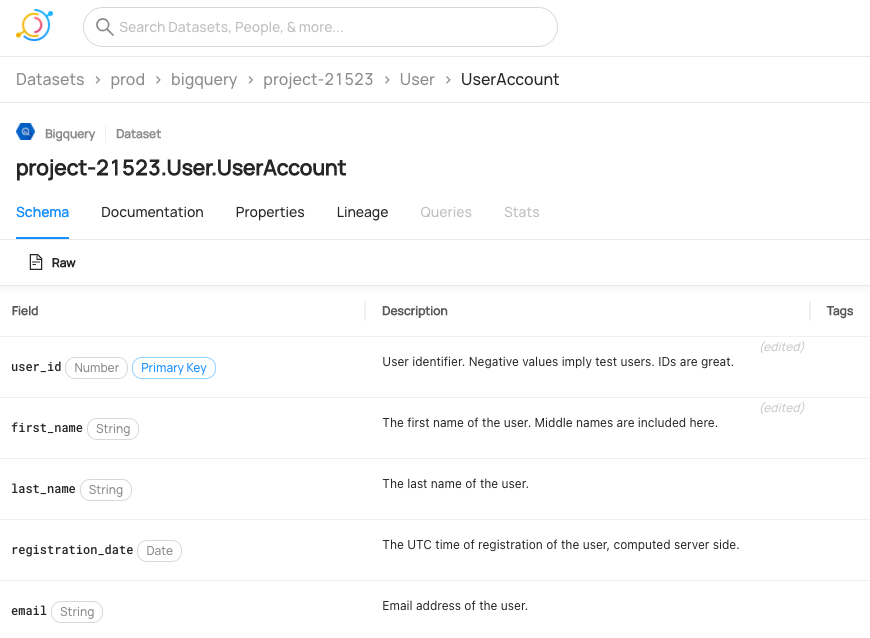
 +
+
+
+
+
+
-
+
+
+
+ 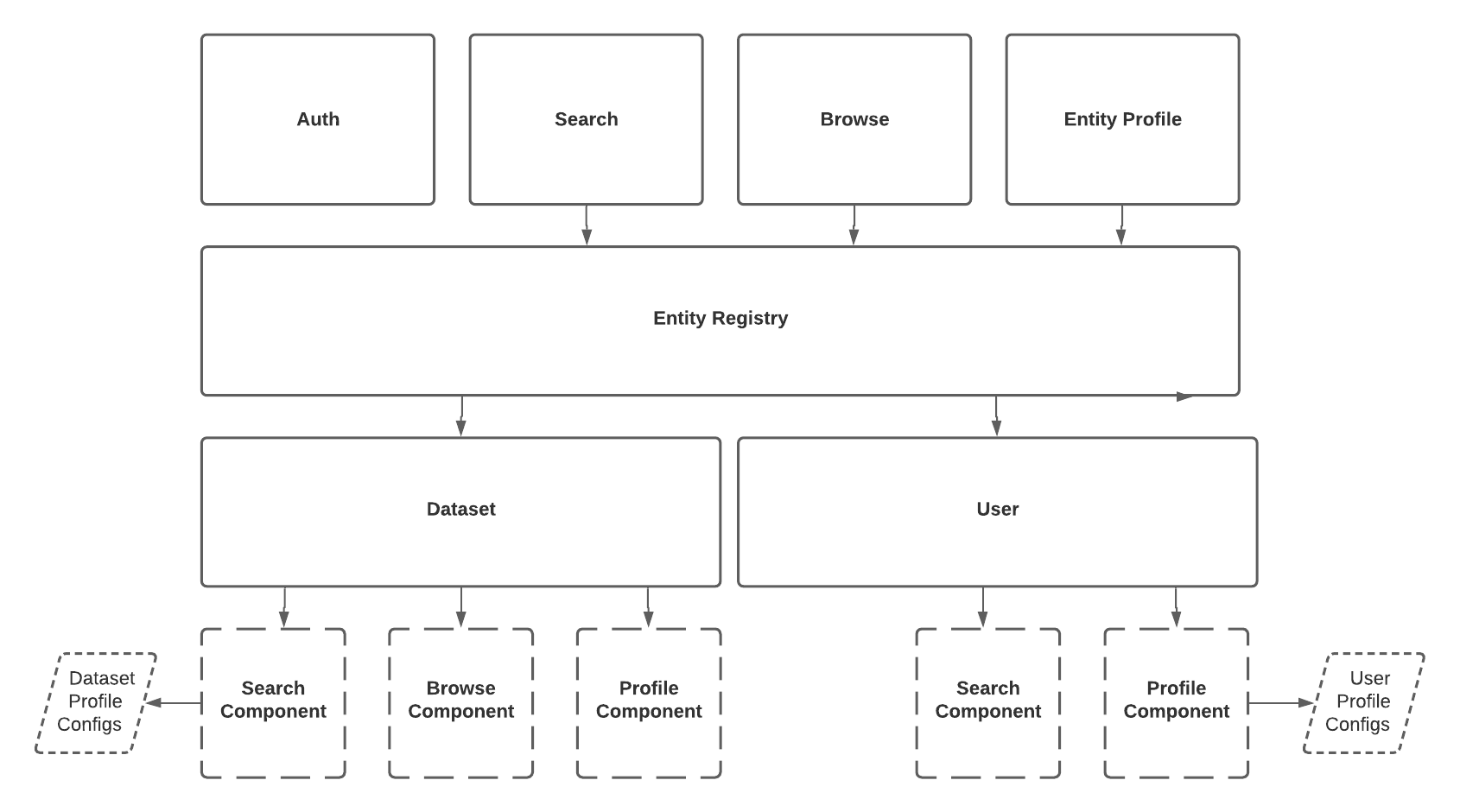 +
+
+
+
+
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+ +
diff --git a/docs-website/versioned_docs/version-0.10.4/docs/act-on-metadata/impact-analysis.md b/docs-website/versioned_docs/version-0.10.4/docs/act-on-metadata/impact-analysis.md new file mode 100644 index 00000000000000..92c307e4a82da0 --- /dev/null +++ b/docs-website/versioned_docs/version-0.10.4/docs/act-on-metadata/impact-analysis.md @@ -0,0 +1,102 @@ +--- +title: About DataHub Lineage Impact Analysis +sidebar_label: Lineage Impact Analysis +slug: /act-on-metadata/impact-analysis +custom_edit_url: >- + https://github.com/datahub-project/datahub/blob/master/docs/act-on-metadata/impact-analysis.md +--- + +import FeatureAvailability from '@site/src/components/FeatureAvailability'; + +# About DataHub Lineage Impact Analysis + +
+ 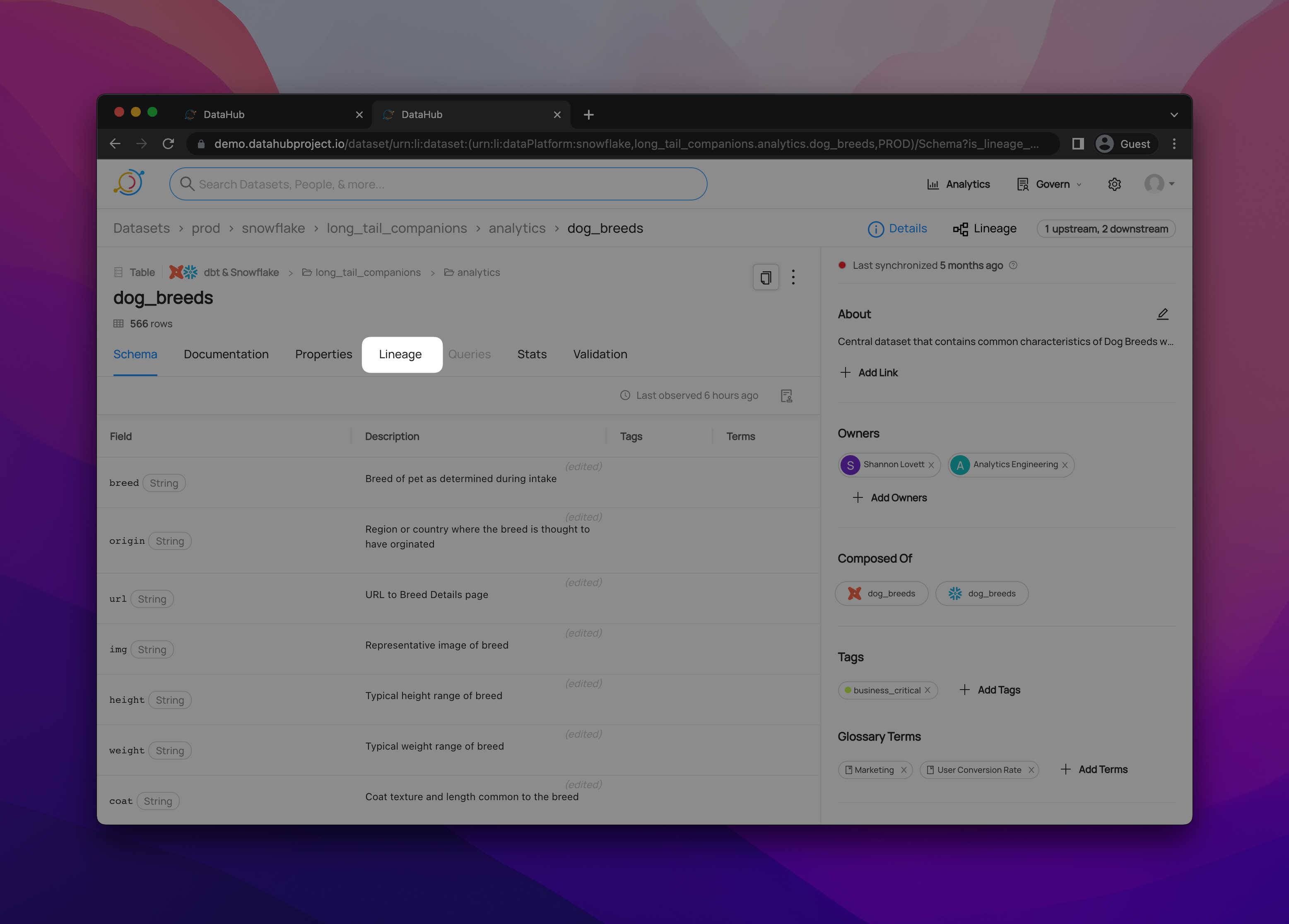 +
+
+ 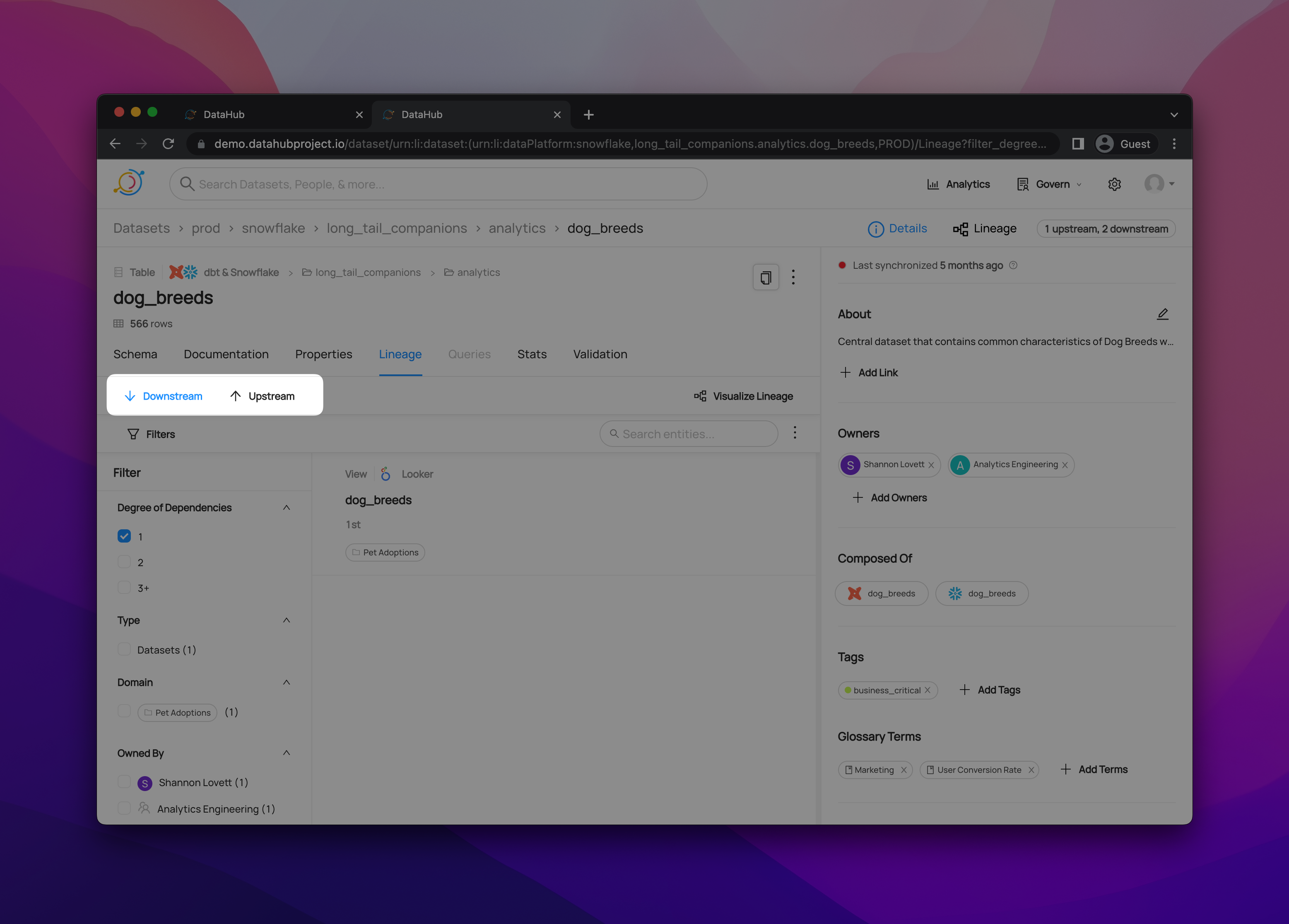 +
+
+ 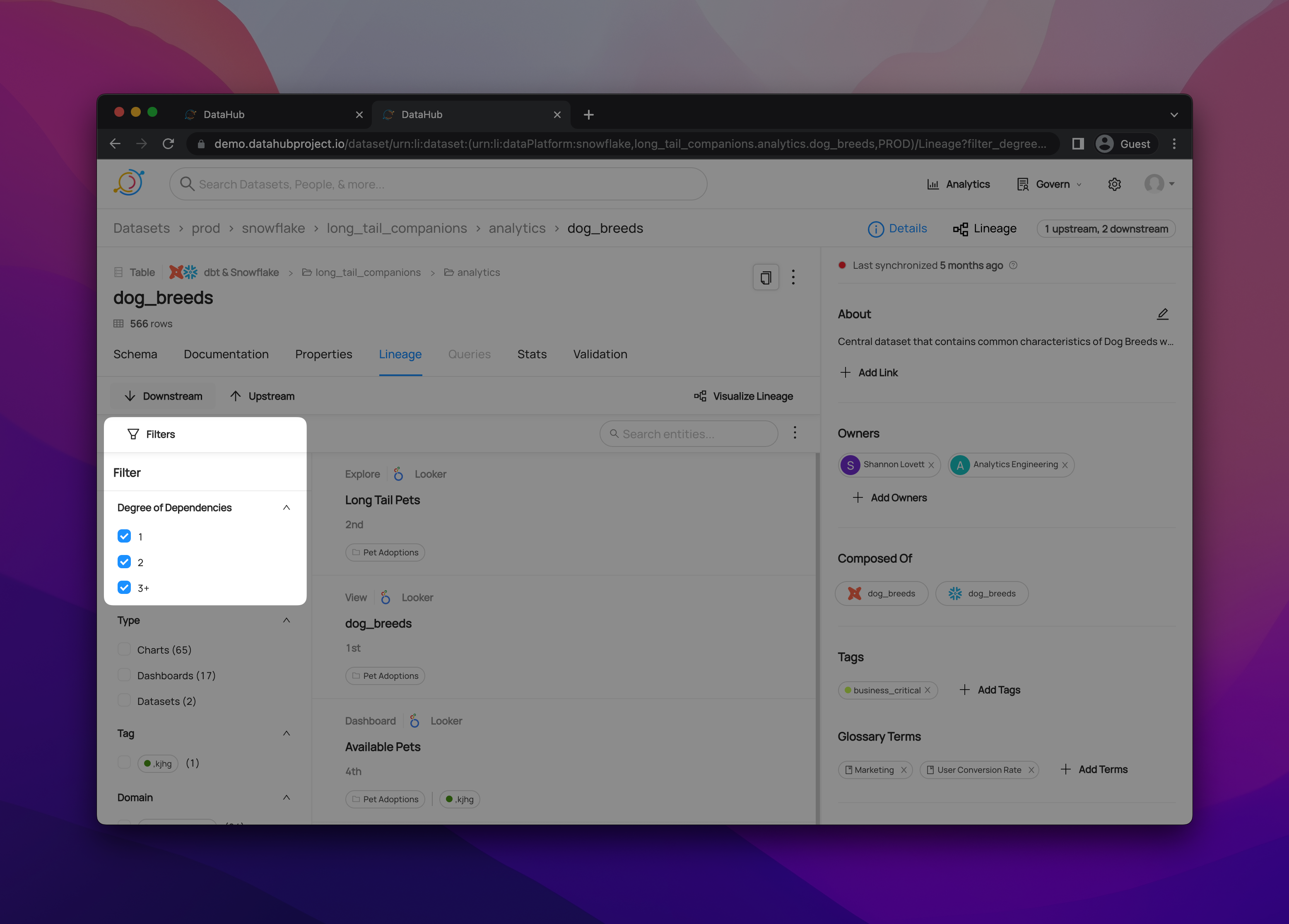 +
+
+ 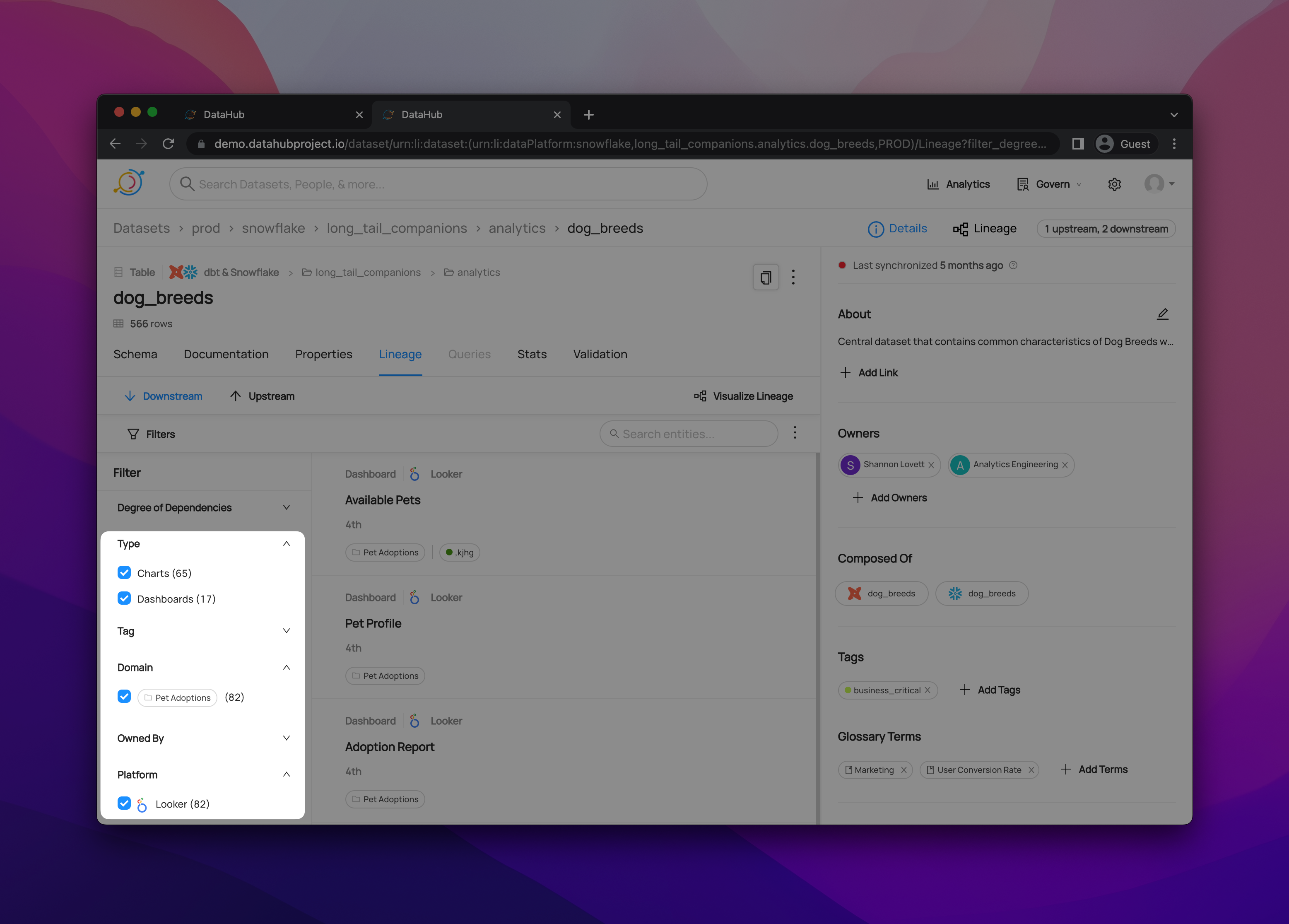 +
+
+ 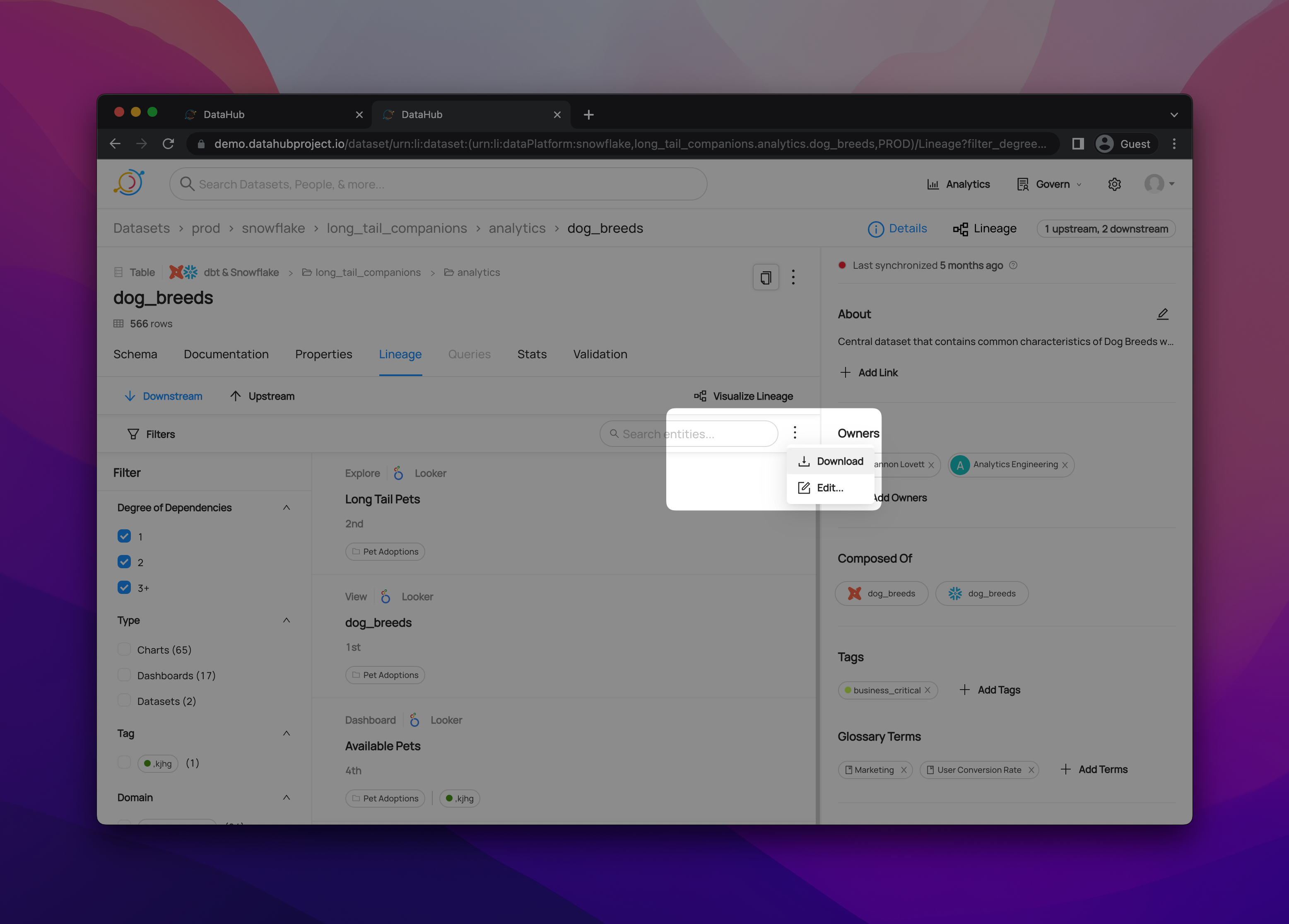 +
+
+ 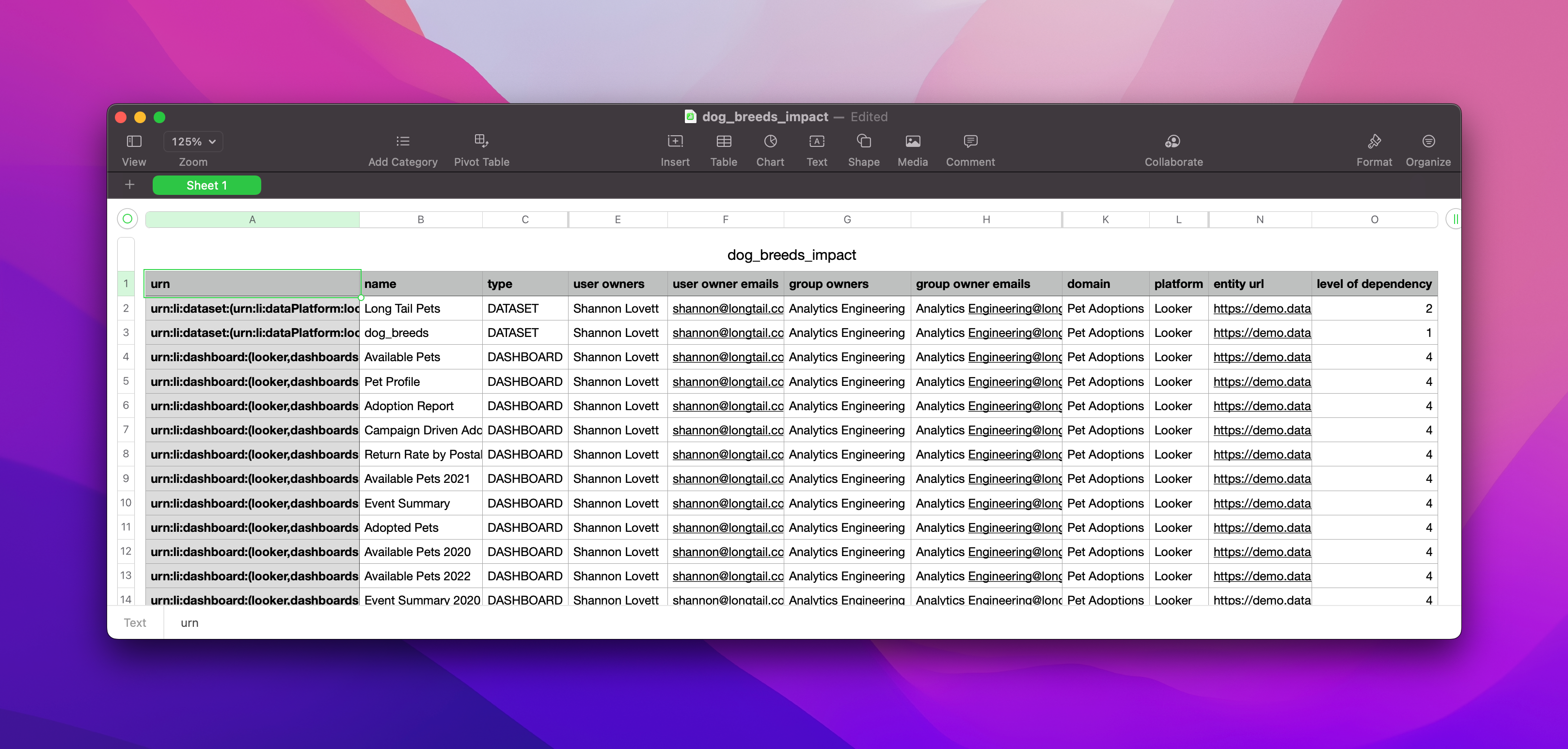 +
+
+ +
+ +### GraphQL + +- [searchAcrossLineage](../../graphql/queries.md#searchacrosslineage) +- [searchAcrossLineageInput](../../graphql/inputObjects.md#searchacrosslineageinput) + +Looking for an example of how to use `searchAcrossLineage` to read lineage? Look [here](../api/tutorials/lineage.md#read-lineage) + +### DataHub Blog + +- [Dependency Impact Analysis, Data Validation Outcomes, and MORE! - Highlights from DataHub v0.8.27 & v.0.8.28](https://blog.datahubproject.io/dependency-impact-analysis-data-validation-outcomes-and-more-1302604da233) + +### FAQ and Troubleshooting + +**The Lineage Tab is greyed out - why can’t I click on it?** + +This means you have not yet ingested Lineage metadata for that entity. Please see the Lineage Guide to get started. + +**Why is my list of exported dependencies incomplete?** + +We currently limit the list of dependencies to 10,000 records; we suggest applying filters to narrow the result set if you hit that limit. + +_Need more help? Join the conversation in [Slack](http://slack.datahubproject.io)!_ + +### Related Features + +- [DataHub Lineage](../lineage/lineage-feature-guide.md) diff --git a/docs-website/versioned_docs/version-0.10.4/docs/actions/README.md b/docs-website/versioned_docs/version-0.10.4/docs/actions/README.md new file mode 100644 index 00000000000000..10040bd1e45dd0 --- /dev/null +++ b/docs-website/versioned_docs/version-0.10.4/docs/actions/README.md @@ -0,0 +1,250 @@ +--- +title: Introduction +slug: /actions +custom_edit_url: "https://github.com/datahub-project/datahub/blob/master/docs/actions/README.md" +--- + +# ⚡ DataHub Actions Framework + +Welcome to DataHub Actions! The Actions framework makes responding to realtime changes in your Metadata Graph easy, enabling you to seamlessly integrate [DataHub](https://github.com/datahub-project/datahub) into a broader events-based architecture. + +For a detailed introduction, check out the [original announcement](https://www.youtube.com/watch?v=7iwNxHgqxtg&t=2189s) of the DataHub Actions Framework at the DataHub April 2022 Town Hall. For a more in-depth look at use cases and concepts, check out [DataHub Actions Concepts](concepts.md). + +## Quickstart + +To get started right away, check out the [DataHub Actions Quickstart](quickstart.md) Guide. + +## Prerequisites + +The DataHub Actions CLI commands