+COPY /truststore-directory /certificates
+```
+
+Building this Dockerfile will result in your own custom docker image on your local machine.
+You will then be able to tag it, publish it to your own registry, etc.
+
+#### Option b) Mount truststore from your host machine using a docker volume
+
+Adapt your docker-compose.yml to include a new volume mount in the `datahub-frontend-react` container
+
+```docker
+ datahub-frontend-react:
+ # ...
+ volumes:
+ # ...
+ - /truststore-directory:/certificates
+```
+
+### Reference new truststore
+
+Add the following environment values to the `datahub-frontend-react` container:
+
+```
+SSL_TRUSTSTORE_FILE=path/to/truststore.jks (e.g. /certificates)
+SSL_TRUSTSTORE_TYPE=jks
+SSL_TRUSTSTORE_PASSWORD=MyTruststorePassword
+```
+
+Once these steps are done, your frontend container will use the new truststore when validating SSL/HTTPS connections.
diff --git a/docs/authentication/guides/sso/configure-oidc-react-azure.md b/docs/authentication/guides/sso/configure-oidc-react-azure.md
index d185957967882..177387327c0e8 100644
--- a/docs/authentication/guides/sso/configure-oidc-react-azure.md
+++ b/docs/authentication/guides/sso/configure-oidc-react-azure.md
@@ -32,7 +32,11 @@ Azure supports more than one redirect URI, so both can be configured at the same
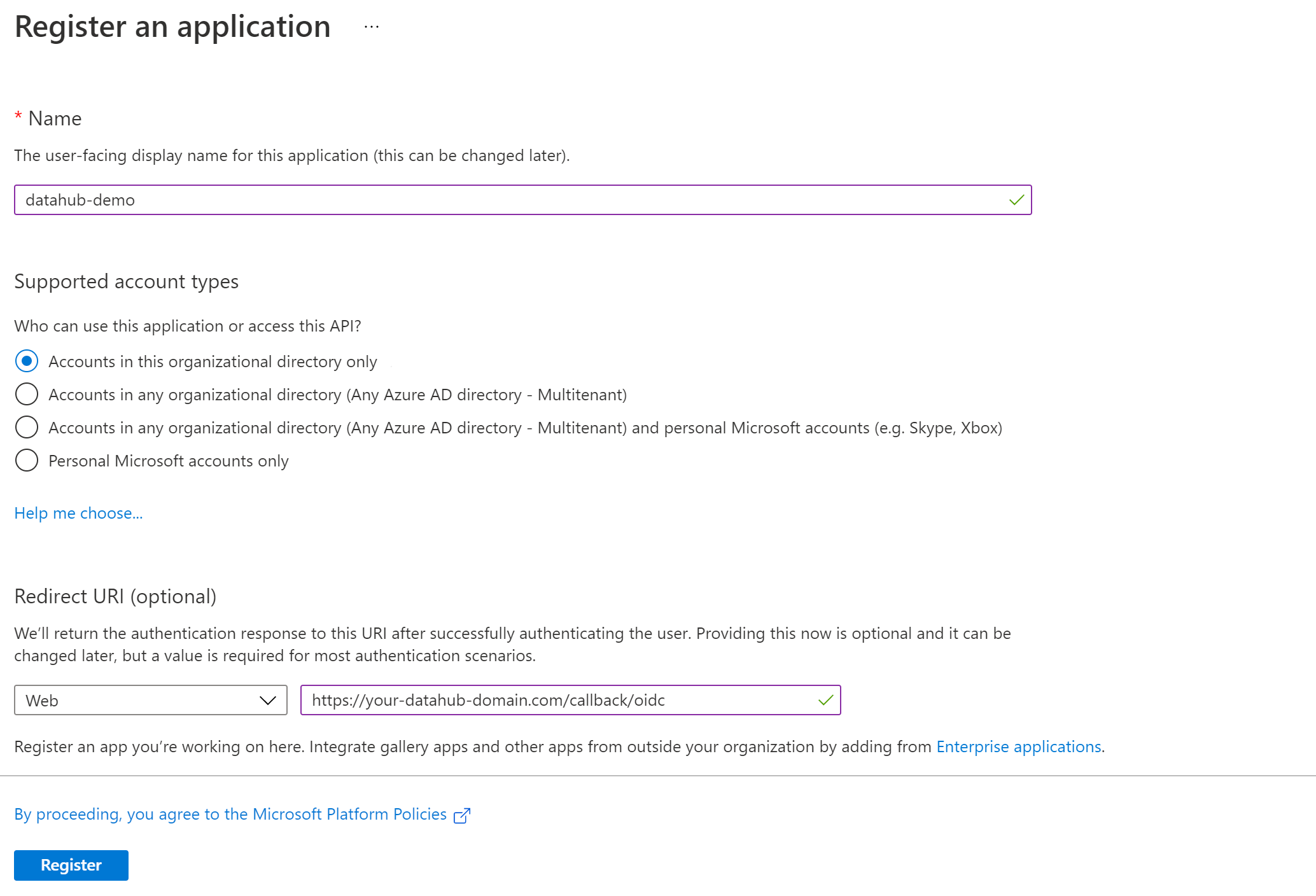
At this point, your app registration should look like the following:
-
+
+
+  +
+
+
e. Click **Register**.
@@ -40,7 +44,11 @@ e. Click **Register**.
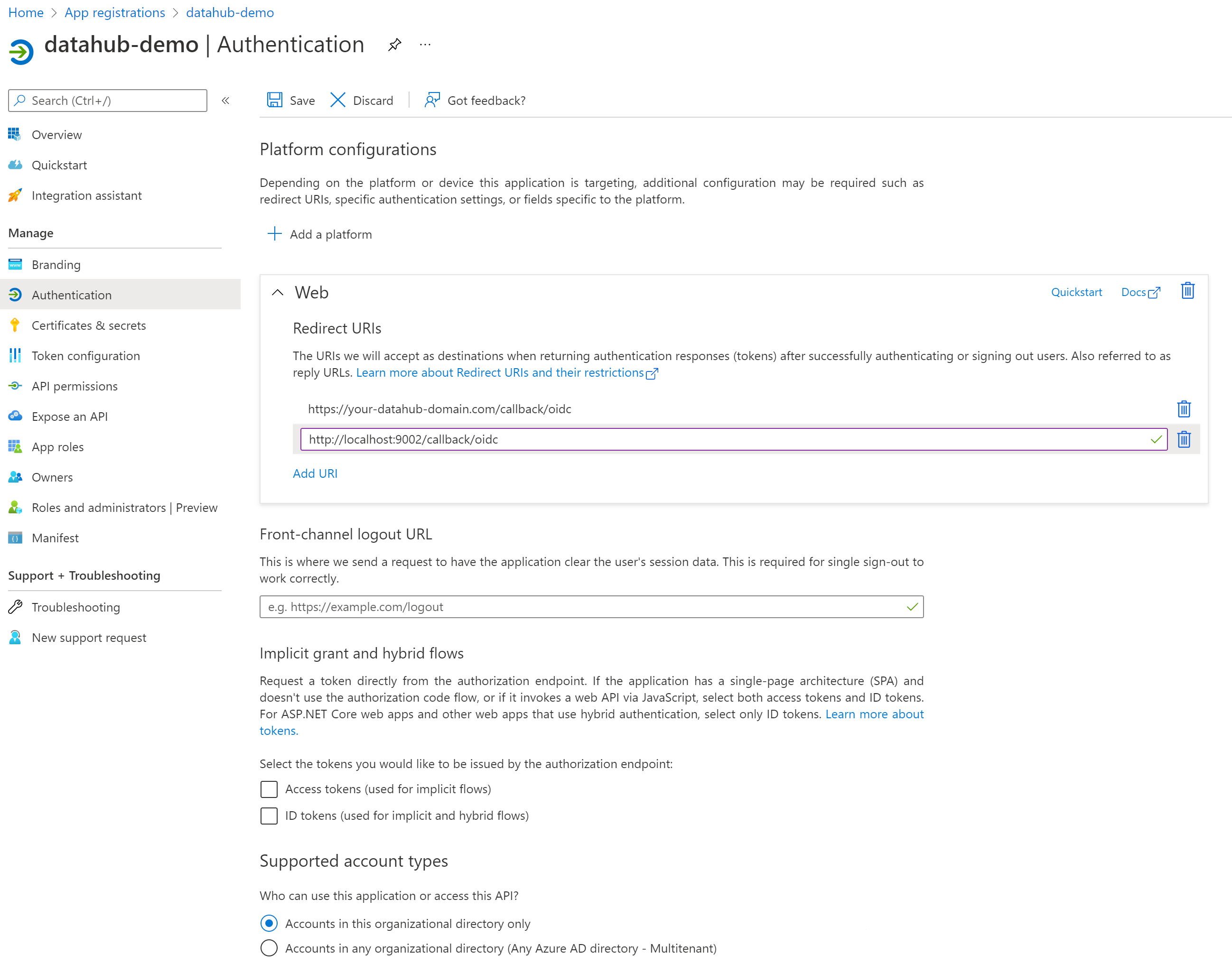
Once registration is done, you will land on the app registration **Overview** tab. On the left-side navigation bar, click on **Authentication** under **Manage** and add extra redirect URIs if need be (if you want to support both local testing and Azure deployments).
-
+
+
+  +
+
+
Click **Save**.
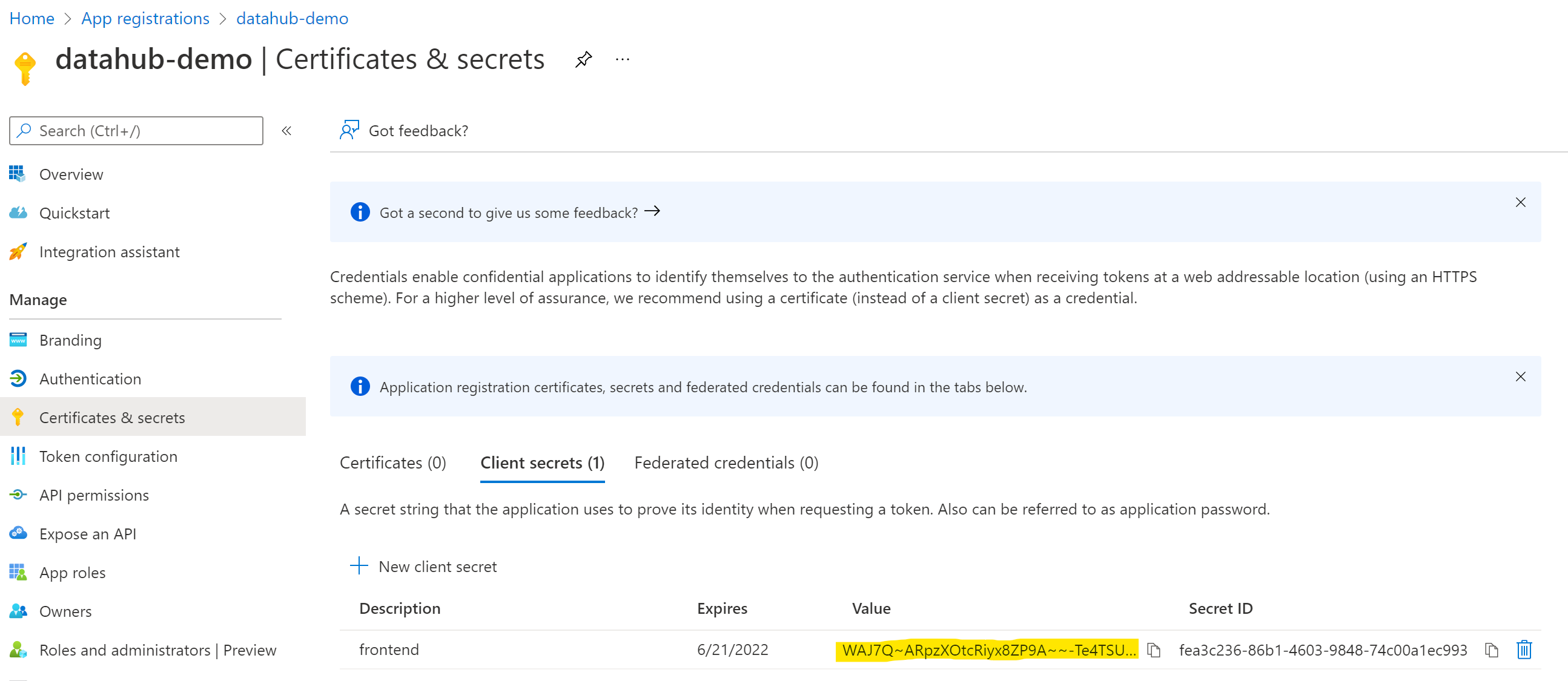
@@ -51,7 +59,11 @@ Select **Client secrets**, then **New client secret**. Type in a meaningful des
**IMPORTANT:** Copy the `value` of your newly create secret since Azure will never display its value afterwards.
-
+
+
+  +
+
+
### 4. Configure API permissions
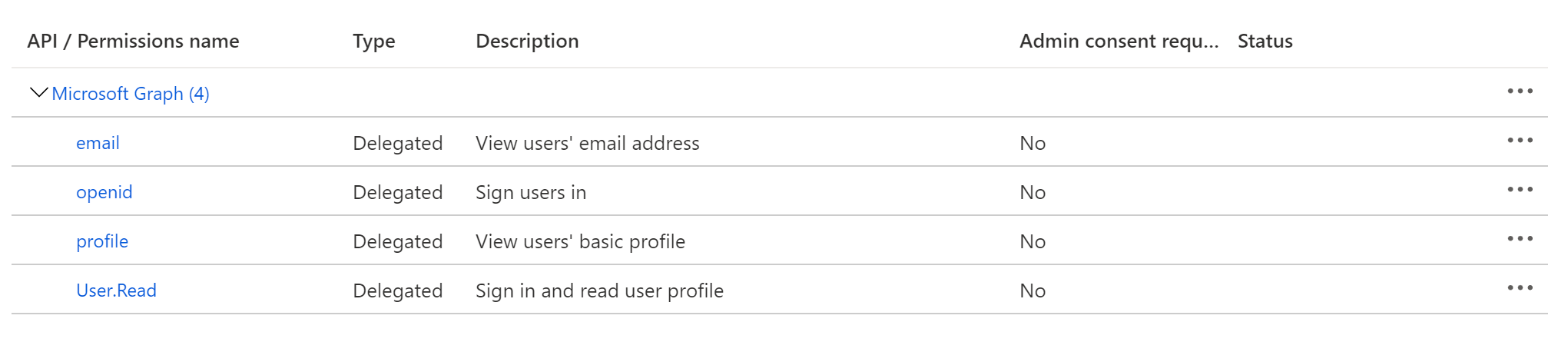
@@ -66,7 +78,11 @@ Click on **Add a permission**, then from the **Microsoft APIs** tab select **Mic
At this point, you should be looking at a screen like the following:
-
+
+
+  +
+
+
### 5. Obtain Application (Client) ID
diff --git a/docs/authentication/guides/sso/configure-oidc-react-google.md b/docs/authentication/guides/sso/configure-oidc-react-google.md
index 474538097aae2..af62185e6e787 100644
--- a/docs/authentication/guides/sso/configure-oidc-react-google.md
+++ b/docs/authentication/guides/sso/configure-oidc-react-google.md
@@ -31,7 +31,11 @@ Note that in order to complete this step you should be logged into a Google acco
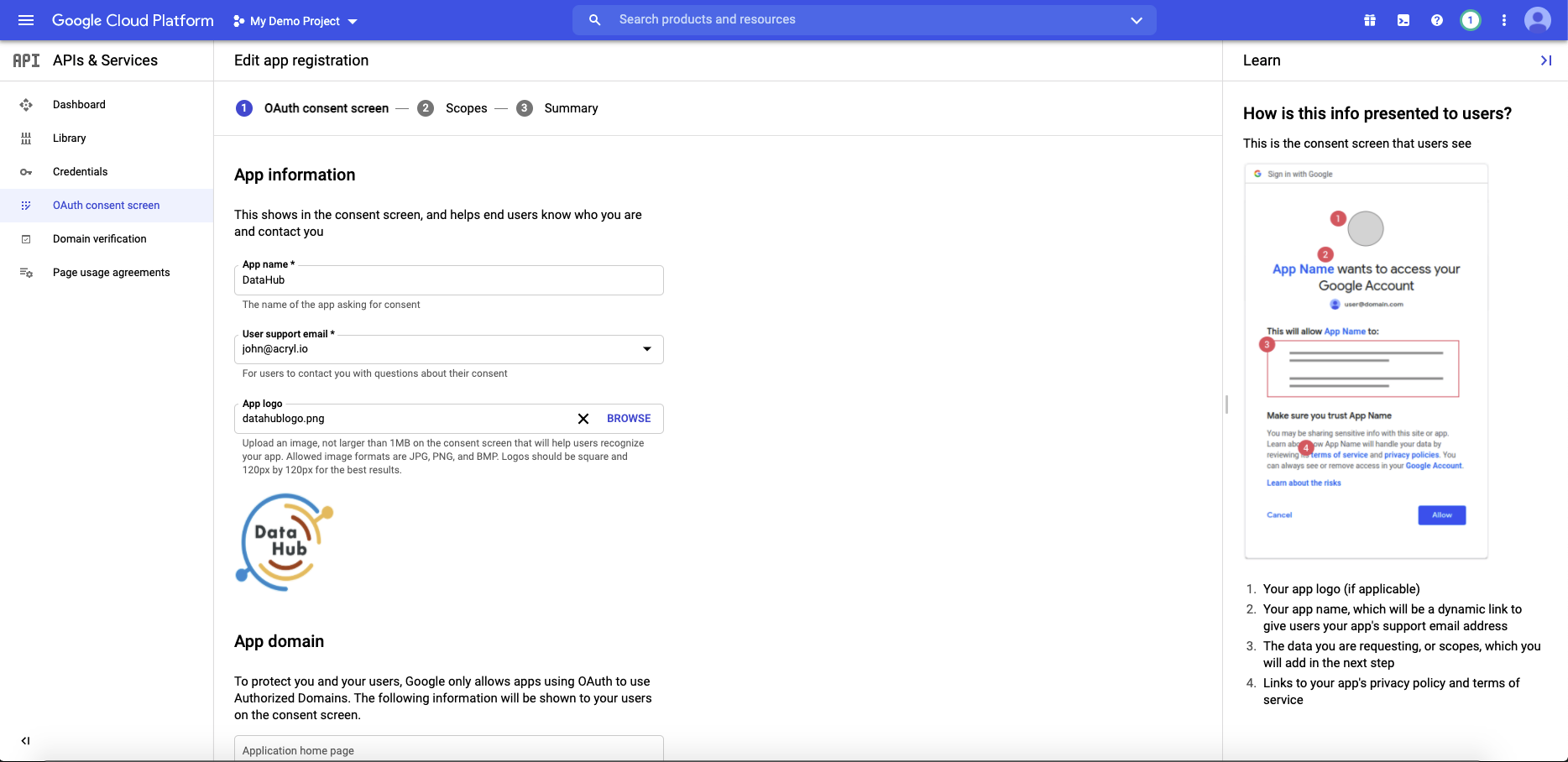
c. Fill out the details in the App Information & Domain sections. Make sure the 'Application Home Page' provided matches where DataHub is deployed
at your organization.
-
+
+
+  +
+
+
Once you've completed this, **Save & Continue**.
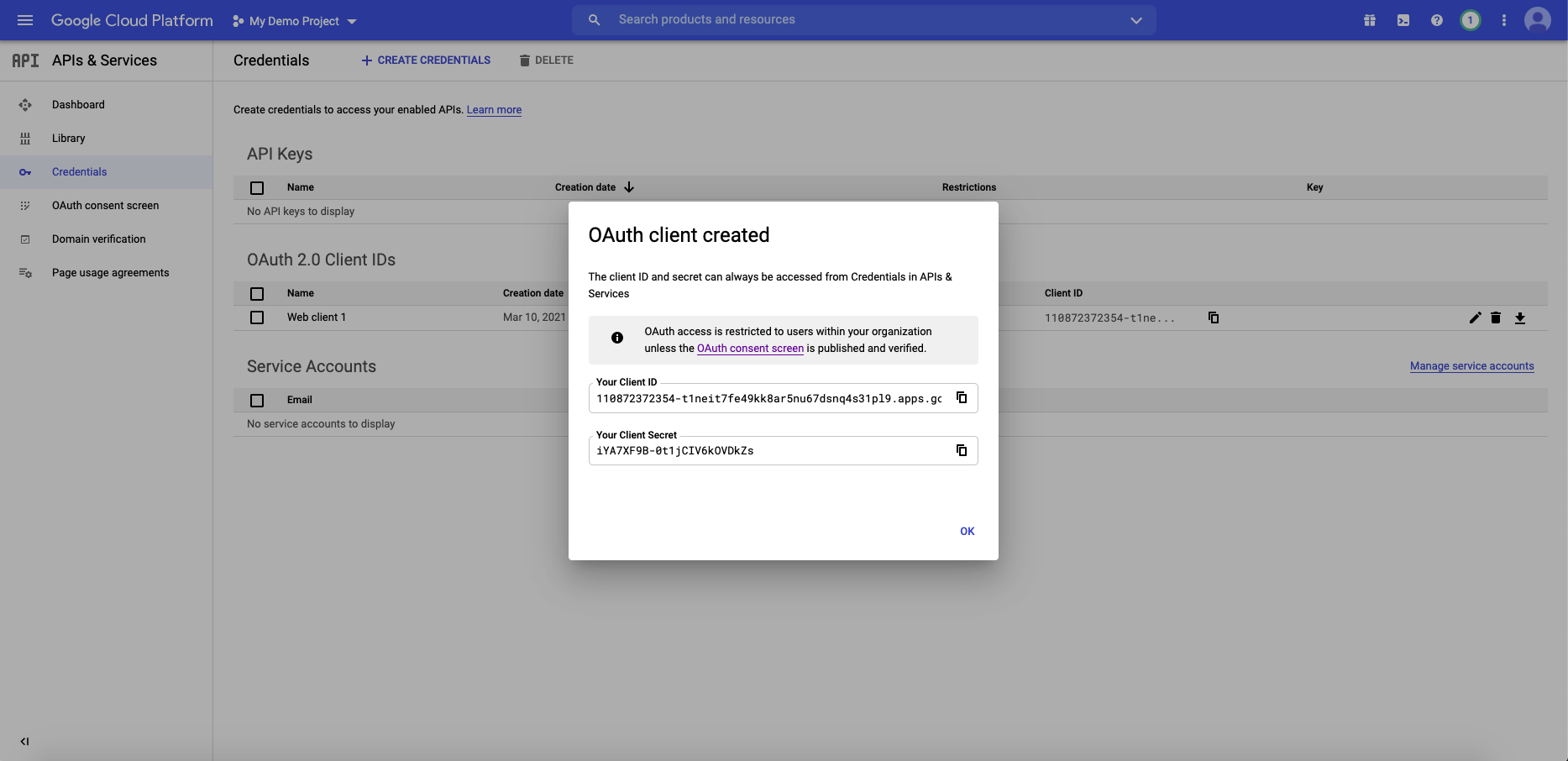
@@ -70,7 +74,11 @@ f. You will now receive a pair of values, a client id and a client secret. Bookm
At this point, you should be looking at a screen like the following:
-
+
+
+  +
+
+
Success!
diff --git a/docs/authentication/guides/sso/configure-oidc-react-okta.md b/docs/authentication/guides/sso/configure-oidc-react-okta.md
index cfede999f1e70..320b887a28f16 100644
--- a/docs/authentication/guides/sso/configure-oidc-react-okta.md
+++ b/docs/authentication/guides/sso/configure-oidc-react-okta.md
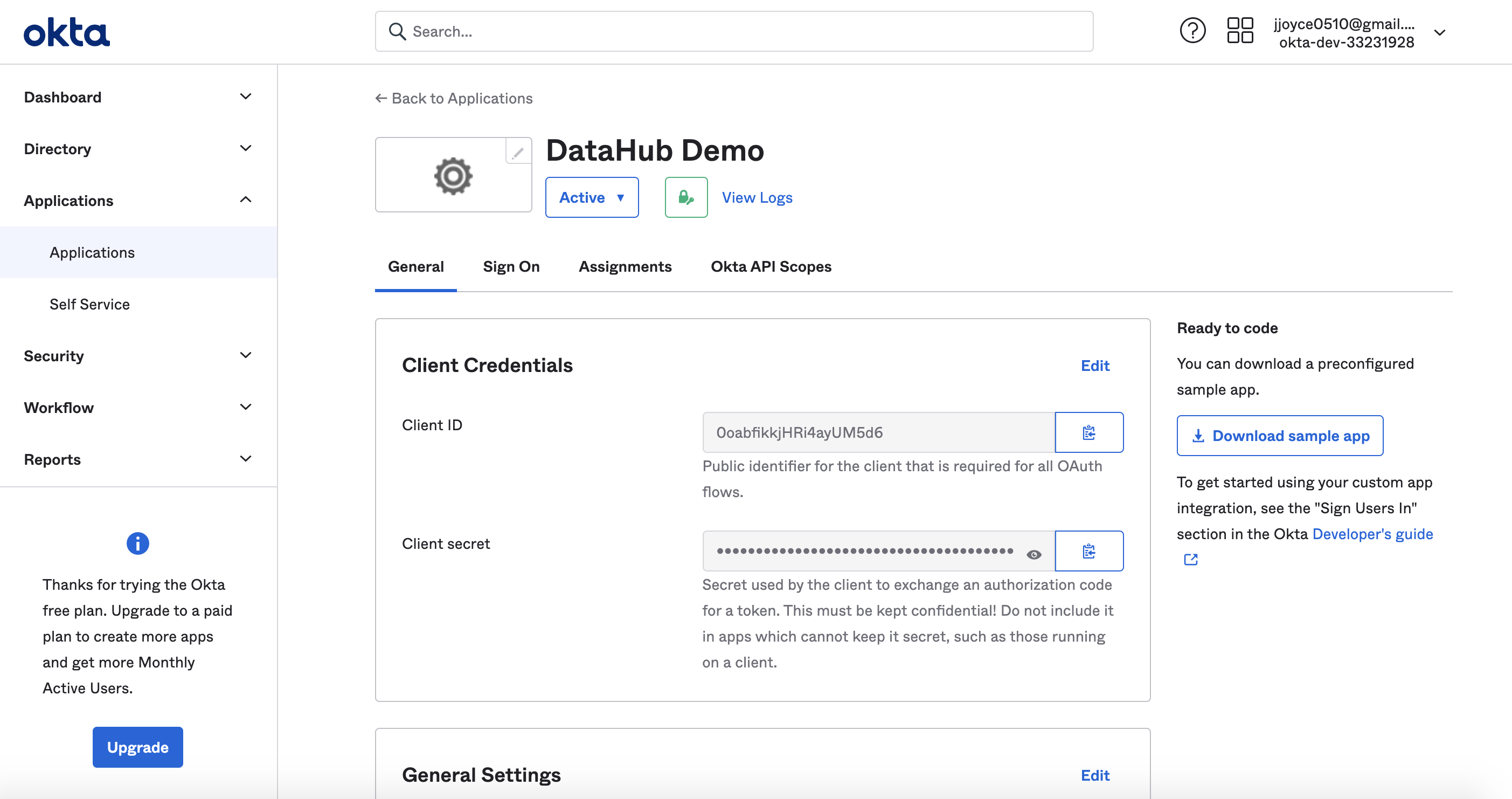
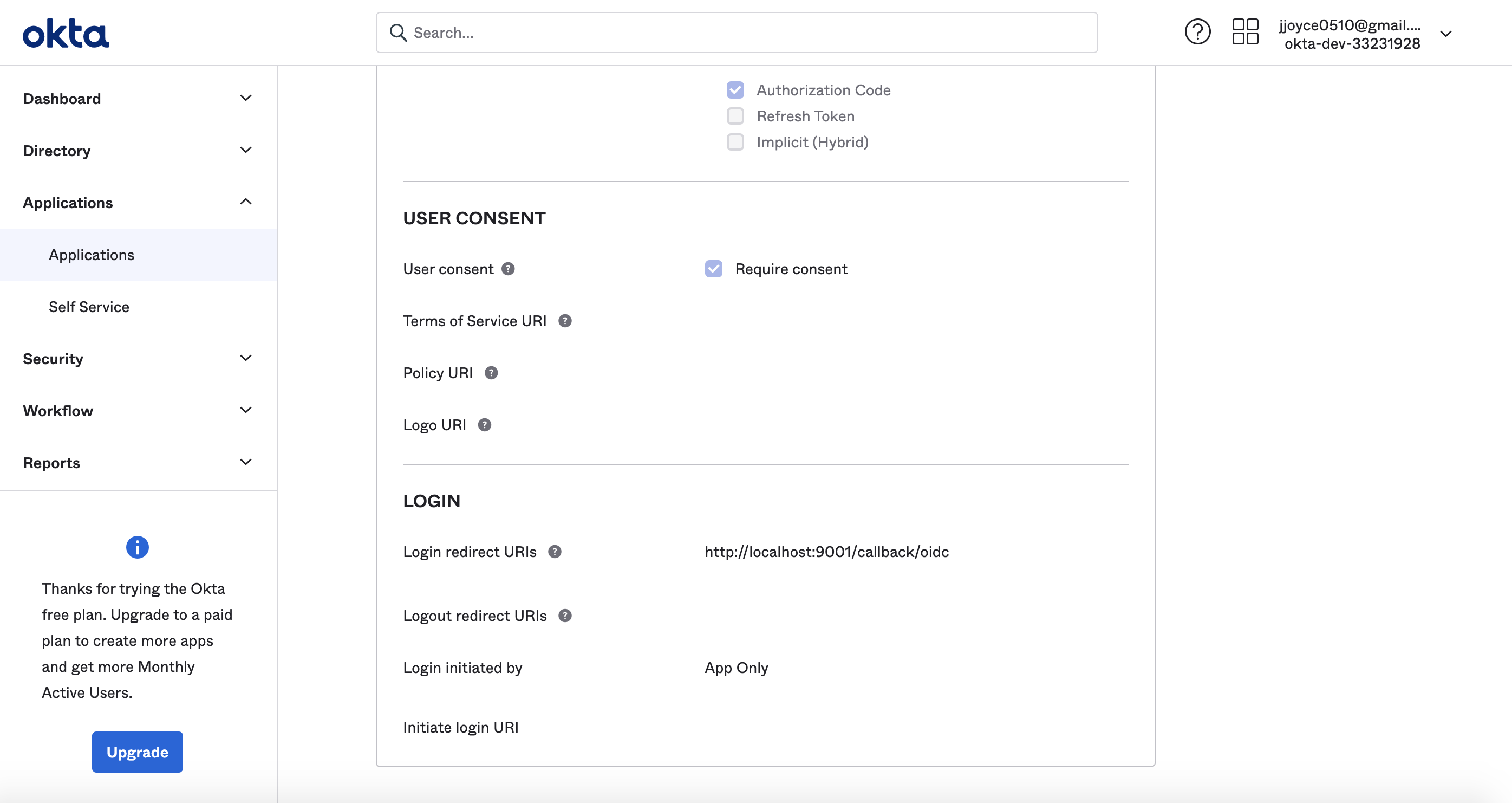
@@ -69,8 +69,16 @@ for example, `https://dev-33231928.okta.com/.well-known/openid-configuration`.
At this point, you should be looking at a screen like the following:
-
-
+
+
+  +
+
+
+
+
+  +
+
+
Success!
@@ -96,7 +104,11 @@ Replacing the placeholders above with the client id & client secret received fro
>
> By default, we assume that the groups will appear in a claim named "groups". This can be customized using the `AUTH_OIDC_GROUPS_CLAIM` container configuration.
>
-> 
+>
+
+ 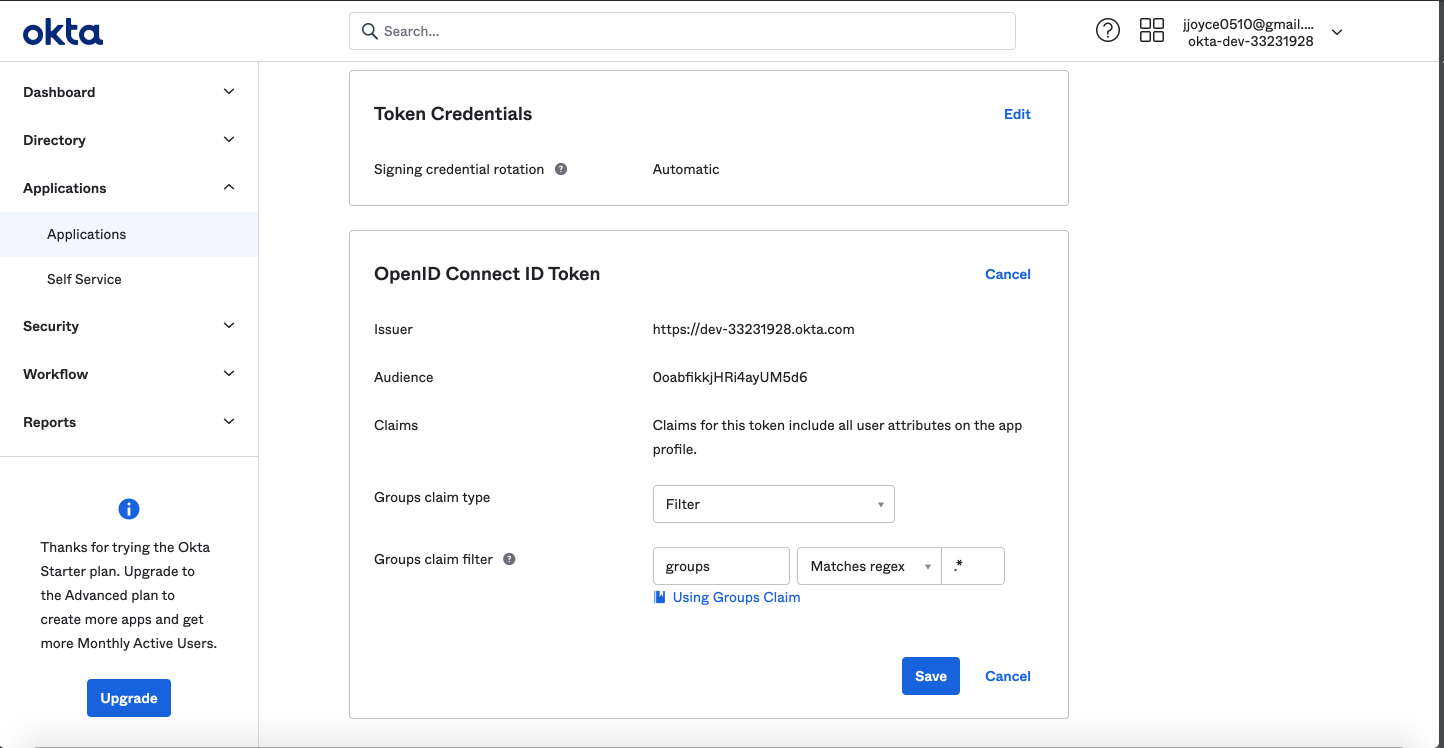 +
+
+
### 5. Restart `datahub-frontend-react` docker container
diff --git a/docs/authentication/guides/sso/img/azure-setup-api-permissions.png b/docs/authentication/guides/sso/img/azure-setup-api-permissions.png
deleted file mode 100755
index 4964b7d48ffec..0000000000000
Binary files a/docs/authentication/guides/sso/img/azure-setup-api-permissions.png and /dev/null differ
diff --git a/docs/authentication/guides/sso/img/azure-setup-app-registration.png b/docs/authentication/guides/sso/img/azure-setup-app-registration.png
deleted file mode 100755
index ffb23a7e3ddec..0000000000000
Binary files a/docs/authentication/guides/sso/img/azure-setup-app-registration.png and /dev/null differ
diff --git a/docs/authentication/guides/sso/img/azure-setup-authentication.png b/docs/authentication/guides/sso/img/azure-setup-authentication.png
deleted file mode 100755
index 2d27ec88fb40b..0000000000000
Binary files a/docs/authentication/guides/sso/img/azure-setup-authentication.png and /dev/null differ
diff --git a/docs/authentication/guides/sso/img/azure-setup-certificates-secrets.png b/docs/authentication/guides/sso/img/azure-setup-certificates-secrets.png
deleted file mode 100755
index db6585d84d8ee..0000000000000
Binary files a/docs/authentication/guides/sso/img/azure-setup-certificates-secrets.png and /dev/null differ
diff --git a/docs/authentication/guides/sso/img/google-setup-1.png b/docs/authentication/guides/sso/img/google-setup-1.png
deleted file mode 100644
index 88c674146f1e4..0000000000000
Binary files a/docs/authentication/guides/sso/img/google-setup-1.png and /dev/null differ
diff --git a/docs/authentication/guides/sso/img/google-setup-2.png b/docs/authentication/guides/sso/img/google-setup-2.png
deleted file mode 100644
index 850512b891d5f..0000000000000
Binary files a/docs/authentication/guides/sso/img/google-setup-2.png and /dev/null differ
diff --git a/docs/authentication/guides/sso/img/okta-setup-1.png b/docs/authentication/guides/sso/img/okta-setup-1.png
deleted file mode 100644
index 3949f18657c5e..0000000000000
Binary files a/docs/authentication/guides/sso/img/okta-setup-1.png and /dev/null differ
diff --git a/docs/authentication/guides/sso/img/okta-setup-2.png b/docs/authentication/guides/sso/img/okta-setup-2.png
deleted file mode 100644
index fa6ea4d991894..0000000000000
Binary files a/docs/authentication/guides/sso/img/okta-setup-2.png and /dev/null differ
diff --git a/docs/authentication/guides/sso/img/okta-setup-groups-claim.png b/docs/authentication/guides/sso/img/okta-setup-groups-claim.png
deleted file mode 100644
index ed35426685e46..0000000000000
Binary files a/docs/authentication/guides/sso/img/okta-setup-groups-claim.png and /dev/null differ
diff --git a/docs/authentication/personal-access-tokens.md b/docs/authentication/personal-access-tokens.md
index 0188aab49444e..dc57a989a4e0c 100644
--- a/docs/authentication/personal-access-tokens.md
+++ b/docs/authentication/personal-access-tokens.md
@@ -71,7 +71,11 @@ curl 'http://localhost:8080/entities/urn:li:corpuser:datahub' -H 'Authorization:
Since authorization happens at the GMS level, this means that ingestion is also protected behind access tokens, to use them simply add a `token` to the sink config property as seen below:
-
+
+
+  +
+
+
:::note
diff --git a/docs/authorization/access-policies-guide.md b/docs/authorization/access-policies-guide.md
index 5820e513a83e3..1eabb64d2878f 100644
--- a/docs/authorization/access-policies-guide.md
+++ b/docs/authorization/access-policies-guide.md
@@ -110,10 +110,13 @@ In the second step, we can simply select the Privileges that this Platform Polic
| Manage Tags | Allow the actor to create and remove any Tags |
| Manage Public Views | Allow the actor to create, edit, and remove any public (shared) Views. |
| Manage Ownership Types | Allow the actor to create, edit, and remove any Ownership Types. |
+| Manage Platform Settings | (Acryl DataHub only) Allow the actor to manage global integrations and notification settings |
+| Manage Monitors | (Acryl DataHub only) Allow the actor to create, remove, start, or stop any entity assertion monitors |
| Restore Indices API[^1] | Allow the actor to restore indices for a set of entities via API |
| Enable/Disable Writeability API[^1] | Allow the actor to enable or disable GMS writeability for use in data migrations |
| Apply Retention API[^1] | Allow the actor to apply aspect retention via API |
+
[^1]: Only active if REST_API_AUTHORIZATION_ENABLED environment flag is enabled
#### Step 3: Choose Policy Actors
@@ -204,8 +207,15 @@ The common Metadata Privileges, which span across entity types, include:
| Edit Status | Allow actor to edit the status of an entity (soft deleted or not). |
| Edit Domain | Allow actor to edit the Domain of an entity. |
| Edit Deprecation | Allow actor to edit the Deprecation status of an entity. |
-| Edit Assertions | Allow actor to add and remove assertions from an entity. |
-| Edit All | Allow actor to edit any information about an entity. Super user privileges. Controls the ability to ingest using API when REST API Authorization is enabled. |
+| Edit Lineage | Allow actor to edit custom lineage edges for the entity. |
+| Edit Data Product | Allow actor to edit the data product that an entity is part of |
+| Propose Tags | (Acryl DataHub only) Allow actor to propose new Tags for the entity. |
+| Propose Glossary Terms | (Acryl DataHub only) Allow actor to propose new Glossary Terms for the entity. |
+| Propose Documentation | (Acryl DataHub only) Allow actor to propose new Documentation for the entity. |
+| Manage Tag Proposals | (Acryl DataHub only) Allow actor to accept or reject proposed Tags for the entity. |
+| Manage Glossary Terms Proposals | (Acryl DataHub only) Allow actor to accept or reject proposed Glossary Terms for the entity. |
+| Manage Documentation Proposals | (Acryl DataHub only) Allow actor to accept or reject proposed Documentation for the entity |
+| Edit Entity | Allow actor to edit any information about an entity. Super user privileges. Controls the ability to ingest using API when REST API Authorization is enabled. |
| Get Timeline API[^1] | Allow actor to get the timeline of an entity via API. |
| Get Entity API[^1] | Allow actor to get an entity via API. |
| Get Timeseries Aspect API[^1] | Allow actor to get a timeseries aspect via API. |
@@ -225,10 +235,19 @@ The common Metadata Privileges, which span across entity types, include:
| Dataset | Edit Dataset Queries | Allow actor to edit the Highlighted Queries on the Queries tab of the dataset. |
| Dataset | View Dataset Usage | Allow actor to access usage metadata about a dataset both in the UI and in the GraphQL API. This includes example queries, number of queries, etc. Also applies to REST APIs when REST API Authorization is enabled. |
| Dataset | View Dataset Profile | Allow actor to access a dataset's profile both in the UI and in the GraphQL API. This includes snapshot statistics like #rows, #columns, null percentage per field, etc. |
+| Dataset | Edit Assertions | Allow actor to change the assertions associated with a dataset. |
+| Dataset | Edit Incidents | (Acryl DataHub only) Allow actor to change the incidents associated with a dataset. |
+| Dataset | Edit Monitors | (Acryl DataHub only) Allow actor to change the assertion monitors associated with a dataset. |
| Tag | Edit Tag Color | Allow actor to change the color of a Tag. |
| Group | Edit Group Members | Allow actor to add and remove members to a group. |
+| Group | Edit Contact Information | Allow actor to change email, slack handle associated with the group. |
+| Group | Manage Group Subscriptions | (Acryl DataHub only) Allow actor to subscribe the group to entities. |
+| Group | Manage Group Notifications | (Acryl DataHub only) Allow actor to change notification settings for the group. |
| User | Edit User Profile | Allow actor to change the user's profile including display name, bio, title, profile image, etc. |
| User + Group | Edit Contact Information | Allow actor to change the contact information such as email & chat handles. |
+| Term Group | Manage Direct Glossary Children | Allow actor to change the direct child Term Groups or Terms of the group. |
+| Term Group | Manage All Glossary Children | Allow actor to change any direct or indirect child Term Groups or Terms of the group. |
+
> **Still have questions about Privileges?** Let us know in [Slack](https://slack.datahubproject.io)!
diff --git a/docs/components.md b/docs/components.md
index ef76729bb37fb..b59dabcf999cc 100644
--- a/docs/components.md
+++ b/docs/components.md
@@ -6,7 +6,11 @@ title: "Components"
The DataHub platform consists of the components shown in the following diagram.
-
+
+
+  +
+
+
## Metadata Store
diff --git a/docs/demo/DataHub-UIOverview.pdf b/docs/demo/DataHub-UIOverview.pdf
deleted file mode 100644
index cd6106e84ac23..0000000000000
Binary files a/docs/demo/DataHub-UIOverview.pdf and /dev/null differ
diff --git a/docs/demo/DataHub_-_Powering_LinkedIn_Metadata.pdf b/docs/demo/DataHub_-_Powering_LinkedIn_Metadata.pdf
deleted file mode 100644
index 71498045f9b5b..0000000000000
Binary files a/docs/demo/DataHub_-_Powering_LinkedIn_Metadata.pdf and /dev/null differ
diff --git a/docs/demo/Data_Discoverability_at_SpotHero.pdf b/docs/demo/Data_Discoverability_at_SpotHero.pdf
deleted file mode 100644
index 83e37d8606428..0000000000000
Binary files a/docs/demo/Data_Discoverability_at_SpotHero.pdf and /dev/null differ
diff --git a/docs/demo/Datahub_-_Strongly_Consistent_Secondary_Indexing.pdf b/docs/demo/Datahub_-_Strongly_Consistent_Secondary_Indexing.pdf
deleted file mode 100644
index 2d6a33a464650..0000000000000
Binary files a/docs/demo/Datahub_-_Strongly_Consistent_Secondary_Indexing.pdf and /dev/null differ
diff --git a/docs/demo/Datahub_at_Grofers.pdf b/docs/demo/Datahub_at_Grofers.pdf
deleted file mode 100644
index c29cece9e250a..0000000000000
Binary files a/docs/demo/Datahub_at_Grofers.pdf and /dev/null differ
diff --git a/docs/demo/Designing_the_next_generation_of_metadata_events_for_scale.pdf b/docs/demo/Designing_the_next_generation_of_metadata_events_for_scale.pdf
deleted file mode 100644
index 0d067eef28d03..0000000000000
Binary files a/docs/demo/Designing_the_next_generation_of_metadata_events_for_scale.pdf and /dev/null differ
diff --git a/docs/demo/Metadata_Use-Cases_at_LinkedIn_-_Lightning_Talk.pdf b/docs/demo/Metadata_Use-Cases_at_LinkedIn_-_Lightning_Talk.pdf
deleted file mode 100644
index 382754f863c8a..0000000000000
Binary files a/docs/demo/Metadata_Use-Cases_at_LinkedIn_-_Lightning_Talk.pdf and /dev/null differ
diff --git a/docs/demo/Saxo Bank Data Workbench.pdf b/docs/demo/Saxo Bank Data Workbench.pdf
deleted file mode 100644
index c43480d32b8f2..0000000000000
Binary files a/docs/demo/Saxo Bank Data Workbench.pdf and /dev/null differ
diff --git a/docs/demo/Taming the Data Beast Using DataHub.pdf b/docs/demo/Taming the Data Beast Using DataHub.pdf
deleted file mode 100644
index d0062465d9220..0000000000000
Binary files a/docs/demo/Taming the Data Beast Using DataHub.pdf and /dev/null differ
diff --git a/docs/demo/Town_Hall_Presentation_-_12-2020_-_UI_Development_Part_2.pdf b/docs/demo/Town_Hall_Presentation_-_12-2020_-_UI_Development_Part_2.pdf
deleted file mode 100644
index fb7bd2b693e87..0000000000000
Binary files a/docs/demo/Town_Hall_Presentation_-_12-2020_-_UI_Development_Part_2.pdf and /dev/null differ
diff --git a/docs/demo/ViasatMetadataJourney.pdf b/docs/demo/ViasatMetadataJourney.pdf
deleted file mode 100644
index ccffd18a06d18..0000000000000
Binary files a/docs/demo/ViasatMetadataJourney.pdf and /dev/null differ
diff --git a/docs/deploy/aws.md b/docs/deploy/aws.md
index 7b01ffa02a744..228fcb51d1a28 100644
--- a/docs/deploy/aws.md
+++ b/docs/deploy/aws.md
@@ -201,7 +201,11 @@ Provision a MySQL database in AWS RDS that shares the VPC with the kubernetes cl
the VPC of the kubernetes cluster. Once the database is provisioned, you should be able to see the following page. Take
a note of the endpoint marked by the red box.
-
+
+
+ 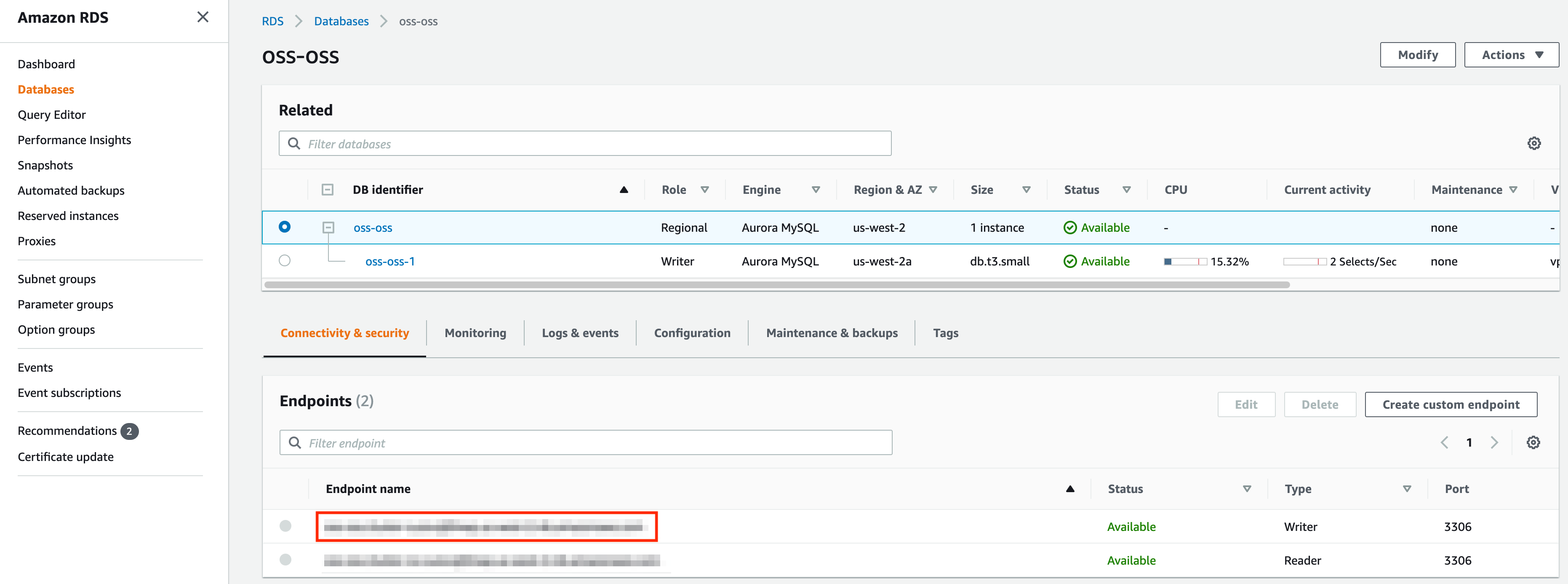 +
+
+
First, add the DB password to kubernetes by running the following.
@@ -234,7 +238,11 @@ Provision an elasticsearch domain running elasticsearch version 7.10 or above th
cluster or has VPC peering set up between the VPC of the kubernetes cluster. Once the domain is provisioned, you should
be able to see the following page. Take a note of the endpoint marked by the red box.
-
+
+
+ 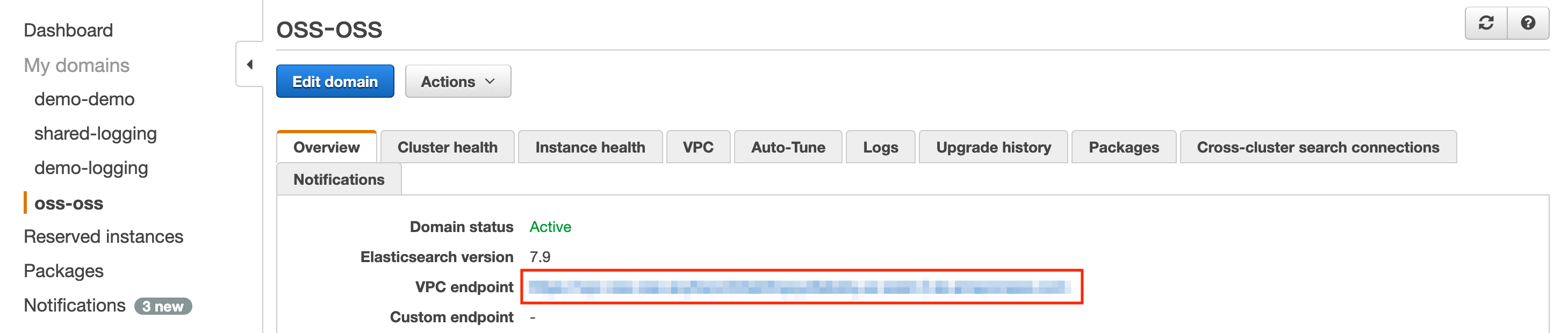 +
+
+
Update the elasticsearch settings under global in the values.yaml as follows.
@@ -330,7 +338,11 @@ Provision an MSK cluster that shares the VPC with the kubernetes cluster or has
the kubernetes cluster. Once the domain is provisioned, click on the “View client information” button in the ‘Cluster
Summary” section. You should see a page like below. Take a note of the endpoints marked by the red boxes.
-
+
+
+ 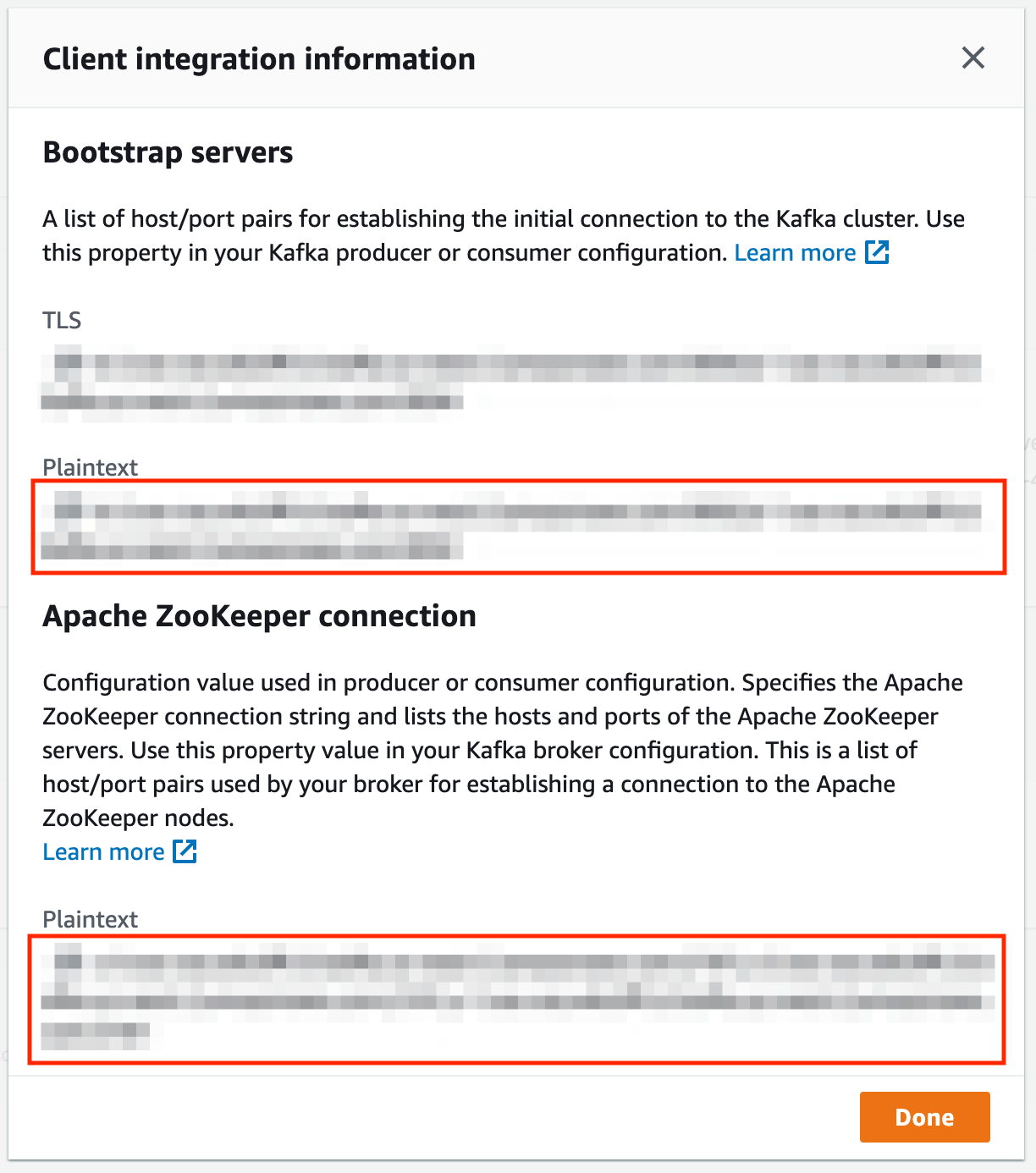 +
+
+
Update the kafka settings under global in the values.yaml as follows.
diff --git a/docs/deploy/confluent-cloud.md b/docs/deploy/confluent-cloud.md
index d93ffcceaecee..794b55d4686bf 100644
--- a/docs/deploy/confluent-cloud.md
+++ b/docs/deploy/confluent-cloud.md
@@ -24,7 +24,11 @@ decommissioned.
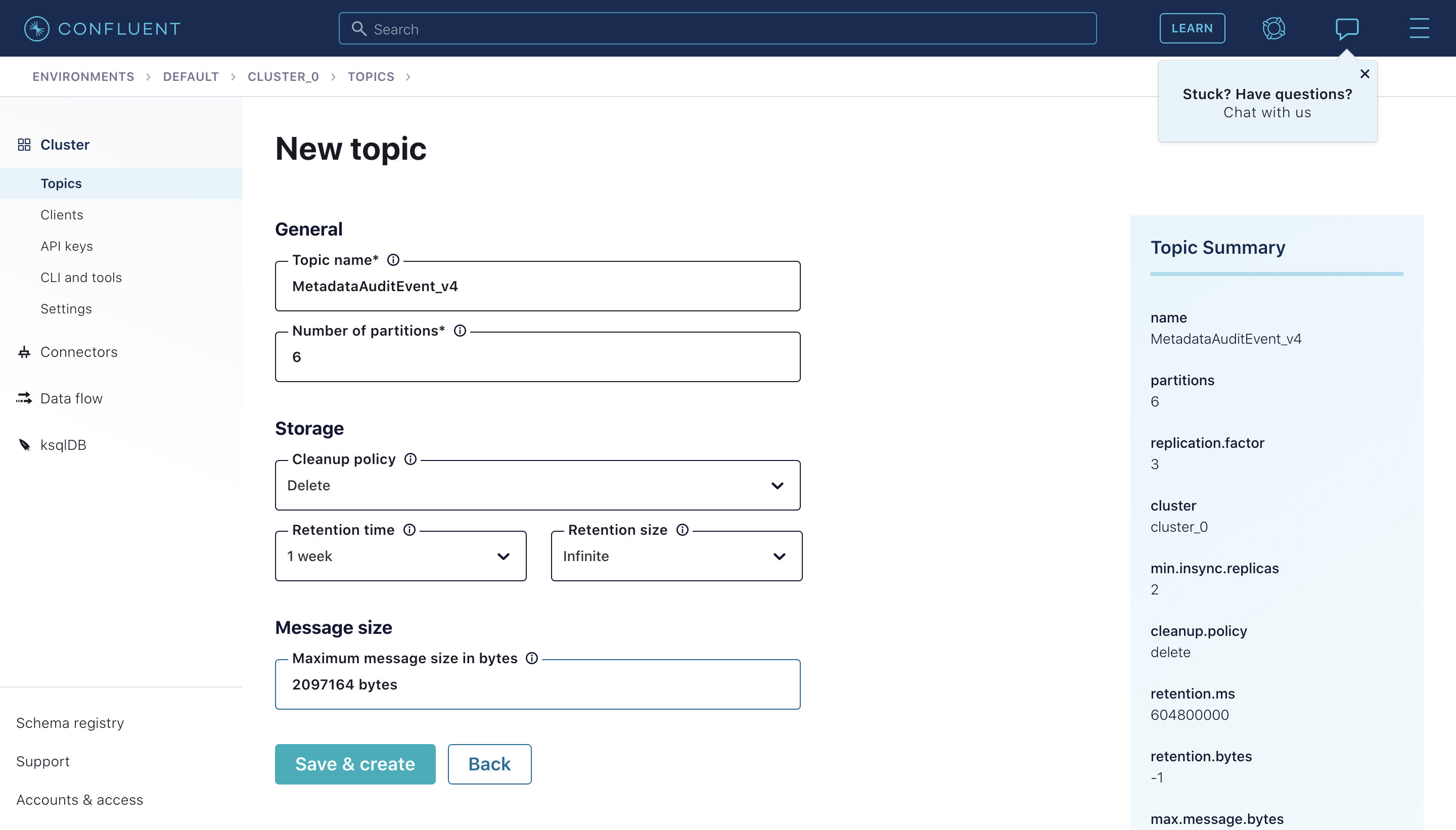
To create the topics, navigate to your **Cluster** and click "Create Topic". Feel free to tweak the default topic configurations to
match your preferences.
-
+
+
+  +
+
+
## Step 2: Configure DataHub Container to use Confluent Cloud Topics
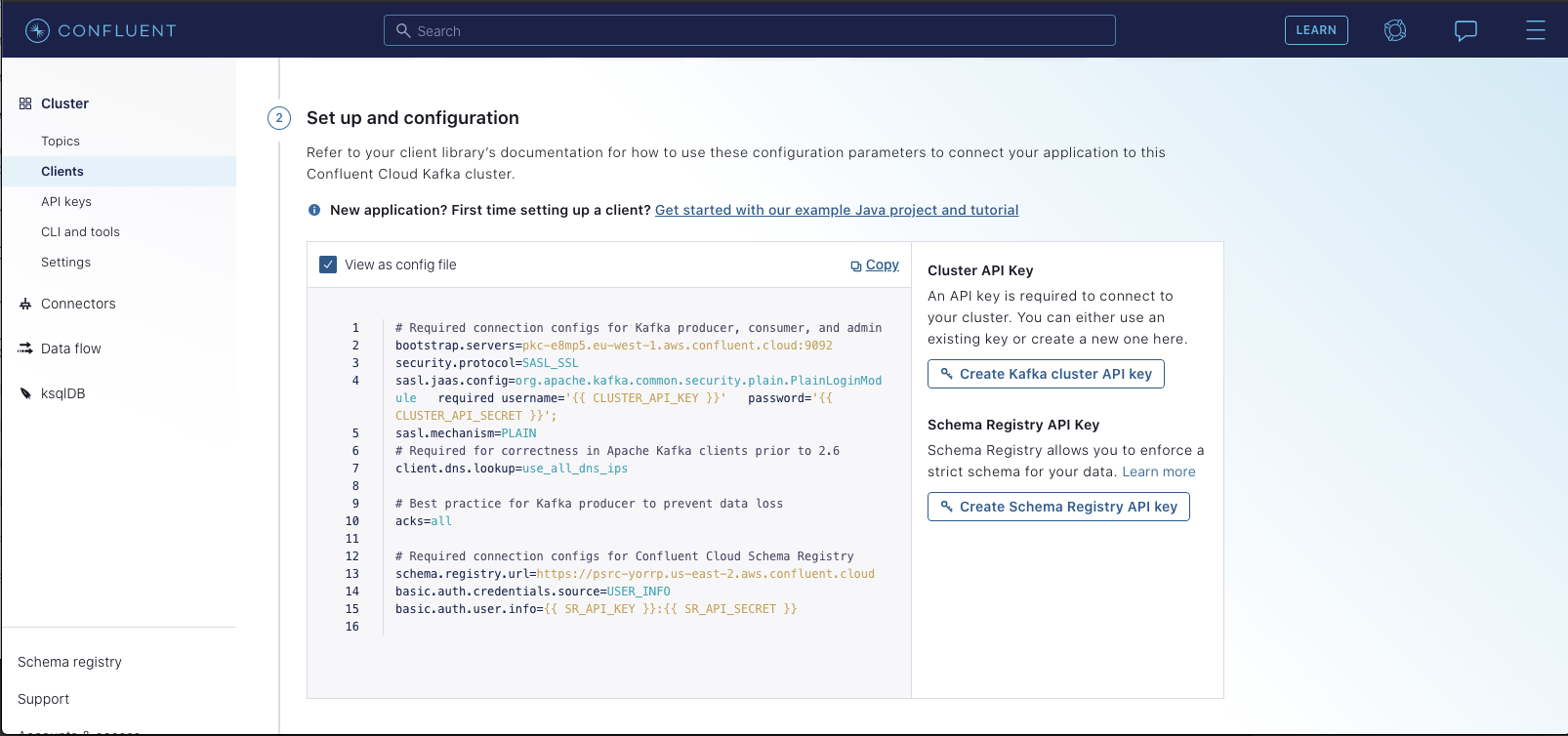
@@ -140,12 +144,20 @@ and another for the user info used for connecting to the schema registry. You'll
select "Clients" -> "Configure new Java Client". You should see a page like the following:
-
+
+
+  +
+
+
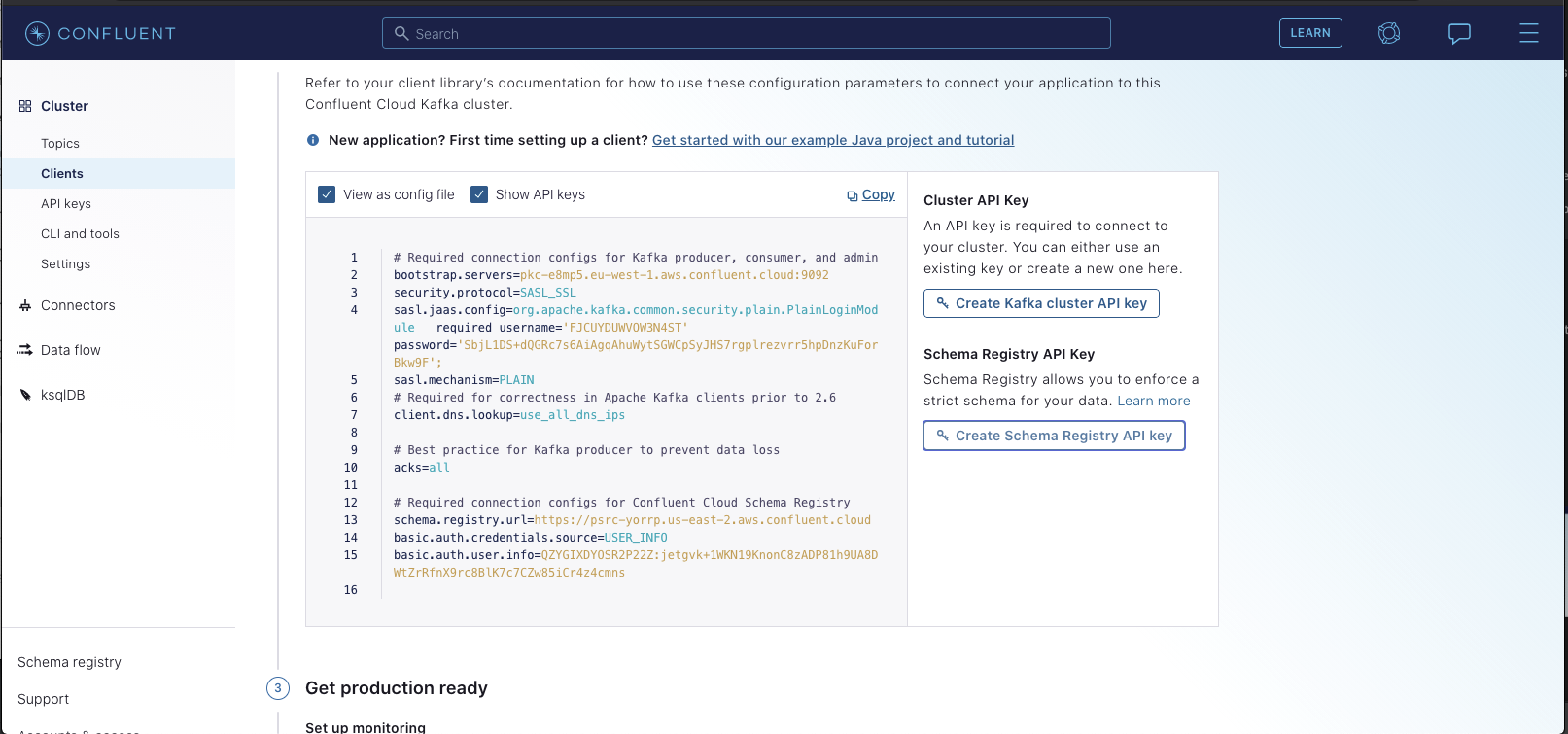
You'll want to generate both a Kafka Cluster API Key & a Schema Registry key. Once you do so,you should see the config
automatically populate with your new secrets:
-
+
+
+  +
+
+
You'll need to copy the values of `sasl.jaas.config` and `basic.auth.user.info`
for the next step.
diff --git a/docs/deploy/gcp.md b/docs/deploy/gcp.md
index 3713d69f90636..0cd3d92a8f3cd 100644
--- a/docs/deploy/gcp.md
+++ b/docs/deploy/gcp.md
@@ -65,16 +65,28 @@ the GKE page on [GCP website](https://console.cloud.google.com/kubernetes/discov
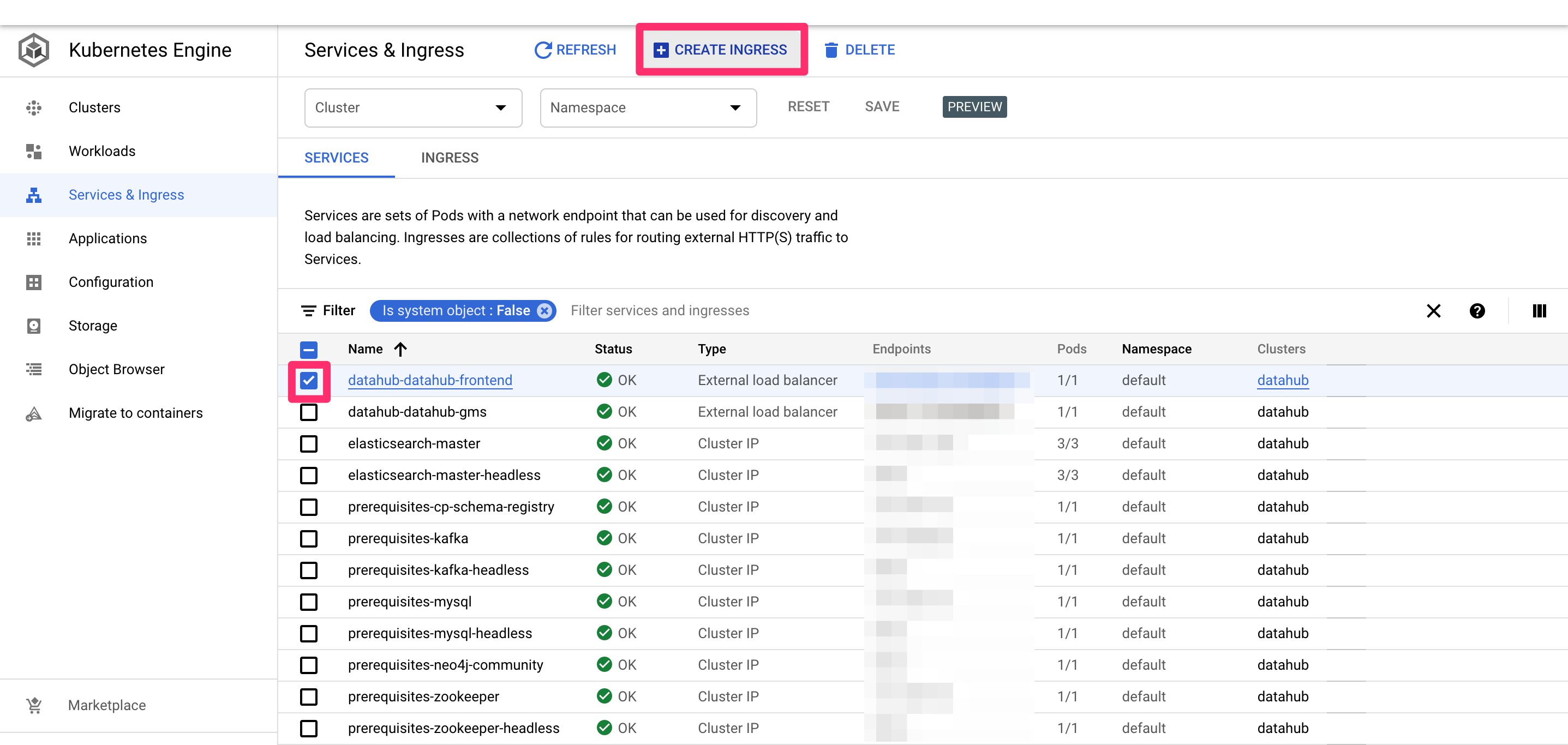
Once all deploy is successful, you should see a page like below in the "Services & Ingress" tab on the left.
-
+
+
+  +
+
+
Tick the checkbox for datahub-datahub-frontend and click "CREATE INGRESS" button. You should land on the following page.
-
+
+
+ 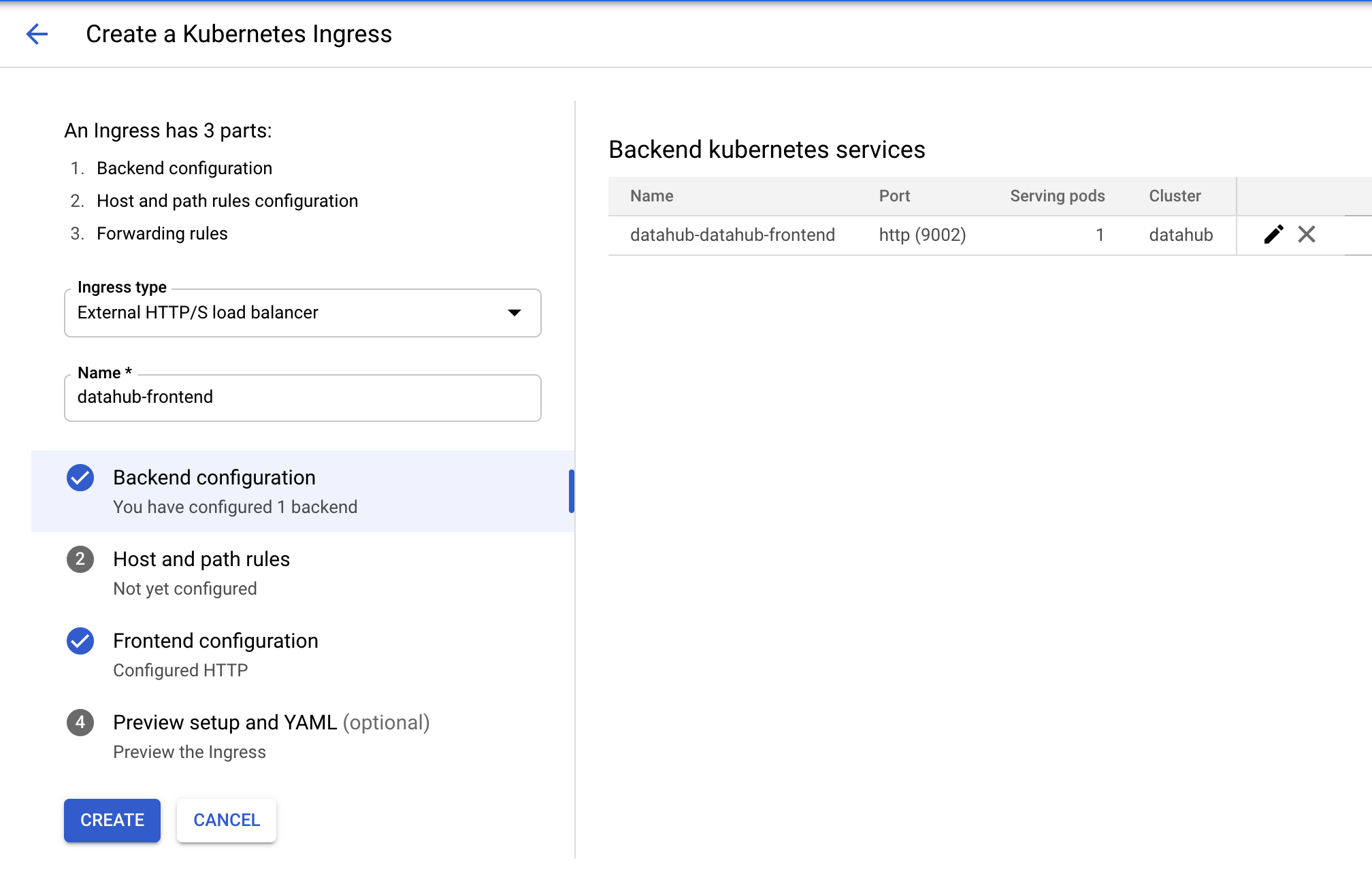 +
+
+
Type in an arbitrary name for the ingress and click on the second step "Host and path rules". You should land on the
following page.
