DLPerf summary of test experience #75
Labels
documentation
Improvements or additions to documentation
Comments
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
踩坑经验总结
1.精确到commit
首先,各个框架存在不同版本;其次,项目代码也在不断维护和更新,我们需要复现一个项目,首先需要熟读项目的readme,然后精确地匹配到对应的commit,保证代码版本和框架版本相匹配,才能将由于代码/框架版本不匹配导致各种问题的概率降至最低。
2.多机问题
多机情况下常见的问题:
horovod/mpi多机运行失败
无论是在物理机还是nvidia-ngc容器中,要运行horovod/mpi,都需要提前在节点之间配置ssh免密登录,保证用于通信的端口可以互相连通。
如:
需要保证节点间ssh可以通过端口10001互相连通
docker容器连通问题
如果是在docker容器中进行多机训练,需要保证docker容器间可以通过指定端口互相ssh免密登录。(如:在10.11.0.2节点的docker容器内可以通过ssh [email protected] -p 10001可以直接登录10.11.0.3节点的docker容器)
而在docker容器里,有两种实现方式:
**
docker的host模式
host模式,需要通过docker run时添加参数 --net=host 指定,该模式下表示容器和物理机共用端口(没有隔离),需要修改容器内ssh服务的通信端口号(vim /etc/ssh/sshd_config),用于docker容器多机通讯,具体方式见:README—SSH配置
docker的bridge模式
即docker的默认模式。该模式下,容器内部和物理机的端口是隔离的,可以通过docker run时增加参数如:-v 9000:9000进行端口映射,表明物理机9000端口映射到容器内9000端口,docker容器多机时即可指定9000端口进行通信。
