diff --git a/docs-website/markdown-link-check-config.json b/docs-website/markdown-link-check-config.json
index 5b98f28501d49f..459f03ed98e21b 100644
--- a/docs-website/markdown-link-check-config.json
+++ b/docs-website/markdown-link-check-config.json
@@ -19,6 +19,9 @@
"pattern": "\\.pdl$"
},
{
+ "pattern": "\\.pdl#.*$"
+ },
+ {
"pattern":"\\.json$"
},
{
@@ -31,7 +34,16 @@
"pattern": "\\.svg$"
},
{
+ "pattern": "\\.java$"
+ },
+ {
"pattern": "\\.md#.*$"
+ },
+ {
+ "pattern": "^https://oauth2.googleapis.com/token"
+ },
+ {
+ "pattern": "^https://login.microsoftonline.com/common/oauth2/na$"
}
],
"aliveStatusCodes": [200, 206, 0, 999, 400, 401, 403]
diff --git a/docs-website/package.json b/docs-website/package.json
index 2252eed07fb737..420510459d8588 100644
--- a/docs-website/package.json
+++ b/docs-website/package.json
@@ -17,7 +17,7 @@
"generate": "rm -rf genDocs genStatic && mkdir genDocs genStatic && yarn _generate-docs && mv docs/* genDocs/ && rmdir docs",
"generate-rsync": "mkdir -p genDocs genStatic && yarn _generate-docs && rsync -v --checksum -r -h -i --delete docs/ genDocs && rm -rf docs",
"lint": "prettier -w generateDocsDir.ts sidebars.js src/pages/index.js",
- "lint-check": "prettier -l generateDocsDir.ts sidebars.js src/pages/index.js && find ../docs -name '*.md' -exec markdown-link-check -q {} -c markdown-link-check-config.json \\;",
+ "lint-check": "prettier -l generateDocsDir.ts sidebars.js src/pages/index.js && find ./genDocs -name '*.md' -exec markdown-link-check -q {} -c markdown-link-check-config.json \\;",
"lint-fix": "prettier --write generateDocsDir.ts sidebars.js src/pages/index.js"
},
"dependencies": {
diff --git a/docs-website/yarn.lock b/docs-website/yarn.lock
index 209a57a43dab03..0613fe71ef78ee 100644
--- a/docs-website/yarn.lock
+++ b/docs-website/yarn.lock
@@ -2986,6 +2986,13 @@
dependencies:
"@types/node" "*"
+"@types/websocket@^1.0.3":
+ version "1.0.6"
+ resolved "https://registry.yarnpkg.com/@types/websocket/-/websocket-1.0.6.tgz#ec8dce5915741632ac3a4b1f951b6d4156e32d03"
+ integrity sha512-JXkliwz93B2cMWOI1ukElQBPN88vMg3CruvW4KVSKpflt3NyNCJImnhIuB/f97rG7kakqRJGFiwkA895Kn02Dg==
+ dependencies:
+ "@types/node" "*"
+
"@types/ws@^8.5.5":
version "8.5.5"
resolved "https://registry.yarnpkg.com/@types/ws/-/ws-8.5.5.tgz#af587964aa06682702ee6dcbc7be41a80e4b28eb"
@@ -7053,7 +7060,6 @@ node-forge@^1:
resolved "https://registry.yarnpkg.com/node-forge/-/node-forge-1.3.1.tgz#be8da2af243b2417d5f646a770663a92b7e9ded3"
integrity sha512-dPEtOeMvF9VMcYV/1Wb8CPoVAXtp6MKMlcbAt4ddqmGqUJ6fQZFXkNZNkNlfevtNkGtaSoXf/vNNNSvgrdXwtA==
-
node-gyp-build@^4.3.0:
version "4.6.1"
resolved "https://registry.yarnpkg.com/node-gyp-build/-/node-gyp-build-4.6.1.tgz#24b6d075e5e391b8d5539d98c7fc5c210cac8a3e"
@@ -9903,6 +9909,10 @@ use-sidecar@^1.1.2:
detect-node-es "^1.1.0"
tslib "^2.0.0"
+use-sync-external-store@^1.2.0:
+ version "1.2.0"
+ resolved "https://registry.yarnpkg.com/use-sync-external-store/-/use-sync-external-store-1.2.0.tgz#7dbefd6ef3fe4e767a0cf5d7287aacfb5846928a"