are an extension of the base `datahub` CLI commands. We recommend +first installing the `datahub` CLI: + +```shell +python3 -m pip install --upgrade pip wheel setuptools +python3 -m pip install --upgrade acryl-datahub +datahub --version +``` + +> Note that the Actions Framework requires a version of `acryl-datahub` >= v0.8.34 + +## Installation + +Next, simply install the `acryl-datahub-actions` package from PyPi: + +```shell +python3 -m pip install --upgrade pip wheel setuptools +python3 -m pip install --upgrade acryl-datahub-actions +datahub actions version +``` + +## Configuring an Action + +Actions are configured using a YAML file, much in the same way DataHub ingestion sources are. An action configuration file consists of the following + +1. Action Pipeline Name (Should be unique and static) +2. Source Configurations +3. Transform + Filter Configurations +4. Action Configuration +5. Pipeline Options (Optional) +6. DataHub API configs (Optional - required for select actions) + +With each component being independently pluggable and configurable. + +```yml +# 1. Required: Action Pipeline Name +name:
+ 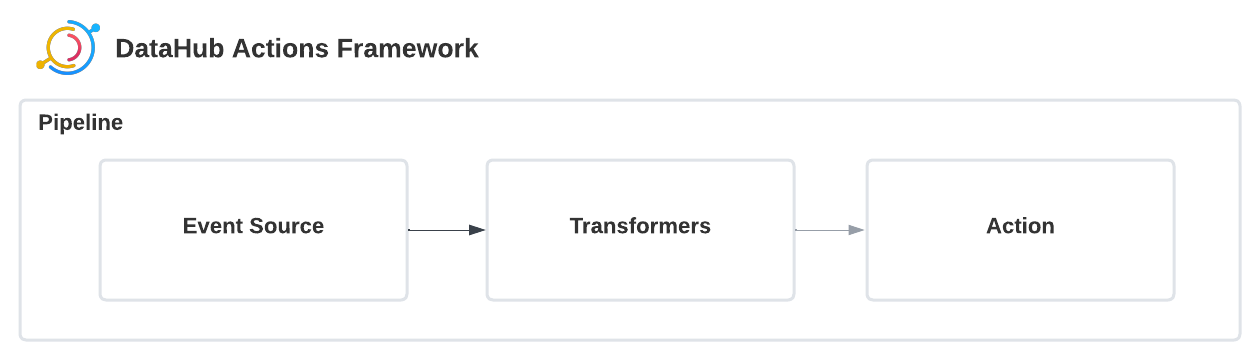 +
+
+ 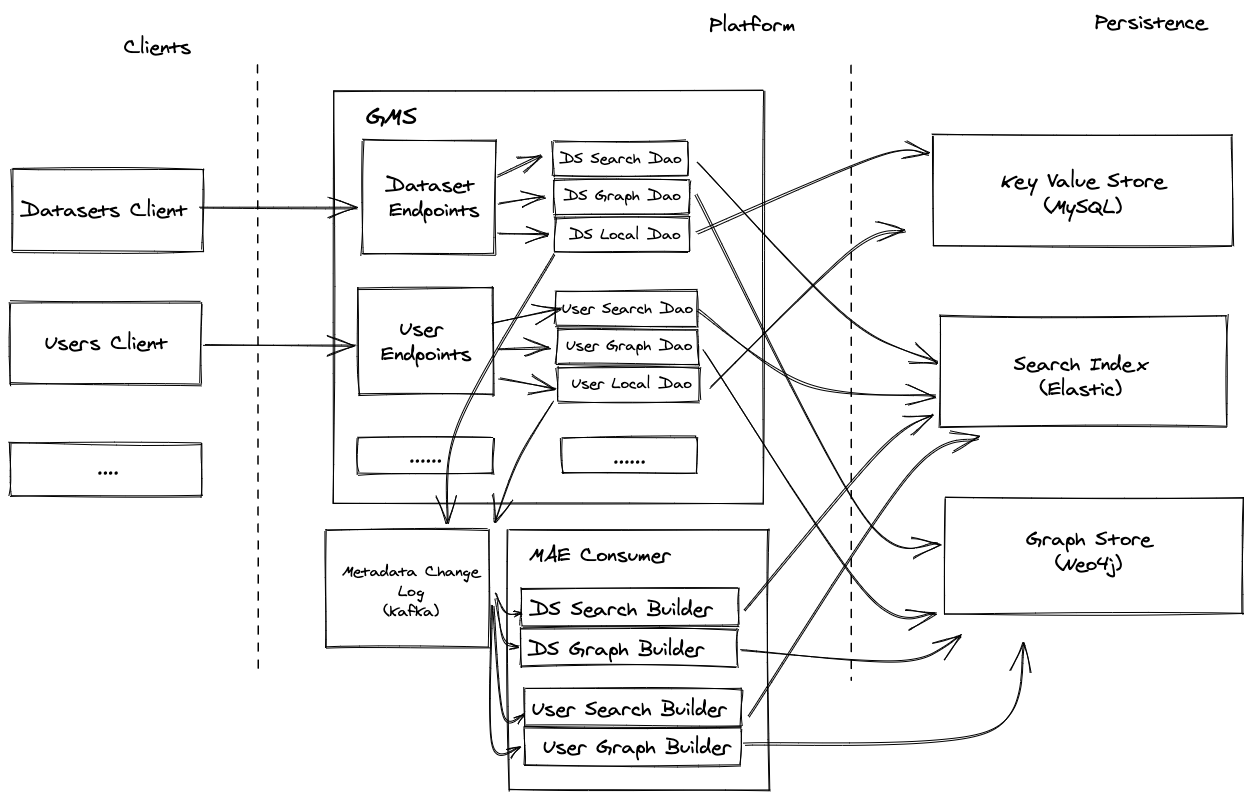 +
+
+ 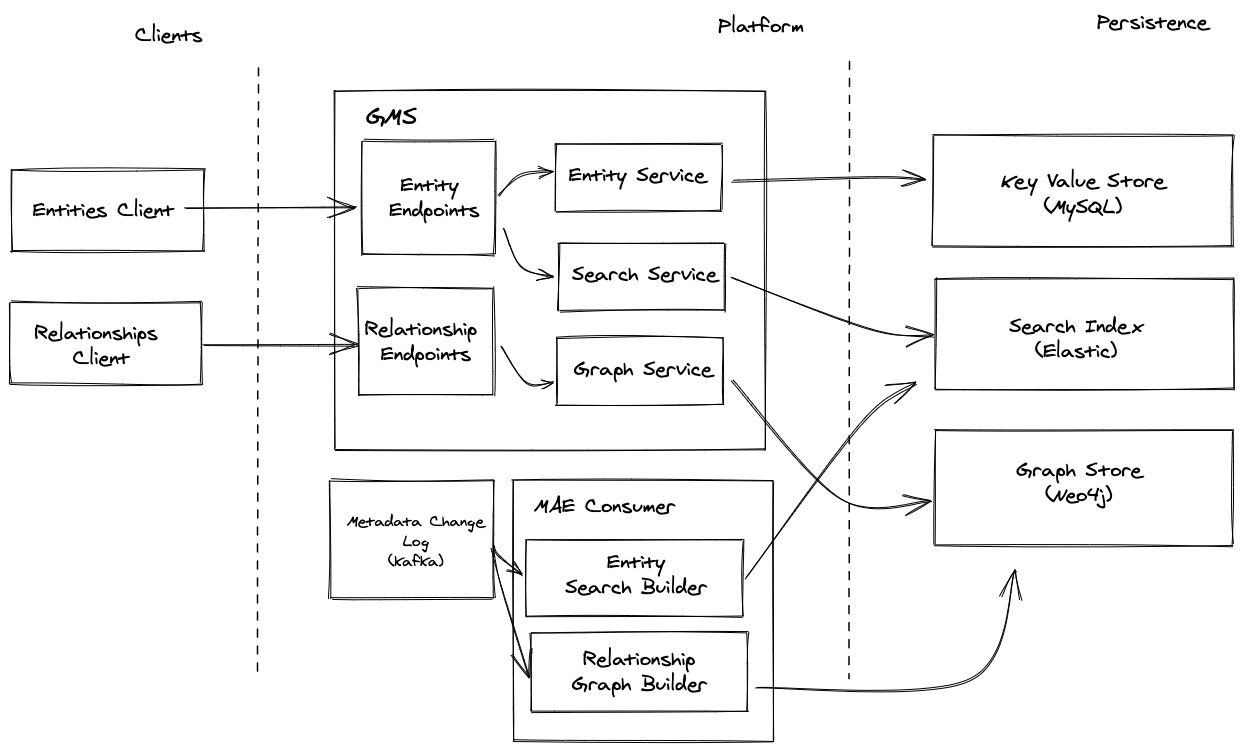 +
+
+ 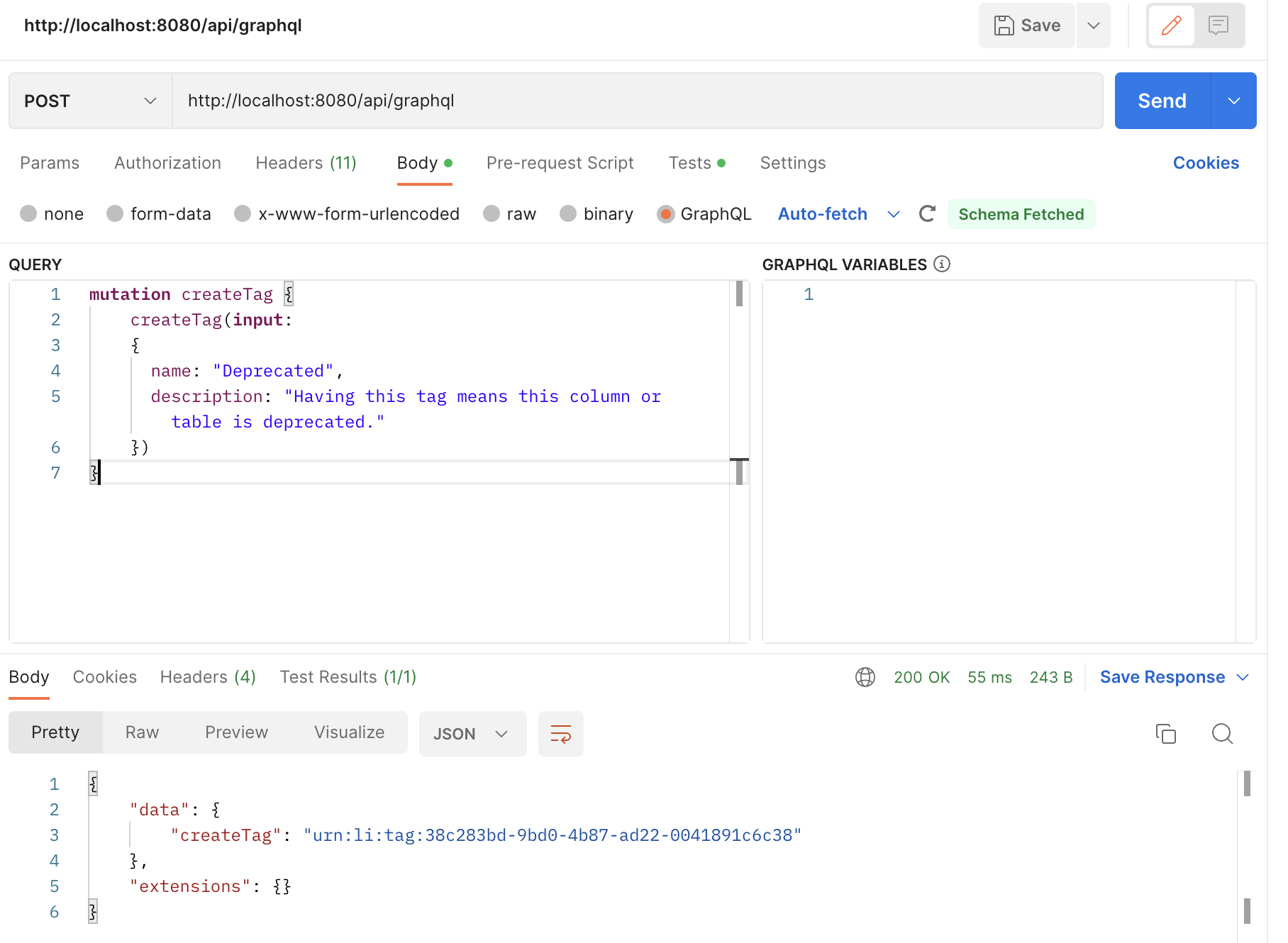 +
+
+ 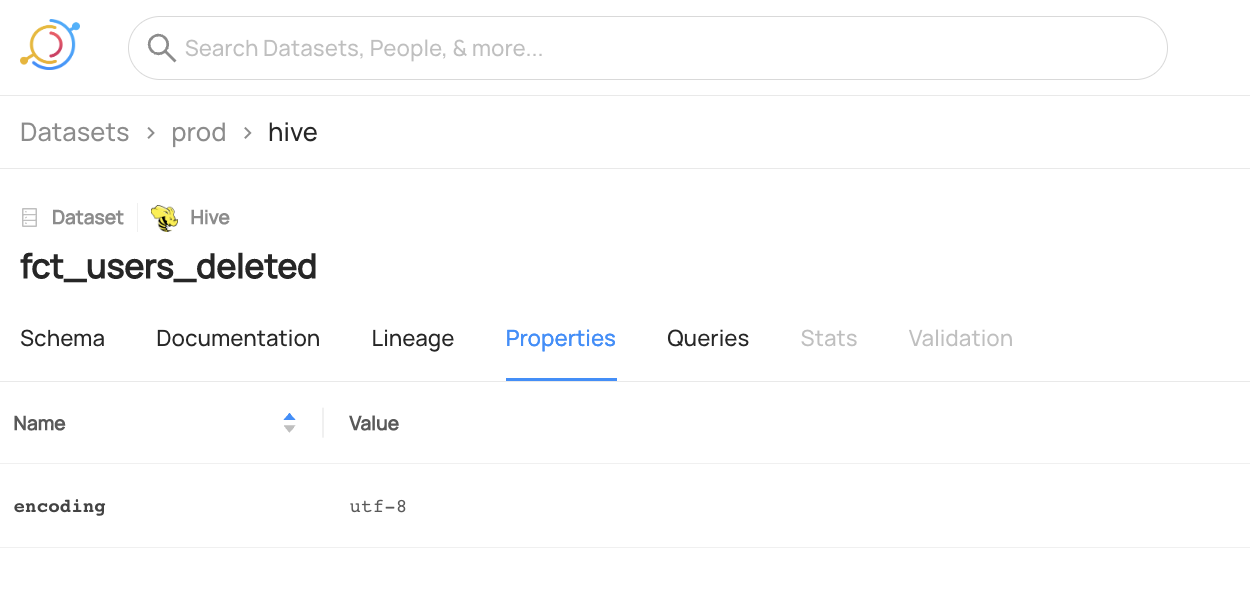 +
+
+ 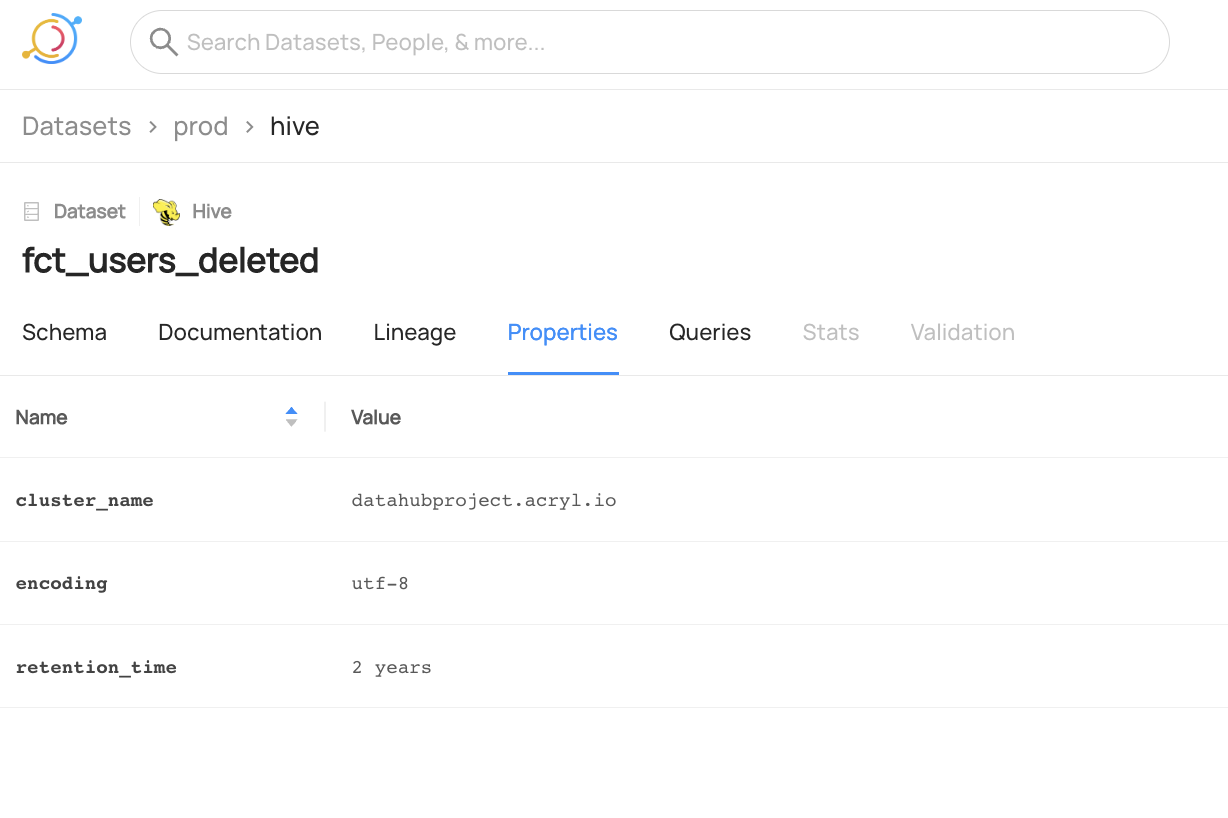 +
+
+ 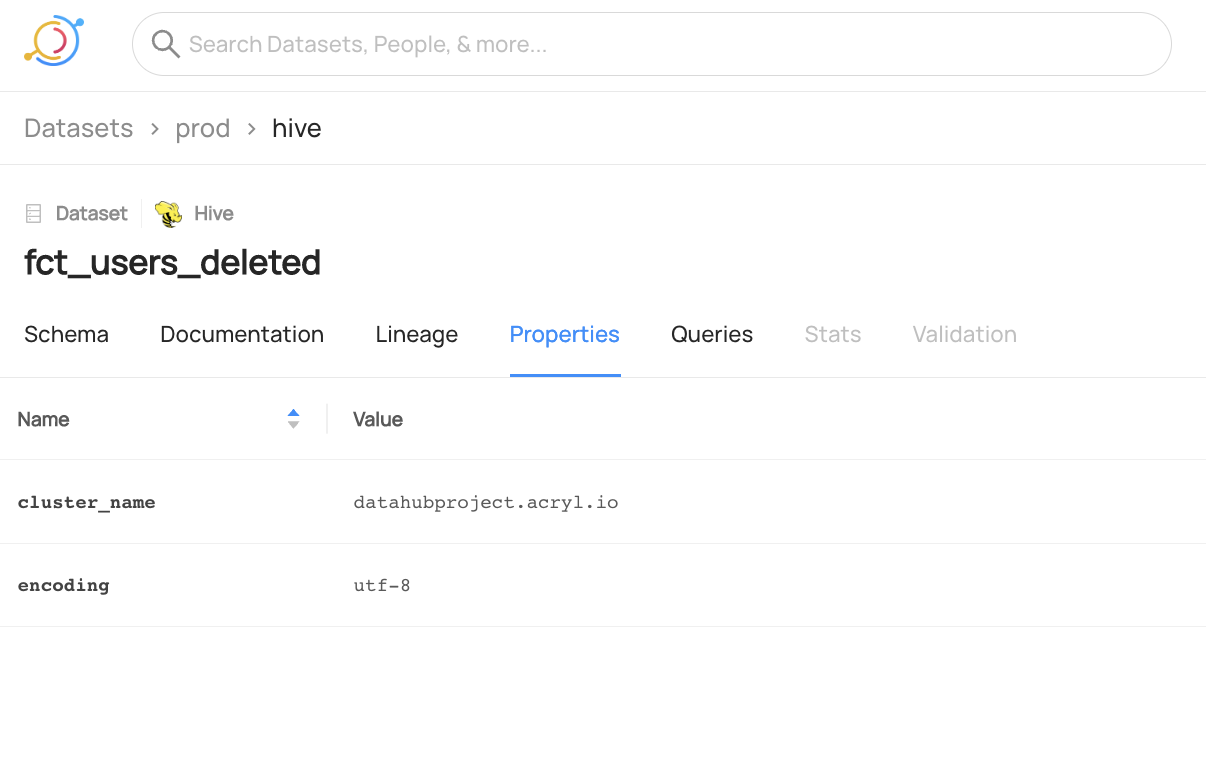 +
+
+ 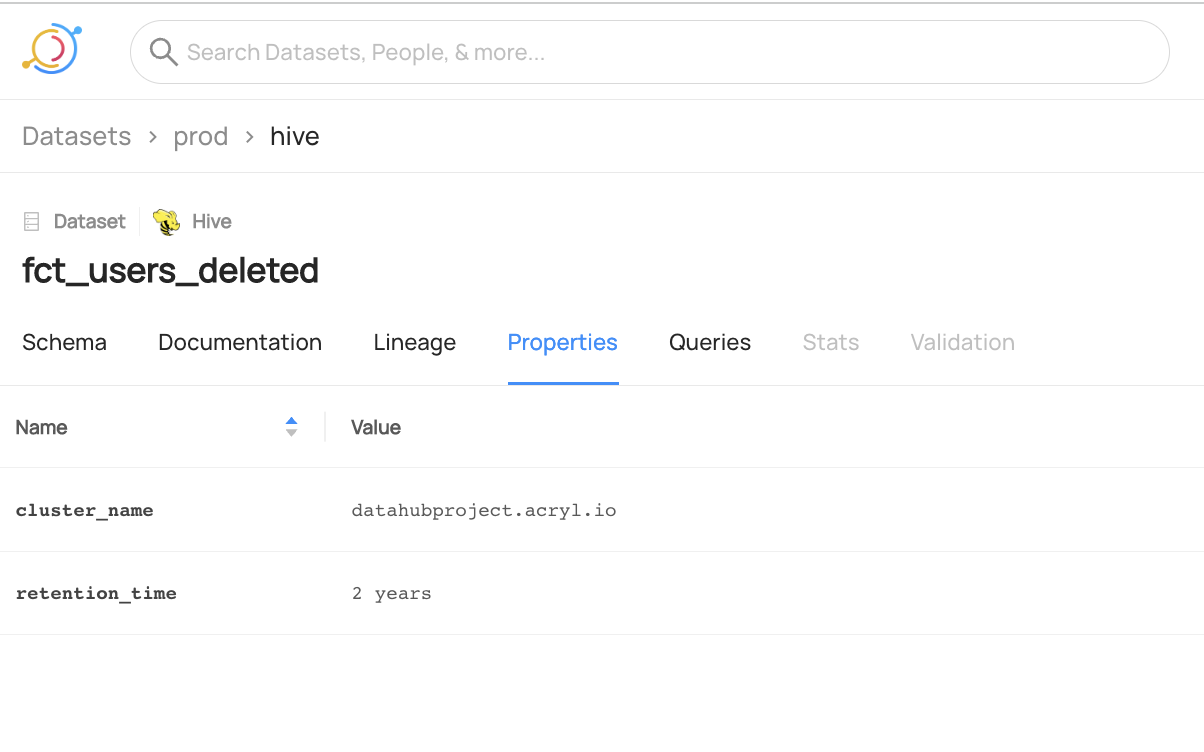 +
+
+ 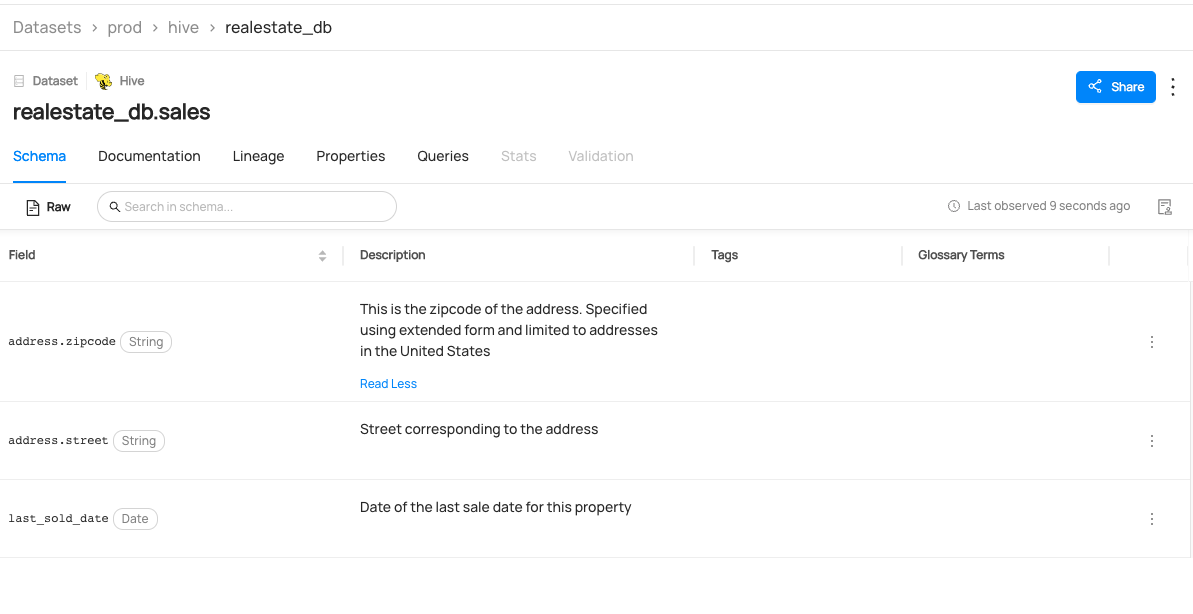 +
+
+ 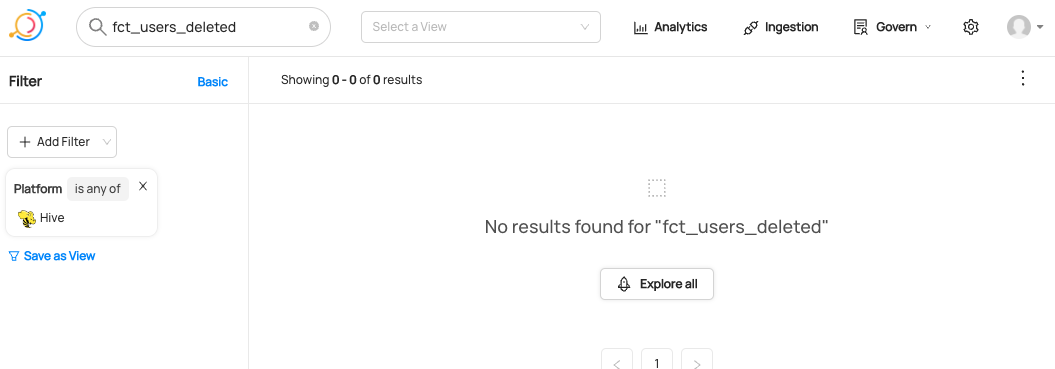 +
+
+ 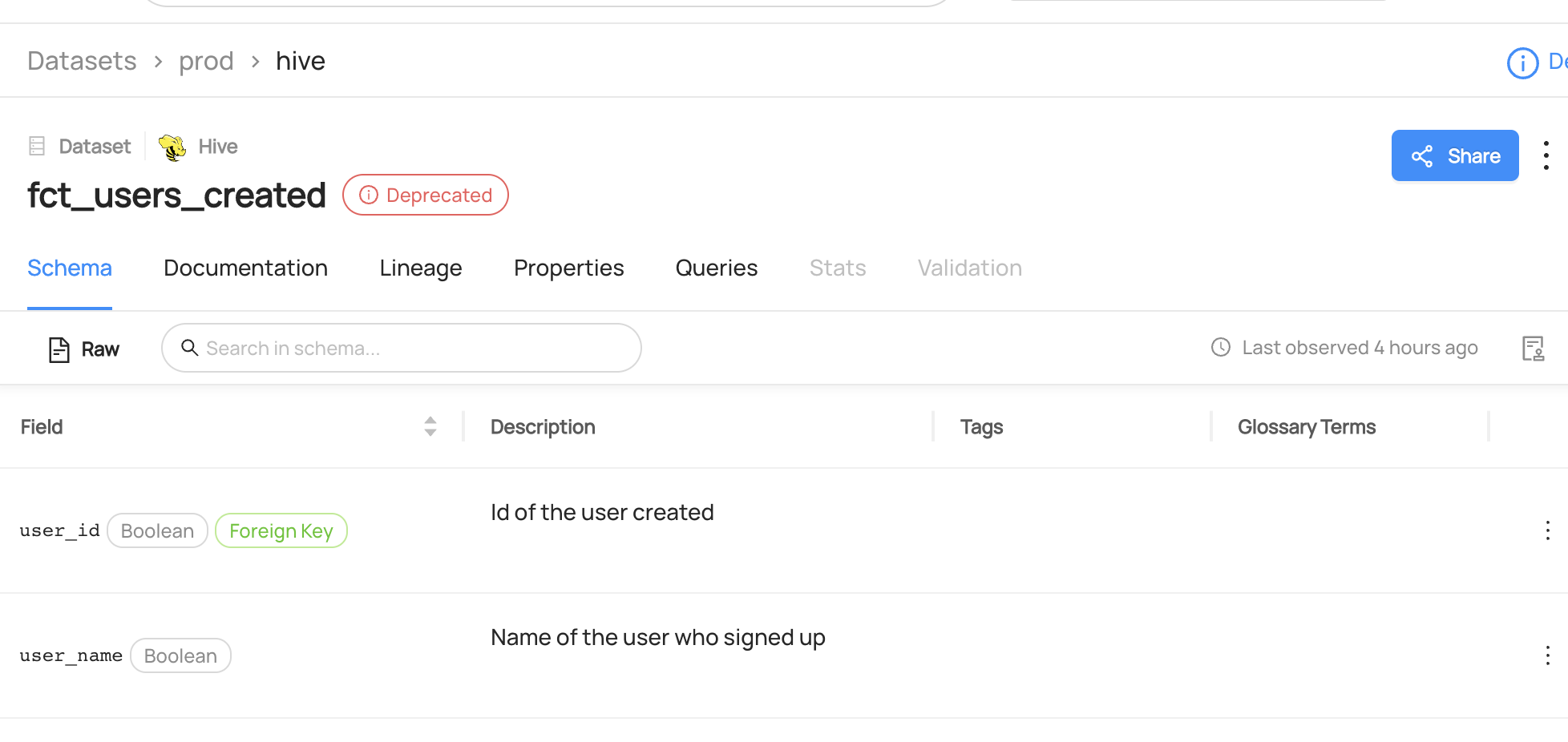 +
+
+ 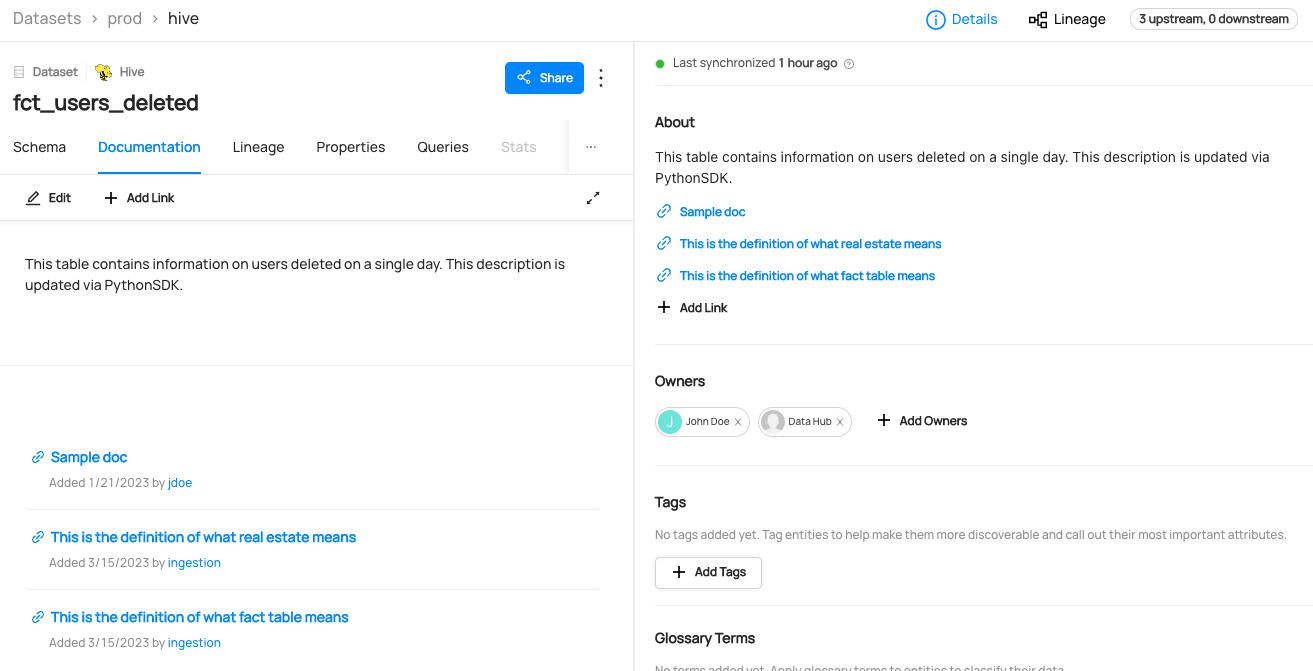 +
+
+ 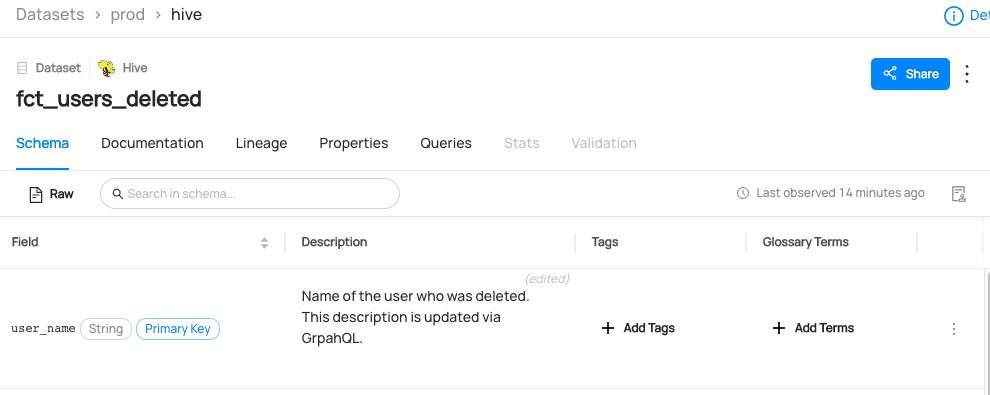 +
+
+ 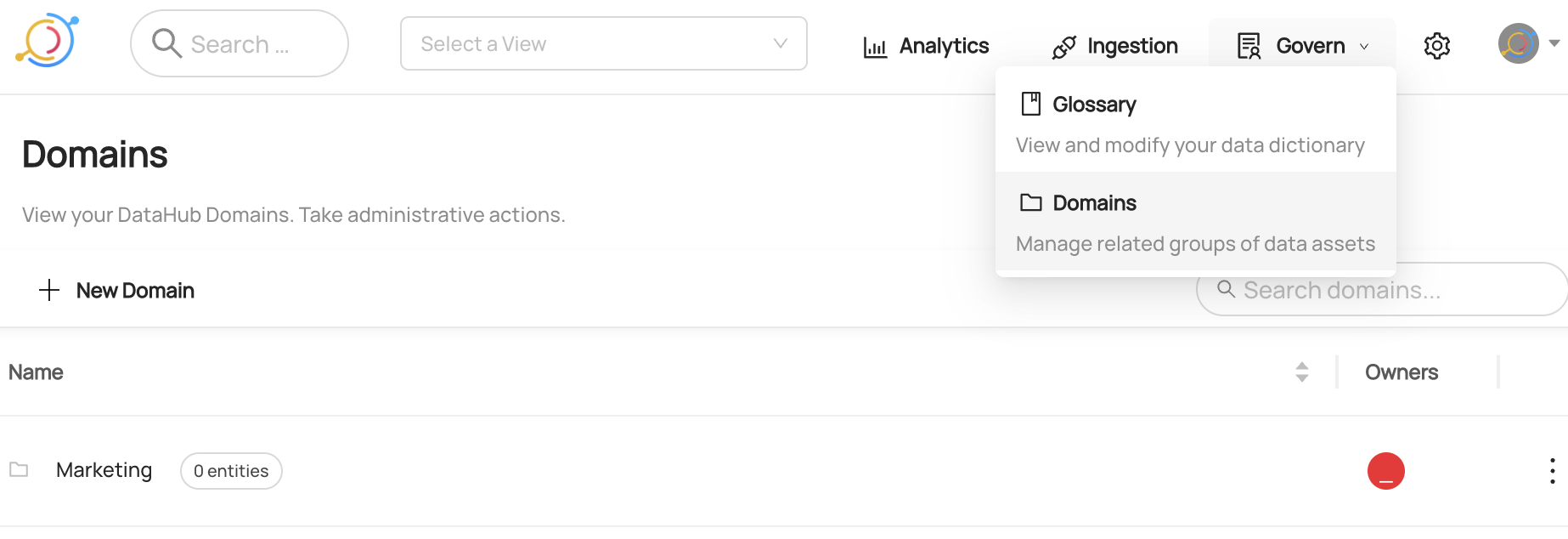 +
+
+ 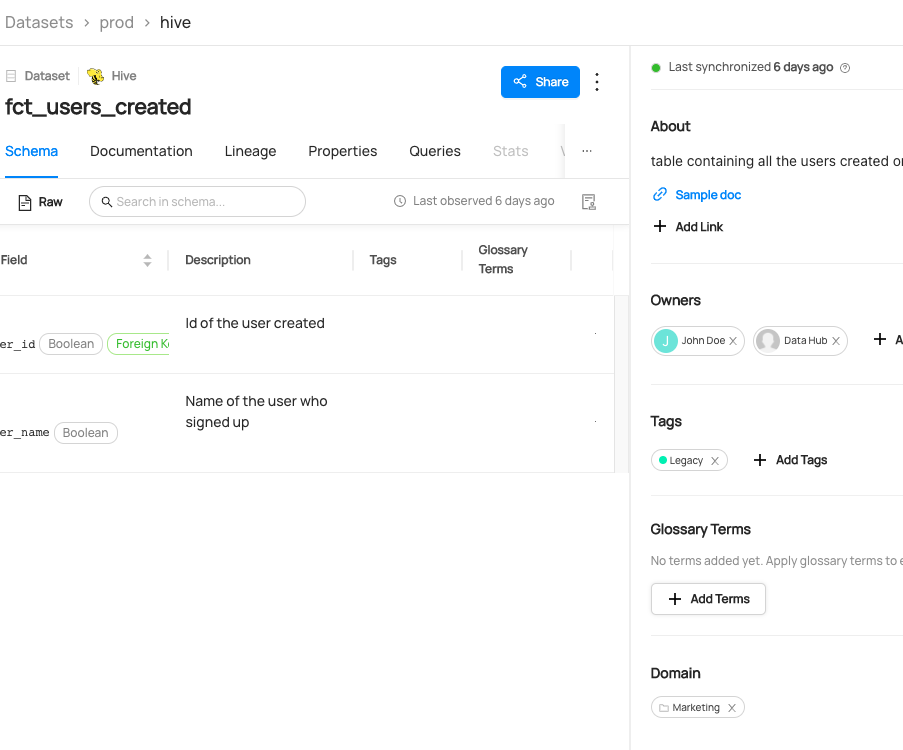 +
+
+ 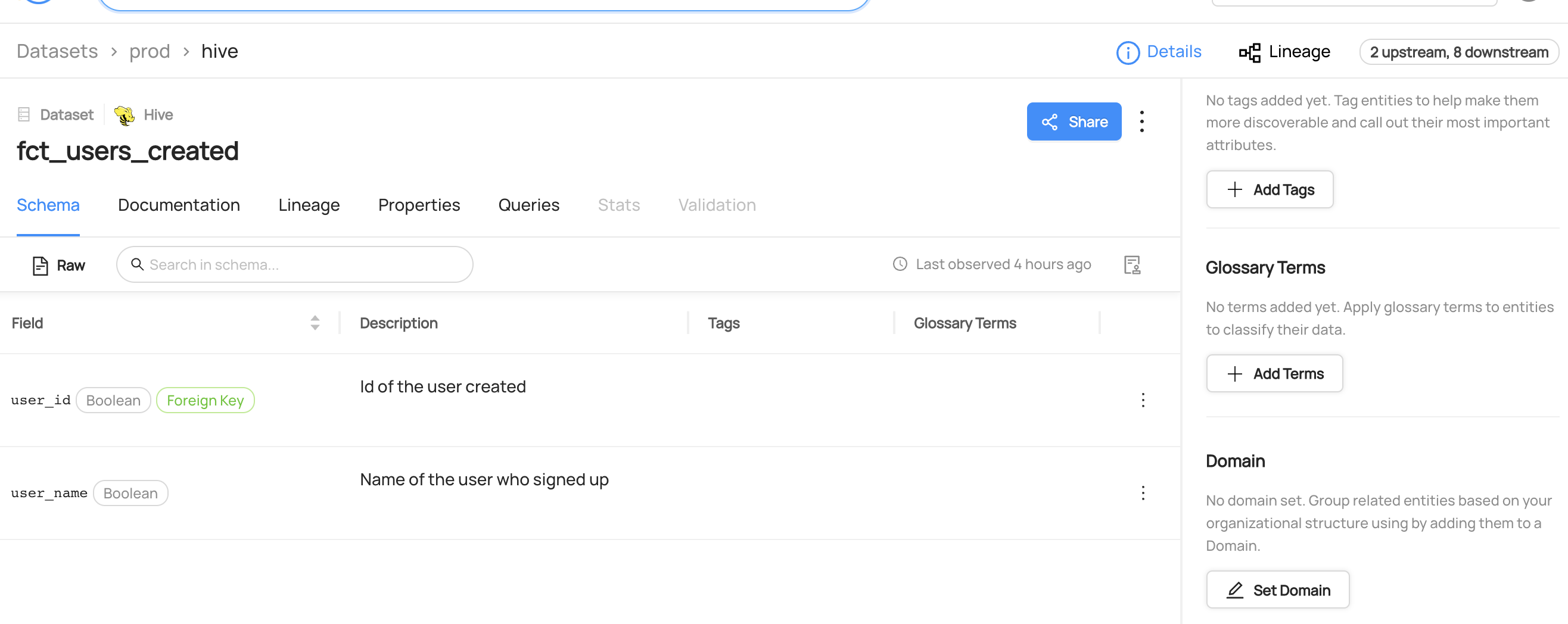 +
+
+ 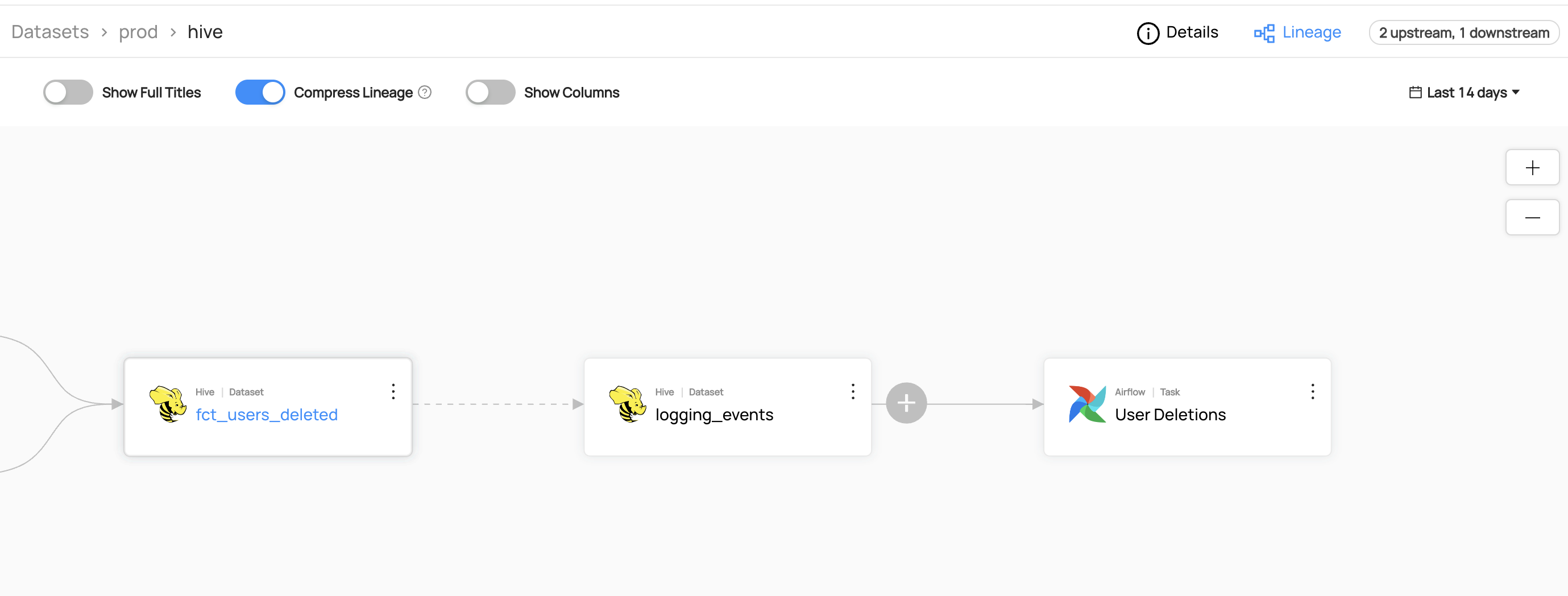 +
+
+ 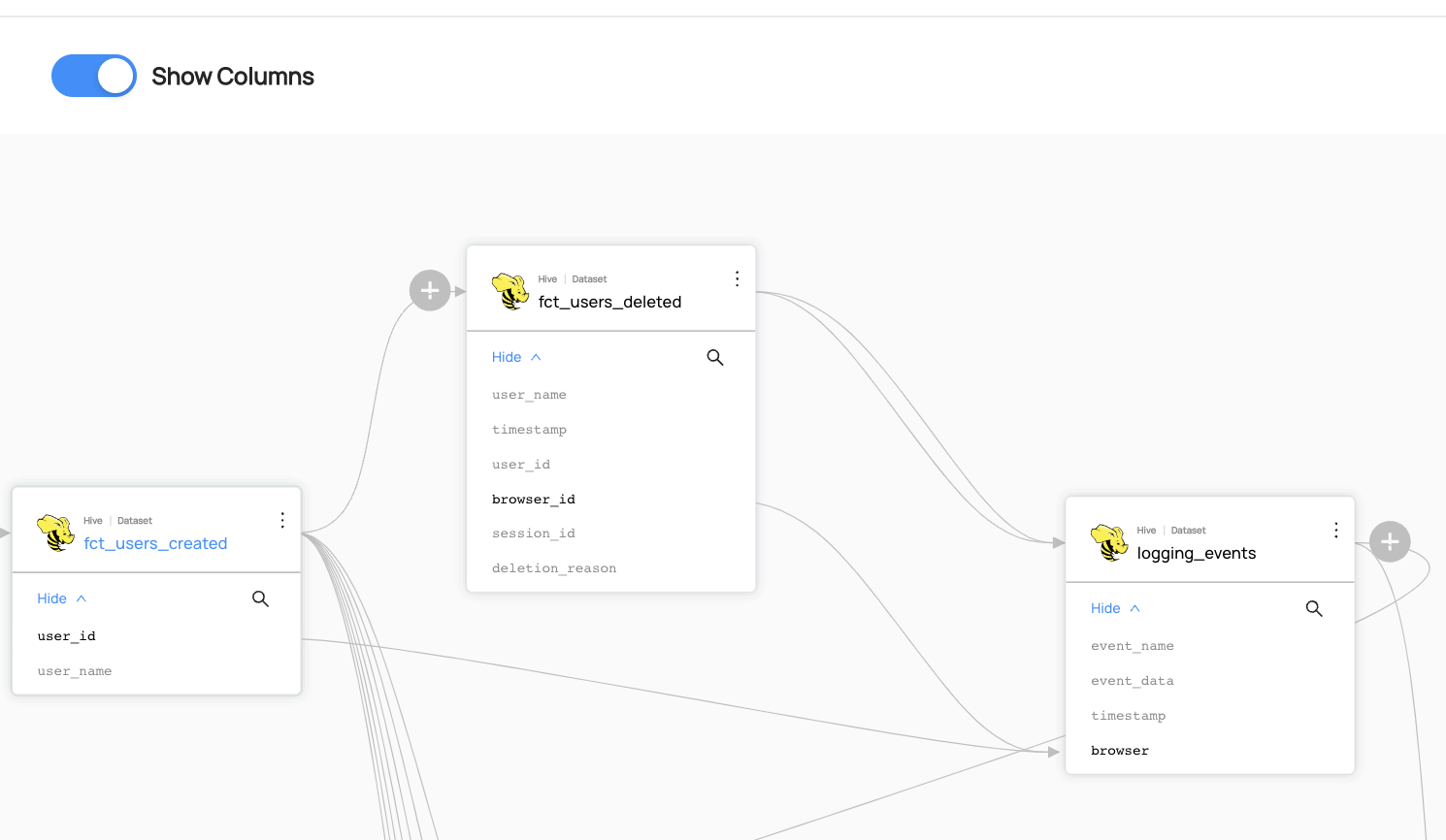 +
+
+ 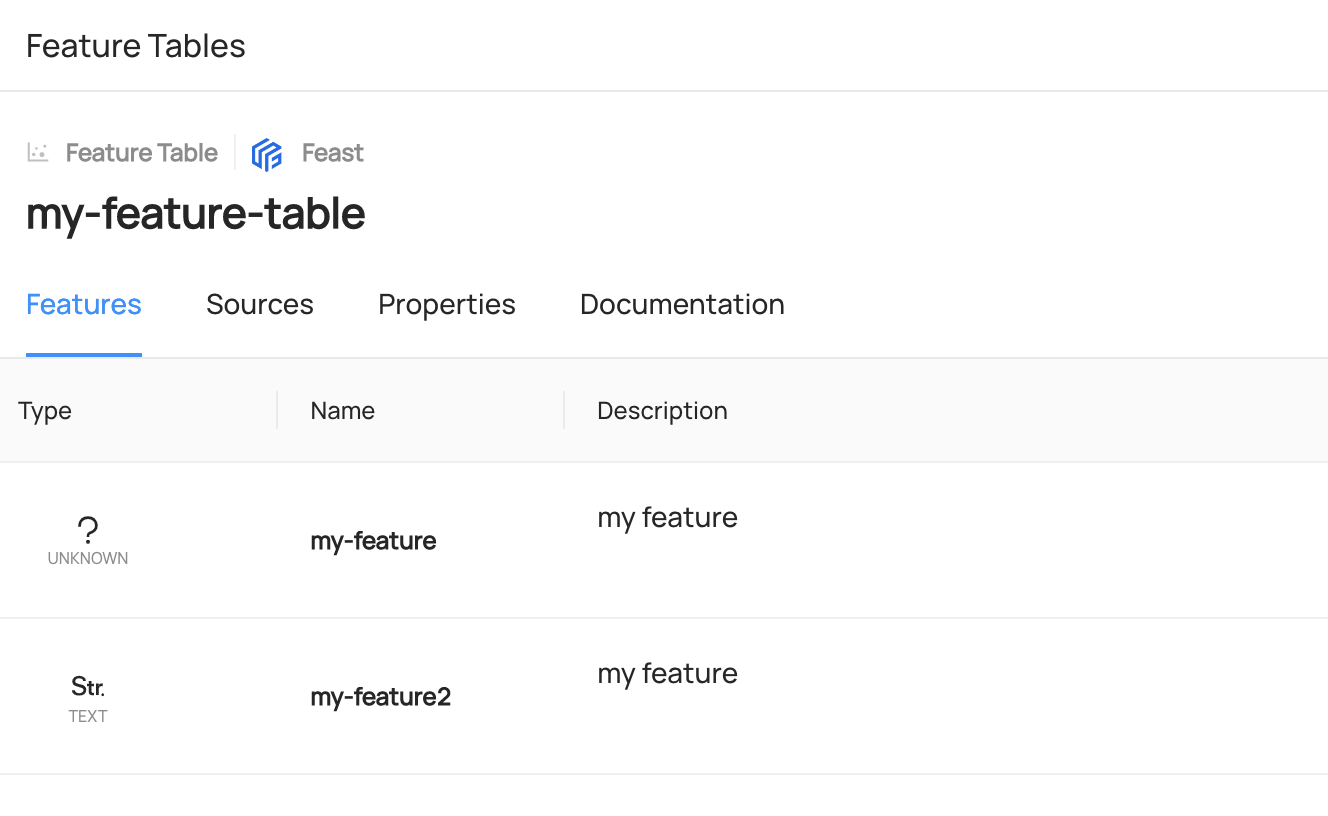 +
+
+ 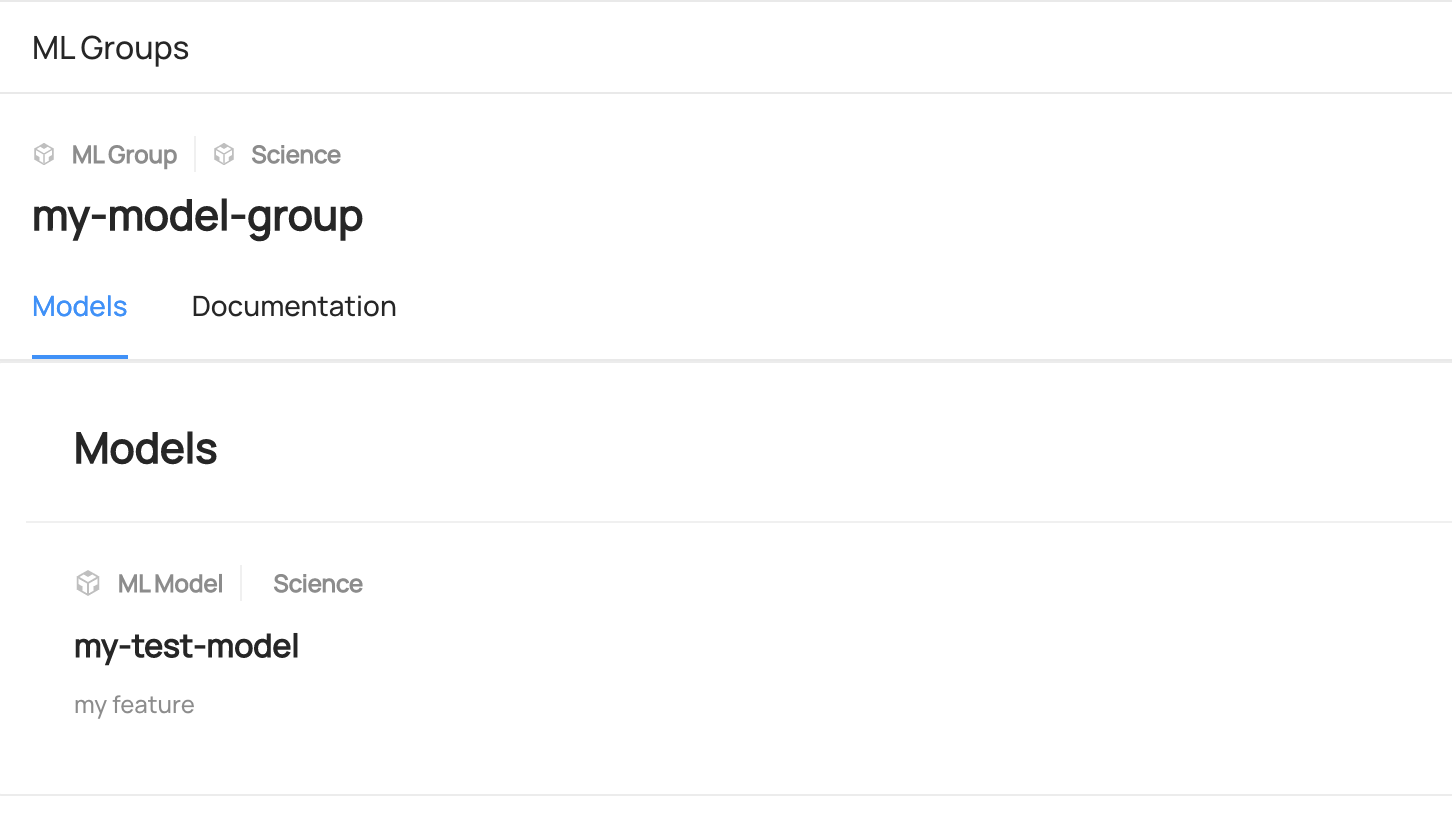 +
+
+ 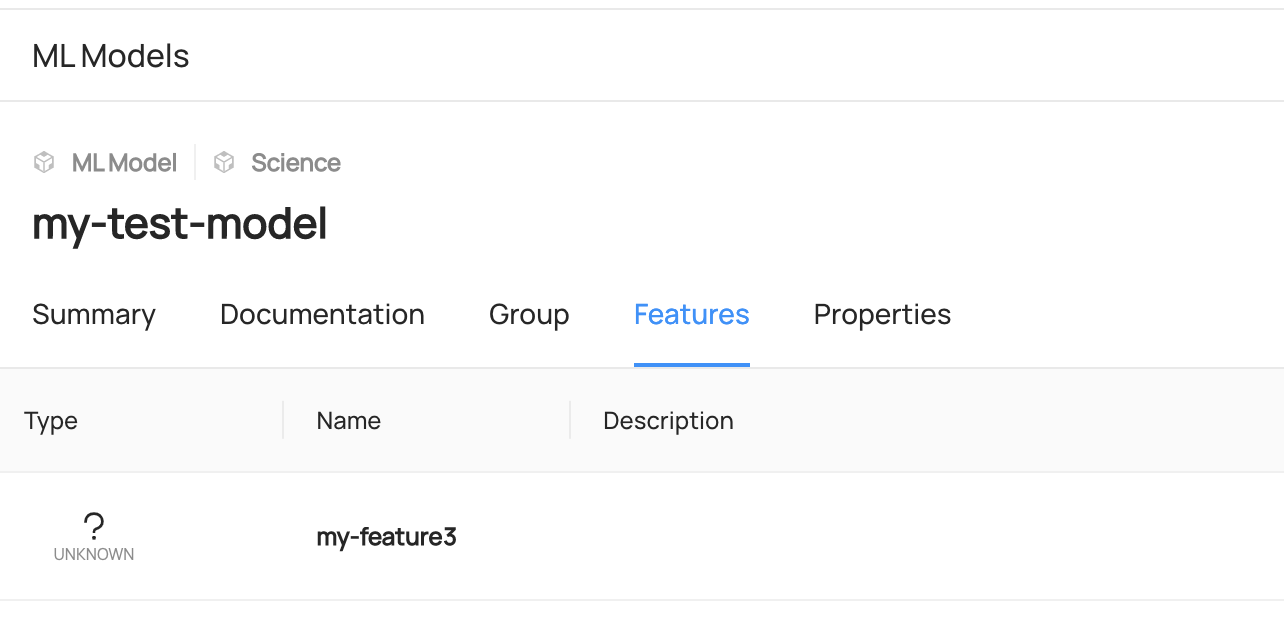 +
+
+ 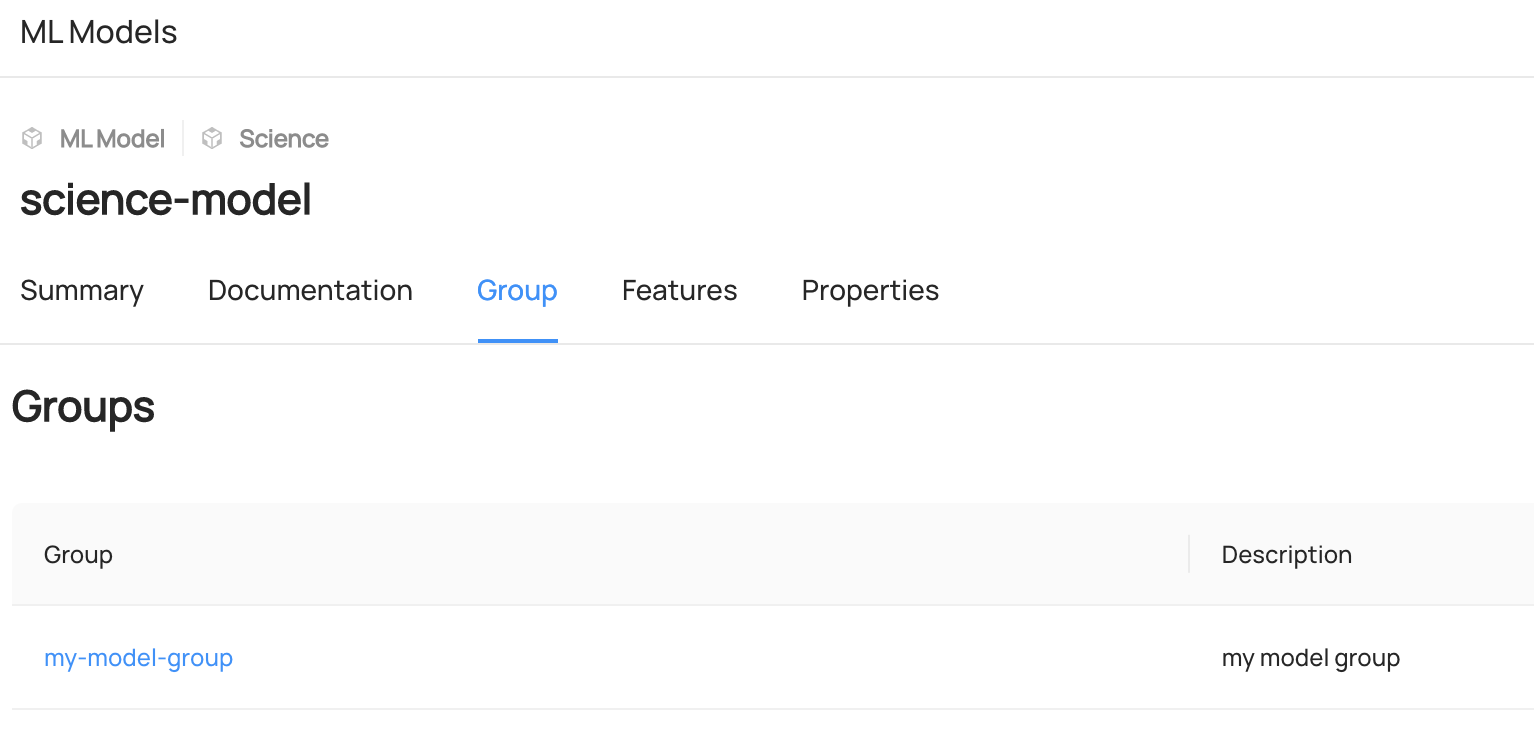 +
+
+ 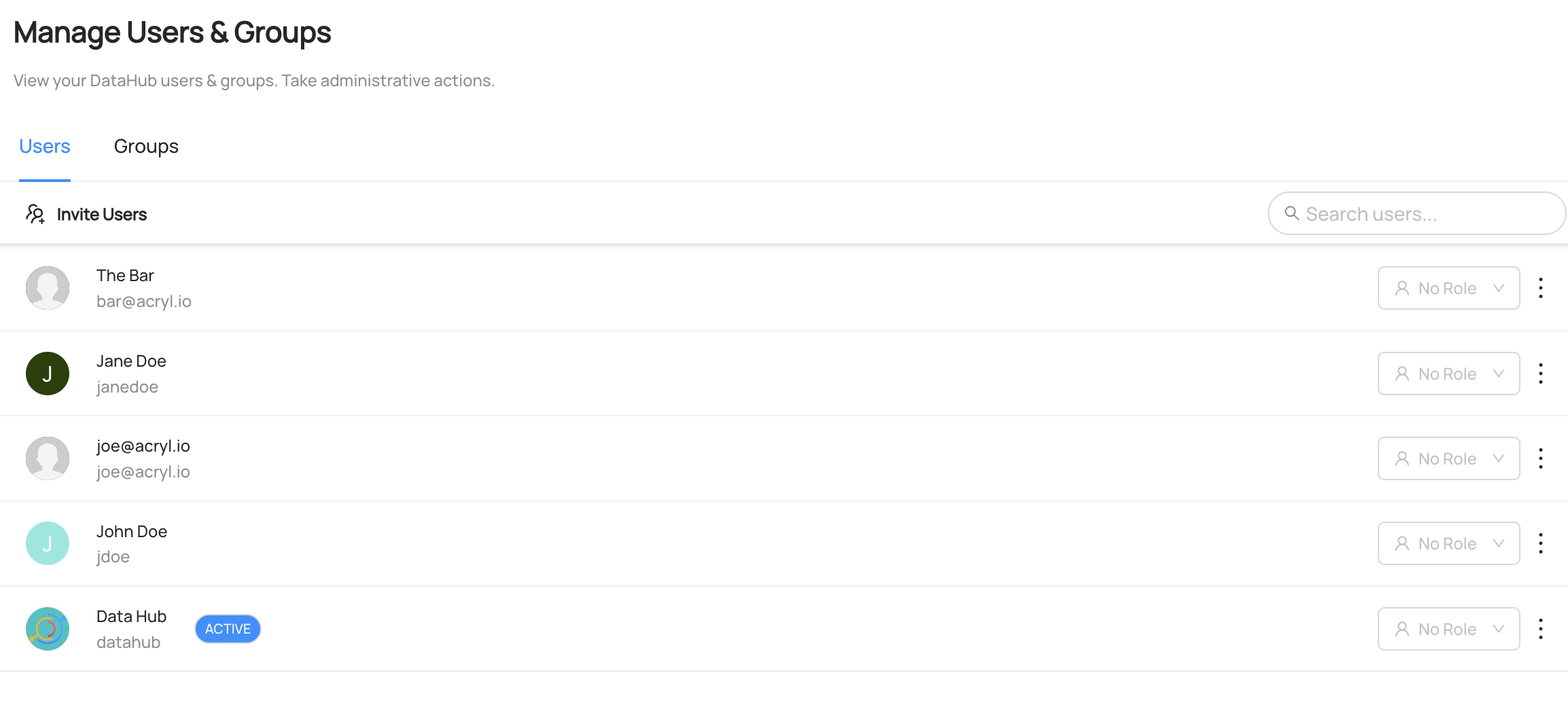 +
+
+ 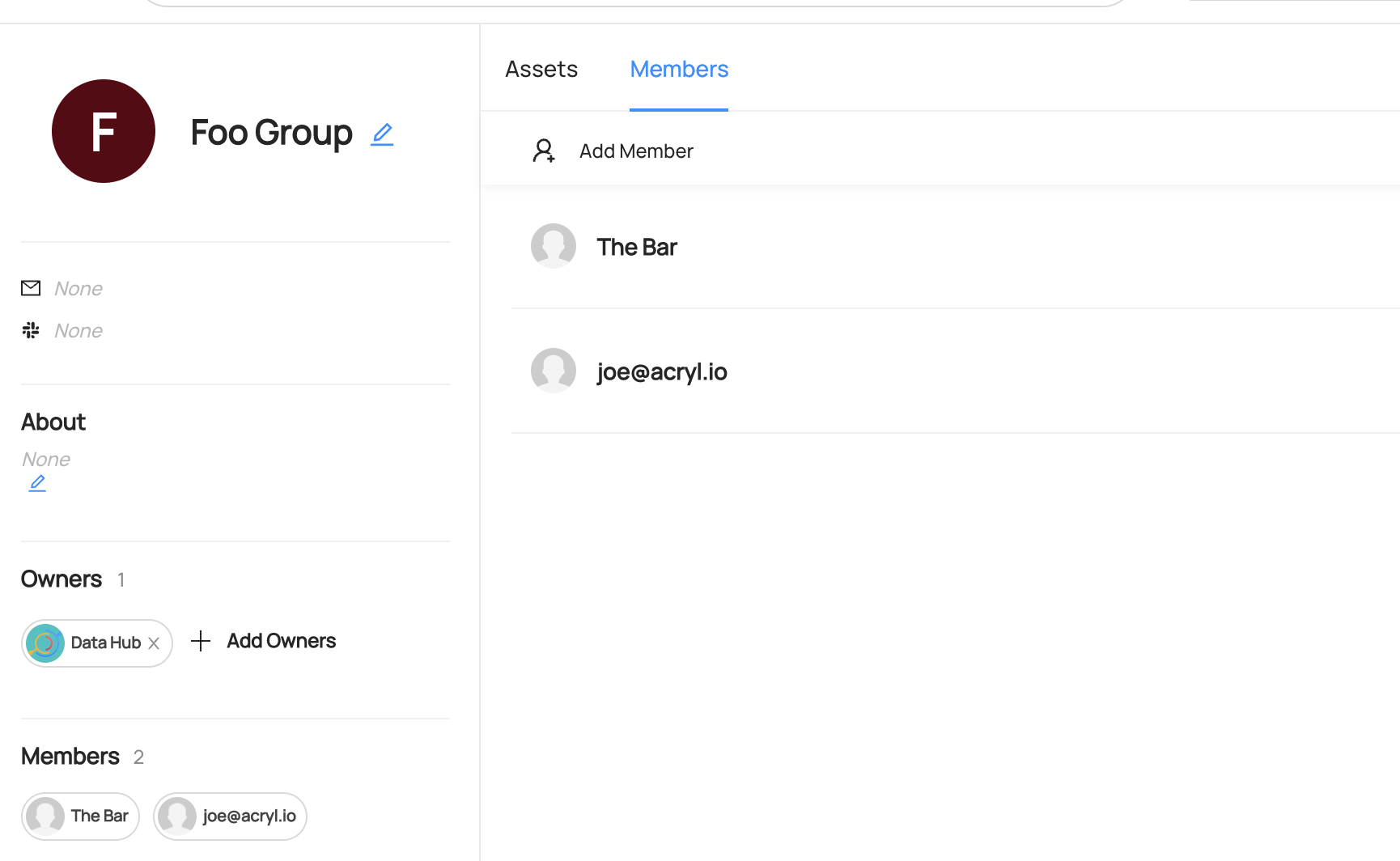 +
+
+ 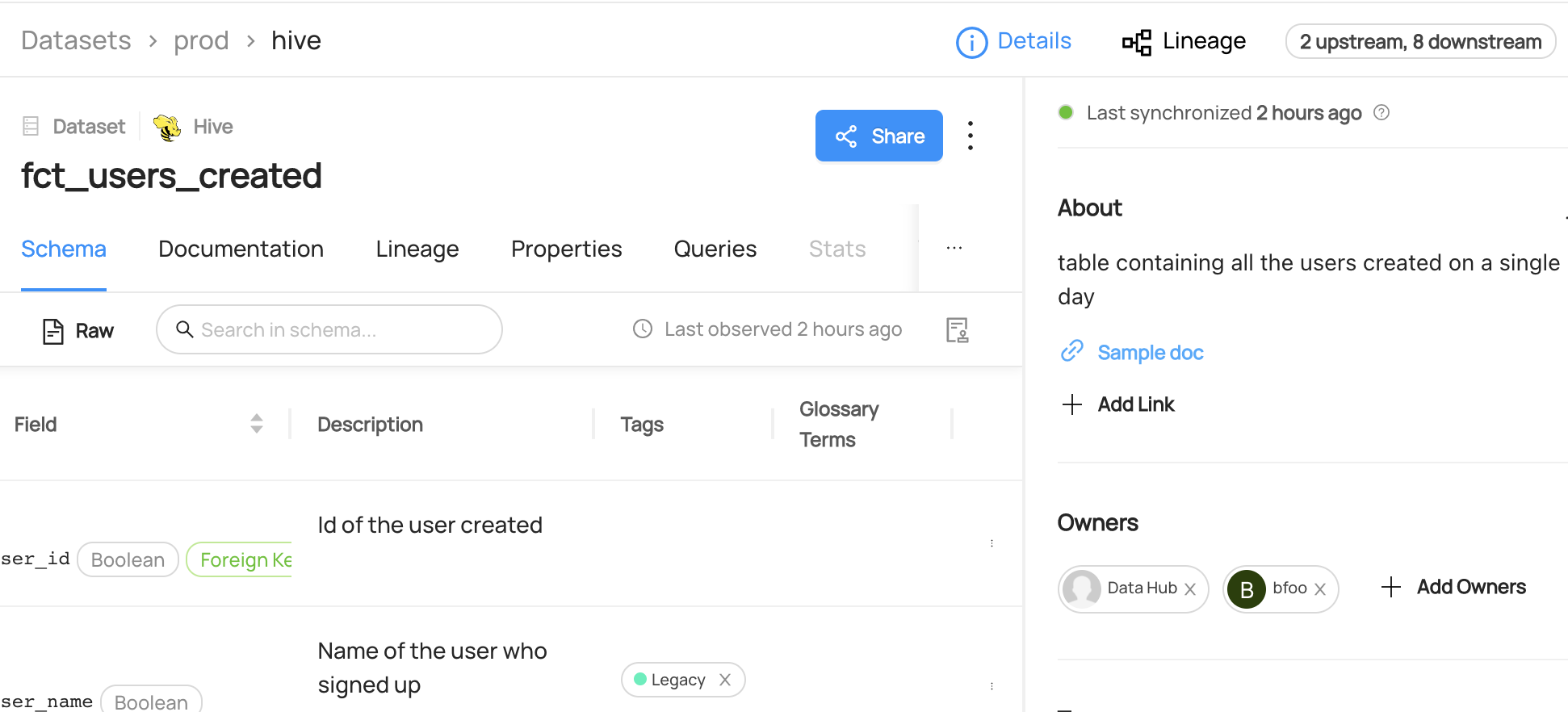 +
+
+ 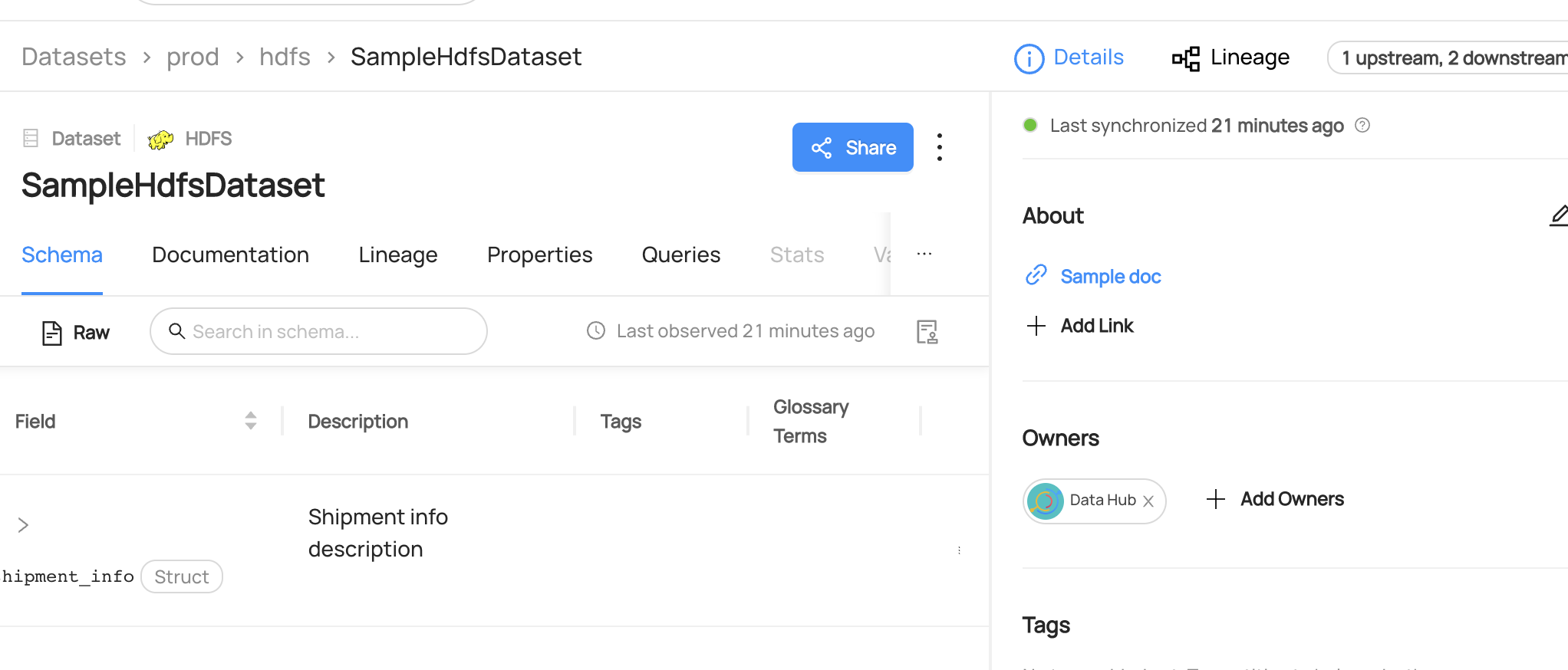 +
+
+ 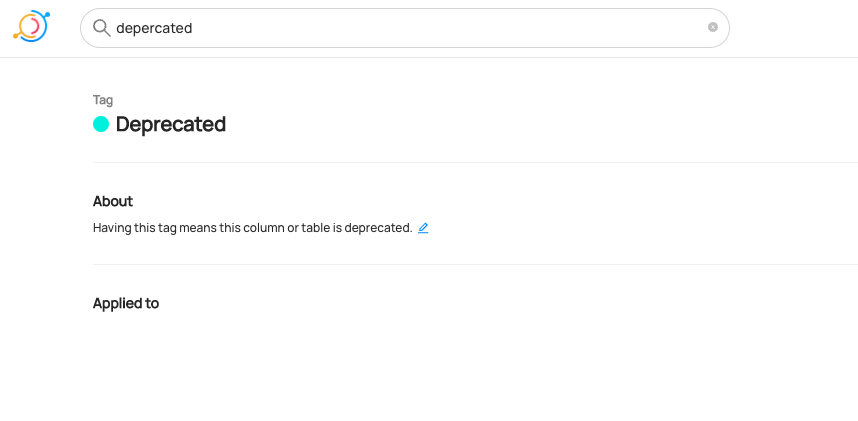 +
+
+ 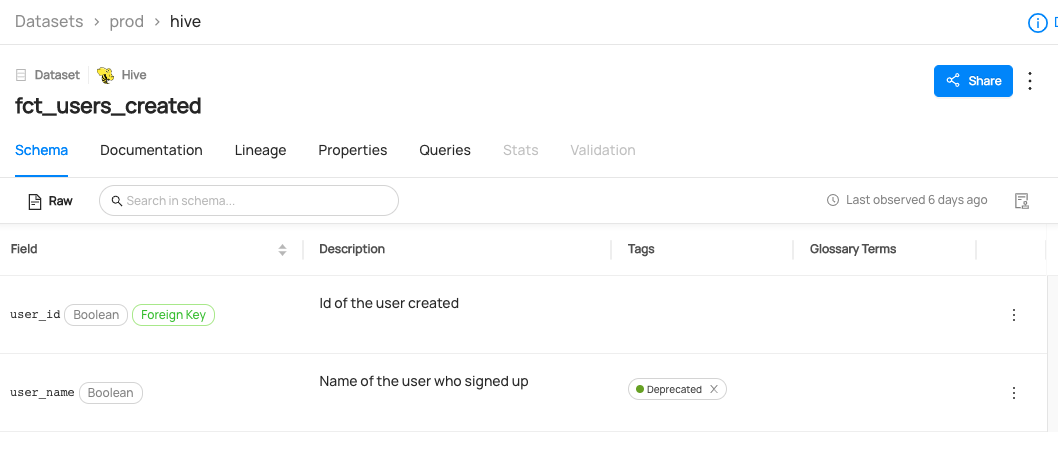 +
+
+ 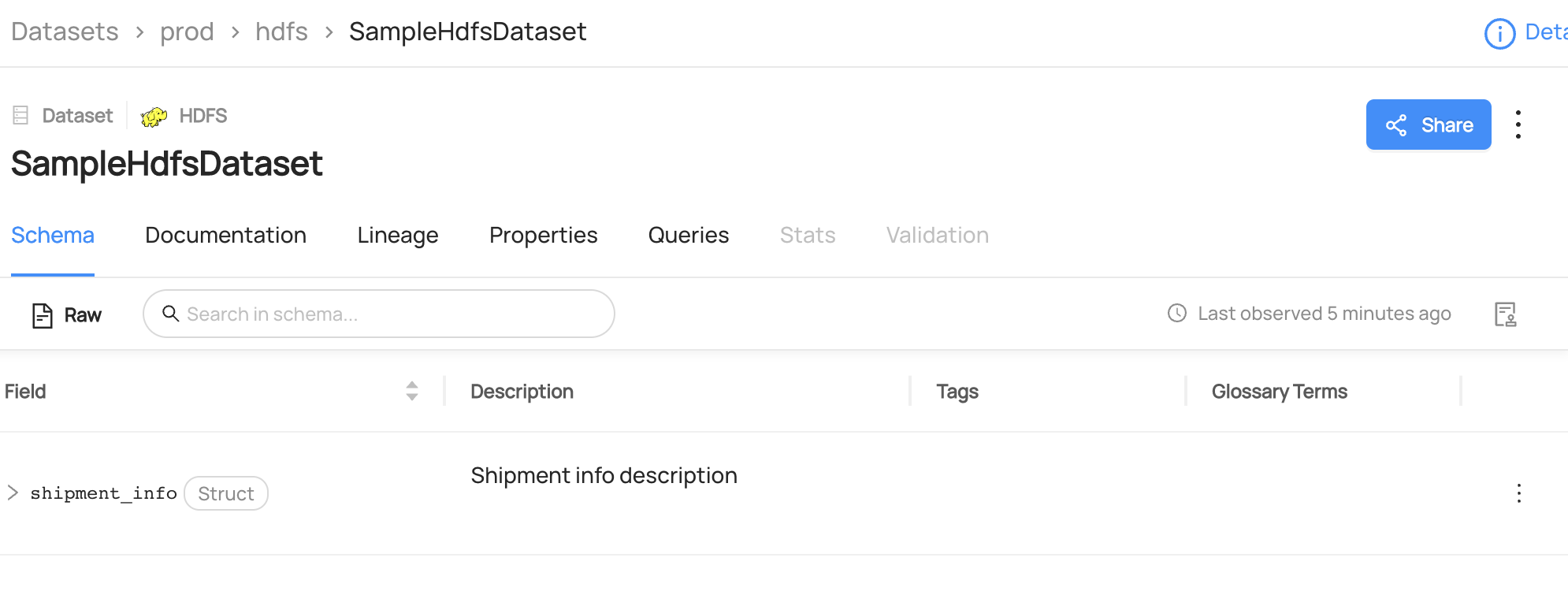 +
+
+ 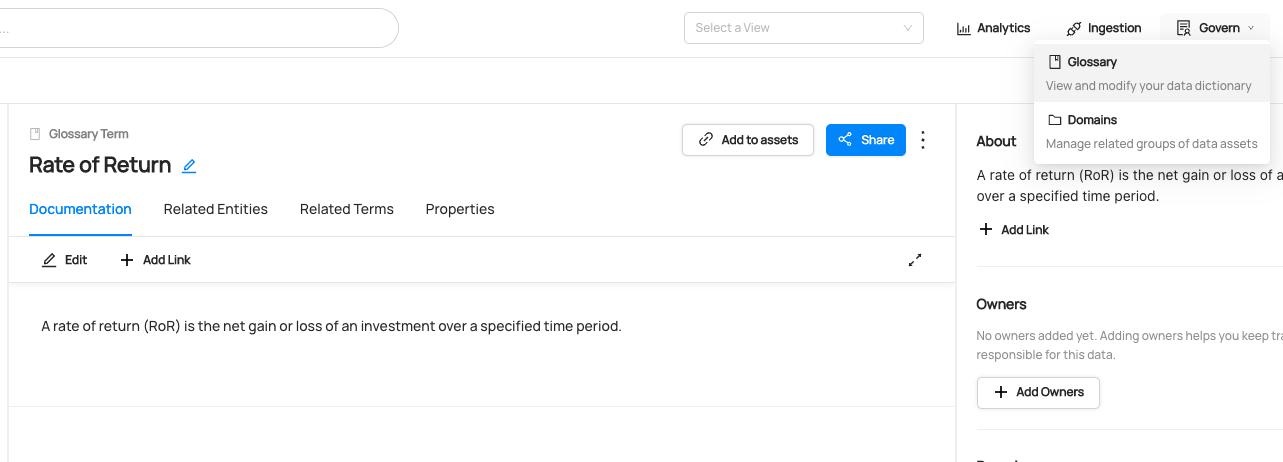 +
+
+ 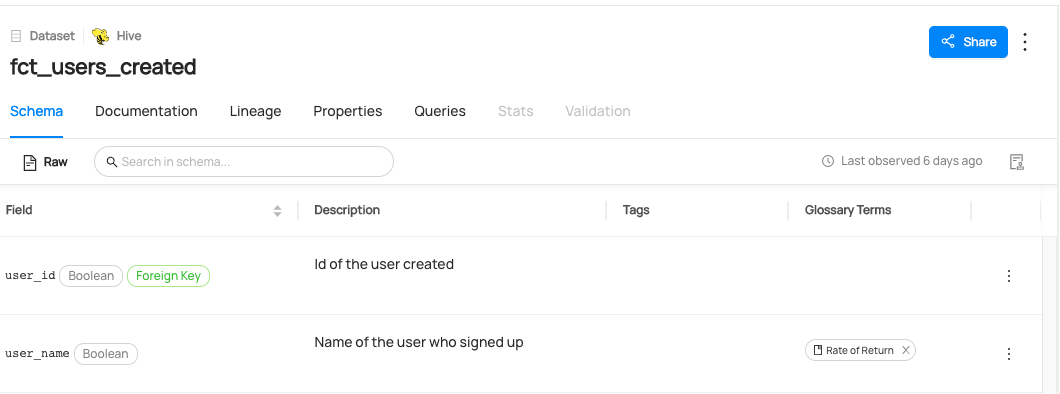 +
+
+ 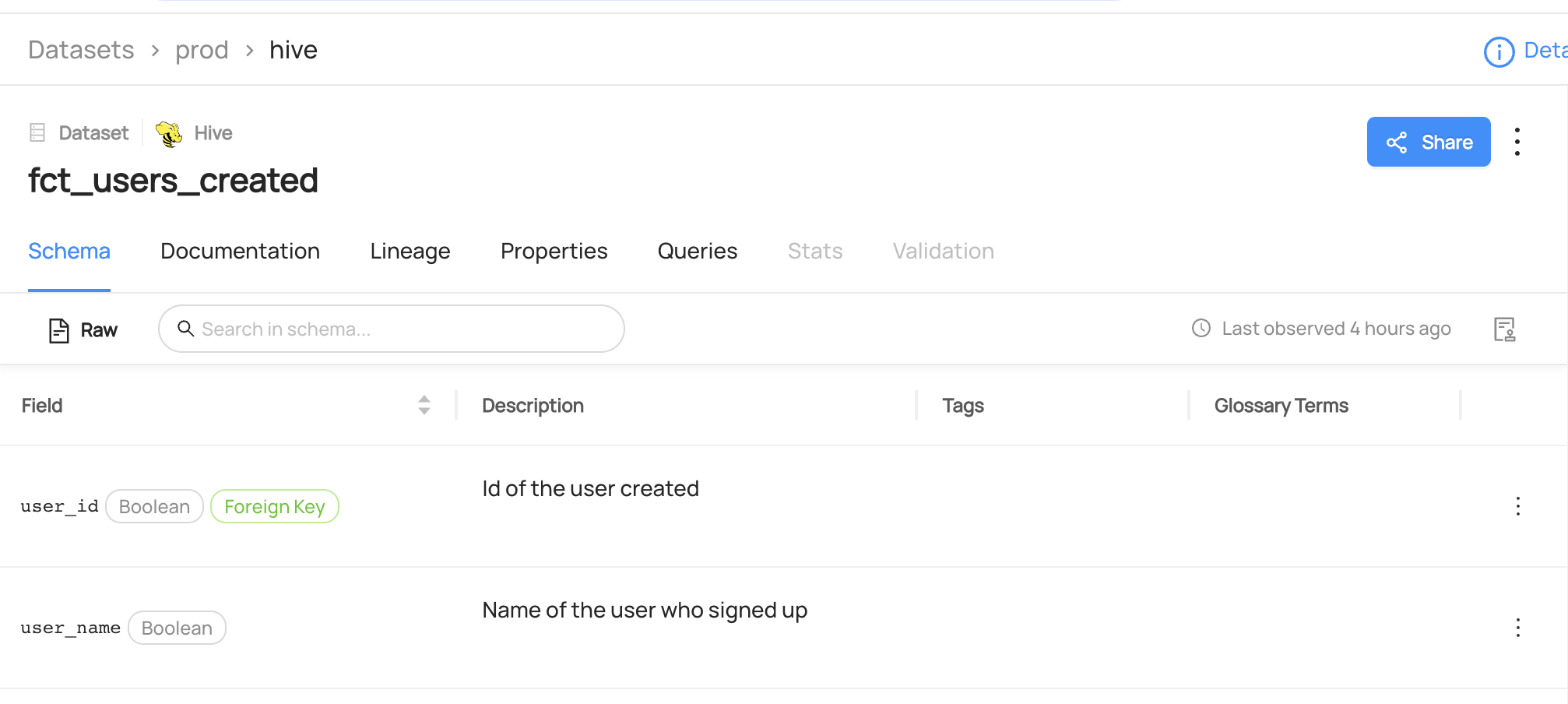 +
+
+ 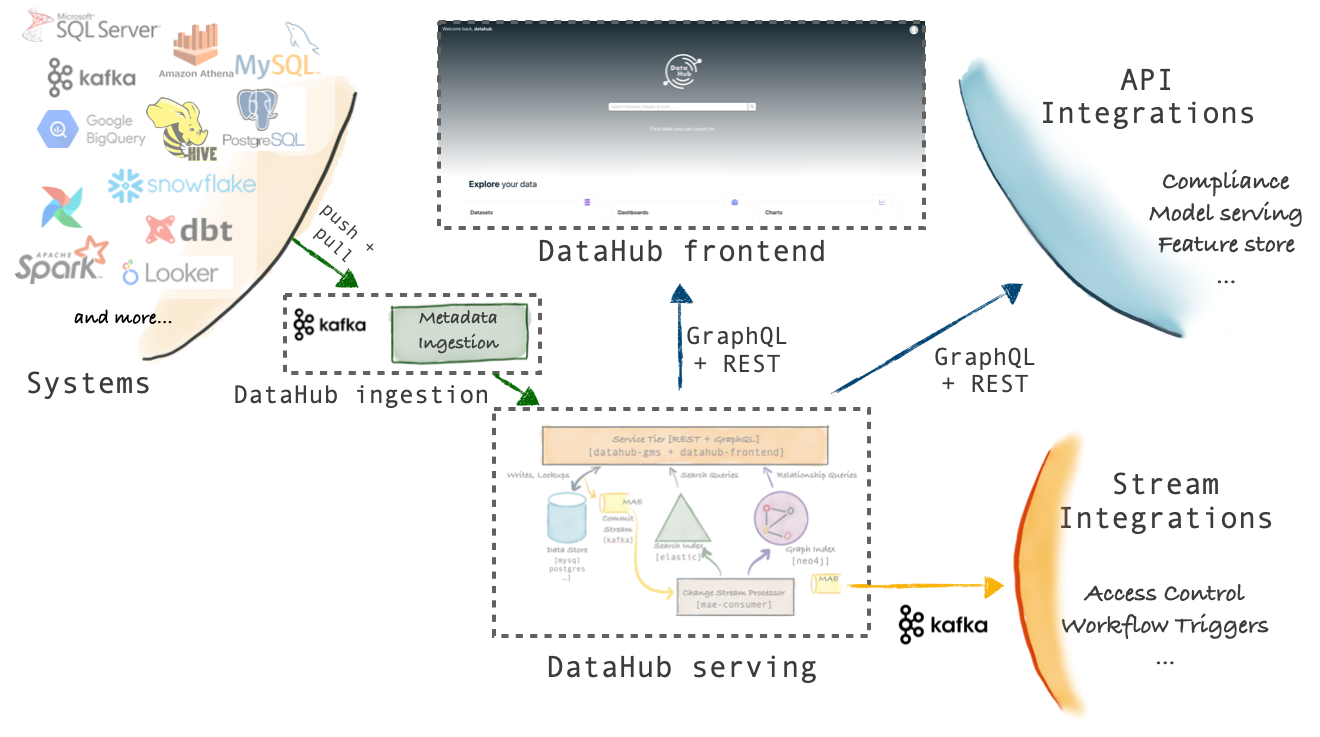 +
+
+ 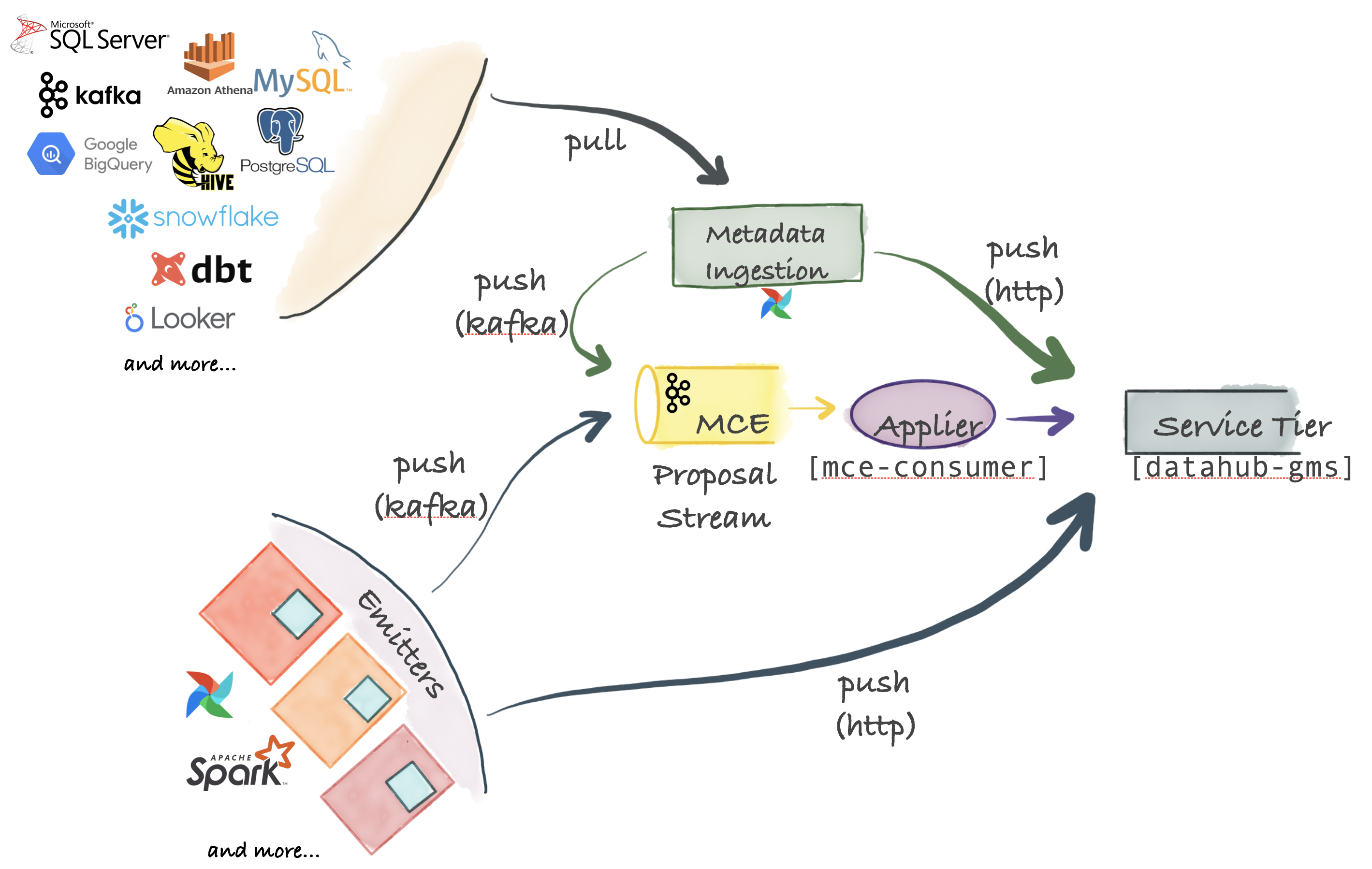 +
+
+ 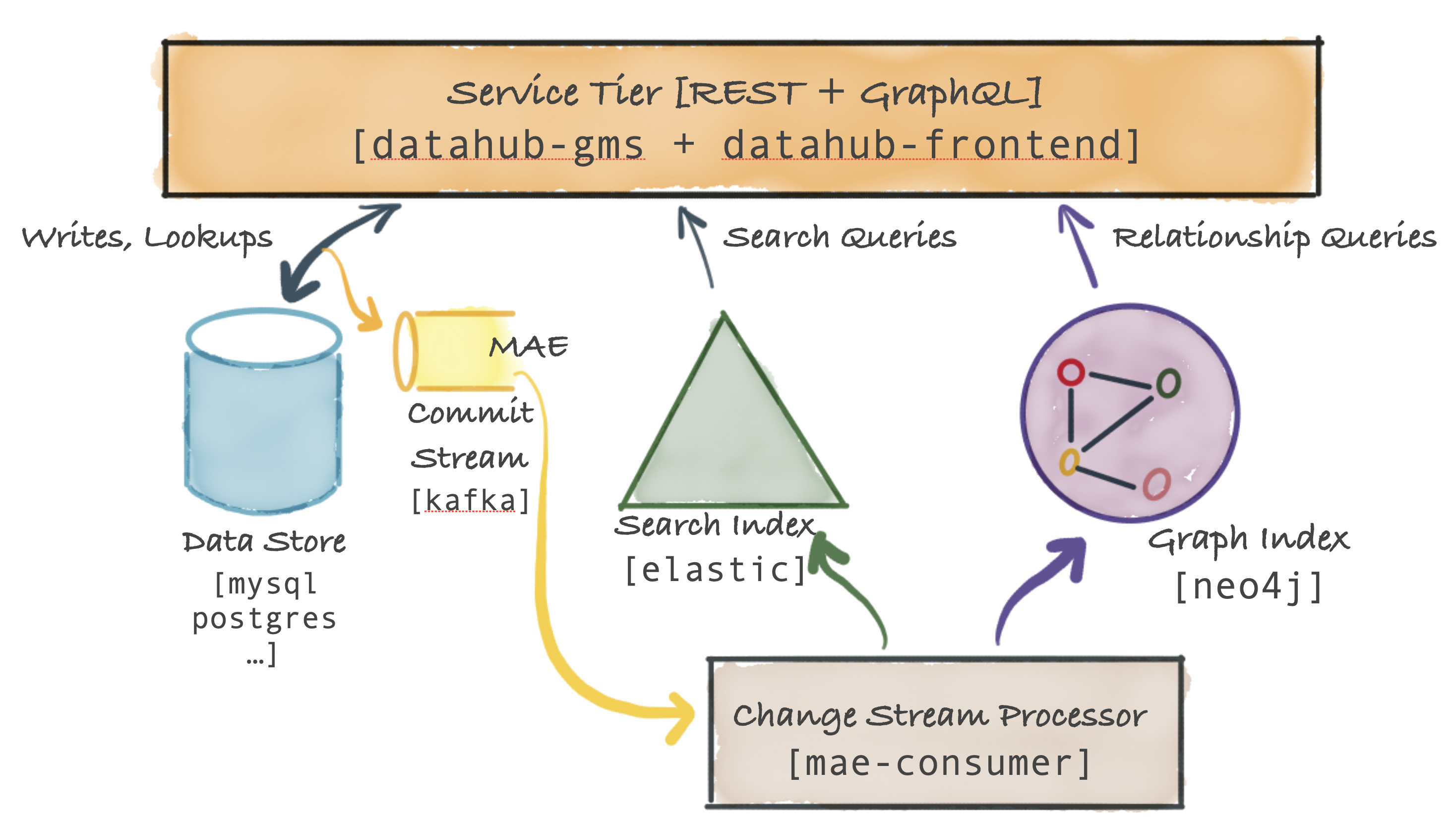 +
+
+  +
+
+  +
+
+ 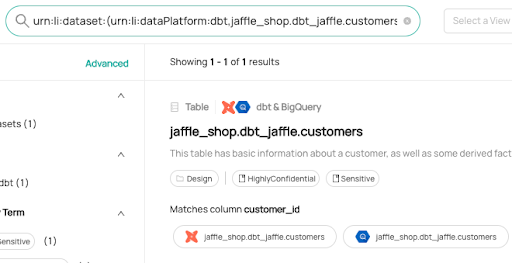 +
+
+ 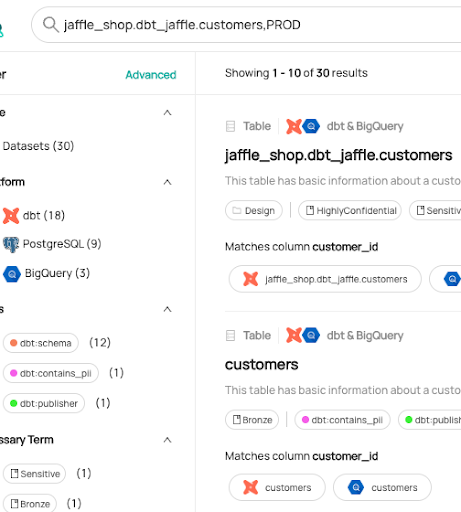 +
+
+  +
+
+  +
+
+  +
+
+  +
+
+ 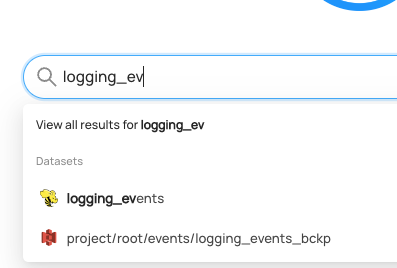 +
+
+ 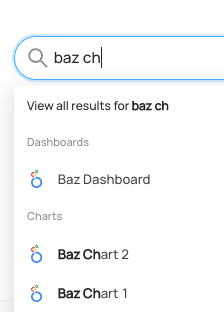 +
+
+ +
+ +## FAQ and Troubleshooting + +_Need more help? Join the conversation in [Slack](http://slack.datahubproject.io)!