should be added instead of a narrow synonym. If there is any uncertainty, start a discussion on the GitHub issue tracker.
The primary definition accurately describes the synonym, but the definition of the synonym may encompass other structures as well. In some cases where a broad synonym is given, it will be a broad synonym for more than one ontology term.
+
For example, Cyst of eyelid has the broad synonym Lesion of the eyelid.
+
Note - when adding a broad synonym, please first consider whether a new superclass should be added instead of a broad synonym. If there is any uncertainty, start a discussion on the GitHub issue tracker.
This scope is applied when a word of phrase has been used synonymously with the primary term name in the literature, but the usage is not strictly correct. That is, the synonym in fact has a slightly different meaning than the primary term name. Since users may not be aware that the synonym was being used incorrectly when searching for a term, related synonyms are included.
+
For example, Autistic behavior has the related synonym Autism spectrum disorder.
Synonyms can also be classified by types. The default is no type. The synonym types vary in each ontology, but some commonly used synonym types include:
+
+
abbreviation - to indicate the synonym is an abbreviation. Note the scope for an acronym should be determined on a case-by-case basis. Not all acronyms are necessarily exact.
+
ambiguous - to indicate the synonym is open to more than one interpretation; may have a double meaning
+
dubious synonym - to indicate the synonym may be suspect
+
layperson term - to indicate the synonym is common language (used by the Human Phenotype Ontology)
+
plural form - indicating the form of the term that means more than one
+
UK spelling - the english language spelling that is used in the United Kingdom (UK) but not in the United States (US)
Whenever possible, database cross-references (dbxrefs) for synonyms should be provided, to indicate the publication that used the synonym. References to PubMed IDs should be in the format PMID:XXXXXXX (no space). However, dbxrefs for synonyms are not mandatory in most ontologies.
Tables and triples seem very different.
+Tables are familiar and predictable.
+Triples are weird and floppy.
+SQL is normal, SPARQL is bizarre, at least at first.
+
Tables are great, and they're the right tool for a lot of jobs,
+but they have their limitations.
+Triples shine when it comes to merging heterogeneous data.
+But it turns out that there's a clear path from tables to triples,
+which should help make RDF make more sense.
You won't be surprised to find out
+that tables have rows and columns.
+Often each row corresponds to some thing
+that we want to talk about,
+such as a fictional character from Star Wars.
+Each column usually corresponds to some sort of property
+that those things might have.
+Then the cells contain the values of those properties
+for their respective row.
+We take some sort of complex information about the world,
+and we break it down along two dimensions:
+the things (rows) and their properties (columns).
Tables are great!
+We can add another name to our table:
+
+
+
+
first_name
+
last_name
+
+
+
+
+
Luke
+
Skywalker
+
+
+
Leia
+
Organa
+
+
+
Darth
+
Vader
+
+
+
Han
+
Solo
+
+
+
Anakin
+
Skywalker
+
+
+
+
Hmm.
+That's a perfectly good table,
+but it's not capturing the information that we wanted.
+It turns out (Spoiler Alert!) that Anakin Skywalker is Darth Vader!
+We might have thought that the rows of our table
+were describing individual people,
+but it turns out that they're just describing individual names.
+A person can change their name
+or have more than one name.
+
We want some sort of identifier
+that lets us pick out the same person,
+and distinguish them from all the other people.
+Sometimes there's a "natural key" that we can use for this purpose:
+some bit of information that uniquely identifies a thing.
+When we don't have a natural key, we can generate an "artificial key".
+Random strings and number can be good artificial keys,
+but sometimes a simple incrementing integer is good enough.
+
The main problem with artificial keys
+is that it's our job to maintain the link
+between the thing and the identifier that we gave it.
+We prefer natural keys because we just have to inspect that thing
+(in some way)
+to figure out what to call it.
+Even when it's possible,
+sometimes that's too much work.
+Maybe we could use a DNA sequence as a natural key for a person,
+but it probably isn't practical.
+We do use fingerprints and facial recognition,
+for similar things, though.
+
(Do people in Star Wars even have DNA?
+Or just midichlorions?)
+
Let's add a column with an artificial key to our table:
+
+
+
+
sw_id
+
first_name
+
last_name
+
+
+
+
+
1
+
Luke
+
Skywalker
+
+
+
2
+
Leia
+
Organa
+
+
+
3
+
Darth
+
Vader
+
+
+
4
+
Han
+
Solo
+
+
+
3
+
Anakin
+
Skywalker
+
+
+
+
This is our table of names,
+allowing a given person to have multiple names.
+But what we thought we wanted was a person table
+with one row for each person, like this:
+
+
+
+
sw_id
+
first_name
+
last_name
+
+
+
+
+
1
+
Luke
+
Skywalker
+
+
+
2
+
Leia
+
Organa
+
+
+
3
+
Darth
+
Vader
+
+
+
4
+
Han
+
Solo
+
+
+
+
In SQL we could assert that the "sw_id" column of the person table
+is a PRIMARY KEY.
+This means it must be unique.
+(It probably shouldn't be NULL either!)
+
The names in the person table could be the primary names
+that we use in our Star Wars database system,
+and we could have another alternative_name table:
Tables are great!
+We can add more columns to our person table:
+
+
+
+
sw_id
+
first_name
+
last_name
+
occupation
+
+
+
+
+
1
+
Luke
+
Skywalker
+
Jedi
+
+
+
2
+
Leia
+
Organa
+
princess
+
+
+
3
+
Darth
+
Vader
+
+
+
+
4
+
Han
+
Solo
+
scoundrel
+
+
+
+
The 2D pattern of a table is a strong one.
+It not only provides a "slot" (cell)
+for every combination of row and column,
+it also makes it very obvious when one of those slots is empty.
+What does it mean for a slot to be empty?
+It could mean many things.
+
For example, in the previous table
+in the row for Darth Vader,
+the cell for the "occupation" column is empty.
+This could mean that:
+
+
we don't know whether he has an occupation
+
we know that he has an occupation, but we don't know which occupation it is.
+
we might know, but we haven't bothered to write it down yet
+
we might know, but it doesn't fit nicely
+ into the New Republic Standard Registry of Occupations;
+ in other words, we know what his occupation is,
+ but including it here would violate a constraint on our database
+
we specifically know that he doesn't have an occupation;
+ we triple-checked
+
we know more generally (Spoiler Alert!!) that he's dead,
+ and dead people can't have an occupation.
+
+
I'm sure I haven't captured all the possibilities.
+The point is that there's lot of possible reasons
+why a cell would be blank.
+So what can we do about it?
+
If our table is stored in a SQL database,
+then we have the option of putting a NULL value in the cell.
+NULL is pretty strange.
+It isn't TRUE and it isn't FALSE.
+Usually NULL values are excluded from SQL query results
+unless you are careful to ask for them.
+
The way that NULL works in SQL eliminates some of the possibilities above.
+SQL uses the "closed-world assumption",
+which is the assumption that if a statement is true then it's known to be true,
+and conversely that if it's not known to be true then it's false.
+So if Anakin's occupation is NULL in a SQL database,
+then as far as SQL is concerned,
+we must know that he doesn't have an occupation.
+That might not be what you were expecting!
+
The Software Carpentry module on
+Missing Data
+has more information.
Tables are great!
+Let's add even more information to our table:
+
+
+
+
sw_id
+
first_name
+
last_name
+
occupation
+
enemy
+
+
+
+
+
1
+
Luke
+
Skywalker
+
Jedi
+
3
+
+
+
2
+
Leia
+
Organa
+
princess
+
3
+
+
+
3
+
Darth
+
Vader
+
+
1,2,4
+
+
+
4
+
Han
+
Solo
+
scoundrel
+
3
+
+
+
+
We're trying to say that Darth Vader is the enemy of everybody else in our table.
+We're using the primary key of the person in the enemy column, which is good,
+but we've ended up with multiple values in the "enemy" column
+for Darth Vader.
+
In any table or SQL database you could
+make the "enemy" column a string,
+pick a delimiter such as the comma,
+and concatenate your values into a comma-separated list.
+This works, but not very well.
+
In some SQL databases, such as Postgres,
+you could given the "enemy" column an array type,
+so it can contain multiple values.
+You get special operators for querying inside arrays.
+This can work pretty well.
+
The usual advice is to break this "one to many" information
+into a new "enemy" table:
+
+
+
+
sw_id
+
enemy
+
+
+
+
+
1
+
3
+
+
+
2
+
3
+
+
+
3
+
1
+
+
+
3
+
2
+
+
+
3
+
4
+
+
+
4
+
1
+
+
+
+
Then you can JOIN the person table to the enemy table as needed.
Tables are great!
+Let's add even more information to our table:
+
+
+
+
sw_id
+
first_name
+
last_name
+
occupation
+
father
+
lightsaber_color
+
ship
+
+
+
+
+
1
+
Luke
+
Skywalker
+
Jedi
+
3
+
green
+
+
+
+
2
+
Leia
+
Organa
+
princess
+
3
+
+
+
+
+
3
+
Darth
+
Vader
+
+
+
red
+
+
+
+
4
+
Han
+
Solo
+
scoundrel
+
+
+
Millennium Falcon
+
+
+
+
A bunch of these columns only apply to a few rows.
+Now we've got a lot more NULLs to deal with.
+As the number of columns increases,
+this can become a problem.
Tables are great!
+If sparse tables are a problem,
+then let's try to apply the same solution
+that worked for the "many to one" problem in the previous section.
+
name table:
+
+
+
+
sw_id
+
first_name
+
last_name
+
+
+
+
+
1
+
Luke
+
Skywalker
+
+
+
2
+
Leia
+
Organa
+
+
+
3
+
Darth
+
Vader
+
+
+
4
+
Han
+
Solo
+
+
+
3
+
Anakin
+
Skywalker
+
+
+
+
occupation table:
+
+
+
+
sw_id
+
occupation
+
+
+
+
+
1
+
Jedi
+
+
+
2
+
princess
+
+
+
4
+
scoundrel
+
+
+
+
enemy table:
+
+
+
+
sw_id
+
enemy
+
+
+
+
+
1
+
3
+
+
+
2
+
3
+
+
+
3
+
1
+
+
+
3
+
2
+
+
+
3
+
4
+
+
+
4
+
1
+
+
+
+
father table:
+
+
+
+
sw_id
+
father
+
+
+
+
+
1
+
3
+
+
+
2
+
3
+
+
+
+
lightsaber_color table:
+
+
+
+
sw_id
+
lightsaber_color
+
+
+
+
+
1
+
green
+
+
+
3
+
red
+
+
+
+
ship table:
+
+
+
+
sw_id
+
ship
+
+
+
+
+
4
+
Millennium Falcon
+
+
+
+
Hmm.
+Yeah, that will work.
+But every query we write will need some JOINs.
+It feels like we've lost something.
Tables are great!
+But there's such a thing as too many tables.
+We started out with a table
+with a bunch of rows and a bunch of columns,
+and ended up with a bunch of tables
+with a bunch of rows but just a few columns.
+
I have a brilliant idea!
+Let's combine all these property tables into just one table,
+by adding a "property" column!
+
+
+
+
sw_id
+
property
+
value
+
+
+
+
+
1
+
first_name
+
Luke
+
+
+
2
+
first_name
+
Leia
+
+
+
3
+
first_name
+
Darth
+
+
+
4
+
first_name
+
Han
+
+
+
5
+
first_name
+
Anakin
+
+
+
1
+
last_name
+
Skywalker
+
+
+
2
+
last_name
+
Skywalker
+
+
+
3
+
last_name
+
Vader
+
+
+
4
+
last_name
+
Solo
+
+
+
5
+
last_name
+
Skywalker
+
+
+
1
+
occupation
+
Jedi
+
+
+
2
+
occupation
+
princess
+
+
+
4
+
occupation
+
scoundrel
+
+
+
1
+
enemy
+
3
+
+
+
2
+
enemy
+
3
+
+
+
3
+
enemy
+
1
+
+
+
3
+
enemy
+
2
+
+
+
3
+
enemy
+
4
+
+
+
4
+
enemy
+
1
+
+
+
1
+
father
+
3
+
+
+
2
+
father
+
3
+
+
+
1
+
lightsaber_color
+
green
+
+
+
3
+
lightsaber_color
+
red
+
+
+
4
+
ship
+
Millenium Falcon
+
+
+
+
It turns out that I'm not the first one to think of this idea.
+People call it "Entity, Attribute, Value" or "EAV".
+People also call it an "anti-pattern",
+in other words: a clear sign that you've made a terrible mistake.
+
There are lots of circumstances in which
+one big, extremely generic table is a bad idea.
+First of all, you can't do very much
+with the datatypes for the property and value columns.
+They kind of have to be strings.
+It's potentially difficult to index.
+And tables like this are miserable to query,
+because you end up with all sorts of self-joins to handle.
+
But there's at least one use case where it turns out to work quite well...
The strong row and column structure of tables
+makes them great for lots of things,
+but not so great for merging data from different sources.
+Before you can merge two tables
+you need to know all about:
+
+
how the columns are structured
+
what the rows mean
+
what the cells mean
+
+
So you need to know the schemas of the two tables
+before you can start merging them together.
+But if you happen to have two EAV tables then,
+as luck would have it,
+they already have the same schema!
+
You also need to know that you're talking about the same things:
+the rows have to be about the same things,
+you need to be using the same property names for the same things,
+and the cell values also need to line up.
+If only there was an open standard for specifying globally unique identifiers...
+
Yes, you guessed it: URLs (and URNs and URIs and IRIs)!
+Let's assume that we use the same URLs for the same things
+across the two tables.
+Since we're a close-knit community,
+we've come to an agreement on a Star Wars data vocabulary.
+
URLs are annoyingly long to use in databases,
+so let's use standard "sw" prefix to shorten them.
+Now we have table 1:
+
+
+
+
sw_id
+
property
+
value
+
+
+
+
+
sw:1
+
sw:first_name
+
Luke
+
+
+
sw:2
+
sw:first_name
+
Leia
+
+
+
sw:3
+
sw:first_name
+
Darth
+
+
+
sw:4
+
sw:first_name
+
Han
+
+
+
sw:5
+
sw:first_name
+
Anakin
+
+
+
sw:1
+
sw:last_name
+
Skywalker
+
+
+
sw:2
+
sw:last_name
+
Skywalker
+
+
+
sw:3
+
sw:last_name
+
Vader
+
+
+
sw:4
+
sw:last_name
+
Solo
+
+
+
sw:5
+
sw:last_name
+
Skywalker
+
+
+
sw:1
+
sw:occupation
+
sw:Jedi
+
+
+
sw:2
+
sw:occupation
+
sw:princess
+
+
+
sw:4
+
sw:occupation
+
sw:scoundrel
+
+
+
+
and table 2:
+
+
+
+
sw_id
+
property
+
value
+
+
+
+
+
sw:1
+
sw:enemy
+
sw:3
+
+
+
sw:2
+
sw:enemy
+
sw:3
+
+
+
sw:3
+
sw:enemy
+
sw:1
+
+
+
sw:3
+
sw:enemy
+
sw:2
+
+
+
sw:3
+
sw:enemy
+
sw:4
+
+
+
sw:4
+
sw:enemy
+
sw:1
+
+
+
sw:1
+
sw:father
+
sw:3
+
+
+
sw:2
+
sw:father
+
sw:3
+
+
+
sw:1
+
sw:lightsaber_color
+
green
+
+
+
sw:3
+
sw:lightsaber_color
+
red
+
+
+
sw:4
+
sw:ship
+
Millenium Falcon
+
+
+
+
To merge these two tables, we simple concatenate them.
+It couldn't be simpler.
These tables are pretty much in RDF format.
+You just have to squint a little!
+
+
sw_id == subject
+
property == predicate
+
value == object
+
+
Each row of the table is a subject-predicate-object triple.
+Our subjects, predicates, and some objects are URLs.
+We also have some literal objects.
+We could turn this table directly into Turtle format
+with a little SQL magic
+(basically just concatenating strings):
Two things we're missing from RDF are
+language tagged literals and typed literals.
+We also haven't used any blank nodes in our triple table.
+These are easy enough to add.
+
The biggest thing that's different about RDF
+is that it uses the "open-world assumption",
+so something may be true even though
+we don't have a triple asserting that it's true.
+The open-world assumption is a better fit
+than the closed-world assumption
+when we're integrating data on the Web.
Tables are great!
+We use them all the time,
+they're strong and rigid,
+and we're comfortable with them.
+
RDF, on the other hand, looks strange at first.
+For most common data processing,
+RDF is too flexible.
+But sometimes flexiblity is the most important thing.
+
The greatest strength of tables is their rigid structure,
+but that's also their greatest weakness.
+We saw a number of problems with tables,
+and how they could be overcome
+by breaking tables apart into smaller tables,
+until we got down to the most basic pattern:
+subject-predicate-object.
+Step by step, we were pushed toward RDF.
+
Merging tables is particularly painful.
+When working with data on the Web,
+merging is one of the most common and important operations,
+and so it makes sense to use RDF for these tasks.
+If self-joins with SQL is the worst problem for EAV tables,
+then SPARQL solves it.
+
These examples show that it's not really very hard
+to convert tables to triples.
+And once you've seen SPARQL, the RDF query language,
+you've seen one good way to convert triples to tables:
+SPARQL SELECT results are just tables!
+
Since it's straightforward to convert
+tables to triples and back again,
+make sure to use the right tool for the right job.
+When you need to merge heterogeneous data, reach for triples.
+For most other data processing tasks, use tables.
+They're great!
Copying-pasting (especially in google docs) can introduce unexpected format changes in row 2 of the template:¶
+
+
Note that these format changes are not always visible.
+
The most common typos are:
+
introduction of space in cells
+
single quotes are changed into apostrophes
+
These errors are most commonly reported as "MANCHESTER PARSE ERROR"
+
+
Restrictions for the first 2 rows of a ROBOT template:¶
+
+
In the same column, it is OK to have a header string (row #1) with no template string (row #2).
+
the information in the column is useful to curators (e.g. term labels) but will be ignored by ROBOT.
+
+
+
+
In the same column, if there is a template string (row #2), there MUST be a header string (row #1)
+
if the row #1 is missing, the error will be reported as: COLUMN MISMATCH ERROR the template string in column 1 must have a corresponding header in table "tmp/merge_template.tsv”
+
+
+
The content of the template break some OBO or Protege rules¶
+
+
for example, Protege only allows one comment on a class. If you are adding new comments to terms via ROBOT, you will get an error if a comment already exists on a term.
+
error will be reported as: OBO STRUCTURE ERROR Ontology does not conform to OBO structure rules: multiple comment tags not allowed.
+
Note: If you run ROBOT and get an error, it may create a blank file. You need to discard the changes and/or open a new branch. The error with the optional “null” is when the mondo-edit file is empty.
+Optional.get() cannot be called on an absent value
+Use the -vvv option to show the stack trace.
+Use the --help option to see usage information
+make: *** [mondo.Makefile:454: merge_template] Error 1
"All structured data from the main, Property, Lexeme, and EntitySchema namespaces is available under the Creative Commons CC0 License; text in the other namespaces is available under the Creative Commons Attribution-ShareAlike License"
+
Adding non-CC0 licensed OBO ontologies in full might be problematic due to
+* License stacking
+
IANL, but my understanding is that as long as only URI mappings are created to OBO ontology terms no licenses are breached (even if the ontology is not CC0)
Wikidata is a hub in the Linked Open Data cloud; it is, thus, a good place to crowdsource database cross references (e.g. between the Cell Ontology and FMA).
+
Wikidata provides direct links between items and Wikipedia, as well as a proxy for how many different Wikipedia languages are available for each concept. These can be acessed via SPARQL queries (e.g https://w.wiki/6Tpd). Wikipedia links are useful for adding explainability to applications, and language count can be a proxy for popularity of concepts.
+
E.g. The top popular concepts with a CL ID are "Cell", "Red Blood Cell" and "Neuron" with over 100 Wikipedia languages each (https://w.wiki/6TyY)
+
+
+
Wikidata is multilingual and most (if not all) OBO ontologies are English-only. Wikidata provides infrastructure to record preferred labels accross 200+ languages (not sure the current number).
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/resources/obook-badge-development.json b/resources/obook-badge-development.json
new file mode 100644
index 000000000..6d3ac2178
--- /dev/null
+++ b/resources/obook-badge-development.json
@@ -0,0 +1 @@
+{"schemaVersion": 1, "label": "OBOOK Maturity Indicator", "message": "Under Development", "color": "red"}
diff --git a/resources/obook-badge-draft.json b/resources/obook-badge-draft.json
new file mode 100644
index 000000000..2eab12734
--- /dev/null
+++ b/resources/obook-badge-draft.json
@@ -0,0 +1 @@
+{"schemaVersion": 1, "label": "OBOOK Maturity Indicator", "message": "Complete Draft", "color": "yellow"}
diff --git a/resources/obook-badge-stable.json b/resources/obook-badge-stable.json
new file mode 100644
index 000000000..2efadb7a5
--- /dev/null
+++ b/resources/obook-badge-stable.json
@@ -0,0 +1 @@
+{"schemaVersion": 1, "label": "OBOOK Maturity Indicator", "message": "Stable", "color": "green"}
diff --git a/resources/odk.bat b/resources/odk.bat
new file mode 100644
index 000000000..eb2321536
--- /dev/null
+++ b/resources/odk.bat
@@ -0,0 +1 @@
+docker run -v %cd%\:/work -w /work/ -e ROBOT_JAVA_ARGS="-Xmx8G" -e JAVA_OPTS="-Xmx8G" --rm -ti obolibrary/odkfull %*
diff --git a/resources/odk.sh b/resources/odk.sh
new file mode 100644
index 000000000..747358c42
--- /dev/null
+++ b/resources/odk.sh
@@ -0,0 +1,17 @@
+#!/bin/sh
+# Wrapper script for docker.
+#
+# This is used primarily for wrapping the GNU Make workflow.
+# Instead of typing "make TARGET", type "./run.sh make TARGET".
+# This will run the make workflow within a docker container.
+#
+# Place this file in the folder from which you want to use the docker container.
+# Note that the ODK will only be able to access files in that particular directory.
+#
+# In your terminal, you first go to the directory that contains this wrapper
+# script - then you can run 'sh odk.sh robot --version' to see if it works.
+# For more experienced developers you can add the odk.sh file to you path and give it access
+#
+# To your entire user directory by adding '-v /Users/username/:/work'
+
+docker run -e ROBOT_JAVA_ARGS='-Xmx25G' -e JAVA_OPTS='-Xmx25G' -v $PWD/:/work -w /work --rm -ti obolibrary/odkfull "$@"
diff --git a/search/search_index.json b/search/search_index.json
new file mode 100644
index 000000000..fc3b1e285
--- /dev/null
+++ b/search/search_index.json
@@ -0,0 +1 @@
+{"config":{"lang":["en"],"separator":"[\\s\\-]+","pipeline":["stopWordFilter"]},"docs":[{"location":"","title":"On becoming an OBO Semantic Engineer","text":"
Welcome to the OBOOK and our OBO Semantic Engineering Training!
"},{"location":"#introduction-to-the-obook-open-biological-and-biomedical-ontologies-organized-knowledge","title":"Introduction to the OBOOK (Open Biological and Biomedical Ontologies Organized Knowledge)","text":"
Documentation in the OBOOK is organised into 4 distinct sections based on the Di\u00e1taxis framework of documentation:
Tutorials: Learning-oriented documentation that contains exercises to help a beginner achieve basic competence in a specific area.
How-to Guides: Task-oriented documentation that functions as directions to guide the reader through the steps to achieve a specific end.
Reference Guides: Information-oriented documentation that describes a single topic in a succinct, technical and orderly way.
Explanations: Understanding-oriented documentation that clarifies, deepens and broadens the reader\u2019s understanding of a subject.
To accommodate for the various training use cases we support, we added the following categories:
Courses: A convenience content type that assembles materials from OBOOK for a specific, taught unit, such as the yearly ICBO tutorials.
Pathways: A kind of course pertaining to a specific role in the OBO-sphere, such as curator or software developer.
Lessons: A collection of materials (tutorials, explanations and how-to guides) that together aim to teach a well defined concept.
Note: We are in the process of transforming the documentation accordingly, so please be patient if some of the documentation is not yet in the correct place. Feel free to create an issue if you find something that you suspect isn't in place.
James Overton, Knocean Inc. James has been a developer of software to support ontology development in and around the OBO sphere for more than a decade and delivers services to the OBO community through his company, Knocean Inc.
Becky Jackson, Bend Informatics. Becky has been a Semantic Software developer and Ontology Pipeline specialist since 2016, now working as an independent consultant.
Nicole Vasilevsky, Critical Path Institute. Nicole is the Associate Director of Data Science and an Ontology Curator for the Mondo Disease Ontology, and contributes to several other ontologies including the Human Phenotype Ontology, Uberon Anatomy Ontology, and Cell Ontology.
Nicolas Matentzoglu, Semanticly, Athens, Greece. Nico is an Ontology Engineer and Ontology Pipeline Specialist, being the Principal Ontology Pipeline Developer for the Monarch Initiative.
Shawn Tan, Novo Nordisk
David Osumi-Sutherland, EMBL-EBI
Sabrina Toro, University of Colorado
If you would like to contribute to this training, please find out more here.
Critical Path Institute (CPI) is an independent, nonprofit organisation dedicated to bringing together experts from regulatory agencies, industry and academia to collaborate and improve the medical product development process.
In April 2021, the CPI has commissioned the first version of this OBO course, contributing not only funding for the preparation and delivery of the materials, but also valuable feedback about the course contents and data for the practical exercises. We thank the CPI for contributing significantly to the OBO community and open science!
https://c-path.org/
"},{"location":"contributing/","title":"Contributing to OBO Semantic Engineering Tutorials","text":"
We rely on our readers to correct our materials and add to them - the hope is to centralise all the usual teaching materials for OBO ontology professionals in one place. Feel free to:
Request new lessons (video/how-to guides) on the issue tracker
Make a pull request if you find errors or want to add some clarifying remarks. All files of the OBOAcademy website can be found in the docs directory. The Table of Contents is edited here.
Join the OBO slack space (#obo-training channel) to ask any questions (you can request access on the issue tracker)
"},{"location":"getting-started-obook/","title":"Getting started for OBOOK editors","text":"
The OBOOK is trying to centralise all OBO documentation in one place. It is, and will be, a big construction site, for years to come. The goal is to iterate and make things better.
We follow two philosophies:
Diataxis for organising our documentation
Flipped classroom for the organisation of training materials
There are three main consequences to this:
Our materials are organised in a certain way (according to the four-way split suggested by Diataxis).
We superimpose three more categories to organise the content across all materials and facilitate self guided studying: Pathways, courses and lessons (see below).
All training materials must be self-contained to ensure that they can be studied without any further guidance by a teacher.
"},{"location":"getting-started-obook/#beyond-diataxis-the-obook-categories","title":"Beyond Diataxis: the OBOOK categories:","text":"
We just introduced a new concept to OBOOK called pathways. The idea is that we provide a linear guide for all 6 roles mentioned on the getting started page through the materials. This will help us also complete the materials and provide a good path to reviewing them regularly.
A step-by-step guide to complete a well-defined mini-project. Examples: ROBOT template tutorial. DOSDP template tutorial. Protege tutorial on using the reasoner.
A collection of materials (tutorials, explanations and how-to-guides) that together seek to teach a well defined concept. Examples: Contributing to OBO ontologies; An Introduction to templates in OBO; An Introduction to OBO Application development. While the distinction to \"tutorial\" is often fuzzy, the main distinguishing feature should be that a lesson conveys a general concept independent of some concrete technology stack. While we use concrete examples in lessons, we do always seek to generalise to problem space.
A convenience content type that allows us to assemble materials from obook for a specific taught unit, such as the yearly ICBO tutorials, or the ongoing Monarch Ontology Tutorials and others. Course pages serve as go-to-pages for course participants and link to all the relevant materials in the documentation. Course usually comprise lessons, tutorials and how-to guides.
A pathway is a kind of course, but without the expectation that it is ever taught in a concrete setting. A pathways pertains to a single concrete role (Ontology Curator, Pipeline Developer etc). It is a collection of materials (lessons, tutorials, how-to-guides) that is ordered in a linear fashion for the convenience of the student. For example, we are developing a pathway for ontology pipeline developers that start by teaching common concepts such as how to make term requests etc, and then go into depth on ROBOT pipelines, ODK and Make.
Items in the explanation section should conceptually start with a Why or a How question.
For ordered lists, only use 1. 1. 1., ever 1. 2. 3. This makes it easier to remove and shuffle items during edits
"},{"location":"getting-started/","title":"How to start with the lessons","text":"
Before you start with the lessons of this course, keep the following in mind:
The materials in this course are all intended to be used for self-study. We sometimes offer flipped-classroom sessions for new members on our teams - this means that we expect them to work through the entire course themselves and then come to us with questions and requests for clarifications.
There is no need to reinvent the wheel: there are a lot of great materials out there already. Providing references to these external resources is an essential part of the course - some lessons primarily comprise external tutorials, blog articles and more - please make sure you take advantage of them.
Some of the materials developed by us are a bit rough around the edges, and we need your help to fix and improve them. To that end, we appreciate anything from suggestions for improvement to pull requests.
Depending on your specific role and interest, you can choose which lessons are relevant to you. There is no specific order, but if you want to start somewhere, we recommend Contributing to OBO ontologies: Protege and Github and/or Using Ontologies and Ontology Terms
"},{"location":"getting-started/#the-different-roles-of-obo-semantic-engineering","title":"The different roles of OBO Semantic Engineering","text":"
There are a wide variety of entry points into the OBO world, for example:
"},{"location":"getting-started/#database-curator-you-are","title":"Database Curator: You are","text":"
using ontologies for annotating datasets, experiments and publications
requesting new terms from ontologies
suggesting corrections to existing ontologies, such as wrong or missing synonyms, typos and definitions
"},{"location":"getting-started/#ontology-curator-you-are","title":"Ontology Curator: You are","text":"
developing and maintaining ontologies
adding terms to ontologies
performing changes to ontologies, like adding or correcting synonyms
responsible for ontology releases
"},{"location":"getting-started/#ontology-engineerdeveloper-you-are","title":"Ontology Engineer/Developer: You are","text":"
developing design patterns for ontologies, specifying the logical structure of terms
responsible for ensuring the specification and consistent application of metadata in your ontologies (which annotation properties to use, minimal metadata standards)
defining quality control checks
"},{"location":"getting-started/#ontology-pipeline-specialist-you-are","title":"Ontology Pipeline Specialist: You are","text":"
developing ontology pipelines with make and ROBOT
building the release and quality control architecture that Engineers and Curators need to do their work.
building infrastructure for application ontologies, implementing dynamic imports modules, transformations of and mappings to other ontologies.
"},{"location":"getting-started/#semantic-etl-engineer-you-are","title":"Semantic ETL Engineer: You are","text":"
building ingests from public life science resources such as Bgee, Panther, UniProt and many more
using ontologies to glue together data from different sources
using ontologies to augment the information in your data sources through inference
"},{"location":"getting-started/#semantic-software-engineer-you-are","title":"(Semantic) Software Engineer: You are","text":"
using ontologies to generate value to end-user applications (user interfaces, semantic faceted search)
building widgets that exploit the logical and graph structure of ontologies, for example phenotypic profile matching
building ontology term browsers such as OLS.
Of course, many of you will occupy more than one of the above \"hats\" or roles. While they all require specialised training, many shared skill requirements exist. This course is being developed to:
Provide basic training for OBO Semantic Engineers of any of the above flavours
Provide an entry point for people new to the field, for example as part of onboarding activities for projects working with ontologies
Capture some of the typical pitfalls and how-to's guides to address common problems across the OBO-sphere
"},{"location":"overview/","title":"Overview","text":""},{"location":"overview/#lessons","title":"Lessons","text":""},{"location":"overview/#using-ontologies-and-ontology-terms","title":"Using Ontologies and Ontology Terms","text":"
Target roles: Database Curators
Skills:
know what ontologies are good for
find good ontologies: ontology repositories, OBO
find good terms: ontology browsers
assess for use: license, quality
map local terms to ontology terms
identify missing terms
use IRIs, prefixes, CURIEs, labels
use Protege?
"},{"location":"overview/#contributing-to-obo-ontologies-1-protege-and-github","title":"Contributing to OBO ontologies 1: Protege and Github","text":"
The goal of this tutorial is to provide a flavor of the OBO landscape, from the OBO Foundry organization to the ontology curators and OBO engineers that are doing the daily ontology development.
The Open Biological and Biomedical Ontologies (OBO) community includes hundreds of open source scientific ontology projects, committed to shared principles and practices for interoperability and FAIR data. An OBO tutorial has been a regular feature of ICBO for a decade, introducing new and experienced ontology users and developers to ontologies in general, and to current OBO tools and techniques specifically. While ICBO attracts many ontology experts, it also includes an audience of ontology beginners, and of ontology users looking to become ontology developers or to further refine their skills. Our OBO tutorial will help beginner and intermediate ontology users with a combination of theory and hands-on practice.
For ICBO 2022 we will host a half-day OBO tutorial consisting of two parts, with a unifying theme of ontology term reuse.
The first part of our tutorial will be introductory, aimed at an audience that is new to ontologies and to the OBO Foundry. We will introduce OBO, its community, principles, resources, and best practices. We will finish the first part with a hands-on lesson in basic tools: ontology browsers, how to contribute to ontologies via GitHub (creating issues and making Pull Requests), and the Protege ontology editor.
The second part will build on the first, addressing an audience that is familiar with ontologies and OBO, and wants to make better use of OBO workflows and tools in their own projects. The focus will be on making best use of OBO community open source software. We will introduce ROBOT, the command-line tool and library for automating ontology development tasks. We will show how the Ontology Development Kit (ODK) is used to standardize ontology projects with a wide range of best practices. The special emphasis of this year's tutorial will be ontology reuse, and specifically on how ROBOT and ODK can be used to manage imports from other ontologies and overcome a number of challenges to term reuse.
This material for this year's OBO Tutorial will build on the content here in the OBO Academy. The OBO Academy offers free, open, online resources with self paced learning materials covering various aspects of ontology development and curation and OBO. Participants are encouraged to continue their learning using this OBO Academy website, and contribute to improving the OBO documentation.
As an outcome of this workshop, we expect that new ontologists will have a clearer understanding of why we need and use ontologies, how to find ontology terms and contribute to ontologies and make basic edits using Protege. Our more advanced participants should be able to apply OBO tools and workflows to their own ontology development practices.
Chris Mungall, Lawrence Berkeley National Laboratory
Nicole Vasilevsky, University of Colorado Anschutz Medical Campus
Nico Matentzoglu, Semanticly, Athens, Greece
Randi Vita, La Jolla Institute for Allergy & Immunology
"},{"location":"courses/icbo2022/#agenda","title":"Agenda","text":"Time Topic Presenter 09:00 am ET Introduction to OBO, its community, principles, resources, and best practices James Overton 09:20 am ET Hands-on lesson in basic tools: see details below Nicole Vasilevsky 10:15 am ET Coffee break 10:30 am ET Introduction to ROBOT Becky Jackson 11:30 pm ET Introduction to the Ontology Development Kit (ODK) and Core Workflows Nico Matentzoglu 12:15 pm ET How to be an open science ontologist (Slides are here) Nico Matentzoglu"},{"location":"courses/icbo2022/#hands-on-lesson-in-basic-tools","title":"Hands on lesson in basic tools","text":"
The Open Biological and Biomedical Ontologies (OBO) community includes hundreds of open source scientific ontology projects, committed to shared principles and practices for interoperability and FAIR data. An OBO tutorial has been a regular feature of ICBO for a decade, introducing new and experienced ontology users and developers to ontologies in general, and to current OBO tools and techniques specifically. While ICBO attracts many ontology experts, it also includes an audience of ontology beginners, and of ontology users looking to become ontology developers or to further refine their skills. Our OBO tutorial will help beginner and intermediate ontology users with a combination of theory and hands-on practice.
For ICBO 2023 we will host a half-day OBO tutorial consisting of two parts.
The first part of our tutorial will be introductory, aimed at an audience that is new to ontologies and to the OBO Foundry. We will introduce OBO, its community, principles, resources, and best practices. We will finish the first part with a hands-on lesson in basic tools: ontology browsers, how to contribute to ontologies via GitHub (creating issues and making Pull Requests), and the Protege ontology editor.
The second part will build on the first, addressing an audience that is familiar with ontologies and OBO, and wants to make better use of OBO workflows and tools in their own projects.
This material for this year's OBO Tutorial will build on the content here in the OBO Academy. The OBO Academy offers free, open, online resources with self paced learning materials covering various aspects of ontology development and curation and OBO. Participants are encouraged to continue their learning using this OBO Academy website, and contribute to improving the OBO documentation.
The tutorial is designed to be 'show and tell' format, but you are welcome to install the following software on your machine in advance, if you'd like to follow along in real time:
GitHub Desktop
Protege
ROBOT
"},{"location":"courses/icbo2023/#agenda","title":"Agenda","text":"Time Topic Presenter Duration 13:30 pm ET Welcome Tiago Lubiana and Nico Matentzoglu 5 min 13:35 pm ET Introduction to OBO, its community, principles, resources, and best practices Darren Natale 20 min 13:55 pm ET Hands-on lesson in basic tools Sabrina Toro 35 min 14:30 pm ET Protege updates and new features Damien Goutte-Gattat 15 min 14:45 pm ET Overview of OBO Dashboard Anita Caron 15 min 15:00 pm ET Break 15 min 15:15 pm ET Introduction to ROBOT Becky Jackson 30 min 15:45 pm ET Role of ChatGPT in OBO Ontology Development Sierra Moxon 15 min 16:00 pm ET How to be an Open Science Engineer Nico Matentzoglu 15 min 16:15 pm ET Discussion and Wrap up Tiago Lubiana 30 min 16:45 pm ET Adjourn"},{"location":"courses/monarch-obo-training/","title":"OBO Academy - Monarch Training Series","text":""},{"location":"courses/monarch-obo-training/#goal","title":"Goal","text":"
The goal of this course is to provide ongoing training for the OBO community. As with previous tutorials, we follow the flipped classroom concept: as organisers, we provide you with materials to look at, and you will work through the materials on your own. During our biweekly meeting, we will answer your questions, provide you with additional demonstrations where needed and go into depth wherever you as a student are curious to learn more. This means that this course can only work if you are actually putting in the time to preparing the materials. That said, we nevertheless welcome anyone to just lurk or ask related questions.
Check which lessons interest you in the upcoming schedule - just participate in the ones you care about
Prepare the lessons (between 3 and 7 hours of preparation time)
Prepare questions for the revision sessions (without questions, the revision sessions will be silent and awkward)
Make detailed issues on our issue tracker when materials are broken, hard to follow or need more details - that is really important as we rely on you to help to improve our materials continuously.
Request new course units from us using the issue tracker.
"},{"location":"courses/monarch-obo-training/#we-tutors-and-organisers","title":"We (Tutors and Organisers)","text":"
Nicole Vasilevsky, Critical Path Institute
Nico Matentzoglu, Semanticly, Athens, Greece
Sabrina Toro, University of Colorado Anschutz Medical Campus
Sarah Gehrke, University of Colorado Anschutz Medical Campus
Prepare the materials for each lesson and provide schedules
Date Lesson Notes Recordings 2023/10/03 Units modelling in and around OBO James Overton 2023/09/19 Improving ontology interoperability with Biomappings Charlie Hoyt 2023/09/05 Modern prefix management with Bioregistry and curies Charlie Hoyt 2023/08/22 How to determine if two entities are the same? Nico (subject open for debate) 2023/08/08 OMOP Vocabulary Management - how does it work and how does it differ from the OBO way of thinking? Nico (subject open for debate) July 2023 Cancelled: Summer break 2023/06/27 Cancelled 2023/06/13 Modelling with Subclass and Equivalent class statements Tutorial by Henriette Harmse slides 2023/05/30 First steps with ChatGPT for semantic engineers and curators Led by Sierra Moxon and Nico Matentzoglu N/A 2023/05/16 Cancelled (Monarch/C-Path workshop) 2023/05/02 Cancelled (No meeting week) 2023/04/18 Overview of Protege 5.6 - the latest features Tutorial by Damien Goutte-Gattat (slides) Here 2023/04/04 Introduction to Exomiser Tutorial by Valentina, Yasemin and Carlo from QMUL. Here 2023/03/21 Introduction to Wikidata Tutorial by experts in the field Andra Waagmeester and Tiago Lubiana Here 2023/03/07 OAK for the Ontology Engineering community Tutorial by Chris Mungall Here 2023/02/21 OBO Academy Clinic Bring your ontology issues and questions to discuss with Sabrina and Nico! Attend the Ontology Summit Seminars instead! 2023/02/07 Querying the Monarch KG using Neo4J Tutorial by Kevin Schaper Here 2023/01/24 OBO Academy Clinic Bring your ontology issues and questions to discuss with Sabrina and Nico! 2023/01/10 Modeling with taxon constraints Tutorial by Jim Balhoff Here 2022/12/27 No Meeting Enjoy the Holidays! 2022/12/13 Introduction to Semantic Entity Matching Slides Here 2022/11/29 OBO Academy hackathon Work on open tickets together. 2022/11/15 Contributing to OBO ontologies - Part 2 Here 2022/11/01 Contributing to OBO ontologies - Part 1 Here 2022/10/18 Introduction to Medical Action Ontology (MAxO) Here 2022/10/04 No meeting - ISB virtual conference: register here 2022/09/20 How to be an open science ontologist Here 2022/09/06 Pull Requests: Part 2 Here 2022/07/26 Pull Requests: Part 1 Here 2022/07/12 Basic introduction to the CLI: Part 2 Due to intermitent connection issues, the first few minutes of this recording are not included. Refer to the Tutorial link for the initial directions. Here 2022/06/28 Basic introduction to the CLI: Part 1 Here 2022/06/14 Application/project ontologies Here 2022/05/31 Contributing to ontologies: annotation properties Here 2022/05/17 Introduction to managing mappings with SSSOM Here 2022/05/03 No meeting 2022/04/19 Disjointness and Unsatisfiability Here 2022/04/05 No meeting 2022/03/22 Creating an ontology from scratch Here 2022/03/08 Obsoletions in OBO ontologies Review Obsoleting an Existing Ontology Term and Merging Ontology Terms. Slides are here. Here 2022/02/22 SPARQL for OBO ontology development Here 2022/02/07 ODK/DOSDPs Here 2022/01/25 Contributing to OBO ontologies This is not new content but we'll start at the beginning again with our previous lessons. Here 2022/01/11 Office hours with Nicole and Sabrina - no formal lesson Bring any open questions. 2021/12/14 Lessons learned from troubleshooting ROBOT Open discussion, no advance preparation is needed. 2021/11/30 Semantics of object properties (including Relations Ontology) 2021/11/16 SPARQL for OBO ontology development Here 2021/11/02 Templating: DOSDPs and ROBOT 2021/10/19 Ontology Design 2021/10/05 Cancelled due to overlap with ISB conference 2021/09/21 Ontology Pipelines with ROBOT 2 2021/09/08 Migrating legacy ontology systems to ODK 2021/09/07 Ontology Pipelines with ROBOT 2021/09/01 Manage dynamic imports the ODK 2021/08/25 Ontology Release Management with the ODK Here 2021/08/24 Contributing to OBO ontologies 2 Here 2021/08/17 Contributing to OBO ontologies"},{"location":"courses/monarch-obo-training/#notes","title":"Notes","text":"
Most of materials used by this course were developed by James Overton, Becky Jackson, Nicole Vasilevsky and Nico Matentzoglu as part of a project with the Critical Path Institute (see here). The materials are improved as part of an internal training program (onboarding and CPD) for the Phenomics First project (NIH / NHGRI #1RM1HG010860-01).
Thanks to Sarah Gehrke for her help with project management.
"},{"location":"courses/ontology-summit-2023/#schedule","title":"Schedule","text":"Date Lesson Tutors Notes 2023/01/25 Introduction to COB Chris Mungall Slides 2023/02/01 Introduction to ROBOT and OAK James Overton and Chris Mungall
ROBOT Slides
OAK Slides 2023/02/08 Managing the Ontology Life Cycle with the Ontology Development Kit Anita Caron, Damien Goutte-Gattat, Philip Stroemert, Nicolas Matentzoglu
09:00am: Introduction and use cases and workflows
09:15am: Overview of the ODK toolbox
09:30am: Setting up your own repo
10:00am: Advanced customisation, adding a custom SPARQL check
2023/02/15 Using Dashboards to monitor OBO ontologies Charlie Hoyt, Nicolas Matentzoglu, Anita Caron
09:05am: The problem of encouraging and monitoring ontology standardisation (@matentzn, @cthoyt)
09:15am: Overview of the OBO Dashboard: Standardising metadata across OBO Foundry ontologies (@matentzn)
09:30am: Other dashboards for standardising metadata (oquat, versions) (@cthoyt)
09:37am: Dashboards for measuring social workflows (OBO health) (@cthoyt)
09:45am: Using the OBO Dashboard Kit to create your own, customised Dashboard (@anitacaron)
2023/02/02 Using OBO Ontologies: Ubergraph and other applications Jim Balhoff
09:00am: Ubergraph: integrating OBO ontologies into a unified semantic graph
09:35am: SSSOM - Open, FAIR and standardised mappings for ontologies, controlled vocabularies and database entities
"},{"location":"explanation/annotation-properties/","title":"Contributing to ontologies: annotation properties","text":"
Editors: Sabrina Toro (@sabrinatoro), Nicolas Matentzoglu (@matentzn) Examples with images can be found here.
"},{"location":"explanation/annotation-properties/#what-are-annotation-properties","title":"What are annotation properties?","text":"
An entity such as an individual, a class, or a property can have annotations, such as labels, synonyms and definitions. An annotation property is used to link the entity to a value, which in turn can be anything from a literal (a string, number, date etc) to another entity (such as, another class).
Here are some examples of frequently used annotation properties: (every element in bold is an annotation property)
"},{"location":"explanation/annotation-properties/#some-useful-things-to-know-about-annotation-properties","title":"Some useful things to know about annotation properties","text":"
Annotation properties have their own IRIs, just like classes and individuals. For example, the IRI of the RDFS built in label property is http://www.w3.org/2000/01/rdf-schema#label. Other examples:
Annotation properties are just like other entities (classes, individuals) and can have their own annotations. For example, the annotation propert http://purl.obolibrary.org/obo/IAO_0000232 has an rdfs:label ('curator note') and a human readable definition (IAO:0000115): 'An administrative note of use for a curator but of no use for a user'.
Annotation properties can be organised in a hierarchical structure.
For example, the annotation property 'synonym_type_property' (http://www.geneontology.org/formats/oboInOwl#SynonymTypeProperty) is the parent property of other, more specific ones (such as \"abbreviation\").
Annotation properties are (usually) used with specific type of annotation values.
Literal: (one can see [type: xsd:string] in the annotation)
xsd:string
e.g. 'definition' (http://purl.obolibrary.org/obo/IAO_0000115)
xds:boolean
e.g. 'owl:deprecated' (http://www.w3.org/2002/07/owl#deprecated)
Entity IRI :
Classes or individuals: e.g. 'has curation status' (http://purl.obolibrary.org/obo/IAO_0000114)
Arbitray URIs, e.g. links to website with the 'term tracker item' (type xsd:anyURI) (http://purl.obolibrary.org/obo/IAO_0000233) property
Or even other annotation properties *
e.g. 'has_synonym_type' (http://www.geneontology.org/formats/oboInOwl#hasSynonymType)
e.g. 'in_subset' (http://purl.obolibrary.org/obo/IAO_0000112)
Note: the type of annotation required for an annotation property can be defined by adding a Range + \"select datatype\" in the Annotation Property's Description e.g. : 'scheduled for obsoletion on or after' (http://purl.obolibrary.org/obo/IAO_0006012)
Annotations do not affect reasoning. No matter what values you connect with your annotation properties, the reasoner will ignore it - even if it is nonsensical.
"},{"location":"explanation/annotation-properties/#annotation-property-vs-data-and-object-properties","title":"Annotation Property vs Data and Object Properties","text":"
Some annotation properties look like data properties (connecting an entity to a literal value) and others look like object properties (connecting an entity to another entity). Other than the fact that statements involving data and object properties look very different in RDF, the key difference from a user perspective is that OWL Reasoners entirely ignore triples involving annotation properties. Data and Object Properties are taken into account by the reasoner.
Object properties are different to annotation properties in that they:
connect pairs of individuals in way that affects reasoning
represent relationship between classes in way that affects reasoning
Example property: 'has part' (http://purl.obolibrary.org/obo/BFO_0000051)
Object Properties can have the following property characteristics: Inverse, Symmetric, Asymmetric, Reflexive, Irreflexive, Functional, Inverse Functional, and Transitive which effect reasoning. Annotation properties cannot have such properties (or if they had, reasoners would ignore them).
Data properties are different to annotation properties in that they:
connect individuals with literals in way that affects reasoning
represent relation between a class and literal in way that affects reasoning
You can use data properties to logically define OWL classes with data ranges. For example, you can define the class of Boomer as all people born between 1946 and 1964. If an individual would be asserted to be a Boomer, but is born earlier than 1946, the reasoner would file a complaint.
Example Data Property: 'hasName', 'hasPrice', 'hasCalories', 'hasSugarContent',...
More details on how to use Data Properties here
"},{"location":"explanation/annotation-properties/#creating-new-annotation-properties","title":"Creating new Annotation Properties","text":"
Note: before creating a new annotation property, it is always a good idea to check for an existing annotation property first.
For example: OBO Metadata Ontology (https://www.ebi.ac.uk/ols/ontologies/omo), which could be imported
Detailed explanations for adding a new annotation property can be found here
"},{"location":"explanation/annotation-properties/#the-term-annotation-in-ontologies-and-data-curation-means-different-things","title":"The term \"Annotation\" in Ontologies and Data Curation means different things.","text":"
The word \"annotation\" is used in different contexts to mean different things. For instance, \"annotation in owl\" (ie annotations to an ontology term) is different from \"annotation in the biocuration sense\" (ie gene-to-disease, gene-to-phenotype, gene-to-function annotations). It is therefore crucial to give context when using the word \"annotation\".
ObjectProperty: r\nClass: D\n EquivalentTo: r some C\nClass: C\n
the semantics of r some C is the set of individuals such that for each individual x there is at least 1 individual y of type C that is linked to x via the object property r.
Based on this semantics, a possible world adhering to our initial equivalence axiom may be:
In this Venn diagram we assume individuals are black dots. Thus, our world consists of 7 individuals, with only 2 classes, namely C and D, as well 2 object properties, namely r and q. In this world, D and thus the class r some C, consist of only 2 individuals. D and r some C consist of only 2 individuals because these are the only individuals linked via object property r to at least 1 individual respectively in C.
In the following we define a pet owner as someone that owns at least 1 pet.
ObjectProperty: owns\nClass: PetOwner\n EquivalentTo: owns some Pet\nClass: Pet\n
If we want to introduce the class DogOwner, assuming we can only use the class Pet and the object property owns (assuming we have not defined PetOwner), we could say that a dog owner is a subset of pet owners:
ObjectProperty: owns\nClass: DogOwner\n SubClassOf: owns some Pet\nClass: Pet\n
In this case we use SubClassOf instead of EquivalentTo because not every pet owner necessarily owns a dog. This is equivalent to stating:
"},{"location":"explanation/existential-restrictions/#variations-on-existential-restrictions","title":"Variations on existential restrictions","text":""},{"location":"explanation/existential-restrictions/#unqualified-existential-restrictions","title":"Unqualified existential restrictions","text":"
In the previous section we modeled a PetOwner as owns some Pet. In the expression owns some PetPet is referred to as the filler of owns and more specifically we say Pet is the owns-filler.
The PetOwner EquivalentTo: owns some Pet state that pet owners are those individuals that own a pet and ignore all other owns-fillers that are not pets. How can we define arbitrary ownership?
ObjectProperty: owns\nClass: Owner\n EquivalentTo: owns some owl:Thing\n
"},{"location":"explanation/existential-restrictions/#existential-restrictions-on-data-properties","title":"Existential restrictions on data properties","text":"
This far we have only considered existential restrictions based on object properties, but it is possible to define existential restrictions based on data properties. As an example, we all expect that persons have at least 1 name. This could be expressed as follows:
DataProperty: name\nClass: Person\n SubClassOf: name some xsd:string\n
"},{"location":"explanation/existential-restrictions/#when-to-use-subclassof-vs-equivalentto-with-existential-restrictions","title":"When to use SubClassOf vs EquivalentTo with existential restrictions","text":"
In our example of Person SubClassOf: name some xsd:string, why did we use SubClassOf rather than EquivalentTo? That is, why did we not use Person EquivalentTo: name some xsd:string? With using the EquivalentTo axiom, any individual that has a name, will be inferred to be an instance of Person. However, there are many things in the world that have names that are not persons. Some examples are pets, places, regions, etc:
Compare this with, for example, DogOwner:
ObjectProperty: owns\nClass: Dog\nClass: DogOwner\n EquivalentTo: owns some Dog\n
"},{"location":"explanation/intro-to-ontologies/","title":"Introduction to ontologies","text":"
Based on CL editors training by David Osumi-Sutherland
"},{"location":"explanation/intro-to-ontologies/#why-do-we-need-ontologies","title":"Why do we need ontologies?","text":"
We face an ever-increasing deluge of biological data analysis. Ensuring that this data and analysis are Findable, Accessible, Interoperable, and Re-usable (FAIR) is a major challenge. Findability, Interoperabiltiy, and Resuability can all be enhanced by standardising metadata. Well-standardised metadata can make it easy to find data and analyses despite variations in terminology ('Clara cell' vs 'nonciliated bronchiolar secretory cell' vs 'club cell') and precision ('bronchial epithelial cell' vs 'club cell'). Understanding which entities are referred to in metadata and how they relate to the annotated material can help users work out if the data or analysis they have found is of interest to them and can aid in its re-use and interoperability with other data and analyses. For example, does an annotation of sample data with a term for breast cancer refer to the health status of the patient from which the sample was derived or that the sample itself comes from a breast cancer tumor?
"},{"location":"explanation/intro-to-ontologies/#we-cant-find-what-were-looking-for","title":"We can't find what we're looking for","text":"
Given variation in terminology and precision, annotation with free text alone is not sufficient for findability. One very lightweight solution to this problem is to rely on user-generated keyword systems, combined with some method of allowing users to choose from previously used keywords. This can produce some degree of annotation alignment but also results in fragmented annotation and varying levels of precision with no clear way to relate annotations.
For example, trying to refer to feces, in NCBI BioSample:
Query Records Feces 22,592 Faeces 1,750 Ordure 2 Dung 19 Manure 154 Excreta 153 Stool 22,756 Stool NOT faeces 21,798 Stool NOT feces 18,314"},{"location":"explanation/intro-to-ontologies/#we-dont-know-what-were-talking-about","title":"We don't know what we're talking about","text":"
Terminology alone can be ambiguous. The same term may be used for completely unrelated or vaguely analogous structures. An insect femur and an mammalian femur are neither evolutionarily related nor structurally similar. Biologists often like to use abbreviations to annotate data, but these can be extremely ambiguous. Drosophila biologists use DA1 to refer to structures in the tracheal system, musculature and nervous system. Outside of Drosophila biology it is used to refer to many other things including a rare disease, and a a neuron type in C.elegans.
Some extreme examples of this ambiguity come from terminological drift in fields with a long history. For example in the male genitalia of a gasteruptiid wasp, these 5 different structures here have each been labeled \"paramere\" by different people, each studying different hymenopteran lineages. How do we know what \"paramere\" means when it is referred to?
This striking example shows that even precise context is not always sufficient for disambiguation.
Rather than rely on users to generate lists of re-usable keywords, we can instead pre-specify a set of terms to use in annotation. This is usually refered to a controlled vocabulary or CV.
Terms are arranged in a hierarchy, typically from general (top) to specific (bottom) with each term having only one parent.
Terms are usually not defined.
Relationships between the terms are usually not named or defined
"},{"location":"explanation/intro-to-ontologies/#example-using-wines-taxonomy-of-wine","title":"Example using wines (Taxonomy of wine)","text":"
Red
Merlot
Zinfandel
Cabernet
Pinot Noir
White
Chardonnay
Pinot Gris
Riesling
Taxonomy describes a hierarchical CV in which hierarchy equals classification. E.g., 'Merlot' is classified as a 'Red' (wine). Not all hierchical CVs are classifications. For example, anatomical atlases often have hierarchical CVs representing \"parthood\". The femur is a part of the leg, but it is not 'a leg'.
"},{"location":"explanation/intro-to-ontologies/#support-for-grouping-and-varying-levels-of-precision","title":"Support for grouping and varying levels of precision","text":"
The use of a hierachical CV in which general terms group more specific terms allows for varying precision (glial cell vs some specific subtype) and simple grouping of annotated content.
For example:
"},{"location":"explanation/intro-to-ontologies/#from-hierarchical-cvs-to-ontologies","title":"From hierarchical CVs to ontologies","text":"
Hierarchical CVs tend to increase in complexity in particular ways:
To support findability, terms in hierarchical CVs often need to be associated with synonyms, or cross-referenced to closely related terms inside the CV.
CV content is often driven by requests from annotators and so expansion is not driven by any unified vision of scheme. This often leads to pressure for hierarchies to support terms having multiple parents, either reflecting multiple relationship types, or multiple types of classification. For example, an anatomical CV could reasonably put 'retinal bipolar cell' under 'retina' based on location and, at the same time, under 'bipolar neuron' and 'glutamatergic neuron' based on cell type classification.
Developers of hierarchical CVs often come to realise that multiple relationship types are represented in the hierarchy and that it can be useful to name these relationship for better distinction. For example, a heart glial cell is a 'type of' glial cell, but is 'part of' the heart.
"},{"location":"explanation/intro-to-ontologies/#what-is-an-ontology","title":"What is an ontology?","text":""},{"location":"explanation/intro-to-ontologies/#definition_1","title":"Definition","text":"
Definitions of ontologies can be controversial. Rather than attempting a comprehensive definition, this tutorial will emphasise ontologies as:
Classifications
Queryable stores of knowledge
"},{"location":"explanation/intro-to-ontologies/#key-features-of-well-structured-ontologies","title":"Key features of well-structured ontologies:","text":"
Terms are arranged in a classification hierarchy
Terms are defined
Terms are richly annotated:
Textual definitions
References
Synonyms
Links
Cross-references
Relationships between terms are defined, allowing logical inference and sophisticated queries as well as graph representations.
Expressed in a knowledge representation language such as RDFS, OBO, or OWL
"},{"location":"explanation/intro-to-ontologies/#non-logical-parts-of-ontologies","title":"Non-logical parts of ontologies","text":"
Terminology can be ambiguous, so text definitions, references, synonyms and images are key to helping users understand the intended meaning of a term.
"},{"location":"explanation/intro-to-ontologies/#identifiers","title":"Identifiers","text":""},{"location":"explanation/intro-to-ontologies/#using-identifiers-devoid-of-intrinsic-meaning","title":"Using identifiers devoid of intrinsic meaning","text":"
Identifiers that do not hold any inherent meaning are important to ontologies. If you ever need to change the names of your terms, you're going to need identifiers that stay the same when the term name changes.
For example:
A microglial cell is also known as: hortega cell, microglia, microgliocyte and brain resident macrophage. In the cell ontology, it is however referred to by a unique identifier: CL:0000129 These identifiers are short ways of referring to IRIs (e.g., CL:000129 = http://purl.obolibrary.org/obo/CL_0000129) This IRI is a unique, resolvable identifier on the web. A group of ontologies - loosely co-ordinated through the OBO Foundry, have standardised their IRIs (e.g. http://purl.obolibrary.org/obo/CL_0000129 - A term in the cell ontology; http://purl.oblibrary.org/obo/cl.owl - The cell ontology)
URI: Unique Resource Identifier - a string of characters, following a standard specification, that unambiguously identifies a particular (web) resource.
IRI: Internationalised Resource Identifier - a URI that can use characters in multiple languages.
URL: Uniform Resource Locator - a web-resolvable URI.
OBO ontologies are mostly written in OWL2 or OBO syntax. The latter is a legacy format that maps completely to OWL.
For a more in-depth explanation of formats (OWL, OBO, RDF etc.) refer to explainer on OWL format variants. In the examples below we will use OWL Manchester syntax, which allows us to express formal logic in English-like sentences.
"},{"location":"explanation/intro-to-ontologies/#an-ontology-as-a-classification","title":"An ontology as a classification","text":"
Ontology terms refer to classes of things in the world. For example, the class of all wings.
Below you will see a classification of parts of the insect and how it is represented in a simple ontology.
We use a SubClassOf (or is_a in obo format) to represent that one class fully subsumes another. For example: OWL: hindwing SubClassOf wing OBO: hindwing is_a wing
In English we might say: \"a hindwing is a type of wing\" or more specifically, \"all instances of hindwing are instances of wing.\" 'Instance' here refers to a single wing of an individual fly.
In the previous section, we talked about different types of relationships. In OWL we can define specific relations (known as object properties). One of the commonest is 'part of' which you can see used below.
English: all (insect) legs are part of a thoracic segment OWL: 'leg' SubClassOf part_of some thoracic segment OBO: 'leg'; relationship: part_of thoracic segment
It might seem odd at first that OWL uses subClassOf here too. The key to understanding this is the concept of an anonymous class - in OWL, we can refer to classes without giving them names. In this case, the anonymous class is the class of all things that are 'part of' (some) 'thoracic segment' (in insects). A vast array of different anatomical structures are subclasses of this anonymous class, some of which, such as wings, legs, and spiracles, are visible in the diagram.
Note the existential quantifier some in OWL format -- it is interpreted as \"there exists\", \"there is at least one\", or \"some\".
The quantifier is important to the direction of relations.
subClassOf: 'wing' SubClassOf part_of some 'thoracic segment' is correct 'thoracic segment' SubClassOf has_part some 'wing' is incorrect as it implies all thoracic segment have wings as a part.
Similarly: 'claw' SubClassOf connected_to some 'tarsal segment' is correct 'tarsal segment' SubClassOf connected_to some 'claw' is incorrect as it implies all tarsal segments are connected to claws (for example, some tarsal segments are connected to other tarsal segments)
These relationships store knowledge in a queryable format. For more information about querying, please refer to guide on DL queries and SPARQL queries.
There are many ways to classify things. For example, a neuron can be classified by structure, electrophysiology, neurotransmitter, lineage, etc. Manually maintaining these multiple inheritances (that occur through multiple classifications) does not scale.
Problems with maintaining multiple inheritance classifications by hand
Doesn\u2019t scale
When adding a new class, how are human editors to know
all of the relevant classifications to add?
how to rearrange the existing class hierarchy?
It is bad for consistency
Reasons for existing classifications often opaque
Hard to check for consistency with distant superclasses
Doesn\u2019t allow for querying
A formalized ontology can be queried for classes with arbitrary sets of properties. A manual classification can not.
The knowledge an ontology contains can be used to automate classification. For example:
English: Any sensory organ that functions in the detection of smell is an olfactory sensory organ OWL:
'olfactory sensory organ'\n EquivalentTo \u2018sensory organ\u2019\nthat\ncapable_of some \u2018detection of smell\u2019\n
If we then have an entity nose that is subClassOf sensory organ and capable_of some detection of smell, it will be automatically classified as an olfactory sensory organ.
"},{"location":"explanation/intro-to-ontologies/#how-to-interpret-an-and-or-an-or","title":"How to interpret an 'and' or an 'or'","text":"
Many classes, especially in the domains of disease and phenotype, describe combinations of multiple classes - but it is very important to carefully distinguish whether this combination follows \"disjunctive\" logic (\"or\") or \"conjunctive\" logic (\"and\"). Both mean something entirely different. Usually where a class has 'and' in the label, such as 'neonatal inflammatory skin and bowel disease' (MONDO:0017411), the class follows a conjunctive logic (as expected), and should be interpreted in a way that someone that presents with this disease has both neonatal inflammatory skin disease and bowel disease at once. This class should be classified as a child of 'bowel disease' and 'neonatal inflammatory skin disease'. Note, however, that naming in many ontologies is not consistent with this logic, and you need to be careful to distinguish wether the interpretation is supposed to be conjunctive or disjunctive (i.e. \"and\" could actually mean \"or\", which is especially often the case for clinical terminologies).
Having asserted multiple SubClassOf axioms means that an instance of the class is a combination of all the SubClass Of statements (conjunctive interpretation, see above). For example, if 'neonatal inflammatory skin and bowel disease' is a subclass of both 'bowel disease' and 'neonatal inflammatory skin disease', then an individual with this disease has 'bowel disease' and 'neonatal inflammatory skin disease'.
If there were a class 'neonatal inflammatory skin or bowel disease', the intention is usually that this class follows disjunctive logic. A class following this logic would be interpreted in a way that an individual with this disease has either bowel disease or neonatal inflammatory skin disease or both. It would not be accurate to classify this class as a child of bowel disease and neonatal inflammatory skin disease. This type of class is often called a \"grouping class\", and is used to aggregate related diseases in a way useful to users, like \"disease\" and \"sequelae of disease\".
David Osumi-Sutherland (original creator of slides)
Nicole Vasilevsky (Critical Path Institute)
Alex Diehl (Buffalo)
Nico Matentzoglu
Matt Brush
Matt Yoder
Carlo Toriniai
Simon Jupp
Chris Mungall (LNBL)
Melissa Haendal (University of Colorado Anschutz Medical Campus)
Jim Balhoff (RENCI)
James Overton - slides, ideas & discussions
Terry Meehan - who edited CL more than anyone
Helen Parkinson (EBI)
Michael Ashburner
"},{"location":"explanation/logical-axiomatization/","title":"Logical axiomatization of classes & use of reasoning","text":"
This explainer requires understanding of ontology classifications. Please see \"an ontology as a classification\" section of the introduction to ontologies documentation if you are unfamiliar with these concepts.
You can watch this video about an introduction to Logical Description.
"},{"location":"explanation/logical-axiomatization/#what-are-logical-axioms","title":"What are logical axioms","text":"
Logical axioms are relational information about classes that are primarily aimed at machines. This is opposed to annotations like textual definitions which are primarily aimed at humans. These logical axioms allow reasoners to assist in and verify classification, lessening the development burden and enabling expressive queries.
"},{"location":"explanation/logical-axiomatization/#what-should-you-axiomatize","title":"What should you axiomatize?","text":"
Ideally, everything in the definition should be axiomatized when possible. For example, if we consider the cell type oxytocin receptor sst GABAergic cortical interneuron, which has the textual definition:
\"An interneuron located in the cerebral cortex that expresses the oxytocin receptor. These interneurons also express somatostatin.\"
The logical axioms should then follow accordingly:
SubClassOf:
interneuron
'has soma location' some 'cerebral cortex'
expresses some 'oxytocin receptor'
expresses some somatostatin
'capable of' some 'gamma-aminobutyric acid secretion, neurotransmission'
These logical axioms allow a reasoner to automatically classify the term. For example, through the logical axioms, we can infer that oxytocin receptor sst GABAergic cortical interneuron is a cerebral cortex GABAergic interneuron.
Axiomatizing definitions well will also allow for accurate querying. For example, if I wanted to find a neuron that expresses oxytocin receptor, having the SubClassOf axioms of interneuron and expresses some 'oxytocin receptor' will allow me to do so on DL query (see tutorial on DL query for more information about DL queries).
"},{"location":"explanation/logical-axiomatization/#what-should-you-not-axiomatize","title":"What should you NOT axiomatize?","text":"
Everything in the logical axioms must be true, (do not axiomatize things that are true to only part of the entity) For example, the cell type chandelier pvalb GABAergic cortical interneuron is found in upper L2/3 and deep L5 of the cerebral cortex. We do not make logical axioms for has soma location some layer 2/3 and layer 5. Axioms with both layers would mean that a cell of that type must be in both layer 2/3 and layer 5, which is an impossibility (a cell cannot be in two seperate locations at once!). Instead we axiomatize a more general location: 'has soma location' some 'cerebral cortex'
"},{"location":"explanation/logical-axiomatization/#equivalent-class-logical-definitions","title":"Equivalent class logical definitions","text":"
An equivalent class axiom is an axiom that defines the class; it is a necessary and sufficient logical axiom that defines the cell type. It means that if a class B fulfils all the criteria/restrictions in the equivalent axiom of class A, class B is by definition a subclass of class A. Equivalent classes allow the reasoner to automatically classify entities.
For example:
chandelier cell has the equivalent class axiom interneuron and ('has characteristic' some 'chandelier cell morphology')
chandelier pvalb GABAergic cortical interneuron has the subclass axioms 'has characteristic' some 'chandelier cell morphology' and interneuron
chandelier pvalb GABAergic cortical interneuron is therefore a subclass of chandelier cell
Equivalent class axioms classification can be very powerful as it takes into consideration complex layers of axioms.
For example:
primary motor cortex pyramidal cell has the equivalent class axiom 'pyramidal neuron' and ('has soma location' some 'primary motor cortex').
Betz cell has the axioms 'has characteristic' some 'standard pyramidal morphology' and 'has soma location' some 'primary motor cortex layer 5'
Betz cell are inferred to be primary motor cortex pyramidal cell through the following chain (you can see this in Prot\u00e9g\u00e9 by pressing the ? button on inferred class):
The ability of the reasoner to infer complex classes helps identify classifications that might have been missed if done manually. However, when creating an equivalent class axiom, you must be sure that it is not overly constrictive (in which case, classes that should be classified under it gets missed) nor too loose (in which case, classes will get wrongly classified under it).
Example of both overly constrictive and overly loose equivalent class axiom:
neuron equivalent to cell and (part_of some 'central nervous system')
This is overly constrictive as there are neurons outside the central nervous system (e.g. peripheral neurons).
This is also too loose as there are cells in the central nervous system that are not neurons (e.g. glial cells).
In such cases, sometimes not having an equivalent class axioms is better (like in the case of neuron), and asserting is the best way to classify a child.
Each ontology has certain styles and conventions in how they axiomatize. This style guide is specific to OBO ontologies. We will also give reasons as to why we choose to axiomatize in the way we do. However, be aware of your local ontology's practices.
"},{"location":"explanation/logical-axiomatization/#respect-the-ontology-style","title":"Respect the ontology style","text":"
It is important to note that ontologies have specific axiomatization styles and may apply to, for example, selecting a preferred relation. This usually reflects their use cases. For example, the Cell Ontology has a guide for what relations to use. An example of an agreement in the community is that while anatomical locations of cells are recorded using part of, neurons should be recorded with has soma location. This is to accommodate for the fact that many neurons have long reaching axons that cover multiple anatomical locations making them difficult to axiomatize using part of.
For example, Betz cell, a well known cell type which defines layer V of the primary motor cortex, synapses lower motor neurons or spinal interneurons (cell types that reside outside the brain). Having the axiom 'Betz cell' part_of 'cortical layer V' is wrong. In this case has soma location is used. Because of cases like these that are common in neurons, all neurons in CL should use has soma location.
Do not add axioms that are not required. If a parent class already has the axiom, it should not be added to the child class too. For example:
retinal bipolar neuron is a child of bipolar neuron
bipolar neuron has the axiom 'has characteristic' some 'cortical bipolar morphology'
Therefore we do not add 'has characteristic' some 'cortical bipolar morphology' to retinal bipolar neuron
Axioms add lines to the ontology, resulting in larger ontologies that are harder to use. They also add redundancy, making the ontology hard to maintain as a single change in classification might require multiple edits.
"},{"location":"explanation/logical-axiomatization/#let-the-reasoner-do-the-work","title":"Let the reasoner do the work","text":"
Asserted is_a parents do not need to be retained as entries in the 'SubClass of' section of the Description window in Prot\u00e9g\u00e9 if the logical definition for a term results in their inference.
For example, cerebral cortex GABAergic interneuron has the following logical axioms:
Equivalent_To\n 'GABAergic interneuron' and\n ('has soma location' some 'cerebral cortex')\n
We do not need to assert that it is a cerebral cortex neuron, CNS interneuron, or neuron of the forebrain as the reasoner automatically does that.
We avoid having asserted subclass axioms as these are redundant lines in the ontology which can result in a larger ontology, making them harder to use.
Good practice to let the reasoner do the work:
1) If you create a logical definition for your term, you should delete all redundant, asserted is_a parent relations by clicking on the X to the right of the term.\n2) If an existing term contains a logical definition and still shows an asserted is_a parent in the 'SubClass of' section, you may delete that asserted parent. Just make sure to run the Reasoner to check that the asserted parent is now replaced with the correct reasoned parent(s).\n3) Once you synchronize the Reasoner, you will see the reasoned classification of your new term, including the inferred is_a parent(s).\n4) If the inferred classification does not contain the correct parentage, or doesn't make sense, then you will need to modify the logical definition.\n
10 min overview of J\u00e9r\u00f4me Euzenat and Pavel Shvaiko ground-breaking Ontology Matching.
"},{"location":"explanation/owl-building-blocks/","title":"The logical building blocks of OWL","text":"
Here we briefly list the building blocks that are used in OWL that enable reasoning.
OWL Semantics Example instance or individual A member of a set. A person called Mary or a dog called Fido. class A set of in dividuals. The Person class consisting of persons or the Dog class consisting of dogs. object property A set of pairs of individuals. The owns object property can link a pet and its owner: Mary owns Fido. data property A set of pairs where each pair consists of an individual linked to a data value. The data property hasAge can link a number representing an age to an individual: hasAge(Mary, 10)."},{"location":"explanation/owl-format-variants/","title":"OWL, OBO, JSON? Base, simple, full, basic? What should you use, and why?","text":"
For reference of the more technical aspects of release artefacts, please see documentation on Release Artefacts
Ontologies come in different serialisations, formalisms, and variants For example, their are a full 9 (!) different release files associated with an ontology released using the default settings of the Ontology Development Kit, which causes a lot of confusion for current and prospective users.
Note: In the OBO Foundry pages, \"variant\" is currently referred to as \"products\", i.e. the way we use \"variant\" here is synonymous with with notion of \"product\".
"},{"location":"explanation/owl-format-variants/#overview-of-the-relevant-concepts","title":"Overview of the relevant concepts","text":"
A formalism or formal language can be used to describe entities and their relationships in an ontology. The most important formalisms we have are:
Web Ontology Language (OWL): OWL is by far the dominant formalism in the biomedical domain due to its inference capabilities.
RDF(S): Is a generally weaker language than OWL, but widely used by triple stores and other SPARQL engines. RDF(S) is lacking some of the strong logical guarantees that come with OWL and should only be used in scenarios where scalability (computation time) is the primary concern.
OBO: OBO used to be the dominant language in the biomedical domain before the advent of OWL. I also used to have its own specific semantics associated with it. OBO semantics have since been mapped into OWL semantics, so that for all practical purposes, we consider \"OBO\" now a dialect of OWL, which means that when you hear 'OBO format' today, we are generally referring to the serialisation (see below), NOT the formalism. Note that when we say OBO ontologies we mean literally Open Biomedical and Biological Ontologies, and NOT Ontology in OBO format.
Some people like to also list SHACL and Shex as ontology languages and formalism. Formalisms define syntax (e.g. grammar rules) and semantics (what does what expression mean?). The analogue in the real world would be natural languages, like English or Greek.
A format, or serialisation of a language is used to write down statements of a formal language in some way. Formats are not formalisms - they simply enable statements in a formalism to be expressed in some (usually textual) way. The most common formats in our domains are:
RDF/XML. This is the default serialisation language of the OWL flavours of OBO ontologies. It is a pretty ugly format, really hard to understand by most users but it has one advantage - it can be understood widely by RDF-focused tools like rdflib, OWL-focused tools like those based on the OWL API
OWL Functional Syntax: This is very common syntax for editing ontologies in OWL, because they look nice in diff tools such as git diff, i.e changes to ontologies in functional syntax are much easier to be reviewed. RDF/XML is not suitable for manual review, due to its verbosity and complexity.
OWL Manchester Syntax: This is the default language for OWL tutorials and for writing class expressions in editors such as Protege
OBO Format: The most easy to read of all the serialisations. In many ontologies such as Mondo and Uberon, we still use OBO as the editors format (as opposed to OWL Functional Syntax, which is more wide-spread). OBO format looks clear and beautiful in diffs such as git diffs, and therefore still continues to be wide-spread. OBO Format does not cover all of owl, and should only be used in conjunction with ontologies that stay within the limit of the OBO format specification.
OBO Graphs JSON: A simple JSON serialisation of ontologies. This format roughly reflects the capabilities of the OBO format, but is intended for consumption by tools. Again, it does not cover all of OWL, but it does cover the parts that are relevant in 99% of the use cases.
The real-world analogue of serialisation or format is the script, i.e. Latin or Cyrillic script (not quite clean analogue).
A variant is a version of the ontology exported for a specific purpose. The most important variants are:
Edit: The variant of the ontology that is edited by ontology curators. Its sole purpose is to be used by ontology editors, and should not be used by any other application. In a ODK-style repository, the edit file is typically located hidden from view, e.g. src/ontology/cl-edit.owl.
Full: The ontology with all its imports merged in, and classified using a reasoner, see docs. The Full variant should be used by users that require the use of reasoners and a guarantee that all the inferences work as intended by the ontology developers. This is the default variant of most OBO ontologies.
Base: The axioms belonging to the ontology, excluding any axioms from imported ontologies, see docs. Base variants are used by ontology repository developers to combine the latest versions of all ontologies in a way that avoids problems due to conflicting versions. Base files should not be used by users that want to use the ontology in downstream tools, such as annotation tools or scientific databases, as they are incomplete, i.e. not fully classified.
Simple: A version of the ontology that only contains only a subset of the ontology (only the direct relations, see docs). The simple variant should be used by most users that build tools that use the ontology, especially when serialised as OBO graphs json. This variant should probably be avoided by power-users working with reasoners, as many of the axioms that drive reasoning are missing.
Basic: A variant of Simple, in that it is reduced to only a specific set of relations, such as subClassOf and partOf. Some users that require the ontology to correspond to acyclic graphs, or deliberately want to focus only on a set of core relations, will want to use this variant, see docs). The formal definition of the basic variant can be found here.
Other variants: Some variants are still used, like \"non-classified\", see docs), but should be avoided. Others like base-plus, a variant that corresponds to base + the inferred axioms, are still under development, and will be explained here when they are fully developed.
Tool developers developing tools that use the ontology (and do not need reasoners), such as database curation tools, web-browsers and similar, should typically use OBO graphs JSON and avoid using OBO format or any of the OWL focussed serialisations (Functional, Manchester or RDF/XML). OWL-focussed serialisations contain a huge deal of axiomatic content that make no sense to most users, and can lead to a variety of mistakes. We have seen it many times that software developers try to interpret OWL axioms somehow to extract relations. Do not do that! Work with the ontologies to ensure they provide the relationships you need in the appropriate form.
Tool developers building tools to work with ontologies should typically ensure that they can read and write RDF/XML - this is the most widely understood serialisation. Work with ontologies means here 'enable operations that change the content of the ontology'.
Tool developers building infrastructure to query across ontologies should consider using base variants - these ensure that you can always use the latest version of each ontology and avoid most of the common version clashes. It is important that such users are keenly aware of the role of OWL reasoning in such a process.
Many users of ontologies think they need the reasoner actually don't. Make sure you consult with an expert before building a system that relies on OWL reasoners to deliver user facing services.
As an ontology developer, it is great practice to provide the above variants in the common serialisations. The Ontology Development Kit provides defaults for all of these.
As an ontology developer, you should avoid publishing your ontology with owl:imports statements - these are easily ignored by your users and make the intended \"content\" of the ontology quite none-transparent.
"},{"location":"explanation/subClassOf-vs-equivalentTo/","title":"SubClassOf vs EquivalentTo","text":""},{"location":"explanation/subClassOf-vs-equivalentTo/#prerequisites","title":"Prerequisites","text":"
This lesson assumes you have basic knowledge wrt ontologies and OWL as explained in:
the semantics of it is given by the following Venn diagram:
Thus, the semantics is given by the subset relationship, stating the C is a subset of D. This means every individual of C is necessarily an individual of D, but not every individual of D is necessarily an individual of C.
There are at least 2 scenarios which at first glance may seem like C SubClassOf D holds, but it does not hold, or using C EquivalentTo D may be a better option.
This is typically where C has many individuals that are in D, but there is at least 1 individual of C that is not in D. The following Venn diagram is an example. Thus, to check whether you may be dealing with this scenario, you can ask the following question: Is there any individual in C that is not in D? If 'yes', you are dealing with this scanario and you should not be using C SubClassOf D.
When you have determined that (1) does not hold, you may deal with the scenario where not only is every individual of C in D, but also every individual in D is in C. This means C and D are equivalent. In the case you rather want to make use of EquivalentTo.
When there is an individual of C that is not in D.
When there is an individual of D that is not in C.
"},{"location":"explanation/taxon-constraints-explainer/","title":"Guide to Taxon Restrictions","text":""},{"location":"explanation/taxon-constraints-explainer/#tutorials","title":"Tutorials","text":""},{"location":"explanation/taxon-constraints-explainer/#monarch-obo-training-tutorial","title":"Monarch OBO training Tutorial","text":""},{"location":"explanation/taxon-constraints-explainer/#modeling-with-taxon-constraints","title":"Modeling with Taxon Constraints","text":""},{"location":"explanation/taxon-constraints-explainer/#what-are-taxon-restrictions","title":"What are taxon restrictions?","text":"
Taxon restrictions (or, \"taxon constraints\") are a formalised way to record what species a term applies to\u2014something crucial in multi-species ontologies.
Even species neutral ontologies (e.g., GO) have classes that have implicit taxon restriction.
GO:0007595 ! Lactation - defined as \u201cThe secretion of milk by the mammary gland.\u201d\n
"},{"location":"explanation/taxon-constraints-explainer/#uses-for-taxon-restrictions","title":"Uses for taxon restrictions","text":"
Finding inconsistencies. Taxon restrictions use terms from the NCBI Taxonomy Ontology, which asserts pairwise disjointness between sibling taxa (e.g., nothing can be both an insect and a rodent). When terms have taxon restrictions, a reasoner can check for inconsistencies.
When GO implemented taxon restrictions, they found 5874 errors!
Defining taxon-specific subclasses. You can define a taxon-specific subclass of a broader concept, e.g., 'human clavicle'. This allows you, for example, to assert relationships for the new term that don't apply to all instances of the broader concept:
'human clavicle' EquivalentTo ('clavicle bone' and ('in taxon' some 'Homo sapiens'))\n'human clavicle' SubClassOf ('connected to' some sternum)\n
Creating SLIMs. Use a reasoner to generate ontology subsets containing only those terms that are logically allowed within a given taxon.
Querying. Facet terms by taxon. E.g., in Brain Data Standards, in_taxon axioms allow faceting cell types by species. (note: there are limitations on this and may be incomplete).
"},{"location":"explanation/taxon-constraints-explainer/#types-of-taxon-restrictions","title":"Types of Taxon Restrictions","text":"
There are, in essence, three categories of taxon-specific knowledge we use across OBO ontologies. Given a class C, which could be anything from an anatomical entity to a biological process, we have the following categories:
Meaning: \"All instances of C are in some instance of taxon T\"
As this is a relation between instances, it may have been more correct to give this property a label such as \"in organism\".
Canonical logical representation:
C SubClassOf (in_taxon some T)\n
Alternative representations: None
Editor guidance: Editors use the canonical logical representation in a SubClassOf axiom to add a taxon restriction, or in a simple (non-nested) EquivalentClass axiom to define a taxon-specific subclass (which will also imply the taxon restriction). When used in a SubClassOf axiom, the taxon should be as specific as possible for the maximum utility, but may still need to be quite broad, as it applies to every instance of C.
"},{"location":"explanation/taxon-constraints-explainer/#the-not-in-restriction-c-subclassof-not-in_taxon-some-t","title":"The NOT-IN restriction: \"C SubClassOf (not (in_taxon some T))\"","text":"
Meaning: \"No instances of C are in taxon T\"
Canonical logical representation:
C SubClassOf (not (in_taxon some T))`\n
Alternative representations:
Alternative EL logical representation: C DisjointWith (in_taxon some T)
EL helper axiom: C SubClassOf (in_taxon some (not T))
Canonical shortcut: AnnotationAssertion: C never_in_taxon T # Editors use this
Editor guidance: Editors use the canonical shortcut (annotation axiom). For never_in_taxon annotations, the taxon should be as broad as possible for the maximum utility, but it must be the case that a C is never found in any subclass of that taxon.
"},{"location":"explanation/taxon-constraints-explainer/#the-some-in-restriction-a-classassertion-c-and-in_taxon-some-t","title":"The SOME-IN restriction: \"a ClassAssertion: C and in_taxon some T\"","text":"
Meaning: \"At least one specific instance of C is in taxon T\".
Canonical logical representation:
IND:a Type (C and (in_taxon some T))`\n
Alternative representations:
Generated subclass for QC purposes: C_in_T SubClassOf (C and (in_taxon some T) (C_in_T will be unsatisifiable if violates taxon constraints)
Canonical shortcut: AnnotationAssertion: C present_in_taxon T # Editors use this
Editor guidance: Editors use the canonical shorcut (annotation axiom). The taxon should be as specific as possible, ideally a species.
"},{"location":"explanation/taxon-constraints-explainer/#how-to-add-taxon-restrictions","title":"How to add taxon restrictions:","text":"
Please see how-to guide on adding taxon restrictions
"},{"location":"explanation/taxon-constraints-explainer/#using-taxon-restrictions-for-quality-control","title":"Using taxon restrictions for Quality Control","text":"
As stated above, one of the major applications for taxon restrictions in OBO is for quality control (QC), by finding logical inconsistencies. Many OBO ontologies consist of a complex web of term relationships, often crossing ontology boundaries (e.g., GO biological process terms referencing Uberon anatomical structures or CHEBI chemical entities). If particular terms are only defined to apply to certain taxa, it is critical to know that a chain of logic implies that the term must exist in some other taxon which should be impossible. Propagating taxon restrictions via logical relationships greatly expands their effectiveness (the GO term above may acquire a taxon restriction via the type of anatomical structure in which it occurs).
It can be helpful to think informally about how taxon restrictions propagate over the class hierarchy. It's different for all three types:
ALL-IN restrictions (in_taxon) include all superclasses of the taxon, and all subclasses of the subject term: %% Future editors, note that link styles are applied according to the link index, so be careful if adding or removing links. graph BT; n1(hair) ; n2(whisker) ; n3(Mammalia) ; n4(Tetrapoda) ; n2--is_a-->n1 ; n3--is_a-->n4 ; n1==in_taxon==>n3 ; n1-.in_taxon.->n4 ; n2-.in_taxon.->n3 ; n2-.in_taxon.->n4 ; linkStyle 0 stroke:#999 ; linkStyle 1 stroke:#999 ; style n1 stroke-width:4px ; style n3 stroke-width:4px ;
NOT-IN restrictions (never_in_taxon) include all subclasses of the taxon, and all subclasses of the subject term: %% Future editors, note that link styles are applied according to the link index, so be careful if adding or removing links. graph BT; n1(facial whisker) ; n2(whisker) ; n3(Homo sapiens) ; n4(Hominidae) ; n1--is_a-->n2 ; n3--is_a-->n4 ; n2==never_in_taxon==>n4 ; n2-.never_in_taxon.->n3 ; n1-.never_in_taxon.->n4 ; n1-.never_in_taxon.->n3 ; linkStyle 0 stroke:#999 ; linkStyle 1 stroke:#999 ; style n2 stroke-width:4px ; style n4 stroke-width:4px ;
SOME-IN restrictions (present_in_taxon) include all superclasses of the taxon, and all superclasses of the subject term: %% Future editors, note that link styles are applied according to the link index, so be careful if adding or removing links. graph BT; n1(hair) ; n2(whisker) ; n3(Felis) ; n4(Carnivora) ; n2--is_a-->n1 ; n3--is_a-->n4 ; n2==present_in_taxon==>n3 ; n1-.present_in_taxon.->n3 ; n2-.present_in_taxon.->n4 ; n1-.present_in_taxon.->n4 ; linkStyle 0 stroke:#999 ; linkStyle 1 stroke:#999 ; style n2 stroke-width:4px ; style n3 stroke-width:4px ;
The Relation Ontology defines number of property chains for the in_taxon property. This allows taxon restrictions to propagate over other relationships. For example, the part_of o in_taxon -> in_taxon chain implies that if a muscle is part of a whisker, then the muscle must be in a mammal, but not in a human, since we know both of these things about whiskers:
%% Future editors, note that link styles are applied according to the link index, so be careful if adding or removing links. graph BT; n1(hair) ; n2(whisker) ; n3(Mammalia) ; n4(Homo sapiens) ; n5(Hominidae) ; n6(whisker muscle) ; n2--is_a-->n1 ; n5--is_a-->n3 ; n4--is_a-->n5 ; n6--part_of-->n2 ; n1==in_taxon==>n3 ; n2==never_in_taxon==>n5 ; n2-.in_taxon.->n3 ; n6-.in_taxon.->n3 ; n6-.never_in_taxon.->n4 ; n2-.never_in_taxon.->n4 ; n6-.never_in_taxon.->n5 ; linkStyle 0 stroke:#999 ; linkStyle 1 stroke:#999 ; linkStyle 2 stroke:#999 ; linkStyle 3 stroke:#008080 ; style n6 stroke-width:4px ;
Property chains are the most common way in which taxon restrictions propagate across ontology boundaries. For example, Gene Ontology uses various subproperties of results in developmental progression of to connect biological processes to Uberon anatomical entities. Any taxonomic restrictions which hold for the anatomical entity will propagate to the biological process via this property.
The graph depictions in the preceding illustrations are informal; in practice never_in_taxon and present_in_taxon annotations are translated into more complex logical constructions using the in_taxon object property, described in the next section. These logical constructs allow the OWL reasoner to determine that a class is unsatisfiable when there are conflicts between taxon restriction inferences.
"},{"location":"explanation/taxon-constraints-explainer/#implementation-and-reasoning-with-taxon-restrictions","title":"Implementation and reasoning with taxon restrictions","text":"
The OWL axioms required to derive the desired entailments for taxon restrictions are somewhat more complicated than one might expect. Much of the complication is the result of workarounds to limitations dictated by the OWL EL profile. Because of the size and complexity of many of the ontologies in the OBO Library, particularly those heavily using taxon restrictions, we primarily rely on the ELK reasoner, which is fast and scalable since it implements OWL EL rather than the complete OWL language. In the following we discuss the particular kinds of axioms required in order for taxon restrictions to work with ELK, with some comments about how it could work with HermiT (which implements the complete OWL language but is much less scalable). We will focus on this example ontology:
There are three classes outlined in red which were created mistakenly; the asserted taxon for each of these conflicts with taxon restrictions in the rest of the ontology:
'whisker in human' \u2014 We expect this to be unsatisfiable since it is a subclass of 'whisker', which has a 'never in Hominidae' restriction. 'Whisker in human' is asserted to be in_taxon 'Homo sapiens', a subclass of 'Hominidae'.
'whisker in catfish' \u2014 We expect this to be unsatisfiable since it is a subclass of 'whisker', and thus a subclass of 'hair'. 'Hair' has an 'only in Mammalia' restriction. 'Whisker in catfish' is asserted to be in_taxon 'Siluriformes' (catfish), which is a subclass of Teleostei and thus disjoint from 'Mammalia'.
'whisker muscle in human' \u2014 We expect this to be unsatisfiable since it is a 'whisker muscle' and thus part of a 'whisker', and thus inherits the 'never in Hominidae' restriction from 'whisker' via the property chain part_of o in_taxon -> in_taxon. This conflicts with its asserted in_taxon 'Homo sapiens', a subclass of 'Hominidae'.
We can start by modeling the two taxon restrictions in the ontology like so:
'hair' 'in_taxon' 'Mammalia': 'hair' SubClassOf (in_taxon some 'Mammalia')
'whisker' 'never_in_taxon' 'Mammalia': 'whisker' SubClassOf (not (in_taxon some 'Hominidae'))
Both HermiT and ELK can derive that 'whisker in human' is unsatisfiable. This is the explanation:
'human whisker' EquivalentTo ('whisker' and (in_taxon some 'Homo sapiens'))
'Homo sapiens' SubClassOf 'Hominidae'
'whisker' SubClassOf (not ('in_taxon' some 'Hominidae'))
Unfortunately, neither reasoner detects the other two problems. We'll address the 'whisker in catfish' first. The reasoner infers that this class is in_taxon both 'Mammalia' and 'Siluriformes'. While these are disjoint classes (all sibling taxa are asserted to be disjoint in the taxonomy ontology), there is nothing in the ontology stating that something can only be in one taxon at a time. The most intuitive solution to this problem would be to assert that in_taxon is a functional property. However, due to limitations of OWL, functional properties can't be used in combination with property chains. Furthermore, functional properties aren't part of OWL EL. There is one solution that works for HermiT, but not ELK. We could add an axiom like the following to every \"always in taxon\" restriction:
'hair' SubClassOf (in_taxon only 'Mammalia')
This would be sufficient for HermiT to detect the unsatisfiability of 'whisker in catfish' (assuming taxon sibling disjointness). Unfortunately, only restrictions are not part of OWL EL. Instead of adding the only restrictions, we can generate an extra disjointness axiom for every taxon disjointness in the taxonomy ontology, e.g.:
(in_taxon some 'Tetrapoda') DisjointWith (in_taxon some 'Teleostei')
The addition of axioms like that is sufficient to detect the unsatisfiability of 'whisker in catfish' in both HermiT and ELK. This is the explanation:
'whisker in catfish' EquivalentTo ('whisker' and (in_taxon some 'Siluriformes'))
'whisker' SubClassOf 'hair'
'hair' SubClassOf (in_taxon some 'Mammalia')
'Mammalia' SubClassOf 'Tetrapoda'
'Siluriformes' SubClassOf 'Teleostei'
(in_taxon some 'Teleostei') DisjointWith (in_taxon some 'Tetrapoda')
While we can now detect two of the unsatisfiable classes, sadly neither HermiT nor ELK yet finds 'whisker muscle in human' to be unsatisfiable, which requires handling the interaction of a \"never\" assertion with a property chain. If we were able to make in_taxon a functional property, HermiT should be able to detect the problem; but as we said before, OWL doesn't allow us to combine functional properties with property chains. The solution is to add even more generated disjointness axioms, one for each taxon (in combination with the extra disjointness we added in the previous case), e.g.,:
(in_taxon some Hominidae) DisjointWith (in_taxon some (not Hominidae))
While that is sufficient for HermiT, for ELK we also need to add another axiom to the translation of each never_in_taxon assertion, e.g.,:
'whisker' SubClassOf (in_taxon some (not 'Hominidae'))
Now both HermiT and ELK can find 'whisker muscle in human' to be unsatisfiable. This is the explanation from ELK:
'whisker muscle in human' EquivalentTo ('whisker muscle' and (in_taxon some 'Homo sapiens'))
'Homo sapiens' SubClassOf 'Hominidae'
'whisker muscle' SubClassOf (part_of some 'whisker')
'whisker' SubClassOf (in_taxon some ('not 'Hominidae'))
part_of o in_taxon SubPropertyOf in_taxon
(in_taxon some 'Hominidae') DisjointWith (in_taxon some (not 'Hominidae'))
The above example didn't incorporate any present_in_taxon (SOME-IN) assertions. These work much the same as ALL-IN in_taxon assertions. However, instead of stating that all instances of a given class are in a taxon (C SubClassOf (in_taxon some X)), we either state that there exists an individual of that class in that taxon, or that there is some subclass of that class whose instances are in that taxon:
<generated individual IRI> Type (C and (in_taxon some X)) \u2014 violations involving this assertion will make the ontology logically inconsistent.
or
<generated class IRI> SubClassOf (C and (in_taxon some X)) \u2014 violations involving this assertion will make the ontology logically incoherent, i.e., a named class is unsatisfiable (here, <generated class IRI>).
Incoherency is easier to debug than inconsistency, so option 2 is the default expansion for present_in_taxon.
In summary, the following constructs are all needed for QC using taxon restrictions:
Relation Ontology
in_taxon property chains for relations which should propagate in_taxon inferences
NCBI Taxonomy Ontology
X DisjointWith Y for all sibling taxa X and Y
(in_taxon some X) DisjointWith (in_taxon some Y) for all sibling taxa X and Y
(in_taxon some X) DisjointWith (in_taxon some (not X)) for every taxon X
Each ALL-IN taxon restriction C in_taxon X
C SubClassOf (in_taxon some X)
Each NOT-IN taxon restriction C never_in_taxon X
C SubClassOf (not (in_taxon some X))
C SubClassOf (in_taxon some (not X))
Each SOME-IN taxon restriction C present_in_taxon X)
<generated class IRI> SubClassOf (C and (in_taxon some X))
"},{"location":"explanation/taxon-constraints-explainer/#employing-taxon-restrictions-in-your-qc-pipeline","title":"Employing taxon restrictions in your QC pipeline","text":"
If you are checking an ontology for coherency in a QC pipeline (such as by running ROBOT within the ODK), you will need to have the required constructs from the previous section present in your import chain:
Relation Ontology \u2014 import as usual
NCBI Taxonomy Ontology
import the main taxonomy (http://purl.obolibrary.org/obo/ncbitaxon.owl)
import http://purl.obolibrary.org/obo/ncbitaxon/subsets/taxslim-disjoint-over-in-taxon.owl (or implement a way to generate the needed disjointness axioms)
Note: that file only covers a subset of the taxonomy, and is missing (in_taxon some X) DisjointWith (in_taxon some (not X)). You may need to implement a way to generate the needed disjointness axioms until this is corrected.
Your own taxon restrictions within your ontology:
ALL-IN taxon restrictions require no expansion. If you are using the never_in_taxon and present_in_taxon shortcut annotation properties, you can expand these into the logical forms using robot expand.
Because present_in_taxon expansions add named classes to your ontology, you will probably want to organize your pipeline in such a way that this expansion only happens in a QC check, and the output is not included in your published ontology.
"},{"location":"explanation/taxon-constraints-explainer/#exploring-taxon-restrictions-in-protege","title":"Exploring taxon restrictions in Prot\u00e9g\u00e9","text":"
Using the DL Query panel and a running reasoner, it is straightforward to check whether a particular taxon restriction holds for a term (such as when someone has requested one be added to your ontology). Given some term of interest, e.g., 'whisker', submit a DL Query such as 'whisker' and (in_taxon some Mammalia). Check the query results:
If Equivalent classes includes owl:Nothing, then a never_in_taxon is implied for that taxon.
If Equivalent classes includes the term of interest itself (and not owl:Nothing), then an in_taxon is implied for that taxon.
If Superclasses includes the term of interest (and the query isn't equivalent to owl:Nothing), then there is no particular taxon restriction involving that taxon.
"},{"location":"explanation/taxon-constraints-explainer/#obo-taxon-constraints-plugin-for-protege","title":"OBO taxon constraints plugin for Prot\u00e9g\u00e9","text":"
To quickly see exactly which taxon restrictions are in effect for a selected term, install the OBO taxon constraints plugin for Prot\u00e9g\u00e9. Once you have the plugin installed, you can add it to your Prot\u00e9g\u00e9 window by going to the menu Window > Views > OBO views > Taxon constraints, and then clicking the location to place the panel. The plugin will show the taxon constraints in effect for the selected OWL class. When a reasoner is running, any inferred taxon constraints will be shown along with directly asserted ones. The plugin executes many reasoner queries behind the scenes, so there may be a delay before the user interface is updated.
"},{"location":"explanation/term-comments/","title":"Term Comments","text":""},{"location":"explanation/term-comments/#what-are-comments","title":"What are comments?","text":"
Comments are annotations that may be added to ontology terms to further explain their intended usage, or include information that is useful but does not fit in areas like definition.
Some examples of comments, and possible standard language for their usage, are:
WARNING: THESE EXAMPLES ARE NOT UNIVERSALLY USED AND CAN BE CONTROVERSIAL IN SOME ONTOLOGIES! PLEASE CHECK WITH THE CONVENTIONS OF YOUR ONTOLOGY BEFORE DOING THIS!
"},{"location":"explanation/term-comments/#do-not-annotate","title":"Do Not Annotate","text":"
This term should not be used for direct annotation. It should be possible to make a more specific annotation to one of the children of this term.
Example: GO:0006810 transport
Note that this term should not be used for direct annotation. It should be possible to make a more specific annotation to one of the children of this term, for e.g. transmembrane transport, microtubule-based transport, vesicle-mediated transport, etc.
"},{"location":"explanation/term-comments/#do-not-manually-annotate","title":"Do Not Manually Annotate","text":"
This term should not be used for direct manual annotation. It should be possible to make a more specific manual annotation to one of the children of this term.
Example: GO:0000910 cytokinesis
Note that this term should not be used for direct annotation. When annotating eukaryotic species, mitotic or meiotic cytokinesis should always be specified for manual annotation and for prokaryotic species use 'FtsZ-dependent cytokinesis; GO:0043093' or 'Cdv-dependent cytokinesis; GO:0061639'. Also, note that cytokinesis does not necessarily result in physical separation and detachment of the two daughter cells from each other.
Information about the term that do not belong belong in the definition or gloss, but are useful for users or editors. This might include information that is adjacent to the class but pertinent to its usage, extended information about the class (eg extended notes about a characteristic of a cell type) that might be useful but does not belong in the definition, important notes on why certain choices were made in the curation of this terms (eg why certain logical axioms were excluded/included in the way they are) (Note: dependent on ontology, some of these might belong in editors_notes, etc.).
Standard language for these are not given as they vary dependent on usage.
"},{"location":"explanation/which-ontology-to-use/","title":"Which biomedical ontologies should we use?","text":"
As a rule of thumb, for every single problem/term/use case, you will have 3-6 options to choose from, in some cases even more. The criteria for selecting a good ontology are very much dependent on your particular use case, but some concerns are generally relevant. A good first pass is to apply to \"10 simple rules for selecting a Bio-ontology\" by Malone et al, but I would further recommend to ask yourself the following:
Do I need the ontology for grouping and semantic analysis? In this case a high quality hierarchy reflecting biological subsumption is imperative. We will explain later what this means, but in essence, you should be able to ask the following question: \"All instances/occurrences of this concept in the ontology are also instances of all its parent classes. Everything that is true about the parent class is always also true about instances of the children.\" It is important for you to understand that, while OWL semantics imply the above, OWL is difficult and many ontologies \"pretend\" that the subclass link means something else (like a rule of thumb grouping relation).
Can I handle multiple inheritance in my analysis? While I personally recommend to always consider multiple inheritance (i.e, allow a term to have more than one parent class), there are some analysis frameworks, in particular in the clinical domain, that make this hard. Some ontologies are inherently poly-hierarchical (such as Mondo), while others strive to be single inheritance (DO, ICD).
Are key resources I am interested in using the ontology? Maybe the most important question that will drastically reduce the amount of data mapping work you will have to do: Does the resource you wish to integrate already annotate to a particular ontology? For example, EBI resources will be annotating phenotype data using EFO, which in turn used HPO identifiers. If your use case demands to integrate EBI databases, it is likely a good idea to consider using HPO as the reference ontology for your phenotype data.
Aside from aspects of your analysis, there is one more thing you should consider carefully: the open-ness of your ontology in question. As a user, you have quite a bit of power on the future trajectory of the domain, and therefore should seek to endorse and promote open standards as much as possible (for egotistic reasons as well: you don't want to have to suddenly pay for the ontologies that drive your semantic analyses). It is true that ontologies such as SNOMED have some great content, and, even more compellingly, some really great coverage. In fact, I would probably compare SNOMED not with any particular disease ontology, but with the OBO Foundry as a whole, and if you do that, it is a) cleaner, b) better integrated. But this comes at a cost. SNOMED is a commercial product - millions are being paid every year in license fees, and the more millions come, the better SNOMED will become - and the more drastic consequences will the lock-in have if one day you are forced to use SNOMED because OBO has fallen too far behind. Right now, the sum of all OBO ontologies is probably still richer and more valuable, given their use in many of the central biological databases (such as the ones hosted by the EBI) - but as SNOMED is seeping into the all aspects of genomics now (for example, it will soon be featured on OLS!) it will become increasingly important to actively promote the use of open biomedical ontologies - by contributing to them as well as by using them.
"},{"location":"explanation/writing-good-issues/","title":"Writing Good Issues","text":"
Based on Intro to GitHub (GO-Centric) with credit to Nomi Harris and Chris Mungall
Writing a good ticket (or issue) is crucial to good management of a repo. In this explainer, we will discuss some good practices in writing a ticket and show examples of what not to do.
Search existing issues before creating a new one -- maybe someone else already reported your problem
Give your issue a short but descriptive and actionable title
Describe the problem and the context and include a repeatable example.
Clearly state what needs to be done to close the ticket
Tickets should ideally be actionable units that can be closed via a PR
Fag relevant people with @ (e.g., @nlharris)
Mention related issues with # (e.g., #123)
use a complete URL to link to tickets in other repos
Make issue titles actionable
eg \"Ontology download page on GO website\" is non-actionable, whereas \"Fix URLs on ontology download page on GO website\" is actionable and hence better a title
"},{"location":"explanation/writing-good-issues/#example-of-a-good-ticket","title":"Example of a good ticket","text":""},{"location":"explanation/writing-good-issues/#example-of-a-bad-ticket","title":"Example of a bad ticket","text":""},{"location":"howto/add-new-slim/","title":"Creating a new Slim (under construction)","text":""},{"location":"howto/add-new-slim/#adding-a-new-subset-also-known-as-a-slim","title":"Adding a new subset (also known as a \"slim\")","text":"
See Daily Curator Workflow for creating branches and basic Prot\u00e9g\u00e9 instructions.
In the main Prot\u00e9g\u00e9 window, click on the \"Entities\" tab. Below that, click the \"Annotation properties\" tab.
Select the subset_property annotation property.
Click on the \"Add sub property\" button.
In the pop-up window, add the name of the new slim. The IRI will automatically populate according to settings in the user's \"New entities\" settings. Click OK.
With the newly created annotation property selected, click on \"Refactor > Rename entity...\" in the menu.
In the pop-up window, select the \"Show full IRI\" checkbox. The IRI will appear. Edit the IRI to fit the following standard:
For example, in CL, the original IRI will appear as:
http://purl.obolibrary.org/obo/CL_1234567
If the subset was labeled \"kidney_slim\", the IRI should be updated to:
http://purl.obolibrary.org/obo/cl#kidney_slim
In the 'Annotations\" window, click the + next to \"Annotations\".
In the pop-up window, select the rdfs:comment annotation property. Under \"Value\" enter a brief descripton for the slim. Under \"Datatype\" select xsd:string. Click OK.
See Daily Curator Workflow section for commit, push and merge instructions.
"},{"location":"howto/add-new-slim/#adding-a-class-term-to-a-subset-slim","title":"Adding a class (term) to a subset (slim)","text":"
See Daily Curator Workflow for creating branches and basic Prot\u00e9g\u00e9 instructions.
In the main Prot\u00e9g\u00e9 window, click on the \"Entities\" tab. Select the class that is to be added to a subset (slim).
In the 'Annotations\" window, click the + next to \"Annotations\".
In the pop-up window, select the in_subset annotation property.
Click on the \u2018Entity IRI\u2019 tab.
Search for the slim label under \"Entity IRI\". In the pop-up that appears, double-click on the desired slim. Ensure that a sub property of subset_property is selected. Click OK.
See Daily Curator Workflow section for commit, push and merge instructions.
Before adding taxon restrictions, please review the types of taxon restrictions documentation.
See Daily Workflow for creating branches and basic Prot\u00e9g\u00e9 instructions.
in taxon relations are added as Subclasses.
Navigate to the term for which you want to add the only in taxon restriction.
In the Description window click on the +.
In the pop-up window type a new relationship (e.g. 'in taxon' some Viridiplantae).
The taxa available are imported ontology terms and can be browsed just like any other ontology term.
never in taxon or present in taxon relations added as Annotations.
Navigate to the taxon term you want to add a restriction on.
Copy the IRI (you can use command U to display this on a Mac)
Navigate to the term for which you want to add the never in taxon restriction.
In the class annotations window, click on the +.
In the left-hand panel, select never_in_taxon or present_in_taxon as appropriate.
In the right-hand panel, in the IRI editor panel, paste in the IRI.
Click OK to save your changes.
(Note - you can achieve the same thing using the Entity IRI tab + navigating to the correct taxon but this is slow and not very practical)
See Daily Workflow section for commit, push and merge instructions.
"},{"location":"howto/change-files-pull-request/","title":"How to change files in an existing pull request","text":""},{"location":"howto/change-files-pull-request/#using-github","title":"Using GitHub","text":"
Warning: You should only use this method if the files you are editing are reasonably small (less than 1 MB).
This method only works if the file you want to edit has already been editing as part of the pull request.
Go to the pull request on GitHub, and click on the \"Files Changed\" tab up top
Find the file you want to edit in the pull request.
On the right, click on on the three ..., and then \"Edit file\".
If this option is greyed out, it means that - you don't have edit rights on the repository - the edit was made from a different fork, and the person that created the pull request did not activate the \"Allow maintainers to make edits\" option when submitting the PR - the pull request has already been merged
Do the edits, and then commit changes, usually to the same branch
On the pull request in GitHub, click the copy button next to the branch name (see example below)
In GitHub Desktop, click the branch switcher button and paste in branch name (or you can type it in).
Now you are on the branch, you can open the files to be edited and make your intended changes and push via the usual workflow.
"},{"location":"howto/change-files-pull-request/#if-the-branch-is-on-a-fork","title":"If the branch is on a fork","text":"
If a user forked the repository and created a branch, you can find that branch by going to the branch switcher button in GitHub Desktop, click on Pull Requests (next to Branches) and looking for that pull request
Select that pull request and edit the appropriate files as needed and push via the usual workflow.
"},{"location":"howto/clone-mondo-repo/","title":"Clone a repository","text":""},{"location":"howto/clone-mondo-repo/#cloning-a-repo","title":"Cloning a repo","text":"
Prerequisite: Install Github Desktop Github Desktop can be downloaded here
For the purpose of going through this how-to guide, we will use Mondo as an example. However, all obo onotlogies can be cloned in a similar way.
Open the GitHub repository where the ontology you want to clone lives, in this case, Mondo GitHub repository
Click Code
Click 'Open with GitHub Desktop'
You will be given an option as to where to save the repository. I have a folder called 'git' where I save all of my local repos.
This will open GitHub Desktop and the repo should start downloading. This could take some time depending on the size of the repository.
"},{"location":"howto/clone-mondo-repo/#open-the-ontology-in-protege","title":"Open the Ontology in Protege","text":"
Open Protege
Go to: File -> Open
Navigate to mondo/src/ontology/mondo-edit.obo and open this file in Protege Note: mondo can be replaced with any ontology that is setup using the ODK as their architecture should be the same.
If this all works okay, you are all set to start editing!
"},{"location":"howto/create-new-term/","title":"Creating a New Ontology Term in Protege","text":"
To create a new term, the 'Asserted view' must be active (not the 'Inferred view').
In the Class hierarchy window, click on the 'Add subclass' button at the upper left of the window.
A pop-up window will appear asking you to enter the Name of the new term. When you enter the term name, you will see your ID automatically populate the IRI box. Once you have entered the term, click 'OK' to save the new term. You will see it appear in the class hierarchy.
In the annotation window add:
Definition
Click on the + next to Annotations
Select defintion (if there are multiple, you should use IAO:0000115)
Add the textual definition in the pop-up box.
Click OK.
2. Add Definition References\n 1. Click on the circle with the \u2018@\u2019 in it next to definition and in the resulting pop-up click on the ```+``` to add a new ref, making sure they are properly formatted with a database abbreviation followed by a colon, followed by the text string or ID. Examples: ```PMID:27450630```.\n 2. Click OK.\n 3. Add each definition reference separately by clicking on the ```+``` sign.\n
3. Add synonyms and dbxrefs following the same procedure if they are required for the term.
Add appropriate logical axioms in the Description by clicking the + sign in the appropriate section (usually SubClass Of) and typing it in, using Tab to autocomplete terms.
Converting to Equivalent To axioms:\nIf you want to convert your SubClassOf axioms to EquivalentTo axioms, you can select the appropriate rows and right click, selecting \"Convert selected rows to defined class\"\n
In some cases, logical axioms reuiqre external ontologies (eg in the above example, the newly added CL term has_soma_location in the cerebellar cortex which is an uberon term), it might be necessary to import the term in. For instructions on how to do this, please see the import managment section of your local ontology documentation (an example of that in CL can be found here: https://obophenotype.github.io/cell-ontology/odk-workflows/UpdateImports/)
When you have finished adding the term, run the reasoner to ensure that nothing is problematic with the axioms you have added (if there is an issue, you will see it being asserted under owl:Nothing)
Save the file on protege and review the changes you have made in your Github Desktop (or use git diff in your terminal if you do not use Github Desktop)
See Daily Workflow section for commit, push and merge instructions.
"},{"location":"howto/create-ontology-from-scratch/","title":"How to create an OBO ontology from scratch","text":"
Editors:
Nicolas Matentzoglu (@matentzn)
Sabrina Toro (@sabrinatoro)
Summary:
This is a guide to build an OBO ontology from scratch. We will focus on the kind of thought processes you want to go through, and providing the following:
Reasons for NOT building an ontology
A basic recipe for getting started
An overview of different starting points on your journey to building an ontology
A guide for deciding what kind of ontology you want to build
An example walk-through of the process.
"},{"location":"howto/create-ontology-from-scratch/#minimal-conditions-for-building-an-ontology","title":"Minimal conditions for building an ontology","text":"
Before reading on, there are three simple rules for when NOT to build an ontology everyone interested in ontologies should master, like a mantra:
Do not build a new ontology if:
one in scope already exists (none-in-scope condition).
something simpler than a full-fledged OWL ontology can do the job (something-simpler-works condition).
there is not at least one glass-clear use case written down which could be addressed by the existence of the ontology (killer-use-case condition).
Scope is one of the hardest and most debated subjects in the OBO Foundry operation calls. There are essentially two aspects to scope:
The entities you intended to model belong to some specific biological categories. For example phenotype, disease, anatomical entity, assay, environmental exposure, biological process, chemical entity. Before setting out to build an ontology, you should get a rough sense of what kind of entities you need to describe your domain. However, this is an iterative process and more entities will be revealed later on.
The subject domain you intend to model. For example, you may want to provide an ontology to describe the domain of Alzheimer's Disease, which will need many different kinds of biological entities (like anatomical entity and disease classes).
As a rule of thumb, you should NOT create a term if another OBO ontology has a branch of for entities of the same kind. For example, if you have to add terms for assays, you should work with the Ontology for Biomedical Investigations to add these to their assay branch.
Remember, the vision of OBO is to build a semantically coherent ontology for all of biology, and the individual ontologies in the OBO Foundry should be considered \"modules\" of this super ontology. You will find that while collaboration is always hard the only way for our community to be sustainable and compete with commercial solutions is to take that hard route and work together.
There are many kinds of semantic artefacts that can work for your use case:
Controlled vocabularies: Creating identifiers for concepts in your domain and without too much concern for logical reasoning. Some examples can be are Linked Open Data Vocabularies (LOV) or schema.org vocabularies. Sometimes a table of identifiers in an SQL database is enough.
Thesauri: Describe the synonyms used in your domain in a standardised fashion.
Taxonomies: Create a hierarchical categorisations for concepts in your domain, without any specific regards for semantics. You just create a hierarchy that \"makes some sense\" for your use case. Examples: ICD10, United Nations Standard Products and Services Code (UNSPSC).
Semantic data models: If you need to define how terms in your database should be constrained in a semantic way (similar to a database schema), then Shape languages like SHEX or SHACL may be much more suitable for your use case. See LinkML tutorials to get a sense of this: you will build a semantic data model in Yaml which can then be exported to SHACL, OWL or JSON Schema (great tutorial, useful to do no matter what).
Ontologies: Sets of logical axioms. If you require formal reasoning (and only then!) does it make sense to jump in the deep pit of ontology engineering. This is, by far, the hardest to build of the bunch. You will have to wrestle with Logic, Open World Assumption and many more arcane subjects.
Think of it in terms of cost. Building a simple vocabulary with minimal axiomatisation is 10x cheaper than building a full fledged domain model in OWL, and helps solving your use case just the same. Do not start building an ontology unless you have some understanding of these alternatives first.
Do not build an ontology because someone tells you to or because you \"think it might be useful\". Write out a proper use case description, for example in the form of an agile user story, convince two or three colleagues this is worthwhile and only then get to work. Many ontologies are created for very vague use cases, and not only do they cost you time to build, they also cost the rest of the community time - time it takes them to figure out that they do not want to use your ontology. Often, someone you trust tells you to build one and you believe they know what they are doing - do not do that. Question the use of building the ontology until you are convinced it is the right thing to do. If you do not care about reasoning (either for validation or for your application), do not build an ontology.
"},{"location":"howto/create-ontology-from-scratch/#basic-recipe-to-start-building-an-ontology","title":"Basic recipe to start building an ontology","text":"
Depending on your specific starting points, the way you start will be slightly different, but some common principles apply.
Write down the use cases for the ontology (see above). This will determine certain design decisions later on. These should be concrete, like: controlled vocabulary for named entity recognition, logical model of a domain, auto-classification of data.
Make a table of all similar ontologies that exist, within and outside OBO (this requires research, and is an essential part of the process). Document exactly in what way they are different from your use case, and why you need to build a new one (see none-in-scope condition above).
Determine whether you have something to start from. Often, you will have a database with entities you may wish to turn into classes in your ontology. See starting points below.
Gather your tools. You need to think about tools for at least two kinds of workflows to start with:
Curation workflows: How will you edit your ontology? Some simple ontologies are edited using tables that link to logical templates. Others are edited primarily with Protege.
Continuous integration and release workflows: How will you import terms from other ontologies? How will you ensure the quality of you ontology moving forward?
Decide on the Ontology ID (important, do not skip). Changing this later can be extremely costly. Refer to the OBO ID policy for details. An ID should be short and unique.
Create a basic set-up for managing your workflows. This comprises (usually) three aspects (you may wish to try and use the Ontology Development Kit - it does exactly that):
Make a GitHub repository.
Add your editors files (owl, tsv, whatever you decided to use) to that repository.
Implement some workflow system, i.e. some way to run commands like release or test, as you will run these repeatedly. A typical system to achieve this is make, and many projects choose to encode their workflows as make targets (ODK, OBI Makfile).
Determine the metadata and logical patterns you wish to employ for your curation. Here it is important that you determine what kind of an ontology you want to build.
Note: Later in the process, you also want to think about the following:
Think about how to manage your ontology project: Which roles you need, and how you manage community contributions.
There are many different starting points for building an ontology:
We have a database or a dataset and want to build an ontology that covers entities in that database. As a variation, you have two or more databases that you need to integrate.
We already have a basic ontology in our domain (a cell ontology, an anatomy ontology), but need to build an extension (e.g. a species specific extension to an existing cross-species ontology).
We have controlled vocabulary or a list of standard or commonly used terms for a domain and want to formalise them in an ontology for interoperability and machine-readability, with versioning support to manage evolution. Sometimes, we may even wish to simply using ontology infrastructure (tools and best practices) to maintain a quite informal vocabulary structure.
There are existing ontologies that are, however, not quite fit for purpose (even if they should be) and there's no way to make any of them right, so I have to create Yet Another Variant.
We have a large, hierarchical enumeration in a datamodel that pulls terms from many ontologies.
We need to build a completely new ontology for a domain that currently does not even have a controlled vocabulary. This case almost never happens nowadays. In this case, all domain knowledge (concepts and their relations) is somewhere in the heads of the experts.
"},{"location":"howto/create-ontology-from-scratch/#what-kind-of-ontology-do-you-need","title":"What kind of ontology do you need?","text":"
There are two fundamentally different kinds of ontologies which need to be distinguished:
Project ontologies (sometimes referred to as application ontologies) are ontologies that are developed to fulfil a specific use case, like:
Grouping data in your project
Indexing search engines or your organisation
Informing Natural Language Processing applications
Populating the biocuration interface your organisation provides to enable curators to annotate data
Domain ontologies are ontologies which seek to model a domain of discourse. In particular they:
Reflect scientific consensus and are therefore social and collaborative enterprises subject to change
Are build with re-use in mind:
They re-use terms from other domain ontologies
They provide terms intended for re-use by other ontologies
They work with other ontologies on implementing consistent logical patterns that apply across all domain ontologies in the community.
Are logically consistent with all ontologies they depend on, refer to, import.
Some things to consider:
It is extremely hard to build domain ontologies. Do not try to do that without a proper sustainability plan (i.e. considerable resources over multiple years).
Project ontologies are not bad domain ontologies. Project ontologies can be build according to the same standards as domain ontologies. While controversial, the OBO Foundry is currently (March 2022) debating whether project ontologies are admissible to the OBO ontology library.
Project ontologies can have huge impact. One of the most impactful ontologies in the biomedical world is the Experimental Factor Ontology (EFO) - a massive project ontology used for many applications from knowledge graph integration to biocuration.
Project ontologies are allowed to change the semantics of imported ontologies, for example by adding additional axioms or even removing some - anything necessary to achieve the use case!
Domain ontologies (in the OBO world) are not allowed to change semantics of imported ontologies.
Project ontologies can import terms from domain ontologies, and coin their own terms where necessary. This can be a good option if resources are scarce, and there is not enough time for consensus building with the community or the often lengthy contribution workflows. \"I just need some terms\" usually points to \"I need a project ontology\".
Domain ontologies seek to model a domain exhaustively: any concept that \"belongs\" to that domain is a strong candidate for a term.
It is imperative that it is clear which of the two you are building. Project ontologies sold as domain ontologies are a very common practice and they cause a lot of harm for open biomedical data integration.
"},{"location":"howto/create-ontology-from-scratch/#example-building-vertebrate-breed-ontology","title":"Example: Building Vertebrate Breed Ontology","text":"
We will re-iterate some of the steps taken to develop the Vertebrate Breed Ontology. At the time of this writing, the VBO is still in early stages, but it nicely illustrates all the points above.
Similar ontologies. While there is no ontology OBO ontology related to breeds, the Livestock Breed Ontology (LBO) served as an inspiration (much different scale). NCBI taxonomy is a more general ontology about existing taxa as they occur in the wild.
We got a list of breeds from DAD-IS, which includes name of the breed, transboundary name, species, country, and more
We first had to understand the data and how the different pieces of data relate to each other.
Some breed names are the same, but refer to either different species and/or different countries
Several breeds share a common \"transboundary name\", which represent the original breed from which they come from
We needed to determine what a single concept / an indentifiable term would be
In order to define a single breed, we needed to include the name of the breed, the transboundary name (when applicable), the species, and the country
We needed to understand the metadata and how each concepts relate to each other
'breed' is an instance of 'species', therefore 'species' should be the parent term of 'breeds' (using a is_a relation)
when applicable, 'transboundary' should be the parent term of 'breeds'
Note about the concept of \"species\": is \"species\" equivalent to the NCBI Taxon representing \"species\"? Design decision: Since species represents the same concept as \u2018species\u2019 in NCBI, the ontology should be built \u2018on top of\u2019 NCBI terms to avoid confusion of concepts and to avoid conflation of terms with the same concept
Warnings based on our experience:
Always retain links to original source ids (encoding problems, update problems)
Always add provenance to as much information as you can (where do labels come from?)
"},{"location":"howto/create-ontology-from-scratch/#gather-your-tools","title":"Gather your tools","text":"
At first, we chose to name the ontology \"Unified Breed Ontology\" (UBO). Which meant that for everything from ODK setup to creating identifiers for our terms, we used the UBO prefix. Later in the process, we decided to change the name to \"Vertebrate Breed Ontology\". Migrating all the terms and the ODK setup from ubo to vbo required some expert knowledge on the workings of the ODK, and created an unnecessary cost. We should have finalised the choice of name first.
"},{"location":"howto/create-ontology-from-scratch/#create-a-basic-set-up","title":"Create a basic set up","text":"
Making a Repo with ODK
Develop a workflow that turns a Google Sheet into a component.
"},{"location":"howto/create-ontology-from-scratch/#determine-the-metadata-and-logical-patterns-you-wish-to-employ","title":"Determine the metadata and logical patterns you wish to employ.","text":"
We decided to build a domain ontology, for the representation of vertebrate breeds.
As our initial data is relatively flat, we decided to use ROBOT templates and Google Sheets to manage them.
"},{"location":"howto/create-ontology-from-scratch/#some-notes-need-to-be-cleaned-up-ignore","title":"Some notes, need to be cleaned up (ignore)","text":"
Creation of components: for basic information: each \u201clayer\u201d is built in a google sheet for example:
Transboundary: are children of species
Breeds: are children of either species or transboundary (therefore we need transboundary and species in order to be able to add breeds)
Addition of new information as we have them
E.g. adding xref and synonym from OMIA
Upcoming: xref and synonym form another database.
Future: Continue to add to the original document and/or create new components
Thank you to Melanie Courtot, Sierra Moxon, John Graybeal, Chris Stoeckert, Lars Vogt and Nomi Harris for their helpful comments on this how-to.
"},{"location":"howto/daily-curator-workflow/","title":"Daily Ontology Curator Workflow with GitHub","text":""},{"location":"howto/daily-curator-workflow/#updating-the-local-copy-of-the-ontology-with-git-pull","title":"Updating the local copy of the ontology with 'git pull'","text":"
Navigate to the ontology directory of go-ontology: cd repos/MY-ONTOLOGY/src/ontology.
If the terminal window is not configured to display the branch name, type: git status. You will see:
On branch [master] [or the name of the branch you are on] Your branch is up-to-date with 'origin/master'.
If you\u2019re not in the master branch, type: git checkout master.
From the master branch, type: git pull. This will update your master branch, and all working branches, with the files that are most current on GitHub, bringing in and merging any changes that were made since you last pulled the repository using the command git pull. You will see something like this:
"},{"location":"howto/daily-curator-workflow/#creating-a-new-working-branch-with-git-checkout","title":"Creating a New Working Branch with 'git checkout'","text":"
When starting to work on a ticket, you should create a new branch of the repository to edit the ontology file.
Make sure you are on the master branch before creating a new branch. If the terminal window is not configured to display the branch name, type: git status to check which is the active branch. If necessary, go to master by typing git checkout master.
To create a new branch, type: git checkout -b issue-NNNNN in the terminal window. For naming branches, we recommend using the string 'issue-' followed by the issue number. For instance, for this issue in the tracker: https://github.com/geneontology/go-ontology/issues/13390, you would create this branch: git checkout -b issue-13390. Typing this command will automatically put you in the new branch. You will see this message in your terminal window:
~/repos/MY-ONTOLOGY/src/ontology(master) $ git checkout -b issue-13390\nSwitched to a new branch 'issue-13390'\n~/repos/MY-ONTOLOGY/src/ontology(issue-13390) $\n
"},{"location":"howto/daily-curator-workflow/#continuing-work-on-an-existing-working-branch","title":"Continuing work on an existing Working Branch","text":"
If you are continuing to do work on an existing branch, in addition to updating master, go to your branch by typing git checkout [branch name]. Note that you can view the existing local branches by typing git branch -l.
OPTIONAL: To update the working branch with respect to the current version of the ontology, type git pull origin master. This step is optional because it is not necessary to work on the current version of the ontology; all changes will be synchronized when git merge is performed.
"},{"location":"howto/daily-curator-workflow/#loading-navigating-and-saving-the-ontology-in-protege","title":"Loading, navigating and saving the Ontology in Prot\u00e9g\u00e9","text":"
Before launching Prot\u00e9g\u00e9, make sure you are in the correct branch. To check the active branch, type git status.
Click on the 'File' pulldown. Open the file: go-edit.obo. The first time, you will have to navigate to repos/MY-ONTOLOGY/src/ontology. Once you have worked on the file, it will show up in the menu under 'Open'/'Recent'.
Click on the 'Classes' tab.
Searching: Use the search box on the upper right to search for a term in the ontology. Wait for autocomplete to work in the pop-up window.
Viewing a term: Double-click on the term. This will reveal the term in the 'Class hierarchy' window after a few seconds.
Launching the reasoner: To see the term in the 'Class hierarchy' (inferred) window, you will need to run the 'ELK reasoner'. 'Reasoner' > select ELK 0.4.3, then click 'Start reasoner'. Close the various pop-up warnings about the ELK reasoner. You will now see the terms in the inferred hierarchy.
After modification of the ontology, synchronize the reasoner. Go to menu: 'Reasoner' > ' Synchronize reasoner'.
NOTE: The only changes that the reasoner will detect are those impacting the ontology structure: changes in equivalence axioms, subclasses, merges, obsoletions, new terms.
TIP: When adding new relations/axioms, 'Synchronize' the reasoner. When deleting relations/axioms, it is more reliable to 'Stop' and 'Start' the reasoner again.
Use File > Save to save your changes.
"},{"location":"howto/daily-curator-workflow/#committing-pushing-and-merging-your-changes-to-the-repository","title":"Committing, pushing and merging your changes to the repository","text":"
Review: Changes made to the ontology can be viewed by typing git diff in the terminal window. If there are changes that have already been committed, the changes in the active branch relative to master can be viewed by typing git diff master.
Commit: Changes can be committed by typing: git commit -m \u2018Meaningful message Fixes #ticketnumber\u2019 go-edit.obo.
For example:
git commit -m \u2018hepatic stellate cell migration and contraction and regulation terms. Fixes #13390\u2019 go-edit.obo\n
This will save the changes to the go-edit.obo file. The terminal window will show something like:
~/repos/MY-ONTOLOGY/src/ontology(issue-13390) $ git commit -m 'Added hepatic stellate cell migration and contraction and regulation terms. Fixes #13390' go-edit.obo\n [issue-13390 dec9df0] Added hepatic stellate cell migration and contraction and regulation terms. Fixes #13390\n 1 file changed, 79 insertions(+)\n ~/repos/MY-ONTOLOGY/src/ontology(issue-13390) $\n
NOTE: The word 'fixes' is a magic word in GitHub; when used in combination with the ticket number, it will automatically close the ticket. In the above example, when the file is merged in GitHub, it will close issue number 13390. Learn more on this GitHub Help Documentation page about 'Closing issues via commit messages'.
'Fixes' is case-insensitive.
If you don't want to close the ticket, just refer to the ticket # without the word 'Fixes'. The commit will be associated with the correct ticket but the ticket will remain open.
NOTE: It is also possible to type a longer message than allowed when using the '-m' argument; to do this, skip the -m, and a vi window (on mac) will open in which an unlimited description may be typed.
TIP: Git needs to know who is committing changes to the repository, so the first time you commit, you may see the following message:
Committer: Kimberly Van Auken vanauken@kimberlukensmbp.dhcp.lbnl.us Your name and email address were configured automatically based on your username and hostname. Please check that they are accurate.
See Configuration instructions to specify your name and email address.
Push: To incorporate the changes into the remote repository, type: git push origin mynewbranch.
Example:
git push origin issue-13390\n
TIP: Once you have pushed your changes to the repository, they are available for everyone to see, so at this stage you can ask for feedback.
Pull
In your browser, return to the GO Ontology repository on GitHub.
Navigate to the tab labeled as 'Code' geneontology/go-ontology/code. You will see your commit listed at the top of the page in a light yellow box. If you don\u2019t see it, click on the 'Branches' link to reveal it in the list, and click on it.
Click the green button 'Compare & pull request' on the right.
You may now add comments and ask a colleague to review your pull request. If you want to have the ticket reviewed before closing it, you can select a reviewer for the ticket before you make the pull request by clicking on the 'Reviewers' list and entering a GitHub identifier (e.g. @superuser1). The reviewer will be notified when the pull request is submitted. Since the Pull Request is also a GitHub issue, the reviewer\u2019s comments will show up in the dialog tab of the pull request, similarly to any other issue filed on the tracker.
The diff for your file is at the bottom of the page. Examine it as a sanity check.
Click on the green box 'Pull request' to generate a pull request.
Wait for the Travis checks to complete (this can take a few minutes). If the Travis checks failed, go back to your working copy and correct the reported errrors.
Merge If the Travis checks are succesful and if you are done working on that branch, merge the pull request. Confirming the merge will close the ticket if you have used the word 'fixes' in your commit comment. NOTE: Merge the branches only when the work is completed. If there is related work to be done as a follow up to the original request, create a new GitHub ticket and start the process from the beginning.
Delete your branch on the repository using the button on the right of the successful merge message.
You may also delete the working branch on your local copy. Note that this step is optional. However, if you wish to delete branches on your local machine, in your terminal window:
Go back to the master branch by typing git checkout master.
Update your local copy of the repository by typing git pull origin master
Delete the branch by typing git branch -d workingbranchname. Example: git branch -d issue-13390
"},{"location":"howto/deal-with-large-ontologies/","title":"Dealing with huge ontologies in your import chain","text":"
Dealing with very large ontologies, such as the Protein Ontology (PR), NCBI Taxonomy (NCBITaxon), Gene Ontology (GO) and the CHEBI Ontology is a big challenge when developing ontologies, especially if we want to import and re-use terms from them. There are two major problems:
It currently takes about 12\u201316 GB of memory to process PR and NCBITaxon \u2013 memory that many of us do not have available.
The files are so large, pulling them over the internet can lead to failures, timeouts and other problems.
There are a few strategies we can employ to deal with the problem of memory consumption:
We try to reduce the memory footprint of the import as much as possible. In other words: we try to not do the fancy stuff ODK does by default when extracting a module, and keep it simple.
We manage the import manually ourselves (no import)
To deal with file size, we:
Instead of importing the whole thing, we import curated subsets.
If available, we use gzipped (compressed) versions.
All four strategies will be discussed in the following. We will then look a bit
"},{"location":"howto/deal-with-large-ontologies/#overwrite-odk-default-less-fancy-custom-modules","title":"Overwrite ODK default: less fancy, custom modules","text":"
The default recipe for creating a module looks something like this:
(Note: This snippet was copied here on 10 February 2021 and may be out of date by the time you read this.)
As you can see, a lot of stuff is going on here: first we run some preprocessing (which is really costly in ROBOT, as we need to load the ontology into Jena, and then back into the OWL API \u2013 so basically the ontology is loaded three times in total), then extract a module, then run more SPARQL queries etc, etc. Costly. For small ontologies, this is fine. All of these processes are important to mitigate some of the shortcomings of module extraction techniques, but even if they could be sorted in ROBOT, it may still not be enough.
So what we can do now is this. In your ont.Makefile (for example, go.Makefile, NOT Makefile), located in src/ontology, you can add a snippet like this:
Note that all the % variables and uses of $* are replaced by the ontology ID in question. Adding this to your ont.Makefile will overwrite the default ODK behaviour in favour of this new recipe.
The ODK supports this reduced module out of the box. To activate it, do this:
This will (a) ensure that PR is pulled from a gzipped location (you have to check whether it exists though. It must correspond to the PURL, followed by the extension .gz, for example http://purl.obolibrary.org/obo/pr.owl.gz) and (b) that it is considered large, so the default handling of large imports is activated for pr, and you don't need to paste anything into ont.Makefile.
If you prefer to do it yourself, in the following sections you can find a few snippets that work for three large ontologies. Just copy and paste them into ont.Makefile, and adjust them however you wish.
Feel free to use an even cheaper approach, even one that does not use ROBOT, as long as it produces the target of the goal (e.g. imports/chebi_import.owl).
"},{"location":"howto/deal-with-large-ontologies/#use-slims-when-they-are-available","title":"Use slims when they are available","text":"
For some ontologies, you can find slims that are much smaller than full ontology. For example, NCBITaxon maintains a slim for OBO here: http://purl.obolibrary.org/obo/ncbitaxon/subsets/taxslim.owl, which smaller than the 1 or 2 GB of the full version. Many ontologies maintain such slims, and if not, probably should. (I would really like to see an OBO slim for Protein Ontology!)
(note the .obo file is even smaller but currently robot has issues getting obo files from the web)
You can also add your favourite taxa to the NCBITaxon slim by simply making a pull request on here: https://github.com/obophenotype/ncbitaxon/blob/master/subsets/taxon-subset-ids.txt
This is a real hack \u2013 and we want to strongly discourage it \u2013 but sometimes, importing an ontology just to import a single term is total overkill. What we do in these cases is to maintain a simple template to \"import\" minimal information. I can't stress enough that we want to avoid this, as such information will necessarily go out of date, but here is a pattern you can use to handle it in a sensible way:
Add this to your src/ontology/ont-odk.yaml:
import_group:\n products:\n - id: my_ncbitaxon\n
Then add this to src/ontology/ont.Makefile:
mirror/my_ncbitaxon.owl:\n echo \"No mirror for $@\"\n\nimports/my_ncbitaxon_import.owl: imports/my_ncbitaxon_import.tsv\n if [ $(IMP) = true ]; then $(ROBOT) template --template $< \\\n --ontology-iri \"$(ONTBASE)/$@\" --output $@.tmp.owl && mv $@.tmp.owl $@; fi\n\n.PRECIOUS: imports/my_ncbitaxon_import.owl\n
Now you can manage your import manually in the template, and the ODK will not include your manually-curated import in your base release. But again, avoid this pattern for anything except the most trivial case (e.g. you need one term from a huge ontology).
"},{"location":"howto/deal-with-large-ontologies/#file-is-too-large-network-timeouts-and-long-runtimes","title":"File is too large: Network timeouts and long runtimes","text":"
Remember that ontologies are text files. While this makes them easy to read in your browser, it also makes them huge: from 500 MB (CHEBI) to 2 GB (NCBITaxon), which is an enormous amount.
Thankfully, ROBOT can automatically read gzipped ontologies without the need of unpacking. To avoid long runtimes and network timeouts, we can do the following two things (with the new ODK 1.2.26):
This will try to append .gz to the default download location (http://purl.obolibrary.org/obo/pr.owl \u2192 http://purl.obolibrary.org/obo/pr.owl.gz). Note that you must make sure that this file actually exists. It does for CHEBI and the Protein Ontology, but not for many others.
If the file exists, but is located elsewhere, you can do this:
You can put any URL in mirror_from (including non-OBO ones!)
"},{"location":"howto/deploy-custom-obo-dashboard/","title":"How to deploy a custom OBO dashboard","text":""},{"location":"howto/deploy-custom-obo-dashboard/#updated-2022-workflow","title":"Updated 2022 Workflow","text":"
We developed a completely automated variant of the Custom OBO Dashboard Workflow, which does not require any local installation.
Create a repository using the Dashboard template repository. (How to create a repository from a template)
Modify the dashboard-config.yml file, in particular the ontologies section:
Important: Add your ontology ID to the ID 'id' field
Add the path to your ontology to the mirror_from field.
Optional: use the profile section to overwrite the custom robot report profile and add custom checks!
Click on Settings > Pages to configure the GitHub pages. Set the Source to deploy from branch, and Branch to build from main (or master if you are still using the old default) and /(root) as directory. Hit Save.
Click on the Actions tab in your repo. On the left, select the Run dashboard workflow and click on the Run workflow button. This action will rebuild the dashboard and make a pull request with the changes.
Review and merge the pull request. Once it is merged, GitHub will automatically rebuild your dashboard website.
After 5 minutes, click on \"Settings\" > \"Pages\" again. You should now a new section with information where your site is deployed:
Click on Visit site and you should find your new shiny dashboard page!
"},{"location":"howto/deploy-custom-obo-dashboard/#troubloushooting","title":"Troubloushooting","text":""},{"location":"howto/deploy-custom-obo-dashboard/#error-on-github-action-run-dashboard-section","title":"Error on GitHub Action - Run dashboard section","text":"
Failed: make dashboard ROBOT_JAR=/tools/robot.jar ROBOT=robot -B with return code 2
There is a known bug at the moment requiring at least one ontology with a warning, error, info and pass, see https://github.com/OBOFoundry/OBO-Dashboard/issues/85.
In your dashboard-config.yml, add a temporary ontology we created to make this work. This is already in the Dashboard template repository.
Clone https://github.com/OBOFoundry/obo-nor.github.io and copy all its contents to a new GitHub repo under your account. Ensure that the .gitignore from the obo-nor.github.io repo is also copied to your new repo (it is frequently skipped or hidden from the user in Finder or when using the cp command) and push to everything to GitHub.
Pull the Ontology Development Kit from Docker Hub (can take a while):
docker pull obolibrary/odkfull\n
Modify the dashboard-config.yml file, in particular the ontologies section:
Important: Add your ontology ID to the ID 'id' field
Add the path to your ontology to the mirror_from field.
Get the \"base uri namespace\" of the ontology using the following steps: a. Open the ontology in Prot\u00e9g\u00e9 b. Select a class and press \"command + u\" (MacOS), the stem of the path would be the base URI namespace (e.g., in EDAM ontology, the base uri namespace is http://edamontology.org/, for Uberon it would be http://purl.obolibrary.org/obo/UBERON_)
Add the base uri namespace to 'base_ns' field of your ontology in the dashboard-config.yml
(As of October 2021 make sure there are multiple ontologies in the dashboard-config.yml, otherwise errors would be reported while running the code. There are currently some bugs in the dashboard code that require at least 2 or 3 ontologies in the list).
In the Makefile uncomment the # before pip install networkx==2.6.2 to ensure the correct network x version is installed.
Run sh run-dash.sh (make sure dashboard folder is empty before running, e.g. rm -rf dashboard/*).
When run successfully, push all changes to GitHub.
Go to GitHub repo you just created, and go to Settings, then Pages, and select your main/master branch as \"source\", and your root directory. You will see a website URL highlighted in green, where your OBO dashboard is deployed.
"},{"location":"howto/edit-in-protege/","title":"Editing a term in protege","text":"
Before you start:
make sure you are working on a branch here.
make sure you have the editor's file open in Protege (in ODK ontologies, located in: ./src/ontology/ONT-edit.owl) where ONT is the name of your ontology (eg mondo-edit.owl for MONDO)
familiarise yourself with the user interface of protege
"},{"location":"howto/edit-in-protege/#adding-editing-annotating-and-deleting-axioms","title":"Adding, editing, annotating and deleting axioms","text":""},{"location":"howto/edit-in-protege/#adding-annotations","title":"Adding annotations","text":"
Using Prot\u00e9g\u00e9 you can add annotations such as labels, definitions, synonyms, database cross references (dbxrefs) to any OWL entity. The panel on the right, named Annotations, is where these annotations are added. OBO Foundry ontologies includes a pre-declared set of annotation properties. The most commonly used annotations are below.
rdfs:label
definition
has_exact_synonym
has_broad_synonym
has_narrow_synonym
has_related synonym
database_cross_reference
rdfs:comment
Note: OBO ontologies allow only one rdfs:label, definition, and comment.
Note, most of these are bold in the annotation property list:
Use this panel to add a definition to the class you created. Select the + button to add an annotation to the selected entity. Click on the annotation 'definition' on the left and copy and paste in the definition to the white editing box on the right. Click OK.
Example (based on MONDO):
Definition: A disorder characterized by episodes of swelling under the skin (angioedema) and an elevated number of the white blood cells known as eosinophils (eosinophilia). During these episodes, symptoms of hives (urticaria), fever, swelling, weight gain and eosinophilia may occur. Symptoms usually appear every 3-4 weeks and resolve on their own within several days. Other cells may be elevated during the episodes, such as neutrophils and lymphocytes. Although the syndrome is often considered a subtype of the idiopathic hypereosinophilic syndromes, it does not typically have organ involvement or lead to other health concerns.
Definitions in OBO ontologies should have a 'database cross reference' (dbxref), which is a reference to the definition source, such as a paper from the primary literature or another database. For references to papers, we cross reference the PubMed Identifier in the format, PMID:XXXXXXXX. (Note, no space)
To add a dbxref to the definition:
Click the @ symbol next to the definition
Click the + button next in the pop-up window
Scroll up on the left hand side until you find 'database_cross_reference', and click it
Add the PMID in the editing box (PMID:25527564). _Note: the PMID should not have any spaces)
Click OK
Add the additional dbxref (e.g., adding GARD:0013029)
The dbxrefs should appear as below.
"},{"location":"howto/edit-in-protege/#add-synonyms-and-database-cross-reference","title":"Add Synonyms and Database cross reference","text":"
To add a synonym:
Select the + button to add an annotation to the selected entity
Add the synonyms as 'has_exact_synonym' (note: use appropriate synonym annotation)
Synonyms should have a reference to it
Click the @ symbol next to the synonym
Click the + button
Select database_cross_reference on the left panel and add your reference to the Literal tab on the right hand side
"},{"location":"howto/edit-in-protege/#the-class-description-view","title":"The Class description view","text":"
We have seen how to add sub/superclasses and annotate the class hierarchy. Another way to do the same thing is via the Class description view. When an OWL class is selected in the entities view, the right-hand side of the tab shows the class description panel. If we select the 'vertebral column disease' class, we see in the class description view that this class is a \"SubClass Of\" (= has a SuperClass) the 'musculoskeletal system disease' class. Using the (+) button beside \"SubClass Of\" we could add another superclass to the 'skeletal system disease' class.
Note the Anonymous Ancestors. These are superclasses that are inherited from the parents. If you hover over the Subclass Of (Anonymous Ancestor) you can see the parent that the class inherited the superclass from.
When you press the '+' button to add a SubClass of axiom, you will notice a few ways you can add a term. The easiest of this is to use the Class expression editor. This allows you to type in the expression utilizing autocomplete. As you start typing, you can press the 'TAB' or '->|' button on your keyboard, and protege will suggest terms. You will also note that the term you enter is not in the ontology, protege will not allow you add it, with the box being highlighted red, and the term underlined red.
"},{"location":"howto/edit-in-protege/#make-a-pull-request","title":"Make a Pull Request","text":"
Make a pull request as usual (instructions here)
"},{"location":"howto/embed-video/","title":"Embed YouTube video into a OBOOK pagetoid","text":"
This guide explains how to embed a YouTube video into a page in this OBO Academy material. Example, see the videos on the Contributing to OBO Ontologies page.
Paste the content into the page where you would like to see it displayed.
The content should look something like this: <iframe width=\"560\" height=\"315\" src=\"https://www.youtube.com/embed/_z8-KGDzZ6U\" title=\"YouTube video player\" frameborder=\"0\" allow=\"accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture\" allowfullscreen></iframe>
The embedded video should look like this:
"},{"location":"howto/filter-text-file/","title":"Command Line Trick: Filter text files based on a list of strings","text":"
Let's say you want to remove some lines from a large text file programmatically. For example, you want to remove every line that contains certain IDs, but you want to keep the rest of the lines intact. You can use the command line utility grep with option -v to find all the lines in the file that do NOT contain your search term(s). You can make a file with a list of several search terms and use that file with grep using the -f option as follows:
grep -v -f your_list.txt target_file.tsv | tee out_file.tsv\n
The target file is your text file from which you wish to remove lines. The text file can be of type csv, tsv, obo etc. For example, you wish to filter a file with these lines:
keep this 1 this line is undesired 2, so you do not wish to keep it keep this 3 keep this 4 keep this 5 keep this 6 something undesired 2 this line is undesired 1 keep this 7
The file your_list.txt is a text file with your list of search terms. Format: one search term per line. For example:
undesired 1 undesired 2
The utility tee will redirect the standard output to both the terminal and write it out to a file.
You expect the out_file.tsv to contain lines:
keep this 1 keep this 3 keep this 4 keep this 5 keep this 6 keep this 7
"},{"location":"howto/filter-text-file/#do-the-filtering-and-updating-of-your-target-file-in-one-step","title":"Do the filtering and updating of your target file in one step","text":"
You can also do a one-step filter-update when you are confident that your filtering works as expected, or if you have a backup copy of your target_file.tsv. Use cat and pipe the contents of your text file as the input for grep. Redirect the results to both your terminal and overwrite your original file so it will contain only the filtered lines.
cat target_file.tsv | grep -v -f your_list.txt | tee target_file.tsv\n
This video illustrates an example of fixing a merge conflict in the Mondo Disease Ontology.
Instructions:
If a merge conflict error appears in your Github.com pull request after committing a change, open GitHub Desktop and select the corresponding repository from the \"Current Repository\" button. If the conflict emerged after editing the ontology outside of Prot\u00e9g\u00e9 5.5.0, see Ad hoc Reserialisation below.
With the repository selected, click the \"Fetch origin\" button to fetch the most up-to-date version of the repository.
Click the \"Current Branch\" button and select the branch with the merge conflict.
From the menu bar, select Branch > \"Update from master\".
A message indicating the file with a conflict should appear along with the option to open the file (owl or obo file) in a text/code editor, such as Sublime Text. Click the button to open the file.
Search the file for conflict markings ( <<<<<<< ======= >>>>>>> ).
Make edits to resolve the conflict, e.g., arrange terms in the correct order.
Remove the conflict markings.
Save the file.
Open the file in Prot\u00e9g\u00e9. If prompted, do not reload any previously opened file. Open as a new file.
Check that the terms involved in the conflict appear OK, i.e., have no obvious errors.
Save the file in Prot\u00e9g\u00e9 using File > 'Save as...' from the menu bar and replace the ontology edit file, e.g., mondo-edit.obo
Return to GitHub Desktop and confirm the conflicts are now resolved. Click the \"Continue Merge\" button and then the \"Push origin\" button.
Return to Github.com and allow the QC queries to rerun.
The conflict should be resolved and the branch allowed to be merged.
Ad hoc Reserialisation
If the owl or obo file involved in the merge conflict was edited using Prot\u00e9g\u00e9 5.5.0, the above instructions should be sufficient. If edited in any other way, such as fixing a conflict in a text editor, the serialisation order may need to be fixed. This can be done as follows:
Reserialise the master file using the Ontology Development Kit (ODK). This requires setting up Docker and ODK. If not already set up, follow the instructions here.
Open Docker.
At the line command (PC) or Terminal (Mac), use the cd (change directory) command to navigate to the repository's src/ontology/ directory. For example,
cd PATH_TO_ONTOLOGY/src/ontology/
Replace \"PATH_TO_ONTOLOGY\" with the actual file path to the ontology. If you need to orient yourself, use the pwd (present working directory) or ls (list) line commands.
If you are resolving a conflict in an .owl file, run:
sh run.sh make normalize_src
If you are resolving a conflict in an .obo file, run:
sh run.sh make normalize_obo_src
In some ontologies (such as the Cell ontology (CL)), edits may result in creating a large amount of unintended differences involving ^^xsd:string. If you see these differences after running the command above, they can be resolved by following the instructions here.
Continue by going to step 1 under the main Instructions above.
"},{"location":"howto/github-actions/","title":"Using Github actions to automate tasks","text":""},{"location":"howto/github-actions/#post-a-comment-with-ontology-differences-on-pull-request","title":"Post a comment with ontology differences on pull request","text":"
The command line tool Robot has a diff tool that compares two ontology files and can print the differences between them in multiple formats, among them markdown.
We can use this tool and GitHub actions to automatically post a comment when a Pull Request to master is created, with the differences between the two ontologies.
To create a new GitHub action, create a folder in your ontology project root folder called .github. Then create a yaml file in a subfolder called workflows, e.g. .github/workflows/diff.yml. This file contains code that will be executed in GitHub when certain conditions are meant, in this case, when a PR to master is submitted. The comments in this file from FYPO will help you write an action for your own repository.
The comment will look something like this.
"},{"location":"howto/github-create-fork/","title":"Fork an ontology for editing","text":"
Note: Creating a fork allows you to create your copy GitHub repository. This example provides instructions on forking the Mondo GitHub reposiitory. You can't break any of the Mondo files by editing your forked copy.
On GitHub, navigate to https://github.com/monarch-initiative/mondo
In the top-right corner of the page, click Fork.
When prompted 'Where should we fork mondo', choose your own repo (eg Nicole Vasilevsky).
Be careful if you have multiple forks (i.e. the original and your own personal fork, as this can cause confusion).
Clone your forked repo:
If you have GitHub Desktop installed - click Code -> Open with GitHub Desktop
How are you planning to use this fork? To contribute to parent project
In GitHub Desktop, create a new branch:
Click Current Branch - > New Branch
Give your branch a name, like c-path-training-1
You will make changes to the Mondo on the branch of your local copy.
Further instructions on forking a repo
"},{"location":"howto/github-create-pull-request/","title":"Create a Pull Request in GitHub","text":""},{"location":"howto/github-create-pull-request/#overview","title":"Overview","text":""},{"location":"howto/github-create-pull-request/#github-workflows","title":"GitHub workflows","text":"
A Git repo consists of a set of branches each with a complete history of all changes ever made to the files and directories. This is true for a local copy you check out to your computer from GitHub or for a copy (fork) you make on GitHub.
A Git repo typically has a master or main branch that is not directly edited. Changes are made by creating a branch from Master (complete copy of the Master + its history) (either a direct branch or via a fork).
"},{"location":"howto/github-create-pull-request/#branch-vs-fork","title":"Branch vs Fork","text":"
You can copy (fork) any GitHub repo to some other location on GitHub without having to ask permission from the owners.\u00a0 If you modify some files in that repo, e.g. to fix a bug in some code, or a typo in a document, you can then suggest to the owners (via a Pull Request) that they adopt (merge) you your changes back into their repo. See the Appendix for instructions on how to make a fork.
If you have permission from the owners, you can instead make a new branch.
"},{"location":"howto/github-create-pull-request/#what-is-a-pull-request","title":"What is a Pull Request?","text":"
A Pull Request (PR) is an event in Git where a contributor (you!) asks a maintainer of a Git repository to review changes (e.g. edits to an ontology file) they want to merge into a project (e.g. the owl file) (see reference). Create a pull request to propose and collaborate on changes to a repository. These changes are proposed in a branch, which ensures that the default branch only contains finished and approved work. See more details here.
"},{"location":"howto/github-create-pull-request/#committing-pushing-and-making-pull-requests","title":"Committing, pushing and making pull requests","text":"
See these instructions on cloning an ontology repo and creating a branch using GitHub Dekstop.
Review: Once changes are made to the ontology file, they can be viewed in GitHub Desktop.
Before committing, check the diff. An example diff from the Cell Ontology (CL) is pasted below. Large diffs are a sign that something went wrong. In this case, do not commit the changes and consider asking the ontology editor team for help instead.
Example 1 (Cell Ontology):
Example 2 (Mondo):
Commit message: Before Committing, you must add a commit message. In GitHub Desktop in the Commit field in the lower left, there is a subject line and a description.
Give a very descriptive title: Add a descriptive title in the subject line. For example: add new class ONTOLOGY:ID [term name] (e.g. add new class MONDO:0000006 heart disease)
Write a great summary of what the change is in the Description box, referring to the issue. The sentence should clearly state how the issue is addressed.
To link the issue, you can use the word 'fixes' or 'closes' in the description of the commit message, followed by the corresponding ticket number (in the format #1234) - these are magic words in GitHub; when used in combination with the ticket number, it will automatically close the ticket. Learn more on this GitHub Help Documentation page about Closing issues via commit messages.
Note: 'Fixes' and \"Closes' are case-insensitive.
If you don't want to close the ticket, just refer to the ticket # without the word 'Fixes' or use 'Addresses'. The commit will be associated with the correct ticket but the ticket will remain open. 7.NOTE: It is also possible to type a longer message than allowed when using the '-m' argument; to do this, skip the -m, and a vi window (on mac) will open in which an unlimited description may be typed.
Click Commit to [branch]. This will save the changes to the ontology edit file.
Push: To incorporate the changes into the remote repository, click Publish branch.
"},{"location":"howto/github-create-pull-request/#make-a-pull-request","title":"Make a Pull Request","text":"
Click: Create Pull Request in GitHub Desktop
This will automatically open GitHub Desktop
Click the green button 'Create pull request'
You may now add comments to your pull request.
The CL editors team will review your PR and either ask for changes or merge it.
The changes will be available in the next release.
"},{"location":"howto/idrange/","title":"Setting up your ID Ranges","text":""},{"location":"howto/idrange/#setting-id-ranges-in-your-ontology","title":"Setting ID ranges in your ontology","text":"
Curators and projects are assigned specific ID ranges within the prefix for your ontology. See the README-editors.md for your ontology
An example: go-idranges.owl
NOTE: You should only use IDs within your range.
If you have only just set up this repository, modify the idranges file and add yourself or other editors.
"},{"location":"howto/idrange/#setting-id-ranges-in-protege","title":"Setting ID ranges in Protege","text":"
Once you have your assigned ID range, you need to configure Protege so that your ID range is recorded in the Preferences menu. Protege does not read the idranges file.
In the Protege menu, select Preferences.
In the resulting pop-up window, click on the New Entities tab and set the values as follows.
Same as label renderer: IRI: http://www.w3.org/2000/01/rdf-schema#label
In the Auto-generated ID section:
Numeric
Prefix GO_
Suffix: leave this blank
Digit Count 7
Start: see go-idranges.owl. Only paste the number after the GO: prefix. Also, note that when you paste in your GO ID range, the number will automatically be converted to a standard number, e.g. pasting 0110001 will be converted to 110,001.)
End: see go-idranges.owl
Remember last ID between Protege sessions: ALWAYS CHECK THIS
(Note: You want the ID to be remembered to prevent clashes when working in parallel on branches.)
"},{"location":"howto/install-protege/","title":"5 step installation guide for Prot\u00e9g\u00e9","text":"
Click here to find latest release of Prot\u00e9g\u00e9. Choose and download the appropriate files for your operating system (Linux, macOS, Windows, platform independent).
Use the PGP signature contained in the appropriate file with an .asc extension to verify the integrity of the downloaded Prot\u00e9g\u00e9 version.
Decompress the downloaded .zip or .tar.gz file with tools appropriate for your operating system.
Follow the steps as needed by your operating system to install the Prot\u00e9g\u00e9 application. For example, on macOS: drag and drop Prot\u00e9g\u00e9.app to the Applications folder and replace any older versions of the software. You may need to right click Prot\u00e9g\u00e9.app and then choose Open from the menu to authorise the programme to run on your machine. Alternatively, go to Preferences -> Security -> General. You need to open the little lock, then click Mac stopped an application from Running (Prot\u00e9g\u00e9) -> Open anyways.
Adjust memory settings if necessary. Memory settings can now be adjusted in a jvm.conf configuration file that can be located either in the .protege/conf directory under your home directory, or in the conf directory within the application bundle itself. For example, to set the maximum amount of memory available for Prot\u00e9g\u00e9 to, say, 12GB, put the following in the jvm.conf file:
# Uncomment the line below to set the maximal heap size to 8G\n#max_heap_size=8G\n
"},{"location":"howto/installing-elk-in-protege/","title":"Install Elk 0.5 in Protege","text":"
Click here to get the latest Protege Plugin latest build (this is available on the bottom of ELK pages. This will download a zipped file.)
When downloaded, unzip and copy puli and elk jars (two .jar files) in the unpacked directory.
Paste these files in your Protege plugin directory.
Remove old org.semanticweb.elk.jar
Install ELK plugin on Mac:
This can be done via one of two ways:
Approach 1
In Terminal: open ~/.Protege, then click on plugins
Click on plugins
Copy and paste the two files into the plugins directory
Remove old elk.jar (Ex. org.semanticweb.elk.jar)
Restart Protege. You should see ELK 0.5 installed in your Reasoner menu.
Approach 2
Paste these files in your Protege plugin directory. This is in one of two locations:
~/.Protege/plugins (note this is usually hidden from finder, but you can see it in the terminal) or
Go to Protege in Applications (Finder), right click, 'Show package contents' -> Java -> plugins
If you go to ~/.Protege and a directory called plugins does not exist in this folder, you can create it.
Copy and paste the two files into the plugins directory
Remove old elk.jar (Ex. org.semanticweb.elk.jar)
Restart Protege. You should see ELK 0.5 installed in your Reasoner menu.
Important: it seems Elk 0.5. Does not work with all versions of Protege, in particular, 5.2 and below. These instructions were only tested with Protege 5.5.
See Daily Workflow for creating branches and basic Prot\u00e9g\u00e9 instructions.
Note Before performing a merge, make sure that you know all of the consequences that the merge will cause. In particular, be sure to look at child terms and any other terms that refer to the \u2018obsoleted\u2019 term. In many cases a simple merge of two terms is not sufficient because it will result in equivalent classes for child terms. For example if obsoleted term X is going to be merged into target term Y and \u2018regulation of X\u2019 and \u2018regulation of Y\u2019 terms exist, then you will need to merge the regulation terms in addition to the primary terms. You will also need to edit any terms that refer to the obsoleted term to be sure that the names and definitions are consistent.
Find the ID of the term in which the obsoleted term will be merged
Navigate to 'winning' term using the Search box. Copy the ID of the winning term somewhere.
Duplicate annotations from the obsoleted terms
Navigate to the term to be obsoleted.
Right click on it and select Duplicate class then OK in the pop up window. This should create a class with the exact same name.
On the duplicated class (you can see this by (CL:XXXX) within your range added), right click and select Change IRI (Rename)
Copy the ID of the winning term (obtained in Step 1).
Be sure to use the underscore _ in the identifier instead of the colon :, for example: GO_1234567. Make sure that the 'change all entities with this URI' box is checked.
Navigate to the winning term IRI, all annotations should be merged.
Change obsoleted term label to a synonym
In the annotations box of the winning term there are now two terms with labels 'rdfs:label'. Click the o to change the label of the obsoleted term.
In the resulting pop-up window, select the appropriate synonym label from the list on the left:
has_broad_synonym
has_exact_synonym
has_narrow_synonym
has_related_synonym (if unsure, this is the safest choice)
Remove duplicated or inappropriate annotations
Check the definition, if there are multiple entries, remove the obsoleted one by clicking on the x on the right.
Check the subclasses and remove inappropriate/duplciated ones by clicking on the x on the right.
Check list of synonyms and remove inappropriate/duplciated ones by clicking on the x on the right.
Note down the created_by and created_date (there can only be one value per term for each of these fields; this will be useful if you need to pick one after the merge is done).
Obsolete old term
Obsolete the old term by following instructions found in obsoletion how to guide..
Ensure that you add a rdfs:comment that states that term was duplicated and to refer to the new new.
Ensure that you add a term replaced by annotations as per the instructions and add the winning merged term.
Synchronize the reasoner and make sure there are no terms that have identical definitions as a result of the merge. These are displayed with an 'equivalent' sign \u2261 in the class hierarchy view on the left hand panel.
Save changes.
See Daily Workflow section for commit, push and merge instructions.
"},{"location":"howto/merge-terms/#merge-using-owltools","title":"Merge using owltools","text":"
To use owltools will need to have Docker installed and running (see instructions here).
This is the workflow that is used in Mondo.
Create a branch and name it issue-### (for example issue-2864)
In Terminal, navigate to your ontology directory: src/ontology
Run your owltools command
Check the output in GitHub desktop
Open a new version of your ontology edit file in Protege
Search for the term that was obsoleted
Add 'term tracker item' (type xsd:anyURI) with a link to the GitHub issue that requested the obsoletion.
Add an obsoletion reason: use the annotation property 'has obsolescence reason' and write 'terms merged' in the literal field.
Search for the 'term replaced by' term
Delete the old ID
Review the annotations to ensure there are no duplicate annotations. If there are, they should be merged.
Review the subClassOf assertions, and make sure there are no duplicates. If there are, they should be merged.
When reviewing the diff, make sure there is not an Alt ID. The diff should only show additions to the merged term and the obsoletion
TROUBLESHOOTING: Travis/Jenkins errors
Merging a term that is used as 'replaced by' for an obsolete term
:: ERROR: ID-mentioned-twice:: GO:0030722 :: ERROR: ID-mentioned-twice:: GO:0048126 GO:0030722 :: ERROR: has-definition: missing definition for id
The cause of this error is that Term A (GO:0048126) was obsoleted and had replace by Term B (GO:0030722). The GO editor tried to merge Term B into a third term term C (GO:0007312). The Jenkins checkk failed because 'Term A replaced by' was an alternative_id rather than by a main_id. Solution: In the ontology, go to the obsolete term A and replace the Term B by term C to have a primary ID as the replace_by.
"},{"location":"howto/obsolete-term/","title":"Obsoleting an Existing Ontology Term","text":"
See Daily Workflow for creating branches and basic Prot\u00e9g\u00e9 instructions.
Warning: Every ontology has their procedures on how they obsolete terms (eg notice periods, notification emails, to_be_obsolete tags, etc.), this how-to guide only serves as a guide on how obsolete a term directly on protege.
For instructions on how to merge terms (i.e., replace a term with another term in the ontology), see instructions here.
"},{"location":"howto/obsolete-term/#pre-obsoletion-process-or-basic-obsoletion-etiquette","title":"PRE OBSOLETION PROCESS (or basic obsoletion etiquette)","text":"
Check if the term (or any of its children) is being used for annotation:
Go to your ontology browser of choice, search for the term, either by label or ID
See which other ontologies use the to be obsolete term
Notify affected groups (usually by adding an issue in their tracker)
Check if the term is used elsewhere in the ontology
In Prot\u00e9g\u00e9, navigate to the term to be obsolete and go to the 'Usage' tab to see if that ID is used elsewhere.
If the term is a parent to other terms or is used in logical definitions, make sure that another term replaces the obsolete term
"},{"location":"howto/obsolete-term/#obsoletion-process-manual","title":"OBSOLETION PROCESS (Manual)","text":"
Warning: some ontologies give advance notice on terms that will be obsoleted through the annotation 'scheduled for obsoletion on or after' instead of directly obsoleting the term. Please check with the conventions of your ontology before obsoleting a term.
Navigate to the term to be obsoleted.
Select Edit > Deprecate entity...
A deprecation wizard will pop up, in here, select GO style, and select continue (note this is specifc to GO style ontologies, if you are working with an OBI style ontology, there is an option for that too, if not use basic. For this how to, we will follow GO style)
Next, enter your reason for deprecation. For this, we advice for you to enter the github issue. (eg https://github.com/obophenotype/cell-ontology/issues/####) This will appear as a rdfs:comment
Next enter a replacement entity if there is one. This will automatically replace axioms in the ontology with the term, and add an 'item replaced by' axiom on the obsolete term.
Your obsolete term should now be stripped of its logical axioms and should look similar to the figure below.
Add any additional annotations needed - this is specific to ontologies and you should consult the conventions of the ontology you are working on.
Examples of additional annotations to add:
IAO:0000233 term tracker item (type xsd:anyURI) - link to GitHub issue
has_obsolence_reason
add \u2018OBSOLETE.\u2019 to the term definition: In the 'Description' window, click on the o on the right-hand side of the definition entry. In the resulting window, in the Literal tab, at the beginning of the definition, type: OBSOLETE.
if the obsoleted term was not replaced by another term in the ontology, but there are existing terms that might be appropriate for annotation, add those term IDs in the 'consider' tag: In the 'Annotations' window, select + to add an annotation. In the resulting menu, select consider and enter the ID of the replacement term.
NOTE: Here you have to add the ID of the entity as an xsd:string, e.g. GO:0005819, not the term label.
"},{"location":"howto/obsolete-term/#obsolete-a-class-using-protege-make-entity-obsolete-function","title":"Obsolete a class (using Protege 'Make entity obsolete' function)","text":"
Navigate to the term to be obsoleted.
In the Protege edit menu-> Make entity obsolete
Prepend the definition with OBSOLETE. For example, OBSOLETE. Chronic form of myeloproliferative neoplasm.
Add a statement about why the term was made obsolete: In the 'Annotations' window, select + to add an annotation. In the resulting menu, select rdfs:comment and select Type: Xsd:string. Consult the wiki documentation for suggestions on standard comments:
If the obsoleted term was replaced by another term in the ontology: In the 'Annotations' window, select + to add an annotation. In the resulting menu, select term replaced by and enter the ID of the replacement term.
If the obsoleted term was not replaced by another term in the ontology, but there are existing terms that might be appropriate for annotation, add those term IDs in the 'consider' tag: In the 'Annotations' window, select + to add an annotation. In the resulting menu, select consider and enter the ID of the replacement term.
NOTE: Here you have to add the ID of the entity as an xsd:string, e.g. GO:0005819, not the term label.
Add any additional annotations needed - this is specific to ontologies and you should consult the conventions of the ontology you are working on.
Examples of additional annotations to add:
IAO:0000233 term tracker item (type xsd:anyURI) - link to GitHub issue
has_obsolence_reason
See Daily Workflow section for commit, push and merge instructions.
"},{"location":"howto/odk-add-orcidio-module/","title":"Import ORCIDIO","text":""},{"location":"howto/odk-add-orcidio-module/#adding-an-orcidio-import-to-your-ontology-with-odk","title":"Adding an ORCIDIO import to your ontology with ODK","text":"
The Open Researcher and Contributor Identifier (ORCID) is a global, unambiguous way to identify a researcher. ORCID URIs (e.g., https://orcid.org/0000-0003-4423-4370) can therefore be used to unambigously and actionably attribute various aspects of ontology terms in combination with DC Terms or IAO predicates. However, URIs themselves are opaque and it is difficult to disambiguate to which person an ORCID corresponds when browsing an ontology (e.g., in Prot\u00e9g\u00e9).
ORCIDIO is an ontology that declares ORCID URIs as named individuals and associates basic metadata (e.g., name, description) to each such that tools like Prot\u00e9g\u00e9 can display a human-readable label rather than the URI itself as in the following example.
In this guide, we discuss how to add ORCIDIO to your ODK setup.
"},{"location":"howto/odk-add-orcidio-module/#1-include-orcidio-as-an-import-into-the-odk-config-file","title":"1. Include ORCIDIO as an import into the ODK config file","text":"
In your ODK configuration (e.g. src/ontology/myont-odk.yaml), add the following to the import_group:
The list of annotation properties, in particular dc:source, is important for the filter module to work (ORCIDIO relies heavily on axiom annotations for provenance).
"},{"location":"howto/odk-add-orcidio-module/#2-update-your-catalog","title":"2. Update your catalog","text":"
TODO: \"as usual\" should be re-written to cross-link to another guide about updating the catalog (or don't say as usual to keep this more self-contained) As usual, add a statement into your catalog (src/ontology/catalog-v001.xml):
"},{"location":"howto/odk-add-orcidio-module/#3-update-the-edit-file","title":"3. Update the edit file","text":"
TODO: \"as usual\" should be re-written to cross-link to another guide about updating the edit file (or don't say as usual to keep this more self-contained) As usual, add an imports declaration to your edit file (src/ontology/myont-edit.owl):
TODO: link to explanation of base merging strategy Note: This is not necessary when using the base merging strategy (you will know what this means when you do use it).
"},{"location":"howto/odk-add-orcidio-module/#4-configure-your-seed","title":"4. Configure your seed:","text":"
Add a new SPARQL query: src/sparql/orcids.sparql. This is used to query for all ORCIDs used in your ontology.
For your specific use-case, it may be necessary to tweak this SPARQL query, for example if your ORCIDs are used on axiom annotation level rather than entity annotation level.
"},{"location":"howto/odk-add-orcidio-module/#5-updating-config-and-orcidio","title":"5. Updating Config and ORCIDIO","text":"
Now run to apply your ODK changes:
sh run.sh make update_repo\n
This will update a number of files in your project, such as the autogenerated Makefile.
Lastly, update your ORCIDIO import to apply the changes:
sh run.sh make refresh-orcidio\n
Commit all the changes to a branch, wait for continuous integration to finish, and enjoy your new ORCIDIO import module.
"},{"location":"howto/odk-create-repo/","title":"Creating a new Repository with the Ontology Development Kit","text":"
This is instructions on how to create an ontology repository in GitHub. This will only need to be done once per project. You may need assistance from someone with basic unix knowledge in following instructions here.
We will walk you though the steps to make a new ontology project
docker: Install Docker and make sure its runnning properly, for example by typing docker ps in your terminal or command line (CMD). If all is ok, you should be seeing something like:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES\n
git, for example bundled with GitHub Desktop
"},{"location":"howto/odk-create-repo/#2-download-the-wrapper-script-and-pull-latest-odk-version","title":"2. Download the wrapper script and pull latest ODK version","text":"
Linux/Mac: seed-via-docker.sh
PC: seed-via-docker.bat
Make sure to save the wrapper script in your working directory and that the filetype is correct.
You should have git installed - for the repo command to work perfectly, it requires a .gitconfig file in your user directory!
First, make sure you have Docker running (you will see the Docker whale in your toolbar on a Mac)
To make sure you have the latest version of the ODK installed, run in the command line
docker pull obolibrary/odkfull
NOTE The very first time you run this it may be slow, while docker downloads necessary images. Don't worry, subsequent runs should be much faster!
NOTE Windows users, occasionally it has been reported that files downloaded on a Windows machine get a wrong file ending, for example seed-via-docker.bat.txt instead of seed-via-docker.bat, or, as we will see later, project.yaml.txt instead of project.yaml. If you have problems, double check your files are named correctly after the download!
"},{"location":"howto/odk-create-repo/#3-run-the-wrapper-script","title":"3. Run the wrapper script","text":"
You can either pass in a configuration file in YAML format that specifies your ontology project setup, or you can pass arguments on the command line. You can use dir in your command line on PC to ensure that your wrapper script, .gitconfig, and project.yaml (if you so choose) are all in the correct directory before running the wrapper script.
"},{"location":"howto/odk-create-repo/#general-instructions-for-both-linux-and-windows","title":"General instructions for both Linux and Windows","text":"
Instead of -u cmungall you should be using your own username (i.e. -u nico), for example for your GitHub or GitLab hosting sites.
You can add a -c (lowercase) just before the -C (capital c) in the command to first delete any previous attempt to generate your ontology with the ODK, and then replaces it with a completely new one. So, -c stands for clean or \"clean up previous attempts before running again\" and -C stands for \"the next parameter is the relative path to my config file\".
In general, we now always recommend the use of config files. The ODK has a rich set of configuration options, most of which can only be set through the config file, but in general the config also serves as documentation and will help with updating your ontology at later stages. To create a config file, you can download for example project.yaml by clicking on the link and then typing command+s on Mac or ctrl+s on Windows to save it in the same directory as your seed-via-docker script. Then you can open the file with a text editor like Notepad++, Atom, Sublime or even nano, and adapt it to your project. Other more comprehensive examples can be found here.
This will create your starter files in target/triffid-behavior-ontology. It will also prepare an initial release and initialize a local repository (not yet pushed to your Git host site such as GitHub or GitLab).
There are three frequently encountered problems at this stage:
No .gitconfig in user directory
Spaces is user path
During download, your filenames got changed (Windows)
"},{"location":"howto/odk-create-repo/#no-gitconfig-in-user-directory","title":"No .gitconfig in user directory","text":"
The seed-via-docker script requires a .gitconfig file in your user directory. If your .gitconfig is in a different directory, you need to change the path in the downloaded seed-via-docker script. For example on Windows (look at seed-via-docker.bat):
%userprofile%/.gitconfig should be changed to the correct path of your local .gitconfig file.
"},{"location":"howto/odk-create-repo/#spaces-is-user-path","title":"Spaces is user path","text":"
We have had reports of users having trouble if there paths (say, D:\\data) contain a space symbol, like D:/Dropbox (Personal) or similar. In this case, we recommend to find a directory you can work in that does not contain a space symbol.
You can customize at this stage, but we recommend to first push the changes to you Git hosting site (see next steps).
"},{"location":"howto/odk-create-repo/#during-download-your-filenames-got-changed-windows","title":"During download, your filenames got changed (Windows)","text":"
Windows users, occasionally it has been reported that files downloaded on a Windows machine get a wrong file ending, for example seed-via-docker.bat.txt instead of seed-via-docker.bat, or, as we will see later, project.yaml.txt instead of project.yaml. If you have problems, double check your files are named correctly after the download!
"},{"location":"howto/odk-create-repo/#4-push-to-git-hosting-website","title":"4. Push to Git hosting website","text":"
The development kit will automatically initialize a git project, add all files and commit.
You will need to create a project on you Git hosting site.
For GitHub:
Go to: https://github.com/new
The owner MUST be the org you selected with the -u option. The name MUST be the one you set with -t, just with lower case letters and dashes instead of spaces. In our example above, the name \"Triffid Behavior Ontology\" translates to triffid-behavior-ontology.
Do not initialize with a README (you already have one)
Click Create
See the section under \"\u2026or push an existing repository from the command line\"
For GitLab:
Go to: https://gitlab.com/projects/new
The owner MUST be the org you selected with the -u option. The name MUST be the one you set with -t.
Do not initialize with a README (you already have one)
Click 'Create project'
See the section under \"Push an existing Git repository\"
Follow the instructions there. E.g. (make sure the location of your remote is exactly correct!).
Note: you can now mv target/triffid-behavior-ontology to anywhere you like in your home directory. Or you can do a fresh checkout from github.
"},{"location":"howto/odk-create-repo/#alternative-recommendation-for-github-by-matentzn","title":"Alternative recommendation for GitHub by @matentzn","text":"
I generally feel its easier and less error prone to deviate from the standard instructions above. I keep having problems with git, passwords, typose etc, so I tend to do it, inofficially, as follows:
When my repo is created I go to my GitHub Desktop
I then do File > Add local repository, and select the directory which contains my newly created repo (e.g. target/triffo).
I then Click on \"Publish repository\".
If I want the code to be public, I deselect \"Keep this code private\". By default, the repo will be uploaded to my own user profile on GitHub, but I can also select another Organization I have access to in the respective Dropdown menu.
NOTE: there seem to be some issues with pushing a GitHub Workflow file recently - you may be asked by GitHub Desktop to provide an additional permission to push the Workflow file.
"},{"location":"howto/odk-create-repo/#next-steps-edit-and-release-cycle","title":"Next Steps: Edit and release cycle","text":"
In your repo you will see a README-editors.md file that has been customized for your project. Follow these instructions.
The assumption here is that you are adhering to OBO principles and want to eventually submit to OBO. Your repo will contain stub metadata files to help you do this.
You can create pull requests for your ontology on the OBO Foundry. See the src/metadata file for more details.
See the README-editors.md file that has been generated for your project.
"},{"location":"howto/odk-setup/","title":"Getting set up with Docker and the Ontology Development Kit","text":""},{"location":"howto/odk-setup/#installation","title":"Installation","text":""},{"location":"howto/odk-setup/#for-windows","title":"For Windows","text":"
Follow the instructions here. Note that you should have Windows 10 Professional installed for this to work. We are not sure Docker Desktop works at all with Windows 10 Home, but we have not tried in a while. If you know what you are doing, you could try to configure Docker toolbox, but we have had many issues with it, and do not recommend it unless absolutely necessary.
If you are unable to install Docker Desktop on your Windows PC (e.g. no admin rights or pohibited by the IT department of your institution) but you have the ability to use the Windows Hyper-V-Manager (possible w/o admin rights) or another virtualization tool, such as VirtualBox, you could set up a Linux virtual machine (VM) to use ODK. We recommend using Lubuntu, as it won't need much computing resources. Although you cannot install Docker Desktop in such a VM, you can install the Docker Engine, which suffices to proceed with the next step.
Once installed, you should be able to open your command line and download the ODK.
Click on your Windows symbol (usually in bottom left corner of screen), type \"cmd\" and you should be able to see and open the Command Line tool.
in the command line type, type docker pull obolibrary/odkfull. This will download the ODK (will take a few minutes, depending on you internet connection).
Executing something in a Docker container can be \"wordy\", because the docker container requires quite a few parameters to be run. To make this easier, we prepared a wrapper script here. You can download this file by clicking on Raw, and then, when the file is open in your browser, CTRL+S to save it. Ideally, you save this file in your project directory, the directory you will be using for your exercises, as it will only allow you to edit files in that very same directory (or one of its sub-directories).
Install docker: Install Docker following the official instructions.
Make sure its running properly, for example by typing docker ps in your terminal or command line (CMD). If all is ok, you should be seeing something like:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES\n
Run docker pull obolibrary/odkfull on your command line to install the ODK. This will take while.
Download an ODK wrapper script. The odk.sh has further instruction on how to best use it.
Now you are ready to go to a directory containing the odk.sh wrapper script and running sh odk.sh robot --version to see whether it works.
The ODK wrapper script is generally useful to have: you can for example enter a ODK container, similar to a virtual machine, by simply running sh odk.sh bash (to leave the ODK container again, simply run exit from within the container). On Windows, use run.bat bash instead. However, for many of the ontologies we develop, we already ship an ODK wrapper script in the ontology repo, so we dont need the odk.sh or odk.bat file. That file is usually called run.sh or run.bat and can be found in your ontology repo in the src/ontology directory and can be used in the exact same way.
"},{"location":"howto/odk-setup/#problems-with-memory-important","title":"Problems with memory (important)","text":"
One of the most frequent problems with running the ODK for the first time is failure because of lack of memory. There are two potential causes for out-of-memory errors:
The application (for example, the ODK release run) needs more memory than assigned to JAVA inside the ODK docker container. This memory is set as part of the ODK wrapper files, i.e. src/ontology/run.bat or src/ontology/run.sh, usually with ODK_JAVA_OPTS.
The application needs more memory than is assigned to your docker installation. On most systems (apart from a handful fo Windows ones based on WSL), you have to set docker memory in the docker preferences. That happens here is that the Java memory above may be set to something like 10GB, while the maximum docker memory is set to 8GB. If the application needs, say, 9GB to run, you have assigned enough Java memory, but docker does not permit more than 8 to be used.
Out-of-memory errors can take many forms, like a Java OutOfMemory exception, but more often than not it will appear as something like an Error 137.
There are two places you need to consider to set your memory:
Your ODK wrapper script (see above), i.e. odk.bat, odk.sh or src/ontology/run.sh (or run.bat) file. You can set the memory in there by adding robot_java_args: '-Xmx8G' to your src/ontology/cl-odk.yaml file, see for example here.
Set your docker memory. By default, it should be about 10-20% more than your robot_java_args variable. You can manage your memory settings by right-clicking on the docker whale in your system bar-->Preferences-->Resources-->Advanced, see picture below.
If your problem is that you do not have enough memory on your machine, the only solution is to try to engineer the pipelines a bit more intelligently, but even that has limits: large ontologies require a lot of memory to process when using ROBOT. For example, handling ncbitaxon as an import in any meaningful way easily consumes up to 12GB alone. Here are some tricks you may want to contemplate to reduce memory:
robot query uses an entirely different framework for representing the ontology, which means that whenever you use ROBOT query, for at least a short moment, you will have the entire ontology in memory twice. Sometimes you can optimse memory by seperating query and other robot commands into seperate commands (i.e. not chained in the same robot command).
The robot reason command consumes a lot of memory. reduce and materialise potentially even more. Use these only ever in the last possible moment in a pipeline.
A new version of the Ontology Development Kit (ODK) is out? This is what you should be doing:
Install the latest version of ODK by pulling the ODK docker images. In your terminal, run:
docker pull obolibrary/odkfull\n
To update your repository, go to your src/ontology directory.
cd myrepo/src/ontology\n
Create a new git branch in your usual way (optional)
Now run the update command TWICE (the first time it may fail, as the update command needs to update itself).
sh run.sh make update_repo\nsh run.sh make update_repo\n
Edit the following file: .github/workflows/qc.yml (from the top level of your repository) and make sure that it is using the latest version of the ODK.
For example, container: obolibrary/odkfull:v1.3.0, if v1.3.0. Is the latest version. If you are unsure what the latest version is, you can find that information here: https://hub.docker.com/r/obolibrary/odkfull/tags
OPTIONAL: if you have any other GitHub actions you would like to update to the latest ODK, now is the time! All of your GitHub actions can be found in the .github/workflows/ directory from the top level of your repo.
Review all the changes and commit them, and make a PR the usual way. 100% wait for the PR to pass QC - ODK updates can be significant!
Send a reminder to all other ontology developers of your repo and tell them to install the latest version of ODK (step 1 only).
"},{"location":"howto/ontology-overview/","title":"How to prepare OBO Academy ontology overview","text":""},{"location":"howto/ontology-overview/#overview","title":"Overview","text":"
This 'how to' guide provides a template for an Ontology Overview for your ontology. Please create a markdown file using this template and share it in your ontology repository, either as part of your ReadMe file or as a separate document in your documentation. The Ontology Overview should include the following three sections:
For example, the Mondo ontology covers concepts in the area of diseases across species and integrates disease terminologies from several underlying sources.
Include a figure of upper level terms (critical: give a list of all the high level terms that the ontology covers (1-2 levels). Eg Mondo: disease or disorder, disease susceptibility, disease characteristic).
Include a figure with exemplary term (using OBO graph)
"},{"location":"howto/ontology-overview/#curation-and-governance-workflows","title":"Curation and governance workflows","text":""},{"location":"howto/ontology-overview/#ontology-curation","title":"Ontology Curation","text":"
Describe the ontology level curation, ie how to add terms. For example, terms are added to the ontology via:
How do people contribute terms directly (ie ROBOT templates, etc) (if applicable)
Note: There is no need for details about QC, ODK unless it is related to curation (ie pipeline that automatically generates mappings, include that)
"},{"location":"howto/ontology-overview/#how-the-ontology-used-in-practice","title":"How the ontology used in practice","text":"
Include 1-3 actual use cases. Please provide concrete examples.
For example:
this group uses the ontology to annotate this data for this purpose
this group uses the ontology to compute phenotypic similarity for prediction of related diseases
The ontology is used for named entity recognition (NER) as a dictionary as a synonym source
"},{"location":"howto/open-science-engineer/","title":"How to be an Open Science Engineer - maximising impact for a better world","text":"
Contributors:
Nicole Vasilevsky
Nicolas Matentzoglu
Bradley Varner
Status: This is a working document! Feel free to add more content!
The Open Science Engineer contributes to the collection and standardisation of publicly available scientific knowledge through curation, community-building and data, ontology and software engineering.
Open Science and all its sub-divisions, including Open Data and Open Ontologies, are central to tackling global challenges from rare disease to climate change. Open licenses are only part of the answer - the really tough part is the standardisation of data (including the unification of ontologies, the FAIRification of data and adoption of common semantic data models) and the organisation of a global, fully decentralised community of Open Science engineers. Here, we will discuss some basic principles on how we can maximise our impact as members of a global community combating the issues of our time:
Principle of Collaboration: How do we create a welcoming and inclusive environment for implementing social workflows and deepen our ties across project boundaries?
Principle of Upstream Fixing: How can we maximise benefits to the global community by pushing fixes as far upstream as possible?
Principle of No-ownership: How do we develop a sense of co-, or -no, ownership for community driven ontologies and ontology tools?
We discuss how to best utilise social workflows to achieve positive impact. We will try to convince you that building a close collaborative international community by spending time on submitting and answering issues on GitHub, helping on Stack Overflow and other online platforms, or just reaching out and donating small amounts of time to other open science efforts can make a huge difference.
"},{"location":"howto/open-science-engineer/#table-of-contents","title":"Table of contents","text":"
"},{"location":"howto/open-science-engineer/#monarch-obo-training-tutorial","title":"Monarch OBO training Tutorial","text":"
How to be an open science ontologist
"},{"location":"howto/open-science-engineer/#principle-of-collaboration","title":"Principle of Collaboration","text":"
The heart and soul of a successful Open Science culture is collaboration. The relative isolation into which many projects are forced due to limitations imposed by certain kinds of funding makes it even more important to develop effective social, collaborative workflows. This involve effective online communication, vocal appreciation (likes, upvotes, comments), documentation and open-ness.
"},{"location":"howto/open-science-engineer/#question-answering-and-documentation","title":"Question answering and documentation","text":"
When you find an answer on Stack Overflow, GitHub issues (or even Hacker News) that helps you, upvote it. It cannot be stressed enough how important this is to let good answers float up to the top (become more visible), and recognise the time and energy people spend formulating answers. If you do not have a Stack Overflow account, make one now.
If you cannot find an answer to a question on GitHub or Stack Overflow, and you figure out a solution consider asking the question and answering it yourself! Consider this: if you provide an answer that will result in only 6 open science people spending one hour less solving a problem (a conservative estimate), you saved the taxpayer 6 hours of salary (not to speak of improving the quality of the solutions)!
Answer questions on GitHub issues even when on trackers not in your purview. People often falsely assume that they should not try to answer queries in an open source project that they are not directly involved with. This is wrong! Open source developers highly (!) appreciate it when you chip in on answering queries, from dealing with errors and exceptions to \"How do I?\" kind of queries. Get involved on other peoples issue trackers!
Before asking questions on slack or issue trackers, always do a basic search first. Consider (1) the project's documentation, (2) open and closed issues on the issue tracker of the project your query is related to. If you do not find the information you need try and craft questions that are concise yet give sufficient context. To enable future users to find these answers, consider using the issue tracker instead of slack! Also it is important to remember that the people that answer your questions have to spend time they could have spend on other Open Science work!
Make yourself responsible for continuously improving open science documentation. If a question was answered on slack or in an issue, consider a 10 minute detour to update the documentation of the project to reflect the solution if you think it could be helpful. This is the only way to scale Open Science projects: as the user base increases, providing support on a 1:1 basis will soon be infeasible.
Good documentation is as important as good quality code, and everyone can help out, even if it is \"only\" about formatting, typos and adding additional links!
"},{"location":"howto/open-science-engineer/#social-conduct-and-review","title":"Social Conduct and review","text":"
Be overly generous with likes. Being a Open Science Engineer can be quite a lonely affair: hundreds of unanswered issues and questions, pull requests that remain un-reviewed for months, projects for which you never really get credit (want to be a QC engineer, anyone?). Even if you do not have time to respond to all issues you scroll through in a day, add a like if you find an answer useful. This goes for slack comments, Tweets and random Pull Requests you have nothing to do with as well. And, perhaps most importantly star all GitHub repos that are useful to you (you could, for example, scroll through https://github.com/topics/obofoundry and star all ontologies and ontology projects useful in your work)! This is a huge deal as it significantly motivates other OSEs and therefore provides fuel to the Open Science movement.
Reduce work for others as much as possible by communicating clearly.
Take the time to write clear responses with just the right amount of detail. The goal of your communication is to get the point across as swiftly as possible, and misunderstandings are a huge time killer.
Again: Sloppy, quick responses can cause more work than not responding at all!
Use bullet lists to structure your response, and checklists for action items.
Hide unnecessary details with <details> tag: <details><summary>[click arrow to expand]</summary>. See example here
Be generous linking external issues to provide context. Example:
Be positive and generous with gratitude and attribution
If a member of the community opens an issue, always thank them for the issue right away. We need to encourage people to open issues.
Don't let issues linger without any response. It is better to respond with a thank you and some instructions for the issuer on what to do to fix the issue themselves than to let it linger. We need our stakeholders to be more involved - first time issuers are especially vulnerable and may not bother to come back if they are ignored.
When giving feedback, be positive, friendly and constructive.
Show appreciation: thank users for issues and thank a PR reviewer for their review. Always.
Attribute, attribute, attribute. If someone helped you sort something out emphasise this publicly!
Contribute your thoughts openly so other people can benefit from it.
Don't put issues on Slack where the public can't see it. Consider moving interesting discussions on Slack into a more public space, like GitHub discussions.
Create public tickets which can be searched and referred to later.
"},{"location":"howto/open-science-engineer/#principle-of-upstream-fixing","title":"Principle of Upstream Fixing","text":"
Maximising impact of your changes is by far the best way you can benefit society as an Open Science Engineer. Open Science projects are a web of mutually dependent efforts, for example:
Ontologies re-use terms and axioms from other ontologies
Software packages provide functionality that help building Knowledge Graphs, ensuring the quality of ontology releases and extract new insights from existing knowledge and scientific facts.
Projects use ontologies for indexing data and making them discoverable.
The key to maximising your impact is to push any fixes as far upstream as possible. Consider the following projects and the way they depend on each other (note that this is a gross simplification for illustration; in reality the number of dependencies is much higher):
Let's think of the following (entirely fabricated) scenario based on the image above.
Open Targets provides evidence for a gene association with some disease.
This association is only supported by the IMPC data source which associates mouse and human phenotypes using the phenodigm algorithm which is based on semantic similarity.
The semantic similarity scores are computed using cross-species axioms provided by the Monarch Initiative, especially uPheno.
The cross-species logical axioms provided by Monarch depend on a range of lexical and logical approaches. This means the structure of uPheno is directly influenced by the naming and synonyms provided by species specific phenotype ontologies (SSPOs), such as the Human Phenotype Ontology (HPO).
It is, therefore, possible that:
A faulty synonym is accidentally added to the HPO...
...which causes a faulty logical axiom candidate in uPheno (again missed by QC measures)...
...which causes a faulty similarity value in Monarch...
...which causes a wrong disease-gene association in IMPC...
...which ultimately leads to a faulty piece of evidence in Open Targets.
Imagine a user of Open Targets that sees this evidence, and reports it to Open Targets as a bug. Open Targets could take the easy way out: remove the erroneous record from the database permanently. This means that the IMPC (itself with hundreds of dependent users and tools), Monarch (again with many dependents), uPheno and HPO (with probably thousands of dependents) would still carry forward that (tiny) mistake. This is the basic idea of maximising impact through Upstream Fixing: The higher up-stream (up the dependency graph) an error is fixed, the more cumulative benefit there is to a huge ecosystem of tools and services.
An even better fix would be to have each fix to the ontology result in a new, shared quality control test. For example, some errors (duplicate labels, missing definition, etc) can be caught by automated testing. Here is a cool story.
"},{"location":"howto/open-science-engineer/#case-study-external-contribution-and-upstream-fixing","title":"Case Study: External contribution and upstream fixing","text":"
Over time, we have developed QC checks that ensure that the same exact synonym cannot be shared between two classes. However the checks where not perfect..
@vasvir (GitHub name), a member of the global community reached out to us on Uberon: https://github.com/obophenotype/uberon/issues/2424. https://github.com/obophenotype/uberon/pull/2640
Instead of fixing the discovered issue by ourselves, we invited @vasvir to fix the issues himself. We gave him some instructions on how to proceed, leading not only to eight new pull requests, but also an entirely new Quality Control check that augments the existing checks with case-insensitivity (Gasserian ganglion and gasserian ganglion where previously considered distinct). Note: before the PRs, @vasvir did not speak any SPARQL.
Members of our team helped @vasvir to see his first pull requests through by instructing them how to use the technology (robot, ODK, docker, SPARQL), and follow our pull request conventions.
Instead of simply deleting the synonyms for his NLP projects, @vasvir instead decided to report the issues straight to the source. This way, hundreds, if not thousands of projects will directly or indirectly benefit from him!
"},{"location":"howto/open-science-engineer/#other-examples-of-upstream-fixing","title":"Other examples of upstream fixing","text":"
Example 1: While curating Mondo, Nicole identified issues relevant to Orphanet and created this issue.
Example 2: There is overlap between Mondo and Human Phenotype Ontology and the Mondo and HPO curators tag each other on relevant tickets.
Example 3: In Mondo, if new classifications are made, Mondo curators report this back to the source ontology to see if they would like to follow our classification.
Have you ever wondered how much impact changing a synonym from exact to related could have? Or the addition of a precise mapping? The fixing of a typo in a label? It can be huge. And this does not only relate to ontologies, this goes for tool development as well. We tend to work around bugs when we are building software. Instead, or at least in addition to, we should always report the bug at the source to make sure it gets fixed eventually.
"},{"location":"howto/open-science-engineer/#principle-of-no-ownership","title":"Principle of No-ownership","text":"
Many of the resources we develop are financed by grants. Grants are financed in the end by the taxpayer. While it is occasionally appropriate to protect open work with creative licenses, it rarely makes sense to restrict access to Open Ontologies work - neither to commercial nor research exploitation (we may want to insist on appropriate attribution to satisfy our grant developers).
On the other side there is always the risk of well-funded commercial endeavours simply \"absorbing\" our work - and then tying stakeholders into their closed, commercial ecosystem. However, this is not our concern. We cannot really call it stealing if it is not really ours to begin with! Instead of trying to prevent unwanted commercialisation and closing, it is better to work with corporations in pre-competitive schemes such as Pistoia Alliance or Allotrope Foundation and lobby for more openness. (Also, grant authorities should probably not allow linking scientific data to less than totally open controlled vocabularies.)
Here, we invite you to embrace the idea that ontologies and many of the tools we develop are actually community-driven, with no particular \"owners\" and \"decision makers\". While we are not yet there (we don't have sufficiently mature governance workflows for full fledged onto-communism), and most ontologies are still \"owned\" by an organisation that provides a major source of funding, we invite you to think of this as a preliminary state. It is better to embrace the idea of \"No-ownership\" and figure out social workflows and governance processes that can handle the problems of decision making.
"},{"location":"howto/open-science-engineer/#take-responsibility-for-your-community-ontologies","title":"Take responsibility for your community (ontologies)","text":"
Ensure that you see your issues and pull requests through to the end. No one will do this for you. Remember - contributors to open source projects, especially ontologies, have their own agendas, and do not automatically care about other peoples work.
Feel empowered to nudge reviewers or experts to help. Get that issue answered and PR merged whatever it takes!
Example: After waiting for the PR to be reviewed, Meghan kindly asked Nicole if she should find a different reviewer. 1. Find review buddies. For every ontology you seek to contribute to pair up with someone who will review your pull requests and you will review their pull requests. Sometimes, it is very difficult to get anyone to review your pull request. Reach out to people directly, and form an alliance for review. It is fun, and you learn new things (and get to know new people!). 1. Be proactive
Problem of decentralization and lack of hierarchial organisation needs proactive and brave decision makers.
No one will do your work for you. See your pull requests and issues through all the way to the release!
Learn the tools necessary to make basic fixes - just try it/do it.
Always have your index finger on the Edit button when reading documentation. There is always something to fix, including typos and content.
"},{"location":"howto/open-science-engineer/#reduce-your-fear-of-breaking-the-ontology","title":"Reduce your fear of \"breaking the ontology\".","text":"
Most of our ontologies have many checks in place, and GitHub has version control. Nothing has ever been broken to the point where it can't be fixed. (Remember to work on a branch!) Example: The QC checks on this PR failed 6 times before it passed.
Perfect is the enemy of good enough.
It's okay if your PR is rejected. Mentally, prepare yourself for having the PR rejected. This is fine - the community always looks to the best possible way to change the ontology. The next PR will be accepted!
If you make a mistake, and it is pointed out during pull request review, consider adding an appropriate QC check to prevent the issue from happening again. And who knows - maybe you have an opportunity to fix past mistakes!
Prettier standardizes the representation and formatting of Markdown. More information is available at https://prettier.io/. Note, these instructions are for a Mac.
"},{"location":"howto/prettify/#prettify-your-files","title":"Prettify your files","text":"
Create a new branch
Navigate to your root directory containing obook
Run npx prettier --write .
Commit to your branch and create a pull request
"},{"location":"howto/protege-browse-search/","title":"Browsing and Searching","text":""},{"location":"howto/protege-browse-search/#open-the-ontology-in-protege","title":"Open the ontology in Prot\u00e9g\u00e9","text":"
Note: Windows users should open Protege using run.bat Note: For the purpose of this how-to, we will be using MONDO as the ontology
Navigate to where you downloaded the repository and open the mondo-edit.obo file (src/ontology/mondo-edit.obo)
When you open Protege, you will be on the Active Ontology tab
Note the Ontology IRI field. The IRI is used to identify the ontology on the Web.
The Prot\u00e9g\u00e9 interface follows a basic paradigm of Tabs and Panels. By default, Prot\u00e9g\u00e9 launches with the main tabs seen below. The layout of tabs and panels is configurable by the user. The Tab list will have slight differences from version to version, and depending on your configuration. It will also reflect your customizations.
To customize your view, go to the Window tab on the toolbar and select Views. Here you can customize which panels you see in each tab. In the tabs view, you can select which tabs you will see. You will commonly want to see the Entities tab, which has the Classes tab and the Object Properties tab.
Note: if you open a new ontology while viewing your current ontology, Prot\u00e9g\u00e9 will ask you if you'd like to open it in a new window. \u00a0For most normal usage you should answer no. This will open in a new window.
The panel in the center is the ontology annotations panel. This panel contains basic metadata about the ontology, such as the authors, a short description and license information.
"},{"location":"howto/protege-browse-search/#running-the-reasoner","title":"Running the reasoner","text":"
Before browsing or searching an ontology, it is useful to run an OWL reasoner first. This ensures that you can view the full, intended classification and allows you to run queries. Navigate to the query menu, and run the ELK reasoner:
You will see various tabs along the top of the screen. Each tab provides a different perspective on the ontology. For the purposes of this tutorial, we care mostly about the Entities tab, the DL query tab and the search tool. OWL Entities include Classes (which we are focussed on editing in this tutorial), relations (OWL Object Properties) and Annotation Properties (terms like, 'definition' and 'label' which we use to annotate OWL entities. Select the Entities tab and then the Classes sub-tab. Now choose the inferred view (as shown below).
The Entities tab is split into two halves. The left-hand side provides a suite of panels for selecting various entities in your ontology. When a particular entity is selected the panels on the right-hand side display information about that entity. The entities panel is context specific, so if you have a class selected (like Thing) then the panels on the right are aimed at editing classes. The panels on the right are customizable. Based on prior use you may see new panes or alternate arrangements. You should see the class OWL:Thing. You could start browsing from here, but the upper level view of the ontology is too abstract for our purposes. To find something more interesting to look at we need to search or query.
"},{"location":"howto/protege-browse-search/#searching-in-protege","title":"Searching in Protege","text":"
You can search for any entity using the search bar on the right:
The search window will open on top of your Protege pane, we recommend resizing it and moving it to the side of the main window so you can view together.
Here's an example search for 'COVID-19':
It shows results found in display names, definitions, synonyms and more. The default results list is truncated. To see full results check the 'Show all results option'. You may need to resize the box to show all results. Double clicking on a result, displays details about it in the entities tab, e.g.
In the Entities, tab, you can browse related types, opening/closing branches and clicking on terms to see details on the right. In the default layout, annotations on a term are displayed in the top panel and logical assertions in the 'Description' panel at the bottom.
Try to find these specific classes:
'congenital heart disease'
'Kindler syndrome'
'kidney failure'
Note - a cool feature in the search tool in Protege is you can search on partial string matching. For example, if you want to search for \u2018down syndrome\u2019, you could search on a partial string: \u2018do synd\u2019.
Try searching for \u2018br car and see what kind of results are returned.
Question: The search will also search on synonyms. Try searching for \u2018shingles\u2019 and see what results are returned. Were you able to find the term?
Note - if the search is slow, you can uncheck the box \u2018Search in annotation values. Try this and search for a term and note if the search is faster. Then search for \u2018shingles\u2019 again and note what results you get.
"},{"location":"howto/revert-commit/","title":"How to revert a commit using GitHub Desktop","text":""},{"location":"howto/revert-commit/#prerequisites","title":"Prerequisites","text":"
You need to have a GitHub account GitHub and download GitHub Desktop
"},{"location":"howto/revert-commit/#background","title":"Background","text":""},{"location":"howto/revert-commit/#reversing-a-commit","title":"Reversing a commit","text":"
Create a new branch in GitHub Desktop (Important step! Never make changes to the master branch!)
Click on History tab.
Find commit you want to revert.
Right click. Click on 'Reverse Changes in Commit' from the drop-down list.
Fix any conflicts.
Commit branch, create pull request and assign a reviewer.
"},{"location":"howto/review-pull-request/","title":"How to review a pull request","text":"
Pull Requests are GitHub's mechanism for allowing one person to propose changes to a file (which could be a chunk of code, documentation, or an ontology) and enabling others to comment on (review) the proposed changes. You can learn more about creating Pull Requests (PRs) here; this document is about reviewing other people's PRs.
One key aspect of reviewing pull requests (aka code review or ontology change review) is that the purpose is not just to improve the quality of the proposed change. It is also about building shared coding habits and practices and improving those practices for all engineers (ontology and software) across a whole organisation (effectively building the breadth of project knowledge of the developers and reducing the amount of hard-to-understand code).
Reviewing is an important aspect of open science and engineering culture that needs to be learned and developed. In the long term, this habit will have an effect on the growth and impact of our tools and ontologies comparable to the engineering itself.
It is central to open science work that we review other people's work outside our immediate team. We recommend choosing a few people with whom to mutually review your work, whether you develpo ontologies, code or both. It is of great importance that pull requests are addressed in a timely manner, ideally within 24 hours of the request. The requestor is likely in the headspace of being receptive to changes and working hard to get the code fixed when they ask for a code review.
Understand the Context: First, read the description of the pull request (PR). It should explain what changes have been made and why. Understand the linked issue or task related to this PR. This will help you understand the context of the changes.
Check the Size: A good PR should not be too large, as this makes it difficult to understand the full impact of the changes. If the PR is very large, it may be a good idea to ask the author to split it into smaller, more manageable PRs.
Review the Code: Go through the code changes line by line. Check the code for clarity, performance, and maintainability. Make sure the code follows the style guide and best practices of your project. Look out for any potential issues such as bugs, security vulnerabilities, or performance bottlenecks.
Check the Tests: The PR should include tests that cover the new functionality or changes. Make sure the tests are meaningful, and they pass. If the project has a continuous integration (CI) system, all tests should pass in the CI environment. In some cases, manual testing may be helpful (see below).
Check the Documentation: If the PR introduces new functionality, it should also update the documentation accordingly. Even for smaller changes, make sure that comments in the code are updated.
Give Feedback: Provide constructive feedback on the changes. If you suggest changes, explain why you think they are necessary. Be clear, respectful, and concise. Remember, your goal is to help improve the quality of the code.
Follow Up: After you have provided feedback, check back to see if the author of the PR has made the suggested changes. You might need to have a discussion or explain your points further.
Approve/Request Changes: If you are satisfied with the changes and all your comments have been addressed, approve the PR. If not, request changes and explain what should be done before the PR can be approved.
Merge the PR: Once the PR is approved and all CI checks pass, it can be merged into the main branch. If your project uses a specific merge strategy (like squash and merge or rebase and merge), make sure it's followed.
"},{"location":"howto/review-pull-request/#how-to-review-the-code-ontology-changes-thoroughly","title":"How to review the code / ontology changes thoroughly","text":"
Ensure that the PR links to a related issue that explains the context of the PR. If there is no issue, request that an issue be created to motivate the change in the PR (gently - accept if the answer is negative).
Understand the Context: Begin by familiarizing yourself with the purpose of the changes. Read the description of the pull request, any linked issues or tasks, and understand the feature or bug that the pull request is addressing.
Ensure that all changes in the PR are intentional. Changes should be small. If there are a lot of unrelated changes, in particular line ending changes, serialisation changes in ontology (e.g. a lot of added xsd:string declarations), request before doing a review to reduce the changes to only the changes pertaining to the specific issue at hand.
Review the Code Structure: Look at the overall structure of the code. Check if the code is organized logically and consistently, follows the project's coding conventions, and the changes are made in the right place.
For software, consider factors like whether the code is in an approporiate location (files, modules). If there are no specific coding standards for the project, suggest that such standards be created.
For ontologies, check that the change is to the right file (edit file, DOSDP patterns, ROBOT templates etc.).
Check the Code Quality: Review the code in detail. Look for any programming errors, potential performance issues, or security vulnerabilities. The code should be clean, efficient, and easy to understand. Pay attention to the naming conventions, error handling, edge cases, and potential bugs.
The two items below are where you should spend most of your time:
Review the Tests: Ensure that the PR includes tests and that they cover all important aspects of the new code. Check if all tests pass, and if the project has a continuous integration (CI) system, ensure all CI checks pass as well.
For ontologies, it is essential that a bug fix is augmented by a test that can recognise the same bug happening again in the future!
For code, it is a bit of a judgment call whether a test is needed, but in general, we have to have at least thorough integration tests that touch the feature affected by the pull request.
Test the Changes Manually (use with care): Depending on the change, it may be a good idea to check out the PR branch and test the changes manually. This can help catch issues that are not covered by automated tests, or may be necessary if the diff is too large for a normal review. Note that this is an instance of Guru Testing and should only be used when there is a sense that automated testing is incomplete. If at all possible, an automated test should be run immediately after the manual review is done. Examples of where this kind of manual review may be appropriate are cases where, for example, a lot of the class hierarchy of an ontology is affected by a change. Manual review may catch issues such as missing superclasses which are hard to capture through automated testing.
Provide Constructive Feedback: Provide clear, respectful, and constructive feedback. Highlight the parts of the code that you think are good and the parts that need improvement. Request changes if necessary, and approve the PR once you're satisfied with the changes.
"},{"location":"howto/review-pull-request/#how-to-review-a-pull-request-in-5-min","title":"How to review a pull request in 5 min","text":"
In many cases, we may not have the time to perform a proper code review. In that case, try at least to achieve this:
Ensure that the PR has a related issue that explains the context of the PR (see above).
Ensure that all changes in the PR are intentional (see above).
File and structure overview: Scan through the files and directories that have been modified. Note the overall structure of the changes, and look for any unusual modifications (e.g., changes in areas not related to the stated purpose of the PR, or large diffs that are not explained by the PR description).
Random code sampling: Instead of trying to read every line, pick a few sections of code at random to review. Pay attention to the cleanliness of the code, and see if there are any glaring issues or departures from the project's coding conventions.
Check automated tests and results: Review the tests that have been added or modified. Check the results of the tests and automated build processes, if available. Even in a quick review, the status of the tests can provide useful information about the quality of the changes.
Provide high-level feedback: Based on your quick review, provide high-level feedback. This could include praising good practices you've noticed, pointing out major concerns or areas that seem off, or simply acknowledging the work with a comment.
"},{"location":"howto/screenshot/","title":"Create Screenshot and paste into an issue","text":""},{"location":"howto/screenshot/#description","title":"Description","text":"
The instructions below describe how to capture a screenshot of your screen, either your entire screen or a partial screenshot. These can be pasted into GitHub issues, pull requests or any markdown file.
Full screen: Hit the Command, Shift and 3 keys together to take a screenshot of the entire screen
Partial screen: Hit the Shift, Control, Command and 4 keys together to take a screenshot of a portion of the screen. Crosshairs will appear and select the portion you would like to capture.
Paste the partial screenshot into comment box in GitHub.
"},{"location":"howto/screenshot/#video-explanation-partial-screenshot-on-a-mac","title":"Video explanation: Partial screenshot on a Mac","text":""},{"location":"howto/screenshot/#screenshot-instructions-pc","title":"Screenshot Instructions (PC)","text":""},{"location":"howto/screenshot/#use-the-snipping-tool-available-with-windows-10","title":"Use the Snipping Tool (available with Windows 10)","text":"
The easiest way to elicit the tool is to press Windows logo key + Shift + S to open a dialog window to select the type of screen capture you would like to do. 1. Options exist for free form, rectangular, window or full screen snips.
After snipping, a notification dialog pops up so the user can select the location to save or annotate the screenshot. Otherwise, the default setting is to save to the clipboard.
"},{"location":"howto/screenshot/#use-your-keyboard","title":"Use your keyboard","text":"
Different keyboards have different keys. One of the following options should work:
Fn + Print Screen is an option on some keyboards
PrtScn or PrtSc
Hit Shift, Window, S keys together to take a screenshot. You will be able to resize the screenshot as needed.
As of February 2023, OBO ontology editors are using Protege version 5.6.1.
"},{"location":"howto/set-up-protege/#download-and-install-protege","title":"Download and install Protege","text":"
Get Protege from protege.stanford.edu
Unzip and move the Protege app to your Applications folder.
See Install_Protege5_Mac for more instructions and troubleshooting common problems.
"},{"location":"howto/set-up-protege/#increase-memory-in-protege-561","title":"Increase memory in Protege 5.6.1","text":"
Protege needs at least 4G of RAM to cope with large ontologie like Mondo, ideally use 12G or 16G if your machine can handle it. Edits to the Protege configuration files will not take effect until Protege is restarted.
If running from Protege.app on a Mac, open the /Applications/Protege-5.6.1/Prot\u00e9g\u00e9.app/Contents/conf/jvm.conf file
set the heap size to 12G: max_heap_size=12G
"},{"location":"howto/set-up-protege/#increase-memory-in-protege-550","title":"Increase memory in Protege 5.5.0","text":"
If running from Protege.app on a Mac, open the /Applications/Protege-5.5.0/Prot\u00e9g\u00e9.app/Contents/info.plist file
Below the line: <string>-Xss16M</string>
Insert another line: <string>-Xmx12G</string>
Some Mac users might find that the edits need to be applied to /Applications/Prot\u00e9g\u00e9.app/Contents/Info.plist.
Taken in part from Memory Management with Prot\u00e9g\u00e9 by Michael DeBellis. Updated by Nicole Vasilevsky.
The following instructions will probably not work if Prot\u00e9g\u00e9 was installed from the platform independent version, which does not include the Java Runtime Environment or a Windows .exe launcher.
Visit https://protege.stanford.edu/
Click orange DOWNLOAD NOW button
Click gray Download for Windows button on subsequent page
Register if desired, or skip registration
Find Protege-<version>-win.zip
most likely in your Downloads directory (or in This PC directory)
current version is Protege-5.5.0-win.zip
Unzip the downloaded file with your favorite file compression utility
You should see the Protege application and a file called 'run'
To open Protege, double-click the 'run' file. This will open cmd.exe and it will take a bit to open the file.