+ integrity sha512-eEgnFxGQ1Ife9bzYs6VLi8/4X6CObHMw9Qr9tPY43iKwsPw8xE8+EFsf/2cFZ5S3esXgpWgtSCtLNS41F+sKPA==
utf-8-validate@^5.0.2:
version "5.0.10"
@@ -9911,12 +9921,6 @@ utf-8-validate@^5.0.2:
dependencies:
node-gyp-build "^4.3.0"
-use-sync-external-store@^1.2.0:
- version "1.2.0"
- resolved "https://registry.yarnpkg.com/use-sync-external-store/-/use-sync-external-store-1.2.0.tgz#7dbefd6ef3fe4e767a0cf5d7287aacfb5846928a"
- integrity sha512-eEgnFxGQ1Ife9bzYs6VLi8/4X6CObHMw9Qr9tPY43iKwsPw8xE8+EFsf/2cFZ5S3esXgpWgtSCtLNS41F+sKPA==
-
-
util-deprecate@^1.0.1, util-deprecate@^1.0.2, util-deprecate@~1.0.1:
version "1.0.2"
resolved "https://registry.yarnpkg.com/util-deprecate/-/util-deprecate-1.0.2.tgz#450d4dc9fa70de732762fbd2d4a28981419a0ccf"
diff --git a/docs/architecture/architecture.md b/docs/architecture/architecture.md
index 6a9c1860d71b09..20f18f09d949be 100644
--- a/docs/architecture/architecture.md
+++ b/docs/architecture/architecture.md
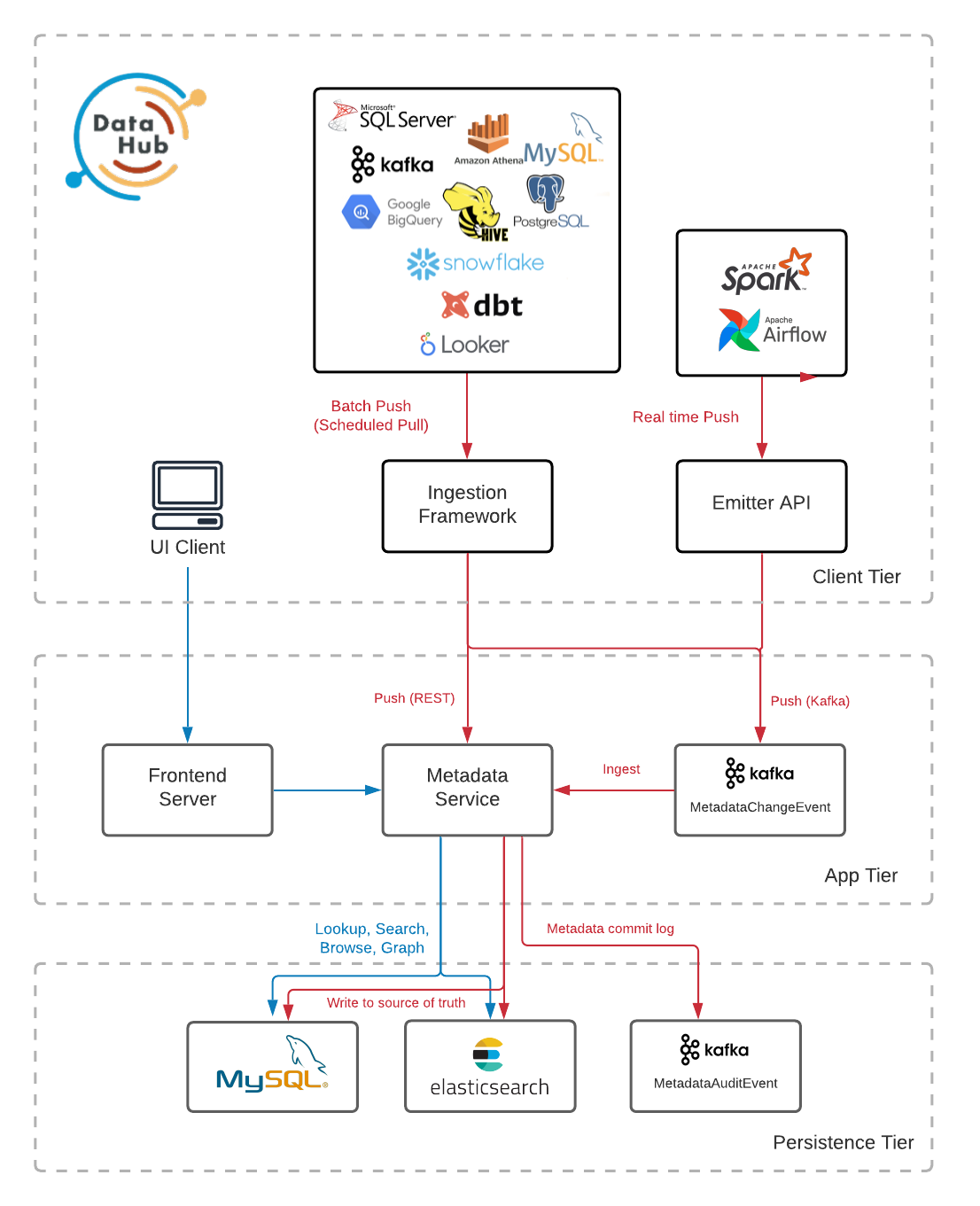
@@ -17,7 +17,7 @@ The figures below describe the high-level architecture of DataHub.
-  +
+ 
diff --git a/docs/authentication/guides/add-users.md b/docs/authentication/guides/add-users.md
index f5dfc832010831..d380cacd6665e4 100644
--- a/docs/authentication/guides/add-users.md
+++ b/docs/authentication/guides/add-users.md
@@ -19,13 +19,13 @@ To do so, navigate to the **Users & Groups** section inside of Settings page. He
do not have the correct privileges to invite users, this button will be disabled.
-  +
+ 
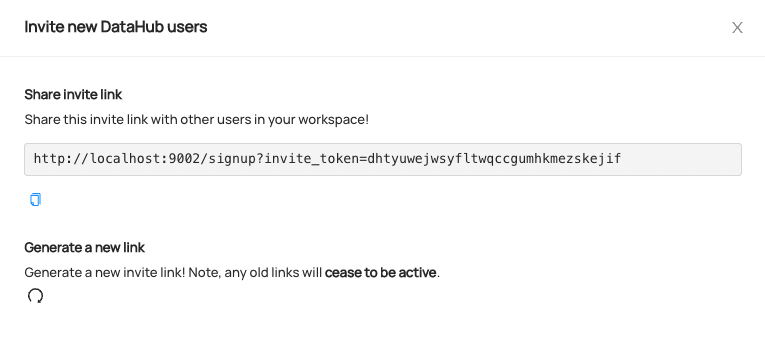
To invite new users, simply share the link with others inside your organization.
-  +
+ 
When a new user visits the link, they will be directed to a sign up screen where they can create their DataHub account.
@@ -37,13 +37,13 @@ and click **Reset user password** inside the menu dropdown on the right hand sid
`Manage User Credentials` [Platform Privilege](../../authorization/access-policies-guide.md) in order to reset passwords.
-  +
+ 
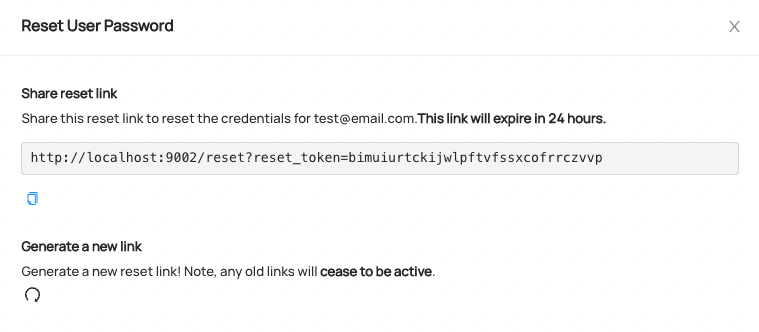
To reset the password, simply share the password reset link with the user who needs to change their password. Password reset links expire after 24 hours.
-  +
+ 
# Configuring Single Sign-On with OpenID Connect
diff --git a/docs/authentication/guides/sso/configure-oidc-react.md b/docs/authentication/guides/sso/configure-oidc-react.md
index d27792ce3967b1..512d6adbf916fc 100644
--- a/docs/authentication/guides/sso/configure-oidc-react.md
+++ b/docs/authentication/guides/sso/configure-oidc-react.md
@@ -26,7 +26,7 @@ please see [this guide](../jaas.md) to mount a custom user.props file for a JAAS
To configure OIDC in React, you will most often need to register yourself as a client with your identity provider (Google, Okta, etc). Each provider may
have their own instructions. Provided below are links to examples for Okta, Google, Azure AD, & Keycloak.
