Welcome to the Generative-QA-Using-Retrieval-Augmented-Generation repository!
We have built a Streamlit application that answers any query related to MyProtein Whey Powder using Generative QA by using the Retrieval-Augmented Generation (RAG) method.
The repository contains the following files:
- VectorUpsert.ipynb: This file contains the code for YouTube transcription, vector conversion, and upsert.
- QA_RAG.py: This file contains the code for the Streamlit interface.
- requirements.txt: This file contains the required Python libraries and their versions.
- README.md: This file contains the information about the repository.
To use the Streamlit application, follow these steps:
- Clone the repository to your local machine.
- Install the required Python libraries using pip install -r requirements.txt.
- Run QA_RAG.py file using the command streamlit run QA_RAG.py.
- Enter your query related to MyProtein Whey Powder in the provided text box and click on the "Submit" button.
The Streamlit application will generate a response that correctly answers your query based on the prompt formed using transcribed YouTube videos.
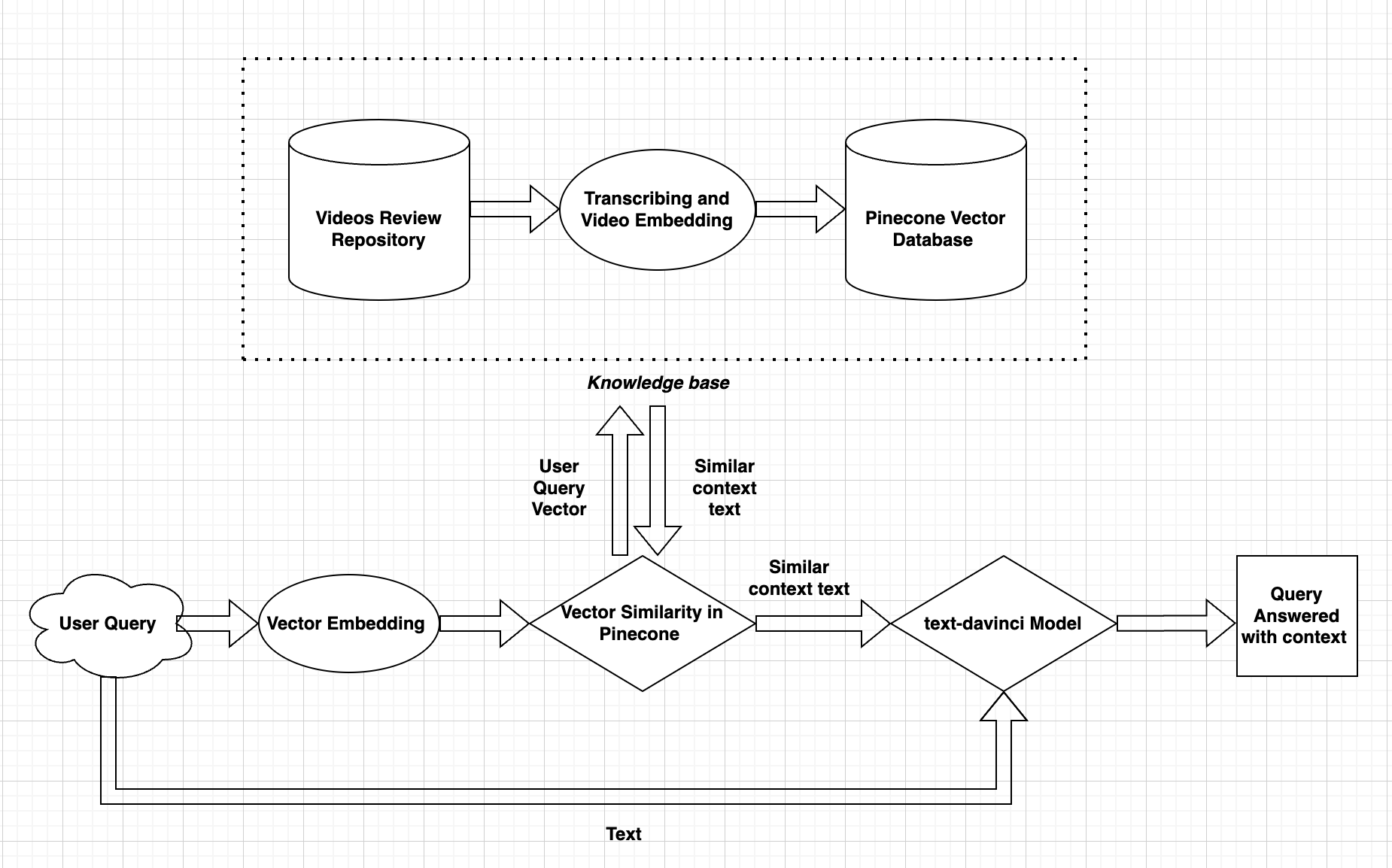
We have used the Whisper model to transcribe the YouTube videos related to MyProtein Whey Powder reviews. These transcriptions are then converted to vector embeddings using the "text-embedding-ada-002" OpenAI model. The vector embeddings are then stored along with the metadata, which consists of the actual text, into the Pinecone database for similarity matching.
When the user makes any query, the query is converted to a vector embedding using the same model, which is used to query the Pinecone database. The Pinecone database returns a response of matching/similar text transcriptions for videos. These transcriptions are then used to form a context for the prompt, which is finally passed to the 'text-davinci-003' model of OpenAI to generate a response that correctly answers the query as per the prompt rather than an uncertain or incorrect response.
We hope this repository will be helpful to anyone who wants to use Generative QA by using the RAG method to answer queries.
If you have any questions or feedback, please feel free to create an issue or pull request in this repository.