diff --git a/site/docs/concepts/connectors.md b/site/docs/concepts/connectors.md
index c57d20f6b6..02b5a696ce 100644
--- a/site/docs/concepts/connectors.md
+++ b/site/docs/concepts/connectors.md
@@ -54,7 +54,7 @@ or any other public image registry provider.
To interface with a connector, the Flow runtime needs to know:
1. The specific image to use, through an image name such as `ghcr.io/estuary/source-postgres:dev`.
- Notice that the image name also conveys the specific image registry and version tag to use.
+ Notice that the image name also conveys the specific image registry and version tag to use.
2. Endpoint configuration such as a database address and account, with meaning that is specific to the connector.
@@ -153,8 +153,9 @@ user: postgres
Storing configuration in separate files serves two important purposes:
- * Re-use of configuration across multiple captures or materializations
- * The ability to protect sensitive credentials
+
+- Re-use of configuration across multiple captures or materializations
+- The ability to protect sensitive credentials
### Protecting secrets
@@ -208,13 +209,13 @@ host: ENC[AES256_GCM,data:K/clly65pThTg2U=,iv:1bNmY8wjtjHFBcXLR1KFcsNMGVXRl5LGTd
password: ENC[AES256_GCM,data:IDDY+fl0/gAcsH+6tjRdww+G,iv:Ye8st7zJ9wsMRMs6BoAyWlaJeNc9qeNjkkjo6BPp/tE=,tag:EPS9Unkdg4eAFICGujlTfQ==,type:str]
user: ENC[AES256_GCM,data:w+F7MMwQhw==,iv:amHhNCJWAJnJaGujZgjhzVzUZAeSchEpUpBau7RVeCg=,tag:62HguhnnSDqJdKdwYnj7mQ==,type:str]
sops:
- # Some items omitted for brevity:
- gcp_kms:
- - resource_id: projects/your-project-id/locations/us-central1/keyRings/your-ring/cryptoKeys/your-key-name
- created_at: "2022-01-05T15:49:45Z"
- enc: CiQAW8BC2GDYWrJTp3ikVGkTI2XaZc6F4p/d/PCBlczCz8BZiUISSQCnySJKIptagFkIl01uiBQp056c
- lastmodified: "2022-01-05T15:49:45Z"
- version: 3.7.1
+ # Some items omitted for brevity:
+ gcp_kms:
+ - resource_id: projects/your-project-id/locations/us-central1/keyRings/your-ring/cryptoKeys/your-key-name
+ created_at: "2022-01-05T15:49:45Z"
+ enc: CiQAW8BC2GDYWrJTp3ikVGkTI2XaZc6F4p/d/PCBlczCz8BZiUISSQCnySJKIptagFkIl01uiBQp056c
+ lastmodified: "2022-01-05T15:49:45Z"
+ version: 3.7.1
```
You then use this `config.yaml` within your Flow specification.
@@ -235,6 +236,7 @@ which is:
```
flow-258@helpful-kingdom-273219.iam.gserviceaccount.com
```
+
:::
#### Example: Protect portions of a configuration
@@ -259,21 +261,21 @@ Next, encrypt only values which have that suffix:
$ sops --encrypt --in-place --encrypted-suffix "_sops" --gcp-kms projects/your-project-id/locations/us-central1/keyRings/your-ring/cryptoKeys/your-key-name config.yaml
```
-`sops` re-writes the file, wrapping only values having a "_sops" suffix and adding its `sops` metadata section:
+`sops` re-writes the file, wrapping only values having a "\_sops" suffix and adding its `sops` metadata section:
```yaml title="config.yaml"
host: my.hostname
password_sops: ENC[AES256_GCM,data:dlfidMrHfDxN//nWQTPCsjoG,iv:DHQ5dXhyOOSKI6ZIzcUM67R6DD/2MSE4LENRgOt6GPY=,tag:FNs2pTlzYlagvz7vP/YcIQ==,type:str]
user: my-user
sops:
- # Some items omitted for brevity:
- encrypted_suffix: _sops
- gcp_kms:
- - resource_id: projects/your-project-id/locations/us-central1/keyRings/your-ring/cryptoKeys/your-key-name
- created_at: "2022-01-05T16:06:36Z"
- enc: CiQAW8BC2Au779CGdMFUjWPhNleCTAj9rL949sBvPQ6eyAC3EdESSQCnySJKD3eWX8XrtrgHqx327
- lastmodified: "2022-01-05T16:06:37Z"
- version: 3.7.1
+ # Some items omitted for brevity:
+ encrypted_suffix: _sops
+ gcp_kms:
+ - resource_id: projects/your-project-id/locations/us-central1/keyRings/your-ring/cryptoKeys/your-key-name
+ created_at: "2022-01-05T16:06:36Z"
+ enc: CiQAW8BC2Au779CGdMFUjWPhNleCTAj9rL949sBvPQ6eyAC3EdESSQCnySJKD3eWX8XrtrgHqx327
+ lastmodified: "2022-01-05T16:06:37Z"
+ version: 3.7.1
```
You then use this `config.yaml` within your Flow specification.
@@ -286,7 +288,14 @@ In some cases, your source or destination endpoint may be within a secure networ
to allow direct access to its port due to your organization's security policy.
:::tip
-If permitted by your organization, a quicker solution is to whitelist the Estuary IP address, `34.121.207.128`.
+If permitted by your organization, a quicker solution is to whitelist the Estuary IP addresses:
+
+```
+34.121.207.128
+35.226.75.135
+34.68.62.148
+```
+
For help completing this task on different cloud hosting platforms,
see the documentation for the [connector](../reference/Connectors/README.md) you're using.
:::
@@ -352,10 +361,10 @@ Users are empowered to write their own connectors for esoteric systems not alrea
Furthermore, implementing a Docker-based community specification brings other important qualities to Estuary connectors:
-* Cross-platform interoperability between Flow, Airbyte, and any other platform that supports the protocol
-* The abilities to write connectors in any language and run them on any machine
-* Built-in solutions for version management (through image tags) and distribution
-* The ability to integrate connectors from different sources at will, without the centralized control of a single company, thanks to container image registries
+- Cross-platform interoperability between Flow, Airbyte, and any other platform that supports the protocol
+- The abilities to write connectors in any language and run them on any machine
+- Built-in solutions for version management (through image tags) and distribution
+- The ability to integrate connectors from different sources at will, without the centralized control of a single company, thanks to container image registries
:::info
In order to be reflected in the Flow web app and used on the managed Flow platform,
diff --git a/site/docs/getting-started/tutorials/real-time-cdc-with-mongodb.md b/site/docs/getting-started/tutorials/real-time-cdc-with-mongodb.md
index 2b5f6b49cb..926d20a753 100644
--- a/site/docs/getting-started/tutorials/real-time-cdc-with-mongodb.md
+++ b/site/docs/getting-started/tutorials/real-time-cdc-with-mongodb.md
@@ -3,6 +3,7 @@ id: real_time_cdc_with_mongodb
title: Real-time CDC with MongoDB
sidebar_position: 2
---
+
import ReactPlayer from "react-player"
@@ -33,7 +34,6 @@ This stream of data is invaluable for keeping downstream systems synchronized an
Optionally, if you are interested in the intricacies of change data capture, head over to [this](https://estuary.dev/cdc-done-correctly/) article, where we explain the theory behind it - this is not a requirement for this tutorial, so if you want to dive in head first, keep on reading!
-
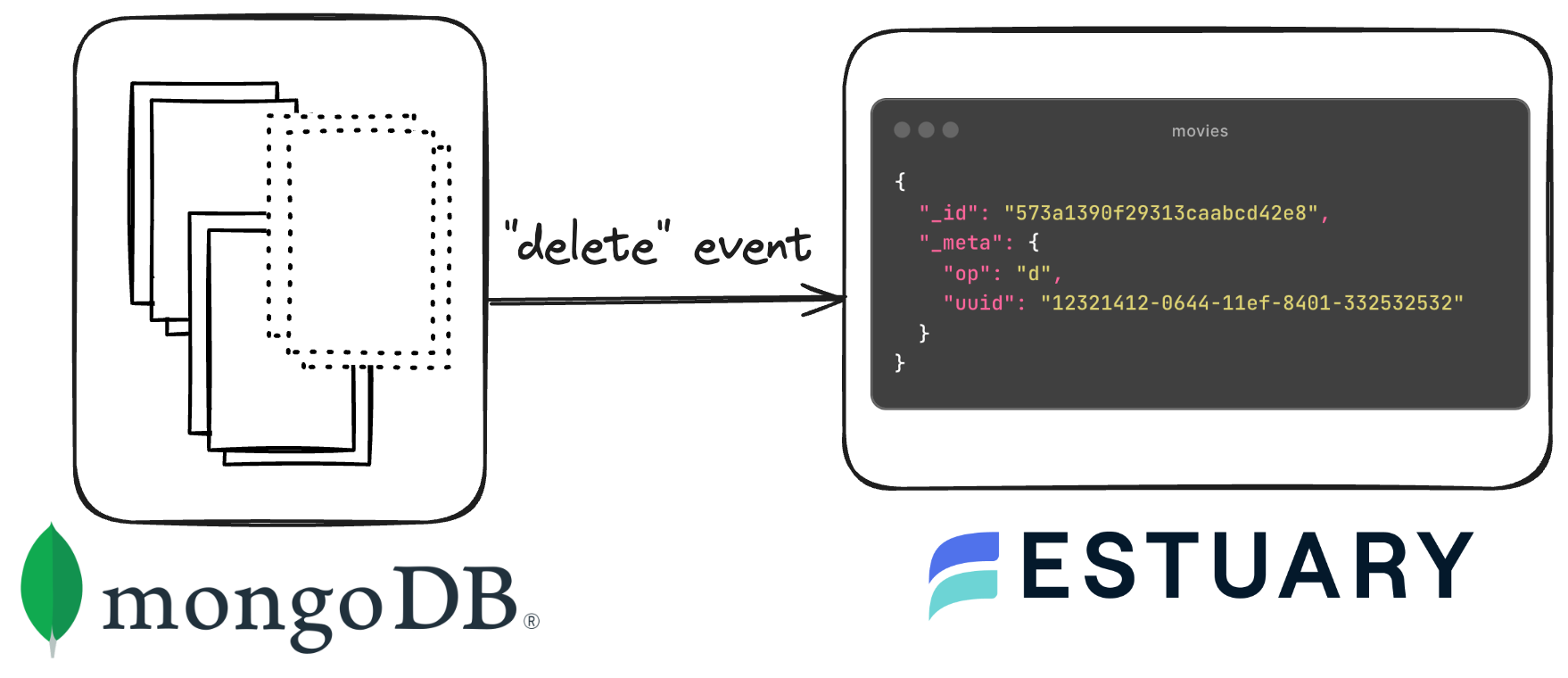
## Understanding Change Events in MongoDB
Change events in MongoDB are notifications triggered by modifications to the database's data, configuration, or structure through a mechanism called [change streams](https://www.mongodb.com/docs/manual/changeStreams/).
@@ -59,7 +59,6 @@ MongoDB supports various types of change events, each catering to different aspe
-
## Introduction to Estuary Flow
Estuary is the best tool for integrating CDC streams from MongoDB. Here are a few reasons why:
@@ -78,7 +77,6 @@ Estuary is the best tool for integrating CDC streams from MongoDB. Here are a fe
Time to build a real-time CDC pipeline!
-
## Prerequisites
To follow along with the tutorial, you’ll need the following:
@@ -87,17 +85,14 @@ To follow along with the tutorial, you’ll need the following:
- A MongoDB Atlas cluster: This tutorial uses Atlas as the source database, but Estuary supports other types of MongoDB deployments as well.
-
## Setting up MongoDB
To prepare MongoDB for Estuary Flow, you need to ensure the following prerequisites are met:
-
### Credentials
Obtain the necessary credentials for connecting to your MongoDB instance and database. This includes credentials for authentication purposes, typically a username and password.
-
### Read Access
Ensure that you have read access to the MongoDB database(s) from which you intend to capture data. MongoDB utilizes Role-Based Access Control (RBAC), so make sure your user account has the appropriate permissions to read data.
@@ -106,13 +101,11 @@ Ensure that you have read access to the MongoDB database(s) from which you inten
In MongoDB Atlas, any of the built-in Roles will work for the tutorial, but Flow needs at least read permissions over the data you wish to capture if you wish to set up more granular, restricted permissions.
-
### Configuration Considerations
1. If you haven't already, make sure you deploy a Replica Set-type MongoDB cluster. **Change streams** require a replica set in order to work. A replica set is a group of MongoDB deployments that maintain the same data set. If you are working following along with a fresh MongoDB Atlas project, you shouldn’t need to configure anything manually for this, as the default free-tier instance is a cluster of 3 replicas. To learn more about replica sets, see the Replication Introduction in the [MongoDB manual](https://www.mongodb.com/docs/manual/replication/).
-2. Ensure that Estuary's IP (`34.121.207.128`) is whitelisted to allow access. We’ll show you how to do this in the next section.
-
+2. Ensure that Estuary's IP addresses (`34.121.207.128, 35.226.75.135, 34.68.62.148`) are whitelisted to allow access. We’ll show you how to do this in the next section.
### Configure MongoDB
@@ -120,7 +113,7 @@ Let’s start by provisioning our database. As you can see, for this tutorial, y
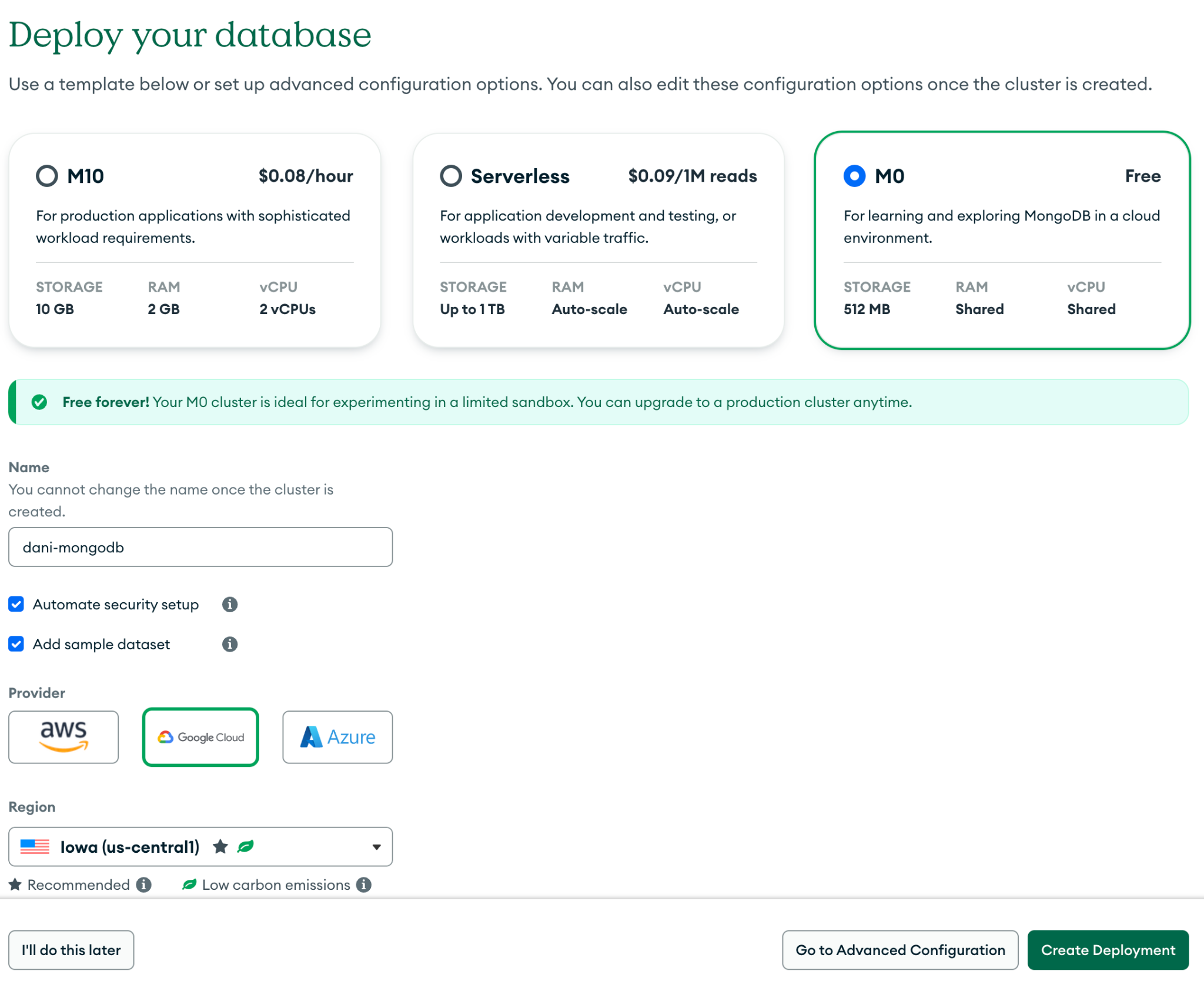
-After the cluster has finished provisioning, we’ll need to make sure that Estuary Flow is able to connect to the database. For this, the only requirement with MongoDB Atlas is allowlisting the public IP used by Flow, `34.121.207.128`.
+After the cluster has finished provisioning, we’ll need to make sure that Estuary Flow is able to connect to the database. For this, the only requirement with MongoDB Atlas is allowlisting the public IP's used by Flow, `34.121.207.128, 35.226.75.135, 34.68.62.148`.
Navigate to the “Network Access” page using the left hand sidebar, and using the “Add new IP address” button, create the list entry which enables the communication between the two services.
@@ -135,7 +128,6 @@ Next, find your connection string by navigating to the `mongosh` setup page by c
Copy the connection string and head over to your [Estuary Flow dashboard](https://dashboard.estuary.dev/) to continue the tutorial.
-
## Setting up Estuary Flow
On the dashboard, create a new capture by navigating to the “Sources” menu using the sidebar, then pressing the “New Capture” button. In the list of available connectors, search for “MongoDB”, then press “Capture”.
@@ -144,7 +136,6 @@ On the dashboard, create a new capture by navigating to the “Sources” menu u
Pressing this button will bring you to the connector configuration page, where you’ll be able to provision your fully managed real-time Data Flow.
-
### MongoDB Capture Configuration
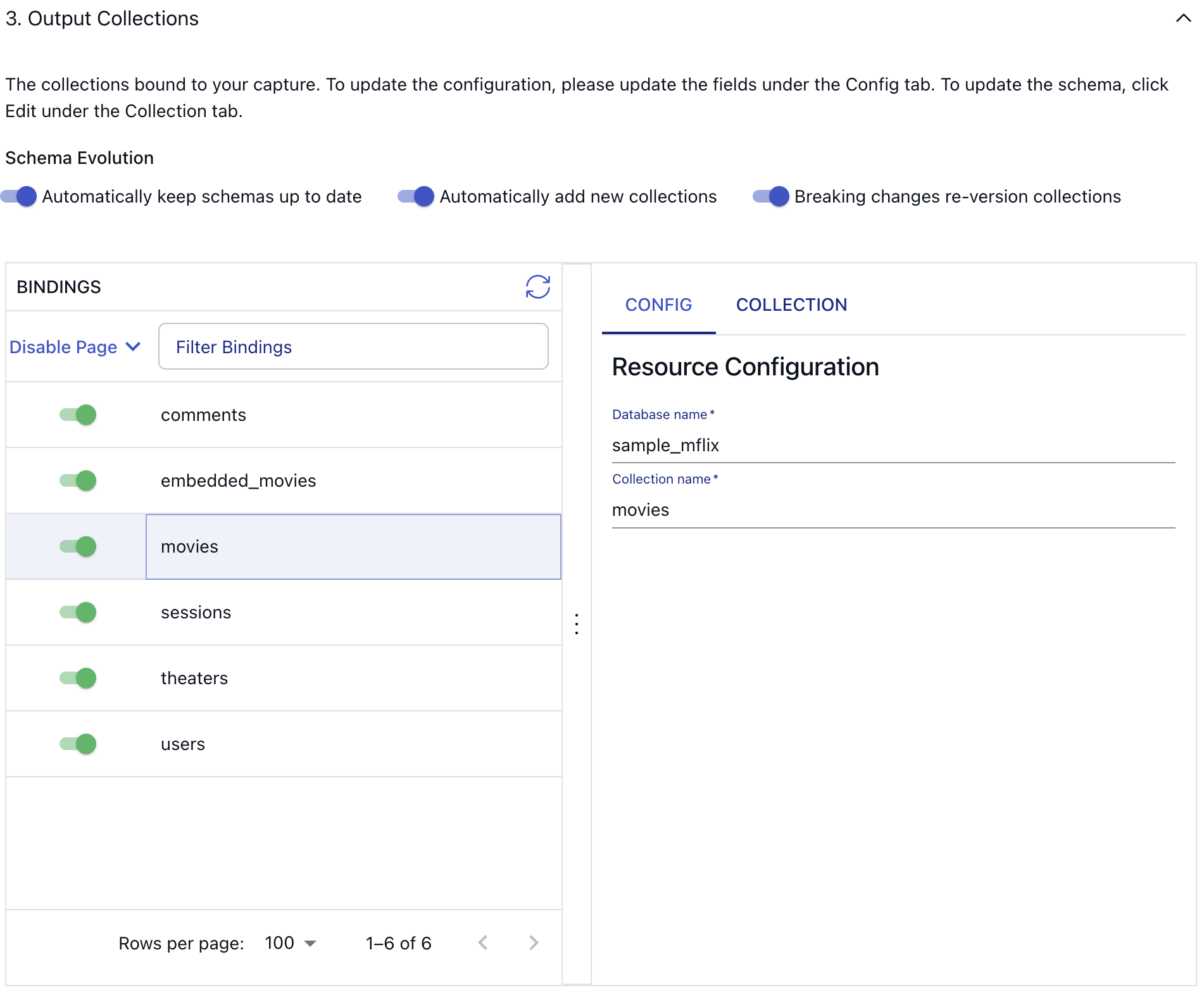
As a first step, in the Capture Details section, name your capture and optionally add a description for it.
@@ -163,7 +154,6 @@ After you press the blue “Next” button in the top right corner, Flow will au
-
### Documents and Collections
Before we initialize the connector, let’s talk a little bit about how incoming data is represented in Flow.
@@ -198,7 +188,6 @@ This specification uses separate [read and write schemas](https://docs.estuary.d
MongoDB documents have a mandatory `_id` field that is used as the key of the collection. But that is essentially the only requirement. You can't know what other fields may exist on MongoDB documents until you've read them. On the UI, for this reason, only three fields are visible initially in the collection schema tab.
-
### Automating schema evolution
In addition to selecting the collections for capture, this interface provides access to three settings that govern schema evolution. In a NoSQL database environment like MongoDB, schema alterations are frequent occurrences. Manually synchronizing source and destination schemas can end up being a lot of maintenance. To help with this, Estuary introduces a more [sophisticated schema evolution strategy](https://docs.estuary.dev/concepts/advanced/evolutions/#what-do-schema-evolutions-do).
@@ -215,7 +204,6 @@ Schema evolutions serve to prevent errors stemming from discrepancies between sp
In these scenarios, the names of destination resources remain unaltered. For instance, a materialization to Postgres would drop and re-establish the affected tables with their original names.
-
### Publishing the Capture
To finalize the connector configuration and kick it off, press the “Save and Publish” button. Flow will test, save and publish your capture. You’ll see a similar screen if everything went well or if there were any issues setting up the connector, you’ll see detailed error messages instead.
@@ -246,118 +234,102 @@ Let’s take a look at the `movies` collection to see what details Flow can tell
You can also check out the generated specification, which is the Flow’s behind-the-scenes declarative way of representing the Collection resource.
For the `movies` collection, this is what it looks like:
+
```json
{
- "writeSchema": {
- "type": "object",
- "required": [
- "_id"
- ],
- "properties": {
- "_id": {
- "type": "string"
- },
- "_meta": {
- "$schema": "http://json-schema.org/draft/2020-12/schema",
- "properties": {
- "op": {
- "type": "string",
- "enum": [
- "c",
- "u",
- "d"
- ],
- "title": "Change Operation",
- "description": "Change operation type: 'c' Create/Insert 'u' Update 'd' Delete."
- }
- },
- "type": "object"
- }
- },
- "x-infer-schema": true
- },
- "readSchema": {
- "allOf": [
- {
- "$ref": "flow://write-schema"
- },
- {
- "$ref": "flow://inferred-schema"
- }
- ]
- },
- "key": [
- "/_id"
- ]
+ "writeSchema": {
+ "type": "object",
+ "required": ["_id"],
+ "properties": {
+ "_id": {
+ "type": "string"
+ },
+ "_meta": {
+ "$schema": "http://json-schema.org/draft/2020-12/schema",
+ "properties": {
+ "op": {
+ "type": "string",
+ "enum": ["c", "u", "d"],
+ "title": "Change Operation",
+ "description": "Change operation type: 'c' Create/Insert 'u' Update 'd' Delete."
+ }
+ },
+ "type": "object"
+ }
+ },
+ "x-infer-schema": true
+ },
+ "readSchema": {
+ "allOf": [
+ {
+ "$ref": "flow://write-schema"
+ },
+ {
+ "$ref": "flow://inferred-schema"
+ }
+ ]
+ },
+ "key": ["/_id"]
}
```
You can see the flexible `readSchema` configuration in action we mentioned above.
-You can use the preview window on the collections “Overview” page to quickly test how change events propagate from MongoDB. Head over to the MongoDB Atlas UI and insert a new document into the `movies` collection.
+You can use the preview window on the collections “Overview” page to quickly test how change events propagate from MongoDB. Head over to the MongoDB Atlas UI and insert a new document into the `movies` collection.
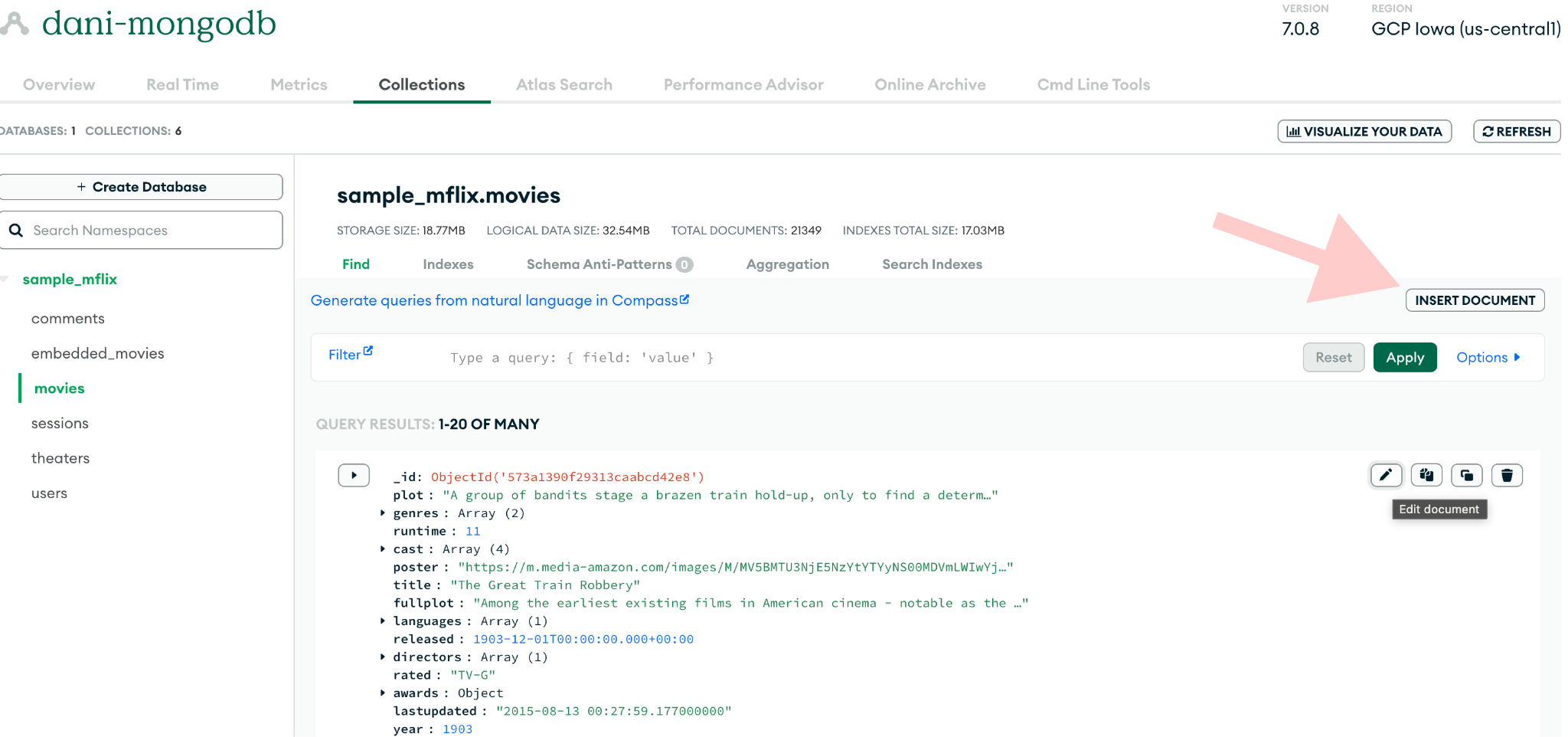
Here’s a sample JSON (describing non-existent but very intriguing movie) you can copy paste into the pop-up modal to spare you the trouble.
+
```json
{
- "title":"Dataflow",
- "fullplot":"In a near-future world driven by data, a team of maverick engineers and programmers set out to revolutionize the way information is processed and transmitted. As they delve deeper into the complexities of real-time data streaming, they uncover dark secrets and face moral dilemmas that threaten to unravel their ambitious project.", "plot":"A team of brilliant engineers embark on a groundbreaking project to develop a real-time data streaming platform, but they soon discover unexpected challenges and threats lurking in the digital realm.",
- "genres":[
- "Drama",
- "Sci-Fi",
- "Thriller"
- ],
- "runtime":135,
- "cast":[
- "Emily Blunt",
- "Michael B. Jordan",
- "Idris Elba",
- "Zendaya",
- "Oscar Isaac"
- ],
- "poster":"https://example.com/posters/real-time-data-streaming.jpg",
- "languages":[
- "English"
- ],
- "released":1739808000000,
- "directors":[
- "Christopher Nolan"
- ],
- "rated":"PG-13",
- "awards":{
- "wins":3,
- "nominations":8,
- "text":"3 wins, 8 nominations"
- },
- "lastupdated":"2024-04-30 10:15:00.000000",
- "year":2024,
- "imdb":{
- "rating":8.5,
- "votes":15234,
- "id":1001
- },
- "countries":[
- "USA",
- "United Kingdom"
- ],
- "type":"movie",
- "tomatoes":{
- "viewer":{
- "rating":4.2,
- "numReviews":3856,
- "meter":82
- },
- "fresh":34,
- "critic":{
- "rating":8.0,
- "numReviews":22,
- "meter":91
- },
- "rotten":2,
- "lastUpdated":1739894400000
- },
- "num_mflix_comments":120
+ "title": "Dataflow",
+ "fullplot": "In a near-future world driven by data, a team of maverick engineers and programmers set out to revolutionize the way information is processed and transmitted. As they delve deeper into the complexities of real-time data streaming, they uncover dark secrets and face moral dilemmas that threaten to unravel their ambitious project.",
+ "plot": "A team of brilliant engineers embark on a groundbreaking project to develop a real-time data streaming platform, but they soon discover unexpected challenges and threats lurking in the digital realm.",
+ "genres": ["Drama", "Sci-Fi", "Thriller"],
+ "runtime": 135,
+ "cast": [
+ "Emily Blunt",
+ "Michael B. Jordan",
+ "Idris Elba",
+ "Zendaya",
+ "Oscar Isaac"
+ ],
+ "poster": "https://example.com/posters/real-time-data-streaming.jpg",
+ "languages": ["English"],
+ "released": 1739808000000,
+ "directors": ["Christopher Nolan"],
+ "rated": "PG-13",
+ "awards": {
+ "wins": 3,
+ "nominations": 8,
+ "text": "3 wins, 8 nominations"
+ },
+ "lastupdated": "2024-04-30 10:15:00.000000",
+ "year": 2024,
+ "imdb": {
+ "rating": 8.5,
+ "votes": 15234,
+ "id": 1001
+ },
+ "countries": ["USA", "United Kingdom"],
+ "type": "movie",
+ "tomatoes": {
+ "viewer": {
+ "rating": 4.2,
+ "numReviews": 3856,
+ "meter": 82
+ },
+ "fresh": 34,
+ "critic": {
+ "rating": 8.0,
+ "numReviews": 22,
+ "meter": 91
+ },
+ "rotten": 2,
+ "lastUpdated": 1739894400000
+ },
+ "num_mflix_comments": 120
}
```
@@ -365,7 +337,6 @@ After you insert the document, check out the collection preview on the Flow UI t
-
## Wrapping up
In this tutorial, you set up a MongoDB Change Data Capture (CDC) integration using Estuary Flow. Throughout the process, you learned about the technical nuances of capturing and synchronizing data changes from MongoDB collections in real-time.
@@ -380,15 +351,14 @@ Key takeaways from this tutorial:
- You learned how Flow continuously monitors MongoDB change streams and executes backfilling processes to capture changes accurately, even in the event of interruptions or schema alterations.
-
## Next Steps
-That’s it! You should have everything you need to know to create your own data pipeline for capturing change events from MongoDB!
+That’s it! You should have everything you need to know to create your own data pipeline for capturing change events from MongoDB!
Now try it out on your own CloudSQL database or other sources.
If you want to learn more, make sure you read through the [Estuary documentation](https://docs.estuary.dev/).
-You’ll find instructions on how to use other connectors [here](https://docs.estuary.dev/). There are more tutorials [here](https://docs.estuary.dev/guides/).
+You’ll find instructions on how to use other connectors [here](https://docs.estuary.dev/). There are more tutorials [here](https://docs.estuary.dev/guides/).
Also, don’t forget to join the [Estuary Slack Community](https://estuary-dev.slack.com/ssb/redirect#/shared-invite/email)!
diff --git a/site/docs/guides/connect-network.md b/site/docs/guides/connect-network.md
index 71bf829e54..3f87b769c1 100644
--- a/site/docs/guides/connect-network.md
+++ b/site/docs/guides/connect-network.md
@@ -1,6 +1,7 @@
---
sidebar_position: 8
---
+
# Configure connections with SSH tunneling
Flow connects to certain types of endpoints — generally databases — using their IP address and port.
@@ -9,7 +10,14 @@ You configure this in the `networkTunnel` section of applicable capture or mater
before you can do so, you need a properly configured SSH server on your internal network or cloud hosting platform.
:::tip
-If permitted by your organization, a quicker way to connect to a secure database is to whitelist the Estuary IP address, `34.121.207.128`.
+If permitted by your organization, a quicker way to connect to a secure database is to whitelist the Estuary IP addresses:
+
+```
+34.121.207.128
+35.226.75.135
+34.68.62.148
+```
+
For help completing this task on different cloud hosting platforms,
see the documentation for the [connector](../reference/Connectors/README.md) you're using.
:::
@@ -23,69 +31,73 @@ to add your SSH server to your capture or materialization definition.
## General setup
1. Activate an [SSH implementation on a server](https://www.ssh.com/academy/ssh/server#availability-of-ssh-servers), if you don't have one already.
-Consult the documentation for your server's operating system and/or cloud service provider, as the steps will vary.
-Configure the server to your organization's standards, or reference the [SSH documentation](https://www.ssh.com/academy/ssh/sshd_config) for
-basic configuration options.
+ Consult the documentation for your server's operating system and/or cloud service provider, as the steps will vary.
+ Configure the server to your organization's standards, or reference the [SSH documentation](https://www.ssh.com/academy/ssh/sshd_config) for
+ basic configuration options.
2. Referencing the config files and shell output, collect the following information:
- * The SSH **user**, which will be used to log into the SSH server, for example, `sshuser`. You may choose to create a new
+- The SSH **user**, which will be used to log into the SSH server, for example, `sshuser`. You may choose to create a new
user for this workflow.
- * The **SSH endpoint** for the SSH server, formatted as `ssh://user@hostname[:port]`. This may look like the any of following:
- * `ssh://sshuser@ec2-198-21-98-1.compute-1.amazonaws.com`
- * `ssh://sshuser@198.21.98.1`
- * `ssh://sshuser@198.21.98.1:22`
- :::info Hint
- The [SSH default port is 22](https://www.ssh.com/academy/ssh/port).
- Depending on where your server is hosted, you may not be required to specify a port,
- but we recommend specifying `:22` in all cases to ensure a connection can be made.
- :::
-
+- The **SSH endpoint** for the SSH server, formatted as `ssh://user@hostname[:port]`. This may look like the any of following:
+ - `ssh://sshuser@ec2-198-21-98-1.compute-1.amazonaws.com`
+ - `ssh://sshuser@198.21.98.1`
+ - `ssh://sshuser@198.21.98.1:22`
+ :::info Hint
+ The [SSH default port is 22](https://www.ssh.com/academy/ssh/port).
+ Depending on where your server is hosted, you may not be required to specify a port,
+ but we recommend specifying `:22` in all cases to ensure a connection can be made.
+ :::
3. In the `.ssh` subdirectory of your user home directory,
look for the PEM file that contains the private SSH key. Check that it starts with `-----BEGIN RSA PRIVATE KEY-----`,
which indicates it is an RSA-based file.
- * If no such file exists, generate one using the command:
+ - If no such file exists, generate one using the command:
```console
ssh-keygen -m PEM -t rsa
- ```
- * If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+ ```
+ - If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
```console
ssh-keygen -p -N "" -m pem -f /path/to/key
- ```
+ ```
- Taken together, these configuration details would allow you to log into the SSH server from your local machine.
- They'll allow the connector to do the same.
+Taken together, these configuration details would allow you to log into the SSH server from your local machine.
+They'll allow the connector to do the same.
5. Configure your internal network to allow the SSH server to access your capture or materialization endpoint.
-6. To grant external access to the SSH server, it's essential to configure your network settings accordingly. The approach you take will be dictated by your organization's IT policies. One recommended step is to whitelist Estuary's IP address, which is `34.121.207.128`. This ensures that connections from this specific IP are permitted through your network's firewall or security measures.
+6. To grant external access to the SSH server, it's essential to configure your network settings accordingly. The approach you take will be dictated by your organization's IT policies. One recommended step is to whitelist Estuary's IP addresses, which are `34.121.207.128, 35.226.75.135, 34.68.62.148`. This ensures that connections from this specific IP are permitted through your network's firewall or security measures.
## Setup for AWS
-To allow SSH tunneling to a database instance hosted on AWS, you'll need to create a virtual computing environment, or *instance*, in Amazon EC2.
+To allow SSH tunneling to a database instance hosted on AWS, you'll need to create a virtual computing environment, or _instance_, in Amazon EC2.
1. Begin by finding your public SSH key on your local machine.
In the `.ssh` subdirectory of your user home directory,
look for the PEM file that contains the private SSH key. Check that it starts with `-----BEGIN RSA PRIVATE KEY-----`,
which indicates it is an RSA-based file.
- * If no such file exists, generate one using the command:
+
+ - If no such file exists, generate one using the command:
+
```console
ssh-keygen -m PEM -t rsa
- ```
- * If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+ ```
+
+ - If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+
```console
ssh-keygen -p -N "" -m pem -f /path/to/key
- ```
+ ```
2. [Import your SSH key into AWS](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-key-pairs.html#how-to-generate-your-own-key-and-import-it-to-aws).
3. [Launch a new instance in EC2](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/LaunchingAndUsingInstances.html). During setup:
- * Configure the security group to allow SSH connection from anywhere.
- * When selecting a key pair, choose the key you just imported.
+
+ - Configure the security group to allow SSH connection from anywhere.
+ - When selecting a key pair, choose the key you just imported.
4. [Connect to the instance](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AccessingInstances.html),
-setting the user name to `ec2-user`.
+ setting the user name to `ec2-user`.
5. Find and note the [instance's public DNS](https://docs.aws.amazon.com/vpc/latest/userguide/vpc-dns.html#vpc-dns-viewing). This will be formatted like: `ec2-198-21-98-1.compute-1.amazonaws.com`.
@@ -97,25 +109,31 @@ To allow SSH tunneling to a database instance hosted on Google Cloud, you must s
In the `.ssh` subdirectory of your user home directory,
look for the PEM file that contains the private SSH key. Check that it starts with `-----BEGIN RSA PRIVATE KEY-----`,
which indicates it is an RSA-based file.
- * If no such file exists, generate one using the command:
+
+ - If no such file exists, generate one using the command:
+
```console
ssh-keygen -m PEM -t rsa
- ```
- * If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+ ```
+
+ - If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+
```console
ssh-keygen -p -N "" -m pem -f /path/to/key
- ```
- * If your Google login differs from your local username, generate a key that includes your Google email address as a comment:
+ ```
+
+ - If your Google login differs from your local username, generate a key that includes your Google email address as a comment:
+
```console
ssh-keygen -m PEM -t rsa -C user@domain.com
- ```
+ ```
2. [Create and start a new VM in GCP](https://cloud.google.com/compute/docs/instances/create-start-instance), [choosing an image that supports OS Login](https://cloud.google.com/compute/docs/images/os-details#user-space-features).
3. [Add your public key to the VM](https://cloud.google.com/compute/docs/connect/add-ssh-keys).
-5. [Reserve an external IP address](https://cloud.google.com/compute/docs/ip-addresses/reserve-static-external-ip-address) and connect it to the VM during setup.
-Note the generated address.
+4. [Reserve an external IP address](https://cloud.google.com/compute/docs/ip-addresses/reserve-static-external-ip-address) and connect it to the VM during setup.
+ Note the generated address.
## Setup for Azure
@@ -125,39 +143,43 @@ To allow SSH tunneling to a database instance hosted on Azure, you'll need to cr
In the `.ssh` subdirectory of your user home directory,
look for the PEM file that contains the private SSH key. Check that it starts with `-----BEGIN RSA PRIVATE KEY-----`,
which indicates it is an RSA-based file.
- * If no such file exists, generate one using the command:
+
+ - If no such file exists, generate one using the command:
+
```console
ssh-keygen -m PEM -t rsa
- ```
- * If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+ ```
+
+ - If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+
```console
ssh-keygen -p -N "" -m pem -f /path/to/key
- ```
+ ```
2. Create and connect to a VM in a [virtual network](https://docs.microsoft.com/en-us/azure/virtual-network/virtual-networks-overview), and add the endpoint database to the network.
1. [Create a new virtual network and subnet](https://docs.microsoft.com/en-us/azure/virtual-network/quick-create-portal).
2. Create a [Linux](https://docs.microsoft.com/en-us/azure/virtual-machines/linux/quick-create-portal) or [Windows](https://docs.microsoft.com/en-us/azure/virtual-machines/windows/quick-create-portal) VM within the virtual network,
- directing the SSH public key source to the public key you generated previously.
+ directing the SSH public key source to the public key you generated previously.
3. Note the VM's public IP; you'll need this later.
3. Create a service endpoint for your database in the same virtual network as your VM.
-Instructions for Azure Database For PostgreSQL can be found [here](https://docs.microsoft.com/en-us/azure/postgresql/howto-manage-vnet-using-portal);
-note that instructions for other database engines may be different.
+ Instructions for Azure Database For PostgreSQL can be found [here](https://docs.microsoft.com/en-us/azure/postgresql/howto-manage-vnet-using-portal);
+ note that instructions for other database engines may be different.
## Configuration
After you've completed the prerequisites, you should have the following parameters:
-* **SSH Endpoint** / `sshEndpoint`: the remote SSH server's hostname, or public IP address, formatted as `ssh://user@hostname[:port]`
+- **SSH Endpoint** / `sshEndpoint`: the remote SSH server's hostname, or public IP address, formatted as `ssh://user@hostname[:port]`
- The [SSH default port is 22](https://www.ssh.com/academy/ssh/port).
- Depending on where your server is hosted, you may not be required to specify a port,
- but we recommend specifying `:22` in all cases to ensure a connection can be made.
+ The [SSH default port is 22](https://www.ssh.com/academy/ssh/port).
+ Depending on where your server is hosted, you may not be required to specify a port,
+ but we recommend specifying `:22` in all cases to ensure a connection can be made.
-* **Private Key** / `privateKey`: the contents of the SSH private key file
+- **Private Key** / `privateKey`: the contents of the SSH private key file
Use these to add SSH tunneling to your capture or materialization definition, either by filling in the corresponding fields
in the web app, or by working with the YAML directly. Reference the [Connectors](../../concepts/connectors/#connecting-to-endpoints-on-secure-networks) page for a YAML sample.
diff --git a/site/docs/reference/Connectors/capture-connectors/MariaDB/MariaDB.md b/site/docs/reference/Connectors/capture-connectors/MariaDB/MariaDB.md
index e7e2767685..53177094ec 100644
--- a/site/docs/reference/Connectors/capture-connectors/MariaDB/MariaDB.md
+++ b/site/docs/reference/Connectors/capture-connectors/MariaDB/MariaDB.md
@@ -1,6 +1,7 @@
---
sidebar_position: 3
---
+
# MariaDB
This is a change data capture (CDC) connector that captures change events from a MariaDB database via the [Binary Log](https://mariadb.com/kb/en/overview-of-the-binary-log/).
@@ -10,22 +11,24 @@ so the same configuration applies, but the setup steps look somewhat different.
This connector is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-mariadb:dev`](https://github.com/estuary/connectors/pkgs/container/source-mariadb) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
## Prerequisites
+
To use this connector, you'll need a MariaDB database setup with the following.
-* [`binlog_format`](https://mariadb.com/kb/en/binary-log-formats/)
+
+- [`binlog_format`](https://mariadb.com/kb/en/binary-log-formats/)
system variable set to `ROW`.
-* [Binary log expiration period](https://mariadb.com/kb/en/using-and-maintaining-the-binary-log/#purging-log-files) set to at least 30 days (2592000 seconds) if at all possible.
+- [Binary log expiration period](https://mariadb.com/kb/en/using-and-maintaining-the-binary-log/#purging-log-files) set to at least 30 days (2592000 seconds) if at all possible.
- This value may be set lower if necessary, but we [strongly discourage](#insufficient-binlog-retention) going below 7 days as this may increase the likelihood of unrecoverable failures.
- MariaDB's default value is 0 (no expiration).
-* A watermarks table. The watermarks table is a small "scratch space"
+ MariaDB's default value is 0 (no expiration).
+- A watermarks table. The watermarks table is a small "scratch space"
to which the connector occasionally writes a small amount of data (a UUID,
specifically) to ensure accuracy when backfilling preexisting table contents.
- The default name is `"flow.watermarks"`, but this can be overridden in `config.json`.
-* A database user with appropriate permissions:
+- A database user with appropriate permissions:
- `REPLICATION CLIENT` and `REPLICATION SLAVE` [privileges](https://mariadb.com/docs/skysql/ref/es10.6/privileges/).
- Permission to insert, update, and delete on the watermarks table.
- Permission to read the tables being captured.
- Permission to read from `information_schema` tables, if automatic discovery is used.
-* If the table(s) to be captured include columns of type `DATETIME`, the `time_zone` system variable
+- If the table(s) to be captured include columns of type `DATETIME`, the `time_zone` system variable
must be set to an IANA zone name or numerical offset or the capture configured with a `timezone` to use by default.
:::tip Configuration Tip
@@ -39,14 +42,17 @@ To configure this connector to capture data from databases hosted on your intern
To meet these requirements, do the following:
1. Create the watermarks table. This table can have any name and be in any database, so long as the capture's `config.json` file is modified accordingly.
+
```sql
CREATE DATABASE IF NOT EXISTS flow;
CREATE TABLE IF NOT EXISTS flow.watermarks (slot INTEGER PRIMARY KEY, watermark TEXT);
```
+
2. Create the `flow_capture` user with replication permission, the ability to read all tables, and the ability to read and write the watermarks table.
- The `SELECT` permission can be restricted to just the tables that need to be
- captured, but automatic discovery requires `information_schema` access as well.
+The `SELECT` permission can be restricted to just the tables that need to be
+captured, but automatic discovery requires `information_schema` access as well.
+
```sql
CREATE USER IF NOT EXISTS flow_capture
IDENTIFIED BY 'secret'
@@ -54,11 +60,15 @@ GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'flow_capture';
GRANT SELECT ON *.* TO 'flow_capture';
GRANT INSERT, UPDATE, DELETE ON flow.watermarks TO 'flow_capture';
```
+
3. Configure the binary log to retain data for 30 days, if previously set lower.
+
```sql
SET PERSIST binlog_expire_logs_seconds = 2592000;
```
+
4. Configure the database's time zone. See [below](#setting-the-mariadb-time-zone) for more information.
+
```sql
SET PERSIST time_zone = '-05:00'
```
@@ -70,19 +80,20 @@ You can use this connector for MariaDB instances on Azure Database for MariaDB u
1. Allow connections to the database from the Estuary Flow IP address.
1. Create a new [firewall rule](https://learn.microsoft.com/en-us/azure/mariadb/howto-manage-firewall-portal)
- that grants access to the IP address `34.121.207.128`.
+ that grants access to the IP addresses: `34.121.207.128, 35.226.75.135, 34.68.62.148`.
:::info
Alternatively, you can allow secure connections via SSH tunneling. To do so:
- * Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above,
- including the additional `networkTunnel` configuration to enable the SSH tunnel.
- See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks)
- for additional details and a sample.
- :::
+
+ - Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above,
+ including the additional `networkTunnel` configuration to enable the SSH tunnel.
+ See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks)
+ for additional details and a sample.
+ :::
2. Set the `binlog_expire_logs_seconds` [server perameter](https://learn.microsoft.com/en-us/azure/mariadb/howto-server-parameters#configure-server-parameters)
-to `2592000`.
+ to `2592000`.
3. Using your preferred MariaDB client, create the watermarks table.
@@ -97,8 +108,9 @@ CREATE TABLE IF NOT EXISTS flow.watermarks (slot INTEGER PRIMARY KEY, watermark
4. Create the `flow_capture` user with replication permission, the ability to read all tables, and the ability to read and write the watermarks table.
- The `SELECT` permission can be restricted to just the tables that need to be
- captured, but automatic discovery requires `information_schema` access as well.
+The `SELECT` permission can be restricted to just the tables that need to be
+captured, but automatic discovery requires `information_schema` access as well.
+
```sql
CREATE USER IF NOT EXISTS flow_capture
IDENTIFIED BY 'secret'
@@ -108,7 +120,7 @@ GRANT INSERT, UPDATE, DELETE ON flow.watermarks TO 'flow_capture';
```
5. Note the instance's host under Server name, and the port under Connection Strings (usually `3306`).
-Together, you'll use the host:port as the `address` property when you configure the connector.
+ Together, you'll use the host:port as the `address` property when you configure the connector.
### Setting the MariaDB time zone
@@ -122,9 +134,9 @@ To avoid this, you must explicitly set the time zone for your database.
You can:
-* Specify a numerical offset from UTC.
+- Specify a numerical offset from UTC.
-* Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
+- Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
For example, if you're located in New Jersey, USA, you could set `time_zone` to `-05:00` or `-04:00`, depending on the time of year.
Because this region observes daylight savings time, you'd be responsible for changing the offset.
@@ -138,7 +150,7 @@ If you are unable to set the `time_zone` in the database and need to capture tab
## Backfills and performance considerations
-When the a MariaDB capture is initiated, by default, the connector first *backfills*, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
+When the a MariaDB capture is initiated, by default, the connector first _backfills_, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
This is desirable in most cases, as in ensures that a complete view of your tables is captured into Flow.
However, you may find it appropriate to skip the backfill, especially for extremely large tables.
@@ -146,6 +158,7 @@ However, you may find it appropriate to skip the backfill, especially for extrem
In this case, you may turn of backfilling on a per-table basis. See [properties](#properties) for details.
## Configuration
+
You configure connectors either in the Flow web app, or by directly editing the catalog specification file.
See [connectors](/concepts/connectors.md#using-connectors) to learn more about using connectors. The values and specification sample below provide configuration details specific to the MariaDB source connector.
@@ -153,26 +166,26 @@ See [connectors](/concepts/connectors.md#using-connectors) to learn more about u
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
-| **`/user`** | Login User | The database user to authenticate as. | string | Required, `"flow_capture"` |
-| **`/password`** | Login Password | Password for the specified database user. | string | Required |
-| `/timezone` | Timezone | Timezone to use when capturing datetime columns. Should normally be left blank to use the database's `'time_zone'` system variable. Only required if the `'time_zone'` system variable cannot be read and columns with type datetime are being captured. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the `'time_zone'` system variable if both are set. | string | |
-| `/advanced/watermarks_table` | Watermarks Table Name | The name of the table used for watermark writes. Must be fully-qualified in '<schema>.<table>' form. | string | `"flow.watermarks"` |
-| `/advanced/dbname` | Database Name | The name of database to connect to. In general this shouldn't matter. The connector can discover and capture from all databases it's authorized to access. | string | `"mysql"` |
-| `/advanced/node_id` | Node ID | Node ID for the capture. Each node in a replication cluster must have a unique 32-bit ID. The specific value doesn't matter so long as it is unique. If unset or zero the connector will pick a value. | integer | |
-| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
-| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `131072` |
-| `/advanced/skip_binlog_retention_check` | Skip Binlog Retention Sanity Check | Bypasses the 'dangerously short binlog retention' sanity check at startup. Only do this if you understand the danger and have a specific need. | boolean | |
+| Property | Title | Description | Type | Required/Default |
+| --------------------------------------- | ---------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------- | -------------------------- |
+| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
+| **`/user`** | Login User | The database user to authenticate as. | string | Required, `"flow_capture"` |
+| **`/password`** | Login Password | Password for the specified database user. | string | Required |
+| `/timezone` | Timezone | Timezone to use when capturing datetime columns. Should normally be left blank to use the database's `'time_zone'` system variable. Only required if the `'time_zone'` system variable cannot be read and columns with type datetime are being captured. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the `'time_zone'` system variable if both are set. | string | |
+| `/advanced/watermarks_table` | Watermarks Table Name | The name of the table used for watermark writes. Must be fully-qualified in '<schema>.<table>' form. | string | `"flow.watermarks"` |
+| `/advanced/dbname` | Database Name | The name of database to connect to. In general this shouldn't matter. The connector can discover and capture from all databases it's authorized to access. | string | `"mysql"` |
+| `/advanced/node_id` | Node ID | Node ID for the capture. Each node in a replication cluster must have a unique 32-bit ID. The specific value doesn't matter so long as it is unique. If unset or zero the connector will pick a value. | integer | |
+| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
+| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `131072` |
+| `/advanced/skip_binlog_retention_check` | Skip Binlog Retention Sanity Check | Bypasses the 'dangerously short binlog retention' sanity check at startup. Only do this if you understand the danger and have a specific need. | boolean | |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|-------|------|------|---------| --------|
-| **`/namespace`** | Namespace | The [database](https://mariadb.com/kb/en/understanding-mariadb-architecture/#databases) in which the table resides. | string | Required |
-| **`/stream`** | Stream | Name of the table to be captured from the database. | string | Required |
-| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental`. | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | --------- | ------------------------------------------------------------------------------------------------------------------- | ------ | ---------------- |
+| **`/namespace`** | Namespace | The [database](https://mariadb.com/kb/en/understanding-mariadb-architecture/#databases) in which the table resides. | string | Required |
+| **`/stream`** | Stream | Name of the table to be captured from the database. | string | Required |
+| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental`. | string | Required |
:::info
When you configure this connector in the web application, the automatic **discovery** process sets up a binding for _most_ tables it finds in your database, but there are exceptions.
@@ -182,6 +195,7 @@ You can add bindings for such tables manually.
:::
### Sample
+
A minimal capture definition will look like the following:
```yaml
diff --git a/site/docs/reference/Connectors/capture-connectors/MariaDB/amazon-rds-mariadb.md b/site/docs/reference/Connectors/capture-connectors/MariaDB/amazon-rds-mariadb.md
index e5556c61eb..09e043d1fc 100644
--- a/site/docs/reference/Connectors/capture-connectors/MariaDB/amazon-rds-mariadb.md
+++ b/site/docs/reference/Connectors/capture-connectors/MariaDB/amazon-rds-mariadb.md
@@ -1,6 +1,7 @@
---
sidebar_position: 3
---
+
# Amazon RDS for MariaDB
This is a change data capture (CDC) connector that captures change events from a MariaDB database via the [Binary Log](https://mariadb.com/kb/en/overview-of-the-binary-log/).
@@ -10,22 +11,24 @@ so the same configuration applies, but the setup steps look somewhat different.
This connector is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-mariadb:dev`](https://github.com/estuary/connectors/pkgs/container/source-mariadb) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
## Prerequisites
+
To use this connector, you'll need a MariaDB database setup with the following.
-* [`binlog_format`](https://mariadb.com/kb/en/binary-log-formats/)
+
+- [`binlog_format`](https://mariadb.com/kb/en/binary-log-formats/)
system variable set to `ROW`.
-* [Binary log expiration period](https://mariadb.com/kb/en/using-and-maintaining-the-binary-log/#purging-log-files) set to at least 30 days (2592000 seconds) if at all possible.
+- [Binary log expiration period](https://mariadb.com/kb/en/using-and-maintaining-the-binary-log/#purging-log-files) set to at least 30 days (2592000 seconds) if at all possible.
- This value may be set lower if necessary, but we [strongly discourage](#insufficient-binlog-retention) going below 7 days as this may increase the likelihood of unrecoverable failures.
- MariaDB's default value is 0 (no expiration).
-* A watermarks table. The watermarks table is a small "scratch space"
+ MariaDB's default value is 0 (no expiration).
+- A watermarks table. The watermarks table is a small "scratch space"
to which the connector occasionally writes a small amount of data (a UUID,
specifically) to ensure accuracy when backfilling preexisting table contents.
- The default name is `"flow.watermarks"`, but this can be overridden in `config.json`.
-* A database user with appropriate permissions:
+- A database user with appropriate permissions:
- `REPLICATION CLIENT` and `REPLICATION SLAVE` [privileges](https://mariadb.com/docs/skysql/ref/es10.6/privileges/).
- Permission to insert, update, and delete on the watermarks table.
- Permission to read the tables being captured.
- Permission to read from `information_schema` tables, if automatic discovery is used.
-* If the table(s) to be captured include columns of type `DATETIME`, the `time_zone` system variable
+- If the table(s) to be captured include columns of type `DATETIME`, the `time_zone` system variable
must be set to an IANA zone name or numerical offset or the capture configured with a `timezone` to use by default.
### Setup
@@ -36,48 +39,52 @@ To use this connector, you'll need a MariaDB database setup with the following.
2. Edit the VPC security group associated with your database, or create a new VPC security group and associate it with the database.
Refer to the [steps in the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create).
- Create a new inbound rule and a new outbound rule that allow all traffic from the IP address `34.121.207.128`.
+ Create a new inbound rule and a new outbound rule that allow all traffic from the IP addresses: `34.121.207.128, 35.226.75.135, 34.68.62.148`.
:::info
Alternatively, you can allow secure connections via SSH tunneling. To do so:
- * Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above,
- including the additional `networkTunnel` configuration to enable the SSH tunnel.
- See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks)
- for additional details and a sample.
- :::
+
+ - Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above,
+ including the additional `networkTunnel` configuration to enable the SSH tunnel.
+ See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks)
+ for additional details and a sample.
+ :::
2. Create a RDS parameter group to enable replication in MariaDB.
1. [Create a parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithDBInstanceParamGroups.html#USER_WorkingWithParamGroups.Creating).
- Create a unique name and description and set the following properties:
- * **Family**: mariadb10.6
- * **Type**: DB Parameter group
+ Create a unique name and description and set the following properties:
+
+ - **Family**: mariadb10.6
+ - **Type**: DB Parameter group
2. [Modify the new parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithDBInstanceParamGroups.html#USER_WorkingWithParamGroups.Modifying) and update the following parameters:
- * binlog_format: ROW
- * binlog_row_metadata: FULL
- * read_only: 0
- 3. If using the primary instance (not recommended), [associate the parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithDBInstanceParamGroups.html#USER_WorkingWithParamGroups.Associating)
- with the database and set [Backup Retention Period](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithAutomatedBackups.html#USER_WorkingWithAutomatedBackups.Enabling) to 7 days.
- Reboot the database to allow the changes to take effect.
+ - binlog_format: ROW
+ - binlog_row_metadata: FULL
+ - read_only: 0
+
+ 3. If using the primary instance (not recommended), [associate the parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithDBInstanceParamGroups.html#USER_WorkingWithParamGroups.Associating)
+ with the database and set [Backup Retention Period](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithAutomatedBackups.html#USER_WorkingWithAutomatedBackups.Enabling) to 7 days.
+ Reboot the database to allow the changes to take effect.
3. Create a read replica with the new parameter group applied (recommended).
1. [Create a read replica](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_ReadRepl.html#USER_ReadRepl.Create)
- of your MariaDB database.
+ of your MariaDB database.
2. [Modify the replica](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html)
- and set the following:
- * **DB parameter group**: choose the parameter group you created previously
- * **Backup retention period**: 7 days
- * **Public access**: Publicly accessible
+ and set the following:
+
+ - **DB parameter group**: choose the parameter group you created previously
+ - **Backup retention period**: 7 days
+ - **Public access**: Publicly accessible
3. Reboot the replica to allow the changes to take effect.
4. Switch to your MariaDB client. Run the following commands to create a new user for the capture with appropriate permissions,
-and set up the watermarks table:
+ and set up the watermarks table:
```sql
CREATE DATABASE IF NOT EXISTS flow;
@@ -90,17 +97,16 @@ GRANT INSERT, UPDATE, DELETE ON flow.watermarks TO 'flow_capture';
```
5. Run the following command to set the binary log retention to 7 days, the maximum value which RDS MariaDB permits:
+
```sql
CALL mysql.rds_set_configuration('binlog retention hours', 168);
```
6. In the [RDS console](https://console.aws.amazon.com/rds/), note the instance's Endpoint and Port. You'll need these for the `address` property when you configure the connector.
-
-
## Backfills and performance considerations
-When the a MariaDB capture is initiated, by default, the connector first *backfills*, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
+When the a MariaDB capture is initiated, by default, the connector first _backfills_, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
This is desirable in most cases, as in ensures that a complete view of your tables is captured into Flow.
However, you may find it appropriate to skip the backfill, especially for extremely large tables.
@@ -108,6 +114,7 @@ However, you may find it appropriate to skip the backfill, especially for extrem
In this case, you may turn of backfilling on a per-table basis. See [properties](#properties) for details.
## Configuration
+
You configure connectors either in the Flow web app, or by directly editing the catalog specification file.
See [connectors](/concepts/connectors.md#using-connectors) to learn more about using connectors. The values and specification sample below provide configuration details specific to the MariaDB source connector.
@@ -115,26 +122,26 @@ See [connectors](/concepts/connectors.md#using-connectors) to learn more about u
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
-| **`/user`** | Login User | The database user to authenticate as. | string | Required, `"flow_capture"` |
-| **`/password`** | Login Password | Password for the specified database user. | string | Required |
-| `/timezone` | Timezone | Timezone to use when capturing datetime columns. Should normally be left blank to use the database's `'time_zone'` system variable. Only required if the `'time_zone'` system variable cannot be read and columns with type datetime are being captured. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the `'time_zone'` system variable if both are set. | string | |
-| `/advanced/watermarks_table` | Watermarks Table Name | The name of the table used for watermark writes. Must be fully-qualified in '<schema>.<table>' form. | string | `"flow.watermarks"` |
-| `/advanced/dbname` | Database Name | The name of database to connect to. In general this shouldn't matter. The connector can discover and capture from all databases it's authorized to access. | string | `"mysql"` |
-| `/advanced/node_id` | Node ID | Node ID for the capture. Each node in a replication cluster must have a unique 32-bit ID. The specific value doesn't matter so long as it is unique. If unset or zero the connector will pick a value. | integer | |
-| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
-| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `131072` |
-| `/advanced/skip_binlog_retention_check` | Skip Binlog Retention Sanity Check | Bypasses the 'dangerously short binlog retention' sanity check at startup. Only do this if you understand the danger and have a specific need. | boolean | |
+| Property | Title | Description | Type | Required/Default |
+| --------------------------------------- | ---------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------- | -------------------------- |
+| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
+| **`/user`** | Login User | The database user to authenticate as. | string | Required, `"flow_capture"` |
+| **`/password`** | Login Password | Password for the specified database user. | string | Required |
+| `/timezone` | Timezone | Timezone to use when capturing datetime columns. Should normally be left blank to use the database's `'time_zone'` system variable. Only required if the `'time_zone'` system variable cannot be read and columns with type datetime are being captured. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the `'time_zone'` system variable if both are set. | string | |
+| `/advanced/watermarks_table` | Watermarks Table Name | The name of the table used for watermark writes. Must be fully-qualified in '<schema>.<table>' form. | string | `"flow.watermarks"` |
+| `/advanced/dbname` | Database Name | The name of database to connect to. In general this shouldn't matter. The connector can discover and capture from all databases it's authorized to access. | string | `"mysql"` |
+| `/advanced/node_id` | Node ID | Node ID for the capture. Each node in a replication cluster must have a unique 32-bit ID. The specific value doesn't matter so long as it is unique. If unset or zero the connector will pick a value. | integer | |
+| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
+| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `131072` |
+| `/advanced/skip_binlog_retention_check` | Skip Binlog Retention Sanity Check | Bypasses the 'dangerously short binlog retention' sanity check at startup. Only do this if you understand the danger and have a specific need. | boolean | |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|-------|------|------|---------| --------|
-| **`/namespace`** | Namespace | The [database](https://mariadb.com/kb/en/understanding-mariadb-architecture/#databases) in which the table resides. | string | Required |
-| **`/stream`** | Stream | Name of the table to be captured from the database. | string | Required |
-| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental`. | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | --------- | ------------------------------------------------------------------------------------------------------------------- | ------ | ---------------- |
+| **`/namespace`** | Namespace | The [database](https://mariadb.com/kb/en/understanding-mariadb-architecture/#databases) in which the table resides. | string | Required |
+| **`/stream`** | Stream | Name of the table to be captured from the database. | string | Required |
+| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental`. | string | Required |
:::info
When you configure this connector in the web application, the automatic **discovery** process sets up a binding for _most_ tables it finds in your database, but there are exceptions.
@@ -144,6 +151,7 @@ You can add bindings for such tables manually.
:::
### Sample
+
A minimal capture definition will look like the following:
```yaml
@@ -168,7 +176,6 @@ Your capture definition will likely be more complex, with additional bindings fo
[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
-
## Troubleshooting Capture Errors
The `source-amazon-rds-mariadb` connector is designed to halt immediately if something wrong or unexpected happens, instead of continuing on and potentially outputting incorrect data. What follows is a non-exhaustive list of some potential failure modes, and what action should be taken to fix these situations:
diff --git a/site/docs/reference/Connectors/capture-connectors/MySQL/MySQL.md b/site/docs/reference/Connectors/capture-connectors/MySQL/MySQL.md
index 203cb294bb..35ae014f5d 100644
--- a/site/docs/reference/Connectors/capture-connectors/MySQL/MySQL.md
+++ b/site/docs/reference/Connectors/capture-connectors/MySQL/MySQL.md
@@ -1,6 +1,7 @@
---
sidebar_position: 5
---
+
# MySQL
This is a change data capture (CDC) connector that captures change events from a MySQL database via the [Binary Log](https://dev.mysql.com/doc/refman/8.0/en/binary-log.html).
@@ -13,30 +14,32 @@ This connector supports MySQL on major cloud providers, as well as self-hosted i
Setup instructions are provided for the following platforms:
-* [Self-hosted MySQL](#self-hosted-mysql)
-* [Amazon RDS](./amazon-rds-mysql/)
-* [Amazon Aurora](#amazon-aurora)
-* [Google Cloud SQL](./google-cloud-sql-mysql/)
-* [Azure Database for MySQL](#azure-database-for-mysql)
+- [Self-hosted MySQL](#self-hosted-mysql)
+- [Amazon RDS](./amazon-rds-mysql/)
+- [Amazon Aurora](#amazon-aurora)
+- [Google Cloud SQL](./google-cloud-sql-mysql/)
+- [Azure Database for MySQL](#azure-database-for-mysql)
## Prerequisites
+
To use this connector, you'll need a MySQL database setup with the following.
-* [`binlog_format`](https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html#sysvar_binlog_format)
+
+- [`binlog_format`](https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html#sysvar_binlog_format)
system variable set to `ROW` (the default value).
-* [Binary log expiration period](https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html#sysvar_binlog_expire_logs_seconds) set to MySQL's default value of 30 days (2592000 seconds) if at all possible.
+- [Binary log expiration period](https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html#sysvar_binlog_expire_logs_seconds) set to MySQL's default value of 30 days (2592000 seconds) if at all possible.
- This value may be set lower if necessary, but we [strongly discourage](#insufficient-binlog-retention) going below 7 days as this may increase the likelihood of unrecoverable failures.
-* A watermarks table. The watermarks table is a small "scratch space"
+- A watermarks table. The watermarks table is a small "scratch space"
to which the connector occasionally writes a small amount of data (a UUID,
specifically) to ensure accuracy when backfilling preexisting table contents.
- The default name is `"flow.watermarks"`, but this can be overridden in `config.json`.
- The watermark table will only ever have one row per capture from that database and that row is updated once per 50k rows scanned in each table during the initial backfill for MySQL databases.
- - As each table backfills, the previous watermark record will be replaced. After the initial backfill, watermark records are updated approximately once per minute. At no time does a watermark table have more than one record.
-* A database user with appropriate permissions:
+ - As each table backfills, the previous watermark record will be replaced. After the initial backfill, watermark records are updated approximately once per minute. At no time does a watermark table have more than one record.
+- A database user with appropriate permissions:
- `REPLICATION CLIENT` and `REPLICATION SLAVE` privileges.
- Permission to insert, update, and delete on the watermarks table.
- Permission to read the tables being captured.
- Permission to read from `information_schema` tables, if automatic discovery is used.
-* If the table(s) to be captured include columns of type `DATETIME`, the `time_zone` system variable
+- If the table(s) to be captured include columns of type `DATETIME`, the `time_zone` system variable
must be set to an IANA zone name or numerical offset or the capture configured with a `timezone` to use by default.
:::tip Configuration Tip
@@ -45,25 +48,28 @@ To configure this connector to capture data from databases hosted on your intern
## Setup
-To meet these requirements, follow the steps for your hosting type.
+To meet these requirements, follow the steps for your hosting type.
-* [Self-hosted MySQL](#self-hosted-mysql)
-* [Amazon RDS](./amazon-rds-mysql/)
-* [Amazon Aurora](#amazon-aurora)
-* [Google Cloud SQL](./google-cloud-sql-mysql/)
-* [Azure Database for MySQL](#azure-database-for-mysql)
+- [Self-hosted MySQL](#self-hosted-mysql)
+- [Amazon RDS](./amazon-rds-mysql/)
+- [Amazon Aurora](#amazon-aurora)
+- [Google Cloud SQL](./google-cloud-sql-mysql/)
+- [Azure Database for MySQL](#azure-database-for-mysql)
### Self-hosted MySQL
1. Create the watermarks table. This table can have any name and be in any database, so long as the capture's `config.json` file is modified accordingly.
+
```sql
CREATE DATABASE IF NOT EXISTS flow;
CREATE TABLE IF NOT EXISTS flow.watermarks (slot INTEGER PRIMARY KEY, watermark TEXT);
```
+
2. Create the `flow_capture` user with replication permission, the ability to read all tables, and the ability to read and write the watermarks table.
- The `SELECT` permission can be restricted to just the tables that need to be
- captured, but automatic discovery requires `information_schema` access as well.
+The `SELECT` permission can be restricted to just the tables that need to be
+captured, but automatic discovery requires `information_schema` access as well.