两种方式都可以,只要保证docker容器间能通过指定端口互相ssh免密登录即可。
多机没连通/长时间卡住没反应
通信库没有正确安装
通常是没有正确地安装多机依赖的通信库(openmpi、nccl)所导致。譬如paddle、tensorflow2.x等框架依赖nccl,则需要在每个机器节点上安装版本一致的nccl,多机训练时,可以通过export NCCL_DEBUG=INFO来查看nccl的日志输出。
openmpi安装
官网:https://www.open-mpi.org/software/ompi/v4.0/
make时,若报错numa相关的.so找不到:
添加到环境变量
horovod安装
官网:https://github.com/horovod/horovod
存在虚拟网卡,nccl需指定网卡类型
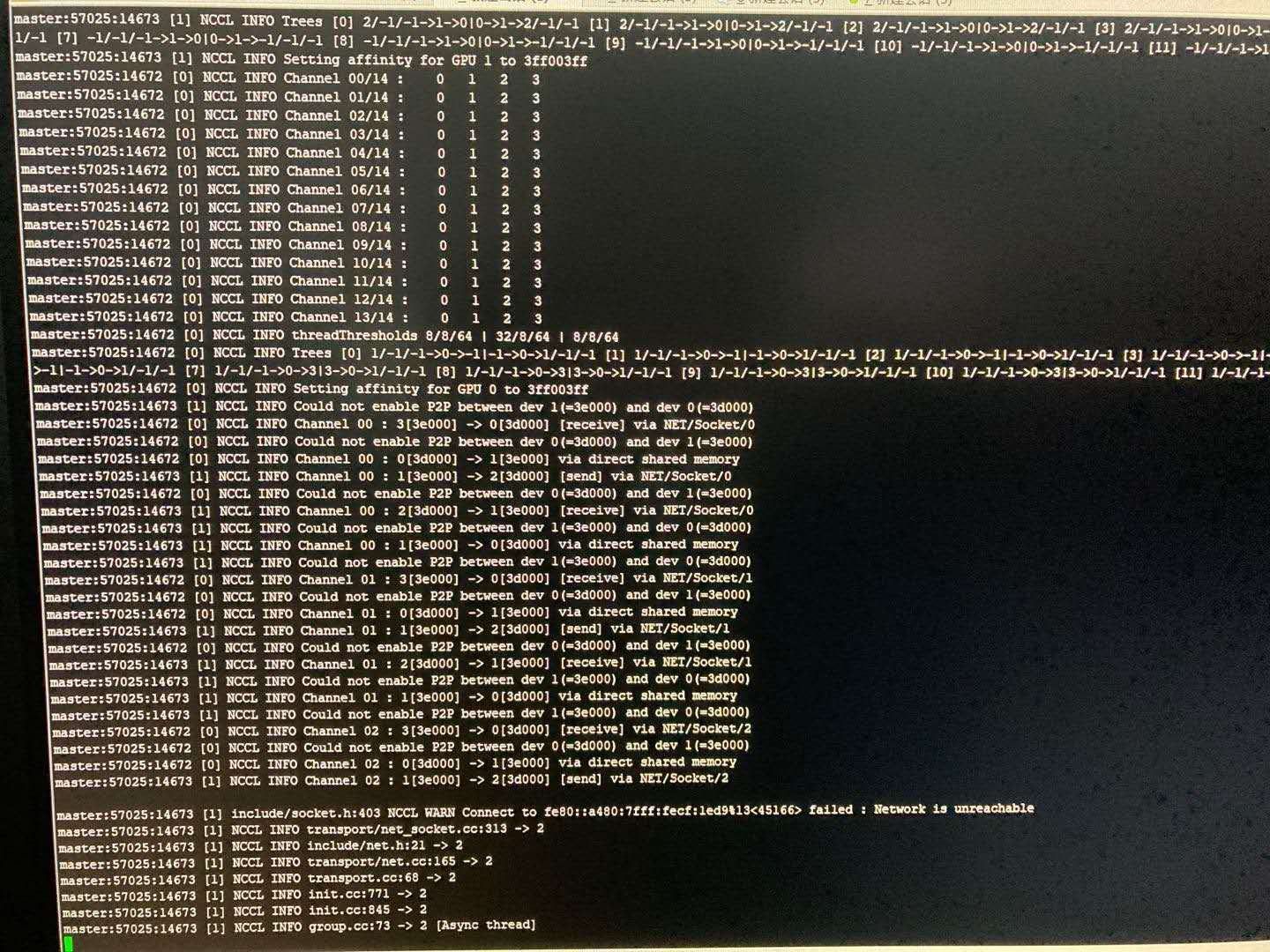
有时,nccl已经正常安装,且节点间可以正常ssh免密登录,且都能互相ping通,不过还是遭遇多机训练长时间卡住的问题,可能是虚拟网卡的问题,当存在虚拟网卡时,如果不指定nccl变量,则多机通信时可能会走虚拟网卡,而导致多机不通的问题。
如下图:
NCCL WARN Connect to fe80::a480:7fff:fecf:1ed9%13<45166> failed : Network is unreachable表明多机下遭遇了网络不能连通的问题。具体地,是经过网卡:fe80::a480:7fff:fecf...通信时不能连通。
通过ifconfig查看当前节点中的所有网卡类型:
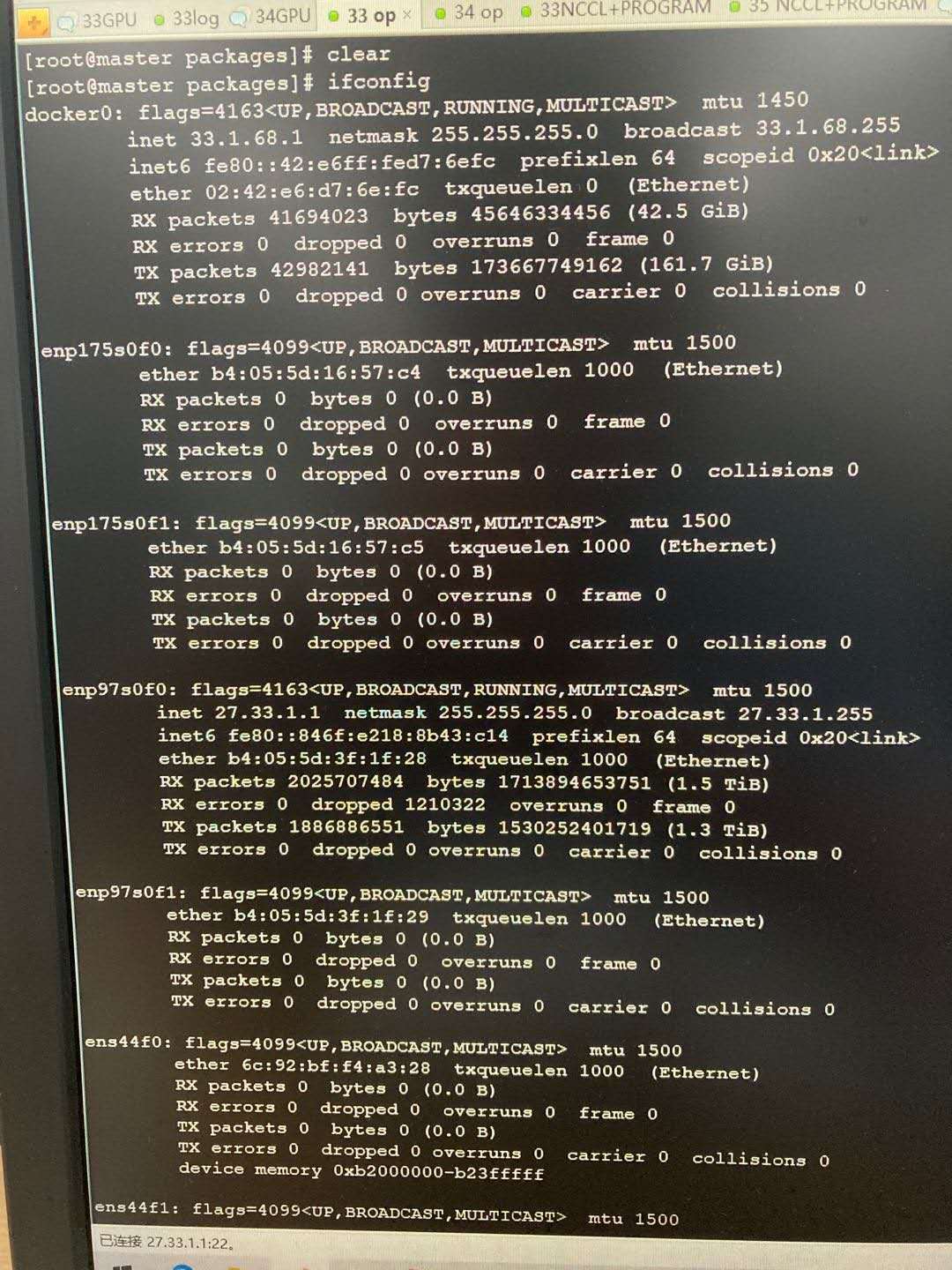
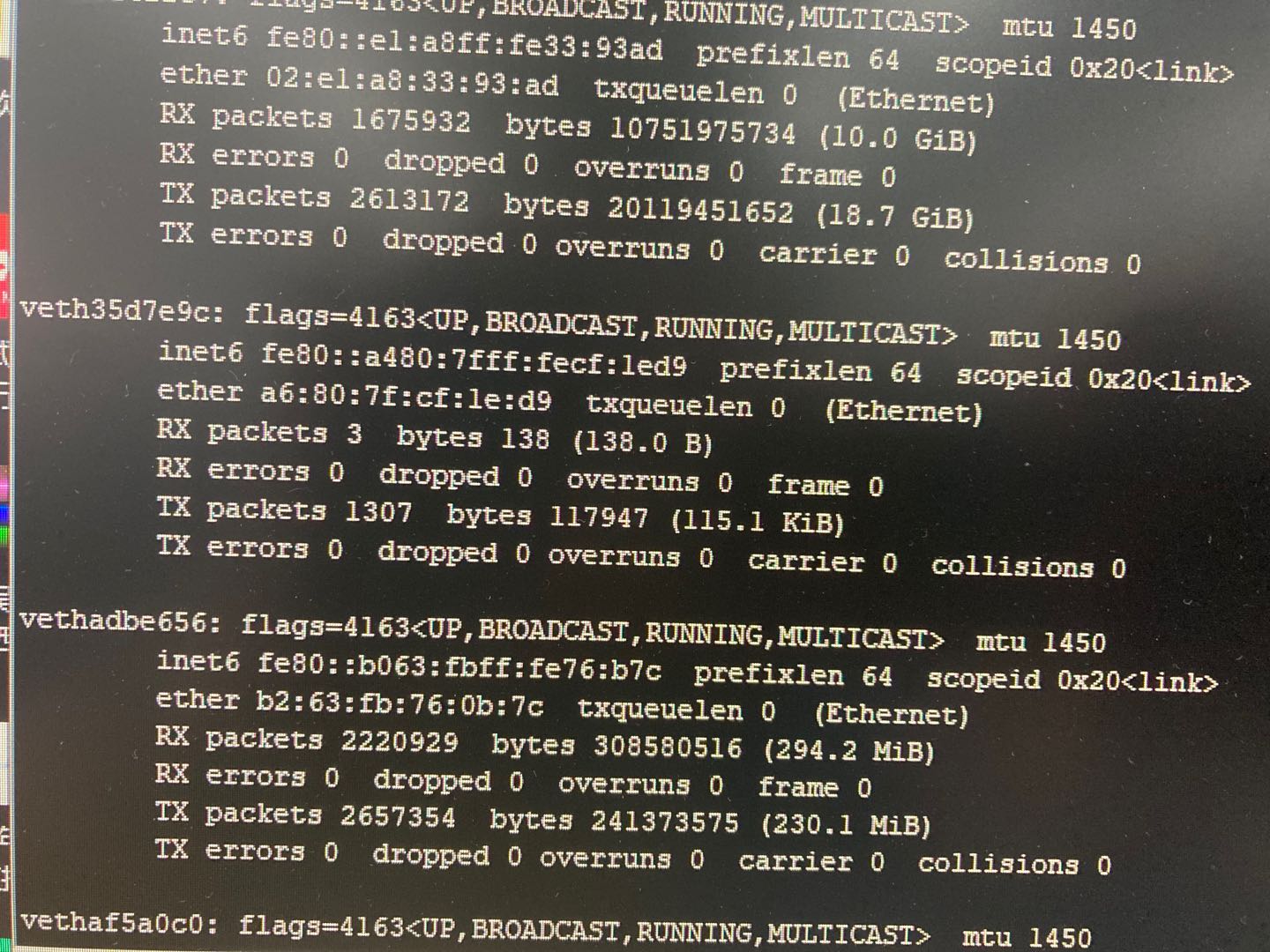
可以发现有很多enp开头的网卡,也有很多veth开头的虚拟网卡,而nccl日志输出中的:fe80::a480:7fff:fecf:1ed9是veth虚拟网卡。
通过查看nccl官网文档发现,我们可以通过指定nccl变量来设定nccl通信使用的网卡类型:
export NCCL_SOCKET_IFNAME=enp加速比低
各框架踩坑记录