-
+
+
+ 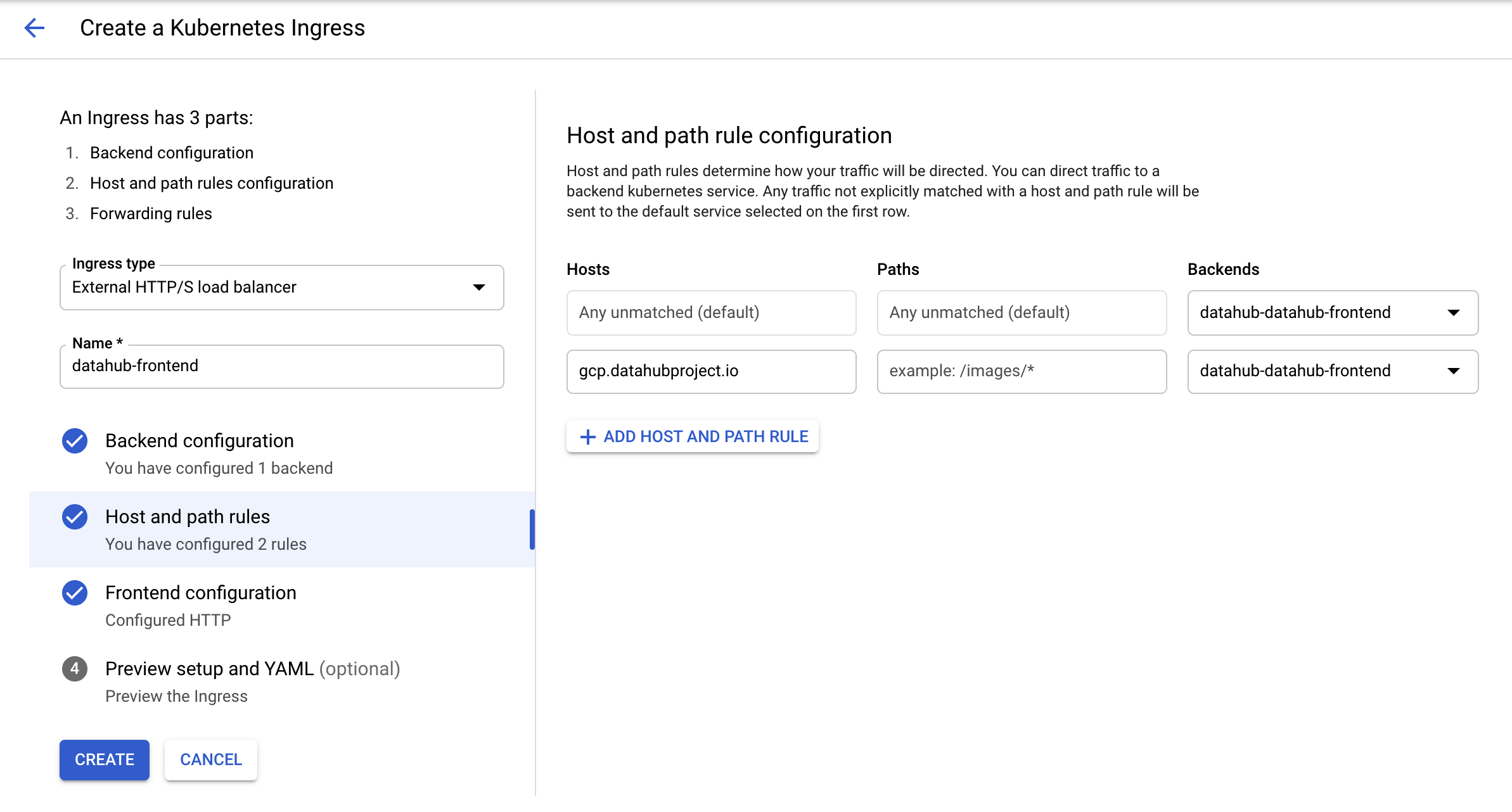 +
+
+
Select "datahub-datahub-frontend" in the dropdown menu for backends, and then click on "ADD HOST AND PATH RULE" button.
In the second row that got created, add in the host name of choice (here gcp.datahubproject.io) and select
@@ -83,14 +95,22 @@ In the second row that got created, add in the host name of choice (here gcp.dat
This step adds the rule allowing requests from the host name of choice to get routed to datahub-frontend service. Click
on step 3 "Frontend configuration". You should land on the following page.
-
+
+
+ 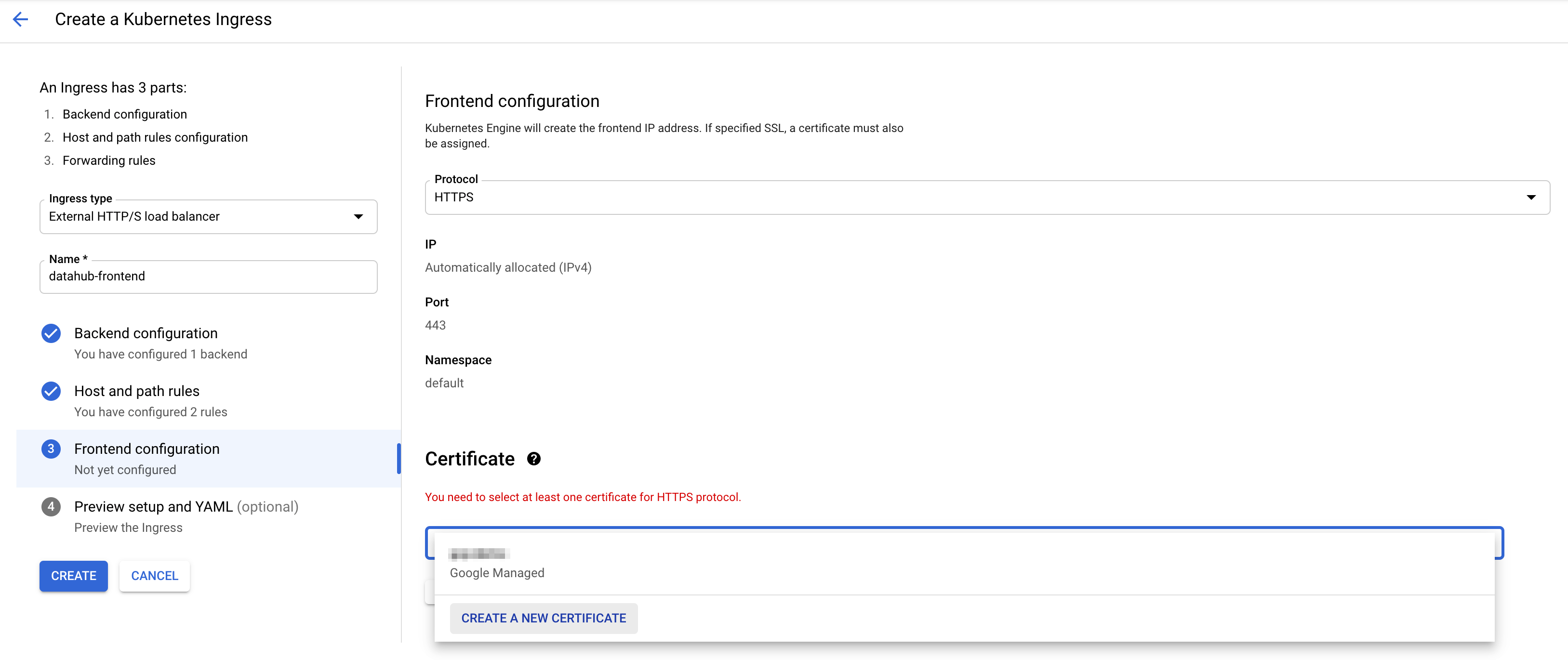 +
+
+
Choose HTTPS in the dropdown menu for protocol. To enable SSL, you need to add a certificate. If you do not have one,
you can click "CREATE A NEW CERTIFICATE" and input the host name of choice. GCP will create a certificate for you.
Now press "CREATE" button on the left to create ingress! After around 5 minutes, you should see the following.
-
+
+
+ 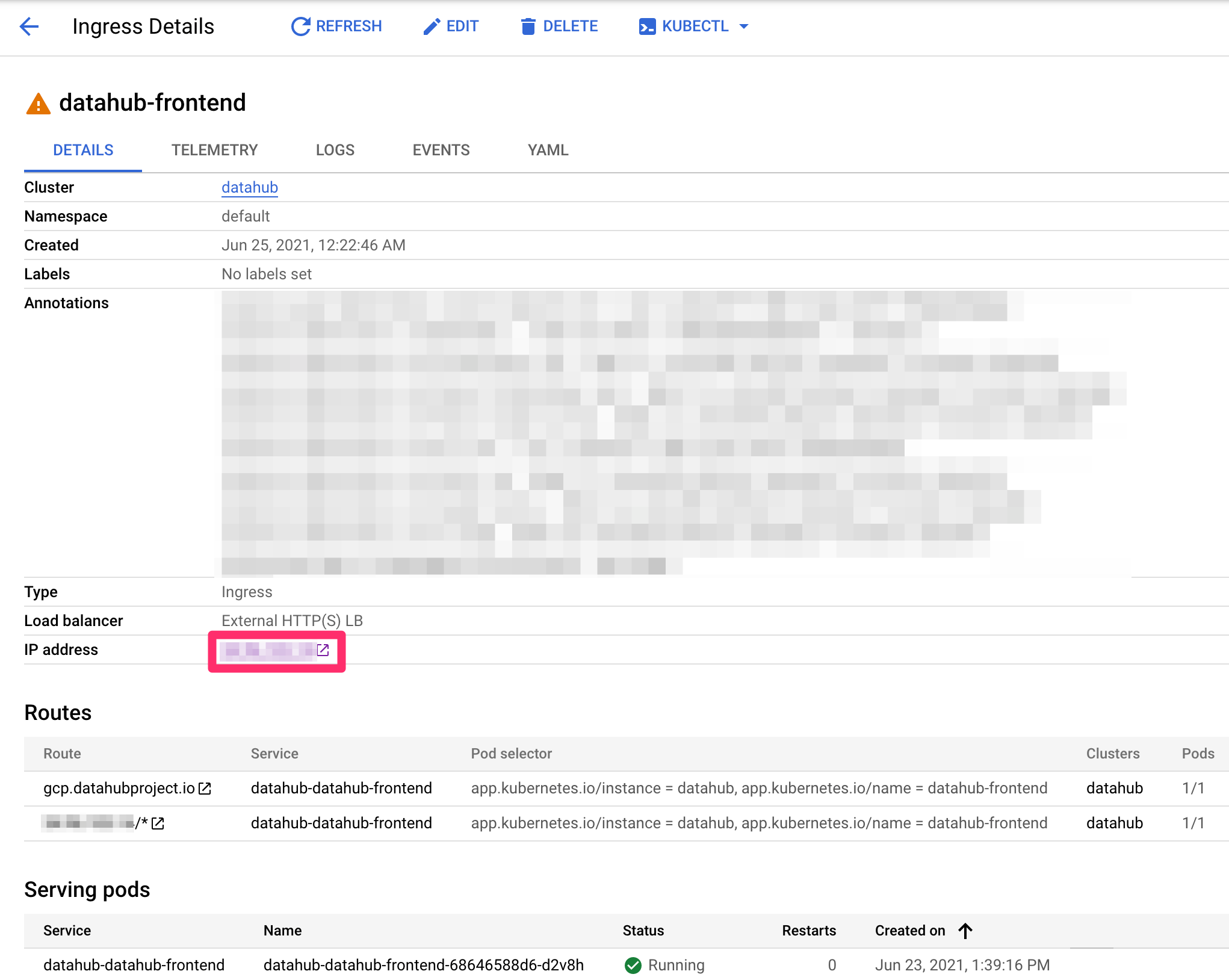 +
+
+
In your domain provider, add an A record for the host name set above using the IP address on the ingress page (noted
with the red box). Once DNS updates, you should be able to access DataHub through the host name!!
@@ -98,5 +118,9 @@ with the red box). Once DNS updates, you should be able to access DataHub throug
Note, ignore the warning icon next to ingress. It takes about ten minutes for ingress to check that the backend service
is ready and show a check mark as follows. However, ingress is fully functional once you see the above page.
-
+
+
+  +
+
+
diff --git a/docs/dev-guides/timeline.md b/docs/dev-guides/timeline.md
index 966e659b90991..829aef1d3eefa 100644
--- a/docs/dev-guides/timeline.md
+++ b/docs/dev-guides/timeline.md
@@ -14,7 +14,11 @@ The Timeline API is available in server versions `0.8.28` and higher. The `cli`
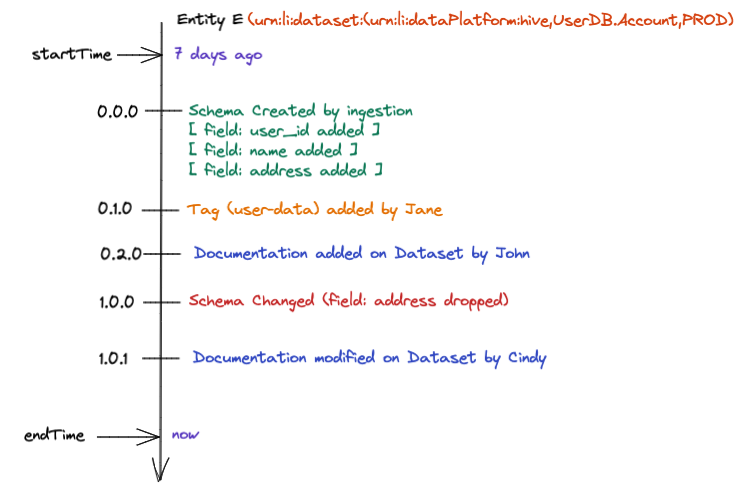
## Entity Timeline Conceptually
For the visually inclined, here is a conceptual diagram that illustrates how to think about the entity timeline with categorical changes overlaid on it.
-
+
+
+  +
+
+
## Change Event
Each modification is modeled as a
@@ -228,8 +232,16 @@ http://localhost:8080/openapi/timeline/v1/urn%3Ali%3Adataset%3A%28urn%3Ali%3Adat
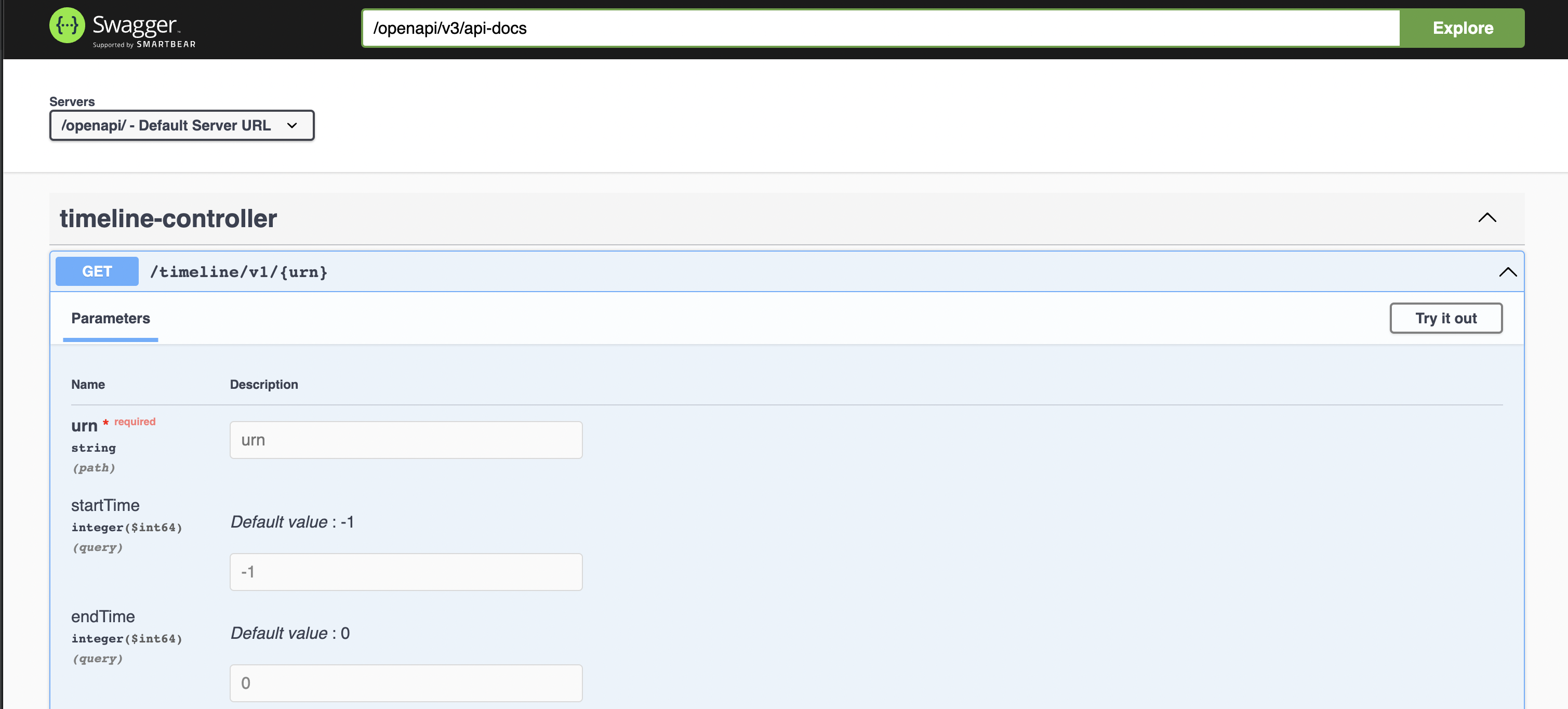
The API is browse-able via the UI through through the dropdown.
Here are a few screenshots showing how to navigate to it. You can try out the API and send example requests.
-
-
+
+
+  +
+
+
+
+
+  +
+
+
# Future Work
diff --git a/docs/docker/development.md b/docs/docker/development.md
index 2153aa9dc613f..91a303744a03b 100644
--- a/docs/docker/development.md
+++ b/docs/docker/development.md
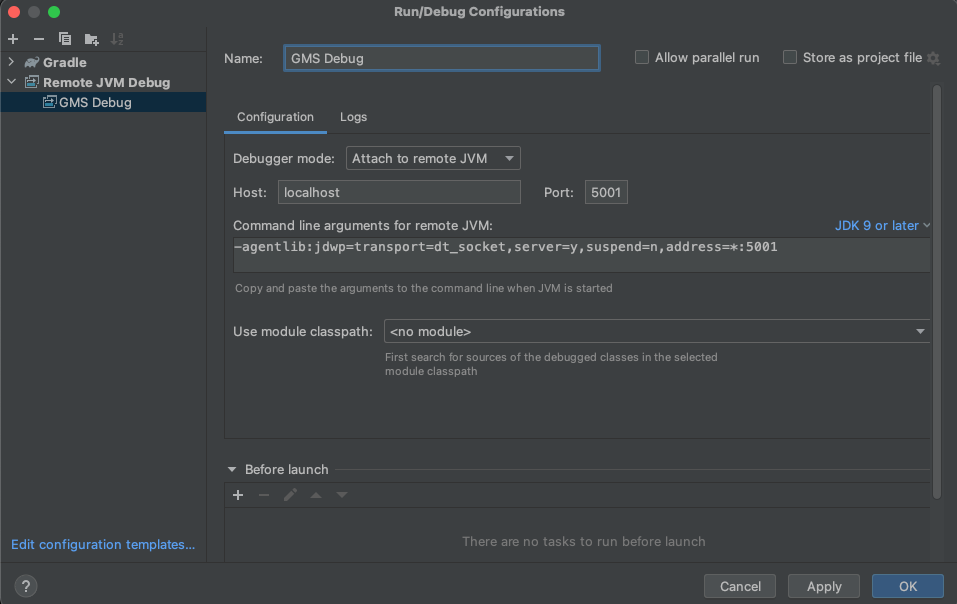
@@ -92,7 +92,11 @@ Environment variables control the debugging ports for GMS and the frontend.
The screenshot shows an example configuration for IntelliJ using the default GMS debugging port of 5001.
-
+
+
+  +
+
+
## Tips for People New To Docker
diff --git a/docs/glossary/business-glossary.md b/docs/glossary/business-glossary.md
index faab6f12fc55e..e10cbed30b913 100644
--- a/docs/glossary/business-glossary.md
+++ b/docs/glossary/business-glossary.md
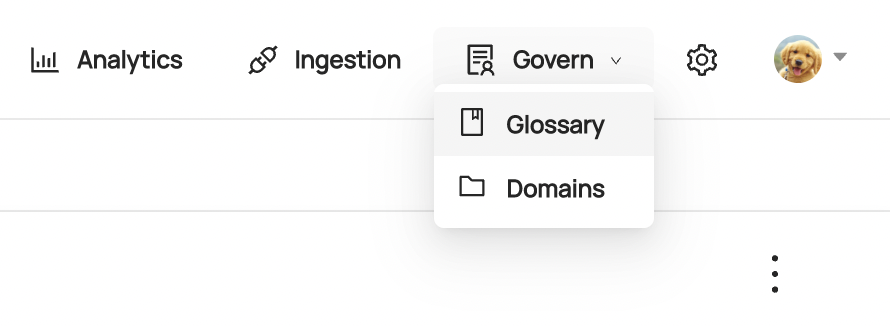
@@ -31,59 +31,103 @@ In order to view a Business Glossary, users must have the Platform Privilege cal
Once granted this privilege, you can access your Glossary by clicking the dropdown at the top of the page called **Govern** and then click **Glossary**:
-
+
+
+  +
+
+
You are now at the root of your Glossary and should see all Terms and Term Groups with no parents assigned to them. You should also notice a hierarchy navigator on the left where you can easily check out the structure of your Glossary!
-
+
+
+ 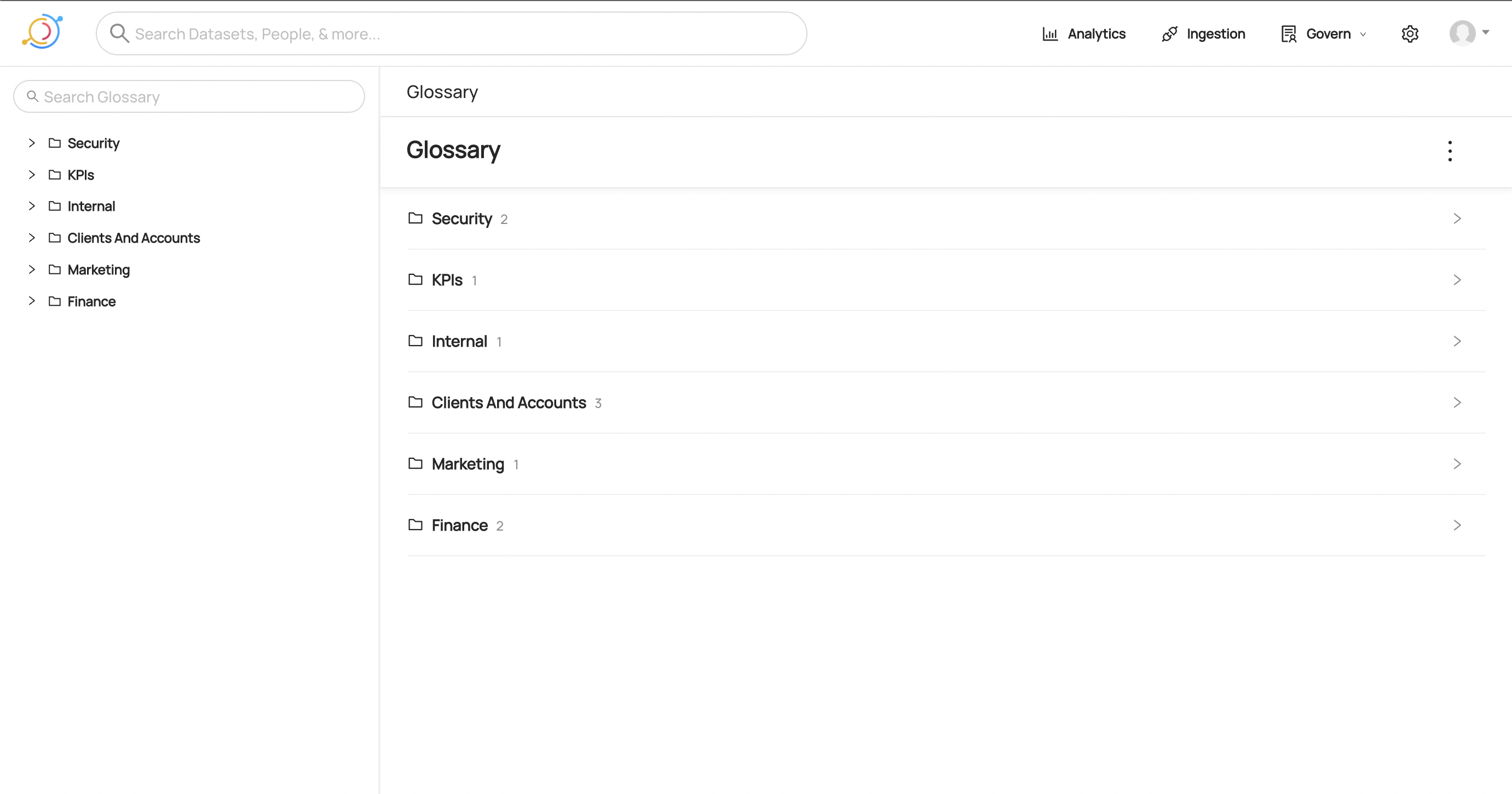 +
+
+
## Creating a Term or Term Group
There are two ways to create Terms and Term Groups through the UI. First, you can create directly from the Glossary home page by clicking the menu dots on the top right and selecting your desired option:
-
+
+
+ 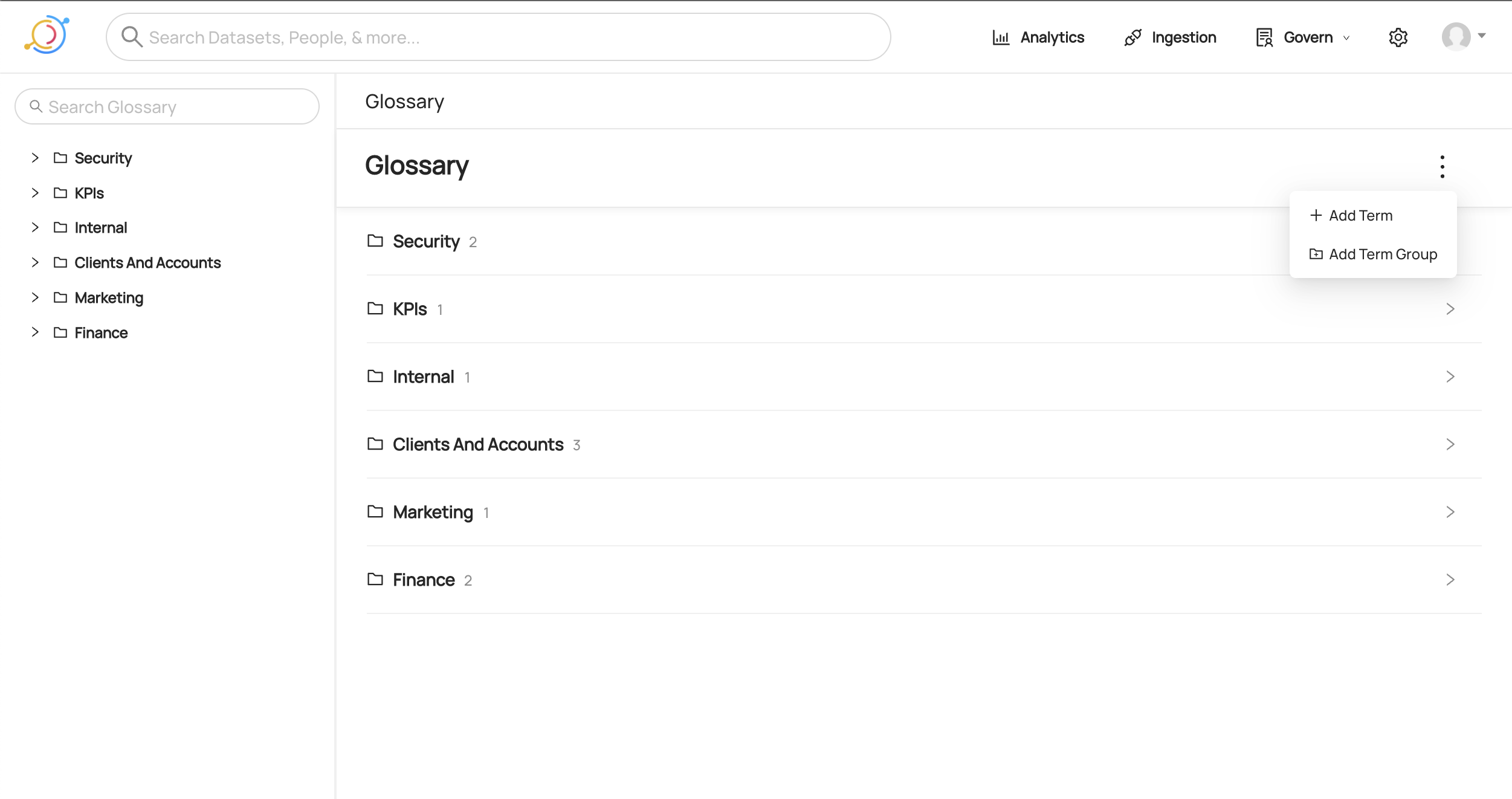 +
+
+
You can also create Terms or Term Groups directly from a Term Group's page. In order to do that you need to click the menu dots on the top right and select what you want:
-
+
+
+ 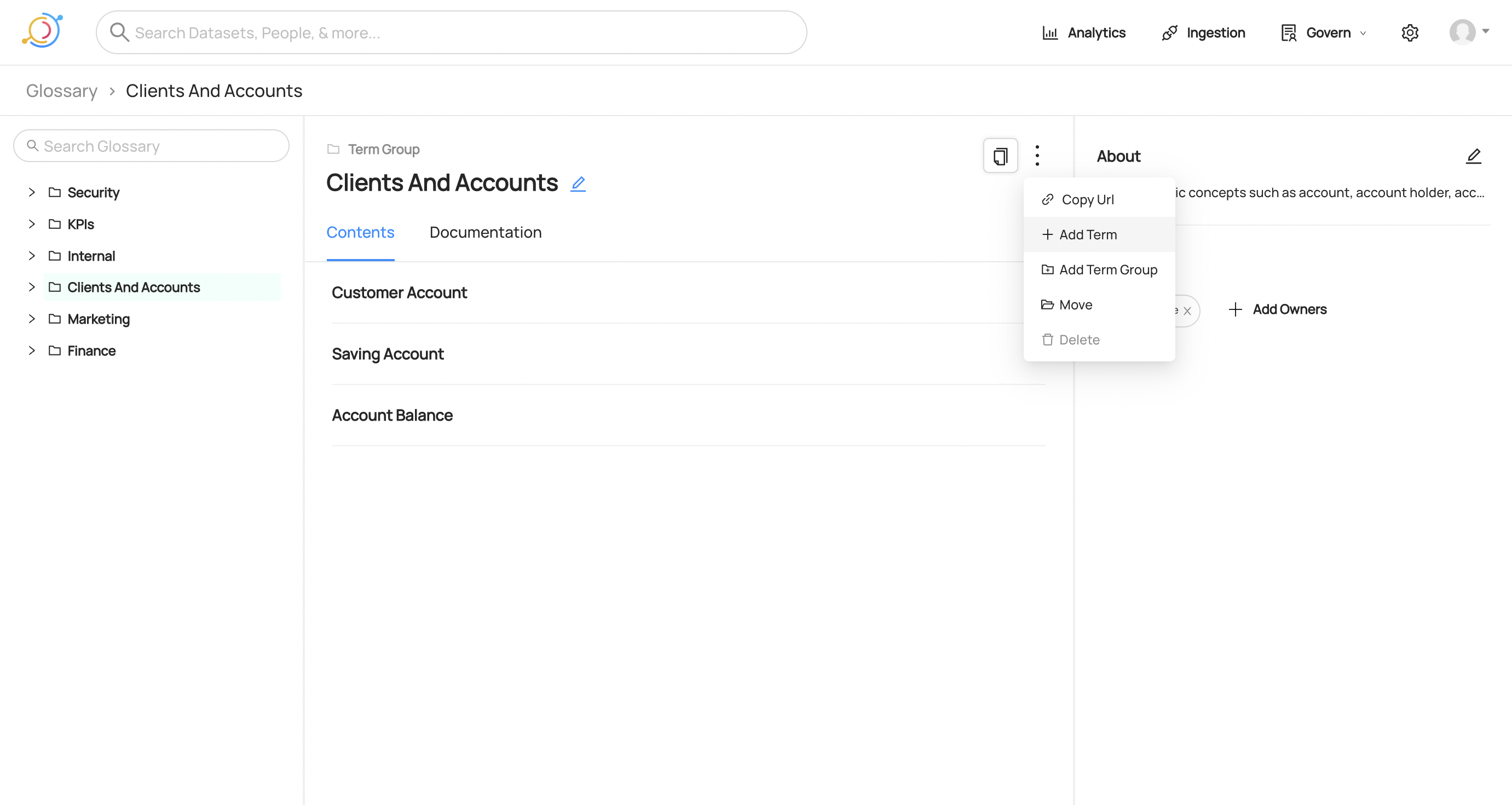 +
+
+
Note that the modal that pops up will automatically set the current Term Group you are in as the **Parent**. You can easily change this by selecting the input and navigating through your Glossary to find your desired Term Group. In addition, you could start typing the name of a Term Group to see it appear by searching. You can also leave this input blank in order to create a Term or Term Group with no parent.
-
+
+
+ 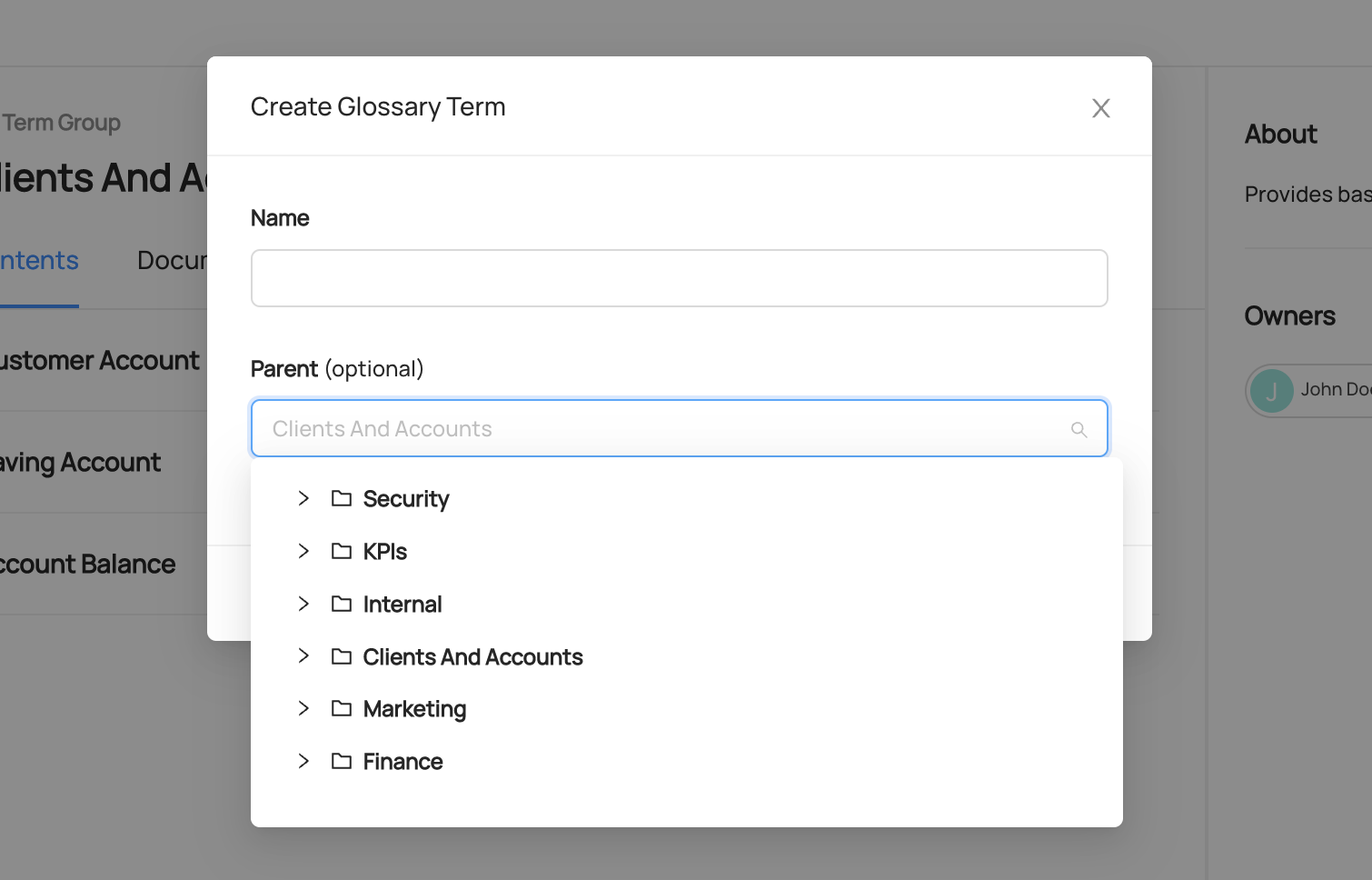 +
+
+
## Editing a Term or Term Group
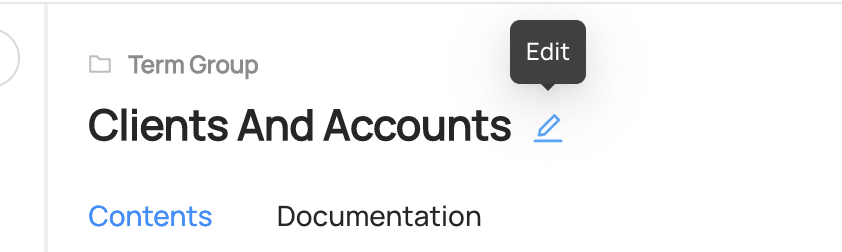
In order to edit a Term or Term Group, you first need to go the page of the Term or Term group you want to edit. Then simply click the edit icon right next to the name to open up an inline editor. Change the text and it will save when you click outside or hit Enter.
-
+
+
+  +
+
+
## Moving a Term or Term Group
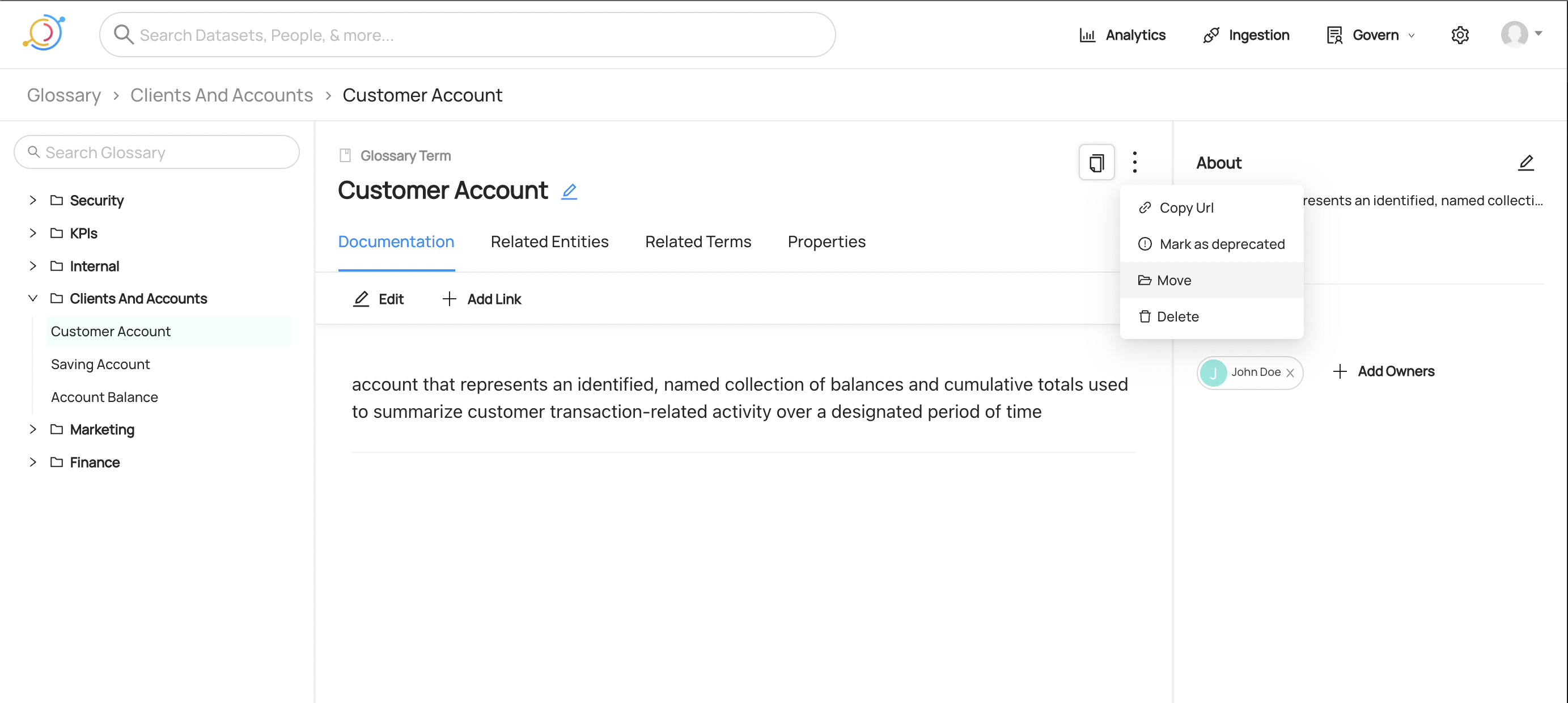
Once a Term or Term Group has been created, you can always move it to be under a different Term Group parent. In order to do this, click the menu dots on the top right of either entity and select **Move**.
-
+
+
+  +
+
+
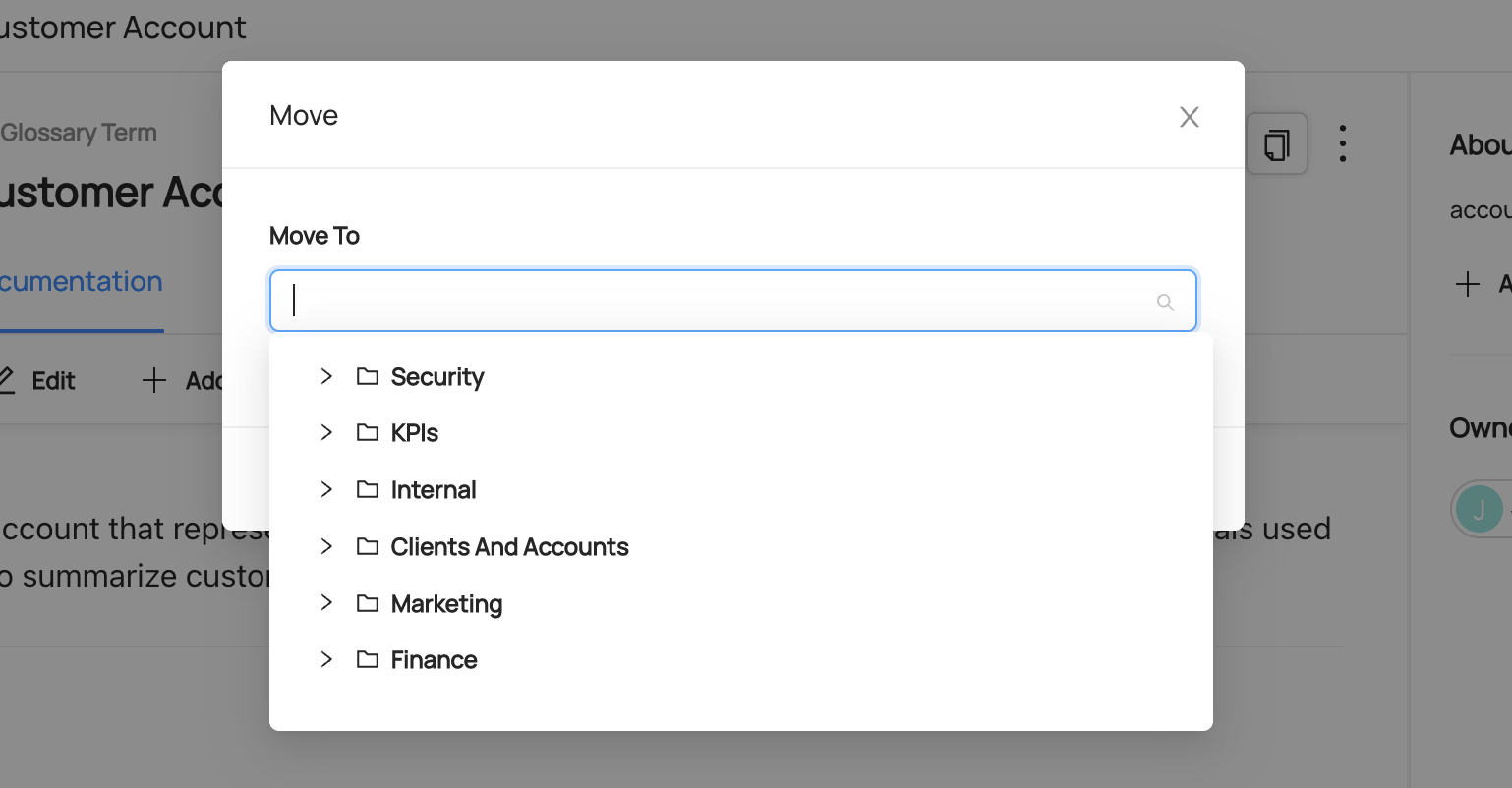
This will open a modal where you can navigate through your Glossary to find your desired Term Group.
-
+
+
+  +
+
+
## Deleting a Term or Term Group
In order to delete a Term or Term Group, you need to go to the entity page of what you want to delete then click the menu dots on the top right. From here you can select **Delete** followed by confirming through a separate modal. **Note**: at the moment we only support deleting Term Groups that do not have any children. Until cascade deleting is supported, you will have to delete all children first, then delete the Term Group.
-
+
+
+  +
+
+
## Adding a Term to an Entity
Once you've defined your Glossary, you can begin attaching terms to data assets. To add a Glossary Term to an asset, go to the entity page of your asset and find the **Add Terms** button on the right sidebar.
-
+
+
+ 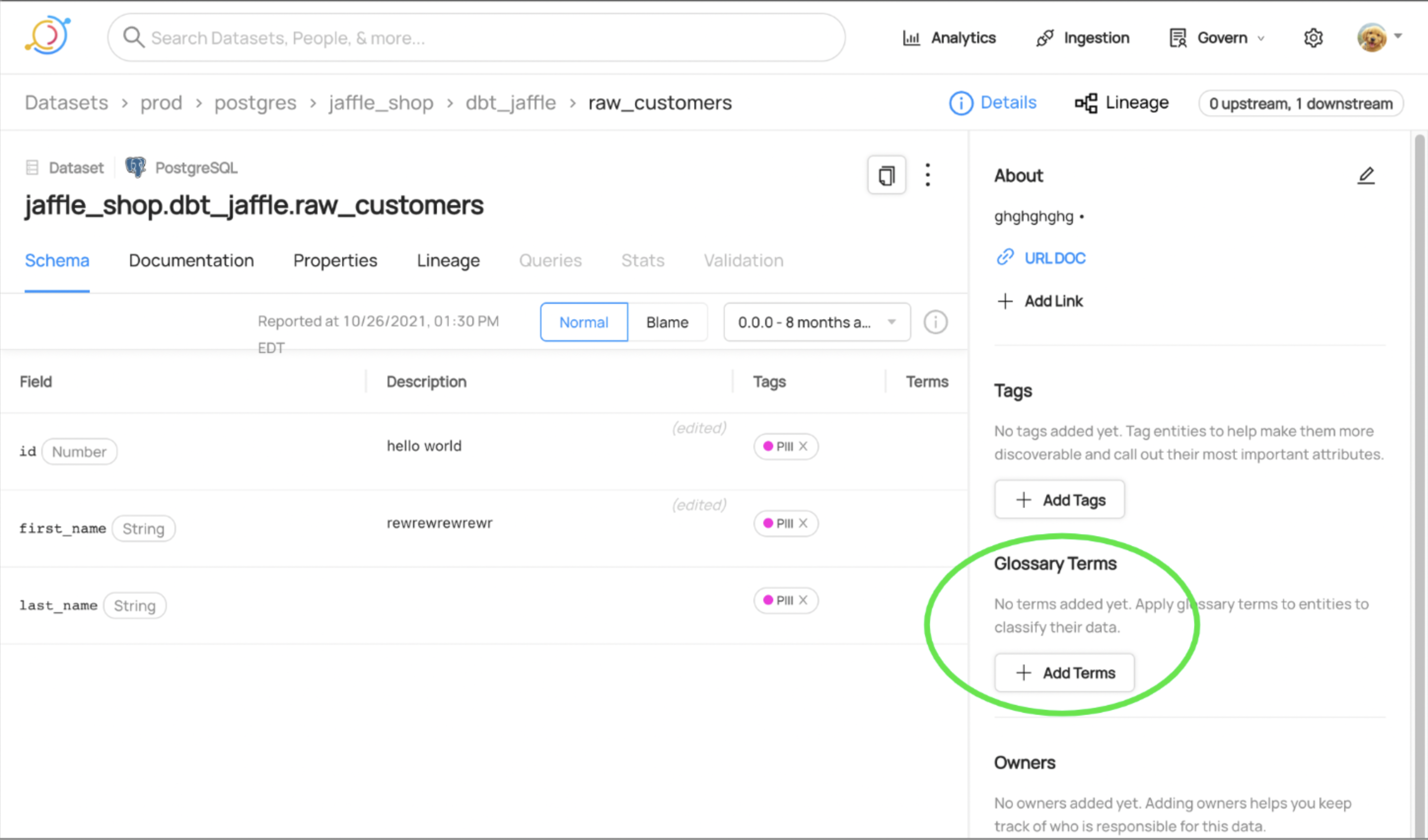 +
+
+
In the modal that pops up you can select the Term you care about in one of two ways:
- Search for the Term by name in the input
- Navigate through the Glossary dropdown that appears after clicking into the input
-
+
+
+ 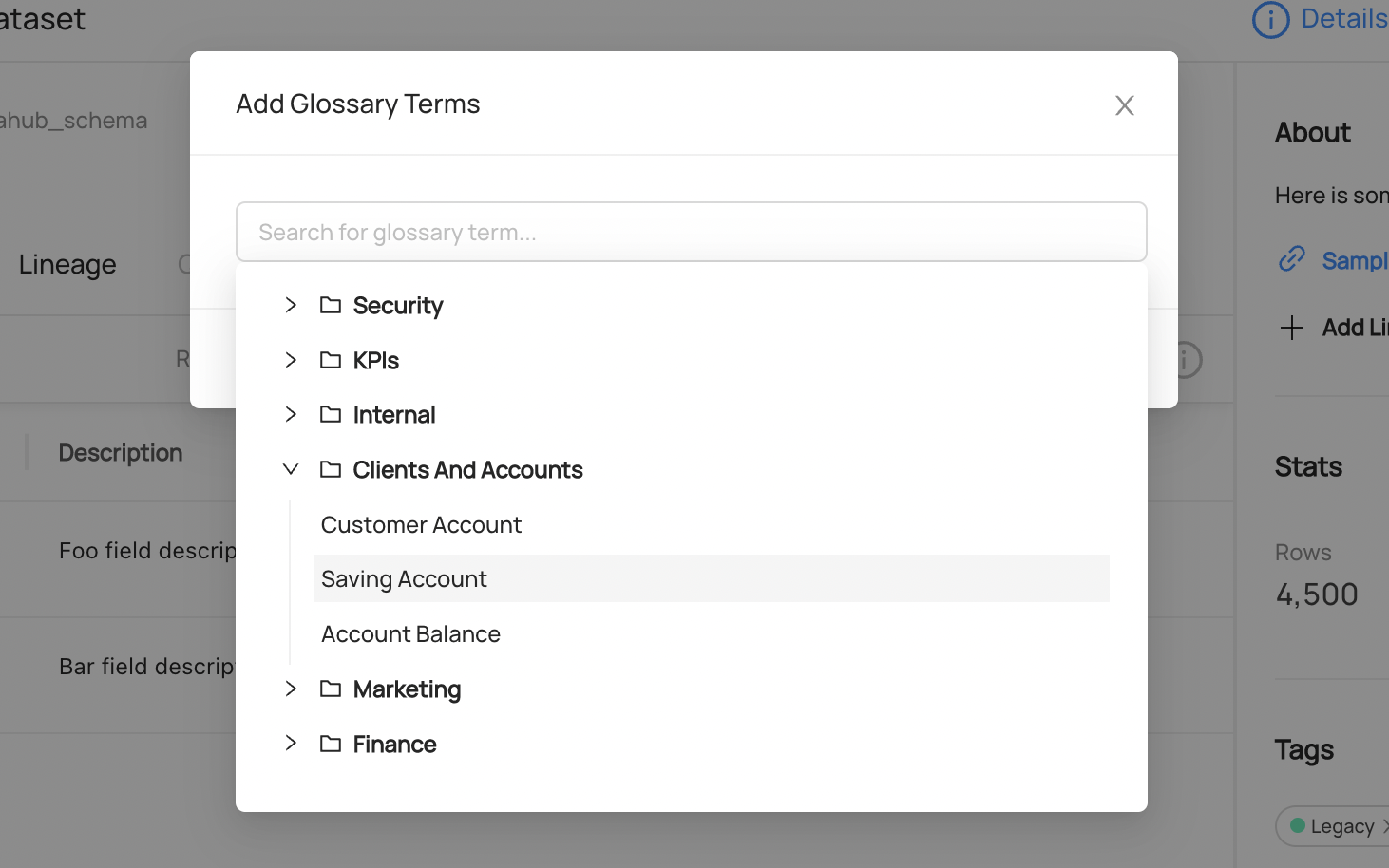 +
+
+
## Privileges
diff --git a/docs/how/configuring-authorization-with-apache-ranger.md b/docs/how/configuring-authorization-with-apache-ranger.md
index 26d3be6d358b2..46f9432e6c18a 100644
--- a/docs/how/configuring-authorization-with-apache-ranger.md
+++ b/docs/how/configuring-authorization-with-apache-ranger.md
@@ -67,7 +67,11 @@ Now, you should have the DataHub plugin registered with Apache Ranger. Next, we'
**DATAHUB** plugin and **ranger_datahub** service is shown in below screenshot:
- 
+
+
+ 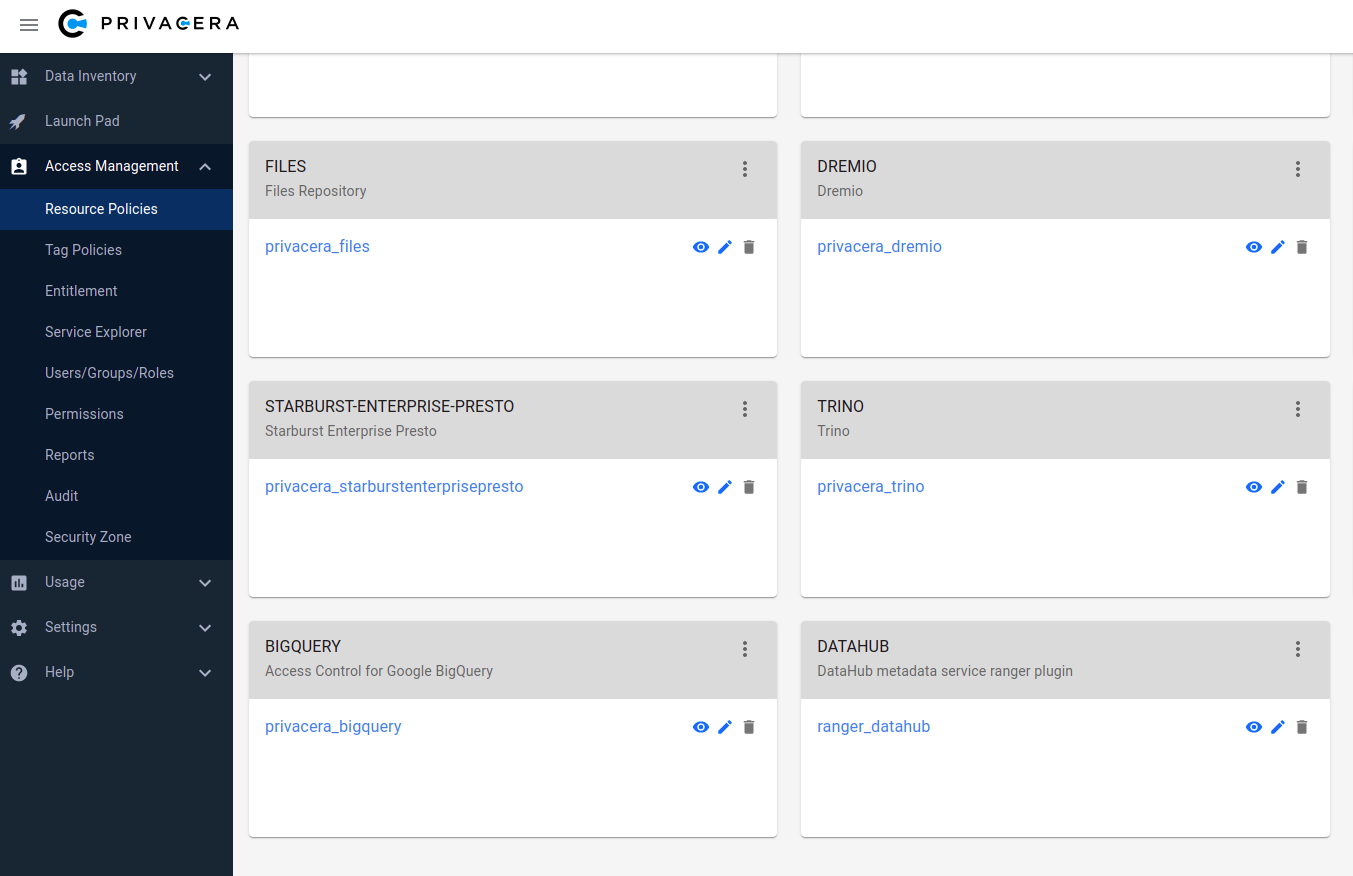 +
+
+
4. Create a new policy under service **ranger_datahub** - this will be used to control DataHub authorization.
5. Create a test user & assign them to a policy. We'll use the `datahub` user, which is the default root user inside DataHub.
@@ -80,7 +84,11 @@ Now, you should have the DataHub plugin registered with Apache Ranger. Next, we'
DataHub platform access policy screenshot:
- 
+
+
+ 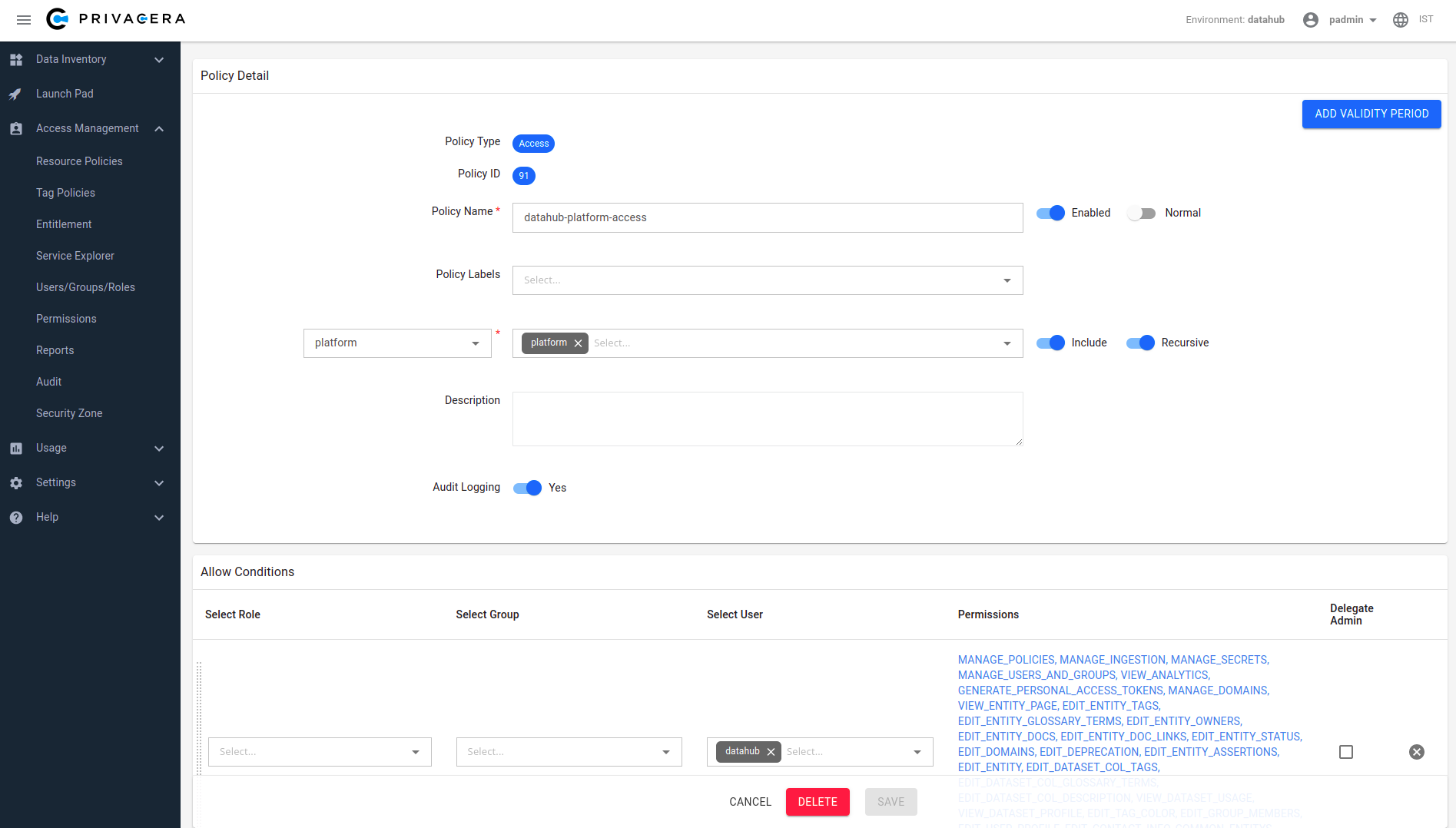 +
+
+
Once we've created our first policy, we can set up DataHub to start authorizing requests using Ranger policies.
@@ -178,7 +186,11 @@ then follow the below sections to undo the configuration steps you have performe
**ranger_datahub** service is shown in below screenshot:
- 
+
+
+
+
+
2. Delete **datahub** plugin: Execute below curl command to delete **datahub** plugin
Replace variables with corresponding values in curl command
diff --git a/docs/how/delete-metadata.md b/docs/how/delete-metadata.md
index acbb573020be0..f720a66ce5765 100644
--- a/docs/how/delete-metadata.md
+++ b/docs/how/delete-metadata.md
@@ -43,6 +43,9 @@ datahub delete --platform snowflake
# Filters can be combined, which will select entities that match all filters.
datahub delete --platform looker --entity-type chart
datahub delete --platform bigquery --env PROD
+
+# You can also do recursive deletes for container and dataPlatformInstance entities.
+datahub delete --urn "urn:li:container:f76..." --recursive
```
When performing hard deletes, you can optionally add the `--only-soft-deleted` flag to only hard delete entities that were previously soft deleted.
@@ -122,6 +125,14 @@ datahub delete --urn "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted
datahub delete --platform snowflake --env DEV
```
+#### Delete everything within a specific Snowflake DB
+
+```shell
+# You can find your container urn by navigating to the relevant
+# DB in the DataHub UI and clicking the "copy urn" button.
+datahub delete --urn "urn:li:container:77644901c4f574845578ebd18b7c14fa" --recursive
+```
+
#### Delete all BigQuery datasets in the PROD environment
```shell
@@ -129,6 +140,13 @@ datahub delete --platform snowflake --env DEV
datahub delete --env PROD --entity-type dataset --platform bigquery
```
+#### Delete everything within a MySQL platform instance
+
+```shell
+# The instance name comes from the `platform_instance` config option in the ingestion recipe.
+datahub delete --urn 'urn:li:dataPlatformInstance:(urn:li:dataPlatform:mysql,my_instance_name)' --recursive
+```
+
#### Delete all pipelines and tasks from Airflow
```shell
@@ -138,6 +156,7 @@ datahub delete --platform "airflow"
#### Delete all containers for a particular platform
```shell
+# Note: this will leave S3 datasets intact.
datahub delete --entity-type container --platform s3
```
diff --git a/docs/how/search.md b/docs/how/search.md
index bf1c8e8632e24..6a5e85e547fc5 100644
--- a/docs/how/search.md
+++ b/docs/how/search.md
@@ -2,14 +2,6 @@ import FeatureAvailability from '@site/src/components/FeatureAvailability';
# About DataHub Search
-
-
-
-
The **search bar** is an important mechanism for discovering data assets in DataHub. From the search bar, you can find Datasets, Columns, Dashboards, Charts, Data Pipelines, and more. Simply type in a term and press 'enter'.
diff --git a/docs/how/updating-datahub.md b/docs/how/updating-datahub.md
index 2b6fd5571cc9e..7ba516c82cf1b 100644
--- a/docs/how/updating-datahub.md
+++ b/docs/how/updating-datahub.md
@@ -15,6 +15,9 @@ This file documents any backwards-incompatible changes in DataHub and assists pe
- #8300: Clickhouse source now inherited from TwoTierSQLAlchemy. In old way we have platform_instance -> container -> co
container db (None) -> container schema and now we have platform_instance -> container database.
- #8300: Added `uri_opts` argument; now we can add any options for clickhouse client.
+- #8659: BigQuery ingestion no longer creates DataPlatformInstance aspects by default.
+ This will only affect users that were depending on this aspect for custom functionality,
+ and can be enabled via the `include_data_platform_instance` config option.