The fonts used by Prot\u00e9g\u00e9 may be very small, especially on some high resolution monitors. To increase the font size, go to File -> Preferences -> Renderer -> Font size.
Exit Prot\u00e9g\u00e9 after confirming that it can be launched.
There should be a Protege.l4j.ini in the same directory as Protege.exe. Opening large ontologies like MONDO will require an increase to Protege's default maximum Java heap size, which is symbolized as -Xmx<size>. 4GB is usually adequate for opening MONDO, as long as 4GB of free memory is really available on your system before you launch Prot\u00e9g\u00e9! Allocating even more memory will improve some tasks, like reasoning. You can check your available memory by launching the Windows Task Manager, clicking on the More details button on the bottom of the window and then checking the Performance tab at the top of the window.
It's recommended to make a backup of Protege.l4j.ini before editing
Open Protege.l4j.ini with a lightweight text editor like Atom or Sublime. Using notepad.exe instead might work, but may change character encodings or the character(s) used to represent End of Line.
After increasing the memory available to Prot\u00e9g\u00e9, Protege.l4j.ini might look like this.
-Xms200M\n-Xmx4G\n-Xss16M\n
Note that there is no whitespace between -Xmx, the numerical amount of memory, and the Megabytes/Gigabytes suffix. Don't forget to save.
Taking advantage of the memory increase requires that Prot\u00e9g\u00e9 is shut down and relaunched, if applicable. The methods discussed here may not apply if Prot\u00e9g\u00e9 is launched through any method other than double clicking Protege.exe from the folder where the edited Protege.l4j.ini resides.
"},{"location":"howto/set-up-protege/#note-on-increasing-memory","title":"Note on increasing memory","text":"
If you have issues opening Protege, then reduce the memory, try 10G (or lower) instead.
See instructions here. Note: Protege 5.6.1 has the ELK reasoner installed.
"},{"location":"howto/set-up-protege/#instructions-for-new-protege-users","title":"Instructions for new Protege users","text":""},{"location":"howto/set-up-protege/#setting-your-id-range","title":"Setting your ID range","text":"
This plugin enables some extra functionality, such as the option to obsolete entities from the menu. To install it:
Go to File > Check for plugins....
Click on OBO Annotations Editor and click on Install.
Restart Protege for the plugin to be active.
You should now have the option to obsolete entities in Edit > Make entity obsolete.
You can see a list of all installed plugins in Preferences > Plugins.
"},{"location":"howto/setup-docker/","title":"Set up docker","text":"
Follow the instructions here (note these instructions are for a Mac).
Once installed, you should be able to open your command line and download the ODK.
Open Terminal
in the command line type, type docker pull obolibrary/odkfull. This will download the ODK (will take a few minutes, depending on you internet connection).
Setting the memory: Set memory ~60% of your system memory, for example, if you have 16GB of RAM, then you should assign 10-11.
"},{"location":"howto/setup-ontology-development-odk/","title":"Getting set up to manage ontology pipelines with the ODK","text":"
Set up docker and install the ODK (howto)
To warm up with ODK development, follow the ODK Tutorial here
"},{"location":"howto/switching-ontologies/","title":"Switching Ontologies in Protege","text":"
When you edit an ontology, you need to make sure you are using the correct prefix and your assigned ID range for that on ontology. Protege (unfortunately) does not remember the last prefix or ID range that you used when you switch between ontologies. Therefore we need to manually update this each time we switch ontologies.
When you switch to a new ontology file, open your preferences in Protege (File -> Preferences).
Be sure you are on the New entities tab.
Add the Prefix for the ontology you are working on.
If you don't know your ID range, go to the ID ranges file for that ontology (it should be in src/ontology/[ontology-name]-idranges.owl. (For example, src/ontology/mondo-idranges.owl.)
Copy and paste in the start and end values for your ID range.
I work on many ontologies, so I keep a note in OneNote (or Evernote) that keeps track of all my ID ranges for quick reference.
You don't need to track the last ID that was used, Protege will know to pick the next ID in your range. For example, if your ID range is 8000000 to 8999999, you can enter that as your range, even if you have already added 10 terms within your range. Protege will know to assign the next ID as 8000011.
"},{"location":"howto/switching-ontologies/#video-explanation","title":"Video Explanation","text":""},{"location":"howto/term-request/","title":"Make term requests to existing ontologies","text":""},{"location":"howto/term-request/#prerequisites","title":"Prerequisites","text":"
You need to have a GitHub account to make term requests. Sign up for a free GitHub account.
This guide on How to select and request terms from ontologies by Chris Mungall provides some helpful background and tips for making term requests.
"},{"location":"howto/term-request/#why-make-a-new-term-request","title":"Why make a new term request?","text":"
Onologies are under constant development and are continuously expanded and iterated upon. You may discover that a term you need is not available in your preferred ontology. In this case, please make a new term request to the ontology.
"},{"location":"howto/term-request/#making-term-requests-to-existing-ontologies","title":"Making term requests to existing ontologies","text":"
In the following text below, we describe best practices for making a term request to an ontology. In general, requests for new terms are make on the ontology GitHub issue tracker. For example, this is the GitHub issue tracker for the Uberon Anatomy onology.
Note: These are suggestions and not strict rules. We appreciate your contributions to extending and improving ontologies. Following best guidelines is appreciated by the curators and developers, and assists them in addressing your issue more quickly. However, we understand if you are not always able to follow these best practices. Please add as much information as possible, and if there are any questions, the ontology developer may follow up with you for further clarification.
"},{"location":"howto/term-request/#making-a-new-term-request","title":"Making a new term request","text":"
Go to the ontology issue tracker in GitHub
Select New issue
Pick appropriate template (if applicable)
If there is a template, fill in the information that is requested on the template below each header.
General information that should be included in a new term request:
Preferred label: Your preferred name or label for the new term. Note- new term request should not match existing terms or synonyms.
Parent: The parent or superclass for that term. Remember that ontologies use subsumption reasoning, meaning that a subclass/child will inherit all the properties of the parent. In most ontologies, terms can have multiple classification, means terms can be classified under more than one parent. Note: You can use a ontology search enginge like OLS to double check your class does not already exist and to search for parent terms in your respective ontology.
Definition: Please write a concise definition of your term (see this guide on writing good ontology definitions).
Definition database cross-reference(s): Indicate the source or database cross-reference(s) or source for the definition, such as a PubMed ID (PMID) or reference to a website.
Synonym(s): an alternative term that has the same or closely related meaning for your new term. Please indicate the synonym scope (see more details below).
Synonym database cross-reference(s): Provide a database cross-reference or source for the synonym, if applicable.
Your ORCID or the URL for your working group, if applicable. If you do not have an ORCID, you can sign up for one for free here. Note: You can link your ORCID in your GitHub profile.
Comments: You can add any additional comments at the end. Please indicate if the comment should be included as a 'comment' annotation on the ontology term.
Click Submit New Issue
An ontology curator will review your issue and follow up with you if more information is needed.
For most ontologies, the preferred term labels should be lowercase (unless it is a proper name or abbreviation)
Write the request below the prompts on the template so the Markdown formatting displays properly
Synonyms should be lowercase (with exceptions above)
Definition source - if from PubMed, please use the format PMID:XXXXXX (no space)
Include the ID and label for the parent term
"},{"location":"howto/term-request/#submitting-other-issues","title":"Submitting other issues","text":"
Users may want to request other types of changes to an ontology such as Mondo beyond just adding a new term.
Other types of requests may include changes to the classification, typos, bugs, etc.
Some ontologies have other templates available on their issue tracker. Select the appropriate template. If there is not an appropriate template available, scroll to the bottom and select 'open a blank issue'.
This page discusses how to update the contents of your imports using the ODK, like adding or removing terms.
Note: This is a specialised how-to for ODK managed ontologies and is replicated from ODK docs to consolidate workflows in the obook. Not all ontologies use ODKs and many ontologies have their own workflows for imports, please also check with your local ontology documents and/or developers.
Note: The extract function in ROBOT can also be used to extract subsets from onotlogies for modular imports without the use of the ODK. For details on that, please refer to the ROBOT documentation
"},{"location":"howto/update-import/#importing-a-new-term","title":"Importing a new term","text":"
Note: some ontologies now use a merged-import system to manage dynamic imports, for these please follow instructions in the section title \"Using the Base Module approach\".
Importing a new term is split into two sub-phases:
Declaring the terms to be imported
Refreshing imports dynamically
"},{"location":"howto/update-import/#declaring-terms-to-be-imported","title":"Declaring terms to be imported","text":"
There are three ways to declare terms that are to be imported from an external ontology. Choose the appropriate one for your particular scenario (all three can be used in parallel if need be):
This workflow is to be avoided, but may be appropriate if the editor does not have access to the ODK docker container. This approach also applies to ontologies that use base module import approach.
Open your ontology (edit file) in Protege (5.5+).
Select 'owl:Thing'
Add a new class as usual.
Paste the full iri in the 'Name:' field, for example, http://purl.obolibrary.org/obo/CHEBI_50906.
Click 'OK'
Now you can use this term for example to construct logical definitions. The next time the imports are refreshed (see how to refresh here), the metadata (labels, definitions, etc) for this term are imported from the respective external source ontology and becomes visible in your ontology.
"},{"location":"howto/update-import/#using-term-files","title":"Using term files","text":"
Every import has, by default a term file associated with it, which can be found in the imports directory. For example, if you have a GO import in src/ontology/go_import.owl, you will also have an associated term file src/ontology/go_terms.txt. You can add terms in there simply as a list:
GO:0008150\nGO:0008151\n
Now you can run the refresh imports workflow) and the two terms will be imported.
"},{"location":"howto/update-import/#using-the-custom-import-template","title":"Using the custom import template","text":"
This workflow is appropriate if:
You prefer to manage all your imported terms in a single file (rather than multiple files like in the \"Using term files\" workflow above).
You wish to augment your imported ontologies with additional information. This requires a cautionary discussion.
To enable this workflow, you add the following to your ODK config file (src/ontology/cl-odk.yaml), and update the repository (using sh run.sh make update_repo):
use_custom_import_module: TRUE\n
Now you can manage your imported terms directly in the custom external terms template, which is located at src/templates/external_import.owl. Note that this file is a ROBOT template, and can, in principle, be extended to include any axioms you like. Before extending the template, however, read the following carefully.
The main purpose of the custom import template is to enable the management off all terms to be imported in a centralised place. To enable that, you do not have to do anything other than maintaining the template. So if you, say current import APOLLO_SV:00000480, and you wish to import APOLLO_SV:00000532, you simply add a row like this:
ID Entity Type\nID TYPE\nAPOLLO_SV:00000480 owl:Class\nAPOLLO_SV:00000532 owl:Class\n
When the imports are refreshed see imports refresh workflow, the term(s) will simply be imported from the configured ontologies.
Now, if you wish to extent the Makefile (which is beyond these instructions) and add, say, synonyms to the imported terms, you can do that, but you need to (a) preserve the ID and ENTITY columns and (b) ensure that the ROBOT template is valid otherwise, see here.
WARNING. Note that doing this is a widespread antipattern (see related issue). You should not change the axioms of terms that do not belong into your ontology unless necessary - such changes should always be pushed into the ontology where they belong. However, since people are doing it, whether the OBO Foundry likes it or not, at least using the custom imports module as described here localises the changes to a single simple template and ensures that none of the annotations added this way are merged into the base file (see format variant documentation for explanation on what base file is)
If you want to refresh the import yourself (this may be necessary to pass the travis tests), and you have the ODK installed, you can do the following (using go as an example):
First, you navigate in your terminal to the ontology directory (underneath src in your hpo root directory).
cd src/ontology\n
Then, you regenerate the import that will now include any new terms you have added. Note: You must have docker installed.
sh run.sh make PAT=false imports/go_import.owl -B\n
Since ODK 1.2.27, it is also possible to simply run the following, which is the same as the above:
sh run.sh make refresh-go\n
Note that in case you changed the defaults, you need to add IMP=true and/or MIR=true to the command below:
sh run.sh make IMP=true MIR=true PAT=false imports/go_import.owl -B\n
If you wish to skip refreshing the mirror, i.e. skip downloading the latest version of the source ontology for your import (e.g. go.owl for your go import) you can set MIR=false instead, which will do the exact same thing as the above, but is easier to remember:
sh run.sh make IMP=true MIR=false PAT=false imports/go_import.owl -B\n
"},{"location":"howto/update-import/#using-the-base-module-approach","title":"Using the Base Module approach","text":"
Since ODK 1.2.31, we support an entirely new approach to generate modules: Using base files. The idea is to only import axioms from ontologies that actually belong to it. A base file is a subset of the ontology that only contains those axioms that nominally belong there. In other words, the base file does not contain any axioms that belong to another ontology. An example would be this:
The base file pipeline is a bit more complex then the normal pipelines, because of the logical interactions between the imported ontologies. This is solved by _first merging all mirrors into one huge file and then extracting one mega module from it.
Example: Let's say we are importing terms from Uberon, GO and RO in our ontologies. When we use the base pipelines, we
First obtain the base (ususally by simply downloading it, but there is also an option now to create it with ROBOT)
We merge all base files into one big pile
Then we extract a single module imports/merged_import.owl
The first implementation of this pipeline is PATO, see https://github.com/pato-ontology/pato/blob/master/src/ontology/pato-odk.yaml.
To check if your ontology uses this method, check src/ontology/cl-odk.yaml to see if use_base_merging: TRUE is declared under import_group
If your ontology uses Base Module approach, please use the following steps:
First, add the term to be imported to the term file associated with it (see above \"Using term files\" section if this is not clear to you)
Next, you navigate in your terminal to the ontology directory (underneath src in your hpo root directory).
cd src/ontology\n
Then refresh imports by running
sh run.sh make imports/merged_import.owl\n
Note: if your mirrors are updated, you can run sh run.sh make no-mirror-refresh-merged
This requires quite a bit of memory on your local machine, so if you encounter an error, it might be a lack of memory on your computer. A solution would be to create a ticket in an issue tracker requesting for the term to be imported, and your one of the local devs should pick this up and run the import for you.
Lastly, restart Protege, and the term should be imported in ready to be used.
"},{"location":"images/","title":"About using images in Git/GitHub","text":"
There are two places you'll probaby want to use images in GitHub, in issue tracker and in markdown files, html etc. The way you handle images in these contexts is quite different, but easy once you get the hang of it.
"},{"location":"images/#in-markdown-files-and-html-etc","title":"In markdown files (and html etc)","text":"
All images referenced in static files such as html and markdown need to be referenced using a URL; dragging and dropping is not supported and could actually cause problems. Keeping images in a single directory enables them to be referenced more readily. Sensible file names are highly recommended, preferably without spaces as these are hard to read when encoded.
An identical file, named in two different ways is shown as an example below. They render in the same way, but the source \"code\" looks ugly when spaces are used in file names.
Eg.
encoding needed no encoding needed 
In this example, the filename is enough of a 'url' because this file (https://ohsu-library.github.io/github-tutorial/howto/images/index.md) and the images are in the same directory https://ohsu-library.github.io/github-tutorial/howto/images/.
To reference/embed an image that is not in the same directory, a more careful approach is needed.
"},{"location":"images/#referencing-images-in-your-repository-and-elsewhere","title":"Referencing images in your repository and elsewhere","text":"Absolute path referencing Relative path referencing 
Each instance of ../ means 'go up one level' in the file tree.
It is also possible to reference an image using an external URL outside your control, in another github organization, or anywhere on the web, however this method can be fragile if the URL changes or could lead to unintended changes. Therefore make your own copies and reference those unless:
You're sure that referencing the originals will not end in broken links or surprising content.
Copying the image is prohibited
The images are too large to make copying worth the hassle/expense.
For example, it is not clear for how long the image below will manage to persist at this EPA link, or sadly, for how long the image will even be an accurate reflection of the current situation in the arctic. https://www.epa.gov/sites/production/files/styles/microsite_banner/public/2016-12/epa-banner-images/science_banner_arctic.png
Images that are embedded into issues can be dragged and dropped in the GitHub issues interface. Once you've done so, it will look something like this with GitHub assigning an arbitrary URL (githubuserassets) for the image.
Ideally, a Markdown document is renderable in a variety of output formats and devices. In some cases, it may be desirable to create non-portable Markdown that uses HTML syntax to position images. This limits the longevity of the artifact, but may be necessary sometimes. We describe how to manage this below.
In order to size images, use the native html syntax: width = with the <img src=, as per below.
"},{"location":"images/#back-to-home","title":"Back to Home","text":""},{"location":"lesson/analysing-linked-data/","title":"Analysing Linked Data (Fundamentals)","text":""},{"location":"lesson/analysing-linked-data/#warning","title":"Warning","text":"
These materials are under construction and incomplete.
"},{"location":"lesson/analysing-linked-data/#tutorials","title":"Tutorials","text":""},{"location":"lesson/analysing-linked-data/#the-linked-data-landscape-from-an-obo-perspective-standards-services-and-tools","title":"The Linked Data landscape from an OBO perspective: Standards, Services and Tools","text":"
In the following we will look a bit at the general Linked Data landscape, and name some of its flagship projects and standards. It is important to be clear that the Semantic Web field is a very heterogenous one:
"},{"location":"lesson/analysing-linked-data/#flagship-projects-of-the-wider-semantic-web-community","title":"Flagship projects of the wider Semantic Web community","text":"
Linked Open Data (LOD) cloud: The flagship project of the Semantic Web. An attempt to make all, or anyways a lot, of Linked Data accessible in one giant knowledge graph. A good overview can be found in this medium article. Note that some people seem to think that the Semantic Web is (or should be) the Linked Open Data cloud. I would question this view, but I am not yet decided what my position is.
Schema.org: General purpose vocabulary for entities on the web, founded by Google, Microsoft, Yahoo and Yandex. To get a better sense of the types of entities and relationships covered see here.
DBpedia: Project that extracts structured data from Wikipedia and makes it available as a giant knowledge graph. The associated ontology, similar to schema.org, covers entities encountered in common sense knowledge.
Wikidata: Free and open knowledge base that can be edited in much the same way as Wikipedia is edited.
While these Semantic Web flagship projects are doubtlessly useful, it is sometimes hard to see how they can help for your biomedical research. We rarely make use of them in our day to day work as ontologists, but there are some notable exceptions:
Where our work involves modelling environmental factors, we sometimes use wikidata as a standard way to refer for example to countries.
For some more common sense knowledge use cases, such as nutrition, consider augmenting your knowledge graph with data from wikidata or dbpedia. While they may be a bit more messy and not directly useful for exploration by humans, it is quite possible that Machine Learning approaches can use the additional context provided by these knowledge graphs to improve embeddings and deliver more meaningful link predictions.
Some OBO ontologies are already on Wikidata - perhaps you can find additional synonyms and labels which help with your data mapping problems!
"},{"location":"lesson/analysing-linked-data/#where-the-obo-and-semantic-web-communities-are-slightly-at-odds","title":"Where the OBO and Semantic Web communities are slightly at odds","text":"
The OBO format is a very popular syntax for representing biomedical ontologies. A lot of tools have been built over the years to hack OBO ontologies on the basis of that format - I still work with it on a daily basis. Although it has semantically been proven to be a subset of OWL (i.e. there is a lossless mapping of OBO into OWL) and can be viewed as just another syntax, it is in many ways idiosyncratic. For starters, you wont find many, if any, IRIs in OBO ontologies. The format itself uses CURIEs which are mapped to the general OBO PURL namespace during transformation to OWL. For example, if you see MONDO:0003847 in an OBO file, and were to translate it to OWL, you will see this term being translated to http://purl.obolibrary.org/obo/MONDO_0003847. Secondly, you have a bunch of built-in properties like BROAD or ABBREVIATION that mapped to a vocabulary called oboInOwl (oio). These are pretty non-standard on the general Semantic Web, and often have to be manually mapped to the more popular counterparts in the Dublin Core or SKOS namespaces.
Having URIs as identifiers is not generally popular in the life sciences. As discussed elsewhere, it is much more likely to encounter CURIEs such as MONDO:0003847 than URIs such as http://purl.obolibrary.org/obo/MONDO_0003847 in biomedical databases.
"},{"location":"lesson/analysing-linked-data/#useful-tools-for-biomedical-research","title":"Useful tools for biomedical research","text":"
Why does the biomedical research, and clinical, community care about the Semantic Web and Linked Data? There are endless lists of applications that try to apply semantic technologies to biomedical problems, but for this week, we only want to look at the broader picture. In our experience, the use cases where Semantic Web standards are applied successfully are:
Where to find ontologies: Ontology repositories
OBO Foundry Ontology Library
BioPortal
CPT Story. The Current Procedural Terminology was the by far most highly accessed Terminology on Bioportal - for many years. Due to license concerns, it had to be withdrawn from the repository. This story serves a cautionary tale of using terminologies with non-open or non-transparent licensing schemes.
AgroPortal: Like BioPortal, but focussed on the Agronomy domain.
Linked Open Data Vocabularies (LOV): Lists the most important vocabularies in the Linked Data space, such as Dublin Core, SKOS and Friend-of-a-Friend (FOAF).
Where to find terms: Term browsers
OLS: The boss of the current term browsers out there. While the code base is a bit dated, it still gives access to a wide range of relevant open biomedical ontology terms. Note, while being a bit painful, it is possible to set up your own OLS (for your organisation) which only contains those terms/ontologies that are relevant for your work.
Ontobee: The default term browser for OBO term purls. For example, click on http://purl.obolibrary.org/obo/OBI_0000070. This will redirect you directly to Ontobee, to show you the terms location in the hierarchy. A key difference between Ontobee and OLS/Bioportal is that Ontobee limits hierarchical relationships to is_a. This means if you are browsing ontologies such as GO, Uberon, CL, ENVO, you will not see part-of links in the hierarchy, and these links are crucial for understanding these ontologies.
AberOWL: Another ontology repository and semantic search engine. Some ontologies such as PhenomeNet can only be found on AberOWL, however, I personally prefer OLS.
identifiers.org: A centralised registry for identifiers used in the life sciences. This is one of the tools that bridge the gap between CURIEs and URLs, but it does not cover (OBO) ontologies very well, and if so, is not aware of the proper URI prefixes (see for example here, and HP term resolution that does not list the proper persistent URL of the HP identifier (http://purl.obolibrary.org/obo/HP_0000001)). Identifiers.org has mainly good coverage for databases/resources that use CURIE type identifiers. But: you can enter any ID you find in your data and it will tell you what it is associated with.
Curate biomedical data. There are a lot of different tools in this space - which we will discuss in a bespoke unit later in the course. Examples:
isatools: The open source ISA framework and tools help to manage an increasingly diverse set of life science, environmental and biomedical experiments that employing one or a combination of technologies.
RightField: System for curating ontology terms in Excel spreadsheets.
CEDAR Templates: Basically a templating system that allows to create templates to record metadata, for example in a lab setting, of course with ontology integration.
Other examples of tabular data to RDF converters, but new ones coming up every year.
Building ontologies
Populous/Webulous: A system to maintain/generate ontologies from spreadsheets. The idea was to basically to define patterns in a (now mostly dead) language called OPPL, and then apply them to spreadsheets to generate OWL axioms. EBI recently discontinued the service, as there is a general exodus to Google Sheets + ROBOT templates instead.
ROBOT templates + Google Sheets and Cogs: A lightweight approach based on a set of tools that allows curating ontologies in spreadsheets (e.g. Google Sheets) which are converted into OWL using ROBOT.
DOSDP tools + Dead Simple Design Patterns (DOSDP): Similar to ROBOT templates, DOSDPs (which really should be called DOSDTs, because they are not really design patterns; they are ontology templates), another system that allows the generation of OWL axioms based on spreadsheet data.
Cleaning messy data
OpenRefine: I have not myself used this ever, but some of my colleagues have. OpenRefine allows you to upload (spreadsheet) data, explore it and clean it (going as far as reconciling terms using Wikidata concepts).
"},{"location":"lesson/analysing-linked-data/#which-biomedical-ontologies-should-we-use","title":"Which biomedical ontologies should we use?","text":"
As a rule of thumb, for every single problem/term/use case, you will have 3-6 options to choose from, in some cases even more. The criteria for selecting a good ontology are very much dependent on your particular use case, but some concerns are generally relevant. A good first pass is to apply to \"10 simple rules for selecting a Bio-ontology\" by Malone et al, but I would further recommend to ask yourself the following:
Do I need the ontology for grouping and semantic analysis? In this case a high quality hierarchy reflecting biological subsumption is imperative. We will explain later what this means, but in essence, you should be able to ask the following question: \"All instances/occurrences of this concept in the ontology are also instances of all its parent classes. Everything that is true about the parent class is always also true about instances of the children.\" It is important for you to understand that, while OWL semantics imply the above, OWL is difficult and many ontologies \"pretend\" that the subclass link means something else (like a rule of thumb grouping relation).
Can I handle multiple inheritance in my analysis? While I personally recommend to always consider multiple inheritance (i.e, allow a term to have more than one parent class), there are some analysis frameworks, in particular in the clinical domain, that make this hard. Some ontologies are inherently ploy-hierarchical (such as Mondo), while others strive to be single inheritance (DO, ICD).
Are key resources I am interested in using the ontology? Maybe the most important question that will drastically reduce the amount of data mapping work you will have to do: Does the resource you wish to integrate already annotate to a particular ontology? For example, EBI resources will be annotating phenotype data using EFO, which in turn used HPO identifiers. If your use case demands to integrate EBI databases, it is likely a good idea to consider using HPO as the reference ontology for your phenotype data.
Aside from aspects of your analysis, there is one more thing you should consider carefully: the open-ness of your ontology in question. As a user, you have quite a bit of power on the future trajectory of the domain, and therefore should seek to endorse and promote open standards as much as possible (for egotistic reasons as well: you don't want to have to suddenly pay for the ontologies that drive your semantic analyses). It is true that ontologies such as SNOMED have some great content, and, even more compellingly, some really great coverage. In fact, I would probably compare SNOMED not with any particular disease ontology, but with the OBO Foundry as a whole, and if you do that, it is a) cleaner, b) better integrated. But this comes at a cost. SNOMED is a commercial product - millions are being payed every year in license fees, and the more millions come, the better SNOMED will become - and the more drastic consequences will the lock-in have if one day you are forced to use SNOMED because OBO has fallen too far behind. Right now, the sum of all OBO ontologies is probably still richer and more valuable, given their use in many of the central biological databases (such as the ones hosted by the EBI) - but as SNOMED is seeping into the all aspects of genomics now (for example, it will soon be featured on OLS!) it will become increasingly important to actively promote the use of open biomedical ontologies - by contributing to them as well as by using them.
We will discuss ontologies in the medical, phenomics and genomics space in more detail in a later session of the course.
Industrial Ontologies Foundry: Something like the OBO Foundry for Industrial Ontologies
OntoCommons: An H2020 CSA project dedicated to the standardisation of data documentation across all domains related to materials and manufacturing.
"},{"location":"lesson/analysing-linked-data/#basic-linked-data-and-semantic-web-concepts-for-the-semantic-data-engineer-in-the-biomedical-domain","title":"Basic Linked data and Semantic Web Concepts for the Semantic Data Engineer in the Biomedical Domain","text":"
In this section we will discuss the following:
Introductory remarks
The advantages of globally unique identifiers
Some success stories of the Semantic Web in the biomedical domain
Some basic concepts you should probably have heard about
The ecosystem of the Semantic Web: Standards, Technologies and Research Areas
Typical tasks of Semantic Data Engineers in the biomedical domain
Note of caution: No two Semantic Web overviews will be equivalent to each other. Some people claim the Semantic Web as an idea is an utter failure, while others praise it as a great success (in the making) - in the end you will have to make up your own mind. In this section I focus on parts of the Semantic Web step particularly valuable to the biomedical domain, and I will omit many relevant topics in the wider Semantic Web area, such as Enterprise Knowledge Graphs, decentralisation and personalisation, and many more. Also, the reader is expected to be familiar with the basic notions of the Semantic Web, and should use this overview mainly to tie some of the ideas together.
The goal of this section is to give the aspiring Semantic Data Engineer in the biomedical domain a rough idea of key concepts around Linked Data and the Semantic Web insofar as they relate to their data science and and data engineering problems. Even after 20 years of Semantic Web research (the seminal paper, conveniently and somewhat ironically behind a paywall, was published in May 2001), the area is still dominated by \"academic types\", although the advent of the Knowledge Graph is already changing that. As I already mentioned above, no two stories of what the Semantic Web is will sound the same. However, there are a few stories that are often told to illustrate why we need semantics. The OpenHPI course names a few:
\"From the web of documents to the web of data\" tells the story of how the original web is essentially a huge heap of (interlinked) natural language text documents which are very hard to understand for search engines: Does the word \"Jaguar\" on this site refer to the car or the cat? Clarifying in your web page that the word Jaguar refers to the concept of \"Jaguar the cat\", for example like this: <span about=\"dbpedia:Jaguar\">Jaguar</span>, will make it easier for the search engine to understand what your site is about and link it to other relevant content. From this kind of mark-up, structured data can be extracted and integrate into a giant, worldwide database, and exposed through SPARQL endpoints, that can then be queried using a suitable query language.
\"From human to machine understandable\": as a Human, we know that a Jaguar is a kind of cat, and all cats have four legs. If you ask a normal search engine: \"Does a Jaguar have four legs?\" it will have a tough time to answer this question correctly (if it cannot find that exact statement anywhere). That is why we need proper semantics, some kind of formalism such that a \"machine\" can deduce from the statements \"Jaguar is a cat; Cat has four legs\" that \"Jaguar has four legs\".
The \"Semantic Layer Cake\": a box/brick diagram showing how Semantic Web Technologies are stacked on top of each other. An engineering centric view that has been used countless times to introduce the Semantic Web, but rarely helped anyone to understand what it is about.
I am not entirely sure anymore that any of these ways (web of data, machine understanding, layered stack of matching standards) to motivate the Semantic Web are particularly effective for the average data scientists or engineer. If I had to explain the Semantic Web stack to my junior self, just having finished my undergraduate, I would explain it as follows (no guarantee though it will help you).
The Semantic Web / Linked Data stack comprises roughly four components that are useful for the aspiring Semantic (Biomedical) Data Engineer/Scientist to distinguish:
"},{"location":"lesson/analysing-linked-data/#a-way-to-refer-to-things-including-entities-and-relations-in-a-global-namespace","title":"A way to refer to things (including entities and relations) in a global namespace.","text":"
You, as a scientist, might be using the term \"gene\" to refer to basic physical and functional unit of heredity, but me, as a German, prefer the term \"Gen\". In the Semantic Web, instead of natural language words, we prefer to use URIs to refer to things such as https://www.wikidata.org/wiki/Q7187: if you say something using the name https://www.wikidata.org/wiki/Q7187, both your German and Japanese colleagues will \"understand\" what you are referring to. More about that in the next chapter.
"},{"location":"lesson/analysing-linked-data/#lots-loaaaads-of-ways-to-make-statements-about-things","title":"Lots (loaaaads!) of ways to make statements about things.","text":"
For example, to express \"a mutation of SHH in humans causes isolated microphthalmia with coloboma-5\" you could say something like (http://purl.obolibrary.org/obo/MONDO_0012709 | \"microphthalmia, isolated, with coloboma 5\")--[http://purl.obolibrary.org/obo/RO_0004020 | \"has basis in dysfunction of\"]-->(https://identifiers.org/HGNC:10848 | \"SSH (gene)\"). Or you could say: (http://purl.obolibrary.org/obo/MONDO_0012709 | \"microphthalmia, isolated, with coloboma 5\")--[http://www.w3.org/2000/01/rdf-schema#subClassOf | \"is a\"]-->(http://purl.obolibrary.org/obo/MONDO_0003847 | \"Mendelian Disease\"). If we use the analogy of \"language\", then the URIs (above) are the words, and the statements are sentences in a language. Unfortunately, there are many languages in the Semantic Web, such as OWL, RDFS, SKOS, SWRL, SHACL, SHEX, and dialects (OWL 2 EL, OWL 2 RL) and a plethora of formats, or serialisations (you can store the exact same sentence in the same language such as RDF, or OWL, in many different ways)- more about that later. In here lies also one of the largest problems of the Semantic Web - lots of overlapping standards means, lots of incompatible data - which raises the bar for actually being able to seamlessly integrate \"statements about things\" across resources.
"},{"location":"lesson/analysing-linked-data/#collections-of-statements-about-things-that-somehow-belong-together-and-provide-some-meaning-or-context-for-those-things","title":"Collections of statements about things that somehow belong together and provide some meaning, or context, for those things.","text":"
Examples include:
controlled vocabularies, that define, for example, how to refer to a disease (e.g., we use http://purl.obolibrary.org/obo/MONDO_0012709 to refer to \"isolated microphthalmia with coloboma 5\"),
terminologies which describe how we humans refer to a disease (How is it called in German? Which other synonyms are used in the literature? How is the term defined in the medical literature?),
taxonomies which define how diseases are related hierarchically (\"microphthalmia, isolated, with coloboma 5 is a kind of Mendelian disease\"),
ontologies which further define how diseases are defined in terms of other entities, for example \"microphthalmia, isolated, with coloboma 5 is a Mendelian disease that has its basis in the dysfunction of SSH\".
Note: In practice, when we say \"ontology\", we mean all of the above together - it is, however, good to know that they are somewhat distinct, and that there are different \"languages\" that can be used for each of these distinctions.
"},{"location":"lesson/analysing-linked-data/#tools-that-do-something-useful-with-these-collections-of-statements","title":"Tools that do something useful with these collections of statements.","text":"
For example (as always, non exhaustive):
Efficient storage (triple stores, in-memory ontology APIs, other databases). Similar to traditional SQL databases, the Semantic Web comes with a number of database solutions that are optimised to deliver \"semantic content\".
Semantically aware querying: Very similar to traditional SQL (which, incidentally is often great to query semantic data), there are various ways to \"interrogate\", or query, your Linked Data, such as SPARQL, DL Querying, Ontology-based data access (OBDA).
Subsetting (module/subset extraction): Often, ontologies (or other collections of Linked Data statements) are very large and cover a lot of entities and knowledge that is not important to your work. There are a number of techniques that allow you to extract meaningful subsets for your use case; for example, you may be interested to get all the information you can about Mendelian diseases, but you don't care about common diseases (e.g. see ROBOT extract).
Visualisation: As a Data Scientist, you are used to looking at your data in tabular form - while a lot of information stored in ontologies can still be inspected this way, in general semantic data is best perceived as a graph - which are notoriously hard to visualise. Fortunately, a lot of Linked Data, in particular ontologies in the biomedical domain are predominantly tree-shaped (you have a disease, and underneath sub-diseases). Term browsers like OLS typically render ontologies as trees.
Data linking/matching: This is key in particular in the biomedical sciences, as there is almost never just one way to refer to the same thing. In my experience, a good rule of thumb is that there are 3-6, e.g. 3-6 URIs that refer to \"Mendelian Disease\", all of which need to be matched together to integrate data across resources. There are many approaches to ontology matching - none of which are anywhere near perfect.
Automated error checking and validation (Syntax, Structure (SHEX, SHACL), logical Consistency (DL Reasoner)): Naturally, writing sentences in any language is hard in the beginning, but this is even more true for highly complex languages such as OWL. In my experience, no-one can write flawless OWL without the help of automatic syntax and semantics checking, at least not consistently. Validation tools are a crucial part of your Semantic Engineering toolbox.
Translate between languages: Often we need to translate from one language, for example OWL, to another, for example SKOS to integrate divergent resources. Translations in the Semantic Web context are nearly always lossy (there are always things you can say in one language, but not in another), but they may be necessary nevertheless.
Discovery of terms (OLS, BioPortal): If you are curating terms, you need to know what ID (URI) to use for \"isolated microphthalmia with coloboma 5\". For that, term browsers such as OLS are perfect. Just type in your natural language search term, and you will find a series of suggestions for URIs you can use for your curation.
Discovery of vocabularies OBO Foundry ontology library, BioPortal): we will have a section later on on how to select appropriate ontologies for your use case, but the general problem of finding vocabularies, or ontologies, is answered by ontology repositories or libraries. Naturally, our favourite ontology library is the OBO Foundry ontology library which contain a lot of high quality ontologies for the biomedical domain.
Make implicit knowledge explicit, aka reasoning:
Deductive (DL Reasoning, Rule-based reasoning such as Datalog, SWRL). One of the major selling points for OWL, for example, in the biomedical domain is the ability to use logical reasoning in a way that is sound (only gives you correct inferences, at all times) and complete (all hidden implications are found, at all times, by the reasoner) - this is particularly great for medical knowledge where mistakes in computer algorithms can have devastating effects. However, I am slowly coming to the conviction that sound and complete reasoning is not the only form of deductive reasoning that is useful - many rule languages can offer value to your work by unveiling hidden relationships in the data without giving such strong \"logical guarantees\".
Inductive (Machine Learning approaches, Knowledge Graph Representation Learning). The new frontier - we will discuss later in the course how our ontology-powered Knowledge Graphs can be leveraged to identify drug targets, novel gene to phenotype associations and more, using a diverse set of Machine Learning-based approaches.
This week will focus on 1 (identifiers) and 4 (applications) - 2 (languages and standards) and 3 (controlled vocabularies and ontologies) will be covered in depth in the following weeks.
Note on the side: Its not always 100% clear what is meant by Linked Data in regular discourse. There are some supposedly \"clear\" definitions (\"method for publishing structured data\", \"collection of interrelated datasets on the Web\"), but when it comes down to the details, there is plenty of confusion (does an OWL ontology constitute Linked Data when it is published on the Web? Is it Linked Data if it does not use RDF? Is it Linked Data if it is less than 5-star - see below). In practice all these debates are academic and won't mean much to you and your daily work. There are entities, statements (context) being said about these entities using some standard (associated with the Semantic Web, such as OWL or RDFS) and tools that do something useful with the stuff being said.
"},{"location":"lesson/analysing-linked-data/#when-i-say-mendelian-disease-i-mean-httppurlobolibraryorgobomondo_0003847","title":"When I say \"Mendelian Disease\" I mean http://purl.obolibrary.org/obo/MONDO_0003847","text":"
One of the top 5 features of the Semantic Web (at least in the context of biomedical sciences) is the fact that we can use URIs as a global identifier scheme that is unambiguous, independent of database implementations, independent of language concerns to refer to the entities in our domain.
For example, if I want to refer to the concept of \"Mendelian Disease\", I simply refer to http://purl.obolibrary.org/obo/MONDO_0003847 - and everyone, in Japan, Germany, China or South Africa, will be able to \"understand\" or look up what I mean. I don't quite like the word \"understanding\" in this context as it is not actually trivial to explain to a human how a particular ID relates to a thing in the real world (semiotics). In my experience, this process is a bit rough in practice - it requires that there is a concept like \"Mendelian Disease\" in the mental model of the person, and it requires some way to link the ID http://purl.obolibrary.org/obo/MONDO_0003847 to that \"mental\" concept - not always as trivial as in this case (where there are standard textbook definitions). The latter is usually achieved (philosophers and linguists please stop reading) by using an annotation that somehow explains the term - either a label or some kind of formal definition - that a person can understand. In any case, not trivial, but thankfully not the worst problem in the biomedical domain where we do have quite a wide range of shared \"mental models\" (more so in Biology than Medical Science..). Using URIs allows us to facilitate this \"understanding\" process by leaving behind some kind of information at the location that is dereferenced by the URI (basically you click on the URI and see what comes up). Note that there is a huge deal of compromise already happening across communities. In the original Semantic Web community, the hope was somehow that dereferencing the URI (clicking on it, navigating to it) would reveal structured information about the entity in question that could used by machines to understand what the entity is all about. In my experience, this was rarely ever realised in the biomedical domain. Some services like Ontobee expose such machine readable data on request (using a technique called content negotiation), but most URIs simply refer to some website that allow humans to understand what it means - which is already a huge deal. For more on names and identifiers I refer the interested reader to James Overton's OBO tutorial here.
Personal note: Some of my experienced friends in the bioinformatics world say that \"IRI have been more pain than benefit\". It is clear that there is no single thing in the Semantic Web is entirely uncontested - everything has its critics and proponents.
"},{"location":"lesson/analysing-linked-data/#the-advent-of-the-curie-and-the-bane-of-the-curie-map","title":"The advent of the CURIE and the bane of the CURIE map","text":"
In reality, few biological resources will contain a reference to http://purl.obolibrary.org/obo/MONDO_0003847. More often, you will find something like MONDO:0003847, which is called a CURIE. You will find CURIEs in many contexts, to make Semantic Web languages easier to read and manage. The premise is basically that your document contains a prefix declaration that says something like this:
In reality, the proliferation of CURIEs has become a big problem for data engineers and data scientists when analysing data. Databases rarely, if ever, ship the CURIE maps with their data required to understand what a prefix effectively stands for, leading to a lot of guess-work in the daily practice of the Semantic Data Engineer (if you ever had to distinguish ICD: ICD10: ICD9: UMLS:, UMLSCUI: without a prefix map, etc you will know what I am talking about). Efforts to bring order to this chaos, essentially globally agreed CURIE maps (e.g. prefixcommons), or ID management services such as identifiers.org exist, but right now there is no one solution - prepare yourself to having to deal with this issue when dealing with data integration efforts in the biomedical sciences. More likely than not, your organisation will build its own curie map and maintain it for the duration of your project.
"},{"location":"lesson/analysing-linked-data/#semantic-web-in-the-biomedical-domain-success-stories","title":"Semantic Web in the biomedical domain: Success stories","text":"
There are probably quite a few divergent opinions on this, but I would like to humbly list the following four use cases as among the most impactful applications of Semantic Web Technology in the biomedical domain.
"},{"location":"lesson/analysing-linked-data/#light-semantics-for-data-aggregation","title":"Light Semantics for data aggregation.","text":"
We can use hierarchical relations in ontology to group data. For example, if I know that http://purl.obolibrary.org/obo/MONDO_0012709 (\"microphthalmia, isolated, with coloboma 5\") http://www.w3.org/2000/01/rdf-schema#subClassOf (\"is a\") http://purl.obolibrary.org/obo/MONDO_0003847 (\"Mendelian Disease\"), then a specialised Semantic Web tool called a reasoner will know that, if I ask for all genes associated with Mendelian diseases, you also want to get those associated with \"microphthalmia, isolated, with coloboma 5\" specifically (note that many query engines such as SPARQL with RDFS entailment regime have simple reasoners embedded in them, but we would not call them \"reasoner\" - just query engine).
"},{"location":"lesson/analysing-linked-data/#heavy-semantics-for-ontology-management","title":"Heavy Semantics for ontology management.","text":"
Ontologies are extremely hard to manage and profit from the sound logical foundation provided by the Web Ontology Language (OWL). We can logically define our classes in terms of other ontologies, and then use a reasoner to classify our ontology automatically. For example, we can define abnormal biological process phenotypes in terms of biological processes (Gene Ontology) and classify our phenotypes entirely using the classification of biological processes in the Gene Ontology (don't worry if you don't understand a thing - we will get to that in a later week).
"},{"location":"lesson/analysing-linked-data/#globally-unique-identifiers-for-data-integration","title":"Globally unique identifiers for data integration.","text":"
Refer to the same thing the same way. While this goal was never reached in total perfection, we have gotten quite close. In my experience, there are roughly 3-6 ways to refer to entities in the biomedical domain (like say, ENSEMBL, HGNC, Entrez for genes; or SNOMED, NCIT, DO, MONDO, UMLS for diseases). So while the \"refer to the same thing the same way\" did not truly happen, a combination of standard identifiers with terminological mappings, i.e. links between terms, can be used to integrate data across resources (more about Ontology Matching later). Again, many of my colleagues disagree - they don't like IRIs, and unfortunately, you will have to build your own position on that.
Personal note: From an evolutionary perspective, I sometimes think that having 2 or 3 competing terminological systems is better than 1, as the competition also drives the improvements in quality, but there is a lot of disagreement on this.
"},{"location":"lesson/analysing-linked-data/#coordinated-development-of-mutually-compatible-ontologies-across-the-biomedical-domain-the-open-biological-and-biomedical-ontologies-obo-foundry","title":"Coordinated development of mutually compatible ontologies across the biomedical domain: The Open Biological and Biomedical Ontologies (OBO) Foundry.","text":"
The OBO Foundry is a community-driven effort to coordinate the development of vocabularies and ontologies across the biomedical domain. It develops standards for the representation of terminological content (like standard properties), and ontological knowledge (shared design patterns) as well as shared systems for quality control. Flagship projects include:
The Relation Ontology (RO) for the standardisation of relationships that connect entities in biomedical ontologies.
The Core Ontology for Biology and Biomedicine (COB): upper ontology to align key entities used throughout biomedical ontologies.
The OBO Metadata Ontology for aligning ontology metadata properties across OBO ontologies.
The OBO Persistent Identifier System: an Identifier scheme for persistent URIs used by many ontologies on the web. The system is used to refer to terms as well as ontologies and their versions.
OBO Dashboard: a system for the monitoring and continued improvement of OBO ontologies with automated Quality Control checks.
"},{"location":"lesson/analysing-linked-data/#semantic-web-and-linked-data-things-you-should-have-heard-about","title":"Semantic Web and Linked Data: Things you should have heard about","text":"
The Semantic Web Layer Cake: A iconic, colourful graphic that describes the layered design of the semantic web, from URIs to Logic. Its not particularly useful, but as a Semantic Web Explorer, you should have seen it.
Linked Data is mostly referred to as a \"method for publishing data\", a key concept in the Semantic Web domain, coined by Tim Berners Lee in 2006. Related concepts:
Linked Data Principles:
Use URIs as names for things
Use HTTP URIs so that people can look up those names.
When someone looks up a URI, provide useful information.
Include links to other URIs. so that they can discover more things.
5-Star system
make your stuff available on the Web (whatever format) under an open license
make it available as structured data (e.g., Excel instead of image scan of a table)
use non-proprietary formats (e.g., CSV instead of Excel)
use URIs to denote things, so that people can point at your stuff
link your data to other data to provide context
FAIR data: Principles defined in 2016, somewhat orthogonal to Linked Data Principles. A nice tutorial, also going a bit more in depth into identifiers than what we did in this section, can be found here. The idea of FAIR data is probably more impactful in the biomedical and pharmaceutical world then the idea of Linked Data. While there are some (slighltly irritating) voices on the sidelines that say that \"It can't be FAIR if its not RDF\", it is probably true that a nicely formatted CSV file on the Web is at least as useful as a (hard to understand) RDF dump containing the same data. Worldwide collaborations between major pharmaceutical corporations promoting FAIR data, such as the Pistoia Alliance do mention Semantic Web Technologies in their White papers, but keep the jargon a bit more hidden from the general public. Data, according to the FAIR principles, should be:
Findable (machine readable metadata, etc)
Accessible (open authentication, authorisation)
Interoperable (integrated with other data, closely related to controlled vocabularies and linked data)
Reusable (metadata, license, provenance)
World Wide Web Consortium (W3C): The World Wide Web Consortium (W3C) is an international community that develops open standards, in particular many of those (but not all!) pertaining to the Semantic Web.
"},{"location":"lesson/analysing-linked-data/#the-ecosystem-of-linked-data-and-semantic-web-standards-technologies-and-research-areas","title":"The Ecosystem of Linked Data and Semantic Web: Standards, Technologies and Research Areas","text":"
In the following, we will list some of the technologies you may find useful, or will be forced to use, as a Semantic Data Engineer. Most of these standards will be covered in the subsequent weeks of this course.
Standard Purpose Use case Web Ontology Language (OWL) Representing Knowledge in Biomedical Ontologies All OBO ontologies must be provided in OWL as well. Resource Description Framework (RDF) Model for data interchange. Triples, the fundamental unit of RDF, are ubiquitous on the Semantic Web SPARQL Query Language for RDF A standard query language for RDF and RDFS. Primary query language to interrogate RDF/RDFS/Linked Data on the Web. Simple Knowledge Organization System (SKOS) Another, more lightweight, knowledge organisation system in many ways competing with OWL. Not as widely used in the biomedical domain as OWL, but increasing uptake of \"matching\" vocabulary (skos:exactMatch, etc). RDF-star A key shortcoming of RDF is that, while I can in principle say everything about everything, I cannot directly talk about edges, for example to attribute provenance: \"microphthalmia, isolated, with coloboma 5 is kind of Mendelian disease\"--source: Wikipedia Use cases here. JSON-LD A method to encoding linked data in JSON format. (Very useful to at least know about). RDFa W3C Recommendation to embed rich semantic metadata in HTML (and XML). I have to admit - in 11 years Semantic Web Work I have not come across much use of RDFa in the biomedical domain. But @jamesaoverton is using it in his tools!
A thorough overview of all the key standards and tools can be found on the Awesome Semantic Web repo.
For a rough sense of current research trends it is always good to look at the accepted papers at one of the major conferences in the area. I like ISWC (2020 papers), but for the aspiring Semantic Data Engineering in the biomedical sphere, it is probably a bit broad and theoretical. Other interesting specialised venues are the Journal of Biomedical Semantics and the International Conference on Biomedical Ontologies, but with the shift of the focus in the whole community towards Knowledge Graphs, other journals and conferences are becoming relevant.
Here are a few key research areas, which are, by no means (!), exhaustive.
How can we combine data and knowledge from different ontologies/knowledge graphs?
Ontology/Knowledge graph alignment: How can we effectively link to ontologies, or knowledge graphs, together?
Ontology merging: combine two ontologies by corresponding concepts and relations.
Ontology matching: A sub-problem of ontology alignment, namely the problem of determining whether two terms (for example two diseases) from different ontologies should be linked together or not.
How can we integrate data from unstructured and semistructured sources such as documents or spreadsheets?
Named Entity Recognition (NER): the process of identifying a named \"thing\" in a text.
Entity linking: The task of associating a named entity, for example the result of a Named Entity Recognition algorithm, or the column of a spreadsheet, to a concept in an ontology. For example, the value \"Mendelian Disease\" is linked to the concept http://purl.obolibrary.org/obo/MONDO_0003847.
Relationship extraction: Once you have identified the genes and diseases in your Pubmed abstracts, you will want to understand how they related to each other. Is the gene the \"basis in dysfunction of\" the disease? Or just randomly co-occurs in the sentence?
Note: Many of the problems in this category are typically associated with the domain of Natural Language Processing rather than Semantic Web.
How can we generate insight from semantically integrated data?
Knowledge Graphs and Machine Learning
Knowledge Graph Embeddings. The number one hype topic in recent years: How do you get from a graph of interrelated entities to a faithful representation in a vector space (basically numbers), so that Machine Learning algorithms can do their magic?
Link predication: Based on what we know, which are the best drug targets for my rare disease of interest?
Logical reasoning: While the research on deductive reasoning, at least the more \"hard-core\" Description Logic kind, seems to be a bit more quiet in recent years (maybe I am wrong here, I just see much less papers coming through my Google Scholar alerts now then I used to), there is still a lot going on in this domain: more efficient SPARQL engines, rule-based reasoning such as the recently commercialised RDFox reasoner and many more.
Other research areas (not in any way exhaustive):
Web decentralisation and privacy:
Solid: Solid (Social Linked Data) is a web decentralization project led by Tim Berners-Lee, with the aim of true ownership of personal data and improved privacy. \"Pods\" are like secure personal web servers for data from which application can request data.
Shape validation: It is very difficult to validate huge Knowledge Graphs of interrelated data efficiently (by validate we can mean a lot of things, such as making sure that your cat does not accidentally end up as someone's \"Mendelian Disease\"). Shape languages such as Shex and SHACL are poised to solve this problem, but the research is ongoing.
New standards and tools: There is always someone proposing a new semantic standard for something or building a new kind of triple store, SPARQL extension or similar.
"},{"location":"lesson/analysing-linked-data/#typical-jobs-of-semantic-data-engineers-in-the-biomedical-domain","title":"Typical Jobs of Semantic Data Engineers in the biomedical domain","text":"
It is useful to get a picture of the typical tasks a Semantic Data Engineer faces when building ontologies are Knowledge Graphs. In my experience, it is unlikely that any particular set of tools will work in all cases - most likely you will have to try and assemble the right toolchain for your use case and refine it over the lifetime of your project. The following are just a few points for consideration of tasks I regularly encountered - which may or may not overlap with the specific problems you will face.
"},{"location":"lesson/analysing-linked-data/#finding-the-right-ontologies","title":"Finding the right ontologies","text":"
There are no simple answers here and it very heavily depends on your use cases. We are discussing some places to look for ontologies here, but it may also be useful to simply upload the terms you are interested in to a service like Zooma and see what the terms map to at a major database provider like EBI.
"},{"location":"lesson/analysing-linked-data/#finding-the-right-data-sources","title":"Finding the right data sources","text":"
This is much harder still than it should have to be. Scientific databases are scattered across institutions that often do not talk to each other. Prepare for some significant work in researching the appropriate databases that could benefit your work, using Google and the scientific literature.
It is rare nowadays that you will have to develop an ontology entirely from scratch - most biomedical sub-domains will have some kind of reasonable ontology to build upon. However, there is often a great need to extend existing ontologies - usually because you have the need of representing certain concepts in much more detail, or your specific problem has not been modelled yet - think for example when how disease ontologies needed to be extended during the Coronavirus Crisis. Extending ontologies usually have two major facets:
If at all possible you should seek to contribute new terms, synonyms and relationships to the ontologies you seek to extend directly. Here, you can use GitHub to make issues requesting new terms, but more boldly, you can also add new terms yourself. We will teach you how to do that in one of the next weeks.
If the knowledge is considered out of scope for the ontology to be extended (for example because the terms are considered too detailed), then you will maintain your own \"branch\" of the ontology. Many tools such as the Ontology Development Kit and ROBOT can help you maintain such a branch but the general instinct should be:
Make a public GitHub repo.
Reach out to the developers of the main ontology
Stay in touch and coordinate releases
"},{"location":"lesson/analysing-linked-data/#mapping-data-into-ontologiesknowledge-graphs","title":"Mapping data into ontologies/knowledge graphs","text":"
Also sometimes more broadly referred to as \"data integration\", this problem involves a variety of tasks, such as:
Named Entity Recognition. If you have a set of documents, such as PubMed abstracts or clinical notes, you may have to first identify the parts of speech that refer to clinical entities.
Entity Linking: Once you have identified the biomedical entities of interest, you may want to link them to your existing knowledge graph. This process is sometimes called entity mapping or data mapping as well. Very often, this task is not fully automated. We have worked on projects where we used approaches to Entity Linking to suggest good mappings to users, which then had to confirm or reject them. It is also good to understand that not all entity linking must be vertical (i.e. between \"equivalent\" entities). Very often, there is no equivalent entity in your knowledge graph to map to, and here you need to decide whether to (a) create a new entity in the knowledge graph to map to or (b) map to a broader entity (for example \"microphthalmia, isolated, with coloboma 5\" to \"Mendelian Disease\"). What is more efficient / useful solely depends on your use case!
To make your data discoverable, it is often useful to extract a view from the ontologies you are using (for example, Gene Ontology, Disease Ontology) that only contains the terms and relationships of relevance to your data. We usually refer to this kind of ontology as an application ontology, or an ontology specific to your application, which will integrate subsets of other ontologies. This process will typically involve the following:
Define a seed, or a set of terms you want to import from your external ontologies of interest.
Extract relevant subsets from ontologies using this seed (for example using ROBOT extract).
Combine and potentially link these subsets together.
Frameworks such as the Ontology Development Kit can help with this task, see for example the Coronavirus Vocabulary maintained by EBI.
"},{"location":"lesson/analysing-linked-data/#leverage-ontologies-and-knowledge-graphs-for-you-data-analysis-problems","title":"Leverage ontologies and knowledge graphs for you data analysis problems","text":"
There are many ways your semantic data can be leveraged for data analysis, but in my experience, two are particularly central:
Data grouping and search: make data about \"microphthalmia, isolated, with coloboma 5\" available when searching for data about \"Mendelian Disease\".
Link prediction: Figure out what additional knowledge is hidden in your data that can drive your research (e.g. possible new therapies or drug targets).
"},{"location":"lesson/analysing-linked-data/#additional-materials-and-resources","title":"Additional materials and resources","text":"
The open courses of the Hasso Plattner Institute (HPI) offer introductions into the concepts around Linked Data, Semantic Web and Knowledge Engineering. There are three courses of relevance to this weeks topics, all of which overlap significantly.
Knowledge Engineering and the Web of Data: The oldest (2015), of the courses, but the most thorough when it comes to logical foundations, semantics and OWL. We will come back to this course in Weeks 4 and 5.
Linked Data Engineering: Overlaps a lot with the Knowledge Engineering and the Web of Data course, with a bit more RDF/Linked Data focus.
Knowledge Graphs: The most up-to-date of the three courses (2020), and will be referred to again in Week 12 of our course here.
"},{"location":"lesson/automating-ontology-workflows/","title":"Automating Ontology Development Workflows: Make, Shell and Automation Thinking","text":""},{"location":"lesson/automating-ontology-workflows/#warning","title":"Warning","text":"
These materials are under construction and incomplete.
"},{"location":"lesson/automating-ontology-workflows/#what-is-delivered-as-part-of-the-course","title":"What is delivered as part of the course","text":"
In this course, you will learn the basics of automation in and around the OBO ontology world - and beyond. The primary goal is to enable ontology pipeline developers to plan the automation of their ontology workflows and data pipelines, but some of the materials are very general and apply to scientific computing more widely. The course serves also as a prerequisite for advanced application ontology development.
Automation is part of the foundation of the modern world. The key to using and building automation is a certain way of thinking about processes, how they can be divided into simple steps, and how they operate on inputs and outputs that must be exactly the same in some respects but different in others.
In this article I want to make some basic points about automation and how to think about it. The focus is on automation with software and data, but not on any particular software or data. Some of these points may seem too basic, especially for experienced programmers, but in 20+ years of programming I've never seen anybody lay out these basic points in quite this way. I hope it's useful.
\"automatos\" from the Greek: \"acting of itself\"
Automation has two key aspects:
make the input the same
process the inputs in the same way
The second part is more visible, and tends to get more attention, but the first part is at least as important. While automation makes much of the modern world possible, it is not new, and there are serious pitfalls to avoid. No system is completely automatic, so it's best to think of automation on a spectrum, and starting thinking about automation at the beginning of a new project.
"},{"location":"lesson/automating-ontology-workflows/#examples-of-automation","title":"Examples of Automation","text":"
To my mind, the word \"automation\" brings images of car factories, with conveyor belts and robotic arms moving parts and welding them together. Soon they might be assembling self-driving (\"autonomous\") cars. Henry Ford is famous for making cars affordable by building the first assembly lines, long before there were any robots. The essential steps for Ford were standardizing the inputs and the processes to get from raw materials to a completed car. The history of the 20th century is full of examples of automation in factories of all sorts.
Automation was essential to the Industrial Revolution, but it didn't start then. We can look to the printing press. We can look to clocks, which regimented lives in monasteries and villages. We can think of recipes, textiles, the logistics of armies, advances in agriculture, banking, the administration of empires, and so on. The scientific revolution was built on repeatable experiments published in letters and journal articles. I think that the humble checklist is also an important relative of automation.
Automation is not new, but it's an increasingly important part of our work and our lives.
"},{"location":"lesson/automating-ontology-workflows/#software-automation-is-special","title":"Software Automation is Special","text":"
Software is almost always written as source code in text files that are compiled and/or interpreted as machine code for a specific set of hardware. Software can drive machines of all sorts, but a lot of software automation stays inside the computer, working on data in files and databases, and across networks. We'll be focused on this kind of software automation, transforming data into data.
The interesting thing about this is that source code is a kind of data, so there are software automation workflows that operate on data that defines software. The upshot is that you can have automation that modifies itself. Doing this on a large scale introduces a lot of complexity, but doing it on a small scale can be a clean solution to certain problems.
Another interesting thing about software is that once we solve an automation problem once we can copy that solution and apply it again and again for almost zero cost. We don't need to build a new factory or a new threshing machine. We can just download a program and run it. Henry Ford could make an accurate estimate of how long it would take to build a car on his assembly line, but software development is not like working on the assembly line, and estimating time and budget for software development is notoriously hard. I think this is because software developers aren't just executing automation, they're building new automation for each new project.
Although we talk about \"bit rot\", and software does require maintenance of a sort, software doesn't break down or wear out in the same ways that physical machines do. So while the Industrial Revolution eliminated many jobs, it also created different jobs, building and maintaining the machines. It's not clear that software automation will work the same way.
Software automation is special because it can operate on itself, and once complete can be cheaply copied. Software development is largely about building automated systems of various sorts, usually out of many existing pieces. We spend most of our time building new systems, or modifying an existing system to handle new inputs, or adapting existing software to a new use case.
"},{"location":"lesson/automating-ontology-workflows/#the-dangers-of-automation","title":"The Dangers of Automation","text":"
To err is human; to really foul things up requires a computer.
An obvious danger of automation is that machines are faster than humans, so broken automation can often do more damage more quickly than a human can. A related problem is that humans usually have much more context and depth of experience, which we might call \"common sense\", and a wider range of sensory inputs than most automated systems. This makes humans much better at recognizing that something has gone wrong with a process and that it's time to stop.
New programmers soon learn that a simple program that performs perfectly when the input is in exactly the right format, becomes a complex program once it's updated to handle a wide range of error conditions. In other words, it's almost always much harder to build automation that can gracefully handler errors and problems than it is to automate just the \"happy path\". Old programmers have learned through bitter experience that it's often practically impossible to predict all the things that can go wrong with an automated system in practise.
I suppose it is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail. -- Abraham Maslow
A less obvious danger of automation comes from the sameness requirement. When you've built a great piece of automation, perfectly suited to inputs of a certain type, it's very tempting to apply that automation more generally. You start paying too much attention to how things are the same, and not enough attention to their differences. You may begin to ignore important differences. You may surrender your common sense and good judgment, to save yourself the work of changing the automated system or making an exception.
Bureaucracies are a form of automation. Everyone has had a bad experience filling out some form that ignores critical information, and with some bureaucrat who would not apply common sense and make an exception.
Keep all this in mind as you build automated systems: a broken machine can do a lot of damage very quickly, and a system built around bad assumptions can do a lot of hidden damage.
"},{"location":"lesson/automating-ontology-workflows/#a-spectrum-of-automation","title":"A Spectrum of Automation","text":"
Let's consider a simple case of automation with software, and build from the most basic sort of automation to a full-fledged system.
Say you have a bunch of text files in a directory, each containing minutes from meetings that we had together over the years. You can remember that I talked about a particular software package that might solve a problem that you just discovered, but you can't remember the name.
"},{"location":"lesson/automating-ontology-workflows/#1-ad-hoc","title":"1. Ad Hoc","text":"
The first thing you try is to just search the directory. On a Mac you would open the Finder, navigate to the directory, and type \"James\" into the search bar. Unfortunately that gives too many results: all the files with the minutes for a meeting where I said something.
The next thing to do is double click some text files, which would open them in Text Edit program, and skim them. You might get lucky!
You know that I the meeting was in 2019, so you can try and filter for files modified in that year. Unfortunately the files have been updated at different times, so the file dates aren't useful.
Now if each file was named with a consistent pattern, including the meeting date, then it would be simple to filter for files with \"2019\" in the name. This isn't automation, but it's the first step in the right direction. Consistent file names are one way to make inputs the same so that you can process them in the same way.
Let's say it works: you filter for files from 2019 with \"James\" in them, skim a few, and find a note where I recommended using Pandoc to convert between document formats. Mission accomplished!
Next week you need to do something very similar: Becky mentioned a website where you can find an important dataset. It's basically the same problem with different inputs. If you remember exactly what you did last time, then you can get the job done quickly. As the job gets more complicated and more distant in time, and as you find yourself doing similar tasks more often, it's nice to have notes about what you did and how you did it.
If I'm using a graphical user interface (GUI) then for each step I'll note the program I used, and the menu item or button I clicked, e.g. \"Preferences > General > Font Size\", or \"Search\" or \"Run\". If I'm using a command-line interface (CLI) then I'll copy-paste the commands into my notes.
I often keep informal notes like this in a text file in the relevant directory. I name the file \"notes.txt\". A \"README\" file is similar. It's used to describe the contents of a directory, often saying which files are which, or what the column headers for a given table mean.
Often the task is more complicated and requires one or more pieces of software that I don't use every day. If there's relevant documentation, I'll put a link to it in my notes, and then a short summmary of exactly what I did.
In this example I look in the directory of minutes and see my \"notes.txt\" file. I read that and remember how I filtered on \"2019\" and searched for \"James\". This time I filter on \"2020\" and search for \"Becky\", and I find the website for the dataset quickly enough.
As a rule of thumb, it might take you three times longer to find your notes file, write down the steps you took, and provide a short description, than it would to just do the job without taking notes. When you're just taking notes for yourself, this often feels like a waste of time (you'll remember, right?!), and sometimes it is a bit of a waste. If you end up using your notes to help with similar tasks in the future, then this will likely be time well spent.
As a rule of thumb, it might take three times longer to write notes for a broader audience than notes for just yourself. This is because you need to take into account the background knowledge of your reader, including her skills and assumptions and context, and especially the possible misunderstandings that you can try to avoid with careful writing. I often start with notes for just myself and then expand them for a wider audience only when needed.
When tasks get more complicated or more important then informal notes are not enough. The next step on the spectrum of automation is the humble checklist.
The most basic checklists are for making sure that each item has been handled. Often the order isn't important, but lists are naturally ordered from top to bottom, and in many cases that order is useful. For example, my mother lays out her shopping lists in the order of the aisles in her local grocery store, making it easier to get each item and check it off without skipping around and perhaps having to backtrack.
I think of a checklist as a basic form of automation. It's like a recipe. It should lay out the things you need to start, then proceed through the required steps in enough detail that you can reproduce them. In some sense, by using the checklist you are becoming the \"machine\". You are executing an algorithm that should take you from the expected inputs to the expected output.
Humble as the checklist is, there's a reason that astronauts, pilots, and surgical teams live by their checklists. Even when the stakes are not so high, it's often nice to \"put your brain on autopilot\" and just work the checklist without having to remember and reconsider the details of each step.
A good checklist is more focused than a file full of notes. A checklist has a goal at the end. It has specific starting conditions. The steps have been carefully considered, so that they have the proper sequence, and none are missing. Perhaps most importantly, a checklist helps you break a complex task down into simple parts. If one of the parts is still too complex, then break it down again into a nested checklist (really a sort of tree structure).
Checklists sometimes include another key element of automation: conditionals. A shopping list might say \"if there's a sale on crackers, then buy three boxes\". If-then conditions let our automated systems adapt to circumstances. The \"then\" part is just another step, but the \"if\" part is a little different. It's a test to determine whether a condition holds. We almost always want the result of the test to be a simple True or False. Given a bunch of inputs, some of which pass the test and some of which fail it, we can think of the test as determining some way in which all the things that pass are the same and all the things that fail are the same. Programmers will also be familiar with more complex conditionals such as if-then-else, if-elseif-else, and \"case\", which divide process execution across multiple \"branches\".
As a rule of thumb, turning notes into a checklist will likely take at least three times as long as simply writing the notes. If the checklist is for a wider audience, expect it to take three times as long to write, for the same reasons mentioned above for notes.
If a task is simple and I can hold all the steps in my head, and I can finish it in one sitting without distractions, then I won't bother with a checklist. But more and more I find myself writing myself a checklist before I begin any non-trivial tasks. I use bullet points in my favourite text editor, or sometimes the Notes app on my iPhone. I lay out the steps in the expected order, and I check them off as I go. Sometimes I start making the checklist days before I need it, so I have lots of time to think about it and improve it. If there's a job that I'm worried about, breaking it down into smaller pieces usually helps to make the job feel more manageable. Actually, I try to start every workday by skimming my (long) To Do list, picking the most important tasks, and making a checklist for what I want to get done by quitting time.
\"Checkscript\" is a word that I think I made up, based on insights from a couple of sources, primarily this blog post on \"Do-nothing scripting: the key to gradual automation\" This is where \"real\" automation kicks in, writing \"real\" code and stuff, but hopefully you'll see that it's just one more step on the spectrum of automation that I'm describing.
The notes and checklists we've been discussing are just text in your favourite text editor. A checkscript is a program. It can be written in whatever programming language you prefer. I'll give examples in Posix Shell, but that blog post uses Python, and it really doesn't matter. You start with a checklist (in your mind at least). The first version of your program should just walk you through your checklist. The program should walk you through each step of your checklist, one by one. That's it.
Here's a checkscript based on the example above. It just prints the first step (echo), waits for you to press any key (read), then prints the next step, and so on.
###!/bin/sh\n\necho \"1. Use Finder to filter for files with '2019' in the name\"\nread -p \"Press enter to continue\"\n\necho \"2. Use finder to search file content for 'James'\"\nread -p \"Press enter to continue\"\n\necho \"3. Open files in Text Edit and search for 'James'\"\nread -p \"Press enter to continue\"\n\necho \"Done!\"\n
So far this is just a more annoying way to use a checklist. The magic happens once you break the steps down into small enough pieces and realize that you know how to tell the computer to do some of the steps instead of doing them all yourself.
For example, you know that the command-line tool grep is used for searching the contents of files, and that you can use \"fileglob\"s to select just the files that you want to search, and that you can send the output of grep to another file to read in your favourite text editor. Now you know how to automate the first two steps. The computer can just do that work without waiting for you:
###!/bin/sh\n\ngrep \"James\" *2019* > search_results.txt\n\necho \"1. Open 'search_results.txt' in Text Edit and search for 'James'\"\nread -p \"Press enter to continue\"\n\necho \"Done!\"\n
Before we were using the Finder, and it is possible to write code to tell the Finder to filter and seach for files. The key advantage of grep here is that we send the search results to another file that we can read now or save for later.
This is also a good time to mention the advantage of text files over word processor files. If the minutes were stored in Word files, for example, then Finder could probably search them and you could use Word to read them, but you wouldn't be able to use grep or easily output the results to another file. Unix tools such as grep treat all text files the same, whether they're source code or meeting minutes, which means that these tools work pretty much the same on any text file. By keeping your data in Word you restrict yourself to a much smaller set of tools and make it harder to automate you work with simple scripts like this one.
Even if you can't get the computer to run any of the steps for you automatically, a checkscript can still be useful by using variables instead of repeating yourself:
###!/bin/sh\n\nFILE_PATTERN=\"*2019*\"\nFILE_CONTENTS=\"James\"\n\necho \"1. Use Finder to filter for files with '${FILE_PATTERN}' in the name\"\nread -p \"Press enter to continue\"\n\necho \"2. Use finder to search file content for '${FILE_CONTENTS}'\"\nread -p \"Press enter to continue\"\n\necho \"3. Open files in Text Edit and search for '${FILE_CONTENTS}'\"\nread -p \"Press enter to continue\"\n\necho \"Done!\"\n
Now if I want to search for \"Becky\" I can just change the FILE_CONTENTS variable in one place. I find this especially useful for dates and version numbers.
This is pretty simple for a checkscript, with very few steps. A more realistic example would be if there were many directories containing the minutes of many meetings, maybe in different file formats and with different naming conventions. In order to be sure that we're searching all of them we might need a longer checkscript.
Writing and using a checkscript instead of a checklist will likely take (you guessed it) about three times as long. But the magic of the checkscript is in the title of the blog post I mentioned: \"gradual automation\". Once you have a checkscript, you can run through it all manually, but you can also automate bits a pieces of the task, saving yourself time and effort next time.
A \"script\" is a kind of program that's easy to edit and run. There are technical distinctions to be made between \"compiled\" programs and \"interpreted\" programs, but they turn out to be more complicated and less helpful than they seem at first. Technically, a checkscript is just a script that waits for you to do the hard parts. In this section I want to talk about \"fully automated\" or \"standalone\" scripts that you just provide some input and execute.
Most useful programs are useful because they call other programs (in the right ways). I like shell scripts because they're basically just commands that are copied and pasted from work I was doing on the command-line. It's really easy to call other programs.
To continue our example, say that our minutes were stored in Word files. There are Python libraries for this, such as python-docx. You can write a little script using this library that works like grep to search for specified text in selected files, and output the results to a search results file.
As you add more and more functionality to a script it can become unwieldy. Scripts work best when they have a simple \"flow\" from beginning to end. They may have some conditionals and some loops, but once you start seeing nested conditionals and loops, then your script is doing too much. There are two main options to consider:
break your script into smaller, simpler scripts
build a specialized tool: the next step on the spectrum of automation
The key difference between a checkscript and a \"standalone\" script is handling problems. A checkscript relies on you to supervise it. A standalone script is expected to work properly without supervision. So the script has to be designed to handle a wider range of inputs and fail gracefully when it gets into trouble. This is a typical case of the \"80% rule\": the last 20% takes 80% of the time. As a rule of thumb, expect it to take three times as long to write a script that can run unsupervised than it takes you to write a checkscript that does \"almost\" the same thing.
When your script needs nested conditionals and loops, then it's probably time to reach for a programming language that's designed to write code \"in the large\". Some languages such as Python can make a pretty smooth transition from a script in a single file to a set of files in a module, working together nicely. You might also choose another language that can provide better performance or efficiency.
It's not just the size and the logical complexity of your script, consider its purpose. The specialized tools that I have in mind have a clear purpose that helps guide their design. This also makes them easier to reuse across multiple projects.
I often divide my specialized tools into two parts: a library and a command-line interface. The library can be used in other programs, and contains the most distinctive and important functionality. But the command-line interface is essential, because it lets me use my specialized tool in the shell and in scripts, so I can build more automation on top of it.
Writing a tool in Java or C++ or Rust usually takes longer than a script in shell or Python because there are more details to worry about such as types and efficient memory management. In return you usually get more reliability and efficiency. But as a rule of thumb, expect it to take three times as long to write a specialized tool than it would to \"just\" write the script. On the other hand, if you already have a script that does most of what you want, and you're already familiar with the target you are moving to, then it can be fairly straightforward to translate from the script to the specialized tool. That's why it's often most efficient to write a prototype script first, do lots of quick experiments to explore the design space, and when you're happy with the design then start on the \"production\" version.
The last step in the spectrum of automation is to bring together all your scripts into a single \"workflow\". My favourite tool for this is the venerable Make. A Makefile is essentially a bunch of small scripts with their input and output files carefully specified. When you ask Make to build a given output file, it will look at the whole tree of scripts, figure out which input files are required to build your requested output file, then which files are required to build those files, and so on until it has determined a sequence of steps. Make is also smart enough to check whether some of the dependencies are already up-to-date, and can skip those steps. Looking at a Makefile you can see everything broken down into simple steps and organized into a tree, through which you can trace various paths. You can make changes at any point, and run Make again to update your project.
I've done this all so many times that now I often start with a Makefile in an empty directory and build from there. I try experiments on the command line. I make notes. I break the larger task into parts with a checklist. I automate the easy parts first, and leave some parts as manual steps with instructions. I write little scripts in the Makefile. I write larger scripts in the src/ directory. If these get too big or complex, I start thinking about building a specialized tool. (And of course, I store everything in version control.) It takes more time at the beginning, but I think that I usually save time later, because I have a nice place to put everything from the start.
In other words, I start thinking about automation at the very beginning of the project, assuming from the start that it will grow, and that I'll need to go back and change things. With a mindset for automation, from the start I'm thinking about how the inputs I care about are the same and different, which similarities I can use for my tests and code, and which differences are important or unimportant.
In the end, my project isn't ever completely automated. It doesn't \"act of itself\". But by making everything clear and explicit I'm telling the computer how to do a lot of the work and other humans (or just my future self) how to do the rest of it. The final secret of automation, especially when it comes to software and data, is communication: expressing things clearly for humans and machines so they can see and do exactly what you did.
"},{"location":"lesson/automating-ontology-workflows/#scientific-computing-an-overview","title":"Scientific Computing: An Overview","text":"
By: James Overton
By \"scientific computing\" we mean using computers to help with key aspect of science such as data collection, cleaning, interpretation, analysis, and visualization. Some people use \"scientific computing\" to mean something more specific, focusing on computational modelling or computationally intensive analysis. We'll be focusing on more general and day-to-day topics: how can a scientist make best use of a computer to do their work well?
These three things apply to lots of fields, but are particularly important to scientists:
reliability
reproducibility
communication
It should be no surprise that automation can help with all of these. When working properly, computers make fewer mistakes than people, and the mistakes they do make are more predictable. If we're careful, our software systems can be easily reproduced, which means that an entire data analysis pipeline can be copied and run by another lab to confirm the results. And scientific publications are increasingly including data and code as part of the review and final publication process. Clear code is one of the best ways to communicate detailed steps.
Automation is critical to scientific instruments and experiments, but we'll focus on the data processing and analysis side: after the data has been generated, how should you deal with it.
Basic information management is always important:
community standard file formats
consistent file naming
documentation, READMEs
backups
version control
More advanced data management is part of this course:
consistent use of versioned
software
reference data
terminology
controlled vocabularies
data dictionaries
ontologies
Some simple rules of thumb can help reduce complexity and confusion:
A lot of data analysis starts with a reference data set. It might be a genome or a proteome. It might be a corpus. It might be a set of papers or data from those papers.
Start by finding that data and selecting a particular version of it. Write that down clearly in your notes. If possible, include a unique identifier such as a (persistent) URL or DOI. If that's not possible, write down the steps you took. If the data isn't too big, keep a copy of it in your fresh new project directory. If the data is a bit too big, keep a compressed copy in a zip or gz file. A lot of software is perfectly happy to read directly from compressed files, and you can compress or uncompress data using piped commands in your shell or script. If the data is really too big, then be extra careful to keep notes on exactly where you can find it again. Consider storing just the hashes of the big files, so you can confirm that they have exactly the same contents.
If you know from the start that you will need to compare your results with someone else's, make sure that you're using the same reference data that they are. This may require a conversation, but trust me that it's better to have this conversation now than later.
"},{"location":"lesson/automating-ontology-workflows/#one-way-data-flow","title":"One-Way Data Flow","text":"
It's much easier to think about processes that flow in one direction. Branches are a little trickier, but usually fine. The real trouble comes with loops. Once a process loops back on itself it's much more difficult to reason about what's happening. Loops are powerful, but with great power comes great responsibility. Keep the systems you design as simple as possible (but no simpler).
In practical terms:
Try not to read then write to the same file. If you have to, try to append rather than overwrite. This is one reason why I prefer tables on disk to databases.
Don't hesitate to write intermediate files. These are very useful for testing and debugging. When you're \"finished\" you can comment out these steps.
"},{"location":"lesson/automating-ontology-workflows/#plan-for-change","title":"Plan for Change","text":"
It's very tempting: you could automate this step, or you could just do it manually. It might take three times as long to automate it, right? So you can save yourself some precious time by just opening Excel and \"fixing\" things by hand.
Sometimes that bet will pay off, but I lose that bet most of the time. I tend to realize my mistake only at the last minute. The submission deadline is tomorrow but the core lab \"fixed\" something and they have a new version of the dataset that we need to use for the figures. Now I really don't have time to automate, so I'm up late clicking through Excel again and hoping that I remembered to redo all the changes that I made last time.
Automating the process would have actually saved me time, but more importantly it would have avoided a lot of stress. By now I should know that the dataset will almost certainly be revised at the last minute. If I have the automation set up, then I just update the data, run the automation again, and quickly check the results.
"},{"location":"lesson/automating-ontology-workflows/#test-from-the-start","title":"Test from the Start","text":"
Tests are another thing that take time to implement.
One of the key benefits to tests is (again) communication. When assessing or trying out some new piece of software I often look to the test files to see examples of how the code is really used, and the shape of the inputs and outputs.
There's a spectrum of tests that apply to different parts of your system:
unit tests: individual functions and methods
regression tests: ensure that fixed bugs do not reappear
integration tests: end-to-end functionality
performance tests: system speed and resource usage
acceptance tests: whether the overall system meets its design goals
Tests should be automated. The test suite should either pass or fail, and if it fails something needs to be fixed before any more development is done. The automated test suite should run before each new version is committed to version control, and ideally more often during development.
Tests come with costs:
development cost of writing the tests
time and resources spent running the tests
maintenance costs of updating the tests
The first is obvious but the other two often more important. A slow test suite is annoying to run, and so it won't get run. A test suite that's hard to update won't get updated, and then failures will be ignored, which defeats the entire purpose.
"},{"location":"lesson/automating-ontology-workflows/#documentation-is-also-for-you","title":"Documentation is also for You","text":"
I tend to forget how bad a memory I have. In the moment, when I'm writing brilliant code nothing could be more obvious than the perfect solution that is pouring forth from my mind all over my keyboard. But when I come back to that code weeks, months, or years later, I often wonder what the heck I was thinking.
We think about the documentation we write as being for other people, but for a lot of small projects it's really for your future self. Be kind to your future self. They may be even more tired, even more stressed than you are today.
There's a range of different forms of documentation, worth a whole discussion of its own. I like this four-way distinction:
tutorials: getting started, basic concepts, an overview
how-to guides: how to do common tasks
explanation: why does it work this way?
reference: looking up the details
You don't need all of these for your small project, but consider a brief explanation of why it works the way it does (aimed at a colleague who knows your field well), and some brief notes on how-to do the stuff this project is for. These could both go in the README of a small project.
"},{"location":"lesson/automating-ontology-workflows/#additional-materials-and-resources","title":"Additional materials and resources","text":"
"},{"location":"lesson/chatgpt-ontology-curation/","title":"Leveraging ChatGPT for ontology curation","text":""},{"location":"lesson/chatgpt-ontology-curation/#lesson-leveraging-chatgpt-for-ontology-curation","title":"Lesson: Leveraging ChatGPT for ontology curation","text":"
In this lesson, we will take a look at the generative capabilities of LLM's in general and ChatGPT in particular, to try and get a beginning sense on how to leverage it to enhance ontology curation workflows.
The goal of the lesson is to give a mental model of what ChatGPT and LLMs are used for (ignoring details on how they work), contextualise the public discourse a bit, and then move on to looking at some concrete examples at its potential for improving curation activties.
To achieve this we engaged in a dialog with ChatGPT to generate almost the entire content of the lesson. The lesson authors provide the general \"structure\" of the lesson, provided to ChatGPT as a series of prompts, and get ChatGPT to provide the content. This content is obviously not as good as it could have been if it was created by a human with infinite resources, but we hope it does get the following points across:
You can get 80% of the way in 20% (or less, in my case) of the time (it took me 90 minutes to write the lesson, while the same scope of lesson would have taken me 8-10 hours without ChatGPT
Beware of hallucinations in particular
ChatGPT is not only good for generating natural language text, but also structured content
Using ChatGPT is fun, which drastically reduces the mental barrier of using it in a professional context
We believe that from a user perspective, prompt engineering will be the most important skill that need to be learned when dealing with generative AI. Not just ChatGPT (which generates text), but also tools that generate images from text such as DALL-E or Midjourney, so this is what we will focus on. In the long term, applications like Monarchs OntoGPT will do some of the heavy lifting around writing perfect prompts, but it seems pretty clear that some basic knowledge of prompt engineering will be useful, or even necessary, for a long time to come.
For a reference of effective ChatGPT prompts for ontology development see here.
Note: - ChatGPT is rapidly evolving. The moment we add an answer, it will probably be outdated. For example, I created the first version of this tutorial on April 17th 2023. On May 27th, almost all answers ChatGPT is giving are completely different from the ones given in the first round. This is also important to remember when building applications around ChatGPT. - Note: https://open-assistant.io/chat is free and can be used to follow this tutorial instead of ChatGPT.
"},{"location":"lesson/chatgpt-ontology-curation/#skills-you-will-learn-in-this-lesson","title":"Skills you will learn in this lesson","text":"
Write basic prompts for ChatGPT and similar LLM-based chatbots
Understand the basic principles of text in -> text out of LLM-based programs
Understand practically the risks of hallucination
Motivate yourself to explore the question: \"How, if at all, can I use this technology to become more efficient/effective in my work? (there is no general answer to that yet!)\"
We use quote syntax with the prompt icon to indicate a concrete prompt for ChatGPT
Comments
We use quote syntax with the comment icon to indicate a comment by the author
Replies by ChatGPT
Replies are given in normal text form. All text after the table of contents, apart from comments, prompts and the section on executable workflows are generated by ChatGPT.
If you have a tiny bit of a technical inclination, we recommend the ca. 60 minute OpenAI/DeepLearning.ai course. It has zero fluff, and is very focussed on some of the core use cases of using ChatGPT as an API.
We recommend to spend 30-60 minutes studying the excellent Learn Prompting, a Free, Open Source Course on Communicating with Artificial Intelligence.
Take a look at this nice introduction to prompt engineering by anthropic
If you want to replicate the contents of this lession, you have to make an account at https://chat.openai.com/
Applications of LLMs and ChatGPT around ontology development
How can we, concretely, enhance the ontology curation process?
Using ChatGPT for ontology mappings
Generating pre-coordinated expressions and schema instances
None of the text in this section is generated with ChatGPT.
In essence, an LLM takes as an input a piece of text, and returns text as an output. A \"prompt\" is a piece of text that is written by an agent. This can be a human, or a software tool, or a combination of the two. In most cases, a human agent will pass the prompt to a specialised tool that pre-processes the prompt in certain ways (like translating it, adding examples, structuring it and more) before passing it to the large language model (LLM). For example, a when a chatbot tool like ChatGPT receives a prompt, it processes the prompt in certain ways, than leveraging the trained LLM to generate the text (which is probably postprocessed) and passed back to the human agent.
There are an infinite number of possible tools you can imagine following this rough paradigm. Monarch's own ontogpt, for example, receives the prompt from the human agent, then augments the prompt in a certain way (by adding additional instructions to it) before passing the augmentd prompt to an LLM like gpt3.5 (or lately even gpt4), which generates an instance of a curation schema. This is a great example for an LLM generating not only human readable text, but structured text. Another example for this is to ask an LLM to generate, for example, a SPARQL query to obtain publications from Wikidata.
Given the wide range of applications LLMs can serve, it is important to get a mental model of how these can be leveraged to improve our ontology and data curation workflows. It makes sense for our domain (semantic engineering and curation) to distinguish four basic models of interacting with LLMs (which are technically not much different):
Using LLM-based tools as advisors (endpoint humans)
Using LLM-based tools as assistants (endpoint humans)
Using LLM-based tools to extract information for automated processing (endpoint application)
Using LLMs as advisors has a huge number of creative applications. An advisor in this sense is a machine that \"knows a lot\" and helps you with your own understanding of the world. Large language models trained on a wide range of inputs are particularly interesting in this regard because of the immense breadth of their knowledge (rather than depth), which is something that can be difficult to get from human advisors. For example, the authors of this article have used ChatGPT and other LLM-based chatbots to help with understanding different domains, and how they might relate to knowledge management and ontologies in order to give specific career advice or to prepare for scientific panel discussions. For ontology curators, LLMs can be used to generate arguments for certain classification decisions (like a disease classification) or even suggest a mapping.
Using LLMs as assistants is probably the most important use of LLM-based tools at the moment, which includes aspects like summarising texts, generating sometimes boring, yet important, creative work (documentation pages, tutorials, blog-posts etc). It is probably not a good idea, at least as of May 2023, to defer to LLM-based tools to classify a term in an ontology, for example because of its tendency to hallucinate. Despite many arguments to the contrary LLMs are not databases. They are programs to generate text.
Using LLMs to extract information, similar to \"LLMs as assistants\", is, similar to the above, also about automating certain tasks, but the endpoint is not a software program rather than a human. It is the most important basic model of LLMs for us curators and software engineers to understand, because it is, in essence, the one that threatens our current work-life the most: What happens if LLMs become better at extracting structured knowledge from papers (or similarly generate software codes for user stories) than us? It is important that this thought is not ignored out of fear, but approached with a realistic and positive mindset.
Training. Apart from the fact that LLMs take text as an input and return text as an output, it is important to be aware how they are trained.
The basic technique for trainig is called \"next token prediction\". In essence, tokens in the text such as words or phrases are masked out by the training function and the LLM is trained to correctly predict these masked out phrases given the previous words in the sentence (or paragraph). The corpus used for this training ranges from specialised databases all the way to a large chunk of the publicly accessible textual information on the internet. Again, it is important to realise that text does not have to be composed of natural language sentences - learning how to generate programming code and structured data works much the same way.
In the following, we will ask ChatGPT or Open Assistant a few questions that are relevant to this lesson, which allows us to make certain points. The main point is that a lot of the work for preparing a useful tutorial can be deferred to ChatGPT is an assistant! Many of the questions explore how these tools could relate to us biocurators and semantic engineers in particular, but non of this should be viewed as written in stone. The most important take away from this lesson is that you should play with these tools yourself!
Can you explain in 3 simple sentences what an LLM is and how it works? [Note this question was asked to [Open Assistant](https://open-assistant.io/chat/) instead of ChatGPT.]
An LLM (Langauge Modell) is a AI model that can be trained to perform specific tasks such as speech recognition, text generation or machine translation. It's called a \"model\" because it is being trained on large sets of data to predict the next step based on previously learned relationships between inputs and outputs. LLMs are designed to recognize patterns in human language by processing input data through multiple layers of artificial neural networks that simulate the way neurons communicate in the brain. The training process involves feeding vast amounts of text into the model so that it can learn to identify underlying structures within the language itself. This allows the model to make predictions about likely next words or phrases given previous context. By continually adjusting its internal weights and biases using gradient descent techniques, the LLM becomes increasingly proficient at generating coherent text based on statistical probabilities derived from its knowledge of the language.
What is interesting here: the LLM actually made a typo, or rather, three: Langauge Modell - missing the first L (large), Langauge instead of Language and Modell with double L (which is German). Note that both words are spellied correctly later in the text.
What are the 5 core concepts relevant for end-users to understand LLMs?
Language Understanding and Generation: LLMs can understand human language inputs and generate text-based responses, allowing for interactive conversations.
Contextual Understanding: LLMs consider the context of the conversation to provide relevant and coherent responses, taking into account previous messages or prompts.
Pretraining: LLMs learn from vast amounts of text data during pretraining, which helps them acquire a general understanding of language, grammar, and context.
Limitations and Potential Bias: LLMs may provide incorrect or biased information as they generate responses based on patterns learned from training data. Users should be mindful of these limitations and critically evaluate the information provided.
Responsible Use and Privacy: Users should use LLMs responsibly, following platform guidelines and being cautious when sharing personal or sensitive information during interactions. Data privacy should be considered while engaging with LLMs.
"},{"location":"lesson/chatgpt-ontology-curation/#what-is-prompt-engineering","title":"What is prompt engineering?","text":"
Describe the idea of prompt engineering in simple terms for an audience of domain experts
Prompt engineering is the process of carefully crafting input queries, or \"prompts,\" to guide the behavior of a large language model (LLM) like GPT-4, ensuring that it provides useful, relevant, and accurate responses. As domain experts, you understand the importance of asking the right questions to extract valuable information. Similarly, with prompt engineering, the goal is to design questions or statements in a way that maximizes the LLM's ability to generate meaningful, high-quality output.
Essentially, prompt engineering serves as a \"communication bridge\" between humans and the LLM, allowing the model to better understand the intent behind the query and generate the desired response. This can involve refining the wording, providing context, or specifying the format of the desired answer, among other techniques.
By focusing on the art and science of prompt engineering, researchers and practitioners can better harness the potential of LLMs and overcome some of the challenges related to biases, incomplete knowledge, and misleading responses.
Providing an effective prompt to ChatGPT is an art form, and as resources like learnprompting.org testify, one that requires cultivation and care. The better you become at writing prompts, the more value you will draw from ChatGPT for your daily ontology curation tasks. How effective our prompts are depends on the exact language models used in ChatGPT (at the moment 3.5 or 4), which means that this lesson will keep evolving.
"},{"location":"lesson/chatgpt-ontology-curation/#what-are-some-basic-tips-for-writing-good-prompts-for-chatgpt","title":"What are some basic tips for writing good prompts for ChatGPT?","text":"
In the excellent 60 minute OpenAI, Deeplearning.ai course on Prompt Engineering, we learn that we should be (1) writing clear an specific instructions and (2) give ChatGPT \"time to think\".
Talking to a LLM is like talking to a teenager
Give clear and specific instructions.
Use different words to get better results the second time.
Give the LLM time to think.
"},{"location":"lesson/chatgpt-ontology-curation/#applications-of-chatgpt-for-ontology-development","title":"Applications of ChatGPT for ontology development","text":"
What are some potential applications of ChatGPT for ontology development?
ChatGPT can be a valuable tool for ontology development in various ways. Some potential applications include:
Concept identification: ChatGPT can help identify and extract relevant concepts from large volumes of unstructured text, providing a list of entities, relationships, and attributes that can be included in an ontology.
Semantic relation extraction: ChatGPT can be employed to detect semantic relationships between concepts, such as \"is-a\" or \"part-of\" relations, facilitating the construction of the ontology's hierarchical structure.
Ontology validation: ChatGPT can assist in validating and refining the structure of an ontology by providing human-like feedback on its consistency and coherence, suggesting improvements, or identifying potential gaps or redundancies.
Automated ontology population: ChatGPT can be used to generate instances of entities and relationships based on examples or descriptions, helping to populate the ontology with relevant data.
Ontology alignment and merging: ChatGPT can help identify similarities and differences between different ontologies, supporting the process of ontology alignment and merging, which is essential when integrating information from diverse sources.
Natural language interfaces: ChatGPT can be utilized to develop natural language interfaces for interacting with ontologies, allowing users to query and explore the ontology using conversational language rather than complex formal queries.
Ontology documentation: ChatGPT can assist in generating human-readable documentation for ontologies, including explanations of concepts, relationships, and properties, making it easier for users to understand and work with the ontology.
Ontology learning: ChatGPT can be trained to learn from examples or other sources of knowledge, supporting the semi-automatic or automatic creation of ontologies based on the input data.
By leveraging the capabilities of ChatGPT, ontology developers can streamline the development process, enhance the quality of their ontologies, and facilitate their adoption and use across various domains.
"},{"location":"lesson/chatgpt-ontology-curation/#how-can-we-concretely-enhance-the-ontology-curation-process","title":"How can we, concretely, enhance the ontology curation process?","text":"
A normal workflow of ontology curation is this:
A concept is required by a biocurator to describe a piece of data, for example, a disease concept, or an anatomical entity.
The biocurator requests the new concept (or term) from the ontology curator, providing a label and perhaps a scientific reference
The ontology curator then adds that concept to the ontology using a tool like Protege, adding a human-readable definition, synonyms and provenance metadata. Most importantly, they define the concept logically, often using a formalism such as OWL specifying super-classes, and other logical relationships
Lastly, the ontology curator runs a number of quality checks to ensure that the added concepts is logically coherent (e.g. the reasoner places it in the intended part of of the class hierarchy).
How can ChatGPT be used concretely to help with that process?
ChatGPT can be incorporated into various stages of the ontology curation workflow to assist biocurators and ontology curators in streamlining and improving the process. Here's how ChatGPT can be used concretely at each step:
Concept identification: ChatGPT can help the biocurator identify relevant concepts based on the data they are working with. By providing information or descriptions related to the data, the biocurator can receive a list of potential concepts or terms, including disease concepts or anatomical entities, that might be suitable for the ontology.
Term request and communication: ChatGPT can facilitate communication between the biocurator and the ontology curator. It can be used to draft the term request, including the label, scientific reference, and any other relevant information, ensuring that the request is clear and complete.
Concept addition and metadata generation: ChatGPT can assist ontology curators in generating human-readable definitions, synonyms, and provenance metadata for the new concept. By providing the initial label and scientific reference, ChatGPT can produce candidate definitions, suggest synonyms, and even help draft metadata descriptions. Additionally, it can provide suggestions for logical relationships, such as super-classes and other connections, using its understanding of the formalism, like OWL.
Quality checks and coherence: While ChatGPT may not directly run quality checks like a reasoner, it can help ontology curators verify the coherence of the added concepts by providing human-like feedback on the logical relationships and overall structure. It can suggest potential issues, such as redundancies or inconsistencies, that the curator may want to address to ensure that the concept is logically coherent and correctly placed in the class hierarchy.
By integrating ChatGPT into the ontology curation workflow, biocurators and ontology curators can benefit from its natural language understanding and generation capabilities, making the process more efficient and accurate. However, it is essential to keep in mind that ChatGPT should be used as a complementary tool and not as a replacement for human expertise or specialized software designed for ontology development and curation.
"},{"location":"lesson/chatgpt-ontology-curation/#using-chatgpt-for-ontology-mappings","title":"Using ChatGPT for ontology mappings","text":"
What about ontology mappings?
LLMs like ChatGPT can be used to identify equivalent or similar concepts across different ontologies by analyzing concept labels, definitions, and other metadata. They can understand and process natural language descriptions and compare them to find potential matches or alignments between concepts. Specifically, LLMs can:
Perform text similarity analysis: By comparing the textual descriptions of concepts, LLMs can calculate similarity scores, identifying closely related concepts across different ontologies.
Understand contextual relationships: LLMs can identify and consider the context in which concepts are used, making it easier to match concepts that have similar meanings or roles within their respective ontologies.
Leverage synonyms and alternative terms: LLMs can use synonyms or alternative terms provided in the ontology metadata to improve concept matching, ensuring that equivalent concepts with different labels can still be identified.
Exploit structured knowledge: LLMs can be trained to understand and work with formalisms like OWL and RDF, which can help them identify matching concepts based on the structured information within ontologies.
By leveraging these capabilities, LLMs can assist ontology curators in the challenging task of concept matching, ultimately enhancing the ontology mapping and alignment process.
Can you provide an example of mapping a concept from the Human Phenotype Ontology to the Mammalian Phenotype Ontology?
Let's consider the concept \"Abnormality of the ear\" in HPO.
HPO Concept:
ID: HP:0000598
Label: Abnormality of the ear
Definition: A structural or functional anomaly of the ear.
Our goal is to find a matching or similar concept in the Mammalian Phenotype Ontology (MPO).
After analyzing the MPO, we find the following concept:
ID: MP:0002161
Label: abnormal ear morphology
Definition: any structural anomaly of the external or middle ear
In this case, both concepts describe abnormalities of the ear in their respective domains (human and mammalian). The labels and definitions are similar, indicating that these concepts might be considered equivalent or closely related.
Thus, we can propose the following mapping:
HPO: HP:0000598 (Abnormality of the ear) <=> MPO: MP:0002161 (abnormal ear morphology)
COMMENT. The 27th May version of ChatGPT is giving a different answer:
Sure, let's consider an example for this mapping:
Human Phenotype Ontology (HPO) is designed to classify and annotate the phenotypic abnormalities encountered in human disease. Each term in HPO describes a specific phenotypic abnormality, such as 'HP:0004322 - Short stature' which describes an abnormality of body height that is less than -2 standard deviations compared to the appropriate reference population.
Mammalian Phenotype Ontology (MPO), on the other hand, is used in the annotation of data from mammalian phenotyping experiments, typically in model organisms like mice. Its equivalent term for short stature might be 'MP:0001265 - decreased body size' which describes a mammal with an overall smaller body size.
So, in this case, 'HP:0004322 - Short stature' in HPO could be mapped to 'MP:0001265 - decreased body size' in MPO.
Please note that this is a simplified example and the actual mapping process could be more complex, due to the nuanced differences between human and mammalian phenotypes and the structure of these ontologies. For actual mappings, it is essential to ensure the descriptions and definitions align appropriately, and the context of use is correctly considered.
Also, there may not always be a one-to-one correspondence between the terms in different ontologies. Sometimes, one term in an ontology may correspond to multiple terms in another, or there may not be an equivalent term at all. This is why ontological mapping is a complex task requiring domain knowledge and careful consideration.
Can you express the above mapping in SSSOM?
The Simple Standard for Sharing Ontology Mappings (SSSOM) is a standard that enables sharing and comparing ontology mappings using a simple tabular format (TSV). Here's the example mapping from Human Phenotype Ontology (HPO) to Mammalian Phenotype Ontology (MPO) expressed in SSSOM format:
subject_id subject_label predicate_id object_id object_label match_type confidence\nHP:0000598 Abnormality of the ear skos:closeMatch MP:0002161 abnormal ear morphology Lexical 0.90\n
In this case, I have used skos:closeMatch as the predicate to represent the close relationship between the two concepts. The match_type is \"Lexical\" since the mapping is based on similar labels and definitions. The confidence score is set to 0.90 to reflect a high degree of similarity between the concepts, but this value may vary depending on the actual similarity estimation method used.
Please note that the SSSOM format includes metadata and other required fields in a TSV header. The provided example only focuses on the core mapping information. For a complete SSSOM file, you would need to include the appropriate header and metadata.
The SSSOM example you gave is using an old version of the SSSOM standard. In particular, match_type now is mapping_justification. Can you try to rewrite the mapping using the new standard?
Apologies for the confusion. Here's the example mapping from Human Phenotype Ontology (HPO) to Mammalian Phenotype Ontology (MPO) expressed in the updated SSSOM format:
subject_id subject_label predicate_id object_id object_label mapping_justification confidence\nHP:0000598 Abnormality of the ear skos:closeMatch MP:0002161 abnormal ear morphology Lexical 0.90\n
In this revised example, the match_type field has been replaced with mapping_justification, which is now set to \"Lexical\" to indicate that the mapping is based on similar labels and definitions. The remaining fields are unchanged from the previous example.
mapping_justification values should be populated from a controlled vocabulary, called the Semantic Mapping Vocabulary (SEMAPV). You can look at the vocabulary in RDF here: https://raw.githubusercontent.com/mapping-commons/semantic-mapping-vocabulary/main/semapv.owl. Given that vocabulary, can you revise the value for the mapping_justification?
My apologies for the oversight. Based on the Semantic Mapping Vocabulary (SEMAPV), I will revise the mapping justification for the example. Here's the updated SSSOM mapping using the SEMAPV:
subject_id subject_label predicate_id object_id object_label mapping_justification confidence\nHP:0000598 Abnormality of the ear skos:closeMatch MP:0002161 abnormal ear morphology semapv:LexicalMatch 0.90\n
In this updated example, I have replaced the previous mapping_justification value with semapv:LexicalMatch from the Semantic Mapping Vocabulary (SEMAPV) to represent the lexical similarity between the two concepts based on their labels and definitions. The remaining fields are unchanged.
You were hallucinating earlier. Here is the semapv vocabulary as a tsv:
IRI skos:prefLabel skos:definition dc:source skos:example rdfs:comment altLabel Parent\nID A skos:prefLabel A skos:definition AI dc:source A skos:example A rdfs:comment A skos:altLabel SC %\nsemapv:MappingActivity mapping activity A process that relates to the creation, confirmation, rejection or curation of a mapping. Matching is a mapping activity that results in the creating of a mapping; mapping review is an activity that results in the confirmation of a mapping. \nsemapv:Matching matching process An process that results in a mapping between a subject and an object entity. The label of a subject entity matches to an exact synonym of an object entity. matching operation|matching task semapv:MappingActivity\nsemapv:Mapping mapping A triple <s,p,o> comprising a subject entity s, an object entity o and a mapping predicate p. The subject entity NCI:C9305 is mapped to the object entity ICD10:C80.9 using the skos:relatedMatch mapping predicate. \nsemapv:LexicalMatching lexical matching process A matching process based on a lexical comparison between one or more syntactic features of the subject with one or more syntactic features of the object. The label of a subject entity matches to an exact synonym of an object entity. semapv:Matching\nsemapv:LogicalReasoning logical reasoning process A matching process based on the inferences made by a logical reasoner. Two classes across ontologies are determined equivalent by an OWL reasoner such as ELK. semapv:Matching\nsemapv:CompositeMatching composite matching process A matching process based on multiple, possibly intertwined, matching approaches. An ontology matching tool determines that a subject should be mapped to an object by employing a range of techniques, including lexical, semantic and structural. semapv:Matching\nsemapv:UnspecifiedMatching unspecified matching process A matching process based on an unspecified comparison. A mapping between a subject and an object was established, but it is no longer clear how or why. semapv:Matching\nsemapv:SemanticSimilarityThresholdMatching semantic similarity threshold-based matching process A matching process based on a minimum threshold of a score from a comparison based on a semantic similarity algorithm. A match between a subject and an object entity was established because they had a Jaccard score higher than 0.8 based on the set of (common) superclasses. semapv:Matching\nsemapv:LexicalSimilarityThresholdMatching lexical similarity threshold-based matching process A lexical matching process based on a minimum threshold of a score from a comparison based on a lexical similarity algorithm. A match between a subject and an object was established because they had a Levenshtein score higher than 0.8. semapv:Matching\nsemapv:StructuralMatching structural matching process https://doi.org/10.1016/j.websem.2009.11.002 A match between a subject and an object was established because of the similarity of their structural features, e.g., the number of direct property of a class. Structural matching does not involve looking at \"values\" of properties. semapv:Matching\nsemapv:InstanceBasedMatching instance-based matching process A matching process based on individual representations (or instances). https://doi.org/10.1007/978-3-642-38721-0 A match between a subject A and an object B was established because they share the same instances. semapv:Matching\nsemapv:BackgroundKnowledgeBasedMatching background knowledge-based matching process A matching process that exploits background knowledge from external resources, commonly referred to as background knowledge resources. This approach is also known as indirect matching, BK-based matching or context-based matching. https://doi.org/10.1016/j.websem.2018.04.001 A match between a subject A and an object B was established because they appear equivalent under consideration of externally provided background knowledge. semapv:Matching\nsemapv:MappingChaining mapping chaining-based matching process A matching process based on the traversing of multiple mappings. A match between a subject A and an object B was established because A was mapped to C, C was mapped to D and D was mapped to B. semapv:Matching\nsemapv:MappingReview mapping review A process that is concerned with determining if a mapping \u201ccandidate\u201d (otherwise determined) is reasonable/correct. A match between a subject A and an object B was established elsewhere, and a human reviewer determined that the mapping is true (or false) based on an independent evaluation. semapv:MappingActivity\nsemapv:ManualMappingCuration manual mapping curation An matching process that is performed by a human agent and is based on human judgement and domain knowledge. A human curator determines that a subject should be mapped to an object by virtue of their domain expertise. semapv:Matching\nsemapv:MatchingPreprocessing matching process pre-processing A preliminary processing of inputs prior to performing matching. semapv:MappingActivity\nsemapv:Stemming stemming The process of reducing a word to its word stem. semapv:Normalization\nsemapv:Lemmatization lemmatization The process of reducing the different forms of a word to one single form. https://doi.org/10.1007/978-3-642-38721-0 semapv:Normalization\nsemapv:StopWordRemoval stop-word removal A preprocessing method transforming a string by removing a list of stop words. https://doi.org/10.1007/978-3-642-38721-0 The stop-words \u201cof, and, is, a\u201d are removed from the label field of the subject entity in the mapping. semapv:Normalization\nsemapv:RegexRemoval regex removal A preprocessing method transforming a string by matching a regular expression and then removing that match. The regex match \u201c[ -]phenotype\u201d is removed from the label field of the subject entity in the mapping. semapv:Normalization\nsemapv:RegexReplacement regex replacement A preprocessing method transforming a string by matching a regular expression and then replacing that match with a specified substitution string. The regex match \u201c[ -]phenotype\u201d is replaced by \u201c-disease\u201d for the label field of the subject entity in the mapping. semapv:Normalization\nsemapv:MatchingPostProcessing matching process post-processing A process applied to a set of mappings, usually with the intention of changing it. semapv:MappingActivity\nsemapv:ThresholdFiltering threshold filtering semapv:MatchingPostProcessing\nsemapv:StableMarriageFiltering stable marriage filtering semapv:MatchingPostProcessing\nsemapv:CardinalityFiltering cardinality filtering semapv:MatchingPostProcessing\nsemapv:LogicalConsistencyFiltering logical consistency filtering semapv:MatchingPostProcessing\nsemapv:Normalization normalization A family of preprocessing techniques for reducing strings to be compared to a common format. https://doi.org/10.1007/978-3-642-38721-0 semapv:MatchingPreprocessing\nsemapv:CaseNormalization case normalization A normalization technique converting each alphabetic character in a string to their lower case counterpart. https://doi.org/10.1007/978-3-642-38721-0 The string 'Ontology' is normalised to 'ontology' (lower case). semapv:Normalization\nsemapv:DiacriticsSuppression diacritics suppression A normalization technique replacing diactritic signs (e.g. accents, hats) with their most frequent replacements. https://doi.org/10.1007/978-3-642-38721-0 The string 'Prot\u00e9g\u00e9' is normalised to 'Protege'. semapv:Normalization\nsemapv:BlankNormalisation blank normalisation A normalization technique replacing all blank characters, such as space, tabulation, carriage return (or sequences of these) into a single blank character. https://doi.org/10.1007/978-3-642-38721-0 The string 'ontology matching' (two spaces between 'ontology' and 'matching) becomes 'ontology matching' (one space). semapv:Normalization\nsemapv:LinkStripping link stripping A normalization technique replacing specific links between words, such as apostrophes, dashes, underscore, etc into dashes or blanks. https://doi.org/10.1007/978-3-642-38721-0 The string 'alzheimer's' becomes 'alzheimers'. semapv:Normalization\nsemapv:DigitSuppression digit suppression A normalization technique removing all numbers in a string. https://doi.org/10.1007/978-3-642-38721-0 The string 'ontology1' becomes 'ontology'. semapv:Normalization\n
Can you use this to pick the right mapping justification?
Apologies for the confusion earlier. Based on the provided SEMAPV vocabulary as a TSV, I will revise the mapping justification for the example. Here's the updated SSSOM mapping using the correct SEMAPV:
subject_id subject_label predicate_id object_id object_label mapping_justification confidence\nHP:0000598 Abnormality of the ear skos:closeMatch MP:0002161 abnormal ear morphology semapv:LexicalMatching 0.90\nIn this updated example, I have replaced the previous mapping_justification value with semapv:LexicalMatching from the provided Semantic Mapping Vocabulary (SEMAPV) to represent the lexical similarity between the two concepts based on their labels and definitions. The remaining fields are unchanged.\n
Please remember that a complete SSSOM file would require the appropriate header and metadata in addition to the core mapping information provided in the example.
Can you add 4 more examples to that SSSOM table
Sure, here are 4 more examples of mappings between the Human Phenotype Ontology (HPO) and the Mammalian Phenotype Ontology (MPO) using SSSOM format:
These examples illustrate mappings between HPO and MPO concepts based on lexical matching, where the similarity between the labels and definitions is considered. Note that the confidence values are provided as an example and may differ in real-world scenarios.
Can you print only the table using markdown table syntax in a way that I can copy paste it
Can you add 100 more examples, this time only providing a markdown table that I can copy paste, with no further comments around it?
Creating 100 mappings with accuracy requires domain expertise and a comprehensive understanding of the ontology mappings. However, I can provide you with 20 examples to help you understand the format. Please note that these examples may not be completely accurate and should not be used for any critical applications.
Here are a few slots in a schema: quality, anatomical_entity and chemical_entity
quality:\ndescription: The property being measured, or changes in this property, for example, amount, level, increased amount, decreased concentration\nannotations:\n prompt.example: amount, level, increased amount, decreased concentration\nrange: Quality\n\nanatomical_entity:\ndescription: The anatomical location that the chemical entity is measured in\nrange: AnatomicalEntity\nannotations:\n prompt.example: liver, heart, brain, finger\n\nchemical_entity:\ndescription: The chemical entity that is being measured\nrange: ChemicalEntity\nannotations:\n prompt.example: lysine, metabolite\n
Can you create a YAML file with those three elements as keys, and extract the contents of the string \"increased blood glucose levels\" into as values to these keys? Output should be just a simple yaml file, like:
"},{"location":"lesson/chatgpt-ontology-curation/#todo-finish-this-section","title":"TODO FINISH THIS SECTION","text":""},{"location":"lesson/chatgpt-ontology-curation/#from-chat-to-exectutable-workflows-what-we-need-to-do-to-leverage-llms","title":"From Chat to exectutable workflows: what we need to do to leverage LLMs","text":"
The above tutorial was a fun case study using ChatGPT with GPT-4. 95% of the content provided was generated by ChatGPT with GPT-4. While certainly not as great as possible, it took a solid ontology engineer (@matentzn) about 90 minutes to write this lesson, which would have usually cost him more than 8 hours.
It is clear that learning how to talk to AI, the process we refer to as \"prompt engineering\" is going to be absolutely essential for ontology curators moving forward - as LLMs improve and understand even complex languages like OWL better, perhaps as important as ontology modelling itself. I dont think there is any doubt that enganging is a good amount of play and study on this subject is both fun and hugely beneficial.
All that said, perceiving LLMs through the lens of a chat bot leaves a lot of potential unexplored. For example, if ChatGPT (or LLMs in general) can generate structured data, why not implement this directly into our curation tools (like Protege)? Tools like GitHub co-pilot are already used to making good programmers a lot more effective, but so far, these tools focus on development environments where the majority of the generated content is text (e.g. software code), and not so much heavily UI driven ones like Protege.
A lot of blog posts have circulated recently on Twitter and LinkedIn explored the potential of LLMs to generate RDF and OWL directly. It is already clear that LLMs can and will do this moving forward. For ontology curation specifically, we will need to develop executable workflows that fit into our general ontology curation process. As a first pass, some members of our community have developed OntoGPT. We will explore how to use OntoGPT in a future lesson.
"},{"location":"lesson/chatgpt-ontology-curation/#some-more-thoughts-on-hallucinations","title":"Some more thoughts on hallucinations","text":"
Update 27 May 2023: It seems that complaints wrt to hallucinations, the chat part of ChatGPT is a bit more sensitive to database like queries:
"},{"location":"lesson/chatgpt-ontology-curation/#cool-applications-the-authors-of-this-tutorial-used","title":"Cool applications the authors of this tutorial used","text":"
The key is that it is generative: the key thing is that we are generating text that is human like
As databases, LLMs are very inefficient (see excellent talk by Denny Vrandecic) and Hallucinate too often (Chat)
Writing emails: shortening
Writing documentations:
Writing docs for a softare tool. Adding background info and context.
Find a good human-readable name for a cluster in ML clustering
Named entity recognition and knowledge extraction
Career planning and discovering stuff you didnt know about at all
ChatGPT for contextualising work and writing use cases
Using it for curation research - but doing it right
Don't ask it to do the curation for you, get it to help you find arguments for and against a modelling decision (\"I will always have to recurate anyways, so what is the point?\")
Always remember that ChatGPT is not a database. It hallucinates and changes its mind all the time. Get it to generate text for you that could be useful in your work.
On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?
"},{"location":"lesson/contributing-to-obo-ontologies/","title":"Contributing to OBO ontologies","text":""},{"location":"lesson/contributing-to-obo-ontologies/#prerequisites","title":"Prerequisites","text":"
Participants will need to have access to the following resources and tools prior to the training:
GitHub account - register for a free GitHub account here
Protege - Install Protege 5.5, download it here
Install ELK 0.5
Install GitHub Desktop Please make sure you have some kind of git client installed on your machine. If you are new to Git, please install GitHub Desktop
"},{"location":"lesson/contributing-to-obo-ontologies/#what-is-delivered-as-part-of-the-course","title":"What is delivered as part of the course","text":"
Description: How to contribute terms to existing ontologies.
Understand basics of ontology development workflows
Browsing and Searching in Protege
Add new terms to an ontology
Initial Protege setup
Protege editing
The Class description view
Use GitHub: make pull requests
Understand ontology design patterns
Use templates: ROBOT, DOSDP (under development)
Basics of OWL
Logic and debugging
"},{"location":"lesson/contributing-to-obo-ontologies/#tutorials","title":"Tutorials","text":""},{"location":"lesson/contributing-to-obo-ontologies/#monarch-obo-training-tutorials","title":"Monarch OBO training Tutorials","text":""},{"location":"lesson/contributing-to-obo-ontologies/#contributing-to-ontologies-part-1","title":"Contributing to Ontologies Part 1","text":""},{"location":"lesson/contributing-to-obo-ontologies/#contributing-to-ontologies-part-2","title":"Contributing to Ontologies Part 2","text":""},{"location":"lesson/contributing-to-obo-ontologies/#additional-materials-and-resources","title":"Additional materials and resources","text":""},{"location":"lesson/contributing-to-obo-ontologies/#contributors","title":"Contributors","text":"
GitHub - distributed version control (Git) + social media for geeks who like to build code/documented collaboratively.
A Git repo consists of a set of branches each with a complete history of all changes ever made to the files and directories. This is true for a local copy you check out to your computer from GitHub or for a copy (fork) you make on GitHub.
A Git repo typically has a master or main branch that is not directly editing. Changes are made by creating a branch from Master (complete copy of the Master + its history).
"},{"location":"lesson/contributing-to-obo-ontologies/#branch-vs-fork","title":"Branch vs Fork","text":"
You can copy (fork) any GitHub repo to some other location on GitHub without having to ask permission from the owners.\u00a0 If you modify some files in that repo, e.g. to fix a bug in some code, or a typo in a document, you can then suggest to the owners (via a Pull Request) that they adopt (merge) you your changes back into their repo.
If you have permission from the owners, you can instead make a new branch. For this training, we gave you access to the repository. See the Appendix for instructions on how to make a fork.
Go to GitHub tracker for the ontology where you'd like to create an issue
Select New issue
Pick appropriate template (if applicable)
Fill in the information that is requested on the template below each header
For a new term request, please include:
The parent ID and label
A definition in the proper format
Sources/cross references for synonyms
Your ORCID
Add any additional comments at the end
If you are requesting changes to an existing term, include as much information as possible, including the term ID and label.
If you use a template, an ontology curator may automatically be assigned.
Tip: you can easily obtain term metadata like OBO ID, IRI, or the term label by clicking the three lines above the Annotations box (next to the term name) in Protege, see screenshot below. You can also copy the IRI in markdown, which is really convenient for pasting into GitHub.
See this example video on creating a new term request to the Mondo Disease Ontology:
"},{"location":"lesson/contributing-to-obo-ontologies/#basic-open-source-etiquette","title":"Basic Open Source etiquette","text":"
Keep in mind that open source ontology repositories on GitHub are public and open to all.
Be respectful in your requests and comments.
Do not include any private information.
GitHub sends notifications to your email, and you can respond via your email client. Keep in mind, the responses are posted publicly. Be sure to delete your email signature that includes any personal information, like your email address or phone number.
Many ontologies have limited resources and personnel for development and maintenance. Please be patient with your requests.
If your ticket/request has been unanswered for a long period of time, feel free to kindly check in by commenting on the ticket.
Including a deadline or priority on the ticket can help the ontology curators with triaging tickets.
A README is a text file that introduces and explains a project. It is intended for everyone, not just the software or ontology developers. Ideally, the README file will include detailed information about the ontology, how to get started with using any of the files, license information and other details. The README is usually on the front page of the GitHub repository.
"},{"location":"lesson/contributing-to-obo-ontologies/#basics-of-ontology-development-workflows","title":"Basics of ontology development workflows","text":""},{"location":"lesson/contributing-to-obo-ontologies/#ontology-development-workflows","title":"Ontology development workflows","text":"
The steps below describe how to make changes to an ontology.
Go to the GitHub repository for your ontology, and clone the repository. The example below describes how to clone the Mondo Disease Ontology repo, but this can be applied to any ontology that is stored in GitHub.
"},{"location":"lesson/contributing-to-obo-ontologies/#clone-the-mondo-repo","title":"Clone the Mondo repo","text":"
Open the Mondo GitHub repository
Click Code
Click 'Open with GitHub Desktop'
You will be given an option as to where to save the repository. I have a folder called 'git' where I save all of my local repos.
This will open GitHub Desktop and the repo should start downloading. This could take some time depending on how big the file is and how much memory your computer has.
"},{"location":"lesson/contributing-to-obo-ontologies/#create-a-branch-using-github-desktop","title":"Create a branch using GitHub Desktop","text":"
Click the little arrow in Current Branch
Click New Branch
Give your branch a name: training-initials (ie training-NV)
"},{"location":"lesson/contributing-to-obo-ontologies/#open-the-ontology-edit-file-in-protege","title":"Open the Ontology edit file in Protege","text":"
Open Protege
Go to: File -> Open
Navigate to [ontology-name]/src/ontology/[ontology-name]-edit.obo and open this file in Protege. For example: mondo/src/ontology/mondo-edit.obo
Note: all ontologies that use the Ontology Development Kit (ODK) will have the 'edit' files stored in the same folder path: src/ontology/[ontology-name]-edit.owl (or [ontology-name]-edit.obo)
"},{"location":"lesson/contributing-to-obo-ontologies/#browsing-and-searching-in-protege","title":"Browsing and Searching in Protege","text":"
The instructions below are using the Mondo Disease Ontology as an example, but this can be applied to any ontology.
"},{"location":"lesson/contributing-to-obo-ontologies/#open-the-mondo-in-protege","title":"Open the Mondo in Prot\u00e9g\u00e9","text":"
Note: Windows users should open Protege using run.bat
Navigate to where you downloaded the repository and open the mondo-edit.obo file (src/ontology/mondo-edit.obo)
When you open Protege, you will be on the Active Ontology tab
Note the Ontology IRI field. The IRI is used to identify the ontology on the Web.
The Prot\u00e9g\u00e9 interface follows a basic paradigm of Tabs and Panels. By default, Prot\u00e9g\u00e9 launches with the main tabs seen below. The layout of tabs and panels is configurable by the user. The Tab list will have slight differences from version to version, and depending on your configuration. It will also reflect your customizations.
To customize your view, go to the Window tab on the toolbar and select Views. Here you can customize which panels you see in each tab. In the tabs view, you can select which tabs you will see. You will commonly want to see the Entities tab, which has the Classes tab and the Object Properties tab.
Note: if you open a new ontology while viewing your current ontology, Prot\u00e9g\u00e9 will ask you if you'd like to open it in a new window. \u00a0For most normal usage you should answer no. This will open in a new window.
The panel in the center is the ontology annotations panel. This panel contains basic metadata about the ontology, such as the authors, a short description and license information.
"},{"location":"lesson/contributing-to-obo-ontologies/#running-the-reasoner","title":"Running the reasoner","text":"
Before browsing or searching an ontology, it is useful to run an OWL reasoner first. This ensures that you can view the full, intended classification and allows you to run queries. Navigate to the query menu, and run the ELK reasoner:
For more details on why it is important to have the reasoner on when using the editors version of an ontology, see the Reasoning reference guide. But for now, you don't need a deeper understanding, just be sure that you always have the reasoner on.
You will see various tabs along the top of the screen. Each tab provides a different perspective on the ontology. For the purposes of this tutorial, we care mostly about the Entities tab, the DL query tab and the search tool. OWL Entities include Classes (which we are focussed on editing in this tutorial), relations (OWL Object Properties) and Annotation Properties (terms like, 'definition' and 'label' which we use to annotate OWL entities. Select the Entities tab and then the Classes sub-tab. Now choose the inferred view (as shown below).
The Entities tab is split into two halves. The left-hand side provides a suite of panels for selecting various entities in your ontology. When a particular entity is selected the panels on the right-hand side display information about that entity. The entities panel is context specific, so if you have a class selected (like Thing) then the panels on the right are aimed at editing classes. The panels on the right are customizable. Based on prior use you may see new panes or alternate arrangements. You should see the class OWL:Thing. You could start browsing from here, but the upper level view of the ontology is too abstract for our purposes. To find something more interesting to look at we need to search or query.
"},{"location":"lesson/contributing-to-obo-ontologies/#searching-in-protege","title":"Searching in Protege","text":"
You can search for any entity using the search bar on the right:
The search window will open on top of your Protege pane, we recommend resizing it and moving it to the side of the main window so you can view together.
Here's an example search for 'COVID-19':
It shows results found in display names, definitions, synonyms and more. The default results list is truncated. To see full results check the 'Show all results option'. You may need to resize the box to show all results. Double clicking on a result, displays details about it in the entities tab, e.g.
In the Entities, tab, you can browse related types, opening/closing branches and clicking on terms to see details on the right. In the default layout, annotations on a term are displayed in the top panel and logical assertions in the 'Description' panel at the bottom.
Try to find these specific classes:
'congenital heart disease'
'Kindler syndrome'
'kidney failure'
Note - a cool feature in the search tool in Protege is you can search on partial string matching. For example, if you want to search for \u2018down syndrome\u2019, you could search on a partial string: \u2018do synd\u2019.
Try searching for \u2018br car and see what kind of results are returned.
Question: The search will also search on synonyms. Try searching for \u2018shingles\u2019 and see what results are returned. Were you able to find the term?
Note - if the search is slow, you can uncheck the box \u2018Search in annotation values. Try this and search for a term and note if the search is faster. Then search for \u2018shingles\u2019 again and note what results you get.
"},{"location":"lesson/contributing-to-obo-ontologies/#use-github-make-pull-requests","title":"Use GitHub: make pull requests","text":""},{"location":"lesson/contributing-to-obo-ontologies/#committing-pushing-and-making-pull-requests","title":"Committing, pushing and making pull requests","text":"
Changes made to the ontology can be viewed in GitHub Desktop.
Before committing, check the diff. Examples of a diff are pasted below. Large diffs are a sign that something went wrong. In this case, do not commit the changes and ask the ontology editors for help instead.
Example 1:
Commit: Add a meaningful message in the Commit field in the lower left, for example: add new class MONDO:0001012 episodic angioedema with eosinophilia
NOTE: You can use the word 'fixes' or 'closes' in the description of the commit message, followed by the corresponding ticket number (in the format #1234) - these are magic words in GitHub; when used in combination with the ticket number, it will automatically close the ticket. Learn more on this GitHub Help Documentation page about Closing issues via commit messages.
Note: 'Fixes' and \"Closes' are case-insensitive.
If you don't want to close the ticket, just refer to the ticket # without the word 'Fixes' or use 'Adresses'. The commit will be associated with the correct ticket but the ticket will remain open. NOTE: It is also possible to type a longer message than allowed when using the '-m' argument; to do this, skip the -m, and a vi window (on mac) will open in which an unlimited description may be typed.
Click Commit to [branch]. This will save the changes to the cl-edit.owl file.
Push: To incorporate the changes into the remote repository, click Publish branch.
"},{"location":"lesson/contributing-to-obo-ontologies/#add-new-terms-to-an-ontology","title":"Add New Terms to an Ontology:","text":"
The instructions below are using the Mondo Disease Ontology as an example, but this can be applied to any ontology.
"},{"location":"lesson/contributing-to-obo-ontologies/#setup","title":"Setup","text":""},{"location":"lesson/contributing-to-obo-ontologies/#setting-preferences-for-new-entities","title":"Setting Preferences for New entities","text":"
Ontology terms have separate names and IDs. The names are annotation values (labels) and the IDs are represented using IRIs. The OBO foundry has a policy on IRI (or ID) generation (http://www.obofoundry.org/principles/fp-003-uris.html). You can set an ID strategy using the \"New Entities\" tab under the Prot\u00e9g\u00e9 Preferences -- on the top toolbar, click the \"Prot\u00e9g\u00e9 dropdown, then click Preferences.
Set your new entity preferences precisely as in the following screenshot of the New Entities tab.
Note - you have been assigned an ID range in the Mondo idranges file\u00a0 - you should be able to find your own range assigned there.
DIY (only if you know what you are doing!)
To add your own ID ranges:
Go into src/ontology
create a branch
Find and edit mondo-idranges.owl by adding the following:
Datatype: idrange:10 #update this to next following integer from previous\n\n Annotations:\n allocatedto: \"Your Name\" #change to your name\n\n EquivalentTo:\n xsd:integer[>= 0806000 , <= 0806999]. #add a range of 999 above the previous integer\n
Be sure to change \"Your Name\" to your actual name! And note that this value should almost always be an individual, and not an organization or group.
create a pull request and add matentzn or nicolevasilevsky as a reviewer
proceed to settting up as below:
Specified IRI: http://purl.obolibrary.org/obo/
Note - if you edit more than one ontology in Protege, you will need to update your Preferences for each ontology before you edit.
"},{"location":"lesson/contributing-to-obo-ontologies/#setting-preferences-for-user-details","title":"Setting Preferences for User details","text":"
User name: click Use supplied user name and enter your username in the field below
Click Use Git user name when available
In the ORCID field, add your ORCID ID (in the format 0000-0000-0000-0000)
"},{"location":"lesson/contributing-to-obo-ontologies/#setting-preferences-for-new-entities-metadata","title":"Setting Preferences for New entities metadata","text":"
The current recommendation of the OBO Foundry Technical Working Group is that an editor who creates a new term SHOULD add a http://purl.org/dc/terms/contributor annotation, set to the ORCID or GitHub username of the editor, and a http://purl.org/dc/terms/date annotation, set to the current date.
You can have Prot\u00e9g\u00e9 automatically add those annotations by setting your preferences to match the screenshot below, in the New entities metadata tab (under preferences).
If you do not have an ORCID, register for for free here: https://orcid.org/
"},{"location":"lesson/contributing-to-obo-ontologies/#protege-editing","title":"Protege editing","text":""},{"location":"lesson/contributing-to-obo-ontologies/#creating-a-new-class","title":"Creating a new class","text":"
Before you start:
make sure you are working on a branch - see quick guide here.
make sure you have the editor's file open in Protege as detailed here.
New classes are created in the Class hierarchy panel on the left.
There are three buttons at the top of the class hierarchy view. These allow you to add a subclass (L-shaped icon), add a sibling class (c-shaped icon), or delete a selected class (x'd circle).
Using Prot\u00e9g\u00e9 you can add annotations such as labels, definitions, synonyms, database cross references (dbxrefs) to any OWL entity. The panel on the right, named Annotations, is where these annotations are added. CL includes a pre-declared set of annotation properties. The most commonly used annotations are below.
rdfs:label
definition
has_exact_synonym
has_broad_synonym
has_narrow_synonym
has_related synonym
database_cross_reference
rdfs:comment
Note, most of these are bold in the annotation property list:
Use this panel to add a definition to the class you created. Select the + button to add an annotation to the selected entity. Click on the annotation 'definition' on the left and copy and paste in the definition to the white editing box on the right. Click OK.
Definition: A disorder characterized by episodes of swelling under the skin (angioedema) and an elevated number of the white blood cells known as eosinophils (eosinophilia). During these episodes, symptoms of hives (urticaria), fever, swelling, weight gain and eosinophilia may occur. Symptoms usually appear every 3-4 weeks and resolve on their own within several days. Other cells may be elevated during the episodes, such as neutrophils and lymphocytes. Although the syndrome is often considered a subtype of the idiopathic hypereosinophilic syndromes, it does not typically have organ involvement or lead to other health concerns.
Definitions in Mondo should have a 'database cross reference' (dbxref), which is a reference to the definition source, such as a paper from the primary literature or another database. For references to papers, we cross reference the PubMed Identifier in the format, PMID:XXXXXXXX. (Note, no space)
To add a dbxref to the definition:
Click the @ symbol next to the definition
Click the + button next in the pop-up window
Scroll up on the left hand side until you find 'database_cross_reference', and click it
Add the PMID in the editing box (PMID:25527564). _Note: the PMID should not have any spaces)
Click OK
Add the additional dbxref: GARD:0013029
The dbxrefs should appear as below.
"},{"location":"lesson/contributing-to-obo-ontologies/#add-synonyms-and-database-cross-reference","title":"Add Synonyms and Database cross reference","text":"
Add synonyms
Click the add annotations button
Add the following synonyms as 'has_exact_synonym':
EAE
Gleich's syndrome
Gleich syndrome
All synonyms in Mondo should have a dbxref on the synonym
Click the @ symbol next to the synonym
Click the + button
Add the dbxref to each synonym: GARD:0013029
Add database cross reference
Click the add annotations button
Add the following database_cross_reference':
GARD:0013029
Click the @ symbol next to the synonym
Click the + button
Add source: MONDO:equivalentTo
"},{"location":"lesson/contributing-to-obo-ontologies/#the-class-description-view","title":"The Class description view","text":"
We have seen how to add sub/superclasses and annotate the class hierarchy. Another way to do the same thing is via the Class description view. When an OWL class is selected in the entities view, the right-hand side of the tab shows the class description panel. If we select the 'vertebral column disease' class, we see in the class description view that this class is a \"SubClass Of\" (= has a SuperClass) the 'musculoskeletal system disease' class. Using the (+) button beside \"SubClass Of\" we could add another superclass to the 'skeletal system disease' class.
Note the Anonymous Ancestors. This is a difficult concept we will return to later, and the contents of this portion may seem confusing at first (some of these may be clearer after you complete the \"Basics of OWL\" section below). These are OWL expressions that are inherited from the parents. If you hover over the Subclass Of (Anonymous Ancestor) you can see the parent that the class inherited the expression from. For many ontologies, you will see some quite abstract expressions in here inherited from upper ontologies, but these can generally be ignored for most purposes.
"},{"location":"lesson/contributing-to-obo-ontologies/#revising-a-superclass","title":"Revising a superclass:","text":"
If you want to revise the superclass, click the 'o' symbol next to the superclass and replace the text. Try to revise 'musculoskeletal system disease' to\u00a0 'disease by anatomical system'.
If you want to delete a superclass, click the 'x' button next to the superclass. Delete the 'disease by anatomical system' superclass.
Close this window without saving.
Save your work.
"},{"location":"lesson/contributing-to-obo-ontologies/#make-a-pull-request","title":"Make a Pull Request","text":"
Click: Create Pull Request in GitHub Desktop
This will automatically open GitHub Desktop
Click the green button 'Create pull request'
You may now add comments to your pull request.
The CL editors team will review your PR and either ask for changes or merge it.
The changes will be available in the next release.
Dead Simple Ontology Design Patterns (DOSDPs) are specifications, written in yaml format, that specify how ontology terms should be created (see article here). They can be used to:
generate documentation
generate new terms
retrofit existing ontology terms
DOSDPs have some key features:
Description: that describes the purpose of the patterns
Examples: Provides examples of terms that use the Patterns
Declared classes: these are the classes that are used in the pattern. Any subclass of the declared class can be used in this pattern.
Declared relationships: the relationships used in the logical axioms
vars: the variable classes that are used in the pattern. Any subclass of the 'var' can be used in this pattern.
Pattern for class name, annotations, text definition and equivalentTo (logical definition): Ontology classes are used as 'fillers' to create new classes that conform to the specific patterns.
"},{"location":"lesson/contributing-to-obo-ontologies/#basics-of-owl","title":"Basics of OWL","text":"
Clone the Ontologies 101 repository, then open the folder BDK14_exercises from your file system
Open basic-subclass/chromosome-parts.owl in Prot\u00e9g\u00e9, then do the following exercises:
Basic Subclass Hierarchy (review) - make sure to look at the \"detailed instructions\" for adding annotations here, as it will go over adding annotations on annotation assertions
Disjointness
Object Properties - note that you will rarely, if ever, be making object properties, as most of the properties you'll ever need are defined in the Relation Ontology
OWL Class Restrictions
Open basic-restriction/er-sec-complex.owl in Prot\u00e9g\u00e9, then do the following exercise:
Basic Restrictions
Open basic-dl-query/cc.owl in Prot\u00e9g\u00e9, then do the following exercises:
DL Query Tab - note that owl:Nothing is defined as the very bottom node of an ontology, therefore the DL query results will show owl:Nothing as a subclass. This is expected and does not mean there is a problem with your ontology! It's only bad when something is a subclass of owl:Nothing and therefore unsatisfiable (more on that below).
Basic DL Queries
Open basic-classification/ubiq-ligase-complex.owl in Prot\u00e9g\u00e9, then do the following exercises:
Basic Classification
Read (I can't get no) satisfiability (~10 minutes)
Optional: Open a new ontology in Prot\u00e9g\u00e9. Try creating an inconsistent ontology using the classes and instances in the first Pets example (hint: you'll also need to create the \"eats\" object property)... what happens when you run the reasoner?
"},{"location":"lesson/contributing-to-obo-ontologies/#logic-and-debugging","title":"Logic and debugging","text":"
Below are exercises to demonstrate how to:
Add equivalent axioms (logical definitions) to ontology terms
Run the reasoner and view the inferred hierarchy
Debugging and viewing explanations
"},{"location":"lesson/contributing-to-obo-ontologies/#practice-adding-logic-and-debugging","title":"Practice adding logic and debugging","text":"
These instructions will use the Mondo disease ontology as an example.
"},{"location":"lesson/contributing-to-obo-ontologies/#practice-1","title":"Practice 1","text":""},{"location":"lesson/contributing-to-obo-ontologies/#add-new-terms-with-an-equivalance-axiom-to-mondo","title":"Add New Terms with an Equivalance Axiom to Mondo:","text":""},{"location":"lesson/contributing-to-obo-ontologies/#creating-a-new-class_1","title":"Creating a new class","text":"
New classes are created in the Class hierarchy panel on the left.
There are three buttons at the top of the class hierarchy view. These allow you to add a subclass (L-shaped icon), add a sibling class (c-shaped icon), or delete a selected class (x'd circle).
"},{"location":"lesson/contributing-to-obo-ontologies/#practice-adding-a-new-term","title":"Practice adding a new term:","text":""},{"location":"lesson/contributing-to-obo-ontologies/#add-the-new-term-mycotoxin-allergy","title":"Add the new term 'mycotoxin allergy'","text":"
Navigate to the Mondo repo in GitHub Desktop, create a branch, and open mondo-edit.obo in Protege.
Search for the parent term 'allergic disease' (see search guide if you are unsure how to do this).
When you are clicked on the term in the Class hierarchy pane, click the add subclass button to add a child class to 'allergic disease'
A dialog will popup. Name this new subclass: mycotoxin allergy. Click \"OK\" to add the class.
"},{"location":"lesson/contributing-to-obo-ontologies/#add-annotations-and-a-logical-axiom","title":"Add annotations and a logical axiom","text":"
Equivalence axioms in Mondo are added according to Dead Simple Ontology Design Patterns (DOSDPs). You can view all of the design patterns in Mondo by going to code/src/patterns/dosdp-patterns/
For this class, we want to follow the design pattern for allergy.
Review this pattern before proceeding.
Based on the pattern specifications, add a text definition to this term.
Add the database cross reference to this term: MONDO:patterns/allergy
Add a synonym that is consistent with this pattern.
Add the equivalence axiom according to the pattern specifications.
Run the reasoner
View the inferred hierarchy. You should see a child of owl:Nothing (and you should see this in the Description pane as well.)
Click on the ? button next to the owl:Nothing in the Description view
The explanation tells you the reason why this is unsatisfiable
Mycotoxin is a child of a 'specifically dependent continuant' and and 'independent continuant' is disjoint with 'specifically dependent continuant'.
This logical axiom uses the relation 'realized in response to stimulus'
Click on this relation in Protege (you can click on the relation name in the equivalence axiom, or you can click on the Object properties tab and search for this relation.
There are domain and range restrictions on this property, where the range has to be a material enity. Chebi mycotoxin is actually a role, so it is not a material entity.
Go back to the Classes or Entities pane and remove the equivalence axiom and run the reasoner again. You should now see no unsatisfiable classes.
"},{"location":"lesson/contributing-to-obo-ontologies/#practice-2","title":"Practice 2","text":""},{"location":"lesson/contributing-to-obo-ontologies/#practice-adding-a-new-term_1","title":"Practice adding a new term:","text":""},{"location":"lesson/contributing-to-obo-ontologies/#add-the-new-term-acquired-alacrima","title":"Add the new term 'acquired alacrima'","text":"
Add 'acquired candidiasis as a subclass of MONDO_0002026 candidiasis.
"},{"location":"lesson/contributing-to-obo-ontologies/#add-annotations-and-a-logical-axiom_1","title":"Add annotations and a logical axiom","text":"
As noted above, equivalence axioms in Mondo are added according to Dead Simple Ontology Design Patterns (DOSDPs). You can view all of the design patterns in Mondo by going to code/src/patterns/dosdp-patterns/
For this class, we want to follow the design pattern for acquired.
Review this pattern before proceeding.
Based on the pattern specifications, add a text definition to this term.
Add the database cross reference to the definition: MONDO:patterns/allergy
Add the equivalence axiom according to the pattern specifications.
Chris Mungall on how to write great textual definitions
"},{"location":"lesson/developing-an-obo-ontology/","title":"Developing an OBO Reference Ontology","text":""},{"location":"lesson/developing-an-obo-ontology/#what-is-delivered-as-part-of-the-course","title":"What is delivered as part of the course?","text":"
Develop skills to lead a new or existing OBO project, or reference ontology develoment.
By the end of this session, you should be able to:
Merge ontology modules & imports with robot merge
Create a classified version of an ontology with robot reason
Add metadata to an ontology with robot annotate
Create a simple release workflow using ROBOT commands in a Makefile
Create a new ontology with ODK
"},{"location":"lesson/developing-an-obo-ontology/#what-is-an-ontology-release","title":"What is an ontology release?","text":"
Like software, official OBO Foundry ontologies have versioned releases. This is important because OBO Foundry ontologies are expected to be shared and reused. Since ontologies are bound to change over time as more terms are added and refined, other developers need stable versions to point to so that there are no surprises. OBO Foundry ontologies use GitHub releases to maintain these stable copies of older versions.
Generally, OBO Foundry ontologies maintain an \"edit\" version of their file that changes without notice and should not be used by external ontology developers because of this. The edit file is used to create releases on a (hopefully) regular basis. The released version of an OBO Foundry ontology is generally a merged and reasoned version of the edit file. This means that all modules and imports are combined into one file, and that file has the inferred class hierarchy actually asserted. It also often has some extra metadata, including a version IRI. OBO Foundry defines the requirements for version IRIs here.
"},{"location":"lesson/developing-an-obo-ontology/#the-release-workflow-process-should-be-stable-and-can-be-written-as-a-series-of-steps-for-example","title":"The release workflow process should be stable and can be written as a series of steps. For example:","text":"
Update modules from templates
Merge ontology modules & the main edit file into one
Assert the inferred class hierarchy
Add a version IRI & other important metadata
"},{"location":"lesson/developing-an-obo-ontology/#this-series-of-steps-can-be-turned-into-robot-commands","title":"This series of steps can be turned into ROBOT commands:","text":"
robot template
robot merge
robot reason
robot annotate
Since we can turn these steps into a series of commands, we can create a Makefile that stores these as \"recipes\" for our ontology release!
"},{"location":"lesson/developing-application-ontologies/","title":"Developing an Application Ontology","text":""},{"location":"lesson/developing-application-ontologies/#warning","title":"Warning","text":"
These materials are under construction and incomplete.
"},{"location":"lesson/developing-application-ontologies/#what-is-delivered-as-part-of-the-course","title":"What is delivered as part of the course","text":"
Description: Combining ontology subsets for use in a project.
in person or video (link videos here as they become available)
"},{"location":"lesson/developing-application-ontologies/#additional-materials-and-resources","title":"Additional materials and resources","text":""},{"location":"lesson/developing-application-ontologies/#contributors","title":"Contributors","text":"
Nico Matentzoglu
"},{"location":"lesson/entity-matching/","title":"Linking across vocabularies: Semantic Entity Matching","text":""},{"location":"lesson/entity-matching/#summary","title":"Summary","text":"
All across the biomedical domain, we refer to domain entities (such as chemicals or anatomical parts) using identifiers, often from controlled vocabularies.
The decentralised evolution of scientific domains has led to to the emergence of disparate \"semantic spaces\" with different annotation practices and reference vocabularies and formalisms.
To bridge between these spaces, entity mappings have emerged, which link, for example, genes from HGNC to ENSEMBL, diseases between OMIM and Mondo and anatomical entities between FMA and Uberon.
Entity matching is the process of establishing a link between an identifier in one semantic space to an identifier in another. There are many cultures of thought around entity matching, including Ontology Matching, Entity Resolution and Entity Linking.
"},{"location":"lesson/entity-matching/#table-of-contents","title":"Table of Contents","text":"
Fundamentals
Basic tutorials
Introduction to entity mapping
How are mappings collected in practice?
A typical workflow for matching
Examples
"},{"location":"lesson/entity-matching/#overview-of-the-terminology","title":"Overview of the terminology","text":"Concept Definition Semantic space A not widely used concept to denote a cluster of related data that can be interpreted using the same ontology. Ontology matching The task of determining corresponding entities across ontologies. Entity mapping Determining and documenting the correspondence of an entity in one semantic space to another. Schema mapping Determining and documenting the translation rules for converting an entity from one semantic space to another. Ontology alignment An ontology alignment is a set of term mappings that links all concepts in a source ontology to their appropriate correspondence in a target ontology, if any. Knowledge graph matching More or less the same as ontology matching - for knowledge graphs Thesaurus building Involves assigning natural language strings (synonym) to a code in a knowledge organisation system (like a taxonomy, terminology, or ontology) Named Entity Recognition and Entity Linking Involve recognising entities (such as diseases) in text and linking them to some identifier. Entity resolution/record linkage Involves determining if records from different data sources represent, in fact, the same entity Schema matching Determines if two objects from different data models (schema elements, schema instances) are semantically related. Value Set Mapping Determines and documents the correspondence of two Value Sets and their respective values (i.e. a 2-level mapping!)."},{"location":"lesson/entity-matching/#fundamentals","title":"Fundamentals","text":"
The excellent OpenHPI course on Knowledge Engineering with Semantic Web Technologies gives a good overview:
Another gentle overview on Ontology Matching was taught as part of the Knowledge & Data course at Vrije Universiteit Amsterdam.
Introduction to processing mappings with SSSOM and sssom-py CLI
Introduction to matching with OAK lexmatch
"},{"location":"lesson/entity-matching/#introduction-to-entity-mapping","title":"Introduction to Entity Mapping","text":"
In the following, we consider a entity a symbol that is intended to refer to a real world entity, for example:
an ontology id like OMOP:441554 corresponds to the concept of \"Vascular calcification\" in the real world. Note that OMOP:441554 may be annotated with the rdfs:label \"Friedreichs Ataxia\". The label itself is not necessarily a term - it could change, for example to \"Friedreichs Ataxia (disease)\", and still retain the same meaning.
\"Friedreich's Ataxia\" (example on the left) may be a term in my controlled vocabulary which I understand to correspond to that respective disease (not all controlled vocabularies have IDs for their terms). This happens for example in clinical data models that do not use formal identifiers to refer to the values of slots in their data model, like \"MARRIED\" in /datamodel/marital_status.
Examples of entities:
IDs of classes in an ontology
elements of a clinical value set
elements of clinical terminologies such as Z63.1
Elements of a schema
TLDR: entities are symbols that correspond to things in the world, and that correspondence is not subject to change. Labels of such entities can change without changing the meaning of the entity.
In our experience, there are roughly four kinds of mappings:
string-string: Relating one string, or label, to another string, or label. Understanding such mappings is fundamental to understanding all the other kinds of mappings.
_string-entity: Relating a specific string or \"label\" to their corresponding entity in a terminology or ontology. We usually refer to these as synonyms, but there may be other words used in this case.
entity-entity_: Relating an entity, for example a class in an ontology, to another entity. This is what most people in the ontology domain would understand when thy hear \"ontology mappings\".
complex mappings: Relating two sets of entities. For example cheese sandwich (wikidata:Q2734068) to sandwich (wikidata:Q111836983) and cheese wikidata:Q10943. These are the rarest and most complicated kinds of mappings and are out of scope for this lesson.
In some ways, these four kinds of mappings can be very different. We do believe, however, that there are enough important commonalities such as common features, widely overlapping use cases and overlapping toolkits to consider them together. In the following, we will discuss these in more detail, including important features of mappings and useful tools.
"},{"location":"lesson/entity-matching/#important-features-of-mappings","title":"Important features of mappings","text":"
Mappings have historically been neglected as second-class citizens in the medical terminology and ontology worlds - the metadata is insufficient to allow for precise analyses and clinical decision support, they are frequently stale and out of date, etc. The question \"Where can I find the canonical mappings between X and Y\"? is often shrugged off and developers are pointed to aggregators such as OxO or UMLS which combine manually curated mappings with automated ones causing \"mapping hairballs\".
There are many important metadata elements to consider, but the ones that are by far the most important to consider one way or another are:
Precision: Is the mapping exact, broad or merely closely related?
Confidence: Do I trust the mapping? Was is done manually by an expert in my domain, or by an algorithm?
Source version: Which version of the entity (or its corresponding ontology) was mapped? Is there a newer mapping which has a more suitable match for my entity?
Whenever you handle mappings (either create, or re-use), make sure you are keenly aware of at least these three metrics, and capture them. You may even want to consider using a proper mapping model like the Simple Shared Standard for Ontology Mappings (SSSOM) which will make your mappings FAIR and reusable.
String-string mappings are mappings that relate two strings. The task of matching two strings is ubiquitous for example in database search fields (where a user search string needs to be mapped to some strings in a database). Most, if not all effective ontology matching techniques will employ some form of string-string matching. For example, to match simple variations of labels such as \"abnormal heart\" and \"heart abnormality\", various techniques such as Stemming and bag of words can be employed effectively. Other techniques such as edit-distance or Levenshtein can be used to quantify the similarity of two strings, which can provide useful insights into mapping candidates.
String-entity mappings relate a specific string or \"label\" to their corresponding term in a terminology or ontology. Here, we refer to these as \"synonyms\", but there may be other cases for string-entity mappings beyond synonymy.
There are a lot of use cases for synonyms so we will name just a few here that are relevant to typical workflows of Semantic Engineers in the life sciences.
Thesauri are reference tools for finding synonyms of terms. Modern ontologies often include very rich thesauri, with some ontologies like Mondo capturing more than 70,000 exact and 35,000 related synonyms. They can provide a huge boost to traditional NLP pipelines by providing synonyms that can be used for both Named Entity Recognition and Entity Resolution. Some insight on how, for example, Uberon was used to boost text mining can be found here.
Entity-entity mappings relate a entity (or identifier), for example a class in an ontology, to another entity, usually from another ontology or database. The entity-entity case of mappings is what most people in the ontology domain would understand when they hear \"ontology mappings\". This is also what most people understand when they here \"Entity Resolution\" in the database world - the task of determining whether, in essence, two rows in a database correspond to the same thing (as an example of a tool doing ER see deepmatcher, or py-entitymatcher). For a list standard entity matching toolkit outside the ontology sphere see here.
"},{"location":"lesson/entity-matching/#monarch-obo-training-tutorials","title":"Monarch OBO Training Tutorials","text":""},{"location":"lesson/entity-matching/#introduction-to-semantic-entity-matching","title":"Introduction to Semantic Entity Matching","text":""},{"location":"lesson/entity-matching/#how-are-mappings-collected-in-practice","title":"How are mappings collected in practice?","text":"
Mappings between terms/identifiers are typically collected in four ways:
Automatically, using terminological matchers (of which ontology matchers one the most important category in our domain).
Manually, by dedicated curators.
By re-using existing mappings. Some semantic spaces have been mapped by organisations such as the Monarch Initiative or UMLS, and it is often worth re-viewing existing mappings before building ones own.
Using a mix of automated and manual approaches, where automated approaches typically generate \"mapping candidates\" which are \"double checked\" by humans before used in production systems.
The main trade-off for mappings is very simple: 1. Automated mappings are very error prone (not only are they hugely incomplete, they are also often faulty). 1. Human curated mappings are very costly.
--> The key for any given mapping project is to determine the highest acceptable error rate, and then distribute the workload between human and automated matching approaches. We will discuss all three ways of collecting mappings in the following.
Aside from the main tradeoff above, there are other issues to keep in mind: - Manually curated mappings are far from perfect. Most of the cost of mapping review lies in the decision how thorough a mapping should be reviewed. For example, a human reviewer may be tasked with reviewing 1000 mappings. If the acceptable error rate is quite high, the review may simply involve the comparison of labels (see here), which may take around 20 seconds. A tireless reviewer could possibly accept or dismiss 1000 mappings just based on the label in around 6 hours. Note that this is hardly better than what most automated approaches could do nowadays. - Some use cases involve so much data that manual curation is nearly out of the question.
"},{"location":"lesson/entity-matching/#manual-curation-of-mappings","title":"Manual curation of mappings","text":"
It is important to remember that matching in its raw form should not be understood to result in semantic mappings. The process of matching, in particular lexical or fuzzy semantic matching is error prone and usually better treated as resulting in candidates for mappings. This means that when we calculate the effort of a mapping project, we should always factor in the often considerable effort required by a human to verify the correctness of a candidate mapping. There are many tools that can help with this process, for example by filtering out conflicting lower-confidence mappings, but in the end the reality is this: due to the fact that source and target do not share the same semantics, mappings will always be a bit wobbly. There are two important kinds of review which are very different:
False positive review (wrong mappings). The goal here is to identify mappings that do not work for our use case, or do not use the correct semantic mapping relation. For example orange juice [wikidata:Q219059] and orange juice (unpasteurized) [FOODON:00001277] may not be considered as the same thing in the sense of skos:exactMatch.
False negative review (missing mappings). The goal here is to understand if we can do anything to improve the matching process by tuning it. For very simple matchers like oak lexmatch this usually involves hacking labels and synonyms by removing or replacing words. More sophisticated matchers like Agreement Maker Light (AML) have many more tuning options, and it requires patience and expertise to find the right ones. One good approach here is to include semantically or lexically similar matches in the results, and review if generally consistent patterns of lexical variation can be spotted. For example: orange juice (liquid) [FOODON:00001001] seems to be exactly what orange juice [wikidata:Q219059] is supposed to mean. The labels are not the same, but lexically similar: a simple lexical distance metric like Levenshtein could have been used to identify these.
Tip: always keep a clear visible list of unmapped classes around to sanity check how good your mapping has been so far.
There are many (many) tools out there that have been developed for entity matching. A great overview can be found in Euzenats Ontology Matching. Most of the matchers apply a mix of lexical and semantic approaches.
As a first pass, we usually rely on a heuristic that an exact match on the label is strong evidence that the two entities correspond to the same thing. Obviously, this cannot always be the case Apple (the fruit) and Apple (the company) are two entirely different things, yet a simple matching tool (like OAK lexmatch) would return these as matching. The reason why this heuristic works in practice is because we usually match between already strongly related semantic spaces, such as two gene databases, two fruit ontologies or two disease terminologies. When the context is narrow, lexical heuristics have a much lower chance to generate excessively noisy mappings.
After lexical matchings are created, other techniques can be employed, including syntactic similarity (match all entities which have labels that are more than 80% similar and end with disease) and semantic similarity (match all entities whose node(+graph)-embedding have a cosine similarity of more than 80%). Automated matching typically results in a large number of false positives that need to be filtered out using more sophisiticated approaches for mapping reconciliation.
"},{"location":"lesson/entity-matching/#a-typical-workflow-for-matching","title":"A typical workflow for matching","text":"
Collecting existing mappings from external sources, if they exist.
Generating mapping candidates using automated matchers (seed mappings).
Iteratively refining mappings while keeping track of:
Anchor mappings (known correct mappings)
Overestimation mappings (mapping candidates)
Negative mappings (known false mappings, as deterimed by tools or human review)
The refinement step may involve automated approaches that are sensitive to the logical content of the sources involved (for example by ensuring that the result does not result in equivalence cliques, or unsatisfiable classes), but more often than not, human curators are employed to curate the mapping candidates generated by the various automated approaches.
"},{"location":"lesson/entity-matching/#some-examples-of-domain-specific-mapping-of-importance-to-the-biomedical-domain","title":"Some examples of domain-specific mapping of importance to the biomedical domain","text":""},{"location":"lesson/entity-matching/#phenotype-ontology-mappings","title":"Phenotype ontology mappings","text":"
Mapping phenotypes across species holds great promise for leveraging the knowledge generated by Model Organism Database communities (MODs) for understanding human disease. There is a lot of work happening at the moment (2021) to provide standard mappings between species specific phenotype ontologies to drive translational research (example). Tools such as Exomiser leverage such mappings to perform clinical diagnostic tasks such as variant prioritisation. Another app you can try out that leverages cross-species mappings is the Monarch Initiatives Phenotype Profile Search.
Medical terminology and ontology mapping is a huge deal in medical informatics (example). Mondo is a particularly rich source of well provenanced disease ontology mappings.
A great overview can be found in \"Tackling the challenges of matching biomedical ontologies\" (Faria et al 2018)
A yearly competition of ontology matching systems is held by the Ontology Alignment Evaluation Initiative (OAEI). The challenge results are a useful guide to identifying systems for matching you may want to try.
The most comprehensive work for anyone serious about entity matching is Euzenats Ontology Matching.
"},{"location":"lesson/getting-hands-on/","title":"Getting Hands on with Ontologies","text":""},{"location":"lesson/getting-hands-on/#prerequisites","title":"Prerequisites","text":"
Optional: If you are unfamiliar with ontologies, this introduction to ontologies explanation may be helpful.
"},{"location":"lesson/getting-hands-on/#what-is-delivered-as-part-of-the-course","title":"What is delivered as part of the course","text":"
Description: The purpose of this lesson is to train biomedical researchers on how to find a term, what to do if they find too many terms, how to decide on which term to use, and what to do if no term is found.
Understand open source ontology community development
Identify the best ontology or ontologies for annotation of biomedical data
Find ontology terms and chose the best ontology term
Make new term requests
"},{"location":"lesson/getting-hands-on/#lesson","title":"Lesson","text":""},{"location":"lesson/getting-hands-on/#introduction-to-community-based-ontology-development","title":"Introduction to Community Based Ontology Development","text":"
This how to guide on How to be an Open Science Engineer - maximizing impact for a better world has a lot of details about the philosophy behind open science ontology engineering. Some key points are summarized below.
The ontologies that I will promote in this lesson are part of the OBO Foundry, a community of ontology developers that are committed to developing open, freely available, community ontologies under a share set of guiding principles, that ensure the ontologies are interoperable, scientifically accurate, amongst other qualities.
A key feature of the success of our ontologies is the community who contributes to them. (I claim they are successful because they are widely used in biomedical curation, databases, bioinformatics and computational analyses.)
Principle of Collaboration:
These ontologies rely on community contributions and many are not funded. We value your expertise in making new term requests, requesting changes or commenting on existing tickets.
The OBO Academy has a lot of self-paced learning material, if you are inclined to learn how to contribute directly to ontologies.
Join Slack channels and email lists.
Reduce work for others as much as possible by communicating clearly.
Be positive and generous with gratitude and attribution.
Promote truly open communication: Create public tickets which can be searched and referred to later.
Principle of Upstream Fixing
Report an bugs or errors to the source ontology.
Make term requests for any missing terms.
Principle of No Ownership:
Ensure that you see your issues through to the end.
Feel free to nudge ontology curators.
"},{"location":"lesson/getting-hands-on/#where-to-find-ontology-terms-and-how-to-chose-the-right-terms","title":"Where to find ontology terms and how to chose the right terms","text":"
See lesson on Using Ontologies and Ontology Terms
"},{"location":"lesson/getting-hands-on/#how-to-make-new-term-requests","title":"How to make new term requests","text":"
See How to guide on Make term requests to existing ontologies
Sign up for a GitHub account if you do not already have one. (Some of the exercises can be done without being signed into GitHub).
Search for an ontology term in OLS:
Search for 'exhaust exposure'. Note how many results you get. Do you have a sense of how to select the appropriate term for your annotations?
Make a new term request for a missing term:
Suppose you want a more general term than already exists: exhuast exposure. Using the instructions in How to guide on Make term requests to existing ontologies, make a new term request to an appropriate GitHub repository for an ontology, such as ECTO. (Note, since this is just for practice, please do not submit the ticket.)
"},{"location":"lesson/hackathon/","title":"OBO Academy Hackathon","text":""},{"location":"lesson/hackathon/#goalslearning-outcomes","title":"Goals/Learning outcomes","text":"
Strengthen social workflows in creating Pull Requests (PRs), including:
We have worked with the University of Manchester to incorporate the Family History Knowledge Base Tutorial fully into OBO Academy.
This is it: OBOAcademy: Family History - Modelling with Object Properties.
In contrast to the Pizza tutorial, the Family history tutorial focuses on modelling with individuals. Chapters 4, 5, 8 and 9 are full of object property modelling, and are not only great to get a basic understanding of using them in your ontology, but also give good hints at where OWL and object properties fall short. We refer to the FHKB in the following and expect you to have completed at least chapter 5 before reading on.
"},{"location":"lesson/modelling-with-object-properties/#the-role-of-object-properties-in-the-obo-sphere","title":"The Role of Object Properties in the OBO-sphere","text":"
To remind ourselves, there are three different types of relations in OWL:
Data properties (DatatypeProperty) connect your classes and individuals to data values, such as strings or numbers. In OBO, these are the least frequently used kinds of properties, used for example by CIDO and ONS.
For some example usage, run the following query in the ontobee OLS endpoint:
Note that many uses of data properties across OBO are a bit questionable, for example, you do never want to attach a modification dates or similar to your classes using data properties, as these fall under OWL semantics. This means that logically, if a superclass has a relation using a DatatypeProperty, then this relation _holds for all subclasses of that class as well.
Annotation properties are similar to data properties, but they are outside of OWL semantics, i.e. OWL reasoners and reasoning do not care, in fact ignore, anything related to annotation properties. This makes them suitable for attaching metadata like labels etc to our classes and properties. We sometimes use annotation properties even to describe relationships between classes if we want reasoners to ignore them. The most typical example is IAO:replaced_by, which connects an obsolete term with its replacement. Widely used annotation properties in the OBO-sphere are standardised in the OBO Metadata Ontology (OMO).
The main type of relation we use in OBO Foundry are object properties. Object properties relate two individuals or classes with each other, for example:
In the same way as annotation properties are maintained in OMO (see above), object properties are maintained in the Relation Ontology (RO).
Object properties are of central importance to all ontological modelling in the OBO sphere, and understanding their semantics is critical for any put the most trivial ontologies. We assume the reader to have completed the Family History Tutorial mentioned above.
"},{"location":"lesson/modelling-with-object-properties/#object-property-semantics-in-obo","title":"Object property semantics in OBO","text":"
In our experience, these are the most widely used characteristics we specify about object properties (OP):
Sub-property: if an OP is a sub-property of another parent OP, it inherits all its semantic characteristics. Most importantly: if OP1 is a sub-property of OP2, then, if (a)--[OP1]-->(b), we infer that (a)--[OP2]-->(b).
Domain: if OP has a domain C, it means that every time (a)--[OP]-->(b), (a) must be a C. For example, ecologically co-occurs with in RO has the domain 'organism or virus or viroid', which means that whenever anything ecologically co-occurs with something else, it will be inferred to be a 'organism or virus or viroid'.
Range: if OP has a range C, it means that every time (a)--[OP]-->(b), (b) must be a C. For example produced by has the domain material entity. Note that in ontologies, ranges are slightly less powerful then domains: If we have a class Moderna Vaccine which is SubClass of 'produced by' some 'Moderna' we get that Moderna Vaccine is a material entity due to the domain constraint, but NOT that Moderna is a material entity due to the range constraint (explanation to this is a bit complicated, sorry).
Transitivity: if an OP is transitive, it means that if (a)--[OP]-->(b)--[OP]-->(c), (a)--[OP]-->(c). For example, if the eye is part of the head, which is part of the body, we can infer that the eye must be part of the body.
Property chains: Similar to transitive properties, property chains allow us to bridge across multiple properties. The FHKB tutorial above is all about amazing property chains so you should have a deep understanding of these if you followed the tutorial.
Other characteristics like functionality and symmetry are used across OBO ontologies, but not nearly to the same extend as the 5 described above.
The Relation Ontology serves two main purposes in the OBO world:
As a place to standardise object properties. The idea is this: many ontologies are modelling mereological relations, such as partonomies, which requires relationships such as \"part of\" and \"has part\". To ensure that ontologies are interoperable, we need to make sure that all ontologies use the same \"part of\" relationship. Historically this is not always been true, and still is not. At the time of this writing, running:
On the OntoBee SPARQL endpoint still reveals a number of ontologies using non-standard part-of relations. In our experience, most of these are accidental due to past format conversions, but not all. This problem was much worse before RO came along, and our goal is to unify the representation of key properties like \"part of\" across all OBO ontologies. The OBO Dashboard checks for object properties that are not aligned with RO.
As a place to encode and negotiate object property semantics. Object properties (OP) can have domains and ranges, can have characteristics such as functionality and transitivity, see above. Arguing the exact semantics of an OP can be a difficult and lengthy collaborative process, esp. since OP semantics can have a huge impact on ontology reasoning. Detailed RO documentation (modelling patterns and practices) can be found in here. The process of how relationships are added to RO is discussed in the next section.
"},{"location":"lesson/modelling-with-object-properties/#adding-relationships-to-ro","title":"Adding relationships to RO","text":"
To add a relationship we usually follow the following process. For details, please refer to the RO documentation.
Check whether the OP is already in RO. Search for synonyms - often the relationship you are looking exist, but under a different name. If you cant find the exact OP, see whether you can find similar OPs - this may help you also identify suitable parent OPs.
Make an RO issue. Take care to not only describe the name of your relationship, but also intended application areas with examples, a good definition, potential parent relationships, domains and ranges. The more detail you provide, the easier it will be for the community to review your request.
Make a pull request. This involves the same steps as usual. If you are unsure what annotations need to be added and how to reflect the intended semantics, it may be useful to look at past pull requests.
Join our quarterly RO calls and check out the RO documentation.
Participants will need to have access to the following resources and tools prior to the training:
GitHub account - register for a free GitHub account here
Protege - Install Protege 5.5, download it here
Install ELK 0.5
Install GitHub Desktop Please make sure you have some kind of git client installed on your machine. If you are new to Git, please install GitHub Desktop
"},{"location":"lesson/ontology-design/#owl-class-restrictions","title":"OWL class restrictions","text":"
In OWL, we use object properties to describe binary relationships between two individuals (or instances). We can also use the properties to describe new classes (or sets of individuals) using restrictions. A restriction describes a class of individuals based on the relationships that members of the class participate in. In other words, a restriction is a kind of class, in the same way that a named class is a kind of class.
For example, we can use a named class to capture all the individuals that are idiopathic diseases. But we could also describe the class of idiopathic disease as all the instances that are 'has modifier' idiopathic disease.
In OWL, there are three main types of restrictions that can be placed on classes. These are quantifier restriction, cardinality restrictions, and hasValue restriction. In this tutorial, we will initially focus on quantifier restrictions.
Quantifier restrictions are further categorized into two types, the existential and the universal restriction.
Existential restrictions describe classes of individuals that participate in at least one relationship along a specified property to individuals that are members of a specified class. For example, the class of individuals that have at least one ( some ) 'has modifier' relationship to members of the idiopathic disease class. In Protege, the keyword 'some' is used to denote existential restrictions.
Universal restrictions describe classes of individuals that for a given property only have relationships along this property to individuals that are members of a specified class. For example, we can say a cellular component is capable of many functions using the existential quantifier, however, OWL semantics assume that there could be more. We can use the universal quantifier to add closure to the existential. That is, we can assert that a cellular component is capable of these functions, and is only capable of those functions and no other. Another example is that the process of hair growth is found only in instances of the class Mammalia. In Protege the keyword 'only' is used.
In this tutorial, we will deal exclusively with the existential (some) quantifier.
Strictly speaking in OWL, you don't make relationships between classes, however, using OWL restrictions we essentially achieve the same thing.
We wanted to capture the knowledge that the named class 'idiopathic achalasia' is an idiopathic disease. In OWL speak, we want to say that every instance of an ' idiopathic achalasia' is also an instance of the class of things that have at least one 'has modifier' relationship to an idiopathic disease. In OWL, we do this by creating an existential restriction on the idiopathic achalasia class.
In the Entities tab, select 'idiopathic achalasia' in the class hierarchy and look at its current class description in the bottom right box.
Note that there are two superclasses (as denoted by the SubClass Of list). ''gastroesophageal disease'' and 'has modifier' some idiopathic.
Run the reasoner.
You should see that this class is now inferred to be an idiopathic disease because of this SubClassOf (superclass) restriction.
"},{"location":"lesson/ontology-design/#equivalence-axioms-and-automatic-classification","title":"Equivalence Axioms and Automatic classification","text":"
This example introduces equivalence axioms or defined classes (also called logical definitions) and automatic classification.
The example involves classification of Mendelian diseases that have a monogenic (single gene) varation. These equivalence axioms are based off the Mondo Design Pattern disease_series_by_gene.
Constructs:
and (intersection)
equivalence (logical definitions)
existential restrictions (e.g. 'disease has basis in dysfunction of')
"},{"location":"lesson/ontology-design/#add-an-equivalence-axiom-to-an-existing-mondo-term","title":"Add an equivalence axiom to an existing Mondo term","text":"
Create a new branch and open (or re-open) mondo-edit.obo
Navigate to the class 'cardioacrofacial dysplasia 1'
According to OMIM, this disease is caused by a variation in the gene PRKACA.
We want to add an equivalence axiom that says every instance of this class is a type of 'cardioacrofacial dysplasia' that has dysfunction in the PRKACA gene.
To do this, click the + next to Equivalent To in the lower right Description box.
Add the following equivalence axiom: 'cardioacrofacial dysplasia' and ('disease has basis in dysfunction of' some PRKACA)
Run the reasoner.
You shouldn't see any change, but try deleting the superclass assertion to 'cardioacrofacial dysplasia' and re-running the reasoner.
You should see that 'cardioacrofacial dysplasia' is an inferred superclass.
Undo the last change, save your work, commmit, and create a pull request.
"},{"location":"lesson/ontology-design/#adding-classes-and-automatically-classifying-them","title":"Adding classes and automatically classifying them","text":"
For teaching purposes, let's say we need a new class that is 'fungal allergy'.
Create a new branch and re-open mondo-edit.obo
Add a new term under owl:Thing named 'fungal allergy'.
Following the design pattern allergy.yaml, add the text definition, synonym and equivalentTo axiom, using the substance ECTO_0000524 'exposure to mycotoxin'.
Run the reasoner and note where the class is automatically classified.
Create a pull request and note in the PR what the parent class is.
By default, OWL assumes that these classes can overlap, i.e. there are individuals who can be instances of more than one of these classes. We want to create a restriction on our ontology that states these classes are different and that no individual can be a member of more than one of these classes. We can say this in OWL by creating a disjoint classes axiom.
Create a branch in the Mondo repo (name it: disjoint-[your initials]. For example: disjoint-nv)
Open the mondo-edit.obo file
Per this ticket, we want to assert that infectious disease and syndromic disease are disjoint.
To do this first search for and select the infectious disease class.
In the class 'Description' view, scroll down and select the (+) button next to Disjoint With. You are presented with the now familiar window allowing you to select, or type, to choose a class. In the Expression editor, add 'syndromic disease' as disjoint with 'infectious disease'.
Run the ELK reasoner.
Scroll to the top of your hierarchy and note that owl:Nothing has turned red. This is because there are unsatisfiable classes.
"},{"location":"lesson/ontology-design/#review-and-fix-one-unsatisfiable-class","title":"Review and fix one unsatisfiable class","text":"
Below we'll review an example of one class and how to fix it. Next you should review and fix another one on your own and create a pull request for Nicole or Nico to review. Note, fixing these may require a bit of review and subjective decision making and the fix described below may not necessarily apply to each case.
Review Bickerstaff brainstem encephalitis: To understand why this class appeared under owl:Nothing, first click the ? next to owl:Nothing in the Description box. (Note, this can take a few minutes).
The explanation is displayed above - it is because this class is a descedent of Guillain-Barre syndrome, which is a child of syndromic disease.
Next, we have to ask if Bickerstaff brainstem encephalitis is an appropriate child of regional variant of Guillain-Barre syndrome. Note, Mondo integrates several disease terminologies and ontologies, and brought in all the subclass hierarchies from these source ontologies. To see the source of this superclass assertion, click the @ next to the assertion.
This source came from Orphanet, see below.
Based on the text definition, there does not seem to be any suggestion that this disease is a type of Guillain-Barre syndrome.
Assuming that this disease is not a type of Guillain-Barre syndrome, we should exclude the superclass regional variant of Guillain-Barre syndrome (see this paper and this paper. It seems a bit unclear what the relationship of BBE is to Guillain-Barre syndrome. This also brings into the question if a disease can be syndromic and an infectious disease - maybe this disjoint axiom is wrong, but let's not worry about this for the teaching purposes.)
To exclude a superclass, follow the instructions here.
"},{"location":"lesson/ontology-development/","title":"Ontology Development: Release Management, Quality Control and Collaborative Methods","text":""},{"location":"lesson/ontology-development/#warning","title":"Warning","text":"
These materials are under construction and incomplete.
"},{"location":"lesson/ontology-development/#what-is-delivered-as-part-of-the-course","title":"What is delivered as part of the course","text":""},{"location":"lesson/ontology-development/#learning-objectives","title":"Learning objectives","text":""},{"location":"lesson/ontology-development/#tutorials","title":"Tutorials","text":""},{"location":"lesson/ontology-development/#additional-materials-and-resources","title":"Additional materials and resources","text":""},{"location":"lesson/ontology-development/#contributors","title":"Contributors","text":""},{"location":"lesson/ontology-fundamentals/","title":"Ontologies: Fundamentals","text":""},{"location":"lesson/ontology-fundamentals/#warning","title":"Warning","text":"
These materials are under construction and incomplete.
We are skipping 5.3: Ontology Learning and both sections on MORE Ontology Evaluation (5.7 and 5.8)
Complete part of the Ontologies 101 Tutorial (~2 hours)
Clone the Ontologies 101 repository, then open the folder BDK14_exercises from your file system
Open basic-subclass/chromosome-parts.owl in Prot\u00e9g\u00e9, then do the following exercises:
Basic Subclass Hierarchy (review) - make sure to look at the \"detailed instructions\" for adding annotations here, as it will go over adding annotations on annotation assertions
Disjointness
Object Properties - note that you will rarely, if ever, be making object properties, as most of the properties you'll ever need are defined in the Relation Ontology
OWL Class Restrictions
Open basic-restriction/er-sec-complex.owl in Prot\u00e9g\u00e9, then do the following exercise:
Basic Restrictions
Open basic-dl-query/cc.owl in Prot\u00e9g\u00e9, then do the following exercises:
DL Query Tab - note that owl:Nothing is defined as the very bottom node of an ontology, therefore the DL query results will show owl:Nothing as a subclass. This is expected and does not mean there is a problem with your ontology! It's only bad when something is a subclass of owl:Nothing and therefore unsatisfiable (more on that below).
Basic DL Queries
Open basic-classification/ubiq-ligase-complex.owl in Prot\u00e9g\u00e9, then do the following exercises:
Basic Classification
Read (I can't get no) satisfiability (~10 minutes)
Optional: Open a new ontology in Prot\u00e9g\u00e9. Try creating an inconsistent ontology using the classes and instances in the first Pets example (hint: you'll also need to create the \"eats\" object property)... what happens when you run the reasoner? Don't spend too much time on this if you get stuck, we'll look at an example of an inconsistent ontology in our session.
"},{"location":"lesson/ontology-fundamentals/#what-is-delivered-as-part-of-the-course","title":"What is delivered as part of the course","text":"
Description: Learn the fundamentals of ontologies.
Converting between serializations with robot convert (Review; ~15 minutes)
Creating modules from existing ontologies (~30 minutes)
What is a module?
How do we use the modules in our ontologies?
Extraction methods: MIREOT vs. SLME
Creating a module to import with robot extract (Review; ~15 minutes)
Ontology design patterns (~15 minutes)
Real world example: Ontology for Biomedical Investigations (OBI)
Using design patterns in robot template (Review; ~15 minutes)
Including your modules in your ontology as imports
"},{"location":"lesson/ontology-fundamentals/#tutorials","title":"Tutorials","text":""},{"location":"lesson/ontology-fundamentals/#additional-materials-and-resources","title":"Additional materials and resources","text":""},{"location":"lesson/ontology-fundamentals/#contributors","title":"Contributors","text":"
add name/ORCID here
"},{"location":"lesson/ontology-pipelines/","title":"Ontology Pipelines with ROBOT and SPARQL","text":""},{"location":"lesson/ontology-pipelines/#warning","title":"Warning","text":"
These materials are under construction and may be incomplete.
Install ROBOT so you can use it outside of Docker (scroll down to the end of the ROBOT page to find the Windows instructions)
Optional Install ODK. The ODK includes ROBOT. In the more advanced parts of the course, you will need the ODK installed for some of the other dependencies it includes, and for Windows users it is often easier to follow the tutorials from inside the docker container rather than the Windows CMD.
Familiarise yourself with the ROBOT documentation, to the point that you are aware of the various commands that exist.
"},{"location":"lesson/ontology-pipelines/#what-is-delivered-as-part-of-the-course","title":"What is delivered as part of the course","text":"
There are two basic ways to edit an ontology: 1. Manually, using tools such as Protege, or 2. Using computational tools such as ROBOT.
Both have their advantages and disadvantages: manual curation is often more practical when the required ontology change follows a non-standard pattern, such as adding a textual definition or a synonym, while automated approaches are usually much more scalable (ensure that all axioms in the ontology are consistent, or that imported terms from external ontologies are up-to-date or that all labels start with a lower-case letter).
Here, we will do a first dive into the \"computational tools\" side of the edit process. We strongly believe that the modern ontology curator should have a basic set of computational tools in their Semantic Engineering toolbox, and many of the lessons in this course should apply to this role of the modern ontology curator.
ROBOT is one of the most important tools in the Semantic Engineering Toolbox. For a bit more background on the tool, please refer to the paper ROBOT: A Tool for Automating Ontology Workflows.
We also recommend to get a basic familiarity with SPARQL, the query language of the semantic web, that can be a powerful combination with ROBOT to perform changes and quality control checks on your ontology.
"},{"location":"lesson/ontology-pipelines/#additional-materials-and-resources","title":"Additional materials and resources","text":""},{"location":"lesson/ontology-pipelines/#contributors","title":"Contributors","text":"
Becky Jackson
Nico Matentzoglu
"},{"location":"lesson/ontology-term-use/","title":"Using Ontologies and Ontology Terms","text":""},{"location":"lesson/ontology-term-use/#warning","title":"Warning","text":"
These materials are under construction and may be incomplete.
"},{"location":"lesson/ontology-term-use/#1-why-ontologies-are-useful","title":"1. Why ontologies are useful","text":"
Ontologies provide a logical classification of information in a particular domain or subject area. Ontologies can be used for data annotations, structuring disparate data types, classifying information, inferencing and reasoning across data, and computational analyses.
"},{"location":"lesson/ontology-term-use/#difference-between-a-terminology-and-an-ontology","title":"Difference between a terminology and an ontology","text":""},{"location":"lesson/ontology-term-use/#terminology","title":"Terminology","text":"
A terminology is a collection of terms; a term can have a definition and synonyms.
An ontology contains a formal classification of terminology in a domain that provides textual and machine readable definitions, and defines the relationships between terms. An ontology is a terminology, but a terminology is not (necessarily) an ontology.
"},{"location":"lesson/ontology-term-use/#2-finding-good-ontologies","title":"2. Finding good ontologies","text":"
Numerous ontologies exist. Some recommended sources to find community developed, high quality, and frequently used ontologies are listed below.
OBO Foundry. Read more below
The Ontology Lookup Service (OLS). The OLS contains over 200 ontologies.
BioPortal. BioPortal aggregates almost 900 biomedical ontologies, and provides a search interface to look up terms. It is a popular repository for ontologies, but as only a fraction of the ontologies are reviewed by the OBO Foundry, you should carefully review any ontologies found on BioPortal before committing to use them.
Ontobee. Ontobee indexes all 200+ OBO Foundry ontologies and is the default browser for OBO: For example, when you click http://purl.obolibrary.org/obo/IAO_0000112, you will be redirected to the a page in the Ontobee browser that describes the annotation property example of usage.
The OBO Foundry is a community of ontology developers that are committed to developing a library of ontologies that are open, interoperable ontologies, logically well-formed and scientifically accurate. OBO Foundry participants follow and contribute to the development of an evolving set of principles including open use, collaborative development, non-overlapping and strictly-scoped content, and common syntax and relations, based on ontology models that work well, such as the Gene Ontology (GO).
The OBO Foundry is overseen by an Operations Committee with Editorial, Technical and Outreach working groups.
"},{"location":"lesson/ontology-term-use/#find-terms-using-ontology-browsers","title":"Find terms using ontology browsers","text":"
Various ontology browsers are available, we recommend using one of the ontology browsers listed below.
Find terms:
Ontology Lookup Service
BioPortal
Ontobee
"},{"location":"lesson/ontology-term-use/#4-assessing-ontologies-for-use","title":"4. Assessing ontologies for use","text":"
Some considerations for determining which ontologies to use include the license and quality of the ontology.
Licenses define how an ontology can legally be used or reused. One requirement for OBO Foundry Ontologies is that they are open, meaning that the ontologies are openly and freely available for use with acknowledgement and without alteration. OBO ontologies are required to be released under a Creative Commons CC-BY license version 3.0 or later, OR released into the public domain under CC0. The license should be clearly stated in the ontology file.
Some criteria that can be applied to determine the quality of an ontology include:
Is there an ontology tracker to report issues? All open ontologies should have some form of an issue tracker to report bugs, make new term requests or request other changes to the ontology. Many ontologies use GitHub to track their issues.
Is it currently active? Are there a large number of open tickets on the ontology tracker that have not been commented on or otherwise addressed? Are the tickets very old, have been sitting for years?
Commmunity involvement On the issue tracker, is there evidence of community involvement, such as issues and comments from outside community members?
Scientifically sound Does the ontology accurately represent the domain in a scientifically sound way?
"},{"location":"lesson/ontology-term-use/#how-to-determine-which-is-the-right-ontology-to-use","title":"How to determine which is the right ontology to use?","text":"
There are multiple ontologies that exist, start by selecting the appropriate ontology, then search and restrict your search to that ontology.
Recommend using ontologies that are open and interoperable. Focusing on OBO foundry ontologies are a good place to start
Make informed decision about which ontology to use
Maybe the ontology you want to use does not have the term you want, so make a term request to that ontology
"},{"location":"lesson/ontology-term-use/#5-mapping-local-terminology-to-ontology-terms","title":"5. Mapping local terminology to ontology terms","text":"
Data can be mapped to ontology terms manually, using spreadsheets, or via curation tools such as:
Zooma
BioPortal Annotator
Canto - a web-based literature curation tools
Textpresso - designed for C. elegans curation
OntoBrowser - an online collaborative curation tool
The figure below by Chris Mungall on his blog post on How to select and request terms from ontologies describes a workflow on searching for identifying missing terms from an ontology.
"},{"location":"lesson/ontology-term-use/#7-make-term-requests-to-existing-ontologies","title":"7. Make term requests to existing ontologies","text":"
See separate lesson on Making term requests to existing ontologies.
"},{"location":"lesson/ontology-term-use/#8-differences-between-iris-curies-and-labels","title":"8. Differences between IRIs, CURIEs, and labels","text":""},{"location":"lesson/ontology-term-use/#uri","title":"URI","text":"
A uniform resource identifier (URI) is a string of characters used to identify a name or a resource.
Path, e.g. /obophenotype/uberon/blob/master/uberon_edit.obo
The protocol tells you how to get the resource. Common protocols for web pages are http (HyperText Transfer Protocol) and https (HTTP Secure). The host is the name of the server to contact (the where), which can be a numeric IP address, but is more often a domain name. The path is the name of the resource on that server (the what), here the Uberon anatomy ontology file.
A Internationalized Resource Identifiers (IRI) is an internet protocol standard that allows permitted characters from a wide range of scripts. While URIs are limited to a subset of the ASCII character set, IRIs may contain characters from the Universal Character Set (Unicode/ISO 10646), including Chinese or Japanese kanji, Korean, Cyrillic characters, and so forth. It is defined by RFC 3987.
A Compact URI (CURIE) consists of a prefix and a suffix, where the prefix stands in place of a longer base IRI.
By converting the prefix and appending the suffix we get back to full IRI. For example, if we define the obo prefix to stand in place of the IRI as: http://purl.obolibrary.org/obo/, then the CURIE obo:UBERON_0002280 can be expanded to http://purl.obolibrary.org/obo/UBERON_0002280, which is the UBERON Anatomy term for \u2018otolith\u2019. Any file that contains CURIEs need to define the prefixes in the file header.
"},{"location":"lesson/semantic-database-fundamentals/#what-is-delivered-as-part-of-the-course","title":"What is delivered as part of the course","text":"
in person or video (link videos here as they become available)
"},{"location":"lesson/semantic-database-fundamentals/#additional-materials-and-resources","title":"Additional materials and resources","text":""},{"location":"lesson/semantic-database-fundamentals/#contributors","title":"Contributors","text":"
Nico Matentzoglu
"},{"location":"lesson/templates-for-obo/","title":"Templating systems for OBO ontologies: a deep dive","text":"
Ontologies are notoriously hard to edit. This makes it a very high burden to edit ontologies for anyone but a select few. However, many of the contents of ontologies are actually best edited by domain experts with often little or known ontological training - editing labels and synonyms, curating definitions, adding references to publications and many more. Furthermore, if we simply remove the burden of writing OWL axioms, editors with very little ontology training can actually curate even logical content: for example, if we want to describe that a class is restricted to a certain taxon (also known as taxon-restriction), the editor is often capable to select the appropriate taxon for a term (say, a \"mouse heart\" is restricted to the taxon of Mus musculus), but maybe they would not know how to \"add that restriction to the ontology\".
Tables are great (for a deep dive into tables and triples see here). Scientists in particular love tables, and, even more importantly, can be trained easily to edit data in spreadsheet tools, such as Google Sheets or Microsoft Excel.
Ontology templating systems, such as DOSDP templates, ROBOT templates and Reasonable Ontology Templates (OTTR) allow separating the raw data in the ontology (labels, synonyms, related ontological entities, descriptions, cross-references and other metadata) from the OWL language patterns that are used to manifest them in the ontology. There are three main ingredients to a templating system:
A way to capture the data. In all the systems we care about, these are tables, usually manifested as spreadsheets in Excel or Google Sheets.
A way to capture the template. In ROBOT templates the templates are captured in a header row of the same table that captures the data, in DOSDP templates the templates are captured in a separate YAML file and in OTTR typically the templates are serialised as and RDF-graph in a format like RDF/XML or Turtle.
A toolkit that can combine the data and the template to generate OWL axioms and annotations. ROBOT templates can be compiled to OWL using ROBOT, DOSDP templates can be compiled using DOSDP tools and OTTR templates using Lutra.
In OBO we are currently mostly concerned with ROBOT templates and DOSDP templates. Before moving on, we recommend to complete a basic tutorial in both:
ROBOT template tutorial
DOSDP template tutorial
"},{"location":"lesson/templates-for-obo/#robot-template-vs-dosdp-template","title":"ROBOT template vs DOSDP template","text":"
Ontologies, especially in the biomedical domain, are complex and, while growing in size, increasingly hard to manage for their curators. In this section, we will look at some of the key differences of two popular templating systems in the OBO domain: Dead Simple Ontology Design Patterns (DOSDPs) and ROBOT templates. We will not cover the rationale for templates in general in much depth (the interested reader should check ontology design patterns and Reasonable Ontology Templates (OTTR): Motivation and Overview, which pertains to a different system, but applies none-the-less in general), and focus on making it easier for developers to pick the right templating approach for their particular use case. We will first discuss in detail representational differences, before we go through the functional ones and delineate use cases.
"},{"location":"lesson/templates-for-obo/#structural-differences-formats-and-tools","title":"Structural differences, formats and tools","text":""},{"location":"lesson/templates-for-obo/#dosdp-templates-structure-and-format","title":"DOSDP templates: structure and format","text":"
DOSDP separates data and templates into two files: a yaml file which defines the template, and a TSV file which holds the data. Lets look at s example.
The template: abnormalAnatomicalEntity
pattern_name: abnormalAnatomicalEntity\npattern_iri: http://purl.obolibrary.org/obo/upheno/patterns/abnormalAnatomicalEntity.yaml\ndescription: \"Any unspecified abnormality of an anatomical entity.\"\n\ncontributors:\n - https://orcid.org/0000-0002-9900-7880\n - https://orcid.org/0000-0001-9076-6015\n - https://orcid.org/0000-0003-4148-4606\n - https://orcid.org/0000-0002-3528-5267\n\nclasses:\n quality: PATO:0000001\n abnormal: PATO:0000460\n anatomical entity: UBERON:0001062\n\nrelations:\n inheres_in_part_of: RO:0002314\n has_modifier: RO:0002573\n has_part: BFO:0000051\n\nannotationProperties:\n exact_synonym: oio:hasExactSynonym\n\nvars:\n anatomical_entity: \"'anatomical entity'\"\n\nname:\n text: \"abnormal %s\"\n vars:\n - anatomical_entity\n\nannotations:\n - annotationProperty: exact_synonym\n text: \"abnormality of %s\"\n vars:\n - anatomical_entity\n\ndef:\n text: \"Abnormality of %s.\"\n vars:\n - anatomical_entity\n\nequivalentTo:\n text: \"'has_part' some ('quality' and ('inheres_in_part_of' some %s) and ('has_modifier' some 'abnormal'))\"\n vars:\n - anatomical_entity\n
ROBOT encodes both the template and the data in the same TSV; after the table header, the second row basically encodes the entire template logic, and the data follows in table row 3.
ID Label EQ Anatomy Label ID LABEL EC 'has_part' some ('quality' and ('inheres_in_part_of' some %) and ('has_modifier' some 'abnormal')) HP:0040286 Abnormal axial muscle morphology UBERON:0003897 axial muscle HP:0011297 Abnormal digit morphology UBERON:0002544 digit
Note that for the Anatomy Label we deliberately left the second row empty, which instructs the ROBOT template tool to completely ignore this column.
"},{"location":"lesson/templates-for-obo/#a-discussion-on-the-main-differences","title":"A discussion on the main differences","text":""},{"location":"lesson/templates-for-obo/#ontology-engineering-perspective","title":"Ontology Engineering perspective","text":"
From an ontology engineering perspective, the essence of the difference between DOSDP and ROBOT templates could be captured as follows:
DOSDP templates are more about generating annotations and axioms, while ROBOT templates are more about curating annotations and axioms.\n
Curating annotations and axioms means that an editor, or ontology curator, manually enters the labels, synonyms, definitions and so forth into the spreadsheet.
Generating axioms in the sense of this section means that we try to automatically generate labels, synonyms, definitions and so forth based on the related logical entities in the patterns. E.g., using the example template above, the label \"abnormal kidney\" would automatically be generated when the Uberon term for kidney is supplied.
While both ROBOT and DOSDP can be used for \"curation\" of annotation of axioms, DOSDP seeks to apply generation rules to automatically generate synonyms, labels, definitions and so forth while for ROBOT template seeks to collect manually curated information in an easy-to-use table which is then compiled into OWL. In other words:
the average DOSDP user will not write their own labels, definitions and synonyms - they will want those to be generated automatically from a set of simple rules;
the average ROBOT template user will not want automatically generated definitions, labels and synonyms - they will want to capture their own.
"},{"location":"lesson/templates-for-obo/#sharing-and-re-use","title":"Sharing and Re-use","text":"
However, there is another dimension in which both approaches differ widely: sharing and re-use. DOSDPs by far the most important feature is that it allows a community of developers to rally around a modelling problem, debate and establish consensus; for example, a pattern can be used to say: this is how we model abnormal anatomical entities. Consensus can be made explicit by \"signing off\" on the pattern (e.g. by adding your ORCId to the list of contributors), and due to the template/data separation, the template can be simply imported using its IRI (for example http://purl.obolibrary.org/obo/upheno/patterns/abnormalAnatomicalEntity.yaml) and re-used by everyone. Furthermore, additional metadata fields including textual descriptions, and more recently \"examples\", make DOSDP template files comparatively easy to understand, even by a less technically inclined editor.
ROBOT templates on the other hand do not lend themselves to community debates in the same way; first of all, they are typically supplied including all data merged in; secondly, they do not provide additional metadata fields that could, for example, conveniently be used to represent a sign off (you could, of course, add the ORCId's into a non-functional column, or as a pipe-separated string into a cell in the first or second row; but its obvious that this would be quite clunky) or a textual description. A yaml file is much easier for a human to read and understand then the header of a TSV file, especially when the template becomes quite large.
However, there is a flipside to the strict separation of data and templates. One is that DOSDP templates are really hard to change. Once, for example, a particular variable name was chosen, renaming the variable will require an excessive community-wide action to rename columns in all associated spreadsheets - which requires them all to be known beforehand (which is not always the case). You don't have such a problem with ROBOT templates; if you change a column name, or a template string, everything will continue to work without any additional coordination.
Both ROBOT templates and DOSDP templates are widely used. The author of this page uses both in most of the projects he is involved in, because of their different strengths and capabilities. You can use the following rules of thumb to inform your choice:
Consider ROBOT templates if your emphasis is on
manually curating labels, definitions, synonyms and axioms or other annotations
managing your templates in the spreadsheet itself is a concern for you (this is often the case, for example, when turning an existing data table into a ROBOT template ad hoc)
Consider DOSDP templates if your emphasis is on
re-use, community-wide implementation of the same templates and community discussion, you should consider DOSDP templates
automatically generating labels, definitions, synonyms from rules in the pattern.
"},{"location":"lesson/templates-for-obo/#detour-concerns-with-managing-tables","title":"Detour: Concerns with Managing Tables","text":"
There is a nice debate going on which questions the use of tables in ontology curation altogether. There are many nuances in this debate, but I want to stylise it here as two schools of thoughts (there are probably hundreds in between, but this makes it easier to follow): The one school (let's call them Tablosceptics) claims that using tables introduces a certain degree of fragility into the development process due to a number of factors, including:
losing the immediateness of QC feedback; Table-based development, so the Tablosceptics, encourages lazy editing (adding stuff to a template and then not reviewing the consequence properly, which we will discuss in more depth later).
losing track of the ID space (in a multi-table world, it becomes increasingly hard to manage IDs, making sure they are not double used etc) and 3) encouraging bad design (relying more on assertion than inference).
They prefer to use tools like Protege that show the curator immediately the consequences of their actions, like reasoning errors (unintended equivalent classes, unsatisfiable classes and other unintended inferences). The Tablophile school of thought responds to these accusations in essence with \"tools\"; they say that tables are essentially a convenient matrix to input the data (which in turns opens ontology curation to a much wider range of people), and it is up to the tools to ensure that QC is run, hierarchies are being presented for review and weird ID space clashes are flagged up. Furthermore, they say, having a controlled input matrix will actually decrease the number of faulty annotations or axioms (which is evidenced by the large number of wrongful annotation assertions across OBO foundry ontologies I see every day as part of my work). At first sight, both template systems are affected equally by the war of the Tablosceptics and the Tablophile. Indeed, in my on practice, the ID space issue is really problematic when we manage 100s and more templates, and so far, I have not seen a nice and clear solution that ensures that no ID used twice unless it is so intended and respects ID spaces which are often semi-formally assigned to individual curators of an ontology.
Generally in this course we do not want to take a 100% stance. The author of this page believes that the advantage of using tables and involving many more people in the development process outweighs any concerns, but tooling is required that can provide more immediate feedback when such tables such as the ones presented here are curated at scale.
"},{"location":"lesson/using-disease-and-phenotype-ontologies/","title":"Finding and using Disease and Phenotype Ontologies","text":""},{"location":"lesson/using-disease-and-phenotype-ontologies/#prerequisites","title":"Prerequisites","text":"
"},{"location":"lesson/using-disease-and-phenotype-ontologies/#what-is-delivered-as-part-of-the-course","title":"What is delivered as part of the course?","text":"
Description: An introduction to the landscape of disease and phenotype terminologies and ontologies, and how they can be used to add value to your analysis.
Video from Disease and Phenotypes c-path lesson 2021-06-16
"},{"location":"lesson/using-disease-and-phenotype-ontologies/#additional-materials-and-resources","title":"Additional materials and resources","text":""},{"location":"lesson/using-disease-and-phenotype-ontologies/#contributors","title":"Contributors","text":"
Nicole Vasilevsky
Nico Matentzoglu
"},{"location":"lesson/using-disease-and-phenotype-ontologies/#major-disease-and-phenotype-ontologies-that-are-available","title":"Major disease and phenotype ontologies that are available","text":"
A landscape analysis of major disease and phenotype ontologies that are currently available is here (also available in Zenodo here).
"},{"location":"lesson/using-disease-and-phenotype-ontologies/#decide-which-phenotype-or-disease-ontology-to-use-for-different-use-cases","title":"Decide which phenotype or disease ontology to use for different use cases","text":"
Different ontologies are built for different purposes and were created for various reasons. For example, some ontologies are built for text mining purposes, some are built for annotating data and downstream computational analysis.
The unified phenotype ontology (uPheno) aggregates species-specific phenotype ontologies into a unified resource. Several species-specific phenotype ontologies exist, such as the Human Phenotype Ontology, Mammalian Phenotype Ontology (http://www.informatics.jax.org/searches/MP_form.shtml), and many more.
Similarly to the phenotype ontologies, there are many disease ontologies that exist that are specific to certain areas of diseases, such as infectious diseases (e.g. Infectious Disease Ontology), cancer (e.g. National Cancer Institute Thesaurus), rare diseases (e.g. Orphanet), etc.
In addition, there are several more general disease ontologies, such as the Mondo Disease Ontology, the Human Disease Ontology (DO), SNOMED, etc.
Different disease ontologies may be built for different purposes; for example, ontologies like Mondo and DO are intended to be used for classifying data, and downstream computational analyses. Some terminologies are used for indexing purposes, such as the International classification of Diseases (ICD). ICD-11 is intended for indexing medical encounters for the purposes of billing and coding. Some of the disease ontologies listed on the landscape contain terms that define diseases, such as Ontology for General Medical Sciences (OGMS) are upper-level ontologies and are intended for integration with other ontologies.
When deciding on which phenotype or disease ontology to use, some things to consider:
Do you need a more specific ontology, such as a species-specific ontology, or do you need a more general ontology that is cross-species or covers more aspects of diseases?
Is the ontology open and free to use?
Does the description of the ontology describe its intended use? For example, some ontologies are built for text mining purposes, some are built for annotating data and downstream computational analysis.
Is the ontology actively maintained?
Does the ontology contain the terms you need? If not, is there a mechanism to request changes or add new terms? Are the ontology developers responsive to change requests on their tracker?
Is the ontology widely used by the community? You can check things like active contributors on GitHub, usages described on the OBO Foundry page (for example http://obofoundry.org/ontology/mondo.html), published papers, and/or citations.
"},{"location":"lesson/using-disease-and-phenotype-ontologies/#understand-how-to-leverage-disease-and-phenotype-ontologies-for-advanced-data-analytics","title":"Understand how to leverage disease and phenotype ontologies for advanced data analytics","text":""},{"location":"lesson/using-disease-and-phenotype-ontologies/#how-to-integrate-other-data","title":"How to integrate other data","text":""},{"location":"pathways/early-career-data-scientist/","title":"Early Career Data Scientist","text":"
# Early Career Data Scientist
Description: A collection of videos, tutorials, training materials, and exercises targeted towards any entry-level, early-career person interested in learning basic skills in data science.
"},{"location":"pathways/early-career-data-scientist/#1-data-science-ethics","title":"1. Data Science Ethics","text":"
Description: Introductory data science ethics videos hosted by Northeat Big Data Innovation Hub.
"},{"location":"pathways/early-career-data-scientist/#2-overview-what-is-data-science","title":"2. Overview: What is Data Science","text":""},{"location":"pathways/early-career-data-scientist/#videos_1","title":"Videos","text":"
IBM OpenDS4All What is Data Science? with Yucen Wang - Part I
IBM OpenDS4All What is Data Science? with Yucen Wang - Part II
Create a GitHub account, see https://docs.github.com/en/get-started/signing-up-for-github/signing-up-for-a-new-github-account
Download and install GitHub Desktop
"},{"location":"pathways/early-career-data-scientist/#tutorials","title":"Tutorials","text":""},{"location":"pathways/early-career-data-scientist/#introduction-to-github","title":"Introduction to GitHub","text":"
Help improve this pathway! Make edits to this OBO Academy page and make a pull request. (For example, find typos to fix, add or revise content to this document, etc.)
Create a GitHub website by forking this repository: https://github.com/laderast/academic_site_workshop
Note: for the tutorials below PC users need to install ODK (instructions are linked from the tutorial)
Tutorial: Very (!) short introduction to the command line for ontology curators and semantic engineers: Part 1
Tutorial: Very (!) short introduction to the command line for ontology curators and semantic engineers: Part 2
"},{"location":"pathways/early-career-data-scientist/#5-introduction-to-ontologies","title":"5. Introduction to Ontologies","text":""},{"location":"pathways/early-career-data-scientist/#articles-to-read","title":"Articles to read","text":"
"},{"location":"pathways/early-career-data-scientist/#effective-communication-in-data-science","title":"Effective Communication in Data Science","text":""},{"location":"pathways/early-career-data-scientist/#tutorials_2","title":"Tutorials","text":"
Description: These guidelines are developed for anyone interested in contributing to ontologies to guide how to contribute to OBO Foundry ontologies.
"},{"location":"pathways/ontology-contributor/#why-should-you-contribute-to-ontology-development-efforts","title":"Why should you contribute to ontology development efforts?","text":"
Ontologies are routinely used for data standardization and in analytical analysis, but the ontologies themselves are under constant revisions and iterative development. Building ontologies is a community effort, and we need expertise from different areas:
Technical expertise
Domain expertise
User experiences
The OBO foundry ontologies are open, meaning anyone can access them and contribute to them. The types of contributions may include reporting issues, identifying bugs, making requests for new terms or changes, and you can also contribute directly to the ontology itself- if you are familiar with ontology editing workflows, you can download our ontologies and make edits on a branch and make a pull request in GitHub.
"},{"location":"pathways/ontology-contributor/#providing-feedback-to-an-ontology","title":"Providing Feedback to an Ontology","text":"
The preferred mechanism for feedback for almost all OBO Foundry ontologies is via the ontology's GitHub issue tracker.
To find the correct GitHub issue tracker, go to the OBO Foundry website website and search for a particular ontology.
For example, click on go (Gene Ontology), and you should see a link to the tracker (https://github.com/geneontology/go-ontology/issues/)
The OBO Metadata also has a link to a contact but this is generally for OBO administrative purposes and should not be used for general questions, new term requests, or general feedback
Some ontologies may have other means of engaging their use community, and these should all be listed in a standard way on the OBO page. This includes mailing lists, slack groups, and Twitter or other social media accounts.
"},{"location":"pathways/ontology-contributor/#getting-started-with-github","title":"Getting Started with GitHub","text":"
Open a free account at https://github.com/.
GitHub Fundamentals for OBO Engineers. Provides an introduction to GitHub including:
how to get started
an overview of the organization of GitHub
an introduction to Markdown (the simple markup language used in GitHub to format text, like bold or italics)
types of content that can be added to GitHub (e.g., you can attach a screenshot to an issue)
Intro to managing and tracking issues in GitHub. This tutorial walks you through creating issues in GitHub.
"},{"location":"pathways/ontology-contributor/#using-ontologies-and-ontology-terms","title":"Using Ontologies and Ontology Terms","text":"
Why ontologies are useful
Finding good ontologies
Ontology repositories
Assessing ontologies for use
"},{"location":"pathways/ontology-contributor/#contributing-to-ontologies","title":"Contributing to Ontologies","text":"
Community feedback is welcome for all open OBO Foundry ontologies. Feedback is often provided in the form of:
New terms requests
Add/revise synonyms, definitions
Reclassify a term
Report a bug
etc.
"},{"location":"pathways/ontology-contributor/#ways-to-provide-feedback","title":"Ways to provide feedback","text":"
Create a new issue on a GitHub issue tracker
See the lesson on Identifying missing terms
See the lesson on Making term requests to existing ontologies
Join the discussion: Comment on tickets or the discussion board
Join the conversation: Attend ontology calls (many ontology developer groups have recurring calls open to the community. Contact the ontology owner to request information about calls.)
Edit the ontology file: make changes on a branch and do a pull request (more advanced)
Note: There is no one single accepted way of doing ontology curation in the OBO-World, see here. This guide reflects the practice of the GO-style ontology curation, as it is used by GO, Uberon, CL, PATO and others.
Note: Work on this document is still in progress, items that are not linked are currently being worked on.
Download and install Protege. See instructions on how to set up Protege here
Install ELK reasoner in protege
Setting up your ID range
Setting up ODK
"},{"location":"pathways/ontology-curator-go-style/#learning","title":"Learning","text":""},{"location":"pathways/ontology-curator-go-style/#learning-about-ontologies","title":"Learning about Ontologies","text":"
Fundamentals of Ontologies
"},{"location":"pathways/ontology-curator-go-style/#learning-git-and-github","title":"Learning Git and GitHub","text":"
Note: There is no one single accepted way of doing ontology curation in the OBO-World, see here. This guide reflects the practice of the OBI-style ontology curation, as it is used by OBI, IAO and others.
"},{"location":"pathways/ontology-curator-obi-style/#getting-set-up","title":"Getting Set-up","text":""},{"location":"pathways/ontology-curator-obi-style/#learning","title":"Learning","text":""},{"location":"pathways/ontology-curator-obi-style/#learning-git-and-github","title":"Learning Git and GitHub","text":"
Fundamentals of GitHub
Github issues
Cloning a Repo
Creating pull requests
"},{"location":"pathways/ontology-curator-obi-style/#learning-how-to-edit-ontologies","title":"Learning how to edit ontologies","text":""},{"location":"pathways/ontology-curator-obi-style/#ontology-curator-how-to-collection","title":"Ontology Curator How To Collection","text":""},{"location":"pathways/ontology-curator/","title":"Ontology Curator Pathway","text":"
There is no one single accepted methodology for building ontologies in the OBO-World. We can distinguish at least two major schools of ontology curation
GO-style ontology curation
OBI-style ontology curation
Note that there are many more variants, probably as many as there are ontologies. Both schools differ only in how they curate their ontologies - the final product is always an ontology in accordance with OBO Principles. These are some of the main differences of the two schools:
GO-style OBI-style Edit format Historically developed in OBO format Developed in an OWL format Annotation properties Many annotation properties from the oboInOwl namespace, for example for synonyms and provenance. Many annotation properties from the IAO namespace. Upper Ontology Hesitant alignment with BFO, often uncommitted. Strong alignment with BFO. Logic Tend do be simple existential restrictions (some), ontologies in OWL 2 EL. No class expression nesting. Simple logical definition patterns geared towards automating classification Tend to use a lot more expressive logic, including only and not. Class expression nesting can be more complex. Examples GO, Uberon, Mondo, HPO, PATO, CL, BSPO OBI, IAO, OGMS
There are a lot of processes happening that are bringing these schools together, sharing best practices (GitHub, documentation) and reconciling metadata conventions and annotation properties in the OBO Metadata Ontology (OMO). The Upper Level alignment is now done by members of both schools through the Core Ontology for Biology and Biomedicine (COB). While these processes are ongoing, we decided to curate separate pathways for both schools:
As a ontology engineer, it would be useful for you to know how curators work, as such, it would be useful to be familiar with all the concepts in the ontology curator pathways document. This pathways will however be focusing on the engineering side of things.
"},{"location":"pathways/ontology-engineer/#ontology-engineer-how-to-collection","title":"Ontology Engineer How To Collection","text":"
This section is a non-ordered collection of how to documents that an engineer might need (this includes everything from the curators list as they may be pertinent knowledge to an engineer).
Adding taxon restrictions
Changing files in pull requests
Cloning a repo
Creating new terms
Daily Curator Workflow
Fixing Conflicts
Creating a github fork
Creating a github pull request
Setting up your ID range
Setting up ELK reasoner in protege
Obsoleting terms
Merging terms
Creating slims
Setting up ODK
Switching ontologies
Dealing with large ontologies
"},{"location":"pathways/pathways/","title":"Introduction to pathways","text":"
Pathways are materials from OBOOK in a linear fashion for the purpose of helping people in different roles finding the materials relevant to their work more easily. To browse through the pathways, look under the \"Pathways\" menu item.
"},{"location":"reference/chatgpt-prompts-for-ontology-development/","title":"Leveraging ChatGPT for ontology curation","text":""},{"location":"reference/chatgpt-prompts-for-ontology-development/#effective-chatgpt-prompts-for-ontology-development","title":"Effective ChatGPT prompts for ontology development","text":"
For a basic tutorial on how to leverage ChatGPT for ontology development see here.
"},{"location":"reference/chatgpt-prompts-for-ontology-development/#act-as-a-mapping-api","title":"Act as a mapping API","text":"
I want you to act as a REST API, which takes natural language searches a an input and returns an SSSOM mapping in valid JSON in a codeblock, no comments, no additional text. An example of a valid mapping is
As a first task, I want you to return a suitable mapping for MONDO:0004975 in ICD 10 CM.
"},{"location":"reference/formatting-license/","title":"Formatting your ontology annotations correctly","text":"
The new OBO Foundry guidelines encourage the annotation of ontologies with an appropriately formatted description, title and license. Here are some examples that can be used as a guide to implement those in your ontology.
Note: these examples purposefully do not include version information, this should not be manually added, instead it should be added by ROBOT as part of a pipeline. An ontology set up with the ODK will take care of all of this for you.
Prefix(:=<http://purl.obolibrary.org/obo/license.owl#>)\nPrefix(owl:=<http://www.w3.org/2002/07/owl#>)\nPrefix(rdf:=<http://www.w3.org/1999/02/22-rdf-syntax-ns#>)\nPrefix(xml:=<http://www.w3.org/XML/1998/namespace>)\nPrefix(xsd:=<http://www.w3.org/2001/XMLSchema#>)\nPrefix(rdfs:=<http://www.w3.org/2000/01/rdf-schema#>)\n\n\nOntology(<http://purl.obolibrary.org/obo/license.owl>\nAnnotation(<http://purl.org/dc/elements/1.1/description> \"An integrated and fictional ontology for the description of abnormal tomato phenotypes.\"^^xsd:string)\nAnnotation(<http://purl.org/dc/elements/1.1/title> \"Tomato Phenotype Ontology (TPO)\"^^xsd:string)\nAnnotation(<http://purl.org/dc/terms/license> <https://creativecommons.org/licenses/by/3.0/>)\n\n)\n
format-version: 1.2\nontology: license\nproperty_value: http://purl.org/dc/elements/1.1/description \"An integrated and fictional ontology for the description of abnormal tomato phenotypes.\" xsd:string\nproperty_value: http://purl.org/dc/elements/1.1/title \"Tomato Phenotype Ontology (TPO)\" xsd:string\nproperty_value: http://purl.org/dc/terms/license https://creativecommons.org/licenses/by/3.0/\n
"},{"location":"reference/frequently-used-odk-commands/","title":"Frequently used ODK commands","text":""},{"location":"reference/frequently-used-odk-commands/#updates-the-makefile-to-the-latest-odk","title":"Updates the Makefile to the latest ODK","text":"
sh run.sh make update_repo\n
"},{"location":"reference/frequently-used-odk-commands/#recreates-and-deploys-the-automated-documentation","title":"Recreates and deploys the automated documentation","text":"
sh run.sh make update_docs\n
"},{"location":"reference/frequently-used-odk-commands/#preparing-a-new-release","title":"Preparing a new release","text":"
sh run.sh make prepare_release\n
"},{"location":"reference/frequently-used-odk-commands/#refreshing-a-single-import","title":"Refreshing a single import","text":"
sh run.sh make refresh-%\n
Example:
sh run.sh make refresh-chebi\n
"},{"location":"reference/frequently-used-odk-commands/#refresh-all-imports","title":"Refresh all imports","text":"
sh run.sh make refresh-imports\n
"},{"location":"reference/frequently-used-odk-commands/#refresh-all-imports-excluding-large-ones","title":"Refresh all imports excluding large ones","text":"
sh run.sh make refresh-imports-excluding-large\n
"},{"location":"reference/frequently-used-odk-commands/#run-all-the-qc-checks","title":"Run all the QC checks","text":"
sh run.sh make test\n
"},{"location":"reference/frequently-used-odk-commands/#print-the-version-of-the-currently-installed-odk","title":"Print the version of the currently installed ODK","text":"
sh run.sh make odkversion\n
"},{"location":"reference/frequently-used-odk-commands/#checks-the-owl2-dl-profile-validity","title":"Checks the OWL2 DL profile validity","text":"
(of a specific file)
sh run.sh make validate_profile_%\n
Example:
sh run.sh make validate_profile_hp-edit.owl\n
"},{"location":"reference/gh-actions-errors/","title":"Common Errors in GitHub actions","text":""},{"location":"reference/gh-actions-errors/#killed-running-out-of-memory","title":"Killed: Running out of memory","text":"
Running the same workflow several times simultaneously (e.g. if two PRs are submitted in a short time, and the second PR triggers the CI workflow while the CI workflow triggered by the first PR is still running) could lead to lack-of-memory situations because all concurrent workflows have to share a single memory limit.
(Note: it isn't really clear with documentation of GitHub Actions on whether concurrent workflow runs share a single memory limit.)