_ diff --git a/docs-website/versioned_docs/version-0.10.4/docs/authentication/README.md b/docs-website/versioned_docs/version-0.10.4/docs/authentication/README.md new file mode 100644 index 00000000000000..e6a79405a12224 --- /dev/null +++ b/docs-website/versioned_docs/version-0.10.4/docs/authentication/README.md @@ -0,0 +1,62 @@ +--- +title: Overview +slug: /authentication +custom_edit_url: >- + https://github.com/datahub-project/datahub/blob/master/docs/authentication/README.md +--- + +# Overview + +Authentication is the process of verifying the identity of a user or service. There are two +places where Authentication occurs inside DataHub: + +1. DataHub frontend service when a user attempts to log in to the DataHub application. +2. DataHub backend service when making API requests to DataHub. + +In this document, we'll tak a closer look at both. + +### Authentication in the Frontend + +Authentication of normal users of DataHub takes place in two phases. + +At login time, authentication is performed by either DataHub itself (via username / password entry) or a third-party Identity Provider. Once the identity +of the user has been established, and credentials validated, a persistent session token is generated for the user and stored +in a browser-side session cookie. + +DataHub provides 3 mechanisms for authentication at login time: + +- **Native Authentication** which uses username and password combinations natively stored and managed by DataHub, with users invited via an invite link. +- [Single Sign-On with OpenID Connect](guides/sso/configure-oidc-react.md) to delegate authentication responsibility to third party systems like Okta or Google/Azure Authentication. This is the recommended approach for production systems. +- [JaaS Authentication](guides/jaas.md) for simple deployments where authenticated users are part of some known list or invited as a [Native DataHub User](guides/add-users.md). + +In subsequent requests, the session token is used to represent the authenticated identity of the user, and is validated by DataHub's backend service (discussed below). +Eventually, the session token is expired (24 hours by default), at which point the end user is required to log in again. + +### Authentication in the Backend (Metadata Service) + +When a user makes a request for Data within DataHub, the request is authenticated by DataHub's Backend (Metadata Service) via a JSON Web Token. This applies to both requests originating from the DataHub application, +and programmatic calls to DataHub APIs. There are two types of tokens that are important: + +1. **Session Tokens**: Generated for users of the DataHub web application. By default, having a duration of 24 hours. + These tokens are encoded and stored inside browser-side session cookies. +2. **Personal Access Tokens**: These are tokens generated via the DataHub settings panel useful for interacting + with DataHub APIs. They can be used to automate processes like enriching documentation, ownership, tags, and more on DataHub. Learn + more about Personal Access Tokens [here](personal-access-tokens.md). + +To learn more about DataHub's backend authentication, check out [Introducing Metadata Service Authentication](introducing-metadata-service-authentication.md). + +Credentials must be provided as Bearer Tokens inside of the **Authorization** header in any request made to DataHub's API layer. To learn + +```shell +Authorization: Bearer
+ 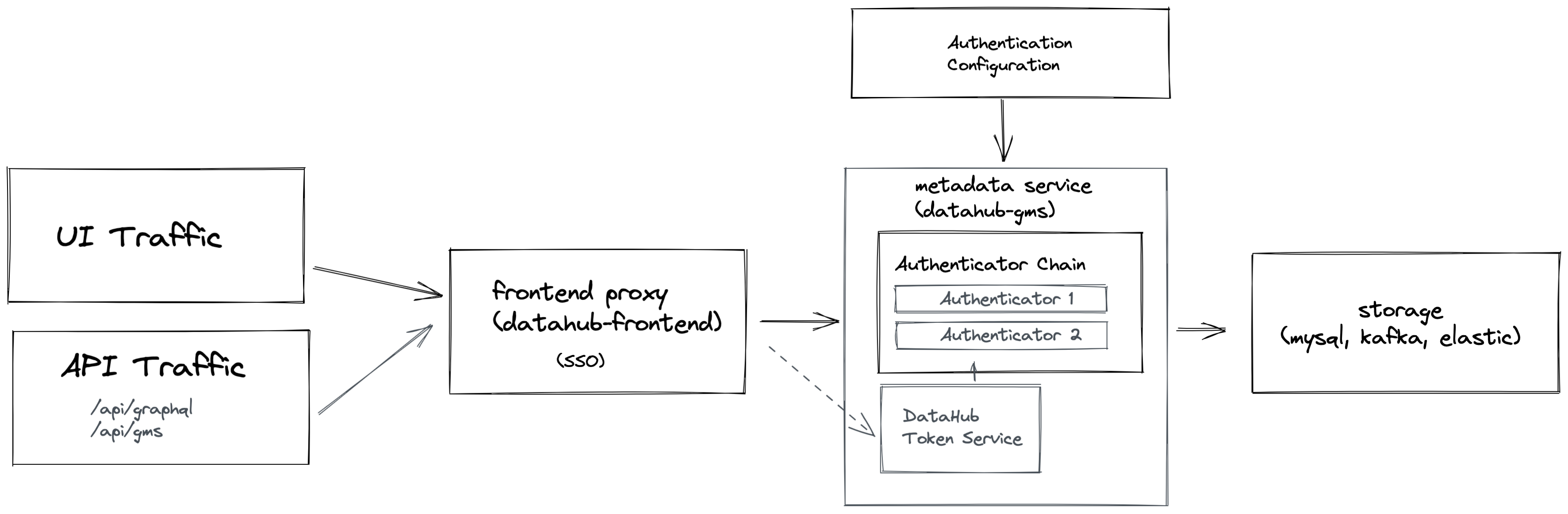 +
+
+  +
+
+  +
+
+  +
+
+  +
+
+ 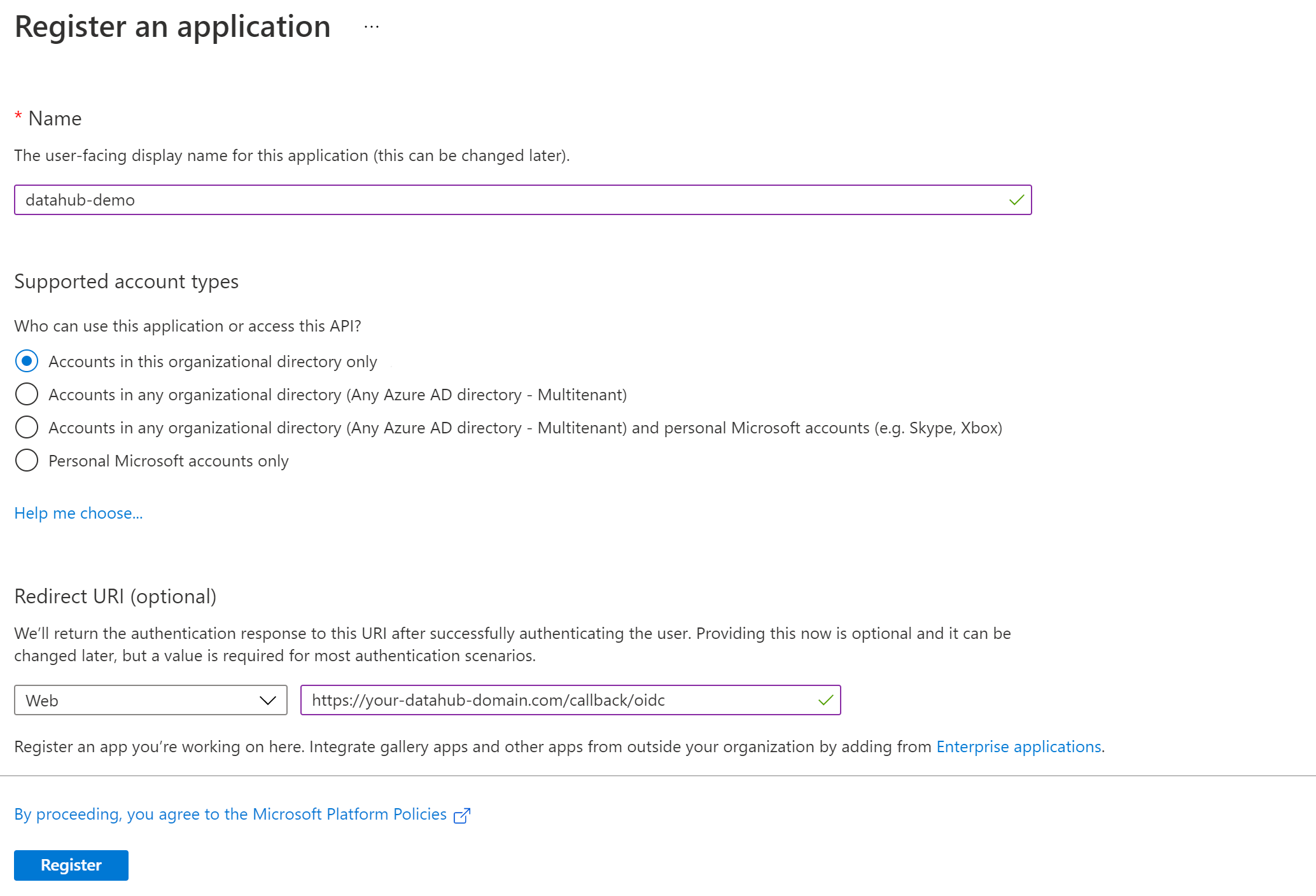 +
+
+ 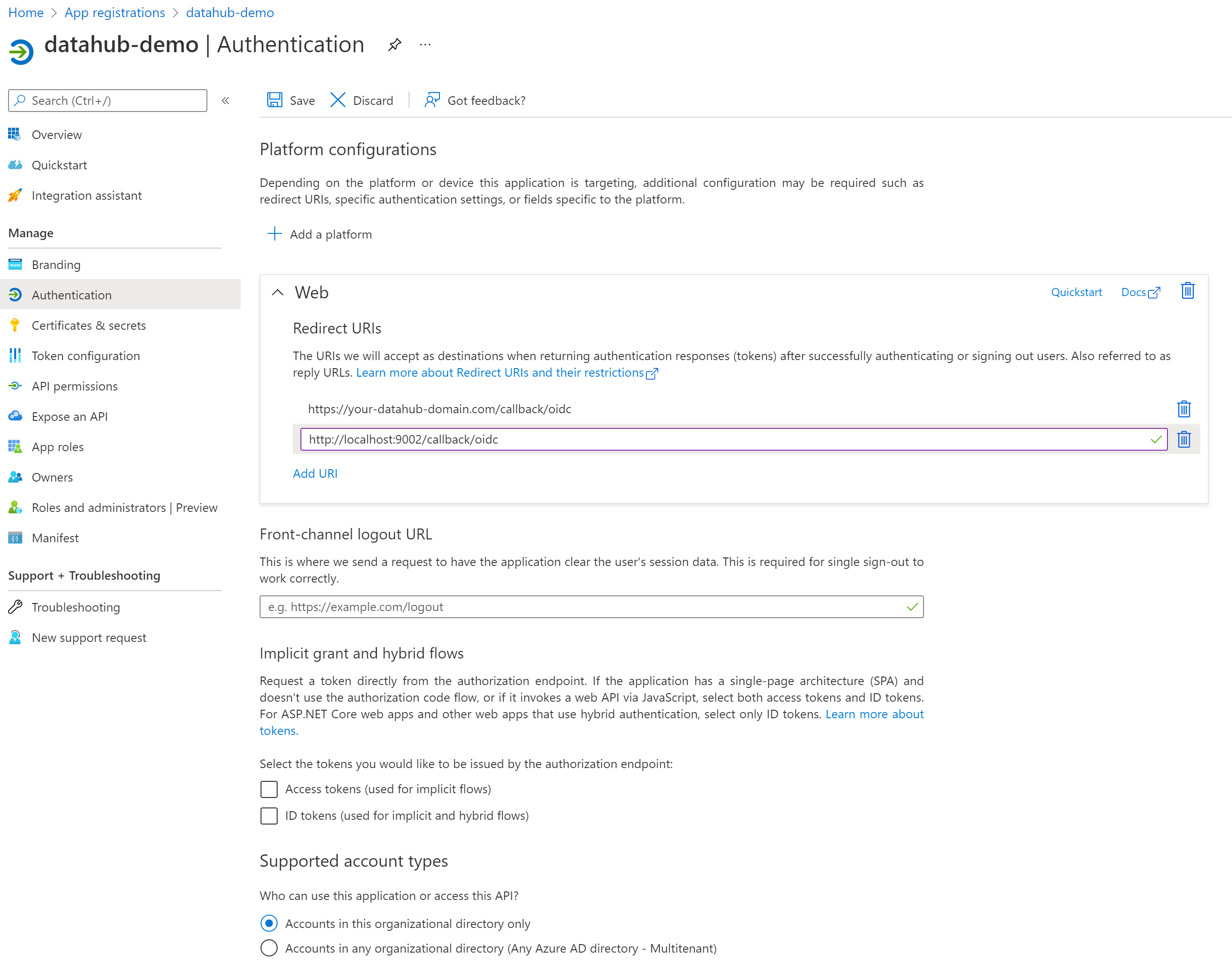 +
+
+ 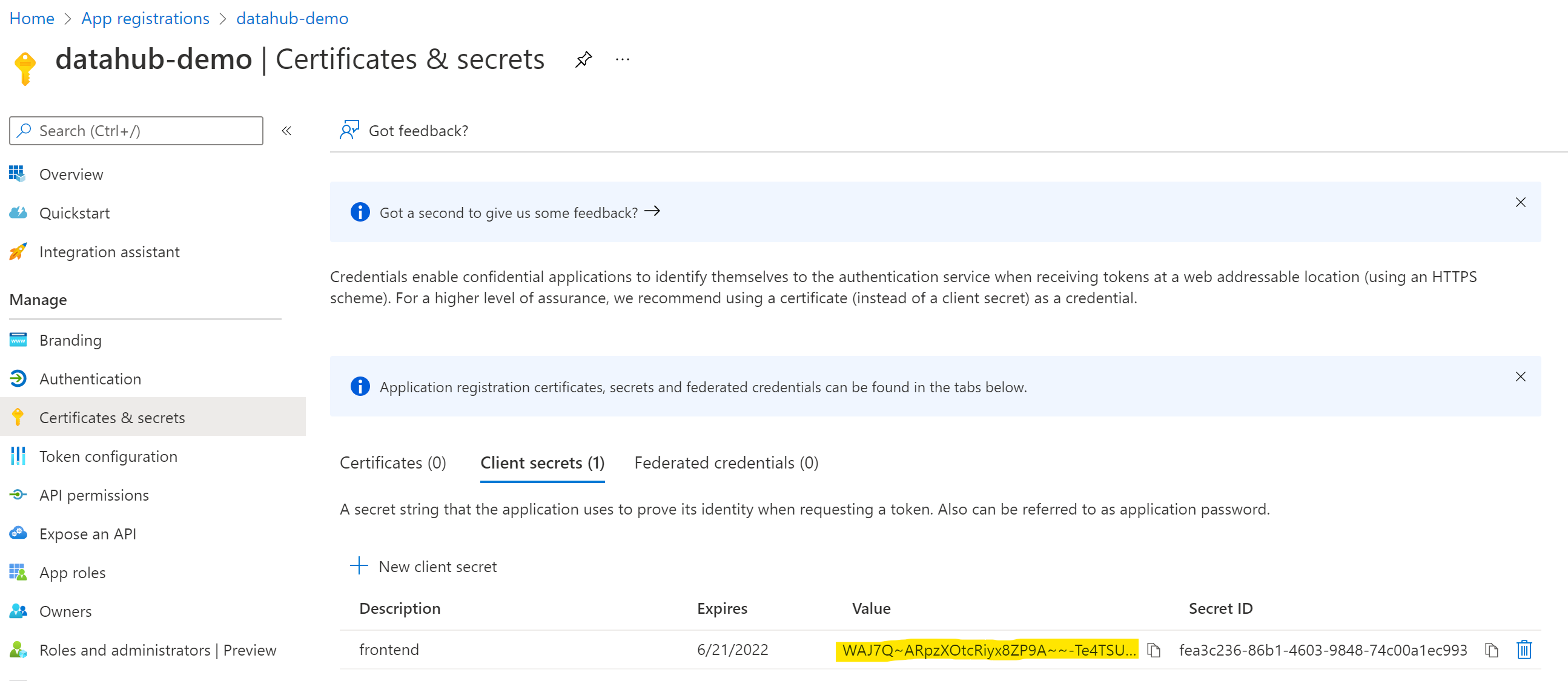 +
+
+ 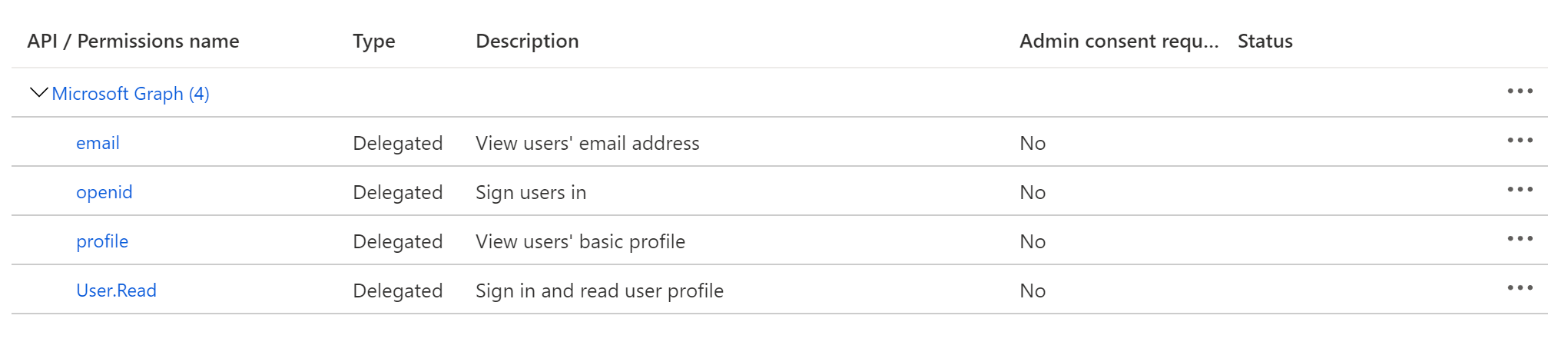 +
+
+ 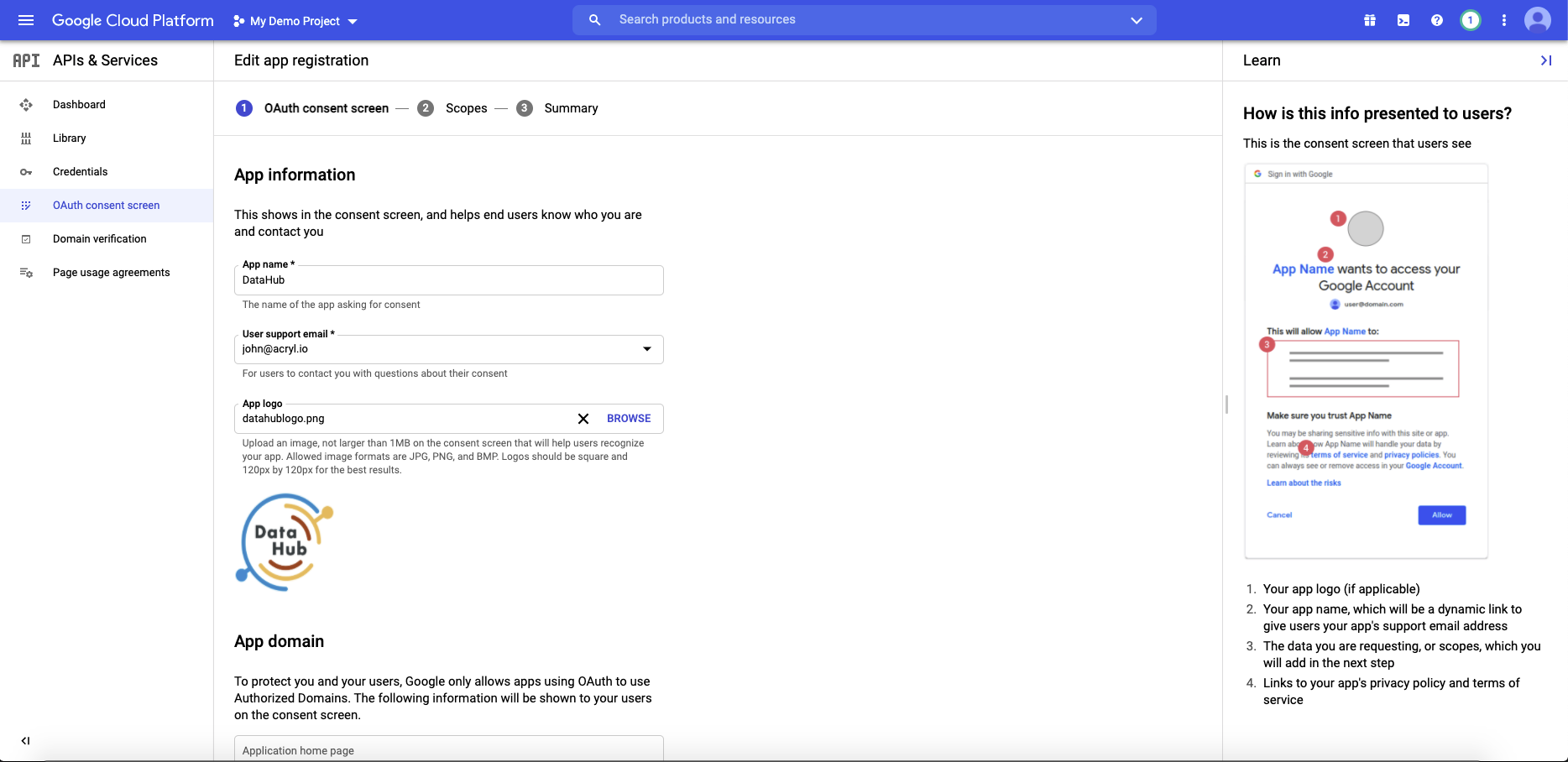 +
+
+ 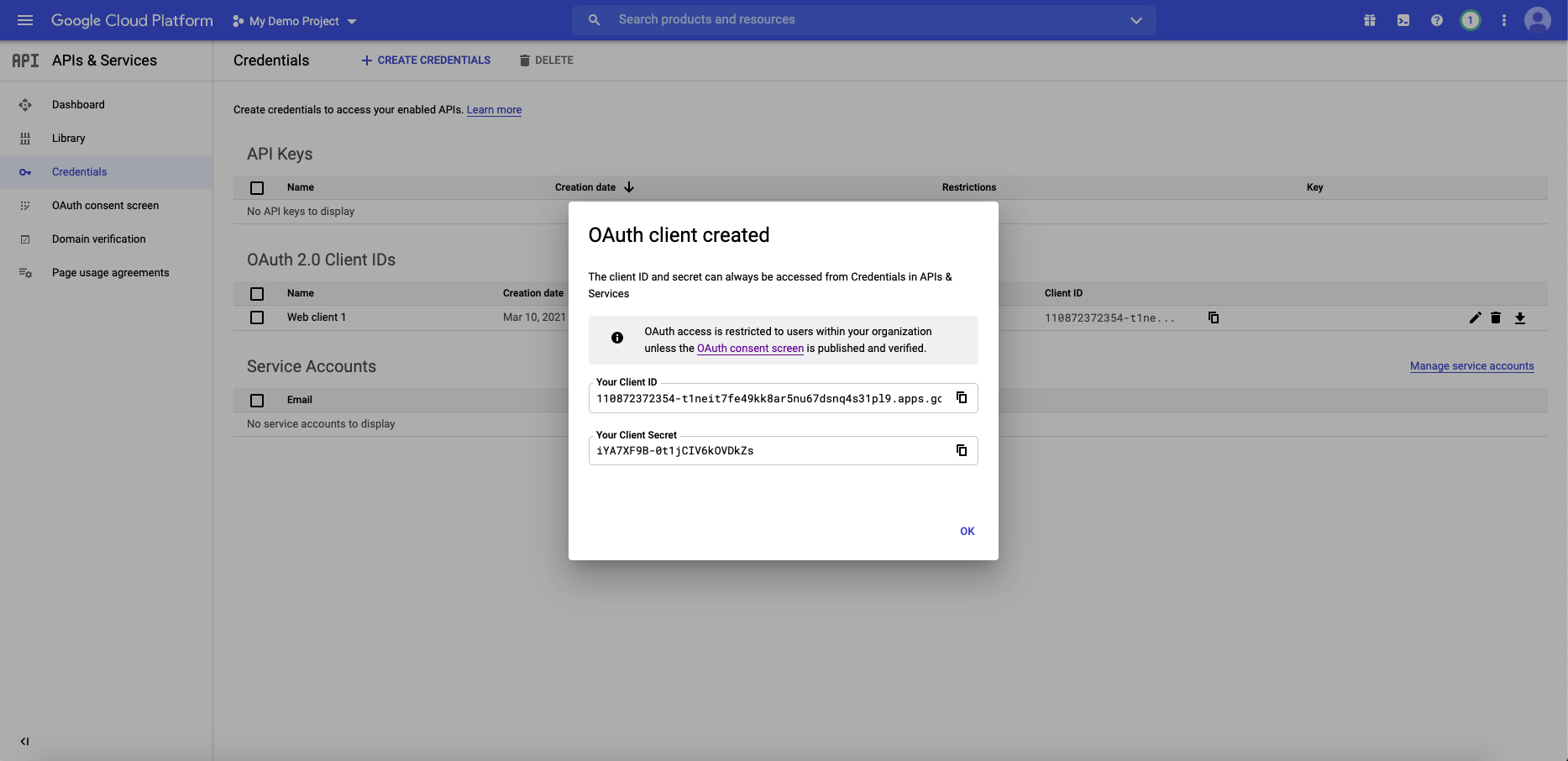 +
+
+ 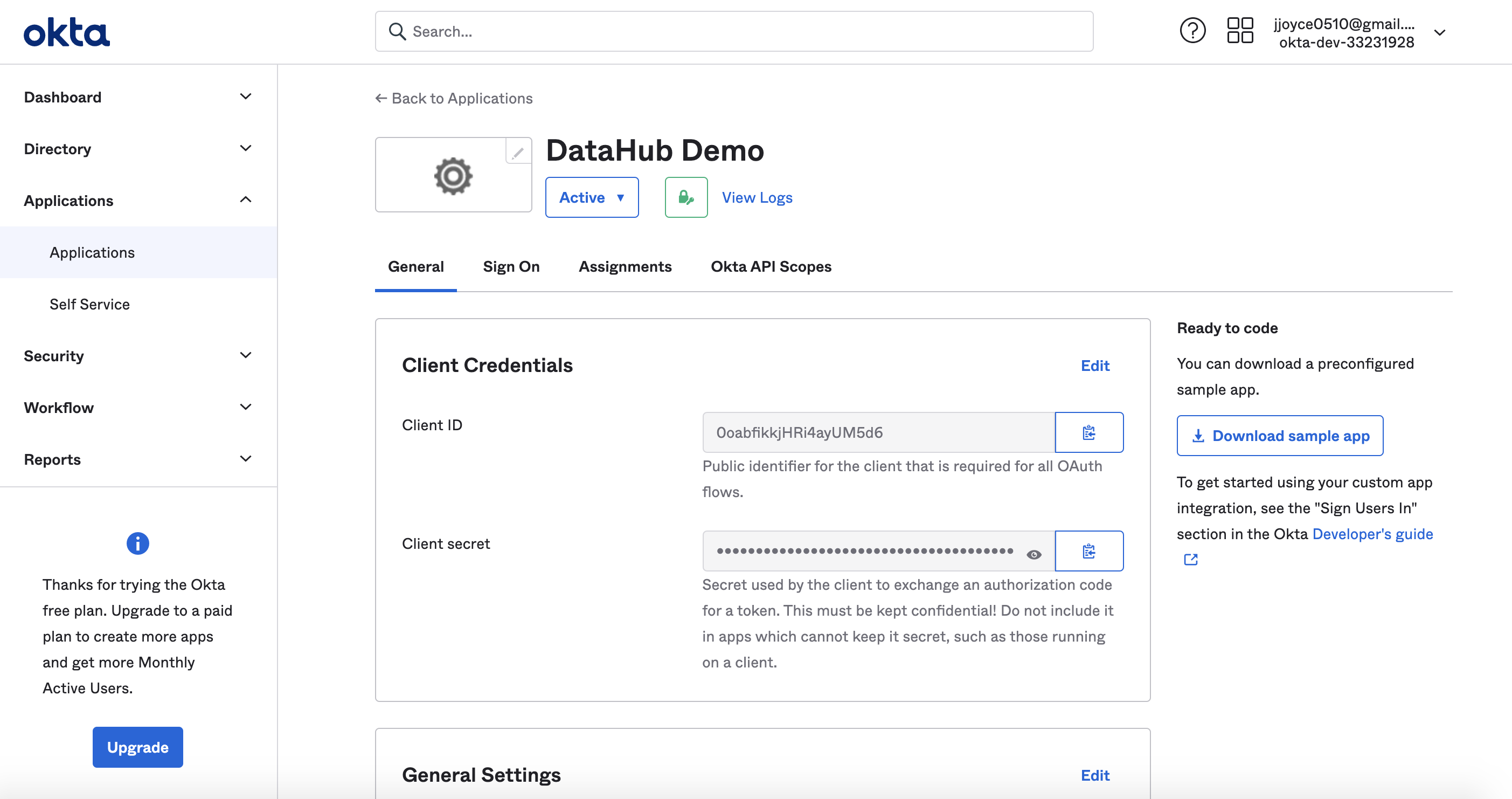 +
+
+ 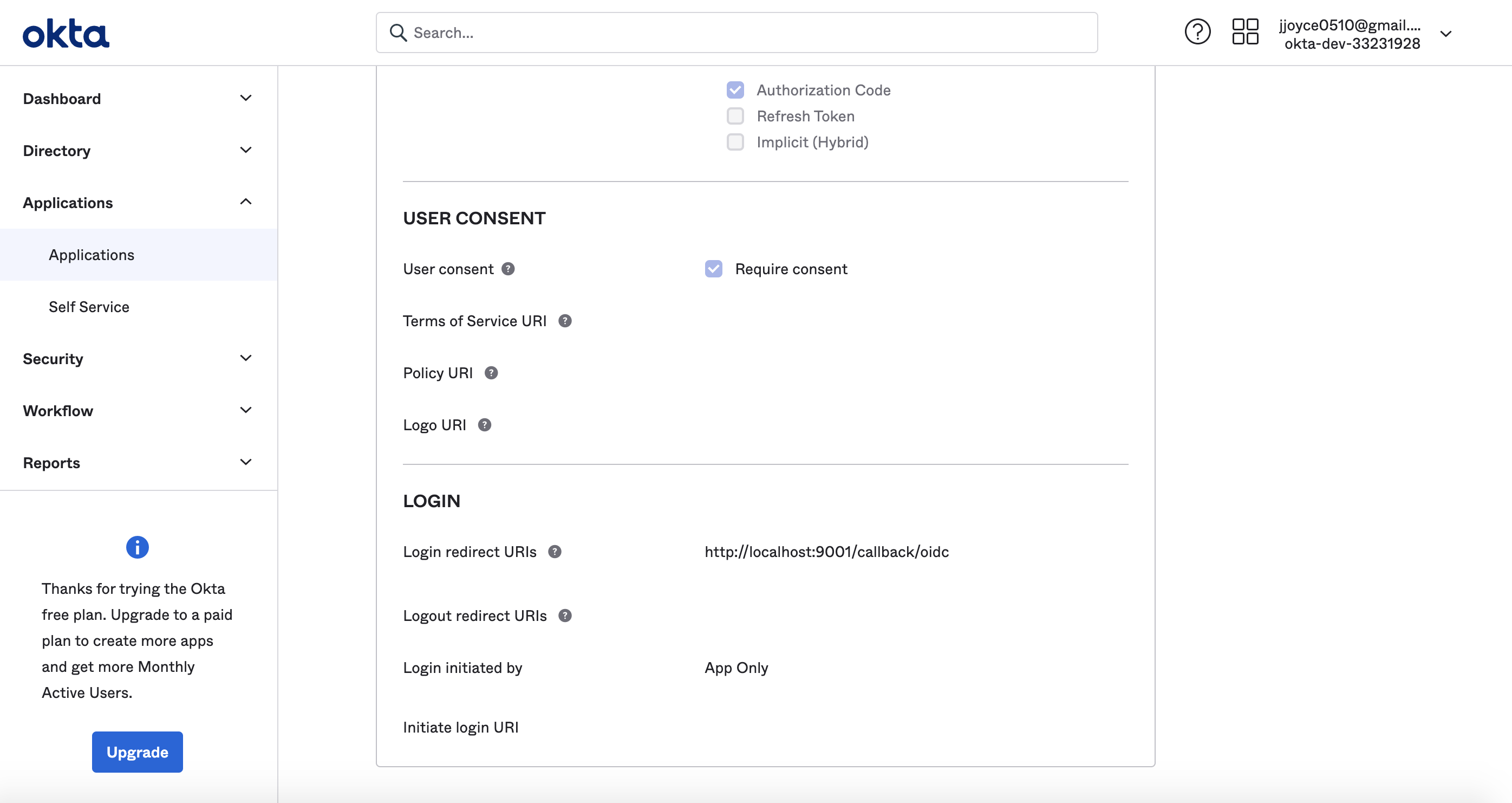 +
+
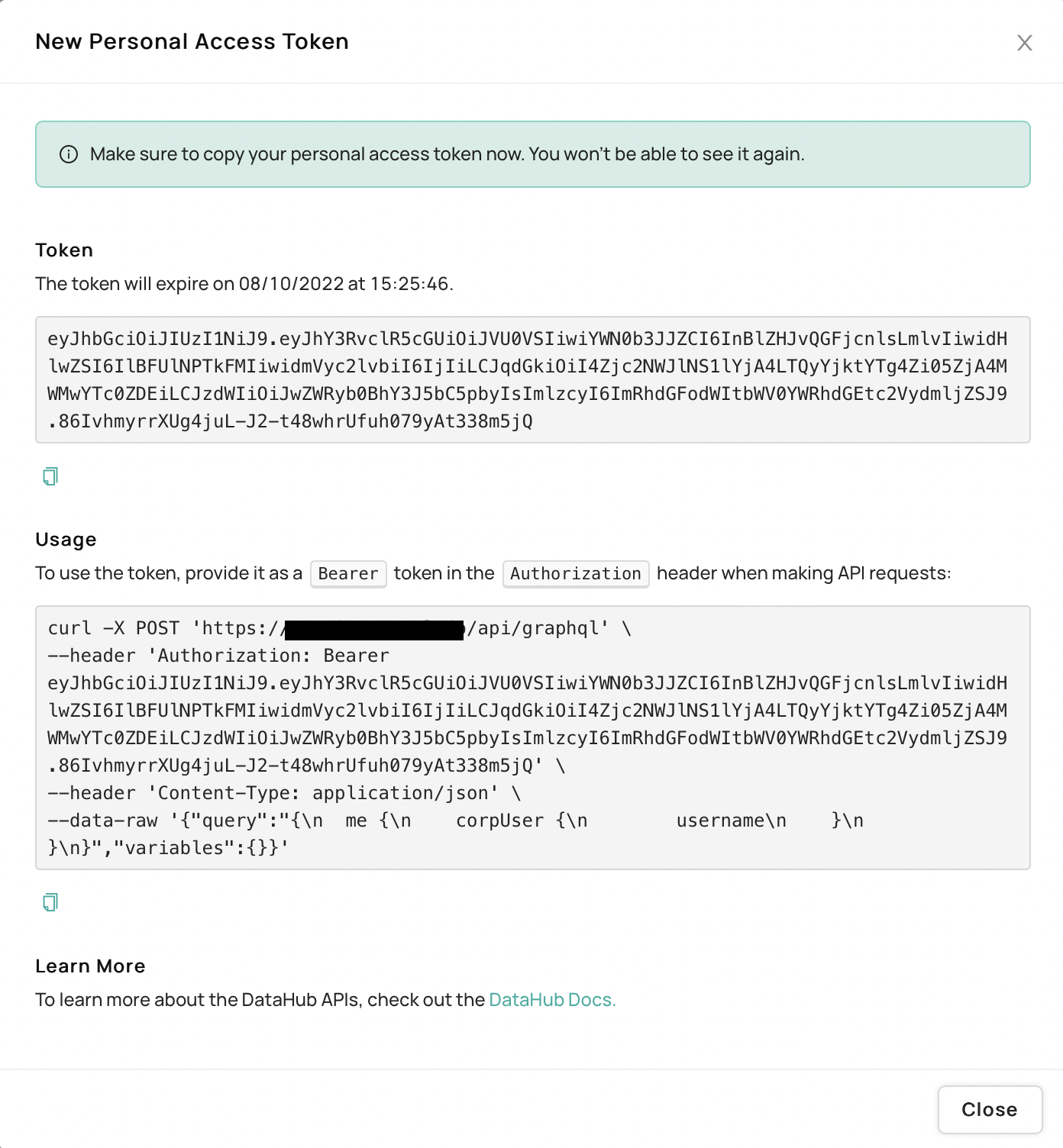