-- [Registering an App in Okta](https://developer.okta.com/docs/guides/add-an-external-idp/apple/register-app-in-okta/)
+- [Registering an App in Okta](https://developer.okta.com/docs/guides/add-an-external-idp/openidconnect/main/)
- [OpenID Connect in Google Identity](https://developers.google.com/identity/protocols/oauth2/openid-connect)
- [OpenID Connect authentication with Azure Active Directory](https://docs.microsoft.com/en-us/azure/active-directory/fundamentals/auth-oidc)
- [Keycloak - Securing Applications and Services Guide](https://www.keycloak.org/docs/latest/securing_apps/)
diff --git a/docs/domains.md b/docs/domains.md
index c846a753417c59..1b2ebc9d47f397 100644
--- a/docs/domains.md
+++ b/docs/domains.md
@@ -22,20 +22,20 @@ You can create this privileges by creating a new [Metadata Policy](./authorizati
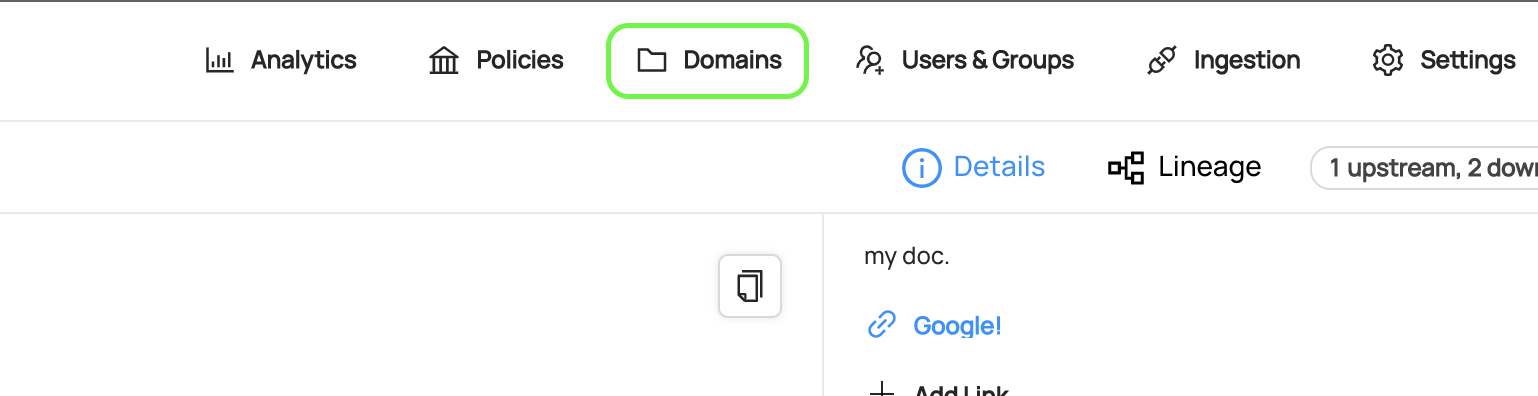
To create a Domain, first navigate to the **Domains** tab in the top-right menu of DataHub.
-  +
+ 
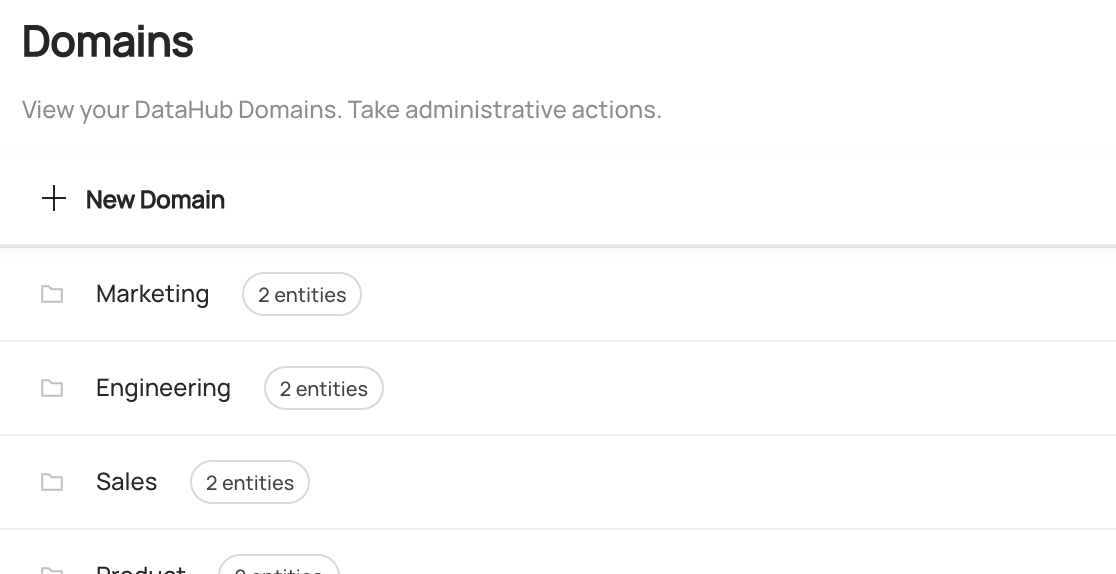
Once you're on the Domains page, you'll see a list of all the Domains that have been created on DataHub. Additionally, you can
view the number of entities inside each Domain.