## 0.10.5
diff --git a/docs/imgs/add-schema-tag.png b/docs/imgs/add-schema-tag.png
deleted file mode 100644
index b6fd273389c90..0000000000000
Binary files a/docs/imgs/add-schema-tag.png and /dev/null differ
diff --git a/docs/imgs/add-tag-search.png b/docs/imgs/add-tag-search.png
deleted file mode 100644
index a129f5eba4271..0000000000000
Binary files a/docs/imgs/add-tag-search.png and /dev/null differ
diff --git a/docs/imgs/add-tag.png b/docs/imgs/add-tag.png
deleted file mode 100644
index 386b4cdcd9911..0000000000000
Binary files a/docs/imgs/add-tag.png and /dev/null differ
diff --git a/docs/imgs/added-tag.png b/docs/imgs/added-tag.png
deleted file mode 100644
index 96ae48318a35a..0000000000000
Binary files a/docs/imgs/added-tag.png and /dev/null differ
diff --git a/docs/imgs/airflow/connection_error.png b/docs/imgs/airflow/connection_error.png
deleted file mode 100644
index c2f3344b8cc45..0000000000000
Binary files a/docs/imgs/airflow/connection_error.png and /dev/null differ
diff --git a/docs/imgs/airflow/datahub_lineage_view.png b/docs/imgs/airflow/datahub_lineage_view.png
deleted file mode 100644
index c7c774c203d2f..0000000000000
Binary files a/docs/imgs/airflow/datahub_lineage_view.png and /dev/null differ
diff --git a/docs/imgs/airflow/datahub_pipeline_entity.png b/docs/imgs/airflow/datahub_pipeline_entity.png
deleted file mode 100644
index 715baefd784ca..0000000000000
Binary files a/docs/imgs/airflow/datahub_pipeline_entity.png and /dev/null differ
diff --git a/docs/imgs/airflow/datahub_pipeline_view.png b/docs/imgs/airflow/datahub_pipeline_view.png
deleted file mode 100644
index 5b3afd13c4ce6..0000000000000
Binary files a/docs/imgs/airflow/datahub_pipeline_view.png and /dev/null differ
diff --git a/docs/imgs/airflow/datahub_task_view.png b/docs/imgs/airflow/datahub_task_view.png
deleted file mode 100644
index 66b3487d87319..0000000000000
Binary files a/docs/imgs/airflow/datahub_task_view.png and /dev/null differ
diff --git a/docs/imgs/airflow/entity_page_screenshot.png b/docs/imgs/airflow/entity_page_screenshot.png
deleted file mode 100644
index a782969a1f17b..0000000000000
Binary files a/docs/imgs/airflow/entity_page_screenshot.png and /dev/null differ
diff --git a/docs/imgs/airflow/find_the_dag.png b/docs/imgs/airflow/find_the_dag.png
deleted file mode 100644
index 37cda041e4b75..0000000000000
Binary files a/docs/imgs/airflow/find_the_dag.png and /dev/null differ
diff --git a/docs/imgs/airflow/finding_failed_log.png b/docs/imgs/airflow/finding_failed_log.png
deleted file mode 100644
index 96552ba1e1983..0000000000000
Binary files a/docs/imgs/airflow/finding_failed_log.png and /dev/null differ
diff --git a/docs/imgs/airflow/paused_dag.png b/docs/imgs/airflow/paused_dag.png
deleted file mode 100644
index c314de5d38d75..0000000000000
Binary files a/docs/imgs/airflow/paused_dag.png and /dev/null differ
diff --git a/docs/imgs/airflow/successful_run.png b/docs/imgs/airflow/successful_run.png
deleted file mode 100644
index b997cc7210ff6..0000000000000
Binary files a/docs/imgs/airflow/successful_run.png and /dev/null differ
diff --git a/docs/imgs/airflow/trigger_dag.png b/docs/imgs/airflow/trigger_dag.png
deleted file mode 100644
index a44999c929d4e..0000000000000
Binary files a/docs/imgs/airflow/trigger_dag.png and /dev/null differ
diff --git a/docs/imgs/airflow/unpaused_dag.png b/docs/imgs/airflow/unpaused_dag.png
deleted file mode 100644
index 8462562f31d97..0000000000000
Binary files a/docs/imgs/airflow/unpaused_dag.png and /dev/null differ
diff --git a/docs/imgs/apache-ranger/datahub-platform-access-policy.png b/docs/imgs/apache-ranger/datahub-platform-access-policy.png
deleted file mode 100644
index 7e3ff6fd372a9..0000000000000
Binary files a/docs/imgs/apache-ranger/datahub-platform-access-policy.png and /dev/null differ
diff --git a/docs/imgs/apache-ranger/datahub-plugin.png b/docs/imgs/apache-ranger/datahub-plugin.png
deleted file mode 100644
index 5dd044c014657..0000000000000
Binary files a/docs/imgs/apache-ranger/datahub-plugin.png and /dev/null differ
diff --git a/docs/imgs/apis/postman-graphql.png b/docs/imgs/apis/postman-graphql.png
deleted file mode 100644
index 1cffd226fdf77..0000000000000
Binary files a/docs/imgs/apis/postman-graphql.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/column-description-added.png b/docs/imgs/apis/tutorials/column-description-added.png
deleted file mode 100644
index ed8cbd3bf5622..0000000000000
Binary files a/docs/imgs/apis/tutorials/column-description-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/column-level-lineage-added.png b/docs/imgs/apis/tutorials/column-level-lineage-added.png
deleted file mode 100644
index 6092436e0a6a8..0000000000000
Binary files a/docs/imgs/apis/tutorials/column-level-lineage-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/custom-properties-added.png b/docs/imgs/apis/tutorials/custom-properties-added.png
deleted file mode 100644
index a7e85d875045c..0000000000000
Binary files a/docs/imgs/apis/tutorials/custom-properties-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/datahub-main-ui.png b/docs/imgs/apis/tutorials/datahub-main-ui.png
deleted file mode 100644
index b058e2683a851..0000000000000
Binary files a/docs/imgs/apis/tutorials/datahub-main-ui.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-created.png b/docs/imgs/apis/tutorials/dataset-created.png
deleted file mode 100644
index 086dd8b7c9b16..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-created.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-deleted.png b/docs/imgs/apis/tutorials/dataset-deleted.png
deleted file mode 100644
index d94ad7e85195f..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-deleted.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-description-added.png b/docs/imgs/apis/tutorials/dataset-description-added.png
deleted file mode 100644
index 41aa9f109115b..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-description-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-properties-added-removed.png b/docs/imgs/apis/tutorials/dataset-properties-added-removed.png
deleted file mode 100644
index 9eb0284776f13..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-properties-added-removed.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-properties-added.png b/docs/imgs/apis/tutorials/dataset-properties-added.png
deleted file mode 100644
index e0d2acbb66eb5..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-properties-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-properties-before.png b/docs/imgs/apis/tutorials/dataset-properties-before.png
deleted file mode 100644
index b4915121a8c65..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-properties-before.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-properties-replaced.png b/docs/imgs/apis/tutorials/dataset-properties-replaced.png
deleted file mode 100644
index 8624689c20ada..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-properties-replaced.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/deprecation-updated.png b/docs/imgs/apis/tutorials/deprecation-updated.png
deleted file mode 100644
index 06fedf746f694..0000000000000
Binary files a/docs/imgs/apis/tutorials/deprecation-updated.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/domain-added.png b/docs/imgs/apis/tutorials/domain-added.png
deleted file mode 100644
index cb2002ec9ab4d..0000000000000
Binary files a/docs/imgs/apis/tutorials/domain-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/domain-created.png b/docs/imgs/apis/tutorials/domain-created.png
deleted file mode 100644
index cafab2a5e8d5c..0000000000000
Binary files a/docs/imgs/apis/tutorials/domain-created.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/domain-removed.png b/docs/imgs/apis/tutorials/domain-removed.png
deleted file mode 100644
index 1b21172be11d2..0000000000000
Binary files a/docs/imgs/apis/tutorials/domain-removed.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/feature-added-to-model.png b/docs/imgs/apis/tutorials/feature-added-to-model.png
deleted file mode 100644
index 311506e4b2783..0000000000000
Binary files a/docs/imgs/apis/tutorials/feature-added-to-model.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/feature-table-created.png b/docs/imgs/apis/tutorials/feature-table-created.png
deleted file mode 100644
index 0541cbe572435..0000000000000
Binary files a/docs/imgs/apis/tutorials/feature-table-created.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/group-upserted.png b/docs/imgs/apis/tutorials/group-upserted.png
deleted file mode 100644
index 5283f6273f02a..0000000000000
Binary files a/docs/imgs/apis/tutorials/group-upserted.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/lineage-added.png b/docs/imgs/apis/tutorials/lineage-added.png
deleted file mode 100644
index b381498bad5ac..0000000000000
Binary files a/docs/imgs/apis/tutorials/lineage-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/model-group-added-to-model.png b/docs/imgs/apis/tutorials/model-group-added-to-model.png
deleted file mode 100644
index 360b7fbb2d922..0000000000000
Binary files a/docs/imgs/apis/tutorials/model-group-added-to-model.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/model-group-created.png b/docs/imgs/apis/tutorials/model-group-created.png
deleted file mode 100644
index 2e0fdcea4803f..0000000000000
Binary files a/docs/imgs/apis/tutorials/model-group-created.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/owner-added.png b/docs/imgs/apis/tutorials/owner-added.png
deleted file mode 100644
index 6508c231cfb4b..0000000000000
Binary files a/docs/imgs/apis/tutorials/owner-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/owner-removed.png b/docs/imgs/apis/tutorials/owner-removed.png
deleted file mode 100644
index a7b6567888caf..0000000000000
Binary files a/docs/imgs/apis/tutorials/owner-removed.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/sample-ingestion.png b/docs/imgs/apis/tutorials/sample-ingestion.png
deleted file mode 100644
index 40aa046904841..0000000000000
Binary files a/docs/imgs/apis/tutorials/sample-ingestion.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/tag-added.png b/docs/imgs/apis/tutorials/tag-added.png
deleted file mode 100644
index fd99a04f6cceb..0000000000000
Binary files a/docs/imgs/apis/tutorials/tag-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/tag-created.png b/docs/imgs/apis/tutorials/tag-created.png
deleted file mode 100644
index 99e3fea8a14e1..0000000000000
Binary files a/docs/imgs/apis/tutorials/tag-created.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/tag-removed.png b/docs/imgs/apis/tutorials/tag-removed.png
deleted file mode 100644
index 31a267549843e..0000000000000
Binary files a/docs/imgs/apis/tutorials/tag-removed.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/term-added.png b/docs/imgs/apis/tutorials/term-added.png
deleted file mode 100644
index 62e285a92e7af..0000000000000
Binary files a/docs/imgs/apis/tutorials/term-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/term-created.png b/docs/imgs/apis/tutorials/term-created.png
deleted file mode 100644
index deff0179b155e..0000000000000
Binary files a/docs/imgs/apis/tutorials/term-created.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/term-removed.png b/docs/imgs/apis/tutorials/term-removed.png
deleted file mode 100644
index dbf9f35f09339..0000000000000
Binary files a/docs/imgs/apis/tutorials/term-removed.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/user-upserted.png b/docs/imgs/apis/tutorials/user-upserted.png
deleted file mode 100644
index 38c5bbb9ad828..0000000000000
Binary files a/docs/imgs/apis/tutorials/user-upserted.png and /dev/null differ
diff --git a/docs/imgs/aws/aws-elasticsearch.png b/docs/imgs/aws/aws-elasticsearch.png
deleted file mode 100644
index e16d5eee26fd8..0000000000000
Binary files a/docs/imgs/aws/aws-elasticsearch.png and /dev/null differ
diff --git a/docs/imgs/aws/aws-msk.png b/docs/imgs/aws/aws-msk.png
deleted file mode 100644
index 96a3173747007..0000000000000
Binary files a/docs/imgs/aws/aws-msk.png and /dev/null differ
diff --git a/docs/imgs/aws/aws-rds.png b/docs/imgs/aws/aws-rds.png
deleted file mode 100644
index ab329952c7756..0000000000000
Binary files a/docs/imgs/aws/aws-rds.png and /dev/null differ
diff --git a/docs/imgs/browse-domains.png b/docs/imgs/browse-domains.png
deleted file mode 100644
index 41444470517d2..0000000000000
Binary files a/docs/imgs/browse-domains.png and /dev/null differ
diff --git a/docs/imgs/cancelled-ingestion.png b/docs/imgs/cancelled-ingestion.png
deleted file mode 100644
index 0c4af7b66a8ff..0000000000000
Binary files a/docs/imgs/cancelled-ingestion.png and /dev/null differ
diff --git a/docs/imgs/confluent-cloud-config-2.png b/docs/imgs/confluent-cloud-config-2.png
deleted file mode 100644
index 543101154f42c..0000000000000
Binary files a/docs/imgs/confluent-cloud-config-2.png and /dev/null differ
diff --git a/docs/imgs/confluent-cloud-config.png b/docs/imgs/confluent-cloud-config.png
deleted file mode 100644
index a2490eab5c6a7..0000000000000
Binary files a/docs/imgs/confluent-cloud-config.png and /dev/null differ
diff --git a/docs/imgs/confluent-create-topic.png b/docs/imgs/confluent-create-topic.png
deleted file mode 100644
index 1972bb3770388..0000000000000
Binary files a/docs/imgs/confluent-create-topic.png and /dev/null differ
diff --git a/docs/imgs/create-domain.png b/docs/imgs/create-domain.png
deleted file mode 100644
index 1db2090fca6b8..0000000000000
Binary files a/docs/imgs/create-domain.png and /dev/null differ
diff --git a/docs/imgs/create-new-ingestion-source-button.png b/docs/imgs/create-new-ingestion-source-button.png
deleted file mode 100644
index c425f0837c51d..0000000000000
Binary files a/docs/imgs/create-new-ingestion-source-button.png and /dev/null differ
diff --git a/docs/imgs/create-secret.png b/docs/imgs/create-secret.png
deleted file mode 100644
index a0cc63e3b4892..0000000000000
Binary files a/docs/imgs/create-secret.png and /dev/null differ
diff --git a/docs/imgs/custom-ingestion-cli-version.png b/docs/imgs/custom-ingestion-cli-version.png
deleted file mode 100644
index 43d4736684abb..0000000000000
Binary files a/docs/imgs/custom-ingestion-cli-version.png and /dev/null differ
diff --git a/docs/imgs/datahub-architecture.png b/docs/imgs/datahub-architecture.png
deleted file mode 100644
index 236f939f74198..0000000000000
Binary files a/docs/imgs/datahub-architecture.png and /dev/null differ
diff --git a/docs/imgs/datahub-architecture.svg b/docs/imgs/datahub-architecture.svg
deleted file mode 100644
index 842194a5e377c..0000000000000
--- a/docs/imgs/datahub-architecture.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/docs/imgs/datahub-components.png b/docs/imgs/datahub-components.png
deleted file mode 100644
index 8b7d0e5330275..0000000000000
Binary files a/docs/imgs/datahub-components.png and /dev/null differ
diff --git a/docs/imgs/datahub-logo-color-mark.svg b/docs/imgs/datahub-logo-color-mark.svg
deleted file mode 100644
index a984092952bae..0000000000000
--- a/docs/imgs/datahub-logo-color-mark.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/docs/imgs/datahub-metadata-ingestion-framework.png b/docs/imgs/datahub-metadata-ingestion-framework.png
deleted file mode 100644
index 1319329710906..0000000000000
Binary files a/docs/imgs/datahub-metadata-ingestion-framework.png and /dev/null differ
diff --git a/docs/imgs/datahub-metadata-model.png b/docs/imgs/datahub-metadata-model.png
deleted file mode 100644
index 59449cd0d4ef5..0000000000000
Binary files a/docs/imgs/datahub-metadata-model.png and /dev/null differ
diff --git a/docs/imgs/datahub-sequence-diagram.png b/docs/imgs/datahub-sequence-diagram.png
deleted file mode 100644
index b5a8f8a9c25ce..0000000000000
Binary files a/docs/imgs/datahub-sequence-diagram.png and /dev/null differ
diff --git a/docs/imgs/datahub-serving.png b/docs/imgs/datahub-serving.png
deleted file mode 100644
index 67a2f8eb3f085..0000000000000
Binary files a/docs/imgs/datahub-serving.png and /dev/null differ
diff --git a/docs/imgs/development/intellij-remote-debug.png b/docs/imgs/development/intellij-remote-debug.png
deleted file mode 100644
index 32a41a75d1dc3..0000000000000
Binary files a/docs/imgs/development/intellij-remote-debug.png and /dev/null differ
diff --git a/docs/imgs/domain-entities.png b/docs/imgs/domain-entities.png
deleted file mode 100644
index 5766d051fa209..0000000000000
Binary files a/docs/imgs/domain-entities.png and /dev/null differ
diff --git a/docs/imgs/domains-tab.png b/docs/imgs/domains-tab.png
deleted file mode 100644
index 20be5b103fdca..0000000000000
Binary files a/docs/imgs/domains-tab.png and /dev/null differ
diff --git a/docs/imgs/entity-registry-diagram.png b/docs/imgs/entity-registry-diagram.png
deleted file mode 100644
index 08cb5edd8e13f..0000000000000
Binary files a/docs/imgs/entity-registry-diagram.png and /dev/null differ
diff --git a/docs/imgs/entity.png b/docs/imgs/entity.png
deleted file mode 100644
index cfe9eb38b2921..0000000000000
Binary files a/docs/imgs/entity.png and /dev/null differ
diff --git a/docs/imgs/example-mysql-recipe.png b/docs/imgs/example-mysql-recipe.png
deleted file mode 100644
index 9cb2cbb169a56..0000000000000
Binary files a/docs/imgs/example-mysql-recipe.png and /dev/null differ
diff --git a/docs/imgs/failed-ingestion.png b/docs/imgs/failed-ingestion.png
deleted file mode 100644
index 4f9de8eb002d2..0000000000000
Binary files a/docs/imgs/failed-ingestion.png and /dev/null differ
diff --git a/docs/imgs/feature-create-new-tag.gif b/docs/imgs/feature-create-new-tag.gif
deleted file mode 100644
index 57b8ad852dd5b..0000000000000
Binary files a/docs/imgs/feature-create-new-tag.gif and /dev/null differ
diff --git a/docs/imgs/feature-datahub-analytics.png b/docs/imgs/feature-datahub-analytics.png
deleted file mode 100644
index 7fe66b84682f9..0000000000000
Binary files a/docs/imgs/feature-datahub-analytics.png and /dev/null differ
diff --git a/docs/imgs/feature-rich-documentation.gif b/docs/imgs/feature-rich-documentation.gif
deleted file mode 100644
index 48ad795670022..0000000000000
Binary files a/docs/imgs/feature-rich-documentation.gif and /dev/null differ
diff --git a/docs/imgs/feature-tag-browse.gif b/docs/imgs/feature-tag-browse.gif
deleted file mode 100644
index e70a30db7d3ba..0000000000000
Binary files a/docs/imgs/feature-tag-browse.gif and /dev/null differ
diff --git a/docs/imgs/feature-validation-timeseries.png b/docs/imgs/feature-validation-timeseries.png
deleted file mode 100644
index 28ce1daec5f32..0000000000000
Binary files a/docs/imgs/feature-validation-timeseries.png and /dev/null differ
diff --git a/docs/imgs/feature-view-entitiy-details-via-lineage-vis.gif b/docs/imgs/feature-view-entitiy-details-via-lineage-vis.gif
deleted file mode 100644
index aad77df373574..0000000000000
Binary files a/docs/imgs/feature-view-entitiy-details-via-lineage-vis.gif and /dev/null differ
diff --git a/docs/imgs/gcp/ingress1.png b/docs/imgs/gcp/ingress1.png
deleted file mode 100644
index 4cb49834af5b6..0000000000000
Binary files a/docs/imgs/gcp/ingress1.png and /dev/null differ
diff --git a/docs/imgs/gcp/ingress2.png b/docs/imgs/gcp/ingress2.png
deleted file mode 100644
index cdf2446b0e923..0000000000000
Binary files a/docs/imgs/gcp/ingress2.png and /dev/null differ
diff --git a/docs/imgs/gcp/ingress3.png b/docs/imgs/gcp/ingress3.png
deleted file mode 100644
index cc3745ad97f5b..0000000000000
Binary files a/docs/imgs/gcp/ingress3.png and /dev/null differ
diff --git a/docs/imgs/gcp/ingress_final.png b/docs/imgs/gcp/ingress_final.png
deleted file mode 100644
index a30ca744c49f7..0000000000000
Binary files a/docs/imgs/gcp/ingress_final.png and /dev/null differ
diff --git a/docs/imgs/gcp/ingress_ready.png b/docs/imgs/gcp/ingress_ready.png
deleted file mode 100644
index d14016e420fd3..0000000000000
Binary files a/docs/imgs/gcp/ingress_ready.png and /dev/null differ
diff --git a/docs/imgs/gcp/services_ingress.png b/docs/imgs/gcp/services_ingress.png
deleted file mode 100644
index 1d9ff2b313715..0000000000000
Binary files a/docs/imgs/gcp/services_ingress.png and /dev/null differ
diff --git a/docs/imgs/glossary/add-term-modal.png b/docs/imgs/glossary/add-term-modal.png
deleted file mode 100644
index e32a9cb8d648c..0000000000000
Binary files a/docs/imgs/glossary/add-term-modal.png and /dev/null differ
diff --git a/docs/imgs/glossary/add-term-to-entity.png b/docs/imgs/glossary/add-term-to-entity.png
deleted file mode 100644
index 7487a68c0d755..0000000000000
Binary files a/docs/imgs/glossary/add-term-to-entity.png and /dev/null differ
diff --git a/docs/imgs/glossary/create-from-node.png b/docs/imgs/glossary/create-from-node.png
deleted file mode 100644
index 70638d083343c..0000000000000
Binary files a/docs/imgs/glossary/create-from-node.png and /dev/null differ
diff --git a/docs/imgs/glossary/create-modal.png b/docs/imgs/glossary/create-modal.png
deleted file mode 100644
index e84fb5a36e2d4..0000000000000
Binary files a/docs/imgs/glossary/create-modal.png and /dev/null differ
diff --git a/docs/imgs/glossary/delete-button.png b/docs/imgs/glossary/delete-button.png
deleted file mode 100644
index 3e0cc2a5b0a54..0000000000000
Binary files a/docs/imgs/glossary/delete-button.png and /dev/null differ
diff --git a/docs/imgs/glossary/edit-term.png b/docs/imgs/glossary/edit-term.png
deleted file mode 100644
index 62b0e425c8c4f..0000000000000
Binary files a/docs/imgs/glossary/edit-term.png and /dev/null differ
diff --git a/docs/imgs/glossary/glossary-button.png b/docs/imgs/glossary/glossary-button.png
deleted file mode 100644
index e4b8fd2393587..0000000000000
Binary files a/docs/imgs/glossary/glossary-button.png and /dev/null differ
diff --git a/docs/imgs/glossary/move-term-button.png b/docs/imgs/glossary/move-term-button.png
deleted file mode 100644
index df03c820340ef..0000000000000
Binary files a/docs/imgs/glossary/move-term-button.png and /dev/null differ
diff --git a/docs/imgs/glossary/move-term-modal.png b/docs/imgs/glossary/move-term-modal.png
deleted file mode 100644
index 0fda501911b2b..0000000000000
Binary files a/docs/imgs/glossary/move-term-modal.png and /dev/null differ
diff --git a/docs/imgs/glossary/root-glossary-create.png b/docs/imgs/glossary/root-glossary-create.png
deleted file mode 100644
index c91f397eb6213..0000000000000
Binary files a/docs/imgs/glossary/root-glossary-create.png and /dev/null differ
diff --git a/docs/imgs/glossary/root-glossary.png b/docs/imgs/glossary/root-glossary.png
deleted file mode 100644
index 1296c16b0dc3d..0000000000000
Binary files a/docs/imgs/glossary/root-glossary.png and /dev/null differ
diff --git a/docs/imgs/ingestion-architecture.png b/docs/imgs/ingestion-architecture.png
deleted file mode 100644
index fc7bc74acacfa..0000000000000
Binary files a/docs/imgs/ingestion-architecture.png and /dev/null differ
diff --git a/docs/imgs/ingestion-logs.png b/docs/imgs/ingestion-logs.png
deleted file mode 100644
index 42211be7379d6..0000000000000
Binary files a/docs/imgs/ingestion-logs.png and /dev/null differ
diff --git a/docs/imgs/ingestion-privileges.png b/docs/imgs/ingestion-privileges.png
deleted file mode 100644
index 8e23868309676..0000000000000
Binary files a/docs/imgs/ingestion-privileges.png and /dev/null differ
diff --git a/docs/imgs/ingestion-tab.png b/docs/imgs/ingestion-tab.png
deleted file mode 100644
index 046068c63bdb7..0000000000000
Binary files a/docs/imgs/ingestion-tab.png and /dev/null differ
diff --git a/docs/imgs/ingestion-with-token.png b/docs/imgs/ingestion-with-token.png
deleted file mode 100644
index 5e1a2cce036f7..0000000000000
Binary files a/docs/imgs/ingestion-with-token.png and /dev/null differ
diff --git a/docs/imgs/invite-users-button.png b/docs/imgs/invite-users-button.png
deleted file mode 100644
index a5d07a1c1e7e7..0000000000000
Binary files a/docs/imgs/invite-users-button.png and /dev/null differ
diff --git a/docs/imgs/invite-users-popup.png b/docs/imgs/invite-users-popup.png
deleted file mode 100644
index 621b1521eae75..0000000000000
Binary files a/docs/imgs/invite-users-popup.png and /dev/null differ
diff --git a/docs/imgs/lineage.png b/docs/imgs/lineage.png
deleted file mode 100644
index 7488c1e04c31b..0000000000000
Binary files a/docs/imgs/lineage.png and /dev/null differ
diff --git a/docs/imgs/list-domains.png b/docs/imgs/list-domains.png
deleted file mode 100644
index 98a28130f8c99..0000000000000
Binary files a/docs/imgs/list-domains.png and /dev/null differ
diff --git a/docs/imgs/locust-example.png b/docs/imgs/locust-example.png
deleted file mode 100644
index bbae3e0ca19d0..0000000000000
Binary files a/docs/imgs/locust-example.png and /dev/null differ
diff --git a/docs/imgs/metadata-model-chart.png b/docs/imgs/metadata-model-chart.png
deleted file mode 100644
index 2fb7483654906..0000000000000
Binary files a/docs/imgs/metadata-model-chart.png and /dev/null differ
diff --git a/docs/imgs/metadata-model-to-fork-or-not-to.png b/docs/imgs/metadata-model-to-fork-or-not-to.png
deleted file mode 100644
index f9d89d555196d..0000000000000
Binary files a/docs/imgs/metadata-model-to-fork-or-not-to.png and /dev/null differ
diff --git a/docs/imgs/metadata-modeling.png b/docs/imgs/metadata-modeling.png
deleted file mode 100644
index cbad7613e04e4..0000000000000
Binary files a/docs/imgs/metadata-modeling.png and /dev/null differ
diff --git a/docs/imgs/metadata-service-auth.png b/docs/imgs/metadata-service-auth.png
deleted file mode 100644
index 15a3ac51876c2..0000000000000
Binary files a/docs/imgs/metadata-service-auth.png and /dev/null differ
diff --git a/docs/imgs/metadata-serving.png b/docs/imgs/metadata-serving.png
deleted file mode 100644
index 54b928a0cff52..0000000000000
Binary files a/docs/imgs/metadata-serving.png and /dev/null differ
diff --git a/docs/imgs/metadata.png b/docs/imgs/metadata.png
deleted file mode 100644
index 45bb0cdce12e9..0000000000000
Binary files a/docs/imgs/metadata.png and /dev/null differ
diff --git a/docs/imgs/name-ingestion-source.png b/docs/imgs/name-ingestion-source.png
deleted file mode 100644
index bde1208248473..0000000000000
Binary files a/docs/imgs/name-ingestion-source.png and /dev/null differ
diff --git a/docs/imgs/no-code-after.png b/docs/imgs/no-code-after.png
deleted file mode 100644
index c0eee88625ace..0000000000000
Binary files a/docs/imgs/no-code-after.png and /dev/null differ
diff --git a/docs/imgs/no-code-before.png b/docs/imgs/no-code-before.png
deleted file mode 100644
index 50315578b1804..0000000000000
Binary files a/docs/imgs/no-code-before.png and /dev/null differ
diff --git a/docs/imgs/platform-instances-for-ingestion.png b/docs/imgs/platform-instances-for-ingestion.png
deleted file mode 100644
index 740249a805fb8..0000000000000
Binary files a/docs/imgs/platform-instances-for-ingestion.png and /dev/null differ
diff --git a/docs/imgs/quickstart-ingestion-config.png b/docs/imgs/quickstart-ingestion-config.png
deleted file mode 100644
index de51777ccddc3..0000000000000
Binary files a/docs/imgs/quickstart-ingestion-config.png and /dev/null differ
diff --git a/docs/imgs/reset-credentials-screen.png b/docs/imgs/reset-credentials-screen.png
deleted file mode 100644
index 4b680837b77ab..0000000000000
Binary files a/docs/imgs/reset-credentials-screen.png and /dev/null differ
diff --git a/docs/imgs/reset-user-password-button.png b/docs/imgs/reset-user-password-button.png
deleted file mode 100644
index 5b1f3ee153d07..0000000000000
Binary files a/docs/imgs/reset-user-password-button.png and /dev/null differ
diff --git a/docs/imgs/reset-user-password-popup.png b/docs/imgs/reset-user-password-popup.png
deleted file mode 100644
index ac2456dde4d4d..0000000000000
Binary files a/docs/imgs/reset-user-password-popup.png and /dev/null differ
diff --git a/docs/imgs/running-ingestion.png b/docs/imgs/running-ingestion.png
deleted file mode 100644
index a03fb444a029e..0000000000000
Binary files a/docs/imgs/running-ingestion.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/10_outputs.png b/docs/imgs/s3-ingestion/10_outputs.png
deleted file mode 100644
index e0d1ed3376ade..0000000000000
Binary files a/docs/imgs/s3-ingestion/10_outputs.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/1_crawler-info.png b/docs/imgs/s3-ingestion/1_crawler-info.png
deleted file mode 100644
index 1288247392047..0000000000000
Binary files a/docs/imgs/s3-ingestion/1_crawler-info.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/2_crawler-type.png b/docs/imgs/s3-ingestion/2_crawler-type.png
deleted file mode 100644
index 4898438417913..0000000000000
Binary files a/docs/imgs/s3-ingestion/2_crawler-type.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/3_data-store.png b/docs/imgs/s3-ingestion/3_data-store.png
deleted file mode 100644
index d29e4b1be05d6..0000000000000
Binary files a/docs/imgs/s3-ingestion/3_data-store.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/4_data-store-2.png b/docs/imgs/s3-ingestion/4_data-store-2.png
deleted file mode 100644
index c0a6f140bedb2..0000000000000
Binary files a/docs/imgs/s3-ingestion/4_data-store-2.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/5_iam.png b/docs/imgs/s3-ingestion/5_iam.png
deleted file mode 100644
index 73a631cb74f56..0000000000000
Binary files a/docs/imgs/s3-ingestion/5_iam.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/6_schedule.png b/docs/imgs/s3-ingestion/6_schedule.png
deleted file mode 100644
index c5df59348fbc6..0000000000000
Binary files a/docs/imgs/s3-ingestion/6_schedule.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/7_output.png b/docs/imgs/s3-ingestion/7_output.png
deleted file mode 100644
index 6201fa40bcfb3..0000000000000
Binary files a/docs/imgs/s3-ingestion/7_output.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/8_review.png b/docs/imgs/s3-ingestion/8_review.png
deleted file mode 100644
index 2d27e79c2128b..0000000000000
Binary files a/docs/imgs/s3-ingestion/8_review.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/9_run.png b/docs/imgs/s3-ingestion/9_run.png
deleted file mode 100644
index 2b0644f6ad038..0000000000000
Binary files a/docs/imgs/s3-ingestion/9_run.png and /dev/null differ
diff --git a/docs/imgs/schedule-ingestion.png b/docs/imgs/schedule-ingestion.png
deleted file mode 100644
index 0e6ec8e268c32..0000000000000
Binary files a/docs/imgs/schedule-ingestion.png and /dev/null differ
diff --git a/docs/imgs/schema-blame-blame-activated.png b/docs/imgs/schema-blame-blame-activated.png
deleted file mode 100644
index 363466c39aedf..0000000000000
Binary files a/docs/imgs/schema-blame-blame-activated.png and /dev/null differ
diff --git a/docs/imgs/schema-history-audit-activated.png b/docs/imgs/schema-history-audit-activated.png
deleted file mode 100644
index f59676b9b8a8f..0000000000000
Binary files a/docs/imgs/schema-history-audit-activated.png and /dev/null differ
diff --git a/docs/imgs/schema-history-latest-version.png b/docs/imgs/schema-history-latest-version.png
deleted file mode 100644
index 0a54df4d520d5..0000000000000
Binary files a/docs/imgs/schema-history-latest-version.png and /dev/null differ
diff --git a/docs/imgs/schema-history-older-version.png b/docs/imgs/schema-history-older-version.png
deleted file mode 100644
index 8d295f176104f..0000000000000
Binary files a/docs/imgs/schema-history-older-version.png and /dev/null differ
diff --git a/docs/imgs/search-by-domain.png b/docs/imgs/search-by-domain.png
deleted file mode 100644
index 4b92e58959187..0000000000000
Binary files a/docs/imgs/search-by-domain.png and /dev/null differ
diff --git a/docs/imgs/search-domain.png b/docs/imgs/search-domain.png
deleted file mode 100644
index b1359e07d5fc2..0000000000000
Binary files a/docs/imgs/search-domain.png and /dev/null differ
diff --git a/docs/imgs/search-tag.png b/docs/imgs/search-tag.png
deleted file mode 100644
index cf4b6b629d1e2..0000000000000
Binary files a/docs/imgs/search-tag.png and /dev/null differ
diff --git a/docs/imgs/select-platform-template.png b/docs/imgs/select-platform-template.png
deleted file mode 100644
index 4f78e2b7309ed..0000000000000
Binary files a/docs/imgs/select-platform-template.png and /dev/null differ
diff --git a/docs/imgs/set-domain-id.png b/docs/imgs/set-domain-id.png
deleted file mode 100644
index 3e1dde4ae51ee..0000000000000
Binary files a/docs/imgs/set-domain-id.png and /dev/null differ
diff --git a/docs/imgs/set-domain.png b/docs/imgs/set-domain.png
deleted file mode 100644
index 1c4460e747835..0000000000000
Binary files a/docs/imgs/set-domain.png and /dev/null differ
diff --git a/docs/imgs/successful-ingestion.png b/docs/imgs/successful-ingestion.png
deleted file mode 100644
index fa8dbdff7501e..0000000000000
Binary files a/docs/imgs/successful-ingestion.png and /dev/null differ
diff --git a/docs/imgs/timeline/dropdown-apis.png b/docs/imgs/timeline/dropdown-apis.png
deleted file mode 100644
index f7aba08bbc061..0000000000000
Binary files a/docs/imgs/timeline/dropdown-apis.png and /dev/null differ
diff --git a/docs/imgs/timeline/swagger-ui.png b/docs/imgs/timeline/swagger-ui.png
deleted file mode 100644
index e52a57e8ca670..0000000000000
Binary files a/docs/imgs/timeline/swagger-ui.png and /dev/null differ
diff --git a/docs/imgs/timeline/timeline-conceptually.png b/docs/imgs/timeline/timeline-conceptually.png
deleted file mode 100644
index 70bd843bf8aed..0000000000000
Binary files a/docs/imgs/timeline/timeline-conceptually.png and /dev/null differ
diff --git a/docs/imgs/user-sign-up-screen.png b/docs/imgs/user-sign-up-screen.png
deleted file mode 100644
index 88c2589203bd1..0000000000000
Binary files a/docs/imgs/user-sign-up-screen.png and /dev/null differ
diff --git a/docs/lineage/airflow.md b/docs/lineage/airflow.md
index ef4071f89c585..49de5352f6d58 100644
--- a/docs/lineage/airflow.md
+++ b/docs/lineage/airflow.md
@@ -62,9 +62,10 @@ lazy_load_plugins = False
| datahub.cluster | prod | name of the airflow cluster |
| datahub.capture_ownership_info | true | If true, the owners field of the DAG will be capture as a DataHub corpuser. |
| datahub.capture_tags_info | true | If true, the tags field of the DAG will be captured as DataHub tags. |
+ | datahub.capture_executions | true | If true, we'll capture task runs in DataHub in addition to DAG definitions. |
| datahub.graceful_exceptions | true | If set to true, most runtime errors in the lineage backend will be suppressed and will not cause the overall task to fail. Note that configuration issues will still throw exceptions. |
-5. Configure `inlets` and `outlets` for your Airflow operators. For reference, look at the sample DAG in [`lineage_backend_demo.py`](../../metadata-ingestion/src/datahub_provider/example_dags/lineage_backend_demo.py), or reference [`lineage_backend_taskflow_demo.py`](../../metadata-ingestion/src/datahub_provider/example_dags/lineage_backend_taskflow_demo.py) if you're using the [TaskFlow API](https://airflow.apache.org/docs/apache-airflow/stable/concepts/taskflow.html).
+5. Configure `inlets` and `outlets` for your Airflow operators. For reference, look at the sample DAG in [`lineage_backend_demo.py`](../../metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/example_dags/lineage_backend_demo.py), or reference [`lineage_backend_taskflow_demo.py`](../../metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/example_dags/lineage_backend_taskflow_demo.py) if you're using the [TaskFlow API](https://airflow.apache.org/docs/apache-airflow/stable/concepts/taskflow.html).
6. [optional] Learn more about [Airflow lineage](https://airflow.apache.org/docs/apache-airflow/stable/lineage.html), including shorthand notation and some automation.
### How to validate installation
@@ -80,9 +81,7 @@ Emitting DataHub ...
If you have created a custom Airflow operator [docs](https://airflow.apache.org/docs/apache-airflow/stable/howto/custom-operator.html) that inherits from the BaseOperator class,
when overriding the `execute` function, set inlets and outlets via `context['ti'].task.inlets` and `context['ti'].task.outlets`.
-The DataHub Airflow plugin will then pick up those inlets and outlets after the task runs.
-
-
+The DataHub Airflow plugin will then pick up those inlets and outlets after the task runs.
```python
class DbtOperator(BaseOperator):
@@ -97,8 +96,8 @@ class DbtOperator(BaseOperator):
def _get_lineage(self):
# Do some processing to get inlets/outlets
-
- return inlets, outlets
+
+ return inlets, outlets
```
If you override the `pre_execute` and `post_execute` function, ensure they include the `@prepare_lineage` and `@apply_lineage` decorators respectively. [source](https://airflow.apache.org/docs/apache-airflow/stable/administration-and-deployment/lineage.html#lineage)
@@ -161,18 +160,17 @@ pip install acryl-datahub[airflow,datahub-kafka]
- `capture_executions` (defaults to false): If true, it captures task runs as DataHub DataProcessInstances.
- `graceful_exceptions` (defaults to true): If set to true, most runtime errors in the lineage backend will be suppressed and will not cause the overall task to fail. Note that configuration issues will still throw exceptions.
-4. Configure `inlets` and `outlets` for your Airflow operators. For reference, look at the sample DAG in [`lineage_backend_demo.py`](../../metadata-ingestion/src/datahub_provider/example_dags/lineage_backend_demo.py), or reference [`lineage_backend_taskflow_demo.py`](../../metadata-ingestion/src/datahub_provider/example_dags/lineage_backend_taskflow_demo.py) if you're using the [TaskFlow API](https://airflow.apache.org/docs/apache-airflow/stable/concepts/taskflow.html).
+4. Configure `inlets` and `outlets` for your Airflow operators. For reference, look at the sample DAG in [`lineage_backend_demo.py`](../../metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/example_dags/lineage_backend_demo.py), or reference [`lineage_backend_taskflow_demo.py`](../../metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/example_dags/lineage_backend_taskflow_demo.py) if you're using the [TaskFlow API](https://airflow.apache.org/docs/apache-airflow/stable/concepts/taskflow.html).
5. [optional] Learn more about [Airflow lineage](https://airflow.apache.org/docs/apache-airflow/stable/lineage.html), including shorthand notation and some automation.
## Emitting lineage via a separate operator
Take a look at this sample DAG:
-- [`lineage_emission_dag.py`](../../metadata-ingestion/src/datahub_provider/example_dags/lineage_emission_dag.py) - emits lineage using the DatahubEmitterOperator.
+- [`lineage_emission_dag.py`](../../metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/example_dags/lineage_emission_dag.py) - emits lineage using the DatahubEmitterOperator.
In order to use this example, you must first configure the Datahub hook. Like in ingestion, we support a Datahub REST hook and a Kafka-based hook. See step 1 above for details.
-
## Debugging
### Incorrect URLs
diff --git a/docs/links.md b/docs/links.md
index f175262b9b5d9..45ba391e557cd 100644
--- a/docs/links.md
+++ b/docs/links.md
@@ -39,7 +39,7 @@
* [Creating Notebook-based Dynamic Dashboards](https://towardsdatascience.com/creating-notebook-based-dynamic-dashboards-91f936adc6f3)
## Talks & Presentations
-* [DataHub: Powering LinkedIn's Metadata](demo/DataHub_-_Powering_LinkedIn_Metadata.pdf) @ [Budapest Data Forum 2020](https://budapestdata.hu/2020/en/)
+* [DataHub: Powering LinkedIn's Metadata](https://github.com/acryldata/static-assets-test/raw/master/imgs/demo/DataHub_-_Powering_LinkedIn_Metadata.pdf) @ [Budapest Data Forum 2020](https://budapestdata.hu/2020/en/)
* [Taming the Data Beast Using DataHub](https://www.youtube.com/watch?v=bo4OhiPro7Y) @ [Data Engineering Melbourne Meetup November 2020](https://www.meetup.com/Data-Engineering-Melbourne/events/kgnvlrybcpbjc/)
* [Metadata Management And Integration At LinkedIn With DataHub](https://www.dataengineeringpodcast.com/datahub-metadata-management-episode-147/) @ [Data Engineering Podcast](https://www.dataengineeringpodcast.com)
* [The evolution of metadata: LinkedIn’s story](https://speakerdeck.com/shirshanka/the-evolution-of-metadata-linkedins-journey-strata-nyc-2019) @ [Strata Data Conference 2019](https://conferences.oreilly.com/strata/strata-ny-2019.html)
diff --git a/docs/managed-datahub/chrome-extension.md b/docs/managed-datahub/chrome-extension.md
index a614327c7fd29..0aa0860d03b67 100644
--- a/docs/managed-datahub/chrome-extension.md
+++ b/docs/managed-datahub/chrome-extension.md
@@ -10,7 +10,11 @@ import FeatureAvailability from '@site/src/components/FeatureAvailability';
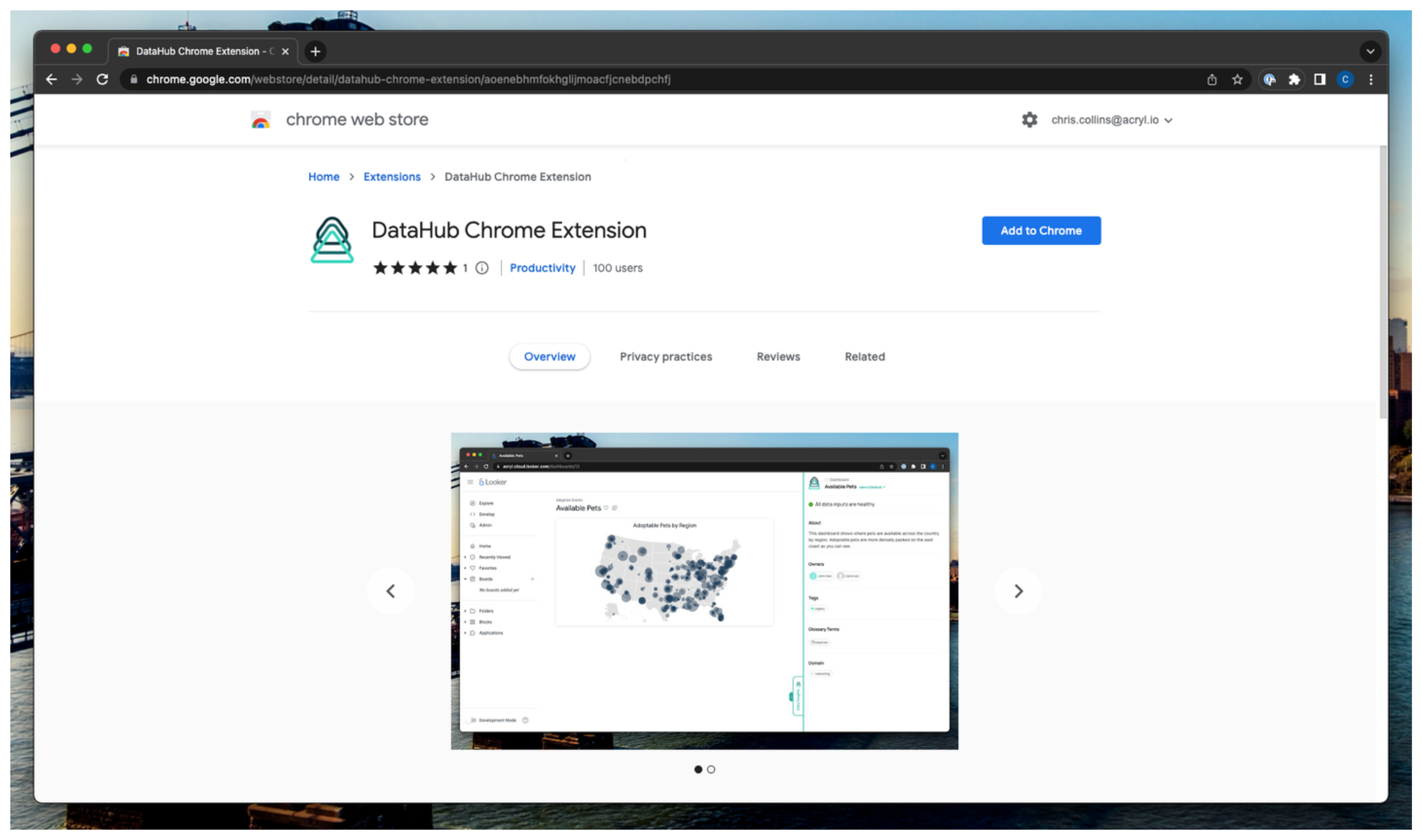
In order to use the Acryl DataHub Chrome extension, you need to download it onto your browser from the Chrome web store [here](https://chrome.google.com/webstore/detail/datahub-chrome-extension/aoenebhmfokhglijmoacfjcnebdpchfj).
-
+
+
+  +
+
+
Simply click "Add to Chrome" then "Add extension" on the ensuing popup.
@@ -20,11 +24,19 @@ Once you have your extension installed, you'll need to configure it to work with
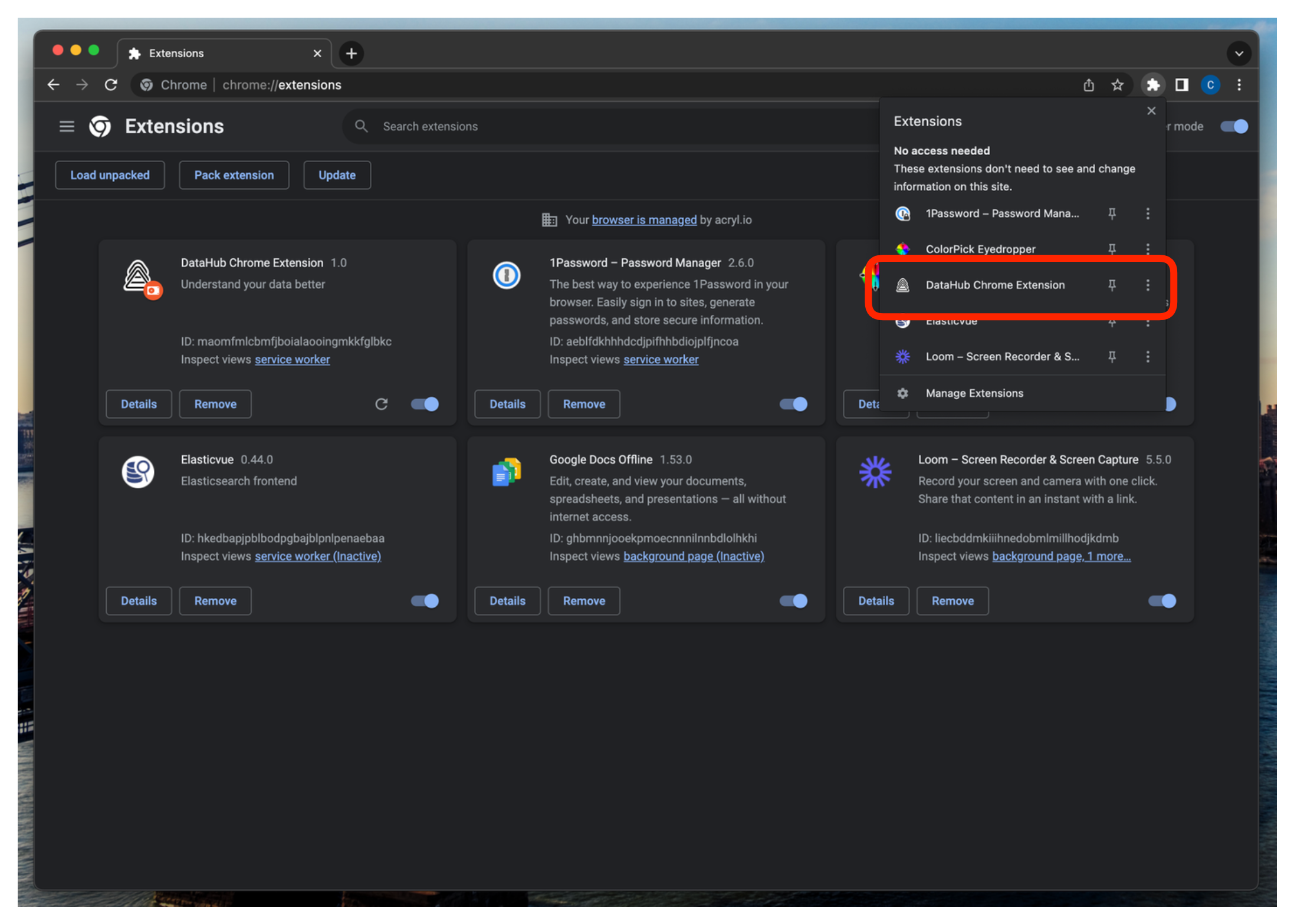
1. Click the extension button on the right of your browser's address bar to view all of your installed extensions. Click on the newly installed DataHub extension.
-
+
+
+  +
+
+
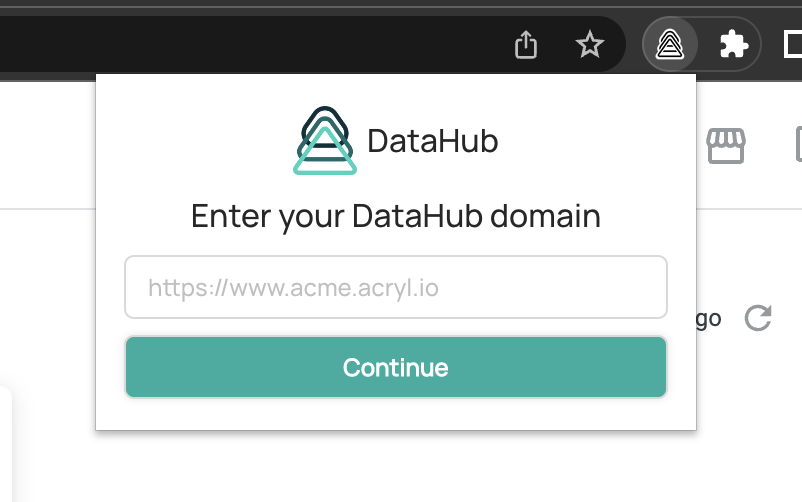
2. Fill in your DataHub domain and click "Continue" in the extension popup that appears.
-
+
+
+  +
+
+
If your organization uses standard SaaS domains for Looker, you should be ready to go!
@@ -34,11 +46,19 @@ Some organizations have custom SaaS domains for Looker and some Acryl DataHub de
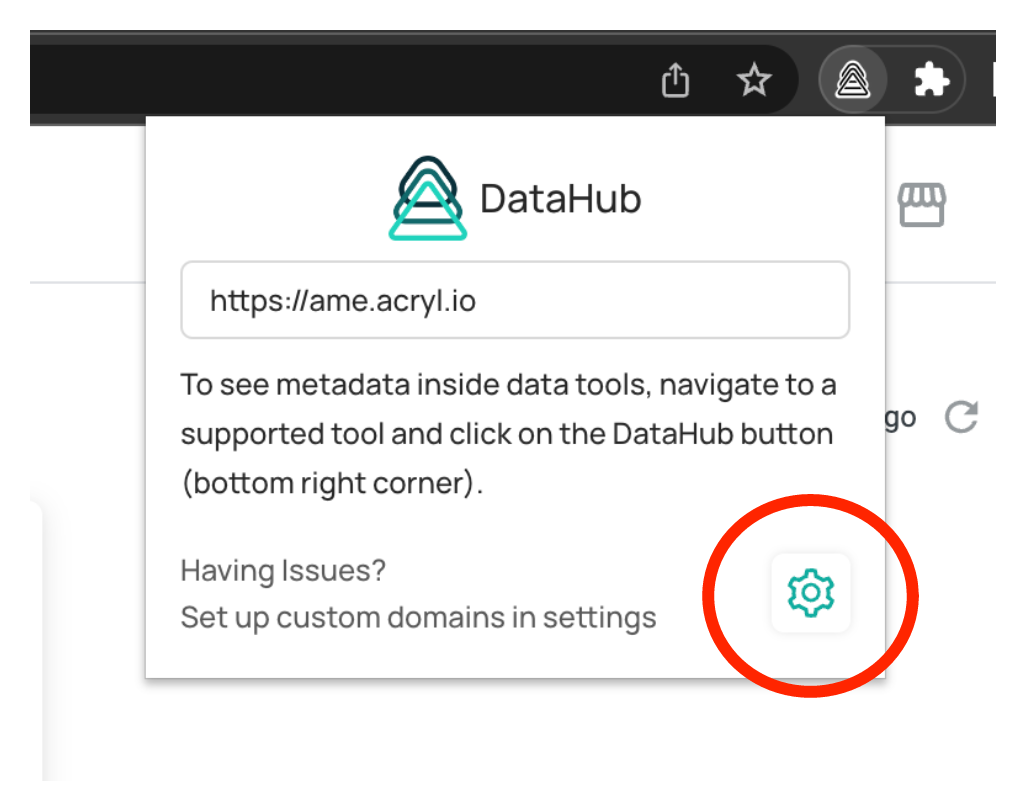
1. Click on the extension button and select your DataHub extension to open the popup again. Now click the settings icon in order to open the configurations page.
-
+
+
+  +
+
+
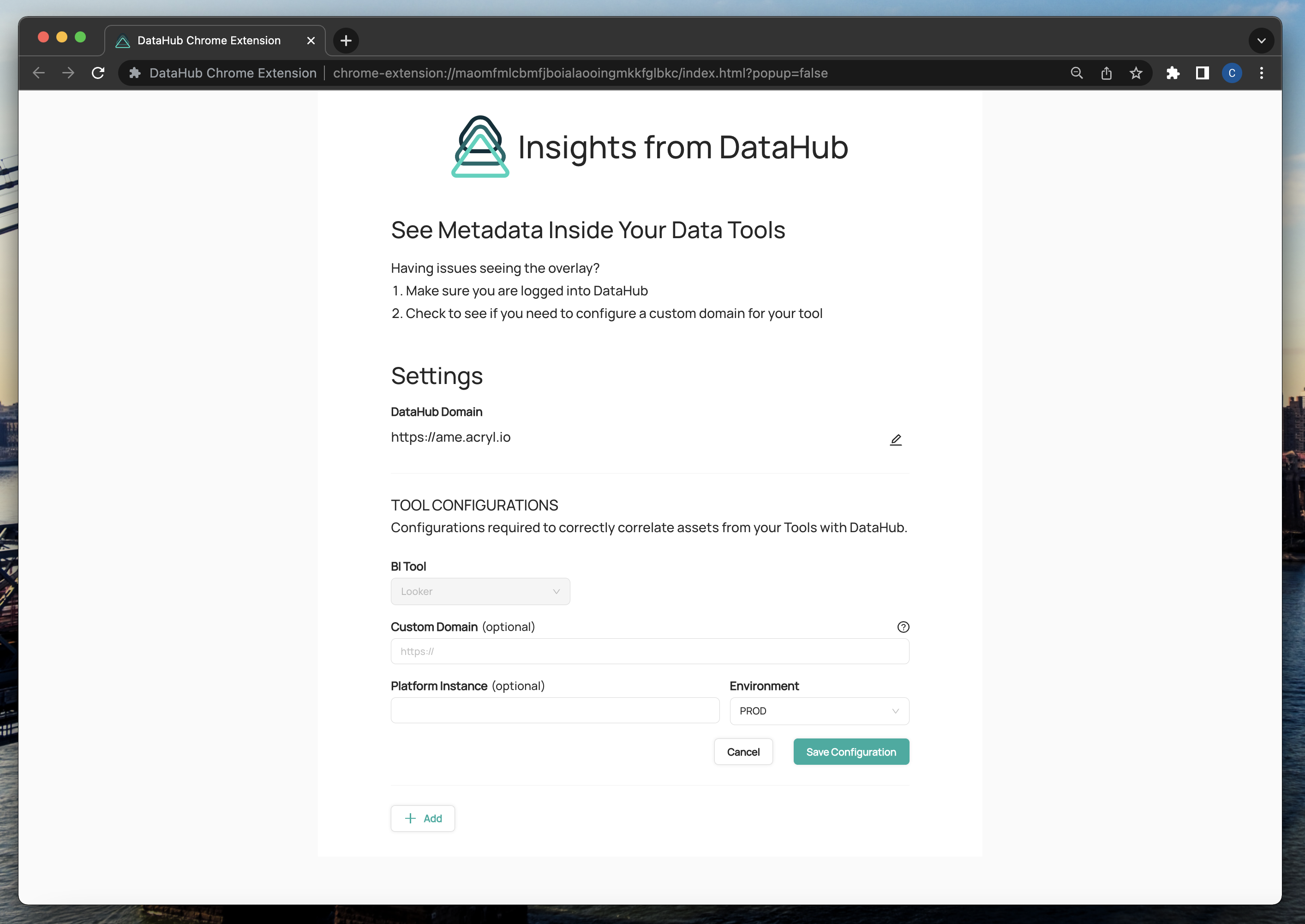
2. Fill out any and save custom configurations you have in the **TOOL CONFIGURATIONS** section. Here you can configure a custom domain, a Platform Instance associated with that domain, and the Environment set on your DataHub assets. If you don't have a custom domain but do have a custom Platform Instance or Environment, feel free to leave the field domain empty.
-
+
+
+  +
+
+
## Using the Extension
@@ -52,7 +72,11 @@ Once you have everything configured on your extension, it's time to use it!
4. Click the Acryl DataHub extension button on the bottom right of your page to open a drawer where you can now see additional information about this asset right from your DataHub instance.
-
+
+
+  +
+
+
## Advanced: Self-Hosted DataHub
diff --git a/docs/managed-datahub/datahub-api/graphql-api/getting-started.md b/docs/managed-datahub/datahub-api/graphql-api/getting-started.md
index 3c57b0a21d96e..736bf6fea6811 100644
--- a/docs/managed-datahub/datahub-api/graphql-api/getting-started.md
+++ b/docs/managed-datahub/datahub-api/graphql-api/getting-started.md
@@ -10,7 +10,11 @@ For a full reference to the Queries & Mutations available for consumption, check
### Connecting to the API
-.png)
+
+
+ .png) +
+
+
When you generate the token you will see an example of `curl` command which you can use to connect to the GraphQL API.
diff --git a/docs/managed-datahub/datahub-api/graphql-api/incidents-api-beta.md b/docs/managed-datahub/datahub-api/graphql-api/incidents-api-beta.md
index 89bacb2009e49..16d83d2f57575 100644
--- a/docs/managed-datahub/datahub-api/graphql-api/incidents-api-beta.md
+++ b/docs/managed-datahub/datahub-api/graphql-api/incidents-api-beta.md
@@ -404,7 +404,11 @@ You can configure Acryl to send slack notifications to a specific channel when i
These notifications are also able to tag the immediate asset's owners, along with the owners of downstream assets consuming it.
-
+
+
+  +
+
+
To do so, simply follow the [Slack Integration Guide](docs/managed-datahub/saas-slack-setup.md) and contact your Acryl customer success team to enable the feature!
diff --git a/docs/managed-datahub/imgs/saas/DataHub-Architecture.png b/docs/managed-datahub/imgs/saas/DataHub-Architecture.png
deleted file mode 100644
index 95b3ab0b06ad6..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/DataHub-Architecture.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-13-at-7.45.56-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-13-at-7.45.56-PM.png
deleted file mode 100644
index 721989a6c37e1..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-13-at-7.45.56-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-24-at-4.35.17-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-24-at-4.35.17-PM.png
deleted file mode 100644
index dffac92f257c7..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-24-at-4.35.17-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-24-at-4.37.22-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-24-at-4.37.22-PM.png
deleted file mode 100644
index ff0c29de1fbad..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-24-at-4.37.22-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-07-at-10.23.31-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-07-at-10.23.31-AM.png
deleted file mode 100644
index 070bfd9f6b897..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-07-at-10.23.31-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.43.25-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.43.25-PM.png
deleted file mode 100644
index b4bb4e2ba60ed..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.43.25-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.44.15-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.44.15-PM.png
deleted file mode 100644
index b0397afd1b3a4..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.44.15-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.46.41-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.46.41-PM.png
deleted file mode 100644
index 9258badb6f088..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.46.41-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.52.55-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.52.55-PM.png
deleted file mode 100644
index 386b4cdcd9911..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.52.55-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.56.50-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.56.50-PM.png
deleted file mode 100644
index a129f5eba4271..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.56.50-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.58.46-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.58.46-PM.png
deleted file mode 100644
index 96ae48318a35a..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.58.46-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-5.01.16-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-5.01.16-PM.png
deleted file mode 100644
index b6fd273389c90..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-5.01.16-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-5.03.36-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-5.03.36-PM.png
deleted file mode 100644
index 0acd4e75bc6d2..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-5.03.36-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-13-at-2.34.24-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-13-at-2.34.24-PM.png
deleted file mode 100644
index 364b9292cfaab..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-13-at-2.34.24-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-7.56.16-AM-(1).png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-7.56.16-AM-(1).png
deleted file mode 100644
index 6a12dc545ec62..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-7.56.16-AM-(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-7.56.16-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-7.56.16-AM.png
deleted file mode 100644
index 6a12dc545ec62..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-7.56.16-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-8.02.55-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-8.02.55-AM.png
deleted file mode 100644
index 83645e00d724a..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-8.02.55-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-24-at-11.02.47-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-24-at-11.02.47-AM.png
deleted file mode 100644
index a2f239ce847e0..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-24-at-11.02.47-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-24-at-12.59.38-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-24-at-12.59.38-PM.png
deleted file mode 100644
index e31d4b089d929..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-24-at-12.59.38-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.21.42-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.21.42-AM.png
deleted file mode 100644
index c003581c9d1b6..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.21.42-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.22.23-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.22.23-AM.png
deleted file mode 100644
index 660dd121dd0a4..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.22.23-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.23.08-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.23.08-AM.png
deleted file mode 100644
index 07e3c71dba262..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.23.08-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.47.57-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.47.57-AM.png
deleted file mode 100644
index 579e7f62af708..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.47.57-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-29-at-6.07.25-PM-(1).png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-29-at-6.07.25-PM-(1).png
deleted file mode 100644
index f85f4d5c79bfb..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-29-at-6.07.25-PM-(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-29-at-6.07.25-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-29-at-6.07.25-PM.png
deleted file mode 100644
index f85f4d5c79bfb..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-29-at-6.07.25-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-4.16.52-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-4.16.52-PM.png
deleted file mode 100644
index cb8b7470cd957..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-4.16.52-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-4.23.32-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-4.23.32-PM.png
deleted file mode 100644
index 1de51e33d87c2..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-4.23.32-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.47-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.47-PM.png
deleted file mode 100644
index df687dabe345c..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.47-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.56-PM-(1).png b/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.56-PM-(1).png
deleted file mode 100644
index a8d9ee37c7a55..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.56-PM-(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.56-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.56-PM.png
deleted file mode 100644
index a8d9ee37c7a55..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.56-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Untitled(1).png b/docs/managed-datahub/imgs/saas/Untitled(1).png
deleted file mode 100644
index 87846e7897f6e..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Untitled(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Untitled-(2)-(1).png b/docs/managed-datahub/imgs/saas/Untitled-(2)-(1).png
deleted file mode 100644
index 7715bf4a51fbe..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Untitled-(2)-(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Untitled-(2).png b/docs/managed-datahub/imgs/saas/Untitled-(2).png
deleted file mode 100644
index a01a1af370442..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Untitled-(2).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Untitled-(3).png b/docs/managed-datahub/imgs/saas/Untitled-(3).png
deleted file mode 100644
index 02d84b326896c..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Untitled-(3).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Untitled-(4).png b/docs/managed-datahub/imgs/saas/Untitled-(4).png
deleted file mode 100644
index a01a1af370442..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Untitled-(4).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Untitled.png b/docs/managed-datahub/imgs/saas/Untitled.png
deleted file mode 100644
index a01a1af370442..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Untitled.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/chrome-store-extension-screenshot.png b/docs/managed-datahub/imgs/saas/chrome-store-extension-screenshot.png
deleted file mode 100644
index e00a4d57f32dd..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/chrome-store-extension-screenshot.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_custom_configs.png b/docs/managed-datahub/imgs/saas/extension_custom_configs.png
deleted file mode 100644
index b3d70dfac00ff..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_custom_configs.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_developer_mode.png b/docs/managed-datahub/imgs/saas/extension_developer_mode.png
deleted file mode 100644
index e740d15912e17..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_developer_mode.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_enter_domain.png b/docs/managed-datahub/imgs/saas/extension_enter_domain.png
deleted file mode 100644
index 3304fa168beaf..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_enter_domain.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_load_unpacked.png b/docs/managed-datahub/imgs/saas/extension_load_unpacked.png
deleted file mode 100644
index 8f56705cd9176..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_load_unpacked.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_open_options_page.png b/docs/managed-datahub/imgs/saas/extension_open_options_page.png
deleted file mode 100644
index c1366d5673b59..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_open_options_page.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_open_popup.png b/docs/managed-datahub/imgs/saas/extension_open_popup.png
deleted file mode 100644
index 216056b847fb5..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_open_popup.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_view_in_looker.png b/docs/managed-datahub/imgs/saas/extension_view_in_looker.png
deleted file mode 100644
index bf854b3e840f7..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_view_in_looker.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/home-(1).png b/docs/managed-datahub/imgs/saas/home-(1).png
deleted file mode 100644
index 88cf2017dd7e7..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/home-(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/home.png b/docs/managed-datahub/imgs/saas/home.png
deleted file mode 100644
index 8ad63deec75c9..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/home.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(1).png b/docs/managed-datahub/imgs/saas/image-(1).png
deleted file mode 100644
index c1a249125fcf7..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(10).png b/docs/managed-datahub/imgs/saas/image-(10).png
deleted file mode 100644
index a580fdc3d6730..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(10).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(11).png b/docs/managed-datahub/imgs/saas/image-(11).png
deleted file mode 100644
index ee95eb4384272..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(11).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(12).png b/docs/managed-datahub/imgs/saas/image-(12).png
deleted file mode 100644
index bbd8e6a66cf85..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(12).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(13).png b/docs/managed-datahub/imgs/saas/image-(13).png
deleted file mode 100644
index bbd8e6a66cf85..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(13).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(14).png b/docs/managed-datahub/imgs/saas/image-(14).png
deleted file mode 100644
index a580fdc3d6730..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(14).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(15).png b/docs/managed-datahub/imgs/saas/image-(15).png
deleted file mode 100644
index f282e2d92c1a1..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(15).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(16).png b/docs/managed-datahub/imgs/saas/image-(16).png
deleted file mode 100644
index 1340c77bd648c..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(16).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(17).png b/docs/managed-datahub/imgs/saas/image-(17).png
deleted file mode 100644
index 6eee2fb2d821f..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(17).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(2).png b/docs/managed-datahub/imgs/saas/image-(2).png
deleted file mode 100644
index cf475edd7b95d..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(2).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(3).png b/docs/managed-datahub/imgs/saas/image-(3).png
deleted file mode 100644
index b08818ff3e97c..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(3).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(4).png b/docs/managed-datahub/imgs/saas/image-(4).png
deleted file mode 100644
index a580fdc3d6730..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(4).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(5).png b/docs/managed-datahub/imgs/saas/image-(5).png
deleted file mode 100644
index 48438c6001e4f..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(5).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(6).png b/docs/managed-datahub/imgs/saas/image-(6).png
deleted file mode 100644
index 54e569e853f24..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(6).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(7).png b/docs/managed-datahub/imgs/saas/image-(7).png
deleted file mode 100644
index 6e89e5881cfa7..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(7).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(8).png b/docs/managed-datahub/imgs/saas/image-(8).png
deleted file mode 100644
index ee0a3c89d58fa..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(8).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(9).png b/docs/managed-datahub/imgs/saas/image-(9).png
deleted file mode 100644
index 301ca98593ef9..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(9).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image.png b/docs/managed-datahub/imgs/saas/image.png
deleted file mode 100644
index a1cfc3e74c5dd..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/settings.png b/docs/managed-datahub/imgs/saas/settings.png
deleted file mode 100644
index ca99984abbbc9..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/settings.png and /dev/null differ
diff --git a/docs/managed-datahub/integrations/oidc-sso-integration.md b/docs/managed-datahub/integrations/oidc-sso-integration.md
index 6a9e085186b44..ec4ca311a0de5 100644
--- a/docs/managed-datahub/integrations/oidc-sso-integration.md
+++ b/docs/managed-datahub/integrations/oidc-sso-integration.md
@@ -42,4 +42,8 @@ To enable the OIDC integration, start by navigating to **Settings > Platform > S
4. If there are any advanced settings you would like to configure, click on the **Advanced** button. These come with defaults, so only input settings here if there is something you need changed from the default configuration.
5. Click **Update** to save your settings.
-.png)
+
+
+ .png) +
+
+
diff --git a/docs/managed-datahub/metadata-ingestion-with-acryl/ingestion.md b/docs/managed-datahub/metadata-ingestion-with-acryl/ingestion.md
index 95ca6e5e33e16..0444d15b3627c 100644
--- a/docs/managed-datahub/metadata-ingestion-with-acryl/ingestion.md
+++ b/docs/managed-datahub/metadata-ingestion-with-acryl/ingestion.md
@@ -56,9 +56,17 @@ In Acryl DataHub deployments, you _must_ use a sink of type `datahub-rest`, whic
2. **token**: a unique API key used to authenticate requests to your instance's REST API
The token can be retrieved by logging in as admin. You can go to Settings page and generate a Personal Access Token with your desired expiration date.
-.png)
-
+
+ .png) +
+
+
+
+
+
+  +
+
+
To configure your instance of DataHub as the destination for ingestion, set the "server" field of your recipe to point to your Acryl instance's domain suffixed by the path `/gms`, as shown below.
A complete example of a DataHub recipe file, which reads from MySQL and writes into a DataHub instance:
diff --git a/docs/managed-datahub/observe/freshness-assertions.md b/docs/managed-datahub/observe/freshness-assertions.md
index 54b3134151d3a..c5d4ca9081b43 100644
--- a/docs/managed-datahub/observe/freshness-assertions.md
+++ b/docs/managed-datahub/observe/freshness-assertions.md
@@ -59,7 +59,7 @@ Tables.
For example, imagine that we work for a company with a Snowflake Table that stores user clicks collected from our e-commerce website.
This table is updated with new data on a specific cadence: once per hour (In practice, daily or even weekly are also common).
In turn, there is a downstream Business Analytics Dashboard in Looker that shows important metrics like
-the number of people clicking our "Daily Sale" banners, and this dashboard pulls is generated from data stored in our "clicks" table.
+the number of people clicking our "Daily Sale" banners, and this dashboard is generated from data stored in our "clicks" table.
It is important that our clicks Table continues to be updated each hour because if it stops being updated, it could mean
that our downstream metrics dashboard becomes incorrect. And the risk of this situation is obvious: our organization
may make bad decisions based on incomplete information.
@@ -122,8 +122,12 @@ Change Source types vary by the platform, but generally fall into these categori
is higher than the previously observed value, in order to determine whether the Table has been changed within a given period of time.
Note that this approach is only supported if the Change Window does not use a fixed interval.
- Using the final 2 approaches - column value queries - to determine whether a Table has changed useful because it can be customized to determine whether
- specific types of important changes have been made to a given Table.
+ - **DataHub Operation**: A DataHub "Operation" aspect contains timeseries information used to describe changes made to an entity. Using this
+ option avoids contacting your data platform, and instead uses the DataHub Operation metadata to evaluate Freshness Assertions.
+ This relies on Operations being reported to DataHub, either via ingestion or via use of the DataHub APIs (see [Report Operation via API](#reporting-operations-via-api)).
+ Note if you have not configured an ingestion source through DataHub, then this may be the only option available.
+
+ Using either of the column value approaches (**Last Modified Column** or **High Watermark Column**) to determine whether a Table has changed can be useful because it can be customized to determine whether specific types of important changes have been made to a given Table.
Because it does not involve system warehouse tables, it is also easily portable across Data Warehouse and Data Lake providers.
Freshness Assertions also have an off switch: they can be started or stopped at any time with the click of button.
@@ -178,7 +182,7 @@ _Check whether the table has changed in a specific window of time_
7. (Optional) Click **Advanced** to customize the evaluation **source**. This is the mechanism that will be used to evaluate
-the check. Each Data Platform supports different options including Audit Log, Information Schema, Last Modified Column, and High Watermark Column.
+the check. Each Data Platform supports different options including Audit Log, Information Schema, Last Modified Column, High Watermark Column, and DataHub Operation.
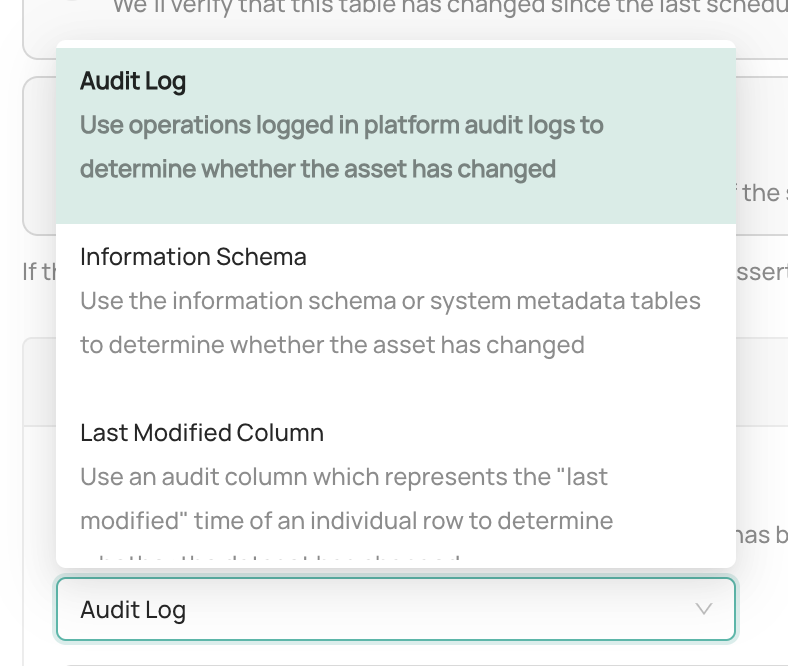 @@ -189,11 +193,12 @@ the check. Each Data Platform supports different options including Audit Log, In
- **Last Modified Column**: Check for the presence of rows using a "Last Modified Time" column, which should reflect the time at which a given row was last changed in the table, to
determine whether the table changed within the evaluation period.
- **High Watermark Column**: Monitor changes to a continuously-increasing "high watermark" column value to determine whether a table
- has been changed. This option is particularly useful for tables that grow consistently with time, for example fact or event (e.g. click-strea) tables. It is not available
+ has been changed. This option is particularly useful for tables that grow consistently with time, for example fact or event (e.g. click-stream) tables. It is not available
when using a fixed lookback period.
+- **DataHub Operation**: Use DataHub Operations to determine whether the table changed within the evaluation period.
-8. Click **Next**
-9. Configure actions that should be taken when the Freshness Assertion passes or fails
+1. Click **Next**
+2. Configure actions that should be taken when the Freshness Assertion passes or fails
@@ -189,11 +193,12 @@ the check. Each Data Platform supports different options including Audit Log, In
- **Last Modified Column**: Check for the presence of rows using a "Last Modified Time" column, which should reflect the time at which a given row was last changed in the table, to
determine whether the table changed within the evaluation period.
- **High Watermark Column**: Monitor changes to a continuously-increasing "high watermark" column value to determine whether a table
- has been changed. This option is particularly useful for tables that grow consistently with time, for example fact or event (e.g. click-strea) tables. It is not available
+ has been changed. This option is particularly useful for tables that grow consistently with time, for example fact or event (e.g. click-stream) tables. It is not available
when using a fixed lookback period.
+- **DataHub Operation**: Use DataHub Operations to determine whether the table changed within the evaluation period.
-8. Click **Next**
-9. Configure actions that should be taken when the Freshness Assertion passes or fails
+1. Click **Next**
+2. Configure actions that should be taken when the Freshness Assertion passes or fails
 @@ -280,7 +285,7 @@ Note that to create or delete Assertions and Monitors for a specific entity on D
In order to create a Freshness Assertion that is being monitored on a specific **Evaluation Schedule**, you'll need to use 2
GraphQL mutation queries to create a Freshness Assertion entity and create an Assertion Monitor entity responsible for evaluating it.
-Start by creating the Freshness Assertion entity using the `createFreshnessAssertion` query and hang on to the 'urn' field of the Assertion entit y
+Start by creating the Freshness Assertion entity using the `createFreshnessAssertion` query and hang on to the 'urn' field of the Assertion entity
you get back. Then continue by creating a Monitor entity using the `createAssertionMonitor`.
##### Examples
@@ -291,10 +296,10 @@ To create a Freshness Assertion Entity that checks whether a table has been upda
mutation createFreshnessAssertion {
createFreshnessAssertion(
input: {
- entityUrn: ""
- type: DATASET_CHANGE
+ entityUrn: "",
+ type: DATASET_CHANGE,
schedule: {
- type: FIXED_INTERVAL
+ type: FIXED_INTERVAL,
fixedInterval: { unit: HOUR, multiple: 8 }
}
}
@@ -337,6 +342,28 @@ After creating the monitor, the new assertion will start to be evaluated every 8
You can delete assertions along with their monitors using GraphQL mutations: `deleteAssertion` and `deleteMonitor`.
+### Reporting Operations via API
+
+DataHub Operations can be used to capture changes made to entities. This is useful for cases where the underlying data platform does not provide a mechanism
+to capture changes, or where the data platform's mechanism is not reliable. In order to report an operation, you can use the `reportOperation` GraphQL mutation.
+
+
+##### Examples
+```json
+mutation reportOperation {
+ reportOperation(
+ input: {
+ urn: "",
+ operationType: INSERT,
+ sourceType: DATA_PLATFORM,
+ timestampMillis: 1693252366489
+ }
+ )
+}
+```
+
+Use the `timestampMillis` field to specify the time at which the operation occurred. If no value is provided, the current time will be used.
+
### Tips
:::info
diff --git a/docs/managed-datahub/observe/volume-assertions.md b/docs/managed-datahub/observe/volume-assertions.md
new file mode 100644
index 0000000000000..5f5aff33a5ce2
--- /dev/null
+++ b/docs/managed-datahub/observe/volume-assertions.md
@@ -0,0 +1,355 @@
+---
+description: This page provides an overview of working with DataHub Volume Assertions
+---
+import FeatureAvailability from '@site/src/components/FeatureAvailability';
+
+
+# Volume Assertions
+
+
+
+
+> ⚠️ The **Volume Assertions** feature is currently in private beta, part of the **Acryl Observe** module, and may only be available to a
+> limited set of design partners.
+>
+> If you are interested in trying it and providing feedback, please reach out to your Acryl Customer Success
+> representative.
+
+## Introduction
+
+Can you remember a time when the meaning of Data Warehouse Table that you depended on fundamentally changed, with little or no notice?
+If the answer is yes, how did you find out? We'll take a guess - someone looking at an internal reporting dashboard or worse, a user using your your product, sounded an alarm when
+a number looked a bit out of the ordinary. Perhaps your table initially tracked purchases made on your company's e-commerce web store, but suddenly began to include purchases made
+through your company's new mobile app.
+
+There are many reasons why an important Table on Snowflake, Redshift, or BigQuery may change in its meaning - application code bugs, new feature rollouts,
+changes to key metric definitions, etc. Often times, these changes break important assumptions made about the data used in building key downstream data products
+like reporting dashboards or data-driven product features.
+
+What if you could reduce the time to detect these incidents, so that the people responsible for the data were made aware of data
+issues _before_ anyone else? With Acryl DataHub **Volume Assertions**, you can.
+
+Acryl DataHub allows users to define expectations about the normal volume, or size, of a particular warehouse Table,
+and then monitor those expectations over time as the table grows and changes.
+
+In this article, we'll cover the basics of monitoring Volume Assertions - what they are, how to configure them, and more - so that you and your team can
+start building trust in your most important data assets.
+
+Let's get started!
+
+## Support
+
+Volume Assertions are currently supported for:
+
+1. Snowflake
+2. Redshift
+3. BigQuery
+
+Note that an Ingestion Source _must_ be configured with the data platform of your choice in Acryl DataHub's **Ingestion**
+tab.
+
+> Note that Volume Assertions are not yet supported if you are connecting to your warehouse
+> using the DataHub CLI or a Remote Ingestion Executor.
+
+## What is a Volume Assertion?
+
+A **Volume Assertion** is a configurable Data Quality rule used to monitor a Data Warehouse Table
+for unexpected or sudden changes in "volume", or row count. Volume Assertions can be particularly useful when you have frequently-changing
+Tables which have a relatively stable pattern of growth or decline.
+
+For example, imagine that we work for a company with a Snowflake Table that stores user clicks collected from our e-commerce website.
+This table is updated with new data on a specific cadence: once per hour (In practice, daily or even weekly are also common).
+In turn, there is a downstream Business Analytics Dashboard in Looker that shows important metrics like
+the number of people clicking our "Daily Sale" banners, and this dashboard is generated from data stored in our "clicks" table.
+It is important that our clicks Table is updated with the correct number of rows each hour, else it could mean
+that our downstream metrics dashboard becomes incorrect. The risk of this situation is obvious: our organization
+may make bad decisions based on incomplete information.
+
+In such cases, we can use a **Volume Assertion** that checks whether the Snowflake "clicks" Table is growing in an expected
+way, and that there are no sudden increases or sudden decreases in the rows being added or removed from the table.
+If too many rows are added or removed within an hour, we can notify key stakeholders and begin to root cause before the problem impacts stakeholders of the data.
+
+### Anatomy of a Volume Assertion
+
+At the most basic level, **Volume Assertions** consist of a few important parts:
+
+1. An **Evaluation Schedule**
+2. A **Volume Condition**
+2. A **Volume Source**
+
+In this section, we'll give an overview of each.
+
+#### 1. Evaluation Schedule
+
+The **Evaluation Schedule**: This defines how often to check a given warehouse Table for its volume. This should usually
+be configured to match the expected change frequency of the Table, although it can also be less frequently depending
+on the requirements. You can also specify specific days of the week, hours in the day, or even
+minutes in an hour.
+
+
+#### 2. Volume Condition
+
+The **Volume Condition**: This defines the type of condition that we'd like to monitor, or when the Assertion
+should result in failure.
+
+There are a 2 different categories of conditions: **Total** Volume and **Change** Volume.
+
+_Total_ volume conditions are those which are defined against the point-in-time total row count for a table. They allow you to specify conditions like:
+
+1. **Table has too many rows**: The table should always have less than 1000 rows
+2. **Table has too few rows**: The table should always have more than 1000 rows
+3. **Table row count is outside a range**: The table should always have between 1000 and 2000 rows.
+
+_Change_ volume conditions are those which are defined against the growth or decline rate of a table, measured between subsequent checks
+of the table volume. They allow you to specify conditions like:
+
+1. **Table growth is too fast**: When the table volume is checked, it should have < 1000 more rows than it had during the previous check.
+2. **Table growth is too slow**: When the table volume is checked, it should have > 1000 more rows than it had during the previous check.
+3. **Table growth is outside a range**: When the table volume is checked, it should have between 1000 and 2000 more rows than it had during the previous check.
+
+For change volume conditions, both _absolute_ row count deltas and relative percentage deltas are supported for identifying
+table that are following an abnormal pattern of growth.
+
+
+#### 3. Volume Source
+
+The **Volume Source**: This is the mechanism that Acryl DataHub should use to determine the table volume (row count). The supported
+source types vary by the platform, but generally fall into these categories:
+
+- **Information Schema**: A system Table that is exposed by the Data Warehouse which contains live information about the Databases
+ and Tables stored inside the Data Warehouse, including their row count. It is usually efficient to check, but can in some cases be slightly delayed to update
+ once a change has been made to a table.
+
+- **Query**: A `COUNT(*)` query is used to retrieve the latest row count for a table, with optional SQL filters applied (depending on platform).
+ This can be less efficient to check depending on the size of the table. This approach is more portable, as it does not involve
+ system warehouse tables, it is also easily portable across Data Warehouse and Data Lake providers.
+
+- **DataHub Dataset Profile**: The DataHub Dataset Profile aspect is used to retrieve the latest row count information for a table.
+ Using this option avoids contacting your data platform, and instead uses the DataHub Dataset Profile metadata to evaluate Volume Assertions.
+ Note if you have not configured an ingestion source through DataHub, then this may be the only option available.
+
+Volume Assertions also have an off switch: they can be started or stopped at any time with the click of button.
+
+
+## Creating a Volume Assertion
+
+### Prerequisites
+
+1. **Permissions**: To create or delete Volume Assertions for a specific entity on DataHub, you'll need to be granted the
+ `Edit Assertions` and `Edit Monitors` privileges for the entity. This is granted to Entity owners by default.
+
+2. **Data Platform Connection**: In order to create a Volume Assertion, you'll need to have an **Ingestion Source** configured to your
+ Data Platform: Snowflake, BigQuery, or Redshift under the **Integrations** tab.
+
+Once these are in place, you're ready to create your Volume Assertions!
+
+### Steps
+
+1. Navigate to the Table that to monitor for volume
+2. Click the **Validations** tab
+
+
@@ -280,7 +285,7 @@ Note that to create or delete Assertions and Monitors for a specific entity on D
In order to create a Freshness Assertion that is being monitored on a specific **Evaluation Schedule**, you'll need to use 2
GraphQL mutation queries to create a Freshness Assertion entity and create an Assertion Monitor entity responsible for evaluating it.
-Start by creating the Freshness Assertion entity using the `createFreshnessAssertion` query and hang on to the 'urn' field of the Assertion entit y
+Start by creating the Freshness Assertion entity using the `createFreshnessAssertion` query and hang on to the 'urn' field of the Assertion entity
you get back. Then continue by creating a Monitor entity using the `createAssertionMonitor`.
##### Examples
@@ -291,10 +296,10 @@ To create a Freshness Assertion Entity that checks whether a table has been upda
mutation createFreshnessAssertion {
createFreshnessAssertion(
input: {
- entityUrn: ""
- type: DATASET_CHANGE
+ entityUrn: "",
+ type: DATASET_CHANGE,
schedule: {
- type: FIXED_INTERVAL
+ type: FIXED_INTERVAL,
fixedInterval: { unit: HOUR, multiple: 8 }
}
}
@@ -337,6 +342,28 @@ After creating the monitor, the new assertion will start to be evaluated every 8
You can delete assertions along with their monitors using GraphQL mutations: `deleteAssertion` and `deleteMonitor`.
+### Reporting Operations via API
+
+DataHub Operations can be used to capture changes made to entities. This is useful for cases where the underlying data platform does not provide a mechanism
+to capture changes, or where the data platform's mechanism is not reliable. In order to report an operation, you can use the `reportOperation` GraphQL mutation.
+
+
+##### Examples
+```json
+mutation reportOperation {
+ reportOperation(
+ input: {
+ urn: "",
+ operationType: INSERT,
+ sourceType: DATA_PLATFORM,
+ timestampMillis: 1693252366489
+ }
+ )
+}
+```
+
+Use the `timestampMillis` field to specify the time at which the operation occurred. If no value is provided, the current time will be used.
+
### Tips
:::info
diff --git a/docs/managed-datahub/observe/volume-assertions.md b/docs/managed-datahub/observe/volume-assertions.md
new file mode 100644
index 0000000000000..5f5aff33a5ce2
--- /dev/null
+++ b/docs/managed-datahub/observe/volume-assertions.md
@@ -0,0 +1,355 @@
+---
+description: This page provides an overview of working with DataHub Volume Assertions
+---
+import FeatureAvailability from '@site/src/components/FeatureAvailability';
+
+
+# Volume Assertions
+
+
+
+
+> ⚠️ The **Volume Assertions** feature is currently in private beta, part of the **Acryl Observe** module, and may only be available to a
+> limited set of design partners.
+>
+> If you are interested in trying it and providing feedback, please reach out to your Acryl Customer Success
+> representative.
+
+## Introduction
+
+Can you remember a time when the meaning of Data Warehouse Table that you depended on fundamentally changed, with little or no notice?
+If the answer is yes, how did you find out? We'll take a guess - someone looking at an internal reporting dashboard or worse, a user using your your product, sounded an alarm when
+a number looked a bit out of the ordinary. Perhaps your table initially tracked purchases made on your company's e-commerce web store, but suddenly began to include purchases made
+through your company's new mobile app.
+
+There are many reasons why an important Table on Snowflake, Redshift, or BigQuery may change in its meaning - application code bugs, new feature rollouts,
+changes to key metric definitions, etc. Often times, these changes break important assumptions made about the data used in building key downstream data products
+like reporting dashboards or data-driven product features.
+
+What if you could reduce the time to detect these incidents, so that the people responsible for the data were made aware of data
+issues _before_ anyone else? With Acryl DataHub **Volume Assertions**, you can.
+
+Acryl DataHub allows users to define expectations about the normal volume, or size, of a particular warehouse Table,
+and then monitor those expectations over time as the table grows and changes.
+
+In this article, we'll cover the basics of monitoring Volume Assertions - what they are, how to configure them, and more - so that you and your team can
+start building trust in your most important data assets.
+
+Let's get started!
+
+## Support
+
+Volume Assertions are currently supported for:
+
+1. Snowflake
+2. Redshift
+3. BigQuery
+
+Note that an Ingestion Source _must_ be configured with the data platform of your choice in Acryl DataHub's **Ingestion**
+tab.
+
+> Note that Volume Assertions are not yet supported if you are connecting to your warehouse
+> using the DataHub CLI or a Remote Ingestion Executor.
+
+## What is a Volume Assertion?
+
+A **Volume Assertion** is a configurable Data Quality rule used to monitor a Data Warehouse Table
+for unexpected or sudden changes in "volume", or row count. Volume Assertions can be particularly useful when you have frequently-changing
+Tables which have a relatively stable pattern of growth or decline.
+
+For example, imagine that we work for a company with a Snowflake Table that stores user clicks collected from our e-commerce website.
+This table is updated with new data on a specific cadence: once per hour (In practice, daily or even weekly are also common).
+In turn, there is a downstream Business Analytics Dashboard in Looker that shows important metrics like
+the number of people clicking our "Daily Sale" banners, and this dashboard is generated from data stored in our "clicks" table.
+It is important that our clicks Table is updated with the correct number of rows each hour, else it could mean
+that our downstream metrics dashboard becomes incorrect. The risk of this situation is obvious: our organization
+may make bad decisions based on incomplete information.
+
+In such cases, we can use a **Volume Assertion** that checks whether the Snowflake "clicks" Table is growing in an expected
+way, and that there are no sudden increases or sudden decreases in the rows being added or removed from the table.
+If too many rows are added or removed within an hour, we can notify key stakeholders and begin to root cause before the problem impacts stakeholders of the data.