What could possibly be done is to forbid a given workflow from ever running as long as there is already a run of the same workflow ongoing, using the concurrency property.
This page aims to consolidate some tips and tricks that ontology editors have found useful in using git. It is not meant to be a tutorial of git, but rather as a page with tips that could help in certain specialised situations.
"},{"location":"reference/git-faq/#reverting-commits","title":"Reverting Commits","text":""},{"location":"reference/git-faq/#reverting-particular-files-back-to-master-version","title":"Reverting particular files back to master version","text":"
If you want to revert only certain files (eg import files), you can do it using Terminal. For this example, we will use uberon_import.owl as the file we want reverted back to the version in master branch, however, this can be done on any file.
Assuming your directory is set to src/ontology, in terminal use: git checkout master -- imports/uberon_import.owl.
Commit the change to the branch as normal.
"},{"location":"reference/git-faq/#reverting-particular-files-back-to-a-previous-version","title":"Reverting particular files back to a previous version","text":"
If you want to revert a file back to a previous version instead of master, you can use the commit ID.
To do this, in Terminal use: git log to list out the previous commits and copy the commit code of the commit you would like to revert to (example: see yellow string of text in screenshot below).
Press q on your keyboard to quit git log (or down arrow to scroll down to continue to find the commit ID you want to revert if it is further down).
In terminal use: git checkout ff18c9482035062bbbbb27aaeb50e658298fb635 -- imports/uberon_import.owl using whichever commit code you want instead of the commit code in this example.
For most of our training activities, we recommend using GitHub Desktop. It provides a very convenient way to push and pull changes, and inspect the \"diff\". It is, however, not mandatory if you are already familiar with other git workflows (such as command line, or Sourcetree).
"},{"location":"reference/github-intro/","title":"Git, GitHub and GitHub Desktop (version control)","text":"
A repository can consist of many files with several users simultaneously editing those files at any moment in time. In order to ensure conflicting edits between the users are not made and a history of the edits are tracked, software classified as a \"distributed version control system\" is used.
All OBO repositories are managed by the Git version control system. This allows users to make their own local branch of the repository, i.e., making a mirror copy of the repository directories and files on their own computers, and make edits as desired. The edits can then be reviewed by other users before the changes are incorporated in the 'main' or 'master' branch of the repository. This process can be executed by running Git line commands and/or by using a web interface (Github.com) along with a desktop application (GitHub Desktop).
Documentation, including an introduction to GitHub, can be found here: Hello World.
"},{"location":"reference/glossary-of-terms/","title":"Glossary of Terms","text":"
This document is a list of terms that you might encounter in the ontology world. It is not an exhaustive list and will continue to evolve. Please create a ticket if there is a term you find missing or a term you encounter that you do not understand, and we will do our best to add them. This list is not arranged in any particular order. Please use the search function to find terms.
Acknowledgement: Many terms are taken directly from OAK documentation with the permission of Chris Mungall. Many descriptions are also taken from https://www.w3.org/TR/owl2-syntax/.
Annotation properties are OWL axioms that are used to place annotations on individuals, class names, property names, and ontology names. They do not affect the logical definition unless they are used as a \"shortcut\" that a pipeline expands to a logical axiom.
If an individual is not expected to be used outside an ontology, one can use an anonymous individual, which is identified by a local node ID rather than a global IRI. Anonymous individuals are analogous to blank nodes in RDF.
Application Programming Interface. An intermediary that allows two or more computer programs to communicate with each other. In ontologies, this usually means an Endpoint in which the ontology can be programmatically accessed.
Axioms are statements that are asserted to be true in the domain being described. For example, using a subclass axiom, one can state that the class a:Student is a subclass of the class a:Person. (Note: in OWL, there are also annotation axioms which does not apply any logical descriptions)
Standardized and organized arrangements of words and phrases that provide a consistent way to describe data. A controlled vocabulary may or may not include definitions. Ontologies can be seen as a controlled vocabulary expressed in an ontological language which includes relations.
A CURIE is a compact URI. For example, CL:0000001 expands to http:purl.obolibrary.org/obo/CL_0000001. For more information, please see https://www.w3.org/TR/curie/.
dataProperty relate OWL entities to literal data (e.g., strings, numbers, datetimes, etc.) as opposed to ObjectProperty which relate individuals to other OWL entities. Unlike AnnotationProperty, dataProperty axioms fall on the logical side of OWL and are hence useable by reasoners.
Datatypes are OWL entities that refer to sets of data values. Thus, datatypes are analogous to classes, the main difference being that the former contain data values such as strings and numbers, rather than individuals. Datatypes are a kind of data range, which allows them to be used in restrictions. For example, the datatype xsd:integer denotes the set of all integers, and can be used with the range of a dataProperty to state that the range of said dataProperty must be an integer.
Description Logics (DL) are a family of formal knowledge representation languages. It provides a logical formalism for ontologies and is what OWL is based on. DL querying can be used to query ontologies in Protege.
Domain, in reference to a dataProperty or ObjectProperty, refers to the restriction on the subject of a triple - if a given property has a given class in its domain this means that any individual that has a value for the property, will be inferred to be an instance of that domain class. For example, if John hasParent Mary and Person is listed in the domain of hasParent, then John will be inferred to be an instance of Person.
A typed, directed link between Nodes in a knowledge graph. Translations of OWL into Knowledge graphs vary, but typically edges are generated for simple triples, relating two individuals or two classes via an AnnotationProperty or ObjectProperty and simple existential restrictions (A SubClassOf R some B), with the edge type corresponding to the property.
A relationship between two classes, A R (some) B, that states that all individuals of class A stand in relation R to at least one individual of class B. For example, neuron has_part some dendrite states that all instances of neuron have at least one individual of type dentrite as a part. In Manchester syntax, the keyword 'some' is used to denote existential restrictions and is interpreted as \"there exists\", \"there is at least one\", or \"some\". See documentation on classifications for more details.
An official syntax of OWL (others are RDF-XML and OWL-XML) in which each line represents and axiom (although things get a little more complex with axiom annotations, and axioms use prefix syntax (order = relation (subject, object)). This is in contrast to in-fix syntax (e.g. Manchester syntax) (order = subject relation object). Functional syntax is the preferred syntax for editor files maintained on GitHub, because it can be safely diff'd and (somewhat) human readable.
Formally a graph is a data structure consisting of Nodes and Edges. There are different forms of graphs, but for our purposes an ontology graph has all Terms as nodes, and relationships connecting terms (is-a, part-of) as edges. Note the concept of an ontology graph and an RDF graph do not necessarily fully align - RDF graphs of OWL ontologies employ numerous blank nodes that obscure the ontology structure.
An OWL entity that represents an instance of a class. For example, the instance \"John\" or \"John's heart\". Note that instances are not commonly represented in ontologies. For instance, \"John\" (an instance of person) or \"John's heart\" (an instance of heart).
A measure of how informative an ontology concept is; broader concepts are less informative as they encompass many things, whereas more specific concepts are more unique. This is usually measured as -log2(Pr(term)). The method of calculating the probability varies, depending on which predicates are taken into account (for many ontologies, it makes sense to use part-of as well as is-a), and whether the probability is the probability of observing a descendant term, or of an entity annotated using that term.
Knowledge Graph Change Language (KGCL) is a data model for communicating desired changes to an ontology. It can also be used to communicate differences between two ontologies. See KGCL docs.
A network of real-world entities (i.e., objects, events, situations, and concepts) that illustrates the relationships between them. Knowledge graphs (in relation to ontologies) are thought of as real data built using an ontology as a framework.
Usually refers to a human-readable text string corresponding to the rdfs:label predicate. Labels are typically unique per ontology. In OBO Format and in the bio-ontology literature, labels are sometimes called Names. Sometimes in the machine learning literature, and in databases such as Neo4J, \"label\" actually refers to a Category.
An Individual that is given an explicit name that can be used in any ontology to refer to the same object; named individuals get IRIs whereas anonymous individuals do not.
An owl entity that is used to related 2 individuals ('my left foot' part_of 'my left leg') or two classes ('foot' part_of some leg) or an individual and a class ('the neuron depicted in this image' (is) has_soma_location some 'primary motor cortex. More rarely it is used to define a class in terms of some individual (the class 'relatives of Shawn' related_to Value Shawn.
Open Biological and Biomedical Ontology. This could refer to the OBO Foundry (e.g. OBO ontologies = ontologies that follow the standards of the OBO Foundry) or OBO Format
A serialization format for ontologies designed for easy viewing, direct editing, and readable diffs. It is popular in bioinformatics, but not widely used or known outside the genomics sphere. OBO is mapped to OWL, but only expresses a subset, and provides some OWL abstractions in a more easy to understand fashion.
Ontology Lookup Service. An Ontology Repository that is a curated collection of multiple biologically relevant ontologies, many from OBO. OLS can be accessed with this link
The systems or platform where various types of ontologies are stored from different sources and provide the ability to data providers and application developers to share and reuse the ontologies.
Web Ontology Language. An ontology language that uses constructs from Description Logic. OWL is not itself an ontology format, it can be serialized through different formats such as Functional Syntax, and it can be mapped to :RDF and serialized via an RDF format.
In the context of OWL, the term Annotation means a piece of metadata that does not have a strict logical interpretation. Annotations can be on entities, for example, Label annotations, or annotations can be on Axioms.
OWL Entities, such as classes, properties, and individuals, are identified by IRIs. They form the primitive terms of an ontology and constitute the basic elements of an ontology. For example, a class a:Person can be used to represent the set of all people. Similarly, the object property a:parentOf can be used to represent the parent-child relationship. Finally, the individual a:Peter can be used to represent a particular person called \"Peter\". The following is a complete list of types of OWL Entities:
An OWL entity that represents the type of a Relationship. Typically corresponds to an ObjectProperty in OWL, but this is not always true; in particular, the is-a relationship type is a builtin construct SubClassOf in OWL Examples:
Range, in reference to a dataProperty or ObjectProperty, refers to the restriction on the object of a triple - if a given property has a given class in its domain this means that any individual that has a value for the property (i.e. is the subject of a relation along the property), will be inferred to be an instance of that domain class. For example, if John hasParent Mary and Person is listed in the domain of hasParent, then John will be inferred to be an instance of Person.
An ontology tool that will perform inference over an ontology to yield new axioms (e.g. new Edges) or to determine if an ontology is logically coherent.
A Relationship is a type connection between two OWL entities. The first element is called the subject, and the second one the Object, with the type of connection being the Relationship Type. Sometimes Relationships are equated with Triples in RDF but this can be confusing, because some relationships map to multiple triples when following the OWL RDF serialization. An example is the relationship \"finger part-of hand\", which in OWL is represented using a Existential Restriction that maps to 4 triples.
A means of measuring similarity between either pairs of ontology concepts, or between entities annotated using ontology concepts. There is a wide variety of different methods for calculating semantic similarity, for example Jaccard Similarity and Information Content based measures.
Semantic SQL is a proposed standardized schema for representing any RDF/OWL ontology, plus a set of tools for building a database conforming to this schema from RDF/OWL files. See Semantic-SQL
A named collection of elements, typically grouped for some purpose. In the ODK/OBO world, there is a standard annotation property and pattern for this, for more information, see the subset documentation.
The process of annotating spans of texts within a text document with references to ontology terms, or the result of this process. This is frequently done automatically. The Bioportal implementation provides text annotation services.
A set of three entities that codifies a statement about semantic data in the form of Subject-predicate-Object expressions (e.g., \"Bob is 35\", or \"Bob knows John\"). Also see Relationship.
A purpose-built database for the storage and retrieval of triples through semantic queries. A triple is a data entity composed of subject\u2013predicate\u2013object, like \"Bob is 35\" or \"Bob knows Fred\".
An integrated OBO ontology Triplestore and a Ontology Repository, with merged set of mutually referential OBO ontologies (see the ubergraph github for list of ontologies included), that allows for SPARQL querying of integrated OBO ontologies.
A Uniform Resource Indicator, a generalization of URL. Most people think of URLs as being solely for addresses for web pages (or APIs) but in semantic web technologies, URLs can serve as actual identifiers for entities like OWL entities. Data models like OWL and RDF use URIs as identifiers. In OAK, URIs are mapped to CURIE
"},{"location":"reference/glossary/","title":"Glossary for concepts in and around OBO","text":"
IMPORTANT NOTE TO EDITORS, MERGE THIS WITH glossary.md.\n
New OBOOK Glossary
"},{"location":"reference/glossary/#tools","title":"Tools","text":"Term Definition Type Docs Ontology Development Kit (ODK) A toolkit and docker image for managing ontology releases. Tool docs ROBOT A toolkit for transforming and interacting with ontologies. Tool docs rdflib A python library to interact with RDF data Library docs OWL API A java-based API to interact with OWL ontologies Library docs Protege A typical ontology development tool used by ontology developers in the OBO-sphere Tool docs ROBOT templates A templating system based on tables, where the templates are integrated in the same table as the data Standard docs Dead Simple Ontology Design Patterns (DOSDP) A templating system for ontologies with well-documented patterns and templates. Standard docs DOSDP tools DOSDP is the open source reference implementation of the DOSDP templating language. Tool docs Reasonable Ontology Templates (OTTR) A system for composable ontology templates and documentation Standard docs Lutra Lutra is the open source reference implementation of the OTTR templating language. Tool docs"},{"location":"reference/go-style-annotation-property-practice/","title":"Recommended metadata properties to use in curating OBO ontologies (GO-style)","text":"
Note that while most of the practices documented here apply to all OBO ontologies this recommendation applies only to ontologies that are developed using GO-style curation workflows.
Type Property to use Required Number/Limit Description Format Annotation Reference/Comments Label rdfs:label Y Max 1 * Full name of the term, must be unique. Free text None * some ontologies have multiple labels for different languages, in which case, there should maximum be one label per language Definition IAO:0000115 Y Max 1 A textual definition of ther term. In most ontologies, must be unique. Free text database_cross_reference: reference materials used and contributors (in ORCID ID link format) See this document for guide on writing definitions Contributor dcterms:contributor N (though highly reccomended) No limit The ORCID ID of people who contributed to the creation of the term. ORCID ID (using full link) None Synonyms http://www.geneontology.org/formats/oboInOwl#hasExactSynonym, http://www.geneontology.org/formats/oboInOwl#hasBroadSynonym, http://www.geneontology.org/formats/oboInOwl#hasNarrowSynonym, http://www.geneontology.org/formats/oboInOwl#hasRelatedSynonym N No limit Synonyms of the term. Free text database_cross_reference: reference material in which the synonymn is used See synonyms documentation for guide on using synonyms Comments rdfs:comment N Max 1 Comments about the term, extended descriptions that might be useful, notes on modelling choices, other misc notes. Free text database_cross_reference: reference material relating to the comment See documentation on comments for more information about comments Editor note IAO:0000116 N Max 1 A note that is not relevant to front users, but might be to editors Free text database_cross_reference: reference material relating to the note Subset http://www.geneontology.org/formats/oboInOwl#inSubset N No limit A tag that marks a term as being part of a subset annotation property that is a subproperty of subset_property (see guide on how to select this) None See Slim documentation for more information on subsets Database Cross Reference http://www.geneontology.org/formats/oboInOwl#hasDbXref N No limit Links out to external references. string and should* take the form {prefix}:{accession}; see db-xrefs yaml for prefixes None *Some ontologies allow full URLS in specific cases, but this is controversial Date created dcterms:created N Max 1 Date in which the term was created ISO-8601 format None Date last updated dcterms:date N Max 1 Date in which the term was last updated ISO-8601 format None Deprecation http://www.w3.org/2002/07/owl#deprecated N Max 1 A tag that marks a term as being obsolete/deprecated xsd:boolean (true/false) None See obsoletion guide for more details Replaced by IAO:0100001 N Max 1 Term that has replaced an obsoleted term IRI/ID (e.g. CL:0000001) None See obsoletion guide and merging terms guide for more details Consider oboInOwl:consider N No limit Term that can be considered from manual replacement of an obsoleted term IRI/ID (e.g. CL:0000001) None See obsoletion guide and merging terms guide for more details"},{"location":"reference/managing-issues/","title":"Tools for Managing Issues","text":"
Based on Intro to GitHub (GO-Centric) with credit to Nomi Harris and Chris Mungall
Labels are a useful tool to help group and organize issues, allowing people to filter issues by grouping. Note: Only project contributors can add/change labels
"},{"location":"reference/managing-issues/#best-practices-for-labels","title":"Best Practices for Labels","text":"
Make use of use GitHub's default labels: bug, question, enhancement, good first issue, etc.
Define new labels as needed for project management
Lightly coordinate labels across repos in an organization
Labels are not ontologies; don\u2019t overload them. A small simple set consistently applied is better than overly specific inconsistently applied labels
Superissues are issues that have checklists (added using -[] on items). These are useful as they show progress towards completion. These can be used for issues that require multiple steps to solve.
Milestones are used for issues with a specific date/deadline. Milestones contain issues and issues can be filtered by milestones. They are also useful for visualizing how many issues in it is completed.
Project boards are a useful tool to organise, as the name implies, projects. They can span multiple repos (though the repos need to be in the same organisation). Notes can also be added.
"},{"location":"reference/medical-ontology-landscape/","title":"Medical Ontology landscape","text":""},{"location":"reference/medical-ontology-landscape/#the-landscape-of-disease-and-phenotype-ontologies","title":"The Landscape of Disease and Phenotype Ontologies","text":"
Compiled by Nicole Vasilevsky. Feel free to make pull requests to suggest edits. Note: This currently just provides an overview of disease and phenotype ontologies. Contributors are welcome to add more descriptions of other medical ontologies. This was last updated in 2021.
"},{"location":"reference/medical-ontology-landscape/#disease-ontologies-terminologies","title":"Disease Ontologies & Terminologies","text":""},{"location":"reference/medical-ontology-landscape/#disease-summary-table","title":"Disease Summary Table","text":"Name Disease Area Artificial Intelligence Rheumatology Consultant System Ontology (AI-RHEUM) Rheumatic diseases Autism DSM-ADI-R Ontology (ADAR) Autism Autism Spectrum Disorder Phenotype Ontology (ASDPTO) Autism Brucellosis Ontology (IDOBRU) brucellosis Cardiovascular Disease Ontology (CVDO) Cardiovascular Chronic Kidney Disease Ontology (CKDO) Chronic kidney disease Chronic Obstructive Pulmonary Disease Ontology (COPDO) Chronic obstructive pulmonary disease (COPD) Coronavirus Infectious Disease Ontology (CIDO) Coronavirus infectious diseases Diagnostic and Statistical Manual of Mental Disorders (DSM) Mental disorders Dispedia Core Ontology (DCO) Rare diseases Experimental Factor Ontology (EFO) Broad disease coverage Fibrotic Interstitial Lung Disease Ontology (FILDO) Fibrotic interstitial lung disease Genetic and Rare Diseases Information Center (GARD) Rare diseases Holistic Ontology of Rare Diseases (HORD) Rare disease Human Dermatological Disease Ontology (DERMO) Dermatology (skin) Human Disease Ontology (DO) Human disease Infectious Disease Ontology (IDO) Infectious disease International Classification of Functioning, Disability and Health (ICF) Cross-discipline, focuses disabilities International Statistical Classification of Diseases and Related Health Problems (ICD-11) Broad coverage International Classification of Diseases for Oncology (ICD-O) Cancer Logical Observation Identifier Names and Codes (LOINC) Broad coverage Medical Subject Headings (MeSH) Broad coverage MedGen Human medical genetics Medical Dictionary for Regulatory Activities (MedDRA) Broad coverage Mental Disease Ontology (MDO) Mental functioning Mondo Disease Ontology (Mondo) Broad coverage, Cross species National Cancer Institute Thesaurus (NCIT) Humam cancer and neoplasms Neurological Disease Ontology (ND) Neurology Online Mendelian Inheritance in Man (OMIM) Mendelian, genetic diseases. Ontology of Cardiovascular Drug Adverse Events (OCVDAE) Cardiovascular Ontology for General Medical Science (OGMS) Broad coverage Ontology for Genetic Susceptibility Factor (OGSF) Genetic disease Ontology of Glucose Metabolism Disorder (OGMD) Metabolic disorders Ontology of Language Disorder in Autism (LDA) Austism The Oral Health and Disease Ontology (OHD) Oral health and disease Orphanet (ORDO) Rare diseases Parkinson Disease Ontology (PDO) Parkinson disease Pathogenic Disease Ontology (PDO) Pathogenic diseases PolyCystic Ovary Syndrome Knowledgebase (PCOSKB) Polycystic ovary syndrome Rat Disease Ontology (RDO) Broad coverage Removable Partial Denture Ontology (RPDO) Oral health Resource of Asian Primary Immunodeficiency Diseases (RPO) Immunodeficiencies Sickle Cell Disease Ontology (SCDO) Sickle Cell Disease SNOMED Clinical Terminology (SNOMED CT) Broad disease representation for human diseases. Symptom Ontology Human diseases Unified Medical Language System Broad coverage"},{"location":"reference/medical-ontology-landscape/#artificial-intelligence-rheumatology-consultant-system-ontology-ai-rheum","title":"Artificial Intelligence Rheumatology Consultant System ontology (AI-RHEUM)","text":"
Description: Contains findings, such as clinical signs, symptoms, laboratory test results, radiologic observations, tissue biopsy results, and intermediate diagnosis hypotheses, for the diagnosis of rheumatic diseases. Disease area: Rheumatic diseases Use Cases: Used by clinicians and informatics researchers. Website: https://bioportal.bioontology.org/ontologies/AI-RHEUM Open: Yes
Description: An ontology of autism spectrum disorder (ASD) and related neurodevelopmental disorders. Disease area: Autism Use Cases: It extends an existing autism ontology to allow automatic inference of ASD phenotypes and Diagnostic and Statistical Manual of Mental Disorders (DSM) criteria based on subjects\u2019 Autism Diagnostic Interview\u2013Revised (ADI-R) assessment data. Website: https://bioportal.bioontology.org/ontologies/ADAR Open: Yes
Description: Encapsulates the ASD behavioral phenotype, informed by the standard ASD assessment instruments and the currently known characteristics of this disorder. Disease area: Autism Use Cases: Intended for use in research settings where extensive phenotypic data have been collected, allowing a concept-based approach to identifying behavioral features of importance and for correlating these with genotypic data. Website: https://bioportal.bioontology.org/ontologies/ASDPTO Open: Yes
Description: Describes the most common zoonotic disease, brucellosis, which is caused by Brucella, a type of facultative intracellular bacteria. Disease area: brucellosis bacteria Use Cases: An extension ontology of the core Infectious Disease Ontology (IDO-core). This project appears to be inactive. Website: https://github.com/biomedontology/idobru Open: Yes
Description: An ontology to describe entities related to cardiovascular diseases. Disease area: Cardiovascular Use Cases: Describes entities related to cardiovascular diseases including the diseases themselves, the underlying disorders, and the related pathological processes. Imports upper level terms from OGMS and imports some terms from Disease Ontology (DO). GitHub repo: https://github.com/OpenLHS/CVDO/ Website: https://github.com/OpenLHS/CVDO OBO Foundry webpage: http://obofoundry.org/ontology/cvdo.html Open: Yes
Description: An ontology of chronic kidney disease in primary care. Disease area: Chronic kidney disease Use Cases: CKDDO was developed to assist routine data studies and case identification of CKD in primary care. Website: http://purl.bioontology.org/ontology/CKDO Open: Yes
Description: Aims to ontologically represent and standardize various aspects of coronavirus infectious diseases, including their etiology, transmission, epidemiology, pathogenesis, diagnosis, prevention, and treatment. Disease area: Coronavirus infectious diseases, including COVID-19, SARS, MERS; covers etiology, transmission, epidemiology, pathogenesis, diagnosis, prevention, and treatment. Use Cases: Used for disease annotations related to coronavirus infections. GitHub repo: https://github.com/cido-ontology/cido OBO Foundry webpage: http://obofoundry.org/ontology/cido.html Open: Yes
"},{"location":"reference/medical-ontology-landscape/#diagnostic-and-statistical-manual-of-mental-disorders-dsm","title":"Diagnostic and Statistical Manual of Mental Disorders (DSM)","text":"
Description: Authoritative source to define and classify mental disorders to improve diagnoses, treatment, and research. Disease area: Mental disorders Use Cases: Used in clinical healthcare and research by pyschiatrists and psychologists. Website: https://www.psychiatry.org/psychiatrists/practice/dsm Open: No, must be purchased
Description: A schema for information brokering and knowledge management in the complex field of rare diseases. DCO describes patients affected by rare diseases and records expertise about diseases in machine-readable form. Disease area: Rare disease Use Cases: DCO was initially created with amyotrophic lateral sclerosis as a use case. Website: http://purl.bioontology.org/ontology/DCO Open: Yes
Description: Provides a systematic description of many experimental variables available in EBI databases, and for projects such as the GWAS catalog. Disease area: Broad disease coverage, integrates the Mondo disease ontology. Use Cases: Application ontology build for European Bioinformatics (EBI) tools and databases and Open Targets Genetics Portal. Website: https://www.ebi.ac.uk/efo/ Open: Yes
Description: An in-progress, four-tiered ontology proposed to standardize the diagnostic classification of patients with fibrotic interstitial lung disease. Disease area: Fibrotic interstitial lung disease Use Cases: Goal is to standardize the diagnostic classification of patients with fibrotic ILD. A paper was published in 2017 and an ontology is not publicly available. Publication: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5803648/ Open: No
"},{"location":"reference/medical-ontology-landscape/#genetic-and-rare-diseases-information-center-gard","title":"Genetic and Rare Diseases Information Center (GARD)","text":"
Description: NIH resource that provides the public with access to current, reliable, and easy-to-understand information about rare or genetic diseases in English or Spanish. Disease area: Rare diseases Use Cases: Patient portal. Integrates defintions and synonyms from Orphanet, maps to HPO phenotypes, and is integrated by Mondo. Website: https://rarediseases.info.nih.gov/ Open: Yes
"},{"location":"reference/medical-ontology-landscape/#holistic-ontology-of-rare-diseases-hord","title":"Holistic Ontology of Rare Diseases (HORD)","text":"
Description: Describes the biopsychosocial state (i.e., disease, psychological, social, and environmental state) of persons with rare diseases in a holistic way. Disease area: Rare disease Use Cases: Rehabilita, Disruptive Technologies for the Rehabilitation of the Future, a project that aims to enhance rehabilitation transforming it to a more personalized, ubiquitous and evidence-based rehabilitation. Website: http://purl.bioontology.org/ontology/HORD Open: Yes
Description: The most comprehensive dermatological disease ontology available, with over 3,500 classes available. There are 20 upper-level disease entities, with features such as anatomical location, heritability, and affected cell or tissue type. Disease area: Dermatology (skin) Use Cases: DermO can be used to extract data from patient electronic health records using text mining, or to translate existing variable-granularity coding such as ICD-10 to allow capture and standardization of patient/disease annotations. Website: https://bioportal.bioontology.org/ontologies/DERMO Open: Yes
Description: An ontology for describing the classification of human diseases organized by etiology. Disease area: Human disease terms, phenotype characteristics and related medical vocabulary disease concepts. Use Cases: Used by Model Organism Databases (MOD), such as Mouse Genome Informatics disease model for diseae annotations, and Alliance for Genome Resources for disease annotations. In 2018, DO tracked over 300 DO project citations suggesting wide adoption and usage for disease annotations. GitHub repo: https://github.com/DiseaseOntology/HumanDiseaseOntology/ Website: http://www.disease-ontology.org/ OBO Foundry webpage: http://obofoundry.org/ontology/doid.html Open: Yes
Description: A set of interoperable ontologies that will together provide coverage of the infectious disease domain. IDO core is the upper-level ontology that hosts terms of general relevance across the domain, while extension ontologies host terms to specific to a particular part of the domain. Disease area: Infectious disease features, such as acute, primary, secondary infection, and chronic, hospital acquired and local infection. Use Cases: Does not seem active, has not been released since 2017. GitHub repo: https://github.com/infectious-disease-ontology/infectious-disease-ontology/ Website: http://www.bioontology.org/wiki/index.php/Infectious_Disease_Ontology OBO Foundry webpage: http://obofoundry.org/ontology/ido.html Open: Yes
"},{"location":"reference/medical-ontology-landscape/#international-classification-of-functioning-disability-and-health-icf","title":"International Classification of Functioning, Disability and Health (ICF)","text":"
Description: Represents diseases and provides a conceptual basis for the definition and measurement of health and disability as organized by patient-oriented outcomes of function and disability. ICF considers environmental factors as well as the relevance of associated health conditions in recognizing major models of disability. Disease area: Cross-discipline, focuses on health and disability Use Cases: ICF is the World Health Organization (WHO) framework for measuring health and disability at both individual and population levels. ICF was officially endorsed by the WHO as the international standard to describe and measure health and disability. Website: https://www.who.int/standards/classifications/international-classification-of-functioning-disability-and-health Open: Yes
"},{"location":"reference/medical-ontology-landscape/#international-statistical-classification-of-diseases-and-related-health-problems-icd-11","title":"International Statistical Classification of Diseases and Related Health Problems (ICD-11)","text":"
Description: A medical classification list by the World Health Organization (WHO) that contains codes for diseases, signs and symptoms, abnormal findings, complaints, social circumstances, and external causes of injury or diseases. Disease area: Broad coverage of human disease features, such as disease of anatomical systems, infectious diseases, injuries, external causes of morbidity and mortality. Use Cases: The main purpose of ICD-11 is for clinical care, billing and coding for insurance companies. Website: https://www.who.int/standards/classifications/classification-of-diseases Open: Yes
"},{"location":"reference/medical-ontology-landscape/#international-classification-of-diseases-for-oncology-icd-o","title":"International Classification of Diseases for Oncology (ICD-O)","text":"
Description: A domain-specific extension of the International Statistical Classification of Diseases and Related Health Problems for tumor diseases. Disease area: A multi-axial classification of the site, morphology, behaviour, and grading of neoplasms. Use Cases: Used principally in tumour or cancer registries for coding the site (topography) and the histology (morphology) of neoplasms, usually obtained from a pathology report. Website: https://www.who.int/standards/classifications/other-classifications/international-classification-of-diseases-for-oncology Open: Yes
"},{"location":"reference/medical-ontology-landscape/#logical-observation-identifier-names-and-codes-loinc","title":"Logical Observation Identifier Names and Codes (LOINC)","text":"
Description: Identifies medical laboratory observations. Disease area: Broad coverage Use Cases: The Regenstrief Institute first developed LOINC in 1994 in response to the demand for an electronic database for clinical care and management. LOINC is publicly available at no cost and is endorsed by the American Clinical Laboratory Association and the College of American Pathologists. Since its inception, LOINC has expanded to include not just medical laboratory code names but also nursing diagnoses, nursing interventions, outcome classifications, and patient care data sets. Website: https://loinc.org/ Open: Yes, registration is required.
Description: Medical Subject Headings (MeSH) thesaurus is a controlled and hierarchically-organized vocabulary produced by the National Library of Medicine. Disease area: Broad coverage Use Cases: It is used for indexing, cataloging, and searching of biomedical and health-related information. Integrated into Mondo. Website: https://meshb.nlm.nih.gov/search Open: Yes
Description: Organizes information related to human medical genetics, such as attributes of conditions and phenotypes of genetic contributions. Disease area: Human medical genetics Use Cases: MedGen is NCBI's portal to information about conditions and phenotypes related to Medical Genetics. Terms from the NIH Genetic Testing Registry (GTR), UMLS, HPO, Orphanet, ClinVar and other sources are aggregated into concepts, each of which is assigned a unique identifier and a preferred name and symbol. The core content of the record may include names, identifiers used by other databases, mode of inheritance, clinical features, and map location of the loci affecting the disorder. The concept identifier (CUI) is used to aggregate information about that concept, similar to the way NCBI Gene serves as a gateway to gene-related information. Website: https://www.ncbi.nlm.nih.gov/medgen/ Open: Yes
"},{"location":"reference/medical-ontology-landscape/#medical-dictionary-for-regulatory-activities-meddra","title":"Medical Dictionary for Regulatory Activities (MedDRA)","text":"
Description: Provides a standardized international medical terminology to be used for regulatory communication and evaluation of data about medicinal products for human use. Disease area: Broad coverage Use Cases: Mainly targeted towards industry and regulatory users. Website: https://www.meddra.org/ Open: Yes
Description: An ontology to describe and classify mental diseases such as schizophrenia, annotated with DSM-IV and ICD codes where applicable. Disease area: Mental functioning, including mental processes such as cognition and traits such as intelligence. Use Cases: The ontology has been partially aligned with the related projects Cognitive Atlas, knowledge base on cognitive science and the Cognitive Paradigm Ontology, which is used in the Brainmap, a database of neuroimaging experiments. GitHub repo: https://github.com/jannahastings/mental-functioning-ontology OBO Foundry webpage: http://obofoundry.org/ontology/mfomd.html Open: yes
Description: An integrated disease ontology that provides precise mappings between source ontologies that comprehensively covers cross-species diseases, from common to rare diseases. Disease area: Cross species, intended to cover all areas of diseases, integrating source ontologies that cover Mendelian diseases (OMIM), rare diseases (Orphanet), neoplasms (NCIt), human diseases (DO), and others. See all sources here. Use Cases: Mondo was developed for usage in the Monarch Initiative, a discovery system that allows navigation of similarities between phenotypes, organisms, and human diseases across many data sources and organisms. Mondo is also used by ClinGen for disease curations, the Kids First Data Resource Portal for disease annotations and others, see an extensive list here. GitHub repo: https://github.com/monarch-initiative/mondo Website: https://mondo.monarchinitiative.org/ OBO Foundry webpage: http://obofoundry.org/ontology/mondo.html Open: yes
"},{"location":"reference/medical-ontology-landscape/#national-cancer-institute-thesaurus-ncit","title":"National Cancer Institute Thesaurus (NCIT)","text":"
Description: NCI Thesaurus (NCIt)is a reference terminology that includes broad coverage of the cancer domain, including cancer related diseases, findings and abnormalities. The NCIt OBO Edition aims to increase integration of the NCIt with OBO Library ontologies. NCIt OBO Edition releases should be considered experimental. Disease area: Cancer and neoplasms Use Cases: NCI Thesaurus (NCIt) provides reference terminology for many National Cancer Institute and other systems. It is used by the Clinical Data Interchange Standards Consortium Terminology (CDISC), the U.S. Food and Drug Administration (FDA), the Federal Medication Terminologies (FMT), and the National Council for Prescription Drug Programs (NCPDP). It provides extensive coverage of neoplasms and cancers. GitHub repo: https://github.com/NCI-Thesaurus/thesaurus-obo-edition/issues Website: https://ncithesaurus.nci.nih.gov/ncitbrowser/pages/home.jsf?version=20.11e OBO Foundry webpage: http://obofoundry.org/ontology/ncit.html Open: Yes
Description: A framework for the representation of key aspects of neurological disease. Disease area: Neurology Use Cases: Goal is to provide a framework to enable representation of aspects of neurological diseases that are relevant to their treatment and study. This project may be inactive, the last commit to GitHub was in 2016. GitHub repo: https://github.com/addiehl/neurological-disease-ontology Open: Yes
"},{"location":"reference/medical-ontology-landscape/#online-mendelian-inheritance-in-man-omim","title":"Online Mendelian Inheritance in Man (OMIM)","text":"
Description: a comprehensive, authoritative compendium of human genes and genetic phenotypes that is freely available and updated daily. Disease area: Mendelian, genetic diseases. Use Cases: Integrated into the disease ontology, used by the Human Phenotype Ontology for disease annotations, patients and researchers. Website: https://omim.org/ Open: yes
"},{"location":"reference/medical-ontology-landscape/#ontology-of-cardiovascular-drug-adverse-events-ocvdae","title":"Ontology of Cardiovascular Drug Adverse Events (OCVDAE)","text":"
Description: A biomedical ontology of cardiovascular drug\u2013associated adverse events. Disease area: Cardiovascular Use Cases: One novel study of the OCVDAE project is the development of the PCR method. Specifically, an AE-specific drug class effect is defined to exist when all the drugs (drug chemical ingredients or drug products) in a drug class are associated with an AE, which is formulated as a proportional class level ratio (\u201cPCR\u201d)\u2009=\u20091. See more information in the paper: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5653862/. This project may be inactive, the last GitHub commit was in 2019. GitHub repo: https://github.com/OCVDAE/OCVDAE Website: https://bioportal.bioontology.org/ontologies/OCVDAE Open: yes
"},{"location":"reference/medical-ontology-landscape/#ontology-for-general-medical-science-ogms","title":"Ontology for General Medical Science (OGMS)","text":"
Description: An ontology of entities involved in a clinical encounter. Use Cases: Provides a formal theory of disease that can be further elaborated by specific disease ontologies. It is intended to be used as a upper level ontology for other disease ontologies. Used by Cardiovascular Disease Ontology. GitHub repo: https://github.com/OGMS/ogms OBO Foundry webpage: http://obofoundry.org/ontology/ogms.html Open: Yes
"},{"location":"reference/medical-ontology-landscape/#ontology-for-genetic-susceptibility-factor-ogsf","title":"Ontology for Genetic Susceptibility Factor (OGSF)","text":"
Description: An application ontology to represent genetic susceptibility to a specific disease, adverse event, or a pathological process. Use Cases: Modeling genetic susceptibility to vaccine adverse events. GitHub repo: https://github.com/linikujp/OGSF OBO Foundry webpage: http://obofoundry.org/ontology/ogsf.html Open: Yes
"},{"location":"reference/medical-ontology-landscape/#ontology-of-glucose-metabolism-disorder-ogmd","title":"Ontology of Glucose Metabolism Disorder (OGMD)","text":"
Description: Represents glucose metabolism disorder and diabetes disease names, phenotypes, and their classifications. Disease area: Metabolic disorders Use Cases: Still under development (last verssion released in BioPortal was in 2021) but there is little information about its usage online. Website: https://bioportal.bioontology.org/ontologies/OGMD Open: Yes
"},{"location":"reference/medical-ontology-landscape/#ontology-of-language-disorder-in-autism-lda","title":"Ontology of Language Disorder in Autism (LDA)","text":"
Description: An ontology assembled from a set of language terms mined from the autism literature. Disease area: Austism Use Cases: This has not been released since 2008 and looks like it is inactive. Website: https://bioportal.bioontology.org/ontologies/LDA Open: Yes
"},{"location":"reference/medical-ontology-landscape/#the-oral-health-and-disease-ontology-ohd","title":"The Oral Health and Disease Ontology (OHD)","text":"
Description: Represents the content of dental practice health records and is intended to be further developed for use in translational medicine. OHD is structured using BFO (Basic Formal Ontology) and uses terms from many ontologies, NCBITaxon, and a subset of terms from the CDT (Current Dental Terminology). Disease area: Oral health and disease Use Cases: Used to represent the content of dental practice health records and is intended to be further developed for use in translation medicine. Appears to be inactive. OBO Foundry webpage: http://www.obofoundry.org/ontology/ohd.html Open: Yes
Description: The portal for rare diseases and orphan drugs. Contains a structured vocabulary for rare diseases capturing relationships between diseases, genes, and other relevant features, jointly developed by Orphanet and the EBI. It contains information on nearly 10,000 cancers and related diseases, 8,000 single agents and combination therapies, and a wide range of other topics related to cancer and biomedical research. Disease area: Rare diseases Use Cases: Used by rare disease research and clinical community. Integrated into the Mondo disease ontology, aligned with OMIM. Website: https://www.orpha.net/consor/cgi-bin/index.php Open: Yes
Description: A comprehensive semantic framework with a subclass-based taxonomic hierarchy, covering the whole breadth of the Parkinson disease knowledge domain from major biomedical concepts to different views on disease features held by molecular biologists, clinicians, and drug developers. Disease area: Parkinson disease Use Cases: This resource has been created for use in the IMI-funded AETIONOMY project. Last release was in 2015, may be inactive. Website: https://bioportal.bioontology.org/ontologies/PDON Open: Yes
Description: Provides information on infectious diseases, disease synonyms, transmission pathways, disease agents, affected populations, and disease properties. Diseases are grouped into syndromic disease categories, organisms are structured hierarchically, and both disease transmission and relevant disease properties are searchable. Disease area: human infectious diseases caused by microbes and the diseases that is related to microbial infection. Use Cases: Has not been released since 2016 and may be inactive. Website: https://bioportal.bioontology.org/ontologies/PDO Open: Yes.
Description: Comprises genes, single nucleotide polymorphisms, diseases, gene ontology terms, and biochemical pathways associated with polycystic ovary syndrome, a major cause of female subfertility worldwide. Disease area: polycystic ovary syndrome Use Cases: Ontology underlying the Polycystic Ovary Syndrome Knowledgebase, a manually curated knowledgebase on PCOS. Website: http://pcoskb.bicnirrh.res.in/go_d.php Open: Yes
Description: Provides the foundation for ten comprehensive disease area\u2013related data sets at the Rat Genome Database Disease Portals. Disease area: Broad coverage including animal diseases, infectious diseases, chemically-induced disorders, occupational diseases, wounds and injuries and more. Use Cases: Developed for use with the Rat Genome Database Disease Portals. Website: https://rgd.mcw.edu/rgdweb/ontology/view.html?acc_id=DOID:4 Open: Yes
Description: Represents knowledge of a patient\u2019s oral conditions and denture component parts, originally developed to create a clinician decision support model. Disease area: Oral health and dentures Use Cases: A paper was published on this in 2016 but it does not appear any other information is available about this ontology on the website, presumably it is an inactive project. Publication: https://www.nature.com/articles/srep27855 Open: No
"},{"location":"reference/medical-ontology-landscape/#resource-of-asian-primary-immunodeficiency-diseases-rpo","title":"Resource of Asian Primary Immunodeficiency Diseases (RPO)","text":"
Description: Represents observed phenotypic terms, sequence variations, and messenger RNA and protein expression levels of all genes involved in primary immunodeficiency diseases. Disease area: Primary immunodeficiency diseases Use Cases: This terminology is used in a freely accessible, dynamic and integrated database for primary immunodeficiency diseases (PID) called Resource of Asian Primary Immunodeficiency Diseases (RAPID), which is available here. Publication: https://academic.oup.com/nar/article/37/suppl_1/D863/1004993 Open: Yes
Description: SCDO establishes (a) community-standardized sickle cell disease terms and descriptions, (b) canonical and hierarchical representation of knowledge on sickle cell disease, and (c) links to other ontologies and bodies of work. Disease area: Sickle Cell Disease (SCD). Use Cases: SCDO is intended to be a comprehensive collection of knowledge on SCD, facilitate exploration of new scientific questions and ideas, facilitate seamless data sharing and collaborations including meta-analysis within the SCD community, support the building of databasing and clinical informatics in SCD. GitHub repo: https://github.com/scdodev/scdo-ontology/issues Website: https://scdontology.h3abionet.org/ OBO Foundry webpage: http://obofoundry.org/ontology/scdo.html Open: Yes
Description: A comprehensive clinical terminology/ontology used in healthcare settings. Disease area: Broad disease representation for human diseases. Use Cases: Main coding system used in Electronic Health Records (EHRs). Website: https://browser.ihtsdotools.org/? Open: No, requires a license for usage.
Description: An ontology of disease symptoms, with symptoms encompasing perceived changes in function, sensations or appearance reported by a patient indicative of a disease. Disease area: Human diseases Use Cases: Developed by the Disease Ontology (DO) team and used for describing symptoms of human diseases in the DO. Website: http://symptomontologywiki.igs.umaryland.edu/mediawiki/index.php/Main_Page OBO Foundry webpage: http://obofoundry.org/ontology/symp.html Open: Yes
"},{"location":"reference/medical-ontology-landscape/#unified-medical-language-system","title":"Unified Medical Language System","text":"
Description: The UMLS integrates and distributes key terminology, classification and coding standards, and associated resources to promote creation of more effective and interoperable biomedical information systems and services. Disease area: Broad coverage Use Cases: Healthcare settings including electronic health records and HL7. Website: https://www.nlm.nih.gov/research/umls/index.html Open: Yes
"},{"location":"reference/medical-ontology-landscape/#phenotype-ontologies","title":"Phenotype ontologies","text":""},{"location":"reference/medical-ontology-landscape/#phenotype-summary-table","title":"Phenotype Summary Table","text":"Name Species Area Ascomycete phenotype ontology (APO) Ascomycota C. elegans phenotype (wbphenotype) C elegans Dictyostelium discoideum phenotype ontology (ddpheno) Dictyostelium discoideum Drosophila Phenotype Ontology (DPO) Drosophila Flora Phenotype Ontology (FLOPO) Viridiplantae Fission Yeast Phenotype Ontology (FYPO) S. pombe Human Phenotype Ontology (HPO) Human HPO - ORDO Ontological Module (HOOM) Human Mammalian Phenotype Ontology (MP) Mammals Ontology of Microbial Phenotypes (OMP) Microbe Ontology of Prokaryotic Phenotypic and Metabolic Characters Prokaryotes Pathogen Host Interaction Phenotype Ontology pathogens Planarian Phenotype Ontology (PLANP) Schmidtea mediterranea Plant Trait Ontology (TO) Viridiplantae Plant Phenology Ontology Plants Unified Phenotype Ontology (uPheno) Cross-species coverage Xenopus Phenotype Ontology (XPO) Xenopus Zebrafish Phenotype Ontology (ZP) Zebrafish"},{"location":"reference/medical-ontology-landscape/#ascomycete-phenotype-ontology-apo","title":"Ascomycete phenotype ontology (APO)","text":"
Description: A structured controlled vocabulary for the phenotypes of Ascomycete fungi. Species: Ascomycota GitHub repo: https://github.com/obophenotype/ascomycete-phenotype-ontology/ Webpage: http://www.yeastgenome.org/ OBO Foundry webpage: http://obofoundry.org/ontology/wbphenotype.html Open: Yes
Description: FYPO is a formal ontology of phenotypes observed in fission yeast. Species: S. pombe GitHub repo: https://github.com/pombase/fypo OBO Foundry webpage: http://obofoundry.org/ontology/fypo.html Open: Yes
Description: HPO provides a standardized vocabulary of phenotypic abnormalities encountered in human disease. Each term in the HPO describes a phenotypic abnormality. Species: Human GitHub repo: https://github.com/obophenotype/human-phenotype-ontology Website: https://hpo.jax.org/app/ OBO Foundry webpage: http://obofoundry.org/ontology/hp.html Open: yes
"},{"location":"reference/medical-ontology-landscape/#hpo-ordo-ontological-module-hoom","title":"HPO - ORDO Ontological Module (HOOM)","text":"
Description: Orphanet provides phenotypic annotations of the rare diseases in the Orphanet nomenclature using the Human Phenotype Ontology (HPO). HOOM is a module that qualifies the annotation between a clinical entity and phenotypic abnormalities according to a frequency and by integrating the notion of diagnostic criterion. In ORDO a clinical entity is either a group of rare disorders, a rare disorder or a subtype of disorder. The phenomes branch of ORDO has been refactored as a logical import of HPO, and the HPO-ORDO phenotype disease-annotations have been provided in a series of triples in OBAN format in which associations, frequency and provenance are modeled. HOOM is provided as an OWL (Ontologies Web Languages) file, using OBAN, the Orphanet Rare Disease Ontology (ORDO), and HPO ontological models. HOOM provides extra possibilities for researchers, pharmaceutical companies and others wishing to co-analyse rare and common disease phenotype associations, or re-use the integrated ontologies in genomic variants repositories or match-making tools. Species: Human Website: http://www.orphadata.org/cgi-bin/img/PDF/WhatIsHOOM.pdf BioPortal: https://bioportal.bioontology.org/ontologies/HOOM Open: yes
Description: Standard terms for annotating mammalian phenotypic data. Species: Mammals (main focus is on mouse and rodents) GitHub repo: https://github.com/obophenotype/mammalian-phenotype-ontology Website: http://www.informatics.jax.org/searches/MP_form.shtml OBO Foundry webpage: http://obofoundry.org/ontology/mp.html Open: Yes
"},{"location":"reference/medical-ontology-landscape/#ontology-of-microbial-phenotypes-omp","title":"Ontology of Microbial Phenotypes (OMP)","text":"
Description: An ontology of phenotypes covering microbes. Species: microbes GitHub repo: https://github.com/microbialphenotypes/OMP-ontology Website: http://microbialphenotypes.org OBO Foundry webpage: http://obofoundry.org/ontology/omp.html Open: Yes
"},{"location":"reference/medical-ontology-landscape/#ontology-of-prokaryotic-phenotypic-and-metabolic-characters","title":"Ontology of Prokaryotic Phenotypic and Metabolic Characters","text":"
Description: An ontology of phenotypes covering microbes. Species: Prokaryotes GitHub repo: https://github.com/microbialphenotypes/OMP-ontology/issues Website: http://microbialphenotypes.org/ OBO Foundry webpage: http://obofoundry.org/ontology/omp.html Open: Yes
Description: An ontology for describing the phenology of individual plants and populations of plants, and for integrating plant phenological data across sources and scales. Species: Plants GitHub repo: https://github.com/PlantPhenoOntology/PPO OBO Foundry webpage: http://obofoundry.org/ontology/ppo.html Open: Yes
Description: XPO represents anatomical, cellular, and gene function phenotypes occurring throughout the development of the African frogs Xenopus laevis and tropicalis. Species: Xenopus GitHub repo: https://github.com/obophenotype/xenopus-phenotype-ontology OBO Foundry webpage: http://obofoundry.org/ontology/xpo.html Open: Yes
Description: The Zebrafish Phenotype Ontology formally defines all phenotypes of the Zebrafish model organism. Species: Zebrafish GitHub repo: https://github.com/obophenotype/zebrafish-phenotype-ontology OBO Foundry webpage: http://obofoundry.org/ontology/zp.html Open: Yes
A Census of Disease Ontologies Melissa A. Haendel, Julie A. McMurry, Rose Relevo, Christopher J. Mungall, Peter N. Robinson, Christopher G. Chute Annual Review of Biomedical Data Science 2018 1:1, 305-331
OMOP2OBO repository
"},{"location":"reference/mungall-blog-radar/","title":"Monkeying around with OWL","text":"
An index page to find some of our favourite articles on Chris' blog. These are not all articles, but I selection we found useful during our every work.
"},{"location":"reference/mungall-blog-radar/#ontology-development-and-modelling","title":"Ontology development and modelling","text":"
OntoTips Series. Must read series for the beginning ontology developer.
Warning about complex modelling. Chris is generally big on Occam's Razor solutions: given two solutions that solve a use case, the simpler is better.
OntoTip: Don\u2019t over-specify OWL definitions. From the above OntoTip series.
Some resources on OBOOK are less well developed than others. We use the OBOOK Maturity Indicator to document this (discussion).
: This page is under development and not yet suitable for self-study or teaching.
: This page is still under development (may be rough around the edges) but complete and suitable for self-study or teaching.
: This page is developed to an extent it can be considered stable (although nothing is ever really stable) and therefore suitable for self-study or teaching.
To add a status badge onto a site, simply paste a badge like this right under the title:
"},{"location":"reference/odk/","title":"Ontology Development Kit (ODK) Reference","text":"
The ODK is essentially two things:
A toolbox. All frequently used tools for managing the ontology life cycle are bundled together into a Docker image: ROBOT, owltools, fastobo-validator, dosdp-tools, riot and many, many more.
A system, you could have say \"methodology\" for managing the ontology life cycle from continious integration and quality control to imports and release management.
The ODK bundles a lot of tools together, such as ROBOT, owltools, fastobo-validator and dosdp-tools. To get a better idea, its best to simply read the Dockerfile specifications of the ODK image:
ODK Lite Image. This contains the most essentials tools related to ODK development. Most of the day to day activities of ontology developers with ROBOT are well covered by odklite.
ODK Full Image. Extends the ODK Lite image with a further round of powerful tools. It contains for example Apache Jena, the OBO Dashboard, the Konclude reasoner and a large array of command line tools.
"},{"location":"reference/odk/#the-system-for-ontology-life-cycle-management","title":"The system for ontology life cycle management","text":"
One of the tools in the toolbox, the \"seed my repo\" function, allows us to generate a complete GitHub repository with everything needed to manage an OBO ontology according to OBO best practices. The two central components are
A Makefile that encodes the rules by which ontology release files should be derived from the source of truth (the edit file).
A support for CI such as GitHub actions or Travis for running continuous integration checks.
Here's a collection of links about the Open Biological and Biomedical Ontologies (OBO), and related topics.
If you're completely new to OBO, I suggest starting with Ontologies 101:
Unit 1: Controlled Vocabularies, Ontologies, and Data Linking (PowerPoint Slides)
Unit 2: An Introduction to OWL (Powerpoint Slides)
Unit 3: Ontology Community (Powerpoint Slides)
BDK14 Ontologies 101 repository
If you're new to scientific computing more generally, then I strongly recommend Software Carpentry, which provides a set of very pragmatic introductions to the Unix command line, git, Python, Make, and other tools widely used by OBO developers.
"},{"location":"reference/other-resources/#open-biological-and-biomedical-ontologies","title":"Open Biological and Biomedical Ontologies","text":"
OBO is a community of people collaborating on open source ontologies for science. We have a set of shared principles and best practises to help people and data work together effectively.
OBO Foundry Homepage
The OBO Foundry: coordinated evolution of ontologies to support biomedical data integration (journal article)
This section is for technical reference, not beginners.
OBO projects use Semantic Web and Linked Data technologies:
W3C Semantic Web overview
Search for W3C data standards
W3C Data on the Web Best Practices
These standards form layers:
IRI: Internationalized Resource Identifiers are a superset of the familiar URLs used to locate resources on the web. Every ontology term has a globally unique IRI.
RDF: Resource Description Format is a standard for combining IRIs into subject-predicate-object \"triples\" that make a statement about some thing. Sets of triples form a graph (i.e. network), and graphs can easily be merged to form larger graphs. SPARQL is the language for querying RDF graphs.
RDF 1.1 Primer
SPARQL 1.1 Overview
RDFS: RDF Schema 1.1 extends RDF with classes, hierarchies, and other features.
XSD: W3C XML Schema Definition Language (XSD) 1.1 Part 2: Datatypes is the common standard for datatypes in RDF
OWL: Web Ontology Language extends RDF and RDFS to provide more powerful logic
OWL 2 Web Ontology Language Primer (Second Edition)
Other useful resources on technical topics:
Monkeying around with OWL Chris Mungall's blog, mostly on technical topics for ontologies.
"},{"location":"reference/outreach/","title":"OBO Academy Outreach","text":""},{"location":"reference/outreach/#cite-us","title":"Cite us","text":"
Nicole Vasilevsky, James Overton, Rebecca Jackson, Sabrina Toro, Shawn Tan, Bradley Varner, David Osumi-Sutherland, & Nicolas Matentzoglu. (2022, August 3). OBO Academy: Training materials for bio-ontologists. 2022 ISMB Bio-Ontologies Community, Madison, WI. https://doi.org/10.5281/zenodo.6955490
"},{"location":"reference/outreach/#generic-obo-academy-slide-deck","title":"Generic OBO Academy slide deck","text":"
Available here. Please feel free to use this slide deck to promote the OBO Academy.
Nicole Vasilevsky, James Overton, Rebecca Jackson, Sabrina Toro, Shawn Tan, David Osumi-Sutherland, Nicolas Matentzoglu. \"OBO Academy: Training materials for Bio-ontologists\". Presentation at OntoCommons, Virtual. June 14, 2023.
Nicole Vasilevsky and Nico Matentzoglu. Panel discussion at Knowledge Graph Conference 2023. May 08, 2023.
Nicole Vasilevsky, James Overton, Rebecca Jackson, Sabrina Toro, Shawn Tan, Bradley Varner, David Osumi-Sutherland, Nicolas Matentzoglu. \"OBO Academy: Training materials for Bio-ontologists.\" [Poster presentation] Biocuration 2022, Virtual. October 04, 2022.
James Overton, Rebecca Jackson, Sabrina Toro, Shawn Tan, Bradley Varner, David Osumi-Sutherland, Nicolas Matentzoglu, Nicole Vasilevsky. \"OBO Academy: Training materials for Bio-ontologists.\" [Lightning talk and Poster presentation] ICBO, Ann Arbor, MI. September 27, 2022. https://zenodo.org/record/7116623
Nicole Vasilevsky, James Overton, Rebecca Jackson, Sabrina Toro, Shawn Tan, Bradley Varner, David Osumi-Sutherland, & Nicolas Matentzoglu. (2022, August 3). \"OBO Academy: Training materials for bio-ontologists.\" Presentation at 2022 ISMB Bio-Ontologies Community, Madison, WI, July 2022
"},{"location":"reference/protege-faq/","title":"Proteg\u00e9 FAQs","text":""},{"location":"reference/protege-faq/#how-to-escape-characters-in-the-class-expression-editor","title":"How to escape characters in the class expression editor","text":"
To add an ontology term (such as a GO term) that contains ' in its name (e.g. RNA-directed 5'-3' RNA polymerase activity) in the class expression editor, you need to escape the ' characters. In Proteg\u00e9 5.5 this is not automatically handled when you auto-complete with tab. To escape the character append \\ before the ' -> RNA-directed 5\\'-3\\' RNA polymerase activity. You won't be able to add the annotation otherwise.
As in Proteg\u00e9 5.5, the \\ characters will show up in the description window, and when hovering over the term, you won't be able to click on it with a link. However, when you save the file, the relationship is saved correctly. You can double-check by going to the ontology text file and see that the term is correctly mentioned in the relationship.
"},{"location":"reference/protege-interface/","title":"Reference document for protege interface","text":"
For this reference, we will use the cell ontology to highlight the key information on the user interface in Protege
Entities are where your \"entries\" in the ontology live and where you can add terms etc.
"},{"location":"reference/reasoning/","title":"Why do we need reasoning?","text":"
A quick personal perspective up-front. When I was finishing my undergrad, I barely had heard the term Semantic Web. What I had heard vaguely intrigued me, so I decided that for my final project, I would try to combine something Semantic Web related with my other major, Law and build a tool that could automatically infer the applicability of a law (written in OWL) given a legal case. Super naively, I just went went ahead, read a few papers about legal ontologies, build a simple one, loaded it into my application and somehow got it to work, with reasoning and all, without even having heard of Description Logic.
In my PhD, I worked on actual reasoning algorithms, which meant, no more avoiding logic. But - I did not get it. Up until this point in my life, I could just study harder and harder, and in the end I was confident with what I learned, but First Order Logic, in particular model theory and proofs, caused me anxiety until the date of my viva. In the end, a very basic understanding of model theory and Tableau did help me with charactering the algorithms I was working with (I was studying the effect of modularity, cutting out logically connected subsets of an ontology, on reasoning performance) but I can confidently say today: I never really, like deeply, understood logical proofs. I still cant read them - and I have a PhD in Reasoning (albeit from an empirical angle).
If you followed the Open HPI courses on logic, and you are anything like me, your head will hurt and you will want to hide under your blankets. Most students feel like that. For a complete education in Semantic Web technologies, going through this part once is essential: it tells you something about how difficult some stuff is under the hood, and how much work has been done to make something like OWL work for knowledge representation. You should have gained some appreciation of the domain, which is no less complex than Machine Learning or Stochastic Processes. But, in my experience, some of the most effective ontology engineers barely understand reasoning - definitely have no idea how it works - and still do amazing work. In that spirit, I would like to invite you at this stage to put logic and reasoning behind you (unless it made you curious of course) - you won't need to know much of that for being an effective Semantic Engineer. In the following, I will summarise some of the key take-aways that I find useful to keep in mind.
Semantics define how to interpret an ontology. For example, in OWL, the statement Human SubClassOf: Mammal means that all instances of the Human class, like me, are also instances of the Mammal class. Or, in other words, from the statements:
Human SubClassOf: Mammal\nNico type: Human\n
Semantics allow as to deduce that Nico:Mammal. What are semantics practically? Show me your semantics? Look at something like the OWL semantics. In there, you will find language statements (syntax) like X SubClassOf: Y and a bunch of formulae from model theory that describe how to interpret it - no easy read, and not really important for you now.
OWL has a number of profiles, basically sub-languages where you can say less things. Why would we want to restrict our \"expressivity\"? Because their is a trade-off. An important slide I remember from when I learned about ontology languages was the triangle of complexity (here only paraphrased from memory):
When expressivity goes up, cognitive complexity and computational complexity go up.
When we want to decrease cognitive complexity (make it easier to build ontologies), expressivity goes down.
When we want reasoners to be faster at making inferences (computational complexity), we need to decrease expressivity. So we need to find a way to balance.
What are the most important practical applications of reasoning? There are many, and there will be many opinions, but in the OBO world, by far (95%) of all uses of reasoners pertain to the following:
Classification. Most, if not all, of our ontologies are conceptually hierarchies of classes we use reasoners to automatically infer hierarchies. Look for example at the Xenopus Phenotype Ontology - the class hierarchy is entirely build with a reasoner - no Human intervention!
Debugging. There are two major threats to ontologies. In the worst case, they can be inconsistent - which means, totally broken. A slightly less bad, but still undesirable situation is that some of the classes in your ontologies break (in parlance, become unsatisfiable). This happens when you say some contradictory things about them. Reasoners help you find these unsatisfiable classes, and there is a special reasoning algorithm that can generate an explanation for you - to help fixing your problem.
So in general, what is reasoning? There are probably a dozen or more official characterisations in the scientific literature, but from the perspective of biomedical ontologies, the question can be roughly split like this:
How can we capture what we know? This is the (research-) area of knowledge representation, logical formalisms, such as First Order Logic, Description Logic, etc. It is concerned with how we write down what we now:
All cars have four wheels\nIf you are a human, you are also a mammal\nIf you are a bird, you can fly (unless you are a penguin)\n
How can we uncover implicit knowledge efficiently? This is the area of reasoning, and while being closely related to the formalisms above, it makes sense to think of them in a distinct manner, as the problems are very different in practice. It can typically be grouped into the following two categories:
deductive reasoning infers by
Lets think about a naive approach: using a fact-, or data-, base.
For explanation of different release artefacts, please see discussion documentation on owl format variants
We made a first stab add defining release artefacts that should cover all use cases community-wide. We need to (1) agree they are all that is needed and (2) they are defined correctly in terms of ROBOT commands. This functionality replaces what was previously done using OORT.
The source ontology is the ontology we are talking about. A release artefact is a version of the ontology modified in some specific way, intended for public use. An import is a module of an external ontology which contains all the axioms necessary for the source ontology. A component is a file containing axioms that belong to the source ontology (but are for one reason or another, like definitions.owl, managed in a separate file). An axiom is said to be foreign if it 'belongs' to a different ontology, and native if it belongs to the source ontology. For example, the source ontology might have, for one reason or another, been physically asserted (rather than imported) the axiom TransitiveObjectProperty(BFO:000005). If the source ontology does not 'own' the BFO namespace, this axiom will be considered foreign.
There are currently 6 release defined in the ODK:
base (required)
full (required)
non-classified (optional)
simple (optional)
basic (optional)
simple-non-classified (optional, transient)
We discuss all of them here in detail.
"},{"location":"reference/release-artefacts/#release-artefact-1-base-required","title":"Release artefact 1: base (required)","text":"
The base file contains all and only native axioms. No further manipulation is performed, in particular no reasoning, redundancy stripping or relaxation. This release artefact is going to be the new backbone of the OBO strategy to combat incompatible imports and consequent lack of interoperability. (Detailed discussions elsewhere, @balhoff has documentation). Every OBO ontology will contain a mandatory base release (should be in the official OBO recommendations as well).
The ROBOT command generating the base artefact: $(SRC): source ontology $(OTHER_SRC): set of component ontologies
"},{"location":"reference/release-artefacts/#release-artefact-2-full-required","title":"Release artefact 2: full (required)","text":"
The full release artefact contains all logical axioms, including inferred subsumptions. Redundancy stripping (i.e. redundant subclass of axioms) and typical relaxation operations are performed. All imports and components are merged into the full release artefact to ensure easy version management. The full release represents most closely the actual ontology as it was intended at the time of release, including all its logical implications. Every OBO ontology will contain a mandatory full release.
The ROBOT command generating the full artefact: $(SRC): source ontology $(OTHER_SRC): set of component ontologies
The non-classified release artefact reflects the 'unmodified state' of the editors file at release time. No operations are performed that modify the axioms in any way, in particular no redundancy stripping. As opposed to the base artefact, both component and imported ontologies are merged into the non-classified release.
The ROBOT command generating the full artefact: $(SRC): source ontology $(OTHER_SRC): set of component ontologies
Many users want a release that can be treated as a simple existential graph of the terms defined in an ontology. This corresponds to the state of OBO ontologies before logical definitions and imports. For example, the only logical axioms in -simple release of CL will contain be of the form CL1 subClassOf CL2 or CL1 subClassOf R some CL3 where R is any objectProperty and CLn is a CL class. This role has be fulfilled by the -simple artefact, which up to now has been supported by OORT.
To construct this, we first need to assert inferred classifications, relax equivalentClass axioms to sets of subClassOf axioms and then strip all axioms referencing foreign (imported) classes. As ontologies occasionally end up with forieign classes and axioms merged into the editors file, we achieve this will a filter based on obo-namespace. (e.g. finding all terms with iri matching http://purl.obolibrary.org/obo/CL_{\\d}7).
The ROBOT command generating the full artefact: $(SRC): source ontology $(OTHER_SRC): set of component ontologies $(SIMPLESEED): all terms that 'belong' to the ontology
NOTES: This requires $(ONTOLOGYTERMS) to include all ObjectProperties usesd. --select parents is required for logical axioms to be retained, but results in a few upper-level classes bleeding through. We hope this will be fixed by further improvments to Monarch.
Some legacy users (e.g. MGI) require an OBO DAG version of -simple. OBO files derived from OWL are not guarenteed to be acyclic, but acyclic graphs can be achieved using judicious filtering of relationships (simple existential restrictions) by objectProperty. The -basic release artefact has historically fulfilled this function as part of OORT driven ontology releases. The default -basic version corresponds to the -simple artefact with only 'part of' relationships (BFO:0000050), but others may be added where ontology editors judge these to be useful and safe to add without adding cycles. We generate by taking the simple release and filtering it
The ROBOT command generating the full artefact: $(SRC): source ontology $(OTHER_SRC): set of component ontologies $(KEEPRELATIONS): all relations that should be preserved. $(SIMPLESEED): all terms that 'belong' to the ontology
This artefact caters to the very special and hopefully transient case of some ontologies that do not yet trust reasoning (MP, HP). The simple-non-classified artefact corresponds to the simple artefact, just without the reasoning step.
$(SRC): source ontology $(OTHER_SRC): set of component ontologies $(ONTOLOGYTERMS): all terms that 'belong' to the ontology
OBO Dashboard: OBO-wide quality control monitor for OBO ontologies.
Automation
GNU Make
Ontology Development Kit (ODK)
DROID: DROID is a web-based interface for working with make, managed by git.
Text editors:
Kakoune text/code editor
Sublime
Atom
SPARQL query tool:
Yasgui
ROBOT query
SPARQL endpoints
Ontobee SPARQL endpoint: Useful to run queries across all OBO Foundry ontologies
Ubergraph SPARQL endpoint: Many key OBO ontologies are loaded here with lots of materialised inferences (docs).
Templating systems
DOSDP with DOSDP Tools
ROBOT template
Ontology Mappings
SSSOM and sssom-py: Toolkit and framework for managing mappings across and beyond ontologies.
AgreementMakerLight (AML): Matching tool for ontologies
RDF Matcher: Experimental SSSOM based matching tool
LogMap: Matching tool for ontologies
Where to find ontologies and terms: Term browsers and ontology repositories
OLS: The boss of the current term browsers out there. While the code base is a bit dated, it still gives access to a wide range of relevant open biomedical ontology terms. Note, while being a bit painful, it is possible to set up your own OLS (for your organisation) which only contains those terms/ontologies that are relevant for your work.
Ontobee: The default term browser for OBO term purls. For example, click on http://purl.obolibrary.org/obo/OBI_0000070. This will redirect you directly to Ontobee, to show you the terms location in the hierarchy. In practice, there is no particular reason why you would favour Ontobee over OLS for example - I just sometimes prefer the way Ontobee presents annotations and \"uses\" by other ontologies, so I use both.
AberOWL: Another ontology repository and semantic search engine. Some ontologies such as PhenomeNet can only be found on AberOWL, however, I personally prefer OLS.
identifiers.org: A centralised registry for identifiers used in the life sciences. This is one of the tools that bridge the gap between CURIEs and URLs, but it does not cover (OBO) ontologies very well, and if so, is not aware of the proper URI prefixes (see for example here, and HP term resolution that does not list the proper persistent URL of the HP identifier (http://purl.obolibrary.org/obo/HP_0000001)). Identifiers.org has mainly good coverage for databases/resources that use CURIE type identifiers. But: you can enter any ID you find in your data and it will tell you what it is associated with.
OBO Foundry Ontology Library. The OBO Foundry works with other repositories and term browsers such as OLS, Ontobee and BioPortal. For example, OLS directly reads the OBO Foundry registry metadata, and automatically loads new ontologies added to the OBO Foundry Ontology Library.
BioPortal
CPT Story. The Current Procedural Terminology was the by far most highly accessed Terminology on Bioportal - for many years. Due to license concerns, it had to be withdrawn from the repository. This story serves a cautionary tale of using terminologies with non-open or non-transparent licensing schemes.
AgroPortal: Like BioPortal, but focussed on the Agronomy domain.
Linked Open Data Vocabularies (LOV): Lists the most important vocabularies in the Linked Data space, such as Dublin Core, SKOS and Friend-of-a-Friend (FOAF).
Ontology visualisation
OBO Graphviz: Library to visualise ontologies in beautifully readable graphics based on Dot.
"},{"location":"reference/semantic-engineering-toolbox/#nicos-top-10-tools-for-the-semantic-obo-engineers-toolbox","title":"Nico's top 10 tools for the Semantic OBO Engineer's Toolbox","text":"
ROBOT
Prot\u00e9g\u00e9
Term browsers (OLS, Ontobee)
Ontology Development Kit (ODK)
SPARQL (e.g. ROBOT query and Yasgui)
GNU Make
Text editor workflows (i.e. Atom, Sublime, VIM): a bit of regex
Basic Shell scripting and pipelining
From tables to ontologies: DOSDP templates and ROBOT templates
GitHub Actions
Other tools in my toolbox
These are a bit less essential than the above, but I consider them still tremendously useful.
Cogs (experimental) for automatically synchronising your spreadsheets with Google Sheets.
Basic Dockerfile development: This can help you automate processes that go beyond usual ODK day-to-day business, such as automated mapping tools, graph machine learning, NLP etc.
GitHub community management and git version control: Learn how to effectively manage your contributors, issue requests and code reviews. Also get your git commands straight - these can be life savers!
Basics in python scripting: This is always useful, and python is our go-to language for most of automation nowadays - this used to be Java. Most of the Java heavy lifting is done in ROBOT now!
SSSOM and sssom-py: Toolkit and framework for managing mappings between ontologies.
DROID: DROID is a web-based interface for working with make, managed by git.
OBO Dashboard: OBO-wide quality control monitor for OBO ontologies.
"},{"location":"reference/semantic-etl/","title":"The 3 phases of Semantic Data Engineering / ETL","text":"
Semantic Data Engineering or Semantic Extract-Transform-Load (ETL) is an engineering discipline that is concerned with extracting information from a variety of sources, linking it together into a knowledge graph and enabling a range of semantic analyses for downstream users such as data scientists or researchers.
Getting Data
Information Extraction from text
Obtaining data from external sources
In-house biocuration
Integrating data
Entity Resolution: Make sure that if your sources talk about the same things, they use the same ontologies to reference those things.
Knowledge merging: Combine the resolved sources into a coherent whole, for example a knowledge graph.
Analysis: Query the integrated data and run advanced analyses using Semantic Technologies (next week).
The following glossary only says how we use the terms we are defining, not how they are defined by some higher authority.
Term Definition Example Entity An entity is a thing in the world, like a molecule, or something more complex, like a disease. Entities do not have to be material, they can be processes as well, like cell proliferation. Marfan syndrome, H2O molecule, Ring finger, Phone Term A term is a sequence of characters (string) that refers to an entity in a precise way. SMOKER (referring to the role of being a smoker), HP:0004934 (see explanations below) Relation A link between two (or more) entities that signifies some kind of interaction. :A :loves :B, :smoking :causes :cancer Property A type of relation. The :causes in :smoking :causes :cancer"},{"location":"reference/semantic-etl/#getting-the-data","title":"Getting the data","text":"
As a Semantic Engineer, you typically coordinate the data collection from three largely separate sources: 1. Unstructured text, for example a corpus of scientific literature 2. External biological databases, such as STRING, a database of Protein-Protein Interaction Networks. 3. Manual in-house bio-curation efforts, i.e. the manual translation and integration of information relevant to biology (or medicine) into a database.
Here, we are mostly concerned with the automated approaches of Semantic ETL, so we briefly touch on these and provide pointers to the others.
"},{"location":"reference/semantic-etl/#information-extraction-from-text","title":"Information Extraction from text","text":"
The task of information extraction is concerned with extracting information from unstructured textual sources to enable identifying entities, like diseases, phenotypes and chemicals, as well as classifying them and storing them in a structured format.
The discipline that is concerned with techniques for extracting information from text is called Natural Language Processing (NLP).
NLP is a super exciting and vast engineering discipline which goes beyond the scope of this course. NLP is concerned with many problems such as document classification, speech recognition and language translation. In the context of information extraction, we are particularly interested in Named Entity Recognition (NER), and Relationship Extraction (ER).
Named Entity Recognition (NER) is the task of identifying and categorising entities in text. NER tooling provides functionality to first isolate parts of sentence that correspond to things in the world, and then assigning them to categories (e.g. Drug, Disease, Publication).
For example, consider this sentence:
As in the X-linked Nettleship-Falls form of ocular albinism (300500), the patients showed reduced visual acuity, photophobia, nystagmus, translucent irides, strabismus, hypermetropic refractive errors, and albinotic fundus with foveal hypoplasia.\n
An NER tool would first identify the relevant sentence parts that belong together:
As in the [X-linked] [Nettleship-Falls] form of [ocular albinism] (300500), the patients showed [reduced visual acuity], [photophobia], [nystagmus], [translucent irides], [strabismus], [hypermetropic refractive errors], and [albinotic fundus] with [foveal hypoplasia].\n
And then categorise them according to some predefined categories:
As in the Phenotype[X-linked] [Nettleship-Falls] form of Disease[ocular albinism] (300500), the patients showed Phenotype[reduced visual acuity], Phenotype[photophobia], Phenotype[nystagmus], Phenotype[translucent irides], Phenotype[strabismus], Phenotype[hypermetropic refractive errors], and Phenotype[albinotic fundus] with Phenotype[foveal hypoplasia].\n
Relationship extraction (RE) is the task of extracting semantic relationships from text. RE is an important component for the construction of Knowledge Graphs from the Scientific Literature, a task that many Semantic Data Engineering projects pursue to augment or inform their manual curation processes.
"},{"location":"reference/semantic-etl/#other-data-sources-and-in-house-curation-efforts","title":"Other data sources and in-house curation efforts","text":"
Scientific data sources relevant to work around genes, phenotypes and diseases are plentiful. See here for an overview of the data sources used by the Monarch Initiative. All of the sources listed are part of a Semantic ETL pipeline involving the extraction of the data from data dumps (like published spreadsheets) or Web APIs, the transformation into a common format (including mapping to ontologies) and its subsequent load into the Monarch Knowledge Graph. More comprehensive lists are being produced in the academic literature, for example here.
In-house biocuration. Biocuration is the task of manual translation and integration of information relevant to biology (or medicine) into some kind of database form. Biocuration can take many forms:
The curation of scientific literature, i.e. extracting structured metadata from scientific papers to increase discoverability of relevant knowledge. The object of the curation is usually a particular publication, which goes through a triage process (Is the paper relevant to my problem? Is it good enough?), an initial metadata extraction phase (titles, authors, etc), and eventually to extracting the scientific knowledge (not unlike what the Named Entity Recongnition and Relation Extraction procedures described above) do.
The focussed curation of specific scientific entities, such as diseases. For example, you may be interested in discovering all therapeutic interventions / drugs used for treating a specific disease.
There is a huge amount of literature and tutorials on the topic of integrating data, the practice of consolidating data from disparate sources into a single dataset. We want to emphasise here two aspects of data integration, which are of particular importance to the Semantic Data engineer.
Entity Resolution: Make sure that if your sources talk about the same things, they use the same ontologies to reference those things.
Knowledge merging: Combine the resolved sources into a coherent whole, for example a knowledge graph.
Entity resolution (ER), sometimes called \"record linking\", is the task of disambiguating records that correspond to real world entities across and within datasets. This task as many dimensions, but for us, the most important one is mapping a string, for example the one that was matched by our Named Entity Recognition pipeline, to ontology terms.
Given our example:
As in the Phenotype[X-linked] Nettleship-Falls form of Phenotype[ocular albinism] (300500), the patients showed Phenotype[reduced visual acuity], Phenotype[photophobia], Phenotype[nystagmus], Phenotype[translucent irides], Phenotype[strabismus], Phenotype[hypermetropic refractive errors], and Phenotype[albinotic fundus] with Phenotype[foveal hypoplasia].\n
We could end up, for example, resolving ocular albinism to HP:0001107.
There are a lot of materials about Entity Resolution in general: - https://www.districtdatalabs.com/basics-of-entity-resolution - https://www.sciencedirect.com/topics/computer-science/entity-resolution
In effect the term Ontology Mapping, which is the focus of this lesson, is Entity Resolution for ontologies - usually we don't have problem to use the two terms synonymously, although you may find that the literature typically favours one or the other.
Knowledge, Knowledge Graph or Ontology Merging are the disciplines concerned with combining all your data sources into a semantically coherent whole. This is a very complex research area, in particular to do this in a way that is semantically consistent. There are essentially two separate problems to be solved to achieve semantic merging: 1. The entities aligned during the entity resolution process must be aligned in the semantically correct way: if you you use logical equivalence to align them (owl:equivalentClasses) the classes must mean absolutely the same thing, or else you may run into the hairball problem, in essence faulty equivalence cliques. In cases of close, narrow or broadly matching classes, the respective specialised semantically correct relationships need to be used in the merging process. 2. The axioms of the merged ontologies must be logically consistent. For example, one ontology may say: a disease is a material entity. Another: a disease is a process. A background, or upper, ontology such as the ubiquitous Basic Formal Ontology (BFO) furthermore says that a process is not a material entity and vice versa. Merging this two ontologies would cause logical inconsistency.
Unfortunately, the literature on ontology and knowledge graph merging is still sparse and very technical. You are probably best off checking out the OpenHPI course on Ontology Alignment, which is closely related.
"},{"location":"reference/sparql-basics/","title":"Basic SPARQL commands useful for OBO Engineers","text":""},{"location":"reference/sparql-basics/#basic-select-query","title":"Basic SELECT query","text":"
A basic SELECT query contains a set of prefixes, a SELECT clause and a WHERE clause.
The SELECT clause defines what you part of you query you want to show, for example, as a table.
SELECT ?term ?value\n
means: \"return\" or \"show\" whatever you find for the variable ?term and the variable ?value.
There are other cool things you can do in the SELECT clause:
Maths. You can count.
"},{"location":"reference/sparql-reference/","title":"Reference templates for SPARQL queries","text":"
This document contains template SPARQL queries that can be adapted. Comments are added in-code with # above each step to explain them so that queries can be spliced together
"},{"location":"reference/sparql-reference/#checksreport-generation","title":"Checks/Report generation","text":""},{"location":"reference/sparql-reference/#all-terms-native-to-ontology","title":"All terms native to ontology","text":"
note: we assume that all native terms here have the same namespace - that of the ontology
# select unique instances of the variable\nSELECT DISTINCT ?term\nWHERE {\n # selecting where the variable term is either used as a subject or object\n { ?s1 ?p1 ?term . }\n UNION\n { ?term ?p2 ?o2 . }\n # filtering out only terms that have the MONDO namespace (assumed to be native terms)\n FILTER(isIRI(?term) && (STRSTARTS(str(?term), \"http://purl.obolibrary.org/obo/MONDO_\")))\n}\n
"},{"location":"reference/sparql-reference/#report-of-terms-with-labels-containing-certain-strings-in-ubergraph","title":"Report of terms with labels containing certain strings in ubergraph","text":"
# adding prefixes used\nprefix owl: <http://www.w3.org/2002/07/owl#>\nprefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>\nprefix BFO: <http://purl.obolibrary.org/obo/BFO_>\n\n# selecting only unique instances of the three variables\nSELECT DISTINCT ?entity ?label WHERE\n{\n # the variable label is a rdfs:label\n VALUES ?property {\n rdfs:label\n }\n\n # only look for uberon terms. note: this is only used in ubergraph, use filter for local ontology instead.\n ?entity rdfs:isDefinedBy <http://purl.obolibrary.org/obo/uberon.owl> .\n\n # defining the order of variables in the triple\n ?entity ?property ?label .\n # entity must be material\n ?entity rdfs:subClassOf BFO:0000040\n # filtering out triples where the variable label has sulcus or incisure, or fissure in it\n FILTER(contains(STR(?label), \"sulcus\")||contains(STR(?label), \"incisure\")||contains(STR(?label), \"fissure\"))\n\n}\n# arrange report by entity variable\nORDER BY ?entity\n
"},{"location":"reference/sparql-reference/#report-of-labels-and-definitions-of-terms-with-certain-namespace","title":"Report of labels and definitions of terms with certain namespace","text":"
prefix label: <http://www.w3.org/2000/01/rdf-schema#label>\nprefix oboInOwl: <http://www.geneontology.org/formats/oboInOwl#>\nprefix definition: <http://purl.obolibrary.org/obo/IAO_0000115>\nprefix owl: <http://www.w3.org/2002/07/owl#>\n\n# select a report with 3 variables\nSELECT DISTINCT ?term ?label ?def\n\n# defining the properties to be used\n WHERE {\n VALUES ?defproperty {\n definition:\n }\n VALUES ?labelproperty {\n label:\n }\n\n# defining the order of the triples\n ?term ?defproperty ?def .\n ?term ?labelproperty ?label .\n\n# selects entities that are in a certain namespace\n FILTER(isIRI(?term) && (STRSTARTS(str(?term), \"http://purl.obolibrary.org/obo/CP_\")))\n}\n\n# arrange report by term variable\nORDER BY ?term\n
# adding prefixes used\nprefix oboInOwl: <http://www.geneontology.org/formats/oboInOwl#>\nprefix definition: <http://purl.obolibrary.org/obo/IAO_0000115>\nprefix owl: <http://www.w3.org/2002/07/owl#>\n\nSELECT ?entity ?property ?value WHERE\n{\n # the variable property has to be defintion (IAO:0000115)\n VALUES ?property {\n definition:\n }\n # defining the order of variables in the triple\n ?entity ?property ?value .\n\n # selecting annotation on definition\n ?def_anno a owl:Axiom ;\n owl:annotatedSource ?entity ;\n owl:annotatedProperty definition: ;\n owl:annotatedTarget ?value .\n\n # filters out definitions which do not have a dbxref annotiton\n FILTER NOT EXISTS {\n ?def_anno oboInOwl:hasDbXref ?x .\n }\n\n # removes triples where entity is blank\n FILTER (!isBlank(?entity))\n # selects entities that are native to ontology (in this case MONDO)\n FILTER (isIRI(?entity) && STRSTARTS(str(?entity), \"http://purl.obolibrary.org/obo/MONDO_\"))\n\n}\n# arrange report by entity variable\nORDER BY ?entity\n
adaptable for checking if there is particular character in annotation
# adding prefixes used\nprefix owl: <http://www.w3.org/2002/07/owl#>\nprefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>\nprefix IAO: <http://purl.obolibrary.org/obo/IAO_>\nprefix definition: <http://purl.obolibrary.org/obo/IAO_0000115>\n\n# selecting only unique instances of the three variables\nSELECT DISTINCT ?entity ?property ?value WHERE\n{\n # the variable property has to be definition (IAO:0000115)\n VALUES ?property {\n definition:\n }\n # defining the order of variables in the triple\n ?entity ?property ?value .\n # filtering out triples where the variable value has _ in it\n FILTER( regex(STR(?value), \"_\"))\n # removes triples where entity is blank\n FILTER (!isBlank(?entity))\n}\n# arrange report by entity variable\nORDER BY ?entity\n
"},{"location":"reference/sparql-reference/#only-allowing-a-fix-set-of-annotation-properties","title":"Only allowing a fix set of annotation properties","text":"
# adding prefixes used\nprefix owl: <http://www.w3.org/2002/07/owl#>\nprefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>\nprefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>\nprefix oboInOwl: <http://www.geneontology.org/formats/oboInOwl#>\nprefix IAO: <http://purl.obolibrary.org/obo/IAO_>\nprefix RO: <http://purl.obolibrary.org/obo/RO_>\nprefix mondo: <http://purl.obolibrary.org/obo/mondo#>\nprefix skos: <http://www.w3.org/2004/02/skos/core#>\nprefix dce: <http://purl.org/dc/elements/1.1/>\nprefix dcterms: <http://purl.org/dc/terms/>\n\n# selecting only unique instances of the three variables\nSELECT DISTINCT ?term ?property ?value WHERE\n{\n # order of the variables in the triple\n ?term ?property ?value .\n # the variable property is an annotation property\n ?property a owl:AnnotationProperty .\n # selects entities that are native to ontology (in this case MONDO)\n FILTER (isIRI(?term) && regex(str(?term), \"^http://purl.obolibrary.org/obo/MONDO_\"))\n # removes triples where the variable value is blank\n FILTER(!isBlank(?value))\n # listing the allowed annotation properties\n FILTER (?property NOT IN (dce:creator, dce:date, IAO:0000115, IAO:0000231, IAO:0100001, mondo:excluded_subClassOf, mondo:excluded_from_qc_check, mondo:excluded_synonym, mondo:pathogenesis, mondo:related, mondo:confidence, dcterms:conformsTo, mondo:should_conform_to, oboInOwl:consider, oboInOwl:created_by, oboInOwl:creation_date, oboInOwl:hasAlternativeId, oboInOwl:hasBroadSynonym, oboInOwl:hasDbXref, oboInOwl:hasExactSynonym, oboInOwl:hasNarrowSynonym, oboInOwl:hasRelatedSynonym, oboInOwl:id, oboInOwl:inSubset, owl:deprecated, rdfs:comment, rdfs:isDefinedBy, rdfs:label, rdfs:seeAlso, RO:0002161, skos:broadMatch, skos:closeMatch, skos:exactMatch, skos:narrowMatch))\n}\n
"},{"location":"reference/sparql-reference/#checking-for-misused-replaced_by","title":"Checking for misused replaced_by","text":"
adaptable for checking that a property is used in a certain way
# adding prefixes used\nPREFIX owl: <http://www.w3.org/2002/07/owl#>\nPREFIX oboInOwl: <http://www.geneontology.org/formats/oboInOwl#>\nPREFIX replacedBy: <http://purl.obolibrary.org/obo/IAO_0100001>\n\n# selecting only unique instances of the three variables\nSELECT DISTINCT ?entity ?property ?value WHERE {\n # the variable property is IAO_0100001 (item replaced by)\n VALUES ?property { replacedBy: }\n\n # order of the variables in the triple\n ?entity ?property ?value .\n # removing entities that have either owl:deprecated true or oboInOwl:ObsoleteClass (these entities are the only ones that should have replaced_by)\n FILTER NOT EXISTS { ?entity owl:deprecated true }\n FILTER (?entity != oboInOwl:ObsoleteClass)\n}\n# arrange report by entity variable\nORDER BY ?entity\n
"},{"location":"reference/sparql-reference/#count","title":"Count","text":""},{"location":"reference/sparql-reference/#count-class-by-prefixes","title":"Count class by prefixes","text":"
# this query counts the number of classes you have with each prefix (eg number of MONDO terms, CL terms, etc.)\n\n# adding prefixes used\nprefix owl: <http://www.w3.org/2002/07/owl#>\nprefix obo: <http://purl.obolibrary.org/obo/>\n\n# selecting 2 variables, prefix and numberOfClasses, where number of classes is a count of distinct cls\nSELECT ?prefix (COUNT(DISTINCT ?cls) AS ?numberOfClasses) WHERE\n{\n # the variable cls is a class\n ?cls a owl:Class .\n # removes any cases where the variable cls is blank\n FILTER (!isBlank(?cls))\n # Binds the variable prefix as the prefix of the class (eg. MONDO, CL, etc.). classes that do not have obo purls will come out as blank in the report.\n BIND( STRBEFORE(STRAFTER(str(?cls),\"http://purl.obolibrary.org/obo/\"), \"_\") AS ?prefix)\n}\n# grouping the count by prefix\nGROUP BY ?prefix\n
"},{"location":"reference/sparql-reference/#counting-subclasses-in-a-namespace","title":"Counting subclasses in a namespace","text":"
# this query counts the number of classes that are subclass of CL:0000003 (native cell) that are in the pcl namespace\n\n# adding prefixes used\nPREFIX owl: <http://www.w3.org/2002/07/owl#>\nPREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>\nPREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>\nPREFIX CL: <http://purl.obolibrary.org/obo/CL_>\nPREFIX PCL: <http://purl.obolibrary.org/obo/PCL_>\n\n# count the number of unique term\nSELECT (COUNT (DISTINCT ?term) as ?pclcells)\nWHERE {\n # the variable term is a class\n ?term a owl:Class .\n # the variable term has to be a subclass of CL:0000003, including those that are subclassof by property path\n ?term rdfs:subClassOf* CL:0000003\n # only count the term if it is in the pcl namespace\n FILTER(isIRI(?term) && (STRSTARTS(str(?term), \"http://purl.obolibrary.org/obo/PCL_\")))\n}\n
"},{"location":"reference/sparql-reference/#removing","title":"Removing","text":""},{"location":"reference/sparql-reference/#removes-all-ro-terms","title":"Removes all RO terms","text":"
adaptable for removing all terms of a particular namespace
# adding prefixes used\nprefix owl: <http://www.w3.org/2002/07/owl#>\nprefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>\n\n# removing triples\nDELETE {\n ?s ?p ?o\n}\nWHERE\n{\n {\n # the variable p must be a rdfs:label\n VALUES ?p {\n rdfs:label\n }\n # the variable s is an object property\n ?s a owl:ObjectProperty ;\n # the other variables can be anything else (note the above value restriction of p)\n ?p ?o\n # filter out triples where ?s starts with \"http://purl.obolibrary.org/obo/RO_\"\n FILTER (isIRI(?s) && STRSTARTS(str(?s), \"http://purl.obolibrary.org/obo/RO_\"))\n }\n}\n
"},{"location":"reference/sparql-reference/#deleting-axiom-annotations-by-prefix","title":"Deleting axiom annotations by prefix","text":"
# adding prefixes used\nprefix owl: <http://www.w3.org/2002/07/owl#>\n\n# delete triples\nDELETE {\n ?anno ?property ?value .\n}\nWHERE {\n # the variable property is either synonym_type: or source:\n VALUES ?property { synonym_type: source: }\n # structure of variable value and variable anno\n ?anno a owl:Axiom ;\n owl:annotatedSource ?s ;\n owl:annotatedProperty ?p ;\n owl:annotatedTarget ?o ;\n ?property ?value .\n # filter out the variable value which start with \"ICD10EXP:\"\n FILTER(STRSTARTS(STR(?value),\"ICD10EXP:\"))\n}\n
"},{"location":"reference/sparql-reference/#replacing","title":"Replacing","text":""},{"location":"reference/sparql-reference/#replace-oboinowlsource-with-oboinowlhasdbxref-in-synonyms-annotations","title":"Replace oboInOwl:source with oboInOwl:hasDbXref in synonyms annotations","text":"
adaptable for replacing annotations properties on particular axioms
# adding prefixes used\nprefix owl: <http://www.w3.org/2002/07/owl#>\nprefix oboInOwl: <http://www.geneontology.org/formats/oboInOwl#>\nprefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>\n\n# delete triples where the relation is oboInOwl:source\nDELETE {\n ?ax oboInOwl:source ?source .\n}\n# insert triples where the variables ax and source defined above are used, but using oboInOwl:hasDbXref instead\nINSERT {\n ?ax oboInOwl:hasDbXref ?source .\n}\nWHERE\n{\n # restricting to triples where the property variable is in this list\n VALUES ?property { oboInOwl:hasExactSynonym oboInOwl:hasNarrowSynonym oboInOwl:hasBroadSynonym oboInOwl:hasCloseSynonym oboInOwl:hasRelatedSynonym } .\n # order of the variables in the triple\n ?entity ?property ?value .\n # structure on which the variable ax and source applies\n ?ax rdf:type owl:Axiom ;\n owl:annotatedSource ?entity ;\n owl:annotatedTarget ?value ;\n owl:annotatedProperty ?property ;\n oboInOwl:source ?source .\n # filtering out triples where entity is an IRI\n FILTER (isIRI(?entity))\n}\n
"},{"location":"reference/synonyms-obo/","title":"Synonyms in OBO","text":"
A synonym indicates an alternative name for a term. Terms can have multiple synonyms.
"},{"location":"reference/synonyms-obo/#the-scope-of-a-synonym-may-fall-into-one-of-four-categories","title":"The scope of a synonym may fall into one of four categories:","text":""},{"location":"reference/synonyms-obo/#exact","title":"Exact","text":"
The definition of the synonym is exactly the same as primary term definition. This is used when the same class can have more than one name.
For example, hereditary Wilms' tumor has the exact synonoym familial Wilms' tumor.
Additionally, translations into other languages are listed as exact synonyms. For example, the Plant Ontology list both Spanish and Japanese translations as exact synonyms; e.g. anther wall has exact synonym \u2018pared de la antera\u2019 (Spanish) and \u2018\u846f\u58c1 \u2018(Japanese).
The definition of the synonym is the same as the primary definition, but has additional qualifiers.
For example, pod is a narrow synonym of fruit.
Note - when adding a narrow synonym, please first consider whether a new subclass should be added instead of a narrow synonym. If there is any uncertainty, start a discussion on the GitHub issue tracker.
The primary definition accurately describes the synonym, but the definition of the synonym may encompass other structures as well. In some cases where a broad synonym is given, it will be a broad synonym for more than one ontology term.
For example, Cyst of eyelid has the broad synonym Lesion of the eyelid.
Note - when adding a broad synonym, please first consider whether a new superclass should be added instead of a broad synonym. If there is any uncertainty, start a discussion on the GitHub issue tracker.
This scope is applied when a word of phrase has been used synonymously with the primary term name in the literature, but the usage is not strictly correct. That is, the synonym in fact has a slightly different meaning than the primary term name. Since users may not be aware that the synonym was being used incorrectly when searching for a term, related synonyms are included.
For example, Autistic behavior has the related synonym Autism spectrum disorder.
Synonyms can also be classified by types. The default is no type. The synonym types vary in each ontology, but some commonly used synonym types include:
abbreviation - to indicate the synonym is an abbreviation. Note the scope for an acronym should be determined on a case-by-case basis. Not all acronyms are necessarily exact.
ambiguous - to indicate the synonym is open to more than one interpretation; may have a double meaning
dubious synonym - to indicate the synonym may be suspect
layperson term - to indicate the synonym is common language (used by the Human Phenotype Ontology)
plural form - indicating the form of the term that means more than one
UK spelling - the english language spelling that is used in the United Kingdom (UK) but not in the United States (US)
Whenever possible, database cross-references (dbxrefs) for synonyms should be provided, to indicate the publication that used the synonym. References to PubMed IDs should be in the format PMID:XXXXXXX (no space). However, dbxrefs for synonyms are not mandatory in most ontologies.
"},{"location":"reference/tables-and-triples/","title":"Tables and Triples","text":"
Tables and triples seem very different. Tables are familiar and predictable. Triples are weird and floppy. SQL is normal, SPARQL is bizarre, at least at first.
Tables are great, and they're the right tool for a lot of jobs, but they have their limitations. Triples shine when it comes to merging heterogeneous data. But it turns out that there's a clear path from tables to triples, which should help make RDF make more sense.
first_name last_name Luke Skywalker Leia Organa Darth Vader Han Solo
You won't be surprised to find out that tables have rows and columns. Often each row corresponds to some thing that we want to talk about, such as a fictional character from Star Wars. Each column usually corresponds to some sort of property that those things might have. Then the cells contain the values of those properties for their respective row. We take some sort of complex information about the world, and we break it down along two dimensions: the things (rows) and their properties (columns).
Tables are great! We can add another name to our table:
first_name last_name Luke Skywalker Leia Organa Darth Vader Han Solo Anakin Skywalker
Hmm. That's a perfectly good table, but it's not capturing the information that we wanted. It turns out (Spoiler Alert!) that Anakin Skywalker is Darth Vader! We might have thought that the rows of our table were describing individual people, but it turns out that they're just describing individual names. A person can change their name or have more than one name.
We want some sort of identifier that lets us pick out the same person, and distinguish them from all the other people. Sometimes there's a \"natural key\" that we can use for this purpose: some bit of information that uniquely identifies a thing. When we don't have a natural key, we can generate an \"artificial key\". Random strings and number can be good artificial keys, but sometimes a simple incrementing integer is good enough.
The main problem with artificial keys is that it's our job to maintain the link between the thing and the identifier that we gave it. We prefer natural keys because we just have to inspect that thing (in some way) to figure out what to call it. Even when it's possible, sometimes that's too much work. Maybe we could use a DNA sequence as a natural key for a person, but it probably isn't practical. We do use fingerprints and facial recognition, for similar things, though.
(Do people in Star Wars even have DNA? Or just midichlorions?)
Let's add a column with an artificial key to our table:
sw_id first_name last_name 1 Luke Skywalker 2 Leia Organa 3 Darth Vader 4 Han Solo 3 Anakin Skywalker
This is our table of names, allowing a given person to have multiple names. But what we thought we wanted was a person table with one row for each person, like this:
sw_id first_name last_name 1 Luke Skywalker 2 Leia Organa 3 Darth Vader 4 Han Solo
In SQL we could assert that the \"sw_id\" column of the person table is a PRIMARY KEY. This means it must be unique. (It probably shouldn't be NULL either!)
The names in the person table could be the primary names that we use in our Star Wars database system, and we could have another alternative_name table:
Tables are great! We can add more columns to our person table:
sw_id first_name last_name occupation 1 Luke Skywalker Jedi 2 Leia Organa princess 3 Darth Vader 4 Han Solo scoundrel
The 2D pattern of a table is a strong one. It not only provides a \"slot\" (cell) for every combination of row and column, it also makes it very obvious when one of those slots is empty. What does it mean for a slot to be empty? It could mean many things.
For example, in the previous table in the row for Darth Vader, the cell for the \"occupation\" column is empty. This could mean that:
we don't know whether he has an occupation
we know that he has an occupation, but we don't know which occupation it is.
we might know, but we haven't bothered to write it down yet
we might know, but it doesn't fit nicely into the New Republic Standard Registry of Occupations; in other words, we know what his occupation is, but including it here would violate a constraint on our database
we specifically know that he doesn't have an occupation; we triple-checked
we know more generally (Spoiler Alert!!) that he's dead, and dead people can't have an occupation.
I'm sure I haven't captured all the possibilities. The point is that there's lot of possible reasons why a cell would be blank. So what can we do about it?
If our table is stored in a SQL database, then we have the option of putting a NULL value in the cell. NULL is pretty strange. It isn't TRUE and it isn't FALSE. Usually NULL values are excluded from SQL query results unless you are careful to ask for them.
The way that NULL works in SQL eliminates some of the possibilities above. SQL uses the \"closed-world assumption\", which is the assumption that if a statement is true then it's known to be true, and conversely that if it's not known to be true then it's false. So if Anakin's occupation is NULL in a SQL database, then as far as SQL is concerned, we must know that he doesn't have an occupation. That might not be what you were expecting!
The Software Carpentry module on Missing Data has more information.
Tables are great! Let's add even more information to our table:
sw_id first_name last_name occupation enemy 1 Luke Skywalker Jedi 3 2 Leia Organa princess 3 3 Darth Vader 1,2,4 4 Han Solo scoundrel 3
We're trying to say that Darth Vader is the enemy of everybody else in our table. We're using the primary key of the person in the enemy column, which is good, but we've ended up with multiple values in the \"enemy\" column for Darth Vader.
In any table or SQL database you could make the \"enemy\" column a string, pick a delimiter such as the comma, and concatenate your values into a comma-separated list. This works, but not very well.
In some SQL databases, such as Postgres, you could given the \"enemy\" column an array type, so it can contain multiple values. You get special operators for querying inside arrays. This can work pretty well.
The usual advice is to break this \"one to many\" information into a new \"enemy\" table:
sw_id enemy 1 3 2 3 3 1 3 2 3 4 4 1
Then you can JOIN the person table to the enemy table as needed.
Tables are great! Let's add even more information to our table:
sw_id first_name last_name occupation father lightsaber_color ship 1 Luke Skywalker Jedi 3 green 2 Leia Organa princess 3 3 Darth Vader red 4 Han Solo scoundrel Millennium Falcon
A bunch of these columns only apply to a few rows. Now we've got a lot more NULLs to deal with. As the number of columns increases, this can become a problem.
Tables are great! If sparse tables are a problem, then let's try to apply the same solution that worked for the \"many to one\" problem in the previous section.
name table:
sw_id first_name last_name 1 Luke Skywalker 2 Leia Organa 3 Darth Vader 4 Han Solo 3 Anakin Skywalker
occupation table:
sw_id occupation 1 Jedi 2 princess 4 scoundrel
enemy table:
sw_id enemy 1 3 2 3 3 1 3 2 3 4 4 1
father table:
sw_id father 1 3 2 3
lightsaber_color table:
sw_id lightsaber_color 1 green 3 red
ship table:
sw_id ship 4 Millennium Falcon
Hmm. Yeah, that will work. But every query we write will need some JOINs. It feels like we've lost something.
Tables are great! But there's such a thing as too many tables. We started out with a table with a bunch of rows and a bunch of columns, and ended up with a bunch of tables with a bunch of rows but just a few columns.
I have a brilliant idea! Let's combine all these property tables into just one table, by adding a \"property\" column!
sw_id property value 1 first_name Luke 2 first_name Leia 3 first_name Darth 4 first_name Han 5 first_name Anakin 1 last_name Skywalker 2 last_name Skywalker 3 last_name Vader 4 last_name Solo 5 last_name Skywalker 1 occupation Jedi 2 occupation princess 4 occupation scoundrel 1 enemy 3 2 enemy 3 3 enemy 1 3 enemy 2 3 enemy 4 4 enemy 1 1 father 3 2 father 3 1 lightsaber_color green 3 lightsaber_color red 4 ship Millenium Falcon
It turns out that I'm not the first one to think of this idea. People call it \"Entity, Attribute, Value\" or \"EAV\". People also call it an \"anti-pattern\", in other words: a clear sign that you've made a terrible mistake.
There are lots of circumstances in which one big, extremely generic table is a bad idea. First of all, you can't do very much with the datatypes for the property and value columns. They kind of have to be strings. It's potentially difficult to index. And tables like this are miserable to query, because you end up with all sorts of self-joins to handle.
But there's at least one use case where it turns out to work quite well...
The strong row and column structure of tables makes them great for lots of things, but not so great for merging data from different sources. Before you can merge two tables you need to know all about:
how the columns are structured
what the rows mean
what the cells mean
So you need to know the schemas of the two tables before you can start merging them together. But if you happen to have two EAV tables then, as luck would have it, they already have the same schema!
You also need to know that you're talking about the same things: the rows have to be about the same things, you need to be using the same property names for the same things, and the cell values also need to line up. If only there was an open standard for specifying globally unique identifiers...
Yes, you guessed it: URLs (and URNs and URIs and IRIs)! Let's assume that we use the same URLs for the same things across the two tables. Since we're a close-knit community, we've come to an agreement on a Star Wars data vocabulary.
URLs are annoyingly long to use in databases, so let's use standard \"sw\" prefix to shorten them. Now we have table 1:
sw_id property value sw:1 sw:first_name Luke sw:2 sw:first_name Leia sw:3 sw:first_name Darth sw:4 sw:first_name Han sw:5 sw:first_name Anakin sw:1 sw:last_name Skywalker sw:2 sw:last_name Skywalker sw:3 sw:last_name Vader sw:4 sw:last_name Solo sw:5 sw:last_name Skywalker sw:1 sw:occupation sw:Jedi sw:2 sw:occupation sw:princess sw:4 sw:occupation sw:scoundrel
These tables are pretty much in RDF format. You just have to squint a little!
sw_id == subject
property == predicate
value == object
Each row of the table is a subject-predicate-object triple. Our subjects, predicates, and some objects are URLs. We also have some literal objects. We could turn this table directly into Turtle format with a little SQL magic (basically just concatenating strings):
Two things we're missing from RDF are language tagged literals and typed literals. We also haven't used any blank nodes in our triple table. These are easy enough to add.
The biggest thing that's different about RDF is that it uses the \"open-world assumption\", so something may be true even though we don't have a triple asserting that it's true. The open-world assumption is a better fit than the closed-world assumption when we're integrating data on the Web.
Tables are great! We use them all the time, they're strong and rigid, and we're comfortable with them.
RDF, on the other hand, looks strange at first. For most common data processing, RDF is too flexible. But sometimes flexiblity is the most important thing.
The greatest strength of tables is their rigid structure, but that's also their greatest weakness. We saw a number of problems with tables, and how they could be overcome by breaking tables apart into smaller tables, until we got down to the most basic pattern: subject-predicate-object. Step by step, we were pushed toward RDF.
Merging tables is particularly painful. When working with data on the Web, merging is one of the most common and important operations, and so it makes sense to use RDF for these tasks. If self-joins with SQL is the worst problem for EAV tables, then SPARQL solves it.
These examples show that it's not really very hard to convert tables to triples. And once you've seen SPARQL, the RDF query language, you've seen one good way to convert triples to tables: SPARQL SELECT results are just tables!
Since it's straightforward to convert tables to triples and back again, make sure to use the right tool for the right job. When you need to merge heterogeneous data, reach for triples. For most other data processing tasks, use tables. They're great!
"},{"location":"reference/troublehooting-robot/","title":"Lessons learned from troubleshooting ROBOT","text":""},{"location":"reference/troublehooting-robot/#prerequisites","title":"Prerequisites","text":"
Review tutorial on Ontology pipelines with ROBOT and SPARQL
Learn common mistakes when using ROBOT and how to troubleshoot and fix them.
"},{"location":"reference/troublehooting-robot/#lessons-learned","title":"Lessons learned","text":""},{"location":"reference/troublehooting-robot/#copying-pasting-especially-in-google-docs-can-introduce-unexpected-format-changes-in-row-2-of-the-template","title":"Copying-pasting (especially in google docs) can introduce unexpected format changes in row 2 of the template:","text":"
Note that these format changes are not always visible.
The most common typos are:
introduction of space in cells
single quotes are changed into apostrophes
These errors are most commonly reported as \"MANCHESTER PARSE ERROR\"
"},{"location":"reference/troublehooting-robot/#restrictions-for-the-first-2-rows-of-a-robot-template","title":"Restrictions for the first 2 rows of a ROBOT template:","text":"
In the same column, it is OK to have a header string (row #1) with no template string (row #2).
the information in the column is useful to curators (e.g. term labels) but will be ignored by ROBOT.
In the same column, if there is a template string (row #2), there MUST be a header string (row #1)
if the row #1 is missing, the error will be reported as: COLUMN MISMATCH ERROR the template string in column 1 must have a corresponding header in table \"tmp/merge_template.tsv\u201d
"},{"location":"reference/troublehooting-robot/#the-content-of-the-template-break-some-obo-or-protege-rules","title":"The content of the template break some OBO or Protege rules","text":"
for example, Protege only allows one comment on a class. If you are adding new comments to terms via ROBOT, you will get an error if a comment already exists on a term.
error will be reported as: OBO STRUCTURE ERROR Ontology does not conform to OBO structure rules: multiple comment tags not allowed.
Note: If you run ROBOT and get an error, it may create a blank file. You need to discard the changes and/or open a new branch. The error with the optional \u201cnull\u201d is when the mondo-edit file is empty. Optional.get() cannot be called on an absent valueUse the -vvv option to show the stack trace.Use the --help option to see usage informationmake: *** [mondo.Makefile:454: merge_template] Error 1
"},{"location":"reference/troublehooting-robot/#new-id-prefix","title":"New ID prefix:","text":"
ROBOT template can be used to add axioms containing terms (and IDs) from other ontologies which were recently imported
The ID prefix is not recognized by ROBOT, and the error is reported as MANCHESTER PARSE ERROR
Resolution: the ontology Makefile should be updated to include the prefix in the merge_template.
Note: If you run ROBOT and get an error, it may create a blank file. You need to discard the changes and/or open a new branch.
"},{"location":"reference/wikidata/","title":"A reference guide to Wikidata","text":""},{"location":"reference/wikidata/#a-reference-guide-to-wikidata-and-its-connection-to-obo","title":"A reference guide to Wikidata and its connection to OBO","text":""},{"location":"reference/wikidata/#introduction-to-wikidata","title":"Introduction to Wikidata","text":"
Wikidata in one page
Wikidata
Wikidata Query Service (UI)
Wikidata Query Serivce (Machine readable)
Wikidata API
"},{"location":"reference/wikidata/#obo-in-wikidata","title":"OBO in Wikidata","text":"
\"All structured data from the main, Property, Lexeme, and EntitySchema namespaces is available under the Creative Commons CC0 License; text in the other namespaces is available under the Creative Commons Attribution-ShareAlike License\"
Adding non-CC0 licensed OBO ontologies in full might be problematic due to * License stacking
IANL, but my understanding is that as long as only URI mappings are created to OBO ontology terms no licenses are breached (even if the ontology is not CC0)
"},{"location":"reference/wikidata/#why-map-obo-uris-to-wikidata","title":"Why map OBO uris to Wikidata?","text":"
Wikidata is a hub in the Linked Open Data cloud; it is, thus, a good place to crowdsource database cross references (e.g. between the Cell Ontology and FMA).
Wikidata provides direct links between items and Wikipedia, as well as a proxy for how many different Wikipedia languages are available for each concept. These can be acessed via SPARQL queries (e.g https://w.wiki/6Tpd). Wikipedia links are useful for adding explainability to applications, and language count can be a proxy for popularity of concepts.
E.g. The top popular concepts with a CL ID are \"Cell\", \"Red Blood Cell\" and \"Neuron\" with over 100 Wikipedia languages each (https://w.wiki/6TyY)
Wikidata is multilingual and most (if not all) OBO ontologies are English-only. Wikidata provides infrastructure to record preferred labels accross 200+ languages (not sure the current number).
"},{"location":"teaching/case-studies/","title":"Learning Outcomes for Critical Path Tutorial","text":"
Understand the value of URIs as global identifiers and the potential shortcomings.
Having a basic picture of the flagship efforts of the Semantic Web.
Being aware of some of the central Semantic Web applications in the biomedical domain.
Having a cursory understanding of how linked data can help to power your Critical Path data analysis problems.
"},{"location":"teaching/case-studies/#interesting-case-studies-to-talk-about","title":"Interesting Case Studies to talk about:","text":"
The Experimental Factor Ontology: from controlled vocabulary to integrated application ontology driving drug target identification.
From barely structured data via data dictionaries to semantic data integration:
International HundredK+ Cohorts Consortium (IHCC) data harmonization case study: How to get from messy, individual data dictionaries for COHORT data to an integrated resource for browsing and grouping.
The EJPRD story:
Registry level integration using a semantic metadata model
Common data elements in rare disease registration.
"},{"location":"teaching/case-studies/#efo-case-study","title":"EFO case study","text":"
Build controlled vocabulary
Look a bit at the anatomy of a term
So what happens now?
The story of scientific database curation
The integrator hub with the killer use case comes along
Now the vocabulary is getting \u201cforced\u201d onto other databases that want to be part (and have to be part)
The number of terms needed shoot up exponentially - external ontologies need two be integrated
Uberon
Mondo
Why Mondo and not DO?
Finally: better, more specialised hierarchies
Its hard to re-use. (Measurement story)
Output data of integrator hub can now be integrated even higher (e.g. disease to gene networks)
Individual sources can also be integrated individually
Stories like this happen all the time: The SCDO story
Rare disease registries are scattered across the web and there is no easy way to search across all
EJPRD is developing two metadata schemas:
On Registry level, they are building the metadata model which is reusing some standard vocabularies such as dcat. There is not that much \"semantics\" here - it really is a metadata model
On Record level, they are building the Clinical Data Elements (CDE) Semantic Model, see for example the core model.
The idea is that registries publish their metadata (and eventually data) as linked data that can be easily queried using the above models. One of the most major problems is the size of the project and competing voices (\"If its not RDF its not FAIR\"), but also the sheer scale of the technical issue: many of the so called registries are essentially excel spreadsheets on an FTP server.
This tutorial is based off https://ontology101tutorial.readthedocs.io/en/latest/DL_QueryTab.html Created by: Melissa Haendel, Chris Mungall, David Osumi-Sutherland, Matt Yoder, Carlo Torniai, and Simon Jupp
The DL query tab shown below provides an interface for querying and searching an ontology. The ontology must be classified by a reasoner before it can be queried in the DL query tab.
For this tutorial, we will be using cc.owl which can be found here.
Open cc.owl in Protege (use Open from URL and enter the https://raw.githubusercontent.com/OHSUBD2K/BDK14-Ontologies-101/master/BDK14_exercises/basic-dl-query/cc.owl). Run the reasoner. Navigate to the DL Query tab.
Type organelle into the box, and make sure subclasses and direct subclasses are ticked.
You can type any valid OWL class expression into the DL query tab. For example, to find all classes whose members are part_of a membrane, type part_of some membrane and click execute. Note the linking underscore for this relation in this ontology. Some ontologies do not use underscores for relations, whereby you'd need single quotes (i.e. part of).
The OWL keyword and can be used to make a class expression that is the intersection of two class expressions. For example, to find the classes in the red area below, we want to find subclasses of the intersection of the class organelle and the class endoplasmic reticulum part
Note that we do not need to use the part grouping classes in the gene ontology (GO). The same results can be obtained by querying for the intersection of the class organelle and the restriction part_of some ER \u2013 try this and see.
We can also ask for superclasses by ticking the boxes as below:
The or keyword is to used to create a class expression that is the union of two class expressions. For example: (WARNING: or is not supported by ELK reasoner)
This is illustrated by the red area in the following Venn diagram:
For further exercises, please see https://ontology101tutorial.readthedocs.io/en/latest/EXERCISE_BasicDL_Queries.html
"},{"location":"tutorial/custom-qc/","title":"Tutorial: How to add custom quality checks with ODK","text":"
This tutorial explains adding quality checks not included in the ROBOT Report.
Identify a quality issue in your ontology. For the sake of this tutorial, we've added the annotation oboInOwl:creation_date to the root_node in the CAT Ontology.
Write the SPARQL query to detect the error you want to check. For example, check the value type for the annotation oboInOwl:creation_date. It will return the class with the annotation if it's not of type xsd:dateTime.
Save the SPARQL query in the src/sparql folder and name it [violation name]-violation.sparql. In the case of the tutorial, date-as-string-violation.sparql
Add the check to the ODK config file. In the previous tutorial, this is located at ~/cato/src/ontology/cato-odk.yaml. Inside robot_report, add custom_sparql_checks
Update the repository. After adding the custom SPARQL check, you need to update your pipeline to take this check when testing the ontology.
sh run.sh make update_repo\n
Test the check. You can run the checks and verify the expected result.
sh run.sh make sparql_test\nFAIL Rule ../sparql/date-as-string-violation.sparql: 1 violation(s)\ncls\nhttp://purl.obolibrary.org/obo/CATO_0000000\n
To fix this issue, we need to change the annotation value to xsd:dateTime, and run the test again to certify everything is good this time.
sh run.sh make sparql_test\nPASS Rule ../sparql/date-as-string-violation.sparql: 0 violation(s)\n
Push the changes to your repository, and the custom checks will run whenever creating a new Pull Request, as detailed here.
"},{"location":"tutorial/custom-qc/#custom-checks-available-in-odk","title":"Custom checks available in ODK","text":"
There are several checks already available in the ODK. If you'd like to add them, add the validation name in your ODK config file.
owldef-self-reference: verify if the term uses its term as equivalent
redundant-subClassOf: verify if there are redundant subclasses between three classes
taxon-range: verify if the annotations present_in_taxon or never_in_taxon always use classes from NCBITaxon
iri-range: verify if the value for the annotations never_in_taxon, present_in_taxon, foaf:depicted_by, oboInOwl:inSubset and dcterms:contributor are not an IRI
iri-range-advanced: same as iri-range plus check for rdfs:seeAlso annotation
label-with-iri: verify if there is IRI in the label
multiple-replaced_by: verify if an obsolete term has multiple replaced_by terms
term-tracker-uri: verify if the value for the annotation term_tracker_item is not URI
illegal-date: verify if the value for the annotations dcterms:date, dcterms:issued and dcterms:created are of type xds:date and use the pattern YYYY-MM-DD
"},{"location":"tutorial/custom-qc/#custom-robot-report-in-odk","title":"Custom ROBOT Report in ODK","text":"
ROBOT report can also have custom quality checks.
First, you need to add custom_profile: TRUE, in the ODK config file.
2. Create a SPARQL query with your quality check and save it at src/sparql. There isn't a restriction on the file name. However, it should return the variables ?entity ?property ?value.
Add the path to the SPARQL query in the src/ontology/profile.txt file.
ERROR file:../sparql/<file name>.sparql\n
For more detail on the profile file, see here.
Test your check. You'll find the failed cases on the same report for the ROBOT report at src/ontology/reports/cato-edit.owl-obo-report.tsv. The Rule Name will be the SPARQL file name.
sh run.sh make test\n
"},{"location":"tutorial/custom-qc/#how-to-choose-between-custom-sparql-or-custom-robot-report","title":"How to choose between Custom SPARQL or Custom ROBOT report","text":"
If your test can return the exact three variables entity, property and value -> ROBOT report
If you need to return more detailed information -> Custom SPARQL
If you want the results of your custom tests in the ROBOT report file -> ROBOT report
Keep in mind that after changing the profile.txt, you won't get any upcoming updates, and you need to update manually.
This tutorial is based off https://ontology101tutorial.readthedocs.io/en/latest/Disjointness.html Created by: Melissa Haendel, Chris Mungall, David Osumi-Sutherland, Matt Yoder, Carlo Torniai, and Simon Jupp
For this excercise, we will be using chromosome-parts-interim.owl file that can be found here
In the chromosome-parts-interim.owl file, at the top of our class hierarchy we have cell, cell part, chromosomal part, intracellular part, organelle and organelle part. By default, OWL assumes that these classes can overlap, i.e. there are individuals who can be instances of more than one of these classes. We want to create a restriction on our ontology that states these classes are different and that no individual can be a member of more than one of these classes. We can say this in OWL by creating a disjoint classes axiom.
If you do not already have it open, load your previous ontology that was derived from the 'interim file'. Note: you can open a recent file by going to File-> Open Recent
We want to assert that organelle and organelle part are disjoint. To do this first select the organelle class. In the class 'Description' view, scroll down and select the (+) button next to Disjoint With. You are presented with the now familiar window allowing you to select, or type, to choose a class. In the hierarchy panel, you can use CTRL to select multiple classes. Select 'organelle part' as disjoint with organelle.
Note that the directionality is irrelevant. Prove this to yourself by deleting the disjoint axiom, and adding it back from organelle part.
"},{"location":"tutorial/disjointness/#reasoning-and-inconsistency-checking","title":"Reasoning and inconsistency checking","text":"
We have introduced a deliberate mistake into the ontology. We previously asserted that intracellular organelle part is a subclass of both organelle part and organelle. We have now added an axiom stating that organelle and organelle part are disjoint. We can use the reasoner to check the consistency of our ontology. The reasoner should detect our contradiction.
Prot\u00e9g\u00e9 comes with several reasoners, and more can be installed via the plugins mechanism (see plugins chapter). Select a reasoner from the Reasoner menu (Elk, HermiT, Pellet, or Fact++ will work - we mostly use ELK). Once a reasoner is highlighted, select 'Start reasoner' from the menu. Note: you may get several pop-boxes/warnings, ignore those.
The intracellular organelle part class will have changed to red indicating that the class is now unsatisfiable.
You can also see unsatisfiable classes by switching to the inferred view.
Here you will a special class called Nothing. When we previously said that all OWL classes are subclasses of OWL Thing. OWL Nothing is a leaf class or bottom class of your ontology. Any classes that are deemed unsatisfiable by the reasoner are shown as subclasses or equivalent to OWL Nothing. The inferred view will show you all subclasses of Nothing.
Once the ontology is classified, inferred statements or axioms are shown in the various panels with a light-yellow shading. The class description for intracellular organelle part should look something like the screen shot below. You will see that the class has been asserted equivalent to the Nothing class. Inside this statement, a small question mark icon appears, clicking this will get an explanation from the reasoner for this inconsistency.
Select the (?) icon to get an explanation for this inconsistency. The explanation shows the axioms involved. We see the disjoint class axiom alongside the two subclass axioms are causing the inconsistency. We can simply repair this ontology by removing the intracellular organelle part subClassOf organelle axiom.
Remove the Disjoint with axiom (click the (x) beside organelle in the Description pane for intracellular organelle part), and resynchronise the reasoner from the reasoner menu.
"},{"location":"tutorial/dosdp-odk/","title":"Using DOSDP templates in ODK Workflows","text":""},{"location":"tutorial/dosdp-odk/#preparation","title":"Preparation","text":"
You are set up for executing ODK workflows
We assume you have a modern ODK-based repository (ODK version >= 1.2.32) set up. For a tutorial on creating a new ontology repo from scratch see here.
We assume you have completed at least one of the general DOSDP tutorials.
This is a very unprofessional video below recorded as part of one of our trainings. It walks you through this tutorial here, with some additional examples being given and a bit of Q&A.
Template: A document with template strings that include variables which can be instantiated my a tool. For example, a ROBOT template may contain the template string SC 'part of' some % which can be instantiated by ROBOT to be transformed into an OWL axiom: SubClassOf(CATO:001 ObjectSomeValuesFrom(BFO:0000051 UBERON:123)). Similarly, DOSDP YAML files are often referred to as \"templates\" (which is appropriate). Unfortunately, we often refer to them as \"patterns\" which is not strictly the right way to name them: they are templates that encode patterns (and that only to a limited extend). We recommend to refer to the DOSDP YAML files as \"templates\".
Template string: See above: a single string with one or more slots for variables that can be instantiated and transformed into something else. The most important template string in DOSDP is the equivalentTo or subClassOf field: It tells DOSDP tools how to generate an OWL axiom, with which variable slots (vars).
Pattern: See above, often misused to mean Template. In fact, a pattern provides a general modelling solution to a problem. Patterns can often be encoded in templates, but this is often incomplete. For example, a template typically does not care about the semantics of the properties it refers to, while this is critical for a pattern. (Avoid using this when talking about DOSDP YAML files).
DOSDP template table: The spreadsheet (typically TSV or CSV) that contains the DOSDP variable data. The DOSDP template table is applied to the template string in the template to generate a set of OWL axioms and annotation assertions.
"},{"location":"tutorial/dosdp-odk/#activate-dosdp-in-odk","title":"Activate DOSDP in ODK","text":"
In your src/ontology/{yourontology}-odk.yaml file, simply add the following:
use_dosdps: true\n
This flag activates DOSDP in ODK - without it, none of the DOSDP workflows in ODK can be used. Technically, this flag tells ODK the following things:
The src/ontology/Makefile is extended as follows:
A set of pipelines, or workflows, for processing patterns, e.g. pattern_schema_checks for validating all DOSDP templates,patterns to regenerate all patterns.
A new directory, src/patterns, is created with the following files:
src/patterns/pattern.owl: This is an ontology of your own patterns. This can be used to browse the your pattern in the form of a class hierarchy, which can help greatly to understand how they relate logically. There are some flaws in this system, like occasional unintended equivalencies between patterns, but for most uses, it is doing ok.
src/patterns/definitions.owl: This is the merged ontology of all your DOSDP generated classes. Basically, if you manage your classes across multiple DOSDP patterns and tables, their generated OWL axioms will all be added to this file.
src/patterns/external.txt: This file can be used to import external patterns. Just add the (p)URL to a pattern to the file, and the DOSDP pipeline will import it when you run it. We use this a lot when sharing DOSDP templates across ontologies.
Two README files: one in the directory of the default DOSDP data pipeline (src/patterns/data/default/) and one in the src/patterns directory. The former points you to the place where you should put, by default, any DOSDP data tables. More about that in the next sections.
To fully activate DOSDP in your ontology, please run:
sh run.sh make update_repo\n
This will:
Update your ontology repository to whatever ODK you have installed in docker (v1.3, for example)
Apply any changes to your configuration file. For example, the fact that you have activated the DOSDP pipeline in your config file will lead to the ODK extending your Makefile in certain ways
"},{"location":"tutorial/dosdp-odk/#adding-a-first-simple-template","title":"Adding a first, simple template","text":"
(1) Create a new file src/patterns/dosdp-patterns/haircoat_colour_pattern.yaml and paste the following content:
pattern_name: haircoat_colour_pattern\npattern_iri: http://purl.obolibrary.org/obo/obo-academy/patterns/haircoat_colour_pattern.yaml\n\ndescription: \"\nCaptures the multicoloured characteristic of the fur, i.e. spotted, dotted, motley etc.\"\n\nclasses:\ncolour_pattern: PATO:0001533\ncoat_of_hair: UBERON:0010166\n\nrelations:\nhas_characteristic: RO:0000053\n\nvars:\ncolour_pattern: \"'colour_pattern'\"\n\nname:\ntext: \"%s coat of hair\"\nvars:\n- colour_pattern\n\ndef:\ntext: \"A coat of hair with a %s colour pattern.\"\nvars:\n- colour_pattern\n\nequivalentTo:\ntext: \"'coat_of_hair' and 'has_characteristic' some %s\"\nvars:\n- colour_pattern\n
(2) Let's also create a simple template table to capture traits for our ontology.
Note: the filename of the DOSDP template file (haircoat_colour_pattern.yaml) excluding the extension must be identical to the filename of the template table (haircoat_colour_pattern.tsv) excluding the extension.
Let's create the new file at src/patterns/data/default/haircoat_colour_pattern.tsv.
We are creating a minimal table here with just two columns:
defined_class refers to the ID for the term that is being modelled by the template (mandatory for all DOSDP templates)
colour_pattern refers to the variable of the same name specified in the vars: section of the DOSDP template YAML file.
"},{"location":"tutorial/dosdp-odk/#dosdp-generate-turning-the-template-tables-into-owl-axioms","title":"DOSDP generate: Turning the template tables into OWL axioms","text":"
Next, we will get a bit used to various commands that help us with DOSDP-based ontology development.
Lets first try to transform the simple table above to OWL using the ODK pipeline (we always use IMP=false to skip refreshing imports, which can be a lengthy process):
sh run.sh make ../patterns/definitions.owl -B IMP=false\n
This process will will create the ../patterns/definitions.owl file, which is the file that contains all axioms generated by all templates you have configured. In our simple scenario, this means a simple single pattern. Let us look at definitions.owl in your favourite text editor first.
Tip: Remember, the `-B` tells `make` to run the make command no matter what - one of the advantages of `make` is that it only runs a command again if something changed, for example, you have added something to a DOSDP template table.\n
Tip: Looking at ontologies in text editors can be very useful, both to reviewing files and making changes! Do not be afraid, the ODK will ensure you wont break anything.\n
Let us look in particular at the following section of the definitions.owl file:
# Class: <http://purl.obolibrary.org/obo/CATO_0000001> (http://purl.obolibrary.org/obo/PATO_0000333 coat of hair)\n\nAnnotationAssertion(<http://purl.obolibrary.org/obo/IAO_0000115> <http://purl.obolibrary.org/obo/CATO_0000001> \"A coat of hair with a http://purl.obolibrary.org/obo/PATO_0000333 colour pattern.\"^^xsd:string)\nAnnotationAssertion(rdfs:label <http://purl.obolibrary.org/obo/CATO_0000001> \"http://purl.obolibrary.org/obo/PATO_0000333 coat of hair\"^^xsd:string)\nEquivalentClasses(<http://purl.obolibrary.org/obo/CATO_0000001> ObjectIntersectionOf(<http://purl.obolibrary.org/obo/UBERON_0010166> ObjectSomeValuesFrom(<http://purl.obolibrary.org/obo/RO_0000053> <http://purl.obolibrary.org/obo/PATO_0000333>)))\n
These are the three axioms / annotation assertions that were created by the DOSDP pipeline. The first annotation is a simple automatically generated definition. What is odd at first glance, is that the definition reads \"A coat of hair with a http://purl.obolibrary.org/obo/PATO_0000333 colour pattern.\" - what does the PATO:0000333 IRI do in the middle of our definition? Understanding this is fundamental to the DODSP pattern workflow, because it is likely that you will have to fix cases like this from time to time.
The DOSDP workflow is about generating axioms automatically from existing terms. For example, in this tutorial we are trying to generate terms for different kinds of hair coats for our cats, using the colour pattern (PATO:0001533) hierarchy in the PATO ontology as a basis. The only one term we have added so far is spotted (PATO:0000333). The problem is though, that dosdp-tools, the tool which is part of the ODK and responsible for the DOSDP workflows, does not know anything about PATO:0000333 unless it is already imported into the ontology. In order to remedy this situation, lets import the term:
sh run.sh make refresh-pato\n
ODK will automatically see that you have used PATO:0000333 in your ontology, and import it for you. Next, let us make sure that the our edit file has the correct import configured. Open your ontology in a text editor, and make sure you can find the following import statement:
Replace cato in the PURL with whatever is the ID of your own ontology. Also, do not forget to update src/ontology/catalog-v001.xml, by adding this line:
Important: Remember that we have not yet told dosdp-tools about the freshly imported PATO:0000333 term. To do that, lets run the DOSDP pipeline again:
sh run.sh make ../patterns/definitions.owl -B IMP=false\n
A quick look at src/patterns/definitions.owl would now reveal your correctly formatted definitions:
AnnotationAssertion(<http://purl.obolibrary.org/obo/IAO_0000115> <http://purl.obolibrary.org/obo/CATO_0000001> \"A coat of hair with a spotted colour pattern.\"^^xsd:string)\n
Now, we are ready to view our ontology (the edit file, i.e. src/ontology/cato-edit.owl) in Protege:
Still a few things to iron out - there is an UBERON term that we still need to import, and our class is not a subclass of the CATO root node, but we had a good start.
"},{"location":"tutorial/dosdp-odk/#re-using-externally-defined-patterns","title":"Re-using externally defined patterns","text":"
Re-using terms is at the heart of the OBO philosophy, but when it comes to re-using axiom patterns, such as the ones we can define as part of a ROBOT template, we are (as of 2022) still in the early stages. One thing we can do to facilitate re-use is to share DOSDP templates between different projects. We do that by simply adding the URL at which the pattern is located to src/patterns/dosdp-patterns/external.txt. Note: if you are copying a URL from GitHub, make sure it is the raw url, i.e.:
Here, we randomly decided to import a pattern defined by the Ontology of Biological Attributes (an ontology of traits such as tail length or head size), for example to represent cat traits in our Cat Ontology. After adding the above URL to our the external.txt file, we can add it to our pipeline:
sh run.sh make update_patterns\n
You will now see the entity_attribute.yaml template in src/patterns/dosdp-patterns. We will not do anything with this template as part of this tutorial, so you can remove it again if you wish (by removing the URL from the external.txt file and physically deleting the src/patterns/dosdp-patterns/entity_attribute.yaml file).
"},{"location":"tutorial/dosdp-odk/#dosdp-pipelines-in-odk","title":"DOSDP pipelines in ODK","text":"
Sometimes, we want to manage more than one DOSDP pipeline at once. For example, in more than one of our projects, we have some patterns that are automatically generated by software tools, and others that are manually curated by ontology developers. In other use cases, we sometimes want to restrict the pattern pipelines to generating only logical axioms. In either case, we can add new pipelines by adding the following to the src/ontology/youront-odk.yaml file:
This does the following: It tells the ODK that you want
"},{"location":"tutorial/dosdp-odk/#reference","title":"Reference","text":""},{"location":"tutorial/dosdp-odk/#a-full-example-odk-configuration","title":"A full example ODK configuration","text":"
"},{"location":"tutorial/dosdp-odk/#odk-configuration-reference-for-dosdp","title":"ODK configuration reference for DOSDP","text":"Flag Explanation use_dosdps: TRUE Activates DOSDP in your ODK repository setup pattern_pipelines_group:products: - id: manual dosdp_tools_options: \"--obo-prefixes=true --restrict-axioms-to=logical\" Adding a manual pipeline to your DOSDP setup in which only logical axioms are generated."},{"location":"tutorial/dosdp-overview/","title":"Getting started with DOSDP templates","text":"
Dead Simple OWL Design patterns (DOSDP) is a templating system for documenting and generating new OWL classes. The templates themselves are designed to be human readable and easy to author. Separate tables (TSV files) are used to specify individual classes.
The complete DOSDP documentation can be found here http://incatools.github.io/dead_simple_owl_design_patterns/.
For another DOSDP tutorial see here.
"},{"location":"tutorial/dosdp-overview/#anatomy-of-a-dosdp-file","title":"Anatomy of a DOSDP file:","text":"
A DOSDP tempaltes are written in YAML) file, an easily editable format for encoding nested data structures. At the top level of nesting is a set of 'keys', which must match those specified in the DOSDP standard. The various types of key and their function are outlined below. Each key is followed by a colon and then a value, which may be a text string, a list or another set of keys. Lists items are indicated using a '-'. Nesting is achieved via indenting using some standard number of spaces (typically 3 or 4). Here's a little illustration:
key1: some text\nkey2:\n- first list item (text; note the indent)\n- second list item\nkey3:\nkey_under_key3: some text\nanother_key_under_key3:\n- first list item (text; note the indent)\n- second list item\nyet_another_key_under_key3:\nkey_under_yet_another_key_under_key3: some more text\n
In the following text, keys and values together are sometimes referred to as 'fields'.
A major aim of the DOSDP system is to produce self-contained, human-readable templates. Templates need IDs in order to be reliably used programatically, but templates that only use IDs are not human readable. DOSDPs therefore include a set of dictionaries that map labels to IDs. Strictly any readable name can be used, but by convention we use class labels. IDs must be OBO curie style e.g. CL:0000001).
Separate dictionaries are required for classes, relations (object properties) & annotationProperties e.g.
These fields specify the names of pattern variables (TSV column names) and map these to a range. e.g. This specifies a variable called 'anatomy' with the range 'anatomical entity':
vars:\nanatomy: \"'anatomical entity'\"\n
The var name (anatomy) corresponds to a column name in the table (TSV file) used in combination with this template, to generate new terms based on the template. The range specifies what type of term is allowed in this column - in this case 'anatomical entity' (UBERON:0001062; as specified in the dictionary) or one of its subclasses, e.g.-
anatomy UBERON:0001154
There are various types of variables:
vars are used to specify OWL classes (see example above). data_vars and data_list_vars are used to specify single pieces or data lists respectively. The range of data_vars is specified using XSD types. e.g.
A table used to specify classes following this pattern could have the following content. Note that in lists, multiple elements are separated by a '|'.
number xrefs 1 pubmed:123456|DOI:10.1016/j.cell.2016.07.054"},{"location":"tutorial/dosdp-overview/#template-fields","title":"Template fields","text":"
Template fields are where the content of classes produced by the template is specified. These mostly follow printf format: A text field has variable slots specified using %s (for strings), %d for integers and %f for floats (decimals). Variables slots are filled, in order of appearance in the text, with values coming from a list of variables in an associated vars field e.g.
name:\ntext: \"%s of %s\"\nvars:\n- neuron\n- brain_region\n
If the value associated with the neuron var is (the class) 'glutamatergic neuron' and the value associated with the = 'brain region' var is 'primary motor cortext', this will generate a classes with the name (label) \"glutamatergic neuron of primary motor cortex\".
DOSDPs include a set of convenience fields for annotation of classes that follow OBO conventions for field names and their mappings to OWL annotation properties. These include name, def, comment, namespace. When the value of a var is an OWL class, the name (label) of the var is used in the substitution. (see example above).
The annotation axioms generated by these template fields can be annotated. One OBO field exists for this purpose: xrefs allows annotation with a list of references using the obo standard xref annotation property (curies)
e.g.
data_list_vars:\nxrefs: xsd:string\n\ndef:\ntext: \"Any %s that has a soma located in the %s\"\nvars:\n- neuron\n- brain_region\nxrefs: xrefs\n
Where a single equivalent Class, subclassOf or GCI axiom is specified, you may use the keys 'EquivalentTo', 'subClassOf' or 'GCI' respectively. If multiple axioms of any type are needed, use the core field logical_axioms.
"},{"location":"tutorial/dosdp-overview/#advanced-usage","title":"Advanced usage:","text":""},{"location":"tutorial/dosdp-overview/#optionals-and-multiples-0-many","title":"Optionals and multiples (0-many)","text":"
TBA
"},{"location":"tutorial/dosdp-overview/#using-dosdp-templates-in-odk-workflows","title":"Using DOSDP templates in ODK Workflows","text":"
The Ontology Development Kit (ODK) comes with a few pre-configured workflows involving DOSDP templates. For a detailed tutorial see here.
Note: This is an updated Version of Jim Balhoff's DOSDP tutorial here.
The main use case for dosdp-tools (and the DOS-DP framework) is managing a set of ontology terms, which all follow a common logical pattern, by simply collecting the unique aspect of each term as a line in a spreadsheet. For example, we may be developing an ontology of environmental exposures. We would like to have terms in our ontology which represent exposure to a variety of stressors, such as chemicals, radiation, social stresses, etc.
"},{"location":"tutorial/dosdp-template/#creating-an-ontology-of-environmental-exposures","title":"Creating an ontology of environmental exposures","text":"
To maximize reuse and facilitate data integration, we can build our exposure concepts by referencing terms from domain-specific ontologies, such as the Chemical Entities of Biological Interest Ontology (ChEBI) for chemicals. By modeling each exposure concept in the same way, we can use a reasoner to leverage the chemical classification provided by ChEBI to provide a classification for our exposure concepts. Since each exposure concept has a logical definition based on our data model for exposure, there is no need to manually manage the classification hierarchy. Let's say our model for exposure concepts holds that an \"exposure\" is an event with a particular input (the thing the subject is exposed to):
'exposure to X' EquivalentTo 'exposure event' and 'has input' some X
If we need an ontology class to represent 'exposure to sarin' (bad news!), we can simply use the term sarin from ChEBI, and create a logical definition:
'exposure to sarin' EquivalentTo 'exposure event' and 'has input' some sarin
We can go ahead and create some other concepts we need for our exposure data:
'exposure to asbestos' EquivalentTo 'exposure event' and 'has input' some asbestos
'exposure to chemical substance' EquivalentTo 'exposure event' and 'has input' some 'chemical substance'
These definitions again can reference terms provided by ChEBI: asbestos and chemical substance
Since the three concepts we've created all follow the same logical model, their hierarchical relationship can be logically determined by the relationships of the chemicals they reference. ChEBI asserts this structure for those terms:
Based on this, an OWL reasoner can automatically tell us the relationships between our exposure concepts:
'exposure to chemical substance'\n |\n |\n --------------------------\n | |\n | |\n'exposure to sarin' 'exposure to asbestos'\n
To support this, we simply need to declare the ChEBI OWL file as an owl:import in our exposure ontology, and use an OWL reasoner such as ELK.
"},{"location":"tutorial/dosdp-template/#managing-terms-with-dosdp-tools","title":"Managing terms with dosdp-tools","text":"
Creating terms by hand like we just did works fine, and relying on the reasoner for the classification will save us a lot of trouble and maintain correctness as our ontology grows. But since all the terms use the same logical pattern, it would be nice to keep this in one place; this will help make sure we always follow the pattern correctly when we create new concepts. We really only need to store the list of inputs (e.g. chemicals) in order to create all our exposure concepts. As we will see later, we may also want to manage separate sets of terms that follow other, different, patterns. To do this with dosdp-tools, we need three main files: a pattern template, a spreadsheet of pattern fillers, and a source ontology. You will also usually need a file of prefix definitions so that the tool knows how to expand your shortened identifiers into IRIs.
For our chemical exposures, getting the source ontology is easy: just download chebi.owl. Note\u2014it's about 450 MB.
For our pattern fillers spreadsheet, we just need to make a tab-delimited file containing the chemical stressors for which we need exposure concepts. The file needs a column for the term IRI to be used for the generated class (this column is always called defined_class), and also a column for the chemical to reference (choose a label according to your data model). It should look like this:
The columns should be tab-separated\u2014you can download a correctly formatted file to follow along. For now you will just maintain this file by hand, adding chemicals by looking up their ID in ChEBI, and manually choosing the next ID for your generated classes. In the future this may be simplified using the DOS-DP table editor, which is under development.
The trickiest part to DOS-DP is creating your pattern template (but it's not so hard). Pattern templates are written in YAML, a simple file format based on keys and values. The keys are text labels; values can be plain values, another key-value structure, or a list. The DOS-DP schema specifies the keys and values which can be used in a pattern file. We'll use most of the common entries in this example. Read the comments (lines starting with #) for explanation of the various fields:
# We can provide a name for this pattern here.\npattern_name: exposure_with_input\n\n# In 'classes', we define the terms we will use in this pattern.\n# In the OBO community the terms often have numeric IDs, so here\n# we can provide human-readable names we can use further in the pattern.\n# The key is the name to be used; the value is the ID in prefixed form (i.e. a CURIE).\nclasses:\nexposure event: ExO:0000002\nThing: owl:Thing\n\n# Use 'relations' the same way as 'classes',\n# but for the object properties used in the pattern.\nrelations:\nhas input: RO:0002233\n\n# The 'vars' section defines the various slots that can be\n# filled in for this pattern. We have only one, which we call 'input'.\n# The value is the range, meaning the class of things that are valid\n# values for this pattern. By specifying owl:Thing, we're allowing any\n# class to be provided as a variable filler. You need a column in your\n# spreadsheet for each variable defined here, in addition to the `defined class` column.\nvars:\ninput: \"Thing\"\n\n# We can provide a template for an `rdfs:label` value to generate\n# for our new term. dosdp-tools will search the source ontology\n# to find the label for the filler term, and fill it into the\n# name template in place of the %s.\nname:\ntext: \"exposure to %s\"\nvars:\n- input\n\n# This works the same as label generation, but instead creates\n# a definition annotation.\ndef:\ntext: \"A exposure event involving the interaction of an exposure receptor to %s. Exposure may be through a variety of means, including through the air or surrounding medium, or through ingestion.\"\nvars:\n- input\n\n# Here we can generate a logical axiom for our new concept. Create an\n# expression using OWL Manchester syntax. The expression can use any\n# of the terms defined at the beginning of the pattern. A reference\n# to the variable value will be inserted in place of the %s.\nequivalentTo:\ntext: \"'exposure event' and 'has input' some %s\"\nvars:\n- input\n
Download the pattern template file to follow along.
Now we only need one more file before we can run dosdp-tools. A file of prefix definitions (also in YAML format) will specify how to expand the CURIEs we used in our spreadsheet and pattern files:
EXPOSO: http://example.org/exposure/\n
Here we are specifying how to expand our EXPOSO prefix (used in our spreadsheet defined_class column). To expand the others, we'll pass a convenience option to dosdp-tools, --obo-prefixes, which will activate some predefined prefixes such as owl:, and handle any other prefixes using the standard expansion for OBO IDs: http://purl.obolibrary.org/obo/PREFIX_. Here's a link to the prefixes file.
Now we're all set to run dosdp-tools! If you've downloaded or created all the necessary files, run this command to generate your ontology of exposures (assuming you've added the dosdp-tools to your Unix PATH):
This will apply the pattern to each line in your spreadsheet, and save the result in an ontology saved at exposure_with_input.owl (it should look something like this). If you take a look at this ontology in a text editor or in Prot\u00e9g\u00e9, you'll see that it contains three classes, each with a generated label, text definition, and equivalent class definition. You're done!
Well... you're sort of done. But wouldn't it be nice if your exposure ontology included some information about the chemicals you referenced? Without this our reasoner can't classify our exposure concepts. As we said above, we could add an owl:import declaration and load all of ChEBI, but your exposure ontology has three classes and ChEBI has over 120,000 classes. Instead, we can use the ROBOT tool to extract a module of just the relevant axioms from ChEBI. Later, we will also see how to use ROBOT to merge the outputs from multiple DOS-DP patterns into one ontology. You can download ROBOT from its homepage.
"},{"location":"tutorial/dosdp-template/#extracting-a-module-from-the-source-ontology","title":"Extracting a module from the source ontology","text":"
ROBOT has a few different methods for extracting a subset from an ontology. We'll use the Syntactic Locality Module Extractor (SLME) to get a set of axioms relevant to the ChEBI terms we've referenced. ROBOT will need a file containing the list of terms. We can use a Unix command to get these out of our spreadsheet file:
sed '1d' exposure_with_input.tsv | cut -f 2 >inputs.txt\n
We'll end up with a simple list:
CHEBI:75701\nCHEBI:46661\nCHEBI:59999\n
Now we can use ROBOT to extract an SLME bottom module for those terms out of ChEBI:
Our ChEBI extract only has 63 classes. Great! If you want, you can merge the ChEBI extract into your exposure ontology before releasing it to the public:
Now you can open exposo.owl in Prot\u00e9g\u00e9, run the reasoner, and see a correct classification for your exposure concepts! You may notice that your ontology is missing labels for ExO:0000002 ('exposure event') and RO:0002233 ('has input'). If you want, you can use ROBOT to extract that information from ExO and RO.
"},{"location":"tutorial/dosdp-template/#working-with-multiple-patterns","title":"Working with multiple patterns","text":"
You will often want to generate ontology modules using more than one DOS-DP pattern. For example, you may want to organize environmental exposures by an additional axis of classification, such as exposure to substances with various biological roles, based on information provided by ChEBI. This requires a slightly different logical expression, so we'll make a new pattern:
pattern_name: exposure_with_input_with_role\n\nclasses:\nexposure event: ExO:0000002\nThing: owl:Thing\n\nrelations:\nhas input: RO:0002233\nhas role: RO:0000087\n\nvars:\ninput: \"Thing\"\n\nname:\ntext: \"exposure to %s\"\nvars:\n- input\n\ndef:\ntext: \"A exposure event involving the interaction of an exposure receptor to a substance with %s role. Exposure may be through a variety of means, including through the air or surrounding medium, or through ingestion.\"\nvars:\n- input\n\nequivalentTo:\ntext: \"'exposure event' and 'has input' some ('has role' some %s)\"\nvars:\n- input\n
Let's create an input file for this pattern, with a single filler, neurotoxin:
If you open the new exposo.owl in Prot\u00e9g\u00e9 and run the reasoner, you'll now see 'exposure to sarin' classified under both 'exposure to chemical substance' and also 'exposure to neurotoxin'.
By using dosdp-tools and robot together, you can effectively develop ontologies which compose parts of ontologies from multiple domains using standard patterns. You will probably want to orchestrate the types of commands used in this tutorial within a Makefile, so that you can automate this process for easy repeatability.
"},{"location":"tutorial/exomiser-tutorial/","title":"Introduction to Exomiser","text":""},{"location":"tutorial/exomiser-tutorial/#tutorial-an-introduction-to-exomiser","title":"Tutorial: an introduction to Exomiser","text":"
Exomiser is a Java program that ranks potential rare Mendelian disease-causing variants from whole-exome or whole-genome sequencing data. Starting from a patient's VCF file and a set of phenotypes encoded using the Human Phenotype Ontology (HPO), it will annotate, filter and prioritise likely causative variants. The program does this based on user-defined criteria such as a variant's predicted pathogenicity, frequency of occurrence in a population and also how closely the given patient's phenotype matches any known phenotype of genes from human disease and model organism data.
In this tutorial, we will learn how to install and run Exomiser with Docker, and how to interpret the results in various output formats detailing the predicted causative genes and variants. If you prefer to work locally, instructions are also provided below for Windows and Linux/Mac users.
The complete Exomiser documentation can be found here, including some relevant references here, and the Exomiser GitHub repository here.
Please note that this tutorial is up-to-date with the current latest release 13.2.0 and data version up to 2302 (Feb 2023).
Docker installed and running on your machine. Check out this simple guide to set up Docker for Windows or Docker for Mac.
We recommend to have Exomiser installed via Docker prior to the tutorial. Open a terminal and run the command below:
docker pull exomiser/exomiser-cli:13.2.0\n
Exomiser-Tutorial files downloaded from our GoogleDrive.
Alternatively:
# download the data via\nwget https://github.com/iQuxLE/Exomiser-Tutorial/raw/main/Exomiser-Tutorial.zip\n# OR clone the repository\ngit clone https://github.com/iQuxLE/Exomiser-Tutorial.git\n\n# unzip\nunzip Exomiser-Tutorial.zip\n
Since the VCF files for parts of the example data are relatively large, you need to download the following separately and put it into the Exomiser-Tutorial folder.
The Exomiser-Tutorial folder contains a directory called exomiser-config (with all the VCF and analysis files) and exomiser-overview (with some introductory slides).
Importantly, we highly recommend downloading the Exomiser data prior to the tutorial in order to follow along. The data required to run Exomiser is ~80GB and will take a while to download and unpack (depending on your internet connection, it may take a few hours). For this tutorial, you only need to download the Exomiser phenotype data and the variant data for the hg19 assembly. If you have your own samples to run with Exomiser and the VCF files are built on the hg38 build, then you will need to download the hg38 variant data as well. The current data version that we will use in this tutorial is 2302 (Feb 2023). This will change in the future. Always make sure that you use the latest data version available. To download the Exomiser data from the terminal:
# create an empty directory for exomiser-data within the Exomiser-Tutorial folder:\ncd /path/to/Exomiser-Tutorial/\nmkdir exomiser-data\ncd exomiser-data\n# download the data\nwget https://data.monarchinitiative.org/exomiser/latest/2302_phenotype.zip # for the phenotype database\nwget https://data.monarchinitiative.org/exomiser/latest/2302_hg19.zip # for the hg19 variant database\n# unzip the data\nunzip \"2302_*.zip\"\n
Otherwise, visit the links and download the data in your own exomiser-data directory:
2302 phenotype database
2302 hg19 variant database
Install 7-Zip for unzipping the database files. The built-in archiving software has issues extracting the zip files. Extract the database files (2302_phenotype.zip, 2302_hg19.zip) by right-clicking the archive and selecting 7-Zip > Extract files\u2026 into the exomiser-data directory.
Your Exomiser-Tutorial directory should now be structured as follows:
(recommended to be installed prior to the tutorial; if you run the command below again, you should receive the message \"Image is up to date for exomiser/exomiser-cli:13.2.0\")
Install 7-Zip for unzipping the archive files. The built-in archiving software has issues extracting the zip files.
Download the exomiser-cli-13.2.0-distribution.zip distribution from Monarch.
Download the variant 2302_hg19.zip and phenotype 2302_phenotype.zip data files from Monarch.
Extract the distribution files by right-clicking exomiser-cli-13.2.0-distribution.zip and selecting 7-Zip > Extract Here
Extract the data files (e.g. 2302_phenotype.zip, 2302_hg19.zip) by right-clicking the archive and selecting 7-Zip > Extract files\u2026 into the exomiser data directory. By default, Exomiser expects this to be \u2018exomiser-cli-13.2.0/data\u2019, but this can be changed in the application.properties.
# download the distribution (won't take long)\nwget https://data.monarchinitiative.org/exomiser/latest/exomiser-cli-13.2.0-distribution.zip\n# download the data (this is ~80GB and will take a while). If you only require a single assembly, only download the relevant files.\nwget https://data.monarchinitiative.org/exomiser/latest/2302_hg19.zip\nwget https://data.monarchinitiative.org/exomiser/latest/2302_phenotype.zip\n# unzip the distribution and data files - this will create a directory called 'exomiser-cli-13.2.0' in the current working directory (with examples and application.properties)\nunzip exomiser-cli-13.2.0-distribution.zip\nunzip '2302_*.zip' -d exomiser-cli-13.2.0/data\n
"},{"location":"tutorial/exomiser-tutorial/#configuring-the-applicationproperties","title":"Configuring the application.properties","text":"
The application.properties file needs to be updated to point to the correct location of the Exomiser data. For the purpose of this tutorial, this is already sorted, pointing to the mounted directory inside the Docker container exomiser.data-directory=/exomiser-data.
Also, you want to make sure to edit the file to use the correct data version (currently 2302):
"},{"location":"tutorial/exomiser-tutorial/#tutorials","title":"Tutorials","text":""},{"location":"tutorial/exomiser-tutorial/#monarch-obo-training-tutorial","title":"Monarch OBO Training Tutorial","text":""},{"location":"tutorial/exomiser-tutorial/#running-exomiser","title":"Running Exomiser","text":"
For this tutorial, we will focus on running Exomiser on a single-sample (whole-exome) VCF file. Additional instructions for running Exomiser on multi-sample VCF data and large jobs are also provided below.
It is recommended to provide Exomiser with the input sample as a Phenopacket. Exomiser will accept this in either JSON or YAML format. We will use the example pfeiffer-phenopacket.yml below:
NOTE: This is an example of a v1.0 phenopacket, there is a more recent release of v2.0. Exomiser can run phenopackets built with either v1.0 or v2.0 schema. You can find out more about the v2.0 phenopacket schema and how to build one with Python or Java here. To convert a phenopacket v1.0 to v2.0, you can use phenopacket-tools.
Below are the default analysis settings from pfeiffer-analysis.yml that we will use in our tutorial:
---\nanalysis:\n#FULL or PASS_ONLY\nanalysisMode: PASS_ONLY\n# In cases where you do not want any cut-offs applied an empty map should be used e.g. inheritanceModes: {}\n# These are the default settings, with values representing the maximum minor allele frequency in percent (%) permitted for an\n# allele to be considered as a causative candidate under that mode of inheritance.\n# If you just want to analyse a sample under a single inheritance mode, delete/comment-out the others. For AUTOSOMAL_RECESSIVE\n# or X_RECESSIVE ensure *both* relevant HOM_ALT and COMP_HET modes are present.\ninheritanceModes: {\n AUTOSOMAL_DOMINANT: 0.1,\n AUTOSOMAL_RECESSIVE_COMP_HET: 2.0,\n AUTOSOMAL_RECESSIVE_HOM_ALT: 0.1,\n X_DOMINANT: 0.1,\n X_RECESSIVE_COMP_HET: 2.0,\n X_RECESSIVE_HOM_ALT: 0.1,\n MITOCHONDRIAL: 0.2\n}\n#Possible frequencySources:\n#Thousand Genomes project http://www.1000genomes.org/\n# THOUSAND_GENOMES,\n#ESP project http://evs.gs.washington.edu/EVS/\n# ESP_AFRICAN_AMERICAN, ESP_EUROPEAN_AMERICAN, ESP_ALL,\n#ExAC project http://exac.broadinstitute.org/about\n# EXAC_AFRICAN_INC_AFRICAN_AMERICAN, EXAC_AMERICAN,\n# EXAC_SOUTH_ASIAN, EXAC_EAST_ASIAN,\n# EXAC_FINNISH, EXAC_NON_FINNISH_EUROPEAN,\n# EXAC_OTHER\n#Possible frequencySources:\n#Thousand Genomes project - http://www.1000genomes.org/ (THOUSAND_GENOMES)\n#TOPMed - https://www.nhlbi.nih.gov/science/precision-medicine-activities (TOPMED)\n#UK10K - http://www.uk10k.org/ (UK10K)\n#ESP project - http://evs.gs.washington.edu/EVS/ (ESP_)\n# ESP_AFRICAN_AMERICAN, ESP_EUROPEAN_AMERICAN, ESP_ALL,\n#ExAC project http://exac.broadinstitute.org/about (EXAC_)\n# EXAC_AFRICAN_INC_AFRICAN_AMERICAN, EXAC_AMERICAN,\n# EXAC_SOUTH_ASIAN, EXAC_EAST_ASIAN,\n# EXAC_FINNISH, EXAC_NON_FINNISH_EUROPEAN,\n# EXAC_OTHER\n#gnomAD - http://gnomad.broadinstitute.org/ (GNOMAD_E, GNOMAD_G)\nfrequencySources: [\nTHOUSAND_GENOMES,\nTOPMED,\nUK10K,\n\nESP_AFRICAN_AMERICAN, ESP_EUROPEAN_AMERICAN, ESP_ALL,\n\nEXAC_AFRICAN_INC_AFRICAN_AMERICAN, EXAC_AMERICAN,\nEXAC_SOUTH_ASIAN, EXAC_EAST_ASIAN,\nEXAC_FINNISH, EXAC_NON_FINNISH_EUROPEAN,\nEXAC_OTHER,\n\nGNOMAD_E_AFR,\nGNOMAD_E_AMR,\n# GNOMAD_E_ASJ,\nGNOMAD_E_EAS,\nGNOMAD_E_FIN,\nGNOMAD_E_NFE,\nGNOMAD_E_OTH,\nGNOMAD_E_SAS,\n\nGNOMAD_G_AFR,\nGNOMAD_G_AMR,\n# GNOMAD_G_ASJ,\nGNOMAD_G_EAS,\nGNOMAD_G_FIN,\nGNOMAD_G_NFE,\nGNOMAD_G_OTH,\nGNOMAD_G_SAS\n]\n# Possible pathogenicitySources: (POLYPHEN, MUTATION_TASTER, SIFT), (REVEL, MVP), CADD, REMM\n# REMM is trained on non-coding regulatory regions\n# *WARNING* if you enable CADD or REMM ensure that you have downloaded and installed the CADD/REMM tabix files\n# and updated their location in the application.properties. Exomiser will not run without this.\npathogenicitySources: [ REVEL, MVP ]\n#this is the standard exomiser order.\n#all steps are optional\nsteps: [\n#hiPhivePrioritiser: {},\n#priorityScoreFilter: {priorityType: HIPHIVE_PRIORITY, minPriorityScore: 0.500},\n#intervalFilter: {interval: 'chr10:123256200-123256300'},\n# or for multiple intervals:\n#intervalFilter: {intervals: ['chr10:123256200-123256300', 'chr10:123256290-123256350']},\n# or using a BED file - NOTE this should be 0-based, Exomiser otherwise uses 1-based coordinates in line with VCF\n#intervalFilter: {bed: /full/path/to/bed_file.bed},\n#genePanelFilter: {geneSymbols: ['FGFR1','FGFR2']},\nfailedVariantFilter: { },\n#qualityFilter: {minQuality: 50.0},\nvariantEffectFilter: {\n remove: [\nFIVE_PRIME_UTR_EXON_VARIANT,\nFIVE_PRIME_UTR_INTRON_VARIANT,\nTHREE_PRIME_UTR_EXON_VARIANT,\nTHREE_PRIME_UTR_INTRON_VARIANT,\nNON_CODING_TRANSCRIPT_EXON_VARIANT,\nUPSTREAM_GENE_VARIANT,\nINTERGENIC_VARIANT,\nREGULATORY_REGION_VARIANT,\nCODING_TRANSCRIPT_INTRON_VARIANT,\nNON_CODING_TRANSCRIPT_INTRON_VARIANT,\nDOWNSTREAM_GENE_VARIANT\n]\n},\n# removes variants represented in the database\n#knownVariantFilter: {},\nfrequencyFilter: {maxFrequency: 2.0},\npathogenicityFilter: {keepNonPathogenic: true},\n# inheritanceFilter and omimPrioritiser should always run AFTER all other filters have completed\ninheritanceFilter: {},\n# omimPrioritiser isn't mandatory.\nomimPrioritiser: {},\n#priorityScoreFilter: {minPriorityScore: 0.4},\n# Other prioritisers: Only combine omimPrioritiser with one of these.\n# Don't include any if you only want to filter the variants.\nhiPhivePrioritiser: {},\n# or run hiPhive in benchmarking mode:\n#hiPhivePrioritiser: {runParams: 'mouse'},\n#phivePrioritiser: {}\n#phenixPrioritiser: {}\n#exomeWalkerPrioritiser: {seedGeneIds: [11111, 22222, 33333]}\n]\noutputOptions:\noutputContributingVariantsOnly: false\n#numGenes options: 0 = all or specify a limit e.g. 500 for the first 500 results\nnumGenes: 0\n#minExomiserGeneScore: 0.7\n# Path to the desired output directory. Will default to the 'results' subdirectory of the exomiser install directory\noutputDirectory: results\n# Filename for the output files. Will default to {input-vcf-filename}-exomiser\noutputFileName: Pfeiffer-HIPHIVE-exome\n#out-format options: HTML, JSON, TSV_GENE, TSV_VARIANT, VCF (default: HTML)\noutputFormats: [HTML, JSON, TSV_GENE, TSV_VARIANT]\n
"},{"location":"tutorial/exomiser-tutorial/#running-via-docker","title":"Running via Docker","text":"
This command will produce Pfeiffer-HIPHIVE-exome.html, Pfeiffer-HIPHIVE-exome.json, Pfeiffer-HIPHIVE-exome.genes.tsv and Pfeiffer-HIPHIVE-exome.variants.tsv in your exomiser-results directory.
"},{"location":"tutorial/exomiser-tutorial/#running-large-jobs-batch","title":"Running large jobs (batch)","text":"
The above commands can be added to a batch file for example in the file Exomiser-Tutorial/exomiser-config/test-analysis-batch-commands.txt. Using it with Docker we recommend creating a new directory for the batch files and mounting that to the Docker container.
The advantage of this is that a single command will be able to analyse many samples in far less time than starting a new JVM for each as there will be no start-up penalty after the initial start and the Java JIT compiler will be able to take advantage of a longer-running process to optimise the runtime code. For maximum throughput on a cluster consider splitting your batch jobs over multiple nodes.
Depending on the output options provided, Exomiser will write out at least an HTML and JSON output file in the results subdirectory of the Exomiser installation (by default) or a user-defined results directory as indicated in the output options.
As a general rule, all output files contain a ranked list of genes and variants with the top-ranked gene/variant displayed first. The exception being the VCF output (if requested in the output options; not requested in this tutorial) which, since version 13.1.0, is sorted according to VCF convention and tabix indexed.
In our tutorial, we requested HTML, JSON, TSV_VARIANT and TSV_GENE output formats which are briefly outlined below.
The JSON file represents the most accurate representation of the results, as it is referenced internally by Exomiser. As such, we don\u2019t provide a schema for this, but it has been pretty stable and breaking changes will only occur with major version changes to the software. Minor additions are to be expected for minor releases, as per the SemVer specification.
We recommend using Python or JQ to extract data from this file. To give you an idea of how you can extract some data with Python, we have provided examples of how you can iterate over the results below. However, there is a lot more information content that you can pull out from the JSON results file, this only provides a snippet of what you can do.
# import json library\nimport json\n\n# to load in the exomiser json result\nwith open(\"path/to/Exomiser-Tutorial/Pfeiffer-HIPHIVE-exome.json\") as exomiser_json_result:\n exomiser_result = json.load(exomiser_json_result)\nexomiser_json_result.close()\n\n# to retrieve all predicted genes and corresponding identifier (ENSEMBL)\ngene_results = []\nfor result in exomiser_result:\n gene_results.append({result[\"geneSymbol\"]: result[\"geneIdentifier\"][\"geneId\"]})\n\n# to retrieve all predicted variants\nvariant_results = []\nfor result in exomiser_result:\n for moi in result[\"geneScores\"]: # iterating over all modes of inheritance\n if \"contributingVariants\" in moi: # checking if there is evidence of contributing variants\n for cv in moi[\"contributingVariants\"]: # iterating over all contributing variants\n variant_results.append({\"chromosome\": cv[\"contigName\"],\n \"start_pos\": cv[\"start\"],\n \"end_pos\": cv[\"end\"],\n \"ref_allele\": cv[\"ref\"],\n \"alt_allele\": cv[\"alt\"]})\n
In the Pfeiffer-HIPHIVE-exome.variants.tsv file it is possible for a variant to appear multiple times, depending on the MOI it is compatible with. For example, in the excerpt of the file below, MUC6 has two variants ranked 7th under the AD model and two ranked 8th under an AR (compound heterozygous) model. In the AD case the CONTRIBUTING_VARIANT column indicates whether the variant was (1) or wasn't (0) used for calculating the EXOMISER_GENE_COMBINED_SCORE and EXOMISER_GENE_VARIANT_SCORE.
In the Pfeiffer-HIPHIVE-exome.genes.tsv file, all the various phenotypic scores and HPO matches from the HUMAN, MOUSE, FISH and PPI comparisons are reported per each gene. It is possible for a gene to appear multiple times, depending on the MOI it is compatible with, given the filtered variants. For example in the example below MUC6 is ranked 7th under the AD model and 8th under an AR model.
#RANK ID GENE_SYMBOL ENTREZ_GENE_ID MOI P-VALUE EXOMISER_GENE_COMBINED_SCORE EXOMISER_GENE_PHENO_SCORE EXOMISER_GENE_VARIANT_SCORE HUMAN_PHENO_SCORE MOUSE_PHENO_SCORE FISH_PHENO_SCORE WALKER_SCORE PHIVE_ALL_SPECIES_SCORE OMIM_SCORE MATCHES_CANDIDATE_GENE HUMAN_PHENO_EVIDENCE MOUSE_PHENO_EVIDENCE FISH_PHENO_EVIDENCE HUMAN_PPI_EVIDENCE MOUSE_PPI_EVIDENCE FISH_PPI_EVIDENCE\n1 FGFR2_AD FGFR2 2263 AD 0.0000 0.9957 0.9187 1.0000 0.8671 0.9187 0.0000 0.5057 0.9187 1.0000 0 Apert syndrome (ORPHA:87): Syndactyly (HP:0001159)-Toe syndactyly (HP:0001770), Strabismus (HP:0000486)-Strabismus (HP:0000486), Hypoplasia of the maxilla (HP:0000327)-Hypoplasia of the maxilla (HP:0000327), Proptosis (HP:0000520)-Proptosis (HP:0000520), Hypertelorism (HP:0000316)-Hypertelorism (HP:0000316), Brachyturricephaly (HP:0000244)-Brachyturricephaly (HP:0000244), Strabismus (HP:0000486)-ocular hypertelorism (MP:0001300), Hypoplasia of the maxilla (HP:0000327)-short maxilla (MP:0000097), Proptosis (HP:0000520)-exophthalmos (MP:0002750), Hypertelorism (HP:0000316)-ocular hypertelorism (MP:0001300), Brachyturricephaly (HP:0000244)-abnormal frontal bone morphology (MP:0000107), Proximity to FGF18 Syndactyly (HP:0001159)-abnormal metatarsal bone morphology (MP:0003072), Strabismus (HP:0000486)-abnormal neurocranium morphology (MP:0000074), Hypoplasia of the maxilla (HP:0000327)-maxilla hypoplasia (MP:0000457), Proptosis (HP:0000520)-abnormal neurocranium morphology (MP:0000074), Hypertelorism (HP:0000316)-abnormal neurocranium morphology (MP:0000074), Brachyturricephaly (HP:0000244)-abnormal neurocranium morphology (MP:0000074),\n2 ZNF366_AD ZNF366 167465 AD 0.0018 0.9237 0.8195 0.7910 0.0000 0.8195 0.0000 0.5015 0.8195 1.0000 0 Syndactyly (HP:0001159)-syndactyly (MP:0000564), Strabismus (HP:0000486)-microphthalmia (MP:0001297), Hypoplasia of the maxilla (HP:0000327)-micrognathia (MP:0002639), Proptosis (HP:0000520)-microphthalmia (MP:0001297), Hypertelorism (HP:0000316)-microphthalmia (MP:0001297), Brachyturricephaly (HP:0000244)-microphthalmia (MP:0001297), Proximity to CTBP1 associated with Wolf-Hirschhorn syndrome (ORPHA:280): Syndactyly (HP:0001159)-Arachnodactyly (HP:0001166), Strabismus (HP:0000486)-Strabismus (HP:0000486), Hypoplasia of the maxilla (HP:0000327)-Micrognathia (HP:0000347), Proptosis (HP:0000520)-Proptosis (HP:0000520), Hypertelorism (HP:0000316)-Hypertelorism (HP:0000316), Brachyturricephaly (HP:0000244)-Calvarial skull defect (HP:0001362),\n3 PKD1_AD PKD1 5310 AD 0.0050 0.8272 0.6597 0.8707 0.0000 0.6597 0.2697 0.5069 0.6597 1.0000 0 Strabismus (HP:0000486)-micrognathia (MP:0002639), Hypoplasia of the maxilla (HP:0000327)-micrognathia (MP:0002639), Proptosis (HP:0000520)-micrognathia (MP:0002639), Hypertelorism (HP:0000316)-micrognathia (MP:0002639), Brachyturricephaly (HP:0000244)-micrognathia (MP:0002639), Hypoplasia of the maxilla (HP:0000327)-mandibular arch skeleton malformed, abnormal (ZP:0001708), Proximity to IFT88 associated with Retinitis pigmentosa (ORPHA:791): Strabismus (HP:0000486)-Ophthalmoplegia (HP:0000602), Hypoplasia of the maxilla (HP:0000327)-Wide nasal bridge (HP:0000431), Proximity to IFT88 Syndactyly (HP:0001159)-polydactyly (MP:0000562), Strabismus (HP:0000486)-supernumerary molars (MP:0010773), Hypoplasia of the maxilla (HP:0000327)-supernumerary molars (MP:0010773), Proptosis (HP:0000520)-supernumerary molars (MP:0010773), Hypertelorism (HP:0000316)-supernumerary molars (MP:0010773), Brachyturricephaly (HP:0000244)-abnormal coronal suture morphology (MP:0003840),\n4 CCDC66_AD CCDC66 285331 AD 0.0051 0.8262 0.5463 0.9984 0.0000 0.5463 0.0000 0.0000 0.5463 1.0000 0 Strabismus (HP:0000486)-abnormal cone electrophysiology (MP:0004022), Hypoplasia of the maxilla (HP:0000327)-abnormal rod electrophysiology (MP:0004021), Proptosis (HP:0000520)-abnormal rod electrophysiology (MP:0004021), Hypertelorism (HP:0000316)-abnormal rod electrophysiology (MP:0004021), Brachyturricephaly (HP:0000244)-abnormal retina photoreceptor layer morphology (MP:0003728),\n5 COL4A1_AD COL4A1 1282 AD 0.0075 0.7762 0.5288 0.9838 0.3882 0.5288 0.0000 0.5047 0.5288 1.0000 0 Brain small vessel disease with or without ocular anomalies (OMIM:175780): Strabismus (HP:0000486)-Exotropia (HP:0000577), Strabismus (HP:0000486)-buphthalmos (MP:0009274), Hypoplasia of the maxilla (HP:0000327)-abnormal cornea morphology (MP:0001312), Proptosis (HP:0000520)-abnormal cornea morphology (MP:0001312), Hypertelorism (HP:0000316)-abnormal cornea morphology (MP:0001312), Brachyturricephaly (HP:0000244)-abnormal retina morphology (MP:0001325), Proximity to COL7A1 associated with Localized dystrophic epidermolysis bullosa, pretibial form (ORPHA:79410): Syndactyly (HP:0001159)-Nail dystrophy (HP:0008404), Hypoplasia of the maxilla (HP:0000327)-Carious teeth (HP:0000670), Proximity to COL7A1 Syndactyly (HP:0001159)-abnormal digit morphology (MP:0002110), Strabismus (HP:0000486)-abnormal tongue morphology (MP:0000762), Hypoplasia of the maxilla (HP:0000327)-abnormal tongue morphology (MP:0000762), Proptosis (HP:0000520)-abnormal tongue morphology (MP:0000762), Hypertelorism (HP:0000316)-abnormal tongue morphology (MP:0000762),\n6 ENPP1_AD ENPP1 5167 AD 0.0079 0.7695 0.5112 0.9996 0.3738 0.5112 0.0000 0.5044 0.5112 1.0000 0 Autosomal recessive hypophosphatemic rickets (ORPHA:289176): Hypoplasia of the maxilla (HP:0000327)-Tooth abscess (HP:0030757), Brachyturricephaly (HP:0000244)-Craniosynostosis (HP:0001363), Syndactyly (HP:0001159)-abnormal elbow joint morphology (MP:0013945), Strabismus (HP:0000486)-abnormal retina morphology (MP:0001325), Hypoplasia of the maxilla (HP:0000327)-abnormal snout skin morphology (MP:0030533), Proptosis (HP:0000520)-abnormal retina morphology (MP:0001325), Hypertelorism (HP:0000316)-abnormal retina morphology (MP:0001325), Brachyturricephaly (HP:0000244)-abnormal retina morphology (MP:0001325), Proximity to DMP1 associated with Autosomal recessive hypophosphatemic rickets (ORPHA:289176): Hypoplasia of the maxilla (HP:0000327)-Tooth abscess (HP:0030757), Brachyturricephaly (HP:0000244)-Craniosynostosis (HP:0001363), Proximity to DMP1 Syndactyly (HP:0001159)-abnormal long bone hypertrophic chondrocyte zone (MP:0000165), Strabismus (HP:0000486)-abnormal dental pulp cavity morphology (MP:0002819), Hypoplasia of the maxilla (HP:0000327)-abnormal dental pulp cavity morphology (MP:0002819), Proptosis (HP:0000520)-abnormal dental pulp cavity morphology (MP:0002819), Hypertelorism (HP:0000316)-abnormal dental pulp cavity morphology (MP:0002819), Brachyturricephaly (HP:0000244)-abnormal dental pulp cavity morphology (MP:0002819),\n7 MUC6_AD MUC6 4588 AD 0.0089 0.7563 0.5046 0.9990 0.0000 0.0000 0.0000 0.5046 0.5046 1.0000 0 Proximity to GALNT2 associated with Congenital disorder of glycosylation, type IIt (OMIM:618885): Syndactyly (HP:0001159)-Sandal gap (HP:0001852), Strabismus (HP:0000486)-Alternating exotropia (HP:0031717), Hypoplasia of the maxilla (HP:0000327)-Tented upper lip vermilion (HP:0010804), Proptosis (HP:0000520)-Hypertelorism (HP:0000316), Hypertelorism (HP:0000316)-Hypertelorism (HP:0000316), Brachyturricephaly (HP:0000244)-Brachycephaly (HP:0000248),\n8 MUC6_AR MUC6 4588 AR 0.0089 0.7562 0.5046 0.9990 0.0000 0.0000 0.0000 0.5046 0.5046 1.0000 0 Proximity to GALNT2 associated with Congenital disorder of glycosylation, type IIt (OMIM:618885): Syndactyly (HP:0001159)-Sandal gap (HP:0001852), Strabismus (HP:0000486)-Alternating exotropia (HP:0031717), Hypoplasia of the maxilla (HP:0000327)-Tented upper lip vermilion (HP:0010804), Proptosis (HP:0000520)-Hypertelorism (HP:0000316), Hypertelorism (HP:0000316)-Hypertelorism (HP:0000316), Brachyturricephaly (HP:0000244)-Brachycephaly (HP:0000248),\n9 DDX56_AD DDX56 54606 AD 0.0091 0.7545 0.5036 0.9992 0.0000 0.0000 0.3788 0.5036 0.5036 1.0000 0 Brachyturricephaly (HP:0000244)-head decreased width, abnormal (ZP:0000407), Proximity to PAK1IP1 Strabismus (HP:0000486)-abnormal maxilla morphology (MP:0000455), Hypoplasia of the maxilla (HP:0000327)-abnormal maxilla morphology (MP:0000455), Proptosis (HP:0000520)-abnormal maxilla morphology (MP:0000455), Hypertelorism (HP:0000316)-abnormal maxilla morphology (MP:0000455), Brachyturricephaly (HP:0000244)-decreased forebrain size (MP:0012138),\n10 BDKRB1_AD BDKRB1 623 AD 0.0093 0.7525 0.5018 1.0000 0.0000 0.0000 0.0000 0.5018 0.5018 1.0000 0 Proximity to OPN4 Strabismus (HP:0000486)-abnormal visual pursuit (MP:0006156), Hypoplasia of the maxilla (HP:0000327)-abnormal visual pursuit (MP:0006156), Proptosis (HP:0000520)-abnormal visual pursuit (MP:0006156), Hypertelorism (HP:0000316)-abnormal visual pursuit (MP:0006156), Brachyturricephaly (HP:0000244)-abnormal retina ganglion cell morphology (MP:0008056),\n
"},{"location":"tutorial/exomiser-tutorial/#docker-for-mac","title":"Docker for Mac","text":"
Follow this link and download the Docker.dmg for your operating system.
The Docker.dmg will be found in your /Downloads directory.
After double-clicking on the Docker.dmg a new window will come up:
Drag and drop the Docker app into your /Applications folder. Double-click on the Docker symbol. Docker Desktop will start in the background, after you allow it to be opened.
Additionally, this window will come up to agree the Docker subscription service agreement.
After running the installation restart your terminal and check the Docker installation again from inside your terminal with:
docker --version\n
If the output gives you a version and no error you are ready to go. If you have not already restarted your terminal do this now, and the error should be fixed.
In case you get an error message like this, please ensure you have downloaded the correct docker.dmg.
Now, whenever you want to pull images make sure that Docker is running in the background. Otherwise, you may get an error stating it's not able to connect to the Docker deamon.
"},{"location":"tutorial/exomiser-tutorial/#docker-for-windows","title":"Docker for Windows","text":"
Follow this link and download the Docker installer for Windows.
Inside your /Downloads directory, search for the Installer and double-click.
To run on Windows Docker requires a virtual machine. Docker recommends using WSL2. More information on this can be found here.
Click \u201cOk\u201d and wait a bit.
Now you will have to restart your computer.
After restarting, Docker should start automatically and the Service Agreement will come up, which you will have to agree to use Docker:
If the Docker desktop app is showing this warning upon start, do not click \u201cRestart\u201d, yet. Instead, follow the link and install the kernel update.
The link should point you to an address with a separate download link.
Start and finish the installation for WSL.
If you still have the Docker Desktop dialog window open in the background, click on Restart. Otherwise, just restart your computer as you normally do.
If Docker Desktop did not start on its own, simply open it from the shortcut on your Desktop. You can do the initial orientation by clicking \"Start\".
After this, your Docker Desktop screen should look like this:
Now, whenever you want to pull images make sure that Docker is running in the background.
"},{"location":"tutorial/fhkb/","title":"Manchester Family History Advanced OWL","text":"
This is a fork of the infamous Manchester Family History Advanced OWL Tutorial version 1.1, located at
The translation to markdown is not without issue, but we are making a start to making the tutorial a bit more accessible. This reproduction is done with kind permission by Robert Stevens.
"},{"location":"tutorial/fhkb/#original-credits-version-11-see-pdf","title":"Original credits (Version 1.1, see pdf):","text":"
Authors:
Robert Stevens
Margaret Stevens
Nicolas Matentzoglu
Simon Jupp
Bio-Health Informatics Group\nSchool of Computer Science\nUniversity of Manchester\nOxford Road\nManchester\nUnited Kingdom\nM13 9PL\nrobert.stevens@manchester.ac.uk\n
This tutorial was realised as part of the Semantic Web Authoring Tool (SWAT) project (see http://www.swatproject.org), which is supported by the UK Engineering and Physical Sciences Research Council (EPSRC) grant EP/G032459/1, to the University of Manchester, the University of Sussex and the Open University.
The \u2018Manchester Family History Advanced OWL Tutorial\u2019 by Robert Stevens, Margaret Stevens, Nicolas Matentzoglu, Simon Jupp is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.
This manual will almost certainly contain errors, defects and infelicities. Do report them to robert.stevens@manchester.ac.uk supplying chapter, section and some actual context in the form of words will help in fixing any of these issues.
As well as the author list, many people have contributed to this work. Any contribution, such as reporting bugs etc., is rewarded by an acknowledgement of contribution (in alphabetical order) when the authors get around to adding them:
This tutorial introduces the tutee to many of the more advanced features of the Web Ontology Language (OWL). The topic of family history is used to take the tutee through various modelling issues and, in doing so, using many features of OWL 2 to build a Family History Knowledge Base (FHKB). The exercises are designed to maximise inference about family history through the use of an automated reasoner on an OWL knowledge base (KB) containing many members of the Stevens family.
The aim, therefore, is to enable people to learn advanced features of OWL 2 in a setting that involves both classes and individuals, while attempting to maximise the use of inference within the FHKB.
By doing this tutorial, a tutee should be able to:
Know about the separation of entities into TBox and ABox;
Use classes and individuals in modelling;
Write fancy class expressions;
Assert facts about individuals;
Use the effects of property hierarchies, property characteristics, domain/range constraints to drive inference;
Use constraints and role chains on inferences about individuals;
Understand and manage the consequences of the open world assumption in the TBox and ABox;
Use nominals in class expressions;
Appreciate some limits of OWL 2.
"},{"location":"tutorial/fhkb/#12-why-family-history","title":"1.2 Why Family History?","text":"
Building an FHKB enables us to meet our learning outcomes through a topic that is accessible to virtually everyone. Family history or genealogy is a good topic for a general tutorial on OWL 2 as it enables us to touch many features of the language and, importantly, it is a field that everyone knows. All people have a family and therefore a family history \u2013 even if they do not know their particular family history. A small caveat was put on the topic being accessible to everyone as some cultures differ, for instance, in the description of cousins and labels given to different siblings. Nevertheless, family history remains a topic that everyone can talk about.
Family history is a good topic for an OWL ontology as it obviously involves both individuals \u2013 the people involved \u2013 and classes of individuals \u2013 people, men and women, cousins, etc. Also, it is an area rich in inference; from only knowing parentage and sex of an individual, it is possible to work out all family relationships \u2013 for example, sharing parents implies a sibling relationship; one\u2019s parent\u2019s brothers are one\u2019s uncles; one\u2019s parent\u2019s parents are one\u2019s grandparents. So, we should be able to construct an ontology that allows us to both express family history, but also to infer family relationships between people from knowing relatively little about them.
As we will learn through the tutorial, OWL 2 cannot actually do all that is needed to create a FHKB. This is unfortunate, but we use it to our advantage to illustrate some of the limitations of OWL 2. We know that rule based systems can do family history with ease, but that is not the point here; we are not advocating OWL DL as an appropriate mechanism for doing family history, but we do use it as a good educational example.
We make the following assumptions about what people know:
We assume that people know OWL to the level that is known at the end of the Pizza tutorial. Some ground will be covered again, but a lot of basic OWL is assumed.
We assume people know how to use Prot\u00e9g\u00e9 or their OWL environment of choice. We do not give \u2018click by click\u2019 instructions. At some places, some guidance is given, but this is not to be relied upon as Prot\u00e9g\u00e9 changes and we will not keep up to date.
We make some simplifying assumptions in this tutorial:
We take a conventional western view of family history. This appears to have most effects on naming of sibling and cousin relationships.
We take a straight-forward view on the sex of people; this is explored further in Chapter 4;
A \u2018conventional\u2019 view of marriage is taken; this is explored further in Chapter 9.
We make no special treatment of time or dates; we are only interested in years and we do not do anything fancy; this is explored more in Chapter 7.
We assume the ancestors of people go back for ever; obviously this is not true, eventually one would get back to a primordial soup and one\u2019s ancestors are not humans (members of the classPerson), but we don\u2019t bother with such niceties.
At the end of the tutorial, you should be able to produce a property hierarchy and a TBox or class hierarchy such as shown in Figure 1.1; all supported by use of the automated reasoner and a lot of OWL 2\u2019s features.
Figure 1.1: A part of the class and property hierarchy of the final FHKB.
"},{"location":"tutorial/fhkb/#13-how-to-use-this-tutorial","title":"1.3 How to use this Tutorial","text":"
Here are some tips on using this manual to the best advantage:
Start at the beginning and work towards the end.
You can just read the tutorial, but building the FHKB will help you learn much more and much more easily
Use the reasoner in each task; a lot of the FHKB tutorial is about using the reasoner and not doing so will detract from the learning outcomes.
The following resources are available at http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial:
A full version of the Stevens FHKB.
Some links to papers about the FHKB.
Some slides about the FHKB tutorial.
A set of OWL resources for each stage of the FHKB.
Some blogs about the FHKB are at http://robertdavidstevens.wordpress.com.
"},{"location":"tutorial/fhkb/#15-conventions-used-in-this-tutorial","title":"1.5 Conventions used in this Tutorial","text":"
All OWL is written in Manchester Syntax.
When we use FHKB entities within text, we use a sans serif typeface.
We use CamelCase for classes and property names.
Class names start with upper case.
Individual names start with a lower case letter and internal underscores to break words.
Property names usually start with \u2018is\u2019 or \u2018has\u2019 and are CamelCase with a lower case initial letter.
Many classes and individuals in the FHKB have annotation properties, usually human readable labels. They show up in some of the examples in Manchester syntax, but are not made explicit as part of the tasks in this tutorial.
Every object property is necessarily a sub-property of topObjectProperty. It does not have to be asserted as such. Nevertheless, there might be situations where this relationship is made explicit in this tutorial for illustrative reasons.
The individuals we are dealing with represent distinct persons. Throughout the tutorial, once the respective axiom is introduced (chapter 7.1.1), the reader should make sure that all his or her individuals are always made distinct, especially when he or she adds a new one.
At the end of each chapter, we note the Description Logic Language (expressivity) needed to represent the ontology and the reasoning times for a number of state of the art reasoning systems. This should get the reader a sense how difficult the FHKB becomes for reasoners to deal with over time.
When there is some scary OWL or the reasoner may find the FHKB hard work, you will see a \u2018here be dragons\u2019 image.1
1 The image comes fromhttp://ancienthomeofdragon.homestead.com/May 2012.
"},{"location":"tutorial/fhkb/#chapter-2","title":"Chapter 2","text":""},{"location":"tutorial/fhkb/#adding-some-individuals-to-the-fhkb","title":"Adding some Individuals to the FHKB","text":"
In this chapter we will start by creating a fresh OWL ontology and adding some individuals that will be surrogates for people in the FHKB. In particular you will:
Create a new OWL ontology for the FHKB;
Add some individuals that will stand for members of the Stevens family.
Describe parentage of people.
Add some facts to specific individuals as to their parentage;
See the reasoner doing some work.
At the moment we will ignore sex; sex will not happen until Chapter 4.
"},{"location":"tutorial/fhkb/#21-a-world-of-objects","title":"2.1 A World of Objects","text":"
The \u2018world\u20192 or field of interest we model in an ontology is made up of objects or individuals. Such objects include, but are not limited to:
People, their pets, the pizzas they eat;
The processes of cooking pizzas, living, running, jumping, undertaking a journey;
The spaces within a room, a bowl, an artery;
The attributes of things such as colour, dimensions, speed, shape of various objects;
Boundaries, love, ideas, plans, hypotheses.
2 we use \u2018world\u2019 as a synonym of \u2018field of interest\u2019 or \u2018domain\u2019. \u2018World\u2019 does not restrict us to modelling the physical world outside our consciousness.
We observe these objects, either outside lying around in the world or in our heads. OWL is all about modelling such individuals. Whenever we make a statement in OWL, when we write down an axiom, we are making statements about individuals. When thinking about the axioms in an ontology it is best to think about the individuals involved, even if OWL individuals do not actually appear in the ontology. All through this tutorial we will always be returning to the individuals being described in order to help us understand what we are doing and to help us make decisions about how to do it.
Biologically, everyone has parents; a mother and a father3. The starting point for family history is parentage; we need to relate the family member objects by object properties. An object property relates two objects, in this case a child object with his or her mother or father object. To do this we need to create three object properties:
Task 1: Creating object properties for parentage
Create a new ontology;
Create an object property hasMother;
Create a property isMotherOf and give hasMother the InverseOf: isMotherOf;
Do the same for the property hasFather;
Create a property hasParent; give it the obvious inverse;
Make hasMother and hasFather sub-properties of hasParent.
Run the reasoner and look at the property hierarchy.
Note how the reasoner has automatically completed the sub-hierarchy for isParentOf:isMotherOf and isFatherOf are inferred to be sub-properties of isParentOf.
The OWL snippet below shows some parentage fact assertions on an individual. Note that rather than being assertions to an anonymous individual via some class, we are giving an assertion to a named individual.
Using the information in Table A.1 (see appendix) about parentage (so the columns about fathers and mothers), enter the fact assertions for the people which appear in rows shaded in grey. We will only use the hasMother and hasFather properties in our fact assertions. You do not need to assert names and birth years yet. This exercise will require you to create an individual for every person we want to talk about, using the Firstname_Secondname_Familyname_Birthyear pattern, as for example in Robert_David_Bright_1965.
While asserting facts about all individuals in the FHKB will be a bit tedious at\ntimes, it might be useful to at least do the task for a subset of the family members.\nFor the impatient reader, there is a convenience snapshot of the ontology including\nthe raw individuals available at http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial\n
If you are working with Prot\u00e9g\u00e9, you may want to look at the Matrix plugin for\nProt\u00e9g\u00e9 at this point. The plugin allows you to add individuals quickly in the\nform of a regular table, and can significantly reduce the effort of adding any type\nof entity to the ontology. In order to install the matrix plugin, open Prot\u00e9g\u00e9 and\ngo to File \u00bb Check for plugins. Select the \u2018Matrix Views\u2019 plugin. Click install,\nwait until the the installation is confirmed, close and re-open Prot\u00e9g\u00e9; go to the\n\u2018Window\u2019 menu item, select \u2018Tabs\u2019 and add the \u2018Individuals matrix\u2019.\n
Now do the following:
Task 3: DL queries
Classify the FHKB.
Issue the DL query hasFather value David_Bright_1934 and look at the answers (remember to check the respective checkbox in Prot\u00e9g\u00e9 to include individuals in your query results).
Issue the DL query isFatherOf value Robert_David_Bright_1965. Look at the answers. 4. Look at the entailed facts on Robert_David_Bright_1965.
You should find the following:
David Bright (1934) is the father of Robert David Bright (1965) and Richard John Bright (1962).
Robert David Bright (1965) has David Bright 1934 as a parent.
Since we have said that isFatherOf has an inverse of hasFather, and we have asserted that Robert_David_Bright_1965 hasFather David_Bright_1934, we have a simple entailment that David_Bright_1934 isFatherOf Robert_David_Bright_1965. So, without asserting the isFatherOf facts, we have been able to ask and get answers for that DL query.
As we asserted that Robert_David_Bright_1965 hasFather David_Bright_1934, we also infer that he hasParentDavid_Bright_1934; this is because hasParent is the super-property of hasFather and the sub-property implies the super-property. This works all the way up the property tree until topObjectProperty, so all individuals are related by topObjectProperty\u2014this is always true. This implication \u2018upwards\u2019 is the way to interpret how the property hierarchies work.
We have now covered the basics of dealing with individuals in OWL ontologies. We have set up some properties, but without domains, ranges, appropriate characteristics and then arranged them in a hierarchy. From only a few assertions in our FHKB, we can already infer many facts about an individual: Simple exploitation of inverses of properties and super-properties of the asserted properties.
We have also encountered some important principles:
We get inverses for free.
The sub-property implies the super-property. So, hasFather implies the hasParent fact between individuals. This entailment of the super-property is very important and will drive much of the inference we do with the FHKB.
Upon reasoning we get the inverses of properties between named individuals for free.
Lots is still open. For example, we do not know the sex of individuals and what other children, other than those described, people in the FHKB may have.
The FHKB ontology at this stage of the tutorial has an expressivity of ALHI.\n
The time to reason with the FHKB at this point (in Prot\u00e9g\u00e9) on a typical desktop\nmachine by HermiT 1.3.8 is approximately 0.026 sec (0.00001 % of final), by Pellet\n2.2.0 0.144 sec (0.00116 % of final) and by FaCT++ 1.6.4 is approximately 0.\nsec (0.000 % of final). 0 sec indicates failure or timeout.\n
"},{"location":"tutorial/fhkb/#chapter-3","title":"Chapter 3","text":""},{"location":"tutorial/fhkb/#ancestors-and-descendants","title":"Ancestors and Descendants","text":"
In this Chapter you will:
Use sub-properties and the transitive property characteristic to infer ancestors of people;
Add properties to the FHKB property hierarchy that will infer ancestors and descendants of a person without adding any more facts to the FHKB;
Explore the use of sub-property chains for grandparents, great grandparents and so on;
Place all of these new object properties in the property hierarchy and in that way learn more about the implications of the property hierarchy.
Find a snapshot of the ontology at this stage at http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial.\n
"},{"location":"tutorial/fhkb/#31-ancestors-and-descendants","title":"3.1 Ancestors and Descendants","text":"
The FHKB has parents established between individuals and we know that all people have two parents. A parent is an ancestor of its children; a person\u2019s parent\u2019s parents are its ancestors; and so on. So, in our FHKB, Robert\u2019s ancestors are David, Margaret, William, Iris, Charles, Violet, James, another Violet, another William, Sarah and so on. If my parent\u2019s parents are my ancestors, then what we need is a transitive version of the hasParent property. Obviously we do not want hasParent to be transitive, as Robert\u2019s grandparents (and so on) would become his parents (and that would be wrong).
We can easily achieve what is necessary. We need a hasAncestor property that has a transitive characteristic. The trick is to make this a super-property of the hasParent property. As explained before, a sub-property implies its super-property. So, if individual x holds a hasParent property with an individual y , then it also holds an instance of its super-property hasAncestor with the individual y. If individual y then holds a hasParent property with another individual z , then there is also, by implication, a hasAncestor property between y and z. As hasAncestor is transitive, x and z also hold a hasAncestor relationship between them.
The inverse of hasAncestor can either be isAncestorOf or hasDescendant. We choose the isAncestorOf option.
Task 4: Object properties: exploiting the semantics
Make a new object property hasRelation, make it symmetric.
Make a new object property hasAncestor.
Make it a sub-property of hasRelation and a super-property of hasParent.
Make hasAncestor transitive.
Create the inverse isAncestorOf. Do not \u2018stitch\u2019 it into the property hierarchy; the reasoner will sort it all out for you.
Run the reasoner and issue the DL query hasAncestor value William_George_Bright_1901.
Issue the query isAncestorOf value Robert_David_Bright_1965.
The hasAncestor object property will look like this:
As usual, it is best to think of the objects or individuals involved in the relationships. Consider the three individuals \u2013 Robert, David and William. Each has a hasFather property, linking Robert to David and then David to William. As hasFather implies its super-property hasParent, Robert also has a hasParent property with David, and David has a hasParent relation to William. Similarly, as hasParent implies hasAncestor, the Robert object has a hasAncestor relation to the David object and the David object has one to the William object. As hasAncestor is transitive, Robert not only holds this property to the David object, but also to the William object (and so on back through Robert\u2019s ancestors).
"},{"location":"tutorial/fhkb/#32-grandparents-and-great-grandparents","title":"3.2 Grandparents and Great Grandparents","text":"
We also want to use a sort of restricted transitivity in order to infer grandparents, great grandparents and so on. My grandparents are my parent\u2019s parents; my grandfathers are my parent\u2019s fathers. My great grandparents are my parent\u2019s parent\u2019s parents. My great grandmothers are my parent\u2019s parent\u2019s mothers. This is sort of like transitivity, but we want to make the paths only a certain length and, in the case of grandfathers, we want to move along two relationships \u2013 hasParent and then hasFather.
We can do this with OWL 2\u2019s sub-property chains. The way to think about sub-property chains is: If we see property x followed by property y linking three objects, then it implies that property z is held between
Figure 3.1: Three blobs representing objects of the classPerson. The three objects are linked by a hasParent property and this implies a hasGrandparent property.
the first and third objects. Figure 3.1 shows this diagrammatically for the hasGrandfather property.
For various grandparent object properties we need the following sets of implications:
My parent\u2019s parents are my grandparents;
My parent\u2019s fathers are my grandfathers;
My parent\u2019s mothers are my grandmothers;
My parent\u2019s parent\u2019s parents are my great grandparents or my grandparent\u2019s parents are my great grandparents.
My parent\u2019s parent\u2019s fathers are my great grandfathers or my parent\u2019s grandfathers are my great grandfathers;
My parent\u2019s parent\u2019s mothers are my great grandmothers (and so on).
Notice that we can trace the paths in several ways, some have more steps than others, though the shorter paths themselves employ paths. Tracing these paths is what OWL 2\u2019s sub-property chains achieve. For the new object property hasGrandparent we write:
ObjectProperty: hasGrandparent SubPropertyChain: hasParent o hasParent\n
We read this as \u2018hasParent followed by hasParent implies hasGrandparent\u2019. We also need to think where the hasGrandparent property fits in our growing hierarchy of object properties. Think about the implications: Does holding a hasParent property between two objects imply that they also hold a hasGrandparent property? Of course the answer is \u2018no\u2019. So, this new property is not a super-property of hasParent. Does the holding of a hasGrandparent property between two objects imply that they also hold an hasAncestor property? The answer is \u2018yes\u2019; so that should be a super-property of hasGrandparent. We need to ask such questions of our existing properties to work out where we put it in the object property hierarchy. At the moment, our hasGrandparent property will look like this:
ObjectProperty: hasGrandParent\nSubPropertyOf: hasAncestor\nSubPropertyChain: hasParent o hasParent\nSuperPropertyOf: hasGrandmother, hasGrandfather\nInverseOf: isGrandParentOf\n
Do the following task:
Task 5: Grandparents object properties
Make the hasGrandparent, hasGrandmother and hasGrandfather object properties and the obvious inverses (see OWL code above);
Go to the individuals tabs and inspects the inferred object property assertions for Robert_David_Bright_1965 and his parents.
Again, think of the objects involved. We can take the same three objects as before: Robert, David and William. Think about the properties that exist, both by assertion and implication, between these objects. We have asserted only hasFather between these objects. The inverse can be inferred between the actual individuals (remember that this is not the case for class level restrictions \u2013 that all instances of a class hold a property does not mean that the filler objects at the other end hold the inverse; the quantification on the restriction tells us this). Remember that:
Robert holds a hasFather property with David;
David holds a hasFather property with William;
By implication through the hasParent super-property of hasFather, Robert holds a hasParent property with David, and the latter holds one with William;
The sub-property chain on hasGrandfather then implies that Robert holds a hasGrandfather property to William. Use the diagram in figure 3.1 to trace the path; there is a hasParent path from Robert to William via David and this implies the hasGrandfather property between Robert and William.
It is also useful to point out that the inverse of hasGrandfather also has the implication of the sub-property chain of the inverses of hasParent. That is, three objects linked by a path of two isParentOf properties implies that an isGrandfatherOf property is established between the first and third object, in this case William and Robert. As the inverses of hasFather are established by the reasoner, all the inverse implications also hold.
It is important when dealing with property hierarchies to think in terms of properties between objects and of the implications \u2018up the hierarchy\u2019. A sub-property implies its super-property. So, in our FHKB, two person objects holding a hasParent property between them, by implication also hold an hasAncestor property between them. In turn, hasAncestor has a super-property hasRelation and the two objects in question also hold, by implication, this property between them as well.
We made hasAncestor transitive. This means that my ancestor\u2019s ancestors are also my ancestors. That a sub-property is transitive does not imply that its super-property is transitive. We have seen that by manipulating the property hierarchy we can generate a lot of inferences without adding any more facts to the individuals in the FHKB. This will be a feature of the whole process \u2013 keep the work to the minimum (well, almost).
In OWL 2, we can also trace \u2018paths\u2019 around objects. Again, think of the objects involved in the path of properties that link objects together. We have done simple paths so far \u2013 Robert linked to David via hasParent and David linked to William via hasFather implies the link between Robert and William of hasGrandfather. If this is true for all cases (for which you have to use your domain knowledge), one can capture this implication in the property hierarchy. Again, we are making our work easier by adding no new explicit facts, but making use of the implication that the reasoner works out for us.
The FHKB ontology at this stage of the tutorial has an expressivity ofALRI+.\n
The time to reason with the FHKB at this point (in Prot\u00e9g\u00e9) on a typical desktop\nmachine by HermiT 1.3.8 is approximately 0.262 sec (0.00014 % of final), by Pellet\n2.2.0 0.030 sec (0.00024 % of final) and by FaCT++ 1.6.4 is approximately 0.004\nsec (0.000 % of final). 0 sec indicates failure or timeout.\n
"},{"location":"tutorial/fhkb/#chapter-4","title":"Chapter 4","text":""},{"location":"tutorial/fhkb/#modelling-the-person-class","title":"Modelling the Person Class","text":"
In this Chapter you will:
Create a Person class;
Describe Sex classes;
Define Man and Woman;
Ask which of the people in the FHKB has a father.
Add domains and ranges to the properties in the FHKB.
Make the FHKB inconsistent.
Add some more defined classes about people and see some equivalence inferred between classes.
These simple classes will form the structure for the whole FHKB.
"},{"location":"tutorial/fhkb/#41-the-class-of-person","title":"4.1 The Class of Person","text":"
For the FHKB, we start by thinking about the objects involved
The people in a family \u2013 Robert, Richard, David, Margaret, William, Iris, Charles, Violet, Eileen, John and Peter;
The sex of each of those people;
The marriages in which they participated;
The locations of their births;
And many more...
There is a class of Person that we will use to represent all these people objects.
Task 6: Create the Person class
Create a class called DomainEntity;
Create a subclass of DomainEntity called Person.
We use DomainEntity as a house-keeping measure. All of our ontology goes underneath this class. We can put other classes \u2018outside\u2019 the ontology, as siblings of DomainEntity, such as \u2018probe\u2019 classes we wish to use to test our ontology.
The main thing to remember about the Person class is that we are using it to represent all \u2018people\u2019 individuals. When we make statements about the Person class, we are making statements about all \u2018people\u2019 individuals.
What do we know about people? All members of the Person class have:
Sex \u2013 they are either male or female;
Everyone has a birth year;
Everyone has a mother and a father.
There\u2019s a lot more we know about people, but we will not mention it here.
"},{"location":"tutorial/fhkb/#42-describing-sex-in-the-fhkb","title":"4.2 Describing Sex in the FHKB","text":"
Each and every person object has a sex. In the FHKB we will take a simple view on sex \u2013 a person is either male or female, with no intersex or administrative sex and so on. Each person only has one sex.
We have two straight-forward options for modelling sex:
Each person object has their own sex object, which is either male or female. Thus Robert\u2019s maleness is different from David\u2019s maleness.
There is only one Maleness object and one Femaleness object and each person object has a relationship to either one of these sex objects, but not both.
We will take the approach of having a class of Maleness objects and a class of Femaleness objects. These are qualities or attributes of self-standing objects such as a person. These two classes are disjoint, and each is a subclass of a class called Sex. The disjointness means that any one instance of Sex cannot be both an instance of Maleness and an instance of Femaleness at once. We also want to put in a covering axiom on the class Sex, which means that any instance of Sex must be either Maleness or Femaleness; there is no other kind of Sex.
Again, notice that we have been thinking at the level of objects. We do the same when thinking about Person and their Sex. Each and every person is related to an instance of Sex. Each Person holds one relationship to a Sex object. To do this we create an object property called hasSex. We make this property functional, which means that any object can hold that property to only one distinct filler object.
We make the domain of hasSex to be Person and the range to be Sex. The domain of Person means that any object holding that property will be inferred to be a member of the class Person. Putting the range of Sex on the hasSex property means that any object at the right-hand end of the hasSex property will be inferred to be of the class Sex. Again, think at the level of individuals or objects.
We now put a restriction on the Person class to state that each and every instance of the class Person holds a hasSex property with an instance of the Sex class. It has an existential operator \u2018some\u2019 in the axiom, but the functional characteristic means that each Person object will hold only one hasSex property to a distinct instance of a Sex object4.
4 An individual could hold two hasSex properties, as long as the sex objects at the right-hand end of the property are not different.
Task 7: Modelling sex
Create a class called Sex;
Make it a subclass of DomainEntity;
Make Person and Sex disjoint;
Create two subclasses of Sex, Maleness and Femaleness;
Make Maleness and Femaleness disjoint;
Put a covering axiom on Sex such that it is equivalent to Maleness or Femaleness.
Create an object property, hasSex , with the domain Person, the range Sex and give it the characteristic of \u2018Functional\u2019;
Add a restriction hasSex some Sex to the class Person.
Class: Person\nSubClassOf: DomainEntity,(hasSex some Sex)\nDisjointWith: Sex\n
"},{"location":"tutorial/fhkb/#43-defining-man-and-woman","title":"4.3 Defining Man and Woman","text":"
We now have some of the foundations for the FHKB. We have the concept of Person, but we also need to have the concepts of Man and Woman. Now we have Person, together with Maleness and Femaleness, we have the necessary components to define Man and Woman. These two classes can be defined as: Any Person object that has a male sex can be recognised to be a man; any Person object that has a female sex can be recognised as a member of the class woman. Again, think about what conditions are sufficient for an object to be recognised to be a member of a class; this is how we create defined classes through the use of OWL equivalence axioms.
To make the Man and Woman classes do the following:
Task 8: Describe men and women
Create a class Man;
Make it equivalent to a Person that hasSex some Maleness;
Do the same, but with Femaleness, to create the Woman class;
A covering axiom can be put on the Person class to indicate that man and woman are the only kinds of person that can exist. (This is not strictly true due to the way Sex has been described.)
Run the reasoner and take a look.
Having run the reasoner, the Man and Woman classes should appear underneath Person5.
5Actually in Prot\u00e9g\u00e9, this might happen without the need to run the reasoner.
The Man and Woman classes will be important for use as domain and range constraints on many of the properties used in the FHKB. To achieve our aim of maximising inference, we should be able to infer that individuals are members of Man, Woman or Person by the properties held by an object. We should not have to state the type of an individual in the FHKB.
The classes for Man and Woman should look like:
Class: Man\nEquivalentTo: Person and (hasSex some Maleness)\n
Class: Woman\nEquivalentTo: Person and (hasSex some Femaleness)\n
"},{"location":"tutorial/fhkb/#44-describing-parentage-in-the-fhkb","title":"4.4 Describing Parentage in the FHKB","text":"
To finish off the foundations of the FHKB we need to describe a person object\u2019s parentage. We know that each and every person has one mother and each and every person has one father. Here we are talking about biological mothers and fathers. The complexities of adoption and step parents are outside the scope of this FHKB tutorial.
Task 9: Describing Parentage
Add the domain Person and the range Woman to the property hasMother.
Do the same for the property hasFather, but give it the range Man;
Give the property hasParent domain and range of Person;
Run the reasoner.
The (inferred) property hierarchy in the FHKB should look like that shown in Figure 4.1. Notice that we have asserted the sub-property axioms on one side of the property hierarchy. Having done so, the reasoner uses those axioms, together with the inverses, to work out the property hierarchy for the \u2018other side\u2019.
We make hasMother functional, as any one person object can hold only one hasMother property to a distinct Woman object. The range of hasMother is Woman, as a mother has to be a woman. The Person object holding the hasMother property can be either a man or a woman, so we have the domain constraint as Person; this means any object holding a hasMother property will be inferred to be a Person. Similarly, any object at the right-hand end of a hasMother property will be inferred to be a Woman, which is the result we need. The same reasoning goes for hasFather and hasParent, with the sex constraints on the latter being only Person. The inverses of the two functional sub-properties of hasParent are not themselves functional. After all, a Woman can be the mother of many Person objects, but each Person object can have only one mother.
Figure 4.1: The property hierarchy with the hasSex and the parentage properties
Figure 4.2: the core TBox for the FHKB with the Person and Sex classes.
Task 10: Restrict Person class
As each and every person has a mother and each and every person has a father, place restrictions on the Person class as shown below.
Class: Person\nSubClassOf: DomainEntity, (hasFather some Man), (hasMother some Woman),\n(hasSex some Sex)\nDisjointWith: Sex\n
Task 11: DL queries for people and sex
Issue the DL queries for Person, Man and Woman; look at the answers and count the numbers in each class; which individuals have no sex and why?
You should find that many people have been inferred to be either Man or Woman, but some are, as we will see below, only inferred to be Person.
The domain and range constraints on our properties have also driven some entailments. We have not asserted that David_Bright_1934 is a member of Man, but the range constraint on hasFather (or the inferred domain constraint on the isFatherOf relation) has enabled this inference to be made. This goes for any individual that is the right-hand-side (either inferred or asserted) of either hasFather or hasMother (where the range is that of Woman). For Robert David Bright, however, he is only the left-hand-side of an hasFather or an hasMother property, so we\u2019ve only entailed that this individual is a member of Person.
"},{"location":"tutorial/fhkb/#45-who-has-a-father","title":"4.5 Who has a father?","text":"
In our description of the Person class we have said that each and every instance of the class Person has a father (the same goes for mothers). So, when we ask the query \u2018which individuals have a father\u2019, we get all the instances of Person back, even though we have said nothing about the specific parentage of each Person. We do not know who their mothers and fathers are, but we know that they have one of each. We know all the individuals so far entered are members of the Person class; when asserting the type to be either Man or Woman (each of which is a subclass of Person), we infer that each is a person. When asserting the type of each individual via the hasSex property, we know each is a Person, as the domain of hasSex is the Person class. As we have also given the right-hand side of hasSex as either Maleness or Femaleness, we have given sufficient information to recognise each of these Person instances to be members of either Man or Woman.
"},{"location":"tutorial/fhkb/#46-filling-in-domains-and-ranges-for-the-fhkb-properties","title":"4.6 Filling in Domains and Ranges for the FHKB Properties","text":"
So far we have not systematically added domains and ranges to the properties in the FHKB. As a reminder, when a property has a domain of X any object holding that property will be inferred to be a member of class X. A domain doesn\u2019t add a constraint that only members of class X hold that property; it is a strong implication of class membership. Similarly, a property holding a range implies that an object acting as right-hand-side to a property will be inferred to be of that class. We have already seen above that we can use domains and ranges to imply the sex of people within the FHKB.
Do the following:
Task 12: Domains and Ranges
Make sure the appropriate Person, Man and Woman are domains and ranges for hasFather, hasMother and hasParent.
Run the reasoner and look at the property hierarchy.
Also look at the properties hasAncestor, hasGrandparent, hasUncle and so on; look to see what domains and ranges are found. Add any domains and ranges explicitly as necessary.
Prot\u00e9g\u00e9 for example in its current version (November 2015) does not visualise\ninherited domains and ranges in the same way as it shows inferred inverse relations.\n
We typically assert more domains and ranges than strictly necessary. For example, if we say that hasParent has the domain Person, this means that every object x that is connected to another object y via the hasParent relation must be a Person. Let us assume the only thing we said about x and y is that they are connected by a hasMother relation. Since this implies that x and y are also connected by a hasParent relation (hasMother is a sub-property of hasParent) we do not have to assert that hasFather has the domain of Person; it is implied by what we know about the domain and range of hasParent.
In order to remove as many assertions as possible, we may therefore choose to assert as much as we know starting from the top of the hierarchy, and only ever adding a domain if we want to constrain the already inferred domain even further (or range respectively). For example, in our case, we could have chosen to assert Person to be the domain of hasRelation. Since hasRelation is symmetric, it will also infer Person to be the range. We do not need to say anything for hasAncestor or hasParent, and only if we want to constrain the domain or range further (like in the case of hasFather by making the range Man) do we need to actually assert something. It is worth noting that because we have built the object property hierarchy from the bottom (hasMother etc.) we have ended up asserting more than necessary.
From the Pizza Tutorial and other work with OWL you should have seen some unsatisfiabilities. In Prot\u00e9g\u00e9 this is highlighted by classes going \u2018red\u2019 and being subclasses ofNothing; that is, they can have no instances in that model.
Task 13: Inconsistencies
Add the fact Robert_David_Bright_1965 hasMother David_Bright_1934.
Run the classifier and see what happens.
Remove that fact and run the classifier again.
Now add the fact that Robert_David_Bright_1965 hasMother Iris_Ellen_Archer_1907
Run the classifier and see what happens.
Add and remove the functional characteristic to these properties and see what happens.
After asserting the first fact it should be reported by the reasoner that the ontology is inconsistent. This means, in lay terms, that the model you\u2019ve provided in the ontology cannot accommodate the facts you\u2019ve provided in the fact assertions in your ABox\u2014that is, there is an inconsistency between the facts and the ontology... The ontology is inconsistent because David_Bright_1934 is being inferred to be a Man and a Woman at the same time which is inconsistent with what we have said in the FHKB.
When we, however, say that Robert David Bright has two different mothers, nothing bad happens! Our domain knowledge says that the two women are different, but the reasoner does not know this as yet... ; Iris Ellen Archer and Margaret Grace Rever may be the same person; we have to tell the reasoner that they are different. For the same reason the functional characteristic also has no effect until the reasoner \u2018knows\u2019 that the individuals are different. We will do this in Section 7.1.1 and live with this \u2018fault\u2019 for the moment.