1.tf2.x-resnet
官方实现:https://github.com/tensorflow/models/tree/r2.3.0/official/vision/image_classification
DLPERF实现:https://github.com/Oneflow-Inc/DLPerf/tree/master/TensorFlow/resnet50v1.5
1.1tensorflow-datasets版本
官方official目录下提供的requirements.txt里并未指定tensorflow-datasets的版本,直接通过pip install -r requirements.txt安装,训练时会报错找不到imagenet数据集信息,可通过指定版本解决:
在requirements.txt中指定tensorflow-datasets==3.0.0即可。
1.2设置PYTHONPATH环境变量
开始训练前,需要将项目路径加入到PYTHONPATH,或者通过vim ~/.bashrc在用户变量中指定。
1.3 cuda-10.1库文件
tf2.3依赖cuda-10.1下的库文件,如果在cuda10.2的环境下运行,会报错:
解决方式:
1.4单机/多机.yaml设置
单机训练策略采取默认的MirroredStrategy策略,多机策略采取:MultiWorkerMirroredStrategy。tf2.x可用的策略详见官方文档:https://tensorflow.google.cn/guide/distributed_training
单机策略
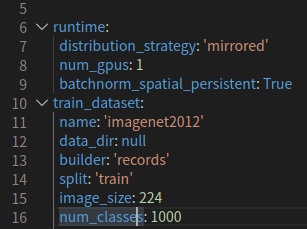
在DLPerf中,我们通过run_single_node.sh脚本运行单机测试,脚本调用single_node_train.sh执行单机训练脚本,其中通过--config_file参数设置训练所需要的yaml配置文件(gpu.yaml或gpu_fp16.yaml)。单机训练时,需要将yaml配置文件中runtime下的distribution_strategy设置为'mirrored',以使用MirroredStrategy策略:
多机策略
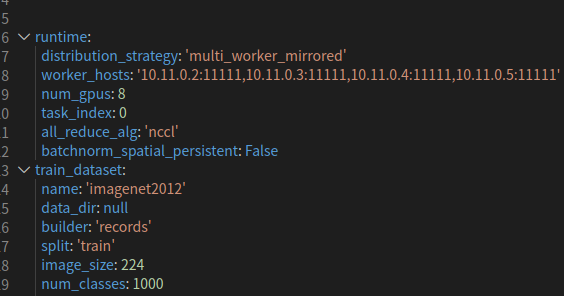
多机器训练时,multi_node_train.sh脚本中通过--config_file参数设置训练所需的yaml配置文件(multi_node_gpu.yaml或multi_node_gpu_fp16.yaml)。多机训练时,需要将yaml配置文件中runtime下的distribution_strategy设置为'multi_worker_mirrored'以使用MultiWorkerMirroredStrategy策略,同时需要增加all_reduce_alg:'nccl'以指定all_reduce过程使用nccl,否则会报错。
2.tf2.x-bert
基本参数设置同tf2.x-resnet,不过无需.yaml配置文件,统一使用run_pretraining.py进行训练。
不过测试过程中我们发现,官方提供的python脚本运行多机时会报错,即使在修改代码后也只能支持
--all_reduce_alg='ring'模式的多机训练(cpu多机),而不能支持'nccl'模式的多gpu训练,故多机的测试暂不开展。详见:https://github.com/Oneflow-Inc/DLPerf/tree/master/TensorFlow/bert#%E5%A4%9A%E6%9C%BA
3.paddle-resnet
3.1 数据集制作
paddle在利用imagenet训练分类网络时,需要对imagenet数据集做一定的处理,将图像和标签文件写入train_list.txt、val_list.txt文件中,具体格式和制作方式参考:官方文档—数据准备
3.2 多进程训练
单机
单机单卡时,可以直接通过
python train.py...训练,单机多卡时,最好使用多进程训练的模式:python -m paddle.distributed.launch train.py...否则训练速度和加速比都会比较差。在单机采用多进程训练时,可以自行调节--reader_thread参数,以达到最优速度,且thread并非越大越好,超过一定数值后thread越大,线程数越多,会导致速度变慢。经测试,单机1卡时thread=8速度较优;4卡时thread=12;8卡时thread=8能达到较优的速度。