+
+### Anatomy of a Volume Assertion
+
+At the most basic level, **Volume Assertions** consist of a few important parts:
+
+1. An **Evaluation Schedule**
+2. A **Volume Condition**
+2. A **Volume Source**
+
+In this section, we'll give an overview of each.
+
+#### 1. Evaluation Schedule
+
+The **Evaluation Schedule**: This defines how often to check a given warehouse Table for its volume. This should usually
+be configured to match the expected change frequency of the Table, although it can also be less frequently depending
+on the requirements. You can also specify specific days of the week, hours in the day, or even
+minutes in an hour.
+
+
+#### 2. Volume Condition
+
+The **Volume Condition**: This defines the type of condition that we'd like to monitor, or when the Assertion
+should result in failure.
+
+There are a 2 different categories of conditions: **Total** Volume and **Change** Volume.
+
+_Total_ volume conditions are those which are defined against the point-in-time total row count for a table. They allow you to specify conditions like:
+
+1. **Table has too many rows**: The table should always have less than 1000 rows
+2. **Table has too few rows**: The table should always have more than 1000 rows
+3. **Table row count is outside a range**: The table should always have between 1000 and 2000 rows.
+
+_Change_ volume conditions are those which are defined against the growth or decline rate of a table, measured between subsequent checks
+of the table volume. They allow you to specify conditions like:
+
+1. **Table growth is too fast**: When the table volume is checked, it should have < 1000 more rows than it had during the previous check.
+2. **Table growth is too slow**: When the table volume is checked, it should have > 1000 more rows than it had during the previous check.
+3. **Table growth is outside a range**: When the table volume is checked, it should have between 1000 and 2000 more rows than it had during the previous check.
+
+For change volume conditions, both _absolute_ row count deltas and relative percentage deltas are supported for identifying
+table that are following an abnormal pattern of growth.
+
+
+#### 3. Volume Source
+
+The **Volume Source**: This is the mechanism that Acryl DataHub should use to determine the table volume (row count). The supported
+source types vary by the platform, but generally fall into these categories:
+
+- **Information Schema**: A system Table that is exposed by the Data Warehouse which contains live information about the Databases
+ and Tables stored inside the Data Warehouse, including their row count. It is usually efficient to check, but can in some cases be slightly delayed to update
+ once a change has been made to a table.
+
+- **Query**: A `COUNT(*)` query is used to retrieve the latest row count for a table, with optional SQL filters applied (depending on platform).
+ This can be less efficient to check depending on the size of the table. This approach is more portable, as it does not involve
+ system warehouse tables, it is also easily portable across Data Warehouse and Data Lake providers.
+
+- **DataHub Dataset Profile**: The DataHub Dataset Profile aspect is used to retrieve the latest row count information for a table.
+ Using this option avoids contacting your data platform, and instead uses the DataHub Dataset Profile metadata to evaluate Volume Assertions.
+ Note if you have not configured an ingestion source through DataHub, then this may be the only option available.
+
+Volume Assertions also have an off switch: they can be started or stopped at any time with the click of button.
+
+
+## Creating a Volume Assertion
+
+### Prerequisites
+
+1. **Permissions**: To create or delete Volume Assertions for a specific entity on DataHub, you'll need to be granted the
+ `Edit Assertions` and `Edit Monitors` privileges for the entity. This is granted to Entity owners by default.
+
+2. **Data Platform Connection**: In order to create a Volume Assertion, you'll need to have an **Ingestion Source** configured to your
+ Data Platform: Snowflake, BigQuery, or Redshift under the **Integrations** tab.
+
+Once these are in place, you're ready to create your Volume Assertions!
+
+### Steps
+
+1. Navigate to the Table that to monitor for volume
+2. Click the **Validations** tab
+
+
+  +
+
+
+3. Click **+ Create Assertion**
+
+
+ 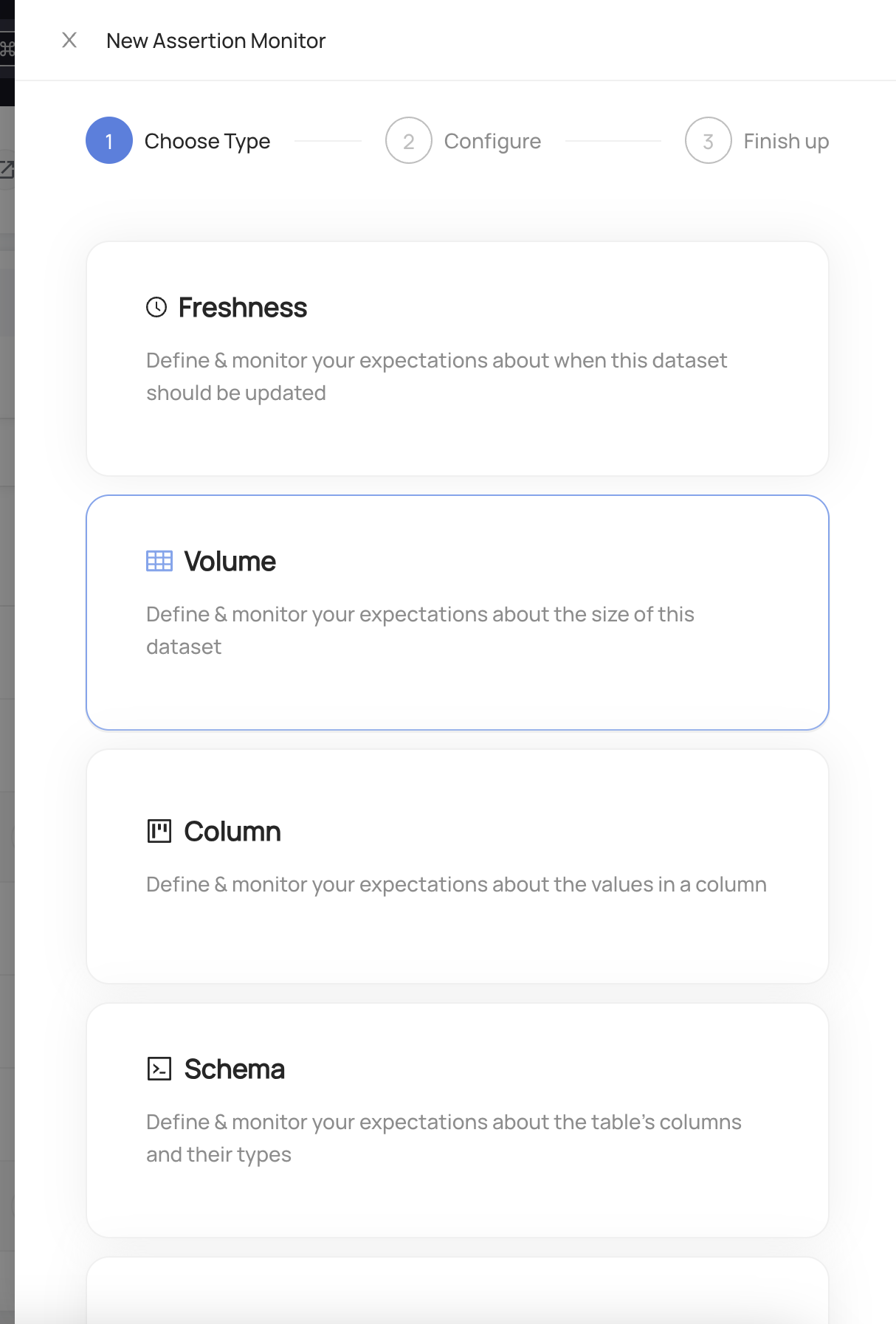 +
+
+
+4. Choose **Volume**
+
+5. Configure the evaluation **schedule**. This is the frequency at which the assertion will be evaluated to produce a pass or fail result, and the times
+ when the table volume will be checked.
+
+6. Configure the evaluation **condition type**. This determines the cases in which the new assertion will fail when it is evaluated.
+
+
+ 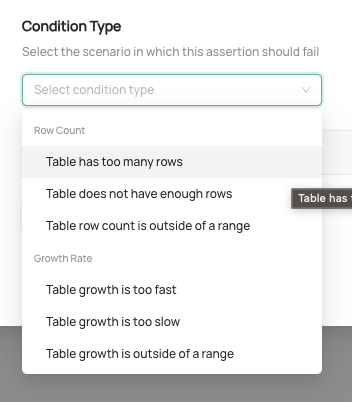 +
+
+
+7. (Optional) Click **Advanced** to customize the volume **source**. This is the mechanism that will be used to obtain the table
+ row count metric. Each Data Platform supports different options including Information Schema, Query, and DataHub Dataset Profile.
+
+
+ 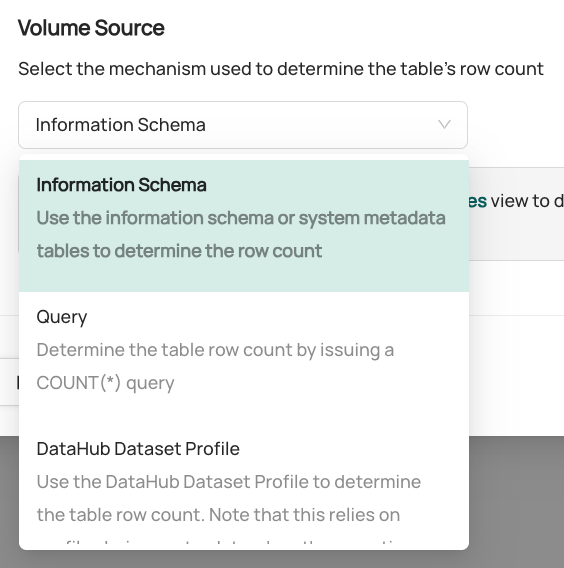 +
+
+
+- **Information Schema**: Check the Data Platform system metadata tables to determine the table row count.
+- **Query**: Issue a `COUNT(*)` query to the table to determine the row count.
+- **DataHub Dataset Profile**: Use the DataHub Dataset Profile metadata to determine the row count.
+
+8. Click **Next**
+9. Configure actions that should be taken when the Volume Assertion passes or fails
+
+
+
+
+
+- **Raise incident**: Automatically raise a new DataHub `Volume` Incident for the Table whenever the Volume Assertion is failing. This
+ may indicate that the Table is unfit for consumption. Configure Slack Notifications under **Settings** to be notified when
+ an incident is created due to an Assertion failure.
+- **Resolve incident**: Automatically resolved any incidents that were raised due to failures in this Volume Assertion. Note that
+ any other incidents will not be impacted.
+
+10. Click **Save**.
+
+And that's it! DataHub will now begin to monitor your Volume Assertion for the table.
+
+To view the time of the next Volume Assertion evaluation, simply click **Volume** and then click on your
+new Assertion:
+
+
+  +
+
+
+Once your assertion has run, you will begin to see Success or Failure status for the Table
+
+
+ 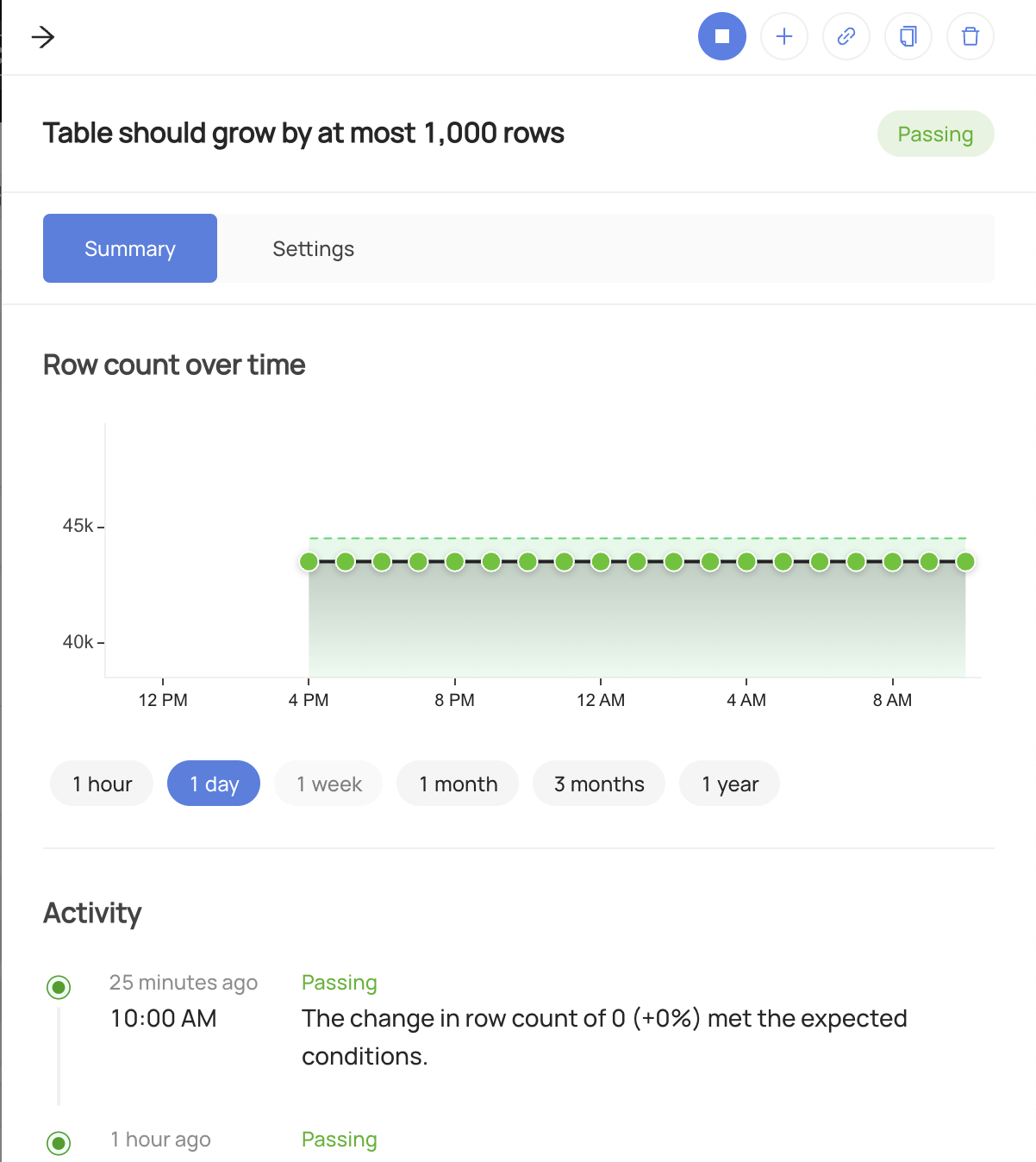 +
+
+
+
+## Stopping a Volume Assertion
+
+In order to temporarily stop the evaluation of a Volume Assertion:
+
+1. Navigate to the **Validations** tab of the Table with the assertion
+2. Click **Volume** to open the Volume Assertions list
+3. Click the three-dot menu on the right side of the assertion you want to disable
+4. Click **Stop**
+
+
+  +
+
+
+To resume the Volume Assertion, simply click **Turn On**.
+
+
+  +
+
+
+
+## Smart Assertions ⚡
+
+As part of the **Acryl Observe** module, Acryl DataHub also provides **Smart Assertions** out of the box. These are
+dynamic, AI-powered Volume Assertions that you can use to monitor the volume of important warehouse Tables, without
+requiring any manual setup.
+
+If Acryl DataHub is able to detect a pattern in the volume of a Snowflake, Redshift, or BigQuery Table, you'll find
+a recommended Smart Assertion under the `Validations` tab on the Table profile page:
+
+
+ 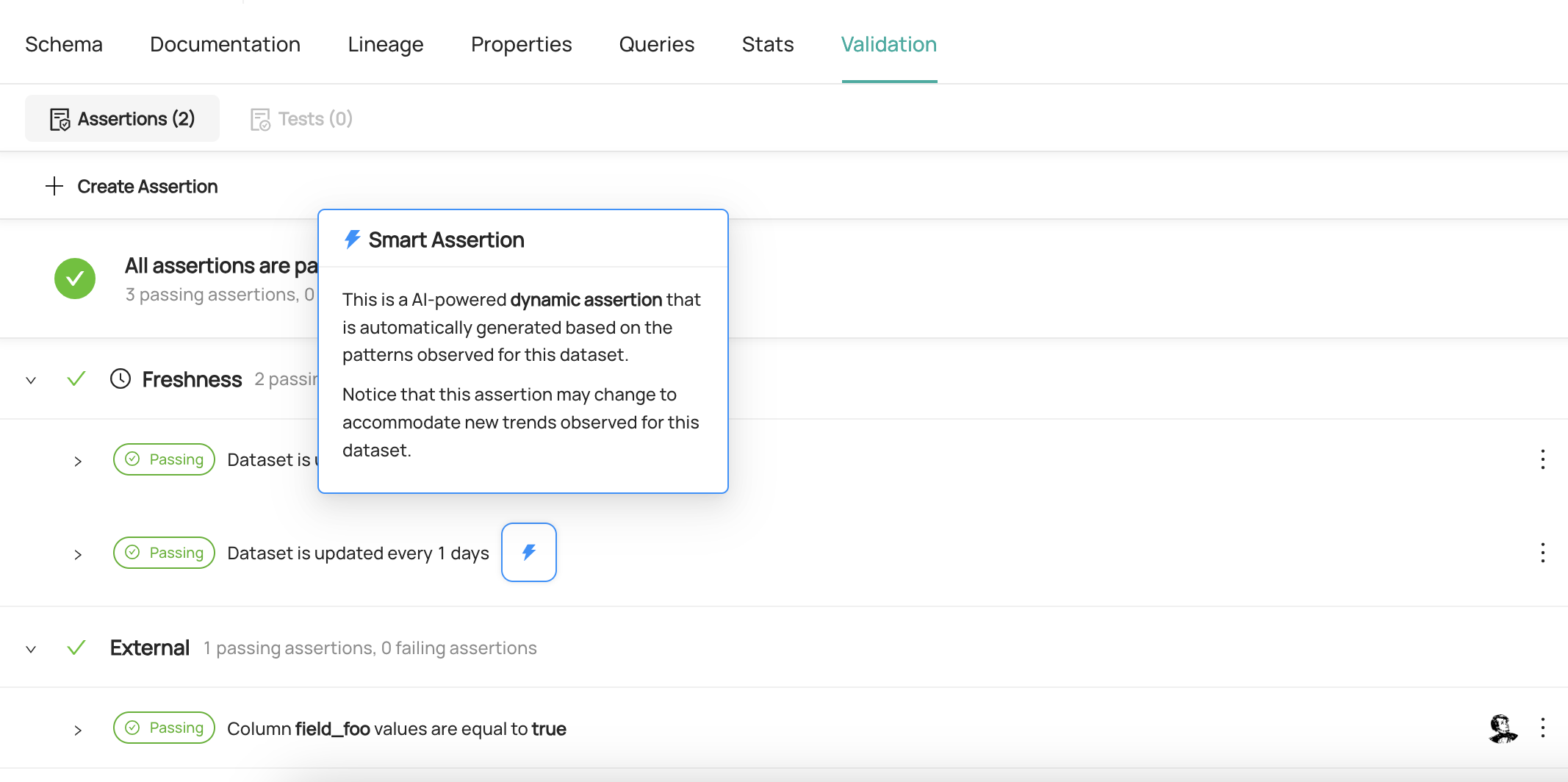 +
+
+
+In order to enable it, simply click **Turn On**. From this point forward, the Smart Assertion will check for changes on a cadence
+based on the Table history.
+
+Don't need it anymore? Smart Assertions can just as easily be turned off by clicking the three-dot "more" button and then **Stop**.
+
+
+## Creating Volume Assertions via API
+
+Under the hood, Acryl DataHub implements Volume Assertion Monitoring using two "entity" concepts:
+
+- **Assertion**: The specific expectation for volume, e.g. "The table was changed int the past 7 hours"
+ or "The table is changed on a schedule of every day by 8am". This is the "what".
+
+- **Monitor**: The process responsible for evaluating the Assertion on a given evaluation schedule and using specific
+ mechanisms. This is the "how".
+
+Note that to create or delete Assertions and Monitors for a specific entity on DataHub, you'll need the
+`Edit Assertions` and `Edit Monitors` privileges for it.
+
+#### GraphQL
+
+In order to create a Volume Assertion that is being monitored on a specific **Evaluation Schedule**, you'll need to use 2
+GraphQL mutation queries to create a Volume Assertion entity and create an Assertion Monitor entity responsible for evaluating it.
+
+Start by creating the Volume Assertion entity using the `createVolumeAssertion` query and hang on to the 'urn' field of the Assertion entity
+you get back. Then continue by creating a Monitor entity using the `createAssertionMonitor`.
+
+##### Examples
+
+To create a Volume Assertion Entity that checks whether a table has been updated in the past 8 hours:
+
+```json
+mutation createVolumeAssertion {
+ createVolumeAssertion(
+ input: {
+ entityUrn: "",
+ type: ROW_COUNT_TOTAL,
+ rowCountTotal: {
+ operator: BETWEEN,
+ parameters: {
+ minValue: {
+ "value": 10,
+ "type": NUMBER
+ },
+ maxValue: {
+ "value": 20,
+ "type": NUMBER
+ }
+ }
+ }
+ }
+ ) {
+ urn
+}
+}
+```
+
+To create an assertion that specifies that the row count total should always fall between 10 and 20.
+
+The supported volume assertion types are `ROW_COUNT_TOTAL` and `ROW_COUNT_CHANGE`. Other (e.g. incrementing segment) types are not yet supported.
+The supported operator types are `GREATER_THAN`, `GREATER_THAN_OR_EQUAL_TO`, `LESS_THAN`, `LESS_THAN_OR_EQUAL_TO`, and `BETWEEN` (requires minValue, maxValue).
+The supported parameter types are `NUMBER`.
+
+To create an Assertion Monitor Entity that evaluates the volume assertion every 8 hours using the Information Schema:
+
+```json
+mutation createAssertionMonitor {
+ createAssertionMonitor(
+ input: {
+ entityUrn: "",
+ assertionUrn: "",
+ schedule: {
+ cron: "0 */8 * * *",
+ timezone: "America/Los_Angeles"
+ },
+ parameters: {
+ type: DATASET_VOLUME,
+ datasetVolumeParameters: {
+ sourceType: INFORMATION_SCHEMA,
+ }
+ }
+ }
+ ) {
+ urn
+ }
+}
+```
+
+This entity defines _when_ to run the check (Using CRON format - every 8th hour) and _how_ to run the check (using the Information Schema).
+
+After creating the monitor, the new assertion will start to be evaluated every 8 hours in your selected timezone.
+
+You can delete assertions along with their monitors using GraphQL mutations: `deleteAssertion` and `deleteMonitor`.
+
+### Tips
+
+:::info
+**Authorization**
+
+Remember to always provide a DataHub Personal Access Token when calling the GraphQL API. To do so, just add the 'Authorization' header as follows:
+
+```
+Authorization: Bearer
+```
+
+**Exploring GraphQL API**
+
+Also, remember that you can play with an interactive version of the Acryl GraphQL API at `https://your-account-id.acryl.io/api/graphiql`
+:::
diff --git a/docs/managed-datahub/operator-guide/setting-up-remote-ingestion-executor-on-aws.md b/docs/managed-datahub/operator-guide/setting-up-remote-ingestion-executor-on-aws.md
index d389ec97d0550..b8fb0ea9e80f1 100644
--- a/docs/managed-datahub/operator-guide/setting-up-remote-ingestion-executor-on-aws.md
+++ b/docs/managed-datahub/operator-guide/setting-up-remote-ingestion-executor-on-aws.md
@@ -17,11 +17,19 @@ Acryl DataHub comes packaged with an Acryl-managed ingestion executor, which is
For example, if an ingestion source is not publicly accessible via the internet, e.g. hosted privately within a specific AWS account, then the Acryl executor will be unable to extract metadata from it.
-.png)
+
+
+ .png) +
+
+
To accommodate these cases, Acryl supports configuring a remote ingestion executor which can be deployed inside of your AWS account. This setup allows you to continue leveraging the Acryl DataHub console to create, schedule, and run metadata ingestion, all while retaining network and credential isolation.
-.png)
+
+
+ .png) +
+
+
## Deploying a Remote Ingestion Executor
1. **Provide AWS Account Id**: Provide Acryl Team with the id of the AWS in which the remote executor will be hosted. This will be used to grant access to private Acryl containers and create a unique SQS queue which your remote agent will subscribe to. The account id can be provided to your Acryl representative via Email or [One Time Secret](https://onetimesecret.com/).
@@ -40,23 +48,39 @@ To accommodate these cases, Acryl supports configuring a remote ingestion execut
Note that the only external secret provider that is currently supported is AWS Secrets Manager.
-
-
+
+ 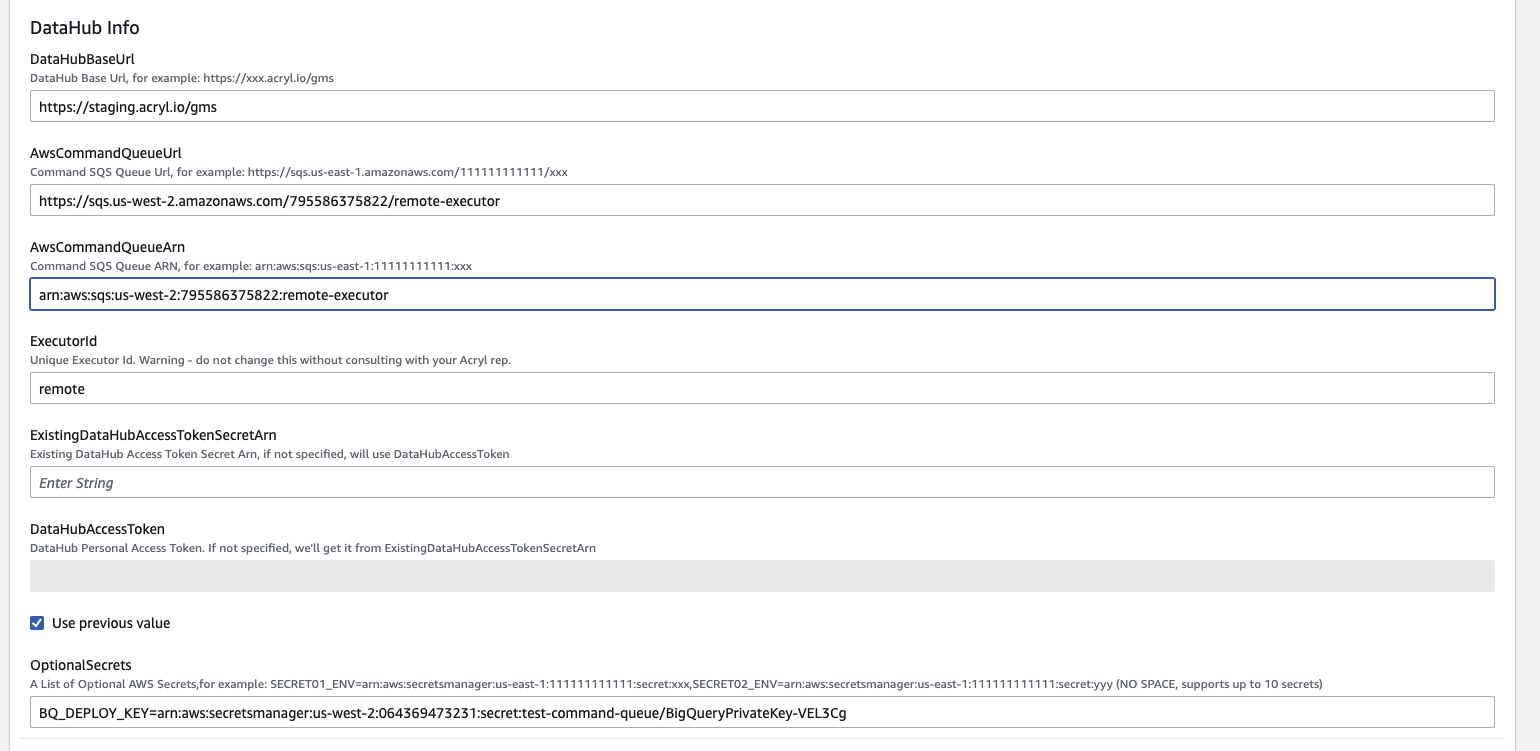 +
+
+
+
+
+
+ 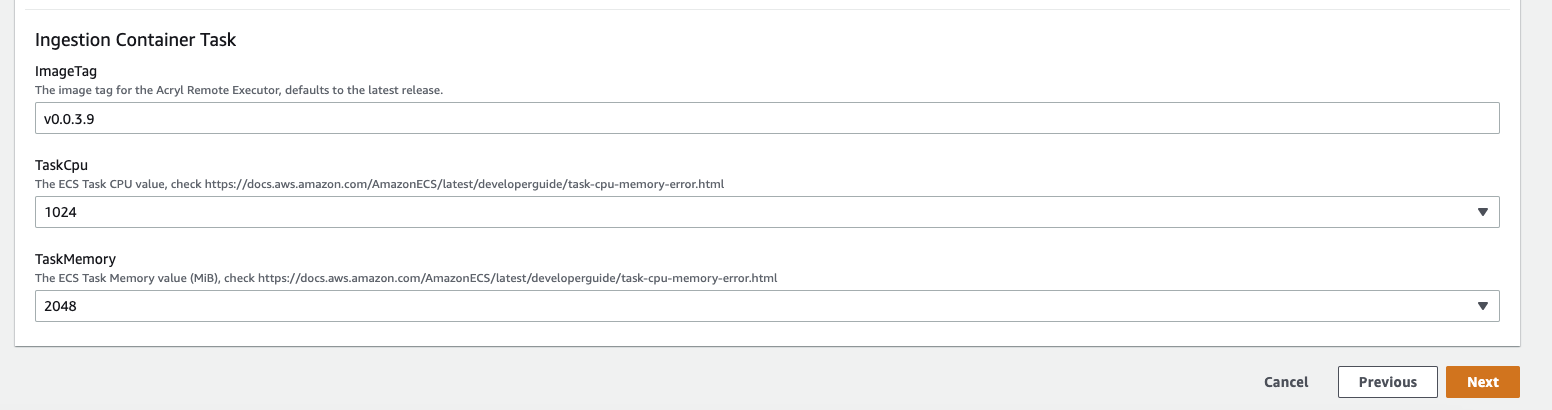 +
+
+
3. **Test the Executor:** To test your remote executor:
1. Create a new Ingestion Source by clicking '**Create new Source**' the '**Ingestion**' tab of the DataHub console. Configure your Ingestion Recipe as though you were running it from inside of your environment.
2. When working with "secret" fields (passwords, keys, etc), you can refer to any "self-managed" secrets by name: `${SECRET_NAME}:`
- 
+
+
+ 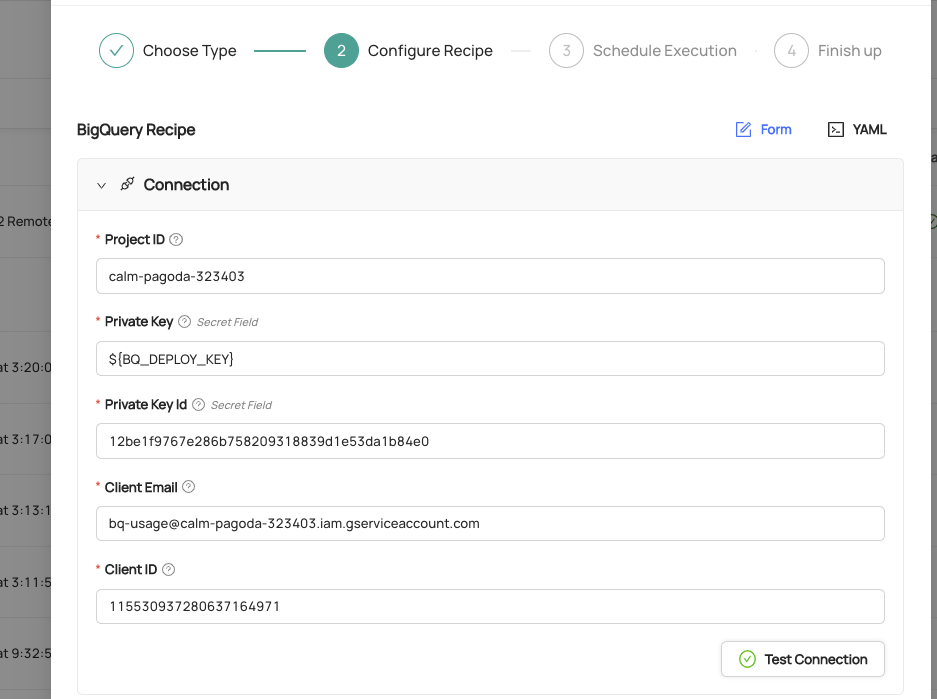 +
+
+
3. In the 'Finish Up' step, click '**Advanced'**.
4. Update the '**Executor Id**' form field to be '**remote**'. This indicates that you'd like to use the remote executor.
5. Click '**Done**'.
Now, simple click '**Execute**' to test out the remote executor. If your remote executor is configured properly, you should promptly see the ingestion task state change to 'Running'.
-
+
+
+ 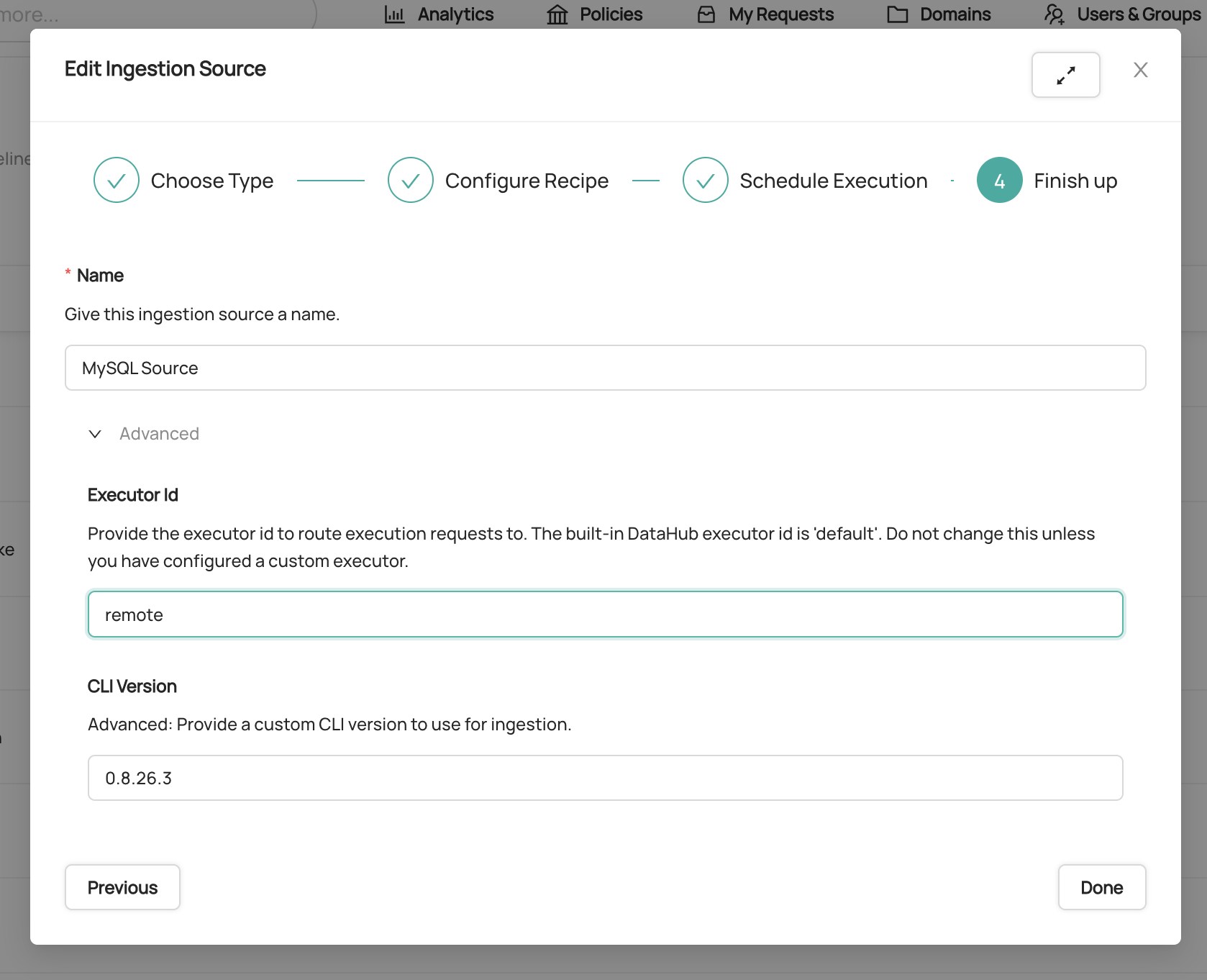 +
+
+
## Updating a Remote Ingestion Executor
In order to update the executor, ie. to deploy a new container version, you'll need to update the CloudFormation Stack to re-deploy the CloudFormation template with a new set of parameters.
### Steps - AWS Console
@@ -66,7 +90,11 @@ In order to update the executor, ie. to deploy a new container version, you'll n
4. Select **Replace Current Template**
5. Select **Upload a template file**
6. Upload a copy of the Acryl Remote Executor [CloudFormation Template](https://raw.githubusercontent.com/acryldata/datahub-cloudformation/master/Ingestion/templates/python.ecs.template.yaml)
-
+
+
+ 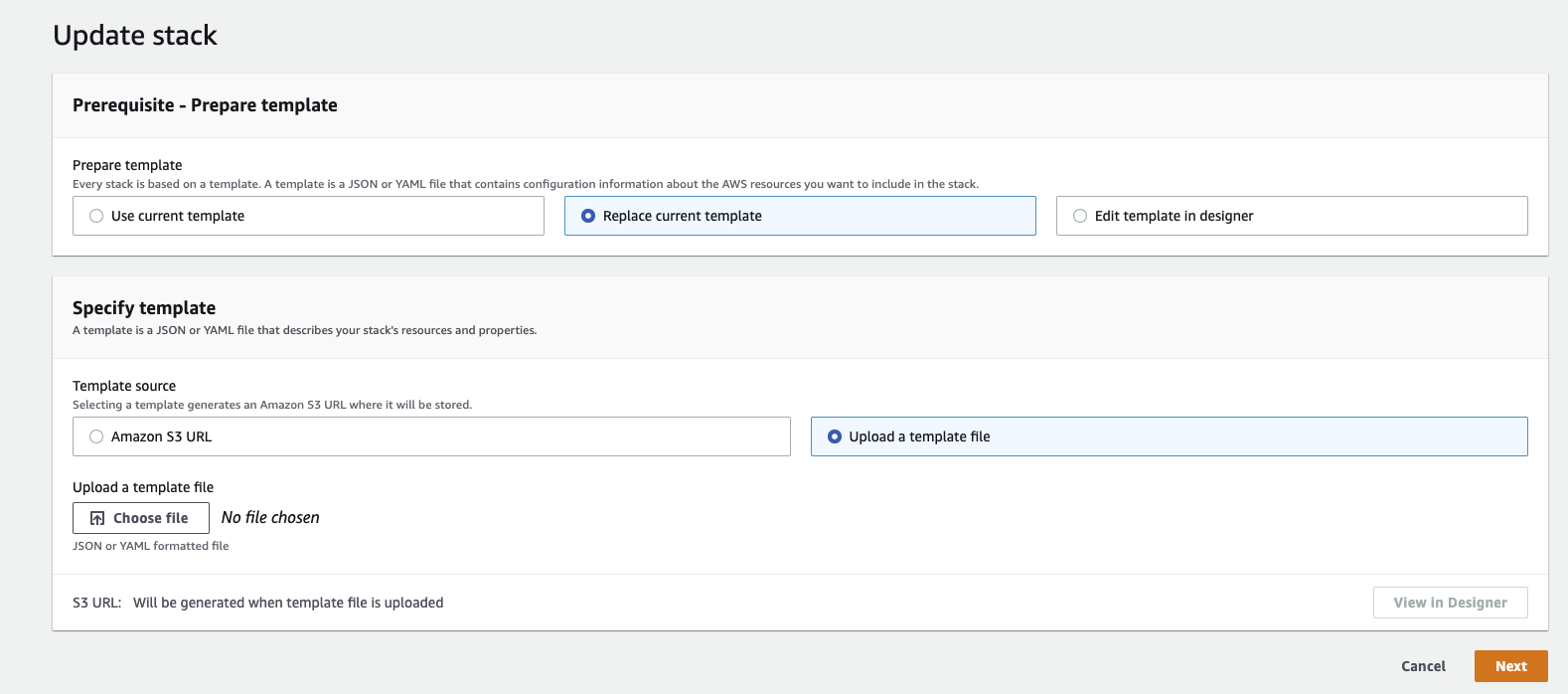 +
+
+
7. Click **Next**
8. Change parameters based on your modifications (e.g. ImageTag, etc)
9. Click **Next**
diff --git a/docs/modeling/extending-the-metadata-model.md b/docs/modeling/extending-the-metadata-model.md
index 32951ab2e41eb..98f70f6d933e4 100644
--- a/docs/modeling/extending-the-metadata-model.md
+++ b/docs/modeling/extending-the-metadata-model.md
@@ -11,7 +11,11 @@ these two concepts prior to making changes.
## To fork or not to fork?
An important question that will arise once you've decided to extend the metadata model is whether you need to fork the main repo or not. Use the diagram below to understand how to make this decision.
-
+
+
+ 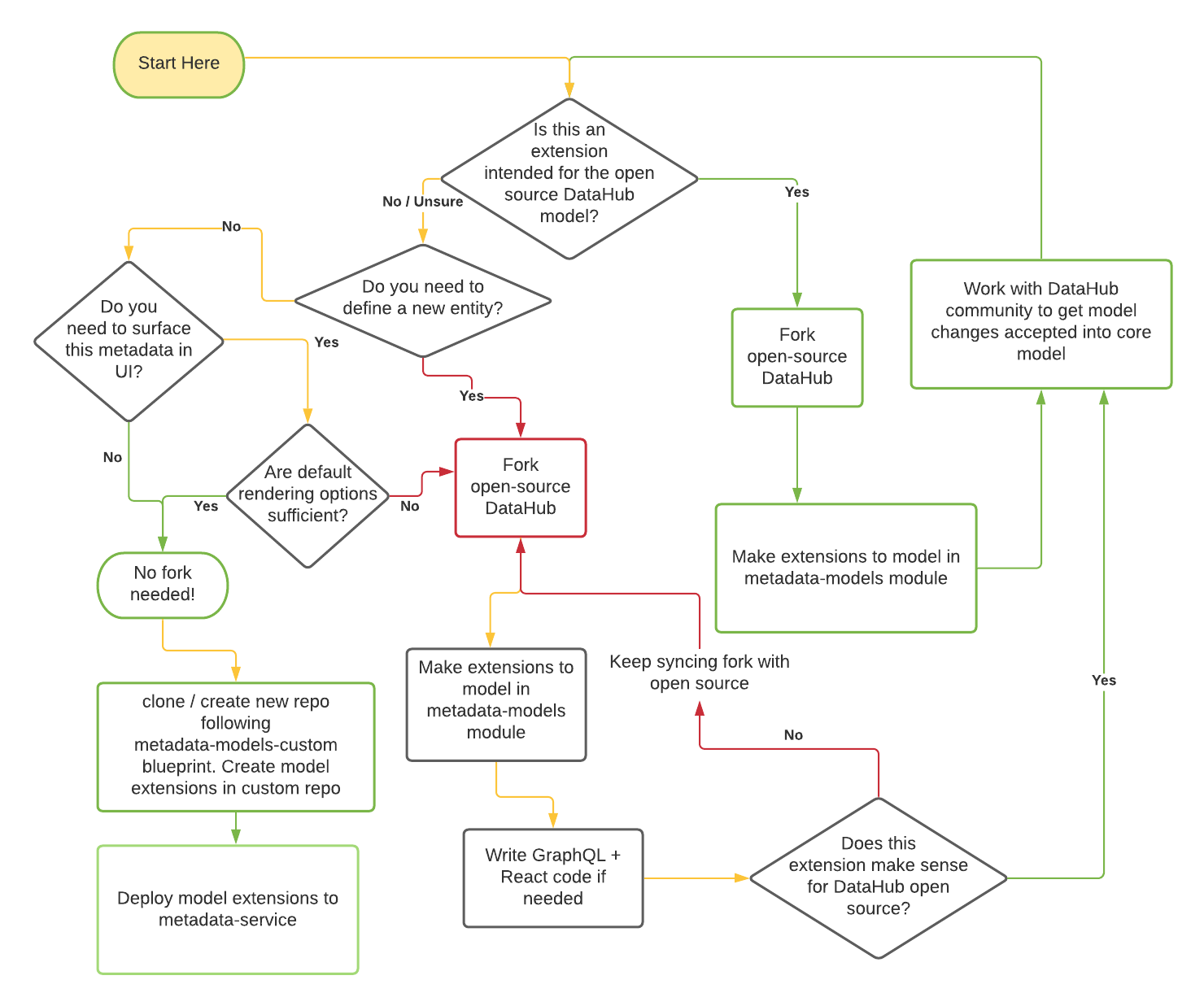 +
+
+
The green lines represent pathways that will lead to lesser friction for you to maintain your code long term. The red lines represent higher risk of conflicts in the future. We are working hard to move the majority of model extension use-cases to no-code / low-code pathways to ensure that you can extend the core metadata model without having to maintain a custom fork of DataHub.
@@ -323,7 +327,7 @@ It takes the following parameters:
annotations. To customize the set of analyzers used to index a certain field, you must add a new field type and define
the set of mappings to be applied in the MappingsBuilder.
- Thus far, we have implemented 10 fieldTypes:
+ Thus far, we have implemented 11 fieldTypes:
1. *KEYWORD* - Short text fields that only support exact matches, often used only for filtering
@@ -332,20 +336,25 @@ It takes the following parameters:
3. *TEXT_PARTIAL* - Text fields delimited by spaces/slashes/periods with partial matching support. Note, partial
matching is expensive, so this field type should not be applied to fields with long values (like description)
- 4. *BROWSE_PATH* - Field type for browse paths. Applies specific mappings for slash delimited paths.
+ 4. *WORD_GRAM* - Text fields delimited by spaces, slashes, periods, dashes, or underscores with partial matching AND
+ word gram support. That is, the text will be split by the delimiters and can be matched with delimited queries
+ matching two, three, or four length tokens in addition to single tokens. As with partial match, this type is
+ expensive, so should not be applied to fields with long values such as description.
+
+ 5. *BROWSE_PATH* - Field type for browse paths. Applies specific mappings for slash delimited paths.
- 5. *URN* - Urn fields where each sub-component inside the urn is indexed. For instance, for a data platform urn like
+ 6. *URN* - Urn fields where each sub-component inside the urn is indexed. For instance, for a data platform urn like
"urn:li:dataplatform:kafka", it will index the platform name "kafka" and ignore the common components
- 6. *URN_PARTIAL* - Urn fields where each sub-component inside the urn is indexed with partial matching support.
+ 7. *URN_PARTIAL* - Urn fields where each sub-component inside the urn is indexed with partial matching support.
- 7. *BOOLEAN* - Boolean fields used for filtering.
+ 8. *BOOLEAN* - Boolean fields used for filtering.
- 8. *COUNT* - Count fields used for filtering.
+ 9. *COUNT* - Count fields used for filtering.
- 9. *DATETIME* - Datetime fields used to represent timestamps.
+ 10. *DATETIME* - Datetime fields used to represent timestamps.
- 10. *OBJECT* - Each property in an object will become an extra column in Elasticsearch and can be referenced as
+ 11. *OBJECT* - Each property in an object will become an extra column in Elasticsearch and can be referenced as
`field.property` in queries. You should be careful to not use it on objects with many properties as it can cause a
mapping explosion in Elasticsearch.
diff --git a/docs/modeling/metadata-model.md b/docs/modeling/metadata-model.md
index 704fce1412329..037c9c7108a6e 100644
--- a/docs/modeling/metadata-model.md
+++ b/docs/modeling/metadata-model.md
@@ -30,7 +30,11 @@ Conceptually, metadata is modeled using the following abstractions
Here is an example graph consisting of 3 types of entity (CorpUser, Chart, Dashboard), 2 types of relationship (OwnedBy, Contains), and 3 types of metadata aspect (Ownership, ChartInfo, and DashboardInfo).
-
+
+
+ 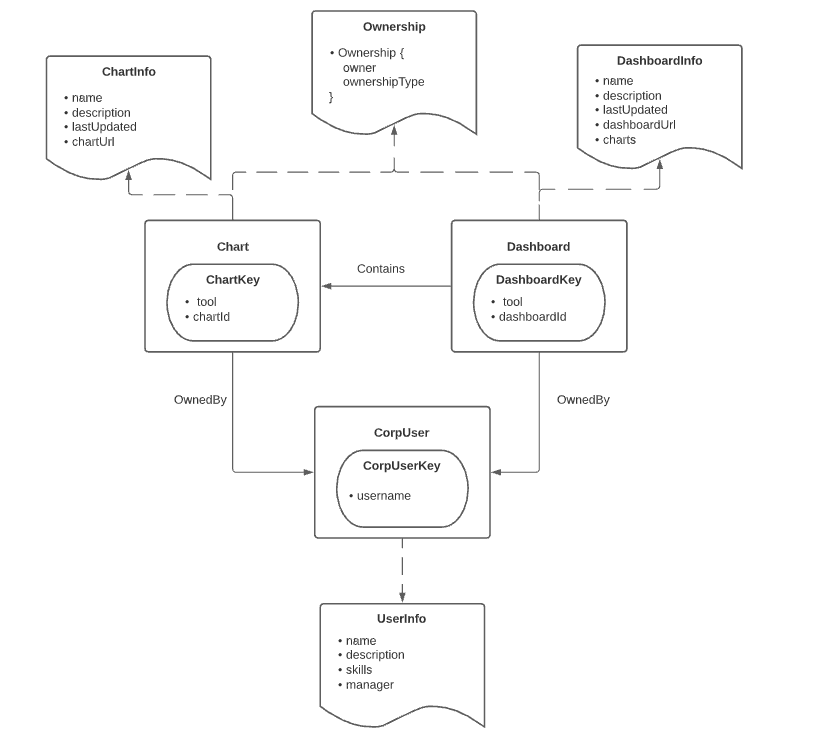 +
+
+
## The Core Entities
@@ -73,7 +77,11 @@ to the YAML configuration, instead of creating new Snapshot / Aspect files.
## Exploring DataHub's Metadata Model
To explore the current DataHub metadata model, you can inspect this high-level picture that shows the different entities and edges between them showing the relationships between them.
-
+
+
+ 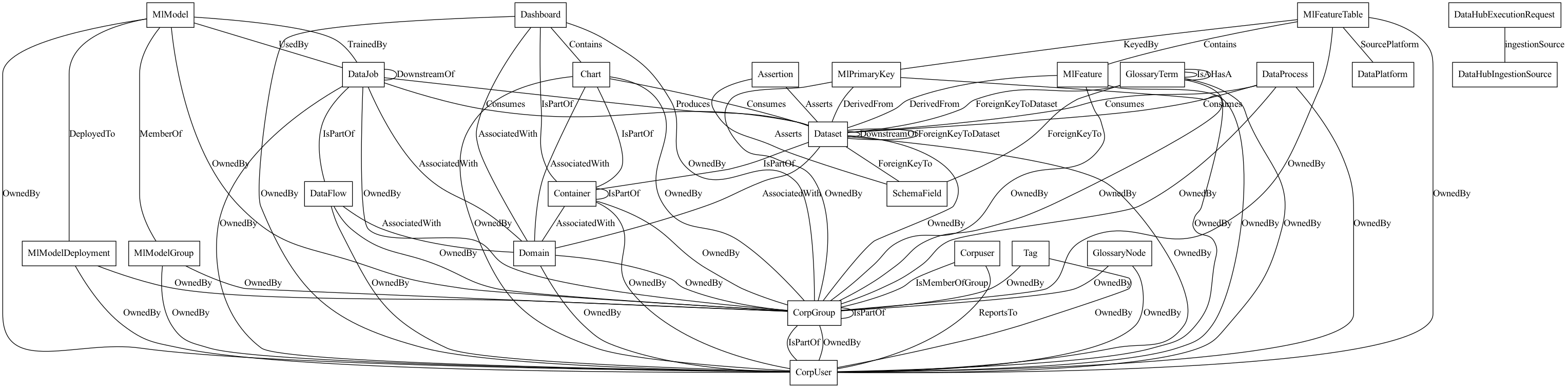 +
+
+
To navigate the aspect model for specific entities and explore relationships using the `foreign-key` concept, you can view them in our demo environment or navigate the auto-generated docs in the **Metadata Modeling/Entities** section on the left.
diff --git a/docs/platform-instances.md b/docs/platform-instances.md
index c6bfe3315de98..0f4515aedae54 100644
--- a/docs/platform-instances.md
+++ b/docs/platform-instances.md
@@ -1,44 +1,48 @@
-# Working With Platform Instances
-
-DataHub's metadata model for Datasets supports a three-part key currently:
-- Data Platform (e.g. urn:li:dataPlatform:mysql)
-- Name (e.g. db.schema.name)
-- Env or Fabric (e.g. DEV, PROD, etc.)
-
-This naming scheme unfortunately does not allow for easy representation of the multiplicity of platforms (or technologies) that might be deployed at an organization within the same environment or fabric. For example, an organization might have multiple Redshift instances in Production and would want to see all the data assets located in those instances inside the DataHub metadata repository.
-
-As part of the `v0.8.24+` releases, we are unlocking the first phase of supporting Platform Instances in the metadata model. This is done via two main additions:
-- The `dataPlatformInstance` aspect that has been added to Datasets which allows datasets to be associated to an instance of a platform
-- Enhancements to all ingestion sources that allow them to attach a platform instance to the recipe that changes the generated urns to go from `urn:li:dataset:(urn:li:dataPlatform:,,ENV)` format to `urn:li:dataset:(urn:li:dataPlatform:,,ENV)` format. Sources that produce lineage to datasets in other platforms (e.g. Looker, Superset etc) also have specific configuration additions that allow the recipe author to specify the mapping between a platform and the instance name that it should be mapped to.
-
-
-
-## Naming Platform Instances
-
-When configuring a platform instance, choose an instance name that is understandable and will be stable for the foreseeable future. e.g. `core_warehouse` or `finance_redshift` are allowed names, as are pure guids like `a37dc708-c512-4fe4-9829-401cd60ed789`. Remember that whatever instance name you choose, you will need to specify it in more than one recipe to ensure that the identifiers produced by different sources will line up.
-
-## Enabling Platform Instances
-
-Read the Ingestion source specific guides for how to enable platform instances in each of them.
-The general pattern is to add an additional optional configuration parameter called `platform_instance`.
-
-e.g. here is how you would configure a recipe to ingest a mysql instance that you want to call `core_finance`
-```yaml
-source:
- type: mysql
- config:
- # Coordinates
- host_port: localhost:3306
- platform_instance: core_finance
- database: dbname
-
- # Credentials
- username: root
- password: example
-
-sink:
- # sink configs
-```
-
-
-##
+# Working With Platform Instances
+
+DataHub's metadata model for Datasets supports a three-part key currently:
+- Data Platform (e.g. urn:li:dataPlatform:mysql)
+- Name (e.g. db.schema.name)
+- Env or Fabric (e.g. DEV, PROD, etc.)
+
+This naming scheme unfortunately does not allow for easy representation of the multiplicity of platforms (or technologies) that might be deployed at an organization within the same environment or fabric. For example, an organization might have multiple Redshift instances in Production and would want to see all the data assets located in those instances inside the DataHub metadata repository.
+
+As part of the `v0.8.24+` releases, we are unlocking the first phase of supporting Platform Instances in the metadata model. This is done via two main additions:
+- The `dataPlatformInstance` aspect that has been added to Datasets which allows datasets to be associated to an instance of a platform
+- Enhancements to all ingestion sources that allow them to attach a platform instance to the recipe that changes the generated urns to go from `urn:li:dataset:(urn:li:dataPlatform:,,ENV)` format to `urn:li:dataset:(urn:li:dataPlatform:,,ENV)` format. Sources that produce lineage to datasets in other platforms (e.g. Looker, Superset etc) also have specific configuration additions that allow the recipe author to specify the mapping between a platform and the instance name that it should be mapped to.
+
+
+
+ 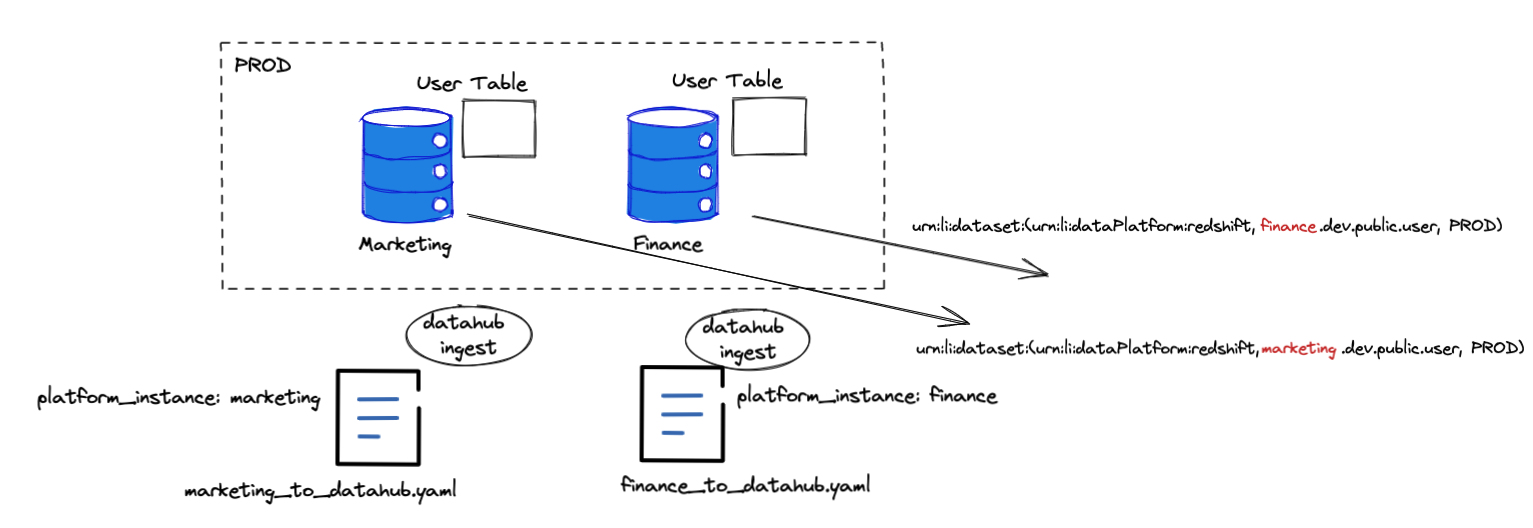 +
+
+
+
+## Naming Platform Instances
+
+When configuring a platform instance, choose an instance name that is understandable and will be stable for the foreseeable future. e.g. `core_warehouse` or `finance_redshift` are allowed names, as are pure guids like `a37dc708-c512-4fe4-9829-401cd60ed789`. Remember that whatever instance name you choose, you will need to specify it in more than one recipe to ensure that the identifiers produced by different sources will line up.
+
+## Enabling Platform Instances
+
+Read the Ingestion source specific guides for how to enable platform instances in each of them.
+The general pattern is to add an additional optional configuration parameter called `platform_instance`.
+
+e.g. here is how you would configure a recipe to ingest a mysql instance that you want to call `core_finance`
+```yaml
+source:
+ type: mysql
+ config:
+ # Coordinates
+ host_port: localhost:3306
+ platform_instance: core_finance
+ database: dbname
+
+ # Credentials
+ username: root
+ password: example
+
+sink:
+ # sink configs
+```
+
+
+##
diff --git a/docs/quickstart.md b/docs/quickstart.md
index b93713c4efa5c..cd91dc8d1ac84 100644
--- a/docs/quickstart.md
+++ b/docs/quickstart.md
@@ -145,6 +145,27 @@ Please refer to [Change the default user datahub in quickstart](authentication/c
We recommend deploying DataHub to production using Kubernetes. We provide helpful [Helm Charts](https://artifacthub.io/packages/helm/datahub/datahub) to help you quickly get up and running. Check out [Deploying DataHub to Kubernetes](./deploy/kubernetes.md) for a step-by-step walkthrough.
+The `quickstart` method of running DataHub is intended for local development and a quick way to experience the features that DataHub has to offer. It is not
+intended for a production environment. This recommendation is based on the following points.
+
+#### Default Credentials
+
+`quickstart` uses docker-compose configuration which includes default credentials for both DataHub, and it's underlying
+prerequisite data stores, such as MySQL. Additionally, other components are unauthenticated out of the box. This is a
+design choice to make development easier and is not best practice for a production environment.
+
+#### Exposed Ports
+
+DataHub's services, and it's backend data stores use the docker default behavior of binding to all interface addresses.
+This makes it useful for development but is not recommended in a production environment.
+
+#### Performance & Management
+
+* `quickstart` is limited by the resources available on a single host, there is no ability to scale horizontally.
+* Rollout of new versions requires downtime.
+* The configuration is largely pre-determined and not easily managed.
+* `quickstart`, by default, follows the most recent builds forcing updates to the latest released and unreleased builds.
+
## Other Common Operations
### Stopping DataHub
diff --git a/docs/schema-history.md b/docs/schema-history.md
index 9fc9ec1af52bb..120d041960186 100644
--- a/docs/schema-history.md
+++ b/docs/schema-history.md
@@ -23,20 +23,32 @@ must have the **View Entity Page** privilege, or be assigned to **any** DataHub
You can view the Schema History for a Dataset by navigating to that Dataset's Schema Tab. As long as that Dataset has more than
one version, you can view what a Dataset looked like at any given version by using the version selector.
Here's an example from DataHub's official Demo environment with the
-[Snowflake pets dataset](https://demo.datahubproject.io/dataset/urn:li:dataset:(urn:li:dataPlatform:snowflake,long_tail_companions.adoption.pets,PROD)/Schema?is_lineage_mode=false).
+Snowflake pets dataset.
+
+
+
+ 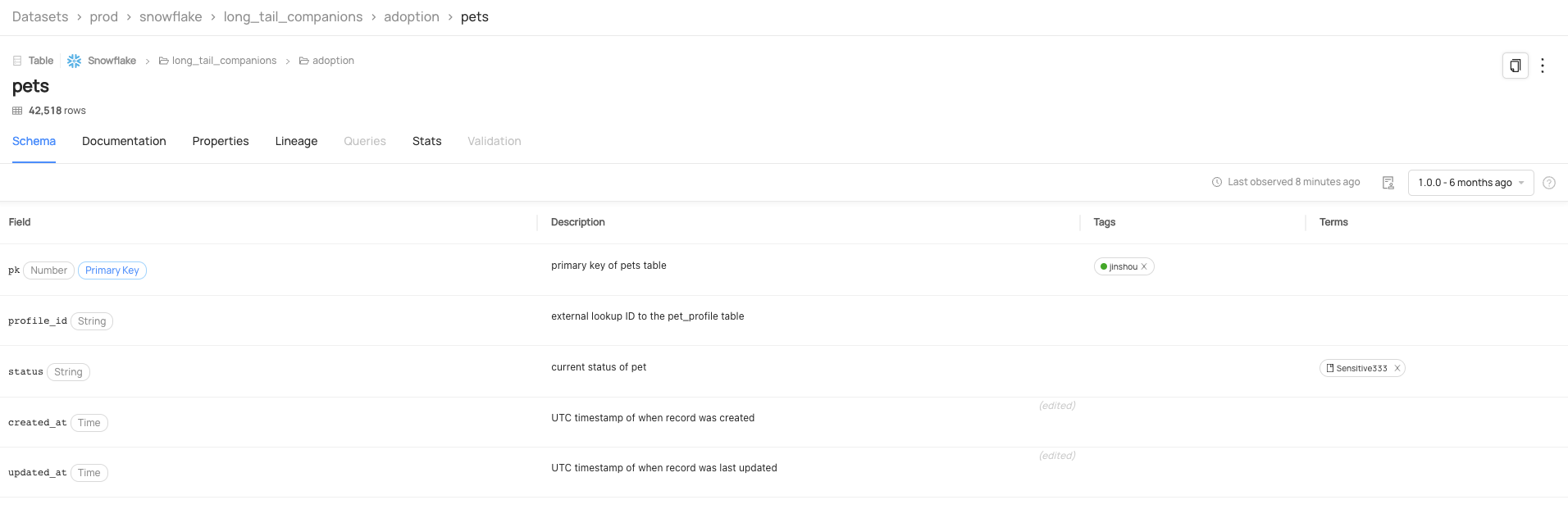 +
+
-
If you click on an older version in the selector, you'll be able to see what the schema looked like back then. Notice
the changes here to the glossary terms for the `status` field, and to the descriptions for the `created_at` and `updated_at`
fields.
-
+
+
+ 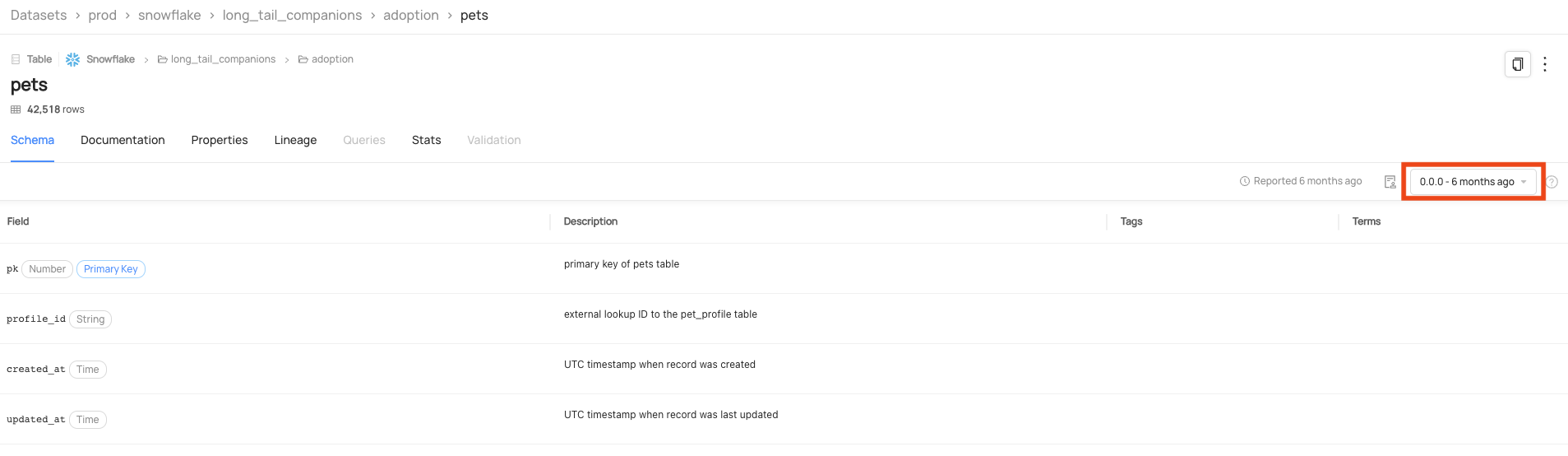 +
+
+
In addition to this, you can also toggle the Audit view that shows you when the most recent changes were made to each field.
You can active this by clicking on the Audit icon you see above the top right of the table.
-
+
+
+ 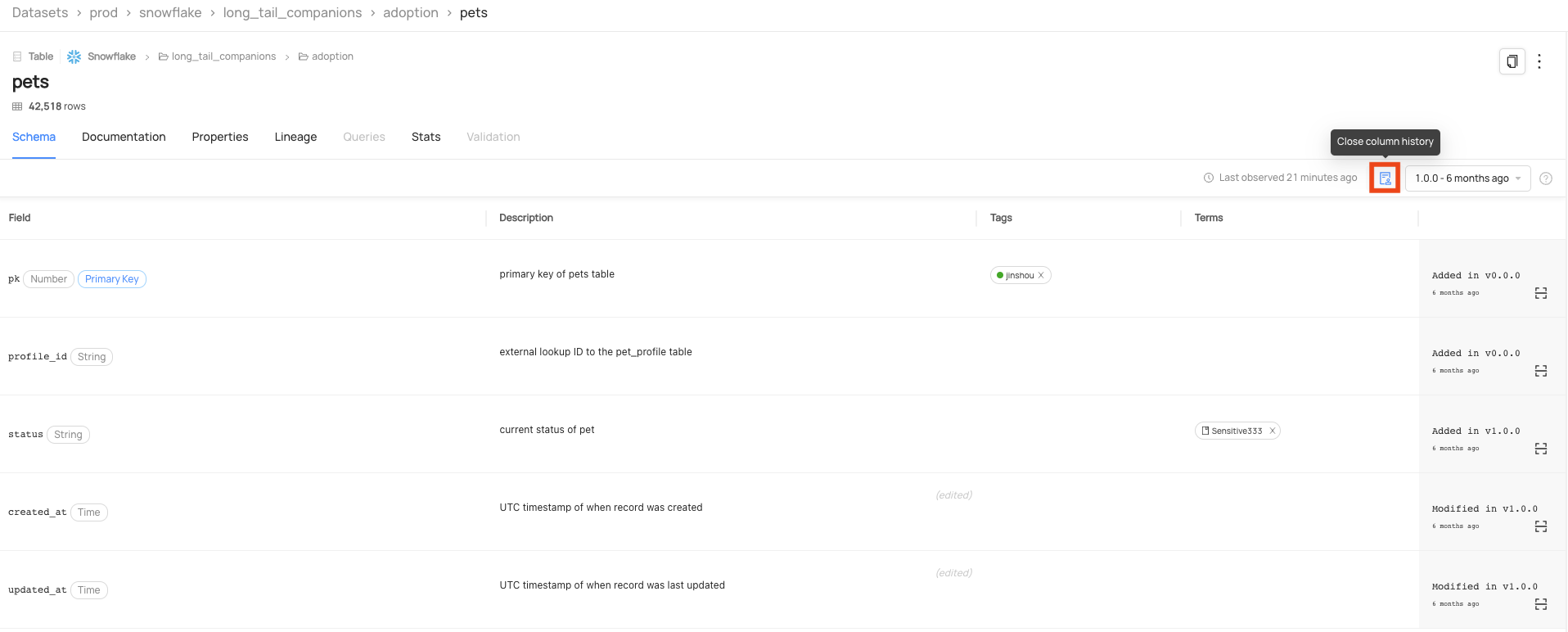 +
+
+
You can see here that some of these fields were added at the oldest dataset version, while some were added only at this latest
version. Some fields were even modified and had a type change at the latest version!
diff --git a/docs/townhall-history.md b/docs/townhall-history.md
index 1da490ca6fa69..e235a70c5d7b9 100644
--- a/docs/townhall-history.md
+++ b/docs/townhall-history.md
@@ -343,8 +343,7 @@ Agenda
- Announcements - 2 mins
- Community Updates ([video](https://youtu.be/r862MZTLAJ0?t=99)) - 10 mins
-- Use-Case: DataHub at Viasat ([slides](demo/ViasatMetadataJourney.pdf),[video](https://youtu.be/2SrDAJnzkjE)) by [Anna Kepler](https://www.linkedin.com/in/akepler) - 15 mins
-- Tech Deep Dive: GraphQL + React RFCs readout and discussion ([slides](https://docs.google.com/presentation/d/e/2PACX-1vRtnINnpi6PvFw7-5iW8PSQoT9Kdf1O_0YW7QAr1_mSdJMNftYFTVCjKL-e3fpe8t6IGkha8UpdmoOI/pub?start=false&loop=false&delayms=3000) ,[video](https://www.youtube.com/watch?v=PrBaFrb7pqA)) by [John Joyce](https://www.linkedin.com/in/john-joyce-759883aa) and [Arun Vasudevan](https://www.linkedin.com/in/arun-vasudevan-55117368/) - 15 mins
+- Use-Case: DataHub at Viasat ([slides](https://github.com/acryldata/static-assets-test/raw/master/imgs/demo/ViasatMetadataJourney.pdf),[video](https://youtu.be/2SrDAJnzkjE)) by [Anna Kepler](https://www.linkedin.com/in/akepler) - 15 mins- Tech Deep Dive: GraphQL + React RFCs readout and discussion ([slides](https://docs.google.com/presentation/d/e/2PACX-1vRtnINnpi6PvFw7-5iW8PSQoT9Kdf1O_0YW7QAr1_mSdJMNftYFTVCjKL-e3fpe8t6IGkha8UpdmoOI/pub?start=false&loop=false&delayms=3000) ,[video](https://www.youtube.com/watch?v=PrBaFrb7pqA)) by [John Joyce](https://www.linkedin.com/in/john-joyce-759883aa) and [Arun Vasudevan](https://www.linkedin.com/in/arun-vasudevan-55117368/) - 15 mins
- General Q&A from sign up sheet, slack, and participants - 15 mins
- Closing remarks - 3 mins
- General Q&A from sign up sheet, slack, and participants - 15 mins
@@ -356,8 +355,8 @@ Agenda
Agenda
- Quick intro - 5 mins
-- [Why did Grofers choose DataHub for their data catalog?](demo/Datahub_at_Grofers.pdf) by [Shubham Gupta](https://www.linkedin.com/in/shubhamg931/) - 15 minutes
-- [DataHub UI development - Part 2](demo/Town_Hall_Presentation_-_12-2020_-_UI_Development_Part_2.pdf) by [Charlie Tran](https://www.linkedin.com/in/charlie-tran/) (LinkedIn) - 20 minutes
+- [Why did Grofers choose DataHub for their data catalog?](https://github.com/acryldata/static-assets-test/raw/master/imgs/demo/Datahub_at_Grofers.pdf) by [Shubham Gupta](https://www.linkedin.com/in/shubhamg931/) - 15 minutes
+- [DataHub UI development - Part 2](https://github.com/acryldata/static-assets-test/raw/master/imgs/demo/Town_Hall_Presentation_-_12-2020_-_UI_Development_Part_2.pdf) by [Charlie Tran](https://www.linkedin.com/in/charlie-tran/) (LinkedIn) - 20 minutes
- General Q&A from sign up sheet, slack, and participants - 15 mins
- Closing remarks - 5 minutes
@@ -368,9 +367,9 @@ Agenda
Agenda
- Quick intro - 5 mins
-- [Lightning talk on Metadata use-cases at LinkedIn](demo/Metadata_Use-Cases_at_LinkedIn_-_Lightning_Talk.pdf) by [Shirshanka Das](https://www.linkedin.com/in/shirshankadas/) (LinkedIn) - 5 mins
-- [Strongly Consistent Secondary Index (SCSI) in GMA](demo/Datahub_-_Strongly_Consistent_Secondary_Indexing.pdf), an upcoming feature by [Jyoti Wadhwani](https://www.linkedin.com/in/jyotiwadhwani/) (LinkedIn) - 15 minutes
-- [DataHub UI overview](demo/DataHub-UIOverview.pdf) by [Ignacio Bona](https://www.linkedin.com/in/ignaciobona) (LinkedIn) - 20 minutes
+- [Lightning talk on Metadata use-cases at LinkedIn](https://github.com/acryldata/static-assets-test/raw/master/imgs/demo/Metadata_Use-Cases_at_LinkedIn_-_Lightning_Talk.pdf) by [Shirshanka Das](https://www.linkedin.com/in/shirshankadas/) (LinkedIn) - 5 mins
+- [Strongly Consistent Secondary Index (SCSI) in GMA](https://github.com/acryldata/static-assets-test/raw/master/imgs/demo/Datahub_-_Strongly_Consistent_Secondary_Indexing.pdf), an upcoming feature by [Jyoti Wadhwani](https://www.linkedin.com/in/jyotiwadhwani/) (LinkedIn) - 15 minutes
+- [DataHub UI overview](https://github.com/acryldata/static-assets-test/raw/master/imgs/demo/DataHub-UIOverview.pdf) by [Ignacio Bona](https://www.linkedin.com/in/ignaciobona) (LinkedIn) - 20 minutes
- General Q&A from sign up sheet, slack, and participants - 10 mins
- Closing remarks - 5 minutes
@@ -382,8 +381,8 @@ Agenda
Agenda
- Quick intro - 5 mins
-- [Data Discoverability at SpotHero](demo/Data_Discoverability_at_SpotHero.pdf) by [Maggie Hays](https://www.linkedin.com/in/maggie-hays/) (SpotHero) - 20 mins
-- [Designing the next generation of metadata events for scale](demo/Designing_the_next_generation_of_metadata_events_for_scale.pdf) by [Chris Lee](https://www.linkedin.com/in/chrisleecmu/) (LinkedIn) - 15 mins
+- [Data Discoverability at SpotHero](https://github.com/acryldata/static-assets-test/raw/master/imgs/demo/Data_Discoverability_at_SpotHero.pdf) by [Maggie Hays](https://www.linkedin.com/in/maggie-hays/) (SpotHero) - 20 mins
+- [Designing the next generation of metadata events for scale](https://github.com/acryldata/static-assets-test/raw/master/imgs/demo/Designing_the_next_generation_of_metadata_events_for_scale.pdf) by [Chris Lee](https://www.linkedin.com/in/chrisleecmu/) (LinkedIn) - 15 mins
- General Q&A from sign up sheet, slack, and participants - 15 mins
- Closing remarks - 5 mins
diff --git a/docs/ui-ingestion.md b/docs/ui-ingestion.md
index 4435f66e514f3..2ecb1e634c79f 100644
--- a/docs/ui-ingestion.md
+++ b/docs/ui-ingestion.md
@@ -14,11 +14,19 @@ This document will describe the steps required to configure, schedule, and execu
To view & manage UI-based metadata ingestion, you must have the `Manage Metadata Ingestion` & `Manage Secrets`
privileges assigned to your account. These can be granted by a [Platform Policy](authorization/policies.md).