"},{"location":"tutorial/fhkb/#48-adding-some-defined-classes-for-ancestors-and-so-on","title":"4.8 Adding Some Defined Classes for Ancestors and so on","text":"Task 14: Adding defined classes
Add a defined class for Ancestor, MaleAncestor, FemaleAncestor;
Add a defined class for Descendant, MaleDescendant and FemaleDescendant;
Run the reasoner and view the resulting hierarchy.
The code for the classes looks like:
Class: Ancestor EquivalentTo: Person and isAncestorOf some Person\nClass: FemaleAncestor EquivalentTo: Woman and isAncestorOf some Person\nClass: Descendant EquivalentTo: Person and hasAncestor some Person\nClass: MaleDescendant EquivalentTo: Man and hasAncestor some Person\n
The TBox after reasoning can be seen in Figure 4.3. Notice that the reasoner has inferred that several of the classes are equivalent or \u2018the same\u2019. These are: Descendant and Person; MaleDescendant and Man, FemaleDescendant and Woman.
The reasoner has used the axioms within the ontology to infer that all the instances of Person are also instances of the class Descendant and that all the instances of Woman are also the same instances as the class Female Descendant. This is intuitively true; all people are descendants \u2013 they all have parents that have parents etc. and thus everyone is a descendant. All women are female people that have parents etc. As usual we should think about the objects within the classes and what we know about them. This time it is useful to think about the statements we have made about Person in this Chapter \u2013 that all instances of Person have a father and a mother; add to this the information from the property hierarchy and we know that all instances of Person have parents and ancestors. We have repeated all of this in our new defined classes for Ancestor and Descendant and the reasoner has highlighted this information.
Figure 4.3: The defined classes from Section 4.8 in the FHKB\u2019s growing class hierarchy
Task 15: More Ancestors
Query for MaleDescendant. You should get Man back - they are equivalent (and this makes sense).
As an additional exercise, also add in properties for forefathers and foremothers. You will follow the same pattern as for hasAncestor, but adding in, for instance, hasFather as the sub-property of the transitive super-property of hasForefather and setting the domains and ranges appropriately (or working out if they\u2019ll be inferred appropriately). Here we interpret a forefather as one\u2019s father\u2019s father etc. This isn\u2019t quite right, as a forefather is any male ancestor, but we\u2019ll do it that way anyway. You might want to play around with DL queries. Because of the blowup in inferred relationships, we decided to not include this pattern in the tutorial version of the FHKB.
Most of what we have done in this chapter is straight-forward OWL, all of which would have been met in the pizza tutorial. It is, however, a useful revision and it sets the stage for refining the FHKB. Figure 4.2 shows the basic set-up we have in the FHKB in terms of classes; we have a class to represent person, man and woman, all set-up with a description of sex, maleness and femaleness. It is important to note, however, the approach we have taken: We have always thought in terms of the objects we are modelling.
Here are some things that should now be understood upon completing this chapter:
Restrictions on a class in our TBox mean we know stuff about individuals that are members of that class, even though we have asserted no facts on those individuals. We have said, for instance, that all members of the class Person have a mother, so any individual asserted to be a Person must have a mother. We do not necessarily know who they are, but we know they have one.
Some precision is missing \u2013 we only know Robert David Bright is a Person, not that he is a Man. This is because, so far, he only has the domain constraint of hasMother and hasFather to help out.
We can cause the ontology to be inconsistent, for example by providing facts that cannot be accommodated by the model of our ontology. In the example, David Bright was inferred to be a member of two disjoint classes.
Finally, we looked at some defined classes. We inferred equivalence between some classes where the extents of the classes were inferred to be the same \u2013 in this case the extents of Person and Descendant are the same. That is, all the objects that can appear in Person will also be members of Descendant. We can check this implication intuitively \u2013 all people are descendants of someone. Perhaps not the most profound inference of all time, but we did no real work to place this observation in the FHKB.
This last point is a good general observation. We can make the reasoner do work\nfor us. The less maintenance we have to do in the FHKB the better. This will be\na principle that works throughout the tutorial.\n
The FHKB ontology at this stage of the tutorial has an expressivity of SRIF.\n
The time to reason with the FHKB at this point (in Prot\u00e9g\u00e9) on a typical desktop\nmachine by HermiT 1.3.8 is approximately 0.884 sec (0.00047 % of final), by Pellet\n2.2.0 0.256 sec (0.00207 % of final) and by FaCT++ 1.6.4 is approximately 0.013\nsec (0.000 % of final). 0 sec indicates failure or timeout.\n
"},{"location":"tutorial/fhkb/#chapter-5","title":"Chapter 5","text":""},{"location":"tutorial/fhkb/#siblings-in-the-fhkb","title":"Siblings in the FHKB","text":"
In this chapter you will:
Explore options for determining finding siblings;
Meet some of the limitations in OWL;
Choose one of the options explored;
Add facts for siblings;
Use sub-property chains to find aunts and uncles;
There is a snapshot of the ontology as required at this point in the tutorial available\nat http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial\n
Create an hasBloodrelation object property, making it a sub-property of hasRelation.
Add appropriate property characteristics.
Make the already existing hasAncestor property a sub-property of hasBloodrelation.
Does a blood relation of Robert have the same relationship to Robert (symmetry)? Is a blood relation of Robert\u2019s blood relation a blood relation of Robert (transitivity)? Think of an aunt by marriage; her children are my cousins and blood relations via my uncle, but my aunt is not my blood relation. My siblings share parents; male siblings are brothers and female siblings are sisters. So far we have asserted parentage facts for the Person in our ABox. Remember that our parentage properties have inverses, so if we have added an hasFather property between a Person and a Man, we infer the isFatherOf property between that Man and that Person.
We should have enough information within the FHKB to infer siblings. We could use a sub-property chain such as:
ObjectProperty: hasSibling\nSubPropertyOf: hasBloodrelation\nCharacteristics: Symmetric, transitive\nSubPropertyChain: hasParent o isParentOf\n
We make a property of hasSibling and make it a sub-property of hasBloodrelation. Remember, think of the objects involved and the implications we want to follow; being a sibling implies being a blood relation, it does not imply any of the other relationships we have in the FHKB.
Note that we have made hasSibling symmetric; if Robert is sibling of Richard, then Richard is sibling of Robert. We should also think about transitivity; if David is sibling of Peter and Peter is sibling of John, then David is sibling of John. So, we make hasSibling symmetric and transitive (see Figure 5.1). However, we must take care of half-siblings: child 1 and child 2 share a mother, but not a father; child 2 and child 3 share the father, but not the mother \u2013 child 1 and child 3 are not even half-siblings. However, at least for the moment, we will simply ignore this inconvenience, largely so that we can explore what happens with different modelling options.
Figure 5.1: Showing the symmetry and transitivity of the hasSibling (siblingof) property by looking at the brothers David, John and Peter
We also have the implication using three objects (see Figure 5.2):
Robert holds a hasParent property with David;
David holds an isFatherOf property with Richard;
This implies that Robert holds a hasSibling property with Richard;
As hasSibling is symmetric, Richard holds an hasSibling property with Robert.
Figure 5.2: Tracing out the sub-property chain for hasSibling; note that Robert is a sibling of himself by this path
Do the following tasks:
Task 17: Siblings
Add the hasSibling property as above;
Run the reasoner;
Ask the DL query hasSibling value Robert_David_Bright_1965.
From this last DL query you should get the answer that both Robert and Richard are siblings of Robert. Think about the objects involved in the sub-property chain: we go from Robert to David via the hasParent and from David to Richard via the isParentOf property; so this is OK. However, we also go from Robert to David and then we can go from David back to Robert again \u2013 so Robert is a sibling of Robert. We do not want this to be true.
We can add another characteristic to the hasSibling property, the one of being irreflexive. This means that an object cannot hold the property with itself.
Task 18: More siblings
Add the irreflexive characteristic to the hasSibling property;
Run the reasoner;
Note that the reasoner claims you have an inconsistent ontology (or in some cases, you might get a message box saying \"Reasoner died\"). Looking at the hasSibling property again, the reason might not be immediately obvious. The reason for the inconsistency lies in the fact that we create a logical contradiction: through the property chain, we say that every Person is a sibling of him or herself, and again disallowing just that by adding the irreflexive characteristic. A different explanation lies within the OWL specification itself: In order to maintain decidability irreflexive properties must be simple - for example, they may not be property chains6.
"},{"location":"tutorial/fhkb/#521-brothers-and-sisters","title":"5.2.1 Brothers and Sisters","text":"
We have only done siblings, but we obviously need to account for brothers and sisters. In an analogous way to motherhood, fatherhood and parenthood, we can talk about sex specific sibling relationships implying the sex neutral hasSibling; holding either a hasBrother or an isSisterOf between two objects would imply that a hasSibling property is also held between those two objects. This means that we can place these two sex specific sibling properties below hasSibling with ease. Note, however, that unlike the hasSibling property, the brother and sister properties are not symmetric. Robert hasBrother Richard and vice versa , but if Daisy hasBrother William, we do not want William to hold an hasBrother property with Daisy. Instead, we create an inverse of hasBrother, isBrotherOf, and the do the same for isSisterOf.
We use similar, object based, thought processes to choose whether to have transitivity as a characteristic of hasBrother. Think of some sibling objects or individuals and place hasBrother properties between them. Make it transitive and see if you get the right answers. Put in a sister to and see if it stil works. If David hasBrother Peter and Peter hasBrother John, then David hasBrother John; so, transitivity works in this case. Think of another example. Daisy hasBrother Frederick, and Frederick hasBrother William, thus Daisy hasBrother William. The inverses work in the same way; William isBrotherOf Frederick and Frederick isBrotherOf Daisy; thus William isBrotherOf Daisy. All this seems reasonable.
Task 19: Brothers and sisters
Create the hasBrother object property as shown below;
Add hasSister in a similar manner; 3. Add appropriate inverses, domains and ranges.
We have some hasSibling properties (even if they are wrong). We also know the sex of many of the people in the FHKB through the domains and ranges of properties such as hasFather, hasMother and their inverses..
Can we use sub-property chains in the same way as we have used them in the hasSibling property? The issue is that of sex; the property isFatherOf is sex neutral at the child end, as is the inverse hasFather (the same obviously goes for the mother properties). We could use a sub-property chain of the form:
ObjectProperty: hasBrother\nSubPropertyChain: hasParent o hasSon\n
A son is a male child and thus that object is a brother of his siblings. At the moment we do not have son or daughter properties. We can construct a property hierarchy as shown in Figure 5.3. This is made up from the following properties:
hasChild and isChildOf
hasSon(range Man and domain Person) and isSonOf;
hasDaughter(range Woman domain Person) and isDaughterOf
Note that hasChild is the equivalent of the existing property isParentOf; if I have a child, then I am its parent. OWL 2 can accommodate this fact. We can add an equivalent property axiom in the following way:
We have no way of inferring the isSonOf and isDaughterOf from what already exists. What we want to happen is the implication of \u2018Man and hasParentPerson implies isSonOf\u2019. OWL 2 and its reasoners cannot do this implication. It has been called the \u2018man man problem\u20197. Solutions for this have been developed [3], but are not part of OWL 2 and its reasoners.
Figure 5.3: The property hierarchy for isChildOf and associated son/daughter properties
Child property Parent Robert David Bright 1965 isSonOf David Bright 1934, Margaret Grace Rever 1934 Richard John Bright 1962 isSonOf David Bright 1934, Margaret Grace Rever 1934 Mark Bright 1956 isSonOf John Bright 1930, Joyce Gosport Ian Bright 1959 isSonOf John Bright 1930, Joyce Gosport Janet Bright 1964 isDaughterOf John Bright 1930, Joyce Gosport William Bright 1970 isSonOf John Bright 1930, Joyce Gosport
Table 5.1: Child property assertions for the FHKB
Thus we must resort to hand assertions of properties to test out our new path:
Task 20: Sons and daughters
Add the property hierarchy shown in Figure 5.3, together with the equivalent property axiom and the obvious inverses.
As a test (after running the reasoner), ask the DL query isChildOf value David_Bright_1934 and you should have the answer of Richard and Robert;
Add the sub-property paths as described in the text;
Add the assertions shown in Table 5.1;
Run the reasoner;
Ask the DL query for the brother of Robert David Bright and the sister of Janet.
Of course, it works, but we see the same problem as above. As usual, think of the objects involved. Robert isSonOf David and David isParentOf Robert, so Robert is his own brother. Irreflexivity again causes problems as it does above (Task 18).
Our option one has lots of problems. So, we have an option of asserting the various levels of sibling. We can take the same basic structure of sibling properties as before, but just fiddle around a bit and rely on more assertion while still trying to infer as much as possible. We will take the following approach:
We will take off the sub-property chains of the sibling properties as they do not work;
We will assert the leaf properties of the sibling sub-hierarchy sparsely and attempt to infer as much as possible.
Person Property Person Robert David Bright 1965 isBrotherOf Richard John Bright 1962 David Bright 1934 isBrotherOf John Bright 1930 David Bright 1934 isBrotherOf Peter William Bright 1941 Janet Bright 1964 isSisterOf Mark Bright 1956 Janet Bright 1964 isSisterOf Ian Bright 1959 Janet Bright 1964 isSisterOf William Bright 1970 Mark Bright 1956 isBrotherOf Ian Bright 1959 Mark Bright 1956 isBrotherOf Janet Bright 1964 Mark Bright 1956 isBrotherOf William Bright 1970
Table 5.2: The sibling relationships to add to the FHKB.
Do the following:
Task 21: Add sibling assertions
Remove the sub-property chains of the sibling properties and the isChildOf assertions as explained above.
Add the Sibling assertions shown in table 5.2;
Run the reasoner;
Ask isBrotherOf value Robert_David_Bright_1965;
Ask isBrotherOf value Richard_John_Bright_1962;
Ask hasBrother value Robert_David_Bright_1965;
Ask hasBrother value Richard_John_Bright_1962;
Ask isSisterOf value William_Bright_1970;
Ask the query Man and hasSibling value Robert_David_Bright_1965.
We can see some problems with this option as well:
With these properties asserted, Richard only has a hasBrother property to Robert. We would really like an isBrotherOf to Robert to hold.
The query Man and hasSibling value Robert only retrieves Robert himself. Because we only asserted that Robert is a brother of Richard, and the domain of isBrotherOf is Man we know that Robert is a Man, but we do not know anything about the Sex of Richard.
"},{"location":"tutorial/fhkb/#531-which-modelling-option-to-choose-for-siblings","title":"5.3.1 Which Modelling Option to Choose for Siblings?","text":"
Which of the two options gives the worse answers and which is the least effort? Option one is obviously the least effort; we only have to assert the same parentage facts as we already have; then the sub-property chains do the rest. It works OK for hasSibling, but we cannot do brothers and sisters adequately; we need Man and hasSibling \u2290 isBrotherOf and we cannot do that implication. This means we cannot ask the questions we need to ask.
So, we do option two, even though it is hard work and is still not perfect for query answering, even though we have gone for a sparse assertion mode. Doing full sibling assertion would work, but is a lot of effort.
We could start again and use the isSonOfandisDaughterOf option, with the sub-property chains described above. This still has the problem of everyone being their own sibling. It can get the sex specific sibling relationships, but requires a wholesale re-assertion of parentage facts. We will continue with option two, largely because it highlights some nice problems later on.
In Section 5.2 we briefly talked about half-siblings. So far, we have assumed full-siblings (or, rather, just talked about siblings and made no distinction). Ideally, we would like to accommodate distinctions between full- and half-siblings; here we use half-siblings, where only one parent is in common between two individuals, as the example. The short-answer is, unfortunately, that OWL 2 cannot deal with half-siblings in the way that we want - that is, such that we can infer properties between named individuals indicating full- or half-sibling relationships.
It is possible to find sets of half-brothers in the FHKB by writing a defined class or DL-query for a particular individual.} The following fragment of OWL defines a class that looks for the half-brothers of an individual called \u2018Percival\u2019:
Class: HalfBrotherOfPercival\nEquivalentTo: Man and (((hasFather some (not (isFatherOf value Percival))) and\n(hasMother some (isMotherOf value Percival))) or ((hasFather some (isFatherOf\nvalue Percival)) and (hasMother some (not (isMotherOf value Percival)))))\n
Here we are asking for any man that either has Percival\u2019s father but not his mother, or his mother, but not his father. This works fine, but is obviously not a general solution. The OWL description is quite complex and the writing will not scale as the number of options (hypothetically, as the number of parents increases... ) increases; it is fine for man/woman, but go any higher and it will become very tedious to write all the combinations.
Another way of doing this half-brother class to find the set of half-brothers of a individual is to use cardinality constraints:
Class: HalfBrotherOfPercival\nEquivalentTo: Man and (hasParent exactly 1 (isParentOf value Percival))\n
This is more succinct. We are asking for a man that has exactly one parent from the class of individuals that are the class of Percival\u2019s parents. This works, but one more constraint has to be present in the FHKB. We need to make sure that there can be only two parents (or indeed, just a specified number of parents for a person). If we leave it open as to the number of parents a person has, the reasoner cannot work out that there is a man that shares exactly one parent, as there may be other parents. We added this constraint to the FHKB in Section 6.2; try out the classes to check that they work.
These two solutions have been about finding sets of half-brothers for an individual. What we really want in the FHKB is to find half-brothers between any given pair of individuals.
Unfortunately we cannot, without rules, ask OWL 2 to distinguish full- and half-siblings \u2013 we cannot count the number of routes taken between siblings via different distinct intermediate parent objects.
"},{"location":"tutorial/fhkb/#55-aunts-and-uncles","title":"5.5 Aunts and Uncles","text":"
An uncle is a brother of either my mother or father. An aunt is a sister of either my mother or father. In common practice, wives and husbands of aunts and uncles are usually uncles and aunts respectively. Formally, these aunts and uncles are aunts-in-law and uncles-in-law. Whatever approach we take, we cannot fully account for aunts and uncles until we have information about marriages, which will not have until Chapter 9. We will, however, do the first part now.
Look at the objects and properties between them for the following facts:
Robert has father David and mother Margaret;
David has brothers Peter and John;
Margaret has a sister Eileen;
Robert thus has the uncles John and Peter and an aunt Eileen.
As we are tracing paths or \u2018chains\u2019 of objects and properties we should use sub-property chains as a solution for the aunts and uncles. We can make an hasUncle property as follows (see Figure 5.4):
ObjectProperty: hasUncle\nSubPropertyOf: hasBloodrelation\nDomain: Man\nRange: Person\nSubPropertyChain: hasParent o hasBrother\nInverseOf: isUncleOf\n
Figure 5.4: Tracing out the path between objects to get the hasUncle sub-property chain.
Notice we have the domain of Man and range of Person. We also have an inverse. As usual, we can read this as \u2018an object that holds an hasParent property, followed by an object holding a hasBrother property, implies that the first object holds an hasUncle property with the last object\u2019.
Note also where the properties (include the ones for aunt) go in the object property hierarchy. Aunts and uncles are not ancestors that are in the direct blood line of a person, but they are blood relations (in the narrower definition that we are using). Thus the aunt and uncle properties go under the hasBloodrelation property (see Figure 5.5). Again, think of the implications between objects holding a property between them; that two objects linked by a property implies that those two objects also hold all the property\u2019s super-properties as well. As long as all the super-properties are true, the place in the object property hierarchy is correct (think about the implications going up, rather than down).
Figure 5.5: The object property hierarchy with the aunt and uncle properties included. On the right side, we can see the hasUncle property as shown by Prot\u00e9g\u00e9.
Do the following tasks:
Task 22: Uncles and Aunts
Add the hasUncle property as above;
Add the hasAunt property as well;
Ask for the uncles of Julie_Bright_1966 and for Mark_Bright_1956;
Add similar properties for hasGreatUncle and hasGreatAunt and place them in the property hierarchy.
We can see this works \u2013 unless we have any gaps in the sibling relationships (you may have to fix these). Great aunts and uncles are simply a matter of adding another \u2018parent\u2019 leg into the sub-property chain. We are not really learning anything new with aunts and uncles, except that we keep gaining a lot for
free through sub-property chains. We just add a new property with its sub-property chain and we get a whole lot more inferences on individuals. To see what we now know about Robert David Bright, do the following:
Task 23: What do we know?
Save the ontology and run the reasoner;
Look at inferences related to the individual Robert David Bright (see warning in the beginning of this chapter).
If you chose to use DL queries in Prot\u00e9g\u00e9, do not forget to tick the appropriate check-boxes.
You can now see lots of facts about Robert David Bright, with only a very few actual assertions directly on Robert David Bright.
We can use just the parentage facts to find siblings, but everyone ends up being their own sibling;
We cannot make the properties irreflexive, as the knowledge base becomes inconsistent;
We would like an implication of Man and hasSibling \u2283 isBrotherOf, but OWL 2 doesn\u2019t do this implication;
Whatever way we model siblings, we end up with a bit of a mess;
OWL 2 cannot do half-siblings;
However, we can get close enough and we can start inferring lots of facts via sub-property chains using the sibling relationships.
The FHKB ontology at this stage of the tutorial has an expressivity ofSRIF.\n
The time to reason with the FHKB at this point (in Prot\u00e9g\u00e9) on a typical desktop\nmachine by HermiT 1.3.8 is approximately 1355.614 sec (0.71682 % of final), by\nPellet 2.2.0 0.206 sec (0.00167 % of final) and by FaCT++ 1.6.4 is approximately\n0.039 sec (0.001 % of final). 0 sec indicates failure or timeout.\n
"},{"location":"tutorial/fhkb/#chapter-6","title":"Chapter 6","text":""},{"location":"tutorial/fhkb/#individuals-in-class-expressions","title":"Individuals in Class Expressions","text":"
In this chapter you will:
Use individuals within class expressions;
Make classes to find Robert and Richard\u2019s parents, ancestors, and so on;
Explore equivalence of such classes;
Re-visit the closed world.
There is a snapshot of the ontology as required at this point in the tutorial available\nat http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial\n
"},{"location":"tutorial/fhkb/#61-richard-and-roberts-parents-and-ancestors","title":"6.1 Richard and Robert\u2019s Parents and Ancestors","text":"
So far we have only used object properties between unspecified objects. We can, however, specify a specific individual to act at the right-hand-side of a class restriction or type assertion on an individual. The basic syntax for so-called nominals is:
Class: ParentOfRobert\nEquivalentTo: Person and isParentOf valueRobert_David_Bright_1965\n
This is an equivalence axiom that recognises any individual that is a Person and a parent of Robert David Bright.
Task 24: Robert and Richards parents
Create the class ParentOfRobert as described above;
Classify \u2013 inspect where the class is placed in the FHKB TBox and look at which individuals classify as members of the class;
Do the same for a class with the value of Richard_John_Bright_1962 and classify;
Finally create a class ParentOfRichardAndRobert, defining it as Person and isParentOf some {Robert_David_Bright_1965 ,Richard_John_Bright_1962 }; again see what happens on classification. Note that the expressions isMotherOf value Robert_David_Bright_1965 and isMotherOf some {Robert_David_Bright_1965 } are practically identical. The only difference is that using value, you can only specify one individual, while some relates to a class (a set of individuals).
We see that these queries work and that we can create more complex nominal based class expressions. The disjunction above is
isParentOf some {Robert_David_Bright_1965, Richard_John_Bright_1965}\n
The \u2018{\u2019 and \u2018}\u2019 are a bit of syntax that says \u2018here\u2019s a class of individual\u2019.
We also see that the classes for the parents of Robert David Bright and Richard John Bright have the same members according to the FHKB, but that the two classes are not inferred to be equivalent. Our domain knowledge indicates the two classes have the same extents (members) and thus the classes are equivalent, but the automated reasoner does not make this inference. As usual, this is because the FHKB has not given the automated reasoner enough information to make such an inference.
"},{"location":"tutorial/fhkb/#62-closing-down-what-we-know-about-parents-and-siblings","title":"6.2 Closing Down What we Know About Parents and Siblings","text":"
The classes describing the parents of Richard and Robert are not equivalent, even though, as humans, we know their classes of parent are the same. We need more constraints so that it is known that the four parents are the only ones that exist. We can try this by closing down what we know about the immediate family of Robert David Bright.
In Chapter 4 we described that a Person has exactly one Woman and exactly one Man as mother and father (by saying that the hasMother and hasFather properties are functional and thus only one of each may be held by any one individual to distinct individuals). The parent properties are defined in terms of hasParent, hasMother and hasFather. The latter two imply hasParent. The two sub-properties are functional, but there are no constraints on hasParent, so an individual can hold many instances of this property. So, there is no information in the FHKB to say a Person has only two parents (we say there is one mother and one father, but not that there are only two parents). Thus Robert and Richard could have other parents and other grandparents than those in the FHKB; we have to close down our descriptions so that only two parents are possible. There are two ways of doing this:
Using qualified cardinality constraints in a class restriction;
Putting a covering axiom on hasParent in the same way as we did for Sex in Chapter 4.
Task 25: Closing the Person class
Add the restriction hasParent exactly 2 Person to the classPerson;
Run the reasoner;
Inspect the hierarchy to see where ParentOfRobert and ParentOfRichard are placed and whether or not they are found to be equivalent;
Now add the restriction hasParent max 2 Person to the class Person;
Run the reasoner (taking note of how long the reasoning takes) and take another look.
We find that these two classes are equivalent; we have supplied enough information to infer that these two classes are equivalent. So, we know that option one above works, but what about option two? This takes a bit of care to think through, but the basic thing is to think about how many ways there are to have a hasParent relationship between two individuals. We know that we can have either a hasFather or a hasMother property between two individuals; we also know that we can have only one of each of these properties between an individual and a distinct individual. However, the open world assumption tells us that there may be other ways of having a hasParent property between two individuals; we\u2019ve not closed the possibilities. By putting on the hasParent exactly 2 Person restriction on the Person class, we are effectively closing down the options for ways that a person can have parents; we know because of the functional characteristic on hasMother and hasFather that we can have only one of each of these and the two restrictions say that one of each must exist. So, we know we have two ways of having a parent on each Person individual. So, when we say that there are exactly two parents (no more and no less) we have closed down the world of having parents\u2014thus these two classes can be inferred to be equivalent. It is also worth noting that this extra axiom on the Person class will make the reasoner run much more slowly.
Finally, for option 2, we have no way of placing a covering axiom on a property. What we\u2019d like to be able to state is something like:
ObjectProperty: hasParent\nEquivalentTo: hasFather or hasMother\n
Add lots more classes using members of the ABox as nominals;
Make complex expressions using nominals;
After each addition of a nominal, classify and see what has been inferred within the FHKB.
See if you can make classes for GrandparentOfRobert and GrandparentOfRichard and make them inferred to be equivalent.
In this chapter we have seen the use of individuals within class expressions. It allows us to make useful queries and class definitions. The main things to note is that it can be done and that there is some syntax involved. More importantly, some inferences may not be as expected due to the open world assumption in OWL.
By now you might have noticed a significant increase in the time the reasoner needs\nto classify. Closing down what we know about family relationships takes its toll on\nthe reasoner performance, especially the usage of 'hasParent exactly 2 Person'. At\nthis point we recommend rewriting this axiom to 'hasParent max 2 Person'. It gives\nus most of what we need, but has a little less negative impact on the reasoning\ntime.\n
The FHKB ontology at this stage of the tutorial has an expressivity of SROIQ.\n
The time to reason with the FHKB at this point (in Prot\u00e9g\u00e9) on a typical desktop\nmachine by HermiT 1.3.8 is approximately 2067.273 sec (1.09313 % of final), by\nPellet 2.2.0 0.529 sec (0.00428 % of final) and by FaCT++ 1.6.4 is approximately\n0.147 sec (0.004 % of final). 0 sec indicates failure or timeout.\n
"},{"location":"tutorial/fhkb/#chapter-7","title":"Chapter 7","text":""},{"location":"tutorial/fhkb/#data-properties-in-the-fhkb","title":"Data Properties in the FHKB","text":"
We now have some individuals with some basic object properties between individuals. OWL 2, however, also has data properties that can relate an object or individual to some item of data. There are data about a Person, such as years of events and names etc. So, in this Chapter you will:
Make some data properties to describe event years to people;
Create some simple defined classes that group people by when they were born;
Try counting the numbers of children people have...
Deal with the open world assumption;
Add given and family names to individuals in the FHKB.
There is a snapshot of the ontology as required at this point in the tutorial available\nat http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial.\n
"},{"location":"tutorial/fhkb/#71-adding-some-data-properties-for-event-years","title":"7.1 Adding Some Data Properties for Event Years","text":"
Everyone has a birth year; death year; and some have a marriage year and so on. We can model these simply with data properties and an integer as a filler. OWL 2 has a DateTime datatype, where it is possible to specify a precise time and date down to a second. 7 This proves cumbersome (see http://robertdavidstevens.wordpress.com/2011/05/05/using-the-datetime-data-type-to-describe-birthdays/ for details); all we need is a simple indication of the year in which a person was born. Of course, the integer type has a zero, which the Gregorian calendar for which we use integer as a proxy does not, but integer is sufficient to our needs. Also, there are various ontological treatments of time and information about people (this extends to names etc. as well), but we gloss over that here\u2014that\u2019s another tutorial.
We can have dates for birth, death and (eventually) marriage (see Chapter 9) and we can just think of these as event years. We can make a little hierarchy of event years as shown in Figure 7.1).
Task 27: Create a data property hierarchy
Create the data property hasEventYear with range integer and domain Person;
Create the data property hasBirthYear and make it a sub-property of hasEventYear (that way, the domain and range of hasEventYear are inherited);
Create the data property hasDeathYear and make it a sub-property of hasEventYear;
For each individual add the birth years shown in Table A.1 (see appendix). You do not actually have to go back to the table\u2014it is easier to read the birth years simply off the individual names.
Again, asserting birth years for all individuals can be a bit tedious. The reader\ncan find a convenience snapshot of the ontology at this stage at http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial\n
We now have an ABox with individuals with fact assertions to data indicating a birth year. We can, if we wish, also add a class restriction to the Person class saying that each and every instance of the class Person holds a data property to an integer and that this property is called \u2018hasBirthYear\u2019. As usual when deciding whether to place such a restriction upon a class, ask whether it is true that each and every instance of the class holds that property; this is exactly the same as we did for the object properties in Chapter 4. Everyone does have a birth year, even if it is not known.
Once birth years have been added to our individuals, we can start asking some questions.
Task 28: DL queries 1. Use a DL query to ask:
Person born after 1960;
Person born in the 1960s;
Person born in the 1800s;
Person that has fewer than three children;
Person that has more than three children.
The DL query for people born in the 1960s is:
Person and hasBirthYear some int[>= 1960, < 1970]\n
This kind of interval is known as a facet.
"},{"location":"tutorial/fhkb/#711-counting-numbers-of-children","title":"7.1.1 Counting Numbers of Children","text":"
The last two queries in the list do not work as expected. We have asked, for instance, for Person that have more than three children, but we get no members of Person in the answer, though we know that there are some in the FHKB (e.g., John_Bright_1930). This is because there is not enough information in the FHKB to tell that this person has more than three different people as children. As humans we can look at the four children of John Bright and know that they are different \u2013 for instance, they all have different birth years. The automated reasoner, however, does not know that a Person can only have one birth year.
Task 29: Make a functional object property
Make the property hasBirthYear functional.
Ask the query for Person that has more than three children again.
This time the query should work. All the other event year properties should be made functional, expect hasEventYear, as one individual can have many event years. As the children have different birth year and an individual can only hold one hasBirthYear property, then these people must be distinct entities.
Of course, making birth year functional is not a reliable way of ensuring that the automated reasoner knows that the individual are different. It is possible for two Person to have the same birth year within the same family \u2013 twins and so on. Peter_William_Bright_1941 has three children, two of which are twins, so will not be a member of the class of people with at least three children. So, we use the different individuals axiom. Most tools, including Prot\u00e9g\u00e9, have a feature that allows all individuals to be made different.
Task 30: Make all individuals different
Make all individuals different;
Ask the above queries again.
From now on, every time you add individuals, make sure the different individuals axiom is updated.
"},{"location":"tutorial/fhkb/#72-the-open-world-assumption","title":"7.2 The Open World Assumption","text":"
We have met again the open world assumption and its importance in the FHKB. In the use of the functional characteristic on the hasBirthYear property, we saw one way of constraining the interpretation of numbers of children. We also introduced the \u2018different individuals\u2019 axiom as a way of making all individuals in a knowledge base distinct. There are more questions, however, for which we need more ways of closing down the openness of OWL 2.
Take the questions:
People that have exactly two children;
People that have only brothers;
People that have only female children.
We can only answer these questions if we locally close the world.We have said that David and Margaret have two children, Richard and Robert, but we have not said that there are not any others. As usual, try not to apply your domain knowledge too much; ask yourself what the automated reasoner actually knows. As we have the open world assumption, the reasoner will assume, unless otherwise said, that there could be more children; it simply doesn\u2019t know.
Think of a railway journey enquiry system. If I ask a standard closed world system about the possible routes by rail, between Manchester and Buenos Aires, the answer will be \u2019none\u2019, as there are none described in the system. With the open world assumption, if there is no information in the system then the answer to the same question will simply be \u2018I don\u2019t know\u2019. We have to explicitly say that there is no railway route from Manchester to Buenos Aires for the right answer to come back.
We have to do the same thing in OWL. We have to say that David and Margaret have only two children. We do this with a type assertion on individuals. So far we have only used fact assertions. A type assertion to close down David Bright\u2019 parentage looks like this:
isParentOf only {Robert_David_Bright_1965,Richard_John_Bright_1962 }\n
This has the same meaning as the closure axioms that you should be familiar with on classes. We are saying that the only fillers that can appear on the right-hand-side of the isParentOf property on this individual are the two individuals for Richard and Robert. We use the braces to represent the set of these two individuals.
Task 31: Make a closure axiom
Add the closure assertion above to David Bright;
Issue the DL query isParentOf exactly 2 Person.
The last query should return the answer of David Bright. Closing down the whole FHKB ABox is a chore and would really have to be done programmatically. OWL scripting languages such as the Ontology Preprocessing Language8 (OPPL) [2] can help here. Also going directly to the OWL API [1]9, if you know what you are doing, is another route.
Adding all these closure type assertions can slow down the reasoner; so think about\nthe needs of your system \u2013 just adding it \u2018because it is right\u2019 is not necessarily the\nright route.\n
8 http://oppl2.sourceforge.net
9 http://owlapi.sourceforge.net/
"},{"location":"tutorial/fhkb/#73-adding-given-and-family-names","title":"7.3 Adding Given and Family Names","text":"
We also want to add some other useful data facts to people \u2013 their names. We have been putting names as part of labels on individuals, but data fact assertions make sense to separate out family and given names so that we can ask questions such as \u2018give me all people with the family name Bright and the first given name of either James or William\u2019. A person\u2019s name is a fact about that person and is more, in this case, than just a label of the representation of that person. So, we want family names and given names. A person may have more than one given name \u2013 \u2018Robert David\u2019, for instance \u2013 and an arbitrary number of given names can be held. For the FHKB, we have simply created two data properties of hasFirstGivenName and hasSecondGivenName). Ideally, it would be good to have some index on the property to given name position, but OWL has no n-ary relationships. Otherwise, we could reify the hasGivenName property into a class of objects, such as the following:
Class: GivenName\nSubClassOf:hasValue some String,\nhasPosition some Integer\n
but it is really rather too much trouble for the resulting query potential.
As already shown, we will use data properties relating instances of Person to strings. We want to distinguish family and given names, and then different positions of given names through simple conflating of position into the property name. Figure 7.1 shows the intended data property hierarchy.
Figure 7.1: The event year and name data property hierarchies in the FHKB.
Do the following:
Task 32: Data properties
Create the data properties as described in Figure 7.1;
Give the hasName property the domain of Person and the range of String;
Make the leaf properties of given names functional;
Add the names shown in Table A.1 (appendix); Again, it may be easier to read the names of the individual names.
Ask the questions:
all the people with the first given name \u2018James\u2019;
all the people with the first given name \u2018William\u2019;
All the people with the given name \u2018William\u2019;
All the people with the given name \u2018William\u2019 and the family name \u2018Bright\u2019.
The name data property hierarchy and the queries using those properties displays what now should be familiar. Sub-properties that imply the super-property. So, when we ask hasFirstGivenName value \"William\" and then the query hasGivenName value value \"William\" we can expect different answers. There are people with \u2018William\u2019 as either first or second given name and asking the question with the super-property for given names will collect both first and second given names.
We have used data properties that link objects to data such as string, integer, floats and Booleans etc. OWL uses the XML data types. We have seen a simple use of data properties to simulate birth years. The full FHKB also uses them to place names (given and family) on individuals as strings. This means one can ask for the Person with the given name \"James\", of which there are many in the FHKB.
Most importantly we have re-visited the open world assumption and its implications for querying an OWL ABox. We have looked at ways in which the ABox can be closed down \u2013 unreliably via the functional characteristic (in this particular case) and more generally via type assertions.
All the DL queries used in this chapter can also serve as defined classes in the TBox. It is a useful exercise to progressively add more defined classes to the FHKB TBox. Make more complex queries, make them into defined classes and inspect where they appear in the class hierarchy.
The FHKB ontology at this stage of the tutorial has an expressivity of SROIQ(D).\n
The time to reason with the FHKB at this point (in Prot\u00e9g\u00e9) on a typical desktop\nmachine by HermiT 1.3.8 is approximately 1891.157 sec (1.00000 % of final), by\nPellet 2.2.0 1.134 sec (0.00917 % of final) and by FaCT++ 1.6.4 is approximately\n0.201 sec (0.006 % of final). 0 sec indicates failure or timeout.\n
Note that we now cover the whole range of expressivity of OWL 2. HermiT at\nleast is impossibly slow by now. This may be because HermiT does more work\nthan the others. For now, we recommend to use either Pellet or FaCT++.\n
"},{"location":"tutorial/fhkb/#chapter-8","title":"Chapter 8","text":""},{"location":"tutorial/fhkb/#cousins-in-the-fhkb","title":"Cousins in the FHKB","text":"
In this Chapter you will
Revise or get to know about degrees and removes of cousin;
Add the properties and sub-property chains for first and second cousins;
Add properties and sub-property chains for some removes of cousins;
Find out that the siblings debacle haunts us still;
Add a defined class that does first cousins properly.
There is a snapshot of the ontology as required at this point in the tutorial available\nat http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial\n
Be warned; from here on the reasoner can start running slowly! Please see warning\nat the beginning of the last chapter for more information.\n
Cousins can be confusing, but here is a brief summary:
First cousins share a grandparent, but are not siblings;
Second cousins share a great grandparent, but are not first cousins or siblings;
Degrees such as first and second cousin give the distance to the nearest common ancestor;
Removes give differences in generation. So, my Dad\u2019s first cousins (his generation) are my (Robert David Bright\u2019s) first cousins once removed.
Simply, my first cousins are my parent\u2019s sibling\u2019s children. As usual, we can think about the objects and put in place some sub-property chains.
"},{"location":"tutorial/fhkb/#82-first-cousins","title":"8.2 First Cousins","text":"
Figure 8.1: Tracing out the sub-property chain for cousins going from a child to a parent, to its sibling, and down to its child, a cousin
Figure 8.1 shows the sub-property chain for first cousins. As usual, think at the object level; to get to the first cousins of Robert David Bright, we go to the parents of Robert David Bright, to their siblings and then to their children. We go up, along and down. The OWL for this could be:
ObjectProperty: hasFirstCousin\nSubPropertyOf: hasCousin\nSubPropertyChain: hasParent o hasSibling o hasChild\nCharacteristics: Symmetric\n
Note that we follow the definitions in Section 8.1 of first cousins sharing a grandparent, but not a parent. The sub-property chain goes up to children of a grandparent (a given person\u2019s parents), along to siblings and down to their children. We do not want this property to be transitive. One\u2019s cousins are not necessarily my cousins. The blood uncles of Robert David Bright have children that are his cousins. These first cousins, however, also have a mother that is not a blood relation of Robert David Bright and the mother\u2019s sibling\u2019s children are not cousins of Robert David Bright.
We do, however, want the property to be symmetric. One\u2019s cousins have one\u2019s-self as a cousin.
We need to place the cousin properties in the growing object property hierarchy. Cousins are obviously blood relations, but not ancestors, so they go off to one side, underneath hasBloodrelation. We should group the different removes and degree of cousin underneath one hasCousin property and this we will do.
Do the following:
Task 33: First cousins
Add the property of hasCousin to the hierarchy underneath hasBloodrelation;
Add hasFirstCousin underneath this property;
Add the sub-property chain as described above;
Run the reasoner and look at the first cousins of Robert David Bright.
You should see the following people as first cousins of Robert David Bright: Mark Anthony Heath, Nicholas Charles Heath, Mark Bright, Ian Bright, Janet Bright, William Bright, James Bright, Julie Bright, Clare Bright, Richard John Bright and Robert David Bright. The last two, as should be expected, are first cousins of Robert David Bright and this is not correct. As David Bright will be his own brother, his children are his own nieces and nephews and thus the cousins of his own children. Our inability to infer siblings correctly in the FHKB haunts us still and will continue to do so.
Although the last query for the cousins of Robert David Bright should return the\nsame results for every reasoner, we have had experiences where the results differ.\n
"},{"location":"tutorial/fhkb/#83-other-degrees-and-removes-of-cousin","title":"8.3 Other Degrees and Removes of Cousin","text":"
Other degrees of cousins follow the same pattern as for first cousins; we go up, along and down. For second cousins we go up from a given individual to children of a great grandparent, along to their siblings and down to their grandchildren. The following object property declaration is for second cousins (note it uses the isGrandparentOf and its inverse properties, though the parent properties could be used) :
ObjectProperty: hasSecondCousin\nSubPropertyOf: hasCousin\nSubPropertyChain: hasGrandParent o hasSibling o isGrandParentOf\nCharacteristics: Symmetric\n
\u2018 Removes \u2019 simply add in another \u2018leg\u2019 of either \u2018up\u2019 or \u2018down\u2019 either side of the \u2018along\u2019\u2014that is, think of the actual individuals involved and draw a little picture of blobs and lines\u2014then trace your finger up, along and down to work out the sub-property chain. The following object property declaration does it for first cousins once removed (note that this has been done by putting this extra \u2018leg\u2019 on to the hasFirstCousin property; the symmetry of the property makes it work either way around so that a given person is the first cousin once removed of his/her first cousins once removed):
ObjectProperty: hasFirstCousinOnceRemoved\nSubPropertyOf: hasCousin\nSubPropertyChain: hasFirstCousin o hasChild\nCharacteristics: Symmetric\n
To exercise the cousin properties do the following:
Task 34: Cousin properties
Add properties for second degree cousins;
Add removes for first and second degree cousins;
Run the reasoner and check what we know about Robert David Bright\u2019 other types of cousin.
You should see that we see some peculiar inferences about Robert David Bright\u2019 cousins \u2013 not only are his brother and himself his own cousins, but so are his father, mother, uncles and so on. This makes sense if we look at the general sibling problem, but also it helps to just trace the paths around. If we go up from one of Robert David Bright\u2019 true first cousins to a grandparent and down one parent relationship, we follow the first cousin once removed path and get to one of Robert David Bright\u2019 parents or uncles. This is not to be expected and we need a tighter definition that goes beyond sub-property chains so that we can exclude some implications from the FHKB.
"},{"location":"tutorial/fhkb/#84-doing-first-cousins-properly","title":"8.4 Doing First Cousins Properly","text":"
As far as inferring first cousin facts for Robert David Bright, we have failed. More precisely, we have recalled all Robert David Bright\u2019s cousins, but the precision is not what we would desire. What we can do is ask for Robert David Bright\u2019 cousins, but then remove the children of Robert David Bright\u2019 parents. The following DL query achieves this:
Person that hasFirstCousin valueRobert_David_Bright_1965\nand (not (hasFather valueDavid_Bright_1934) or not (hasMother valueMar-\ngaret_Grace_Rever_1934)\n
This works, but only for a named individual. We could make a defined class for this query; we could also make a defined class FirstCousin, but it is not of much utility. We would have to make sure that people whose parents are not known to have siblings with children are excluded. That is, people are not \u2018first cousins\u2019 whose only first cousins are themselves and their siblings. The following class does this:
Class: FirstCousin\nEquivalentTo: Person that hasFirstCousin some Person\n
Task 35: Roberts first cousins
Make a defined class FirstCousin as shown above;
Make a defined class FirstCousinOfRobert;
Create a DL query that looks at Robert_David_Bright_1965 first cousins and takes away the children of Robert_David_Bright_1965\u2019 parents as shown above.
This gives some practice with negation. One is making a class and then \u2018taking\u2019 some of it away \u2013 \u2018these, but not those\u2019.
We have now expanded the FHKB to include most blood relationships. We have also found that cousins are hard to capture just using object properties and sub-property chains. Our broken sibling inferences mean that we have too many cousins inferred at the instance level. We can get cousins right at the class level by using our inference based cousins, then excluding some using negation. Perhaps not neat, but it works.
We have reinforced that we can just add more and more relationships to individuals by just adding more properties to our FHKB object property hierarchy and adding more sub-property chains that use the object properties we have built up upon parentage and sibling properties; this is as it should be.
The FHKB ontology at this stage of the tutorial has an expressivity of SROIQ(D).\n
The time to reason with the FHKB at this point (in Prot\u00e9g\u00e9) on a typical desktop\nmachine by HermiT 1.3.8 is approximately 0.000 sec (0.00000 % of final), by Pellet\n2.2.0 111.395 sec (0.90085 % of final) and by FaCT++ 1.6.4 is approximately 0.868\nsec (0.024 % of final). 0 sec indicates failure or timeout.\n
"},{"location":"tutorial/fhkb/#chapter-9","title":"Chapter 9","text":""},{"location":"tutorial/fhkb/#marriage-in-the-fhkb","title":"Marriage in the FHKB","text":"
In this chapter you will:
Model marriages and relationships;
Establish object properties for husbands, wives and various in-laws;
Re-visit aunts and uncles to do them properly;
Use more than one sub-property chain on a given property.
There is a snapshot of the ontology as required at this point in the tutorial available\nat http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial\n
Much of what is in this chapter is really revision; it is more of the same - making\nlots of properties and using lots of sub-property chains. However, it is worth it as\nit will test your growing skills and it also makes the reasoners and yourself work\nhard. There are also some good questions to ask of the FHKB as a result of adding\nmarriages.\n
Marriage is a culturally complex situation to model. The FHKB started with a conservative model of a marriage involving only one man and one woman.10 Later versions are more permissive; a marriage simply has a minimum of two partners. This leaves it open to numbers and sex of the people involved. In fact, \u2018marriage\u2019 is probably not the right name for it. Using BreedingRelationship as a label (the one favoured by the main author\u2019s mother) may be a little too stark and might be a little exclusive.... In any case, some more generic name is probably better and various subclasses of the FHKB\u2019s Marriage class are probably necessary.
10 There being no funny stuff in the Stevens family.
To model marriage do the following:
Task 36: Marriage
Create a class Marriage, subclass of DomainEntity;
Create the properties:
hasPartner(domain Marriage and range Person) and isPartnerIn
hasFemalePartner(domain Marriage and range Woman, sub-property of hasPartner) and its inverse isFemalePartnerIn;
a sub-property of hasPartner has MalePartner (domain Marriage and range Man)and its inverse isMalePartnerIn;
Create the data property hasMarriageYear, making us a sub-property of hasEventYear,make it functional;
Create an individual m001 with the label Marriage of David and Margaret and add the facts:
hasMalePartner David_Bright_1934;
hasFemalePartner Margaret_Grace_Rever_1934
hasMarriageYear 1958;
Create an individual m002 with the label Marriage of John and Joyce and add the facts:
hasMalePartnerJohn_Bright_1930;
hasFemalePartnerJoyce_Gosport(you may have to add Joyce if you did not already did that);
hasMarriageYear1955;
Create an individual m003 with the label Marriage of Peter and Diana and add the facts:
hasMalePartnerPeter_William_Bright_1941;
hasFemalePartnerDiana_Pool(you may have to add Diana if you did not already did that);
hasMarriageYear1964;
We have the basic infrastructure for marriages. We can ask the usual kinds of questions; try the following:
Task 37: DL queries
Ask the following DL queries:
The Women partners in marriages;
Marriages that happened before 1960 (see example below);
Marriages that happened after 1960;
Marriages that involved a man with the family name \u2018Bright\u2019.
DL query: Marriage and hasMarriageYear some int[<= 1960]\n
This marriage infrastructure can be used to infer some slightly more interesting things for actual people. While we want marriage objects so that we can talk about marriage years and even locations, should we want to, we also want to be able to have the straight-forward spouse relationships one would expect. We can use sub-property chains in the usual manner; do the following:
Task 38: Wifes and Husbands
Create a property hasSpouse with two sub-properties hasHusband and hasWife.
Create the inverses isSpouseOf, isWifeOf and isHusbandOf.
To the hasWife property, add the sub-property chain isMalePartnerIn o hasFemalePartner.
Follow the same pattern for the hasHusband property.
Figure 9.1 shows what is happening with the sub-property chains. Note that the domains and ranges of the spouse properties come from the elements of the sub-property chains. Note also that the hasSpouse relationship will be implied from its sub-property chains.
The following questions can now be asked:
Is wife of David Bright;
Has a husband born before 1940;
The wife of an uncle of William Bright 1970.
Figure 9.1: The sub-property chain path used to infer the spouse relationships via the marriage partnerships.
and many more. This is really a chance to explore your querying abilities and make some complex nested queries that involve going up and down the hierarchy and tracing routes through the graph of relationships between the individuals you\u2019ve inferred.
Now we have spouses, we can also have in-laws. The path is simple: isSpouseOf o hasMother implies hasMotherInLaw. The path involved in mother-in-laws can be seen in Figure 9.2. The following OWL code establishes the sub-property chains for hasMotherInLaw:
ObjectProperty: hasMotherInLaw\nSubPropertyOf: hasParentInLaw\nSubPropertyChain: isSpouseOf o hasMother\nDomain: Person\nRange: Woman\nInverseOf: isMotherInLawOf\n
Figure 9.2: Tracing out the path between objects to make the sub-property chain for mother-in-laws
Do the following to make the parent in-law properties:
Task 39: Parents in-law
Create hasParentInLaw with two sub-properties of hasMotherInLaw and hasFatherInLaw;
Create the inverses, but remember to let the reasoner infer the hierarchy on that side of the hierarchy;
Add the sub-property chains as described in the pattern for hasMotherInLaw above;
Run the reasoner and check that the mother-in-law of Margaret Grace Rever is Iris Ellen Archer.
"},{"location":"tutorial/fhkb/#93-brothers-and-sisters-in-law","title":"9.3 Brothers and Sisters In-Law","text":"
Brothers and sisters in law have the interesting addition of having more than one path between objects to establish a sister or brother in law relationship. The OWL code below establishes the relationships for \u2018is sister in law of\u2019:
ObjectProperty: hasSisterInLaw\nSubPropertyOf: hasSiblingInLaw\nSubPropertyChain: hasSpouse o hasSister\nSubPropertyChain: hasSibling o isWifeOf\n
A wife\u2019s husband\u2019s sister is a sister in law of the wife. Figure 9.3 shows the two routes to being a sister-in-law. In addition, the wife is a sister in law of the husband\u2019s siblings. One can add as many sub-property chains to a property as one needs. You should add the properties for hasSiblingInLawOf and its obvious sub-properties following the inverse of the pattern above.
Task 40: Siblings in-law
Create the relationships for siblings-in-law as indicated in the owl code above.
By now, chances are high that the realisation takes a long time. We recommend to\nremove the very computationally expensive restriction `hasParent` exactly 2 Person\non the `Person` class, if you have not done it so far.\n
Figure 9.3: The two routes to being a sister-in-law.
"},{"location":"tutorial/fhkb/#94-aunts-and-uncles-in-law","title":"9.4 Aunts and Uncles in-Law","text":"
The uncle of Robert David Bright has a wife, but she is not the aunt of Robert David Bright, she is the aunt-in-law. This is another kith relationship, not a kin relationship. The pattern has a familiar feel:
ObjectProperty: isAuntInLawOf\nSubPropertyOf: isInLawOf\nSubPropertyChain: isWifeOf o isBrotherOf o isParentOf\n
Task 41: Uncles and aunts in-law
Create hasAuntInLaw and hasUncleInLaw in the usual way;
Test in the usual way;
Tidy up the top of the property hierarchy so that it looks like Figure 9.4. We have a top property of hasRelation and two sub-properties of isBloodRelationOf and isInLawOf to establish the kith and kin relationships respectively;
All the properties created in this chapter (except for spouses) should be underneath isInLawOf.
Figure 9.4: The object property hierarchy after adding the various in-law properties.
This has really been a revision chapter; nothing new has really been introduced. We have added a lot of new object properties and one new data property. The latest object property hierarchy with the \u2018in-law\u2019 branch can be seen in Figure 9.4. Highlights have been:
Having an explicit marriage object so that we can say things about the marriage itself, not just the people in the marriage;
We have seen that more than one property chain can be added to a property;
We have added a lot of kith relationships to join the kin or blood relationships;
As usual, the reasoner can establish the hierarchy for the inverses and put a lot of the domain and ranges in for free.
The FHKB ontology at this stage of the tutorial has an expressivity of SROIQ(D).\n
The time to reason with the FHKB at this point (in Prot\u00e9g\u00e9) on a typical desktop\nmachine by HermiT 1.3.8 is approximately 0.000 sec (0.00000 % of final), by Pellet\n2.2.0 123.655 sec (1.00000 % of final) and by FaCT++ 1.6.4 is approximately 1.618\nsec (0.046 % of final). 0 sec indicates failure or timeout.\n
"},{"location":"tutorial/fhkb/#chapter-10","title":"Chapter 10","text":""},{"location":"tutorial/fhkb/#extending-the-tbox","title":"Extending the TBox","text":"
In this chapter you will:
Just add lots of defined classes for all the aspects we have covered in this FHKB tutorial;
You will learn that the properties used in these defined classes must be chosen with care.
There is a snapshot of the ontology as required at this point in the tutorial available\nat http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial\n
"},{"location":"tutorial/fhkb/#101-adding-defined-classes","title":"10.1 Adding Defined Classes","text":"
Add the following defined classes:
Task 42: Adding defined classes
Relation and blood relation;
Forefather and Foremother;
Grandparent, Grandfather and Grandmother;
GreatGrandparent, GreatGrandfather and GreatGrandmother;
GreatGrandparentOfRobert, GreatGrandfatherOfRobert and GreatGrandMotherOfRobert
Daughter, Son, Brother, Sister, Child;
Aunt, Uncle, AuntInLaw, UncleInLaw, GreatAunt and GreatUncle;
Any defined class for any property in the hierarchy and any nominal variant of these classes.
The three classes of Child, Son and Daughter are of note. They are coded in the following way:
Class: Child EquivalentTo: Person that hasParent Some Person\nClass: Son EquivalentTo: Man that hasParent Some Person\nClass: Daughter EquivalentTo: Woman that hasParent Some Person\n
After running the reasoner, you will find that Person is found to be equivalent to Child; Daughter is equivalent to Woman and that Son is equivalent to Man. This does, of course, make sense \u2013 each and every person is someone\u2019s child, each and every woman is someone\u2019s daughter. We will forget evolutionary time-scales where this might be thought to break down at some point \u2013 all Person individuals are also Descendant individuals, but do we expect some molecule in some prebiotic soup to be a member of this class?
Nevertheless, within the scope of the FHKB, such inferred equivalences are not unreasonable. They are also instructive; it is possible to have different intentional descriptions of a class and for them to have the same logical extents. You can see another example of this happening in the amino acids ontology, but for different reasons.
Taking Grandparent as an example class, there are two ways of writing the defined class:
Class: Grandparent EquivalentTo: Person and isGrandparentOf some Person\nClass: Grandparent EquivalentTo: Person and (isParentOf some (Person and (is-\nParentOf some Person))\n
Each comes out at a different place in the class hierarchy. They both capture the right individuals as members (that is, those individuals in the ABox that are holding a isGrandparentOf property), but the class hierarchy is not correct. By definition, all grandparents are also parents, but the way the object property hierarchy works means that the first way of writing the defined class (with the isGrandparentOf property) is not subsumed by the class Parent. We want this to happen in any sensible class hierarchy, so we have to use the second pattern for all the classes, spelling out the sub-property path that implies the property such as isGrandparentOf within the equivalence axiom.
The reason for this need for the \u2018long-form\u2019 is that the isGrandparentOf does not imply the isParentOf property. As described in Chapter 3 if this implication were the case, being a grandparent of Robert David Bright, for instance, would also imply that the same Person were a parent of Robert David Bright; an implication we do not want. As these two properties (isParentOf and isGrandparentOf) do not subsume each other means that the defined classes written according to pattern one above will not subsume each other in the class hierarchy. Thus we use the second pattern. If we look at the class for grandparents of Robert:
Class: GrandparentOfRobert\nEquivalentTo: Person that isParentOf some (Person that isParentOf value Robert\nDavid Bright)\n
If we make the equivalent class for Richard John Bright, apply the reasoner and look at the hierarchy, we see that the two classes are not logically equivalent, even though they have the same extents of William George Bright, Iris Ellen Archer, Charles Herbert Rever and Violet Sylvia Steward. We looked at this example in Section 6.2, where there is an explanation and solutions.
We can add defined classes based on each property we have put into the object property hierarchy. We see the expected hierarchy; as can be seen from Figure 10.1 it has an obvious symmetry based on sex. We also see a lot of equivalences inferred \u2013 all women are daughters, as well as women descendants. Perhaps not the greatest insight ever gained, but it at least makes sense; all women must be daughters. It is instructive to use the explanation feature in Prot\u00e9g\u00e9 to look at why the reasoner has made these inferences. For example, take a look at the class hasGrandmother some Woman \u2013 it is instructive to see how many there are.
Like the Chapter on marriage and in-law (Chapter 9), this chapter has largely been revision. One thing of note is, however, that we must not use the object properties that are inferred through sub-property chains as definitions in the TBox; we must spell out the sub-property chain in the definition, otherwise the implications do not work properly.
One thing is almost certain; the resulting TBox is rather complex and would be almost impossible to maintain by hand.
Figure 10.1: The full TBox hierarchy of the FHKB
The FHKB ontology at this stage of the tutorial has an expressivity of SROIQ(D).\n
The time to reason with the FHKB at this point (in Prot\u00e9g\u00e9) on a typical desktop\nmachine by HermiT 1.3.8 is approximately 0.000 sec (0.00000 % of final), by Pellet\n2.2.0 0.000 sec (0.00000 % of final) and by FaCT++ 1.6.4 is approximately 35.438\nsec (1.000 % of final). 0 sec indicates failure or timeout.\n
If you have done all the tasks within this tutorial, then you will have touched most parts of OWL 2. Unusually for most uses of OWL we have concentrated on individuals, rather than just on the TBox. One note of warning \u2013 the full FHKB has some 450 members of the Bright family and takes a reasonably long time to classify, even on a sensible machine. The FHKB is not scalable in its current form.
One reason for this is that we have deliberately maximised inference. We have attempted not to explicitly type the individuals, but drive that through domain and range constraints. We are making the property hierarchy do lots of work. For the individual Robert David Bright, we only have a couple of assertions, but we infer some 1 500 facts between Robert David Bright and other named individuals in the FHKB\u2013displaying this in Prot\u00e9g\u00e9 causes problems. We have various complex classes in the TBox and so on.
We probably do not wish to drive a genealogical application using an FHKB in this form. Its purpose is educational. It touches most of OWL 2 and shows a lot of what it can do, but also a considerable amount of what it cannot do. As inference is maximised, the FHKB breaks most of the OWL 2 reasoners at the time of writing.However, it serves its role to teach about OWL 2.
OWL 2 on its own and using it in this style, really does not work for family history. We have seen that siblings and cousins cause problems. rules in various forms can do this kind of thing easily\u2014it is one of the primary examples for learning about Prolog. Nevertheless, the FHKB does show how much inference between named individuals can be driven from a few fact assertions and a property hierarchy. Assuming a powerful enough reasoner and the ability to deal with many individuals, it would be possible to make a family history application using the FHKB; as long as one hid the long and sometimes complex queries and manipulations that would be necessary to \u2018prune\u2019 some of the \u2018extra\u2019 facts found about individuals. However, the FHKB does usefully show the power of OWL 2, touch a great deal of the language and demonstrate some of its limitations.
"},{"location":"tutorial/fhkb/#appendix-a","title":"Appendix A","text":""},{"location":"tutorial/fhkb/#fhkb-family-data","title":"FHKB Family Data","text":"
Table A.1: The list of individuals in the FHKB
Person First given name Second given name Family name Birth year Mother Father Alec John Archer 1927 Alec John Archer 1927 Violet Heath 1887 James Alexander Archer 1882 Charles Herbert Rever 1895 Charles Herbert Rever 1895 Elizabeth Frances Jessop 1869 William Rever 1870 Charlotte Caroline Jane Bright 1894 Charlotte Caroline Jane Bright 1894 Charlotte Hewett 1863 Henry Edmund Bright 1862 Charlotte Hewett 1863 Charlotte none Hewett 1863 not specified not specified Clare Bright 1966 Clare none Bright 1966 Diana Pool Peter William Bright 1941 Diana Pool Diana none Pool none not specified not specified David Bright 1934 David none Bright 1934 Iris Ellen Archer 1906 William George Bright 1901 Dereck Heath Dereck none Heath 1927 not specified not specified Eileen Mary Rever 1929 Eileen Mary Rever 1929 Violet Sylvia Steward 1894 Charles Herbert Rever 1895 Elizabeth Frances Jessop 1869 Elizabeth Frances Jessop 1869 not specified not specified Ethel Archer 1912 Ethel none Archer 1912 Violet Heath 1887 James Alexander Archer 1882 Frederick Herbert Bright 1889 Frederick Herbert Bright 1889 Charlotte Hewett 1863 Henry Edmund Bright 1862 Henry Edmund Bright 1862 Henry Edmund Bright 1862 not specified not specified Henry Edmund Bright 1887 Henry Edmund Bright 1887 Charlotte Hewett 1863 Henry Edmund Bright 1862 Ian Bright 1959 Ian none Bright 1959 Joyce Gosport John Bright 1930 Iris Ellen Archer 1906 Iris Ellen Archer 1906 Violet Heath 1887 James Alexander Archer 1882 James Alexander Archer 1882 James Alexander Archer 1882 not specified not specified James Bright 1964 James none Bright 1964 Diana Pool Peter William Bright 1941 James Frank Hayden Bright 1891 James Frank Bright 1891 Charlotte Hewett 1863 Henry Edmund Bright 1862 Janet Bright 1964 Janet none Bright 1964 Joyce Gosport John Bright 1930 John Bright 1930 John none Bright 1930 Iris Ellen Archer 1906 William George Bright 1901 John Tacey Steward 1873 John Tacey Steward 1873 not specified not specified Joyce Archer 1921 Joyce none Archer 1921 Violet Heath 1887 James Alexander Archer 1882 Joyce Gosport Joyce none Gosport not specified not specified not specified Julie Bright 1966 Julie none Bright 1966 Diana Pool Peter William Bright 1941 Kathleen Minnie Bright 1904 Kathleen Minnie Bright 1904 Charlotte Hewett 1863 Henry Edmund Bright 1862 Leonard John Bright 1890 Leonard John Bright 1890 Charlotte Hewett 1863 Henry Edmund Bright 1862 Lois Green 1871 Lois none Green 1871 not specified not specified Margaret Grace Rever 1934 Margaret Grace Rever 1934 Violet Sylvia Steward 1894 Charles Herbert Rever 1895 Mark Anthony Heath 1960 Mark Anthony Heath 1960 Eileen Mary Rever 1929 Dereck Heath Mark Bright 1956 Mark none Bright 1956 Joyce Gosport John Bright 1930 Nicholas Charles Heath 1964 Nicholas Charles Heath 1964 Eileen Mary Rever 1929 Dereck Heath Nora Ada Bright 1899 Nora Ada Bright 1899 Charlotte Hewett 1863 Henry Edmund Bright 1862 Norman James Archer 1909 Norman James Archer 1909 Violet Heath 1887 James Alexander Archer 1882 Peter William Bright 1941 Peter William Bright 1941 Iris Ellen Archer 1906 William George Bright 1901 Richard John Bright 1962 Richard John Bright 1962 Margaret Grace Rever 1934 David Bright 1934 Robert David Bright 1965 Robert David Bright 1965 Margaret Grace Rever 1934 David Bright 1934 Violet Heath 1887 Violet none Heath 1887 not specified not specified Violet Sylvia Steward 1894 Violet Sylvia Steward 1894 Lois Green 1871 John Tacey Steward 1873 William Bright 1970 William none Bright 1970 Joyce Gosport John Bright 1930 William George Bright 1901 William George Bright 1901 Charlotte Hewett 1863 Henry Edmund Bright 1862 William Rever 1870 William none Rever 1870 not specified not specified"},{"location":"tutorial/fhkb/#bibliography","title":"Bibliography","text":"
[1] M. Horridge and S. Bechhofer. The owl api: a java api for working with owl 2 ontologies. Proc. of OWL Experiences and Directions , 2009, 2009.
[2] Luigi Iannone, Alan Rector, and Robert Stevens. Embedding knowledge patterns into owl. In European Semantic Web Conference (ESWC09) , pages 218\u2013232, 2009.
[3] Dmitry Tsarkov, Uli Sattler, Margaret Stevens, and Robert Stevens. A Solution for the Man-Man Problem in the Family History Knowledge Base. In Sixth International Workshop on OWL: Experiences and Directions 2009 , 2009.
"},{"location":"tutorial/github-fundamentals/","title":"GitHub Fundamentals for OBO Engineers","text":""},{"location":"tutorial/github-fundamentals/#introduction-to-github","title":"Introduction to GitHub","text":""},{"location":"tutorial/github-fundamentals/#back-to-getting-started","title":"Back to Getting Started","text":""},{"location":"tutorial/github-fundamentals/#back-to-main-repo","title":"Back to Main Repo","text":""},{"location":"tutorial/github-fundamentals/#overview","title":"Overview:","text":"
GitHub is increasingly used by software developers, programmers and project managers for uploading and sharing content, as well as basic project management. You build a profile, upload projects to share and connect with other users by \"following\" their accounts. Many users store programs and code projects, but you can also upload text documents or other file types in your project folders to share publicly (or privately). It is capable of storing any file type from text, to structured data, to software. And more features are being added by the day. The real power of Git, however, is less about individuals publishing content (many places can do that, including google docs etc). It is more about that content being easily shared, built upon, and credited in a way that is robust to the realities of distributed collaboration. You don't have to know how to code or use the command line. It is a powerful way to organize projects with multiple participants.
Git supports the following types of primary entities:
Individual: A person who contributes to GitHub (that's you!)
Example individual http://github.com/nicolevasilevsky
Organization: An entity that may correspond to an actual organization (such as a university) or to a meaningful grouping of repositories. Organizations are like individuals except that they can establish teams.
Example organization: https://github.com/monarch-initiative
Repository: A collection of versioned files (of any type)
Example repository https://github.com/monarch-initiative/mondo/
Teams: A group of individuals assembled by the administrators of an organization. An individual may participate in many teams and organizations, however a team is always bound to a single organization. Nesting teams saves time; instructions here.
The relationships between any combination of these entities is many-to-many, with the nuanced exception of repositories. For our purposes today we will oversimplify by saying that a repositoy belongs either to a single organization or to a single individual.
Content in GitHub is written using Markdown, a text-to-HTML conversion tool for web writers (ref).
For more help with Markdown, see this GitHub guide.
Raw markup syntax As rendered Header - use # for H1, ## for H2, etc. # Header, ## Header (note, the header is not displaying properly in this table) Emphasis, aka italics, with *asterisks* or _underscores_. Emphasis, aka italics, with asterisks or underscores. Strong emphasis, aka bold, with **asterisks** or __underscores__. Strong emphasis, aka bold, with asterisks or underscores. Combined emphasis with **asterisks and _underscores_**. Combined emphasis with asterisks and underscores. Strikethrough uses two tildes. ~~Scratch this.~~ Strikethrough uses two tildes. ~~Scratch this.~~
Lists: To introduce line breaks in markdown, add two spaces For a bulleted list, use * or - (followed by a space)
GitHub can store any kind of content, provided it isn't too big. (And now even this is possible). However, it is more capable for some filetypes than it is for others. Certain filetypes can be viewed 'natively' within the GitHub interface. These are:
Images: png, jpg, svg
GEOJSON
CSV, TSV (note that files named type '.tab' will not render properly in the UI.)
Markdown
Software code (eg. including json, HTML, xml etc)
"},{"location":"tutorial/github-fundamentals/#task-create-a-new-github-repository","title":"Task - create a new GitHub repository","text":"
Create your GitHub account if you do not already have one
Customize your avatar if you haven't already
Go to settings and upload any picture (it doesn't have to be your face)
Create a repository
"},{"location":"tutorial/github-fundamentals/#task-update-the-content-in-your-readme","title":"Task - update the content in your README","text":"
Go back to the repository you just created
Click the pencil icon in the right corner of your README.md file
Add some content to your file that includes a header, italics, bold, strikethrough, and lists
You can preview your changes before committing by clicking 'Preview changes'.
Commit your changes by clicking the commit button at the bottom of the page.
"},{"location":"tutorial/github-fundamentals/#task-add-content-to-your-repository","title":"Task - add content to your repository","text":"
Click on the code button
Click upload file
Upload a file by dragging and dropping or browse for file
Trying uploading an Excel file vs a TSV or CSV file. How are these displayed differently?
"},{"location":"tutorial/github-issues/","title":"GitHub Issue for OBO Engineers","text":""},{"location":"tutorial/github-issues/#intro-to-managing-and-tracking-issues-in-github","title":"Intro to managing and tracking issues in GitHub","text":""},{"location":"tutorial/github-issues/#overview","title":"Overview","text":"
Why: \"Issues are a great way to keep track of tasks, enhancements, and bugs for your projects or for anyone else's. As long as you are a registered GitHub user you can log an issue, or comment on an issue for any open repo on GitHub. Issues are a bit like email\u2014except they can be shared, intelligently organized, and discussed with the rest of your team. GitHub\u2019s tracker is called Issues, and has its own section in every repository.\" (From: https://guides.github.com/features/issues/)
How:
How to create an issue in GitHub:
We will practice creating tickets in this repository https://github.com/nicolevasilevsky/c-path-practice
Click \"issues\"
Click \"New Issue\" (note the word 'issue' and 'ticket' are frequently used interchangeably)
Write an informative title
Write a detailed explanation of your issue
In the case of reporting software bugs, provide some context in which the issue was encountered (e.g. bug detected when using Google Chrome on a Mac OS)
If you know the sub-tasks that are involved, list these using - [ ] markdown syntax before each bullet. Note, you can also add sub-tasks by clicking the 'add a task list' button in the tool bar. The status of the tasks in an issue (eg. https://github.com/nicolevasilevsky/c-path-practice/issues/1 will then be reflected in any summary view. Eg. https://github.com/nicolevasilevsky/c-path-practice/issues.
Click Submit new issue
Edit the issue (if needed) (Note that post-hoc edits will not propagate to email notifications).
Your turn:
Follow the instructions above to create a ticket about a hypothetical issue (such as an improvement to this tutorial) that includes a sub-task list.
You can assign issues to yourself or other people who are part of the repository
In the box, start typing type their name or GitHub handle
It is possible to assign up to 10 handles at once (assignment to a team is currently not supported)
Add labels
On the top right hand side, click \"Labels\"
Assign a relevant label to your ticket
Note, by default, every GitHub repo comes with some standard labels
You can also create new labels that are specific to your project. For example see the labels on the Mondo GitHub tracker
New Labels
In GitHub, navigate to the Issues page or the pull requests tab
Click Labels button next to the search field
Click New Label to create a new label, or click Edit to edit an existing one.
In the text box, type your new label name.
Select a color for the label from the color bar. You can customize this color by editing the hexadecimal number above the color bar. For a list of hexadecimal numbers see HTML color codes
Click Create Label to save the new label.
Your turn:
On the ticket you previously created:
Assign the ticket to someone
Add a label for an enhancement
Create a new label and add it to the ticket
"},{"location":"tutorial/github-issues/#communicate-about-issues","title":"Communicate about issues","text":"
Back to top
Comment on issues
Click on an issue in the issue tracker in the https://github.com/nicolevasilevsky/c-path-practice/issues repo
Scroll to the bottom of the issue, and add content in the \"Leave a comment\" field
Use the top tool bar to format your text, add bold, italic, lists etc.
Preview your text to see how your formatting looks
Click Comment.
Close issues
If an issue has been addressed, click Close Issue. Best practice is to point to the work (whether code, documentation, etc) that has been done to close it.
Only close the ticket if the issue has been resolved, usually someone will write a comment describing the action they did to close the issue and click Close Issue.
The issue will no longer be dispalyed in the list of open issue, but will be archived.
When making a change to code or documentation in GitHub, it is possible to automatically couple a change to an issue and close it. Just use 'fixes' or 'closes' followed by the issue number.
Use direct @ mentions
You can mention someone in a issue without assigning it to them
In the comments section, type @github handle. For example, to mention Nicole, you would type @nicolevasilevsky. You can either start typing their name or GitHub handle and GitHub will autosuggest their handle.
Link documents
You can link documents and files by:
copy and pasting URL
you can attach files by dragging and dropping
You can link one issue to another in the same repo by typing '#' followed by the title of the ticket
This approach also works across repos but you need to use the full URL (no autocomplete available). Doing this will also cause the referent issue to display that it has been referenced.
Cross reference to another ticket
If your ticket is a duplicate or related to another ticket, you can cross reference another ticket
Type # and you will see a list of other tickets in that repo
Type #TicketNumber and that will link to the other ticket.
Before saving your changes, you can preview the comment to ensure the correct formatting.
Your turn:
Follow the instructions above to comment on a ticket that someone created.
Mention Nicole
Attach a picture (such as a picture you copy from the internet, or attach a picture you have saved on your computer)
Include a comment that says, 'related to #1' and link to ticket #1
To create a milestone, navigate to the issues page in your repository
Next to the search field, click Milestones
Click New Milestone to create a new milestone, click Edit to edit an existing one
Create a milestone that is broad enough to be meaningful, but specific enough to be actionable.
Set a due date for the milestone (note that specific tasks can not be formally assigned due dates, though you can mention a desired due date in the narrative text of a ticket.
Each ticket can only be associated to ONE milestone, however it can have as many labels as appropriate.
A given issue can be part of multiple \"project\" boards (see below)
Your turn
Create a new milestone, and add the milestone to an existing ticket.
Projects
Projects is a lot like Trello, it uses cards on a list that you can name and organize as you see fit.
You can create as many projects within a repository as you like
To create project:
Click on Projects
Click New Project
Name the project
Write a description of the project
Create columns and give them names
Add 'cards' to the columns
Your turn
Create a new project and add columns and add cards to the columns.
Once you start using GitHub for lots of things it is easy to get overwhelmed by the number of issues. The query dashboard https://github.com/issues allows you to filter on tickets.
All issues assigned to me: https://github.com/issues/assigned
All issues on which I am @ mentioned: https://github.com/issues/mentioned
More complex queries are also possible.
All issues either assigned to me OR on which I have commented OR am mentioned: https://github.com/issues?utf8=%E2%9C%93&q=is%3Aopen+is%3Aissue+involves%3Anicolevasilevsky+
Note, you must be signed in to GitHub to view the above links.
When you join a repository, by default, you are 'watching' all activity. You can change the setting to 'Participating and @mentions' to only get notifications that mention you
You can set rules in your email to filter for emails that mention you, ie @username.
You may find the answers you seek in StackOverflow, although it is primarily geared towards programmers.
GitHub kind of monitors https://github.com/isaacs/github/issues/ but not with any rigor.
To be safe, contact GitHub directly at https://github.com/contact, but recognize that they support literally millions of users and responsiveness is not guaranteed. Forums like isaacs sometimes offer some help because other users can help identify workarounds, for instance, as shown here.
"},{"location":"tutorial/intro-cli-1/","title":"Tutorial: Very (!) short introduction to the command line for ontology curators and semantic engineers: Part 1","text":"
As a modern ontology curator, you are an engineer - you are curating computable knowledge, testing the integrity of your curation using quality control testing, and are responsible for critical components of modern knowledge systems that directly affect user experience - the ontologies.
Scientific computing is a big, scary world comprising many different tools, methodologies, training resources and philosophies, but nearly all modern workflows share one key aspect: the ability to execute commands that help you find and manipulate data with the command line. Some examples of that include:
Running and Ontology Development Kit (ODK) commands like sh run.sh make prepare_release
Creating a new branch in git and committing changes
Downloading a file with curl or wget
Finding which file in my ontology repository mentions HP:0000118 to figure out where that \"weird axiom is coming from\"
Searching for strange symbols in the ontology
Filtering and sorting text files
Here we are doing a basic hands on tutorial which will walk you through the must-know commands. For a more comprehensives introduction into thinking about automation please see our lesson on Automating Ontology Development Workflows: Make, Shell and Automation Thinking
The tutorial uses example tailored for users of UNIX systems, like Mac and Linux. Users of Windows generally have analogous steps - wherever we talk about an sh file in the following there exists a corresponding bat file that can be run in the windows powershell, or CMD.
"},{"location":"tutorial/intro-cli-1/#baby-steps-whoami-pwd-and-ls","title":"Baby steps: whoami, pwd and ls","text":"
We are not going to discuss here in any detail what the command line is. We will focus on what you can do with it: for more information skip to the further reading section.
The basic idea behind the command line is that you run a command to achieve a goal. Among the most common goals relevant to you as a semantic engineer will be:
Navigating the file system (changing directories, logging into remote servers and more)
Reading and writing files
Searching stuff
Most commands result in some kind of printed statement. Lets try one. Open your terminal (a terminal is the program you use to enter commands. For a nice overview of how shell, terminal, command line and console relate, see here). On Mac, you can type CMD+Space to search for programs and then type \"terminal\". For this tutorial we use the default Terminal.app, but there are many others, including iterm2. For this introduction, it does not matter which terminal you use. When first opening the terminal you will see something like this:
or
Note that your terminal window may look slightly different, depending on your configuration. More on that later.
Let's type our first command and hit enter:
whoami\n
On my machine I get
(base) matentzn@mbp.local:~ $ whoami\nmatentzn\n
This does not seem like a useful command, but sometimes, we forget who we are, and it is good to be reminded. So, what happened here? We ran a command, named whoami and our command line executed that command which is implemented somewhere on our machine as a program. That program simply determined who I am in some way, and then printed the result again.
Ok so, lets lets look a bit closer at the command prompt itself:
matentzn@mbp.local:~ $\n
Two interesting things to not here for today:
The ~. This universally (on all Unix systems) refers to your user directory on your computer. In this case here, it tells you that in your terminal, you are \"in your user directory\".
The $ sign. It simply denotes where your command line starts (everything before the $ is information provided to you, everything will be about your commands). Make sure that you do not accidentally copy based the $ sign from the examples on the web into your command prompt:
Ok, based on the ~ we know that we are \"in the user home directory\". Let as become a bit more confident about that and ask the command prompt where we are:
matentzn@mbp.local:~ $ pwd\n/Users/matentzn\n
The pwd command prints out the full path of our current location in the terminal. As you can see, the default location when opening the command prompt is, indeed, the home director, located in /Users/matentzn. We will use it later again.
A word about paths. /Users/matentzn is what we call a path. On UNIX systems, / separates one directory from another. So matentzn is a directory inside of the Users directory.
Let us now take a look what our current directory contains (type ls and hit enter):
-l is a short command line option which allows you specify that you would like print the results in a different format (a long list). We will not go into any detail here what this means but a few things to not in the output: You can see some pieces of information that are interesting, like when the file or directory was last modified (i.e. 31. July 2020), who modified it (me) and, of course, the name e.g. Applications.
Before we move on to the next section, let us clear the current terminal from all the command outputs we ran:
clear\n
Your command prompt should now be empty again.
"},{"location":"tutorial/intro-cli-1/#working-with-files-and-directories","title":"Working with files and directories","text":"
In the previous section we learned how to figure out who we are (whoami), where we are (pwd) and how to see what is inside the current directory (ls -l) and how to clear all the output (clear).
Let us know look at how we can programmatically create a new directory and change the location in our terminal.
First let us create a new directory:
mkdir tutorial-my\n
Now if we list the contents of our current directory again (ls -l), we will see our newly created directory listed! Unfortunately, we just realised that we chose the wrong name for our directory! It should have been my-tutorial instead of tutorial-my! So, let us rename it. In the command prompt, rather than \"renaming\" files and directories, we \"move\" them (mv).
mv tutorial-my my-tutorial\n
Now, lets enter our newly created directory using the _c_hange _d_irectory command (cd), and create another sub-directory in my-tutorial, called \"data\" (mkdir data):
cd my-tutorial\nmkdir data\n
You can check again with ls -l. If you see the data directory listed, we are all set! Feel free to run clear again to get rid of all the current output on the command prompt.
Let us also enter this directory now: cd data.
If we want to leave the directory again, feel free to do that like this:
cd ..\n
The two dots (..) mean: \"parent directory.\" This is very important to remember during your command line adventures: .. stands for \"parent directory\", and . stands for \"current/this directory\" (see more on that below).
Now, let's get into something more advanced: downloading files.
"},{"location":"tutorial/intro-cli-1/#downloading-and-searching-files","title":"Downloading and searching files","text":"
Our first task is to download the famous Human Phenotype Ontology Gene to Phenotype Annotations (aka HPOA). As you should already now, whenever we download ontologies, or ontology related files, we should always use a persistent URL, if available! This is the one for HPOA: http://purl.obolibrary.org/obo/hp/hpoa/genes_to_phenotype.txt.
There are two very popular commands for downloading content: curl and wget. I think most of my colleagues prefer curl, but I like wget because it simpler for beginners. So I will use it here. Lets us try downloading the file!
The -O parameter is optional and specifies a filename. If you do not add the parameter, wget will try to guess the filename from the URL. This does not always go so well with complex URLs, so I personally recommend basically always specifying the -O parameter.
You can also use the curl equivalent of the wget command;
Move the downloaded file genes_to_phenotype.txt to the data directory you previously created.
Change into the data directory.
Download the OBO format version of the Human Phenotype Ontology from its PURL.
Do not move on to the next step unless your data directory looks similar to this:
matentzn@mbp.local:~/my-tutorial/data $ pwd\n/Users/matentzn/my-tutorial/data\nmatentzn@mbp.local:~/my-tutorial/data $ ls -l\ntotal 53968\n-rw-r--r-- 1 matentzn staff 19788987 11 Jun 19:09 genes_to_phenotype.txt\n-rw-r--r-- 1 matentzn staff 7836327 27 Jun 22:50 hp.obo\n
Ok, let us look at the first 10 lines of genes_to_phenotype.txt using the head command:
head genes_to_phenotype.txt\n
head is a great command to familiarise yourself with a file. You can use a parameter to print more or less lines:
head -3 genes_to_phenotype.txt\n
This will print the first 3 lines of the genes_to_phenotype.txt file. There is another analogous command that allows us to look at the last lines off a file:
tail genes_to_phenotype.txt\n
head, tail. Easy to remember.
Next, we will learn the most important of all standard commands on the command line: grep. grep stands for \"Global regular expression print\" and allows us to search files, and print the search results to the command line. Let us try some simple commands first.
grep diabetes genes_to_phenotype.txt\n
You will see a list of hundreds of lines out output. Each line corresponds to a line in the genes_to_phenotype.txt file which contains the word \"diabetes\".
grep is case sensitive. It wont find matches like Diabetes, with capital D!\n\nUse the `-i` parameter in the grep command to instruct grep to\nperform case insensitive matches.\n
There is a lot more to grep than we can cover here today, but one super cool thing is searching across an entire directory.
grep -r \"Elevated circulating follicle\" .\n
Assuming you are in the data directory, you should see something like this:
The -r option (\"recursive\") allows is to search a directory and all directories within in.
The . in the beginning. Remember, in the previous use of the grep command we had the name of a file in the place where now the . is. The . means \"this directory\" - i.e. the directory you are in right now (if lost, remember pwd).
As you can see, grep does not only list the line of the file in which the match was found, it also tells us which filename it was found in! We can make this somewhat more easy to read as well by only showing filenames using the -l parameter:
"},{"location":"tutorial/intro-cli-1/#the-dark-art-of-piping-and-redirects","title":"The Dark Art of Piping and Redirects","text":"
The final lesson for today is about one of the most powerful features of the command line: the ability to chain commands together. Let us start with a simple example (make sure you are inside the data directory):
grep -r \"Elevated circulating follicle\" . | head -3\n
So, what is happening here? First, we use the grep command to find \"Elevated circulating follicle\" in our data directory. As you may remember, there are more than 10 results for this command. So the grep command now wants to print these 10 results for you, but the | pipe symbol intercepts the result from grep and passes it on to the next command, which is head. Remember head and tail from above? Its exactly the same thing, only that, rather than printing the first lines of a file, we print the first lines of the output of the previous command. You can do incredible things with pipes. Here a taster which is beyond this first tutorial, but should give you a sense:
grep is looking for \"Elevated circulating follicle\" in all files in the directory, then \"|\" is passing the output on to
cut, which extracts the second column of the table (how cool?), then \"|\" is passing the output on to
sort, which sorts the output, then \"|\" is passing the output on to
uniq, which removes all duplicate values from the output, then \"|\" is passing the output on to
head, which is printing only the first 3 rows of the result.
Another super cool use of piping is searching your command history. Try running:
history\n
This will show you all the commands you have recently run. Now if you want to simply look for some very specific commands that you have run in the past you can combine history with grep:
history | grep follicle\n
This will print every command you ran in the last hour that contains the word \"follicle\". Super useful if you, like me, keep forgetting your commands!
The last critical feature of the command line we cover today is the \"file redirect\". Instead of printing the output to file, we may chose to redirect the results to a file instead:
> gene.txt basically tells the command line: instead of printing the results to the command line, \"print\" them into a file which is called gene.txt.
"},{"location":"tutorial/intro-cli-1/#videos","title":"Videos","text":""},{"location":"tutorial/intro-cli-1/#sam-bail-intro-to-terminal","title":"Sam Bail: Intro to Terminal","text":"
Sam also did here PhD in and around ontologies but has moved entirely to data engineering since. I really liked her 1 hour introduction into the terminal, this should fill some of the yawning gaps in this introduction here.
Automating Ontology Development Workflows: Make, Shell and Automation Thinking
Data Science at the Command Line: Free online book that covers everything you need to know to be a command line magician
A whirlwind introduction to the command line by James Overton
"},{"location":"tutorial/intro-cli-2/","title":"Tutorial: Very (!) short introduction to the command line for ontology curators and semantic engineers: Part 2","text":"
Today we will pick up where we left off after the first CLI tutorial, and discuss some more usages of the command line. In particular, we will:
Introduce you into the art of managing your shell profile
Learn how to manage your path
Talk about how to make your shell hacking more efficient with aliases and functions.
(Optional) installed the amazing ohmyzsh! - advanced CLI for managing your ZSH profile. Important: Before installing ohmyzsh, back up you ~/.zshrc file in case you have had any previous customisations you wish to preserve.
"},{"location":"tutorial/intro-cli-2/#monarch-obo-training-tutorial","title":"Monarch OBO Training Tutorial","text":"
For advanced windows users with docker installed, you can:
Follow the instructions here to set yourself up for ODK development.
Place odk.bat as instructed above in some directory on your machine (the path to the odk.bat file should have no spaces!)
Create a new file .bash_profile in the same directory as your odk.bat file.
Add something like -v %cd%\\.bash_profile:/root/.bash_profile to the odk.bat file (this is mounting the .bash_profile file inside your ODK container). There is already a similar -v statement in this file, just copy it right after
Enter the ODK using odk.bat bash on your CMD (first, cd to the directory containing the odk.bat file).
Now you can follow most of this tutorial here as well.
If you have not done so, install https://ohmyz.sh/. It is not strictly speaking necessary to use ohmyzsh to follow the rest of this tutorial, but it is a nice way to managing your Zsh (z-shell) configuration. Note that the ODK is using the much older bash, but it should be fine for you to work with anyways.
"},{"location":"tutorial/intro-cli-2/#managing-the-path-a-first-peak-at-your-shell-profile","title":"Managing the \"Path\": A first peak at your shell profile","text":"
As Semantic Engineers or Ontology Curators we frequently have to install custom tools like ROBOT, owltools, and more on our computer. These are frequently downloaded from the internet as \"binaries\", for example as Java \"jar\" files. In order for our shell to \"know\" about these downloaded programs, we have to \"add them to the path\".
Let us first look at what we currently have loaded in our path:
echo $PATH\n
What you see here is a list of paths. To read this list a bit more easily, let us remember our lesson on piping commands:
echo $PATH | tr ':' '\\n' | sort\n
What we do here:
Using the echo command to print the contents of the $PATH variable. In Unix systems, the $signifies the beginning of a variable name (if you are curious about what other \"environment variables\" are currently active on your system, use theprintenvcommand). The output of theecho command is piped to the next command (tr).
The tr \u2013 translate characters command copies the input of the previous command to the next with substitution or deletion of selected characters. Here, we substitute the : character, which is used to separate the different directory paths in the $PATH variable, with \"\\n\", which is the all important character that denotes a \"new line\".
Just because, we also sort the output alphabetically to make it more readable.
So, how do we change the \"$PATH\"? Let's try and install ROBOT and see! Before we download ROBOT, let us think how we will organise our custom tools moving forward. Everyone has their own preferences, but I like to create a tools directory right in my Users directory, and use this for all my tools moving forward. In this spirit, lets us first go to our user directory in the terminal, and then create a \"tools\" directory:
cd ~\nmkdir -p tools\n
The -p parameter simply means: create the tools directory only if it does not exist. Now, let us go inside the tools directory (cd ~/tools) and continue following the instructions provided here.
First, let us download the latest ROBOT release using the curl command:
ROBOT is written in the Java programming language, and packaged up as an executable JAR file. It is still quite cumbersome to directly run a command with that JAR file, but for the hell of it, let us just do it (for fun):
java -jar robot.jar --version\n
If you have worked with ROBOT before, this looks quite a bit more ugly then simply writing:
robot --version\n
If you get this (or a similar) error:
zsh: permission denied: robot\n
You will have to run the following command as well, which makes the robot wrapper script executable:
chmod +x ~/tools/robot\n
So, how can we achieve this? The answer is, we download a \"wrapper script\" and place it in the same folder as the Jar. Many tools provide such wrapper scripts, and they can sometimes do many more things than just \"running the jar file\". Let us know download the latest wrapper script:
If everything went well, you should be able to print the contents of that file to the terminal using cat:
cat robot\n
You should see something like:
#!/bin/sh\n\n## Check for Cygwin, use grep for a case-insensitive search\nIS_CYGWIN=\"FALSE\"\nif uname | grep -iq cygwin; then\n IS_CYGWIN=\"TRUE\"\nfi\n\n# Variable to hold path to this script\n# Start by assuming it was the path invoked.\nROBOT_SCRIPT=\"$0\"\n\n# Handle resolving symlinks to this script.\n# Using ls instead of readlink, because bsd and gnu flavors\n# have different behavior.\nwhile [ -h \"$ROBOT_SCRIPT\" ] ; do\n ls=`ls -ld \"$ROBOT_SCRIPT\"`\n # Drop everything prior to ->\n link=`expr \"$ls\" : '.*-> \\(.*\\)$'`\n if expr \"$link\" : '/.*' > /dev/null; then\n ROBOT_SCRIPT=\"$link\"\n else\n ROBOT_SCRIPT=`dirname \"$ROBOT_SCRIPT\"`/\"$link\"\n fi\ndone\n\n# Directory that contains the this script\nDIR=$(dirname \"$ROBOT_SCRIPT\")\n\nif [ $IS_CYGWIN = \"TRUE\" ]\nthen\n exec java $ROBOT_JAVA_ARGS -jar \"$(cygpath -w $DIR/robot.jar)\" \"$@\"\nelse\n exec java $ROBOT_JAVA_ARGS -jar \"$DIR/robot.jar\" \"$@\"\nfi\n
We are not getting into the details of what this wrapper script does, but note that, you can fine the actually call the the ROBOT jar file towards the end: java $ROBOT_JAVA_ARGS -jar \"$DIR/robot.jar\" \"$@\". The cool thing is, we do not need to ever worry about this script, but it is good for use to know, as Semantic Engineers, that it exists.
Now, we have downloaded the ROBOT jar file and the wrapper script into the ~/tools directory. The last step remaining is to add the ~/tools directory to your path. It makes sense to try to at least understand the basic idea behind environment variables: variables that are \"loaded\" or \"active\" in your environment (your shell). The first thing you could try to do is change the variable right here in your terminal. To do that, we can use the export command:
export PATH=$PATH:~/tools\n
What you are doing here is using the export command to set the PATH variable to $PATH:~/tools, which is the old path ($PATH), a colon (:) and the new directory we want to add (~/tools). And, indeed, if we now look at our path again:
echo $PATH | tr ':' '\\n' | sort\n
We will see the path added. We can now move around to any directory on our machine and invoke the robot command. Try it before moving on!
Unfortunately, the change we have now applied to the $PATH variable is not persistent: if you open a new tab in your Terminal, your $PATH variable is back to what it was. What we have to do in order to make this persistent is to add the export command to a special script which is run every time the you open a new terminal: your shell profile.
There is a lot to say about your shell profiles, and we are taking a very simplistic view here that covers 95% of what we need: If you are using zsh your profile is managed using the ~/.zshrc file, and if you are using bash, your profile is managed using the ~/.bash_profile file. In this tutorial I will assume you are using zsh, and, in particular, after installing \"oh-my-zsh\". Let us look at the first 5 lines of the ~/.zshrc file:
head ~/.zshrc\n
If you have installed oh-my-zsh, the output will look something like:
# If you come from bash you might have to change your $PATH.\n# export PATH=$HOME/bin:/usr/local/bin:$PATH\n\n# Path to your oh-my-zsh installation.\nexport ZSH=\"$HOME/.oh-my-zsh\"\n\n# Set name of the theme to load --- if set to \"random\", it will\n# load a random theme each time oh-my-zsh is loaded, in which case,\n# to know which specific one was loaded, run: echo $RANDOM_THEME\n# See https://github.com/ohmyzsh/ohmyzsh/wiki/Themes\n
This ~/.zshrc profile script is loaded every time you open up a new shell. What we want to do is add our export command above to this script, so that it is running every time. That is the basic concept of a shell profile: providing a series of commands that is run every time a new shell (terminal window, tab) is opened.
For this tutorial, we use nano to edit the file, but feel free to use your text editor of choice. For example, you can open the profile file using TextEdit on Mac like this:
open -a TextEdit ~/.zshrc\n
We will proceed using nano, but feel free to use any editor.
nano ~/.zshrc\n
Using terminal-based editors like nano or, even worse, vim, involves a bit of a learning curve. nano is by far the least powerful and simple to use. If you typed the above command, you should see its contents on the terminal. The next step is to copy the following (remember, we already used it earlier)
export PATH=$PATH:~/tools\n
and paste it somewhere into the file. Usually, there is a specific section of the file that is concerned with setting up your path. Eventually, as you become more of an expert, you will start organising your profile according to your own preferences! Today we will just copy the command anywhere, for example:
# If you come from bash you might have to change your $PATH.\n# export PATH=$HOME/bin:/usr/local/bin:$PATH\nexport PATH=~/tutorial:$PATH\n# ..... other lines in the file\n
Note that the # symbol denotes the beginning of a \"comment\" which is ignored by the shell/CLI. After you have pasted the above, you use the following keyboard key-combinations to safe and close the file:
control + O\n
This saves the file. Confirm with Enter.
control + x\n
This closes the file. Now, we need to tell the shell we are currently in that it should reload our profile we have just edited. We do that using the source command.
source ~/.zshrc\n
Great! You should be able open a new tab in your terminal (with command+t on a Mac, for example) and run the following command:
robot --version\n
"},{"location":"tutorial/intro-cli-2/#managing-aliases-and-custom-commands-in-your-shell-profile","title":"Managing aliases and custom commands in your shell profile","text":"
This section will only give a sense of the kinds of things you can do with your shell profile - in the end you will have to jump into the cold water and build your skills up yourself. Let us start with a very powerful concept: aliases. Aliases are short names for your commands you can use if you use them repeatedly but are annoyed typing them out every time. For example, tired of typing out long paths all the time to jump between your Cell Ontology and Human Phenotype Ontology directories? Instead of:
cd /Users/matentzn/ws/human-phenotype-ontology/src/ontology\n
wouldn't it be nice to be able to use, instead,
cdhp\n
or, if you are continuously checking git status, why not implement a alias gits? Or activating your python environment (source ~/.pyenv/versions/oak/bin/activate) with a nice env-oak? To achieve this we do the following:
(1) Open your profile in a text editor of your choice, e.g.
nano ~/.zshrc\n
add the following lines:
alias cdt='cd ~/tools'\nalias hg='history | grep'\n
Save (control+o) and close (control+x) the profile. Reload the profile:
source ~/.zshrc\n
(Alternatively, just open a new tab in your Terminal.) Now, lets try our new aliases:
cdt\n
Will bring you straight to your tools directory you created in the previous lesson above.
hg robot\n
Will search your terminal command history for every command you have executed involving robot.
"},{"location":"tutorial/intro-cli-2/#list-of-ideas-for-aliases","title":"List of ideas for aliases","text":"
In the following, we provide a list of aliases we find super useful:
alias cdt='cd ~/tools' - add shortcuts to all directories you frequently visit!
alias orcid='echo '\\''https://orcid.org/0000-0002-7356-1779'\\'' | tr -d '\\''\\n'\\'' | pbcopy' - if you keep having to look up your ORCID, your favourite ontologies PURL or the your own zoom room, why not add a shortcut that copies it straight into your clipboard?
alias opent='open ~/tools' - why not open your favourite directory in finder without faving to search the User Interface? You can use the same idea to open your favourite ontology from wherever you are, i.e. alias ohp='open ~/ws/human-phenotype-ontology/src/ontology/hp-edit.owl'.
alias env-linkml='source ~/.pyenv/versions/linkml/bin/activate' - use simple shortcuts to active your python environments. This will become more important if you learn to master special python tools like OAK.
alias update_repo='sh run.sh make update_repo' - for users of ODK - alias all your long ODK commands!
The most advanced thought we want to cover today is \"functions\". You can not only manage simple aliases, but you can actually add proper functions into your shell profile. Here is an example of one that I use:
ols() {\n open https://www.ebi.ac.uk/ols/search?q=\"$1\"\n}\n
This is a simple function in my bash profile that I can use to search on OLS:
The possibilities are endless. Some power-users have hundreds of such functions in their shell profiles, and they can do amazing things with them. Let us know about your own ideas for functions on the OBOOK issue tracker. Or, why not add a function to create a new, titled issue on OBOOK?
obook-issue() {\n open https://github.com/OBOAcademy/obook/issues/new?title=\"$1\"\n}\n
Automating Ontology Development Workflows: Make, Shell and Automation Thinking
Data Science at the Command Line: Free online book that covers everything you need to know to be a command line magician
A whirlwind introduction to the command line by James Overton
"},{"location":"tutorial/lexmatch-tutorial/","title":"Practical introduction to OAK Lexmatch","text":"
In this tutorial, we will learn to use a very basic lexical matching tool (OAK Lexmatch). The goal is not only to enable the learner to design their own matching pipelines, but also to to think about how they fit into their mapping efforts. Note that this tutorial is not about how to do proper matching: the goal here is simply to introduce you to the general workflow. Proper ontology matching is a major discipline with many tools, preprocessing and tuning approaches and often intricate interplay between matching tools and human curators. Today, you will just get a sense of the general method.
In this tutorial, you will learn how to match fruit juices in Wikidata with FOODON using a simple lexical matching tool (OAK). The idea is simple: We obtain the ontologies we like to match, ask OAK to generate the matches and then curate the results.
Setting up OAK, preparing the ontology: You will learn how to install OAK into a new Python environment, and create a simple Makefile to prepare your input ontology with ROBOT.
Download Ontologies and extract subsets: Prepare the data/ontologies you want to match.
Generate the matches with OAK: Generate the matches using a simple tool.
Curating matching results: Manually review the results of the mars
"},{"location":"tutorial/lexmatch-tutorial/#setting-up-oak-preparing-the-ontology","title":"Setting up OAK, preparing the ontology","text":"
Setting up oak is described in its documentation. Note that, aside from oak itself, you also need relation-graph, rdftab and riot installed, see https://incatools.github.io/ontology-access-kit/intro/tutorial07.html#without-docker. This tutorial requires OAK version 0.1.59 or higher.
Note that if you are using the ODK docker image, oaklib is already installed. In the following, we will use the ODK wrapper to ensure that everyone has a consistent experience. If you want to use the local (non-docker) setup, you have to follow the instructions above before continuing and ignore the sh odk.sh part of the commands.
"},{"location":"tutorial/lexmatch-tutorial/#important-for-users-of-odk-132","title":"IMPORTANT for users of ODK < 1.3.2:","text":"
ODK 1.3.1, the version still active on the 8th December 2022, does not have the latest dependencies of OAK installed. To follow the tutorial you have to use the ODK development snapshot.
Install the ODK Development snapshot:
docker pull obolibrary/odkfull:dev\n
After downloading https://raw.githubusercontent.com/OBOAcademy/obook/master/docs/resources/odk.sh into your local working directory, open it with a text editor and change:
docker ... obolibrary/odkfull ...\n
to
docker ... obolibrary/odkfull:dev ...\n
"},{"location":"tutorial/lexmatch-tutorial/#download-ontologies-and-extract-subsets","title":"Download Ontologies and extract subsets","text":"
First, we download FOODON ontology. You can do this in whatever way you want, for example with wget:
sh odk.sh wget http://purl.obolibrary.org/obo/foodon.owl -O foodon.owl\n
Next, we extract the subset of FOODON that is relevant to our task at hand: relevant terms about fruit juices. The right method of subset extraction will differ from task to task. For this tutorial, we are using ROBOT extract to obtain a MIREOT module containing all the fruit juices. We do this by selecting everything between fruit juice food product as the upper-term and fruit juices (apple juice, orange juice and grapefruit juice) as the lower-term of the FOODON subset.
If you open fruit_juice_food_foodon.owl in Protege, you will see something similar to:
Next, we use OAK to extract juices and their labels from wikidata by selecting the descendants of juice from wikidata, store the result as a ttl file and then convert it to OWL using ROBOT.
Note that you wont be able to see anything when opening juice_wd.owl in wikidata, because it does not have any OWL types (class, individual assertions) attached to it. However, you can convince yourself all is well by opening juice_wd.owl in a text editor, and see expressions such as:
<rdf:Description rdf:about=\"http://www.wikidata.org/entity/Q10374646\">\n <rdfs:label>cashew apple juice</rdfs:label>\n</rdf:Description>\n
The last preparation step is merging the two subsets (from FOODON and wikidata) into a single file using ROBOT:
sh odk.sh robot merge -i fruit_juice_food_foodon.owl -i juice_wd.owl -o foodon_wd.owl\n
"},{"location":"tutorial/lexmatch-tutorial/#generate-the-matches-with-oak","title":"Generate the matches with OAK","text":"
Now we are ready to create our first set of matches. First, let's run oak's lexmatch command to generate lexical matches between the contents of the merged file:
sh odk.sh runoak -i sqlite:foodon_wd.owl lexmatch -o foodon_wd_lexmatch.tsv\n
This will generate an SSSOM tsv file with the mapped contents as shown below:
subject_id subject_label predicate_id object_id object_label mapping_justification mapping_tool confidence subject_match_field object_match_field match_string FOODON:00001059 apple juice skos:closeMatch wikidata:Q618355 apple juice semapv:LexicalMatching oaklib 0.5 rdfs:label rdfs:label apple juice FOODON:00001059 apple juice skos:closeMatch wikidata:Q618355 apple juice semapv:LexicalMatching oaklib 0.5 oio:hasExactSynonym rdfs:label apple juice FOODON:03301103 orange juice skos:closeMatch wikidata:Q219059 orange juice semapv:LexicalMatching oaklib 0.5 rdfs:label rdfs:label orange juice FOODON:03306174 grapefruit juice skos:closeMatch wikidata:Q1138468 grapefruit juice semapv:LexicalMatching oaklib 0.5 rdfs:label rdfs:label grapefruit juice wikidata:Q15823640 cherry juice skos:closeMatch wikidata:Q62030277 cherry juice semapv:LexicalMatching oaklib 0.5 rdfs:label rdfs:label cherry juice wikidata:Q18201657 must skos:closeMatch wikidata:Q278818 must semapv:LexicalMatching oaklib 0.5 rdfs:label rdfs:label must
This is great - we get a few mappings without much work. If you need some help interpreting this table, please refer to the SSSOM tutorials for details.
Just eyeballing the labels in our ontology with OAK:
sh odk.sh runoak -i sqlite:foodon_wd.owl terms | grep juice\n
We notice rows like:
...\nFOODON:00001001 ! orange juice (liquid)\n...\n
It may be beneficial for us to pre-process the labels a bit before performing the matches, for example, by excluding comments in the labels provided in brackets (essentially removing (liquid)).
To do this, we will define a few simple mapping rules in a file called matcher_rules.yaml. OAK provides a standard for representing the matching rules. You can see an example here.
Here is an example file:
rules:\n- description: default\npostconditions:\npredicate_id: skos:closeMatch\nweight: 0.0\n\n- description: exact to exact\npreconditions:\nsubject_match_field_one_of:\n- oio:hasExactSynonym\n- rdfs:label\n- skos:prefLabel\nobject_match_field_one_of:\n- oio:hasExactSynonym\n- rdfs:label\n- skos:prefLabel\npostconditions:\npredicate_id: skos:exactMatch\nweight: 2.0\n\n- preconditions:\nsubject_match_field_one_of:\n- oio:hasExactSynonym\n- rdfs:label\nobject_match_field_one_of:\n- oio:hasBroadSynonym\npostconditions:\npredicate_id: skos:broadMatch\nweight: 2.0\n\n- synonymizer:\nthe_rule: Remove parentheses bound info from the label.\nmatch: r'\\([^)]*\\)'\nmatch_scope: \"*\"\nreplacement: \"\"\n\n- synonymizer:\nthe_rule: Replace \"'s\" by \"s\" in the label.\nmatch: r'\\'s'\nmatch_scope: \"*\"\nreplacement: \"s\"\n
As you can see, there are basically two kinds of rules: normal ones, and synonimizer ones. The normal rules provide preconditions and postconditions. For example, the second rule says: if an exact synonym, preferred label or label of the subject matches an exact synonym, preferred label or label of the object, then assert a skos:exactMatch. The synonimizer rules are preprocessing rules which are applied to the labels and synonyms prior to matching. Let's now run the matcher again:
subject_id subject_label predicate_id object_id object_label mapping_justification mapping_tool confidence subject_match_field object_match_field match_string subject_preprocessing object_preprocessing FOODON:00001001 orange juice (liquid) skos:exactMatch FOODON:00001277 orange juice (unpasteurized) semapv:LexicalMatching oaklib 0.8497788951776651 rdfs:label rdfs:label orange juice semapv:RegularExpressionReplacement semapv:RegularExpressionReplacement FOODON:00001001 orange juice (liquid) skos:exactMatch FOODON:03301103 orange juice semapv:LexicalMatching oaklib 0.8497788951776651 rdfs:label rdfs:label orange juice semapv:RegularExpressionReplacement FOODON:00001001 orange juice (liquid) skos:exactMatch wikidata:Q219059 orange juice semapv:LexicalMatching oaklib 0.8497788951776651 rdfs:label rdfs:label orange juice semapv:RegularExpressionReplacement FOODON:00001059 apple juice skos:exactMatch wikidata:Q618355 apple juice semapv:LexicalMatching oaklib 0.8497788951776651 rdfs:label rdfs:label apple juice FOODON:00001059 apple juice skos:exactMatch wikidata:Q618355 apple juice semapv:LexicalMatching oaklib 0.8 oio:hasExactSynonym rdfs:label apple juice FOODON:00001277 orange juice (unpasteurized) skos:exactMatch FOODON:03301103 orange juice semapv:LexicalMatching oaklib 0.8497788951776651 rdfs:label rdfs:label orange juice semapv:RegularExpressionReplacement FOODON:00001277 orange juice (unpasteurized) skos:exactMatch wikidata:Q219059 orange juice semapv:LexicalMatching oaklib 0.8497788951776651 rdfs:label rdfs:label orange juice semapv:RegularExpressionReplacement FOODON:00002403 food material skos:exactMatch FOODON:03430109 food (liquid, low viscosity) semapv:LexicalMatching oaklib 0.8 oio:hasExactSynonym rdfs:label food semapv:RegularExpressionReplacement FOODON:00002403 food material skos:exactMatch FOODON:03430130 food (liquid) semapv:LexicalMatching oaklib 0.8 oio:hasExactSynonym rdfs:label food semapv:RegularExpressionReplacement FOODON:03301103 orange juice skos:exactMatch wikidata:Q219059 orange juice semapv:LexicalMatching oaklib 0.8497788951776651 rdfs:label rdfs:label orange juice FOODON:03306174 grapefruit juice skos:exactMatch wikidata:Q1138468 grapefruit juice semapv:LexicalMatching oaklib 0.8497788951776651 rdfs:label rdfs:label grapefruit juice FOODON:03430109 food (liquid, low viscosity) skos:exactMatch FOODON:03430130 food (liquid) semapv:LexicalMatching oaklib 0.8497788951776651 rdfs:label rdfs:label food semapv:RegularExpressionReplacement semapv:RegularExpressionReplacement wikidata:Q15823640 cherry juice skos:exactMatch wikidata:Q62030277 cherry juice semapv:LexicalMatching oaklib 0.8497788951776651 rdfs:label rdfs:label cherry juice wikidata:Q18201657 must skos:exactMatch wikidata:Q278818 must semapv:LexicalMatching oaklib 0.8497788951776651 rdfs:label rdfs:label must "},{"location":"tutorial/lexmatch-tutorial/#curate","title":"Curate","text":"
As we have described in detail in our introduction to Semantic Matching, it is important to remember that matching in its raw form should not be understood to result in semantic mappings: they are better understood as mapping candidates. Therefore, it is always to plan for a review of false positives and false negatives:
False positive review (wrong mappings). The goal here is to identify mappings that do not work for our use case, or do not use the correct semantic mapping relation. If you look carefully through the matched files, you'll notice that manual intervention is definitely required for the matches to be accurate. For example, orange juice [wikidata:Q219059] and orange juice (unpasteurized) [FOODON:00001277] may not be considered as the same thing in the sense of skos:exactMatch.
False negative review (missing mappings). The goal here is to understand if we can do anything to improve the matching process by tuning it. Here, we did a little bit of that earlier when we were looking at the labels of the wikidata and FOODON juice hierarchies.
For a more detailed introduction into manual mapping curation with SSSOM we recommend following this tutorial: https://mapping-commons.github.io/sssom/tutorial/.
"},{"location":"tutorial/linking-data/","title":"Tutorial: From Tables to Linked Data","text":"
These are the kinds of things that I do when I need to work with a new dataset. My goal is to have data that makes good sense and that I can integrate with other data using standard technologies: Linked Data.
The boss just sent me this new table to figure out:
datetime investigator subject species strain sex group protocol organ disease qualifier comment 1/1/14 10:21 AM JAO 12 RAT F 344/N FEMALE 1 HISTOPATHOLOGY LUNG ADENOCARCINOMA SEVERE 1/1/14 10:30 AM JO 31 MOUSE B6C3F1 MALE 2 HISTOPATHOLOGY NOSE INFLAMMATION MILD 1/1/14 10:45 AM JAO 45 RAT F 344/N MALE 1 HISTOPATHOLOGY ADRENAL CORTEX NECROSIS MODERATE
It doesn't seem too bad, but there's lots of stuff that I don't quite understand. Where to start?
Before I do anything else, I'm going to set up a new project for working with this data. Maybe I'll change my mind later and want to merge the new project with an existing project, but it never hurts to start from a nice clean state.
I'll make a new directory in a sensible place with a sensible name. In my case I have a ~/Repositories/ directory, with subdirectories for GitHub and various GitLab servers, a local directory for projects I don't plan to share, and a temp directory for projects that I don't need to keep. I'm not sure if I'm going to share this work, so it can go in a new subdirectory of local. I'll call it \"linking-data-tutorial\" for now.
Then I'll run git init to turn that directory into a git repository. For now I'm just going to work locally, but later I can make a repository on GitHub and push my local repository there.
Next I'll create a README.md file where I'll keep notes for myself to read later. My preferred editor is Kakoune.
So I'll open a terminal and run these commands:
$ cd ~/Repositories/local/\n$ mkdir linking-data-tutorial\n$ cd linking-data-tutorial\n$ git init\n$ kak README.md\n
In the README I'll start writing something like this:
# Linking Data Tutorial\n\nAn example of how to convert a dataset to Linked Data.\n\nThe source data is available from\n<https://github.com/jamesaoverton/obook/tree/master/03-RDF/data.csv>\n
Maybe this information should go somewhere else eventually, but the README is a good place to start.
Data has an annoying tendency to get changed. You don't want it changing out from under you while you're in the middle of something. So the next thing to do is get a copy of the data and store it locally. If it's big, you can store a compressed copy. If it's too big to fit on your local machine, well keep the best notes you can of how to get to the data, and what operations you're doing on it.
I'm going to make a cache directory and store all my \"upstream\" data there. I'm going to fetch the data and that's it -- I'm not going to edit these files. When I want to change the data I'll make copies in another directory. I don't want git to track the cached data, so I'll add /cache/ to .gitignore and tell git to track that. Then I'll use curl to download the file.
$ mkdir cache\n$ echo \"/cache/\" >> .gitignore\n$ git add .gitignore\n$ git commit -m \"Ignore /cache/ directory\"\n$ cd cache\n$ curl -LO \"https://github.com/jamesaoverton/obook/raw/master/03-RDF/data.csv\"\n$ ls\ndata.csv\n$ cd ..\n$ ls -a\n.gitignore data README.md\n
"},{"location":"tutorial/linking-data/#3-getting-my-bearings","title":"3. Getting My Bearings","text":"
The first thing to do is look at the data. In this case I have just one table in CSV format, so I can use any number of tools to open the file and look around. I bet the majority of people would reach for Excel. My (idiosyncratic) preference is VisiData.
What am I looking for? A bunch of different things:
what do the rows represent?
what columns do I have?
for each column, what sorts of values do I have?
In my README file I'll make a list of the columns like this:
- datetime: American-style dates, D/M/Y or M/D/Y?\n- investigator: initials, ORCID?\n- subject: integer ID\n- species: common name for species, NCBITaxon?\n- strain: some sort of code with letters, numbers, spaces, some punctuation\n- sex: string female/male\n- group: integer ID\n- protocol: string, OBI?\n- organ: string, UBERON?\n- disease: string, DO/MONDO?\n- qualifier: string, PATO?\n- comment: ???\n
You can see that I'm trying to figure out what's in each column. I'm also thinking ahead to OBO ontologies that I know of that may have terms that I can use for each column.
In the end, I want to have nice, clean Linked Data. But I don't have to get there in one giant leap. Instead I'll take a bunch of small, incremental steps.
There's lots of tools I can use, but this time I'll use SQLite.
First I'll set up some more directories. I'll create a build directory where I'll store temporary files. I don't want git to track this directory, so I'll add it to .gitignore.
Note that I didn't even specify a schema for data_csv. It uses the first row as the column names, and the type of every column is TEXT. Here's the schema I end up with:
I'm going to want to update src/data.sql then rebuild the database over and over. It's small, so this will only take a second. If it was big, then I would copy a subset into build/data.csv for now so that I the script still runs in a second or two and I can iterate quickly. I'll write a src/build.sh script to make life a little easier:
Now I have a script that executes a SQL file that loads the source data into a new database. I'll modify the src/data.sql file in a series of small steps until it has the structure that I want.
In the real world, data is always a mess. It takes real work to clean it up. And really, it's almost never perfectly clean.
It's important to recognize that cleaning data has diminishing returns. There's low hanging fruit: easy to clean, often with code, and bringing big benefits. Then there's tough stuff that requires an expert to work through the details, row by row.
The first thing to do is figure out the schema you want. I'll create a new data table and start with the default schema from data_csv. Notice that in the default schema all the column names are quoted. That's kind of annoying. But when I remove the quotation marks I realize that one of the column names is \"datetime\", but datetime is a keyword in SQLite! You can't use it as a column name without quoting. I'll rename it to \"assay_datetime\". I have the same problem with \"group\". I'll rename \"group\" to \"group_id\" and \"subject\" to \"subject_id\". The rest of the column names seem fine.
I want \"assay_datetime\" to be in standard ISO datetime format, but SQLite stores these as TEXT. The \"subject\" and \"group\" columns are currently integers, but I plan to make them into URIs to CURIEs. So everything will still be TEXT.
The dates currently look like \"1/1/14 10:21 AM\". Say I know that they were done on Eastern Standard Time. How do I convert to ISO dates like \"2014-01-01 10:21:00-0500\"? Well SQLite isn't the right tool for this. The Unix date command does a nice job, though:
$ date -d \"1/1/14 10:21 AM EST\" +\"%Y-%m-%d %H:%M:%S%z\"\n2014-01-01 10:21:00-0500\n
I can run that over each line of the file using awk. So I update the src/build.sh to rework the build/data.csv before I import:
One more problem I could clean up is that \"JO\" should really be \"JAO\" -- that's just a typo, and they should both refer to James A. Overton. I could make that change in src/build.sh, but I'll do it in src/data.sql instead. I'll write a query to copy all the rows of data_csv into data and then I'll update data with some fixes.
-- copy from data_csv to data\nINSERT INTO data SELECT * FROM data_csv;\n\n-- clean data\nUPDATE data SET investigator=\"JAO\" WHERE investigator=\"JO\";\n
Honestly, it took me quite a while to write that awk command. It's a very powerful tool, but I don't use it enough to remember how it works. You might prefer to write yourself a Python script, or some R code. You could use that instead of this SQL UPDATE as well. I just wanted to show you two of the thousands of ways to do this. If there's a lot of replacements like \"JO\", then you might also consider listing them in another table that you can read into your script.
The important part is to automate your cleaning!
Why didn't I just edit cache/data.csv in Excel? In step 2 I saved a copy of the data because I didn't want it to change while I was working on it, but I do expect it to change! By automating the cleaning process, I should be able to just update cache/data.csv run everything again, and the fixes will be applied again. I don't want to do all this work manually every time the upstream data is updated.
It's pretty easy to convert a table structure to triples. The hard part is converting the table contents. There are some identifiers in the table that would be better as URLs, and there's a bunch of terminology that would be better if it was linked to an ontology or other system.
I'll start with the identifiers that are local to this data: subject_id and group_id. I can convert them to URLs by defining a prefix and then just using that prefix. I'll use string concatenation to update the table:
-- update subject and groupd IDs\nUPDATE data SET subject_id='ex:subject-' || subject_id;\nUPDATE data SET group_id='ex:group-' || group_id;\n
I should take a moment to tell you, that while I was writing the Turtle conversion code later in this essay, I had to come back here and change these identifiers. The thing is that Turtle is often more strict than I expect about identifier syntax. Turtle identifiers look like CURIEs, but they're actually QNames. CURIEs are pretty much just just URLs shortened with a prefix, so almost anything goes. QNames come from XML, and Turtle identifiers have to be valid XML element names.
I always remember that I need to stick to alphanumeric characters, and that I have to replace whitespace and punctuation with a - or _. I didn't remember that the local part (aka \"suffix\", aka \"NCName\") can't start with a digit. So I tried to use \"subject:12\" and \"group:1\" as my identifiers. That worked fine until I generated Turtle. The Turtle looked fine, so it took me quite a while to figure out why it looked very wrong when I converted it into RDXML format.
This kind of thing happens to me all the time. I'm almost always using a mixture of technologies based on different sets of assumptions, and there are always things that don't line up. That's why I like to work in small iterations, checking my work as I go (preferrably with automated tests), and keeping everything in version control. When I need to make a change like this one, I just circle back and iterate again.
The next thing is to tackle the terminology. First I'll just make a list of the terms I'm using from the relevant columns in build/term.tsv:
```sh #collect $ sqlite3 build/data.db << EOF > build/term.tsv SELECT investigator FROM data UNION SELECT species FROM data UNION SELECT strain FROM data UNION SELECT strain FROM data UNION SELECT sex FROM data UNION SELECT protocol FROM data UNION SELECT organ FROM data UNION SELECT disease FROM data UNION SELECT qualifier FROM data; EOF
It's a lot of work to go through all those terms\nand find good ontology terms.\nI'm going to do that hard work for you\n(just this once!)\nso we can keep moving.\nI'll add this table to `src/term.tsv`\n\n| id | code | label |\n| ------------------------- | -------------- | ------------------ |\n| obo:NCBITaxon_10116 | RAT | Rattus norvegicus |\n| obo:NCBITaxon_10090 | MOUSE | Mus musculus |\n| ex:F344N | F 344/N | F 344/N |\n| ex:B6C3F1 | B6C3F1 | B6C3F1 |\n| obo:PATO_0000383 | FEMALE | female |\n| obo:PATO_0000384 | MALE | male |\n| obo:OBI_0600020 | HISTOPATHOLOGY | histology |\n| obo:UBERON_0002048 | LUNG | lung |\n| obo:UBERON_0007827 | NOSE | external nose |\n| obo:UBERON_0001235 | ADRENAL CORTEX | adrenal cortex |\n| obo:MPATH_268 | ADENOCARCINOMA | adenocarcinoma |\n| obo:MPATH_212 | INFLAMMATION | inflammation |\n| obo:MPATH_4 | NECROSIS | necrosis |\n| obo:PATO_0000396 | SEVERE | severe intensity |\n| obo:PATO_0000394 | MILD | mild intensity |\n| obo:PATO_0000395 | MODERATE | moderate intensity |\n| orcid:0000-0001-5139-5557 | JAO | James A. Overton |\n\nAnd I'll add these prefixes to `src/prefix.tsv`:\n\n| prefix | base |\n| ------- | ------------------------------------------- |\n| rdf | http://www.w3.org/1999/02/22-rdf-syntax-ns# |\n| rdfs | http://www.w3.org/2000/01/rdf-schema# |\n| xsd | http://www.w3.org/2001/XMLSchema# |\n| owl | http://www.w3.org/2002/07/owl# |\n| obo | http://purl.obolibrary.org/obo/ |\n| orcid | http://orcid.org/ |\n| ex | https://example.com/ |\n| subject | https://example.com/subject/ |\n| group | https://example.com/group/ |\n\nNow I can import these tables into SQL\nand use the term table as a FOREIGN KEY constraint\non data:\n\n```sql\n.mode tabs\n\nCREATE TABLE prefix (\n prefix TEXT PRIMARY KEY,\n base TEXT UNIQUE\n);\n.import --skip 1 src/prefix.tsv prefix\n\nCREATE TABLE term (\n id TEXT PRIMARY KEY,\n code TEXT UNIQUE,\n label TEXT UNIQUE\n);\n.import --skip 1 src/term.tsv term\n\nCREATE TABLE data(\n assay_datetime TEXT,\n investigator TEXT,\n subject_id TEXT,\n species TEXT,\n strain TEXT,\n sex TEXT,\n group_id TEXT,\n protocol TEXT,\n organ TEXT,\n disease TEXT,\n qualifier TEXT,\n comment TEXT,\n FOREIGN KEY(investigator) REFERENCES term(investigator),\n FOREIGN KEY(species) REFERENCES term(species),\n FOREIGN KEY(strain) REFERENCES term(strain),\n FOREIGN KEY(sex) REFERENCES term(sex),\n FOREIGN KEY(protocol) REFERENCES term(protocol),\n FOREIGN KEY(organ) REFERENCES term(organ),\n FOREIGN KEY(disease) REFERENCES term(disease),\n FOREIGN KEY(qualifier) REFERENCES term(qualifier)\n);\n\n-- copy from data_csv to data\nINSERT INTO data SELECT * FROM data_csv;\n\n-- clean data\nUPDATE data SET investigator='JAO' WHERE investigator='JO';\n\n-- update subject and groupd IDs\nUPDATE data SET subject_id='ex:subject-' || subject_id;\nUPDATE data SET group_id='ex:group-' || group_id;\n
I'll update the README:
See `src/` for:\n\n- `prefix.tsv`: shared prefixes\n- `term.tsv`: terminology\n
I'll commit my work in progress:
$ git add src/prefix.tsv src/term.tsv\n$ git add --update\n$ git commit -m \"Add and apply prefix and term tables\"\n
Now all the terms are linked to controlled vocabularies of one sort or another. If I want to see the IDs for those links instead of the \"codes\" I can define a VIEW:
CREATE VIEW linked_data_id AS\nSELECT assay_datetime,\ninvestigator_term.id AS investigator,\nsubject_id,\nspecies_term.id AS species,\nstrain_term.id AS strain,\nsex_term.id AS sex,\ngroup_id,\nprotocol_term.id AS protocol,\norgan_term.id AS organ,\ndisease_term.id AS disease,\nqualifier_term.id AS qualifier\nFROM data\nJOIN term as investigator_term ON data.investigator = investigator_term.code\nJOIN term as species_term ON data.species = species_term.code\nJOIN term as strain_term ON data.strain = strain_term.code\nJOIN term as sex_term ON data.sex = sex_term.code\nJOIN term as protocol_term ON data.protocol = protocol_term.code\nJOIN term as organ_term ON data.organ = organ_term.code\nJOIN term as disease_term ON data.disease = disease_term.code\nJOIN term as qualifier_term ON data.qualifier = qualifier_term.code;\n
I can also define a similar view for their \"official\" labels:
CREATE VIEW linked_data_label AS\nSELECT assay_datetime,\ninvestigator_term.label AS investigator,\nsubject_id,\nspecies_term.label AS species,\nstrain_term.label AS strain,\nsex_term.label AS sex,\ngroup_id,\nprotocol_term.label AS protocol,\norgan_term.label AS organ,\ndisease_term.label AS disease,\nqualifier_term.label AS qualifier\nFROM data\nJOIN term as investigator_term ON data.investigator = investigator_term.code\nJOIN term as species_term ON data.species = species_term.code\nJOIN term as strain_term ON data.strain = strain_term.code\nJOIN term as sex_term ON data.sex = sex_term.code\nJOIN term as protocol_term ON data.protocol = protocol_term.code\nJOIN term as organ_term ON data.organ = organ_term.code\nJOIN term as disease_term ON data.disease = disease_term.code\nJOIN term as qualifier_term ON data.qualifier = qualifier_term.code;\n
I'll check:
$ sqlite3 build/data.db <<< \"SELECT * FROM linked_data_label LIMIT 1;\"\n2014-01-01 10:21:00-0500|James A. Overton|ex:subject-12|Rattus norvegicus|F 344/N|female|ex:group-1|histology|lung|adenocarcinoma|severe intensity\n
SQL tables aren't an official Linked Data format. Of all the RDF formats, I prefer Turtle. It's tedious but not difficult to get Turtle out of SQL. These query do what I need them to do, but note that if the literal data contained quotation marks (for instance) then I'd have to do more work to escape those. First I create a triple table:
CREATE TABLE triple (\nsubject TEXT,\npredicate TEXT,\nobject TEXT,\nliteral INTEGER -- 0 for object IRI, 1 for object literal\n);\n\n-- create triples from term table\nINSERT INTO triple(subject, predicate, object, literal)\nSELECT id, 'rdfs:label', label, 1\nFROM term;\n\n-- create triples from data table\nINSERT INTO triple(subject, predicate, object, literal)\nSELECT 'ex:assay-' || data.rowid, 'ex:column-assay_datetime', assay_datetime, 1\nFROM data;\n\nINSERT INTO triple(subject, predicate, object, literal)\nSELECT 'ex:assay-' || data.rowid, 'ex:column-investigator', term.id, 0\nFROM data\nJOIN term AS term ON data.investigator = term.code;\n\nINSERT INTO triple(subject, predicate, object, literal)\nSELECT 'ex:assay-' || data.rowid, 'ex:column-subject_id', subject_id, 0\nFROM data;\n\nINSERT INTO triple(subject, predicate, object, literal)\nSELECT 'ex:assay-' || data.rowid, 'ex:column-species', term.id, 0\nFROM data\nJOIN term AS term ON data.species = term.code;\n\nINSERT INTO triple(subject, predicate, object, literal)\nSELECT 'ex:assay-' || data.rowid, 'ex:column-strain', term.id, 0\nFROM data\nJOIN term AS term ON data.strain = term.code;\n\nINSERT INTO triple(subject, predicate, object, literal)\nSELECT 'ex:assay-' || data.rowid, 'ex:column-sex', term.id, 0\nFROM data\nJOIN term AS term ON data.sex = term.code;\n\nINSERT INTO triple(subject, predicate, object, literal)\nSELECT 'ex:assay-' || data.rowid, 'ex:column-group_id', group_id, 0\nFROM data;\n\nINSERT INTO triple(subject, predicate, object, literal)\nSELECT 'ex:assay-' || data.rowid, 'ex:column-protocol', term.id, 0\nFROM data\nJOIN term AS term ON data.protocol = term.code;\n\nINSERT INTO triple(subject, predicate, object, literal)\nSELECT 'ex:assay-' || data.rowid, 'ex:column-organ',term.id, 0\nFROM data\nJOIN term AS term ON data.organ= term.code;\n\nINSERT INTO triple(subject, predicate, object, literal)\nSELECT 'ex:assay-' || data.rowid, 'ex:column-disease', term.id, 0\nFROM data\nJOIN term AS term ON data.disease = term.code;\n\nINSERT INTO triple(subject, predicate, object, literal)\nSELECT 'ex:assay-' || data.rowid, 'ex:column-qualifier', term.id, 0\nFROM data\nJOIN term AS term ON data.qualifier = term.code;\n
Then I can turn triples into Turtle using string concatenation:
SQL is not a particularly expressive language. Building the triple table is straightforward but verbose. I could have done the same thing with much less Python code. (Or I could have been clever and generated some SQL to execute!)
The table I started with is very much focused on the data: there was some sort of assay done, and this is the information that someone recorded about it. The Turtle I just ended up with is basically the same.
Other people may have assay data. They may have tables that they converted into Turtle. So can I just merge them? Technically yes: I can put all these triples in one graph together. But I'll still just have \"flat\" chunks of data representing rows sitting next to other rows, without really linking together.
The next thing I would do with this data is reorganized it based on the thing it's talking about. I know that:
there was an assay
the assay was performed at a certain time, using a certain protocol
there was a person who performed the assay
there was a subject animal of some species, strain, and sex
the subject animal belonged to a study group
the subject animal had some organs
the assay resulted in some measurements
Most of these are things that I could point to in the world, or could have pointed to if I was in the right place at the right time.
By thinking about these things, I'm stepping beyond what it was convenient for someone to record, and thinking about what happened in the world. If somebody else has some assay data, then they might have recorded it differently for whatever reason, and so it wouldn't line up with my rows. I'm trying my best to use the same terms for the same things. I also want to use the same \"shapes\" for the same things. When trying to come to an agreement about what is connected to what, life is easier if I can point to the things I want to talk about: \"See, here is the person, and the mouse came from here, and he did this and this.\"
I could model the data in SQL by breaking the big table into smaller tables. I could have tables for:
person
group
subject: species, strain, sex, group
assay: date, investigator, subject, protocol
measurement: assay, organ, disease, qualifier
Then I would convert each table to triples more carefully. That's a good idea. Actually it's a better idea than what I'm about to do...
Since we're getting near the end, I'm going to show you how you can do that modelling in SPARQL. SPARQL has a CONSTRUCT operation that you use to build triples. There's lots of tools that I could use to run SPARQL but I'll use ROBOT. I'll start with the \"flat\" triples in build/data.ttl, select them with my WHERE clause, then CONSTRUCT better triples, and save them in build/model.ttl.
"},{"location":"tutorial/linking-data/#9-getting-it-done","title":"9. Getting It Done","text":"
That was a lot of work for a small table. And I did all the hard work of mapping the terminology to ontology terms for you!
There's lots more I can do. The SPARQL is just one big chunk, but it would be better in smaller pieces. The modelling isn't all that great yet. Before changing that I want to run it past the boss and see what she thinks.
It's getting close to the end of the day. Before I quit I should update the README, clean up anything that's no longer relevant or correct, and make any necessary notes to my future self:
"},{"location":"tutorial/managing-dynamic-imports-odk/","title":"Managing Dynamic Imports with the Ontology Development Kit","text":"
In this tutorial, we discuss the general workflow of managing dynamic imports, i.e. importing terms from other ontologies which can be kept up to date.
Follow instructions for the PATO dynamic import process here.
"},{"location":"tutorial/managing-ontology-project/","title":"Tutorial on Managing OBO Ontology Projects","text":"
This tutorial is not about editing ontologies and managing the evolution of its content (aka ontology curation), but the general process of managing an ontology project overall. In this lesson, we will cover the following:
How to effectively manage an ontology project using GitHub projects and teams
How to coordinate the evolution of ontologies across projects and grants
It is important to understand that the following is just one good way of doing project management for OBO ontologies, and most projects will do it slightly differently. We do however believe that thinking about your project management process and the roles involved will benefit your work in the long term, and hope that the following will help you as a starting point.
"},{"location":"tutorial/managing-ontology-project/#roles-in-obo-ontology-project-management-activities","title":"Roles in OBO Ontology project management activities","text":"
Ontology Editor (OE): manage the content of ontologies and interact with users
Principal Ontology Editor (POE): coordinate the curation activities and have always fixed hours assigned to the project.
Ontology Pipeline Developer (OPD): Manage the technical workflows around ontologies, such as release workflows, continuous integration and QC, and setting up data pipelines. Also helps with bulk editing activities.
Principal Investigators (PI): Manage the projects that fund ontology curation activities.
For an effective management of an ontology, the following criteria are recommended:
There should be at least one Principal Ontology Editor for every ontology project. The importance is not whether this editor (or sometimes called 'ontology curator') has a specific number of hours per week allocated to the project (although based on our experience, 1 day per week is minimum), but whether the editor has a sense of ownership, i.e. they understand that they are the primary responsible person for maintaining the ontology moving forward. Because of potential grant overlapping issues, we recommend to have at least 1 Principal Ontology Editor for every grant/funded project that has a stake in the ontology.
Every effective ontology needs at least a few hours per week from an Ontology Pipeline Developer (OPD). More on that role later. The OPD does not always have as strong a sense of ownership of the ontology project, but typically has a strong sense of responsibility to members of the curation team.
There should be separate meetings for curation and technical activities - both problems are hard, and need different team members being present. We recommend at least monthly technical and biweekly curation calls, but for many of the most effective ontology projects we manage, weekly technical and weekly curation calls are normal.
Without the above minimum criteria, the following recommendations will be very hard to implement.
We make use of three tools in the following recommendation:
Project boards: Project boards, sometimes referred to as Kanban boards, GitHub boards or agile boards, are a great way to organise outstanding tickets and help maintain a clear overview of what work needs to be done. They are usually realised with either GitHub projects or ZenHub. If you have not worked with project boards before, we highly recommend watching a quick tutorial on Youtube, such as:
GitHub teams. GitHub teams, alongside with organisations, are a powerfull too to organise collaborative workflows on GitHub. They allow you to communicate and organise permissions for editing your ontology in a transparent way. You can get a sense of GitHub teams by watching one of the the numerous tutorials on GitHub, such as:
Markdown-based documentation system. Writing great documentation is imperative for a sustainable project. Across many of our recent projects, were are using mkdocs, which we have also integrated with the Ontology Development Kit, but there are others to consider. We deeply recommend to complete a very short introduction to Markdown, this tutorial on YouTube.
"},{"location":"tutorial/managing-ontology-project/#what-do-you-need-for-your-project","title":"What do you need for your project?","text":"
Every ontology or group of related ontologies (sometimes it is easier to manage multiple ontologies at once, because their scope or technical workflows are quite uniform or they are heavily interrelated) should have:
at least two teams, an Editorial Team and a Technical Team, with clearly defined members. We recommend to create two teams on GitHub and keep their members always up to date (i.e. remove members that are not actively participating), but many of our projects merely maintain a \"core team\", which is a more liberal team containing everyone from stakeholders, principal investigators, editors and users (for managing write permissions see later in the \"best practice\" section) and listing the members of the Editorial and Technical Teams on a page in the documentation (example). Note that it is a good idea to be careful of who on your team has \"admin\" rights on your repo, so sometimes, a distinct \"admin\" team can be very helpful. Admins are allowed to do \"dangerous\" things like deleting the repository.
two distinct project boards. We recommend two distinct project boards, one for the Curation/Editorial Team, and one for the Technical Team. The details on how to design the boards is up to the respective teams, but we found a simple 4 stage board with sections for To Do (issues that are important but not urgent), Priority (issues that are important and urgent), In Progress (issues that are being worked on) and Under review (issues that need review). From years of experience with project boards, we recommend against the common practice of keeping a Backlog column (issues that are neither important nor urgent nor likely to be addressed in the next 6 months), nor a Done column (to keep track of closed issues) - they just clutter the view.
A documentation system (often realised using mkdocs in OBO projects) with a page listing the members of the team (example). This page should provide links to all related team pages from Github and their project boards, as well as a table listing all current team members with the following information:
Name
ORCiD
Funding Information
Allocated FTEs (0 if on volunteering basis)
Associated teams
Role
Responsibilities (What kind of issues can they be assigned to review? How are they involved in the Project?)
Effective Ontology Pipeline Developers (OPDs) are extremely rare and are typically active across many different projects. Therefore their attention is scattered. Understanding and accepting this is key for the following points.
Principal Investigators explicitly assign target weekly hours for Ontology Editors and Ontology Pipeline Developers to the project. These should be captured on the documentation systems team page (see above).
The Ontology Editors are responsible for the entire Curation Team Board and the To Do and Priority columns of the Technical Team. The later is important: it is the job of the curation team to prioritise the technical issues. The Technical Team can add tickets to the To Do and Priority columns, but this usually happens only in response to a request from the Curation Team.
When the technical team meets, the Principal Ontology Editor(s) (POE) are present, i.e. the POEs are members of the technical team as well. They will help clarifying the Priority tickets. The Technical Team is responsible to
assign issues and reviewers among themselves (ideally, the reviewer should be decided at the same time the issue is assigned)
move issues from the Priority to the In Progress and later to the Done section.
communicate through the POE to the PIs when resources are insufficient to address Priority issues.
The Principal Ontology Editor is responsible for ensuring that new issues on the issue tracker are dealt with. Usually this happens in the following ways:
They ensure that each external issue (i.e. an issue from anyone outside the core team) is (a) responded to in a polite manner and (b) assigned to someone appropriate or politely rejected due to lack of resources.
They ensure that each internal issue is assigned to the person that made them. No issue should appear unassigned.
The ensure that pull requests are (a) assigned to someone to handle and (b) merged in a timely manner. Too many open PRs cause problems with conflicts.
The To Do issues should first be moved to the Priority section before being addressed. This prevents focusing on easy to solve tickets in favour of important ones.
Even if Google Docs are used to manage team meetings, at the end of each meetings all open issues must be captured as GitHub tickets and placed in the appropriate box on the board. We recommend that Backlog items are not added at all to the board - if they ever become important, they tend to resurface all by themselves.
The single most important point of failure is the absence of an Principal Ontology Editor with a strong sense of ownership. This should be the projects priority to determine first.
All new members of the project should undergo an onboarding. It is a good idea to prepare walkthroughs of the project (as video or pages in the documentation system) covering everything from Curation to Technical and Project Management.
The Principal Ontology Editor responsible for dealing with external issues should be named explicitly on the team page.
We recommend the following practices for write permissions:
The main (formerly master) branch should be write protected with suitable rules. For example, requiring QC to pass and 1 approving review as a minimum.
The curation and technical teams are mainly for social organisation, they do not have to physically exist. However, having a small team with \"admin rights\" and a team (e.g. the core team mentioned above) with \"write\" rights greatly helps with organising the permissions in a transparent manner.
"},{"location":"tutorial/managing-ontology-releases-odk/","title":"Managing Ontology Releases with the Ontology Development Kit","text":"
In this tutorial, we discuss the general workflow of ontology releases.
Follow instructions for the PATO release process here.
"},{"location":"tutorial/migrating-ontology-to-odk/","title":"Migrating your old Ontology Release System to the Ontology Development Kit","text":"
Content TBP, recording exists on request.
"},{"location":"tutorial/monarch-kg-neo4j-basics/","title":"Neo4j tutorial","text":""},{"location":"tutorial/monarch-kg-neo4j-basics/#running-locally-your-very-own-monarch-graph","title":"Running locally (your very own Monarch Graph)","text":"
The new Monarch Knowledge Graph has a more streamlined focus on the core Monarch data model, centering on Diseases, Phenotypes and Genes and the associations between them. This has the benefit of being a graph that can be build in 2 hours instead of 2 days, and that you can run locally on your laptop.
Note: As of the writing of this tutorial, (Feb 2023), the graph is just starting to move from its initial construction phrase into real use, and so there are still bugs to find. Some of which show up in this tutorial.
"},{"location":"tutorial/monarch-kg-neo4j-basics/#check-out-the-repository","title":"Check out the repository","text":"
Download monarch.neo4j.dump from data.monarchinitiative.org and put in the dumps directory
"},{"location":"tutorial/monarch-kg-neo4j-basics/#set-up-the-environment-file","title":"Set up the environment file","text":"
copy dot_env_template to .env and edit the values to look like:
# This Environment Variable file is referenced by the docker-compose.yaml build\n\n# Set this variable to '1' to trigger an initial loading of a Neo4j dump\nDO_LOAD=1\n\n# Name of Neo4j dump file to load, assumed to be accessed from within\n# the 'dumps' internal Volume path within the Docker container\nNEO4J_DUMP_FILENAME=monarch-kg.neo4j.dump\n
That should mean uncommenting DO_LOAD and NEO4j_DUMP_FILENAME
"},{"location":"tutorial/monarch-kg-neo4j-basics/#optional-plugin-setup","title":"Optional Plugin Setup","text":"You may wish to install additional plugins
#### Download plugins * Download the [APOC plugin jar file](https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/download/4.4.0.13/apoc-4.4.0.13-all.jar) and put in the `plugins` directory * Download, the [GDS plugin](https://graphdatascience.ninja/neo4j-graph-data-science-2.3.0.zip), unzip the download and copy jar file to the `plugins` directory #### Environment setup In addition to the changes above to .env, you will need to uncomment the following lines in the .env file:
"},{"location":"tutorial/monarch-kg-neo4j-basics/#tutorials","title":"Tutorials","text":""},{"location":"tutorial/monarch-kg-neo4j-basics/#monarch-obo-training-tutorials","title":"Monarch OBO training Tutorials","text":""},{"location":"tutorial/monarch-kg-neo4j-basics/#querying-the-monarch-kg-using-neo4j","title":"Querying the Monarch KG using Neo4J","text":""},{"location":"tutorial/monarch-kg-neo4j-basics/#start-neo4j","title":"Start Neo4j","text":"
On the command line, from the root of the monarch-neo4j repository you can launch the neo4j with:
docker-compose up\n
"},{"location":"tutorial/monarch-kg-neo4j-basics/#querying","title":"Querying","text":""},{"location":"tutorial/monarch-kg-neo4j-basics/#return-details-for-a-single-disease","title":"Return details for a single disease","text":"
Nodes in a cypher query are expressed with () and the basic form of a query is MATCH (n) RETURN n. To limit the results to just our disease of interest, we can restrict by a property, in this case the id property.
MATCH (d {id: 'MONDO:0007038'}) RETURN d\n
This returns a single bubble, but by exploring the controls just to the left of the returned query, you can see a json or table representation of the returned node.
"},{"location":"tutorial/monarch-kg-neo4j-basics/#connections-out-from-our-disease","title":"Connections out from our disease","text":"
Clicking back to the graph view, you can expand to see direct connections out from the node by clicking on the node and then clicking on the graph icon. This will return all nodes connected to the disease by a single edge.
Tip: the node images may not be labeled the way you expect. Clicking on the node reveals a panel on the right, clicking on that node label at the top of the panel will reveal a pop-up that lets you pick which property is used as the caption in the graph view.
"},{"location":"tutorial/monarch-kg-neo4j-basics/#querying-for-connections-out-from-our-disease","title":"Querying for connections out from our disease","text":"
In cypher, nodes are represented by () and edges are represented by [] in the form of ()-[]-(), and your query is a little chance to express yourself with ascii art. To get the same results as the expanded graph view, you can query for any edge connecting to any node. Note that the query also asks for the connected node to be returned.
MATCH (d {id: 'MONDO:0007038'})-[]-(n) RETURN d, n\n
"},{"location":"tutorial/monarch-kg-neo4j-basics/#expanding-out-further-and-restricting-the-relationship-direction","title":"Expanding out further and restricting the relationship direction","text":"
It's possible to add another edge to the query to expand out further. In this case, we're adding a second edge to the query, and restricting the direction of the second edge to be outgoing. This will return all nodes connected to the disease by a single edge, and then all nodes connected to those nodes by a single outgoing edge. It's important to note that without limiting the direction of the association, this query will traverse up, and then back down the subclass tree.
MATCH (d {id: 'MONDO:0007038'})-[]->(n)-[]->(m) RETURN d,n,m\n
"},{"location":"tutorial/monarch-kg-neo4j-basics/#exploring-the-graph-schema","title":"Exploring the graph schema","text":"
Sometimes, we don't know what kind of questions to ask without seeing the shape of the data. Neo4j provides a graph representation of the schema by calling a procedure
CALL db.schema.visualization\n
If you tug on nodes and zoom, you may find useful information, but it's not a practical way to explore the schema.
"},{"location":"tutorial/monarch-kg-neo4j-basics/#whats-connected-to-a-gene","title":"What's connected to a gene?","text":"
We can explore the kinds of connections available for a given category of node. Using property restriction again, but this time instead of restricting by the ID, we'll restrict by the category. Also, instead of returning nodes themselves, we'll return the categories of those nodes.
MATCH (g:`biolink:Gene`)-[]->(n) RETURN DISTINCT labels(n)\n
Tip: the DISTINCT keyword is used to remove duplicate results. In this case, we're only interested in the unique categories of nodes connected to genes.
"},{"location":"tutorial/monarch-kg-neo4j-basics/#also-how-is-it-connected","title":"Also, how is it connected?","text":"
Expanding on the query above, we can also return the type of relationship connecting the gene to the node.
MATCH (g:`biolink:Gene`)-[rel]->(n) RETURN DISTINCT type(rel), labels(n)\n
Note: the DISTINCT keyword will only remove duplicate results if the entire result is the same. In this case, we're interested in the unique combinations of relationship type and node category.
"},{"location":"tutorial/monarch-kg-neo4j-basics/#kinds-of-associations-between-two-entity-types","title":"Kinds of associations between two entity types","text":"
Further constraining on the type of the connecting node, we can ask what kinds of associations exist between two entity types. For example, what kinds of associations exist between genes and diseases?
MATCH (g:`biolink:Gene`)-[rel]->(n:`biolink:Disease`) RETURN DISTINCT type(rel)\n
"},{"location":"tutorial/monarch-kg-neo4j-basics/#diseases-associated-with-a-gene","title":"Diseases associated with a gene","text":"
MATCH (g:`biolink:Gene`{id:\"HGNC:1100\"})-[]-(d:`biolink:Disease`) RETURN g,d\n
"},{"location":"tutorial/monarch-kg-neo4j-basics/#phenotypes-associated-with-diseases-associated-with-a-gene","title":"Phenotypes associated with diseases associated with a gene","text":"
MATCH (g:`biolink:Gene`{id:\"HGNC:1100\"})-[]->(d:`biolink:Disease`)-[]->(p:`biolink:PhenotypicFeature`) RETURN g,d,p\n
Why doesn't this return results? This is a great opportunity to track down an unexpected problem.
First, try a less constrained query, so that the 3rd node can be anything:
MATCH (g:`biolink:Gene`{id:\"HGNC:1100\"})-[]->(d:`biolink:Disease`)-[]->(p) RETURN g,d,p\n
With a little tugging and stretching, a good picture emerges, and by clicking our phenotype bubbles, they look like they're showing as PhenotypicQuality rather than PhenotypicFeature. This is likely a bug, but a sensible alternative for this same intent might be:
MATCH (g:`biolink:Gene`{id:\"HGNC:1100\"})-[]->(d:`biolink:Disease`)-[:`biolink:has_phenotype`]->(p) RETURN g,d,p\n
Sometimes, we don't know the specific number of hops. What if we want to answer the question \"What genes affect the risk for an inherited auditory system disease?\"
First, lets find out how are diseases connected to one another. Name the relationship to query for just the predicates.
MATCH (d:`biolink:Disease`)-[rel]-(d2:`biolink:Disease`) RETURN DISTINCT type(rel)\n
(* Please ignore biolink:gene_associated_with_condition and biolink:risk_affected_by showing up here, those are due to a bug in our OMIM ingest)
We'll construct a query that fixes the super class disease, then connects at any distance to any subclass of that disease, and then brings genes that affect risk for those diseases. To avoid a big hairball graph being returned, we can return the results as a table showing the diseases and genes.
MATCH (d:`biolink:Disease`{id:\"MONDO:0002409\"})<-[:`biolink:subclass_of`*]-(d2:`biolink:Disease`)<-[`biolink:risk_affected_by`]-(g:`biolink:Gene`) RETURN d.id, d.name, d2.id, d2.name,g.symbol,g.id\n
once you trust the query, you can also use the DISTINCT keyword again focus in on just the gene list
MATCH (d:`biolink:Disease`{id:\"MONDO:0002409\"})<-[:`biolink:subclass_of`*]-(d2:`biolink:Disease`)<-[`biolink:risk_affected_by`]-(g:`biolink:Gene`) RETURN DISTINCT g.id\n
"},{"location":"tutorial/monarch-kg-neo4j-basics/#gene-to-gene-associations","title":"Gene to Gene Associations","text":"
First, we can ask what kind of associations we have between genes.
MATCH (g:`biolink:Gene`)-[rel]->(g2:`biolink:Gene`) RETURN DISTINCT type(rel)\n
Again, please ignore biolink:gene_associated_with_condition and biolink:risk_affected_by.
Let's say that from the list above, we're super interested in the DIABLO gene, because, obviously, it has a cool name. We can find it's orthologues by querying through the biolink:orthologous_to relationship.
MATCH (g {id:\"HGNC:21528\"})-[:`biolink:orthologous_to`]-(o:`biolink:Gene`) RETURN g,o
We can then make the question more interesting, by finding phenotypes associated with these orthologues.
MATCH (g {id:\"HGNC:21528\"})-[:`biolink:orthologous_to`]-(og:`biolink:Gene`)-[:`biolink:has_phenotype`]->(p) RETURN g,og,p\n
That was a dead end. What about gene expression?
MATCH (g {id:\"HGNC:21528\"})-[:`biolink:orthologous_to`]-(og:`biolink:Gene`)-[:`biolink:expressed_in`]->(a) RETURN g,og,a\n
We can add this one step further by connecting our gene expression list in UBERON terms
MATCH (g {id:\"HGNC:21528\"})-[:`biolink:orthologous_to`]-(og:`biolink:Gene`)-[:`biolink:expressed_in`]->(a)-[`biolink:subclass_of`]-(u) WHERE u.id STARTS WITH 'UBERON:'\nRETURN distinct u.id, u.name\n
In particular, it's a nice confirmation to see that we started at the high level MONDO term \"inherited auditory system disease\", passed through subclass relationships to more specific diseases, connected to genes that affect risk for those diseases, focused on a single gene, and were able to find that it is expressed in the cochlea.
"},{"location":"tutorial/odk-toolbox/","title":"Using the ODK Toolbox","text":"
This tutorial will show you how to use the tools that are made available by the ODK Docker images, independently of an ODK-generated repository and of ODK-managed workflows.
Let\u2019s check which Docker images, if any, are available in your Docker installation:
$ docker images\nREPOSITORY TAG IMAGE ID CREATED SIZE\n
Here, the listing comes up empty, meaning there are no images at all. This is what you would expect if you have just installed Docker and have yet to do anything with it.
Let\u2019s download the main ODK image:
$ docker pull obolibrary/odkfull\nUsing default tag: latest\nlatest: Pulling from obolibrary/odkfull\n[\u2026 Output truncated for brevity \u2026]\nDigest: sha256:272d3f788c18bc98647627f9e6ac7311ade22f35f0d4cd48280587c15843beee\nStatus: Downloaded newer image for obolibrary/odkfull:latest\ndocker.io/obolibrary/odkfull:latest\n
Let\u2019s see the images list again:
$ docker images\nREPOSITORY TAG IMAGE ID CREATED SIZE\nobolibrary/odkfull latest 0947360954dc 6 months ago 2.81GB\n
Docker images can exist in several versions, which are called tags in Docker parlance. In our pull command, since we have not specified any tag, Docker had automatically defaulted to the latest tag, which by convention is the latest ODK release.
To download a specific version, append the tag after the image name (you can check which tags are available on DockerHub). For example, let\u2019s download the 1.3.1 release from June 2022:
$ docker pull obolibrary/odkfull:v1.3.1\nv1.3.1: Pulling from obolibrary/odkfull\nDigest: sha256:272d3f788c18bc98647627f9e6ac7311ade22f35f0d4cd48280587c15843beee\nStatus: Downloaded newer image for obolibrary/odkfull:v1.3.1\ndocker.io/obolibrary/odkfull:v1.3.1\n
Again, let\u2019s see the output of docker images:
$ docker images\nREPOSITORY TAG IMAGE ID CREATED SIZE\nobolibrary/odkfull latest 0947360954dc 6 months ago 2.81GB\nobolibrary/odkfull v1.3.1 0947360954dc 6 months ago 2.81GB\n
Note how both the latest and the v1.3.1 images have the same ID. This is because, at the time of this writing, the 1.3.1 release is the latest ODK release, so the latest tag actually points to the same image as the v1.3.1 tag. This will change when the ODK v1.3.2 is released: then, using latest (explicitly or by not specifying any tag at all) will point to the new release, while v1.3.1 will forever continue to point to the June 2022 release.
In the rest of this tutorial, we will always use the latest image, and so we will dispense with the explicit tag. But remember that anywhere you see obolibrary/odkfull in one of the commands below, you can always use obolibrary/odkfull:TAG to force Docker to use a specific ODK version.
"},{"location":"tutorial/odk-toolbox/#starting-a-container","title":"Starting a container","text":"
Now that we have the ODK image available, let\u2019s try to start it. The command for that is docker run, which has the following syntax:
docker run [OPTIONS] <IMAGE> [COMMAND [ARGUMENTS...]]\n
where IMAGE is the name of the image to use (in our case, always obolibrary/odkfull).
With the ODK, you will always need the --rm option. It instructs the Docker engine to automatically remove the container it creates to run a command, once that command terminates. (Not using the --rm option would lead to those \u201cspent\u201d containers to accumulate on your system, ultimately forcing you to manually remove them with the docker container rm command.)
If we don\u2019t specify an explicit command, the simplest command line we can have is thus:
$ docker run --rm obolibrary/odkfull\nUsage: odk.py [OPTIONS] COMMAND [ARGS]...\n\nOptions:\n --help Show this message and exit.\n\nCommands:\n create-dynfile For testing purposes\n create-makefile For testing purposes\n dump-schema Dumps the python schema as json schema.\n export-project For testing purposes\n seed Seeds an ontology project\n$\n
In the absence of an explicit command, the default command odk.py is automatically invoked by Docker. Since it has been invoked without any argument, odk.py does nothing but printing its \u201cusage\u201d message before terminating. When it terminates, the Docker container terminates as well, and we are back at the terminal prompt.
To invoke one of the tools available in the toolbox (we\u2019ll see what those tools are later in this document), just complete the command line as needed. For example, to test that ROBOT is there (and to see which version we have):
$ docker run --rm obolibrary/odkfull robot --version\nROBOT version 1.9.0\n
"},{"location":"tutorial/odk-toolbox/#accessing-your-files-from-within-the-container","title":"Accessing your files from within the container","text":"
Since we have ROBOT, let\u2019s use it. Move to a directory containing some ontology files (here, I\u2019ll use a file from the Drosophila Anatomy Ontology, because if you have to pick an ontology, why not picking an ontology that describes the One True Model Organism?).
$ ls\nfbbt.obo\n
We want to convert that OBO file to a file in, say, the OWL Functional Syntax. So we call ROBOT with the appropriate command and options:
$ docker run ---rm obolibrary/odkfull robot convert -i fbbt.obo -f ofn -o fbbt.ofn\norg.semanticweb.owlapi.io.OWLOntologyInputSourceException: java.io.FileNotFoundException: fbbt.obo (No such file or directory)\nUse the -vvv option to show the stack trace.\nUse the --help option to see usage information.\n
Huh? Why the \u201cNo such file or directory\u201d error? We just checked that fbbt.obo is present in the current directory, why can\u2019t ROBOT find it?
Because Docker containers run isolated from the rest of the system \u2013 that\u2019s kind of the entire point of such containers in general! From within a container, programs can, by default, only access files from the image from which the container has been started.
For the ODK Toolbox to be at all useful, we need to explicitly allow the container to access some parts of our machine. This is done with the -v option, as in the following example:
$ docker run --rm -v /home/alice/fbbt:/work [\u2026rest of the command omitted for now\u2026]\n
This -v /home/alice/fbbt:/work has the effect of binding the directory /home/alice/fbbt from our machine to the directory /work inside the container. This means that if a program that runs within the container tries to have a look at the /work directory, what this program will actually see is the contents of the /home/alice/fbbt directory. Figuratively, the -v option opens a window in the container\u2019s wall, allowing to see parts of what\u2019s outside from within the container.
With that window, and assuming our fbbt.obo file is within the /home/alice/fbbt directory, we can try again invoking the conversion command:
This time, ROBOT was able to find out fbbt.obo file, and to convert it as we asked.
We can slightly simplify the last command line in two ways.
First, instead of explicitly specifying the full pathname to the current directory (/home/alice/fbbt), we can use the shell variable $PWD, which is automatically expanded to that pathname: -v $PWD:/work.
Second, to avoid having to explicitly refer to the /work directory in the command, we can ask the Docker engine to run our command as if the current directory, within the container, was already /work. This is done with the -w /work option.
This is the typical method of invoking a tool from the ODK Toolbox to work on files from the current directory.
In fact, this is exactly how the src/ontology/run.sh wrapper script, that is automatically created in an ODK-generated repository, works. If you work with an ODK-managed ontology, you can invoke an arbitrary ODK tool by using the run.sh instead of calling docker run yourself. Assuming for example that you already are in the src/ontology directory of an ODK-managed ontology, you could use:
If you want to use the ODK toolbox with ontologies that are not managed by the ODK (so, where a run.sh script is not readily available), you can set up an independent wrapper script, as explained in the Setting up the ODK tutorial.
"},{"location":"tutorial/odk-toolbox/#running-a-shell-session-within-the-container","title":"Running a shell session within the container","text":"
If you have several commands to invoke in a row involving files from the same directory, you do not have to repeatedly invoke docker run once for each command. Instead, you can invoke a shell, from which you will be able to run successively as many commands as you need:
The -ti options allow to use your current terminal to control the shell that is started within the container. This is confirmed by the modified prompt that you can see above, which indicates that you are now \u201cin\u201d the container. You can now directly use all the tools that you need:
When you are done, exit the shell by hitting Ctrl-D or with the exit command. The shell will terminate, and with it, the container will terminate as well, sending you back to your original terminal.
"},{"location":"tutorial/odk-toolbox/#whats-in-the-toolbox-actually","title":"What\u2019s in the toolbox, actually?","text":"
Now that you know how to invoke any tool from the ODK Toolbox, here\u2019s a quick overview of which tools are available.
For a definitive list, the authoritative source is the ODK repository, especially the Dockerfile and requirements.txt.full files. And if you miss a tool that you think should be present in the toolbox, don\u2019t hesitate to open a ticket to suggest that the tool be added in a future ODK release!
"},{"location":"tutorial/odk-toolbox/#programming-language-and-associated-tools","title":"Programming language and associated tools","text":"
"},{"location":"tutorial/odk-tutorial-2/","title":"ODK in 20 minutes: a complete walk through the core workflows","text":"
The goal of this tutorial is to quickly showcase key ODK workflows. It is not geared at explaining individual steps in detail. For a much more detailed tutorial for creating a fresh ODK repo, see here for a tutorial for setting up your first workflow. We recommend to complete this tutorial before attempting this one.
Download an example ODK config or create one yourself. Save it in the directory created above.
Important: in the cato-odk.yaml change github_org to your GitHub username. If you dont do this, some ODK features wont work perfectly, like documentation.
Open the term file src/ontology/imports/cob_terms.txt in your favourite text editor
Add COB:0000082 to the term file (this is the planned process class in COB).
From within the src/ontology directory, run sh run.sh make refresh-cob.
Inspect the diff. Rather than importing just one term, it seems that we have important a whole bunch. This is because by default, ODK is using the SLME module extraction technique, which ensures that not only the terms we explicitly request are imported - but all the logically dependent ones as well.
In src/ontology/cato-odk.yaml, locate the entry for importing cob and switch it to a different module type: filter.
Run sh run.sh make update_repo to apply the changes. Check out the git diff to the Makefile to convince yourself that the new extraction method has been applied.
Let us refresh the COB import again: From within the src/ontology directory, run sh run.sh make refresh-cob. Convince yourself that now only the planned process term is imported.
Great, we have done our change, now we are ready to make a release!
Switch to the main branch in git.
Make sure you you pull all changes (git pull).
In src/ontology execute the release workflow: sh run.sh make prepare_release_fast (we are using fast release here which skips refreshing imports again - we just did that).
Inspect the changes. You should see that the planned process class has been added to all ontology release artefacts.
Create a branch and commit the changes. Push. Create pull request. Request review (skipped in this tutorial). Wait for QC to pass. Merge.
On GitHub (repository front page), click on \"Create a new release\".
In the next Window in the \"Choose a tag\" field select v2022-09-01. Note the leading v. Select the correct date (the date you made the release, YYYY-MM-dd). Fill in all the other form elements as you see fit. Click Publish release.
With our ODK setup, we also have a completely customisable documentation system installed. We just need to do a tiny change to the GitHub pages settings:
On your GitHub repo page, click on \"Settings\".
In the menu on the left, click on \"Pages\".
On the right, under Build and deployment select Deploy from branch.
Underneath, select gg-pages as the branch (this is where ODK deploys to), and /(root) as the directory.
Hit Save.
Wait for about 4 minutes for the site to be deployed (you can click on Actions in the main menu to follow the build process).
Go back to the Pages section in Settings. You should see a button Visit site. Click on it. If everything went correctly, you should see your new page:
Let's make a quick change: On the main page, click on the pen in the top right corner (this only works if you have correctly configured your github_org, see seeding). If you have not configured your repo, go to the GitHub front page of your repo, go into the docs directory, click on index.md and edit it from here. Make a small random edit.
Commit the change straight to main or do it properly, create a branch, PR, ask for reviews, merge.
After the ODK updates your site, you should be able to see your changes reflected on the life site!
A project ontology, sometimes and controversially referred to as an application ontology, is an ontology which is composed of other ontologies for a particular use case, such as Natural Language Processing applications, Semantic Search and Knowledge Graph integration. A defining feature of a project ontology is that it is not intended to be used as a domain ontology. Concretely, this means that content from project ontologies (such as terms or axioms) is not to be re-used by domain ontologies (under no circumstances). Project ontology developers have the freedom to slice & dice, delete and add relationships, change labels etc as their use case demands it. Usually, such processing is minimal, and in a well developed environment such as OBO, new project ontology-specific terms are usually kept at a minimum.
In this tutorial, we discuss the fundamental building blocks of application ontologies and show you how to build one using the Ontology Development Kit as one of several options.
Understand how to plan a project ontology project independent of any particular methodology
Develop an application ontology using the Ontology Development Kit (ODK)
Be aware off pitfalls when dealing with very large application ontologies
"},{"location":"tutorial/project-ontology-development/#table-of-contents","title":"Table of Contents","text":"
Why do we need project ontologies?
Overview
The three \"ingredients\" of project ontologies
The five \"phases\" of project ontology development
"},{"location":"tutorial/project-ontology-development/#why-do-we-need-project-ontologies","title":"Why do we need project ontologies?","text":"
There are a few reasons for developing project ontologies. Here are two that are popular in our domain:
Semantic integration. You have curated a lot of data using standard ontologies and now you wish to access this data using the \"semantic fabric\" provided by the ontology. Concrete examples:
Adding a \"semantic layer to your knowledge graph\". For example, your data is annotated using specific anatomy terms, and you wish to query your knowledge graph through anatomical groupings, such as \"anatomical entities that are part of the cardio-vascular system\".
Offering \"semantic search\". For example, you may want to restrict a certain search widget to \"diseases\" only, or try to figure out whether a user is searching for phenotypes associated with diseases. A concrete example is populating a Solr or elastic-search index using not only the labels and synonyms of an ontology, but also their relationships. Try it: https://platform.opentargets.org/, https://monarchinitiative.org/.
Example ontologies:
https://github.com/monarch-initiative/phenio
https://github.com/EBISPOT/efo
https://github.com/EBISPOT/scatlas_ontology
Natural language processing (NLP). You are developing an NLP application such as an annotator for text. Here, you may like to use ontologies to tag specific phrases in your documents, like those related to COVID. Ontologies in these cases serve essentially as more or less sophisticated dictionaries. But there are some more sophisticated uses of ontologies for NER.
Example ontologies:
https://github.com/berkeleybop/bero
https://github.com/EBISPOT/covoc
Mapping work. When developing mappings across ontologies and terminologies, it is often useful to have access to all of them at once. This helps to explore the consequences of mapping decisions, as well providing a single interface for ontology matching tools which usually operate on single ontologies. Advanced Machine Learning based approaches are used to generate graph embeddings on such merged ontologies. Example ontologies:
"},{"location":"tutorial/project-ontology-development/#basic-architecture","title":"Basic architecture","text":""},{"location":"tutorial/project-ontology-development/#three-ingredients-of-project-ontologies","title":"Three \"ingredients\" of project ontologies","text":"
Any application ontology will be concerned with at least 3 ingredients:
The seed. This is a the set of terms you wish to import into your application ontology. The seed can take many forms:
a simple list of terms, e.g. MONDO:123, MONDO:231
a list of terms including additional relational selectors, e.g. MONDO:123, incl. all children
a list of terms including a logical selector, MONDO:123, incl. all terms that are in some way logically related to MONDO:123
a general selector, like \"all classes\" or simply \"everything\".
There are probably more, but these are the main ones we work with in the context of biomedical application ontologies.
The source ontologies, often referred to as \"mirrors\" (at least by those working with ODK). These are the full ontologies which we want to use in our application ontology. For example, we may want to include anatomical entities from the Uberon ontology into our application ontology. These are usually downloaded from the internet into the application ontology workspace, and then processed by the application ontology extraction workflow (see later).
Additional ontology metadata and customisations, such as axioms used to connect entities (classes) across your source ontologies to fulfil a use case, but also your regular ontology metadata (title, comments, etc).
"},{"location":"tutorial/project-ontology-development/#the-five-phases-of-project-ontology-development","title":"The five \"phases\" of project ontology development","text":"
There are five phases on project ontology development which we will discuss in detail in this section:
Managing the seed
Extracting modules
Managing metadata and customisations
Merging and post-processing
Validation
There are other concerns, like continuous integration (basically making sure that changes to the seed or project ontology pipelines do not break anything) and release workflows which are not different from any other ontology.
"},{"location":"tutorial/project-ontology-development/#managing-the-seed","title":"Managing the seed","text":"
As described above, the seed is the set of terms that should be extracted from the source ontologies into the project ontology. The seed comprises any of the following:
terms, such as MONDO:0000001
selectors, such as all, children, descendants, ancestors, annotations
combinations of the two (a term with all its children)
Users of ODK will be mostly familiar with term files located in the imports directory, such as src/ontology/imports/go_terms.txt. Selectors are usually hidden from the user by the ODK build system, but they are much more important now when building project ontologies.
Regardless of which system you use to build your project ontology, it makes sense to carefully plan your seed management. In the following, we will discuss some examples:
Using annotated data. For the Single Cell Atlas Ontology (SCAO) we already have a spreadsheet with the raw data, annotated with the ontology terms we wish to import. We only want to import these exact terms. Our strategy therefore is to extract the ontology terms from table and use these as our seed.
User requests. For the Experimental Factor Ontology (EFO), we rely on user requests. Curators provide us with individual term requests, or lists of terms they need for curating their data. We usually include these terms along with their parents to maintain rich hierarchies.
Use case specific considerations. For the Phenomics Integrated Ontology (PHENIO) we wish to combine all disease, phenotype and anatomy terms together and furthermore pull in related chemicals and biological processes (and more).
It makes sense to document your seed management plan. You should usually account for the possibility of changes (terms being added or removed) during the design phase.
Module extraction is the process for selecting an appropriate subset from an ontology. There are many ways to extracting subsets from an ontology:
Using logical modules (SLME, pronounced 'slime'): this will allow you to extract not only all the terms in your seed, but furthermore all logical axioms that could theoretically impact reasoning. SLME modules are typically much larger than what you would expect from a 'relevant' subset.
Using ROBOT filter, a system to first select entities in your seed, then selectively including or excluding descendants, annotations.
Using MIREOT, a technique that will extract terms and their subClass relationships, without any attempt to include other kinds of axioms.
You can consult the ROBOT documentation for some details on module extraction.
Let's be honest - none of these module extraction techniques are really ideal for project ontologies. SLME modules are typically used for domain ontology development to ensure logical consistency with imported ontologies, but otherwise contain too much information (for most project ontology use cases). ROBOT filter has a hard time with dealing with closures of existential restrictions: for example you cant be sure that, if you import \"endocardial endothelium\" and \"heart\" using filter, that the one former is still part of the latter (it is only indirectly a part) - a lot of research and work has being going on to make this easier. The next version of ROBOT (1.8.5) is going to contain a new module extraction command which will ensure that such links are not broken.
One of the design confusions in this part of the process is that most use cases of application ontologies really do not care at all about OWL. Remember, OWL really only matters for the design of domain ontologies, to ensure a consistent representation of the domain and enable reasoning-based classification. So it is, at least slightly, unsatisfactory that we have to use OWL tools to do something that may as well be done by something simpler, more akin to \"graph-walking\".
"},{"location":"tutorial/project-ontology-development/#managing-metadata-and-customisations","title":"Managing metadata and customisations","text":"
Just like any other ontology, a project ontology should be well annotated according to the standards of FAIR Semantics, for example using the OBO Foundry conventions. In particular, project ontologies should be
annotated with a title, a license, a description
versioned and annotated with versionIRIs
get associated with some PURL system (OBO Foundry often wont accept such ontologies, but other free options like https://w3id.org/ exist)
Furthermore, it is often necessary to add additional terms to the ontology which are not covered by other upstream ontologies. Here we need to distinguish two cases:
The need to quickly add terms that belong somewhere else
Adding terms that have no obvious home in any of your declared source ontologies.
With our OBO hat on, if you start adding terms \"quickly\", you should develop a procedure to get these terms into suitable upstream ontologies at a later stage. This is not so much a necessity as a matter of \"open data ethics\": if you use other people's work to make your life easier, its good to give back!
Lastly, our use cases sometimes require us to add additional links between the terms in our ontologies. For example, we may have to add subClassOf links between classes of different ontologies that cover the same domain. Or we want to add additional information. As with \"quickly adding terms\", if the information is generally useful, you should consider to add them to the respective upstream source ontology (synonyms of disease terms from Mondo, for example). We often manage such axioms as ROBOT templates and curate them as simple to read tables.
"},{"location":"tutorial/project-ontology-development/#merging-and-post-processing","title":"Merging and post-processing","text":"
Just like with most ontologies, the last part of the process is merging the various pieces (modules from external sources, customisations, metadata) together into a single whole. During this phase a few things can happen, but these are the most common ones:
Merging: All separate parts are merged into one file.
Restructure: Sometimes, we run additional processes to update the structure of the final ontology. One common post-processing step is to remove obsolete classes that may have come in during the extraction phase, add additional links between classes using approaches such as relation graph or prune away unsatisfiability-causing axioms such as disjointness axioms and negation. The latter is sometimes necessary when terms from multiple logically incompatible ontologies are imported.
Annotate version information: owl:versionInfo and versionIRI annotations are added to the merged ontology.
One thing to remember is that you are not building a domain ontology. You are usually not concerned with typical issues in ontology engineering, such as logical consistency (or coherence, i.e. the absence of unsatisfiable classes). The key for validating an application ontology comes from its intended use case: Can the ontology deliver the use case it promised? There are many approaches to ensure that, chief among them competency questions. What we usually do is try to express competency questions as SPARQL queries, and ensure that there is at least one result. For example, for one of the project ontologies the author is involved with (CPONT), we have developed a synthetic data generator, which we combine with the ontology to ask questions such as: \"Give me all patients which has a recorded diagnosis of scoliosis\" (SPARQL). So the ontology does a \"good job\" if it is able to return, say, at least 100 patients in our synthetic data for which we know that they are diagnoses with scoliosis or one of its subtypes.
"},{"location":"tutorial/project-ontology-development/#frameworks-for-building-project-ontologies","title":"Frameworks for building project ontologies","text":"
The perfect framework for building project ontologies does not exist yet. The Ontology Development Kit (ODK) has all the tools you need set up a basic application ontology, but the absence of a \"perfect\" module extraction algorithm for this use case is still unsatisfactory. However, for many use cases, filter modules like the ones described above are actually good enough. Here we will go through a simple example.
An alternative framework for application ontology development based on a Web User Interface and tables for managing the seed is developed by James Overton at (ontodev).
Another potential alternative is to go all the way to graph-land and build the application ontology with KGX and LinkML. See here for an example. Creating a project ontology this way feels more like a Knowledge Graph ETL task than building an ontology!
"},{"location":"tutorial/project-ontology-development/#example-application-ontology-with-odk","title":"Example application ontology with ODK","text":"
Set up a basic ODK ontology. We are not covering this again in this tutorial, please refer to the tutorial on setting up your ODK repo.
"},{"location":"tutorial/project-ontology-development/#dealing-with-large-imports","title":"Dealing with large imports","text":"
Many of the larger imports in application ontologies do not fit into the normal GitHub file size limit. In this cases it is better to attach them to a GitHub release rather than to check them into version control.
TBD
"},{"location":"tutorial/project-ontology-development/#additional-materials-and-resources","title":"Additional materials and resources","text":"
Participants will need to have access to the following resources and tools prior to the training:
GitHub account - register for a free GitHub account here
Install GitHub Desktop Please make sure you have some kind of git client installed on your machine. If you are new to Git, please install GitHub Desktop
"},{"location":"tutorial/pull-requests/#tutorials","title":"Tutorials","text":""},{"location":"tutorial/pull-requests/#monarch-obo-training-tutorials","title":"Monarch OBO training Tutorials","text":""},{"location":"tutorial/pull-requests/#pull-requests-part-1","title":"Pull Requests Part 1","text":""},{"location":"tutorial/pull-requests/#pull-requests-part-2","title":"Pull Requests Part 2","text":""},{"location":"tutorial/pull-requests/#how-to-create-a-really-good-pull-request","title":"How to create a really good pull request","text":""},{"location":"tutorial/pull-requests/#what-is-a-pull-request","title":"What is a Pull Request?","text":"
A pull request (PR) is an event in Git where a contributor (you!) asks a maintainer of a Git repository to review changes (e.g. edits to an ontology file) they want to merge into a project (e.g. the owl file) (see reference). A contributor creates a pull request to propose and collaborate on changes to a repository. These changes are proposed in a branch, which ensures that the default branch only contains finished and approved work. See more details here.
"},{"location":"tutorial/pull-requests/#how-to-write-a-great-descriptive-title","title":"How to write a great descriptive title","text":"
When committing a pull request, you must include a title and a description (more details in the workflow below.) Tips below (adapted from Hugo Dias):
The title of the PR should be self-explanatory
Do: Describe what was changed in the pull request
Example: Add new term: MONDO:0100503 DPH5-related diphthamide-deficiency syndrome`
Don't: write a vague title that has very little meaning.
Example: Add new term
Don't: use the branch name in the pull request (sometimes GitHub will offer this as a default name)
Example: issue-5024
"},{"location":"tutorial/pull-requests/#what-kind-of-information-to-include-in-the-description","title":"What kind of information to include in the description","text":"
Describe what was changed in the pull request
Explain why this PR exists
Make it clear how it does what it sets out to do. E.g., Does it edit the ontology-edit.owl file? Does it edit another file(s)?
What was your motivation for the chosen solution?
Use screenshots to demonstrate what has changed. See How to guide on creating screenshots
Follow the Single Responsibility Principle: The pull request should do only one thing.
Note: sometimes a small edit can change a lot of code, for example, if you want to change all of the created_by annotations to dc:creator. That's okay.
The pull request should be atomic: it should be small and self contained with simple changes that affect a little code a possible
Whenever possible, break pull-requests into smaller ones
Commit early, commit often
Include specific information like the ID and label for terms changed. Note, you can easily obtain term metadata like OBO ID, IRI, or the term label in Protege by clicking the three lines above the Annotations box (next to the term name), see screenshot below. You can also copy the IRI in markdown, which is really convenient for pasting into GitHub.
Don't:
Make additional changes on a single PR that goes beyond the scope of the ticket or PR. For example, if you are adding a new term, don't also fix definitions or formatting for other terms.
"},{"location":"tutorial/pull-requests/#github-pull-request-workflow","title":"GitHub Pull Request Workflow","text":""},{"location":"tutorial/pull-requests/#update-the-local-copy-of-the-ontology","title":"Update the local copy of the ontology","text":"
In GitHub Desktop, navigate to your local ontology directory of your ontology
Make sure you are on the master/main branch and click Pull origin (or Fetch origin)
"},{"location":"tutorial/pull-requests/#create-a-new-working-branch","title":"Create a New Working Branch","text":"
When starting to work on a ticket or making edits to an ontology, you should create a new branch of the repository to edit the ontology file.
Make sure you are on the master branch before creating a new branch. Please do not create a new branch off of an existing branch (unless the situation explicitly calls for it).
To create a new branch, click on Current Branch and select New Branch
Name your branch. Some recommended best practices for branch name are to name the branch after the issue number, for example issue-206. If you are not addressing a ticket per se, you could name the branch: 'initals-edits-date', e.g. nv-edits_2022-07-12, or give it a name specific to what you are doing, e.g. fix-typos-2022-07-12.
"},{"location":"tutorial/pull-requests/#continuing-work-on-an-existing-working-branch","title":"Continuing work on an existing Working Branch","text":"
If you are continuing to do work on an existing branch, in addition to updating master, go to your branch by selecting Current Branch in GitHub Desktop and either search for or browse for the branch name.
OPTIONAL: To update the working branch with respect to the current version of the ontology, select Branch from the top menu, Update from master. This step is optional because it is not necessary to work on the current version of the ontology; all changes will be synchronized when git merge is performed.
"},{"location":"tutorial/pull-requests/#editing-an-ontology-on-a-branch","title":"Editing an ontology on a branch","text":"
Create a new branch, open Protege. Protege will display your branch name in the lower left corner (or it will show Git: master)
Make necessary edits in Protege.
"},{"location":"tutorial/pull-requests/#committing-pushing-and-making-pull-requests","title":"Committing, pushing and making pull requests","text":"
Review: GitHub Desktop will display the diff or changes made to the ontology.
Before committing, view the diff and ensure the changes were intended. Examples of a diff are pasted below. Large diffs are a sign that something went wrong. In this case, do not commit the changes and ask for help instead or consider discarding your changes and starting the edits again. To discard changes, right click on the changed file name and select Discard changes.
Example diffs:
Example 1 (Cell Ontology):
Example 2 (Mondo):
"},{"location":"tutorial/pull-requests/#write-a-good-commit-messages","title":"Write a good commit messages","text":"
Commit message: Before Committing, you must add a commit message. In GitHub Desktop in the Commit field in the lower left, there is a subject line and a description.
Give a very descriptive title: Add a descriptive title in the subject line. For example: add new class ONTOLOGY:ID [term name] (e.g. add new class MONDO:0000006 heart disease)
Write a detailed summary of what the change is in the Description box, referring to the issue. The sentence should clearly state how the issue is addressed.
NOTE: You can use the word \u2018fixes\u2019 or \u2018closes\u2019 in the commit message - these are magic words in GitHub; when used in combination with the ticket number, it will automatically close the ticket. Learn more on this GitHub Help Documentation page about Closing issues via commit messages.
\u2018Fixes\u2019 and \u201cCloses\u2019 is case-insensitive and can be plural or singular (fixes, closes, fix, close).
If you don\u2019t want to close the ticket, just refer to the ticket # without the word \u2018fixes\u2019 or use \u2018adresses\u2019 or 'addresses'. The commit will be associated with the correct ticket but the ticket will remain open.
Push: To incorporate the changes into the remote repository, click Commit to [branch name], then click Push.
"},{"location":"tutorial/pull-requests/#make-a-pull-request-pr","title":"Make a pull request (PR)","text":"
You can either make a pull request (PR) directly from GitHub Desktop, or via the GitHub web browser.
To make a PR from GitHub Desktop, click the button 'Create Pull Request'. You will be directed to your web browser and GitHub repo.
Click Create Pull Request.
If your PR is a work-in-progress and not ready for review, you can save it as a draft PR and convert it to a PR when it is ready for review.
If you do not create a PR directly from GitHub Dekstop, you can go to your GitHub repo and you will see a yellow banner on top that notifies you of a pending PR.
Navigate to the tab labeled as \u2018Code\u2019. You should see your commit listed at the top of the page in a light yellow box. If you don\u2019t see it, click on the \u2018Branches\u2019 link to reveal it in the list, and click on it.
Click the green button \u2018Compare & pull request\u2019 on the right.
You may now add comments, if applicable and request a reviewer. See section below on reviewers.
You can see the diff for your file by clicking 'Files Changed'. Examine it as a sanity check.
Go back to the Conversation tab.
Click on the green box \u2018Pull request\u2019 to generate a pull request.
"},{"location":"tutorial/pull-requests/#how-to-find-a-reviewer-for-your-pull-request-in-an-open-source-environment","title":"How to find a reviewer for your pull request in an open source environment","text":"
Publicly managed ontologies do not have a structure in place to automatically deal with PRs.
If you make a PR to an open source project, you should open a separate social channel to the developers to notify them of your PR (e.g. find the project mailing list, Slack, etc.). You should introduce yourself and give some context.
Depending on the level of your permissions for the repository, you may or may not be able to assign a reviewer yourself.
If you have write access to the repository, you can assign a reviewer.
Otherwise, you can tag people in the description of your pull request.
Tips for finding reviewers:
An ontology repository should have an owner assigned. This may be described in the ReadMe file or on the OBO Foundry website. For example, the contact person for Mondo is Nicole Vasilevsky.
The primary owner can likely review your PR or triage your request to the appropriate person.
If you are addressing a specific ticket, you may want to assign the person who created the ticket to review.
"},{"location":"tutorial/pull-requests/#how-to-review-a-pull-request-pr","title":"How to review a pull request (PR)","text":"
If you are assigned to review a pull request, you should receive an email notification. You can also check for PRs assigned to you by going to https://github.com/pulls/assigned.
"},{"location":"tutorial/pull-requests/#what-kind-of-person-do-we-need-for-what-kind-of-pull-request","title":"What kind of person do we need for what kind of pull request?","text":"
It depends on what the pull request is addressing. Remember the QC checks will check for things like unsatisfiable classes and many other checks (that vary between ontologies). Your job as a reviewer is to check for things that the QC checks won't pick up and need human judgement.
If it is content changes, like adding new terms, or reclassifying a term, an ontology curator could review your PR.
If the PR is addressing quality control or technical aspects, one of the ontology semantic engineers would probably be a good fit.
If you don't know who to assign, we recommend assigning the ontology contact person and they can triage the request.
To review a PR, you should view the 'Files changed' and view the diff(s). You can review changes in a pull request one file at a time.
While reviewing the files in a pull request, you can leave individual comments on specific changes.
Example:
"},{"location":"tutorial/pull-requests/#things-to-look-out-for-when-reviewing-a-pr","title":"Things to look out for when reviewing a PR:","text":"
Make sure the changes made address the ticket. In the example above, Sabrina addressed a ticket that requested adding a new term to Mondo, which is what she did on the PR (see https://github.com/monarch-initiative/mondo/pull/5078).
Examples of things to look for in content changes (like adding new terms or revising existing terms):
Poorly written definitions
Missing or misformatted database cross-references
Incorrectly scoped synonyms
appropriate annotations
Make sure there are not any unintended or unwanted changes on the PR. See example below. Protege reordered the location of a term in the file.
Check that the logic is correct. This can be a difficult thing to do. Some tips:
Open the branch in Protege and examine the hierarchy in Protege
Compare the logic that was use to the logic used in an existing term
If the ontology uses Design Patterns, ensure the logic is consistent with the Design Patterns
Ask an expert in ontology logic to help review the PR
Remember there is no magic bullet to ensuring an ontology is logically sound, but do the best you can
"},{"location":"tutorial/pull-requests/#adding-your-review","title":"Adding your review","text":"
After you finish reviewing each file, you can mark the file as viewed. This collapses the file, helping you identify the files you still need to review.
A progress bar in the pull request header shows the number of files you've viewed.
You can leave comments and requests for changes on the PR inline for on the PR when viewing the 'Files changed'.
You can add a single comment, or start a review if you have multiple comments.
After reviewing the file(s), you can approve the pull request or request additional changes by submitting your review with a summary comment.
Comment (Submit general feedback without explicit approval)
Approve (Submit feedback and approve merging these changes)
Request changes (Submit feedback that must be addressed before merging)
In addition or instead of adding inline comments, you can leave comments on the Conversation page. The conversation page is a good place to discuss the PR, and for the original creator to respond to the reviewer comments.
GitHub added a 'suggested Changes' feature that allows a PR reviewer to suggest an exact change in a comment in a PR. You can add inline comments and commit your comment using 'inline commits'. Read more about it here.
Go to the 'Files changed' tab of a pull request
Hover over the line you want to fix, and a blue box with a plus sign appears near the gutter on the left
Click that to display the normal line comment form
Click the button with a plus and minus sign, it adds a suggestion block to the comment text area with the existing text
You can make changes to the text inside the suggestion box. Note that you can add context for your suggested changes outside of the suggestion block
When you create the comment, it will show up to the maintainer as a diff
The maintainer can see what changes you are suggesting and accept them with a click
"},{"location":"tutorial/pull-requests/#when-are-you-done-with-your-review","title":"When are you done with your review?","text":"
If you review the PR and the changes properly address what was described in the description, then it should be sufficient. Not every PR needs comments, it can be approved without any comments or requests for changes. Feel free to ask for help with your review, and/or assign additional reviewers.
Some of the content above was adapted from GitHub Docs.
"},{"location":"tutorial/pull-requests/#how-to-change-a-pull-request-in-response-to-review","title":"How to change a pull request in response to review","text":"
Check out your branch in GitHub Desktop and open the file in Protege.
Make the suggested changes.
Check the diff.
Commit your changes on your branch.
Note, you do not need to create another PR, your commits will show up on the same PR.
Resolve the comments on the PR.
Notify the reviewer that your PR is ready for re-review.
"},{"location":"tutorial/pull-requests/#how-to-update-from-master","title":"How to update from master","text":"
In GitHub Desktop, navigate to your branch.
In the top file menu, select Branch -> Update from master.
"},{"location":"tutorial/pull-requests/#resolve-conflicts-on-branch","title":"Resolve conflicts on branch","text":"
Conflicts arise when edits are made on two separate branches to the same line in a file. (reference). When editing an ontology file (owl file or obo file), conflicts often arise when adding new terms to an ontology file on separate branches, or when there are a lot of open pull requests.
Conflicts in ontology files can be fixed either on the command line or using GitHub Desktop. In this lesson, we describe how to fix conflicts using GitHub Desktop.
"},{"location":"tutorial/pull-requests/#fix-conflicts-in-github-desktop","title":"Fix conflicts in GitHub desktop","text":"
In GitHub Desktop, go to your master/main branch and fetch pull.
Go to branch with conflict.
Pull branch.
Branch -> update from master.
Open in Sublime or Atom.
Make changes in file (open the ontology file in a text editor (like Sublime) and search for the conflicts. These are usually preceded by <<<<<. Fix the conflicts, then save).
In GitHub Desktop, continue merge.
Push.
In terminal: open [ontology file name] (e.g.open mondo-edit.obo) or open in Protege manually.
Save as (nothing should have changed in the diff).
"},{"location":"tutorial/pull-requests/#the-anatomy-of-a-perfect-pull-request","title":"The anatomy of a perfect pull request","text":"
Blog post by Hugo Dias
"},{"location":"tutorial/pull-requests/#suggesting-changes-on-github-includes-description-of-how-to-make-inline-commits","title":"Suggesting Changes on GitHub - includes description of how to make inline commits","text":""},{"location":"tutorial/robot-tutorial-1/","title":"ROBOT Mini-Tutorial 1: Convert, Extract and Template","text":"
This tutorial covers three ROBOT commands:
Convert
Extract
Template
Before starting this tutorial, either:
make sure Docker is running and you are in the container
download and install ROBOT for your operating system
We will be using the files from the Ontologies 101 Tutorial. In your terminal, navigate to the repository that you cloned and then into the BDK14_exercises folder.
So far, we have been saving our ontologies in Protege using the default RDF/XML syntax, but there are many flavors of OWL. We will discuss each of these serializations in more detail during the class session, but ROBOT supports the following:
Navigate to the basic-subclass/ folder. Open chromosome-parts.owl in your text editor and you will see it's in RDF/XML format. We're going to take this file and convert it to Turtle (ttl) serialization. Return to your terminal and enter the following command:
ROBOT convert is smart about detecting formats, so since the output file ends with .ttl, the --format ttl parameter isn't really required. If you wanted to use a different file ending, say .owl, you will need to include the format flag to force ROBOT to write Turtle.
Now open chromosome-parts.ttl in your text editor and see what's changed! RDF/XML and Turtle are very different serializations, but the actual data that is contained in these two files is exactly the same.
"},{"location":"tutorial/robot-tutorial-1/#on-your-own","title":"On Your Own","text":"
Convert chromosome-parts.owl into the following formats: obo (OBO Format), ofn (OWL Functional), and omn (OWL Manchester).
Open each file and take a minute to scroll through (we don't expect you to be able to read these, they're mostly meant for computers!)
Why do you think we need these different serializations? What do you think the purpose of OWL Manchester vs. RDF/XML is?
Sometimes we only want to browse or share a subset of an ontology, especially with some of the larger OBO Foundry ontologies. There are two main methods for creating subsets:
MIREOT
SLME
Right now, we will use use MIREOT and talk more about SLME in our class session. MIREOT makes sure that you have the minimal amount of information you need to reuse an existing ontology term. It allows us to extract a small portion of the class hierarchy by specifying upper and lower boundaries, which you will see in the example below. We need to know the identifiers (as CURIEs) of the terms that we want to set as our boundaries.
Open chromosome-parts.owl in Protege and open the Class hierarchy. We are going to create a subset relevant to the term \"chromosome\". First, we will find the CURIE of our desired term. Search for \"chromosome\" and find the \"id\" annotation property. This will be our lower term. Right now, we won't set an upper boundary. That means this subset will go all the way up to the top-level ancestor of \"chromosome\".
Return to your terminal and enter the following command (where the --lower-term is the CURIE that we just found):
Now open chromosome-full.owl in Protege and open the Class hierarchy. When you open the \"cellular_component\" node, you'll notice that most of the terms are gone! Both \"organelle\" and \"intracellular part\" remain because they are in the path between \"chromosome\" and the top-level \"cellular_component\". Keep clicking down and you'll find \"chromosome\" at the very bottom. Since \"chromosome\" has two named parents, both of those parents are included, which is why we ended up with \"organelle\" and \"intracellular part\".
Now let's try it with an upper term. This time, we want \"organelle\" to be the upper boundary. Find the CURIE for \"organelle\".
Return to your terminal and enter the following command (where the --upper-term is the new CURIE we just found):
Open chromosome.owl and again return to the Class hierarchy. This time, we see \"organelle\" directly below owl:Thing. \"intracellular part\" is also now missing because it does not fall under \"organelle\".
"},{"location":"tutorial/robot-tutorial-1/#on-your-own_1","title":"On Your Own","text":"
Play with different upper- and lower-level terms to create different subsets
Compare the terms that are in the subsets to the terms in the original chromosome-parts.owl file.
What is missing from the terms in the subsets? What has been included as our \"minimal\" information?
Most of the knowledge encapsulated in ontologies comes from domain experts. Often, these domain experts are not computer scientists and are not familiar with the command line. Luckily, most domain experts are familiar with spreadsheets!
ROBOT provides a way to convert spreadsheets into OWL ontologies using template strings. We'll get more into these during the class session, but if you want to get a head start, they are all documented here. Essentially, the first row of a ROBOT template is a human-readable header. The second row is the ROBOT template string. Each row below that represents an entity to be created in the output ontology. We can create new entities by giving them new IDs, but we can also reference existing entities just by label. For now, we're going to create a new, small ontology with new terms using a template.
Download (or copy/paste) the animals.tsv file and move it to the basic-subclass/ folder (or whatever folder you would like to work in; we will not be using any of the Ontology 101 files anymore). This contains the following data:
CURIE Label Parent Comment ID LABEL SC % A rdfs:comment obo:0000001 animal Any animal in the world. obo:0000002 canine animal A member of the genus Canis. obo:0000003 feline animal A member of the genus Felis.
In the first column, we use the special ID keyword to say that this is our term's unique identifier. The second column contains the LABEL keyword which is a shortcut for the rdfs:label annotation property. The third column uses the SC keyword to state that this column will be a subclass statement. The % sign is replaced by the value in the cell. We'll talk more about this keyword and the % symbol during the class session. Finally, the last column begins with A to denote that this will be an annotation, and then is followed by the annotation property we're using.
Just looking at the template, you can begin to predict what a class hierarchy using these terms would look like in an ontology. We can turn this into reality!
Note that in this command, we don't use the --input parameter. That parameter is reserved for input ontologies, and we are not using one right now. More on this later.
Open animals.owl in Protege, and you'll be able to see the class hierarchy we defined in the template as an actual structure.
Now let's make another small ontology that reuses some terms from our animals.owl file. Download (or copy/paste) animals2.tsv into the same folder. This contains the following:
CURIE Label Parent Comment ID LABEL SC % A rdfs:comment obo:0000004 dog canine A member of the subspecies Canis lupus familiaris. obo:0000005 cat feline A member of the species Felis catus.
You'll notice that we are referencing two terms from our other spreadsheet in this one.
This time, we did use the --input parameter and provided the animals ontology we just created. This allows us to use any term in the animals.owl file in our animals2.tsv template and ROBOT will know what we're talking about.
Go ahead and open animals2.owl in Protege. What's missing? The parent classes for \"dog\" and \"cat\" don't have labels, and the \"animal\" term is missing entirely. This is because, even though ROBOT knew about these classes, we didn't ask for the original ontology to be included in the output, so no axioms from that ontology can be found in this newly-created one. Next week, we'll learn about combining ontologies with the Merge command.
For now, let's add the original animals.owl file as an import:
Go to the \"Active ontology\" tab and find the \"Imported ontologies\" section at the bottom
Click the + next to \"Direct imports\"
Select \"Import an ontology contained in a local file\" and click Continue
Browse for the path to animals.owl, click Continue, and then click Finish
Prot\u00e9g\u00e9 will now load animals.owl as an import. When you return to the Entities tab, you'll see all those upper-level terms. Note the difference in how the terms are displayed in the class hierarchy.
"},{"location":"tutorial/robot-tutorial-1/#on-your-own_2","title":"On Your Own","text":"
Try adding another class or two to the animals.tsv template and regenerating animals.owl.
Can you create your own template?
"},{"location":"tutorial/robot-tutorial-2/","title":"ROBOT Tutorial 2: Annotate, Merge, Reason and Diff","text":"
In week 6, we got some hands-on experience with ROBOT using convert, extract, and template. This week, we will learn four new ROBOT commands:
Annotate
Merge
Reason
Diff
The goal of these and previous commands is to build up to creating an ontology release workflow.
Before starting this tutorial, either:
make sure Docker is running and you are in the container
download and install ROBOT for your operating system
To start, we will be working in the same folder as the first ROBOT Mini-Tutorial. Navigate to this folder in your terminal and list the contents of the current directory by running ls. You should see catalog-v001.xml listed as one of these files. We want to delete this so that we can fix the ontology IRI problem we ran into last week! Before going any further with this tutorial, do this by running either del catalog-v001.xml for Windows or rm catalog-v001.xml if you're using Docker, MacOS, or other Linux system.
The annotate command allows you to attach metadata to your ontology in the form of IRIs and ontology annotations. Like the annotations on a term, ontology annotations help users to understand how they can use the ontology.
As we discussed during previous parts of the course, ontology IRIs are very important! We saw how importing an ontology without an IRI into another ontology without an IRI can cause some problems in the catalog-v001.xml file. We're going to fix that problem by giving IRIs to both our animals.owl and animals2.owl files.
You'll notice we gave the same file name as the input file; we're just updating our previous file so we don't need to do this in a separate OWL file.
On your own, give animals2.owl the ontology IRI http://example.com/animals2.owl. Remember that, in reality, we always want our ontology IRIs to be resolvable, so these would be pretty bad IRIs for an actual ontology.
Let's fix our import statement now. Open animals2.owl in Prot\u00e9g\u00e9 and go to the Entities tab. You'll see that even though we still have the import statement in the Active ontology tab, the top-level terms are no longer labeled. Since we changed the ontology IRI, Prot\u00e9g\u00e9 can no longer resolve our local file (because the catalog-v001.xml file was not updated). Go back to the Active ontology tab and click the X to the right of our original import. Then, re-add animals.owl as an import using the same steps as last time. When you return to the Entities tab, you'll once again see the labels of the top-level terms.
When we release our ontologies, we want to make sure to include a version IRI. Like the ontology IRI, this should always resolve to the version of the ontology at the time of the release. For clarity, we usually use dates in our version IRIs in the OBO Foundry. That way, you know when you navigate to a specific version IRI, that's what the ontology looked like on that date. (Note: edit files don't usually have version IRIs as they are always changing, and we don't expect to be able to point to a stable version)
While you can add a version IRI in Prot\u00e9g\u00e9, if you're trying to create an automated release workflow, this is a manual step you don't want to have to include. Keeping it in your release workflow also makes sure that the verion IRIs are consistent (we'll see how to do this with make later). For now, let's add a version IRI to animals.owl (feel free to replace the 2021-05-20 with today's date):
Let's break down this version IRI. We have the host (http://example.com/) followed by our ontology's namespace (animals). Next, we provided the date in the format of YYYY-MM-DD. Finally, we have the name of the file. This is standard for OBO Foundry, except with a different host. For example, you can find a release of OBI from April 6, 2021 at http://purl.obolibrary.org/obo/obi/2021-04-06/obi.owl. In this case, the host is http://purl.obolibrary.org/obo/. Of course, you may see different patterns in non-OBO-Foundry ontologies, but they should always resolve (hopefully!).
Go ahead and open or reload animals.owl in Protege. You'll see in the Active Ontology tab that now both the ontology IRI and version IRI fields are filled out.
In addition to ontology and version IRIs, you may also want to add some other metadata to your ontology. For example, when we were introduced to report, we added a description to the ontology to fix one of the report problems. The three ontology annotations that are required by the OBO Foundry are:
Title (dc11:title)
License (dc:license)
Description (dc11:description)
These three annotation properties all come from the Dublin Core, but they have slightly different namespaces. This is because DC is split into two parts: the /terms/ and /elements/1.1/ namespaces. Just remember to double check that you're using the correct namespace. If you click on the DC link, you can find the complete list of DC terms in their respective namespaces.
ROBOT contains some built-in prefixes, which can be found here. The prefix dc: corresponds to the /terms/ namespace and dc11: to /elements/1.1/. You may see different prefixes used (for example, /terms/ is sometimes dcterms: or just terms:), but the full namespace is what really matters as long as the prefix is defined somewhere.
Let's go ahead and add a title and description to our animals.owl file. We'll do this using the --annotation option, which expects two arguments: (1) the CURIE of the annotation property, (2) the value of the annotation. The value of the annotation must be enclosed in double quotes if there are spaces. You can use any annotation property you want here, and include as many as you want! For now, we'll start with two:
--annotation adds these as strings, but remember that an annotation can also point to an link or IRI. We want our license to be a link, so we'll use --link-annotation instead to add that:
OBO Foundry recommends using Creative Commons for all licenses. We just gave our ontology the most permissive of these, CC-BY.
When you open animals.owl in Prot\u00e9g\u00e9 again, you'll see these annotations added to the Active ontology tab. You can also click on the CC-BY link!
We've already learned how to include external ontologies as imports. Usually, for the released version of an ontology, the imports are merged in so that all contents are in one file.
Another reason you may want to merge two ontologies is if you're adding new terms to an ontology using template, like how we created new animal terms in animals2.tsv last time. We're going to demonstrate two methods of merging now. The first involves merging two (or more!) separate files and the second involves merging all imports into the current input ontology.
First, copy animals2.owl to animals-new.owl. In Windows, this command is copy animals2.owl animals-new.owl. For Docker and other Linux operating systems, this is cp animals2.owl animals-new.owl. Open animals-new.owl in Prot\u00e9g\u00e9 and remove the import we added last time. This is done in the Imported ontologies section of the Active ontology tab. Just click the X on the right side of the imported animals ontology. Don't forget to save!
Continuing with the animals.owl file we created last week, now run the following command:
When you just import an external ontology into your ontology, you'll notice in the Prot\u00e9g\u00e9 class hierarchy that all terms from the external ontology are a less-bold text than internal terms. This can be seen when you open animals2.owl, where we imported animals.owl. This is simply Prot\u00e9g\u00e9's way of telling us that these terms are not part of your current ontology. Now that we've merged these two ontologies together, when you open animals-full.owl in Prot\u00e9g\u00e9, you'll see that all the terms are bold.
By default, the output ontology will get the ontology IRI of the first input ontology. We picked animals.owl as our first ontology here because this is the ontology that we're adding terms to, so we want our new output ontology to replace the original while keeping the same IRI. merge will also copy over all the ontology annotations from animals.owl (the first input) into the new file. The annotations from animals2.owl are ignored, but we'll talk more about this in our class session.
If we were editing an ontology in the wild, we'd probably now replace the original with this new file using cp or copy. For now, don't replace animals.owl because we'll need it for this next part.
IMPORTANT: Be very careful to check that the format is the same if you're replacing a file! Remember, you can always output OWL Functional syntax or another syntax by ending your output with .ofn, for example: --output animals-full.ofn.
When we want to merge all our imports into our working ontology, we call this collapsing the import closure. Luckily (since we're lazy), you don't need to type out each of your imports as an input to do this.
We already have animals.owl imported into animals2.owl. Let's collapse the import closure:
Even though we gave this a different file name, if you open animals-full-2.owl in Prot\u00e9g\u00e9, you'll notice that it's exactly the same as animals-full.owl! This is because we merged the same files together, just in a slightly different way. This time, though, the ontology IRI is the one for animals2.owl, not animals.owl. That is because that was our first input file.
As we saw in the prepwork for Week 5, running a reasoner in Prot\u00e9g\u00e9 creates an inferred class hierarchy. In the OBO Foundry, releases versions of ontologies usually have this inferred hierarchy asserted, so you see the full inferred hierarchy when you open the ontology without running the reasoner. ROBOT reason allows us to output a version of the ontology with these inferences asserted.
As we discussed, ELK and HermiT are the two main reasoners you'll be using. Instead of using our example ontologies (the asserted and inferred hierarchies for these will look exactly the same), we're going to use another ontology from the Ontologies 101 tutorial from week 5. Navigate back to that directory and then navigate to BDK14_exercises/basic-classification.
Like running the reasoner in Prot\u00e9g\u00e9, running reason does three things:
Check for inconsistency
Check for unsatisfiable classes
Assert the inferred class hierarchy
Remember, when we run the reasoner in Prot\u00e9g\u00e9, if the ontology is inconsistent, reason will fail. If there are unsatisfiable classes, these will be asserted as owl:Nothing. ROBOT will always fail in both cases, but has some tools to help us figure out why. Let's introduce an unsatifiable class into our test and see what happens.
First, let's make a copy of ubiq-ligase-complex.owl and call this new file unreasoned.owl (copy or cp).
Open unreasoned.owl in Prot\u00e9g\u00e9 and follow the steps below. These are things we've covered in past exercises, but if you get stuck, please don't hesitate to reach out.
Find 'organelle' in the class hierarchy below 'cellular_component' (or just search for it by label)
Make 'organelle' disjoint with 'organelle part' (either use the class hierarchy or type it in the expression editor)
Find 'intracellular organelle part' below 'intracellular part' or 'organelle part' (or search for it by label)
Add 'organelle' as a parent class to 'intracellular organelle part' (remember that you only need to include the single quotes if the label has spaces)
Like we did in the Disjointness part of the Ontologies 101 tutorial, we've made 'intracellular organelle part' a subclass of two classes that should have no overlap based on the disjointness axiom. Save the ontology and return to your terminal. Now, we'll run reason. The default reasoner is ELK, but you can specify the reasoner you want to use with the --reasoner option. For now, we'll just use ELK.
You'll notice that ROBOT printed an error message telling us that the term with the IRI http://purl.obolibrary.org/obo/GO_0044446 is unsatisfiable and ROBOT didn't create unsatisfiable.owl. This is ideal for automated pipelines where we don't want to be releasing unsatisfiable classes.
We can still use ROBOT to investigate the issue, though. It already gave us the IRI, but we can get more details using the --dump-unsatisfiable option. We won't provide an output this time because we know it won't succeed.
You can open unsatisfiable.owl in Prot\u00e9g\u00e9 and see that 'intracellular organelle part' is not the only term included, even though it was the only unsatisfiable class. Like with the SLME method of extraction, all the terms used in unsatisfiable class or classes logic are included in this unsatisfiable module. We can then use Prot\u00e9g\u00e9 to dig a little deeper in this small module. This is especially useful when working with large ontologies and/or the HermiT reasoner, which both can take quite some time. By extracting a smaller module, we can run the reasoner again in Prot\u00e9g\u00e9 to get detailed explanations. In this case, we already know the problem, so we don't need to investigate any more.
Now let's reason over the original ubiq-ligase-complex.owl and see what happens:
If you just open reasoned.owl in Prot\u00e9g\u00e9, you won't really notice a different between this and the input file unless you do some digging. This takes us to our next command...
The diff command can be used to compare the axioms in two ontologies to see what has been added and what has been removed. While the diffs on GitHub are useful for seeing what changed, it can be really tough for a human to read the raw OWL formats. Using ROBOT, we can output these diffs in a few different formats (using the --format option):
plain: plain text with just the added and removed axioms listed in OWL functional syntax (still tough for a human to read, but could be good for passing to other scripts)
pretty: similar to plain, but the IRIs are replaced with CURIEs and labels where available (still hard to read)
html: a nice, sharable HTML file with the diffs sorted by term
markdown: like the HTML diff, but in markdown for easy sharing on platforms like GitHub (perfect for pull requests!)
We're going to generate an HTML diff of ubiq-ligase-complex.owl compared to the new reasoned.owl file to see what inferences have been asserted. diff takes a left (\"original\") and a right (\"new\") input to compare.
Quality control is a very large concern in ontologies. For example, we want to make sure that our editors use the right annotation properties to attach metadata to terms (such as a date, or a label), or to make sure that our last edit did not accidentally introduce a logical error. In ROBOT, we have four commands that help us in particular to ensure the quality of our ontologies:
ROBOT validate-profile: Ensures that your ontology is a syntactically valid OWL ontology.
ROBOT verify: Define \"bad examples\", i.e. situations you want to avoid as SPARQL queries and use verify to ensure they do not appear in your ontology.
ROBOT report: Use dozens of time tested best practice checks curated by the OBO Technical Working Group to check your ontology for typical errors, like missing labels or wrong license declarations.
ROBOT reason: Use reason to ensure that your ontology is consistent and coherent and test the \"unique name assumption\".
In the following, we will learn about all of these and how they fit in the wider concerns of ontology quality control.
"},{"location":"tutorial/robot-tutorial-qc/#download-test-ontology","title":"Download test ontology","text":"
Download example.owl, or get it via the command line:
ROBOT validate-profile: Ensures that your ontology is a syntactically valid OWL ontology. This is the absolute minimum check - some \"violations\" to OWL 2 DL validity cause the reasoner to behave in unexpected and wrong ways!
OWL 2 DL Profile Report: [Ontology and imports closure in profile]\n
This check is overlooked by a lot of OWL Ontology developers despite its importance to ensure both a predictable behaviour of the reasoner and of parsing tools. See here for an example where an ontology was not in OWL DL profile, causing various problems for parsing and computation: https://github.com/Orphanet/ORDO/issues/32.
And it will provide you with a report file, report.html
Let us look at the file in a browser (simply double-click on the html file the way you would open a PDF). Your report should look similar to this:
While there are other formats you can export your report to, HTML is a great format which not only offers useful colour coding, but also allows us to click on the related classes and properties and, more importantly, the checks to find our what they mean (for an overview of all ROBOT report checks see here).
We will leave it to the reader as an exercise to try and fix all the errors indicated by the report!
"},{"location":"tutorial/robot-tutorial-qc/#advanced-usage-of-robot-report","title":"Advanced usage of ROBOT report","text":""},{"location":"tutorial/robot-tutorial-qc/#customisation","title":"Customisation","text":"
While by far the most widely spread usage of ROBOT report is to check for OBO best practices, it is possible to customise the report by removing certain OBO ontology checks and adding custom ones.
Lets first create a simple profile.txt in our directory and add the following lines:
In particular, some checks like missing_superclass which we did not care about for our use case are not shown at all anymore, and others, such as missing_definition are now considered ERROR (red) rather than WARN (warning, yellow) because for our use case, we have decided that definitions on terms are mandatory.
ROBOT verify allows us to define QC checks for undesirable situation (we sometimes call this \"anti-pattern\") using the SPARQL query language. The idea is simple: we write a SPARQL query for the thing we do not want. For example, we can use SPARQL to look for classes with more than one label. Then, we feed this query to ROBOT verify. ROBOT verify than ensures that the query has no answers, i.e the thing we do not want actually does not happen:
Now the cool thing with verify is that we can basically feed SPARQL SELECT queries in whatever shape or form we want. To make error messages more readable for curators, you can even encode a proper error message:
PREFIX owl: <http://www.w3.org/2002/07/owl#>\nPREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>\n\nSELECT DISTINCT ?error WHERE {\n VALUES ?property { rdfs:label }\n ?entity ?property ?value .\n ?entity ?property ?value2 .\n FILTER (?value != ?value2) .\n FILTER NOT EXISTS { ?entity owl:deprecated true }\n FILTER (!isBlank(?entity))\n BIND(CONCAT(\"Entity \",STR(?entity),\" uses two different labels: (1) \",STR(?value),\" and (2) \",STR(?value2)) as ?error)\n}\nORDER BY ?entity\n
This time, when running the query, we get:
FAIL Rule bad_labels.sparql: 2 violation(s)\nerror\nEntity http://purl.obolibrary.org/obo/OBI_0002986 uses two different labels: (1) CT scan and (2) computed tomography imaging assay\nEntity http://purl.obolibrary.org/obo/OBI_0002986 uses two different labels: (1) computed tomography imaging assay and (2) CT scan\n
Which appears much more readable! You can tweak the output in whatever way you think is best. Two things about this:
You cannot do this very well with ROBOT report: despite the ability to include custom queries, all queries must start with:
SELECT DISTINCT ?entity ?property ?value WHERE\n
This is one of the reasons we still like using ROBOT verify, despite the fact that ROBOT report can also be extended with custom checks.
Another cool thing about verify is that you can add the --output-dir results/ parameter to your query to get ROBOT to export the query results as TSV files. This can be useful if you have many QC queries and need to work with them independently of the checks.
Note that ROBOT notices two errors despite there being only 1, technically speaking. This is because the WHERE clause in SPARQL which twice (one where label 1 is first, one where label 2 is first). You can be smart about it and get around it by sorting your results before binding them, but for most use cases this hack is hardly worth the effort.