+> 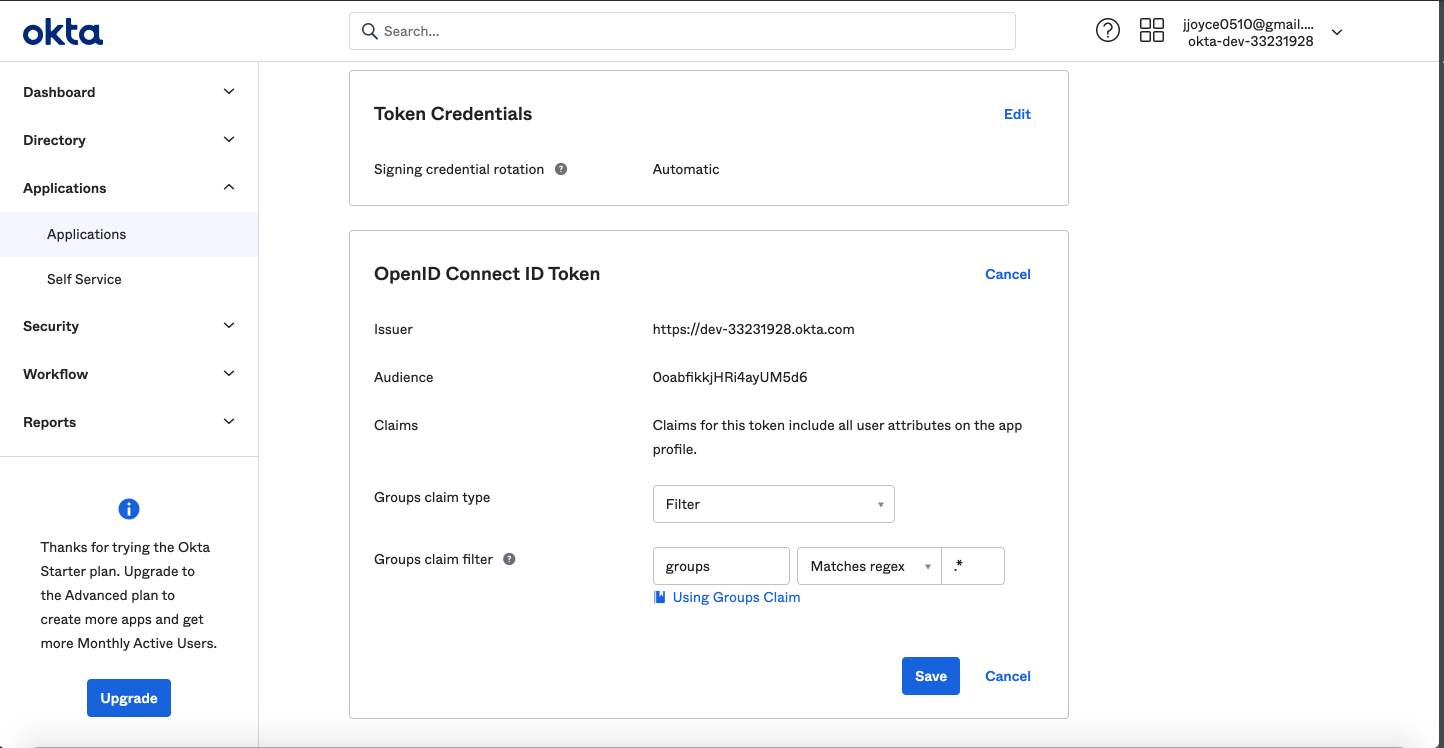 +
+
+
+
+ 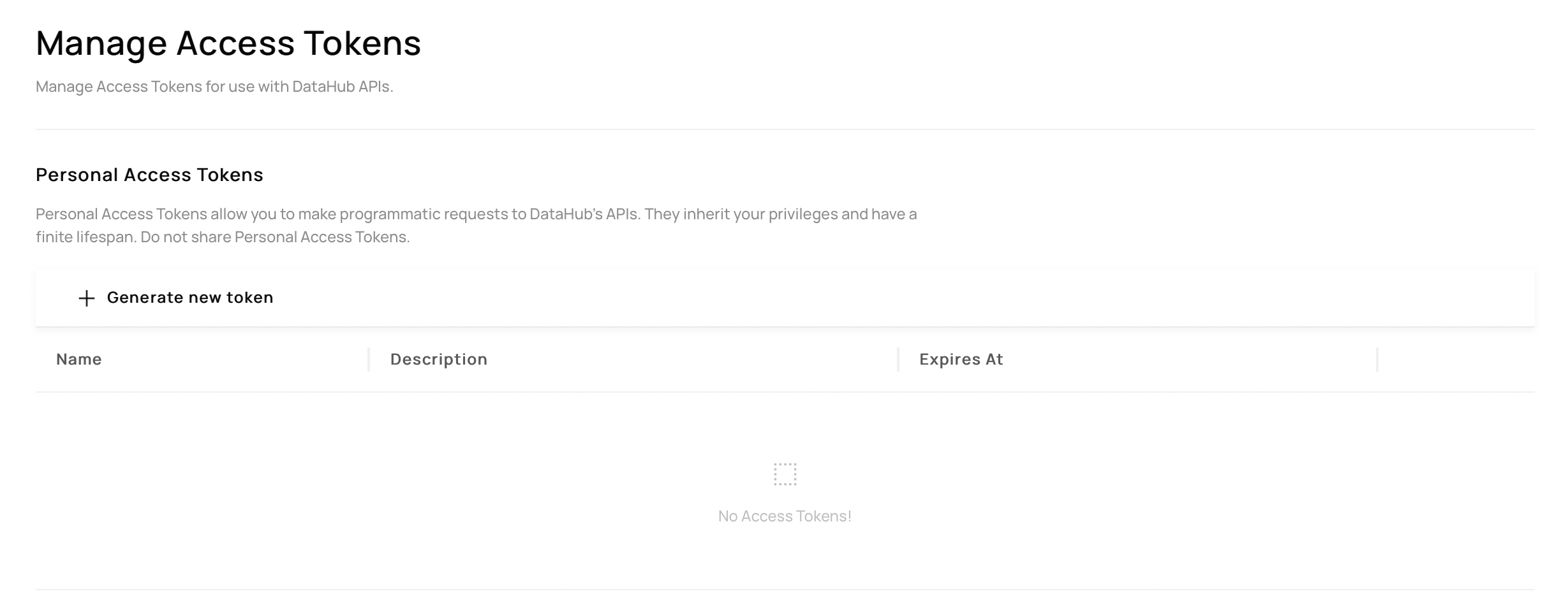 +
+
+ 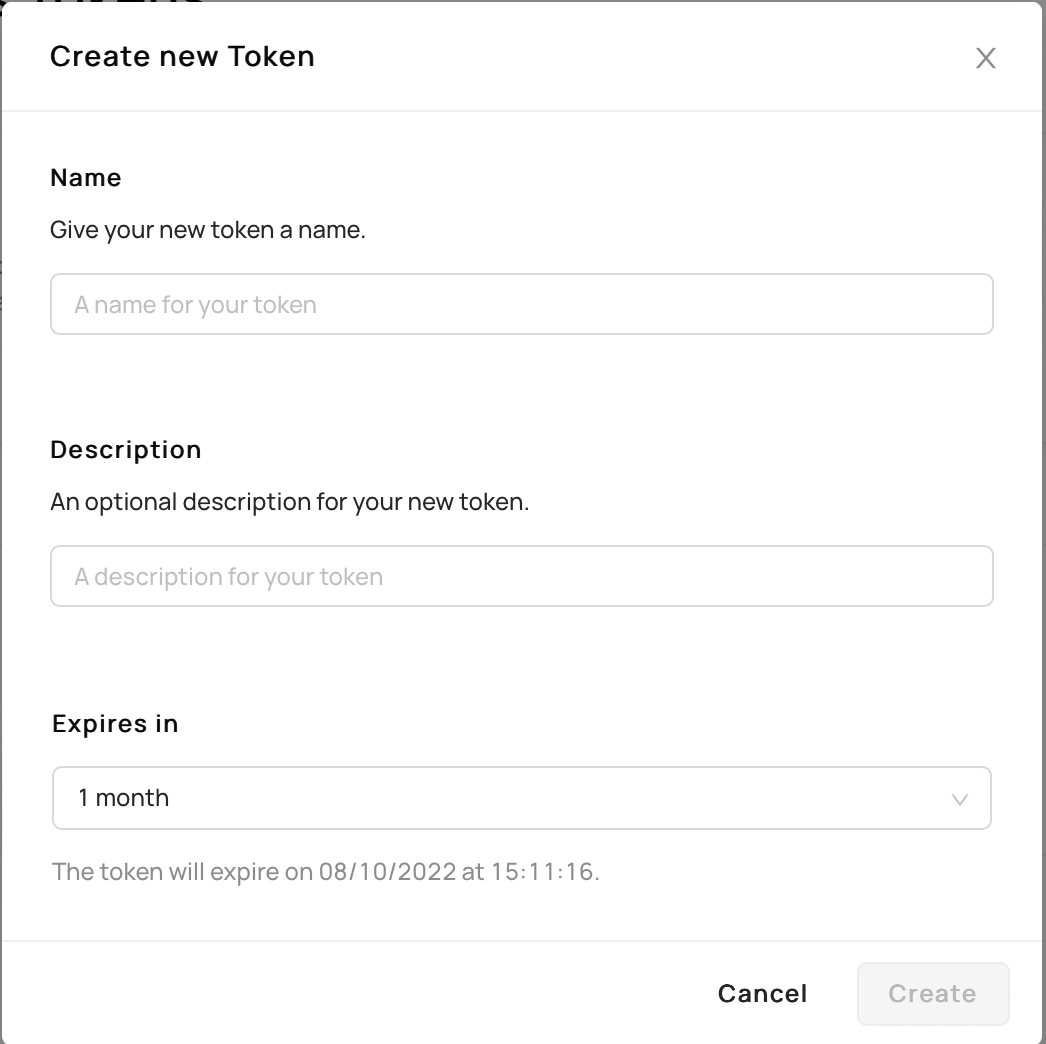 +
+
+ 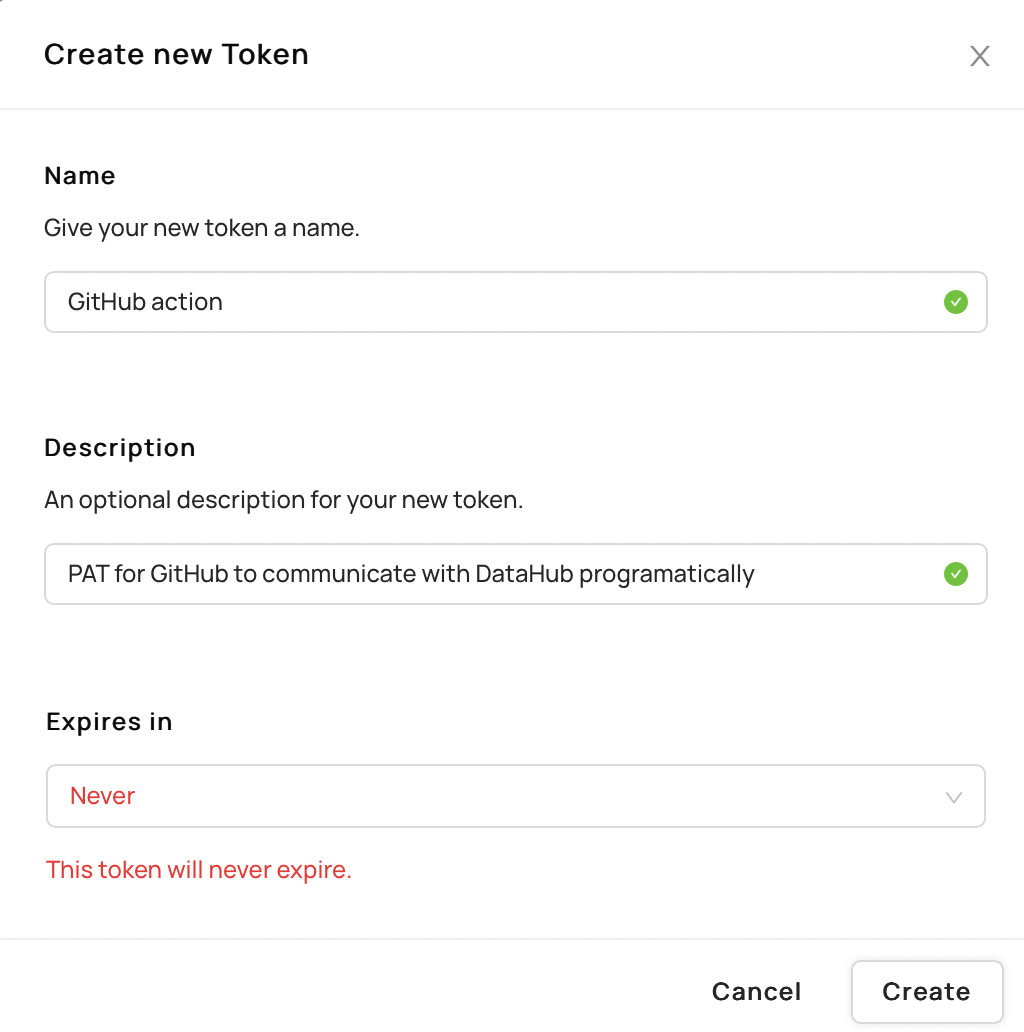 +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+ 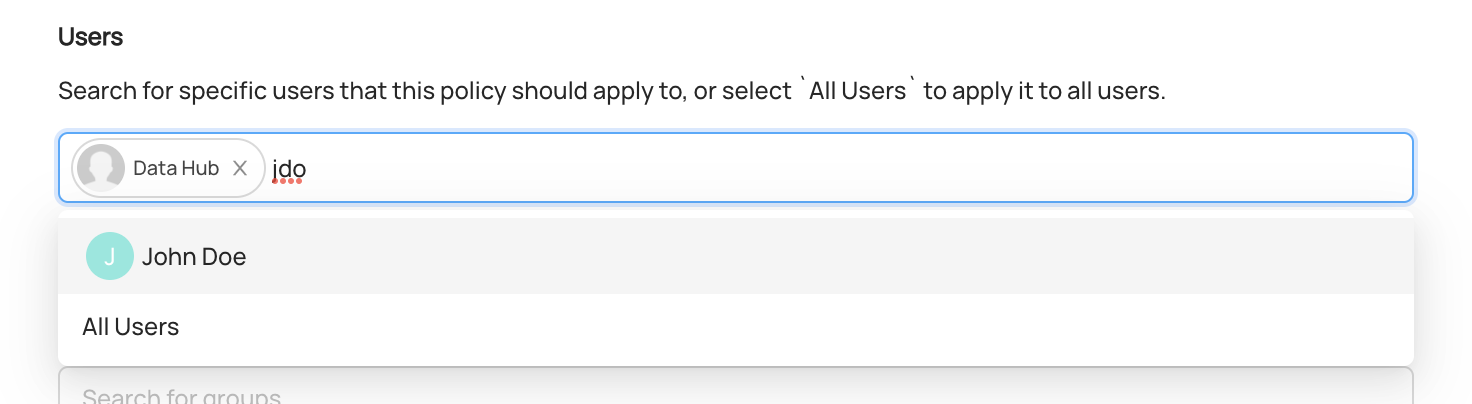 +
+
+ 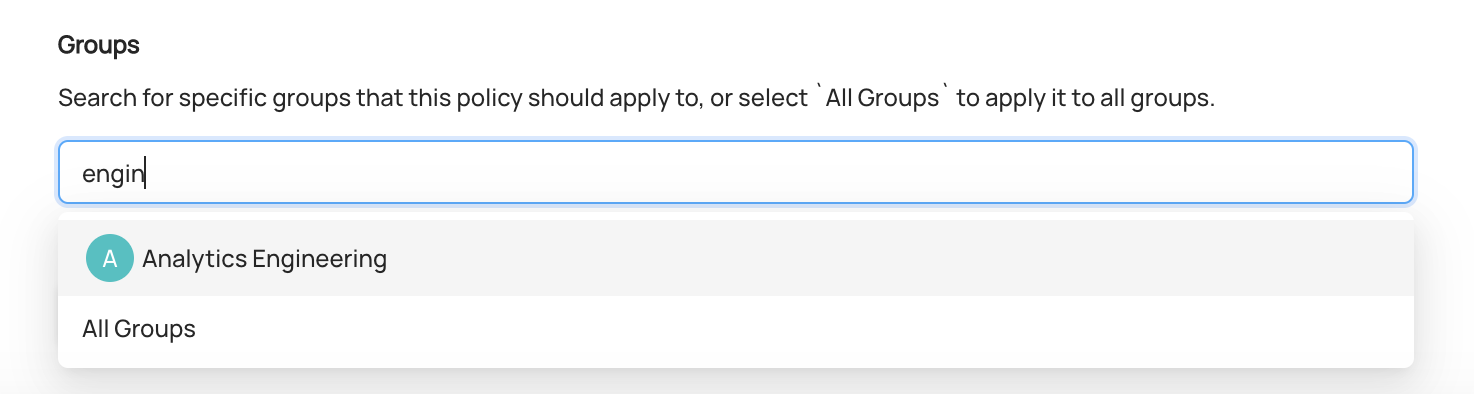 +
+
+ 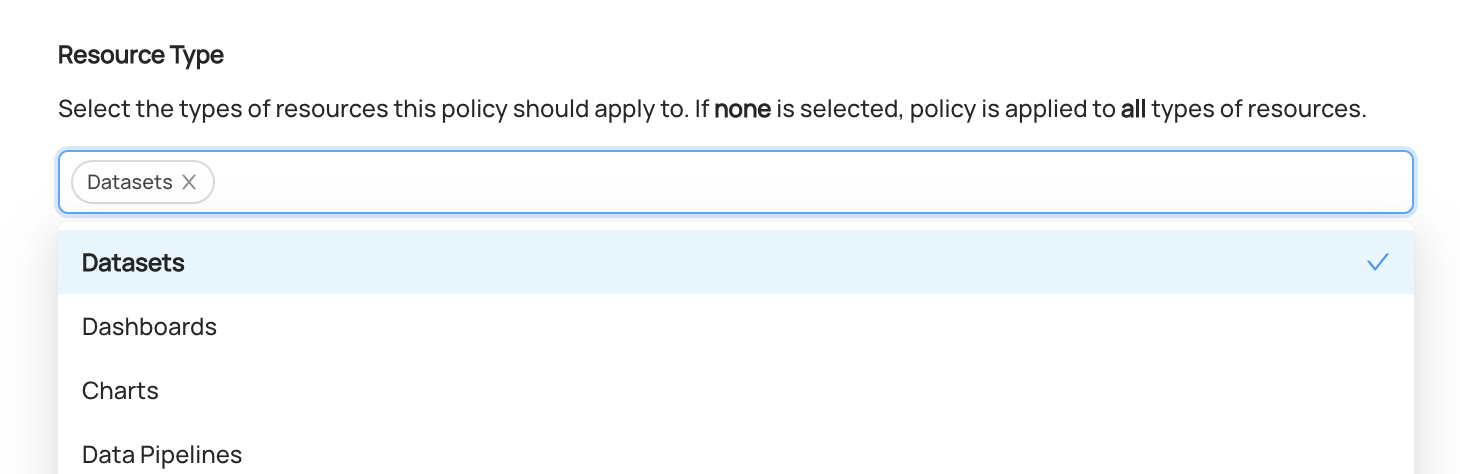 +
+
+ 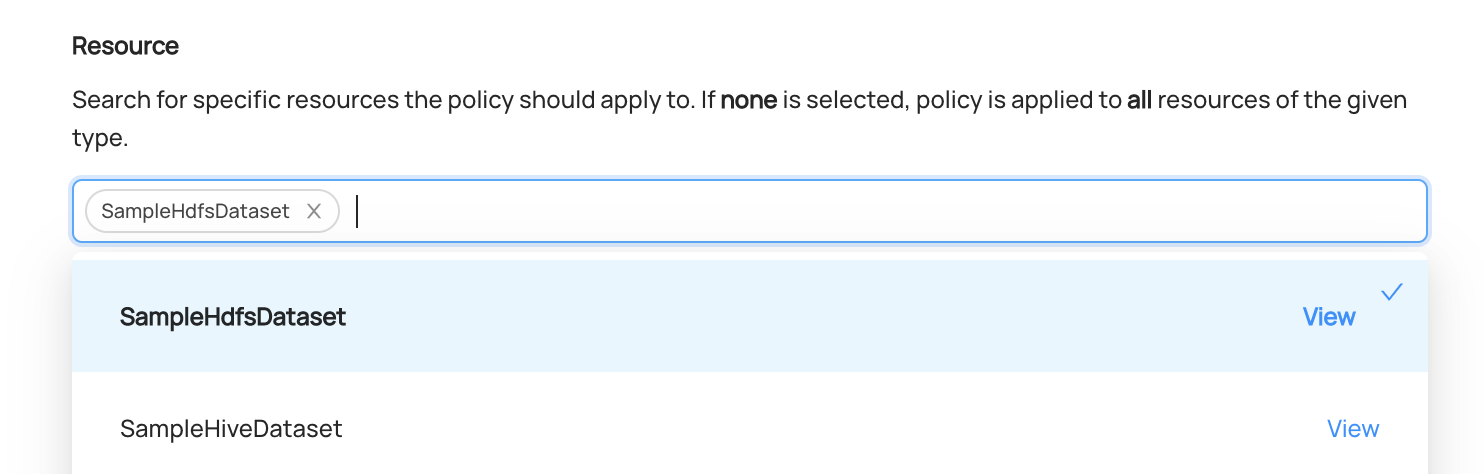 +
+
+ 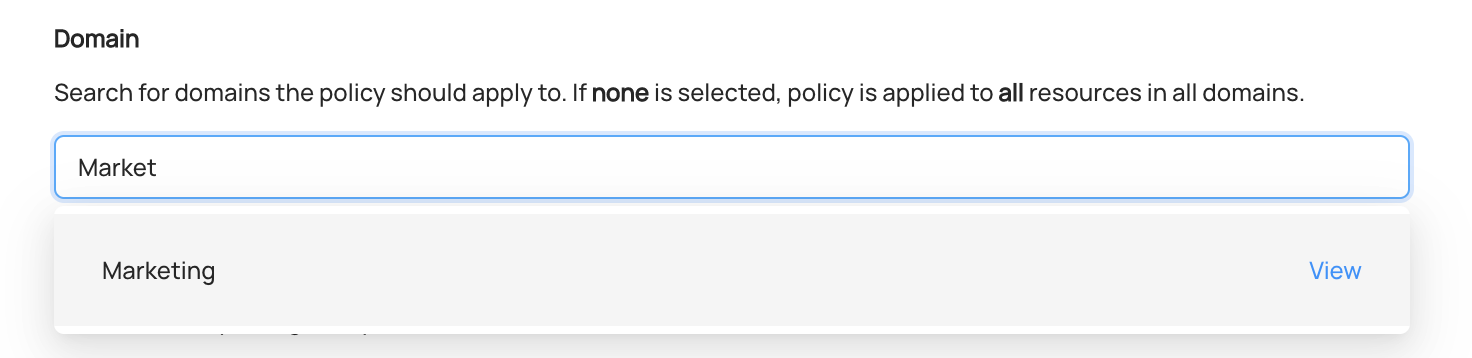 +
+
+ 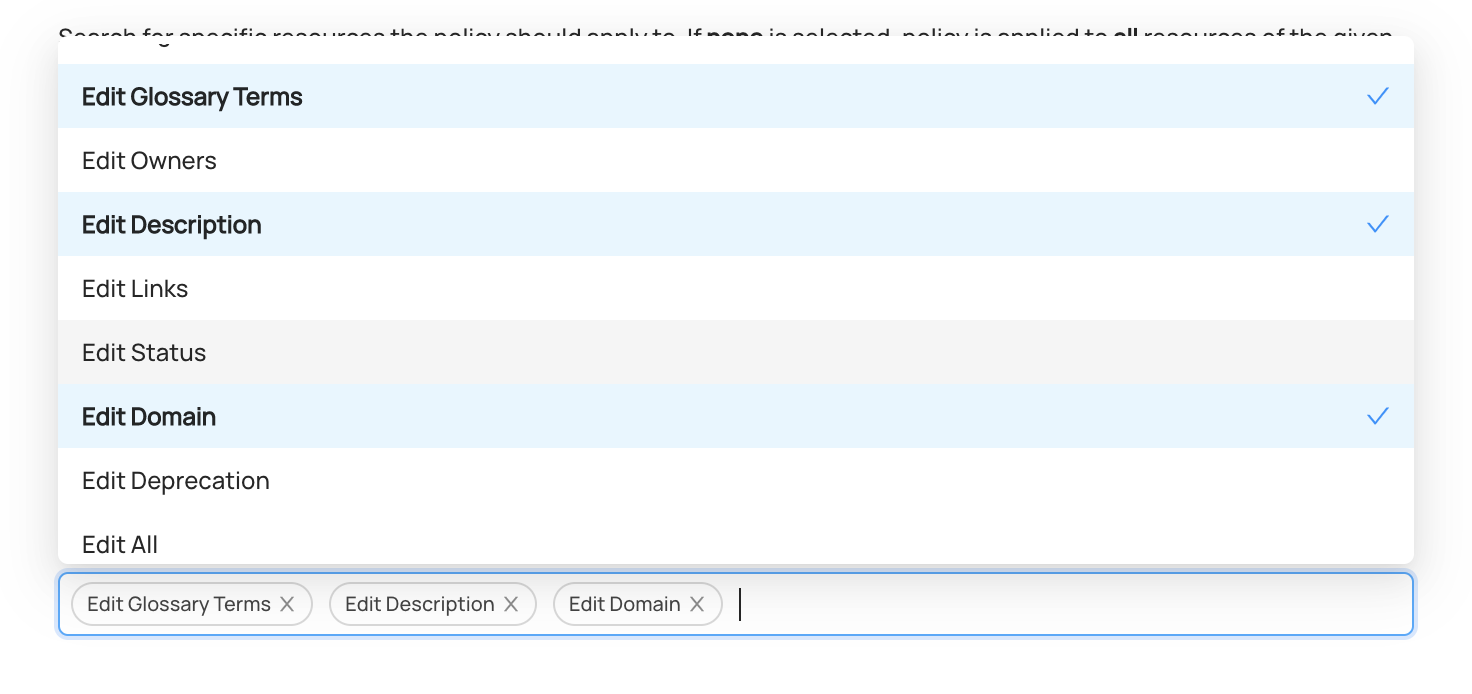 +
+
+
+
+
+
+  +
+
+ 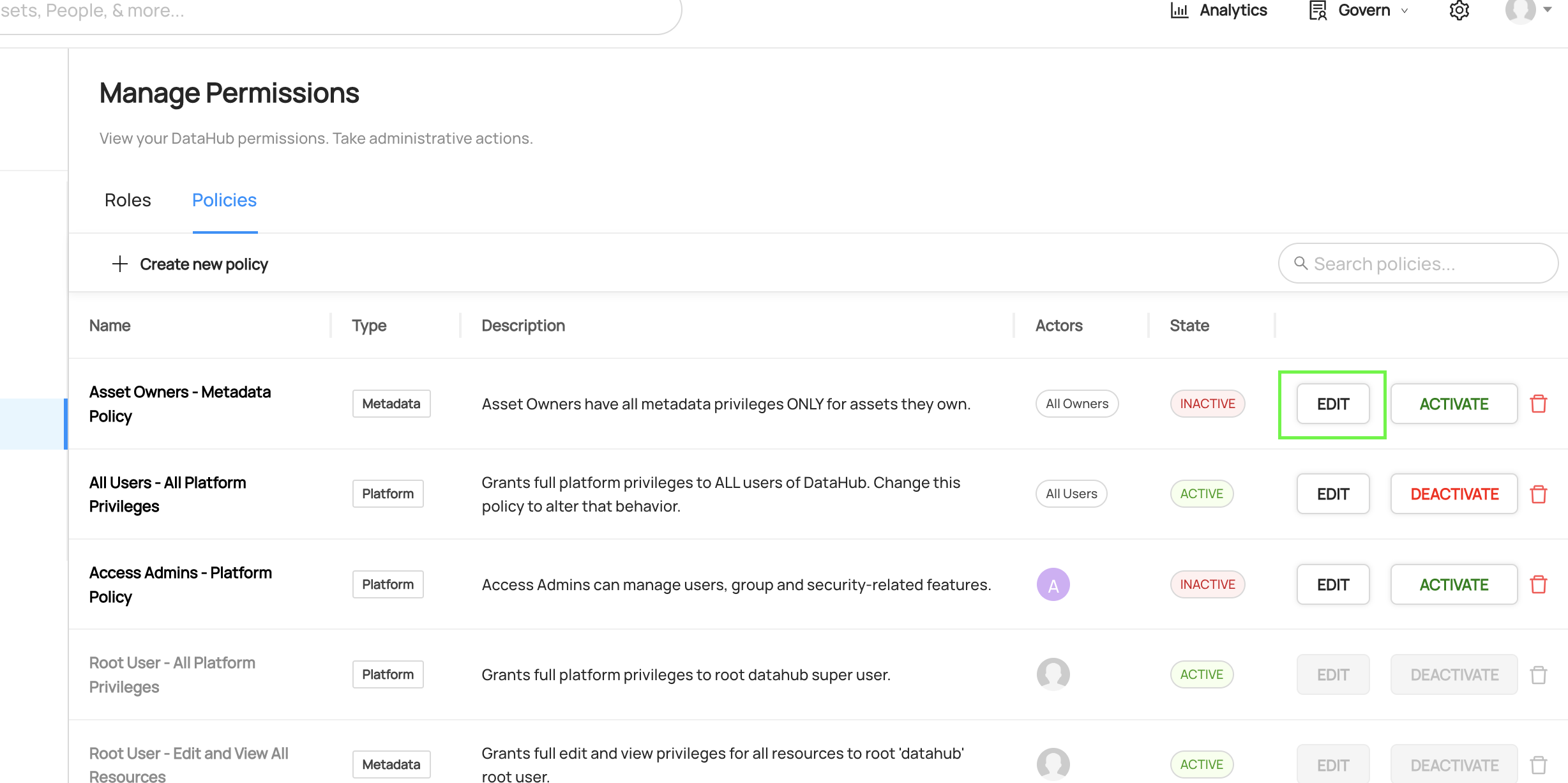 +
+
+ 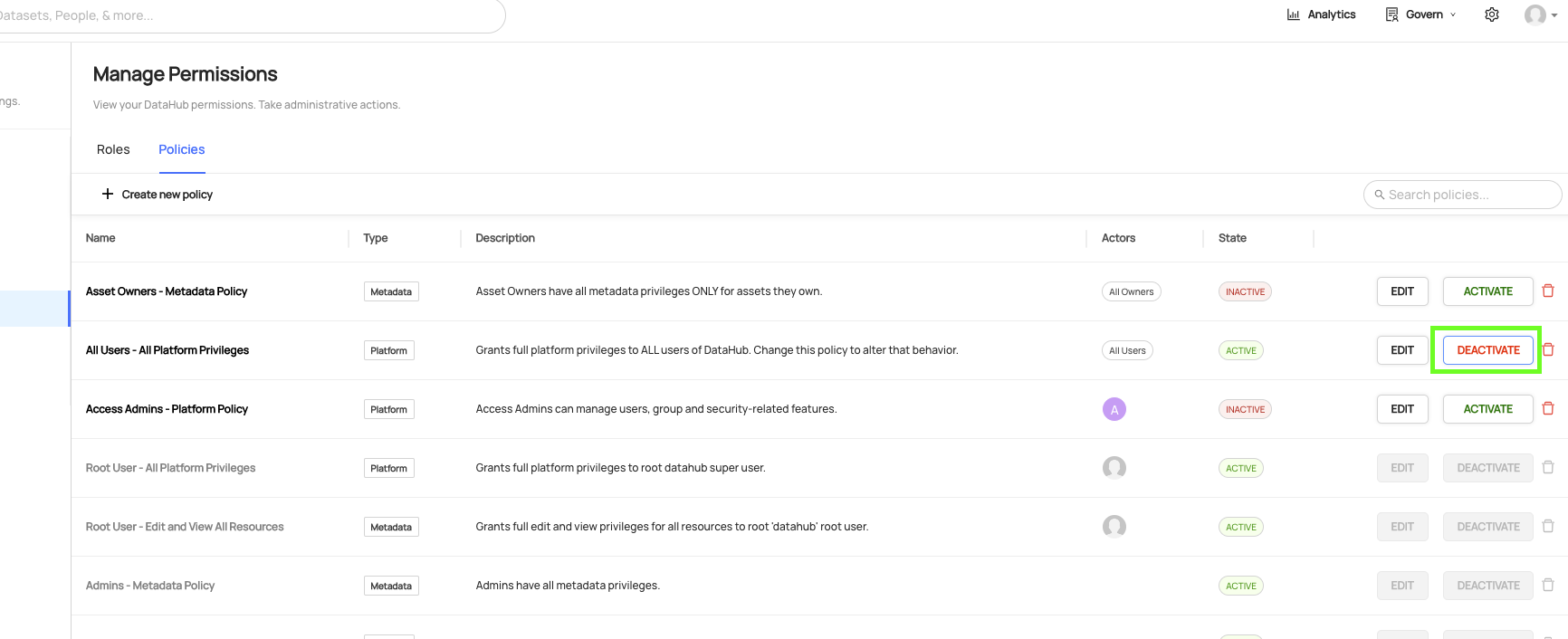 +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+ 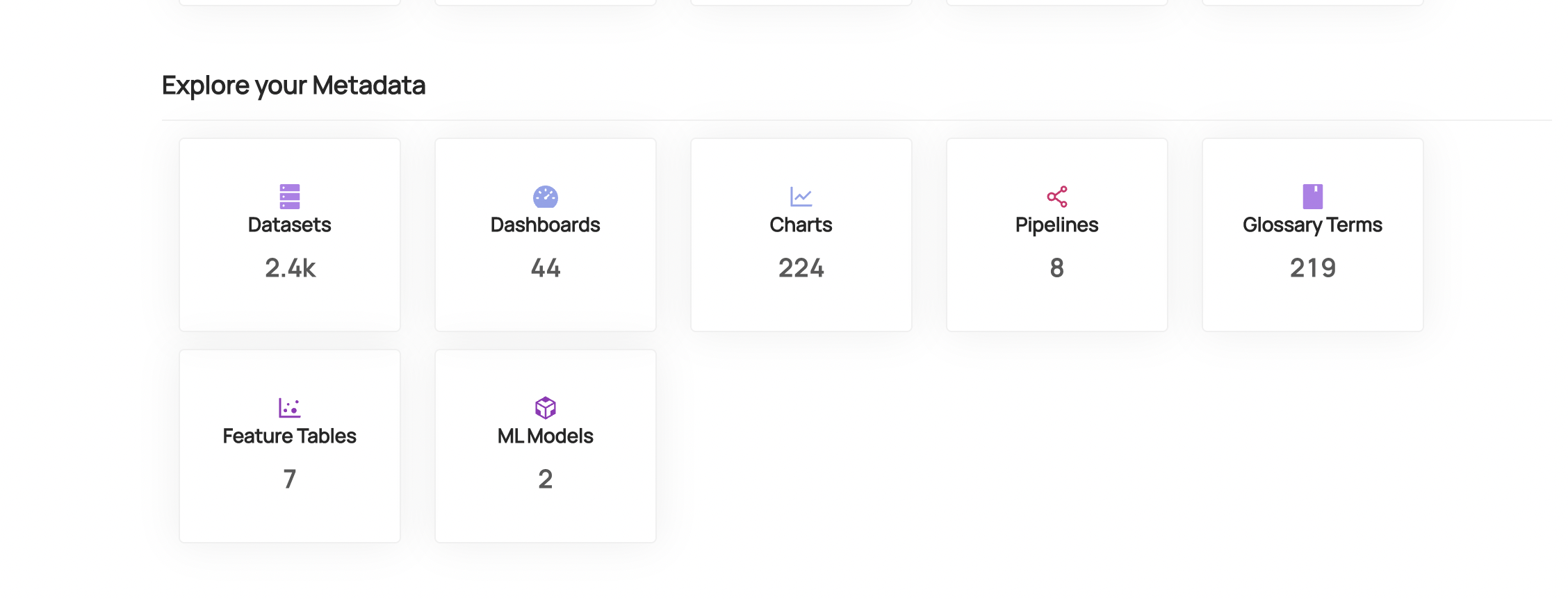 +
+
+ 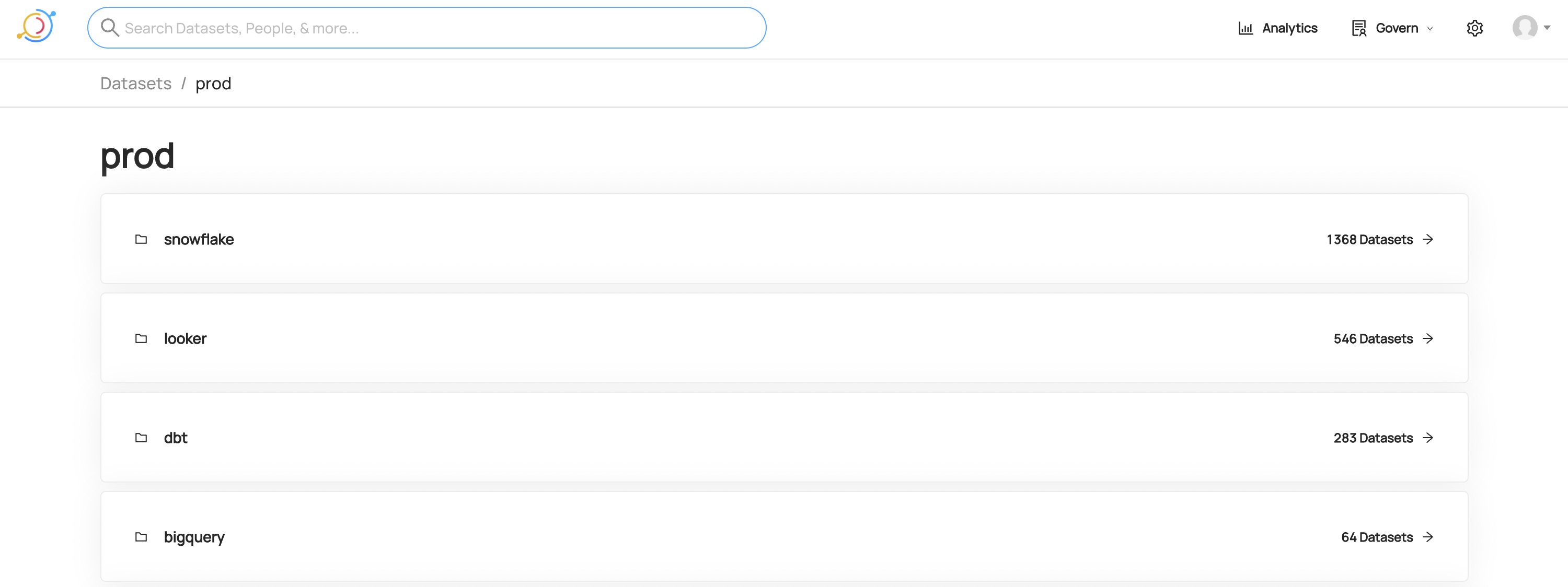 +
+
+ 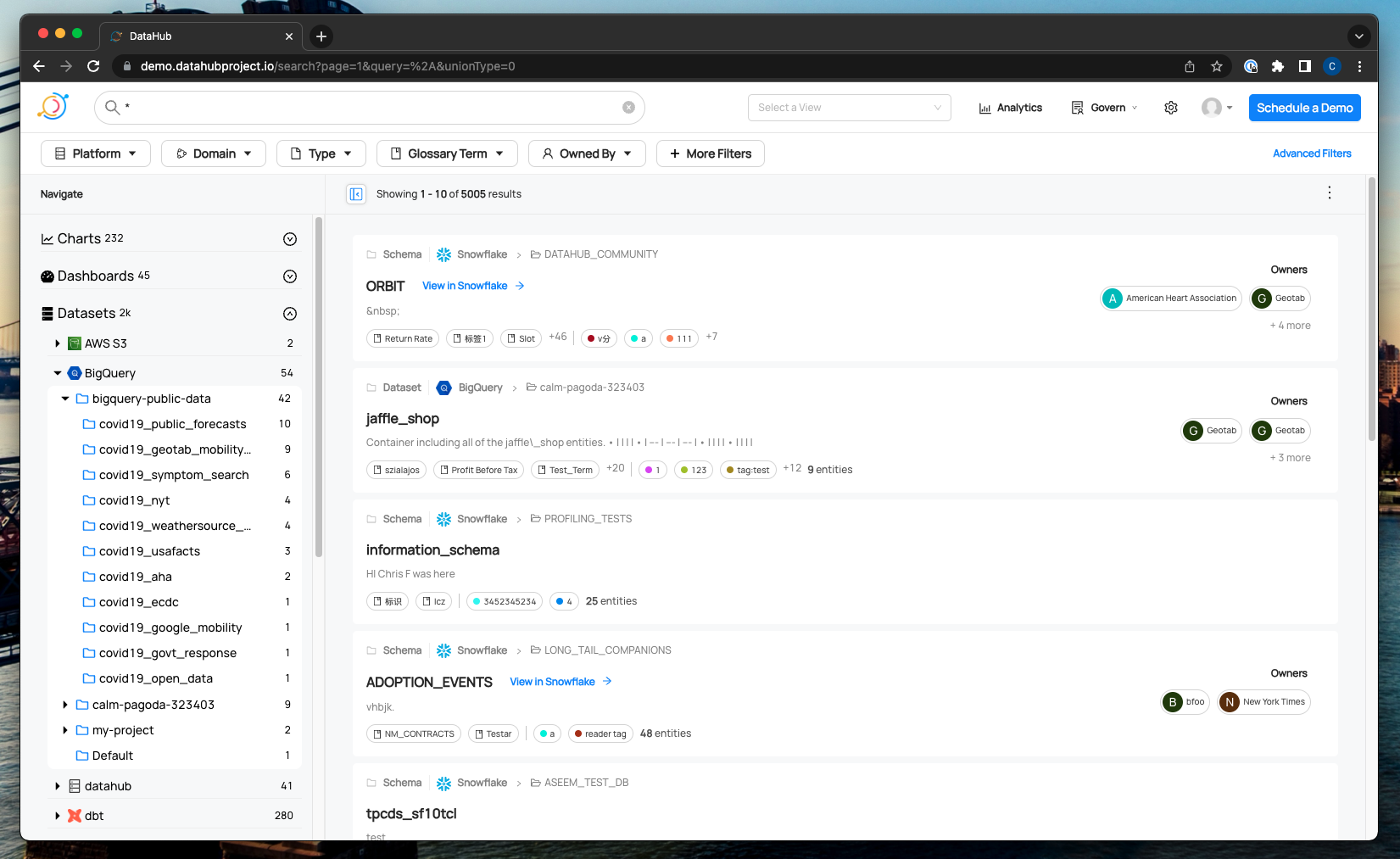 +
+
+  +
+
+ 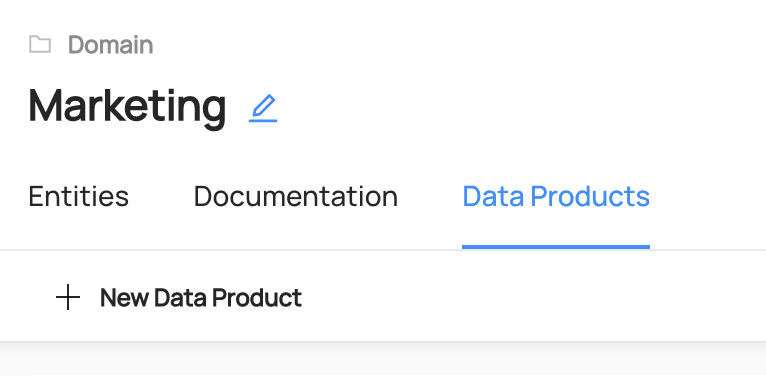 +
+
+ 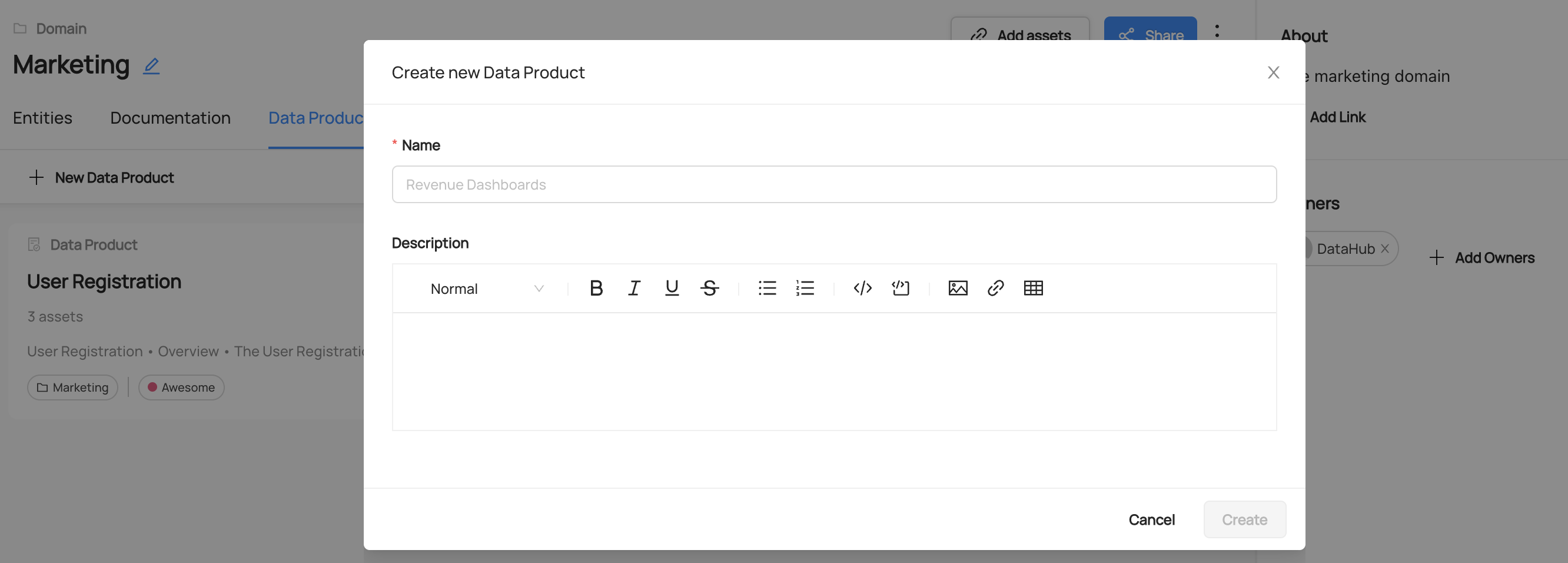 +
+
+ 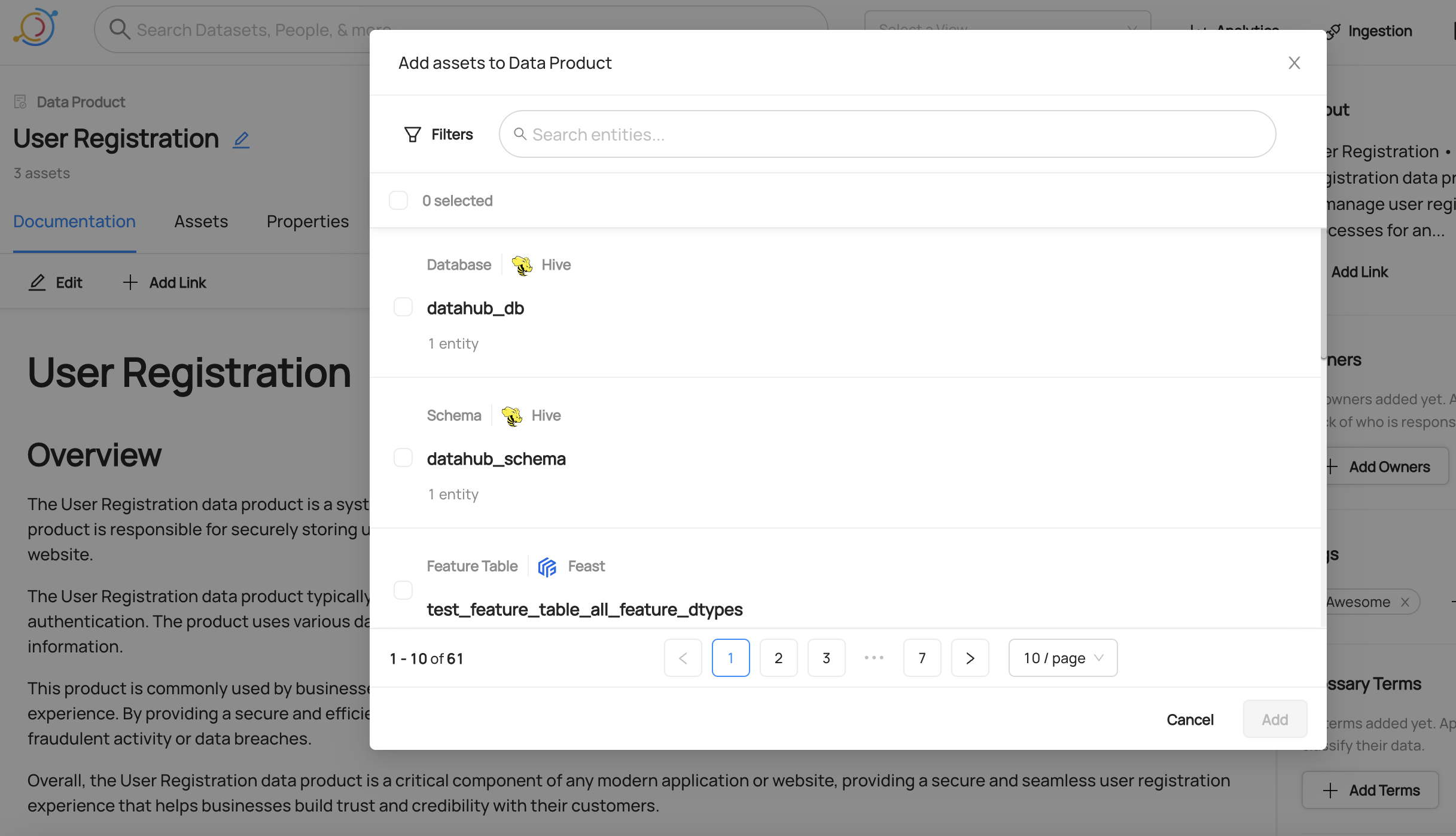 +
+
+ 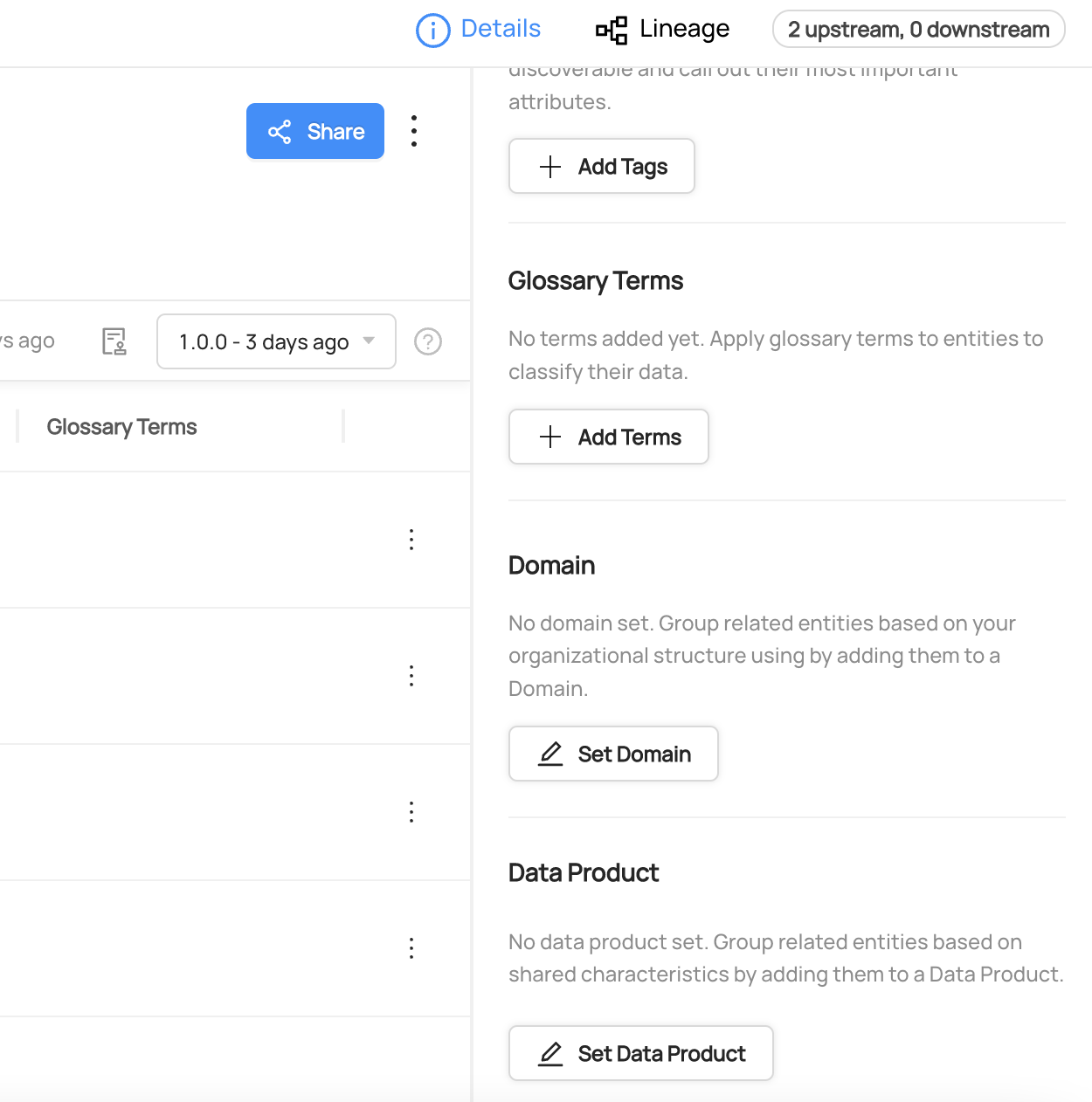 +
+
+ 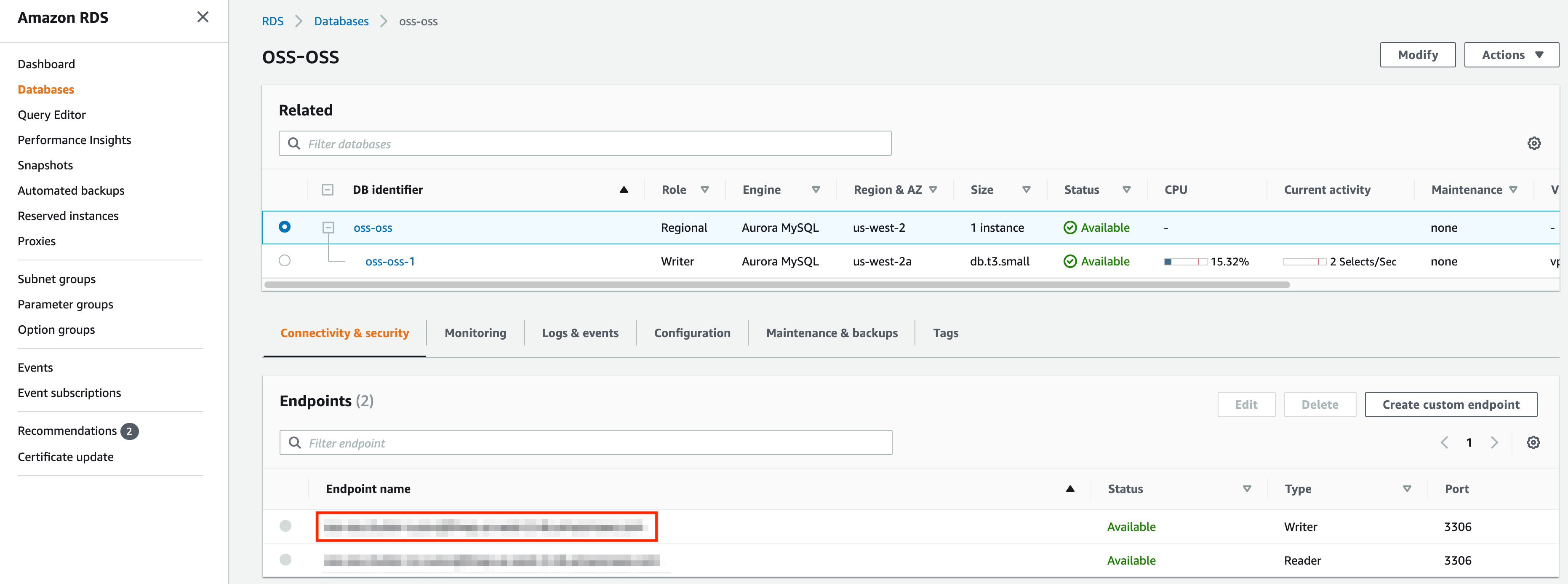 +
+
+ 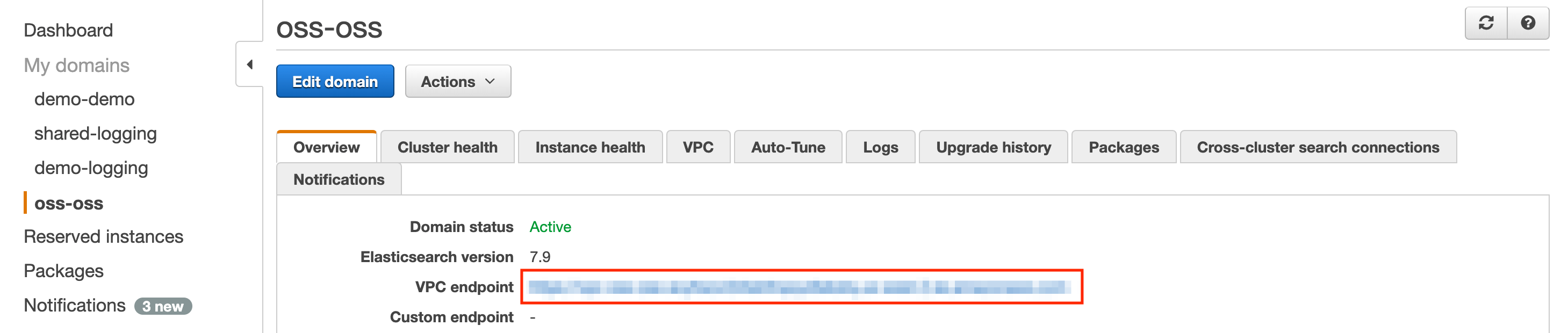 +
+
+ 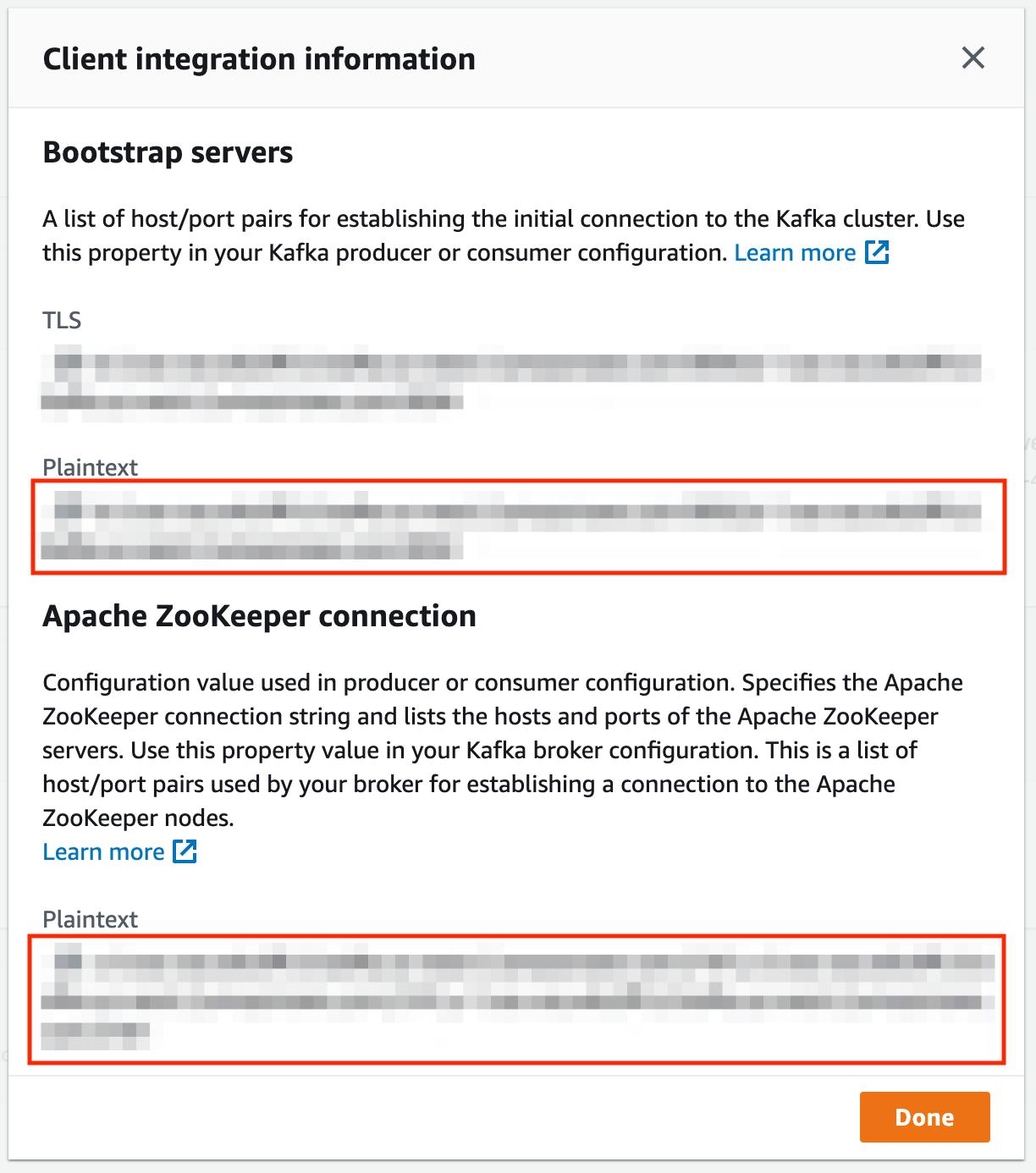 +
+
+ 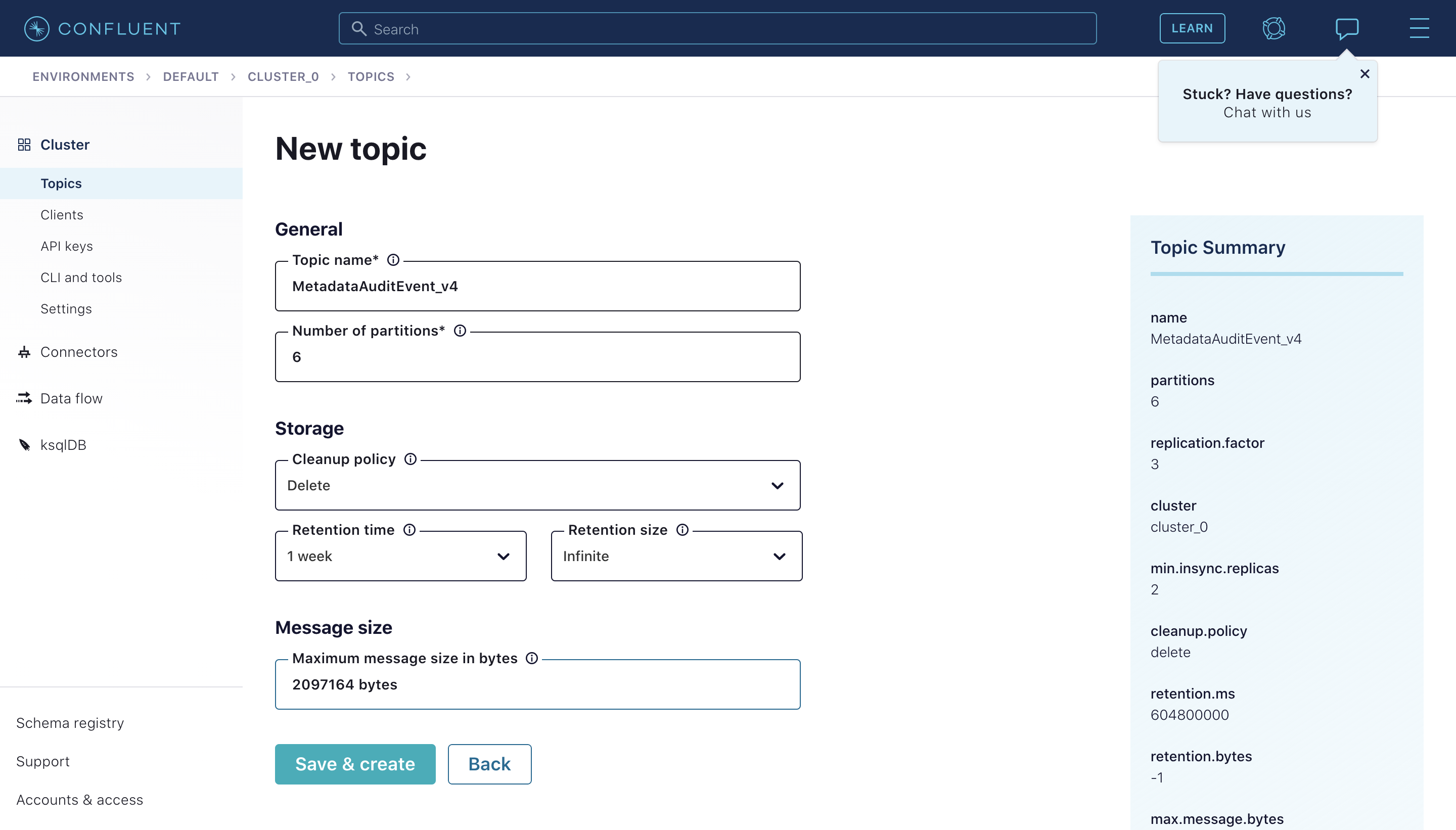 +
+
+ 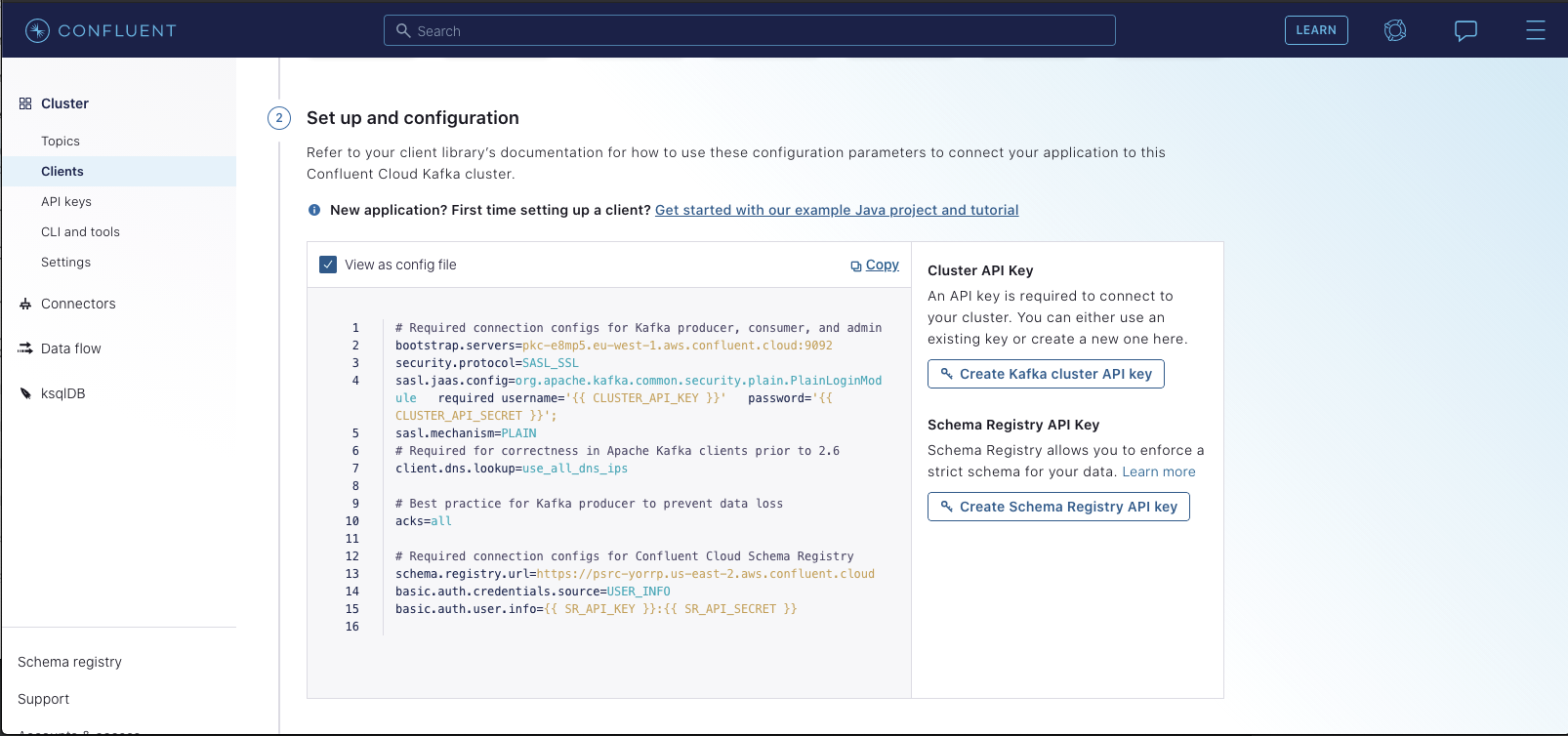 +
+
+ 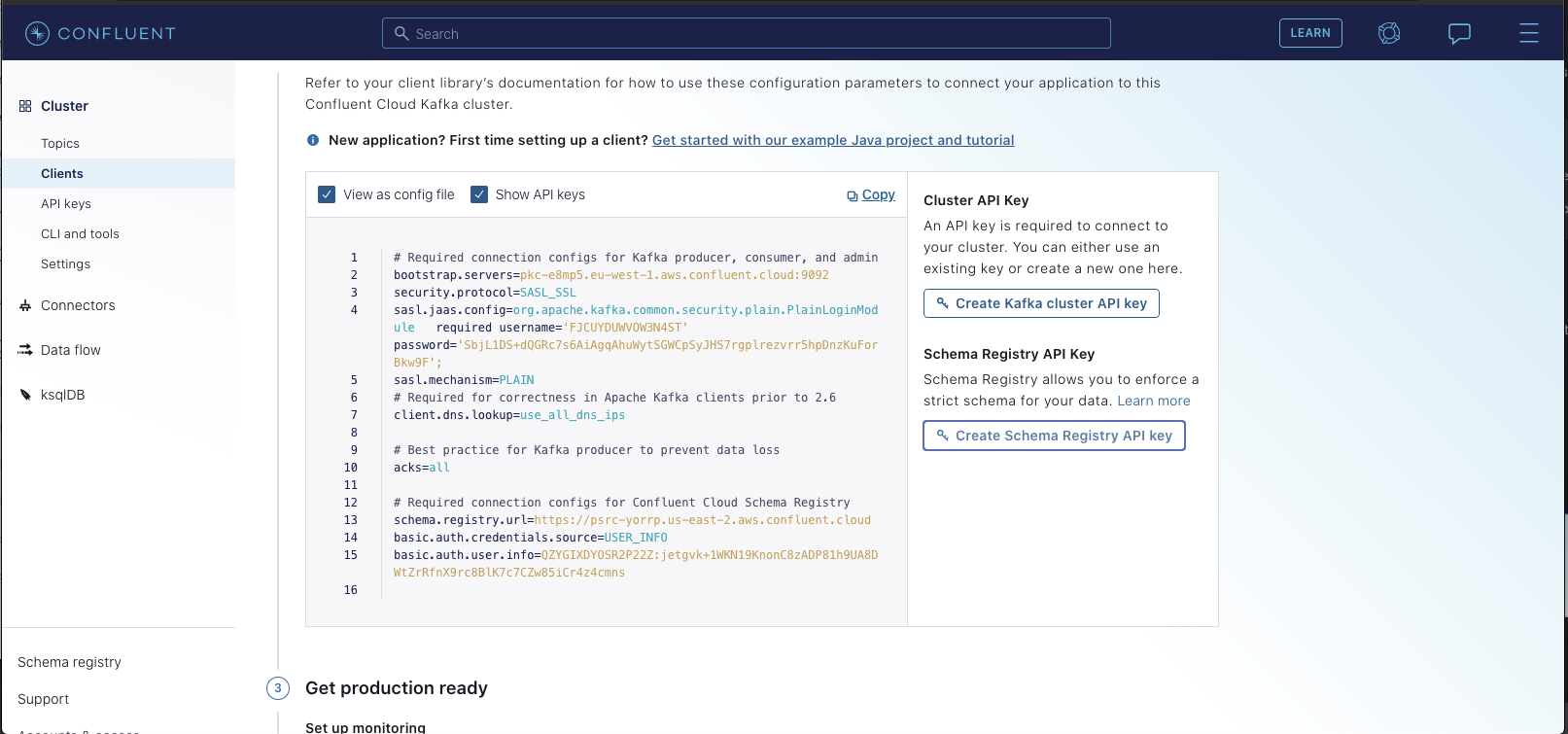 +
+
+ 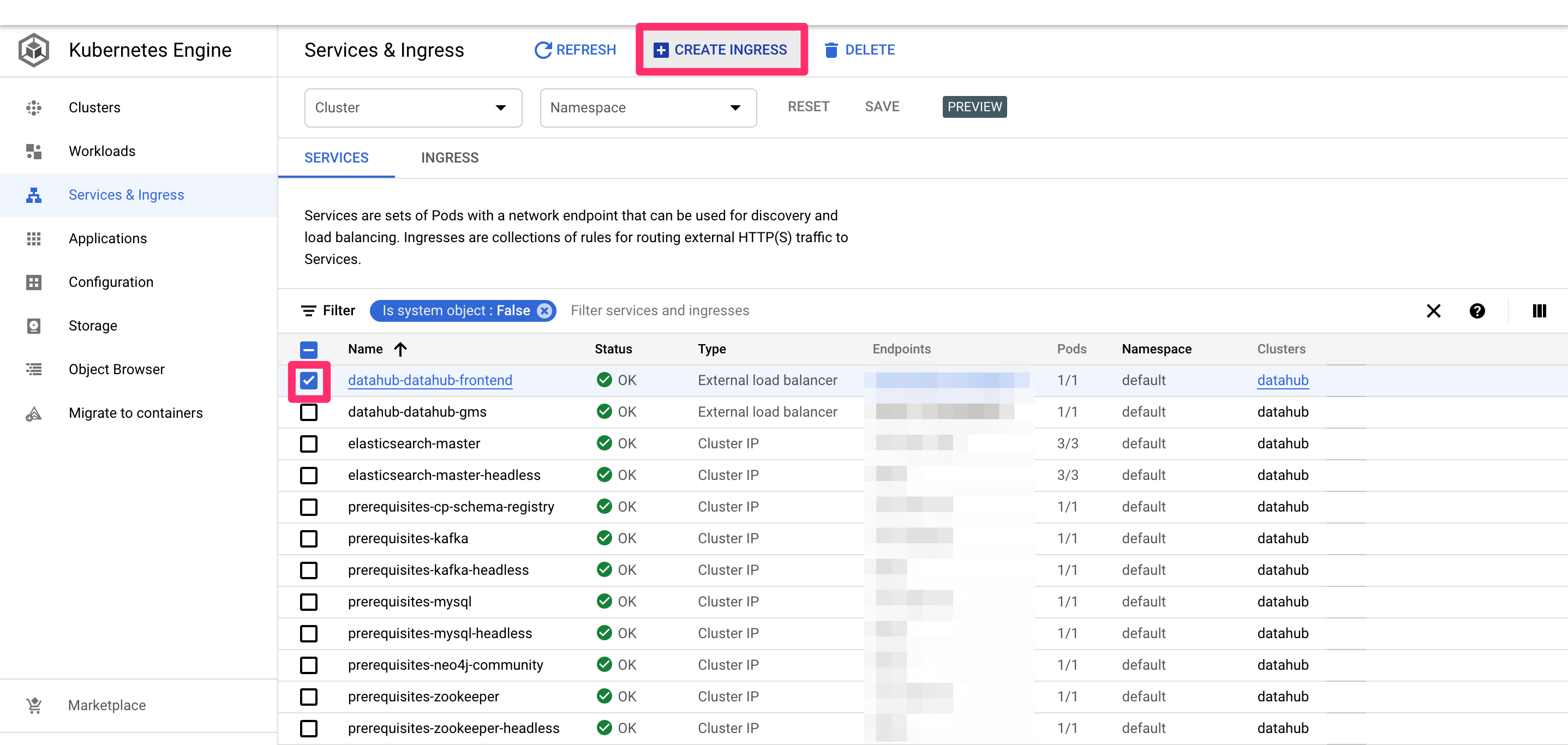 +
+
+ 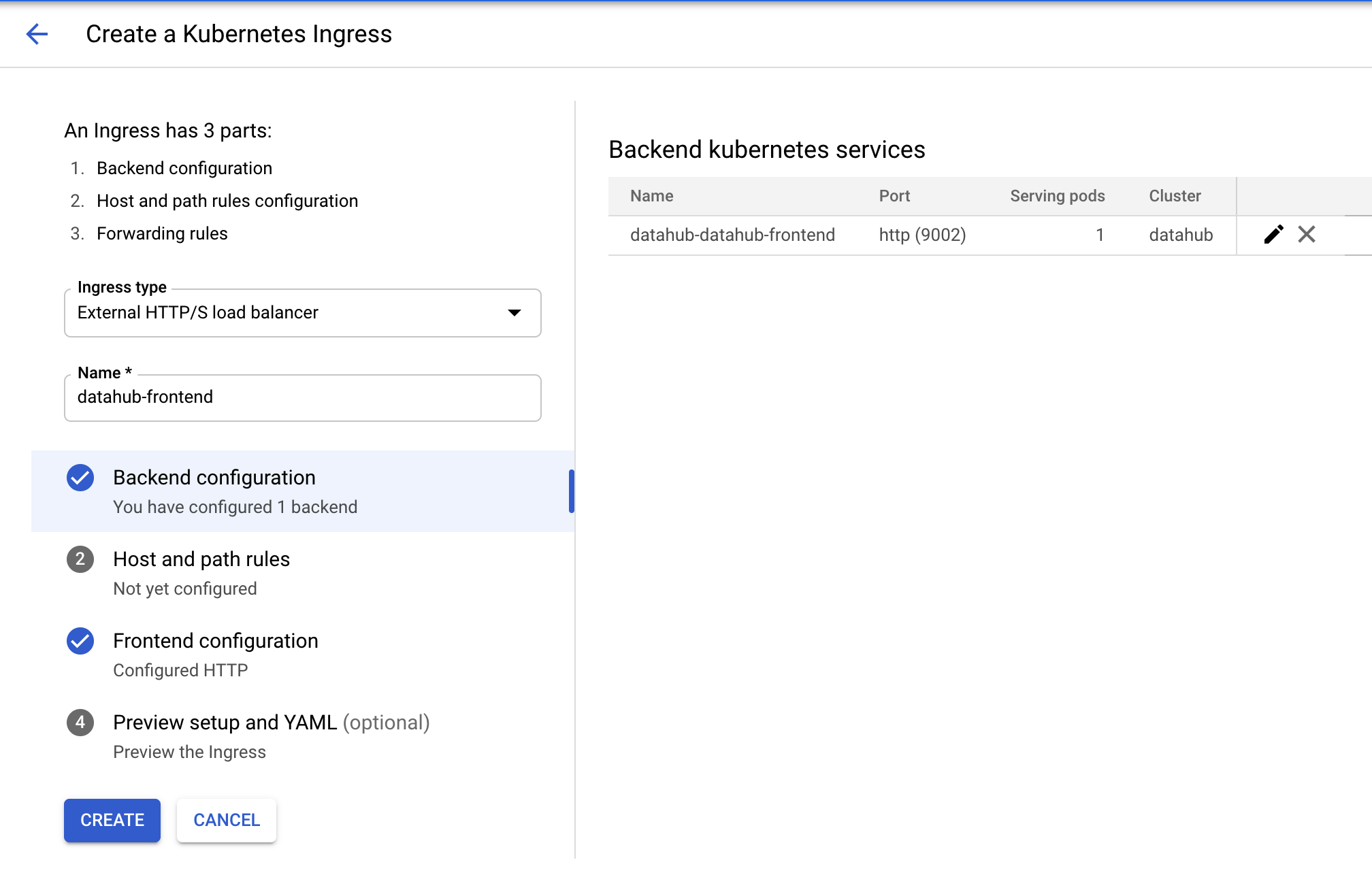 +
+
+ 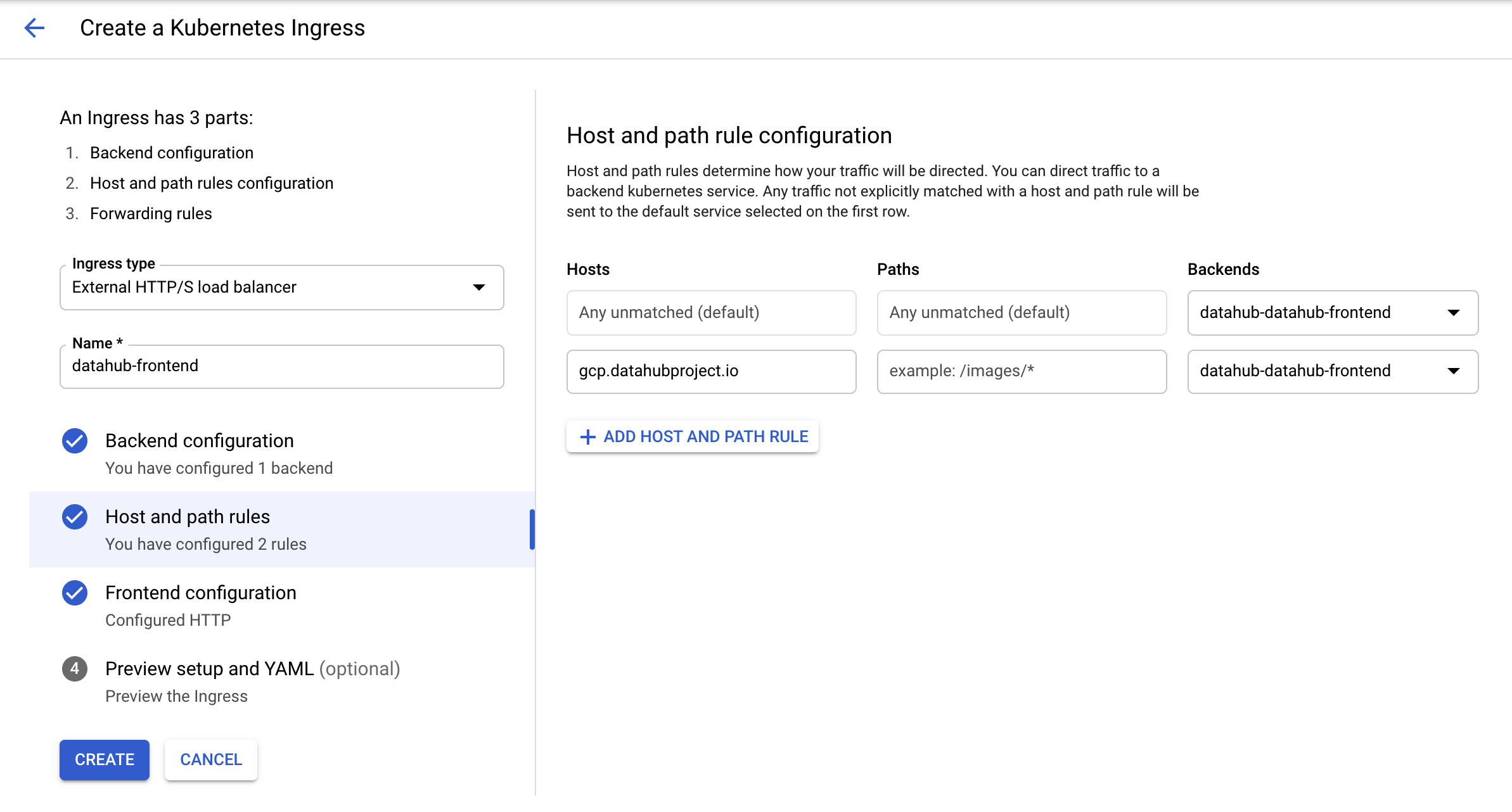 +
+
+ 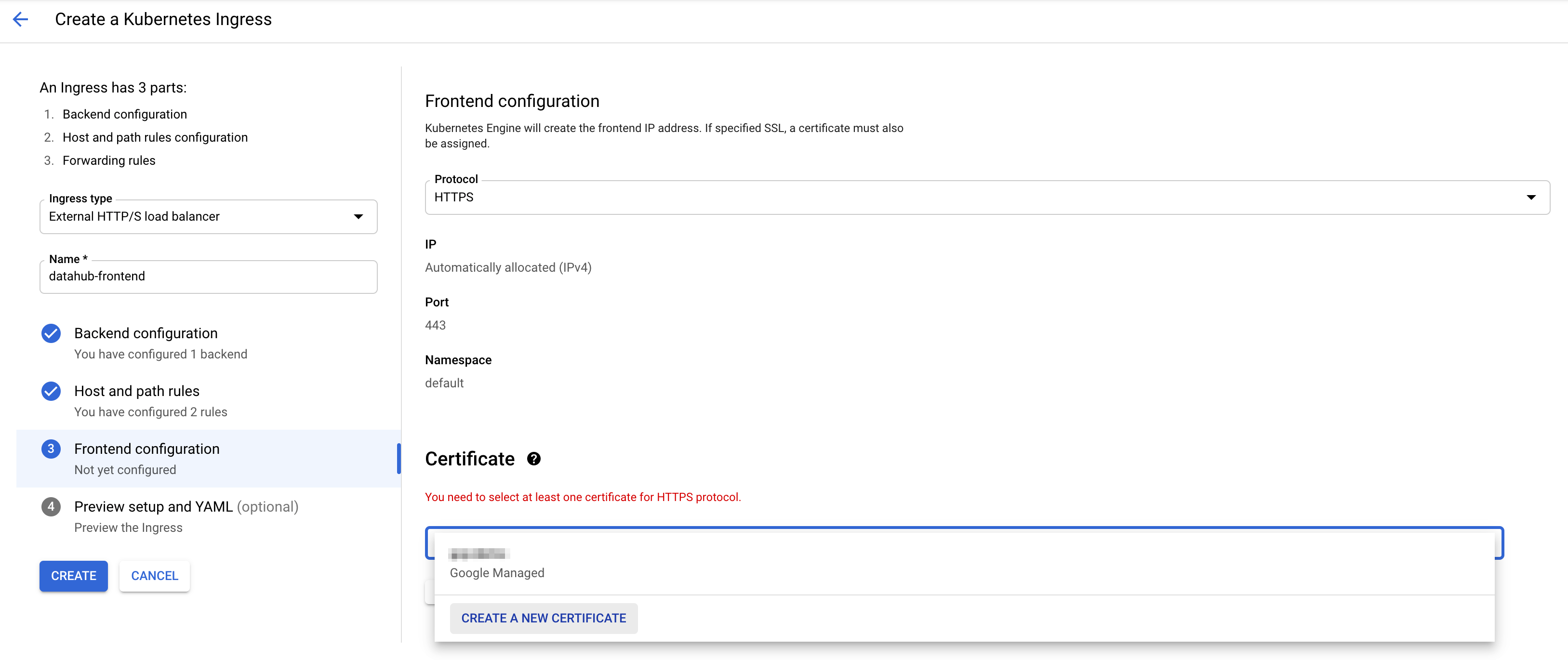 +
+
+ 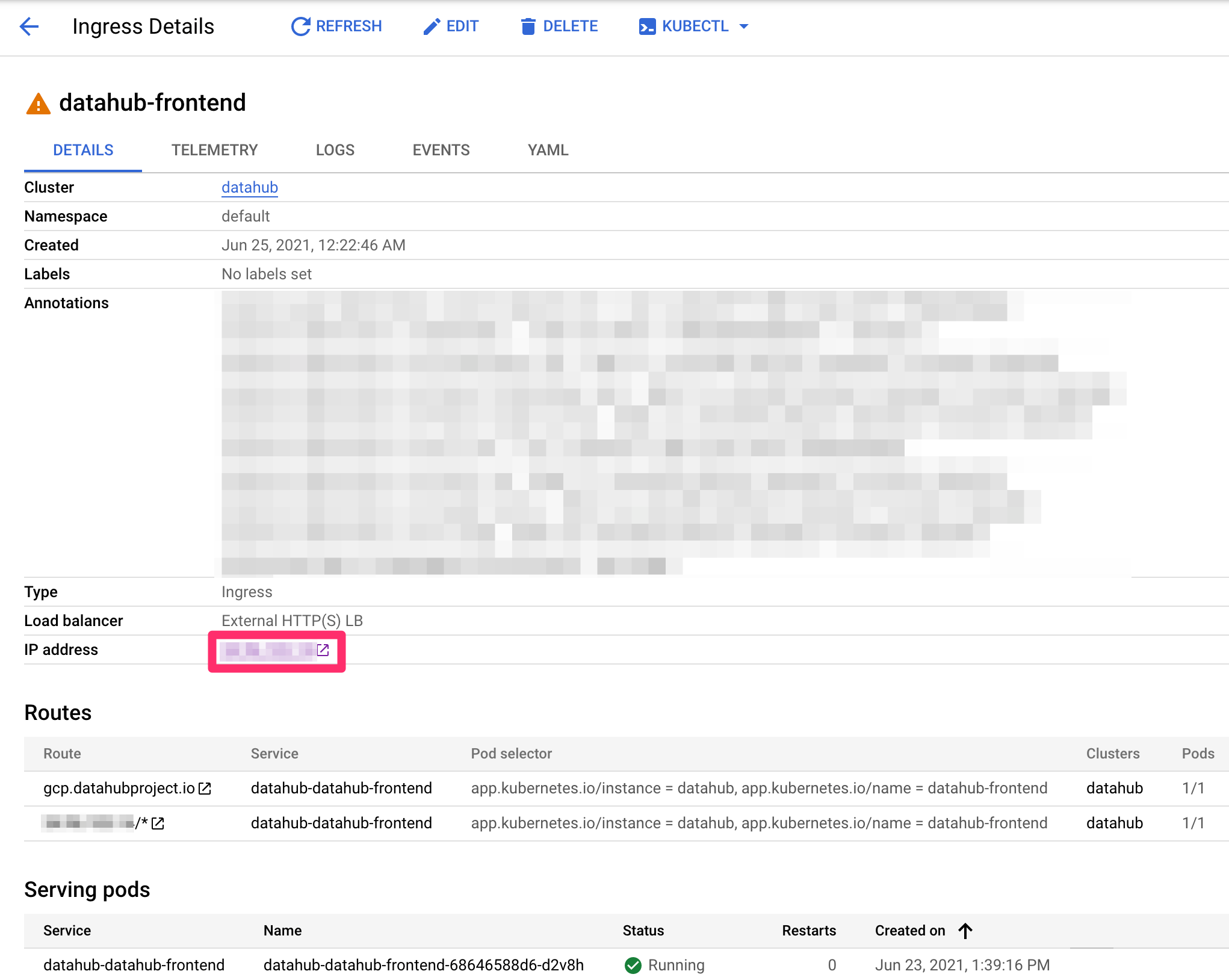 +
+
+  +
+
+ 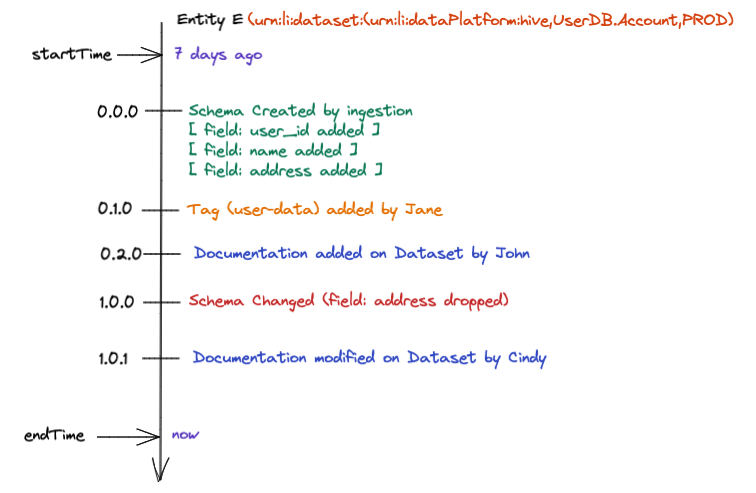 +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
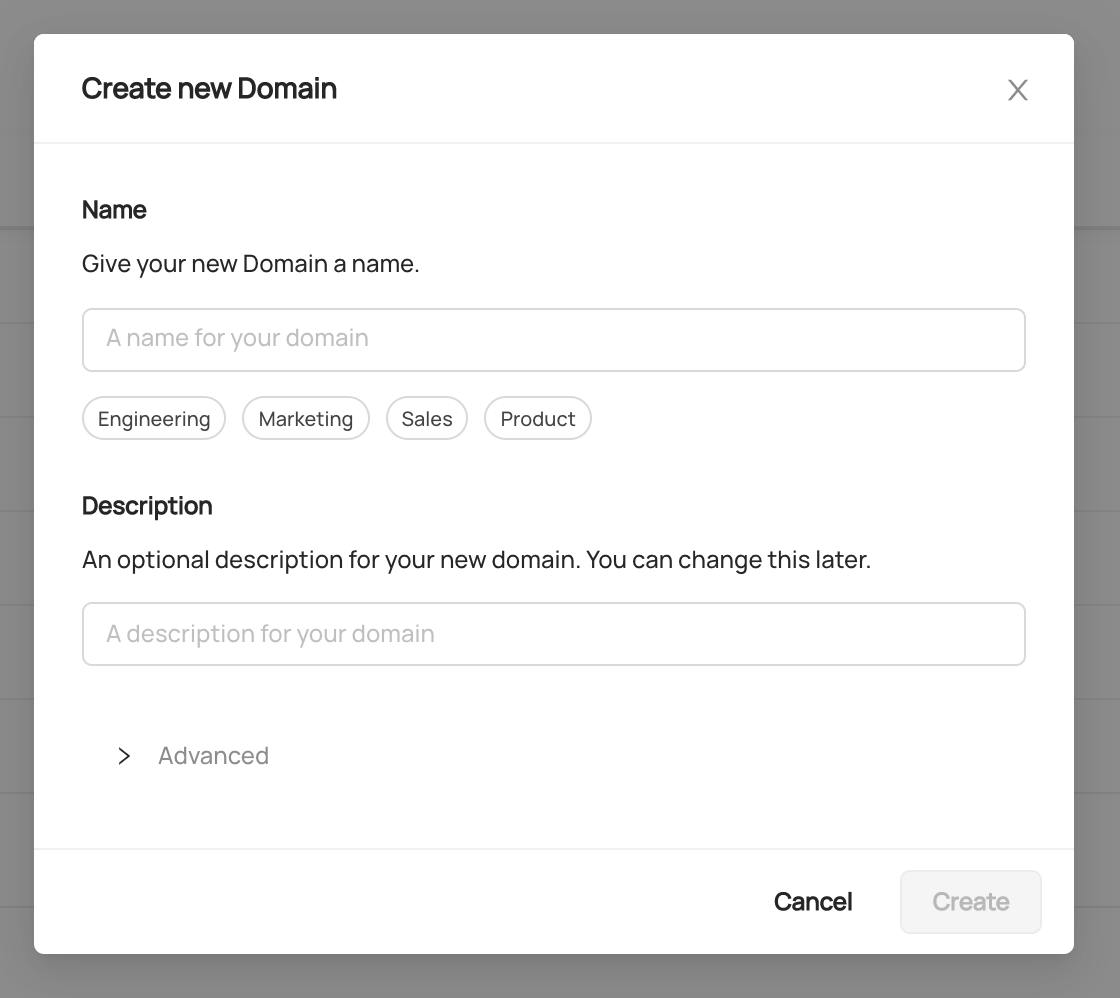
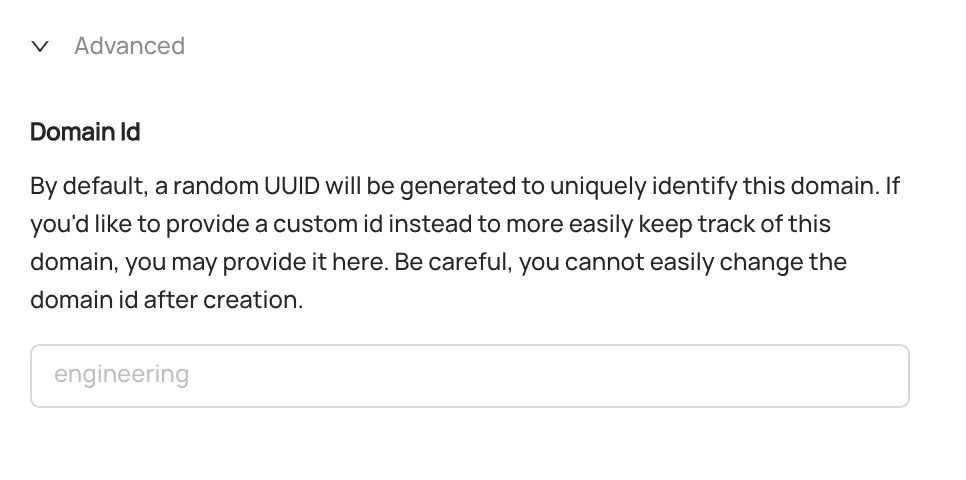
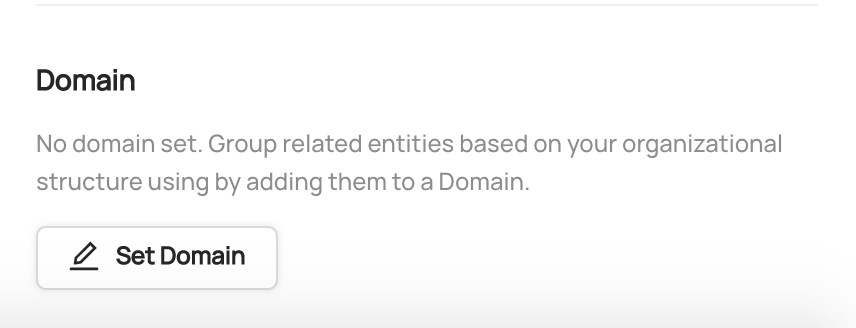
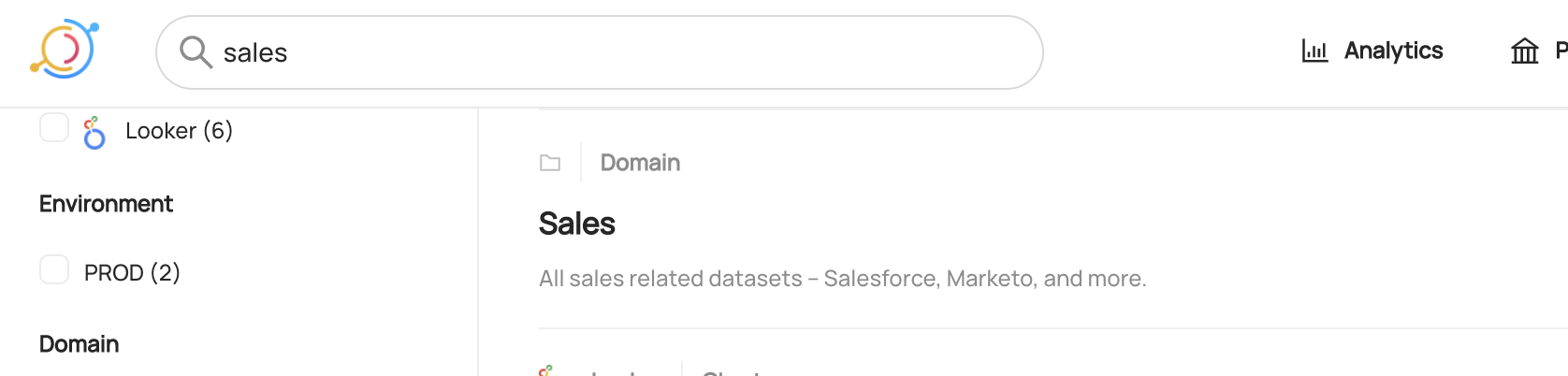
+ +
+ +### GraphQL + +- [domain](../graphql/queries.md#domain) +- [listDomains](../graphql/queries.md#listdomains) +- [createDomains](../graphql/mutations.md#createdomain) +- [setDomain](../graphql/mutations.md#setdomain) +- [unsetDomain](../graphql/mutations.md#unsetdomain) + +#### Examples + +**Creating a Domain** + +```graphql +mutation createDomain { + createDomain( + input: { name: "My New Domain", description: "An optional description" } + ) +} +``` + +This query will return an `urn` which you can use to fetch the Domain details. + +**Fetching a Domain by Urn** + +```graphql +query getDomain { + domain(urn: "urn:li:domain:engineering") { + urn + properties { + name + description + } + entities { + total + } + } +} +``` + +**Adding a Dataset to a Domain** + +```graphql +mutation setDomain { + setDomain( + entityUrn: "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)" + domainUrn: "urn:li:domain:engineering" + ) +} +``` + +> Pro Tip! You can try out the sample queries by visiting `
+  +
+
+  +
+
+  +
+
+  +
+
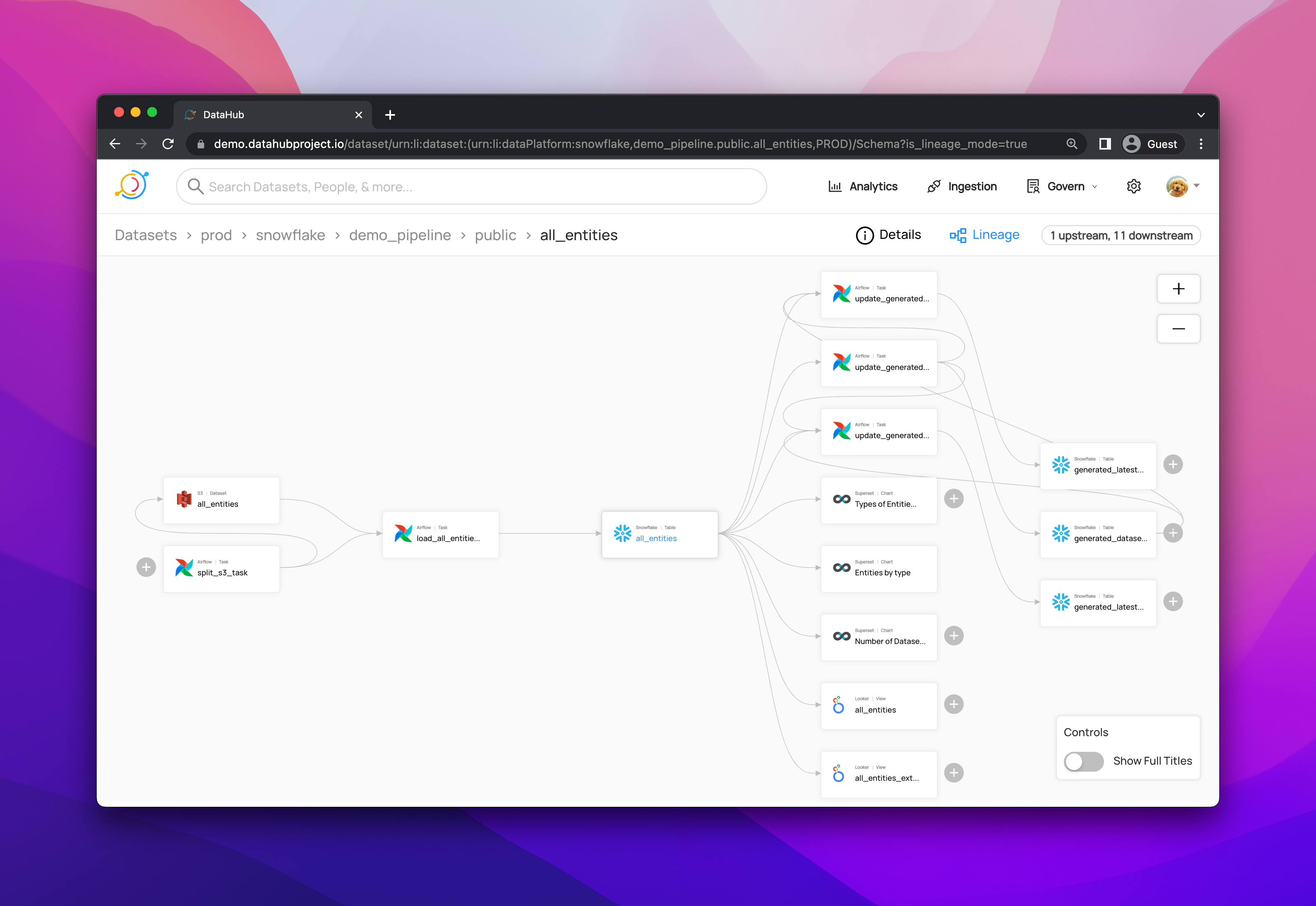
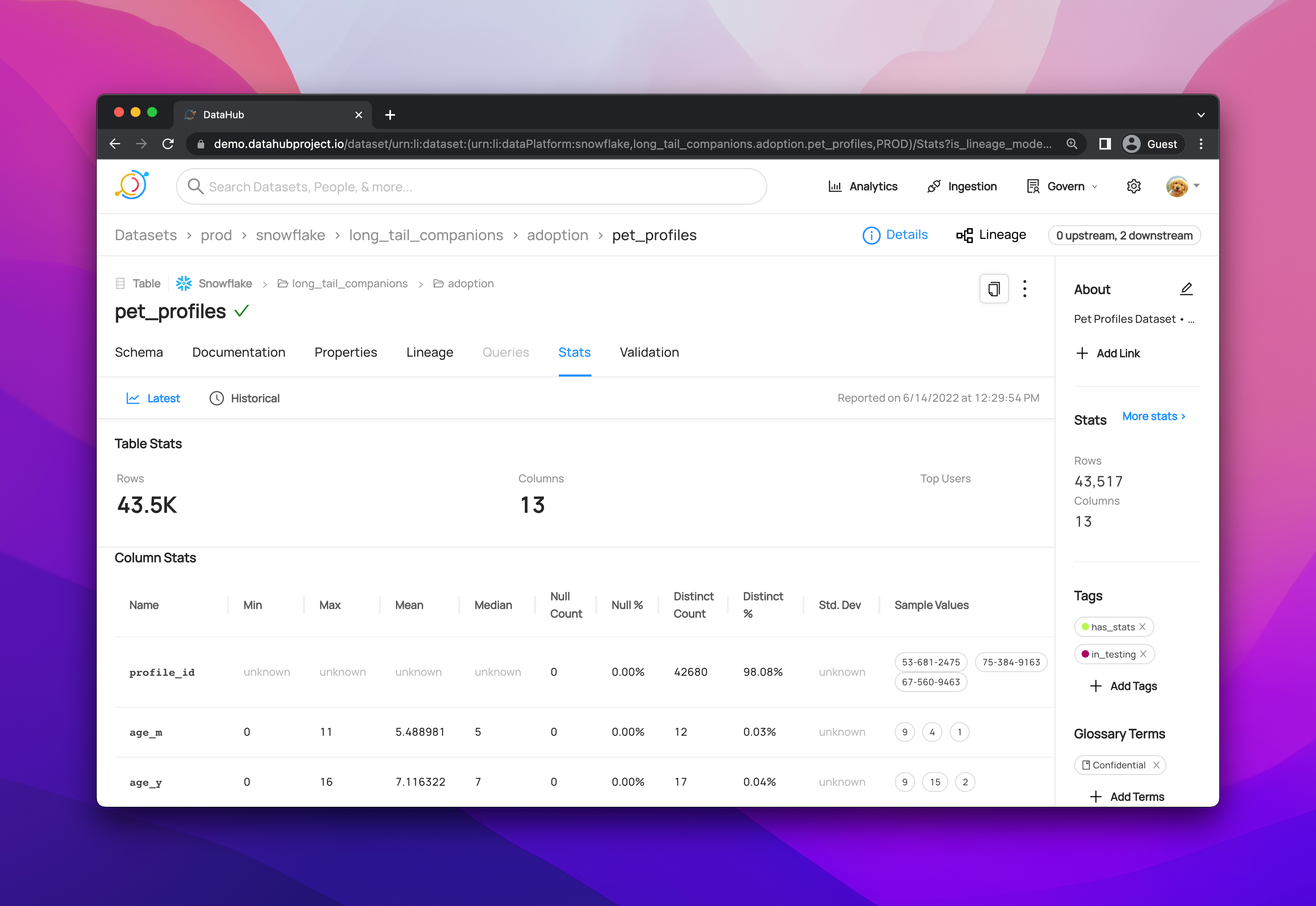
+ +
+ +Leverage DataHub's **Schema Version History** to track changes to the physical structure of data over time + ++ +
+ +--- + +## Modern Data Governance + +### **Govern in Real Time** + +[The Actions Framework](./actions/README.md) powers the following real-time use cases: + +- **Notifications:** Generate organization-specific notifications when a change is made on DataHub. For example, send an email to the governance team when a "PII" tag is added to any data asset. +- **Workflow Integration:** Integrate DataHub into your organization's internal workflows. For example, create a Jira ticket when specific Tags or Terms are proposed on a Dataset. +- **Synchronization:** Sync changes made in DataHub into a 3rd party system. For example, reflect Tag additions in DataHub into Snowflake. +- **Auditing:** Audit who is making what changes on DataHub through time. + ++ +