-  +
+ 
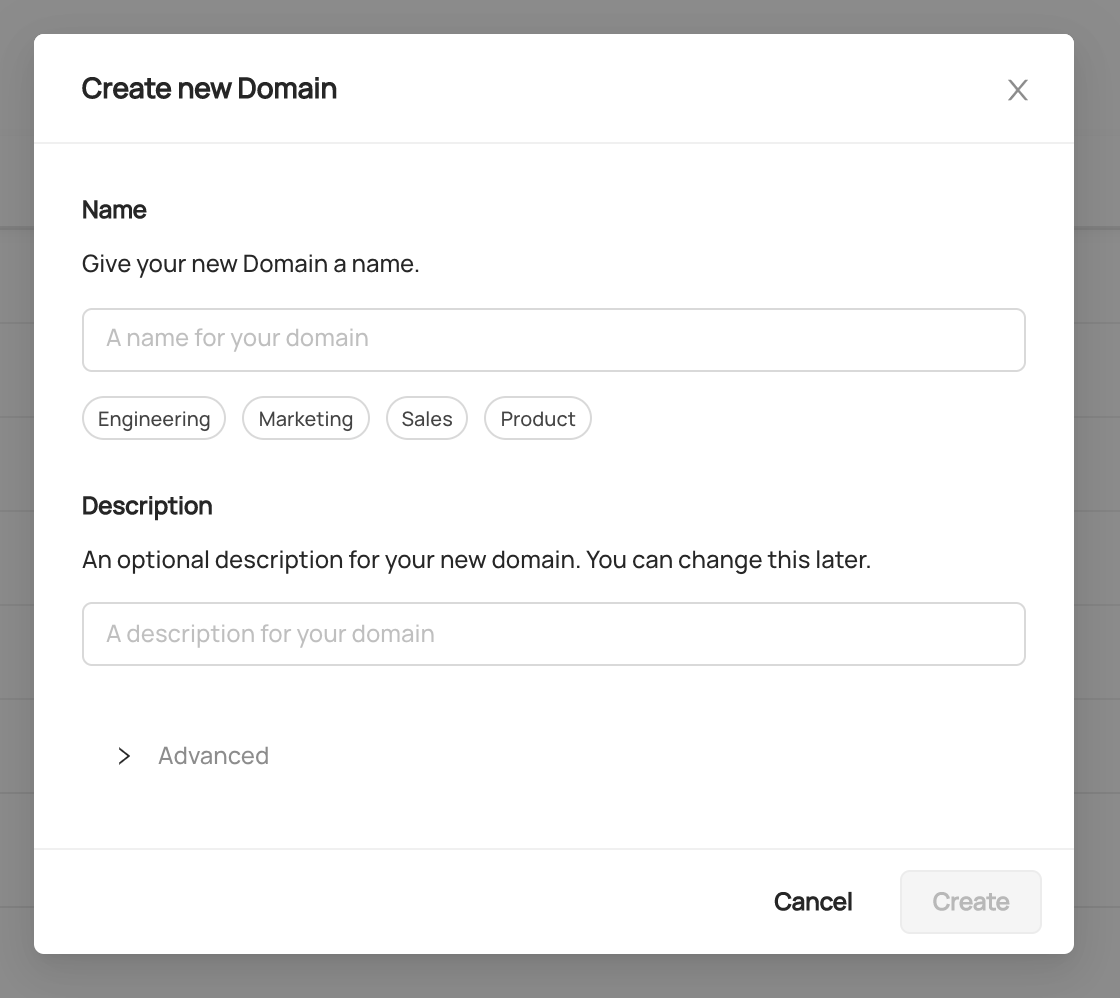
To create a new Domain, click '+ New Domain'.
-  +
+ 
Inside the form, you can choose a name for your Domain. Most often, this will align with your business units or groups, for example
@@ -48,7 +48,7 @@ for the Domain. This option is useful if you intend to refer to Domains by a com
key to be human-readable. Proceed with caution: once you select a custom id, it cannot be easily changed.
-  +
+ 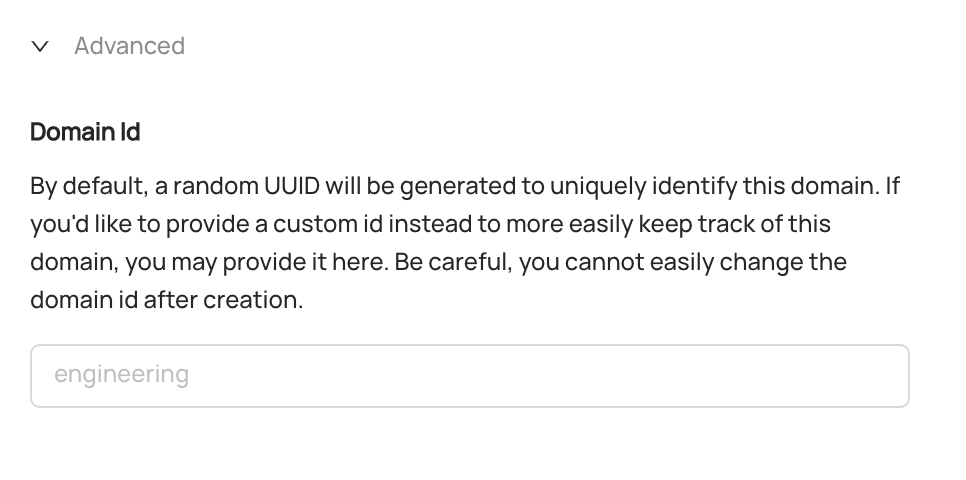
By default, you don't need to worry about this. DataHub will auto-generate a unique Domain id for you.
@@ -64,7 +64,7 @@ To assign an asset to a Domain, simply navigate to the asset's profile page. At
see a 'Domain' section. Click 'Set Domain', and then search for the Domain you'd like to add to. When you're done, click 'Add'.
-  +
+ 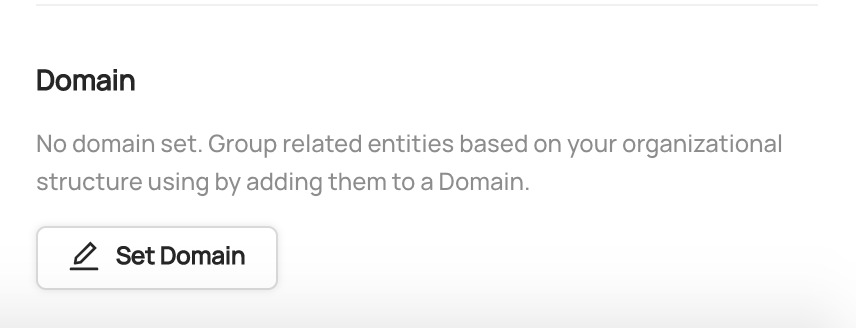
To remove an asset from a Domain, click the 'x' icon on the Domain tag.
@@ -149,27 +149,27 @@ source:
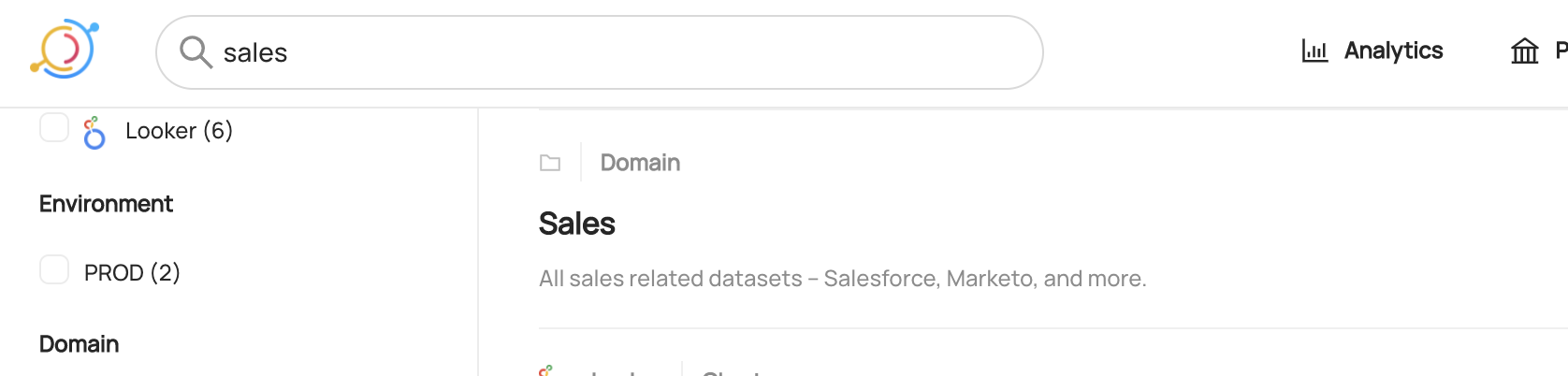
Once you've created a Domain, you can use the search bar to find it.