-
+
+
+ 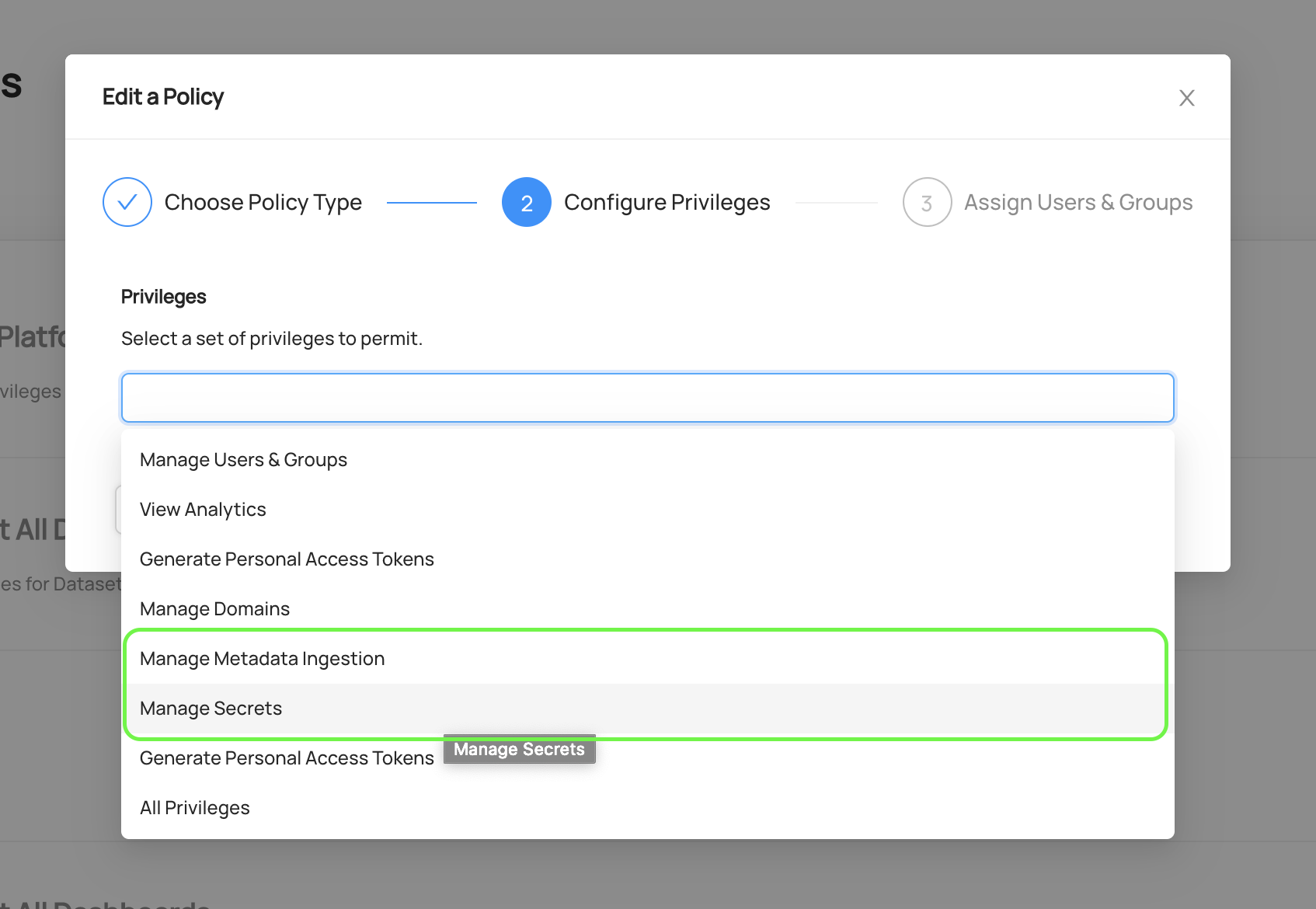 +
+
+
Once you have these privileges, you can begin to manage ingestion by navigating to the 'Ingestion' tab in DataHub.
-
+
+
+  +
+
+
On this page, you'll see a list of active **Ingestion Sources**. An Ingestion Sources is a unique source of metadata ingested
into DataHub from an external source like Snowflake, Redshift, or BigQuery.
@@ -33,7 +41,11 @@ your first **Ingestion Source**.
Before ingesting any metadata, you need to create a new Ingestion Source. Start by clicking **+ Create new source**.
-
+
+
+ 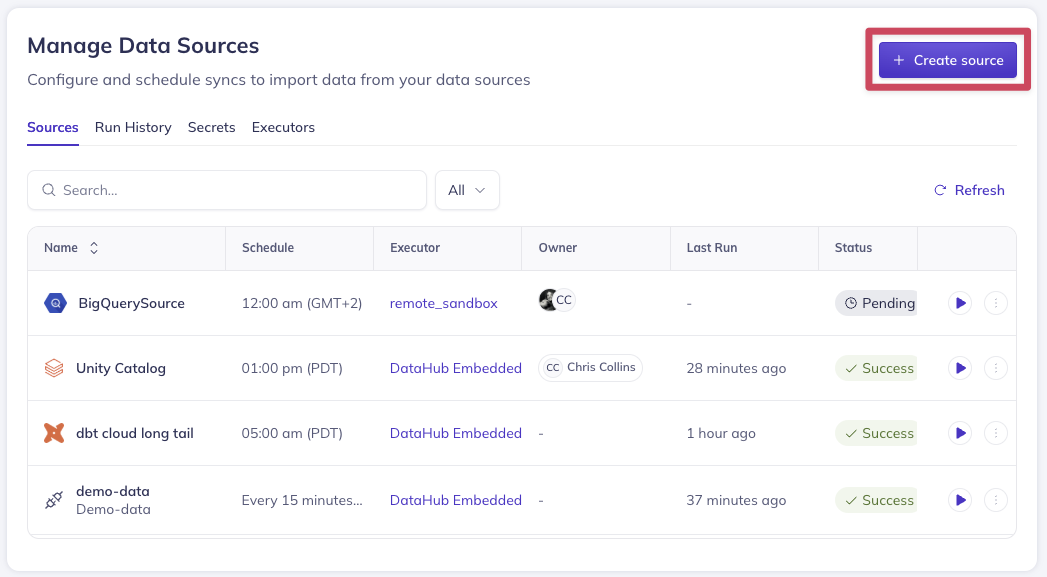 +
+
+
#### Step 1: Select a Platform Template
@@ -41,7 +53,11 @@ In the first step, select a **Recipe Template** corresponding to the source type
a variety of natively supported integrations, from Snowflake to Postgres to Kafka.
Select `Custom` to construct an ingestion recipe from scratch.
-
+
+
+ 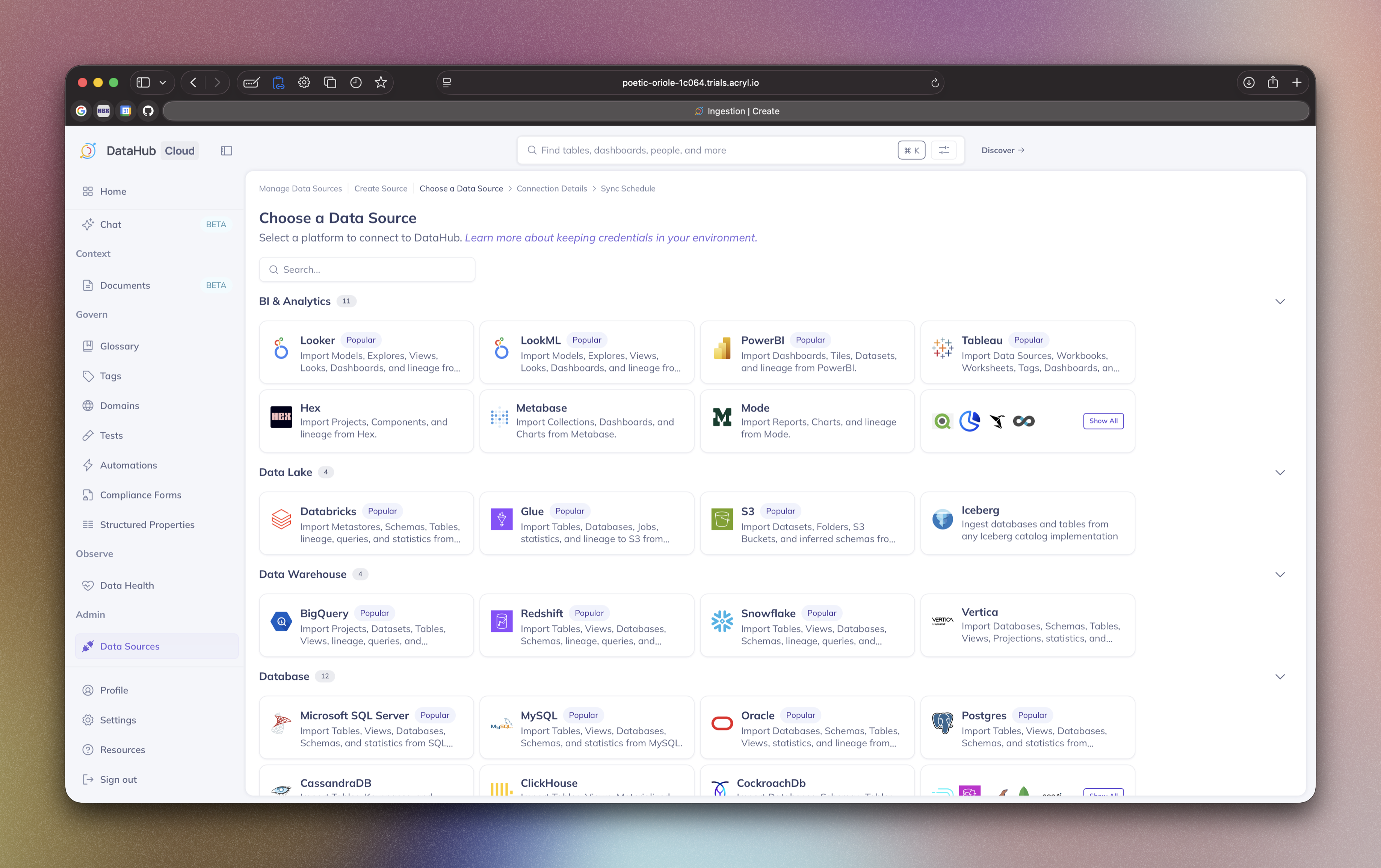 +
+
+
Next, you'll configure an ingestion **Recipe**, which defines _how_ and _what_ to extract from the source system.
@@ -68,7 +84,11 @@ used by DataHub to extract metadata from a 3rd party system. It most often consi
A sample of a full recipe configured to ingest metadata from MySQL can be found in the image below.
-
+
+
+ 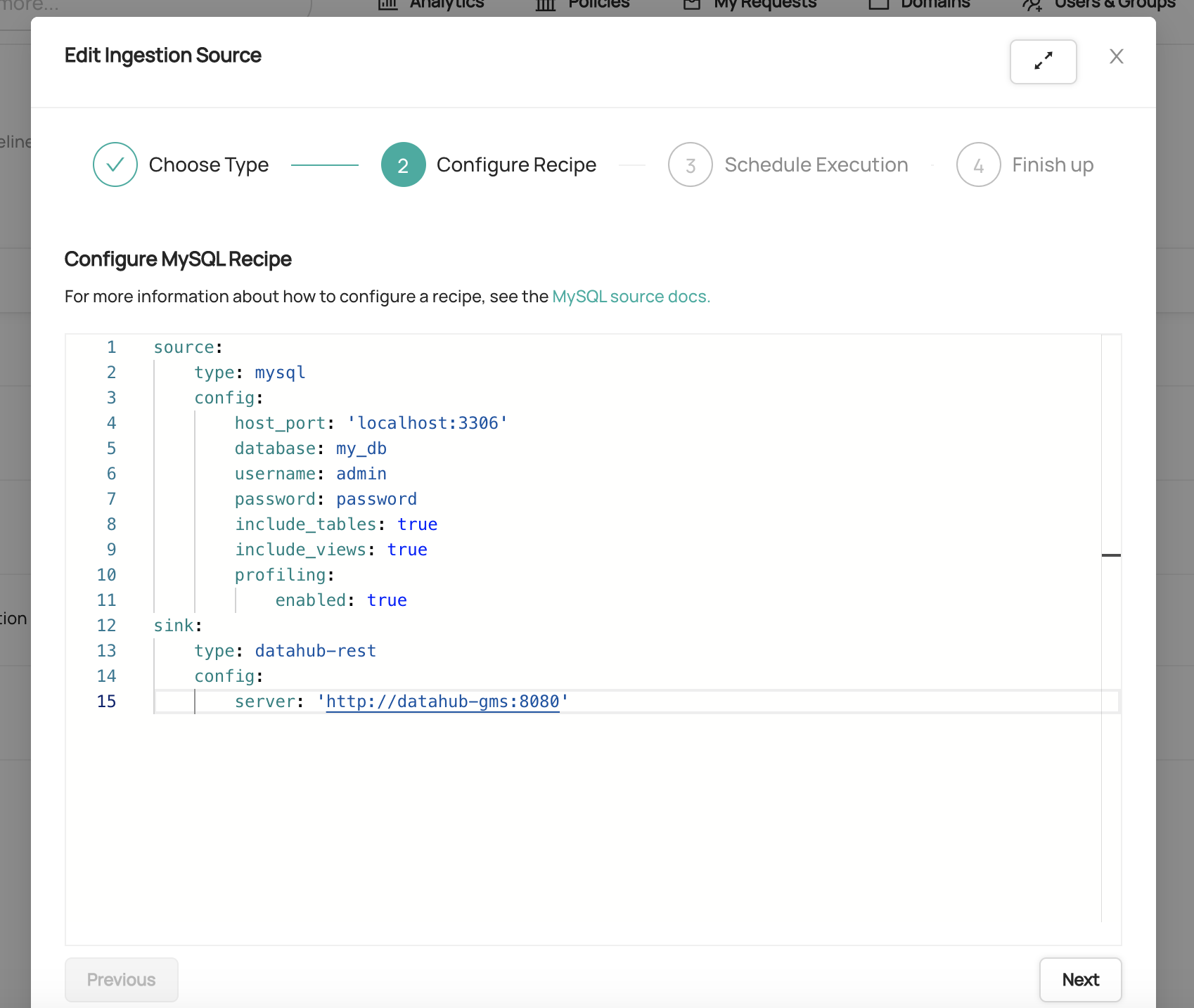 +
+
+
Detailed configuration examples & documentation for each source type can be found on the [DataHub Docs](https://datahubproject.io/docs/metadata-ingestion/) website.
@@ -80,7 +100,11 @@ that are encrypted and stored within DataHub's storage layer.
To create a secret, first navigate to the 'Secrets' tab. Then click `+ Create new secret`.
-
+
+
+ 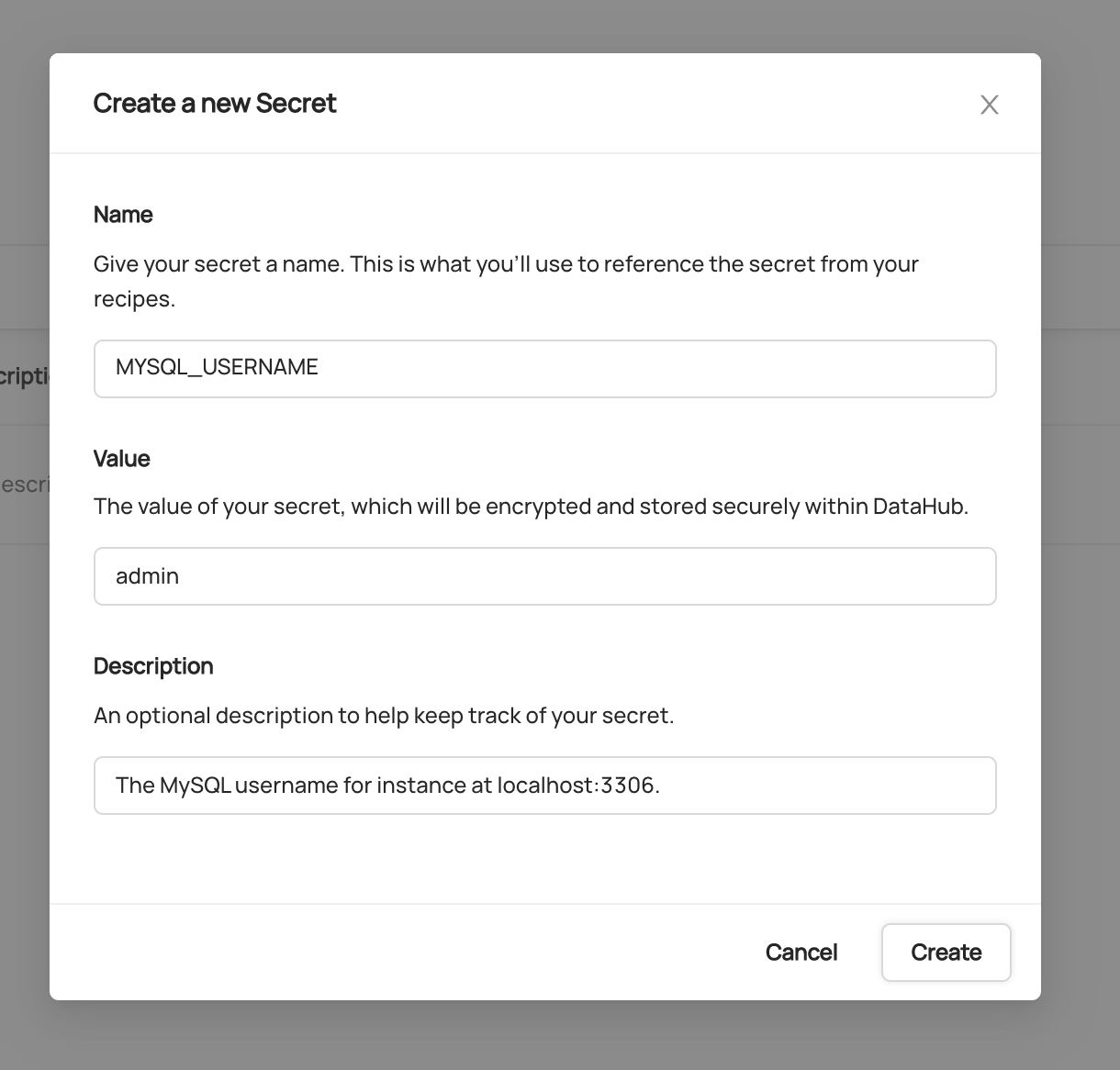 +
+
+
_Creating a Secret to store the username for a MySQL database_
@@ -123,7 +147,11 @@ Secret values are not persisted to disk beyond execution time, and are never tra
Next, you can optionally configure a schedule on which to execute your new Ingestion Source. This enables to schedule metadata extraction on a monthly, weekly, daily, or hourly cadence depending on the needs of your organization.
Schedules are defined using CRON format.
-
+
+
+ 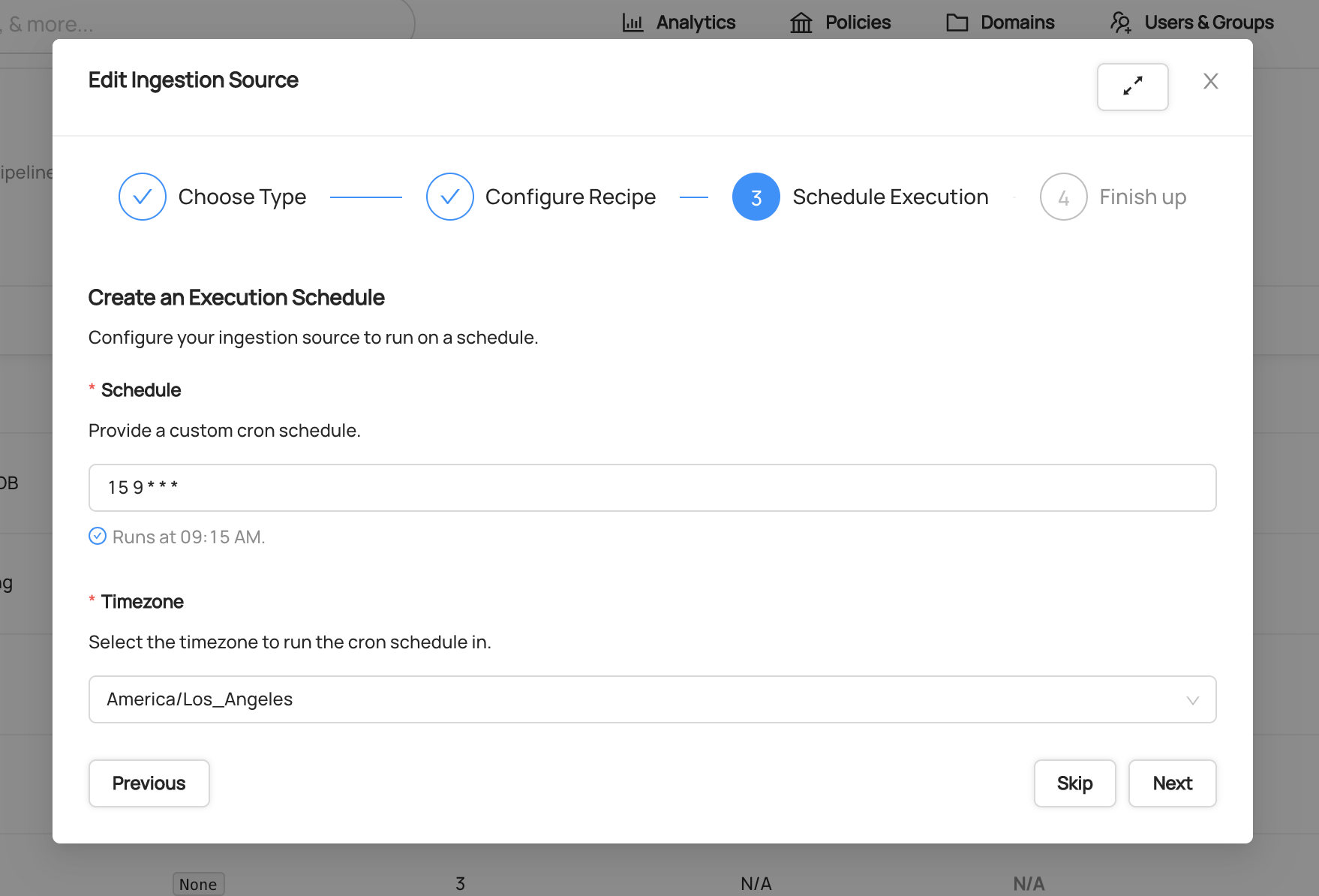 +
+
+
_An Ingestion Source that is executed at 9:15am every day, Los Angeles time_
@@ -136,7 +164,11 @@ you can always come back and change this.
Finally, give your Ingestion Source a name.
-
+
+
+  +
+
+
Once you're happy with your configurations, click 'Done' to save your changes.
@@ -149,7 +181,11 @@ with the server. However, you can override the default package version using the
To do so, simply click 'Advanced', then change the 'CLI Version' text box to contain the exact version
of the DataHub CLI you'd like to use.
-
+
+
+ 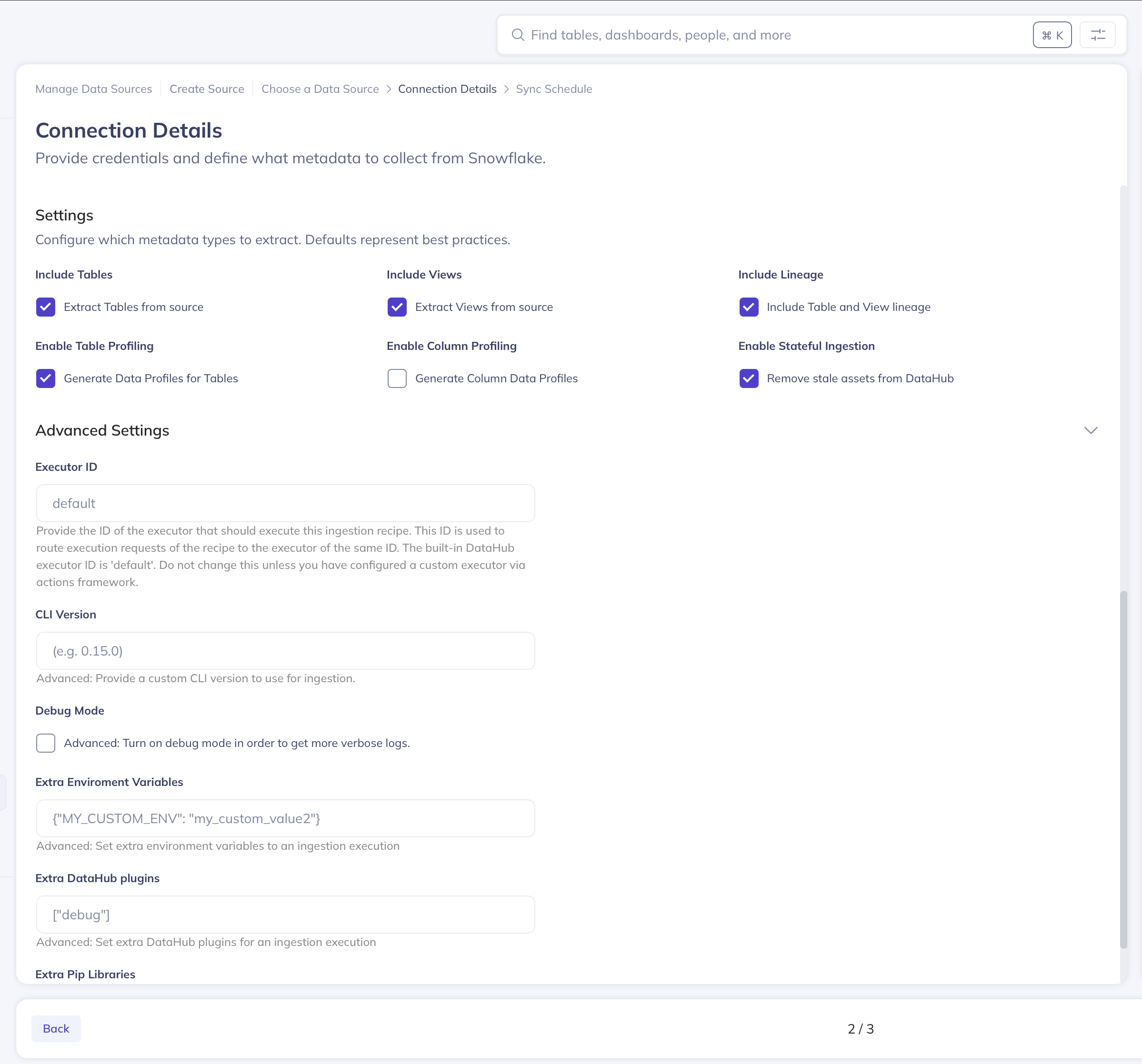 +
+
+
_Pinning the CLI version to version `0.8.23.2`_
Once you're happy with your changes, simply click 'Done' to save.
@@ -200,11 +236,19 @@ Once you've created your Ingestion Source, you can run it by clicking 'Execute'.
you should see the 'Last Status' column of the ingestion source change from `N/A` to `Running`. This
means that the request to execute ingestion has been successfully picked up by the DataHub ingestion executor.
-
+
+
+  +
+
+
If ingestion has executed successfully, you should see it's state shown in green as `Succeeded`.
-
+
+
+  +
+
+
### Cancelling an Ingestion Run
@@ -212,14 +256,22 @@ If ingestion has executed successfully, you should see it's state shown in green
If your ingestion run is hanging, there may a bug in the ingestion source, or another persistent issue like exponential timeouts. If these situations,
you can cancel ingestion by clicking **Cancel** on the problematic run.
-
+
+
+  +
+
+
Once cancelled, you can view the output of the ingestion run by clicking **Details**.
### Debugging a Failed Ingestion Run
-
+
+
+  +
+
+
A variety of things can cause an ingestion run to fail. Common reasons for failure include:
@@ -235,12 +287,20 @@ A variety of things can cause an ingestion run to fail. Common reasons for failu
4. **Authentication**: If you've enabled [Metadata Service Authentication](authentication/introducing-metadata-service-authentication.md), you'll need to provide a Personal Access Token
in your Recipe Configuration. To so this, set the 'token' field of the sink configuration to contain a Personal Access Token:
- 
+
+
+
+
+
The output of each run is captured and available to view in the UI for easier debugging. To view output logs, click **DETAILS**
on the corresponding ingestion run.
-
+
+
+ 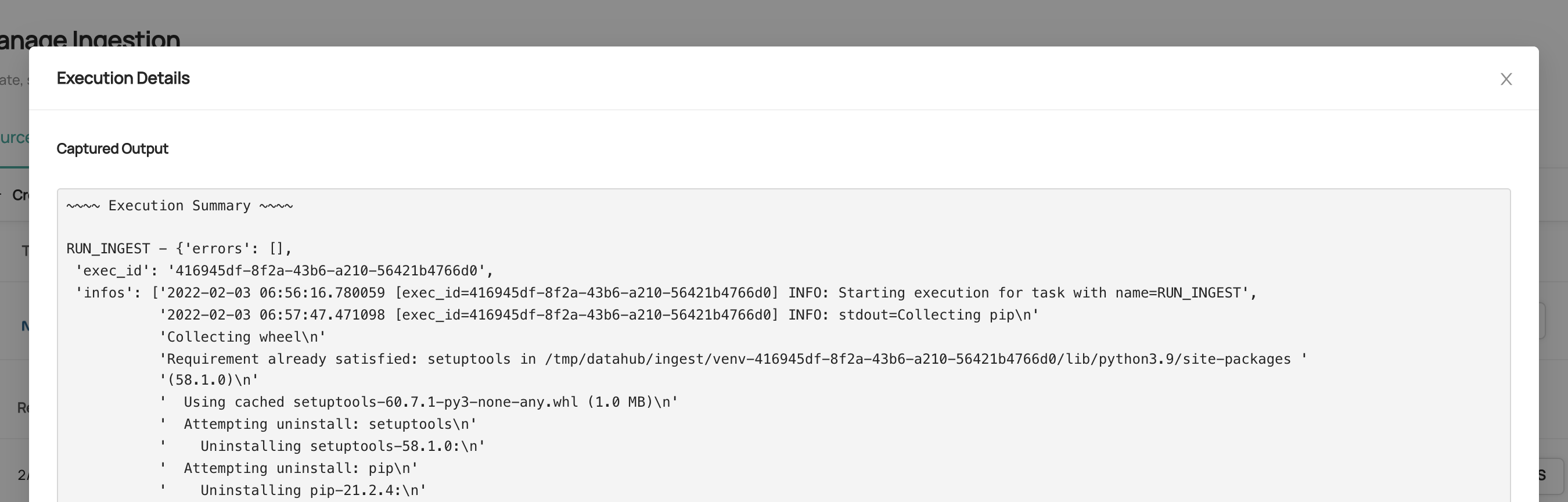 +
+
+
## FAQ
@@ -250,7 +310,11 @@ If not due to one of the reasons outlined above, this may be because the executo
to reach DataHub's backend using the default configurations. Try changing your ingestion recipe to make the `sink.config.server` variable point to the Docker
DNS name for the `datahub-gms` pod:
-
+
+
+  +
+
+
### I see 'N/A' when I try to run ingestion. What do I do?
diff --git a/docs/what/relationship.md b/docs/what/relationship.md
index 1908bbd6ce75f..dcfe093a1b124 100644
--- a/docs/what/relationship.md
+++ b/docs/what/relationship.md
@@ -2,7 +2,11 @@
A relationship is a named associate between exactly two [entities](entity.md), a source and a destination.
-
+
+
+ 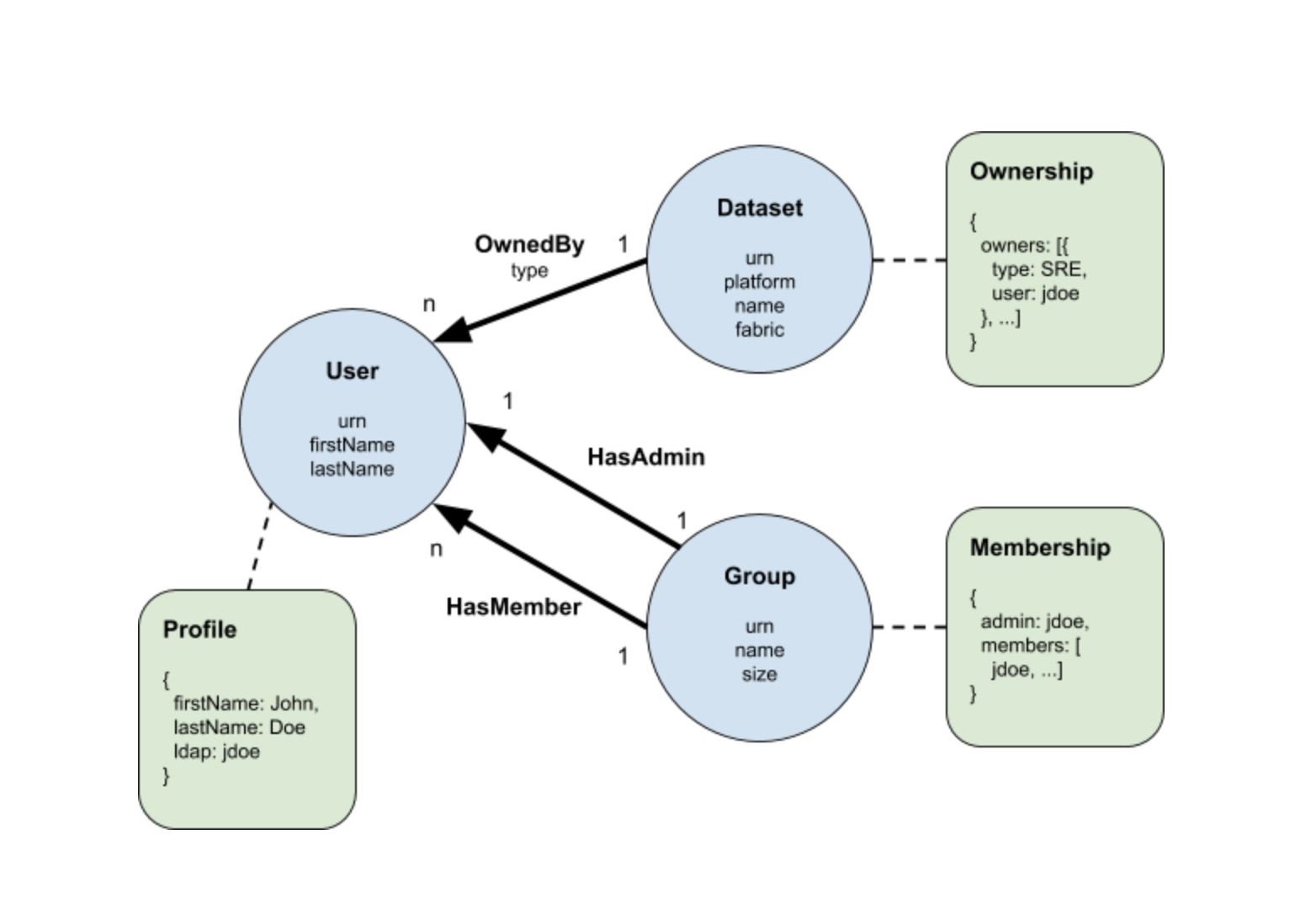 +
+
+
From the above graph, a `Group` entity can be linked to a `User` entity via a `HasMember` relationship.
Note that the name of the relationship reflects the direction, i.e. pointing from `Group` to `User`.
diff --git a/entity-registry/build.gradle b/entity-registry/build.gradle
index af742d240d1e6..3da0bf5bb4fb8 100644
--- a/entity-registry/build.gradle
+++ b/entity-registry/build.gradle
@@ -1,16 +1,17 @@
apply plugin: 'pegasus'
+apply plugin: 'java-library'
dependencies {
- compile spec.product.pegasus.data
- compile spec.product.pegasus.generator
- compile project(path: ':metadata-models')
+ implementation spec.product.pegasus.data
+ implementation spec.product.pegasus.generator
+ api project(path: ':metadata-models')
implementation externalDependency.slf4jApi
compileOnly externalDependency.lombok
- compile externalDependency.guava
- compile externalDependency.jacksonDataBind
- compile externalDependency.jacksonDataFormatYaml
- compile externalDependency.reflections
- compile externalDependency.jsonPatch
+ implementation externalDependency.guava
+ implementation externalDependency.jacksonDataBind
+ implementation externalDependency.jacksonDataFormatYaml
+ implementation externalDependency.reflections
+ implementation externalDependency.jsonPatch
constraints {
implementation(externalDependency.snakeYaml) {
because("previous versions are vulnerable to CVE-2022-25857")
@@ -19,12 +20,13 @@ dependencies {
dataModel project(':li-utils')
annotationProcessor externalDependency.lombok
- compile externalDependency.mavenArtifact
+ api externalDependency.mavenArtifact
- testCompile project(':test-models')
- testCompile externalDependency.testng
- testCompile externalDependency.mockito
- testCompile externalDependency.mockitoInline
+ testImplementation project(':test-models')
+ testImplementation project(path: ':test-models', configuration: 'testDataTemplate')
+ testImplementation externalDependency.testng
+ testImplementation externalDependency.mockito
+ testImplementation externalDependency.mockitoInline
}
compileTestJava.dependsOn tasks.getByPath(':entity-registry:custom-test-model:modelDeploy')
diff --git a/entity-registry/custom-test-model/build.gradle b/entity-registry/custom-test-model/build.gradle
index 90f50fe1f2992..778e2e42b95c4 100644
--- a/entity-registry/custom-test-model/build.gradle
+++ b/entity-registry/custom-test-model/build.gradle
@@ -23,11 +23,11 @@ if (project.hasProperty('projVersion')) {
dependencies {
- compile spec.product.pegasus.data
+ implementation spec.product.pegasus.data
// Uncomment these if you want to depend on models defined in core datahub
- //compile project(':li-utils')
+ //implementation project(':li-utils')
//dataModel project(':li-utils')
- //compile project(':metadata-models')
+ //implementation project(':metadata-models')
//dataModel project(':metadata-models')
}
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/models/SearchableFieldSpecExtractor.java b/entity-registry/src/main/java/com/linkedin/metadata/models/SearchableFieldSpecExtractor.java
index 2ffd9283ed456..8f2f42cd69cae 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/models/SearchableFieldSpecExtractor.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/models/SearchableFieldSpecExtractor.java
@@ -155,7 +155,8 @@ private void extractSearchableAnnotation(final Object annotationObj, final DataS
annotation.getBoostScore(),
annotation.getHasValuesFieldName(),
annotation.getNumValuesFieldName(),
- annotation.getWeightsPerFieldValue());
+ annotation.getWeightsPerFieldValue(),
+ annotation.getFieldNameAliases());
}
}
log.debug("Searchable annotation for field: {} : {}", schemaPathSpec, annotation);
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/models/annotation/SearchableAnnotation.java b/entity-registry/src/main/java/com/linkedin/metadata/models/annotation/SearchableAnnotation.java
index f2e65c771c6eb..d5e5044f95c23 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/models/annotation/SearchableAnnotation.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/models/annotation/SearchableAnnotation.java
@@ -4,7 +4,10 @@
import com.google.common.collect.ImmutableSet;
import com.linkedin.data.schema.DataSchema;
import com.linkedin.metadata.models.ModelValidationException;
+
+import java.util.ArrayList;
import java.util.Arrays;
+import java.util.List;
import java.util.Map;
import java.util.Optional;
import java.util.Set;
@@ -19,9 +22,10 @@
@Value
public class SearchableAnnotation {
+ public static final String FIELD_NAME_ALIASES = "fieldNameAliases";
public static final String ANNOTATION_NAME = "Searchable";
private static final Set DEFAULT_QUERY_FIELD_TYPES =
- ImmutableSet.of(FieldType.TEXT, FieldType.TEXT_PARTIAL, FieldType.URN, FieldType.URN_PARTIAL);
+ ImmutableSet.of(FieldType.TEXT, FieldType.TEXT_PARTIAL, FieldType.WORD_GRAM, FieldType.URN, FieldType.URN_PARTIAL);
// Name of the field in the search index. Defaults to the field name in the schema
String fieldName;
@@ -47,6 +51,8 @@ public class SearchableAnnotation {
Optional numValuesFieldName;
// (Optional) Weights to apply to score for a given value
Map weightsPerFieldValue;
+ // (Optional) Aliases for this given field that can be used for sorting etc.
+ List fieldNameAliases;
public enum FieldType {
KEYWORD,
@@ -59,7 +65,8 @@ public enum FieldType {
COUNT,
DATETIME,
OBJECT,
- BROWSE_PATH_V2
+ BROWSE_PATH_V2,
+ WORD_GRAM
}
@Nonnull
@@ -93,6 +100,7 @@ public static SearchableAnnotation fromPegasusAnnotationObject(@Nonnull final Ob
final Optional numValuesFieldName = AnnotationUtils.getField(map, "numValuesFieldName", String.class);
final Optional
*
* @param searchSourceBuilder {@link SearchSourceBuilder} that needs to be populated with sort order
@@ -187,13 +196,24 @@ public static void buildSortOrder(@Nonnull SearchSourceBuilder searchSourceBuild
final SortOrder esSortOrder =
(sortCriterion.getOrder() == com.linkedin.metadata.query.filter.SortOrder.ASCENDING) ? SortOrder.ASC
: SortOrder.DESC;
- searchSourceBuilder.sort(new FieldSortBuilder(sortCriterion.getField()).order(esSortOrder));
+ searchSourceBuilder.sort(new FieldSortBuilder(sortCriterion.getField()).order(esSortOrder).unmappedType(KEYWORD_TYPE));
}
if (sortCriterion == null || !sortCriterion.getField().equals(DEFAULT_SEARCH_RESULTS_SORT_BY_FIELD)) {
searchSourceBuilder.sort(new FieldSortBuilder(DEFAULT_SEARCH_RESULTS_SORT_BY_FIELD).order(SortOrder.ASC));
}
}
+ /**
+ * Populates source field of search query with the suggestions query so that we get search suggestions back.
+ * Right now we are only supporting suggestions based on the virtual _entityName field alias.
+ */
+ public static void buildNameSuggestions(@Nonnull SearchSourceBuilder searchSourceBuilder, @Nullable String textInput) {
+ SuggestionBuilder builder = SuggestBuilders.termSuggestion(ENTITY_NAME_FIELD).text(textInput);
+ SuggestBuilder suggestBuilder = new SuggestBuilder();
+ suggestBuilder.addSuggestion(NAME_SUGGESTION, builder);
+ searchSourceBuilder.suggest(suggestBuilder);
+ }
+
/**
* Escapes the Elasticsearch reserved characters in the given input string.
*
diff --git a/metadata-io/src/main/java/com/linkedin/metadata/search/utils/SearchUtils.java b/metadata-io/src/main/java/com/linkedin/metadata/search/utils/SearchUtils.java
index 35a322d37b2fd..8b56ae0beb3f1 100644
--- a/metadata-io/src/main/java/com/linkedin/metadata/search/utils/SearchUtils.java
+++ b/metadata-io/src/main/java/com/linkedin/metadata/search/utils/SearchUtils.java
@@ -78,7 +78,7 @@ public static Map getRequestMap(@Nullable Filter requestParams)
return criterionArray.stream().collect(Collectors.toMap(Criterion::getField, Criterion::getValue));
}
- static boolean isUrn(@Nonnull String value) {
+ public static boolean isUrn(@Nonnull String value) {
// TODO(https://github.com/datahub-project/datahub-gma/issues/51): This method is a bit of a hack to support searching for
// URNs that have commas in them, while also using commas a delimiter for search. We should stop supporting commas
// as delimiter, and then we can stop using this hack.
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/ESSampleDataFixture.java b/metadata-io/src/test/java/com/linkedin/metadata/ESSampleDataFixture.java
index 847029bc180eb..ef9992db1fb25 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/ESSampleDataFixture.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/ESSampleDataFixture.java
@@ -46,6 +46,7 @@
import java.util.Map;
import static com.linkedin.metadata.Constants.*;
+import static com.linkedin.metadata.ESTestConfiguration.REFRESH_INTERVAL_SECONDS;
import static org.mockito.ArgumentMatchers.anySet;
import static org.mockito.Mockito.mock;
import static org.mockito.Mockito.when;
@@ -54,6 +55,13 @@
@TestConfiguration
@Import(ESTestConfiguration.class)
public class ESSampleDataFixture {
+ /**
+ * Interested in adding more fixtures? Here's what you will need to update?
+ * 1. Create a new indexPrefix and FixtureName. Both are needed or else all fixtures will load on top of each other,
+ * overwriting each other
+ * 2. Create a new IndexConvention, IndexBuilder, and EntityClient. These are needed
+ * to index a different set of entities.
+ */
@Autowired
private ESBulkProcessor _bulkProcessor;
@@ -61,6 +69,9 @@ public class ESSampleDataFixture {
@Autowired
private RestHighLevelClient _searchClient;
+ @Autowired
+ private RestHighLevelClient _longTailSearchClient;
+
@Autowired
private SearchConfiguration _searchConfiguration;
@@ -68,24 +79,54 @@ public class ESSampleDataFixture {
private CustomSearchConfiguration _customSearchConfiguration;
@Bean(name = "sampleDataPrefix")
- protected String indexPrefix() {
+ protected String sampleDataPrefix() {
return "smpldat";
}
+ @Bean(name = "longTailPrefix")
+ protected String longTailIndexPrefix() {
+ return "lngtl";
+ }
+
@Bean(name = "sampleDataIndexConvention")
protected IndexConvention indexConvention(@Qualifier("sampleDataPrefix") String prefix) {
return new IndexConventionImpl(prefix);
}
+ @Bean(name = "longTailIndexConvention")
+ protected IndexConvention longTailIndexConvention(@Qualifier("longTailPrefix") String prefix) {
+ return new IndexConventionImpl(prefix);
+ }
+
@Bean(name = "sampleDataFixtureName")
- protected String fixtureName() {
+ protected String sampleDataFixtureName() {
return "sample_data";
}
+ @Bean(name = "longTailFixtureName")
+ protected String longTailFixtureName() {
+ return "long_tail";
+ }
+
@Bean(name = "sampleDataEntityIndexBuilders")
protected EntityIndexBuilders entityIndexBuilders(
@Qualifier("entityRegistry") EntityRegistry entityRegistry,
@Qualifier("sampleDataIndexConvention") IndexConvention indexConvention
+ ) {
+ return entityIndexBuildersHelper(entityRegistry, indexConvention);
+ }
+
+ @Bean(name = "longTailEntityIndexBuilders")
+ protected EntityIndexBuilders longTailEntityIndexBuilders(
+ @Qualifier("longTailEntityRegistry") EntityRegistry longTailEntityRegistry,
+ @Qualifier("longTailIndexConvention") IndexConvention indexConvention
+ ) {
+ return entityIndexBuildersHelper(longTailEntityRegistry, indexConvention);
+ }
+
+ protected EntityIndexBuilders entityIndexBuildersHelper(
+ EntityRegistry entityRegistry,
+ IndexConvention indexConvention
) {
GitVersion gitVersion = new GitVersion("0.0.0-test", "123456", Optional.empty());
ESIndexBuilder indexBuilder = new ESIndexBuilder(_searchClient, 1, 0, 1,
@@ -100,6 +141,23 @@ protected ElasticSearchService entitySearchService(
@Qualifier("entityRegistry") EntityRegistry entityRegistry,
@Qualifier("sampleDataEntityIndexBuilders") EntityIndexBuilders indexBuilders,
@Qualifier("sampleDataIndexConvention") IndexConvention indexConvention
+ ) throws IOException {
+ return entitySearchServiceHelper(entityRegistry, indexBuilders, indexConvention);
+ }
+
+ @Bean(name = "longTailEntitySearchService")
+ protected ElasticSearchService longTailEntitySearchService(
+ @Qualifier("longTailEntityRegistry") EntityRegistry longTailEntityRegistry,
+ @Qualifier("longTailEntityIndexBuilders") EntityIndexBuilders longTailEndexBuilders,
+ @Qualifier("longTailIndexConvention") IndexConvention longTailIndexConvention
+ ) throws IOException {
+ return entitySearchServiceHelper(longTailEntityRegistry, longTailEndexBuilders, longTailIndexConvention);
+ }
+
+ protected ElasticSearchService entitySearchServiceHelper(
+ EntityRegistry entityRegistry,
+ EntityIndexBuilders indexBuilders,
+ IndexConvention indexConvention
) throws IOException {
CustomConfiguration customConfiguration = new CustomConfiguration();
customConfiguration.setEnabled(true);
@@ -107,7 +165,7 @@ protected ElasticSearchService entitySearchService(
CustomSearchConfiguration customSearchConfiguration = customConfiguration.resolve(new YAMLMapper());
ESSearchDAO searchDAO = new ESSearchDAO(entityRegistry, _searchClient, indexConvention, false,
- ELASTICSEARCH_IMPLEMENTATION_ELASTICSEARCH, _searchConfiguration, customSearchConfiguration);
+ ELASTICSEARCH_IMPLEMENTATION_ELASTICSEARCH, _searchConfiguration, customSearchConfiguration);
ESBrowseDAO browseDAO = new ESBrowseDAO(entityRegistry, _searchClient, indexConvention, _searchConfiguration, _customSearchConfiguration);
ESWriteDAO writeDAO = new ESWriteDAO(entityRegistry, _searchClient, indexConvention, _bulkProcessor, 1);
return new ElasticSearchService(indexBuilders, searchDAO, browseDAO, writeDAO);
@@ -120,9 +178,30 @@ protected SearchService searchService(
@Qualifier("sampleDataEntitySearchService") ElasticSearchService entitySearchService,
@Qualifier("sampleDataEntityIndexBuilders") EntityIndexBuilders indexBuilders,
@Qualifier("sampleDataPrefix") String prefix,
- @Qualifier("sampleDataFixtureName") String fixtureName
+ @Qualifier("sampleDataFixtureName") String sampleDataFixtureName
) throws IOException {
+ return searchServiceHelper(entityRegistry, entitySearchService, indexBuilders, prefix, sampleDataFixtureName);
+ }
+ @Bean(name = "longTailSearchService")
+ @Nonnull
+ protected SearchService longTailSearchService(
+ @Qualifier("longTailEntityRegistry") EntityRegistry longTailEntityRegistry,
+ @Qualifier("longTailEntitySearchService") ElasticSearchService longTailEntitySearchService,
+ @Qualifier("longTailEntityIndexBuilders") EntityIndexBuilders longTailIndexBuilders,
+ @Qualifier("longTailPrefix") String longTailPrefix,
+ @Qualifier("longTailFixtureName") String longTailFixtureName
+ ) throws IOException {
+ return searchServiceHelper(longTailEntityRegistry, longTailEntitySearchService, longTailIndexBuilders, longTailPrefix, longTailFixtureName);
+ }
+
+ public SearchService searchServiceHelper(
+ EntityRegistry entityRegistry,
+ ElasticSearchService entitySearchService,
+ EntityIndexBuilders indexBuilders,
+ String prefix,
+ String fixtureName
+ ) throws IOException {
int batchSize = 100;
SearchRanker ranker = new SimpleRanker();
CacheManager cacheManager = new ConcurrentMapCacheManager();
@@ -147,6 +226,7 @@ protected SearchService searchService(
.bulkProcessor(_bulkProcessor)
.fixtureName(fixtureName)
.targetIndexPrefix(prefix)
+ .refreshIntervalSeconds(REFRESH_INTERVAL_SECONDS)
.build()
.read();
@@ -159,6 +239,24 @@ protected EntityClient entityClient(
@Qualifier("sampleDataSearchService") SearchService searchService,
@Qualifier("sampleDataEntitySearchService") ElasticSearchService entitySearchService,
@Qualifier("entityRegistry") EntityRegistry entityRegistry
+ ) {
+ return entityClientHelper(searchService, entitySearchService, entityRegistry);
+ }
+
+ @Bean(name = "longTailEntityClient")
+ @Nonnull
+ protected EntityClient longTailEntityClient(
+ @Qualifier("sampleDataSearchService") SearchService searchService,
+ @Qualifier("sampleDataEntitySearchService") ElasticSearchService entitySearchService,
+ @Qualifier("longTailEntityRegistry") EntityRegistry longTailEntityRegistry
+ ) {
+ return entityClientHelper(searchService, entitySearchService, longTailEntityRegistry);
+ }
+
+ private EntityClient entityClientHelper(
+ SearchService searchService,
+ ElasticSearchService entitySearchService,
+ EntityRegistry entityRegistry
) {
CachingEntitySearchService cachingEntitySearchService = new CachingEntitySearchService(
new ConcurrentMapCacheManager(),
@@ -173,7 +271,7 @@ protected EntityClient entityClient(
preProcessHooks.setUiEnabled(true);
return new JavaEntityClient(
new EntityServiceImpl(mockAspectDao, null, entityRegistry, true, null,
- preProcessHooks),
+ preProcessHooks),
null,
entitySearchService,
cachingEntitySearchService,
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/ESSearchLineageFixture.java b/metadata-io/src/test/java/com/linkedin/metadata/ESSearchLineageFixture.java
index ee3be08d82a1f..ade7435bf6652 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/ESSearchLineageFixture.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/ESSearchLineageFixture.java
@@ -48,6 +48,7 @@
import java.util.Map;
import static com.linkedin.metadata.Constants.*;
+import static com.linkedin.metadata.ESTestConfiguration.REFRESH_INTERVAL_SECONDS;
@TestConfiguration
@@ -154,6 +155,7 @@ protected LineageSearchService lineageSearchService(
.bulkProcessor(_bulkProcessor)
.fixtureName(fixtureName)
.targetIndexPrefix(prefix)
+ .refreshIntervalSeconds(REFRESH_INTERVAL_SECONDS)
.build()
.read();
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/ESTestConfiguration.java b/metadata-io/src/test/java/com/linkedin/metadata/ESTestConfiguration.java
index 0d7ac506599af..327447341badf 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/ESTestConfiguration.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/ESTestConfiguration.java
@@ -6,6 +6,7 @@
import com.linkedin.metadata.config.search.ExactMatchConfiguration;
import com.linkedin.metadata.config.search.PartialConfiguration;
import com.linkedin.metadata.config.search.SearchConfiguration;
+import com.linkedin.metadata.config.search.WordGramConfiguration;
import com.linkedin.metadata.config.search.custom.CustomSearchConfiguration;
import com.linkedin.metadata.models.registry.ConfigEntityRegistry;
import com.linkedin.metadata.models.registry.EntityRegistry;
@@ -35,7 +36,7 @@
@TestConfiguration
public class ESTestConfiguration {
private static final int HTTP_PORT = 9200;
- private static final int REFRESH_INTERVAL_SECONDS = 5;
+ public static final int REFRESH_INTERVAL_SECONDS = 5;
public static void syncAfterWrite(ESBulkProcessor bulkProcessor) throws InterruptedException {
bulkProcessor.flush();
@@ -55,11 +56,17 @@ public SearchConfiguration searchConfiguration() {
exactMatchConfiguration.setCaseSensitivityFactor(0.7f);
exactMatchConfiguration.setEnableStructured(true);
+ WordGramConfiguration wordGramConfiguration = new WordGramConfiguration();
+ wordGramConfiguration.setTwoGramFactor(1.2f);
+ wordGramConfiguration.setThreeGramFactor(1.5f);
+ wordGramConfiguration.setFourGramFactor(1.8f);
+
PartialConfiguration partialConfiguration = new PartialConfiguration();
partialConfiguration.setFactor(0.4f);
partialConfiguration.setUrnFactor(0.5f);
searchConfiguration.setExactMatch(exactMatchConfiguration);
+ searchConfiguration.setWordGram(wordGramConfiguration);
searchConfiguration.setPartial(partialConfiguration);
return searchConfiguration;
}
@@ -137,4 +144,10 @@ public EntityRegistry entityRegistry() throws EntityRegistryException {
return new ConfigEntityRegistry(
ESTestConfiguration.class.getClassLoader().getResourceAsStream("entity-registry.yml"));
}
+
+ @Bean(name = "longTailEntityRegistry")
+ public EntityRegistry longTailEntityRegistry() throws EntityRegistryException {
+ return new ConfigEntityRegistry(
+ ESTestConfiguration.class.getClassLoader().getResourceAsStream("entity-registry.yml"));
+ }
}
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/ESTestFixtureUtils.java b/metadata-io/src/test/java/com/linkedin/metadata/ESTestFixtureUtils.java
index 1f0b7b24397ca..914c5be9f5b09 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/ESTestFixtureUtils.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/ESTestFixtureUtils.java
@@ -15,6 +15,7 @@
import java.io.IOException;
import java.util.Set;
+import static com.linkedin.metadata.ESTestConfiguration.REFRESH_INTERVAL_SECONDS;
import static com.linkedin.metadata.ESTestUtils.environmentRestClientBuilder;
@TestConfiguration
@@ -111,6 +112,7 @@ private void reindexTestFixtureData() throws IOException {
FixtureReader reader = FixtureReader.builder()
.bulkProcessor(bulkProcessor)
.fixtureName("long_tail")
+ .refreshIntervalSeconds(REFRESH_INTERVAL_SECONDS)
.build();
reader.read();
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/ESTestUtils.java b/metadata-io/src/test/java/com/linkedin/metadata/ESTestUtils.java
index 79496888650e1..45c4c16864b07 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/ESTestUtils.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/ESTestUtils.java
@@ -77,6 +77,11 @@ public static SearchResult searchAcrossEntities(SearchService searchService, Str
100, new SearchFlags().setFulltext(true).setSkipCache(true), facets);
}
+ public static SearchResult searchAcrossCustomEntities(SearchService searchService, String query, List searchableEntities) {
+ return searchService.searchAcrossEntities(searchableEntities, query, null, null, 0,
+ 100, new SearchFlags().setFulltext(true).setSkipCache(true));
+ }
+
public static SearchResult search(SearchService searchService, String query) {
return search(searchService, SEARCHABLE_ENTITIES, query);
}
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/search/LineageSearchServiceTest.java b/metadata-io/src/test/java/com/linkedin/metadata/search/LineageSearchServiceTest.java
index 7b2978b747011..faff9f780e31c 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/search/LineageSearchServiceTest.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/search/LineageSearchServiceTest.java
@@ -317,6 +317,83 @@ public void testSearchService() throws Exception {
}
+ @Test
+ public void testScrollAcrossLineage() throws Exception {
+ when(_graphService.getLineage(eq(TEST_URN), eq(LineageDirection.DOWNSTREAM), anyInt(), anyInt(),
+ anyInt(), eq(null), eq(null))).thenReturn(mockResult(Collections.emptyList()));
+ LineageScrollResult scrollResult = scrollAcrossLineage(null, TEST1);
+ assertEquals(scrollResult.getNumEntities().intValue(), 0);
+ assertNull(scrollResult.getScrollId());
+ scrollResult = scrollAcrossLineage(null, TEST1);
+ assertEquals(scrollResult.getNumEntities().intValue(), 0);
+ assertNull(scrollResult.getScrollId());
+ clearCache(false);
+
+ when(_graphService.getLineage(eq(TEST_URN), eq(LineageDirection.DOWNSTREAM), anyInt(), anyInt(),
+ anyInt(), eq(null), eq(null))).thenReturn(
+ mockResult(ImmutableList.of(new LineageRelationship().setEntity(TEST_URN).setType("test").setDegree(1))));
+ // just testing null input does not throw any exception
+ scrollAcrossLineage(null, null);
+
+ scrollResult = scrollAcrossLineage(null, TEST);
+ assertEquals(scrollResult.getNumEntities().intValue(), 0);
+ assertNull(scrollResult.getScrollId());
+ scrollResult = scrollAcrossLineage(null, TEST1);
+ assertEquals(scrollResult.getNumEntities().intValue(), 0);
+ assertNull(scrollResult.getScrollId());
+ clearCache(false);
+
+ Urn urn = new TestEntityUrn("test1", "urn1", "VALUE_1");
+ ObjectNode document = JsonNodeFactory.instance.objectNode();
+ document.set("urn", JsonNodeFactory.instance.textNode(urn.toString()));
+ document.set("keyPart1", JsonNodeFactory.instance.textNode("test"));
+ document.set("textFieldOverride", JsonNodeFactory.instance.textNode("textFieldOverride"));
+ document.set("browsePaths", JsonNodeFactory.instance.textNode("/a/b/c"));
+ _elasticSearchService.upsertDocument(ENTITY_NAME, document.toString(), urn.toString());
+ syncAfterWrite(_bulkProcessor);
+
+ when(_graphService.getLineage(eq(TEST_URN), eq(LineageDirection.DOWNSTREAM), anyInt(), anyInt(),
+ anyInt(), eq(null), eq(null))).thenReturn(mockResult(Collections.emptyList()));
+ scrollResult = scrollAcrossLineage(null, TEST1);
+ assertEquals(scrollResult.getNumEntities().intValue(), 0);
+ assertEquals(scrollResult.getEntities().size(), 0);
+ assertNull(scrollResult.getScrollId());
+ clearCache(false);
+
+ when(_graphService.getLineage(eq(TEST_URN), eq(LineageDirection.DOWNSTREAM), anyInt(), anyInt(),
+ anyInt(), eq(null), eq(null))).thenReturn(
+ mockResult(ImmutableList.of(new LineageRelationship().setEntity(urn).setType("test").setDegree(1))));
+ scrollResult = scrollAcrossLineage(null, TEST1);
+ assertEquals(scrollResult.getNumEntities().intValue(), 1);
+ assertEquals(scrollResult.getEntities().get(0).getEntity(), urn);
+ assertEquals(scrollResult.getEntities().get(0).getDegree().intValue(), 1);
+ assertNull(scrollResult.getScrollId());
+
+ scrollResult = scrollAcrossLineage(QueryUtils.newFilter("degree.keyword", "1"), TEST1);
+ assertEquals(scrollResult.getNumEntities().intValue(), 1);
+ assertEquals(scrollResult.getEntities().get(0).getEntity(), urn);
+ assertEquals(scrollResult.getEntities().get(0).getDegree().intValue(), 1);
+ assertNull(scrollResult.getScrollId());
+
+ scrollResult = scrollAcrossLineage(QueryUtils.newFilter("degree.keyword", "2"), TEST1);
+ assertEquals(scrollResult.getNumEntities().intValue(), 0);
+ assertEquals(scrollResult.getEntities().size(), 0);
+ assertNull(scrollResult.getScrollId());
+ clearCache(false);
+
+ // Cleanup
+ _elasticSearchService.deleteDocument(ENTITY_NAME, urn.toString());
+ syncAfterWrite(_bulkProcessor);
+
+ when(_graphService.getLineage(eq(TEST_URN), eq(LineageDirection.DOWNSTREAM), anyInt(), anyInt(),
+ anyInt())).thenReturn(
+ mockResult(ImmutableList.of(new LineageRelationship().setEntity(urn).setType("test1").setDegree(1))));
+ scrollResult = scrollAcrossLineage(null, TEST1);
+
+ assertEquals(scrollResult.getNumEntities().intValue(), 0);
+ assertNull(scrollResult.getScrollId());
+ }
+
@Test
public void testLightningSearchService() throws Exception {
// Mostly this test ensures the code path is exercised
@@ -731,6 +808,16 @@ private LineageSearchResult searchAcrossLineage(@Nullable Filter filter, @Nullab
new SearchFlags().setSkipCache(true));
}
+ private LineageScrollResult scrollAcrossLineage(@Nullable Filter filter, @Nullable String input, String scrollId, int size) {
+ return _lineageSearchService.scrollAcrossLineage(TEST_URN, LineageDirection.DOWNSTREAM, ImmutableList.of(), input,
+ null, filter, null, scrollId, "5m", size, null, null,
+ new SearchFlags().setSkipCache(true));
+ }
+
+ private LineageScrollResult scrollAcrossLineage(@Nullable Filter filter, @Nullable String input) {
+ return scrollAcrossLineage(filter, input, null, 10);
+ }
+
@Test
public void testCanDoLightning() throws Exception {
Map platformCounts = new HashMap<>();
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/fixtures/ElasticSearchGoldenTest.java b/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/fixtures/ElasticSearchGoldenTest.java
new file mode 100644
index 0000000000000..d720c95fef84d
--- /dev/null
+++ b/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/fixtures/ElasticSearchGoldenTest.java
@@ -0,0 +1,167 @@
+package com.linkedin.metadata.search.elasticsearch.fixtures;
+
+import com.linkedin.common.urn.Urn;
+import com.linkedin.datahub.graphql.generated.EntityType;
+import com.linkedin.datahub.graphql.resolvers.EntityTypeMapper;
+import com.linkedin.entity.client.EntityClient;
+import com.linkedin.metadata.ESSampleDataFixture;
+import com.linkedin.metadata.models.registry.EntityRegistry;
+import com.linkedin.metadata.search.MatchedFieldArray;
+import com.linkedin.metadata.search.SearchEntityArray;
+import com.linkedin.metadata.search.SearchResult;
+import com.linkedin.metadata.search.SearchService;
+import org.elasticsearch.client.RestHighLevelClient;
+import org.springframework.beans.factory.annotation.Autowired;
+import org.springframework.beans.factory.annotation.Qualifier;
+import org.springframework.context.annotation.Import;
+import org.springframework.test.context.testng.AbstractTestNGSpringContextTests;
+import org.testng.annotations.Test;
+
+import java.util.List;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+import static com.linkedin.metadata.ESTestUtils.*;
+import static org.testng.Assert.assertTrue;
+import static org.testng.AssertJUnit.*;
+
+@Import(ESSampleDataFixture.class)
+public class ElasticSearchGoldenTest extends AbstractTestNGSpringContextTests {
+
+ private static final List SEARCHABLE_LONGTAIL_ENTITIES = Stream.of(EntityType.CHART, EntityType.CONTAINER,
+ EntityType.DASHBOARD, EntityType.DATASET, EntityType.DOMAIN, EntityType.TAG
+ ).map(EntityTypeMapper::getName)
+ .collect(Collectors.toList());
+ @Autowired
+ private RestHighLevelClient _searchClient;
+
+ @Autowired
+ @Qualifier("longTailSearchService")
+ protected SearchService searchService;
+
+ @Autowired
+ @Qualifier("longTailEntityClient")
+ protected EntityClient entityClient;
+
+ @Autowired
+ @Qualifier("longTailEntityRegistry")
+ private EntityRegistry entityRegistry;
+
+ @Test
+ public void testNameMatchPetProfiles() {
+ /*
+ Searching for "pet profiles" should return "pet_profiles" as the first 2 search results
+ */
+ assertNotNull(searchService);
+ assertNotNull(entityRegistry);
+ SearchResult searchResult = searchAcrossCustomEntities(searchService, "pet profiles", SEARCHABLE_LONGTAIL_ENTITIES);
+ assertTrue(searchResult.getEntities().size() >= 2);
+ Urn firstResultUrn = searchResult.getEntities().get(0).getEntity();
+ Urn secondResultUrn = searchResult.getEntities().get(1).getEntity();
+
+ assertTrue(firstResultUrn.toString().contains("pet_profiles"));
+ assertTrue(secondResultUrn.toString().contains("pet_profiles"));
+ }
+
+ @Test
+ public void testNameMatchPetProfile() {
+ /*
+ Searching for "pet profile" should return "pet_profiles" as the first 2 search results
+ */
+ assertNotNull(searchService);
+ SearchResult searchResult = searchAcrossEntities(searchService, "pet profile", SEARCHABLE_LONGTAIL_ENTITIES);
+ assertTrue(searchResult.getEntities().size() >= 2);
+ Urn firstResultUrn = searchResult.getEntities().get(0).getEntity();
+ Urn secondResultUrn = searchResult.getEntities().get(1).getEntity();
+
+ assertTrue(firstResultUrn.toString().contains("pet_profiles"));
+ assertTrue(secondResultUrn.toString().contains("pet_profiles"));
+ }
+
+ @Test
+ public void testGlossaryTerms() {
+ /*
+ Searching for "ReturnRate" should return all tables that have the glossary term applied before
+ anything else
+ */
+ assertNotNull(searchService);
+ SearchResult searchResult = searchAcrossEntities(searchService, "ReturnRate", SEARCHABLE_LONGTAIL_ENTITIES);
+ SearchEntityArray entities = searchResult.getEntities();
+ assertTrue(searchResult.getEntities().size() >= 4);
+ MatchedFieldArray firstResultMatchedFields = entities.get(0).getMatchedFields();
+ MatchedFieldArray secondResultMatchedFields = entities.get(1).getMatchedFields();
+ MatchedFieldArray thirdResultMatchedFields = entities.get(2).getMatchedFields();
+ MatchedFieldArray fourthResultMatchedFields = entities.get(3).getMatchedFields();
+
+ assertTrue(firstResultMatchedFields.toString().contains("ReturnRate"));
+ assertTrue(secondResultMatchedFields.toString().contains("ReturnRate"));
+ assertTrue(thirdResultMatchedFields.toString().contains("ReturnRate"));
+ assertTrue(fourthResultMatchedFields.toString().contains("ReturnRate"));
+ }
+
+ @Test
+ public void testNameMatchPartiallyQualified() {
+ /*
+ Searching for "analytics.pet_details" (partially qualified) should return the fully qualified table
+ name as the first search results before any others
+ */
+ assertNotNull(searchService);
+ SearchResult searchResult = searchAcrossEntities(searchService, "analytics.pet_details", SEARCHABLE_LONGTAIL_ENTITIES);
+ assertTrue(searchResult.getEntities().size() >= 2);
+ Urn firstResultUrn = searchResult.getEntities().get(0).getEntity();
+ Urn secondResultUrn = searchResult.getEntities().get(1).getEntity();
+
+ assertTrue(firstResultUrn.toString().contains("snowflake,long_tail_companions.analytics.pet_details"));
+ assertTrue(secondResultUrn.toString().contains("dbt,long_tail_companions.analytics.pet_details"));
+ }
+
+ @Test
+ public void testNameMatchCollaborativeActionitems() {
+ /*
+ Searching for "collaborative actionitems" should return "collaborative_actionitems" as the first search
+ result, followed by "collaborative_actionitems_old"
+ */
+ assertNotNull(searchService);
+ SearchResult searchResult = searchAcrossEntities(searchService, "collaborative actionitems", SEARCHABLE_LONGTAIL_ENTITIES);
+ assertTrue(searchResult.getEntities().size() >= 2);
+ Urn firstResultUrn = searchResult.getEntities().get(0).getEntity();
+ Urn secondResultUrn = searchResult.getEntities().get(1).getEntity();
+
+ // Checks that the table name is not suffixed with anything
+ assertTrue(firstResultUrn.toString().contains("collaborative_actionitems,"));
+ assertTrue(secondResultUrn.toString().contains("collaborative_actionitems_old"));
+
+ Double firstResultScore = searchResult.getEntities().get(0).getScore();
+ Double secondResultScore = searchResult.getEntities().get(1).getScore();
+
+ // Checks that the scores aren't tied so that we are matching on table name more than column name
+ assertTrue(firstResultScore > secondResultScore);
+ }
+
+ @Test
+ public void testNameMatchCustomerOrders() {
+ /*
+ Searching for "customer orders" should return "customer_orders" as the first search
+ result, not suffixed by anything
+ */
+ assertNotNull(searchService);
+ SearchResult searchResult = searchAcrossEntities(searchService, "customer orders", SEARCHABLE_LONGTAIL_ENTITIES);
+ assertTrue(searchResult.getEntities().size() >= 2);
+ Urn firstResultUrn = searchResult.getEntities().get(0).getEntity();
+
+ // Checks that the table name is not suffixed with anything
+ assertTrue(firstResultUrn.toString().contains("customer_orders,"));
+
+ Double firstResultScore = searchResult.getEntities().get(0).getScore();
+ Double secondResultScore = searchResult.getEntities().get(1).getScore();
+
+ // Checks that the scores aren't tied so that we are matching on table name more than column name
+ assertTrue(firstResultScore > secondResultScore);
+ }
+
+ /*
+ Tests that should pass but do not yet can be added below here, with the following annotation:
+ @Test(enabled = false)
+ */
+
+}
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/fixtures/SampleDataFixtureTests.java b/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/fixtures/SampleDataFixtureTests.java
index dada13bd6f479..450378b247cea 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/fixtures/SampleDataFixtureTests.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/fixtures/SampleDataFixtureTests.java
@@ -82,6 +82,7 @@ public class SampleDataFixtureTests extends AbstractTestNGSpringContextTests {
protected EntityClient entityClient;
@Autowired
+ @Qualifier("entityRegistry")
private EntityRegistry entityRegistry;
@Test
@@ -160,6 +161,7 @@ public void testSearchFieldConfig() throws IOException {
// this is a subfield therefore cannot have a subfield
assertFalse(test.hasKeywordSubfield());
assertFalse(test.hasDelimitedSubfield());
+ assertFalse(test.hasWordGramSubfields());
String[] fieldAndSubfield = test.fieldName().split("[.]", 2);
@@ -357,6 +359,84 @@ public void testDelimitedSynonym() throws IOException {
}).collect(Collectors.toList());
}
+ @Test
+ public void testNegateAnalysis() throws IOException {
+ String queryWithMinus = "logging_events -bckp";
+ AnalyzeRequest request = AnalyzeRequest.withIndexAnalyzer(
+ "smpldat_datasetindex_v2",
+ "query_word_delimited", queryWithMinus
+ );
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()),
+ List.of("logging_events -bckp", "logging_ev", "-bckp", "log", "event", "bckp"));
+
+ request = AnalyzeRequest.withIndexAnalyzer(
+ "smpldat_datasetindex_v2",
+ "word_gram_3", queryWithMinus
+ );
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()), List.of("logging events -bckp"));
+
+ request = AnalyzeRequest.withIndexAnalyzer(
+ "smpldat_datasetindex_v2",
+ "word_gram_4", queryWithMinus
+ );
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()), List.of());
+
+ }
+
+ @Test
+ public void testWordGram() throws IOException {
+ String text = "hello.cat_cool_customer";
+ AnalyzeRequest request = AnalyzeRequest.withIndexAnalyzer("smpldat_datasetindex_v2", "word_gram_2", text);
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()), List.of("hello cat", "cat cool", "cool customer"));
+ request = AnalyzeRequest.withIndexAnalyzer("smpldat_datasetindex_v2", "word_gram_3", text);
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()), List.of("hello cat cool", "cat cool customer"));
+ request = AnalyzeRequest.withIndexAnalyzer("smpldat_datasetindex_v2", "word_gram_4", text);
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()), List.of("hello cat cool customer"));
+
+ String testMoreSeparators = "quick.brown:fox jumped-LAZY_Dog";
+ request = AnalyzeRequest.withIndexAnalyzer("smpldat_datasetindex_v2", "word_gram_2", testMoreSeparators);
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()),
+ List.of("quick brown", "brown fox", "fox jumped", "jumped lazy", "lazy dog"));
+ request = AnalyzeRequest.withIndexAnalyzer("smpldat_datasetindex_v2", "word_gram_3", testMoreSeparators);
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()),
+ List.of("quick brown fox", "brown fox jumped", "fox jumped lazy", "jumped lazy dog"));
+ request = AnalyzeRequest.withIndexAnalyzer("smpldat_datasetindex_v2", "word_gram_4", testMoreSeparators);
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()),
+ List.of("quick brown fox jumped", "brown fox jumped lazy", "fox jumped lazy dog"));
+
+ String textWithQuotesAndDuplicateWord = "\"my_db.my_exact_table\"";
+ request = AnalyzeRequest.withIndexAnalyzer("smpldat_datasetindex_v2", "word_gram_2", textWithQuotesAndDuplicateWord);
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()), List.of("my db", "db my", "my exact", "exact table"));
+ request = AnalyzeRequest.withIndexAnalyzer("smpldat_datasetindex_v2", "word_gram_3", textWithQuotesAndDuplicateWord);
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()), List.of("my db my", "db my exact", "my exact table"));
+ request = AnalyzeRequest.withIndexAnalyzer("smpldat_datasetindex_v2", "word_gram_4", textWithQuotesAndDuplicateWord);
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()), List.of("my db my exact", "db my exact table"));
+
+ String textWithParens = "(hi) there";
+ request = AnalyzeRequest.withIndexAnalyzer("smpldat_datasetindex_v2", "word_gram_2", textWithParens);
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()), List.of("hi there"));
+
+ String oneWordText = "hello";
+ for (String analyzer : List.of("word_gram_2", "word_gram_3", "word_gram_4")) {
+ request = AnalyzeRequest.withIndexAnalyzer("smpldat_datasetindex_v2", analyzer, oneWordText);
+ assertEquals(getTokens(request)
+ .map(AnalyzeResponse.AnalyzeToken::getTerm).collect(Collectors.toList()), List.of());
+ }
+ }
+
@Test
public void testUrnSynonym() throws IOException {
List expectedTokens = List.of("bigquery");
@@ -1266,6 +1346,53 @@ public void testParens() {
String.format("%s - Expected search results to include matched fields", query));
assertEquals(result.getEntities().size(), 2);
}
+ @Test
+ public void testGram() {
+ String query = "jaffle shop customers";
+ SearchResult result = searchAcrossEntities(searchService, query);
+ assertTrue(result.hasEntities() && !result.getEntities().isEmpty(),
+ String.format("%s - Expected search results", query));
+
+ assertEquals(result.getEntities().get(0).getEntity().toString(),
+ "urn:li:dataset:(urn:li:dataPlatform:dbt,cypress_project.jaffle_shop.customers,PROD)",
+ "Expected exact match in 1st position");
+
+ query = "shop customers source";
+ result = searchAcrossEntities(searchService, query);
+ assertTrue(result.hasEntities() && !result.getEntities().isEmpty(),
+ String.format("%s - Expected search results", query));
+
+ assertEquals(result.getEntities().get(0).getEntity().toString(),
+ "urn:li:dataset:(urn:li:dataPlatform:dbt,cypress_project.jaffle_shop.customers_source,PROD)",
+ "Expected ngram match in 1st position");
+
+ query = "jaffle shop stg customers";
+ result = searchAcrossEntities(searchService, query);
+ assertTrue(result.hasEntities() && !result.getEntities().isEmpty(),
+ String.format("%s - Expected search results", query));
+
+ assertEquals(result.getEntities().get(0).getEntity().toString(),
+ "urn:li:dataset:(urn:li:dataPlatform:dbt,cypress_project.jaffle_shop.stg_customers,PROD)",
+ "Expected ngram match in 1st position");
+
+ query = "jaffle shop transformers customers";
+ result = searchAcrossEntities(searchService, query);
+ assertTrue(result.hasEntities() && !result.getEntities().isEmpty(),
+ String.format("%s - Expected search results", query));
+
+ assertEquals(result.getEntities().get(0).getEntity().toString(),
+ "urn:li:dataset:(urn:li:dataPlatform:dbt,cypress_project.jaffle_shop.transformers_customers,PROD)",
+ "Expected ngram match in 1st position");
+
+ query = "shop raw customers";
+ result = searchAcrossEntities(searchService, query);
+ assertTrue(result.hasEntities() && !result.getEntities().isEmpty(),
+ String.format("%s - Expected search results", query));
+
+ assertEquals(result.getEntities().get(0).getEntity().toString(),
+ "urn:li:dataset:(urn:li:dataPlatform:dbt,cypress_project.jaffle_shop.raw_customers,PROD)",
+ "Expected ngram match in 1st position");
+ }
@Test
public void testPrefixVsExact() {
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/indexbuilder/MappingsBuilderTest.java b/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/indexbuilder/MappingsBuilderTest.java
index ed72b46e98c46..0b33185549299 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/indexbuilder/MappingsBuilderTest.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/indexbuilder/MappingsBuilderTest.java
@@ -16,7 +16,7 @@ public void testMappingsBuilder() {
Map result = MappingsBuilder.getMappings(TestEntitySpecBuilder.getSpec());
assertEquals(result.size(), 1);
Map properties = (Map) result.get("properties");
- assertEquals(properties.size(), 17);
+ assertEquals(properties.size(), 19);
assertEquals(properties.get("urn"), ImmutableMap.of("type", "keyword",
"fields",
ImmutableMap.of("delimited",
@@ -66,6 +66,11 @@ public void testMappingsBuilder() {
assertTrue(textFieldSubfields.containsKey("delimited"));
assertTrue(textFieldSubfields.containsKey("keyword"));
+ // TEXT with addToFilters aliased under "_entityName"
+ Map textFieldAlias = (Map) properties.get("_entityName");
+ assertEquals(textFieldAlias.get("type"), "alias");
+ assertEquals(textFieldAlias.get("path"), "textFieldOverride");
+
// TEXT_PARTIAL
Map textArrayField = (Map) properties.get("textArrayField");
assertEquals(textArrayField.get("type"), "keyword");
@@ -76,6 +81,19 @@ public void testMappingsBuilder() {
assertTrue(textArrayFieldSubfields.containsKey("ngram"));
assertTrue(textArrayFieldSubfields.containsKey("keyword"));
+ // WORD_GRAM
+ Map wordGramField = (Map) properties.get("wordGramField");
+ assertEquals(wordGramField.get("type"), "keyword");
+ assertEquals(wordGramField.get("normalizer"), "keyword_normalizer");
+ Map wordGramFieldSubfields = (Map) wordGramField.get("fields");
+ assertEquals(wordGramFieldSubfields.size(), 6);
+ assertTrue(wordGramFieldSubfields.containsKey("delimited"));
+ assertTrue(wordGramFieldSubfields.containsKey("ngram"));
+ assertTrue(wordGramFieldSubfields.containsKey("keyword"));
+ assertTrue(wordGramFieldSubfields.containsKey("wordGrams2"));
+ assertTrue(wordGramFieldSubfields.containsKey("wordGrams3"));
+ assertTrue(wordGramFieldSubfields.containsKey("wordGrams4"));
+
// URN
Map foreignKey = (Map) properties.get("foreignKey");
assertEquals(foreignKey.get("type"), "text");
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/query/request/AggregationQueryBuilderTest.java b/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/query/request/AggregationQueryBuilderTest.java
index 10b4ee42b1a71..36c8bb8f9a676 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/query/request/AggregationQueryBuilderTest.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/query/request/AggregationQueryBuilderTest.java
@@ -31,7 +31,8 @@ public void testGetDefaultAggregationsHasFields() {
1.0,
Optional.of("hasTest"),
Optional.empty(),
- Collections.emptyMap()
+ Collections.emptyMap(),
+ Collections.emptyList()
);
SearchConfiguration config = new SearchConfiguration();
@@ -60,7 +61,8 @@ public void testGetDefaultAggregationsFields() {
1.0,
Optional.empty(),
Optional.empty(),
- Collections.emptyMap()
+ Collections.emptyMap(),
+ Collections.emptyList()
);
SearchConfiguration config = new SearchConfiguration();
@@ -89,7 +91,8 @@ public void testGetSpecificAggregationsHasFields() {
1.0,
Optional.of("hasTest1"),
Optional.empty(),
- Collections.emptyMap()
+ Collections.emptyMap(),
+ Collections.emptyList()
);
SearchableAnnotation annotation2 = new SearchableAnnotation(
@@ -104,7 +107,8 @@ public void testGetSpecificAggregationsHasFields() {
1.0,
Optional.empty(),
Optional.empty(),
- Collections.emptyMap()
+ Collections.emptyMap(),
+ Collections.emptyList()
);
SearchConfiguration config = new SearchConfiguration();
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/query/request/SearchQueryBuilderTest.java b/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/query/request/SearchQueryBuilderTest.java
index a2ec396c34b2d..282b1d8bb6778 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/query/request/SearchQueryBuilderTest.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/query/request/SearchQueryBuilderTest.java
@@ -4,6 +4,7 @@
import com.linkedin.metadata.config.search.ExactMatchConfiguration;
import com.linkedin.metadata.config.search.PartialConfiguration;
import com.linkedin.metadata.config.search.SearchConfiguration;
+import com.linkedin.metadata.config.search.WordGramConfiguration;
import com.linkedin.metadata.config.search.custom.CustomSearchConfiguration;
import com.fasterxml.jackson.dataformat.yaml.YAMLMapper;
import com.google.common.collect.ImmutableList;
@@ -18,6 +19,7 @@
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.MatchAllQueryBuilder;
import org.elasticsearch.index.query.MatchPhrasePrefixQueryBuilder;
+import org.elasticsearch.index.query.MatchPhraseQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryStringQueryBuilder;
import org.elasticsearch.index.query.SimpleQueryStringBuilder;
@@ -46,11 +48,17 @@ public class SearchQueryBuilderTest {
exactMatchConfiguration.setCaseSensitivityFactor(0.7f);
exactMatchConfiguration.setEnableStructured(true);
+ WordGramConfiguration wordGramConfiguration = new WordGramConfiguration();
+ wordGramConfiguration.setTwoGramFactor(1.2f);
+ wordGramConfiguration.setThreeGramFactor(1.5f);
+ wordGramConfiguration.setFourGramFactor(1.8f);
+
PartialConfiguration partialConfiguration = new PartialConfiguration();
partialConfiguration.setFactor(0.4f);
partialConfiguration.setUrnFactor(0.7f);
testQueryConfig.setExactMatch(exactMatchConfiguration);
+ testQueryConfig.setWordGram(wordGramConfiguration);
testQueryConfig.setPartial(partialConfiguration);
}
public static final SearchQueryBuilder TEST_BUILDER = new SearchQueryBuilder(testQueryConfig, null);
@@ -70,16 +78,17 @@ public void testQueryBuilderFulltext() {
assertEquals(keywordQuery.value(), "testQuery");
assertEquals(keywordQuery.analyzer(), "keyword");
Map keywordFields = keywordQuery.fields();
- assertEquals(keywordFields.size(), 8);
+ assertEquals(keywordFields.size(), 9);
assertEquals(keywordFields, Map.of(
- "urn", 10.f,
- "textArrayField", 1.0f,
- "customProperties", 1.0f,
- "nestedArrayArrayField", 1.0f,
- "textFieldOverride", 1.0f,
- "nestedArrayStringField", 1.0f,
- "keyPart1", 10.0f,
- "esObjectField", 1.0f
+ "urn", 10.f,
+ "textArrayField", 1.0f,
+ "customProperties", 1.0f,
+ "wordGramField", 1.0f,
+ "nestedArrayArrayField", 1.0f,
+ "textFieldOverride", 1.0f,
+ "nestedArrayStringField", 1.0f,
+ "keyPart1", 10.0f,
+ "esObjectField", 1.0f
));
SimpleQueryStringBuilder urnComponentQuery = (SimpleQueryStringBuilder) analyzerGroupQuery.should().get(1);
@@ -99,7 +108,8 @@ public void testQueryBuilderFulltext() {
"nestedArrayArrayField.delimited", 0.4f,
"urn.delimited", 7.0f,
"textArrayField.delimited", 0.4f,
- "nestedArrayStringField.delimited", 0.4f
+ "nestedArrayStringField.delimited", 0.4f,
+ "wordGramField.delimited", 0.4f
));
BoolQueryBuilder boolPrefixQuery = (BoolQueryBuilder) shouldQueries.get(1);
@@ -109,21 +119,30 @@ public void testQueryBuilderFulltext() {
if (prefixQuery instanceof MatchPhrasePrefixQueryBuilder) {
MatchPhrasePrefixQueryBuilder builder = (MatchPhrasePrefixQueryBuilder) prefixQuery;
return Pair.of(builder.fieldName(), builder.boost());
- } else {
+ } else if (prefixQuery instanceof TermQueryBuilder) {
// exact
TermQueryBuilder builder = (TermQueryBuilder) prefixQuery;
return Pair.of(builder.fieldName(), builder.boost());
+ } else { // if (prefixQuery instanceof MatchPhraseQueryBuilder) {
+ // ngram
+ MatchPhraseQueryBuilder builder = (MatchPhraseQueryBuilder) prefixQuery;
+ return Pair.of(builder.fieldName(), builder.boost());
}
}).collect(Collectors.toList());
- assertEquals(prefixFieldWeights.size(), 22);
+ assertEquals(prefixFieldWeights.size(), 28);
List.of(
Pair.of("urn", 100.0f),
Pair.of("urn", 70.0f),
Pair.of("keyPart1.delimited", 16.8f),
Pair.of("keyPart1.keyword", 100.0f),
- Pair.of("keyPart1.keyword", 70.0f)
+ Pair.of("keyPart1.keyword", 70.0f),
+ Pair.of("wordGramField.wordGrams2", 1.44f),
+ Pair.of("wordGramField.wordGrams3", 2.25f),
+ Pair.of("wordGramField.wordGrams4", 3.2399998f),
+ Pair.of("wordGramField.keyword", 10.0f),
+ Pair.of("wordGramField.keyword", 7.0f)
).forEach(p -> assertTrue(prefixFieldWeights.contains(p), "Missing: " + p));
// Validate scorer
@@ -144,7 +163,7 @@ public void testQueryBuilderStructured() {
assertEquals(keywordQuery.queryString(), "testQuery");
assertNull(keywordQuery.analyzer());
Map keywordFields = keywordQuery.fields();
- assertEquals(keywordFields.size(), 16);
+ assertEquals(keywordFields.size(), 21);
assertEquals(keywordFields.get("keyPart1").floatValue(), 10.0f);
assertFalse(keywordFields.containsKey("keyPart3"));
assertEquals(keywordFields.get("textFieldOverride").floatValue(), 1.0f);
@@ -196,10 +215,14 @@ public void testCustomExactMatch() {
List queries = boolPrefixQuery.should().stream().map(prefixQuery -> {
if (prefixQuery instanceof MatchPhrasePrefixQueryBuilder) {
+ // prefix
return (MatchPhrasePrefixQueryBuilder) prefixQuery;
- } else {
+ } else if (prefixQuery instanceof TermQueryBuilder) {
// exact
return (TermQueryBuilder) prefixQuery;
+ } else { // if (prefixQuery instanceof MatchPhraseQueryBuilder) {
+ // ngram
+ return (MatchPhraseQueryBuilder) prefixQuery;
}
}).collect(Collectors.toList());
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/query/request/SearchRequestHandlerTest.java b/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/query/request/SearchRequestHandlerTest.java
index d66d6a0ab0e76..db56e2d34881b 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/query/request/SearchRequestHandlerTest.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/search/elasticsearch/query/request/SearchRequestHandlerTest.java
@@ -7,6 +7,7 @@
import com.linkedin.data.template.StringArray;
import com.linkedin.metadata.ESTestConfiguration;
import com.linkedin.metadata.TestEntitySpecBuilder;
+import com.linkedin.metadata.config.search.WordGramConfiguration;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Collections;
@@ -65,11 +66,17 @@ public class SearchRequestHandlerTest extends AbstractTestNGSpringContextTests {
exactMatchConfiguration.setCaseSensitivityFactor(0.7f);
exactMatchConfiguration.setEnableStructured(true);
+ WordGramConfiguration wordGramConfiguration = new WordGramConfiguration();
+ wordGramConfiguration.setTwoGramFactor(1.2f);
+ wordGramConfiguration.setThreeGramFactor(1.5f);
+ wordGramConfiguration.setFourGramFactor(1.8f);
+
PartialConfiguration partialConfiguration = new PartialConfiguration();
partialConfiguration.setFactor(0.4f);
partialConfiguration.setUrnFactor(0.7f);
testQueryConfig.setExactMatch(exactMatchConfiguration);
+ testQueryConfig.setWordGram(wordGramConfiguration);
testQueryConfig.setPartial(partialConfiguration);
}
@@ -113,10 +120,10 @@ public void testSearchRequestHandler() {
HighlightBuilder highlightBuilder = sourceBuilder.highlighter();
List fields =
highlightBuilder.fields().stream().map(HighlightBuilder.Field::name).collect(Collectors.toList());
- assertEquals(fields.size(), 20);
+ assertEquals(fields.size(), 22);
List highlightableFields =
ImmutableList.of("keyPart1", "textArrayField", "textFieldOverride", "foreignKey", "nestedForeignKey",
- "nestedArrayStringField", "nestedArrayArrayField", "customProperties", "esObjectField");
+ "nestedArrayStringField", "nestedArrayArrayField", "customProperties", "esObjectField", "wordGramField");
highlightableFields.forEach(field -> {
assertTrue(fields.contains(field), "Missing: " + field);
assertTrue(fields.contains(field + ".*"), "Missing: " + field + ".*");
diff --git a/metadata-io/src/test/java/io/datahub/test/fixtures/elasticsearch/FixtureReader.java b/metadata-io/src/test/java/io/datahub/test/fixtures/elasticsearch/FixtureReader.java
index 2b37d86f058db..a0c551b28b507 100644
--- a/metadata-io/src/test/java/io/datahub/test/fixtures/elasticsearch/FixtureReader.java
+++ b/metadata-io/src/test/java/io/datahub/test/fixtures/elasticsearch/FixtureReader.java
@@ -36,6 +36,8 @@ public class FixtureReader {
@Builder.Default
private String targetIndexPrefix = "";
+ private long refreshIntervalSeconds;
+
public Set read() throws IOException {
try (Stream files = Files.list(Paths.get(String.format("%s/%s", inputBase, fixtureName)))) {
return files.map(file -> {
@@ -64,7 +66,7 @@ public Set read() throws IOException {
} finally {
bulkProcessor.flush();
try {
- Thread.sleep(1000);
+ Thread.sleep(1000 * refreshIntervalSeconds);
} catch (InterruptedException ignored) {
}
}
diff --git a/metadata-jobs/mae-consumer-job/build.gradle b/metadata-jobs/mae-consumer-job/build.gradle
index e7941a04224e3..ca099eea5a8a3 100644
--- a/metadata-jobs/mae-consumer-job/build.gradle
+++ b/metadata-jobs/mae-consumer-job/build.gradle
@@ -11,22 +11,27 @@ ext {
}
dependencies {
+ implementation project(':metadata-service:factories')
implementation project(':metadata-jobs:mae-consumer')
// TODO: Extract PE consumer into separate pod.
implementation project(':metadata-jobs:pe-consumer')
+
implementation(externalDependency.springBootStarterWeb) {
exclude module: "spring-boot-starter-tomcat"
}
implementation externalDependency.springBootStarterJetty
implementation externalDependency.springKafka
+ implementation externalDependency.springBootAutoconfigure
+ implementation externalDependency.springActuator
implementation externalDependency.slf4jApi
implementation externalDependency.log4j2Api
compileOnly externalDependency.lombok
implementation externalDependency.logbackClassic
+ testImplementation project(':metadata-dao-impl:kafka-producer')
testImplementation externalDependency.springBootTest
- testCompile externalDependency.mockito
- testCompile externalDependency.testng
+ testImplementation externalDependency.mockito
+ testImplementation externalDependency.testng
}
bootJar {
@@ -43,6 +48,8 @@ docker {
include 'docker/monitoring/*'
include "docker/${docker_repo}/*"
include 'metadata-models/src/main/resources/*'
+ }.exclude {
+ i -> i.file.isHidden() || i.file == buildDir
}
tag("Debug", "${docker_registry}/${docker_repo}:debug")
@@ -55,7 +62,7 @@ tasks.getByName("docker").dependsOn([bootJar])
task cleanLocalDockerImages {
doLast {
- rootProject.ext.cleanLocalDockerImages(docker_registry, docker_repo, "v${version}".toString())
+ rootProject.ext.cleanLocalDockerImages(docker_registry, docker_repo, "${version}")
}
}
dockerClean.finalizedBy(cleanLocalDockerImages)
\ No newline at end of file
diff --git a/metadata-jobs/mae-consumer/build.gradle b/metadata-jobs/mae-consumer/build.gradle
index 26b3d82b8570a..69fe2255a6916 100644
--- a/metadata-jobs/mae-consumer/build.gradle
+++ b/metadata-jobs/mae-consumer/build.gradle
@@ -11,40 +11,41 @@ configurations {
dependencies {
avro project(path: ':metadata-models', configuration: 'avroSchema')
- compile project(':li-utils')
- compile (project(':metadata-service:factories')) {
+ implementation project(':li-utils')
+ implementation(project(':metadata-service:factories')) {
exclude group: 'org.neo4j.test'
}
- compile project(':metadata-service:auth-config')
- compile project(':metadata-service:restli-client')
- compile project(':metadata-io')
- compile project(':ingestion-scheduler')
- compile project(':metadata-utils')
- compile project(":entity-registry")
- compile project(':metadata-events:mxe-avro-1.7')
- compile project(':metadata-events:mxe-registration')
- compile project(':metadata-events:mxe-utils-avro-1.7')
+ implementation project(':metadata-service:auth-config')
+ implementation project(':metadata-service:restli-client')
+ implementation project(':metadata-io')
+ implementation project(':ingestion-scheduler')
+ implementation project(':metadata-utils')
+ implementation project(":entity-registry")
+ implementation project(':metadata-events:mxe-avro-1.7')
+ implementation project(':metadata-events:mxe-registration')
+ implementation project(':metadata-events:mxe-utils-avro-1.7')
+ implementation project(':datahub-graphql-core')
- compile externalDependency.elasticSearchRest
- compile externalDependency.kafkaAvroSerde
+ implementation externalDependency.elasticSearchRest
+ implementation externalDependency.kafkaAvroSerde
implementation externalDependency.protobuf
- compile externalDependency.neo4jJavaDriver
+ implementation externalDependency.neo4jJavaDriver
- compile externalDependency.springKafka
- compile externalDependency.springActuator
+ implementation externalDependency.springKafka
+ implementation externalDependency.springActuator
implementation externalDependency.slf4jApi
compileOnly externalDependency.lombok
annotationProcessor externalDependency.lombok
- runtime externalDependency.logbackClassic
+ runtimeOnly externalDependency.logbackClassic
- testCompile externalDependency.mockito
+ testImplementation externalDependency.mockito
implementation externalDependency.awsMskIamAuth
testImplementation externalDependency.springBootTest
- testRuntime externalDependency.logbackClassic
+ testRuntimeOnly externalDependency.logbackClassic
}
task avroSchemaSources(type: Copy) {
diff --git a/metadata-jobs/mce-consumer-job/build.gradle b/metadata-jobs/mce-consumer-job/build.gradle
index 5981284e9da3f..b72d4baff23d6 100644
--- a/metadata-jobs/mce-consumer-job/build.gradle
+++ b/metadata-jobs/mce-consumer-job/build.gradle
@@ -21,6 +21,8 @@ dependencies {
}
implementation externalDependency.springBootStarterJetty
implementation externalDependency.springKafka
+ implementation externalDependency.springBootAutoconfigure
+ implementation externalDependency.springActuator
implementation spec.product.pegasus.restliDocgen
implementation spec.product.pegasus.restliSpringBridge
implementation externalDependency.slf4jApi
@@ -28,15 +30,16 @@ dependencies {
compileOnly externalDependency.lombok
implementation externalDependency.logbackClassic
- runtime externalDependency.mariadbConnector
- runtime externalDependency.mysqlConnector
- runtime externalDependency.postgresql
+ runtimeOnly externalDependency.mariadbConnector
+ runtimeOnly externalDependency.mysqlConnector
+ runtimeOnly externalDependency.postgresql
annotationProcessor externalDependency.lombok
+ testImplementation project(':metadata-dao-impl:kafka-producer')
testImplementation externalDependency.springBootTest
- testCompile externalDependency.mockito
- testCompile externalDependency.testng
+ testImplementation externalDependency.mockito
+ testImplementation externalDependency.testng
}
bootJar {
@@ -56,6 +59,8 @@ docker {
include 'docker/monitoring/*'
include "docker/${docker_repo}/*"
include 'metadata-models/src/main/resources/*'
+ }.exclude {
+ i -> i.file.isHidden() || i.file == buildDir
}
tag("Debug", "${docker_registry}/${docker_repo}:debug")
@@ -68,7 +73,7 @@ tasks.getByName("docker").dependsOn([bootJar])
task cleanLocalDockerImages {
doLast {
- rootProject.ext.cleanLocalDockerImages(docker_registry, docker_repo, "v${version}".toString())
+ rootProject.ext.cleanLocalDockerImages(docker_registry, docker_repo, "${version}")
}
}
dockerClean.finalizedBy(cleanLocalDockerImages)
\ No newline at end of file
diff --git a/metadata-jobs/mce-consumer/build.gradle b/metadata-jobs/mce-consumer/build.gradle
index 467d1dbdd3717..0bca55e0e5f92 100644
--- a/metadata-jobs/mce-consumer/build.gradle
+++ b/metadata-jobs/mce-consumer/build.gradle
@@ -11,24 +11,24 @@ configurations {
dependencies {
avro project(path: ':metadata-models', configuration: 'avroSchema')
- compile project(':li-utils')
- compile (project(':metadata-service:factories')) {
+ implementation project(':li-utils')
+ implementation(project(':metadata-service:factories')) {
exclude group: 'org.neo4j.test'
}
- compile project(':metadata-utils')
- compile project(':metadata-events:mxe-schemas')
- compile project(':metadata-events:mxe-avro-1.7')
- compile project(':metadata-events:mxe-registration')
- compile project(':metadata-events:mxe-utils-avro-1.7')
- compile project(':metadata-io')
- compile project(':metadata-service:restli-client')
- compile spec.product.pegasus.restliClient
- compile spec.product.pegasus.restliCommon
- compile externalDependency.elasticSearchRest
+ implementation project(':metadata-utils')
+ implementation project(':metadata-events:mxe-schemas')
+ implementation project(':metadata-events:mxe-avro-1.7')
+ implementation project(':metadata-events:mxe-registration')
+ implementation project(':metadata-events:mxe-utils-avro-1.7')
+ implementation project(':metadata-io')
+ implementation project(':metadata-service:restli-client')
+ implementation spec.product.pegasus.restliClient
+ implementation spec.product.pegasus.restliCommon
+ implementation externalDependency.elasticSearchRest
implementation externalDependency.protobuf
- compile externalDependency.springKafka
- compile externalDependency.springActuator
+ implementation externalDependency.springKafka
+ implementation externalDependency.springActuator
implementation externalDependency.slf4jApi
compileOnly externalDependency.lombok
diff --git a/metadata-jobs/pe-consumer/build.gradle b/metadata-jobs/pe-consumer/build.gradle
index 517b021353f9d..1899a4de15635 100644
--- a/metadata-jobs/pe-consumer/build.gradle
+++ b/metadata-jobs/pe-consumer/build.gradle
@@ -9,21 +9,21 @@ configurations {
dependencies {
avro project(path: ':metadata-models', configuration: 'avroSchema')
- compile project(':li-utils')
- compile project(':metadata-events:mxe-avro-1.7')
- compile project(':metadata-events:mxe-registration')
- compile project(':metadata-events:mxe-utils-avro-1.7')
- compile (project(':metadata-service:factories')) {
+ implementation project(':li-utils')
+ implementation project(':metadata-events:mxe-avro-1.7')
+ implementation project(':metadata-events:mxe-registration')
+ implementation project(':metadata-events:mxe-utils-avro-1.7')
+ implementation(project(':metadata-service:factories')) {
exclude group: 'org.neo4j.test'
}
- compile externalDependency.springKafka
- compile externalDependency.springActuator
+ implementation externalDependency.springKafka
+ implementation externalDependency.springActuator
implementation externalDependency.slf4jApi
compileOnly externalDependency.lombok
annotationProcessor externalDependency.lombok
- runtime externalDependency.logbackClassic
- testCompile externalDependency.mockito
- testRuntime externalDependency.logbackClassic
+ runtimeOnly externalDependency.logbackClassic
+ testImplementation externalDependency.mockito
+ testRuntimeOnly externalDependency.logbackClassic
}
task avroSchemaSources(type: Copy) {
diff --git a/metadata-models-custom/build.gradle b/metadata-models-custom/build.gradle
index 4af866502f5dc..95a00766039a8 100644
--- a/metadata-models-custom/build.gradle
+++ b/metadata-models-custom/build.gradle
@@ -11,10 +11,10 @@ buildscript {
plugins {
id 'base'
+ id 'maven-publish'
}
apply plugin: 'pegasus'
-
if (project.hasProperty('projVersion')) {
project.version = project.projVersion
} else {
@@ -23,11 +23,11 @@ if (project.hasProperty('projVersion')) {
dependencies {
- compile spec.product.pegasus.data
+ implementation spec.product.pegasus.data
// Uncomment these if you want to depend on models defined in core datahub
- //compile project(':li-utils')
+ //implementation project(':li-utils')
//dataModel project(':li-utils')
- //compile project(':metadata-models')
+ //implementation project(':metadata-models')
//dataModel project(':metadata-models')
}
@@ -69,6 +69,6 @@ task modelDeploy(type: Copy) {
modelDeploy.dependsOn modelArtifact
-install.dependsOn modelDeploy
+publish.dependsOn modelDeploy
diff --git a/metadata-models-validator/build.gradle b/metadata-models-validator/build.gradle
index bd1ec9449fb19..c8d1d2e6651d6 100644
--- a/metadata-models-validator/build.gradle
+++ b/metadata-models-validator/build.gradle
@@ -1,13 +1,13 @@
apply plugin: 'java'
dependencies {
- compile project(":entity-registry")
- compile spec.product.pegasus.data
- compile spec.product.pegasus.generator
+ implementation project(":entity-registry")
+ implementation spec.product.pegasus.data
+ implementation spec.product.pegasus.generator
- compile externalDependency.commonsIo
- compile externalDependency.findbugsAnnotations
- compile externalDependency.guava
+ implementation externalDependency.commonsIo
+ implementation externalDependency.findbugsAnnotations
+ implementation externalDependency.guava
implementation externalDependency.slf4jApi
runtimeOnly externalDependency.logbackClassic
diff --git a/metadata-models/build.gradle b/metadata-models/build.gradle
index 432823852a263..2e8efae9b7bce 100644
--- a/metadata-models/build.gradle
+++ b/metadata-models/build.gradle
@@ -1,6 +1,6 @@
import io.datahubproject.GenerateJsonSchemaTask
-
+apply plugin: 'java-library'
apply plugin: 'pegasus'
tasks.withType(JavaCompile).configureEach {
@@ -15,16 +15,16 @@ tasks.withType(Test).configureEach {
}
dependencies {
- compile spec.product.pegasus.data
+ api spec.product.pegasus.data
constraints {
implementation('org.apache.commons:commons-text:1.10.0') {
because 'Vulnerability Issue'
}
}
- compile project(':li-utils')
+ api project(':li-utils')
dataModel project(':li-utils')
- testCompile externalDependency.guava
+ testImplementation externalDependency.guava
}
mainAvroSchemaJar.dependsOn generateAvroSchema
diff --git a/metadata-models/src/main/pegasus/com/linkedin/chart/ChartInfo.pdl b/metadata-models/src/main/pegasus/com/linkedin/chart/ChartInfo.pdl
index 4339a186f1304..9fea71003ae6e 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/chart/ChartInfo.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/chart/ChartInfo.pdl
@@ -20,8 +20,9 @@ record ChartInfo includes CustomProperties, ExternalReference {
* Title of the chart
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
- "enableAutocomplete": true
+ "fieldType": "WORD_GRAM",
+ "enableAutocomplete": true,
+ "fieldNameAliases": [ "_entityName" ]
}
title: string
diff --git a/metadata-models/src/main/pegasus/com/linkedin/container/ContainerProperties.pdl b/metadata-models/src/main/pegasus/com/linkedin/container/ContainerProperties.pdl
index 26745fe46caaa..526878cbe60d3 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/container/ContainerProperties.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/container/ContainerProperties.pdl
@@ -15,9 +15,10 @@ record ContainerProperties includes CustomProperties, ExternalReference {
* Display name of the Asset Container
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: string
@@ -25,7 +26,7 @@ record ContainerProperties includes CustomProperties, ExternalReference {
* Fully-qualified name of the Container
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
"boostScore": 10.0
}
@@ -61,4 +62,4 @@ record ContainerProperties includes CustomProperties, ExternalReference {
}
}
lastModified: optional TimeStamp
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/dashboard/DashboardInfo.pdl b/metadata-models/src/main/pegasus/com/linkedin/dashboard/DashboardInfo.pdl
index 5cb306039506e..c436011eb58db 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/dashboard/DashboardInfo.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/dashboard/DashboardInfo.pdl
@@ -22,9 +22,10 @@ record DashboardInfo includes CustomProperties, ExternalReference {
* Title of the dashboard
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
title: string
@@ -126,4 +127,4 @@ record DashboardInfo includes CustomProperties, ExternalReference {
* The time when this dashboard last refreshed
*/
lastRefreshed: optional Time
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/datajob/DataFlowInfo.pdl b/metadata-models/src/main/pegasus/com/linkedin/datajob/DataFlowInfo.pdl
index 481240740876a..2ff3e8cd930af 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/datajob/DataFlowInfo.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/datajob/DataFlowInfo.pdl
@@ -17,9 +17,10 @@ record DataFlowInfo includes CustomProperties, ExternalReference {
* Flow name
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: string
diff --git a/metadata-models/src/main/pegasus/com/linkedin/datajob/DataJobInfo.pdl b/metadata-models/src/main/pegasus/com/linkedin/datajob/DataJobInfo.pdl
index 8737dd4d9ef52..250fb76003777 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/datajob/DataJobInfo.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/datajob/DataJobInfo.pdl
@@ -18,9 +18,10 @@ record DataJobInfo includes CustomProperties, ExternalReference {
* Job name
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: string
diff --git a/metadata-models/src/main/pegasus/com/linkedin/dataplatform/DataPlatformInfo.pdl b/metadata-models/src/main/pegasus/com/linkedin/dataplatform/DataPlatformInfo.pdl
index acc40e9f693ec..5dd35c7f49520 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/dataplatform/DataPlatformInfo.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/dataplatform/DataPlatformInfo.pdl
@@ -15,9 +15,10 @@ record DataPlatformInfo {
*/
@validate.strlen.max = 15
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": false,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: string
@@ -25,7 +26,7 @@ record DataPlatformInfo {
* The name that will be used for displaying a platform type.
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
"boostScore": 10.0
}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/dataplatforminstance/DataPlatformInstanceProperties.pdl b/metadata-models/src/main/pegasus/com/linkedin/dataplatforminstance/DataPlatformInstanceProperties.pdl
index d7ce5565103ee..b24e220ac3bcf 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/dataplatforminstance/DataPlatformInstanceProperties.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/dataplatforminstance/DataPlatformInstanceProperties.pdl
@@ -16,9 +16,10 @@ record DataPlatformInstanceProperties includes CustomProperties, ExternalReferen
* Display name of the Data Platform Instance
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: optional string
diff --git a/metadata-models/src/main/pegasus/com/linkedin/dataprocess/DataProcessInstanceProperties.pdl b/metadata-models/src/main/pegasus/com/linkedin/dataprocess/DataProcessInstanceProperties.pdl
index 72eefd5e294e4..c63cb1a97c017 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/dataprocess/DataProcessInstanceProperties.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/dataprocess/DataProcessInstanceProperties.pdl
@@ -19,7 +19,7 @@ record DataProcessInstanceProperties includes CustomProperties, ExternalReferenc
* Process name
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
"boostScore": 10.0
}
@@ -31,6 +31,7 @@ record DataProcessInstanceProperties includes CustomProperties, ExternalReferenc
@Searchable = {
"fieldType": "KEYWORD",
"addToFilters": true,
+ "fieldName": "processType",
"filterNameOverride": "Process Type"
}
type: optional enum DataProcessType {
diff --git a/metadata-models/src/main/pegasus/com/linkedin/dataproduct/DataProductProperties.pdl b/metadata-models/src/main/pegasus/com/linkedin/dataproduct/DataProductProperties.pdl
index 3861b7def7669..b2d26094fd0b7 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/dataproduct/DataProductProperties.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/dataproduct/DataProductProperties.pdl
@@ -13,9 +13,10 @@ record DataProductProperties includes CustomProperties, ExternalReference {
* Display name of the Data Product
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: optional string
diff --git a/metadata-models/src/main/pegasus/com/linkedin/dataset/DatasetProperties.pdl b/metadata-models/src/main/pegasus/com/linkedin/dataset/DatasetProperties.pdl
index 57b1fe7693129..ad8705a29d4ed 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/dataset/DatasetProperties.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/dataset/DatasetProperties.pdl
@@ -17,9 +17,10 @@ record DatasetProperties includes CustomProperties, ExternalReference {
* Display name of the Dataset
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: optional string
@@ -27,7 +28,7 @@ record DatasetProperties includes CustomProperties, ExternalReference {
* Fully-qualified name of the Dataset
*/
@Searchable = {
- "fieldType": "TEXT",
+ "fieldType": "WORD_GRAM",
"addToFilters": false,
"enableAutocomplete": true,
"boostScore": 10.0
@@ -77,4 +78,4 @@ record DatasetProperties includes CustomProperties, ExternalReference {
*/
@deprecated = "Use GlobalTags aspect instead."
tags: array[string] = [ ]
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/domain/DomainProperties.pdl b/metadata-models/src/main/pegasus/com/linkedin/domain/DomainProperties.pdl
index 5a0b8657ecb47..5c8c8a4912e4c 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/domain/DomainProperties.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/domain/DomainProperties.pdl
@@ -14,9 +14,10 @@ record DomainProperties {
* Display name of the Domain
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: string
diff --git a/metadata-models/src/main/pegasus/com/linkedin/glossary/GlossaryNodeInfo.pdl b/metadata-models/src/main/pegasus/com/linkedin/glossary/GlossaryNodeInfo.pdl
index 1e840e5a1df7e..c3388d4f462d4 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/glossary/GlossaryNodeInfo.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/glossary/GlossaryNodeInfo.pdl
@@ -35,9 +35,10 @@ record GlossaryNodeInfo {
*/
@Searchable = {
"fieldName": "displayName",
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: optional string
@@ -49,4 +50,4 @@ record GlossaryNodeInfo {
}
id: optional string
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/glossary/GlossaryTermInfo.pdl b/metadata-models/src/main/pegasus/com/linkedin/glossary/GlossaryTermInfo.pdl
index aa2a8b31e3dde..e987a71be7131 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/glossary/GlossaryTermInfo.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/glossary/GlossaryTermInfo.pdl
@@ -23,9 +23,10 @@ record GlossaryTermInfo includes CustomProperties {
* Display name of the term
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: optional string
@@ -75,4 +76,4 @@ record GlossaryTermInfo includes CustomProperties {
*/
@deprecated
rawSchema: optional string
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/identity/CorpGroupInfo.pdl b/metadata-models/src/main/pegasus/com/linkedin/identity/CorpGroupInfo.pdl
index 8d764604237da..28b87476c61bd 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/identity/CorpGroupInfo.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/identity/CorpGroupInfo.pdl
@@ -21,7 +21,8 @@ record CorpGroupInfo {
"fieldType": "TEXT_PARTIAL"
"queryByDefault": true,
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
displayName: optional string
diff --git a/metadata-models/src/main/pegasus/com/linkedin/identity/CorpUserEditableInfo.pdl b/metadata-models/src/main/pegasus/com/linkedin/identity/CorpUserEditableInfo.pdl
index 6b050f484fedd..48ee53377e582 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/identity/CorpUserEditableInfo.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/identity/CorpUserEditableInfo.pdl
@@ -45,7 +45,7 @@ record CorpUserEditableInfo {
* DataHub-native display name
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"queryByDefault": true,
"boostScore": 10.0
}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/identity/CorpUserInfo.pdl b/metadata-models/src/main/pegasus/com/linkedin/identity/CorpUserInfo.pdl
index 1cb705d426cc0..382b120fa942a 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/identity/CorpUserInfo.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/identity/CorpUserInfo.pdl
@@ -26,10 +26,11 @@ record CorpUserInfo includes CustomProperties {
* displayName of this user , e.g. Hang Zhang(DataHQ)
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"queryByDefault": true,
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
displayName: optional string
@@ -89,7 +90,7 @@ record CorpUserInfo includes CustomProperties {
* Common name of this user, format is firstName + lastName (split by a whitespace)
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"queryByDefault": true,
"enableAutocomplete": true,
"boostScore": 10.0
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/CorpGroupKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/CorpGroupKey.pdl
index 075cc14ddc83b..9e65b8f6e9929 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/CorpGroupKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/CorpGroupKey.pdl
@@ -11,10 +11,10 @@ record CorpGroupKey {
* The URL-encoded name of the AD/LDAP group. Serves as a globally unique identifier within DataHub.
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"queryByDefault": true,
"enableAutocomplete": true,
"boostScore": 10.0
}
name: string
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/CorpUserKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/CorpUserKey.pdl
index d1a8a4bb5bb23..476a0ad9704b3 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/CorpUserKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/CorpUserKey.pdl
@@ -12,7 +12,7 @@ record CorpUserKey {
*/
@Searchable = {
"fieldName": "ldap",
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"boostScore": 2.0,
"enableAutocomplete": true
}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DataFlowKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DataFlowKey.pdl
index bcdb92f75d055..d8342630248b6 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DataFlowKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DataFlowKey.pdl
@@ -19,7 +19,7 @@ record DataFlowKey {
* Unique Identifier of the data flow
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true
}
flowId: string
@@ -31,4 +31,4 @@ record DataFlowKey {
"fieldType": "TEXT_PARTIAL"
}
cluster: string
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DataJobKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DataJobKey.pdl
index d0ac7dbca0f99..60ec51b464dcc 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DataJobKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DataJobKey.pdl
@@ -27,7 +27,7 @@ record DataJobKey {
* Unique Identifier of the data job
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true
}
jobId: string
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DataProcessKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DataProcessKey.pdl
index a5c05029352c2..4df1364a04ebe 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DataProcessKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DataProcessKey.pdl
@@ -13,7 +13,7 @@ record DataProcessKey {
* Process name i.e. an ETL job name
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
"boostScore": 4.0
}
@@ -37,4 +37,4 @@ record DataProcessKey {
"queryByDefault": false
}
origin: FabricType
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DatasetKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DatasetKey.pdl
index ea1f9510ed438..70c5d174171af 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DatasetKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/DatasetKey.pdl
@@ -25,7 +25,7 @@ record DatasetKey {
//This is no longer to be used for Dataset native name. Use name, qualifiedName from DatasetProperties instead.
@Searchable = {
"fieldName": "id"
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
"boostScore": 10.0
}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/GlossaryNodeKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/GlossaryNodeKey.pdl
index 88697fe3ff364..51a3bc00f4e9e 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/GlossaryNodeKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/GlossaryNodeKey.pdl
@@ -12,9 +12,9 @@ import com.linkedin.common.FabricType
record GlossaryNodeKey {
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true
}
name: string
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/GlossaryTermKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/GlossaryTermKey.pdl
index a9f35146da18e..61bcd60cbc754 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/GlossaryTermKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/GlossaryTermKey.pdl
@@ -13,10 +13,10 @@ record GlossaryTermKey {
* The term name, which serves as a unique id
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
"fieldName": "id"
}
name: string
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLFeatureKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLFeatureKey.pdl
index 579f1966977a9..050b954c89fb8 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLFeatureKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLFeatureKey.pdl
@@ -20,9 +20,10 @@ record MLFeatureKey {
* Name of the feature
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 8.0
+ "boostScore": 8.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: string
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLFeatureTableKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLFeatureTableKey.pdl
index 1f786ad417be7..175a7b0d31b00 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLFeatureTableKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLFeatureTableKey.pdl
@@ -22,9 +22,10 @@ record MLFeatureTableKey {
* Name of the feature table
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 8.0
+ "boostScore": 8.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: string
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLModelDeploymentKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLModelDeploymentKey.pdl
index 7c36f410fede3..daa1deceb5fc3 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLModelDeploymentKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLModelDeploymentKey.pdl
@@ -19,9 +19,10 @@ record MLModelDeploymentKey {
* Name of the MLModelDeployment
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: string
@@ -35,4 +36,4 @@ record MLModelDeploymentKey {
"queryByDefault": false
}
origin: FabricType
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLModelGroupKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLModelGroupKey.pdl
index 17c401c0b8c48..582a899633c2a 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLModelGroupKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLModelGroupKey.pdl
@@ -19,9 +19,10 @@ record MLModelGroupKey {
* Name of the MLModelGroup
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: string
@@ -33,4 +34,4 @@ record MLModelGroupKey {
"queryByDefault": false
}
origin: FabricType
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLModelKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLModelKey.pdl
index 55fd2bc370846..f097bbda738a2 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLModelKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLModelKey.pdl
@@ -19,9 +19,10 @@ record MLModelKey {
* Name of the MLModel
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: string
@@ -35,4 +36,4 @@ record MLModelKey {
"queryByDefault": false
}
origin: FabricType
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLPrimaryKeyKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLPrimaryKeyKey.pdl
index 9eb67eaf5f651..ef812df206b46 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLPrimaryKeyKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/MLPrimaryKeyKey.pdl
@@ -21,9 +21,10 @@ record MLPrimaryKeyKey {
* Name of the primary key
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 8.0
+ "boostScore": 8.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: string
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/TagKey.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/TagKey.pdl
index 47f1a631b4a2c..4622e32dce67b 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/key/TagKey.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/key/TagKey.pdl
@@ -11,10 +11,10 @@ record TagKey {
* The tag name, which serves as a unique id
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
"boostScore": 10.0,
"fieldName": "id"
}
name: string
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/query/SearchFlags.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/query/SearchFlags.pdl
index 05a94b8fabc4b..be1a30c7f082c 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/query/SearchFlags.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/query/SearchFlags.pdl
@@ -28,4 +28,9 @@ record SearchFlags {
* Whether to skip aggregates/facets
*/
skipAggregates:optional boolean = false
+
+ /**
+ * Whether to request for search suggestions on the _entityName virtualized field
+ */
+ getSuggestions:optional boolean = false
}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/search/SearchResultMetadata.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/search/SearchResultMetadata.pdl
index 718d80ba4cb36..60f1b568f586a 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/metadata/search/SearchResultMetadata.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/search/SearchResultMetadata.pdl
@@ -12,4 +12,9 @@ record SearchResultMetadata {
*/
aggregations: array[AggregationMetadata] = []
+ /**
+ * A list of search query suggestions based on the given query
+ */
+ suggestions: array[SearchSuggestion] = []
+
}
\ No newline at end of file
diff --git a/metadata-models/src/main/pegasus/com/linkedin/metadata/search/SearchSuggestion.pdl b/metadata-models/src/main/pegasus/com/linkedin/metadata/search/SearchSuggestion.pdl
new file mode 100644
index 0000000000000..7776ec54fe03e
--- /dev/null
+++ b/metadata-models/src/main/pegasus/com/linkedin/metadata/search/SearchSuggestion.pdl
@@ -0,0 +1,24 @@
+namespace com.linkedin.metadata.search
+
+/**
+ * The model for the search result
+ */
+record SearchSuggestion {
+
+ /**
+ * The suggestion text for this search query
+ */
+ text: string
+
+ /**
+ * The score for how close this suggestion is to the original search query.
+ * The closer to 1 means it is closer to the original query and 0 is further away.
+ */
+ score: float
+
+ /**
+ * How many matches there are with the suggested text for the given field
+ */
+ frequency: long
+
+}
\ No newline at end of file
diff --git a/metadata-models/src/main/pegasus/com/linkedin/mxe/SystemMetadata.pdl b/metadata-models/src/main/pegasus/com/linkedin/mxe/SystemMetadata.pdl
index b9cf7d58d434e..e0f355229c912 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/mxe/SystemMetadata.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/mxe/SystemMetadata.pdl
@@ -14,6 +14,11 @@ record SystemMetadata {
*/
runId: optional string = "no-run-id-provided"
+ /**
+ * The ingestion pipeline id that produced the metadata. Populated in case of batch ingestion.
+ */
+ pipelineName: optional string
+
/**
* The model registry name that was used to process this event
*/
diff --git a/metadata-models/src/main/pegasus/com/linkedin/notebook/NotebookInfo.pdl b/metadata-models/src/main/pegasus/com/linkedin/notebook/NotebookInfo.pdl
index 1f4dcf975f48c..8ec5f262890f3 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/notebook/NotebookInfo.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/notebook/NotebookInfo.pdl
@@ -18,9 +18,10 @@ record NotebookInfo includes CustomProperties, ExternalReference {
* Title of the Notebook
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
title: string
diff --git a/metadata-models/src/main/pegasus/com/linkedin/ownership/OwnershipTypeInfo.pdl b/metadata-models/src/main/pegasus/com/linkedin/ownership/OwnershipTypeInfo.pdl
index 004df6e399be4..3e7b53beff531 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/ownership/OwnershipTypeInfo.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/ownership/OwnershipTypeInfo.pdl
@@ -14,7 +14,7 @@ record OwnershipTypeInfo {
* Display name of the Ownership Type
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
"boostScore": 10.0
}
@@ -54,4 +54,4 @@ record OwnershipTypeInfo {
}
}
lastModified: AuditStamp
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/query/QueryProperties.pdl b/metadata-models/src/main/pegasus/com/linkedin/query/QueryProperties.pdl
index bb7e22900e168..3ba19d348913b 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/query/QueryProperties.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/query/QueryProperties.pdl
@@ -29,7 +29,7 @@ record QueryProperties {
* Optional display name to identify the query.
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
"boostScore": 10.0
}
@@ -69,4 +69,4 @@ record QueryProperties {
}
}
lastModified: AuditStamp
-}
\ No newline at end of file
+}
diff --git a/metadata-models/src/main/pegasus/com/linkedin/role/RoleProperties.pdl b/metadata-models/src/main/pegasus/com/linkedin/role/RoleProperties.pdl
index acebdf5558c59..8422d3c49046c 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/role/RoleProperties.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/role/RoleProperties.pdl
@@ -14,9 +14,10 @@ record RoleProperties {
* Display name of the IAM Role in the external system
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: string
diff --git a/metadata-models/src/main/pegasus/com/linkedin/tag/TagProperties.pdl b/metadata-models/src/main/pegasus/com/linkedin/tag/TagProperties.pdl
index 41c500c6fff2f..9df47fac3928a 100644
--- a/metadata-models/src/main/pegasus/com/linkedin/tag/TagProperties.pdl
+++ b/metadata-models/src/main/pegasus/com/linkedin/tag/TagProperties.pdl
@@ -11,9 +11,10 @@ record TagProperties {
* Display name of the tag
*/
@Searchable = {
- "fieldType": "TEXT_PARTIAL",
+ "fieldType": "WORD_GRAM",
"enableAutocomplete": true,
- "boostScore": 10.0
+ "boostScore": 10.0,
+ "fieldNameAliases": [ "_entityName" ]
}
name: string
diff --git a/metadata-service/auth-config/build.gradle b/metadata-service/auth-config/build.gradle
index 2e9210804bed9..c7a1128897dd5 100644
--- a/metadata-service/auth-config/build.gradle
+++ b/metadata-service/auth-config/build.gradle
@@ -1,9 +1,9 @@
apply plugin: 'java'
dependencies {
- compile project(path: ':metadata-models')
- compile project(path: ':metadata-auth:auth-api')
- compile externalDependency.guava
+ implementation project(path: ':metadata-models')
+ implementation project(path: ':metadata-auth:auth-api')
+ implementation externalDependency.guava
implementation externalDependency.slf4jApi
compileOnly externalDependency.lombok
annotationProcessor externalDependency.lombok
diff --git a/metadata-service/auth-filter/build.gradle b/metadata-service/auth-filter/build.gradle
index 2c77850209205..2dd07ef10274c 100644
--- a/metadata-service/auth-filter/build.gradle
+++ b/metadata-service/auth-filter/build.gradle
@@ -1,15 +1,17 @@
apply plugin: 'java'
dependencies {
- compile project(':metadata-auth:auth-api');
- compile project(path: ':metadata-service:auth-config')
- compile project(path: ':metadata-service:factories')
+ implementation project(':metadata-auth:auth-api')
+ implementation project(':metadata-service:auth-impl')
+ implementation project(path: ':metadata-service:auth-config')
+ implementation project(path: ':metadata-service:factories')
- compile externalDependency.servletApi
+ implementation externalDependency.servletApi
implementation externalDependency.slf4jApi
compileOnly externalDependency.lombok
- compile externalDependency.springWeb
+ implementation externalDependency.springWeb
+ implementation externalDependency.guice
annotationProcessor externalDependency.lombok
- testCompile externalDependency.mockito
+ testImplementation externalDependency.mockito
}
\ No newline at end of file
diff --git a/metadata-service/auth-impl/build.gradle b/metadata-service/auth-impl/build.gradle
index aefbf81577a9b..1ffeb99e7ad4a 100644
--- a/metadata-service/auth-impl/build.gradle
+++ b/metadata-service/auth-impl/build.gradle
@@ -6,11 +6,14 @@ compileJava {
}
dependencies {
- compile project(path: ':metadata-models')
- compile project(path: ':metadata-auth:auth-api')
- compile project(path: ':metadata-service:auth-config')
- compile project(path: ':metadata-io')
-
+ implementation project(path: ':metadata-models')
+ implementation project(path: ':metadata-auth:auth-api')
+ implementation project(path: ':metadata-service:auth-config')
+ implementation project(path: ':metadata-io')
+
+ implementation(externalDependency.mixpanel) {
+ exclude group: 'org.json', module: 'json'
+ }
implementation 'io.jsonwebtoken:jjwt-api:0.11.2'
runtimeOnly 'io.jsonwebtoken:jjwt-impl:0.11.2',
'io.jsonwebtoken:jjwt-jackson:0.11.2'
@@ -20,6 +23,5 @@ dependencies {
annotationProcessor externalDependency.lombok
- testCompile externalDependency.mockito
-
+ testImplementation externalDependency.mockito
}
\ No newline at end of file
diff --git a/metadata-service/auth-impl/src/main/java/com/datahub/authorization/DataHubAuthorizer.java b/metadata-service/auth-impl/src/main/java/com/datahub/authorization/DataHubAuthorizer.java
index 690528059b555..f653ccf72cf54 100644
--- a/metadata-service/auth-impl/src/main/java/com/datahub/authorization/DataHubAuthorizer.java
+++ b/metadata-service/auth-impl/src/main/java/com/datahub/authorization/DataHubAuthorizer.java
@@ -250,11 +250,11 @@ private void addPoliciesToCache(final Map> cache
private void addPolicyToCache(final Map> cache, final DataHubPolicyInfo policy) {
final List privileges = policy.getPrivileges();
for (String privilege : privileges) {
- List existingPolicies = cache.getOrDefault(privilege, new ArrayList<>());
+ List existingPolicies = cache.containsKey(privilege) ? new ArrayList<>(cache.get(privilege)) : new ArrayList<>();
existingPolicies.add(policy);
cache.put(privilege, existingPolicies);
}
- List existingPolicies = cache.getOrDefault(ALL, new ArrayList<>());
+ List existingPolicies = cache.containsKey(ALL) ? new ArrayList<>(cache.get(ALL)) : new ArrayList<>();
existingPolicies.add(policy);
cache.put(ALL, existingPolicies);
}
diff --git a/metadata-service/auth-servlet-impl/build.gradle b/metadata-service/auth-servlet-impl/build.gradle
index 3338f3a5c6b94..7945b3b4e9a06 100644
--- a/metadata-service/auth-servlet-impl/build.gradle
+++ b/metadata-service/auth-servlet-impl/build.gradle
@@ -1,15 +1,17 @@
apply plugin: 'java'
dependencies {
- compile project(':metadata-auth:auth-api')
- compile project(':metadata-service:factories')
+ implementation project(':metadata-auth:auth-api')
+ implementation project(':metadata-service:auth-impl')
+ implementation project(':metadata-service:factories')
- compile externalDependency.springCore
- compile externalDependency.springWeb
- compile externalDependency.springWebMVC
- compile externalDependency.graphqlJava
- compile externalDependency.springBeans
- compile externalDependency.springContext
+ implementation externalDependency.springCore
+ implementation externalDependency.springWeb
+ implementation externalDependency.springWebMVC
+ implementation externalDependency.graphqlJava
+ implementation externalDependency.springBeans
+ implementation externalDependency.springContext
+ implementation externalDependency.guice
implementation externalDependency.slf4jApi
compileOnly externalDependency.lombok
diff --git a/metadata-service/configuration/build.gradle b/metadata-service/configuration/build.gradle
index 8623e53d2554a..30fa3079d29a4 100644
--- a/metadata-service/configuration/build.gradle
+++ b/metadata-service/configuration/build.gradle
@@ -3,7 +3,7 @@ plugins {
}
dependencies {
- compile externalDependency.jacksonDataBind
+ implementation externalDependency.jacksonDataBind
implementation externalDependency.slf4jApi
implementation externalDependency.springCore
diff --git a/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/SearchResultVisualConfig.java b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/SearchResultVisualConfig.java
new file mode 100644
index 0000000000000..7094bbd710f75
--- /dev/null
+++ b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/SearchResultVisualConfig.java
@@ -0,0 +1,11 @@
+package com.linkedin.metadata.config;
+
+import lombok.Data;
+
+@Data
+public class SearchResultVisualConfig {
+ /**
+ * The default tab to show first on a Domain entity profile. Defaults to React code sorting if not present.
+ */
+ public Boolean enableNameHighlight;
+}
diff --git a/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/VisualConfiguration.java b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/VisualConfiguration.java
index d1c357186e1ae..14ac2406c2256 100644
--- a/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/VisualConfiguration.java
+++ b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/VisualConfiguration.java
@@ -22,4 +22,9 @@ public class VisualConfiguration {
* Queries tab related configurations
*/
public EntityProfileConfig entityProfile;
+
+ /**
+ * Search result related configurations
+ */
+ public SearchResultVisualConfig searchResult;
}
diff --git a/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/search/SearchConfiguration.java b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/search/SearchConfiguration.java
index 1a56db1bd68b0..b2b5260dc5e70 100644
--- a/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/search/SearchConfiguration.java
+++ b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/search/SearchConfiguration.java
@@ -11,4 +11,5 @@ public class SearchConfiguration {
private PartialConfiguration partial;
private CustomConfiguration custom;
private GraphQueryConfiguration graph;
+ private WordGramConfiguration wordGram;
}
diff --git a/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/search/WordGramConfiguration.java b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/search/WordGramConfiguration.java
new file mode 100644
index 0000000000000..624d2a4c63c4c
--- /dev/null
+++ b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/search/WordGramConfiguration.java
@@ -0,0 +1,11 @@
+package com.linkedin.metadata.config.search;
+
+import lombok.Data;
+
+
+@Data
+public class WordGramConfiguration {
+ private float twoGramFactor;
+ private float threeGramFactor;
+ private float fourGramFactor;
+}
diff --git a/metadata-service/configuration/src/main/resources/application.yml b/metadata-service/configuration/src/main/resources/application.yml
index 9f7bf92039fdc..f49498bfa2325 100644
--- a/metadata-service/configuration/src/main/resources/application.yml
+++ b/metadata-service/configuration/src/main/resources/application.yml
@@ -111,6 +111,8 @@ visualConfig:
entityProfile:
# we only support default tab for domains right now. In order to implement for other entities, update React code
domainDefaultTab: ${DOMAIN_DEFAULT_TAB:} # set to DOCUMENTATION_TAB to show documentation tab first
+ searchResult:
+ enableNameHighlight: ${SEARCH_RESULT_NAME_HIGHLIGHT_ENABLED:true} # Enables visual highlighting on search result names/descriptions.
# Storage Layer
@@ -198,6 +200,10 @@ elasticsearch:
prefixFactor: ${ELASTICSEARCH_QUERY_EXACT_MATCH_PREFIX_FACTOR:1.6} # boost multiplier when exact prefix
caseSensitivityFactor: ${ELASTICSEARCH_QUERY_EXACT_MATCH_CASE_FACTOR:0.7} # stacked boost multiplier when case mismatch
enableStructured: ${ELASTICSEARCH_QUERY_EXACT_MATCH_ENABLE_STRUCTURED:true} # enable exact match on structured search
+ wordGram:
+ twoGramFactor: ${ELASTICSEARCH_QUERY_TWO_GRAM_FACTOR:1.2} # boost multiplier when match on 2-gram tokens
+ threeGramFactor: ${ELASTICSEARCH_QUERY_THREE_GRAM_FACTOR:1.5} # boost multiplier when match on 3-gram tokens
+ fourGramFactor: ${ELASTICSEARCH_QUERY_FOUR_GRAM_FACTOR:1.8} # boost multiplier when match on 4-gram tokens
# Field weight annotations are typically calibrated for exact match, if partial match is possible on the field use these adjustments
partial:
urnFactor: ${ELASTICSEARCH_QUERY_PARTIAL_URN_FACTOR:0.5} # multiplier on Urn token match, a partial match on Urn > non-Urn is assumed
@@ -288,8 +294,8 @@ featureFlags:
alwaysEmitChangeLog: ${ALWAYS_EMIT_CHANGE_LOG:false} # Enables always emitting a MCL even when no changes are detected. Used for Time Based Lineage when no changes occur.
searchServiceDiffModeEnabled: ${SEARCH_SERVICE_DIFF_MODE_ENABLED:true} # Enables diff mode for search document writes, reduces amount of writes to ElasticSearch documents for no-ops
readOnlyModeEnabled: ${READ_ONLY_MODE_ENABLED:false} # Enables read only mode for an instance. Right now this only affects ability to edit user profile image URL but can be extended
- showSearchFiltersV2: ${SHOW_SEARCH_FILTERS_V2:false} # Enables showing the search filters V2 experience.
- showBrowseV2: ${SHOW_BROWSE_V2:false} # Enables showing the browse v2 sidebar experience.
+ showSearchFiltersV2: ${SHOW_SEARCH_FILTERS_V2:true} # Enables showing the search filters V2 experience.
+ showBrowseV2: ${SHOW_BROWSE_V2:true} # Enables showing the browse v2 sidebar experience.
preProcessHooks:
uiEnabled: ${PRE_PROCESS_HOOKS_UI_ENABLED:true} # Circumvents Kafka for processing index updates for UI changes sourced from GraphQL to avoid processing delays
showAcrylInfo: ${SHOW_ACRYL_INFO:false} # Show different CTAs within DataHub around moving to Managed DataHub. Set to true for the demo site.
@@ -318,4 +324,4 @@ cache:
search:
lineage:
ttlSeconds: ${CACHE_SEARCH_LINEAGE_TTL_SECONDS:86400} # 1 day
- lightningThreshold: ${CACHE_SEARCH_LINEAGE_LIGHTNING_THRESHOLD:300}
\ No newline at end of file
+ lightningThreshold: ${CACHE_SEARCH_LINEAGE_LIGHTNING_THRESHOLD:300}
diff --git a/metadata-service/factories/build.gradle b/metadata-service/factories/build.gradle
index 796b6ee436b78..f848a5e339781 100644
--- a/metadata-service/factories/build.gradle
+++ b/metadata-service/factories/build.gradle
@@ -1,54 +1,64 @@
-apply plugin: 'java'
+apply plugin: 'java-library'
apply from: "../../gradle/versioning/versioning.gradle"
dependencies {
- compile project(':metadata-io')
- compile project(':metadata-utils')
- compile project(':metadata-service:auth-impl')
- compile project(':metadata-service:auth-config')
- compile project(':metadata-service:plugin')
- compile project(':metadata-service:configuration')
- compile project(':datahub-graphql-core')
- compile project(':metadata-service:restli-servlet-impl')
- compile project(':metadata-dao-impl:kafka-producer')
- compile project(':ingestion-scheduler')
-
- compile (externalDependency.awsGlueSchemaRegistrySerde) {
+ api project(':metadata-io')
+ api project(':metadata-utils')
+ implementation project(':metadata-service:auth-impl')
+ api project(':metadata-service:auth-config')
+ api project(':metadata-service:plugin')
+ api project(':metadata-service:configuration')
+ implementation project(':datahub-graphql-core')
+ implementation project(':metadata-service:restli-servlet-impl')
+ implementation project(':metadata-dao-impl:kafka-producer')
+ implementation project(':ingestion-scheduler')
+
+ implementation (externalDependency.awsGlueSchemaRegistrySerde) {
exclude group: 'org.json', module: 'json'
}
- compile externalDependency.elasticSearchRest
- compile externalDependency.httpClient
- compile externalDependency.gson
+ implementation externalDependency.elasticSearchRest
+ implementation externalDependency.httpClient
+ implementation externalDependency.gson
implementation (externalDependency.hazelcast) {
exclude group: 'org.json', module: 'json'
}
- compile externalDependency.hazelcastSpring
- compile externalDependency.kafkaClients
- compile externalDependency.kafkaAvroSerde
+ implementation externalDependency.hazelcastSpring
+ implementation externalDependency.kafkaClients
+ implementation externalDependency.kafkaAvroSerde
compileOnly externalDependency.lombok
- compile externalDependency.servletApi
- compile externalDependency.springBeans
- compile externalDependency.springBootAutoconfigure
- compile externalDependency.springBootStarterCache
- compile externalDependency.springContext
- compile externalDependency.springCore
- compile externalDependency.springKafka
- compile externalDependency.springWeb
+ implementation externalDependency.servletApi
+ api externalDependency.springBeans
+ implementation externalDependency.springBootAutoconfigure
+ implementation externalDependency.springBootStarterCache
+ api externalDependency.springContext
+ api externalDependency.springCore
+ api externalDependency.springKafka
+ api externalDependency.springWeb
implementation externalDependency.awsPostgresIamAuth
implementation externalDependency.awsRds
+ implementation(externalDependency.mixpanel) {
+ exclude group: 'org.json', module: 'json'
+ }
annotationProcessor externalDependency.lombok
- compile spec.product.pegasus.restliSpringBridge
+ implementation spec.product.pegasus.restliSpringBridge
implementation spec.product.pegasus.restliDocgen
+ implementation externalDependency.jline
+ implementation externalDependency.common
testImplementation externalDependency.springBootTest
+ testImplementation externalDependency.mockito
+ testImplementation externalDependency.testng
+ testImplementation externalDependency.hazelcastTest
+ testImplementation externalDependency.javatuples
- testCompile externalDependency.mockito
- testCompile externalDependency.testng
- testCompile externalDependency.hazelcastTest
- implementation externalDependency.jline
- implementation externalDependency.common
+
+ constraints {
+ implementation(externalDependency.snappy) {
+ because("previous versions are vulnerable to CVE-2023-34453 through CVE-2023-34455")
+ }
+ }
}
configurations.all{
diff --git a/metadata-service/factories/src/main/java/com/linkedin/metadata/boot/OnBootApplicationListener.java b/metadata-service/factories/src/main/java/com/linkedin/metadata/boot/OnBootApplicationListener.java
index 0f52bc3816c2d..980cafaceae27 100644
--- a/metadata-service/factories/src/main/java/com/linkedin/metadata/boot/OnBootApplicationListener.java
+++ b/metadata-service/factories/src/main/java/com/linkedin/metadata/boot/OnBootApplicationListener.java
@@ -1,6 +1,7 @@
package com.linkedin.metadata.boot;
import com.linkedin.gms.factory.config.ConfigurationProvider;
+import com.linkedin.gms.factory.kafka.schemaregistry.InternalSchemaRegistryFactory;
import java.io.IOException;
import java.util.Set;
import java.util.concurrent.ExecutorService;
@@ -48,12 +49,17 @@ public class OnBootApplicationListener {
public void onApplicationEvent(@Nonnull ContextRefreshedEvent event) {
log.warn("OnBootApplicationListener context refreshed! {} event: {}",
ROOT_WEB_APPLICATION_CONTEXT_ID.equals(event.getApplicationContext().getId()), event);
+ String schemaRegistryType = provider.getKafka().getSchemaRegistry().getType();
if (ROOT_WEB_APPLICATION_CONTEXT_ID.equals(event.getApplicationContext().getId())) {
- executorService.submit(isSchemaRegistryAPIServeletReady());
+ if (InternalSchemaRegistryFactory.TYPE.equals(schemaRegistryType)) {
+ executorService.submit(isSchemaRegistryAPIServletReady());
+ } else {
+ _bootstrapManager.start();
+ }
}
}
- public Runnable isSchemaRegistryAPIServeletReady() {
+ public Runnable isSchemaRegistryAPIServletReady() {
return () -> {
final HttpGet request = new HttpGet(provider.getKafka().getSchemaRegistry().getUrl());
int timeouts = 30;
diff --git a/metadata-service/graphql-servlet-impl/build.gradle b/metadata-service/graphql-servlet-impl/build.gradle
index ff64f9a8a8233..52fd20ef32389 100644
--- a/metadata-service/graphql-servlet-impl/build.gradle
+++ b/metadata-service/graphql-servlet-impl/build.gradle
@@ -1,16 +1,19 @@
apply plugin: 'java'
dependencies {
- compile project(':datahub-graphql-core')
- compile project(':metadata-auth:auth-api')
- compile project(':metadata-service:factories')
+ implementation project(':datahub-graphql-core')
+ implementation project(':metadata-auth:auth-api')
+ implementation project(':metadata-service:auth-impl')
+ implementation project(':metadata-service:factories')
- compile externalDependency.springCore
- compile externalDependency.springWeb
- compile externalDependency.springWebMVC
- compile externalDependency.graphqlJava
- compile externalDependency.springBeans
- compile externalDependency.springContext
+ implementation externalDependency.servletApi
+ implementation externalDependency.springCore
+ implementation externalDependency.springWeb
+ implementation externalDependency.springWebMVC
+ implementation externalDependency.graphqlJava
+ implementation externalDependency.springBeans
+ implementation externalDependency.springContext
+ implementation externalDependency.guice
implementation externalDependency.slf4jApi
compileOnly externalDependency.lombok
annotationProcessor externalDependency.lombok
diff --git a/metadata-service/health-servlet/build.gradle b/metadata-service/health-servlet/build.gradle
index 3237c56779ada..6095f724b3cd4 100644
--- a/metadata-service/health-servlet/build.gradle
+++ b/metadata-service/health-servlet/build.gradle
@@ -2,16 +2,17 @@ apply plugin: 'java'
dependencies {
- compile project(':metadata-service:factories')
+ implementation project(':metadata-service:factories')
- compile externalDependency.reflections
- compile externalDependency.springBoot
- compile externalDependency.springCore
- compile externalDependency.springDocUI
- compile externalDependency.springWeb
- compile externalDependency.springWebMVC
- compile externalDependency.springBeans
- compile externalDependency.springContext
+ implementation externalDependency.guava
+ implementation externalDependency.reflections
+ implementation externalDependency.springBoot
+ implementation externalDependency.springCore
+ implementation externalDependency.springDocUI
+ implementation externalDependency.springWeb
+ implementation externalDependency.springWebMVC
+ implementation externalDependency.springBeans
+ implementation externalDependency.springContext
implementation externalDependency.slf4jApi
compileOnly externalDependency.lombok
implementation externalDependency.antlr4Runtime
diff --git a/metadata-service/health-servlet/src/main/java/com/datahub/health/controller/HealthCheckController.java b/metadata-service/health-servlet/src/main/java/com/datahub/health/controller/HealthCheckController.java
index 45edcb2a6a5d9..02ca5182cd2be 100644
--- a/metadata-service/health-servlet/src/main/java/com/datahub/health/controller/HealthCheckController.java
+++ b/metadata-service/health-servlet/src/main/java/com/datahub/health/controller/HealthCheckController.java
@@ -10,6 +10,7 @@
import java.util.Map;
import java.util.concurrent.TimeUnit;
import java.util.function.Supplier;
+
import org.elasticsearch.action.admin.cluster.health.ClusterHealthRequest;
import org.elasticsearch.action.admin.cluster.health.ClusterHealthResponse;
import org.elasticsearch.client.RequestOptions;
diff --git a/metadata-service/openapi-servlet/build.gradle b/metadata-service/openapi-servlet/build.gradle
index 7cd022f97247c..1909b4862d294 100644
--- a/metadata-service/openapi-servlet/build.gradle
+++ b/metadata-service/openapi-servlet/build.gradle
@@ -2,36 +2,38 @@ apply plugin: 'java'
dependencies {
- compile project(':metadata-auth:auth-api')
- compile project(':metadata-service:factories')
- compile project(':metadata-service:schema-registry-api')
+ implementation project(':metadata-auth:auth-api')
+ implementation project(':metadata-service:auth-impl')
+ implementation project(':metadata-service:factories')
+ implementation project(':metadata-service:schema-registry-api')
- compile externalDependency.reflections
- compile externalDependency.springBoot
- compile externalDependency.springCore
- compile(externalDependency.springDocUI) {
+ implementation externalDependency.reflections
+ implementation externalDependency.springBoot
+ implementation externalDependency.springCore
+ implementation(externalDependency.springDocUI) {
exclude group: 'org.springframework.boot'
}
- compile externalDependency.springWeb
- compile externalDependency.springWebMVC
- compile externalDependency.springBeans
- compile externalDependency.springContext
+ implementation externalDependency.springWeb
+ implementation externalDependency.springWebMVC
+ implementation externalDependency.springBeans
+ implementation externalDependency.springContext
implementation externalDependency.slf4jApi
compileOnly externalDependency.lombok
implementation externalDependency.antlr4Runtime
implementation externalDependency.antlr4
+ implementation externalDependency.swaggerAnnotations
annotationProcessor externalDependency.lombok
testImplementation externalDependency.springBootTest
testImplementation project(':mock-entity-registry')
- testCompile externalDependency.springBoot
- testCompile externalDependency.testContainers
- testCompile externalDependency.springKafka
- testCompile externalDependency.testng
- testCompile externalDependency.mockito
- testCompile externalDependency.logbackClassic
- testCompile externalDependency.jacksonCore
- testCompile externalDependency.jacksonDataBind
- testCompile externalDependency.springBootStarterWeb
+ testImplementation externalDependency.springBoot
+ testImplementation externalDependency.testContainers
+ testImplementation externalDependency.springKafka
+ testImplementation externalDependency.testng
+ testImplementation externalDependency.mockito
+ testImplementation externalDependency.logbackClassic
+ testImplementation externalDependency.jacksonCore
+ testImplementation externalDependency.jacksonDataBind
+ testImplementation externalDependency.springBootStarterWeb
}
\ No newline at end of file
diff --git a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/relationships/RelationshipsController.java b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/relationships/RelationshipsController.java
index 796a7774da303..1e37170f37b3b 100644
--- a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/relationships/RelationshipsController.java
+++ b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/relationships/RelationshipsController.java
@@ -18,8 +18,11 @@
import com.linkedin.metadata.search.utils.QueryUtils;
import com.linkedin.metadata.utils.metrics.MetricUtils;
import io.datahubproject.openapi.exception.UnauthorizedException;
-import io.swagger.annotations.ApiOperation;
+import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
+import io.swagger.v3.oas.annotations.media.Content;
+import io.swagger.v3.oas.annotations.media.Schema;
+import io.swagger.v3.oas.annotations.responses.ApiResponse;
import io.swagger.v3.oas.annotations.tags.Tag;
import java.net.URLDecoder;
import java.nio.charset.Charset;
@@ -94,7 +97,8 @@ private RelatedEntitiesResult getRelatedEntities(String rawUrn, List rel
}
@GetMapping(value = "/", produces = MediaType.APPLICATION_JSON_VALUE)
- @ApiOperation(code = 0, response = RelatedEntitiesResult.class, value = "")
+ @Operation(responses = { @ApiResponse(responseCode = "0", description = "",
+ content = @Content(schema = @Schema(implementation = RelatedEntitiesResult.class)))})
public ResponseEntity getRelationships(
@Parameter(name = "urn", required = true,
description = "The urn for the entity whose relationships are being queried")
diff --git a/metadata-service/plugin/src/test/sample-test-plugins/build.gradle b/metadata-service/plugin/src/test/sample-test-plugins/build.gradle
index 7d4b43402a586..f299a35db0f64 100644
--- a/metadata-service/plugin/src/test/sample-test-plugins/build.gradle
+++ b/metadata-service/plugin/src/test/sample-test-plugins/build.gradle
@@ -7,6 +7,7 @@ dependencies {
implementation project(path: ':metadata-auth:auth-api')
implementation externalDependency.lombok
implementation externalDependency.logbackClassic;
+ implementation 'com.google.code.findbugs:jsr305:3.0.2'
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
diff --git a/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.aspects.snapshot.json b/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.aspects.snapshot.json
index 7aeca546af3c9..ee6318026e27d 100644
--- a/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.aspects.snapshot.json
+++ b/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.aspects.snapshot.json
@@ -72,6 +72,11 @@
"doc" : "The run id that produced the metadata. Populated in case of batch-ingestion.",
"default" : "no-run-id-provided",
"optional" : true
+ }, {
+ "name" : "pipelineName",
+ "type" : "string",
+ "doc" : "The ingestion pipeline id that produced the metadata. Populated in case of batch ingestion.",
+ "optional" : true
}, {
"name" : "registryName",
"type" : "string",
@@ -341,7 +346,8 @@
"doc" : "Title of the chart",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1279,7 +1285,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1405,7 +1412,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1464,7 +1472,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1865,7 +1874,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "qualifiedName",
@@ -1876,7 +1886,7 @@
"addToFilters" : false,
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -2061,7 +2071,8 @@
"boostScore" : 10.0,
"enableAutocomplete" : true,
"fieldName" : "displayName",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "id",
@@ -2097,7 +2108,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "definition",
@@ -2161,6 +2173,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
+ "fieldNameAliases" : [ "_entityName" ],
"fieldType" : "TEXT_PARTIAL",
"queryByDefault" : true
}
@@ -2288,7 +2301,7 @@
"optional" : true,
"Searchable" : {
"boostScore" : 10.0,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2340,7 +2353,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2403,7 +2417,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2496,7 +2510,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
} ],
@@ -2516,7 +2530,7 @@
"boostScore" : 2.0,
"enableAutocomplete" : true,
"fieldName" : "ldap",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -2562,7 +2576,7 @@
"doc" : "Unique Identifier of the data flow",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "cluster",
@@ -2599,7 +2613,7 @@
"doc" : "Unique Identifier of the data job",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -3174,7 +3188,7 @@
"type" : "string",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -3192,7 +3206,7 @@
"Searchable" : {
"enableAutocomplete" : true,
"fieldName" : "id",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -3217,7 +3231,8 @@
"Searchable" : {
"boostScore" : 8.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -3282,7 +3297,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "origin",
@@ -3849,7 +3865,7 @@
"boostScore" : 10.0,
"enableAutocomplete" : true,
"fieldName" : "id",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -3867,7 +3883,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
diff --git a/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.entities.snapshot.json b/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.entities.snapshot.json
index 83ecaf41022c4..d63a938bbce9d 100644
--- a/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.entities.snapshot.json
+++ b/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.entities.snapshot.json
@@ -94,7 +94,8 @@
"doc" : "Title of the chart",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1326,7 +1327,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1471,7 +1473,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1530,7 +1533,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1922,7 +1926,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : false,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
},
"validate" : {
"strlen" : {
@@ -1937,7 +1942,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "type",
@@ -2111,7 +2116,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "qualifiedName",
@@ -2122,7 +2128,7 @@
"addToFilters" : false,
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -2417,7 +2423,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
} ],
@@ -2437,6 +2443,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
+ "fieldNameAliases" : [ "_entityName" ],
"fieldType" : "TEXT_PARTIAL",
"queryByDefault" : true
}
@@ -2555,7 +2562,7 @@
"boostScore" : 2.0,
"enableAutocomplete" : true,
"fieldName" : "ldap",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -2585,7 +2592,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2648,7 +2656,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2709,7 +2717,7 @@
"optional" : true,
"Searchable" : {
"boostScore" : 10.0,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2870,7 +2878,7 @@
"doc" : "Unique Identifier of the data flow",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "cluster",
@@ -2933,7 +2941,7 @@
"doc" : "Unique Identifier of the data job",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -2986,7 +2994,7 @@
"boostScore" : 10.0,
"enableAutocomplete" : true,
"fieldName" : "id",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "origin",
@@ -3599,7 +3607,7 @@
"Searchable" : {
"boostScore" : 4.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "orchestrator",
@@ -3704,7 +3712,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "origin",
@@ -4302,7 +4311,8 @@
"Searchable" : {
"boostScore" : 8.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -4390,7 +4400,8 @@
"Searchable" : {
"boostScore" : 8.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -4484,7 +4495,8 @@
"Searchable" : {
"boostScore" : 8.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -4590,7 +4602,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "origin",
@@ -4696,7 +4709,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "origin",
@@ -4778,7 +4792,7 @@
"boostScore" : 10.0,
"enableAutocomplete" : true,
"fieldName" : "id",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -4796,7 +4810,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -4851,7 +4866,7 @@
"Searchable" : {
"enableAutocomplete" : true,
"fieldName" : "id",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -4879,7 +4894,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "definition",
@@ -5057,7 +5073,7 @@
"type" : "string",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -5096,7 +5112,8 @@
"boostScore" : 10.0,
"enableAutocomplete" : true,
"fieldName" : "displayName",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "id",
@@ -5710,6 +5727,12 @@
"doc" : "Whether to skip aggregates/facets",
"default" : false,
"optional" : true
+ }, {
+ "name" : "getSuggestions",
+ "type" : "boolean",
+ "doc" : "Whether to request for search suggestions on the _entityName virtualized field",
+ "default" : false,
+ "optional" : true
} ]
}, {
"type" : "enum",
@@ -6081,6 +6104,31 @@
},
"doc" : "A list of search result metadata such as aggregations",
"default" : [ ]
+ }, {
+ "name" : "suggestions",
+ "type" : {
+ "type" : "array",
+ "items" : {
+ "type" : "record",
+ "name" : "SearchSuggestion",
+ "doc" : "The model for the search result",
+ "fields" : [ {
+ "name" : "text",
+ "type" : "string",
+ "doc" : "The suggestion text for this search query"
+ }, {
+ "name" : "score",
+ "type" : "float",
+ "doc" : "The score for how close this suggestion is to the original search query.\nThe closer to 1 means it is closer to the original query and 0 is further away."
+ }, {
+ "name" : "frequency",
+ "type" : "long",
+ "doc" : "How many matches there are with the suggested text for the given field"
+ } ]
+ }
+ },
+ "doc" : "A list of search query suggestions based on the given query",
+ "default" : [ ]
} ]
},
"doc" : "Metadata specific to the browse result of the queried path"
@@ -6187,7 +6235,7 @@
"type" : "int",
"doc" : "The total number of entities directly under searched path"
} ]
- }, "com.linkedin.metadata.search.SearchResultMetadata", "com.linkedin.metadata.snapshot.ChartSnapshot", "com.linkedin.metadata.snapshot.CorpGroupSnapshot", "com.linkedin.metadata.snapshot.CorpUserSnapshot", "com.linkedin.metadata.snapshot.DashboardSnapshot", "com.linkedin.metadata.snapshot.DataFlowSnapshot", "com.linkedin.metadata.snapshot.DataHubPolicySnapshot", "com.linkedin.metadata.snapshot.DataHubRetentionSnapshot", "com.linkedin.metadata.snapshot.DataJobSnapshot", "com.linkedin.metadata.snapshot.DataPlatformSnapshot", "com.linkedin.metadata.snapshot.DataProcessSnapshot", "com.linkedin.metadata.snapshot.DatasetSnapshot", "com.linkedin.metadata.snapshot.GlossaryNodeSnapshot", "com.linkedin.metadata.snapshot.GlossaryTermSnapshot", "com.linkedin.metadata.snapshot.MLFeatureSnapshot", "com.linkedin.metadata.snapshot.MLFeatureTableSnapshot", "com.linkedin.metadata.snapshot.MLModelDeploymentSnapshot", "com.linkedin.metadata.snapshot.MLModelGroupSnapshot", "com.linkedin.metadata.snapshot.MLModelSnapshot", "com.linkedin.metadata.snapshot.MLPrimaryKeySnapshot", "com.linkedin.metadata.snapshot.SchemaFieldSnapshot", "com.linkedin.metadata.snapshot.Snapshot", "com.linkedin.metadata.snapshot.TagSnapshot", "com.linkedin.ml.metadata.BaseData", "com.linkedin.ml.metadata.CaveatDetails", "com.linkedin.ml.metadata.CaveatsAndRecommendations", "com.linkedin.ml.metadata.DeploymentStatus", "com.linkedin.ml.metadata.EthicalConsiderations", "com.linkedin.ml.metadata.EvaluationData", "com.linkedin.ml.metadata.HyperParameterValueType", "com.linkedin.ml.metadata.IntendedUse", "com.linkedin.ml.metadata.IntendedUserType", "com.linkedin.ml.metadata.MLFeatureProperties", "com.linkedin.ml.metadata.MLFeatureTableProperties", "com.linkedin.ml.metadata.MLHyperParam", "com.linkedin.ml.metadata.MLMetric", "com.linkedin.ml.metadata.MLModelDeploymentProperties", "com.linkedin.ml.metadata.MLModelFactorPrompts", "com.linkedin.ml.metadata.MLModelFactors", "com.linkedin.ml.metadata.MLModelGroupProperties", "com.linkedin.ml.metadata.MLModelProperties", "com.linkedin.ml.metadata.MLPrimaryKeyProperties", "com.linkedin.ml.metadata.Metrics", "com.linkedin.ml.metadata.QuantitativeAnalyses", "com.linkedin.ml.metadata.ResultsType", "com.linkedin.ml.metadata.SourceCode", "com.linkedin.ml.metadata.SourceCodeUrl", "com.linkedin.ml.metadata.SourceCodeUrlType", "com.linkedin.ml.metadata.TrainingData", {
+ }, "com.linkedin.metadata.search.SearchResultMetadata", "com.linkedin.metadata.search.SearchSuggestion", "com.linkedin.metadata.snapshot.ChartSnapshot", "com.linkedin.metadata.snapshot.CorpGroupSnapshot", "com.linkedin.metadata.snapshot.CorpUserSnapshot", "com.linkedin.metadata.snapshot.DashboardSnapshot", "com.linkedin.metadata.snapshot.DataFlowSnapshot", "com.linkedin.metadata.snapshot.DataHubPolicySnapshot", "com.linkedin.metadata.snapshot.DataHubRetentionSnapshot", "com.linkedin.metadata.snapshot.DataJobSnapshot", "com.linkedin.metadata.snapshot.DataPlatformSnapshot", "com.linkedin.metadata.snapshot.DataProcessSnapshot", "com.linkedin.metadata.snapshot.DatasetSnapshot", "com.linkedin.metadata.snapshot.GlossaryNodeSnapshot", "com.linkedin.metadata.snapshot.GlossaryTermSnapshot", "com.linkedin.metadata.snapshot.MLFeatureSnapshot", "com.linkedin.metadata.snapshot.MLFeatureTableSnapshot", "com.linkedin.metadata.snapshot.MLModelDeploymentSnapshot", "com.linkedin.metadata.snapshot.MLModelGroupSnapshot", "com.linkedin.metadata.snapshot.MLModelSnapshot", "com.linkedin.metadata.snapshot.MLPrimaryKeySnapshot", "com.linkedin.metadata.snapshot.SchemaFieldSnapshot", "com.linkedin.metadata.snapshot.Snapshot", "com.linkedin.metadata.snapshot.TagSnapshot", "com.linkedin.ml.metadata.BaseData", "com.linkedin.ml.metadata.CaveatDetails", "com.linkedin.ml.metadata.CaveatsAndRecommendations", "com.linkedin.ml.metadata.DeploymentStatus", "com.linkedin.ml.metadata.EthicalConsiderations", "com.linkedin.ml.metadata.EvaluationData", "com.linkedin.ml.metadata.HyperParameterValueType", "com.linkedin.ml.metadata.IntendedUse", "com.linkedin.ml.metadata.IntendedUserType", "com.linkedin.ml.metadata.MLFeatureProperties", "com.linkedin.ml.metadata.MLFeatureTableProperties", "com.linkedin.ml.metadata.MLHyperParam", "com.linkedin.ml.metadata.MLMetric", "com.linkedin.ml.metadata.MLModelDeploymentProperties", "com.linkedin.ml.metadata.MLModelFactorPrompts", "com.linkedin.ml.metadata.MLModelFactors", "com.linkedin.ml.metadata.MLModelGroupProperties", "com.linkedin.ml.metadata.MLModelProperties", "com.linkedin.ml.metadata.MLPrimaryKeyProperties", "com.linkedin.ml.metadata.Metrics", "com.linkedin.ml.metadata.QuantitativeAnalyses", "com.linkedin.ml.metadata.ResultsType", "com.linkedin.ml.metadata.SourceCode", "com.linkedin.ml.metadata.SourceCodeUrl", "com.linkedin.ml.metadata.SourceCodeUrlType", "com.linkedin.ml.metadata.TrainingData", {
"type" : "record",
"name" : "SystemMetadata",
"namespace" : "com.linkedin.mxe",
@@ -6204,6 +6252,11 @@
"doc" : "The run id that produced the metadata. Populated in case of batch-ingestion.",
"default" : "no-run-id-provided",
"optional" : true
+ }, {
+ "name" : "pipelineName",
+ "type" : "string",
+ "doc" : "The ingestion pipeline id that produced the metadata. Populated in case of batch ingestion.",
+ "optional" : true
}, {
"name" : "registryName",
"type" : "string",
diff --git a/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.entitiesV2.snapshot.json b/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.entitiesV2.snapshot.json
index de65aa841876f..0b31bf9683d0c 100644
--- a/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.entitiesV2.snapshot.json
+++ b/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.entitiesV2.snapshot.json
@@ -117,6 +117,11 @@
"doc" : "The run id that produced the metadata. Populated in case of batch-ingestion.",
"default" : "no-run-id-provided",
"optional" : true
+ }, {
+ "name" : "pipelineName",
+ "type" : "string",
+ "doc" : "The ingestion pipeline id that produced the metadata. Populated in case of batch ingestion.",
+ "optional" : true
}, {
"name" : "registryName",
"type" : "string",
diff --git a/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.entitiesVersionedV2.snapshot.json b/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.entitiesVersionedV2.snapshot.json
index b7bcd8db99691..24a4ec2cc6802 100644
--- a/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.entitiesVersionedV2.snapshot.json
+++ b/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.entitiesVersionedV2.snapshot.json
@@ -126,6 +126,11 @@
"doc" : "The run id that produced the metadata. Populated in case of batch-ingestion.",
"default" : "no-run-id-provided",
"optional" : true
+ }, {
+ "name" : "pipelineName",
+ "type" : "string",
+ "doc" : "The ingestion pipeline id that produced the metadata. Populated in case of batch ingestion.",
+ "optional" : true
}, {
"name" : "registryName",
"type" : "string",
diff --git a/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.runs.snapshot.json b/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.runs.snapshot.json
index b1489df3db55e..b20953749ac35 100644
--- a/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.runs.snapshot.json
+++ b/metadata-service/restli-api/src/main/snapshot/com.linkedin.entity.runs.snapshot.json
@@ -94,7 +94,8 @@
"doc" : "Title of the chart",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1032,7 +1033,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1158,7 +1160,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1217,7 +1220,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1618,7 +1622,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "qualifiedName",
@@ -1629,7 +1634,7 @@
"addToFilters" : false,
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1806,7 +1811,8 @@
"boostScore" : 10.0,
"enableAutocomplete" : true,
"fieldName" : "displayName",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "id",
@@ -1842,7 +1848,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "definition",
@@ -1906,6 +1913,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
+ "fieldNameAliases" : [ "_entityName" ],
"fieldType" : "TEXT_PARTIAL",
"queryByDefault" : true
}
@@ -2033,7 +2041,7 @@
"optional" : true,
"Searchable" : {
"boostScore" : 10.0,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2085,7 +2093,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2148,7 +2157,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2241,7 +2250,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
} ],
@@ -2261,7 +2270,7 @@
"boostScore" : 2.0,
"enableAutocomplete" : true,
"fieldName" : "ldap",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -2307,7 +2316,7 @@
"doc" : "Unique Identifier of the data flow",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "cluster",
@@ -2344,7 +2353,7 @@
"doc" : "Unique Identifier of the data job",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -2919,7 +2928,7 @@
"type" : "string",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -2937,7 +2946,7 @@
"Searchable" : {
"enableAutocomplete" : true,
"fieldName" : "id",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -2962,7 +2971,8 @@
"Searchable" : {
"boostScore" : 8.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -3027,7 +3037,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "origin",
@@ -3594,7 +3605,7 @@
"boostScore" : 10.0,
"enableAutocomplete" : true,
"fieldName" : "id",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -3612,7 +3623,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
diff --git a/metadata-service/restli-api/src/main/snapshot/com.linkedin.operations.operations.snapshot.json b/metadata-service/restli-api/src/main/snapshot/com.linkedin.operations.operations.snapshot.json
index f4c2d16f84747..e29dd6809b968 100644
--- a/metadata-service/restli-api/src/main/snapshot/com.linkedin.operations.operations.snapshot.json
+++ b/metadata-service/restli-api/src/main/snapshot/com.linkedin.operations.operations.snapshot.json
@@ -94,7 +94,8 @@
"doc" : "Title of the chart",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1032,7 +1033,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1158,7 +1160,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1217,7 +1220,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1618,7 +1622,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "qualifiedName",
@@ -1629,7 +1634,7 @@
"addToFilters" : false,
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1800,7 +1805,8 @@
"boostScore" : 10.0,
"enableAutocomplete" : true,
"fieldName" : "displayName",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "id",
@@ -1836,7 +1842,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "definition",
@@ -1900,6 +1907,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
+ "fieldNameAliases" : [ "_entityName" ],
"fieldType" : "TEXT_PARTIAL",
"queryByDefault" : true
}
@@ -2027,7 +2035,7 @@
"optional" : true,
"Searchable" : {
"boostScore" : 10.0,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2079,7 +2087,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2142,7 +2151,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2235,7 +2244,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
} ],
@@ -2255,7 +2264,7 @@
"boostScore" : 2.0,
"enableAutocomplete" : true,
"fieldName" : "ldap",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -2301,7 +2310,7 @@
"doc" : "Unique Identifier of the data flow",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "cluster",
@@ -2338,7 +2347,7 @@
"doc" : "Unique Identifier of the data job",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -2913,7 +2922,7 @@
"type" : "string",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -2931,7 +2940,7 @@
"Searchable" : {
"enableAutocomplete" : true,
"fieldName" : "id",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -2956,7 +2965,8 @@
"Searchable" : {
"boostScore" : 8.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -3021,7 +3031,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "origin",
@@ -3588,7 +3599,7 @@
"boostScore" : 10.0,
"enableAutocomplete" : true,
"fieldName" : "id",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -3606,7 +3617,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
diff --git a/metadata-service/restli-api/src/main/snapshot/com.linkedin.platform.platform.snapshot.json b/metadata-service/restli-api/src/main/snapshot/com.linkedin.platform.platform.snapshot.json
index 2676c2687bd72..8391af60f8ece 100644
--- a/metadata-service/restli-api/src/main/snapshot/com.linkedin.platform.platform.snapshot.json
+++ b/metadata-service/restli-api/src/main/snapshot/com.linkedin.platform.platform.snapshot.json
@@ -94,7 +94,8 @@
"doc" : "Title of the chart",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1326,7 +1327,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1471,7 +1473,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1530,7 +1533,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -1922,7 +1926,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : false,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
},
"validate" : {
"strlen" : {
@@ -1937,7 +1942,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "type",
@@ -2111,7 +2116,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "qualifiedName",
@@ -2122,7 +2128,7 @@
"addToFilters" : false,
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -2411,7 +2417,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
} ],
@@ -2431,6 +2437,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
+ "fieldNameAliases" : [ "_entityName" ],
"fieldType" : "TEXT_PARTIAL",
"queryByDefault" : true
}
@@ -2549,7 +2556,7 @@
"boostScore" : 2.0,
"enableAutocomplete" : true,
"fieldName" : "ldap",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -2579,7 +2586,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2642,7 +2650,7 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2703,7 +2711,7 @@
"optional" : true,
"Searchable" : {
"boostScore" : 10.0,
- "fieldType" : "TEXT_PARTIAL",
+ "fieldType" : "WORD_GRAM",
"queryByDefault" : true
}
}, {
@@ -2864,7 +2872,7 @@
"doc" : "Unique Identifier of the data flow",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "cluster",
@@ -2927,7 +2935,7 @@
"doc" : "Unique Identifier of the data job",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -2980,7 +2988,7 @@
"boostScore" : 10.0,
"enableAutocomplete" : true,
"fieldName" : "id",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "origin",
@@ -3593,7 +3601,7 @@
"Searchable" : {
"boostScore" : 4.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "orchestrator",
@@ -3698,7 +3706,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "origin",
@@ -4296,7 +4305,8 @@
"Searchable" : {
"boostScore" : 8.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -4384,7 +4394,8 @@
"Searchable" : {
"boostScore" : 8.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -4478,7 +4489,8 @@
"Searchable" : {
"boostScore" : 8.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -4584,7 +4596,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "origin",
@@ -4690,7 +4703,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "origin",
@@ -4772,7 +4786,7 @@
"boostScore" : 10.0,
"enableAutocomplete" : true,
"fieldName" : "id",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -4790,7 +4804,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "description",
@@ -4845,7 +4860,7 @@
"Searchable" : {
"enableAutocomplete" : true,
"fieldName" : "id",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -4873,7 +4888,8 @@
"Searchable" : {
"boostScore" : 10.0,
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "definition",
@@ -5051,7 +5067,7 @@
"type" : "string",
"Searchable" : {
"enableAutocomplete" : true,
- "fieldType" : "TEXT_PARTIAL"
+ "fieldType" : "WORD_GRAM"
}
} ],
"Aspect" : {
@@ -5090,7 +5106,8 @@
"boostScore" : 10.0,
"enableAutocomplete" : true,
"fieldName" : "displayName",
- "fieldType" : "TEXT_PARTIAL"
+ "fieldNameAliases" : [ "_entityName" ],
+ "fieldType" : "WORD_GRAM"
}
}, {
"name" : "id",
diff --git a/metadata-service/restli-client/build.gradle b/metadata-service/restli-client/build.gradle
index 263d4b49197f4..45cf008d3ca7d 100644
--- a/metadata-service/restli-client/build.gradle
+++ b/metadata-service/restli-client/build.gradle
@@ -1,18 +1,19 @@
apply plugin: 'pegasus'
+apply plugin: 'java-library'
dependencies {
- compile project(':metadata-service:restli-api')
- compile project(':metadata-auth:auth-api')
- compile project(path: ':metadata-service:restli-api', configuration: 'restClient')
- compile project(':metadata-events:mxe-schemas')
- compile project(':metadata-utils')
+ api project(':metadata-service:restli-api')
+ api project(':metadata-auth:auth-api')
+ api project(path: ':metadata-service:restli-api', configuration: 'restClient')
+ api project(':metadata-events:mxe-schemas')
+ api project(':metadata-utils')
implementation externalDependency.slf4jApi
compileOnly externalDependency.lombok
annotationProcessor externalDependency.lombok
- compile spec.product.pegasus.restliClient
+ implementation spec.product.pegasus.restliClient
- testCompile externalDependency.mockito
- testCompile externalDependency.testng
+ testImplementation externalDependency.mockito
+ testImplementation externalDependency.testng
}
diff --git a/metadata-service/restli-servlet-impl/build.gradle b/metadata-service/restli-servlet-impl/build.gradle
index 1028f7c3dcce4..cb307863748c3 100644
--- a/metadata-service/restli-servlet-impl/build.gradle
+++ b/metadata-service/restli-servlet-impl/build.gradle
@@ -11,7 +11,7 @@ sourceSets {
idea {
module {
testSourceDirs += file('src/integTest/java')
- scopes.TEST.plus += [ configurations.integTestCompile ]
+ scopes.TEST.plus += [ configurations.integTestCompileOnly ]
}
}
@@ -19,6 +19,10 @@ idea {
configurations {
integTestImplementation.extendsFrom implementation
integTestRuntimeOnly.extendsFrom runtimeOnly
+ integTestCompileOnly {
+ extendsFrom compileOnly
+ canBeResolved = true
+ }
modelValidation
}
@@ -32,34 +36,37 @@ dependencies {
}
}
- compile project(':metadata-service:restli-api')
- compile project(':metadata-auth:auth-api')
- compile project(path: ':metadata-service:restli-api', configuration: 'dataTemplate')
- compile project(':li-utils')
- compile project(':metadata-models')
- compile project(':metadata-utils')
- compile project(':metadata-io')
- compile spec.product.pegasus.restliServer
+ implementation project(':metadata-service:restli-api')
+ implementation project(':metadata-auth:auth-api')
+ implementation project(path: ':metadata-service:restli-api', configuration: 'dataTemplate')
+ implementation project(':li-utils')
+ implementation project(':metadata-models')
+ implementation project(':metadata-utils')
+ implementation project(':metadata-io')
+ implementation spec.product.pegasus.restliServer
implementation externalDependency.slf4jApi
- // This is compile and not compileOnly because of restli
- compile externalDependency.lombok
- compile externalDependency.neo4jJavaDriver
- compile externalDependency.opentelemetryAnnotations
+ implementation externalDependency.dropwizardMetricsCore
+ implementation externalDependency.dropwizardMetricsJmx
+
+ compileOnly externalDependency.lombok
+ implementation externalDependency.neo4jJavaDriver
+ implementation externalDependency.opentelemetryAnnotations
runtimeOnly externalDependency.logbackClassic
annotationProcessor externalDependency.lombok
- testCompile project(':test-models')
+ testImplementation project(':test-models')
+ testImplementation project(path: ':test-models', configuration: 'testDataTemplate')
testImplementation project(':mock-entity-registry')
- testCompile externalDependency.mockito
- testCompile externalDependency.testng
+ testImplementation externalDependency.mockito
+ testImplementation externalDependency.testng
integTestImplementation externalDependency.junitJupiterApi
integTestRuntimeOnly externalDependency.junitJupiterEngine
- integTestCompile externalDependency.junitJupiterApi
- integTestCompile externalDependency.junitJupiterParams
+ integTestCompileOnly externalDependency.junitJupiterApi
+ integTestCompileOnly externalDependency.junitJupiterParams
modelValidation project(path: ':metadata-models-validator')
dataModel project(path: ':metadata-models', configuration: 'dataTemplate')
diff --git a/metadata-service/schema-registry-api/build.gradle b/metadata-service/schema-registry-api/build.gradle
index e60ca7d348b5c..7bf1e558c8906 100644
--- a/metadata-service/schema-registry-api/build.gradle
+++ b/metadata-service/schema-registry-api/build.gradle
@@ -3,26 +3,26 @@ apply plugin: 'org.hidetake.swagger.generator'
dependencies {
// Dependencies for open api
- compile externalDependency.reflections
- compile externalDependency.springBoot
- compile externalDependency.springCore
- compile externalDependency.springWeb
- compile externalDependency.springWebMVC
- compile externalDependency.springBeans
- compile externalDependency.springContext
+ implementation externalDependency.reflections
+ implementation externalDependency.springBoot
+ implementation externalDependency.springCore
+ implementation externalDependency.springWeb
+ implementation externalDependency.springWebMVC
+ implementation externalDependency.springBeans
+ implementation externalDependency.springContext
implementation externalDependency.antlr4Runtime
implementation externalDependency.antlr4
- compile externalDependency.javaxValidation
- compile externalDependency.servletApi
- compile group: 'javax.annotation', name: 'javax.annotation-api', version: '1.3.2'
- compile externalDependency.jacksonDataBind
- compile externalDependency.slf4jApi
+ implementation externalDependency.javaxValidation
+ implementation externalDependency.servletApi
+ implementation group: 'javax.annotation', name: 'javax.annotation-api', version: '1.3.2'
+ implementation externalDependency.jacksonDataBind
+ implementation externalDependency.slf4jApi
// End of dependencies
- compile externalDependency.swaggerAnnotations
- swaggerCodegen 'io.swagger.codegen.v3:swagger-codegen-cli:3.0.33'
+ implementation externalDependency.swaggerAnnotations
+ swaggerCodegen 'io.swagger.codegen.v3:swagger-codegen-cli:3.0.46'
- testCompile externalDependency.assertJ
+ testImplementation externalDependency.assertJ
}
tasks.register('generateOpenApiPojos', GenerateSwaggerCode) {
diff --git a/metadata-service/schema-registry-servlet/build.gradle b/metadata-service/schema-registry-servlet/build.gradle
index ec62203ddf0c5..554ac696c94fd 100644
--- a/metadata-service/schema-registry-servlet/build.gradle
+++ b/metadata-service/schema-registry-servlet/build.gradle
@@ -1,19 +1,20 @@
apply plugin: 'java'
dependencies {
- compile project(':metadata-service:factories')
- compile project(':metadata-service:schema-registry-api')
+ implementation project(':metadata-service:factories')
+ implementation project(':metadata-service:schema-registry-api')
- compile externalDependency.reflections
- compile externalDependency.springBoot
- compile externalDependency.springCore
- compile(externalDependency.springDocUI) {
+ implementation externalDependency.reflections
+ implementation externalDependency.springBoot
+ implementation externalDependency.springCore
+ implementation(externalDependency.springDocUI) {
exclude group: 'org.springframework.boot'
}
- compile externalDependency.springWeb
- compile externalDependency.springWebMVC
- compile externalDependency.springBeans
- compile externalDependency.springContext
+ implementation externalDependency.springWeb
+ implementation externalDependency.springWebMVC
+ implementation externalDependency.springBeans
+ implementation externalDependency.springContext
+ implementation externalDependency.springBootAutoconfigure
implementation externalDependency.slf4jApi
compileOnly externalDependency.lombok
implementation externalDependency.antlr4Runtime
@@ -23,14 +24,14 @@ dependencies {
testImplementation externalDependency.springBootTest
testImplementation project(':mock-entity-registry')
- testCompile externalDependency.springBoot
- testCompile externalDependency.testContainers
- testCompile externalDependency.testContainersKafka
- testCompile externalDependency.springKafka
- testCompile externalDependency.testng
- testCompile externalDependency.mockito
- testCompile externalDependency.logbackClassic
- testCompile externalDependency.jacksonCore
- testCompile externalDependency.jacksonDataBind
- testCompile externalDependency.springBootStarterWeb
+ testImplementation externalDependency.springBoot
+ testImplementation externalDependency.testContainers
+ testImplementation externalDependency.testContainersKafka
+ testImplementation externalDependency.springKafka
+ testImplementation externalDependency.testng
+ testImplementation externalDependency.mockito
+ testImplementation externalDependency.logbackClassic
+ testImplementation externalDependency.jacksonCore
+ testImplementation externalDependency.jacksonDataBind
+ testImplementation externalDependency.springBootStarterWeb
}
\ No newline at end of file
diff --git a/metadata-service/services/build.gradle b/metadata-service/services/build.gradle
index adc7b7bf09d99..99345d6f6bc3f 100644
--- a/metadata-service/services/build.gradle
+++ b/metadata-service/services/build.gradle
@@ -7,32 +7,33 @@ configurations {
dependencies {
implementation externalDependency.jsonPatch
- compile project(':entity-registry')
- compile project(':metadata-utils')
- compile project(':metadata-events:mxe-avro-1.7')
- compile project(':metadata-events:mxe-registration')
- compile project(':metadata-events:mxe-utils-avro-1.7')
- compile project(':metadata-models')
- compile project(':metadata-service:restli-client')
- compile project(':metadata-service:configuration')
+ implementation project(':entity-registry')
+ implementation project(':metadata-utils')
+ implementation project(':metadata-events:mxe-avro-1.7')
+ implementation project(':metadata-events:mxe-registration')
+ implementation project(':metadata-events:mxe-utils-avro-1.7')
+ implementation project(':metadata-models')
+ implementation project(':metadata-service:restli-client')
+ implementation project(':metadata-service:configuration')