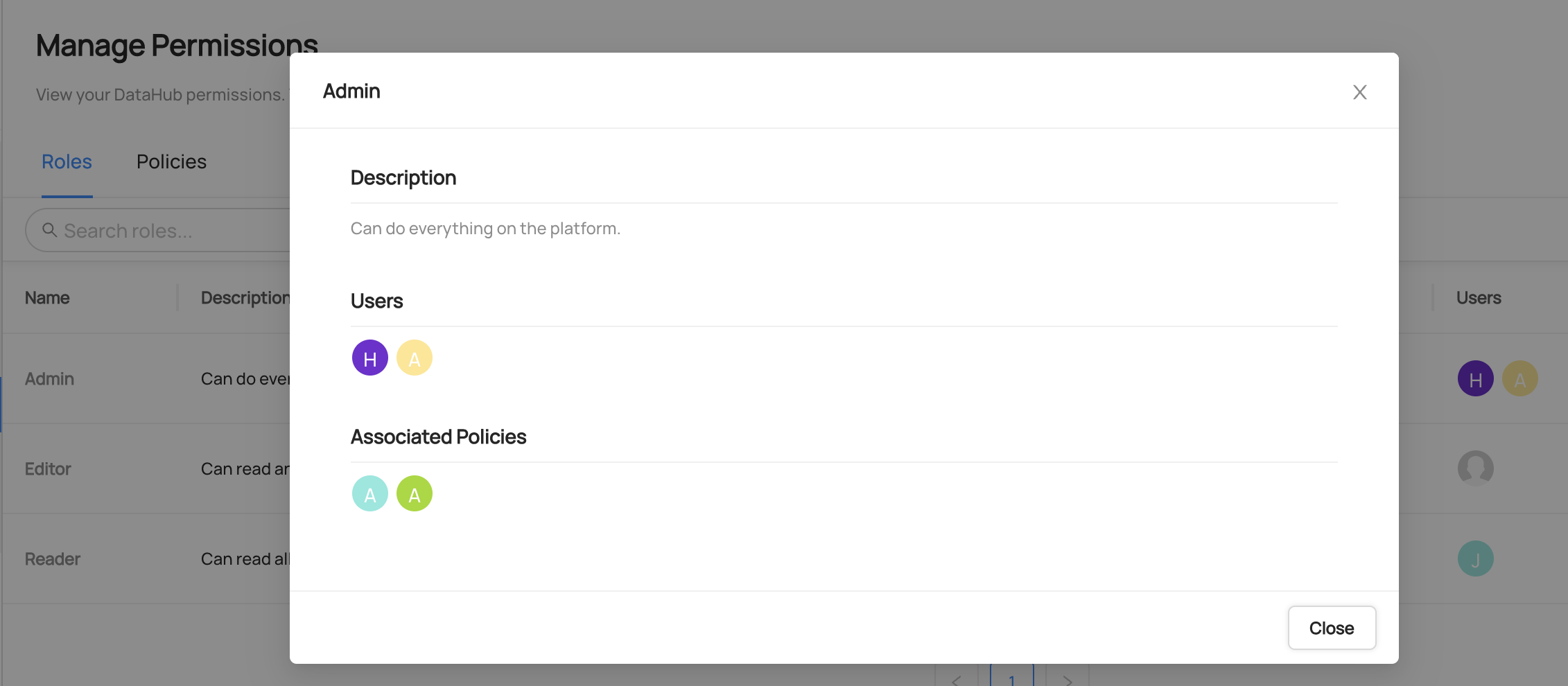
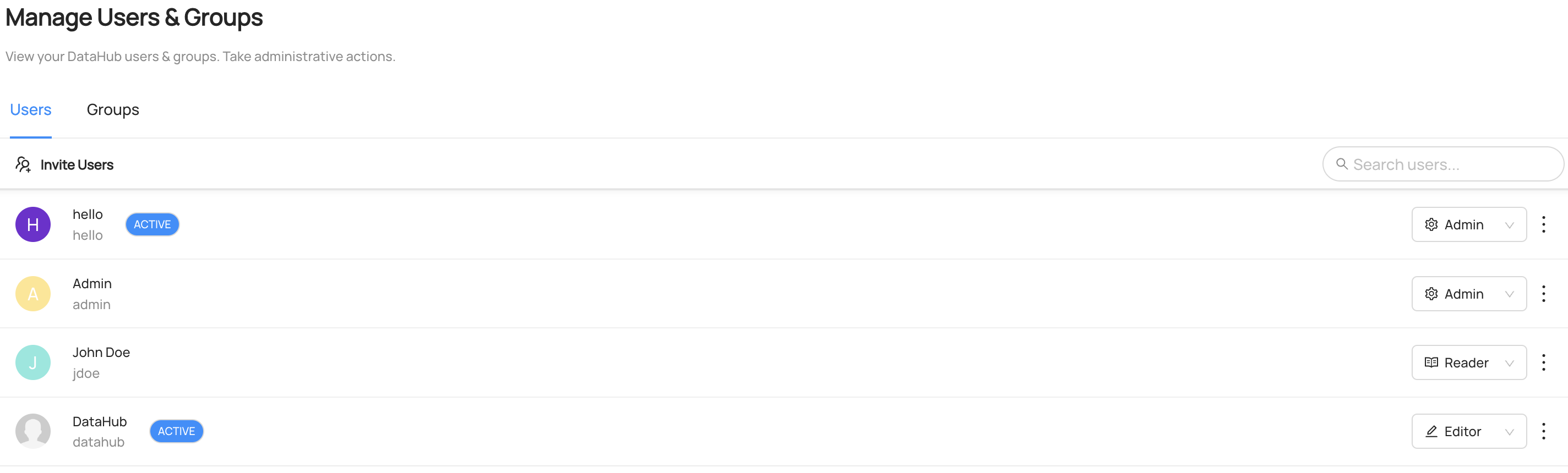
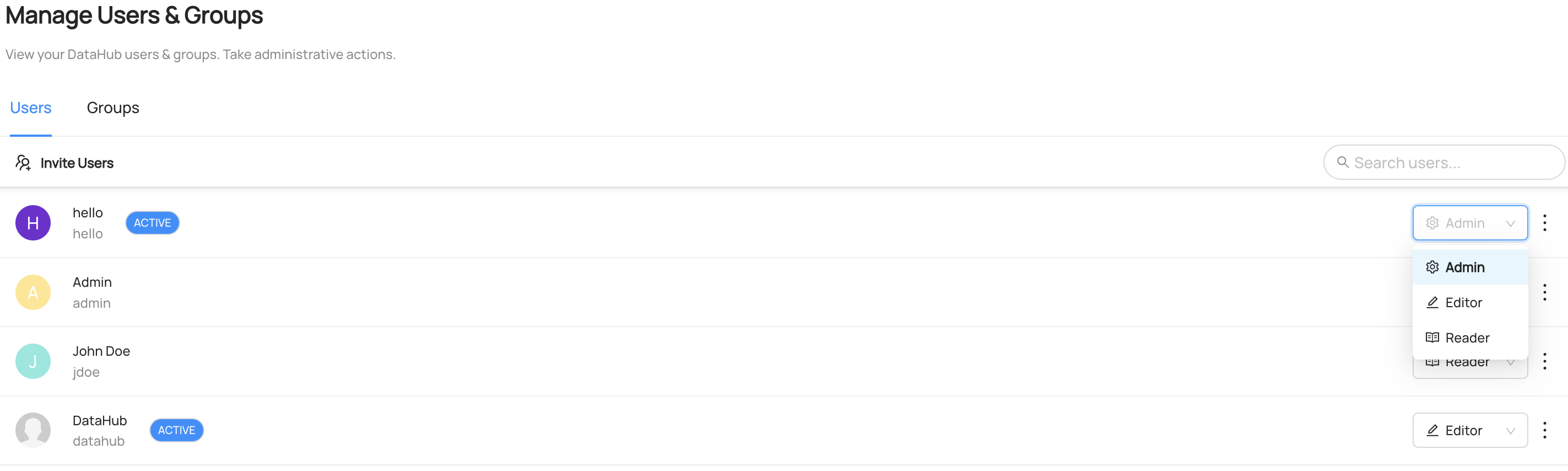
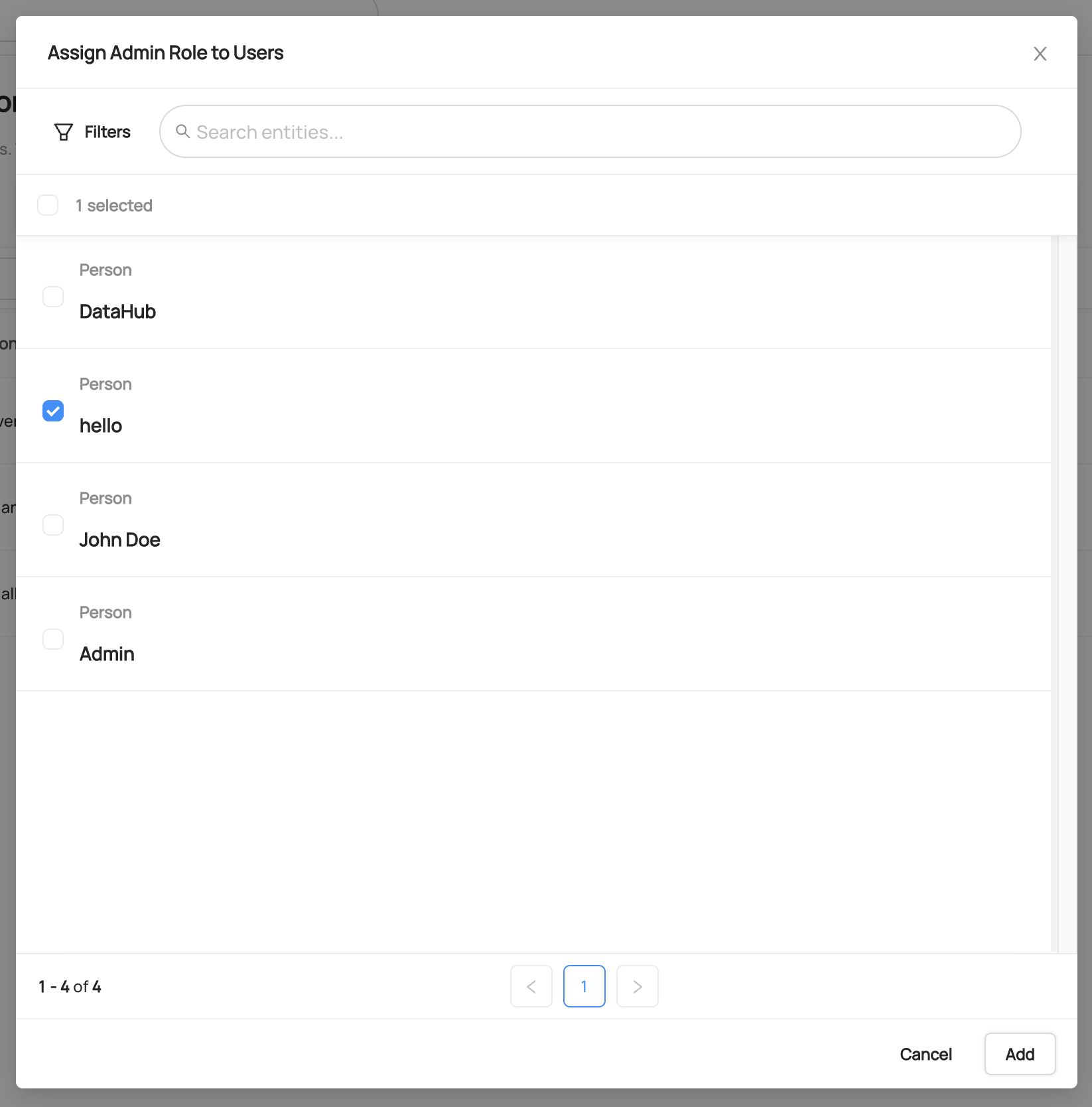
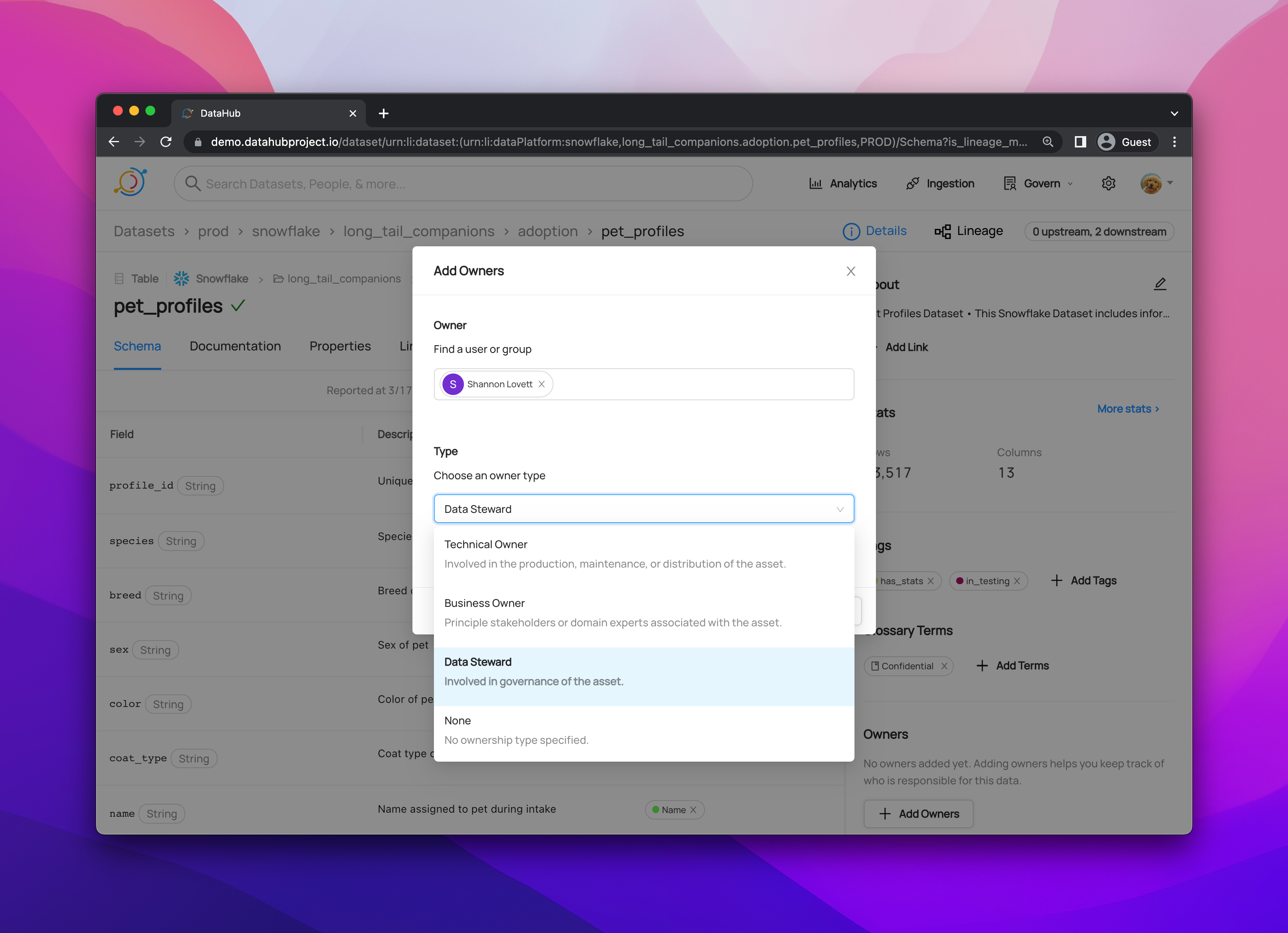
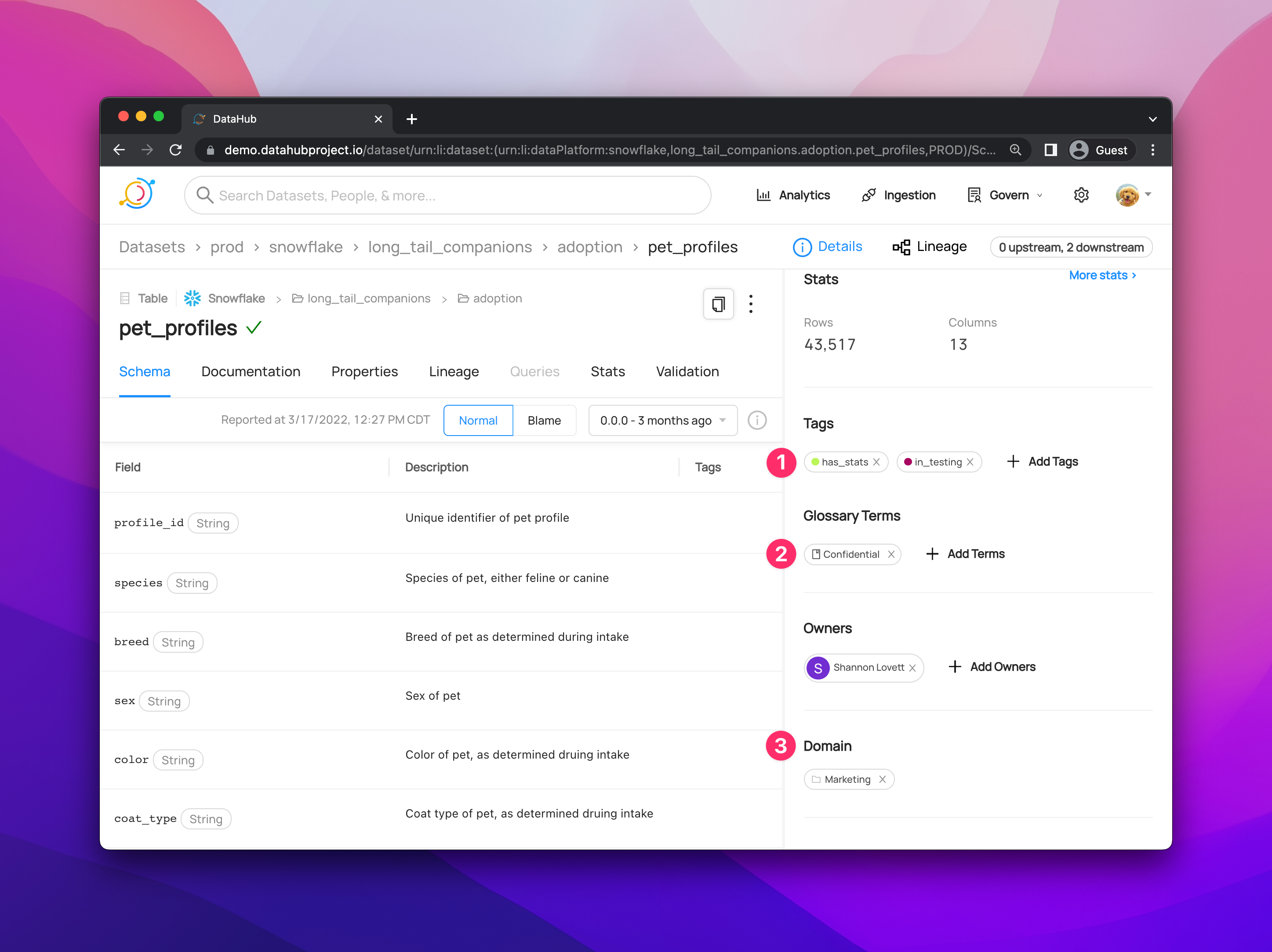
+ +### **Manage Entity Ownership** + +Quickly and easily assign entity ownership to users and user groups. + +
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+ +
+ +### GraphQL + +-
+  +
+
+  +
+
+  +
+
| Source Module | Documentation |
| + +`clickhouse` + + | ++ +This plugin extracts the following: + +- Metadata for tables, views, materialized views and dictionaries +- Column types associated with each table(except \*AggregateFunction and DateTime with timezone) +- Table, row, and column statistics via optional SQL profiling. +- Table, view, materialized view and dictionary(with CLICKHOUSE source_type) lineage + +:::tip + +You can also get fine-grained usage statistics for ClickHouse using the `clickhouse-usage` source described below. + +::: + +[Read more...](#module-clickhouse) + + | +
| + +`clickhouse-usage` + + | ++ +This plugin has the below functionalities - + +1. For a specific dataset this plugin ingests the following statistics - + 1. top n queries. + 2. top users. + 3. usage of each column in the dataset. +2. Aggregation of these statistics into buckets, by day or hour granularity. + +Usage information is computed by querying the system.query_log table. In case you have a cluster or need to apply additional transformation/filters you can create a view and put to the `query_log_table` setting. + +:::note + +This source only does usage statistics. To get the tables, views, and schemas in your ClickHouse warehouse, ingest using the `clickhouse` source described above. + +::: + +[Read more...](#module-clickhouse-usage) + + | +
+
+  +
+
+
+
| Source Module | Documentation |
| + +`dbt` + + | ++ +The artifacts used by this source are: + +- [dbt manifest file](https://docs.getdbt.com/reference/artifacts/manifest-json) + - This file contains model, source, tests and lineage data. +- [dbt catalog file](https://docs.getdbt.com/reference/artifacts/catalog-json) + - This file contains schema data. + - dbt does not record schema data for Ephemeral models, as such datahub will show Ephemeral models in the lineage, however there will be no associated schema for Ephemeral models +- [dbt sources file](https://docs.getdbt.com/reference/artifacts/sources-json) + - This file contains metadata for sources with freshness checks. + - We transfer dbt's freshness checks to DataHub's last-modified fields. + - Note that this file is optional – if not specified, we'll use time of ingestion instead as a proxy for time last-modified. +- [dbt run_results file](https://docs.getdbt.com/reference/artifacts/run-results-json) + - This file contains metadata from the result of a dbt run, e.g. dbt test + - When provided, we transfer dbt test run results into assertion run events to see a timeline of test runs on the dataset + [Read more...](#module-dbt) + + | +