-  +
+ 
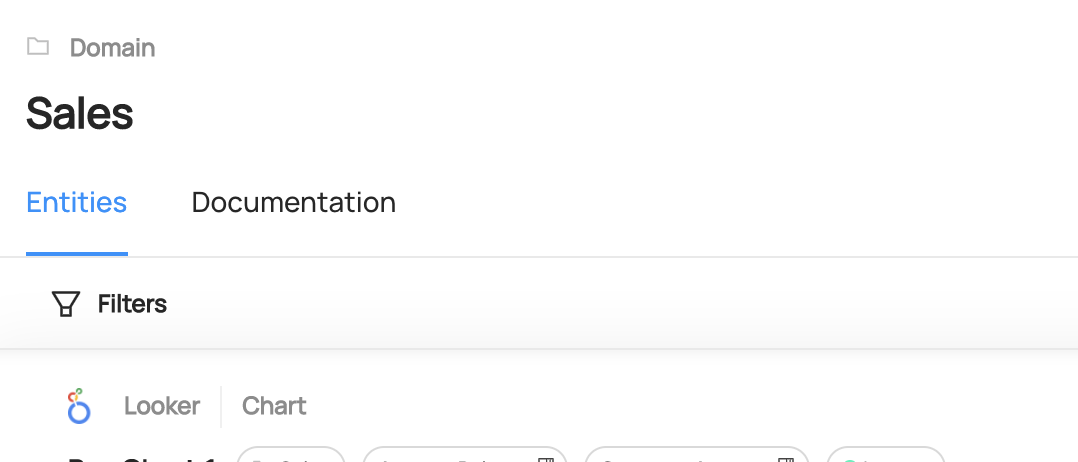
Clicking on the search result will take you to the Domain's profile, where you
can edit its description, add / remove owners, and view the assets inside the Domain.
-  +
+ 
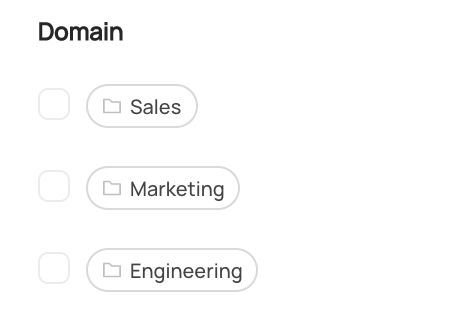
Once you've added assets to a Domain, you can filter search results to limit to those Assets
within a particular Domain using the left-side search filters.
-  +
+ 
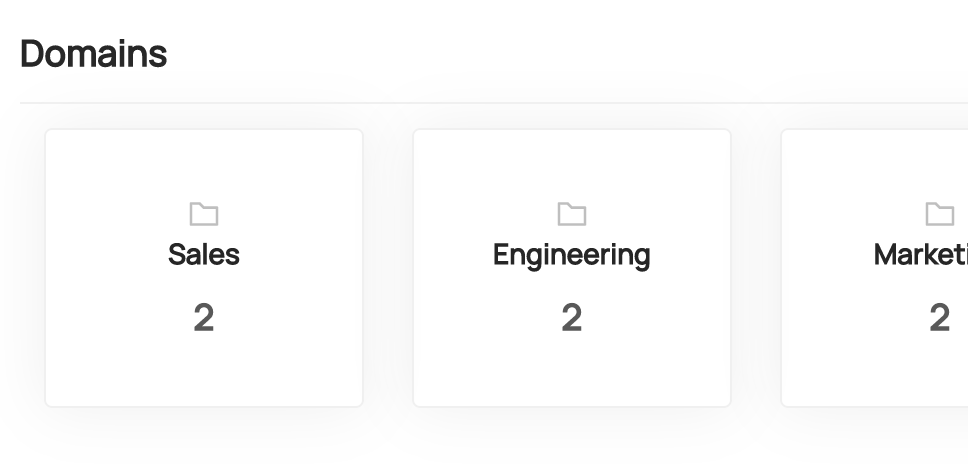
On the homepage, you'll also find a list of the most popular Domains in your organization.
-  +
+ 
## Additional Resources
@@ -242,7 +242,6 @@ DataHub supports Tags, Glossary Terms, & Domains as distinct types of Metadata t
- **Tags**: Informal, loosely controlled labels that serve as a tool for search & discovery. Assets may have multiple tags. No formal, central management.
- **Glossary Terms**: A controlled vocabulary, with optional hierarchy. Terms are typically used to standardize types of leaf-level attributes (i.e. schema fields) for governance. E.g. (EMAIL_PLAINTEXT)
- **Domains**: A set of top-level categories. Usually aligned to business units / disciplines to which the assets are most relevant. Central or distributed management. Single Domain assignment per data asset.
-
*Need more help? Join the conversation in [Slack](http://slack.datahubproject.io)!*
### Related Features
diff --git a/docs/how/add-new-aspect.md b/docs/how/add-new-aspect.md
index 6ea7256ed75cc0..6453812ea327a2 100644
--- a/docs/how/add-new-aspect.md
+++ b/docs/how/add-new-aspect.md
@@ -1,7 +1,7 @@
# How to add a new metadata aspect?
Adding a new metadata [aspect](../what/aspect.md) is one of the most common ways to extend an existing [entity](../what/entity.md).
-We'll use the [CorpUserEditableInfo](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/identity/CorpUserEditableInfo.pdl) as an example here.
+We'll use the CorpUserEditableInfo as an example here.
1. Add the aspect model to the corresponding namespace (e.g. [`com.linkedin.identity`](https://github.com/datahub-project/datahub/tree/master/metadata-models/src/main/pegasus/com/linkedin/identity))
@@ -14,7 +14,7 @@ We'll use the [CorpUserEditableInfo](https://github.com/datahub-project/datahub/
4. To surface the new aspect at the top-level [resource endpoint](https://linkedin.github.io/rest.li/user_guide/restli_server#writing-resources), extend the resource data model (e.g. [`CorpUser`](https://github.com/datahub-project/datahub/blob/master/gms/api/src/main/pegasus/com/linkedin/identity/CorpUser.pdl)) with an optional field (e.g. [`editableInfo`](https://github.com/datahub-project/datahub/blob/master/gms/api/src/main/pegasus/com/linkedin/identity/CorpUser.pdl#L21)). You'll also need to extend the `toValue` & `toSnapshot` methods of the top-level resource (e.g. [`CorpUsers`](https://github.com/datahub-project/datahub/blob/master/gms/impl/src/main/java/com/linkedin/metadata/resources/identity/CorpUsers.java)) to convert between the snapshot & value models.