implementation externalDependency.slf4jApi
implementation externalDependency.swaggerAnnotations
- runtime externalDependency.logbackClassic
+ runtimeOnly externalDependency.logbackClassic
compileOnly externalDependency.lombok
implementation externalDependency.commonsCollections
- compile externalDependency.javatuples
- compile externalDependency.javaxValidation
- compile externalDependency.opentelemetryAnnotations
+ implementation externalDependency.javatuples
+ implementation externalDependency.javaxValidation
+ implementation externalDependency.opentelemetryAnnotations
annotationProcessor externalDependency.lombok
- testCompile externalDependency.testng
- testCompile externalDependency.junit
- testCompile externalDependency.mockito
- testCompile externalDependency.mockitoInline
+ testImplementation externalDependency.testng
+ testImplementation externalDependency.junit
+ testImplementation externalDependency.mockito
+ testImplementation externalDependency.mockitoInline
testCompileOnly externalDependency.lombok
- testCompile project(':test-models')
+ testImplementation project(':test-models')
+ testImplementation project(path: ':test-models', configuration: 'testDataTemplate')
testImplementation project(':datahub-graphql-core')
// logback >=1.3 required due to `testcontainers` only
testImplementation 'ch.qos.logback:logback-classic:1.4.7'
diff --git a/metadata-service/services/src/main/java/com/linkedin/metadata/service/TagService.java b/metadata-service/services/src/main/java/com/linkedin/metadata/service/TagService.java
index b52d68e2e75ee..9e12fc80a3cdb 100644
--- a/metadata-service/services/src/main/java/com/linkedin/metadata/service/TagService.java
+++ b/metadata-service/services/src/main/java/com/linkedin/metadata/service/TagService.java
@@ -20,7 +20,7 @@
import java.util.Map;
import java.util.Optional;
import java.util.stream.Collectors;
-import com.linkedin.entity.client.EntityClient;
+import com.linkedin.entity.client.EntityClient;
import com.datahub.authentication.Authentication;
import javax.annotation.Nonnull;
import lombok.extern.slf4j.Slf4j;
diff --git a/metadata-service/servlet/build.gradle b/metadata-service/servlet/build.gradle
index 9242d21201886..eb2cd9c2d3de7 100644
--- a/metadata-service/servlet/build.gradle
+++ b/metadata-service/servlet/build.gradle
@@ -1,13 +1,16 @@
apply plugin: 'java'
dependencies {
- compile project(':metadata-io')
- compile externalDependency.httpClient
- compile externalDependency.servletApi
- compile externalDependency.gson
- compile externalDependency.jacksonDataBind
- compile externalDependency.springWebMVC
+ implementation project(':metadata-io')
+ implementation project(':datahub-graphql-core')
+ implementation project(':entity-registry')
+ implementation project(':metadata-service:factories')
+
+ implementation externalDependency.httpClient
+ implementation externalDependency.servletApi
+ implementation externalDependency.gson
+ implementation externalDependency.jacksonDataBind
+ implementation externalDependency.springWebMVC
+ compileOnly externalDependency.lombok
annotationProcessor externalDependency.lombok
- compile project(':entity-registry')
- compile project(':metadata-service:factories')
}
diff --git a/metadata-service/war/build.gradle b/metadata-service/war/build.gradle
index 7e9aa90664611..ae207e0260e60 100644
--- a/metadata-service/war/build.gradle
+++ b/metadata-service/war/build.gradle
@@ -12,33 +12,33 @@ ext {
ext.apiProject = project(':metadata-service:restli-api')
dependencies {
- runtime project(':metadata-service:factories')
- runtime project(':metadata-service:auth-filter')
- runtime project(':metadata-service:servlet')
- runtime project(':metadata-service:auth-servlet-impl')
- runtime project(':metadata-service:graphql-servlet-impl')
- runtime project(':metadata-service:health-servlet')
- runtime project(':metadata-service:openapi-servlet')
- runtime project(':metadata-service:schema-registry-servlet')
- runtime project(':metadata-jobs:mce-consumer')
- runtime project(':metadata-jobs:mae-consumer')
- runtime project(':metadata-jobs:pe-consumer')
+ runtimeOnly project(':metadata-service:factories')
+ runtimeOnly project(':metadata-service:auth-filter')
+ runtimeOnly project(':metadata-service:servlet')
+ runtimeOnly project(':metadata-service:auth-servlet-impl')
+ runtimeOnly project(':metadata-service:graphql-servlet-impl')
+ runtimeOnly project(':metadata-service:health-servlet')
+ runtimeOnly project(':metadata-service:openapi-servlet')
+ runtimeOnly project(':metadata-service:schema-registry-servlet')
+ runtimeOnly project(':metadata-jobs:mce-consumer')
+ runtimeOnly project(':metadata-jobs:mae-consumer')
+ runtimeOnly project(':metadata-jobs:pe-consumer')
- runtime externalDependency.awsSecretsManagerJdbc
- runtime externalDependency.h2
- runtime externalDependency.mariadbConnector
- runtime externalDependency.mysqlConnector
- runtime externalDependency.postgresql
- runtime externalDependency.springWebMVC
+ runtimeOnly externalDependency.awsSecretsManagerJdbc
+ runtimeOnly externalDependency.h2
+ runtimeOnly externalDependency.mariadbConnector
+ runtimeOnly externalDependency.mysqlConnector
+ runtimeOnly externalDependency.postgresql
+ runtimeOnly externalDependency.springWebMVC
- runtime spec.product.pegasus.restliDocgen
- runtime spec.product.pegasus.restliSpringBridge
+ runtimeOnly spec.product.pegasus.restliDocgen
+ runtimeOnly spec.product.pegasus.restliSpringBridge
- runtime externalDependency.log4jCore
- runtime externalDependency.log4j2Api
- runtime externalDependency.logbackClassic
+ runtimeOnly externalDependency.log4jCore
+ runtimeOnly externalDependency.log4j2Api
+ runtimeOnly externalDependency.logbackClassic
implementation externalDependency.awsMskIamAuth
- testRuntime externalDependency.logbackClassic
+ testRuntimeOnly externalDependency.logbackClassic
implementation externalDependency.charle
}
configurations.all{
@@ -72,6 +72,8 @@ docker {
include 'docker/monitoring/*'
include "docker/${docker_repo}/*"
include 'metadata-models/src/main/resources/*'
+ }.exclude {
+ i -> i.file.isHidden() || i.file == buildDir
}
tag("Debug", "${docker_registry}/${docker_repo}:debug")
@@ -84,7 +86,7 @@ tasks.getByName("docker").dependsOn([build, war])
task cleanLocalDockerImages {
doLast {
- rootProject.ext.cleanLocalDockerImages(docker_registry, docker_repo, "v${version}")
+ rootProject.ext.cleanLocalDockerImages(docker_registry, docker_repo, "${version}")
}
}
dockerClean.finalizedBy(cleanLocalDockerImages)
diff --git a/metadata-service/war/src/main/resources/boot/policies.json b/metadata-service/war/src/main/resources/boot/policies.json
index 3fddf3456ecd7..3cda0269b79f1 100644
--- a/metadata-service/war/src/main/resources/boot/policies.json
+++ b/metadata-service/war/src/main/resources/boot/policies.json
@@ -19,6 +19,7 @@
"GENERATE_PERSONAL_ACCESS_TOKENS",
"MANAGE_ACCESS_TOKENS",
"MANAGE_DOMAINS",
+ "MANAGE_GLOBAL_ANNOUNCEMENTS",
"MANAGE_TESTS",
"MANAGE_GLOSSARIES",
"MANAGE_USER_CREDENTIALS",
@@ -102,6 +103,7 @@
"VIEW_ANALYTICS",
"GENERATE_PERSONAL_ACCESS_TOKENS",
"MANAGE_DOMAINS",
+ "MANAGE_GLOBAL_ANNOUNCEMENTS",
"MANAGE_TESTS",
"MANAGE_GLOSSARIES",
"MANAGE_TAGS",
@@ -190,6 +192,7 @@
"GENERATE_PERSONAL_ACCESS_TOKENS",
"MANAGE_ACCESS_TOKENS",
"MANAGE_DOMAINS",
+ "MANAGE_GLOBAL_ANNOUNCEMENTS",
"MANAGE_TESTS",
"MANAGE_GLOSSARIES",
"MANAGE_USER_CREDENTIALS",
@@ -283,6 +286,7 @@
"privileges":[
"GENERATE_PERSONAL_ACCESS_TOKENS",
"MANAGE_DOMAINS",
+ "MANAGE_GLOBAL_ANNOUNCEMENTS",
"MANAGE_GLOSSARIES",
"MANAGE_TAGS"
],
diff --git a/metadata-utils/build.gradle b/metadata-utils/build.gradle
index 3b04a5dc53d75..9f8ef70a0e728 100644
--- a/metadata-utils/build.gradle
+++ b/metadata-utils/build.gradle
@@ -1,30 +1,31 @@
-apply plugin: 'java'
+apply plugin: 'java-library'
dependencies {
- compile externalDependency.avro_1_7
- compile externalDependency.commonsLang
- compile externalDependency.dropwizardMetricsCore
- compile externalDependency.dropwizardMetricsJmx
- compile externalDependency.elasticSearchRest
- compile externalDependency.httpClient
- compile externalDependency.neo4jJavaDriver
- compile externalDependency.json
-
- compile spec.product.pegasus.restliClient
- compile spec.product.pegasus.restliCommon
- compile spec.product.pegasus.restliServer
-
- compile project(':li-utils')
- compile project(':entity-registry')
- compile project(':metadata-events:mxe-avro-1.7')
- compile project(':metadata-events:mxe-utils-avro-1.7')
+ api externalDependency.avro_1_7
+ implementation externalDependency.commonsLang
+ api externalDependency.dropwizardMetricsCore
+ implementation externalDependency.dropwizardMetricsJmx
+ api externalDependency.elasticSearchRest
+ implementation externalDependency.httpClient
+ api externalDependency.neo4jJavaDriver
+ api externalDependency.json
+
+ implementation spec.product.pegasus.restliClient
+ implementation spec.product.pegasus.restliCommon
+ implementation spec.product.pegasus.restliServer
+
+ api project(':li-utils')
+ api project(':entity-registry')
+ api project(':metadata-events:mxe-avro-1.7')
+ api project(':metadata-events:mxe-utils-avro-1.7')
implementation externalDependency.slf4jApi
compileOnly externalDependency.lombok
annotationProcessor externalDependency.lombok
- testCompile project(':test-models')
+ testImplementation project(':test-models')
+ testImplementation project(path: ':test-models', configuration: 'testDataTemplate')
constraints {
implementation(externalDependency.log4jCore) {
diff --git a/metadata-utils/src/main/java/com/linkedin/metadata/authorization/PoliciesConfig.java b/metadata-utils/src/main/java/com/linkedin/metadata/authorization/PoliciesConfig.java
index c46d02a6eadf0..0b0d462f079bf 100644
--- a/metadata-utils/src/main/java/com/linkedin/metadata/authorization/PoliciesConfig.java
+++ b/metadata-utils/src/main/java/com/linkedin/metadata/authorization/PoliciesConfig.java
@@ -64,6 +64,11 @@ public class PoliciesConfig {
"Manage Domains",
"Create and remove Asset Domains.");
+ public static final Privilege MANAGE_GLOBAL_ANNOUNCEMENTS_PRIVILEGE = Privilege.of(
+ "MANAGE_GLOBAL_ANNOUNCEMENTS",
+ "Manage Home Page Posts",
+ "Create and delete home page posts");
+
public static final Privilege MANAGE_TESTS_PRIVILEGE = Privilege.of(
"MANAGE_TESTS",
"Manage Tests",
@@ -113,6 +118,7 @@ public class PoliciesConfig {
MANAGE_USERS_AND_GROUPS_PRIVILEGE,
VIEW_ANALYTICS_PRIVILEGE,
MANAGE_DOMAINS_PRIVILEGE,
+ MANAGE_GLOBAL_ANNOUNCEMENTS_PRIVILEGE,
MANAGE_INGESTION_PRIVILEGE,
MANAGE_SECRETS_PRIVILEGE,
GENERATE_PERSONAL_ACCESS_TOKENS_PRIVILEGE,
@@ -192,8 +198,8 @@ public class PoliciesConfig {
public static final Privilege EDIT_ENTITY_PRIVILEGE = Privilege.of(
"EDIT_ENTITY",
- "Edit All",
- "The ability to edit any information about an entity. Super user privileges.");
+ "Edit Entity",
+ "The ability to edit any information about an entity. Super user privileges for the entity.");
public static final Privilege DELETE_ENTITY_PRIVILEGE = Privilege.of(
"DELETE_ENTITY",
diff --git a/perf-test/README.md b/perf-test/README.md
index 24fb064d3e28a..191833361eae9 100644
--- a/perf-test/README.md
+++ b/perf-test/README.md
@@ -58,7 +58,9 @@ locust -f perf-test/locustfiles/ingest.py
This will set up the web interface in http://localhost:8089 (unless the port is already taken). Once you click into it,
you should see the following
-
+
+  +
+
Input the number of users you would like to spawn and the spawn rate. Point the host to the deployed DataHub GMS (
locally, it should be http://localhost:8080). Click on the "Start swarming" button to start the load test.
diff --git a/smoke-test/run-quickstart.sh b/smoke-test/run-quickstart.sh
index 050b5d2db95c9..d40e4a5e7a4aa 100755
--- a/smoke-test/run-quickstart.sh
+++ b/smoke-test/run-quickstart.sh
@@ -15,4 +15,4 @@ echo "test_user:test_pass" >> ~/.datahub/plugins/frontend/auth/user.props
echo "DATAHUB_VERSION = $DATAHUB_VERSION"
DATAHUB_TELEMETRY_ENABLED=false \
DOCKER_COMPOSE_BASE="file://$( dirname "$DIR" )" \
-datahub docker quickstart --version ${DATAHUB_VERSION} --standalone_consumers --dump-logs-on-failure --kafka-setup
+datahub docker quickstart --version ${DATAHUB_VERSION} --standalone_consumers --dump-logs-on-failure --kafka-setup
\ No newline at end of file
diff --git a/smoke-test/tests/cypress/cypress/e2e/lineage/lineage_column_level.js b/smoke-test/tests/cypress/cypress/e2e/lineage/lineage_column_level.js
new file mode 100644
index 0000000000000..2a8fe045f154e
--- /dev/null
+++ b/smoke-test/tests/cypress/cypress/e2e/lineage/lineage_column_level.js
@@ -0,0 +1,51 @@
+const DATASET_ENTITY_TYPE = 'dataset';
+const DATASET_URN = 'urn:li:dataset:(urn:li:dataPlatform:hive,SampleCypressHiveDataset,PROD)';
+
+describe("column-level lineage graph test", () => {
+
+ it("navigate to lineage graph view and verify that column-level lineage is showing correctly", () => {
+ cy.login();
+ cy.goToEntityLineageGraph(DATASET_ENTITY_TYPE, DATASET_URN);
+ //verify columns not shown by default
+ cy.waitTextVisible("SampleCypressHdfs");
+ cy.waitTextVisible("SampleCypressHive");
+ cy.waitTextVisible("cypress_logging");
+ cy.ensureTextNotPresent("shipment_info");
+ cy.ensureTextNotPresent("field_foo");
+ cy.ensureTextNotPresent("field_baz");
+ cy.ensureTextNotPresent("event_name");
+ cy.ensureTextNotPresent("event_data");
+ cy.ensureTextNotPresent("timestamp");
+ cy.ensureTextNotPresent("browser");
+ cy.clickOptionWithTestId("column-toggle")
+ //verify columns appear and belong co correct dataset
+ cy.waitTextVisible("shipment_info");
+ cy.waitTextVisible("shipment_info.date");
+ cy.waitTextVisible("shipment_info.target");
+ cy.waitTextVisible("shipment_info.destination");
+ cy.waitTextVisible("shipment_info.geo_info");
+ cy.waitTextVisible("field_foo");
+ cy.waitTextVisible("field_baz");
+ cy.waitTextVisible("event_name");
+ cy.waitTextVisible("event_data");
+ cy.waitTextVisible("timestamp");
+ cy.waitTextVisible("browser");
+ //verify columns can be hidden and shown again
+ cy.contains("Hide").click({ force:true });
+ cy.ensureTextNotPresent("field_foo");
+ cy.ensureTextNotPresent("field_baz");
+ cy.get("[aria-label='down']").eq(1).click({ force:true });
+ cy.waitTextVisible("field_foo");
+ cy.waitTextVisible("field_baz");
+ //verify columns can be disabled successfully
+ cy.clickOptionWithTestId("column-toggle")
+ cy.ensureTextNotPresent("shipment_info");
+ cy.ensureTextNotPresent("field_foo");
+ cy.ensureTextNotPresent("field_baz");
+ cy.ensureTextNotPresent("event_name");
+ cy.ensureTextNotPresent("event_data");
+ cy.ensureTextNotPresent("timestamp");
+ cy.ensureTextNotPresent("browser");
+ });
+
+});
\ No newline at end of file
diff --git a/smoke-test/tests/cypress/cypress/e2e/mutations/deprecations.js b/smoke-test/tests/cypress/cypress/e2e/mutations/deprecations.js
index 1d41d155440e8..2fa11654a3c3e 100644
--- a/smoke-test/tests/cypress/cypress/e2e/mutations/deprecations.js
+++ b/smoke-test/tests/cypress/cypress/e2e/mutations/deprecations.js
@@ -1,19 +1,29 @@
-describe("deprecation", () => {
+describe("dataset deprecation", () => {
it("go to dataset and check deprecation works", () => {
const urn = "urn:li:dataset:(urn:li:dataPlatform:hive,cypress_logging_events,PROD)";
const datasetName = "cypress_logging_events";
cy.login();
-
cy.goToDataset(urn, datasetName);
cy.openThreeDotDropdown();
cy.clickOptionWithText("Mark as deprecated");
cy.addViaFormModal("test deprecation", "Add Deprecation Details");
-
- cy.goToDataset(urn, datasetName);
- cy.contains("DEPRECATED");
-
+ cy.waitTextVisible("Deprecation Updated");
+ cy.waitTextVisible("DEPRECATED")
cy.openThreeDotDropdown();
cy.clickOptionWithText("Mark as un-deprecated");
+ cy.waitTextVisible("Deprecation Updated");
+ cy.ensureTextNotPresent("DEPRECATED");
+ cy.openThreeDotDropdown();
+ cy.clickOptionWithText("Mark as deprecated");
+ cy.addViaFormModal("test deprecation", "Add Deprecation Details");
+ cy.waitTextVisible("Deprecation Updated");
+ cy.waitTextVisible("DEPRECATED");
+ cy.contains("DEPRECATED").trigger("mouseover", { force: true });
+ cy.waitTextVisible("Deprecation note");
+ cy.get("[role='tooltip']").contains("Mark as un-deprecated").click();
+ cy.waitTextVisible("Confirm Mark as un-deprecated");
+ cy.get("button").contains("Yes").click();
+ cy.waitTextVisible("Marked assets as un-deprecated!");
cy.ensureTextNotPresent("DEPRECATED");
- });
+ });
});
diff --git a/smoke-test/tests/cypress/cypress/e2e/mutations/edit_documentation.js b/smoke-test/tests/cypress/cypress/e2e/mutations/edit_documentation.js
new file mode 100644
index 0000000000000..e4e5a39ce1100
--- /dev/null
+++ b/smoke-test/tests/cypress/cypress/e2e/mutations/edit_documentation.js
@@ -0,0 +1,97 @@
+const test_id = Math.floor(Math.random() * 100000);
+const documentation_edited = `This is test${test_id} documentation EDITED`;
+const wrong_url = "https://www.linkedincom";
+const correct_url = "https://www.linkedin.com";
+
+describe("edit documentation and link to dataset", () => {
+ it("open test dataset page, edit documentation", () => {
+ //edit documentation and verify changes saved
+ cy.loginWithCredentials();
+ cy.visit(
+ "/dataset/urn:li:dataset:(urn:li:dataPlatform:hive,SampleCypressHiveDataset,PROD)/Schema"
+ );
+ cy.get("[role='tab']").contains("Documentation").click();
+ cy.waitTextVisible("my hive dataset");
+ cy.waitTextVisible("Sample doc");
+ cy.clickOptionWithText("Edit");
+ cy.focused().clear();
+ cy.focused().type(documentation_edited);
+ cy.get("button").contains("Save").click();
+ cy.waitTextVisible("Description Updated");
+ cy.waitTextVisible(documentation_edited);
+ //return documentation to original state
+ cy.clickOptionWithText("Edit");
+ cy.focused().clear().wait(1000);
+ cy.focused().type("my hive dataset");
+ cy.get("button").contains("Save").click();
+ cy.waitTextVisible("Description Updated");
+ cy.waitTextVisible("my hive dataset");
+ });
+
+ it("open test dataset page, remove and add dataset link", () => {
+ cy.loginWithCredentials();
+ cy.visit(
+ "/dataset/urn:li:dataset:(urn:li:dataPlatform:hive,SampleCypressHiveDataset,PROD)/Schema"
+ );
+ cy.get("[role='tab']").contains("Documentation").click();
+ cy.contains("Sample doc").trigger("mouseover", { force: true });
+ cy.get('[data-icon="delete"]').click();
+ cy.waitTextVisible("Link Removed");
+ cy.get("button").contains("Add Link").click();
+ cy.get("#addLinkForm_url").type(wrong_url);
+ cy.waitTextVisible("This field must be a valid url.");
+ cy.focused().clear();
+ cy.waitTextVisible("A URL is required.");
+ cy.focused().type(correct_url);
+ cy.ensureTextNotPresent("This field must be a valid url.");
+ cy.get("#addLinkForm_label").type("Sample doc");
+ cy.get('[role="dialog"] button').contains("Add").click();
+ cy.waitTextVisible("Link Added");
+ cy.get("[role='tab']").contains("Documentation").click();
+ cy.get(`[href='${correct_url}']`).should("be.visible");
+ });
+
+ it("open test domain page, remove and add dataset link", () => {
+ cy.loginWithCredentials();
+ cy.visit("/domain/urn:li:domain:marketing/Entities");
+ cy.get("[role='tab']").contains("Documentation").click();
+ cy.get("button").contains("Add Link").click();
+ cy.get("#addLinkForm_url").type(wrong_url);
+ cy.waitTextVisible("This field must be a valid url.");
+ cy.focused().clear();
+ cy.waitTextVisible("A URL is required.");
+ cy.focused().type(correct_url);
+ cy.ensureTextNotPresent("This field must be a valid url.");
+ cy.get("#addLinkForm_label").type("Sample doc");
+ cy.get('[role="dialog"] button').contains("Add").click();
+ cy.waitTextVisible("Link Added");
+ cy.get("[role='tab']").contains("Documentation").click();
+ cy.get(`[href='${correct_url}']`).should("be.visible");
+ cy.contains("Sample doc").trigger("mouseover", { force: true });
+ cy.get('[data-icon="delete"]').click();
+ cy.waitTextVisible("Link Removed");
+ });
+
+ it("edit field documentation", () => {
+ cy.loginWithCredentials();
+ cy.visit(
+ "/dataset/urn:li:dataset:(urn:li:dataPlatform:hive,SampleCypressHiveDataset,PROD)/Schema"
+ );
+ cy.get("tbody [data-icon='edit']").first().click({ force: true });
+ cy.waitTextVisible("Update description");
+ cy.waitTextVisible("Foo field description has changed");
+ cy.focused().clear().wait(1000);
+ cy.focused().type(documentation_edited);
+ cy.get("button").contains("Update").click();
+ cy.waitTextVisible("Updated!");
+ cy.waitTextVisible(documentation_edited);
+ cy.waitTextVisible("(edited)");
+ cy.get("tbody [data-icon='edit']").first().click({ force: true });
+ cy.focused().clear().wait(1000);
+ cy.focused().type("Foo field description has changed");
+ cy.get("button").contains("Update").click();
+ cy.waitTextVisible("Updated!");
+ cy.waitTextVisible("Foo field description has changed");
+ cy.waitTextVisible("(edited)");
+ });
+});
diff --git a/smoke-test/tests/cypress/cypress/e2e/mutations/managed_ingestion.js b/smoke-test/tests/cypress/cypress/e2e/mutations/managed_ingestion.js
index ddda8626fba2f..24a24cc21138d 100644
--- a/smoke-test/tests/cypress/cypress/e2e/mutations/managed_ingestion.js
+++ b/smoke-test/tests/cypress/cypress/e2e/mutations/managed_ingestion.js
@@ -31,8 +31,7 @@ describe("run managed ingestion", () => {
cy.waitTextVisible(testName)
cy.contains(testName).parent().within(() => {
- // TODO: Skipping until disk size resolved
- // cy.contains("Succeeded", {timeout: 30000})
+ cy.contains("Succeeded", {timeout: 180000})
cy.clickOptionWithTestId("delete-button");
})
cy.clickOptionWithText("Yes")
diff --git a/smoke-test/tests/cypress/cypress/e2e/settings/managing_groups.js b/smoke-test/tests/cypress/cypress/e2e/settings/managing_groups.js
index 7686acfe50de0..9559435ff01c8 100644
--- a/smoke-test/tests/cypress/cypress/e2e/settings/managing_groups.js
+++ b/smoke-test/tests/cypress/cypress/e2e/settings/managing_groups.js
@@ -64,6 +64,7 @@ describe("create and manage group", () => {
});
it("update group info", () => {
+ var expected_name = Cypress.env('ADMIN_USERNAME');
cy.loginWithCredentials();
cy.visit("/settings/identities/groups");
cy.clickOptionWithText(group_name);
@@ -77,13 +78,13 @@ describe("create and manage group", () => {
cy.contains("Test group description EDITED").should("be.visible");
cy.clickOptionWithText("Add Owners");
cy.contains("Search for users or groups...").click({ force: true });
- cy.focused().type(Cypress.env('ADMIN_USERNAME'));
- cy.get(".ant-select-item-option").contains(Cypress.env('ADMIN_USERNAME'), { matchCase: false }).click();
+ cy.focused().type(expected_name);
+ cy.get(".ant-select-item-option").contains(expected_name, { matchCase: false }).click();
cy.focused().blur();
- cy.contains(Cypress.env('ADMIN_USERNAME')).should("have.length", 1);
+ cy.contains(expected_name).should("have.length", 1);
cy.get('[role="dialog"] button').contains("Done").click();
cy.waitTextVisible("Owners Added");
- cy.contains(Cypress.env('ADMIN_USERNAME'), { matchCase: false }).should("be.visible");
+ cy.contains(expected_name, { matchCase: false }).should("be.visible");
cy.clickOptionWithText("Edit Group");
cy.waitTextVisible("Edit Profile");
cy.get("#email").type(`${test_id}@testemail.com`);
diff --git a/smoke-test/tests/cypress/data.json b/smoke-test/tests/cypress/data.json
index c6606519e8d73..3b2ee1afaba58 100644
--- a/smoke-test/tests/cypress/data.json
+++ b/smoke-test/tests/cypress/data.json
@@ -2012,4 +2012,4 @@
},
"systemMetadata": null
}
-]
+]
\ No newline at end of file
diff --git a/test-models/build.gradle b/test-models/build.gradle
index 4cfbcc1399e7d..c74f7249fa1d9 100644
--- a/test-models/build.gradle
+++ b/test-models/build.gradle
@@ -1,5 +1,5 @@
apply plugin: 'pegasus'
-apply plugin: 'java'
+apply plugin: 'java-library'
tasks.withType(JavaCompile).configureEach {
javaCompiler = javaToolchains.compilerFor {
@@ -13,8 +13,8 @@ tasks.withType(Test).configureEach {
}
dependencies {
- compile spec.product.pegasus.data
- compile externalDependency.commonsIo
+ implementation spec.product.pegasus.data
+ implementation externalDependency.commonsIo
dataModel project(':metadata-models')
dataModel project(':li-utils')
}
diff --git a/test-models/src/main/pegasus/com/datahub/test/TestEntityInfo.pdl b/test-models/src/main/pegasus/com/datahub/test/TestEntityInfo.pdl
index ed30244c31b17..6dff14133ee60 100644
--- a/test-models/src/main/pegasus/com/datahub/test/TestEntityInfo.pdl
+++ b/test-models/src/main/pegasus/com/datahub/test/TestEntityInfo.pdl
@@ -14,7 +14,8 @@ record TestEntityInfo includes CustomProperties {
@Searchable = {
"fieldName": "textFieldOverride",
"fieldType": "TEXT",
- "addToFilters": true
+ "addToFilters": true,
+ "fieldNameAliases": [ "_entityName" ]
}
textField: optional string
@@ -25,6 +26,11 @@ record TestEntityInfo includes CustomProperties {
}
textArrayField: optional array[string]
+ @Searchable = {
+ "fieldType": "WORD_GRAM"
+ }
+ wordGramField: optional string
+
@Relationship = {
"name": "foreignKey",
"entityTypes": []
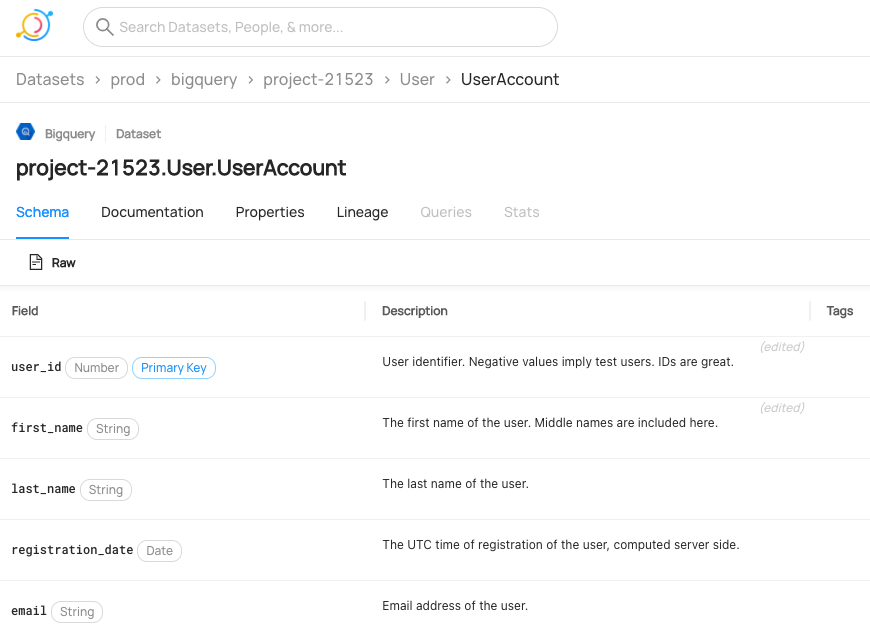 +
+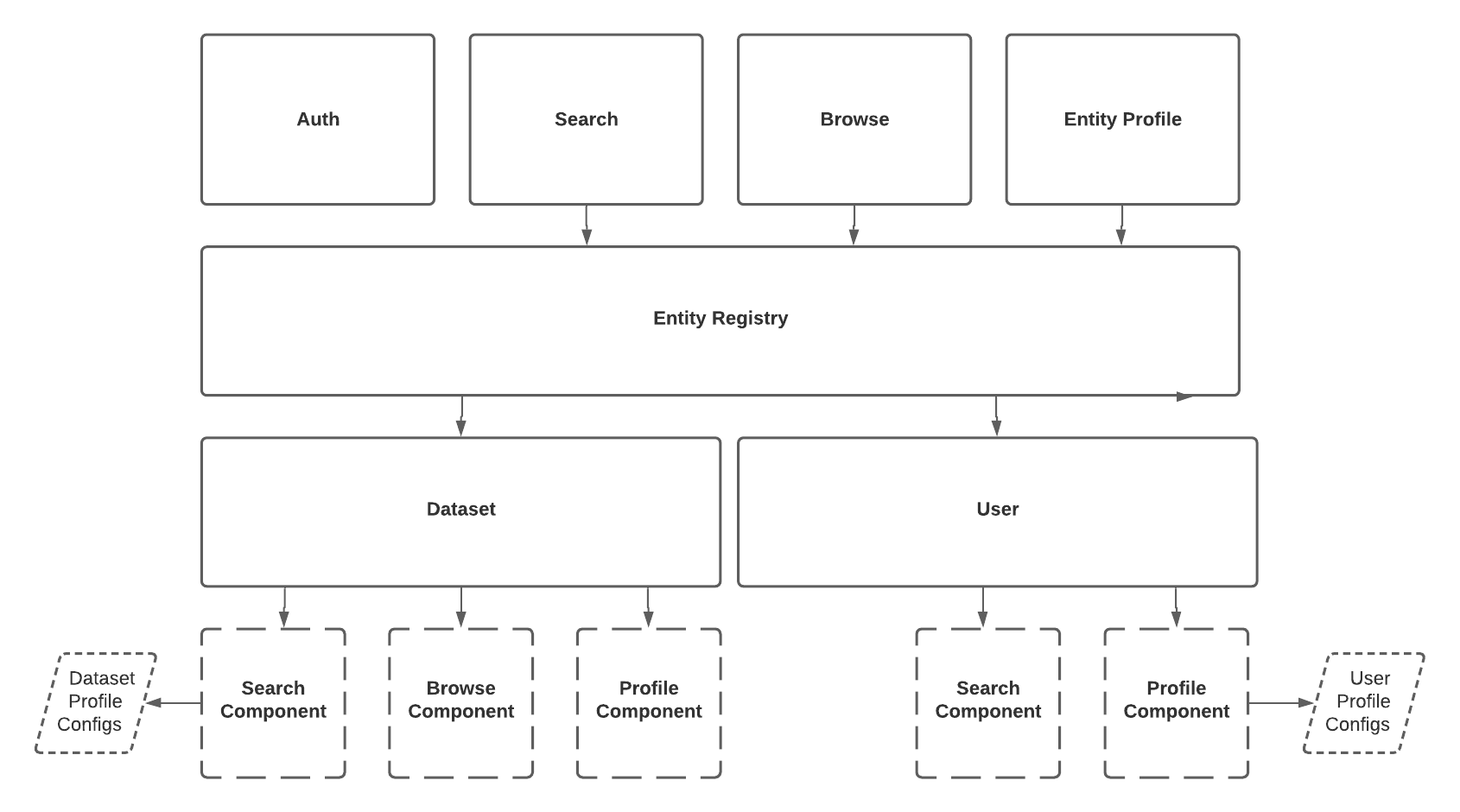 +
+ +
+ +
+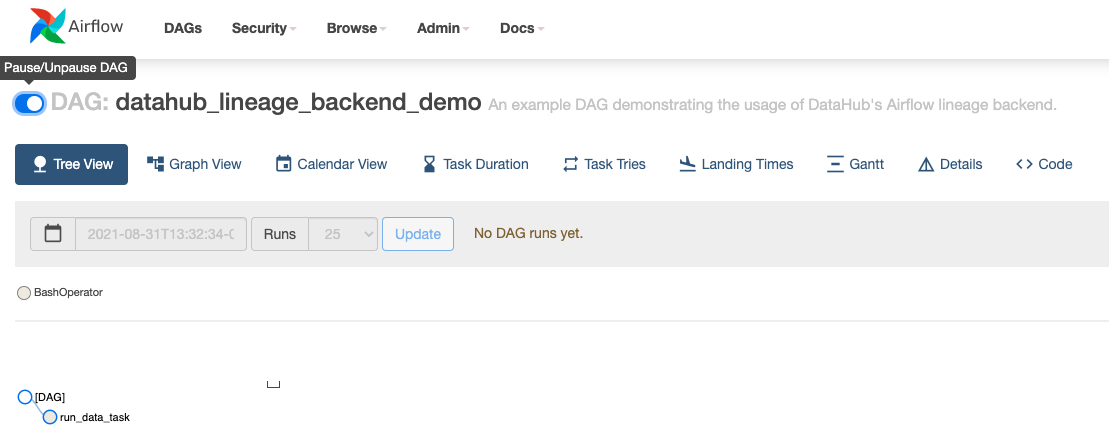 +
+ +
+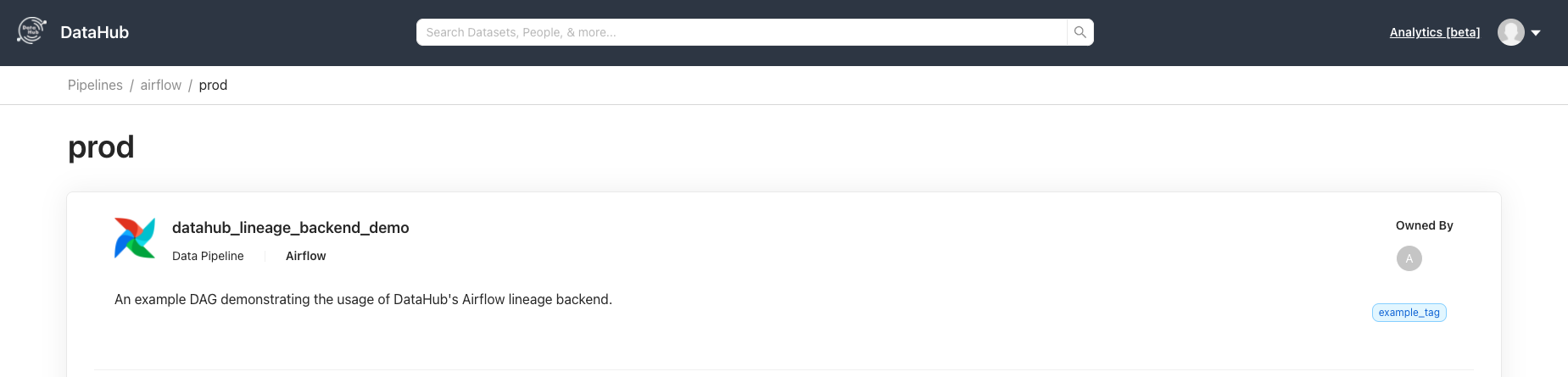 +
+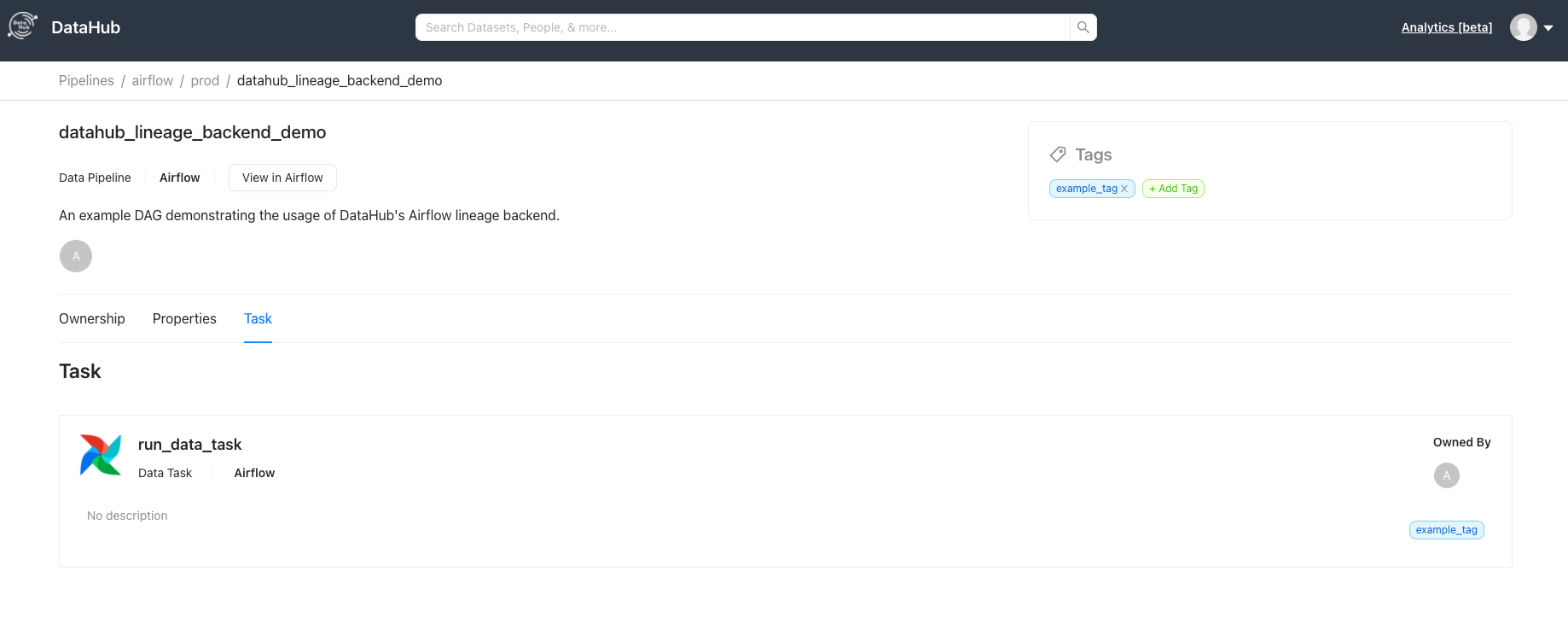 +
+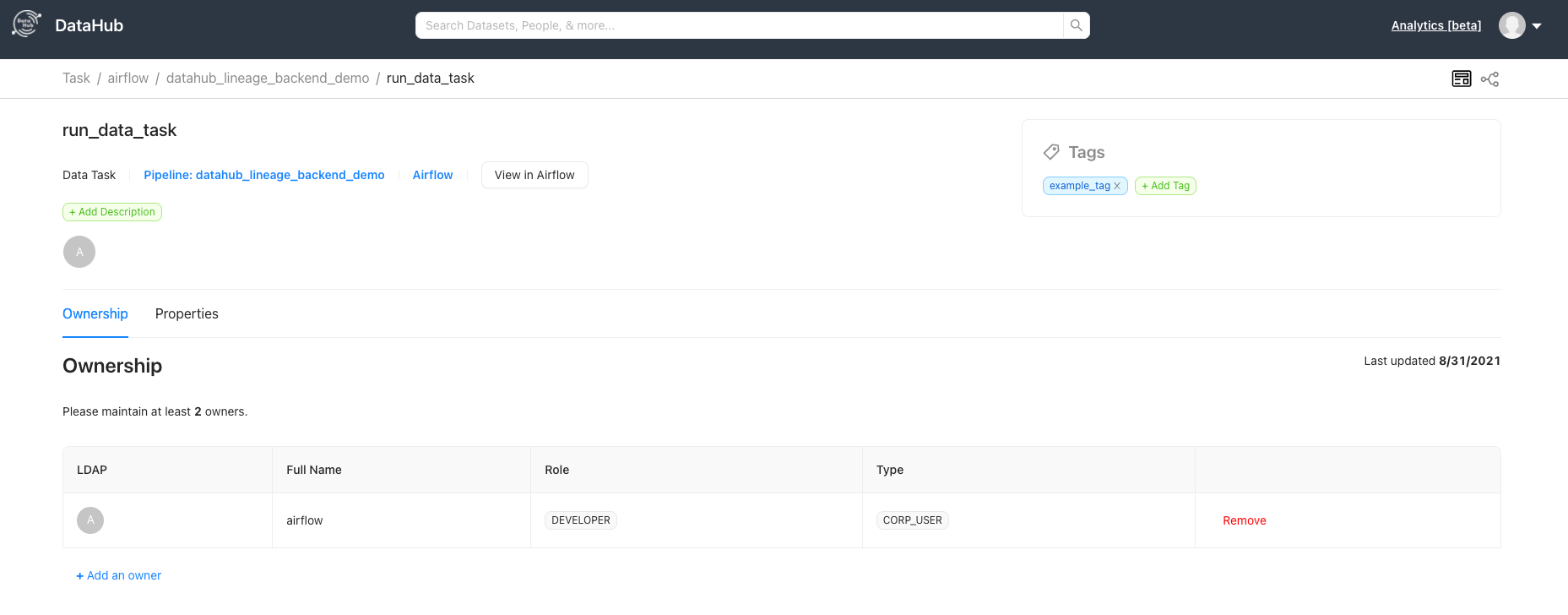 +
+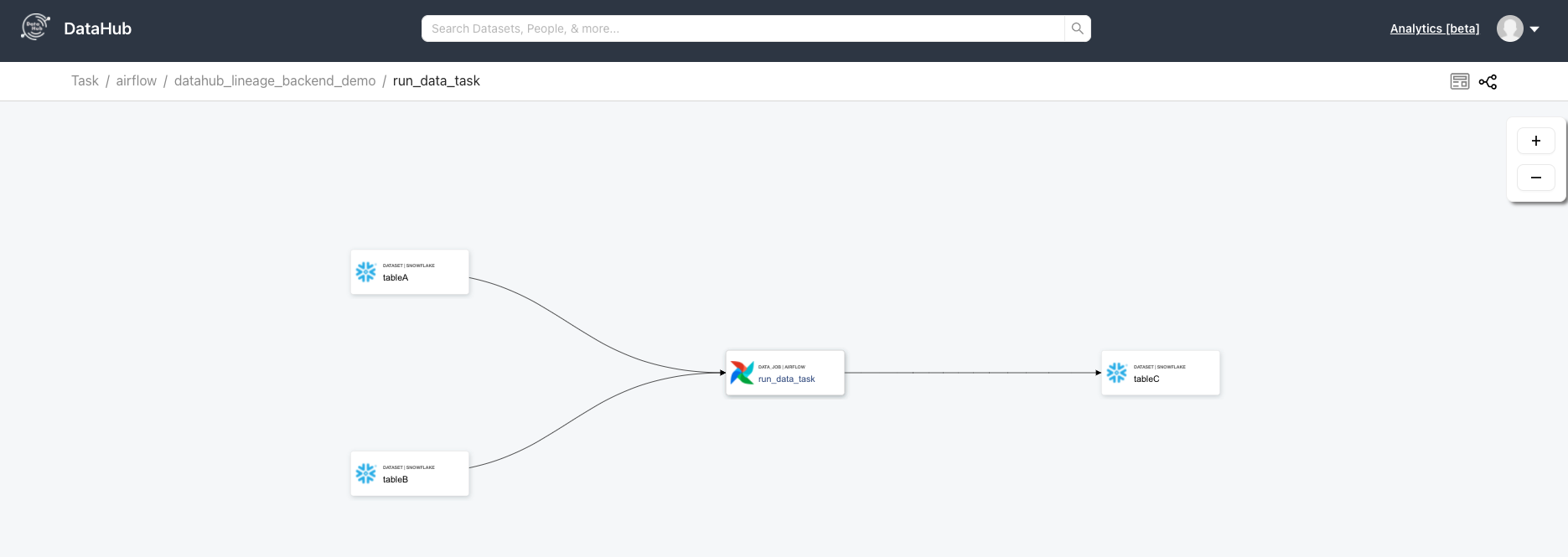 +
+ +
+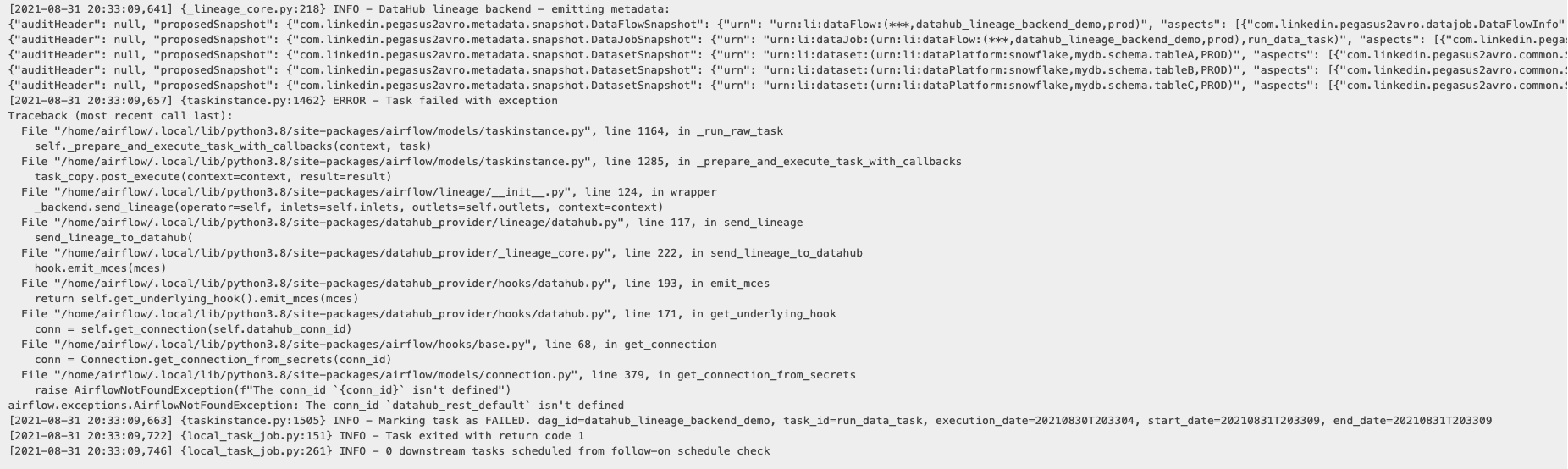 +
+ +
+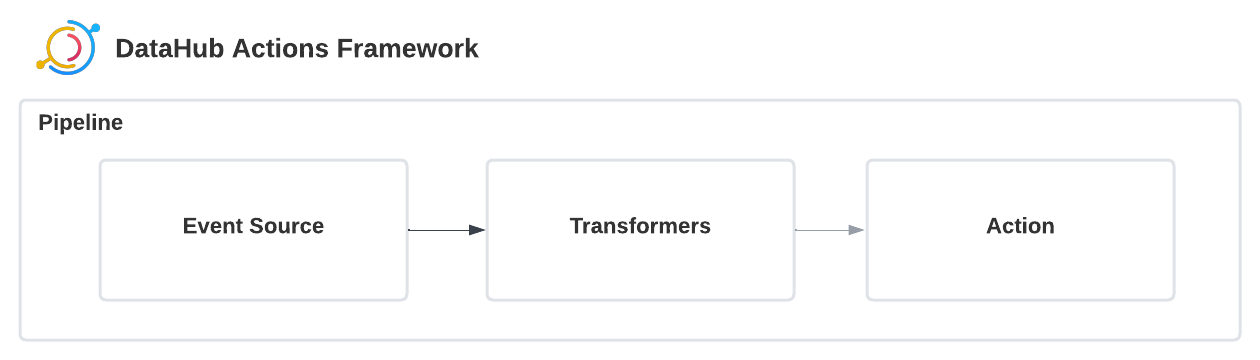 +
+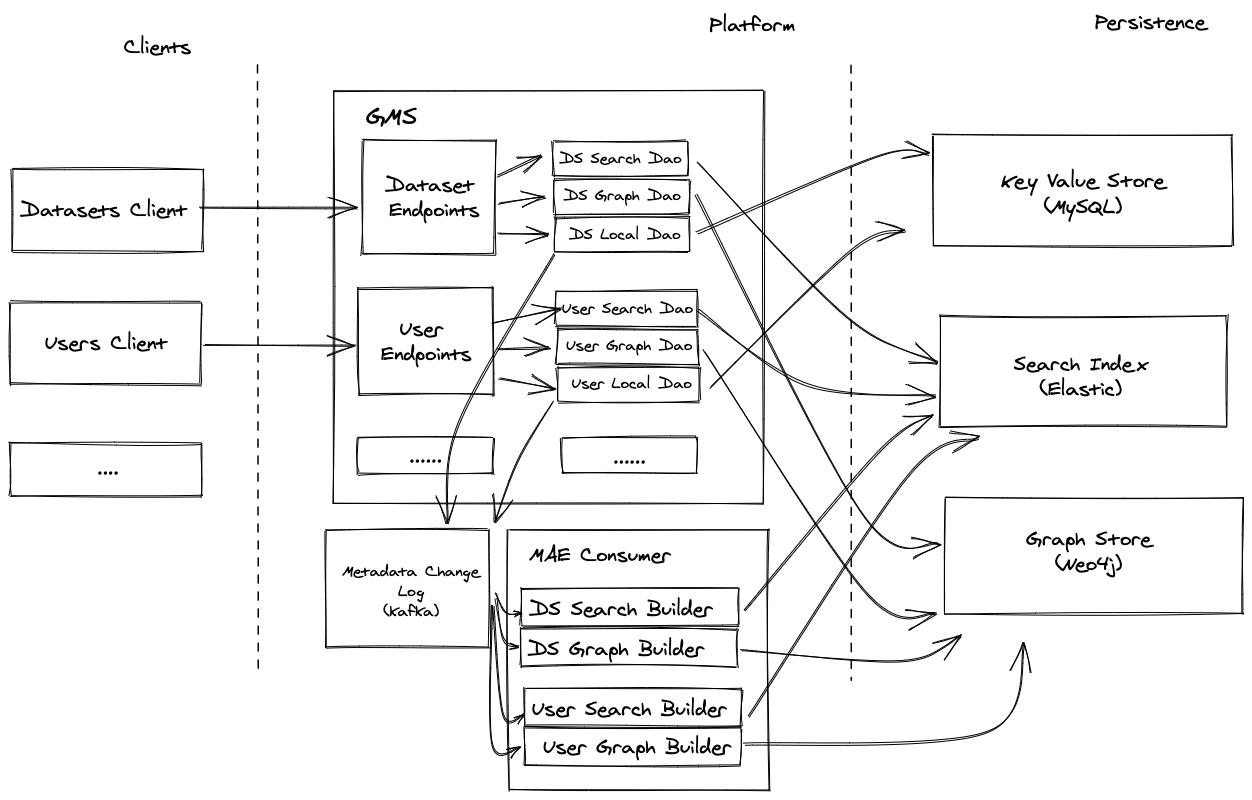 +
+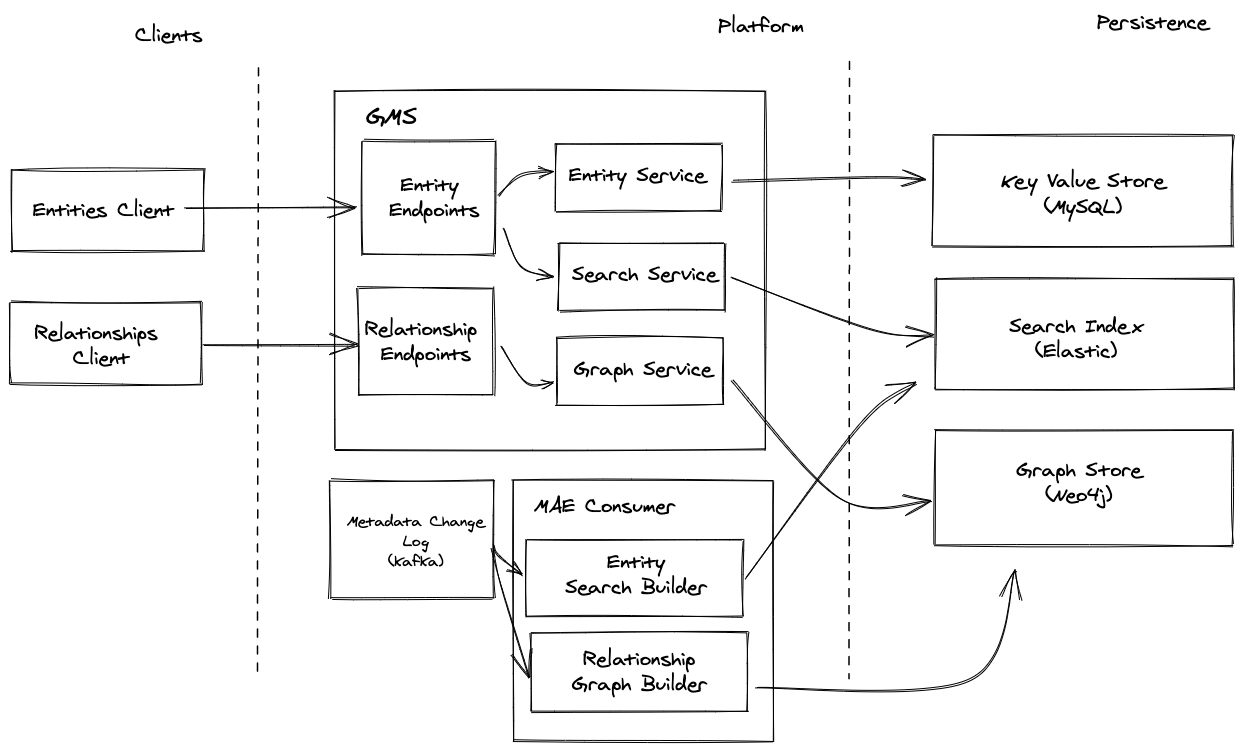 +
+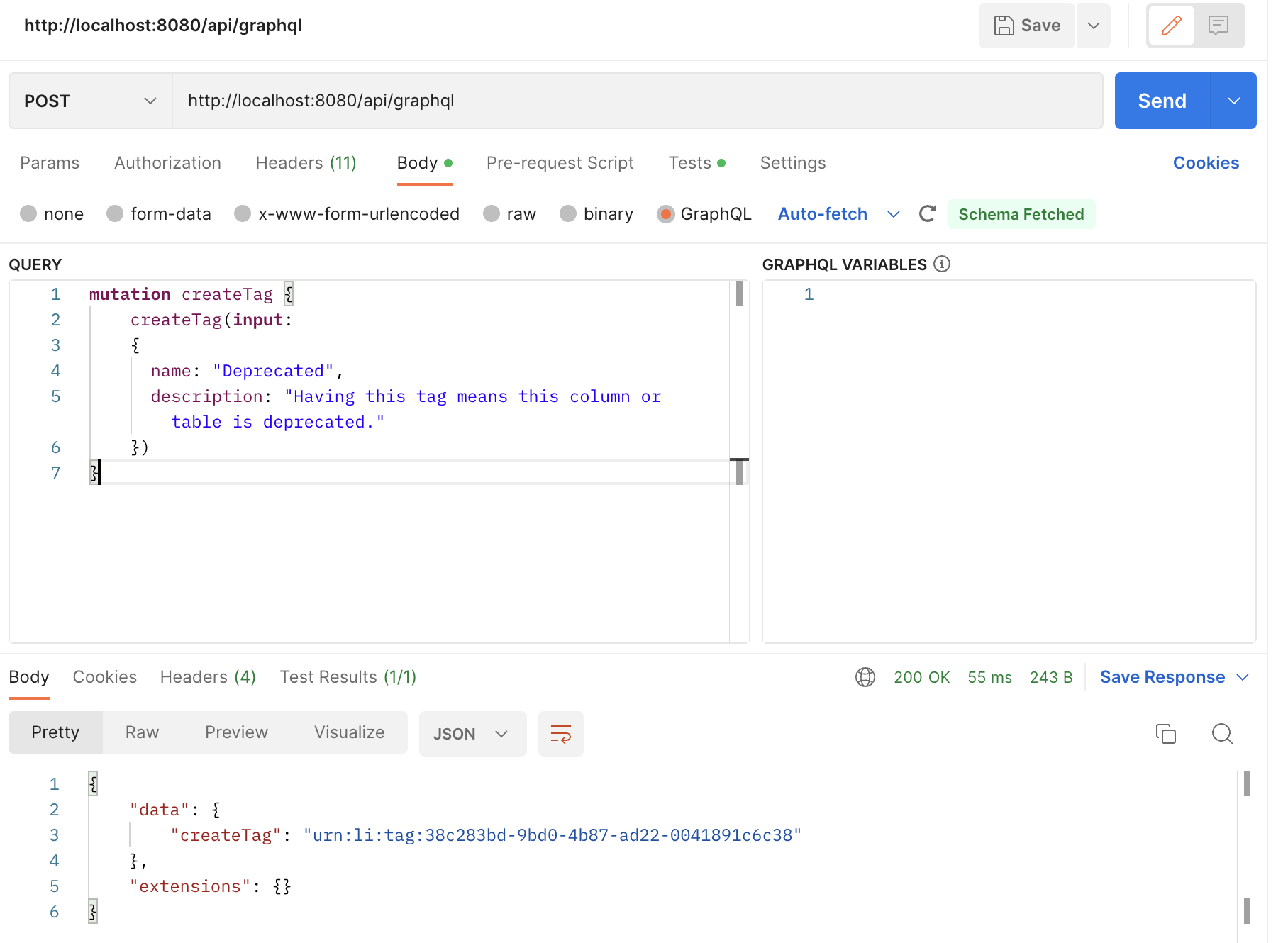 +
+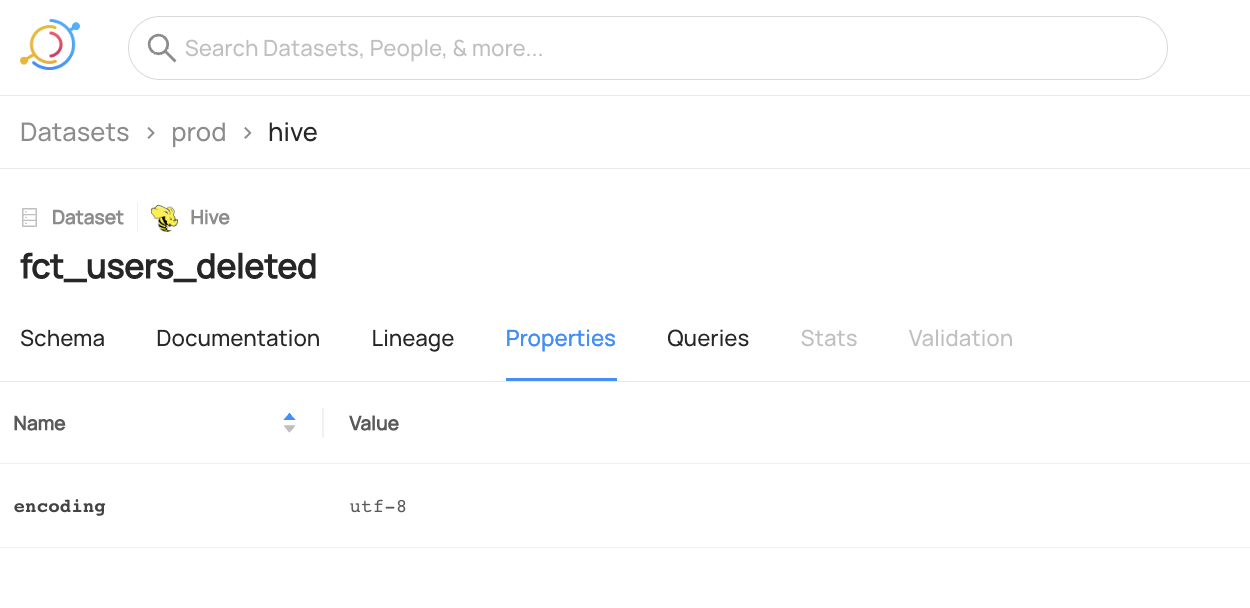 +
+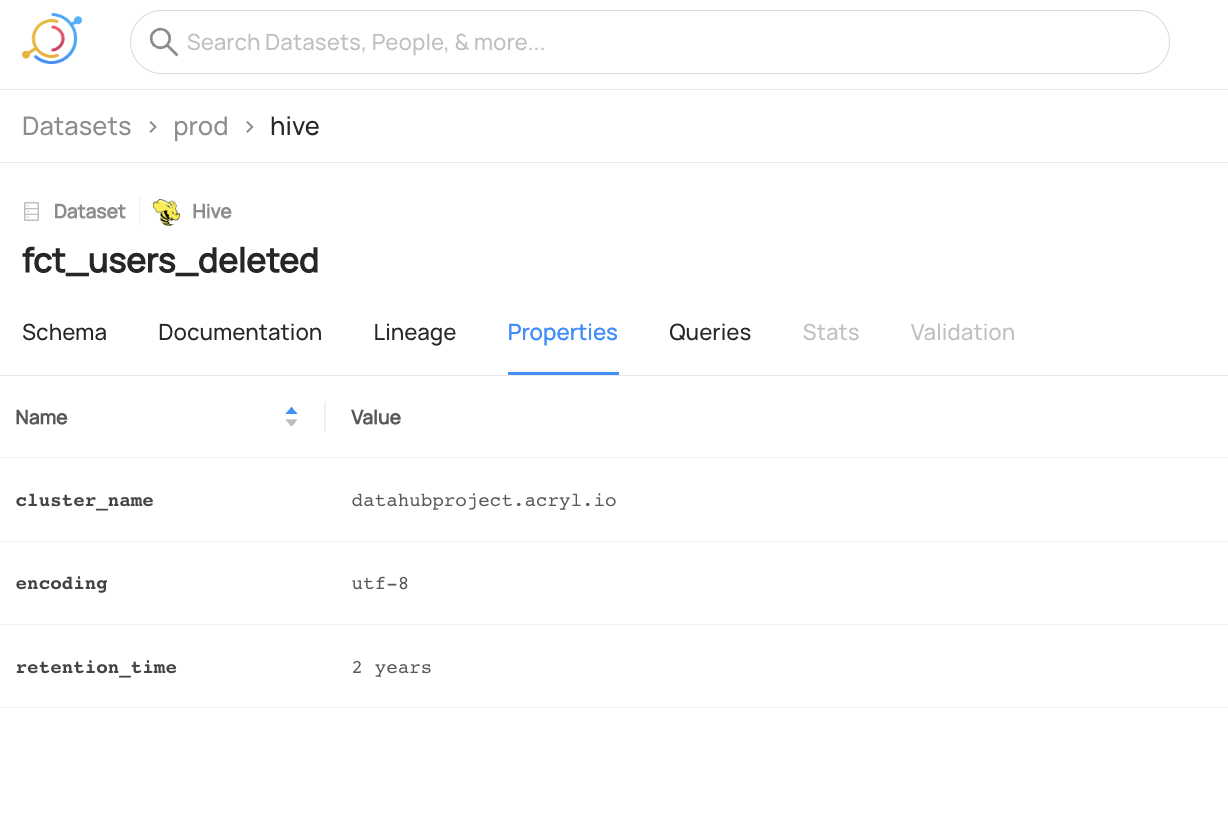 +
+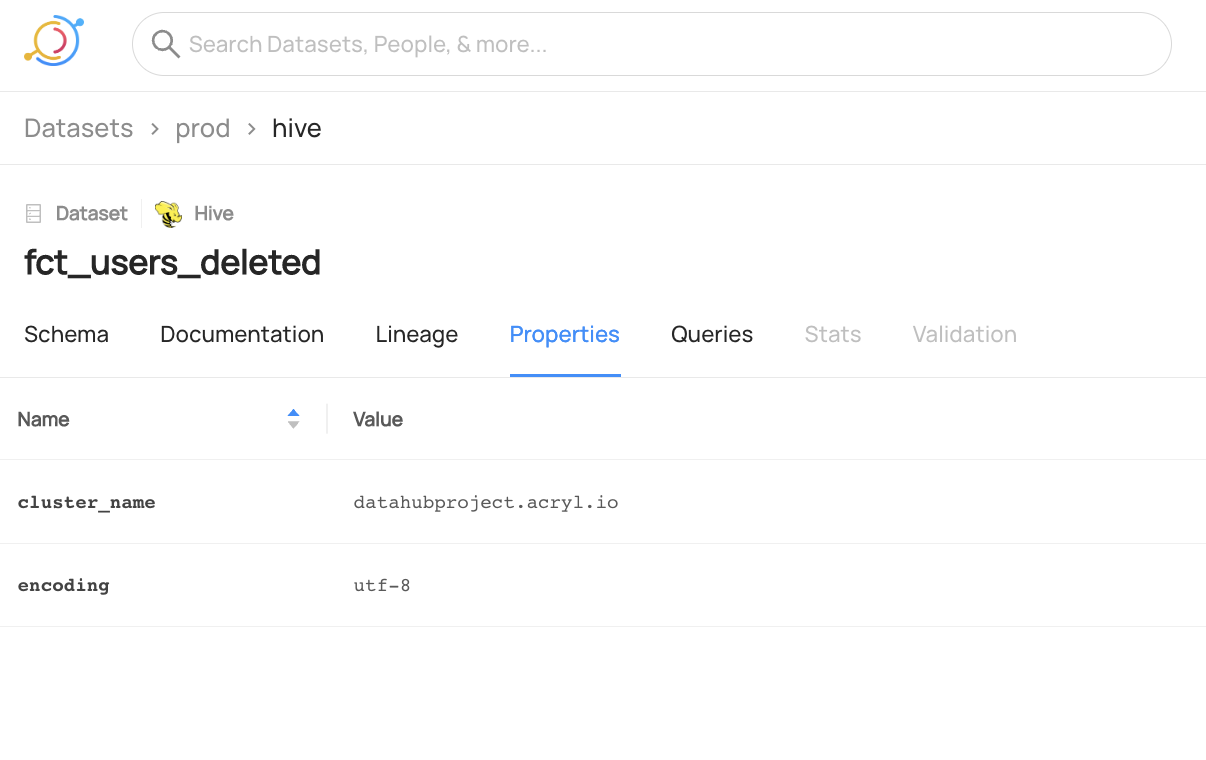 +
+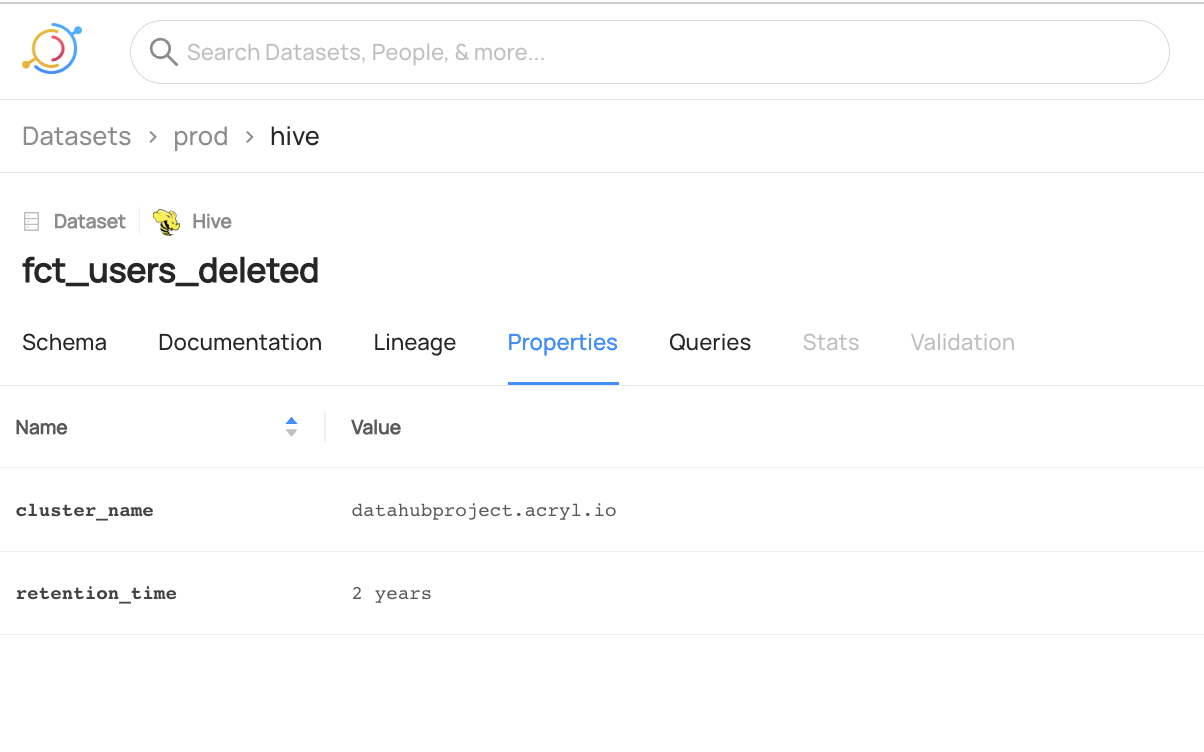 +
+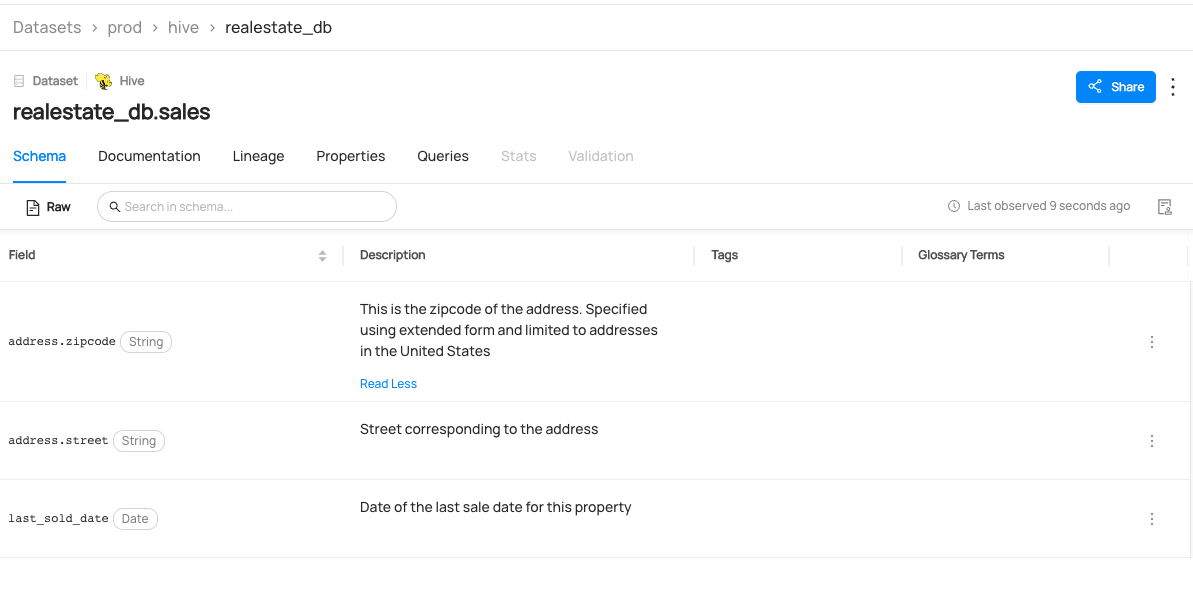 +
+ +
+ +
+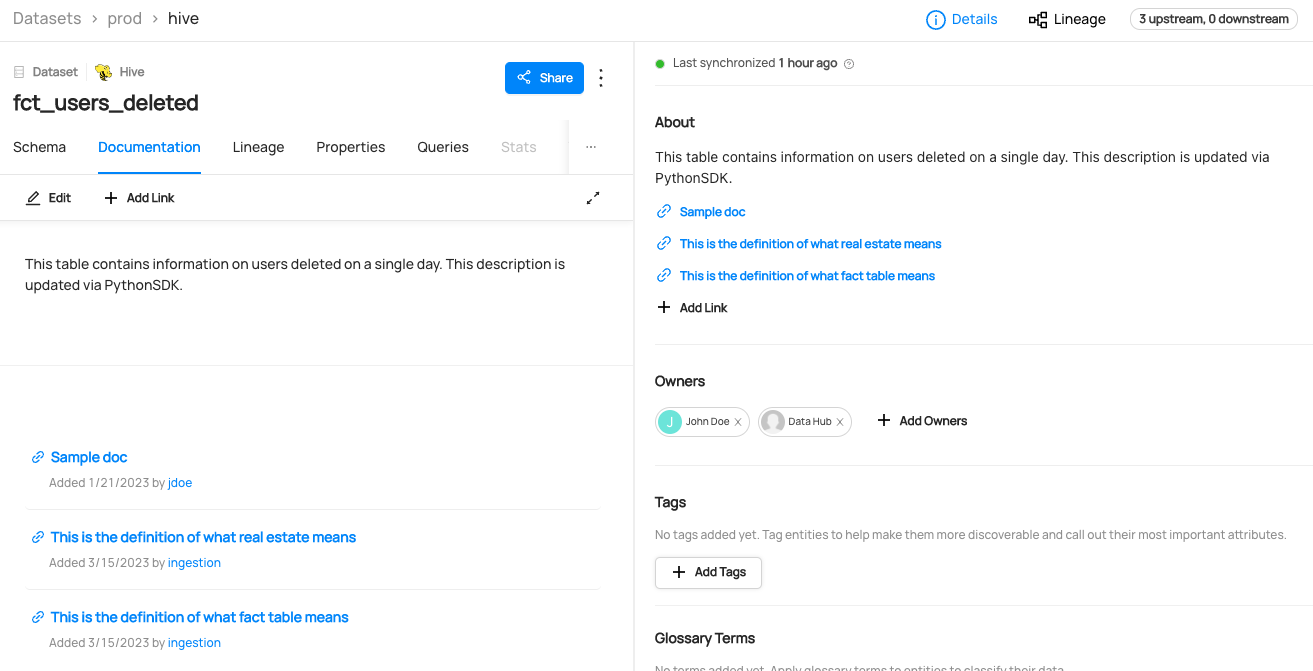 +
+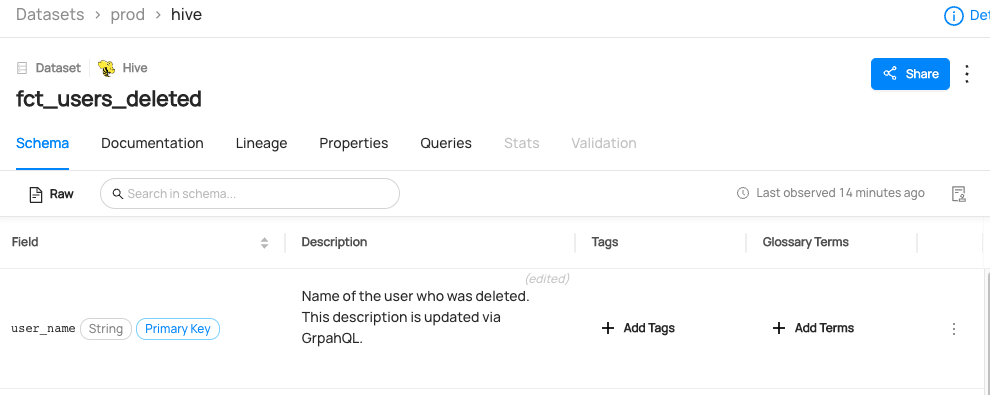 +
+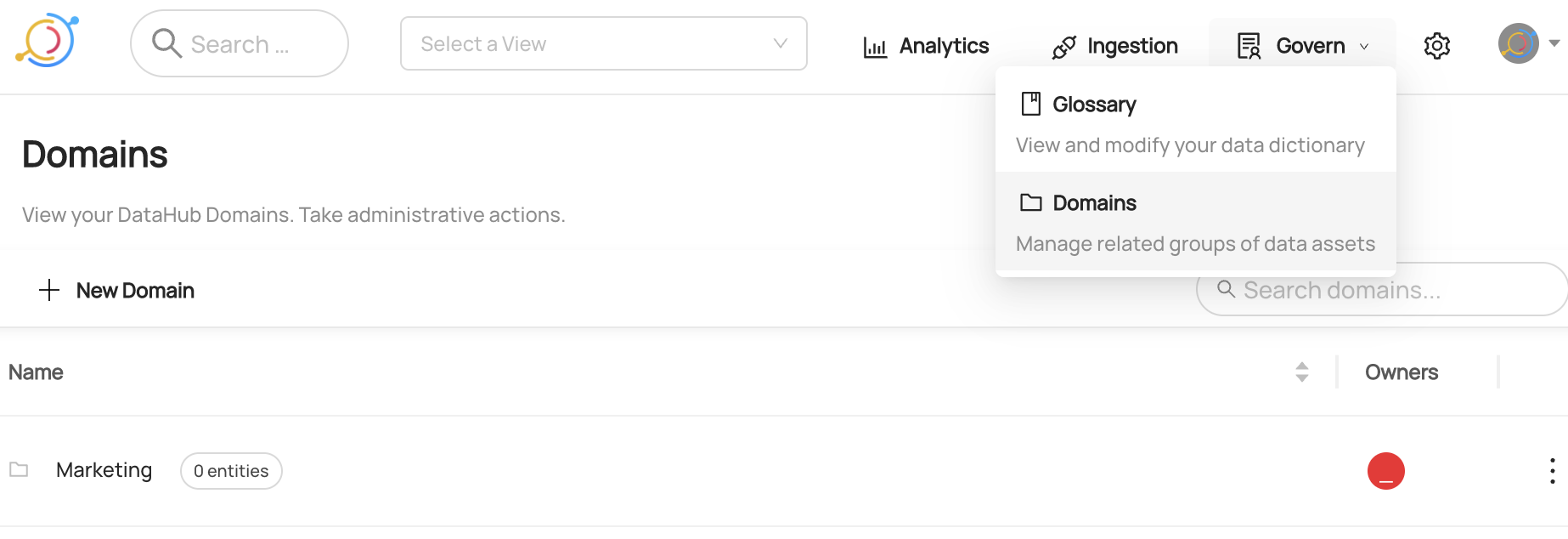 +
+ +
+ +
+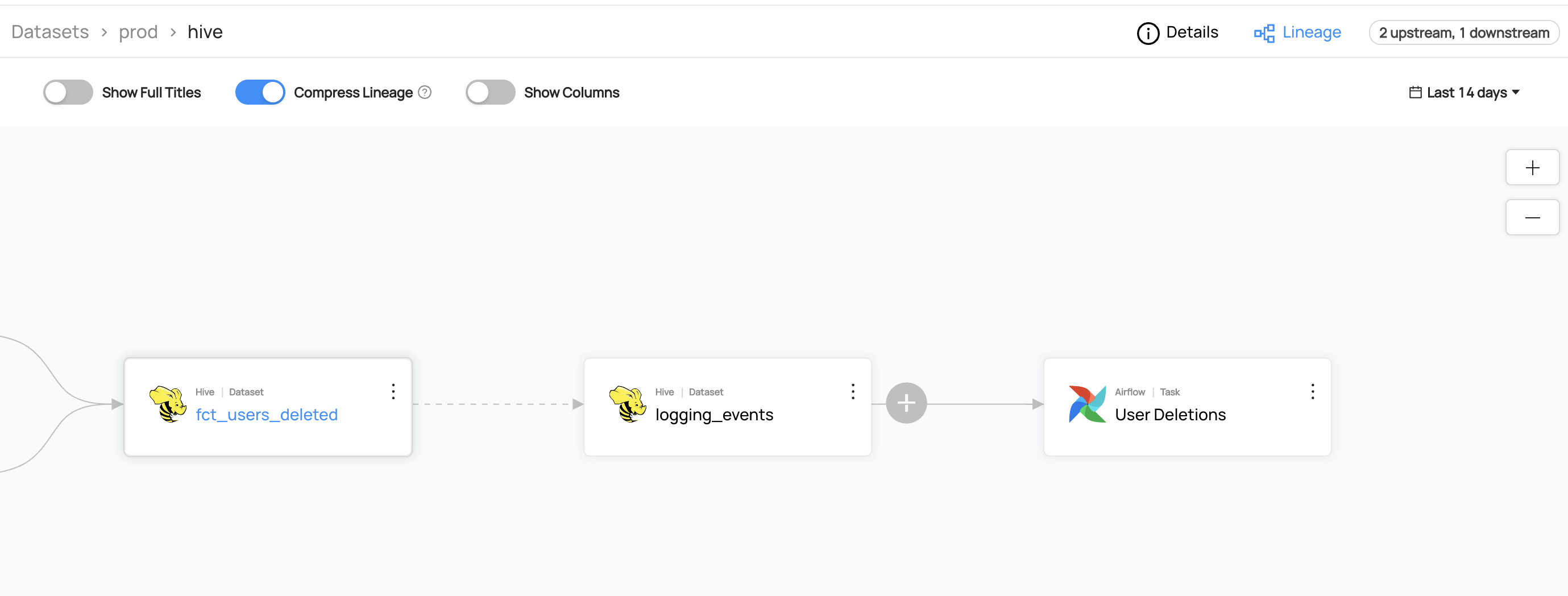 +
+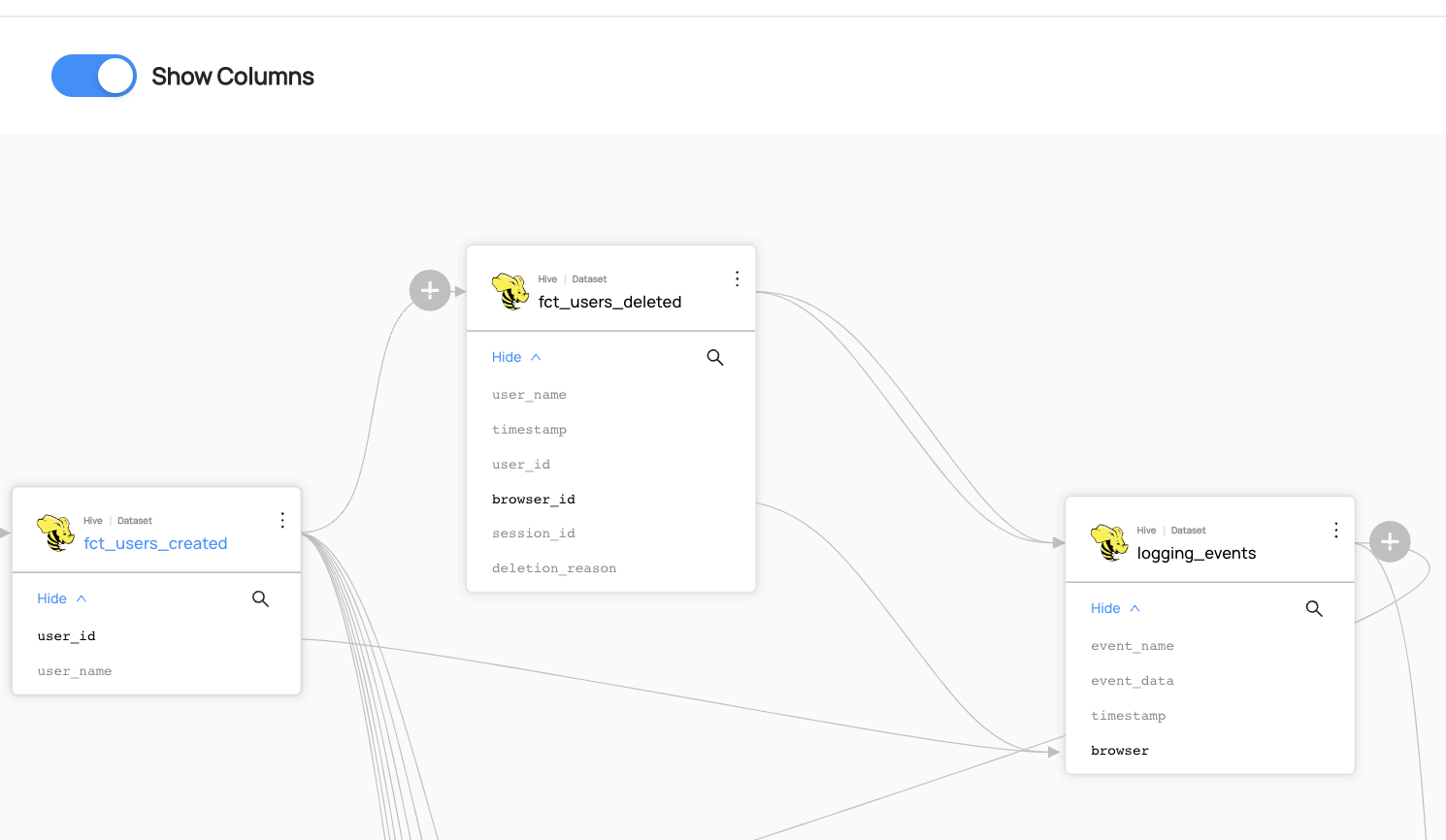 +
+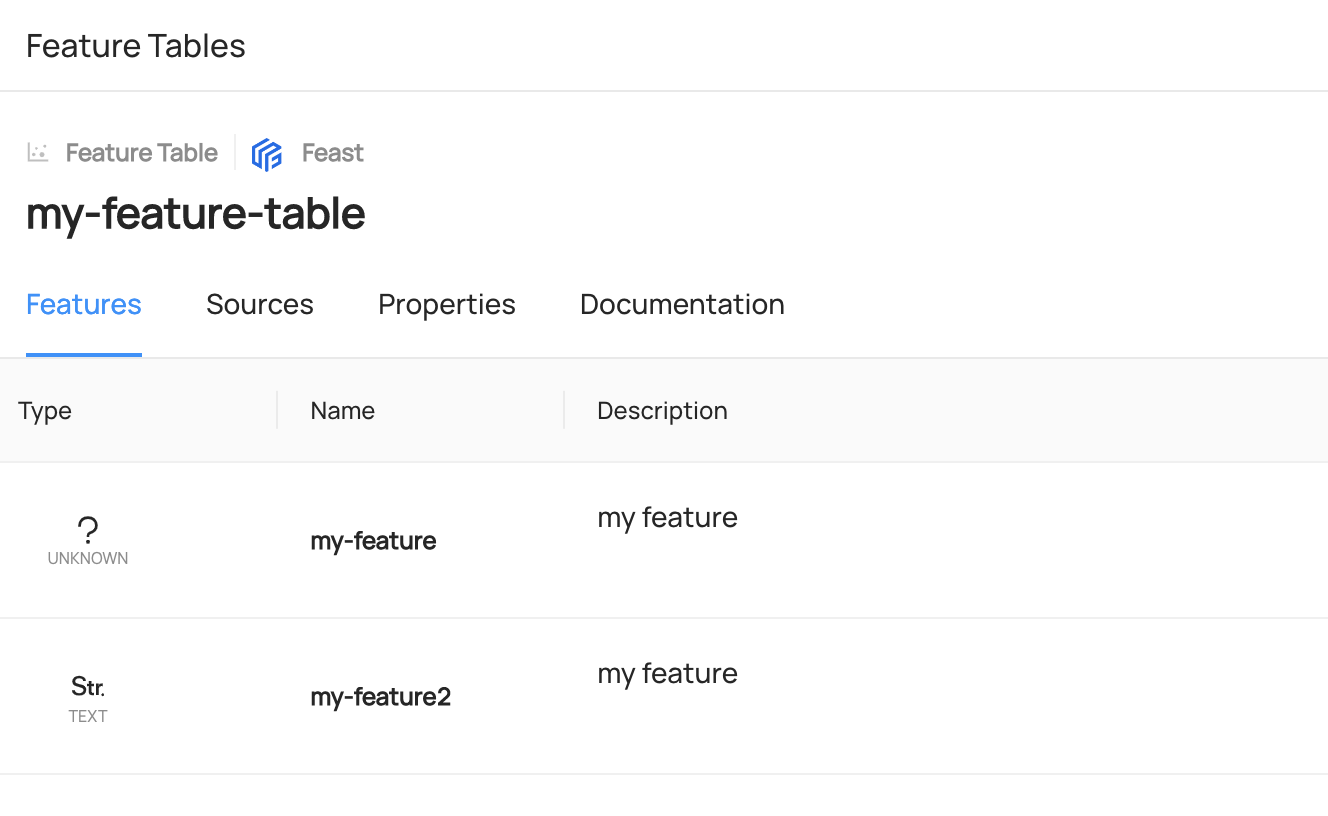 +
+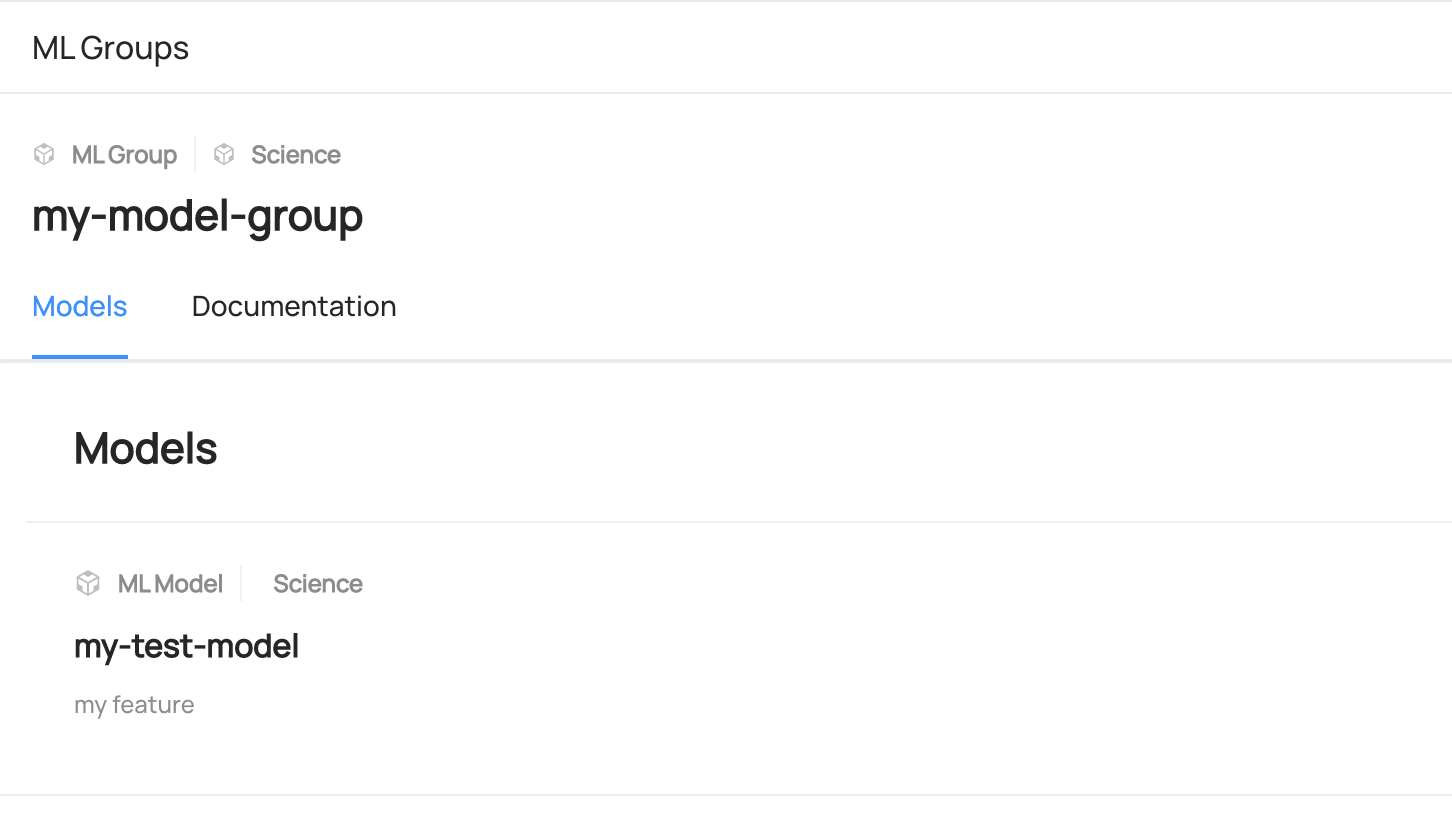 +
+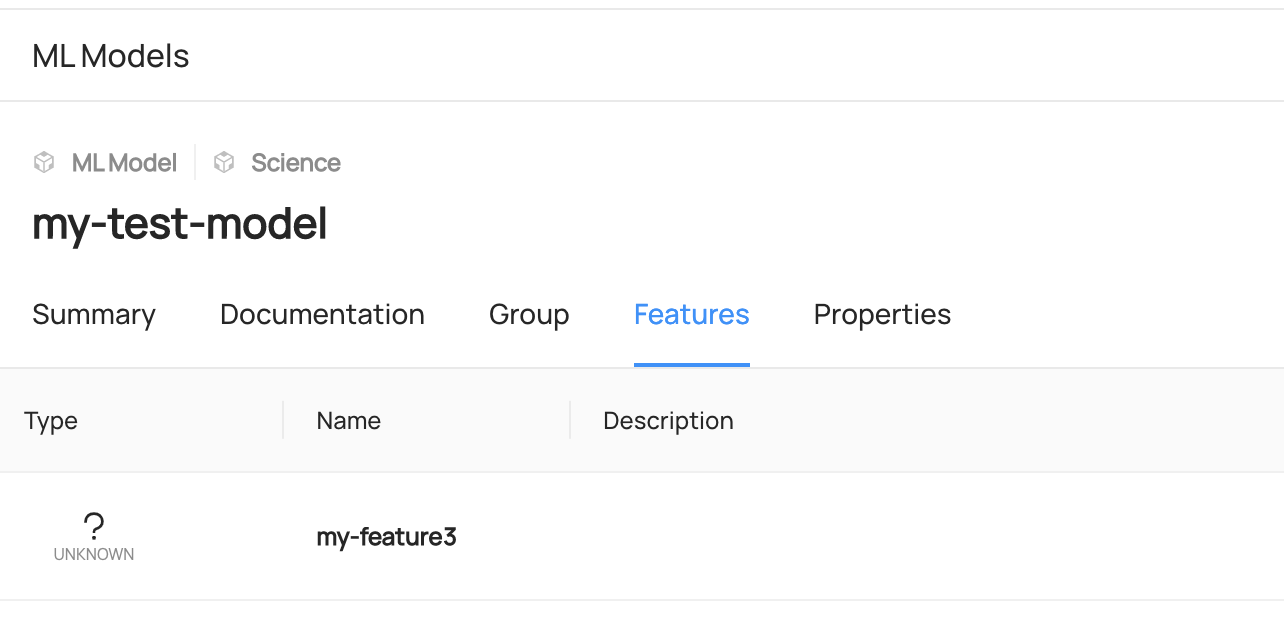 +
+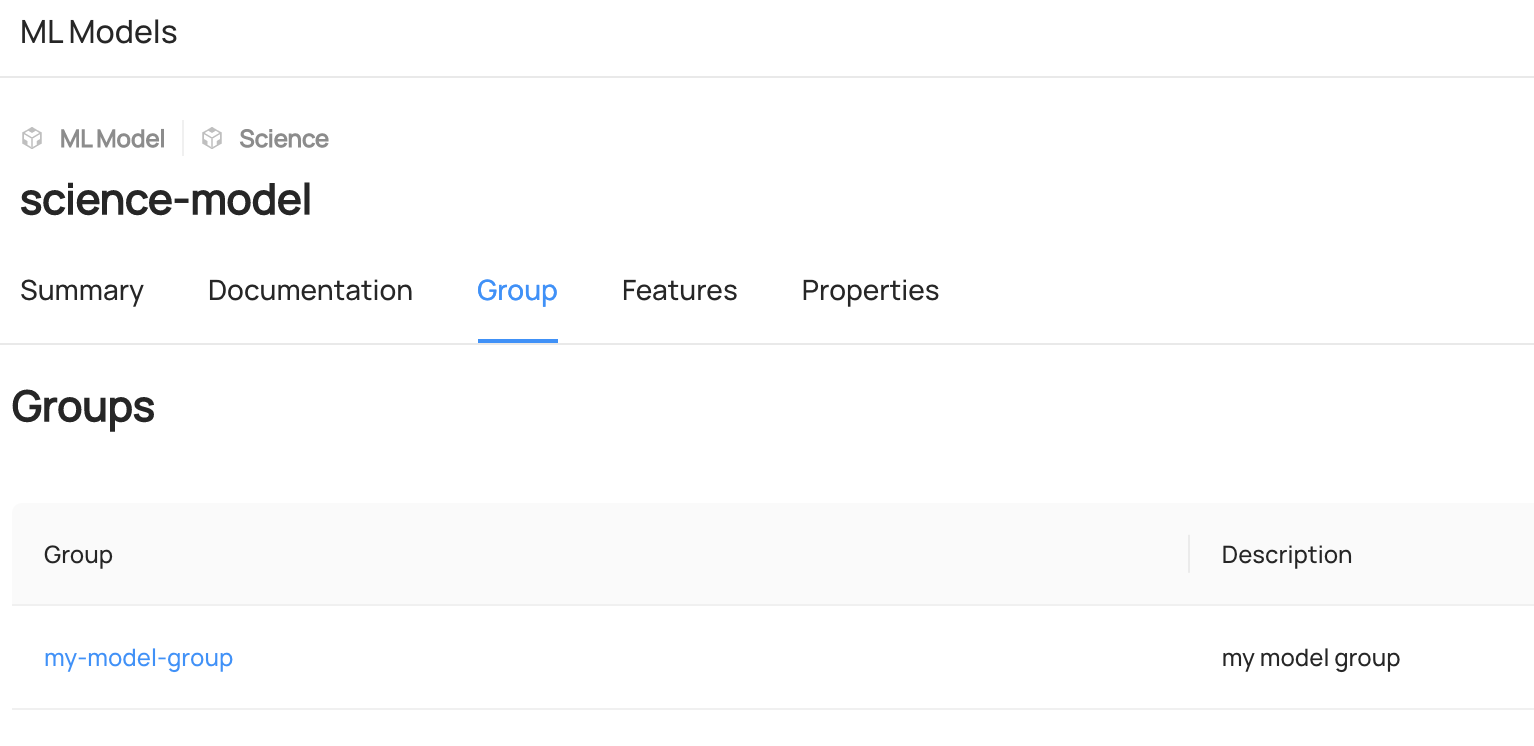 +
+ +
+ +
+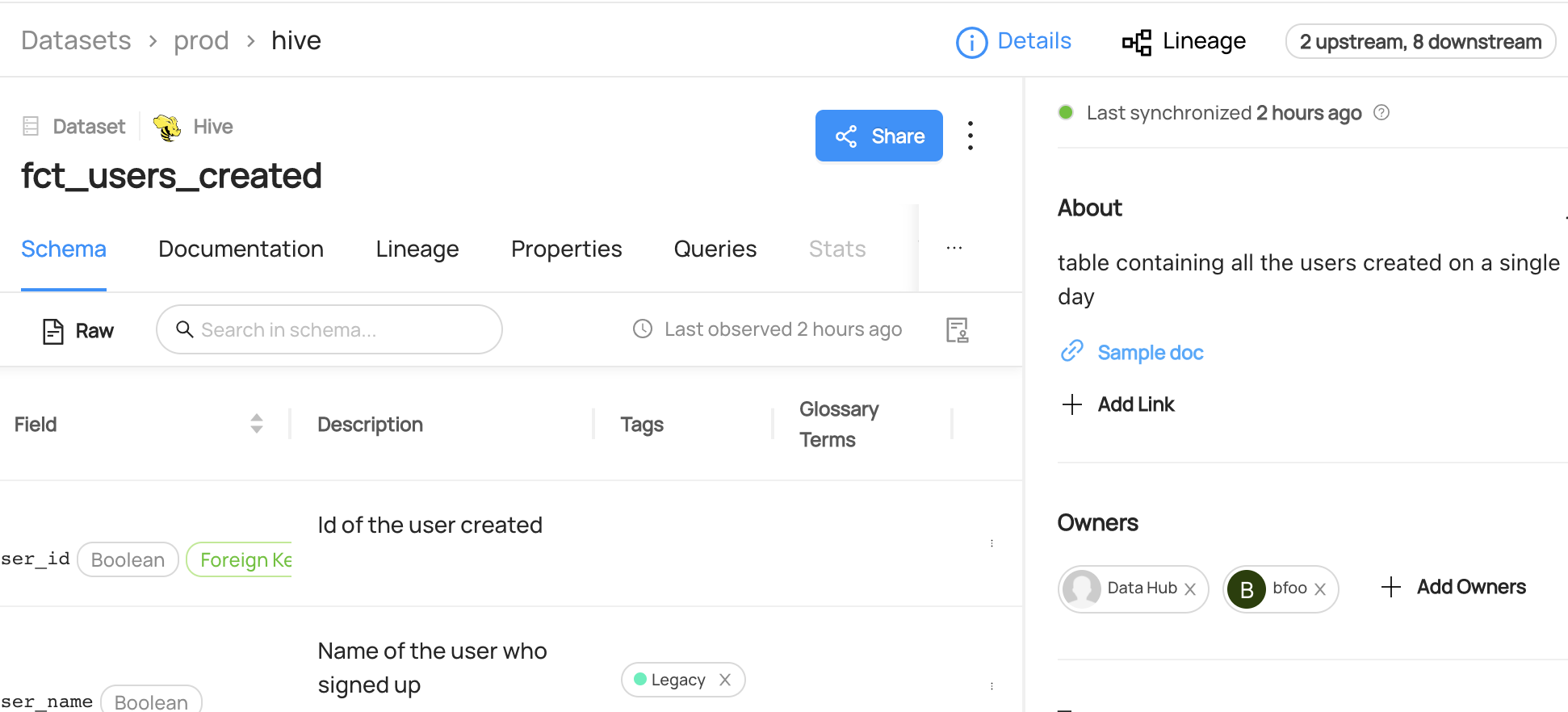 +
+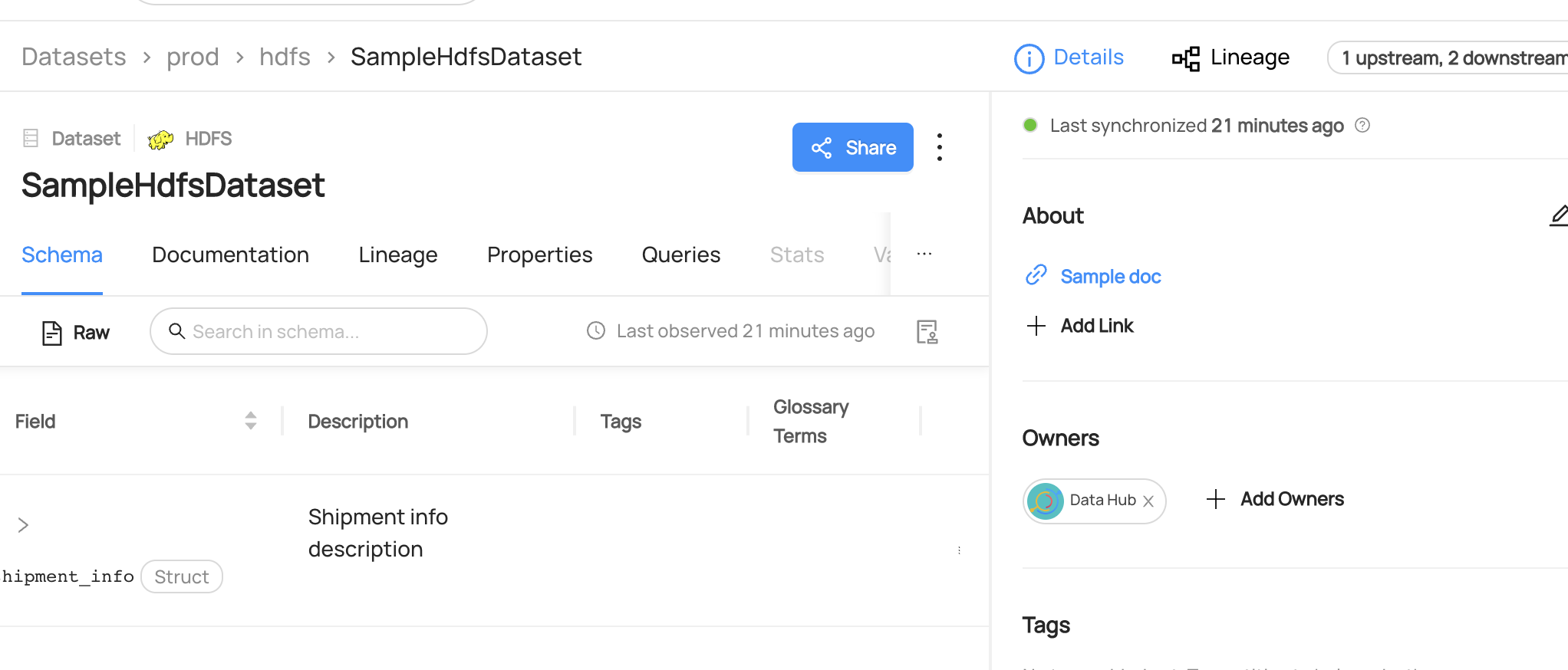 +
+ +
+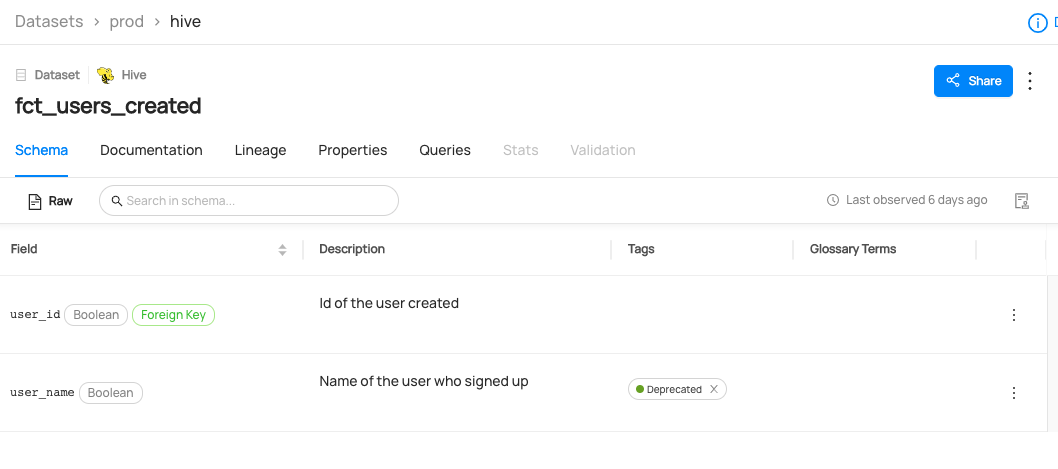 +
+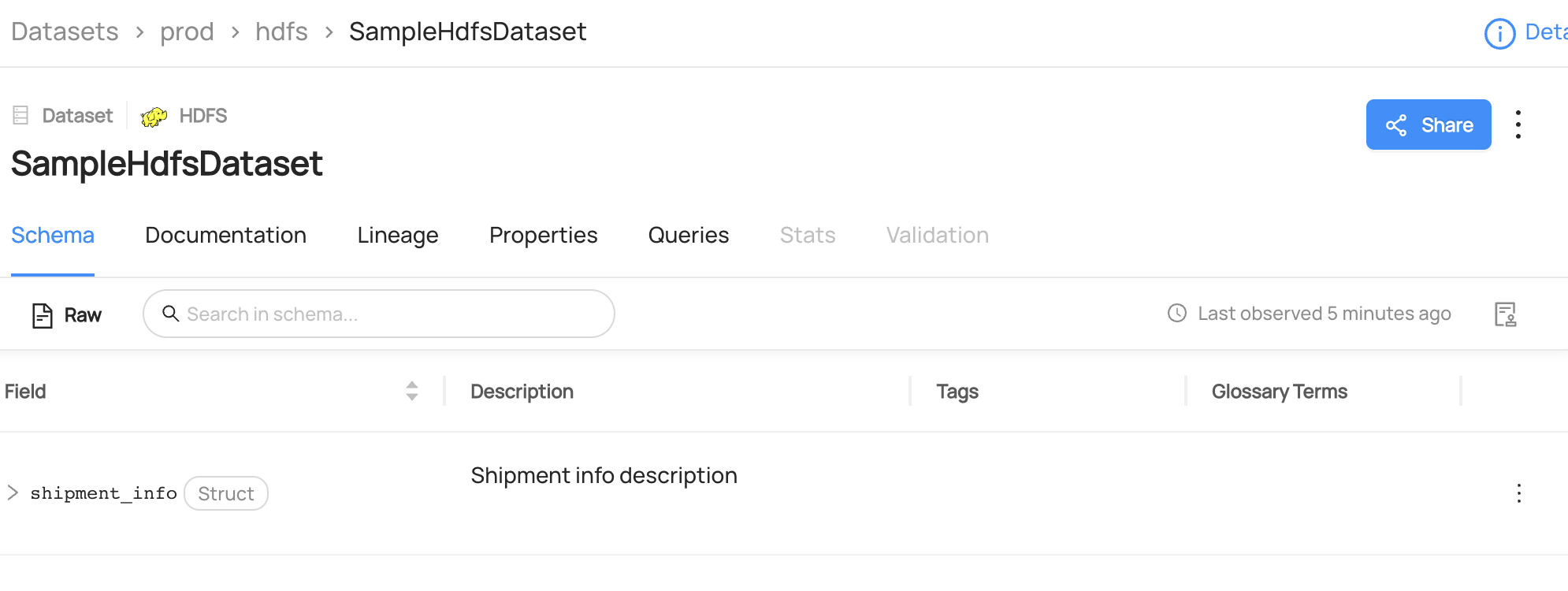 +
+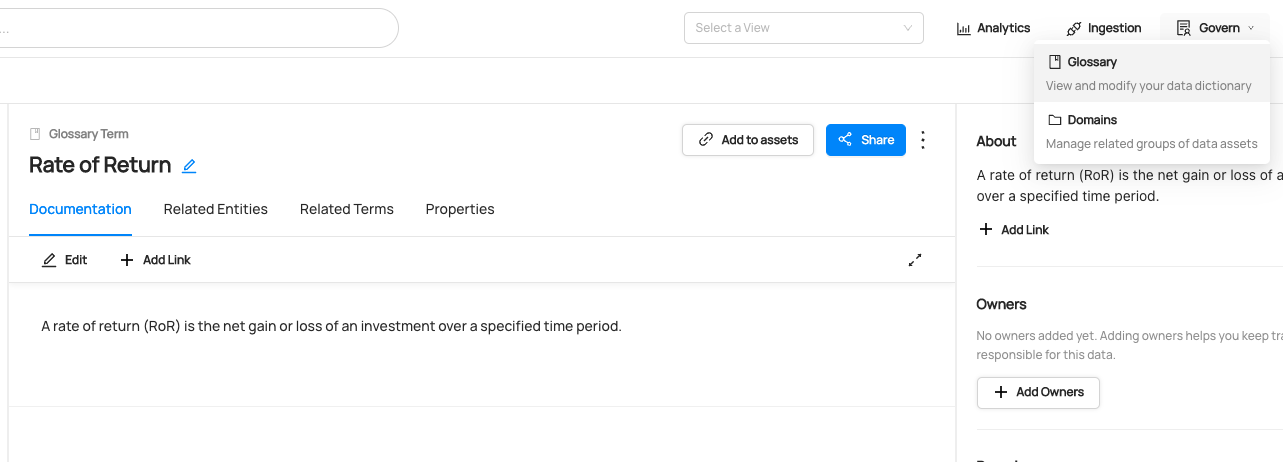 +
+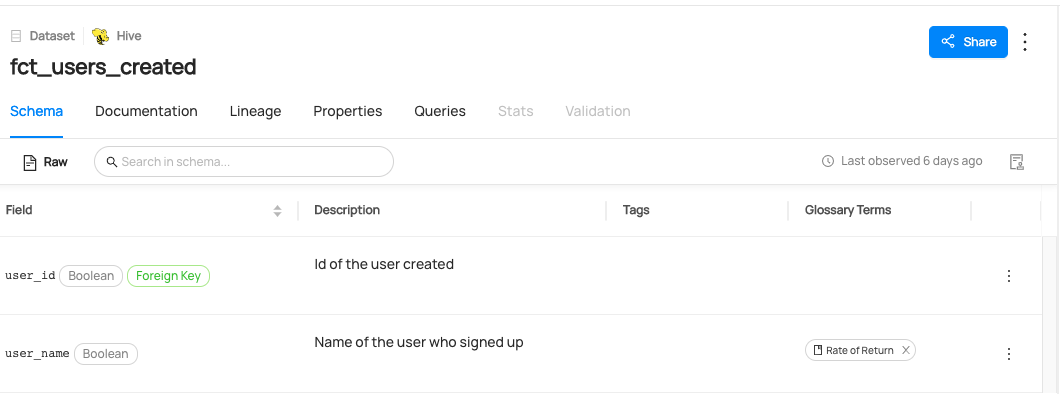 +
+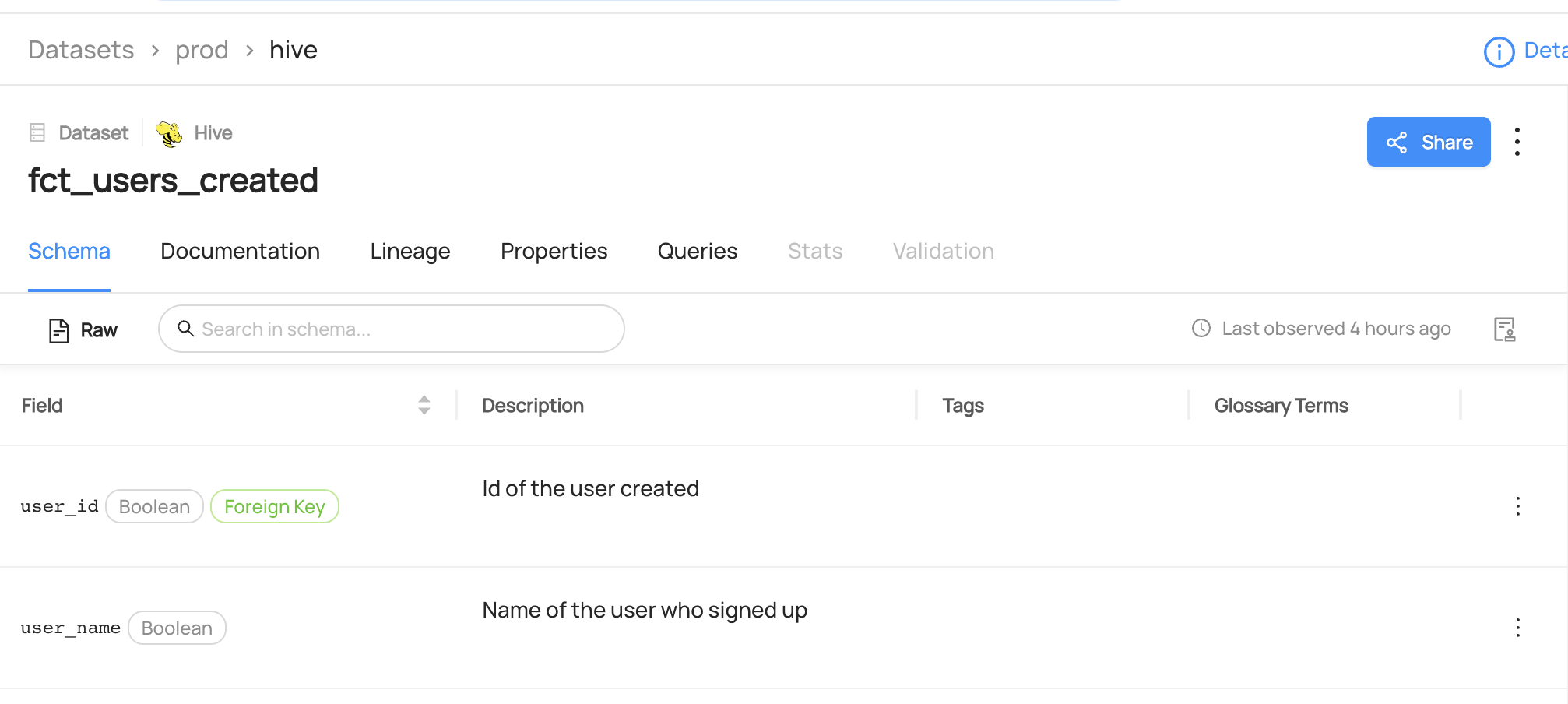 +
+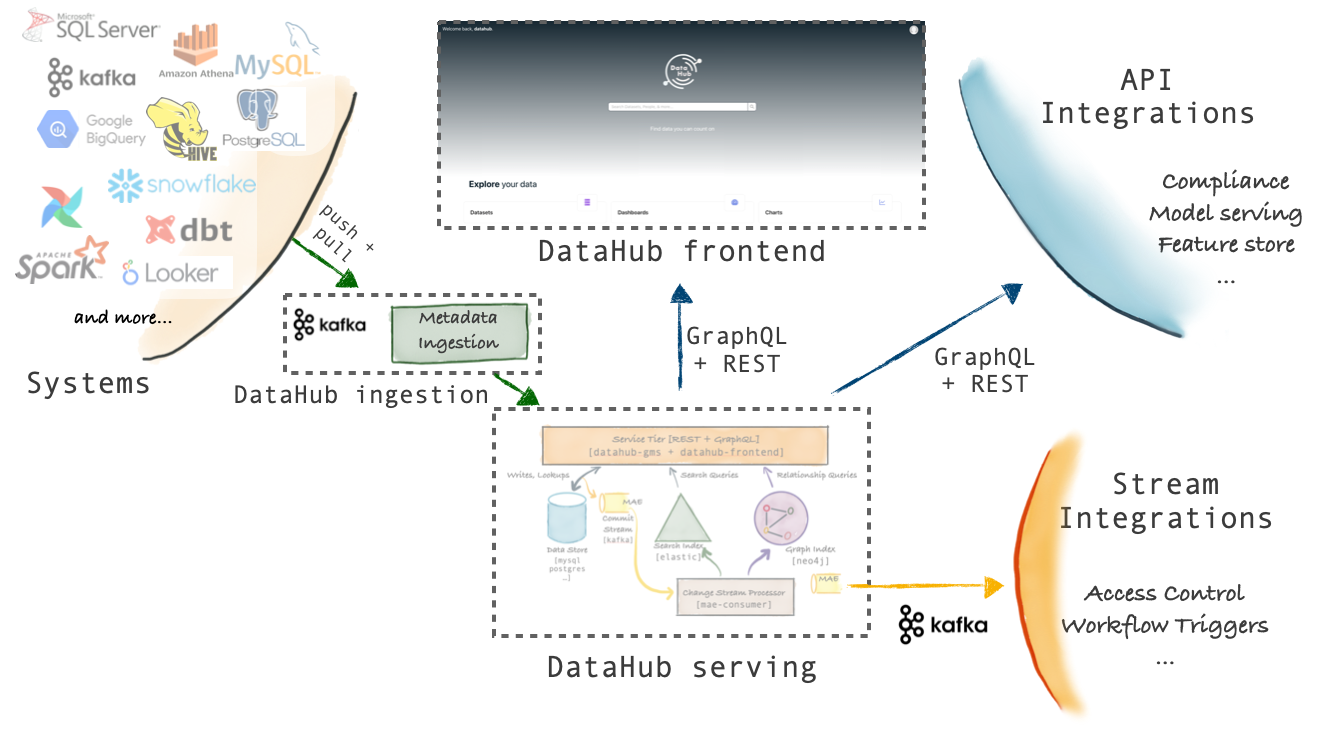 +
+ +
+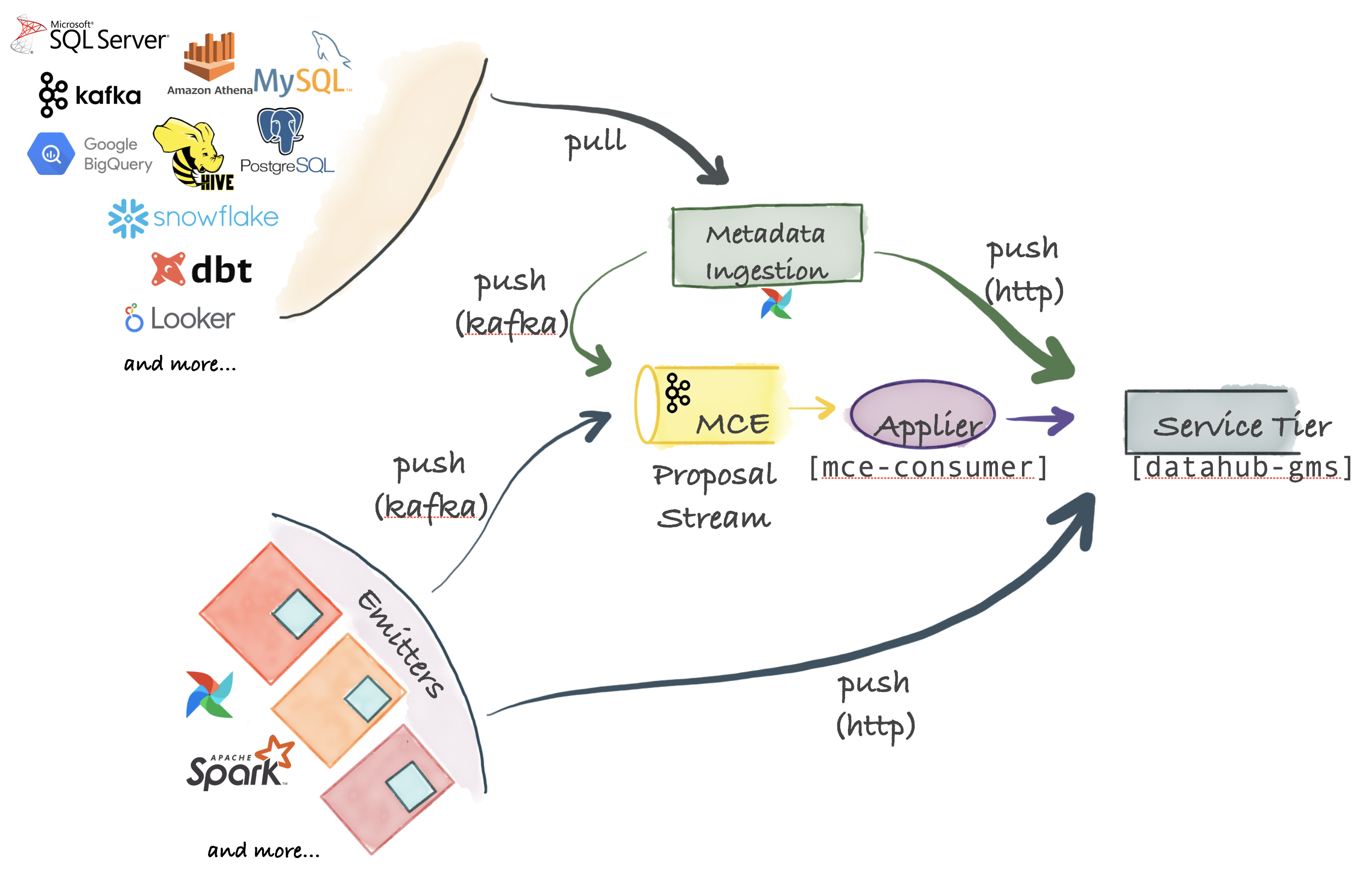 +
+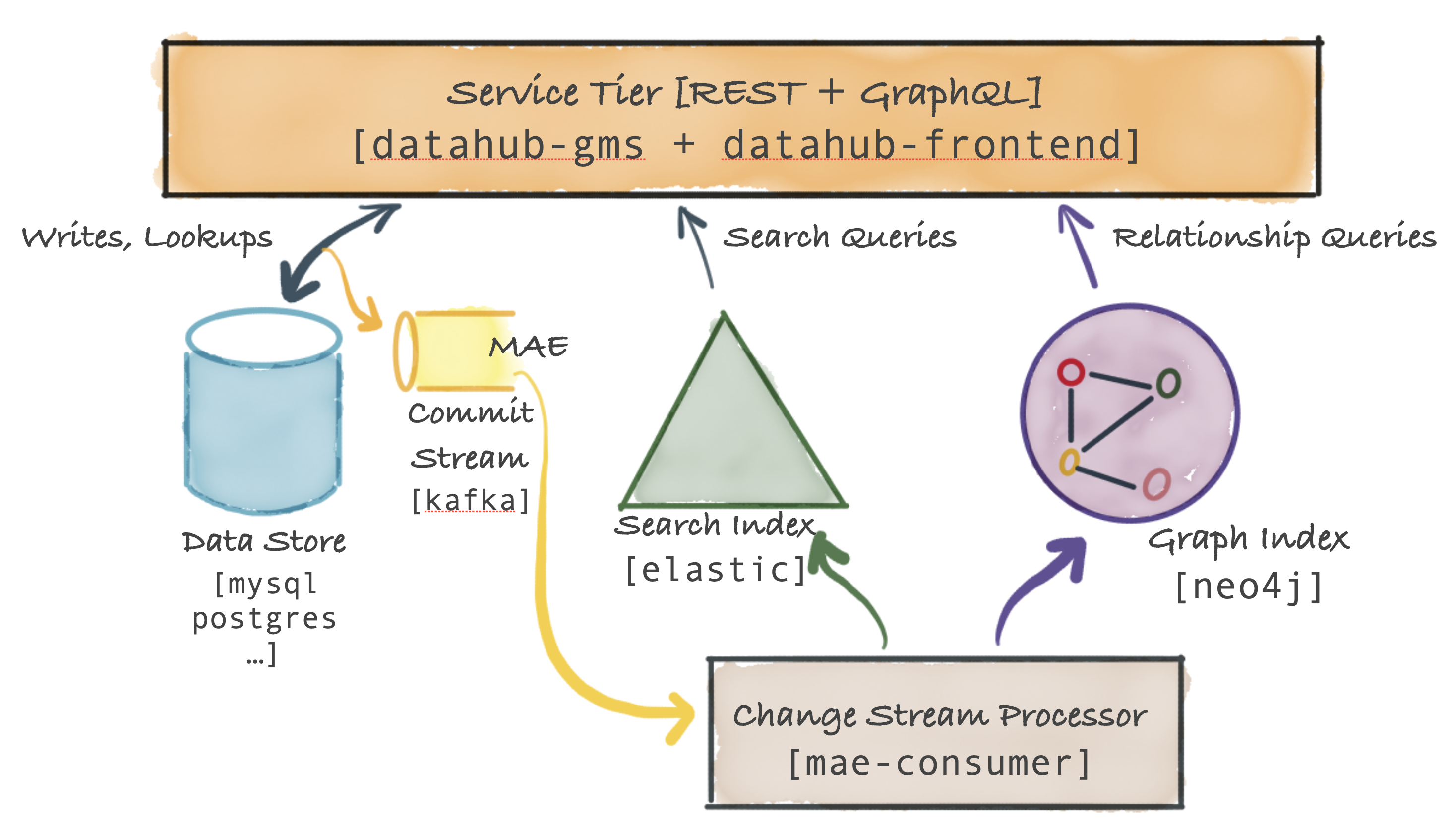 +
+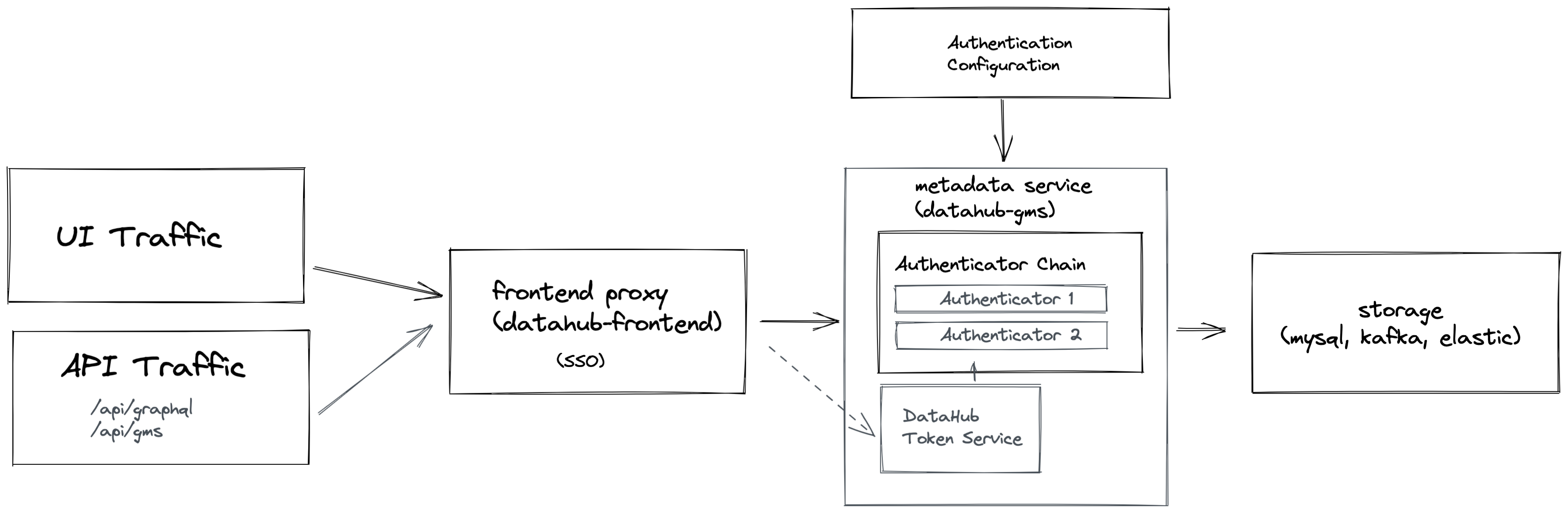 +
+