diff --git a/2327609.ipynb b/2327609.ipynb
new file mode 100644
index 00000000..7b2e97ec
--- /dev/null
+++ b/2327609.ipynb
@@ -0,0 +1,671 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": [
+ "# 基于神经网络算法的用电量预测\n",
+ "\n",
+ "作者信息:linsl1986 (https://github.com/linsl1986)\n",
+ "\n",
+ "我在AI Studio上获得白银等级,点亮1个徽章,来互关呀~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/134639\n",
+ "\n",
+ "## 1. 简要介绍\n",
+ "\n",
+ "开展电力系统用电量及负荷预测的目的是:为了电力系统供电范围内电力工业的发展能够适应国民经济和社会发展的需要。\n",
+ "\n",
+ "用电量及负荷预测是电力工业生产建设计划及经营管理的基础,又是电力系统规划设计的基础。\n",
+ "\n",
+ "本项目以A地区一年的用电量和相应的气象因素为依据,使用神经网络算法进行电量及负荷预测。\n",
+ " \n",
+ "\n",
+ "\n",
+ "本项目使用神经网络模型进行预测,其基本流程如图\n",
+ "\n",
+ "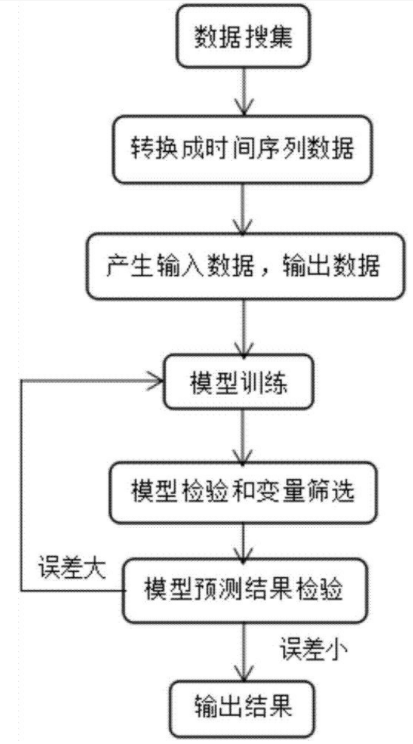\n",
+ "\n",
+ "神经网络模型预测的基本原理如下\n",
+ "\n",
+ "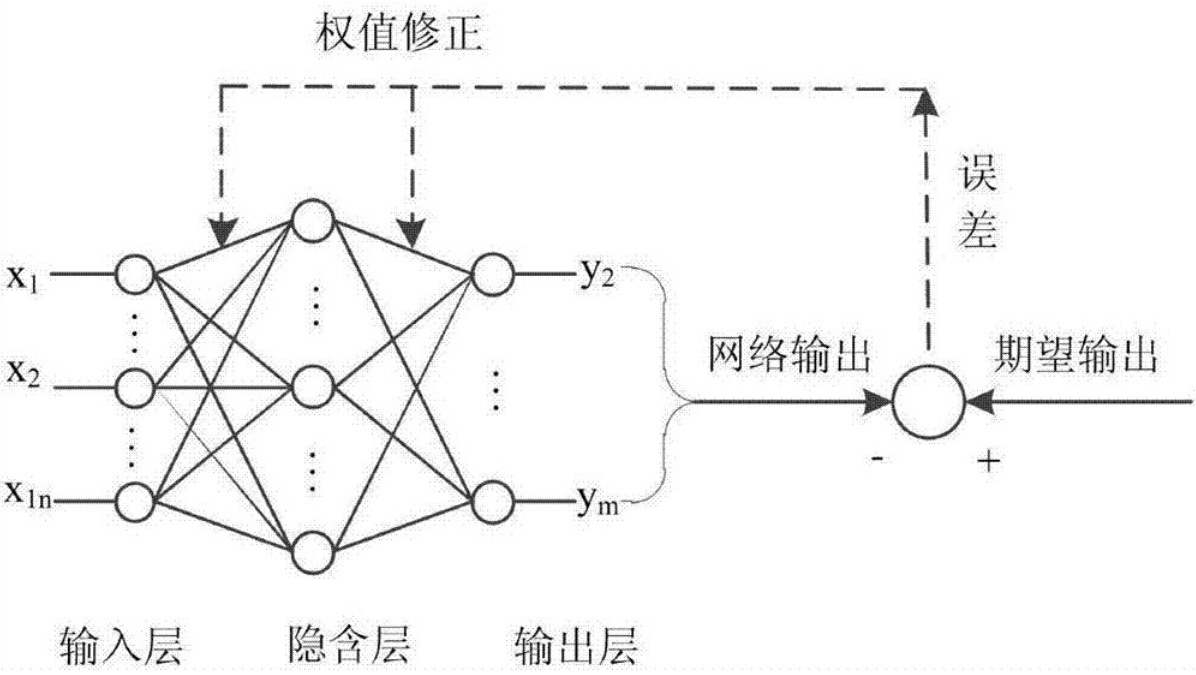\n",
+ " \n",
+ "## 2. 环境设置\n",
+ "导入包,设置所用的归一化方法、神经网络结构、训练轮数和预测时间段等信息\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [],
+ "source": [
+ "import pandas as pd\r\n",
+ "import numpy as np\r\n",
+ "import paddle\r\n",
+ "import paddle.fluid as fluid\r\n",
+ "import numpy as np\r\n",
+ "import pickle\r\n",
+ "from tqdm import tqdm\r\n",
+ "import matplotlib.pyplot as plt\r\n",
+ "# 选择归一化方法\r\n",
+ "normalization=1 # 0表示Max-min归一化, 1表示Zscore归一化\r\n",
+ "# 选择神经网络\r\n",
+ "flag = 1 # 0表示全连接神经网络, 1表示LSTM神经网络\r\n",
+ "day_num = 1 # 选择前一天的特征作为输入数据。\r\n",
+ "# 训练参数设置\r\n",
+ "BATCH_SIZE = 5\r\n",
+ "learning_rate = 0.001\r\n",
+ "EPOCH_NUM = 200\r\n",
+ "\r\n",
+ "# 可视化天数选择,建议大于7,这样才能展示一周的预测情况\r\n",
+ "date_n = 7"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": [
+ "\n",
+ "## 3. 数据集\n",
+ "本数据集包含了近一年A地区用电量以及气象要素的原始数据,每天有96个时刻的温度,湿度,风速,降雨和用电量。\n",
+ "具体步骤包括:\n",
+ "\n",
+ "1、从excel中读取数据\n",
+ "\n",
+ "\n",
+ "\n",
+ "2、划分训练集和测试集。由于本项目是基于N天的用电量和气象要素等信息预测N+1天的用电量,因此训练集和测试集的数据是需要连续若干天的,这里有别于多元线性回归时的训练集和测试集的划分过程。\n",
+ "\n",
+ "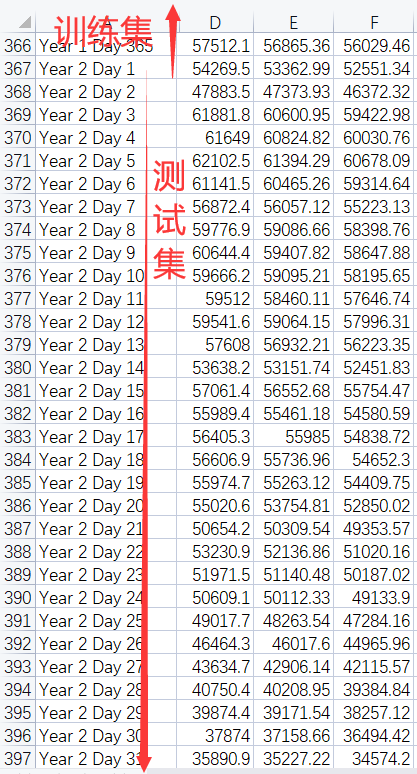\n",
+ "\n",
+ "\n",
+ "3、数据集调整思路\n",
+ "* 减少特征,也就是不考虑温度,湿度,风速,降雨和负荷数据中的一种或者多种,重新构建输入特征\n",
+ "* 使用前几天的数据预测性后一天的负荷,修改上面的day_num数值\n",
+ "* 由于温度,湿度,风速,降雨等数据是可以预测得到的,因此在输入特征中添加后一天的温度,湿度,风速,降雨。\n",
+ "\n",
+ "讲述数据集的一些基础信息,描述数据集组成等。进行数据集的下载、抽样查看、数据集定义等。\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "(365, 96)\n",
+ "(31, 96)\n"
+ ]
+ }
+ ],
+ "source": [
+ "# 从excel中读取温度,湿度,风速,降雨和用电量数据\r\n",
+ "train_set = []\r\n",
+ "test_set = []\r\n",
+ "for i in range(5):\r\n",
+ " sheet = pd.read_excel('work/Load_Forcast.xlsx',\r\n",
+ " sheet_name = i,usecols = range(1,97))\r\n",
+ " train_set.append(sheet[0:365].values)#对应excel中的第2行到366行\r\n",
+ " test_set.append(sheet[365:365+31].values)#对应excel中第367行到397行\r\n",
+ "print(train_set[0].shape)\r\n",
+ "print(test_set[0].shape)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [],
+ "source": [
+ "#生成训练集和测试集\r\n",
+ "def data_pro(train_set, test_set, day_num):\r\n",
+ " # 定义训练标签数据\r\n",
+ " train_y = train_set[4]\r\n",
+ " # 数据为一年的用电量数据,共365天,由于前一天day_num的数据作为输入,因此需要删去第一天的数据\r\n",
+ " train_y = train_y[day_num:, :]\r\n",
+ " print(train_y.shape)\r\n",
+ " # print(train_y[0]) #检验是否已经删除了第一天的数据\r\n",
+ "\r\n",
+ " # 选择特征,定义训练的输入数据\r\n",
+ " # train_set[0]表示温度数据,train_set[1]:表示湿度数据,train_set[2]:表示风速数据, train_set[3]:表示降雨数据, train_set[4]:表示用电量数据, \r\n",
+ "\r\n",
+ " \r\n",
+ " temperature_data = train_set[0]\r\n",
+ " humidity_data = train_set[1]\r\n",
+ " wind_velocity_data = train_set[2]\r\n",
+ " rainfall_data = train_set[3]\r\n",
+ " load_data = train_set[4]\r\n",
+ "\r\n",
+ " # 将温度,湿度,风速,降雨,用电量合并,成为输入的特征向量,所以有96*5=480列数据\r\n",
+ " train_x_temp = np.concatenate((temperature_data,humidity_data, wind_velocity_data, rainfall_data, load_data),axis = 1)\r\n",
+ " temp = []\r\n",
+ " for x in range(day_num):\r\n",
+ " temp.append(train_x_temp[x:(365-day_num+x), :]) # 训练集的输入train_x中删除第一年的最后一天的数据\r\n",
+ " \r\n",
+ " train_x = np.concatenate(temp, axis=1)\r\n",
+ " print(train_x.shape)\r\n",
+ " # print(train_x[363])#检验训练集的输入train_x最后一组数据\r\n",
+ "\r\n",
+ "\r\n",
+ " # 根据选择特征的定义,修改测试集的数据\r\n",
+ " # 修改测试集的标签数据\r\n",
+ " test_y = test_set[0-day_num]\r\n",
+ " test_y = test_y[day_num:, :]\r\n",
+ " print(test_y.shape)\r\n",
+ " # 修改测试集的输入数据\r\n",
+ " temperature_data = test_set[0]\r\n",
+ " humidity_data = test_set[1]\r\n",
+ " wind_velocity_data = test_set[2]\r\n",
+ " rainfall_data = test_set[3]\r\n",
+ " load_data = test_set[4]\r\n",
+ " test_x_temp = np.concatenate((temperature_data,humidity_data, wind_velocity_data, rainfall_data, load_data),axis = 1)\r\n",
+ "\r\n",
+ " temp = []\r\n",
+ " for x in range(day_num):\r\n",
+ " temp.append(test_x_temp[x:(31-day_num+x), :])\r\n",
+ " # print(test_x_temp[x:(31-day_num+x), :].shape)\r\n",
+ " \r\n",
+ " test_x = np.concatenate(temp, axis=1)\r\n",
+ " print(test_x.shape)\r\n",
+ "\r\n",
+ "\r\n",
+ " return train_x, train_y, test_x, test_y\r\n",
+ "\r\n",
+ "\r\n",
+ "train_x, train_y, test_x, test_y = data_pro(train_set=train_set, test_set=test_set, day_num=day_num)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [],
+ "source": [
+ "#本部分为数据归一化的代码,一般不需要修改\r\n",
+ "if normalization==0: # 使用Max-min归一化处理函数\r\n",
+ " def normalization_Maxmin(train_x):\r\n",
+ " Min = np.min(train_x, axis=0)\r\n",
+ " Max = np.max(train_x, axis=0)\r\n",
+ " train_x = (train_x-Min)/ (Max - Min)\r\n",
+ " # 处理异常情况\r\n",
+ " train_x[np.isnan(train_x)] = 0\r\n",
+ " train_x[np.isinf(train_x)] = 0\r\n",
+ " return train_x, Min, Max\r\n",
+ "\r\n",
+ " # 对输入数据进行归一化处理\r\n",
+ " train_x, Min_x, Max_x = normalization_Maxmin(train_x)\r\n",
+ " test_x = (test_x -Min_x)/ (Max_x - Min_x)\r\n",
+ " # 对输出数据进行归一化处理\r\n",
+ " train_y, Min_y, Max_y = normalization_Maxmin(train_y)\r\n",
+ " test_y = (test_y-Min_y)/ (Max_y - Min_y)\r\n",
+ "else:#zscore归一化处理函数,适用于数据服从正态分布\r\n",