多机
多机训练时,必须采用多进程训练的模式,多机通讯走nccl。同样,可以自行测试,以选取最优化的--reader_thread参数,在DLPerf的多机测试时,默认使用--reader_thread=8。
4.paddle-bert
数据集制作过程见:DLPerf文档;单机、多机训练说明可参考:官方文档 其他按照正常流程走即可,没有需要特别注意的地方。
5.nvidia-mxnet-resnet
5.1 多机配置ssh免密登录
当需要在NGC容器间进行多机测试时,容器间需要配置ssh免密登录,具体参考DLPerf的README—SSH 免密。
5.2 安装IB驱动(可选)
如果服务器之间支持IB(InfiniBand)网络,则可以安装IB驱动,使得多机情况下各个节点间的通信速率明显提升,从而加速框架在多机环境下的训练,提升加速比。
具体安装方式可参考:IB驱动安装(可选)
5.3 修改部分代码
容器内提供的代码可能和官方代码不完全同步,需要作一些修改才能正确运行,详见README—额外准备。
5.4 mxnet环境变量
在用mxnet进行resnet50测试时,需要加上一系列mxnet默认的环境变量,否则速度可能不够理想,这些变量已经在脚本runner.sh(Line:70~Line:81)中包含,可自行修改以设定最优化的值。
6.nvidia-tf-resnet
6.1 多机配置ssh免密登录
当需要在NGC容器间进行多机测试时,容器间需要配置ssh免密登录,具体参考DLPerf的README—SSH配置(可选)。
6.2 安装IB驱动(可选)
如果服务器之间支持IB(InfiniBand)网络,则可以安装IB驱动,使得多机情况下各个节点间的通信速率明显提升,从而加速框架在多机环境下的训练,提升加速比。
具体安装方式可参考:IB驱动安装(可选)
7.nvidia-tf-bert
7.1 多机配置ssh免密登录
当需要在NGC容器间进行多机测试时,容器间需要配置ssh免密登录,具体参考DLPerf的README—SSH配置(可选)。