-5. (Optional) If there's need to update the aspect via API (instead of/in addition to MCE), add a [sub-resource](https://linkedin.github.io/rest.li/user_guide/restli_server#sub-resources) endpoint for the new aspect (e.g. [`CorpUsersEditableInfoResource`](https://github.com/datahub-project/datahub/blob/master/gms/impl/src/main/java/com/linkedin/metadata/resources/identity/CorpUsersEditableInfoResource.java)). The sub-resource endpiont also allows you to retrieve previous versions of the aspect as well as additional metadata such as the audit stamp.
+5. (Optional) If there's need to update the aspect via API (instead of/in addition to MCE), add a [sub-resource](https://linkedin.github.io/rest.li/user_guide/restli_server#sub-resources) endpoint for the new aspect (e.g. `CorpUsersEditableInfoResource`). The sub-resource endpiont also allows you to retrieve previous versions of the aspect as well as additional metadata such as the audit stamp.
-6. After rebuilding & restarting [gms](https://github.com/datahub-project/datahub/tree/master/gms), [mce-consumer-job](https://github.com/datahub-project/datahub/tree/master/metadata-jobs/mce-consumer-job) & [mae-consumer-job](https://github.com/datahub-project/datahub/tree/master/metadata-jobs/mae-consumer-job),
+6. After rebuilding & restarting gms, [mce-consumer-job](https://github.com/datahub-project/datahub/tree/master/metadata-jobs/mce-consumer-job) & [mae-consumer-job](https://github.com/datahub-project/datahub/tree/master/metadata-jobs/mae-consumer-job),z
you should be able to start emitting [MCE](../what/mxe.md) with the new aspect and have it automatically ingested & stored in DB.
diff --git a/docs/modeling/extending-the-metadata-model.md b/docs/modeling/extending-the-metadata-model.md
index a232b034e639b9..be2d7d795de701 100644
--- a/docs/modeling/extending-the-metadata-model.md
+++ b/docs/modeling/extending-the-metadata-model.md
@@ -82,14 +82,14 @@ Because they are aspects, keys need to be annotated with an @Aspect annotation,
can be a part of.
The key can also be annotated with the two index annotations: @Relationship and @Searchable. This instructs DataHub
-infra to use the fields in the key to create relationships and index fields for search. See [Step 3](#step_3) for more details on
+infra to use the fields in the key to create relationships and index fields for search. See [Step 3](#step-3-define-custom-aspects-or-attach-existing-aspects-to-your-entity) for more details on
the annotation model.
**Constraints**: Note that each field in a Key Aspect MUST be of String or Enum type.
### Step 2: Create the new entity with its key aspect
-Define the entity within an `entity-registry.yml` file. Depending on your approach, the location of this file may vary. More on that in steps [4](#step-4-choose-a-place-to-store-your-model-extension) and [5](#step_5).
+Define the entity within an `entity-registry.yml` file. Depending on your approach, the location of this file may vary. More on that in steps [4](#step-4-choose-a-place-to-store-your-model-extension) and [5](#step-5-attaching-your-non-key-aspects-to-the-entity).
Example:
```yaml
diff --git a/docs/modeling/metadata-model.md b/docs/modeling/metadata-model.md
index e6cc13df6233de..a8958985a0a724 100644
--- a/docs/modeling/metadata-model.md
+++ b/docs/modeling/metadata-model.md
@@ -433,7 +433,7 @@ aggregation query against a timeseries aspect.
The *@TimeseriesField* and the *@TimeseriesFieldCollection* are two new annotations that can be attached to a field of
a *Timeseries aspect* that allows it to be part of an aggregatable query. The kinds of aggregations allowed on these
annotated fields depends on the type of the field, as well as the kind of aggregation, as
-described [here](#Performing-an-aggregation-on-a-Timeseries-aspect.).
+described [here](#performing-an-aggregation-on-a-timeseries-aspect).
* `@TimeseriesField = {}` - this annotation can be used with any type of non-collection type field of the aspect such as
primitive types and records (see the fields *stat*, *strStat* and *strArray* fields
@@ -515,7 +515,7 @@ my_emitter = DatahubRestEmitter("http://localhost:8080")
my_emitter.emit(mcpw)
```
-###### Performing an aggregation on a Timeseries aspect.
+###### Performing an aggregation on a Timeseries aspect
Aggreations on timeseries aspects can be performed by the GMS REST API for `/analytics?action=getTimeseriesStats` which
accepts the following params.
diff --git a/docs/tags.md b/docs/tags.md
index 945b514dc7b473..cb08c9fafea490 100644
--- a/docs/tags.md
+++ b/docs/tags.md
@@ -27,25 +27,25 @@ You can create these privileges by creating a new [Metadata Policy](./authorizat
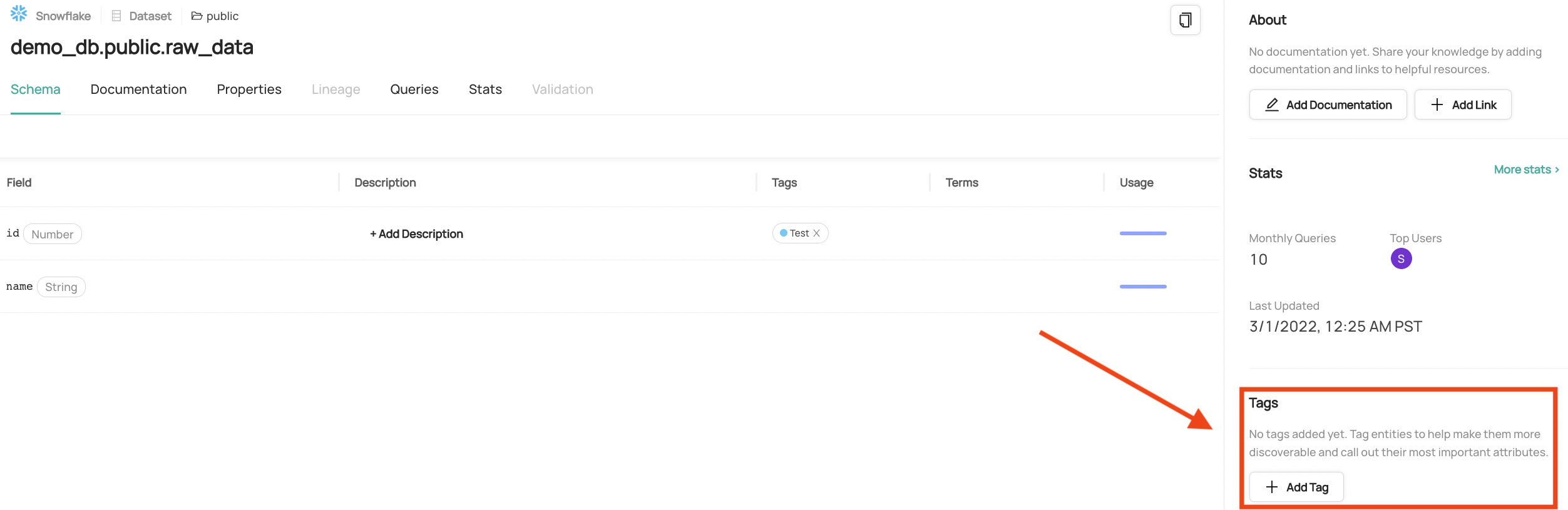
To add a tag at the dataset or container level, simply navigate to the page for that entity and click on the **Add Tag** button.
-  +
+ 
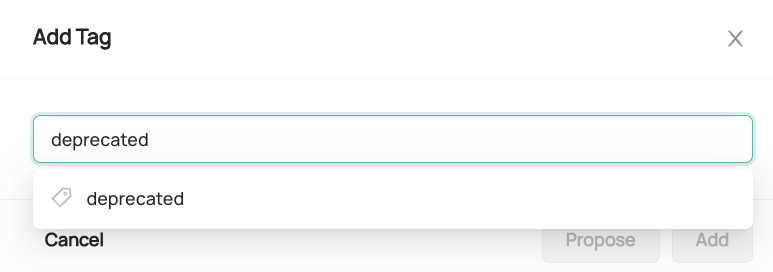
Type in the name of the tag you want to add. You can add a new tag, or add a tag that already exists (the autocomplete will pull up the tag if it already exists).
-  +
+ 
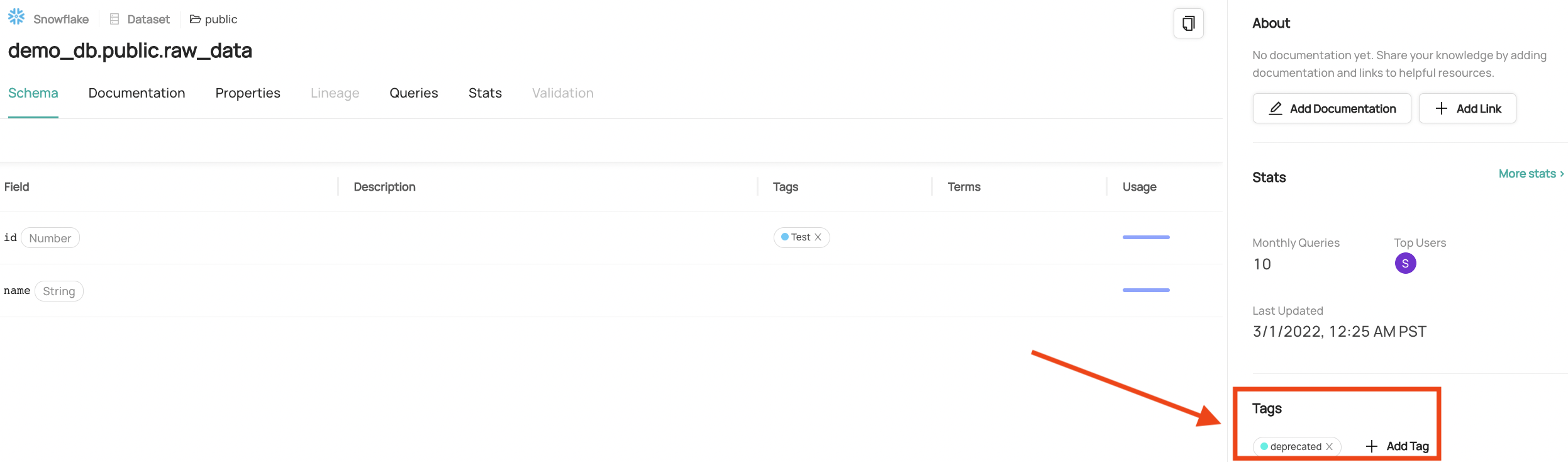
Click on the "Add" button and you'll see the tag has been added!
-  +
+ 
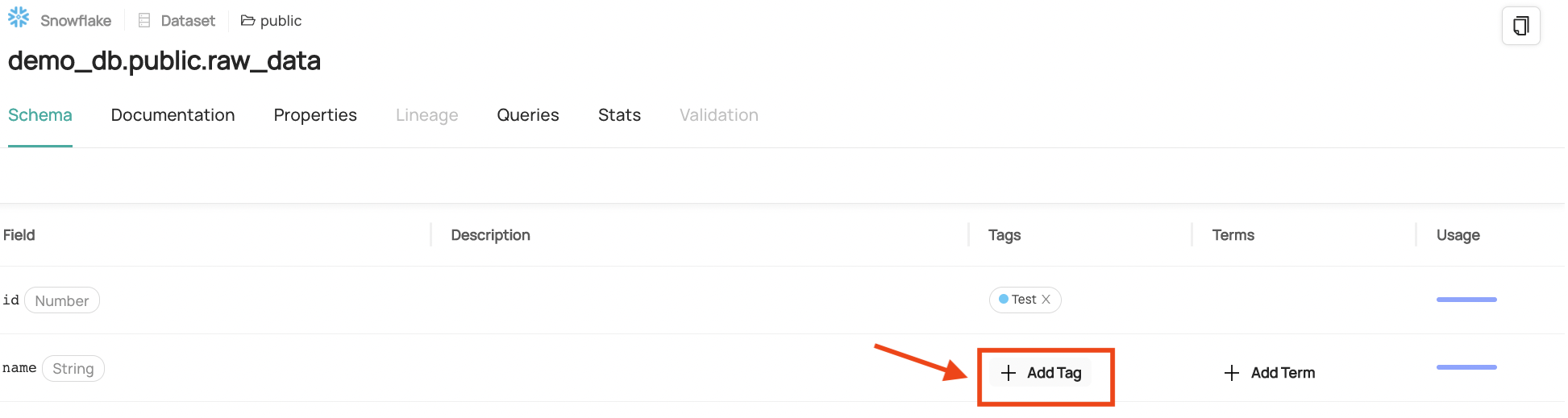
If you would like to add a tag at the schema level, hover over the "Tags" column for a schema until the "Add Tag" button shows up, and then follow the same flow as above.
-  +
+ 
### Removing a Tag
@@ -57,7 +57,7 @@ To remove a tag, simply click on the "X" button in the tag. Then click "Yes" whe
You can search for a tag in the search bar, and even filter entities by the presence of a specific tag.
-  +
+ 
## Additional Resources
diff --git a/docs/what/gms.md b/docs/what/gms.md
index 9e1cea1b9540e8..d7d3499643f465 100644
--- a/docs/what/gms.md
+++ b/docs/what/gms.md
@@ -2,6 +2,4 @@
Metadata for [entities](entity.md) [onboarded](../modeling/metadata-model.md) to [GMA](gma.md) is served through microservices known as Generalized Metadata Service (GMS). GMS typically provides a [Rest.li](http://rest.li) API and must access the metadata using [GMA DAOs](../architecture/metadata-serving.md).
-While a GMS is completely free to define its public APIs, we do provide a list of [resource base classes](https://github.com/datahub-project/datahub-gma/tree/master/restli-resources/src/main/java/com/linkedin/metadata/restli) to leverage for common patterns.
-
GMA is designed to support a distributed fleet of GMS, each serving a subset of the [GMA graph](graph.md). However, for simplicity we include a single centralized GMS ([datahub-gms](../../gms)) that serves all entities.
diff --git a/metadata-ingestion/docs/sources/gcs/README.md b/metadata-ingestion/docs/sources/gcs/README.md
index 2d021950e83de0..d6bb8147f076da 100644
--- a/metadata-ingestion/docs/sources/gcs/README.md
+++ b/metadata-ingestion/docs/sources/gcs/README.md
@@ -9,8 +9,8 @@ and uses DataHub S3 Data Lake integration source under the hood. Refer section [
This ingestion source maps the following Source System Concepts to DataHub Concepts:
| Source Concept | DataHub Concept | Notes |
-| ------------------------------------------ | ------------------------------------------------------------------------------------------ | -------------------- |
-| `"Google Cloud Storage"` | [Data Platform](https://datahubproject.io/docs/generated/metamodel/entities/dataPlatform/) | |
+| ------------------------------------------ |--------------------------------------------------------------------------------------------| -------------------- |
+| `"Google Cloud Storage"` | [Data Platform](https://datahubproject.io/docs/generated/metamodel/entities/dataplatform/) | |
| GCS object / Folder containing GCS objects | [Dataset](https://datahubproject.io/docs/generated/metamodel/entities/dataset/) | |
| GCS bucket | [Container](https://datahubproject.io/docs/generated/metamodel/entities/container/) | Subtype `GCS bucket` |
| GCS folder | [Container](https://datahubproject.io/docs/generated/metamodel/entities/container/) | Subtype `Folder` |
diff --git a/metadata-ingestion/docs/sources/kafka-connect/README.md b/metadata-ingestion/docs/sources/kafka-connect/README.md
index ac3728b6eacba6..5031bff5a3fac0 100644
--- a/metadata-ingestion/docs/sources/kafka-connect/README.md
+++ b/metadata-ingestion/docs/sources/kafka-connect/README.md
@@ -10,11 +10,11 @@ This plugin extracts the following:
This ingestion source maps the following Source System Concepts to DataHub Concepts:
-| Source Concept | DataHub Concept | Notes |
-| --------------------------- | ------------------------------------------------------------- | --------------------------------------------------------------------------- |
-| `"kafka-connect"` | [Data Platform](https://datahubproject.io/docs/generated/metamodel/entities/dataPlatform/) | |
-| [Connector](https://kafka.apache.org/documentation/#connect_connectorsandtasks) | [DataFlow](https://datahubproject.io/docs/generated/metamodel/entities/dataflow/) | |
-| Kafka Topic | [Dataset](https://datahubproject.io/docs/generated/metamodel/entities/dataset/) | |
+| Source Concept | DataHub Concept | Notes |
+| --------------------------- |--------------------------------------------------------------------------------------------| --------------------------------------------------------------------------- |
+| `"kafka-connect"` | [Data Platform](https://datahubproject.io/docs/generated/metamodel/entities/dataplatform/) | |
+| [Connector](https://kafka.apache.org/documentation/#connect_connectorsandtasks) | [DataFlow](https://datahubproject.io/docs/generated/metamodel/entities/dataflow/) | |
+| Kafka Topic | [Dataset](https://datahubproject.io/docs/generated/metamodel/entities/dataset/) | |
## Current limitations
diff --git a/metadata-ingestion/docs/sources/s3/README.md b/metadata-ingestion/docs/sources/s3/README.md
index 17fed8a70abb49..8d65e1cf8b943e 100644
--- a/metadata-ingestion/docs/sources/s3/README.md
+++ b/metadata-ingestion/docs/sources/s3/README.md
@@ -6,8 +6,8 @@ To specify the group of files that form a dataset, use `path_specs` configuratio
This ingestion source maps the following Source System Concepts to DataHub Concepts:
| Source Concept | DataHub Concept | Notes |
-| ---------------------------------------- | ------------------------------------------------------------------------------------------ | ------------------- |
-| `"s3"` | [Data Platform](https://datahubproject.io/docs/generated/metamodel/entities/dataPlatform/) | |
+| ---------------------------------------- |--------------------------------------------------------------------------------------------| ------------------- |
+| `"s3"` | [Data Platform](https://datahubproject.io/docs/generated/metamodel/entities/dataplatform/) | |
| s3 object / Folder containing s3 objects | [Dataset](https://datahubproject.io/docs/generated/metamodel/entities/dataset/) | |
| s3 bucket | [Container](https://datahubproject.io/docs/generated/metamodel/entities/container/) | Subtype `S3 bucket` |
| s3 folder | [Container](https://datahubproject.io/docs/generated/metamodel/entities/container/) | Subtype `Folder` |
diff --git a/metadata-ingestion/src/datahub/ingestion/source/usage/starburst_trino_usage.py b/metadata-ingestion/src/datahub/ingestion/source/usage/starburst_trino_usage.py
index 9394a8bba5e0b6..6591ef8a3fc4f5 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/usage/starburst_trino_usage.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/usage/starburst_trino_usage.py
@@ -112,9 +112,6 @@ class TrinoUsageSource(Source):
#### Prerequsities
1. You need to setup Event Logger which saves audit logs into a Postgres db and setup this db as a catalog in Trino
- Here you can find more info about how to setup:
- https://docs.starburst.io/354-e/security/event-logger.html#security-event-logger--page-root
- https://docs.starburst.io/354-e/security/event-logger.html#analyzing-the-event-log
2. Install starbust-trino-usage plugin
Run pip install 'acryl-datahub[starburst-trino-usage]'.