This is not an exhaustive tutorial for ROBOT reason (for more, see here). We only want to get across two checks that we feel absolutely every ontology developer should know about.
In most cases, we do not want to define the exact same concept twice. There are some exceptions, for example when we align ontologies such as CHEBI and GO which may have overlapping scope, but in 99.9% of the cases, having the reasoner infer that two classes are the same points to a mistake in the axiomatisation. Let us check that we do not have any such unintended equivalencies in our ontology:
ERROR No equivalent class axioms are allowed\nERROR Equivalence: <http://purl.obolibrary.org/obo/TEST_0600047> == <http://purl.obolibrary.org/obo/OBI_0600047>\n
Further investigation in Protege will reveal that TEST_0600047 and OBI_0600047 are subclasses of each other, which causes the reasoner to infer that they are equivalent.
"},{"location":"tutorial/setting-up-project-odk/","title":"Tutorial: How to get started with your own ODK-style repository","text":"
Preparation: Installing docker, installing ODK and setting memory. Follow the steps here.
Creating your first ontology repository
The tutorial uses example tailored for users of UNIX systems, like Mac and Linux. Users of Windows generally have analogous steps - wherever we talk about an sh file in the following there exists a corresponding bat file that can be run in the windows powershell, or CMD.
A recording of a demo of creating a ODK-repo is available here
"},{"location":"tutorial/setting-up-project-odk/#your-first-repository","title":"Your first repository","text":"
Create temporary directory to get started
On your machine, create a new folder somewhere:
cd ~\nmkdir odk_tutorial\ncd odk_tutorial\n
Download the seed-my-repo wrapper script
Now download the seed-my-repo wrapper script from the ODK GitHub repository. A detailed explanation of how to do that can be found here. For simplicity, we just use wget here to download the seed-my-repo file, but you can do it manually:
Download a basic config to start from and start building your own
The last ingredient we need is an ODK config file. While you can, in theory, create an empty repo entirely without a config file (one will be generated for you), we recommend to just start right with one. You can find many examples of configs here. For the sake of this tutorial, we will start with a simple config:
Safe this config file as in your temporary directory, e.g. ~/odk_tutorial/cato-odk.yaml.
Most of your work managing your ODK in the future will involve editing this file. There are dozens of cool options that do magical things in there. For now, lets focus on the most essential:
The id is essential, as it will determine how files will be named, which default term IDs to assume, and many more. It should be a lowercase string which is, by convention at least 4 characters long - 5 is not unheard of. The title field is used to generate various default values in the repository, like the README and others. There are other fields, like description, but let's start minimal for now. A full list of elements can be found in this schema:
The github_org (the GitHub or GitLab organisation) and the repo (repository name) will be used for some basic config of the git repo. Enter your own github_org here rather than obophenotype. Your default github_org is your GitHub username. If you are not creating a new repo, but working on a repo that predates renaming the GitHub main branch from master to main, you may want to set the git_main_branch as well.
With this configuration, we tell the ODK that we wish to automatically generate the base, full and simple release files for our ontology. We also say that we want the primary_release to be the full release (which is also the default). The primary release will be materialised as cato.owl, and is what most users of your ontology will interact with. More information and what these are can be found here. We always want to create a base, i.e. the release variant that contains all the axioms that belong to the ontology, and none of the imported ones, but we do not want to make it the primary_release, because it will be unclassified and missing a lot of the important inferences.
We also configure export products: we always want to export to OWL (owl), but we can also chose to export to OBO (obo) format and OBOGraphs JSON (json).
This is a central part of the ODK, and the section of the config file you will interact with the most. Please see here for details. What we are asking the ODK here, in essence, to set us up for dynamically importing from the Relation Ontology (RO), the Phenotype And Trait Ontology (PATO) and the OBO Metadata Ontology (OMO).
Here we say that we allow ROBOT to consume up to 8GB of memory. Make sure that your docker is set up to permit at least ~20% more memory than that, i.e. 9GB or 10GB, otherwise, some cryptic Docker errors may come up.
If you use GitHub Desktop, you can now simply add this repo by selecting File -> Add local repository and select the directory you moved the repo to (as an aside, you should really have a nice workspace directory like ~/git or ~/ws or some such to organise your projects).
Then click Publish the repository on
"},{"location":"tutorial/setting-up-project-odk/#using-the-command-line","title":"Using the Command Line","text":"
Follow the instructions you see on the Terminal (they are printed after your seed-my-repo run).
Start editing ~/cato/src/ontology/cato-edit.owl using Protege.
Run a release
"},{"location":"tutorial/sparql-report-odk/","title":"Generating SPARQL table reports with ODK","text":"
This tutorial will teach you how to create report tables using SPARQL and the ODK. Report tables are TSV files that can be viewed by programs such as Excel or Google Sheets.
For a tutorial on how to generate reports independent of ODK please see here.
We assume you have a modern ODK-based repository (ODK version >= 1.2.32) set up. For a tutorial on creating a new ontology repo from scratch see here.
Finish the ROBOT tutorial on queries
"},{"location":"tutorial/sparql-report-odk/#tutorial","title":"Tutorial","text":""},{"location":"tutorial/sparql-report-odk/#adding-a-configuration-to-the-odk-yaml-file","title":"Adding a configuration to the ODK YAML file:","text":"
This will tell the ODK that you no longer wish to generate the ODK default reports (synonyms, xrefs, etc), but instead:
One of the custom reports (basic-report)
and a new custom report, called my-cat-report.
Now, we can apply these changes as usual:
sh run.sh make update_repo\n
"},{"location":"tutorial/sparql-report-odk/#adding-the-actual-table-report","title":"Adding the actual table report","text":"
Similar to our ROBOT tutorial on queries, let us now add a simple table report for the terms and labels in our ontology. To do that, let us safe the following file in our src/sparql directory (standard ODK setup), i.e. src/sparql/my-cat-report.sparql (you must use the same name as the one you speciefied in your ODK yaml file above):
Now, let's generate our report (you have to be, as always, in src/ontology/):
sh run.sh make custom_reports\n
This will generate all custom reports you have configured in one go and save them in the src/ontology/reports directory. reports/my-cat-report.tsv looks probably something like this for you:
That is all there is. You can configure as many reports as you want, and they will all be generated with the custom_reports command above, or as part of your ontology releases.
"},{"location":"tutorial/sparql-report-robot/","title":"Generating SPARQL table reports with ROBOT","text":""},{"location":"tutorial/sparql-report-robot/#preparation","title":"Preparation","text":"
Creating table outputs from your ontology helps with many issues, for example during ontology curation (it is often easier to look at tables of related ontology terms rather than a hierarchy), for data aggregation (you want to know how many synonyms there are, and which) and simply to share \"a list of all terms with labels\". There are two major tools to help here:
ROBOT export: Exporting standardised tables for typical use cases, like labels, definitions and similar. For details, please look at the documentation which should provide all the information for producing table reports.
ROBOT query: Generating reports using SPARQL. This is the focus of the tutorial here.
"},{"location":"tutorial/sparql-report-robot/#download-test-ontology","title":"Download test ontology","text":"
Download example.owl, or get it via the command line:
When looking at labels.tsv (in a text editor, or Excel, or whatever table editor you prefer), we notice that some properties are included in our list and decide to change that by restricting the results to classes:
Now, when running the robot query command again, we see only the terms we want.
Note that you could have achieved all this with a simple ROBOT export command. However, there are many cool ways you can tweak your reports when you learn how to build them manually during SPARQL. Your only limit is essentially SPARQL itself, which gives you access too most things in your ontology, aside from perhaps complex logical axioms.
"},{"location":"tutorial/sparql/","title":"Basic SPARQL for OBO Engineers","text":"
In this tutorial we introduce SPARQL, with a particular spin on how we use it across OBO ontologies. Following this tutorial should give you a sense of how we use SPARQL across OBO, without going too much into technical details. You can find concrete tutorials on how to generate reports or QC checks with ROBOT and ODK towards the end of this page.
"},{"location":"tutorial/sparql/#sparql-tools-for-obo-engineers","title":"SPARQL tools for OBO Engineers","text":"
RENCI Ubergraph Endpoint: Many key OBO ontologies are loaded here with lots of materialised inferences (docs).
Ontobee SPARQL endpoint: Useful to run queries across all OBO Foundry ontologies.
Yasgui: Yasgui is a simple and beautiful front-end for SPARQL endpoints which can be used not only to query, but also to share queries with others. For example this simple SPARQL query runs across the RENCI Ubergraph Endpoint.
GTF: A UI that allows one to run SPARQL queries on TTL files on the web, or upload them. Looks like its based on Yasgui, as it shares the same share functionality.
ROBOT query: ROBOT method to generate TSV reports from SPARQL queries, and applying data transformations (--update). ROBOT uses Jena internally to execute SPARQL queries.
ROBOT verify: ROBOT method to run SPARQL QC queries. If the query returns a result, the QC test fails.
ROBOT report: ROBOT report is a more powerful approach to running OBO QC queries. The default OBO report which ships with ROBOT can be customised by changing the error level, removing a test entirely and even extending the report to custom (SPARQL) checks. Robot report can generate beautiful HTML reports which are easy to read.
"},{"location":"tutorial/sparql/#sparql-in-the-obo-sphere","title":"SPARQL in the OBO-sphere","text":"
SPARQL has many uses in the OBO-sphere, but the following in particular:
Quality control checking
Creating summary tables for ontologies
Sophisticated data transformations in ontology pipelines
We will discuss each of these in the following and give examples. An informal discussion of SPARQL in OBO can be followed in video below.
"},{"location":"tutorial/sparql/#quality-control-checking","title":"Quality control checking","text":"
For us, ROBOT + SPARQL were a game changer for our quality control (QC) pipelines. This is how it works. First, we encode the error in the form of a SPARQL query (we sometimes call this \"anti-pattern\", i.e. an undesirable (anti-) representation). For example, the following check simply looks for entities that have more than one definition:
This is a typical workflow. Think of an ontology editor working on an ontology. Often, that curator notices that the same problem happens repeatedly and tell us, the Ontology Pipeline Developer, that they would like a check to prevent the error. We then capture the erroneous situation as a SPARQL query. Then, we add it to our ontology repository, and execute it with ROBOT report or ROBOT verify (see above) in our CI pipelines, usually based on GitHub actions or Travis. Note that the Ontology Development Kit provides a built-in framework for for such queries build on ROBOT verify and report.
"},{"location":"tutorial/sparql/#creating-summary-tables-for-ontologies","title":"Creating summary tables for ontologies","text":"
Many times, we need to create tabular reports of our ontologies to share with stakeholders or to help with internal reviews, e.g.:
create lists of ontology terms with their definitions and labels
create summaries of ontologies, like aggregate statistics
Sometimes using Yasgui, for example in conjunction with the RENCI Ubergraph Endpoint, is enough, but often, using ROBOT query is the better choice, especially if you want to make sure the right version of the ontology is used (Ubergraph occasionally is out of date).
Using ROBOT in conjunction with a Workflows Automation system like Github actions helps with generating up-to-date reports. Here is an example of a GitHub action that generates a few reports with ROBOT and pushes them back to the repository.
"},{"location":"tutorial/sparql/#a-note-for-data-scientists","title":"A note for Data Scientists","text":"
In many cases we are asked how to best \"load an ontology\" into a python notebook or similar. Very often the answer is that it is best to first extract the content of the ontology into a table form, and then load it using a CSV reader like pandas. In this scenario, the workflow for interacting with ontologies is:
Define the information you want in the form of a SPARQL query.
Extract the the information as a TSV table using ROBOT query.
Load the information into your notebook.
If combined with for example a Makefile, you can always ensure that the report generation process is fully reproducible as well.
"},{"location":"tutorial/sparql/#sophisticated-data-transformations-in-ontology-pipelines","title":"Sophisticated data transformations in ontology pipelines","text":"
Lastly, we use ROBOT query to implement complex ontology transformation processes. For example the following complex query transforms related synonyms to exact synonyms if some complex condition is met:
This can be a very useful tool for bulk editing the ontology, in particular where it is difficult or impossible to achieve the same using regular expressions or other forms of \"replacement\"-techniques. Here are some example queries we collected to do such mass operations in Mondo.
"},{"location":"tutorial/sssom-toolkit/","title":"Introduction to the SSSOM Toolkit","text":"
A basic tutorial
Documentation
"},{"location":"tutorial/sssom-tutorial/","title":"Practical introduction to SSSOM","text":""},{"location":"tutorial/sssom-tutorial/#tutorials-and-explainers","title":"Tutorials and Explainers","text":"
The Experimental Factor Ontology: from controlled vocabulary to integrated application ontology driving drug target identification.
+
From barely structured data via data dictionaries to semantic data integration:
+
International HundredK+ Cohorts Consortium (IHCC) data harmonization case study: How to get from messy, individual data dictionaries for COHORT data to an integrated resource for browsing and grouping.
Rare disease registries are scattered across the web and there is no easy way to search across all
+
EJPRD is developing two metadata schemas:
+
On Registry level, they are building the metadata model which is reusing some standard vocabularies such as dcat. There is not that much "semantics" here - it really is a metadata model
The idea is that registries publish their metadata (and eventually data) as linked data that can be easily queried using the above models. One of the most major problems is the size of the project and competing voices ("If its not RDF its not FAIR"), but also the sheer scale of the technical issue: many of the so called registries are essentially excel spreadsheets on an FTP server.
This tutorial is based off https://ontology101tutorial.readthedocs.io/en/latest/DL_QueryTab.html
+Created by: Melissa Haendel, Chris Mungall, David Osumi-Sutherland, Matt Yoder, Carlo Torniai, and Simon Jupp
The DL query tab shown below provides an interface for querying and searching an ontology. The ontology must be classified by a reasoner before it can be queried in the DL query tab.
+
For this tutorial, we will be using cc.owl which can be found here.
+
Open cc.owl in Protege (use Open from URL and enter the https://raw.githubusercontent.com/OHSUBD2K/BDK14-Ontologies-101/master/BDK14_exercises/basic-dl-query/cc.owl). Run the reasoner. Navigate to the DL Query tab.
+
+
Type organelle into the box, and make sure subclasses and direct subclasses are ticked.
+
+
You can type any valid OWL class expression into the DL query tab. For example, to find all classes whose members are part_of a membrane, type part_of some membrane and click execute. Note the linking underscore for this relation in this ontology. Some ontologies do not use underscores for relations, whereby you'd need single quotes (i.e. part of).
+
+
The OWL keyword and can be used to make a class expression that is the intersection of two class expressions. For example, to find the classes in the red area below, we want to find subclasses of the intersection of the class organelle and the class endoplasmic reticulum part
+
+
+
Note that we do not need to use the part grouping classes in the gene ontology (GO). The same results can be obtained by querying for the intersection of the class organelle and the restriction part_of some ER – try this and see.
+
+
We can also ask for superclasses by ticking the boxes as below:
+
+
The or keyword is to used to create a class expression that is the union of two class expressions. For example:
+(WARNING: or is not supported by ELK reasoner)
+
+
This is illustrated by the red area in the following Venn diagram:
+
+
For further exercises, please see https://ontology101tutorial.readthedocs.io/en/latest/EXERCISE_BasicDL_Queries.html
Identify a quality issue in your ontology. For the sake of this tutorial, we've added the annotation oboInOwl:creation_date to the root_node in the CAT Ontology.
+
+
+
+
Write the SPARQL query to detect the error you want to check. For example, check the value type for the annotation oboInOwl:creation_date. It will return the class with the annotation if it's not of type xsd:dateTime.
Save the SPARQL query in the src/sparql folder and name it [violation name]-violation.sparql. In the case of the tutorial, date-as-string-violation.sparql
+
+
+
Add the check to the ODK config file. In the previous tutorial, this is located at ~/cato/src/ontology/cato-odk.yaml. Inside robot_report, add custom_sparql_checks
There are several checks already available in the ODK. If you'd like to add them, add the validation name in your ODK config file.
+
+
owldef-self-reference: verify if the term uses its term as equivalent
+
redundant-subClassOf: verify if there are redundant subclasses between three classes
+
taxon-range: verify if the annotations present_in_taxon or never_in_taxon always use classes from NCBITaxon
+
iri-range: verify if the value for the annotations never_in_taxon, present_in_taxon, foaf:depicted_by, oboInOwl:inSubset and dcterms:contributor are not an IRI
+
iri-range-advanced: same as iri-range plus check for rdfs:seeAlso annotation
+
label-with-iri: verify if there is IRI in the label
+
multiple-replaced_by: verify if an obsolete term has multiple replaced_by terms
+
term-tracker-uri: verify if the value for the annotation term_tracker_item is not URI
+
illegal-date: verify if the value for the annotations dcterms:date, dcterms:issued and dcterms:created are of type xds:date and use the pattern YYYY-MM-DD
+2. Create a SPARQL query with your quality check and save it at src/sparql. There isn't a restriction on the file name. However, it should return the variables ?entity ?property ?value.
+
Add the path to the SPARQL query in the src/ontology/profile.txt file.
+
+
ERROR file:../sparql/<file name>.sparql
+
+For more detail on the profile file, see here.
+
+
Test your check. You'll find the failed cases on the same report for the ROBOT report at src/ontology/reports/cato-edit.owl-obo-report.tsv. The Rule Name will be the SPARQL file name.
+
+
shrun.shmaketest
+
+
How to choose between Custom SPARQL or Custom ROBOT report¶
+
+
If your test can return the exact three variables entity, property and value -> ROBOT report
+
If you need to return more detailed information -> Custom SPARQL
+
If you want the results of your custom tests in the ROBOT report file -> ROBOT report
+
+
Keep in mind that after changing the profile.txt, you won't get any upcoming updates, and you need to update manually.
This tutorial is based off https://ontology101tutorial.readthedocs.io/en/latest/Disjointness.html
+Created by: Melissa Haendel, Chris Mungall, David Osumi-Sutherland, Matt Yoder, Carlo Torniai, and Simon Jupp
+
For this excercise, we will be using chromosome-parts-interim.owl file that can be found here
In the chromosome-parts-interim.owl file, at the top of our class hierarchy we have cell, cell part, chromosomal part, intracellular part, organelle and organelle part. By default, OWL assumes that these classes can overlap, i.e. there are individuals who can be instances of more than one of these classes. We want to create a restriction on our ontology that states these classes are different and that no individual can be a member of more than one of these classes. We can say this in OWL by creating a disjoint classes axiom.
+
If you do not already have it open, load your previous ontology that was derived from the 'interim file'. Note: you can open a recent file by going to File-> Open Recent
+
We want to assert that organelle and organelle part are disjoint. To do this first select the organelle class. In the class 'Description' view, scroll down and select the (+) button next to Disjoint With. You are presented with the now familiar window allowing you to select, or type, to choose a class. In the hierarchy panel, you can use CTRL to select multiple classes. Select 'organelle part' as disjoint with organelle.
+
+
Note that the directionality is irrelevant. Prove this to yourself by deleting the disjoint axiom, and adding it back from organelle part.
We have introduced a deliberate mistake into the ontology. We previously asserted that intracellular organelle part is a subclass of both organelle part and organelle. We have now added an axiom stating that organelle and organelle part are disjoint. We can use the reasoner to check the consistency of our ontology. The reasoner should detect our contradiction.
+
Protégé comes with several reasoners, and more can be installed via the plugins mechanism (see plugins chapter). Select a reasoner from the Reasoner menu (Elk, HermiT, Pellet, or Fact++ will work - we mostly use ELK). Once a reasoner is highlighted, select 'Start reasoner' from the menu. Note: you may get several pop-boxes/warnings, ignore those.
+
The intracellular organelle part class will have changed to red indicating that the class is now unsatisfiable.
+
+
You can also see unsatisfiable classes by switching to the inferred view.
+
+
Here you will a special class called Nothing. When we previously said that all OWL classes are subclasses of OWL Thing. OWL Nothing is a leaf class or bottom class of your ontology. Any classes that are deemed unsatisfiable by the reasoner are shown as subclasses or equivalent to OWL Nothing. The inferred view will show you all subclasses of Nothing.
+
+
Once the ontology is classified, inferred statements or axioms are shown in the various panels with a light-yellow shading. The class description for intracellular organelle part should look something like the screen shot below. You will see that the class has been asserted equivalent to the Nothing class. Inside this statement, a small question mark icon appears, clicking this will get an explanation from the reasoner for this inconsistency.
+
+
Select the (?) icon to get an explanation for this inconsistency. The explanation shows the axioms involved. We see the disjoint class axiom alongside the two subclass axioms are causing the inconsistency. We can simply repair this ontology by removing the intracellular organelle part subClassOf organelle axiom.
+
+
Remove the Disjoint with axiom (click the (x) beside organelle in the Description pane for intracellular organelle part), and resynchronise the reasoner from the reasoner menu.
This is a very unprofessional video below recorded as part of one of our trainings. It walks you through this tutorial here, with some additional examples being given and a bit of Q&A.
Template: A document with template strings that include variables which can be instantiated my a tool. For example, a ROBOT template may contain the template string SC 'part of' some % which can be instantiated by ROBOT to be transformed into an OWL axiom: SubClassOf(CATO:001 ObjectSomeValuesFrom(BFO:0000051 UBERON:123)). Similarly, DOSDP YAML files are often referred to as "templates" (which is appropriate). Unfortunately, we often refer to them as "patterns" which is not strictly the right way to name them: they are templates that encode patterns (and that only to a limited extend). We recommend to refer to the DOSDP YAML files as "templates".
+
Template string: See above: a single string with one or more slots for variables that can be instantiated and transformed into something else. The most important template string in DOSDP is the equivalentTo or subClassOffield: It tells DOSDP tools how to generate an OWL axiom, with which variable slots (vars).
+
Pattern: See above, often misused to mean Template. In fact, a pattern provides a general modelling solution to a problem. Patterns can often be encoded in templates, but this is often incomplete. For example, a template typically does not care about the semantics of the properties it refers to, while this is critical for a pattern. (Avoid using this when talking about DOSDP YAML files).
+
DOSDP template table: The spreadsheet (typically TSV or CSV) that contains the DOSDP variable data. The DOSDP template table is applied to the template string in the template to generate a set of OWL axioms and annotation assertions.
In your src/ontology/{yourontology}-odk.yaml file, simply add the following:
+
use_dosdps:true
+
+
This flag activates DOSDP in ODK - without it, none of the DOSDP workflows in ODK can be used. Technically, this flag tells ODK the following things:
+
+
The src/ontology/Makefile is extended as follows:
+
A set of pipelines, or workflows, for processing patterns, e.g. pattern_schema_checks for validating all DOSDP templates,patterns to regenerate all patterns.
+
A new directory, src/patterns, is created with the following files:
+
src/patterns/pattern.owl: This is an ontology of your own patterns. This can be used to browse the your pattern in the form of a class hierarchy, which can help greatly to understand how they relate logically. There are some flaws in this system, like occasional unintended equivalencies between patterns, but for most uses, it is doing ok.
+
src/patterns/definitions.owl: This is the merged ontology of all your DOSDP generated classes. Basically, if you manage your classes across multiple DOSDP patterns and tables, their generated OWL axioms will all be added to this file.
+
src/patterns/external.txt: This file can be used to import external patterns. Just add the (p)URL to a pattern to the file, and the DOSDP pipeline will import it when you run it. We use this a lot when sharing DOSDP templates across ontologies.
+
Two README files: one in the directory of the default DOSDP data pipeline (src/patterns/data/default/) and one in the src/patterns directory. The former points you to the place where you should put, by default, any DOSDP data tables. More about that in the next sections.
+
+
To fully activate DOSDP in your ontology, please run:
+
sh run.sh make update_repo
+
+
This will:
+
+
Update your ontology repository to whatever ODK you have installed in docker (v1.3, for example)
+
Apply any changes to your configuration file. For example, the fact that you have activated the DOSDP pipeline in your config file will lead to the ODK extending your Makefile in certain ways
(2) Let's also create a simple template table to capture traits for our ontology.
+
Note: the filename of the DOSDP template file (haircoat_colour_pattern.yaml) excluding the extension must be identical
+to the filename of the template table (haircoat_colour_pattern.tsv) excluding the extension.
+
Let's create the new file at src/patterns/data/default/haircoat_colour_pattern.tsv.
We are creating a minimal table here with just two columns:
+
+
defined_class refers to the ID for the term that is being modelled by the template (mandatory for all DOSDP templates)
+
colour_pattern refers to the variable of the same name specified in the vars: section of the DOSDP template YAML file.
+
+
DOSDP generate: Turning the template tables into OWL axioms¶
+
Next, we will get a bit used to various commands that help us with DOSDP-based ontology development.
+
Lets first try to transform the simple table above to OWL using the ODK pipeline (we always use IMP=false to skip refreshing imports, which can be a lengthy process):
+
sh run.sh make ../patterns/definitions.owl -B IMP=false
+
+
This process will will create the ../patterns/definitions.owl file, which is the file that contains all axioms generated by all templates you have configured. In our simple scenario, this means a simple single pattern. Let us look at definitions.owl in your favourite text editor first.
+
Tip: Remember, the `-B` tells `make` to run the make command no matter what - one of the advantages of `make` is that it only runs a command again if something changed, for example, you have added something to a DOSDP template table.
+
+
Tip: Looking at ontologies in text editors can be very useful, both to reviewing files and making changes! Do not be afraid, the ODK will ensure you wont break anything.
+
+
Let us look in particular at the following section of the definitions.owl file:
+
# Class: <http://purl.obolibrary.org/obo/CATO_0000001> (http://purl.obolibrary.org/obo/PATO_0000333 coat of hair)
+
+AnnotationAssertion(<http://purl.obolibrary.org/obo/IAO_0000115> <http://purl.obolibrary.org/obo/CATO_0000001> "A coat of hair with a http://purl.obolibrary.org/obo/PATO_0000333 colour pattern."^^xsd:string)
+AnnotationAssertion(rdfs:label <http://purl.obolibrary.org/obo/CATO_0000001> "http://purl.obolibrary.org/obo/PATO_0000333 coat of hair"^^xsd:string)
+EquivalentClasses(<http://purl.obolibrary.org/obo/CATO_0000001> ObjectIntersectionOf(<http://purl.obolibrary.org/obo/UBERON_0010166> ObjectSomeValuesFrom(<http://purl.obolibrary.org/obo/RO_0000053> <http://purl.obolibrary.org/obo/PATO_0000333>)))
+
+
These are the three axioms / annotation assertions that were created by the DOSDP pipeline. The first annotation is a simple automatically generated definition. What is odd at first glance, is that the definition reads "A coat of hair with a http://purl.obolibrary.org/obo/PATO_0000333 colour pattern." - what does the PATO:0000333 IRI do in the middle of our definition? Understanding this is fundamental to the DODSP pattern workflow, because it is likely that you will have to fix cases like this from time to time.
+
The DOSDP workflow is about generating axioms automatically from existing terms. For example, in this tutorial we are trying to generate terms for different kinds of hair coats for our cats, using the colour pattern (PATO:0001533) hierarchy in the PATO ontology as a basis. The only one term we have added so far is spotted (PATO:0000333). The problem is though, that dosdp-tools, the tool which is part of the ODK and responsible for the DOSDP workflows, does not know anything about PATO:0000333 unless it is already imported into the ontology. In order to remedy this situation, lets import the term:
+
sh run.sh make refresh-pato
+
+
ODK will automatically see that you have used PATO:0000333 in your ontology, and import it for you. Next, let us make sure that the our edit file has the correct import configured. Open your ontology in a text editor, and make sure you can find the following import statement:
Replace cato in the PURL with whatever is the ID of your own ontology. Also, do not forget to update src/ontology/catalog-v001.xml, by adding this line:
Important: Remember that we have not yet told dosdp-tools about the freshly imported PATO:0000333 term. To do that, lets run the DOSDP pipeline again:
+
sh run.sh make ../patterns/definitions.owl -B IMP=false
+
+
A quick look at src/patterns/definitions.owl would now reveal your correctly formatted definitions:
+
AnnotationAssertion(<http://purl.obolibrary.org/obo/IAO_0000115> <http://purl.obolibrary.org/obo/CATO_0000001> "A coat of hair with a spotted colour pattern."^^xsd:string)
+
+
Now, we are ready to view our ontology (the edit file, i.e. src/ontology/cato-edit.owl) in Protege:
+
+
Still a few things to iron out - there is an UBERON term that we still need to import, and our class is not a subclass of the CATO root node, but we had a good start.
Re-using terms is at the heart of the OBO philosophy, but when it comes to re-using axiom patterns, such as the ones we can define as part of a ROBOT template, we are (as of 2022) still in the early stages. One thing we can do to facilitate re-use is to share DOSDP templates between different projects. We do that by simply adding the URL at which the pattern is located to src/patterns/dosdp-patterns/external.txt. Note: if you are copying a URL from GitHub, make sure it is the raw url, i.e.:
Here, we randomly decided to import a pattern defined by the Ontology of Biological Attributes (an ontology of traits such as tail length or head size), for example to represent cat traits in our Cat Ontology. After adding the above URL to our the external.txt file, we can add it to our pipeline:
+
sh run.sh make update_patterns
+
+
You will now see the entity_attribute.yaml template in src/patterns/dosdp-patterns. We will not do anything with this template as part of this tutorial, so you can remove it again if you wish (by removing the URL from the external.txt file and physically deleting the src/patterns/dosdp-patterns/entity_attribute.yaml file).
Sometimes, we want to manage more than one DOSDP pipeline at once. For example, in more than one of our projects, we have some patterns that are automatically generated by software tools, and others that are manually curated by ontology developers. In other use cases, we sometimes want to restrict the pattern pipelines to generating only logical axioms. In either case, we can add new pipelines by adding the following to the src/ontology/youront-odk.yaml file:
Dead Simple OWL Design patterns (DOSDP) is a templating system for documenting and generating new OWL classes. The templates themselves are designed to be human readable and easy to author. Separate tables (TSV files) are used to specify individual classes.
+
The complete DOSDP documentation can be found here http://incatools.github.io/dead_simple_owl_design_patterns/.
A DOSDP tempaltes are written in YAML) file, an easily editable format for encoding nested data structures. At the top level of nesting is a set of 'keys', which must match those specified in the DOSDP standard. The various types of key and their function are outlined below. Each key is followed by a colon and then a value, which may be a text string, a list or another set of keys. Lists items are indicated using a '-'. Nesting is achieved via indenting using some standard number of spaces (typically 3 or 4). Here's a little illustration:
+
key1:some text
+key2:
+-first list item (text; note the indent)
+-second list item
+key3:
+key_under_key3:some text
+another_key_under_key3:
+-first list item (text; note the indent)
+-second list item
+yet_another_key_under_key3:
+key_under_yet_another_key_under_key3:some more text
+
+
In the following text, keys and values together are sometimes referred to as 'fields'.
A major aim of the DOSDP system is to produce self-contained, human-readable templates. Templates need IDs in order to be reliably used programatically, but templates that only use IDs are not human readable. DOSDPs therefore include a set of dictionaries that map labels to IDs. Strictly any readable name can be used, but by convention we use class labels. IDs must be OBO curie style e.g. CL:0000001).
+
Separate dictionaries are required for classes, relations (object properties) & annotationProperties
+e.g.
These fields specify the names of pattern variables (TSV column names) and map these to a range. e.g. This specifies a variable called 'anatomy' with the range 'anatomical entity':
+
vars:
+anatomy:"'anatomicalentity'"
+
+
The var name (anatomy) corresponds to a column name in the table (TSV file) used in combination with this template, to generate new terms based on the template. The range specifies what type of term is allowed in this column - in this case 'anatomical entity' (UBERON:0001062; as specified in the dictionary) or one of its subclasses, e.g.-
vars are used to specify OWL classes (see example above). data_vars and data_list_vars are used to specify single pieces or data lists respectively. The range of data_vars is specified using XSD types. e.g.
Template fields are where the content of classes produced by the template is specified. These mostly follow printf format: A text field has variable slots specified using %s (for strings), %d for integers and %f for floats (decimals). Variables slots are filled, in order of appearance in the text, with values coming from a list of variables in an associated vars field e.g.
If the value associated with the neuron var is (the class) 'glutamatergic neuron' and the value associated with the = 'brain region' var is 'primary motor cortext', this will generate a classes with the name (label) "glutamatergic neuron of primary motor cortex".
DOSDPs include a set of convenience fields for annotation of classes that follow OBO conventions for field names and their mappings to OWL annotation properties. These include name, def, comment, namespace. When the value of a var is an OWL class, the name (label) of the var is used in the substitution. (see example above).
+
The annotation axioms generated by these template fields can be annotated. One OBO field exists for this purpose: xrefs allows annotation with a list of references using the obo standard xref annotation property (curies)
Where a single equivalent Class, subclassOf or GCI axiom is specified, you may use the keys 'EquivalentTo', 'subClassOf' or 'GCI' respectively. If multiple axioms of any type are needed, use the core field logical_axioms.
Note: This is an updated Version of Jim Balhoff's DOSDP tutorial here.
+
The main use case for dosdp-tools (and the DOS-DP framework) is managing a set of ontology terms, which all follow a common logical pattern, by simply collecting the unique aspect of each term as a line in a spreadsheet. For example, we may be developing an ontology of environmental exposures. We would like to have terms in our ontology which represent exposure to a variety of stressors, such as chemicals, radiation, social stresses, etc.
To maximize reuse and facilitate data integration, we can build our exposure concepts by referencing terms from domain-specific ontologies, such as the Chemical Entities of Biological Interest Ontology (ChEBI) for chemicals. By modeling each exposure concept in the same way, we can use a reasoner to leverage the chemical classification provided by ChEBI to provide a classification for our exposure concepts. Since each exposure concept has a logical definition based on our data model for exposure, there is no need to manually manage the classification hierarchy. Let's say our model for exposure concepts holds that an "exposure" is an event with a particular input (the thing the subject is exposed to):
+
'exposure to X' EquivalentTo 'exposure event' and 'has input' some X
+
If we need an ontology class to represent 'exposure to sarin' (bad news!), we can simply use the term sarin from ChEBI, and create a logical definition:
+
'exposure to sarin' EquivalentTo 'exposure event' and 'has input' some sarin
+
We can go ahead and create some other concepts we need for our exposure data:
+
'exposure to asbestos' EquivalentTo 'exposure event' and 'has input' some asbestos
+
'exposure to chemical substance' EquivalentTo 'exposure event' and 'has input' some 'chemical substance'
Since the three concepts we've created all follow the same logical model, their hierarchical relationship can be logically determined by the relationships of the chemicals they reference. ChEBI asserts this structure for those terms:
Creating terms by hand like we just did works fine, and relying on the reasoner for the classification will save us a lot of trouble and maintain correctness as our ontology grows. But since all the terms use the same logical pattern, it would be nice to keep this in one place; this will help make sure we always follow the pattern correctly when we create new concepts. We really only need to store the list of inputs (e.g. chemicals) in order to create all our exposure concepts. As we will see later, we may also want to manage separate sets of terms that follow other, different, patterns. To do this with dosdp-tools, we need three main files: a pattern template, a spreadsheet of pattern fillers, and a source ontology. You will also usually need a file of prefix definitions so that the tool knows how to expand your shortened identifiers into IRIs.
+
For our chemical exposures, getting the source ontology is easy: just download chebi.owl. Note—it's about 450 MB.
+
For our pattern fillers spreadsheet, we just need to make a tab-delimited file containing the chemical stressors for which we need exposure concepts. The file needs a column for the term IRI to be used for the generated class (this column is always called defined_class), and also a column for the chemical to reference (choose a label according to your data model). It should look like this:
The columns should be tab-separated—you can download a correctly formatted file to follow along. For now you will just maintain this file by hand, adding chemicals by looking up their ID in ChEBI, and manually choosing the next ID for your generated classes. In the future this may be simplified using the DOS-DP table editor, which is under development.
+
The trickiest part to DOS-DP is creating your pattern template (but it's not so hard). Pattern templates are written in YAML, a simple file format based on keys and values. The keys are text labels; values can be plain values, another key-value structure, or a list. The DOS-DP schema specifies the keys and values which can be used in a pattern file. We'll use most of the common entries in this example. Read the comments (lines starting with #) for explanation of the various fields:
+
# We can provide a name for this pattern here.
+pattern_name:exposure_with_input
+
+# In 'classes', we define the terms we will use in this pattern.
+# In the OBO community the terms often have numeric IDs, so here
+# we can provide human-readable names we can use further in the pattern.
+# The key is the name to be used; the value is the ID in prefixed form (i.e. a CURIE).
+classes:
+exposure event:ExO:0000002
+Thing:owl:Thing
+
+# Use 'relations' the same way as 'classes',
+# but for the object properties used in the pattern.
+relations:
+has input:RO:0002233
+
+# The 'vars' section defines the various slots that can be
+# filled in for this pattern. We have only one, which we call 'input'.
+# The value is the range, meaning the class of things that are valid
+# values for this pattern. By specifying owl:Thing, we're allowing any
+# class to be provided as a variable filler. You need a column in your
+# spreadsheet for each variable defined here, in addition to the `defined class` column.
+vars:
+input:"Thing"
+
+# We can provide a template for an `rdfs:label` value to generate
+# for our new term. dosdp-tools will search the source ontology
+# to find the label for the filler term, and fill it into the
+# name template in place of the %s.
+name:
+text:"exposureto%s"
+vars:
+-input
+
+# This works the same as label generation, but instead creates
+# a definition annotation.
+def:
+text:"Aexposureeventinvolvingtheinteractionofanexposurereceptorto%s.Exposuremaybethroughavarietyofmeans,includingthroughtheairorsurroundingmedium,orthroughingestion."
+vars:
+-input
+
+# Here we can generate a logical axiom for our new concept. Create an
+# expression using OWL Manchester syntax. The expression can use any
+# of the terms defined at the beginning of the pattern. A reference
+# to the variable value will be inserted in place of the %s.
+equivalentTo:
+text:"'exposureevent'and'hasinput'some%s"
+vars:
+-input
+
Now we only need one more file before we can run dosdp-tools. A file of prefix definitions (also in YAML format) will specify how to expand the CURIEs we used in our spreadsheet and pattern files:
+
EXPOSO:http://example.org/exposure/
+
+
Here we are specifying how to expand our EXPOSO prefix (used in our spreadsheet defined_class column). To expand the others, we'll pass a convenience option to dosdp-tools, --obo-prefixes, which will activate some predefined prefixes such as owl:, and handle any other prefixes using the standard expansion for OBO IDs: http://purl.obolibrary.org/obo/PREFIX_. Here's a link to the prefixes file.
+
Now we're all set to run dosdp-tools! If you've downloaded or created all the necessary files, run this command to generate your ontology of exposures (assuming you've added the dosdp-tools to your Unix PATH):
This will apply the pattern to each line in your spreadsheet, and save the result in an ontology saved at exposure_with_input.owl (it should look something like this). If you take a look at this ontology in a text editor or in Protégé, you'll see that it contains three classes, each with a generated label, text definition, and equivalent class definition. You're done!
+
Well... you're sort of done. But wouldn't it be nice if your exposure ontology included some information about the chemicals you referenced? Without this our reasoner can't classify our exposure concepts. As we said above, we could add an owl:import declaration and load all of ChEBI, but your exposure ontology has three classes and ChEBI has over 120,000 classes. Instead, we can use the ROBOT tool to extract a module of just the relevant axioms from ChEBI. Later, we will also see how to use ROBOT to merge the outputs from multiple DOS-DP patterns into one ontology. You can download ROBOT from its homepage.
ROBOT has a few different methods for extracting a subset from an ontology. We'll use the Syntactic Locality Module Extractor (SLME) to get a set of axioms relevant to the ChEBI terms we've referenced. ROBOT will need a file containing the list of terms. We can use a Unix command to get these out of our spreadsheet file:
Our ChEBI extract only has 63 classes. Great! If you want, you can merge the ChEBI extract into your exposure ontology before releasing it to the public:
Now you can open exposo.owl in Protégé, run the reasoner, and see a correct classification for your exposure concepts! You may notice that your ontology is missing labels for ExO:0000002 ('exposure event') and RO:0002233 ('has input'). If you want, you can use ROBOT to extract that information from ExO and RO.
You will often want to generate ontology modules using more than one DOS-DP pattern. For example, you may want to organize environmental exposures by an additional axis of classification, such as exposure to substances with various biological roles, based on information provided by ChEBI. This requires a slightly different logical expression, so we'll make a new pattern:
If you open the new exposo.owl in Protégé and run the reasoner, you'll now see 'exposure to sarin' classified under both 'exposure to chemical substance' and also 'exposure to neurotoxin'.
By using dosdp-tools and robot together, you can effectively develop ontologies which compose parts of ontologies from multiple domains using standard patterns. You will probably want to orchestrate the types of commands used in this tutorial within a Makefile, so that you can automate this process for easy repeatability.
Exomiser is a Java program that ranks potential rare Mendelian disease-causing variants from whole-exome or whole-genome sequencing data. Starting from a patient's VCF file and a set of phenotypes encoded using the Human Phenotype Ontology (HPO), it will annotate, filter and prioritise likely causative variants. The program does this based on user-defined criteria such as a variant's predicted pathogenicity, frequency of occurrence in a population and also how closely the given patient's phenotype matches any known phenotype of genes from human disease and model organism data.
+
In this tutorial, we will learn how to install and run Exomiser with Docker, and how to interpret the results in various output formats detailing the predicted causative genes and variants. If you prefer to work locally, instructions are also provided below for Windows and Linux/Mac users.
+
The complete Exomiser documentation can be found here, including some relevant references here, and the Exomiser GitHub repository here.
+
Please note that this tutorial is up-to-date with the current latest release 13.2.0 and data version up to 2302 (Feb 2023).
# download the data via
+wgethttps://github.com/iQuxLE/Exomiser-Tutorial/raw/main/Exomiser-Tutorial.zip
+# OR clone the repository
+gitclonehttps://github.com/iQuxLE/Exomiser-Tutorial.git
+
+# unzip
+unzipExomiser-Tutorial.zip
+
+Since the VCF files for parts of the example data are relatively large, you need to download the following separately and put it into the Exomiser-Tutorial folder.
+
The Exomiser-Tutorial folder contains a directory called exomiser-config (with all the VCF and analysis files)
+and exomiser-overview (with some introductory slides).
+
+
Importantly, we highly recommend downloading the Exomiser data prior to the tutorial in order to follow along. The data required to run Exomiser is ~80GB and will take a while to download and unpack (depending on your internet connection, it may take a few hours). For this tutorial, you only need to download the Exomiser phenotype data and the variant data for the hg19 assembly. If you have your own samples to run with Exomiser and the VCF files are built on the hg38 build, then you will need to download the hg38 variant data as well. The current data version that we will use in this tutorial is 2302 (Feb 2023). This will change in the future. Always make sure that you use the latest data version available. To download the Exomiser data from the terminal:
+
+
# create an empty directory for exomiser-data within the Exomiser-Tutorial folder:
+cd/path/to/Exomiser-Tutorial/
+mkdirexomiser-data
+cdexomiser-data
+# download the data
+wgethttps://data.monarchinitiative.org/exomiser/latest/2302_phenotype.zip# for the phenotype database
+wgethttps://data.monarchinitiative.org/exomiser/latest/2302_hg19.zip# for the hg19 variant database
+# unzip the data
+unzip"2302_*.zip"
+
+
Otherwise, visit the links and download the data in your own exomiser-data directory:
Install 7-Zip for unzipping the database files. The built-in archiving software has issues extracting the zip files. Extract the database files (2302_phenotype.zip, 2302_hg19.zip) by right-clicking the archive and selecting 7-Zip > Extract files… into the exomiser-data directory.
+
Your Exomiser-Tutorial directory should now be structured as follows:
(recommended to be installed prior to the tutorial; if you run the command below again, you should receive the message "Image is up to date for exomiser/exomiser-cli:13.2.0")
Install 7-Zip for unzipping the archive files. The built-in archiving software has issues extracting the zip files.
+
Download the exomiser-cli-13.2.0-distribution.zip distribution from Monarch.
+
Download the variant 2302_hg19.zip and phenotype 2302_phenotype.zip data files from Monarch.
+
Extract the distribution files by right-clicking exomiser-cli-13.2.0-distribution.zip and selecting 7-Zip > Extract Here
+
Extract the data files (e.g. 2302_phenotype.zip, 2302_hg19.zip) by right-clicking the archive and selecting 7-Zip > Extract files… into the exomiser data directory. By default, Exomiser expects this to be ‘exomiser-cli-13.2.0/data’, but this can be changed in the application.properties.
# download the distribution (won't take long)
+wgethttps://data.monarchinitiative.org/exomiser/latest/exomiser-cli-13.2.0-distribution.zip
+# download the data (this is ~80GB and will take a while). If you only require a single assembly, only download the relevant files.
+wgethttps://data.monarchinitiative.org/exomiser/latest/2302_hg19.zip
+wgethttps://data.monarchinitiative.org/exomiser/latest/2302_phenotype.zip
+# unzip the distribution and data files - this will create a directory called 'exomiser-cli-13.2.0' in the current working directory (with examples and application.properties)
+unzipexomiser-cli-13.2.0-distribution.zip
+unzip'2302_*.zip'-dexomiser-cli-13.2.0/data
+
The application.properties file needs to be updated to point to the correct location of the Exomiser data. For the purpose of this tutorial, this is already sorted, pointing to the mounted directory inside the Docker container exomiser.data-directory=/exomiser-data.
+
Also, you want to make sure to edit the file to use the correct data version (currently 2302):
For this tutorial, we will focus on running Exomiser on a single-sample (whole-exome) VCF file. Additional instructions for running Exomiser on multi-sample VCF data and large jobs are also provided below.
It is recommended to provide Exomiser with the input sample as a Phenopacket. Exomiser will accept this in either JSON
+or YAML format. We will use the example pfeiffer-phenopacket.yml below:
NOTE: This is an example of a v1.0 phenopacket, there is a more recent release of v2.0. Exomiser can run
+phenopackets built with either v1.0 or v2.0 schema. You can find out more about the v2.0 phenopacket schema and how to
+build one with Python or Java here. To convert a phenopacket
+v1.0 to v2.0, you can use phenopacket-tools.
Below are the default analysis settings from pfeiffer-analysis.yml that we will use in our tutorial:
+
---
+analysis:
+#FULL or PASS_ONLY
+analysisMode:PASS_ONLY
+# In cases where you do not want any cut-offs applied an empty map should be used e.g. inheritanceModes: {}
+# These are the default settings, with values representing the maximum minor allele frequency in percent (%) permitted for an
+# allele to be considered as a causative candidate under that mode of inheritance.
+# If you just want to analyse a sample under a single inheritance mode, delete/comment-out the others. For AUTOSOMAL_RECESSIVE
+# or X_RECESSIVE ensure *both* relevant HOM_ALT and COMP_HET modes are present.
+inheritanceModes:{
+ AUTOSOMAL_DOMINANT:0.1,
+ AUTOSOMAL_RECESSIVE_COMP_HET:2.0,
+ AUTOSOMAL_RECESSIVE_HOM_ALT:0.1,
+ X_DOMINANT:0.1,
+ X_RECESSIVE_COMP_HET:2.0,
+ X_RECESSIVE_HOM_ALT:0.1,
+ MITOCHONDRIAL:0.2
+}
+#Possible frequencySources:
+#Thousand Genomes project http://www.1000genomes.org/
+# THOUSAND_GENOMES,
+#ESP project http://evs.gs.washington.edu/EVS/
+# ESP_AFRICAN_AMERICAN, ESP_EUROPEAN_AMERICAN, ESP_ALL,
+#ExAC project http://exac.broadinstitute.org/about
+# EXAC_AFRICAN_INC_AFRICAN_AMERICAN, EXAC_AMERICAN,
+# EXAC_SOUTH_ASIAN, EXAC_EAST_ASIAN,
+# EXAC_FINNISH, EXAC_NON_FINNISH_EUROPEAN,
+# EXAC_OTHER
+#Possible frequencySources:
+#Thousand Genomes project - http://www.1000genomes.org/ (THOUSAND_GENOMES)
+#TOPMed - https://www.nhlbi.nih.gov/science/precision-medicine-activities (TOPMED)
+#UK10K - http://www.uk10k.org/ (UK10K)
+#ESP project - http://evs.gs.washington.edu/EVS/ (ESP_)
+# ESP_AFRICAN_AMERICAN, ESP_EUROPEAN_AMERICAN, ESP_ALL,
+#ExAC project http://exac.broadinstitute.org/about (EXAC_)
+# EXAC_AFRICAN_INC_AFRICAN_AMERICAN, EXAC_AMERICAN,
+# EXAC_SOUTH_ASIAN, EXAC_EAST_ASIAN,
+# EXAC_FINNISH, EXAC_NON_FINNISH_EUROPEAN,
+# EXAC_OTHER
+#gnomAD - http://gnomad.broadinstitute.org/ (GNOMAD_E, GNOMAD_G)
+frequencySources:[
+THOUSAND_GENOMES,
+TOPMED,
+UK10K,
+
+ESP_AFRICAN_AMERICAN,ESP_EUROPEAN_AMERICAN,ESP_ALL,
+
+EXAC_AFRICAN_INC_AFRICAN_AMERICAN,EXAC_AMERICAN,
+EXAC_SOUTH_ASIAN,EXAC_EAST_ASIAN,
+EXAC_FINNISH,EXAC_NON_FINNISH_EUROPEAN,
+EXAC_OTHER,
+
+GNOMAD_E_AFR,
+GNOMAD_E_AMR,
+# GNOMAD_E_ASJ,
+GNOMAD_E_EAS,
+GNOMAD_E_FIN,
+GNOMAD_E_NFE,
+GNOMAD_E_OTH,
+GNOMAD_E_SAS,
+
+GNOMAD_G_AFR,
+GNOMAD_G_AMR,
+# GNOMAD_G_ASJ,
+GNOMAD_G_EAS,
+GNOMAD_G_FIN,
+GNOMAD_G_NFE,
+GNOMAD_G_OTH,
+GNOMAD_G_SAS
+]
+# Possible pathogenicitySources: (POLYPHEN, MUTATION_TASTER, SIFT), (REVEL, MVP), CADD, REMM
+# REMM is trained on non-coding regulatory regions
+# *WARNING* if you enable CADD or REMM ensure that you have downloaded and installed the CADD/REMM tabix files
+# and updated their location in the application.properties. Exomiser will not run without this.
+pathogenicitySources:[REVEL,MVP]
+#this is the standard exomiser order.
+#all steps are optional
+steps:[
+#hiPhivePrioritiser: {},
+#priorityScoreFilter: {priorityType: HIPHIVE_PRIORITY, minPriorityScore: 0.500},
+#intervalFilter: {interval: 'chr10:123256200-123256300'},
+# or for multiple intervals:
+#intervalFilter: {intervals: ['chr10:123256200-123256300', 'chr10:123256290-123256350']},
+# or using a BED file - NOTE this should be 0-based, Exomiser otherwise uses 1-based coordinates in line with VCF
+#intervalFilter: {bed: /full/path/to/bed_file.bed},
+#genePanelFilter: {geneSymbols: ['FGFR1','FGFR2']},
+failedVariantFilter:{},
+#qualityFilter: {minQuality: 50.0},
+variantEffectFilter:{
+ remove:[
+FIVE_PRIME_UTR_EXON_VARIANT,
+FIVE_PRIME_UTR_INTRON_VARIANT,
+THREE_PRIME_UTR_EXON_VARIANT,
+THREE_PRIME_UTR_INTRON_VARIANT,
+NON_CODING_TRANSCRIPT_EXON_VARIANT,
+UPSTREAM_GENE_VARIANT,
+INTERGENIC_VARIANT,
+REGULATORY_REGION_VARIANT,
+CODING_TRANSCRIPT_INTRON_VARIANT,
+NON_CODING_TRANSCRIPT_INTRON_VARIANT,
+DOWNSTREAM_GENE_VARIANT
+]
+},
+# removes variants represented in the database
+#knownVariantFilter: {},
+frequencyFilter:{maxFrequency:2.0},
+pathogenicityFilter:{keepNonPathogenic:true},
+# inheritanceFilter and omimPrioritiser should always run AFTER all other filters have completed
+inheritanceFilter:{},
+# omimPrioritiser isn't mandatory.
+omimPrioritiser:{},
+#priorityScoreFilter: {minPriorityScore: 0.4},
+# Other prioritisers: Only combine omimPrioritiser with one of these.
+# Don't include any if you only want to filter the variants.
+hiPhivePrioritiser:{},
+# or run hiPhive in benchmarking mode:
+#hiPhivePrioritiser: {runParams: 'mouse'},
+#phivePrioritiser: {}
+#phenixPrioritiser: {}
+#exomeWalkerPrioritiser: {seedGeneIds: [11111, 22222, 33333]}
+]
+outputOptions:
+outputContributingVariantsOnly:false
+#numGenes options: 0 = all or specify a limit e.g. 500 for the first 500 results
+numGenes:0
+#minExomiserGeneScore: 0.7
+# Path to the desired output directory. Will default to the 'results' subdirectory of the exomiser install directory
+outputDirectory:results
+# Filename for the output files. Will default to {input-vcf-filename}-exomiser
+outputFileName:Pfeiffer-HIPHIVE-exome
+#out-format options: HTML, JSON, TSV_GENE, TSV_VARIANT, VCF (default: HTML)
+outputFormats:[HTML,JSON,TSV_GENE,TSV_VARIANT]
+
This command will produce Pfeiffer-HIPHIVE-exome.html, Pfeiffer-HIPHIVE-exome.json, Pfeiffer-HIPHIVE-exome.genes.tsv and Pfeiffer-HIPHIVE-exome.variants.tsv in your exomiser-results directory.
The above commands can be added to a batch file for example in the
+file Exomiser-Tutorial/exomiser-config/test-analysis-batch-commands.txt. Using it with Docker we recommend creating a
+new directory for the batch files and mounting that to the Docker container.
The advantage of this is that a single command will be able to analyse many samples in far less time than starting a new
+JVM for each as there will be no start-up penalty after the initial start and the Java JIT compiler will be able to take
+advantage of a longer-running process to optimise the runtime code. For maximum throughput on a cluster consider
+splitting your batch jobs over multiple nodes.
Depending on the output options provided, Exomiser will write out at least an HTML and JSON output file in the results subdirectory of the Exomiser installation (by default) or a user-defined results directory as indicated in the output options.
+
As a general rule, all output files contain a ranked list of genes and variants with the top-ranked gene/variant displayed first. The exception being the VCF output (if requested in the output options; not requested in this tutorial) which, since version 13.1.0, is sorted according to VCF convention and tabix indexed.
+
In our tutorial, we requested HTML, JSON, TSV_VARIANT and TSV_GENE output formats which are briefly outlined below.
The JSON file represents the most accurate representation of the results, as it is referenced internally by Exomiser. As
+such, we don’t provide a schema for this, but it has been pretty stable and breaking changes will only occur with major
+version changes to the software. Minor additions are to be expected for minor releases, as per the SemVer specification.
+
We recommend using Python or JQ to extract data from this file. To give you an idea of how you can extract some data with Python, we have provided examples of how you can iterate over the results below. However, there is a lot more information content that you can pull out from the JSON results file, this only provides a snippet of what you can do.
+
# import json library
+importjson
+
+# to load in the exomiser json result
+withopen("path/to/Exomiser-Tutorial/Pfeiffer-HIPHIVE-exome.json")asexomiser_json_result:
+ exomiser_result=json.load(exomiser_json_result)
+exomiser_json_result.close()
+
+# to retrieve all predicted genes and corresponding identifier (ENSEMBL)
+gene_results=[]
+forresultinexomiser_result:
+ gene_results.append({result["geneSymbol"]:result["geneIdentifier"]["geneId"]})
+
+# to retrieve all predicted variants
+variant_results=[]
+forresultinexomiser_result:
+ formoiinresult["geneScores"]:# iterating over all modes of inheritance
+ if"contributingVariants"inmoi:# checking if there is evidence of contributing variants
+ forcvinmoi["contributingVariants"]:# iterating over all contributing variants
+ variant_results.append({"chromosome":cv["contigName"],
+ "start_pos":cv["start"],
+ "end_pos":cv["end"],
+ "ref_allele":cv["ref"],
+ "alt_allele":cv["alt"]})
+
In the Pfeiffer-HIPHIVE-exome.variants.tsv file it is possible for a variant to appear multiple times, depending on the MOI it is compatible with. For example, in the excerpt of the file below, MUC6 has two variants ranked 7th under the AD model and two ranked 8th under an AR (compound heterozygous) model. In the AD case the CONTRIBUTING_VARIANT column indicates whether the variant was (1) or wasn't (0) used for calculating the EXOMISER_GENE_COMBINED_SCORE and EXOMISER_GENE_VARIANT_SCORE.
In the Pfeiffer-HIPHIVE-exome.genes.tsv file, all the various phenotypic scores and HPO matches from the HUMAN, MOUSE, FISH and PPI comparisons are reported per each gene. It is possible for a gene to appear multiple times, depending on the MOI it is compatible with, given the filtered variants. For example in the example below MUC6 is ranked 7th under the AD model and 8th under an AR model.
+
#RANK ID GENE_SYMBOL ENTREZ_GENE_ID MOI P-VALUE EXOMISER_GENE_COMBINED_SCORE EXOMISER_GENE_PHENO_SCORE EXOMISER_GENE_VARIANT_SCORE HUMAN_PHENO_SCORE MOUSE_PHENO_SCORE FISH_PHENO_SCORE WALKER_SCORE PHIVE_ALL_SPECIES_SCORE OMIM_SCORE MATCHES_CANDIDATE_GENE HUMAN_PHENO_EVIDENCE MOUSE_PHENO_EVIDENCE FISH_PHENO_EVIDENCE HUMAN_PPI_EVIDENCE MOUSE_PPI_EVIDENCE FISH_PPI_EVIDENCE
+1 FGFR2_AD FGFR2 2263 AD 0.0000 0.9957 0.9187 1.0000 0.8671 0.9187 0.0000 0.5057 0.9187 1.0000 0 Apert syndrome (ORPHA:87): Syndactyly (HP:0001159)-Toe syndactyly (HP:0001770), Strabismus (HP:0000486)-Strabismus (HP:0000486), Hypoplasia of the maxilla (HP:0000327)-Hypoplasia of the maxilla (HP:0000327), Proptosis (HP:0000520)-Proptosis (HP:0000520), Hypertelorism (HP:0000316)-Hypertelorism (HP:0000316), Brachyturricephaly (HP:0000244)-Brachyturricephaly (HP:0000244), Strabismus (HP:0000486)-ocular hypertelorism (MP:0001300), Hypoplasia of the maxilla (HP:0000327)-short maxilla (MP:0000097), Proptosis (HP:0000520)-exophthalmos (MP:0002750), Hypertelorism (HP:0000316)-ocular hypertelorism (MP:0001300), Brachyturricephaly (HP:0000244)-abnormal frontal bone morphology (MP:0000107), Proximity to FGF18 Syndactyly (HP:0001159)-abnormal metatarsal bone morphology (MP:0003072), Strabismus (HP:0000486)-abnormal neurocranium morphology (MP:0000074), Hypoplasia of the maxilla (HP:0000327)-maxilla hypoplasia (MP:0000457), Proptosis (HP:0000520)-abnormal neurocranium morphology (MP:0000074), Hypertelorism (HP:0000316)-abnormal neurocranium morphology (MP:0000074), Brachyturricephaly (HP:0000244)-abnormal neurocranium morphology (MP:0000074),
+2 ZNF366_AD ZNF366 167465 AD 0.0018 0.9237 0.8195 0.7910 0.0000 0.8195 0.0000 0.5015 0.8195 1.0000 0 Syndactyly (HP:0001159)-syndactyly (MP:0000564), Strabismus (HP:0000486)-microphthalmia (MP:0001297), Hypoplasia of the maxilla (HP:0000327)-micrognathia (MP:0002639), Proptosis (HP:0000520)-microphthalmia (MP:0001297), Hypertelorism (HP:0000316)-microphthalmia (MP:0001297), Brachyturricephaly (HP:0000244)-microphthalmia (MP:0001297), Proximity to CTBP1 associated with Wolf-Hirschhorn syndrome (ORPHA:280): Syndactyly (HP:0001159)-Arachnodactyly (HP:0001166), Strabismus (HP:0000486)-Strabismus (HP:0000486), Hypoplasia of the maxilla (HP:0000327)-Micrognathia (HP:0000347), Proptosis (HP:0000520)-Proptosis (HP:0000520), Hypertelorism (HP:0000316)-Hypertelorism (HP:0000316), Brachyturricephaly (HP:0000244)-Calvarial skull defect (HP:0001362),
+3 PKD1_AD PKD1 5310 AD 0.0050 0.8272 0.6597 0.8707 0.0000 0.6597 0.2697 0.5069 0.6597 1.0000 0 Strabismus (HP:0000486)-micrognathia (MP:0002639), Hypoplasia of the maxilla (HP:0000327)-micrognathia (MP:0002639), Proptosis (HP:0000520)-micrognathia (MP:0002639), Hypertelorism (HP:0000316)-micrognathia (MP:0002639), Brachyturricephaly (HP:0000244)-micrognathia (MP:0002639), Hypoplasia of the maxilla (HP:0000327)-mandibular arch skeleton malformed, abnormal (ZP:0001708), Proximity to IFT88 associated with Retinitis pigmentosa (ORPHA:791): Strabismus (HP:0000486)-Ophthalmoplegia (HP:0000602), Hypoplasia of the maxilla (HP:0000327)-Wide nasal bridge (HP:0000431), Proximity to IFT88 Syndactyly (HP:0001159)-polydactyly (MP:0000562), Strabismus (HP:0000486)-supernumerary molars (MP:0010773), Hypoplasia of the maxilla (HP:0000327)-supernumerary molars (MP:0010773), Proptosis (HP:0000520)-supernumerary molars (MP:0010773), Hypertelorism (HP:0000316)-supernumerary molars (MP:0010773), Brachyturricephaly (HP:0000244)-abnormal coronal suture morphology (MP:0003840),
+4 CCDC66_AD CCDC66 285331 AD 0.0051 0.8262 0.5463 0.9984 0.0000 0.5463 0.0000 0.0000 0.5463 1.0000 0 Strabismus (HP:0000486)-abnormal cone electrophysiology (MP:0004022), Hypoplasia of the maxilla (HP:0000327)-abnormal rod electrophysiology (MP:0004021), Proptosis (HP:0000520)-abnormal rod electrophysiology (MP:0004021), Hypertelorism (HP:0000316)-abnormal rod electrophysiology (MP:0004021), Brachyturricephaly (HP:0000244)-abnormal retina photoreceptor layer morphology (MP:0003728),
+5 COL4A1_AD COL4A1 1282 AD 0.0075 0.7762 0.5288 0.9838 0.3882 0.5288 0.0000 0.5047 0.5288 1.0000 0 Brain small vessel disease with or without ocular anomalies (OMIM:175780): Strabismus (HP:0000486)-Exotropia (HP:0000577), Strabismus (HP:0000486)-buphthalmos (MP:0009274), Hypoplasia of the maxilla (HP:0000327)-abnormal cornea morphology (MP:0001312), Proptosis (HP:0000520)-abnormal cornea morphology (MP:0001312), Hypertelorism (HP:0000316)-abnormal cornea morphology (MP:0001312), Brachyturricephaly (HP:0000244)-abnormal retina morphology (MP:0001325), Proximity to COL7A1 associated with Localized dystrophic epidermolysis bullosa, pretibial form (ORPHA:79410): Syndactyly (HP:0001159)-Nail dystrophy (HP:0008404), Hypoplasia of the maxilla (HP:0000327)-Carious teeth (HP:0000670), Proximity to COL7A1 Syndactyly (HP:0001159)-abnormal digit morphology (MP:0002110), Strabismus (HP:0000486)-abnormal tongue morphology (MP:0000762), Hypoplasia of the maxilla (HP:0000327)-abnormal tongue morphology (MP:0000762), Proptosis (HP:0000520)-abnormal tongue morphology (MP:0000762), Hypertelorism (HP:0000316)-abnormal tongue morphology (MP:0000762),
+6 ENPP1_AD ENPP1 5167 AD 0.0079 0.7695 0.5112 0.9996 0.3738 0.5112 0.0000 0.5044 0.5112 1.0000 0 Autosomal recessive hypophosphatemic rickets (ORPHA:289176): Hypoplasia of the maxilla (HP:0000327)-Tooth abscess (HP:0030757), Brachyturricephaly (HP:0000244)-Craniosynostosis (HP:0001363), Syndactyly (HP:0001159)-abnormal elbow joint morphology (MP:0013945), Strabismus (HP:0000486)-abnormal retina morphology (MP:0001325), Hypoplasia of the maxilla (HP:0000327)-abnormal snout skin morphology (MP:0030533), Proptosis (HP:0000520)-abnormal retina morphology (MP:0001325), Hypertelorism (HP:0000316)-abnormal retina morphology (MP:0001325), Brachyturricephaly (HP:0000244)-abnormal retina morphology (MP:0001325), Proximity to DMP1 associated with Autosomal recessive hypophosphatemic rickets (ORPHA:289176): Hypoplasia of the maxilla (HP:0000327)-Tooth abscess (HP:0030757), Brachyturricephaly (HP:0000244)-Craniosynostosis (HP:0001363), Proximity to DMP1 Syndactyly (HP:0001159)-abnormal long bone hypertrophic chondrocyte zone (MP:0000165), Strabismus (HP:0000486)-abnormal dental pulp cavity morphology (MP:0002819), Hypoplasia of the maxilla (HP:0000327)-abnormal dental pulp cavity morphology (MP:0002819), Proptosis (HP:0000520)-abnormal dental pulp cavity morphology (MP:0002819), Hypertelorism (HP:0000316)-abnormal dental pulp cavity morphology (MP:0002819), Brachyturricephaly (HP:0000244)-abnormal dental pulp cavity morphology (MP:0002819),
+7 MUC6_AD MUC6 4588 AD 0.0089 0.7563 0.5046 0.9990 0.0000 0.0000 0.0000 0.5046 0.5046 1.0000 0 Proximity to GALNT2 associated with Congenital disorder of glycosylation, type IIt (OMIM:618885): Syndactyly (HP:0001159)-Sandal gap (HP:0001852), Strabismus (HP:0000486)-Alternating exotropia (HP:0031717), Hypoplasia of the maxilla (HP:0000327)-Tented upper lip vermilion (HP:0010804), Proptosis (HP:0000520)-Hypertelorism (HP:0000316), Hypertelorism (HP:0000316)-Hypertelorism (HP:0000316), Brachyturricephaly (HP:0000244)-Brachycephaly (HP:0000248),
+8 MUC6_AR MUC6 4588 AR 0.0089 0.7562 0.5046 0.9990 0.0000 0.0000 0.0000 0.5046 0.5046 1.0000 0 Proximity to GALNT2 associated with Congenital disorder of glycosylation, type IIt (OMIM:618885): Syndactyly (HP:0001159)-Sandal gap (HP:0001852), Strabismus (HP:0000486)-Alternating exotropia (HP:0031717), Hypoplasia of the maxilla (HP:0000327)-Tented upper lip vermilion (HP:0010804), Proptosis (HP:0000520)-Hypertelorism (HP:0000316), Hypertelorism (HP:0000316)-Hypertelorism (HP:0000316), Brachyturricephaly (HP:0000244)-Brachycephaly (HP:0000248),
+9 DDX56_AD DDX56 54606 AD 0.0091 0.7545 0.5036 0.9992 0.0000 0.0000 0.3788 0.5036 0.5036 1.0000 0 Brachyturricephaly (HP:0000244)-head decreased width, abnormal (ZP:0000407), Proximity to PAK1IP1 Strabismus (HP:0000486)-abnormal maxilla morphology (MP:0000455), Hypoplasia of the maxilla (HP:0000327)-abnormal maxilla morphology (MP:0000455), Proptosis (HP:0000520)-abnormal maxilla morphology (MP:0000455), Hypertelorism (HP:0000316)-abnormal maxilla morphology (MP:0000455), Brachyturricephaly (HP:0000244)-decreased forebrain size (MP:0012138),
+10 BDKRB1_AD BDKRB1 623 AD 0.0093 0.7525 0.5018 1.0000 0.0000 0.0000 0.0000 0.5018 0.5018 1.0000 0 Proximity to OPN4 Strabismus (HP:0000486)-abnormal visual pursuit (MP:0006156), Hypoplasia of the maxilla (HP:0000327)-abnormal visual pursuit (MP:0006156), Proptosis (HP:0000520)-abnormal visual pursuit (MP:0006156), Hypertelorism (HP:0000316)-abnormal visual pursuit (MP:0006156), Brachyturricephaly (HP:0000244)-abnormal retina ganglion cell morphology (MP:0008056),
+
Follow this link and download the Docker.dmg for your operating
+system.
+
+
The Docker.dmg will be found in your /Downloads directory.
+
+
After double-clicking on the Docker.dmg a new window will come up:
+
+
Drag and drop the Docker app into your /Applications folder.
+Double-click on the Docker symbol.
+Docker Desktop will start in the background, after you allow it to be opened.
+
+
Additionally, this window will come up to agree the Docker subscription service agreement.
+
+
After running the installation restart your terminal and check the Docker installation again from inside your
+terminal with:
+
docker--version
+
+
If the output gives you a version and no error you are ready to go. If you have not already restarted your terminal do
+this now,
+and the error should be fixed.
+
In case you get an error message like this, please ensure you have downloaded the correct docker.dmg.
+
+
Now, whenever you want to pull images make sure that Docker is running in the background. Otherwise, you may get an
+error stating it's not able to connect to the Docker deamon.
After restarting, Docker should start automatically and the Service Agreement will come up, which you will have to agree
+to use Docker:
+
+
If the Docker desktop app is showing this warning upon start, do not click “Restart”, yet. Instead, follow the link and
+install the kernel update.
+
+
The link should point you to an address with a separate download link.
+
+
Start and finish the installation for WSL.
+
+
If you still have the Docker Desktop dialog window open in the background, click on Restart. Otherwise, just restart
+your computer as you normally do.
+
+
If Docker Desktop did not start on its own, simply open it from the shortcut on your Desktop. You can do the initial
+orientation by clicking "Start".
+
+
After this, your Docker Desktop screen should look like this:
+
+
Now, whenever you want to pull images make sure that Docker is running in the background.
The translation to markdown is not without issue, but we are making a start to making the tutorial a bit more accessible.
+This reproduction is done with kind permission by Robert Stevens.
Bio-Health Informatics Group
+School of Computer Science
+University of Manchester
+Oxford Road
+Manchester
+United Kingdom
+M13 9PL
+robert.stevens@manchester.ac.uk
+
This tutorial was realised as part of the Semantic Web Authoring Tool (SWAT) project (see http://www.swatproject.org),
+which is supported by the UK Engineering and Physical Sciences Research
+Council (EPSRC) grant EP/G032459/1, to the University of Manchester, the University of Sussex and
+the Open University.
The ‘Manchester Family History Advanced OWL Tutorial’ by Robert Stevens, Margaret Stevens, Nicolas
+Matentzoglu, Simon Jupp is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported
+License.
This manual will almost certainly contain errors, defects and infelicities. Do report them to robert.stevens@manchester.ac.uk supplying chapter, section and some actual context in the form of words will help in fixing any of these issues.
As well as the author list, many people have contributed to this work. Any contribution, such as reporting bugs etc., is rewarded by an acknowledgement of contribution (in alphabetical order) when the authors get around to adding them:
This tutorial introduces the tutee to many of the more advanced features of the Web Ontology Language (OWL). The topic of family history is used to take the tutee through various modelling issues and, in doing so, using many features of OWL 2 to build a Family History Knowledge Base (FHKB). The exercises are designed to maximise inference about family history through the use of an automated reasoner on an OWL knowledge base (KB) containing many members of the Stevens family.
+
The aim, therefore, is to enable people to learn advanced features of OWL 2 in a setting that involves both classes and individuals, while attempting to maximise the use of inference within the FHKB.
Building an FHKB enables us to meet our learning outcomes through a topic that is accessible to virtually everyone. Family history or genealogy is a good topic for a general tutorial on OWL 2 as it enables us to touch many features of the language and, importantly, it is a field that everyone knows. All people have a family and therefore a family history – even if they do not know their particular family history. A small caveat was put on the topic being accessible to everyone as some cultures differ, for instance, in the description of cousins and labels given to different siblings. Nevertheless, family history remains a topic that everyone can talk about.
+
Family history is a good topic for an OWL ontology as it obviously involves both individuals – the people involved – and classes of individuals – people, men and women, cousins, etc. Also, it is an area rich in inference; from only knowing parentage and sex of an individual, it is possible to work out all family relationships – for example, sharing parents implies a sibling relationship; one’s parent’s brothers are one’s uncles; one’s parent’s parents are one’s grandparents. So, we should be able to construct an ontology that allows us to both express family history, but also to infer family relationships between people from knowing relatively little about them.
+
As we will learn through the tutorial, OWL 2 cannot actually do all that is needed to create a FHKB. This is unfortunate, but we use it to our advantage to illustrate some of the limitations of OWL 2. We know that rule based systems can do family history with ease, but that is not the point here; we are not advocating OWL DL as an appropriate mechanism for doing family history, but we do use it as a good educational example.
+
We make the following assumptions about what people know:
+
+
We assume that people know OWL to the level that is known at the end of the Pizza tutorial.
+ Some ground will be covered again, but a lot of basic OWL is assumed.
+
We assume people know how to use Protégé or their OWL environment of choice. We do not give
+ ‘click by click’ instructions. At some places, some guidance is given, but this is not to be relied
+ upon as Protégé changes and we will not keep up to date.
+
+
We make some simplifying assumptions in this tutorial:
+
+
We take a conventional western view of family history. This appears to have most effects on naming
+ of sibling and cousin relationships.
+
We take a straight-forward view on the sex of people; this is explored further in Chapter 4;
+
A ‘conventional’ view of marriage is taken; this is explored further in Chapter 9.
+
We make no special treatment of time or dates; we are only interested in years and we do not do
+ anything fancy; this is explored more in Chapter 7.
+
We assume the ancestors of people go back for ever; obviously this is not true, eventually one would
+ get back to a primordial soup and one’s ancestors are not humans (members of the classPerson),
+ but we don’t bother with such niceties.
+
+
At the end of the tutorial, you should be able to produce a property hierarchy and a TBox or class hierarchy such as shown in Figure 1.1; all supported by use of the automated reasoner and a lot of OWL 2’s features.
+
+
Figure 1.1: A part of the class and property hierarchy of the final FHKB.
When we use FHKB entities within text, we use a sans serif typeface.
+
We use CamelCase for classes and property names.
+
Class names start with upper case.
+
Individual names start with a lower case letter and internal underscores to break words.
+
Property names usually start with ‘is’ or ‘has’ and are CamelCase with a lower case initial letter.
+
Many classes and individuals in the FHKB have annotation properties, usually human readable labels. They show up in some of the examples in Manchester syntax, but are not made explicit as part of the tasks in this tutorial.
+
Every object property is necessarily a sub-property of topObjectProperty. It does not have to be asserted as such. Nevertheless, there might be situations where this relationship is made explicit in this tutorial for illustrative reasons.
+
The individuals we are dealing with represent distinct persons. Throughout the tutorial, once the respective axiom is introduced (chapter 7.1.1), the reader should make sure that all his or her individuals are always made distinct, especially when he or she adds a new one.
+
At the end of each chapter, we note the Description Logic Language (expressivity) needed to represent the ontology and the reasoning times for a number of state of the art reasoning systems. This should get the reader a sense how difficult the FHKB becomes for reasoners to deal with over time.
+
When there is some scary OWL or the reasoner may find the FHKB hard work, you will see a ‘here
+ be dragons’ image.1
+
+
1 The image comes fromhttp://ancienthomeofdragon.homestead.com/May 2012.
In this chapter we will start by creating a fresh OWL ontology and adding some individuals that will be
+surrogates for people in the FHKB. In particular you will:
+
+
Create a new OWL ontology for the FHKB;
+
Add some individuals that will stand for members of the Stevens family.
+
Describe parentage of people.
+
Add some facts to specific individuals as to their parentage;
+
See the reasoner doing some work.
+
At the moment we will ignore sex; sex will not happen until Chapter 4.
The ‘world’2 or field of interest we model in an ontology is made up of objects or individuals. Such objects include, but are not limited to:
+
+
People, their pets, the pizzas they eat;
+
The processes of cooking pizzas, living, running, jumping, undertaking a journey;
+
The spaces within a room, a bowl, an artery;
+
The attributes of things such as colour, dimensions, speed, shape of various objects;
+
Boundaries, love, ideas, plans, hypotheses.
+
+
2 we use ‘world’ as a synonym of ‘field of interest’ or ‘domain’. ‘World’ does not restrict us to modelling the physical world outside our consciousness.
+
We observe these objects, either outside lying around in the world or in our heads. OWL is all about modelling such individuals. Whenever we make a statement in OWL, when we write down an axiom, we are making statements about individuals. When thinking about the axioms in an ontology it is best to think about the individuals involved, even if OWL individuals do not actually appear in the ontology. All through this tutorial we will always be returning to the individuals being described in order to help us understand what we are doing and to help us make decisions about how to do it.
Biologically, everyone has parents; a mother and a father3. The starting point for family history is parentage; we need to relate the family member objects by object properties. An object property relates two objects, in this case a child object with his or her mother or father object. To do this we need to create three object properties:
+
+
+
+
Task 1: Creating object properties for parentage
+
+
+
+
+
Create a new ontology;
Create an object property hasMother;
Create a property isMotherOf and give hasMother the InverseOf: isMotherOf;
Do the same for the property hasFather;
Create a property hasParent; give it the obvious inverse;
Make hasMother and hasFather sub-properties of hasParent.
Run the reasoner and look at the property hierarchy.
+
+
+
+
Note how the reasoner has automatically completed the sub-hierarchy for isParentOf:isMotherOf and isFatherOf are inferred to be sub-properties of isParentOf.
+
The OWL snippet below shows some parentage fact assertions on an individual. Note that rather than being assertions to an anonymous individual via some class, we are giving an assertion to a named individual.
Using the information in Table A.1 (see appendix) about parentage (so the columns about fathers and mothers), enter the fact assertions for the people which appear in rows shaded in grey. We will only use the hasMother and hasFather properties in our fact assertions. You do not need to assert names and birth years yet. This exercise will require you to create an individual for every person we want to talk about, using the Firstname_Secondname_Familyname_Birthyear pattern, as for example in Robert_David_Bright_1965.
+
+
+
+
+
While asserting facts about all individuals in the FHKB will be a bit tedious at
+times, it might be useful to at least do the task for a subset of the family members.
+For the impatient reader, there is a convenience snapshot of the ontology including
+the raw individuals available at http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial
+
+
+
If you are working with Protégé, you may want to look at the Matrix plugin for
+Protégé at this point. The plugin allows you to add individuals quickly in the
+form of a regular table, and can significantly reduce the effort of adding any type
+of entity to the ontology. In order to install the matrix plugin, open Protégé and
+go to File » Check for plugins. Select the ‘Matrix Views’ plugin. Click install,
+wait until the the installation is confirmed, close and re-open Protégé; go to the
+‘Window’ menu item, select ‘Tabs’ and add the ‘Individuals matrix’.
+
+
Now do the following:
+
+
+
+
Task 3: DL queries
+
+
+
+
+
Classify the FHKB.
Issue the DL query hasFather value David_Bright_1934 and look at the answers (remember to check the respective checkbox in Protégé to include individuals in your query results).
Issue the DL query isFatherOf value Robert_David_Bright_1965. Look at the answers. 4. Look at the entailed facts on Robert_David_Bright_1965.
+
+
+
+
You should find the following:
+
+
David Bright (1934) is the father of Robert David Bright (1965) and Richard John Bright (1962).
+
Robert David Bright (1965) has David Bright 1934 as a parent.
+
+
Since we have said that isFatherOf has an inverse of hasFather, and we have asserted that Robert_David_Bright_1965 hasFather David_Bright_1934, we have a simple entailment that David_Bright_1934 isFatherOf Robert_David_Bright_1965. So, without asserting the isFatherOf facts, we have been able to ask and get answers for that DL query.
+
As we asserted that Robert_David_Bright_1965 hasFather David_Bright_1934, we also infer that he hasParentDavid_Bright_1934; this is because hasParent is the super-property of hasFather and the sub-property implies the super-property. This works all the way up the property tree until topObjectProperty, so all individuals are related by topObjectProperty—this is always true. This implication ‘upwards’ is the way to interpret how the property hierarchies work.
We have now covered the basics of dealing with individuals in OWL ontologies. We have set up some properties, but without domains, ranges, appropriate characteristics and then arranged them in a hierarchy. From only a few assertions in our FHKB, we can already infer many facts about an individual: Simple exploitation of inverses of properties and super-properties of the asserted properties.
+
We have also encountered some important principles:
+
+
We get inverses for free.
+
The sub-property implies the super-property. So, hasFather implies the hasParent fact between individuals. This entailment of the super-property is very important and will drive much of the inference we do with the FHKB.
+
Upon reasoning we get the inverses of properties between named individuals for free.
+
Lots is still open. For example, we do not know the sex of individuals and what other children, other than those described, people in the FHKB may have.
+
+
+
The FHKB ontology at this stage of the tutorial has an expressivity of ALHI.
+
+
+
The time to reason with the FHKB at this point (in Protégé) on a typical desktop
+machine by HermiT 1.3.8 is approximately 0.026 sec (0.00001 % of final), by Pellet
+2.2.0 0.144 sec (0.00116 % of final) and by FaCT++ 1.6.4 is approximately 0.
+sec (0.000 % of final). 0 sec indicates failure or timeout.
+
The FHKB has parents established between individuals and we know that all people have two parents. A parent is an ancestor of its children; a person’s parent’s parents are its ancestors; and so on. So, in our FHKB, Robert’s ancestors are David, Margaret, William, Iris, Charles, Violet, James, another Violet, another William, Sarah and so on. If my parent’s parents are my ancestors, then what we need is a transitive version of the hasParent property. Obviously we do not want hasParent to be transitive, as Robert’s grandparents (and so on) would become his parents (and that would be wrong).
+
We can easily achieve what is necessary. We need a hasAncestor property that has a transitive characteristic. The trick is to make this a super-property of the hasParent property. As explained before, a sub-property implies its super-property. So, if individual x holds a hasParent property with an individual y , then it also holds an instance of its super-property hasAncestor with the individual y. If individual y then holds a hasParent property with another individual z , then there is also, by implication, a hasAncestor property between y and z. As hasAncestor is transitive, x and z also hold a hasAncestor relationship between them.
+
The inverse of hasAncestor can either be isAncestorOf or hasDescendant. We choose the isAncestorOf option.
+
+
+
+
Task 4: Object properties: exploiting the semantics
+
+
+
+
+
Make a new object property hasRelation, make it symmetric.
Make a new object property hasAncestor.
Make it a sub-property of hasRelation and a super-property of hasParent.
Make hasAncestor transitive.
Create the inverse isAncestorOf. Do not ‘stitch’ it into the property hierarchy; the reasoner will sort it all out for you.
Run the reasoner and issue the DL query hasAncestor value William_George_Bright_1901.
Issue the query isAncestorOf value Robert_David_Bright_1965.
+
+
+
+
The hasAncestor object property will look like this:
As usual, it is best to think of the objects or individuals involved in the relationships. Consider the three individuals – Robert, David and William. Each has a hasFather property, linking Robert to David and then David to William. As hasFather implies its super-property hasParent, Robert also has a hasParent property with David, and David has a hasParent relation to William. Similarly, as hasParent implies hasAncestor, the Robert object has a hasAncestor relation to the David object and the David object has one to the William object. As hasAncestor is transitive, Robert not only holds this property to the David object, but also to the William object (and so on back through Robert’s ancestors).
We also want to use a sort of restricted transitivity in order to infer grandparents, great grandparents and so on. My grandparents are my parent’s parents; my grandfathers are my parent’s fathers. My great grandparents are my parent’s parent’s parents. My great grandmothers are my parent’s parent’s mothers. This is sort of like transitivity, but we want to make the paths only a certain length and, in the case of grandfathers, we want to move along two relationships – hasParent and then hasFather.
+
We can do this with OWL 2’s sub-property chains. The way to think about sub-property chains is: If we
+see property x followed by property y linking three objects, then it implies that property z is held between
+
+
Figure 3.1: Three blobs representing objects of the classPerson. The three objects are linked by a hasParent
+property and this implies a hasGrandparent property.
+
the first and third objects. Figure 3.1 shows this diagrammatically for the hasGrandfather property.
+
For various grandparent object properties we need the following sets of implications:
+
+
My parent’s parents are my grandparents;
+
My parent’s fathers are my grandfathers;
+
My parent’s mothers are my grandmothers;
+
My parent’s parent’s parents are my great grandparents or my grandparent’s parents are my great
+ grandparents.
+
My parent’s parent’s fathers are my great grandfathers or my parent’s grandfathers are my great
+ grandfathers;
+
My parent’s parent’s mothers are my great grandmothers (and so on).
+
+
Notice that we can trace the paths in several ways, some have more steps than others, though the shorter
+paths themselves employ paths. Tracing these paths is what OWL 2’s sub-property chains achieve. For
+the new object property hasGrandparent we write:
+
ObjectProperty: hasGrandparent SubPropertyChain: hasParent o hasParent
+
+
We read this as ‘hasParent followed by hasParent implies hasGrandparent’. We also need to think where the hasGrandparent property fits in our growing hierarchy of object properties. Think about the implications: Does holding a hasParent property between two objects imply that they also hold a hasGrandparent property? Of course the answer is ‘no’. So, this new property is not a super-property of hasParent. Does the holding of a hasGrandparent property between two objects imply that they also hold an hasAncestor property? The answer is ‘yes’; so that should be a super-property of hasGrandparent. We need to ask such questions of our existing properties to work out where we put it in the object property hierarchy. At the moment, our hasGrandparent property will look like this:
Make the hasGrandparent, hasGrandmother and hasGrandfather object properties and the obvious inverses (see OWL code above);
Go to the individuals tabs and inspects the inferred object property assertions for Robert_David_Bright_1965 and his parents.
+
+
+
+
Again, think of the objects involved. We can take the same three objects as before: Robert, David and William. Think about the properties that exist, both by assertion and implication, between these objects. We have asserted only hasFather between these objects. The inverse can be inferred between the actual individuals (remember that this is not the case for class level restrictions – that all instances of a class hold a property does not mean that the filler objects at the other end hold the inverse; the quantification on the restriction tells us this). Remember that:
+
+
Robert holds a hasFather property with David;
+
David holds a hasFather property with William;
+
By implication through the hasParent super-property of hasFather, Robert holds a hasParent property with David, and the latter holds one with William;
+
The sub-property chain on hasGrandfather then implies that Robert holds a hasGrandfather property to William. Use the diagram in figure 3.1 to trace the path; there is a hasParent path from Robert to William via David and this implies the hasGrandfather property between Robert and William.
+
+
It is also useful to point out that the inverse of hasGrandfather also has the implication of the sub-property chain of the inverses of hasParent. That is, three objects linked by a path of two isParentOf properties implies that an isGrandfatherOf property is established between the first and third object, in
+this case William and Robert. As the inverses of hasFather are established by the reasoner, all the inverse implications also hold.
It is important when dealing with property hierarchies to think in terms of properties between objects and of the implications ‘up the hierarchy’. A sub-property implies its super-property. So, in our FHKB, two person objects holding a hasParent property between them, by implication also hold an hasAncestor
+property between them. In turn, hasAncestor has a super-property hasRelation and the two objects in
+question also hold, by implication, this property between them as well.
+
We made hasAncestor transitive. This means that my ancestor’s ancestors are also my ancestors. That a sub-property is transitive does not imply that its super-property is transitive. We have seen that by manipulating the property hierarchy we can generate a lot of inferences without adding any more facts to the individuals in the FHKB. This will be a feature of the whole process – keep the work to the minimum (well, almost).
+
In OWL 2, we can also trace ‘paths’ around objects. Again, think of the objects involved in the path of properties that link objects together. We have done simple paths so far – Robert linked to David via hasParent and David linked to William via hasFather implies the link between Robert and William of hasGrandfather. If this is true for all cases (for which you have to use your domain knowledge), one can capture this implication in the property hierarchy. Again, we are making our work easier by adding no new explicit facts, but making use of the implication that the reasoner works out for us.
+
+
The FHKB ontology at this stage of the tutorial has an expressivity ofALRI+.
+
+
+
The time to reason with the FHKB at this point (in Protégé) on a typical desktop
+machine by HermiT 1.3.8 is approximately 0.262 sec (0.00014 % of final), by Pellet
+2.2.0 0.030 sec (0.00024 % of final) and by FaCT++ 1.6.4 is approximately 0.004
+sec (0.000 % of final). 0 sec indicates failure or timeout.
+
For the FHKB, we start by thinking about the objects involved
+
+
The people in a family – Robert, Richard, David, Margaret, William, Iris, Charles, Violet, Eileen,
+ John and Peter;
+
The sex of each of those people;
+
The marriages in which they participated;
+
The locations of their births;
+
And many more...
+
+
There is a class of Person that we will use to represent all these people objects.
+
+
+
+
Task 6: Create the Person class
+
+
+
+
+
Create a class called DomainEntity;
Create a subclass of DomainEntity called Person.
+
+
+
+
We use DomainEntity as a house-keeping measure. All of our ontology goes underneath this class. We can put other classes ‘outside’ the ontology, as siblings of DomainEntity, such as ‘probe’ classes we wish to use to test our ontology.
+
The main thing to remember about the Person class is that we are using it to represent all ‘people’ individuals. When we make statements about the Person class, we are making statements about all ‘people’ individuals.
+
What do we know about people? All members of the Person class have:
+
+
Sex – they are either male or female;
+
Everyone has a birth year;
+
Everyone has a mother and a father.
+
+
There’s a lot more we know about people, but we will not mention it here.
Each and every person object has a sex. In the FHKB we will take a simple view on sex – a person is either male or female, with no intersex or administrative sex and so on. Each person only has one sex.
+
We have two straight-forward options for modelling sex:
+
+
Each person object has their own sex object, which is either male or female. Thus Robert’s maleness is different from David’s maleness.
+
There is only one Maleness object and one Femaleness object and each person object has a relationship to either one of these sex objects, but not both.
+
+
We will take the approach of having a class of Maleness objects and a class of Femaleness objects. These are qualities or attributes of self-standing objects such as a person. These two classes are disjoint, and each is a subclass of a class called Sex. The disjointness means that any one instance of Sex cannot be both an instance of Maleness and an instance of Femaleness at once. We also want to put in a covering axiom on the class Sex, which means that any instance of Sex must be either Maleness or Femaleness; there is no other kind of Sex.
+
+
Again, notice that we have been thinking at the level of objects. We do the same when thinking about Person and their Sex. Each and every person is related to an instance of Sex. Each Person holds one relationship to a Sex object. To do this we create an object property called hasSex. We make this property functional, which means that any object can hold that property to only one distinct filler object.
+
We make the domain of hasSex to be Person and the range to be Sex. The domain of Person means that any object holding that property will be inferred to be a member of the class Person. Putting the range of Sex on the hasSex property means that any object at the right-hand end of the hasSex property will be inferred to be of the class Sex. Again, think at the level of individuals or objects.
+
We now put a restriction on the Person class to state that each and every instance of the class Person holds a hasSex property with an instance of the Sex class. It has an existential operator ‘some’ in the axiom, but the functional characteristic means that each Person object will hold only one hasSex property to a distinct instance of a Sex object4.
+
4 An individual could hold two hasSex properties, as long as the sex objects at the right-hand end of the property are not
+different.
+
+
+
+
Task 7: Modelling sex
+
+
+
+
+
Create a class called Sex;
Make it a subclass of DomainEntity;
Make Person and Sex disjoint;
Create two subclasses of Sex, Maleness and Femaleness;
Make Maleness and Femaleness disjoint;
Put a covering axiom on Sex such that it is equivalent to Maleness or Femaleness.
Create an object property, hasSex , with the domain Person, the range Sex and give it the characteristic of ‘Functional’;
Add a restriction hasSex some Sex to the class Person.
+
+
+
+
The hasSex property looks like:
+
ObjectProperty: hasSex
+Characteristics: Functional
+Domain: Person
+Range: Sex
+
+
The Person class looks like:
+
Class: Person
+SubClassOf: DomainEntity,(hasSex some Sex)
+DisjointWith: Sex
+
We now have some of the foundations for the FHKB. We have the concept of Person, but we also need to have the concepts of Man and Woman. Now we have Person, together with Maleness and Femaleness, we have the necessary components to define Man and Woman. These two classes can be defined as: Any Person object that has a male sex can be recognised to be a man; any Person object that has a female sex can be recognised as a member of the class woman. Again, think about what conditions are sufficient for an object to be recognised to be a member of a class; this is how we create defined classes through the use of OWL equivalence axioms.
+
To make the Man and Woman classes do the following:
+
+
+
+
Task 8: Describe men and women
+
+
+
+
+
Create a class Man;
Make it equivalent to a Person that hasSex some Maleness;
Do the same, but with Femaleness, to create the Woman class;
A covering axiom can be put on the Person class to indicate that man and woman are the only kinds of person that can exist. (This is not strictly true due to the way Sex has been described.)
Run the reasoner and take a look.
+
+
+
+
Having run the reasoner, the Man and Woman classes should appear underneath Person5.
+
5Actually in Protégé, this might happen without the need to run the reasoner.
+
The Man and Woman classes will be important for use as domain and range constraints on many of the properties used in the FHKB. To achieve our aim of maximising inference, we should be able to infer that individuals are members of Man, Woman or Person by the properties held by an object. We should not have to state the type of an individual in the FHKB.
+
The classes for Man and Woman should look like:
+
Class: Man
+EquivalentTo: Person and (hasSex some Maleness)
+
+
Class: Woman
+EquivalentTo: Person and (hasSex some Femaleness)
+
To finish off the foundations of the FHKB we need to describe a person object’s parentage. We know that each and every person has one mother and each and every person has one father. Here we are talking about biological mothers and fathers. The complexities of adoption and step parents are outside the scope of this FHKB tutorial.
+
+
+
+
Task 9: Describing Parentage
+
+
+
+
+
Add the domain Person and the range Woman to the property hasMother.
Do the same for the property hasFather, but give it the range Man;
Give the property hasParent domain and range of Person;
Run the reasoner.
+
+
+
+
The (inferred) property hierarchy in the FHKB should look like that shown in Figure 4.1. Notice that we have asserted the sub-property axioms on one side of the property hierarchy. Having done so, the reasoner uses those axioms, together with the inverses, to work out the property hierarchy for the ‘other side’.
+
We make hasMother functional, as any one person object can hold only one hasMother property to a distinct Woman object. The range of hasMother is Woman, as a mother has to be a woman. The Person object holding the hasMother property can be either a man or a woman, so we have the domain constraint as Person; this means any object holding a hasMother property will be inferred to be a Person. Similarly, any object at the right-hand end of a hasMother property will be inferred to be a Woman, which is the result we need. The same reasoning goes for hasFather and hasParent, with the sex constraints on the latter being only Person. The inverses of the two functional sub-properties of hasParent are not themselves functional. After all, a Woman can be the mother of many Person objects, but each Person object can have only one mother.
+
+
Figure 4.1: The property hierarchy with the hasSex and the parentage properties
+
+
Figure 4.2: the core TBox for the FHKB with the Person and Sex classes.
+
+
+
+
Task 10: Restrict Person class
+
+
+
+
+
As each and every person has a mother and each and every person has a father, place restrictions on the Person class as shown below.
+
+
+
+
Class: Person
+SubClassOf: DomainEntity, (hasFather some Man), (hasMother some Woman),
+(hasSex some Sex)
+DisjointWith: Sex
+
+
+
+
+
Task 11: DL queries for people and sex
+
+
+
+
+
Issue the DL queries for Person, Man and Woman; look at the answers and count the numbers in each class; which individuals have no sex and why?
You should find that many people have been inferred to be either Man or Woman, but some are, as we will see below, only inferred to be Person.
+
+
+
+
The domain and range constraints on our properties have also driven some entailments. We have not asserted that David_Bright_1934 is a member of Man, but the range constraint on hasFather (or the inferred domain constraint on the isFatherOf relation) has enabled this inference to be made. This goes for any individual that is the right-hand-side (either inferred or asserted) of either hasFather or hasMother (where the range is that of Woman). For Robert David Bright, however, he is only the left-hand-side of an hasFather or an hasMother property, so we’ve only entailed that this individual is a member of Person.
In our description of the Person class we have said that each and every instance of the class Person has a father (the same goes for mothers). So, when we ask the query ‘which individuals have a father’, we get all the instances of Person back, even though we have said nothing about the specific parentage of each Person. We do not know who their mothers and fathers are, but we know that they have one of each. We know all the individuals so far entered are members of the Person class; when asserting the type to be either Man or Woman (each of which is a subclass of Person), we infer that each is a person. When asserting the type of each individual via the hasSex property, we know each is a Person, as the domain of hasSex is the Person class. As we have also given the right-hand side of hasSex as either Maleness or Femaleness, we have given sufficient information to recognise each of these Person instances to be members of either Man or Woman.
+
4.6 Filling in Domains and Ranges for the FHKB Properties¶
+
So far we have not systematically added domains and ranges to the properties in the FHKB. As a reminder, when a property has a domain of X any object holding that property will be inferred to be a member of class X. A domain doesn’t add a constraint that only members of class X hold that property; it is a strong implication of class membership. Similarly, a property holding a range implies that an object acting as right-hand-side to a property will be inferred to be of that class. We have already seen above that we can use domains and ranges to imply the sex of people within the FHKB.
+
Do the following:
+
+
+
+
Task 12: Domains and Ranges
+
+
+
+
+
Make sure the appropriate Person, Man and Woman are domains and ranges for hasFather, hasMother and hasParent.
Run the reasoner and look at the property hierarchy.
Also look at the properties hasAncestor, hasGrandparent, hasUncle and so on; look to see what domains and ranges are found. Add any domains and ranges explicitly as necessary.
+
+
+
+
+
Protégé for example in its current version (November 2015) does not visualise
+inherited domains and ranges in the same way as it shows inferred inverse relations.
+
+
We typically assert more domains and ranges than strictly necessary. For example, if we say that hasParent has the domain Person, this means that every object x that is connected to another object y via the hasParent relation must be a Person. Let us assume the only thing we said about x and y is that they are connected by a hasMother relation. Since this implies that x and y are also connected by a hasParent relation (hasMother is a sub-property of hasParent) we do not have to assert that hasFather has the domain of Person; it is implied by what we know about the domain and range of hasParent.
+
In order to remove as many assertions as possible, we may therefore choose to assert as much as we know starting from the top of the hierarchy, and only ever adding a domain if we want to constrain the already inferred domain even further (or range respectively). For example, in our case, we could have chosen to assert Person to be the domain of hasRelation. Since hasRelation is symmetric, it will also infer Person to be the range. We do not need to say anything for hasAncestor or hasParent, and only if we want to constrain the domain or range further (like in the case of hasFather by making the range Man) do we need to actually assert something. It is worth noting that because we have built the object property hierarchy from the bottom (hasMother etc.) we have ended up asserting more than necessary.
From the Pizza Tutorial and other work with OWL you should have seen some unsatisfiabilities. In Protégé this is highlighted by classes going ‘red’ and being subclasses ofNothing; that is, they can have no instances in that model.
+
+
+
+
Task 13: Inconsistencies
+
+
+
+
+
Add the fact Robert_David_Bright_1965 hasMother David_Bright_1934.
Run the classifier and see what happens.
Remove that fact and run the classifier again.
Now add the fact that Robert_David_Bright_1965 hasMother Iris_Ellen_Archer_1907
Run the classifier and see what happens.
Add and remove the functional characteristic to these properties and see what happens.
+
+
+
+
After asserting the first fact it should be reported by the reasoner that the ontology is inconsistent. This means, in lay terms, that the model you’ve provided in the ontology cannot accommodate the facts you’ve provided in the fact assertions in your ABox—that is, there is an inconsistency between the facts and the ontology... The ontology is inconsistent because David_Bright_1934 is being inferred to be a Man and a Woman at the same time which is inconsistent with what we have said in the FHKB.
+
When we, however, say that Robert David Bright has two different mothers, nothing bad happens! Our domain knowledge says that the two women are different, but the reasoner does not know this as yet... ; Iris Ellen Archer and Margaret Grace Rever may be the same person; we have to tell the reasoner that they are different. For the same reason the functional characteristic also has no effect until the reasoner ‘knows’ that the individuals are different. We will do this in Section 7.1.1 and live with this ‘fault’ for the moment.
+
+
4.8 Adding Some Defined Classes for Ancestors and so on¶
+
+
+
+
Task 14: Adding defined classes
+
+
+
+
+
Add a defined class for Ancestor, MaleAncestor, FemaleAncestor;
Add a defined class for Descendant, MaleDescendant and FemaleDescendant;
Run the reasoner and view the resulting hierarchy.
+
+
+
+
The code for the classes looks like:
+
Class: Ancestor EquivalentTo: Person and isAncestorOf some Person
+Class: FemaleAncestor EquivalentTo: Woman and isAncestorOf some Person
+Class: Descendant EquivalentTo: Person and hasAncestor some Person
+Class: MaleDescendant EquivalentTo: Man and hasAncestor some Person
+
+
The TBox after reasoning can be seen in Figure 4.3. Notice that the reasoner has inferred that several of the classes are equivalent or ‘the same’. These are: Descendant and Person; MaleDescendant and Man, FemaleDescendant and Woman.
+
The reasoner has used the axioms within the ontology to infer that all the instances of Person are also instances of the class Descendant and that all the instances of Woman are also the same instances as the class Female Descendant. This is intuitively true; all people are descendants – they all have parents that have parents etc. and thus everyone is a descendant. All women are female people that have parents etc. As usual we should think about the objects within the classes and what we know about them. This time it is useful to think about the statements we have made about Person in this Chapter – that all instances of Person have a father and a mother; add to this the information from the property hierarchy and we know that all instances of Person have parents and ancestors. We have repeated all of this in our new defined classes for Ancestor and Descendant and the reasoner has highlighted this information.
+
+
Figure 4.3: The defined classes from Section 4.8 in the FHKB’s growing class hierarchy
+
+
+
+
Task 15: More Ancestors
+
+
+
+
+
Query for MaleDescendant. You should get Man back - they are equivalent (and this makes sense).
As an additional exercise, also add in properties for forefathers and foremothers. You will follow the same pattern as for hasAncestor, but adding in, for instance, hasFather as the sub-property of the transitive super-property of hasForefather and setting the domains and ranges appropriately (or working out if they’ll be inferred appropriately). Here we interpret a forefather as one’s father’s father etc. This isn’t quite right, as a forefather is any male ancestor, but we’ll do it that way anyway. You might want to play around with DL queries. Because of the blowup in inferred relationships, we decided to not include this pattern in the tutorial version of the FHKB.
Most of what we have done in this chapter is straight-forward OWL, all of which would have been met in the pizza tutorial. It is, however, a useful revision and it sets the stage for refining the FHKB. Figure 4.2 shows the basic set-up we have in the FHKB in terms of classes; we have a class to represent person, man and woman, all set-up with a description of sex, maleness and femaleness. It is important to note, however, the approach we have taken: We have always thought in terms of the objects we are modelling.
+
Here are some things that should now be understood upon completing this chapter:
+
+
Restrictions on a class in our TBox mean we know stuff about individuals that are members of that class, even though we have asserted no facts on those individuals. We have said, for instance, that all members of the class Person have a mother, so any individual asserted to be a Person must have a mother. We do not necessarily know who they are, but we know they have one.
+
Some precision is missing – we only know Robert David Bright is a Person, not that he is a Man. This is because, so far, he only has the domain constraint of hasMother and hasFather to help out.
+
We can cause the ontology to be inconsistent, for example by providing facts that cannot be accommodated by the model of our ontology. In the example, David Bright was inferred to be a member of two disjoint classes.
+
+
Finally, we looked at some defined classes. We inferred equivalence between some classes where the extents of the classes were inferred to be the same – in this case the extents of Person and Descendant are the same. That is, all the objects that can appear in Person will also be members of Descendant. We can check this implication intuitively – all people are descendants of someone. Perhaps not the most profound inference of all time, but we did no real work to place this observation in the FHKB.
+
+
This last point is a good general observation. We can make the reasoner do work
+for us. The less maintenance we have to do in the FHKB the better. This will be
+a principle that works throughout the tutorial.
+
+
+
The FHKB ontology at this stage of the tutorial has an expressivity of SRIF.
+
+
+
The time to reason with the FHKB at this point (in Protégé) on a typical desktop
+machine by HermiT 1.3.8 is approximately 0.884 sec (0.00047 % of final), by Pellet
+2.2.0 0.256 sec (0.00207 % of final) and by FaCT++ 1.6.4 is approximately 0.013
+sec (0.000 % of final). 0 sec indicates failure or timeout.
+
Create an hasBloodrelation object property, making it a sub-property of hasRelation.
Add appropriate property characteristics.
Make the already existing hasAncestor property a sub-property of hasBloodrelation.
+
+
+
+
Does a blood relation of Robert have the same relationship to Robert (symmetry)? Is a blood relation of Robert’s blood relation a blood relation of Robert (transitivity)? Think of an aunt by marriage; her children are my cousins and blood relations via my uncle, but my aunt is not my blood relation. My siblings share parents; male siblings are brothers and female siblings are sisters. So far we have asserted parentage facts for the Person in our ABox. Remember that our parentage properties have inverses, so if we have added an hasFather property between a Person and a Man, we infer the isFatherOf property between that Man and that Person.
We make a property of hasSibling and make it a sub-property of hasBloodrelation. Remember, think of the objects involved and the implications we want to follow; being a sibling implies being a blood relation, it does not imply any of the other relationships we have in the FHKB.
+
Note that we have made hasSibling symmetric; if Robert is sibling of Richard, then Richard is sibling of Robert. We should also think about transitivity; if David is sibling of Peter and Peter is sibling of John, then David is sibling of John. So, we make hasSibling symmetric and transitive (see Figure 5.1). However, we must take care of half-siblings: child 1 and child 2 share a mother, but not a father; child 2 and child 3 share the father, but not the mother – child 1 and child 3 are not even half-siblings. However, at least for the moment, we will simply ignore this inconvenience, largely so that we can explore what happens with different modelling options.
+
+
+
Figure 5.1: Showing the symmetry and transitivity of the hasSibling (siblingof) property by looking at the brothers David, John and Peter
+
We also have the implication using three objects (see Figure 5.2):
+
+
Robert holds a hasParent property with David;
+
David holds an isFatherOf property with Richard;
+
This implies that Robert holds a hasSibling property with Richard;
+
As hasSibling is symmetric, Richard holds an hasSibling property with Robert.
+
+
+
Figure 5.2: Tracing out the sub-property chain for hasSibling; note that Robert is a sibling of himself by this
+path
+
Do the following tasks:
+
+
+
+
Task 17: Siblings
+
+
+
+
+
Add the hasSibling property as above;
Run the reasoner;
Ask the DL query hasSibling value Robert_David_Bright_1965.
+
+
+
+
From this last DL query you should get the answer that both Robert and Richard are siblings of Robert. Think about the objects involved in the sub-property chain: we go from Robert to David via the hasParent and from David to Richard via the isParentOf property; so this is OK. However, we also go from Robert to David and then we can go from David back to Robert again – so Robert is a sibling of Robert. We do not want this to be true.
+
+
We can add another characteristic to the hasSibling property, the one of being irreflexive. This means that an object cannot hold the property with itself.
+
+
+
+
Task 18: More siblings
+
+
+
+
+
Add the irreflexive characteristic to the hasSibling property;
Run the reasoner;
+
+
+
+
Note that the reasoner claims you have an inconsistent ontology (or in some cases, you might get a message box saying "Reasoner died"). Looking at the hasSibling property again, the reason might not be immediately obvious. The reason for the inconsistency lies in the fact that we create a logical contradiction: through the property chain, we say that every Person is a sibling of him or herself, and again disallowing just that by adding the irreflexive characteristic. A different explanation lies within the OWL specification itself: In order to maintain decidability irreflexive properties must be simple - for example, they may not be property chains6.
We have only done siblings, but we obviously need to account for brothers and sisters. In an analogous way to motherhood, fatherhood and parenthood, we can talk about sex specific sibling relationships implying the sex neutral hasSibling; holding either a hasBrother or an isSisterOf between two objects would imply that a hasSibling property is also held between those two objects. This means that we can place these two sex specific sibling properties below hasSibling with ease. Note, however, that unlike the hasSibling property, the brother and sister properties are not symmetric. Robert hasBrother Richard and vice versa , but if Daisy hasBrother William, we do not want William to hold an hasBrother property with Daisy. Instead, we create an inverse of hasBrother, isBrotherOf, and the do the same for isSisterOf.
+
We use similar, object based, thought processes to choose whether to have transitivity as a characteristic of hasBrother. Think of some sibling objects or individuals and place hasBrother properties between them. Make it transitive and see if you get the right answers. Put in a sister to and see if it stil works. If David hasBrother Peter and Peter hasBrother John, then David hasBrother John; so, transitivity works in this case. Think of another example. Daisy hasBrother Frederick, and Frederick hasBrother William, thus Daisy hasBrother William. The inverses work in the same way; William isBrotherOf Frederick and Frederick isBrotherOf Daisy; thus William isBrotherOf Daisy. All this seems reasonable.
+
+
+
+
Task 19: Brothers and sisters
+
+
+
+
+
Create the hasBrother object property as shown below;
Add hasSister in a similar manner; 3. Add appropriate inverses, domains and ranges.
We have some hasSibling properties (even if they are wrong). We also know the sex of many of the people in the FHKB through the domains and ranges of properties such as hasFather, hasMother and their inverses..
+
Can we use sub-property chains in the same way as we have used them in the hasSibling property? The issue is that of sex; the property isFatherOf is sex neutral at the child end, as is the inverse hasFather (the same obviously goes for the mother properties). We could use a sub-property chain of the form:
+
ObjectProperty: hasBrother
+SubPropertyChain: hasParent o hasSon
+
+
A son is a male child and thus that object is a brother of his siblings. At the moment we do not have son or daughter properties. We can construct a property hierarchy as shown in Figure 5.3. This is made up from the following properties:
+
+
hasChild and isChildOf
+
hasSon(range Man and domain Person) and isSonOf;
+
hasDaughter(range Woman domain Person) and isDaughterOf
+
+
Note that hasChild is the equivalent of the existing property isParentOf; if I have a child, then I am its
+parent. OWL 2 can accommodate this fact. We can add an equivalent property axiom in the following
+way:
We have no way of inferring the isSonOf and isDaughterOf from what already exists. What we want
+to happen is the implication of ‘Man and hasParentPerson implies isSonOf’. OWL 2 and its reasoners
+cannot do this implication. It has been called the ‘man man problem’7. Solutions for this have been
+developed [3], but are not part of OWL 2 and its reasoners.
+
+
Figure 5.3: The property hierarchy for isChildOf and associated son/daughter properties
Thus we must resort to hand assertions of properties to test out our new path:
+
+
+
+
Task 20: Sons and daughters
+
+
+
+
+
Add the property hierarchy shown in Figure 5.3, together with the equivalent property axiom and the obvious inverses.
As a test (after running the reasoner), ask the DL query isChildOf value David_Bright_1934 and you should have the answer of Richard and Robert;
Add the sub-property paths as described in the text;
Add the assertions shown in Table 5.1;
Run the reasoner;
Ask the DL query for the brother of Robert David Bright and the sister of Janet.
+
+
+
+
Of course, it works, but we see the same problem as above. As usual, think of the objects involved.
+Robert isSonOf David and David isParentOf Robert, so Robert is his own brother. Irreflexivity again
+causes problems as it does above (Task 18).
Our option one has lots of problems. So, we have an option of asserting the various levels of sibling. We
+can take the same basic structure of sibling properties as before, but just fiddle around a bit and rely on
+more assertion while still trying to infer as much as possible. We will take the following approach:
+
+
We will take off the sub-property chains of the sibling properties as they do not work;
+
We will assert the leaf properties of the sibling sub-hierarchy sparsely and attempt to infer as much
+ as possible.
+
+
+
+
+
Person
+
Property
+
Person
+
+
+
+
+
Robert David Bright 1965
+
isBrotherOf
+
Richard John Bright 1962
+
+
+
David Bright 1934
+
isBrotherOf
+
John Bright 1930
+
+
+
David Bright 1934
+
isBrotherOf
+
Peter William Bright 1941
+
+
+
Janet Bright 1964
+
isSisterOf
+
Mark Bright 1956
+
+
+
Janet Bright 1964
+
isSisterOf
+
Ian Bright 1959
+
+
+
Janet Bright 1964
+
isSisterOf
+
William Bright 1970
+
+
+
Mark Bright 1956
+
isBrotherOf
+
Ian Bright 1959
+
+
+
Mark Bright 1956
+
isBrotherOf
+
Janet Bright 1964
+
+
+
Mark Bright 1956
+
isBrotherOf
+
William Bright 1970
+
+
+
+
Table 5.2: The sibling relationships to add to the FHKB.
+
Do the following:
+
+
+
+
Task 21: Add sibling assertions
+
+
+
+
+
Remove the sub-property chains of the sibling properties and the isChildOf assertions as explained above.
Add the Sibling assertions shown in table 5.2;
Run the reasoner;
Ask isBrotherOf value Robert_David_Bright_1965;
Ask isBrotherOf value Richard_John_Bright_1962;
Ask hasBrother value Robert_David_Bright_1965;
Ask hasBrother value Richard_John_Bright_1962;
Ask isSisterOf value William_Bright_1970;
Ask the query Man and hasSibling value Robert_David_Bright_1965.
+
+
+
+
We can see some problems with this option as well:
+
+
With these properties asserted, Richard only has a hasBrother property to Robert. We would really like an isBrotherOf to Robert to hold.
+
The query Man and hasSibling value Robert only retrieves Robert himself. Because we only asserted that Robert is a brother of Richard, and the domain of isBrotherOf is Man we know that Robert is a Man, but we do not know anything about the Sex of Richard.
+
+
5.3.1 Which Modelling Option to Choose for Siblings?¶
+
Which of the two options gives the worse answers and which is the least effort? Option one is obviously the least effort; we only have to assert the same parentage facts as we already have; then the sub-property chains do the rest. It works OK for hasSibling, but we cannot do brothers and sisters adequately; we need Man and hasSibling ⊐ isBrotherOf and we cannot do that implication. This means we cannot ask the questions we need to ask.
+
+
So, we do option two, even though it is hard work and is still not perfect for query answering, even though we have gone for a sparse assertion mode. Doing full sibling assertion would work, but is a lot of effort.
+
We could start again and use the isSonOfandisDaughterOf option, with the sub-property chains described above. This still has the problem of everyone being their own sibling. It can get the sex specific sibling relationships, but requires a wholesale re-assertion of parentage facts. We will continue with option two, largely because it highlights some nice problems later on.
In Section 5.2 we briefly talked about half-siblings. So far, we have assumed full-siblings (or, rather, just talked about siblings and made no distinction). Ideally, we would like to accommodate distinctions between full- and half-siblings; here we use half-siblings, where only one parent is in common between two individuals, as the example. The short-answer is, unfortunately, that OWL 2 cannot deal with half-siblings in the way that we want - that is, such that we can infer properties between named individuals indicating full- or half-sibling relationships.
+
It is possible to find sets of half-brothers in the FHKB by writing a defined class or DL-query for a particular individual.} The following fragment of OWL defines a class that looks for the half-brothers of an individual called ‘Percival’:
+
+
Class: HalfBrotherOfPercival
+EquivalentTo: Man and (((hasFather some (not (isFatherOf value Percival))) and
+(hasMother some (isMotherOf value Percival))) or ((hasFather some (isFatherOf
+value Percival)) and (hasMother some (not (isMotherOf value Percival)))))
+
+
Here we are asking for any man that either has Percival’s father but not his mother, or his mother, but not his father. This works fine, but is obviously not a general solution. The OWL description is quite complex and the writing will not scale as the number of options (hypothetically, as the number of parents increases... ) increases; it is fine for man/woman, but go any higher and it will become very tedious to write all the combinations.
+
Another way of doing this half-brother class to find the set of half-brothers of a individual is to use cardinality constraints:
+
Class: HalfBrotherOfPercival
+EquivalentTo: Man and (hasParent exactly 1 (isParentOf value Percival))
+
+
This is more succinct. We are asking for a man that has exactly one parent from the class of individuals that are the class of Percival’s parents. This works, but one more constraint has to be present in the FHKB. We need to make sure that there can be only two parents (or indeed, just a specified number of parents for a person). If we leave it open as to the number of parents a person has, the reasoner cannot work out that there is a man that shares exactly one parent, as there may be other parents. We added this constraint to the FHKB in Section 6.2; try out the classes to check that they work.
+
These two solutions have been about finding sets of half-brothers for an individual. What we really want
+in the FHKB is to find half-brothers between any given pair of individuals.
+
Unfortunately we cannot, without rules, ask OWL 2 to distinguish full- and half-siblings – we cannot
+count the number of routes taken between siblings via different distinct intermediate parent objects.
An uncle is a brother of either my mother or father. An aunt is a sister of either my mother or father. In common practice, wives and husbands of aunts and uncles are usually uncles and aunts respectively. Formally, these aunts and uncles are aunts-in-law and uncles-in-law. Whatever approach we take, we cannot fully account for aunts and uncles until we have information about marriages, which will not have until Chapter 9. We will, however, do the first part now.
+
Look at the objects and properties between them for the following facts:
+
+
Robert has father David and mother Margaret;
+
David has brothers Peter and John;
+
Margaret has a sister Eileen;
+
Robert thus has the uncles John and Peter and an aunt Eileen.
+
+
As we are tracing paths or ‘chains’ of objects and properties we should use sub-property chains as a solution for the aunts and uncles. We can make an hasUncle property as follows (see Figure 5.4):
+
ObjectProperty: hasUncle
+SubPropertyOf: hasBloodrelation
+Domain: Man
+Range: Person
+SubPropertyChain: hasParent o hasBrother
+InverseOf: isUncleOf
+
+
+
Figure 5.4: Tracing out the path between objects to get the hasUncle sub-property chain.
+
Notice we have the domain of Man and range of Person. We also have an inverse. As usual, we can read this as ‘an object that holds an hasParent property, followed by an object holding a hasBrother property, implies that the first object holds an hasUncle property with the last object’.
+
Note also where the properties (include the ones for aunt) go in the object property hierarchy. Aunts and uncles are not ancestors that are in the direct blood line of a person, but they are blood relations (in the narrower definition that we are using). Thus the aunt and uncle properties go under the hasBloodrelation property (see Figure 5.5). Again, think of the implications between objects holding a property between them; that two objects linked by a property implies that those two objects also hold all the property’s super-properties as well. As long as all the super-properties are true, the place in the object property hierarchy is correct (think about the implications going up, rather than down).
+
+
Figure 5.5: The object property hierarchy with the aunt and uncle properties included. On the right side, we
+can see the hasUncle property as shown by Protégé.
+
Do the following tasks:
+
+
+
+
Task 22: Uncles and Aunts
+
+
+
+
+
Add the hasUncle property as above;
Add the hasAunt property as well;
Ask for the uncles of Julie_Bright_1966 and for Mark_Bright_1956;
Add similar properties for hasGreatUncle and hasGreatAunt and place them in the property hierarchy.
+
+
+
+
We can see this works – unless we have any gaps in the sibling relationships (you may have to fix these). Great aunts and uncles are simply a matter of adding another ‘parent’ leg into the sub-property chain. We are not really learning anything new with aunts and uncles, except that we keep gaining a lot for
+
free through sub-property chains. We just add a new property with its sub-property chain and we get a whole lot more inferences on individuals. To see what we now know about Robert David Bright, do the following:
+
+
+
+
Task 23: What do we know?
+
+
+
+
+
Save the ontology and run the reasoner;
Look at inferences related to the individual Robert David Bright (see warning in the beginning of this chapter).
If you chose to use DL queries in Protégé, do not forget to tick the appropriate check-boxes.
+
+
+
+
You can now see lots of facts about Robert David Bright, with only a very few actual assertions directly on Robert David Bright.
We can use just the parentage facts to find siblings, but everyone ends up being their own sibling;
+
We cannot make the properties irreflexive, as the knowledge base becomes inconsistent;
+
We would like an implication of Man and hasSibling ⊃ isBrotherOf, but OWL 2 doesn’t do this implication;
+
Whatever way we model siblings, we end up with a bit of a mess;
+
OWL 2 cannot do half-siblings;
+
However, we can get close enough and we can start inferring lots of facts via sub-property chains using the sibling relationships.
+
+
+
The FHKB ontology at this stage of the tutorial has an expressivity ofSRIF.
+
+
+
The time to reason with the FHKB at this point (in Protégé) on a typical desktop
+machine by HermiT 1.3.8 is approximately 1355.614 sec (0.71682 % of final), by
+Pellet 2.2.0 0.206 sec (0.00167 % of final) and by FaCT++ 1.6.4 is approximately
+0.039 sec (0.001 % of final). 0 sec indicates failure or timeout.
+
So far we have only used object properties between unspecified objects. We can, however, specify a specific individual to act at the right-hand-side of a class restriction or type assertion on an individual. The basic syntax for so-called nominals is:
+
Class: ParentOfRobert
+EquivalentTo: Person and isParentOf valueRobert_David_Bright_1965
+
+
This is an equivalence axiom that recognises any individual that is a Person and a parent of Robert David Bright.
+
+
+
+
Task 24: Robert and Richards parents
+
+
+
+
+
Create the class ParentOfRobert as described above;
Classify – inspect where the class is placed in the FHKB TBox and look at which individuals classify as members of the class;
Do the same for a class with the value of Richard_John_Bright_1962 and classify;
Finally create a class ParentOfRichardAndRobert, defining it as Person and isParentOf some {Robert_David_Bright_1965 ,Richard_John_Bright_1962 }; again see what happens on classification. Note that the expressions isMotherOf value Robert_David_Bright_1965 and isMotherOf some {Robert_David_Bright_1965 } are practically identical. The only difference is that using value, you can only specify one individual, while some relates to a class (a set of individuals).
+
+
+
+
We see that these queries work and that we can create more complex nominal based class expressions. The disjunction above is
+
isParentOf some {Robert_David_Bright_1965, Richard_John_Bright_1965}
+
+
The ‘{’ and ‘}’ are a bit of syntax that says ‘here’s a class of individual’.
+
We also see that the classes for the parents of Robert David Bright and Richard John Bright have the same members according to the FHKB, but that the two classes are not inferred to be equivalent. Our domain knowledge indicates the two classes have the same extents (members) and thus the classes are equivalent, but the automated reasoner does not make this inference. As usual, this is because the FHKB has not given the automated reasoner enough information to make such an inference.
+
6.2 Closing Down What we Know About Parents and Siblings¶
+
The classes describing the parents of Richard and Robert are not equivalent, even though, as humans, we know their classes of parent are the same. We need more constraints so that it is known that the four parents are the only ones that exist. We can try this by closing down what we know about the immediate family of Robert David Bright.
+
In Chapter 4 we described that a Person has exactly one Woman and exactly one Man as mother and father (by saying that the hasMother and hasFather properties are functional and thus only one of each may be held by any one individual to distinct individuals). The parent properties are defined in terms of hasParent, hasMother and hasFather. The latter two imply hasParent. The two sub-properties are functional, but there are no constraints on hasParent, so an individual can hold many instances of this property. So, there is no information in the FHKB to say a Person has only two parents (we say there is one mother and one father, but not that there are only two parents). Thus Robert and Richard could have other parents and other grandparents than those in the FHKB; we have to close down our descriptions so that only two parents are possible. There are two ways of doing this:
+
+
Using qualified cardinality constraints in a class restriction;
+
Putting a covering axiom on hasParent in the same way as we did for Sex in Chapter 4.
+
+
+
+
+
Task 25: Closing the Person class
+
+
+
+
+
Add the restriction hasParent exactly 2 Person to the classPerson;
Run the reasoner;
Inspect the hierarchy to see where ParentOfRobert and ParentOfRichard are placed and whether or not they are found to be equivalent;
Now add the restriction hasParent max 2 Person to the class Person;
Run the reasoner (taking note of how long the reasoning takes) and take another look.
+
+
+
+
+
We find that these two classes are equivalent; we have supplied enough information to infer that these two classes are equivalent. So, we know that option one above works, but what about option two? This takes a bit of care to think through, but the basic thing is to think about how many ways there are to have a hasParent relationship between two individuals. We know that we can have either a hasFather or a hasMother property between two individuals; we also know that we can have only one of each of these properties between an individual and a distinct individual. However, the open world assumption tells us that there may be other ways of having a hasParent property between two individuals; we’ve not closed the possibilities. By putting on the hasParent exactly 2 Person restriction on the Person class, we are effectively closing down the options for ways that a person can have parents; we know because of the functional characteristic on hasMother and hasFather that we can have only one of each of these and the two restrictions say that one of each must exist. So, we know we have two ways of having a parent on each Person individual. So, when we say that there are exactly two parents (no more and no less) we have closed down the world of having parents—thus these two classes can be inferred to be equivalent. It is also worth noting that this extra axiom on the Person class will make the reasoner run much more slowly.
+
Finally, for option 2, we have no way of placing a covering axiom on a property. What we’d like to be
+able to state is something like:
+
ObjectProperty: hasParent
+EquivalentTo: hasFather or hasMother
+
Add lots more classes using members of the ABox as nominals;
Make complex expressions using nominals;
After each addition of a nominal, classify and see what has been inferred within the FHKB.
See if you can make classes for GrandparentOfRobert and GrandparentOfRichard and make them inferred to be equivalent.
+
+
+
+
In this chapter we have seen the use of individuals within class expressions. It allows us to make useful queries and class definitions. The main things to note is that it can be done and that there is some syntax involved. More importantly, some inferences may not be as expected due to the open world assumption in OWL.
+
+
By now you might have noticed a significant increase in the time the reasoner needs
+to classify. Closing down what we know about family relationships takes its toll on
+the reasoner performance, especially the usage of 'hasParent exactly 2 Person'. At
+this point we recommend rewriting this axiom to 'hasParent max 2 Person'. It gives
+us most of what we need, but has a little less negative impact on the reasoning
+time.
+
+
+
The FHKB ontology at this stage of the tutorial has an expressivity of SROIQ.
+
+
+
The time to reason with the FHKB at this point (in Protégé) on a typical desktop
+machine by HermiT 1.3.8 is approximately 2067.273 sec (1.09313 % of final), by
+Pellet 2.2.0 0.529 sec (0.00428 % of final) and by FaCT++ 1.6.4 is approximately
+0.147 sec (0.004 % of final). 0 sec indicates failure or timeout.
+
We now have some individuals with some basic object properties between individuals. OWL 2, however, also has data properties that can relate an object or individual to some item of data. There are data about a Person, such as years of events and names etc. So, in this Chapter you will:
+
+
Make some data properties to describe event years to people;
+
Create some simple defined classes that group people by when they were born;
+
Try counting the numbers of children people have...
+
Deal with the open world assumption;
+
Add given and family names to individuals in the FHKB.
+
+
+
There is a snapshot of the ontology as required at this point in the tutorial available
+at http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial.
+
Everyone has a birth year; death year; and some have a marriage year and so on. We can model these simply with data properties and an integer as a filler. OWL 2 has a DateTime datatype, where it is possible to specify a precise time and date down to a second. 7 This proves cumbersome (see http://robertdavidstevens.wordpress.com/2011/05/05/using-the-datetime-data-type-to-describe-birthdays/ for details); all we need is a simple indication of the year in which a person was born. Of course, the integer type has a zero, which the Gregorian calendar for which we use integer as a proxy does not, but integer is sufficient to our needs. Also, there are various ontological treatments of time and information about people (this extends to names etc. as well), but we gloss over that here—that’s another tutorial.
We can have dates for birth, death and (eventually) marriage (see Chapter 9) and we can just think of these as event years. We can make a little hierarchy of event years as shown in Figure 7.1).
+
+
+
+
Task 27: Create a data property hierarchy
+
+
+
+
+
Create the data property hasEventYear with range integer and domain Person;
Create the data property hasBirthYear and make it a sub-property of hasEventYear (that way, the domain and range of hasEventYear are inherited);
Create the data property hasDeathYear and make it a sub-property of hasEventYear;
For each individual add the birth years shown in Table A.1 (see appendix). You do not actually have to go back to the table—it is easier to read the birth years simply off the individual names.
+
+
+
+
+
Again, asserting birth years for all individuals can be a bit tedious. The reader
+can find a convenience snapshot of the ontology at this stage at http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial
+
+
We now have an ABox with individuals with fact assertions to data indicating a birth year. We can, if we wish, also add a class restriction to the Person class saying that each and every instance of the class Person holds a data property to an integer and that this property is called ‘hasBirthYear’. As usual when deciding whether to place such a restriction upon a class, ask whether it is true that each and every instance of the class holds that property; this is exactly the same as we did for the object properties in Chapter 4. Everyone does have a birth year, even if it is not known.
+
Once birth years have been added to our individuals, we can start asking some questions.
+
+
+
+
Task 28: DL queries
+
+
+
+
+
1. Use a DL query to ask:
Person born after 1960;
Person born in the 1960s;
Person born in the 1800s;
Person that has fewer than three children;
Person that has more than three children.
+
+
+
+
The DL query for people born in the 1960s is:
+
Person and hasBirthYear some int[>= 1960, < 1970]
+
The last two queries in the list do not work as expected. We have asked, for instance, for Person that have more than three children, but we get no members of Person in the answer, though we know that there are some in the FHKB (e.g., John_Bright_1930). This is because there is not enough information in the FHKB to tell that this person has more than three different people as children. As humans we can look at the four children of John Bright and know that they are different – for instance, they all have different birth years. The automated reasoner, however, does not know that a Person can only have one birth year.
+
+
+
+
Task 29: Make a functional object property
+
+
+
+
+
Make the property hasBirthYear functional.
Ask the query for Person that has more than three children again.
+
+
+
+
This time the query should work. All the other event year properties should be made functional, expect hasEventYear, as one individual can have many event years. As the children have different birth year and an individual can only hold one hasBirthYear property, then these people must be distinct entities.
+
Of course, making birth year functional is not a reliable way of ensuring that the automated reasoner knows that the individual are different. It is possible for two Person to have the same birth year within the same family – twins and so on. Peter_William_Bright_1941 has three children, two of which are twins, so will not be a member of the class of people with at least three children. So, we use the different individuals axiom. Most tools, including Protégé, have a feature that allows all individuals to be made different.
+
+
+
+
Task 30: Make all individuals different
+
+
+
+
+
Make all individuals different;
Ask the above queries again.
+
+
+
+
From now on, every time you add individuals, make sure the different individuals axiom is updated.
We have met again the open world assumption and its importance in the FHKB. In the use of the functional characteristic on the hasBirthYear property, we saw one way of constraining the interpretation of numbers of children. We also introduced the ‘different individuals’ axiom as a way of making all individuals in a knowledge base distinct. There are more questions, however, for which we need more ways of closing down the openness of OWL 2.
+
Take the questions:
+
+
People that have exactly two children;
+
People that have only brothers;
+
People that have only female children.
+
+
+
We can only answer these questions if we locally close the world.We have said that David and Margaret have two children, Richard and Robert, but we have not said that there are not any others. As usual, try not to apply your domain knowledge too much; ask yourself what the automated reasoner actually knows. As we have the open world assumption, the reasoner will assume, unless otherwise said, that there could be more children; it simply doesn’t know.
+
Think of a railway journey enquiry system. If I ask a standard closed world system about the possible routes by rail, between Manchester and Buenos Aires, the answer will be ’none’, as there are none described in the system. With the open world assumption, if there is no information in the system then the answer to the same question will simply be ‘I don’t know’. We have to explicitly say that there is no railway route from Manchester to Buenos Aires for the right answer to come back.
+
We have to do the same thing in OWL. We have to say that David and Margaret have only two children. We do this with a type assertion on individuals. So far we have only used fact assertions. A type assertion to close down David Bright’ parentage looks like this:
+
isParentOf only {Robert_David_Bright_1965,Richard_John_Bright_1962 }
+
+
+
This has the same meaning as the closure axioms that you should be familiar with on classes. We are saying that the only fillers that can appear on the right-hand-side of the isParentOf property on this individual are the two individuals for Richard and Robert. We use the braces to represent the set of these two individuals.
+
+
+
+
Task 31: Make a closure axiom
+
+
+
+
+
Add the closure assertion above to David Bright;
Issue the DL query isParentOf exactly 2 Person.
+
+
+
+
The last query should return the answer of David Bright. Closing down the whole FHKB ABox is a chore and would really have to be done programmatically. OWL scripting languages such as the Ontology Preprocessing Language8 (OPPL) [2] can help here. Also going directly to the OWL API [1]9, if you know what you are doing, is another route.
+
+
Adding all these closure type assertions can slow down the reasoner; so think about
+the needs of your system – just adding it ‘because it is right’ is not necessarily the
+right route.
+
We also want to add some other useful data facts to people – their names. We have been putting names as part of labels on individuals, but data fact assertions make sense to separate out family and given names so that we can ask questions such as ‘give me all people with the family name Bright and the first given name of either James or William’. A person’s name is a fact about that person and is more, in this case, than just a label of the representation of that person. So, we want family names and given names. A person may have more than one given name – ‘Robert David’, for instance – and an arbitrary number of given names can be held. For the FHKB, we have simply created two data properties of hasFirstGivenName and hasSecondGivenName). Ideally, it would be good to have some index on the property to given name position, but OWL has no n-ary relationships. Otherwise, we could reify the hasGivenName property into a class of objects, such as the following:
+
Class: GivenName
+SubClassOf:hasValue some String,
+hasPosition some Integer
+
+
but it is really rather too much trouble for the resulting query potential.
+
As already shown, we will use data properties relating instances of Person to strings. We want to distinguish family and given names, and then different positions of given names through simple conflating of position into the property name. Figure 7.1 shows the intended data property hierarchy.
+
+
Figure 7.1: The event year and name data property hierarchies in the FHKB.
+
Do the following:
+
+
+
+
Task 32: Data properties
+
+
+
+
+
Create the data properties as described in Figure 7.1;
Give the hasName property the domain of Person and the range of String;
Make the leaf properties of given names functional;
Add the names shown in Table A.1 (appendix); Again, it may be easier to read the names of the individual names.
Ask the questions:
all the people with the first given name ‘James’;
all the people with the first given name ‘William’;
All the people with the given name ‘William’;
All the people with the given name ‘William’ and the family name ‘Bright’.
+
+
+
+
The name data property hierarchy and the queries using those properties displays what now should be familiar. Sub-properties that imply the super-property. So, when we ask hasFirstGivenName value "William" and then the query hasGivenName value value "William" we can expect different answers. There are people with ‘William’ as either first or second given name and asking the question with the super-property for given names will collect both first and second given names.
We have used data properties that link objects to data such as string, integer, floats and Booleans etc. OWL uses the XML data types. We have seen a simple use of data properties to simulate birth years. The full FHKB also uses them to place names (given and family) on individuals as strings. This means one can ask for the Person with the given name "James", of which there are many in the FHKB.
+
Most importantly we have re-visited the open world assumption and its implications for querying an OWL ABox. We have looked at ways in which the ABox can be closed down – unreliably via the functional characteristic (in this particular case) and more generally via type assertions.
+
All the DL queries used in this chapter can also serve as defined classes in the TBox. It is a useful exercise to progressively add more defined classes to the FHKB TBox. Make more complex queries, make them into defined classes and inspect where they appear in the class hierarchy.
+
+
The FHKB ontology at this stage of the tutorial has an expressivity of SROIQ(D).
+
+
+
The time to reason with the FHKB at this point (in Protégé) on a typical desktop
+machine by HermiT 1.3.8 is approximately 1891.157 sec (1.00000 % of final), by
+Pellet 2.2.0 1.134 sec (0.00917 % of final) and by FaCT++ 1.6.4 is approximately
+0.201 sec (0.006 % of final). 0 sec indicates failure or timeout.
+
+
+
Note that we now cover the whole range of expressivity of OWL 2. HermiT at
+least is impossibly slow by now. This may be because HermiT does more work
+than the others. For now, we recommend to use either Pellet or FaCT++.
+
Figure 8.1: Tracing out the sub-property chain for cousins going from a child to a parent, to its sibling, and
+down to its child, a cousin
+
Figure 8.1 shows the sub-property chain for first cousins. As usual, think at the object level; to get to the first cousins of Robert David Bright, we go to the parents of Robert David Bright, to their siblings and then to their children. We go up, along and down. The OWL for this could be:
+
ObjectProperty: hasFirstCousin
+SubPropertyOf: hasCousin
+SubPropertyChain: hasParent o hasSibling o hasChild
+Characteristics: Symmetric
+
+
Note that we follow the definitions in Section 8.1 of first cousins sharing a grandparent, but not a parent. The sub-property chain goes up to children of a grandparent (a given person’s parents), along to siblings and down to their children. We do not want this property to be transitive. One’s cousins are not necessarily my cousins. The blood uncles of Robert David Bright have children that are his cousins. These first cousins, however, also have a mother that is not a blood relation of Robert David Bright and the mother’s sibling’s children are not cousins of Robert David Bright.
+
We do, however, want the property to be symmetric. One’s cousins have one’s-self as a cousin.
+
We need to place the cousin properties in the growing object property hierarchy. Cousins are obviously blood relations, but not ancestors, so they go off to one side, underneath hasBloodrelation. We should group the different removes and degree of cousin underneath one hasCousin property and this we will do.
+
Do the following:
+
+
+
+
Task 33: First cousins
+
+
+
+
+
Add the property of hasCousin to the hierarchy underneath hasBloodrelation;
Add hasFirstCousin underneath this property;
Add the sub-property chain as described above;
Run the reasoner and look at the first cousins of Robert David Bright.
+
+
+
+
You should see the following people as first cousins of Robert David Bright: Mark Anthony Heath,
+Nicholas Charles Heath, Mark Bright, Ian Bright, Janet Bright, William Bright, James Bright, Julie
+Bright, Clare Bright, Richard John Bright and Robert David Bright. The last two, as should be expected,
+are first cousins of Robert David Bright and this is not correct. As David Bright will be his own brother,
+his children are his own nieces and nephews and thus the cousins of his own children. Our inability to
+infer siblings correctly in the FHKB haunts us still and will continue to do so.
+
+
Although the last query for the cousins of Robert David Bright should return the
+same results for every reasoner, we have had experiences where the results differ.
+
Other degrees of cousins follow the same pattern as for first cousins; we go up, along and down. For second cousins we go up from a given individual to children of a great grandparent, along to their siblings and down to their grandchildren. The following object property declaration is for second cousins (note it uses the isGrandparentOf and its inverse properties, though the parent properties could be used) :
+
ObjectProperty: hasSecondCousin
+SubPropertyOf: hasCousin
+SubPropertyChain: hasGrandParent o hasSibling o isGrandParentOf
+Characteristics: Symmetric
+
+
‘ Removes ’ simply add in another ‘leg’ of either ‘up’ or ‘down’ either side of the ‘along’—that is, think of the actual individuals involved and draw a little picture of blobs and lines—then trace your finger up, along and down to work out the sub-property chain. The following object property declaration does it for first cousins once removed (note that this has been done by putting this extra ‘leg’ on to the hasFirstCousin property; the symmetry of the property makes it work either way around so that a given person is the first cousin once removed of his/her first cousins once removed):
To exercise the cousin properties do the following:
+
+
+
+
Task 34: Cousin properties
+
+
+
+
+
Add properties for second degree cousins;
Add removes for first and second degree cousins;
Run the reasoner and check what we know about Robert David Bright’ other types of cousin.
+
+
+
+
You should see that we see some peculiar inferences about Robert David Bright’ cousins – not only are his brother and himself his own cousins, but so are his father, mother, uncles and so on. This makes sense if we look at the general sibling problem, but also it helps to just trace the paths around. If we go up from one of Robert David Bright’ true first cousins to a grandparent and down one parent relationship, we follow the first cousin once removed path and get to one of Robert David Bright’ parents or uncles. This is not to be expected and we need a tighter definition that goes beyond sub-property chains so that we can exclude some implications from the FHKB.
As far as inferring first cousin facts for Robert David Bright, we have failed. More precisely, we have recalled all Robert David Bright’s cousins, but the precision is not what we would desire. What we can do is ask for Robert David Bright’ cousins, but then remove the children of Robert David Bright’ parents. The following DL query achieves this:
+
Person that hasFirstCousin valueRobert_David_Bright_1965
+and (not (hasFather valueDavid_Bright_1934) or not (hasMother valueMar-
+garet_Grace_Rever_1934)
+
+
This works, but only for a named individual. We could make a defined class for this query; we could also make a defined class FirstCousin, but it is not of much utility. We would have to make sure that people whose parents are not known to have siblings with children are excluded. That is, people are not ‘first cousins’ whose only first cousins are themselves and their siblings. The following class does this:
+
Class: FirstCousin
+EquivalentTo: Person that hasFirstCousin some Person
+
+
+
+
+
Task 35: Roberts first cousins
+
+
+
+
+
Make a defined class FirstCousin as shown above;
Make a defined class FirstCousinOfRobert;
Create a DL query that looks at Robert_David_Bright_1965 first cousins and takes away the children of Robert_David_Bright_1965’ parents as shown above.
+
+
+
+
+
This gives some practice with negation. One is making a class and then ‘taking’ some of it away – ‘these, but not those’.
We have now expanded the FHKB to include most blood relationships. We have also found that cousins are hard to capture just using object properties and sub-property chains. Our broken sibling inferences mean that we have too many cousins inferred at the instance level. We can get cousins right at the class level by using our inference based cousins, then excluding some using negation. Perhaps not neat, but it works.
+
We have reinforced that we can just add more and more relationships to individuals by just adding more properties to our FHKB object property hierarchy and adding more sub-property chains that use the object properties we have built up upon parentage and sibling properties; this is as it should be.
+
+
The FHKB ontology at this stage of the tutorial has an expressivity of SROIQ(D).
+
+
+
The time to reason with the FHKB at this point (in Protégé) on a typical desktop
+machine by HermiT 1.3.8 is approximately 0.000 sec (0.00000 % of final), by Pellet
+2.2.0 111.395 sec (0.90085 % of final) and by FaCT++ 1.6.4 is approximately 0.868
+sec (0.024 % of final). 0 sec indicates failure or timeout.
+
Establish object properties for husbands, wives and various in-laws;
+
Re-visit aunts and uncles to do them properly;
+
Use more than one sub-property chain on a given property.
+
+
+
There is a snapshot of the ontology as required at this point in the tutorial available
+at http://owl.cs.manchester.ac.uk/tutorials/fhkbtutorial
+
+
+
Much of what is in this chapter is really revision; it is more of the same - making
+lots of properties and using lots of sub-property chains. However, it is worth it as
+it will test your growing skills and it also makes the reasoners and yourself work
+hard. There are also some good questions to ask of the FHKB as a result of adding
+marriages.
+
Marriage is a culturally complex situation to model. The FHKB started with a conservative model of a marriage involving only one man and one woman.10 Later versions are more permissive; a marriage simply has a minimum of two partners. This leaves it open to numbers and sex of the people involved. In fact, ‘marriage’ is probably not the right name for it. Using BreedingRelationship as a label (the one favoured by the main author’s mother) may be a little too stark and might be a little exclusive.... In any case, some more generic name is probably better and various subclasses of the FHKB’s Marriage class are probably necessary.
+
10 There being no funny stuff in the Stevens family.
+
To model marriage do the following:
+
+
+
+
Task 36: Marriage
+
+
+
+
+
Create a class Marriage, subclass of DomainEntity;
Create the properties:
hasPartner(domain Marriage and range Person) and isPartnerIn
hasFemalePartner(domain Marriage and range Woman, sub-property of hasPartner) and its inverse isFemalePartnerIn;
a sub-property of hasPartner has MalePartner (domain Marriage and range Man)and its inverse isMalePartnerIn;
Create the data property hasMarriageYear, making us a sub-property of hasEventYear,make it functional;
Create an individual m001 with the label Marriage of David and Margaret and add the facts:
hasMalePartner David_Bright_1934;
hasFemalePartner Margaret_Grace_Rever_1934
hasMarriageYear 1958;
Create an individual m002 with the label Marriage of John and Joyce and add the facts:
hasMalePartnerJohn_Bright_1930;
hasFemalePartnerJoyce_Gosport(you may have to add Joyce if you did not already did that);
hasMarriageYear1955;
Create an individual m003 with the label Marriage of Peter and Diana and add the facts:
hasMalePartnerPeter_William_Bright_1941;
hasFemalePartnerDiana_Pool(you may have to add Diana if you did not already did that);
hasMarriageYear1964;
+
+
+
+
We have the basic infrastructure for marriages. We can ask the usual kinds of questions; try the following:
+
+
+
+
Task 37: DL queries
+
+
+
+
+
Ask the following DL queries:
The Women partners in marriages;
Marriages that happened before 1960 (see example below);
Marriages that happened after 1960;
Marriages that involved a man with the family name ‘Bright’.
+
+
+
+
DL query: Marriage and hasMarriageYear some int[<= 1960]
+
This marriage infrastructure can be used to infer some slightly more interesting things for actual people. While we want marriage objects so that we can talk about marriage years and even locations, should we want to, we also want to be able to have the straight-forward spouse relationships one would expect. We can use sub-property chains in the usual manner; do the following:
+
+
+
+
Task 38: Wifes and Husbands
+
+
+
+
+
Create a property hasSpouse with two sub-properties hasHusband and hasWife.
Create the inverses isSpouseOf, isWifeOf and isHusbandOf.
To the hasWife property, add the sub-property chain isMalePartnerIn o hasFemalePartner.
Follow the same pattern for the hasHusband property.
+
+
+
+
Figure 9.1 shows what is happening with the sub-property chains. Note that the domains and ranges of the spouse properties come from the elements of the sub-property chains. Note also that the hasSpouse relationship will be implied from its sub-property chains.
+
The following questions can now be asked:
+
+
Is wife of David Bright;
+
Has a husband born before 1940;
+
The wife of an uncle of William Bright 1970.
+
+
+
Figure 9.1: The sub-property chain path used to infer the spouse relationships via the marriage partnerships.
+
and many more. This is really a chance to explore your querying abilities and make some complex
+nested queries that involve going up and down the hierarchy and tracing routes through the graph of
+relationships between the individuals you’ve inferred.
Now we have spouses, we can also have in-laws. The path is simple: isSpouseOf o hasMother implies hasMotherInLaw. The path involved in mother-in-laws can be seen in Figure 9.2. The following OWL code establishes the sub-property chains for hasMotherInLaw:
+
ObjectProperty: hasMotherInLaw
+SubPropertyOf: hasParentInLaw
+SubPropertyChain: isSpouseOf o hasMother
+Domain: Person
+Range: Woman
+InverseOf: isMotherInLawOf
+
+
+
Figure 9.2: Tracing out the path between objects to make the sub-property chain for mother-in-laws
+
Do the following to make the parent in-law properties:
+
+
+
+
Task 39: Parents in-law
+
+
+
+
+
Create hasParentInLaw with two sub-properties of hasMotherInLaw and hasFatherInLaw;
Create the inverses, but remember to let the reasoner infer the hierarchy on that side of the hierarchy;
Add the sub-property chains as described in the pattern for hasMotherInLaw above;
Run the reasoner and check that the mother-in-law of Margaret Grace Rever is Iris Ellen Archer.
Brothers and sisters in law have the interesting addition of having more than one path between objects to establish a sister or brother in law relationship. The OWL code below establishes the relationships for ‘is sister in law of’:
+
ObjectProperty: hasSisterInLaw
+SubPropertyOf: hasSiblingInLaw
+SubPropertyChain: hasSpouse o hasSister
+SubPropertyChain: hasSibling o isWifeOf
+
+
A wife’s husband’s sister is a sister in law of the wife. Figure 9.3 shows the two routes to being a sister-in-law. In addition, the wife is a sister in law of the husband’s siblings. One can add as many sub-property chains to a property as one needs. You should add the properties for hasSiblingInLawOf and its obvious sub-properties following the inverse of the pattern above.
+
+
+
+
Task 40: Siblings in-law
+
+
+
+
+
Create the relationships for siblings-in-law as indicated in the owl code above.
+
+
+
+
+
By now, chances are high that the realisation takes a long time. We recommend to
+remove the very computationally expensive restriction `hasParent` exactly 2 Person
+on the `Person` class, if you have not done it so far.
+
+
+
Figure 9.3: The two routes to being a sister-in-law.
The uncle of Robert David Bright has a wife, but she is not the aunt of Robert David Bright, she is the aunt-in-law. This is another kith relationship, not a kin relationship. The pattern has a familiar feel:
+
ObjectProperty: isAuntInLawOf
+SubPropertyOf: isInLawOf
+SubPropertyChain: isWifeOf o isBrotherOf o isParentOf
+
+
+
+
+
Task 41: Uncles and aunts in-law
+
+
+
+
+
Create hasAuntInLaw and hasUncleInLaw in the usual way;
Test in the usual way;
Tidy up the top of the property hierarchy so that it looks like Figure 9.4. We have a top property of hasRelation and two sub-properties of isBloodRelationOf and isInLawOf to establish the kith and kin relationships respectively;
All the properties created in this chapter (except for spouses) should be underneath isInLawOf.
+
+
+
+
+
Figure 9.4: The object property hierarchy after adding the various in-law properties.
This has really been a revision chapter; nothing new has really been introduced. We have added a lot of new object properties and one new data property. The latest object property hierarchy with the ‘in-law’ branch can be seen in Figure 9.4. Highlights have been:
+
+
Having an explicit marriage object so that we can say things about the marriage itself, not just the people in the marriage;
+
We have seen that more than one property chain can be added to a property;
+
We have added a lot of kith relationships to join the kin or blood relationships;
+
As usual, the reasoner can establish the hierarchy for the inverses and put a lot of the domain and ranges in for free.
+
+
+
The FHKB ontology at this stage of the tutorial has an expressivity of SROIQ(D).
+
+
+
The time to reason with the FHKB at this point (in Protégé) on a typical desktop
+machine by HermiT 1.3.8 is approximately 0.000 sec (0.00000 % of final), by Pellet
+2.2.0 123.655 sec (1.00000 % of final) and by FaCT++ 1.6.4 is approximately 1.618
+sec (0.046 % of final). 0 sec indicates failure or timeout.
+
Any defined class for any property in the hierarchy and any nominal variant of these classes.
+
+
+
+
The three classes of Child, Son and Daughter are of note. They are coded in the following way:
+
Class: Child EquivalentTo: Person that hasParent Some Person
+Class: Son EquivalentTo: Man that hasParent Some Person
+Class: Daughter EquivalentTo: Woman that hasParent Some Person
+
+
After running the reasoner, you will find that Person is found to be equivalent to Child; Daughter is equivalent to Woman and that Son is equivalent to Man. This does, of course, make sense – each and every person is someone’s child, each and every woman is someone’s daughter. We will forget evolutionary time-scales where this might be thought to break down at some point – all Person individuals are also Descendant individuals, but do we expect some molecule in some prebiotic soup to be a member of this class?
+
Nevertheless, within the scope of the FHKB, such inferred equivalences are not unreasonable. They are
+also instructive; it is possible to have different intentional descriptions of a class and for them to have the
+same logical extents. You can see another example of this happening in the amino acids ontology, but
+for different reasons.
+
Taking Grandparent as an example class, there are two ways of writing the defined class:
+
Class: Grandparent EquivalentTo: Person and isGrandparentOf some Person
+Class: Grandparent EquivalentTo: Person and (isParentOf some (Person and (is-
+ParentOf some Person))
+
+
Each comes out at a different place in the class hierarchy. They both capture the right individuals as members (that is, those individuals in the ABox that are holding a isGrandparentOf property), but the class hierarchy is not correct. By definition, all grandparents are also parents, but the way the object property hierarchy works means that the first way of writing the defined class (with the isGrandparentOf property) is not subsumed by the class Parent. We want this to happen in any sensible class hierarchy, so we have to use the second pattern for all the classes, spelling out the sub-property path that implies the property such as isGrandparentOf within the equivalence axiom.
+
The reason for this need for the ‘long-form’ is that the isGrandparentOf does not imply the isParentOf property. As described in Chapter 3 if this implication were the case, being a grandparent of Robert David Bright, for instance, would also imply that the same Person were a parent of Robert David Bright; an implication we do not want. As these two properties (isParentOf and isGrandparentOf) do not subsume each other means that the defined classes written according to pattern one above will not subsume each other in the class hierarchy. Thus we use the second pattern. If we look at the class for grandparents of Robert:
+
Class: GrandparentOfRobert
+EquivalentTo: Person that isParentOf some (Person that isParentOf value Robert
+David Bright)
+
+
If we make the equivalent class for Richard John Bright, apply the reasoner and look at the hierarchy, we see that the two classes are not logically equivalent, even though they have the same extents of William George Bright, Iris Ellen Archer, Charles Herbert Rever and Violet Sylvia Steward. We looked at this example in Section 6.2, where there is an explanation and solutions.
We can add defined classes based on each property we have put into the object property hierarchy. We see the expected hierarchy; as can be seen from Figure 10.1 it has an obvious symmetry based on sex. We also see a lot of equivalences inferred – all women are daughters, as well as women descendants. Perhaps not the greatest insight ever gained, but it at least makes sense; all women must be daughters. It is instructive to use the explanation feature in Protégé to look at why the reasoner has made these inferences. For example, take a look at the class hasGrandmother some Woman – it is instructive to see how many there are.
+
Like the Chapter on marriage and in-law (Chapter 9), this chapter has largely been revision. One thing of note is, however, that we must not use the object properties that are inferred through sub-property chains as definitions in the TBox; we must spell out the sub-property chain in the definition, otherwise the implications do not work properly.
+
One thing is almost certain; the resulting TBox is rather complex and would be almost impossible to maintain by hand.
+
+
Figure 10.1: The full TBox hierarchy of the FHKB
+
+
The FHKB ontology at this stage of the tutorial has an expressivity of SROIQ(D).
+
+
+
The time to reason with the FHKB at this point (in Protégé) on a typical desktop
+machine by HermiT 1.3.8 is approximately 0.000 sec (0.00000 % of final), by Pellet
+2.2.0 0.000 sec (0.00000 % of final) and by FaCT++ 1.6.4 is approximately 35.438
+sec (1.000 % of final). 0 sec indicates failure or timeout.
+
If you have done all the tasks within this tutorial, then you will have touched most parts of OWL 2. Unusually for most uses of OWL we have concentrated on individuals, rather than just on the TBox. One note of warning – the full FHKB has some 450 members of the Bright family and takes a reasonably long time to classify, even on a sensible machine. The FHKB is not scalable in its current form.
+
One reason for this is that we have deliberately maximised inference. We have attempted not to explicitly type the individuals, but drive that through domain and range constraints. We are making the property hierarchy do lots of work. For the individual Robert David Bright, we only have a couple of assertions, but we infer some 1 500 facts between Robert David Bright and other named individuals in the FHKB–displaying this in Protégé causes problems. We have various complex classes in the TBox and so on.
+
+
We probably do not wish to drive a genealogical application using an FHKB in this form. Its purpose is educational. It touches most of OWL 2 and shows a lot of what it can do, but also a considerable amount of what it cannot do. As inference is maximised, the FHKB breaks most of the OWL 2 reasoners at the time of writing.However, it serves its role to teach about OWL 2.
+
OWL 2 on its own and using it in this style, really does not work for family history. We have seen that siblings and cousins cause problems. rules in various forms can do this kind of thing easily—it is one of the primary examples for learning about Prolog. Nevertheless, the FHKB does show how much inference between named individuals can be driven from a few fact assertions and a property hierarchy. Assuming a powerful enough reasoner and the ability to deal with many individuals, it would be possible to make a family history application using the FHKB; as long as one hid the long and sometimes complex queries and manipulations that would be necessary to ‘prune’ some of the ‘extra’ facts found about individuals. However, the FHKB does usefully show the power of OWL 2, touch a great deal of the language and demonstrate some of its limitations.
[1] M. Horridge and S. Bechhofer. The owl api: a java api for working with owl 2 ontologies. Proc. of
+OWL Experiences and Directions , 2009, 2009.
+
[2] Luigi Iannone, Alan Rector, and Robert Stevens. Embedding knowledge patterns into owl. In European
+Semantic Web Conference (ESWC09) , pages 218–232, 2009.
+
[3] Dmitry Tsarkov, Uli Sattler, Margaret Stevens, and Robert Stevens. A Solution for the Man-Man
+Problem in the Family History Knowledge Base. In Sixth International Workshop on OWL: Experiences and Directions 2009 , 2009.
GitHub is increasingly used by software developers, programmers and project managers for uploading and sharing content, as well as basic project management. You build a profile, upload projects to share and connect with other users by "following" their accounts. Many users store programs and code projects, but you can also upload text documents or other file types in your project folders to share publicly (or privately). It is capable of storing any file type from text, to structured data, to software. And more features are being added by the day. The real power of Git, however, is less about individuals publishing content (many places can do that, including google docs etc). It is more about that content being easily shared, built upon, and credited in a way that is robust to the realities of distributed collaboration. You don't have to know how to code or use the command line. It is a powerful way to organize projects with multiple participants.
Organization: An entity that may correspond to an actual organization (such as a university) or to a meaningful grouping of repositories. Organizations are like individuals except that they can establish teams.
Teams: A group of individuals assembled by the administrators of an organization. An individual may participate in many teams and organizations, however a team is always bound to a single organization. Nesting teams saves time; instructions here.
+
+
The relationships between any combination of these entities is many-to-many, with the nuanced exception of repositories.
+For our purposes today we will oversimplify by saying that a repositoy belongs either to a single organization or to a single individual.
GitHub can store any kind of content, provided it isn't too big. (And now even this is possible).
+However, it is more capable for some filetypes than it is for others. Certain filetypes can be viewed 'natively' within the GitHub interface. These are:
+
+
Images: png, jpg, svg
+
GEOJSON
+
CSV, TSV (note that files named type '.tab' will not render properly in the UI.)
Why:
+"Issues are a great way to keep track of tasks, enhancements, and bugs for your projects or for anyone else's. As long as you are a registered GitHub user you can log an issue, or comment on an issue for any open repo on GitHub. Issues are a bit like email—except they can be shared, intelligently organized, and discussed with the rest of your team. GitHub’s tracker is called Issues, and has its own section in every repository." (From: https://guides.github.com/features/issues/)
Click "New Issue" (note the word 'issue' and 'ticket' are frequently used interchangeably)
+
Write an informative title
+
Write a detailed explanation of your issue
+
In the case of reporting software bugs, provide some context in which the issue was encountered (e.g. bug detected when using Google Chrome on a Mac OS)
Click New Label to create a new label, or click Edit to edit an existing one.
+
In the text box, type your new label name.
+
Select a color for the label from the color bar. You can customize this color by editing the hexadecimal number above the color bar. For a list of hexadecimal numbers see HTML color codes
Scroll to the bottom of the issue, and add content in the "Leave a comment" field
+
Use the top tool bar to format your text, add bold, italic, lists etc.
+
Preview your text to see how your formatting looks
+
Click Comment.
+
+
Close issues
+
+
If an issue has been addressed, click Close Issue. Best practice is to point to the work (whether code, documentation, etc) that has been done to close it.
+
Only close the ticket if the issue has been resolved, usually someone will write a comment describing the action they did to close the issue and click Close Issue.
+
The issue will no longer be dispalyed in the list of open issue, but will be archived.
+
When making a change to code or documentation in GitHub, it is possible to automatically couple a change to an issue and close it. Just use 'fixes' or 'closes' followed by the issue number.
+
+
Use direct @ mentions
+
+
You can mention someone in a issue without assigning it to them
+
In the comments section, type @github handle. For example, to mention Nicole, you would type @nicolevasilevsky. You can either start typing their name or GitHub handle and GitHub will autosuggest their handle.
+
+
Link documents
+
You can link documents and files by:
+
+
copy and pasting URL
+
you can attach files by dragging and dropping
+
You can link one issue to another in the same repo by typing '#' followed by the title of the ticket
+
This approach also works across repos but you need to use the full URL (no autocomplete available). Doing this will also cause the referent issue to display that it has been referenced.
+
+
Cross reference to another ticket
+
+
If your ticket is a duplicate or related to another ticket, you can cross reference another ticket
+
Type # and you will see a list of other tickets in that repo
+
Type #TicketNumber and that will link to the other ticket.
+
+
Before saving your changes, you can preview the comment to ensure the correct formatting.
+
Your turn:
+
+
Follow the instructions above to comment on a ticket that someone created.
+
Mention Nicole
+
Attach a picture (such as a picture you copy from the internet, or attach a picture you have saved on your computer)
+
Include a comment that says, 'related to #1' and link to ticket #1
To create a milestone, navigate to the issues page in your repository
+
Next to the search field, click Milestones
+
Click New Milestone to create a new milestone, click Edit to edit an existing one
+
Create a milestone that is broad enough to be meaningful, but specific enough to be actionable.
+
Set a due date for the milestone (note that specific tasks can not be formally assigned due dates, though you can mention a desired due date in the narrative text of a ticket.
+
Each ticket can only be associated to ONE milestone, however it can have as many labels as appropriate.
+
A given issue can be part of multiple "project" boards (see below)
+
+
Your turn
+
Create a new milestone, and add the milestone to an existing ticket.
+
Projects
+
+
Projects is a lot like Trello, it uses cards on a list that you can name and organize as you see fit.
+
You can create as many projects within a repository as you like
+
+
To create project:
+
+
Click on Projects
+
Click New Project
+
Name the project
+
Write a description of the project
+
Create columns and give them names
+
Add 'cards' to the columns
+
+
Your turn
+
Create a new project and add columns and add cards to the columns.
Once you start using GitHub for lots of things it is easy to get overwhelmed by the number of issues. The query dashboard https://github.com/issues allows you to filter on tickets.
When you join a repository, by default, you are 'watching' all activity. You can change the setting to 'Participating and @mentions' to only get notifications that mention you
+
You can set rules in your email to filter for emails that mention you, ie @username.
To be safe, contact GitHub directly at https://github.com/contact, but recognize that they support literally millions of users and responsiveness is not guaranteed. Forums like isaacs sometimes offer some help because other users can help identify workarounds, for instance, as shown here.
Tutorial: Very (!) short introduction to the command line for ontology curators and semantic engineers: Part 1¶
+
As a modern ontology curator, you are an engineer - you are curating computable knowledge, testing the integrity of your curation using quality control testing, and are responsible for critical components of modern knowledge systems that directly affect user experience - the ontologies.
+
Scientific computing is a big, scary world comprising many different tools, methodologies, training resources and philosophies, but nearly all modern workflows share one key aspect: the ability to execute commands that help you find and manipulate data with the command line. Some examples of that include:
+
+
Running and Ontology Development Kit (ODK) commands like sh run.sh make prepare_release
+
Creating a new branch in git and committing changes
+
Downloading a file with curl or wget
+
Finding which file in my ontology repository mentions HP:0000118 to figure out where that "weird axiom is coming from"
The tutorial uses example tailored for users of UNIX systems, like Mac and Linux.
+Users of Windows generally have analogous steps - wherever we talk about an sh file in the following
+there exists a corresponding bat file that can be run in the windows powershell, or CMD.
We are not going to discuss here in any detail what the command line is. We will focus on what you can do with it: for more information skip to the further reading section.
+
The basic idea behind the command line is that you run a command to achieve a goal. Among the most common goals relevant to you as a semantic engineer will be:
+
+
Navigating the file system (changing directories, logging into remote servers and more)
+
Reading and writing files
+
Searching stuff
+
+
Most commands result in some kind of printed statement. Lets try one. Open your terminal (a terminal is the program you use to enter commands. For a nice overview of how shell, terminal, command line and console relate, see here). On Mac, you can type CMD+Space to search for programs and then type "terminal". For this tutorial we use the default Terminal.app, but there are many others, including iterm2. For this introduction, it does not matter which terminal you use. When first opening the terminal you will see something like this:
+
+
or
+
+
Note that your terminal window may look slightly different, depending on your configuration. More on that later.
+
Let's type our first command and hit enter:
+
whoami
+
+
On my machine I get
+
(base)matentzn@mbp.local:~ $ whoami
+matentzn
+
+
This does not seem like a useful command, but sometimes, we forget who we are, and it is good to be reminded. So, what happened here? We ran a command, named whoami and our command line executed that command which is implemented somewhere on our machine as a program. That program simply determined who I am in some way, and then printed the result again.
+
Ok so, lets lets look a bit closer at the command prompt itself:
+
matentzn@mbp.local:~ $
+
+
Two interesting things to not here for today:
+
+
The ~. This universally (on all Unix systems) refers to your user directory on your computer. In this case here, it tells you that in your terminal, you are "in your user directory".
+
The $ sign. It simply denotes where your command line starts (everything before the $ is information provided to you, everything will be about your commands). Make sure that you do not accidentally copy based the $ sign from the examples on the web into your command prompt:
+
+
(base)matentzn@mbp.local:~ $ $ whoami
+-bash: $: command not found
+(base)matentzn@mbp.local:~ $
+
+
whoami did not do anything.
+
Ok, based on the ~ we know that we are "in the user home directory". Let as become a bit more confident about that and ask the command prompt where we are:
+
matentzn@mbp.local:~ $ pwd
+/Users/matentzn
+
+
The pwd command prints out the full path of our current location in the terminal. As you can see, the default location when opening the command prompt is, indeed, the home director, located in /Users/matentzn. We will use it later again.
+
A word about paths. /Users/matentzn is what we call a path. On UNIX systems, / separates one directory from another. So matentzn is a directory inside of the Users directory.
+
Let us now take a look what our current directory contains (type ls and hit enter):
+
matentzn@mbp.local:~ $ ls
+Applications Library ...
+
+
This command will simply list all of the files in your directory as a big list. We can do this a bit nicer:
-l is a short command line option which allows you specify that you would like print the results in a different format (a long list). We will not go into any detail here what this means but a few things to not in the output: You can see some pieces of information that are interesting, like when the file or directory was last modified (i.e. 31. July 2020), who modified it (me) and, of course, the name e.g. Applications.
+
Before we move on to the next section, let us clear the current terminal from all the command outputs we ran:
In the previous section we learned how to figure out who we are (whoami), where we are (pwd) and how to see what is inside the current directory (ls -l) and how to clear all the output (clear).
+
Let us know look at how we can programmatically create a new directory and change the location in our terminal.
+
First let us create a new directory:
+
mkdir tutorial-my
+
+
Now if we list the contents of our current directory again (ls -l), we will see our newly created directory listed! Unfortunately, we just realised that we chose the wrong name for our directory! It should have been my-tutorial instead of tutorial-my! So, let us rename it. In the command prompt, rather than "renaming" files and directories, we "move" them (mv).
+
mv tutorial-my my-tutorial
+
+
Now, lets enter our newly created directory using the _c_hange _d_irectory command (cd), and create another sub-directory in my-tutorial, called "data" (mkdir data):
+
cd my-tutorial
+mkdir data
+
+
You can check again with ls -l. If you see the data directory listed, we are all set! Feel free to run clear again to get rid of all the current output on the command prompt.
+
Let us also enter this directory now: cd data.
+
If we want to leave the directory again, feel free to do that like this:
+
cd ..
+
+
The two dots (..) mean: "parent directory." This is very important to remember during your command line adventures: .. stands for "parent directory", and . stands for "current/this directory" (see more on that below).
+
Now, let's get into something more advanced: downloading files.
Our first task is to download the famous Human Phenotype Ontology Gene to Phenotype Annotations (aka HPOA). As you should already now, whenever we download ontologies, or ontology related files, we should always use a persistent URL, if available! This is the one for HPOA: http://purl.obolibrary.org/obo/hp/hpoa/genes_to_phenotype.txt.
+
There are two very popular commands for downloading content: curl and wget. I think most of my colleagues prefer curl, but I like wget because it simpler for beginners. So I will use it here. Lets us try downloading the file!
The -O parameter is optional and specifies a filename. If you do not add the parameter, wget will try to guess the filename from the URL. This does not always go so well with complex URLs, so I personally recommend basically always specifying the -O parameter.
+
You can also use the curl equivalent of the wget command;
Ok, let us look at the first 10 lines of genes_to_phenotype.txt using the head command:
+
head genes_to_phenotype.txt
+
+
head is a great command to familiarise yourself with a file. You can use a parameter to print more or less lines:
+
head -3 genes_to_phenotype.txt
+
+
This will print the first 3 lines of the genes_to_phenotype.txt file. There is another analogous command that allows us to look at the last lines off a file:
+
tail genes_to_phenotype.txt
+
+
head, tail. Easy to remember.
+
Next, we will learn the most important of all standard commands on the command line: grep. grep stands for "Global regular expression print" and allows us to search files, and print the search results to the command line. Let us try some simple commands first.
+
grep diabetes genes_to_phenotype.txt
+
+
You will see a list of hundreds of lines out output. Each line corresponds to a line in the genes_to_phenotype.txt file which contains the word "diabetes".
+
grep is case sensitive. It wont find matches like Diabetes, with capital D!
+
+Use the `-i` parameter in the grep command to instruct grep to
+perform case insensitive matches.
+
+
There is a lot more to grep than we can cover here today, but one super cool thing is searching across an entire directory.
+
grep -r "Elevated circulating follicle" .
+
+
Assuming you are in the data directory, you should see something like this:
The -r option ("recursive") allows is to search a directory and all directories within in.
+
The . in the beginning. Remember, in the previous use of the grep command we had the name of a file in the place where now the . is. The . means "this directory" - i.e. the directory you are in right now (if lost, remember pwd).
+
+
As you can see, grep does not only list the line of the file in which the match was found, it also tells us which filename it was found in!
+We can make this somewhat more easy to read as well by only showing filenames using the -l parameter:
The final lesson for today is about one of the most powerful features of the command line: the ability to chain commands together. Let us start with a simple example (make sure you are inside the data directory):
+
grep -r "Elevated circulating follicle" . | head -3
+
So, what is happening here? First, we use the grep command to find "Elevated circulating follicle" in our data directory. As you may remember, there are more than 10 results for this command. So the grep command now wants to print these 10 results for you, but the | pipe symbol intercepts the result from grep and passes it on to the next command, which is head. Remember head and tail from above? Its exactly the same thing, only that, rather than printing the first lines of a file, we print the first lines of the output of the previous command. You can do incredible things with pipes. Here a taster which is beyond this first tutorial, but should give you a sense:
grep is looking for "Elevated circulating follicle" in all files in the directory, then "|" is passing the output on to
+
cut, which extracts the second column of the table (how cool?), then "|" is passing the output on to
+
sort, which sorts the output, then "|" is passing the output on to
+
uniq, which removes all duplicate values from the output, then "|" is passing the output on to
+
head, which is printing only the first 3 rows of the result.
+
+
Another super cool use of piping is searching your command history. Try running:
+
history
+
+
This will show you all the commands you have recently run. Now if you want to simply look for some very specific commands that you have run in the past you can combine history with grep:
+
history | grep follicle
+
+
This will print every command you ran in the last hour that contains the word "follicle". Super useful if you, like me, keep forgetting your commands!
+
The last critical feature of the command line we cover today is the "file redirect". Instead of printing the output to file, we may chose to redirect the results to a file instead:
Sam also did here PhD in and around ontologies but has moved entirely to data engineering since. I really liked her 1 hour introduction into the terminal, this should fill some of the yawning gaps in this introduction here.
(Optional) installed the amazing ohmyzsh! - advanced CLI for managing your ZSH profile. Important: Before installing ohmyzsh, back up you ~/.zshrc file in case you have had any previous customisations you wish to preserve.
For advanced windows users with docker installed, you can:
+
Follow the instructions here to set yourself up for ODK development.
+
Place odk.bat as instructed above in some directory on your machine (the path to the odk.bat file should have no spaces!)
+
Create a new file .bash_profile in the same directory as your odk.bat file.
+
Add something like -v %cd%\.bash_profile:/root/.bash_profile to the odk.bat file (this is mounting the .bash_profile file inside your ODK container). There is already a similar -v statement in this file, just copy it right after
+
Enter the ODK using odk.bat bash on your CMD (first, cd to the directory containing the odk.bat file).
+
Now you can follow most of this tutorial here as well.
If you have not done so, install https://ohmyz.sh/. It is not strictly speaking necessary to use ohmyzsh to follow the rest of this tutorial, but it is a nice way to managing your Zsh (z-shell) configuration. Note that the ODK is using the much older bash, but it should be fine for you to work with anyways.
+
+
Managing the "Path": A first peak at your shell profile¶
+
As Semantic Engineers or Ontology Curators we frequently have to install custom tools like ROBOT, owltools, and more on our computer. These are frequently downloaded from the internet as "binaries", for example as Java "jar" files. In order for our shell to "know" about these downloaded programs, we have to "add them to the path".
+
Let us first look at what we currently have loaded in our path:
+
echo $PATH
+
+
What you see here is a list of paths. To read this list a bit more easily, let us remember our lesson on piping commands:
+
echo $PATH | tr ':' '\n' | sort
+
+
What we do here:
+
+
Using the echo command to print the contents of the $PATH variable. In Unix systems, the $signifies the beginning of a variable name (if you are curious about what other "environment variables" are currently active on your system, use theprintenvcommand). The output of theecho command is piped to the next command (tr).
+
The tr – translate characters command copies the input of the previous command to the next with substitution or deletion of selected characters. Here, we substitute the : character, which is used to separate the different directory paths in the $PATH variable, with "\n", which is the all important character that denotes a "new line".
+
Just because, we also sort the output alphabetically to make it more readable.
+
+
So, how do we change the "$PATH"? Let's try and install ROBOT and see! Before we download ROBOT, let us think how we will organise our custom tools moving forward. Everyone has their own preferences, but I like to create a tools directory right in my Users directory, and use this for all my tools moving forward. In this spirit, lets us first go to our user directory in the terminal, and then create a "tools" directory:
+
cd ~
+mkdir -p tools
+
+
The -p parameter simply means: create the tools directory only if it does not exist. Now, let us go inside the tools directory (cd ~/tools) and continue following the instructions provided here.
+
First, let us download the latest ROBOT release using the curl command:
ROBOT is written in the Java programming language, and packaged up as an executable JAR file. It is still quite cumbersome to directly run a command with that JAR file, but for the hell of it, let us just do it (for fun):
+
java -jar robot.jar --version
+
+
If you have worked with ROBOT before, this looks quite a bit more ugly then simply writing:
+
robot --version
+
+
If you get this (or a similar) error:
+
zsh: permission denied: robot
+
+
You will have to run the following command as well, which makes the robot wrapper script executable:
+
chmod +x ~/tools/robot
+
+
So, how can we achieve this? The answer is, we download a "wrapper script" and place it in the same folder as the Jar. Many tools provide such wrapper scripts, and they can sometimes do many more things than just "running the jar file". Let us know download the latest wrapper script:
We are not getting into the details of what this wrapper script does, but note that, you can fine the actually call the the ROBOT jar file towards the end: java $ROBOT_JAVA_ARGS -jar "$DIR/robot.jar" "$@". The cool thing is, we do not need to ever worry about this script, but it is good for use to know, as Semantic Engineers, that it exists.
+
Now, we have downloaded the ROBOT jar file and the wrapper script into the ~/tools directory. The last step remaining is to add the ~/tools directory to your path. It makes sense to try to at least understand the basic idea behind environment variables: variables that are "loaded" or "active" in your environment (your shell). The first thing you could try to do is change the variable right here in your terminal. To do that, we can use the export command:
+
export PATH=$PATH:~/tools
+
+
What you are doing here is using the export command to set the PATH variable to $PATH:~/tools, which is the old path ($PATH), a colon (:) and the new directory we want to add (~/tools). And, indeed, if we now look at our path again:
+
echo $PATH | tr ':' '\n' | sort
+
+
We will see the path added. We can now move around to any directory on our machine and invoke the robot command. Try it before moving on!
+
Unfortunately, the change we have now applied to the $PATH variable is not persistent: if you open a new tab in your Terminal, your $PATH variable is back to what it was. What we have to do in order to make this persistent is to add the export command to a special script which is run every time the you open a new terminal: your shell profile.
+
There is a lot to say about your shell profiles, and we are taking a very simplistic view here that covers 95% of what we need: If you are using zsh your profile is managed using the ~/.zshrc file, and if you are using bash, your profile is managed using the ~/.bash_profile file. In this tutorial I will assume you are using zsh, and, in particular, after installing "oh-my-zsh". Let us look at the first 5 lines of the ~/.zshrc file:
+
head ~/.zshrc
+
+
If you have installed oh-my-zsh, the output will look something like:
+
# If you come from bash you might have to change your $PATH.
+# export PATH=$HOME/bin:/usr/local/bin:$PATH
+
+# Path to your oh-my-zsh installation.
+export ZSH="$HOME/.oh-my-zsh"
+
+# Set name of the theme to load --- if set to "random", it will
+# load a random theme each time oh-my-zsh is loaded, in which case,
+# to know which specific one was loaded, run: echo $RANDOM_THEME
+# See https://github.com/ohmyzsh/ohmyzsh/wiki/Themes
+
+
This ~/.zshrc profile script is loaded every time you open up a new shell. What we want to do is add our export command above to this script, so that it is running every time. That is the basic concept of a shell profile: providing a series of commands that is run every time a new shell (terminal window, tab) is opened.
+
For this tutorial, we use nano to edit the file, but feel free to use your text editor of choice. For example, you can open the profile file using TextEdit on Mac like this:
+
open -a TextEdit ~/.zshrc
+
+
We will proceed using nano, but feel free to use any editor.
+
nano ~/.zshrc
+
+
Using terminal-based editors like nano or, even worse, vim, involves a bit of a learning curve. nano is by far the least powerful and simple to use. If you typed the above command, you should see its contents on the terminal. The next step is to copy the following (remember, we already used it earlier)
+
export PATH=$PATH:~/tools
+
+
and paste it somewhere into the file. Usually, there is a specific section of the file that is concerned with setting up your path. Eventually, as you become more of an expert, you will start organising your profile according to your own preferences! Today we will just copy the command anywhere, for example:
Note that the # symbol denotes the beginning of a "comment" which is ignored by the shell/CLI. After you have pasted the above, you use the following keyboard key-combinations to safe and close the file:
+
control + O
+
+
This saves the file. Confirm with Enter.
+
control + x
+
+
This closes the file. Now, we need to tell the shell we are currently in that it should reload our profile we have just edited. We do that using the source command.
+
source ~/.zshrc
+
+
Great! You should be able open a new tab in your terminal (with command+t on a Mac, for example) and run the following command:
+
robot --version
+
+
+
Managing aliases and custom commands in your shell profile¶
+
This section will only give a sense of the kinds of things you can do with your shell profile - in the end you will have to jump into the cold water and build your skills up yourself. Let us start with a very powerful concept: aliases. Aliases are short names for your commands you can use if you use them repeatedly but are annoyed typing them out every time. For example, tired of typing out long paths all the time to jump between your Cell Ontology and Human Phenotype Ontology directories? Instead of:
+
cd /Users/matentzn/ws/human-phenotype-ontology/src/ontology
+
+
wouldn't it be nice to be able to use, instead,
+
cdhp
+
+
or, if you are continuously checking git status, why not implement a alias gits? Or activating your python environment (source ~/.pyenv/versions/oak/bin/activate) with a nice env-oak? To achieve this we do the following:
+
(1) Open your profile in a text editor of your choice, e.g.
+
nano ~/.zshrc
+
+
add the following lines:
+
alias cdt='cd ~/tools'
+alias hg='history | grep'
+
+
Save (control+o) and close (control+x) the profile. Reload the profile:
+
source ~/.zshrc
+
+
(Alternatively, just open a new tab in your Terminal.) Now, lets try our new aliases:
+
cdt
+
+
Will bring you straight to your tools directory you created in the previous lesson above.
+
hg robot
+
+
Will search your terminal command history for every command you have executed involving robot.
In the following, we provide a list of aliases we find super useful:
+
+
alias cdt='cd ~/tools' - add shortcuts to all directories you frequently visit!
+
alias orcid='echo '\''https://orcid.org/0000-0002-7356-1779'\'' | tr -d '\''\n'\'' | pbcopy' - if you keep having to look up your ORCID, your favourite ontologies PURL or the your own zoom room, why not add a shortcut that copies it straight into your clipboard?
+
alias opent='open ~/tools' - why not open your favourite directory in finder without faving to search the User Interface? You can use the same idea to open your favourite ontology from wherever you are, i.e. alias ohp='open ~/ws/human-phenotype-ontology/src/ontology/hp-edit.owl'.
+
alias env-linkml='source ~/.pyenv/versions/linkml/bin/activate' - use simple shortcuts to active your python environments. This will become more important if you learn to master special python tools like OAK.
+
alias update_repo='sh run.sh make update_repo' - for users of ODK - alias all your long ODK commands!
The most advanced thought we want to cover today is "functions". You can not only manage simple aliases, but you can actually add proper functions into your shell profile. Here is an example of one that I use:
+
ols() {
+ open https://www.ebi.ac.uk/ols/search?q="$1"
+}
+
+
This is a simple function in my bash profile that I can use to search on OLS:
The possibilities are endless. Some power-users have hundreds of such functions in their shell profiles, and they can do amazing things with them. Let us know about your own ideas for functions on the OBOOK issue tracker. Or, why not add a function to create a new, titled issue on OBOOK?
+
obook-issue() {
+ open https://github.com/OBOAcademy/obook/issues/new?title="$1"
+}
+
In this tutorial, we will learn to use a very basic lexical matching tool (OAK Lexmatch). The goal is not only to enable the learner to design their own matching pipelines, but also to to think about how they fit into their mapping efforts. Note that this tutorial is not about how to do proper matching: the goal here is simply to introduce you to the general workflow. Proper ontology matching is a major discipline with many tools, preprocessing and tuning approaches and often intricate interplay between matching tools and human curators. Today, you will just get a sense of the general method.
In this tutorial, you will learn how to match fruit juices in Wikidata with FOODON using a simple lexical matching tool (OAK). The idea is simple: We obtain the ontologies we like to match, ask OAK to generate the matches and then curate the results.
+
+
Setting up OAK, preparing the ontology: You will learn how to install OAK into a new Python environment, and create a simple Makefile to prepare your input ontology with ROBOT.
Setting up oak is described in its documentation. Note that, aside from oak itself, you also need relation-graph, rdftab and riot installed, see https://incatools.github.io/ontology-access-kit/intro/tutorial07.html#without-docker.
+This tutorial requires OAK version 0.1.59 or higher.
+
Note that if you are using the ODK docker image, oaklib is already installed. In the following, we will use the ODK wrapper to ensure that everyone has a consistent experience. If you want to use the local (non-docker) setup, you have to follow the instructions above before continuing and ignore the sh odk.sh part of the commands.
ODK 1.3.1, the version still active on the 8th December 2022, does not have the latest dependencies of OAK installed.
+To follow the tutorial you have to use the ODK development snapshot.
+
Install the ODK Development snapshot:
+
docker pull obolibrary/odkfull:dev
+
+
After downloading https://raw.githubusercontent.com/OBOAcademy/obook/master/docs/resources/odk.sh into your local working directory, open it with a text editor and change:
First, we download FOODON ontology. You can do this in whatever way you want, for example with wget:
+
sh odk.sh wget http://purl.obolibrary.org/obo/foodon.owl -O foodon.owl
+
+
Next, we extract the subset of FOODON that is relevant to our task at hand: relevant terms about fruit juices. The right method of subset extraction will differ from task to task. For this tutorial, we are using ROBOT extract to obtain a MIREOT module containing all the fruit juices. We do this by selecting everything between fruit juice food product as the upper-term and fruit juices (apple juice, orange juice and grapefruit juice) as the lower-term of the FOODON subset.
If you open fruit_juice_food_foodon.owl in Protege, you will see something similar to:
+
+
Next, we use OAK to extract juices and their labels from wikidata by selecting the descendants of juice from wikidata, store the result as a ttl file and then convert it to OWL using ROBOT.
Note that you wont be able to see anything when opening juice_wd.owl in wikidata, because it does not have any OWL types (class, individual assertions) attached to it. However, you can convince yourself all is well by opening juice_wd.owl in a text editor, and see expressions such as:
+
<rdf:Description rdf:about="http://www.wikidata.org/entity/Q10374646">
+ <rdfs:label>cashew apple juice</rdfs:label>
+</rdf:Description>
+
+
The last preparation step is merging the two subsets (from FOODON and wikidata) into a single file using ROBOT:
Now we are ready to create our first set of matches. First, let's run oak's lexmatch command to generate lexical matches between the contents of the merged file:
+
sh odk.sh runoak -i sqlite:foodon_wd.owl lexmatch -o foodon_wd_lexmatch.tsv
+
+
This will generate an SSSOM tsv file with the mapped contents as shown below:
This is great - we get a few mappings without much work. If you need some help interpreting this table, please refer to the SSSOM tutorials for details.
+
Just eyeballing the labels in our ontology with OAK:
+
sh odk.sh runoak -i sqlite:foodon_wd.owl terms | grep juice
+
+
We notice rows like:
+
...
+FOODON:00001001 ! orange juice (liquid)
+...
+
+
It may be beneficial for us to pre-process the labels a bit before performing the matches, for example, by excluding comments in the labels provided in brackets (essentially removing (liquid)).
rules:
+-description:default
+postconditions:
+predicate_id:skos:closeMatch
+weight:0.0
+
+-description:exact to exact
+preconditions:
+subject_match_field_one_of:
+-oio:hasExactSynonym
+-rdfs:label
+-skos:prefLabel
+object_match_field_one_of:
+-oio:hasExactSynonym
+-rdfs:label
+-skos:prefLabel
+postconditions:
+predicate_id:skos:exactMatch
+weight:2.0
+
+-preconditions:
+subject_match_field_one_of:
+-oio:hasExactSynonym
+-rdfs:label
+object_match_field_one_of:
+-oio:hasBroadSynonym
+postconditions:
+predicate_id:skos:broadMatch
+weight:2.0
+
+-synonymizer:
+the_rule:Remove parentheses bound info from the label.
+match:r'\([^)]*\)'
+match_scope:"*"
+replacement:""
+
+-synonymizer:
+the_rule:Replace "'s" by "s" in the label.
+match:r'\'s'
+match_scope:"*"
+replacement:"s"
+
+
As you can see, there are basically two kinds of rules: normal ones, and synonimizer ones. The normal rules provide preconditions and postconditions. For example, the second rule says: if an exact synonym, preferred label or label of the subject matches an exact synonym, preferred label or label of the object, then assert a skos:exactMatch. The synonimizer rules are preprocessing rules which are applied to the labels and synonyms prior to matching. Let's now run the matcher again:
As we have described in detail in our introduction to Semantic Matching, it is important to remember that matching in its raw form should not be understood to result in semantic mappings: they are better understood as mapping candidates. Therefore, it is always to plan for a review of false positives and false negatives:
+
+
False positive review (wrong mappings). The goal here is to identify mappings that do not work for our use case, or do not use the correct semantic mapping relation. If you look carefully through the matched files, you'll notice that manual intervention is definitely required for the matches to be accurate. For example, orange juice [wikidata:Q219059] and orange juice (unpasteurized) [FOODON:00001277] may not be considered as the same thing in the sense of skos:exactMatch.
+
False negative review (missing mappings). The goal here is to understand if we can do anything to improve the matching process by tuning it. Here, we did a little bit of that earlier when we were looking at the labels of the wikidata and FOODON juice hierarchies.
+
+
For a more detailed introduction into manual mapping curation with SSSOM we recommend following this tutorial: https://mapping-commons.github.io/sssom/tutorial/.
These are the kinds of things that I do
+when I need to work with a new dataset.
+My goal is to have data that makes good sense
+and that I can integrate with other data
+using standard technologies:
+Linked Data.
Before I do anything else,
+I'm going to set up a new project for working with this data.
+Maybe I'll change my mind later
+and want to merge the new project with an existing project,
+but it never hurts to start from a nice clean state.
+
I'll make a new directory in a sensible place
+with a sensible name.
+In my case I have a ~/Repositories/ directory,
+with subdirectories for GitHub and various GitLab servers,
+a local directory for projects I don't plan to share,
+and a temp directory for projects that I don't need to keep.
+I'm not sure if I'm going to share this work,
+so it can go in a new subdirectory of local.
+I'll call it "linking-data-tutorial" for now.
+
Then I'll run git init to turn that directory into a git repository.
+For now I'm just going to work locally,
+but later I can make a repository on GitHub
+and push my local repository there.
+
Next I'll create a README.md file
+where I'll keep notes for myself to read later.
+My preferred editor is Kakoune.
In the README I'll start writing something like this:
+
# Linking Data Tutorial
+
+An example of how to convert a dataset to Linked Data.
+
+The source data is available from
+<https://github.com/jamesaoverton/obook/tree/master/03-RDF/data.csv>
+
+
Maybe this information should go somewhere else eventually,
+but the README is a good place to start.
Data has an annoying tendency to get changed.
+You don't want it changing out from under you
+while you're in the middle of something.
+So the next thing to do is get a copy of the data
+and store it locally.
+If it's big, you can store a compressed copy.
+If it's too big to fit on your local machine,
+well keep the best notes you can of how to get to the data,
+and what operations you're doing on it.
+
I'm going to make a cache directory
+and store all my "upstream" data there.
+I'm going to fetch the data and that's it --
+I'm not going to edit these files.
+When I want to change the data I'll make copies in another directory.
+I don't want git to track the cached data,
+so I'll add /cache/ to .gitignore
+and tell git to track that.
+Then I'll use curl to download the file.
The first thing to do is look at the data.
+In this case I have just one table in CSV format,
+so I can use any number of tools to open the file and look around.
+I bet the majority of people would reach for Excel.
+My (idiosyncratic) preference is VisiData.
+
What am I looking for?
+A bunch of different things:
+
+
what do the rows represent?
+
what columns do I have?
+
for each column, what sorts of values do I have?
+
+
In my README file I'll make a list of the columns
+like this:
-datetime: American-style dates, D/M/Y or M/D/Y?
+-investigator: initials, ORCID?
+-subject: integer ID
+-species: common name for species, NCBITaxon?
+-strain: some sort of code with letters, numbers, spaces, some punctuation
+-sex: string female/male
+-group: integer ID
+-protocol: string, OBI?
+-organ: string, UBERON?
+-disease: string, DO/MONDO?
+-qualifier: string, PATO?
+-comment: ???
+
+
You can see that I'm trying to figure out what's in each column.
+I'm also thinking ahead to OBO ontologies that I know of
+that may have terms that I can use for each column.
In the end, I want to have nice, clean Linked Data.
+But I don't have to get there in one giant leap.
+Instead I'll take a bunch of small, incremental steps.
+
There's lots of tools I can use,
+but this time I'll use SQLite.
+
First I'll set up some more directories.
+I'll create a build directory
+where I'll store temporary files.
+I don't want git to track this directory,
+so I'll add it to .gitignore.
This will create a build/data.db file
+and import build/data.csv into a data_csv table.
+Does it work?
+
$sqlite3build/data.db<src/data.sql
+$sqlite3build/data.db<<<"SELECT * FROM data_csv LIMIT 1;"
+2014-01-0110:21:00-0500|JAO|12|RAT|F344/N|FEMALE|1|HISTOPATHOLOGY|LUNG|ADENOCARCINOMA|SEVERE|
+
+
Nice!
+
Note that I didn't even specify a schema for data_csv.
+It uses the first row as the column names,
+and the type of every column is TEXT.
+Here's the schema I end up with:
I'm going to want to update src/data.sql
+then rebuild the database over and over.
+It's small, so this will only take a second.
+If it was big,
+then I would copy a subset into build/data.csv for now
+so that I the script still runs in a second or two
+and I can iterate quickly.
+I'll write a src/build.sh script to make life a little easier:
$gitaddsrc/data.sqlsrc/build.sh
+$gitadd--update
+$gitcommit-m"Load data.csv into SQLite"
+
+
Now I have a script
+that executes a SQL file
+that loads the source data into a new database.
+I'll modify the src/data.sql file
+in a series of small steps
+until it has the structure that I want.
In the real world, data is always a mess.
+It takes real work to clean it up.
+And really, it's almost never perfectly clean.
+
It's important to recognize that cleaning data has diminishing returns.
+There's low hanging fruit:
+easy to clean, often with code, and bringing big benefits.
+Then there's tough stuff
+that requires an expert to work through the details,
+row by row.
+
The first thing to do is figure out the schema you want.
+I'll create a new data table
+and start with the default schema from data_csv.
+Notice that in the default schema all the column names are quoted.
+That's kind of annoying.
+But when I remove the quotation marks
+I realize that one of the column names is "datetime",
+but datetime is a keyword in SQLite!
+You can't use it as a column name without quoting.
+I'll rename it to "assay_datetime".
+I have the same problem with "group".
+I'll rename "group" to "group_id"
+and "subject" to "subject_id".
+The rest of the column names seem fine.
+
I want "assay_datetime" to be in standard ISO datetime format,
+but SQLite stores these as TEXT.
+The "subject" and "group" columns are currently integers,
+but I plan to make them into URIs to CURIEs.
+So everything will still be TEXT.
The dates currently look like "1/1/14 10:21 AM".
+Say I know that they were done on Eastern Standard Time.
+How do I convert to ISO dates like "2014-01-01 10:21:00-0500"?
+Well SQLite isn't the right tool for this.
+The Unix date command does a nice job, though:
+
$date-d"1/1/14 10:21 AM EST"+"%Y-%m-%d %H:%M:%S%z"
+2014-01-0110:21:00-0500
+
+
I can run that over each line of the file using awk.
+So I update the src/build.sh
+to rework the build/data.csv before I import:
One more problem I could clean up
+is that "JO" should really be "JAO" --
+that's just a typo,
+and they should both refer to James A. Overton.
+I could make that change in src/build.sh,
+but I'll do it in src/data.sql instead.
+I'll write a query to copy all the rows of data_csv into data
+and then I'll update data with some fixes.
+
-- copy from data_csv to data
+INSERTINTOdataSELECT*FROMdata_csv;
+
+-- clean data
+UPDATEdataSETinvestigator="JAO"WHEREinvestigator="JO";
+
+
Honestly, it took me quite a while to write that awk command.
+It's a very powerful tool,
+but I don't use it enough to remember how it works.
+You might prefer to write yourself a Python script, or some R code.
+You could use that instead of this SQL UPDATE as well.
+I just wanted to show you two of the thousands of ways to do this.
+If there's a lot of replacements like "JO",
+then you might also consider listing them in another table
+that you can read into your script.
+
The important part is to automate your cleaning!
+
Why didn't I just edit cache/data.csv in Excel?
+In step 2 I saved a copy of the data
+because I didn't want it to change while I was working on it,
+but I do expect it to change!
+By automating the cleaning process,
+I should be able to just update cache/data.csv
+run everything again,
+and the fixes will be applied again.
+I don't want to do all this work manually
+every time the upstream data is updated.
It's pretty easy to convert a table structure to triples.
+The hard part is converting the table contents.
+There are some identifiers in the table that would be better as URLs,
+and there's a bunch of terminology that would be better
+if it was linked to an ontology or other system.
+
I'll start with the identifiers that are local to this data:
+subject_id and group_id.
+I can convert them to URLs by defining a prefix
+and then just using that prefix.
+I'll use string concatenation to update the table:
+
-- update subject and groupd IDs
+UPDATEdataSETsubject_id='ex:subject-'||subject_id;
+UPDATEdataSETgroup_id='ex:group-'||group_id;
+
+
Now I'll check my work:
+
$sqlite3build/data.db<<<"SELECT * FROM data_csv LIMIT 1;"
+2014-01-0110:21:00-0500|JAO|ex:subject-12|RAT|F344/N|FEMALE|ex:group-1|HISTOPATHOLOGY|LUNG|ADENOCARCINOMA|SEVERE|
+
+
I should take a moment to tell you,
+that while I was writing the Turtle conversion code later in this essay,
+I had to come back here and change these identifiers.
+The thing is that Turtle is often more strict than I expect
+about identifier syntax.
+Turtle identifiers look like
+CURIEs,
+but they're actually
+QNames.
+CURIEs are pretty much just just URLs shortened with a prefix,
+so almost anything goes.
+QNames come from XML,
+and Turtle identifiers have to be valid XML element names.
+
I always remember that I need to stick to alphanumeric characters,
+and that I have to replace whitespace and punctuation with a - or _.
+I didn't remember that the local part (aka "suffix", aka "NCName")
+can't start with a digit.
+So I tried to use "subject:12" and "group:1" as my identifiers.
+That worked fine until I generated Turtle.
+The Turtle looked fine,
+so it took me quite a while to figure out why
+it looked very wrong when I converted it into RDXML format.
+
This kind of thing happens to me all the time.
+I'm almost always using a mixture of technologies
+based on different sets of assumptions,
+and there are always things that don't line up.
+That's why I like to work in small iterations,
+checking my work as I go
+(preferrably with automated tests),
+and keeping everything in version control.
+When I need to make a change like this one,
+I just circle back and iterate again.
+
The next thing is to tackle the terminology.
+First I'll just make a list of the terms I'm using
+from the relevant columns in build/term.tsv:
+
```sh #collect
+$ sqlite3 build/data.db << EOF > build/term.tsv
+SELECT investigator FROM data
+UNION SELECT species FROM data
+UNION SELECT strain FROM data
+UNION SELECT strain FROM data
+UNION SELECT sex FROM data
+UNION SELECT protocol FROM data
+UNION SELECT organ FROM data
+UNION SELECT disease FROM data
+UNION SELECT qualifier FROM data;
+EOF
+
It's a lot of work to go through all those terms
+and find good ontology terms.
+I'm going to do that hard work for you
+(just this once!)
+so we can keep moving.
+I'll add this table to `src/term.tsv`
+
+| id | code | label |
+| ------------------------- | -------------- | ------------------ |
+| obo:NCBITaxon_10116 | RAT | Rattus norvegicus |
+| obo:NCBITaxon_10090 | MOUSE | Mus musculus |
+| ex:F344N | F 344/N | F 344/N |
+| ex:B6C3F1 | B6C3F1 | B6C3F1 |
+| obo:PATO_0000383 | FEMALE | female |
+| obo:PATO_0000384 | MALE | male |
+| obo:OBI_0600020 | HISTOPATHOLOGY | histology |
+| obo:UBERON_0002048 | LUNG | lung |
+| obo:UBERON_0007827 | NOSE | external nose |
+| obo:UBERON_0001235 | ADRENAL CORTEX | adrenal cortex |
+| obo:MPATH_268 | ADENOCARCINOMA | adenocarcinoma |
+| obo:MPATH_212 | INFLAMMATION | inflammation |
+| obo:MPATH_4 | NECROSIS | necrosis |
+| obo:PATO_0000396 | SEVERE | severe intensity |
+| obo:PATO_0000394 | MILD | mild intensity |
+| obo:PATO_0000395 | MODERATE | moderate intensity |
+| orcid:0000-0001-5139-5557 | JAO | James A. Overton |
+
+And I'll add these prefixes to `src/prefix.tsv`:
+
+| prefix | base |
+| ------- | ------------------------------------------- |
+| rdf | http://www.w3.org/1999/02/22-rdf-syntax-ns# |
+| rdfs | http://www.w3.org/2000/01/rdf-schema# |
+| xsd | http://www.w3.org/2001/XMLSchema# |
+| owl | http://www.w3.org/2002/07/owl# |
+| obo | http://purl.obolibrary.org/obo/ |
+| orcid | http://orcid.org/ |
+| ex | https://example.com/ |
+| subject | https://example.com/subject/ |
+| group | https://example.com/group/ |
+
+Now I can import these tables into SQL
+and use the term table as a FOREIGN KEY constraint
+on data:
+
+```sql
+.mode tabs
+
+CREATE TABLE prefix (
+ prefix TEXT PRIMARY KEY,
+ base TEXT UNIQUE
+);
+.import --skip 1 src/prefix.tsv prefix
+
+CREATE TABLE term (
+ id TEXT PRIMARY KEY,
+ code TEXT UNIQUE,
+ label TEXT UNIQUE
+);
+.import --skip 1 src/term.tsv term
+
+CREATE TABLE data(
+ assay_datetime TEXT,
+ investigator TEXT,
+ subject_id TEXT,
+ species TEXT,
+ strain TEXT,
+ sex TEXT,
+ group_id TEXT,
+ protocol TEXT,
+ organ TEXT,
+ disease TEXT,
+ qualifier TEXT,
+ comment TEXT,
+ FOREIGN KEY(investigator) REFERENCES term(investigator),
+ FOREIGN KEY(species) REFERENCES term(species),
+ FOREIGN KEY(strain) REFERENCES term(strain),
+ FOREIGN KEY(sex) REFERENCES term(sex),
+ FOREIGN KEY(protocol) REFERENCES term(protocol),
+ FOREIGN KEY(organ) REFERENCES term(organ),
+ FOREIGN KEY(disease) REFERENCES term(disease),
+ FOREIGN KEY(qualifier) REFERENCES term(qualifier)
+);
+
+-- copy from data_csv to data
+INSERT INTO data SELECT * FROM data_csv;
+
+-- clean data
+UPDATE data SET investigator='JAO' WHERE investigator='JO';
+
+-- update subject and groupd IDs
+UPDATE data SET subject_id='ex:subject-' || subject_id;
+UPDATE data SET group_id='ex:group-' || group_id;
+
+
I'll update the README:
+
See `src/` for:
+
+-`prefix.tsv`: shared prefixes
+-`term.tsv`: terminology
+
+
I'll commit my work in progress:
+
$gitaddsrc/prefix.tsvsrc/term.tsv
+$gitadd--update
+$gitcommit-m"Add and apply prefix and term tables"
+
+
Now all the terms are linked to controlled vocabularies
+of one sort or another.
+If I want to see the IDs for those links instead of the "codes"
+I can define a VIEW:
SQL tables aren't an official Linked Data format.
+Of all the RDF formats, I prefer Turtle.
+It's tedious but not difficult to get Turtle out of SQL.
+These query do what I need them to do,
+but note that if the literal data contained quotation marks
+(for instance)
+then I'd have to do more work to escape those.
+First I create a triple table:
@prefixrdfs:<http://www.w3.org/2000/01/rdf-schema#>.
+
+orcid:0000-0001-5139-5557rdfs:label"James A. Overton".
+assay:1column:assay_datetime"2014-01-01 10:21:00-0500"^^xsd:datetime.
+assay:1column:investigatororcid:0000-0001-5139-5557.
+
+
SQL is not a particularly expressive language.
+Building the triple table is straightforward but verbose.
+I could have done the same thing with much less Python code.
+(Or I could have been clever and generated some SQL to execute!)
+
I'll commit my work in progress:
+
$gitaddsrc/turtle.sql
+$gitadd--update
+$gitcommit-m"Convert to Turtle"
+
+
So technically I have a Turtle file.
+Linked Data!
+Right?
+Well, it's kind of "flat".
+It still looks more like a table than a graph.
The table I started with is very much focused on the data:
+there was some sort of assay done,
+and this is the information that someone recorded about it.
+The Turtle I just ended up with is basically the same.
+
Other people may have assay data.
+They may have tables that they converted into Turtle.
+So can I just merge them?
+Technically yes:
+I can put all these triples in one graph together.
+But I'll still just have "flat" chunks of data
+representing rows
+sitting next to other rows,
+without really linking together.
+
The next thing I would do with this data
+is reorganized it based on the thing it's talking about.
+I know that:
+
+
there was an assay
+
the assay was performed at a certain time,
+ using a certain protocol
+
there was a person who performed the assay
+
there was a subject animal of some species, strain, and sex
+
the subject animal belonged to a study group
+
the subject animal had some organs
+
the assay resulted in some measurements
+
+
Most of these are things that I could point to in the world,
+or could have pointed to
+if I was in the right place at the right time.
+
By thinking about these things,
+I'm stepping beyond what it was convenient for someone to record,
+and thinking about what happened in the world.
+If somebody else has some assay data,
+then they might have recorded it differently
+for whatever reason,
+and so it wouldn't line up with my rows.
+I'm trying my best to use the same terms for the same things.
+I also want to use the same "shapes" for the same things.
+When trying to come to an agreement about what is connected to what,
+life is easier if I can point to the things I want to talk about:
+"See, here is the person, and the mouse came from here, and he did this and this."
+
I could model the data in SQL
+by breaking the big table into smaller tables.
+I could have tables for:
+
+
person
+
group
+
subject: species, strain, sex, group
+
assay: date, investigator, subject, protocol
+
measurement: assay, organ, disease, qualifier
+
+
Then I would convert each table to triples more carefully.
+That's a good idea.
+Actually it's a better idea than what I'm about to do...
+
Since we're getting near the end,
+I'm going to show you how you can do that modelling in SPARQL.
+SPARQL has a CONSTRUCT operation that you use to build triples.
+There's lots of tools that I could use to run SPARQL
+but I'll use ROBOT.
+I'll start with the "flat" triples in build/data.ttl,
+select them with my WHERE clause,
+then CONSTRUCT better triples,
+and save them in build/model.ttl.
## Modelling
+
+The data refers to:
+
+-investigator
+-subject
+-group
+-assay
+-measurement data
+-subject organ
+-disease
+
+TODO: A pretty diagram.
+
That was a lot of work for a small table.
+And I did all the hard work of mapping
+the terminology to ontology terms for you!
+
There's lots more I can do.
+The SPARQL is just one big chunk,
+but it would be better in smaller pieces.
+The modelling isn't all that great yet.
+Before changing that
+I want to run it past the boss
+and see what she thinks.
+
It's getting close to the end of the day.
+Before I quit I should update the README,
+clean up anything that's no longer relevant or correct,
+and make any necessary notes to my future self:
Managing Dynamic Imports with the Ontology Development Kit¶
+
In this tutorial, we discuss the general workflow of managing dynamic imports, i.e. importing terms from other ontologies which can be kept up to date.
This tutorial is not about editing ontologies and managing the evolution of its content (aka ontology curation), but the general process of managing an ontology project overall. In this lesson, we will cover the following:
+
+
How to effectively manage an ontology project using GitHub projects and teams
+
How to coordinate the evolution of ontologies across projects and grants
+
+
It is important to understand that the following is just one good way of doing project management for OBO ontologies, and most projects will do it slightly differently. We do however believe that thinking about your project management process and the roles involved will benefit your work in the long term, and hope that the following will help you as a starting point.
+
Roles in OBO Ontology project management activities¶
+
+
Ontology Editor (OE): manage the content of ontologies and interact with users
+
Principal Ontology Editor (POE): coordinate the curation activities and have always fixed hours assigned to the project.
+
Ontology Pipeline Developer (OPD): Manage the technical workflows around ontologies, such as release workflows, continuous integration and QC, and setting up data pipelines. Also helps with bulk editing activities.
+
Principal Investigators (PI): Manage the projects that fund ontology curation activities.
+
+
For an effective management of an ontology, the following criteria are recommended:
+
+
There should be at least one Principal Ontology Editor for every ontology project. The importance is not whether this editor (or sometimes called 'ontology curator') has a specific number of hours per week allocated to the project (although based on our experience, 1 day per week is minimum), but whether the editor has a sense of ownership, i.e. they understand that they are the primary responsible person for maintaining the ontology moving forward. Because of potential grant overlapping issues, we recommend to have at least 1 Principal Ontology Editor for every grant/funded project that has a stake in the ontology.
+
Every effective ontology needs at least a few hours per week from an Ontology Pipeline Developer (OPD). More on that role later. The OPD does not always have as strong a sense of ownership of the ontology project, but typically has a strong sense of responsibility to members of the curation team.
+
There should be separate meetings for curation and technical activities - both problems are hard, and need different team members being present. We recommend at least monthly technical and biweekly curation calls, but for many of the most effective ontology projects we manage, weekly technical and weekly curation calls are normal.
+
+
Without the above minimum criteria, the following recommendations will be very hard to implement.
We make use of three tools in the following recommendation:
+
Project boards:
+Project boards, sometimes referred to as Kanban boards, GitHub boards or agile boards, are a great way to organise outstanding tickets and help maintain a clear overview of what work needs to be done. They are usually realised with either GitHub projects or ZenHub. If you have not worked with project boards before, we highly recommend watching a quick tutorial on Youtube, such as:
+
+
+
GitHub teams.
+GitHub teams, alongside with organisations, are a powerfull too to organise collaborative workflows on GitHub. They allow you to communicate and organise permissions for editing your ontology in a transparent way. You can get a sense of GitHub teams by watching one of the the numerous tutorials on GitHub, such as:
+
+
+
Markdown-based documentation system.
+Writing great documentation is imperative for a sustainable project. Across many of our recent projects, were are using mkdocs, which we have also integrated with the Ontology Development Kit, but there are others to consider. We deeply recommend to complete a very short introduction to Markdown, this tutorial on YouTube.
Every ontology or group of related ontologies (sometimes it is easier to manage multiple ontologies at once, because their scope or technical workflows are quite uniform or they are heavily interrelated) should have:
+
+
at least two teams, an Editorial Team and a Technical Team, with clearly defined members. We recommend to create two teams on GitHub and keep their members always up to date (i.e. remove members that are not actively participating), but many of our projects merely maintain a "core team", which is a more liberal team containing everyone from stakeholders, principal investigators, editors and users (for managing write permissions see later in the "best practice" section) and listing the members of the Editorial and Technical Teams on a page in the documentation (example). Note that it is a good idea to be careful of who on your team has "admin" rights on your repo, so sometimes, a distinct "admin" team can be very helpful. Admins are allowed to do "dangerous" things like deleting the repository.
+
two distinct project boards. We recommend two distinct project boards, one for the Curation/Editorial Team, and one for the Technical Team. The details on how to design the boards is up to the respective teams, but we found a simple 4 stage board with sections for To Do (issues that are important but not urgent), Priority (issues that are important and urgent), In Progress (issues that are being worked on) and Under review (issues that need review). From years of experience with project boards, we recommend against the common practice of keeping a Backlog column (issues that are neither important nor urgent nor likely to be addressed in the next 6 months), nor a Done column (to keep track of closed issues) - they just clutter the view.
+
A documentation system (often realised using mkdocs in OBO projects) with a page listing the members of the team (example). This page should provide links to all related team pages from Github and their project boards, as well as a table listing all current team members with the following information:
+
Name
+
ORCiD
+
Funding Information
+
Allocated FTEs (0 if on volunteering basis)
+
Associated teams
+
Role
+
Responsibilities (What kind of issues can they be assigned to review? How are they involved in the Project?)
Effective Ontology Pipeline Developers (OPDs) are extremely rare and are typically active across many different projects. Therefore their attention is scattered. Understanding and accepting this is key for the following points.
+
Principal Investigators explicitly assign target weekly hours for Ontology Editors and Ontology Pipeline Developers to the project. These should be captured on the documentation systems team page (see above).
+
The Ontology Editors are responsible for the entire Curation Team Board and the To Do and Priority columns of the Technical Team. The later is important: it is the job of the curation team to prioritise the technical issues. The Technical Team can add tickets to the To Do and Priority columns, but this usually happens only in response to a request from the Curation Team.
+
When the technical team meets, the Principal Ontology Editor(s) (POE) are present, i.e. the POEs are members of the technical team as well. They will help clarifying the Priority tickets. The Technical Team is responsible to
+
assign issues and reviewers among themselves (ideally, the reviewer should be decided at the same time the issue is assigned)
+
move issues from the Priority to the In Progress and later to the Done section.
+
communicate through the POE to the PIs when resources are insufficient to address Priority issues.
+
The Principal Ontology Editor is responsible for ensuring that new issues on the issue tracker are dealt with. Usually this happens in the following ways:
+
They ensure that each external issue (i.e. an issue from anyone outside the core team) is (a) responded to in a polite manner and (b) assigned to someone appropriate or politely rejected due to lack of resources.
+
They ensure that each internal issue is assigned to the person that made them. No issue should appear unassigned.
+
The ensure that pull requests are (a) assigned to someone to handle and (b) merged in a timely manner. Too many open PRs cause problems with conflicts.
The To Do issues should first be moved to the Priority section before being addressed. This prevents focusing on easy to solve tickets in favour of important ones.
+
Even if Google Docs are used to manage team meetings, at the end of each meetings all open issues must be captured as GitHub tickets and placed in the appropriate box on the board. We recommend that Backlog items are not added at all to the board - if they ever become important, they tend to resurface all by themselves.
+
The single most important point of failure is the absence of an Principal Ontology Editor with a strong sense of ownership. This should be the projects priority to determine first.
+
All new members of the project should undergo an onboarding. It is a good idea to prepare walkthroughs of the project (as video or pages in the documentation system) covering everything from Curation to Technical and Project Management.
+
The Principal Ontology Editor responsible for dealing with external issues should be named explicitly on the team page.