7.2 安装IB驱动(可选)
如果服务器之间支持IB(InfiniBand)网络,则可以安装IB驱动,使得多机情况下各个节点间的通信速率明显提升,从而加速框架在多机环境下的训练,提升加速比。
具体安装方式可参考:IB驱动安装(可选)
**
在bert的测试中发现,安装IB驱动后,2机、4机情况下的加速比提升明显
8.gluon-mxnet-bert
8.1horovod安装
horovod是支持pytorch,tensorflow,mxnet多机分布式训练的库,其底层机器间通讯依赖nccl或mpi,所以安装前通常需要先安装好nccl、openmpi,且至少安装了一种深度学习框架,譬如mxnet:
安装完mxnet以及gluonnlp后,可进行horovod的安装。horovod安装时,需为NCCL指定相关变量,否则运行时可能不会走nccl通讯导致速度很慢。在DLPerf中如何安装horovod,可直接参考README-环境安装 。
8.2 修改部分代码
具体参考:README—额外准备部分
其他分享
1.GPU拓扑
nvidia-smi topo -m
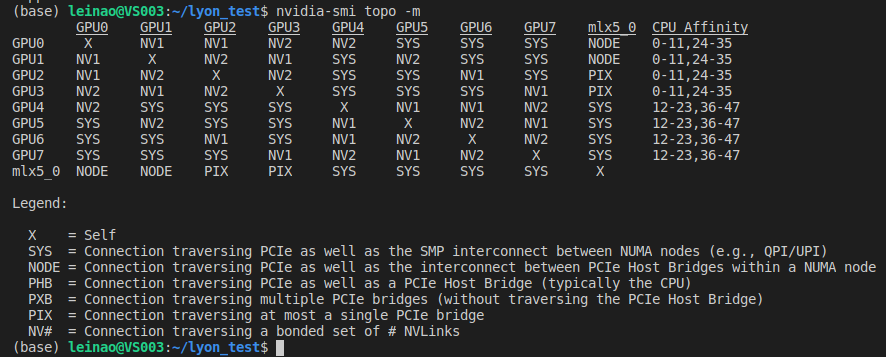
可以看出,此台机器包含8块GPU(GPU0~7),mlx5_0是Mellanox ConnectX-4 PCIe网卡设备(10/25/40/50千兆以太网适配器,另外该公司是IBA芯片的主要厂商)。图的上半部分表示GPU间的连接方式,如gpu1和gpu0通过NV1互联,gpu4和gpu1通过SYS互联;图的下半部分为连接方式的具体说明,如NV表示通过nvlink互联,PIX通过至多一个PCIe网桥互联。
在图的下半部分,理论上GPU间的连接速度从上到下依次加快,最底层的NV表示通过nvlink互联,速度最快;最上层SYS表示通过pcie以及穿过NUMA节点间的SMP互联(即走了PCie又走了QPI总线),速度最慢。
2.NCCL
The text was updated successfully, but these errors were encountered: