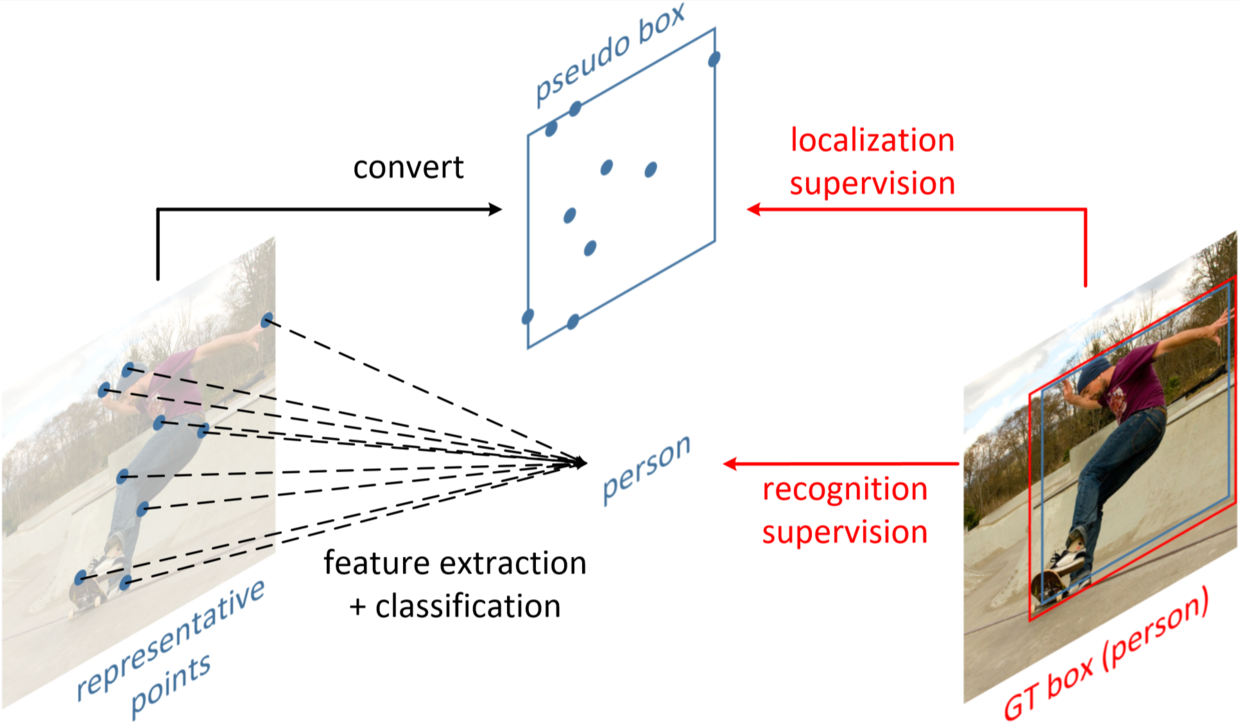
Modern object detectors rely heavily on rectangular bounding boxes, such as anchors, proposals and the final predictions, to represent objects at various recognition stages. The bounding box is convenient to use but provides only a coarse localization of objects and leads to a correspondingly coarse extraction of object features. In this paper, we present \textbf{RepPoints} (representative points), a new finer representation of objects as a set of sample points useful for both localization and recognition. Given ground truth localization and recognition targets for training, RepPoints learn to automatically arrange themselves in a manner that bounds the spatial extent of an object and indicates semantically significant local areas. They furthermore do not require the use of anchors to sample a space of bounding boxes. We show that an anchor-free object detector based on RepPoints can be as effective as the state-of-the-art anchor-based detection methods, with 46.5 AP and 67.4 AP50 on the COCO test-dev detection benchmark, using ResNet-101 model.
DOTA1.0
| Backbone | mAP | Angle | lr schd | Mem (GB) | Inf Time (fps) | Aug | Batch Size | Configs | Download |
|---|---|---|---|---|---|---|---|---|---|
| ResNet50 (1024,1024,200) | 59.44 | oc | 1x | 3.45 | 15.6 | - | 2 | rotated_reppoints_r50_fpn_1x_dota_oc | model | log |
@inproceedings{yang2019reppoints,
title={RepPoints: Point Set Representation for Object Detection},
author={Yang, Ze and Liu, Shaohui and Hu, Han and Wang, Liwei and Lin, Stephen},
booktitle={The IEEE International Conference on Computer Vision (ICCV)},
month={Oct},
year={2019}
}