+ " def normalization_zscore(train_x):\r\n",
+ " mu = np.mean(train_x, axis=0)\r\n",
+ " sigma = np.std(train_x, axis=0)\r\n",
+ " train_x = (train_x-mu)/sigma\r\n",
+ " # 处理异常情况\r\n",
+ " train_x[np.isnan(train_x)] = 0\r\n",
+ " train_x[np.isinf(train_x)] = 0\r\n",
+ " return train_x, mu, sigma\r\n",
+ "\r\n",
+ " # 对输入数据进行归一化处理\r\n",
+ " train_x, mu_x, sgma_x = normalization_zscore(train_x)\r\n",
+ " test_x = (test_x - mu_x)/sgma_x\r\n",
+ " # 对输出数据进行归一化处理\r\n",
+ " train_y, mu_y, sgma_y = normalization_zscore(train_y)\r\n",
+ " test_y = (test_y-mu_y)/sgma_y"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": [
+ "## 4. 模型组网\n",
+ "下面的示例中,使用全连接神经网络,可以修改成其他神经网络,例如LSTM。**注意,因为预测的负荷十五分钟一个时刻,一天共96个时刻,所以输出的维度必须为96。**\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [],
+ "source": [
+ "# 定义全连接神经网络 \r\n",
+ "def Full_connected(input): \r\n",
+ " hidden1 = fluid.layers.fc(input=input, size=50, act='relu') \r\n",
+ " hidden2 = fluid.layers.fc(input=hidden1, size=50, act='relu')\r\n",
+ " hidden3 = fluid.layers.fc(input=hidden2, size=50, act='relu')\r\n",
+ " hidden4 = fluid.layers.fc(input=hidden3, size=50, act='relu')\r\n",
+ " prediction = fluid.layers.fc(input=hidden2, size=96, act=None) \r\n",
+ " return prediction\r\n",
+ "\r\n",
+ "# 定义LSTM\r\n",
+ "def LSTM_pre(x):\r\n",
+ " # Lstm layer\r\n",
+ " fc0 = fluid.layers.fc(input=x, size=16)\r\n",
+ " lstm_h, c = fluid.layers.dynamic_lstm(input=fc0, size=16, is_reverse=False)\r\n",
+ "\r\n",
+ " # max pooling layer\r\n",
+ " lstm_max = fluid.layers.sequence_pool(input=lstm_h, pool_type='max')\r\n",
+ " lstm_max_tanh = fluid.layers.tanh(lstm_max)\r\n",
+ "\r\n",
+ " # full connect layer\r\n",
+ " # lstm_max_tanh = fluid.layers.fc(input=lstm_max_tanh, size=16, act='relu')\r\n",
+ " prediction = fluid.layers.fc(input=lstm_max_tanh, size=96, act=None)# 'tanh')\r\n",
+ " return prediction\r\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": [
+ "## 5. 模型训练\n",
+ "使用模型网络结构和数据集进行模型训练。具体包括如下步骤\n",
+ "\n",
+ "1、定义数据生成器\n",
+ "\n",
+ "2、定义训练时数据的读取方式、损失函数和优化器\n",
+ "\n",
+ "3、定义训练程序\n",
+ "\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [],
+ "source": [
+ "#定义数据生成器\r\n",
+ "def readers(x, y):\r\n",
+ " def reader():\r\n",
+ " for i in range(x.shape[0]):\r\n",
+ " yield x[i], y[i]\r\n",
+ " return reader"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [],
+ "source": [
+ "# 定义数据读取方式\n",
+ "trainer_reader = readers(train_x, train_y)\n",
+ "train_reader = paddle.batch(\n",
+ " paddle.reader.shuffle(\n",
+ " reader=trainer_reader,buf_size=300),\n",
+ " batch_size=BATCH_SIZE)\n",
+ "\n",
+ "paddle.enable_static()# PaddlePaddle 2.x需要使用这句话才能进行静态模型\n",
+ "\n",
+ "# 搭建神经网络\n",
+ "if flag==0: # 使用全连接神经网络\n",
+ " # 定义神经网络输入和输出, 注意输入的维度必须和选择特征的维度一致, 输出的维度必须为96\n",
+ " x = fluid.layers.data(name='x', shape=[480*day_num], dtype='float32')\n",
+ " y = fluid.layers.data(name='y', shape=[96], dtype='float32')\n",
+ "\n",
+ " # 选择神经网络\n",
+ " pred = Full_connected(x)\n",
+ "else:\n",
+ " # 定义神经网络输入和输出, 注意输入的维度必须和选择特征的维度一致, 输出的维度必须为96\n",
+ " x = fluid.layers.data(name='x', shape=[1], dtype='float32', lod_level=1)\n",
+ " y = fluid.layers.data(name='y', shape=[96], dtype='float32')\n",
+ "\n",
+ " # 选择神经网络\n",
+ " pred = LSTM_pre(x)\n",
+ "\n",
+ "# 定义损失函数\n",
+ "cost = fluid.layers.square_error_cost(input=pred, label=y)\n",
+ "avg_cost = fluid.layers.mean(cost)\n",
+ "\n",
+ "# 选择优化器https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/fluid/optimizer/MomentumOptimizer_cn.html\n",
+ "optimizer = fluid.optimizer.MomentumOptimizer(learning_rate=learning_rate, momentum=0.9)\n",
+ "opts = optimizer.minimize(avg_cost)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [],
+ "source": [
+ "# 定义训练程序\r\n",
+ "test_program = fluid.default_main_program().clone(for_test=True)\r\n",
+ "use_cuda = False\r\n",
+ "place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()\r\n",
+ "exe = fluid.Executor(place)\r\n",
+ "exe.run(fluid.default_startup_program())\r\n",
+ "\r\n",
+ "feeder = fluid.DataFeeder(place=place, feed_list=[x, y])\r\n",
+ "\r\n",
+ "losses = []\r\n",
+ "for pass_id in range(EPOCH_NUM):\r\n",
+ " loss = []\r\n",
+ " for batch_id, data in enumerate(train_reader()):\r\n",
+ " train_cost = exe.run(program=fluid.default_main_program(), feed=feeder.feed(data), fetch_list=[avg_cost]) \r\n",
+ " loss.append(train_cost[0][0]) \r\n",
+ " losses.append(np.mean(loss))\r\n",
+ " if pass_id % 10==0:\r\n",
+ " print('Epoch:', pass_id, 'loss:', np.mean(loss))\r\n",
+ "\r\n",
+ "fluid.io.save_inference_model('./pd', ['x'], [pred], exe)\r\n",
+ "\r\n",
+ "plt.figure(dpi=50,figsize=(24,8))\r\n",
+ "plt.plot(range(EPOCH_NUM), losses)\r\n",
+ "plt.xlabel('epoch')\r\n",
+ "plt.ylabel('Loss')\r\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": [
+ "效果如下\n",
+ "\n",
+ "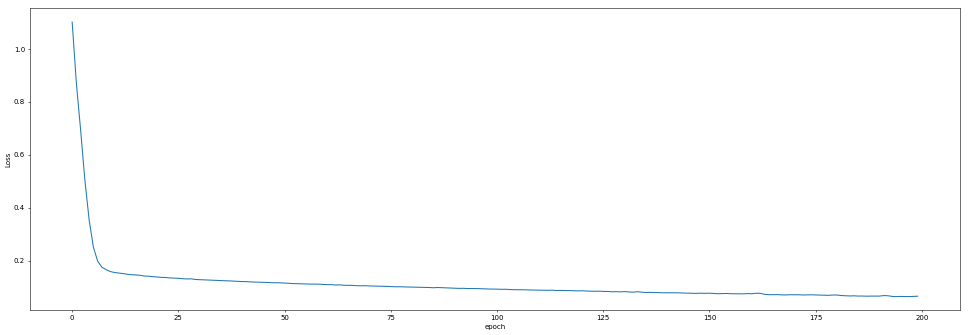"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": [
+ "## 6. 模型评估\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [],
+ "source": [
+ "infer_exe = fluid.Executor(place)\r\n",
+ "inference_scope = fluid.core.Scope()\r\n",
+ "def convert2LODTensor(temp_arr, len_list):\r\n",
+ " temp_arr = np.array(temp_arr) \r\n",
+ " temp_arr = temp_arr.flatten().reshape((-1, 1))#把测试样本的array平坦化到一维数据[N,1]的格式\r\n",
+ " print(temp_arr.shape)\r\n",
+ " return fluid.create_lod_tensor(\r\n",
+ " data=temp_arr,#对测试样本来说这里表示样本的平坦化数据列表,维度为[N,1]\r\n",
+ " recursive_seq_lens =[len_list],#对于测试样本来说这里labels列的数量\r\n",
+ " place=fluid.CPUPlace()\r\n",
+ " )#返回:A fluid LoDTensor object with tensor data and recursive_seq_lens info\r\n",
+ " \r\n",
+ "def get_tensor_label(mini_batch): \r\n",
+ " tensor = None\r\n",
