diff --git a/README.md b/README.md
index f0314c0ed90e1..3b381ebc8dc89 100644
--- a/README.md
+++ b/README.md
@@ -80,7 +80,9 @@ Please follow the [DataHub Quickstart Guide](https://datahubproject.io/docs/quic
If you're looking to build & modify datahub please take a look at our [Development Guide](https://datahubproject.io/docs/developers).
-[](https://demo.datahubproject.io/)
+
+
+
## Source Code and Repositories
diff --git a/docker/airflow/local_airflow.md b/docker/airflow/local_airflow.md
index d0a2b18cff2d2..cbd93660468f0 100644
--- a/docker/airflow/local_airflow.md
+++ b/docker/airflow/local_airflow.md
@@ -138,25 +138,41 @@ Successfully added `conn_id`=datahub_rest_default : datahub_rest://:@http://data
Navigate the Airflow UI to find the sample Airflow dag we just brought in
-
+
+
+
By default, Airflow loads all DAG-s in paused status. Unpause the sample DAG to use it.
-
-
+
+
+
+
+
+
Then trigger the DAG to run.
-
+
+
+
After the DAG runs successfully, go over to your DataHub instance to see the Pipeline and navigate its lineage.
-
+
## TroubleShooting
@@ -164,9 +180,13 @@ Most issues are related to connectivity between Airflow and DataHub.
Here is how you can debug them.
-
+
+
+
-
+
+
+
In this case, clearly the connection `datahub-rest` has not been registered. Looks like we forgot to register the connection with Airflow!
Let's execute Step 4 to register the datahub connection with Airflow.
@@ -175,4 +195,6 @@ In case the connection was registered successfully but you are still seeing `Fai
After re-running the DAG, we see success!
-
+
+
+
diff --git a/docs/advanced/no-code-modeling.md b/docs/advanced/no-code-modeling.md
index e1fadee6d371a..ceb51511ad678 100644
--- a/docs/advanced/no-code-modeling.md
+++ b/docs/advanced/no-code-modeling.md
@@ -1,47 +1,46 @@
-# No Code Metadata
+# No Code Metadata
## Summary of changes
-As part of the No Code Metadata Modeling initiative, we've made radical changes to the DataHub stack.
+As part of the No Code Metadata Modeling initiative, we've made radical changes to the DataHub stack.
-Specifically, we've
+Specifically, we've
-- Decoupled the persistence layer from Java + Rest.li specific concepts
+- Decoupled the persistence layer from Java + Rest.li specific concepts
- Consolidated the per-entity Rest.li resources into a single general-purpose Entity Resource
-- Consolidated the per-entity Graph Index Writers + Readers into a single general-purpose Neo4J DAO
-- Consolidated the per-entity Search Index Writers + Readers into a single general-purpose ES DAO.
+- Consolidated the per-entity Graph Index Writers + Readers into a single general-purpose Neo4J DAO
+- Consolidated the per-entity Search Index Writers + Readers into a single general-purpose ES DAO.
- Developed mechanisms for declaring search indexing configurations + foreign key relationships as annotations
-on PDL models themselves.
-- Introduced a special "Browse Paths" aspect that allows the browse configuration to be
-pushed into DataHub, as opposed to computed in a blackbox lambda sitting within DataHub
+ on PDL models themselves.
+- Introduced a special "Browse Paths" aspect that allows the browse configuration to be
+ pushed into DataHub, as opposed to computed in a blackbox lambda sitting within DataHub
- Introduced special "Key" aspects for conveniently representing the information that identifies a DataHub entities via
-a normal struct.
+ a normal struct.
- Removed the need for hand-written Elastic `settings.json` and `mappings.json`. (Now generated at runtime)
- Removed the need for the Elastic Set Up container (indexes are not registered at runtime)
- Simplified the number of models that need to be maintained for each DataHub entity. We removed the need for
- 1. Relationship Models
- 2. Entity Models
- 3. Urn models + the associated Java container classes
- 4. 'Value' models, those which are returned by the Rest.li resource
+ 1. Relationship Models
+ 2. Entity Models
+ 3. Urn models + the associated Java container classes
+ 4. 'Value' models, those which are returned by the Rest.li resource
In doing so, dramatically reducing the level of effort required to add or extend an existing entity.
For more on the design considerations, see the **Design** section below.
-
## Engineering Spec
This section will provide a more in-depth overview of the design considerations that were at play when working on the No
-Code initiative.
+Code initiative.
# Use Cases
Who needs what & why?
-| As a | I want to | because
-| ---------------- | ------------------------ | ------------------------------
-| DataHub Operator | Add new entities | The default domain model does not match my business needs
-| DataHub Operator | Extend existing entities | The default domain model does not match my business needs
+| As a | I want to | because |
+| ---------------- | ------------------------ | --------------------------------------------------------- |
+| DataHub Operator | Add new entities | The default domain model does not match my business needs |
+| DataHub Operator | Extend existing entities | The default domain model does not match my business needs |
What we heard from folks in the community is that adding new entities + aspects is just **too difficult**.
@@ -62,15 +61,19 @@ Achieve the primary goal in a way that does not require a fork.
### Must-Haves
1. Mechanisms for **adding** a browsable, searchable, linkable GMS entity by defining one or more PDL models
- - GMS Endpoint for fetching entity
- - GMS Endpoint for fetching entity relationships
- - GMS Endpoint for searching entity
- - GMS Endpoint for browsing entity
-2. Mechanisms for **extending** a ****browsable, searchable, linkable GMS ****entity by defining one or more PDL models
- - GMS Endpoint for fetching entity
- - GMS Endpoint for fetching entity relationships
- - GMS Endpoint for searching entity
- - GMS Endpoint for browsing entity
+
+- GMS Endpoint for fetching entity
+- GMS Endpoint for fetching entity relationships
+- GMS Endpoint for searching entity
+- GMS Endpoint for browsing entity
+
+2. Mechanisms for **extending** a \***\*browsable, searchable, linkable GMS \*\***entity by defining one or more PDL models
+
+- GMS Endpoint for fetching entity
+- GMS Endpoint for fetching entity relationships
+- GMS Endpoint for searching entity
+- GMS Endpoint for browsing entity
+
3. Mechanisms + conventions for introducing a new **relationship** between 2 GMS entities without writing code
4. Clear documentation describing how to perform actions in #1, #2, and #3 above published on [datahubproject.io](http://datahubproject.io)
@@ -78,8 +81,9 @@ Achieve the primary goal in a way that does not require a fork.
1. Mechanisms for automatically generating a working GraphQL API using the entity PDL models
2. Ability to add / extend GMS entities without a fork.
- - e.g. **Register** new entity / extensions *at runtime*. (Unlikely due to code generation)
- - or, **configure** new entities at *deploy time*
+
+- e.g. **Register** new entity / extensions _at runtime_. (Unlikely due to code generation)
+- or, **configure** new entities at _deploy time_
## What Success Looks Like
@@ -88,7 +92,6 @@ Achieve the primary goal in a way that does not require a fork.
3. Adding a new relationship among 2 GMS entities takes 1 dev < 15 minutes
4. [Bonus] Implementing the `datahub-frontend` GraphQL API for a new / extended entity takes < 10 minutes
-
## Design
## State of the World
@@ -104,7 +107,8 @@ Currently, there are various models in GMS:
5. [Entities](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/metadata/entity/DatasetEntity.pdl) - Records with fields derived from the URN. Used only in graph / relationships
6. [Relationships](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/metadata/relationship/Relationship.pdl) - Edges between 2 entities with optional edge properties
7. [Search Documents](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/metadata/search/ChartDocument.pdl) - Flat documents for indexing within Elastic index
- - And corresponding index [mappings.json](https://github.com/datahub-project/datahub/blob/master/gms/impl/src/main/resources/index/chart/mappings.json), [settings.json](https://github.com/datahub-project/datahub/blob/master/gms/impl/src/main/resources/index/chart/settings.json)
+
+- And corresponding index [mappings.json](https://github.com/datahub-project/datahub/blob/master/gms/impl/src/main/resources/index/chart/mappings.json), [settings.json](https://github.com/datahub-project/datahub/blob/master/gms/impl/src/main/resources/index/chart/settings.json)
Various components of GMS depend on / make assumptions about these model types:
@@ -122,7 +126,7 @@ Various components of GMS depend on / make assumptions about these model types:
Additionally, there are some implicit concepts that require additional caveats / logic:
1. Browse Paths - Requires defining logic in an entity-specific index builder to generate.
-2. Urns - Requires defining a) an Urn PDL model and b) a hand-written Urn class
+2. Urns - Requires defining a) an Urn PDL model and b) a hand-written Urn class
As you can see, there are many tied up concepts. Fundamentally changing the model would require a serious amount of refactoring, as it would require new versions of numerous components.
@@ -132,25 +136,25 @@ The challenge is, how can we meet the requirements without fundamentally alterin
In a nutshell, the idea is to consolidate the number of models + code we need to write on a per-entity basis.
We intend to achieve this by making search index + relationship configuration declarative, specified as part of the model
-definition itself.
+definition itself.
-We will use this configuration to drive more generic versions of the index builders + rest resources,
-with the intention of reducing the overall surface area of GMS.
+We will use this configuration to drive more generic versions of the index builders + rest resources,
+with the intention of reducing the overall surface area of GMS.
During this initiative, we will also seek to make the concepts of Browse Paths and Urns declarative. Browse Paths
-will be provided using a special BrowsePaths aspect. Urns will no longer be strongly typed.
+will be provided using a special BrowsePaths aspect. Urns will no longer be strongly typed.
-To achieve this, we will attempt to generify many components throughout the stack. Currently, many of them are defined on
-a *per-entity* basis, including
+To achieve this, we will attempt to generify many components throughout the stack. Currently, many of them are defined on
+a _per-entity_ basis, including
- Rest.li Resources
- Index Builders
- Graph Builders
- Local, Search, Browse, Graph DAOs
-- Clients
+- Clients
- Browse Path Logic
-along with simplifying the number of raw data models that need defined, including
+along with simplifying the number of raw data models that need defined, including
- Rest.li Resource Models
- Search Document Models
@@ -159,39 +163,43 @@ along with simplifying the number of raw data models that need defined, includin
From an architectural PoV, we will move from a before that looks something like this:
-
+
+
+
to an after that looks like this
-
+
+
+
-That is, a move away from patterns of strong-typing-everywhere to a more generic + flexible world.
+That is, a move away from patterns of strong-typing-everywhere to a more generic + flexible world.
### How will we do it?
We will accomplish this by building the following:
1. Set of custom annotations to permit declarative entity, search, graph configurations
- - @Entity & @Aspect
- - @Searchable
- - @Relationship
+ - @Entity & @Aspect
+ - @Searchable
+ - @Relationship
2. Entity Registry: In-memory structures for representing, storing & serving metadata associated with a particular Entity, including search and relationship configurations.
-3. Generic Entity, Search, Graph Service classes: Replaces traditional strongly-typed DAOs with flexible, pluggable APIs that can be used for CRUD, search, and graph across all entities.
-2. Generic Rest.li Resources:
- - 1 permitting reading, writing, searching, autocompleting, and browsing arbitrary entities
- - 1 permitting reading of arbitrary entity-entity relationship edges
-2. Generic Search Index Builder: Given a MAE and a specification of the Search Configuration for an entity, updates the search index.
-3. Generic Graph Index Builder: Given a MAE and a specification of the Relationship Configuration for an entity, updates the graph index.
-4. Generic Index + Mappings Builder: Dynamically generates index mappings and creates indices on the fly.
-5. Introduce of special aspects to address other imperative code requirements
- - BrowsePaths Aspect: Include an aspect to permit customization of the indexed browse paths.
- - Key aspects: Include "virtual" aspects for representing the fields that uniquely identify an Entity for easy
- reading by clients of DataHub.
+3. Generic Entity, Search, Graph Service classes: Replaces traditional strongly-typed DAOs with flexible, pluggable APIs that can be used for CRUD, search, and graph across all entities.
+4. Generic Rest.li Resources:
+ - 1 permitting reading, writing, searching, autocompleting, and browsing arbitrary entities
+ - 1 permitting reading of arbitrary entity-entity relationship edges
+5. Generic Search Index Builder: Given a MAE and a specification of the Search Configuration for an entity, updates the search index.
+6. Generic Graph Index Builder: Given a MAE and a specification of the Relationship Configuration for an entity, updates the graph index.
+7. Generic Index + Mappings Builder: Dynamically generates index mappings and creates indices on the fly.
+8. Introduce of special aspects to address other imperative code requirements
+ - BrowsePaths Aspect: Include an aspect to permit customization of the indexed browse paths.
+ - Key aspects: Include "virtual" aspects for representing the fields that uniquely identify an Entity for easy
+ reading by clients of DataHub.
### Final Developer Experience: Defining an Entity
We will outline what the experience of adding a new Entity should look like. We will imagine we want to define a "Service" entity representing
-online microservices.
+online microservices.
#### Step 1. Add aspects
@@ -236,7 +244,7 @@ record ServiceInfo {
/**
* Description of the service
*/
- @Searchable = {}
+ @Searchable = {}
description: string
/**
@@ -244,7 +252,7 @@ record ServiceInfo {
*/
@Relationship = {
"name": "OwnedBy",
- "entityTypes": ["corpUser"]
+ "entityTypes": ["corpUser"]
}
owner: Urn
}
@@ -310,7 +318,7 @@ namespace com.linkedin.metadata.snapshot
* A union of all supported metadata snapshot types.
*/
typeref Snapshot = union[
- ...
+ ...
ServiceSnapshot
]
```
@@ -321,7 +329,7 @@ typeref Snapshot = union[
```
curl 'http://localhost:8080/entities?action=ingest' -X POST -H 'X-RestLi-Protocol-Version:2.0.0' --data '{
- "entity":{
+ "entity":{
"value":{
"com.linkedin.metadata.snapshot.ServiceSnapshot":{
"urn": "urn:li:service:mydemoservice",
@@ -329,7 +337,7 @@ curl 'http://localhost:8080/entities?action=ingest' -X POST -H 'X-RestLi-Protoco
{
"com.linkedin.service.ServiceInfo":{
"description":"My demo service",
- "owner": "urn:li:corpuser:user1"
+ "owner": "urn:li:corpuser:user1"
}
},
{
@@ -400,4 +408,3 @@ curl --location --request POST 'http://localhost:8080/entities?action=browse' \
curl --location --request GET 'http://localhost:8080/relationships?direction=INCOMING&urn=urn%3Ali%3Acorpuser%3Auser1&types=OwnedBy' \
--header 'X-RestLi-Protocol-Version: 2.0.0'
```
-
diff --git a/docs/api/graphql/how-to-set-up-graphql.md b/docs/api/graphql/how-to-set-up-graphql.md
index 562e8edb9f5d9..e9d264c5b04bf 100644
--- a/docs/api/graphql/how-to-set-up-graphql.md
+++ b/docs/api/graphql/how-to-set-up-graphql.md
@@ -62,7 +62,9 @@ Postman is a popular API client that provides a graphical user interface for sen
Within Postman, you can create a `POST` request and set the request URL to the `/api/graphql` endpoint.
In the request body, select the `GraphQL` option and enter your GraphQL query in the request body.
-
+
+
+
Please refer to [Querying with GraphQL](https://learning.postman.com/docs/sending-requests/graphql/graphql/) in the Postman documentation for more information.
diff --git a/docs/api/tutorials/custom-properties.md b/docs/api/tutorials/custom-properties.md
index dbc07bfaa712e..672fc568ea8b5 100644
--- a/docs/api/tutorials/custom-properties.md
+++ b/docs/api/tutorials/custom-properties.md
@@ -34,7 +34,9 @@ In this example, we will add some custom properties `cluster_name` and `retentio
After you have ingested sample data, the dataset `fct_users_deleted` should have a custom properties section with `encoding` set to `utf-8`.
-
+
+
+
```shell
datahub get --urn "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)" --aspect datasetProperties
@@ -80,7 +82,9 @@ The following code adds custom properties `cluster_name` and `retention_time` to
You can now see the two new properties are added to `fct_users_deleted` and the previous property `encoding` is unchanged.
-
+
+
+
We can also verify this operation by programmatically checking the `datasetProperties` aspect after running this code using the `datahub` cli.
@@ -130,7 +134,9 @@ The following code shows you how can add and remove custom properties in the sam
You can now see the `cluster_name` property is added to `fct_users_deleted` and the `retention_time` property is removed.
-
+
+
+
We can also verify this operation programmatically by checking the `datasetProperties` aspect using the `datahub` cli.
@@ -179,7 +185,9 @@ The following code replaces the current custom properties with a new properties
You can now see the `cluster_name` and `retention_time` properties are added to `fct_users_deleted` but the previous `encoding` property is no longer present.
-
+
+
+
We can also verify this operation programmatically by checking the `datasetProperties` aspect using the `datahub` cli.
diff --git a/docs/api/tutorials/datasets.md b/docs/api/tutorials/datasets.md
index 62b30e97c8020..0d41da741a5f5 100644
--- a/docs/api/tutorials/datasets.md
+++ b/docs/api/tutorials/datasets.md
@@ -42,7 +42,9 @@ For detailed steps, please refer to [Datahub Quickstart Guide](/docs/quickstart.
You can now see `realestate_db.sales` dataset has been created.
-
+
+
+
## Delete Dataset
@@ -110,4 +112,6 @@ Expected Response:
The dataset `fct_users_deleted` has now been deleted, so if you search for a hive dataset named `fct_users_delete`, you will no longer be able to see it.
-
+
+
+
diff --git a/docs/api/tutorials/deprecation.md b/docs/api/tutorials/deprecation.md
index 6a8f7c8a1d2be..590ad707969ca 100644
--- a/docs/api/tutorials/deprecation.md
+++ b/docs/api/tutorials/deprecation.md
@@ -155,4 +155,6 @@ Expected Response:
You can now see the dataset `fct_users_created` has been marked as `Deprecated.`
-
+
+
+
diff --git a/docs/api/tutorials/descriptions.md b/docs/api/tutorials/descriptions.md
index 46f42b7a05be6..6247b61d3b300 100644
--- a/docs/api/tutorials/descriptions.md
+++ b/docs/api/tutorials/descriptions.md
@@ -202,16 +202,16 @@ Expected Response:
```graphql
mutation updateDataset {
updateDataset(
- urn:"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)",
+ urn: "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"
input: {
editableProperties: {
- description: "## The Real Estate Sales Dataset\nThis is a really important Dataset that contains all the relevant information about sales that have happened organized by address.\n"
+ description: "## The Real Estate Sales Dataset\nThis is a really important Dataset that contains all the relevant information about sales that have happened organized by address.\n"
}
institutionalMemory: {
elements: {
author: "urn:li:corpuser:jdoe"
- url: "https://wikipedia.com/real_estate"
- description: "This is the definition of what real estate means"
+ url: "https://wikipedia.com/real_estate"
+ description: "This is the definition of what real estate means"
}
}
}
@@ -275,7 +275,9 @@ Expected Response:
You can now see the description is added to `fct_users_deleted`.
-
+
+
+
## Add Description on Column
@@ -357,4 +359,6 @@ Expected Response:
You can now see column description is added to `user_name` column of `fct_users_deleted`.
-
+
+
+
diff --git a/docs/api/tutorials/domains.md b/docs/api/tutorials/domains.md
index c8c47f85c570f..29c77a35ff0e1 100644
--- a/docs/api/tutorials/domains.md
+++ b/docs/api/tutorials/domains.md
@@ -74,7 +74,9 @@ Expected Response:
You can now see `Marketing` domain has been created under `Govern > Domains`.
-
+
+
+
## Read Domains
@@ -209,7 +211,9 @@ Expected Response:
You can now see `Marketing` domain has been added to the dataset.
-
+
+
+
## Remove Domains
@@ -259,4 +263,6 @@ curl --location --request POST 'http://localhost:8080/api/graphql' \
You can now see a domain `Marketing` has been removed from the `fct_users_created` dataset.
-
+
+
+
diff --git a/docs/api/tutorials/lineage.md b/docs/api/tutorials/lineage.md
index e37986af7bbbd..80f46a3131d11 100644
--- a/docs/api/tutorials/lineage.md
+++ b/docs/api/tutorials/lineage.md
@@ -112,7 +112,9 @@ Expected Response:
You can now see the lineage between `fct_users_deleted` and `logging_events`.
-
+
+
+
## Add Column-level Lineage
@@ -130,7 +132,9 @@ You can now see the lineage between `fct_users_deleted` and `logging_events`.
You can now see the column-level lineage between datasets. Note that you have to enable `Show Columns` to be able to see the column-level lineage.
-
+
+
+
## Read Lineage
@@ -171,7 +175,7 @@ mutation searchAcrossLineage {
}
```
-This example shows using lineage degrees as a filter, but additional search filters can be included here as well.
+This example shows using lineage degrees as a filter, but additional search filters can be included here as well.
diff --git a/docs/api/tutorials/ml.md b/docs/api/tutorials/ml.md
index b16f2669b30c7..a5020d6c8f241 100644
--- a/docs/api/tutorials/ml.md
+++ b/docs/api/tutorials/ml.md
@@ -94,9 +94,13 @@ Please note that an MlModelGroup serves as a container for all the runs of a sin
You can search the entities in DataHub UI.
-
+
## Read ML Entities
@@ -499,6 +503,10 @@ Expected Response: (Note that this entity does not exist in the sample ingestion
You can access to `Features` or `Group` Tab of each entity to view the added entities.
-
+
diff --git a/docs/api/tutorials/owners.md b/docs/api/tutorials/owners.md
index 3c7a46b136d76..71f908a85a864 100644
--- a/docs/api/tutorials/owners.md
+++ b/docs/api/tutorials/owners.md
@@ -77,7 +77,10 @@ Update succeeded for urn urn:li:corpuser:datahub.
### Expected Outcomes of Upserting User
You can see the user `The bar` has been created and the user `Datahub` has been updated under `Settings > Access > Users & Groups`
-
+
+
+
+
## Upsert Group
@@ -125,7 +128,10 @@ Update succeeded for group urn:li:corpGroup:foogroup@acryl.io.
### Expected Outcomes of Upserting Group
You can see the group `Foo Group` has been created under `Settings > Access > Users & Groups`
-
+
+
+
+
## Read Owners
@@ -272,7 +278,9 @@ curl --location --request POST 'http://localhost:8080/api/graphql' \
You can now see `bfoo` has been added as an owner to the `fct_users_created` dataset.
-
+
+
+
## Remove Owners
@@ -340,4 +348,6 @@ curl --location --request POST 'http://localhost:8080/api/graphql' \
You can now see `John Doe` has been removed as an owner from the `fct_users_created` dataset.
-
+
+
+
diff --git a/docs/api/tutorials/tags.md b/docs/api/tutorials/tags.md
index 2f80a833136c1..fa8ea6e0c39a7 100644
--- a/docs/api/tutorials/tags.md
+++ b/docs/api/tutorials/tags.md
@@ -91,7 +91,9 @@ Expected Response:
You can now see the new tag `Deprecated` has been created.
-
+
+
+
We can also verify this operation by programmatically searching `Deprecated` tag after running this code using the `datahub` cli.
@@ -307,7 +309,9 @@ Expected Response:
You can now see `Deprecated` tag has been added to `user_name` column.
-
+
+
+
We can also verify this operation programmatically by checking the `globalTags` aspect using the `datahub` cli.
@@ -359,7 +363,9 @@ curl --location --request POST 'http://localhost:8080/api/graphql' \
You can now see `Deprecated` tag has been removed to `user_name` column.
-
+
+
+
We can also verify this operation programmatically by checking the `gloablTags` aspect using the `datahub` cli.
diff --git a/docs/api/tutorials/terms.md b/docs/api/tutorials/terms.md
index 207e14ea4afe8..ba2be76195c62 100644
--- a/docs/api/tutorials/terms.md
+++ b/docs/api/tutorials/terms.md
@@ -95,7 +95,9 @@ Expected Response:
You can now see the new term `Rate of Return` has been created.
-
+
+
+
We can also verify this operation by programmatically searching `Rate of Return` term after running this code using the `datahub` cli.
@@ -289,7 +291,9 @@ Expected Response:
You can now see `Rate of Return` term has been added to `user_name` column.
-
+
+
+
## Remove Terms
@@ -361,4 +365,6 @@ curl --location --request POST 'http://localhost:8080/api/graphql' \
You can now see `Rate of Return` term has been removed to `user_name` column.
-
+
+
+
diff --git a/docs/architecture/architecture.md b/docs/architecture/architecture.md
index 6b76b995cc427..13ce50d6806e4 100644
--- a/docs/architecture/architecture.md
+++ b/docs/architecture/architecture.md
@@ -10,7 +10,9 @@ disparate tools & systems.
The figures below describe the high-level architecture of DataHub.
-
+
+
+

For a more detailed look at the components that make up the Architecture, check out [Components](../components.md).
diff --git a/docs/architecture/metadata-ingestion.md b/docs/architecture/metadata-ingestion.md
index 2b60383319c68..c4b3c834937b7 100644
--- a/docs/architecture/metadata-ingestion.md
+++ b/docs/architecture/metadata-ingestion.md
@@ -4,14 +4,17 @@ title: "Ingestion Framework"
# Metadata Ingestion Architecture
-DataHub supports an extremely flexible ingestion architecture that can support push, pull, asynchronous and synchronous models.
-The figure below describes all the options possible for connecting your favorite system to DataHub.
-
+DataHub supports an extremely flexible ingestion architecture that can support push, pull, asynchronous and synchronous models.
+The figure below describes all the options possible for connecting your favorite system to DataHub.
-## Metadata Change Proposal: The Center Piece
+
+
+
-The center piece for ingestion are [Metadata Change Proposal]s which represent requests to make a metadata change to an organization's Metadata Graph.
-Metadata Change Proposals can be sent over Kafka, for highly scalable async publishing from source systems. They can also be sent directly to the HTTP endpoint exposed by the DataHub service tier to get synchronous success / failure responses.
+## Metadata Change Proposal: The Center Piece
+
+The center piece for ingestion are [Metadata Change Proposal]s which represent requests to make a metadata change to an organization's Metadata Graph.
+Metadata Change Proposals can be sent over Kafka, for highly scalable async publishing from source systems. They can also be sent directly to the HTTP endpoint exposed by the DataHub service tier to get synchronous success / failure responses.
## Pull-based Integration
@@ -25,7 +28,7 @@ As long as you can emit a [Metadata Change Proposal (MCP)] event to Kafka or mak
### Applying Metadata Change Proposals to DataHub Metadata Service (mce-consumer-job)
-DataHub comes with a Spring job, [mce-consumer-job], which consumes the Metadata Change Proposals and writes them into the DataHub Metadata Service (datahub-gms) using the `/ingest` endpoint.
+DataHub comes with a Spring job, [mce-consumer-job], which consumes the Metadata Change Proposals and writes them into the DataHub Metadata Service (datahub-gms) using the `/ingest` endpoint.
[Metadata Change Proposal (MCP)]: ../what/mxe.md#metadata-change-proposal-mcp
[Metadata Change Proposal]: ../what/mxe.md#metadata-change-proposal-mcp
@@ -33,4 +36,3 @@ DataHub comes with a Spring job, [mce-consumer-job], which consumes the Metadata
[equivalent Pegasus format]: https://linkedin.github.io/rest.li/how_data_is_represented_in_memory#the-data-template-layer
[mce-consumer-job]: ../../metadata-jobs/mce-consumer-job
[Python emitters]: ../../metadata-ingestion/README.md#using-as-a-library
-
diff --git a/docs/architecture/metadata-serving.md b/docs/architecture/metadata-serving.md
index ada41179af4e0..a677ca111e71f 100644
--- a/docs/architecture/metadata-serving.md
+++ b/docs/architecture/metadata-serving.md
@@ -4,21 +4,23 @@ title: "Serving Tier"
# DataHub Serving Architecture
-The figure below shows the high-level system diagram for DataHub's Serving Tier.
+The figure below shows the high-level system diagram for DataHub's Serving Tier.
-
+
+
+
-The primary component is called [the Metadata Service](../../metadata-service) and exposes a REST API and a GraphQL API for performing CRUD operations on metadata. The service also exposes search and graph query API-s to support secondary-index style queries, full-text search queries as well as relationship queries like lineage. In addition, the [datahub-frontend](../../datahub-frontend) service expose a GraphQL API on top of the metadata graph.
+The primary component is called [the Metadata Service](../../metadata-service) and exposes a REST API and a GraphQL API for performing CRUD operations on metadata. The service also exposes search and graph query API-s to support secondary-index style queries, full-text search queries as well as relationship queries like lineage. In addition, the [datahub-frontend](../../datahub-frontend) service expose a GraphQL API on top of the metadata graph.
## DataHub Serving Tier Components
### Metadata Storage
-The DataHub Metadata Service persists metadata in a document store (an RDBMS like MySQL, Postgres, or Cassandra, etc.).
+The DataHub Metadata Service persists metadata in a document store (an RDBMS like MySQL, Postgres, or Cassandra, etc.).
### Metadata Change Log Stream (MCL)
-The DataHub Service Tier also emits a commit event [Metadata Change Log] when a metadata change has been successfully committed to persistent storage. This event is sent over Kafka.
+The DataHub Service Tier also emits a commit event [Metadata Change Log] when a metadata change has been successfully committed to persistent storage. This event is sent over Kafka.
The MCL stream is a public API and can be subscribed to by external systems (for example, the Actions Framework) providing an extremely powerful way to react in real-time to changes happening in metadata. For example, you could build an access control enforcer that reacts to change in metadata (e.g. a previously world-readable dataset now has a pii field) to immediately lock down the dataset in question.
Note that not all MCP-s will result in an MCL, because the DataHub serving tier will ignore any duplicate changes to metadata.
@@ -26,7 +28,7 @@ Note that not all MCP-s will result in an MCL, because the DataHub serving tier
### Metadata Index Applier (mae-consumer-job)
[Metadata Change Log]s are consumed by another Spring job, [mae-consumer-job], which applies the changes to the [graph] and [search index] accordingly.
-The job is entity-agnostic and will execute corresponding graph & search index builders, which will be invoked by the job when a specific metadata aspect is changed.
+The job is entity-agnostic and will execute corresponding graph & search index builders, which will be invoked by the job when a specific metadata aspect is changed.
The builder should instruct the job how to update the graph and search index based on the metadata change.
To ensure that metadata changes are processed in the correct chronological order, MCLs are keyed by the entity [URN] — meaning all MAEs for a particular entity will be processed sequentially by a single thread.
@@ -44,13 +46,10 @@ Primary-key based reads (e.g. getting schema metadata for a dataset based on the
[GMS]: ../what/gms.md
[Metadata Change Log]: ../what/mxe.md#metadata-change-log-mcl
[rest.li]: https://rest.li
-
-
[Metadata Change Proposal (MCP)]: ../what/mxe.md#metadata-change-proposal-mcp
[Metadata Change Log (MCL)]: ../what/mxe.md#metadata-change-log-mcl
[MCP]: ../what/mxe.md#metadata-change-proposal-mcp
[MCL]: ../what/mxe.md#metadata-change-log-mcl
-
[equivalent Pegasus format]: https://linkedin.github.io/rest.li/how_data_is_represented_in_memory#the-data-template-layer
[graph]: ../what/graph.md
[search index]: ../what/search-index.md
diff --git a/docs/authentication/concepts.md b/docs/authentication/concepts.md
index 715e94c7e0380..5ce20546ed612 100644
--- a/docs/authentication/concepts.md
+++ b/docs/authentication/concepts.md
@@ -11,7 +11,9 @@ We introduced a few important concepts to the Metadata Service to make authentic
In following sections, we'll take a closer look at each individually.
-
+
+
+
*High level overview of Metadata Service Authentication*
## What is an Actor?
@@ -53,7 +55,7 @@ There can be many types of Authenticator. For example, there can be Authenticato
- Verify the authenticity of access tokens (ie. issued by either DataHub itself or a 3rd-party IdP)
- Authenticate username / password credentials against a remote database (ie. LDAP)
-and more! A key goal of the abstraction is *extensibility*: a custom Authenticator can be developed to authenticate requests
+and more! A key goal of the abstraction is _extensibility_: a custom Authenticator can be developed to authenticate requests
based on an organization's unique needs.
DataHub ships with 2 Authenticators by default:
@@ -75,13 +77,13 @@ The Authenticator Chain can be configured in the `application.yml` file under `a
```
authentication:
- ....
+ ....
authenticators:
- # Configure the Authenticators in the chain
+ # Configure the Authenticators in the chain
- type: com.datahub.authentication.Authenticator1
...
- - type: com.datahub.authentication.Authenticator2
- ....
+ - type: com.datahub.authentication.Authenticator2
+ ....
```
## What is the AuthenticationFilter?
@@ -91,7 +93,6 @@ It does so by constructing and invoking an **AuthenticatorChain**, described abo
If an Actor is unable to be resolved by the AuthenticatorChain, then a 401 unauthorized exception will be returned by the filter.
-
## What is a DataHub Token Service? What are Access Tokens?
Along with Metadata Service Authentication comes an important new component called the **DataHub Token Service**. The purpose of this
@@ -114,10 +115,10 @@ Today, Access Tokens are granted by the Token Service under two scenarios:
1. **UI Login**: When a user logs into the DataHub UI, for example via [JaaS](guides/jaas.md) or
[OIDC](guides/sso/configure-oidc-react.md), the `datahub-frontend` service issues an
- request to the Metadata Service to generate a SESSION token *on behalf of* of the user logging in. (*Only the frontend service is authorized to perform this action).
+ request to the Metadata Service to generate a SESSION token _on behalf of_ of the user logging in. (\*Only the frontend service is authorized to perform this action).
2. **Generating Personal Access Tokens**: When a user requests to generate a Personal Access Token (described below) from the UI.
> At present, the Token Service supports the symmetric signing method `HS256` to generate and verify tokens.
Now that we're familiar with the concepts, we will talk concretely about what new capabilities have been built on top
-of Metadata Service Authentication.
\ No newline at end of file
+of Metadata Service Authentication.
diff --git a/docs/authentication/guides/sso/configure-oidc-react-azure.md b/docs/authentication/guides/sso/configure-oidc-react-azure.md
index d185957967882..10601769a9d3d 100644
--- a/docs/authentication/guides/sso/configure-oidc-react-azure.md
+++ b/docs/authentication/guides/sso/configure-oidc-react-azure.md
@@ -1,5 +1,6 @@
# Configuring Azure Authentication for React App (OIDC)
-*Authored on 21/12/2021*
+
+_Authored on 21/12/2021_
`datahub-frontend` server can be configured to authenticate users over OpenID Connect (OIDC). As such, it can be configured to
delegate authentication responsibility to identity providers like Microsoft Azure.
@@ -24,53 +25,63 @@ b. Select **App registrations**, then **New registration** to register a new app
c. Name your app registration and choose who can access your application.
d. Select `Web` as the **Redirect URI** type and enter the following:
+
```
https://your-datahub-domain.com/callback/oidc
```
+
If you are just testing locally, the following can be used: `http://localhost:9002/callback/oidc`.
Azure supports more than one redirect URI, so both can be configured at the same time from the **Authentication** tab once the registration is complete.
At this point, your app registration should look like the following:
-
+
+
+
e. Click **Register**.
### 2. Configure Authentication (optional)
-Once registration is done, you will land on the app registration **Overview** tab. On the left-side navigation bar, click on **Authentication** under **Manage** and add extra redirect URIs if need be (if you want to support both local testing and Azure deployments).
+Once registration is done, you will land on the app registration **Overview** tab. On the left-side navigation bar, click on **Authentication** under **Manage** and add extra redirect URIs if need be (if you want to support both local testing and Azure deployments).
-
+
+
+
Click **Save**.
### 3. Configure Certificates & secrets
On the left-side navigation bar, click on **Certificates & secrets** under **Manage**.
-Select **Client secrets**, then **New client secret**. Type in a meaningful description for your secret and select an expiry. Click the **Add** button when you are done.
+Select **Client secrets**, then **New client secret**. Type in a meaningful description for your secret and select an expiry. Click the **Add** button when you are done.
**IMPORTANT:** Copy the `value` of your newly create secret since Azure will never display its value afterwards.
-
+
+
+
### 4. Configure API permissions
-On the left-side navigation bar, click on **API permissions** under **Manage**. DataHub requires the following four Microsoft Graph APIs:
+On the left-side navigation bar, click on **API permissions** under **Manage**. DataHub requires the following four Microsoft Graph APIs:
-1. `User.Read` *(should be already configured)*
+1. `User.Read` _(should be already configured)_
2. `profile`
3. `email`
4. `openid`
-Click on **Add a permission**, then from the **Microsoft APIs** tab select **Microsoft Graph**, then **Delegated permissions**. From the **OpenId permissions** category, select `email`, `openid`, `profile` and click **Add permissions**.
+Click on **Add a permission**, then from the **Microsoft APIs** tab select **Microsoft Graph**, then **Delegated permissions**. From the **OpenId permissions** category, select `email`, `openid`, `profile` and click **Add permissions**.
At this point, you should be looking at a screen like the following:
-
+
+
+
### 5. Obtain Application (Client) ID
-On the left-side navigation bar, go back to the **Overview** tab. You should see the `Application (client) ID`. Save its value for the next step.
+On the left-side navigation bar, go back to the **Overview** tab. You should see the `Application (client) ID`. Save its value for the next step.
### 6. Obtain Discovery URI
@@ -108,4 +119,5 @@ docker-compose -p datahub -f docker-compose.yml -f docker-compose.override.yml
Navigate to your DataHub domain to see SSO in action.
## Resources
-- [Microsoft identity platform and OpenID Connect protocol](https://docs.microsoft.com/en-us/azure/active-directory/develop/v2-protocols-oidc/)
\ No newline at end of file
+
+- [Microsoft identity platform and OpenID Connect protocol](https://docs.microsoft.com/en-us/azure/active-directory/develop/v2-protocols-oidc/)
diff --git a/docs/authentication/guides/sso/configure-oidc-react-google.md b/docs/authentication/guides/sso/configure-oidc-react-google.md
index 474538097aae2..16bf66dfc3101 100644
--- a/docs/authentication/guides/sso/configure-oidc-react-google.md
+++ b/docs/authentication/guides/sso/configure-oidc-react-google.md
@@ -1,8 +1,9 @@
# Configuring Google Authentication for React App (OIDC)
-*Authored on 3/10/2021*
-`datahub-frontend` server can be configured to authenticate users over OpenID Connect (OIDC). As such, it can be configured to delegate
-authentication responsibility to identity providers like Google.
+_Authored on 3/10/2021_
+
+`datahub-frontend` server can be configured to authenticate users over OpenID Connect (OIDC). As such, it can be configured to delegate
+authentication responsibility to identity providers like Google.
This guide will provide steps for configuring DataHub authentication using Google.
@@ -17,40 +18,42 @@ please see [this guide](../jaas.md) to mount a custom user.props file for a JAAS
### 1. Create a project in the Google API Console
-Using an account linked to your organization, navigate to the [Google API Console](https://console.developers.google.com/) and select **New project**.
-Within this project, we will configure the OAuth2.0 screen and credentials.
+Using an account linked to your organization, navigate to the [Google API Console](https://console.developers.google.com/) and select **New project**.
+Within this project, we will configure the OAuth2.0 screen and credentials.
### 2. Create OAuth2.0 consent screen
-a. Navigate to `OAuth consent screen`. This is where you'll configure the screen your users see when attempting to
-log in to DataHub.
+a. Navigate to `OAuth consent screen`. This is where you'll configure the screen your users see when attempting to
+log in to DataHub.
-b. Select `Internal` (if you only want your company users to have access) and then click **Create**.
-Note that in order to complete this step you should be logged into a Google account associated with your organization.
+b. Select `Internal` (if you only want your company users to have access) and then click **Create**.
+Note that in order to complete this step you should be logged into a Google account associated with your organization.
c. Fill out the details in the App Information & Domain sections. Make sure the 'Application Home Page' provided matches where DataHub is deployed
-at your organization.
+at your organization.
-
+
+
+
-Once you've completed this, **Save & Continue**.
+Once you've completed this, **Save & Continue**.
d. Configure the scopes: Next, click **Add or Remove Scopes**. Select the following scopes:
-
+
- `.../auth/userinfo.email`
- `.../auth/userinfo.profile`
- `openid`
-Once you've selected these, **Save & Continue**.
+Once you've selected these, **Save & Continue**.
### 3. Configure client credentials
-Now navigate to the **Credentials** tab. This is where you'll obtain your client id & secret, as well as configure info
-like the redirect URI used after a user is authenticated.
+Now navigate to the **Credentials** tab. This is where you'll obtain your client id & secret, as well as configure info
+like the redirect URI used after a user is authenticated.
a. Click **Create Credentials** & select `OAuth client ID` as the credential type.
-b. On the following screen, select `Web application` as your Application Type.
+b. On the following screen, select `Web application` as your Application Type.
c. Add the domain where DataHub is hosted to your 'Authorized Javascript Origins'.
@@ -58,7 +61,7 @@ c. Add the domain where DataHub is hosted to your 'Authorized Javascript Origins
https://your-datahub-domain.com
```
-d. Add the domain where DataHub is hosted with the path `/callback/oidc` appended to 'Authorized Redirect URLs'.
+d. Add the domain where DataHub is hosted with the path `/callback/oidc` appended to 'Authorized Redirect URLs'.
```
https://your-datahub-domain.com/callback/oidc
@@ -70,7 +73,9 @@ f. You will now receive a pair of values, a client id and a client secret. Bookm
At this point, you should be looking at a screen like the following:
-
+
+
+
Success!
@@ -78,7 +83,7 @@ Success!
a. Open the file `docker/datahub-frontend/env/docker.env`
-b. Add the following configuration values to the file:
+b. Add the following configuration values to the file:
```
AUTH_OIDC_ENABLED=true
@@ -91,20 +96,18 @@ AUTH_OIDC_USER_NAME_CLAIM=email
AUTH_OIDC_USER_NAME_CLAIM_REGEX=([^@]+)
```
-Replacing the placeholders above with the client id & client secret received from Google in Step 3f.
-
+Replacing the placeholders above with the client id & client secret received from Google in Step 3f.
### 5. Restart `datahub-frontend-react` docker container
-Now, simply restart the `datahub-frontend-react` container to enable the integration.
+Now, simply restart the `datahub-frontend-react` container to enable the integration.
```
docker-compose -p datahub -f docker-compose.yml -f docker-compose.override.yml up datahub-frontend-react
```
-Navigate to your DataHub domain to see SSO in action.
-
+Navigate to your DataHub domain to see SSO in action.
## References
-- [OpenID Connect in Google Identity](https://developers.google.com/identity/protocols/oauth2/openid-connect)
\ No newline at end of file
+- [OpenID Connect in Google Identity](https://developers.google.com/identity/protocols/oauth2/openid-connect)
diff --git a/docs/authentication/guides/sso/configure-oidc-react-okta.md b/docs/authentication/guides/sso/configure-oidc-react-okta.md
index cfede999f1e70..54d2b54357aad 100644
--- a/docs/authentication/guides/sso/configure-oidc-react-okta.md
+++ b/docs/authentication/guides/sso/configure-oidc-react-okta.md
@@ -1,5 +1,6 @@
# Configuring Okta Authentication for React App (OIDC)
-*Authored on 3/10/2021*
+
+_Authored on 3/10/2021_
`datahub-frontend` server can be configured to authenticate users over OpenID Connect (OIDC). As such, it can be configured to
delegate authentication responsibility to identity providers like Okta.
@@ -52,7 +53,6 @@ If you're just testing locally, this can be `http://localhost:9002`.
i. Click **Save**
-
### 2. Obtain Client Credentials
On the subsequent screen, you should see the client credentials. Bookmark the `Client id` and `Client secret` for the next step.
@@ -69,8 +69,12 @@ for example, `https://dev-33231928.okta.com/.well-known/openid-configuration`.
At this point, you should be looking at a screen like the following:
-
-
+
+
+
+
+
+
Success!
@@ -91,12 +95,15 @@ AUTH_OIDC_SCOPE="openid profile email groups"
Replacing the placeholders above with the client id & client secret received from Okta in Step 2.
-> **Pro Tip!** You can easily enable Okta to return the groups that a user is associated with, which will be provisioned in DataHub, along with the user logging in. This can be enabled by setting the `AUTH_OIDC_EXTRACT_GROUPS_ENABLED` flag to `true`.
+> **Pro Tip!** You can easily enable Okta to return the groups that a user is associated with, which will be provisioned in DataHub, along with the user logging in. This can be enabled by setting the `AUTH_OIDC_EXTRACT_GROUPS_ENABLED` flag to `true`.
> if they do not already exist in DataHub. You can enable your Okta application to return a 'groups' claim from the Okta Console at Applications > Your Application -> Sign On -> OpenID Connect ID Token Settings (Requires an edit).
->
-> By default, we assume that the groups will appear in a claim named "groups". This can be customized using the `AUTH_OIDC_GROUPS_CLAIM` container configuration.
->
-> 
+>
+> By default, we assume that the groups will appear in a claim named "groups". This can be customized using the `AUTH_OIDC_GROUPS_CLAIM` container configuration.
+>
+>
+>
+
+
### 5. Restart `datahub-frontend-react` docker container
@@ -109,4 +116,5 @@ docker-compose -p datahub -f docker-compose.yml -f docker-compose.override.yml
Navigate to your DataHub domain to see SSO in action.
## Resources
+
- [OAuth 2.0 and OpenID Connect Overview](https://developer.okta.com/docs/concepts/oauth-openid/)
diff --git a/docs/authentication/personal-access-tokens.md b/docs/authentication/personal-access-tokens.md
index 0188aab49444e..8fdce8a83507d 100644
--- a/docs/authentication/personal-access-tokens.md
+++ b/docs/authentication/personal-access-tokens.md
@@ -4,15 +4,16 @@ import FeatureAvailability from '@site/src/components/FeatureAvailability';
-Personal Access Tokens, or PATs for short, allow users to represent themselves in code and programmatically use DataHub's APIs in deployments where security is a concern.
+Personal Access Tokens, or PATs for short, allow users to represent themselves in code and programmatically use DataHub's APIs in deployments where security is a concern.
Used along-side with [authentication-enabled metadata service](introducing-metadata-service-authentication.md), PATs add a layer of protection to DataHub where only authorized users are able to perform actions in an automated way.
## Personal Access Tokens Setup, Prerequisites, and Permissions
To use PATs, two things are required:
- 1. Metadata Authentication must have been enabled in GMS. See `Configuring Metadata Service Authentication` in [authentication-enabled metadata service](introducing-metadata-service-authentication.md).
- 2. Users must have been granted the `Generate Personal Access Tokens` or `Manage All Access Tokens` Privilege via a [DataHub Policy](../authorization/policies.md).
+
+1. Metadata Authentication must have been enabled in GMS. See `Configuring Metadata Service Authentication` in [authentication-enabled metadata service](introducing-metadata-service-authentication.md).
+2. Users must have been granted the `Generate Personal Access Tokens` or `Manage All Access Tokens` Privilege via a [DataHub Policy](../authorization/policies.md).
Once configured, users should be able to navigate to **'Settings'** > **'Access Tokens'** > **'Generate Personal Access Token'** to generate a token:
@@ -54,7 +55,7 @@ Once a token has been generated, the user that created it will subsequently be a
the generated Access Token as a Bearer token in the `Authorization` header:
```
-Authorization: Bearer
+Authorization: Bearer
```
For example, using a curl to the frontend proxy (preferred in production):
@@ -71,7 +72,9 @@ curl 'http://localhost:8080/entities/urn:li:corpuser:datahub' -H 'Authorization:
Since authorization happens at the GMS level, this means that ingestion is also protected behind access tokens, to use them simply add a `token` to the sink config property as seen below:
-
+
+
+
:::note
@@ -87,8 +90,8 @@ is enabled.
### GraphQL
- - Have a look at [Token Management in GraphQL](../api/graphql/token-management.md) to learn how to manage tokens programatically!
-
+- Have a look at [Token Management in GraphQL](../api/graphql/token-management.md) to learn how to manage tokens programatically!
+
## FAQ and Troubleshooting
**The button to create tokens is greyed out - why can’t I click on it?**
@@ -104,5 +107,4 @@ A PAT represents a user in DataHub, if that user does not have permissions for a
Yes, although not through the UI correctly, you will have to use the [token management graphQL API](../api/graphql/token-management.md) and the user making the request must have `Manage All Access Tokens` permissions.
-*Need more help? Join the conversation in [Slack](http://slack.datahubproject.io)!*
-
+_Need more help? Join the conversation in [Slack](http://slack.datahubproject.io)!_
diff --git a/docs/components.md b/docs/components.md
index ef76729bb37fb..a425d10015102 100644
--- a/docs/components.md
+++ b/docs/components.md
@@ -4,56 +4,58 @@ title: "Components"
# DataHub Components Overview
-The DataHub platform consists of the components shown in the following diagram.
+The DataHub platform consists of the components shown in the following diagram.
-
+
+
+
-## Metadata Store
+## Metadata Store
The Metadata Store is responsible for storing the [Entities & Aspects](https://datahubproject.io/docs/metadata-modeling/metadata-model/) comprising the Metadata Graph. This includes
exposing an API for [ingesting metadata](https://datahubproject.io/docs/metadata-service#ingesting-entities), [fetching Metadata by primary key](https://datahubproject.io/docs/metadata-service#retrieving-entities), [searching entities](https://datahubproject.io/docs/metadata-service#search-an-entity), and [fetching Relationships](https://datahubproject.io/docs/metadata-service#get-relationships-edges) between
entities. It consists of a Spring Java Service hosting a set of [Rest.li](https://linkedin.github.io/rest.li/) API endpoints, along with
-MySQL, Elasticsearch, & Kafka for primary storage & indexing.
+MySQL, Elasticsearch, & Kafka for primary storage & indexing.
-Get started with the Metadata Store by following the [Quickstart Guide](https://datahubproject.io/docs/quickstart/).
+Get started with the Metadata Store by following the [Quickstart Guide](https://datahubproject.io/docs/quickstart/).
## Metadata Models
Metadata Models are schemas defining the shape of the Entities & Aspects comprising the Metadata Graph, along with the relationships between them. They are defined
using [PDL](https://linkedin.github.io/rest.li/pdl_schema), a modeling language quite similar in form to Protobuf while serializes to JSON. Entities represent a specific class of Metadata
-Asset such as a Dataset, a Dashboard, a Data Pipeline, and beyond. Each *instance* of an Entity is identified by a unique identifier called an `urn`. Aspects represent related bundles of data attached
-to an instance of an Entity such as its descriptions, tags, and more. View the current set of Entities supported [here](https://datahubproject.io/docs/metadata-modeling/metadata-model#exploring-datahubs-metadata-model).
+Asset such as a Dataset, a Dashboard, a Data Pipeline, and beyond. Each _instance_ of an Entity is identified by a unique identifier called an `urn`. Aspects represent related bundles of data attached
+to an instance of an Entity such as its descriptions, tags, and more. View the current set of Entities supported [here](https://datahubproject.io/docs/metadata-modeling/metadata-model#exploring-datahubs-metadata-model).
-Learn more about DataHub models Metadata [here](https://datahubproject.io/docs/metadata-modeling/metadata-model/).
+Learn more about DataHub models Metadata [here](https://datahubproject.io/docs/metadata-modeling/metadata-model/).
## Ingestion Framework
The Ingestion Framework is a modular, extensible Python library for extracting Metadata from external source systems (e.g.
Snowflake, Looker, MySQL, Kafka), transforming it into DataHub's [Metadata Model](https://datahubproject.io/docs/metadata-modeling/metadata-model/), and writing it into DataHub via
either Kafka or using the Metadata Store Rest APIs directly. DataHub supports an [extensive list of Source connectors](https://datahubproject.io/docs/metadata-ingestion/#installing-plugins) to choose from, along with
-a host of capabilities including schema extraction, table & column profiling, usage information extraction, and more.
+a host of capabilities including schema extraction, table & column profiling, usage information extraction, and more.
Getting started with the Ingestion Framework is as simple: just define a YAML file and execute the `datahub ingest` command.
-Learn more by heading over the the [Metadata Ingestion](https://datahubproject.io/docs/metadata-ingestion/) guide.
+Learn more by heading over the the [Metadata Ingestion](https://datahubproject.io/docs/metadata-ingestion/) guide.
## GraphQL API
The [GraphQL](https://graphql.org/) API provides a strongly-typed, entity-oriented API that makes interacting with the Entities comprising the Metadata
-Graph simple, including APIs for adding and removing tags, owners, links & more to Metadata Entities! Most notably, this API is consumed by the User Interface (discussed below) for enabling Search & Discovery, Governance, Observability
-and more.
+Graph simple, including APIs for adding and removing tags, owners, links & more to Metadata Entities! Most notably, this API is consumed by the User Interface (discussed below) for enabling Search & Discovery, Governance, Observability
+and more.
-To get started using the GraphQL API, check out the [Getting Started with GraphQL](https://datahubproject.io/docs/api/graphql/getting-started) guide.
+To get started using the GraphQL API, check out the [Getting Started with GraphQL](https://datahubproject.io/docs/api/graphql/getting-started) guide.
## User Interface
DataHub comes with a React UI including an ever-evolving set of features to make Discovering, Governing, & Debugging your Data Assets easy & delightful.
For a full overview of the capabilities currently supported, take a look at the [Features](https://datahubproject.io/docs/features/) overview. For a look at what's coming next,
-head over to the [Roadmap](https://datahubproject.io/docs/roadmap/).
+head over to the [Roadmap](https://datahubproject.io/docs/roadmap/).
## Learn More
Learn more about the specifics of the [DataHub Architecture](./architecture/architecture.md) in the Architecture Overview. Learn about using & developing the components
-of the Platform by visiting the Module READMEs.
+of the Platform by visiting the Module READMEs.
## Feedback / Questions / Concerns
diff --git a/docs/deploy/aws.md b/docs/deploy/aws.md
index 7b01ffa02a744..399db2de8edc0 100644
--- a/docs/deploy/aws.md
+++ b/docs/deploy/aws.md
@@ -13,8 +13,7 @@ skip the corresponding sections.
This guide requires the following tools:
- [kubectl](https://kubernetes.io/docs/tasks/tools/) to manage kubernetes resources
-- [helm](https://helm.sh/docs/intro/install/) to deploy the resources based on helm charts. Note, we only support Helm
- 3.
+- [helm](https://helm.sh/docs/intro/install/) to deploy the resources based on helm charts. Note, we only support Helm 3.
- [eksctl](https://eksctl.io/introduction/#installation) to create and manage clusters on EKS
- [AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-install.html) to manage AWS resources
@@ -63,7 +62,7 @@ steps in this [guide](kubernetes.md)
Now that all the pods are up and running, you need to expose the datahub-frontend end point by setting
up [ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/). To do this, you need to first set up an
ingress controller. There are
-many [ingress controllers](https://kubernetes.io/docs/concepts/services-networking/ingress-controllers/) to choose
+many [ingress controllers](https://kubernetes.io/docs/concepts/services-networking/ingress-controllers/) to choose
from, but here, we will follow
this [guide](https://docs.aws.amazon.com/eks/latest/userguide/aws-load-balancer-controller.html) to set up the AWS
Application Load Balancer(ALB) Controller.
@@ -94,7 +93,7 @@ eksctl create iamserviceaccount \
--name=aws-load-balancer-controller \
--attach-policy-arn=arn:aws:iam::<>:policy/AWSLoadBalancerControllerIAMPolicy \
--override-existing-serviceaccounts \
- --approve
+ --approve
```
Install the TargetGroupBinding custom resource definition by running the following.
@@ -201,7 +200,9 @@ Provision a MySQL database in AWS RDS that shares the VPC with the kubernetes cl
the VPC of the kubernetes cluster. Once the database is provisioned, you should be able to see the following page. Take
a note of the endpoint marked by the red box.
-
+
+
+
First, add the DB password to kubernetes by running the following.
@@ -234,7 +235,9 @@ Provision an elasticsearch domain running elasticsearch version 7.10 or above th
cluster or has VPC peering set up between the VPC of the kubernetes cluster. Once the domain is provisioned, you should
be able to see the following page. Take a note of the endpoint marked by the red box.
-
+
+
+
Update the elasticsearch settings under global in the values.yaml as follows.
@@ -274,11 +277,15 @@ Then use the settings below.
secretRef: elasticsearch-secrets
secretKey: elasticsearch-password
```
+
If you have access control enabled with IAM auth, enable AWS auth signing in Datahub
+
```
- OPENSEARCH_USE_AWS_IAM_AUTH=true
+ OPENSEARCH_USE_AWS_IAM_AUTH=true
```
+
Then use the settings below.
+
```
elasticsearch:
host: <>
@@ -310,9 +317,9 @@ in datahub to point to the specific ES instance -
1. If you are using `docker quickstart` you can modify the hostname and port of the ES instance in docker compose
quickstart files located [here](../../docker/quickstart/).
- 1. Once you have modified the quickstart recipes you can run the quickstart command using a specific docker compose
- file. Sample command for that is
- - `datahub docker quickstart --quickstart-compose-file docker/quickstart/docker-compose-without-neo4j.quickstart.yml`
+ 1. Once you have modified the quickstart recipes you can run the quickstart command using a specific docker compose
+ file. Sample command for that is
+ - `datahub docker quickstart --quickstart-compose-file docker/quickstart/docker-compose-without-neo4j.quickstart.yml`
2. If you are not using quickstart recipes, you can modify environment variable in GMS to point to the ES instance. The
env files for datahub-gms are located [here](../../docker/datahub-gms/env/).
@@ -330,7 +337,9 @@ Provision an MSK cluster that shares the VPC with the kubernetes cluster or has
the kubernetes cluster. Once the domain is provisioned, click on the “View client information” button in the ‘Cluster
Summary” section. You should see a page like below. Take a note of the endpoints marked by the red boxes.
-
+
+
+
Update the kafka settings under global in the values.yaml as follows.
@@ -421,7 +430,7 @@ The minimum permissions required looks like this
}
```
-The latter part is required to have "*" as the resource because of an issue in the AWS Glue schema registry library.
+The latter part is required to have "\*" as the resource because of an issue in the AWS Glue schema registry library.
Refer to [this issue](https://github.com/awslabs/aws-glue-schema-registry/issues/68) for any updates.
Glue currently doesn't support AWS Signature V4. As such, we cannot use service accounts to give permissions to access
diff --git a/docs/deploy/confluent-cloud.md b/docs/deploy/confluent-cloud.md
index d93ffcceaecee..df31df09be64c 100644
--- a/docs/deploy/confluent-cloud.md
+++ b/docs/deploy/confluent-cloud.md
@@ -1,4 +1,4 @@
-# Integrating with Confluent Cloud
+# Integrating with Confluent Cloud
DataHub provides the ability to easily leverage Confluent Cloud as your Kafka provider. To do so, you'll need to configure DataHub to talk to a broker and schema registry hosted by Confluent.
@@ -8,7 +8,7 @@ Doing this is a matter of configuring the Kafka Producer and Consumers used by D
First, you'll need to create following new topics in the [Confluent Control Center](https://docs.confluent.io/platform/current/control-center/index.html). By default they have the following names:
-1. **MetadataChangeProposal_v1**
+1. **MetadataChangeProposal_v1**
2. **FailedMetadataChangeProposal_v1**
3. **MetadataChangeLog_Versioned_v1**
4. **MetadataChangeLog_Timeseries_v1**
@@ -18,13 +18,15 @@ First, you'll need to create following new topics in the [Confluent Control Cent
8. (Deprecated) **FailedMetadataChangeEvent_v4**: Failed to process #1 event
The first five are the most important, and are explained in more depth in [MCP/MCL](../advanced/mcp-mcl.md). The final topics are
-those which are deprecated but still used under certain circumstances. It is likely that in the future they will be completely
-decommissioned.
+those which are deprecated but still used under certain circumstances. It is likely that in the future they will be completely
+decommissioned.
To create the topics, navigate to your **Cluster** and click "Create Topic". Feel free to tweak the default topic configurations to
match your preferences.
-
+
+
+
## Step 2: Configure DataHub Container to use Confluent Cloud Topics
@@ -62,7 +64,7 @@ KAFKA_PROPERTIES_BASIC_AUTH_USER_INFO=P2ETAN5QR2LCWL14:RTjqw7AfETDl0RZo/7R0123Lh
```
Note that this step is only required if `DATAHUB_ANALYTICS_ENABLED` environment variable is not explicitly set to false for the datahub-frontend
-container.
+container.
If you're deploying with Docker Compose, you do not need to deploy the Zookeeper, Kafka Broker, or Schema Registry containers that ship by default.
@@ -72,16 +74,16 @@ Configuring Confluent Cloud for DataHub Actions requires some additional edits t
source connection config you will need to add the Python style client connection information:
```yaml
- connection:
- bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
- schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
- consumer_config:
- security.protocol: ${KAFKA_PROPERTIES_SECURITY_PROTOCOL:-PLAINTEXT}
- sasl.mechanism: ${KAFKA_PROPERTIES_SASL_MECHANISM:-PLAIN}
- sasl.username: ${KAFKA_PROPERTIES_SASL_USERNAME}
- sasl.password: ${KAFKA_PROPERTIES_SASL_PASSWORD}
- schema_registry_config:
- basic.auth.user.info: ${KAFKA_PROPERTIES_BASIC_AUTH_USER_INFO}
+connection:
+ bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
+ schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
+ consumer_config:
+ security.protocol: ${KAFKA_PROPERTIES_SECURITY_PROTOCOL:-PLAINTEXT}
+ sasl.mechanism: ${KAFKA_PROPERTIES_SASL_MECHANISM:-PLAIN}
+ sasl.username: ${KAFKA_PROPERTIES_SASL_USERNAME}
+ sasl.password: ${KAFKA_PROPERTIES_SASL_PASSWORD}
+ schema_registry_config:
+ basic.auth.user.info: ${KAFKA_PROPERTIES_BASIC_AUTH_USER_INFO}
```
Specifically `sasl.username` and `sasl.password` are the differences from the base `executor.yaml` example file.
@@ -115,7 +117,7 @@ First, disable the `cp-schema-registry` service:
```
cp-schema-registry:
- enabled: false
+ enabled: false
```
Next, disable the `kafkaSetupJob` service:
@@ -139,13 +141,16 @@ Next, you'll want to create 2 new Kubernetes secrets, one for the JaaS configura
and another for the user info used for connecting to the schema registry. You'll find the values for each within the Confluent Control Center. Specifically,
select "Clients" -> "Configure new Java Client". You should see a page like the following:
-
-
+
+
+
You'll want to generate both a Kafka Cluster API Key & a Schema Registry key. Once you do so,you should see the config
automatically populate with your new secrets:
-
+
+
+
You'll need to copy the values of `sasl.jaas.config` and `basic.auth.user.info`
for the next step.
@@ -165,7 +170,7 @@ kubectl create secret generic confluent-secrets --from-literal=basic_auth_user_i
```
Finally, we'll configure our containers to pick up the Confluent Kafka Configs by changing two config blocks in our `values.yaml` file. You
-should see these blocks commented at the bottom of the template. You'll want to uncomment them and set them to the following values:
+should see these blocks commented at the bottom of the template. You'll want to uncomment them and set them to the following values:
```
credentialsAndCertsSecrets:
@@ -182,7 +187,7 @@ springKafkaConfigurationOverrides:
basic.auth.credentials.source: USER_INFO
```
-Then simply apply the updated `values.yaml` to your K8s cluster via `kubectl apply`.
+Then simply apply the updated `values.yaml` to your K8s cluster via `kubectl apply`.
#### DataHub Actions
@@ -190,16 +195,16 @@ Configuring Confluent Cloud for DataHub Actions requires some additional edits t
source connection config you will need to add the Python style client connection information:
```yaml
- connection:
- bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
- schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
- consumer_config:
- security.protocol: ${KAFKA_PROPERTIES_SECURITY_PROTOCOL:-PLAINTEXT}
- sasl.mechanism: ${KAFKA_PROPERTIES_SASL_MECHANISM:-PLAIN}
- sasl.username: ${KAFKA_PROPERTIES_SASL_USERNAME}
- sasl.password: ${KAFKA_PROPERTIES_SASL_PASSWORD}
- schema_registry_config:
- basic.auth.user.info: ${KAFKA_PROPERTIES_BASIC_AUTH_USER_INFO}
+connection:
+ bootstrap: ${KAFKA_BOOTSTRAP_SERVER:-localhost:9092}
+ schema_registry_url: ${SCHEMA_REGISTRY_URL:-http://localhost:8081}
+ consumer_config:
+ security.protocol: ${KAFKA_PROPERTIES_SECURITY_PROTOCOL:-PLAINTEXT}
+ sasl.mechanism: ${KAFKA_PROPERTIES_SASL_MECHANISM:-PLAIN}
+ sasl.username: ${KAFKA_PROPERTIES_SASL_USERNAME}
+ sasl.password: ${KAFKA_PROPERTIES_SASL_PASSWORD}
+ schema_registry_config:
+ basic.auth.user.info: ${KAFKA_PROPERTIES_BASIC_AUTH_USER_INFO}
```
Specifically `sasl.username` and `sasl.password` are the differences from the base `executor.yaml` example file.
@@ -222,8 +227,9 @@ credentialsAndCertsSecrets:
The Actions pod will automatically pick these up in the correctly named environment variables when they are named this exact way.
## Contribution
+
Accepting contributions for a setup script compatible with Confluent Cloud!
The kafka-setup-job container we ship with is only compatible with a distribution of Kafka wherein ZooKeeper
-is exposed and available. A version of the job using the [Confluent CLI](https://docs.confluent.io/confluent-cli/current/command-reference/kafka/topic/confluent_kafka_topic_create.html)
-would be very useful for the broader community.
\ No newline at end of file
+is exposed and available. A version of the job using the [Confluent CLI](https://docs.confluent.io/confluent-cli/current/command-reference/kafka/topic/confluent_kafka_topic_create.html)
+would be very useful for the broader community.
diff --git a/docs/deploy/gcp.md b/docs/deploy/gcp.md
index 3713d69f90636..6b01236007408 100644
--- a/docs/deploy/gcp.md
+++ b/docs/deploy/gcp.md
@@ -13,8 +13,7 @@ skip the corresponding sections.
This guide requires the following tools:
- [kubectl](https://kubernetes.io/docs/tasks/tools/) to manage kubernetes resources
-- [helm](https://helm.sh/docs/intro/install/) to deploy the resources based on helm charts. Note, we only support Helm
- 3.
+- [helm](https://helm.sh/docs/intro/install/) to deploy the resources based on helm charts. Note, we only support Helm 3.
- [gcloud](https://cloud.google.com/sdk/docs/install) to manage GCP resources
Follow the
@@ -65,16 +64,22 @@ the GKE page on [GCP website](https://console.cloud.google.com/kubernetes/discov
Once all deploy is successful, you should see a page like below in the "Services & Ingress" tab on the left.
-
+
+
+
Tick the checkbox for datahub-datahub-frontend and click "CREATE INGRESS" button. You should land on the following page.
-
+
+
+
Type in an arbitrary name for the ingress and click on the second step "Host and path rules". You should land on the
following page.
-
+
+
+
Select "datahub-datahub-frontend" in the dropdown menu for backends, and then click on "ADD HOST AND PATH RULE" button.
In the second row that got created, add in the host name of choice (here gcp.datahubproject.io) and select
@@ -83,20 +88,25 @@ In the second row that got created, add in the host name of choice (here gcp.dat
This step adds the rule allowing requests from the host name of choice to get routed to datahub-frontend service. Click
on step 3 "Frontend configuration". You should land on the following page.
-
+
+
+
Choose HTTPS in the dropdown menu for protocol. To enable SSL, you need to add a certificate. If you do not have one,
you can click "CREATE A NEW CERTIFICATE" and input the host name of choice. GCP will create a certificate for you.
Now press "CREATE" button on the left to create ingress! After around 5 minutes, you should see the following.
-
+
+
+
In your domain provider, add an A record for the host name set above using the IP address on the ingress page (noted
with the red box). Once DNS updates, you should be able to access DataHub through the host name!!
Note, ignore the warning icon next to ingress. It takes about ten minutes for ingress to check that the backend service
-is ready and show a check mark as follows. However, ingress is fully functional once you see the above page.
-
-
+is ready and show a check mark as follows. However, ingress is fully functional once you see the above page.
+
+
+
diff --git a/docs/dev-guides/timeline.md b/docs/dev-guides/timeline.md
index 966e659b90991..2c8c5d6e875d1 100644
--- a/docs/dev-guides/timeline.md
+++ b/docs/dev-guides/timeline.md
@@ -12,14 +12,18 @@ The Timeline API is available in server versions `0.8.28` and higher. The `cli`
# Concepts
## Entity Timeline Conceptually
+
For the visually inclined, here is a conceptual diagram that illustrates how to think about the entity timeline with categorical changes overlaid on it.
-
+
+
+
## Change Event
-Each modification is modeled as a
+
+Each modification is modeled as a
[ChangeEvent](../../metadata-service/services/src/main/java/com/linkedin/metadata/timeline/data/ChangeEvent.java)
-which are grouped under [ChangeTransactions](../../metadata-service/services/src/main/java/com/linkedin/metadata/timeline/data/ChangeTransaction.java)
+which are grouped under [ChangeTransactions](../../metadata-service/services/src/main/java/com/linkedin/metadata/timeline/data/ChangeTransaction.java)
based on timestamp. A `ChangeEvent` consists of:
- `changeType`: An operational type for the change, either `ADD`, `MODIFY`, or `REMOVE`
@@ -31,10 +35,11 @@ based on timestamp. A `ChangeEvent` consists of:
- `changeDetails`: A loose property map of additional details about the change
### Change Event Examples
-- A tag was applied to a *field* of a dataset through the UI:
+
+- A tag was applied to a _field_ of a dataset through the UI:
- `changeType`: `ADD`
- `target`: `urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:,,),)` -> The field the tag is being added to
- - `category`: `TAG`
+ - `category`: `TAG`
- `elementId`: `urn:li:tag:` -> The ID of the tag being added
- `semVerChange`: `MINOR`
- A tag was added directly at the top-level to a dataset through the UI:
@@ -47,20 +52,22 @@ based on timestamp. A `ChangeEvent` consists of:
Note the `target` and `elementId` fields in the examples above to familiarize yourself with the semantics.
## Change Transaction
+
Each `ChangeTransaction` is assigned a computed semantic version based on the `ChangeEvents` that occurred within it,
-starting at `0.0.0` and updating based on whether the most significant change in the transaction is a `MAJOR`, `MINOR`, or
-`PATCH` change. The logic for what changes constitute a Major, Minor or Patch change are encoded in the category specific `Differ` implementation.
+starting at `0.0.0` and updating based on whether the most significant change in the transaction is a `MAJOR`, `MINOR`, or
+`PATCH` change. The logic for what changes constitute a Major, Minor or Patch change are encoded in the category specific `Differ` implementation.
For example, the [SchemaMetadataDiffer](../../metadata-io/src/main/java/com/linkedin/metadata/timeline/eventgenerator/SchemaMetadataChangeEventGenerator.java) has baked-in logic for determining what level of semantic change an event is based on backwards and forwards incompatibility. Read on to learn about the different categories of changes, and how semantic changes are interpreted in each.
# Categories
+
ChangeTransactions contain a `category` that represents a kind of change that happened. The `Timeline API` allows the caller to specify which categories of changes they are interested in. Categories allow us to abstract away the low-level technical change that happened in the metadata (e.g. the `schemaMetadata` aspect changed) to a high-level semantic change that happened in the metadata (e.g. the `Technical Schema` of the dataset changed). Read on to learn about the different categories that are supported today.
The Dataset entity currently supports the following categories:
## Technical Schema
-- Any structural changes in the technical schema of the dataset, such as adding, dropping, renaming columns.
-- Driven by the `schemaMetadata` aspect.
+- Any structural changes in the technical schema of the dataset, such as adding, dropping, renaming columns.
+- Driven by the `schemaMetadata` aspect.
- Changes are marked with the appropriate semantic version marker based on well-understood rules for backwards and forwards compatibility.
**_NOTE_**: Changes in field descriptions are not communicated via this category, use the Documentation category for that.
@@ -69,6 +76,7 @@ The Dataset entity currently supports the following categories:
We have provided some example scripts that demonstrate making changes to an aspect within each category and use then use the Timeline API to query the result.
All examples can be found in [smoke-test/test_resources/timeline](../../smoke-test/test_resources/timeline) and should be executed from that directory.
+
```console
% ./test_timeline_schema.sh
[2022-02-24 15:31:52,617] INFO {datahub.cli.delete_cli:130} - DataHub configured with http://localhost:8080
@@ -95,14 +103,15 @@ http://localhost:8080/openapi/timeline/v1/urn%3Ali%3Adataset%3A%28urn%3Ali%3Adat
## Ownership
-- Any changes in ownership of the dataset, adding an owner, or changing the type of the owner.
-- Driven by the `ownership` aspect.
+- Any changes in ownership of the dataset, adding an owner, or changing the type of the owner.
+- Driven by the `ownership` aspect.
- All changes are currently marked as `MINOR`.
### Example Usage
We have provided some example scripts that demonstrate making changes to an aspect within each category and use then use the Timeline API to query the result.
All examples can be found in [smoke-test/test_resources/timeline](../../smoke-test/test_resources/timeline) and should be executed from that directory.
+
```console
% ./test_timeline_ownership.sh
[2022-02-24 15:40:25,367] INFO {datahub.cli.delete_cli:130} - DataHub configured with http://localhost:8080
@@ -141,7 +150,7 @@ http://localhost:8080/openapi/timeline/v1/urn%3Ali%3Adataset%3A%28urn%3Ali%3Adat
## Tags
-- Any changes in tags applied to the dataset or to fields of the dataset.
+- Any changes in tags applied to the dataset or to fields of the dataset.
- Driven by the `schemaMetadata`, `editableSchemaMetadata` and `globalTags` aspects.
- All changes are currently marked as `MINOR`.
@@ -149,6 +158,7 @@ http://localhost:8080/openapi/timeline/v1/urn%3Ali%3Adataset%3A%28urn%3Ali%3Adat
We have provided some example scripts that demonstrate making changes to an aspect within each category and use then use the Timeline API to query the result.
All examples can be found in [smoke-test/test_resources/timeline](../../smoke-test/test_resources/timeline) and should be executed from that directory.
+
```console
% ./test_timeline_tags.sh
[2022-02-24 15:44:04,279] INFO {datahub.cli.delete_cli:130} - DataHub configured with http://localhost:8080
@@ -169,7 +179,7 @@ http://localhost:8080/openapi/timeline/v1/urn%3Ali%3Adataset%3A%28urn%3Ali%3Adat
## Documentation
-- Any changes to documentation at the dataset level or at the field level.
+- Any changes to documentation at the dataset level or at the field level.
- Driven by the `datasetProperties`, `institutionalMemory`, `schemaMetadata` and `editableSchemaMetadata`.
- Addition or removal of documentation or links is marked as `MINOR` while edits to existing documentation are marked as `PATCH` changes.
@@ -177,6 +187,7 @@ http://localhost:8080/openapi/timeline/v1/urn%3Ali%3Adataset%3A%28urn%3Ali%3Adat
We have provided some example scripts that demonstrate making changes to an aspect within each category and use then use the Timeline API to query the result.
All examples can be found in [smoke-test/test_resources/timeline](../../smoke-test/test_resources/timeline) and should be executed from that directory.
+
```console
% ./test_timeline_documentation.sh
[2022-02-24 15:45:53,950] INFO {datahub.cli.delete_cli:130} - DataHub configured with http://localhost:8080
@@ -198,7 +209,7 @@ http://localhost:8080/openapi/timeline/v1/urn%3Ali%3Adataset%3A%28urn%3Ali%3Adat
## Glossary Terms
-- Any changes to applied glossary terms to the dataset or to fields in the dataset.
+- Any changes to applied glossary terms to the dataset or to fields in the dataset.
- Driven by the `schemaMetadata`, `editableSchemaMetadata`, `glossaryTerms` aspects.
- All changes are currently marked as `MINOR`.
@@ -206,6 +217,7 @@ http://localhost:8080/openapi/timeline/v1/urn%3Ali%3Adataset%3A%28urn%3Ali%3Adat
We have provided some example scripts that demonstrate making changes to an aspect within each category and use then use the Timeline API to query the result.
All examples can be found in [smoke-test/test_resources/timeline](../../smoke-test/test_resources/timeline) and should be executed from that directory.
+
```console
% ./test_timeline_glossary.sh
[2022-02-24 15:44:56,152] INFO {datahub.cli.delete_cli:130} - DataHub configured with http://localhost:8080
@@ -228,8 +240,13 @@ http://localhost:8080/openapi/timeline/v1/urn%3Ali%3Adataset%3A%28urn%3Ali%3Adat
The API is browse-able via the UI through through the dropdown.
Here are a few screenshots showing how to navigate to it. You can try out the API and send example requests.
-
-
+
+
+
+
+
+
+
# Future Work
@@ -238,4 +255,3 @@ Here are a few screenshots showing how to navigate to it. You can try out the AP
- Adding GraphQL API support
- Supporting materialization of computed versions for entity categories (compared to the current read-time version computation)
- Support in the UI to visualize the timeline in various places (e.g. schema history, etc.)
-
diff --git a/docs/docker/development.md b/docs/docker/development.md
index 329bda2c06bac..2cb7233090809 100644
--- a/docs/docker/development.md
+++ b/docs/docker/development.md
@@ -11,7 +11,7 @@ The `docker-compose.dev.yml` file bypasses the need to rebuild docker images by
and other data. These dev images, tagged with `debug` will use your _locally built code_ with gradle.
Building locally and bypassing the need to rebuild the Docker images should be much faster.
-We highly recommend you just invoke `./gradlew quickstartDebug` task.
+We highly recommend you just invoke `./gradlew quickstartDebug` task.
```shell
./gradlew quickstartDebug
@@ -20,12 +20,12 @@ We highly recommend you just invoke `./gradlew quickstartDebug` task.
This task is defined in `docker/build.gradle` and executes the following steps:
1. Builds all required artifacts to run DataHub. This includes both application code such as the GMS war, the frontend
-distribution zip which contains javascript, as wel as secondary support docker containers.
-
+ distribution zip which contains javascript, as wel as secondary support docker containers.
+
1. Locally builds Docker images with the expected `debug` tag required by the docker compose files.
1. Runs the special `docker-compose.dev.yml` and supporting docker-compose files to mount local files directly in the
-containers with remote debugging ports enabled.
+ containers with remote debugging ports enabled.
Once the `debug` docker images are constructed you'll see images similar to the following:
@@ -45,6 +45,7 @@ At this point it is possible to view the DataHub UI at `http://localhost:9002` a
Next, perform the desired modifications and rebuild the frontend and/or GMS components.
**Builds GMS**
+
```shell
./gradlew :metadata-service:war:build
```
@@ -57,7 +58,7 @@ Including javascript components.
./gradlew :datahub-frontend:build
```
-After building the artifacts only a restart of the container(s) is required to run with the updated code.
+After building the artifacts only a restart of the container(s) is required to run with the updated code.
The restart can be performed using a docker UI, the docker cli, or the following gradle task.
```shell
@@ -69,11 +70,13 @@ The restart can be performed using a docker UI, the docker cli, or the following
The following commands can pause the debugging environment to release resources when not needed.
Pause containers and free resources.
+
```shell
docker compose -p datahub stop
```
Resume containers for further debugging.
+
```shell
docker compose -p datahub start
```
@@ -92,8 +95,9 @@ Environment variables control the debugging ports for GMS and the frontend.
The screenshot shows an example configuration for IntelliJ using the default GMS debugging port of 5001.
-
-
+
+
+
## Tips for People New To Docker
@@ -125,9 +129,11 @@ running. If you, for some reason, wish to change this behavior, check out these
```
docker-compose -p datahub -f docker-compose.yml -f docker-compose.override.yml -f docker-compose-without-neo4j.m1.yml -f docker-compose.dev.yml up datahub-gms
```
+
Will only start `datahub-gms` and its dependencies.
```
docker-compose -p datahub -f docker-compose.yml -f docker-compose.override.yml -f docker-compose-without-neo4j.m1.yml -f docker-compose.dev.yml up --no-deps datahub-gms
```
+
Will only start `datahub-gms`, without dependencies.
diff --git a/docs/domains.md b/docs/domains.md
index c846a753417c5..f668f5da5d919 100644
--- a/docs/domains.md
+++ b/docs/domains.md
@@ -4,17 +4,16 @@ import FeatureAvailability from '@site/src/components/FeatureAvailability';
-Starting in version `0.8.25`, DataHub supports grouping data assets into logical collections called **Domains**. Domains are curated, top-level folders or categories where related assets can be explicitly grouped. Management of Domains can be centralized, or distributed out to Domain owners Currently, an asset can belong to only one Domain at a time.
+Starting in version `0.8.25`, DataHub supports grouping data assets into logical collections called **Domains**. Domains are curated, top-level folders or categories where related assets can be explicitly grouped. Management of Domains can be centralized, or distributed out to Domain owners Currently, an asset can belong to only one Domain at a time.
## Domains Setup, Prerequisites, and Permissions
What you need to create and add domains:
-* **Manage Domains** platform privilege to add domains at the entity level
+- **Manage Domains** platform privilege to add domains at the entity level
You can create this privileges by creating a new [Metadata Policy](./authorization/policies.md).
-
## Using Domains
### Creating a Domain
@@ -22,20 +21,20 @@ You can create this privileges by creating a new [Metadata Policy](./authorizati
To create a Domain, first navigate to the **Domains** tab in the top-right menu of DataHub.
-
+
Once you're on the Domains page, you'll see a list of all the Domains that have been created on DataHub. Additionally, you can
-view the number of entities inside each Domain.
+view the number of entities inside each Domain.
-
+
To create a new Domain, click '+ New Domain'.
-
+
Inside the form, you can choose a name for your Domain. Most often, this will align with your business units or groups, for example
@@ -45,34 +44,36 @@ Inside the form, you can choose a name for your Domain. Most often, this will al
Click on 'Advanced' to show the option to set a custom Domain id. The Domain id determines what will appear in the DataHub 'urn' (primary key)
for the Domain. This option is useful if you intend to refer to Domains by a common name inside your code, or you want the primary
-key to be human-readable. Proceed with caution: once you select a custom id, it cannot be easily changed.
+key to be human-readable. Proceed with caution: once you select a custom id, it cannot be easily changed.
-
+
-By default, you don't need to worry about this. DataHub will auto-generate a unique Domain id for you.
+By default, you don't need to worry about this. DataHub will auto-generate a unique Domain id for you.
-Once you've chosen a name and a description, click 'Create' to create the new Domain.
+Once you've chosen a name and a description, click 'Create' to create the new Domain.
### Assigning an Asset to a Domain
-You can assign assets to Domain using the UI or programmatically using the API or during ingestion.
+You can assign assets to Domain using the UI or programmatically using the API or during ingestion.
#### UI-Based Assignment
-To assign an asset to a Domain, simply navigate to the asset's profile page. At the bottom left-side menu bar, you'll
+
+To assign an asset to a Domain, simply navigate to the asset's profile page. At the bottom left-side menu bar, you'll
see a 'Domain' section. Click 'Set Domain', and then search for the Domain you'd like to add to. When you're done, click 'Add'.
-
+
-To remove an asset from a Domain, click the 'x' icon on the Domain tag.
+To remove an asset from a Domain, click the 'x' icon on the Domain tag.
> Notice: Adding or removing an asset from a Domain requires the `Edit Domain` Metadata Privilege, which can be granted
> by a [Policy](authorization/policies.md).
#### Ingestion-time Assignment
+
All SQL-based ingestion sources support assigning domains during ingestion using the `domain` configuration. Consult your source's configuration details page (e.g. [Snowflake](./generated/ingestion/sources/snowflake.md)), to verify that it supports the Domain capability.
:::note
@@ -81,7 +82,6 @@ Assignment of domains during ingestion will overwrite domains that you have assi
:::
-
Here is a quick example of a snowflake ingestion recipe that has been enhanced to attach the **Analytics** domain to all tables in the **long_tail_companions** database in the **analytics** schema, and the **Finance** domain to all tables in the **long_tail_companions** database in the **ecommerce** schema.
```yaml
@@ -90,7 +90,7 @@ source:
config:
username: ${SNOW_USER}
password: ${SNOW_PASS}
- account_id:
+ account_id:
warehouse: COMPUTE_WH
role: accountadmin
database_pattern:
@@ -149,27 +149,27 @@ source:
Once you've created a Domain, you can use the search bar to find it.
-
+
Clicking on the search result will take you to the Domain's profile, where you
-can edit its description, add / remove owners, and view the assets inside the Domain.
+can edit its description, add / remove owners, and view the assets inside the Domain.
-
+
Once you've added assets to a Domain, you can filter search results to limit to those Assets
-within a particular Domain using the left-side search filters.
+within a particular Domain using the left-side search filters.
-
+
On the homepage, you'll also find a list of the most popular Domains in your organization.
-
+
## Additional Resources
@@ -184,11 +184,11 @@ On the homepage, you'll also find a list of the most popular Domains in your org
### GraphQL
-* [domain](../graphql/queries.md#domain)
-* [listDomains](../graphql/queries.md#listdomains)
-* [createDomains](../graphql/mutations.md#createdomain)
-* [setDomain](../graphql/mutations.md#setdomain)
-* [unsetDomain](../graphql/mutations.md#unsetdomain)
+- [domain](../graphql/queries.md#domain)
+- [listDomains](../graphql/queries.md#listdomains)
+- [createDomains](../graphql/mutations.md#createdomain)
+- [setDomain](../graphql/mutations.md#setdomain)
+- [unsetDomain](../graphql/mutations.md#unsetdomain)
#### Examples
@@ -196,11 +196,13 @@ On the homepage, you'll also find a list of the most popular Domains in your org
```graphql
mutation createDomain {
- createDomain(input: { name: "My New Domain", description: "An optional description" })
+ createDomain(
+ input: { name: "My New Domain", description: "An optional description" }
+ )
}
```
-This query will return an `urn` which you can use to fetch the Domain details.
+This query will return an `urn` which you can use to fetch the Domain details.
**Fetching a Domain by Urn**
@@ -209,11 +211,11 @@ query getDomain {
domain(urn: "urn:li:domain:engineering") {
urn
properties {
- name
- description
+ name
+ description
}
entities {
- total
+ total
}
}
}
@@ -223,7 +225,10 @@ query getDomain {
```graphql
mutation setDomain {
- setDomain(entityUrn: "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)", domainUrn: "urn:li:domain:engineering")
+ setDomain(
+ entityUrn: "urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)"
+ domainUrn: "urn:li:domain:engineering"
+ )
}
```
@@ -231,7 +236,7 @@ mutation setDomain {
### DataHub Blog
-* [Just Shipped: UI-Based Ingestion, Data Domains & Containers, Tableau support, and MORE!](https://blog.datahubproject.io/just-shipped-ui-based-ingestion-data-domains-containers-and-more-f1b1c90ed3a)
+- [Just Shipped: UI-Based Ingestion, Data Domains & Containers, Tableau support, and MORE!](https://blog.datahubproject.io/just-shipped-ui-based-ingestion-data-domains-containers-and-more-f1b1c90ed3a)
## FAQ and Troubleshooting
@@ -243,9 +248,9 @@ DataHub supports Tags, Glossary Terms, & Domains as distinct types of Metadata t
- **Glossary Terms**: A controlled vocabulary, with optional hierarchy. Terms are typically used to standardize types of leaf-level attributes (i.e. schema fields) for governance. E.g. (EMAIL_PLAINTEXT)
- **Domains**: A set of top-level categories. Usually aligned to business units / disciplines to which the assets are most relevant. Central or distributed management. Single Domain assignment per data asset.
-*Need more help? Join the conversation in [Slack](http://slack.datahubproject.io)!*
+_Need more help? Join the conversation in [Slack](http://slack.datahubproject.io)!_
### Related Features
-* [Glossary Terms](./glossary/business-glossary.md)
-* [Tags](./tags.md)
+- [Glossary Terms](./glossary/business-glossary.md)
+- [Tags](./tags.md)
diff --git a/docs/glossary/business-glossary.md b/docs/glossary/business-glossary.md
index faab6f12fc55e..6a3244cd847e1 100644
--- a/docs/glossary/business-glossary.md
+++ b/docs/glossary/business-glossary.md
@@ -12,7 +12,7 @@ import FeatureAvailability from '@site/src/components/FeatureAvailability';
When working in complex data ecosystems, it is very useful to organize data assets using a shared vocabulary. The Business Glossary feature in DataHub helps you do this, by providing a framework for defining a standardized set of data concepts and then associating them with the physical assets that exist within your data ecosystem.
-Within this document, we'll introduce the core concepts comprising DataHub's Business Glossary feature and show you how to put it to work in your organization.
+Within this document, we'll introduce the core concepts comprising DataHub's Business Glossary feature and show you how to put it to work in your organization.
### Terms & Term Groups
@@ -31,59 +31,82 @@ In order to view a Business Glossary, users must have the Platform Privilege cal
Once granted this privilege, you can access your Glossary by clicking the dropdown at the top of the page called **Govern** and then click **Glossary**:
-
+
+
+
You are now at the root of your Glossary and should see all Terms and Term Groups with no parents assigned to them. You should also notice a hierarchy navigator on the left where you can easily check out the structure of your Glossary!
-
+
+
+
## Creating a Term or Term Group
There are two ways to create Terms and Term Groups through the UI. First, you can create directly from the Glossary home page by clicking the menu dots on the top right and selecting your desired option:
-
+
+
+
You can also create Terms or Term Groups directly from a Term Group's page. In order to do that you need to click the menu dots on the top right and select what you want:
-
+
+
+
Note that the modal that pops up will automatically set the current Term Group you are in as the **Parent**. You can easily change this by selecting the input and navigating through your Glossary to find your desired Term Group. In addition, you could start typing the name of a Term Group to see it appear by searching. You can also leave this input blank in order to create a Term or Term Group with no parent.
-
+
+
+
## Editing a Term or Term Group
In order to edit a Term or Term Group, you first need to go the page of the Term or Term group you want to edit. Then simply click the edit icon right next to the name to open up an inline editor. Change the text and it will save when you click outside or hit Enter.
-
+
+
+
## Moving a Term or Term Group
Once a Term or Term Group has been created, you can always move it to be under a different Term Group parent. In order to do this, click the menu dots on the top right of either entity and select **Move**.
-
+
+
+
This will open a modal where you can navigate through your Glossary to find your desired Term Group.
-
+
+
+
## Deleting a Term or Term Group
In order to delete a Term or Term Group, you need to go to the entity page of what you want to delete then click the menu dots on the top right. From here you can select **Delete** followed by confirming through a separate modal. **Note**: at the moment we only support deleting Term Groups that do not have any children. Until cascade deleting is supported, you will have to delete all children first, then delete the Term Group.
-
+
+
+
## Adding a Term to an Entity
Once you've defined your Glossary, you can begin attaching terms to data assets. To add a Glossary Term to an asset, go to the entity page of your asset and find the **Add Terms** button on the right sidebar.
-
+
+
+
In the modal that pops up you can select the Term you care about in one of two ways:
+
- Search for the Term by name in the input
- Navigate through the Glossary dropdown that appears after clicking into the input
-
+
+
+
## Privileges
@@ -92,7 +115,7 @@ Glossary Terms and Term Groups abide by metadata policies like other entities. H
- **Manage Direct Glossary Children**: If a user has this privilege on a Glossary Term Group, they will be able to create, edit, and delete Terms and Term Groups directly underneath the Term Group they have this privilege on.
- **Manage All Glossary Children**: If a user has this privilege on a Glossary Term Group, they will be able to create, edit, and delete any Term or Term Group anywhere underneath the Term Group they have this privilege on. This applies to the children of a child Term Group as well (and so on).
-## Managing Glossary with Git
+## Managing Glossary with Git
In many cases, it may be preferable to manage the Business Glossary in a version-control system like git. This can make
managing changes across teams easier, by funneling all changes through a change management and review process.
@@ -103,43 +126,41 @@ the glossary file, and how to ingest it into DataHub, check out the [Business Gl
## About Glossary Term Relationships
-DataHub supports 2 different kinds of relationships _between_ individual Glossary Terms: **Inherits From** and **Contains**.
+DataHub supports 2 different kinds of relationships _between_ individual Glossary Terms: **Inherits From** and **Contains**.
**Contains** can be used to relate two Glossary Terms when one is a _superset_ of or _consists_ of another.
For example: **Address** Term _Contains_ **Zip Code** Term, **Street** Term, & **City** Term (_Has-A_ style relationship)
**Inherits** can be used to relate two Glossary Terms when one is a _sub-type_ or _sub-category_ of another.
-For example: **Email** Term _Inherits From_ **PII** Term (_Is-A_ style relationship)
+For example: **Email** Term _Inherits From_ **PII** Term (_Is-A_ style relationship)
These relationship types allow you to map the concepts existing within your organization, enabling you to
change the mapping between concepts behind the scenes, without needing to change the Glossary Terms
-that are attached to individual Data Assets and Columns.
+that are attached to individual Data Assets and Columns.
For example, you can define a very specific, concrete Glossary Term like `Email Address` to represent a physical
-data type, and then associate this with a higher-level `PII` Glossary Term via an `Inheritance` relationship.
-This allows you to easily maintain a set of all Data Assets that contain or process `PII`, while keeping it easy to add
+data type, and then associate this with a higher-level `PII` Glossary Term via an `Inheritance` relationship.
+This allows you to easily maintain a set of all Data Assets that contain or process `PII`, while keeping it easy to add
and remove new Terms from the `PII` Classification, e.g. without requiring re-annotation of individual Data Assets or Columns.
-
-
-
## Demo
Check out [our demo site](https://demo.datahubproject.io/glossary) to see an example Glossary and how it works!
### GraphQL
-* [addTerm](../../graphql/mutations.md#addterm)
-* [addTerms](../../graphql/mutations.md#addterms)
-* [batchAddTerms](../../graphql/mutations.md#batchaddterms)
-* [removeTerm](../../graphql/mutations.md#removeterm)
-* [batchRemoveTerms](../../graphql/mutations.md#batchremoveterms)
-* [createGlossaryTerm](../../graphql/mutations.md#createglossaryterm)
-* [createGlossaryNode](../../graphql/mutations.md#createglossarynode) (Term Group)
+- [addTerm](../../graphql/mutations.md#addterm)
+- [addTerms](../../graphql/mutations.md#addterms)
+- [batchAddTerms](../../graphql/mutations.md#batchaddterms)
+- [removeTerm](../../graphql/mutations.md#removeterm)
+- [batchRemoveTerms](../../graphql/mutations.md#batchremoveterms)
+- [createGlossaryTerm](../../graphql/mutations.md#createglossaryterm)
+- [createGlossaryNode](../../graphql/mutations.md#createglossarynode) (Term Group)
You can easily fetch the Glossary Terms for an entity with a given its URN using the **glossaryTerms** property. Check out [Working with Metadata Entities](../api/graphql/how-to-set-up-graphql.md#querying-for-glossary-terms-of-an-asset) for an example.
## Resources
+
- [Creating a Business Glossary and Putting it to use in DataHub](https://blog.datahubproject.io/creating-a-business-glossary-and-putting-it-to-use-in-datahub-43a088323c12)
- [Tags and Terms: Two Powerful DataHub Features, Used in Two Different Scenarios](https://medium.com/datahub-project/tags-and-terms-two-powerful-datahub-features-used-in-two-different-scenarios-b5b4791e892e)
diff --git a/docs/how/configuring-authorization-with-apache-ranger.md b/docs/how/configuring-authorization-with-apache-ranger.md
index 26d3be6d358b2..c26dd1a516445 100644
--- a/docs/how/configuring-authorization-with-apache-ranger.md
+++ b/docs/how/configuring-authorization-with-apache-ranger.md
@@ -2,7 +2,9 @@
title: "Configuring Authorization with Apache Ranger"
hide_title: true
---
+
# Configuring Authorization with Apache Ranger
+
DataHub integration with Apache Ranger allows DataHub Authorization policies to be controlled inside Apache Ranger.
Admins can create users, groups and roles on Apache Ranger, and then assign them to Ranger policies to control the authorization of requests to DataHub.
@@ -13,218 +15,249 @@ We'll break down configuration of the DataHub Apache Ranger Plugin into two part
> Disclaimer: All configurations shown in this documented were tested against [Privacera Platform](https://privacera.com/) v6.3.0.1.
-# Prerequisites
-- User identifier present in CorpRole URN should be the name of the AD/LDAP user. For example in URN **urn:li:corpuser:datahub**, the **datahub** should present as name of user in AD/LDAP
+# Prerequisites
+
+- User identifier present in CorpRole URN should be the name of the AD/LDAP user. For example in URN **urn:li:corpuser:datahub**, the **datahub** should present as name of user in AD/LDAP
- Apache Ranger and DataHub are configured for authentication via same IDP (either LDAP + JaaS or OIDC SSO)
- Apache Ranger service available via HTTP
- Basic authentication is enabled on Apache Ranger Service
-# Configuration
+# Configuration
## Configuring your Apache Ranger Deployment
Perform the following steps to configure an Apache Ranger deployment to support creating access policies compatible with DataHub.
For kubernetes example command, please replace the <ranger-pod-name> and <namespace> as per your environment.
-1. Download the **datahub-ranger-plugin** from [Maven](https://mvnrepository.com/artifact/io.acryl/datahub-ranger-plugin)
-2. Create a "datahub" directory inside the "ranger-plugins" directory where Apache Ranger is deployed. For example, to do this in a Privacera container
+1. Download the **datahub-ranger-plugin** from [Maven](https://mvnrepository.com/artifact/io.acryl/datahub-ranger-plugin)
+2. Create a "datahub" directory inside the "ranger-plugins" directory where Apache Ranger is deployed. For example, to do this in a Privacera container
+
+ _Docker command:_
- *Docker command:*
```bash
docker exec privacera_ranger_1 mkdir ews/webapp/WEB-INF/classes/ranger-plugins/datahub
```
- *Kubernetes command:*
+
+ _Kubernetes command:_
+
```bash
- kubectl exec mkdir ews/webapp/WEB-INF/classes/ranger-plugins/datahub -n
- ```
-3. Copy the downloaded **datahub-ranger-plugin** jar into the newly created "datahub" directory. For example, to do this in a Privacera container
+ kubectl exec mkdir ews/webapp/WEB-INF/classes/ranger-plugins/datahub -n
+ ```
+
+3. Copy the downloaded **datahub-ranger-plugin** jar into the newly created "datahub" directory. For example, to do this in a Privacera container
+
+ _Docker command:_
- *Docker command:*
```bash
docker cp datahub-ranger-plugin-.jar privacera_ranger_1:/opt/ranger/ranger-2.1.0-admin/ews/webapp/WEB-INF/classes/ranger-plugins/datahub/
```
- *Kubernetes command:*
+
+ _Kubernetes command:_
+
```bash
- kubectl cp datahub-ranger-plugin-.jar :/opt/ranger/ranger-2.1.0-admin/ews/webapp/WEB-INF/classes/ranger-plugins/datahub/ -n
- ```
-4. Download the [service definition file](https://github.com/acryldata/datahub-ranger-auth-plugin/blob/main/datahub-ranger-plugin/conf/servicedef.json). This service definition is the ranger service definition JSON file for datahub-ranger-plugin-<version>.jar
-5. Register the downloaded service definition file with Apache Ranger Service. To do this executes the below curl command
-Replace variables with corresponding values in curl command
- - <ranger-admin-username>
- - <ranger-admin-password>
- - <ranger-host>
- ```bash
- curl -u : -X POST -H "Accept: application/json" -H "Content-Type: application/json" --data @servicedef.json http://:6080/service/public/v2/api/servicedef
+ kubectl cp datahub-ranger-plugin-.jar :/opt/ranger/ranger-2.1.0-admin/ews/webapp/WEB-INF/classes/ranger-plugins/datahub/ -n
```
+4. Download the [service definition file](https://github.com/acryldata/datahub-ranger-auth-plugin/blob/main/datahub-ranger-plugin/conf/servicedef.json). This service definition is the ranger service definition JSON file for datahub-ranger-plugin-<version>.jar
+5. Register the downloaded service definition file with Apache Ranger Service. To do this executes the below curl command
+ Replace variables with corresponding values in curl command
+
+ - <ranger-admin-username>
+ - <ranger-admin-password>
+ - <ranger-host>
+
+ ```bash
+ curl -u : -X POST -H "Accept: application/json" -H "Content-Type: application/json" --data @servicedef.json http://:6080/service/public/v2/api/servicedef
+ ```
+
### Defining a Ranger Policy
Now, you should have the DataHub plugin registered with Apache Ranger. Next, we'll create a sample user and add them to our first resource policy.
-1. Login into the Apache Ranger UI (Privacera Portal) to performs below steps.
-2. Verify **datahub-ranger-plugin** is registered successfully: The **datahub-ranger-plugin** should be visible as **DATAHUB** in *Access Management -> Resource Policies*.
+1. Login into the Apache Ranger UI (Privacera Portal) to performs below steps.
+2. Verify **datahub-ranger-plugin** is registered successfully: The **datahub-ranger-plugin** should be visible as **DATAHUB** in _Access Management -> Resource Policies_.
3. Create a service under the plugin **DATAHUB** with name **ranger_datahub**
- **DATAHUB** plugin and **ranger_datahub** service is shown in below screenshot:
-
- 
+ **DATAHUB** plugin and **ranger_datahub** service is shown in below screenshot:
+
+
+
+
-4. Create a new policy under service **ranger_datahub** - this will be used to control DataHub authorization.
+4. Create a new policy under service **ranger_datahub** - this will be used to control DataHub authorization.
5. Create a test user & assign them to a policy. We'll use the `datahub` user, which is the default root user inside DataHub.
To do this performs below steps
- - Create a user **datahub**
- - Create a policy under **ranger_datahub** service. To assign [Platform Privileges](../authorization/policies.md#privileges) (e.g. Admin privileges), simply use the "platform" resource type which is defined. To test the flow, we can simply assign the **datahub** user all platform privileges that are available through the Ranger UI. This will enable the "datahub" to have full platform admin privileges.
- > To define fine-grained resource privileges, e.g. for DataHub Datasets, Dashboards, Charts, and more, you can simply select the appropriate Resource Type in the Ranger policy builder. You should also see a list of privileges that are supported for each resource type, which correspond to the actions that you can perform. To learn more about supported privileges, check out the DataHub [Policies Guide](../authorization/policies.md#privileges).
-
- DataHub platform access policy screenshot:
-
- 
+ - Create a user **datahub**
+ - Create a policy under **ranger_datahub** service. To assign [Platform Privileges](../authorization/policies.md#privileges) (e.g. Admin privileges), simply use the "platform" resource type which is defined. To test the flow, we can simply assign the **datahub** user all platform privileges that are available through the Ranger UI. This will enable the "datahub" to have full platform admin privileges.
+
+ > To define fine-grained resource privileges, e.g. for DataHub Datasets, Dashboards, Charts, and more, you can simply select the appropriate Resource Type in the Ranger policy builder. You should also see a list of privileges that are supported for each resource type, which correspond to the actions that you can perform. To learn more about supported privileges, check out the DataHub [Policies Guide](../authorization/policies.md#privileges).
-Once we've created our first policy, we can set up DataHub to start authorizing requests using Ranger policies.
+ DataHub platform access policy screenshot:
+
+
+
+
+Once we've created our first policy, we can set up DataHub to start authorizing requests using Ranger policies.
## Configuring your DataHub Deployment
Perform the following steps to configure DataHub to send incoming requests to Apache Ranger for authorization.
1. Download Apache Ranger security xml [ranger-datahub-security.xml](https://github.com/acryldata/datahub-ranger-auth-plugin/blob/main/datahub-ranger-plugin/conf/ranger-datahub-security.xml)
-2. In **ranger-datahub-security.xml** edit the value of property *ranger.plugin.datahub.policy.rest.url*. Sample snippet is shown below
- ```xml
-
- ranger.plugin.datahub.policy.rest.url
- http://199.209.9.70:6080
-
- URL to Ranger Admin
-
-
- ```
+2. In **ranger-datahub-security.xml** edit the value of property _ranger.plugin.datahub.policy.rest.url_. Sample snippet is shown below
+ ```xml
+
+ ranger.plugin.datahub.policy.rest.url
+ http://199.209.9.70:6080
+
+ URL to Ranger Admin
+
+
+ ```
As per your deployment follow either Docker or Kubernetes section below
+
### Docker
-
+
**Build Ranger Authorizer Plugin**
+
1. Clone DataHub Repo: Clone the DataHub repository
```shell
cd ~/
git clone https://github.com/acryldata/datahub-ranger-auth-plugin.git
```
-2. Go inside the datahub directory: You should be inside the `datahub-ranger-auth-plugin` directory to execute build command
+2. Go inside the datahub directory: You should be inside the `datahub-ranger-auth-plugin` directory to execute build command
```shell
cd ~/datahub-ranger-auth-plugin/
```
-3. Build plugin: Execute below gradle command to build Ranger Authorizer Plugin jar
+3. Build plugin: Execute below gradle command to build Ranger Authorizer Plugin jar
+
```shell
./gradlew apache-ranger-plugin:shadowJar
```
- This step will generate a jar file i.e. ./apache-ranger-plugin/build/libs/apache-ranger-plugin-<version>-SNAPSHOT.jar.
- Let's call this jar as ranger-plugin-jar. We need this jar in below step (Configure Ranger Authorizer Plugin)
+ This step will generate a jar file i.e. ./apache-ranger-plugin/build/libs/apache-ranger-plugin-<version>-SNAPSHOT.jar.
+ Let's call this jar as ranger-plugin-jar. We need this jar in below step (Configure Ranger Authorizer Plugin)
**Configure Ranger Authorizer Plugin**
On the host where `datahub-gms` is deployed, follow these steps:
-1. Create directory `~/.datahub/plugins/auth/apache-ranger-authorizer/`: Executes below command
- ```bash
- mkdir -p ~/.datahub/plugins/auth/apache-ranger-authorizer/
+
+1. Create directory `~/.datahub/plugins/auth/apache-ranger-authorizer/`: Executes below command
+ ```bash
+ mkdir -p ~/.datahub/plugins/auth/apache-ranger-authorizer/
```
2. Copy `ranger-datahub-security.xml` file to `~/.datahub/plugins/auth/apache-ranger-authorizer/`
-3. Copy ranger-plugin-jar: Copy the apache-ranger-plugin-<version>-SNAPSHOT.jar
- ```bash
+3. Copy ranger-plugin-jar: Copy the apache-ranger-plugin-<version>-SNAPSHOT.jar
+ ```bash
cp ./apache-ranger-plugin/build/libs/apache-ranger-plugin--SNAPSHOT.jar ~/.datahub/plugins/auth/apache-ranger-authorizer/apache-ranger-authorizer.jar
```
4. Create `config.yml`: Create config.yml if not exist
- ```shell
- touch ~/.datahub/plugins/auth/config.yml
- ```
+ ```shell
+ touch ~/.datahub/plugins/auth/config.yml
+ ```
5. Set Apache Ranger Plugin config: Add below entry in config.yml file. Set username and password to Apache Ranger user credentials
- ```yaml
- plugins:
- - name: "apache-ranger-authorizer"
- type: "authorizer"
- enabled: "true"
- params:
- className: "com.datahub.authorization.ranger.RangerAuthorizer"
- configs:
- username: ""
- password: ""
+ ```yaml
+ plugins:
+ - name: "apache-ranger-authorizer"
+ type: "authorizer"
+ enabled: "true"
+ params:
+ className: "com.datahub.authorization.ranger.RangerAuthorizer"
+ configs:
+ username: ""
+ password: ""
```
6. Restart DataHub GMS container (i.e. `datahub-gms`)
-
### Kubernetes
Helm support is coming soon.
-
-That's it! Now we can test out the integration.
+That's it! Now we can test out the integration.
### Validating your Setup
-To verify that things are working as expected, we can test that the root **datahub** user has all Platform Privileges and is able to perform all operations: managing users & groups, creating domains, and more. To do this, simply log into your DataHub deployment via the root DataHub user.
-# Revert the Configuration
-If you want to revert your deployment configuration and don't want Apache Ranger to control the authorization of your DataHub deployment
-then follow the below sections to undo the configuration steps you have performed in section *Configuring Authorization with Apache Ranger*
+To verify that things are working as expected, we can test that the root **datahub** user has all Platform Privileges and is able to perform all operations: managing users & groups, creating domains, and more. To do this, simply log into your DataHub deployment via the root DataHub user.
+
+# Revert the Configuration
+
+If you want to revert your deployment configuration and don't want Apache Ranger to control the authorization of your DataHub deployment
+then follow the below sections to undo the configuration steps you have performed in section _Configuring Authorization with Apache Ranger_
1. Revert Configuration of your Apache Ranger Deployment
2. Revert Configuration of your DataHub Deployment
## Revert Configuration of your Apache Ranger Deployment
- For kubernetes example command, please replace the <ranger-pod-name> and <namespace> as per your environment.
- 1. Delete **ranger_datahub** service: Login into the Privacera Portal and delete service **ranger_datahub**
+For kubernetes example command, please replace the <ranger-pod-name> and <namespace> as per your environment.
- **ranger_datahub** service is shown in below screenshot:
+1. Delete **ranger_datahub** service: Login into the Privacera Portal and delete service **ranger_datahub**
- 
+ **ranger_datahub** service is shown in below screenshot:
- 2. Delete **datahub** plugin: Execute below curl command to delete **datahub** plugin
- Replace variables with corresponding values in curl command
- - <ranger-admin-username>
- - <ranger-admin-password>
- - <ranger-host>
+
+
+
- ```bash
- curl -u : -X DELETE -H "Accept: application/json" -H "Content-Type: application/json" http://:6080/service/public/v2/api/servicedef/name/datahub
- ```
- 3. Delete **datahub** plugin directory: Execute below command to delete the **datahub** plugin directory from Apache Ranger
+2. Delete **datahub** plugin: Execute below curl command to delete **datahub** plugin
+ Replace variables with corresponding values in curl command
- *Docker command:*
- ```bash
- docker exec privacera_ranger_1 rm -rf ews/webapp/WEB-INF/classes/ranger-plugins/datahub
- ```
- *Kubernetes command:*
- ```bash
- kubectl exec -n -- sh -c 'rm -rf ews/webapp/WEB-INF/classes/ranger-plugins/datahub'
- ```
+ - <ranger-admin-username>
+ - <ranger-admin-password>
+ - <ranger-host>
+
+ ```bash
+ curl -u : -X DELETE -H "Accept: application/json" -H "Content-Type: application/json" http://:6080/service/public/v2/api/servicedef/name/datahub
+ ```
+
+3. Delete **datahub** plugin directory: Execute below command to delete the **datahub** plugin directory from Apache Ranger
+
+ _Docker command:_
+
+ ```bash
+ docker exec privacera_ranger_1 rm -rf ews/webapp/WEB-INF/classes/ranger-plugins/datahub
+ ```
+
+ _Kubernetes command:_
+
+ ```bash
+ kubectl exec -n -- sh -c 'rm -rf ews/webapp/WEB-INF/classes/ranger-plugins/datahub'
+ ```
-
## Revert Configuration of your DataHub Deployment
-### Docker
- 1. Remove Apache Ranger Plugin entry: From `config.yml` file remove the entry which was added for Apache Ranger Plugin
- 2. Redeploy DataHub (`datahub-gms`)
+
+### Docker
+
+1. Remove Apache Ranger Plugin entry: From `config.yml` file remove the entry which was added for Apache Ranger Plugin
+2. Redeploy DataHub (`datahub-gms`)
+
### Kubernetes
- For kubernetes example command, please replace the <namespace> as per your environment.
+
+For kubernetes example command, please replace the <namespace> as per your environment.
+
1. Open deployment editor: Execute below command
- ```bash
- kubectl edit deployment datahub-datahub-gms -n
- ```
-2. Remove below environments variables
+ ```bash
+ kubectl edit deployment datahub-datahub-gms -n
+ ```
+2. Remove below environments variables
1. AUTH_POLICIES_ENABLED
2. RANGER_AUTHORIZER_ENABLED
3. RANGER_USERNAME
4. RANGER_PASSWORD
-3. Remove below volumes related settings
- 1. volumes
+3. Remove below volumes related settings
+ 1. volumes
2. volumeMounts
4. Save and quit the editor and use below command to check status of **datahub-datahub-gms** deployment rollout
- ```bash
- kubectl rollout status deployment/datahub-datahub-gms -n
- ```
- On successful rollout you should see a message *deployment "datahub-datahub-gms" successfully rolled out*
-
+ ```bash
+ kubectl rollout status deployment/datahub-datahub-gms -n
+ ```
+ On successful rollout you should see a message _deployment "datahub-datahub-gms" successfully rolled out_
### Validating your Setup
-To verify that things are working as expected, we can test that the root **datahub** user has all Platform Privileges and is able to perform all operations: managing users & groups, creating domains, and more. To do this, simply log into your DataHub deployment via the root DataHub user.
+
+To verify that things are working as expected, we can test that the root **datahub** user has all Platform Privileges and is able to perform all operations: managing users & groups, creating domains, and more. To do this, simply log into your DataHub deployment via the root DataHub user.
diff --git a/docs/imgs/add-schema-tag.png b/docs/imgs/add-schema-tag.png
deleted file mode 100644
index b6fd273389c90..0000000000000
Binary files a/docs/imgs/add-schema-tag.png and /dev/null differ
diff --git a/docs/imgs/add-tag-search.png b/docs/imgs/add-tag-search.png
deleted file mode 100644
index a129f5eba4271..0000000000000
Binary files a/docs/imgs/add-tag-search.png and /dev/null differ
diff --git a/docs/imgs/add-tag.png b/docs/imgs/add-tag.png
deleted file mode 100644
index 386b4cdcd9911..0000000000000
Binary files a/docs/imgs/add-tag.png and /dev/null differ
diff --git a/docs/imgs/added-tag.png b/docs/imgs/added-tag.png
deleted file mode 100644
index 96ae48318a35a..0000000000000
Binary files a/docs/imgs/added-tag.png and /dev/null differ
diff --git a/docs/imgs/airflow/connection_error.png b/docs/imgs/airflow/connection_error.png
deleted file mode 100644
index c2f3344b8cc45..0000000000000
Binary files a/docs/imgs/airflow/connection_error.png and /dev/null differ
diff --git a/docs/imgs/airflow/datahub_lineage_view.png b/docs/imgs/airflow/datahub_lineage_view.png
deleted file mode 100644
index c7c774c203d2f..0000000000000
Binary files a/docs/imgs/airflow/datahub_lineage_view.png and /dev/null differ
diff --git a/docs/imgs/airflow/datahub_pipeline_entity.png b/docs/imgs/airflow/datahub_pipeline_entity.png
deleted file mode 100644
index 715baefd784ca..0000000000000
Binary files a/docs/imgs/airflow/datahub_pipeline_entity.png and /dev/null differ
diff --git a/docs/imgs/airflow/datahub_pipeline_view.png b/docs/imgs/airflow/datahub_pipeline_view.png
deleted file mode 100644
index 5b3afd13c4ce6..0000000000000
Binary files a/docs/imgs/airflow/datahub_pipeline_view.png and /dev/null differ
diff --git a/docs/imgs/airflow/datahub_task_view.png b/docs/imgs/airflow/datahub_task_view.png
deleted file mode 100644
index 66b3487d87319..0000000000000
Binary files a/docs/imgs/airflow/datahub_task_view.png and /dev/null differ
diff --git a/docs/imgs/airflow/entity_page_screenshot.png b/docs/imgs/airflow/entity_page_screenshot.png
deleted file mode 100644
index a782969a1f17b..0000000000000
Binary files a/docs/imgs/airflow/entity_page_screenshot.png and /dev/null differ
diff --git a/docs/imgs/airflow/find_the_dag.png b/docs/imgs/airflow/find_the_dag.png
deleted file mode 100644
index 37cda041e4b75..0000000000000
Binary files a/docs/imgs/airflow/find_the_dag.png and /dev/null differ
diff --git a/docs/imgs/airflow/finding_failed_log.png b/docs/imgs/airflow/finding_failed_log.png
deleted file mode 100644
index 96552ba1e1983..0000000000000
Binary files a/docs/imgs/airflow/finding_failed_log.png and /dev/null differ
diff --git a/docs/imgs/airflow/paused_dag.png b/docs/imgs/airflow/paused_dag.png
deleted file mode 100644
index c314de5d38d75..0000000000000
Binary files a/docs/imgs/airflow/paused_dag.png and /dev/null differ
diff --git a/docs/imgs/airflow/successful_run.png b/docs/imgs/airflow/successful_run.png
deleted file mode 100644
index b997cc7210ff6..0000000000000
Binary files a/docs/imgs/airflow/successful_run.png and /dev/null differ
diff --git a/docs/imgs/airflow/trigger_dag.png b/docs/imgs/airflow/trigger_dag.png
deleted file mode 100644
index a44999c929d4e..0000000000000
Binary files a/docs/imgs/airflow/trigger_dag.png and /dev/null differ
diff --git a/docs/imgs/airflow/unpaused_dag.png b/docs/imgs/airflow/unpaused_dag.png
deleted file mode 100644
index 8462562f31d97..0000000000000
Binary files a/docs/imgs/airflow/unpaused_dag.png and /dev/null differ
diff --git a/docs/imgs/apache-ranger/datahub-platform-access-policy.png b/docs/imgs/apache-ranger/datahub-platform-access-policy.png
deleted file mode 100644
index 7e3ff6fd372a9..0000000000000
Binary files a/docs/imgs/apache-ranger/datahub-platform-access-policy.png and /dev/null differ
diff --git a/docs/imgs/apache-ranger/datahub-plugin.png b/docs/imgs/apache-ranger/datahub-plugin.png
deleted file mode 100644
index 5dd044c014657..0000000000000
Binary files a/docs/imgs/apache-ranger/datahub-plugin.png and /dev/null differ
diff --git a/docs/imgs/apis/postman-graphql.png b/docs/imgs/apis/postman-graphql.png
deleted file mode 100644
index 1cffd226fdf77..0000000000000
Binary files a/docs/imgs/apis/postman-graphql.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/column-description-added.png b/docs/imgs/apis/tutorials/column-description-added.png
deleted file mode 100644
index ed8cbd3bf5622..0000000000000
Binary files a/docs/imgs/apis/tutorials/column-description-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/column-level-lineage-added.png b/docs/imgs/apis/tutorials/column-level-lineage-added.png
deleted file mode 100644
index 6092436e0a6a8..0000000000000
Binary files a/docs/imgs/apis/tutorials/column-level-lineage-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/custom-properties-added.png b/docs/imgs/apis/tutorials/custom-properties-added.png
deleted file mode 100644
index a7e85d875045c..0000000000000
Binary files a/docs/imgs/apis/tutorials/custom-properties-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/datahub-main-ui.png b/docs/imgs/apis/tutorials/datahub-main-ui.png
deleted file mode 100644
index b058e2683a851..0000000000000
Binary files a/docs/imgs/apis/tutorials/datahub-main-ui.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-created.png b/docs/imgs/apis/tutorials/dataset-created.png
deleted file mode 100644
index 086dd8b7c9b16..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-created.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-deleted.png b/docs/imgs/apis/tutorials/dataset-deleted.png
deleted file mode 100644
index d94ad7e85195f..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-deleted.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-description-added.png b/docs/imgs/apis/tutorials/dataset-description-added.png
deleted file mode 100644
index 41aa9f109115b..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-description-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-properties-added-removed.png b/docs/imgs/apis/tutorials/dataset-properties-added-removed.png
deleted file mode 100644
index 9eb0284776f13..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-properties-added-removed.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-properties-added.png b/docs/imgs/apis/tutorials/dataset-properties-added.png
deleted file mode 100644
index e0d2acbb66eb5..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-properties-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-properties-before.png b/docs/imgs/apis/tutorials/dataset-properties-before.png
deleted file mode 100644
index b4915121a8c65..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-properties-before.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/dataset-properties-replaced.png b/docs/imgs/apis/tutorials/dataset-properties-replaced.png
deleted file mode 100644
index 8624689c20ada..0000000000000
Binary files a/docs/imgs/apis/tutorials/dataset-properties-replaced.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/deprecation-updated.png b/docs/imgs/apis/tutorials/deprecation-updated.png
deleted file mode 100644
index 06fedf746f694..0000000000000
Binary files a/docs/imgs/apis/tutorials/deprecation-updated.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/domain-added.png b/docs/imgs/apis/tutorials/domain-added.png
deleted file mode 100644
index cb2002ec9ab4d..0000000000000
Binary files a/docs/imgs/apis/tutorials/domain-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/domain-created.png b/docs/imgs/apis/tutorials/domain-created.png
deleted file mode 100644
index cafab2a5e8d5c..0000000000000
Binary files a/docs/imgs/apis/tutorials/domain-created.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/domain-removed.png b/docs/imgs/apis/tutorials/domain-removed.png
deleted file mode 100644
index 1b21172be11d2..0000000000000
Binary files a/docs/imgs/apis/tutorials/domain-removed.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/feature-added-to-model.png b/docs/imgs/apis/tutorials/feature-added-to-model.png
deleted file mode 100644
index 311506e4b2783..0000000000000
Binary files a/docs/imgs/apis/tutorials/feature-added-to-model.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/feature-table-created.png b/docs/imgs/apis/tutorials/feature-table-created.png
deleted file mode 100644
index 0541cbe572435..0000000000000
Binary files a/docs/imgs/apis/tutorials/feature-table-created.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/group-upserted.png b/docs/imgs/apis/tutorials/group-upserted.png
deleted file mode 100644
index 5283f6273f02a..0000000000000
Binary files a/docs/imgs/apis/tutorials/group-upserted.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/lineage-added.png b/docs/imgs/apis/tutorials/lineage-added.png
deleted file mode 100644
index b381498bad5ac..0000000000000
Binary files a/docs/imgs/apis/tutorials/lineage-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/model-group-added-to-model.png b/docs/imgs/apis/tutorials/model-group-added-to-model.png
deleted file mode 100644
index 360b7fbb2d922..0000000000000
Binary files a/docs/imgs/apis/tutorials/model-group-added-to-model.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/model-group-created.png b/docs/imgs/apis/tutorials/model-group-created.png
deleted file mode 100644
index 2e0fdcea4803f..0000000000000
Binary files a/docs/imgs/apis/tutorials/model-group-created.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/owner-added.png b/docs/imgs/apis/tutorials/owner-added.png
deleted file mode 100644
index 6508c231cfb4b..0000000000000
Binary files a/docs/imgs/apis/tutorials/owner-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/owner-removed.png b/docs/imgs/apis/tutorials/owner-removed.png
deleted file mode 100644
index a7b6567888caf..0000000000000
Binary files a/docs/imgs/apis/tutorials/owner-removed.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/sample-ingestion.png b/docs/imgs/apis/tutorials/sample-ingestion.png
deleted file mode 100644
index 40aa046904841..0000000000000
Binary files a/docs/imgs/apis/tutorials/sample-ingestion.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/tag-added.png b/docs/imgs/apis/tutorials/tag-added.png
deleted file mode 100644
index fd99a04f6cceb..0000000000000
Binary files a/docs/imgs/apis/tutorials/tag-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/tag-created.png b/docs/imgs/apis/tutorials/tag-created.png
deleted file mode 100644
index 99e3fea8a14e1..0000000000000
Binary files a/docs/imgs/apis/tutorials/tag-created.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/tag-removed.png b/docs/imgs/apis/tutorials/tag-removed.png
deleted file mode 100644
index 31a267549843e..0000000000000
Binary files a/docs/imgs/apis/tutorials/tag-removed.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/term-added.png b/docs/imgs/apis/tutorials/term-added.png
deleted file mode 100644
index 62e285a92e7af..0000000000000
Binary files a/docs/imgs/apis/tutorials/term-added.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/term-created.png b/docs/imgs/apis/tutorials/term-created.png
deleted file mode 100644
index deff0179b155e..0000000000000
Binary files a/docs/imgs/apis/tutorials/term-created.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/term-removed.png b/docs/imgs/apis/tutorials/term-removed.png
deleted file mode 100644
index dbf9f35f09339..0000000000000
Binary files a/docs/imgs/apis/tutorials/term-removed.png and /dev/null differ
diff --git a/docs/imgs/apis/tutorials/user-upserted.png b/docs/imgs/apis/tutorials/user-upserted.png
deleted file mode 100644
index 38c5bbb9ad828..0000000000000
Binary files a/docs/imgs/apis/tutorials/user-upserted.png and /dev/null differ
diff --git a/docs/imgs/aws/aws-elasticsearch.png b/docs/imgs/aws/aws-elasticsearch.png
deleted file mode 100644
index e16d5eee26fd8..0000000000000
Binary files a/docs/imgs/aws/aws-elasticsearch.png and /dev/null differ
diff --git a/docs/imgs/aws/aws-msk.png b/docs/imgs/aws/aws-msk.png
deleted file mode 100644
index 96a3173747007..0000000000000
Binary files a/docs/imgs/aws/aws-msk.png and /dev/null differ
diff --git a/docs/imgs/aws/aws-rds.png b/docs/imgs/aws/aws-rds.png
deleted file mode 100644
index ab329952c7756..0000000000000
Binary files a/docs/imgs/aws/aws-rds.png and /dev/null differ
diff --git a/docs/imgs/browse-domains.png b/docs/imgs/browse-domains.png
deleted file mode 100644
index 41444470517d2..0000000000000
Binary files a/docs/imgs/browse-domains.png and /dev/null differ
diff --git a/docs/imgs/cancelled-ingestion.png b/docs/imgs/cancelled-ingestion.png
deleted file mode 100644
index 0c4af7b66a8ff..0000000000000
Binary files a/docs/imgs/cancelled-ingestion.png and /dev/null differ
diff --git a/docs/imgs/confluent-cloud-config-2.png b/docs/imgs/confluent-cloud-config-2.png
deleted file mode 100644
index 543101154f42c..0000000000000
Binary files a/docs/imgs/confluent-cloud-config-2.png and /dev/null differ
diff --git a/docs/imgs/confluent-cloud-config.png b/docs/imgs/confluent-cloud-config.png
deleted file mode 100644
index a2490eab5c6a7..0000000000000
Binary files a/docs/imgs/confluent-cloud-config.png and /dev/null differ
diff --git a/docs/imgs/confluent-create-topic.png b/docs/imgs/confluent-create-topic.png
deleted file mode 100644
index 1972bb3770388..0000000000000
Binary files a/docs/imgs/confluent-create-topic.png and /dev/null differ
diff --git a/docs/imgs/create-domain.png b/docs/imgs/create-domain.png
deleted file mode 100644
index 1db2090fca6b8..0000000000000
Binary files a/docs/imgs/create-domain.png and /dev/null differ
diff --git a/docs/imgs/create-new-ingestion-source-button.png b/docs/imgs/create-new-ingestion-source-button.png
deleted file mode 100644
index c425f0837c51d..0000000000000
Binary files a/docs/imgs/create-new-ingestion-source-button.png and /dev/null differ
diff --git a/docs/imgs/create-secret.png b/docs/imgs/create-secret.png
deleted file mode 100644
index a0cc63e3b4892..0000000000000
Binary files a/docs/imgs/create-secret.png and /dev/null differ
diff --git a/docs/imgs/custom-ingestion-cli-version.png b/docs/imgs/custom-ingestion-cli-version.png
deleted file mode 100644
index 43d4736684abb..0000000000000
Binary files a/docs/imgs/custom-ingestion-cli-version.png and /dev/null differ
diff --git a/docs/imgs/datahub-architecture.png b/docs/imgs/datahub-architecture.png
deleted file mode 100644
index 236f939f74198..0000000000000
Binary files a/docs/imgs/datahub-architecture.png and /dev/null differ
diff --git a/docs/imgs/datahub-architecture.svg b/docs/imgs/datahub-architecture.svg
deleted file mode 100644
index 842194a5e377c..0000000000000
--- a/docs/imgs/datahub-architecture.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/docs/imgs/datahub-components.png b/docs/imgs/datahub-components.png
deleted file mode 100644
index 8b7d0e5330275..0000000000000
Binary files a/docs/imgs/datahub-components.png and /dev/null differ
diff --git a/docs/imgs/datahub-logo-color-mark.svg b/docs/imgs/datahub-logo-color-mark.svg
deleted file mode 100644
index a984092952bae..0000000000000
--- a/docs/imgs/datahub-logo-color-mark.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/docs/imgs/datahub-metadata-ingestion-framework.png b/docs/imgs/datahub-metadata-ingestion-framework.png
deleted file mode 100644
index 1319329710906..0000000000000
Binary files a/docs/imgs/datahub-metadata-ingestion-framework.png and /dev/null differ
diff --git a/docs/imgs/datahub-metadata-model.png b/docs/imgs/datahub-metadata-model.png
deleted file mode 100644
index 59449cd0d4ef5..0000000000000
Binary files a/docs/imgs/datahub-metadata-model.png and /dev/null differ
diff --git a/docs/imgs/datahub-sequence-diagram.png b/docs/imgs/datahub-sequence-diagram.png
deleted file mode 100644
index b5a8f8a9c25ce..0000000000000
Binary files a/docs/imgs/datahub-sequence-diagram.png and /dev/null differ
diff --git a/docs/imgs/datahub-serving.png b/docs/imgs/datahub-serving.png
deleted file mode 100644
index 67a2f8eb3f085..0000000000000
Binary files a/docs/imgs/datahub-serving.png and /dev/null differ
diff --git a/docs/imgs/development/intellij-remote-debug.png b/docs/imgs/development/intellij-remote-debug.png
deleted file mode 100644
index 32a41a75d1dc3..0000000000000
Binary files a/docs/imgs/development/intellij-remote-debug.png and /dev/null differ
diff --git a/docs/imgs/domain-entities.png b/docs/imgs/domain-entities.png
deleted file mode 100644
index 5766d051fa209..0000000000000
Binary files a/docs/imgs/domain-entities.png and /dev/null differ
diff --git a/docs/imgs/domains-tab.png b/docs/imgs/domains-tab.png
deleted file mode 100644
index 20be5b103fdca..0000000000000
Binary files a/docs/imgs/domains-tab.png and /dev/null differ
diff --git a/docs/imgs/entity-registry-diagram.png b/docs/imgs/entity-registry-diagram.png
deleted file mode 100644
index 08cb5edd8e13f..0000000000000
Binary files a/docs/imgs/entity-registry-diagram.png and /dev/null differ
diff --git a/docs/imgs/entity.png b/docs/imgs/entity.png
deleted file mode 100644
index cfe9eb38b2921..0000000000000
Binary files a/docs/imgs/entity.png and /dev/null differ
diff --git a/docs/imgs/example-mysql-recipe.png b/docs/imgs/example-mysql-recipe.png
deleted file mode 100644
index 9cb2cbb169a56..0000000000000
Binary files a/docs/imgs/example-mysql-recipe.png and /dev/null differ
diff --git a/docs/imgs/failed-ingestion.png b/docs/imgs/failed-ingestion.png
deleted file mode 100644
index 4f9de8eb002d2..0000000000000
Binary files a/docs/imgs/failed-ingestion.png and /dev/null differ
diff --git a/docs/imgs/feature-create-new-tag.gif b/docs/imgs/feature-create-new-tag.gif
deleted file mode 100644
index 57b8ad852dd5b..0000000000000
Binary files a/docs/imgs/feature-create-new-tag.gif and /dev/null differ
diff --git a/docs/imgs/feature-datahub-analytics.png b/docs/imgs/feature-datahub-analytics.png
deleted file mode 100644
index 7fe66b84682f9..0000000000000
Binary files a/docs/imgs/feature-datahub-analytics.png and /dev/null differ
diff --git a/docs/imgs/feature-rich-documentation.gif b/docs/imgs/feature-rich-documentation.gif
deleted file mode 100644
index 48ad795670022..0000000000000
Binary files a/docs/imgs/feature-rich-documentation.gif and /dev/null differ
diff --git a/docs/imgs/feature-tag-browse.gif b/docs/imgs/feature-tag-browse.gif
deleted file mode 100644
index e70a30db7d3ba..0000000000000
Binary files a/docs/imgs/feature-tag-browse.gif and /dev/null differ
diff --git a/docs/imgs/feature-validation-timeseries.png b/docs/imgs/feature-validation-timeseries.png
deleted file mode 100644
index 28ce1daec5f32..0000000000000
Binary files a/docs/imgs/feature-validation-timeseries.png and /dev/null differ
diff --git a/docs/imgs/feature-view-entitiy-details-via-lineage-vis.gif b/docs/imgs/feature-view-entitiy-details-via-lineage-vis.gif
deleted file mode 100644
index aad77df373574..0000000000000
Binary files a/docs/imgs/feature-view-entitiy-details-via-lineage-vis.gif and /dev/null differ
diff --git a/docs/imgs/gcp/ingress1.png b/docs/imgs/gcp/ingress1.png
deleted file mode 100644
index 4cb49834af5b6..0000000000000
Binary files a/docs/imgs/gcp/ingress1.png and /dev/null differ
diff --git a/docs/imgs/gcp/ingress2.png b/docs/imgs/gcp/ingress2.png
deleted file mode 100644
index cdf2446b0e923..0000000000000
Binary files a/docs/imgs/gcp/ingress2.png and /dev/null differ
diff --git a/docs/imgs/gcp/ingress3.png b/docs/imgs/gcp/ingress3.png
deleted file mode 100644
index cc3745ad97f5b..0000000000000
Binary files a/docs/imgs/gcp/ingress3.png and /dev/null differ
diff --git a/docs/imgs/gcp/ingress_final.png b/docs/imgs/gcp/ingress_final.png
deleted file mode 100644
index a30ca744c49f7..0000000000000
Binary files a/docs/imgs/gcp/ingress_final.png and /dev/null differ
diff --git a/docs/imgs/gcp/ingress_ready.png b/docs/imgs/gcp/ingress_ready.png
deleted file mode 100644
index d14016e420fd3..0000000000000
Binary files a/docs/imgs/gcp/ingress_ready.png and /dev/null differ
diff --git a/docs/imgs/gcp/services_ingress.png b/docs/imgs/gcp/services_ingress.png
deleted file mode 100644
index 1d9ff2b313715..0000000000000
Binary files a/docs/imgs/gcp/services_ingress.png and /dev/null differ
diff --git a/docs/imgs/glossary/add-term-modal.png b/docs/imgs/glossary/add-term-modal.png
deleted file mode 100644
index e32a9cb8d648c..0000000000000
Binary files a/docs/imgs/glossary/add-term-modal.png and /dev/null differ
diff --git a/docs/imgs/glossary/add-term-to-entity.png b/docs/imgs/glossary/add-term-to-entity.png
deleted file mode 100644
index 7487a68c0d755..0000000000000
Binary files a/docs/imgs/glossary/add-term-to-entity.png and /dev/null differ
diff --git a/docs/imgs/glossary/create-from-node.png b/docs/imgs/glossary/create-from-node.png
deleted file mode 100644
index 70638d083343c..0000000000000
Binary files a/docs/imgs/glossary/create-from-node.png and /dev/null differ
diff --git a/docs/imgs/glossary/create-modal.png b/docs/imgs/glossary/create-modal.png
deleted file mode 100644
index e84fb5a36e2d4..0000000000000
Binary files a/docs/imgs/glossary/create-modal.png and /dev/null differ
diff --git a/docs/imgs/glossary/delete-button.png b/docs/imgs/glossary/delete-button.png
deleted file mode 100644
index 3e0cc2a5b0a54..0000000000000
Binary files a/docs/imgs/glossary/delete-button.png and /dev/null differ
diff --git a/docs/imgs/glossary/edit-term.png b/docs/imgs/glossary/edit-term.png
deleted file mode 100644
index 62b0e425c8c4f..0000000000000
Binary files a/docs/imgs/glossary/edit-term.png and /dev/null differ
diff --git a/docs/imgs/glossary/glossary-button.png b/docs/imgs/glossary/glossary-button.png
deleted file mode 100644
index e4b8fd2393587..0000000000000
Binary files a/docs/imgs/glossary/glossary-button.png and /dev/null differ
diff --git a/docs/imgs/glossary/move-term-button.png b/docs/imgs/glossary/move-term-button.png
deleted file mode 100644
index df03c820340ef..0000000000000
Binary files a/docs/imgs/glossary/move-term-button.png and /dev/null differ
diff --git a/docs/imgs/glossary/move-term-modal.png b/docs/imgs/glossary/move-term-modal.png
deleted file mode 100644
index 0fda501911b2b..0000000000000
Binary files a/docs/imgs/glossary/move-term-modal.png and /dev/null differ
diff --git a/docs/imgs/glossary/root-glossary-create.png b/docs/imgs/glossary/root-glossary-create.png
deleted file mode 100644
index c91f397eb6213..0000000000000
Binary files a/docs/imgs/glossary/root-glossary-create.png and /dev/null differ
diff --git a/docs/imgs/glossary/root-glossary.png b/docs/imgs/glossary/root-glossary.png
deleted file mode 100644
index 1296c16b0dc3d..0000000000000
Binary files a/docs/imgs/glossary/root-glossary.png and /dev/null differ
diff --git a/docs/imgs/ingestion-architecture.png b/docs/imgs/ingestion-architecture.png
deleted file mode 100644
index fc7bc74acacfa..0000000000000
Binary files a/docs/imgs/ingestion-architecture.png and /dev/null differ
diff --git a/docs/imgs/ingestion-logs.png b/docs/imgs/ingestion-logs.png
deleted file mode 100644
index 42211be7379d6..0000000000000
Binary files a/docs/imgs/ingestion-logs.png and /dev/null differ
diff --git a/docs/imgs/ingestion-privileges.png b/docs/imgs/ingestion-privileges.png
deleted file mode 100644
index 8e23868309676..0000000000000
Binary files a/docs/imgs/ingestion-privileges.png and /dev/null differ
diff --git a/docs/imgs/ingestion-tab.png b/docs/imgs/ingestion-tab.png
deleted file mode 100644
index 046068c63bdb7..0000000000000
Binary files a/docs/imgs/ingestion-tab.png and /dev/null differ
diff --git a/docs/imgs/ingestion-with-token.png b/docs/imgs/ingestion-with-token.png
deleted file mode 100644
index 5e1a2cce036f7..0000000000000
Binary files a/docs/imgs/ingestion-with-token.png and /dev/null differ
diff --git a/docs/imgs/invite-users-button.png b/docs/imgs/invite-users-button.png
deleted file mode 100644
index a5d07a1c1e7e7..0000000000000
Binary files a/docs/imgs/invite-users-button.png and /dev/null differ
diff --git a/docs/imgs/invite-users-popup.png b/docs/imgs/invite-users-popup.png
deleted file mode 100644
index 621b1521eae75..0000000000000
Binary files a/docs/imgs/invite-users-popup.png and /dev/null differ
diff --git a/docs/imgs/lineage.png b/docs/imgs/lineage.png
deleted file mode 100644
index 7488c1e04c31b..0000000000000
Binary files a/docs/imgs/lineage.png and /dev/null differ
diff --git a/docs/imgs/list-domains.png b/docs/imgs/list-domains.png
deleted file mode 100644
index 98a28130f8c99..0000000000000
Binary files a/docs/imgs/list-domains.png and /dev/null differ
diff --git a/docs/imgs/locust-example.png b/docs/imgs/locust-example.png
deleted file mode 100644
index bbae3e0ca19d0..0000000000000
Binary files a/docs/imgs/locust-example.png and /dev/null differ
diff --git a/docs/imgs/metadata-model-chart.png b/docs/imgs/metadata-model-chart.png
deleted file mode 100644
index 2fb7483654906..0000000000000
Binary files a/docs/imgs/metadata-model-chart.png and /dev/null differ
diff --git a/docs/imgs/metadata-model-to-fork-or-not-to.png b/docs/imgs/metadata-model-to-fork-or-not-to.png
deleted file mode 100644
index f9d89d555196d..0000000000000
Binary files a/docs/imgs/metadata-model-to-fork-or-not-to.png and /dev/null differ
diff --git a/docs/imgs/metadata-modeling.png b/docs/imgs/metadata-modeling.png
deleted file mode 100644
index cbad7613e04e4..0000000000000
Binary files a/docs/imgs/metadata-modeling.png and /dev/null differ
diff --git a/docs/imgs/metadata-service-auth.png b/docs/imgs/metadata-service-auth.png
deleted file mode 100644
index 15a3ac51876c2..0000000000000
Binary files a/docs/imgs/metadata-service-auth.png and /dev/null differ
diff --git a/docs/imgs/metadata-serving.png b/docs/imgs/metadata-serving.png
deleted file mode 100644
index 54b928a0cff52..0000000000000
Binary files a/docs/imgs/metadata-serving.png and /dev/null differ
diff --git a/docs/imgs/metadata.png b/docs/imgs/metadata.png
deleted file mode 100644
index 45bb0cdce12e9..0000000000000
Binary files a/docs/imgs/metadata.png and /dev/null differ
diff --git a/docs/imgs/name-ingestion-source.png b/docs/imgs/name-ingestion-source.png
deleted file mode 100644
index bde1208248473..0000000000000
Binary files a/docs/imgs/name-ingestion-source.png and /dev/null differ
diff --git a/docs/imgs/no-code-after.png b/docs/imgs/no-code-after.png
deleted file mode 100644
index c0eee88625ace..0000000000000
Binary files a/docs/imgs/no-code-after.png and /dev/null differ
diff --git a/docs/imgs/no-code-before.png b/docs/imgs/no-code-before.png
deleted file mode 100644
index 50315578b1804..0000000000000
Binary files a/docs/imgs/no-code-before.png and /dev/null differ
diff --git a/docs/imgs/platform-instances-for-ingestion.png b/docs/imgs/platform-instances-for-ingestion.png
deleted file mode 100644
index 740249a805fb8..0000000000000
Binary files a/docs/imgs/platform-instances-for-ingestion.png and /dev/null differ
diff --git a/docs/imgs/quickstart-ingestion-config.png b/docs/imgs/quickstart-ingestion-config.png
deleted file mode 100644
index de51777ccddc3..0000000000000
Binary files a/docs/imgs/quickstart-ingestion-config.png and /dev/null differ
diff --git a/docs/imgs/reset-credentials-screen.png b/docs/imgs/reset-credentials-screen.png
deleted file mode 100644
index 4b680837b77ab..0000000000000
Binary files a/docs/imgs/reset-credentials-screen.png and /dev/null differ
diff --git a/docs/imgs/reset-user-password-button.png b/docs/imgs/reset-user-password-button.png
deleted file mode 100644
index 5b1f3ee153d07..0000000000000
Binary files a/docs/imgs/reset-user-password-button.png and /dev/null differ
diff --git a/docs/imgs/reset-user-password-popup.png b/docs/imgs/reset-user-password-popup.png
deleted file mode 100644
index ac2456dde4d4d..0000000000000
Binary files a/docs/imgs/reset-user-password-popup.png and /dev/null differ
diff --git a/docs/imgs/running-ingestion.png b/docs/imgs/running-ingestion.png
deleted file mode 100644
index a03fb444a029e..0000000000000
Binary files a/docs/imgs/running-ingestion.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/10_outputs.png b/docs/imgs/s3-ingestion/10_outputs.png
deleted file mode 100644
index e0d1ed3376ade..0000000000000
Binary files a/docs/imgs/s3-ingestion/10_outputs.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/1_crawler-info.png b/docs/imgs/s3-ingestion/1_crawler-info.png
deleted file mode 100644
index 1288247392047..0000000000000
Binary files a/docs/imgs/s3-ingestion/1_crawler-info.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/2_crawler-type.png b/docs/imgs/s3-ingestion/2_crawler-type.png
deleted file mode 100644
index 4898438417913..0000000000000
Binary files a/docs/imgs/s3-ingestion/2_crawler-type.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/3_data-store.png b/docs/imgs/s3-ingestion/3_data-store.png
deleted file mode 100644
index d29e4b1be05d6..0000000000000
Binary files a/docs/imgs/s3-ingestion/3_data-store.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/4_data-store-2.png b/docs/imgs/s3-ingestion/4_data-store-2.png
deleted file mode 100644
index c0a6f140bedb2..0000000000000
Binary files a/docs/imgs/s3-ingestion/4_data-store-2.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/5_iam.png b/docs/imgs/s3-ingestion/5_iam.png
deleted file mode 100644
index 73a631cb74f56..0000000000000
Binary files a/docs/imgs/s3-ingestion/5_iam.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/6_schedule.png b/docs/imgs/s3-ingestion/6_schedule.png
deleted file mode 100644
index c5df59348fbc6..0000000000000
Binary files a/docs/imgs/s3-ingestion/6_schedule.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/7_output.png b/docs/imgs/s3-ingestion/7_output.png
deleted file mode 100644
index 6201fa40bcfb3..0000000000000
Binary files a/docs/imgs/s3-ingestion/7_output.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/8_review.png b/docs/imgs/s3-ingestion/8_review.png
deleted file mode 100644
index 2d27e79c2128b..0000000000000
Binary files a/docs/imgs/s3-ingestion/8_review.png and /dev/null differ
diff --git a/docs/imgs/s3-ingestion/9_run.png b/docs/imgs/s3-ingestion/9_run.png
deleted file mode 100644
index 2b0644f6ad038..0000000000000
Binary files a/docs/imgs/s3-ingestion/9_run.png and /dev/null differ
diff --git a/docs/imgs/schedule-ingestion.png b/docs/imgs/schedule-ingestion.png
deleted file mode 100644
index 0e6ec8e268c32..0000000000000
Binary files a/docs/imgs/schedule-ingestion.png and /dev/null differ
diff --git a/docs/imgs/schema-blame-blame-activated.png b/docs/imgs/schema-blame-blame-activated.png
deleted file mode 100644
index 363466c39aedf..0000000000000
Binary files a/docs/imgs/schema-blame-blame-activated.png and /dev/null differ
diff --git a/docs/imgs/schema-history-audit-activated.png b/docs/imgs/schema-history-audit-activated.png
deleted file mode 100644
index f59676b9b8a8f..0000000000000
Binary files a/docs/imgs/schema-history-audit-activated.png and /dev/null differ
diff --git a/docs/imgs/schema-history-latest-version.png b/docs/imgs/schema-history-latest-version.png
deleted file mode 100644
index 0a54df4d520d5..0000000000000
Binary files a/docs/imgs/schema-history-latest-version.png and /dev/null differ
diff --git a/docs/imgs/schema-history-older-version.png b/docs/imgs/schema-history-older-version.png
deleted file mode 100644
index 8d295f176104f..0000000000000
Binary files a/docs/imgs/schema-history-older-version.png and /dev/null differ
diff --git a/docs/imgs/search-by-domain.png b/docs/imgs/search-by-domain.png
deleted file mode 100644
index 4b92e58959187..0000000000000
Binary files a/docs/imgs/search-by-domain.png and /dev/null differ
diff --git a/docs/imgs/search-domain.png b/docs/imgs/search-domain.png
deleted file mode 100644
index b1359e07d5fc2..0000000000000
Binary files a/docs/imgs/search-domain.png and /dev/null differ
diff --git a/docs/imgs/search-tag.png b/docs/imgs/search-tag.png
deleted file mode 100644
index cf4b6b629d1e2..0000000000000
Binary files a/docs/imgs/search-tag.png and /dev/null differ
diff --git a/docs/imgs/select-platform-template.png b/docs/imgs/select-platform-template.png
deleted file mode 100644
index 4f78e2b7309ed..0000000000000
Binary files a/docs/imgs/select-platform-template.png and /dev/null differ
diff --git a/docs/imgs/set-domain-id.png b/docs/imgs/set-domain-id.png
deleted file mode 100644
index 3e1dde4ae51ee..0000000000000
Binary files a/docs/imgs/set-domain-id.png and /dev/null differ
diff --git a/docs/imgs/set-domain.png b/docs/imgs/set-domain.png
deleted file mode 100644
index 1c4460e747835..0000000000000
Binary files a/docs/imgs/set-domain.png and /dev/null differ
diff --git a/docs/imgs/successful-ingestion.png b/docs/imgs/successful-ingestion.png
deleted file mode 100644
index fa8dbdff7501e..0000000000000
Binary files a/docs/imgs/successful-ingestion.png and /dev/null differ
diff --git a/docs/imgs/timeline/dropdown-apis.png b/docs/imgs/timeline/dropdown-apis.png
deleted file mode 100644
index f7aba08bbc061..0000000000000
Binary files a/docs/imgs/timeline/dropdown-apis.png and /dev/null differ
diff --git a/docs/imgs/timeline/swagger-ui.png b/docs/imgs/timeline/swagger-ui.png
deleted file mode 100644
index e52a57e8ca670..0000000000000
Binary files a/docs/imgs/timeline/swagger-ui.png and /dev/null differ
diff --git a/docs/imgs/timeline/timeline-conceptually.png b/docs/imgs/timeline/timeline-conceptually.png
deleted file mode 100644
index 70bd843bf8aed..0000000000000
Binary files a/docs/imgs/timeline/timeline-conceptually.png and /dev/null differ
diff --git a/docs/imgs/user-sign-up-screen.png b/docs/imgs/user-sign-up-screen.png
deleted file mode 100644
index 88c2589203bd1..0000000000000
Binary files a/docs/imgs/user-sign-up-screen.png and /dev/null differ
diff --git a/docs/managed-datahub/chrome-extension.md b/docs/managed-datahub/chrome-extension.md
index a614327c7fd29..d5851e8fb9391 100644
--- a/docs/managed-datahub/chrome-extension.md
+++ b/docs/managed-datahub/chrome-extension.md
@@ -1,16 +1,20 @@
---
description: Learn how to upload and use the Acryl DataHub Chrome extension (beta) locally before it's available on the Chrome store.
---
+
import FeatureAvailability from '@site/src/components/FeatureAvailability';
# Acryl DataHub Chrome Extension
+
## Installing the Extension
In order to use the Acryl DataHub Chrome extension, you need to download it onto your browser from the Chrome web store [here](https://chrome.google.com/webstore/detail/datahub-chrome-extension/aoenebhmfokhglijmoacfjcnebdpchfj).
-
+
+
+
Simply click "Add to Chrome" then "Add extension" on the ensuing popup.
@@ -20,11 +24,15 @@ Once you have your extension installed, you'll need to configure it to work with
1. Click the extension button on the right of your browser's address bar to view all of your installed extensions. Click on the newly installed DataHub extension.
-
+
+
+
2. Fill in your DataHub domain and click "Continue" in the extension popup that appears.
-
+
+
+
If your organization uses standard SaaS domains for Looker, you should be ready to go!
@@ -34,11 +42,15 @@ Some organizations have custom SaaS domains for Looker and some Acryl DataHub de
1. Click on the extension button and select your DataHub extension to open the popup again. Now click the settings icon in order to open the configurations page.
-
+
+
+
2. Fill out any and save custom configurations you have in the **TOOL CONFIGURATIONS** section. Here you can configure a custom domain, a Platform Instance associated with that domain, and the Environment set on your DataHub assets. If you don't have a custom domain but do have a custom Platform Instance or Environment, feel free to leave the field domain empty.
-
+
+
+
## Using the Extension
@@ -52,7 +64,9 @@ Once you have everything configured on your extension, it's time to use it!
4. Click the Acryl DataHub extension button on the bottom right of your page to open a drawer where you can now see additional information about this asset right from your DataHub instance.
-
+
+
+
## Advanced: Self-Hosted DataHub
@@ -67,4 +81,4 @@ AUTH_COOKIE_SAME_SITE="NONE"
AUTH_COOKIE_SECURE=true
```
-Once your re-deploy your `datahub-frontend` container with these values, you should be good to go!
\ No newline at end of file
+Once your re-deploy your `datahub-frontend` container with these values, you should be good to go!
diff --git a/docs/managed-datahub/datahub-api/graphql-api/getting-started.md b/docs/managed-datahub/datahub-api/graphql-api/getting-started.md
index 3c57b0a21d96e..881a7492f341a 100644
--- a/docs/managed-datahub/datahub-api/graphql-api/getting-started.md
+++ b/docs/managed-datahub/datahub-api/graphql-api/getting-started.md
@@ -10,7 +10,9 @@ For a full reference to the Queries & Mutations available for consumption, check
### Connecting to the API
-.png)
+
+
+
When you generate the token you will see an example of `curl` command which you can use to connect to the GraphQL API.
diff --git a/docs/managed-datahub/datahub-api/graphql-api/incidents-api-beta.md b/docs/managed-datahub/datahub-api/graphql-api/incidents-api-beta.md
index 89bacb2009e49..909fee7d6020f 100644
--- a/docs/managed-datahub/datahub-api/graphql-api/incidents-api-beta.md
+++ b/docs/managed-datahub/datahub-api/graphql-api/incidents-api-beta.md
@@ -1,10 +1,11 @@
---
description: This page provides an overview of working with the DataHub Incidents API.
---
-import FeatureAvailability from '@site/src/components/FeatureAvailability';
+import FeatureAvailability from '@site/src/components/FeatureAvailability';
# Incidents API (Beta)
+
## Introduction
@@ -37,7 +38,7 @@ To create (i.e. raise) a new incident for a data asset, simply create a GraphQL
```
type Mutation {
"""
- Raise a new incident for a data asset
+ Raise a new incident for a data asset
"""
raiseIncident(input: RaiseIncidentInput!): String! # Returns new Incident URN.
}
@@ -173,7 +174,7 @@ type Dataset {
"""
Optional start offset, defaults to 20.
"""
- count: Int): EntityIncidentsResult # Returns a list of incidents.
+ count: Int): EntityIncidentsResult # Returns a list of incidents.
}
```
@@ -323,7 +324,7 @@ _Request_
```
mutation updateIncidentStatus {
- updateIncidentStatus(urn: "urn:li:incident:bfecab62-dc10-49a6-a305-78ce0cc6e5b1",
+ updateIncidentStatus(urn: "urn:li:incident:bfecab62-dc10-49a6-a305-78ce0cc6e5b1",
input: {
state: RESOLVED
message: "Dataset is now passing validations. Verified by John Joyce on Data Platform eng."
@@ -379,7 +380,7 @@ json = {
response = datahub_session.post(f"https://your-account.acryl.io/api/graphql", headers=headers, json=json)
response.raise_for_status()
-res_data = response.json() # Get result as JSON
+res_data = response.json() # Get result as JSON
```
## Tips
@@ -404,7 +405,8 @@ You can configure Acryl to send slack notifications to a specific channel when i
These notifications are also able to tag the immediate asset's owners, along with the owners of downstream assets consuming it.
-
-
-To do so, simply follow the [Slack Integration Guide](docs/managed-datahub/saas-slack-setup.md) and contact your Acryl customer success team to enable the feature!
+
+
+
+To do so, simply follow the [Slack Integration Guide](docs/managed-datahub/saas-slack-setup.md) and contact your Acryl customer success team to enable the feature!
diff --git a/docs/managed-datahub/imgs/saas/DataHub-Architecture.png b/docs/managed-datahub/imgs/saas/DataHub-Architecture.png
deleted file mode 100644
index 95b3ab0b06ad6..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/DataHub-Architecture.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-13-at-7.45.56-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-13-at-7.45.56-PM.png
deleted file mode 100644
index 721989a6c37e1..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-13-at-7.45.56-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-24-at-4.35.17-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-24-at-4.35.17-PM.png
deleted file mode 100644
index dffac92f257c7..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-24-at-4.35.17-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-24-at-4.37.22-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-24-at-4.37.22-PM.png
deleted file mode 100644
index ff0c29de1fbad..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-01-24-at-4.37.22-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-07-at-10.23.31-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-07-at-10.23.31-AM.png
deleted file mode 100644
index 070bfd9f6b897..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-07-at-10.23.31-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.43.25-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.43.25-PM.png
deleted file mode 100644
index b4bb4e2ba60ed..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.43.25-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.44.15-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.44.15-PM.png
deleted file mode 100644
index b0397afd1b3a4..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.44.15-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.46.41-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.46.41-PM.png
deleted file mode 100644
index 9258badb6f088..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-03-22-at-6.46.41-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.52.55-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.52.55-PM.png
deleted file mode 100644
index 386b4cdcd9911..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.52.55-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.56.50-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.56.50-PM.png
deleted file mode 100644
index a129f5eba4271..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.56.50-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.58.46-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.58.46-PM.png
deleted file mode 100644
index 96ae48318a35a..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-4.58.46-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-5.01.16-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-5.01.16-PM.png
deleted file mode 100644
index b6fd273389c90..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-5.01.16-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-5.03.36-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-5.03.36-PM.png
deleted file mode 100644
index 0acd4e75bc6d2..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-05-at-5.03.36-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-13-at-2.34.24-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-13-at-2.34.24-PM.png
deleted file mode 100644
index 364b9292cfaab..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-04-13-at-2.34.24-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-7.56.16-AM-(1).png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-7.56.16-AM-(1).png
deleted file mode 100644
index 6a12dc545ec62..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-7.56.16-AM-(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-7.56.16-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-7.56.16-AM.png
deleted file mode 100644
index 6a12dc545ec62..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-7.56.16-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-8.02.55-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-8.02.55-AM.png
deleted file mode 100644
index 83645e00d724a..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-13-at-8.02.55-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-24-at-11.02.47-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-24-at-11.02.47-AM.png
deleted file mode 100644
index a2f239ce847e0..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-24-at-11.02.47-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-24-at-12.59.38-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-24-at-12.59.38-PM.png
deleted file mode 100644
index e31d4b089d929..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-06-24-at-12.59.38-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.21.42-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.21.42-AM.png
deleted file mode 100644
index c003581c9d1b6..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.21.42-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.22.23-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.22.23-AM.png
deleted file mode 100644
index 660dd121dd0a4..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.22.23-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.23.08-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.23.08-AM.png
deleted file mode 100644
index 07e3c71dba262..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.23.08-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.47.57-AM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.47.57-AM.png
deleted file mode 100644
index 579e7f62af708..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-22-at-11.47.57-AM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-29-at-6.07.25-PM-(1).png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-29-at-6.07.25-PM-(1).png
deleted file mode 100644
index f85f4d5c79bfb..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-29-at-6.07.25-PM-(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-29-at-6.07.25-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-29-at-6.07.25-PM.png
deleted file mode 100644
index f85f4d5c79bfb..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2022-08-29-at-6.07.25-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-4.16.52-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-4.16.52-PM.png
deleted file mode 100644
index cb8b7470cd957..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-4.16.52-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-4.23.32-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-4.23.32-PM.png
deleted file mode 100644
index 1de51e33d87c2..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-4.23.32-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.47-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.47-PM.png
deleted file mode 100644
index df687dabe345c..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.47-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.56-PM-(1).png b/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.56-PM-(1).png
deleted file mode 100644
index a8d9ee37c7a55..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.56-PM-(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.56-PM.png b/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.56-PM.png
deleted file mode 100644
index a8d9ee37c7a55..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Screen-Shot-2023-01-19-at-5.12.56-PM.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Untitled(1).png b/docs/managed-datahub/imgs/saas/Untitled(1).png
deleted file mode 100644
index 87846e7897f6e..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Untitled(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Untitled-(2)-(1).png b/docs/managed-datahub/imgs/saas/Untitled-(2)-(1).png
deleted file mode 100644
index 7715bf4a51fbe..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Untitled-(2)-(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Untitled-(2).png b/docs/managed-datahub/imgs/saas/Untitled-(2).png
deleted file mode 100644
index a01a1af370442..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Untitled-(2).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Untitled-(3).png b/docs/managed-datahub/imgs/saas/Untitled-(3).png
deleted file mode 100644
index 02d84b326896c..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Untitled-(3).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Untitled-(4).png b/docs/managed-datahub/imgs/saas/Untitled-(4).png
deleted file mode 100644
index a01a1af370442..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Untitled-(4).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/Untitled.png b/docs/managed-datahub/imgs/saas/Untitled.png
deleted file mode 100644
index a01a1af370442..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/Untitled.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/chrome-store-extension-screenshot.png b/docs/managed-datahub/imgs/saas/chrome-store-extension-screenshot.png
deleted file mode 100644
index e00a4d57f32dd..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/chrome-store-extension-screenshot.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_custom_configs.png b/docs/managed-datahub/imgs/saas/extension_custom_configs.png
deleted file mode 100644
index b3d70dfac00ff..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_custom_configs.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_developer_mode.png b/docs/managed-datahub/imgs/saas/extension_developer_mode.png
deleted file mode 100644
index e740d15912e17..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_developer_mode.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_enter_domain.png b/docs/managed-datahub/imgs/saas/extension_enter_domain.png
deleted file mode 100644
index 3304fa168beaf..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_enter_domain.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_load_unpacked.png b/docs/managed-datahub/imgs/saas/extension_load_unpacked.png
deleted file mode 100644
index 8f56705cd9176..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_load_unpacked.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_open_options_page.png b/docs/managed-datahub/imgs/saas/extension_open_options_page.png
deleted file mode 100644
index c1366d5673b59..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_open_options_page.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_open_popup.png b/docs/managed-datahub/imgs/saas/extension_open_popup.png
deleted file mode 100644
index 216056b847fb5..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_open_popup.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/extension_view_in_looker.png b/docs/managed-datahub/imgs/saas/extension_view_in_looker.png
deleted file mode 100644
index bf854b3e840f7..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/extension_view_in_looker.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/home-(1).png b/docs/managed-datahub/imgs/saas/home-(1).png
deleted file mode 100644
index 88cf2017dd7e7..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/home-(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/home.png b/docs/managed-datahub/imgs/saas/home.png
deleted file mode 100644
index 8ad63deec75c9..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/home.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(1).png b/docs/managed-datahub/imgs/saas/image-(1).png
deleted file mode 100644
index c1a249125fcf7..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(1).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(10).png b/docs/managed-datahub/imgs/saas/image-(10).png
deleted file mode 100644
index a580fdc3d6730..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(10).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(11).png b/docs/managed-datahub/imgs/saas/image-(11).png
deleted file mode 100644
index ee95eb4384272..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(11).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(12).png b/docs/managed-datahub/imgs/saas/image-(12).png
deleted file mode 100644
index bbd8e6a66cf85..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(12).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(13).png b/docs/managed-datahub/imgs/saas/image-(13).png
deleted file mode 100644
index bbd8e6a66cf85..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(13).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(14).png b/docs/managed-datahub/imgs/saas/image-(14).png
deleted file mode 100644
index a580fdc3d6730..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(14).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(15).png b/docs/managed-datahub/imgs/saas/image-(15).png
deleted file mode 100644
index f282e2d92c1a1..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(15).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(16).png b/docs/managed-datahub/imgs/saas/image-(16).png
deleted file mode 100644
index 1340c77bd648c..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(16).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(17).png b/docs/managed-datahub/imgs/saas/image-(17).png
deleted file mode 100644
index 6eee2fb2d821f..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(17).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(2).png b/docs/managed-datahub/imgs/saas/image-(2).png
deleted file mode 100644
index cf475edd7b95d..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(2).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(3).png b/docs/managed-datahub/imgs/saas/image-(3).png
deleted file mode 100644
index b08818ff3e97c..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(3).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(4).png b/docs/managed-datahub/imgs/saas/image-(4).png
deleted file mode 100644
index a580fdc3d6730..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(4).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(5).png b/docs/managed-datahub/imgs/saas/image-(5).png
deleted file mode 100644
index 48438c6001e4f..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(5).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(6).png b/docs/managed-datahub/imgs/saas/image-(6).png
deleted file mode 100644
index 54e569e853f24..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(6).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(7).png b/docs/managed-datahub/imgs/saas/image-(7).png
deleted file mode 100644
index 6e89e5881cfa7..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(7).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(8).png b/docs/managed-datahub/imgs/saas/image-(8).png
deleted file mode 100644
index ee0a3c89d58fa..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(8).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image-(9).png b/docs/managed-datahub/imgs/saas/image-(9).png
deleted file mode 100644
index 301ca98593ef9..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image-(9).png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/image.png b/docs/managed-datahub/imgs/saas/image.png
deleted file mode 100644
index a1cfc3e74c5dd..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/image.png and /dev/null differ
diff --git a/docs/managed-datahub/imgs/saas/settings.png b/docs/managed-datahub/imgs/saas/settings.png
deleted file mode 100644
index ca99984abbbc9..0000000000000
Binary files a/docs/managed-datahub/imgs/saas/settings.png and /dev/null differ
diff --git a/docs/managed-datahub/integrations/oidc-sso-integration.md b/docs/managed-datahub/integrations/oidc-sso-integration.md
index 6a9e085186b44..81a5cc4a557ce 100644
--- a/docs/managed-datahub/integrations/oidc-sso-integration.md
+++ b/docs/managed-datahub/integrations/oidc-sso-integration.md
@@ -3,12 +3,12 @@ description: >-
This page will help you set up OIDC SSO with your identity provider to log
into Acryl Data
---
-import FeatureAvailability from '@site/src/components/FeatureAvailability';
+import FeatureAvailability from '@site/src/components/FeatureAvailability';
# OIDC SSO Integration
-
+
_Note that we do not yet support LDAP or SAML authentication. Please let us know if either of these integrations would be useful for your organization._
@@ -25,7 +25,7 @@ To set up the OIDC integration, you will need the following pieces of informatio
The callback URL to register in your Identity Provider will be
```
-https://.acryl.io/callback/oidc
+https://.acryl.io/callback/oidc
```
### Configuring OIDC SSO
@@ -42,4 +42,6 @@ To enable the OIDC integration, start by navigating to **Settings > Platform > S
4. If there are any advanced settings you would like to configure, click on the **Advanced** button. These come with defaults, so only input settings here if there is something you need changed from the default configuration.
5. Click **Update** to save your settings.
-.png)
+
+
+
diff --git a/docs/managed-datahub/metadata-ingestion-with-acryl/ingestion.md b/docs/managed-datahub/metadata-ingestion-with-acryl/ingestion.md
index 95ca6e5e33e16..62d466467327e 100644
--- a/docs/managed-datahub/metadata-ingestion-with-acryl/ingestion.md
+++ b/docs/managed-datahub/metadata-ingestion-with-acryl/ingestion.md
@@ -56,9 +56,14 @@ In Acryl DataHub deployments, you _must_ use a sink of type `datahub-rest`, whic
2. **token**: a unique API key used to authenticate requests to your instance's REST API
The token can be retrieved by logging in as admin. You can go to Settings page and generate a Personal Access Token with your desired expiration date.
-.png)
-
+
+
+
+
+
+
+
To configure your instance of DataHub as the destination for ingestion, set the "server" field of your recipe to point to your Acryl instance's domain suffixed by the path `/gms`, as shown below.
A complete example of a DataHub recipe file, which reads from MySQL and writes into a DataHub instance:
diff --git a/docs/managed-datahub/operator-guide/setting-up-remote-ingestion-executor-on-aws.md b/docs/managed-datahub/operator-guide/setting-up-remote-ingestion-executor-on-aws.md
index d389ec97d0550..c4056a04e9ab9 100644
--- a/docs/managed-datahub/operator-guide/setting-up-remote-ingestion-executor-on-aws.md
+++ b/docs/managed-datahub/operator-guide/setting-up-remote-ingestion-executor-on-aws.md
@@ -4,9 +4,11 @@ description: >-
executor, which allows you to ingest metadata from private metadata sources
using private credentials via the DataHub UI.
---
+
import FeatureAvailability from '@site/src/components/FeatureAvailability';
# Setting up Remote Ingestion Executor on AWS
+
## Overview
@@ -17,56 +19,80 @@ Acryl DataHub comes packaged with an Acryl-managed ingestion executor, which is
For example, if an ingestion source is not publicly accessible via the internet, e.g. hosted privately within a specific AWS account, then the Acryl executor will be unable to extract metadata from it.
-.png)
+
+
+
To accommodate these cases, Acryl supports configuring a remote ingestion executor which can be deployed inside of your AWS account. This setup allows you to continue leveraging the Acryl DataHub console to create, schedule, and run metadata ingestion, all while retaining network and credential isolation.
-.png)
+
+
+
## Deploying a Remote Ingestion Executor
-1. **Provide AWS Account Id**: Provide Acryl Team with the id of the AWS in which the remote executor will be hosted. This will be used to grant access to private Acryl containers and create a unique SQS queue which your remote agent will subscribe to. The account id can be provided to your Acryl representative via Email or [One Time Secret](https://onetimesecret.com/).
-
-2. **Provision an Acryl Executor** (ECS)**:** Acryl team will provide a [Cloudformation Template](https://github.com/acryldata/datahub-cloudformation/blob/master/Ingestion/templates/python.ecs.template.yaml) that you can run to provision an ECS cluster with a single remote ingestion task. It will also provision an AWS role for the task which grants the permissions necessary to read and delete from the private SQS queue created for you, along with reading the secrets you've specified. At minimum, the template requires the following parameters:
- 1. **Deployment Location:** The AWS VPC + subnet in which the Acryl Executor task is to be provisioned.
- 2. **SQS Queue ARN**: Reference to your private SQS command queue. This is provided by Acryl and is used to configure IAM policies enabling the Task role to read from the shared queue.
- 3. **SQS Queue URL**: The URL referring to your private SQS command queue. This is provided by Acryl and is used to read messages.
- 4. **DataHub Personal Access Token**: A valid DataHub PAT. This can be generated inside of **Settings > Access Tokens** of DataHub web application. You can alternatively create a secret in AWS Secrets Manager and refer to that by ARN.
- 5. **Acryl DataHub URL**: The URL for your DataHub instance, e.g. `.acryl.io/gms`. Note that you MUST enter the trailing /gms when configuring the executor.
- 6. **Acryl Remote Executor Version:** The version of the remote executor to deploy. This is converted into a container image tag. It will be set to the latest version of the executor by default.
- 7. **Ingestion Source Secrets:** The template accepts up to 10 named secrets which live inside your environment. Secrets are specified using the **OptionalSecrets** parameter in the following form: `SECRET_NAME=SECRET_ARN` with multiple separated by comma, e.g. `SECRET_NAME_1=SECRET_ARN_1,SECRET_NAME_2,SECRET_ARN_2.`
- 8. **Environment Variables:** The template accepts up to 10 arbitrary environment variables. These can be used to inject properties into your ingestion recipe from within your environment. Environment variables are specified using the **OptionalEnvVars** parameter in the following form: `ENV_VAR_NAME=ENV_VAR_VALUE` with multiple separated by comma, e.g. `ENV_VAR_NAME_1=ENV_VAR_VALUE_1,ENV_VAR_NAME_2,ENV_VAR_VALUE_2.`
- ``
- ``Providing secrets enables you to manage ingestion sources from the DataHub UI without storing credentials inside DataHub. Once defined, secrets can be referenced by name inside of your DataHub Ingestion Source configurations using the usual convention: `${SECRET_NAME}`.
-
- Note that the only external secret provider that is currently supported is AWS Secrets Manager.
-
-
-
-
+
+1. **Provide AWS Account Id**: Provide Acryl Team with the id of the AWS in which the remote executor will be hosted. This will be used to grant access to private Acryl containers and create a unique SQS queue which your remote agent will subscribe to. The account id can be provided to your Acryl representative via Email or [One Time Secret](https://onetimesecret.com/).
+
+2. **Provision an Acryl Executor** (ECS)**:** Acryl team will provide a [Cloudformation Template](https://github.com/acryldata/datahub-cloudformation/blob/master/Ingestion/templates/python.ecs.template.yaml) that you can run to provision an ECS cluster with a single remote ingestion task. It will also provision an AWS role for the task which grants the permissions necessary to read and delete from the private SQS queue created for you, along with reading the secrets you've specified. At minimum, the template requires the following parameters:
+
+ 1. **Deployment Location:** The AWS VPC + subnet in which the Acryl Executor task is to be provisioned.
+ 2. **SQS Queue ARN**: Reference to your private SQS command queue. This is provided by Acryl and is used to configure IAM policies enabling the Task role to read from the shared queue.
+ 3. **SQS Queue URL**: The URL referring to your private SQS command queue. This is provided by Acryl and is used to read messages.
+ 4. **DataHub Personal Access Token**: A valid DataHub PAT. This can be generated inside of **Settings > Access Tokens** of DataHub web application. You can alternatively create a secret in AWS Secrets Manager and refer to that by ARN.
+ 5. **Acryl DataHub URL**: The URL for your DataHub instance, e.g. `.acryl.io/gms`. Note that you MUST enter the trailing /gms when configuring the executor.
+ 6. **Acryl Remote Executor Version:** The version of the remote executor to deploy. This is converted into a container image tag. It will be set to the latest version of the executor by default.
+ 7. **Ingestion Source Secrets:** The template accepts up to 10 named secrets which live inside your environment. Secrets are specified using the **OptionalSecrets** parameter in the following form: `SECRET_NAME=SECRET_ARN` with multiple separated by comma, e.g. `SECRET_NAME_1=SECRET_ARN_1,SECRET_NAME_2,SECRET_ARN_2.`
+ 8. **Environment Variables:** The template accepts up to 10 arbitrary environment variables. These can be used to inject properties into your ingestion recipe from within your environment. Environment variables are specified using the **OptionalEnvVars** parameter in the following form: `ENV_VAR_NAME=ENV_VAR_VALUE` with multiple separated by comma, e.g. `ENV_VAR_NAME_1=ENV_VAR_VALUE_1,ENV_VAR_NAME_2,ENV_VAR_VALUE_2.`
+ `
+
+ `Providing secrets enables you to manage ingestion sources from the DataHub UI without storing credentials inside DataHub. Once defined, secrets can be referenced by name inside of your DataHub Ingestion Source configurations using the usual convention: `${SECRET_NAME}`.
+
+ Note that the only external secret provider that is currently supported is AWS Secrets Manager.
+
+
+
+
+
+
+
+
3. **Test the Executor:** To test your remote executor:
1. Create a new Ingestion Source by clicking '**Create new Source**' the '**Ingestion**' tab of the DataHub console. Configure your Ingestion Recipe as though you were running it from inside of your environment.
- 2. When working with "secret" fields (passwords, keys, etc), you can refer to any "self-managed" secrets by name: `${SECRET_NAME}:`
+ 2. When working with "secret" fields (passwords, keys, etc), you can refer to any "self-managed" secrets by name: `${SECRET_NAME}:`
+
+
+
+
- 
3. In the 'Finish Up' step, click '**Advanced'**.
- 4. Update the '**Executor Id**' form field to be '**remote**'. This indicates that you'd like to use the remote executor.
+ 4. Update the '**Executor Id**' form field to be '**remote**'. This indicates that you'd like to use the remote executor.
5. Click '**Done**'.
Now, simple click '**Execute**' to test out the remote executor. If your remote executor is configured properly, you should promptly see the ingestion task state change to 'Running'.
-
+
+
+
+
## Updating a Remote Ingestion Executor
+
In order to update the executor, ie. to deploy a new container version, you'll need to update the CloudFormation Stack to re-deploy the CloudFormation template with a new set of parameters.
+
### Steps - AWS Console
+
1. Navigate to CloudFormation in AWS Console
2. Select the stack dedicated to the remote executor
3. Click **Update**
4. Select **Replace Current Template**
5. Select **Upload a template file**
6. Upload a copy of the Acryl Remote Executor [CloudFormation Template](https://raw.githubusercontent.com/acryldata/datahub-cloudformation/master/Ingestion/templates/python.ecs.template.yaml)
-
+
+
+
+
+
7. Click **Next**
8. Change parameters based on your modifications (e.g. ImageTag, etc)
9. Click **Next**
@@ -74,26 +100,30 @@ In order to update the executor, ie. to deploy a new container version, you'll n
## FAQ
-### If I need to change (or add) a secret that is stored in AWS Secrets Manager, e.g. for rotation, will the new secret automatically get picked up by Acryl's executor?**
+### If I need to change (or add) a secret that is stored in AWS Secrets Manager, e.g. for rotation, will the new secret automatically get picked up by Acryl's executor?\*\*
Unfortunately, no. Secrets are wired into the executor container at deployment time, via environment variables. Therefore, the ECS Task will need to be restarted (either manually or via a stack parameter update) whenever your secrets change.
-### I want to deploy multiple Acryl Executors. Is this currently possible?**
+### I want to deploy multiple Acryl Executors. Is this currently possible?\*\*
This is possible, but requires a new SQS queue is maintained (on per executor). Please contact your Acryl representative for more information.
-### I've run the CloudFormation Template, how can I tell that the container was successfully deployed?**
+### I've run the CloudFormation Template, how can I tell that the container was successfully deployed?\*\*
We recommend verifying in AWS Console by navigating to **ECS > Cluster > Stack Name > Services > Logs.**
When you first deploy the executor, you should a single log line to indicate success:
+
```
Starting AWS executor consumer..
```
+
This indicates that the remote executor has established a successful connection to your DataHub instance and is ready to execute ingestion runs.
If you DO NOT see this log line, but instead see something else, please contact your Acryl representative for support.
## Release Notes
+
This is where release notes for the Acryl Remote Executor Container will live.
### v0.0.3.9
+
Bumping to the latest version of acryl-executor, which includes smarter messaging around OOM errors.
diff --git a/docs/modeling/extending-the-metadata-model.md b/docs/modeling/extending-the-metadata-model.md
index 32951ab2e41eb..41d58eb626b69 100644
--- a/docs/modeling/extending-the-metadata-model.md
+++ b/docs/modeling/extending-the-metadata-model.md
@@ -11,7 +11,10 @@ these two concepts prior to making changes.
## To fork or not to fork?
An important question that will arise once you've decided to extend the metadata model is whether you need to fork the main repo or not. Use the diagram below to understand how to make this decision.
-
+
+
+
+
The green lines represent pathways that will lead to lesser friction for you to maintain your code long term. The red lines represent higher risk of conflicts in the future. We are working hard to move the majority of model extension use-cases to no-code / low-code pathways to ensure that you can extend the core metadata model without having to maintain a custom fork of DataHub.
@@ -88,10 +91,11 @@ the annotation model.
Define the entity within an `entity-registry.yml` file. Depending on your approach, the location of this file may vary. More on that in steps [4](#step_4) and [5](#step_5).
Example:
+
```yaml
- - name: dashboard
- doc: A container of related data assets.
- keyAspect: dashboardKey
+- name: dashboard
+ doc: A container of related data assets.
+ keyAspect: dashboardKey
```
- name: The entity name/type, this will be present as a part of the Urn.
@@ -192,8 +196,8 @@ The Aspect has four key components: its properties, the @Aspect annotation, the
can be defined as PDL primitives, enums, records, or collections (
see [pdl schema documentation](https://linkedin.github.io/rest.li/pdl_schema))
references to other entities, of type Urn or optionally `Urn`
-- **@Aspect annotation**: Declares record is an Aspect and includes it when serializing an entity. Unlike the following
- two annotations, @Aspect is applied to the entire record, rather than a specific field. Note, you can mark an aspect
+- **@Aspect annotation**: Declares record is an Aspect and includes it when serializing an entity. Unlike the following
+ two annotations, @Aspect is applied to the entire record, rather than a specific field. Note, you can mark an aspect
as a timeseries aspect. Check out this [doc](metadata-model.md#timeseries-aspects) for details.
- **@Searchable annotation**: This annotation can be applied to any primitive field or a map field to indicate that it
should be indexed in Elasticsearch and can be searched on. For a complete guide on using the search annotation, see
@@ -201,7 +205,7 @@ The Aspect has four key components: its properties, the @Aspect annotation, the
- **@Relationship annotation**: These annotations create edges between the Entity’s Urn and the destination of the
annotated field when the entities are ingested. @Relationship annotations must be applied to fields of type Urn. In
the case of DashboardInfo, the `charts` field is an Array of Urns. The @Relationship annotation cannot be applied
- directly to an array of Urns. That’s why you see the use of an Annotation override (`”/*”:) to apply the @Relationship
+ directly to an array of Urns. That’s why you see the use of an Annotation override (`”/\*”:) to apply the @Relationship
annotation to the Urn directly. Read more about overrides in the annotation docs further down on this page.
After you create your Aspect, you need to attach to all the entities that it applies to.
@@ -227,7 +231,7 @@ entities:
- keyAspect: dashBoardKey
aspects:
# the name of the aspect must be the same as that on the @Aspect annotation on the class
- - dashboardInfo
+ - dashboardInfo
```
Previously, you were required to add all aspects for the entity into an Aspect union. You will see examples of this pattern throughout the code-base (e.g. `DatasetAspect`, `DashboardAspect` etc.). This is no longer required.
@@ -297,9 +301,9 @@ It takes the following parameters:
- **autoRender**: boolean (optional) - defaults to false. When set to true, the aspect will automatically be displayed
on entity pages in a tab using a default renderer. **_This is currently only supported for Charts, Dashboards, DataFlows, DataJobs, Datasets, Domains, and GlossaryTerms_**.
- **renderSpec**: RenderSpec (optional) - config for autoRender aspects that controls how they are displayed. **_This is currently only supported for Charts, Dashboards, DataFlows, DataJobs, Datasets, Domains, and GlossaryTerms_**. Contains three fields:
- - **displayType**: One of `tabular`, `properties`. Tabular should be used for a list of data elements, properties for a single data bag.
- - **displayName**: How the aspect should be referred to in the UI. Determines the name of the tab on the entity page.
- - **key**: For `tabular` aspects only. Specifies the key in which the array to render may be found.
+ - **displayType**: One of `tabular`, `properties`. Tabular should be used for a list of data elements, properties for a single data bag.
+ - **displayName**: How the aspect should be referred to in the UI. Determines the name of the tab on the entity page.
+ - **key**: For `tabular` aspects only. Specifies the key in which the array to render may be found.
##### Example
@@ -325,29 +329,28 @@ It takes the following parameters:
Thus far, we have implemented 10 fieldTypes:
- 1. *KEYWORD* - Short text fields that only support exact matches, often used only for filtering
+ 1. _KEYWORD_ - Short text fields that only support exact matches, often used only for filtering
- 2. *TEXT* - Text fields delimited by spaces/slashes/periods. Default field type for string variables.
+ 2. _TEXT_ - Text fields delimited by spaces/slashes/periods. Default field type for string variables.
- 3. *TEXT_PARTIAL* - Text fields delimited by spaces/slashes/periods with partial matching support. Note, partial
- matching is expensive, so this field type should not be applied to fields with long values (like description)
+ 3. _TEXT_PARTIAL_ - Text fields delimited by spaces/slashes/periods with partial matching support. Note, partial
+ matching is expensive, so this field type should not be applied to fields with long values (like description)
- 4. *BROWSE_PATH* - Field type for browse paths. Applies specific mappings for slash delimited paths.
+ 4. _BROWSE_PATH_ - Field type for browse paths. Applies specific mappings for slash delimited paths.
- 5. *URN* - Urn fields where each sub-component inside the urn is indexed. For instance, for a data platform urn like
- "urn:li:dataplatform:kafka", it will index the platform name "kafka" and ignore the common components
+ 5. _URN_ - Urn fields where each sub-component inside the urn is indexed. For instance, for a data platform urn like
+ "urn:li:dataplatform:kafka", it will index the platform name "kafka" and ignore the common components
- 6. *URN_PARTIAL* - Urn fields where each sub-component inside the urn is indexed with partial matching support.
+ 6. _URN_PARTIAL_ - Urn fields where each sub-component inside the urn is indexed with partial matching support.
- 7. *BOOLEAN* - Boolean fields used for filtering.
+ 7. _BOOLEAN_ - Boolean fields used for filtering.
- 8. *COUNT* - Count fields used for filtering.
-
- 9. *DATETIME* - Datetime fields used to represent timestamps.
+ 8. _COUNT_ - Count fields used for filtering.
+ 9. _DATETIME_ - Datetime fields used to represent timestamps.
- 10. *OBJECT* - Each property in an object will become an extra column in Elasticsearch and can be referenced as
- `field.property` in queries. You should be careful to not use it on objects with many properties as it can cause a
- mapping explosion in Elasticsearch.
+ 10. _OBJECT_ - Each property in an object will become an extra column in Elasticsearch and can be referenced as
+ `field.property` in queries. You should be careful to not use it on objects with many properties as it can cause a
+ mapping explosion in Elasticsearch.
- **fieldName**: string (optional) - The name of the field in search index document. Defaults to the field name where
the annotation resides.
@@ -392,13 +395,13 @@ Now, when Datahub ingests Dashboards, it will index the Dashboard’s title in E
Dashboards, that query will be used to search on the title index and matching Dashboards will be returned.
Note, when @Searchable annotation is applied to a map, it will convert it into a list with "key.toString()
-=value.toString()" as elements. This allows us to index map fields, while not increasing the number of columns indexed.
+=value.toString()" as elements. This allows us to index map fields, while not increasing the number of columns indexed.
This way, the keys can be queried by `aMapField:key1=value1`.
-You can change this behavior by specifying the fieldType as OBJECT in the @Searchable annotation. It will put each key
-into a column in Elasticsearch instead of an array of serialized kay-value pairs. This way the query would look more
+You can change this behavior by specifying the fieldType as OBJECT in the @Searchable annotation. It will put each key
+into a column in Elasticsearch instead of an array of serialized kay-value pairs. This way the query would look more
like `aMapField.key1:value1`. As this method will increase the number of columns with each unique key - large maps can
-cause a mapping explosion in Elasticsearch. You should *not* use the object fieldType if you expect your maps to get
+cause a mapping explosion in Elasticsearch. You should _not_ use the object fieldType if you expect your maps to get
large.
#### @Relationship
diff --git a/docs/modeling/metadata-model.md b/docs/modeling/metadata-model.md
index 704fce1412329..74101aff049a9 100644
--- a/docs/modeling/metadata-model.md
+++ b/docs/modeling/metadata-model.md
@@ -6,37 +6,36 @@ slug: /metadata-modeling/metadata-model
# How does DataHub model metadata?
-DataHub takes a schema-first approach to modeling metadata. We use the open-source Pegasus schema language ([PDL](https://linkedin.github.io/rest.li/pdl_schema)) extended with a custom set of annotations to model metadata. The DataHub storage, serving, indexing and ingestion layer operates directly on top of the metadata model and supports strong types all the way from the client to the storage layer.
+DataHub takes a schema-first approach to modeling metadata. We use the open-source Pegasus schema language ([PDL](https://linkedin.github.io/rest.li/pdl_schema)) extended with a custom set of annotations to model metadata. The DataHub storage, serving, indexing and ingestion layer operates directly on top of the metadata model and supports strong types all the way from the client to the storage layer.
Conceptually, metadata is modeled using the following abstractions
- **Entities**: An entity is the primary node in the metadata graph. For example, an instance of a Dataset or a CorpUser is an Entity. An entity is made up of a type, e.g. 'dataset', a unique identifier (e.g. an 'urn') and groups of metadata attributes (e.g. documents) which we call aspects.
-
- **Aspects**: An aspect is a collection of attributes that describes a particular facet of an entity. They are the smallest atomic unit of write in DataHub. That is, multiple aspects associated with the same Entity can be updated independently. For example, DatasetProperties contains a collection of attributes that describes a Dataset. Aspects can be shared across entities, for example "Ownership" is an aspect that is re-used across all the Entities that have owners. Common aspects include
- - [ownership](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/Ownership.pdl): Captures the users and groups who own an Entity.
- - [globalTags](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/GlobalTags.pdl): Captures references to the Tags associated with an Entity.
- - [glossaryTerms](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/GlossaryTerms.pdl): Captures references to the Glossary Terms associated with an Entity.
- - [institutionalMemory](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/InstitutionalMemory.pdl): Captures internal company Documents associated with an Entity (e.g. links!)
- - [status](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/Status.pdl): Captures the "deletion" status of an Entity, i.e. whether it should be soft-deleted.
- - [subTypes](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/SubTypes.pdl): Captures one or more "sub types" of a more generic Entity type. An example can be a "Looker Explore" Dataset, a "View" Dataset. Specific sub types can imply that certain additional aspects are present for a given Entity.
-
-
-- **Relationships**: A relationship represents a named edge between 2 entities. They are declared via foreign key attributes within Aspects along with a custom annotation (@Relationship). Relationships permit edges to be traversed bi-directionally. For example, a Chart may refer to a CorpUser as its owner via a relationship named "OwnedBy". This edge would be walkable starting from the Chart *or* the CorpUser instance.
+ - [ownership](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/Ownership.pdl): Captures the users and groups who own an Entity.
+ - [globalTags](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/GlobalTags.pdl): Captures references to the Tags associated with an Entity.
+ - [glossaryTerms](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/GlossaryTerms.pdl): Captures references to the Glossary Terms associated with an Entity.
+ - [institutionalMemory](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/InstitutionalMemory.pdl): Captures internal company Documents associated with an Entity (e.g. links!)
+ - [status](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/Status.pdl): Captures the "deletion" status of an Entity, i.e. whether it should be soft-deleted.
+ - [subTypes](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/SubTypes.pdl): Captures one or more "sub types" of a more generic Entity type. An example can be a "Looker Explore" Dataset, a "View" Dataset. Specific sub types can imply that certain additional aspects are present for a given Entity.
-- **Identifiers (Keys & Urns)**: A key is a special type of aspect that contains the fields that uniquely identify an individual Entity. Key aspects can be serialized into *Urns*, which represent a stringified form of the key fields used for primary-key lookup. Moreover, *Urns* can be converted back into key aspect structs, making key aspects a type of "virtual" aspect. Key aspects provide a mechanism for clients to easily read fields comprising the primary key, which are usually generally useful like Dataset names, platform names etc. Urns provide a friendly handle by which Entities can be queried without requiring a fully materialized struct.
+- **Relationships**: A relationship represents a named edge between 2 entities. They are declared via foreign key attributes within Aspects along with a custom annotation (@Relationship). Relationships permit edges to be traversed bi-directionally. For example, a Chart may refer to a CorpUser as its owner via a relationship named "OwnedBy". This edge would be walkable starting from the Chart _or_ the CorpUser instance.
+- **Identifiers (Keys & Urns)**: A key is a special type of aspect that contains the fields that uniquely identify an individual Entity. Key aspects can be serialized into _Urns_, which represent a stringified form of the key fields used for primary-key lookup. Moreover, _Urns_ can be converted back into key aspect structs, making key aspects a type of "virtual" aspect. Key aspects provide a mechanism for clients to easily read fields comprising the primary key, which are usually generally useful like Dataset names, platform names etc. Urns provide a friendly handle by which Entities can be queried without requiring a fully materialized struct.
Here is an example graph consisting of 3 types of entity (CorpUser, Chart, Dashboard), 2 types of relationship (OwnedBy, Contains), and 3 types of metadata aspect (Ownership, ChartInfo, and DashboardInfo).
-
+
+
+
## The Core Entities
-DataHub's "core" Entity types model the Data Assets that comprise the Modern Data Stack. They include
+DataHub's "core" Entity types model the Data Assets that comprise the Modern Data Stack. They include
-1. **[Data Platform](docs/generated/metamodel/entities/dataPlatform.md)**: A type of Data "Platform". That is, an external system that is involved in processing, storing, or visualizing Data Assets. Examples include MySQL, Snowflake, Redshift, and S3.
+1. **[Data Platform](docs/generated/metamodel/entities/dataPlatform.md)**: A type of Data "Platform". That is, an external system that is involved in processing, storing, or visualizing Data Assets. Examples include MySQL, Snowflake, Redshift, and S3.
2. **[Dataset](docs/generated/metamodel/entities/dataset.md)**: A collection of data. Tables, Views, Streams, Document Collections, and Files are all modeled as "Datasets" on DataHub. Datasets can have tags, owners, links, glossary terms, and descriptions attached to them. They can also have specific sub-types, such as "View", "Collection", "Stream", "Explore", and more. Examples include Postgres Tables, MongoDB Collections, or S3 files.
3. **[Chart](docs/generated/metamodel/entities/chart.md)**: A single data vizualization derived from a Dataset. A single Chart can be a part of multiple Dashboards. Charts can have tags, owners, links, glossary terms, and descriptions attached to them. Examples include a Superset or Looker Chart.
4. **[Dashboard](docs/generated/metamodel/entities/dashboard.md)**: A collection of Charts for visualization. Dashboards can have tags, owners, links, glossary terms, and descriptions attached to them. Examples include a Superset or Mode Dashboard.
@@ -47,54 +46,57 @@ See the **Metadata Modeling/Entities** section on the left to explore the entire
## The Entity Registry
-Where are Entities and their aspects defined in DataHub? Where does the Metadata Model "live"? The Metadata Model is stitched together by means
+Where are Entities and their aspects defined in DataHub? Where does the Metadata Model "live"? The Metadata Model is stitched together by means
of an **Entity Registry**, a catalog of Entities that comprise the Metadata Graph along with the aspects associated with each. Put
-simply, this is where the "schema" of the model is defined.
+simply, this is where the "schema" of the model is defined.
-Traditionally, the Entity Registry was constructed using [Snapshot](https://github.com/datahub-project/datahub/tree/master/metadata-models/src/main/pegasus/com/linkedin/metadata/snapshot) models, which are schemas that explicitly tie
-an Entity to the Aspects associated with it. An example is [DatasetSnapshot](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/metadata/snapshot/DatasetSnapshot.pdl), which defines the core `Dataset` Entity.
-The Aspects of the Dataset entity are captured via a union field inside a special "Aspect" schema. An example is
+Traditionally, the Entity Registry was constructed using [Snapshot](https://github.com/datahub-project/datahub/tree/master/metadata-models/src/main/pegasus/com/linkedin/metadata/snapshot) models, which are schemas that explicitly tie
+an Entity to the Aspects associated with it. An example is [DatasetSnapshot](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/metadata/snapshot/DatasetSnapshot.pdl), which defines the core `Dataset` Entity.
+The Aspects of the Dataset entity are captured via a union field inside a special "Aspect" schema. An example is
[DatasetAspect](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/metadata/aspect/DatasetAspect.pdl).
-This file associates dataset-specific aspects (like [DatasetProperties](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/dataset/DatasetProperties.pdl)) and common aspects (like [Ownership](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/Ownership.pdl),
-[InstitutionalMemory](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/InstitutionalMemory.pdl),
-and [Status](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/Status.pdl))
-to the Dataset Entity. This approach to defining Entities will soon be deprecated in favor of a new approach.
+This file associates dataset-specific aspects (like [DatasetProperties](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/dataset/DatasetProperties.pdl)) and common aspects (like [Ownership](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/Ownership.pdl),
+[InstitutionalMemory](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/InstitutionalMemory.pdl),
+and [Status](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/Status.pdl))
+to the Dataset Entity. This approach to defining Entities will soon be deprecated in favor of a new approach.
As of January 2022, DataHub has deprecated support for Snapshot models as a means of adding new entities. Instead,
the Entity Registry is defined inside a YAML configuration file called [entity-registry.yml](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/resources/entity-registry.yml),
-which is provided to DataHub's Metadata Service at start up. This file declares Entities and Aspects by referring to their [names](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/Ownership.pdl#L7).
-At boot time, DataHub validates the structure of the registry file and ensures that it can find PDL schemas associated with
-each aspect name provided by configuration (via the [@Aspect](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/Ownership.pdl#L6) annotation).
-
-By moving to this format, evolving the Metadata Model becomes much easier. Adding Entities & Aspects becomes a matter of adding a
-to the YAML configuration, instead of creating new Snapshot / Aspect files.
+which is provided to DataHub's Metadata Service at start up. This file declares Entities and Aspects by referring to their [names](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/Ownership.pdl#L7).
+At boot time, DataHub validates the structure of the registry file and ensures that it can find PDL schemas associated with
+each aspect name provided by configuration (via the [@Aspect](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/common/Ownership.pdl#L6) annotation).
+By moving to this format, evolving the Metadata Model becomes much easier. Adding Entities & Aspects becomes a matter of adding a
+to the YAML configuration, instead of creating new Snapshot / Aspect files.
## Exploring DataHub's Metadata Model
-To explore the current DataHub metadata model, you can inspect this high-level picture that shows the different entities and edges between them showing the relationships between them.
-
+To explore the current DataHub metadata model, you can inspect this high-level picture that shows the different entities and edges between them showing the relationships between them.
+
+
+
+
To navigate the aspect model for specific entities and explore relationships using the `foreign-key` concept, you can view them in our demo environment or navigate the auto-generated docs in the **Metadata Modeling/Entities** section on the left.
-For example, here are helpful links to the most popular entities in DataHub's metadata model:
-* [Dataset](docs/generated/metamodel/entities/dataset.md): [Profile](https://demo.datahubproject.io/dataset/urn:li:dataset:(urn:li:dataPlatform:datahub,Dataset,PROD)/Schema?is_lineage_mode=false) [Documentation](https://demo.datahubproject.io/dataset/urn:li:dataset:(urn:li:dataPlatform:datahub,Dataset,PROD)/Documentation?is_lineage_mode=false)
-* [Dashboard](docs/generated/metamodel/entities/dashboard.md): [Profile](https://demo.datahubproject.io/dataset/urn:li:dataset:(urn:li:dataPlatform:datahub,Dashboard,PROD)/Schema?is_lineage_mode=false) [Documentation](https://demo.datahubproject.io/dataset/urn:li:dataset:(urn:li:dataPlatform:datahub,Dashboard,PROD)/Documentation?is_lineage_mode=false)
-* [User (a.k.a CorpUser)](docs/generated/metamodel/entities/corpuser.md): [Profile](https://demo.datahubproject.io/dataset/urn:li:dataset:(urn:li:dataPlatform:datahub,Corpuser,PROD)/Schema?is_lineage_mode=false) [Documentation](https://demo.datahubproject.io/dataset/urn:li:dataset:(urn:li:dataPlatform:datahub,Corpuser,PROD)/Documentation?is_lineage_mode=false)
-* [Pipeline (a.k.a DataFlow)](docs/generated/metamodel/entities/dataFlow.md): [Profile](https://demo.datahubproject.io/dataset/urn:li:dataset:(urn:li:dataPlatform:datahub,DataFlow,PROD)/Schema?is_lineage_mode=false) [Documentation](https://demo.datahubproject.io/dataset/urn:li:dataset:(urn:li:dataPlatform:datahub,DataFlow,PROD)/Documentation?is_lineage_mode=false)
-* [Feature Table (a.k.a. MLFeatureTable)](docs/generated/metamodel/entities/mlFeatureTable.md): [Profile](https://demo.datahubproject.io/dataset/urn:li:dataset:(urn:li:dataPlatform:datahub,MlFeatureTable,PROD)/Schema?is_lineage_mode=false) [Documentation](https://demo.datahubproject.io/dataset/urn:li:dataset:(urn:li:dataPlatform:datahub,MlFeatureTable,PROD)/Documentation?is_lineage_mode=false)
-* For the full list of entities in the metadata model, browse them [here](https://demo.datahubproject.io/browse/dataset/prod/datahub/entities) or use the **Metadata Modeling/Entities** section on the left.
+For example, here are helpful links to the most popular entities in DataHub's metadata model:
+
+- [Dataset](docs/generated/metamodel/entities/dataset.md): [Profile]() [Documentation]()
+- [Dashboard](docs/generated/metamodel/entities/dashboard.md): [Profile]() [Documentation]()
+- [User (a.k.a CorpUser)](docs/generated/metamodel/entities/corpuser.md): [Profile]() [Documentation]()
+- [Pipeline (a.k.a DataFlow)](docs/generated/metamodel/entities/dataFlow.md): [Profile]() [Documentation]()
+- [Feature Table (a.k.a. MLFeatureTable)](docs/generated/metamodel/entities/mlFeatureTable.md): [Profile]() [Documentation]()
+- For the full list of entities in the metadata model, browse them [here](https://demo.datahubproject.io/browse/dataset/prod/datahub/entities) or use the **Metadata Modeling/Entities** section on the left.
### Generating documentation for the Metadata Model
- This website: Metadata model documentation for this website is generated using `./gradlew :docs-website:yarnBuild`, which delegates the model doc generation to the `modelDocGen` task in the `metadata-ingestion` module.
- Uploading documentation to a running DataHub Instance: The metadata model documentation can be generated and uploaded into a running DataHub instance using the command `./gradlew :metadata-ingestion:modelDocUpload`. **_NOTE_**: This will upload the model documentation to the DataHub instance running at the environment variable `$DATAHUB_SERVER` (http://localhost:8080 by default)
-## Querying the Metadata Graph
+## Querying the Metadata Graph
DataHub’s modeling language allows you to optimize metadata persistence to align with query patterns.
-There are three supported ways to query the metadata graph: by primary key lookup, a search query, and via relationship traversal.
+There are three supported ways to query the metadata graph: by primary key lookup, a search query, and via relationship traversal.
> New to [PDL](https://linkedin.github.io/rest.li/pdl_schema) files? Don't fret. They are just a way to define a JSON document "schema" for Aspects in DataHub. All Data ingested to DataHub's Metadata Service is validated against a PDL schema, with each @Aspect corresponding to a single schema. Structurally, PDL is quite similar to [Protobuf](https://developers.google.com/protocol-buffers) and conveniently maps to JSON.
@@ -102,24 +104,24 @@ There are three supported ways to query the metadata graph: by primary key looku
#### Fetching Latest Entity Aspects (Snapshot)
-Querying an Entity by primary key means using the "entities" endpoint, passing in the
-urn of the entity to retrieve.
+Querying an Entity by primary key means using the "entities" endpoint, passing in the
+urn of the entity to retrieve.
-For example, to fetch a Chart entity, we can use the following `curl`:
+For example, to fetch a Chart entity, we can use the following `curl`:
```
curl --location --request GET 'http://localhost:8080/entities/urn%3Ali%3Achart%3Acustomers
```
-This request will return a set of versioned aspects, each at the latest version.
+This request will return a set of versioned aspects, each at the latest version.
-As you'll notice, we perform the lookup using the url-encoded *Urn* associated with an entity.
+As you'll notice, we perform the lookup using the url-encoded _Urn_ associated with an entity.
The response would be an "Entity" record containing the Entity Snapshot (which in turn contains the latest aspects associated with the Entity).
#### Fetching Versioned Aspects
-DataHub also supports fetching individual pieces of metadata about an Entity, which we call aspects. To do so,
-you'll provide both an Entity's primary key (urn) along with the aspect name and version that you'd like to retrieve.
+DataHub also supports fetching individual pieces of metadata about an Entity, which we call aspects. To do so,
+you'll provide both an Entity's primary key (urn) along with the aspect name and version that you'd like to retrieve.
For example, to fetch the latest version of a Dataset's SchemaMetadata aspect, you would issue the following query:
@@ -151,7 +153,7 @@ curl 'http://localhost:8080/aspects/urn%3Ali%3Adataset%3A(urn%3Ali%3AdataPlatfor
"type":{
"type":{
"com.linkedin.schema.StringType":{
-
+
}
}
},
@@ -203,19 +205,17 @@ curl -X POST 'http://localhost:8080/aspects?action=getTimeseriesAspectValues' \
```
You'll notice that the aspect itself is serialized as escaped JSON. This is part of a shift toward a more generic set of READ / WRITE APIs
-that permit serialization of aspects in different ways. By default, the content type will be JSON, and the aspect can be deserialized into a normal JSON object
-in the language of your choice. Note that this will soon become the de-facto way to both write and read individual aspects.
-
-
+that permit serialization of aspects in different ways. By default, the content type will be JSON, and the aspect can be deserialized into a normal JSON object
+in the language of your choice. Note that this will soon become the de-facto way to both write and read individual aspects.
### Search Query
-A search query allows you to search for entities matching an arbitrary string.
+A search query allows you to search for entities matching an arbitrary string.
For example, to search for entities matching the term "customers", we can use the following CURL:
```
-curl --location --request POST 'http://localhost:8080/entities?action=search' \
+curl --location --request POST 'http://localhost:8080/entities?action=search' \
--header 'X-RestLi-Protocol-Version: 2.0.0' \
--header 'Content-Type: application/json' \
--data-raw '{
@@ -238,26 +238,26 @@ For example, to find the owners of a particular Chart, we can use the following
curl --location --request GET --header 'X-RestLi-Protocol-Version: 2.0.0' 'http://localhost:8080/relationships?direction=OUTGOING&urn=urn%3Ali%3Achart%3Acustomers&types=List(OwnedBy)'
```
-The notable parameters are `direction`, `urn` and `types`. The response contains *Urns* associated with all entities connected
+The notable parameters are `direction`, `urn` and `types`. The response contains _Urns_ associated with all entities connected
to the primary entity (urn:li:chart:customer) by an relationship named "OwnedBy". That is, it permits fetching the owners of a given
-chart.
+chart.
### Special Aspects
-There are a few special aspects worth mentioning:
+There are a few special aspects worth mentioning:
-1. Key aspects: Contain the properties that uniquely identify an Entity.
+1. Key aspects: Contain the properties that uniquely identify an Entity.
2. Browse Paths aspect: Represents a hierarchical path associated with an Entity.
#### Key aspects
-As introduced above, Key aspects are structs / records that contain the fields that uniquely identify an Entity. There are
+As introduced above, Key aspects are structs / records that contain the fields that uniquely identify an Entity. There are
some constraints about the fields that can be present in Key aspects:
- All fields must be of STRING or ENUM type
- All fields must be REQUIRED
-Keys can be created from and turned into *Urns*, which represent the stringified version of the Key record.
+Keys can be created from and turned into _Urns_, which represent the stringified version of the Key record.
The algorithm used to do the conversion is straightforward: the fields of the Key aspect are substituted into a
string template based on their index (order of definition) using the following template:
@@ -266,16 +266,16 @@ string template based on their index (order of definition) using the following t
urn:li::key-field-1
// Case 2: # key fields > 1
-urn:li::(key-field-1, key-field-2, ... key-field-n)
+urn:li::(key-field-1, key-field-2, ... key-field-n)
```
By convention, key aspects are defined under [metadata-models/src/main/pegasus/com/linkedin/metadata/key](https://github.com/datahub-project/datahub/tree/master/metadata-models/src/main/pegasus/com/linkedin/metadata/key).
##### Example
-A CorpUser can be uniquely identified by a "username", which should typically correspond to an LDAP name.
+A CorpUser can be uniquely identified by a "username", which should typically correspond to an LDAP name.
-Thus, it's Key Aspect is defined as the following:
+Thus, it's Key Aspect is defined as the following:
```aidl
namespace com.linkedin.metadata.key
@@ -294,7 +294,7 @@ record CorpUserKey {
}
```
-and it's Entity Snapshot model is defined as
+and it's Entity Snapshot model is defined as
```aidl
/**
@@ -318,13 +318,13 @@ record CorpUserSnapshot {
}
```
-Using a combination of the information provided by these models, we are able to generate the Urn corresponding to a CorpUser as
+Using a combination of the information provided by these models, we are able to generate the Urn corresponding to a CorpUser as
```
urn:li:corpuser:
```
-Imagine we have a CorpUser Entity with the username "johnsmith". In this world, the JSON version of the Key Aspect associated with the Entity would be
+Imagine we have a CorpUser Entity with the username "johnsmith". In this world, the JSON version of the Key Aspect associated with the Entity would be
```aidl
{
@@ -335,18 +335,18 @@ Imagine we have a CorpUser Entity with the username "johnsmith". In this world,
and its corresponding Urn would be
```aidl
-urn:li:corpuser:johnsmith
+urn:li:corpuser:johnsmith
```
#### BrowsePaths aspect
The BrowsePaths aspect allows you to define a custom "browse path" for an Entity. A browse path is a way to hierarchically organize
-entities. They manifest within the "Explore" features on the UI, allowing users to navigate through trees of related entities of a given type.
+entities. They manifest within the "Explore" features on the UI, allowing users to navigate through trees of related entities of a given type.
-To support browsing a particular entity, add the "browsePaths" aspect to the entity in your `entity-registry.yml` file.
+To support browsing a particular entity, add the "browsePaths" aspect to the entity in your `entity-registry.yml` file.
```aidl
-/// entity-registry.yml
+/// entity-registry.yml
entities:
- name: dataset
doc: Datasets represent logical or physical data assets stored or represented in various data platforms. Tables, Views, Streams are all instances of datasets.
@@ -370,21 +370,22 @@ curl --location --request POST 'http://localhost:8080/entities?action=browse' \
}'
```
-Please note you must provide:
+Please note you must provide:
+
- The "/"-delimited root path for which to fetch results.
-- An entity "type" using its common name ("dataset" in the example above).
+- An entity "type" using its common name ("dataset" in the example above).
### Types of Aspect
-There are 2 "types" of Metadata Aspects. Both are modeled using PDL schemas, and both can be ingested in the same way.
-However, they differ in what they represent and how they are handled by DataHub's Metadata Service.
+There are 2 "types" of Metadata Aspects. Both are modeled using PDL schemas, and both can be ingested in the same way.
+However, they differ in what they represent and how they are handled by DataHub's Metadata Service.
#### 1. Versioned Aspects
-
+
Versioned Aspects each have a **numeric version** associated with them. When a field in an aspect changes, a new
version is automatically created and stored within DataHub's backend. In practice, all versioned aspects are stored inside a relational database
that can be backed up and restored. Versioned aspects power much of the UI experience you're used to, including Ownership, Descriptions,
-Tags, Glossary Terms, and more. Examples include Ownership, Global Tags, and Glossary Terms.
+Tags, Glossary Terms, and more. Examples include Ownership, Global Tags, and Glossary Terms.
#### 2. Timeseries Aspects
@@ -411,34 +412,36 @@ to [DatasetProfile](https://github.com/datahub-project/datahub/tree/master/metad
to see an example of a timeseries aspect.
Because timeseries aspects are updated on a frequent basis, ingests of these aspects go straight to elastic search (
-instead of being stored in local DB).
+instead of being stored in local DB).
-You can retrieve timeseries aspects using the "aspects?action=getTimeseriesAspectValues" end point.
+You can retrieve timeseries aspects using the "aspects?action=getTimeseriesAspectValues" end point.
##### Aggregatable Timeseries aspects
-Being able to perform SQL like *group by + aggregate* operations on the timeseries aspects is a very natural use-case for
+
+Being able to perform SQL like _group by + aggregate_ operations on the timeseries aspects is a very natural use-case for
this kind of data (dataset profiles, usage statistics etc.). This section describes how to define, ingest and perform an
aggregation query against a timeseries aspect.
###### Defining a new aggregatable Timeseries aspect.
-The *@TimeseriesField* and the *@TimeseriesFieldCollection* are two new annotations that can be attached to a field of
-a *Timeseries aspect* that allows it to be part of an aggregatable query. The kinds of aggregations allowed on these
+The _@TimeseriesField_ and the _@TimeseriesFieldCollection_ are two new annotations that can be attached to a field of
+a _Timeseries aspect_ that allows it to be part of an aggregatable query. The kinds of aggregations allowed on these
annotated fields depends on the type of the field, as well as the kind of aggregation, as
described [here](#Performing-an-aggregation-on-a-Timeseries-aspect).
-* `@TimeseriesField = {}` - this annotation can be used with any type of non-collection type field of the aspect such as
- primitive types and records (see the fields *stat*, *strStat* and *strArray* fields
+- `@TimeseriesField = {}` - this annotation can be used with any type of non-collection type field of the aspect such as
+ primitive types and records (see the fields _stat_, _strStat_ and _strArray_ fields
of [TestEntityProfile.pdl](https://github.com/datahub-project/datahub/blob/master/test-models/src/main/pegasus/com/datahub/test/TestEntityProfile.pdl)).
-* The `@TimeseriesFieldCollection {"key":""}` annotation allows for
-aggregation support on the items of a collection type (supported only for the array type collections for now), where the
-value of `"key"` is the name of the field in the collection item type that will be used to specify the group-by clause (
-see *userCounts* and *fieldCounts* fields of [DatasetUsageStatistics.pdl](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/dataset/DatasetUsageStatistics.pdl)).
+- The `@TimeseriesFieldCollection {"key":""}` annotation allows for
+ aggregation support on the items of a collection type (supported only for the array type collections for now), where the
+ value of `"key"` is the name of the field in the collection item type that will be used to specify the group-by clause (
+ see _userCounts_ and _fieldCounts_ fields of [DatasetUsageStatistics.pdl](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/dataset/DatasetUsageStatistics.pdl)).
In addition to defining the new aspect with appropriate Timeseries annotations,
the [entity-registry.yml](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/resources/entity-registry.yml)
file needs to be updated as well. Just add the new aspect name under the list of aspects against the appropriate entity as shown below, such as `datasetUsageStatistics` for the aspect DatasetUsageStatistics.
+
```yaml
entities:
- name: dataset
@@ -449,6 +452,7 @@ entities:
```
###### Ingesting a Timeseries aspect
+
The timeseries aspects can be ingested via the GMS REST endpoint `/aspects?action=ingestProposal` or via the python API.
Example1: Via GMS REST API using curl.
@@ -470,7 +474,9 @@ curl --location --request POST 'http://localhost:8080/aspects?action=ingestPropo
}
}'
```
+
Example2: Via Python API to Kafka(or REST)
+
```python
from datahub.metadata.schema_classes import (
ChangeTypeClass,
@@ -511,40 +517,42 @@ my_emitter.emit(mcpw)
Aggreations on timeseries aspects can be performed by the GMS REST API for `/analytics?action=getTimeseriesStats` which
accepts the following params.
-* `entityName` - The name of the entity the aspect is associated with.
-* `aspectName` - The name of the aspect.
-* `filter` - Any pre-filtering criteria before grouping and aggregations are performed.
-* `metrics` - A list of aggregation specification. The `fieldPath` member of an aggregation specification refers to the
+
+- `entityName` - The name of the entity the aspect is associated with.
+- `aspectName` - The name of the aspect.
+- `filter` - Any pre-filtering criteria before grouping and aggregations are performed.
+- `metrics` - A list of aggregation specification. The `fieldPath` member of an aggregation specification refers to the
field name against which the aggregation needs to be performed, and the `aggregationType` specifies the kind of aggregation.
-* `buckets` - A list of grouping bucket specifications. Each grouping bucket has a `key` field that refers to the field
+- `buckets` - A list of grouping bucket specifications. Each grouping bucket has a `key` field that refers to the field
to use for grouping. The `type` field specifies the kind of grouping bucket.
We support three kinds of aggregations that can be specified in an aggregation query on the Timeseries annotated fields.
The values that `aggregationType` can take are:
-* `LATEST`: The latest value of the field in each bucket. Supported for any type of field.
-* `SUM`: The cumulative sum of the field in each bucket. Supported only for integral types.
-* `CARDINALITY`: The number of unique values or the cardinality of the set in each bucket. Supported for string and
+- `LATEST`: The latest value of the field in each bucket. Supported for any type of field.
+- `SUM`: The cumulative sum of the field in each bucket. Supported only for integral types.
+- `CARDINALITY`: The number of unique values or the cardinality of the set in each bucket. Supported for string and
record types.
We support two types of grouping for defining the buckets to perform aggregations against:
-* `DATE_GROUPING_BUCKET`: Allows for creating time-based buckets such as by second, minute, hour, day, week, month,
- quarter, year etc. Should be used in conjunction with a timestamp field whose value is in milliseconds since *epoch*.
+- `DATE_GROUPING_BUCKET`: Allows for creating time-based buckets such as by second, minute, hour, day, week, month,
+ quarter, year etc. Should be used in conjunction with a timestamp field whose value is in milliseconds since _epoch_.
The `timeWindowSize` param specifies the date histogram bucket width.
-* `STRING_GROUPING_BUCKET`: Allows for creating buckets grouped by the unique values of a field. Should always be used in
+- `STRING_GROUPING_BUCKET`: Allows for creating buckets grouped by the unique values of a field. Should always be used in
conjunction with a string type field.
The API returns a generic SQL like table as the `table` member of the output that contains the results of
the `group-by/aggregate` query, in addition to echoing the input params.
-* `columnNames`: the names of the table columns. The group-by `key` names appear in the same order as they are specified
+- `columnNames`: the names of the table columns. The group-by `key` names appear in the same order as they are specified
in the request. Aggregation specifications follow the grouping fields in the same order as specified in the request,
and will be named `_`.
-* `columnTypes`: the data types of the columns.
-* `rows`: the data values, each row corresponding to the respective bucket(s).
+- `columnTypes`: the data types of the columns.
+- `rows`: the data values, each row corresponding to the respective bucket(s).
Example: Latest unique user count for each day.
+
```shell
# QUERY
curl --location --request POST 'http://localhost:8080/analytics?action=getTimeseriesStats' \
@@ -617,7 +625,5 @@ curl --location --request POST 'http://localhost:8080/analytics?action=getTimese
}
}
```
-For more examples on the complex types of group-by/aggregations, refer to the tests in the group `getAggregatedStats` of [ElasticSearchTimeseriesAspectServiceTest.java](https://github.com/datahub-project/datahub/blob/master/metadata-io/src/test/java/com/linkedin/metadata/timeseries/elastic/ElasticSearchTimeseriesAspectServiceTest.java).
-
-
+For more examples on the complex types of group-by/aggregations, refer to the tests in the group `getAggregatedStats` of [ElasticSearchTimeseriesAspectServiceTest.java](https://github.com/datahub-project/datahub/blob/master/metadata-io/src/test/java/com/linkedin/metadata/timeseries/elastic/ElasticSearchTimeseriesAspectServiceTest.java).
diff --git a/docs/platform-instances.md b/docs/platform-instances.md
index c6bfe3315de98..ca7e39f1210ca 100644
--- a/docs/platform-instances.md
+++ b/docs/platform-instances.md
@@ -1,44 +1,48 @@
-# Working With Platform Instances
-
-DataHub's metadata model for Datasets supports a three-part key currently:
-- Data Platform (e.g. urn:li:dataPlatform:mysql)
-- Name (e.g. db.schema.name)
-- Env or Fabric (e.g. DEV, PROD, etc.)
-
-This naming scheme unfortunately does not allow for easy representation of the multiplicity of platforms (or technologies) that might be deployed at an organization within the same environment or fabric. For example, an organization might have multiple Redshift instances in Production and would want to see all the data assets located in those instances inside the DataHub metadata repository.
-
-As part of the `v0.8.24+` releases, we are unlocking the first phase of supporting Platform Instances in the metadata model. This is done via two main additions:
-- The `dataPlatformInstance` aspect that has been added to Datasets which allows datasets to be associated to an instance of a platform
-- Enhancements to all ingestion sources that allow them to attach a platform instance to the recipe that changes the generated urns to go from `urn:li:dataset:(urn:li:dataPlatform:,,ENV)` format to `urn:li:dataset:(urn:li:dataPlatform:,,ENV)` format. Sources that produce lineage to datasets in other platforms (e.g. Looker, Superset etc) also have specific configuration additions that allow the recipe author to specify the mapping between a platform and the instance name that it should be mapped to.
-
-
-
-## Naming Platform Instances
-
-When configuring a platform instance, choose an instance name that is understandable and will be stable for the foreseeable future. e.g. `core_warehouse` or `finance_redshift` are allowed names, as are pure guids like `a37dc708-c512-4fe4-9829-401cd60ed789`. Remember that whatever instance name you choose, you will need to specify it in more than one recipe to ensure that the identifiers produced by different sources will line up.
-
-## Enabling Platform Instances
-
-Read the Ingestion source specific guides for how to enable platform instances in each of them.
-The general pattern is to add an additional optional configuration parameter called `platform_instance`.
-
-e.g. here is how you would configure a recipe to ingest a mysql instance that you want to call `core_finance`
-```yaml
-source:
- type: mysql
- config:
- # Coordinates
- host_port: localhost:3306
- platform_instance: core_finance
- database: dbname
-
- # Credentials
- username: root
- password: example
-
-sink:
- # sink configs
-```
-
-
-##
+# Working With Platform Instances
+
+DataHub's metadata model for Datasets supports a three-part key currently:
+
+- Data Platform (e.g. urn:li:dataPlatform:mysql)
+- Name (e.g. db.schema.name)
+- Env or Fabric (e.g. DEV, PROD, etc.)
+
+This naming scheme unfortunately does not allow for easy representation of the multiplicity of platforms (or technologies) that might be deployed at an organization within the same environment or fabric. For example, an organization might have multiple Redshift instances in Production and would want to see all the data assets located in those instances inside the DataHub metadata repository.
+
+As part of the `v0.8.24+` releases, we are unlocking the first phase of supporting Platform Instances in the metadata model. This is done via two main additions:
+
+- The `dataPlatformInstance` aspect that has been added to Datasets which allows datasets to be associated to an instance of a platform
+- Enhancements to all ingestion sources that allow them to attach a platform instance to the recipe that changes the generated urns to go from `urn:li:dataset:(urn:li:dataPlatform:,,ENV)` format to `urn:li:dataset:(urn:li:dataPlatform:,,ENV)` format. Sources that produce lineage to datasets in other platforms (e.g. Looker, Superset etc) also have specific configuration additions that allow the recipe author to specify the mapping between a platform and the instance name that it should be mapped to.
+
+
+
+
+
+## Naming Platform Instances
+
+When configuring a platform instance, choose an instance name that is understandable and will be stable for the foreseeable future. e.g. `core_warehouse` or `finance_redshift` are allowed names, as are pure guids like `a37dc708-c512-4fe4-9829-401cd60ed789`. Remember that whatever instance name you choose, you will need to specify it in more than one recipe to ensure that the identifiers produced by different sources will line up.
+
+## Enabling Platform Instances
+
+Read the Ingestion source specific guides for how to enable platform instances in each of them.
+The general pattern is to add an additional optional configuration parameter called `platform_instance`.
+
+e.g. here is how you would configure a recipe to ingest a mysql instance that you want to call `core_finance`
+
+```yaml
+source:
+ type: mysql
+ config:
+ # Coordinates
+ host_port: localhost:3306
+ platform_instance: core_finance
+ database: dbname
+
+ # Credentials
+ username: root
+ password: example
+
+sink:
+ # sink configs
+```
+
+##
diff --git a/docs/schema-history.md b/docs/schema-history.md
index 9fc9ec1af52bb..2c92e7a8f29e9 100644
--- a/docs/schema-history.md
+++ b/docs/schema-history.md
@@ -13,7 +13,7 @@ along with informing Data Practitioners when these changes happened.
Schema History uses DataHub's [Timeline API](https://datahubproject.io/docs/dev-guides/timeline/) to compute schema changes.
-## Schema History Setup, Prerequisites, and Permissions
+## Schema History Setup, Prerequisites, and Permissions
Schema History is viewable in the DataHub UI for any Dataset that has had at least one schema change. To view a Dataset, a user
must have the **View Entity Page** privilege, or be assigned to **any** DataHub Role.
@@ -23,33 +23,40 @@ must have the **View Entity Page** privilege, or be assigned to **any** DataHub
You can view the Schema History for a Dataset by navigating to that Dataset's Schema Tab. As long as that Dataset has more than
one version, you can view what a Dataset looked like at any given version by using the version selector.
Here's an example from DataHub's official Demo environment with the
-[Snowflake pets dataset](https://demo.datahubproject.io/dataset/urn:li:dataset:(urn:li:dataPlatform:snowflake,long_tail_companions.adoption.pets,PROD)/Schema?is_lineage_mode=false).
+[Snowflake pets dataset]().
-
+
+
+
If you click on an older version in the selector, you'll be able to see what the schema looked like back then. Notice
the changes here to the glossary terms for the `status` field, and to the descriptions for the `created_at` and `updated_at`
fields.
-
+
+
+
In addition to this, you can also toggle the Audit view that shows you when the most recent changes were made to each field.
You can active this by clicking on the Audit icon you see above the top right of the table.
-
+
+
+
You can see here that some of these fields were added at the oldest dataset version, while some were added only at this latest
version. Some fields were even modified and had a type change at the latest version!
### GraphQL
-* [getSchemaBlame](../graphql/queries.md#getSchemaBlame)
-* [getSchemaVersionList](../graphql/queries.md#getSchemaVersionList)
+- [getSchemaBlame](../graphql/queries.md#getSchemaBlame)
+- [getSchemaVersionList](../graphql/queries.md#getSchemaVersionList)
## FAQ and Troubleshooting
**What updates are planned for the Schema History feature?**
In the future, we plan on adding the following features
+
- Supporting a linear timeline view where you can see what changes were made to various schema fields over time
- Adding a diff viewer that highlights the differences between two versions of a Dataset
diff --git a/docs/tags.md b/docs/tags.md
index 945b514dc7b47..720e56b9a4a75 100644
--- a/docs/tags.md
+++ b/docs/tags.md
@@ -8,15 +8,15 @@ Tags are informal, loosely controlled labels that help in search & discovery. Th
Tags can help help you in:
-* Querying: Tagging a dataset with a phrase that a co-worker can use to query the same dataset
-* Mapping assets to a category or group of your choice
+- Querying: Tagging a dataset with a phrase that a co-worker can use to query the same dataset
+- Mapping assets to a category or group of your choice
## Tags Setup, Prerequisites, and Permissions
What you need to add tags:
-* **Edit Tags** metadata privilege to add tags at the entity level
-* **Edit Dataset Column Tags** to edit tags at the column level
+- **Edit Tags** metadata privilege to add tags at the entity level
+- **Edit Dataset Column Tags** to edit tags at the column level
You can create these privileges by creating a new [Metadata Policy](./authorization/policies.md).
@@ -27,25 +27,25 @@ You can create these privileges by creating a new [Metadata Policy](./authorizat
To add a tag at the dataset or container level, simply navigate to the page for that entity and click on the **Add Tag** button.
-
+
Type in the name of the tag you want to add. You can add a new tag, or add a tag that already exists (the autocomplete will pull up the tag if it already exists).
-
+
Click on the "Add" button and you'll see the tag has been added!
-
+
If you would like to add a tag at the schema level, hover over the "Tags" column for a schema until the "Add Tag" button shows up, and then follow the same flow as above.
-
+
### Removing a Tag
@@ -57,7 +57,7 @@ To remove a tag, simply click on the "X" button in the tag. Then click "Yes" whe
You can search for a tag in the search bar, and even filter entities by the presence of a specific tag.
-
+
## Additional Resources
@@ -72,21 +72,21 @@ You can search for a tag in the search bar, and even filter entities by the pres
### GraphQL
-* [addTag](../graphql/mutations.md#addtag)
-* [addTags](../graphql/mutations.md#addtags)
-* [batchAddTags](../graphql/mutations.md#batchaddtags)
-* [removeTag](../graphql/mutations.md#removetag)
-* [batchRemoveTags](../graphql/mutations.md#batchremovetags)
-* [createTag](../graphql/mutations.md#createtag)
-* [updateTag](../graphql/mutations.md#updatetag)
-* [deleteTag](../graphql/mutations.md#deletetag)
+- [addTag](../graphql/mutations.md#addtag)
+- [addTags](../graphql/mutations.md#addtags)
+- [batchAddTags](../graphql/mutations.md#batchaddtags)
+- [removeTag](../graphql/mutations.md#removetag)
+- [batchRemoveTags](../graphql/mutations.md#batchremovetags)
+- [createTag](../graphql/mutations.md#createtag)
+- [updateTag](../graphql/mutations.md#updatetag)
+- [deleteTag](../graphql/mutations.md#deletetag)
-You can easily fetch the Tags for an entity with a given its URN using the **tags** property. Check out [Working with Metadata Entities](./api/graphql/how-to-set-up-graphql.md#querying-for-tags-of-an-asset) for an example.
+You can easily fetch the Tags for an entity with a given its URN using the **tags** property. Check out [Working with Metadata Entities](./api/graphql/how-to-set-up-graphql.md#querying-for-tags-of-an-asset) for an example.
### DataHub Blog
-* [Tags and Terms: Two Powerful DataHub Features, Used in Two Different Scenarios
-Managing PII in DataHub: A Practitioner’s Guide](https://blog.datahubproject.io/tags-and-terms-two-powerful-datahub-features-used-in-two-different-scenarios-b5b4791e892e)
+- [Tags and Terms: Two Powerful DataHub Features, Used in Two Different Scenarios
+ Managing PII in DataHub: A Practitioner’s Guide](https://blog.datahubproject.io/tags-and-terms-two-powerful-datahub-features-used-in-two-different-scenarios-b5b4791e892e)
## FAQ and Troubleshooting
@@ -96,16 +96,16 @@ DataHub Tags are informal, loosely controlled labels while Terms are part of a c
Usage and applications:
-* An asset may have multiple tags.
-* Tags serve as a tool for search & discovery while Terms are typically used to standardize types of leaf-level attributes (i.e. schema fields) for governance. E.g. (EMAIL_PLAINTEXT)
+- An asset may have multiple tags.
+- Tags serve as a tool for search & discovery while Terms are typically used to standardize types of leaf-level attributes (i.e. schema fields) for governance. E.g. (EMAIL_PLAINTEXT)
**How are DataHub Tags different from Domains?**
Domains are a set of top-level categories usually aligned to business units/disciplines to which the assets are most relevant. They rely on central or distributed management. A single domain is assigned per data asset.
-*Need more help? Join the conversation in [Slack](http://slack.datahubproject.io)!*
+_Need more help? Join the conversation in [Slack](http://slack.datahubproject.io)!_
### Related Features
-* [Glossary Terms](./glossary/business-glossary.md)
-* [Domains](./domains.md)
+- [Glossary Terms](./glossary/business-glossary.md)
+- [Domains](./domains.md)
diff --git a/docs/ui-ingestion.md b/docs/ui-ingestion.md
index 235f1521c070a..50cc8e5207686 100644
--- a/docs/ui-ingestion.md
+++ b/docs/ui-ingestion.md
@@ -1,44 +1,52 @@
-# UI Ingestion Guide
+# UI Ingestion Guide
-## Introduction
+## Introduction
Starting in version `0.8.25`, DataHub supports creating, configuring, scheduling, & executing batch metadata ingestion using the DataHub user interface. This makes
-getting metadata into DataHub easier by minimizing the overhead required to operate custom integration pipelines.
+getting metadata into DataHub easier by minimizing the overhead required to operate custom integration pipelines.
-This document will describe the steps required to configure, schedule, and execute metadata ingestion inside the UI.
+This document will describe the steps required to configure, schedule, and execute metadata ingestion inside the UI.
## Running Metadata Ingestion
### Prerequisites
To view & manage UI-based metadata ingestion, you must have the `Manage Metadata Ingestion` & `Manage Secrets`
- privileges assigned to your account. These can be granted by a [Platform Policy](authorization/policies.md).
+privileges assigned to your account. These can be granted by a [Platform Policy](authorization/policies.md).
-
+
+
+
-Once you have these privileges, you can begin to manage ingestion by navigating to the 'Ingestion' tab in DataHub.
+Once you have these privileges, you can begin to manage ingestion by navigating to the 'Ingestion' tab in DataHub.
-
+
+
+
On this page, you'll see a list of active **Ingestion Sources**. An Ingestion Sources is a unique source of metadata ingested
into DataHub from an external source like Snowflake, Redshift, or BigQuery.
If you're just getting started, you won't have any sources. In the following sections, we'll describe how to create
-your first **Ingestion Source**.
+your first **Ingestion Source**.
### Creating an Ingestion Source
Before ingesting any metadata, you need to create a new Ingestion Source. Start by clicking **+ Create new source**.
-
+
+
+
#### Step 1: Select a Platform Template
In the first step, select a **Recipe Template** corresponding to the source type that you'd like to extract metadata from. Choose among
a variety of natively supported integrations, from Snowflake to Postgres to Kafka.
-Select `Custom` to construct an ingestion recipe from scratch.
+Select `Custom` to construct an ingestion recipe from scratch.
-
+
+
+
Next, you'll configure an ingestion **Recipe**, which defines _how_ and _what_ to extract from the source system.
@@ -49,23 +57,23 @@ used by DataHub to extract metadata from a 3rd party system. It most often consi
1. A source **type**: The type of system you'd like to extract metadata from (e.g. snowflake, mysql, postgres). If you've chosen a native template, this will already be populated for you.
To view a full list of currently supported **types**, check out [this list](https://datahubproject.io/docs/metadata-ingestion/#installing-plugins).
-
-2. A source **config**: A set of configurations specific to the source **type**. Most sources support the following types of configuration values:
- - **Coordinates**: The location of the system you want to extract metadata from
- - **Credentials**: Authorized credentials for accessing the system you want to extract metadata from
- - **Customizations**: Customizations regarding the metadata that will be extracted, e.g. which databases or tables to scan in a relational DB
+2. A source **config**: A set of configurations specific to the source **type**. Most sources support the following types of configuration values:
+ - **Coordinates**: The location of the system you want to extract metadata from
+ - **Credentials**: Authorized credentials for accessing the system you want to extract metadata from
+ - **Customizations**: Customizations regarding the metadata that will be extracted, e.g. which databases or tables to scan in a relational DB
3. A sink **type**: A type of sink to route the metadata extracted from the source type. The officially supported DataHub sink
- types are `datahub-rest` and `datahub-kafka`.
-
+ types are `datahub-rest` and `datahub-kafka`.
4. A sink **config**: Configuration required to send metadata to the provided sink type. For example, DataHub coordinates and credentials.
-
+
A sample of a full recipe configured to ingest metadata from MySQL can be found in the image below.
-
+
+
+
Detailed configuration examples & documentation for each source type can be found on the [DataHub Docs](https://datahubproject.io/docs/metadata-ingestion/) website.
@@ -75,15 +83,16 @@ For production use cases, sensitive configuration values, such as database usern
should be hidden from plain view within your ingestion recipe. To accomplish this, you can create & embed **Secrets**. Secrets are named values
that are encrypted and stored within DataHub's storage layer.
-To create a secret, first navigate to the 'Secrets' tab. Then click `+ Create new secret`.
+To create a secret, first navigate to the 'Secrets' tab. Then click `+ Create new secret`.
-
+
+
+
_Creating a Secret to store the username for a MySQL database_
Inside the form, provide a unique name for the secret along with the value to be encrypted, and an optional description. Click **Create** when you are done.
-This will create a Secret which can be referenced inside your ingestion recipe using its name.
-
+This will create a Secret which can be referenced inside your ingestion recipe using its name.
##### Referencing a Secret
@@ -92,53 +101,56 @@ to substitute secrets for a MySQL username and password into a Recipe, your Reci
```yaml
source:
- type: mysql
- config:
- host_port: 'localhost:3306'
- database: my_db
- username: ${MYSQL_USERNAME}
- password: ${MYSQL_PASSWORD}
- include_tables: true
- include_views: true
- profiling:
- enabled: true
+ type: mysql
+ config:
+ host_port: "localhost:3306"
+ database: my_db
+ username: ${MYSQL_USERNAME}
+ password: ${MYSQL_PASSWORD}
+ include_tables: true
+ include_views: true
+ profiling:
+ enabled: true
sink:
- type: datahub-rest
- config:
- server: 'http://datahub-gms:8080'
+ type: datahub-rest
+ config:
+ server: "http://datahub-gms:8080"
```
+
_Referencing DataHub Secrets from a Recipe definition_
When the Ingestion Source with this Recipe executes, DataHub will attempt to 'resolve' Secrets found within the YAML. If a secret can be resolved, the reference is substituted for its decrypted value prior to execution.
Secret values are not persisted to disk beyond execution time, and are never transmitted outside DataHub.
-> **Attention**: Any DataHub users who have been granted the `Manage Secrets` [Platform Privilege](authorization/policies.md) will be able to retrieve plaintext secret values using the GraphQL API.
-
+> **Attention**: Any DataHub users who have been granted the `Manage Secrets` [Platform Privilege](authorization/policies.md) will be able to retrieve plaintext secret values using the GraphQL API.
-#### Step 3: Schedule Execution
+#### Step 3: Schedule Execution
Next, you can optionally configure a schedule on which to execute your new Ingestion Source. This enables to schedule metadata extraction on a monthly, weekly, daily, or hourly cadence depending on the needs of your organization.
-Schedules are defined using CRON format.
+Schedules are defined using CRON format.
-
+
+
+
_An Ingestion Source that is executed at 9:15am every day, Los Angeles time_
To learn more about the CRON scheduling format, check out the [Wikipedia](https://en.wikipedia.org/wiki/Cron) overview.
-If you plan to execute ingestion on an ad-hoc basis, you can click **Skip** to skip the scheduling step entirely. Don't worry -
-you can always come back and change this.
+If you plan to execute ingestion on an ad-hoc basis, you can click **Skip** to skip the scheduling step entirely. Don't worry -
+you can always come back and change this.
#### Step 4: Finishing Up
-Finally, give your Ingestion Source a name.
+Finally, give your Ingestion Source a name.
-
+
+
+
Once you're happy with your configurations, click 'Done' to save your changes.
-
-##### Advanced: Running with a specific CLI version
+##### Advanced: Running with a specific CLI version
DataHub comes pre-configured to use the latest version of the DataHub CLI ([acryl-datahub](https://pypi.org/project/acryl-datahub/)) that is compatible
with the server. However, you can override the default package version using the 'Advanced' source configurations.
@@ -146,11 +158,13 @@ with the server. However, you can override the default package version using the
To do so, simply click 'Advanced', then change the 'CLI Version' text box to contain the exact version
of the DataHub CLI you'd like to use.
-
-_Pinning the CLI version to version `0.8.23.2`_
+
+
+
-Once you're happy with your changes, simply click 'Done' to save.
+_Pinning the CLI version to version `0.8.23.2`_
+Once you're happy with your changes, simply click 'Done' to save.
### Running an Ingestion Source
@@ -158,47 +172,54 @@ Once you've created your Ingestion Source, you can run it by clicking 'Execute'.
you should see the 'Last Status' column of the ingestion source change from `N/A` to `Running`. This
means that the request to execute ingestion has been successfully picked up by the DataHub ingestion executor.
-
+
+
+
-If ingestion has executed successfully, you should see it's state shown in green as `Succeeded`.
-
-
+If ingestion has executed successfully, you should see it's state shown in green as `Succeeded`.
+
+
+
### Cancelling an Ingestion Run
-If your ingestion run is hanging, there may a bug in the ingestion source, or another persistent issue like exponential timeouts. If these situations,
+If your ingestion run is hanging, there may a bug in the ingestion source, or another persistent issue like exponential timeouts. If these situations,
you can cancel ingestion by clicking **Cancel** on the problematic run.
-
-
-Once cancelled, you can view the output of the ingestion run by clicking **Details**.
+
+
+
+Once cancelled, you can view the output of the ingestion run by clicking **Details**.
### Debugging a Failed Ingestion Run
-
+
+
+
-A variety of things can cause an ingestion run to fail. Common reasons for failure include:
+A variety of things can cause an ingestion run to fail. Common reasons for failure include:
1. **Recipe Misconfiguration**: A recipe has not provided the required or expected configurations for the ingestion source. You can refer
to the [Metadata Ingestion Framework](https://datahubproject.io/docs/metadata-ingestion) source docs to learn more about the configurations required for your source type.
-
-2. **Failure to resolve Secrets**: If DataHub is unable to find secrets that were referenced by your Recipe configuration, the ingestion run will fail.
- Verify that the names of the secrets referenced in your recipe match those which have been created.
-
+2. **Failure to resolve Secrets**: If DataHub is unable to find secrets that were referenced by your Recipe configuration, the ingestion run will fail.
+ Verify that the names of the secrets referenced in your recipe match those which have been created.
3. **Connectivity / Network Reachability**: If DataHub is unable to reach a data source, for example due to DNS resolution
failures, metadata ingestion will fail. Ensure that the network where DataHub is deployed has access to the data source which
- you are trying to reach.
-
-4. **Authentication**: If you've enabled [Metadata Service Authentication](authentication/introducing-metadata-service-authentication.md), you'll need to provide a Personal Access Token
- in your Recipe Configuration. To so this, set the 'token' field of the sink configuration to contain a Personal Access Token:
- 
+ you are trying to reach.
+4. **Authentication**: If you've enabled [Metadata Service Authentication](authentication/introducing-metadata-service-authentication.md), you'll need to provide a Personal Access Token
+in your Recipe Configuration. To so this, set the 'token' field of the sink configuration to contain a Personal Access Token:
+
+
+
-The output of each run is captured and available to view in the UI for easier debugging. To view output logs, click **DETAILS**
-on the corresponding ingestion run.
+The output of each run is captured and available to view in the UI for easier debugging. To view output logs, click **DETAILS**
+on the corresponding ingestion run.
-
+
+
+
## FAQ
@@ -206,14 +227,16 @@ on the corresponding ingestion run.
If not due to one of the reasons outlined above, this may be because the executor running ingestion is unable
to reach DataHub's backend using the default configurations. Try changing your ingestion recipe to make the `sink.config.server` variable point to the Docker
-DNS name for the `datahub-gms` pod:
+DNS name for the `datahub-gms` pod:
-
+
+
+
### I see 'N/A' when I try to run ingestion. What do I do?
-If you see 'N/A', and the ingestion run state never changes to 'Running', this may mean
-that your executor (`datahub-actions`) container is down.
+If you see 'N/A', and the ingestion run state never changes to 'Running', this may mean
+that your executor (`datahub-actions`) container is down.
This container is responsible for executing requests to run ingestion when they come in, either
on demand on a particular schedule. You can verify the health of the container using `docker ps`. Moreover, you can inspect the container logs using by finding the container id
diff --git a/docs/what/relationship.md b/docs/what/relationship.md
index 1908bbd6ce75f..c52aa05ee489d 100644
--- a/docs/what/relationship.md
+++ b/docs/what/relationship.md
@@ -1,19 +1,21 @@
# What is a relationship?
-A relationship is a named associate between exactly two [entities](entity.md), a source and a destination.
-
-
-
-From the above graph, a `Group` entity can be linked to a `User` entity via a `HasMember` relationship.
-Note that the name of the relationship reflects the direction, i.e. pointing from `Group` to `User`.
-This is due to the fact that the actual metadata aspect holding this information is associated with `Group`, rather than User.
-Had the direction been reversed, the relationship would have been named `IsMemberOf` instead.
-See [Direction of Relationships](#direction-of-relationships) for more discussions on relationship directionality.
-A specific instance of a relationship, e.g. `urn:li:corpGroup:group1` has a member `urn:li:corpuser:user1`,
+A relationship is a named associate between exactly two [entities](entity.md), a source and a destination.
+
+
+
+
+
+From the above graph, a `Group` entity can be linked to a `User` entity via a `HasMember` relationship.
+Note that the name of the relationship reflects the direction, i.e. pointing from `Group` to `User`.
+This is due to the fact that the actual metadata aspect holding this information is associated with `Group`, rather than User.
+Had the direction been reversed, the relationship would have been named `IsMemberOf` instead.
+See [Direction of Relationships](#direction-of-relationships) for more discussions on relationship directionality.
+A specific instance of a relationship, e.g. `urn:li:corpGroup:group1` has a member `urn:li:corpuser:user1`,
corresponds to an edge in the metadata graph.
-Similar to an entity, a relationship can also be associated with optional attributes that are derived from the metadata.
-For example, from the `Membership` metadata aspect shown below, we’re able to derive the `HasMember` relationship that links a specific `Group` to a specific `User`. We can also include additional attribute to the relationship, e.g. importance, which corresponds to the position of the specific member in the original membership array. This allows complex graph query that travel only relationships that match certain criteria, e.g. "returns only the top-5 most important members of this group."
+Similar to an entity, a relationship can also be associated with optional attributes that are derived from the metadata.
+For example, from the `Membership` metadata aspect shown below, we’re able to derive the `HasMember` relationship that links a specific `Group` to a specific `User`. We can also include additional attribute to the relationship, e.g. importance, which corresponds to the position of the specific member in the original membership array. This allows complex graph query that travel only relationships that match certain criteria, e.g. "returns only the top-5 most important members of this group."
Similar to the entity attributes, relationship attributes should only be added based on the expected query patterns to reduce the indexing cost.
```
@@ -38,12 +40,13 @@ record Membership {
}
```
-Relationships are meant to be "entity-neutral". In other words, one would expect to use the same `OwnedBy` relationship to link a `Dataset` to a `User` and to link a `Dashboard` to a `User`. As Pegasus doesn’t allow typing a field using multiple URNs (because they’re all essentially strings), we resort to using generic URN type for the source and destination.
+Relationships are meant to be "entity-neutral". In other words, one would expect to use the same `OwnedBy` relationship to link a `Dataset` to a `User` and to link a `Dashboard` to a `User`. As Pegasus doesn’t allow typing a field using multiple URNs (because they’re all essentially strings), we resort to using generic URN type for the source and destination.
We also introduce a `@pairings` [annotation](https://linkedin.github.io/rest.li/pdl_migration#shorthand-for-custom-properties) to limit the allowed source and destination URN types.
While it’s possible to model relationships in rest.li as [association resources](https://linkedin.github.io/rest.li/modeling/modeling#association), which often get stored as mapping tables, it is far more common to model them as "foreign keys" field in a metadata aspect. For instance, the `Ownership` aspect is likely to contain an array of owner’s corpuser URNs.
Below is an example of how a relationship is modeled in PDL. Note that:
+
1. As the `source` and `destination` are of generic URN type, we’re able to factor them out to a common `BaseRelationship` model.
2. Each model is expected to have a `@pairings` annotation that is an array of all allowed source-destination URN pairs.
3. Unlike entity attributes, there’s no requirement on making all relationship attributes optional since relationships do not support partial updates.
@@ -85,20 +88,20 @@ record HasMembership includes BaseRelationship
/**
* The importance of the membership
*/
- importance: int
+ importance: int
}
```
## Direction of Relationships
-As relationships are modeled as directed edges between nodes, it’s natural to ask which way should it be pointing,
-or should there be edges going both ways? The answer is, "doesn’t really matter." It’s rather an aesthetic choice than technical one.
+As relationships are modeled as directed edges between nodes, it’s natural to ask which way should it be pointing,
+or should there be edges going both ways? The answer is, "doesn’t really matter." It’s rather an aesthetic choice than technical one.
For one, the actual direction doesn’t really impact the execution of graph queries. Most graph DBs are fully capable of traversing edges in reverse direction efficiently.
That being said, generally there’s a more "natural way" to specify the direction of a relationship, which closely relate to how the metadata is stored. For example, the membership information for an LDAP group is generally stored as a list in group’s metadata. As a result, it’s more natural to model a `HasMember` relationship that points from a group to a member, instead of a `IsMemberOf` relationship pointing from member to group.
-Since all relationships are explicitly declared, it’s fairly easy for a user to discover what relationships are available and their directionality by inspecting
+Since all relationships are explicitly declared, it’s fairly easy for a user to discover what relationships are available and their directionality by inspecting
the [relationships directory](../../metadata-models/src/main/pegasus/com/linkedin/metadata/relationship). It’s also possible to provide a UI for the catalog of entities and relationships for analysts who are interested in building complex graph queries to gain insights into the metadata.
## High Cardinality Relationships
diff --git a/metadata-ingestion/developing.md b/metadata-ingestion/developing.md
index 67041d23a21b1..9b79ee31e31bf 100644
--- a/metadata-ingestion/developing.md
+++ b/metadata-ingestion/developing.md
@@ -74,7 +74,9 @@ The syntax for installing plugins is slightly different in development. For exam
## Architecture
-
+
+
+
The architecture of this metadata ingestion framework is heavily inspired by [Apache Gobblin](https://gobblin.apache.org/) (also originally a LinkedIn project!). We have a standardized format - the MetadataChangeEvent - and sources and sinks which respectively produce and consume these objects. The sources pull metadata from a variety of data systems, while the sinks are primarily for moving this metadata into DataHub.
@@ -99,6 +101,7 @@ mypy src/ tests/
```
or you can run from root of the repository
+
```shell
./gradlew :metadata-ingestion:lintFix
```
diff --git a/perf-test/README.md b/perf-test/README.md
index 24fb064d3e28a..7b1f962e208f3 100644
--- a/perf-test/README.md
+++ b/perf-test/README.md
@@ -58,7 +58,9 @@ locust -f perf-test/locustfiles/ingest.py
This will set up the web interface in http://localhost:8089 (unless the port is already taken). Once you click into it,
you should see the following
-
+
+
+
Input the number of users you would like to spawn and the spawn rate. Point the host to the deployed DataHub GMS (
locally, it should be http://localhost:8080). Click on the "Start swarming" button to start the load test.
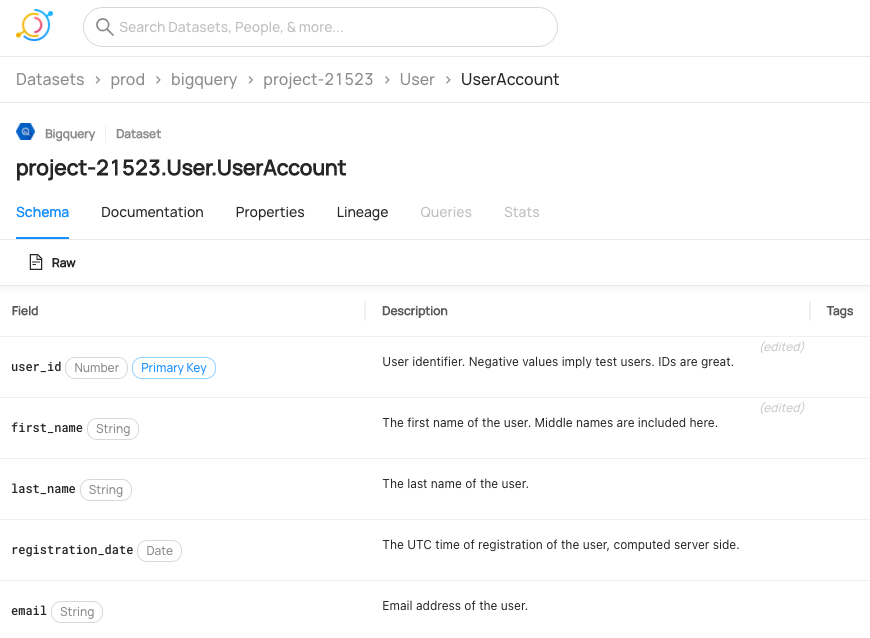 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+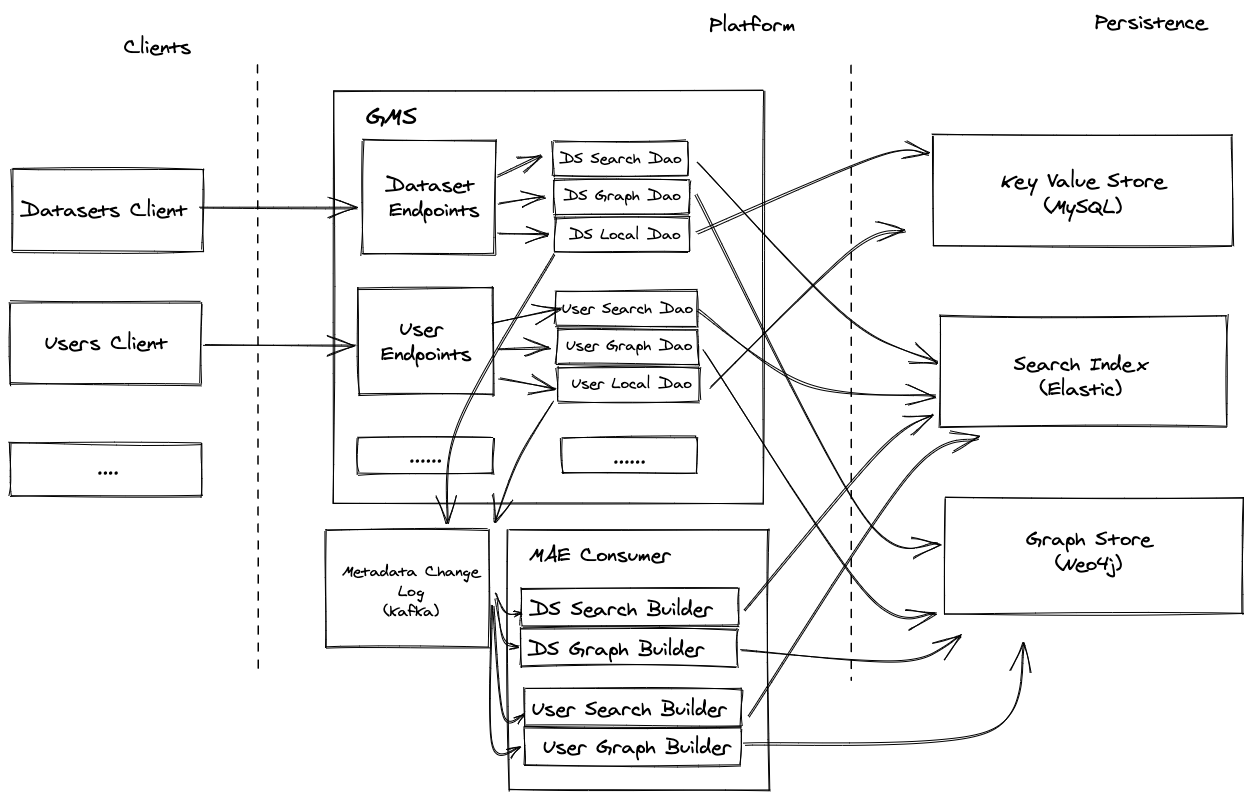 +
+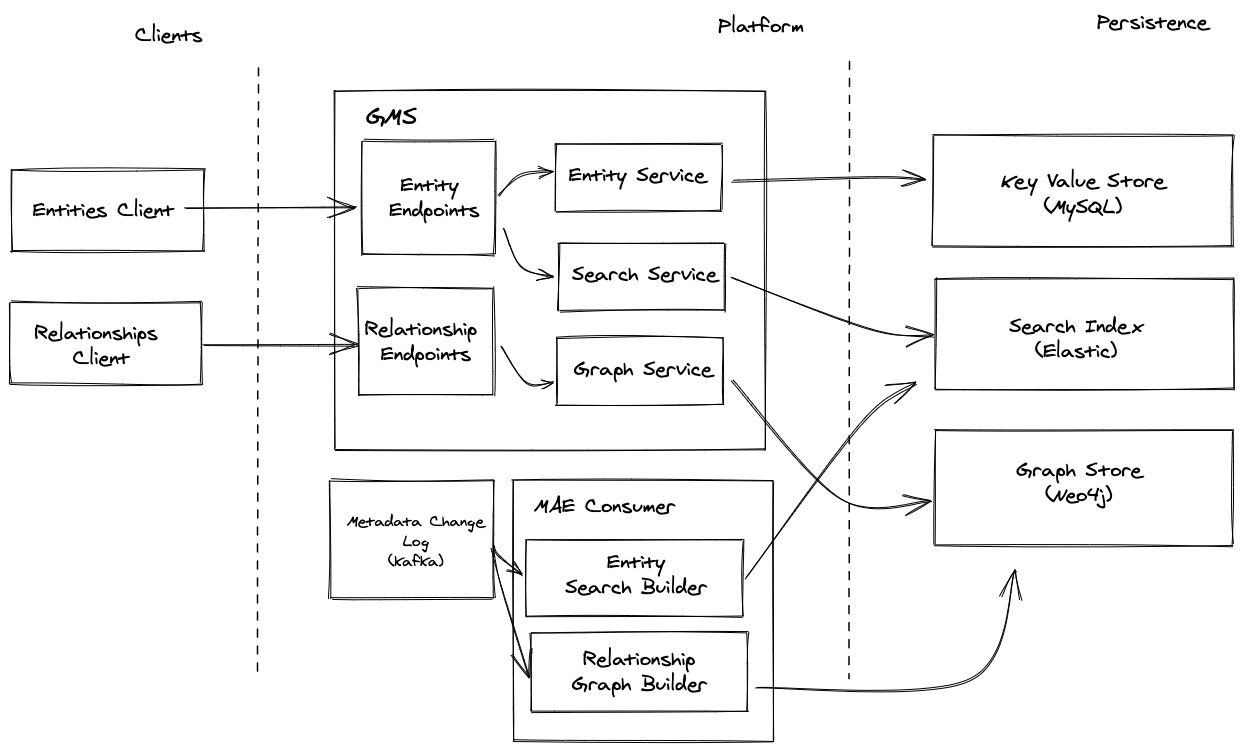 +
+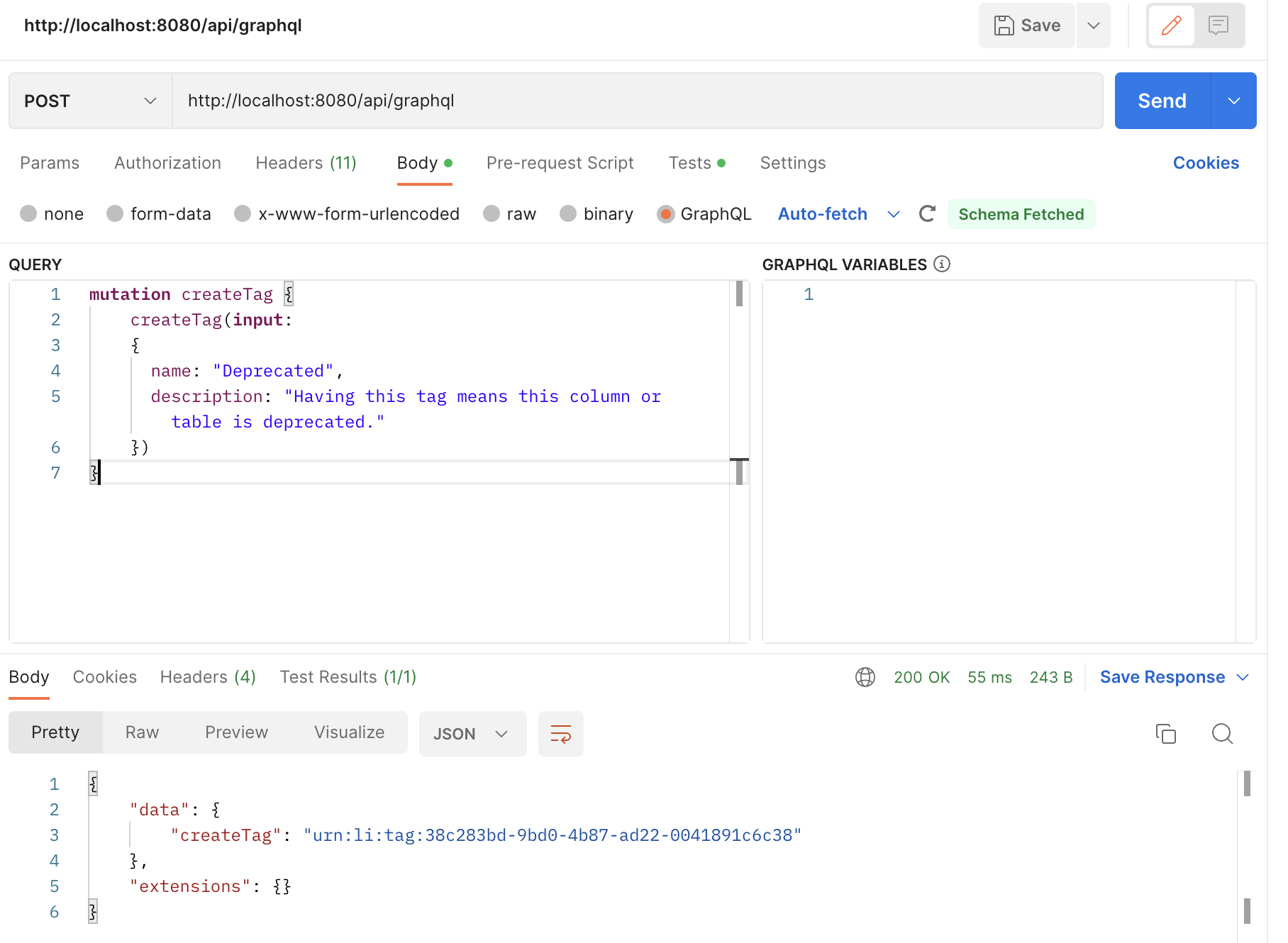 +
+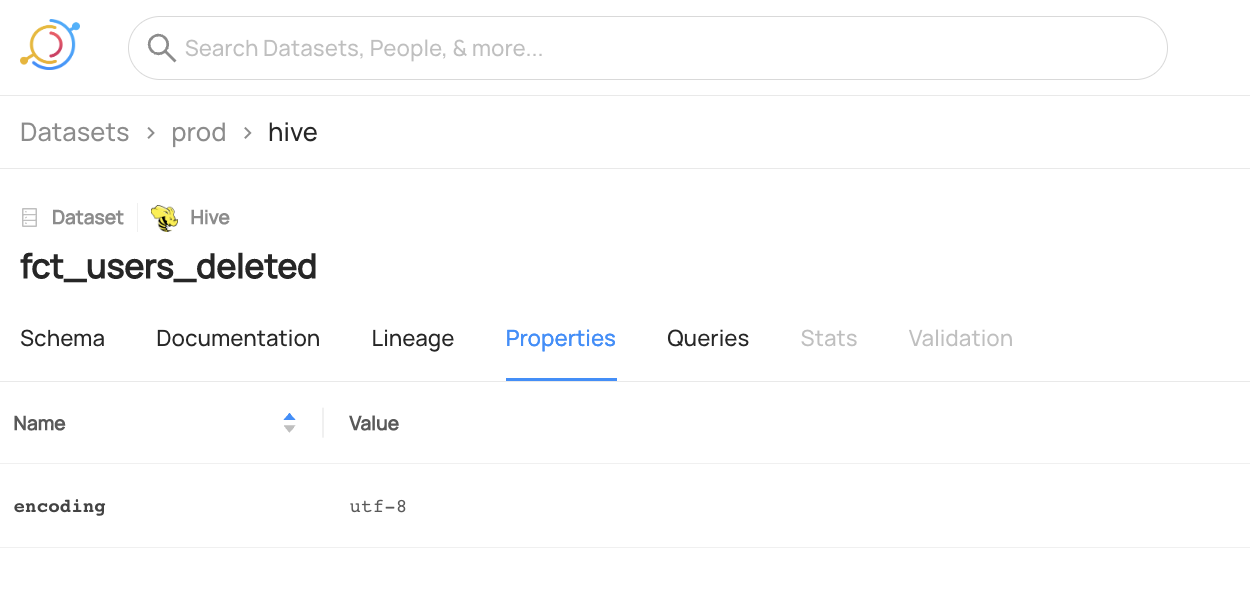 +
+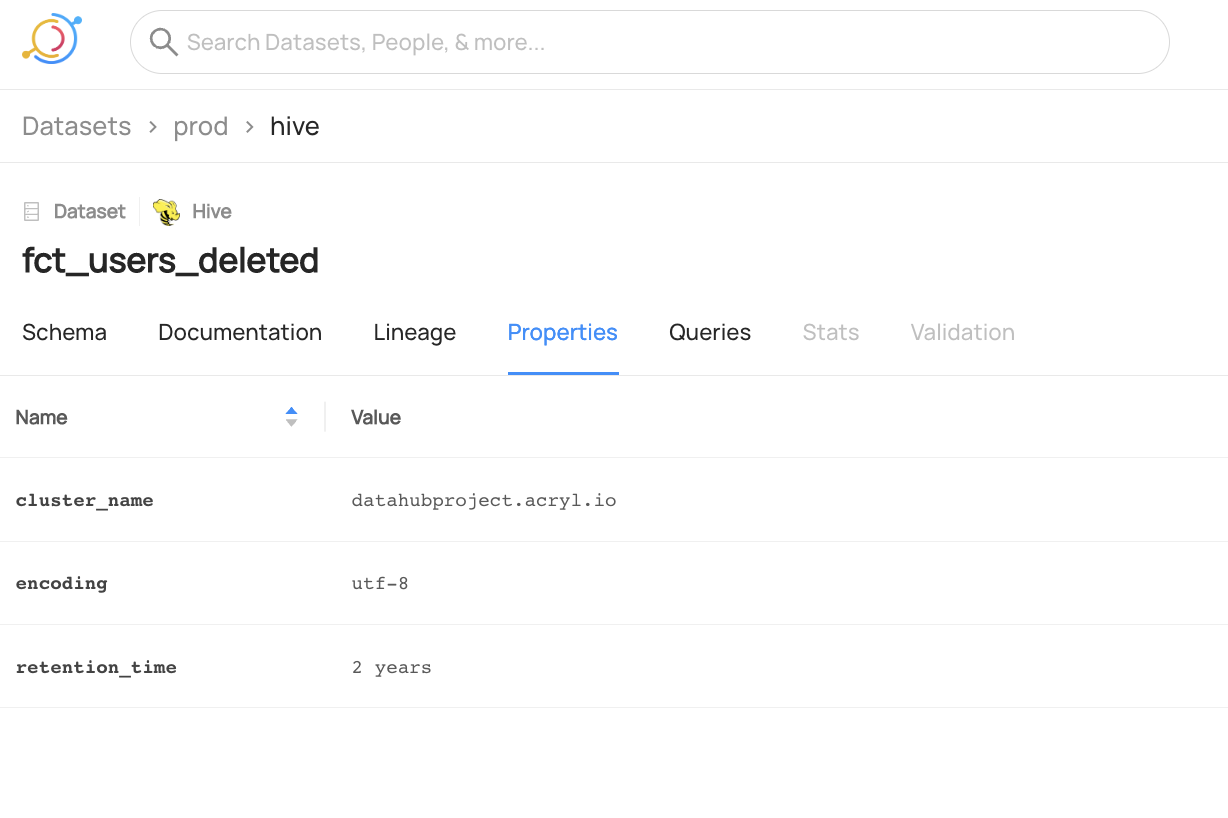 +
+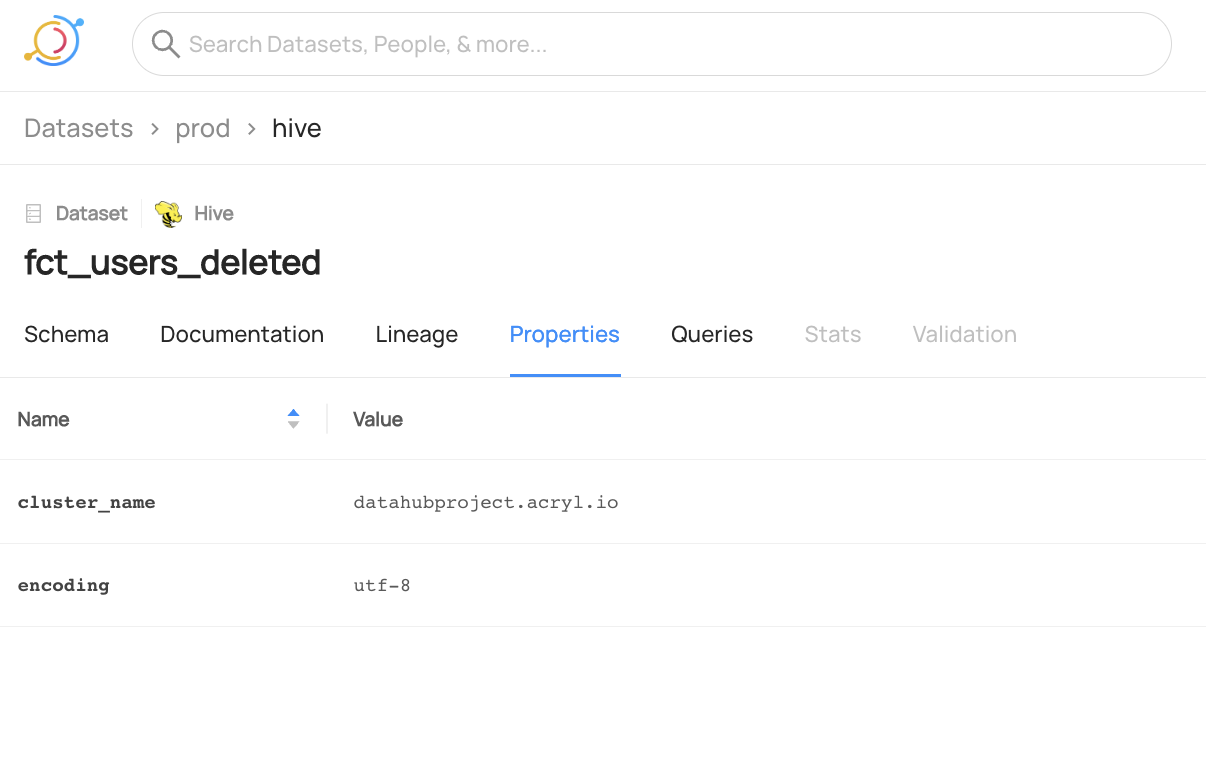 +
+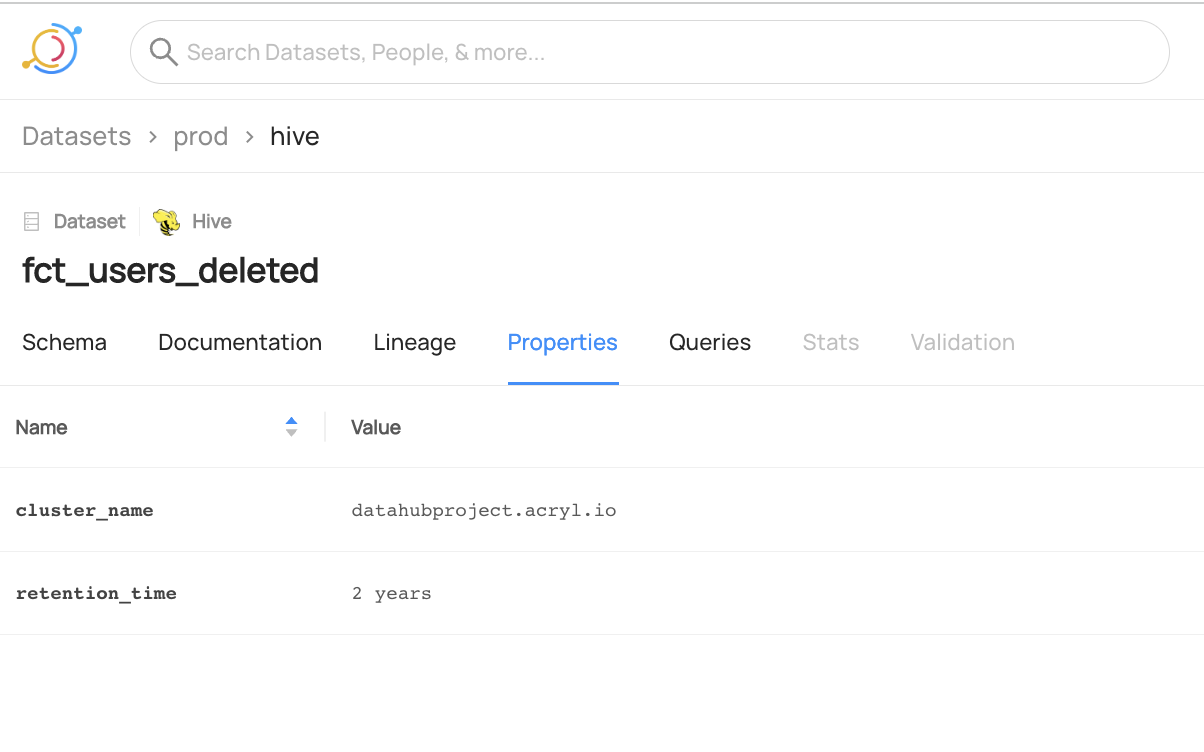 +
+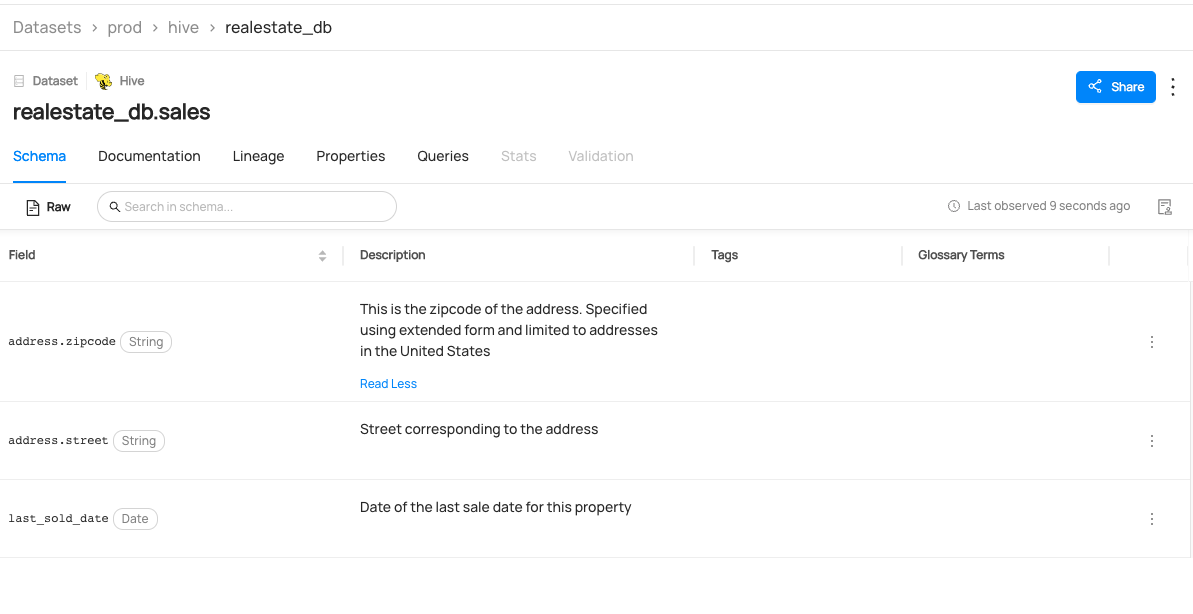 +
+ +
+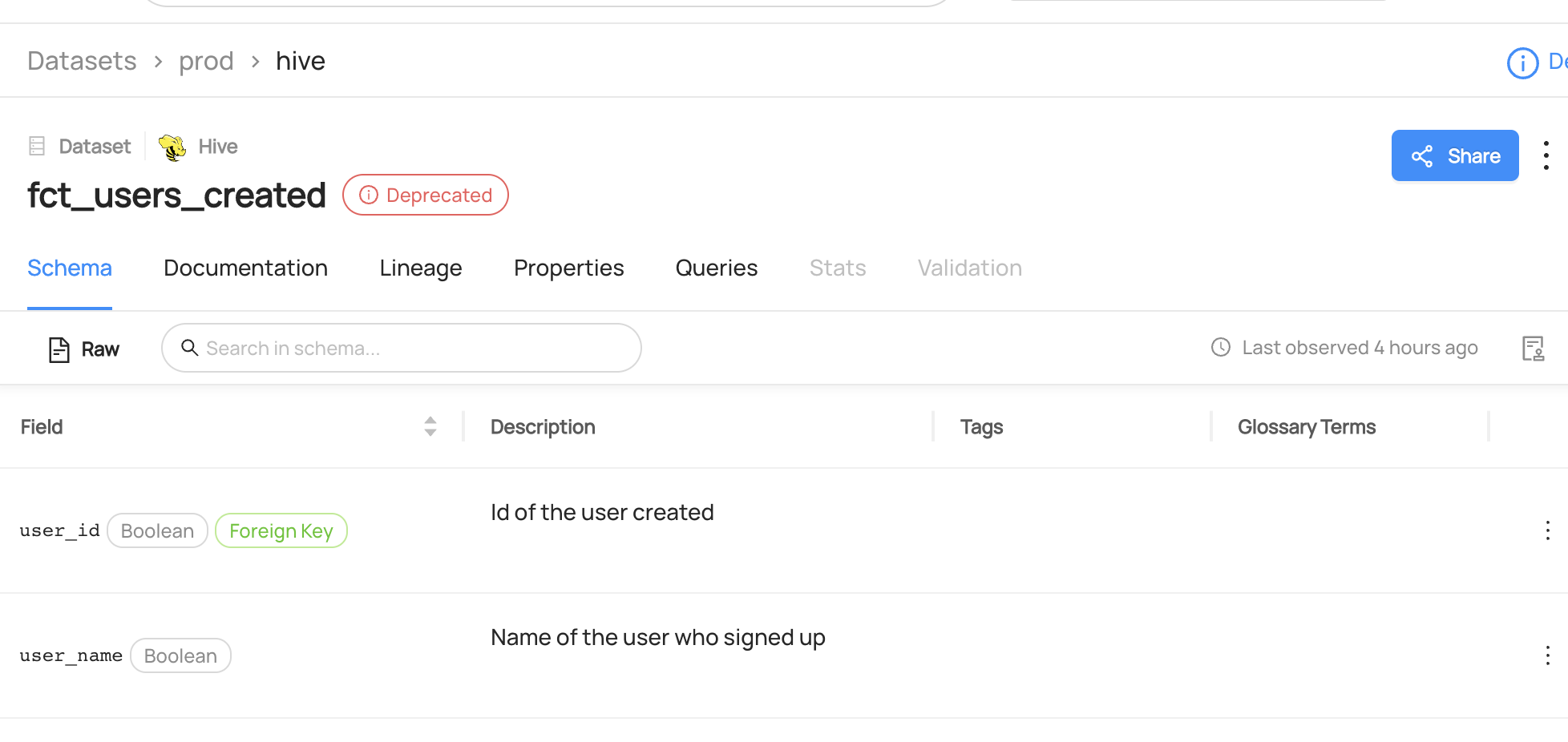 +
+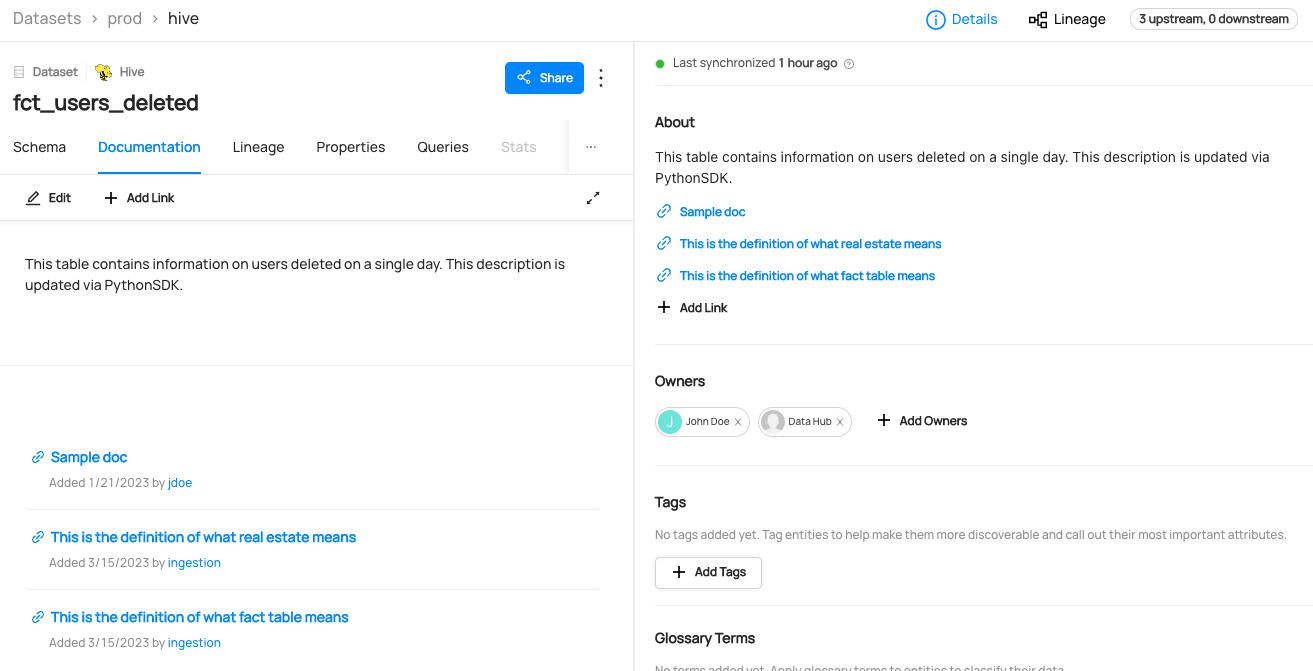 +
+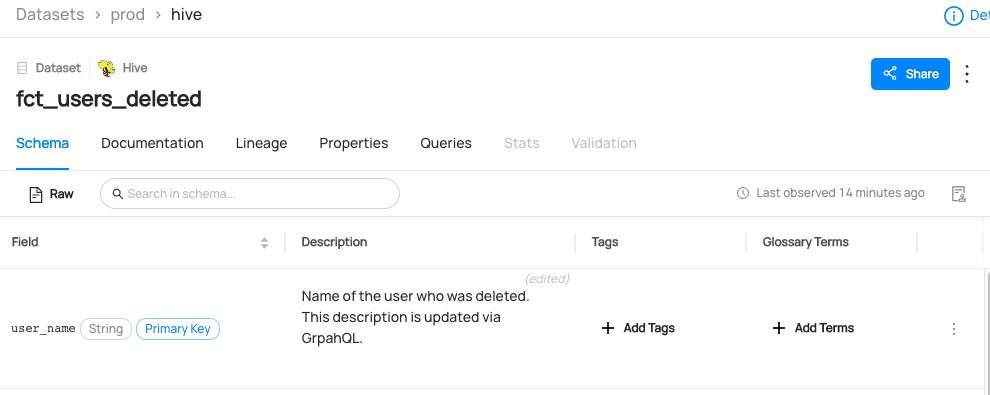 +
+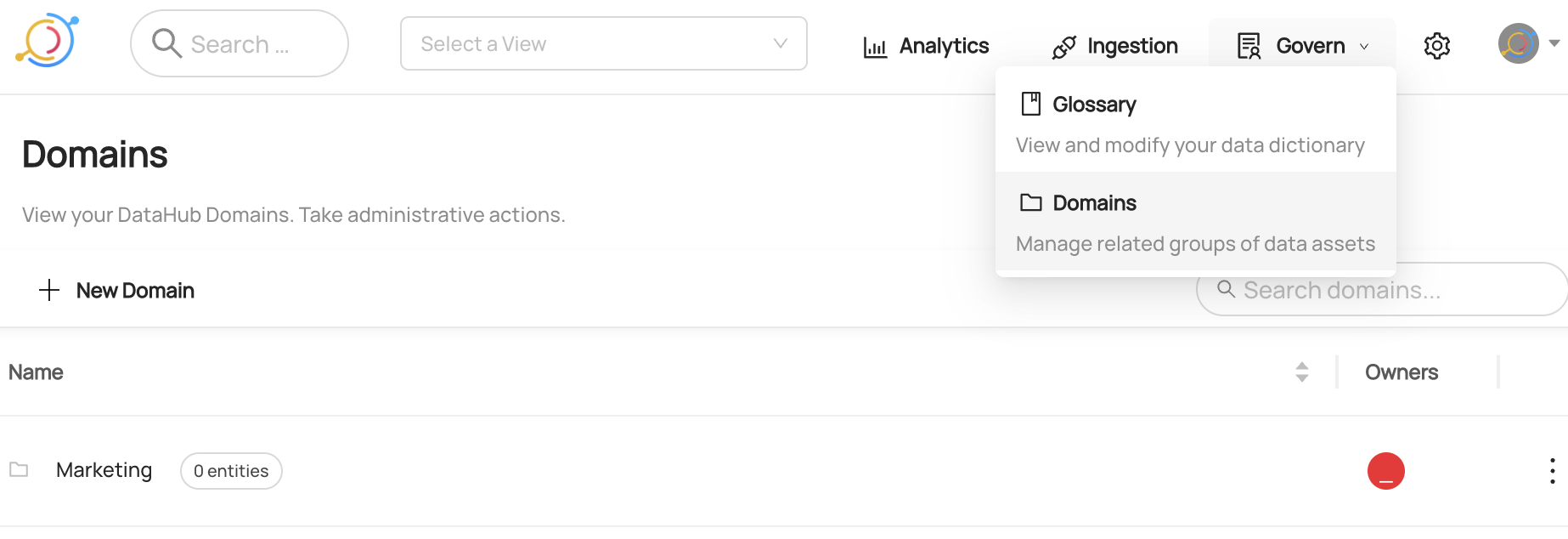 +
+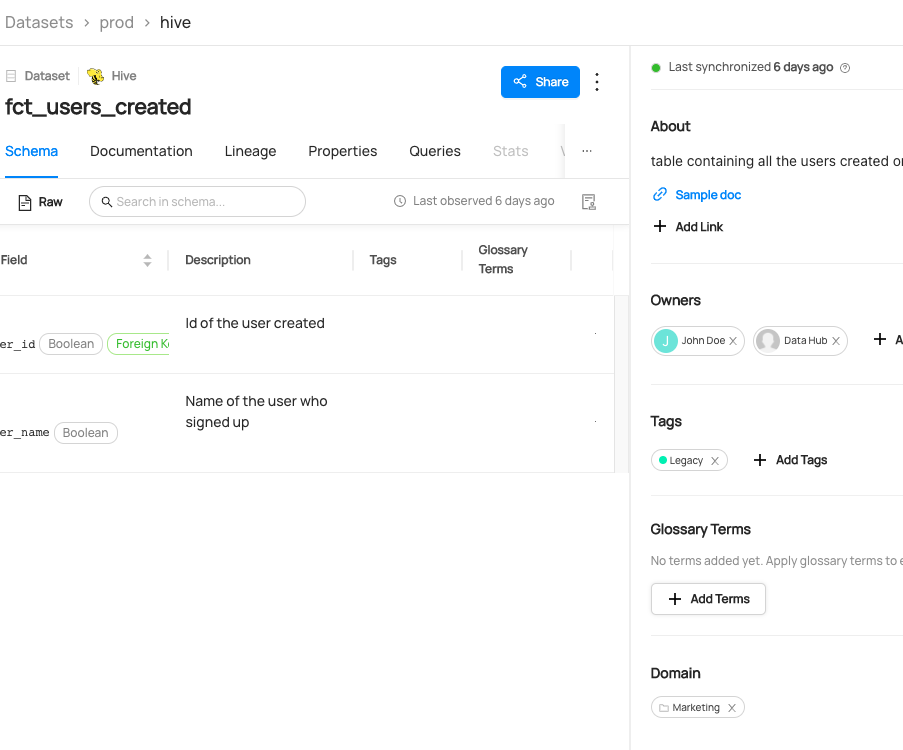 +
+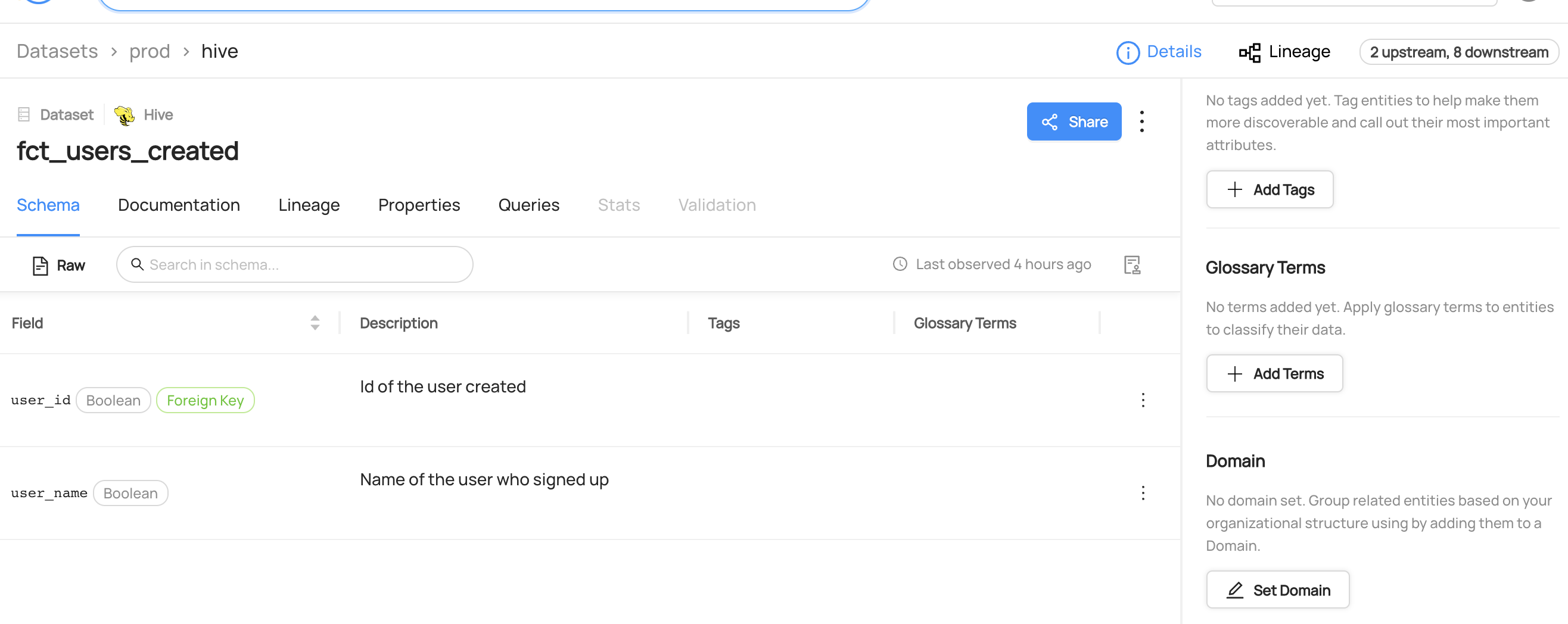 +
+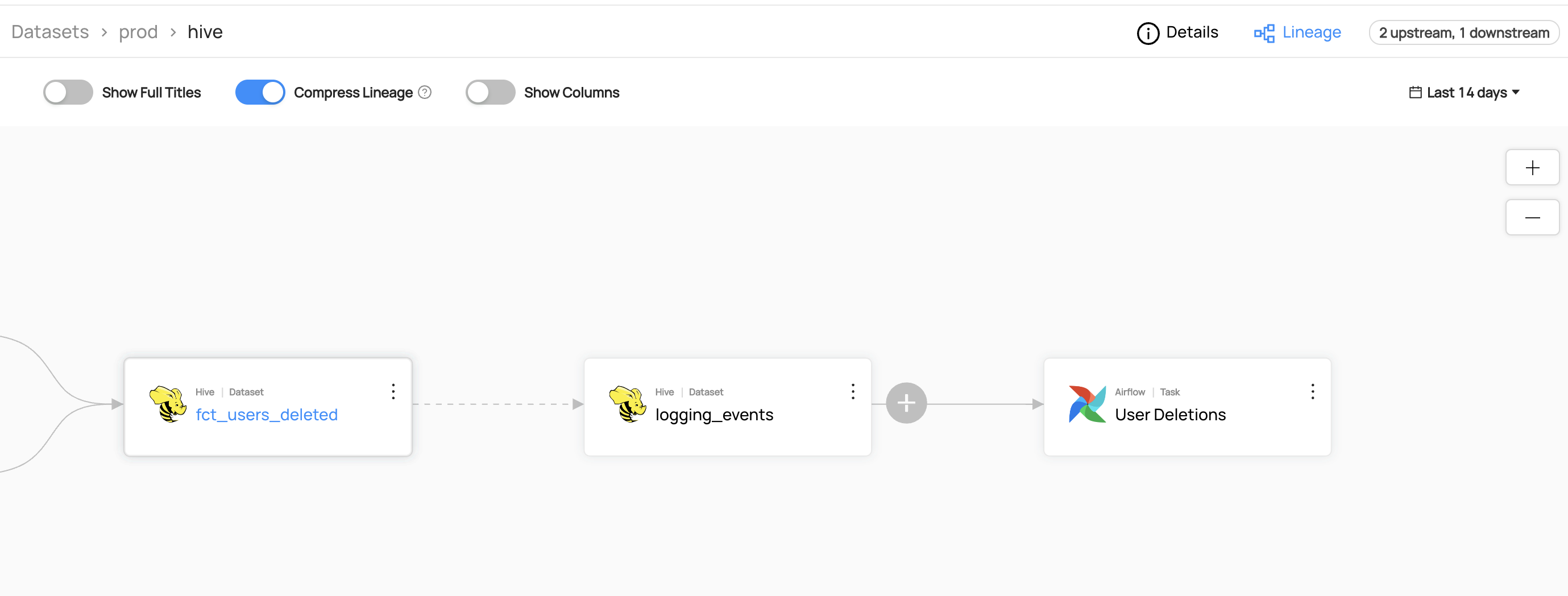 +
+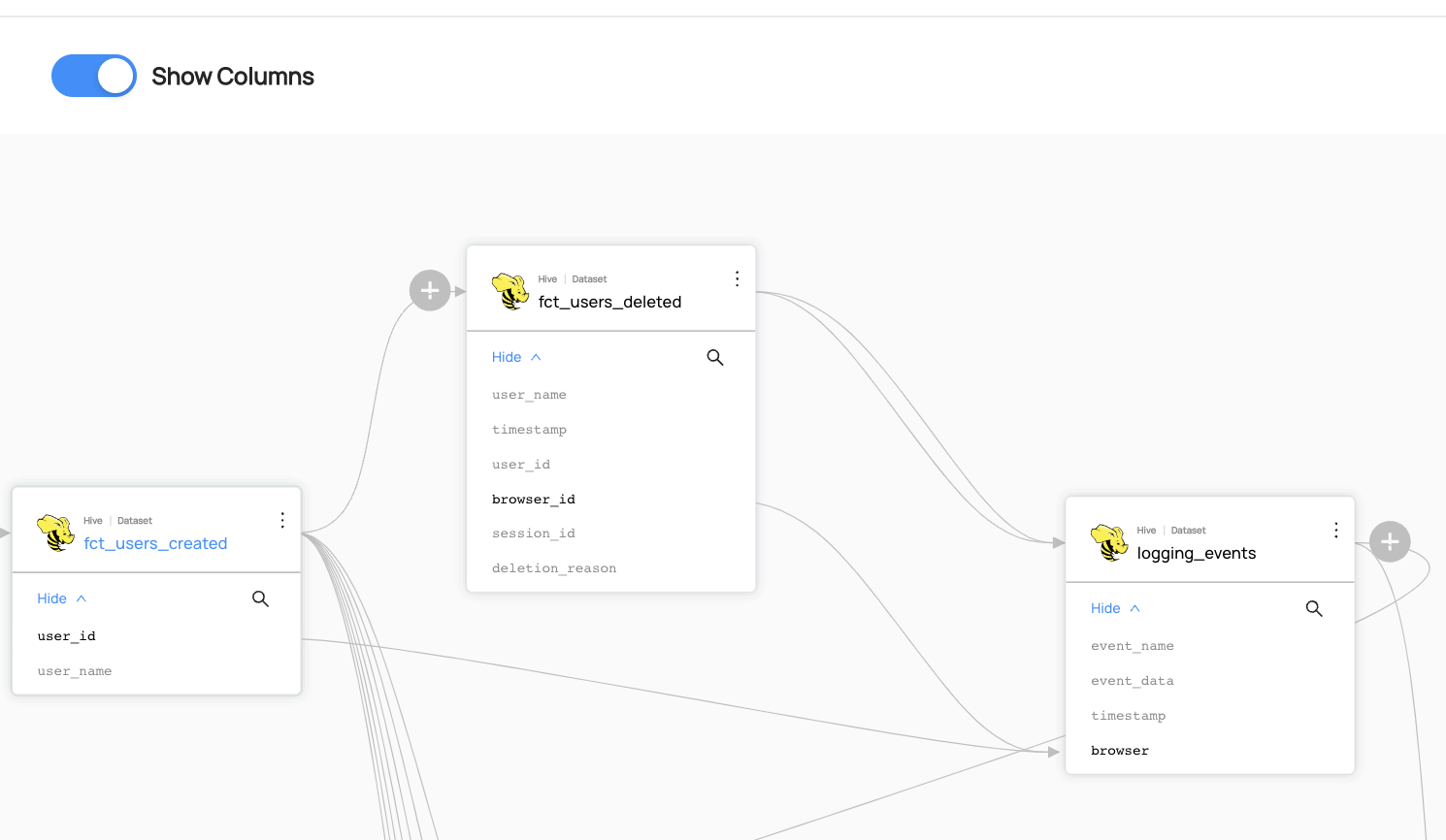 +
+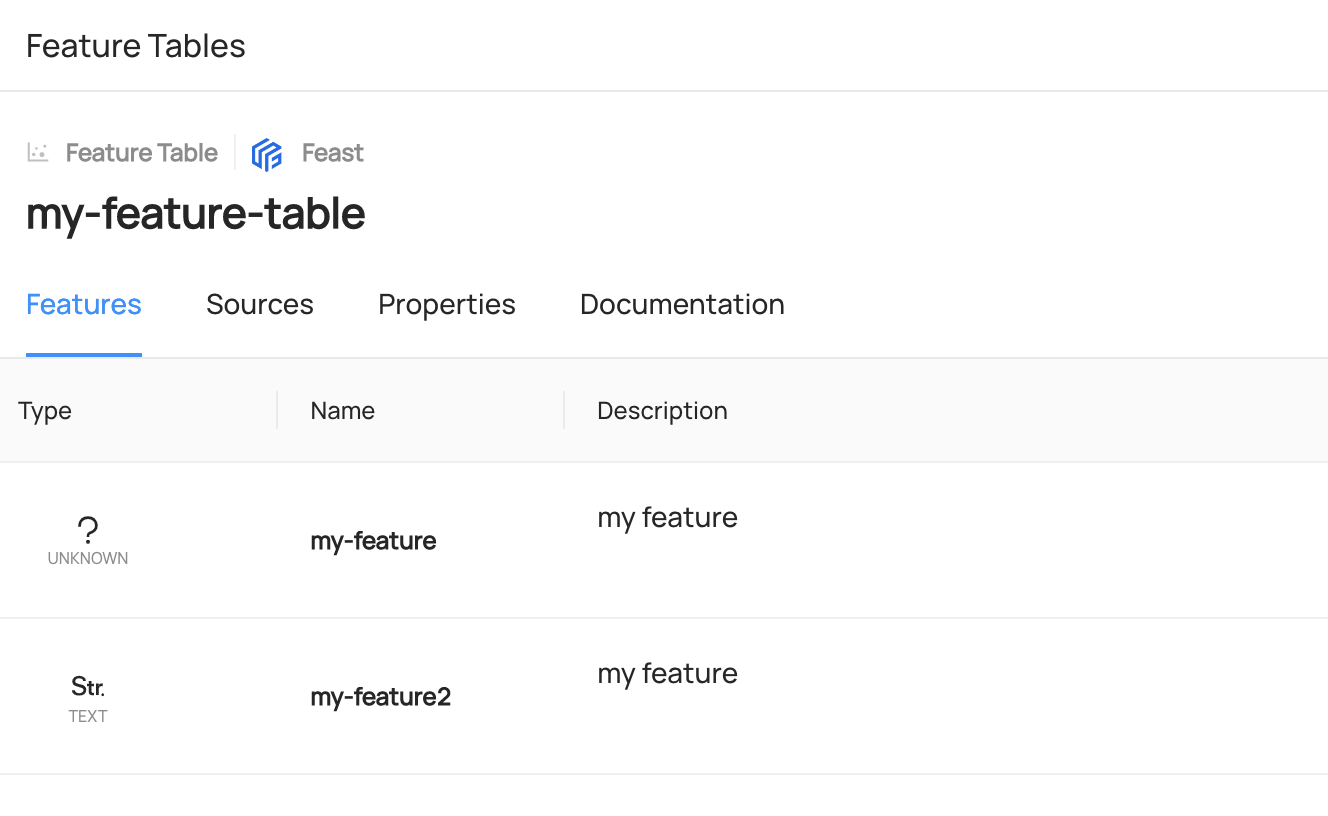 +
+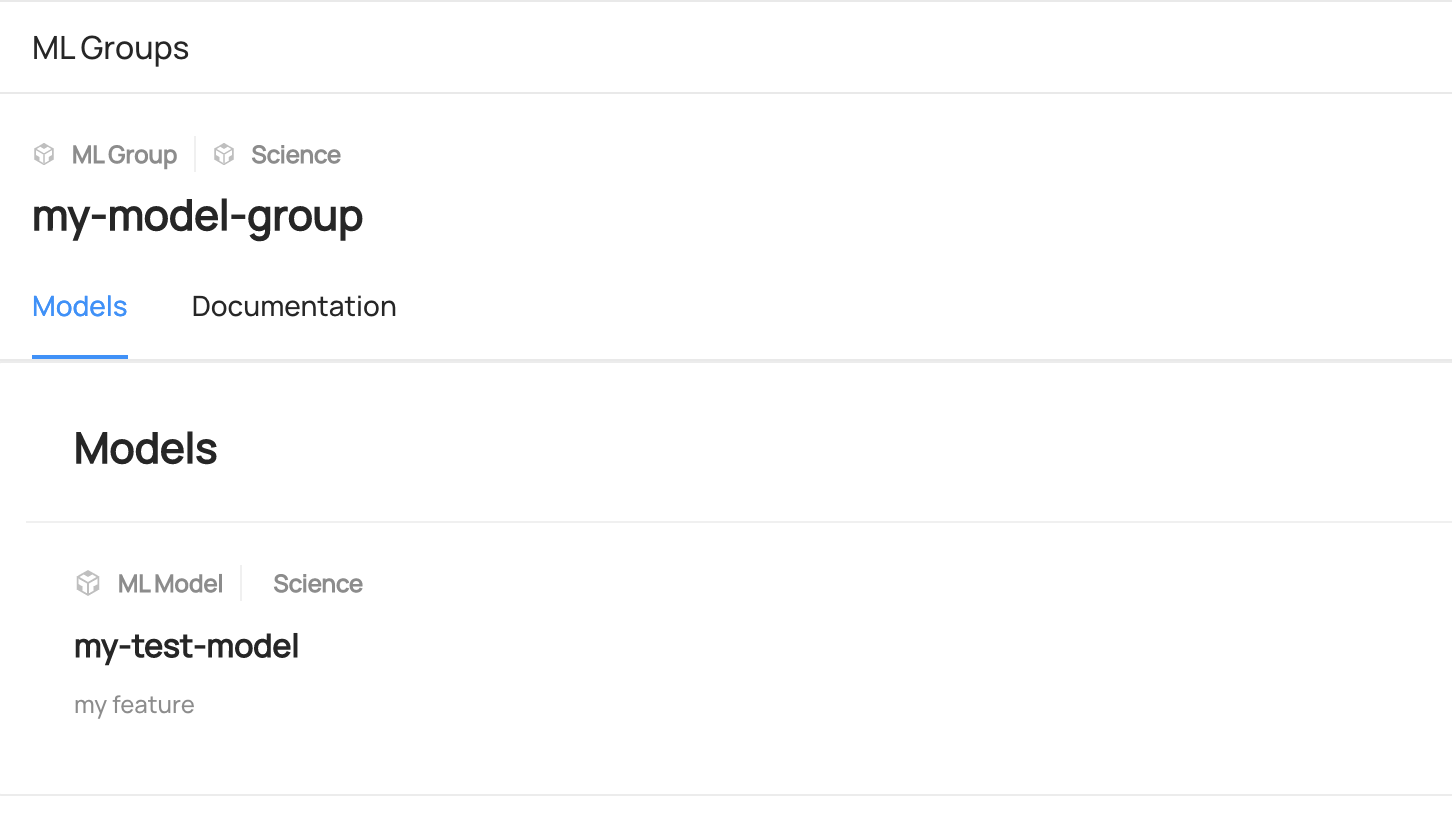 +
+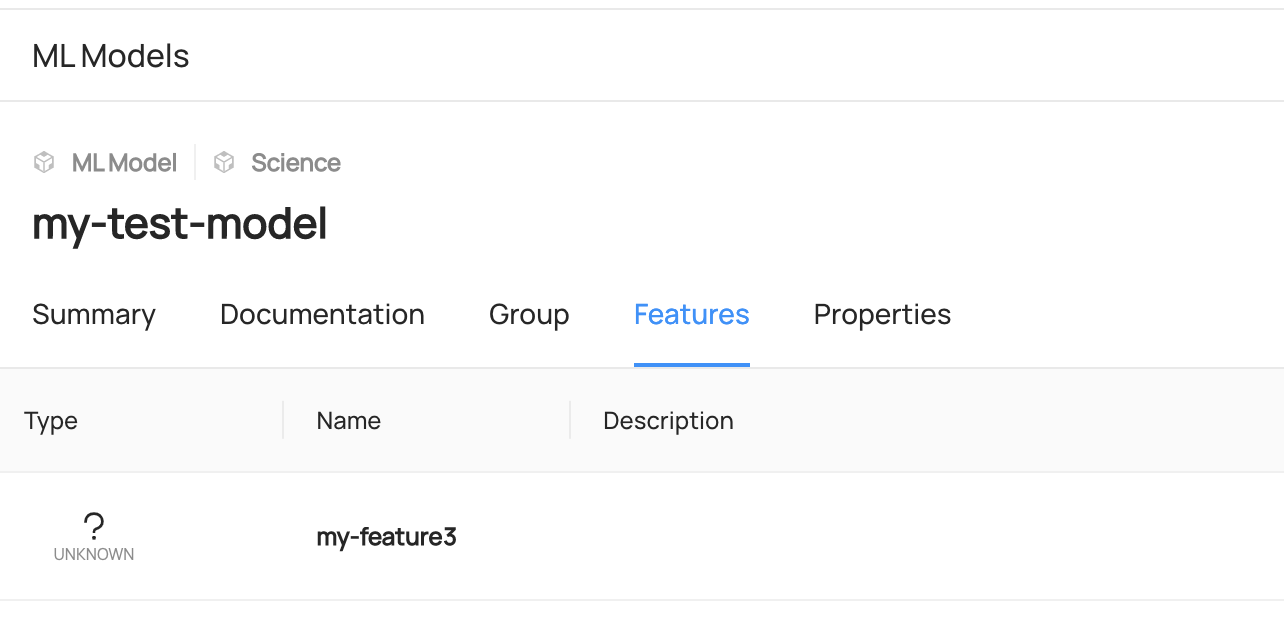 +
+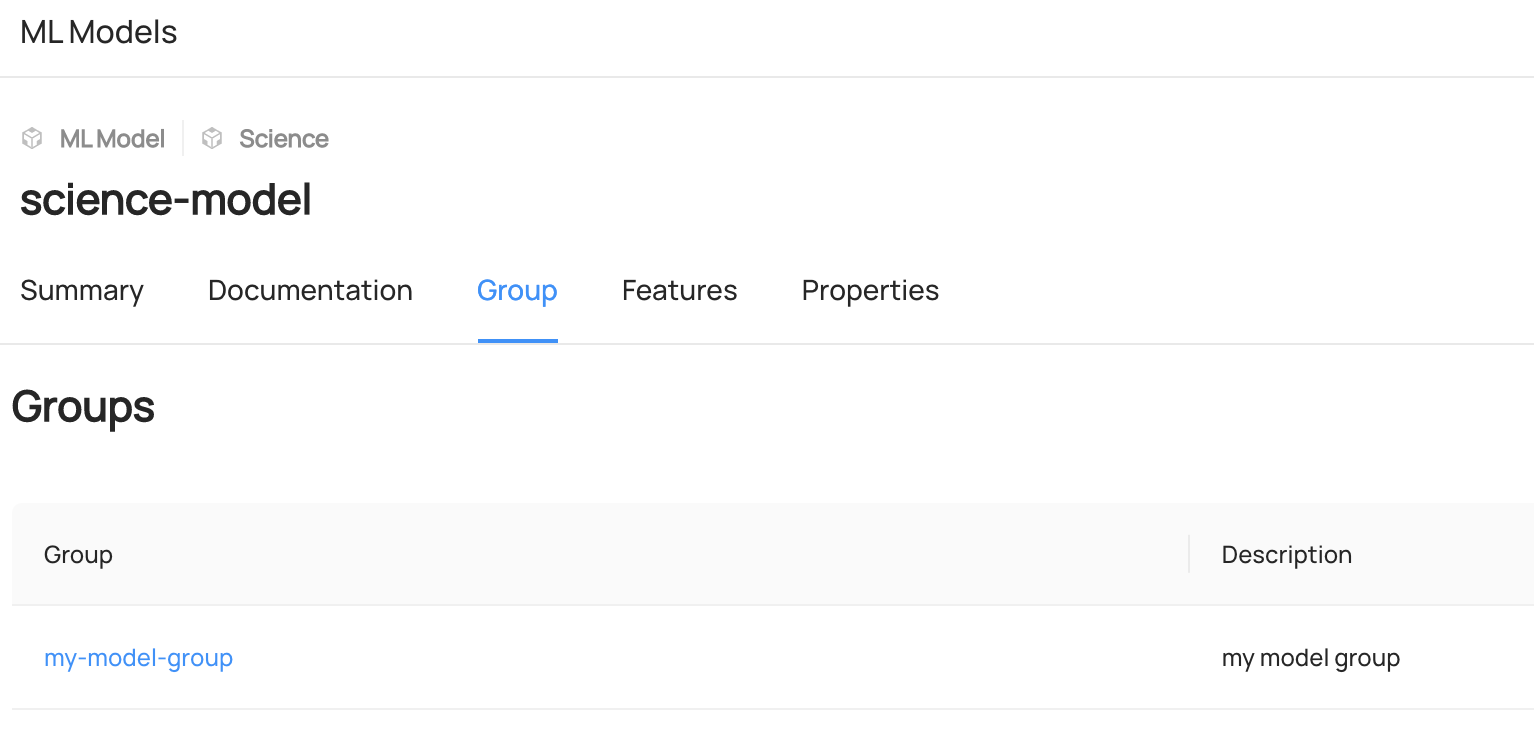 +
+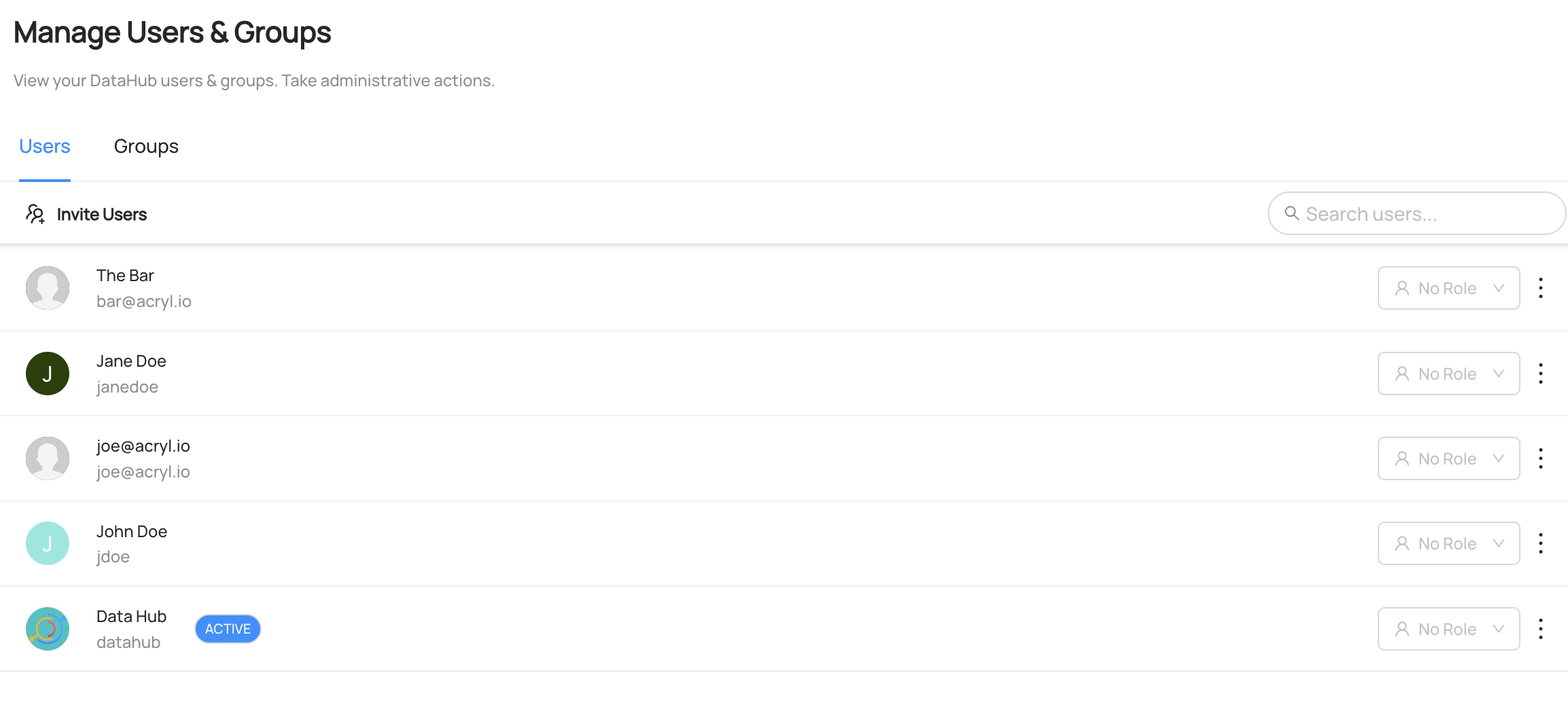 +
+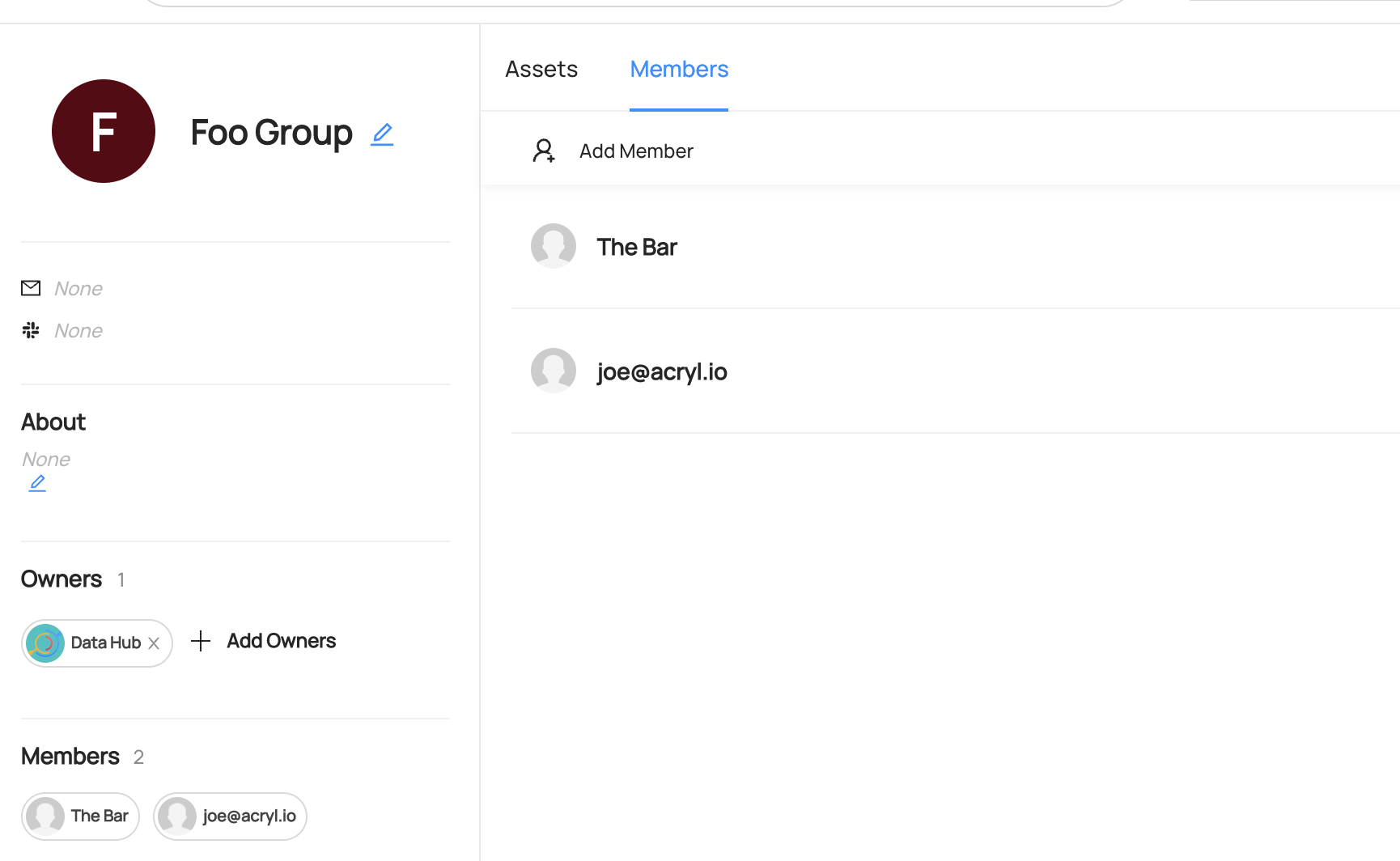 +
+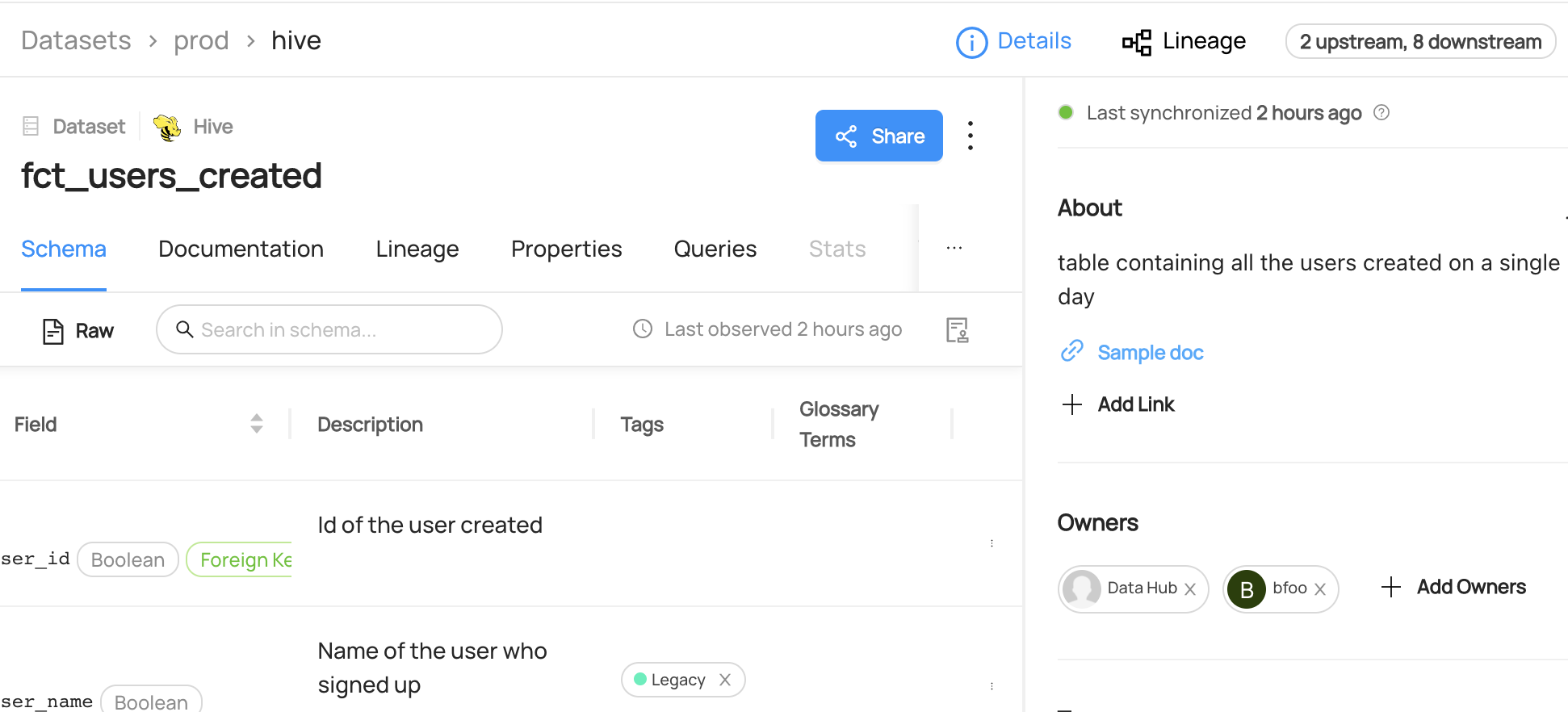 +
+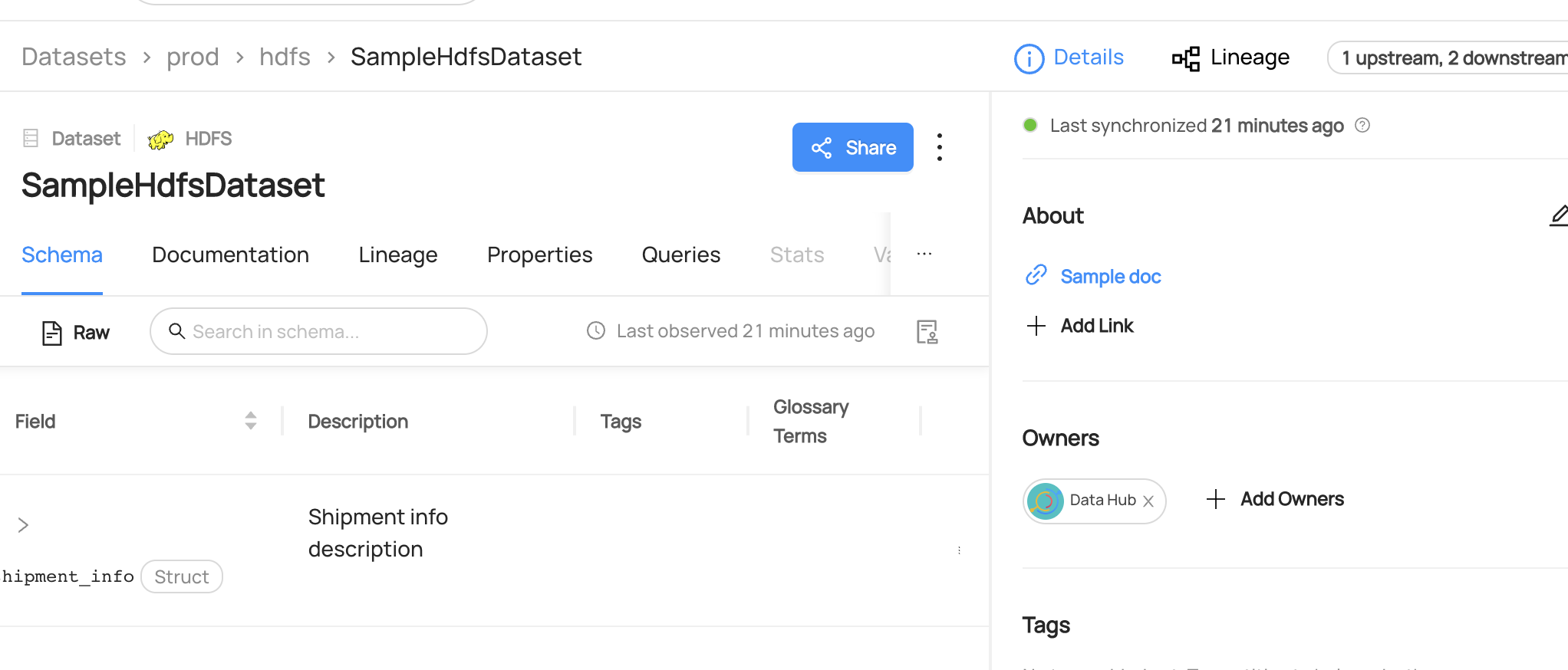 +
+ +
+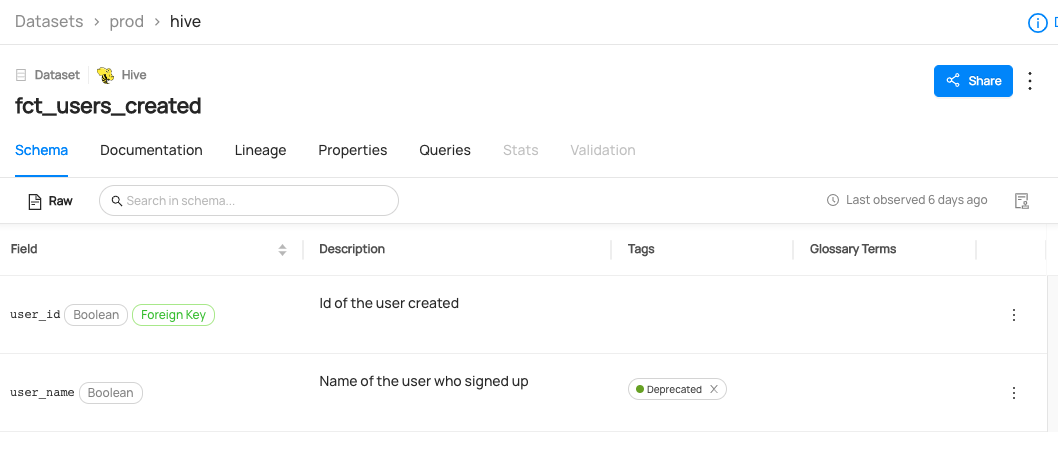 +
+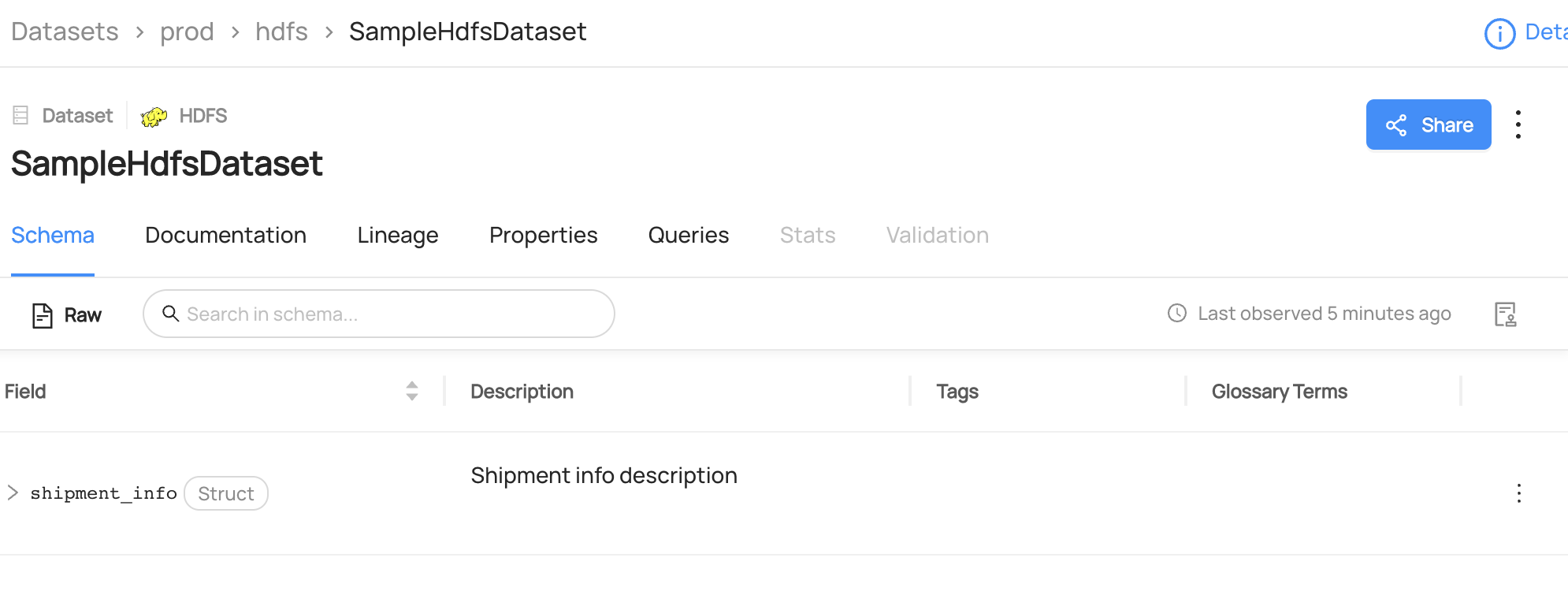 +
+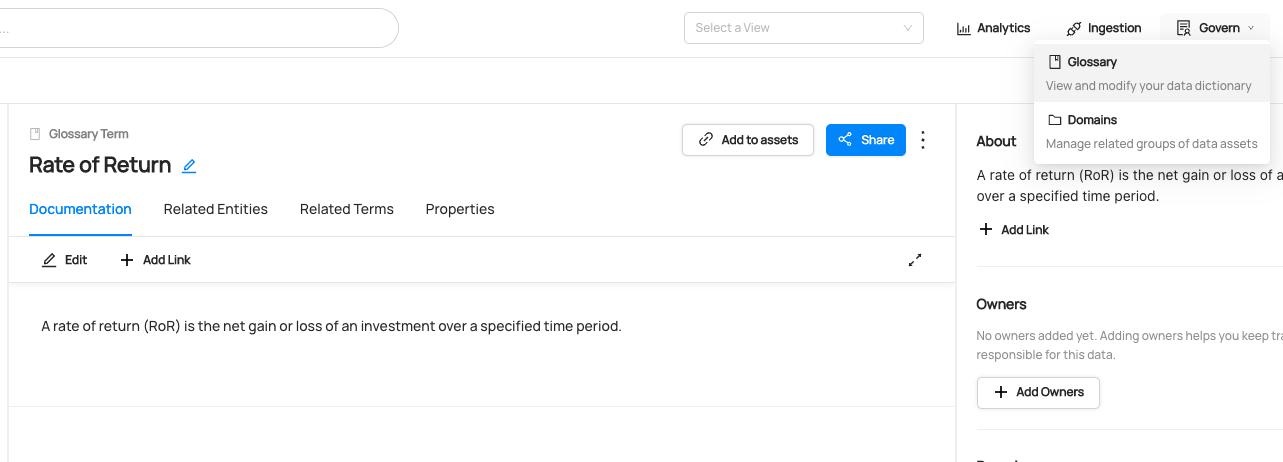 +
+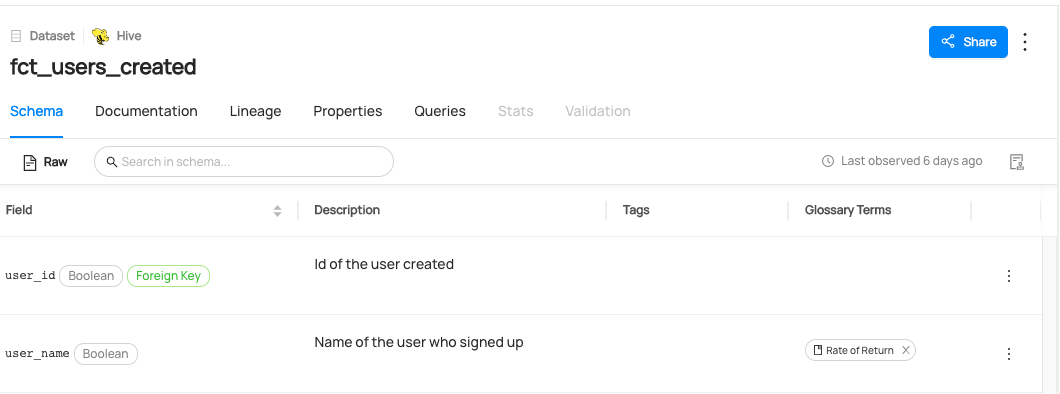 +
+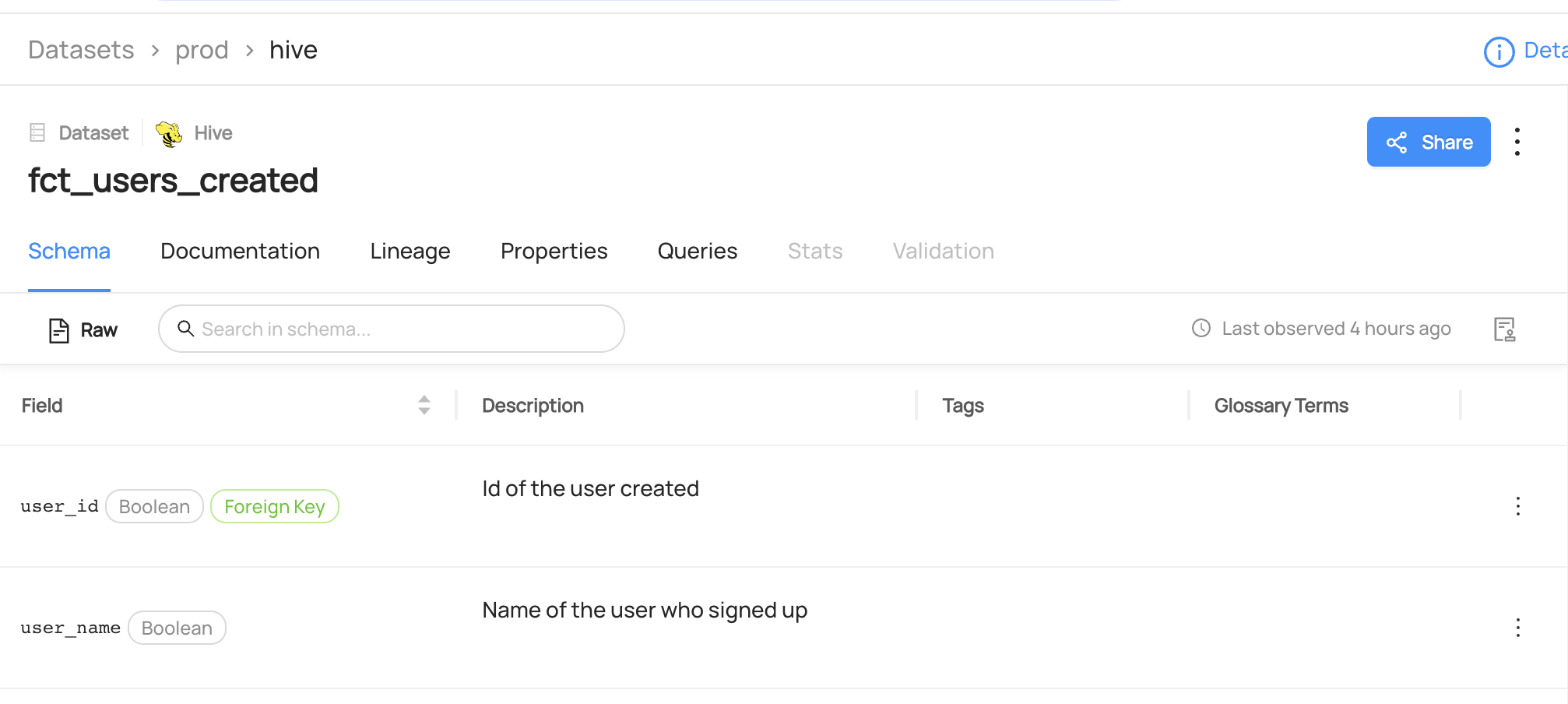 +
+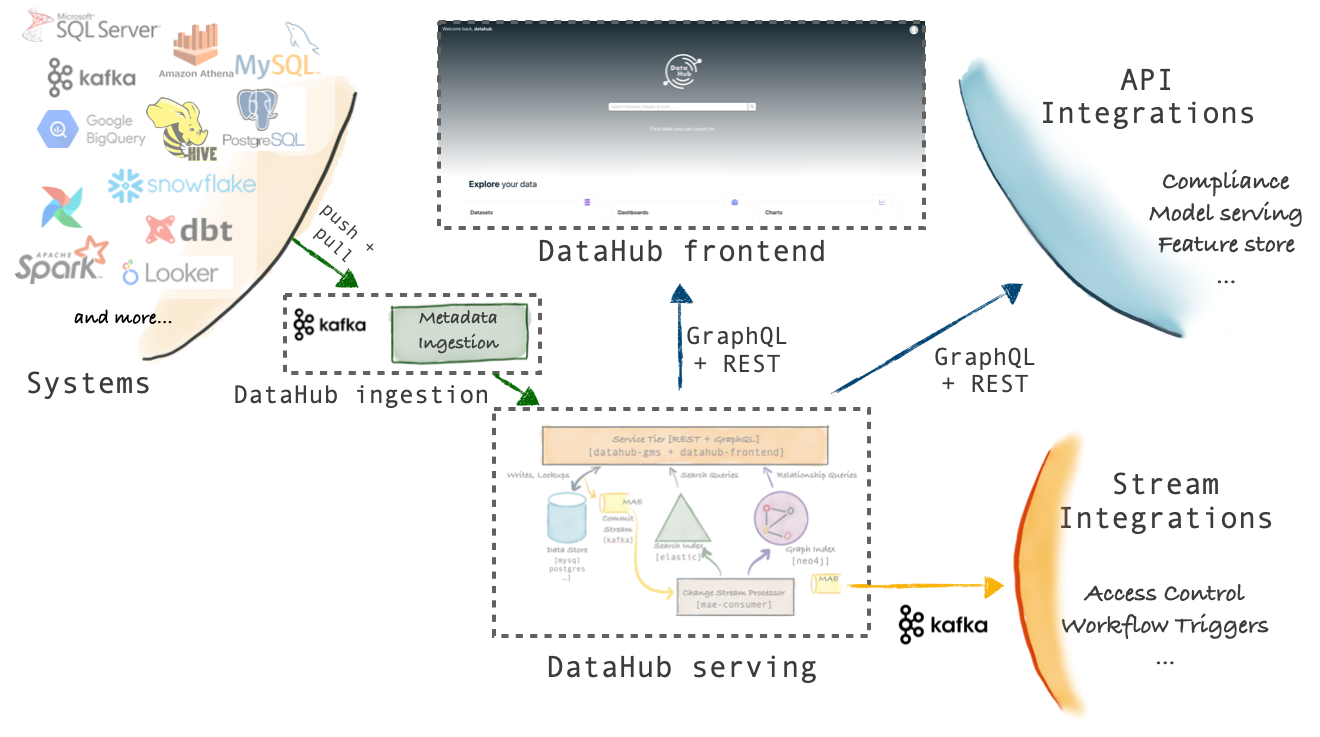 +
+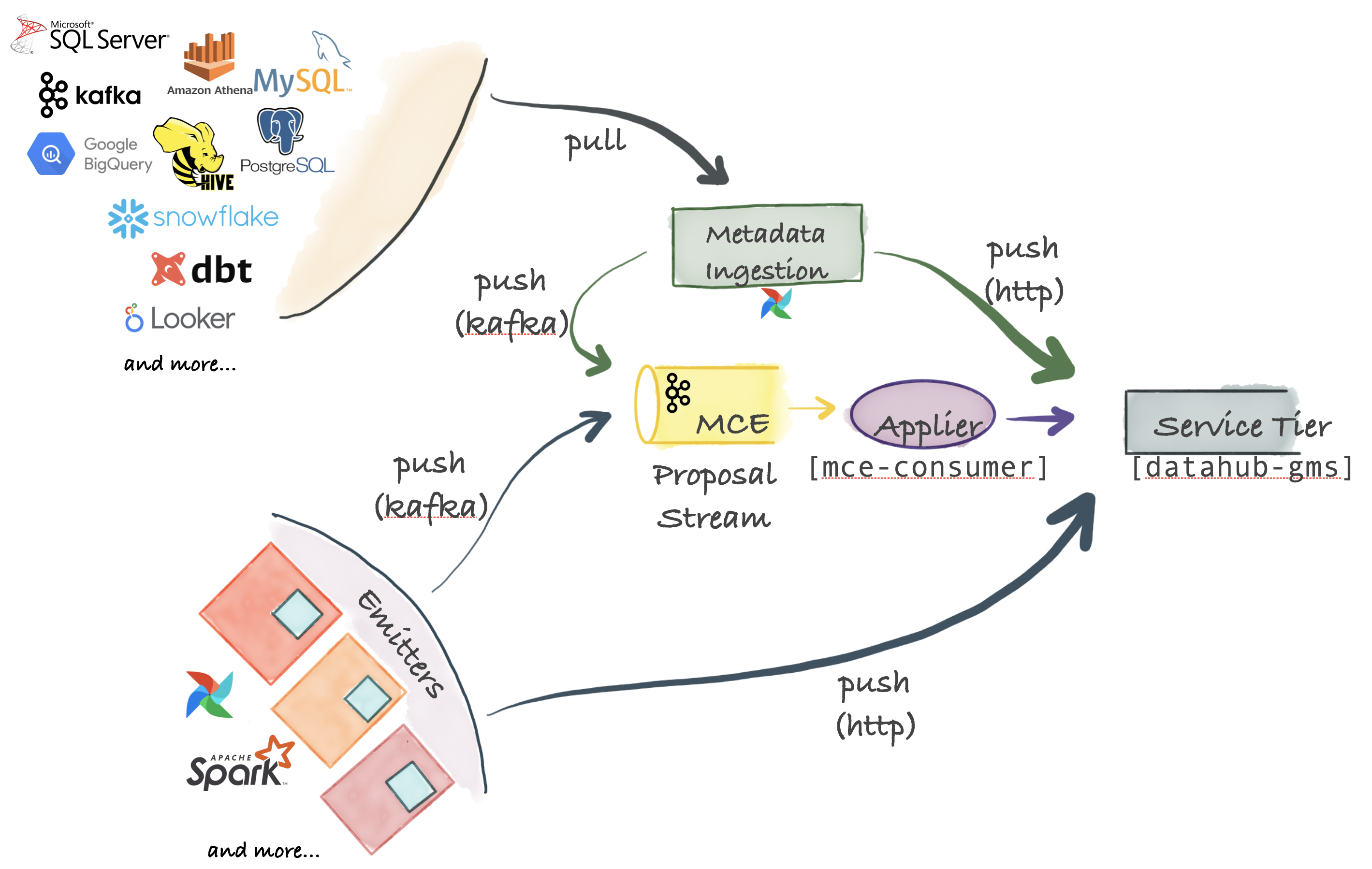 +
+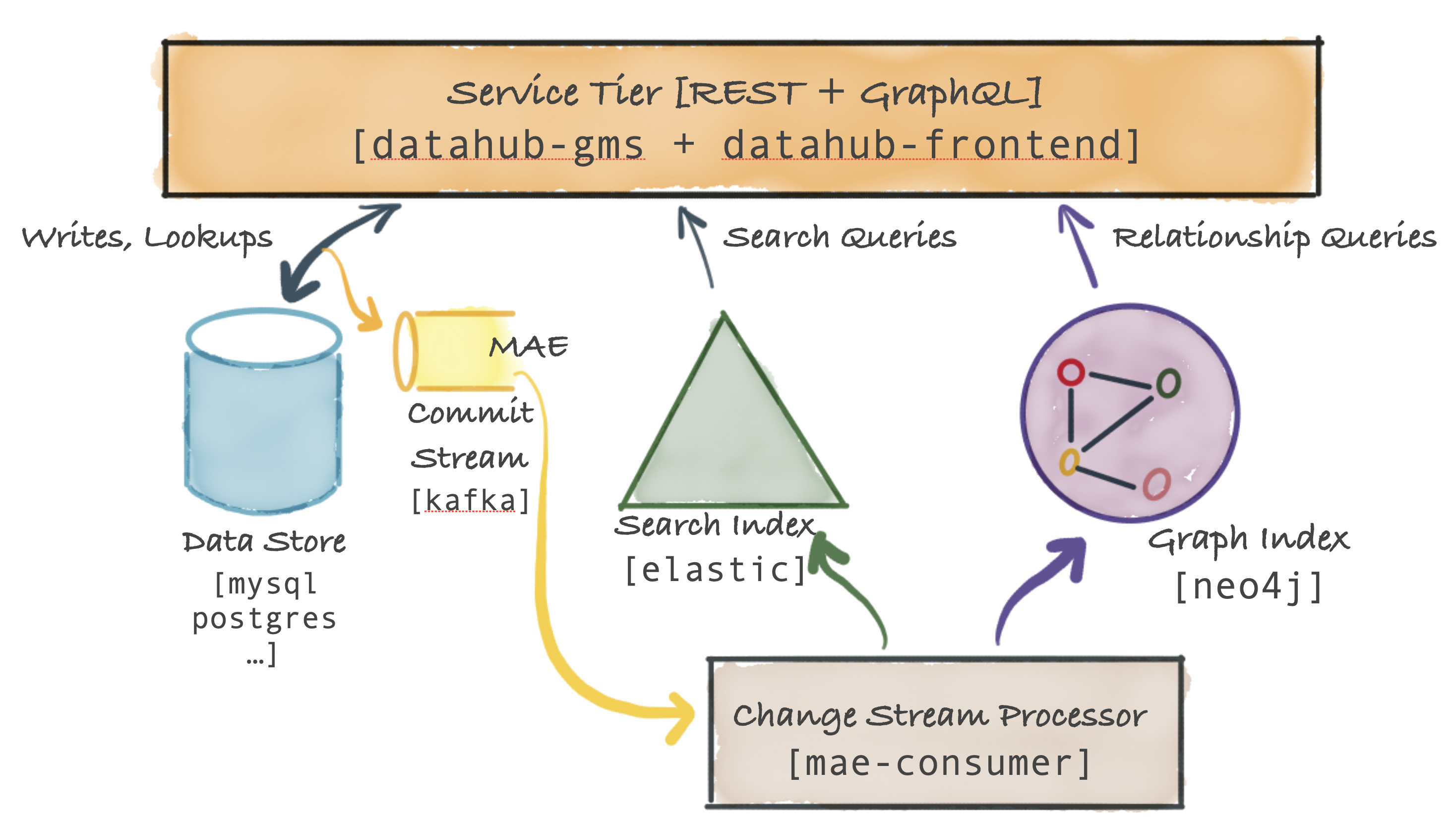 +
+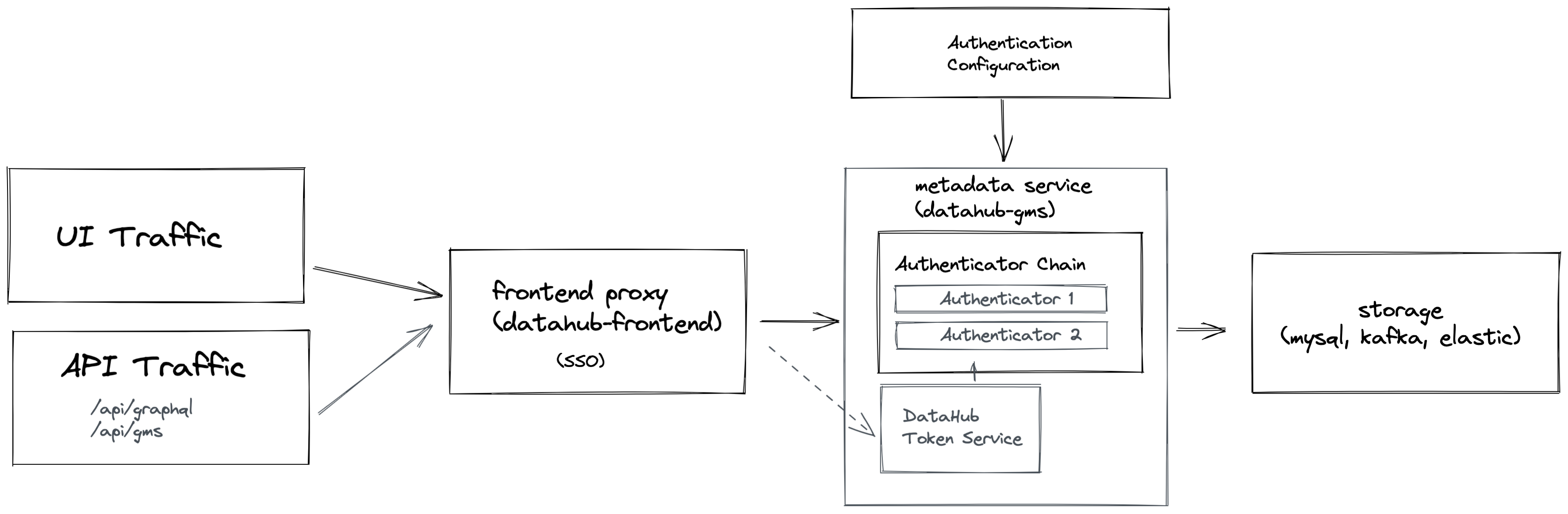 +
+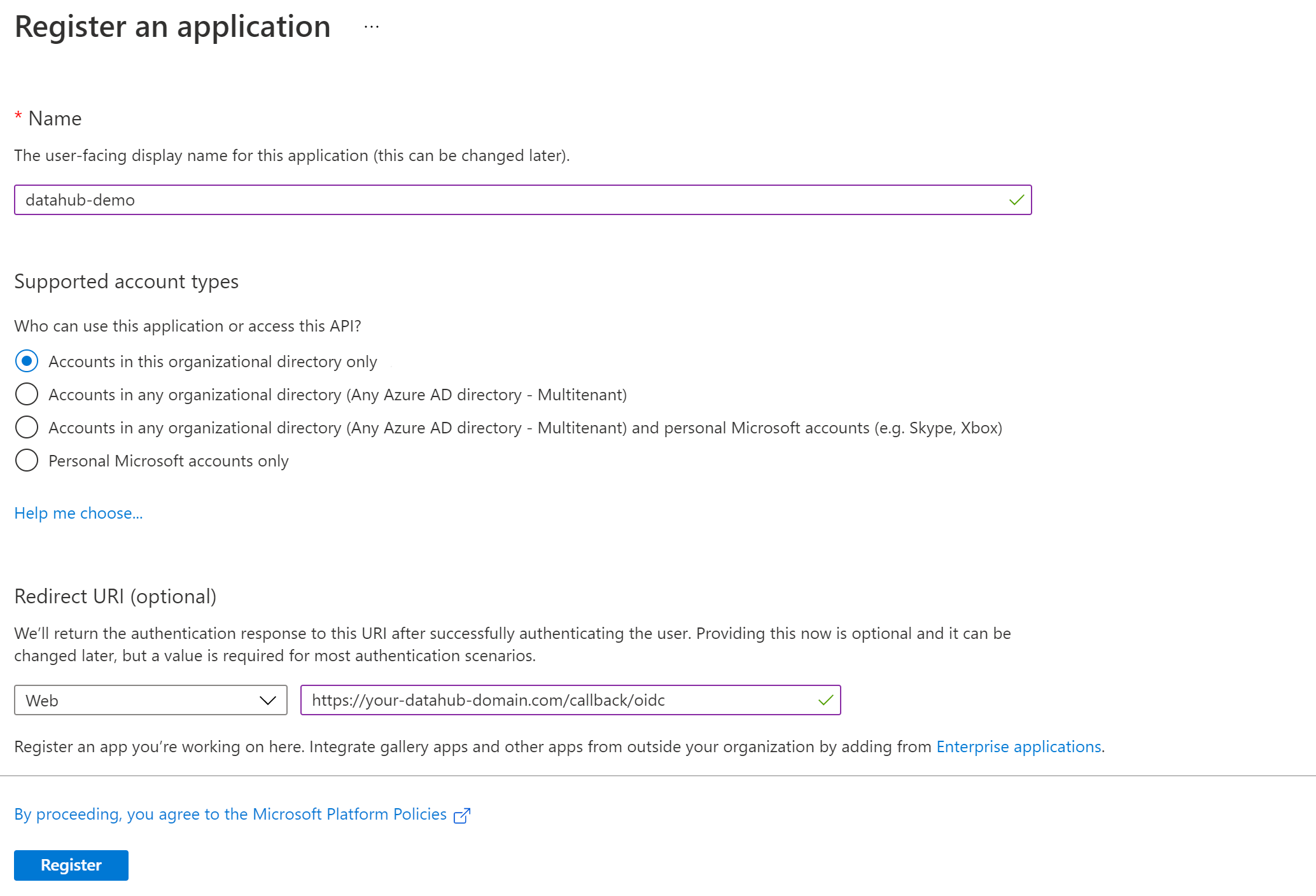 +
+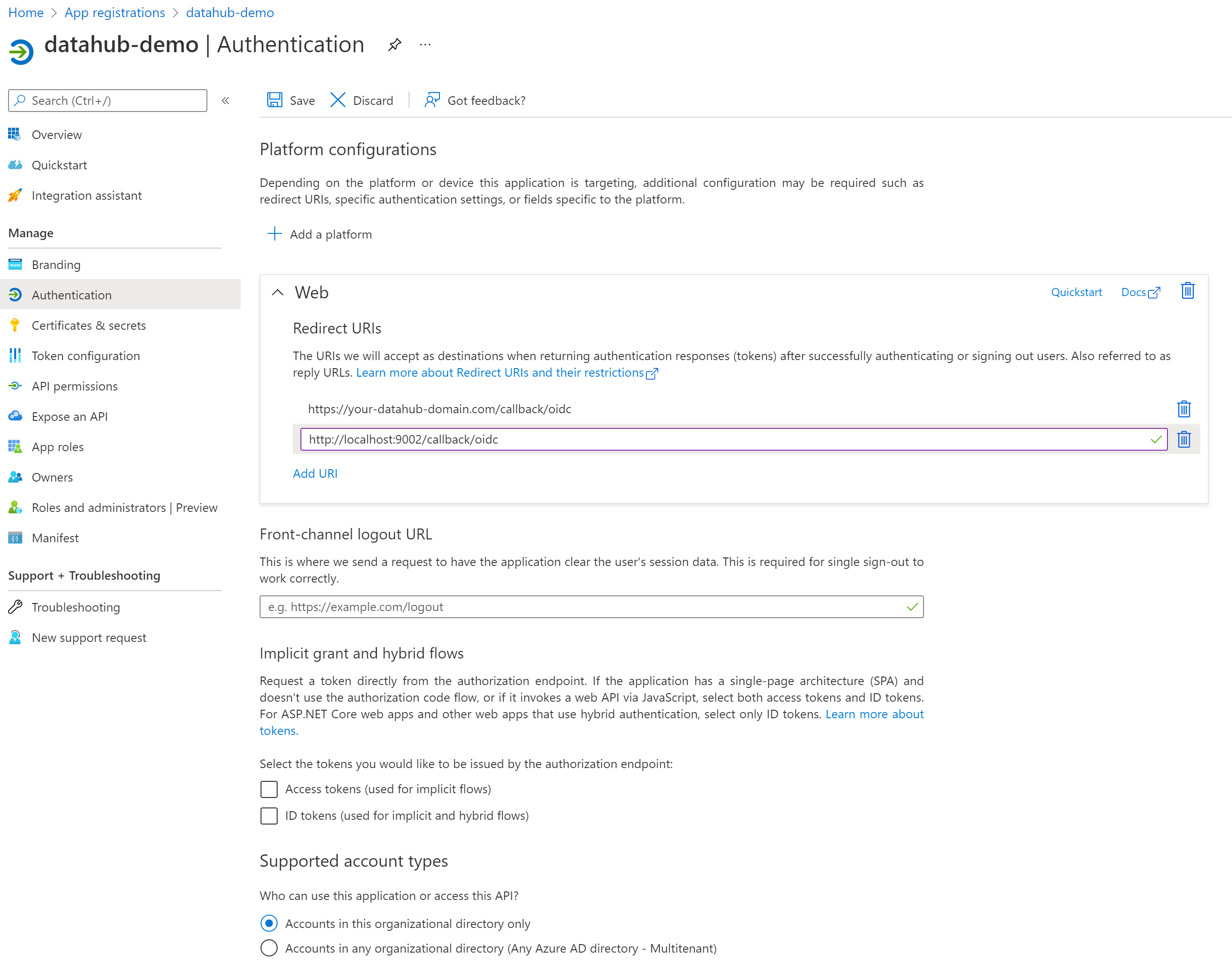 +
+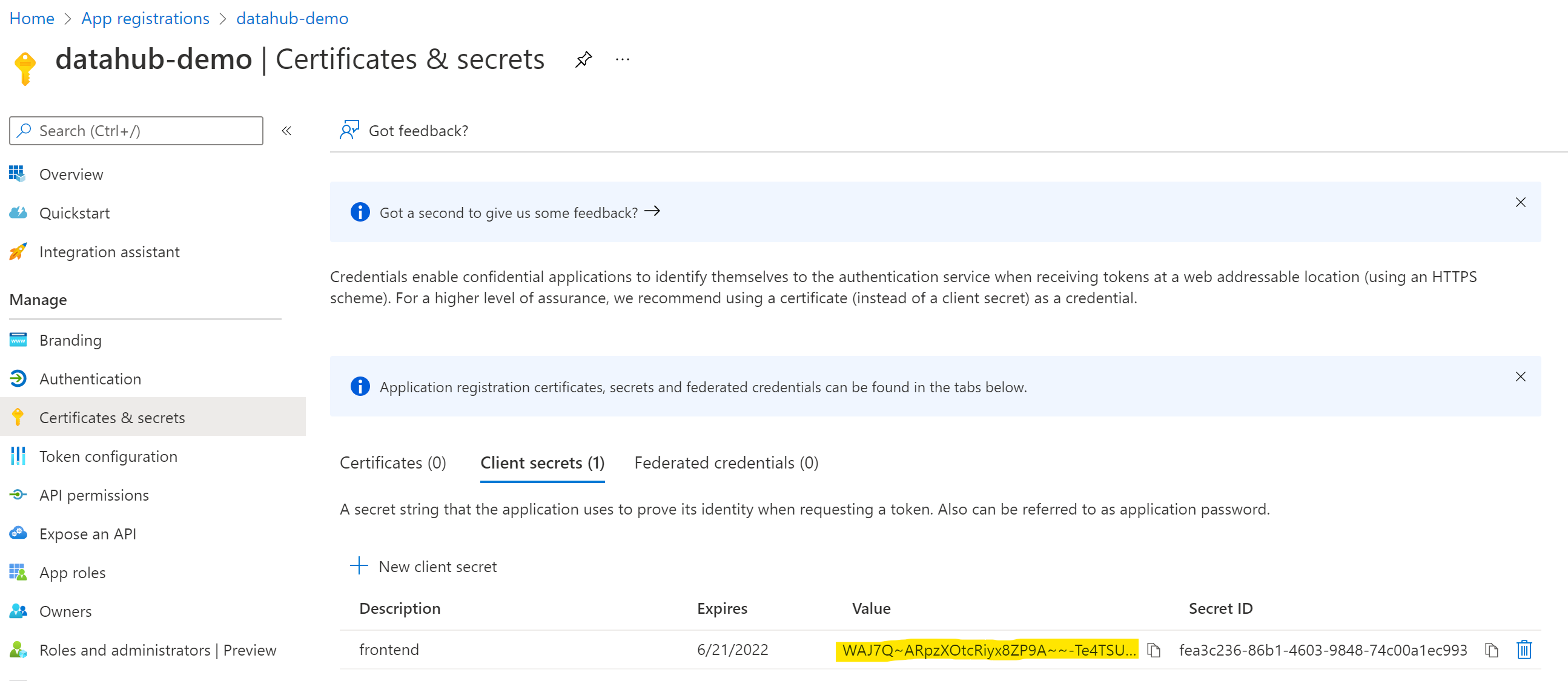 +
+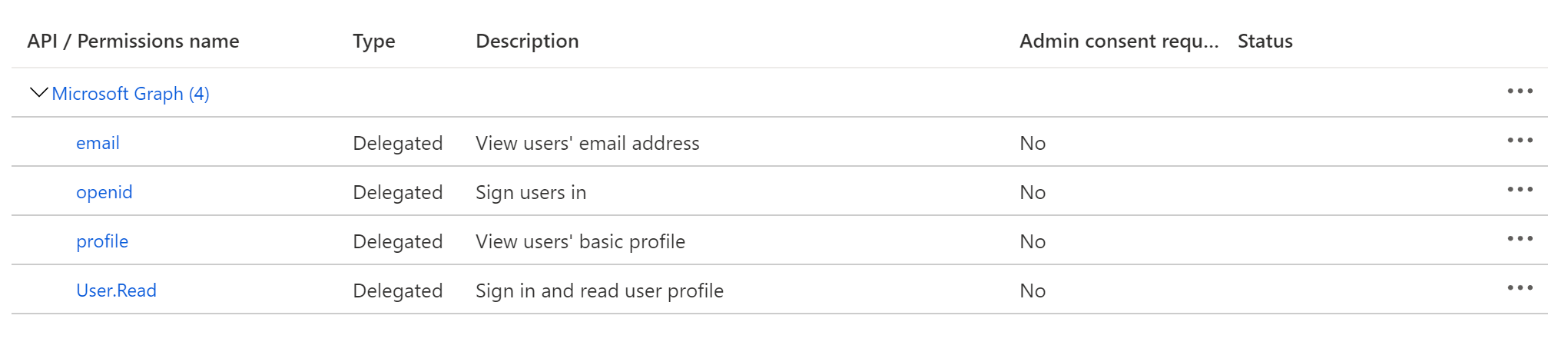 +
+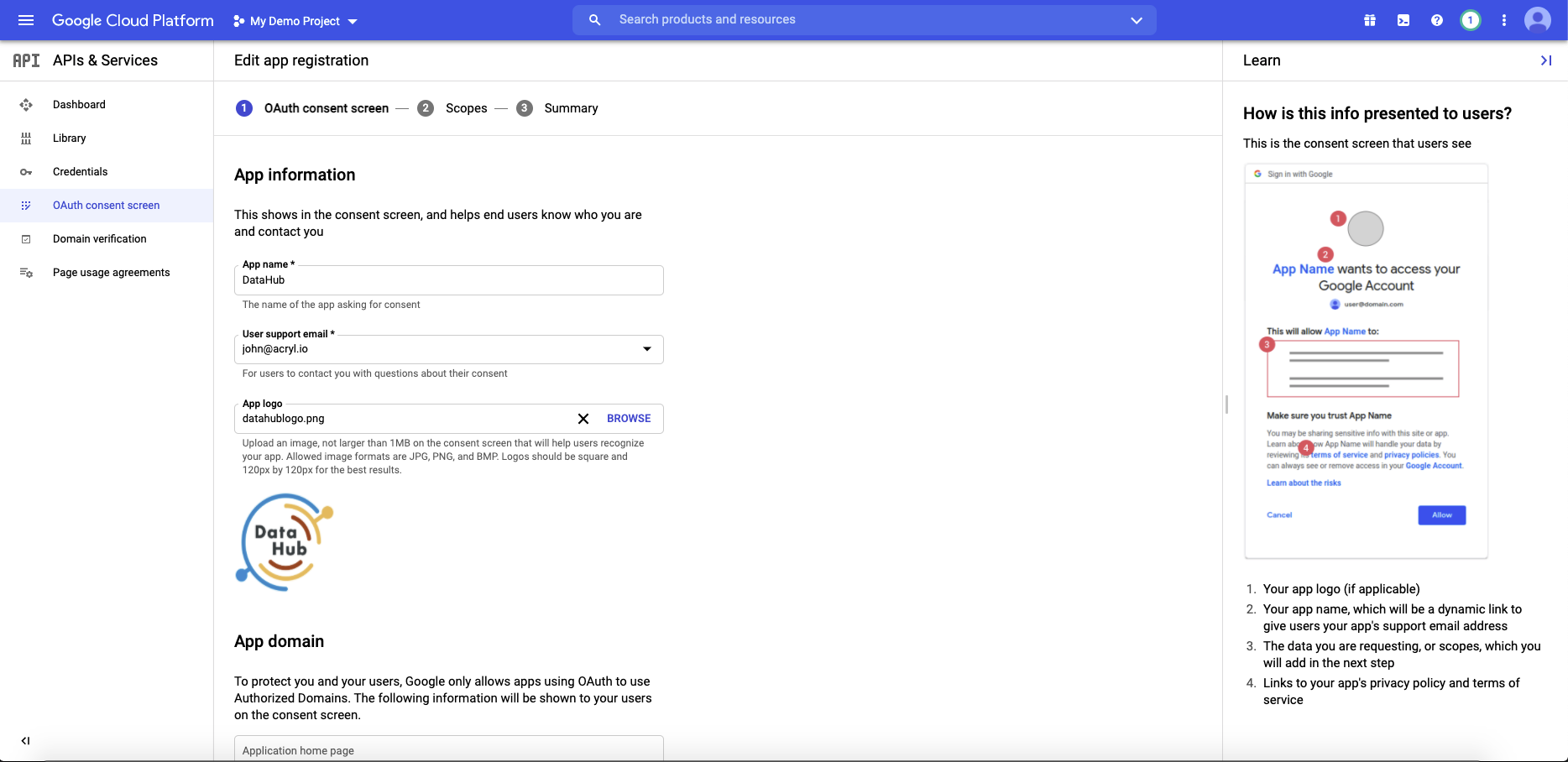 +
+ +
+ +
+ +
+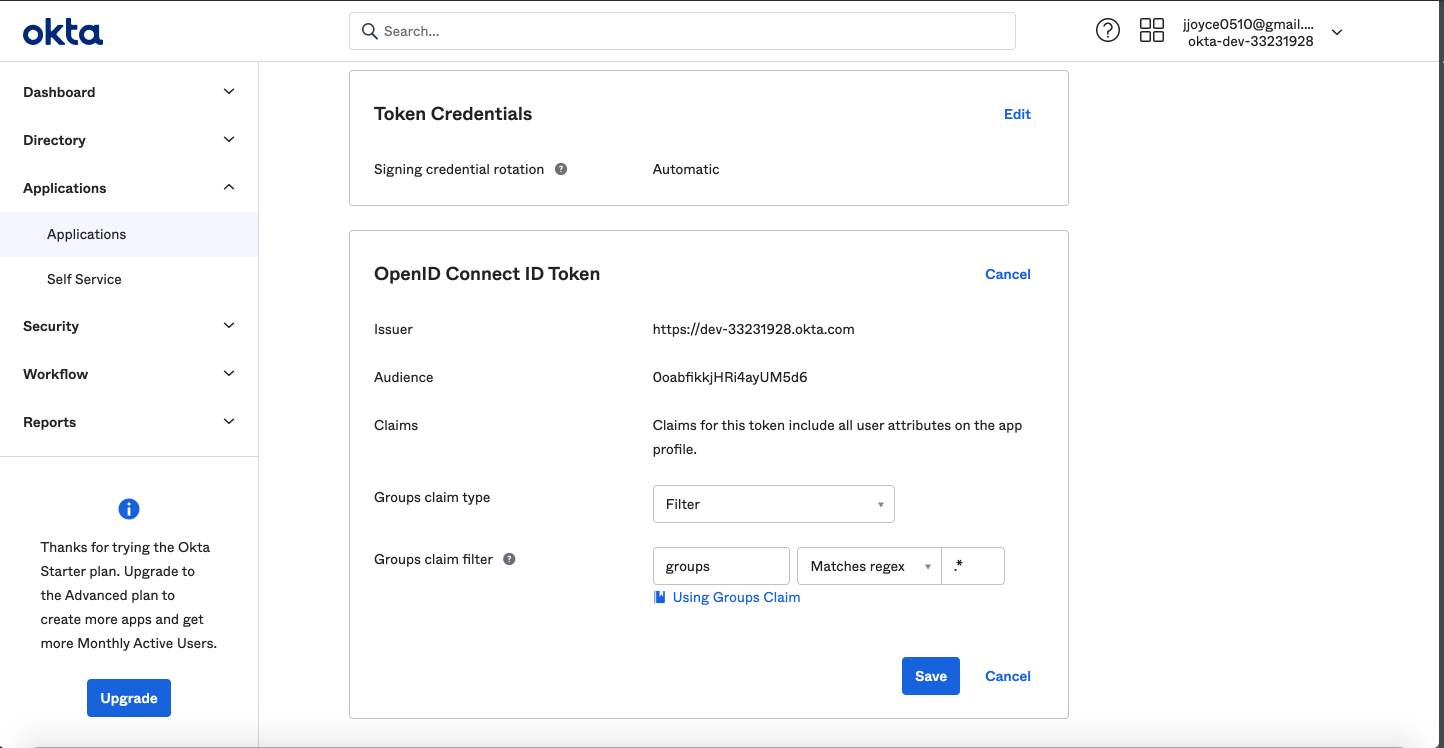 +
+
+
+ +
+ +
+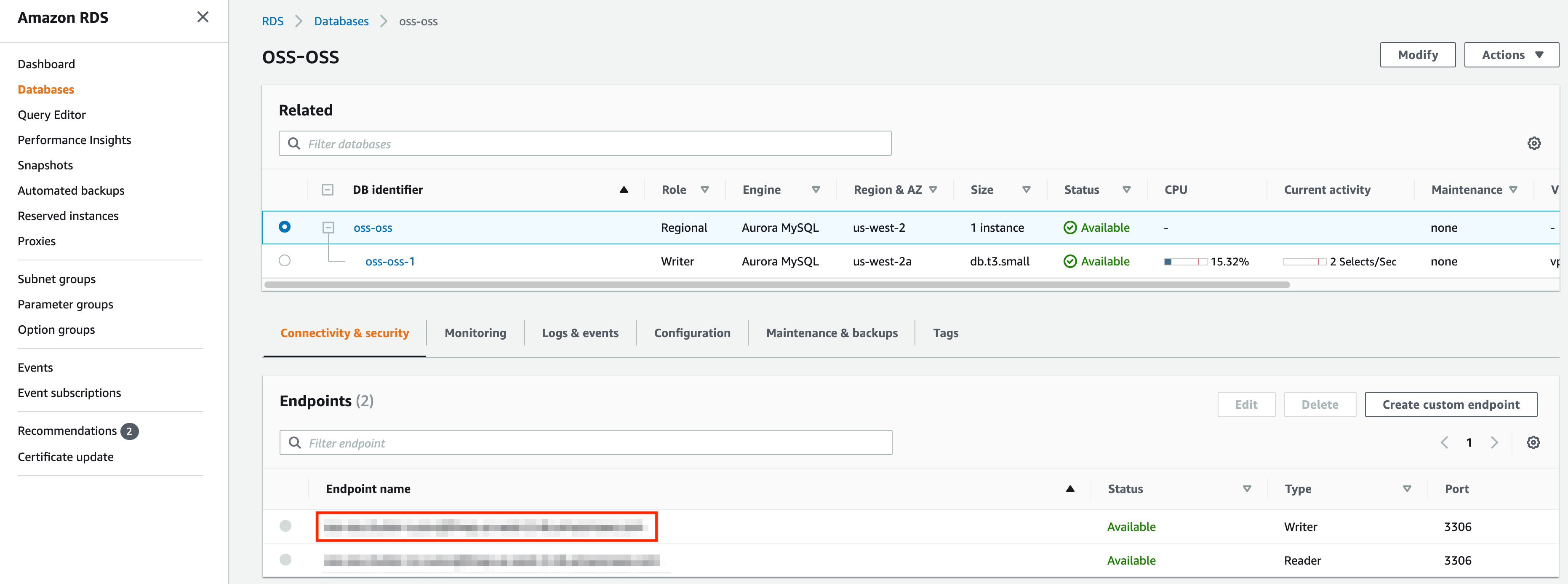 +
+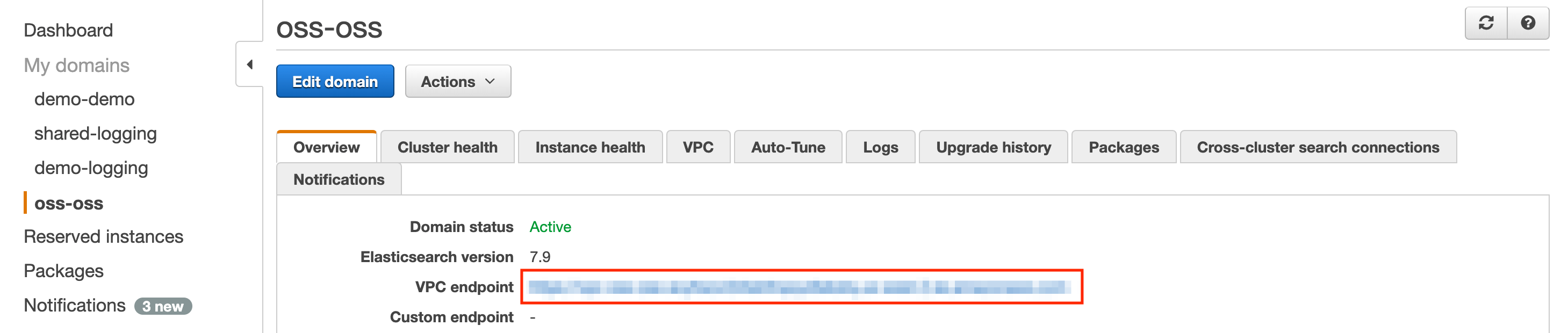 +
+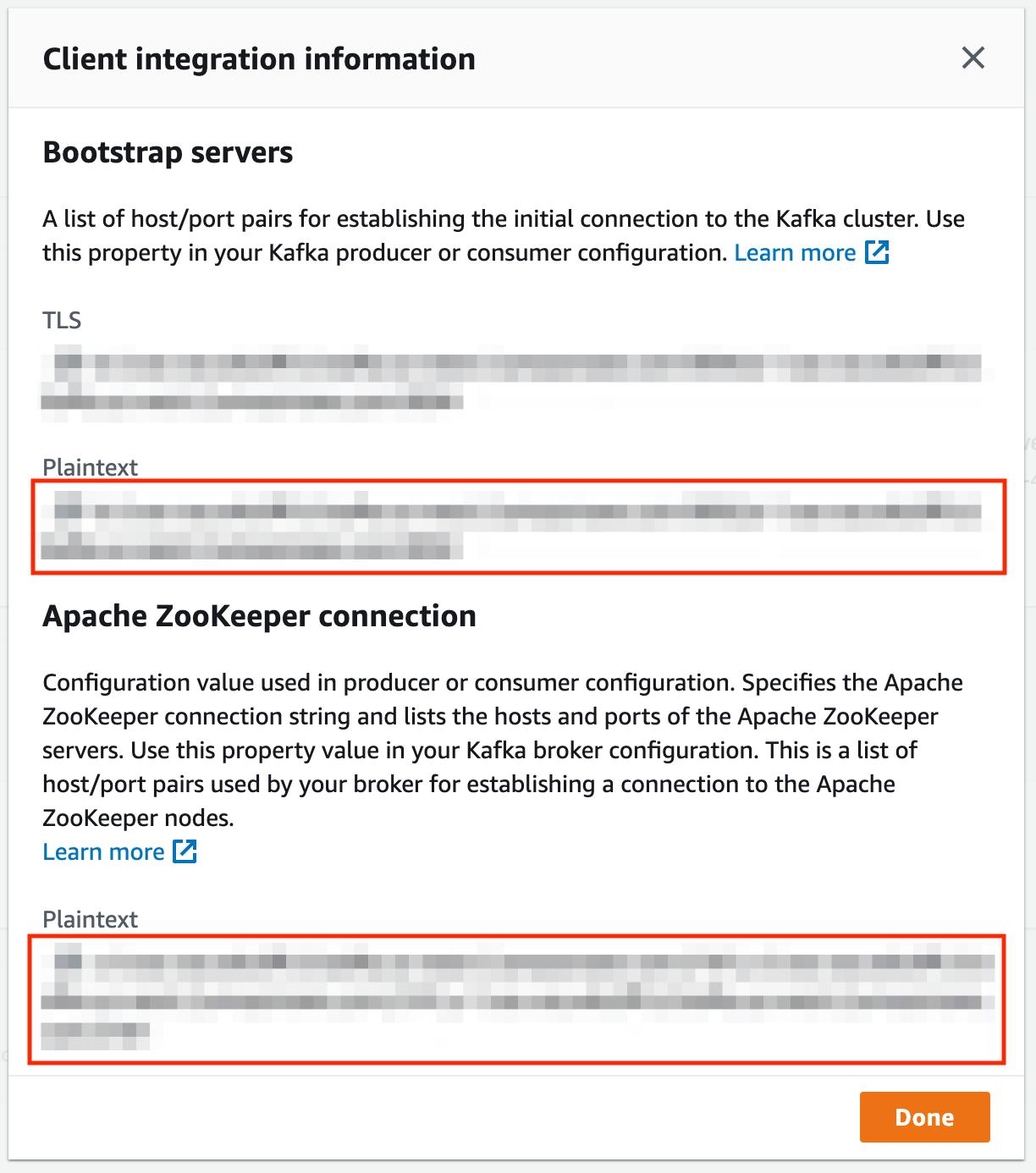 +
+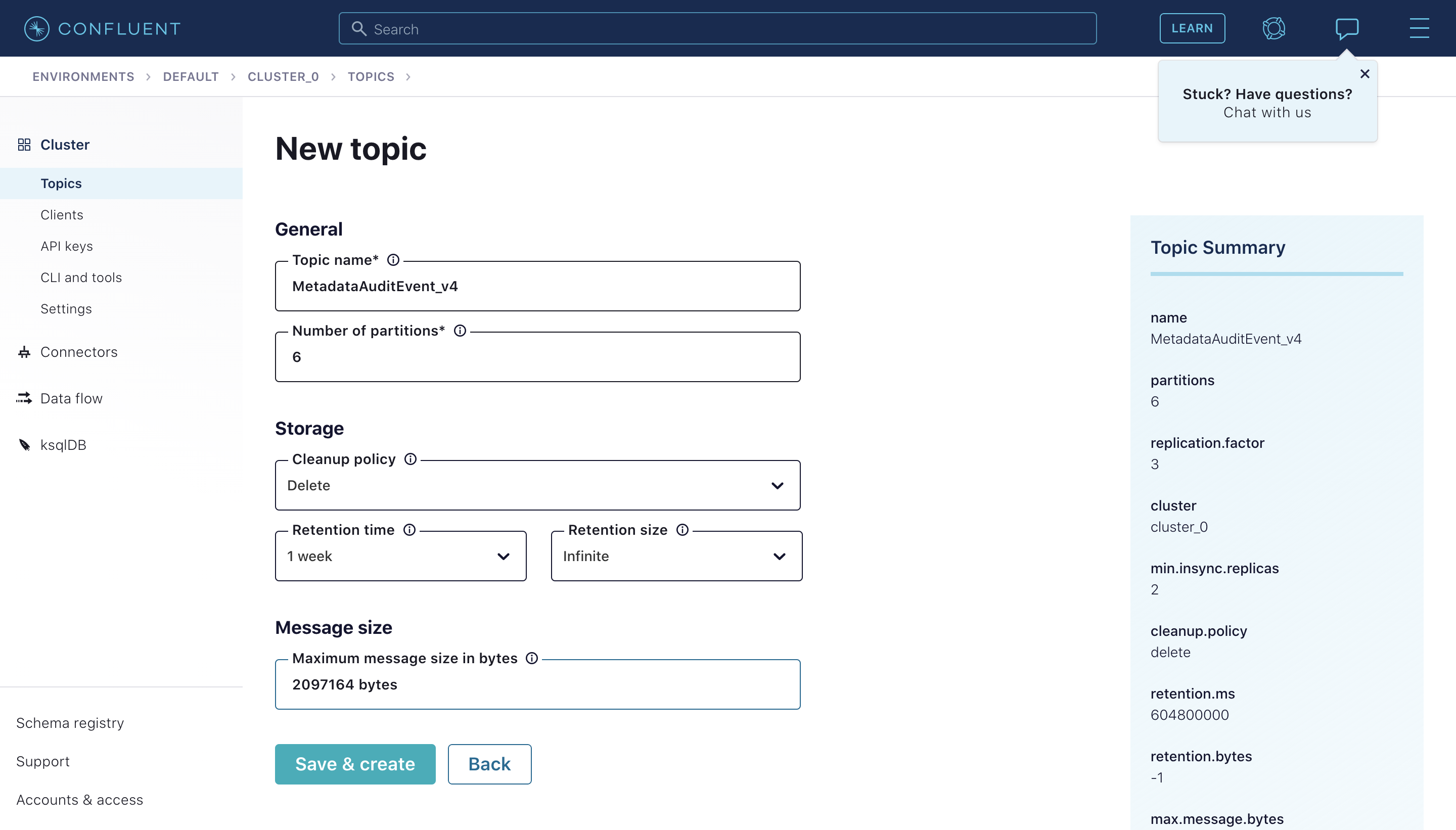 +
+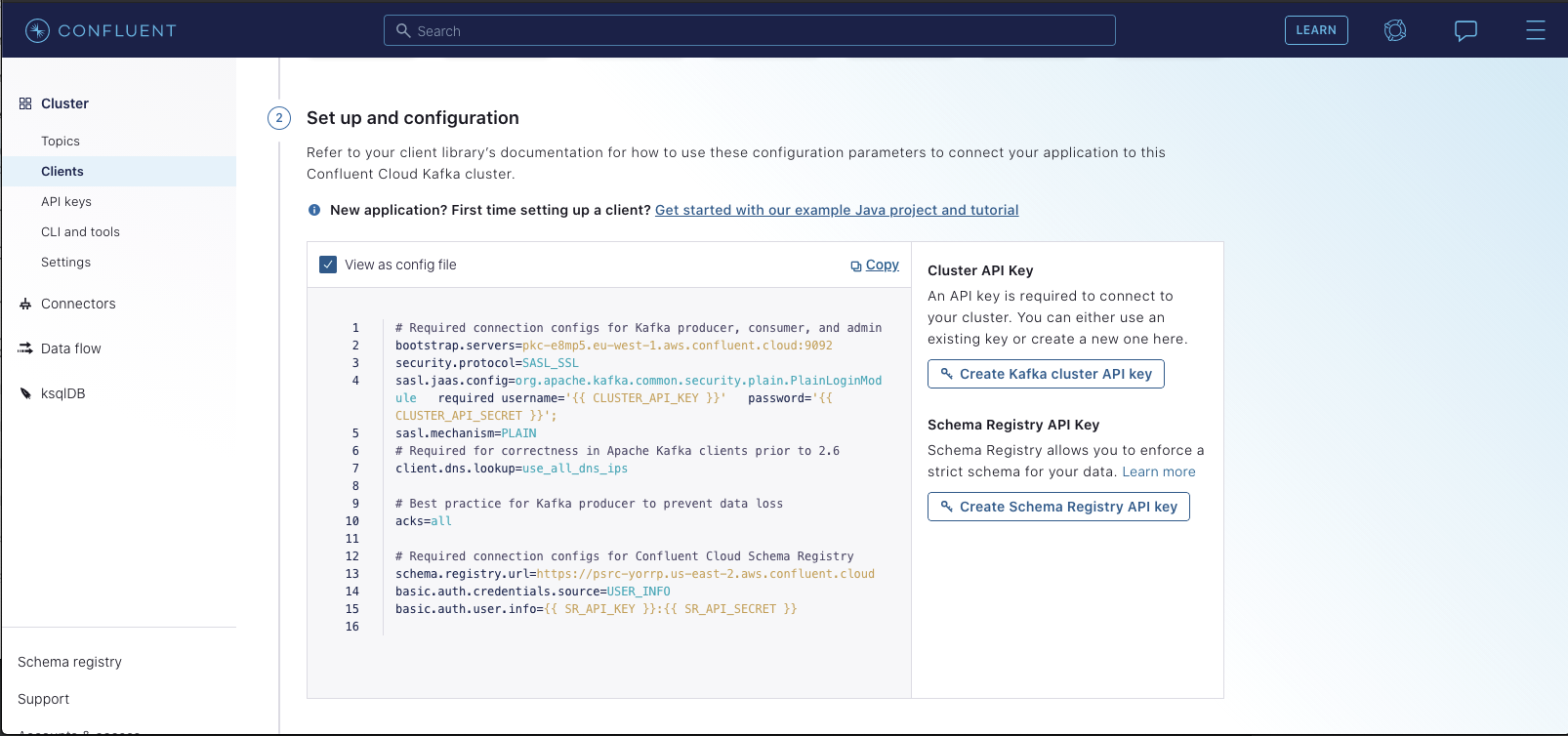 +
+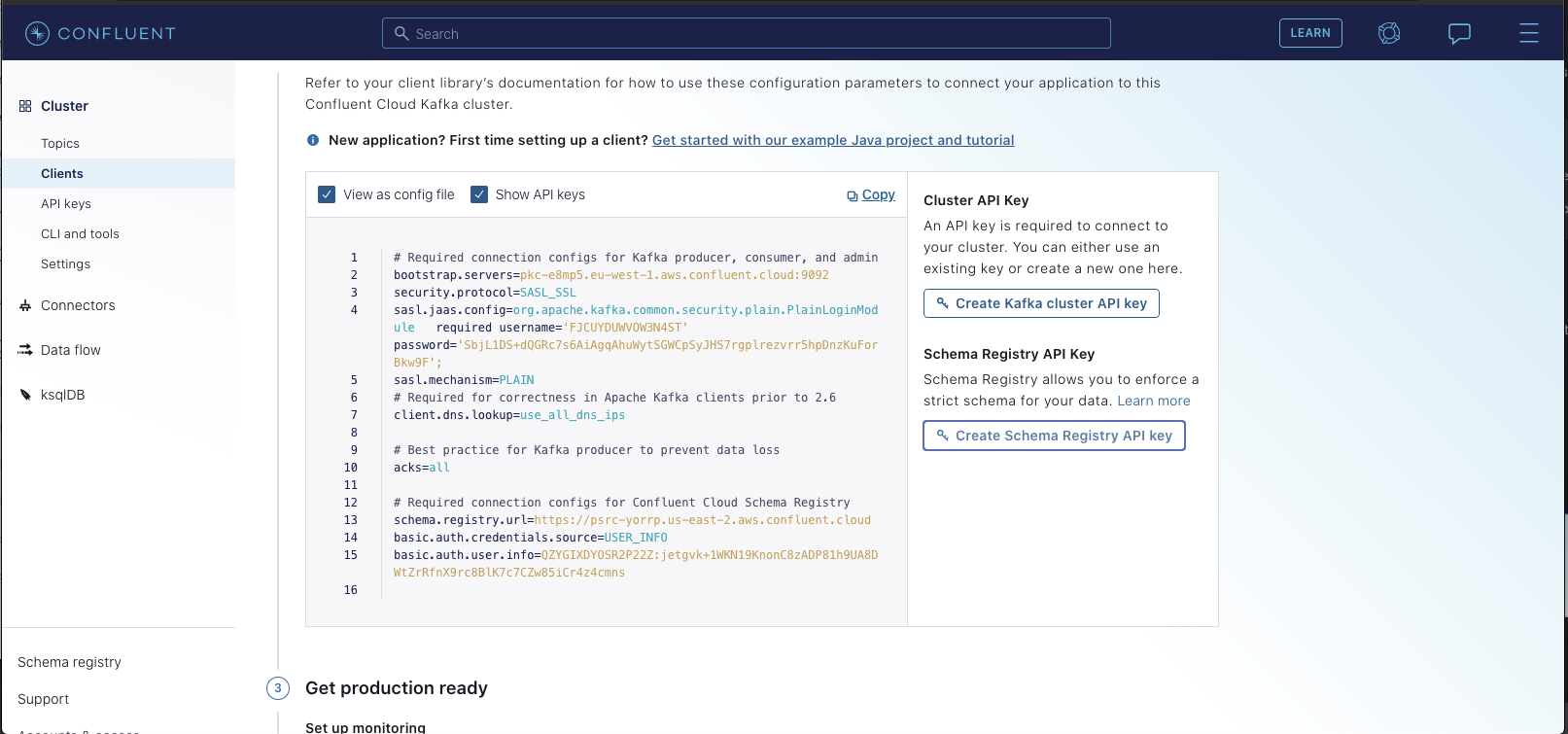 +
+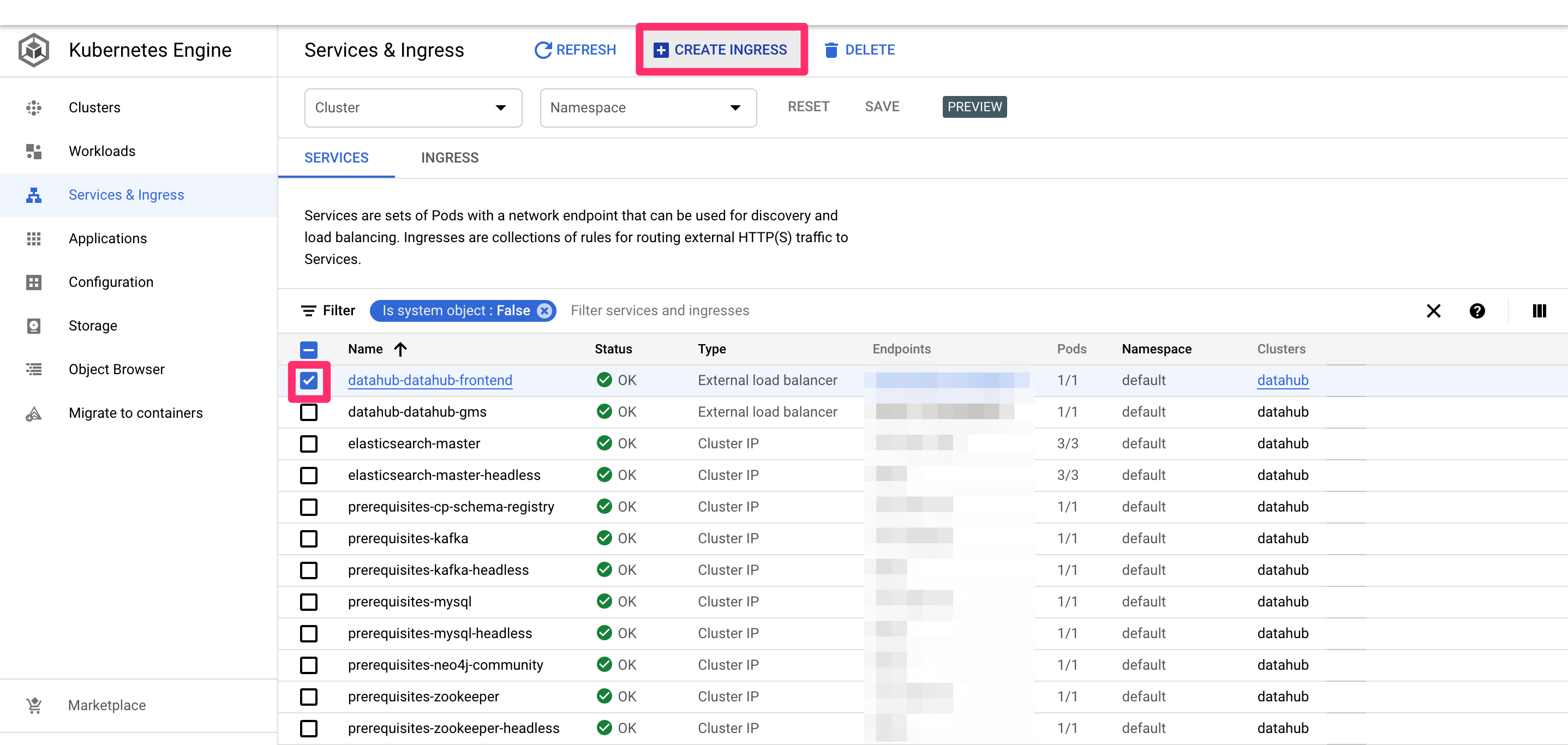 +
+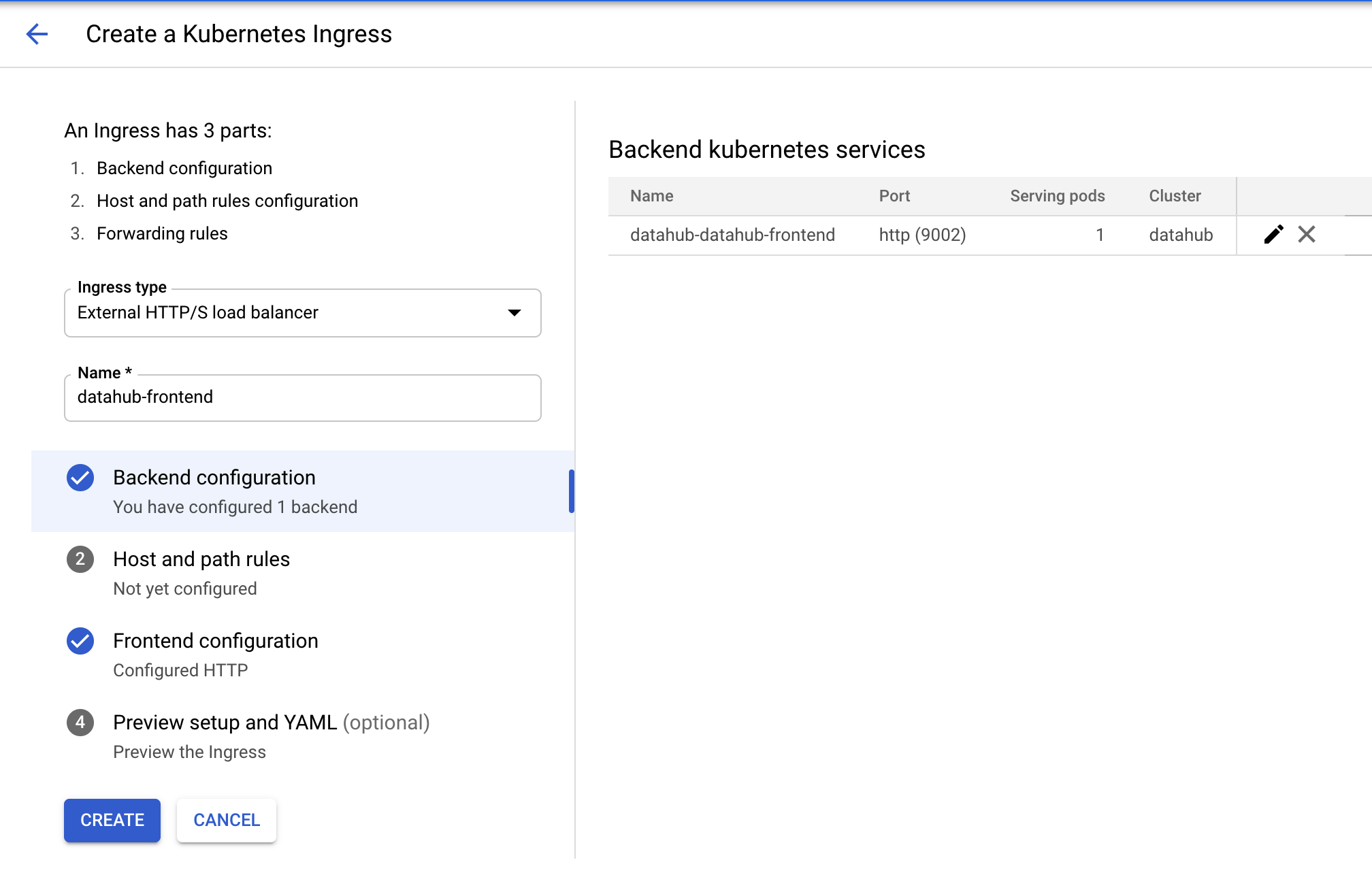 +
+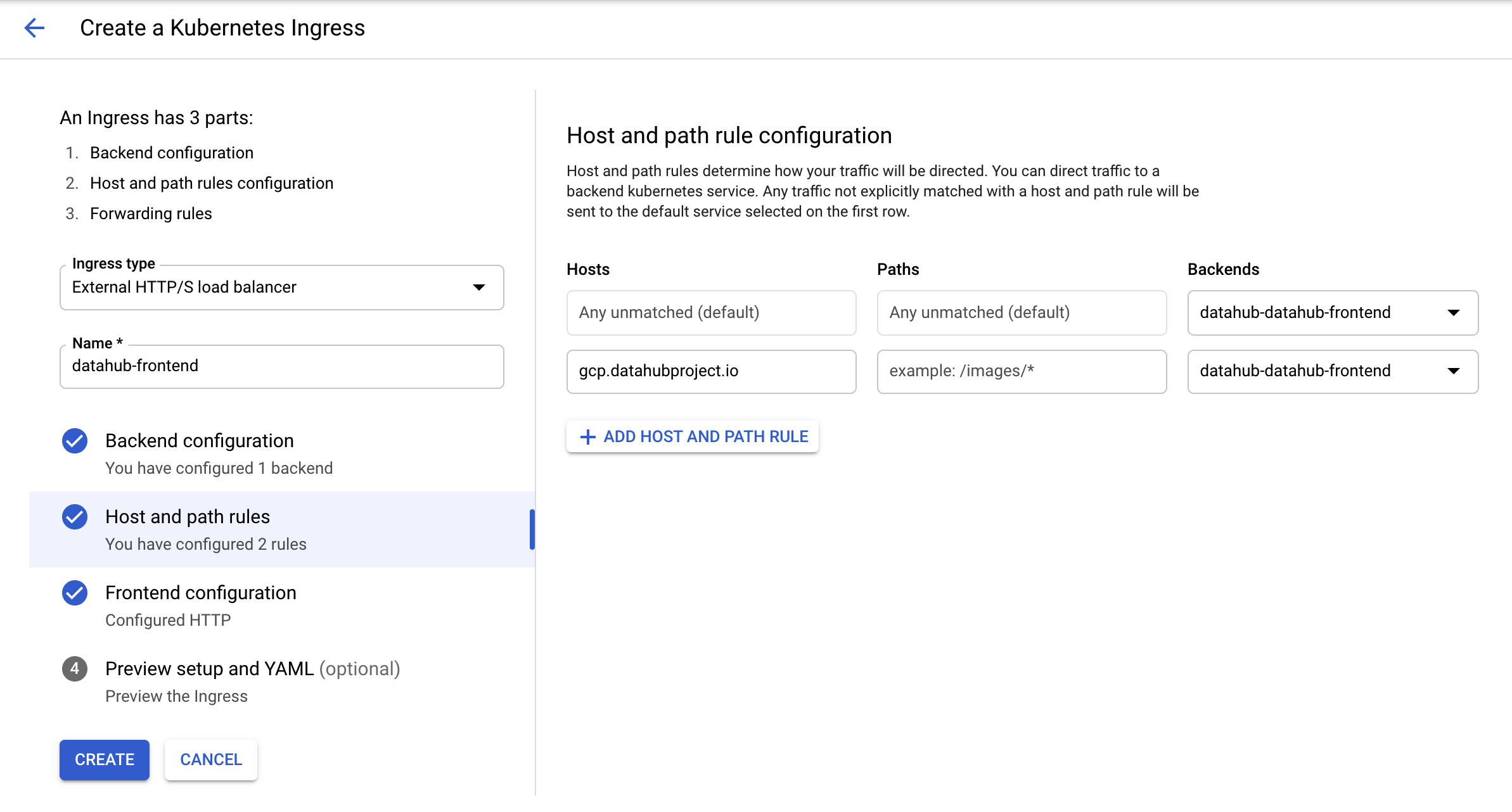 +
+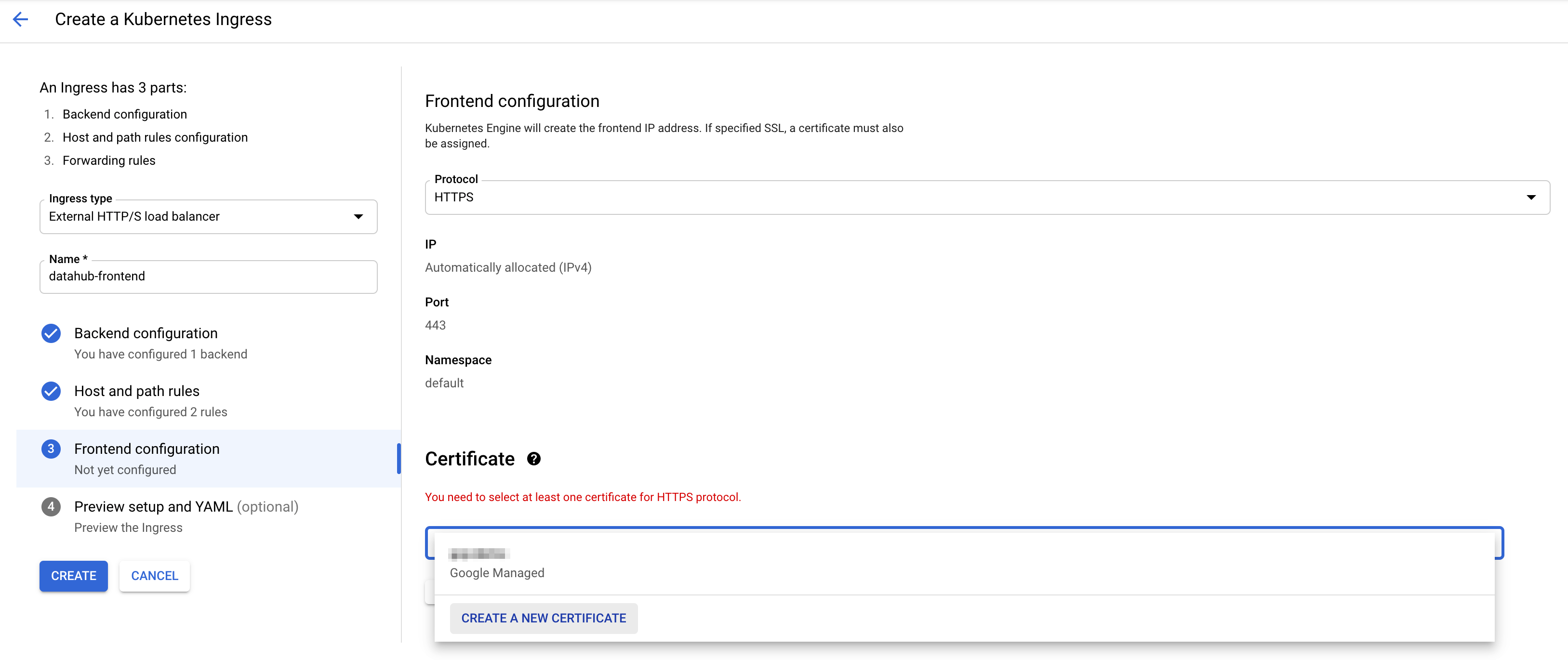 +
+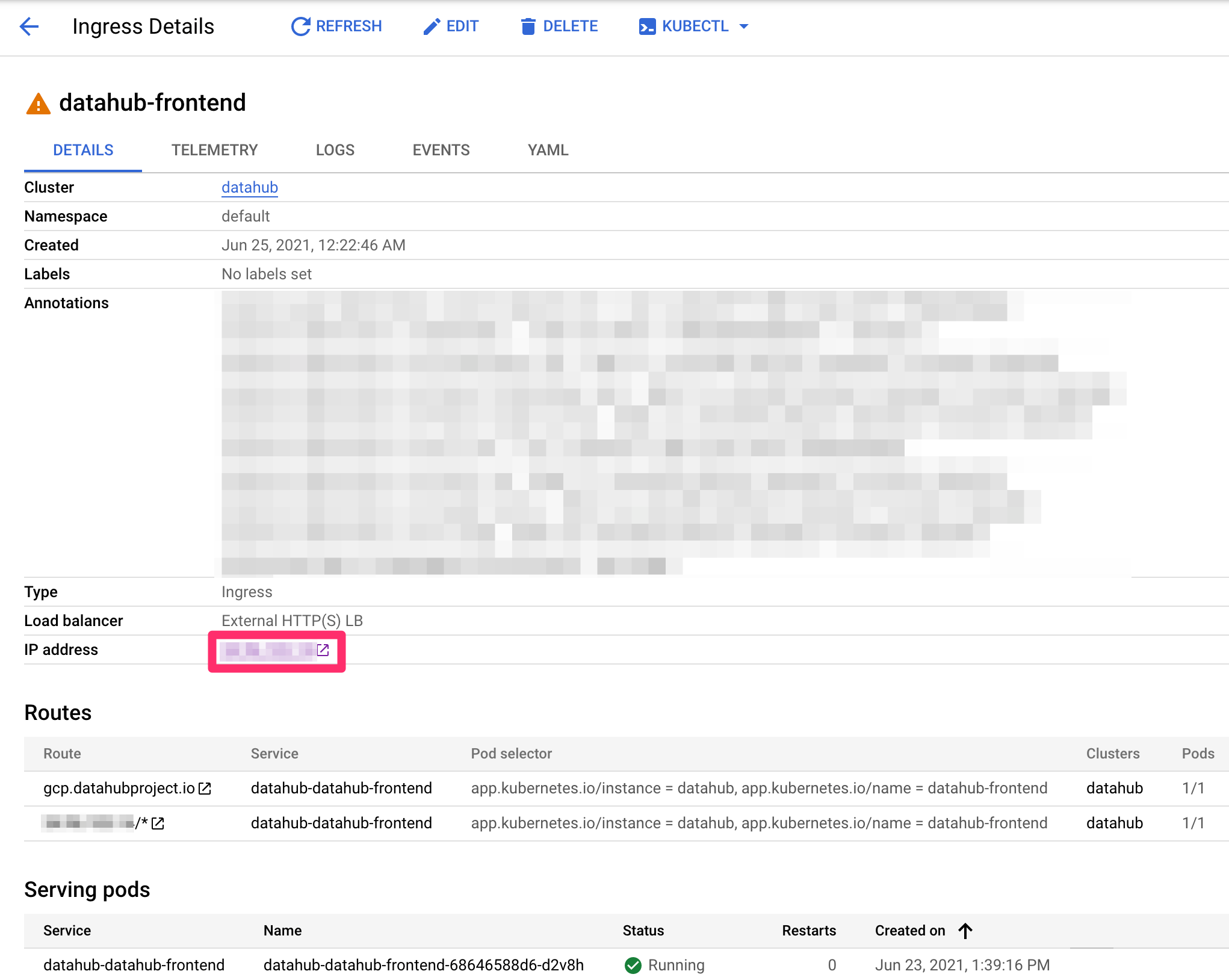 +
+ +
+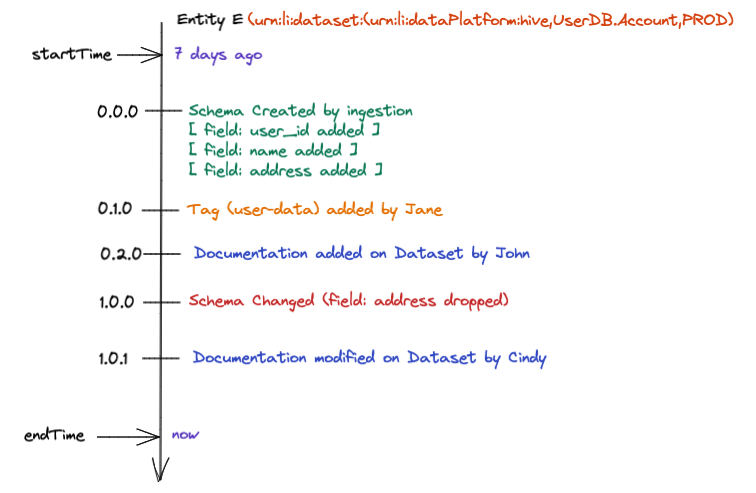 +
+ +
+ +
+ +
+ +
+ 
 +
+ 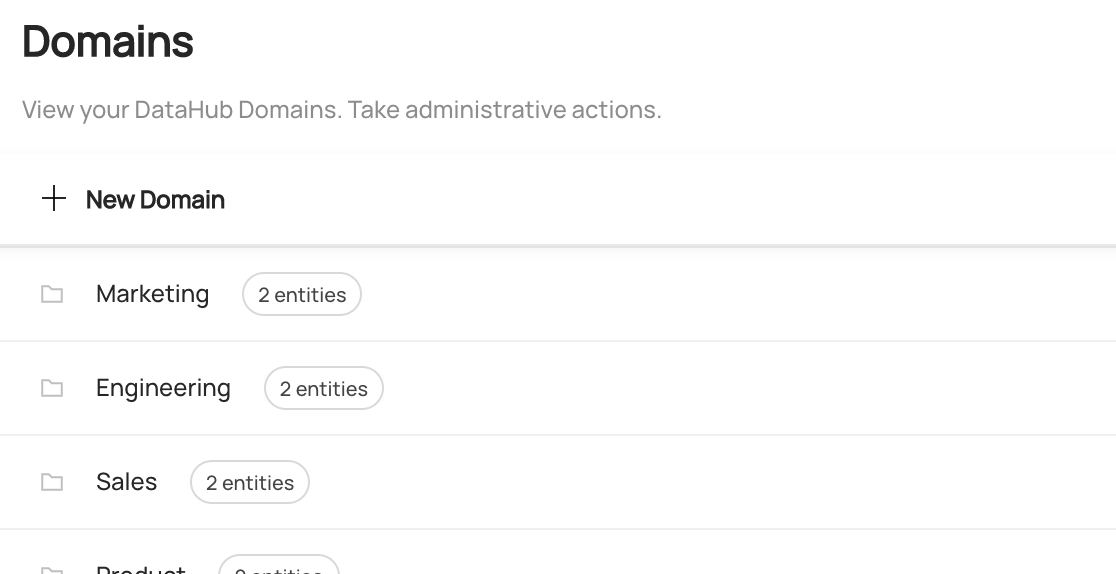
 +
+ 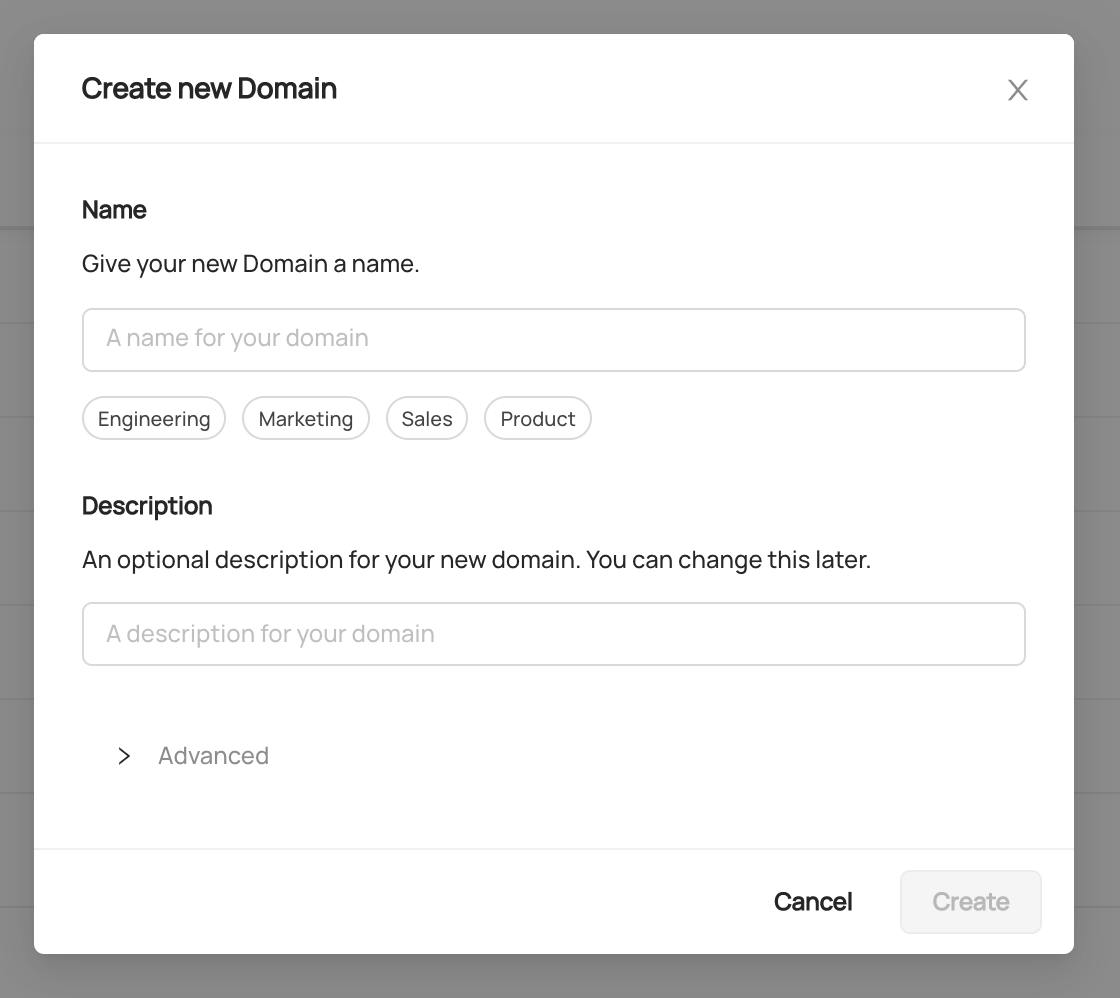
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ +
+ +
+ +
+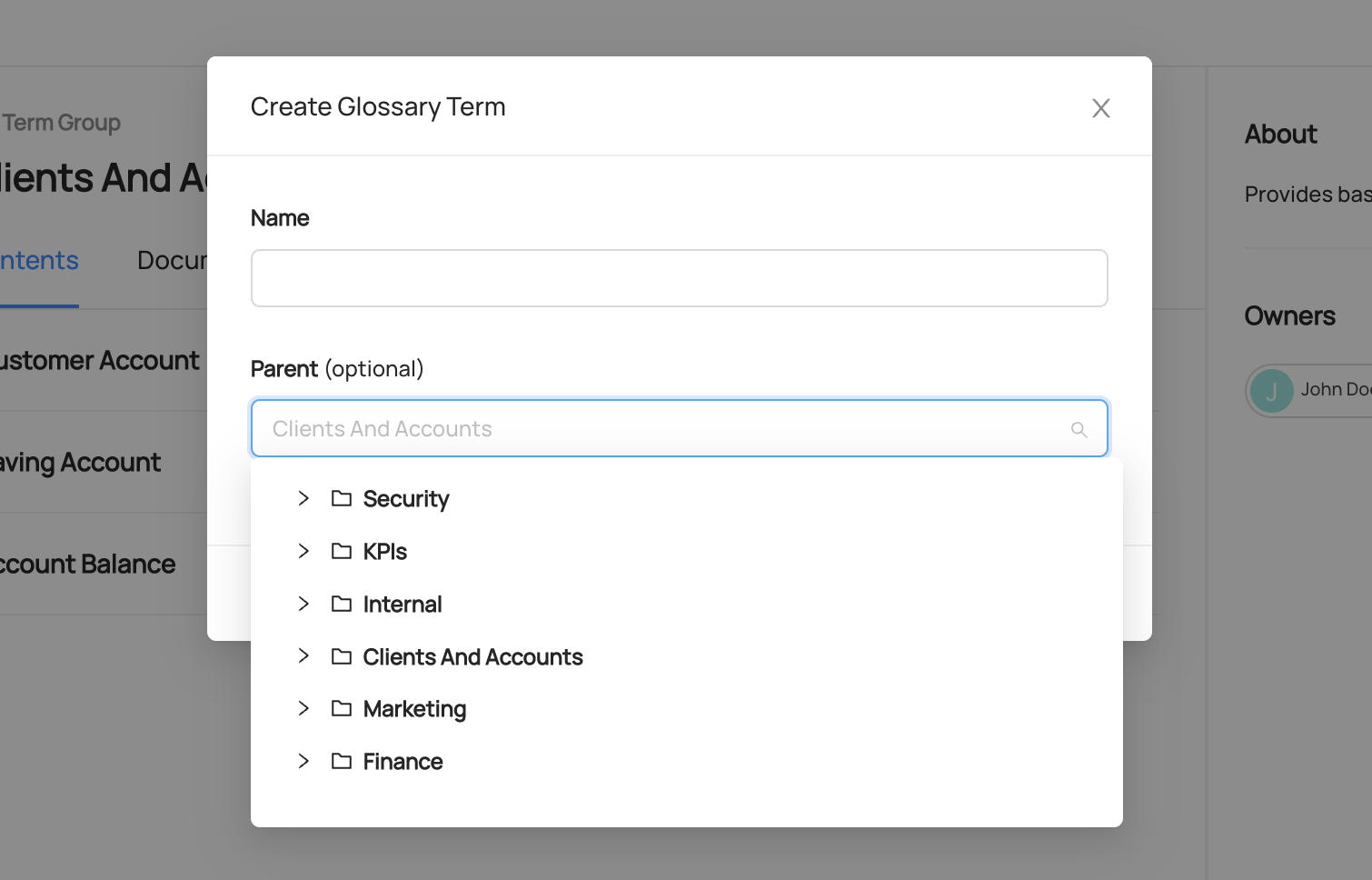 +
+ +
+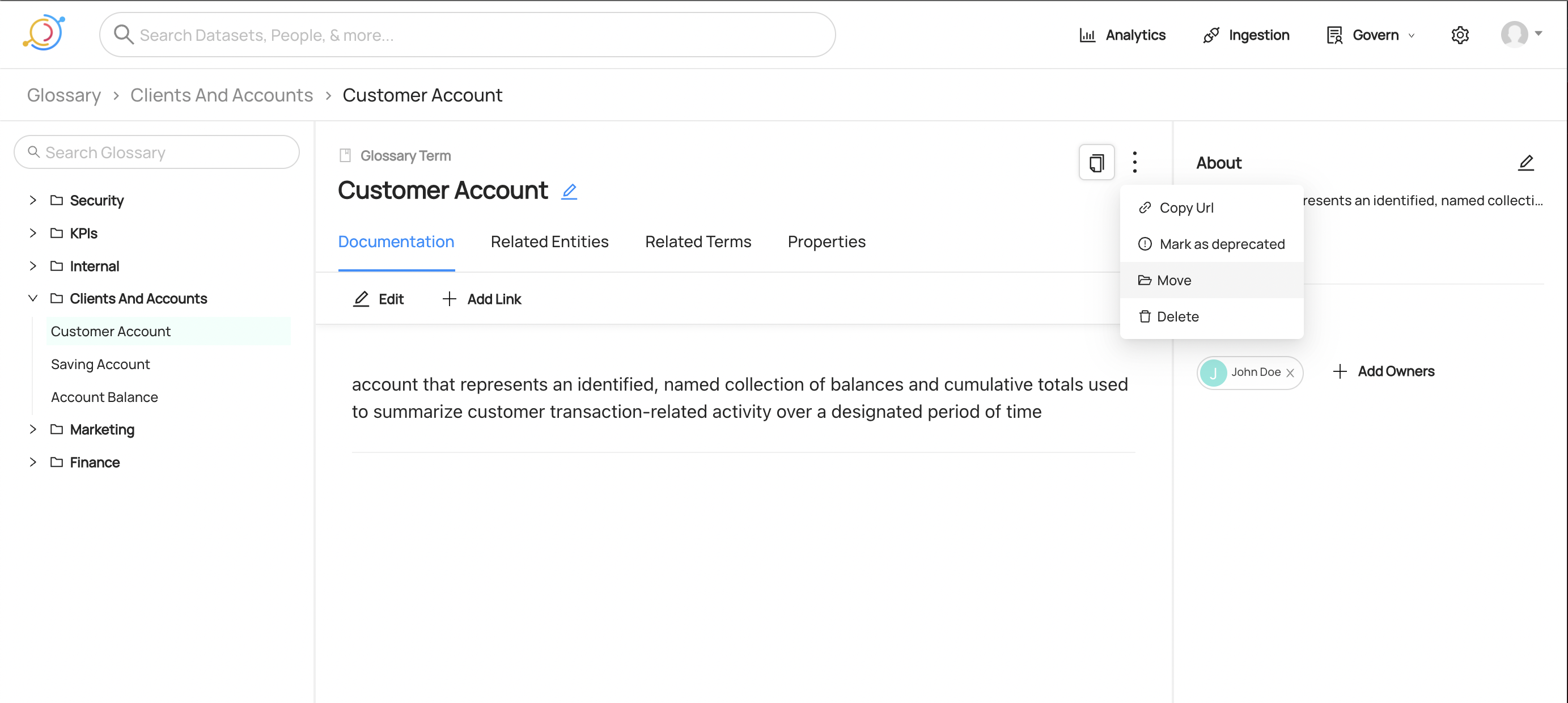 +
+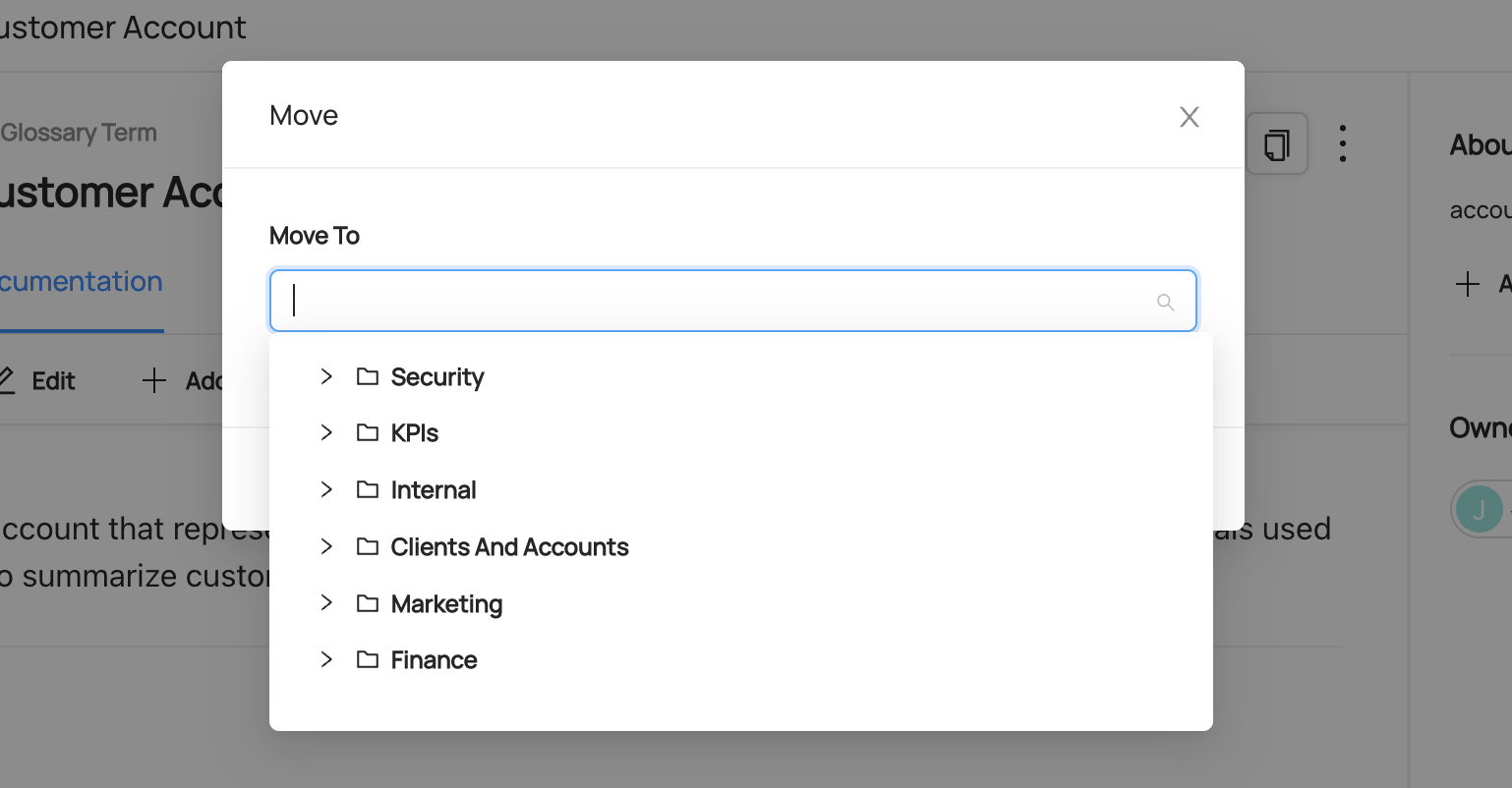 +
+ +
+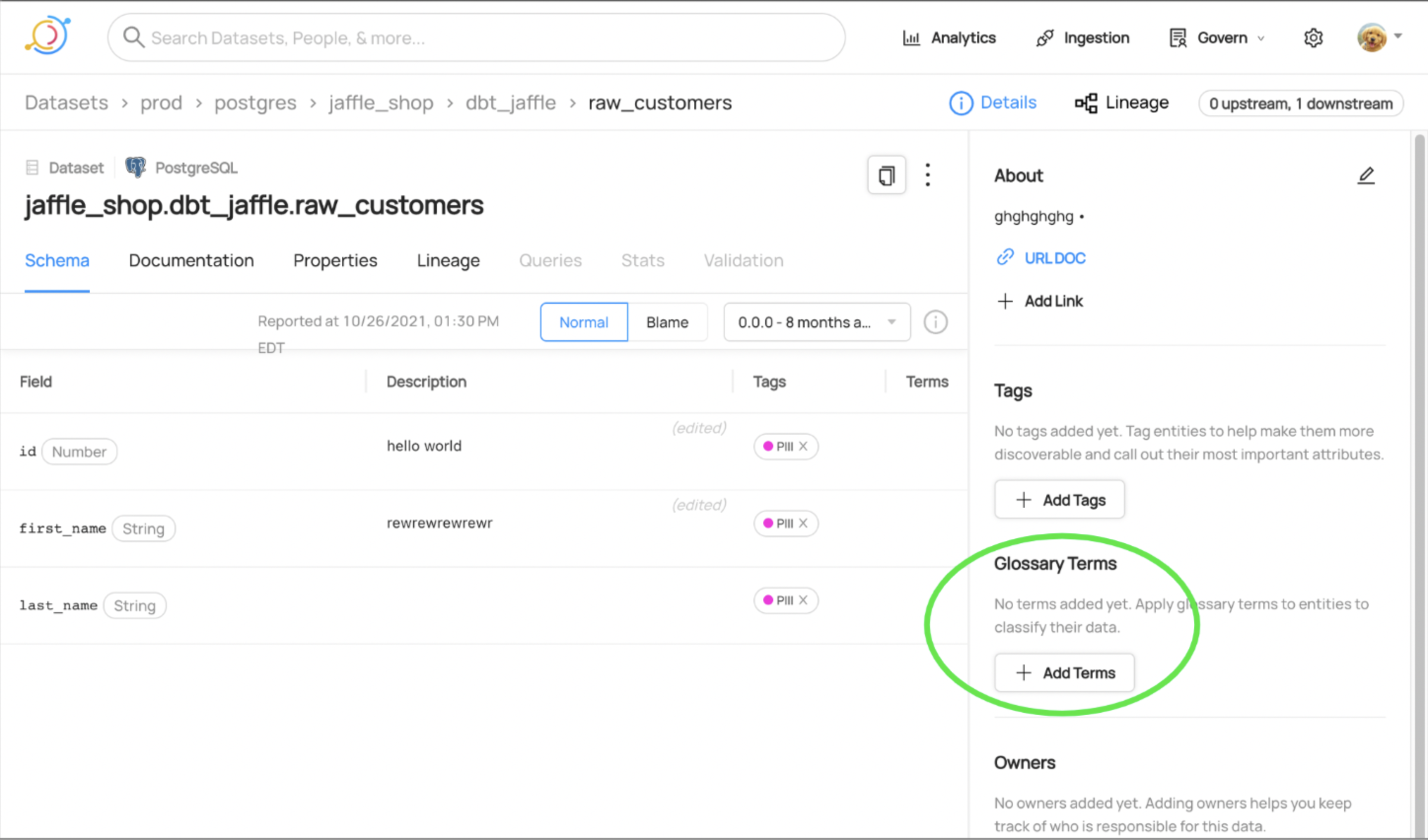 +
+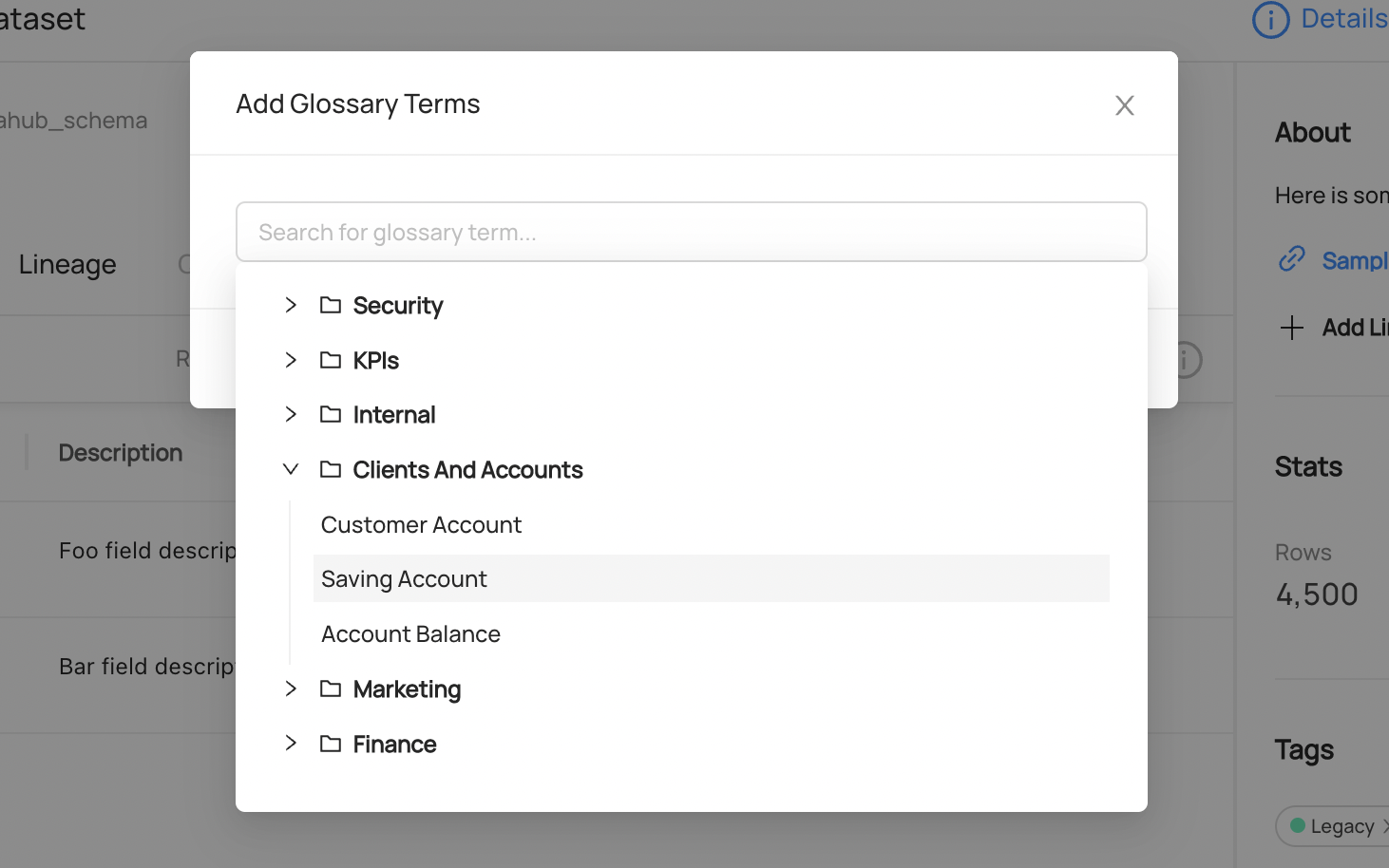 +
+ +
+ 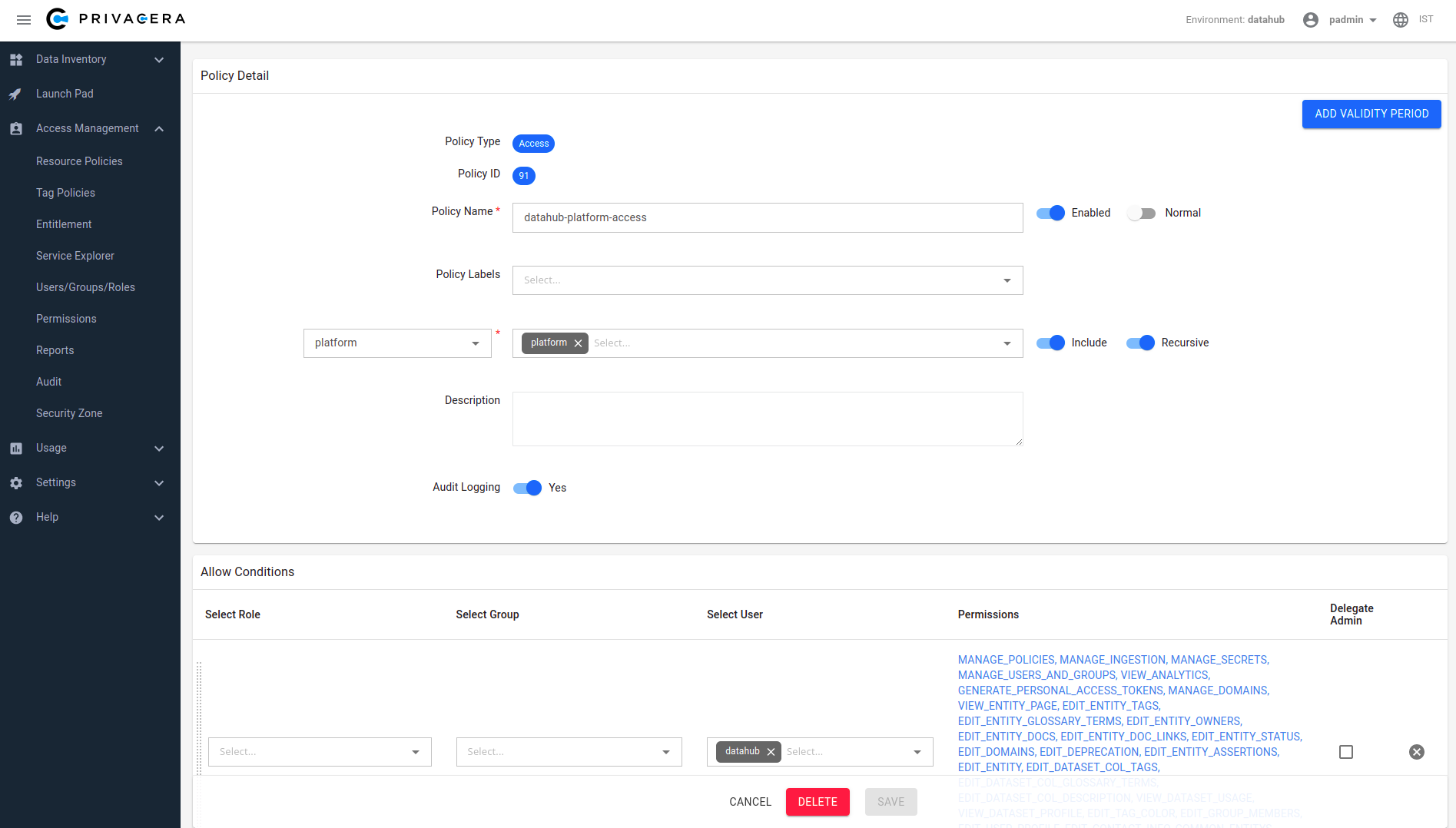 +
+  +
+ +
+ +
+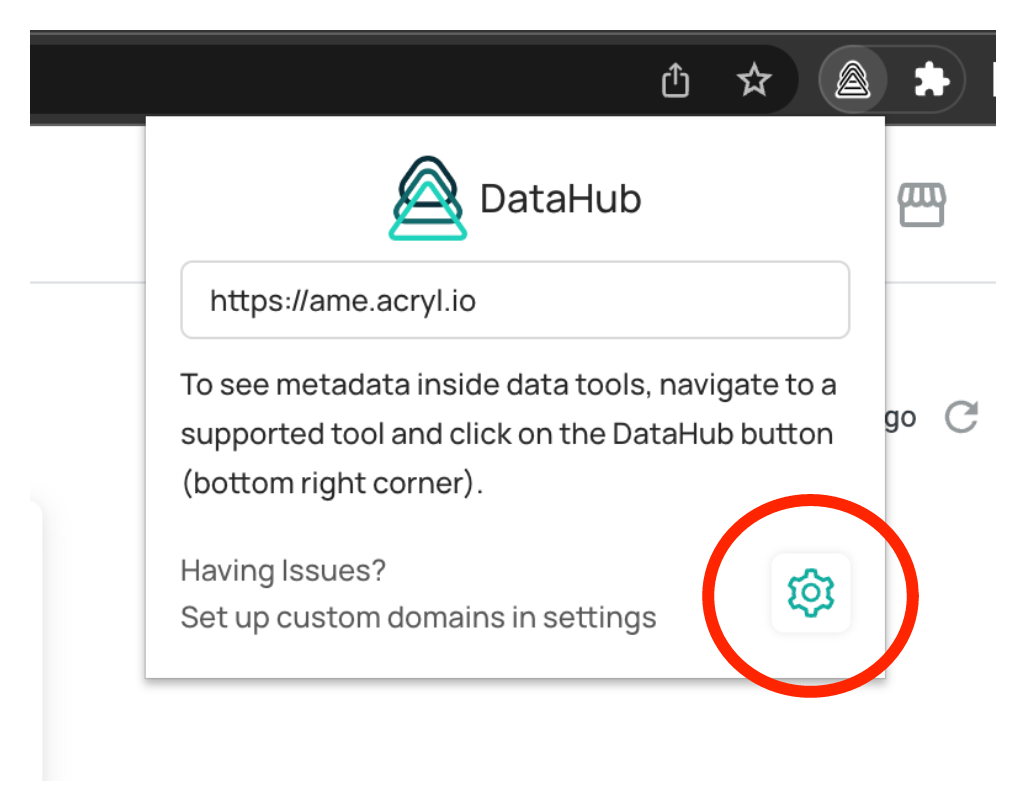 +
+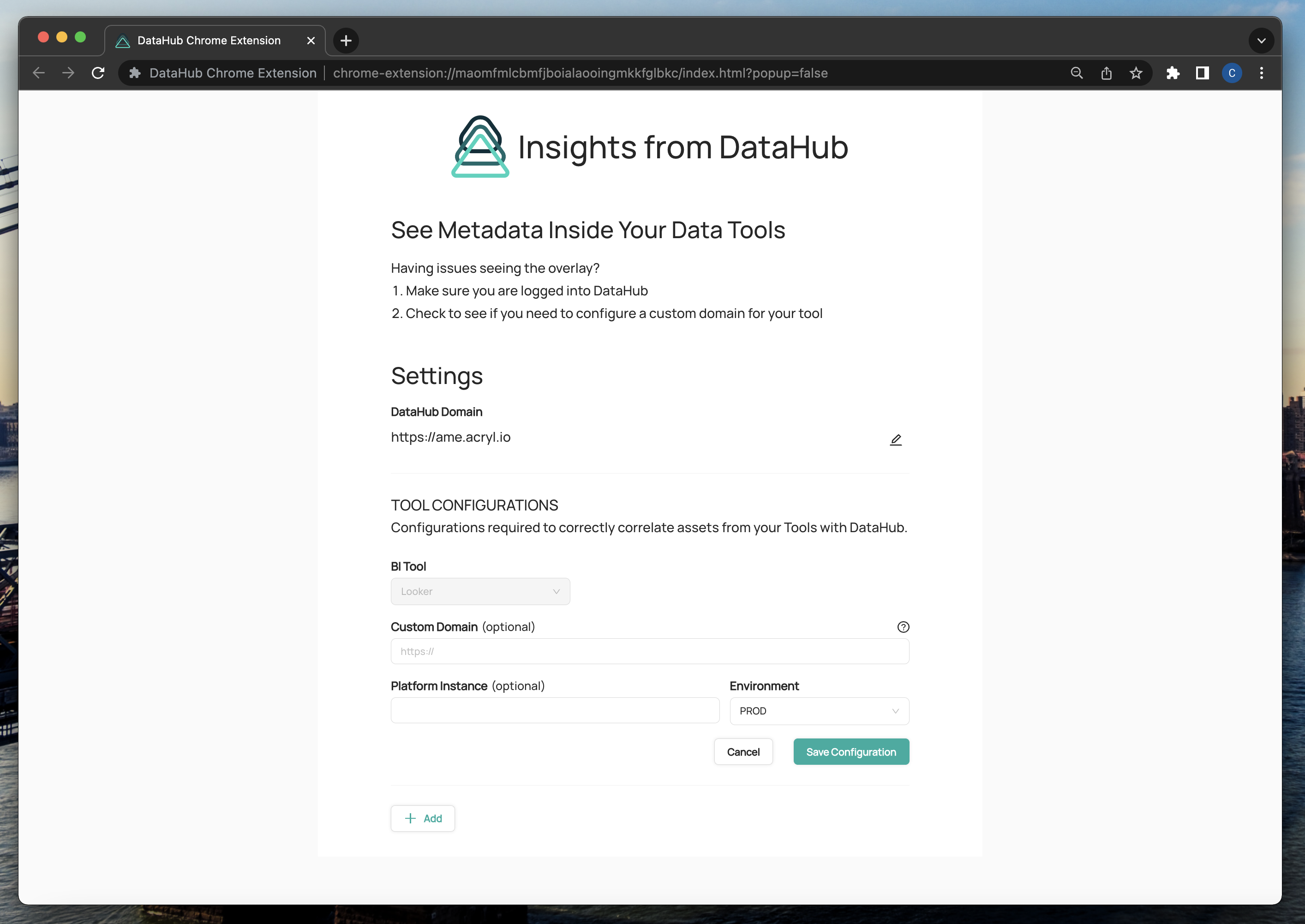 +
+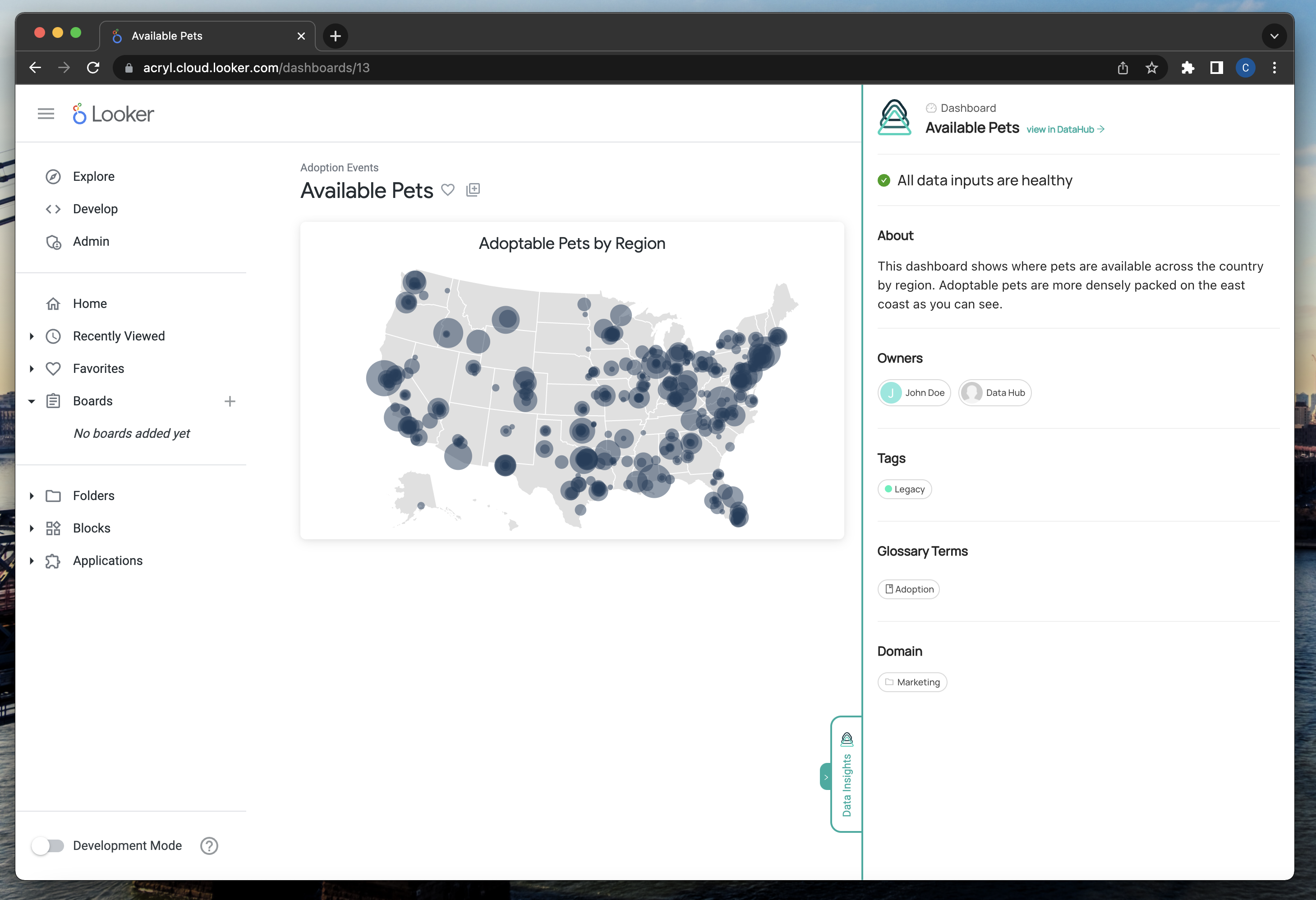 +
+.png) +
+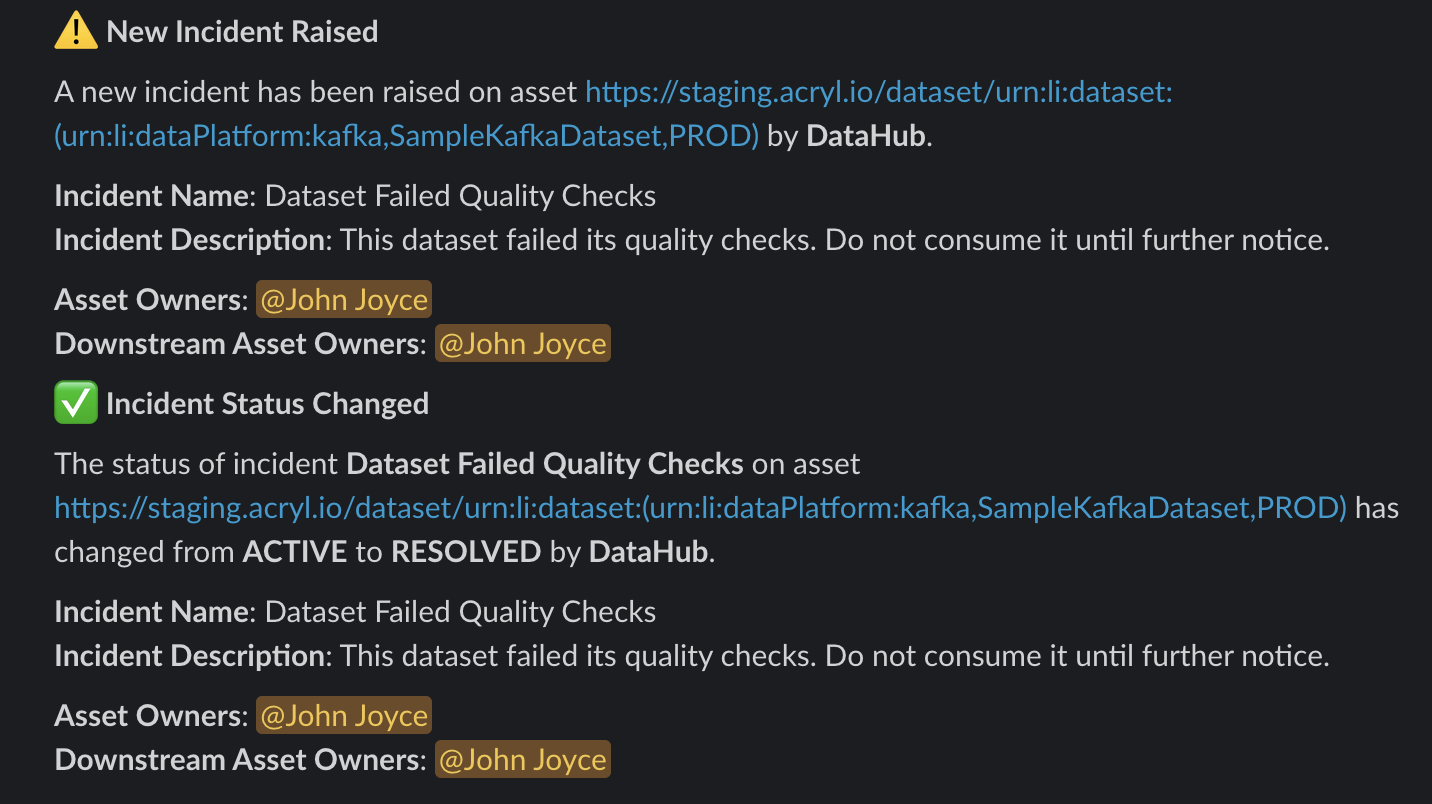 +
+.png) +
+.png) +
+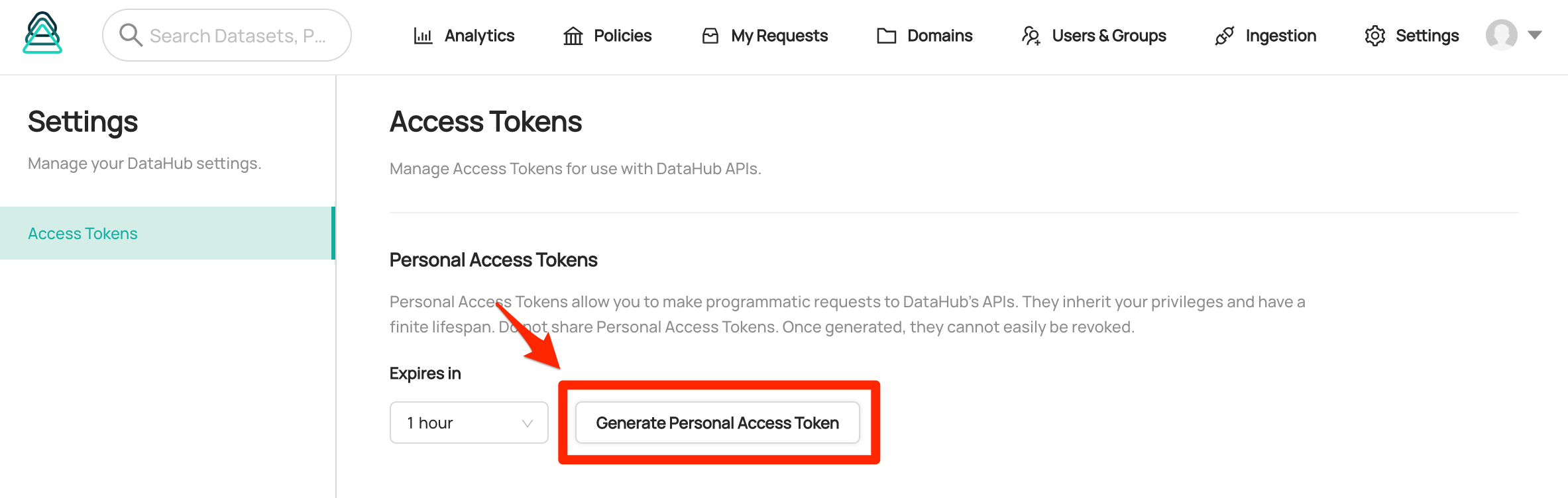 +
+.png) +
+.png) +
+ +
+ +
+ +
+  +
+ +
+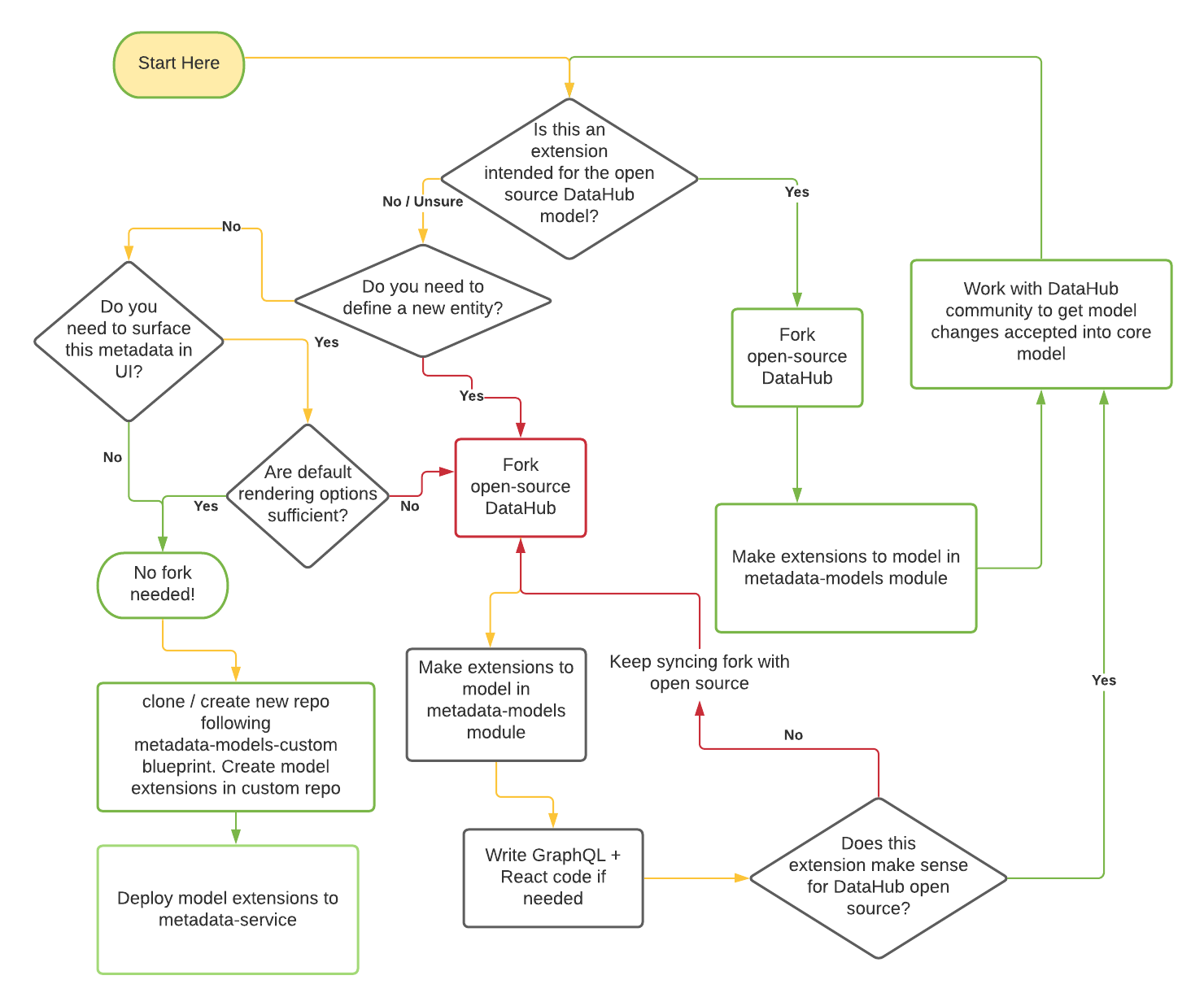 +
+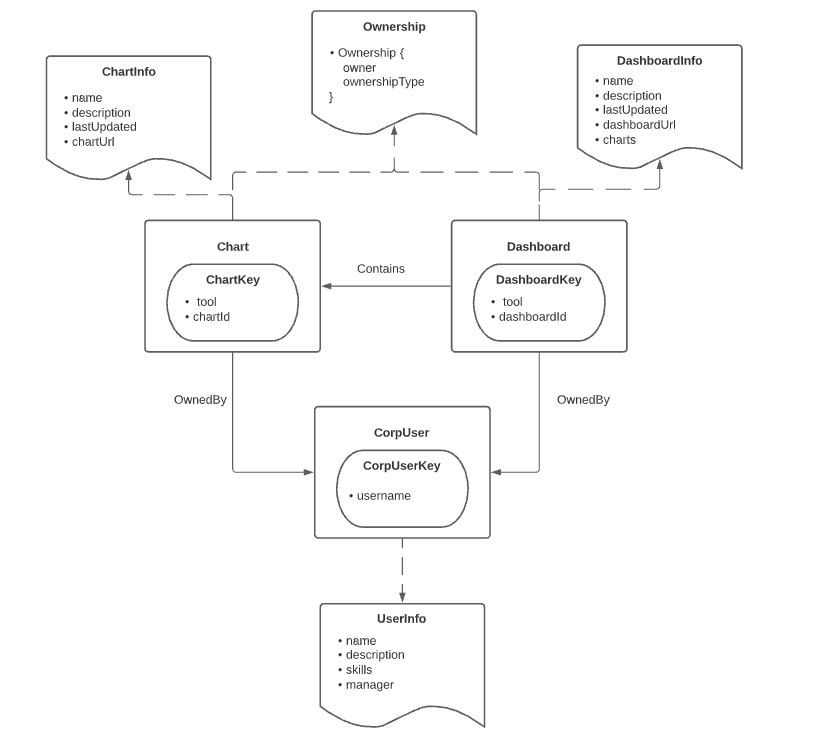 +
+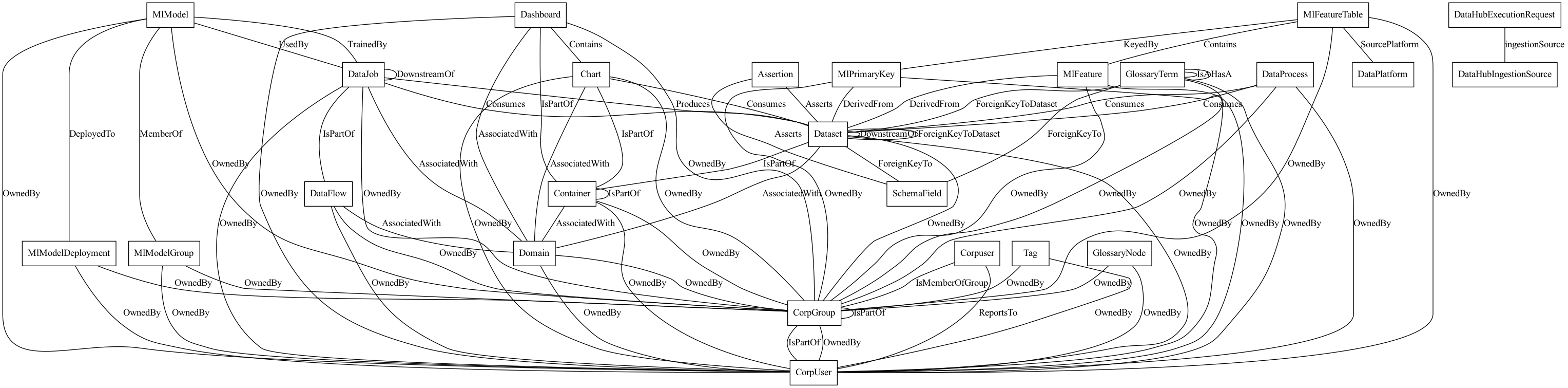 +
+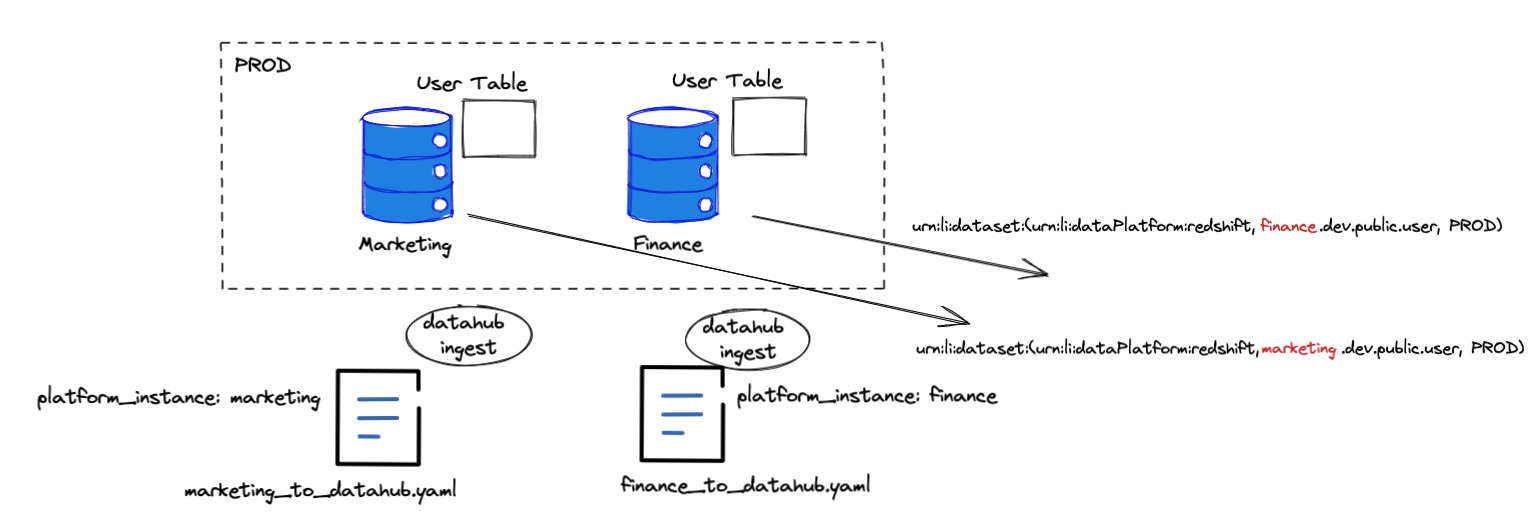 +
+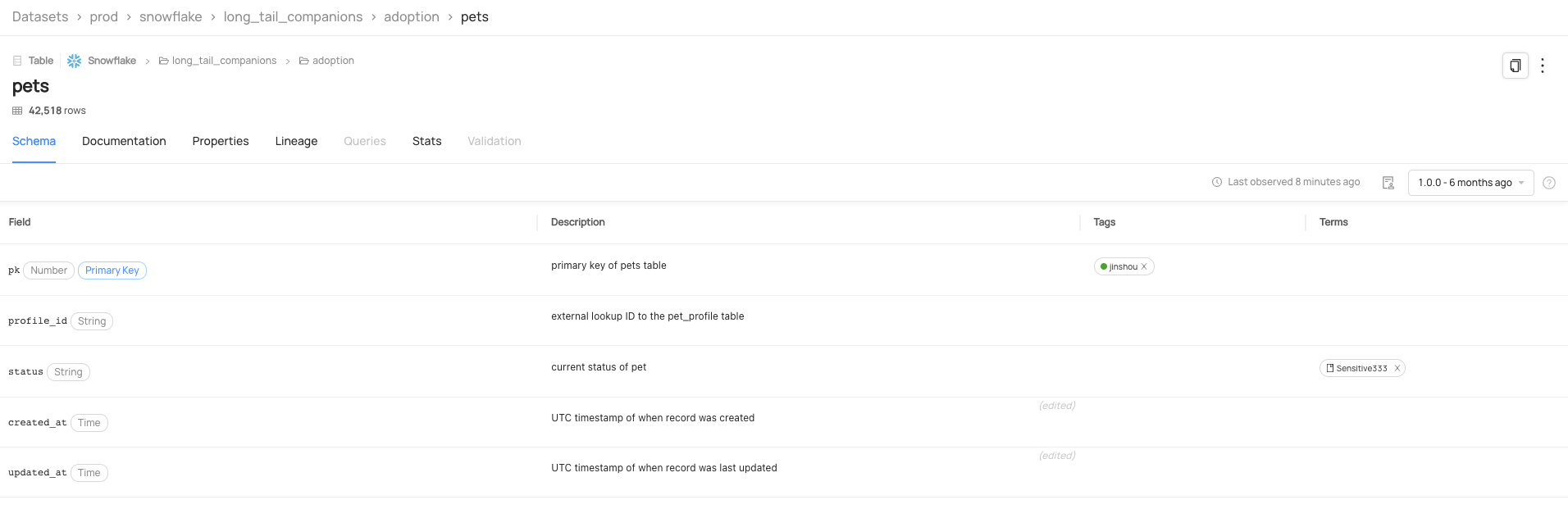 +
+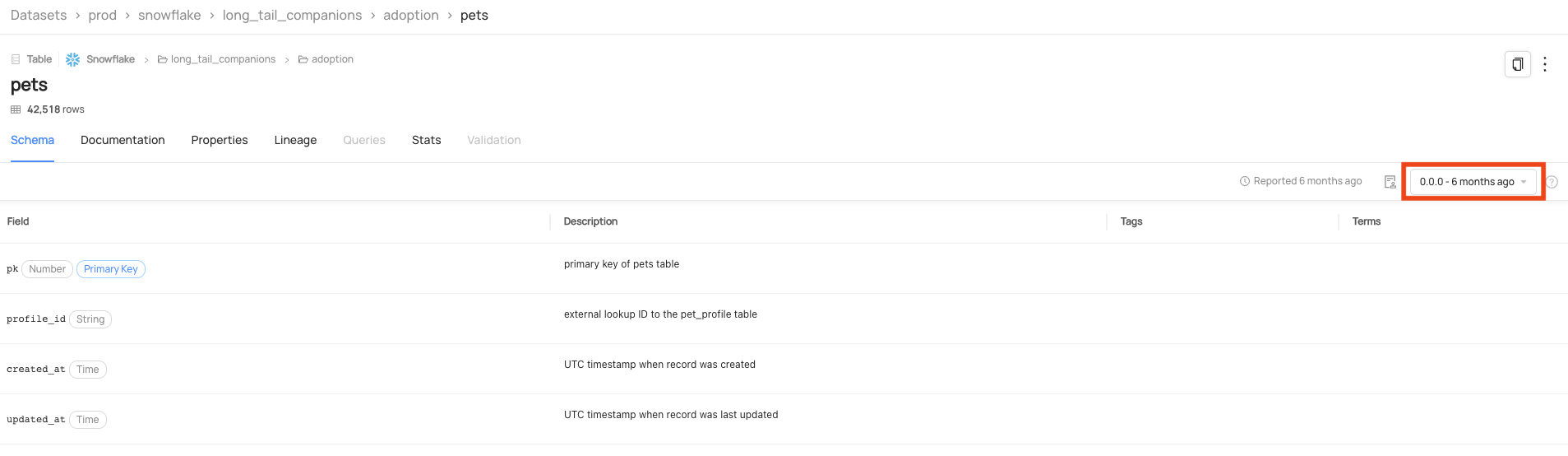 +
+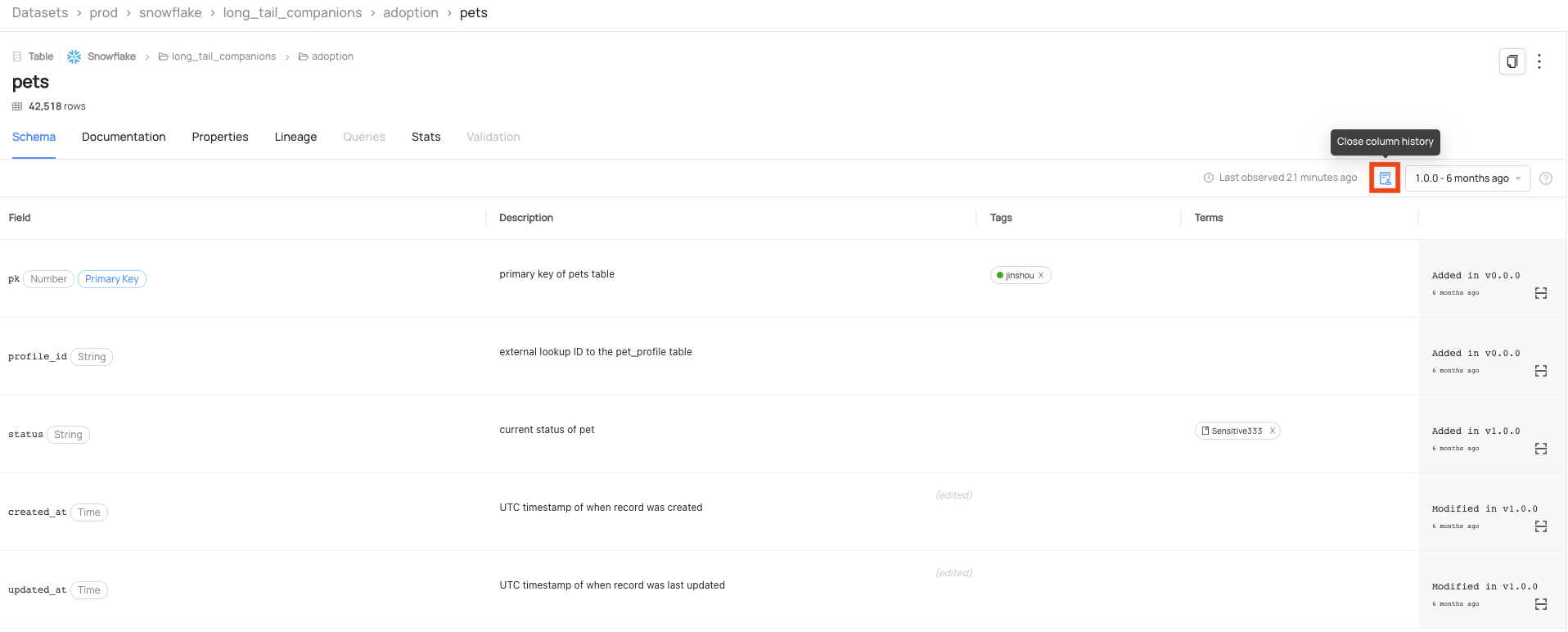 +
+ +
+ 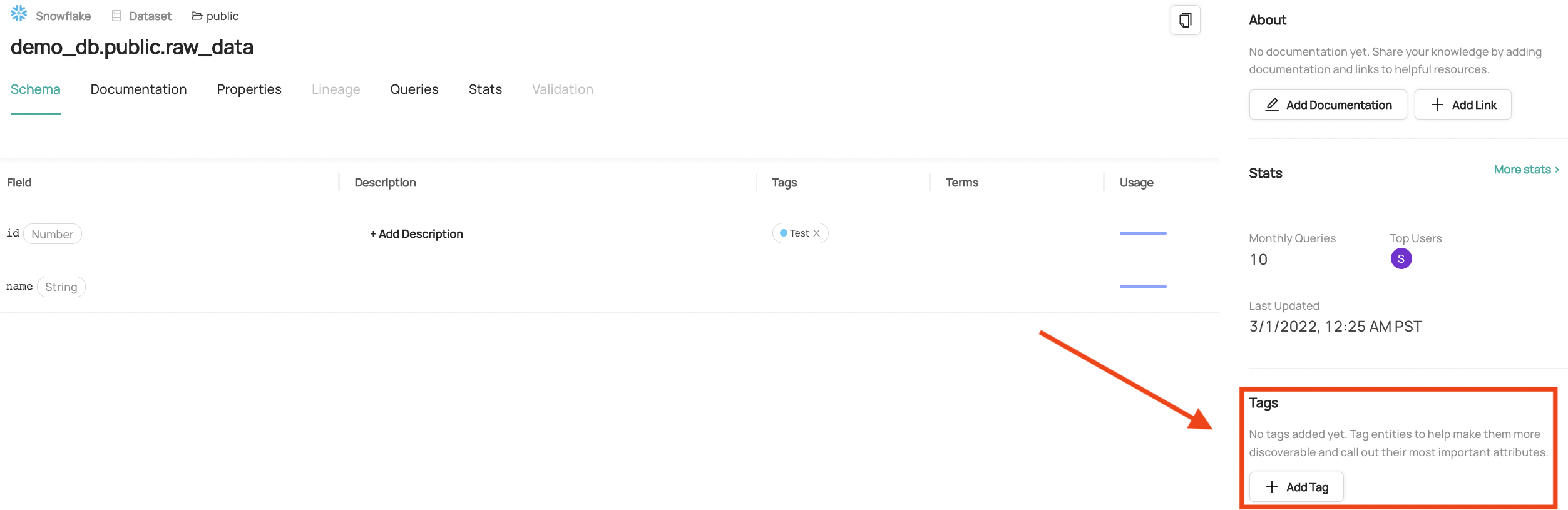
 +
+ 
 +
+ 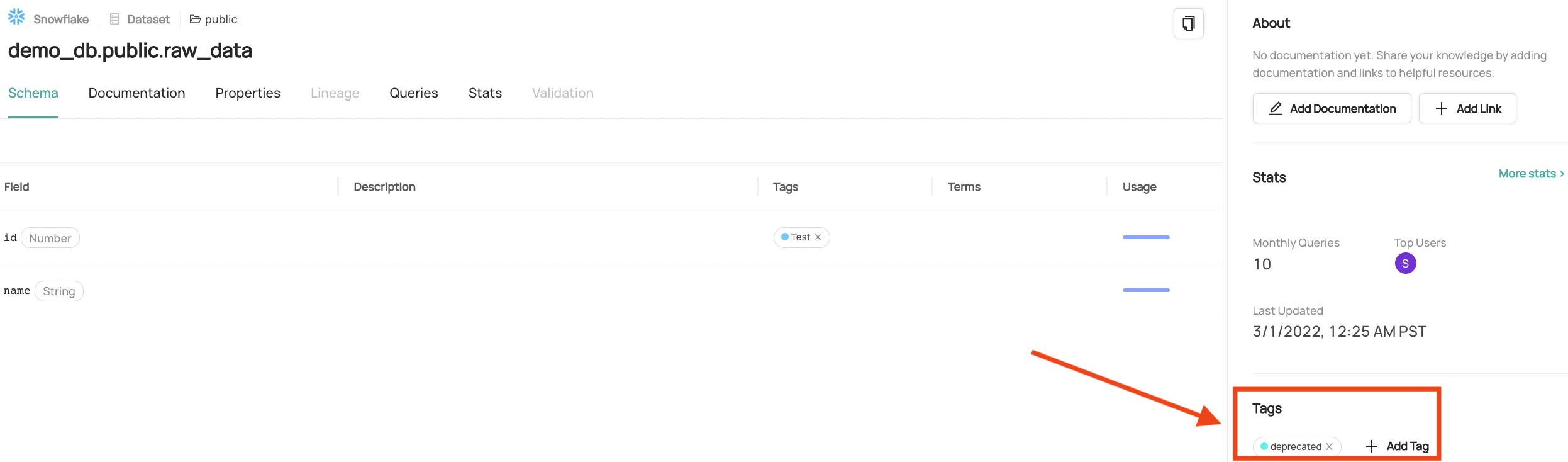
 +
+ 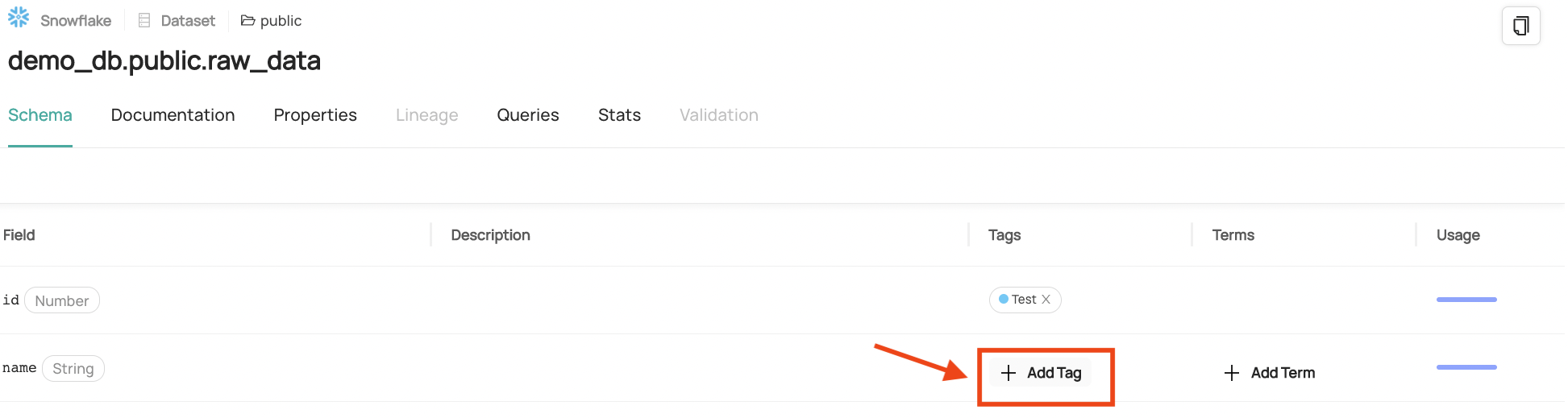
 +
+ 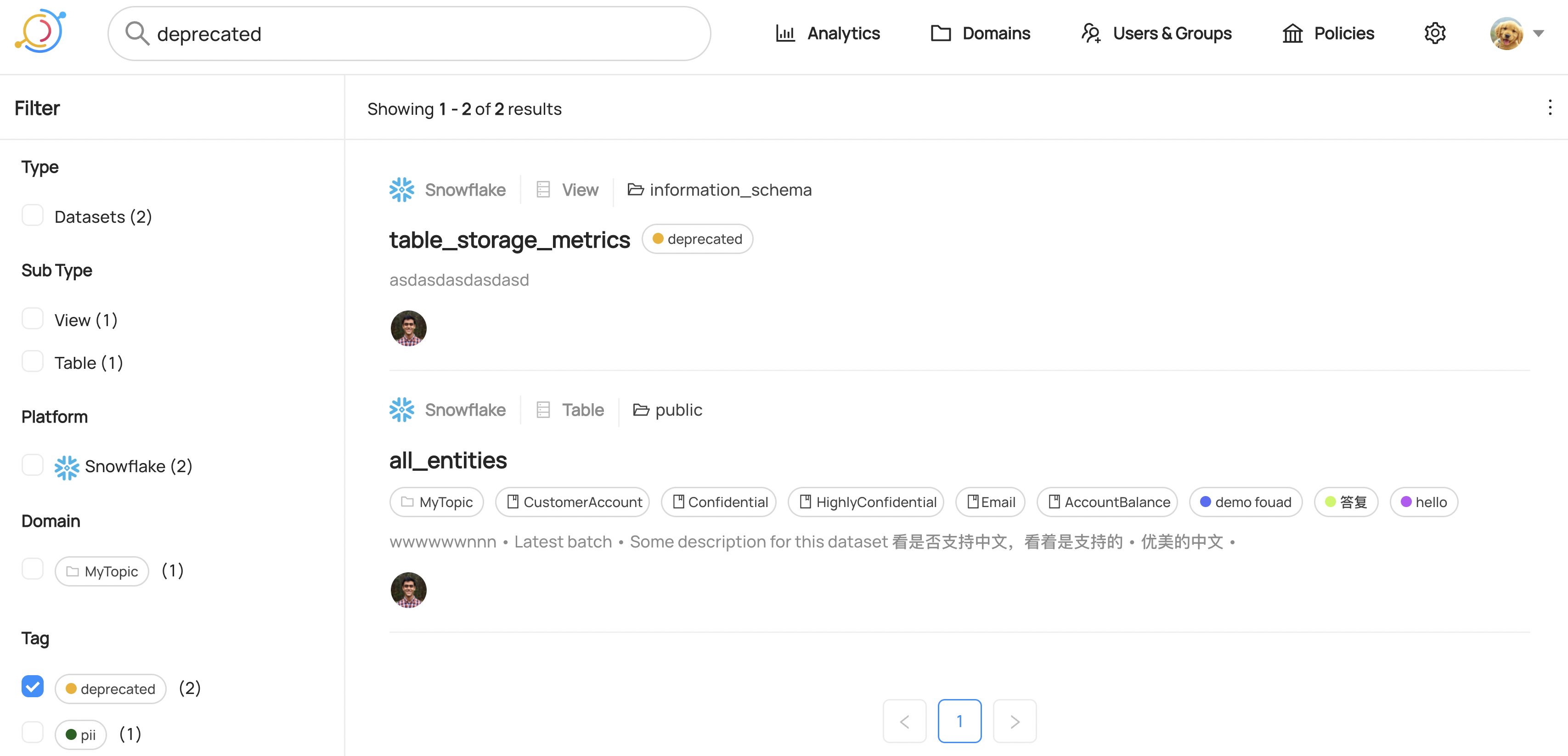
 +
+ +
+ +
+ +
+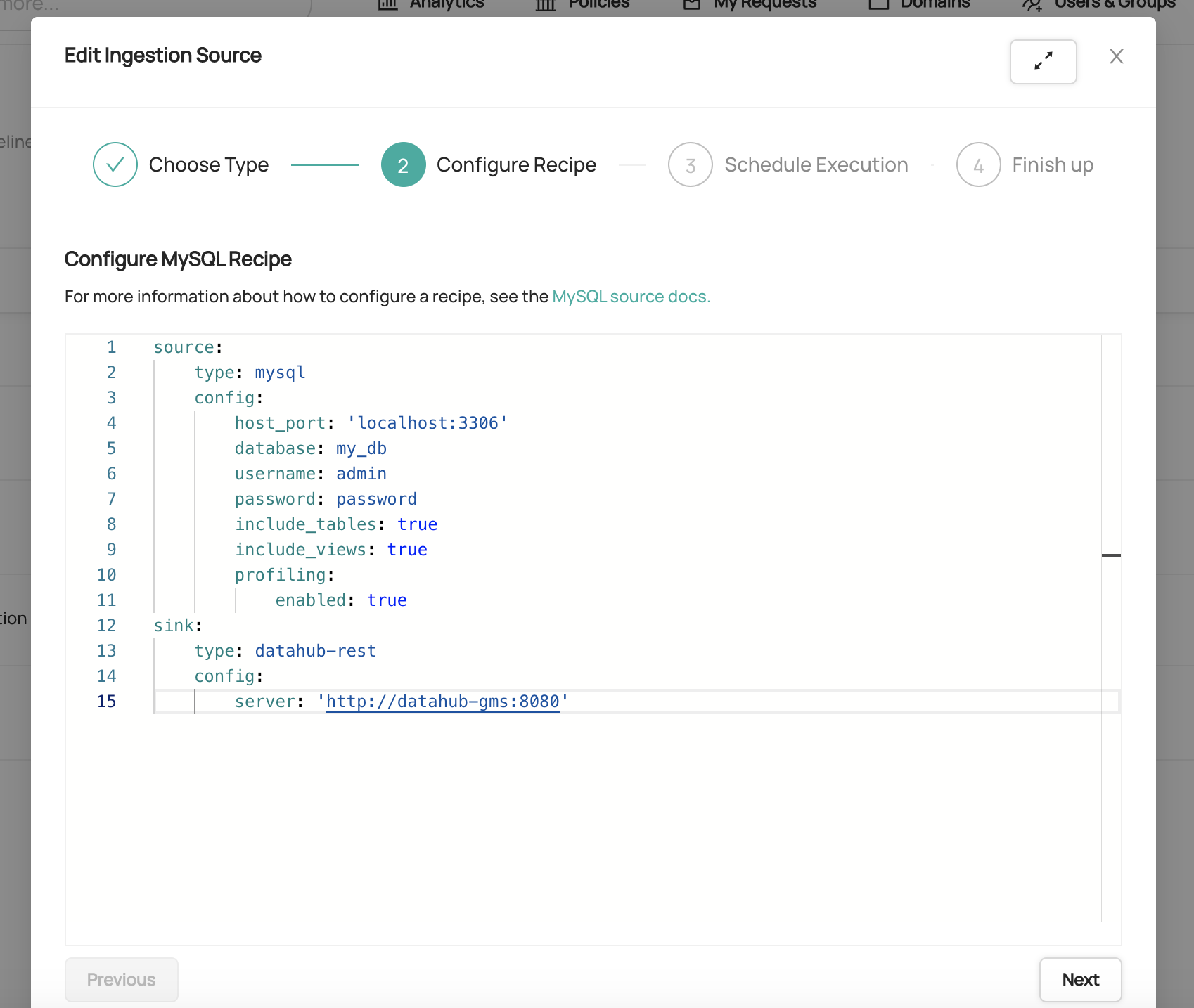 +
+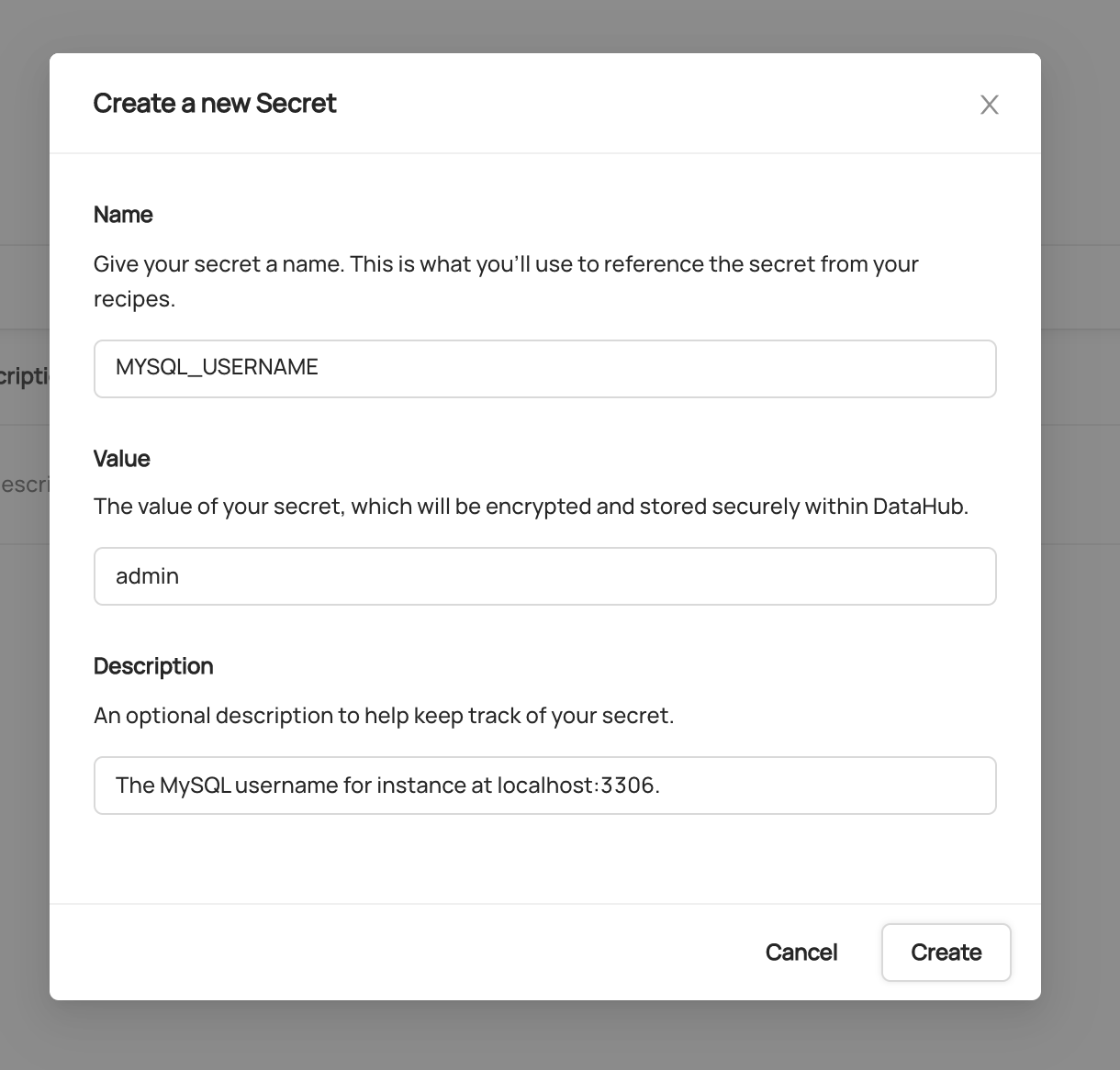 +
+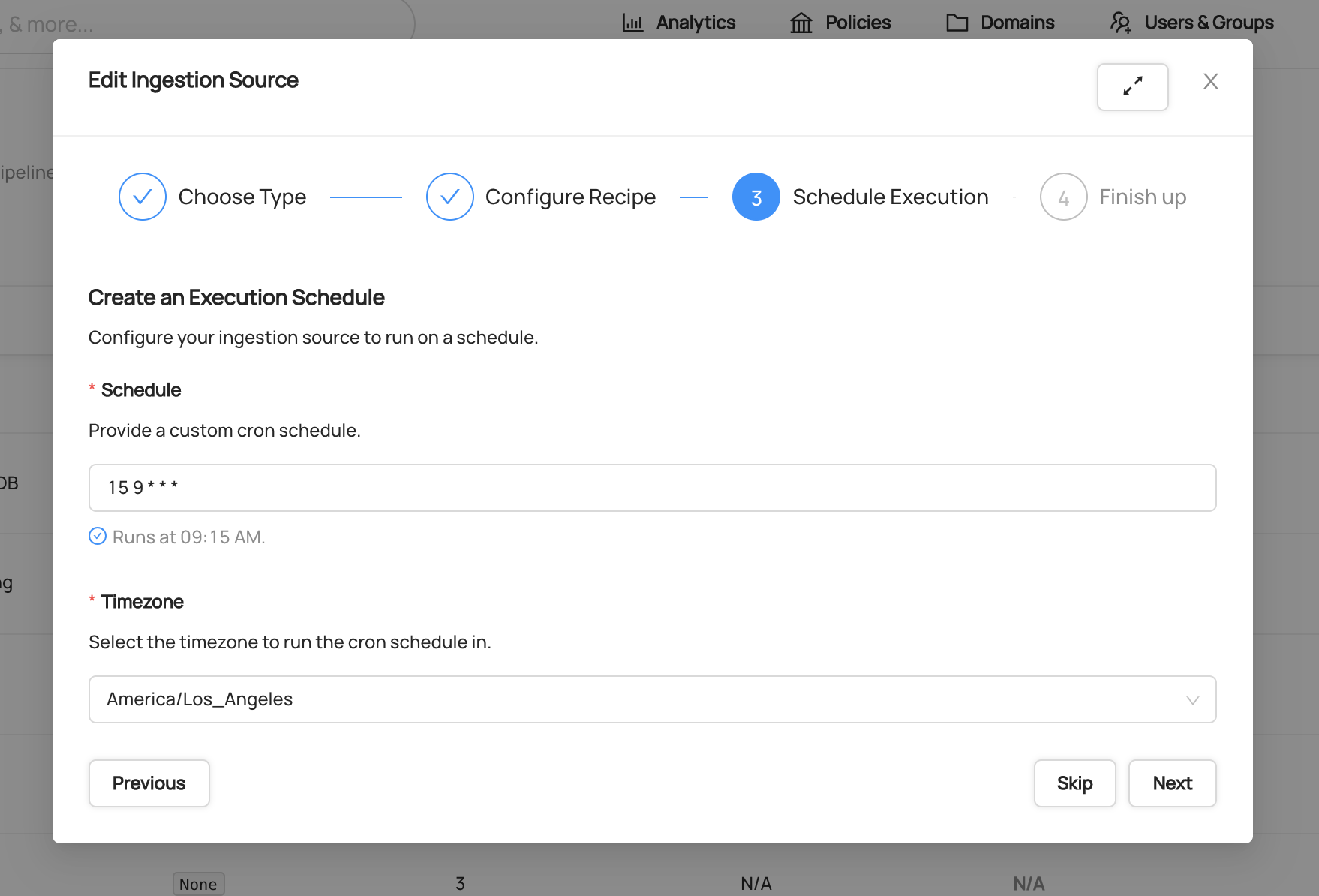 +
+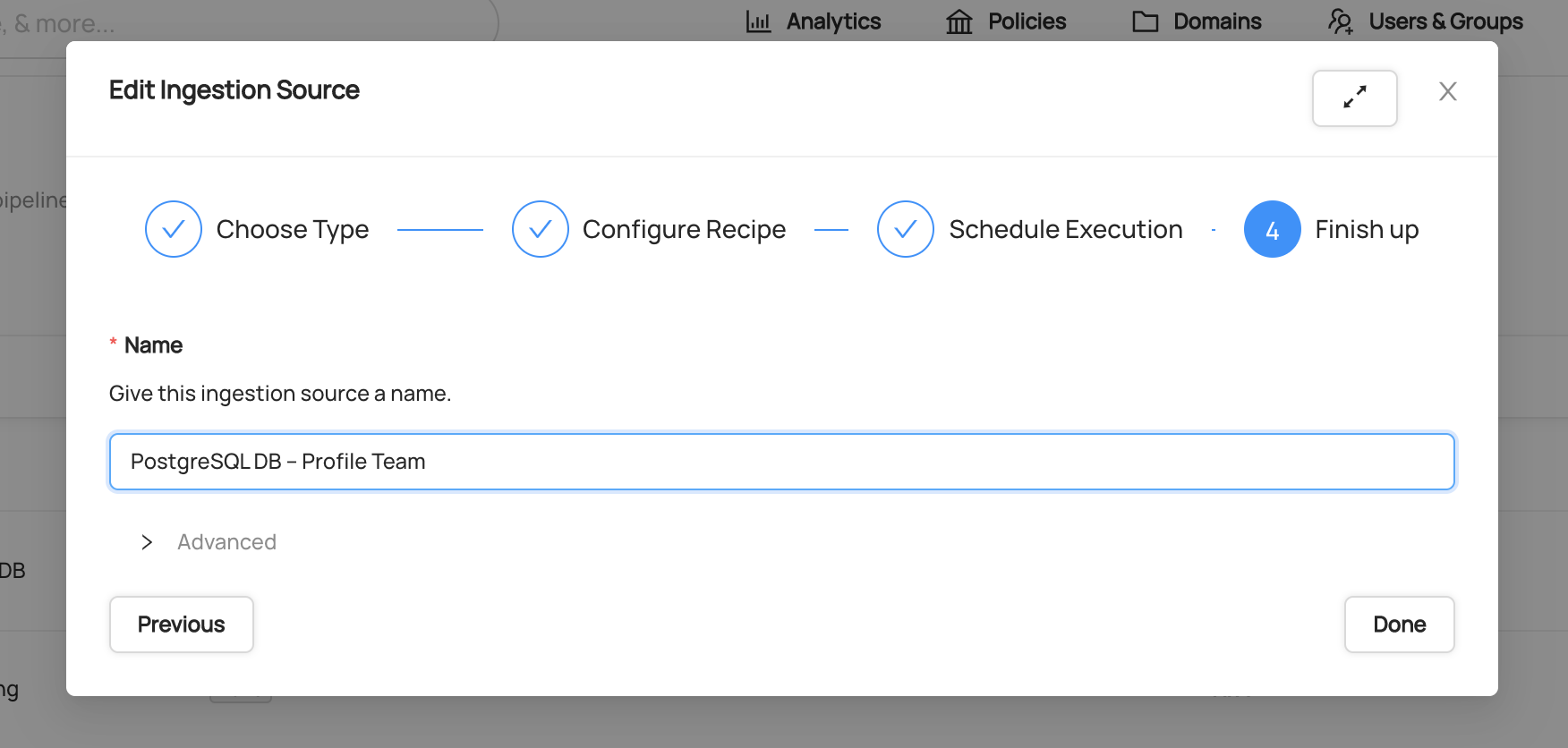 +
+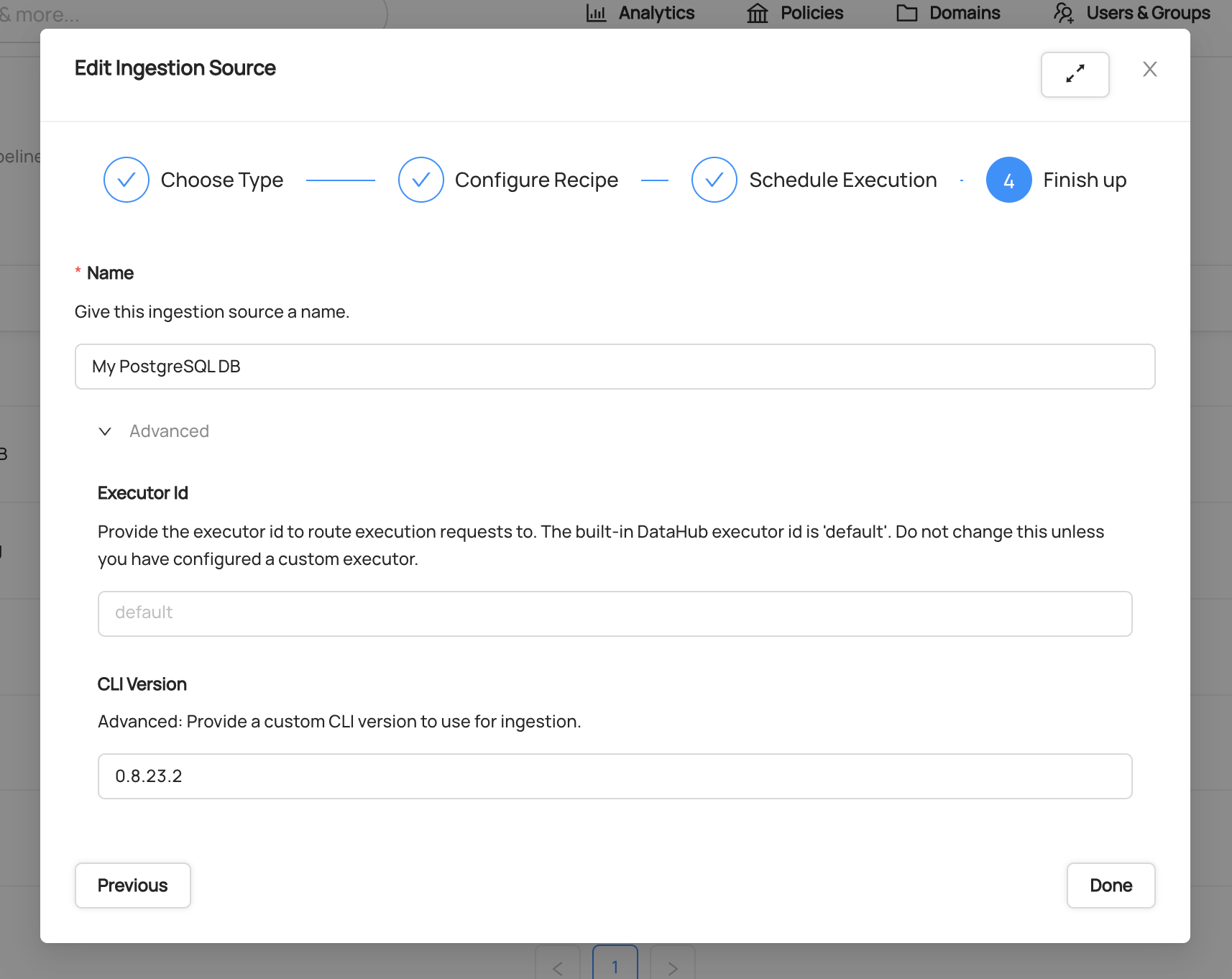 +
+ +
+ +
+ +
+ +
+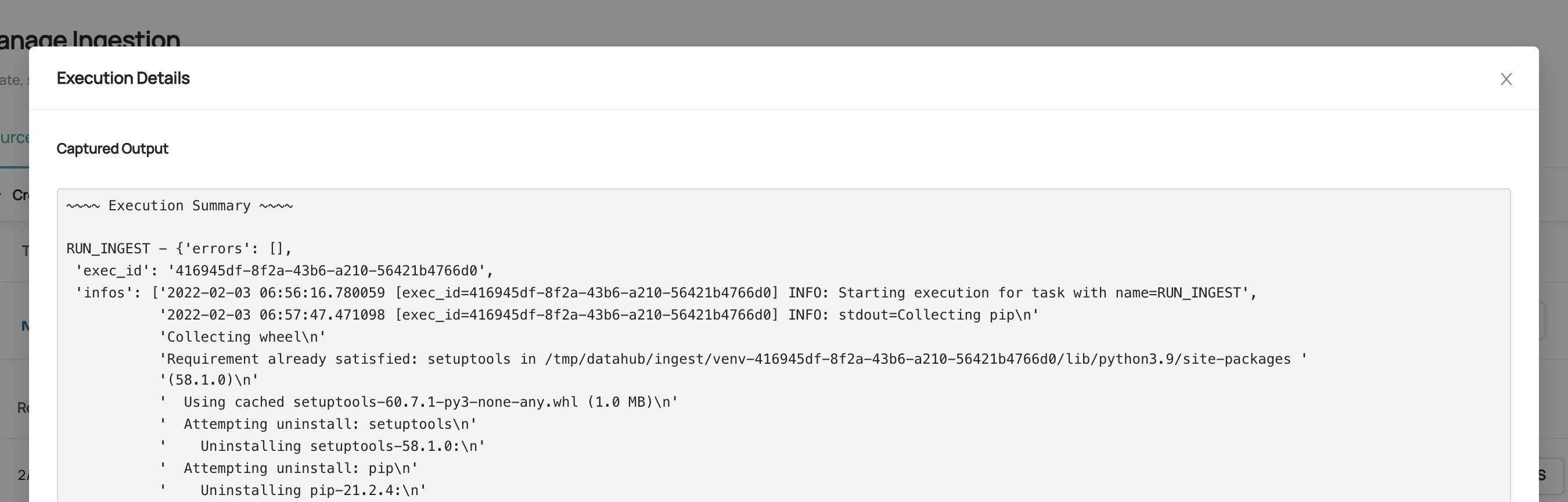 +
+ +
+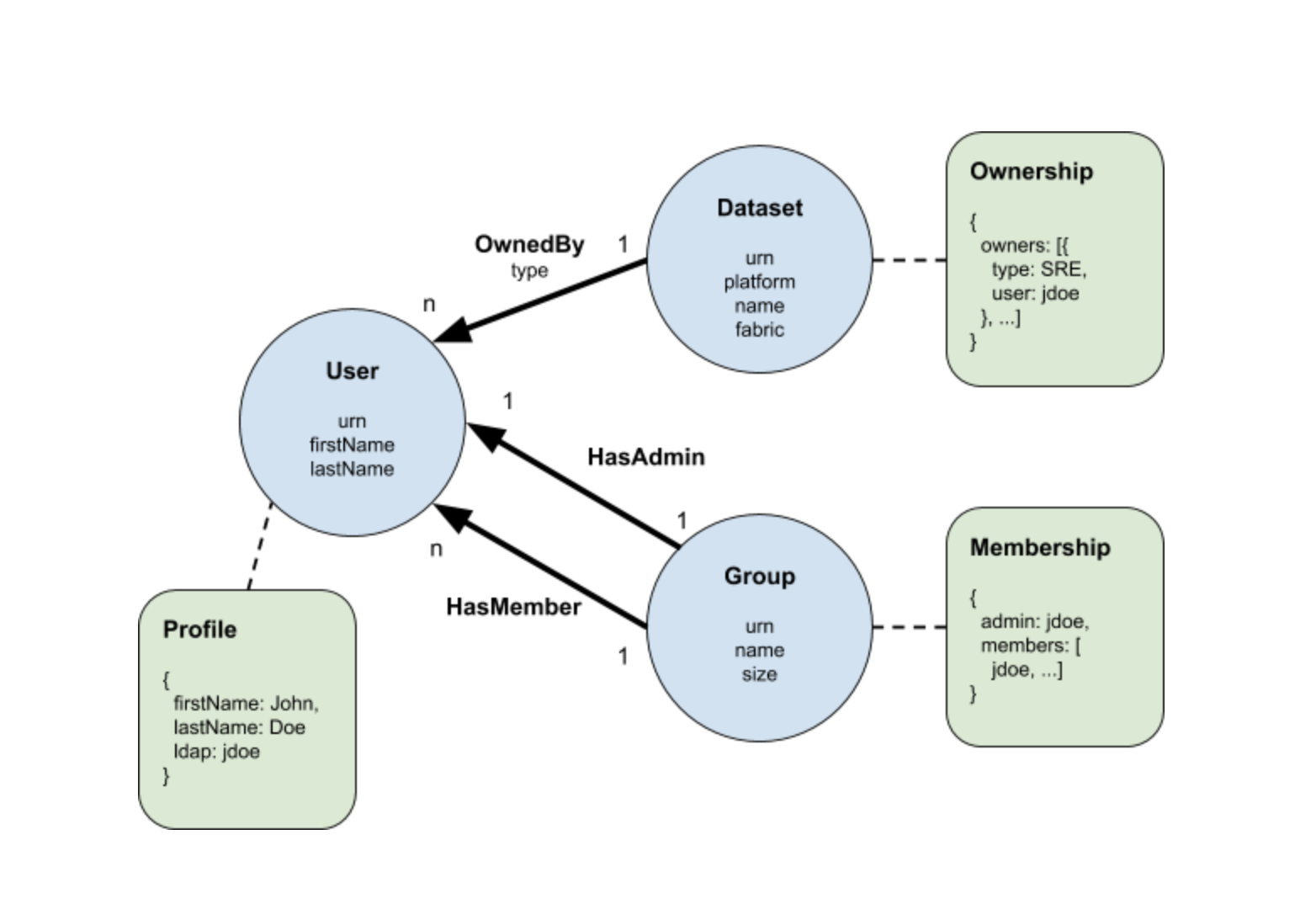 +
+ +
+ +
+