| + +`dbt-cloud` + + | ++ +This source pulls dbt metadata directly from the dbt Cloud APIs. + +You'll need to have a dbt Cloud job set up to run your dbt project, and "Generate docs on run" should be enabled. + +The token should have the "read metadata" permission. + +To get the required IDs, go to the job details page (this is the one with the "Run History" table), and look at the URL. +It should look something like this: https://cloud.getdbt.com/next/deploy/107298/projects/175705/jobs/148094. +In this example, the account ID is 107298, the project ID is 175705, and the job ID is 148094. +[Read more...](#module-dbt-cloud) + + | +
| Source Module | Documentation |
| + +`looker` + + | ++ +This plugin extracts the following: + +- Looker dashboards, dashboard elements (charts) and explores +- Names, descriptions, URLs, chart types, input explores for the charts +- Schemas and input views for explores +- Owners of dashboards + +:::note +To get complete Looker metadata integration (including Looker views and lineage to the underlying warehouse tables), you must ALSO use the `lookml` module. +::: +[Read more...](#module-looker) + + | +
| + +`lookml` + + | ++ +This plugin extracts the following: + +- LookML views from model files in a project +- Name, upstream table names, metadata for dimensions, measures, and dimension groups attached as tags +- If API integration is enabled (recommended), resolves table and view names by calling the Looker API, otherwise supports offline resolution of these names. + +:::note +To get complete Looker metadata integration (including Looker dashboards and charts and lineage to the underlying Looker views, you must ALSO use the `looker` source module. +::: +[Read more...](#module-lookml) + + | +
+  +
+
| Source Module | Documentation |
| + +`powerbi` + + | ++ +This plugin extracts the following: + +- Power BI dashboards, tiles and datasets +- Names, descriptions and URLs of dashboard and tile +- Owners of dashboards + [Read more...](#module-powerbi) + + | +
| + +`powerbi-report-server` + + | ++ +Use this plugin to connect to [PowerBI Report Server](https://powerbi.microsoft.com/en-us/report-server/). +It extracts the following: + +Metadata that can be ingested: + +- report name +- report description +- ownership(can add existing users in DataHub as owners) +- transfer folders structure to DataHub as it is in Report Server +- webUrl to report in Report Server + +Due to limits of PBIRS REST API, it's impossible to ingest next data for now: + +- tiles info +- datasource of report +- dataset of report + +Next types of report can be ingested: + +- PowerBI report(.pbix) +- Paginated report(.rdl) +- Linked report + [Read more...](#module-powerbi-report-server) + + | +
| Source Module | Documentation |
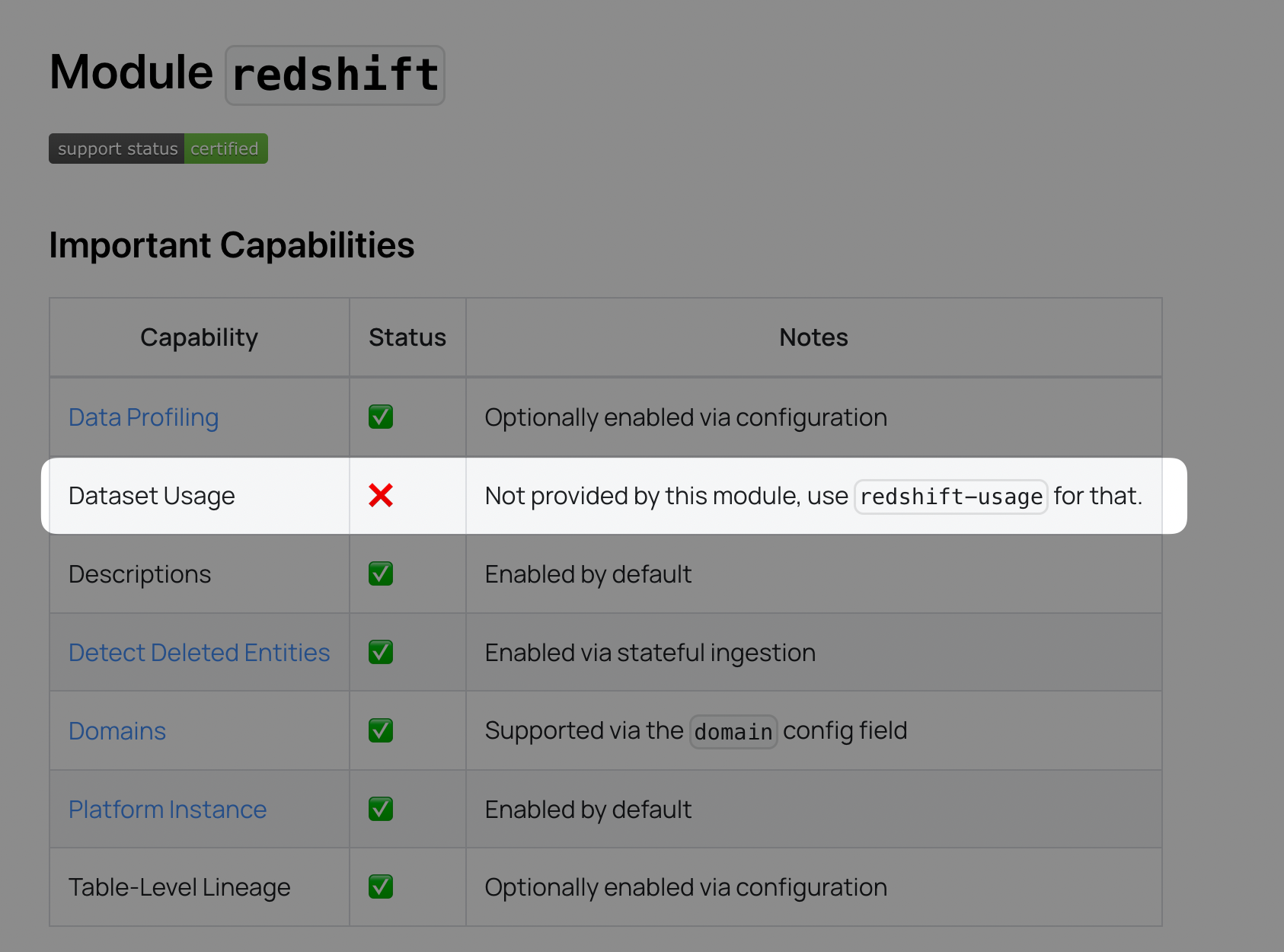
| + +`redshift` + + | ++ +This plugin extracts the following: + +- Metadata for databases, schemas, views and tables +- Column types associated with each table +- Table, row, and column statistics via optional SQL profiling +- Table lineage +- Usage statistics + +### Prerequisites + +This source needs to access system tables that require extra permissions. +To grant these permissions, please alter your datahub Redshift user the following way: + +```sql +ALTER USER datahub_user WITH SYSLOG ACCESS UNRESTRICTED; +GRANT SELECT ON pg_catalog.svv_table_info to datahub_user; +GRANT SELECT ON pg_catalog.svl_user_info to datahub_user; +``` + +:::note + +Giving a user unrestricted access to system tables gives the user visibility to data generated by other users. For example, STL_QUERY and STL_QUERYTEXT contain the full text of INSERT, UPDATE, and DELETE statements. + +::: + +### Lineage + +There are multiple lineage collector implementations as Redshift does not support table lineage out of the box. + +#### stl_scan_based + +The stl_scan based collector uses Redshift's [stl_insert](https://docs.aws.amazon.com/redshift/latest/dg/r_STL_INSERT.html) and [stl_scan](https://docs.aws.amazon.com/redshift/latest/dg/r_STL_SCAN.html) system tables to +discover lineage between tables. +Pros: + +- Fast +- Reliable + +Cons: + +- Does not work with Spectrum/external tables because those scans do not show up in stl_scan table. +- If a table is depending on a view then the view won't be listed as dependency. Instead the table will be connected with the view's dependencies. + +#### sql_based + +The sql_based based collector uses Redshift's [stl_insert](https://docs.aws.amazon.com/redshift/latest/dg/r_STL_INSERT.html) to discover all the insert queries +and uses sql parsing to discover the dependecies. + +Pros: + +- Works with Spectrum tables +- Views are connected properly if a table depends on it + +Cons: + +- Slow. +- Less reliable as the query parser can fail on certain queries + +#### mixed + +Using both collector above and first applying the sql based and then the stl_scan based one. + +Pros: + +- Works with Spectrum tables +- Views are connected properly if a table depends on it +- A bit more reliable than the sql_based one only + +Cons: + +- Slow +- May be incorrect at times as the query parser can fail on certain queries + +:::note + +The redshift stl redshift tables which are used for getting data lineage only retain approximately two to five days of log history. This means you cannot extract lineage from queries issued outside that window. + +::: + +### Profiling + +Profiling runs sql queries on the redshift cluster to get statistics about the tables. To be able to do that, the user needs to have read access to the tables that should be profiled. + +If you don't want to grant read access to the tables you can enable table level profiling which will get table statistics without reading the data. + +```yaml +profiling: + profile_table_level_only: true +``` + +[Read more...](#module-redshift) + + | +
| + +`redshift-legacy` + + | ++ +This plugin extracts the following: + +- Metadata for databases, schemas, views and tables +- Column types associated with each table +- Also supports PostGIS extensions +- Table, row, and column statistics via optional SQL profiling +- Table lineage + +:::tip + +You can also get fine-grained usage statistics for Redshift using the `redshift-usage` source described below. + +::: + +### Prerequisites + +This source needs to access system tables that require extra permissions. +To grant these permissions, please alter your datahub Redshift user the following way: + +```sql +ALTER USER datahub_user WITH SYSLOG ACCESS UNRESTRICTED; +GRANT SELECT ON pg_catalog.svv_table_info to datahub_user; +GRANT SELECT ON pg_catalog.svl_user_info to datahub_user; +``` + +:::note + +Giving a user unrestricted access to system tables gives the user visibility to data generated by other users. For example, STL_QUERY and STL_QUERYTEXT contain the full text of INSERT, UPDATE, and DELETE statements. + +::: + +### Lineage + +There are multiple lineage collector implementations as Redshift does not support table lineage out of the box. + +#### stl_scan_based + +The stl_scan based collector uses Redshift's [stl_insert](https://docs.aws.amazon.com/redshift/latest/dg/r_STL_INSERT.html) and [stl_scan](https://docs.aws.amazon.com/redshift/latest/dg/r_STL_SCAN.html) system tables to +discover lineage between tables. +Pros: + +- Fast +- Reliable + +Cons: + +- Does not work with Spectrum/external tables because those scans do not show up in stl_scan table. +- If a table is depending on a view then the view won't be listed as dependency. Instead the table will be connected with the view's dependencies. + +#### sql_based + +The sql_based based collector uses Redshift's [stl_insert](https://docs.aws.amazon.com/redshift/latest/dg/r_STL_INSERT.html) to discover all the insert queries +and uses sql parsing to discover the dependecies. + +Pros: + +- Works with Spectrum tables +- Views are connected properly if a table depends on it + +Cons: + +- Slow. +- Less reliable as the query parser can fail on certain queries + +#### mixed + +Using both collector above and first applying the sql based and then the stl_scan based one. + +Pros: + +- Works with Spectrum tables +- Views are connected properly if a table depends on it +- A bit more reliable than the sql_based one only + +Cons: + +- Slow +- May be incorrect at times as the query parser can fail on certain queries + +:::note + +The redshift stl redshift tables which are used for getting data lineage only retain approximately two to five days of log history. This means you cannot extract lineage from queries issued outside that window. + +::: + +[Read more...](#module-redshift-legacy) + + | +
| + +`redshift-usage-legacy` + + | ++ +This plugin extracts usage statistics for datasets in Amazon Redshift. + +Note: Usage information is computed by querying the following system tables - + +1. stl_scan +2. svv_table_info +3. stl_query +4. svl_user_info + +To grant access this plugin for all system tables, please alter your datahub Redshift user the following way: + +```sql +ALTER USER datahub_user WITH SYSLOG ACCESS UNRESTRICTED; +``` + +This plugin has the below functionalities - + +1. For a specific dataset this plugin ingests the following statistics - + 1. top n queries. + 2. top users. +2. Aggregation of these statistics into buckets, by day or hour granularity. + +:::note + +This source only does usage statistics. To get the tables, views, and schemas in your Redshift warehouse, ingest using the `redshift` source described above. + +::: + +:::note + +Redshift system tables have some latency in getting data from queries. In addition, these tables only maintain logs for 2-5 days. You can find more information from the official documentation [here](https://aws.amazon.com/premiumsupport/knowledge-center/logs-redshift-database-cluster/). + +::: + +[Read more...](#module-redshift-usage-legacy) + + | +
| Source Module | Documentation |
| + +`trino` + + | ++ +This plugin extracts the following: + +- Metadata for databases, schemas, and tables +- Column types and schema associated with each table +- Table, row, and column statistics via optional SQL profiling + +[Read more...](#module-trino) + + | +
| + +`starburst-trino-usage` + + | ++ +If you are using Starburst Trino you can collect usage stats the following way. + +#### Prerequsities + +1. You need to setup Event Logger which saves audit logs into a Postgres db and setup this db as a catalog in Trino + Here you can find more info about how to setup: + https://docs.starburst.io/354-e/security/event-logger.html#security-event-logger--page-root + https://docs.starburst.io/354-e/security/event-logger.html#analyzing-the-event-log + +2. Install starbust-trino-usage plugin + Run pip install 'acryl-datahub[starburst-trino-usage]'. + +[Read more...](#module-starburst-trino-usage) + + | +
 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+