+ " labels = []\r\n",
+ " \r\n",
+ " temp_arr = []\r\n",
+ " len_list = []\r\n",
+ " for _ in mini_batch: #mini_batch表示测试样本数据\r\n",
+ " labels.append(_[1]) #收集 label----y----------1维\r\n",
+ " temp_arr.append(_[0]) #收集序列本身--x---------96维\r\n",
+ " len_list.append(len(_[0])) #收集每个序列x的长度,和上边x的维度对应,这里全为6\r\n",
+ " tensor = convert2LODTensor(temp_arr, len_list) \r\n",
+ " return tensor, labels\r\n",
+ "\r\n",
+ "\r\n",
+ "if flag==0: # 全连接神经网络的数据处理\r\n",
+ " tester_reader = readers(test_x, test_y)\r\n",
+ " test_reader = paddle.batch(tester_reader, batch_size=31)\r\n",
+ " test_data = next(test_reader())\r\n",
+ " test_x = np.array([data[0] for data in test_data]).astype(\"float32\")\r\n",
+ " test_y= np.array([data[1] for data in test_data]).astype(\"float32\")\r\n",
+ "else: # LSTM 网络的数据处理\r\n",
+ " test_x = test_x.astype(\"float32\")\r\n",
+ " test_y= test_y.astype(\"float32\")\r\n",
+ " tester_reader = readers(test_x, test_y)\r\n",
+ " test_reader = paddle.batch(tester_reader, batch_size=31-day_num)#一次性把样本取完\r\n",
+ " for mini_batch in test_reader():\r\n",
+ " test_x,labels = get_tensor_label(mini_batch)#其实就是变成tensor格式的x和y\r\n",
+ " break\r\n",
+ " \r\n",
+ " \r\n",
+ "print(test_x.shape)\r\n",
+ "with fluid.scope_guard(inference_scope):\r\n",
+ " [inference_program, feed_target_names, fetch_targets] =\\\r\n",
+ " fluid.io.load_inference_model('./pd', infer_exe)\r\n",
+ " results = infer_exe.run(inference_program,\r\n",
+ " feed={feed_target_names[0]: test_x},\r\n",
+ " fetch_list=fetch_targets)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [],
+ "source": [
+ "# print(results)\r\n",
+ "if normalization==0: \r\n",
+ " results= (Max_y - Min_y)*results+Min_y\r\n",
+ " test_y= (Max_y - Min_y)*test_y+Min_y\r\n",
+ "else:\r\n",
+ " results = results*sgma_y+mu_y\r\n",
+ " test_y = test_y*sgma_y + mu_y\r\n",
+ "print(test_y.shape)\r\n",
+ "\r\n",
+ "y1 = np.reshape(results, (1,test_y.shape[0]*test_y.shape[1]))\r\n",
+ "y2 = np.reshape(test_y, (1,test_y.shape[0]*test_y.shape[1]))\r\n",
+ "print(y1[0, :].shape)\r\n",
+ "plt.figure(dpi=50,figsize=(24,8))\r\n",
+ "plt.plot(range(date_n*96), y1[0, :date_n*96], color='r', label='Real')\r\n",
+ "plt.plot(range(date_n*96), y2[0, :date_n*96], color='g', label='Predict') #绿线为预测值\r\n",
+ "plt.xlabel('Time', fontsize = 20)\r\n",
+ "plt.ylabel('Load', fontsize = 20)\r\n",
+ "plt.legend()\r\n",
+ "plt.show()\r\n",
+ "\r\n",
+ "print(results.shape)\r\n",
+ "# print(test_y)\r\n",
+ "s = \"真值-预测分割线 \"\r\n",
+ "# print(\"{:*^90}\".format(s))\r\n",
+ "# print(results)\r\n",
+ "mape = np.mean(np.abs((results - test_y) / test_y)) * 100\r\n",
+ "error = abs(results - test_y)\r\n",
+ "# print(mape)\r\n",
+ "print(results.shape)\r\n",
+ "test_y.resize((31-day_num,96))\r\n",
+ "results.resize((31-day_num,96))\r\n",
+ "error.resize((31-day_num,96))\r\n",
+ "# print(mape)\r\n",
+ "# print(error)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": [
+ "使用评估数据评估训练好的模型,检查预测值与真实值的差异。\n",
+ "\n",
+ "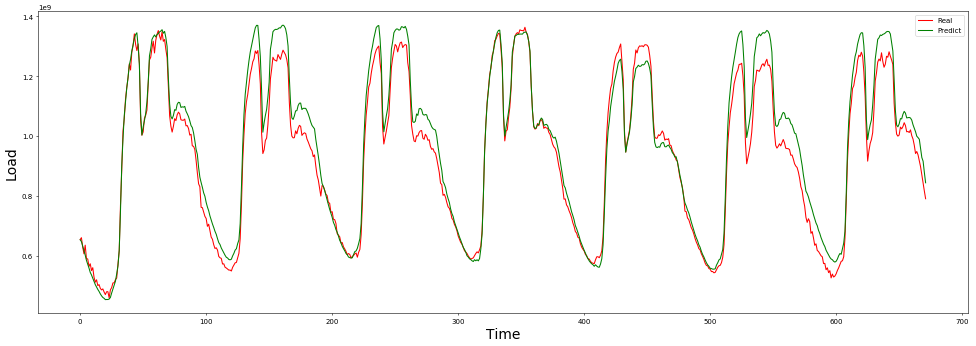\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": [
+ "\n",
+ "## 7. 模型预测\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [],
+ "source": [
+ "df_test_y = pd.DataFrame(test_y)\r\n",
+ "df_results = pd.DataFrame(results)\r\n",
+ "df_error = pd.DataFrame(error)\r\n",
+ "# print(df_results)\r\n",
+ "\r\n",
+ "from mpl_toolkits.mplot3d import Axes3D\r\n",
+ "import matplotlib.pyplot as plt\r\n",
+ "import pandas as pd\r\n",
+ "import seaborn as sns\r\n",
+ "%matplotlib inline\r\n",
+ "my_dpi=96\r\n",
+ "plt.figure(figsize=(480/my_dpi, 480/my_dpi), dpi=my_dpi)\r\n",
+ "data = df_test_y\r\n",
+ "df=data.unstack().reset_index() \r\n",
+ "df.columns=[\"X\",\"Y\",\"Z\"]\r\n",
+ " \r\n",
+ "df['X']=pd.Categorical(df['X'])\r\n",
+ "df['X']=df['X'].cat.codes\r\n",
+ " \r\n",
+ "fig = plt.figure(figsize=(15,5))\r\n",
+ "ax = fig.gca(projection='3d')\r\n",
+ "#交换X,Y,可以旋转90度\r\n",
+ "surf=ax.plot_trisurf(df['X'], df['Y'], df['Z'], cmap=plt.cm.viridis, linewidth=0.2)\r\n",
+ "# surf=surf.rotate(90)\r\n",
+ "fig.colorbar( surf, shrink=0.5, aspect=5)\r\n",
+ "ax.set_xlabel('Time', fontsize = 15)\r\n",
+ "ax.set_ylabel('Day', fontsize = 15)\r\n",
+ "ax.set_zlabel('Load', fontsize = 15)\r\n",
+ "ax.set_title('Actual value of load', fontsize = 20)\r\n",
+ "\r\n",
+ "plt.show()\r\n",
+ "#********************\r\n",
+ "data = df_results\r\n",
+ "df=data.unstack().reset_index() \r\n",
+ "df.columns=[\"X\",\"Y\",\"Z\"]\r\n",
+ " \r\n",
+ "df['X']=pd.Categorical(df['X'])\r\n",
+ "df['X']=df['X'].cat.codes\r\n",
+ " \r\n",
+ "fig = plt.figure(figsize=(15,5))\r\n",
+ "ax = fig.gca(projection='3d')\r\n",
+ "#交换X,Y,可以旋转90度\r\n",
+ "surf=ax.plot_trisurf(df['X'], df['Y'], df['Z'], cmap=plt.cm.viridis, linewidth=0.2)\r\n",
+ "# surf=surf.rotate(90)\r\n",
+ "ax.set_xlabel('Time', fontsize = 15)\r\n",
+ "ax.set_ylabel('Day', fontsize = 15)\r\n",
+ "ax.set_zlabel('Load', fontsize = 15)\r\n",
+ "ax.set_title('Predicted value of load', fontsize = 20)\r\n",
+ "fig.colorbar( surf, shrink=0.5, aspect=5)\r\n",
+ "plt.show()\r\n",
+ "#********************\r\n",
+ "data = df_error\r\n",
+ "df=data.unstack().reset_index() \r\n",
+ "df.columns=[\"X\",\"Y\",\"Z\"]\r\n",
+ " \r\n",
+ "df['X']=pd.Categorical(df['X'])\r\n",
+ "df['X']=df['X'].cat.codes\r\n",
+ " \r\n",
+ "fig = plt.figure(figsize=(15,5))\r\n",
+ "ax = fig.gca(projection='3d')\r\n",
+ "# ax = fig.gca(projection='2d')\r\n",
+ "#交换X,Y,可以旋转90度\r\n",
+ "surf=ax.plot_trisurf(df['Y'], df['X'], df['Z'], cmap=plt.cm.viridis, linewidth=0.2)\r\n",
+ "# surf=surf.rotate(90)\r\n",
+ "# cax = ax.matshow(surf, cmap='GnBu')\r\n",
+ "ax.set_xlabel('Time', fontsize = 15)\r\n",
+ "ax.set_ylabel('Day', fontsize = 15)\r\n",
+ "ax.set_zlabel('Load', fontsize = 15)\r\n",
+ "ax.set_title('Predicted error of load', fontsize = 20)\r\n",
+ "fig.colorbar( surf, shrink=0.5, aspect=10)\r\n",
+ "plt.show()\r\n",
+ "#********************画误差图"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": [
+ "利用模型对30天后的用电量进行预测,展示效果如下。\n",
+ "\n",
+ "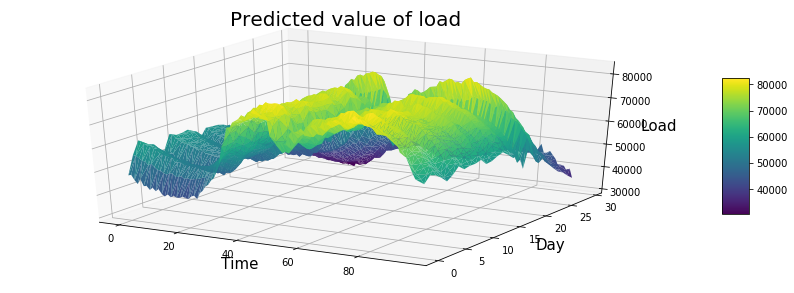\n",
+ "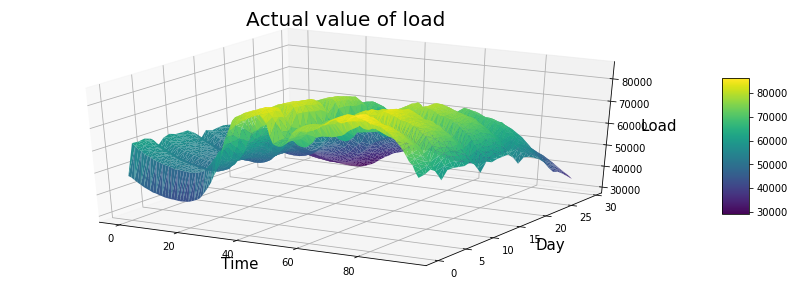\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": [
+ "## 8. 心得总结\n",
+ "本项目利用前几天的气象因素和用电量预测未来一段时间的用电量,从原理上比简单的时间序列预测模型更加可靠,因为仅凭历年同一天的用电量去预测其他年份当天的用电量未能从用电量的众多影响因素去建立模型,未来有望在空气质量预测以及水环境质量预测等领域应用。\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": [
+ "请点击[此处](https://ai.baidu.com/docs#/AIStudio_Project_Notebook/a38e5576)查看本环境基本用法.
\n",
+ "Please click [here ](https://ai.baidu.com/docs#/AIStudio_Project_Notebook/a38e5576) for more detailed instruction``s. "
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "py35-paddle1.2.0"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 1
+}
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 00000000..261eeb9e
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/Load_Forcast(1).xlsx b/Load_Forcast(1).xlsx
new file mode 100644
index 00000000..05a0abf9
Binary files /dev/null and b/Load_Forcast(1).xlsx differ
diff --git a/Prediction-of-electricity-consumption-based-on-neural-network-algorithm-main b/Prediction-of-electricity-consumption-based-on-neural-network-algorithm-main
new file mode 100644
index 00000000..ad41b933
--- /dev/null
+++ b/Prediction-of-electricity-consumption-based-on-neural-network-algorithm-main
@@ -0,0 +1,477 @@
+# 基于神经网络算法的用电量预测
+
+作者信息:linsl1986 (https://github.com/linsl1986)
+
+我在AI Studio上获得白银等级,点亮1个徽章,来互关呀~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/134639
+
+## 1. 简要介绍
+开展电力系统用电量及负荷预测的目的是:为了电力系统供电范围内电力工业的发展能够适应国民经济和社会发展的需要。
+
+用电量及负荷预测是电力工业生产建设计划及经营管理的基础,又是电力系统规划设计的基础。
+
+本项目以A地区一年的用电量和相应的气象因素为依据,使用神经网络算法进行电量及负荷预测。
+
+
+
+本项目使用神经网络模型进行预测,其基本流程如图
+
+
+
+神经网络模型预测的基本原理如下
+
+
+
+
+## 2. 环境设置
+导入包,设置所用的归一化方法、神经网络结构、训练轮数和预测时间段等信息
+
+```python
+import pandas as pd
+import numpy as np
+import paddle
+import paddle.fluid as fluid
+import numpy as np
+import pickle
+from tqdm import tqdm
+import matplotlib.pyplot as plt
+# 选择归一化方法
+normalization=1 # 0表示Max-min归一化, 1表示Zscore归一化
+# 选择神经网络
+flag = 0 # 0表示全连接神经网络, 1表示LSTM神经网络
+day_num = 1 # 选择前一天的特征作为输入数据。
+# 训练参数设置
+BATCH_SIZE = 5
+learning_rate = 0.001
+EPOCH_NUM = 200
+
+# 可视化天数选择,建议大于7,这样才能展示一周的预测情况
+date_n = 7
+```
+
+
+## 3. 数据集
+本数据集包含了近一年A地区用电量以及气象要素的原始数据,每天有96个时刻的温度,湿度,风速,降雨和用电量。
+具体步骤包括:
+
+1、从excel中读取数据
+
+
+
+2、划分训练集和测试集。由于本项目是基于N天的用电量和气象要素等信息预测N+1天的用电量,因此训练集和测试集的数据是需要连续若干天的,这里有别于多元线性回归时的训练集和测试集的划分过程。
+
+
+
+
+3、数据集调整思路
+* 减少特征,也就是不考虑温度,湿度,风速,降雨和负荷数据中的一种或者多种,重新构建输入特征
+* 使用前几天的数据预测性后一天的负荷,修改上面的day_num数值
+* 由于温度,湿度,风速,降雨等数据是可以预测得到的,因此在输入特征中添加后一天的温度,湿度,风速,降雨。
+
+讲述数据集的一些基础信息,描述数据集组成等。进行数据集的下载、抽样查看、数据集定义等。
+
+```python
+# 从excel中读取温度,湿度,风速,降雨和用电量数据
+train_set = []
+test_set = []
+for i in range(5):
+ sheet = pd.read_excel('work/Load_Forcast.xlsx',
+ sheet_name = i,usecols = range(1,97))
+ train_set.append(sheet[0:365].values)#对应excel中的第2行到366行
+ test_set.append(sheet[365:365+31].values)#对应excel中第367行到397行
+print(train_set[0].shape)
+print(test_set[0].shape)
+```
+```python
+#生成训练集和测试集
+def data_pro(train_set, test_set, day_num):
+ # 定义训练标签数据
+ train_y = train_set[4]
+ # 数据为一年的用电量数据,共365天,由于前一天day_num的数据作为输入,因此需要删去第一天的数据
+ train_y = train_y[day_num:, :]
+ print(train_y.shape)
+ # print(train_y[0]) #检验是否已经删除了第一天的数据
+
+ # 选择特征,定义训练的输入数据
+ # train_set[0]表示温度数据,train_set[1]:表示湿度数据,train_set[2]:表示风速数据, train_set[3]:表示降雨数据, train_set[4]:表示用电量数据,
+
+
+ temperature_data = train_set[0]
+ humidity_data = train_set[1]
+ wind_velocity_data = train_set[2]
+ rainfall_data = train_set[3]
+ load_data = train_set[4]
+
+ # 将温度,湿度,风速,降雨,用电量合并,成为输入的特征向量,所以有96*5=480列数据
+ train_x_temp = np.concatenate((temperature_data,humidity_data, wind_velocity_data, rainfall_data, load_data),axis = 1)
+ temp = []
+ for x in range(day_num):
+ temp.append(train_x_temp[x:(365-day_num+x), :]) # 训练集的输入train_x中删除第一年的最后一天的数据
+
+ train_x = np.concatenate(temp, axis=1)
+ print(train_x.shape)
+ # print(train_x[363])#检验训练集的输入train_x最后一组数据
+
+
+ # 根据选择特征的定义,修改测试集的数据
+ # 修改测试集的标签数据
+ test_y = test_set[0-day_num]
+ test_y = test_y[day_num:, :]
+ print(test_y.shape)
+ # 修改测试集的输入数据
+ temperature_data = test_set[0]
+ humidity_data = test_set[1]
+ wind_velocity_data = test_set[2]
+ rainfall_data = test_set[3]
+ load_data = test_set[4]
+ test_x_temp = np.concatenate((temperature_data,humidity_data, wind_velocity_data, rainfall_data, load_data),axis = 1)
+
+ temp = []
+ for x in range(day_num):
+ temp.append(test_x_temp[x:(31-day_num+x), :])
+ # print(test_x_temp[x:(31-day_num+x), :].shape)
+
+ test_x = np.concatenate(temp, axis=1)
+ print(test_x.shape)
+
+
+ return train_x, train_y, test_x, test_y
+
+
+train_x, train_y, test_x, test_y = data_pro(train_set=train_set, test_set=test_set, day_num=day_num)
+```
+
+```python
+#本部分为数据归一化的代码,一般不需要修改
+if normalization==0: # 使用Max-min归一化处理函数
+ def normalization_Maxmin(train_x):
+ Min = np.min(train_x, axis=0)
+ Max = np.max(train_x, axis=0)
+ train_x = (train_x-Min)/ (Max - Min)
+ # 处理异常情况
+ train_x[np.isnan(train_x)] = 0
+ train_x[np.isinf(train_x)] = 0
+ return train_x, Min, Max
+
+ # 对输入数据进行归一化处理
+ train_x, Min_x, Max_x = normalization_Maxmin(train_x)
+ test_x = (test_x -Min_x)/ (Max_x - Min_x)
+ # 对输出数据进行归一化处理
+ train_y, Min_y, Max_y = normalization_Maxmin(train_y)
+ test_y = (test_y-Min_y)/ (Max_y - Min_y)
+else:#zscore归一化处理函数,适用于数据服从正态分布
+ def normalization_zscore(train_x):
+ mu = np.mean(train_x, axis=0)
+ sigma = np.std(train_x, axis=0)
+ train_x = (train_x-mu)/sigma
+ # 处理异常情况
+ train_x[np.isnan(train_x)] = 0
+ train_x[np.isinf(train_x)] = 0
+ return train_x, mu, sigma
+
+ # 对输入数据进行归一化处理
+ train_x, mu_x, sgma_x = normalization_zscore(train_x)
+ test_x = (test_x - mu_x)/sgma_x
+ # 对输出数据进行归一化处理
+ train_y, mu_y, sgma_y = normalization_zscore(train_y)
+ test_y = (test_y-mu_y)/sgma_y
+
+```
+
+## 4. 模型组网
+下面的示例中,使用全连接神经网络,可以修改成其他神经网络,例如LSTM。**注意,因为预测的负荷十五分钟一个时刻,一天共96个时刻,所以输出的维度必须为96。**
+
+```python
+# 定义全连接神经网络
+def Full_connected(input):
+ hidden1 = fluid.layers.fc(input=input, size=50, act='relu')
+ hidden2 = fluid.layers.fc(input=hidden1, size=50, act='relu')
+ hidden3 = fluid.layers.fc(input=hidden2, size=50, act='relu')
+ hidden4 = fluid.layers.fc(input=hidden3, size=50, act='relu')
+ prediction = fluid.layers.fc(input=hidden2, size=96, act=None)
+ return prediction
+
+# 定义LSTM
+def LSTM_pre(x):
+ # Lstm layer
+ fc0 = fluid.layers.fc(input=x, size=16)
+ lstm_h, c = fluid.layers.dynamic_lstm(input=fc0, size=16, is_reverse=False)
+
+ # max pooling layer
+ lstm_max = fluid.layers.sequence_pool(input=lstm_h, pool_type='max')
+ lstm_max_tanh = fluid.layers.tanh(lstm_max)
+
+ # full connect layer
+ # lstm_max_tanh = fluid.layers.fc(input=lstm_max_tanh, size=16, act='relu')
+ prediction = fluid.layers.fc(input=lstm_max_tanh, size=96, act=None)# 'tanh')
+ return prediction
+
+```
+## 5. 模型训练
+使用模型网络结构和数据集进行模型训练。具体包括如下步骤
+
+1、定义数据生成器
+
+2、定义训练时数据的读取方式、损失函数和优化器
+
+3、定义训练程序
+
+
+```python
+#定义数据生成器
+def readers(x, y):
+ def reader():
+ for i in range(x.shape[0]):
+ yield x[i], y[i]
+ return reader
+
+# 定义数据读取方式
+trainer_reader = readers(train_x, train_y)
+train_reader = paddle.batch(
+ paddle.reader.shuffle(
+ reader=trainer_reader,buf_size=300),
+ batch_size=BATCH_SIZE)
+
+paddle.enable_static()# PaddlePaddle 2.x需要使用这句话才能进行静态模型
+
+# 搭建神经网络
+if flag==0: # 使用全连接神经网络
+ # 定义神经网络输入和输出, 注意输入的维度必须和选择特征的维度一致, 输出的维度必须为96
+ x = fluid.layers.data(name='x', shape=[480*day_num], dtype='float32')
+ y = fluid.layers.data(name='y', shape=[96], dtype='float32')
+
+ # 选择神经网络
+ pred = Full_connected(x)
+else:
+ # 定义神经网络输入和输出, 注意输入的维度必须和选择特征的维度一致, 输出的维度必须为96
+ x = fluid.layers.data(name='x', shape=[1], dtype='float32', lod_level=1)
+ y = fluid.layers.data(name='y', shape=[96], dtype='float32')
+
+ # 选择神经网络
+ pred = LSTM_pre(x)
+
+# 定义损失函数
+cost = fluid.layers.square_error_cost(input=pred, label=y)
+avg_cost = fluid.layers.mean(cost)
+
+# 选择优化器https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/fluid/optimizer/MomentumOptimizer_cn.html
+optimizer = fluid.optimizer.MomentumOptimizer(learning_rate=learning_rate, momentum=0.9)
+opts = optimizer.minimize(avg_cost)
+
+
+# 定义训练程序
+test_program = fluid.default_main_program().clone(for_test=True)
+use_cuda = False
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+exe = fluid.Executor(place)
+exe.run(fluid.default_startup_program())
+
+feeder = fluid.DataFeeder(place=place, feed_list=[x, y])
+
+losses = []
+for pass_id in range(EPOCH_NUM):
+ loss = []
+ for batch_id, data in enumerate(train_reader()):
+ train_cost = exe.run(program=fluid.default_main_program(), feed=feeder.feed(data), fetch_list=[avg_cost])
+ loss.append(train_cost[0][0])
+ losses.append(np.mean(loss))
+ if pass_id % 10==0:
+ print('Epoch:', pass_id, 'loss:', np.mean(loss))
+
+fluid.io.save_inference_model('./pd', ['x'], [pred], exe)
+
+plt.figure(dpi=50,figsize=(24,8))
+plt.plot(range(EPOCH_NUM), losses)
+plt.xlabel('epoch')
+plt.ylabel('Loss')
+plt.show()
+
+```
+
+效果如下
+
+
+
+
+## 6. 模型评估
+使用评估数据评估训练好的模型,检查预测值与真实值的差异。
+
+
+
+```python
+infer_exe = fluid.Executor(place)
+inference_scope = fluid.core.Scope()
+def convert2LODTensor(temp_arr, len_list):
+ temp_arr = np.array(temp_arr)
+ temp_arr = temp_arr.flatten().reshape((-1, 1))#把测试样本的array平坦化到一维数据[N,1]的格式
+ print(temp_arr.shape)
+ return fluid.create_lod_tensor(
+ data=temp_arr,#对测试样本来说这里表示样本的平坦化数据列表,维度为[N,1]
+ recursive_seq_lens =[len_list],#对于测试样本来说这里labels列的数量
+ place=fluid.CPUPlace()
+ )#返回:A fluid LoDTensor object with tensor data and recursive_seq_lens info
+
+def get_tensor_label(mini_batch):
+ tensor = None
+ labels = []
+
+ temp_arr = []
+ len_list = []
+ for _ in mini_batch: #mini_batch表示测试样本数据
+ labels.append(_[1]) #收集 label----y----------1维
+ temp_arr.append(_[0]) #收集序列本身--x---------96维
+ len_list.append(len(_[0])) #收集每个序列x的长度,和上边x的维度对应,这里全为6
+ tensor = convert2LODTensor(temp_arr, len_list)
+ return tensor, labels
+
+
+if flag==0: # 全连接神经网络的数据处理
+ tester_reader = readers(test_x, test_y)
+ test_reader = paddle.batch(tester_reader, batch_size=31)
+ test_data = next(test_reader())
+ test_x = np.array([data[0] for data in test_data]).astype("float32")
+ test_y= np.array([data[1] for data in test_data]).astype("float32")
+else: # LSTM 网络的数据处理
+ test_x = test_x.astype("float32")
+ test_y= test_y.astype("float32")
+ tester_reader = readers(test_x, test_y)
+ test_reader = paddle.batch(tester_reader, batch_size=31-day_num)#一次性把样本取完
+ for mini_batch in test_reader():
+ test_x,labels = get_tensor_label(mini_batch)#其实就是变成tensor格式的x和y
+ break
+
+
+print(test_x.shape)
+with fluid.scope_guard(inference_scope):
+ [inference_program, feed_target_names, fetch_targets] =\
+ fluid.io.load_inference_model('./pd', infer_exe)
+ results = infer_exe.run(inference_program,
+ feed={feed_target_names[0]: test_x},
+ fetch_list=fetch_targets)
+
+```
+
+```python
+
+# print(results)
+if normalization==0:
+ results= (Max_y - Min_y)*results+Min_y
+ test_y= (Max_y - Min_y)*test_y+Min_y
+else:
+ results = results*sgma_y+mu_y
+ test_y = test_y*sgma_y + mu_y
+print(test_y.shape)
+
+y1 = np.reshape(results, (1,test_y.shape[0]*test_y.shape[1]))
+y2 = np.reshape(test_y, (1,test_y.shape[0]*test_y.shape[1]))
+print(y1[0, :].shape)
+plt.figure(dpi=50,figsize=(24,8))
+plt.plot(range(date_n*96), y1[0, :date_n*96], color='r', label='Real')
+plt.plot(range(date_n*96), y2[0, :date_n*96], color='g', label='Predict') #绿线为预测值
+plt.xlabel('Time', fontsize = 20)
+plt.ylabel('Load', fontsize = 20)
+plt.legend()
+plt.show()
+
+print(results.shape)
+# print(test_y)
+s = "真值-预测分割线 "
+# print("{:*^90}".format(s))
+# print(results)
+mape = np.mean(np.abs((results - test_y) / test_y)) * 100
+error = abs(results - test_y)
+# print(mape)
+print(results.shape)
+test_y.resize((31-day_num,96))
+results.resize((31-day_num,96))
+error.resize((31-day_num,96))
+# print(mape)
+# print(error)
+
+```
+
+
+
+## 7. 模型预测
+利用模型对30天后的用电量进行预测,
+
+```python
+df_test_y = pd.DataFrame(test_y)
+df_results = pd.DataFrame(results)
+df_error = pd.DataFrame(error)
+# print(df_results)
+
+from mpl_toolkits.mplot3d import Axes3D
+import matplotlib.pyplot as plt
+import pandas as pd
+import seaborn as sns
+%matplotlib inline
+my_dpi=96
+plt.figure(figsize=(480/my_dpi, 480/my_dpi), dpi=my_dpi)
+data = df_test_y
+df=data.unstack().reset_index()
+df.columns=["X","Y","Z"]
+
+df['X']=pd.Categorical(df['X'])
+df['X']=df['X'].cat.codes
+
+fig = plt.figure(figsize=(15,5))
+ax = fig.gca(projection='3d')
+#交换X,Y,可以旋转90度
+surf=ax.plot_trisurf(df['X'], df['Y'], df['Z'], cmap=plt.cm.viridis, linewidth=0.2)
+# surf=surf.rotate(90)
+fig.colorbar( surf, shrink=0.5, aspect=5)
+ax.set_xlabel('Time', fontsize = 15)
+ax.set_ylabel('Day', fontsize = 15)
+ax.set_zlabel('Load', fontsize = 15)
+ax.set_title('Actual value of load', fontsize = 20)
+
+plt.show()
+#********************
+data = df_results
+df=data.unstack().reset_index()
+df.columns=["X","Y","Z"]
+
+df['X']=pd.Categorical(df['X'])
+df['X']=df['X'].cat.codes
+
+fig = plt.figure(figsize=(15,5))
+ax = fig.gca(projection='3d')
+#交换X,Y,可以旋转90度
+surf=ax.plot_trisurf(df['X'], df['Y'], df['Z'], cmap=plt.cm.viridis, linewidth=0.2)
+# surf=surf.rotate(90)
+ax.set_xlabel('Time', fontsize = 15)
+ax.set_ylabel('Day', fontsize = 15)
+ax.set_zlabel('Load', fontsize = 15)
+ax.set_title('Predicted value of load', fontsize = 20)
+fig.colorbar( surf, shrink=0.5, aspect=5)
+plt.show()
+#********************
+data = df_error
+df=data.unstack().reset_index()
+df.columns=["X","Y","Z"]
+
+df['X']=pd.Categorical(df['X'])
+df['X']=df['X'].cat.codes
+
+fig = plt.figure(figsize=(15,5))
+ax = fig.gca(projection='3d')
+# ax = fig.gca(projection='2d')
+#交换X,Y,可以旋转90度
+surf=ax.plot_trisurf(df['Y'], df['X'], df['Z'], cmap=plt.cm.viridis, linewidth=0.2)
+# surf=surf.rotate(90)
+# cax = ax.matshow(surf, cmap='GnBu')
+ax.set_xlabel('Time', fontsize = 15)
+ax.set_ylabel('Day', fontsize = 15)
+ax.set_zlabel('Load', fontsize = 15)
+ax.set_title('Predicted error of load', fontsize = 20)
+fig.colorbar( surf, shrink=0.5, aspect=10)
+plt.show()
+#********************画误差图
+
+```
+
+展示效果如下。
+
+
+
+
diff --git a/Prediction-of-electricity-consumption-based-on-neural-network-algorithm-main.zip b/Prediction-of-electricity-consumption-based-on-neural-network-algorithm-main.zip
new file mode 100644
index 00000000..ad1e9ffe
Binary files /dev/null and b/Prediction-of-electricity-consumption-based-on-neural-network-algorithm-main.zip differ
diff --git a/README.md b/README.md
index b4a2f6ff..3631d258 100644
--- a/README.md
+++ b/README.md
@@ -1,72 +1,475 @@
-# Deep Learning with PaddlePaddle
+# 基于神经网络算法的用电量预测
-[](https://travis-ci.org/PaddlePaddle/book)
-[](https://github.com/PaddlePaddle/book/blob/develop/README.md)
-[](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md)
+作者信息:linsl1986 (https://github.com/linsl1986)
-1. [Fit a Line](https://www.paddlepaddle.org.cn/documentation/docs/en/develop/beginners_guide/basics/fit_a_line/README.html)
-1. [Recognize Digits](https://www.paddlepaddle.org.cn/documentation/docs/en/develop/beginners_guide/basics/recognize_digits/README.html)
-1. [Image Classification](https://www.paddlepaddle.org.cn/documentation/docs/en/develop/beginners_guide/basics/image_classification/index_en.html)
-1. [Word to Vector](https://www.paddlepaddle.org.cn/documentation/docs/en/develop/beginners_guide/basics/word2vec/index_en.html)
-1. [Recommender System](https://www.paddlepaddle.org.cn/documentation/docs/en/develop/beginners_guide/basics/recommender_system/index_en.html)
-1. [Understand Sentiment](https://www.paddlepaddle.org.cn/documentation/docs/en/develop/beginners_guide/basics/understand_sentiment/index_en.html)
-1. [Label Semantic Roles](https://www.paddlepaddle.org.cn/documentation/docs/en/develop/beginners_guide/basics/label_semantic_roles/index_en.html)
-1. [Machine Translation](https://www.paddlepaddle.org.cn/documentation/docs/en/develop/beginners_guide/basics/machine_translation/index_en.html)
+我在AI Studio上获得白银等级,点亮1个徽章,来互关呀~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/134639
-## Running the Book
+## 1. 简要介绍
-This book you are reading is interactive -- each chapter can run as a Jupyter Notebook.
+开展电力系统用电量及负荷预测的目的是:为了电力系统供电范围内电力工业的发展能够适应国民经济和社会发展的需要。
-We packed this book, Jupyter, PaddlePaddle, and all dependencies into a Docker image. So you don't need to install anything except Docker. If you are using Windows, please follow [this installation guide](https://www.docker.com/docker-windows). If you are running Mac, please follow [this](https://www.docker.com/docker-mac). For various Linux distros, please refer to https://www.docker.com. If you are using Windows or Mac, you might want to give Docker [more memory and CPUs/cores](http://stackoverflow.com/a/39720010/724872).
+用电量及负荷预测是电力工业生产建设计划及经营管理的基础,又是电力系统规划设计的基础。
-Just type
+本项目以A地区一年的用电量和相应的气象因素为依据,使用神经网络算法进行电量及负荷预测。
+
+
-```bash
-docker run -d -p 8888:8888 paddlepaddle/book
+本项目使用神经网络模型进行预测,其基本流程如图
+
+
+神经网络模型预测的基本原理如下
+
+
+
+
+## 2. 环境设置
+导入包,设置所用的归一化方法、神经网络结构、训练轮数和预测时间段等信息
+
+```python
+import pandas as pd
+import numpy as np
+import paddle
+import paddle.fluid as fluid
+import numpy as np
+import pickle
+from tqdm import tqdm
+import matplotlib.pyplot as plt
+# 选择归一化方法
+normalization=1 # 0表示Max-min归一化, 1表示Zscore归一化
+# 选择神经网络
+flag = 0 # 0表示全连接神经网络, 1表示LSTM神经网络
+day_num = 1 # 选择前一天的特征作为输入数据。
+# 训练参数设置
+BATCH_SIZE = 5
+learning_rate = 0.001
+EPOCH_NUM = 200
+
+# 可视化天数选择,建议大于7,这样才能展示一周的预测情况
+date_n = 7
```
-This command will download the pre-built Docker image from DockerHub.com and run it in a container. Please direct your Web browser to http://localhost:8888 to read the book.
-If you are living in somewhere slow to access DockerHub.com, you might try our mirror server hub.baidubce.com:
+## 3. 数据集
+本数据集包含了近一年A地区用电量以及气象要素的原始数据,每天有96个时刻的温度,湿度,风速,降雨和用电量。
+具体步骤包括:
+
+1、从excel中读取数据
+
+
+
+2、划分训练集和测试集。由于本项目是基于N天的用电量和气象要素等信息预测N+1天的用电量,因此训练集和测试集的数据是需要连续若干天的,这里有别于多元线性回归时的训练集和测试集的划分过程。
-```bash
-docker run -d -p 8888:8888 hub.baidubce.com/paddlepaddle/book
+
+
+3、数据集调整思路
+* 减少特征,也就是不考虑温度,湿度,风速,降雨和负荷数据中的一种或者多种,重新构建输入特征
+* 使用前几天的数据预测性后一天的负荷,修改上面的day_num数值
+* 由于温度,湿度,风速,降雨等数据是可以预测得到的,因此在输入特征中添加后一天的温度,湿度,风速,降雨。
+
+讲述数据集的一些基础信息,描述数据集组成等。进行数据集的下载、抽样查看、数据集定义等。
+
+```python
+# 从excel中读取温度,湿度,风速,降雨和用电量数据
+train_set = []
+test_set = []
+for i in range(5):
+ sheet = pd.read_excel('work/Load_Forcast.xlsx',
+ sheet_name = i,usecols = range(1,97))
+ train_set.append(sheet[0:365].values)#对应excel中的第2行到366行
+ test_set.append(sheet[365:365+31].values)#对应excel中第367行到397行
+print(train_set[0].shape)
+print(test_set[0].shape)
```
+```python
+#生成训练集和测试集
+def data_pro(train_set, test_set, day_num):
+ # 定义训练标签数据
+ train_y = train_set[4]
+ # 数据为一年的用电量数据,共365天,由于前一天day_num的数据作为输入,因此需要删去第一天的数据
+ train_y = train_y[day_num:, :]
+ print(train_y.shape)
+ # print(train_y[0]) #检验是否已经删除了第一天的数据
+
+ # 选择特征,定义训练的输入数据
+ # train_set[0]表示温度数据,train_set[1]:表示湿度数据,train_set[2]:表示风速数据, train_set[3]:表示降雨数据, train_set[4]:表示用电量数据,
+
+
+ temperature_data = train_set[0]
+ humidity_data = train_set[1]
+ wind_velocity_data = train_set[2]
+ rainfall_data = train_set[3]
+ load_data = train_set[4]
+
+ # 将温度,湿度,风速,降雨,用电量合并,成为输入的特征向量,所以有96*5=480列数据
+ train_x_temp = np.concatenate((temperature_data,humidity_data, wind_velocity_data, rainfall_data, load_data),axis = 1)
+ temp = []
+ for x in range(day_num):
+ temp.append(train_x_temp[x:(365-day_num+x), :]) # 训练集的输入train_x中删除第一年的最后一天的数据
+
+ train_x = np.concatenate(temp, axis=1)
+ print(train_x.shape)
+ # print(train_x[363])#检验训练集的输入train_x最后一组数据
-### Training with GPU
-By default we are using CPU for training, if you want to train with GPU, the steps are a little different.
+ # 根据选择特征的定义,修改测试集的数据
+ # 修改测试集的标签数据
+ test_y = test_set[0-day_num]
+ test_y = test_y[day_num:, :]
+ print(test_y.shape)
+ # 修改测试集的输入数据
+ temperature_data = test_set[0]
+ humidity_data = test_set[1]
+ wind_velocity_data = test_set[2]
+ rainfall_data = test_set[3]
+ load_data = test_set[4]
+ test_x_temp = np.concatenate((temperature_data,humidity_data, wind_velocity_data, rainfall_data, load_data),axis = 1)
-To make sure GPU can be successfully used from inside container, please install [nvidia-docker](https://github.com/NVIDIA/nvidia-docker). Then run:
+ temp = []
+ for x in range(day_num):
+ temp.append(test_x_temp[x:(31-day_num+x), :])
+ # print(test_x_temp[x:(31-day_num+x), :].shape)
+
+ test_x = np.concatenate(temp, axis=1)
+ print(test_x.shape)
-```bash
-nvidia-docker run -d -p 8888:8888 paddlepaddle/book:latest-gpu
+
+ return train_x, train_y, test_x, test_y
+
+
+train_x, train_y, test_x, test_y = data_pro(train_set=train_set, test_set=test_set, day_num=day_num)
+```
+
+```python
+#本部分为数据归一化的代码,一般不需要修改
+if normalization==0: # 使用Max-min归一化处理函数
+ def normalization_Maxmin(train_x):
+ Min = np.min(train_x, axis=0)
+ Max = np.max(train_x, axis=0)
+ train_x = (train_x-Min)/ (Max - Min)
+ # 处理异常情况
+ train_x[np.isnan(train_x)] = 0
+ train_x[np.isinf(train_x)] = 0
+ return train_x, Min, Max
+
+ # 对输入数据进行归一化处理
+ train_x, Min_x, Max_x = normalization_Maxmin(train_x)
+ test_x = (test_x -Min_x)/ (Max_x - Min_x)
+ # 对输出数据进行归一化处理
+ train_y, Min_y, Max_y = normalization_Maxmin(train_y)
+ test_y = (test_y-Min_y)/ (Max_y - Min_y)
+else:#zscore归一化处理函数,适用于数据服从正态分布
+ def normalization_zscore(train_x):
+ mu = np.mean(train_x, axis=0)
+ sigma = np.std(train_x, axis=0)
+ train_x = (train_x-mu)/sigma
+ # 处理异常情况
+ train_x[np.isnan(train_x)] = 0
+ train_x[np.isinf(train_x)] = 0
+ return train_x, mu, sigma
+
+ # 对输入数据进行归一化处理
+ train_x, mu_x, sgma_x = normalization_zscore(train_x)
+ test_x = (test_x - mu_x)/sgma_x
+ # 对输出数据进行归一化处理
+ train_y, mu_y, sgma_y = normalization_zscore(train_y)
+ test_y = (test_y-mu_y)/sgma_y
```
-Or you can use the image registry mirror in China:
+## 4. 模型组网
+下面的示例中,使用全连接神经网络,可以修改成其他神经网络,例如LSTM。**注意,因为预测的负荷十五分钟一个时刻,一天共96个时刻,所以输出的维度必须为96。**
-```bash
-nvidia-docker run -d -p 8888:8888 hub.baidubce.com/paddlepaddle/book:latest-gpu
+```python
+# 定义全连接神经网络
+def Full_connected(input):
+ hidden1 = fluid.layers.fc(input=input, size=50, act='relu')
+ hidden2 = fluid.layers.fc(input=hidden1, size=50, act='relu')
+ hidden3 = fluid.layers.fc(input=hidden2, size=50, act='relu')
+ hidden4 = fluid.layers.fc(input=hidden3, size=50, act='relu')
+ prediction = fluid.layers.fc(input=hidden2, size=96, act=None)
+ return prediction
+
+# 定义LSTM
+def LSTM_pre(x):
+ # Lstm layer
+ fc0 = fluid.layers.fc(input=x, size=16)
+ lstm_h, c = fluid.layers.dynamic_lstm(input=fc0, size=16, is_reverse=False)
+
+ # max pooling layer
+ lstm_max = fluid.layers.sequence_pool(input=lstm_h, pool_type='max')
+ lstm_max_tanh = fluid.layers.tanh(lstm_max)
+
+ # full connect layer
+ # lstm_max_tanh = fluid.layers.fc(input=lstm_max_tanh, size=16, act='relu')
+ prediction = fluid.layers.fc(input=lstm_max_tanh, size=96, act=None)# 'tanh')
+ return prediction
```
+## 5. 模型训练
+使用模型网络结构和数据集进行模型训练。具体包括如下步骤
+
+1、定义数据生成器
+
+2、定义训练时数据的读取方式、损失函数和优化器
+
+3、定义训练程序
+
+
-Change the code in the chapter that you are reading from
```python
+#定义数据生成器
+def readers(x, y):
+ def reader():
+ for i in range(x.shape[0]):
+ yield x[i], y[i]
+ return reader
+
+# 定义数据读取方式
+trainer_reader = readers(train_x, train_y)
+train_reader = paddle.batch(
+ paddle.reader.shuffle(
+ reader=trainer_reader,buf_size=300),
+ batch_size=BATCH_SIZE)
+
+paddle.enable_static()# PaddlePaddle 2.x需要使用这句话才能进行静态模型
+
+# 搭建神经网络
+if flag==0: # 使用全连接神经网络
+ # 定义神经网络输入和输出, 注意输入的维度必须和选择特征的维度一致, 输出的维度必须为96
+ x = fluid.layers.data(name='x', shape=[480*day_num], dtype='float32')
+ y = fluid.layers.data(name='y', shape=[96], dtype='float32')
+
+ # 选择神经网络
+ pred = Full_connected(x)
+else:
+ # 定义神经网络输入和输出, 注意输入的维度必须和选择特征的维度一致, 输出的维度必须为96
+ x = fluid.layers.data(name='x', shape=[1], dtype='float32', lod_level=1)
+ y = fluid.layers.data(name='y', shape=[96], dtype='float32')
+
+ # 选择神经网络
+ pred = LSTM_pre(x)
+
+# 定义损失函数
+cost = fluid.layers.square_error_cost(input=pred, label=y)
+avg_cost = fluid.layers.mean(cost)
+
+# 选择优化器https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/fluid/optimizer/MomentumOptimizer_cn.html
+optimizer = fluid.optimizer.MomentumOptimizer(learning_rate=learning_rate, momentum=0.9)
+opts = optimizer.minimize(avg_cost)
+
+
+# 定义训练程序
+test_program = fluid.default_main_program().clone(for_test=True)
use_cuda = False
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+exe = fluid.Executor(place)
+exe.run(fluid.default_startup_program())
+
+feeder = fluid.DataFeeder(place=place, feed_list=[x, y])
+
+losses = []
+for pass_id in range(EPOCH_NUM):
+ loss = []
+ for batch_id, data in enumerate(train_reader()):
+ train_cost = exe.run(program=fluid.default_main_program(), feed=feeder.feed(data), fetch_list=[avg_cost])
+ loss.append(train_cost[0][0])
+ losses.append(np.mean(loss))
+ if pass_id % 10==0:
+ print('Epoch:', pass_id, 'loss:', np.mean(loss))
+
+fluid.io.save_inference_model('./pd', ['x'], [pred], exe)
+
+plt.figure(dpi=50,figsize=(24,8))
+plt.plot(range(EPOCH_NUM), losses)
+plt.xlabel('epoch')
+plt.ylabel('Loss')
+plt.show()
+
```
+效果如下
+
+
+
+## 6. 模型评估
+使用评估数据评估训练好的模型,检查预测值与真实值的差异。
-to:
```python
-use_cuda = True
+infer_exe = fluid.Executor(place)
+inference_scope = fluid.core.Scope()
+def convert2LODTensor(temp_arr, len_list):
+ temp_arr = np.array(temp_arr)
+ temp_arr = temp_arr.flatten().reshape((-1, 1))#把测试样本的array平坦化到一维数据[N,1]的格式
+ print(temp_arr.shape)
+ return fluid.create_lod_tensor(
+ data=temp_arr,#对测试样本来说这里表示样本的平坦化数据列表,维度为[N,1]
+ recursive_seq_lens =[len_list],#对于测试样本来说这里labels列的数量
+ place=fluid.CPUPlace()
+ )#返回:A fluid LoDTensor object with tensor data and recursive_seq_lens info
+
+def get_tensor_label(mini_batch):
+ tensor = None
+ labels = []
+
+ temp_arr = []
+ len_list = []
+ for _ in mini_batch: #mini_batch表示测试样本数据
+ labels.append(_[1]) #收集 label----y----------1维
+ temp_arr.append(_[0]) #收集序列本身--x---------96维
+ len_list.append(len(_[0])) #收集每个序列x的长度,和上边x的维度对应,这里全为6
+ tensor = convert2LODTensor(temp_arr, len_list)
+ return tensor, labels
+
+
+if flag==0: # 全连接神经网络的数据处理
+ tester_reader = readers(test_x, test_y)
+ test_reader = paddle.batch(tester_reader, batch_size=31)
+ test_data = next(test_reader())
+ test_x = np.array([data[0] for data in test_data]).astype("float32")
+ test_y= np.array([data[1] for data in test_data]).astype("float32")
+else: # LSTM 网络的数据处理
+ test_x = test_x.astype("float32")
+ test_y= test_y.astype("float32")
+ tester_reader = readers(test_x, test_y)
+ test_reader = paddle.batch(tester_reader, batch_size=31-day_num)#一次性把样本取完
+ for mini_batch in test_reader():
+ test_x,labels = get_tensor_label(mini_batch)#其实就是变成tensor格式的x和y
+ break
+
+
+print(test_x.shape)
+with fluid.scope_guard(inference_scope):
+ [inference_program, feed_target_names, fetch_targets] =\
+ fluid.io.load_inference_model('./pd', infer_exe)
+ results = infer_exe.run(inference_program,
+ feed={feed_target_names[0]: test_x},
+ fetch_list=fetch_targets)
+
+```
+
+```python
+
+# print(results)
+if normalization==0:
+ results= (Max_y - Min_y)*results+Min_y
+ test_y= (Max_y - Min_y)*test_y+Min_y
+else:
+ results = results*sgma_y+mu_y
+ test_y = test_y*sgma_y + mu_y
+print(test_y.shape)
+
+y1 = np.reshape(results, (1,test_y.shape[0]*test_y.shape[1]))
+y2 = np.reshape(test_y, (1,test_y.shape[0]*test_y.shape[1]))
+print(y1[0, :].shape)
+plt.figure(dpi=50,figsize=(24,8))
+plt.plot(range(date_n*96), y1[0, :date_n*96], color='r', label='Real')
+plt.plot(range(date_n*96), y2[0, :date_n*96], color='g', label='Predict') #绿线为预测值
+plt.xlabel('Time', fontsize = 20)
+plt.ylabel('Load', fontsize = 20)
+plt.legend()
+plt.show()
+
+print(results.shape)
+# print(test_y)
+s = "真值-预测分割线 "
+# print("{:*^90}".format(s))
+# print(results)
+mape = np.mean(np.abs((results - test_y) / test_y)) * 100
+error = abs(results - test_y)
+# print(mape)
+print(results.shape)
+test_y.resize((31-day_num,96))
+results.resize((31-day_num,96))
+error.resize((31-day_num,96))
+# print(mape)
+# print(error)
+
```
-## Contribute
+
+
+## 7. 模型预测
+利用模型对30天后的用电量进行预测,
+
+```python
+df_test_y = pd.DataFrame(test_y)
+df_results = pd.DataFrame(results)
+df_error = pd.DataFrame(error)
+# print(df_results)
+
+from mpl_toolkits.mplot3d import Axes3D
+import matplotlib.pyplot as plt
+import pandas as pd
+import seaborn as sns
+%matplotlib inline
+my_dpi=96
+plt.figure(figsize=(480/my_dpi, 480/my_dpi), dpi=my_dpi)
+data = df_test_y
+df=data.unstack().reset_index()
+df.columns=["X","Y","Z"]
+
+df['X']=pd.Categorical(df['X'])
+df['X']=df['X'].cat.codes
+
+fig = plt.figure(figsize=(15,5))
+ax = fig.gca(projection='3d')
+#交换X,Y,可以旋转90度
+surf=ax.plot_trisurf(df['X'], df['Y'], df['Z'], cmap=plt.cm.viridis, linewidth=0.2)
+# surf=surf.rotate(90)
+fig.colorbar( surf, shrink=0.5, aspect=5)
+ax.set_xlabel('Time', fontsize = 15)
+ax.set_ylabel('Day', fontsize = 15)
+ax.set_zlabel('Load', fontsize = 15)
+ax.set_title('Actual value of load', fontsize = 20)
+
+plt.show()
+#********************
+data = df_results
+df=data.unstack().reset_index()
+df.columns=["X","Y","Z"]
+
+df['X']=pd.Categorical(df['X'])
+df['X']=df['X'].cat.codes
+
+fig = plt.figure(figsize=(15,5))
+ax = fig.gca(projection='3d')
+#交换X,Y,可以旋转90度
+surf=ax.plot_trisurf(df['X'], df['Y'], df['Z'], cmap=plt.cm.viridis, linewidth=0.2)
+# surf=surf.rotate(90)
+ax.set_xlabel('Time', fontsize = 15)
+ax.set_ylabel('Day', fontsize = 15)
+ax.set_zlabel('Load', fontsize = 15)
+ax.set_title('Predicted value of load', fontsize = 20)
+fig.colorbar( surf, shrink=0.5, aspect=5)
+plt.show()
+#********************
+data = df_error
+df=data.unstack().reset_index()
+df.columns=["X","Y","Z"]
+
+df['X']=pd.Categorical(df['X'])
+df['X']=df['X'].cat.codes
+
+fig = plt.figure(figsize=(15,5))
+ax = fig.gca(projection='3d')
+# ax = fig.gca(projection='2d')
+#交换X,Y,可以旋转90度
+surf=ax.plot_trisurf(df['Y'], df['X'], df['Z'], cmap=plt.cm.viridis, linewidth=0.2)
+# surf=surf.rotate(90)
+# cax = ax.matshow(surf, cmap='GnBu')
+ax.set_xlabel('Time', fontsize = 15)
+ax.set_ylabel('Day', fontsize = 15)
+ax.set_zlabel('Load', fontsize = 15)
+ax.set_title('Predicted error of load', fontsize = 20)
+fig.colorbar( surf, shrink=0.5, aspect=10)
+plt.show()
+#********************画误差图
+
+```
+展示效果如下。
-Your contribution is welcome! Please feel free to file Pull Requests to add your chapter as a directory under `/pending`. Once it is going stable, the community would like to move it to `/`.
+
+
-To write, run, and debug your chapters, you will need Python 2.x, Go >1.5. You can build the Docker image using [this script](https://github.com/PaddlePaddle/book/blob/develop/.tools/convert-markdown-into-ipynb-and-test.sh).
-This tutorial is contributed by PaddlePaddle, and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.