+
We recommend the following practices for write permissions:
+
The main (formerly master) branch should be write protected with suitable rules. For example, requiring QC to pass and 1 approving review as a minimum.
+
The curation and technical teams are mainly for social organisation, they do not have to physically exist. However, having a small team with "admin rights" and a team (e.g. the core team mentioned above) with "write" rights greatly helps with organising the permissions in a transparent manner.
The new Monarch Knowledge Graph has a more streamlined focus on the core Monarch data model, centering on Diseases, Phenotypes and Genes and the associations between them. This has the benefit of being a graph that can be build in 2 hours instead of 2 days, and that you can run locally on your laptop.
+
+
Note: As of the writing of this tutorial, (Feb 2023), the graph is just starting to move from its initial construction phrase into real use, and so there are still bugs to find. Some of which show up in this tutorial.
copy dot_env_template to .env and edit the values to look like:
+
# This Environment Variable file is referenced by the docker-compose.yaml build
+
+# Set this variable to '1' to trigger an initial loading of a Neo4j dump
+DO_LOAD=1
+
+# Name of Neo4j dump file to load, assumed to be accessed from within
+# the 'dumps' internal Volume path within the Docker container
+NEO4J_DUMP_FILENAME=monarch-kg.neo4j.dump
+
+
That should mean uncommenting DO_LOAD and NEO4j_DUMP_FILENAME
+
+#### Download plugins
+
+* Download the [APOC plugin jar file](https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/download/4.4.0.13/apoc-4.4.0.13-all.jar) and put in the `plugins` directory
+
+* Download, the [GDS plugin](https://graphdatascience.ninja/neo4j-graph-data-science-2.3.0.zip), unzip the download and copy jar file to the `plugins` directory
+
+#### Environment setup
+
+In addition to the changes above to .env, you will need to uncomment the following lines in the .env file:
+
+
Nodes in a cypher query are expressed with () and the basic form of a query is MATCH (n) RETURN n. To limit the results to just our disease of interest, we can restrict by a property, in this case the id property.
+
MATCH(d{id:'MONDO:0007038'})RETURNd
+
+
This returns a single bubble, but by exploring the controls just to the left of the returned query, you can see a json or table representation of the returned node.
Clicking back to the graph view, you can expand to see direct connections out from the node by clicking on the node and then clicking on the graph icon. This will return all nodes connected to the disease by a single edge.
+
+
Tip: the node images may not be labeled the way you expect. Clicking on the node reveals a panel on the right, clicking on that node label at the top of the panel will reveal a pop-up that lets you pick which property is used as the caption in the graph view.
In cypher, nodes are represented by () and edges are represented by [] in the form of ()-[]-(), and your query is a little chance to express yourself with ascii art. To get the same results as the expanded graph view, you can query for any edge connecting to any node. Note that the query also asks for the connected node to be returned.
+
MATCH(d{id:'MONDO:0007038'})-[]-(n)RETURNd,n
+
+
Expanding out further and restricting the relationship direction¶
+
It's possible to add another edge to the query to expand out further. In this case, we're adding a second edge to the query, and restricting the direction of the second edge to be outgoing. This will return all nodes connected to the disease by a single edge, and then all nodes connected to those nodes by a single outgoing edge. It's important to note that without limiting the direction of the association, this query will traverse up, and then back down the subclass tree.
Sometimes, we don't know what kind of questions to ask without seeing the shape of the data. Neo4j provides a graph representation of the schema by calling a procedure
+
CALLdb.schema.visualization
+
+
If you tug on nodes and zoom, you may find useful information, but it's not a practical way to explore the schema.
We can explore the kinds of connections available for a given category of node. Using property restriction again, but this time instead of restricting by the ID, we'll restrict by the category. Also, instead of returning nodes themselves, we'll return the categories of those nodes.
Tip: the DISTINCT keyword is used to remove duplicate results. In this case, we're only interested in the unique categories of nodes connected to genes.
Note: the DISTINCT keyword will only remove duplicate results if the entire result is the same. In this case, we're interested in the unique combinations of relationship type and node category.
Further constraining on the type of the connecting node, we can ask what kinds of associations exist between two entity types. For example, what kinds of associations exist between genes and diseases?
With a little tugging and stretching, a good picture emerges, and by clicking our phenotype bubbles, they look like they're showing as PhenotypicQuality rather than PhenotypicFeature. This is likely a bug, but a sensible alternative for this same intent might be:
Sometimes, we don't know the specific number of hops. What if we want to answer the question "What genes affect the risk for an inherited auditory system disease?"
+
First, lets find out how are diseases connected to one another. Name the relationship to query for just the predicates.
+
MATCH (d:`biolink:Disease`)-[rel]-(d2:`biolink:Disease`) RETURN DISTINCT type(rel)
+
(* Please ignore biolink:gene_associated_with_condition and biolink:risk_affected_by showing up here, those are due to a bug in our OMIM ingest)
+
We'll construct a query that fixes the super class disease, then connects at any distance to any subclass of that disease, and then brings genes that affect risk for those diseases. To avoid a big hairball graph being returned, we can return the results as a table showing the diseases and genes.
Again, please ignore biolink:gene_associated_with_condition and biolink:risk_affected_by.
+
+
Let's say that from the list above, we're super interested in the DIABLO gene, because, obviously, it has a cool name. We can find it's orthologues by querying through the biolink:orthologous_to relationship.
In particular, it's a nice confirmation to see that we started at the high level MONDO term "inherited auditory system disease", passed through subclass relationships to more specific diseases, connected to genes that affect risk for those diseases, focused on a single gene, and were able to find that it is expressed in the cochlea.
This tutorial will show you how to use the tools that are made available by
+the ODK Docker images, independently of an ODK-generated repository and of
+ODK-managed workflows.
Let’s check which Docker images, if any, are available in your Docker
+installation:
+
$dockerimages
+REPOSITORYTAGIMAGEIDCREATEDSIZE
+
+
Here, the listing comes up empty, meaning there are no images at all. This is
+what you would expect if you have just installed Docker and have yet to do
+anything with it.
Docker images can exist in several versions, which are called tags in Docker
+parlance. In our pull command, since we have not specified any tag, Docker
+had automatically defaulted to the latest tag, which by convention is the
+latest ODK release.
+
To download a specific version, append the tag after the image name (you can
+check which tags are available on
+DockerHub). For example,
+let’s download the 1.3.1 release from June 2022:
Note how both the latest and the v1.3.1 images have the same ID. This is
+because, at the time of this writing, the 1.3.1 release is the latest ODK
+release, so the latest tag actually points to the same image as the v1.3.1
+tag. This will change when the ODK v1.3.2 is released: then, using latest
+(explicitly or by not specifying any tag at all) will point to the new
+release, while v1.3.1 will forever continue to point to the June 2022
+release.
+
In the rest of this tutorial, we will always use the latest image, and so we
+will dispense with the explicit tag. But remember that anywhere you see
+obolibrary/odkfull in one of the commands below, you can always use
+obolibrary/odkfull:TAG to force Docker to use a specific ODK version.
Now that we have the ODK image available, let’s try to start it. The command
+for that is docker run, which has the following syntax:
+
docker run [OPTIONS] <IMAGE> [COMMAND [ARGUMENTS...]]
+
+
where IMAGE is the name of the image to use (in our case, always
+obolibrary/odkfull).
+
With the ODK, you will always need the --rm option. It instructs the Docker
+engine to automatically remove the container it creates to run a command, once
+that command terminates. (Not using the --rm option would lead to those
+“spent” containers to accumulate on your system, ultimately forcing you to
+manually remove them with the docker container rm command.)
+
If we don’t specify an explicit command, the simplest command line we can have
+is thus:
In the absence of an explicit command, the default command odk.py is
+automatically invoked by Docker. Since it has been invoked without any
+argument, odk.py does nothing but printing its “usage” message before
+terminating. When it terminates, the Docker container terminates as well, and
+we are back at the terminal prompt.
+
To invoke one of the tools available in the toolbox (we’ll see what those
+tools are later in this document), just complete the command line as needed.
+For example, to test that ROBOT is there (and to see which version we have):
Since we have ROBOT, let’s use it. Move to a directory containing some
+ontology files (here, I’ll use a file from the Drosophila Anatomy Ontology,
+because if you have to pick an ontology, why not picking an ontology that
+describes the One True Model Organism?).
+
$ls
+fbbt.obo
+
+
We want to convert that OBO file to a file in, say, the OWL Functional Syntax.
+So we call ROBOT with the appropriate command and options:
Huh? Why the “No such file or directory” error? We just checked that
+fbbt.obo is present in the current directory, why can’t ROBOT find it?
+
Because Docker containers run isolated from the rest of the system – that’s
+kind of the entire point of such containers in general! From within a
+container, programs can, by default, only access files from the image from
+which the container has been started.
+
For the ODK Toolbox to be at all useful, we need to explicitly allow the
+container to access some parts of our machine. This is done with the -v
+option, as in the following example:
This -v /home/alice/fbbt:/work has the effect of binding the directory
+/home/alice/fbbt from our machine to the directory /work inside the
+container. This means that if a program that runs within the container tries
+to have a look at the /work directory, what this program will actually see
+is the contents of the /home/alice/fbbt directory. Figuratively, the -v
+option opens a window in the container’s wall, allowing to see parts of what’s
+outside from within the container.
+
With that window, and assuming our fbbt.obo file is within the
+/home/alice/fbbt directory, we can try again invoking the conversion
+command:
This time, ROBOT was able to find out fbbt.obo file, and to convert it as we
+asked.
+
We can slightly simplify the last command line in two ways.
+
First, instead of explicitly specifying the full pathname to the current
+directory (/home/alice/fbbt), we can use the shell variable $PWD, which is
+automatically expanded to that pathname: -v $PWD:/work.
+
Second, to avoid having to explicitly refer to the /work directory in the
+command, we can ask the Docker engine to run our command as if the current
+directory, within the container, was already /work. This is done with the
+-w /work option.
This is the typical method of invoking a tool from the ODK Toolbox to work on
+files from the current directory.
+
In fact, this is exactly how the src/ontology/run.sh wrapper script, that is
+automatically created in an ODK-generated repository, works. If you work with
+an ODK-managed ontology, you can invoke an arbitrary ODK tool by using the
+run.sh instead of calling docker run yourself. Assuming for example that
+you already are in the src/ontology directory of an ODK-managed ontology,
+you could use:
+
./run.shrobotconvert-ifbbt.obo-fofn-ofbbt.ofn
+
+
If you want to use the ODK toolbox with ontologies that are not managed by
+the ODK (so, where a run.sh script is not readily available), you can set up
+an independent wrapper script, as explained in the Setting up the
+ODK tutorial.
If you have several commands to invoke in a row involving files from the same
+directory, you do not have to repeatedly invoke docker run once for each
+command. Instead, you can invoke a shell, from which you will be able to run
+successively as many commands as you need:
The -ti options allow to use your current terminal to control the shell that
+is started within the container. This is confirmed by the modified prompt that
+you can see above, which indicates that you are now “in” the container. You
+can now directly use all the tools that you need:
When you are done, exit the shell by hitting Ctrl-D or with the exit
+command. The shell will terminate, and with it, the container will terminate
+as well, sending you back to your original terminal.
Now that you know how to invoke any tool from the ODK Toolbox, here’s a quick
+overview of which tools are available.
+
For a definitive list, the authoritative source is the ODK
+repository, especially
+the Dockerfile and requirements.txt.full files. And if you miss a tool
+that you think should be present in the toolbox, don’t hesitate to open a
+ticket to
+suggest that the tool be added in a future ODK release!
ODK in 20 minutes: a complete walk through the core workflows¶
+
The goal of this tutorial is to quickly showcase key ODK workflows.
+It is not geared at explaining individual steps in detail. For a much more detailed tutorial for creating a fresh ODK repo, see here for a tutorial for setting up your first workflow. We recommend to complete this tutorial before attempting this one.
Download an example ODK config or create one yourself. Save it in the directory created above.
+
Important: in the cato-odk.yaml change github_org to your GitHub username. If you dont do this, some ODK features wont work perfectly, like documentation.
+
Open the term file src/ontology/imports/cob_terms.txt in your favourite text editor
+
Add COB:0000082 to the term file (this is the planned process class in COB).
+
From within the src/ontology directory, run sh run.sh make refresh-cob.
+
Inspect the diff. Rather than importing just one term, it seems that we have important a whole bunch. This is because by default, ODK is using the SLME module extraction technique, which ensures that not only the terms we explicitly request are imported - but all the logically dependent ones as well.
+
In src/ontology/cato-odk.yaml, locate the entry for importing cob and switch it to a different module type: filter.
+
Run sh run.sh make update_repo to apply the changes. Check out the git diff to the Makefile to convince yourself that the new extraction method has been applied.
+
Let us refresh the COB import again: From within the src/ontology directory, run sh run.sh make refresh-cob. Convince yourself that now only the planned process term is imported.
Great, we have done our change, now we are ready to make a release!
+
+
Switch to the main branch in git.
+
Make sure you you pull all changes (git pull).
+
In src/ontology execute the release workflow: sh run.sh make prepare_release_fast (we are using fast release here which skips refreshing imports again - we just did that).
+
Inspect the changes. You should see that the planned process class has been added to all ontology release artefacts.
+
Create a branch and commit the changes. Push. Create pull request. Request review (skipped in this tutorial). Wait for QC to pass. Merge.
+
On GitHub (repository front page), click on "Create a new release".
+
In the next Window in the "Choose a tag" field select v2022-09-01. Note the leading v. Select the correct date (the date you made the release, YYYY-MM-dd). Fill in all the other form elements as you see fit. Click Publish release.
With our ODK setup, we also have a completely customisable documentation system installed. We just need to do a tiny change to the GitHub pages settings:
+
+
On your GitHub repo page, click on "Settings".
+
In the menu on the left, click on "Pages".
+
On the right, under Build and deployment select Deploy from branch.
+
Underneath, select gg-pages as the branch (this is where ODK deploys to), and /(root) as the directory.
+
+
Hit Save.
+
Wait for about 4 minutes for the site to be deployed (you can click on Actions in the main menu to follow the build process).
+
Go back to the Pages section in Settings. You should see a button Visit site. Click on it. If everything went correctly, you should see your new page:
+
+
Let's make a quick change: On the main page, click on the pen in the top right corner (this only works if you have correctly configured your github_org, see seeding). If you have not configured your repo, go to the GitHub front page of your repo, go into the docs directory, click on
+index.md and edit it from here. Make a small random edit.
+
Commit the change straight to main or do it properly, create a branch, PR, ask for reviews, merge.
+
After the ODK updates your site, you should be able to see your changes reflected on the life site!
A project ontology, sometimes and controversially referred to as an application ontology, is an ontology which is composed of other ontologies for a particular use case, such as Natural Language Processing applications, Semantic Search and Knowledge Graph integration. A defining feature of a project ontology is that it is not intended to be used as a domain ontology. Concretely, this means that content from project ontologies (such as terms or axioms) is not to be re-used by domain ontologies (under no circumstances). Project ontology developers have the freedom to slice & dice, delete and add relationships, change labels etc as their use case demands it. Usually, such processing is minimal, and in a well developed environment such as OBO, new project ontology-specific terms are usually kept at a minimum.
+
In this tutorial, we discuss the fundamental building blocks of application ontologies and show you how to build one using the Ontology Development Kit as one of several options.
There are a few reasons for developing project ontologies. Here are two that are popular in our domain:
+
+
Semantic integration. You have curated a lot of data using standard ontologies and now you wish to access this data using the "semantic fabric" provided by the ontology. Concrete examples:
+
Adding a "semantic layer to your knowledge graph". For example, your data is annotated using specific anatomy terms, and you wish to query your knowledge graph through anatomical groupings, such as "anatomical entities that are part of the cardio-vascular system".
+
Offering "semantic search". For example, you may want to restrict a certain search widget to "diseases" only, or try to figure out whether a user is searching for phenotypes associated with diseases. A concrete example is populating a Solr or elastic-search index using not only the labels and synonyms of an ontology, but also their relationships. Try it: https://platform.opentargets.org/, https://monarchinitiative.org/.
+
Example ontologies:
+
https://github.com/monarch-initiative/phenio
+
https://github.com/EBISPOT/efo
+
https://github.com/EBISPOT/scatlas_ontology
+
+
+
Natural language processing (NLP). You are developing an NLP application such as an annotator for text. Here, you may like to use ontologies to tag specific phrases in your documents, like those related to COVID. Ontologies in these cases serve essentially as more or less sophisticated dictionaries. But there are some more sophisticated uses of ontologies for NER.
+
Example ontologies:
+
https://github.com/berkeleybop/bero
+
https://github.com/EBISPOT/covoc
+
+
+
Mapping work. When developing mappings across ontologies and terminologies, it is often useful to have access to all of them at once. This helps to explore the consequences of mapping decisions, as well providing a single interface for ontology matching tools which usually operate on single ontologies. Advanced Machine Learning based approaches are used to generate graph embeddings on such merged ontologies. Example ontologies:
Any application ontology will be concerned with at least 3 ingredients:
+
+
The seed. This is a the set of terms you wish to import into your application ontology. The seed can take many forms:
+
a simple list of terms, e.g. MONDO:123, MONDO:231
+
a list of terms including additional relational selectors, e.g. MONDO:123, incl. all children
+
a list of terms including a logical selector, MONDO:123, incl. all terms that are in some way logically related to MONDO:123
+
a general selector, like "all classes" or simply "everything".
+
There are probably more, but these are the main ones we work with in the context of biomedical application ontologies.
+
The source ontologies, often referred to as "mirrors" (at least by those working with ODK). These are the full ontologies which we want to use in our application ontology. For example, we may want to include anatomical entities from the Uberon ontology into our application ontology. These are usually downloaded from the internet into the application ontology workspace, and then processed by the application ontology extraction workflow (see later).
+
Additional ontology metadata and customisations, such as axioms used to connect entities (classes) across your source ontologies to fulfil a use case, but also your regular ontology metadata (title, comments, etc).
+
+
+
The five "phases" of project ontology development¶
+
There are five phases on project ontology development which we will discuss in detail in this section:
There are other concerns, like continuous integration (basically making sure that changes to the seed or project ontology pipelines do not break anything) and release workflows which are not different from any other ontology.
As described above, the seed is the set of terms that should be extracted from the source ontologies into the project ontology. The seed comprises any of the following:
+
+
terms, such as MONDO:0000001
+
selectors, such as all, children, descendants, ancestors, annotations
+
combinations of the two (a term with all its children)
+
+
Users of ODK will be mostly familiar with term files located in the imports directory, such as src/ontology/imports/go_terms.txt. Selectors are usually hidden from the user by the ODK build system, but they are much more important now when building project ontologies.
+
Regardless of which system you use to build your project ontology, it makes sense to carefully plan your seed management. In the following, we will discuss some examples:
+
+
Using annotated data. For the Single Cell Atlas Ontology (SCAO) we already have a spreadsheet with the raw data, annotated with the ontology terms we wish to import. We only want to import these exact terms. Our strategy therefore is to extract the ontology terms from table and use these as our seed.
+
User requests. For the Experimental Factor Ontology (EFO), we rely on user requests. Curators provide us with individual term requests, or lists of terms they need for curating their data. We usually include these terms along with their parents to maintain rich hierarchies.
+
Use case specific considerations. For the Phenomics Integrated Ontology (PHENIO) we wish to combine all disease, phenotype and anatomy terms together and furthermore pull in related chemicals and biological processes (and more).
+
+
It makes sense to document your seed management plan. You should usually account for the possibility of changes (terms being added or removed) during the design phase.
Module extraction is the process for selecting an appropriate subset from an ontology. There are many ways to extracting subsets from an ontology:
+
+
Using logical modules (SLME, pronounced 'slime'): this will allow you to extract not only all the terms in your seed, but furthermore all logical axioms that could theoretically impact reasoning. SLME modules are typically much larger than what you would expect from a 'relevant' subset.
+
Using ROBOT filter, a system to first select entities in your seed, then selectively including or excluding descendants, annotations.
+
Using MIREOT, a technique that will extract terms and their subClass relationships, without any attempt to include other kinds of axioms.
+
+
You can consult the ROBOT documentation for some details on module extraction.
+
Let's be honest - none of these module extraction techniques are really ideal for project ontologies. SLME modules are typically used for domain ontology development to ensure logical consistency with imported ontologies, but otherwise contain too much information (for most project ontology use cases). ROBOT filter has a hard time with dealing with closures of existential restrictions: for example you cant be sure that, if you import "endocardial endothelium" and "heart" using filter, that the one former is still part of the latter (it is only indirectly a part) - a lot of research and work has being going on to make this easier. The next version of ROBOT (1.8.5) is going to contain a new module extraction command which will ensure that such links are not broken.
+
One of the design confusions in this part of the process is that most use cases of application ontologies really do not care at all about OWL. Remember, OWL really only matters for the design of domain ontologies, to ensure a consistent representation of the domain and enable reasoning-based classification. So it is, at least slightly, unsatisfactory that we have to use OWL tools to do something that may as well be done by something simpler, more akin to "graph-walking".
Just like any other ontology, a project ontology should be well annotated according to the standards of FAIR Semantics, for example using the OBO Foundry conventions. In particular, project ontologies should be
+
+
annotated with a title, a license, a description
+
versioned and annotated with versionIRIs
+
get associated with some PURL system (OBO Foundry often wont accept such ontologies, but other free options like https://w3id.org/ exist)
+
+
Furthermore, it is often necessary to add additional terms to the ontology which are not covered by other upstream ontologies. Here we need to distinguish two cases:
+
+
The need to quickly add terms that belong somewhere else
+
Adding terms that have no obvious home in any of your declared source ontologies.
+
+
With our OBO hat on, if you start adding terms "quickly", you should develop a procedure to get these terms into suitable upstream ontologies at a later stage. This is not so much a necessity as a matter of "open data ethics": if you use other people's work to make your life easier, its good to give back!
+
Lastly, our use cases sometimes require us to add additional links between the terms in our ontologies. For example, we may have to add subClassOf links between classes of different ontologies that cover the same domain. Or we want to add additional information. As with "quickly adding terms", if the information is generally useful, you should consider to add them to the respective upstream source ontology (synonyms of disease terms from Mondo, for example). We often manage such axioms as ROBOT templates and curate them as simple to read tables.
Just like with most ontologies, the last part of the process is merging the various pieces (modules from external sources, customisations, metadata) together into a single whole. During this phase a few things can happen, but these are the most common ones:
+
+
Merging: All separate parts are merged into one file.
+
Restructure: Sometimes, we run additional processes to update the structure of the final ontology. One common post-processing step is to remove obsolete classes that may have come in during the extraction phase, add additional links between classes using approaches such as relation graph or prune away unsatisfiability-causing axioms such as disjointness axioms and negation. The latter is sometimes necessary when terms from multiple logically incompatible ontologies are imported.
+
Annotate version information: owl:versionInfo and versionIRI annotations are added to the merged ontology.
One thing to remember is that you are not building a domain ontology. You are usually not concerned with typical issues in ontology engineering, such as logical consistency (or coherence, i.e. the absence of unsatisfiable classes). The key for validating an application ontology comes from its intended use case: Can the ontology deliver the use case it promised? There are many approaches to ensure that, chief among them competency questions. What we usually do is try to express competency questions as SPARQL queries, and ensure that there is at least one result. For example, for one of the project ontologies the author is involved with (CPONT), we have developed a synthetic data generator, which we combine with the ontology to ask questions such as: "Give me all patients which has a recorded diagnosis of scoliosis" (SPARQL). So the ontology does a "good job" if it is able to return, say, at least 100 patients in our synthetic data for which we know that they are diagnoses with scoliosis or one of its subtypes.
The perfect framework for building project ontologies does not exist yet. The Ontology Development Kit (ODK) has all the tools you need set up a basic application ontology, but the absence of a "perfect" module extraction algorithm for this use case is still unsatisfactory. However, for many use cases, filter modules like the ones described above are actually good enough. Here we will go through a simple example.
+
An alternative framework for application ontology development based on a Web User Interface and tables for managing the seed is developed by James Overton at (ontodev).
+
Another potential alternative is to go all the way to graph-land and build the application ontology with KGX and LinkML. See here for an example. Creating a project ontology this way feels more like a Knowledge Graph ETL task than building an ontology!
Many of the larger imports in application ontologies do not fit into the normal GitHub file size limit. In this cases it is better to attach them to a GitHub release rather than to check them into version control.
Participants will need to have access to the following resources and tools prior to the training:
+
+
GitHub account - register for a free GitHub account here
+
Install GitHub Desktop Please make sure you have some kind of git client installed on your machine. If you are new to Git, please install GitHub Desktop
A pull request (PR) is an event in Git where a contributor (you!) asks a maintainer of a Git repository to review changes (e.g. edits to an ontology file) they want to merge into a project (e.g. the owl file) (see reference). A contributor creates a pull request to propose and collaborate on changes to a repository. These changes are proposed in a branch, which ensures that the default branch only contains finished and approved work. See more details here.
Follow the Single Responsibility Principle: The pull request should do only one thing.
+
Note: sometimes a small edit can change a lot of code, for example, if you want to change all of the created_by annotations to dc:creator. That's okay.
+
+
+
The pull request should be atomic: it should be small and self contained with simple changes that affect a little code a possible
+
Whenever possible, break pull-requests into smaller ones
+
Commit early, commit often
+
Include specific information like the ID and label for terms changed. Note, you can easily obtain term metadata like OBO ID, IRI, or the term label in Protege by clicking the three lines above the Annotations box (next to the term name), see screenshot below. You can also copy the IRI in markdown, which is really convenient for pasting into GitHub.
+
+
+
+
Don't:
+
Make additional changes on a single PR that goes beyond the scope of the ticket or PR. For example, if you are adding a new term, don't also fix definitions or formatting for other terms.
When starting to work on a ticket or making edits to an ontology, you should create a new branch of the repository to edit the ontology file.
+
Make sure you are on the master branch before creating a new branch. Please do not create a new branch off of an existing branch (unless the situation explicitly calls for it).
+
To create a new branch, click on Current Branch and select New Branch
+
+
+
+
Name your branch. Some recommended best practices for branch name are to name the branch after the issue number, for example issue-206. If you are not addressing a ticket per se, you could name the branch: 'initals-edits-date', e.g. nv-edits_2022-07-12, or give it a name specific to what you are doing, e.g. fix-typos-2022-07-12.
If you are continuing to do work on an existing branch, in addition to updating master, go to your branch by selecting Current Branch in GitHub Desktop and either search for or browse for the branch name.
OPTIONAL: To update the working branch with respect to the current version of the ontology, select Branch from the top menu, Update from master. This step is optional because it is not necessary to work on the current version of the ontology; all changes will be synchronized when git merge is performed.
Review: GitHub Desktop will display the diff or changes made to the ontology.
+
Before committing, view the diff and ensure the changes were intended. Examples of a diff are pasted below. Large diffs are a sign that something went wrong. In this case, do not commit the changes and ask for help instead or consider discarding your changes and starting the edits again. To discard changes, right click on the changed file name and select Discard changes.
Commit message: Before Committing, you must add a commit message. In GitHub Desktop in the Commit field in the lower left, there is a subject line and a description.
+
+
+
Give a very descriptive title: Add a descriptive title in the subject line. For example: add new class ONTOLOGY:ID [term name] (e.g. add new class MONDO:0000006 heart disease)
+
+
+
Write a detailed summary of what the change is in the Description box, referring to the issue. The sentence should clearly state how the issue is addressed.
+
+
+
NOTE: You can use the word ‘fixes’ or ‘closes’ in the commit message - these are magic words in GitHub; when used in combination with the ticket number, it will automatically close the ticket. Learn more on this GitHub Help Documentation page about Closing issues via commit messages.
+
+
+
‘Fixes’ and “Closes’ is case-insensitive and can be plural or singular (fixes, closes, fix, close).
+
+
+
+
+
+
If you don’t want to close the ticket, just refer to the ticket # without the word ‘fixes’ or use ‘adresses’ or 'addresses'. The commit will be associated with the correct ticket but the ticket will remain open.
+
+
+
Push: To incorporate the changes into the remote repository, click Commit to [branch name], then click Push.
You can either make a pull request (PR) directly from GitHub Desktop, or via the GitHub web browser.
+
To make a PR from GitHub Desktop, click the button 'Create Pull Request'. You will be directed to your web browser and GitHub repo.
+
Click Create Pull Request.
+
+
+
+
If your PR is a work-in-progress and not ready for review, you can save it as a draft PR and convert it to a PR when it is ready for review.
+
+
+
+
If you do not create a PR directly from GitHub Dekstop, you can go to your GitHub repo and you will see a yellow banner on top that notifies you of a pending PR.
+
Navigate to the tab labeled as ‘Code’. You should see your commit listed at the top of the page in a light yellow box. If you don’t see it, click on the ‘Branches’ link to reveal it in the list, and click on it.
+
+
+
+
Click the green button ‘Compare & pull request’ on the right.
+
You may now add comments, if applicable and request a reviewer. See section below on reviewers.
+
You can see the diff for your file by clicking 'Files Changed'. Examine it as a sanity check.
+
Go back to the Conversation tab.
+
Click on the green box ‘Pull request’ to generate a pull request.
+
+
How to find a reviewer for your pull request in an open source environment¶
+
+
Publicly managed ontologies do not have a structure in place to automatically deal with PRs.
+
If you make a PR to an open source project, you should open a separate social channel to the developers to notify them of your PR (e.g. find the project mailing list, Slack, etc.). You should introduce yourself and give some context.
+
Depending on the level of your permissions for the repository, you may or may not be able to assign a reviewer yourself.
+
If you have write access to the repository, you can assign a reviewer.
+
Otherwise, you can tag people in the description of your pull request.
+
+
Tips for finding reviewers:
+
+
+
An ontology repository should have an owner assigned. This may be described in the ReadMe file or on the OBO Foundry website. For example, the contact person for Mondo is Nicole Vasilevsky.
+
+
The primary owner can likely review your PR or triage your request to the appropriate person.
+
If you are addressing a specific ticket, you may want to assign the person who created the ticket to review.
If you are assigned to review a pull request, you should receive an email notification. You can also check for PRs assigned to you by going to https://github.com/pulls/assigned.
+
What kind of person do we need for what kind of pull request?¶
+
It depends on what the pull request is addressing. Remember the QC checks will check for things like unsatisfiable classes and many other checks (that vary between ontologies). Your job as a reviewer is to check for things that the QC checks won't pick up and need human judgement.
+
+
If it is content changes, like adding new terms, or reclassifying a term, an ontology curator could review your PR.
+
If the PR is addressing quality control or technical aspects, one of the ontology semantic engineers would probably be a good fit.
+
+
If you don't know who to assign, we recommend assigning the ontology contact person and they can triage the request.
+
+
+
To review a PR, you should view the 'Files changed' and view the diff(s). You can review changes in a pull request one file at a time.
+
+
While reviewing the files in a pull request, you can leave individual comments on specific changes.
Make sure the changes made address the ticket. In the example above, Sabrina addressed a ticket that requested adding a new term to Mondo, which is what she did on the PR (see https://github.com/monarch-initiative/mondo/pull/5078).
+
+
+
Examples of things to look for in content changes (like adding new terms or revising existing terms):
+
+
Poorly written definitions
+
Missing or misformatted database cross-references
+
Incorrectly scoped synonyms
+
+
appropriate annotations
+
+
+
Make sure there are not any unintended or unwanted changes on the PR. See example below. Protege reordered the location of a term in the file.
+
+
+
+
+
Check that the logic is correct. This can be a difficult thing to do. Some tips:
+
Open the branch in Protege and examine the hierarchy in Protege
+
Compare the logic that was use to the logic used in an existing term
+
If the ontology uses Design Patterns, ensure the logic is consistent with the Design Patterns
+
Ask an expert in ontology logic to help review the PR
+
Remember there is no magic bullet to ensuring an ontology is logically sound, but do the best you can
After you finish reviewing each file, you can mark the file as viewed. This collapses the file, helping you identify the files you still need to review.
+
A progress bar in the pull request header shows the number of files you've viewed.
+
You can leave comments and requests for changes on the PR inline for on the PR when viewing the 'Files changed'.
+
You can add a single comment, or start a review if you have multiple comments.
+
+
After reviewing the file(s), you can approve the pull request or request additional changes by submitting your review with a summary comment.
+
+
+
Comment (Submit general feedback without explicit approval)
+
+
Approve (Submit feedback and approve merging these changes)
+
+
Request changes (Submit feedback that must be addressed before merging)
+
+
+
In addition or instead of adding inline comments, you can leave comments on the Conversation page. The conversation page is a good place to discuss the PR, and for the original creator to respond to the reviewer comments.
GitHub added a 'suggested Changes' feature that allows a PR reviewer to suggest an exact change in a comment in a PR. You can add inline comments and commit your comment using 'inline commits'. Read more about it here.
+
+
Go to the 'Files changed' tab of a pull request
+
Hover over the line you want to fix, and a blue box with a plus sign appears near the gutter on the left
+
Click that to display the normal line comment form
+
Click the button with a plus and minus sign, it adds a suggestion block to the comment text area with the existing text
+
+
+
+
You can make changes to the text inside the suggestion box. Note that you can add context for your suggested changes outside of the suggestion block
+
When you create the comment, it will show up to the maintainer as a diff
+
The maintainer can see what changes you are suggesting and accept them with a click
If you review the PR and the changes properly address what was described in the description, then it should be sufficient. Not every PR needs comments, it can be approved without any comments or requests for changes. Feel free to ask for help with your review, and/or assign additional reviewers.
+
Some of the content above was adapted from GitHub Docs.
+
How to change a pull request in response to review¶
+
+
Check out your branch in GitHub Desktop and open the file in Protege.
+
Make the suggested changes.
+
Check the diff.
+
Commit your changes on your branch.
+
Note, you do not need to create another PR, your commits will show up on the same PR.
+
Resolve the comments on the PR.
+
Notify the reviewer that your PR is ready for re-review.
Conflicts arise when edits are made on two separate branches to the same line in a file. (reference). When editing an ontology file (owl file or obo file), conflicts often arise when adding new terms to an ontology file on separate branches, or when there are a lot of open pull requests.
+
Conflicts in ontology files can be fixed either on the command line or using GitHub Desktop. In this lesson, we describe how to fix conflicts using GitHub Desktop.
In GitHub Desktop, go to your master/main branch and fetch pull.
+
Go to branch with conflict.
+
Pull branch.
+
Branch -> update from master.
+
Open in Sublime or Atom.
+
Make changes in file (open the ontology file in a text editor (like Sublime) and search for the conflicts. These are usually preceded by <<<<<. Fix the conflicts, then save).
+
In GitHub Desktop, continue merge.
+
Push.
+
In terminal: open [ontology file name] (e.g.open mondo-edit.obo) or open in Protege manually.
+
Save as (nothing should have changed in the diff).
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/tutorial/resources/BDK14-exercises/basic-classification/ubiq-ligase-complex.owl b/tutorial/resources/BDK14-exercises/basic-classification/ubiq-ligase-complex.owl
new file mode 100644
index 000000000..ab1e25d32
--- /dev/null
+++ b/tutorial/resources/BDK14-exercises/basic-classification/ubiq-ligase-complex.owl
@@ -0,0 +1,1137 @@
+
+
+
+
+
+
+
+
+
+
+]>
+
+
+
+
+ 1.2
+
+
+
+
+
+
+
+ Systematic synonym
+
+
+
+
+ shorthand
+
+
+ in_subset
+
+
+ Catalytic activity terms in need of attention
+
+
+
+ has_scope
+
+
+ has_obo_format_version
+
+
+ definition
+
+
+ database_cross_reference
+
+
+ Generic GO slim
+
+
+
+ Aspergillus GO slim
+
+
+
+ has_alternative_id
+
+
+ Prokaryotic GO subset
+
+
+
+ has_obo_namespace
+
+
+ subset_property
+
+
+
+ PIR GO slim
+
+
+
+ synonym_type_property
+
+
+
+ has_exact_synonym
+
+
+
+ Plant GO slim
+
+
+
+ Candida GO slim
+
+
+
+ has_related_synonym
+
+
+ has_narrow_synonym
+
+
+ High-level terms not to be used for direct annotation
+
+
+
+ has_broad_synonym
+
+
+ Yeast GO slim
+
+
+
+ Fission yeast GO slim
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ part_of
+ BFO:0000050
+ OBO_REL:part_of
+ gene_ontology
+ part_of
+ part_of
+
+
+
+
+
+
+
+
+
+
+
+
+ ubiquitin ligase complex
+
+
+ A protein complex that includes a ubiquitin-protein ligase and other proteins that may confer substrate specificity on the complex.
+ GO:0000151
+ cellular_component
+
+
+
+
+ A protein complex that includes a ubiquitin-protein ligase and other proteins that may confer substrate specificity on the complex.
+ PMID:9529603
+
+
+
+
+
+
+
+
+
+ ER ubiquitin ligase complex
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ A ubiquitin ligase complex found in the ER.
+ GO:0000835
+ cellular_component
+
+
+ A ubiquitin ligase complex found in the ER.
+ GOC:elh
+
+
+
+
+
+
+
+
+
+ cellular_component
+ GO:0005575
+ GO:0008372
+ NIF_Subcellular:sao1337158144
+ Note that, in addition to forming the root of the cellular component ontology, this term is recommended for use for the annotation of gene products whose cellular component is unknown. Note that when this term is used for annotation, it indicates that no information was available about the cellular component of the gene product annotated as of the date the annotation was made; the evidence code ND, no data, is used to indicate this.
+ The part of a cell or its extracellular environment in which a gene product is located. A gene product may be located in one or more parts of a cell and its location may be as specific as a particular macromolecular complex, that is, a stable, persistent association of macromolecules that function together.
+ cellular component
+ cellular component unknown
+ cellular_component
+
+
+
+
+
+
+
+
+
+ GOC:go_curators
+ The part of a cell or its extracellular environment in which a gene product is located. A gene product may be located in one or more parts of a cell and its location may be as specific as a particular macromolecular complex, that is, a stable, persistent association of macromolecules that function together.
+
+
+
+
+
+
+
+
+
+ intracellular
+
+ GO:0005622
+ The living contents of a cell; the matter contained within (but not including) the plasma membrane, usually taken to exclude large vacuoles and masses of secretory or ingested material. In eukaryotes it includes the nucleus and cytoplasm.
+ Wikipedia:Intracellular
+ cellular_component
+ internal to cell
+ nucleocytoplasm
+ protoplasm
+ protoplast
+
+
+
+
+
+
+ GOC:mah
+ nucleocytoplasm
+
+
+
+
+ GOC:mah
+ protoplast
+
+
+
+
+ ISBN:0198506732
+ The living contents of a cell; the matter contained within (but not including) the plasma membrane, usually taken to exclude large vacuoles and masses of secretory or ingested material. In eukaryotes it includes the nucleus and cytoplasm.
+
+
+
+
+
+
+
+
+
+ cell
+
+ GO:0005623
+ NIF_Subcellular:sao1813327414
+ The basic structural and functional unit of all organisms. Includes the plasma membrane and any external encapsulating structures such as the cell wall and cell envelope.
+ Wikipedia:Cell_(biology)
+ cellular_component
+
+
+
+
+
+ GOC:go_curators
+ The basic structural and functional unit of all organisms. Includes the plasma membrane and any external encapsulating structures such as the cell wall and cell envelope.
+
+
+
+
+
+
+
+
+
+ nucleus
+
+ A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent.
+ GO:0005634
+ NIF_Subcellular:sao1702920020
+ Wikipedia:Cell_nucleus
+ cell nucleus
+ cellular_component
+
+
+
+
+
+
+
+
+ A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent.
+ GOC:go_curators
+
+
+
+
+
+
+
+
+
+ anaphase-promoting complex
+
+
+
+ A ubiquitin ligase complex that degrades mitotic cyclins and anaphase inhibitory protein, thereby triggering sister chromatid separation and exit from mitosis. Substrate recognition by APC occurs through degradation signals, the most common of which is termed the Dbox degradation motif, originally discovered in cyclin B.
+ APC
+ GO:0005680
+ Note that the synonym 'APC' should not be confused with the abbreviation for the adenomatous polyposis coli gene and protein.
+ Wikipedia:Anaphase-promoting_complex
+ anaphase promoting complex
+ cellular_component
+ cyclosome
+
+
+ A ubiquitin ligase complex that degrades mitotic cyclins and anaphase inhibitory protein, thereby triggering sister chromatid separation and exit from mitosis. Substrate recognition by APC occurs through degradation signals, the most common of which is termed the Dbox degradation motif, originally discovered in cyclin B.
+ GOC:jh
+ GOC:vw
+ PMID:10465783
+ PMID:10611969
+
+
+
+
+
+
+
+
+
+ cytoplasm
+
+ All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures.
+ GO:0005737
+ Wikipedia:Cytoplasm
+ cellular_component
+
+
+
+
+
+
+
+ All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures.
+ ISBN:0198547684
+
+
+
+
+
+
+
+
+
+ endoplasmic reticulum
+
+
+ ER
+ GO:0005783
+ NIF_Subcellular:sao1036339110
+ The irregular network of unit membranes, visible only by electron microscopy, that occurs in the cytoplasm of many eukaryotic cells. The membranes form a complex meshwork of tubular channels, which are often expanded into slitlike cavities called cisternae. The ER takes two forms, rough (or granular), with ribosomes adhering to the outer surface, and smooth (with no ribosomes attached).
+ Wikipedia:Endoplasmic_reticulum
+ cellular_component
+
+
+
+
+
+
+
+
+ ISBN:0198506732
+ The irregular network of unit membranes, visible only by electron microscopy, that occurs in the cytoplasm of many eukaryotic cells. The membranes form a complex meshwork of tubular channels, which are often expanded into slitlike cavities called cisternae. The ER takes two forms, rough (or granular), with ribosomes adhering to the outer surface, and smooth (with no ribosomes attached).
+
+
+
+
+
+
+
+
+
+ endoplasmic reticulum membrane
+
+
+
+
+
+
+
+
+
+ ER membrane
+ GO:0005789
+ The lipid bilayer surrounding the endoplasmic reticulum.
+ cellular_component
+
+
+ GOC:mah
+ The lipid bilayer surrounding the endoplasmic reticulum.
+
+
+
+
+
+
+
+
+
+ endomembrane system
+
+ A collection of membranous structures involved in transport within the cell. The main components of the endomembrane system are endoplasmic reticulum, Golgi bodies, vesicles, cell membrane and nuclear envelope. Members of the endomembrane system pass materials through each other or though the use of vesicles.
+ GO:0012505
+ Wikipedia:Endomembrane_system
+ cellular_component
+
+
+
+
+
+ A collection of membranous structures involved in transport within the cell. The main components of the endomembrane system are endoplasmic reticulum, Golgi bodies, vesicles, cell membrane and nuclear envelope. Members of the endomembrane system pass materials through each other or though the use of vesicles.
+ GOC:lh
+
+
+
+
+
+
+
+
+
+ membrane
+
+ Double layer of lipid molecules that encloses all cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins.
+ GO:0016020
+ Wikipedia:Biological_membrane
+ cellular_component
+
+
+
+
+
+
+
+
+ Double layer of lipid molecules that encloses all cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins.
+ GOC:mah
+ ISBN:0815316194
+
+
+
+
+
+
+
+
+
+ SCF ubiquitin ligase complex
+
+ A ubiquitin ligase complex in which a cullin from the Cul1 subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by a Skp1 adaptor and an F-box protein. SCF complexes are involved in targeting proteins for degradation by the proteasome. The best characterized complexes are those from yeast and mammals (with core subunits named Cdc53/Cul1, Rbx1/Hrt1/Roc1).
+ CDL1 complex
+ CRL1 complex
+ Cul1-RING ubiquitin ligase complex
+ GO:0019005
+ SCF complex
+ SCF complex substrate recognition subunit
+ Skp1/Cul1/F-box protein complex
+ Wikipedia:SCF_complex
+ cellular_component
+ cullin-RING ligase 1
+
+
+ A ubiquitin ligase complex in which a cullin from the Cul1 subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by a Skp1 adaptor and an F-box protein. SCF complexes are involved in targeting proteins for degradation by the proteasome. The best characterized complexes are those from yeast and mammals (with core subunits named Cdc53/Cul1, Rbx1/Hrt1/Roc1).
+ PMID:15571813
+ PMID:15688063
+
+
+
+
+
+
+
+
+
+ VCB complex
+
+
+ A protein complex that possesses ubiquitin ligase activity; the complex is usually pentameric; for example, in mammals the subunits are pVHL, elongin B, elongin C, cullin-2 (Cul2), and Rbx1.
+ GO:0030891
+ VHL complex
+ cellular_component
+ pVHL-elongin C-elongin B complex
+ von Hippel-Lindau tumor suppressor complex
+
+
+ A protein complex that possesses ubiquitin ligase activity; the complex is usually pentameric; for example, in mammals the subunits are pVHL, elongin B, elongin C, cullin-2 (Cul2), and Rbx1.
+ GOC:mah
+ PMID:11865071
+
+
+
+
+
+
+
+
+
+ organelle membrane
+
+
+
+
+
+
+
+
+ GO:0031090
+ The lipid bilayer surrounding an organelle.
+ cellular_component
+
+
+
+ GOC:mah
+ The lipid bilayer surrounding an organelle.
+
+
+
+
+
+
+
+
+
+ BRCA1-BARD1 complex
+
+
+ A heterodimeric complex comprising BRCA1 and BARD1, which possesses ubiquitin ligase activity and is involved in genome maintenance, possibly by functioning in surveillance for DNA damage.
+ GO:0031436
+ cellular_component
+
+
+ A heterodimeric complex comprising BRCA1 and BARD1, which possesses ubiquitin ligase activity and is involved in genome maintenance, possibly by functioning in surveillance for DNA damage.
+ PMID:12787778
+
+
+
+
+
+
+
+
+
+ cullin-RING ubiquitin ligase complex
+
+ Any ubiquitin ligase complex in which the catalytic core consists of a member of the cullin family and a RING domain protein; the core is associated with one or more additional proteins that confer substrate specificity.
+ CRL complex
+ GO:0031461
+ cellular_component
+ cullin complex
+ cullin-RING ligase
+
+
+ Any ubiquitin ligase complex in which the catalytic core consists of a member of the cullin family and a RING domain protein; the core is associated with one or more additional proteins that confer substrate specificity.
+ PMID:15571813
+ PMID:15688063
+
+
+
+
+
+
+
+
+
+ macromolecular complex
+
+ A stable assembly of two or more macromolecules, i.e. proteins, nucleic acids, carbohydrates or lipids, in which the constituent parts function together.
+ GO:0032991
+ cellular_component
+ macromolecule complex
+
+
+
+
+ A stable assembly of two or more macromolecules, i.e. proteins, nucleic acids, carbohydrates or lipids, in which the constituent parts function together.
+ GOC:mah
+
+
+
+
+
+
+
+
+
+ SUMO-targeted ubiquitin ligase complex
+
+
+ A nuclear ubiquitin ligase complex that specifically targets SUMOylated proteins; the complex is formed of homodimers or heterodimers of RNF4 family ubiquitin ligases and is conserved in eukaryotes.
+ GO:0033768
+ cellular_component
+
+
+ A nuclear ubiquitin ligase complex that specifically targets SUMOylated proteins; the complex is formed of homodimers or heterodimers of RNF4 family ubiquitin ligases and is conserved in eukaryotes.
+ GOC:vw
+ PMID:17762864
+ PMID:17762865
+
+
+
+
+
+
+
+
+
+ nuclear outer membrane-endoplasmic reticulum membrane network
+
+
+
+
+
+
+
+
+ GO:0042175
+ NE-ER continuum
+ NE-ER network
+ The continuous network of membranes encompassing the nuclear outer membrane and the endoplasmic reticulum membrane.
+ cellular_component
+ nuclear envelope-ER network
+ nuclear envelope-endoplasmic reticulum continuum
+ nuclear envelope-endoplasmic reticulum network
+ nuclear membrane-ER network
+ nuclear membrane-endoplasmic reticulum continuum
+
+
+ GOC:mah
+ nuclear membrane-ER network
+
+
+
+
+ GOC:mah
+ nuclear envelope-endoplasmic reticulum network
+
+
+
+
+ GOC:bf
+ GOC:jl
+ GOC:mah
+ GOC:mcc
+ GOC:pr
+ GOC:vw
+ The continuous network of membranes encompassing the nuclear outer membrane and the endoplasmic reticulum membrane.
+
+
+
+
+ GOC:mah
+ nuclear membrane-endoplasmic reticulum continuum
+
+
+
+
+
+
+
+
+
+ cytoplasmic SCF ubiquitin ligase complex
+
+
+
+
+
+
+
+
+
+
+
+ A ubiquitin ligase complex, located in the cytoplasm, in which a cullin from the Cul1 subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by a Skp1 adaptor and an F-box protein. SCF complexes are involved in targeting proteins for degradation by the proteasome. The best characterized complexes are those from yeast and mammals (with core subunits named Cdc53/Cul1, Rbx1/Hrt1/Roc1).
+ GO:0043223
+ cellular_component
+ cytoplasmic SCF complex
+ cytoplasmic Skp1/Cul1/F-box protein complex
+ cytoplasmic cullin complex
+
+
+ A ubiquitin ligase complex, located in the cytoplasm, in which a cullin from the Cul1 subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by a Skp1 adaptor and an F-box protein. SCF complexes are involved in targeting proteins for degradation by the proteasome. The best characterized complexes are those from yeast and mammals (with core subunits named Cdc53/Cul1, Rbx1/Hrt1/Roc1).
+ PMID:15571813
+ PMID:15688063
+
+
+
+
+
+
+
+
+
+ nuclear SCF ubiquitin ligase complex
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ A ubiquitin ligase complex, located in the nucleus, in which a cullin from the Cul1 subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by a Skp1 adaptor and an F-box protein. SCF complexes are involved in targeting proteins for degradation by the proteasome. The best characterized complexes are those from yeast and mammals (with core subunits named Cdc53/Cul1, Rbx1/Hrt1/Roc1).
+ GO:0043224
+ cellular_component
+ nuclear SCF complex
+ nuclear Skp1/Cul1/F-box protein complex
+ nuclear cullin complex
+
+
+ A ubiquitin ligase complex, located in the nucleus, in which a cullin from the Cul1 subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by a Skp1 adaptor and an F-box protein. SCF complexes are involved in targeting proteins for degradation by the proteasome. The best characterized complexes are those from yeast and mammals (with core subunits named Cdc53/Cul1, Rbx1/Hrt1/Roc1).
+ PMID:15571813
+ PMID:15688063
+
+
+
+
+
+
+
+
+
+ organelle
+
+ GO:0043226
+ NIF_Subcellular:sao1539965131
+ Organized structure of distinctive morphology and function. Includes the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton, and prokaryotic structures such as anammoxosomes and pirellulosomes. Excludes the plasma membrane.
+ Wikipedia:Organelle
+ cellular_component
+
+
+
+
+
+ GOC:go_curators
+ Organized structure of distinctive morphology and function. Includes the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton, and prokaryotic structures such as anammoxosomes and pirellulosomes. Excludes the plasma membrane.
+
+
+
+
+
+
+
+
+
+ membrane-bounded organelle
+
+ GO:0043227
+ NIF_Subcellular:sao414196390
+ Organized structure of distinctive morphology and function, bounded by a single or double lipid bilayer membrane. Includes the nucleus, mitochondria, plastids, vacuoles, and vesicles. Excludes the plasma membrane.
+ cellular_component
+ membrane-enclosed organelle
+
+
+
+ GOC:go_curators
+ Organized structure of distinctive morphology and function, bounded by a single or double lipid bilayer membrane. Includes the nucleus, mitochondria, plastids, vacuoles, and vesicles. Excludes the plasma membrane.
+
+
+
+
+
+
+
+
+
+ intracellular organelle
+
+
+ GO:0043229
+ Organized structure of distinctive morphology and function, occurring within the cell. Includes the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton. Excludes the plasma membrane.
+ cellular_component
+
+
+
+
+ GOC:go_curators
+ Organized structure of distinctive morphology and function, occurring within the cell. Includes the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton. Excludes the plasma membrane.
+
+
+
+
+
+
+
+
+
+ intracellular membrane-bounded organelle
+
+
+ GO:0043231
+ Organized structure of distinctive morphology and function, bounded by a single or double lipid bilayer membrane and occurring within the cell. Includes the nucleus, mitochondria, plastids, vacuoles, and vesicles. Excludes the plasma membrane.
+ cellular_component
+ intracellular membrane-enclosed organelle
+
+
+
+
+ GOC:go_curators
+ Organized structure of distinctive morphology and function, bounded by a single or double lipid bilayer membrane and occurring within the cell. Includes the nucleus, mitochondria, plastids, vacuoles, and vesicles. Excludes the plasma membrane.
+
+
+
+
+
+
+
+
+
+ protein complex
+
+ Any macromolecular complex composed of two or more polypeptide subunits, which may or may not be identical. Protein complexes may have other associated non-protein prosthetic groups, such as nucleotides, metal ions or other small molecules.
+ GO:0043234
+ Wikipedia:Protein_complex
+ cellular_component
+ protein-protein complex
+
+
+
+
+
+ Any macromolecular complex composed of two or more polypeptide subunits, which may or may not be identical. Protein complexes may have other associated non-protein prosthetic groups, such as nucleotides, metal ions or other small molecules.
+ GOC:go_curators
+
+
+
+
+
+
+
+
+
+ organelle part
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of an organelle, an organized structure of distinctive morphology and function. Includes constituent parts of the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton, but excludes the plasma membrane.
+ GO:0044422
+ cellular_component
+
+
+
+ Any constituent part of an organelle, an organized structure of distinctive morphology and function. Includes constituent parts of the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton, but excludes the plasma membrane.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ intracellular part
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of the living contents of a cell; the matter contained within (but not including) the plasma membrane, usually taken to exclude large vacuoles and masses of secretory or ingested material. In eukaryotes it includes the nucleus and cytoplasm.
+ GO:0044424
+ cellular_component
+
+
+
+ Any constituent part of the living contents of a cell; the matter contained within (but not including) the plasma membrane, usually taken to exclude large vacuoles and masses of secretory or ingested material. In eukaryotes it includes the nucleus and cytoplasm.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ membrane part
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of a membrane, a double layer of lipid molecules that encloses all cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins.
+ GO:0044425
+ cellular_component
+
+
+
+ Any constituent part of a membrane, a double layer of lipid molecules that encloses all cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ nuclear part
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of the nucleus, a membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated.
+ GO:0044428
+ cellular_component
+ nucleus component
+
+
+ Any constituent part of the nucleus, a membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ endoplasmic reticulum part
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of the endoplasmic reticulum, the irregular network of unit membranes, visible only by electron microscopy, that occurs in the cytoplasm of many eukaryotic cells. The membranes form a complex meshwork of tubular channels, which are often expanded into slitlike cavities called cisternae.
+ ER component
+ GO:0044432
+ cellular_component
+
+
+ Any constituent part of the endoplasmic reticulum, the irregular network of unit membranes, visible only by electron microscopy, that occurs in the cytoplasm of many eukaryotic cells. The membranes form a complex meshwork of tubular channels, which are often expanded into slitlike cavities called cisternae.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ cytoplasmic part
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of the cytoplasm, all of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures.
+ GO:0044444
+ cellular_component
+ cytoplasm component
+
+
+
+ Any constituent part of the cytoplasm, all of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ intracellular organelle part
+
+
+
+
+
+
+
+
+ A constituent part of an intracellular organelle, an organized structure of distinctive morphology and function, occurring within the cell. Includes constituent parts of the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton but excludes the plasma membrane.
+ GO:0044446
+ cellular_component
+
+
+
+ A constituent part of an intracellular organelle, an organized structure of distinctive morphology and function, occurring within the cell. Includes constituent parts of the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton but excludes the plasma membrane.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ cell part
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of a cell, the basic structural and functional unit of all organisms.
+ GO:0044464
+ cellular_component
+ protoplast
+
+
+
+
+ GOC:mah
+ protoplast
+
+
+
+
+ Any constituent part of a cell, the basic structural and functional unit of all organisms.
+ GOC:jl
+
+
+
+
+
+
+
+
+
diff --git a/tutorial/resources/BDK14-exercises/basic-disjoint/bad-chromosome.owl b/tutorial/resources/BDK14-exercises/basic-disjoint/bad-chromosome.owl
new file mode 100644
index 000000000..4041611d1
--- /dev/null
+++ b/tutorial/resources/BDK14-exercises/basic-disjoint/bad-chromosome.owl
@@ -0,0 +1,1053 @@
+
+
+
+
+
+
+
+
+
+
+]>
+
+
+
+
+ 1.2
+
+
+
+
+
+
+
+
+
+
+
+
+ definition
+
+
+
+
+
+
+
+ Aspergillus GO slim
+
+
+
+
+
+
+
+
+ Candida GO slim
+
+
+
+
+
+
+
+
+ Generic GO slim
+
+
+
+
+
+
+
+
+ PIR GO slim
+
+
+
+
+
+
+
+
+ Plant GO slim
+
+
+
+
+
+
+
+
+ Fission yeast GO slim
+
+
+
+
+
+
+
+
+ Yeast GO slim
+
+
+
+
+
+
+
+
+ Prokaryotic GO subset
+
+
+
+
+
+
+
+
+ High-level terms not to be used for direct annotation
+
+
+
+
+
+
+
+
+ Catalytic activity terms in need of attention
+
+
+
+
+
+
+
+
+ Systematic synonym
+
+
+
+
+
+
+
+
+
+ subset_property
+
+
+
+
+
+
+
+ synonym_type_property
+
+
+
+
+
+
+
+ has_alternative_id
+
+
+
+
+
+
+
+ has_broad_synonym
+
+
+
+
+
+
+
+ database_cross_reference
+
+
+
+
+
+
+
+ has_exact_synonym
+
+
+
+
+
+
+
+ has_narrow_synonym
+
+
+
+
+
+
+
+ has_obo_format_version
+
+
+
+
+
+
+
+ has_obo_namespace
+
+
+
+
+
+
+
+ has_related_synonym
+
+
+
+
+
+
+
+ has_scope
+
+
+
+
+
+
+
+
+
+
+
+
+
+ in_subset
+
+
+
+
+
+
+
+ shorthand
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ part_of
+ BFO:0000050
+ OBO_REL:part_of
+ gene_ontology
+ part_of
+ part_of
+
+
+
+
+
+
+
+
+
+
+
+
+ cellular_component
+ GO:0005575
+ GO:0008372
+ NIF_Subcellular:sao1337158144
+ Note that, in addition to forming the root of the cellular component ontology, this term is recommended for use for the annotation of gene products whose cellular component is unknown. Note that when this term is used for annotation, it indicates that no information was available about the cellular component of the gene product annotated as of the date the annotation was made; the evidence code ND, no data, is used to indicate this.
+ The part of a cell or its extracellular environment in which a gene product is located. A gene product may be located in one or more parts of a cell and its location may be as specific as a particular macromolecular complex, that is, a stable, persistent association of macromolecules that function together.
+ cellular component
+ cellular component unknown
+ cellular_component
+
+
+
+
+
+
+
+
+
+ GOC:go_curators
+ The part of a cell or its extracellular environment in which a gene product is located. A gene product may be located in one or more parts of a cell and its location may be as specific as a particular macromolecular complex, that is, a stable, persistent association of macromolecules that function together.
+
+
+
+
+
+
+
+
+
+ intracellular
+
+ GO:0005622
+ The living contents of a cell; the matter contained within (but not including) the plasma membrane, usually taken to exclude large vacuoles and masses of secretory or ingested material. In eukaryotes it includes the nucleus and cytoplasm.
+ Wikipedia:Intracellular
+ cellular_component
+ internal to cell
+ nucleocytoplasm
+ protoplasm
+ protoplast
+
+
+
+
+
+
+ GOC:mah
+ nucleocytoplasm
+
+
+
+
+ ISBN:0198506732
+ The living contents of a cell; the matter contained within (but not including) the plasma membrane, usually taken to exclude large vacuoles and masses of secretory or ingested material. In eukaryotes it includes the nucleus and cytoplasm.
+
+
+
+
+ GOC:mah
+ protoplast
+
+
+
+
+
+
+
+
+
+ cell
+
+ GO:0005623
+ NIF_Subcellular:sao1813327414
+ The basic structural and functional unit of all organisms. Includes the plasma membrane and any external encapsulating structures such as the cell wall and cell envelope.
+ Wikipedia:Cell_(biology)
+ cellular_component
+
+
+
+
+
+ GOC:go_curators
+ The basic structural and functional unit of all organisms. Includes the plasma membrane and any external encapsulating structures such as the cell wall and cell envelope.
+
+
+
+
+
+
+
+
+
+ nucleus
+
+ A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent.
+ GO:0005634
+ NIF_Subcellular:sao1702920020
+ Wikipedia:Cell_nucleus
+ cell nucleus
+ cellular_component
+
+
+
+
+
+
+
+
+ A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent.
+ GOC:go_curators
+
+
+
+
+
+
+
+
+
+ chromosome
+
+
+
+ A structure composed of a very long molecule of DNA and associated proteins (e.g. histones) that carries hereditary information.
+ GO:0005694
+ Wikipedia:Chromosome
+ cellular_component
+ chromatid
+ interphase chromosome
+ prophase chromosome
+
+
+
+
+
+
+
+
+ A structure composed of a very long molecule of DNA and associated proteins (e.g. histones) that carries hereditary information.
+ ISBN:0198547684
+
+
+
+
+
+
+
+
+
+ cytoplasm
+
+ All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures.
+ GO:0005737
+ Wikipedia:Cytoplasm
+ cellular_component
+
+
+
+
+
+
+
+ All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures.
+ ISBN:0198547684
+
+
+
+
+
+
+
+
+
+ mitochondrion
+
+
+ A semiautonomous, self replicating organelle that occurs in varying numbers, shapes, and sizes in the cytoplasm of virtually all eukaryotic cells. It is notably the site of tissue respiration.
+ GO:0005739
+ NIF_Subcellular:sao1860313010
+ Wikipedia:Mitochondrion
+ cellular_component
+ mitochondria
+
+
+
+
+
+
+
+
+ A semiautonomous, self replicating organelle that occurs in varying numbers, shapes, and sizes in the cytoplasm of virtually all eukaryotic cells. It is notably the site of tissue respiration.
+ ISBN:0198506732
+
+
+
+
+
+
+
+
+
+ plasma membrane
+
+
+
+
+
+
+
+ GO:0005886
+ GO:0005904
+ NIF_Subcellular:sao1663586795
+ The membrane surrounding a cell that separates the cell from its external environment. It consists of a phospholipid bilayer and associated proteins.
+ Wikipedia:Cell_membrane
+ bacterial inner membrane
+ cell membrane
+ cellular_component
+ cytoplasmic membrane
+ inner endospore membrane
+ juxtamembrane
+ plasma membrane lipid bilayer
+ plasmalemma
+
+
+
+
+
+
+
+
+ ISBN:0716731363
+ The membrane surrounding a cell that separates the cell from its external environment. It consists of a phospholipid bilayer and associated proteins.
+
+
+
+
+ GOC:mah
+ plasma membrane lipid bilayer
+
+
+
+
+
+
+
+
+
+ membrane
+
+ Double layer of lipid molecules that encloses all cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins.
+ GO:0016020
+ Wikipedia:Biological_membrane
+ cellular_component
+
+
+
+
+
+
+
+
+ Double layer of lipid molecules that encloses all cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins.
+ GOC:mah
+ ISBN:0815316194
+
+
+
+
+
+
+
+
+
+ organelle
+
+ GO:0043226
+ NIF_Subcellular:sao1539965131
+ Organized structure of distinctive morphology and function. Includes the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton, and prokaryotic structures such as anammoxosomes and pirellulosomes. Excludes the plasma membrane.
+ Wikipedia:Organelle
+ cellular_component
+
+
+
+
+
+ GOC:go_curators
+ Organized structure of distinctive morphology and function. Includes the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton, and prokaryotic structures such as anammoxosomes and pirellulosomes. Excludes the plasma membrane.
+
+
+
+
+
+
+
+
+
+ membrane-bounded organelle
+
+ GO:0043227
+ NIF_Subcellular:sao414196390
+ Organized structure of distinctive morphology and function, bounded by a single or double lipid bilayer membrane. Includes the nucleus, mitochondria, plastids, vacuoles, and vesicles. Excludes the plasma membrane.
+ cellular_component
+ membrane-enclosed organelle
+
+
+
+ GOC:go_curators
+ Organized structure of distinctive morphology and function, bounded by a single or double lipid bilayer membrane. Includes the nucleus, mitochondria, plastids, vacuoles, and vesicles. Excludes the plasma membrane.
+
+
+
+
+
+
+
+
+
+ non-membrane-bounded organelle
+
+ GO:0043228
+ NIF_Subcellular:sao1456184038
+ Organized structure of distinctive morphology and function, not bounded by a lipid bilayer membrane. Includes ribosomes, the cytoskeleton and chromosomes.
+ cellular_component
+ non-membrane-enclosed organelle
+
+
+
+ GOC:go_curators
+ Organized structure of distinctive morphology and function, not bounded by a lipid bilayer membrane. Includes ribosomes, the cytoskeleton and chromosomes.
+
+
+
+
+
+
+
+
+
+ intracellular organelle
+
+
+ GO:0043229
+ Organized structure of distinctive morphology and function, occurring within the cell. Includes the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton. Excludes the plasma membrane.
+ cellular_component
+
+
+
+
+ GOC:go_curators
+ Organized structure of distinctive morphology and function, occurring within the cell. Includes the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton. Excludes the plasma membrane.
+
+
+
+
+
+
+
+
+
+ intracellular membrane-bounded organelle
+
+
+ GO:0043231
+ Organized structure of distinctive morphology and function, bounded by a single or double lipid bilayer membrane and occurring within the cell. Includes the nucleus, mitochondria, plastids, vacuoles, and vesicles. Excludes the plasma membrane.
+ cellular_component
+ intracellular membrane-enclosed organelle
+
+
+
+
+ GOC:go_curators
+ Organized structure of distinctive morphology and function, bounded by a single or double lipid bilayer membrane and occurring within the cell. Includes the nucleus, mitochondria, plastids, vacuoles, and vesicles. Excludes the plasma membrane.
+
+
+
+
+
+
+
+
+
+ intracellular non-membrane-bounded organelle
+
+
+ GO:0043232
+ Organized structure of distinctive morphology and function, not bounded by a lipid bilayer membrane and occurring within the cell. Includes ribosomes, the cytoskeleton and chromosomes.
+ cellular_component
+ intracellular non-membrane-enclosed organelle
+
+
+
+
+ GOC:go_curators
+ Organized structure of distinctive morphology and function, not bounded by a lipid bilayer membrane and occurring within the cell. Includes ribosomes, the cytoskeleton and chromosomes.
+
+
+
+
+
+
+
+
+
+ organelle part
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of an organelle, an organized structure of distinctive morphology and function. Includes constituent parts of the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton, but excludes the plasma membrane.
+ GO:0044422
+ cellular_component
+
+
+
+ Any constituent part of an organelle, an organized structure of distinctive morphology and function. Includes constituent parts of the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton, but excludes the plasma membrane.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ intracellular part
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of the living contents of a cell; the matter contained within (but not including) the plasma membrane, usually taken to exclude large vacuoles and masses of secretory or ingested material. In eukaryotes it includes the nucleus and cytoplasm.
+ GO:0044424
+ cellular_component
+
+
+
+ Any constituent part of the living contents of a cell; the matter contained within (but not including) the plasma membrane, usually taken to exclude large vacuoles and masses of secretory or ingested material. In eukaryotes it includes the nucleus and cytoplasm.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ membrane part
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of a membrane, a double layer of lipid molecules that encloses all cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins.
+ GO:0044425
+ cellular_component
+
+
+
+ Any constituent part of a membrane, a double layer of lipid molecules that encloses all cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ nuclear part
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of the nucleus, a membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated.
+ GO:0044428
+ cellular_component
+ nucleus component
+
+
+ Any constituent part of the nucleus, a membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ mitochondrial part
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of a mitochondrion, a semiautonomous, self replicating organelle that occurs in varying numbers, shapes, and sizes in the cytoplasm of virtually all eukaryotic cells. It is notably the site of tissue respiration.
+ GO:0044429
+ cellular_component
+ mitochondrion component
+
+
+ Any constituent part of a mitochondrion, a semiautonomous, self replicating organelle that occurs in varying numbers, shapes, and sizes in the cytoplasm of virtually all eukaryotic cells. It is notably the site of tissue respiration.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ cytoplasmic part
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of the cytoplasm, all of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures.
+ GO:0044444
+ cellular_component
+ cytoplasm component
+
+
+
+ Any constituent part of the cytoplasm, all of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ intracellular organelle part
+
+
+
+
+
+
+
+
+ A constituent part of an intracellular organelle, an organized structure of distinctive morphology and function, occurring within the cell. Includes constituent parts of the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton but excludes the plasma membrane.
+ GO:0044446
+ cellular_component
+
+
+
+ A constituent part of an intracellular organelle, an organized structure of distinctive morphology and function, occurring within the cell. Includes constituent parts of the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton but excludes the plasma membrane.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ plasma membrane part
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of the plasma membrane, the membrane surrounding a cell that separates the cell from its external environment. It consists of a phospholipid bilayer and associated proteins.
+ GO:0044459
+ cellular_component
+
+
+
+ Any constituent part of the plasma membrane, the membrane surrounding a cell that separates the cell from its external environment. It consists of a phospholipid bilayer and associated proteins.
+ GOC:jl
+
+
+
+
+
+
+
+
+
+ cell part
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Any constituent part of a cell, the basic structural and functional unit of all organisms.
+ GO:0044464
+ cellular_component
+ protoplast
+
+
+
+
+ Any constituent part of a cell, the basic structural and functional unit of all organisms.
+ GOC:jl
+
+
+
+
+ GOC:mah
+ protoplast
+
+
+
+
+
+
+
+
+
+ cell periphery
+
+ GO:0071944
+ The part of a cell encompassing the cell cortex, the plasma membrane, and any external encapsulating structures.
+ cellular_component
+
+
+ GOC:mah
+ The part of a cell encompassing the cell cortex, the plasma membrane, and any external encapsulating structures.
+
+
+
+
+
+
+
+
+
diff --git a/tutorial/resources/BDK14-exercises/basic-dl-query/cc.owl b/tutorial/resources/BDK14-exercises/basic-dl-query/cc.owl
new file mode 100644
index 000000000..65a2862f8
--- /dev/null
+++ b/tutorial/resources/BDK14-exercises/basic-dl-query/cc.owl
@@ -0,0 +1,53553 @@
+Prefix: xsd:
+Prefix: owl:
+Prefix: oboInOwl:
+Prefix: :
+Prefix: obo:
+Prefix: xml:
+Prefix: rdf:
+Prefix: rdfs:
+Prefix: go:
+
+
+
+Ontology:
+
+
+AnnotationProperty: obo:go#systematic_synonym
+
+ Annotations:
+ rdfs:label "Systematic synonym"^^xsd:string,
+ oboInOwl:hasScope
+
+ Annotations:
+ oboInOwl:hasScope ,
+ rdfs:label "Systematic synonym"^^xsd:string
+
+ SubPropertyOf:
+ oboInOwl:SynonymTypeProperty
+
+
+AnnotationProperty: oboInOwl:shorthand
+
+ Annotations:
+ rdfs:label "shorthand"^^xsd:string
+
+ Annotations:
+ rdfs:label "shorthand"^^xsd:string
+
+
+AnnotationProperty: oboInOwl:inSubset
+
+ Annotations:
+ rdfs:label "in_subset"^^xsd:string
+
+ Annotations:
+ rdfs:label "in_subset"^^xsd:string
+
+
+AnnotationProperty: obo:go#mf_needs_review
+
+ Annotations:
+ rdfs:comment "Catalytic activity terms in need of attention"^^xsd:string
+
+ Annotations:
+ rdfs:comment "Catalytic activity terms in need of attention"^^xsd:string
+
+ SubPropertyOf:
+ oboInOwl:SubsetProperty
+
+
+AnnotationProperty: oboInOwl:hasScope
+
+ Annotations:
+ rdfs:label "has_scope"^^xsd:string
+
+ Annotations:
+ rdfs:label "has_scope"^^xsd:string
+
+
+AnnotationProperty: oboInOwl:hasOBOFormatVersion
+
+ Annotations:
+ rdfs:label "has_obo_format_version"^^xsd:string
+
+ Annotations:
+ rdfs:label "has_obo_format_version"^^xsd:string
+
+
+AnnotationProperty: obo:IAO_0000115
+
+ Annotations:
+ rdfs:label "definition"^^xsd:string
+
+ Annotations:
+ rdfs:label "definition"^^xsd:string
+
+
+AnnotationProperty: oboInOwl:hasDbXref
+
+ Annotations:
+ rdfs:label "database_cross_reference"^^xsd:string
+
+ Annotations:
+ rdfs:label "database_cross_reference"^^xsd:string
+
+
+AnnotationProperty: obo:go#goslim_generic
+
+ Annotations:
+ rdfs:comment "Generic GO slim"^^xsd:string
+
+ Annotations:
+ rdfs:comment "Generic GO slim"^^xsd:string
+
+ SubPropertyOf:
+ oboInOwl:SubsetProperty
+
+
+AnnotationProperty: obo:go#goslim_aspergillus
+
+ Annotations:
+ rdfs:comment "Aspergillus GO slim"^^xsd:string
+
+ Annotations:
+ rdfs:comment "Aspergillus GO slim"^^xsd:string
+
+ SubPropertyOf:
+ oboInOwl:SubsetProperty
+
+
+AnnotationProperty: oboInOwl:hasAlternativeId
+
+ Annotations:
+ rdfs:label "has_alternative_id"^^xsd:string
+
+ Annotations:
+ rdfs:label "has_alternative_id"^^xsd:string
+
+
+AnnotationProperty: obo:go#gosubset_prok
+
+ Annotations:
+ rdfs:comment "Prokaryotic GO subset"^^xsd:string
+
+ Annotations:
+ rdfs:comment "Prokaryotic GO subset"^^xsd:string
+
+ SubPropertyOf:
+ oboInOwl:SubsetProperty
+
+
+AnnotationProperty: oboInOwl:hasOBONamespace
+
+ Annotations:
+ rdfs:label "has_obo_namespace"^^xsd:string
+
+ Annotations:
+ rdfs:label "has_obo_namespace"^^xsd:string
+
+
+AnnotationProperty: oboInOwl:SubsetProperty
+
+ Annotations:
+ rdfs:label "subset_property"^^xsd:string
+
+ Annotations:
+ rdfs:label "subset_property"^^xsd:string
+
+
+AnnotationProperty: oboInOwl:id
+
+
+AnnotationProperty: obo:go#goslim_pir
+
+ Annotations:
+ rdfs:comment "PIR GO slim"^^xsd:string
+
+ Annotations:
+ rdfs:comment "PIR GO slim"^^xsd:string
+
+ SubPropertyOf:
+ oboInOwl:SubsetProperty
+
+
+AnnotationProperty: oboInOwl:SynonymTypeProperty
+
+ Annotations:
+ rdfs:label "synonym_type_property"^^xsd:string
+
+ Annotations:
+ rdfs:label "synonym_type_property"^^xsd:string
+
+
+AnnotationProperty: rdfs:label
+
+
+AnnotationProperty: oboInOwl:hasExactSynonym
+
+ Annotations:
+ rdfs:label "has_exact_synonym"^^xsd:string
+
+ Annotations:
+ rdfs:label "has_exact_synonym"^^xsd:string
+
+
+AnnotationProperty: rdfs:comment
+
+
+AnnotationProperty: obo:go#goslim_plant
+
+ Annotations:
+ rdfs:comment "Plant GO slim"^^xsd:string
+
+ Annotations:
+ rdfs:comment "Plant GO slim"^^xsd:string
+
+ SubPropertyOf:
+ oboInOwl:SubsetProperty
+
+
+AnnotationProperty: obo:go#goslim_candida
+
+ Annotations:
+ rdfs:comment "Candida GO slim"^^xsd:string
+
+ Annotations:
+ rdfs:comment "Candida GO slim"^^xsd:string
+
+ SubPropertyOf:
+ oboInOwl:SubsetProperty
+
+
+AnnotationProperty: oboInOwl:hasRelatedSynonym
+
+ Annotations:
+ rdfs:label "has_related_synonym"^^xsd:string
+
+ Annotations:
+ rdfs:label "has_related_synonym"^^xsd:string
+
+
+AnnotationProperty: oboInOwl:hasNarrowSynonym
+
+ Annotations:
+ rdfs:label "has_narrow_synonym"^^xsd:string
+
+ Annotations:
+ rdfs:label "has_narrow_synonym"^^xsd:string
+
+
+AnnotationProperty: obo:go#high_level_annotation_qc
+
+ Annotations:
+ rdfs:comment "High-level terms not to be used for direct annotation"^^xsd:string
+
+ Annotations:
+ rdfs:comment "High-level terms not to be used for direct annotation"^^xsd:string
+
+ SubPropertyOf:
+ oboInOwl:SubsetProperty
+
+
+AnnotationProperty: oboInOwl:hasBroadSynonym
+
+ Annotations:
+ rdfs:label "has_broad_synonym"^^xsd:string
+
+ Annotations:
+ rdfs:label "has_broad_synonym"^^xsd:string
+
+
+AnnotationProperty: obo:go#goslim_yeast
+
+ Annotations:
+ rdfs:comment "Yeast GO slim"^^xsd:string
+
+ Annotations:
+ rdfs:comment "Yeast GO slim"^^xsd:string
+
+ SubPropertyOf:
+ oboInOwl:SubsetProperty
+
+
+AnnotationProperty: obo:go#goslim_pombe
+
+ Annotations:
+ rdfs:comment "Fission yeast GO slim"^^xsd:string
+
+ Annotations:
+ rdfs:comment "Fission yeast GO slim"^^xsd:string
+
+ SubPropertyOf:
+ oboInOwl:SubsetProperty
+
+
+Datatype: xsd:string
+
+
+ObjectProperty: obo:BFO_0000050
+
+ Annotations:
+ oboInOwl:shorthand "part_of"^^xsd:string,
+ oboInOwl:hasDbXref "BFO:0000050"^^xsd:string,
+ oboInOwl:hasOBONamespace "gene_ontology"^^xsd:string,
+ rdfs:label "part_of"^^xsd:string,
+ oboInOwl:hasDbXref "OBO_REL:part_of"^^xsd:string,
+ oboInOwl:id "part_of"^^xsd:string
+
+ Characteristics:
+ Transitive
+
+
+ObjectProperty: obo:BFO_0000051
+
+ Annotations:
+ oboInOwl:hasDbXref "OBO_REL:has_part"^^xsd:string,
+ oboInOwl:hasDbXref "BFO:0000051"^^xsd:string,
+ oboInOwl:hasOBONamespace "gene_ontology"^^xsd:string,
+ oboInOwl:id "has_part"^^xsd:string,
+ oboInOwl:shorthand "has_part"^^xsd:string,
+ rdfs:label "has_part"^^xsd:string
+
+ Characteristics:
+ Transitive
+
+
+Class: obo:GO_0070603
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "SWI-SNF-type complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16155938"^^xsd:string
+ obo:IAO_0000115 "A chromatin remodeling complex that contains an ortholog of the Saccharomyces ATPase Swi2/Snf2 as one of the core components."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:224"^^xsd:string
+ oboInOwl:hasRelatedSynonym "SWI-SNF global transcription activator complex "^^xsd:string,
+ rdfs:label "SWI/SNF-type complex"^^xsd:string,
+ oboInOwl:id "GO:0070603"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016585
+
+
+Class: obo:GO_0070604
+
+ Annotations:
+ rdfs:label "PBAF complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:565"^^xsd:string
+ oboInOwl:hasExactSynonym "SWI/SNF complex B"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16155938"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8895581"^^xsd:string
+ obo:IAO_0000115 "A SWI/SNF-type complex that contains the ATPase product of the mammalian BAF180 gene."^^xsd:string,
+ oboInOwl:id "GO:0070604"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:565"^^xsd:string
+ oboInOwl:hasExactSynonym "Polybromo- and BAF containing complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070603
+
+
+Class: obo:GO_0071189
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15347688"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the cell adhesion molecules protocadherin-alpha-v7 and protocadherin-gamma-a3, and is involved in the regulation of protein localization to the plasma membrane."^^xsd:string,
+ oboInOwl:id "GO:0071189"^^xsd:string,
+ rdfs:label "protocadherin-alpha-v7-protocadherin-gamma-a3 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1019"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Pcdha7-Pcdhga3 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071183
+
+
+Class: obo:GO_0071188
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071188"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1021"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Pcdha7-Pcdhga1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15347688"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the cell adhesion molecules protocadherin-alpha-v7 and protocadherin-gamma-a1, and is involved in the regulation of protein localization to the plasma membrane."^^xsd:string,
+ rdfs:label "protocadherin-alpha-v7-protocadherin-gamma-a1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071183
+
+
+Class: obo:GO_0071187
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1017"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Pcdhga1-Pcdhgb4 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "protocadherin-alpha-v4-protocadherin-gamma-b4 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15347688"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the cell adhesion molecules protocadherin-alpha-v4 and protocadherin-gamma-b4, and is involved in the regulation of protein localization to the plasma membrane."^^xsd:string,
+ oboInOwl:id "GO:0071187"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071183
+
+
+Class: obo:GO_0071196
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "Kv4.3-KChIP1 channel complex"^^xsd:string,
+ oboInOwl:id "GO:0071196"^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:3091"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15356203"^^xsd:string
+ obo:IAO_0000115 "A voltage-gated potassium channel complex that contains the Kv channel interacting protein KChIP1 associated with the channel via interaction with the Kv alpha subunit 4.3."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008076
+
+
+Class: obo:GO_0071197
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15356203"^^xsd:string
+ obo:IAO_0000115 "A voltage-gated potassium channel complex that contains the Kv alpha subunits 4.2 and 4.3."^^xsd:string,
+ rdfs:label "Kv4.2-Kv4.3 channel complex"^^xsd:string,
+ oboInOwl:id "GO:0071197"^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:609"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008076
+
+
+Class: obo:GO_0071194
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071194"^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:608"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15356203"^^xsd:string
+ obo:IAO_0000115 "A voltage-gated potassium channel complex that contains the Kv channel interacting protein KChIP3 associated with the channel via interaction with the Kv alpha subunit 4.2."^^xsd:string,
+ rdfs:label "Kv4.2-KChIP3 channel complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008076
+
+
+Class: obo:GO_0030906
+
+ Annotations:
+ rdfs:label "retromer complex, inner shell"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030906"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9700157"^^xsd:string
+ obo:IAO_0000115 "One of two subcomplexes that combine to form the retromer, believed to be closely associated with the membrane. In budding yeast the complex comprises Vps35p, Vps29p, and Vps26p."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0030904,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071195
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "Kv4.2-KChIP4 channel complex"^^xsd:string,
+ oboInOwl:id "GO:0071195"^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:3090"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15356203"^^xsd:string
+ obo:IAO_0000115 "A voltage-gated potassium channel complex that contains the Kv channel interacting protein KChIP4 associated with the channel via interaction with the Kv alpha subunit 4.2."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008076
+
+
+Class: obo:GO_0030907
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "Mlu1-box binding factor"^^xsd:string,
+ rdfs:label "MBF transcription complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "DSC1 transcription factor complex"^^xsd:string,
+ oboInOwl:id "GO:0030907"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11206552"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15838511"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18160399"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9343385"^^xsd:string
+ obo:IAO_0000115 "A protein complex that binds to the Mlu1 cell cycle box (MCB) promoter element, consensus sequence ACGCGN, and is involved in regulation of transcription during the G1/S transition of the cell cycle. In Saccharomyces, the complex contains a heterodimer of the DNA binding protein Mbp1p and the activator Swi4p, and is associated with additional proteins known as Nrm1p, Msa1p, and Msa2p; in Schizosaccharomyces the complex contains Res1p, Res2p, and Cdc10p."^^xsd:string,
+ oboInOwl:hasExactSynonym "MBF"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005667
+
+
+Class: obo:GO_0071192
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15356203"^^xsd:string
+ obo:IAO_0000115 "A voltage-gated potassium channel complex that contains the Kv channel interacting protein KChIP1 associated with the channel via interaction with the Kv alpha subunit 4.2."^^xsd:string,
+ rdfs:label "Kv4.2-KChIP1 channel complex"^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:606"^^xsd:string,
+ oboInOwl:id "GO:0071192"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008076
+
+
+Class: obo:GO_0030904
+
+ Annotations:
+ rdfs:label "retromer complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9700157"^^xsd:string
+ obo:IAO_0000115 "A conserved multimeric membrane-associated complex involved in retrograde transport from endosomes to the Golgi apparatus. For example, the budding yeast retromer comprises Vps35p, Vps29p, Vps26p, Vps5p, and Vps17p."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0030904"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0012505,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071193
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15356203"^^xsd:string
+ obo:IAO_0000115 "A voltage-gated potassium channel complex that contains the Kv channel interacting protein KChIP2 associated with the channel via interaction with the Kv alpha subunit 4.2."^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:607"^^xsd:string,
+ rdfs:label "Kv4.2-KChIP2 channel complex"^^xsd:string,
+ oboInOwl:id "GO:0071193"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008076
+
+
+Class: obo:GO_0030905
+
+ Annotations:
+ rdfs:label "retromer complex, outer shell"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9700157"^^xsd:string
+ obo:IAO_0000115 "One of two subcomplexes that combine to form the retromer, believed to be peripherally associated with the membrane. The budding yeast complex comprises Vps5p and Vps17p, and may contain multiple copies of a Vps5p/Vps17p dimer."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030905"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0030904,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071190
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15347688"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the cell adhesion molecules protocadherin-alpha-v7 and protocadherin-gamma-b2, and is involved in the regulation of protein localization to the plasma membrane."^^xsd:string,
+ oboInOwl:id "GO:0071190"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1018"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Pcdha7-Pcdhgb4 complex"^^xsd:string,
+ rdfs:label "protocadherin-alpha-v7-protocadherin-gamma-b2 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071183
+
+
+Class: obo:GO_0071191
+
+ Annotations:
+ rdfs:label "protocadherin-alpha-v7-protocadherin-gamma-b4 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1020"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Pcdha7-Pcdhgb2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15347688"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the cell adhesion molecules protocadherin-alpha-v7 and protocadherin-gamma-b4, and is involved in the regulation of protein localization to the plasma membrane."^^xsd:string,
+ oboInOwl:id "GO:0071191"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071183
+
+
+Class: obo:GO_0016035
+
+ Annotations:
+ oboInOwl:id "GO:0016035"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16631579"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16971464"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric DNA polymerase complex that catalyzes error-prone DNA synthesis in contexts such as translesion synthesis and double-stranded break repair. First characterized in Saccharomyces, in which the subunits are Rev3p and Rev7p; a third protein, Rev1p, is often associated with the polymerase dimer."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "zeta DNA polymerase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042575,
+ obo:GO_0044446
+
+
+Class: obo:GO_0070618
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070618"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2545"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Grb2-mSos1 complex"^^xsd:string,
+ rdfs:label "Grb2-Sos complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7798267"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8940013"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains Grb2 and the guanine nucleotide exchange factor Sos (or an ortholog thereof, such as mSos1), and is involved in linking EGFR activation to the p21-Ras pathway."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0008091
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0008091"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao536287099"^^xsd:string,
+ rdfs:label "spectrin"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Spectrin"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:curators"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "Membrane associated dimeric protein (240 and 220 kDa) of erythrocytes. Forms a complex with ankyrin, actin and probably other components of the membrane cytoskeleton, so that there is a mesh of proteins underlying the plasma membrane, potentially restricting the lateral mobility of integral proteins."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0030864,
+ obo:GO_0044430,
+ obo:GO_0044448
+
+
+Class: obo:GO_0070619
+
+ Annotations:
+ rdfs:label "Shc-Grb2-Sos complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2553"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Shc-Grb2-mSos1 complex, EGF stimulated"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070619"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7970708"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8940013"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains Grb2, the adaptor protein Shc and the guanine nucleotide exchange factor Sos (or an ortholog thereof, such as mSos1), and is involved in linking EGFR activation to the p21-Ras pathway."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071177
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "MAML2-RBP-Jkappa-ICN3 complex"^^xsd:string,
+ oboInOwl:id "GO:0071177"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3218"^^xsd:string
+ oboInOwl:hasExactSynonym "MAML2-RBP-Jkappa-Notch3 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12370315"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of the intracellular domain of Notch3 (ICN3), the DNA-binding transcription factor RBP-Jkappa, and the transcriptional coactivator Mastermind-like-2 (MAML2); the complex is involved in transcriptional activation in response to Notch-mediated signaling."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044451,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071176
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "MAML2-RBP-Jkappa-ICN2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3217"^^xsd:string
+ oboInOwl:hasExactSynonym "MAML2-RBP-Jkappa-Notch2 complex"^^xsd:string,
+ oboInOwl:id "GO:0071176"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12370315"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of the intracellular domain of Notch2 (ICN2), the DNA-binding transcription factor RBP-Jkappa, and the transcriptional coactivator Mastermind-like-2 (MAML2); the complex is involved in transcriptional activation in response to Notch-mediated signaling."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044451,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071179
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3220"^^xsd:string
+ oboInOwl:hasExactSynonym "MAML3-RBP-Jkappa-Notch1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12370315"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of the intracellular domain of Notch1 (ICN1), the DNA-binding transcription factor RBP-Jkappa, and the transcriptional coactivator Mastermind-like-3 (MAML3); the complex is involved in transcriptional activation in response to Notch-mediated signaling."^^xsd:string,
+ oboInOwl:id "GO:0071179"^^xsd:string,
+ rdfs:label "MAML3-RBP-Jkappa-ICN1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044451,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071178
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3219"^^xsd:string
+ oboInOwl:hasExactSynonym "MAML2-RBP-Jkappa-Notch4 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071178"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12370315"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of the intracellular domain of Notch4 (ICN4), the DNA-binding transcription factor RBP-Jkappa, and the transcriptional coactivator Mastermind-like-2 (MAML2); the complex is involved in transcriptional activation in response to Notch-mediated signaling."^^xsd:string,
+ rdfs:label "MAML2-RBP-Jkappa-ICN4 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044451,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071183
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15347688"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains two cell adhesion molecules, a protocadherin-alpha and a protocadherin-gamma, and is involved in the regulation of protein localization to the plasma membrane."^^xsd:string,
+ rdfs:label "protocadherin-alpha-protocadherin-gamma complex"^^xsd:string,
+ oboInOwl:id "GO:0071183"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071184
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1014"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Pcdhga1-Pcdha4 complex"^^xsd:string,
+ rdfs:label "protocadherin-alpha-v4-protocadherin-gamma-a1 complex"^^xsd:string,
+ oboInOwl:id "GO:0071184"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15347688"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the cell adhesion molecules protocadherin-alpha-v4 and protocadherin-gamma-a1, and is involved in the regulation of protein localization to the plasma membrane."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071183
+
+
+Class: obo:GO_0071185
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1016"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Pcdhga1-Pcdhga3 complex"^^xsd:string,
+ rdfs:label "protocadherin-alpha-v4-protocadherin-gamma-a3 complex"^^xsd:string,
+ oboInOwl:id "GO:0071185"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15347688"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the cell adhesion molecules protocadherin-alpha-v4 and protocadherin-gamma-a3, and is involved in the regulation of protein localization to the plasma membrane."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071183
+
+
+Class: obo:GO_0071186
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1015"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Pcdhga1-Pcdhgb2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15347688"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the cell adhesion molecules protocadherin-alpha-v4 and protocadherin-gamma-b2, and is involved in the regulation of protein localization to the plasma membrane."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "protocadherin-alpha-v4-protocadherin-gamma-b2 complex"^^xsd:string,
+ oboInOwl:id "GO:0071186"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071183
+
+
+Class: obo:GO_0071180
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:12370315"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of the intracellular domain of Notch2 (ICN2), the DNA-binding transcription factor RBP-Jkappa, and the transcriptional coactivator Mastermind-like-3 (MAML3); the complex is involved in transcriptional activation in response to Notch-mediated signaling."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "MAML3-RBP-Jkappa-ICN2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3221"^^xsd:string
+ oboInOwl:hasExactSynonym "MAML3-RBP-Jkappa-Notch2 complex"^^xsd:string,
+ oboInOwl:id "GO:0071180"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044451,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030914
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "See also the cellular component term 'SAGA complex ; GO:0000124'."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11564863"^^xsd:string
+ obo:IAO_0000115 "A large multiprotein complex that possesses histone acetyltransferase and is involved in regulation of transcription. The composition is similar to that of the SAGA complex; for example, the human complex contains the transcription-transformation cofactor TRRAP, hGCN5L acetylase, novel human ADA-like and SPT-like cofactors, and a subset of TAFs."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18838386"^^xsd:string
+ oboInOwl:hasExactSynonym "SPT3-TAF9-GCN5 acetylase complex"^^xsd:string,
+ rdfs:label "STAGA complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "STAGA coactivator complex"^^xsd:string,
+ oboInOwl:id "GO:0030914"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070461
+
+
+Class: obo:GO_0071181
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12370315"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of the intracellular domain of Notch3 (ICN3), the DNA-binding transcription factor RBP-Jkappa, and the transcriptional coactivator Mastermind-like-3 (MAML3); the complex is involved in transcriptional activation in response to Notch-mediated signaling."^^xsd:string,
+ rdfs:label "MAML3-RBP-Jkappa-ICN3 complex"^^xsd:string,
+ oboInOwl:id "GO:0071181"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3222"^^xsd:string
+ oboInOwl:hasExactSynonym "MAML3-RBP-Jkappa-Notch3 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044451,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030915
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "Smc5-Smc6 complex"^^xsd:string,
+ oboInOwl:id "GO:0030915"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14701739"^^xsd:string
+ obo:IAO_0000115 "A conserved complex that contains a heterodimer of SMC proteins (Smc5p and Smc6p, or homologs thereof) and several other proteins, and is involved in DNA repair and maintaining cell cycle arrest following DNA damage. In S. cerevisiae, this is an octameric complex called Mms21-Smc5-Smc6 complex, with at least five of its subunits conserved in fission yeast and humans."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:GO_0043234,
+ obo:BFO_0000050 some obo:GO_0000793
+
+
+Class: obo:GO_0071182
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3223"^^xsd:string
+ oboInOwl:hasExactSynonym "MAML3-RBP-Jkappa-Notch4 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "MAML3-RBP-Jkappa-ICN4 complex"^^xsd:string,
+ oboInOwl:id "GO:0071182"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12370315"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of the intracellular domain of Notch4 (ICN4), the DNA-binding transcription factor RBP-Jkappa, and the transcriptional coactivator Mastermind-like-3 (MAML3); the complex is involved in transcriptional activation in response to Notch-mediated signaling."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044451,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070519
+
+ Annotations:
+ rdfs:label "alpha4-beta1 integrin-CD63 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2424"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA4-ITGB1-CD63 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8757325"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha4-beta1 integrin complex bound to membrane protein CD63, a member of the tetraspan family."^^xsd:string,
+ oboInOwl:id "GO:0070519"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070517
+
+ Annotations:
+ rdfs:label "DNA replication factor C core complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:278"^^xsd:string
+ oboInOwl:hasExactSynonym "RFC core complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0070517"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8692848"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9228079"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9582326"^^xsd:string
+ obo:IAO_0000115 "A protein complex containing three of the five subunits of eukaryotic replication factor C, those corresponding to human p40, p38, and p37."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:BFO_0000050 some obo:GO_0043599,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070518
+
+ Annotations:
+ rdfs:label "alpha4-beta1 integrin-CD53 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2420"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA4-ITGB1-CD53 complex"^^xsd:string,
+ oboInOwl:id "GO:0070518"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8757325"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha4-beta1 integrin complex bound to membrane protein CD53, a member of the tetraspan family."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070515
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alphaIIb-beta3 integrin-talin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2378"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA2b-ITGB3-TLN1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8663236"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaIIb-beta3 integrin complex bound to talin."^^xsd:string,
+ oboInOwl:id "GO:0070515"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070516
+
+ Annotations:
+ rdfs:label "CAK-ERCC2 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8692841"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8692842"^^xsd:string
+ obo:IAO_0000115 "A protein complex formed by the association of the cyclin-dependent protein kinase activating kinase (CAK) holoenzyme complex with ERCC2."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "cyclin-dependent protein kinase activating kinase holoenzyme-ERCC2 complex"^^xsd:string,
+ oboInOwl:id "GO:0070516"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070514
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8617811"^^xsd:string
+ obo:IAO_0000115 "A transcription factor complex that contains the serum response factor (SRF) and the basic helix-loop-helix proteins myogenin and E12, and is involved in activating transcription of muscle-specific genes."^^xsd:string,
+ rdfs:label "SRF-myogenin-E12 complex"^^xsd:string,
+ oboInOwl:id "GO:0070514"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005667
+
+
+Class: obo:GO_0031988
+
+ Annotations:
+ oboInOwl:inSubset ,
+ rdfs:label "membrane-bounded vesicle"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031988"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Any small, fluid-filled, spherical organelle enclosed by a lipid bilayer."^^xsd:string,
+ oboInOwl:hasExactSynonym "membrane-enclosed vesicle"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031982
+
+
+Class: obo:GO_0070621
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "EGFR-Shc-Grb2-Sos complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7798267"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8940013"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the epidermal growth factor receptor (EGFR), Grb2, the adaptor protein SHC and the guanine nucleotide exchange factor Sos (or an ortholog thereof, such as mSos1), and is involved in linking EGFR activation to the p21-Ras pathway."^^xsd:string,
+ oboInOwl:id "GO:0070621"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031985
+
+ Annotations:
+ rdfs:label "Golgi cisterna"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031985"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Any of the thin, flattened membrane-bounded compartments that form the central portion of the Golgi complex."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005795,
+ obo:GO_0044431,
+ obo:GO_0031984
+
+
+Class: obo:GO_0070622
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "UDP-N-acetylglucosamine-lysosomal-enzyme N-acetylglucosaminephosphotransferase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8940155"^^xsd:string
+ oboInOwl:hasExactSynonym "UDP-N-acetylglucosamine:lysosomal-enzyme N-acetylglucosamine-1-phosphotransferase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:406"^^xsd:string
+ oboInOwl:hasRelatedSynonym "N-acetylglucosamine-1-phosphotransferase complex"^^xsd:string,
+ oboInOwl:id "GO:0070622"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8940155"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses UDP-N-acetylglucosamine-lysosomal-enzyme N-acetylglucosaminephosphotransferase activity; the bovine complex contains disulfide-linked homodimers of 166- and 51-kDa subunits and two identical, noncovalently associated 56-kDa subunits."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044437,
+ obo:BFO_0000050 some obo:GO_0005764,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031986
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Proteinoplast"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031986"^^xsd:string,
+ rdfs:label "proteinoplast"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pz"^^xsd:string
+ obo:IAO_0000115 "A leucoplast in which protein is stored."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009536
+
+
+Class: obo:GO_0031983
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao797538226"^^xsd:string,
+ oboInOwl:id "GO:0031983"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membrane or protein that forms a vesicle."^^xsd:string,
+ rdfs:label "vesicle lumen"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0031988,
+ obo:GO_0043233
+
+
+Class: obo:GO_0070620
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2548"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Egfr-Grb2-mSos1 complex, EGF stimulated"^^xsd:string,
+ rdfs:label "EGFR-Grb2-Sos complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7798267"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8940013"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the epidermal growth factor receptor (EGFR), Grb2 and the guanine nucleotide exchange factor Sos (or an ortholog thereof, such as mSos1), and is involved in linking EGFR activation to the p21-Ras pathway."^^xsd:string,
+ oboInOwl:id "GO:0070620"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031984
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that this term refers to membrane-bounded compartments that are not considered organelles in their own right, but form parts of larger organelles."^^xsd:string,
+ oboInOwl:id "GO:0031984"^^xsd:string,
+ oboInOwl:hasExactSynonym "suborganelle compartment"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pz"^^xsd:string
+ obo:IAO_0000115 "A compartment that consists of a lumen and an enclosing membrane, and is part of an organelle."^^xsd:string,
+ rdfs:label "organelle subcompartment"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044446,
+ obo:BFO_0000050 some obo:GO_0043227
+
+
+Class: obo:GO_0017109
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "EC:6.3.2.2"^^xsd:string
+ obo:IAO_0000115 "An enzyme complex that catalyzes the ligation of glutamate to cysteine, forming glutamylcysteine."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "glutamate-cysteine ligase complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "gamma-glutamylcysteine synthetase complex"^^xsd:string,
+ oboInOwl:id "GO:0017109"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444,
+ obo:GO_0043234
+
+
+Class: obo:GO_0017101
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16169847"^^xsd:string
+ obo:IAO_0000115 "A multienzyme complex found in all multicellular eukaryotes composed of eight proteins with aminoacyl-tRNA synthetase activities (abbreviated as: ArgRS, AspRS, GluProRS, GlnRS, IleRS, LeuRS, LysRS, MetRS where RS is the enzyme, preceded by the amino acid it uses as a substrate) as well as three non-synthetase proteins (p43, p38, and p18) with diverse functions. Several of these subunits are known dimers, so the total polypeptide count in the multisynthetase complex is at least fifteen. All of the enzymes in this assembly catalyze the same reaction, the covalent attachment of an amino acid to either the 2'- or 3'-hydroxyl of the 3'-terminal adenosine of tRNA, but using different substrates."^^xsd:string,
+ oboInOwl:id "GO:0017101"^^xsd:string,
+ oboInOwl:hasExactSynonym "aminoacyl-tRNA synthetase complex"^^xsd:string,
+ rdfs:label "aminoacyl-tRNA synthetase multienzyme complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "multisynthetase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0017102
+
+ Annotations:
+ rdfs:label "methionyl glutamyl tRNA synthetase complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0017102"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mcc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11069915"^^xsd:string
+ obo:IAO_0000115 "A complex consisting of methionyl- and glutamyl-tRNA synthetases. The tRNA synthetases present in the complex bind to their cognate tRNAs more efficiently than they do as monomers."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0043509
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "activin A complex"^^xsd:string,
+ rdfs:comment "Note that the actions of the activin complex are the opposite of those of the inhibin complex, which is a dimer of an inhibin beta-A or inhibin beta-B subunit and an inhibin alpha subunit. See also the cellular component term 'inhibin complex ; GO:0043511'."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:go_curators"^^xsd:string
+ obo:IAO_0000115 "A nonsteroidal regulator, composed of two covalently linked inhibin beta-A subunits (sometimes known as activin beta-A or activin/inhibin beta-A)."^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0048181"^^xsd:string,
+ oboInOwl:id "GO:0043509"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0048180
+
+
+Class: obo:GO_0070505
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:rph"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12930826"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15012271"^^xsd:string
+ obo:IAO_0000115 "A layer of extracellular matrix deposited onto the surface of the pollen wall upon disintegration of the tapetal layer of the anther wall in the late stages of pollen development. The composition of this material is highly heterogeneous and includes waxes, lipid droplets, small aromatic molecules, and proteins. The pollen coat is proposed to have many functions, such as holding pollen in the anther until dispersal, facilitation of pollen dispersal, protection of pollen from water loss and UV radiation, and facilitation of adhesion of pollen to the stigma."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15012271"^^xsd:string
+ oboInOwl:hasExactSynonym "pollenkitt"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15012271"^^xsd:string
+ oboInOwl:hasExactSynonym "tryphine"^^xsd:string,
+ rdfs:label "pollen coat"^^xsd:string,
+ oboInOwl:id "GO:0070505"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044420
+
+
+Class: obo:GO_0071199
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:15911355"^^xsd:string
+ obo:IAO_0000115 "A voltage-gated potassium channel complex that contains the peptidase-related protein DPP10 associated with the channel via interaction with the Kv alpha subunit 4.1."^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:601"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071199"^^xsd:string,
+ rdfs:label "Kv4.1-DPP10 channel complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15911355"^^xsd:string
+ oboInOwl:hasExactSynonym "Kv4.1-DPPY channel complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008076
+
+
+Class: obo:GO_0031976
+
+ Annotations:
+ rdfs:label "plastid thylakoid"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pz"^^xsd:string
+ obo:IAO_0000115 "Any thylakoid within a plastid."^^xsd:string,
+ oboInOwl:id "GO:0031976"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0009579
+ and (obo:BFO_0000050 some obo:GO_0009536)
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:GO_0009579,
+ obo:GO_0031984
+
+
+Class: obo:GO_0071198
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:15911355"^^xsd:string
+ obo:IAO_0000115 "A voltage-gated potassium channel complex that contains the peptidase-related protein DPP6 associated with the channel via interaction with the Kv alpha subunit 4.1."^^xsd:string,
+ rdfs:label "Kv4.1-DPP6 channel complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:600"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15911355"^^xsd:string
+ oboInOwl:hasExactSynonym "Kv4.1-DPPX channel complex"^^xsd:string,
+ oboInOwl:id "GO:0071198"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008076
+
+
+Class: obo:GO_0031977
+
+ Annotations:
+ rdfs:label "thylakoid lumen"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pz"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by a thylakoid membrane."^^xsd:string,
+ oboInOwl:id "GO:0031977"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044436
+
+
+Class: obo:GO_0031978
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "plastid thylakoid lumen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by a plastid thylakoid membrane."^^xsd:string,
+ oboInOwl:id "GO:0031978"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:GO_0031977,
+ obo:BFO_0000050 some obo:GO_0031976
+
+
+Class: obo:GO_0001891
+
+ Annotations:
+ oboInOwl:id "GO:0001891"^^xsd:string,
+ rdfs:label "phagocytic cup"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10358769"^^xsd:string
+ obo:IAO_0000115 "An invagination of the cell membrane formed by an actin dependent process during phagocytosis. Following internalization it is converted into a phagosome."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459
+
+
+Class: obo:GO_0031979
+
+ Annotations:
+ rdfs:label "plasma membrane-derived thylakoid lumen"^^xsd:string,
+ oboInOwl:hasExactSynonym "plasma membrane thylakoid lumen"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by a plasma membrane-derived thylakoid."^^xsd:string,
+ oboInOwl:id "GO:0031979"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031977,
+ obo:GO_0044459,
+ obo:GO_0060205,
+ obo:BFO_0000050 some obo:GO_0030075
+
+
+Class: obo:GO_0031972
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The region between the inner and outer lipid bilayers of a chloroplast envelope."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "chloroplast envelope lumen"^^xsd:string,
+ rdfs:label "chloroplast intermembrane space"^^xsd:string,
+ oboInOwl:id "GO:0031972"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009941,
+ obo:GO_0044434,
+ obo:GO_0009529
+
+
+Class: obo:GO_0031973
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The region between the inner and outer lipid bilayers of a chromoplast envelope."^^xsd:string,
+ oboInOwl:hasExactSynonym "chromoplast envelope lumen"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "chromoplast intermembrane space"^^xsd:string,
+ oboInOwl:id "GO:0031973"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0031898,
+ obo:GO_0009529
+
+
+Class: obo:GO_0043505
+
+ Annotations:
+ oboInOwl:id "GO:0043505"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:go_curators"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15175412"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16183641"^^xsd:string
+ obo:IAO_0000115 "A form of nucleosome located only at the centromere, in which the histone H3 is replaced by the variant form CENP-A (sometimes known as CenH3)."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "centromere-specific nucleosome"^^xsd:string,
+ oboInOwl:hasExactSynonym "centromeric nucleosome"^^xsd:string,
+ oboInOwl:hasExactSynonym "centromere specific nucleosome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000786,
+ obo:BFO_0000050 some obo:GO_0000939
+
+
+Class: obo:GO_0031974
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The enclosed volume within a sealed membrane or between two sealed membranes. Encompasses the volume enclosed by the membranes of a particular organelle, e.g. endoplasmic reticulum lumen, or the space between the two lipid bilayers of a double membrane surrounding an organelle, e.g. nuclear envelope lumen."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031974"^^xsd:string,
+ rdfs:label "membrane-enclosed lumen"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005575
+
+
+Class: obo:GO_0031975
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pz"^^xsd:string
+ obo:IAO_0000115 "A multilayered structure surrounding all or part of a cell; encompasses one or more lipid bilayers, and may include a cell wall layer; also includes the space between layers."^^xsd:string,
+ oboInOwl:id "GO:0031975"^^xsd:string,
+ rdfs:label "envelope"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0031982
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0031982"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pz"^^xsd:string
+ obo:IAO_0000115 "Any small, fluid-filled, spherical organelle enclosed by membrane or protein."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Vesicle_(biology)"^^xsd:string,
+ rdfs:label "vesicle"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao221389602"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043226
+
+
+Class: obo:GO_0017117
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "ssDNA-dependent ATP-dependent DNA helicase complex"^^xsd:string,
+ oboInOwl:id "GO:0017117"^^xsd:string,
+ rdfs:label "single-stranded DNA-dependent ATP-dependent DNA helicase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses single-stranded DNA-dependent DNA helicase activity."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033202
+
+
+Class: obo:GO_0031981
+
+ Annotations:
+ rdfs:label "nuclear lumen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pz"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the nuclear inner membrane."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031981"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0070013
+
+
+Class: obo:GO_0070118
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "organellar chromatophore thylakoid membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "Paulinella-type chromatophore thylakoid membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer membrane of any thylakoid within an organellar chromatophore."^^xsd:string,
+ oboInOwl:id "GO:0070118"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042651,
+ obo:BFO_0000050 some obo:GO_0070116,
+ obo:GO_0044433
+
+
+Class: obo:GO_0070117
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by an organellar chromatophore thylakoid membrane."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "Paulinella-type chromatophore thylakoid lumen"^^xsd:string,
+ rdfs:label "organellar chromatophore thylakoid lumen"^^xsd:string,
+ oboInOwl:id "GO:0070117"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0070116,
+ obo:GO_0031977,
+ obo:GO_0044433
+
+
+Class: obo:GO_0043510
+
+ Annotations:
+ oboInOwl:hasAlternativeId "GO:0048182"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that the actions of the activin complex are the opposite of those of the inhibin complex, which is a dimer of an inhibin beta-A or inhibin beta-B subunit and a inhibin alpha subunit. See 'inhibin complex ; GO:0043511'."^^xsd:string,
+ oboInOwl:id "GO:0043510"^^xsd:string,
+ rdfs:label "activin B complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:go_curators"^^xsd:string
+ obo:IAO_0000115 "A nonsteroidal regulator, composed of two covalently linked inhibin beta-B subunits (sometimes known as activin beta-B or activin/inhibin beta-B)."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0048180
+
+
+Class: obo:GO_0017119
+
+ Annotations:
+ rdfs:label "Golgi transport complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Sec34/35 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9792665"^^xsd:string
+ obo:IAO_0000115 "A complex of proteins that, in vitro, stimulates intra-Golgi transport; a 13S complex, about 800 kDa in size and consists of at least five polypeptides. In yeast, this complex is called the Sec34/35 complex and is composed of eight subunits (Sec34p, Sec35p, Dor1p, Cod1p, Cod2p, Cod3p, Cod4p, and Cod5p)."^^xsd:string,
+ oboInOwl:hasExactSynonym "COG complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "conserved oligomeric Golgi complex"^^xsd:string,
+ oboInOwl:id "GO:0017119"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044431,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070114
+
+ Annotations:
+ oboInOwl:id "GO:0070114"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "Paulinella-type chromatophore outer membrane"^^xsd:string,
+ rdfs:label "organellar chromatophore outer membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The outer, i.e. cytoplasm-facing, of the two lipid bilayers surrounding an organellar chromatophore."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043661,
+ obo:GO_0070112
+
+
+Class: obo:GO_0070113
+
+ Annotations:
+ oboInOwl:id "GO:0070113"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "Paulinella-type chromatophore inner membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The inner, i.e. lumen-facing, of the two lipid bilayers surrounding an organellar chromatophore."^^xsd:string,
+ rdfs:label "organellar chromatophore inner membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070112
+
+
+Class: obo:GO_0070116
+
+ Annotations:
+ oboInOwl:id "GO:0070116"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "organellar chromatophore thylakoid"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "Paulinella-type chromatophore thylakoid"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A thylakoid located in an organellar chromatophore."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009579,
+ obo:BFO_0000050 some obo:GO_0070111,
+ obo:GO_0044433
+
+
+Class: obo:GO_0045009
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "chitosome"^^xsd:string,
+ oboInOwl:id "GO:0045009"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8970154"^^xsd:string
+ obo:IAO_0000115 "An intracellular membrane-bounded particle found in fungi and containing chitin synthase; it synthesizes chitin microfibrils. Chitin synthase activity exists in chitosomes and they are proposed to act as a reservoir for regulated transport of chitin synthase enzymes to the division septum."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016023
+
+
+Class: obo:GO_0070115
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The region between the inner and outer lipid bilayers that surround an organellar chromatophore."^^xsd:string,
+ oboInOwl:id "GO:0070115"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "Paulinella-type chromatophore intermembrane space"^^xsd:string,
+ rdfs:label "organellar chromatophore intermembrane space"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0070111,
+ obo:GO_0044433
+
+
+Class: obo:GO_0070110
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:rl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12707266"^^xsd:string
+ obo:IAO_0000115 "A protein complex that acts as a receptor for the cytokine ciliary neurotrophic factor (CNTF). In humans the receptor complex is a hexamer composed of two molecules each of CNTF and CNTFR and one molecule each of gp130 and LIFR."^^xsd:string,
+ oboInOwl:id "GO:0070110"^^xsd:string,
+ rdfs:label "ciliary neurotrophic factor receptor complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005887,
+ obo:GO_0044459,
+ obo:GO_0043235
+
+
+Class: obo:GO_0070112
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "Paulinella-type chromatophore membrane"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Either of the lipid bilayers that surround an organellar chromatophore."^^xsd:string,
+ oboInOwl:id "GO:0070112"^^xsd:string,
+ rdfs:label "organellar chromatophore membrane"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0070111,
+ obo:GO_0030659
+
+
+Class: obo:GO_0070111
+
+ Annotations:
+ rdfs:label "organellar chromatophore"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070111"^^xsd:string,
+ oboInOwl:hasExactSynonym "Paulinella-type chromatophore"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:expert_mm"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18356055"^^xsd:string
+ obo:IAO_0000115 "A bacteroid-containing symbiosome in which the bacterial component is a genetically highly reduced cyanobacterium that is photosynthetically active and incapable of an independent existence outside its host. The chromatophore functions as a photosynthetic organelle, and has been found and characterized in the amoeba Paulinella chromatophora."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043660
+
+
+Class: obo:GO_0071149
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11358867"^^xsd:string
+ obo:IAO_0000115 "A transcription factor complex that is composed of the DNA biding protein TEAD-2 and the transcriptional coactivator YAP."^^xsd:string,
+ oboInOwl:id "GO:0071149"^^xsd:string,
+ rdfs:label "TEAD-2-YAP complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005667
+
+
+Class: obo:GO_0071147
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2870"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11358867"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of the DNA binding protein TEAD-2 bound to 12 other polypeptides including the transcriptional coactivator YAP, the multi-PDZ domain protein MPDZ (also called MUPP1), a 14-3-3 domain protein, and others."^^xsd:string,
+ oboInOwl:id "GO:0071147"^^xsd:string,
+ rdfs:label "TEAD-2 multiprotein complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071148
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "TEAD-1-YAP complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11358867"^^xsd:string
+ obo:IAO_0000115 "A transcription factor complex that is composed of the DNA biding protein TEAD-1 and the transcriptional coactivator YAP."^^xsd:string,
+ oboInOwl:id "GO:0071148"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005667
+
+
+Class: obo:GO_0071145
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9670020"^^xsd:string
+ obo:IAO_0000115 "A heteromeric SMAD protein complex that contains SMAD2 and SMAD4."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3001"^^xsd:string
+ oboInOwl:hasExactSynonym "SMAD2-SMAD4 heteromer complex"^^xsd:string,
+ rdfs:label "SMAD2-SMAD4 protein complex"^^xsd:string,
+ oboInOwl:id "GO:0071145"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071141
+
+
+Class: obo:GO_0034245
+
+ Annotations:
+ oboInOwl:hasExactSynonym "mitochondrial RNA polymerase holoenzyme complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "mitochondrial DNA-directed RNA polymerase complex"^^xsd:string,
+ oboInOwl:id "GO:0034245"^^xsd:string,
+ oboInOwl:hasBroadSynonym "mitochondrial RNA polymerase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7929382"^^xsd:string
+ obo:IAO_0000115 "A DNA-directed RNA polymerase complex located in the mitochondrion. Mitochondrial RNA polymerase is composed of two subunits, a catalytic core, which resembles the enzymes from bacteriophage T7 and T3, and a specificity factor required for promoter recognition, which is similar to members of the eubacterial sigma factor family. In S. cerevisiae, these are encoded by the nuclear genes RPO41 and MTF1 and the specificity factor, required for promoter recognition and initiation, is not present in the elongating form."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000428
+ and (obo:BFO_0000050 some obo:GO_0005739)
+
+ SubClassOf:
+ obo:GO_0000428,
+ obo:GO_0044429
+
+
+Class: obo:GO_0031968
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The outer, i.e. cytoplasm-facing in a cellular organelle, lipid bilayer of an organelle envelope."^^xsd:string,
+ rdfs:label "organelle outer membrane"^^xsd:string,
+ oboInOwl:id "GO:0031968"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0019867,
+ obo:GO_0044424,
+ obo:GO_0031090,
+ obo:BFO_0000050 some obo:GO_0031967
+
+
+Class: obo:GO_0071146
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3002"^^xsd:string
+ oboInOwl:hasExactSynonym "SMAD3-SMAD4 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9670020"^^xsd:string
+ obo:IAO_0000115 "A heteromeric SMAD protein complex that contains SMAD3 and SMAD4."^^xsd:string,
+ rdfs:label "SMAD3-SMAD4 protein complex"^^xsd:string,
+ oboInOwl:id "GO:0071146"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071141
+
+
+Class: obo:GO_0070533
+
+ Annotations:
+ rdfs:label "BRCA1-C complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15485915"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16391231"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the BRCA1-BARD1 heterodimer, CtIP and Mre11/Rad50/NBS1 (M/R/N) complex, and binds to DNA at DNA damage sites. BRCA1-C binding ta damaged DNA is required for DNA damage-induced Chk1 phosphorylation and the G2/M transition checkpoint."^^xsd:string,
+ oboInOwl:id "GO:0070533"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031967
+
+ Annotations:
+ rdfs:label "organelle envelope"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pz"^^xsd:string
+ obo:IAO_0000115 "A double membrane structure enclosing an organelle, including two lipid bilayers and the region between them. In some cases, an organelle envelope may have more than two membranes."^^xsd:string,
+ oboInOwl:id "GO:0031967"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044446,
+ obo:BFO_0000050 some obo:GO_0043227,
+ obo:GO_0031975
+
+
+Class: obo:GO_0071143
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "SMAD3 protein complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9670020"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of a SMAD3 homotrimer."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3003"^^xsd:string
+ oboInOwl:hasExactSynonym "SMAD3 homotrimer complex"^^xsd:string,
+ oboInOwl:id "GO:0071143"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071141
+
+
+Class: obo:GO_0070532
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "BRCA1-B complex"^^xsd:string,
+ oboInOwl:id "GO:0070532"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16391231"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the BRCA1-BARD1 heterodimer, BACH1 and TopBP1, and binds to DNA during S phase at DNA damage sites."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031966
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "mitochondrial membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Either of the lipid bilayers that surround the mitochondrion and form the mitochondrial envelope."^^xsd:string,
+ oboInOwl:id "GO:0031966"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005740,
+ obo:GO_0031090,
+ obo:GO_0044429
+
+
+Class: obo:GO_0071144
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3000"^^xsd:string
+ oboInOwl:hasExactSynonym "SMAD2-SMAD3 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9670020"^^xsd:string
+ obo:IAO_0000115 "A heteromeric SMAD protein complex that contains SMAD2 and SMAD3."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "SMAD2-SMAD3 protein complex"^^xsd:string,
+ oboInOwl:id "GO:0071144"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071141
+
+
+Class: obo:GO_0070531
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "BRCA1-A complex"^^xsd:string,
+ oboInOwl:id "GO:0070531"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19261749"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the BRCA1-BARD1 heterodimer, RAP80/UIMC1, BRCC3/BRCC36, BRE/BRCC45, FAM175A/CCDC98/Abraxas and MERIT40/NBA1, and specifically recognizes and binds K63-linked polyubiquitin chains present on histone H2A and H2AX at DNA damage sites."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031965
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pz"^^xsd:string
+ obo:IAO_0000115 "Either of the lipid bilayers that surround the nucleus and form the nuclear envelope; excludes the intermembrane space."^^xsd:string,
+ rdfs:label "nuclear membrane"^^xsd:string,
+ oboInOwl:id "GO:0031965"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1687101204"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005635,
+ obo:GO_0031090,
+ obo:GO_0044428
+
+
+Class: obo:GO_0031969
+
+ Annotations:
+ oboInOwl:id "GO:0031969"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "chloroplast membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pz"^^xsd:string
+ obo:IAO_0000115 "Either of the lipid bilayers that surround a chloroplast and form the chloroplast envelope."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Chloroplast_membrane"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009941,
+ obo:GO_0044434,
+ obo:GO_0042170
+
+
+Class: obo:GO_0070648
+
+ Annotations:
+ rdfs:label "formin-nucleated actin cable"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:14671023"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16959963"^^xsd:string
+ obo:IAO_0000115 "An actin filament bundle that consists of short filaments organized into bundles of uniform polarity, and is nucleated by formins. In fungal cells, myosin motors transport cargo along actin cables toward sites of polarized cell growth; actin cables may play a similar role in pollen tube growth."^^xsd:string,
+ oboInOwl:id "GO:0070648"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032432
+
+
+Class: obo:GO_0070645
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070645"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:14612572"^^xsd:string
+ oboInOwl:hasExactSynonym "orbicule"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ecd"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14612572"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16524248"^^xsd:string
+ obo:IAO_0000115 "A small, granular structure that is found in the extracellular matrix of cell of the secretory tapetal layer that surrounds developing pollen grains. Ubisch bodies have a sporopollenin coat, are attached to the peritapetal wall, and may play a role in pollen development."^^xsd:string,
+ rdfs:label "Ubisch body"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044420
+
+
+Class: obo:GO_0030018
+
+ Annotations:
+ rdfs:label "Z disc"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "Platelike region of a muscle sarcomere to which the plus ends of actin filaments are attached."^^xsd:string,
+ oboInOwl:hasExactSynonym "Z band"^^xsd:string,
+ oboInOwl:hasExactSynonym "Z line"^^xsd:string,
+ oboInOwl:hasExactSynonym "Z disk"^^xsd:string,
+ oboInOwl:id "GO:0030018"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044449,
+ obo:BFO_0000050 some obo:GO_0031674
+
+
+Class: obo:GO_0030017
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Sarcomere"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "sarcomere"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "The repeating unit of a myofibril in a muscle cell, composed of an array of overlapping thick and thin filaments between two adjacent Z discs."^^xsd:string,
+ oboInOwl:id "GO:0030017"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044449,
+ obo:BFO_0000050 some obo:GO_0030016
+
+
+Class: obo:GO_0030016
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "striated muscle fibre"^^xsd:string,
+ rdfs:label "myofibril"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Myofibril"^^xsd:string,
+ oboInOwl:hasExactSynonym "striated muscle fiber"^^xsd:string,
+ oboInOwl:id "GO:0030016"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "The contractile element of skeletal and cardiac muscle; a long, highly organized bundle of actin, myosin, and other proteins that contracts by a sliding filament mechanism."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043292
+
+
+Class: obo:GO_0030015
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:11113136"^^xsd:string
+ obo:IAO_0000115 "The core of the CCR4-NOT transcription factor complex. In Saccharomyces the CCR4-NOT core complex comprises Ccr4p, Caf1p, Not1p, Not2p, Not3p, Not4p, and Not5p."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030015"^^xsd:string,
+ rdfs:label "CCR4-NOT core complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0030014,
+ obo:GO_0044451,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030014
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030014"^^xsd:string,
+ rdfs:label "CCR4-NOT complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11113136"^^xsd:string
+ obo:IAO_0000115 "A large multimeric transcription factor complex that can regulate transcription positively or negatively; consists of a core complex plus additional proteins; may interact with other proteins to control initiation of transcription. In Saccharomyces the core complex comprises Ccr4p, Caf1p, Not1p, Not2p, Not3p, Not4p, and Not5p; Caf4p, Caf16p, and several less well characterized proteins."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005667
+
+
+Class: obo:GO_0071153
+
+ Annotations:
+ oboInOwl:id "GO:0071153"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12509430"^^xsd:string
+ obo:IAO_0000115 "A protein complex formed by the association of the guanine nucleotide exchange factor synembrin with the alpha(o) subunit of a heterotrimeric G protein."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:174"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Ric-8A G(o) alpha-2 subunit complex"^^xsd:string,
+ rdfs:label "G-protein alpha(o)-synembrin complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:172"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Ric-8A G(o) alpha-1 subunit complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071152
+
+ Annotations:
+ oboInOwl:id "GO:0071152"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12509430"^^xsd:string
+ obo:IAO_0000115 "A protein complex formed by the association of the guanine nucleotide exchange factor synembrin with the alpha(q) subunit of a heterotrimeric G protein."^^xsd:string,
+ rdfs:label "G-protein alpha(q)-synembrin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:175"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Ric-8A G(q) alpha subunit complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071151
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11358867"^^xsd:string
+ obo:IAO_0000115 "A transcription factor complex that is composed of the DNA biding protein TEAD-4 and the transcriptional coactivator YAP."^^xsd:string,
+ oboInOwl:id "GO:0071151"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "TEAD-4-YAP complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005667
+
+
+Class: obo:GO_0071150
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071150"^^xsd:string,
+ rdfs:label "TEAD-3-YAP complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11358867"^^xsd:string
+ obo:IAO_0000115 "A transcription factor complex that is composed of the DNA biding protein TEAD-3 and the transcriptional coactivator YAP."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005667
+
+
+Class: obo:GO_0031970
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "organelle envelope lumen"^^xsd:string,
+ oboInOwl:id "GO:0031970"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The region between the inner and outer lipid bilayers of an organelle envelope."^^xsd:string,
+ oboInOwl:hasExactSynonym "organelle intermembrane space"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044446,
+ obo:BFO_0000050 some obo:GO_0031967,
+ obo:GO_0031974
+
+
+Class: obo:GO_0031143
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Pseudopod"^^xsd:string,
+ oboInOwl:hasExactSynonym "pseudopod"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "A temporary protrusion or retractile process of a cell, associated with flowing movements of the protoplasm, and serving for locomotion and feeding."^^xsd:string,
+ rdfs:label "pseudopodium"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0031143"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042995
+
+
+Class: obo:GO_0071136
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3105"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA7-ITGB1-LAMA2 complex"^^xsd:string,
+ oboInOwl:id "GO:0071136"^^xsd:string,
+ rdfs:label "alpha7-beta1 integrin-laminin alpha-2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:17598176"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha7-beta1 integrin complex bound to laminin alpha-2."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071137
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:18032696"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaV-beta3 integrin complex bound to the cell surface antigen CD98."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071137"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3103"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB3-SLC3A2 complex"^^xsd:string,
+ rdfs:label "alphaV-beta3 integrin-CD98 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070652
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mm2"^^xsd:string
+ oboInOwl:hasExactSynonym "HAUS augmin complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "HAUS complex"^^xsd:string,
+ oboInOwl:id "GO:0070652"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:19427217"^^xsd:string
+ obo:IAO_0000115 "A protein complex that localizes to interphase centrosomes and to mitotic spindle tubules and regulates mitotic spindle assembly and centrosome integrity; in human, the complex consists of eight subunits, some of which are homologous to subunits of the Drosophila Augmin complex."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005875
+
+
+Class: obo:GO_0071138
+
+ Annotations:
+ rdfs:label "alpha5-beta5-fibronectin-SFRP2 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071138"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:14709558"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha5-beta5 integrin complex bound to fibronectin and secreted frizzled-related protein 2."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2388"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA5-ITGB5-FN-1-SFRP2 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071132
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3114"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAX-ITGB2-ICAM4 complex"^^xsd:string,
+ oboInOwl:id "GO:0071132"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alphaX-beta2 integrin-ICAM-4 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16985175"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaX-beta2 integrin complex bound to intercellular adhesion molecule 4."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070521
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:8757325"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha4-beta1 integrin complex bound to membrane protein CD82, a member of the tetraspan family."^^xsd:string,
+ oboInOwl:id "GO:0070521"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alpha4-beta1 integrin-CD82 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071133
+
+ Annotations:
+ oboInOwl:id "GO:0071133"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2989"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA9-ITGB1-ADAM8 complex"^^xsd:string,
+ rdfs:label "alpha9-beta1 integrin-ADAM8 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16995821"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha9-beta1 integrin complex bound to the transmembrane metallopeptidase ADAM8."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070520
+
+ Annotations:
+ oboInOwl:id "GO:0070520"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10229664"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8757325"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha4-beta1 integrin complex bound to membrane protein CD81, a member of the tetraspan family."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2419"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA4-ITGB1-CD81 complex"^^xsd:string,
+ rdfs:label "alpha4-beta1 integrin-CD81 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071134
+
+ Annotations:
+ oboInOwl:id "GO:0071134"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:17413041"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha9-beta1 integrin complex bound to thrombospondin-1."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alpha9-beta1 integrin-thrombospondin-1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2967"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA9-ITGB1-THBS1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071135
+
+ Annotations:
+ oboInOwl:id "GO:0071135"^^xsd:string,
+ rdfs:label "alpha7-beta1 integrin-focal adhesion kinase complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3106"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA7-ITGB1-PTK2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:17598176"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha7-beta1 integrin complex bound to focal adhesion kinase."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070522
+
+ Annotations:
+ rdfs:comment "Note that process and function information are included in the term and definition for the purpose of describing and distinguishing the complex."^^xsd:string,
+ oboInOwl:id "GO:0070522"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "ERCC4-ERCC1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "Rad1-Rad10 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:14734547"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric nucleotide-excision repair complex that has endonuclease activity specific for bubble structures characteristic of certain DNA lesions. The subunits are known as XPF/ERCC4 and ERCC1 in mammals, and Rad1p and Rad10p in S. cerevisiae."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:14734547"^^xsd:string
+ oboInOwl:hasExactSynonym "XPF-ERCC1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000109
+
+
+Class: obo:GO_0060204
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membrane of the clathrin sculpted glutamate transport vesicle."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "clathrin sculpted glutamate constitutive secretory pathway transport vesicle lumen"^^xsd:string,
+ oboInOwl:id "GO:0060204"^^xsd:string,
+ rdfs:label "clathrin sculpted glutamate transport vesicle lumen"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0060205,
+ obo:BFO_0000050 some obo:GO_0060199
+
+
+Class: obo:GO_0060205
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0060205"^^xsd:string,
+ rdfs:label "cytoplasmic membrane-bounded vesicle lumen"^^xsd:string,
+ oboInOwl:hasExactSynonym "cytoplasmic membrane-enclosed vesicle lumen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membrane of a cytoplasmic membrane-bounded vesicle."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0016023,
+ obo:GO_0044433,
+ obo:GO_0031983
+
+
+Class: obo:GO_0060202
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0060202"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membrane of the clathrin sculpted acetylcholine transport vesicle."^^xsd:string,
+ rdfs:label "clathrin sculpted acetylcholine transport vesicle lumen"^^xsd:string,
+ oboInOwl:hasExactSynonym "clathrin sculpted acetylcholine constitutive secretory pathway transport vesicle lumen"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0060200,
+ obo:GO_0060205
+
+
+Class: obo:GO_0060203
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding a clathrin sculpted glutamate transport vesicle."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "clathrin sculpted glutamate constitutive secretory pathway transport vesicle membrane"^^xsd:string,
+ oboInOwl:id "GO:0060203"^^xsd:string,
+ rdfs:label "clathrin sculpted glutamate transport vesicle membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030658,
+ obo:GO_0030665,
+ obo:BFO_0000050 some obo:GO_0060199
+
+
+Class: obo:GO_0060200
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "clathrin sculpted acetylcholine transport vesicle"^^xsd:string,
+ oboInOwl:hasExactSynonym "clathrin sculpted acetylcholine constitutive secretory pathway transport vesicle"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string
+ obo:IAO_0000115 "A clathrin sculpted lipid bilayer membrane-enclosed vesicle after clathrin release and containing acetylcholine."^^xsd:string,
+ oboInOwl:id "GO:0060200"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030133,
+ obo:GO_0060198
+
+
+Class: obo:GO_0060201
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding a clathrin sculpted acetylcholine transport vesicle."^^xsd:string,
+ rdfs:label "clathrin sculpted acetylcholine transport vesicle membrane"^^xsd:string,
+ oboInOwl:hasExactSynonym "clathrin sculpted acetylcholine constitutive secretory pathway transport vesicle membrane"^^xsd:string,
+ oboInOwl:id "GO:0060201"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030658,
+ obo:GO_0030665,
+ obo:BFO_0000050 some obo:GO_0060200
+
+
+Class: obo:GO_0090406
+
+ Annotations:
+ rdfs:comment "Carries the male gametes to into or near the ovule. May be branched in gymnosperms. This term replaces the obsolete term PO:0006345. Part of pollen tube cell (PO:0025195)."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:tb"^^xsd:string,
+ oboInOwl:hasDbXref "PO:0025195"^^xsd:string,
+ oboInOwl:hasDbXref "PO:0025281"^^xsd:string
+ obo:IAO_0000115 "A tubular cell projection that is part of a pollen tube cell and extends from a pollen grain."^^xsd:string,
+ oboInOwl:id "GO:0090406"^^xsd:string,
+ rdfs:label "pollen tube"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042995
+
+
+Class: obo:GO_0030008
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030008"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17287728"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9564032"^^xsd:string
+ obo:IAO_0000115 "A large complex present on the cis-Golgi that acts prior to SNARE complex assembly to mediate vesicle docking and fusion. Ras guanyl-nucleotide exchange factor activity has been demonstrated for this complex in S. cerevisiae."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:TRAPP_complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ oboInOwl:hasNarrowSynonym "TRAPP2"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ oboInOwl:hasNarrowSynonym "TRAPP1"^^xsd:string,
+ oboInOwl:hasExactSynonym "transport protein particle"^^xsd:string,
+ rdfs:label "TRAPP complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005801,
+ obo:GO_0043234,
+ obo:GO_0044431
+
+
+Class: obo:GO_0090405
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0090405"^^xsd:string,
+ rdfs:comment "Unicellular trichome branch is part of unicellular trichome, which is a narrow synonym of trichome cell (PO:0008030). For a cell that forms a branch of a multicellular trichome, see multicellular trichome branch cell (PO:0025163)."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:tb"^^xsd:string
+ obo:IAO_0000115 "A cell projection part that is a branch of a unicellular trichome."^^xsd:string,
+ rdfs:label "unicellular trichome branch"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044463
+
+
+Class: obo:GO_0009656
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:lr"^^xsd:string
+ obo:IAO_0000115 "Pigment-protein complex primarily associated to PSII in plants, green algae and cyanobacteria. Involved in state transitions that cause migration to PSI under certain environmental conditions such as high light."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "PSII associated light-harvesting complex II, peripheral complex"^^xsd:string,
+ oboInOwl:id "GO:0009656"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044436,
+ obo:GO_0044425,
+ obo:GO_0044434,
+ obo:BFO_0000050 some obo:GO_0009517,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030956
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030956"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string
+ oboInOwl:hasRelatedSynonym "AdT"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string
+ oboInOwl:hasNarrowSynonym "GatCAB"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string
+ oboInOwl:hasNarrowSynonym "GatFAB"^^xsd:string,
+ rdfs:label "glutamyl-tRNA(Gln) amidotransferase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mlg"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses glutamyl-tRNA(Gln) amidotransferase activity, and therefore creates Gln-tRNA by amidating Glu-tRNA; usually composed of 3 subunits: A, B, and C. Note that the C subunit may not be required in all organisms."^^xsd:string,
+ rdfs:comment "Note that this term represents a location and not a function; the activity possessed by this complex is mentioned in the definition for the purpose of describing and distinguishing the complex. The function possessed by this complex is represented by the molecular function term 'glutaminyl-tRNA synthase (glutamine-hydrolyzing) activity ; GO:0050567'."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0090404
+
+ Annotations:
+ oboInOwl:id "GO:0090404"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "pollen tube tip"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:tb"^^xsd:string,
+ oboInOwl:hasDbXref "PO:0025195"^^xsd:string,
+ oboInOwl:hasDbXref "PO:0025281"^^xsd:string
+ obo:IAO_0000115 "The region at growing end of the pollen tube cell, where polarized growth occurs."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044463,
+ obo:BFO_0000050 some obo:GO_0090406,
+ obo:GO_0035838
+
+
+Class: obo:GO_0071142
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9670020"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of a SMAD2 homotrimer."^^xsd:string,
+ oboInOwl:id "GO:0071142"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "SMAD2 protein complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2999"^^xsd:string
+ oboInOwl:hasExactSynonym "SMAD2 homotrimer complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071141
+
+
+Class: obo:GO_0071141
+
+ Annotations:
+ oboInOwl:id "GO:0071141"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9670020"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of SMAD proteins; may be homomeric or heteromeric."^^xsd:string,
+ rdfs:label "SMAD protein complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "SMAD complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030958
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "RITS complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:14704433"^^xsd:string
+ obo:IAO_0000115 "A protein complex required for heterochromatin assembly; contains an Argonaute homolog, a chromodomain protein, and at least one additional protein; named for RNA-induced initiation of transcriptional gene silencing."^^xsd:string,
+ oboInOwl:id "GO:0030958"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005720,
+ obo:GO_0044454,
+ obo:GO_0031332
+
+
+Class: obo:GO_0009655
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "PSII associated light-harvesting complex II, core complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "PSII associated light-harvesting complex II, core complex, LHCIIc subcomplex"^^xsd:string,
+ oboInOwl:id "GO:0009655"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:lr"^^xsd:string
+ obo:IAO_0000115 "The pigment-protein complex primarily associated to PSII in higher plants, green algae and cyanobacteria that directly transfers electrons to the reaction center."^^xsd:string,
+ oboInOwl:hasNarrowSynonym "PSII associated light-harvesting complex II, core complex, LHCIIa subcomplex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "PSII associated light-harvesting complex II, core complex, LHCIId subcomplex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044436,
+ obo:GO_0044425,
+ obo:GO_0044434,
+ obo:BFO_0000050 some obo:GO_0009517,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009654
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Oxygen_evolving_complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009654"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "InterPro:IPR002683"^^xsd:string
+ obo:IAO_0000115 "A complex, composed of a cluster of manganese, calcium and chloride ions bound to extrinsic proteins, that catalyzes the splitting of water to O2 and 4 H+. In cyanobacteria there are five extrinsic proteins in OEC (PsbO, PsbP-like, PsbQ-like, PsbU and PsbV), while in plants there are only three (PsbO, PsbP and PsbQ)."^^xsd:string,
+ rdfs:label "oxygen evolving complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044436,
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0009523,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070556
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8858156"^^xsd:string
+ obo:IAO_0000115 "A transcription factor TFIID complex that contains the TBP-associated factor TAF4B (also known as TAFII105 in human), a cell-type-specific variant of TAF4."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:485"^^xsd:string
+ oboInOwl:hasRelatedSynonym "TFIID complex, B-cell specific"^^xsd:string,
+ rdfs:label "TAF4B-containing transcription factor TFIID complex"^^xsd:string,
+ oboInOwl:id "GO:0070556"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005669
+
+
+Class: obo:GO_0030424
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:nln"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "The long process of a neuron that conducts nerve impulses, usually away from the cell body to the terminals and varicosities, which are sites of storage and release of neurotransmitter."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Axon"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1770195789"^^xsd:string,
+ rdfs:label "axon"^^xsd:string,
+ oboInOwl:id "GO:0030424"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043005
+
+
+Class: obo:GO_0070554
+
+ Annotations:
+ rdfs:label "synaptobrevin 2-SNAP-25-syntaxin-3-complexin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8824312"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains synaptobrevin 2 (VAMP2), SNAP-25, syntaxin 3, and a complexin (or orthologs thereof)."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070554"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:842"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Stx3-Snap25-Vamp2-Cplx1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:842"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Stx3, Snap25, Vamp2, Cplx1)"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0070552
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "BRISC complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19214193"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the FAM175B/ABRO1, BRCC3/BRCC36, BRE/BRCC45 and MERIT40/NBA1 proteins, and specifically cleaves K63-linked polyubiquitin chains."^^xsd:string,
+ oboInOwl:id "GO:0070552"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030427
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Any part of a cell where non-isotropic growth takes place."^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0030483"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ oboInOwl:hasAlternativeId "GO:0000134"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "site of polarized growth"^^xsd:string,
+ oboInOwl:id "GO:0030427"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0014803
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0014803"^^xsd:string,
+ rdfs:label "longitudinal sarcoplasmic reticulum lumen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string
+ obo:IAO_0000115 "The region between the inner and outer lipid bilayers of the longitudinal sarcoplasmic reticulum envelope. The longitudinal sarcoplasmic reticulum lumen is continuous with the lumen contained within the terminal cisternae."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0014801,
+ obo:GO_0033018
+
+
+Class: obo:GO_0031942
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:16247555"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16267274"^^xsd:string
+ obo:IAO_0000115 "Protease complex of the mitochondrial inner membrane whose catalytic residues lie on the intermembrane space side of the inner membrane; involved in mitochondrial protein turnover. Contains a subunit belonging to the AAA family of ATP-dependent metalloproteases."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "i-AAA complex"^^xsd:string,
+ oboInOwl:id "GO:0031942"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044455,
+ obo:GO_0043234,
+ obo:BFO_0000050 some obo:GO_0005743
+
+
+Class: obo:GO_0030428
+
+ Annotations:
+ oboInOwl:hasExactSynonym "cross wall"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:clt"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0471940526"^^xsd:string
+ obo:IAO_0000115 "A structure composed of peptidoglycan and often chitin in addition to other materials. It usually forms perpendicular to the long axis of a cell or hypha and grows centripetally from the cell wall to the center of the cell and often functions in the compartmentalization of a cell into two daughter cells."^^xsd:string,
+ oboInOwl:id "GO:0030428"^^xsd:string,
+ rdfs:label "cell septum"^^xsd:string,
+ oboInOwl:hasBroadSynonym "septum"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0014804
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0014804"^^xsd:string,
+ rdfs:label "terminal cisterna lumen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string
+ obo:IAO_0000115 "The region between the inner and outer lipid bilayers of the terminal cisterna envelope. This space is enriched in calsequestrin."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033018,
+ obo:BFO_0000050 some obo:GO_0014802
+
+
+Class: obo:GO_0031941
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A two-stranded helical polymer of the protein actin."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Actin"^^xsd:string,
+ oboInOwl:hasExactSynonym "F-actin"^^xsd:string,
+ rdfs:label "filamentous actin"^^xsd:string,
+ rdfs:comment "Note that this term refers only to the actin portion of a microfilament, and does not encompass associated proteins. See also the cellular component term 'actin filament ; GO:0005884'."^^xsd:string,
+ oboInOwl:id "GO:0031941"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005884,
+ obo:GO_0044430,
+ obo:GO_0043234
+
+
+Class: obo:GO_0014801
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string
+ obo:IAO_0000115 "The portion of the free sarcoplasmic reticulum consisting of longitudinal tubules that connect terminal cisternae."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0014801"^^xsd:string,
+ rdfs:label "longitudinal sarcoplasmic reticulum"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0016529,
+ obo:GO_0044432
+
+
+Class: obo:GO_0030425
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Dendrite"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1211023249"^^xsd:string,
+ rdfs:label "dendrite"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dos"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:nln"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "A neuron projection that has a short, tapering, often branched, morphology, receives and integrates signals from other neurons or from sensory stimuli, and conducts a nerve impulse towards the axon or the cell body. In most neurons, the impulse is conveyed from dendrites to axon via the cell body, but in some types of unipolar neuron, the impulse does not travel via the cell body."^^xsd:string,
+ oboInOwl:id "GO:0030425"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043005
+
+
+Class: obo:GO_0000399
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string
+ obo:IAO_0000115 "Any of a series of septin structures that are localized in the bud neck of a budding fungal cell during the cell cycle."^^xsd:string,
+ oboInOwl:id "GO:0000399"^^xsd:string,
+ rdfs:label "cellular bud neck septin structure"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032155,
+ obo:BFO_0000050 some obo:GO_0005935
+
+
+Class: obo:GO_0014802
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Terminal_cisterna"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0014802"^^xsd:string,
+ rdfs:label "terminal cisterna"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string
+ obo:IAO_0000115 "The portion of sarcoplasmic reticulum devoted to calcium ion storage and calcium ion release."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0016529,
+ obo:GO_0044432,
+ obo:GO_0031984
+
+
+Class: obo:GO_0030426
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Growth_cone"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030426"^^xsd:string,
+ rdfs:label "growth cone"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "The migrating motile tip of a growing nerve cell axon or dendrite."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0043005,
+ obo:GO_0044463,
+ obo:GO_0030427
+
+
+Class: obo:GO_0070559
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1379"^^xsd:string
+ oboInOwl:hasNarrowSynonym "GALNS-lysosomal hydrolase 1.27 MDa complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "lysosomal multienzyme complex"^^xsd:string,
+ oboInOwl:id "GO:0070559"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8910459"^^xsd:string
+ obo:IAO_0000115 "A protein complex found in the lysosome that contains beta-galactosidase, cathepsin A, alpha-neuraminidase and N-acetylgalactosamine-6-sulfate sulfatase, and is involved in glycosaminoglycan catabolism."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044437,
+ obo:BFO_0000050 some obo:GO_0005764,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070558
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070558"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2153"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAM-ITGB2-CD63 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8871662"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaM-beta2 integrin complex bound to membrane protein CD63, a member of the tetraspan family."^^xsd:string,
+ rdfs:label "alphaM-beta2 integrin-CD63 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070557
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070557"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7911228"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7915843"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the cyclin-dependent protein kinase inhibitor p21WAF1/CIP1 bound to PCNA; formation of the complex inhibits DNA replication."^^xsd:string,
+ rdfs:label "PCNA-p21 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031160
+
+ Annotations:
+ oboInOwl:hasExactSynonym "spore coat"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031160"^^xsd:string,
+ rdfs:label "spore wall"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pg"^^xsd:string
+ obo:IAO_0000115 "The specialized envelope lying outside the cell membrane of a spore."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005618
+
+
+Class: obo:GO_0031165
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "integral to contractile vacuolar membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pg"^^xsd:string
+ obo:IAO_0000115 "Located such that some or all of the gene product itself penetrates at least one phospholipid bilayer of the contractile vacuolar membrane. May also refer to the state of being buried in the bilayer with no exposure outside the bilayer."^^xsd:string,
+ oboInOwl:id "GO:0031165"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031311,
+ obo:GO_0031166
+
+
+Class: obo:GO_0031166
+
+ Annotations:
+ rdfs:label "integral to vacuolar membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Located such that some or all of the gene product itself penetrates at least one phospholipid bilayer of the vacuolar membrane. May also refer to the state of being buried in the bilayer with no exposure outside the bilayer."^^xsd:string,
+ oboInOwl:id "GO:0031166"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031301,
+ obo:GO_0031310
+
+
+Class: obo:GO_0071175
+
+ Annotations:
+ rdfs:label "MAML2-RBP-Jkappa-ICN1 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071175"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12370315"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of the intracellular domain of Notch1 (ICN1), the DNA-binding transcription factor RBP-Jkappa, and the transcriptional coactivator Mastermind-like-2 (MAML2); the complex is involved in transcriptional activation in response to Notch-mediated signaling."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1949"^^xsd:string
+ oboInOwl:hasExactSynonym "MAML2-RBP-Jkappa-Notch1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044451,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030430
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030430"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The cytoplasm of a host cell."^^xsd:string,
+ rdfs:label "host cell cytoplasm"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033646
+
+
+Class: obo:GO_0031164
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:pg"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding the contractile vacuole."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031164"^^xsd:string,
+ rdfs:label "contractile vacuolar membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pf"^^xsd:string
+ oboInOwl:hasExactSynonym "contractile vacuole membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005774,
+ obo:BFO_0000050 some obo:GO_0000331,
+ obo:GO_0044433
+
+
+Class: obo:GO_0030929
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "ADPG pyrophosphorylase complex"^^xsd:string,
+ oboInOwl:id "GO:0030929"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:tb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9680965"^^xsd:string
+ obo:IAO_0000115 "Complex that possesses ADPG pyrophosphorylase activity. In all organisms where it has been found, the complex is a tetramer. In bacteria, it is a homotetramer. In plants, the complex is a heterotetramer composed small and large subunits."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071154
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:170"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Ric-8A G(i) alpha-1 subunit complex"^^xsd:string,
+ rdfs:label "G-protein alpha(i)1-synembrin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12509430"^^xsd:string
+ obo:IAO_0000115 "A protein complex formed by the association of the guanine nucleotide exchange factor synembrin with the alpha(i)1 subunit of a heterotrimeric G protein."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:171"^^xsd:string
+ oboInOwl:hasRelatedSynonym "Ric-8A G(i) alpha-2 subunit complex"^^xsd:string,
+ oboInOwl:id "GO:0071154"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031933
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "telomeric heterochromatin"^^xsd:string,
+ oboInOwl:id "GO:0031933"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Heterochromatic regions of the chromosome found at the telomeres."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000792
+ and (obo:BFO_0000050 some obo:GO_0000781)
+
+ SubClassOf:
+ obo:GO_0000792,
+ obo:BFO_0000050 some obo:GO_0000781
+
+
+Class: obo:GO_0097085
+
+ Annotations:
+ rdfs:label "interferon regulatory factor 3-interferon regulatory factor 5 complex"^^xsd:string,
+ oboInOwl:id "GO:0097085"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "IRF3:IRF5 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:cna"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12138184"^^xsd:string
+ obo:IAO_0000115 "An interferon regulatory factor complex that consists of a heterodimer of interferon regulatory factor 3 and interferon regulatory factor 5."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0097071
+
+
+Class: obo:GO_0071155
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:176"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Ric-8A G alpha 13 subunit complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "G-protein alpha(13)-synembrin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12509430"^^xsd:string
+ obo:IAO_0000115 "A protein complex formed by the association of the guanine nucleotide exchange factor synembrin with the alpha(13) subunit of a heterotrimeric G protein."^^xsd:string,
+ oboInOwl:id "GO:0071155"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031932
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:21548787"^^xsd:string
+ oboInOwl:hasExactSynonym "TORC2"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:21548787"^^xsd:string
+ oboInOwl:hasExactSynonym "rapamycin and nutrient-insensitive TOR complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "TOR complex 2"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031932"^^xsd:string,
+ rdfs:label "TORC2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:20496258"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:21548787"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mTORC2"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:jh"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14736892"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15780592"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16469695"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:21548787"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains at least TOR (target of rapamycin) and Rictor (rapamycin-insensitive companion of TOR), or orthologs of, in complex with other signaling components. Mediates the phosphorylation and activation of PKB (also called AKT). In Saccharomyces, the complex contains Avo1p, Avo2p, Tsc11p, Lst8p, Bit61p, Slm1p, Slm2p, and Tor2p."^^xsd:string,
+ oboInOwl:hasExactSynonym "TORC 2 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070545
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16043514"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17353269"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is involved in coordinating ribosome biogenesis with cell cycle progression. In human, it is composed of Pes1, Bop1, and WDR12; in Saccharomyces the proteins are known as Nop7p, Erb1 and Ytm1 respectively."^^xsd:string,
+ rdfs:label "PeBoW complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070545"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044452,
+ obo:BFO_0000050 some obo:GO_0030686,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031934
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031934"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Heterochromatic regions of the chromosome found at silenced mating-type loci."^^xsd:string,
+ rdfs:label "mating-type region heterochromatin"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000792
+
+
+Class: obo:GO_0071159
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "NF-kappaB complex"^^xsd:string,
+ oboInOwl:id "GO:0071159"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0849327946"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of a homo- or heterodimer of members of a family of structurally related proteins that contain a conserved N-terminal region called the Rel homology domain (RHD). In the nucleus, NF-kappaB complexes act as transcription factors. In unstimulated cells, NF-kappaB dimers are sequestered in the cytoplasm by IkappaB monomers; signals that induce NF-kappaB activity cause degradation of IkappaB, allowing NF-kappaB dimers to translocate to the nucleus and induce gene expression."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031931
+
+ Annotations:
+ oboInOwl:hasExactSynonym "TORC 1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:21548787"^^xsd:string
+ oboInOwl:hasExactSynonym "TORC1"^^xsd:string,
+ oboInOwl:id "GO:0031931"^^xsd:string,
+ rdfs:label "TORC1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jh"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15780592"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16469695"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:21548787"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains at least TOR (target of rapamycin) and Raptor (regulatory-associated protein of TOR), or orthologs of, in complex with other signaling components. Mediates the phosphorylation and activation of S6K. In Saccharomyces, the complex contains Kog1p, Lst8p, Tco89p, and either Tor1p or Tor2p."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:17183368"^^xsd:string
+ oboInOwl:hasNarrowSynonym "dTORC1"^^xsd:string,
+ oboInOwl:hasExactSynonym "TOR complex 1"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:21548787"^^xsd:string
+ oboInOwl:hasExactSynonym "rapamycin and nutrient-sensitive TOR complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:18765678"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:21548787"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mTORC1"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:17183368"^^xsd:string
+ oboInOwl:hasNarrowSynonym "dTOR/dRaptor complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "nutrient sensitive complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070161
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "anchoring cell junction"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815332181"^^xsd:string
+ obo:IAO_0000115 "A cell junction that mechanically attaches a cell (and its cytoskeleton) to neighboring cells or to the extracellular matrix."^^xsd:string,
+ rdfs:label "anchoring junction"^^xsd:string,
+ oboInOwl:id "GO:0070161"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030054
+
+
+Class: obo:GO_0070160
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "occluding cell junction"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "occluding junction"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815332181"^^xsd:string
+ obo:IAO_0000115 "A cell-cell junction that seals cells together in an epithelium in a way that prevents even small molecules from leaking from one side of the sheet to the other."^^xsd:string,
+ oboInOwl:id "GO:0070160"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005911
+
+
+Class: obo:GO_0030930
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "A protein complex composed of four identical subunits that possesses ADPG pyrophosphorylase activity. Examples of this component are found in Bacterial species."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030930"^^xsd:string,
+ rdfs:label "homotetrameric ADPG pyrophosphorylase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030929
+
+
+Class: obo:GO_0030027
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "lamellipodium"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "A thin sheetlike process extended by the leading edge of a crawling fibroblast; contains a dense meshwork of actin filaments."^^xsd:string,
+ oboInOwl:id "GO:0030027"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Lamellipodia"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0031252,
+ obo:GO_0042995
+
+
+Class: obo:GO_0030932
+
+ Annotations:
+ oboInOwl:id "GO:0030932"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "amyloplast ADPG pyrophosphorylase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "An ADPG pyrophosphorylase complex found in the amyloplast."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0030929
+ and (obo:BFO_0000050 some obo:GO_0009501)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009501,
+ obo:GO_0031009
+
+
+Class: obo:GO_0030931
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030931"^^xsd:string,
+ rdfs:label "heterotetrameric ADPG pyrophosphorylase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "A protein complex composed of four different subunits that possesses ADPG pyrophosphorylase activity. An example of this process is found in Mus musculus."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030929
+
+
+Class: obo:GO_0030934
+
+ Annotations:
+ oboInOwl:id "GO:0030934"^^xsd:string,
+ rdfs:label "anchoring collagen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0721639976"^^xsd:string
+ obo:IAO_0000115 "Any collagen polymer which links one collagen assembly, such as a collagen fibril or sheet, to other structures."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0721639976"^^xsd:string
+ oboInOwl:hasExactSynonym "connecting collagen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0721639976"^^xsd:string
+ oboInOwl:hasExactSynonym "linking collagen"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005581
+
+
+Class: obo:GO_0030933
+
+ Annotations:
+ oboInOwl:id "GO:0030933"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "An ADPG pyrophosphorylase complex found in the chloroplast."^^xsd:string,
+ rdfs:label "chloroplast ADPG pyrophosphorylase complex"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0030929
+ and (obo:BFO_0000050 some obo:GO_0009507)
+
+ SubClassOf:
+ obo:GO_0031009,
+ obo:GO_0044434
+
+
+Class: obo:GO_0030936
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0721639976"^^xsd:string
+ obo:IAO_0000115 "Any collagen polymer that passes through a lipid bilayer membrane."^^xsd:string,
+ rdfs:label "transmembrane collagen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198599587"^^xsd:string
+ oboInOwl:hasExactSynonym "MACIT"^^xsd:string,
+ oboInOwl:id "GO:0030936"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005581
+
+
+Class: obo:GO_0030935
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "sheet-forming collagen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ oboInOwl:hasExactSynonym "network-forming collagen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0721639976"^^xsd:string
+ obo:IAO_0000115 "Any collagen polymer in which collagen triple helices associate to form sheet-like networks."^^xsd:string,
+ oboInOwl:id "GO:0030935"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005581
+
+
+Class: obo:GO_0030938
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "collagen type XVIII"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0721639976"^^xsd:string
+ obo:IAO_0000115 "A collagen homotrimer of alpha1(XVIII) chains."^^xsd:string,
+ oboInOwl:id "GO:0030938"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030934
+
+
+Class: obo:GO_0030937
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "collagen type XVII"^^xsd:string,
+ oboInOwl:id "GO:0030937"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0721639976"^^xsd:string
+ obo:IAO_0000115 "A collagen homotrimer of alpha1(XVII) chains; type XVII collagen triple helices associate with hemidesmosomes and the basal lamina."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030936
+
+
+Class: obo:GO_0071162
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:19228417"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the GINS complex, Cdc45p, and the heterohexameric MCM complex, and that is involved in unwinding DNA during replication."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071162"^^xsd:string,
+ rdfs:label "CMG complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:19228417"^^xsd:string
+ oboInOwl:hasExactSynonym "unwindosome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044451,
+ obo:GO_0044454,
+ obo:BFO_0000051 some obo:GO_0042555,
+ obo:BFO_0000051 some obo:GO_0000811,
+ obo:GO_0043234
+
+
+Class: obo:GO_0034206
+
+ Annotations:
+ rdfs:label "enhanceosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Enhanceosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11250145"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17574024"^^xsd:string
+ obo:IAO_0000115 "A protein-DNA complex formed by the association of a distinct set of general and specific transcription factors with a region of enhancer DNA. The cooperative assembly of an enhanceosome confers specificity of transcriptional regulation."^^xsd:string,
+ oboInOwl:id "GO:0034206"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032993
+
+
+Class: obo:GO_0043564
+
+ Annotations:
+ oboInOwl:hasExactSynonym "Ku70:Ku80 heterodimer"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12518983"^^xsd:string
+ obo:IAO_0000115 "Heterodimeric protein complex composed of a 70 kDa and a 80 kDa subunit, binds DNA through a channel formed by the heterodimer. Functions in DNA double stranded break repair, chromosome maintenance, transcription regulation, V(D)J recombination, and activation of DNA-PK."^^xsd:string,
+ oboInOwl:id "GO:0043564"^^xsd:string,
+ rdfs:label "Ku70:Ku80 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0000329
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "fungal-type vacuolar membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding a vacuole, the shape of which correlates with cell cycle phase. The membrane separates its contents from the cytoplasm of the cell. An example of this structure is found in Saccharomyces cerevisiae."^^xsd:string,
+ oboInOwl:id "GO:0000329"^^xsd:string,
+ oboInOwl:hasExactSynonym "membrane of vacuole with cell cycle-correlated morphology"^^xsd:string,
+ rdfs:label "fungal-type vacuole membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005774,
+ obo:BFO_0000050 some obo:GO_0000324
+
+
+Class: obo:GO_0070691
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Sgv1/Bur2 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070691"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16721054"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19328067"^^xsd:string
+ obo:IAO_0000115 "A positive transcription elongation factor complex b that comprises two subunits; an example is the budding yeast complex containing Svg1p (also called Bur1p) and Bur2p."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16721054"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19328067"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Bur1/Bur2 complex"^^xsd:string,
+ rdfs:label "dimeric positive transcription elongation factor complex b"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008024
+
+
+Class: obo:GO_0033655
+
+ Annotations:
+ oboInOwl:hasBroadSynonym "cytoplasm component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pamgo_curators"^^xsd:string
+ obo:IAO_0000115 "Any constituent part of the host cell cytoplasm, all of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. The host is defined as the larger of the organisms involved in a symbiotic interaction."^^xsd:string,
+ oboInOwl:id "GO:0033655"^^xsd:string,
+ rdfs:label "host cell cytoplasm part"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0030430,
+ obo:GO_0033646
+
+
+Class: obo:GO_0000325
+
+ Annotations:
+ oboInOwl:id "GO:0000325"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815316208"^^xsd:string
+ obo:IAO_0000115 "A closed structure that is completely surrounded by a unit membrane, contains liquid, and retains the same shape regardless of cell cycle phase. An example of this structure is found in Arabidopsis thaliana."^^xsd:string,
+ rdfs:label "plant-type vacuole"^^xsd:string,
+ oboInOwl:hasExactSynonym "vacuole, cell cycle-independent morphology"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005773
+
+
+Class: obo:GO_0000326
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000326"^^xsd:string,
+ rdfs:label "protein storage vacuole"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11739409"^^xsd:string
+ obo:IAO_0000115 "A storage vacuole that contains a lytic vacuole; identified in plants."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000325,
+ obo:GO_0000322
+
+
+Class: obo:GO_0042151
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "DOI:10.1139/z02-135"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "An organelle found in cnidoblast (nematoblast) cells. When matured, these stinging organelles store toxins and can deliver them when the cnidocil (a short extension of the cnidocyst) is stimulated by a prey or another stimulus."^^xsd:string,
+ oboInOwl:id "GO:0042151"^^xsd:string,
+ rdfs:label "nematocyst"^^xsd:string,
+ oboInOwl:hasExactSynonym "cnidocyst"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Cnidocyte"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044448,
+ obo:GO_0043232
+
+
+Class: obo:GO_0000327
+
+ Annotations:
+ oboInOwl:id "GO:0000327"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11739490"^^xsd:string
+ obo:IAO_0000115 "A membrane-bounded compartment containing crystals of phytic acid and proteins characteristic of a lytic vacuole, found within a storage vacuole."^^xsd:string,
+ rdfs:label "lytic vacuole within protein storage vacuole"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000323
+ and (obo:BFO_0000050 some obo:GO_0000326)
+
+ SubClassOf:
+ obo:GO_0044437,
+ obo:GO_0000323,
+ obo:BFO_0000050 some obo:GO_0000326
+
+
+Class: obo:GO_0000328
+
+ Annotations:
+ oboInOwl:id "GO:0000328"^^xsd:string,
+ rdfs:label "fungal-type vacuole lumen"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "lumen of vacuole with cell cycle-correlated morphology"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed within the vacuolar membrane of a vacuole, the shape of which correlates with cell cycle phase. An example of this structure is found in Saccharomyces cerevisiae."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005775,
+ obo:BFO_0000050 some obo:GO_0000324
+
+
+Class: obo:GO_0008021
+
+ Annotations:
+ oboInOwl:id "GO:0008021"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "synaptic vesicle"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Synaptic_vesicle"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1071221672"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10099709"^^xsd:string
+ obo:IAO_0000115 "A secretory organelle, some 50 nm in diameter, of presynaptic nerve terminals; accumulates in high concentrations of neurotransmitters and is secreted these into the synaptic cleft by fusion with the 'active zone' of the presynaptic plasma membrane."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0031982
+ and (obo:BFO_0000050 some obo:GO_0045202)
+
+ SubClassOf:
+ obo:GO_0044456,
+ obo:GO_0030136
+
+
+Class: obo:GO_0034673
+
+ Annotations:
+ oboInOwl:id "GO:0034673"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10746731"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of inhibin, type III transforming growth factor beta receptor (also known as betaglycan), and the type II activin receptor ActRII. The complex is thought to negatively regulate the activity of activin B."^^xsd:string,
+ rdfs:label "inhibin-betaglycan-ActRII complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0008023
+
+ Annotations:
+ oboInOwl:id "GO:0008023"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "transcription elongation factor complex"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "Any protein complex that interacts with RNA polymerase II to increase (positive transcription elongation factor) or reduce (negative transcription elongation factor) the rate of transcription elongation."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044451,
+ obo:GO_0043234
+
+
+Class: obo:GO_0042568
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "insulin-like growth factor binary complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "IGF binary complex"^^xsd:string,
+ oboInOwl:id "GO:0042568"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12239079"^^xsd:string
+ obo:IAO_0000115 "A complex of two proteins, which in animals is 50kDa and consists of the insulin-like growth factor (IGF) and one of the insulin-like growth factor binding protein-1 (IGFBP-1), -2 (IGFBP-2), -4 (IGFBP-4) and -6 (IGFBP-6). The complex plays a role in growth and development."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016942
+
+
+Class: obo:GO_0034676
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2323"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA6-ITGB4 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alpha6-beta4 integrin complex"^^xsd:string,
+ oboInOwl:id "GO:0034676"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alpha6 subunit and one beta1 subunit."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0065010
+
+ Annotations:
+ rdfs:label "extracellular membrane-bounded organelle"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0065010"^^xsd:string,
+ oboInOwl:hasExactSynonym "extracellular membrane-enclosed organelle"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:isa_complete"^^xsd:string
+ obo:IAO_0000115 "Organized structure of distinctive morphology and function, bounded by a lipid bilayer membrane and occurring outside the cell."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043227,
+ obo:GO_0043230
+
+
+Class: obo:GO_0042567
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12239079"^^xsd:string
+ obo:IAO_0000115 "A complex of three proteins, which in animals is approximately 150kDa and consists of the insulin-like growth factor (IGF), the insulin-like growth factor binding protein-3 (IGFBP-3), or -5 (IGFBP-5) and an acid-labile subunit (ALS). The complex plays a role in growth and development."^^xsd:string,
+ rdfs:label "insulin-like growth factor ternary complex"^^xsd:string,
+ oboInOwl:id "GO:0042567"^^xsd:string,
+ oboInOwl:hasExactSynonym "IGF ternary complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016942
+
+
+Class: obo:GO_0034677
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0034677"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "ITGA7-ITGB1 complex"^^xsd:string,
+ rdfs:label "alpha7-beta1 integrin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alpha7 subunit and one beta1 subunit."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0008024
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:10766736"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16721054"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17079683"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19328067"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7759473"^^xsd:string
+ obo:IAO_0000115 "A transcription elongation factor complex that facilitates the transition from abortive to productive elongation by phosphorylating the CTD domain of the large subunit of DNA-directed RNA polymerase II, holoenzyme. Contains cyclin T and a cyclin-dependent protein kinase catalytic subunit."^^xsd:string,
+ rdfs:comment "See also the cellular component terms 'cyclin-dependent protein kinase activating kinase holoenzyme complex ; GO:0019907' and 'DNA-directed RNA polymerase II, holoenzyme ; GO:0016591'."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0008024"^^xsd:string,
+ rdfs:label "positive transcription elongation factor complex b"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:7759473"^^xsd:string
+ oboInOwl:hasExactSynonym "P-TEFb"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032806,
+ obo:GO_0008023
+
+
+Class: obo:GO_0042566
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0042566"^^xsd:string,
+ rdfs:label "hydrogenosome"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Hydrogenosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11197234"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11293569"^^xsd:string
+ obo:IAO_0000115 "A spherical, membrane-bounded organelle found in some anaerobic protozoa, which participates in ATP and molecular hydrogen formation."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043231,
+ obo:GO_0044444
+
+
+Class: obo:GO_0034674
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alpha5-beta1 integrin complex"^^xsd:string,
+ oboInOwl:id "GO:0034674"^^xsd:string,
+ oboInOwl:hasExactSynonym "VLA-5 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alpha5 subunit and one beta1 subunit."^^xsd:string,
+ oboInOwl:hasNarrowSynonym "ITGA5-ITGB1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0042565
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "RNA nuclear export complex"^^xsd:string,
+ oboInOwl:id "GO:0042565"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9323123"^^xsd:string
+ obo:IAO_0000115 "A complex which usually consists of three components, e.g. in Xenopus and yeast, the export receptor CRM1 (also known as exportin 1), the Ran protein and any RNA with a nuclear export sequence (NES). The complex acts to export RNA molecules with a NES from the nucleus through a nuclear pore."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031074
+
+
+Class: obo:GO_0034675
+
+ Annotations:
+ rdfs:label "alpha6-beta1 integrin complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2413"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA6-ITGB1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:2649503"^^xsd:string
+ oboInOwl:hasExactSynonym "VLA-6 complex"^^xsd:string,
+ oboInOwl:id "GO:0034675"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alpha6 subunit and one beta1 subunit."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0034669
+
+ Annotations:
+ rdfs:label "alpha4-beta7 integrin complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "ITGA4-ITGB7 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alpha4 subunit and one beta7 subunit."^^xsd:string,
+ oboInOwl:id "GO:0034669"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0042575
+
+ Annotations:
+ rdfs:label "DNA polymerase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12045093"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses DNA polymerase activity and is involved in template directed synthesis of DNA."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0042575"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0034668
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alpha4 subunit and one beta1 subunit."^^xsd:string,
+ rdfs:label "alpha4-beta1 integrin complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "VLA-4 complex"^^xsd:string,
+ oboInOwl:id "GO:0034668"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "ITGA4-ITGB1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0034667
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alpha3 subunit and one beta1 subunit."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2406"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA3-ITGB1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:3546305"^^xsd:string
+ oboInOwl:hasExactSynonym "VLA-3 complex"^^xsd:string,
+ rdfs:label "alpha3-beta1 integrin complex"^^xsd:string,
+ oboInOwl:id "GO:0034667"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0042571
+
+ Annotations:
+ rdfs:label "immunoglobulin complex, circulating"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Antibody"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042571"^^xsd:string,
+ rdfs:comment "Note that an immunoglobulin complex has the function of antigen binding if a suitable antigen is available."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0781735149"^^xsd:string
+ obo:IAO_0000115 "An immunoglobulin complex that is secreted into extracellular space and found in mucosal areas or other tissues or circulating in the blood or lymph. In its canonical form, a circulating immunoglobulin complex is composed of two identical heavy chains and two identical light chains, held together by disulfide bonds. Some forms of are polymers of the basic structure and contain additional components such as J-chain and the secretory component."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasExactSynonym "antibody"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421,
+ obo:BFO_0000050 some obo:GO_0005615,
+ obo:GO_0019814
+
+
+Class: obo:GO_0018995
+
+ Annotations:
+ oboInOwl:id "GO:0018995"^^xsd:string,
+ oboInOwl:hasExactSynonym "host organism"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "Any organism in which another organism, especially a parasite or symbiont, spends part or all of its life cycle and from which it obtains nourishment and/or protection."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Host_(biology)"^^xsd:string,
+ rdfs:label "host"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044215
+
+
+Class: obo:GO_0070685
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:pf"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9044041"^^xsd:string
+ oboInOwl:hasExactSynonym "crown"^^xsd:string,
+ oboInOwl:id "GO:0070685"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12538772"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16968738"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9044041"^^xsd:string
+ obo:IAO_0000115 "A cell projection that forms at the site of macropinocytosis, a form of endocytosis that results in the uptake of relatively large amounts of extracellular fluid. The macropinocytic cup membrane selectively excludes certain proteins, such as H36 or PM4C4 in Dictyostelium, and the underlying cytoskeleton is enriched in F-actin and coronin."^^xsd:string,
+ rdfs:label "macropinocytic cup"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042995
+
+
+Class: obo:GO_0000333
+
+ Annotations:
+ oboInOwl:id "GO:0000333"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "telomerase catalytic core complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11884619"^^xsd:string
+ obo:IAO_0000115 "The minimal catalytic core of telomerase is a ribonucleoprotein complex composed of a catalytic reverse transcriptase subunit and an RNA subunit that provides the template for telomeric DNA addition."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005697
+
+
+Class: obo:GO_0070686
+
+ Annotations:
+ oboInOwl:id "GO:0070686"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "macropinocytic cup membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The portion of the plasma membrane surrounding a macropinocytic cup."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "crown membrane"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0070685,
+ obo:GO_0031253
+
+
+Class: obo:GO_0070687
+
+ Annotations:
+ rdfs:label "macropinocytic cup cytoskeleton"^^xsd:string,
+ oboInOwl:id "GO:0070687"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The part of the cortical actin cytoskeleton that forms part of a macropinocytic cup."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "crown cytoskeleton"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0070685,
+ obo:GO_0044463,
+ obo:BFO_0000050 some obo:GO_0030864,
+ obo:GO_0044430,
+ obo:GO_0044448
+
+
+Class: obo:GO_0070688
+
+ Annotations:
+ oboInOwl:id "GO:0070688"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19377461"^^xsd:string
+ obo:IAO_0000115 "A protein complex that can methylate lysine-4 of histone H3 and plays an essential role in retinoic-acid-induced granulopoiesis. MLL5 is the catalytic methyltransferase subunit, and the complex also contains serine/threonine kinase 38 (STK38), protein phosphatase 1 catalytic subunits, the host cell factor-1 N-terminal subunit, beta-actin, and O-GlcNAc transferase; the human genes encoding the subunits are MLL5, STK38, PPP1CA, PPP1CB, PPP1CC, HCFC1, ACTB and OGT, respectively."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "MLL5-L complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0035097
+
+
+Class: obo:GO_0000331
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000331"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10503189"^^xsd:string
+ obo:IAO_0000115 "A specialized vacuole of eukaryotic cells, especially Protozoa, that fills with water from the cytoplasm and then discharges this externally by the opening of contractile vacuole pores. Its function is probably osmoregulatory."^^xsd:string,
+ rdfs:label "contractile vacuole"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Contractile_vacuole"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005773,
+ obo:GO_0016023
+
+
+Class: obo:GO_0030446
+
+ Annotations:
+ rdfs:label "hyphal cell wall"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "See also the Fungal Anatomy Ontology term 'hypha ; FAO:0001001'."^^xsd:string,
+ oboInOwl:id "GO:0030446"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The cell wall surrounding a fungal hypha."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009277
+
+
+Class: obo:GO_0070578
+
+ Annotations:
+ rdfs:label "RISC-loading complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string
+ oboInOwl:hasExactSynonym "miRLC"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasRelatedSynonym "RLC"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070578"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18178619"^^xsd:string
+ obo:IAO_0000115 "A trimeric ribonucleoprotein complex that and is required for the formation of a mature RNA induced silencing complex (RISC). In humans the complex is composed of the endonuclease Dicer (DICER1) and TRBP (TARBP2) in association with the Argonaute protein Ago2 (EIF2C2/AGO2). Within the complex, Dicer and TRBP are required to process precursor miRNAs (pre-miRNAs) to mature miRNAs and then load them onto Ago2. Ago2 bound to the mature miRNA constitutes the minimal RISC and may subsequently dissociate from Dicer and TRBP."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string
+ oboInOwl:hasExactSynonym "microRNA loading complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030529
+
+
+Class: obo:GO_0000330
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed within the vacuolar membrane of a vacuole that retains the same shape regardless of cell cycle phase. An example of this is found in Arabidopsis thaliana."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000330"^^xsd:string,
+ oboInOwl:hasExactSynonym "lumen of vacuole with cell cycle-independent morphology"^^xsd:string,
+ rdfs:label "plant-type vacuole lumen"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005775,
+ obo:BFO_0000050 some obo:GO_0000325
+
+
+Class: obo:GO_0030445
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mcc"^^xsd:string
+ obo:IAO_0000115 "The wall surrounding a cell of a dimorphic fungus growing in the single-cell budding yeast form, in contrast to the filamentous or hyphal form."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "See also the Fungal Anatomy Ontology term 'vegetative cell ; FAO:0000032'."^^xsd:string,
+ rdfs:label "yeast-form cell wall"^^xsd:string,
+ oboInOwl:id "GO:0030445"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009277
+
+
+Class: obo:GO_0034680
+
+ Annotations:
+ rdfs:label "alpha10-beta1 integrin complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alpha10 subunit and one beta1 subunit."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3057"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA10-ITGB1 complex"^^xsd:string,
+ oboInOwl:id "GO:0034680"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0034681
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3058"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA11-ITGB1 complex"^^xsd:string,
+ oboInOwl:id "GO:0034681"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alpha11-beta1 integrin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alpha11 subunit and one beta1 subunit."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0034682
+
+ Annotations:
+ oboInOwl:id "GO:0034682"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alphav subunit and one beta1 subunit."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2436"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB1 complex"^^xsd:string,
+ rdfs:label "alphav-beta1 integrin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0034683
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alphav subunit and one beta3 subunit."^^xsd:string,
+ oboInOwl:id "GO:0034683"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alphav-beta3 integrin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2816"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB3 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0034684
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alphav subunit and one beta5 subunit."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0034684"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2350"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB5 complex"^^xsd:string,
+ rdfs:label "alphav-beta5 integrin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0017177
+
+ Annotations:
+ rdfs:comment "Note that alpha-glucosidase I functions as a monomer, and therefore does not have a corresponding cellular component term."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:19605557"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ oboInOwl:hasRelatedSynonym "alpha-glucosidase II complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0017177"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10464333"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8910335"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric complex that catalyzes the trimming of glucose residues from N-linked core glycans on newly synthesized glycoproteins."^^xsd:string,
+ rdfs:label "glucosidase II complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044432,
+ obo:GO_0043234
+
+
+Class: obo:GO_0034685
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2354"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB6 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0034685"^^xsd:string,
+ rdfs:label "alphav-beta6 integrin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alphav subunit and one beta6 subunit."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0034686
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alphav subunit and one beta8 subunit."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0034686"^^xsd:string,
+ rdfs:label "alphav-beta8 integrin complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB8 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0034687
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0034687"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alphaL subunit and one beta2 subunit."^^xsd:string,
+ rdfs:label "alphaL-beta2 integrin complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Itgal-Itgb2 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0042579
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "Cytoplasmic organelles, spherical or oval in shape, that are bounded by a single membrane and contain oxidative enzymes, especially those utilizing hydrogen peroxide (H2O2)."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Microbody"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "microbody"^^xsd:string,
+ oboInOwl:id "GO:0042579"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043231,
+ obo:GO_0044444
+
+
+Class: obo:GO_0034688
+
+ Annotations:
+ rdfs:label "alphaM-beta2 integrin complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Itgam-Itgb2 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alphaM subunit and one beta2 subunit."^^xsd:string,
+ oboInOwl:id "GO:0034688"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0042583
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19158310"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:1961743"^^xsd:string
+ obo:IAO_0000115 "Specialized secretory vesicle found in the cells of adrenal glands and various other organs, which is concerned with the synthesis, storage, metabolism, and secretion of epinephrine and norepinephrine."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042583"^^xsd:string,
+ rdfs:label "chromaffin granule"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030141
+
+
+Class: obo:GO_0034679
+
+ Annotations:
+ oboInOwl:hasNarrowSynonym "ITGA9-ITGB1 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alpha9-beta1 integrin complex"^^xsd:string,
+ oboInOwl:id "GO:0034679"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alpha9 subunit and one beta1 subunit."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0042584
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding a chromaffin granule, a specialized secretory vesicle found in the cells of adrenal glands and various other organs, which is concerned with the synthesis, storage, metabolism, and secretion of epinephrine and norepinephrine."^^xsd:string,
+ oboInOwl:id "GO:0042584"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "chromaffin granule membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030667,
+ obo:BFO_0000050 some obo:GO_0042583
+
+
+Class: obo:GO_0034678
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2439"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA8-ITGB1 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alpha8-beta1 integrin complex"^^xsd:string,
+ oboInOwl:id "GO:0034678"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alpha8 subunit and one beta1 subunit."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0010319
+
+ Annotations:
+ oboInOwl:hasRelatedSynonym "Stroma-filled tubule"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Stromule"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "stromule"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15272881"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15699062"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16582010"^^xsd:string
+ obo:IAO_0000115 "Thin filamentous structure extending from the surface of all plastid types examined so far, including chloroplast, proplastid, etioplast, leucoplast, amyloplast, and chromoplast. In general, stromules are more abundant in tissues containing non-green plastids, and in cells containing smaller plastids. The primary function of stromules is still unresolved, although the presence of stromules markedly increases the plastid surface area, potentially increasing transport to and from the cytosol. Other functions of stromules, such as transfer of macromolecules between plastids and starch granule formation in cereal endosperm, may be restricted to particular tissues and cell types."^^xsd:string,
+ oboInOwl:id "GO:0010319"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:BFO_0000050 some obo:GO_0009526
+
+
+Class: obo:GO_0042585
+
+ Annotations:
+ oboInOwl:id "GO:0042585"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "germinal vesicle"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19019837"^^xsd:string
+ obo:IAO_0000115 "The enlarged, fluid filled nucleus of a primary oocyte, the development of which is suspended in prophase I of the first meiotic division between embryohood and sexual maturity."^^xsd:string,
+ oboInOwl:hasExactSynonym "primary oocyte nucleus"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0001674
+
+
+Class: obo:GO_0010318
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:2170409"^^xsd:string
+ obo:IAO_0000115 "Refers to the beta subunit of the heterodimeric complex that possesses pyrophosphate-dependent phosphofructokinase activity."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0010318"^^xsd:string,
+ rdfs:label "pyrophosphate-dependent phosphofructokinase complex, beta-subunit complex"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "PFK complex, beta-subunit"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0010316,
+ obo:GO_0043234
+
+
+Class: obo:GO_0010317
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:2170409"^^xsd:string
+ obo:IAO_0000115 "Refers to the alpha subunit of the heterodimeric complex that possesses pyrophosphate-dependent phosphofructokinase activity."^^xsd:string,
+ rdfs:label "pyrophosphate-dependent phosphofructokinase complex, alpha-subunit complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0010317"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "PFK complex, alpha-subunit"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0010316,
+ obo:GO_0043234
+
+
+Class: obo:GO_0034271
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11157979"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16421251"^^xsd:string
+ obo:IAO_0000115 "A protein complex that posseses phosphatidylinositol 3-kinase activity and is involved in autophagy. In budding yeast, this complex consists of Vps30p, Vps34p, Atg14p and Vps15p."^^xsd:string,
+ rdfs:label "phosphatidylinositol 3-kinase complex I"^^xsd:string,
+ oboInOwl:hasExactSynonym "PtdIns-3-kinase complex I"^^xsd:string,
+ oboInOwl:id "GO:0034271"^^xsd:string,
+ rdfs:comment "Note that this term should not be confused with '1-phosphatidylinositol-4-phosphate 3-kinase, class IA complex; GO:0005943' or '1-phosphatidylinositol-4-phosphate 3-kinase, class IB complex ; GO:0005944'."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005942
+
+
+Class: obo:GO_0010316
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:2170409"^^xsd:string
+ obo:IAO_0000115 "Heterodimeric complex that catalyzes the pyrophosphate-dependent phosphorylation of D-fructose 6-phosphate into D-fructose 1,6-bisphosphate."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "PFK complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "pyrophosphate-dependent phosphofructokinase complex"^^xsd:string,
+ oboInOwl:id "GO:0010316"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0042580
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11912051"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9799531"^^xsd:string
+ obo:IAO_0000115 "A specialised tubular organelle, assembled in hexagonal bundles within an external membrane. Mannosomes are specific to molluscs and are thought to be involved in a general stress reaction."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "mannosome"^^xsd:string,
+ oboInOwl:id "GO:0042580"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005777
+
+
+Class: obo:GO_0034270
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "CVT complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15659643"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is involved in the CVT pathway. In budding yeast, the CVT complex consists of multimers of preApe1p."^^xsd:string,
+ oboInOwl:id "GO:0034270"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444,
+ obo:GO_0043234
+
+
+Class: obo:GO_0042581
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042581"^^xsd:string,
+ rdfs:label "specific granule"^^xsd:string,
+ oboInOwl:hasExactSynonym "secondary granule"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Specific_granule"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0721662544"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7334549"^^xsd:string
+ obo:IAO_0000115 "Granule with a membranous, tubular internal structure, found primarily in mature neutrophil cells. Most are released into the extracellular fluid. Specific granules contain lactoferrin, lysozyme, vitamin B12 binding protein and elastase."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030141
+
+
+Class: obo:GO_0034273
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "Atg1p signalling complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15743910"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains a protein kinase and is required for the autophagosome formation. In budding yeast this complex consists of the kinase Atg1p, Atg13p and Atg17p."^^xsd:string,
+ oboInOwl:id "GO:0034273"^^xsd:string,
+ rdfs:label "Atg1p signaling complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0042582
+
+ Annotations:
+ oboInOwl:hasExactSynonym "primary granule"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17152095"^^xsd:string
+ obo:IAO_0000115 "Primary lysosomal granule found in neutrophil granulocytes. Contains a wide range of hydrolytic enzymes and is released into the extracellular fluid."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042582"^^xsd:string,
+ rdfs:label "azurophil granule"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030141,
+ obo:GO_0005766
+
+
+Class: obo:GO_0034272
+
+ Annotations:
+ rdfs:label "phosphatidylinositol 3-kinase complex II"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "PtdIns-3-kinase complex II"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11157979"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16421251"^^xsd:string
+ obo:IAO_0000115 "A protein complex that posseses phosphatidylinositol 3-kinase activity and is involved in vacuolar protein sorting (VPS) via endosomes. In budding yeast, this complex consists of Vps30p, Vps34p, VPS38 and Vps15p."^^xsd:string,
+ oboInOwl:id "GO:0034272"^^xsd:string,
+ rdfs:comment "Note that this term should not be confused with '1-phosphatidylinositol-4-phosphate 3-kinase, class IA complex; GO:0005943' or '1-phosphatidylinositol-4-phosphate 3-kinase, class IB complex ; GO:0005944'."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005942
+
+
+Class: obo:GO_0000346
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11979277"^^xsd:string
+ obo:IAO_0000115 "The transcription export (TREX) complex couples transcription elongation by RNA polymerase II to mRNA export. The complex associates with the polymerase and travels with it along the length of the transcribed gene. TREX is composed of the THO transcription elongation complex as well as other proteins that couple THO to mRNA export proteins. The TREX complex is known to be found in a wide range of eukaryotes, including S. cerevisiae and metazoans."^^xsd:string,
+ oboInOwl:id "GO:0000346"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "TREX complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "transcription export complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0034274
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0034274"^^xsd:string,
+ rdfs:label "Atg12-Atg5-Atg16 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17986448"^^xsd:string
+ obo:IAO_0000115 "A protein complex required for the expansion of the autophagosomal membrane. In budding yeast, this complex consists of Atg12p, Atg5p and Atg16p."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444,
+ obo:GO_0043234
+
+
+Class: obo:GO_0000345
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0000345"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11158566"^^xsd:string
+ obo:IAO_0000115 "The eubacterial DNA-directed RNA polymerase is a multisubunit complex with a core composed of the essential subunits beta-prime, beta, and two copies of alpha and a fifth nonessential subunit called omega. An additional subunit, a sigma factor, is required for promoter recognition and specificity."^^xsd:string,
+ rdfs:label "cytosolic DNA-directed RNA polymerase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000428,
+ obo:GO_0044445
+
+
+Class: obo:GO_0000344
+
+ Annotations:
+ oboInOwl:id "GO:0000344"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10946105"^^xsd:string
+ obo:IAO_0000115 "A plastid-encoded DNA-directed RNA polymerase complex that resembles eubacterial multisubunit RNA polymerases with a core composed of alpha, beta, and beta-prime subunits. An additional subunit, a sigma factor, is required for promoter recognition. PEP-B is distinguished from PEP-A by its sensitivity to the antibiotic rifampicin. PEP-B is found in both etioplasts and chloroplasts, but is the predominate form in etioplasts. It forms the core of the PEP-A form; the conversion from PEP-B to PEP-A occurs during chloroplast maturation."^^xsd:string,
+ oboInOwl:hasExactSynonym "PEP-B"^^xsd:string,
+ rdfs:label "plastid-encoded plastid RNA polymerase complex B"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000427
+
+
+Class: obo:GO_0000343
+
+ Annotations:
+ oboInOwl:id "GO:0000343"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "PEP-A"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10946105"^^xsd:string
+ obo:IAO_0000115 "A plastid-encoded DNA-directed RNA polymerase complex that resembles eubacterial multisubunit RNA polymerases, with a core composed of alpha, beta, and beta-prime subunits. An additional subunit, a sigma factor, is required for promoter recognition. PEP-A is generated from the PEP-B form during chloroplast maturation to generate a complex composed of at least thirteen polypeptides that is not sensitive to the antibiotic rifampicin, like its precursor form the PEP-B complex."^^xsd:string,
+ rdfs:label "plastid-encoded plastid RNA polymerase complex A"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000427
+
+
+Class: obo:GO_0070695
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that the gene/protein name 'APC' should not be confused with the abbreviation for 'anaphase promoting complex'."^^xsd:string,
+ rdfs:label "FHF complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18799622"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is composed of AKTIP/FTS, FAM160A2/p107FHIP, and one or more members of the Hook family of proteins, HOOK1, HOOK2, and HOOK3. The complex is thought to promote vesicle trafficking and/or fusion, and associates with the homotypic vesicular sorting complex (the HOPS complex)."^^xsd:string,
+ oboInOwl:id "GO:0070695"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0070692
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:16721054"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19328067"^^xsd:string
+ oboInOwl:hasNarrowSynonym "CTDK-I complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "trimeric positive transcription elongation factor complex b"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16721054"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Ctk complex"^^xsd:string,
+ oboInOwl:id "GO:0070692"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16721054"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19328067"^^xsd:string
+ obo:IAO_0000115 "A positive transcription elongation factor complex b that comprises three subunits; an example is the budding yeast Ctk complex, which consists of Ctk1p, Ctk2p and Ctk3p."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008024
+
+
+Class: obo:GO_0033675
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "pericanalicular vesicle"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15763347"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9790571"^^xsd:string
+ obo:IAO_0000115 "A membrane-bounded vesicle found near the apical, or pericanalicular, membrane of a hepatocyte; contains proteins involved in bile salt transport and other fluid and solute transport processes."^^xsd:string,
+ oboInOwl:id "GO:0033675"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016023
+
+
+Class: obo:GO_0070693
+
+ Annotations:
+ rdfs:label "P-TEFb-cap methyltransferase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ oboInOwl:hasNarrowSynonym "P-TEFb-Pcm1 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Cdk9-Pcm1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:17332744"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19328067"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is formed by the association of positive transcription elongation factor complex b (P-TEFb) with the mRNA capping methyltransferase."^^xsd:string,
+ oboInOwl:id "GO:0070693"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070565
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:pde"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19179534"^^xsd:string
+ obo:IAO_0000115 "A complex of DNA and protein located at the end of a linear chromosome that enables replication of the telomeric repeat sequences at the end of a linear chromosome."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "telomere-telomerase complex"^^xsd:string,
+ oboInOwl:id "GO:0070565"^^xsd:string,
+ rdfs:comment "Note that this term can be used in place of the obsolete cellular component term 'telomere ; GO:0005696'. Use with caution because this term refers to a specific protein complex and not a region of the chromosome."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:BFO_0000050 some obo:GO_0000781,
+ obo:GO_0032993
+
+
+Class: obo:GO_0042175
+
+ Annotations:
+ oboInOwl:id "GO:0042175"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "nuclear membrane-endoplasmic reticulum continuum"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "NE-ER continuum"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "nuclear envelope-endoplasmic reticulum continuum"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasRelatedSynonym "nuclear envelope-endoplasmic reticulum network"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mcc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pr"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ obo:IAO_0000115 "The continuous network of membranes encompassing the nuclear outer membrane and the endoplasmic reticulum membrane."^^xsd:string,
+ oboInOwl:hasRelatedSynonym "nuclear envelope-ER network"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "NE-ER network"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "nuclear membrane-ER network"^^xsd:string,
+ rdfs:label "nuclear outer membrane-endoplasmic reticulum membrane network"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016020,
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0012505
+
+
+Class: obo:GO_0000347
+
+ Annotations:
+ rdfs:label "THO complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11060033"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11979277"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16983072"^^xsd:string
+ obo:IAO_0000115 "The THO complex is a nuclear complex that is required for transcription elongation through genes containing tandemly repeated DNA sequences. The THO complex is also part of the TREX (TRanscription EXport) complex that is involved in coupling transcription to export of mRNAs to the cytoplasm. In S. cerevisiae, it is composed of four subunits: Hpr1p, Tho2p, Thp1p, and Mft1p, while the human complex is composed of 7 subunits."^^xsd:string,
+ oboInOwl:id "GO:0000347"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0045495
+
+ Annotations:
+ oboInOwl:hasNarrowSynonym "germ plasm"^^xsd:string,
+ oboInOwl:id "GO:0045495"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "pole plasm"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:kmv"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17113380"^^xsd:string
+ obo:IAO_0000115 "Differentiated cytoplasm associated with a pole (animal, vegetal, anterior, or posterior) of an oocyte, egg or early embryo."^^xsd:string,
+ oboInOwl:hasExactSynonym "polar plasm"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005737
+
+
+Class: obo:GO_0008043
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0008043"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19154717"^^xsd:string
+ obo:IAO_0000115 "A ferritin complex located in the cell. Intracellular ferritin complexes contain 24 subunits, in a mixture of L (light) chains and H (heavy) chains."^^xsd:string,
+ rdfs:label "intracellular ferritin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0070288
+
+
+Class: obo:GO_0042170
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "plastid membrane"^^xsd:string,
+ oboInOwl:id "GO:0042170"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Either of the lipid bilayers that surround a plastid and form the plastid envelope."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:GO_0031090,
+ obo:BFO_0000050 some obo:GO_0009526
+
+
+Class: obo:GO_0001411
+
+ Annotations:
+ oboInOwl:id "GO:0001411"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "hyphal tip"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mcc"^^xsd:string
+ obo:IAO_0000115 "The end, or tip, of a fungal hypha, where polarized growth occurs during hyphal elongation."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030427
+
+
+Class: obo:GO_0001405
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mcc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14517234"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14638855"^^xsd:string
+ obo:IAO_0000115 "Protein complex located on the matrix side of the mitochondrial inner membrane and associated with the presequence translocase complex; hydrolyzes ATP to provide the force to drive import of proteins into the mitochondrial matrix."^^xsd:string,
+ oboInOwl:hasExactSynonym "pre-sequence translocase-associated import motor"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "PAM complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "mitochondrial import motor"^^xsd:string,
+ rdfs:label "presequence translocase-associated import motor"^^xsd:string,
+ oboInOwl:id "GO:0001405"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044455,
+ obo:BFO_0000050 some obo:GO_0005744,
+ obo:GO_0043234
+
+
+Class: obo:GO_0034646
+
+ Annotations:
+ oboInOwl:id "GO:0034646"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A lipid monolayer that surrounds and encloses an organelle."^^xsd:string,
+ rdfs:label "organelle-enclosing lipid monolayer"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044446
+
+
+Class: obo:GO_0035796
+
+ Annotations:
+ oboInOwl:id "GO:0035796"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string
+ oboInOwl:hasExactSynonym "ATP-binding cassette (ABC) transporter complex, ECF-type"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:21135102"^^xsd:string
+ oboInOwl:hasExactSynonym "energy coupling factor (ECF)-type ABC transporter"^^xsd:string,
+ rdfs:comment "The ECF-type transporters differs from other types of ABC transporters because the substrate-binding subunit lies integral to the membrane."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:18931129"^^xsd:string
+ oboInOwl:hasExactSynonym "energy-coupling factor transporter"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:18931129"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20972419"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:21135102"^^xsd:string
+ obo:IAO_0000115 "A complex for the transport of metabolites into the cell, consisting of 4 subunits: a transmembrane substrate-binding protein (known as the S component), and an energy-coupling module that comprises two ATP-binding proteins (known as the A and A' components) and a transmembrane protein (known as the T component). Transport of the substrate across the membrane is driven by the hydrolysis of ATP."^^xsd:string,
+ rdfs:label "ATP-binding cassette (ABC) transporter complex, transmembrane substrate-binding subunit-containing"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043190
+
+
+Class: obo:GO_0033643
+
+ Annotations:
+ oboInOwl:inSubset ,
+ rdfs:label "host cell part"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0033643"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pamgo_curators"^^xsd:string
+ obo:IAO_0000115 "Any constituent part of a host cell. The host is defined as the larger of the organisms involved in a symbiotic interaction."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005575
+ and (obo:BFO_0000050 some obo:GO_0043657)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0043657,
+ obo:GO_0044217
+
+
+Class: obo:GO_0035792
+
+ Annotations:
+ rdfs:label "other organism postsynaptic membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ecd"^^xsd:string
+ obo:IAO_0000115 "A postsynaptic membrane that is part of another organism, i.e. a secondary organism with which the first organism is interacting. A postsynaptic membrane is a specialized area of membrane facing the presynaptic membrane on the tip of the nerve ending and separated from it by a minute cleft (the synaptic cleft). Neurotransmitters transmit the signal across the synaptic cleft to the postsynaptic membrane."^^xsd:string,
+ oboInOwl:id "GO:0035792"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044218
+
+
+Class: obo:GO_0043591
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ oboInOwl:hasBroadSynonym "spore wall"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ oboInOwl:hasExactSynonym "peptidoglycan-based spore wall"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "endospore wall"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0043591"^^xsd:string,
+ rdfs:label "endospore external encapsulating structure"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0055030"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:go_curators"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15035041"^^xsd:string
+ obo:IAO_0000115 "The structures that lie outside the inner membrane and surround the entire endospore; consists of a peptidoglycan-containing inner layer (the endospore cortex) surrounded by a multilayered proteinaceous coat. An exosporium may be present as an extreme outer layer."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031160
+
+
+Class: obo:GO_0043592
+
+ Annotations:
+ oboInOwl:inSubset ,
+ rdfs:label "exosporium"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "exospore"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "epispore"^^xsd:string,
+ oboInOwl:id "GO:0043592"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "perispore"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mlg"^^xsd:string
+ obo:IAO_0000115 "The outermost layer of a bacterial endospore, which is loosely attached and located outside of the endospore coat. It is generally composed of protein, carbohydrate, and perhaps lipid."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044426,
+ obo:BFO_0000050 some obo:GO_0043591
+
+
+Class: obo:GO_0033648
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0033648"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pamgo_curators"^^xsd:string
+ obo:IAO_0000115 "Organized structure of distinctive morphology and function, as found in host cells, bounded by a single or double lipid bilayer membrane and occurring within the cell. Includes the nucleus, mitochondria, plastids, vacuoles, and vesicles. Excludes the plasma membrane. The host is defined as the larger of the organisms involved in a symbiotic interaction."^^xsd:string,
+ oboInOwl:hasExactSynonym "host intracellular membrane-enclosed organelle"^^xsd:string,
+ rdfs:label "host intracellular membrane-bounded organelle"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033647
+
+
+Class: obo:GO_0043593
+
+ Annotations:
+ rdfs:label "endospore coat"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mlg"^^xsd:string
+ obo:IAO_0000115 "The layer in a bacterial endospore that lies under the exosporium, and is impermeable to many toxic molecules. The coat may also contain enzymes that are involved in endospore germination."^^xsd:string,
+ oboInOwl:id "GO:0043593"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044426,
+ obo:BFO_0000050 some obo:GO_0043591
+
+
+Class: obo:GO_0043594
+
+ Annotations:
+ oboInOwl:inSubset ,
+ rdfs:label "outer endospore membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0043594"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mlg"^^xsd:string
+ obo:IAO_0000115 "The outer membrane around a bacterial endospore, located between the endospore cortex and endospore coat."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0019867
+ and (obo:BFO_0000050 some obo:GO_0043591)
+
+ SubClassOf:
+ obo:GO_0019867,
+ obo:GO_0044426,
+ obo:BFO_0000050 some obo:GO_0043591
+
+
+Class: obo:GO_0043595
+
+ Annotations:
+ oboInOwl:inSubset ,
+ rdfs:label "endospore cortex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0043595"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mlg"^^xsd:string
+ obo:IAO_0000115 "A layer surrounding a bacterial endospore found inside the outer endospore membrane, but outside the membrane surrounding the endospore core. It consists of peptidoglycan of a different chemical nature than that found in vegetative cell walls which results in less cross-linking of peptidoglycan."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044426,
+ obo:BFO_0000050 some obo:GO_0043591
+
+
+Class: obo:GO_0033645
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0033645"^^xsd:string,
+ rdfs:label "host cell endomembrane system"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pamgo_curators"^^xsd:string
+ obo:IAO_0000115 "A collection of membranous structures involved in transport within the host cell. The main components of the endomembrane system are endoplasmic reticulum, Golgi bodies, vesicles, cell membrane and nuclear envelope. Members of the endomembrane system pass materials through each other or though the use of vesicles. The host is defined as the larger of the organisms involved in a symbiotic interaction."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033644
+
+
+Class: obo:GO_0030485
+
+ Annotations:
+ oboInOwl:hasExactSynonym "smooth muscle fibre"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "smooth muscle contractile fiber"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The contractile fiber of smooth muscle cells."^^xsd:string,
+ oboInOwl:hasBroadSynonym "smooth muscle fiber"^^xsd:string,
+ oboInOwl:id "GO:0030485"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043292,
+ obo:GO_0044449
+
+
+Class: obo:GO_0043596
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "The Y-shaped region of a nuclear replicating DNA molecule, resulting from the separation of the DNA strands and in which the synthesis of new strands takes place. Also includes associated protein complexes."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "nuclear replication fork"^^xsd:string,
+ oboInOwl:id "GO:0043596"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005657
+ and (obo:BFO_0000050 some obo:GO_0005634)
+
+ SubClassOf:
+ obo:BFO_0000051 some obo:GO_0071162,
+ obo:GO_0044454,
+ obo:GO_0005657
+
+
+Class: obo:GO_0033644
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "host cell membrane"^^xsd:string,
+ oboInOwl:id "GO:0033644"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pamgo_curators"^^xsd:string
+ obo:IAO_0000115 "Double layer of lipid molecules as it encloses host cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins. The host is defined as the larger of the organisms involved in a symbiotic interaction."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044218,
+ obo:GO_0033643
+
+
+Class: obo:GO_0030486
+
+ Annotations:
+ rdfs:label "smooth muscle dense body"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "Electron-dense region associated with a smooth muscle contractile fiber."^^xsd:string,
+ oboInOwl:id "GO:0030486"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044449,
+ obo:BFO_0000050 some obo:GO_0030485
+
+
+Class: obo:GO_0043597
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "The Y-shaped region of a cytoplasmic replicating DNA molecule, resulting from the separation of the DNA strands and in which the synthesis of new strands takes place. Also includes associated protein complexes."^^xsd:string,
+ rdfs:label "cytoplasmic replication fork"^^xsd:string,
+ oboInOwl:id "GO:0043597"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005657
+ and (obo:BFO_0000050 some obo:GO_0005737)
+
+ SubClassOf:
+ obo:GO_0005657,
+ obo:BFO_0000050 some obo:GO_0000229,
+ obo:GO_0044444
+
+
+Class: obo:GO_0033647
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:pamgo_curators"^^xsd:string
+ obo:IAO_0000115 "Organized structure of distinctive morphology and function, occurring within the host cell. Includes the nucleus, mitochondria, plastids, vacuoles, vesicles, ribosomes and the cytoskeleton. Excludes the plasma membrane. The host is defined as the larger of the organisms involved in a symbiotic interaction."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0033647"^^xsd:string,
+ rdfs:label "host intracellular organelle"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033646
+
+
+Class: obo:GO_0043598
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0043598"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14646196"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16172520"^^xsd:string
+ obo:IAO_0000115 "A cytoplasmic complex of two polypeptides that loads the DNA polymerase processivity factor proliferating cell nuclear antigen (PCNA) onto DNA, thereby permitting processive DNA synthesis catalyzed by DNA polymerase. Examples of this component are found in prokaryotic species."^^xsd:string,
+ rdfs:label "cytoplasmic DNA replication factor C complex"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005663
+ and (obo:BFO_0000050 some obo:GO_0005737)
+
+ SubClassOf:
+ obo:GO_0005663,
+ obo:BFO_0000050 some obo:GO_0043600,
+ obo:GO_0044444
+
+
+Class: obo:GO_0033646
+
+ Annotations:
+ oboInOwl:hasExactSynonym "host cell intracellular part"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0033646"^^xsd:string,
+ rdfs:label "host intracellular part"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pamgo_curators"^^xsd:string
+ obo:IAO_0000115 "Any constituent part of the living contents of a host cell; the matter contained within (but not including) the plasma membrane, usually taken to exclude large vacuoles and masses of secretory or ingested material. In eukaryotes it includes the nucleus and cytoplasm. The host is defined as the larger of the organisms involved in a symbiotic interaction."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0043656,
+ obo:GO_0033643
+
+
+Class: obo:GO_0042555
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11282021"^^xsd:string
+ obo:IAO_0000115 "A hexameric protein complex required for the initiation and regulation of DNA replication."^^xsd:string,
+ rdfs:label "MCM complex"^^xsd:string,
+ oboInOwl:id "GO:0042555"^^xsd:string,
+ oboInOwl:hasExactSynonym "mini-chromosome maintenance complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044451,
+ obo:GO_0044454,
+ obo:GO_0043234
+
+
+Class: obo:GO_0034663
+
+ Annotations:
+ oboInOwl:id "GO:0034663"^^xsd:string,
+ oboInOwl:hasExactSynonym "ER chaperone complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12475965"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is located in the endoplasmic reticulum and is composed of chaperone proteins, including BiP, GRP94; CaBP1, protein disulfide isomerase (PDI), ERdj3, cyclophilin B, ERp72, GRP170, UDP-glucosyltransferase, and SDF2-L1."^^xsd:string,
+ rdfs:label "endoplasmic reticulum chaperone complex"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "endoplasmic reticulum network complex"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "ER network complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044432,
+ obo:GO_0043234
+
+
+Class: obo:GO_0034664
+
+ Annotations:
+ oboInOwl:id "GO:0034664"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "Ig heavy chain-bound ER chaperone complex"^^xsd:string,
+ rdfs:label "Ig heavy chain-bound endoplasmic reticulum chaperone complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12475965"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is located in the endoplasmic reticulum (ER) and is formed by the association of an immunoglobulin heavy chain with the proteins of the ER chaperone complex; the latter include BiP, GRP94; CaBP1, protein disulfide isomerase (PDI), ERdj3, cyclophilin B, ERp72, GRP170, UDP-glucosyltransferase, and SDF2-L1."^^xsd:string,
+ oboInOwl:hasExactSynonym "immunoglobulin heavy chain-bound endoplasmic reticulum chaperone complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044432,
+ obo:GO_0043234
+
+
+Class: obo:GO_0034665
+
+ Annotations:
+ oboInOwl:hasNarrowSynonym "ITGA1-ITGB1 complex"^^xsd:string,
+ oboInOwl:id "GO:0034665"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "VLA-1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alpha1 subunit and one beta1 subunit."^^xsd:string,
+ rdfs:label "alpha1-beta1 integrin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0034666
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0034666"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2432"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA2-ITGB1 complex"^^xsd:string,
+ rdfs:label "alpha2-beta1 integrin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:3546305"^^xsd:string
+ oboInOwl:hasExactSynonym "VLA-2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alpha2 subunit and one beta1 subunit."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0001400
+
+ Annotations:
+ oboInOwl:id "GO:0001400"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "conjugation tube base"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "base of shmoo tip"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mcc"^^xsd:string
+ obo:IAO_0000115 "The region where the mating projection meets the bulk of the cell, in unicellular fungi exposed to mating pheromone."^^xsd:string,
+ rdfs:label "mating projection base"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005937,
+ obo:GO_0044463
+
+
+Class: obo:GO_0043590
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "bacterial nucleoid"^^xsd:string,
+ oboInOwl:id "GO:0043590"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "The region of a bacterial cell to which the DNA is confined."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009295
+
+
+Class: obo:GO_0034662
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16129695"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16798722"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16926444"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains ezrin, Na+/H+ exchanger regulatory factor (NHERF, also called EBP50), and two copies of the cystic fibrosis transmembrane conductance regulator (CFTR). The CFTR molecules interact with NHERF via their cytoplasmic tail domains; the complex is thought to link the CFTR channel to the actin cytoskeleton and contribute to the regulation of channel activity."^^xsd:string,
+ oboInOwl:id "GO:0034662"^^xsd:string,
+ rdfs:label "CFTR-NHERF-ezrin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0001401
+
+ Annotations:
+ rdfs:label "mitochondrial sorting and assembly machinery complex"^^xsd:string,
+ rdfs:comment "See also the cellular component term 'mitochondrial outer membrane translocase complex ; GO:0005742'."^^xsd:string,
+ oboInOwl:id "GO:0001401"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "SAM complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "TOB complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12891361"^^xsd:string
+ obo:IAO_0000115 "A large complex of the mitochondrial outer membrane that mediates sorting of some imported proteins to the outer membrane and their assembly in the membrane; functions after import of incoming proteins by the mitochondrial outer membrane translocase complex."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044455,
+ obo:BFO_0000050 some obo:GO_0005741,
+ obo:GO_0043234
+
+
+Class: obo:GO_0045098
+
+ Annotations:
+ oboInOwl:hasNarrowSynonym "peripherin"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "glial fibrillary acidic protein"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "type III intermediate filament associated protein"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0716731363"^^xsd:string
+ obo:IAO_0000115 "A type of intermediate filament, typically made up of one or more of the proteins vimentin, desmin, glial fibrillary acidic protein (GFAP), and peripherin. Unlike the keratins, the type III proteins can form both homo- and heteropolymeric IF filaments."^^xsd:string,
+ rdfs:label "type III intermediate filament"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "vimentin"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "desmin"^^xsd:string,
+ oboInOwl:id "GO:0045098"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005882
+
+
+Class: obo:GO_0034657
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "GID complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12686616"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18508925"^^xsd:string
+ obo:IAO_0000115 "A protein complex with ubiquitin ligase activity that is involved in proteasomal degradation of fructose-1,6-bisphosphatase (FBPase) and phosphoenolpyruvate carboxykinase during the transition from gluconeogenic to glycolytic growth conditions. In S. cerevisiae, the GID (Glucose Induced degradation Deficient) complex consists of Vid30p, Rmd5p, Vid24p, Vid28p, Gid7p, Gid8p, and Fyv10p."^^xsd:string,
+ oboInOwl:id "GO:0034657"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0042563
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9323123"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9323134"^^xsd:string
+ obo:IAO_0000115 "A protein complex which usually consists of three components, e.g. in Xenopus, the importin alpha-subunit/CAS/Ran, and which functions to shuttle the importin alpha-subunit out of the nucleus through the nuclear pore."^^xsd:string,
+ oboInOwl:id "GO:0042563"^^xsd:string,
+ rdfs:label "importin alpha-subunit nuclear export complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031074
+
+
+Class: obo:GO_0042564
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042564"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9323123"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9323134"^^xsd:string
+ obo:IAO_0000115 "A protein complex which usually consists of three components, e.g. in Xenopus, the importin alpha and beta-subunits and any protein which has a nuclear localization sequence (NLS). The complex acts to import proteins with an NLS into the nucleus through a nuclear pore."^^xsd:string,
+ rdfs:label "NLS-dependent protein nuclear import complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031074
+
+
+Class: obo:GO_0033651
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "host cell plastid"^^xsd:string,
+ oboInOwl:id "GO:0033651"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pamgo_curators"^^xsd:string
+ obo:IAO_0000115 "Any member of a family of organelles as found in the cytoplasm of host cells, which are membrane-bounded and contain DNA. The host is defined as the larger of the organisms involved in a symbiotic interaction."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033648,
+ obo:GO_0033655
+
+
+Class: obo:GO_0030479
+
+ Annotations:
+ oboInOwl:id "GO:0030479"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "actin cortical patch"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0005857"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879693568"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879693649"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16959963"^^xsd:string
+ obo:IAO_0000115 "A discrete actin-containing structure found at the plasma membrane in cells, at sites of endocytosis; formed of networks of branched actin filaments that lie just beneath the plasma membrane and assemble, move, and disassemble rapidly. An example of this is the actin cortical patch found in Saccharomyces cerevisiae."^^xsd:string,
+ oboInOwl:hasExactSynonym "actin patch"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0030864,
+ obo:GO_0044430,
+ obo:GO_0044448
+
+
+Class: obo:GO_0045092
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasExactSynonym "IL-18 receptor complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12759435"^^xsd:string
+ obo:IAO_0000115 "A protein complex that binds interleukin-18; comprises an alpha and a beta subunit."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0045092"^^xsd:string,
+ rdfs:label "interleukin-18 receptor complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005887,
+ obo:GO_0044459,
+ obo:GO_0043235
+
+
+Class: obo:GO_0033652
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pamgo_curators"^^xsd:string
+ obo:IAO_0000115 "A chlorophyll-containing plastid as found within host cells with thylakoids organized into grana and frets, or stroma thylakoids, and embedded in a stroma. The host is defined as the larger of the organisms involved in a symbiotic interaction."^^xsd:string,
+ oboInOwl:id "GO:0033652"^^xsd:string,
+ rdfs:label "host cell chloroplast"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033651
+
+
+Class: obo:GO_0030478
+
+ Annotations:
+ oboInOwl:id "GO:0030478"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0000143"^^xsd:string,
+ rdfs:label "actin cap"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:10652251"^^xsd:string
+ obo:IAO_0000115 "Polarized accumulation of cytoskeletal proteins (including F-actin) and regulatory proteins in a cell. An example of this is the actin cap found in Saccharomyces cerevisiae."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0030864,
+ obo:GO_0044430,
+ obo:GO_0044448
+
+
+Class: obo:GO_0033653
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "host chloroplast component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pamgo_curators"^^xsd:string
+ obo:IAO_0000115 "Any constituent part of a chloroplast as it is found in host cells and which are a chlorophyll-containing plastid with thylakoids organized into grana and frets, or stroma thylakoids, and embedded in a stroma. The host is defined as the larger of the organisms involved in a symbiotic interaction."^^xsd:string,
+ oboInOwl:id "GO:0033653"^^xsd:string,
+ rdfs:label "host cell chloroplast part"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033652
+
+
+Class: obo:GO_0033654
+
+ Annotations:
+ rdfs:label "host cell chloroplast thylakoid membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0033654"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pamgo_curators"^^xsd:string
+ obo:IAO_0000115 "Any sac-like membranous structures (cisternae) in a chloroplast found in host cells, combined into stacks (grana) and present singly in the stroma (stroma thylakoids or frets) as interconnections between grana. The host is defined as the larger of the organisms involved in a symbiotic interaction."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044160,
+ obo:GO_0033653
+
+
+Class: obo:GO_0045095
+
+ Annotations:
+ rdfs:label "keratin filament"^^xsd:string,
+ oboInOwl:id "GO:0045095"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "acidic keratin"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "basic/neutral keratin"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0716731363"^^xsd:string
+ obo:IAO_0000115 "A filament composed of acidic and basic keratins (types I and II), typically expressed in epithelial cells. The keratins are the most diverse classes of IF proteins, with a large number of keratin isoforms being expressed. Each type of epithelium always expresses a characteristic combination of type I and type II keratins."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005882
+
+
+Class: obo:GO_0033650
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "host cell mitochondrion"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pamgo_curators"^^xsd:string
+ obo:IAO_0000115 "A semiautonomous, self replicating organelle as found in host cells that occurs in varying numbers, shapes, and sizes in the cell cytoplasm. The host is defined as the larger of the organisms involved in a symbiotic interaction."^^xsd:string,
+ oboInOwl:hasExactSynonym "host mitochondria"^^xsd:string,
+ oboInOwl:id "GO:0033650"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033648,
+ obo:GO_0033655
+
+
+Class: obo:GO_0017122
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "UDP-N-acetylglucosamine-peptide N-acetylglucosaminyltransferase"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "protein N-acetylglucosaminyltransferase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15247246"^^xsd:string
+ obo:IAO_0000115 "Heterotrimeric enzyme complex, which in humans is composed of two large subunits of the same size, and one smaller subunit. Functions in the addition of nucleotide-activated sugars onto the polypeptide."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "O-GlcNAc transferase complex"^^xsd:string,
+ oboInOwl:id "GO:0017122"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0036007
+
+ Annotations:
+ oboInOwl:id "GO:0036007"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "scintillon"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mag"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:4501583"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:5642469"^^xsd:string
+ obo:IAO_0000115 "A body present in the cytoplasm of some dinoflagellates, which is the source of bioluminescence; emits light on acidification in the presence of oxygen."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444
+
+
+Class: obo:GO_0016528
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198547684"^^xsd:string
+ obo:IAO_0000115 "The cytoplasm of a muscle cell; includes the sarcoplasmic reticulum."^^xsd:string,
+ oboInOwl:id "GO:0016528"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Sarcoplasm"^^xsd:string,
+ rdfs:label "sarcoplasm"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005737
+
+
+Class: obo:GO_0016529
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Endoplasmic_reticulum#Sarcoplasmic_reticulum"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0008221"^^xsd:string,
+ oboInOwl:id "GO:0016529"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0124325653"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198547684"^^xsd:string
+ obo:IAO_0000115 "A fine reticular network of membrane-limited elements that pervades the sarcoplasm of a muscle cell; continuous over large portions of the cell and with the nuclear envelope; that part of the endoplasmic reticulum specialized for calcium release, uptake and storage."^^xsd:string,
+ rdfs:label "sarcoplasmic reticulum"^^xsd:string,
+ rdfs:comment "See also the cellular component terms 'sarcoplasm ; GO:0016528', 'nuclear envelope ; GO:0005635' and 'endoplasmic reticulum ; GO:0005783'."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0016528,
+ obo:GO_0005783
+
+
+Class: obo:GO_0036000
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mag"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10723937"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:4629881"^^xsd:string
+ obo:IAO_0000115 "A small subcellular vesicle, surrounded by a membrane, in the pellicle of ciliate protozoans that discharges a mucus-like secretion."^^xsd:string,
+ oboInOwl:id "GO:0036000"^^xsd:string,
+ rdfs:label "mucocyst"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030141
+
+
+Class: obo:GO_0016942
+
+ Annotations:
+ oboInOwl:hasExactSynonym "IGF binding protein complex"^^xsd:string,
+ rdfs:label "insulin-like growth factor binding protein complex"^^xsd:string,
+ oboInOwl:id "GO:0016942"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "A complex of proteins which includes the insulin-like growth factor (IGF) and a number of IGF-binding proteins. The complex plays a role in growth and development."^^xsd:string,
+ oboInOwl:inSubset
+
+ SubClassOf:
+ obo:GO_0044421,
+ obo:BFO_0000050 some obo:GO_0005615,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030496
+
+ Annotations:
+ rdfs:label "midbody"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "A thin cytoplasmic bridge formed between daughter cells at the end of cytokinesis. The midbody forms where the contractile ring constricts, and may persist for some time before finally breaking to complete cytokinesis."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Midbody_(cell_biology)"^^xsd:string,
+ oboInOwl:id "GO:0030496"^^xsd:string,
+ oboInOwl:inSubset
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0035770
+
+ Annotations:
+ oboInOwl:hasExactSynonym "RNP granule"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:go_curators"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:sp"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16520386"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20368989"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:21436445"^^xsd:string
+ obo:IAO_0000115 "A non-membranous macromolecular complex containing proteins and translationally silenced mRNAs. RNA granules contain proteins that control the localization, stability, and translation of their RNA cargo. Different types of RNA granules (RGs) exist, depending on the cell type and cellular conditions."^^xsd:string,
+ rdfs:label "ribonucleoprotein granule"^^xsd:string,
+ oboInOwl:id "GO:0035770"^^xsd:string,
+ oboInOwl:hasExactSynonym "mRNP granule"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "RNA granule"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030529,
+ obo:GO_0043232,
+ obo:GO_0044444
+
+
+Class: obo:GO_0016939
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "http://www.csfic.mi.cnr.it/centro/lines/8/ric.html"^^xsd:string
+ obo:IAO_0000115 "A complex consisting of two distinct motor subunits that form a heterodimer complexed with a third non-motor accessory subunit, the kinesin associated protein or KAP; the KIF3 heterodimer interacts via its C-terminal portion with KAP, which is thought to regulate the binding of the motor to cargo membranes."^^xsd:string,
+ oboInOwl:id "GO:0016939"^^xsd:string,
+ rdfs:label "kinesin II complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005871
+
+
+Class: obo:GO_0043513
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "Heterodimeric hormone composed of an inhibin alpha subunit complexed with an inhibin beta-B subunit."^^xsd:string,
+ rdfs:comment "Note that the actions of the inhibin complex are the opposite of those of the activin complex, which is a dimer of an inhibin beta-A and/or inhibin beta-B subunit. See also the cellular component term 'activin complex ; GO:0048180'."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0043513"^^xsd:string,
+ rdfs:label "inhibin B complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043511
+
+
+Class: obo:GO_0016938
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "http://www.csfic.mi.cnr.it/centro/lines/8/ric.html"^^xsd:string
+ obo:IAO_0000115 "A complex of two kinesin heavy chains and two kinesin light chains."^^xsd:string,
+ oboInOwl:id "GO:0016938"^^xsd:string,
+ rdfs:label "kinesin I complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005871
+
+
+Class: obo:GO_0043514
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "p35"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:ebc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12948519"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:1381512"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is composed of an interleukin-12 alpha (p35, product of the IL12A gene) and an interleukin-12 beta subunit (p40, product of the IL12B gene) and is secreted into the extracellular space."^^xsd:string,
+ oboInOwl:id "GO:0043514"^^xsd:string,
+ rdfs:label "interleukin-12 complex"^^xsd:string,
+ rdfs:comment "Note that this heterodimeric cytokine utilizes the IL-12p35 subunit as its alpha chain, which is also used by IL-35 as its alpha chain, and utilizes the IL-12p40 subunit as its beta chain, which is also used by IL-23 as its beta chain."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "IL12B"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "IL12A"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "IL-12 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "p40"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421,
+ obo:BFO_0000050 some obo:GO_0005615,
+ obo:GO_0043234
+
+
+Class: obo:GO_0033620
+
+ Annotations:
+ oboInOwl:id "GO:0033620"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "Mei2 nuclear dot"^^xsd:string,
+ oboInOwl:hasExactSynonym "Mei2 dot"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12808043"^^xsd:string
+ obo:IAO_0000115 "A nuclear body that forms during meiotic prophase in a fixed position in the horsetail nucleus; contains Mei2 and meiRNA. May play a role in the progression of meiosis I."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016604
+
+
+Class: obo:GO_0043511
+
+ Annotations:
+ rdfs:comment "Note that the actions of the inhibin complex are the opposite of those of the activin complex, which is a dimer of an inhibin beta-A and/or inhibin beta-B subunit. See also the cellular component term 'activin complex ; GO:0048180'."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "inhibin complex"^^xsd:string,
+ oboInOwl:id "GO:0043511"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "Heterodimeric hormone composed of an inhibin alpha subunit complexed with either an inhibin beta-A subunit, to form inhibin A, or an inhibin beta-B subunit, to form inhibin B."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421,
+ obo:BFO_0000050 some obo:GO_0005615,
+ obo:GO_0043234
+
+
+Class: obo:GO_0043512
+
+ Annotations:
+ rdfs:comment "Note that the actions of the inhibin complex are the opposite of those of the activin complex, which is a dimer of an inhibin beta-A and/or inhibin beta-B subunit. See also the cellular component term 'activin complex ; GO:0048180'."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0043512"^^xsd:string,
+ rdfs:label "inhibin A complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "Heterodimeric hormone composed of an inhibin alpha subunit complexed with an inhibin beta-A subunit."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043511
+
+
+Class: obo:GO_0016935
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "glycine-gated chloride channel complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A protein complex that forms a transmembrane channel through which chloride ions may pass in response to glycine binding to the channel complex or one of its constituent parts."^^xsd:string,
+ oboInOwl:id "GO:0016935"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005887,
+ obo:GO_0044459,
+ obo:GO_0034707
+
+
+Class: obo:GO_0045025
+
+ Annotations:
+ rdfs:label "mitochondrial degradosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10397341"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9829834"^^xsd:string
+ oboInOwl:hasExactSynonym "mtEXO"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10397341"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9829834"^^xsd:string
+ obo:IAO_0000115 "A mitochondrial protein complex with 3' to 5' exoribonuclease activity that participates in intron-independent turnover and processing of mitochondrial transcripts. In humans, the mitochondrial degradosome is a pentameric complex, and in yeast it exists as a heterodimer."^^xsd:string,
+ oboInOwl:id "GO:0045025"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044429,
+ obo:GO_0000177
+
+
+Class: obo:GO_0016533
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15689152"^^xsd:string
+ obo:IAO_0000115 "A protein complex that activates cyclin-dependent kinase 5; composed of regulatory and catalytic subunits."^^xsd:string,
+ rdfs:label "cyclin-dependent protein kinase 5 holoenzyme complex"^^xsd:string,
+ oboInOwl:id "GO:0016533"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0019908,
+ obo:GO_0000307
+
+
+Class: obo:GO_0072324
+
+ Annotations:
+ oboInOwl:id "GO:0072324"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that this term is an is_a child of 'extracellular region part' because it is part of the ascus that lies external to spores, each of which is a cell."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "DOI:10.1016/S0953-7562(96)80057-8"^^xsd:string
+ obo:IAO_0000115 "An extracellular part that consist of ascus cytoplasm that is not packaged into ascospores."^^xsd:string,
+ rdfs:label "ascus epiplasm"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421
+
+
+Class: obo:GO_0017133
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "A protein complex located in the mitochondrion. It contains flavin adenine dinucleotide (FAD) that, together with an acyl-CoA dehydrogenase, forms a system that oxidizes an acyl-CoA molecule and reduces ubiquinone and other acceptors in the mitochondrial electron transport system."^^xsd:string,
+ oboInOwl:id "GO:0017133"^^xsd:string,
+ rdfs:label "mitochondrial electron transfer flavoprotein complex"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0045251
+ and (obo:BFO_0000050 some obo:GO_0005739)
+
+ SubClassOf:
+ obo:GO_0044429,
+ obo:BFO_0000050 some obo:GO_0005759,
+ obo:GO_0045251
+
+
+Class: obo:GO_0020002
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "The plasma membrane surrounding a host cell."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "host cell plasma membrane"^^xsd:string,
+ oboInOwl:id "GO:0020002"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033644
+
+
+Class: obo:GO_0020003
+
+ Annotations:
+ rdfs:label "symbiont-containing vacuole"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that this term does not have a relationship to 'vacuole ; GO:0005773' because it does not fit the definition of a vacuole; the parasitophorous vacuole was so named because it resembles a vacuole in the microscope."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "Membrane-bounded vacuole within a host cell in which a symbiont organism resides. The vacuole membrane is derived from both the host and symbiont."^^xsd:string,
+ oboInOwl:id "GO:0020003"^^xsd:string,
+ oboInOwl:hasExactSynonym "parasitophorous vacuole"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033655,
+ obo:GO_0065010
+
+
+Class: obo:GO_0016007
+
+ Annotations:
+ oboInOwl:id "GO:0016007"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ma"^^xsd:string
+ obo:IAO_0000115 "The major and minor mitochondrial derivatives are the mitochondria of the sperm tail and derive by the unfolding of the Nebenkern during flagellum elongation."^^xsd:string,
+ rdfs:label "mitochondrial derivative"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005739
+
+
+Class: obo:GO_0016008
+
+ Annotations:
+ oboInOwl:id "GO:0016008"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17123504"^^xsd:string
+ obo:IAO_0000115 "The larger of the two mitochondrial derivatives that arise by the unfolding of the Nebenkern during flagellum elongation; the major mitochondrial derivative is ovoid and darker than the minor derivative."^^xsd:string,
+ rdfs:label "major mitochondrial derivative"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016007
+
+
+Class: obo:GO_0016009
+
+ Annotations:
+ oboInOwl:id "GO:0016009"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "minor mitochondrial derivative"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17123504"^^xsd:string
+ obo:IAO_0000115 "The smaller of the two mitochondrial derivatives that arise by the unfolding of the Nebenkern during flagellum elongation."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016007
+
+
+Class: obo:GO_0016006
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0016006"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ma"^^xsd:string
+ obo:IAO_0000115 "A product of the fusion of the mitochondria during spermatogenesis. After the completion of meiosis the mitochondria of the spermatid collect along side the nucleus and fuse into two masses; these wrap around each other to produce the spherical Nebenkern. During flagellum elongation the Nebenkern unfolds and the two derivatives (major and minor mitochondrial derivatives) elongate down the axoneme."^^xsd:string,
+ rdfs:label "Nebenkern"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005739
+
+
+Class: obo:GO_0043527
+
+ Annotations:
+ rdfs:label "tRNA methyltransferase complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "A multimeric protein complex involved in the methylation of specific nucleotides in tRNA."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0043527"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0034708,
+ obo:GO_0044444
+
+
+Class: obo:GO_0043528
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "tRNA (m2G10) methyltransferase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15899842"^^xsd:string
+ obo:IAO_0000115 "A protein complex required for the methylation of the guanosine nucleotide at position 10 (m2G10) in tRNA. In S. cerevisiae, this complex consists of at least two subunits, Trm11p and Trm112p."^^xsd:string,
+ oboInOwl:id "GO:0043528"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043527
+
+
+Class: obo:GO_0043529
+
+ Annotations:
+ oboInOwl:hasExactSynonym "Golgi to ER Traffic complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16269340"^^xsd:string
+ obo:IAO_0000115 "A multisubunit complex involved in ER/Golgi trafficking (Golgi to ER Traffic). In yeast, includes Get1p, Get2p and Get3p proteins."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "GET complex"^^xsd:string,
+ oboInOwl:id "GO:0043529"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044432,
+ obo:GO_0043234
+
+
+Class: obo:GO_0000300
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that this term refers to disrupted cells, and does not necessarily correspond to any specific structure(s) in an intact cell."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10512869"^^xsd:string
+ obo:IAO_0000115 "Peripheral to that fraction of cells, prepared by disruptive biochemical methods, that includes the plasma and other membranes; can be extracted from membrane fraction with high concentrations of salt or high pH."^^xsd:string,
+ oboInOwl:id "GO:0000300"^^xsd:string,
+ rdfs:label "peripheral to membrane of membrane fraction"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005624
+
+
+Class: obo:GO_0042589
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding a zymogen granule."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "zymogen granule membrane"^^xsd:string,
+ oboInOwl:id "GO:0042589"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030667,
+ obo:BFO_0000050 some obo:GO_0042588
+
+
+Class: obo:GO_0036024
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:ans"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15853774"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric protein complex that contains protein C inhibitor (SERPINA5) and transmembrane protease serine 7 (TMPRSS7); formation of the complex inhibits the serine protease activity of transmembrane protease serine 7."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "PCI-TMPRSS7 complex"^^xsd:string,
+ oboInOwl:id "GO:0036024"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "protein C inhibitor-TMPRSS7 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "plasma serine protease inhibitor-TMPRSS7 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000016461"^^xsd:string
+ oboInOwl:hasExactSynonym "protein C inhibitor-transmembrane protease serine 7 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "serpin A5-TMPRSS7 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15853774"^^xsd:string,
+ oboInOwl:hasDbXref "PR:000016461"^^xsd:string
+ oboInOwl:hasExactSynonym "protein C inhibitor-matriptase-3 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "SERPINA5-TMPRSS7 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0097180
+
+
+Class: obo:GO_0042587
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12179957"^^xsd:string,
+ oboInOwl:hasDbXref "http://148.216.10.83/cellbio/the_mi19.gif"^^xsd:string
+ obo:IAO_0000115 "Cytoplasmic bead-like structures of animal cells, visible by electron microscope. Each granule is a functional unit with the biosynthesis and catabolism of glycogen being catalyzed by enzymes bound to the granule surface."^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1081228141"^^xsd:string,
+ rdfs:label "glycogen granule"^^xsd:string,
+ oboInOwl:hasExactSynonym "glycogen particle"^^xsd:string,
+ oboInOwl:id "GO:0042587"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444
+
+
+Class: obo:GO_0036026
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "PCI-PLAT complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "SERPINA5-PLAT complex"^^xsd:string,
+ oboInOwl:id "GO:0036026"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10340997"^^xsd:string,
+ oboInOwl:hasDbXref "PR:000012825"^^xsd:string
+ oboInOwl:hasExactSynonym "protein C inhibitor-tissue-type plasminogen activator complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ans"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10340997"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric protein complex that contains protein C inhibitor (SERPINA5) and tissue-type plasminogen activator (PLAT); formation of the complex inhibits the serine protease activity of tissue-type plasminogen activator."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "plasma serine protease inhibitor-PLAT complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10340997"^^xsd:string,
+ oboInOwl:hasDbXref "PR:000012825"^^xsd:string
+ oboInOwl:hasExactSynonym "protein C inhibitor-tPA complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "serpin A5-PLAT complex"^^xsd:string,
+ rdfs:label "protein C inhibitor-PLAT complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0097180
+
+
+Class: obo:GO_0042588
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "A membrane-bounded, cytoplasmic secretory granule found in enzyme-secreting cells and visible by light microscopy. Contain zymogen, an inactive enzyme precursor, often of a digestive enzyme."^^xsd:string,
+ rdfs:label "zymogen granule"^^xsd:string,
+ oboInOwl:id "GO:0042588"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030141
+
+
+Class: obo:GO_0036025
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:ans"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15328353"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric protein complex that contains protein C inhibitor (SERPINA5) and transmembrane protease serine 11E (TMPRSS11E); formation of the complex inhibits the serine protease activity of transmembrane protease serine 11E."^^xsd:string,
+ rdfs:label "protein C inhibitor-TMPRSS11E complex"^^xsd:string,
+ oboInOwl:id "GO:0036025"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000016451"^^xsd:string
+ oboInOwl:hasExactSynonym "protein C inhibitor-transmembrane protease serine 11E complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "PCI-TMPRSS11E complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "plasma serine protease inhibitor-TMPRSS11E complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "SERPINA5-TMPRSS11E complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "serpin A5-TMPRSS11E complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0097180
+
+
+Class: obo:GO_0016507
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0016507"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ma"^^xsd:string
+ obo:IAO_0000115 "A complex that includes the long-chain 3-hydroxyacyl-CoA dehydrogenase and long-chain enoyl-CoA hydratase activities in two subunits (alpha and beta), catalyzing two steps of the fatty acid beta-oxidation cycle within the mitochondrial matrix."^^xsd:string,
+ rdfs:label "fatty acid beta-oxidation multienzyme complex"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "trifunctional enzyme"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044429,
+ obo:BFO_0000050 some obo:GO_0005759,
+ obo:GO_0043234
+
+
+Class: obo:GO_0036028
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PR:000007299"^^xsd:string
+ oboInOwl:hasExactSynonym "protein C inhibitor-F2 complex"^^xsd:string,
+ rdfs:label "protein C inhibitor-thrombin complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0036028"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ans"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:6323392"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric protein complex that contains protein C inhibitor (SERPINA5) and thrombin (F2); formation of the complex inhibits the serine protease activity of thrombin."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "PCI-thrombin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "SERPINA5-thrombin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "plasma serine protease inhibitor-thrombin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000007299"^^xsd:string
+ oboInOwl:hasExactSynonym "protein C inhibitor-coagulation factor II complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "serpin A5-thrombin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0097180
+
+
+Class: obo:GO_0016012
+
+ Annotations:
+ oboInOwl:hasExactSynonym "sarcoglycan-sarcospan complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15117830"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16710609"^^xsd:string
+ obo:IAO_0000115 "A protein complex formed of four sarcoglycans plus sarcospan; there are six known sarcoglycans: alpha-, beta-, gamma-, delta-, epsilon- and zeta-sarcoglycan; all are N-glycosylated single-pass transmembrane proteins. The sarcoglycan-sarcospan complex is a subcomplex of the dystrophin glycoprotein complex, and is fixed to the dystrophin axis by a lateral association with the dystroglycan complex."^^xsd:string,
+ rdfs:label "sarcoglycan complex"^^xsd:string,
+ oboInOwl:id "GO:0016012"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0016011,
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0036027
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PR:000012826"^^xsd:string
+ oboInOwl:hasExactSynonym "protein C inhibitor-urokinase-type plasminogen activator complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "SERPINA5-PLAU complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000012826"^^xsd:string
+ oboInOwl:hasExactSynonym "protein C inhibitor-uPA complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "serpin A5-PLAU complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "plasma serine protease inhibitor-PLAU complex"^^xsd:string,
+ oboInOwl:id "GO:0036027"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "PCI-PLAU complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000012826"^^xsd:string
+ oboInOwl:hasExactSynonym "protein C inhibitor-U-plasminogen activator complex"^^xsd:string,
+ rdfs:label "protein C inhibitor-PLAU complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ans"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10340997"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:3501295"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8536714"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric protein complex that contains protein C inhibitor (SERPINA5) and urokinase-type plasminogen activator (PLAU); formation of the complex inhibits the serine protease activity of urokinase-type plasminogen activator."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0097180
+
+
+Class: obo:GO_0008087
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9223679"^^xsd:string
+ obo:IAO_0000115 "A protein complex that forms a transmembrane channel through which calcium ions may cross a cell membrane in response to changes in membrane potential generated in response to a light stimulus."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "light-activated voltage-sensitive calcium channel complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "light-activated voltage gated calcium channel complex"^^xsd:string,
+ rdfs:label "light-activated voltage-gated calcium channel complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "light-activated voltage-dependent calcium channel complex"^^xsd:string,
+ oboInOwl:id "GO:0008087"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005891
+
+
+Class: obo:GO_0016013
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "http://www.dmd.nl/DGC.html#syn"^^xsd:string
+ obo:IAO_0000115 "A protein complex that includes alpha-, beta1-, beta2-syntrophins and syntrophin-like proteins; the syntrophin complex binds to the second half of the carboxy-terminal domain of dystrophin; also associates with neuronal nitric oxide synthase."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:416"^^xsd:string
+ oboInOwl:hasRelatedSynonym "nitric oxide synthase-dystrophin complex, skeletal muscle"^^xsd:string,
+ rdfs:label "syntrophin complex"^^xsd:string,
+ oboInOwl:id "GO:0016013"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0016010,
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0034693
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "18S U11/U12 snRNP"^^xsd:string,
+ oboInOwl:id "GO:0034693"^^xsd:string,
+ rdfs:label "U11/U12 snRNP"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "snRNP U11/U12"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15146077"^^xsd:string
+ obo:IAO_0000115 "A ribonucleoprotein complex formed by the association of the U11 and U12 small nuclear ribonucleoproteins."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030532
+
+
+Class: obo:GO_0016010
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "DGC"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "dystrophin-associated glycoprotein complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15117830"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16710609"^^xsd:string
+ obo:IAO_0000115 "A multiprotein complex that forms a strong mechanical link between the cytoskeleton and extracellular matrix; typical of, but not confined to, muscle cells. The complex is composed of transmembrane, cytoplasmic, and extracellular proteins, including dystrophin, sarcoglycans, dystroglycan, dystrobrevins, syntrophins, sarcospan, caveolin-3, and NO synthase."^^xsd:string,
+ oboInOwl:hasExactSynonym "dystrophin glycoprotein complex"^^xsd:string,
+ oboInOwl:id "GO:0016010"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0017146
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "http://www.bris.ac.uk/Depts/Synaptic/info/glutamate.html"^^xsd:string
+ obo:IAO_0000115 "An assembly of four or five subunits which form a structure with an extracellular N-terminus and a large loop that together form the ligand binding domain. The C-terminus is intracellular. The ionotropic glutamate receptor complex itself acts as a ligand gated ion channel; on binding glutamate, charged ions pass through a channel in the center of the receptor complex. NMDA receptors are composed of assemblies of NR1 subunits (Figure 3) and NR2 subunits, which can be one of four separate gene products (NR2A-D). Expression of both subunits are required to form functional channels. The glutamate binding domain is formed at the junction of NR1 and NR2 subunits. NMDA receptors are permeable to calcium ions as well as being permeable to other ions. Thus NMDA receptor activation leads to a calcium influx into the post-synaptic cells, a signal thought to be crucial for the induction of NMDA-receptor dependent LTP and LTD."^^xsd:string,
+ rdfs:label "N-methyl-D-aspartate selective glutamate receptor complex"^^xsd:string,
+ oboInOwl:id "GO:0017146"^^xsd:string,
+ oboInOwl:hasExactSynonym "NMDA-selective glutamate receptor"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008328
+
+
+Class: obo:GO_0036029
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "protein C inhibitor-KLK3 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000003015"^^xsd:string
+ oboInOwl:hasExactSynonym "protein C inhibitor-prostate-specific antigen complex"^^xsd:string,
+ oboInOwl:id "GO:0036029"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "SERPINA5-KLK3 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000003015"^^xsd:string
+ oboInOwl:hasExactSynonym "protein C inhibitor-kallikrein-3 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "serpin A5-KLK3 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "PCI-KLK3 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ans"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:1725227"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric protein complex that contains protein C inhibitor (SERPINA5) and prostate-specific antigen (KLK3); formation of the complex inhibits the serine protease activity of prostate-specific antigen."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PR:000014685"^^xsd:string
+ oboInOwl:hasExactSynonym "plasma serine protease inhibitor-KLK3 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0097180
+
+
+Class: obo:GO_0034692
+
+ Annotations:
+ rdfs:label "E.F.G complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8641291"^^xsd:string
+ obo:IAO_0000115 "A protein complex that comprises three core spliceosomal proteins, designated E, F, and G. Formation of the E.F.G complex is essential but not sufficient for the formation of a stable U1 snRNP complex."^^xsd:string,
+ oboInOwl:id "GO:0034692"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0016011
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "dystroglycan complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15117830"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16710609"^^xsd:string
+ obo:IAO_0000115 "A protein complex that includes alpha- and beta-dystroglycan, which are alternative products of the same gene; the laminin-binding component of the dystrophin-associated glycoprotein complex, providing a link between the subsarcolemmal cytoskeleton (in muscle cells) and the extracellular matrix. Alpha-dystroglycan is an extracellular protein binding to alpha-laminin and to beta-dystroglycan; beta-dystroglycan is a transmembrane protein which binds alpha-dystroglycan and dystrophin."^^xsd:string,
+ oboInOwl:id "GO:0016011"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0016010,
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0035749
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0035749"^^xsd:string,
+ rdfs:label "myelin sheath adaxonal region"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20237282"^^xsd:string
+ obo:IAO_0000115 "The region of the myelin sheath nearest to the axon."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464,
+ obo:BFO_0000050 some obo:GO_0043209
+
+
+Class: obo:GO_0034691
+
+ Annotations:
+ oboInOwl:id "GO:0034691"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alphaE subunit and one beta7 subunit."^^xsd:string,
+ rdfs:label "alphaE-beta7 integrin complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Itgae-Itgb7 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0034690
+
+ Annotations:
+ oboInOwl:hasNarrowSynonym "Itgad-Itgb2 complex"^^xsd:string,
+ oboInOwl:id "GO:0034690"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alphaD-beta2 integrin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alphaD subunit and one beta2 subunit."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0000306
+
+ Annotations:
+ rdfs:label "extrinsic to vacuolar membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000306"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Loosely bound to one or the other surface of the vacuolar membrane, but not integrated into the hydrophobic region."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031312,
+ obo:GO_0044437,
+ obo:BFO_0000050 some obo:GO_0005774
+
+
+Class: obo:GO_0016014
+
+ Annotations:
+ rdfs:label "dystrobrevin complex"^^xsd:string,
+ oboInOwl:id "GO:0016014"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15117830"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16710609"^^xsd:string
+ obo:IAO_0000115 "A protein complex comprising alpha- and beta-dystrobrevin; forms part of the dystrophin glycoprotein complex."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0016010,
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0036020
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "endolysosome membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pde"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding an endolysosome. An endolysosome is a transient hybrid organelle formed by fusion of a late endosome with a lysosome."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string
+ oboInOwl:hasExactSynonym "endolysosomal membrane"^^xsd:string,
+ oboInOwl:id "GO:0036020"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005765,
+ obo:BFO_0000050 some obo:GO_0036019,
+ obo:GO_0010008
+
+
+Class: obo:GO_0000308
+
+ Annotations:
+ rdfs:label "cytoplasmic cyclin-dependent protein kinase holoenzyme complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000308"^^xsd:string,
+ oboInOwl:hasBroadSynonym "CDK holoenzyme"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string
+ obo:IAO_0000115 "Cyclin-dependent protein kinase (CDK) complex found in the cytoplasm."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000307
+ and (obo:BFO_0000050 some obo:GO_0005737)
+
+ SubClassOf:
+ obo:GO_0000307,
+ obo:GO_0044444
+
+
+Class: obo:GO_0000307
+
+ Annotations:
+ oboInOwl:id "GO:0000307"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasExactSynonym "CDK holoenzyme"^^xsd:string,
+ rdfs:label "cyclin-dependent protein kinase holoenzyme complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11602261"^^xsd:string
+ obo:IAO_0000115 "Cyclin-dependent protein kinases (CDKs) are heterodimeric enzymes that contain a kinase catalytic subunit associated with a regulatory cyclin partner."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0043541
+
+ Annotations:
+ oboInOwl:id "GO:0043541"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rn"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19129246"^^xsd:string
+ obo:IAO_0000115 "A multienzyme, heterooligomeric complex involved in dolichyl-linked oligosaccharide synthesis. In yeast the complex is composed of Alg7p, which catalyzes the first step (GlcNAc1-PP-Dol from dolichol-phosphate and UDP-GlcNAc), and Alg13p plus Alg14p, the catalytic and anchoring subunits respectively, which together catalyze the second step (GlcNAc2-PP-dolichol from GlcNAc1-PP-Dol and UDP-GlcNAc) of dolichyl-linked oligosaccharide synthesis."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "UDP-N-acetylglucosamine transferase complex"^^xsd:string,
+ rdfs:comment "See also the molecular function term 'N-acetylglucosaminyldiphosphodolichol N-acetylglucosaminyltransferase activity ; GO:0004577'."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005789,
+ obo:GO_0044425,
+ obo:GO_0044432,
+ obo:GO_0043234
+
+
+Class: obo:GO_0043540
+
+ Annotations:
+ rdfs:label "6-phosphofructo-2-kinase/fructose-2,6-biphosphatase 1 complex"^^xsd:string,
+ oboInOwl:id "GO:0043540"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:so"^^xsd:string
+ obo:IAO_0000115 "A homodimeric, bifunctional enzyme complex which catalyzes the synthesis and degradation of fructose 2,6-bisphosphate, and is required for both glycolysis and gluconeogenesis."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044445,
+ obo:GO_0043234
+
+
+Class: obo:GO_0036021
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string
+ oboInOwl:hasExactSynonym "endolysosomal lumen"^^xsd:string,
+ rdfs:label "endolysosome lumen"^^xsd:string,
+ oboInOwl:id "GO:0036021"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pde"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membrane of an endolysosome. An endolysosome is a transient hybrid organelle formed by fusion of a late endosome with a lysosome."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0036019,
+ obo:GO_0043202,
+ obo:GO_0031904
+
+
+Class: obo:GO_0035748
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0035748"^^xsd:string,
+ rdfs:label "myelin sheath abaxonal region"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20237282"^^xsd:string
+ obo:IAO_0000115 "The region of the myelin sheath furthest from the axon."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464,
+ obo:BFO_0000050 some obo:GO_0043209
+
+
+Class: obo:GO_0042995
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "http://www.cogsci.princeton.edu/~wn/"^^xsd:string
+ obo:IAO_0000115 "A prolongation or process extending from a cell, e.g. a flagellum or axon."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0042995"^^xsd:string,
+ oboInOwl:hasBroadSynonym "cellular process"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasBroadSynonym "cell process"^^xsd:string,
+ oboInOwl:hasExactSynonym "cellular projection"^^xsd:string,
+ rdfs:label "cell projection"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0016914
+
+ Annotations:
+ oboInOwl:hasExactSynonym "follicle stimulating hormone complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "follicle-stimulating hormone complex"^^xsd:string,
+ oboInOwl:id "GO:0016914"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198547684"^^xsd:string
+ obo:IAO_0000115 "A gonadotrophic glycoprotein hormone secreted, in mammals, by the anterior pituitary gland; consists of alpha and beta subunits, the latter of which confers hormonal specificity."^^xsd:string,
+ oboInOwl:hasExactSynonym "FSH complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421,
+ obo:GO_0043234
+
+
+Class: obo:GO_0000311
+
+ Annotations:
+ rdfs:label "plastid large ribosomal subunit"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mcc"^^xsd:string
+ obo:IAO_0000115 "The larger of the two subunits of a plastid ribosome. Two sites on the ribosomal large subunit are involved in translation: the aminoacyl site (A site) and peptidyl site (P site)."^^xsd:string,
+ oboInOwl:id "GO:0000311"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0015934
+ and (obo:BFO_0000050 some obo:GO_0009547)
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:BFO_0000050 some obo:GO_0009547,
+ obo:GO_0000315
+
+
+Class: obo:GO_0015935
+
+ Annotations:
+ rdfs:label "small ribosomal subunit"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0015935"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The smaller of the two subunits of a ribosome."^^xsd:string,
+ oboInOwl:hasExactSynonym "ribosomal small subunit"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044391,
+ obo:GO_0044446
+
+
+Class: obo:GO_0000312
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mcc"^^xsd:string
+ obo:IAO_0000115 "The smaller of the two subunits of a plastid ribosome."^^xsd:string,
+ rdfs:label "plastid small ribosomal subunit"^^xsd:string,
+ oboInOwl:id "GO:0000312"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0015935
+ and (obo:BFO_0000050 some obo:GO_0009547)
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:BFO_0000050 some obo:GO_0009547,
+ obo:GO_0000314
+
+
+Class: obo:GO_0015934
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "ribosomal large subunit"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "The larger of the two subunits of a ribosome. Two sites on the ribosomal large subunit are involved in translation, namely the aminoacyl site (A site) and peptidyl site (P site)."^^xsd:string,
+ oboInOwl:id "GO:0015934"^^xsd:string,
+ rdfs:label "large ribosomal subunit"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044391,
+ obo:GO_0044446
+
+
+Class: obo:GO_0000313
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mcc"^^xsd:string
+ obo:IAO_0000115 "A ribosome contained within a subcellular membrane-bounded organelle."^^xsd:string,
+ rdfs:label "organellar ribosome"^^xsd:string,
+ oboInOwl:id "GO:0000313"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005840
+ and (obo:BFO_0000050 some obo:GO_0043226)
+
+ SubClassOf:
+ obo:GO_0005840,
+ obo:GO_0044422
+
+
+Class: obo:GO_0016516
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasExactSynonym "IL-4 receptor complex"^^xsd:string,
+ oboInOwl:id "GO:0016516"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10358772"^^xsd:string
+ obo:IAO_0000115 "A protein complex that binds interleukin-4 (IL-4) and consists of an alpha chain that binds IL-4 with high affinity and a gamma common chain that also forms part of the interleukin-2 receptor."^^xsd:string,
+ rdfs:label "interleukin-4 receptor complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005887,
+ obo:GO_0044459,
+ obo:GO_0043235
+
+
+Class: obo:GO_0042597
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:go_curators"^^xsd:string
+ obo:IAO_0000115 "The region between the inner (cytoplasmic) and outer membrane (Gram-negative Bacteria) or inner membrane and cell wall (Fungi)."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0005620"^^xsd:string,
+ oboInOwl:hasExactSynonym "periplasm"^^xsd:string,
+ rdfs:label "periplasmic space"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0042597"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0034689
+
+ Annotations:
+ oboInOwl:hasNarrowSynonym "Itgax-Itgb2 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alphaX-beta2 integrin complex"^^xsd:string,
+ oboInOwl:id "GO:0034689"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alphaX subunit and one beta2 subunit."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0016514
+
+ Annotations:
+ rdfs:label "SWI/SNF complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12672490"^^xsd:string
+ obo:IAO_0000115 "A SWI/SNF-type complex that contains nine or more proteins, including both conserved (core) and nonconserved components; the Swi2/Snf2 ATPase is one of the core components."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0016514"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "SWI-SNF complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070603
+
+
+Class: obo:GO_0016513
+
+ Annotations:
+ oboInOwl:hasNarrowSynonym "AML1 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15156179"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8497254"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric transcription factor complex that contains an alpha subunit (Runx1, Runx2 or Runx3 in human) that binds DNA and a non-DNA-binding beta subunit (CBFbeta), and binds to a consensus sequence 5'-YGYGGTY-3' found in several enhancers and promoters; the beta subunit enhances the DNA binding of the alpha subunit."^^xsd:string,
+ oboInOwl:hasExactSynonym "CBF complex"^^xsd:string,
+ oboInOwl:id "GO:0016513"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "PEPB2 complex"^^xsd:string,
+ rdfs:label "core-binding factor complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005667
+
+
+Class: obo:GO_0042598
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "Any of the small, heterogeneous, artifactual, vesicular particles that are formed when some cells are homogenized."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that this term refers to disrupted cells, and does not necessarily correspond to any specific structure(s) in an intact cell."^^xsd:string,
+ oboInOwl:id "GO:0042598"^^xsd:string,
+ rdfs:label "vesicular fraction"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005624
+
+
+Class: obo:GO_0042599
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:cjm"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12243725"^^xsd:string,
+ oboInOwl:hasDbXref "http://en.wikipedia.org/wiki/Lamellar_granule"^^xsd:string
+ obo:IAO_0000115 "A membrane-bounded organelle, specialized for the storage and secretion of various substances (surfactant phospholipids, glycoproteins and acid phosphates) which are arranged in the form of tightly packed, concentric, membrane sheets or lamellae. Has some similar properties to, but is distinct from, a lysosome."^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1379604862"^^xsd:string,
+ oboInOwl:id "GO:0042599"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Odland body"^^xsd:string,
+ oboInOwl:hasExactSynonym "membrane-coating granule"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "keratinosome"^^xsd:string,
+ rdfs:label "lamellar body"^^xsd:string,
+ oboInOwl:hasExactSynonym "lamellar granule"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030141
+
+
+Class: obo:GO_0036014
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string
+ oboInOwl:hasExactSynonym "cyanelle envelope lumen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:18976493"^^xsd:string
+ oboInOwl:hasExactSynonym "cyanelle periplasm"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0036014"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:aa"^^xsd:string
+ obo:IAO_0000115 "The region between the inner and outer lipid bilayers of the cyanelle envelope; includes the peptidoglycan layer."^^xsd:string,
+ rdfs:label "cyanelle intermembrane space"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0033112,
+ obo:GO_0009529
+
+
+Class: obo:GO_0036013
+
+ Annotations:
+ oboInOwl:id "GO:0036013"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:aa"^^xsd:string
+ obo:IAO_0000115 "The outer, i.e. cytoplasm-facing, lipid bilayer of the cyanelle envelope."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cyanelle outer membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033113,
+ obo:GO_0009527
+
+
+Class: obo:GO_0036012
+
+ Annotations:
+ oboInOwl:id "GO:0036012"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:18976493"^^xsd:string
+ oboInOwl:hasExactSynonym "cyanelle inner envelope membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:aa"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18976493"^^xsd:string
+ obo:IAO_0000115 "The inner, i.e. lumen-facing, lipid bilayer of the cyanelle envelope; also faces the cyanelle stroma."^^xsd:string,
+ rdfs:label "cyanelle inner membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033113,
+ obo:GO_0009528
+
+
+Class: obo:GO_0016020
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Biological_membrane"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "Double layer of lipid molecules that encloses all cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0016020"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0036019
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:pde"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:21878991"^^xsd:string
+ obo:IAO_0000115 "An transient hybrid organelle formed by fusion of a late endosome with a lysosome, and in which active degradation takes place."^^xsd:string,
+ rdfs:label "endolysosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0036019"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005764,
+ obo:GO_0005768
+
+
+Class: obo:GO_0016021
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasRelatedSynonym "transmembrane"^^xsd:string,
+ rdfs:label "integral to membrane"^^xsd:string,
+ oboInOwl:id "GO:0016021"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Transmembrane_protein"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:go_curators"^^xsd:string
+ obo:IAO_0000115 "Penetrating at least one phospholipid bilayer of a membrane. May also refer to the state of being buried in the bilayer with no exposure outside the bilayer. When used to describe a protein, indicates that all or part of the peptide sequence is embedded in the membrane."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031224
+
+
+Class: obo:GO_0016023
+
+ Annotations:
+ oboInOwl:hasExactSynonym "cytoplasmic membrane bounded vesicle"^^xsd:string,
+ rdfs:label "cytoplasmic membrane-bounded vesicle"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ai"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A membrane-bounded vesicle found in the cytoplasm of the cell."^^xsd:string,
+ oboInOwl:hasExactSynonym "cytoplasmic membrane-enclosed vesicle"^^xsd:string,
+ oboInOwl:id "GO:0016023"^^xsd:string,
+ oboInOwl:inSubset
+
+ EquivalentTo:
+ obo:GO_0031988
+ and (obo:BFO_0000050 some obo:GO_0005737)
+
+ SubClassOf:
+ obo:GO_0043231,
+ obo:GO_0031988,
+ obo:GO_0031410
+
+
+Class: obo:GO_0008076
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A protein complex that forms a transmembrane channel through which potassium ions may cross a cell membrane in response to changes in membrane potential."^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao371494298"^^xsd:string,
+ rdfs:label "voltage-gated potassium channel complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "voltage gated potassium channel complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "voltage-dependent potassium channel complex"^^xsd:string,
+ oboInOwl:id "GO:0008076"^^xsd:string,
+ oboInOwl:hasExactSynonym "voltage-sensitive potassium channel complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005887,
+ obo:GO_0034705,
+ obo:GO_0044459
+
+
+Class: obo:GO_0000315
+
+ Annotations:
+ oboInOwl:id "GO:0000315"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mcc"^^xsd:string
+ obo:IAO_0000115 "The larger of the two subunits of an organellar ribosome. Two sites on the ribosomal large subunit are involved in translation: the aminoacyl site (A site) and peptidyl site (P site)."^^xsd:string,
+ rdfs:label "organellar large ribosomal subunit"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0015934
+ and (obo:BFO_0000050 some obo:GO_0000313)
+
+ SubClassOf:
+ obo:GO_0015934,
+ obo:BFO_0000050 some obo:GO_0000313
+
+
+Class: obo:GO_0016027
+
+ Annotations:
+ oboInOwl:id "GO:0016027"^^xsd:string,
+ oboInOwl:hasExactSynonym "inaD signalling complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "inaD signaling complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:hb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9010208"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9796815"^^xsd:string
+ obo:IAO_0000115 "A complex of proteins that are involved in phototransduction and attached to the transient receptor potential (TRP) channel. The protein connections are mediated through inaD."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044463,
+ obo:GO_0019897,
+ obo:BFO_0000050 some obo:GO_0016028,
+ obo:GO_0043234
+
+
+Class: obo:GO_0033607
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15233914"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16790527"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric protein complex formed of superoxide dismutase 1 and Bcl-2. Complex formation is thought to link superoxide dismutase to an apoptotic pathway."^^xsd:string,
+ rdfs:label "SOD1-Bcl-2 complex"^^xsd:string,
+ oboInOwl:id "GO:0033607"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0000314
+
+ Annotations:
+ oboInOwl:id "GO:0000314"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "organellar small ribosomal subunit"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mcc"^^xsd:string
+ obo:IAO_0000115 "The smaller of the two subunits of an organellar ribosome."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0015935
+ and (obo:BFO_0000050 some obo:GO_0000313)
+
+ SubClassOf:
+ obo:GO_0015935,
+ obo:BFO_0000050 some obo:GO_0000313
+
+
+Class: obo:GO_0016028
+
+ Annotations:
+ rdfs:label "rhabdomere"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0016028"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:hb"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:sart"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8646774"^^xsd:string
+ obo:IAO_0000115 "The specialized microvilli-containing organelle on the apical surfaces of a photoreceptor cell containing the visual pigment rhodopsin and most of the proteins involved in phototransduction."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042995
+
+
+Class: obo:GO_0016029
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0016029"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11707492"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8646774"^^xsd:string
+ obo:IAO_0000115 "A membrane-bounded compartment that is found at the base of the rhabdomere and contains stored calcium, InsP3 receptors and smooth endoplasmic reticulum Ca2+-ATPase."^^xsd:string,
+ oboInOwl:hasRelatedSynonym "SMC"^^xsd:string,
+ rdfs:label "subrhabdomeral cisterna"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11707492"^^xsd:string
+ oboInOwl:hasExactSynonym "submicrovillar cisterna"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044463,
+ obo:BFO_0000050 some obo:GO_0016028,
+ obo:BFO_0000050 some obo:GO_0005790,
+ obo:GO_0044432,
+ obo:GO_0031984
+
+
+Class: obo:GO_0000323
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string
+ obo:IAO_0000115 "A vacuole that is maintained at an acidic pH and which contains degradative enzymes, including a wide variety of acid hydrolases."^^xsd:string,
+ oboInOwl:id "GO:0000323"^^xsd:string,
+ rdfs:label "lytic vacuole"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005773
+
+
+Class: obo:GO_0000324
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "vacuole, cell cycle-correlated morphology"^^xsd:string,
+ rdfs:label "fungal-type vacuole"^^xsd:string,
+ oboInOwl:id "GO:0000324"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879693649"^^xsd:string
+ obo:IAO_0000115 "A vacuole that has both lytic and storage functions. The fungal vacuole is a large, membrane-bounded organelle that functions as a reservoir for the storage of small molecules (including polyphosphate, amino acids, several divalent cations (e.g. calcium), other ions, and other small molecules) as well as being the primary compartment for degradation. It is an acidic compartment, containing an ensemble of acid hydrolases. At least in S. cerevisiae, there are indications that the morphology of the vacuole is variable and correlated with the cell cycle, with logarithmically growing cells having a multilobed, reticulated vacuole, while stationary phase cells contain a single large structure."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000323,
+ obo:GO_0000322
+
+
+Class: obo:GO_0000322
+
+ Annotations:
+ rdfs:label "storage vacuole"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string
+ obo:IAO_0000115 "A vacuole that functions primarily in the storage of materials, including nutrients, pigments, waste products, and small molecules."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000322"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005773
+
+
+Class: obo:GO_0008074
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0008074"^^xsd:string,
+ rdfs:comment "See also the molecular function term 'guanylate cyclase activity ; GO:0004383'."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Complex that possesses guanylate cyclase activity and is not bound to a membrane."^^xsd:string,
+ rdfs:label "guanylate cyclase complex, soluble"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044445,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009289
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Pilus"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pamgo_curators"^^xsd:string
+ obo:IAO_0000115 "A proteinaceous hair-like appendage on the surface of bacteria ranging from 2-8 nm in diameter."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "fimbria"^^xsd:string,
+ oboInOwl:hasExactSynonym "pili"^^xsd:string,
+ oboInOwl:hasExactSynonym "fimbriae"^^xsd:string,
+ oboInOwl:hasExactSynonym "fimbrium"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0009289"^^xsd:string,
+ rdfs:label "pilus"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042995
+
+
+Class: obo:GO_0016465
+
+ Annotations:
+ rdfs:label "chaperonin ATPase complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0016465"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "EC:3.6.4.9"^^xsd:string
+ obo:IAO_0000115 "Multisubunit protein complex with 2x7 (Type I, in most cells) or 2x8 (Type II, in Archaea) ATP-binding sites involved in maintaining an unfolded polypeptide structure before folding or to entry into mitochondria and chloroplasts."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044445,
+ obo:GO_0043234
+
+
+Class: obo:GO_0020038
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "subpellicular network"^^xsd:string,
+ oboInOwl:id "GO:0020038"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11420112"^^xsd:string
+ obo:IAO_0000115 "A mechanically stable cytoskeletal structure associated with the cytoplasmic face of the pellicle and surrounding the microtubule-based cytoskeleton."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0020039,
+ obo:GO_0044430
+
+
+Class: obo:GO_0009288
+
+ Annotations:
+ oboInOwl:inSubset ,
+ rdfs:label "bacterial-type flagellum"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jh2"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7787060"^^xsd:string
+ obo:IAO_0000115 "A motor complex composed of an extracellular helical protein filament coupled to a rotary motor embedded in the cell envelope."^^xsd:string,
+ oboInOwl:hasExactSynonym "flagellin-based flagellum"^^xsd:string,
+ oboInOwl:id "GO:0009288"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043232,
+ obo:GO_0019861
+
+
+Class: obo:GO_0016469
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0716743663"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16691483"^^xsd:string
+ obo:IAO_0000115 "A large protein complex that catalyzes the synthesis or hydrolysis of ATP by a rotational mechanism, coupled to the transport of protons across a membrane. The complex comprises a membrane sector (F0, V0, or A0) that carries out proton transport and a cytoplasmic compartment sector (F1, V1, or A1) that catalyzes ATP synthesis or hydrolysis. Two major types have been characterized: V-type ATPases couple ATP hydrolysis to the transport of protons across a concentration gradient, whereas F-type ATPases, also known as ATP synthases, normally run in the reverse direction to utilize energy from a proton concentration or electrochemical gradient to synthesize ATP. A third type, A-type ATPases have been found in archaea, and are closely related to eukaryotic V-type ATPases but are reversible."^^xsd:string,
+ oboInOwl:hasExactSynonym "hydrogen-transporting two-sector ATPase complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "proton-transporting two-sector ATPase complex"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "vacuolar hydrogen-transporting ATPase"^^xsd:string,
+ oboInOwl:id "GO:0016469"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:GO_0043234
+
+
+Class: obo:GO_0020039
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "The structure enclosing an apicomplexan parasite cell; consists of the cell membrane with its associated infrastructure of microtubules, microfilaments and other organelles."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0020039"^^xsd:string,
+ rdfs:label "pellicle"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0016460
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "ISBN:96235764"^^xsd:string,
+ oboInOwl:hasDbXref "http://www.mrc-lmb.cam.ac.uk/myosin/Review/Reviewframeset.html"^^xsd:string
+ obo:IAO_0000115 "A myosin complex containing two class II myosin heavy chains, two myosin essential light chains and two myosin regulatory light chains. Also known as classical myosin or conventional myosin, the myosin II class includes the major muscle myosin of vertebrate and invertebrate muscle, and is characterized by alpha-helical coiled coil tails that self assemble to form a variety of filament structures."^^xsd:string,
+ oboInOwl:id "GO:0016460"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "conventional myosin"^^xsd:string,
+ rdfs:label "myosin II complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016459
+
+
+Class: obo:GO_0016461
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0005860"^^xsd:string,
+ rdfs:label "unconventional myosin complex"^^xsd:string,
+ oboInOwl:id "GO:0016461"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ma"^^xsd:string
+ obo:IAO_0000115 "A portmanteau term for myosins other than myosin II."^^xsd:string,
+ oboInOwl:hasRelatedSynonym "non-muscle myosin"^^xsd:string,
+ rdfs:comment "Note that this term is retained because it is widely used by biologists."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016459
+
+
+Class: obo:GO_0035301
+
+ Annotations:
+ oboInOwl:id "GO:0035301"^^xsd:string,
+ oboInOwl:hasExactSynonym "Hedgehog signalling complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10825151"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15057936"^^xsd:string
+ obo:IAO_0000115 "A multiprotein complex that binds microtubules in a Hedgehog-dependent manner, and is required for signal transduction by members of the Hedgehog family of proteins. The core components of the complex are the serine/threonine protein kinase Fused, the kinesin motor protein Costal2 (Cos2), and a zinc finger transcription factor (Gli family members in humans, and Cubitus interruptus (Ci) in Drosophila)."^^xsd:string,
+ oboInOwl:hasExactSynonym "HSC"^^xsd:string,
+ rdfs:label "Hedgehog signaling complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031596
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A proteasome found in the endoplasmic reticulum of a cell."^^xsd:string,
+ oboInOwl:id "GO:0031596"^^xsd:string,
+ rdfs:label "ER proteasome complex"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000502
+ and (obo:BFO_0000050 some obo:GO_0005783)
+
+ SubClassOf:
+ obo:GO_0000502,
+ obo:GO_0044432
+
+
+Class: obo:GO_0031597
+
+ Annotations:
+ rdfs:label "cytosolic proteasome complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "A proteasome complex found in the cytosol of a cell."^^xsd:string,
+ oboInOwl:id "GO:0031597"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000502,
+ obo:GO_0044445
+
+
+Class: obo:GO_0016456
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:ma"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "An RNA-protein complex localized to the X chromosome of males where it is required for the hyper-transcriptional activation of the X chromosome. An example of this is found in Drosophila melanogaster."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasBroadSynonym "dosage compensation complex"^^xsd:string,
+ oboInOwl:id "GO:0016456"^^xsd:string,
+ rdfs:label "X chromosome located dosage compensation complex, transcription activating"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0000805,
+ obo:GO_0030529,
+ obo:GO_0046536
+
+
+Class: obo:GO_0031594
+
+ Annotations:
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1124888485"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Neuromuscular_junction"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:nln"^^xsd:string
+ obo:IAO_0000115 "The junction between the axon of a motor neuron and a muscle fiber. In response to the arrival of action potentials, the presynaptic button releases molecules of neurotransmitters into the synaptic cleft. These diffuse across the cleft and transmit the signal to the postsynaptic membrane of the muscle fiber, leading to a post-synaptic potential responsible of the muscle contraction."^^xsd:string,
+ rdfs:label "neuromuscular junction"^^xsd:string,
+ oboInOwl:id "GO:0031594"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0045202
+
+
+Class: obo:GO_0031595
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "nuclear proteasome complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A proteasome found in the nucleus of a cell."^^xsd:string,
+ oboInOwl:id "GO:0031595"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000502
+ and (obo:BFO_0000050 some obo:GO_0005634)
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0000502,
+ obo:BFO_0000050 some obo:GO_0031981
+
+
+Class: obo:GO_0031592
+
+ Annotations:
+ rdfs:comment "Note that the centrosomal corona has been observed in Dictyostelium, and is the functional equivalent of pericentriolar material."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031592"^^xsd:string,
+ rdfs:label "centrosomal corona"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:kp"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "An amorphous structure surrounding the core of the centrosome, from which microtubules are nucleated; contains gamma-tubulin."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044450,
+ obo:BFO_0000050 some obo:GO_0005813
+
+
+Class: obo:GO_0016459
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0016459"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:96235764"^^xsd:string,
+ oboInOwl:hasDbXref "http://www.mrc-lmb.cam.ac.uk/myosin/Review/Reviewframeset.html"^^xsd:string
+ obo:IAO_0000115 "A protein complex, formed of one or more myosin heavy chains plus associated light chains and other proteins, that functions as a molecular motor; uses the energy of ATP hydrolysis to move actin filaments or to move vesicles or other cargo on fixed actin filaments; has magnesium-ATPase activity and binds actin. Myosin classes are distinguished based on sequence features of the motor, or head, domain, but also have distinct tail regions that are believed to bind specific cargoes."^^xsd:string,
+ rdfs:label "myosin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044430,
+ obo:BFO_0000050 some obo:GO_0015629,
+ obo:GO_0043234
+
+
+Class: obo:GO_0020026
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mb"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "Electron-dense organelle with a granular internal matrix found throughout the merozoite life cycle stage of apicomplexan parasites; contains proteins destined to be secreted into the parasitophorous vacuole following parasite invasion of a host cell."^^xsd:string,
+ oboInOwl:hasExactSynonym "dense body"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0020026"^^xsd:string,
+ rdfs:label "merozoite dense granule"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016023
+
+
+Class: obo:GO_0033098
+
+ Annotations:
+ rdfs:label "amyloplast inner membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0033098"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ecd"^^xsd:string
+ obo:IAO_0000115 "The inner, i.e. lumen-facing, lipid bilayer of the amyloplast envelope; also faces the amyloplast stroma."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033097,
+ obo:GO_0009528
+
+
+Class: obo:GO_0033097
+
+ Annotations:
+ oboInOwl:id "GO:0033097"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ecd"^^xsd:string
+ obo:IAO_0000115 "Either of the lipid bilayers that surround an amyloplast and form the amyloplast envelope."^^xsd:string,
+ rdfs:label "amyloplast membrane"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0033096,
+ obo:GO_0042170
+
+
+Class: obo:GO_0033099
+
+ Annotations:
+ oboInOwl:id "GO:0033099"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "attachment organelle"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11325545"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12003948"^^xsd:string,
+ oboInOwl:hasDbXref "http://authors.library.caltech.edu/3529/"^^xsd:string
+ obo:IAO_0000115 "A membrane-bounded extension of the cell, originally characterized in Mycoplasma species, that contains an electron-dense core that is part of the cytoskeleton and is oriented lengthwise and ends distally in a bulbous knob (terminal button). Required for adherence to host cells and involved in gliding motility and cell division."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043231
+
+
+Class: obo:GO_0020036
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "Maurers cleft"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16705161"^^xsd:string
+ obo:IAO_0000115 "A disk-like structure that appears at the periphery of a red blood cell infected by an apicomplexan parasite, characterized by a translucent lumen and an electron-dense coat of variable thickness; often appears to be tethered to the host cell membrane by fibrous connections with the erythrocyte cytoskeleton."^^xsd:string,
+ oboInOwl:id "GO:0020036"^^xsd:string,
+ rdfs:label "Maurer's cleft"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033655
+
+
+Class: obo:GO_0033093
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Weibel-Palade_body"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "Weibel-Palade body"^^xsd:string,
+ oboInOwl:id "GO:0033093"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11935287"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16087708"^^xsd:string
+ obo:IAO_0000115 "A large, elongated, rod-shaped secretory granule characteristic of vascular endothelial cells that contain a number of structurally and functionally distinct proteins, of which the best characterized are von Willebrand factor (VWF) and P-selectin. Weibel-Palade bodies are formed from the trans-Golgi network in a process that depends on VWF, which is densely packed in a highly organized manner, and on coat proteins that remain associated with the granules. Upon cell stimulation, regulated exocytosis releases the contained proteins to the cell surface, where they act in the recruitment of platelets and leukocytes and in inflammatory and vasoactive responses."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030141,
+ obo:GO_0030136
+
+
+Class: obo:GO_0009295
+
+ Annotations:
+ rdfs:label "nucleoid"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009295"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ma"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:3540076689"^^xsd:string
+ obo:IAO_0000115 "The region of a bacterial cell, mitochondrion or chloroplast to which the DNA is confined."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Nucleoid"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043232
+
+
+Class: obo:GO_0033096
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The double lipid bilayer enclosing the amyloplast and separating its contents from the rest of the cytoplasm; includes the intermembrane space."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0033096"^^xsd:string,
+ rdfs:label "amyloplast envelope"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009501,
+ obo:GO_0009526
+
+
+Class: obo:GO_0033095
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "aleurone grain"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "http://ejournal.sinica.edu.tw/bbas/content/2004/1/bot451-08.pdf"^^xsd:string,
+ oboInOwl:hasDbXref "http://www.springerlink.com/content/q7183h5vr7358278/"^^xsd:string
+ obo:IAO_0000115 "A membrane-bounded storage granule found in cells of the aleurone layer in plants; contains either a protein matrix, protein-carbohydrate bodies and/or globoids. Aleurone grains are formed by the vacuole, rough endoplasmic reticulum and dictyosomes."^^xsd:string,
+ oboInOwl:hasExactSynonym "aleurone body"^^xsd:string,
+ oboInOwl:id "GO:0033095"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016023
+
+
+Class: obo:GO_0020032
+
+ Annotations:
+ oboInOwl:hasExactSynonym "lower polar ring of apical complex"^^xsd:string,
+ oboInOwl:id "GO:0020032"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "basal ring of apical complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16518471"^^xsd:string
+ obo:IAO_0000115 "An electron dense ring at the most posterior position of the apical complex, from which the subpellicular microtubules originate; formed during an invasive life cycle stage of an apicomplexan parasite."^^xsd:string,
+ oboInOwl:hasExactSynonym "preconoidal ring of apical complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "posterior polar ring of apical complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0020007,
+ obo:GO_0044464
+
+
+Class: obo:GO_0020031
+
+ Annotations:
+ oboInOwl:id "GO:0020031"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "upper polar ring of apical complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16518471"^^xsd:string
+ obo:IAO_0000115 "An electron dense ring at the most anterior position of the apical complex, from which the conoid fibers originate; formed during an invasive life cycle stage of an apicomplexan parasite."^^xsd:string,
+ rdfs:label "polar ring of apical complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "anterior polar ring of apical complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0020007,
+ obo:GO_0044464
+
+
+Class: obo:GO_0020030
+
+ Annotations:
+ oboInOwl:id "GO:0020030"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "infected host cell surface knob"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "Protrusion that develops in the plasma membrane of a parasitized erythrocyte. An example of this component is found in Plasmodium species."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033655
+
+
+Class: obo:GO_0031588
+
+ Annotations:
+ oboInOwl:id "GO:0031588"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Snf1 kinase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses AMP-dependent protein kinase activity."^^xsd:string,
+ rdfs:label "AMP-activated protein kinase complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "5'-AMP-activated protein kinase complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Snf1 serine/threonine protein kinase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0020015
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasDbXref "Wikipedia:Glycosome"^^xsd:string,
+ oboInOwl:id "GO:0020015"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "A membrane-bounded organelle found in organisms from the order Kinetoplastida that houses the enzymes of glycolysis."^^xsd:string,
+ rdfs:label "glycosome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005777
+
+
+Class: obo:GO_0046540
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:11867543"^^xsd:string
+ obo:IAO_0000115 "A ribonucleoprotein complex formed by the association of the U4/U6 and U5 small nuclear ribonucleoproteins."^^xsd:string,
+ oboInOwl:id "GO:0046540"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "U4/U6 x U5 tri-snRNP complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "U4/U6.U5 snRNP complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000051 some obo:GO_0071001,
+ obo:BFO_0000051 some obo:GO_0005682,
+ obo:GO_0030532
+
+
+Class: obo:GO_0020016
+
+ Annotations:
+ rdfs:label "flagellar pocket"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "Invagination of the plasma membrane from which a flagellum protrudes."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0020016"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044442
+
+
+Class: obo:GO_0020017
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "flagellar membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "The portion of the plasma membrane surrounding the flagellum."^^xsd:string,
+ oboInOwl:id "GO:0020017"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031090,
+ obo:GO_0044442,
+ obo:GO_0031253
+
+
+Class: obo:GO_0020018
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "flagellar pocket membrane"^^xsd:string,
+ oboInOwl:id "GO:0020018"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "That part of the plasma membrane found in the flagellar pocket."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0020017,
+ obo:BFO_0000050 some obo:GO_0020016
+
+
+Class: obo:GO_0016442
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:10749213"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15145345"^^xsd:string
+ obo:IAO_0000115 "A ribonucleoprotein complex that contains members of the Argonaute family of proteins, small interfering RNAs (siRNAs) or microRNAs (miRNAs), and miRNA or siRNA-complementary mRNAs, in addition to a number of accessory factors. The RISC complex is involved in posttranscriptional repression of gene expression through downregulation of translation or induction of mRNA degradation."^^xsd:string,
+ oboInOwl:id "GO:0016442"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:RNA-induced_silencing_complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "RISC complex"^^xsd:string,
+ rdfs:label "RNA-induced silencing complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031332
+
+
+Class: obo:GO_0042101
+
+ Annotations:
+ oboInOwl:id "GO:0042101"^^xsd:string,
+ oboInOwl:hasExactSynonym "T-cell receptor complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0781735149"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains a disulfide-linked heterodimer of T cell receptor (TCR) chains, which are members of the immunoglobulin superfamily, and mediates antigen recognition, ultimately resulting in T cell activation. The TCR heterodimer is associated with the CD3 complex, which consists of the nonpolymorphic polypeptides gamma, delta, epsilon, zeta, and, in some cases, eta (an RNA splice variant of zeta) or Fc epsilon chains."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "T cell receptor complex"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:T_cell_receptor"^^xsd:string,
+ oboInOwl:hasExactSynonym "T-lymphocyte receptor complex"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "TCR"^^xsd:string,
+ oboInOwl:hasExactSynonym "T lymphocyte receptor complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043235
+
+
+Class: obo:GO_0031599
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The regulatory subcomplex of a proteasome located in the endoplasmic reticulum of a cell."^^xsd:string,
+ oboInOwl:id "GO:0031599"^^xsd:string,
+ rdfs:label "ER proteasome regulatory particle"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005838
+ and (obo:BFO_0000050 some obo:GO_0005783)
+
+ SubClassOf:
+ obo:GO_0005838,
+ obo:BFO_0000050 some obo:GO_0031596,
+ obo:GO_0044432
+
+
+Class: obo:GO_0046536
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0046536"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:kmv"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A protein or protein-RNA complex that localizes to one or more of the sex chromosome(s), where it acts to normalize transcription between different sexes."^^xsd:string,
+ rdfs:label "dosage compensation complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0000803,
+ obo:GO_0044427,
+ obo:GO_0044428,
+ obo:GO_0032991
+
+
+Class: obo:GO_0031598
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The regulatory subcomplex of a proteasome located in the nucleus of a cell."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031598"^^xsd:string,
+ rdfs:label "nuclear proteasome regulatory particle"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005838
+ and (obo:BFO_0000050 some obo:GO_0005634)
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:BFO_0000050 some obo:GO_0031595,
+ obo:GO_0005838
+
+
+Class: obo:GO_0020020
+
+ Annotations:
+ rdfs:label "food vacuole"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "Vacuole within a parasite used for digestion of the host cell cytoplasm. An example of this component is found in the Apicomplexa."^^xsd:string,
+ oboInOwl:id "GO:0020020"^^xsd:string,
+ oboInOwl:hasExactSynonym "digestive vacuole"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0005772"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032010
+
+
+Class: obo:GO_0035324
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9635420"^^xsd:string
+ obo:IAO_0000115 "An intercellular bridge that connects the germline cells of a female cyst."^^xsd:string,
+ oboInOwl:id "GO:0035324"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "ovarian ring canal"^^xsd:string,
+ rdfs:label "female germline ring canal"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "nurse cell ring canal"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0045172
+
+
+Class: obo:GO_0020023
+
+ Annotations:
+ oboInOwl:id "GO:0020023"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "A sub-structure within the large single mitochondrion of kinetoplastid parasites and which is closely associated with the flagellar pocket and basal body of the flagellum."^^xsd:string,
+ rdfs:label "kinetoplast"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Kinetoplast"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044429
+
+
+Class: obo:GO_0035323
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0035323"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9635420"^^xsd:string
+ obo:IAO_0000115 "An intercellular bridge that connects the germline cells of a male cyst."^^xsd:string,
+ oboInOwl:hasNarrowSynonym "spermatocyte ring canal"^^xsd:string,
+ rdfs:label "male germline ring canal"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "testicular ring canal"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0045172
+
+
+Class: obo:GO_0020022
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0020022"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "An electron-dense acidic membrane-bounded organelle which contains a matrix of pyrophosphate and polyphosphates with bound calcium and other cations."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15738951"^^xsd:string
+ oboInOwl:hasExactSynonym "metachromatic granule"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15738951"^^xsd:string
+ oboInOwl:hasExactSynonym "volutin granule"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15738951"^^xsd:string
+ oboInOwl:hasRelatedSynonym "polyphosphate vacuole"^^xsd:string,
+ rdfs:label "acidocalcisome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043231,
+ obo:GO_0044444
+
+
+Class: obo:GO_0020025
+
+ Annotations:
+ oboInOwl:id "GO:0020025"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "Singlet microtubules that lie underneath the inner membrane complex and emanate from the basal ring of the conoid."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "subpellicular microtubule"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0020007,
+ obo:GO_0005874
+
+
+Class: obo:GO_0009277
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mcc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:3540601864"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11283274"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16927300"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:3319422"^^xsd:string
+ obo:IAO_0000115 "A rigid yet dynamic structure surrounding the plasma membrane that affords protection from stresses and contributes to cell morphogenesis, consisting of extensively cross-linked glycoproteins and carbohydrates. The glycoproteins may be modified with N- or O-linked carbohydrates, or glycosylphosphatidylinositol (GPI) anchors; the polysaccharides are primarily branched glucans, including beta-linked and alpha-linked glucans, and may also include chitin and other carbohydrate polymers, but not cellulose or pectin. Enzymes involved in cell wall biosynthesis are also found in the cell wall. Note that some forms of fungi develop a capsule outside of the cell wall under certain circumstances; this is considered a separate structure."^^xsd:string,
+ rdfs:label "fungal-type cell wall"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "chitin-containing cell wall"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "beta-glucan-containing cell wall"^^xsd:string,
+ oboInOwl:id "GO:0009277"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "chitin- and beta-glucan-containing cell wall"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005618
+
+
+Class: obo:GO_0020006
+
+ Annotations:
+ oboInOwl:id "GO:0020006"^^xsd:string,
+ oboInOwl:hasExactSynonym "parasitophorous vacuolar membrane network"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "tubulovesicular network"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "symbiont-containing vacuole membrane network"^^xsd:string,
+ rdfs:label "symbiont-containing vacuolar membrane network"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:3528173"^^xsd:string
+ obo:IAO_0000115 "Tubular network of extensions from the symbiont-containing vacuole membrane that protrude into the host cytoplasm."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044437,
+ obo:BFO_0000050 some obo:GO_0020005,
+ obo:GO_0044425,
+ obo:GO_0033643
+
+
+Class: obo:GO_0009276
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mlg"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815108893"^^xsd:string
+ obo:IAO_0000115 "The peptidoglycan layer of the Gram-negative cell envelope. In Gram-negative cells the peptidoglycan is relatively thin (1-2nm) and is linked to the outer membrane by lipoproteins. In Gram-negative cells the peptidoglycan is too thin to retain the primary stain in the Gram staining procedure and therefore cells appear red after Gram stain."^^xsd:string,
+ rdfs:label "Gram-negative-bacterium-type cell wall"^^xsd:string,
+ oboInOwl:hasExactSynonym "cell wall inner membrane"^^xsd:string,
+ oboInOwl:id "GO:0009276"^^xsd:string,
+ oboInOwl:hasExactSynonym "1-2nm peptidoglycan-based cell wall"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009274,
+ obo:BFO_0000050 some obo:GO_0030313
+
+
+Class: obo:GO_0020007
+
+ Annotations:
+ oboInOwl:id "GO:0020007"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16518471"^^xsd:string
+ obo:IAO_0000115 "A group of cytoskeletal structures and associated membrane-bounded organelles found at the anterior end of adult obligate intracellular protozoan parasites in the phylum Apicomplexa. The apical complex is involved in attachment to and penetration of the host cell, and in parasite proliferation."^^xsd:string,
+ rdfs:label "apical complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0045177,
+ obo:GO_0044464
+
+
+Class: obo:GO_0035327
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0035327"^^xsd:string,
+ rdfs:label "transcriptionally active chromatin"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:sart"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17965872"^^xsd:string
+ obo:IAO_0000115 "The ordered and organized complex of DNA and protein that forms regions of the chromosome that are being actively transcribed."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000785
+
+
+Class: obo:GO_0009275
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mlg"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0051406910"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815108893"^^xsd:string
+ obo:IAO_0000115 "A layer of peptidoglycan found outside of the cytoplasmic membrane. The peptidoglycan is relatively thick (20-80nm) and retains the primary stain of the Gram procedure, thus cells appear blue after Gram stain. The cell walls often contain teichoic acids (acidic anionic polysaccharides) bound to the peptidoglycan. Examples of this component are found in Gram-positive bacteria."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "20-80nm peptidoglycan-based cell wall"^^xsd:string,
+ rdfs:label "Gram-positive-bacterium-type cell wall"^^xsd:string,
+ oboInOwl:hasExactSynonym "cell wall of Gram-positive Bacteria"^^xsd:string,
+ oboInOwl:id "GO:0009275"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009274
+
+
+Class: obo:GO_0020004
+
+ Annotations:
+ oboInOwl:hasRelatedSynonym "symbiont-containing vacuole space"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0020004"^^xsd:string,
+ oboInOwl:hasExactSynonym "parasitophorous vacuolar space"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "The space between a symbiont plasma membrane and the symbiont-containing vacuole membrane."^^xsd:string,
+ rdfs:label "symbiont-containing vacuolar space"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033643,
+ obo:GO_0044422,
+ obo:BFO_0000050 some obo:GO_0020003
+
+
+Class: obo:GO_0035328
+
+ Annotations:
+ rdfs:label "transcriptionally silent chromatin"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "transcriptionally inactive chromatin"^^xsd:string,
+ oboInOwl:id "GO:0035328"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:sart"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17965872"^^xsd:string
+ obo:IAO_0000115 "The ordered and organized complex of DNA and protein that forms regions of the chromosome that are not being actively transcribed."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000785
+
+
+Class: obo:GO_0009274
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mlg"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815108893"^^xsd:string
+ obo:IAO_0000115 "A protective structure outside the cytoplasmic membrane composed of peptidoglycan (also known as murein), a molecule made up of a glycan (sugar) backbone of repetitively alternating N-acetylglucosamine and N-acetylmuramic acid with short, attached, cross-linked peptide chains containing unusual amino acids. An example of this component is found in Escherichia coli."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasBroadSynonym "envelope"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "peptidoglycan"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "murein sacculus"^^xsd:string,
+ oboInOwl:id "GO:0009274"^^xsd:string,
+ rdfs:label "peptidoglycan-based cell wall"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005618
+
+
+Class: obo:GO_0020005
+
+ Annotations:
+ rdfs:label "symbiont-containing vacuole membrane"^^xsd:string,
+ oboInOwl:id "GO:0020005"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "parasitophorous vacuolar membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mb"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding a symbiont-containing vacuole, derived from both the host and symbiont."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005774,
+ obo:GO_0033643,
+ obo:BFO_0000050 some obo:GO_0020003
+
+
+Class: obo:GO_0009279
+
+ Annotations:
+ rdfs:label "cell outer membrane"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "outer membrane of cell"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0135712254"^^xsd:string
+ obo:IAO_0000115 "A lipid bilayer that forms the outermost layer of the cell envelope; enriched in polysaccharide and protein; the outer leaflet of the membrane contains specific lipopolysaccharide structures."^^xsd:string,
+ oboInOwl:id "GO:0009279"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0019867
+ and (obo:BFO_0000050 some obo:GO_0030313)
+
+ SubClassOf:
+ obo:GO_0019867,
+ obo:GO_0044462,
+ obo:BFO_0000050 some obo:GO_0030313
+
+
+Class: obo:GO_0010369
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12384572"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15053486"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16831888"^^xsd:string
+ obo:IAO_0000115 "A region in which centric, heterochromatic portions of one or more chromosomes form a compact structure."^^xsd:string,
+ oboInOwl:id "GO:0010369"^^xsd:string,
+ rdfs:label "chromocenter"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427
+
+
+Class: obo:GO_0020008
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "rhoptry"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Rhoptry"^^xsd:string,
+ oboInOwl:id "GO:0020008"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "toxoneme"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0521664470"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11801218"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16002398"^^xsd:string
+ obo:IAO_0000115 "A large, club-shaped secretory organelle that forms part of the apical complex of an apicomplexan parasite, and consists of a bulbous body and a narrow electron-dense neck that extends through the conoid at the apical tip of the parasite. The rhoptry necks serve as ducts through which the contents of the rhoptries are secreted after attachment to the host has been completed and at the commencement of invasion. Rhoptry proteins function in the biogenesis and host organellar association of the parasitophorous vacuole."^^xsd:string,
+ oboInOwl:hasRelatedSynonym "paired organelles"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0020007,
+ obo:GO_0044464
+
+
+Class: obo:GO_0010368
+
+ Annotations:
+ rdfs:label "chloroplast isoamylase complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0010368"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:tair_curators"^^xsd:string
+ obo:IAO_0000115 "A protein complex whose composition varies amongst species; in rice it probably exists in a homo-tetramer to homo-hexamer form and in Gram negative bacteria as a dimer. Functions in the hydrolysis of alpha-(1,6)-D-glucosidic branch linkages. Isoamylases in plants are intracellular and probably chloroplast localized."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0043033
+ and (obo:BFO_0000050 some obo:GO_0009507)
+
+ SubClassOf:
+ obo:GO_0043033,
+ obo:GO_0044434
+
+
+Class: obo:GO_0020009
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0521664470"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11801218"^^xsd:string
+ obo:IAO_0000115 "A small, elongated secretory organelle that forms part of the apical complex, located along the main axis of an apicomplexan parasite cell within the extreme apical region and at the periphery under the inner membrane complex. Of the specialized secretory compartments identified in apicomplexans, micronemes discharge their contents first, during initial contact of the parasite's apical pole with the host cell surface. Micronemal proteins function during parasite attachment and penetration into the target cell."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Microneme"^^xsd:string,
+ oboInOwl:id "GO:0020009"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "sarconeme"^^xsd:string,
+ rdfs:label "microneme"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0020007,
+ obo:GO_0043231
+
+
+Class: obo:GO_0010370
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "perinucleolar chromocenter"^^xsd:string,
+ oboInOwl:id "GO:0010370"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15805479"^^xsd:string
+ obo:IAO_0000115 "A chromocenter adjacent to the nucleolus."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0010369
+
+
+Class: obo:GO_0020010
+
+ Annotations:
+ rdfs:label "conoid"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0020010"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:expert_dr"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11901169"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16518471"^^xsd:string
+ obo:IAO_0000115 "A spiral cytoskeletal structure located at the apical end of the apical complex in some apicomplexan parasites. Fibers form a left-handed spiral, and are comprised of tubulin protofilaments organized in a ribbon-like structure that differs from the conventional tubular structure characteristic of microtubules."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0020007,
+ obo:GO_0044430
+
+
+Class: obo:GO_0020011
+
+ Annotations:
+ oboInOwl:id "GO:0020011"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0521664470"^^xsd:string
+ obo:IAO_0000115 "The plastid organelle found in apicomplexans."^^xsd:string,
+ rdfs:label "apicoplast"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Apicoplast"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009536
+
+
+Class: obo:GO_0000798
+
+ Annotations:
+ rdfs:label "nuclear cohesin complex"^^xsd:string,
+ oboInOwl:id "GO:0000798"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that this term and its children should be used to annotate gene products found in cohesin complexes in organisms that undergo closed mitosis (i.e. where the nuclear envelope does not break down, as in fungi). For organisms in which the nuclear envelope breaks down during mitosis, the parent should be used."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A cohesin complex required for cohesion between sister chromatids that remain in the nucleus."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0008278
+ and (obo:BFO_0000050 some obo:GO_0005634)
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:GO_0008278,
+ obo:BFO_0000050 some obo:GO_0000794
+
+
+Class: obo:GO_0000799
+
+ Annotations:
+ oboInOwl:id "GO:0000799"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "nuclear condensin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A multisubunit protein complex that plays a central role in the condensation of chromosomes that remain in the nucleus."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000796
+ and (obo:BFO_0000050 some obo:GO_0005634)
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:GO_0000796,
+ obo:BFO_0000050 some obo:GO_0000794
+
+
+Class: obo:GO_0005971
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005971"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "ribonucleotide reductase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "RNR complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "BRENDA:1.17.4.1"^^xsd:string
+ obo:IAO_0000115 "An enzyme complex composed of 2-4 or more subunits, which usually contains nonheme iron and requires ATP for catalysis. Catalyzes the formation of 2'-deoxyribonucleoside diphosphate and thioredoxin disulfide from ribonucleoside diphosphate and thioredoxin."^^xsd:string,
+ rdfs:label "ribonucleoside-diphosphate reductase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444,
+ obo:GO_0043234
+
+
+Class: obo:GO_0005969
+
+ Annotations:
+ oboInOwl:hasNarrowSynonym "serine-pyruvate aminotransferase, type 2B complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "EC:2.6.1.51"^^xsd:string
+ obo:IAO_0000115 "An enzyme complex that catalyzes the formation of hydroxypyruvate and alanine from serine and pyruvate."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005969"^^xsd:string,
+ rdfs:label "serine-pyruvate aminotransferase complex"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0005970"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "serine-pyruvate aminotransferase, type 1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444,
+ obo:GO_0043234
+
+
+Class: obo:GO_0005968
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "Rab-protein geranylgeranyltransferase complex"^^xsd:string,
+ oboInOwl:id "GO:0005968"^^xsd:string,
+ oboInOwl:hasExactSynonym "RAB-protein geranylgeranyltransferase complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "RabGGTase complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "GGTase-II complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11886217"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric enzyme complex, which in mammals is composed of an alpha and a beta subunit, and which associates with an accessory protein Rep (Rab escort protein). Catalyzes of the transfer of a geranyl-geranyl group from geranylgeranyl pyrophosphate to a Rab protein."^^xsd:string,
+ oboInOwl:hasExactSynonym "Rab geranylgeranyltransferase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071665
+
+ Annotations:
+ rdfs:label "gamma-catenin-TCF7L2 complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "gamma-catenin-TCF4 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:14661054"^^xsd:string
+ oboInOwl:hasExactSynonym "plakoglobin-TCF4 complex"^^xsd:string,
+ oboInOwl:id "GO:0071665"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vk"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14661054"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains gamma-catenin and TCF7L2 (TCF4), binds to the TCF DNA motif within a promoter element, and is involved in the regulation of WNT target gene transcription."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071664
+
+
+Class: obo:GO_0071664
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vk"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14661054"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains a catenin and TCF7L2 (TCF4), binds to the TCF DNA motif within a promoter element, and is involved in the regulation of WNT target gene transcription."^^xsd:string,
+ rdfs:label "catenin-TCF7L2 complex"^^xsd:string,
+ oboInOwl:id "GO:0071664"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "catenin-TCF4 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044445,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031533
+
+ Annotations:
+ oboInOwl:id "GO:0031533"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10347220"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an RNA 5' triphosphatase and a guanyl transferase (Cet1p and Ceg1p in S. cerevisiae; Pct1 and Ceg1 in S. pombe) and is involved in mRNA capping."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ oboInOwl:hasExactSynonym "mRNA capping enzyme complex"^^xsd:string,
+ rdfs:label "mRNA cap methyltransferase complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "mRNA (guanine-N7) methyltransferase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0034708,
+ obo:GO_0044428
+
+
+Class: obo:GO_0010367
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "extracellular isoamylase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:tair_curators"^^xsd:string
+ obo:IAO_0000115 "A protein complex whose composition varies amongst species; in rice it probably exists in a homo-tetramer to homo-hexamer form and in Gram negative bacteria as a dimer. Functions in the hydrolysis of alpha-(1,6)-D-glucosidic branch linkages. Isoamylases in animals are localized in the extracellular space."^^xsd:string,
+ oboInOwl:id "GO:0010367"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0043033
+ and (obo:BFO_0000050 some obo:GO_0005576)
+
+ SubClassOf:
+ obo:GO_0043033,
+ obo:GO_0044421
+
+
+Class: obo:GO_0071666
+
+ Annotations:
+ rdfs:label "Slit-Robo signaling complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "Slit-Robo signalling complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:sart"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17062560"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18359766"^^xsd:string
+ obo:IAO_0000115 "A protein-carbohydrate complex that consists of a transmembrane roundabout (Robo) receptor, an extracellular Slit ligand and heparin/heparan sulfate."^^xsd:string,
+ oboInOwl:id "GO:0071666"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032992
+
+
+Class: obo:GO_0043599
+
+ Annotations:
+ oboInOwl:id "GO:0043599"^^xsd:string,
+ rdfs:label "nuclear DNA replication factor C complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14614842"^^xsd:string
+ obo:IAO_0000115 "A nuclear complex of five polypeptides that loads the DNA polymerase processivity factor proliferating cell nuclear antigen (PCNA) onto DNA, thereby permitting processive DNA synthesis catalyzed by DNA polymerase delta or epsilon. In Saccharomyces and several other species, the subunits are known as Rfc1p-Rfc5p, although subunit names do not necessarily correspond between different species."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005663
+ and (obo:BFO_0000050 some obo:GO_0005634)
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:GO_0005663,
+ obo:BFO_0000050 some obo:GO_0043601
+
+
+Class: obo:GO_0042106
+
+ Annotations:
+ oboInOwl:hasExactSynonym "gamma-delta T-cell receptor complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "gamma-delta TCR complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "gamma-delta T lymphocyte receptor complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "gamma-delta T-lymphocyte receptor complex"^^xsd:string,
+ rdfs:label "gamma-delta T cell receptor complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0781735149"^^xsd:string
+ obo:IAO_0000115 "A T cell receptor complex in which the TCR heterodimer comprises gamma and delta chains, associated with the CD3 complex; recognizes antigen directly, without a requirement for processing and presentation by an MHC protein."^^xsd:string,
+ oboInOwl:id "GO:0042106"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042101
+
+
+Class: obo:GO_0042105
+
+ Annotations:
+ oboInOwl:hasExactSynonym "alpha-beta T lymphocyte receptor complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "alpha-beta TCR complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0781735149"^^xsd:string
+ obo:IAO_0000115 "A T cell receptor complex in which the TCR heterodimer comprises alpha and beta chains, associated with the CD3 complex; recognizes a complex consisting of an antigen-derived peptide bound to a class I or class II MHC protein."^^xsd:string,
+ oboInOwl:hasExactSynonym "alpha-beta T-lymphocyte receptor complex"^^xsd:string,
+ oboInOwl:id "GO:0042105"^^xsd:string,
+ rdfs:label "alpha-beta T cell receptor complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "alpha-beta T-cell receptor complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042101
+
+
+Class: obo:GO_0005960
+
+ Annotations:
+ oboInOwl:id "GO:0005960"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "glycine cleavage complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "glycine decarboxylase complex"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "glycine dehydrogenase complex (decarboxylating)"^^xsd:string,
+ oboInOwl:hasExactSynonym "glycine dehydrogenase (decarboxylating) complex"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0070015"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "MetaCyc:GCVMULTI-CPLX"^^xsd:string
+ obo:IAO_0000115 "A protein complex that catalyzes the reversible oxidation of glycine. In E. coli, it has four components: dihydrolipoamide dehydrogenase, glycine dehydrogenase (decarboxylating), lipoyl-GcvH-protein and aminomethyltransferase, also known as L, P, H, and T."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Glycine_decarboxylase_complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "glycine cleavage system"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0005961"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasExactSynonym "glycine synthase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0000789
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20404130"^^xsd:string
+ obo:IAO_0000115 "The ordered and organized complex of DNA, protein, and sometimes RNA, that forms the chromosome in the cytoplasm."^^xsd:string,
+ oboInOwl:id "GO:0000789"^^xsd:string,
+ rdfs:label "cytoplasmic chromatin"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000785
+ and (obo:BFO_0000050 some obo:GO_0005737)
+
+ SubClassOf:
+ obo:GO_0000785,
+ obo:GO_0044444,
+ obo:BFO_0000050 some obo:GO_0000229
+
+
+Class: obo:GO_0005962
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "Mitochondrial complex that possesses isocitrate dehydrogenase (NAD+) activity."^^xsd:string,
+ oboInOwl:id "GO:0005962"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "mitochondrial isocitrate dehydrogenase complex (NAD+)"^^xsd:string,
+ rdfs:comment "Note that this term represents a location and not a function; the activity possessed by this complex is mentioned in the definition for the purpose of describing and distinguishing the complex. The function of this complex is represented by the molecular function term 'isocitrate dehydrogenase (NAD+) activity ; GO:0004449'."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0045242
+ and (obo:BFO_0000050 some obo:GO_0005739)
+
+ SubClassOf:
+ obo:GO_0030062,
+ obo:GO_0045242
+
+
+Class: obo:GO_0000787
+
+ Annotations:
+ rdfs:label "cytoplasmic nucleosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A complex comprised of DNA wound around a multisubunit core and associated proteins, which forms the primary packing unit of DNA in the cytoplasm into higher order structures."^^xsd:string,
+ oboInOwl:id "GO:0000787"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000786
+ and (obo:BFO_0000050 some obo:GO_0005737)
+
+ SubClassOf:
+ obo:GO_0000786,
+ obo:BFO_0000050 some obo:GO_0000789,
+ obo:GO_0044444
+
+
+Class: obo:GO_0005963
+
+ Annotations:
+ oboInOwl:id "GO:0005963"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "magnesium-dependent protein serine/threonine phosphatase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "EC:3.1.3.16"^^xsd:string
+ obo:IAO_0000115 "An enzyme complex that catalyzes the removal of serine- or threonine-bound phosphate groups from a wide range of phosphoproteins, including a number of enzymes that have been phosphorylated under the action of a kinase."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0008287
+
+
+Class: obo:GO_0000788
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "nuclear nucleosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A complex comprised of DNA wound around a multisubunit core and associated proteins, which forms the primary packing unit of DNA in the nucleus into higher order structures."^^xsd:string,
+ oboInOwl:id "GO:0000788"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000786
+ and (obo:BFO_0000050 some obo:GO_0005634)
+
+ SubClassOf:
+ obo:GO_0000786,
+ obo:BFO_0000050 some obo:GO_0000790,
+ obo:GO_0044454
+
+
+Class: obo:GO_0005964
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005964"^^xsd:string,
+ rdfs:label "phosphorylase kinase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "EC:2.7.11.19"^^xsd:string
+ obo:IAO_0000115 "An enzyme complex that catalyzes the phosphorylation of phosphorylase b to form phosphorylase a."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0005965
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005965"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses protein farnesyltransferase activity."^^xsd:string,
+ rdfs:label "protein farnesyltransferase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0005966
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cyclic-nucleotide phosphodiesterase complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "photoreceptor cyclic-nucleotide phosphodiesterase complex"^^xsd:string,
+ oboInOwl:id "GO:0005966"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "EC:3.1.4.-"^^xsd:string
+ obo:IAO_0000115 "An enzyme complex that catalyzes the hydrolysis of bonds in a cyclic nucleotide."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464,
+ obo:GO_0043234
+
+
+Class: obo:GO_0005967
+
+ Annotations:
+ oboInOwl:hasBroadSynonym "pyruvate dehydrogenase complex (lipoamide)"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0471331309"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0716720094"^^xsd:string
+ obo:IAO_0000115 "Complex that carries out the oxidative decarboxylation of pyruvate to form acetyl-CoA in eukaryotes; includes subunits possessing three catalytic activities: pyruvate dehydrogenase (E1), dihydrolipoamide S-acetyltransferase (E2), and dihydrolipoamide dehydrogenase (E3). The This Eukaryotic form usually contains more subunits than its bacterial counterpart; for example, one known complex contains 30 E1 dimers, 60 E2 monomers, and 6 E3 dimers as well as a few copies of pyruvate dehydrogenase kinase and pyruvate dehydrogenase phosphatase."^^xsd:string,
+ rdfs:label "mitochondrial pyruvate dehydrogenase complex"^^xsd:string,
+ oboInOwl:id "GO:0005967"^^xsd:string,
+ rdfs:comment "Note that this term represents a location and not a function; the activity possessed by this complex is mentioned in the definition for the purpose of describing and distinguishing the complex. The functions of this complex are represented by the molecular function terms 'pyruvate dehydrogenase (lipoamide) activity ; GO:0004739', 'dihydrolipoamide S-acetyltransferase activity ; GO:0004742', and 'dihydrolipoamide dehydrogenase activity ; GO:0004148'."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0045254
+ and (obo:BFO_0000050 some obo:GO_0005739)
+
+ SubClassOf:
+ obo:GO_0045254,
+ obo:GO_0044429,
+ obo:BFO_0000050 some obo:GO_0005759
+
+
+Class: obo:GO_0005958
+
+ Annotations:
+ oboInOwl:hasAlternativeId "GO:0005959"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "DNA-dependent protein kinase-DNA ligase 4 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10854421"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12235392"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17072889"^^xsd:string
+ obo:IAO_0000115 "A large protein complex which is involved in the repair of DNA double-strand breaks and, in mammals, V(D)J recombination events. It consists of the DNA-dependent protein kinase catalytic subunit (DNA-PKcs), the DNA end-binding heterodimer Ku, the nuclear phosphoprotein XRCC4 or a homolog thereof, and DNA ligase IV."^^xsd:string,
+ oboInOwl:id "GO:0005958"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070419,
+ obo:GO_0044428
+
+
+Class: obo:GO_0000793
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "metaphase chromosome"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "mitotic chromosome"^^xsd:string,
+ rdfs:label "condensed chromosome"^^xsd:string,
+ rdfs:comment "Note that this term can be used to annotate gene products that localize to a mitotic chromosome in an organism that undergoes an 'open mitosis' in which the nuclear envelope breaks down during mitosis."^^xsd:string,
+ oboInOwl:hasRelatedSynonym "cytoplasmic mitotic chromosome"^^xsd:string,
+ oboInOwl:id "GO:0000793"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A highly compacted molecule of DNA and associated proteins resulting in a cytologically distinct structure."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005694
+
+
+Class: obo:GO_0000792
+
+ Annotations:
+ rdfs:label "heterochromatin"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao581845896"^^xsd:string,
+ oboInOwl:id "GO:0000792"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A compact and highly condensed form of chromatin."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Heterochromatin"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000785
+
+
+Class: obo:GO_0000791
+
+ Annotations:
+ rdfs:label "euchromatin"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Euchromatin"^^xsd:string,
+ oboInOwl:id "GO:0000791"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao445485807"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A dispersed and relatively uncompacted form of chromatin."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000785
+
+
+Class: obo:GO_0000790
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20404130"^^xsd:string
+ obo:IAO_0000115 "The ordered and organized complex of DNA, protein, and sometimes RNA, that forms the chromosome in the nucleus."^^xsd:string,
+ oboInOwl:id "GO:0000790"^^xsd:string,
+ rdfs:label "nuclear chromatin"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000785
+ and (obo:BFO_0000050 some obo:GO_0005634)
+
+ SubClassOf:
+ obo:GO_0000785,
+ obo:GO_0044454
+
+
+Class: obo:GO_0000797
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "The core heterodimer of a condensin complex, a multisubunit protein complex that plays a central role in chromosome condensation."^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Smc2-Smc4 complex"^^xsd:string,
+ rdfs:label "condensin core heterodimer"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "8S condensin complex"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0008621"^^xsd:string,
+ oboInOwl:id "GO:0000797"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0043234
+ and (obo:BFO_0000050 some obo:GO_0000796)
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:BFO_0000050 some obo:GO_0000796,
+ obo:GO_0043234
+
+
+Class: obo:GO_0000796
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "condensin complex"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A multisubunit protein complex that plays a central role in chromosome condensation."^^xsd:string,
+ oboInOwl:hasRelatedSynonym "SMC complex"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0005676"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0008620"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "13S condensin complex"^^xsd:string,
+ oboInOwl:id "GO:0000796"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:GO_0043234,
+ obo:BFO_0000050 some obo:GO_0000793
+
+
+Class: obo:GO_0000795
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Synaptonemal_complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A proteinaceous scaffold found between homologous chromosomes during meiosis."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000795"^^xsd:string,
+ rdfs:label "synaptonemal complex"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0005716"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:BFO_0000050 some obo:GO_0000794
+
+
+Class: obo:GO_0000794
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A highly compacted molecule of DNA and associated proteins resulting in a cytologically distinct structure that remains in the nucleus."^^xsd:string,
+ rdfs:comment "Note that this term and its children can be used to annotate gene products that localize to a mitotic chromosome in an organism that undergoes a 'closed mitosis' in which the nuclear envelope does not break down during mitosis and for gene products that localize to a meiotic chromosome."^^xsd:string,
+ oboInOwl:id "GO:0000794"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "nuclear mitotic chromosome"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "meiotic chromosome"^^xsd:string,
+ rdfs:label "condensed nuclear chromosome"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000793
+ and (obo:BFO_0000050 some obo:GO_0005634)
+
+ SubClassOf:
+ obo:GO_0000793,
+ obo:GO_0000228
+
+
+Class: obo:GO_0008623
+
+ Annotations:
+ oboInOwl:hasAlternativeId "GO:0016588"^^xsd:string,
+ oboInOwl:hasExactSynonym "CHRAC"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0008623"^^xsd:string,
+ rdfs:label "chromatin accessibility complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "ISW2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9252192"^^xsd:string
+ obo:IAO_0000115 "A multisubunit complex that uses ATP to increase the general accessibility of DNA in chromatin. Unlike other known chromatin remodeling complexes, CHRAC can also function during chromatin assembly; it uses ATP to convert irregular chromatin into a regular array of nucleosomes with even spacing."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016585
+
+
+Class: obo:GO_0008622
+
+ Annotations:
+ rdfs:label "epsilon DNA polymerase complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0008622"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:420"^^xsd:string
+ oboInOwl:hasExactSynonym "DNA polymerase epsilon complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15814431"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9745046"^^xsd:string
+ obo:IAO_0000115 "A heterotetrameric DNA polymerase complex that catalyzes processive DNA synthesis in the absence of PCNA, but is further stimulated in the presence of PCNA. The complex contains a large catalytic subunit and three small subunits, and is best characterized in Saccharomyces, in which the subunits are named Pol2p, Dpb2p, Dpb3p, and Dpb4p. Some evidence suggests that DNA polymerase epsilon is the leading strand polymerase; it is also involved in nucleotide-excision repair and mismatch repair."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042575,
+ obo:GO_0044454,
+ obo:BFO_0000050 some obo:GO_0000109,
+ obo:BFO_0000050 some obo:GO_0043601
+
+
+Class: obo:GO_0033698
+
+ Annotations:
+ rdfs:label "Rpd3L complex"^^xsd:string,
+ oboInOwl:id "GO:0033698"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ oboInOwl:hasExactSynonym "Clr6 histone deacetylase complex I/I'"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "Rpd3C(L)"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17450151"^^xsd:string
+ obo:IAO_0000115 "A histone deacetylase complex which deacetylates histones across gene coding regions. Composed of a catalytic histone deacetylase subunit, an Sds-3 family protein, a SIN3 family co-repressor, a WD repeat protein, and a zf- PHD finger (Clr6, Sds3, Pst1, Prw1, Png2 in Schizosaccharomyces pombe; Rpd3p, Sin3p, Ume1p, Pho23p, Sap30p, Sds3p, Cti6p, Rxt2p, Rxt3p, Dep1p, Ume6p and Ash1p in Saccharomyces cerevisiae)."^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0000508"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:19040720"^^xsd:string
+ oboInOwl:hasExactSynonym "Clr6L complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070822
+
+
+Class: obo:GO_0046581
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0046581"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0721662544"^^xsd:string
+ obo:IAO_0000115 "An extremely narrow tubular channel located between adjacent cells. An instance of this is the secretory canaliculi occurring between adjacent parietal cells in the gastric mucosa of vertebrates."^^xsd:string,
+ rdfs:label "intercellular canaliculus"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005911
+
+
+Class: obo:GO_0005955
+
+ Annotations:
+ oboInOwl:id "GO:0005955"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "calcium-dependent protein serine/threonine phosphatase complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "protein phosphatase type 2B complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:019859951"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric calcium ion and calmodulin dependent protein phosphatase composed of catalytic and regulatory subunits; the regulatory subunit is very similar in sequence to calmodulin."^^xsd:string,
+ rdfs:label "calcineurin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0008287
+
+
+Class: obo:GO_0010339
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:tb"^^xsd:string
+ obo:IAO_0000115 "The side of the cell wall that is opposite to the side that faces the cell and its contents."^^xsd:string,
+ oboInOwl:id "GO:0010339"^^xsd:string,
+ rdfs:label "external side of cell wall"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044426,
+ obo:BFO_0000050 some obo:GO_0009986
+
+
+Class: obo:GO_0034615
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0034615"^^xsd:string,
+ oboInOwl:hasExactSynonym "GTP cyclohydrolase I complex"^^xsd:string,
+ rdfs:label "GCH1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16696853"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses GTP cyclohydrolase I activity. In E. coli and human, the complex is a homodecamer, and monomers are catalytically inactive."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0005956
+
+ Annotations:
+ oboInOwl:id "GO:0005956"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "protein kinase CK2 complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "casein kinase II complex"^^xsd:string,
+ rdfs:comment "Note that this term represents a location and not a function; the activity possessed by this complex is mentioned in the definition for the purpose of describing and distinguishing the complex."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10994779"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses protein serine/threonine kinase activity, and contains two catalytic alpha subunits and two regulatory beta subunits. Protein kinase CK2 complexes are found in nearly every subcellular compartment, and can phosphorylate many protein substrates in addition to casein."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0005953
+
+ Annotations:
+ rdfs:label "CAAX-protein geranylgeranyltransferase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9781874"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric enzyme, composed of an alpha and a beta subunit. Participates in the post-translational C-terminal modification of several small GTPases, allowing their targeting to the membrane."^^xsd:string,
+ oboInOwl:id "GO:0005953"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031560
+
+ Annotations:
+ oboInOwl:id "GO:0031560"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cellular bud neck polarisome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9632790"^^xsd:string
+ obo:IAO_0000115 "Protein complex that has a role in determining cell polarity, found at the neck of a fungal bud before and during cytokinesis."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000133
+ and (obo:BFO_0000050 some obo:GO_0005935)
+
+ SubClassOf:
+ obo:GO_0000133,
+ obo:BFO_0000050 some obo:GO_0005935
+
+
+Class: obo:GO_0005954
+
+ Annotations:
+ oboInOwl:hasExactSynonym "calcium/calmodulin-dependent protein kinase complex"^^xsd:string,
+ oboInOwl:id "GO:0005954"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "CaMKII"^^xsd:string,
+ oboInOwl:hasExactSynonym "CAMK2"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "EC:2.7.11.17"^^xsd:string
+ obo:IAO_0000115 "An enzyme complex which in eukaryotes is composed of four different chains: alpha, beta, gamma, and delta. The different isoforms assemble into homo- or heteromultimeric holoenzymes composed of 8 to 12 subunits. Catalyzes the phosphorylation of proteins to O-phosphoproteins."^^xsd:string,
+ rdfs:label "calcium- and calmodulin-dependent protein kinase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0005951
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "arginine-specific carbamoyl phosphate synthetase complex"^^xsd:string,
+ rdfs:label "carbamoyl-phosphate synthase complex"^^xsd:string,
+ oboInOwl:id "GO:0005951"^^xsd:string,
+ oboInOwl:hasExactSynonym "carbamoyl phosphate synthase complex"^^xsd:string,
+ rdfs:comment "Note that in higher eukaryotes, carbamoyl-phosphate synthase is usually a single polypeptide, not a complex, and should therefore not be annotated to this component term."^^xsd:string,
+ oboInOwl:hasNarrowSynonym "carbamoyl-phosphate synthase arginine-specific complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8626695"^^xsd:string
+ obo:IAO_0000115 "A protein complex that catalyzes the formation of carbamoyl phosphate; comprises a small subunit that binds and cleaves glutamine, and a large subunit that accepts the ammonia group cleaved from glutamine, binds all of the remaining substrates and effectors, and carries out all of the other catalytic events."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0000776
+
+ Annotations:
+ oboInOwl:hasAlternativeId "GO:0005699"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000776"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasDbXref "Wikipedia:Kinetochore"^^xsd:string,
+ rdfs:label "kinetochore"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A multisubunit complex that is located at the centromeric region of DNA and provides an attachment point for the spindle microtubules."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:GO_0043232,
+ obo:BFO_0000050 some obo:GO_0000775,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031562
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15976451"^^xsd:string
+ obo:IAO_0000115 "Protein complex that has a role in determining cell polarity, found at the tip of a growing fungal hypha."^^xsd:string,
+ oboInOwl:id "GO:0031562"^^xsd:string,
+ rdfs:label "hyphal tip polarisome"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000133
+ and (obo:BFO_0000050 some obo:GO_0001411)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0001411,
+ obo:GO_0000133
+
+
+Class: obo:GO_0005952
+
+ Annotations:
+ oboInOwl:hasExactSynonym "3',5'-cAMP-dependent protein kinase complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "cyclic AMP-dependent protein kinase complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "adenosine 3',5'-cyclophosphate-dependent protein kinase complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005952"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "EC:2.7.11.11"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "An enzyme complex, composed of regulatory and catalytic subunits, that catalyzes protein phosphorylation. Inactive forms of the enzyme have two regulatory chains and two catalytic chains; activation by cAMP produces two active catalytic monomers and a regulatory dimer."^^xsd:string,
+ oboInOwl:hasExactSynonym "3',5' cAMP-dependent protein kinase complex"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "PKA"^^xsd:string,
+ rdfs:label "cAMP-dependent protein kinase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0000777
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000777"^^xsd:string,
+ rdfs:label "condensed chromosome kinetochore"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A multisubunit complex that is located at the centromeric region of a condensed chromosome and provides an attachment point for the spindle microtubules."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000776
+ and (obo:BFO_0000050 some obo:GO_0000793)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0000779,
+ obo:GO_0000776
+
+
+Class: obo:GO_0031561
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cellular bud tip polarisome"^^xsd:string,
+ oboInOwl:id "GO:0031561"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9632790"^^xsd:string
+ obo:IAO_0000115 "Protein complex that has a role in determining cell polarity, found at the tip of a growing fungal bud."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000133
+ and (obo:BFO_0000050 some obo:GO_0005934)
+
+ SubClassOf:
+ obo:GO_0000133,
+ obo:BFO_0000050 some obo:GO_0005934
+
+
+Class: obo:GO_0000778
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A multisubunit complex that is located at the centromeric region of a condensed chromosome in the nucleus and provides an attachment point for the spindle microtubules."^^xsd:string,
+ oboInOwl:id "GO:0000778"^^xsd:string,
+ rdfs:label "condensed nuclear chromosome kinetochore"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000776
+ and (obo:BFO_0000050 some obo:GO_0000794)
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:BFO_0000050 some obo:GO_0000780,
+ obo:GO_0000777
+
+
+Class: obo:GO_0005950
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "EC:4.1.3.27"^^xsd:string,
+ oboInOwl:hasDbXref "MetaCyc:ANTHRANSYN-CPLX"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:4886290"^^xsd:string
+ obo:IAO_0000115 "A heterotetrameric enzyme complex made up of two components I and two components II. Catalyzes the formation of anthranilate, pyruvate and L-glutamate from chorismate and L-glutamine."^^xsd:string,
+ oboInOwl:id "GO:0005950"^^xsd:string,
+ rdfs:label "anthranilate synthase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0000779
+
+ Annotations:
+ rdfs:label "condensed chromosome, centromeric region"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "condensed chromosome, pericentric region"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000779"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "condensed chromosome, centromere"^^xsd:string,
+ oboInOwl:hasExactSynonym "condensed chromosome, centric region"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:kmv"^^xsd:string
+ obo:IAO_0000115 "The region of a condensed chromosome that includes the centromere and associated proteins, including the kinetochore. In monocentric chromosomes, this region corresponds to a single area of the chromosome, whereas in holocentric chromosomes, it is evenly distributed along the chromosome."^^xsd:string,
+ rdfs:comment "Note that this term can be used in place of the obsolete cellular component term 'centromere ; GO:0005698'. Use with caution because this term refers to a specific region of the chromosome and not a protein complex."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000775
+ and (obo:BFO_0000050 some obo:GO_0000793)
+
+ SubClassOf:
+ obo:GO_0000775,
+ obo:BFO_0000050 some obo:GO_0000793
+
+
+Class: obo:GO_0031563
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031563"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:14734532"^^xsd:string
+ obo:IAO_0000115 "Protein complex that has a role in determining cell polarity, found at the tip of the mating projection in unicellular fungi exposed to mating pheromone."^^xsd:string,
+ rdfs:label "mating projection tip polarisome"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000133
+ and (obo:BFO_0000050 some obo:GO_0043332)
+
+ SubClassOf:
+ obo:GO_0044463,
+ obo:GO_0000133,
+ obo:BFO_0000050 some obo:GO_0043332
+
+
+Class: obo:GO_0071687
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15030757"^^xsd:string
+ obo:IAO_0000115 "The part of the horsetail nucleus where telomeres cluster under the SPB and that leads horsetail movement. The horsetail nucleus is the elongated nucleus which forms during the rapid oscillatory movement at meiotic prophase; characterized in Schizosaccharomyces pombe."^^xsd:string,
+ oboInOwl:id "GO:0071687"^^xsd:string,
+ rdfs:label "horsetail nucleus leading edge"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:BFO_0000050 some obo:GO_0071686
+
+
+Class: obo:GO_0000784
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "The terminal region of a linear chromosome in the nucleus that includes the telomeric DNA repeats and associated proteins."^^xsd:string,
+ oboInOwl:hasExactSynonym "nuclear chromosome, telomere"^^xsd:string,
+ rdfs:comment "Note that this term can be used in place of the obsolete cellular component term 'telomere ; GO:0005696'. Use with caution because this term refers to a specific region of the chromosome and not a protein complex."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "nuclear chromosome, telomeric region"^^xsd:string,
+ oboInOwl:id "GO:0000784"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000781
+ and (obo:BFO_0000050 some obo:GO_0005634)
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:GO_0000781
+
+
+Class: obo:GO_0071686
+
+ Annotations:
+ rdfs:label "horsetail nucleus"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071686"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15030757"^^xsd:string
+ obo:IAO_0000115 "The elongated nucleus which forms during the rapid oscillatory movement at meiotic prophase; characterized in Schizosaccharomyces pombe."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005634
+
+
+Class: obo:GO_0000783
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A complex of DNA and protein located at the end of a linear chromosome in the nucleus that protects and stabilizes a linear chromosome."^^xsd:string,
+ rdfs:label "nuclear telomere cap complex"^^xsd:string,
+ oboInOwl:id "GO:0000783"^^xsd:string,
+ rdfs:comment "Note that this term can be used in place of the obsolete cellular component term 'telomere ; GO:0005696'. Use with caution because this term refers to a specific protein complex and not a region of the chromosome."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000782
+ and (obo:BFO_0000050 some obo:GO_0005634)
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:GO_0000782,
+ obo:BFO_0000050 some obo:GO_0000784
+
+
+Class: obo:GO_0000786
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Nucleosome"^^xsd:string,
+ rdfs:label "nucleosome"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0000786"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0005718"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A complex comprised of DNA wound around a multisubunit core and associated proteins, which forms the primary packing unit of DNA into higher order structures."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:GO_0032993,
+ obo:BFO_0000050 some obo:GO_0000785
+
+
+Class: obo:GO_0000785
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20404130"^^xsd:string
+ obo:IAO_0000115 "The ordered and organized complex of DNA, protein, and sometimes RNA, that forms the chromosome."^^xsd:string,
+ rdfs:label "chromatin"^^xsd:string,
+ oboInOwl:id "GO:0000785"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "chromosome scaffold"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1615953555"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0005717"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427
+
+
+Class: obo:GO_0071683
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dos"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:kmv"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A dendrite that is found on a sensory neuron, and directly transduces a sensory signal from the sensory neuron to another neuron."^^xsd:string,
+ rdfs:label "sensory dendrite"^^xsd:string,
+ oboInOwl:id "GO:0071683"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030425
+
+
+Class: obo:GO_0033062
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ obo:IAO_0000115 "A conserved heterodimeric DNA recombinase mediator complex that contains the RecA family proteins Rhp55p and Rph57 in Schizosaccharomyces, or orthologs thereof (e.g. Rad55p and Rad57p in Saccharomyces)."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "Rad55-Rad57 complex"^^xsd:string,
+ oboInOwl:id "GO:0033062"^^xsd:string,
+ rdfs:label "Rhp55-Rhp57 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033061
+
+
+Class: obo:GO_0000780
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "condensed nuclear chromosome, centric region"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "condensed nuclear chromosome, centromere"^^xsd:string,
+ rdfs:label "condensed nuclear chromosome, centromeric region"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:kmv"^^xsd:string
+ obo:IAO_0000115 "The region of a condensed chromosome in the nucleus that includes the centromere and associated proteins, including the kinetochore. In monocentric chromosomes, this region corresponds to a single area of the chromosome, whereas in holocentric chromosomes, it is evenly distributed along the chromosome."^^xsd:string,
+ oboInOwl:hasRelatedSynonym "condensed nuclear chromosome, pericentric region"^^xsd:string,
+ rdfs:comment "Note that this term can be used in place of the obsolete cellular component term 'centromere ; GO:0005698'. Use with caution because this term refers to a specific region of the chromosome and not a protein complex."^^xsd:string,
+ oboInOwl:id "GO:0000780"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000779
+ and (obo:BFO_0000050 some obo:GO_0000794)
+ and (obo:BFO_0000050 some obo:GO_0005634)
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:BFO_0000050 some obo:GO_0000794,
+ obo:GO_0000779
+
+
+Class: obo:GO_0071682
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pde"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membrane of an endocytic vesicle."^^xsd:string,
+ rdfs:label "endocytic vesicle lumen"^^xsd:string,
+ oboInOwl:id "GO:0071682"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0030139,
+ obo:GO_0060205
+
+
+Class: obo:GO_0033063
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "BCDX2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16093548"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17114795"^^xsd:string
+ obo:IAO_0000115 "A DNA recombinase mediator complex that contains the Rad51 paralogs RAD51B, RAD51C, RAD51D, and XRCC2, or orthologs thereof."^^xsd:string,
+ oboInOwl:id "GO:0033063"^^xsd:string,
+ rdfs:label "Rad51B-Rad51C-Rad51D-XRCC2 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033061
+
+
+Class: obo:GO_0005948
+
+ Annotations:
+ oboInOwl:hasExactSynonym "acetohydroxyacid synthase complex"^^xsd:string,
+ rdfs:comment "See also the molecular function term 'acetolactate synthase activity ; GO:0003984'."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "BRENDA:2.2.1.6"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16458324"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8756689"^^xsd:string
+ obo:IAO_0000115 "A dimeric (a large and a small chain) or tetrameric (two large and two small chains) enzyme complex. Catalyzes the formation of acetolactate from pyruvate."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "acetolactate synthase complex"^^xsd:string,
+ oboInOwl:id "GO:0005948"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0071685
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "NADH dehydrogenase complex (plastoquinone)"^^xsd:string,
+ oboInOwl:id "GO:0071685"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "DOI:10.1078/0176-1617-00593"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "An NADH dehydrogenase complex that catalyzes the transfer of electrons to plastoquinone. The complex is involved in the non-photochemical reduction of plastoquinones and the cyclic electron transport around photosystem I, and is found in plastid thylakoids."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044436,
+ obo:GO_0030964,
+ obo:BFO_0000050 some obo:GO_0031976
+
+
+Class: obo:GO_0005947
+
+ Annotations:
+ rdfs:label "mitochondrial alpha-ketoglutarate dehydrogenase complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasBroadSynonym "2-oxoglutarate dehydrogenase complex"^^xsd:string,
+ oboInOwl:id "GO:0005947"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "Mitochondrial complex that possesses alpha-ketoglutarate dehydrogenase activity."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0045240
+ and (obo:BFO_0000050 some obo:GO_0005739)
+
+ SubClassOf:
+ obo:GO_0030062,
+ obo:GO_0045240
+
+
+Class: obo:GO_0000782
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A complex of DNA and protein located at the end of a linear chromosome that protects and stabilizes a linear chromosome."^^xsd:string,
+ rdfs:label "telomere cap complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:comment "Note that this term can be used in place of the obsolete cellular component term 'telomere ; GO:0005696'. Use with caution because this term refers to a specific protein complex and not a region of the chromosome."^^xsd:string,
+ oboInOwl:id "GO:0000782"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:BFO_0000050 some obo:GO_0000781,
+ obo:GO_0032993
+
+
+Class: obo:GO_0033061
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ obo:IAO_0000115 "A protein complex that promotes nucleoprotein filament formation during homologous recombination; most known examples contain two or more RecA family proteins (often Rad51 paralogs)."^^xsd:string,
+ rdfs:label "DNA recombinase mediator complex"^^xsd:string,
+ oboInOwl:id "GO:0033061"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0005946
+
+ Annotations:
+ rdfs:label "alpha,alpha-trehalose-phosphate synthase complex (UDP-forming)"^^xsd:string,
+ oboInOwl:hasExactSynonym "UDP-glucose-glucosephosphate glucosyltransferase complex"^^xsd:string,
+ rdfs:comment "See also the molecular function term 'alpha,alpha-trehalose-phosphate synthase (UDP-forming) activity ; GO:0003825'."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "trehalose-6-phosphate synthase complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "trehalose-6-phosphate synthase/phosphatase"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9837904"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses alpha,alpha-trehalose-phosphate synthase (UDP-forming) and trehalose-phosphatase activities, and thus catalyzes two reactions in trehalose biosynthesis. In the complex identified in Saccharomyces, Tps1p has alpha,alpha-trehalose-phosphate synthase (UDP-forming) activity, Tps2p has trehalose 6-phosphate phosphatase activity; Tps3p is a regulatory subunit, and an additional subunit, Tsl1p, may be present."^^xsd:string,
+ oboInOwl:id "GO:0005946"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444,
+ obo:GO_0043234
+
+
+Class: obo:GO_0000781
+
+ Annotations:
+ rdfs:comment "Note that this term can be used in place of the obsolete cellular component term 'telomere ; GO:0005696'. Use with caution because this term refers to a specific region of the chromosome and not a protein complex."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "The terminal region of a linear chromosome that includes the telomeric DNA repeats and associated proteins."^^xsd:string,
+ oboInOwl:hasRelatedSynonym "telomere"^^xsd:string,
+ oboInOwl:id "GO:0000781"^^xsd:string,
+ rdfs:label "chromosome, telomeric region"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427
+
+
+Class: obo:GO_0033066
+
+ Annotations:
+ oboInOwl:id "GO:0033066"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16093548"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17114795"^^xsd:string
+ obo:IAO_0000115 "A DNA recombinase mediator complex that contains the Rad51 paralogs RAD51B and RAD51C, or orthologs thereof."^^xsd:string,
+ oboInOwl:hasExactSynonym "BC complex"^^xsd:string,
+ rdfs:label "Rad51B-Rad51C complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033061
+
+
+Class: obo:GO_0033064
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0033064"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16093548"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric DNA recombinase mediator complex that contains the Rad51 paralogs RAD51D and XRCC2, or orthologs thereof; conserved from fission yeast to human but absent from budding yeast."^^xsd:string,
+ rdfs:label "XRCC2-RAD51D complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "DX2 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033061
+
+
+Class: obo:GO_0033065
+
+ Annotations:
+ rdfs:label "Rad51C-XRCC3 complex"^^xsd:string,
+ oboInOwl:id "GO:0033065"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16093548"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17114795"^^xsd:string
+ obo:IAO_0000115 "A DNA recombinase mediator complex that contains the Rad51 paralogs RAD51C and XRCC3, or orthologs thereof."^^xsd:string,
+ oboInOwl:hasExactSynonym "CX3 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033061
+
+
+Class: obo:GO_0016473
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "sodium ion-transporting F-type ATPase complex"^^xsd:string,
+ oboInOwl:id "GO:0016473"^^xsd:string,
+ oboInOwl:hasExactSynonym "sodium-translocating F-type ATPase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14656431"^^xsd:string
+ obo:IAO_0000115 "A sodium ion-transporting two-sector ATPase complex that catalyzes the phosphorylation of ADP to ATP. The complex comprises a membrane sector (F0) that carries out proton transport and a cytoplasmic compartment sector (F1) that catalyzes ATP synthesis by a rotational mechanism."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016472
+
+
+Class: obo:GO_0016472
+
+ Annotations:
+ oboInOwl:hasExactSynonym "sodium-transporting two-sector ATPase complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14656431"^^xsd:string
+ obo:IAO_0000115 "A large protein complex that catalyzes the synthesis or hydrolysis of ATP by a rotational mechanism, coupled to the transport of sodium ions across a membrane. The complex comprises a membrane sector (F0 or V0) that carries out ion transport and a cytoplasmic compartment sector (F1 or V1) that catalyzes ATP synthesis or hydrolysis."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0016472"^^xsd:string,
+ rdfs:label "sodium ion-transporting two-sector ATPase complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0016021,
+ obo:GO_0044425,
+ obo:GO_0043234
+
+
+Class: obo:GO_0016474
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "sodium-translocating V-type ATPase complex"^^xsd:string,
+ oboInOwl:id "GO:0016474"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15802565"^^xsd:string
+ obo:IAO_0000115 "A sodium ion-transporting two-sector ATPase complex that couples ATP hydrolysis to the transport of sodium ions across a concentration gradient. The complex comprises a membrane sector (V0) that carries out proton transport and a cytoplasmic compartment sector (V1) that catalyzes ATP hydrolysis."^^xsd:string,
+ rdfs:label "sodium ion-transporting V-type ATPase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016472
+
+
+Class: obo:GO_0016471
+
+ Annotations:
+ rdfs:comment "See also the cellular component terms 'vacuolar proton-transporting V-type ATPase, V1 domain ; GO:0000221' and 'vacuolar proton-transporting V-type ATPase, V0 domain ; GO:0000220' and the molecular function term 'hydrogen ion transporting ATPase activity, rotational mechanism ; GO:0046961'."^^xsd:string,
+ oboInOwl:hasExactSynonym "vacuolar hydrogen-translocating V-type ATPase complex"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0716743663"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16449553"^^xsd:string
+ obo:IAO_0000115 "A proton-transporting two-sector ATPase complex found in the vacuolar membrane, where it acts as a proton pump to mediate acidification of the vacuolar lumen."^^xsd:string,
+ rdfs:label "vacuolar proton-transporting V-type ATPase complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0016471"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0033176
+ and (obo:BFO_0000050 some obo:GO_0005773)
+
+ SubClassOf:
+ obo:GO_0044437,
+ obo:GO_0033176,
+ obo:BFO_0000050 some obo:GO_0005774
+
+
+Class: obo:GO_0005942
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:curators"^^xsd:string
+ oboInOwl:hasExactSynonym "phosphoinositide 3-kinase complex"^^xsd:string,
+ oboInOwl:id "GO:0005942"^^xsd:string,
+ oboInOwl:hasExactSynonym "PI3K complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "1-phosphatidylinositol 3-kinase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:439"^^xsd:string
+ oboInOwl:hasNarrowSynonym "PIK3CA-PIK3R1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string
+ obo:IAO_0000115 "A complex containing a heterodimer of a catalytic subunit and a regulatory (adaptor) subunit of any phosphatidylinositol 3-kinase (PI3K)."^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:429"^^xsd:string
+ oboInOwl:hasNarrowSynonym "PIK3C3-PIK3R4 complex"^^xsd:string,
+ rdfs:label "phosphatidylinositol 3-kinase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2575"^^xsd:string
+ oboInOwl:hasNarrowSynonym "PI3-kinase p85-subunit alpha- PI3-kinase p110 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044445,
+ obo:GO_0043234
+
+
+Class: obo:GO_0005943
+
+ Annotations:
+ oboInOwl:id "GO:0005943"^^xsd:string,
+ oboInOwl:hasExactSynonym "class IA PI3K complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "phosphoinositide 3-kinase complex, class IA"^^xsd:string,
+ rdfs:label "1-phosphatidylinositol-4-phosphate 3-kinase, class IA complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9255069"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9759495"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric protein complex that possesses 1-phosphatidylinositol-4-phosphate 3-kinase activity; comprises a catalytic Class IA phosphoinositide 3-kinase (PI3K) subunit of 110-120 kDa and an associated SH2 domain-containing regulatory subunit that is a member of a family of related proteins often called p85 proteins. Class I PI3Ks phosphorylate phosphatidylinositol [PI], phosphatidylinositol-4-phosphate [PI(4)P] and phosphatidylinositol-4,5-bisphosphate [PI(4,5)P2], and are divided into subclasses A and B according to the type of adaptor subunit with which they associate. Through the interaction with the SH2-containing adaptor subunits, Class IA PI3K catalytic subunits are linked to tyrosine kinase signaling pathways."^^xsd:string,
+ oboInOwl:hasExactSynonym "1-phosphatidylinositol-4-phosphate kinase, class IA complex"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0035030"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005942
+
+
+Class: obo:GO_0005944
+
+ Annotations:
+ rdfs:label "1-phosphatidylinositol-4-phosphate 3-kinase, class IB complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9255069"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9759495"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric protein complex that possesses 1-phosphatidylinositol-4-phosphate 3-kinase activity; comprises a catalytic Class IB phosphoinositide 3-kinase (PI3K) subunit of 110-120 kDa and an associated regulatory subunit that is larger than, and unrelated to, the p85 proteins present in class IA complexes. Class I PI3Ks phosphorylate phosphatidylinositol [PI], phosphatidylinositol-4-phosphate [PI(4)P] and phosphatidylinositol-4,5-bisphosphate [PI(4,5)P2] and are divided into subclasses A and B according to the type of adaptor subunit with which they associate. Class IB PI3Ks are stimulated by G-proteins and do not interact with the SH2-domain containing adaptors that bind to Class IA PI3Ks."^^xsd:string,
+ oboInOwl:hasExactSynonym "class IB PI3K complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005944"^^xsd:string,
+ oboInOwl:hasExactSynonym "phosphoinositide 3-kinase complex, class IB"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "1-phosphatidylinositol-4-phosphate kinase, class IB complex"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0035031"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005942
+
+
+Class: obo:GO_0005945
+
+ Annotations:
+ oboInOwl:id "GO:0005945"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses 6-phosphofructokinase activity; homodimeric, homooctameric, and allosteric homotetrameric forms are known."^^xsd:string,
+ rdfs:label "6-phosphofructokinase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044445,
+ obo:GO_0043234
+
+
+Class: obo:GO_0005940
+
+ Annotations:
+ oboInOwl:hasAlternativeId "GO:0030481"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005940"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Septin_ring"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16009555"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16151244"^^xsd:string
+ obo:IAO_0000115 "A tight ring-shaped structure that forms in the division plane at the site of cytokinesis; composed of members of the conserved family of filament-forming proteins called septins as well as septin-associated proteins. This type of septin structure is observed at the bud neck of budding fungal cells, at the site of cell division in animal cells, at the junction between the mother cell and a pseudohyphal projection, and also within hyphae of filamentous fungi at sites where a septum will form."^^xsd:string,
+ rdfs:label "septin ring"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044430,
+ obo:GO_0032156,
+ obo:GO_0044448
+
+
+Class: obo:GO_0000775
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "centromere"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "chromosome, pericentric region"^^xsd:string,
+ oboInOwl:id "GO:0000775"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:kmv"^^xsd:string
+ obo:IAO_0000115 "The region of a chromosome that includes the centromeric DNA and associated proteins. In monocentric chromosomes, this region corresponds to a single area of the chromosome, whereas in holocentric chromosomes, it is evenly distributed along the chromosome."^^xsd:string,
+ oboInOwl:hasExactSynonym "chromosome, centric region"^^xsd:string,
+ rdfs:label "chromosome, centromeric region"^^xsd:string,
+ rdfs:comment "Note that this term can be used in place of the obsolete cellular component term 'centromere ; GO:0005698'. Use with caution because this term refers to a specific region of the chromosome and not a protein complex."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427
+
+
+Class: obo:GO_0051285
+
+ Annotations:
+ oboInOwl:hasExactSynonym "cell cortex of cell end"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cell cortex of cell tip"^^xsd:string,
+ oboInOwl:id "GO:0051285"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ai"^^xsd:string
+ obo:IAO_0000115 "The region directly beneath the plasma membrane at the cell tip. The cell tip is the region at either end of the longest axis of a cylindrical or elongated cell."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0044448
+ and (obo:BFO_0000050 some obo:GO_0051286)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0051286,
+ obo:GO_0044448
+
+
+Class: obo:GO_0051286
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ai"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The region at either end of the longest axis of a cylindrical or elongated cell."^^xsd:string,
+ oboInOwl:id "GO:0051286"^^xsd:string,
+ rdfs:comment "Note that this term differs from 'cell pole ; GO:0060187' in that it is applicable to a narrower range of cell shapes."^^xsd:string,
+ rdfs:label "cell tip"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "cell end"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0060187
+
+
+Class: obo:GO_0008004
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0008004"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "A layer of the basal lamina that contains collagen fibrils and connects the basal lamina to the underlying connective tissue."^^xsd:string,
+ rdfs:label "lamina reticularis"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044420,
+ obo:BFO_0000050 some obo:GO_0005605
+
+
+Class: obo:GO_0010330
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12514238"^^xsd:string
+ obo:IAO_0000115 "The multimeric protein complex, organized in a rosette, which catalyzes the biosynthesis of cellulose for the plant cell wall."^^xsd:string,
+ rdfs:label "cellulose synthase complex"^^xsd:string,
+ oboInOwl:id "GO:0010330"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0005935
+
+ Annotations:
+ oboInOwl:id "GO:0005935"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The constriction between the mother cell and daughter cell (bud) in an organism that reproduces by budding."^^xsd:string,
+ rdfs:label "cellular bud neck"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030427,
+ obo:BFO_0000050 some obo:GO_0005933
+
+
+Class: obo:GO_0008002
+
+ Annotations:
+ rdfs:label "lamina lucida"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Lamina_lucida"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "The electron-lucent layer of the basal lamina adjacent to the basal plasma membrane of the cells that rest on the lamina."^^xsd:string,
+ oboInOwl:id "GO:0008002"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044420,
+ obo:BFO_0000050 some obo:GO_0005605
+
+
+Class: obo:GO_0005938
+
+ Annotations:
+ oboInOwl:id "GO:0005938"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Cell_cortex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "peripheral cytoplasm"^^xsd:string,
+ rdfs:label "cell cortex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ oboInOwl:hasRelatedSynonym "cell periphery"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "The region of a cell that lies just beneath the plasma membrane and often, but not always, contains a network of actin filaments and associated proteins."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0071944,
+ obo:GO_0044444
+
+
+Class: obo:GO_0008003
+
+ Annotations:
+ rdfs:label "lamina densa"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "The electron-dense layer of the basal lamina; lies just below the lamina lucida."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Lamina_densa"^^xsd:string,
+ oboInOwl:id "GO:0008003"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044420,
+ obo:BFO_0000050 some obo:GO_0005605
+
+
+Class: obo:GO_0005937
+
+ Annotations:
+ oboInOwl:id "GO:0005937"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mcc"^^xsd:string
+ obo:IAO_0000115 "The projection formed by unicellular fungi in response to mating pheromone."^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "mating projection"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "conjugation tube"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "shmoo"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042995
+
+
+Class: obo:GO_0071627
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Located such that some or all of the gene product itself penetrates at least one phospholipid bilayer of the fungal-type vacuolar membrane. May also refer to the state of being buried in the bilayer with no exposure outside the bilayer."^^xsd:string,
+ rdfs:label "integral to fungal-type vacuolar membrane"^^xsd:string,
+ oboInOwl:id "GO:0071627"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071628,
+ obo:GO_0031166
+
+
+Class: obo:GO_0097059
+
+ Annotations:
+ oboInOwl:id "GO:0097059"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "sCNTFR-CLC complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11285233"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is composed of two soluble ciliary neurotrophic factor receptor alpha subunits (product of the CNTFR gene) and two molecules of cardiotrophin-like cytokine factor 1 (product of the CLCF1 gene). The complex is secreted into the extracellular space."^^xsd:string,
+ rdfs:label "CNTFR-CLCF1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421,
+ obo:BFO_0000050 some obo:GO_0005615,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071628
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071628"^^xsd:string,
+ rdfs:label "intrinsic to fungal-type vacuolar membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Located in the fungal-type vacuolar membrane such that some covalently attached portion of the gene product, for example part of a peptide sequence or some other covalently attached group such as a GPI anchor, spans or is embedded in one or both leaflets of the membrane."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0000329,
+ obo:GO_0031310
+
+
+Class: obo:GO_0033001
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasBroadSynonym "IgG receptor complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0781735149"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11244038"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12413532"^^xsd:string
+ obo:IAO_0000115 "A protein complex composed of an Fc-gamma RIII alpha chain and an Fc-epsilon RI gamma chain dimer with or without an Fc-epsilon RI beta chain and additional signaling components. The complex functions primarily as an activating receptor for IgG."^^xsd:string,
+ oboInOwl:hasBroadSynonym "immunoglobulin G receptor complex"^^xsd:string,
+ oboInOwl:id "GO:0033001"^^xsd:string,
+ oboInOwl:hasExactSynonym "FcgRIII complex"^^xsd:string,
+ rdfs:label "Fc-gamma receptor III complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032997
+
+
+Class: obo:GO_0033000
+
+ Annotations:
+ rdfs:label "Fc-gamma receptor I complex"^^xsd:string,
+ oboInOwl:hasBroadSynonym "IgG receptor complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasBroadSynonym "immunoglobulin G receptor complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0781735149"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11244038"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12413532"^^xsd:string
+ obo:IAO_0000115 "A protein complex composed of an Fc-gamma RI alpha chain and an Fc-epsilon RI gamma chain dimer with or without additional signaling components. The complex functions primarily as an activating receptor for IgG."^^xsd:string,
+ oboInOwl:id "GO:0033000"^^xsd:string,
+ oboInOwl:hasExactSynonym "FcgRI complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032997
+
+
+Class: obo:GO_0043159
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8949900"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9139729"^^xsd:string
+ obo:IAO_0000115 "A structural framework, or 'dense core' at the interior of an acrosome. May regulate the distribution of hydrolases within the acrosome and their release during the acrosome reaction."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0043159"^^xsd:string,
+ rdfs:label "acrosomal matrix"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044437,
+ obo:GO_0044433,
+ obo:BFO_0000050 some obo:GO_0001669
+
+
+Class: obo:GO_0005924
+
+ Annotations:
+ oboInOwl:id "GO:0005924"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "hemi-adherens junction"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:hb"^^xsd:string
+ obo:IAO_0000115 "An adherens junction which connects a cell to the extracellular matrix."^^xsd:string,
+ rdfs:label "cell-substrate adherens junction"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005912,
+ obo:GO_0030055
+
+
+Class: obo:GO_0030874
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030874"^^xsd:string,
+ rdfs:label "nucleolar chromatin"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The portion of nuclear chromatin associated with the nucleolus; includes the DNA encoding the ribosomal RNA."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044452,
+ obo:BFO_0000050 some obo:GO_0000790,
+ obo:GO_0044454
+
+
+Class: obo:GO_0005925
+
+ Annotations:
+ oboInOwl:id "GO:0005925"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "hemi-adherens junction"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0008357"^^xsd:string,
+ oboInOwl:hasExactSynonym "focal contact"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Focal_adhesion"^^xsd:string,
+ rdfs:label "focal adhesion"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0124325653"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815316208"^^xsd:string
+ obo:IAO_0000115 "Small region on the surface of a cell that anchors the cell to the extracellular matrix and that forms a point of termination of actin filaments."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005924
+
+
+Class: obo:GO_0002169
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:hjd"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15868465"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric complex having 3-methylcrotonyl-CoA carboxylase activity. The alpha subunit has a covalently bound biotin essential for the ATP-dependent carboxylation. The beta subunit possess carboxyltransferase activity which presumably is essential for binding to 3-methylcrotonyl-CoA."^^xsd:string,
+ oboInOwl:id "GO:0002169"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "3-methylcrotonyl-CoA carboxylase complex, mitochondrial"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044429,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030875
+
+ Annotations:
+ oboInOwl:hasExactSynonym "ribosomal DNA protrusion"^^xsd:string,
+ oboInOwl:id "GO:0030875"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "rDNA protrusion"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:1629244"^^xsd:string
+ obo:IAO_0000115 "Any of the tandem arrays of rDNA localized at the periphery of the nucleus and protruding into the nucleolus, and associated proteins. May be visible as a single or double spot by DAPI staining."^^xsd:string,
+ rdfs:comment "Note that this component is characterized in Schizosaccharomyces, particularly with respect to the DAPI staining pattern."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044452,
+ obo:GO_0044454,
+ obo:BFO_0000050 some obo:GO_0030874
+
+
+Class: obo:GO_0005926
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "http://flybase.bio.indiana.edu/allied-data/lk/interactive-fly/aignfam/junction.htm"^^xsd:string
+ obo:IAO_0000115 "A cell-substrate adherens junction, also known as a hemiadherens junction (HAJ) that forms one of a pair of junctions in opposing cells that are separated by only 30-40nm, with a thin line of extracellular electron-dense material in between; found where muscles attach to epidermal cells directly (in insects)."^^xsd:string,
+ oboInOwl:id "GO:0005926"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "connecting hemi-adherens junction"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005924
+
+
+Class: obo:GO_0005927
+
+ Annotations:
+ oboInOwl:id "GO:0005927"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "myotendinous junction"^^xsd:string,
+ rdfs:label "muscle tendon junction"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12842007"^^xsd:string
+ obo:IAO_0000115 "A cell-substrate junction found at the terminal anchorage site of skeletal muscle cells to tendons."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005924
+
+
+Class: obo:GO_0070057
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14702385"^^xsd:string
+ obo:IAO_0000115 "The region of the prospore membrane to which the spindle pole body (SPB) is anchored; the prospore membrane extends from the SPB attachment site to surround the spore nucleus."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "prospore membrane spindle pole body attachment site"^^xsd:string,
+ oboInOwl:id "GO:0070057"^^xsd:string,
+ oboInOwl:hasExactSynonym "forespore membrane SPB attachment site"^^xsd:string,
+ oboInOwl:hasExactSynonym "prospore membrane SPB attachment site"^^xsd:string,
+ oboInOwl:hasExactSynonym "forespore membrane spindle pole body attachment site"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0005628
+
+
+Class: obo:GO_0005928
+
+ Annotations:
+ rdfs:label "apical hemi-adherens junction"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "apical dense plaque"^^xsd:string,
+ oboInOwl:id "GO:0005928"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11700298"^^xsd:string
+ obo:IAO_0000115 "A cell-substrate adherens junction found in the apical region of a cell, such as those found in cuticle-secreting epithelia, which connect the apical membrane to the cuticle."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "apical cell-substrate adherens junction"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005924
+
+
+Class: obo:GO_0070056
+
+ Annotations:
+ rdfs:label "prospore membrane leading edge"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "forespore membrane leading edge"^^xsd:string,
+ oboInOwl:id "GO:0070056"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14702385"^^xsd:string
+ obo:IAO_0000115 "The region of the prospore membrane that extends to surround the spore nucleus; coated with specific proteins that are thought to play a role in prospore membrane organization."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0005628
+
+
+Class: obo:GO_0005929
+
+ Annotations:
+ rdfs:label "cilium"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Cilium"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao787716553"^^xsd:string,
+ oboInOwl:id "GO:0005929"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:kmv"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198547684"^^xsd:string
+ obo:IAO_0000115 "A specialized eukaryotic organelle that consists of a filiform extrusion of the cell surface. Each cilium is bounded by an extrusion of the cytoplasmic membrane, and contains a regular longitudinal array of microtubules, anchored basally in a centriole."^^xsd:string,
+ oboInOwl:inSubset
+
+ SubClassOf:
+ obo:GO_0042995
+
+
+Class: obo:GO_0030876
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasExactSynonym "IL-20 receptor complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030876"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A protein complex that binds interleukin-20; comprises an alpha and a beta subunit."^^xsd:string,
+ rdfs:label "interleukin-20 receptor complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005887,
+ obo:GO_0044459,
+ obo:GO_0043235
+
+
+Class: obo:GO_0002167
+
+ Annotations:
+ rdfs:label "VRK3/VHR/ERK complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:hjd"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16845380"^^xsd:string
+ obo:IAO_0000115 "A ternary complex consisting of VRK3, VHR (Dusp3), and ERK1 (Mapk3) existing in neuronal cells, and is involved in regulation of the ERK signaling pathway."^^xsd:string,
+ oboInOwl:id "GO:0002167"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0030877
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:14600025"^^xsd:string
+ obo:IAO_0000115 "A cytoplasmic protein complex containing glycogen synthase kinase-3-beta (GSK-3-beta), the adenomatous polyposis coli protein (APC), and the scaffolding protein axin, among others; phosphorylates beta-catenin, targets it for degradation by the proteasome."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030877"^^xsd:string,
+ oboInOwl:hasExactSynonym "beta-catenin degradation complex"^^xsd:string,
+ rdfs:label "beta-catenin destruction complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0005930
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "axoneme"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198547684"^^xsd:string
+ obo:IAO_0000115 "The bundle of microtubules and associated proteins that forms the core of cilia and flagella in eukaryotic cells and is responsible for their movements."^^xsd:string,
+ oboInOwl:id "GO:0005930"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Axoneme"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044463,
+ obo:BFO_0000050 some obo:GO_0043231,
+ obo:GO_0044424,
+ obo:GO_0044422
+
+
+Class: obo:GO_0070062
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "extracellular vesicular exosome"^^xsd:string,
+ oboInOwl:id "GO:0070062"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15908444"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17641064"^^xsd:string
+ obo:IAO_0000115 "A membrane-bounded vesicle that is released into the extracellular region by fusion of the limiting endosomal membrane of a multivesicular body with the plasma membrane."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031988,
+ obo:GO_0065010
+
+
+Class: obo:GO_0005932
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "microtubule basal body"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:clt"^^xsd:string
+ obo:IAO_0000115 "A short cylindrical array of microtubules and associated proteins found at the base of a eukaryotic cilium or flagellum that is similar in structure to a centriole. The basal body serves as a nucleation site for axoneme growth."^^xsd:string,
+ oboInOwl:id "GO:0005932"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao11978067"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005815
+ and (obo:BFO_0000050 some obo:GO_0042995)
+
+ SubClassOf:
+ obo:GO_0044463,
+ obo:GO_0005815
+
+
+Class: obo:GO_0030057
+
+ Annotations:
+ oboInOwl:hasExactSynonym "spot desmosome"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Desmosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "macula adherens"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815332181"^^xsd:string
+ obo:IAO_0000115 "A cell-cell junction in which: on the cytoplasmic surface of each interacting plasma membrane is a dense plaque composed of a mixture of intracellular anchor proteins; a bundle of keratin intermediate filaments is attached to the surface of each plaque; transmembrane adhesion proteins of the cadherin family bind to the plaques and interact through their extracellular domains to hold the adjacent membranes together by a Ca2+-dependent mechanism."^^xsd:string,
+ rdfs:label "desmosome"^^xsd:string,
+ oboInOwl:id "GO:0030057"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005911,
+ obo:GO_0070161
+
+
+Class: obo:GO_0097060
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20410104"^^xsd:string
+ obo:IAO_0000115 "A specialized area of membrane on either the presynaptic or the postsynaptic side of a synapse, the junction between a nerve fiber of one neuron and another neuron or muscle fiber or glial cell."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0097060"^^xsd:string,
+ rdfs:label "synaptic membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016020,
+ obo:GO_0044456
+
+
+Class: obo:GO_0005931
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "A protein complex found in the axoneme of eukaryotic cilia and flagella. It forms interconnections between the microtubule outer doublets that surround the inner central pair of microtubules."^^xsd:string,
+ rdfs:label "nexin complex"^^xsd:string,
+ oboInOwl:id "GO:0005931"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044447,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030056
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "http://www.wormatlas.org/glossaries/hglossary.htm#hemiadherensjunction"^^xsd:string
+ oboInOwl:hasRelatedSynonym "hemi-adherens junction"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "hemidesmosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815316208"^^xsd:string
+ obo:IAO_0000115 "A cell-substrate junction that forms a point of contact between the basal surface of epithelial cells and the basal lamina. Morphologically resembles desmosomes; attached to intermediate filaments."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Hemidesmosome"^^xsd:string,
+ oboInOwl:id "GO:0030056"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030055,
+ obo:BFO_0000050 some obo:GO_0009925
+
+
+Class: obo:GO_0005934
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The end of a cellular bud distal to the site of attachment to the mother cell."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cellular bud tip"^^xsd:string,
+ oboInOwl:id "GO:0005934"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030427,
+ obo:BFO_0000050 some obo:GO_0005933
+
+
+Class: obo:GO_0030055
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:hb"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A cell junction that forms a connection between a cell and the extracellular matrix."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cell-substrate junction"^^xsd:string,
+ oboInOwl:hasExactSynonym "cell-matrix junction"^^xsd:string,
+ oboInOwl:id "GO:0030055"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030054,
+ obo:BFO_0000050 some obo:GO_0016323
+
+
+Class: obo:GO_0030880
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasExactSynonym "multisubunit RNA polymerase"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "RNA polymerase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Any complex that possesses RNA polymerase activity; generally comprises a catalytic subunit and one or more additional subunits."^^xsd:string,
+ oboInOwl:id "GO:0030880"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0005933
+
+ Annotations:
+ rdfs:label "cellular bud"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0005933"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:sgd_curators"^^xsd:string
+ obo:IAO_0000115 "A protuberance from a cell of an organism that reproduces by budding, which will grow larger and become a separate daughter cell after nuclear division, cytokinesis, and cell wall formation (when appropriate). The daughter cell may completely separate from the mother cell, or the mother and daughter cells may remain associated."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0030054
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cell junction"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string,
+ oboInOwl:hasDbXref "http://www.vivo.colostate.edu/hbooks/cmb/cells/pmemb/junctions_a.html"^^xsd:string
+ obo:IAO_0000115 "A plasma membrane part that forms a specialized region of connection between two cells or between a cell and the extracellular matrix. At a cell junction, anchoring proteins extend through the plasma membrane to link cytoskeletal proteins in one cell to cytoskeletal proteins in neighboring cells or to proteins in the extracellular matrix."^^xsd:string,
+ oboInOwl:id "GO:0030054"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Cell_junction"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005575
+
+
+Class: obo:GO_0071212
+
+ Annotations:
+ rdfs:label "subsynaptic reticulum"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:1460464"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18171947"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19244343"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7946331"^^xsd:string
+ obo:IAO_0000115 "An elaborate tubulolamellar membrane system that underlies the postsynaptic cell membrane."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:19244343"^^xsd:string
+ oboInOwl:hasExactSynonym "SSR"^^xsd:string,
+ oboInOwl:id "GO:0071212"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0061174,
+ obo:GO_0033267,
+ obo:GO_0044456,
+ obo:GO_0043231,
+ obo:GO_0044444
+
+
+Class: obo:GO_0031105
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "septin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15385632"^^xsd:string
+ obo:IAO_0000115 "Any of several heterooligomeric complexes containing multiple septins."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0031105"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044430,
+ obo:BFO_0000050 some obo:GO_0032156,
+ obo:GO_0044448,
+ obo:GO_0043234
+
+
+Class: obo:GO_0043160
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "acrosomal lumen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:go_curators"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed within the acrosome membrane."^^xsd:string,
+ oboInOwl:id "GO:0043160"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0034774,
+ obo:GO_0043202,
+ obo:BFO_0000050 some obo:GO_0001669
+
+
+Class: obo:GO_0033016
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "rhoptry membrane"^^xsd:string,
+ oboInOwl:id "GO:0033016"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding a rhoptry."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0020008,
+ obo:GO_0031090
+
+
+Class: obo:GO_0030869
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "RENT complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12196389"^^xsd:string
+ obo:IAO_0000115 "A protein complex that mediates transcriptional silencing at the rDNA locus (the name derives from regulator of nucleolar silencing and telophase). In Saccharomyces the complex contains Net1p, Sir2p, Cdc14p, and at least one more subunit."^^xsd:string,
+ oboInOwl:id "GO:0030869"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044452,
+ obo:GO_0005677
+
+
+Class: obo:GO_0033012
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15090256"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16563225"^^xsd:string
+ obo:IAO_0000115 "A permanent cup-shaped structure at the cell plasma membrane in secretory cells. Following a secretory stimulus, secretory vesicles transiently dock and fuse at the base of porosomes and release intravesicular contents dictated by the turgor pressure generated from the swelling of secretory vesicles."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Porosome"^^xsd:string,
+ rdfs:label "porosome"^^xsd:string,
+ oboInOwl:id "GO:0033012"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459
+
+
+Class: obo:GO_0033011
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:17289678"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8025156"^^xsd:string
+ obo:IAO_0000115 "A condensed cytoplasmic structure that covers the nucleus of mammalian spermatozoa except for a narrow zone around the insertion of the tail. It shows two distinct regions, a subacrosomal layer and, continuing caudally beyond the acrosomic system, the postacrosomal sheath. The perinuclear theca has been considered a cytoskeletal scaffold responsible for maintaining the overall architecture of the mature sperm head; however, recent studies indicate that the bulk of its constituent proteins are not traditional cytoskeletal proteins but rather a variety of cytosolic proteins."^^xsd:string,
+ rdfs:label "perinuclear theca"^^xsd:string,
+ oboInOwl:id "GO:0033011"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005856,
+ obo:BFO_0000050 some obo:GO_0048471,
+ obo:GO_0044444
+
+
+Class: obo:GO_0033010
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11395001"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14630217"^^xsd:string
+ obo:IAO_0000115 "A highly specialized cell-cell junction found in vertebrates, which forms between a neuron and a glial cell, and has structural similarity to Drosophila septate junctions. It flanks the node of Ranvier in myelinated nerve and electrically isolates the myelinated from unmyelinated nerve segments and physically separates the voltage-gated sodium channels at the node from the cluster of potassium channels underneath the myelin sheath."^^xsd:string,
+ oboInOwl:id "GO:0033010"^^xsd:string,
+ rdfs:label "paranodal junction"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005911
+
+
+Class: obo:GO_0070048
+
+ Annotations:
+ rdfs:label "endobrevin-SNAP-25-syntaxin-1a complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10336434"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains endobrevin (VAMP8), SNAP-25, and syntaxin 1a (or orthologs thereof)."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:854"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Stx1a-Snap25-Vamp8 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:854"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Stx1a, Snap25, Vamp8)"^^xsd:string,
+ oboInOwl:id "GO:0070048"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0005915
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "intermediate junction"^^xsd:string,
+ oboInOwl:id "GO:0005915"^^xsd:string,
+ oboInOwl:hasExactSynonym "belt desmosome"^^xsd:string,
+ rdfs:label "zonula adherens"^^xsd:string,
+ oboInOwl:hasExactSynonym "zonula adhaerens"^^xsd:string,
+ oboInOwl:hasExactSynonym "adhesion belt"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1400623473"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815316208"^^xsd:string
+ obo:IAO_0000115 "A cell-cell adherens junction which forms a continuous belt near the apex of epithelial cells."^^xsd:string,
+ oboInOwl:hasExactSynonym "fascia adhaerens"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005913,
+ obo:BFO_0000050 some obo:GO_0043296
+
+
+Class: obo:GO_0070047
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "synaptobrevin 2-SNAP-25-syntaxin-4 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:853"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Stx4, Snap25, Vamp2)"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10336434"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains synaptobrevin 2 (VAMP2), SNAP-25, and syntaxin 4 (or orthologs thereof)."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:853"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Stx4-Snap25-Vamp2 complex"^^xsd:string,
+ oboInOwl:id "GO:0070047"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0005916
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005916"^^xsd:string,
+ rdfs:label "fascia adherens"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Fascia_adherens"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11732910"^^xsd:string
+ obo:IAO_0000115 "A cell-cell junction that contains the transmembrane protein N-cadherin, which interacts with identical molecules from neighboring cells to form a tight mechanical intercellular link; forms a large portion of the intercalated disc, the structure at which myofibrils terminate in cardiomyocytes."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0014704,
+ obo:GO_0005913
+
+
+Class: obo:GO_0005913
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cell-cell adherens junction"^^xsd:string,
+ oboInOwl:id "GO:0005913"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:hb"^^xsd:string
+ obo:IAO_0000115 "An adherens junction which connects two cells to each other."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005912,
+ obo:GO_0005911
+
+
+Class: obo:GO_0030863
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030863"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The portion of the cytoskeleton that lies just beneath the plasma membrane."^^xsd:string,
+ rdfs:label "cortical cytoskeleton"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005856,
+ obo:GO_0044448
+
+
+Class: obo:GO_0070049
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:855"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Stx2, Snap25, Vamp8)"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10336434"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains endobrevin (VAMP8), SNAP-25, and syntaxin 2 (or orthologs thereof)."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:855"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Stx2-Snap25-Vamp8 complex"^^xsd:string,
+ oboInOwl:id "GO:0070049"^^xsd:string,
+ rdfs:label "endobrevin-SNAP-25-syntaxin-2 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0005914
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:11700298"^^xsd:string
+ obo:IAO_0000115 "A small junction assembled during the cellularization stage of insect embyrogenesis; spot adherens junctions later fuse to form the zonula adherens."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "punctum adherens"^^xsd:string,
+ oboInOwl:id "GO:0005914"^^xsd:string,
+ rdfs:label "spot adherens junction"^^xsd:string,
+ oboInOwl:hasBroadSynonym "dense plaque"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005913
+
+
+Class: obo:GO_0030864
+
+ Annotations:
+ rdfs:label "cortical actin cytoskeleton"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The portion of the actin cytoskeleton, comprising filamentous actin and associated proteins, that lies just beneath the plasma membrane."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030864"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0030863
+ and (obo:BFO_0000050 some obo:GO_0015629)
+
+ SubClassOf:
+ obo:GO_0044430,
+ obo:GO_0030863,
+ obo:BFO_0000050 some obo:GO_0015629
+
+
+Class: obo:GO_0070044
+
+ Annotations:
+ rdfs:label "synaptobrevin 2-SNAP-25-syntaxin-1a complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:998"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Snap25, Stx1a, Vamp2)"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:841"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Stx1a, SNAP25, VAMP)"^^xsd:string,
+ oboInOwl:id "GO:0070044"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:841"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Stx1a-SNAP25-VAMP complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Snap25-Stx1a-Vamp2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10336434"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains synaptobrevin 2 (VAMP2), SNAP-25, and syntaxin 1a (or orthologs thereof)."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0005919
+
+ Annotations:
+ oboInOwl:id "GO:0005919"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "pleated desmosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11700298"^^xsd:string
+ obo:IAO_0000115 "A septate junction in which regular arrays of electron-dense septae span the intermembrane space."^^xsd:string,
+ rdfs:label "pleated septate junction"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005918
+
+
+Class: obo:GO_0031500
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:15936270"^^xsd:string
+ obo:IAO_0000115 "A high molecular weight complex characterized in S. pombe containing the cell-end anchoring protein Tea1. This complex is transported to the cell ends by microtubules and is involved in bipolar growth and the maintennce of normal cell polarity."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "Tea1 cell-end complex"^^xsd:string,
+ oboInOwl:id "GO:0031500"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0000133,
+ obo:GO_0044448,
+ obo:GO_0005875
+
+
+Class: obo:GO_0070046
+
+ Annotations:
+ rdfs:label "synaptobrevin 2-SNAP-25-syntaxin-3 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10336434"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains synaptobrevin 2 (VAMP2), SNAP-25, and syntaxin 3 (or orthologs thereof)."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070046"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:852"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Stx3, Snap25, Vamp2)"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:852"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Stx3-Snap25-Vamp2 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0005917
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:8314002"^^xsd:string
+ oboInOwl:hasRelatedSynonym "nephrocyte junction"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005917"^^xsd:string,
+ rdfs:label "nephrocyte diaphragm"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:sart"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18971929"^^xsd:string
+ obo:IAO_0000115 "A specialized cell-cell junction found between nephrocytes of the insect kidney, which is adapted for filtration of hemolymph. The insect nephrocyte is anatomically and functionally similarity to the glomerular podocyte of vertebrates."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0036056
+
+
+Class: obo:GO_0030867
+
+ Annotations:
+ oboInOwl:id "GO:0030867"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "rough ER membrane"^^xsd:string,
+ rdfs:label "rough endoplasmic reticulum membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding the rough endoplasmic reticulum."^^xsd:string,
+ oboInOwl:hasExactSynonym "RER membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005789,
+ obo:BFO_0000050 some obo:GO_0005791
+
+
+Class: obo:GO_0031502
+
+ Annotations:
+ oboInOwl:hasExactSynonym "protein O-mannosyltransferase complex"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "PMT family mannosyltransferase complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031502"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15948957"^^xsd:string
+ obo:IAO_0000115 "A complex that possesses dolichyl-phosphate-mannose-protein mannosyltransferase activity; usually includes members of the PMT1 and PMT2 protein subfamilies."^^xsd:string,
+ rdfs:label "dolichyl-phosphate-mannose-protein mannosyltransferase complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005789,
+ obo:GO_0044425,
+ obo:GO_0044432,
+ obo:GO_0031501
+
+
+Class: obo:GO_0070045
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:10336434"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains synaptobrevin 2 (VAMP2), SNAP-25, and syntaxin 2 (or orthologs thereof)."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:851"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Stx2-Snap25-Vamp2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:851"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Stx2, Snap25, Vamp2)"^^xsd:string,
+ oboInOwl:id "GO:0070045"^^xsd:string,
+ rdfs:label "synaptobrevin 2-SNAP-25-syntaxin-2 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0005918
+
+ Annotations:
+ oboInOwl:id "GO:0005918"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815332181"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11700298"^^xsd:string
+ obo:IAO_0000115 "A cell-cell junction that forms a continuous band around each cell in an epithelium; within the septate junction the membranes of adjacent cells maintain a constant distance of approximately 15 nm; found in invertebrates."^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao427941916"^^xsd:string,
+ rdfs:label "septate junction"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "septate desmosome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070160,
+ obo:BFO_0000050 some obo:GO_0043296
+
+
+Class: obo:GO_0031501
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A complex that posseses mannosyltransferase activity."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031501"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "mannosyltransferase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030868
+
+ Annotations:
+ oboInOwl:id "GO:0030868"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding the smooth endoplasmic reticulum."^^xsd:string,
+ oboInOwl:hasExactSynonym "SER membrane"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1596955044"^^xsd:string,
+ oboInOwl:hasExactSynonym "smooth ER membrane"^^xsd:string,
+ rdfs:label "smooth endoplasmic reticulum membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005789,
+ obo:BFO_0000050 some obo:GO_0005790
+
+
+Class: obo:GO_0030062
+
+ Annotations:
+ rdfs:label "mitochondrial tricarboxylic acid cycle enzyme complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030062"^^xsd:string,
+ oboInOwl:hasBroadSynonym "TCA cycle enzyme complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "Any of the heteromeric enzymes, located in the mitochondrion, that act in the tricarboxylic acid (TCA) cycle."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0045239
+ and (obo:BFO_0000050 some obo:GO_0005739)
+
+ SubClassOf:
+ obo:GO_0044429,
+ obo:BFO_0000050 some obo:GO_0005759,
+ obo:GO_0045239
+
+
+Class: obo:GO_0030061
+
+ Annotations:
+ oboInOwl:hasExactSynonym "mitochondrial cristae"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao333328131"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "Any of the inward folds of the mitochondrial inner membrane. Their number, extent, and shape differ in mitochondria from different tissues and organisms. They appear to be devices for increasing the surface area of the mitochondrial inner membrane, where the enzymes of electron transport and oxidative phosphorylation are found. Their shape can vary with the respiratory state of the mitochondria."^^xsd:string,
+ oboInOwl:id "GO:0030061"^^xsd:string,
+ rdfs:label "mitochondrial crista"^^xsd:string,
+ rdfs:comment "See also the cellular component term 'mitochondrial inner membrane ; GO:0005743'."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044455,
+ obo:BFO_0000050 some obo:GO_0005743
+
+
+Class: obo:GO_0005923
+
+ Annotations:
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1939999134"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "zonula occludens"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815332181"^^xsd:string
+ obo:IAO_0000115 "An occluding cell-cell junction that is composed of a branching network of sealing strands that completely encircles the apical end of each cell in an epithelial sheet; the outer leaflets of the two interacting plasma membranes are seen to be tightly apposed where sealing strands are present. Each sealing strand is composed of a long row of transmembrane adhesion proteins embedded in each of the two interacting plasma membranes."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Tight_junction"^^xsd:string,
+ rdfs:label "tight junction"^^xsd:string,
+ oboInOwl:id "GO:0005923"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070160,
+ obo:BFO_0000050 some obo:GO_0043296
+
+
+Class: obo:GO_0005922
+
+ Annotations:
+ rdfs:label "connexon complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11146276"^^xsd:string
+ obo:IAO_0000115 "An assembly of six molecules of connexin, made in the Golgi apparatus and subsequently transported to the plasma membrane, where docking of two connexons on apposed plasma membranes across the extracellular space forms a gap junction."^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao445019788"^^xsd:string,
+ oboInOwl:id "GO:0005922"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:BFO_0000050 some obo:GO_0005921,
+ obo:GO_0043234
+
+
+Class: obo:GO_0097072
+
+ Annotations:
+ oboInOwl:id "GO:0097072"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:cna"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12855817"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14556004"^^xsd:string,
+ oboInOwl:hasDbXref "Reactome:REACT_7146"^^xsd:string
+ obo:IAO_0000115 "An interferon regulatory factor complex that consists of a homodimer of interferon regulatory factor 3."^^xsd:string,
+ rdfs:label "interferon regulatory factor 3 complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "IRF3:IRF3 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0097071
+
+
+Class: obo:GO_0005921
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815332181"^^xsd:string,
+ oboInOwl:hasDbXref "http://www.vivo.colostate.edu/hbooks/cmb/cells/pmemb/junctions_g.html"^^xsd:string
+ obo:IAO_0000115 "A cell-cell junction that is composed of an array of small channels that permit small molecules to pass from one cell to another. At gap junctions, the membranes of two adjacent cells are separated by a uniform narrow gap of about 2-4 nm that is spanned by channel-forming proteins called connexins, which form hexagonal tubes called connexons."^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao118541872"^^xsd:string,
+ rdfs:label "gap junction"^^xsd:string,
+ oboInOwl:hasExactSynonym "zonula communicans"^^xsd:string,
+ oboInOwl:hasExactSynonym "macula communicans"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Gap_junction"^^xsd:string,
+ oboInOwl:id "GO:0005921"^^xsd:string,
+ oboInOwl:hasExactSynonym "communicating junction"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005911
+
+
+Class: obo:GO_0097071
+
+ Annotations:
+ oboInOwl:hasExactSynonym "IRF complex"^^xsd:string,
+ oboInOwl:id "GO:0097071"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "interferon regulatory factor complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:cna"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20043992"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of two interferon regulatory proteins (IRFs); may be homodimeric or heterodimeric. The activation of a latent closed conformation of IRF in the cytoplasm is triggered by phosphorylation of Ser/Thr residues in a C-terminal region. Phosphorylation stimulates the C-terminal autoinhibitory domain to attain a highly extended conformation triggering dimerization through extensive contacts to a second subunit."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0005920
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "zonula continua"^^xsd:string,
+ rdfs:label "smooth septate junction"^^xsd:string,
+ oboInOwl:id "GO:0005920"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11700298"^^xsd:string
+ obo:IAO_0000115 "A septate junction that lacks the regular arrays of electron-dense septae found in pleated septate junctions."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005918
+
+
+Class: obo:GO_0030870
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11988766"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17674145"^^xsd:string
+ obo:IAO_0000115 "Trimeric protein complex that possesses endonuclease activity; involved in meiotic recombination, DNA repair and checkpoint signaling. In Saccharomyces cerevisiae, the complex comprises Mre11p, Rad50p, and Xrs2p; complexes identified in other species generally contain proteins orthologous to the Saccharomyces cerevisiae proteins."^^xsd:string,
+ rdfs:label "Mre11 complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "Rad50 complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "Rad50-Rad32-Nbs1 complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "RMX complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "MRX complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2767"^^xsd:string
+ oboInOwl:hasExactSynonym "RAD50-MRE11-NBN complex"^^xsd:string,
+ oboInOwl:id "GO:0030870"^^xsd:string,
+ oboInOwl:hasExactSynonym "MRN complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0097074
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:cna"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18068231"^^xsd:string,
+ oboInOwl:hasDbXref "Reactome:REACT_21965"^^xsd:string
+ obo:IAO_0000115 "An interferon regulatory factor complex that consists of a homodimer of interferon regulatory factor 7."^^xsd:string,
+ rdfs:label "interferon regulatory factor 7 complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "IRF7:IRF7 complex"^^xsd:string,
+ oboInOwl:id "GO:0097074"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0097071
+
+
+Class: obo:GO_0097073
+
+ Annotations:
+ oboInOwl:hasExactSynonym "IRF5:IRF5 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "interferon regulatory factor 5 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:cna"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12138184"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16751392"^^xsd:string
+ obo:IAO_0000115 "An interferon regulatory factor complex that consists of a homodimer of interferon regulatory factor 5."^^xsd:string,
+ oboInOwl:id "GO:0097073"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0097071
+
+
+Class: obo:GO_0097076
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:cna"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16410796"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17496917"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18021073"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses protein kinase activity and activates the I-kappa B kinase complex (IKK) and mitogen-activated protein (MAP) kinases in response to TRAF6 signaling. It comprises the catalytic subunit TAK1 complexed to the regulatory subunits, termed TABs (TAK1-binding subunits)."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "transforming growth factor beta activated kinase 1 complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "TAK1 kinase complex"^^xsd:string,
+ oboInOwl:id "GO:0097076"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0097075
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "IRF3:IRF7 complex"^^xsd:string,
+ oboInOwl:id "GO:0097075"^^xsd:string,
+ rdfs:label "interferon regulatory factor 3-interferon regulatory factor 7 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:cna"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18068231"^^xsd:string,
+ oboInOwl:hasDbXref "Reactome:REACT_26957"^^xsd:string
+ obo:IAO_0000115 "An interferon regulatory factor complex that consists of a heterodimer of interferon regulatory factor 3 and interferon regulatory factor 7."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0097071
+
+
+Class: obo:GO_0097078
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:21576267"^^xsd:string
+ obo:IAO_0000115 "A protein complex involved in the 18S rRNA biogenesis. In S. cerevisiae this complex consists of Fal1p and Sgd1p and in humans this complex consists of NOM1 and eIF4AIII subunits."^^xsd:string,
+ oboInOwl:id "GO:0097078"^^xsd:string,
+ rdfs:label "FAl1-SGD1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0033009
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:16760254"^^xsd:string
+ obo:IAO_0000115 "A small, vestigial nucleus found in some plastids that derive from a eukaryotic endosymbiont. Observed in chlorarachniophytes and cryptomonads, which acquired their plastids from a green and red alga respectively."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0033009"^^xsd:string,
+ rdfs:label "nucleomorph"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Nucleomorph"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:GO_0043231
+
+
+Class: obo:GO_0002180
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:19075240"^^xsd:string
+ obo:IAO_0000115 "An nuclear membrane protein complex having arachidonate 5-lipoxygenase activity."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "5-lipoxygenase complex"^^xsd:string,
+ oboInOwl:id "GO:0002180"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044453,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031519
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasExactSynonym "Polycomb Group protein complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9372908"^^xsd:string
+ obo:IAO_0000115 "A chromatin-associated multiprotein complex containing Polycomb Group proteins. In Drosophila, Polycomb group proteins are involved in the long-term maintenance of gene repression, and PcG protein complexes associate with Polycomb group response elements (PREs) in target genes to regulate higher-order chromatin structure."^^xsd:string,
+ oboInOwl:id "GO:0031519"^^xsd:string,
+ rdfs:label "PcG protein complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031518
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:13679521"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9407032"^^xsd:string
+ obo:IAO_0000115 "A multisubunit protein complex that binds to centromeric DNA and initiates kinetochore assembly. In yeast, this complex consists of four subunits, namely Ctf13p, Skp1p, Cep3p and Cbf2p."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "CBF3 complex"^^xsd:string,
+ oboInOwl:id "GO:0031518"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:GO_0043234,
+ obo:BFO_0000050 some obo:GO_0000775
+
+
+Class: obo:GO_0002186
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cytosolic creatine kinase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:173175"^^xsd:string
+ obo:IAO_0000115 "A dimeric protein complex having creatine kinase activity."^^xsd:string,
+ oboInOwl:id "GO:0002186"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0002185,
+ obo:GO_0044445
+
+
+Class: obo:GO_0097038
+
+ Annotations:
+ rdfs:label "perinuclear endoplasmic reticulum"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0097038"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mcc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pr"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ obo:IAO_0000115 "The portion of endoplasmic reticulum, the intracellular network of tubules and cisternae, that occurs near the nucleus. The lumen of the perinuclear endoplasmic reticulum is contiguous with the nuclear envelope lumen (also called perinuclear space), the region between the inner and outer nuclear membranes."^^xsd:string,
+ oboInOwl:hasExactSynonym "perinuclear ER"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0048471,
+ obo:GO_0044432
+
+
+Class: obo:GO_0002185
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "creatine kinase complex"^^xsd:string,
+ oboInOwl:id "GO:0002185"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:hjd"^^xsd:string
+ obo:IAO_0000115 "A protein complex having creatine kinase activity."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0031513
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031513"^^xsd:string,
+ rdfs:label "nonmotile primary cilium"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:curators"^^xsd:string
+ oboInOwl:hasExactSynonym "sensory cilium"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:curators"^^xsd:string
+ oboInOwl:hasExactSynonym "nonmotile primary cilia"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dgh"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:kmv"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17009929"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20144998"^^xsd:string
+ obo:IAO_0000115 "A primary cilium which contains a variable array of axonemal microtubules but does not contain molecular motors. Nonmotile primary cilia are found on many different cell types and function as sensory organelles that concentrate and organize sensory signaling molecules."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:curators"^^xsd:string
+ oboInOwl:hasExactSynonym "immotile primary cilium"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0072372
+
+
+Class: obo:GO_0002187
+
+ Annotations:
+ oboInOwl:id "GO:0002187"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16236486"^^xsd:string
+ obo:IAO_0000115 "An octomeric protein complex having creatine kinase activity."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "mitochondrial creatine kinase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0002185,
+ obo:GO_0044429
+
+
+Class: obo:GO_0031512
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031512"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:curators"^^xsd:string
+ oboInOwl:hasRelatedSynonym "nodal cilium"^^xsd:string,
+ rdfs:label "motile primary cilium"^^xsd:string,
+ rdfs:comment "Note that this term should not be confused with 'motile cilium ; GO:0031514': Motile primary cilia are distinct from motile cilia (GO:0031514) that are typically present on epithelial cells in multiple copies and move in a whip-like, as opposed to rotational, manner."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dgh"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:kmv"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17009929"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20144998"^^xsd:string
+ obo:IAO_0000115 "A primary cilium which may contain a variable array of axonemal microtubules and also contains molecular motors. Motile primary cilia display a distinct twirling motion that directs fluid flow asymmetrically across the cellular surface to affect asymmetric body plan organization."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:curators"^^xsd:string
+ oboInOwl:hasExactSynonym "motile primary cilia"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0072372
+
+
+Class: obo:GO_0031511
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:21445296"^^xsd:string
+ oboInOwl:hasExactSynonym "Mis6-Mal2-Sim4 centromere complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Mis6 centromere subcomplex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031511"^^xsd:string,
+ rdfs:label "Mis6-Sim4 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12719471"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15897182"^^xsd:string
+ obo:IAO_0000115 "A protein complex that forms part of the inner centromere, which is involved in the loading of the centromeric histone h3 variant CENP-A onto centromeres and in centromere specific heterochromatin formation. The complex contains about 12 proteins, of which two are known as Mis6 and Sim4 in S. pombe and CENP-I and CENP-H in human."^^xsd:string,
+ oboInOwl:hasExactSynonym "Sim4 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:BFO_0000050 some obo:GO_0000939,
+ obo:GO_0043234
+
+
+Class: obo:GO_0002189
+
+ Annotations:
+ oboInOwl:id "GO:0002189"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "In mammals, the complex consists of two non-identical catalytic subunits and two non-identical regulatory subunits."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9348095"^^xsd:string
+ oboInOwl:hasExactSynonym "PRPP synthetase complex"^^xsd:string,
+ rdfs:label "ribose phosphate diphosphokinase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GO:hjd"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9348095"^^xsd:string
+ obo:IAO_0000115 "A protein complex having ribose phosphate diphosphokinase activity."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9348095"^^xsd:string
+ oboInOwl:hasExactSynonym "phosphoribosylpyrophosphate synthetase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0031510
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031510"^^xsd:string,
+ rdfs:label "SUMO activating enzyme complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "SUMO E1 activator enzyme complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15601841"^^xsd:string
+ obo:IAO_0000115 "A conserved heterodimeric complex with SUMO activating enzyme activity."^^xsd:string,
+ oboInOwl:hasExactSynonym "SAE"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0005902
+
+ Annotations:
+ rdfs:comment "Note that this term refers to a projection from a single cell, and should not be confused with 'microvillus' as used to refer to a multicellular structure such as that found in the placenta."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005902"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0813516194"^^xsd:string
+ obo:IAO_0000115 "Thin cylindrical membrane-covered projections on the surface of an animal cell containing a core bundle of actin filaments. Present in especially large numbers on the absorptive surface of intestinal cells."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasDbXref "Wikipedia:Microvillus"^^xsd:string,
+ rdfs:label "microvillus"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042995
+
+
+Class: obo:GO_0005903
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005903"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:sl"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "Dense covering of microvilli on the apical surface of epithelial cells in tissues such as the intestine, kidney, and choroid plexus; the microvilli aid absorption by increasing the surface area of the cell."^^xsd:string,
+ rdfs:label "brush border"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Brush_border"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042995
+
+
+Class: obo:GO_0031515
+
+ Annotations:
+ oboInOwl:id "GO:0031515"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "tRNA (m1A) methyltransferase complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10779558"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14739239"^^xsd:string
+ obo:IAO_0000115 "A protein complex involved in the catalysis of the formation of the modified nucleotide 1-methyladenosine (m1A) in tRNA. In yeast, it is a heterotetramer of two subunits, Gcd10p and Gcd14p, while in bacteria and archaea it is a homotetramer."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043527
+
+
+Class: obo:GO_0005905
+
+ Annotations:
+ rdfs:label "coated pit"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005905"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10559856"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17284835"^^xsd:string
+ obo:IAO_0000115 "A part of the endomembrane system in the form of an invagination of a membrane upon which a clathrin coat forms, and that can be converted by vesicle budding into a clathrin-coated vesicle. Coated pits form on the plasma membrane, where they are involved in receptor-mediated selective transport of many proteins and other macromolecules across the cell membrane, in the trans-Golgi network, and on some endosomes."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0012505
+
+
+Class: obo:GO_0031514
+
+ Annotations:
+ rdfs:label "motile cilium"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dgh"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:kmv"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17009929"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20144998"^^xsd:string
+ obo:IAO_0000115 "A cilium which has a variable arrangement of axonemal microtubules, contains molecular motors, and beats with a characteristic whip-like pattern that promotes cell motility or transport of fluids and other cells across a cell surface. Motile cilia are typically found in multiple copies on epithelial cells that line the lumenal ducts of various tissues. Motile cilia may also function as sensory organelles."^^xsd:string,
+ oboInOwl:id "GO:0031514"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:curators"^^xsd:string
+ oboInOwl:hasRelatedSynonym "motile secondary cilium"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:curators"^^xsd:string
+ oboInOwl:hasExactSynonym "motile cilia"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that this term should not be confused with 'motile primary cilium ; GO:0031512': Motile cilia are distinct from motile primary cilia (GO:0031512) that are typically present during embryogenesis in a single copy per cell, affect asymmetric body plan organization, and move in a rotational manner, as opposed to a whip-like, manner."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005929
+
+
+Class: obo:GO_0070081
+
+ Annotations:
+ oboInOwl:hasExactSynonym "clathrin sculpted monoamine constitutive secretory pathway transport vesicle"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "clathrin sculpted monoamine transport vesicle"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mg2"^^xsd:string
+ obo:IAO_0000115 "A clathrin sculpted lipid bilayer membrane-enclosed vesicle after clathrin release and containing monoamines."^^xsd:string,
+ oboInOwl:id "GO:0070081"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030133,
+ obo:GO_0060198
+
+
+Class: obo:GO_0043189
+
+ Annotations:
+ oboInOwl:id "GO:0043189"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A multisubunit complex that catalyzes the acetylation of histones H4 and H2A."^^xsd:string,
+ oboInOwl:hasExactSynonym "H4/H2A HAT complex"^^xsd:string,
+ rdfs:label "H4/H2A histone acetyltransferase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000123
+
+
+Class: obo:GO_0030079
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "light-harvesting complex, peripheral complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:lr"^^xsd:string
+ obo:IAO_0000115 "Bacteriochlorophyll a binding complex that is peripherally associated to the bacterial reaction center."^^xsd:string,
+ oboInOwl:id "GO:0030079"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030077
+
+
+Class: obo:GO_0070082
+
+ Annotations:
+ rdfs:label "clathrin sculpted monoamine transport vesicle lumen"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "clathrin sculpted monoamine constitutive secretory pathway transport vesicle lumen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mg2"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membrane of the clathrin sculpted monoamine transport vesicle."^^xsd:string,
+ oboInOwl:id "GO:0070082"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0070081,
+ obo:GO_0060205
+
+
+Class: obo:GO_0043188
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ obo:IAO_0000115 "The cell wall material that surrounds the septum in fungal cells."^^xsd:string,
+ oboInOwl:id "GO:0043188"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cell septum edging"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044426,
+ obo:BFO_0000050 some obo:GO_0009277
+
+
+Class: obo:GO_0030078
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "light-harvesting complex, core complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:lr"^^xsd:string
+ obo:IAO_0000115 "Light harvesting complex associated with the reaction complex of photosynthetic purple bacteria."^^xsd:string,
+ oboInOwl:id "GO:0030078"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030077
+
+
+Class: obo:GO_0005912
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string,
+ oboInOwl:hasDbXref "http://www.vivo.colostate.edu/hbooks/cmb/cells/pmemb/junctions_a.html"^^xsd:string
+ obo:IAO_0000115 "A cell junction at which anchoring proteins (cadherins or integrins) extend through the plasma membrane and are attached to actin filaments."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005912"^^xsd:string,
+ rdfs:label "adherens junction"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070161
+
+
+Class: obo:GO_0030077
+
+ Annotations:
+ oboInOwl:inSubset ,
+ rdfs:label "plasma membrane light-harvesting complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "A plasma membrane protein-pigment complex that may be closely or peripherally associated to photosynthetic reaction centers that participate in harvesting and transferring radiant energy to the reaction center. Examples of this complex are found in bacterial species."^^xsd:string,
+ oboInOwl:id "GO:0030077"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030076,
+ obo:BFO_0000050 some obo:GO_0042716,
+ obo:GO_0044433
+
+
+Class: obo:GO_0005911
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "intercellular junction"^^xsd:string,
+ oboInOwl:id "GO:0005911"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dgh"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:hb"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A cell junction that forms a connection between two cells; excludes direct cytoplasmic junctions such as ring canals."^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1922892319"^^xsd:string,
+ rdfs:label "cell-cell junction"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030054
+
+
+Class: obo:GO_0030076
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Light-harvesting_complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "antenna complex"^^xsd:string,
+ rdfs:label "light-harvesting complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:lr"^^xsd:string
+ obo:IAO_0000115 "A protein-pigment complex that may be closely or peripherally associated to photosynthetic reaction centers that participate in harvesting and transferring radiant energy to the reaction center."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0030076"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030075
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "A thylakoid that is derived from and attached to, but not necessarily continuous with, the plasma membrane, and is not enclosed in a plastid. It bears the photosynthetic pigments in photosynthetic cyanobacteria."^^xsd:string,
+ rdfs:label "plasma membrane-derived thylakoid"^^xsd:string,
+ oboInOwl:id "GO:0030075"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009579,
+ obo:GO_0043232
+
+
+Class: obo:GO_0031520
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "plasma membrane of cell tip"^^xsd:string,
+ oboInOwl:id "GO:0031520"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The portion of the plasma membrane surrounding the cell tip."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:BFO_0000050 some obo:GO_0051286
+
+
+Class: obo:GO_0070083
+
+ Annotations:
+ oboInOwl:hasExactSynonym "clathrin sculpted monoamine constitutive secretory pathway transport vesicle membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "clathrin sculpted monoamine transport vesicle membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mg2"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding a clathrin sculpted monoamine transport vesicle."^^xsd:string,
+ oboInOwl:id "GO:0070083"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0070081,
+ obo:GO_0030658,
+ obo:GO_0030665
+
+
+Class: obo:GO_0043187
+
+ Annotations:
+ oboInOwl:hasBroadSynonym "septum surface"^^xsd:string,
+ rdfs:label "cell septum surface"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0043187"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:go_curators"^^xsd:string
+ obo:IAO_0000115 "The extracellular (rather than the intracellular) exterior of a dividing septum; this surface is usually composed of cell wall material, for example, lineal (1,3)-beta-D-glucan in S. pombe."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044457
+
+
+Class: obo:GO_0043186
+
+ Annotations:
+ oboInOwl:hasExactSynonym "germline granule"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0018994"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0043186"^^xsd:string,
+ oboInOwl:hasBroadSynonym "nuage"^^xsd:string,
+ rdfs:label "P granule"^^xsd:string,
+ oboInOwl:hasExactSynonym "polar granule"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:kmv"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11262230"^^xsd:string
+ obo:IAO_0000115 "A small cytoplasmic, non-membranous RNA/protein complex aggregates in the primordial germ cells of many higher eukaryotes."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0035770,
+ obo:BFO_0000050 some obo:GO_0060293
+
+
+Class: obo:GO_0097047
+
+ Annotations:
+ oboInOwl:hasExactSynonym "TER"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "DNA replication termination region"^^xsd:string,
+ oboInOwl:id "GO:0097047"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mcc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pr"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20797631"^^xsd:string
+ obo:IAO_0000115 "A chromosomal region that contains fork pausing elements influencing the progression and merging of DNA replication forks."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427
+
+
+Class: obo:GO_0033017
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0033017"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rph"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding the sarcoplasmic reticulum."^^xsd:string,
+ rdfs:label "sarcoplasmic reticulum membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005789,
+ obo:BFO_0000050 some obo:GO_0016529
+
+
+Class: obo:GO_0033018
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0033018"^^xsd:string,
+ rdfs:label "sarcoplasmic reticulum lumen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rph"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membranes of the sarcoplasmic reticulum."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005788,
+ obo:BFO_0000050 some obo:GO_0016529
+
+
+Class: obo:GO_0097042
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "extrinsic to fungal-type vacuolar membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jh"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:21454883"^^xsd:string
+ obo:IAO_0000115 "Loosely bound to one surface of the fungal-type vacuolar membrane, but not integrated into the hydrophobic region."^^xsd:string,
+ oboInOwl:id "GO:0097042"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0000329,
+ obo:GO_0000306
+
+
+Class: obo:GO_0030849
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Autosome"^^xsd:string,
+ rdfs:comment "Note that this term is mainly relevant in organisms that have both sex chromosomes and non-sex-determining chromosomes in an individual organism."^^xsd:string,
+ oboInOwl:id "GO:0030849"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Any chromosome other than a sex chromosome."^^xsd:string,
+ rdfs:label "autosome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005694
+
+
+Class: obo:GO_0070066
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:11839770"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains cellubrevin (VAMP3), VAMP4, endobrevin (VAMP8), and syntaxin 6 (or orthologs thereof)."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:874"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Vamp3, Vamp4, Vam8, Stx6)"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:874"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Vamp3-Vamp4-Vam8-Stx6 complex"^^xsd:string,
+ oboInOwl:id "GO:0070066"^^xsd:string,
+ rdfs:label "cellubrevin-VAMP4-endobrevin-syntaxin-6 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0002179
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:hjd"^^xsd:string
+ obo:IAO_0000115 "A homodimeric complex which transfers a palmitoyl group onto serine, forming 3-dehydro-D-sphinganine."^^xsd:string,
+ oboInOwl:id "GO:0002179"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "homodimeric serine palmitoyltransferase complex"^^xsd:string,
+ rdfs:comment "This complex occurs primarily in bacteria."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0002178
+
+
+Class: obo:GO_0031522
+
+ Annotations:
+ oboInOwl:id "GO:0031522"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that this term represents the protein complex involved in transport of proteins across the cytoplasmic membrane. For proteins involved in bacterial Type II secretion across the outer membrane, consider annotating to 'type II protein secretion complex ; GO:0015628'. For proteins involved in Sec-complex dependent translocation into the eukaryotic endoplasmic reticulum, consider annotating to 'endoplasmic reticulum Sec complex ; GO:0031205'."^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Sec translocation complex"^^xsd:string,
+ oboInOwl:hasBroadSynonym "Sec complex"^^xsd:string,
+ rdfs:label "cell envelope Sec protein transport complex"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "plasma membrane Sec complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15223057"^^xsd:string
+ obo:IAO_0000115 "A transmembrane protein complex involved in the translocation of proteins across the cytoplasmic membrane. In Gram-negative bacteria, Sec-translocated proteins are subsequently secreted via the type II, IV, or V secretion systems. Sec complex components include SecA, D, E, F, G, Y and YajC."^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Sec secretion complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070065
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:875"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Vamp3-Vamp4-Stx16 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:875"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Vamp3, Vamp4, Stx16)"^^xsd:string,
+ oboInOwl:id "GO:0070065"^^xsd:string,
+ rdfs:label "cellubrevin-VAMP4-syntaxin-16 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11839770"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains cellubrevin (VAMP3), VAMP4, and syntaxin 16 (or orthologs thereof)."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0002178
+
+ Annotations:
+ oboInOwl:id "GO:0002178"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:hjd"^^xsd:string
+ obo:IAO_0000115 "A protein complex with palmitoyltransferase activity."^^xsd:string,
+ rdfs:label "palmitoyltransferase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0031521
+
+ Annotations:
+ rdfs:label "spitzenkorper"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031521"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15701784"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15976451"^^xsd:string
+ obo:IAO_0000115 "Structure within the hyphal tip of filamentous fungi that acts as an organizing center for hyphal tip growth; may function to supply vesicles to the elongating tip and/or to organize cytoskeletal microfilaments."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0001411,
+ obo:GO_0044464,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070068
+
+ Annotations:
+ rdfs:label "VAMP4-syntaxin-6-syntaxin-16-Vti1a complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:877"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Vamp4, Stx6, Stx16, Vti1a)"^^xsd:string,
+ oboInOwl:id "GO:0070068"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:877"^^xsd:string
+ oboInOwl:hasRelatedSynonym "Vamp4-Stx6-Stx16-Vti1a complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11839770"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains VAMP4, syntaxin 6, syntaxin 16, and Vti1a (or orthologs thereof)."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0002177
+
+ Annotations:
+ oboInOwl:id "GO:0002177"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15018141"^^xsd:string
+ obo:IAO_0000115 "A conical shaped array of microtubules that completely covers the nucleus of a spermatid, thought to be involved in sperm head elongation."^^xsd:string,
+ rdfs:label "manchette"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0015630,
+ obo:GO_0044430
+
+
+Class: obo:GO_0070067
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070067"^^xsd:string,
+ rdfs:label "syntaxin-6-syntaxin-16-Vti1a complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11839770"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains syntaxin 6, syntaxin 16, and Vti1a (or orthologs thereof)."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0031523
+
+ Annotations:
+ oboInOwl:id "GO:0031523"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12490953"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15545624"^^xsd:string
+ obo:IAO_0000115 "A multisubunit complex consisting of Myb and other proteins that regulates site specific DNA replication, gene amplification and transcriptional repression."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "Myeloblastosis proto-oncogene protein complex"^^xsd:string,
+ rdfs:label "Myb complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031526
+
+ Annotations:
+ rdfs:label "brush border membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031526"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The portion of the plasma membrane surrounding the brush border."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005903,
+ obo:GO_0031253
+
+
+Class: obo:GO_0070069
+
+ Annotations:
+ rdfs:label "cytochrome complex"^^xsd:string,
+ oboInOwl:id "GO:0070069"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A protein complex in which at least one of the proteins is a cytochrome, i.e. a heme-containing protein involved in catalysis of redox reactions."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0031528
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031528"^^xsd:string,
+ rdfs:label "microvillus membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The portion of the plasma membrane surrounding a microvillus."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005902,
+ obo:GO_0031253
+
+
+Class: obo:GO_0031527
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031527"^^xsd:string,
+ rdfs:label "filopodium membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The portion of the plasma membrane surrounding a filopodium."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0030175,
+ obo:GO_0031253
+
+
+Class: obo:GO_0005901
+
+ Annotations:
+ oboInOwl:hasExactSynonym "caveolae"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "caveolar membrane"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0016599"^^xsd:string,
+ oboInOwl:id "GO:0005901"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0721662544"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16645198"^^xsd:string
+ obo:IAO_0000115 "A membrane raft that forms small pit, depression, or invagination that communicates with the outside of a cell and extends inward, indenting the cytoplasm and the cell membrane. Examples include any of the minute pits or incuppings of the cell membrane formed during pinocytosis. Such caveolae may be pinched off to form free vesicles within the cytoplasm."^^xsd:string,
+ rdfs:label "caveola"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Caveolae"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0045121
+
+
+Class: obo:GO_0005900
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8999038"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric receptor for the cytokine oncostatin-M (OSM). In humans the receptor complex is made up of the gene products gp130 and OSMR-beta."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "oncostatin-M receptor complex"^^xsd:string,
+ oboInOwl:id "GO:0005900"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005887,
+ obo:GO_0044459,
+ obo:GO_0043235
+
+
+Class: obo:GO_0030089
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11734882"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Phycobilisome"^^xsd:string
+ obo:IAO_0000115 "Any of the granules, approximately 32 nm x 48 nm and consisting of highly aggregated phycobiliproteins, that are attached in arrays to the external face of a thylakoid membrane in algae of the phyla Cyanophyta and Rhodophyta, where they function as light-harvesting devices in photosynthesis. Excitation energy in the phycobilisome flows in the sequence: phycoerythrin, phycocyanin, allophycocyanin before passing to the antenna chlorophyll of photosystem II."^^xsd:string,
+ oboInOwl:id "GO:0030089"^^xsd:string,
+ rdfs:label "phycobilisome"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Phycobilisome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044436,
+ obo:BFO_0000050 some obo:GO_0042651,
+ obo:GO_0030076,
+ obo:GO_0044425
+
+
+Class: obo:GO_0043198
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "dendritic shaft"^^xsd:string,
+ oboInOwl:id "GO:0043198"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:nln"^^xsd:string
+ obo:IAO_0000115 "Cylindric portion of the dendrite, directly stemming from the perikaryon, and carrying the dendritic spines."^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao2034472720"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044463,
+ obo:BFO_0000050 some obo:GO_0030425
+
+
+Class: obo:GO_0030084
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8825475"^^xsd:string
+ obo:IAO_0000115 "A pigment protein complex that forms part of the photosystem I associated light-harvesting complex I; contains two proteins (usually about 20 kDa); has a fluorescence maximum of 730 nm."^^xsd:string,
+ rdfs:label "PSI associated light-harvesting complex I, LHCIb subcomplex"^^xsd:string,
+ oboInOwl:id "GO:0030084"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009518
+
+
+Class: obo:GO_0043197
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "dendrite spine"^^xsd:string,
+ oboInOwl:id "GO:0043197"^^xsd:string,
+ rdfs:label "dendritic spine"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:nln"^^xsd:string
+ obo:IAO_0000115 "Protrusion from a dendrite. Spines are specialised subcellular compartments involved in the synaptic transmission. They are linked to the dendritic shaft by a restriction. Because of their bulb shape, they function as a biochemical and an electrical compartment. Spine remodeling is though to be involved in synaptic plasticity."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Dendritic_spine"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1799103720"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044463,
+ obo:GO_0044309,
+ obo:BFO_0000050 some obo:GO_0030425
+
+
+Class: obo:GO_0030083
+
+ Annotations:
+ rdfs:label "PSI associated light-harvesting complex I, LHCIa subcomplex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8825475"^^xsd:string
+ obo:IAO_0000115 "A pigment protein complex that forms part of the photosystem I associated light-harvesting complex I; contains two proteins (usually about 24 and 21.5 kDa); has a fluorescence maximum between 680 and 690 nm."^^xsd:string,
+ oboInOwl:id "GO:0030083"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009518
+
+
+Class: obo:GO_0070074
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18048320"^^xsd:string
+ obo:IAO_0000115 "A secretory organelle that forms part of the apical complex; a small, threadlike structure located is close proximity to the subpellicular microtubules. Its contents include a rhomboid protease (PfROM1 in Plasmodium falciparum) that moves from the lateral asymmetric localization to the merozoite apical pole and the posterior pole upon release of merozoites from schizonts."^^xsd:string,
+ rdfs:label "mononeme"^^xsd:string,
+ oboInOwl:id "GO:0070074"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0020007,
+ obo:GO_0043231
+
+
+Class: obo:GO_0051233
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "spindle equator"^^xsd:string,
+ rdfs:label "spindle midzone"^^xsd:string,
+ oboInOwl:id "GO:0051233"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:14528012"^^xsd:string
+ oboInOwl:hasExactSynonym "central spindle"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ai"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15296749"^^xsd:string
+ obo:IAO_0000115 "The area in the center of the spindle where the spindle microtubules from opposite poles overlap."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044430,
+ obo:BFO_0000050 some obo:GO_0005819
+
+
+Class: obo:GO_0043196
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:nln"^^xsd:string
+ obo:IAO_0000115 "Non-terminal inflated portion of the axon, containing the specialized apparatus necessary to release neurotransmitters."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "varicosity"^^xsd:string,
+ oboInOwl:id "GO:0043196"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033267,
+ obo:BFO_0000050 some obo:GO_0044304
+
+
+Class: obo:GO_0043195
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0043195"^^xsd:string,
+ oboInOwl:hasExactSynonym "terminal bouton"^^xsd:string,
+ oboInOwl:hasExactSynonym "synaptic bouton"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:nln"^^xsd:string
+ obo:IAO_0000115 "Terminal inflated portion of the axon, containing the specialized apparatus necessary to release neurotransmitters. The axon terminus is considered to be the whole region of thickening and the terminal button is a specialized region of it."^^xsd:string,
+ oboInOwl:hasExactSynonym "presynaptic bouton"^^xsd:string,
+ oboInOwl:hasExactSynonym "bouton"^^xsd:string,
+ rdfs:label "terminal button"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0043679,
+ obo:GO_0033267,
+ obo:GO_0044456
+
+
+Class: obo:GO_0030085
+
+ Annotations:
+ rdfs:label "PSII associated light-harvesting complex II, peripheral complex, LHCIIb subcomplex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030085"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8825475"^^xsd:string
+ obo:IAO_0000115 "A pigment protein complex that forms part of the photosystem II associated light-harvesting complex II; contains two proteins (usually about 28 and 27 kDa), and may contain a third; peripherally located relative to other LHC polypeptides."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044436,
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0009656,
+ obo:GO_0044434,
+ obo:GO_0043234
+
+
+Class: obo:GO_0043194
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "initial segment"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:nln"^^xsd:string
+ obo:IAO_0000115 "Portion of the axon proximal to the neuronal cell body, at the level of the axon hillock. The action potentials that propagate along the axon are generated at the level of this initial segment."^^xsd:string,
+ oboInOwl:id "GO:0043194"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao256000789"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033267,
+ obo:BFO_0000050 some obo:GO_0044304
+
+
+Class: obo:GO_0030080
+
+ Annotations:
+ oboInOwl:hasExactSynonym "LH1 complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0030080"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "B875 antenna complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:kd"^^xsd:string
+ obo:IAO_0000115 "Protein complex that surrounds and transfers excitation energy directly to the bacterial reaction center; binds bacteriochlorophyll a and has a single absorption band between 870 and 890 nm."^^xsd:string,
+ oboInOwl:hasExactSynonym "light harvesting complex I"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0030078,
+ obo:GO_0044433,
+ obo:GO_0043234
+
+
+Class: obo:GO_0097058
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10966616"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric protein complex that is composed of cardiotrophin-like cytokine factor 1 (product of the CLCF1 gene) and cytokine receptor-like factor 1 (product of the CRLF gene) and is secreted into the extracellular space. The CRLF-CLCF1 complex is a ligand for the ciliary neurotrophic factor (CNTF) receptor complex."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "CRLF-CLCF1 complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "CLF-CLC complex"^^xsd:string,
+ oboInOwl:id "GO:0097058"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421,
+ obo:BFO_0000050 some obo:GO_0005615,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030082
+
+ Annotations:
+ oboInOwl:hasExactSynonym "LH2 complex"^^xsd:string,
+ oboInOwl:id "GO:0030082"^^xsd:string,
+ rdfs:label "B800-850 antenna complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:kd"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:lr"^^xsd:string
+ obo:IAO_0000115 "Protein-pigment complex that absorbs light at 800 and 850 nm; is peripherally associated to the bacterial reaction center; transfers excitation energy to the B875 antenna complex."^^xsd:string,
+ oboInOwl:hasExactSynonym "light harvesting complex II"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044433,
+ obo:BFO_0000050 some obo:GO_0030079,
+ obo:GO_0043234
+
+
+Class: obo:GO_0097057
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "TRAF2-GSTP1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16636664"^^xsd:string
+ obo:IAO_0000115 "A protein complex comprising tumor necrosis factor (TNF) receptor-associated factor 2 (TRAF2) and glutathione S-transferase pi 1 (GSTP1). This complex is thought to disrupt the TNF signaling cascade, thus down-regulating inflammatory responses."^^xsd:string,
+ oboInOwl:id "GO:0097057"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0030081
+
+ Annotations:
+ oboInOwl:id "GO:0030081"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "light harvesting complex III"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:kd"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:lr"^^xsd:string
+ obo:IAO_0000115 "Protein-pigment complex that absorbs light at 800 and 820 nm; is peripherally associated to the bacterial reaction center; transfers excitation energy to the B875 antenna complex."^^xsd:string,
+ oboInOwl:hasExactSynonym "LH3 complex"^^xsd:string,
+ rdfs:label "B800-820 antenna complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044433,
+ obo:BFO_0000050 some obo:GO_0030079,
+ obo:GO_0043234
+
+
+Class: obo:GO_0043190
+
+ Annotations:
+ oboInOwl:inSubset ,
+ rdfs:label "ATP-binding cassette (ABC) transporter complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11421269"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15111107"^^xsd:string
+ obo:IAO_0000115 "A complex for the transport of metabolites into and out of the cell, typically comprised of four domains; two membrane-associated domains and two ATP-binding domains at the intracellular face of the membrane, that form a central pore through the plasma membrane. Each of the four core domains may be encoded as a separate polypeptide or the domains can be fused in any one of a number of ways into multidomain polypeptides. In Bacteria and Archaebacteria, ABC transporters also include substrate binding proteins to bind substrate external to the cytoplasm and deliver it to the transporter."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasNarrowSynonym "ABC-type uptake permease complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "ABC-type efflux permease complex"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "ATP-binding cassette (ABC) transporter complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "ABC-type efflux porter complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "mating pheromone exporter"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0043192"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0043191"^^xsd:string,
+ oboInOwl:id "GO:0043190"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:GO_0043234
+
+
+Class: obo:GO_0012510
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ai"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding a vesicle transporting substances between the trans-Golgi network and other parts of the cell."^^xsd:string,
+ oboInOwl:hasExactSynonym "TGN transport vesicle membrane"^^xsd:string,
+ rdfs:label "trans-Golgi network transport vesicle membrane"^^xsd:string,
+ oboInOwl:id "GO:0012510"^^xsd:string,
+ oboInOwl:hasExactSynonym "trans-Golgi network constitutive secretory pathway transport vesicle membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030658,
+ obo:GO_0030665,
+ obo:GO_0030660,
+ obo:BFO_0000050 some obo:GO_0030140
+
+
+Class: obo:GO_0060171
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:rph"^^xsd:string
+ obo:IAO_0000115 "The portion of the plasma membrane surrounding a stereocilium."^^xsd:string,
+ rdfs:label "stereocilium membrane"^^xsd:string,
+ oboInOwl:id "GO:0060171"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:BFO_0000050 some obo:GO_0032420,
+ obo:GO_0044422,
+ obo:GO_0031528
+
+
+Class: obo:GO_0060170
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:rph"^^xsd:string
+ obo:IAO_0000115 "The portion of the plasma membrane surrounding a cilium."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cilium membrane"^^xsd:string,
+ oboInOwl:id "GO:0060170"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044441,
+ obo:GO_0031253
+
+
+Class: obo:GO_0012511
+
+ Annotations:
+ oboInOwl:hasExactSynonym "oil body"^^xsd:string,
+ oboInOwl:hasExactSynonym "oleosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "spherosome"^^xsd:string,
+ oboInOwl:hasExactSynonym "oilbody"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Oil_body"^^xsd:string,
+ rdfs:label "monolayer-surrounded lipid storage body"^^xsd:string,
+ oboInOwl:id "GO:0012511"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0943088372"^^xsd:string
+ obo:IAO_0000115 "A subcellular organelle of plant cells surrounded by 'half-unit' or a monolayer membrane instead of the more usual bilayer. The storage body has a droplet of triglyceride surrounded by a monolayer of phospholipids, interacting with the triglycerides and the hydrophilic head groups facing the cytosol, and containing major protein components called oleosins."^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0009520"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043231,
+ obo:GO_0005811
+
+
+Class: obo:GO_0097015
+
+ Annotations:
+ rdfs:label "bacterial-type flagellar cytoplasm"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string
+ obo:IAO_0000115 "All of the contents of a bacterial-type flagellum, excluding the plasma membrane surrounding the flagellum."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "bacterial-type flagellum cytoplasm"^^xsd:string,
+ oboInOwl:id "GO:0097015"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044461,
+ obo:GO_0032838
+
+
+Class: obo:GO_0097025
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0097025"^^xsd:string,
+ rdfs:label "MPP7-DLG1-LIN7 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17237226"^^xsd:string
+ obo:IAO_0000115 "A heterotrimeric protein complex formed by the association of MMP7, DLG1 and either LIN7A or LIN7C; regulates the stability and localization of DLG1 to cell junctions."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:BFO_0000050 some obo:GO_0005912,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030093
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "chloroplast photosystem I"^^xsd:string,
+ oboInOwl:id "GO:0030093"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jid"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "Photosystem located in the chloroplast that functions as a light-dependent plastocyanin-ferredoxin oxidoreductase, transferring electrons from plastocyanin to ferredoxin. An example of this is found in Arabidopsis thaliana."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0009522
+ and (obo:BFO_0000050 some obo:GO_0009507)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009535,
+ obo:GO_0009522,
+ obo:GO_0044434
+
+
+Class: obo:GO_0012506
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding any membrane-bounded vesicle in the cell."^^xsd:string,
+ rdfs:label "vesicle membrane"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1153182838"^^xsd:string,
+ oboInOwl:id "GO:0012506"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0031988,
+ obo:BFO_0000050 some obo:GO_0012505,
+ obo:GO_0031090
+
+
+Class: obo:GO_0030096
+
+ Annotations:
+ oboInOwl:id "GO:0030096"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jid"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "A protein complex, located in the membrane-derived thylakoid, containing the P680 reaction center. In the light, PSII functions as a water-plastoquinone oxidoreductase, transferring electrons from water to plastoquinone."^^xsd:string,
+ rdfs:label "plasma membrane-derived thylakoid photosystem II"^^xsd:string,
+ oboInOwl:hasExactSynonym "plasma membrane photosystem II"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0009523
+ and (obo:BFO_0000050 some obo:GO_0030075)
+
+ SubClassOf:
+ obo:GO_0009523,
+ obo:GO_0044459,
+ obo:BFO_0000050 some obo:GO_0030075,
+ obo:GO_0044422,
+ obo:GO_0044444
+
+
+Class: obo:GO_0012507
+
+ Annotations:
+ oboInOwl:hasExactSynonym "endoplasmic reticulum-Golgi transport vesicle membrane"^^xsd:string,
+ oboInOwl:hasExactSynonym "COPII coated vesicle membrane"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0030664"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "ER to Golgi transport vesicle membrane"^^xsd:string,
+ oboInOwl:hasExactSynonym "ER to Golgi constitutive secretory pathway transport vesicle membrane"^^xsd:string,
+ oboInOwl:hasExactSynonym "endoplasmic reticulum to Golgi transport vesicle membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ai"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:ascb_2009"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:dph"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:tb"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding a vesicle transporting substances from the endoplasmic reticulum to the Golgi."^^xsd:string,
+ oboInOwl:id "GO:0012507"^^xsd:string,
+ oboInOwl:hasExactSynonym "ER-Golgi transport vesicle membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030658,
+ obo:GO_0030662,
+ obo:BFO_0000050 some obo:GO_0030134
+
+
+Class: obo:GO_0012508
+
+ Annotations:
+ oboInOwl:hasExactSynonym "Golgi to endoplasmic reticulum transport vesicle membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ai"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding a vesicle transporting substances from the Golgi to the ER."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "Golgi to ER constitutive secretory pathway transport vesicle membrane"^^xsd:string,
+ oboInOwl:hasExactSynonym "Golgi-ER transport vesicle membrane"^^xsd:string,
+ oboInOwl:hasExactSynonym "Golgi-endoplasmic reticulum transport vesicle membrane"^^xsd:string,
+ rdfs:label "Golgi to ER transport vesicle membrane"^^xsd:string,
+ oboInOwl:id "GO:0012508"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030658,
+ obo:GO_0030663,
+ obo:BFO_0000050 some obo:GO_0030142
+
+
+Class: obo:GO_0030094
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jid"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "A protein complex located in the plasma membrane-derived thylakoid. The photosystem functions as a light-dependent plastocyanin-ferredoxin oxidoreductase, transferring electrons from plastocyanin to ferredoxin. Examples of this complex are found in bacterial species."^^xsd:string,
+ oboInOwl:id "GO:0030094"^^xsd:string,
+ oboInOwl:hasExactSynonym "plasma membrane photosystem I"^^xsd:string,
+ rdfs:label "plasma membrane-derived photosystem I"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0009522
+ and (obo:BFO_0000050 some obo:GO_0005886)
+
+ SubClassOf:
+ obo:GO_0009522,
+ obo:GO_0044459,
+ obo:BFO_0000050 some obo:GO_0030075,
+ obo:GO_0044422,
+ obo:GO_0044444
+
+
+Class: obo:GO_0012509
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "inter-Golgi transport vesicle membrane"^^xsd:string,
+ oboInOwl:hasExactSynonym "inter-Golgi transport constitutive secretory pathway transport vesicle membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ai"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding a vesicle transporting substances within the Golgi."^^xsd:string,
+ oboInOwl:id "GO:0012509"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030663,
+ obo:GO_0030658,
+ obo:BFO_0000050 some obo:GO_0030143
+
+
+Class: obo:GO_0030095
+
+ Annotations:
+ oboInOwl:id "GO:0030095"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "chloroplast photosystem II"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jid"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "An integral chloroplast membrane complex containing the P680 reaction center. In the light, PSII functions as a water-plastoquinone oxidoreductase, transferring electrons from water to plastoquinone."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0009523
+ and (obo:BFO_0000050 some obo:GO_0009507)
+
+ SubClassOf:
+ obo:GO_0009523,
+ obo:BFO_0000050 some obo:GO_0009535,
+ obo:GO_0044434
+
+
+Class: obo:GO_0035339
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:20182505"^^xsd:string
+ obo:IAO_0000115 "A multiprotein complex at least composed of serine palmitoyltransferases and ORM proteins (known as ORMDL proteins in mammals and other higher vertebrates) that plays a key role in sphingolipid homeostasis."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "SPOTS complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "serine palmitoyltransferase, Orm1/2, Tsc3 and Sac1 complex"^^xsd:string,
+ oboInOwl:id "GO:0035339"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0017059
+
+
+Class: obo:GO_0012505
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ rdfs:label "endomembrane system"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:lh"^^xsd:string
+ obo:IAO_0000115 "A collection of membranous structures involved in transport within the cell. The main components of the endomembrane system are endoplasmic reticulum, Golgi bodies, vesicles, cell membrane and nuclear envelope. Members of the endomembrane system pass materials through each other or though the use of vesicles."^^xsd:string,
+ oboInOwl:id "GO:0012505"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasDbXref "Wikipedia:Endomembrane_system"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0070088
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070088"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "PHB granule"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15762612"^^xsd:string
+ obo:IAO_0000115 "An inclusion body located in the cytoplasm that consists of polyhydroxyalkanoate (PHA) molecules and associated proteins, surrounded by a phospholipid monolayer; the proteins include PHA synthase, PHA depolymerase and 3HB-oligomer hydroxylase, phasins (PhaPs), which are thought to be the major structural proteins of the membrane surrounding the inclusion, and the regulator of phasin expression PhaR."^^xsd:string,
+ rdfs:label "PHA granule"^^xsd:string,
+ oboInOwl:hasExactSynonym "polyhydroxyalkanoate granule"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043231,
+ obo:GO_0016234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0035354
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "Toll-like receptor 1-Toll-like receptor 2 protein complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17889651"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric protein complex containing Toll-like receptor 1 (TLR1) and Toll-like receptor 2 (TLR2)."^^xsd:string,
+ oboInOwl:id "GO:0035354"^^xsd:string,
+ oboInOwl:hasExactSynonym "TLR1-TLR2 protein complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0035355
+
+ Annotations:
+ oboInOwl:hasExactSynonym "TLR2-TLR6 protein complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "Toll-like receptor 2-Toll-like receptor 6 protein complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19931471"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric protein complex containing Toll-like receptor 2 (TLR2) and Toll-like receptor 6 (TLR6)."^^xsd:string,
+ oboInOwl:id "GO:0035355"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0002199
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:hjd"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:21880732"^^xsd:string
+ obo:IAO_0000115 "A multisubunit complex comprising the chaperonin-containing T-complex and several other components involved in mediating sperm-oocyte Interaction."^^xsd:string,
+ oboInOwl:id "GO:0002199"^^xsd:string,
+ rdfs:label "sperm protein complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000051 some obo:GO_0005832,
+ obo:GO_0043234
+
+
+Class: obo:GO_0002197
+
+ Annotations:
+ oboInOwl:id "GO:0002197"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "xanthine dehydrogenase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:hjd"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8224915"^^xsd:string
+ obo:IAO_0000115 "A homodimeric protein complex having xanthine dehydrogenase activity."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0002193
+
+ Annotations:
+ oboInOwl:hasExactSynonym "MAML1-RBP-Jkappa-Notch1 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2949"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16510869"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of the intracellular domain of Notch1 (ICN1), the DNA-binding transcription factor RBP-Jkappa, and the transcriptional coactivator Mastermind-like-1 (MAML1); the complex is involved in transcriptional activation in response to Notch-mediated signaling."^^xsd:string,
+ oboInOwl:id "GO:0002193"^^xsd:string,
+ rdfs:label "MAML1-RBP-Jkappa- ICN1 complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "MAML1-CSL-Notch1 complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "MAML1-CSL-ICN1"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0001114
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:txnOH"^^xsd:string
+ obo:IAO_0000115 "A macromolecular complex containing protein, DNA, and RNA molecules."^^xsd:string,
+ oboInOwl:id "GO:0001114"^^xsd:string,
+ rdfs:label "protein-DNA-RNA complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032991
+
+
+Class: obo:GO_0070090
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The intracellular plane, located halfway between the poles of the spindle, where chromosomes align during metaphase of mitotic or meiotic nuclear division."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070090"^^xsd:string,
+ rdfs:label "metaphase plate"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424
+
+
+Class: obo:GO_0071601
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:7758244"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8349728"^^xsd:string
+ obo:IAO_0000115 "A nuclear body that is found in the germinal vesicles of amphibian oocytes, and consist of three major parts: a remarkably spherical body about 5-10 pm in diameter, smaller spherical or nearly spherical granules on the surface, and inclusions of various sizes that strongly resemble the surface granules. The parts of the sphere organelle have distinct compositions, including splicing snRNAs and proteins."^^xsd:string,
+ oboInOwl:id "GO:0071601"^^xsd:string,
+ rdfs:label "sphere organelle"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016604
+
+
+Class: obo:GO_0048475
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jid"^^xsd:string
+ obo:IAO_0000115 "A single or double lipid bilayer with any of several different proteinaceous coats that can associate with membranes. Membrane coats include those formed by clathrin plus an adaptor complex, the COPI and COPII complexes."^^xsd:string,
+ oboInOwl:id "GO:0048475"^^xsd:string,
+ rdfs:label "coated membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016020
+
+
+Class: obo:GO_0048476
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:11207366"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12374758"^^xsd:string
+ obo:IAO_0000115 "A protein complex that mediates the conversion of a Holliday junction into two separate duplex DNA molecules; the complex includes a single- or multisubunit helicase that catalyzes the extension of heteroduplex DNA by branch migration and a nuclease that resolves the junction by nucleolytic cleavage."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Mus81-Eme1 complex"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11207366"^^xsd:string
+ oboInOwl:hasExactSynonym "resolvasome"^^xsd:string,
+ oboInOwl:id "GO:0048476"^^xsd:string,
+ rdfs:label "Holliday junction resolvase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0035363
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "histone locus body"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16533947"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18927579"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19620235"^^xsd:string
+ oboInOwl:hasExactSynonym "HLB"^^xsd:string,
+ oboInOwl:id "GO:0035363"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:sart"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16533947"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18927579"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19620235"^^xsd:string
+ obo:IAO_0000115 "A nuclear body associated with the histone gene locus that is thought to contain all of the factors necessary for histone mRNA transcription and pre-mRNA processing. In Drosophila, U7 snRNP is located in the histone locus body rather than the distinct Cajal body."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016604
+
+
+Class: obo:GO_0035369
+
+ Annotations:
+ rdfs:comment "Despite its name, the pre-BCR is not a receptor complex, as it appears to provide a low level of signal not dependent on a ligand, but rather simply on correct assembly of the complex as a measure for correct Ig heavy chain recombination and folding. A significant proportion of pre-BCR complexes fail to reach the cell surface, and in some cases may provide their signaling function from the trans-Golgi network or lysosome."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0781765196"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16464608"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17306522"^^xsd:string
+ obo:IAO_0000115 "An immunoglobulin-like complex that is present in at least the plasma membrane of pre-B cells, and that is composed of two identical immunoglobulin heavy chains and two surrogate light chains, each composed of the lambda-5 and VpreB proteins, and a signaling subunit, a heterodimer of the Ig-alpha and Ig-beta proteins."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "pre-BCR"^^xsd:string,
+ rdfs:label "pre-B cell receptor complex"^^xsd:string,
+ oboInOwl:id "GO:0035369"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030897
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10944212"^^xsd:string
+ obo:IAO_0000115 "A multimeric protein complex that associates with the vacuolar membrane and is involved in homotypic vacuole fusion and vacuole protein sorting. For example, the Saccharomyces complex contains Vps41p, Vam6p, Pep5p, Vps16p, Pep3p, and Vps33p."^^xsd:string,
+ rdfs:label "HOPS complex"^^xsd:string,
+ oboInOwl:id "GO:0030897"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044437,
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0005774,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030896
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "checkpoint clamp complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "Rad9-Hus1-Rad1 (9-1-1) clamp complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12531008"^^xsd:string
+ obo:IAO_0000115 "Conserved heterotrimeric complex of PCNA-like proteins that is loaded onto DNA at sites of DNA damage."^^xsd:string,
+ oboInOwl:id "GO:0030896"^^xsd:string,
+ oboInOwl:hasExactSynonym "CCC"^^xsd:string,
+ rdfs:comment "Note that the following subunit names have been used: human RAD9/RAD1/HUS1; S. pombe Rad9/Rad1/Hus1; S. cerevisiae Ddc1p/Rad17p/Mec3p."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:BFO_0000050 some obo:GO_0000794,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030895
+
+ Annotations:
+ rdfs:label "apolipoprotein B mRNA editing enzyme complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10781591"^^xsd:string
+ obo:IAO_0000115 "Protein complex that mediates editing of the mRNA encoding apolipoprotein B; catalyzes the deamination of C to U (residue 6666 in the human mRNA). Contains a catalytic subunit, APOBEC-1, and other proteins (e.g. human ASP; rat ASP and KSRP)."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "apoB mRNA editing enzyme complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "APOBEC"^^xsd:string,
+ oboInOwl:id "GO:0030895"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030894
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:309"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12006500"^^xsd:string
+ oboInOwl:hasRelatedSynonym "RC complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:309"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12006500"^^xsd:string
+ oboInOwl:hasRelatedSynonym "replication-competent complex"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Replisome"^^xsd:string,
+ rdfs:label "replisome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ obo:IAO_0000115 "A multi-component enzymatic machine at the replication fork which mediates DNA replication. Includes DNA primase, one or more DNA polymerases, DNA helicases, and other proteins."^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1001"^^xsd:string
+ oboInOwl:hasRelatedSynonym "DNA synthesome complex"^^xsd:string,
+ oboInOwl:id "GO:0030894"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:BFO_0000050 some obo:GO_0005657,
+ obo:GO_0032993
+
+
+Class: obo:GO_0022626
+
+ Annotations:
+ oboInOwl:hasAlternativeId "GO:0005830"^^xsd:string,
+ rdfs:label "cytosolic ribosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0030871"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0009281"^^xsd:string,
+ oboInOwl:id "GO:0022626"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "80S ribosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "A ribosome located in the cytosol."^^xsd:string,
+ oboInOwl:hasNarrowSynonym "70S ribosome"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005840
+ and (obo:BFO_0000050 some obo:GO_0005829)
+
+ SubClassOf:
+ obo:GO_0005840,
+ obo:GO_0044445
+
+
+Class: obo:GO_0022627
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "40S ribosomal subunit"^^xsd:string,
+ rdfs:label "cytosolic small ribosomal subunit"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0030873"^^xsd:string,
+ oboInOwl:id "GO:0022627"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "prokaryotic small ribosomal subunit"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0005843"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "30S ribosomal subunit"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0009283"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0030499"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "eukaryotic ribosomal SSU"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "The small subunit of a ribosome located in the cytosol."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0015935
+ and (obo:BFO_0000050 some obo:GO_0022626)
+
+ SubClassOf:
+ obo:GO_0015935,
+ obo:BFO_0000050 some obo:GO_0022626
+
+
+Class: obo:GO_0022628
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "chloroplast ribosomal large subunit complex"^^xsd:string,
+ oboInOwl:id "GO:0022628"^^xsd:string,
+ oboInOwl:hasExactSynonym "chloroplast ribosomal LSU complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "The large subunit of a ribosome contained within a chloroplast."^^xsd:string,
+ rdfs:label "chloroplast large ribosomal subunit"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0015934
+ and (obo:BFO_0000050 some obo:GO_0043253)
+
+ SubClassOf:
+ obo:GO_0000311,
+ obo:GO_0044434,
+ obo:BFO_0000050 some obo:GO_0043253
+
+
+Class: obo:GO_0022629
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "The small subunit of a ribosome contained within a chloroplast."^^xsd:string,
+ rdfs:label "chloroplast small ribosomal subunit"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "chloroplast ribosomal SSU complex"^^xsd:string,
+ oboInOwl:id "GO:0022629"^^xsd:string,
+ oboInOwl:hasExactSynonym "chloroplast ribosomal small subunit complex"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0015935
+ and (obo:BFO_0000050 some obo:GO_0043253)
+
+ SubClassOf:
+ obo:GO_0000312,
+ obo:GO_0044434,
+ obo:BFO_0000050 some obo:GO_0043253
+
+
+Class: obo:GO_0048471
+
+ Annotations:
+ oboInOwl:id "GO:0048471"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jid"^^xsd:string
+ obo:IAO_0000115 "Cytoplasm situated near, or occurring around, the nucleus."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that this term should not be confused with the cellular component term 'nuclear membrane lumen ; GO:0005641', which has the synonym 'perinuclear space'."^^xsd:string,
+ rdfs:label "perinuclear region of cytoplasm"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444
+
+
+Class: obo:GO_0035361
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "Cul8-RING ubiquitin ligase complex"^^xsd:string,
+ oboInOwl:id "GO:0035361"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20139071"^^xsd:string
+ obo:IAO_0000115 "A ubiquitin ligase complex in which a cullin from the Cul8 subfamily and a RING domain protein form the catalytic core. In S. cerevisiae, Mms1p acts as the adaptor protein and substrate specificity is conferred by any of a number of different proteins."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031461
+
+
+Class: obo:GO_0022623
+
+ Annotations:
+ rdfs:label "proteasome-activating nucleotidase complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "PAN"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "A multisubunit complex that recognizes and unfolds core proteasome substrate proteins, and translocates them to the core complex in an ATP dependent manner."^^xsd:string,
+ oboInOwl:id "GO:0022623"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:BFO_0000050 some obo:GO_0022624,
+ obo:GO_0043234
+
+
+Class: obo:GO_0022624
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "proteasome accessory complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "A protein complex, that caps one or both ends of the proteasome core complex and regulates entry into, or exit from, the proteasome core complex."^^xsd:string,
+ oboInOwl:id "GO:0022624"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:BFO_0000050 some obo:GO_0000502,
+ obo:GO_0043234
+
+
+Class: obo:GO_0022625
+
+ Annotations:
+ oboInOwl:hasAlternativeId "GO:0030498"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0030872"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "prokaryotic large ribosomal subunit"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "60S ribosomal subunit"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "50S ribosomal subunit"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "eukaryotic ribosomal LSU"^^xsd:string,
+ oboInOwl:id "GO:0022625"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0005842"^^xsd:string,
+ rdfs:label "cytosolic large ribosomal subunit"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "The large subunit of a ribosome located in the cytosol."^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0009282"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0015934
+ and (obo:BFO_0000050 some obo:GO_0022626)
+
+ SubClassOf:
+ obo:GO_0015934,
+ obo:BFO_0000050 some obo:GO_0022626
+
+
+Class: obo:GO_0097002
+
+ Annotations:
+ oboInOwl:id "GO:0097002"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "mitochondrial inner boundary membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mcc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16054341"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19019989"^^xsd:string
+ obo:IAO_0000115 "The portion of the mitochondrial inner membrane that is not invaginated to form cristae. The inner boundary membrane lies parallel to the outer membrane."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044455,
+ obo:BFO_0000050 some obo:GO_0005743
+
+
+Class: obo:GO_0060187
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string
+ obo:IAO_0000115 "Either of two different areas at opposite ends of an axis of a cell."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that this term differs from 'cell tip ; GO:0051286' in that it is applicable to a broader range of cell shapes."^^xsd:string,
+ oboInOwl:id "GO:0060187"^^xsd:string,
+ rdfs:label "cell pole"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0043913
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "chromosome segregation-directing complex"^^xsd:string,
+ oboInOwl:id "GO:0043913"^^xsd:string,
+ oboInOwl:hasExactSynonym "longitudinal peptidoglycan synthesis-directing complex"^^xsd:string,
+ oboInOwl:hasDbXref "IMG:02994"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15612918"^^xsd:string
+ obo:IAO_0000115 "A trimeric protein complex which in E. coli is composed of the subunits MreB, MreC and MreD. The complex directs longitudinal cell wall synthesis, maintaining cell morphology."^^xsd:string,
+ oboInOwl:hasExactSynonym "chromosome segregation directing complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "MreBCD complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:GO_0043234
+
+
+Class: obo:GO_0035370
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0035370"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:amm"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16129784"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric ubiquitin conjugating enzyme complex that catalyzes assembly of K63-linked polyubiquitin chains and is involved in NF-kappaB activation. In humans at least, the complex comprises the ubiquitin-conjugating enzyme UBC13 and ubiquitin-conjugating enzyme variant 1A (UEV1A)."^^xsd:string,
+ rdfs:label "UBC13-UEV1A complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031371
+
+
+Class: obo:GO_0035371
+
+ Annotations:
+ oboInOwl:hasExactSynonym "microtubule plus-end"^^xsd:string,
+ oboInOwl:hasExactSynonym "growing microtubule plus end"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:lb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12700769"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16643273"^^xsd:string
+ obo:IAO_0000115 "The growing (plus) end of a microtubule. In vitro, microtubules polymerize more quickly at the plus end than at the minus end. In vivo, microtubule growth occurs only at the plus end, and the plus end switches between periods of growth and shortening, a behavior known as dynamic instability."^^xsd:string,
+ oboInOwl:id "GO:0035371"^^xsd:string,
+ rdfs:label "microtubule plus end"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005874,
+ obo:GO_0044430
+
+
+Class: obo:GO_0071202
+
+ Annotations:
+ rdfs:label "Kv4.3-DPP10 channel complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15911355"^^xsd:string
+ obo:IAO_0000115 "A voltage-gated potassium channel complex that contains the peptidase-related protein DPP10 associated with the channel via interaction with the Kv alpha subunit 4.3."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15911355"^^xsd:string
+ oboInOwl:hasExactSynonym "Kv4.3-DPPY channel complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071202"^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:598"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008076
+
+
+Class: obo:GO_0071203
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:sp"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19922875"^^xsd:string
+ obo:IAO_0000115 "A protein complex that localizes at the surface of endosomes, where it recruits and activates the Arp2/3 complex to induce actin polymerization. In human, the WASH complex is composed of F-actin-capping protein subunits alpha and beta, WASH1, FAM21, KIAA1033, KIAA0196 and CCDC53."^^xsd:string,
+ rdfs:label "WASH complex"^^xsd:string,
+ oboInOwl:id "GO:0071203"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0097013
+
+ Annotations:
+ rdfs:label "phagocytic vesicle lumen"^^xsd:string,
+ oboInOwl:id "GO:0097013"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rs"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membrane of a phagocytic vesicle."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0031974
+ and (obo:BFO_0000050 some obo:GO_0045335)
+
+ SubClassOf:
+ obo:GO_0071682,
+ obo:BFO_0000050 some obo:GO_0045335
+
+
+Class: obo:GO_0071204
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19470752"^^xsd:string
+ obo:IAO_0000115 "A ribonucleoprotein that binds to specific sites in, and is required for cleavage of, the 3'-end of histone pre-mRNAs. The complex contains the U7 snRNP and additional proteins, including the stem-loop binding protein (SLBP) and the exonuclease 3'hExo/Eri-1."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "histone 3'end pre-mRNA complex"^^xsd:string,
+ oboInOwl:id "GO:0071204"^^xsd:string,
+ rdfs:label "histone pre-mRNA 3'end processing complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030529,
+ obo:GO_0044428
+
+
+Class: obo:GO_0097014
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0097014"^^xsd:string,
+ rdfs:label "microtubule-based flagellar cytoplasm"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17895364"^^xsd:string
+ obo:IAO_0000115 "All of the contents of a microtubule-based flagellum, excluding the plasma membrane surrounding the flagellum."^^xsd:string,
+ oboInOwl:hasNarrowSynonym "microtubule-based flagellum matrix"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "microtubule-based flagellar matrix"^^xsd:string,
+ oboInOwl:hasExactSynonym "microtubule-based flagellum cytoplasm"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032838,
+ obo:GO_0044442
+
+
+Class: obo:GO_0071200
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:12575952"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15911355"^^xsd:string
+ obo:IAO_0000115 "A voltage-gated potassium channel complex that contains the peptidase-related protein DPP6 associated with the channel via interaction with the Kv alpha subunit 4.2."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15911355"^^xsd:string
+ oboInOwl:hasExactSynonym "Kv4.2-DPPX channel complex"^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:603"^^xsd:string,
+ oboInOwl:id "GO:0071200"^^xsd:string,
+ rdfs:label "Kv4.2-DPP6 channel complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008076
+
+
+Class: obo:GO_0071201
+
+ Annotations:
+ rdfs:label "Kv4.3-DPP6 channel complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12575952"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15911355"^^xsd:string
+ obo:IAO_0000115 "A voltage-gated potassium channel complex that contains the peptidase-related protein DPP6 associated with the channel via interaction with the Kv alpha subunit 4.3."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071201"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15911355"^^xsd:string
+ oboInOwl:hasExactSynonym "Kv4.3-DPPX channel complex"^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:599"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008076
+
+
+Class: obo:GO_0030891
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11865071"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses ubiquitin ligase activity; the complex is usually pentameric; for example, in mammals the subunits are pVHL, elongin B, elongin C, cullin-2 (Cul2), and Rbx1."^^xsd:string,
+ oboInOwl:id "GO:0030891"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "VHL complex"^^xsd:string,
+ rdfs:label "VCB complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "von Hippel-Lindau tumor suppressor complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "pVHL-elongin C-elongin B complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000153
+
+
+Class: obo:GO_0030892
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12750522"^^xsd:string
+ obo:IAO_0000115 "A cohesin complex that mediates sister chromatid cohesion during mitosis; has a subunit composition distinct from that of the meiotic cohesin complex."^^xsd:string,
+ oboInOwl:id "GO:0030892"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "mitotic cohesin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008278
+
+
+Class: obo:GO_0030893
+
+ Annotations:
+ oboInOwl:id "GO:0030893"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12750522"^^xsd:string
+ obo:IAO_0000115 "A cohesin complex that mediates sister chromatid cohesion during meiosis; has a subunit composition distinct from that of the mitotic cohesin complex."^^xsd:string,
+ rdfs:label "meiotic cohesin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008278
+
+
+Class: obo:GO_0060198
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string
+ obo:IAO_0000115 "A clathrin sculpted lipid bilayer membrane-enclosed vesicle after clathrin release."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0060198"^^xsd:string,
+ rdfs:label "clathrin sculpted vesicle"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030136
+
+
+Class: obo:GO_0060199
+
+ Annotations:
+ oboInOwl:id "GO:0060199"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "clathrin sculpted glutamate constitutive secretory pathway transport vesicle"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string
+ obo:IAO_0000115 "A clathrin sculpted lipid bilayer membrane-enclosed vesicle after clathrin release and containing glutamate."^^xsd:string,
+ rdfs:label "clathrin sculpted glutamate transport vesicle"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030133,
+ obo:GO_0060198
+
+
+Class: obo:GO_0048787
+
+ Annotations:
+ oboInOwl:hasExactSynonym "pre-synaptic active zone membrane"^^xsd:string,
+ oboInOwl:id "GO:0048787"^^xsd:string,
+ oboInOwl:hasExactSynonym "active zone pre-synaptic plasma membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "presynaptic active zone membrane"^^xsd:string,
+ oboInOwl:hasExactSynonym "active zone presynaptic plasma membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12812759"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12923177"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:3152289"^^xsd:string
+ obo:IAO_0000115 "The membrane portion of the presynaptic active zone; it is the site where docking and fusion of synaptic vesicles occurs for the release of neurotransmitters."^^xsd:string,
+ oboInOwl:hasExactSynonym "active zone plasma membrane"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0048786,
+ obo:GO_0042734
+
+
+Class: obo:GO_0048788
+
+ Annotations:
+ oboInOwl:id "GO:0048788"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "CAZ"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "pre-synaptic cytoskeletal matrix assembled at active zones"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16384719"^^xsd:string
+ oboInOwl:hasNarrowSynonym "T-bar ribbon"^^xsd:string,
+ oboInOwl:hasExactSynonym "presynaptic cytomatrix assembled at active zones"^^xsd:string,
+ rdfs:label "presynaptic cytoskeletal matrix assembled at active zones"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:20127822"^^xsd:string
+ oboInOwl:hasNarrowSynonym "T-bar"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:19264728"^^xsd:string
+ oboInOwl:hasNarrowSynonym "synaptic ribbon"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16709774"^^xsd:string
+ oboInOwl:hasNarrowSynonym "presynaptic dense body"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dh"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:dl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:ef"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:jid"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10944438"^^xsd:string
+ obo:IAO_0000115 "The specialized cytoskeletal matrix assembled at the active zones of the presynaptic nerve terminal. The cytoskeletal matrix is a proteinaceous structure involved in organizing synaptic events such as immobilisation or translocation of synaptic vesicles, and assembling active zone components. The cytomatrix protein exclusively assembled at active zones, is thought to form a molecular scaffold that organizes neurotransmitter release sites."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0030863
+ and (obo:BFO_0000050 some obo:GO_0048786)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0048786,
+ obo:GO_0044456,
+ obo:GO_0030863
+
+
+Class: obo:GO_0071089
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3095"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB3-TGM2 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10684262"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaV-beta3 integrin complex bound to tissue transglutaminase."^^xsd:string,
+ oboInOwl:id "GO:0071089"^^xsd:string,
+ rdfs:label "alphaV-beta3 integrin-tissue transglutaminase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071088
+
+ Annotations:
+ rdfs:label "alpha5-beta1 integrin-tissue transglutaminase complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10684262"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha5-beta1 integrin complex bound to tissue transglutaminase."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2433"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA5-ITGB1-TGM2 complex"^^xsd:string,
+ oboInOwl:id "GO:0071088"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070743
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "IL23A"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "p19"^^xsd:string,
+ rdfs:label "interleukin-23 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasExactSynonym "IL-23 complex"^^xsd:string,
+ oboInOwl:id "GO:0070743"^^xsd:string,
+ rdfs:comment "Note that this heterodimeric cytokine utilizes the same beta subunit as IL-12."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "IL12B"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11114383"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15999093"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is composed of an interleukin-23 alpha (p19, product of the IL23A gene) and an interleukin-12 beta (p40, product of the IL12B gene) subunit and is secreted into the extracellular space."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "p40"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421,
+ obo:BFO_0000050 some obo:GO_0005615,
+ obo:GO_0043234
+
+
+Class: obo:GO_0048786
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "pre-synaptic active zone"^^xsd:string,
+ rdfs:label "presynaptic active zone"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao792027222"^^xsd:string,
+ oboInOwl:id "GO:0048786"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dh"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:dl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:ef"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:jid"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:3152289"^^xsd:string
+ obo:IAO_0000115 "A specialized region of the plasma membrane and cell cortex of a presynaptic neuron; encompasses a region of the plasma membrane where synaptic vesicles dock and fuse, synaptic vesicles, and a specialized cortical cytoskeletal matrix."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044456
+
+
+Class: obo:GO_0070744
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasExactSynonym "IL-27 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070744"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15999093"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19161428"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is composed of an interleukin-27p28 subunit (product of the IL27 gene) and an EBI3 subunit and is secreted into the extracellular space."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "IL27"^^xsd:string,
+ rdfs:comment "Note that this heterodimeric cytokine utilizes the same EBI3 subunit (product of EBI3, Epstein-Barr virus induced gene 3) as its beta chain as IL-35 uses for its beta chain. Also note that the product of the IL27 gene is the alpha subunit of IL-27. The functional IL-27 protein complex requires both subunits."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "EBI3"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "p28"^^xsd:string,
+ rdfs:label "interleukin-27 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421,
+ obo:BFO_0000050 some obo:GO_0005615,
+ obo:GO_0043234
+
+
+Class: obo:GO_0045121
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Lipid_raft"^^xsd:string,
+ rdfs:label "membrane raft"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "lipid raft"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "glycolipid-enriched membrane domain"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16645198"^^xsd:string
+ obo:IAO_0000115 "Any of the small (10-200 nm), heterogeneous, highly dynamic, sterol- and sphingolipid-enriched membrane domains that compartmentalize cellular processes. Small rafts can sometimes be stabilized to form larger platforms through protein-protein and protein-lipid interactions."^^xsd:string,
+ oboInOwl:id "GO:0045121"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "GEM domain"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425
+
+
+Class: obo:GO_0070745
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasExactSynonym "IL-35 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "p35"^^xsd:string,
+ rdfs:comment "Note that this heterodimeric cytokine utilizes the same IL-12p35 subunit as its alpha chain as IL-12 uses and the same EBI3 subunit (product of EBI3, Epstein-Barr virus induced gene 3) as its beta chain as IL-27 uses. IL-35 requires both subunits -- there is no separate IL35 gene."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "interleukin-35 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19161428"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19161429"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is composed of an interleukin-12 alpha subunit (p35, product of the IL12A gene) and an EBI3 subunit and is secreted into the extracellular space."^^xsd:string,
+ oboInOwl:id "GO:0070745"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "IL12A"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string
+ oboInOwl:hasNarrowSynonym "EBI3"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421,
+ obo:BFO_0000050 some obo:GO_0005615,
+ obo:GO_0043234
+
+
+Class: obo:GO_0045120
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Pronucleus"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "The nucleus of either the ovum or the spermatozoon following fertilization. Thus, in the fertilized ovum, there are two pronuclei, one originating from the ovum, the other from the spermatozoon that brought about fertilization; they approach each other, but do not fuse until just before the first cleavage, when each pronucleus loses its membrane to release its contents."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0045120"^^xsd:string,
+ rdfs:label "pronucleus"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005634
+
+
+Class: obo:GO_0031083
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "BLOC-1 complex"^^xsd:string,
+ oboInOwl:id "GO:0031083"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15102850"^^xsd:string
+ obo:IAO_0000115 "A protein complex required for the biogenesis of specialized organelles of the endosomal-lysosomal system, such as melanosomes and platelet dense granules. Many of the protein subunits are conserved between mouse and human; the mouse complex contains the Pallidin, Muted, Cappuccino, Dysbindin, Snapin, BLOS1, BLOS2, AND BLOS3 proteins."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031082
+
+
+Class: obo:GO_0031082
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:15102850"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15261680"^^xsd:string
+ obo:IAO_0000115 "Any of several protein complexes required for the biogenesis of specialized organelles of the endosomal-lysosomal system, such as melanosomes, platelet dense granules, and other related organelles; acronym for biogenesis of lysosomal-related organelles complex."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "BLOC complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0031082"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044445,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031080
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031080"^^xsd:string,
+ oboInOwl:hasExactSynonym "Nup84 complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "Nup107-120 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10747086"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11823431"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15226438"^^xsd:string
+ obo:IAO_0000115 "A subcomplex of the nuclear pore complex (NPC) involved in mRNA export and NPC assembly. Contains conserved nucleoporins and other proteins; for example, the Saccharomyces complex contains Nup84p, Nup85p, Nup120p, Nup145p-C, Seh1p, Sec13p, and Nup133p."^^xsd:string,
+ rdfs:label "Nup107-160 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0005643,
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009548
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The portion of the plasma membrane surrounding a plasmodesma."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009548"^^xsd:string,
+ rdfs:label "plasmodesmatal plasma membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:BFO_0000050 some obo:GO_0009506
+
+
+Class: obo:GO_0071090
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alphaIIb-beta3 integrin-fibronectin-tissue transglutaminase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10684262"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaIIb-beta3 integrin complex bound to fibronectin and tissue transglutaminase."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2376"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA2b-ITGB3-FN1-TGM2 complex"^^xsd:string,
+ oboInOwl:id "GO:0071090"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009549
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cellulose microfibril"^^xsd:string,
+ oboInOwl:id "GO:0009549"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jid"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0943088399"^^xsd:string
+ obo:IAO_0000115 "A microfibril composed of cellulose arranged in orthogonal layers. Cellulose is a straight chain polysaccharide composed of B(14) linked glucose subunits. It is a major component of plant cell walls. Higher plant microfibrils are about 10nm in diameter and extremely long in relation to their width. The cellulose molecules are oriented parallel to the long axis of the microfibril in a paracrystalline array, which provides great tensile strength. The microfibrils are held in place by the wall matrix and their orientation is closely controlled by the cell."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044426,
+ obo:BFO_0000050 some obo:GO_0009505
+
+
+Class: obo:GO_0009546
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "http://biology.kenyon.edu/edwards/project/greg/pd.htm"^^xsd:string
+ obo:IAO_0000115 "The space between the plasma membrane and the desmotubule of a plasmodesma."^^xsd:string,
+ rdfs:label "plasmodesmatal cytoplasmic sleeve"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009546"^^xsd:string,
+ oboInOwl:hasExactSynonym "plasmodesmatal cytoplasmic annulus"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:BFO_0000050 some obo:GO_0009506
+
+
+Class: obo:GO_0009547
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:tair_curators"^^xsd:string
+ obo:IAO_0000115 "A ribosome contained within a plastid."^^xsd:string,
+ oboInOwl:id "GO:0009547"^^xsd:string,
+ rdfs:label "plastid ribosome"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005840
+ and (obo:BFO_0000050 some obo:GO_0009536)
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:BFO_0000050 some obo:GO_0009532,
+ obo:GO_0000313
+
+
+Class: obo:GO_0071093
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:10684262"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha5-beta1 integrin complex bound to fibronectin and tissue transglutaminase."^^xsd:string,
+ oboInOwl:id "GO:0071093"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alpha5-beta1 integrin-fibronectin-tissue transglutaminase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2383"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA5-ITGB1-FN1-TGM2 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009544
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009544"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:019854768"^^xsd:string
+ obo:IAO_0000115 "The protein complex that catalyzes the phosphorylation of ADP to ATP in chloroplasts."^^xsd:string,
+ rdfs:label "chloroplast ATP synthase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044436,
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0009535,
+ obo:GO_0044434,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071094
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071094"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2770"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA6-ITGB4-CD9 complex"^^xsd:string,
+ rdfs:label "alpha6-beta4 integrin-CD9 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10711425"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha6-beta4 integrin complex bound to the cell surface protein CD9."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009545
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0140514031"^^xsd:string
+ obo:IAO_0000115 "A leucoplast in which oil is stored."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Elaioplast"^^xsd:string,
+ oboInOwl:id "GO:0009545"^^xsd:string,
+ rdfs:label "elaioplast"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009536
+
+
+Class: obo:GO_0071091
+
+ Annotations:
+ oboInOwl:id "GO:0071091"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2894"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA1-ITGB1-TGM2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10684262"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha1-beta1 integrin complex bound to tissue transglutaminase."^^xsd:string,
+ rdfs:label "alpha1-beta1 integrin-tissue transglutaminase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009542
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "granum"^^xsd:string,
+ oboInOwl:id "GO:0009542"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:014051403"^^xsd:string
+ obo:IAO_0000115 "Distinct stack of lamellae seen within chloroplasts. Grana contain the pigments, electron transfer compounds, and enzymes essential to the light-dependent reactions of photosynthesis."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044434
+
+
+Class: obo:GO_0014731
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0014731"^^xsd:string,
+ rdfs:label "spectrin-associated cytoskeleton"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15970557"^^xsd:string
+ obo:IAO_0000115 "The part of the cytoskeleton composed of spectrin, protein 4.1 and ankyrin. Spectrin-associated cytoskeleton is associated with the plasma membrane."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005856
+
+
+Class: obo:GO_0031089
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membrane of the platelet dense granule."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "platelet dense granule lumen"^^xsd:string,
+ oboInOwl:id "GO:0031089"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0034774,
+ obo:BFO_0000050 some obo:GO_0042827
+
+
+Class: obo:GO_0071092
+
+ Annotations:
+ oboInOwl:id "GO:0071092"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2402"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA3-ITGB1-TGM2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10684262"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha3-beta1 integrin complex bound to tissue transglutaminase."^^xsd:string,
+ rdfs:label "alpha3-beta1 integrin-tissue transglutaminase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009543
+
+ Annotations:
+ rdfs:label "chloroplast thylakoid lumen"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009543"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:006501037"^^xsd:string
+ obo:IAO_0000115 "The cavity enclosed within the chloroplast thylakoid membrane. An example of this component is found in Arabidopsis thaliana."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009534,
+ obo:GO_0031978,
+ obo:GO_0044434
+
+
+Class: obo:GO_0031088
+
+ Annotations:
+ rdfs:label "platelet dense granule membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding the platelet dense granule."^^xsd:string,
+ oboInOwl:id "GO:0031088"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030667,
+ obo:BFO_0000050 some obo:GO_0042827
+
+
+Class: obo:GO_0071097
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2363"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB3-PXN-PTK2b complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alphaV-beta3 integrin-paxillin-Pyk2 complex"^^xsd:string,
+ oboInOwl:id "GO:0071097"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11683411"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaV-beta3 integrin complex bound to paxillin and the FAK-related kinase Pyk2."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071098
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2321"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA6-ITGB4-FYN complex"^^xsd:string,
+ oboInOwl:id "GO:0071098"^^xsd:string,
+ rdfs:label "alpha6-beta4 integrin-Fyn complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11684709"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha6-beta4 integrin complex bound to the Src family tyrosine kinase Fyn."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009541
+
+ Annotations:
+ oboInOwl:id "GO:0009541"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "etioplast prolamellar body"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0140514031"^^xsd:string
+ obo:IAO_0000115 "A three dimensional regular lattice found in etioplasts. It is composed of a continuous system of tubules but when exposed to light the symmetrical arrangement is rapidly lost as tubules become pinched off into two dimensional sections of lattice. These for perforated sheets of membrane that move apart, extend and increase, finally establishing the typical granal and intergranal lamellae of the mature chloroplast."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009513,
+ obo:GO_0044435
+
+
+Class: obo:GO_0071095
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071095"^^xsd:string,
+ rdfs:label "alpha3-beta1 integrin-thrombospondin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11358957"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha3-beta1 integrin complex bound to thrombospondin."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2401"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA3-ITGB1-THBS1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031085
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031085"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12756248"^^xsd:string
+ obo:IAO_0000115 "A protein complex required for the biogenesis of specialized organelles of the endosomal-lysosomal system, such as melanosomes and platelet dense granules. The human complex contains the Hps1 and Hps4 proteins."^^xsd:string,
+ rdfs:label "BLOC-3 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031082
+
+
+Class: obo:GO_0071096
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:11577104"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaV-beta3 integrin complex bound to gelsolin."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alphaV-beta3 integrin-gelsolin complex"^^xsd:string,
+ oboInOwl:id "GO:0071096"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2360"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB3-Gsn complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031084
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "BLOC-2 complex"^^xsd:string,
+ oboInOwl:id "GO:0031084"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12548288"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14718540"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15031569"^^xsd:string
+ obo:IAO_0000115 "A protein complex required for the biogenesis of specialized organelles of the endosomal-lysosomal system, such as melanosomes and platelet dense granules. The human complex contains the Hps3, Hps5, and Hps6 proteins; the mouse complex contains ru2 and ru."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031082
+
+
+Class: obo:GO_0071078
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2375"^^xsd:string
+ oboInOwl:hasNarrowSynonym "FN-TGM2 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10684262"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of fibronectin bound to tissue transglutaminase, and is involved in cell adhesion."^^xsd:string,
+ oboInOwl:id "GO:0071078"^^xsd:string,
+ rdfs:label "fibronectin-tissue transglutaminase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071079
+
+ Annotations:
+ rdfs:label "alpha2-beta1 integrin-chondroadherin complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2430"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA2-ITGB1-CHAD complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9281592"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha2-beta1 integrin complex bound to the cartilage matrix protein chondroadherin."^^xsd:string,
+ oboInOwl:id "GO:0071079"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0048770
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0048770"^^xsd:string,
+ rdfs:label "pigment granule"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jid"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mh"^^xsd:string
+ obo:IAO_0000115 "A small, subcellular membrane-bounded vesicle containing pigment and/or pigment precursor molecules. Pigment granule biogenesis is poorly understood, as pigment granules are derived from multiple sources including the endoplasmic reticulum, coated vesicles, lysosomes, and endosomes."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016023
+
+
+Class: obo:GO_0031092
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031092"^^xsd:string,
+ oboInOwl:hasExactSynonym "platelet alpha-granule membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8467233"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding the platelet alpha granule."^^xsd:string,
+ rdfs:label "platelet alpha granule membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030667,
+ obo:BFO_0000050 some obo:GO_0031091
+
+
+Class: obo:GO_0031091
+
+ Annotations:
+ rdfs:label "platelet alpha granule"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031091"^^xsd:string,
+ oboInOwl:hasExactSynonym "platelet alpha-granule"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Platelet_alpha-granule"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8467233"^^xsd:string
+ obo:IAO_0000115 "A secretory organelle found in blood platelets, which is unique in that it exhibits further compartmentalization and acquires its protein content via two distinct mechanisms: (1) biosynthesis predominantly at the megakaryocyte (MK) level (with some vestigial platelet synthesis) (e.g. platelet factor 4) and (2) endocytosis and pinocytosis at both the MK and circulating platelet levels (e.g. fibrinogen (Fg) and IgG)."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030141
+
+
+Class: obo:GO_0031094
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031094"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "platelet dense tubular network"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:1322202"^^xsd:string
+ obo:IAO_0000115 "A network of membrane-bounded compartments found in blood platelets, where they regulate platelet activation by sequestering or releasing calcium. The dense tubular network exists as thin elongated membranes in resting platelets, and undergoes a major ultrastructural change, to a rounded vesicular form, upon addition of thrombin."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043231
+
+
+Class: obo:GO_0031093
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "platelet alpha granule lumen"^^xsd:string,
+ oboInOwl:id "GO:0031093"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8467233"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membrane of the platelet alpha granule."^^xsd:string,
+ oboInOwl:hasExactSynonym "platelet alpha-granule lumen"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0034774,
+ obo:BFO_0000050 some obo:GO_0031091
+
+
+Class: obo:GO_0002102
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:12837608"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15890982"^^xsd:string
+ obo:IAO_0000115 "An actin-rich adhesion structure characterized by formation upon cell substrate contact and localization at the substrate-attached part of the cell, contain an F-actin-rich core surrounded by a ring structure containing proteins such as vinculin and talin, and have a diameter of 0.5 mm."^^xsd:string,
+ rdfs:label "podosome"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Podosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that podosomes can be distinguished from other F-actin-rich structures or from other matrix contacts. For example, focal adhesions and focal contacts do not display a core structure of F-actin. Unlike focal adhesions, podosome assembly does not require de novo protein synthesis. However, most of the podosome ring components are found in focal adhesions and other cell-matrix contacts. Podosomes are typically found in cells that cross tissue boundaries, recruited to the leading edge of migrating cells, and are often sites of extracellular matrix degradation."^^xsd:string,
+ oboInOwl:id "GO:0002102"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044430,
+ obo:BFO_0000050 some obo:GO_0015629,
+ obo:GO_0043232,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031090
+
+ Annotations:
+ oboInOwl:id "GO:0031090"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "organelle membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding an organelle."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016020,
+ obo:BFO_0000050 some obo:GO_0043227,
+ obo:GO_0044422
+
+
+Class: obo:GO_0071080
+
+ Annotations:
+ oboInOwl:id "GO:0071080"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2398"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA3-ITGB1-BSG complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9360995"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha3-beta1 integrin complex bound to the cell surface protein basigin."^^xsd:string,
+ rdfs:label "alpha3-beta1 integrin-basigin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071081
+
+ Annotations:
+ rdfs:label "alpha3-beta1 integrin-CD63 complex"^^xsd:string,
+ oboInOwl:id "GO:0071081"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:7629079"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha3-beta1 integrin complex bound to the tetraspanin CD63."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2399"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA3-ITGB1-CD63 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071082
+
+ Annotations:
+ oboInOwl:id "GO:0071082"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9565552"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha9-beta1 integrin complex bound to the extracellular matrix protein tenascin."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2443"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA9-ITGB1-TNC complex"^^xsd:string,
+ rdfs:label "alpha9-beta1 integrin-tenascin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071083
+
+ Annotations:
+ rdfs:label "alphaV-beta3 integrin-CD47-FCER2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10037797"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaV-beta3 integrin complex bound to the cell surface protein CD47 and the low-affinity immunoglobulin epsilon Fc receptor (FCER2)."^^xsd:string,
+ oboInOwl:id "GO:0071083"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2355"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB3-CD447-FCER2 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071084
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10397731"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha2-beta1 integrin complex bound to the cell surface protein CD47."^^xsd:string,
+ oboInOwl:id "GO:0071084"^^xsd:string,
+ rdfs:label "alpha2-beta1 integrin-CD47 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2429"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA2-ITGB1-CD47 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031096
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:1322202"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membranes of the platelet dense tubular network."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "platelet dense tubular network lumen"^^xsd:string,
+ oboInOwl:id "GO:0031096"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070013,
+ obo:BFO_0000050 some obo:GO_0031094
+
+
+Class: obo:GO_0071085
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alphaIIb-beta3 integrin-CD9 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2370"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA2b-ITGB3-CD9 complex"^^xsd:string,
+ oboInOwl:id "GO:0071085"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10429193"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaIIb-beta3 integrin complex bound to the cell surface protein CD9."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009550
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009550"^^xsd:string,
+ oboInOwl:hasExactSynonym "simple plasmodesma"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15012255"^^xsd:string
+ obo:IAO_0000115 "A plasmodesma that consists of a simple, single channel; found predominantly in young tissue and formed as a function of cell plate formation during cytokinesis."^^xsd:string,
+ rdfs:label "primary plasmodesma"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009506
+
+
+Class: obo:GO_0031095
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:1322202"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding the platelet dense tubular network."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031095"^^xsd:string,
+ rdfs:label "platelet dense tubular network membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0031090,
+ obo:BFO_0000050 some obo:GO_0031094
+
+
+Class: obo:GO_0071086
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071086"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2872"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA2b-ITGB3-CD9-GP1b-CD47 complex"^^xsd:string,
+ rdfs:label "alphaIIb-beta3 integrin-CD9-CD47-platelet glycoprotein Ib complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10429193"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaIIb-beta3 integrin complex bound to the cell surface proteins CD9 and CD47, and the heterodimeric platelet glycoprotein Ib."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009551
+
+ Annotations:
+ oboInOwl:id "GO:0009551"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15012255"^^xsd:string
+ obo:IAO_0000115 "A plasmodesma with a branched structure, often with many channels leading into a larger central cavity; found in older tissues and usually derived from preexisting primary plasmodesmata."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "secondary plasmodesma"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009506
+
+
+Class: obo:GO_0071087
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:10464311"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha11-beta1 integrin complex bound to a type I collagen."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alpha11-beta1 integrin-collagen type I complex"^^xsd:string,
+ oboInOwl:id "GO:0071087"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3059"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA11-ITGB1-COL1A1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031097
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "medial cortex"^^xsd:string,
+ oboInOwl:id "GO:0031097"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15572668"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19474789"^^xsd:string
+ obo:IAO_0000115 "A medial cortical band overlaying the nucleus which acts as a landmark for contractile ring positioning and plays a role in cell cycle regulation."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string
+ oboInOwl:hasExactSynonym "medial ring"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032155,
+ obo:GO_0044448
+
+
+Class: obo:GO_0070720
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070720"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8943348"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the receptor adaptor proteins Grb2 and SHP-2, and is involved signaling via the PDGFR signaling pathway."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3186"^^xsd:string
+ oboInOwl:hasNarrowSynonym "GRB2-SHP-2 complex, PDGF stimulated"^^xsd:string,
+ rdfs:label "Grb2-SHP-2 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070721
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8943351"^^xsd:string
+ obo:IAO_0000115 "A transcription factor complex that consists of a Stat1-Stat2 heterodimer and the IRF9 protein."^^xsd:string,
+ rdfs:label "ISGF3 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:60"^^xsd:string
+ oboInOwl:hasExactSynonym "interferon-stimulated gene factor 3 transcription complex"^^xsd:string,
+ oboInOwl:id "GO:0070721"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005667
+
+
+Class: obo:GO_0071069
+
+ Annotations:
+ rdfs:label "alpha4-beta1 integrin-thrombospondin-1 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11980922"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha4-beta1 integrin complex bound to thrombospondin-1."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2426"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA4-ITGB1-THBS1 complex"^^xsd:string,
+ oboInOwl:id "GO:0071069"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071068
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10944520"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha9-beta1 integrin complex bound to the transmembrane metallopeptidase ADAM12."^^xsd:string,
+ rdfs:label "alpha9-beta1 integrin-ADAM12 complex"^^xsd:string,
+ oboInOwl:id "GO:0071068"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2447"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA9-ITGB1-ADAM12 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071067
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2364"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB3-ADAM23 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alphav-beta3 integrin-ADAM23 complex"^^xsd:string,
+ oboInOwl:id "GO:0071067"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10749942"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphav-beta3 integrin complex bound to the transmembrane metallopeptidase ADAM23."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070724
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "bone morphogenetic protein receptor complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070724"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mh"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19377468"^^xsd:string
+ obo:IAO_0000115 "A protein complex that acts as a receptor for bone morphogenetic proteins (BMPs); a homo- or heterodimer of type I and/or type II BMP receptor subunits."^^xsd:string,
+ rdfs:label "BMP receptor complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005887,
+ obo:GO_0044459,
+ obo:GO_0043235
+
+
+Class: obo:GO_0070725
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070725"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:sart"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19433453"^^xsd:string
+ obo:IAO_0000115 "A cytoplasmic part that appears as an electron-dense sphere of around 1.5 micron diameter containing Yb protein found in somatic cells of ovary and testis. There are one to two Yb bodies per cell."^^xsd:string,
+ rdfs:label "Yb body"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424
+
+
+Class: obo:GO_0070722
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3130"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8955148"^^xsd:string
+ oboInOwl:hasExactSynonym "Grg3b-Grg5 complex"^^xsd:string,
+ oboInOwl:id "GO:0070722"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8955148"^^xsd:string
+ obo:IAO_0000115 "A transcriptional repressor complex that consists of a heterodimer of the proteins Tle3 (also known as Grg3b) and Aes (Grg5), which are homologs of the Drosophila groucho gene product."^^xsd:string,
+ rdfs:label "Tle3-Aes complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0017053
+
+
+Class: obo:GO_0042603
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042603"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Capsule_(microbiology)"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0042604"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0030113"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mlg"^^xsd:string
+ obo:IAO_0000115 "A protective structure surrounding some fungi and bacteria, attached externally to the cell wall and composed primarily of polysaccharides. Capsules are highly organized structures that adhere strongly to cells and can not be easily removed. Capsules play important roles in pathogenicity, preventing phagocytosis by other cells, adherance, and resistance to dessication."^^xsd:string,
+ rdfs:label "capsule"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030112
+
+
+Class: obo:GO_0048269
+
+ Annotations:
+ oboInOwl:id "GO:0048269"^^xsd:string,
+ oboInOwl:hasExactSynonym "MAT complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "EC:2.5.1.6"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:jid"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10644686"^^xsd:string
+ obo:IAO_0000115 "A multimeric enzyme complex composed of variable numbers of catalytic alpha subunits, and noncatalytic beta subunits. The beta subunits are believed to have a regulatory function. The enzyme complex catalyzes the synthesis of S-adenosylmethionine (AdoMet), which is the major methyl group donor, participating in the methylation of proteins, DNA, RNA, phospholipids, and other small molecules."^^xsd:string,
+ rdfs:label "methionine adenosyltransferase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009568
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "amyloplast starch grain"^^xsd:string,
+ oboInOwl:hasExactSynonym "amyloplast starch granule"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11217978"^^xsd:string
+ obo:IAO_0000115 "Plant storage body for amylose and amylopectin, 1-100um in diameter, and located in amyloplasts. Also contains small amounts of enzymes, amino acids, lipids and nucleic acids. The shape of the grain varies widely amongst species, but is often spherical or disk-shaped."^^xsd:string,
+ oboInOwl:id "GO:0009568"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0043036
+ and (obo:BFO_0000050 some obo:GO_0009501)
+
+ SubClassOf:
+ obo:GO_0043036,
+ obo:BFO_0000050 some obo:GO_0009501
+
+
+Class: obo:GO_0009569
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "Plant storage body for amylose and amylopectin, 1-100um in diameter, and located in chloroplasts. Also contains small amounts of enzymes, amino acids, lipids and nucleic acids. The shape of the grain varies widely amongst species, but is often spherical or disk-shaped."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "chloroplast starch grain"^^xsd:string,
+ oboInOwl:hasExactSynonym "chloroplast starch granule"^^xsd:string,
+ oboInOwl:id "GO:0009569"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0043036
+ and (obo:BFO_0000050 some obo:GO_0009507)
+
+ SubClassOf:
+ obo:GO_0043036,
+ obo:GO_0044434
+
+
+Class: obo:GO_0042601
+
+ Annotations:
+ rdfs:label "endospore-forming forespore"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042601"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0697286029"^^xsd:string
+ obo:IAO_0000115 "Portion of the cell formed during the process of bacterial sporulation that will ultimately become the core of the endospore. An endospore is a type of dormant cell that is resistant to adverse conditions."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042763
+
+
+Class: obo:GO_0042600
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0721662544"^^xsd:string
+ obo:IAO_0000115 "A protective, noncellular membrane that surrounds the eggs of various animals including insects and fish."^^xsd:string,
+ oboInOwl:id "GO:0042600"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:comment "Note that this term does not refer to the extraembryonic membrane surrounding the embryo of amniote vertebrates as this is an anatomical structure and is therefore not covered by GO."^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "chorion"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030312
+
+
+Class: obo:GO_0071075
+
+ Annotations:
+ rdfs:label "CUGBP1-eIF2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16931514"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the eukaryotic translation initiation factor 2 complex (EIF2), CUG binding protein 1, and several endoplasmic reticulum proteins; the complex is involved in the regulation of translation."^^xsd:string,
+ oboInOwl:id "GO:0071075"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071070
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11980922"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha4-beta1 integrin complex bound to thrombospondin-2."^^xsd:string,
+ oboInOwl:id "GO:0071070"^^xsd:string,
+ rdfs:label "alpha4-beta1 integrin-thrombospondin-2 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2428"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA4-ITGB1-THBS2 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071059
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2411"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA6-ITGB1-CD151 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071059"^^xsd:string,
+ rdfs:label "alpha6-beta1 integrin-CD151 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11884516"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha6-beta1 integrin complex bound to the tetraspanin CD151."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070732
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "spindle envelope"^^xsd:string,
+ oboInOwl:id "GO:0070732"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:sart"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19417004"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:6428889"^^xsd:string
+ obo:IAO_0000115 "An organelle envelope that surrounds the chromosomes and the central part of the spindle apparatus during mitosis and meiosis; observed in many invertebrates. The spindle envelope consists of membrane layers, called parafusorial membranes, derived from endoplasmic reticulum membrane; in male meiosis it forms during prometaphase and persists until early in the ensuing interphase."^^xsd:string,
+ oboInOwl:inSubset
+
+ SubClassOf:
+ obo:GO_0031967
+
+
+Class: obo:GO_0071056
+
+ Annotations:
+ oboInOwl:id "GO:0071056"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2445"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA9-ITGB1-ADAM15 complex"^^xsd:string,
+ rdfs:label "alpha9-beta1 integrin-ADAM15 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11882657"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha9-beta1 integrin complex bound to the transmembrane metallopeptidase ADAM15."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071055
+
+ Annotations:
+ oboInOwl:id "GO:0071055"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2440"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA9-ITGB1-ADAM9 complex"^^xsd:string,
+ rdfs:label "alpha9-beta1 integrin-ADAM9 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11882657"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha9-beta1 integrin complex bound to the transmembrane metallopeptidase ADAM9."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071058
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2400"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA3-ITGB1-CD151 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10811835"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11884516"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha3-beta1 integrin complex bound to the tetraspanin CD151."^^xsd:string,
+ oboInOwl:id "GO:0071058"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alpha3-beta1 integrin-CD151 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009570
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198547684"^^xsd:string
+ obo:IAO_0000115 "The space enclosed by the double membrane of a chloroplast but excluding the thylakoid space. It contains DNA, ribosomes and some temporary products of photosynthesis."^^xsd:string,
+ oboInOwl:id "GO:0009570"^^xsd:string,
+ rdfs:label "chloroplast stroma"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009532,
+ obo:GO_0044434
+
+
+Class: obo:GO_0071057
+
+ Annotations:
+ oboInOwl:id "GO:0071057"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2359"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB3-ADAM15 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10944520"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11882657"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphav-beta3 integrin complex bound to the transmembrane metallopeptidase ADAM15."^^xsd:string,
+ rdfs:label "alphav-beta3 integrin-ADAM15 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0045111
+
+ Annotations:
+ rdfs:label "intermediate filament cytoskeleton"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0716731363"^^xsd:string
+ obo:IAO_0000115 "Cytoskeletal structure made from intermediate filaments, typically organized in the cytosol as an extended system that stretches from the nuclear envelope to the plasma membrane. Some intermediate filaments run parallel to the cell surface, while others traverse the cytosol; together they form an internal framework that helps support the shape and resilience of the cell."^^xsd:string,
+ oboInOwl:id "GO:0045111"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005856
+
+
+Class: obo:GO_0009579
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Thylakoid"^^xsd:string,
+ rdfs:comment "A thylakoid is not considered an organelle, but some thylakoids are part of organelles."^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ds"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "A membranous cellular structure that bears the photosynthetic pigments in plants, algae, and cyanobacteria. In cyanobacteria thylakoids are of various shapes and are attached to, or continuous with, the plasma membrane. In eukaryotes they are flattened, membrane-bounded disk-like structures located in the chloroplasts; in the chloroplasts of higher plants the thylakoids form dense stacks called grana. Isolated thylakoid preparations can carry out photosynthetic electron transport and the associated phosphorylation."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ oboInOwl:hasRelatedSynonym "photosynthetic membrane"^^xsd:string,
+ oboInOwl:id "GO:0009579"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "thylakoid"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424
+
+
+Class: obo:GO_0042613
+
+ Annotations:
+ oboInOwl:id "GO:0042613"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "MHC class II protein complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0120781859"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15928678"^^xsd:string
+ obo:IAO_0000115 "A transmembrane protein complex composed of an MHC class II alpha and MHC class II beta chain, and with or without a bound peptide or polysaccharide antigen."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042611
+
+
+Class: obo:GO_0042612
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0120781859"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0781735149"^^xsd:string
+ obo:IAO_0000115 "A transmembrane protein complex composed of a MHC class I alpha chain and an invariant beta2-microglobin chain, and with or without a bound peptide antigen. Class I here refers to classical class I molecules."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "MHC class I protein complex"^^xsd:string,
+ oboInOwl:id "GO:0042612"^^xsd:string,
+ rdfs:comment "See also the cellular component term 'MHC class I peptide loading complex ; GO:0042824'."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042611
+
+
+Class: obo:GO_0042611
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042611"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:add"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0781735149"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15928678"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16153240"^^xsd:string
+ obo:IAO_0000115 "A transmembrane protein complex composed of an MHC alpha chain and, in most cases, either an MHC class II beta chain or an invariant beta2-microglobin chain, and with or without a bound peptide, lipid, or polysaccharide antigen."^^xsd:string,
+ rdfs:label "MHC protein complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071062
+
+ Annotations:
+ oboInOwl:id "GO:0071062"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10835423"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphav-beta3 integrin complex bound to vitronectin."^^xsd:string,
+ rdfs:label "alphav-beta3 integrin-vitronectin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2826"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB3-VTN complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009571
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009571"^^xsd:string,
+ rdfs:label "proplastid stroma"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "The space enclosed by the double membrane of a proplastid."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009532,
+ obo:BFO_0000050 some obo:GO_0009537
+
+
+Class: obo:GO_0031074
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Any complex that acts to move proteins or RNAs into or out of the nucleus through nuclear pores."^^xsd:string,
+ rdfs:label "nucleocytoplasmic shuttling complex"^^xsd:string,
+ oboInOwl:id "GO:0031074"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071064
+
+ Annotations:
+ oboInOwl:id "GO:0071064"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10837471"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaE-beta7 integrin complex bound to E-cadherin."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alphaE-beta7 integrin-E-cadherin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1834"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAE-ITGB7-CDH1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009573
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mlg"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "A complex, located in the chloroplast, containing either both large and small subunits or just small subunits which carries out the activity of producing 3-phosphoglycerate from carbon dioxide and ribulose-1,5-bisphosphate. An example of this component is found in Arabidopsis thaliana."^^xsd:string,
+ oboInOwl:hasExactSynonym "chloroplast RubisCO complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009573"^^xsd:string,
+ rdfs:label "chloroplast ribulose bisphosphate carboxylase complex"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0048492
+ and (obo:BFO_0000050 some obo:GO_0009507)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009570,
+ obo:GO_0048492,
+ obo:GO_0044434
+
+
+Class: obo:GO_0071065
+
+ Annotations:
+ oboInOwl:id "GO:0071065"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2442"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA9-ITGB1-VCAM1 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alpha9-beta1 integrin-vascular cell adhesion molecule-1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10209034"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha9-beta1 integrin complex bound to vascular cell adhesion molecule-1."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009574
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009574"^^xsd:string,
+ rdfs:label "preprophase band"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Preprophase_band"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "A dense band of microtubules, 1-3 pm wide, that appears just beneath the cell membrane before the start of cell division in the cells of higher plants. It precedes the onset of prophase and then disappears as mitosis begins, yet it somehow determines the plane of orientation of the new cell plate forming in late telophase and marks the zone of the parental cell wall where fusion with the growing cell plate ultimately occurs."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0015630,
+ obo:GO_0044430,
+ obo:GO_0044444
+
+
+Class: obo:GO_0009575
+
+ Annotations:
+ rdfs:label "chromoplast stroma"^^xsd:string,
+ oboInOwl:id "GO:0009575"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "The space enclosed by the double membrane of a chromoplast but excluding the photosynthetic material."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009532,
+ obo:BFO_0000050 some obo:GO_0009509
+
+
+Class: obo:GO_0009576
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The space enclosed by the double membrane of a leucoplast."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009576"^^xsd:string,
+ rdfs:label "leucoplast stroma"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009532,
+ obo:BFO_0000050 some obo:GO_0009516
+
+
+Class: obo:GO_0071060
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:11884516"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha7-beta1 integrin complex bound to the tetraspanin CD151."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2395"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA7-ITGB1-CD151 complex"^^xsd:string,
+ oboInOwl:id "GO:0071060"^^xsd:string,
+ rdfs:label "alpha7-beta1 integrin-CD151 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009577
+
+ Annotations:
+ rdfs:label "elaioplast stroma"^^xsd:string,
+ oboInOwl:id "GO:0009577"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The space enclosed by the double membrane of an elaioplast."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009532,
+ obo:BFO_0000050 some obo:GO_0009545
+
+
+Class: obo:GO_0071061
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10811835"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha6-beta4 integrin complex bound to the tetraspanin CD151."^^xsd:string,
+ oboInOwl:id "GO:0071061"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2320"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA6-ITGB4-CD151 complex"^^xsd:string,
+ rdfs:label "alpha6-beta4 integrin-CD151 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009578
+
+ Annotations:
+ oboInOwl:id "GO:0009578"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "The space enclosed by the double membrane of an etioplast but excluding the prothylakoid space. It contains the etioplast DNA."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "etioplast stroma"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009513,
+ obo:GO_0009532
+
+
+Class: obo:GO_0070031
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:7592829"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphav-beta5 integrin complex bound to osteopontin."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alphav-beta5 integrin-osteopontin complex"^^xsd:string,
+ oboInOwl:id "GO:0070031"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2347"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB5-SPP1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070030
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2885"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB1-SPP1 complex"^^xsd:string,
+ rdfs:label "alphav-beta1 integrin-osteopontin complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070030"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:7592829"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphav-beta1 integrin complex bound to osteopontin."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070439
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "Mad-Max-mSin3A complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:7889570"^^xsd:string
+ obo:IAO_0000115 "A transcriptional repressor complex that contains a heterodimer of the bHLH-ZIP proteins Mad and Max, plus mSin3A, a homolog of the yeast Sin3p."^^xsd:string,
+ oboInOwl:id "GO:0070439"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0017053
+
+
+Class: obo:GO_0070438
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "mTOR-FKBP12-rapamycin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2987"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Fkbp1a-Frap1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:sl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20005306"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7822316"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the mTOR (mammalian target of rapamycin) serine/threonine kinase, the peptidyl-prolyl cis-trans isomerase FKBP12 (FKBP1A) and rapamycin (sirolimus)."^^xsd:string,
+ oboInOwl:id "GO:0070438"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070437
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7798267"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains Grb2 and the adaptor protein Shc, and is involved in linking epidermal growth factor receptor (EGFR) activation to the p21-Ras pathway."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2888"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Grb2-Shc complex, EGF stimulated"^^xsd:string,
+ rdfs:label "Grb2-Shc complex"^^xsd:string,
+ oboInOwl:id "GO:0070437"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070436
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2889"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Grb2-Egfr complex, EGF stimulated"^^xsd:string,
+ rdfs:label "Grb2-EGFR complex"^^xsd:string,
+ oboInOwl:id "GO:0070436"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7798267"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the epidermal growth factor receptor (EGFR) and Grb2, and is involved in linking EGFR activation to the p21-Ras pathway."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070435
+
+ Annotations:
+ oboInOwl:id "GO:0070435"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7798267"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the epidermal growth factor receptor (EGFR) and the adaptor protein Shc, and is involved in linking EGFR activation to the p21-Ras pathway."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2887"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Shc-Egfr complex, EGF stimulated"^^xsd:string,
+ rdfs:label "Shc-EGFR complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031039
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "macronucleus"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ns"^^xsd:string
+ obo:IAO_0000115 "A membrane-bounded organelle of ciliated protozoan cells that contains polyploid copies of a portion of the cell's complete genome. Transcription of genes occurs in macronuclei. Some ciliate species may contain multiple macronuclei per cell."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Macronucleus"^^xsd:string,
+ oboInOwl:id "GO:0031039"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005634
+
+
+Class: obo:GO_0009501
+
+ Annotations:
+ rdfs:label "amyloplast"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Amyloplast"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0140514031"^^xsd:string
+ obo:IAO_0000115 "A plastid whose main function is to synthesize and store starch."^^xsd:string,
+ oboInOwl:id "GO:0009501"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009536
+
+
+Class: obo:GO_0042629
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12360215"^^xsd:string,
+ oboInOwl:hasDbXref "http://www.ijp-online.com/archives/1969/001/02/r0000-0000tc.htm"^^xsd:string
+ obo:IAO_0000115 "Coarse, bluish-black staining cytoplasmic granules, bounded by a plasma membrane and found in mast cells and basophils. Contents include histamine, heparin, chondroitin sulfates, chymase and tryptase."^^xsd:string,
+ rdfs:label "mast cell granule"^^xsd:string,
+ oboInOwl:id "GO:0042629"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005764
+
+
+Class: obo:GO_0031045
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031045"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:kmv"^^xsd:string
+ oboInOwl:hasExactSynonym "dense core vesicle"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:14690495"^^xsd:string
+ obo:IAO_0000115 "Electron-dense organelle with a granular internal matrix; contains proteins destined to be secreted."^^xsd:string,
+ rdfs:label "dense core granule"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030141
+
+
+Class: obo:GO_0071054
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2965"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA9-ITGB1-ADAM3 complex"^^xsd:string,
+ oboInOwl:id "GO:0071054"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11882657"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha9-beta1 integrin complex bound to the transmembrane metallopeptidase ADAM3."^^xsd:string,
+ rdfs:label "alpha9-beta1 integrin-ADAM3 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071053
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11882657"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha9-beta1 integrin complex bound to the transmembrane metallopeptidase ADAM2."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2441"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA9-ITGB1-ADAM2 complex"^^xsd:string,
+ rdfs:label "alpha9-beta1 integrin-ADAM2 complex"^^xsd:string,
+ oboInOwl:id "GO:0071053"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071052
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11882657"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha9-beta1 integrin complex bound to the transmembrane metallopeptidase ADAM1."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2964"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA9-ITGB1-ADAM1 complex"^^xsd:string,
+ oboInOwl:id "GO:0071052"^^xsd:string,
+ rdfs:label "alpha9-beta1 integrin-ADAM1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070029
+
+ Annotations:
+ rdfs:label "alphav-beta3 integrin-osteopontin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2358"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB3-SPP1 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:7532190"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphav-beta3 integrin complex bound to osteopontin."^^xsd:string,
+ oboInOwl:id "GO:0070029"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031040
+
+ Annotations:
+ rdfs:label "micronucleus"^^xsd:string,
+ oboInOwl:id "GO:0031040"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Micronucleus"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ns"^^xsd:string
+ obo:IAO_0000115 "A membrane-bounded organelle of ciliated protozoan cells that contains a diploid copy of the cell's complete genome. Sections of contiguous sequence in the macronucleus are often interrupted by internal eliminated sequences (IES), and may be permuted, in micronuclei. Genic transcription is not found in micronuclei. Some ciliate species may contain multiple micronuclei per cell."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005634
+
+
+Class: obo:GO_0009509
+
+ Annotations:
+ oboInOwl:id "GO:0009509"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Chromoplast"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0471245208"^^xsd:string
+ obo:IAO_0000115 "A plastid containing pigments other than chlorophyll, usually yellow and orange carotenoid pigments."^^xsd:string,
+ rdfs:label "chromoplast"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009536
+
+
+Class: obo:GO_0002137
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "nuclear cluster"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9413993"^^xsd:string
+ obo:IAO_0000115 "Discrete hetero-chromatin-containing foci in interphase nuclei, which comprise clusters of centromeric DNA (as defined by gamma-satellite sequences and the abundance of heterochromatin protein 1 (HP-1)."^^xsd:string,
+ oboInOwl:id "GO:0002137"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:BFO_0000050 some obo:GO_0031618
+
+
+Class: obo:GO_0009508
+
+ Annotations:
+ oboInOwl:id "GO:0009508"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0943883999"^^xsd:string
+ obo:IAO_0000115 "A circular DNA molecule containing plastid encoded genes."^^xsd:string,
+ rdfs:label "plastid chromosome"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005694
+ and (obo:BFO_0000050 some obo:GO_0009536)
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:GO_0000229,
+ obo:BFO_0000050 some obo:GO_0042646
+
+
+Class: obo:GO_0042622
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042622"^^xsd:string,
+ rdfs:label "photoreceptor outer segment membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "The membrane surrounding the outer segment of a vertebrate photoreceptor."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016020,
+ obo:BFO_0000050 some obo:GO_0001750,
+ obo:GO_0044441
+
+
+Class: obo:GO_0009507
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0471245208"^^xsd:string
+ obo:IAO_0000115 "A chlorophyll-containing plastid with thylakoids organized into grana and frets, or stroma thylakoids, and embedded in a stroma."^^xsd:string,
+ oboInOwl:id "GO:0009507"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "chloroplast"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Chloroplast"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009536
+
+
+Class: obo:GO_0002139
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "stereocilia coupling link"^^xsd:string,
+ oboInOwl:id "GO:0002139"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:16775142"^^xsd:string
+ obo:IAO_0000115 "A structure involved in coupling stereocilia to one another in sensory hair cells There are four morphologically distinct types: tip links, horizontal top connectors, shaft connectors and ankle links. Tip links and horizontal top connectors are the only inter-stereocilia links associated with mature cochlea, whereas ankle links appear during development of the auditory hair bundle."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0009506
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Plasmodesma"^^xsd:string,
+ oboInOwl:id "GO:0009506"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "plasmodesma"^^xsd:string,
+ oboInOwl:hasExactSynonym "plasmodesmata"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "A fine cytoplasmic channel, found in all higher plants, that connects the cytoplasm of one cell to that of an adjacent cell."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005911,
+ obo:BFO_0000050 some obo:GO_0055044
+
+
+Class: obo:GO_0070023
+
+ Annotations:
+ oboInOwl:hasExactSynonym "IL12-IL12 receptor complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2020"^^xsd:string
+ oboInOwl:hasNarrowSynonym "IL12B-IL12RB1-IL12RB2 complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0070023"^^xsd:string,
+ rdfs:label "interleukin-12-interleukin-12 receptor complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11900991"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is formed by the association of a heterodimeric interleukin-12 receptor complex with an interleukin-12 heterodimer."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009505
+
+ Annotations:
+ rdfs:label "plant-type cell wall"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009505"^^xsd:string,
+ oboInOwl:hasExactSynonym "cellulose and pectin-containing cell wall"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0471245208"^^xsd:string
+ obo:IAO_0000115 "A more or less rigid stucture lying outside the cell membrane of a cell and composed of cellulose and pectin and other organic and inorganic substances."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005618
+
+
+Class: obo:GO_0070024
+
+ Annotations:
+ rdfs:label "CD19-Vav-PIK3R1 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2574"^^xsd:string
+ oboInOwl:hasExactSynonym "CD19-Vav-PI 3-kinase (p85 subunit) complex"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "PMID:7528218"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains the cell surface signaling molecule CD19, the Ras guanine nucleotide exchange factor Vav, and the regulatory subunit alpha of phosphatidylinositol 3-kinase (PI3K)."^^xsd:string,
+ oboInOwl:id "GO:0070024"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0002133
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:hjd"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11901144"^^xsd:string
+ obo:IAO_0000115 "A stable heterodimeric complex composed of polycystin-1 and polycystin-2."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0002133"^^xsd:string,
+ rdfs:label "polycystin complex"^^xsd:string,
+ rdfs:comment "Different forms of the complex differing in type of N-glycosylation of polycystin-1 can exist (endoglycosidase sensitive and endoglycosidase resistant)."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0009504
+
+ Annotations:
+ rdfs:label "cell plate"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009504"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198547684"^^xsd:string
+ obo:IAO_0000115 "The nascent cell membrane and cell wall structure that forms between two daughter nuclei near the center of a dividing plant cell. It develops at the equitorial region of the phragmoplast. It grows outwards to join with the lateral walls and form two daughter cells."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Cell_plate"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444
+
+
+Class: obo:GO_0070021
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasExactSynonym "TGF-beta receptor II-TGF-beta receptor I-TGF-beta1 complex"^^xsd:string,
+ rdfs:label "transforming growth factor beta1-type II receptor-type I receptor complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "TGF-beta1-type II receptor-type I receptor complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "Reactome:REACT_7425"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is formed by the association of a ligand-bound TGF-beta type II receptor dimer with a TGF-beta type I receptor dimer."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "Reactome:REACT_7425"^^xsd:string
+ oboInOwl:hasExactSynonym "TGF-beta 1:type II receptor:type I receptor complex"^^xsd:string,
+ oboInOwl:id "GO:0070021"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009503
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198547684"^^xsd:string
+ obo:IAO_0000115 "A thylakoid membrane complex of chlorophylls a and b together with chlorophyll a-b binding proteins. In addition, LHCs contain a number of other proteins, the function of which is speculative, together with accessory pigments. The LHCs capture and transfer energy to photosystems I and II. An example of this is found in Arabidopsis thaliana."^^xsd:string,
+ oboInOwl:id "GO:0009503"^^xsd:string,
+ rdfs:label "thylakoid light-harvesting complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044436,
+ obo:GO_0030076,
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0009535,
+ obo:GO_0044434
+
+
+Class: obo:GO_0070022
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "Reactome:REACT_7415"^^xsd:string,
+ oboInOwl:hasDbXref "Reactome:REACT_7737"^^xsd:string
+ obo:IAO_0000115 "A dimeric receptor complex that binds transforming growth factor beta (TGF-beta); consists of two TGF-beta receptor monomers."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "transforming growth factor beta receptor complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "TGF-beta receptor complex"^^xsd:string,
+ oboInOwl:id "GO:0070022"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005887,
+ obo:GO_0044459,
+ obo:GO_0043235
+
+
+Class: obo:GO_0042627
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:rl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10580165"^^xsd:string,
+ oboInOwl:hasDbXref "http://biotech.icmb.utexas.edu/search/dict-search.html"^^xsd:string
+ obo:IAO_0000115 "A large lipoprotein particle (diameter 75-1200 nm) composed of a central core of triglycerides and cholesterol surrounded by a protein-phospholipid coating. The proteins include one molecule of apolipoprotein B-48 and may include a variety of apolipoproteins, including APOAs, APOCs and APOE. Chylomicrons are found in blood or lymph and carry lipids from the intestines into other body tissues."^^xsd:string,
+ oboInOwl:id "GO:0042627"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Chylomicron"^^xsd:string,
+ rdfs:label "chylomicron"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0034358
+
+
+Class: obo:GO_0060342
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0060342"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:dph"^^xsd:string
+ obo:IAO_0000115 "The membrane surrounding the outer segment of a vertebrate photoreceptor. The photoreceptor inner segment contains mitochondria, ribosomes and membranes where opsin molecules are assembled and passed to be part of the outer segment discs."^^xsd:string,
+ rdfs:label "photoreceptor inner segment membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016020,
+ obo:BFO_0000050 some obo:GO_0001917
+
+
+Class: obo:GO_0042641
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:go_curators"^^xsd:string
+ obo:IAO_0000115 "Any complex of actin, myosin, and accessory proteins."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042641"^^xsd:string,
+ oboInOwl:hasExactSynonym "actomyosin complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "actomyosin structure"^^xsd:string,
+ rdfs:label "actomyosin"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044430,
+ obo:BFO_0000050 some obo:GO_0015629
+
+
+Class: obo:GO_0090123
+
+ Annotations:
+ oboInOwl:id "GO:0090123"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ascb_2009"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:dph"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:tb"^^xsd:string
+ obo:IAO_0000115 "The polysaccharide-based coating on the inner side of a lysosomal membrane that protects it from digestion by lysosomal enzymes."^^xsd:string,
+ rdfs:label "lysosomal glycocalyx"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044437,
+ obo:BFO_0000050 some obo:GO_0005764
+
+
+Class: obo:GO_0070422
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070422"^^xsd:string,
+ rdfs:comment "See also the cellular component term 'heterotrimeric G-protein complex ; GO:0005834'."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7782277"^^xsd:string
+ obo:IAO_0000115 "A protein complex formed by the association of the serine-threonine protein kinase Raf-1 with the beta and gamma subunits of a heterotrimeric G protein."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1539"^^xsd:string
+ oboInOwl:hasRelatedSynonym "G protein complex (GNG2, GNB2L1, RAF1)"^^xsd:string,
+ rdfs:label "G-protein beta/gamma-Raf-1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0070421
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "DNA ligase III-XRCC1 complex"^^xsd:string,
+ oboInOwl:id "GO:0070421"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15141024"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7760816"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains DNA ligase III and XRCC1, and is involved in base excision repair."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030312
+
+ Annotations:
+ oboInOwl:id "GO:0030312"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "external encapsulating structure"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:go_curators"^^xsd:string
+ obo:IAO_0000115 "A structure that lies outside the plasma membrane and surrounds the entire cell."^^xsd:string,
+ oboInOwl:inSubset
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0071944,
+ obo:GO_0044464
+
+
+Class: obo:GO_0030313
+
+ Annotations:
+ oboInOwl:id "GO:0030313"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ds"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mlg"^^xsd:string,
+ oboInOwl:hasDbXref "http://pathmicro.med.sc.edu/fox/cell_envelope.htm"^^xsd:string
+ obo:IAO_0000115 "An envelope that surrounds a bacterial cell and includes the cytoplasmic membrane and everything external, encompassing the periplasmic space, cell wall, and outer membrane if present."^^xsd:string,
+ rdfs:label "cell envelope"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Cell_envelope"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000051 some obo:GO_0005886,
+ obo:GO_0031975
+
+
+Class: obo:GO_0030314
+
+ Annotations:
+ oboInOwl:id "GO:0030314"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11535622"^^xsd:string
+ obo:IAO_0000115 "Complex formed in muscle cells between the membrane of the sarcoplasmic reticulum and invaginations of the plasma membrane (T-tubules)."^^xsd:string,
+ rdfs:label "junctional membrane complex"^^xsd:string,
+ oboInOwl:hasBroadSynonym "triad junction"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0016528,
+ obo:GO_0044444,
+ obo:GO_0043234
+
+
+Class: obo:GO_0030315
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0030315"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:T-tubule"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "Invagination of the plasma membrane of a muscle cell that extends inward from the cell surface around each myofibril. The ends of T-tubules make contact with the sarcoplasmic reticulum membrane."^^xsd:string,
+ oboInOwl:hasRelatedSynonym "triad"^^xsd:string,
+ rdfs:label "T-tubule"^^xsd:string,
+ oboInOwl:hasExactSynonym "transverse tubule"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:BFO_0000050 some obo:GO_0042383
+
+
+Class: obo:GO_0070420
+
+ Annotations:
+ oboInOwl:id "GO:0070420"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17938628"^^xsd:string
+ obo:IAO_0000115 "A nonhomologous end joining complex that contains one or more Ku monomers and one or more DNA ligase molecules from the LigC or LigD family, and mediates nonhomologous end joining in bacteria."^^xsd:string,
+ rdfs:label "Ku-DNA ligase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070419
+
+
+Class: obo:GO_0002141
+
+ Annotations:
+ rdfs:label "stereocilia ankle link"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0002141"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:17567809"^^xsd:string
+ obo:IAO_0000115 "A stereocilia coupling link that is composed of a fine filament present in developing stereocilia that couples the bases of individual stereocilia to one another. They are not present in mature stereocilia."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0002139
+
+
+Class: obo:GO_0009510
+
+ Annotations:
+ oboInOwl:hasAlternativeId "GO:0009572"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "http://biology.kenyon.edu/edwards/project/greg/pd.htm"^^xsd:string
+ obo:IAO_0000115 "A tightly wound cylinder of membrane that is located within the plasmodesmal pore and runs the length of the plasmodesma. The desmotubule likely provides a rigid stability to plasmodesmata and confers a fixed diameter and pore size to the plasmodesmal canal, and is linked to the endoplasmic reticulum in each of the adjacent cell."^^xsd:string,
+ rdfs:label "plasmodesmatal desmotubule"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "desmotubule central rod"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009510"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0044432,
+ obo:BFO_0000050 some obo:GO_0009506
+
+
+Class: obo:GO_0002142
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:16775142"^^xsd:string
+ obo:IAO_0000115 "A complex of proteins that connect growing stereocilia in developing cochlear hair cells, composed of Vlgr1, usherin, vezatin, and whirlin."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "stereocilia ankle link complex"^^xsd:string,
+ oboInOwl:id "GO:0002142"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0002141,
+ obo:GO_0044464,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009512
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasExactSynonym "cytochrome b6-f complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "cyt b6f complex"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Cytochrome_b6f_complex"^^xsd:string,
+ rdfs:label "cytochrome b6f complex"^^xsd:string,
+ oboInOwl:id "GO:0009512"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0943883999"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16228398"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16352458"^^xsd:string
+ obo:IAO_0000115 "Complex that transfers electrons from reduced plastoquinone to oxidized plastocyanin and translocates protons from the stroma to the lumen. The complex contains a core structure of three catalytic subunits: cytochrome b, the Rieske iron sulfur protein (ISP), and cytochrome f, which are arranged in an integral membrane-bound dimeric complex; additional subunits are present, and vary among different species."^^xsd:string,
+ oboInOwl:hasExactSynonym "cyt b6-f complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "cytochrome b(6)f complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "cyt b6/f complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "cytochrome b6/f complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "cyt b(6)f complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044436,
+ obo:GO_0043234
+
+
+Class: obo:GO_0014701
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string
+ obo:IAO_0000115 "The part of the sarcoplasmic reticulum membrane that contains calcium release channels, is devoted to calcium release and is juxtaposed to transverse tubule membrane. The junctional sarcoplasmic reticulum membrane consists of the junctional region of the terminal cisterna membrane."^^xsd:string,
+ rdfs:label "junctional sarcoplasmic reticulum membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0014701"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033017
+
+
+Class: obo:GO_0002140
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "stereocilia tip link"^^xsd:string,
+ oboInOwl:id "GO:0002140"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:1108787"^^xsd:string
+ obo:IAO_0000115 "A stereocilia link that is formed by a fine filament running more or less vertically upward from the tip of each shorter stereocilium to attach at a higher point on its adjacent taller neighbor. Tilting the bundle puts tension on the filaments, which pull on mechanically gated ion channels in the membrane of the stereocilia."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0002139
+
+
+Class: obo:GO_0009511
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ai"^^xsd:string
+ obo:IAO_0000115 "Endoplasmic reticulum found in plasmodesmata, junctions connecting the cytoplasm of adjacent plant cells."^^xsd:string,
+ oboInOwl:hasExactSynonym "plasmodesmatal ER"^^xsd:string,
+ rdfs:label "plasmodesmatal endoplasmic reticulum"^^xsd:string,
+ oboInOwl:id "GO:0009511"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009510,
+ obo:GO_0044459,
+ obo:GO_0005783,
+ obo:GO_0044432
+
+
+Class: obo:GO_0009518
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:lr"^^xsd:string
+ obo:IAO_0000115 "Protein-pigment complex associated with photosystem I."^^xsd:string,
+ oboInOwl:id "GO:0009518"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "LHCI"^^xsd:string,
+ rdfs:label "PSI associated light-harvesting complex I"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009503
+
+
+Class: obo:GO_0009517
+
+ Annotations:
+ oboInOwl:id "GO:0009517"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:lr"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0582227089"^^xsd:string
+ obo:IAO_0000115 "Protein-pigment complex associated with photosystem II."^^xsd:string,
+ oboInOwl:hasExactSynonym "LHCII"^^xsd:string,
+ rdfs:label "PSII associated light-harvesting complex II"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009503
+
+
+Class: obo:GO_0009519
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0471245208"^^xsd:string
+ obo:IAO_0000115 "Layer of intercellular material, chiefly pectic substances, cementing together the primary walls of contiguous cells."^^xsd:string,
+ oboInOwl:id "GO:0009519"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "middle lamella"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Middle_lamella"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421,
+ obo:BFO_0000050 some obo:GO_0005615
+
+
+Class: obo:GO_0070032
+
+ Annotations:
+ rdfs:label "synaptobrevin 2-SNAP-25-syntaxin-1a-complexin I complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:7553862"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains synaptobrevin 2 (VAMP2), SNAP-25, syntaxin 1a, and complexin I (or orthologs thereof)."^^xsd:string,
+ oboInOwl:id "GO:0070032"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:795"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Vamp2-Snap25-Stx1a-Cplx1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:795"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Vamp2, Snap25, Stx1a, Cplx1)"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0009514
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:dhl"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0140514031"^^xsd:string
+ obo:IAO_0000115 "A specialized form of peroxisome that contains the enzymes of the glyoxylate pathway. The glyoxysome is found in some plant cells, notably the cells of germinating seeds."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009514"^^xsd:string,
+ rdfs:label "glyoxysome"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Glyoxysome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005777
+
+
+Class: obo:GO_0070033
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:796"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Vamp2-Snap25-Stx1a-Cplx2 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070033"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:7553862"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains synaptobrevin 2 (VAMP2), SNAP-25, syntaxin 1a, and complexin II (or orthologs thereof)."^^xsd:string,
+ rdfs:label "synaptobrevin 2-SNAP-25-syntaxin-1a-complexin II complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:796"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Vamp2, Snap25, Stx1a, Cplx2)"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0009513
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009513"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0943883999"^^xsd:string
+ obo:IAO_0000115 "A plastid arrested in the development of chloroplasts from proplastids due to absence of light or low light conditions."^^xsd:string,
+ rdfs:label "etioplast"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Etioplast"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009536
+
+
+Class: obo:GO_0009516
+
+ Annotations:
+ rdfs:label "leucoplast"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0943883999"^^xsd:string
+ obo:IAO_0000115 "A colorless plastid involved in the synthesis of monoterpenes."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009516"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Leucoplast"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009536
+
+
+Class: obo:GO_0002144
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:18391219"^^xsd:string
+ obo:IAO_0000115 "A complex of two proteins involved in the thiolation of U34 in glutamate, lysine, and glutamine tRNAs of eukaryotes."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasBroadSynonym "tRNA thiouridylase"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Cut1-Cut2 complex"^^xsd:string,
+ oboInOwl:id "GO:0002144"^^xsd:string,
+ rdfs:label "cytosolic tRNA wobble base thiouridylase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044445,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009515
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:lr"^^xsd:string
+ obo:IAO_0000115 "Appressed thylakoid membranes that are part of a granum (stacked regions). A characteristic of these appressed regions is the preferential localization of photosystem II."^^xsd:string,
+ oboInOwl:hasExactSynonym "chloroplast stacked thylakoid"^^xsd:string,
+ oboInOwl:id "GO:0009515"^^xsd:string,
+ rdfs:label "granal stacked thylakoid"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0009534
+ and (obo:BFO_0000050 some obo:GO_0009542)
+
+ SubClassOf:
+ obo:GO_0009534,
+ obo:BFO_0000050 some obo:GO_0009542
+
+
+Class: obo:GO_0042650
+
+ Annotations:
+ oboInOwl:id "GO:0042650"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11532175"^^xsd:string
+ obo:IAO_0000115 "The membrane of prothylakoids, underdeveloped thylakoids found in etioplasts, lacking competent photosynthetic membranes."^^xsd:string,
+ rdfs:label "prothylakoid membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0055035,
+ obo:BFO_0000050 some obo:GO_0042649
+
+
+Class: obo:GO_0042652
+
+ Annotations:
+ oboInOwl:hasBroadSynonym "NADH-Q oxidoreductase complex, peripheral segment"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042652"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jid"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0716749556"^^xsd:string
+ obo:IAO_0000115 "The peripheral segment of respiratory chain complex I located in the mitochondrion. Respiratory chain complex I is an enzyme of the respiratory chain, consisting of at least 34 polypeptide chains. The electrons of NADH enter the chain at this complex. The complete complex is L-shaped, with a horizontal arm lying in the membrane and a vertical arm that projects into the matrix."^^xsd:string,
+ rdfs:label "mitochondrial respiratory chain complex I, peripheral segment"^^xsd:string,
+ oboInOwl:hasBroadSynonym "NADH dehydrogenase (ubiquinone) complex, peripheral segment"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044455,
+ obo:BFO_0000050 some obo:GO_0005747,
+ obo:GO_0043234
+
+
+Class: obo:GO_0042651
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "The pigmented membrane of any thylakoid."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0042651"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "thylakoid membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0034357
+
+
+Class: obo:GO_0070769
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2379"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA2B-ITGB3-CIB1 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9030514"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaIIb-beta3 integrin complex bound to CIB, a protein that binds calcium as well as the alphaIIb-beta3 integrin."^^xsd:string,
+ oboInOwl:id "GO:0070769"^^xsd:string,
+ rdfs:label "alphaIIb-beta3 integrin-CIB complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070768
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8999968"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains synaptotagmin, synaptobrevin 2 (VAMP2), SNAP-25, syntaxin 1a, syntaxin1b, and Unc13b (or orthologs thereof)."^^xsd:string,
+ rdfs:label "synaptotagmin-synaptobrevin 2-SNAP-25-syntaxin-1a-syntaxin-1b-Unc13 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1873"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Snap25-Syt1-Unc13b-Vamp2-Stx1b2-Stx1a complex"^^xsd:string,
+ oboInOwl:id "GO:0070768"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1873"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Snap25, Syt1, Unc13b, Vamp2, Stx1b2, Stx1a)"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0070767
+
+ Annotations:
+ rdfs:label "BRCA1-Rad51 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9008167"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains BRCA1 and Rad 51, and is involved in the control of recombination and of genome integrity."^^xsd:string,
+ oboInOwl:id "GO:0070767"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070419
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "non-homologous end joining complex"^^xsd:string,
+ rdfs:label "nonhomologous end joining complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17072889"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17938628"^^xsd:string
+ obo:IAO_0000115 "A protein complex that plays a role in DNA double-strand break repair via nonhomologous end joining. Such complexes typically contain a specialized DNA ligase (e.g. Lig4 in eukaryotes) and one or more proteins that bind to DNA ends."^^xsd:string,
+ oboInOwl:id "GO:0070419"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "NHEJ complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070766
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1876"^^xsd:string
+ oboInOwl:hasNarrowSynonym "SNARE complex (Stx4, Napa, Vamp3, Nsf, Vamp2)"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1876"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Stx4-Napa-Vamp3-Nsf-Vamp2 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "endobrevin-synaptobrevin 2-alpha-SNAP-NSF-syntaxin-4 complex"^^xsd:string,
+ oboInOwl:id "GO:0070766"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8973549"^^xsd:string
+ obo:IAO_0000115 "A SNARE complex that contains endobrevin (VAMP8), synaptobrevin 2 (VAMP2), alpha-SNAP, NSF, and syntaxin 4 (or orthologs thereof)."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031201
+
+
+Class: obo:GO_0070418
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "DNA-PK complex"^^xsd:string,
+ rdfs:label "DNA-dependent protein kinase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:355"^^xsd:string
+ oboInOwl:hasExactSynonym "DNA-PK-Ku antigen complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "DNA-dependent protein kinase, DNA-end-binding complex"^^xsd:string,
+ oboInOwl:id "GO:0070418"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10854421"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12235392"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is involved in the repair of DNA double-strand breaks and, in mammals, V(D)J recombination events. It consists of the DNA-dependent protein kinase catalytic subunit (DNA-PKcs) and the DNA end-binding heterodimer Ku."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070765
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "CORUM:142"^^xsd:string
+ oboInOwl:hasNarrowSynonym "CD147-gamma-secretase complex (APH-1a, PS-1, PEN-2, NCT variant)"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15286082"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15890777"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17047368"^^xsd:string
+ obo:IAO_0000115 "A protein complex that has aspartic-type endopeptidase activity, and contains a catalytic subunit, presenilin (PS), that is a prototypical member of the GxGD-type aspartyl peptidases. The complex also contains additional subunits, including nicastrin, APH-1, PEN-2, and a regulatory subunit, CD147. Gamma-secretase cleaves several transmembrane proteins including the cell surface receptor Notch and the beta-amyloid precursor protein."^^xsd:string,
+ oboInOwl:id "GO:0070765"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3128"^^xsd:string
+ oboInOwl:hasRelatedSynonym "gamma-secretase complex (APH1B, PSEN1, PSENEN, NCSTN)"^^xsd:string,
+ rdfs:label "gamma-secretase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:130"^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:2891"^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:43"^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:45"^^xsd:string,
+ oboInOwl:hasDbXref "CORUM:466"^^xsd:string
+ oboInOwl:hasNarrowSynonym "gamma-secretase complex (APH1A, PSEN1, PSENEN, NCSTN variant)"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:467"^^xsd:string
+ oboInOwl:hasNarrowSynonym "gamma-secretase complex (APH1B, PSEN2, PSENEN, NCSTN)"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:468"^^xsd:string
+ oboInOwl:hasNarrowSynonym "gamma-secretase complex (APH1A, PSEN2, PSENEN, NCSTN)"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0014704
+
+ Annotations:
+ oboInOwl:id "GO:0014704"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Intercalated_disc"^^xsd:string,
+ rdfs:label "intercalated disc"^^xsd:string,
+ oboInOwl:hasExactSynonym "intercalated disk"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11732910"^^xsd:string
+ obo:IAO_0000115 "A complex cell-cell junction at which myofibrils terminate in cardiomyocytes; mediates mechanical and electrochemical integration between individual cardiomyocytes. The intercalated disc contains regions of tight mechanical attachment (fasciae adherentes and desmosomes) and electrical coupling (gap junctions) between adjacent cells."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044291
+
+
+Class: obo:GO_0070764
+
+ Annotations:
+ oboInOwl:id "GO:0070764"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "gamma-secretase-Delta1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12794186"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is formed by the association of the Notch ligand Delta1 with the gamma-secretase complex."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0014705
+
+ Annotations:
+ oboInOwl:id "GO:0014705"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "C zone"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string
+ obo:IAO_0000115 "A region of the A band in which myosin-binding protein C is located and that can be seen by electron microscopy. This is a functional zone that also includes myosin."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0031672,
+ obo:GO_0044449
+
+
+Class: obo:GO_0070763
+
+ Annotations:
+ oboInOwl:id "GO:0070763"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12794186"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of homodimer of the Notch ligand Delta1."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3271"^^xsd:string
+ oboInOwl:hasExactSynonym "Delta1 homodimer complex"^^xsd:string,
+ rdfs:label "Delta1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0014702
+
+ Annotations:
+ oboInOwl:id "GO:0014702"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "free sarcoplasmic reticulum membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_muscle"^^xsd:string
+ obo:IAO_0000115 "The part of the sarcoplasmic reticulum membrane that contains calcium pumps and is devoted to calcium uptake. The free sarcoplasmic reticulum membrane consists of the longitudinal sarcoplasmic reticulum membrane and the non-junctional region of the terminal cisterna membrane."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033017
+
+
+Class: obo:GO_0070762
+
+ Annotations:
+ oboInOwl:id "GO:0070762"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "NDC1 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19414609"^^xsd:string
+ obo:IAO_0000115 "A protein complex that forms part of the nuclear pore complex, and contains three transmembrane nucleoporins, encoded in S. cerevisiae by Ndc1p, Pom152p and Pom34p."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:19414609"^^xsd:string
+ oboInOwl:hasExactSynonym "NDC1 subcomplex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005643,
+ obo:GO_0044425,
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031015
+
+ Annotations:
+ oboInOwl:id "GO:0031015"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "karyopherin docking complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Asm4p-containing complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11867631"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9864357"^^xsd:string
+ obo:IAO_0000115 "A subcomplex of the nuclear pore complex that interacts with karyopherin-cargo complexes; a well-characterized example in Saccharomyces contains Asm4p, Nup53p, and Nup170p."^^xsd:string,
+ oboInOwl:hasBroadSynonym "nuclear pore subcomplex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0005643,
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071024
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ obo:IAO_0000115 "A ribonucleoprotein complex that contains spliced leader (SL) RNA."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0071024"^^xsd:string,
+ rdfs:label "SL snRNP"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030532
+
+
+Class: obo:GO_0070761
+
+ Annotations:
+ rdfs:label "pre-snoRNP complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:rl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17636026"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17709390"^^xsd:string
+ obo:IAO_0000115 "A ribonucleoprotein complex that contains a precursor small nucleolar RNA (pre-snoRNA) and associated proteins, and forms during small nucleolar ribonucleoprotein complex (snoRNP) assembly. Pre-snoRNP complexes may contain proteins not found in the corresponding mature snoRNP complexes."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070761"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rl"^^xsd:string
+ oboInOwl:hasExactSynonym "pre-small nucleolar ribonucleoprotein complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030529
+
+
+Class: obo:GO_0071022
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian U12-type spliceosomal complex C2"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "minor post-spliceosomal complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasNarrowSynonym "AT-AC post-spliceosomal complex"^^xsd:string,
+ oboInOwl:id "GO:0071022"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ obo:IAO_0000115 "A spliceosomal complex that is formed following the second splicing event and contains the spliced product, the excised intron, and three snRNPs, including U5."^^xsd:string,
+ rdfs:label "U12-type post-spliceosomal complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "yeast U12-type spliceosomal complex A2-3"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000051 some obo:GO_0005693,
+ obo:GO_0071020,
+ obo:GO_0005689,
+ obo:BFO_0000051 some obo:GO_0005691
+
+
+Class: obo:GO_0071023
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ obo:IAO_0000115 "A spliceosomal complex that forms during the addition of a specific spliced leader (SL) sequence to the 5'-end of a messenger RNA primary transcript, a process which occurs in a number of eukaryotic organisms, including trypanosomatid protozoans, euglenoids, nematodes, trematodes, and chordates."^^xsd:string,
+ oboInOwl:id "GO:0071023"^^xsd:string,
+ rdfs:label "trans spliceosomal complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005681,
+ obo:BFO_0000051 some obo:GO_0005682,
+ obo:BFO_0000051 some obo:GO_0071024,
+ obo:BFO_0000051 some obo:GO_0005686,
+ obo:BFO_0000051 some obo:GO_0005688,
+ obo:BFO_0000051 some obo:GO_0005687
+
+
+Class: obo:GO_0031019
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12139607"^^xsd:string
+ obo:IAO_0000115 "An mRNA editing complex found in the mitochondrion. The best characterized example is that of Trypanosoma brucei, which catalyzes the insertion and deletion of uridylates."^^xsd:string,
+ oboInOwl:hasExactSynonym "mitochondrial editosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031019"^^xsd:string,
+ rdfs:label "mitochondrial mRNA editing complex"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0045293
+ and (obo:BFO_0000050 some obo:GO_0005739)
+
+ SubClassOf:
+ obo:GO_0045293,
+ obo:GO_0044429
+
+
+Class: obo:GO_0031020
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "An mRNA editing complex found in a plastid."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031020"^^xsd:string,
+ rdfs:label "plastid mRNA editing complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "plastid editosome"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0045293
+ and (obo:BFO_0000050 some obo:GO_0009536)
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:GO_0045293
+
+
+Class: obo:GO_0031021
+
+ Annotations:
+ oboInOwl:hasExactSynonym "interphase microtubule organising center"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "interphase MTOC"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15068790"^^xsd:string
+ obo:IAO_0000115 "A microtubule organizing center found in interphase cells, which organize a longitudinal array of three to five MT bundles from the nuclear envelope during interphase. Each MT bundle is composed of two to seven MTs arranged in an antiparallel configuration, with the dynamic MT plus ends extending toward the cell tips and stable minus ends near the nucleus."^^xsd:string,
+ oboInOwl:id "GO:0031021"^^xsd:string,
+ oboInOwl:hasExactSynonym "iMTOC"^^xsd:string,
+ rdfs:label "interphase microtubule organizing center"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005815
+
+
+Class: obo:GO_0009523
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:ds"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0943088399"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9821949"^^xsd:string
+ obo:IAO_0000115 "A photosystem that contains a pheophytin-quinone reaction center with associated accessory pigments and electron carriers. In cyanobacteria and chloroplasts, in the presence of light, PSII functions as a water-plastoquinone oxidoreductase, transferring electrons from water to plastoquinone, whereas other photosynthetic bacteria carry out anoxygenic photosynthesis and oxidize other compounds to re-reduce the photoreaction center."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0009523"^^xsd:string,
+ rdfs:label "photosystem II"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Photosystem_II"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009521
+
+
+Class: obo:GO_0009522
+
+ Annotations:
+ rdfs:label "photosystem I"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ds"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0140514031"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9821949"^^xsd:string
+ obo:IAO_0000115 "A photosystem that contains an iron-sulfur reaction center associated with accessory pigments and electron carriers. In cyanobacteria and chloroplasts, photosystem I functions as a light-dependent plastocyanin-ferredoxin oxidoreductase, transferring electrons from plastocyanin to ferredoxin; in photosynthetic bacteria that have only a single type I photosystem, such as the green sulfur bacteria, electrons can go either to ferredoxin (Fd) -> NAD+ or to menaquinone (MK) -> Cytb/FeS -> Cytc555 -> photosystem I (cyclic photophosphorylation)."^^xsd:string,
+ oboInOwl:id "GO:0009522"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009521
+
+
+Class: obo:GO_0009521
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ds"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0140514031"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9821949"^^xsd:string
+ obo:IAO_0000115 "A complex located in a photosynthetic membrane that consists of a photoreaction center associated with accessory pigments and electron carriers. Examples of this component are found in Arabidopsis thaliana and in photosynthetic bacterial and archaeal species."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Photosystem"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "photosystem"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "reaction center"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "reaction centre"^^xsd:string,
+ oboInOwl:id "GO:0009521"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0030090"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044436,
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0034357,
+ obo:GO_0043234
+
+
+Class: obo:GO_0042646
+
+ Annotations:
+ rdfs:label "plastid nucleoid"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "The region of a plastid to which the DNA is confined."^^xsd:string,
+ oboInOwl:id "GO:0042646"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0009295
+ and (obo:BFO_0000050 some obo:GO_0009536)
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:BFO_0000050 some obo:GO_0009532,
+ obo:GO_0009295
+
+
+Class: obo:GO_0009527
+
+ Annotations:
+ oboInOwl:id "GO:0009527"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:lr"^^xsd:string
+ obo:IAO_0000115 "The outer, i.e. cytoplasm-facing, lipid bilayer of the plastid envelope."^^xsd:string,
+ rdfs:label "plastid outer membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031968,
+ obo:GO_0042170
+
+
+Class: obo:GO_0042647
+
+ Annotations:
+ rdfs:label "proplastid nucleoid"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "The region of a proplastid to which the DNA is confined."^^xsd:string,
+ oboInOwl:id "GO:0042647"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0009295
+ and (obo:BFO_0000050 some obo:GO_0009537)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009571,
+ obo:GO_0042646
+
+
+Class: obo:GO_0002111
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0002111"^^xsd:string,
+ rdfs:label "BRCA2-BRAF35 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:hjd"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11207365"^^xsd:string
+ obo:IAO_0000115 "A heterodimeric complex of BRCA2 and BRAF35 (BRCA2-associated factor 35). The BRCA2-BRAF35 complex is often associated with condensed chromatin during mitosis."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009526
+
+ Annotations:
+ rdfs:label "plastid envelope"^^xsd:string,
+ oboInOwl:id "GO:0009526"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jy"^^xsd:string
+ obo:IAO_0000115 "The double lipid bilayer enclosing a plastid and separating its contents from the rest of the cytoplasm; includes the intermembrane space."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:GO_0031967
+
+
+Class: obo:GO_0042648
+
+ Annotations:
+ rdfs:label "chloroplast chromosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042648"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "A circular DNA molecule containing chloroplast encoded genes."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005694
+ and (obo:BFO_0000050 some obo:GO_0009507)
+
+ SubClassOf:
+ obo:GO_0009508,
+ obo:BFO_0000050 some obo:GO_0042644,
+ obo:GO_0044434
+
+
+Class: obo:GO_0009525
+
+ Annotations:
+ oboInOwl:id "GO:0009525"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "phragmosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0943883999"^^xsd:string
+ obo:IAO_0000115 "A flattened membranous vesicle containing cell wall components."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Phragmosome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444
+
+
+Class: obo:GO_0042649
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "prothylakoid"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11532175"^^xsd:string
+ obo:IAO_0000115 "Underdeveloped thylakoids found in etioplasts, lacking competent photosynthetic membranes. Rapidly develop into mature thylakoids in the presence of light."^^xsd:string,
+ oboInOwl:id "GO:0042649"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009513,
+ obo:GO_0031976
+
+
+Class: obo:GO_0009524
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Phragmoplast"^^xsd:string,
+ oboInOwl:id "GO:0009524"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0471245208"^^xsd:string
+ obo:IAO_0000115 "Fibrous structure (light microscope view) that arises between the daughter nuclei at telophase and within which the initial partition (cell plate), dividing the mother cell in two (cytokinesis), is formed. Appears at first as a spindle connected to the two nuclei, but later spreads laterally in the form of a ring. Consists of microtubules."^^xsd:string,
+ rdfs:label "phragmoplast"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444
+
+
+Class: obo:GO_0042642
+
+ Annotations:
+ rdfs:label "actomyosin, myosin complex part"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:go_curators"^^xsd:string
+ obo:IAO_0000115 "The myosin part of any complex of actin, myosin, and accessory proteins."^^xsd:string,
+ oboInOwl:id "GO:0042642"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0016459
+ and (obo:BFO_0000050 some obo:GO_0042641)
+
+ SubClassOf:
+ obo:GO_0016459,
+ obo:BFO_0000050 some obo:GO_0042641
+
+
+Class: obo:GO_0042643
+
+ Annotations:
+ rdfs:label "actomyosin, actin part"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:go_curators"^^xsd:string
+ obo:IAO_0000115 "The actin part of any complex of actin, myosin, and accessory proteins."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042643"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0005884
+ and (obo:BFO_0000050 some obo:GO_0042641)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0042641,
+ obo:GO_0005884
+
+
+Class: obo:GO_0042644
+
+ Annotations:
+ rdfs:label "chloroplast nucleoid"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042644"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "The region of a chloroplast to which the DNA is confined."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0009295
+ and (obo:BFO_0000050 some obo:GO_0009507)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009570,
+ obo:GO_0042646,
+ obo:GO_0044434
+
+
+Class: obo:GO_0002116
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:hjd"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10934324"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12367632"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12613544"^^xsd:string
+ obo:IAO_0000115 "A stable binary complex of a neurophilin and a plexin, together forming a functional semaphorin receptor."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "semaphorin receptor complex"^^xsd:string,
+ oboInOwl:id "GO:0002116"^^xsd:string,
+ oboInOwl:hasExactSynonym "plexin-neurophilin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043235
+
+
+Class: obo:GO_0009529
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:lr"^^xsd:string
+ obo:IAO_0000115 "The region between the inner and outer lipid bilayers of the plastid envelope."^^xsd:string,
+ rdfs:label "plastid intermembrane space"^^xsd:string,
+ oboInOwl:id "GO:0009529"^^xsd:string,
+ oboInOwl:hasExactSynonym "plastid envelope lumen"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:BFO_0000050 some obo:GO_0009526,
+ obo:GO_0031970
+
+
+Class: obo:GO_0042645
+
+ Annotations:
+ rdfs:label "mitochondrial nucleoid"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string
+ obo:IAO_0000115 "The region of a mitochondrion to which the DNA is confined."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0042645"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0009295
+ and (obo:BFO_0000050 some obo:GO_0005739)
+
+ SubClassOf:
+ obo:GO_0044429,
+ obo:BFO_0000050 some obo:GO_0005759,
+ obo:GO_0009295
+
+
+Class: obo:GO_0009528
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:lr"^^xsd:string
+ obo:IAO_0000115 "The inner, i.e. lumen-facing, lipid bilayer of the plastid envelope; also faces the plastid stroma."^^xsd:string,
+ oboInOwl:id "GO:0009528"^^xsd:string,
+ rdfs:label "plastid inner membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0019866,
+ obo:GO_0042170
+
+
+Class: obo:GO_0031838
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A protein complex formed by the stable binding of a haptoglobin to hemoglobin."^^xsd:string,
+ rdfs:label "haptoglobin-hemoglobin complex"^^xsd:string,
+ oboInOwl:id "GO:0031838"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0071019
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16201866"^^xsd:string
+ obo:IAO_0000115 "A spliceosomal complex that is formed following the release of the spliced product from the post-spliceosomal complex and contains the excised intron and the U12, U5 and U6atac snRNPs."^^xsd:string,
+ oboInOwl:id "GO:0071019"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasNarrowSynonym "AT-AC post-mRNA release spliceosomal complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "minor post-mRNA release spliceosomal complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian U12-type spliceosomal complex I"^^xsd:string,
+ rdfs:label "U12-type post-mRNA release spliceosomal complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005693,
+ obo:GO_0005691,
+ obo:GO_0005689,
+ obo:GO_0071014
+
+
+Class: obo:GO_0070020
+
+ Annotations:
+ oboInOwl:id "GO:0070020"^^xsd:string,
+ oboInOwl:hasExactSynonym "TGF-beta receptor II-TGF-beta1 complex"^^xsd:string,
+ rdfs:label "transforming growth factor beta1-type II receptor complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "Reactome:REACT_7218"^^xsd:string
+ oboInOwl:hasExactSynonym "TGF-beta1-type II receptor complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "Reactome:REACT_7218"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of a dimeric transforming growth factor beta (TGF-beta) type II receptor bound to a TGF-beta1 dimer."^^xsd:string,
+ oboInOwl:inSubset
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071015
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19239890"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian U12-type spliceosomal complex A"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "yeast U12-type spliceosomal complex B"^^xsd:string,
+ rdfs:label "U12-type prespliceosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10197985"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16201866"^^xsd:string
+ obo:IAO_0000115 "A spliceosomal complex that is formed by the cooperative binding of the heterodimeric U11/U12 snRNP to the 5' splice site and the branch point sequence. The U12-type prespliceosome includes many proteins in addition to those found in the U11/U12 heterodimeric snRNPs. Commitment to a given pair of 5' and 3' splice sites occurs at the time of prespliceosome formation."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasNarrowSynonym "AT-AC prespliceosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "minor prespliceosome"^^xsd:string,
+ oboInOwl:id "GO:0071015"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071010,
+ obo:BFO_0000051 some obo:GO_0034693,
+ obo:GO_0005689
+
+
+Class: obo:GO_0031027
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "glutamate synthase complex (NADH)"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7047525"^^xsd:string
+ obo:IAO_0000115 "A protein complex that in yeast consists of a large and a small subunit. Possesses glutamate synthase (NADH) activity."^^xsd:string,
+ oboInOwl:id "GO:0031027"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031026
+
+
+Class: obo:GO_0071016
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasNarrowSynonym "AT-AC precatalytic spliceosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian U12-type spliceosomal complex B1"^^xsd:string,
+ rdfs:label "U12-type precatalytic spliceosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19239890"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian U12-type spliceosomal complex B"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "minor precatalytic spliceosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "yeast U12-type spliceosomal complex A2-1"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16201866"^^xsd:string
+ obo:IAO_0000115 "A spliceosomal complex that is formed by the recruitment of the preassembled U4atac/U6atac.U5 tri-snRNP to the U12-type prespliceosome. Although all 5 snRNPs are present, the precatalytic spliceosome is catalytically inactive. The precatalytic spliceosome includes many proteins in addition to those found in the U11, U12 and U4atac/U6atac.U5 snRNPs."^^xsd:string,
+ oboInOwl:id "GO:0071016"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000051 some obo:GO_0005692,
+ obo:BFO_0000051 some obo:GO_0005693,
+ obo:BFO_0000051 some obo:GO_0071009,
+ obo:GO_0005689,
+ obo:GO_0071011
+
+
+Class: obo:GO_0031026
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A complex that possesses glutamate synthase activity."^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "glutamate synthase complex"^^xsd:string,
+ oboInOwl:id "GO:0031026"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071017
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "yeast U12-type spliceosomal complex A1"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasNarrowSynonym "AT-AC catalytic step 1 spliceosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian U12-type spliceosomal complex B2"^^xsd:string,
+ rdfs:label "U12-type catalytic step 1 spliceosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "minor catalytic step 1 spliceosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasExactSynonym "U12-type activated spliceosome"^^xsd:string,
+ oboInOwl:id "GO:0071017"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16201866"^^xsd:string
+ obo:IAO_0000115 "A spliceosomal complex that is formed by the displacement of the U11 and U4atac snRNPs from the precatalytic spliceosome; the U12, U5 and U6atac snRNPs remain associated with the mRNA. This complex, sometimes called the activated spliceosome, is the catalytically active form of the spliceosome, and includes many proteins in addition to those found in the U12, and U5 and U6atac snRNPs."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19239890"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian U12-type spliceosomal complex B*"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000051 some obo:GO_0005693,
+ obo:GO_0005689,
+ obo:GO_0071012,
+ obo:BFO_0000051 some obo:GO_0005691
+
+
+Class: obo:GO_0070776
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:18794358"^^xsd:string
+ obo:IAO_0000115 "A histone acetyltransferase complex that has histone H3 acetyltransferase and coactivator activities. Subunits of the human complex include MYST3/MOZ, MYST4/MORF, ING5, EAF6 and one of BRPF1, BRD1/BRPF2 and BRPF3."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "MOZ/MORF histone acetyltransferase complex"^^xsd:string,
+ oboInOwl:id "GO:0070776"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070775
+
+
+Class: obo:GO_0071018
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian U12-type spliceosomal complex C1"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasNarrowSynonym "AT-AC catalytic step 2 spliceosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16201866"^^xsd:string
+ obo:IAO_0000115 "A spliceosomal complex that contains the U12, U5 and U6atac snRNPs bound to a splicing intermediate in which the first catalytic cleavage of the 5' splice site has occurred. The precise subunit composition differs significantly from that of the catalytic step 1, or activated, spliceosome, and includes many proteins in addition to those found in the U12, U5 and U6atac snRNPs."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19239890"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian U12-type spliceosomal complex C"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "yeast U12-type spliceosomal complex A2-2"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "minor catalytic step 2 spliceosome"^^xsd:string,
+ rdfs:label "U12-type catalytic step 2 spliceosome"^^xsd:string,
+ oboInOwl:id "GO:0071018"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000051 some obo:GO_0005693,
+ obo:GO_0005689,
+ obo:BFO_0000051 some obo:GO_0005691,
+ obo:GO_0071013
+
+
+Class: obo:GO_0070775
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "H3 HAT complex"^^xsd:string,
+ rdfs:label "H3 histone acetyltransferase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A multisubunit complex that catalyzes the acetylation of histone H3."^^xsd:string,
+ oboInOwl:id "GO:0070775"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000123
+
+
+Class: obo:GO_0071011
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19239890"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian spliceosomal complex B"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "precatalytic spliceosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian spliceosomal complex B1"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "yeast spliceosomal complex A2-1"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18322460"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19239890"^^xsd:string
+ obo:IAO_0000115 "A spliceosomal complex that is formed by the recruitment of a preassembled U5-containing tri-snRNP to the prespliceosome. Although all 5 snRNPs are present, the precatalytic spliceosome is catalytically inactive. The precatalytic spliceosome includes many proteins in addition to those found in the associated snRNPs."^^xsd:string,
+ oboInOwl:id "GO:0071011"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005681
+
+
+Class: obo:GO_0070770
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:9169439"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaIIb-beta3 integrin complex bound to the cell surface antigen CD47 and the kinase FAK."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2896"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA2b-ITGB3-CD47-FAK complex"^^xsd:string,
+ oboInOwl:id "GO:0070770"^^xsd:string,
+ rdfs:label "alphaIIb-beta3 integrin-CD47-FAK complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071012
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasExactSynonym "activated spliceosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18322460"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19239890"^^xsd:string
+ obo:IAO_0000115 "A spliceosomal complex that is formed by the displacement of the two snRNPs from the precatalytic spliceosome; three snRNPs including U5 remain associated with the mRNA. This complex, sometimes called the activated spliceosome, is the catalytically active form of the spliceosome, and includes many proteins in addition to those found in the associated snRNPs."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian spliceosomal complex B2"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "yeast spliceosomal complex A1"^^xsd:string,
+ oboInOwl:id "GO:0071012"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19239890"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian spliceosomal complex B*"^^xsd:string,
+ rdfs:label "catalytic step 1 spliceosome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005681,
+ obo:BFO_0000051 some obo:GO_0005682,
+ obo:BFO_0000051 some obo:GO_0000974
+
+
+Class: obo:GO_0071013
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "yeast spliceosomal complex A2-2"^^xsd:string,
+ rdfs:label "catalytic step 2 spliceosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian spliceosomal complex C1"^^xsd:string,
+ oboInOwl:id "GO:0071013"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18322460"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19239890"^^xsd:string
+ obo:IAO_0000115 "A spliceosomal complex that contains three snRNPs, including U5, bound to a splicing intermediate in which the first catalytic cleavage of the 5' splice site has occurred. The precise subunit composition differs significantly from that of the catalytic step 1, or activated, spliceosome, and includes many proteins in addition to those found in the associated snRNPs."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19239890"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian spliceosomal complex C"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005681,
+ obo:BFO_0000051 some obo:GO_0005682,
+ obo:BFO_0000051 some obo:GO_0000974
+
+
+Class: obo:GO_0070772
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "PAS complex"^^xsd:string,
+ oboInOwl:id "GO:0070772"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:18950639"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19037259"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19158662"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains a phosphatidylinositol-3-phosphate 5-kinase subunit (Fab1p in yeast; PIKfyve in mammals), a kinase activator, and a phosphatase, and may also contain additional proteins; it is involved in regulating the synthesis and turnover of phosphatidylinositol 3,5-bisphosphate. In mammals the complex is composed of PIKFYVE, FIG4 and VAC14. In yeast it is composed of Atg18p, Fig4p, Fab1p, Vac14p and Vac7p."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044437,
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0005774,
+ obo:GO_0043234
+
+
+Class: obo:GO_0071014
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:ab"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:19239890"^^xsd:string
+ obo:IAO_0000115 "A spliceosomal complex that is formed following the release of the spliced product from the post-spliceosomal complex and contains the excised intron and three snRNPs, including U5."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "post-mRNA release spliceosomal complex"^^xsd:string,
+ oboInOwl:id "GO:0071014"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian spliceosomal complex I"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005681,
+ obo:BFO_0000051 some obo:GO_0005682
+
+
+Class: obo:GO_0070771
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:9169439"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphaIIb-beta3 integrin complex bound to the cell surface antigen CD47 and the kinase c-Src."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alphaIIb-beta3 integrin-CD47-Src complex"^^xsd:string,
+ oboInOwl:id "GO:0070771"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2377"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA2b-ITGB3-CD47-SRC complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070018
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070018"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "Reactome:REACT_7737"^^xsd:string
+ oboInOwl:hasExactSynonym "TGF-beta type I receptor dimer"^^xsd:string,
+ rdfs:label "transforming growth factor beta type I receptor complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "TGF-beta type I receptor complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "Reactome:REACT_7737"^^xsd:string
+ obo:IAO_0000115 "A receptor complex that consists of two transforming growth factor beta (TGF-beta) type I receptor monomers. TGF-beta type I receptor dimers form in the presence or absence of ligand, and can associate with ligand-bound TGF-beta type II receptor dimers."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070022
+
+
+Class: obo:GO_0070019
+
+ Annotations:
+ rdfs:label "transforming growth factor beta type II receptor complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "TGF-beta type II receptor complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070019"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "Reactome:REACT_7415"^^xsd:string
+ obo:IAO_0000115 "A receptor complex that consists of two transforming growth factor beta (TGF-beta) type II receptor monomers. TGF-beta type II receptor dimers form in the presence or absence of ligand, and upon ligand binding can associate with TGF-beta type I receptor dimers."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "Reactome:REACT_7415"^^xsd:string
+ oboInOwl:hasExactSynonym "TGF-beta type II receptor dimer"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070022
+
+
+Class: obo:GO_0071021
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "yeast U2-type spliceosomal complex A2-3"^^xsd:string,
+ rdfs:label "U2-type post-spliceosomal complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ obo:IAO_0000115 "A spliceosomal complex that is formed following the second splicing event and contains the spliced product, the excised intron, and three snRNPs, including U5."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasNarrowSynonym "GT-AG post-spliceosomal complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "major post-spliceosomal complex"^^xsd:string,
+ oboInOwl:id "GO:0071021"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian U2-type spliceosomal complex C2"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005684,
+ obo:GO_0071020,
+ obo:BFO_0000051 some obo:GO_0005686,
+ obo:BFO_0000051 some obo:GO_0005688
+
+
+Class: obo:GO_0009530
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jid"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9442872"^^xsd:string
+ obo:IAO_0000115 "A plant cell wall that is still able to expand, permitting cell growth. Primary cell walls contain more pectin than secondary walls and no lignin is present."^^xsd:string,
+ oboInOwl:id "GO:0009530"^^xsd:string,
+ rdfs:label "primary cell wall"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0048196,
+ obo:GO_0009505
+
+
+Class: obo:GO_0071020
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "yeast spliceosomal complex A2-3"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ obo:IAO_0000115 "A spliceosomal complex that is formed following the second splicing event and contains the spliced product, the excised intron, and three snRNPs, including U5."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879695897"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0879697393"^^xsd:string
+ oboInOwl:hasNarrowSynonym "mammalian spliceosomal complex C2"^^xsd:string,
+ rdfs:label "post-spliceosomal complex"^^xsd:string,
+ oboInOwl:id "GO:0071020"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005681,
+ obo:BFO_0000051 some obo:GO_0005682
+
+
+Class: obo:GO_0035182
+
+ Annotations:
+ oboInOwl:hasNarrowSynonym "nurse cell ring canal outer rim"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "ovarian ring canal outer rim"^^xsd:string,
+ oboInOwl:id "GO:0035182"^^xsd:string,
+ rdfs:comment "See also the fly_anatomy.ontology term 'outer nurse cell ring canal rim ; FBbt:00004882'."^^xsd:string,
+ rdfs:label "female germline ring canal outer rim"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12435357"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7925006"^^xsd:string
+ obo:IAO_0000115 "An electron opaque backbone of the insect ovarian ring canal that is a part of or adjacent to the plasma membrane. The outer rim is established as the cleavage furrow is arrested, and contains F-actin, anillin, glycoproteins and at least one a protein with a high content of phosphorylated tyrosine residues."^^xsd:string,
+ oboInOwl:hasBroadSynonym "germline ring canal outer rim"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421,
+ obo:BFO_0000050 some obo:GO_0035324
+
+
+Class: obo:GO_0035183
+
+ Annotations:
+ oboInOwl:hasNarrowSynonym "ovarian ring canal inner rim"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10556087"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7925006"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9093858"^^xsd:string
+ obo:IAO_0000115 "A proteinaceous actin-rich layer of the insect ovarian ring canal that forms subcortically to the outer rim. The electron dense inner rim accumulates after the final mitotic division of each germline syncytia, and contains actin, a phosphotyrosine protein, and a number of cytoskeletal proteins."^^xsd:string,
+ oboInOwl:hasNarrowSynonym "nurse cell ring canal inner rim"^^xsd:string,
+ rdfs:label "female germline ring canal inner rim"^^xsd:string,
+ rdfs:comment "See also the fly_anatomy.ontology term 'inner nurse cell ring canal rim ; FBbt:00004881'."^^xsd:string,
+ oboInOwl:hasBroadSynonym "germline ring canal inner rim"^^xsd:string,
+ oboInOwl:id "GO:0035183"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421,
+ obo:BFO_0000050 some obo:GO_0035324
+
+
+Class: obo:GO_0009532
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:047142520"^^xsd:string
+ obo:IAO_0000115 "The proteinaceous ground substance of plastids."^^xsd:string,
+ oboInOwl:id "GO:0009532"^^xsd:string,
+ rdfs:label "plastid stroma"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044435
+
+
+Class: obo:GO_0009531
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "secondary cell wall"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jid"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0943088399"^^xsd:string
+ obo:IAO_0000115 "A plant cell wall that is no longer able to expand and so does not permit growth. Secondary cell walls contain less pectin that primary cell walls. The secondary cell is mostly composed of cellulose and is strengthened with lignin."^^xsd:string,
+ oboInOwl:id "GO:0009531"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Secondary_cell_wall"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0048196,
+ obo:GO_0009505
+
+
+Class: obo:GO_0009534
+
+ Annotations:
+ rdfs:label "chloroplast thylakoid"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0943883999"^^xsd:string
+ obo:IAO_0000115 "Sac-like membranous structures (cisternae) in a chloroplast combined into stacks (grana) and present singly in the stroma (stroma thylakoids or frets) as interconnections between grana. An example of this component is found in Arabidopsis thaliana."^^xsd:string,
+ oboInOwl:id "GO:0009534"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0009579
+ and (obo:BFO_0000050 some obo:GO_0009507)
+
+ SubClassOf:
+ obo:GO_0031976,
+ obo:GO_0044434
+
+
+Class: obo:GO_0009533
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "chloroplast stromal thylakoid"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0943883999"^^xsd:string
+ obo:IAO_0000115 "Unstacked thylakoids that connect the grana stacks through the stroma."^^xsd:string,
+ oboInOwl:id "GO:0009533"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0009534
+ and (obo:BFO_0000050 some obo:GO_0009570)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009570,
+ obo:GO_0009534
+
+
+Class: obo:GO_0009536
+
+ Annotations:
+ oboInOwl:id "GO:0009536"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198547684"^^xsd:string
+ obo:IAO_0000115 "Any member of a family of organelles found in the cytoplasm of plants and some protists, which are membrane-bounded and contain DNA. Plant plastids develop from a common type, the proplastid."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ rdfs:label "plastid"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasDbXref "Wikipedia:Plastid"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043231,
+ obo:GO_0044444
+
+
+Class: obo:GO_0009535
+
+ Annotations:
+ oboInOwl:id "GO:0009535"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "chloroplast thylakoid membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:lr"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string
+ obo:IAO_0000115 "The pigmented membrane of a chloroplast thylakoid. An example of this component is found in Arabidopsis thaliana."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009534,
+ obo:GO_0055035,
+ obo:GO_0044434
+
+
+Class: obo:GO_0035189
+
+ Annotations:
+ rdfs:label "Rb-E2F complex"^^xsd:string,
+ oboInOwl:id "GO:0035189"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:14616073"^^xsd:string
+ obo:IAO_0000115 "A multiprotein complex containing a heterodimeric E2F transcription factor and a Retinoblastoma (Rb) family member. This complex is capable of repressing transcription of E2F-regulated genes in order to regulate cell cycle progression."^^xsd:string,
+ oboInOwl:hasExactSynonym "retinoblastoma-E2F complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005667
+
+
+Class: obo:GO_0009538
+
+ Annotations:
+ oboInOwl:id "GO:0009538"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "photosystem I reaction center"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:kd"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0943088399"^^xsd:string
+ obo:IAO_0000115 "A photochemical system containing P700, the chlorophyll a dimer that functions as a primary electron donor. Functioning as a light-dependent plastocyanin-ferredoxin oxidoreductase, it transfers electrons from plastocyanin to ferredoxin."^^xsd:string,
+ oboInOwl:hasExactSynonym "photosystem I reaction centre"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044436,
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0009522,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070013
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "An organelle lumen that is part of an intracellular organelle."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "intracellular organelle lumen"^^xsd:string,
+ oboInOwl:id "GO:0070013"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044446,
+ obo:GO_0043233
+
+
+Class: obo:GO_0009537
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0943883999"^^xsd:string
+ obo:IAO_0000115 "The precursor of other plastids."^^xsd:string,
+ oboInOwl:id "GO:0009537"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "proplastid"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009536
+
+
+Class: obo:GO_0070014
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Sucrase-isomaltase"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:3366777"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses oligo-1,6-glucosidase activity; the complex is a heterodimer located in the cell membrane, and is formed by proteolytic cleavage of a single precursor polypeptide. The two subunits have different substrate specificities."^^xsd:string,
+ oboInOwl:id "GO:0070014"^^xsd:string,
+ rdfs:label "sucrase-isomaltase complex"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "oligo-1,6-glucosidase complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005887,
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0009539
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "photosystem II reaction center"^^xsd:string,
+ oboInOwl:hasExactSynonym "photosystem II reaction centre"^^xsd:string,
+ oboInOwl:id "GO:0009539"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:kd"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0943088399"^^xsd:string
+ obo:IAO_0000115 "An integral membrane complex containing P680, the chlorophyll a molecule that functions as a primary electron donor. In the light, functioning as a water-plastoquinone oxidoreductase, it transfers electrons from water to plastoquinone."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044436,
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0009523,
+ obo:GO_0043234
+
+
+Class: obo:GO_0042653
+
+ Annotations:
+ oboInOwl:hasBroadSynonym "NADH-Q oxidoreductase complex, membrane segment"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:jid"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0716749556"^^xsd:string
+ obo:IAO_0000115 "The mitochondrial membrane segment of respiratory chain complex I. Respiratory chain complex I is an enzyme of the respiratory chain, consisting of at least 34 polypeptide chains. The electrons of NADH enter the chain at this complex. The complete complex is L-shaped, with a horizontal arm lying in the membrane and a vertical arm that projects into the matrix."^^xsd:string,
+ oboInOwl:id "GO:0042653"^^xsd:string,
+ rdfs:label "mitochondrial respiratory chain complex I, membrane segment"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044455,
+ obo:BFO_0000050 some obo:GO_0005747,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070017
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:2478219"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphav-beta3 integrin complex bound to thrombospondin."^^xsd:string,
+ oboInOwl:id "GO:0070017"^^xsd:string,
+ rdfs:label "alphav-beta3 integrin-thrombospondin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2846"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGAV-ITGB3-THBS1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0019012
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0781718325"^^xsd:string
+ obo:IAO_0000115 "The complete fully infectious extracellular virus particle."^^xsd:string,
+ oboInOwl:id "GO:0019012"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Virus"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "virion"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasExactSynonym "complete virus particle"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005575
+
+
+Class: obo:GO_0001534
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0124325653"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9450971"^^xsd:string
+ obo:IAO_0000115 "Protein complex that links the outer microtubule doublet of the ciliary or flagellum axoneme with the sheath that surrounds the central pair of microtubules. Composed of a stalk that attaches to each doublet microtubule and a globular structure (spoke head) that projects toward the central pair of microtubules."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0001534"^^xsd:string,
+ rdfs:label "radial spoke"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Radial_spoke"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044447,
+ obo:GO_0043234
+
+
+Class: obo:GO_0044084
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "MITRE:tk"^^xsd:string
+ obo:IAO_0000115 "Any small opening in a host cell membrane that allows the passage of gases and/or liquids, composed of host proteins."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "host cell membrane pore complex"^^xsd:string,
+ oboInOwl:id "GO:0044084"^^xsd:string,
+ oboInOwl:hasExactSynonym "pore complex in host cell membrane"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0033643,
+ obo:BFO_0000050 some obo:GO_0033644
+
+
+Class: obo:GO_0001533
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "cornified envelope"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11112355"^^xsd:string
+ obo:IAO_0000115 "An insoluble protein structure formed under the plasma membrane of cornifying epithelial cells."^^xsd:string,
+ oboInOwl:id "GO:0001533"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005856
+
+
+Class: obo:GO_0015030
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Cajal_body"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10944589"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11031238"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7559785"^^xsd:string,
+ oboInOwl:hasDbXref "http://genetics.cwru.edu/matera3.html"^^xsd:string
+ obo:IAO_0000115 "A class of nuclear body, first seen after silver staining by Ramon y Cajal in 1903, enriched in small nuclear ribonucleoproteins, and certain general RNA polymerase II transcription factors; ultrastructurally, they appear as a tangle of coiled, electron-dense threads roughly 0.5 micrometers in diameter; involved in aspects of snRNP biogenesis; the protein coilin serves as a marker for Cajal bodies. Some argue that Cajal bodies are the sites for preassembly of transcriptosomes, unitary particles involved in transcription and processing of RNA."^^xsd:string,
+ oboInOwl:hasExactSynonym "Gems"^^xsd:string,
+ oboInOwl:hasExactSynonym "coiled body"^^xsd:string,
+ rdfs:label "Cajal body"^^xsd:string,
+ oboInOwl:id "GO:0015030"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016604
+
+
+Class: obo:GO_0019013
+
+ Annotations:
+ oboInOwl:hasExactSynonym "nucleocapsid"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0781702534"^^xsd:string
+ obo:IAO_0000115 "The complete protein-nucleic acid complex that is the packaged form of the genome in a virus particle."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0019013"^^xsd:string,
+ oboInOwl:hasBroadSynonym "core"^^xsd:string,
+ rdfs:label "viral nucleocapsid"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0019014"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0019028,
+ obo:GO_0044423
+
+
+Class: obo:GO_0019016
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pk"^^xsd:string
+ obo:IAO_0000115 "A viral genome that consists of one continuous nucleic acid molecule."^^xsd:string,
+ oboInOwl:id "GO:0019016"^^xsd:string,
+ rdfs:label "non-segmented viral genome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0019015
+
+
+Class: obo:GO_0019015
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "viral genome"^^xsd:string,
+ oboInOwl:id "GO:0019015"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "The whole of the genetic information of a virus, contained as either DNA or RNA."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044423
+
+
+Class: obo:GO_0019018
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0121585336"^^xsd:string
+ obo:IAO_0000115 "A segmented viral genome consisting of two sub-genomic nucleic acids but each nucleic acid is packaged into a different virion."^^xsd:string,
+ oboInOwl:id "GO:0019018"^^xsd:string,
+ rdfs:label "bipartite viral genome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0019017
+
+
+Class: obo:GO_0019017
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0121585336"^^xsd:string
+ obo:IAO_0000115 "A viral genome that is divided into two or more physically separate molecules of nucleic acid and packaged into a single virion."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "segmented viral genome"^^xsd:string,
+ oboInOwl:id "GO:0019017"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0019015
+
+
+Class: obo:GO_0019019
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0121585336"^^xsd:string
+ obo:IAO_0000115 "A segmented viral genome consisting of three sub-genomic nucleic acids but each nucleic acid is packaged into a different virion."^^xsd:string,
+ oboInOwl:id "GO:0019019"^^xsd:string,
+ rdfs:label "tripartite viral genome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0019017
+
+
+Class: obo:GO_0070477
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15035041"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18035610"^^xsd:string
+ obo:IAO_0000115 "An intracellular part that represents the innermost portion of an endospore; the endospore core is dehydrated, enriched in dipicolinic acid and divalent cations, and metabolically inactive."^^xsd:string,
+ rdfs:label "endospore core"^^xsd:string,
+ oboInOwl:id "GO:0070477"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424
+
+
+Class: obo:GO_0001527
+
+ Annotations:
+ oboInOwl:hasRelatedSynonym "fibrillin"^^xsd:string,
+ oboInOwl:hasExactSynonym "extended fibrils"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0001527"^^xsd:string,
+ rdfs:label "microfibril"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "http://www.xrefer.com/entry/490235"^^xsd:string
+ obo:IAO_0000115 "Extracellular matrix components occurring independently or along with elastin. Thought to have force-bearing functions in tendon. In addition to fibrillins, microfibrils may contain other associated proteins."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043205
+
+
+Class: obo:GO_0019005
+
+ Annotations:
+ oboInOwl:hasExactSynonym "cullin-RING ligase 1"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0019005"^^xsd:string,
+ oboInOwl:hasExactSynonym "CRL1 complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "Skp1/Cul1/F-box protein complex"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:SCF_complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:15571813"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15688063"^^xsd:string
+ obo:IAO_0000115 "A ubiquitin ligase complex in which a cullin from the Cul1 subfamily and a RING domain protein form the catalytic core; substrate specificity is conferred by a Skp1 adaptor and an F-box protein. SCF complexes are involved in targeting proteins for degradation by the proteasome. The best characterized complexes are those from yeast and mammals (with core subunits named Cdc53/Cul1, Rbx1/Hrt1/Roc1)."^^xsd:string,
+ oboInOwl:hasExactSynonym "SCF complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "SCF complex substrate recognition subunit"^^xsd:string,
+ rdfs:label "SCF ubiquitin ligase complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "Cul1-RING ubiquitin ligase complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "CDL1 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031461
+
+
+Class: obo:GO_0001520
+
+ Annotations:
+ rdfs:label "outer dense fiber"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0824072820"^^xsd:string
+ obo:IAO_0000115 "Structure or material found in the flagella of mammalian sperm that surrounds each of the nine microtubule doublets, giving a 9 + 9 + 2 arrangement rather than the 9 + 2 pattern usually seen. These dense fibers are stiff and noncontractile."^^xsd:string,
+ oboInOwl:id "GO:0001520"^^xsd:string,
+ oboInOwl:hasExactSynonym "outer dense fibre"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044447
+
+
+Class: obo:GO_0070470
+
+ Annotations:
+ oboInOwl:id "GO:0070470"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:curators"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198547684"^^xsd:string
+ obo:IAO_0000115 "A respiratory chain located in the plasma membrane of a cell; made up of the protein complexes that form the mitochondrial electron transport system (the respiratory chain), associated with the plasma membrane. The respiratory chain complexes transfer electrons from an electron donor to an electron acceptor and are associated with a proton pump to create a transmembrane electrochemical gradient."^^xsd:string,
+ rdfs:label "plasma membrane respiratory chain"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "plasma membrane electron transport chain"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0070469
+
+
+Class: obo:GO_0019008
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasAlternativeId "GO:0019009"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12571227"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:15709772"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses molybdopterin synthase activity. In E. coli, the complex is a heterotetramer consisting of two MoaD and two MoaE subunits."^^xsd:string,
+ oboInOwl:id "GO:0019008"^^xsd:string,
+ oboInOwl:hasExactSynonym "molybdopterin converting factor complex"^^xsd:string,
+ rdfs:label "molybdopterin synthase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464,
+ obo:GO_0043234
+
+
+Class: obo:GO_0035658
+
+ Annotations:
+ rdfs:label "Mon1-Ccz1 complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0035658"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20797862"^^xsd:string
+ obo:IAO_0000115 "A protein complex that functions as a guanine nucleotide exchange factor (GEF) and converts Rab-GDP to Rab-GTP. In S. cerevisiae, this complex consists of at least Mon1 and Ccz1, and serves as a GEF for the Rab Ypt7p."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005770,
+ obo:GO_0044440,
+ obo:GO_0043234
+
+
+Class: obo:GO_0033768
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17762864"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17762865"^^xsd:string
+ obo:IAO_0000115 "A nuclear ubiquitin ligase complex that specifically targets SUMOylated proteins; the complex is formed of homodimers or heterodimers of RNF4 family ubiquitin ligases and is conserved in eukaryotes."^^xsd:string,
+ rdfs:label "SUMO-targeted ubiquitin ligase complex"^^xsd:string,
+ oboInOwl:id "GO:0033768"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000152
+
+
+Class: obo:GO_0035657
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:17008308"^^xsd:string
+ oboInOwl:hasExactSynonym "eRF1 MTase complex"^^xsd:string,
+ oboInOwl:id "GO:0035657"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17008308"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20400505"^^xsd:string
+ obo:IAO_0000115 "A protein complex required for the methylation of a glutamine (Gln) residue in the protein release factor eRF1. In S. cerevisiae, this complex consists of at least Trm112p and Mtq2p."^^xsd:string,
+ rdfs:label "eRF1 methyltransferase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0034708
+
+
+Class: obo:GO_0070467
+
+ Annotations:
+ rdfs:label "RC-1 DNA recombination complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:364"^^xsd:string
+ oboInOwl:hasExactSynonym "RC-1 complex (recombination complex 1)"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8392064"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8670910"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains DNA ligase III, DNA polymerase epsilon, a 5'-3' exonuclease, and the SMC1 and SMC2 proteins, and is involved in recombinational repair of deletions and gaps in DNA."^^xsd:string,
+ oboInOwl:id "GO:0070467"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "DNA recombination complex RC-1"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070465
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2434"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA1-ITGB1-COL6A3 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8387021"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha1-beta1 integrin complex bound to a type VI collagen triple helix containing an alpha3(VI) chain."^^xsd:string,
+ rdfs:label "alpha1-beta1 integrin-alpha3(VI) complex"^^xsd:string,
+ oboInOwl:id "GO:0070465"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0033774
+
+ Annotations:
+ oboInOwl:id "GO:0033774"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:sart"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11640882"^^xsd:string
+ obo:IAO_0000115 "A region in the lower half of some cells formed from extensive infoldings of the basal plasma membrane; includes cytoplasm adjacent to the infolded membrane."^^xsd:string,
+ rdfs:label "basal labyrinth"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0045178,
+ obo:GO_0044464
+
+
+Class: obo:GO_0070466
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "alpha2-beta1 integrin-alpha3(VI) complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8387021"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alpha2-beta1 integrin complex bound to a type VI collagen triple helix containing an alpha3(VI) chain."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2431"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA2-ITGB1-COL6A3 complex"^^xsd:string,
+ oboInOwl:id "GO:0070466"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070464
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070464"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8387021"^^xsd:string
+ obo:IAO_0000115 "A protein complex that consists of an alphav-beta3 integrin complex bound to the alpha3 chain of type VI collagen; the integrin binds most strongly to unfolded collagen."^^xsd:string,
+ rdfs:label "alphav-beta3 integrin-collagen alpha3(VI) complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0070461
+
+ Annotations:
+ rdfs:label "SAGA-type complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:17337012"^^xsd:string
+ oboInOwl:hasExactSynonym "SAGA family complex"^^xsd:string,
+ oboInOwl:id "GO:0070461"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10637607"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17337012"^^xsd:string
+ obo:IAO_0000115 "A histone acetyltransferase complex that acetylates nucleosomal H3 and H2B and is required for the expression of a subset of Pol II-transcribed genes. The budding yeast complex includes the acetyltransferase Gcn5p, several proteins of the Spt and Ada families, and several TBP-associate proteins (TAFs); analogous complexes in other species have analogous compositions, and usually contain homologs of the yeast proteins."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000123
+
+
+Class: obo:GO_0033553
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0033553"^^xsd:string,
+ rdfs:label "rDNA heterochromatin"^^xsd:string,
+ oboInOwl:hasExactSynonym "ribosomal DNA heterochromatin"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A region of heterochromatin located at the rDNA repeats in a chromosome."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000792
+
+
+Class: obo:GO_0016600
+
+ Annotations:
+ oboInOwl:id "GO:0016600"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:17206938"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17600709"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains flotillin-1 and flotillin-2, and may contain associated proteins. Flotillins associate into membrane microdomains resembling caveolae."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "flotillin complex"^^xsd:string,
+ rdfs:comment "See also the cellular component term 'caveola ; GO:0005901'."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:BFO_0000050 some obo:GO_0005901,
+ obo:GO_0043234
+
+
+Class: obo:GO_0001518
+
+ Annotations:
+ oboInOwl:hasExactSynonym "voltage-sensitive sodium channel complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "voltage gated sodium channel complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "voltage-gated sodium channel complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "voltage-dependent sodium channel complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "A sodium channel in a cell membrane whose opening is governed by the membrane potential."^^xsd:string,
+ oboInOwl:id "GO:0001518"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao785001660"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005887,
+ obo:GO_0044459,
+ obo:GO_0034706
+
+
+Class: obo:GO_0016602
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:7828851"^^xsd:string
+ obo:IAO_0000115 "A heteromeric transcription factor complex that binds to the CCAAT-box upstream of promoters; in Saccharomyces it activates the transcription of genes in response to growth in a nonfermentable carbon source; consists of four known subunits: HAP2, HAP3, HAP4 and HAP5."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0016602"^^xsd:string,
+ rdfs:label "CCAAT-binding factor complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005667
+
+
+Class: obo:GO_0070469
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:ecd"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198547684"^^xsd:string
+ obo:IAO_0000115 "The protein complexes that form the electron transport system (the respiratory chain), associated with a cell membrane, usually the plasma membrane (in prokaryotes) or the inner mitochondrial membrane (on eukaryotes). The respiratory chain complexes transfer electrons from an electron donor to an electron acceptor and are associated with a proton pump to create a transmembrane electrochemical gradient."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "membrane electron transport chain"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070469"^^xsd:string,
+ rdfs:label "respiratory chain"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425
+
+
+Class: obo:GO_0033551
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17627824"^^xsd:string
+ obo:IAO_0000115 "A protein complex required for clamping microtubule binding sites, ensuring orientation of sister kinetochores to the same pole (mono-orientation) during meiosis I. In the yeast S. cerevisiae this complex consists of Csm1p, Lrs4p, Hrr25p and Mam1p; in S. pombe Psc1 and Mde4 have been identified as subunits."^^xsd:string,
+ oboInOwl:id "GO:0033551"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "monopolin complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "monopolin subcomplex Csm1/Lrs4"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Pcs1/Mde4 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:BFO_0000050 some obo:GO_0000777,
+ obo:GO_0043234
+
+
+Class: obo:GO_0016604
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0016604"^^xsd:string,
+ rdfs:label "nuclear body"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ma"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10330182"^^xsd:string
+ obo:IAO_0000115 "Extra-nucleolar nuclear domains usually visualized by confocal microscopy and fluorescent antibodies to specific proteins."^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao505137457"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044451
+
+
+Class: obo:GO_0015050
+
+ Annotations:
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "BRENDA:1.14.13.25"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses methane monooxygenase activity; dimeric and trimeric complexes have been characterized."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "methane monooxygenase complex"^^xsd:string,
+ oboInOwl:id "GO:0015050"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464,
+ obo:GO_0043234
+
+
+Class: obo:GO_0032590
+
+ Annotations:
+ rdfs:label "dendrite membrane"^^xsd:string,
+ oboInOwl:id "GO:0032590"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The portion of the plasma membrane surrounding a dendrite."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032589
+
+
+Class: obo:GO_0016607
+
+ Annotations:
+ oboInOwl:hasNarrowSynonym "speckle domain"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "http://www.cellnucleus.com/"^^xsd:string
+ obo:IAO_0000115 "A discrete extra-nucleolar subnuclear domain, 20-50 in number, in which splicing factors are seen to be localized by immunofluorescence microscopy."^^xsd:string,
+ oboInOwl:hasExactSynonym "nuclear speckles"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "speckle focus"^^xsd:string,
+ rdfs:label "nuclear speck"^^xsd:string,
+ oboInOwl:hasExactSynonym "splicing speckle"^^xsd:string,
+ oboInOwl:id "GO:0016607"^^xsd:string,
+ oboInOwl:hasExactSynonym "nuclear speckle"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016604
+
+
+Class: obo:GO_0016606
+
+ Annotations:
+ rdfs:label "LYSP100-associated nuclear domain"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10921892"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:8695863"^^xsd:string
+ obo:IAO_0000115 "A nuclear body that is enriched in the lymphoid cell-specific protein LYSp100B; LANDs are globular, electron-dense structures and are morphologically distinct from the annular structures characteristic of PML bodies."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8695863"^^xsd:string
+ oboInOwl:hasExactSynonym "LANDs"^^xsd:string,
+ oboInOwl:id "GO:0016606"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016604
+
+
+Class: obo:GO_0016605
+
+ Annotations:
+ oboInOwl:hasExactSynonym "ND10"^^xsd:string,
+ rdfs:label "PML body"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "nuclear dot"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ma"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10944585"^^xsd:string
+ obo:IAO_0000115 "A class of nuclear body; they react against SP100 auto-antibodies (PML, promyelocytic leukemia); cells typically contain 10-30 PML bodies per nucleus; alterations in the localization of PML bodies occurs after viral infection."^^xsd:string,
+ oboInOwl:hasExactSynonym "PML nuclear body"^^xsd:string,
+ oboInOwl:id "GO:0016605"^^xsd:string,
+ oboInOwl:hasExactSynonym "PML NB"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016604
+
+
+Class: obo:GO_0032593
+
+ Annotations:
+ oboInOwl:hasRelatedSynonym "IRC"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "GSC"^^xsd:string,
+ rdfs:label "insulin-responsive compartment"^^xsd:string,
+ oboInOwl:hasExactSynonym "GLUT4 storage compartment"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:17644329"^^xsd:string
+ obo:IAO_0000115 "A small membrane-bounded vesicle that releases its contents by exocytosis in response to insulin stimulation; the contents are enriched in GLUT4, IRAP and VAMP2."^^xsd:string,
+ oboInOwl:id "GO:0032593"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030141
+
+
+Class: obo:GO_0010009
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "external side of endosome membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:lr"^^xsd:string
+ obo:IAO_0000115 "The external (cytoplasmic face) of an endosome membrane."^^xsd:string,
+ oboInOwl:id "GO:0010009"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0010008,
+ obo:GO_0044440
+
+
+Class: obo:GO_0032591
+
+ Annotations:
+ rdfs:label "dendritic spine membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The portion of the plasma membrane surrounding a dendritic spine."^^xsd:string,
+ oboInOwl:id "GO:0032591"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032589,
+ obo:BFO_0000050 some obo:GO_0043197
+
+
+Class: obo:GO_0032592
+
+ Annotations:
+ rdfs:label "integral to mitochondrial membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Located such that some or all of the gene product itself penetrates at least one phospholipid bilayer of a mitochondrial membrane. May also refer to the state of being buried in the bilayer with no exposure outside the bilayer."^^xsd:string,
+ oboInOwl:id "GO:0032592"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044455,
+ obo:GO_0031301
+
+
+Class: obo:GO_0000446
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11060033"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11979277"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16983072"^^xsd:string
+ obo:IAO_0000115 "The THO complex when it is acting as a nuclear complex that is required for transcription elongation through genes containing tandemly repeated DNA sequences. In S. cerevisiae, it is composed of four subunits: Hpr1, Tho2, Thp1, and Mft1, while the human complex is composed of 7 subunits."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000446"^^xsd:string,
+ rdfs:label "nucleoplasmic THO complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000347,
+ obo:GO_0008023
+
+
+Class: obo:GO_0010005
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0943088399"^^xsd:string
+ obo:IAO_0000115 "Arrays of microtubules underlying and connected to the plasma membrane, in the cortical cytosol, oriented mainly with their axes transverse to the long axis of the cell (and root in plants). In plants it influences the direction of cellulose microfibril deposition."^^xsd:string,
+ rdfs:label "cortical microtubule, transverse to long axis"^^xsd:string,
+ oboInOwl:id "GO:0010005"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0055028
+
+
+Class: obo:GO_0010006
+
+ Annotations:
+ rdfs:label "Toc complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:10646606"^^xsd:string
+ obo:IAO_0000115 "Protein translocon complex at the chloroplast outer membrane."^^xsd:string,
+ oboInOwl:id "GO:0010006"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009707,
+ obo:GO_0044425,
+ obo:GO_0044434,
+ obo:GO_0043234
+
+
+Class: obo:GO_0042272
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "NXF1-NXT1 complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "Mex67-Mtr2 complex"^^xsd:string,
+ rdfs:label "nuclear RNA export factor complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11780633"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains two proteins (know in several organisms, including Drosophila, as NXF1 and NXF2) and is required for the export of the majority of mRNAs from the nucleus to the cytoplasm; localized in the nucleoplasm and at both the nucleoplasmic and cytoplasmic faces of the nuclear pore complex; shuttles between the nucleus and the cytoplasm."^^xsd:string,
+ oboInOwl:hasExactSynonym "TAP-p15 complex"^^xsd:string,
+ oboInOwl:id "GO:0042272"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044451,
+ obo:GO_0043234
+
+
+Class: obo:GO_0010007
+
+ Annotations:
+ rdfs:label "magnesium chelatase complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11842180"^^xsd:string
+ obo:IAO_0000115 "A heterotrimeric enzyme complex composed of three subunits, all of which are required for enzyme activity, which catalyzes the chelation of Mg by proto IX in an ATP-dependent manner."^^xsd:string,
+ oboInOwl:id "GO:0010007"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044434,
+ obo:GO_0043234
+
+
+Class: obo:GO_0010008
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "endosome membrane"^^xsd:string,
+ oboInOwl:id "GO:0010008"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding an endosome."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031090,
+ obo:GO_0044440
+
+
+Class: obo:GO_0070450
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasExactSynonym "IL4-IL4 receptor complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1515"^^xsd:string
+ oboInOwl:hasNarrowSynonym "IL4-IL4R-IL2RG complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0070450"^^xsd:string,
+ rdfs:label "interleukin4-interleukin-4 receptor complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:10358772"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is formed by the association of a heterodimeric interleukin-4 receptor complex with an interleukin-4 molecule."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044459,
+ obo:GO_0043234
+
+
+Class: obo:GO_0035693
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "NOS2-CD74 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18003616"^^xsd:string
+ obo:IAO_0000115 "A protein complex comprising nitric oxide synthase 2 and CD74. This stable complex formation is thought to prevent CD74 degradation by caspases."^^xsd:string,
+ oboInOwl:id "GO:0035693"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0070451
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasNarrowSynonym "imaginal disc-derived wing hair"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0070451"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:11526084"^^xsd:string
+ obo:IAO_0000115 "A long, thin cell projection that contains F-actin and tubulin, with microtubules centrally located and F-actin peripherally located."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Membrane_nanotube"^^xsd:string,
+ rdfs:label "cell hair"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string
+ oboInOwl:hasExactSynonym "non-sensory hair"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042995
+
+
+Class: obo:GO_0032589
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The portion of the plasma membrane surrounding a neuron projection."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "neuron projection membrane"^^xsd:string,
+ oboInOwl:id "GO:0032589"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0043005,
+ obo:GO_0031256,
+ obo:GO_0031253
+
+
+Class: obo:GO_0032588
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "Golgi trans face membrane"^^xsd:string,
+ oboInOwl:id "GO:0032588"^^xsd:string,
+ oboInOwl:hasExactSynonym "trans Golgi network membrane"^^xsd:string,
+ rdfs:label "trans-Golgi network membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding any of the compartments that make up the trans-Golgi network."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005802,
+ obo:GO_0000139
+
+
+Class: obo:GO_0045180
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string
+ obo:IAO_0000115 "The region that lies just beneath the plasma membrane on the basal edge of a cell."^^xsd:string,
+ oboInOwl:id "GO:0045180"^^xsd:string,
+ rdfs:label "basal cortex"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0044448
+ and (obo:BFO_0000050 some obo:GO_0045178)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0045178,
+ obo:GO_0044448
+
+
+Class: obo:GO_0016612
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "EC:1.18.6.1"^^xsd:string
+ obo:IAO_0000115 "An enzyme complex containing a molybdenum-iron cluster found in many species. It is composed of two proteins, dinitrogenase and nitrogenase reductase; dinitrogenase, the molybdenum-iron protein, is tetrameric with an alpha2-beta2 structure, and nitrogenase reductase is a homodimer."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0016612"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "molybdenum-iron nitrogenase activity"^^xsd:string,
+ rdfs:label "molybdenum-iron nitrogenase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016610
+
+
+Class: obo:GO_0016613
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0016613"^^xsd:string,
+ rdfs:label "vanadium-iron nitrogenase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "EC:1.18.6.1"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:3474027"^^xsd:string
+ obo:IAO_0000115 "An enzyme complex containing a vanadium-iron cluster found in some species, such as Azotobacter vinelandii. It is composed of two proteins, dinitrogenase and nitrogenase reductase; dinitrogenase, the vanadium-iron protein, is tetrameric with an alpha2-beta2 structure, and nitrogenase reductase is a homodimer."^^xsd:string,
+ oboInOwl:hasRelatedSynonym "vanadium-iron nitrogenase activity"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016610
+
+
+Class: obo:GO_0016610
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0016610"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "EC:1.18.6.1"^^xsd:string,
+ oboInOwl:hasDbXref "MetaCyc:CPLX-186"^^xsd:string,
+ oboInOwl:hasDbXref "MetaCyc:CPLX-525"^^xsd:string
+ obo:IAO_0000115 "An enzyme complex composed of two proteins, dinitrogenase and nitrogenase reductase; dinitrogenase is tetrameric with an alpha2-beta2 structure and nitrogenase reductase is a homodimer, and both are associated with metal ions, which differ between species. Both proteins are required for the enzyme activity of the complex, the formation of oxidized ferredoxin and ammonia from reduced ferredoxin and nitrogen."^^xsd:string,
+ rdfs:label "nitrogenase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044424,
+ obo:GO_0043234
+
+
+Class: obo:GO_0016611
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "iron-iron nitrogenase complex"^^xsd:string,
+ oboInOwl:id "GO:0016611"^^xsd:string,
+ rdfs:comment "Note that it is not established whether the nitrogenase exists in vivo in a specific particle or whether the nitrogenase proteins are bound nonspecifically to the membranes of some cells."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "EC:1.18.6.1"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:jl"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11848850"^^xsd:string
+ obo:IAO_0000115 "An enzyme complex containing an iron-iron cluster found in species such as the photosynthetic bacterium Rhodobacter capsulatus. It is composed of two main subunits, dinitrogenase and nitrogenase reductase. Dinitrogenase, the iron-iron containing subunit, has an alpha1-beta2 or alpha2-beta2 structure, and the nitrogenase reductase subunit is a homodimer. Functions in the catalysis of the formation of oxidized ferredoxin and ammonia from reduced ferredoxin and nitrogen."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016610
+
+
+Class: obo:GO_0035692
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12782713"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17045821"^^xsd:string
+ obo:IAO_0000115 "A protein complex that binds macrophage migration inhibitory factor. Comprises CD74 and CD44 cell surface proteins."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0035692"^^xsd:string,
+ rdfs:label "macrophage migration inhibitory factor receptor complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043235
+
+
+Class: obo:GO_0070441
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "G-protein beta/gamma-Btk complex"^^xsd:string,
+ oboInOwl:id "GO:0070441"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:3195"^^xsd:string
+ oboInOwl:hasRelatedSynonym "G protein complex (Btk, Gng2, Gnb1)"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7972043"^^xsd:string
+ obo:IAO_0000115 "A protein complex formed by the association of the Bruton tyrosine protein kinase Btk, which is implicated in mammalian X-linked immunodeficiencies, with the beta and gamma subunits of a heterotrimeric G protein."^^xsd:string,
+ rdfs:comment "See also the cellular component term 'heterotrimeric G-protein complex ; GO:0005834'."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:1615"^^xsd:string
+ oboInOwl:hasRelatedSynonym "G protein complex (BTK, GNG1, GNG2)"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234,
+ obo:GO_0044444
+
+
+Class: obo:GO_0072588
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasRelatedSynonym "box H/ACA snoRNP pseudouridylase complex"^^xsd:string,
+ oboInOwl:id "GO:0072588"^^xsd:string,
+ rdfs:label "box H/ACA RNP complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17284456"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20227365"^^xsd:string
+ oboInOwl:hasNarrowSynonym "sRNP complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17284456"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20227365"^^xsd:string
+ obo:IAO_0000115 "A ribonucleoprotein complex that contains an RNA of the box H/ACA type, a subtype of the small nucleolar RNA (snoRNA) family. RNA pseudouridylation (isomerization of uridine to pseudouridine) is the major, and most likely the ancestral, function of H/ACA RNPs, although some have evolved other functions. Pseudouridylation targets include both large and small ribosomal RNAs (rRNAs), and on U2 small nuclear RNA (U2 snRNA)."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005732
+
+
+Class: obo:GO_0072589
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "box H/ACA scaRNP complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:vw"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20227365"^^xsd:string
+ oboInOwl:hasExactSynonym "nucleoplasmic box H/ACA RNP pseudouridylase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17284456"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20227365"^^xsd:string
+ obo:IAO_0000115 "A box H/ACA RNP complex that is located in the Cajal body of the nucleoplasm. In higher eukaryotes, box H/ACA RNP located in Cajal bodies mediate pseudouridylation of spliceosomal snRNAs."^^xsd:string,
+ oboInOwl:id "GO:0072589"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0072588,
+ obo:GO_0044451,
+ obo:BFO_0000050 some obo:GO_0015030
+
+
+Class: obo:GO_0070442
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070442"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12297042"^^xsd:string
+ obo:IAO_0000115 "An integrin complex that comprises one alphaIIb subunit and one beta3 subunit."^^xsd:string,
+ rdfs:label "alphaIIb-beta3 integrin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:2381"^^xsd:string
+ oboInOwl:hasNarrowSynonym "ITGA2B-ITGB3 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008305
+
+
+Class: obo:GO_0070440
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0070440"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:7889570"^^xsd:string
+ obo:IAO_0000115 "A transcriptional repressor complex that contains a heterodimer of the bHLH-ZIP proteins Mad and Max, plus mSin3B, a homolog of the yeast Sin3p."^^xsd:string,
+ rdfs:label "Mad-Max-mSin3B complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0017053
+
+
+Class: obo:GO_0070443
+
+ Annotations:
+ oboInOwl:id "GO:0070443"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "Mad-Max complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8224841"^^xsd:string
+ obo:IAO_0000115 "A transcriptional repressor complex that consists of a heterodimer of the bHLH-ZIP proteins Mad and Max."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0017053
+
+
+Class: obo:GO_0035686
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string
+ oboInOwl:hasExactSynonym "flagellum fibrous sheath"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20731842"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:3282552"^^xsd:string
+ obo:IAO_0000115 "A cytoskeletal structure surrounding the axoneme and outer dense fibers of the sperm flagellum. Consists of two longitudinal columns connected by closely arrayed semicircular ribs that assemble from distal to proximal throughout spermiogenesis. The fibrous sheath probably influences the degree of flexibility, plane of flagellar motion, and the shape of the flagellar beat."^^xsd:string,
+ rdfs:label "flagellar fibrous sheath"^^xsd:string,
+ oboInOwl:id "GO:0035686"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044442
+
+
+Class: obo:GO_0070449
+
+ Annotations:
+ rdfs:label "elongin complex"^^xsd:string,
+ rdfs:comment "See also the cellular component terms 'cyclin-dependent protein kinase activating kinase holoenzyme complex ; GO:0019907' and 'DNA-directed RNA polymerase II, holoenzyme ; GO:0016591'."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12676794"^^xsd:string
+ obo:IAO_0000115 "A transcription elongation factor complex that suppresses RNA polymerase II pausing, and may act by promoting proper alignment of the 3'-end of nascent transcripts with the polymerase catalytic site. Consists of a transcriptionally active Elongin A subunit (abut 100 kDa)and two smaller Elongin B (about 18 kDa) and Elongin C (about 15 kDa)subunits."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:8244996"^^xsd:string
+ oboInOwl:hasExactSynonym "transcription elongation factor SIII complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "CORUM:56"^^xsd:string
+ oboInOwl:hasExactSynonym "elongin (SIII) complex"^^xsd:string,
+ oboInOwl:id "GO:0070449"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0008023
+
+
+Class: obo:GO_0000427
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "plastid-encoded plastid RNA polymerase complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:pj"^^xsd:string
+ obo:IAO_0000115 "An RNA polymerase complex containing polypeptides encoded by the plastid genome. Plastid-encoded DNA-directed RNA polymerases resemble eubacterial multisubunit RNA polymerases, with a core composed of alpha, beta, and beta-prime subunits. Some forms contain multiple additional subunits. An additional sigma factor subunit is required for promoter recognition."^^xsd:string,
+ oboInOwl:id "GO:0000427"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000428
+ and (obo:BFO_0000050 some obo:GO_0009536)
+
+ SubClassOf:
+ obo:GO_0044435,
+ obo:GO_0000428
+
+
+Class: obo:GO_0000428
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string
+ obo:IAO_0000115 "A protein complex that possesses DNA-directed RNA polymerase activity."^^xsd:string,
+ oboInOwl:id "GO:0000428"^^xsd:string,
+ rdfs:label "DNA-directed RNA polymerase complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0030880
+
+
+Class: obo:GO_0046610
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "lysosomal proton-transporting V-type ATPase, V0 domain"^^xsd:string,
+ oboInOwl:hasExactSynonym "lysosomal hydrogen ion-transporting ATPase V0 domain"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The V0 domain of a proton-transporting V-type ATPase found in the lysosomal membrane."^^xsd:string,
+ oboInOwl:id "GO:0046610"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0033179
+ and (obo:BFO_0000050 some obo:GO_0005764)
+
+ SubClassOf:
+ obo:GO_0000220,
+ obo:BFO_0000050 some obo:GO_0046611
+
+
+Class: obo:GO_0005786
+
+ Annotations:
+ oboInOwl:hasExactSynonym "signal sequence receptor complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "A ribonucleoprotein particle of 325 kDa composed of a 7S (300 nucleotide) RNA molecule and a complex of six different polypeptides. This binds both to the N-terminal signal peptide for proteins destined for the endoplasmic reticulum as they emerge from the large ribosomal subunit and also to the ribosome. This binding arrests further translation thereby preventing the proteins from being released into the cytosol. The SRP-ribosome complex then diffuses to the endoplasmic reticulum where it is bound to the signal recognition particle receptor, which allows resumption of protein synthesis and facilitates the passage of the growing polypeptide chain through the translocon. Through a process involving GTP hydrolysis, the SRP-SRP receptor complex dissociates and SRP returns to the cytosol. Of the six polypeptides of SRP the 54 kDa subunit (SRP54) is the central player. It contains an N-terminal GTPase domain and a C-terminal domain that binds directly to the signal peptide and the SRP RNA. Examples of this component are found in Mus musculus, Saccharomyces cerevisiae and Arabidopsis thaliana."^^xsd:string,
+ oboInOwl:hasExactSynonym "SRP"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0005855"^^xsd:string,
+ rdfs:label "signal recognition particle, endoplasmic reticulum targeting"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Signal_recognition_particle"^^xsd:string,
+ oboInOwl:id "GO:0005786"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0048500
+
+
+Class: obo:GO_0005787
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:sgd_curators"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:1846444"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7615509"^^xsd:string
+ obo:IAO_0000115 "A protein complex that is located in the endoplasmic reticulum membrane and cleaves the signal sequence from precursor proteins following their transport out of the cytoplasmic space."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005787"^^xsd:string,
+ rdfs:label "signal peptidase complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005789,
+ obo:GO_0044425,
+ obo:GO_0044432,
+ obo:GO_0043234
+
+
+Class: obo:GO_0046612
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The V1 domain of a proton-transporting V-type ATPase found in the lysosomal membrane."^^xsd:string,
+ rdfs:label "lysosomal proton-transporting V-type ATPase, V1 domain"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "lysosomal hydrogen ion-transporting ATPase V1 domain"^^xsd:string,
+ oboInOwl:id "GO:0046612"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0033180
+ and (obo:BFO_0000050 some obo:GO_0005764)
+
+ SubClassOf:
+ obo:GO_0000221,
+ obo:BFO_0000050 some obo:GO_0046611
+
+
+Class: obo:GO_0005784
+
+ Annotations:
+ rdfs:label "Sec61 translocon complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ oboInOwl:hasNarrowSynonym "Sec61p-Sbh1p-Sss1p complex"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:id "GO:0005784"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:18166647"^^xsd:string
+ obo:IAO_0000115 "A translocon complex that contains a core heterotrimer of conserved alpha, beta and gamma subunits, and may contain additional proteins (translocon-associated proteins or TRAPs); in budding yeast the core proteins are Sec61p, Sbh1p, and Sss1p. The Sec61 translocon complex functions in cotranslational and posttranslational translocation events."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0071256
+
+
+Class: obo:GO_0000800
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:ascb_2009"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:dph"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:tb"^^xsd:string
+ oboInOwl:hasExactSynonym "axial element"^^xsd:string,
+ rdfs:label "lateral element"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A proteinaceous core found between sister chromatids during meiotic prophase."^^xsd:string,
+ oboInOwl:id "GO:0000800"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:BFO_0000050 some obo:GO_0000795
+
+
+Class: obo:GO_0046611
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0716743663"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16449553"^^xsd:string
+ obo:IAO_0000115 "A proton-transporting two-sector ATPase complex found in the lysosomal membrane, where it acts as a proton pump to mediate acidification of the lysosomal lumen."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "lysosomal hydrogen-translocating V-type ATPase complex"^^xsd:string,
+ oboInOwl:id "GO:0046611"^^xsd:string,
+ oboInOwl:hasBroadSynonym "lysosomal membrane hydrogen-transporting ATPase"^^xsd:string,
+ rdfs:label "lysosomal proton-transporting V-type ATPase complex"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0033176
+ and (obo:BFO_0000050 some obo:GO_0005764)
+
+ SubClassOf:
+ obo:GO_0016471,
+ obo:BFO_0000050 some obo:GO_0005765
+
+
+Class: obo:GO_0005785
+
+ Annotations:
+ rdfs:label "signal recognition particle receptor complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "docking protein complex"^^xsd:string,
+ oboInOwl:id "GO:0005785"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "A transmembrane heterodimeric protein located in the membrane of the rough endoplasmic reticulum. Both subunits contain GTPase domains with which signal recognition particle interacts. In the presence of GTP and SRP receptor, SRP is released from the ribosome-nascent chain complex."^^xsd:string,
+ oboInOwl:hasExactSynonym "SR complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0030867,
+ obo:GO_0043235,
+ obo:GO_0044432
+
+
+Class: obo:GO_0000801
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A structural unit of the synaptonemal complex found between the lateral elements."^^xsd:string,
+ oboInOwl:id "GO:0000801"^^xsd:string,
+ rdfs:label "central element"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:BFO_0000050 some obo:GO_0000795
+
+
+Class: obo:GO_0000802
+
+ Annotations:
+ rdfs:label "transverse filament"^^xsd:string,
+ oboInOwl:id "GO:0000802"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A structural unit of the synaptonemal complex that spans the regions between the lateral elements and connects them."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:BFO_0000050 some obo:GO_0000795
+
+
+Class: obo:GO_0045169
+
+ Annotations:
+ rdfs:label "fusome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12655376"^^xsd:string
+ obo:IAO_0000115 "A large intracellular spectrin-rich structure that has been found in insect germline cells and mammalian hematopoietic cells. The fusome is an elongated, branched structure, formed from the spherical spectrosome organelle."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0045169"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044444
+
+
+Class: obo:GO_0000803
+
+ Annotations:
+ oboInOwl:id "GO:0000803"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A chromosome involved in sex determination."^^xsd:string,
+ rdfs:label "sex chromosome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005694
+
+
+Class: obo:GO_0005788
+
+ Annotations:
+ oboInOwl:hasExactSynonym "cisternal lumen"^^xsd:string,
+ oboInOwl:hasExactSynonym "ER lumen"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "ER cisterna"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198547684"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membranes of the endoplasmic reticulum."^^xsd:string,
+ rdfs:label "endoplasmic reticulum lumen"^^xsd:string,
+ oboInOwl:hasExactSynonym "endoplasmic reticulum cisterna"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0016022"^^xsd:string,
+ oboInOwl:id "GO:0005788"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070013,
+ obo:GO_0044432
+
+
+Class: obo:GO_0000804
+
+ Annotations:
+ oboInOwl:id "GO:0000804"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0321000382"^^xsd:string
+ obo:IAO_0000115 "The sex chromosome present in females of species in which the female is the heterogametic sex; generally, the sex chromosome that pairs with the Z chromosome in the heterogametic sex. The W chromosome is absent from the cells of males and present in one copy in the somatic cells of females."^^xsd:string,
+ rdfs:label "W chromosome"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:ZW_sex-determination_system"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000803
+
+
+Class: obo:GO_0005789
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "endoplasmic reticulum membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The lipid bilayer surrounding the endoplasmic reticulum."^^xsd:string,
+ oboInOwl:hasExactSynonym "ER membrane"^^xsd:string,
+ oboInOwl:id "GO:0005789"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:GO_0031090,
+ obo:BFO_0000050 some obo:GO_0042175,
+ obo:GO_0044432
+
+
+Class: obo:GO_0000805
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000805"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:X_chromosome"^^xsd:string,
+ rdfs:label "X chromosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0582227089"^^xsd:string
+ obo:IAO_0000115 "The sex chromosome present in both sexes of species in which the male is the heterogametic sex. Two copies of the X chromosome are present in each somatic cell of females and one copy is present in males."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000803
+
+
+Class: obo:GO_0035632
+
+ Annotations:
+ rdfs:label "mitochondrial prohibitin complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:kmv"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12237468"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:21164222"^^xsd:string
+ obo:IAO_0000115 "A complex composed of two proteins, prohibitin 1 and prohibitin 2 (PHB1/PHB-1 and PHB2/PHB-2) that is highly conserved amongst eukaryotes and associated with the inner mitochondrial membrane. The mitochondrial prohibitin complex is a macromolecular supercomplex composed of repeating heterodimeric subunits of PHB1 and PHB2. The mitochondrial prohibitin complex plays a role in a number of biological processes, including mitochondrial biogenesis and function, development, replicative senescence, and cell death."^^xsd:string,
+ oboInOwl:id "GO:0035632"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string
+ oboInOwl:hasExactSynonym "mitochondrial inner membrane prohibitin complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044455,
+ obo:BFO_0000050 some obo:GO_0005743,
+ obo:GO_0043234
+
+
+Class: obo:GO_0000806
+
+ Annotations:
+ rdfs:label "Y chromosome"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0582227089"^^xsd:string
+ obo:IAO_0000115 "The sex chromosome present in males of species in which the male is the heterogametic sex; generally, the sex chromosome that pairs with the X chromosome in the heterogametic sex. The Y chromosome is absent from the cells of females and present in one copy in the somatic cells of males."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Y_chromosome"^^xsd:string,
+ oboInOwl:id "GO:0000806"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000803
+
+
+Class: obo:GO_0035631
+
+ Annotations:
+ oboInOwl:id "GO:0035631"^^xsd:string,
+ rdfs:label "CD40 receptor complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:BHF"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:20614026"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9221764"^^xsd:string
+ obo:IAO_0000115 "A protein complex that contains at least CD40 (a cell surface receptor of the tumour necrosis factor receptor (TNFR) superfamily), and other signaling molecules."^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0005887,
+ obo:GO_0044459,
+ obo:GO_0043235
+
+
+Class: obo:GO_0000807
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0321000382"^^xsd:string
+ obo:IAO_0000115 "The sex chromosome present in both sexes of species in which the female is the heterogametic sex. Two copies of the Z chromosome are present in each somatic cell of males and one copy is present in females."^^xsd:string,
+ rdfs:label "Z chromosome"^^xsd:string,
+ oboInOwl:id "GO:0000807"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:ZW_sex-determination_system"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0000803
+
+
+Class: obo:GO_0000808
+
+ Annotations:
+ oboInOwl:hasExactSynonym "ORC"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:hasExactSynonym "origin of replication recognition complex"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Origin_recognition_complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A multisubunit complex that is located at the replication origins of a chromosome."^^xsd:string,
+ rdfs:label "origin recognition complex"^^xsd:string,
+ oboInOwl:id "GO:0000808"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:GO_0043234
+
+
+Class: obo:GO_0000809
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasExactSynonym "cytoplasmic ORC"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "prokaryotic ORC"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:elh"^^xsd:string
+ obo:IAO_0000115 "A multisubunit complex that is located at the replication origins of a chromosome in the cytoplasm."^^xsd:string,
+ oboInOwl:id "GO:0000809"^^xsd:string,
+ rdfs:label "cytoplasmic origin of replication recognition complex"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000808
+ and (obo:BFO_0000050 some obo:GO_0005737)
+
+ SubClassOf:
+ obo:GO_0000808,
+ obo:GO_0044444,
+ obo:BFO_0000050 some obo:GO_0000229
+
+
+Class: obo:GO_0045160
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9438839"^^xsd:string,
+ oboInOwl:hasDbXref "http://www.mrc-lmb.cam.ac.uk/myosin/Review/Reviewframeset.html"^^xsd:string
+ obo:IAO_0000115 "A myosin complex containing a class I myosin heavy chain and associated light chains; myosin I heavy chains are single-headed, possess tails of various lengths, and do not self-associate into bipolar filaments; myosin I complexes are involved in diverse processes related to membrane traffic and cell movement."^^xsd:string,
+ rdfs:label "myosin I complex"^^xsd:string,
+ oboInOwl:id "GO:0045160"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016461
+
+
+Class: obo:GO_0005782
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005782"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0031909"^^xsd:string,
+ rdfs:label "peroxisomal matrix"^^xsd:string,
+ oboInOwl:hasExactSynonym "peroxisomal lumen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:curators"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "The volume contained within the membranes of a peroxisome; in many cells the matrix contains a crystalloid core largely composed of urate oxidase."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044439,
+ obo:GO_0031907
+
+
+Class: obo:GO_0005783
+
+ Annotations:
+ rdfs:label "endoplasmic reticulum"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "The irregular network of unit membranes, visible only by electron microscopy, that occurs in the cytoplasm of many eukaryotic cells. The membranes form a complex meshwork of tubular channels, which are often expanded into slitlike cavities called cisternae. The ER takes two forms, rough (or granular), with ribosomes adhering to the outer surface, and smooth (with no ribosomes attached)."^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Endoplasmic_reticulum"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005783"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ oboInOwl:hasExactSynonym "ER"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1036339110"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043231,
+ obo:GO_0044444
+
+
+Class: obo:GO_0005780
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005780"^^xsd:string,
+ rdfs:label "extrinsic to intraperoxisomal membrane"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "intra-peroxisomal peripheral membrane"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Loosely bound to the intraperoxisomal surface of the peroxisomal membrane, but not integrated into the hydrophobic region."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031312,
+ obo:GO_0044439,
+ obo:BFO_0000050 some obo:GO_0005778
+
+
+Class: obo:GO_0035619
+
+ Annotations:
+ oboInOwl:hasExactSynonym "root hair cell tip"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0035619"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PO:0000029"^^xsd:string
+ obo:IAO_0000115 "The tip portion of an outgrowth of a root epidermal cell."^^xsd:string,
+ rdfs:label "root hair tip"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044463,
+ obo:BFO_0000050 some obo:GO_0035618
+
+
+Class: obo:GO_0000438
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14500720"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7813015"^^xsd:string
+ obo:IAO_0000115 "The core TFIIH complex when it is part of the general transcription factor TFIIH. In S. cerevisiae, it is composed of Rad3p, Tfb1p, Tfb2p, Ssl1p and Tfb4p. In humans, it is composed of ERCC2, p62, p55, p44, p34."^^xsd:string,
+ rdfs:label "core TFIIH complex portion of holo TFIIH complex"^^xsd:string,
+ oboInOwl:id "GO:0000438"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000439
+ and (obo:BFO_0000050 some obo:GO_0005675)
+
+ SubClassOf:
+ obo:GO_0044451,
+ obo:BFO_0000050 some obo:GO_0000443,
+ obo:GO_0000439
+
+
+Class: obo:GO_0035618
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PO:0000256"^^xsd:string,
+ oboInOwl:hasDbXref "http://www.jstor.org/stable/4354264"^^xsd:string
+ obo:IAO_0000115 "A long, thin projection from a root epidermal cell that contains F-actin and tubulin, and a cell wall."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0035618"^^xsd:string,
+ rdfs:label "root hair"^^xsd:string,
+ rdfs:comment "This term is a child of 'cell projection' and not 'cell hair' to distinguish it from animal cell hairs, which are morphologically distinct."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042995
+
+
+Class: obo:GO_0000439
+
+ Annotations:
+ rdfs:label "core TFIIH complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14500720"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7813015"^^xsd:string
+ obo:IAO_0000115 "The 5 subunit core of TFIIH that has tightly associated subunits and is found in both the general transcription factor holo-TFIIH and in the nucleotide-excision repair factor 3 complex. In S. cerevisiae, it is composed of Rad3, Tfb1, Tfb2, Ssl1, Tfb4. In humans, it is composed of XPD, p62, p55, p44, p34."^^xsd:string,
+ oboInOwl:id "GO:0000439"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0032806,
+ obo:BFO_0000050 some obo:GO_0000441
+
+
+Class: obo:GO_0033503
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "HULC complex"^^xsd:string,
+ oboInOwl:id "GO:0033503"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17363370"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17374714"^^xsd:string
+ obo:IAO_0000115 "A ubiquitin-conjugating enzyme complex that contains two RING finger proteins, which have ubiquitin ligase activity, in addition to a protein with ubiquitin-conjugating enzyme activity; catalyzes the ubiquitination of histone H2B at lysine 119 (or the equivalent residue). In Schizosaccharomyces the subunits are Rhp1, Brl2/Rfp1 and Brl1/Rfp2."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:GO_0031371,
+ obo:BFO_0000050 some obo:GO_0000792,
+ obo:GO_0000151
+
+
+Class: obo:GO_0045177
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0045177"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "apical part of cell"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "The region of a polarized cell that forms a tip or is distal to a base. For example, in a polarized epithelial cell, the apical region has an exposed surface and lies opposite to the basal lamina that separates the epithelium from other tissue."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0005795
+
+ Annotations:
+ oboInOwl:hasNarrowSynonym "dictyosome"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "Golgi cisternae"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "The set of thin, flattened membrane-bounded compartments, called cisternae, that form the central portion of the Golgi complex. The stack usually comprises cis, medial, and trans cisternae; the cis- and trans-Golgi networks are not considered part of the stack."^^xsd:string,
+ oboInOwl:id "GO:0005795"^^xsd:string,
+ oboInOwl:hasAlternativeId "GO:0016940"^^xsd:string,
+ rdfs:label "Golgi stack"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044431
+
+
+Class: obo:GO_0000811
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rn"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12730134"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16990792"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:17467990"^^xsd:string
+ obo:IAO_0000115 "A heterotetrameric protein complex that associates with replication origins, where it is required for the initiation of DNA replication, and with replication forks."^^xsd:string,
+ rdfs:label "GINS complex"^^xsd:string,
+ oboInOwl:hasExactSynonym "Go, Ichi, Ni and San complex"^^xsd:string,
+ oboInOwl:id "GO:0000811"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044454,
+ obo:GO_0043234
+
+
+Class: obo:GO_0045178
+
+ Annotations:
+ oboInOwl:id "GO:0045178"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:inSubset ,
+ rdfs:label "basal part of cell"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string,
+ oboInOwl:hasDbXref "ISBN:0185316194"^^xsd:string
+ obo:IAO_0000115 "The region of a cell situated near the base. For example, in a polarized epithelial cell, the basal surface rests on the basal lamina that separates the epithelium from other tissue."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044464
+
+
+Class: obo:GO_0005796
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005796"^^xsd:string,
+ rdfs:label "Golgi lumen"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "The volume enclosed by the membranes of any cisterna or subcompartment of the Golgi apparatus, including the cis- and trans-Golgi networks."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0070013,
+ obo:GO_0044431
+
+
+Class: obo:GO_0000812
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:14645854"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14690608"^^xsd:string
+ obo:IAO_0000115 "A multisubunit protein complex that is involved in chromatin remodeling. It is required for the incorporation of the histone variant H2AZ into chromatin. In S. cerevisiae, the complex contains Swr1p, a Swi2/Snf2-related ATPase, and 12 additional subunits."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "SWR-C"^^xsd:string,
+ rdfs:label "Swr1 complex"^^xsd:string,
+ oboInOwl:id "GO:0000812"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0000790,
+ obo:GO_0016585,
+ obo:GO_0044454
+
+
+Class: obo:GO_0005797
+
+ Annotations:
+ rdfs:label "Golgi medial cisterna"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005797"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0815316194"^^xsd:string
+ obo:IAO_0000115 "The middle Golgi cisterna (or cisternae)."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0031985
+
+
+Class: obo:GO_0005798
+
+ Annotations:
+ rdfs:comment "Note that this definition includes vesicles that are transiently associated with the Golgi."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasRelatedSynonym "Golgi vesicle"^^xsd:string,
+ rdfs:label "Golgi-associated vesicle"^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao819927218"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:mah"^^xsd:string
+ obo:IAO_0000115 "Any vesicle associated with the Golgi complex and involved in mediating transport within the Golgi or between the Golgi and other parts of the cell."^^xsd:string,
+ oboInOwl:id "GO:0005798"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0016023,
+ obo:GO_0044431
+
+
+Class: obo:GO_0000815
+
+ Annotations:
+ oboInOwl:hasBroadSynonym "Endosomal Sorting Complex Required for Transport"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "ESCRT III complex"^^xsd:string,
+ oboInOwl:id "GO:0000815"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12892785"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12900393"^^xsd:string
+ obo:IAO_0000115 "An endosomal sorting complex required for transport. Consists of two soluble subcomplexes of highly charged coiled-coil proteins and is required for sorting and/or concentration of multivesicular body (MVB) cargoes."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0010008,
+ obo:GO_0044440,
+ obo:GO_0043234
+
+
+Class: obo:GO_0045179
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string
+ obo:IAO_0000115 "The region that lies just beneath the plasma membrane on the apical edge of a cell."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0045179"^^xsd:string,
+ rdfs:label "apical cortex"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0044448
+ and (obo:BFO_0000050 some obo:GO_0045177)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0045177,
+ obo:GO_0044448
+
+
+Class: obo:GO_0000813
+
+ Annotations:
+ oboInOwl:hasBroadSynonym "Endosomal Sorting Complex Required for Transport"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "ESCRT I complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12892785"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12900393"^^xsd:string
+ obo:IAO_0000115 "An endosomal sorting complex required for transport. It consists of the class E vacuolar protein sorting (Vps) proteins and interacts with ubiquitinated cargoes."^^xsd:string,
+ oboInOwl:id "GO:0000813"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0010008,
+ obo:GO_0044440,
+ obo:GO_0043234
+
+
+Class: obo:GO_0000814
+
+ Annotations:
+ oboInOwl:hasBroadSynonym "Endosomal Sorting Complex Required for Transport"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:rb"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12892785"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12900393"^^xsd:string
+ obo:IAO_0000115 "An endosomal sorting complex required for transport and functions downstream of ESCRT I complex. It consists of the class E vacuolar protein sorting (Vps) proteins and is required for the membrane recruitment of ESCRT III complex and binds to ubiquitinated cargoes."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "ESCRT II complex"^^xsd:string,
+ oboInOwl:id "GO:0000814"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044425,
+ obo:BFO_0000050 some obo:GO_0010008,
+ obo:GO_0044440,
+ obo:GO_0043234
+
+
+Class: obo:GO_0000440
+
+ Annotations:
+ oboInOwl:id "GO:0000440"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "core TFIIH complex portion of NEF3 complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14500720"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7813015"^^xsd:string
+ obo:IAO_0000115 "The core TFIIH complex when it is part of the nucleotide-excision repair factor 3 (NEF3). In S. cerevisiae, it is composed of Rad3p, Tfb1p, Tfb2p, Ssl1p, and Tfb4p. In humans, it is composed of ERCC2, p62, p55, p44, p34."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000439
+ and (obo:BFO_0000050 some obo:GO_0000112)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0000442,
+ obo:GO_0000439
+
+
+Class: obo:GO_0045170
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:bf"^^xsd:string
+ obo:IAO_0000115 "A germline specific spherical organelle, rich in membrane skeletal proteins. Precursor to the fusome."^^xsd:string,
+ oboInOwl:id "GO:0045170"^^xsd:string,
+ rdfs:label "spectrosome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043232,
+ obo:GO_0044444
+
+
+Class: obo:GO_0000441
+
+ Annotations:
+ oboInOwl:id "GO:0000441"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "SSL2-core TFIIH complex"^^xsd:string,
+ oboInOwl:inSubset ,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14500720"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7813015"^^xsd:string
+ obo:IAO_0000115 "A complex which is part of both the general transcription factor TFIIH and the nucleotide-excision repair factor 3 complex. It is composed of the tightly associated 5 subunit core TFIIH subcomplex plus one additional, more loosely associated subunit. The subunits are well conserved from yeast to humans. In S. cerevisiae, the 5-subunit core is composed of Rad3, Tfb1, Tfb2, Ssl1, Tfb4 and the loosely associated subunit is Ssl2p (also called Rad25). In humans, the 5 subunit core is composed of ERCC2, p62, p55, p44, p34 and the loosely associated subunit is XPB."^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043234
+
+
+Class: obo:GO_0000817
+
+ Annotations:
+ rdfs:label "COMA complex"^^xsd:string,
+ oboInOwl:id "GO:0000817"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:se"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14633972"^^xsd:string
+ obo:IAO_0000115 "A multiprotein complex in yeast consisting of Ctf19p, Okp1p, Mcm21p, and Ame1p. This complex bridges the subunits that are in contact with centromeric DNA and the subunits bound to microtubules during kinetochore assembly."^^xsd:string,
+ oboInOwl:hasExactSynonym "Ctf19p-Okp1p-Mcm1p-Ame1p complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0000778,
+ obo:GO_0044454,
+ obo:GO_0043234
+
+
+Class: obo:GO_0005790
+
+ Annotations:
+ oboInOwl:id "GO:0005790"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "smooth ER"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Endoplasmic_reticulum#Smooth_endoplasmic_reticulum"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "The smooth endoplasmic reticulum (ER) has with no ribosomes attached to it. The smooth is the recipient of the proteins synthesized in the rough ER. Those proteins to be exported are passed to the Golgi complex, the resident proteins are returned to the rough ER and the lysosomal proteins after phosphorylation of their mannose residues are passed to the lysosomes. Glycosylation of the glycoproteins also continues. The smooth ER is the site of synthesis of lipids, including the phospholipids. The membranes of the smooth ER also contain enzymes that catalyze a series of reactions to detoxify both lipid-soluble drugs and harmful products of metabolism. Large quantities of certain compounds such as phenobarbital cause an increase in the amount of the smooth ER."^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao710427438"^^xsd:string,
+ oboInOwl:hasExactSynonym "SER"^^xsd:string,
+ rdfs:label "smooth endoplasmic reticulum"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005783
+
+
+Class: obo:GO_0000818
+
+ Annotations:
+ oboInOwl:hasExactSynonym "MIND complex"^^xsd:string,
+ rdfs:label "nuclear MIS12/MIND type complex"^^xsd:string,
+ oboInOwl:id "GO:0000818"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:hasExactSynonym "Mtw1p Including Nnf1p-Nsl1p-Dsn1p complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "GOC:se"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14633972"^^xsd:string
+ obo:IAO_0000115 "A multiprotein kinetochore subcomplex that binds to centromeric chromatin and forms part of the inner kinetochore of a chromosome in the nucleus. It helps to recruit outer kinetochore subunits that will bind to microtubules. Nuclear localization arises in some organisms because the nuclear envelope is not broken down during mitosis. In S. cerevisiae, it consists of at least four proteins: Mtw1p, Nnf1p, Nsl1p, and Dsn1."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000444
+ and (obo:BFO_0000050 some obo:GO_0005634)
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0000778,
+ obo:GO_0044454,
+ obo:GO_0000444
+
+
+Class: obo:GO_0031899
+
+ Annotations:
+ rdfs:label "chromoplast inner membrane"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pz"^^xsd:string
+ obo:IAO_0000115 "The inner, i.e. lumen-facing, lipid bilayer of the chromoplast envelope; also faces the chromoplast stroma."^^xsd:string,
+ oboInOwl:id "GO:0031899"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0046862,
+ obo:GO_0009528
+
+
+Class: obo:GO_0005791
+
+ Annotations:
+ oboInOwl:hasDbXref "NIF_Subcellular:sao1881364067"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005791"^^xsd:string,
+ rdfs:label "rough endoplasmic reticulum"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Endoplasmic_reticulum#Rough_endoplasmic_reticulum"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "The rough (or granular) endoplasmic reticulum (ER) has ribosomes adhering to the outer surface; the ribosomes are the site of translation of the mRNA for those proteins which are either to be retained within the cisternae (ER-resident proteins), the proteins of the lysosomes, or the proteins destined for export from the cell. Glycoproteins undergo their initial glycosylation within the cisternae."^^xsd:string,
+ oboInOwl:hasExactSynonym "rough ER"^^xsd:string,
+ oboInOwl:hasExactSynonym "RER"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0005783
+
+
+Class: obo:GO_0000444
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14633972"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16585270"^^xsd:string
+ obo:IAO_0000115 "A multiprotein kinetochore subcomplex that binds to centromeric chromatin and forms part of the inner kinetochore. It helps to recruit outer kinetochore subunits that will bind to microtubules. In humans, it consists of MIS12, DSN1, NSL1 and PMF1."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000444"^^xsd:string,
+ rdfs:label "MIS12/MIND type complex"^^xsd:string,
+ oboInOwl:hasNarrowSynonym "Mis12 complex"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044427,
+ obo:BFO_0000050 some obo:GO_0000777,
+ obo:GO_0043234
+
+
+Class: obo:GO_0031898
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:pz"^^xsd:string
+ obo:IAO_0000115 "The double lipid bilayer enclosing the chromoplast and separating its contents from the rest of the cytoplasm; includes the intermembrane space."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031898"^^xsd:string,
+ rdfs:label "chromoplast envelope"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0009526,
+ obo:BFO_0000050 some obo:GO_0009509
+
+
+Class: obo:GO_0005792
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005792"^^xsd:string,
+ rdfs:comment "Note that this term refers to disrupted cells, and does not necessarily correspond to any specific structure(s) in an intact cell."^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "Any of the small, heterogeneous, artifactual, vesicular particles, 50-150 nm in diameter, that are formed when some eukaryotic cells are homogenized and that sediment on centrifugation at 100000 g."^^xsd:string,
+ oboInOwl:hasRelatedSynonym "microsomal membrane"^^xsd:string,
+ rdfs:label "microsome"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Microsome"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0042598
+
+
+Class: obo:GO_0000445
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0000445"^^xsd:string,
+ oboInOwl:hasExactSynonym "THO complex part of TREX complex"^^xsd:string,
+ rdfs:label "THO complex part of transcription export complex"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11060033"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:11979277"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16983072"^^xsd:string
+ obo:IAO_0000115 "The THO complex when it is part of the TREX (TRanscription EXport) complex that is involved in coupling transcription to export of mRNAs to the cytoplasm. In S. cerevisiae, it is composed of four subunits: Hpr1, Tho2, Thp1, and Mft1, while the human complex is composed of 7 subunits."^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000347
+ and (obo:BFO_0000050 some obo:GO_0000346)
+
+ SubClassOf:
+ obo:GO_0000347,
+ obo:BFO_0000050 some obo:GO_0000346
+
+
+Class: obo:GO_0031897
+
+ Annotations:
+ rdfs:label "Tic complex"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0031897"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "PMID:12180471"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:12393016"^^xsd:string
+ obo:IAO_0000115 "The translocon of the inner envelope of chloroplasts, which facilitates the import of proteins across the chloroplast inner membrane."^^xsd:string,
+ oboInOwl:hasExactSynonym "chloroplast inner membrane translocase complex"^^xsd:string
+
+ SubClassOf:
+ obo:BFO_0000050 some obo:GO_0009706,
+ obo:GO_0044425,
+ obo:GO_0044434,
+ obo:GO_0043234
+
+
+Class: obo:GO_0045171
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "PMID:9635420"^^xsd:string
+ obo:IAO_0000115 "A direct link between the cytoplasms of sister cells that allows cells to communicate with one another. Germline intercellular bridges facilitate the passage of cytoplasmic components between cells during development. Intercellular bridges have also been found connecting somatic cells."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ rdfs:label "intercellular bridge"^^xsd:string,
+ oboInOwl:id "GO:0045171"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0044421
+
+
+Class: obo:GO_0005793
+
+ Annotations:
+ oboInOwl:hasDbXref "Wikipedia:Vesicular-tubular_cluster"^^xsd:string,
+ rdfs:label "endoplasmic reticulum-Golgi intermediate compartment"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "Wikipedia:Vesicular-tubular_cluster"^^xsd:string
+ oboInOwl:hasExactSynonym "vesicular-tubular cluster"^^xsd:string,
+ oboInOwl:id "GO:0005793"^^xsd:string,
+ oboInOwl:hasExactSynonym "ERGIC"^^xsd:string,
+ oboInOwl:hasExactSynonym "pre-Golgi intermediate compartment"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:pr"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:16723730"^^xsd:string
+ obo:IAO_0000115 "A complex system of membrane-bounded compartments located between endoplasmic reticulum (ER) and the Golgi complex, with a distinctive membrane protein composition; involved in ER-to-Golgi transport."^^xsd:string,
+ oboInOwl:hasExactSynonym "ER-Golgi intermediate compartment"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0043231,
+ obo:GO_0044444
+
+
+Class: obo:GO_0000442
+
+ Annotations:
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "GOC:krc"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:14500720"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:7813015"^^xsd:string
+ obo:IAO_0000115 "The SSL2-core TFIIH complex when it is part of the nucleotide-excision repair factor 3 (NEF3). It is composed of the tightly associated 5 subunit core TFIIH subcomplex plus one additional, less tighly associated subunit. The subunits are well conserved from yeast to humans. In S. cerevisiae, the 5-subunit core is composed of Rad3, Tfb1, Tfb2, Ssl1, Tfb4 and the loosely associated subunit is Ssl2p (also called Rad25). In humans, the 5 subunit core is composed of ERCC2, p62, p55, p44, p34 and the loosely associated subunit is XPB."^^xsd:string,
+ oboInOwl:id "GO:0000442"^^xsd:string,
+ rdfs:label "SSL2-core TFIIH complex portion of NEF3 complex"^^xsd:string
+
+ EquivalentTo:
+ obo:GO_0000441
+ and (obo:BFO_0000050 some obo:GO_0000112)
+
+ SubClassOf:
+ obo:GO_0044428,
+ obo:BFO_0000050 some obo:GO_0000112,
+ obo:GO_0000441
+
+
+Class: obo:GO_0045172
+
+ Annotations:
+
+ Annotations: oboInOwl:hasDbXref "GOC:mtg_sensu"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9635420"^^xsd:string,
+ oboInOwl:hasDbXref "PMID:9655801"^^xsd:string
+ obo:IAO_0000115 "Germline specific intercellular bridge. During cyst formation in insects, ring canals interconnect the cells of the cyst, facilitating the passage of cytoplasmic components between cells."^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0045172"^^xsd:string,
+ rdfs:label "germline ring canal"^^xsd:string
+
+ SubClassOf:
+ obo:GO_0045171
+
+
+Class: obo:GO_0005794
+
+ Annotations:
+ oboInOwl:inSubset ,
+ oboInOwl:hasNarrowSynonym "Golgi ribbon"^^xsd:string,
+ rdfs:label "Golgi apparatus"^^xsd:string,
+ oboInOwl:hasDbXref "Wikipedia:Golgi_apparatus"^^xsd:string,
+
+ Annotations: oboInOwl:hasDbXref "ISBN:0198506732"^^xsd:string
+ obo:IAO_0000115 "A compound membranous cytoplasmic organelle of eukaryotic cells, consisting of flattened, ribosome-free vesicles arranged in a more or less regular stack. The Golgi apparatus differs from the endoplasmic reticulum in often having slightly thicker membranes, appearing in sections as a characteristic shallow semicircle so that the convex side (cis or entry face) abuts the endoplasmic reticulum, secretory vesicles emerging from the concave side (trans or exit face). In vertebrate cells there is usually one such organelle, while in invertebrates and plants, where they are known usually as dictyosomes, there may be several scattered in the cytoplasm. The Golgi apparatus processes proteins produced on the ribosomes of the rough endoplasmic reticulum; such processing includes modification of the core oligosaccharides of glycoproteins, and the sorting and packaging of proteins for transport to a variety of cellular locations. Three different regions of the Golgi are now recognized both in terms of structure and function: cis, in the vicinity of the cis face, trans, in the vicinity of the trans face, and medial, lying between the cis and trans regions."^^xsd:string,
+ oboInOwl:hasDbXref "NIF_Subcellular:sao451912436"^^xsd:string,
+ oboInOwl:hasBroadSynonym "Golgi"^^xsd:string,
+ oboInOwl:hasOBONamespace "cellular_component"^^xsd:string,
+ oboInOwl:id "GO:0005794"^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset ,
+ rdfs:comment "Note that the Golgi apparatus can be located in various places in the cytoplasm. In plants and lower animal cells, the Golgi apparatus exists as many copies of discrete stacks dispersed throughout the cytoplasm, while the Golgi apparatus of interphase mammalian cells is a juxtanuclear, often pericentriolar reticulum, where the discrete Golgi stacks are stitched together to form a compact and interconnected ribbon, sometimes called the Golgi ribbon."^^xsd:string,
+ oboInOwl:inSubset ,
+ oboInOwl:inSubset








































 3. Add synonyms and dbxrefs following the same procedure if they are required for the term.
3. Add synonyms and dbxrefs following the same procedure if they are required for the term.







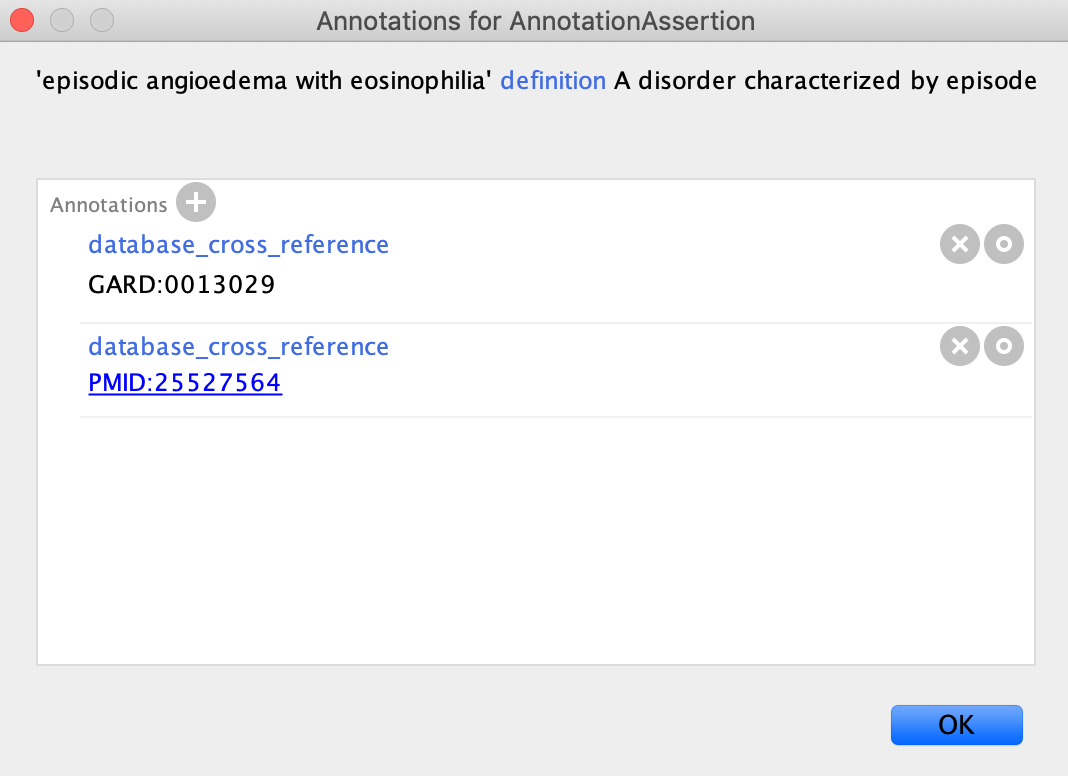
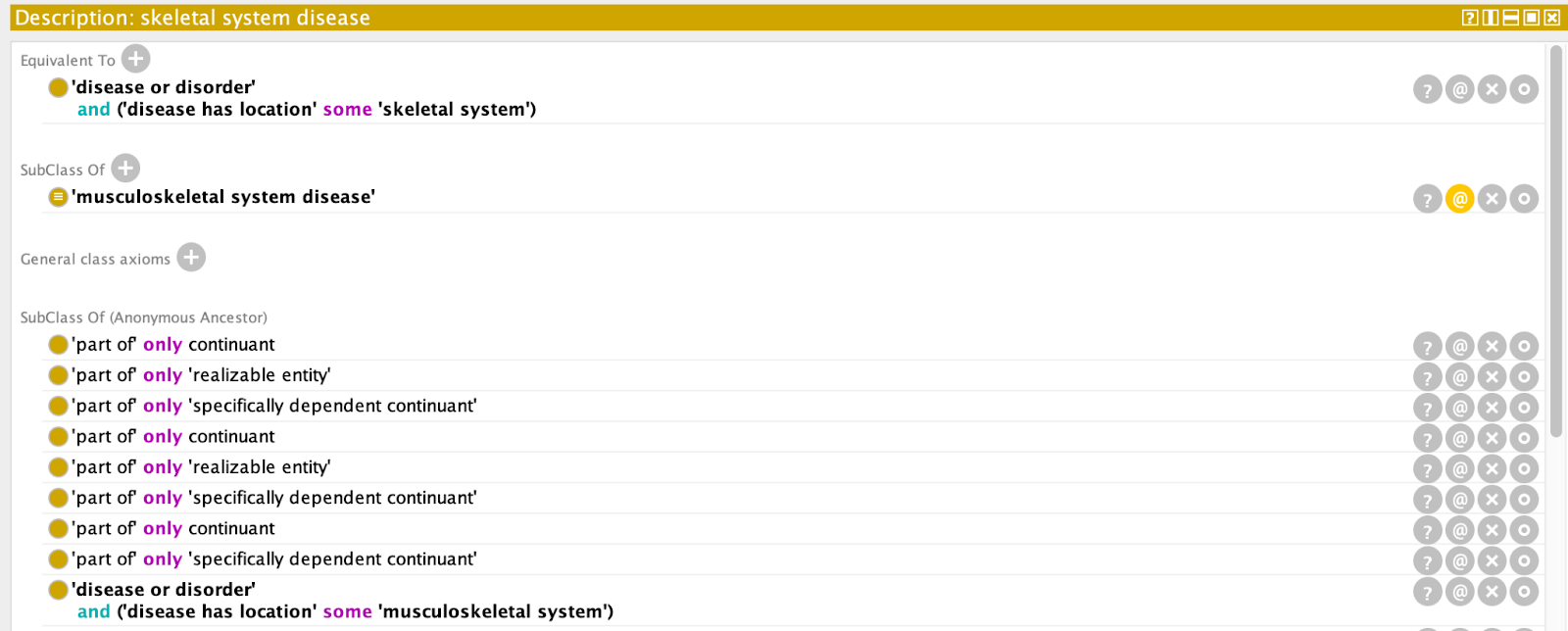















 +
+



 +1. Find review buddies. For every ontology you seek to contribute to pair up with someone who will review your pull requests and you will review their pull requests. Sometimes, it is very difficult to get anyone to review your pull request. Reach out to people directly, and form an alliance for review. It is fun, and you learn new things (and get to know new people!).
+1. Be proactive
+1. Find review buddies. For every ontology you seek to contribute to pair up with someone who will review your pull requests and you will review their pull requests. Sometimes, it is very difficult to get anyone to review your pull request. Reach out to people directly, and form an alliance for review. It is fun, and you learn new things (and get to know new people!).
+1. Be proactive 














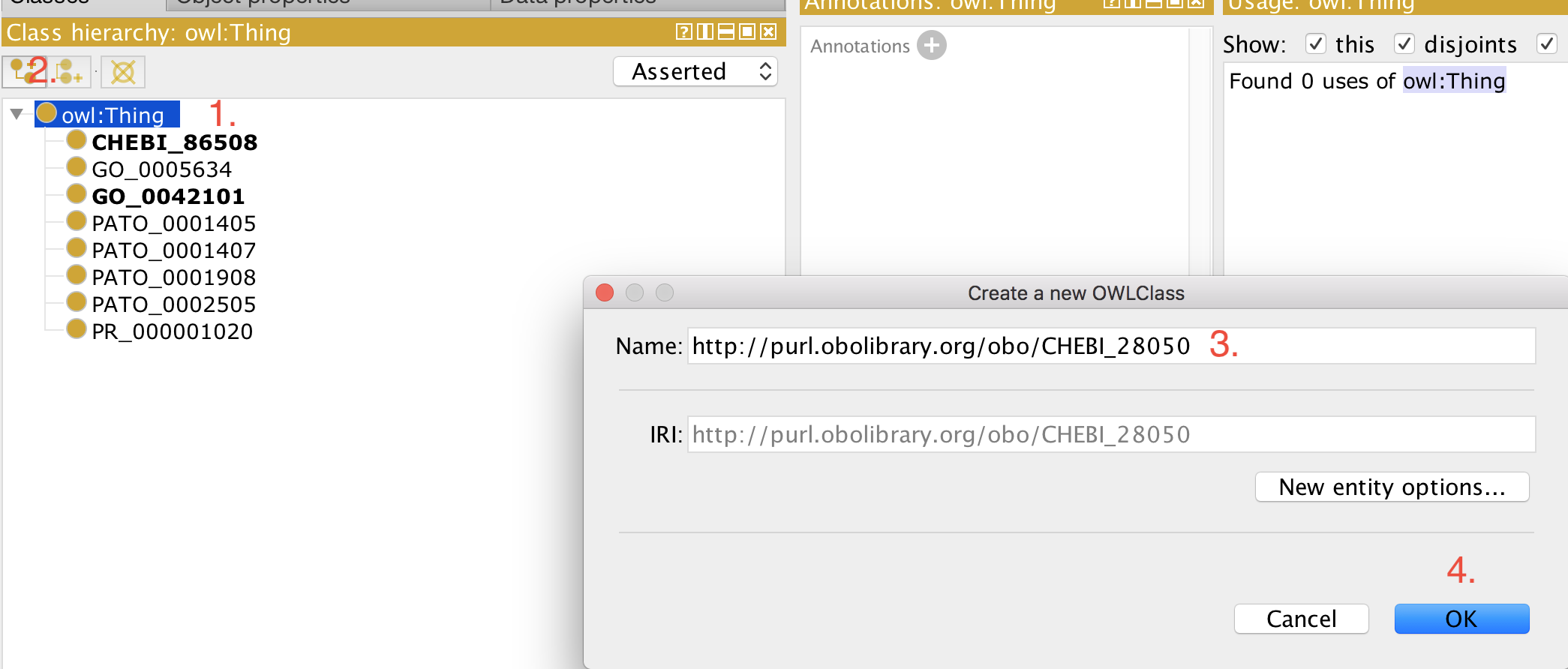


































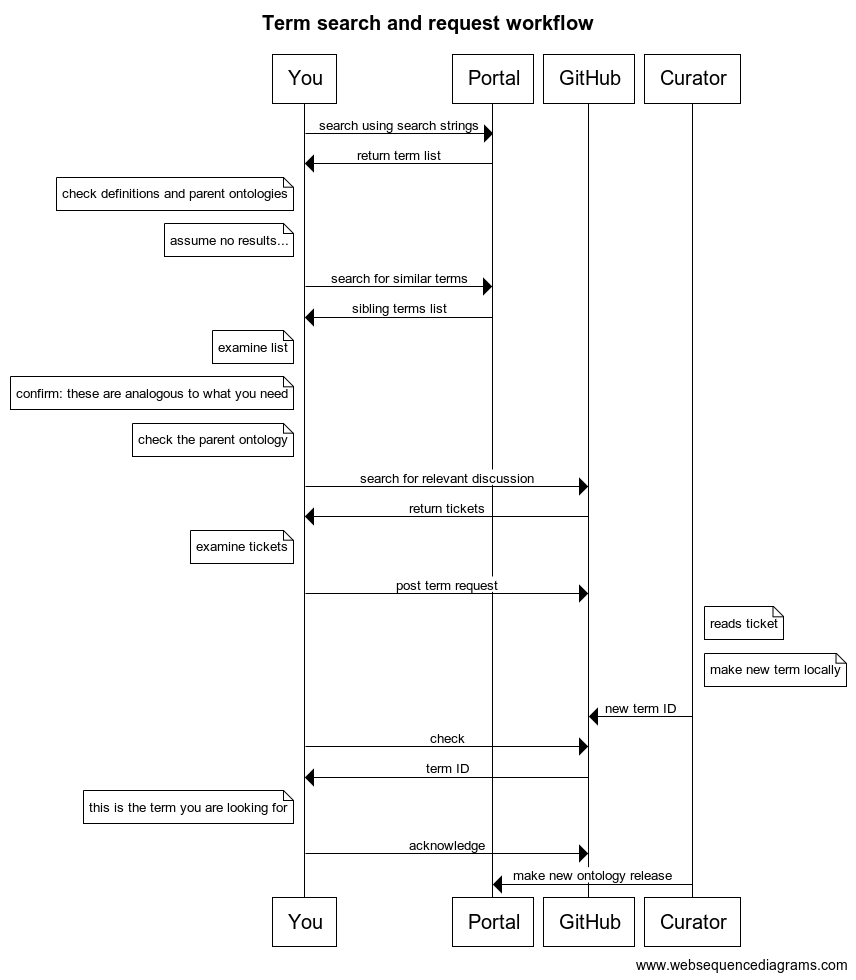




























 +
+ +
+




















 +
+


 +
+


















 + Feel free to click on details to see what is happening!
+ Feel free to click on details to see what is happening!
















 +
+ +
+ +
+