+
```sql
CREATE USER IF NOT EXISTS flow_capture
IDENTIFIED BY 'secret'
@@ -72,11 +78,15 @@ GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'flow_capture';
GRANT SELECT ON *.* TO 'flow_capture';
GRANT INSERT, UPDATE, DELETE ON flow.watermarks TO 'flow_capture';
```
+
3. Configure the binary log to retain data for the default MySQL setting of 30 days, if previously set lower.
+
```sql
SET PERSIST binlog_expire_logs_seconds = 2592000;
```
+
4. Configure the database's time zone. See [below](#setting-the-mysql-time-zone) for more information.
+
```sql
SET PERSIST time_zone = '-05:00'
```
@@ -89,33 +99,36 @@ For each step, take note of which entity you're working with.
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * [Modify the instance](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Modifying.html#Aurora.Modifying.Instance), choosing **Publicly accessible** in the **Connectivity** settings.
- * Edit the VPC security group associated with your instance, or create a new VPC security group and associate it with the instance as described in [the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create). Create a new inbound rule and a new outbound rule that allow all traffic from the IP address `34.121.207.128`.
+
+ - [Modify the instance](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Modifying.html#Aurora.Modifying.Instance), choosing **Publicly accessible** in the **Connectivity** settings.
+ - Edit the VPC security group associated with your instance, or create a new VPC security group and associate it with the instance as described in [the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create). Create a new inbound rule and a new outbound rule that allow all traffic from the IP addresses `34.121.207.128, 35.226.75.135, 34.68.62.148`.
2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
2. Create a RDS parameter group to enable replication on your Aurora DB cluster.
1. [Create a parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.CreatingCluster).
- Create a unique name and description and set the following properties:
- * **Family**: aurora-mysql8.0
- * **Type**: DB ClusterParameter group
+ Create a unique name and description and set the following properties:
+
+ - **Family**: aurora-mysql8.0
+ - **Type**: DB ClusterParameter group
2. [Modify the new parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.ModifyingCluster) and update the following parameters:
- * binlog_format: ROW
- * binlog_row_metadata: FULL
- * read_only: 0
- 3. [Associate the parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.AssociatingCluster)
- with the DB cluster.
- While you're modifying the cluster, also set [Backup Retention Period](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Managing.Backups.html) to 7 days.
+ - binlog_format: ROW
+ - binlog_row_metadata: FULL
+ - read_only: 0
+
+ 3. [Associate the parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.AssociatingCluster)
+ with the DB cluster.
+ While you're modifying the cluster, also set [Backup Retention Period](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Managing.Backups.html) to 7 days.
4. Reboot the cluster to allow the changes to take effect.
-4. Switch to your MySQL client. Run the following commands to create a new user for the capture with appropriate permissions,
-and set up the watermarks table:
+3. Switch to your MySQL client. Run the following commands to create a new user for the capture with appropriate permissions,
+ and set up the watermarks table:
```sql
CREATE DATABASE IF NOT EXISTS flow;
@@ -129,26 +142,27 @@ GRANT INSERT, UPDATE, DELETE ON flow.watermarks TO 'flow_capture';
```
5. Run the following command to set the binary log retention to 7 days, the maximum value Aurora permits:
+
```sql
CALL mysql.rds_set_configuration('binlog retention hours', 168);
```
6. In the [RDS console](https://console.aws.amazon.com/rds/), note the instance's Endpoint and Port. You'll need these for the `address` property when you configure the connector.
-
### Azure Database for MySQL
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * Create a new [firewall rule](https://docs.microsoft.com/en-us/azure/mysql/flexible-server/how-to-manage-firewall-portal#create-a-firewall-rule-after-server-is-created) that grants access to the IP address `34.121.207.128`.
+
+ - Create a new [firewall rule](https://docs.microsoft.com/en-us/azure/mysql/flexible-server/how-to-manage-firewall-portal#create-a-firewall-rule-after-server-is-created) that grants access to the IP addresses `34.121.207.128, 35.226.75.135, 34.68.62.148`.
2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
2. Set the `binlog_expire_logs_seconds` [server perameter](https://docs.microsoft.com/en-us/azure/mysql/single-server/concepts-server-parameters#configurable-server-parameters)
-to `2592000`.
+ to `2592000`.
3. Using [MySQL workbench](https://docs.microsoft.com/en-us/azure/mysql/single-server/connect-workbench) or your preferred client, create the watermarks table.
@@ -163,8 +177,9 @@ CREATE TABLE IF NOT EXISTS flow.watermarks (slot INTEGER PRIMARY KEY, watermark
4. Create the `flow_capture` user with replication permission, the ability to read all tables, and the ability to read and write the watermarks table.
- The `SELECT` permission can be restricted to just the tables that need to be
- captured, but automatic discovery requires `information_schema` access as well.
+The `SELECT` permission can be restricted to just the tables that need to be
+captured, but automatic discovery requires `information_schema` access as well.
+
```sql
CREATE USER IF NOT EXISTS flow_capture
IDENTIFIED BY 'secret'
@@ -175,8 +190,7 @@ GRANT INSERT, UPDATE, DELETE ON flow.watermarks TO 'flow_capture';
```
4. Note the instance's host under Server name, and the port under Connection Strings (usually `3306`).
-Together, you'll use the host:port as the `address` property when you configure the connector.
-
+ Together, you'll use the host:port as the `address` property when you configure the connector.
### Setting the MySQL time zone
@@ -189,15 +203,16 @@ To avoid this, you must explicitly set the time zone for your database.
You can:
-* Specify a numerical offset from UTC.
- - For MySQL version 8.0.19 or higher, values from `-13:59` to `+14:00`, inclusive, are permitted.
- - Prior to MySQL 8.0.19, values from `-12:59` to `+13:00`, inclusive, are permitted
+- Specify a numerical offset from UTC.
-* Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
+ - For MySQL version 8.0.19 or higher, values from `-13:59` to `+14:00`, inclusive, are permitted.
+ - Prior to MySQL 8.0.19, values from `-12:59` to `+13:00`, inclusive, are permitted
-* If you're using Amazon Aurora, create or modify the [DB cluster parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html)
-associated with your MySQL database.
-[Set](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.ModifyingCluster) the `time_zone` parameter to the correct value.
+- Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
+
+- If you're using Amazon Aurora, create or modify the [DB cluster parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html)
+ associated with your MySQL database.
+ [Set](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.ModifyingCluster) the `time_zone` parameter to the correct value.
For example, if you're located in New Jersey, USA, you could set `time_zone` to `-05:00` or `-04:00`, depending on the time of year.
Because this region observes daylight savings time, you'd be responsible for changing the offset.
@@ -211,7 +226,7 @@ If you are unable to set the `time_zone` in the database and need to capture tab
## Backfills and performance considerations
-When the a MySQL capture is initiated, by default, the connector first *backfills*, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
+When the a MySQL capture is initiated, by default, the connector first _backfills_, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
This is desirable in most cases, as in ensures that a complete view of your tables is captured into Flow.
However, you may find it appropriate to skip the backfill, especially for extremely large tables.
@@ -219,6 +234,7 @@ However, you may find it appropriate to skip the backfill, especially for extrem
In this case, you may turn of backfilling on a per-table basis. See [properties](#properties) for details.
## Configuration
+
You configure connectors either in the Flow web app, or by directly editing the catalog specification file.
See [connectors](/concepts/connectors.md#using-connectors) to learn more about using connectors. The values and specification sample below provide configuration details specific to the MySQL source connector.
@@ -227,26 +243,26 @@ See [connectors](/concepts/connectors.md#using-connectors) to learn more about u
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
-| **`/user`** | Login User | The database user to authenticate as. | string | Required, `"flow_capture"` |
-| **`/password`** | Login Password | Password for the specified database user. | string | Required |
-| `/timezone` | Timezone | Timezone to use when capturing datetime columns. Should normally be left blank to use the database's `'time_zone'` system variable. Only required if the `'time_zone'` system variable cannot be read and columns with type datetime are being captured. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the `'time_zone'` system variable if both are set. | string | |
-| `/advanced/watermarks_table` | Watermarks Table Name | The name of the table used for watermark writes. Must be fully-qualified in '<schema>.<table>' form. | string | `"flow.watermarks"` |
-| `/advanced/dbname` | Database Name | The name of database to connect to. In general this shouldn't matter. The connector can discover and capture from all databases it's authorized to access. | string | `"mysql"` |
-| `/advanced/node_id` | Node ID | Node ID for the capture. Each node in a replication cluster must have a unique 32-bit ID. The specific value doesn't matter so long as it is unique. If unset or zero the connector will pick a value. | integer | |
-| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
-| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `131072` |
-| `/advanced/skip_binlog_retention_check` | Skip Binlog Retention Sanity Check | Bypasses the 'dangerously short binlog retention' sanity check at startup. Only do this if you understand the danger and have a specific need. | boolean | |
+| Property | Title | Description | Type | Required/Default |
+| --------------------------------------- | ---------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------- | -------------------------- |
+| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
+| **`/user`** | Login User | The database user to authenticate as. | string | Required, `"flow_capture"` |
+| **`/password`** | Login Password | Password for the specified database user. | string | Required |
+| `/timezone` | Timezone | Timezone to use when capturing datetime columns. Should normally be left blank to use the database's `'time_zone'` system variable. Only required if the `'time_zone'` system variable cannot be read and columns with type datetime are being captured. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the `'time_zone'` system variable if both are set. | string | |
+| `/advanced/watermarks_table` | Watermarks Table Name | The name of the table used for watermark writes. Must be fully-qualified in '<schema>.<table>' form. | string | `"flow.watermarks"` |
+| `/advanced/dbname` | Database Name | The name of database to connect to. In general this shouldn't matter. The connector can discover and capture from all databases it's authorized to access. | string | `"mysql"` |
+| `/advanced/node_id` | Node ID | Node ID for the capture. Each node in a replication cluster must have a unique 32-bit ID. The specific value doesn't matter so long as it is unique. If unset or zero the connector will pick a value. | integer | |
+| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
+| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `131072` |
+| `/advanced/skip_binlog_retention_check` | Skip Binlog Retention Sanity Check | Bypasses the 'dangerously short binlog retention' sanity check at startup. Only do this if you understand the danger and have a specific need. | boolean | |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|-------|------|------|---------| --------|
-| **`/namespace`** | Namespace | The [database/schema](https://dev.mysql.com/doc/refman/8.0/en/show-databases.html) in which the table resides. | string | Required |
-| **`/stream`** | Stream | Name of the table to be captured from the database. | string | Required |
-| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental`. | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | --------- | -------------------------------------------------------------------------------------------------------------- | ------ | ---------------- |
+| **`/namespace`** | Namespace | The [database/schema](https://dev.mysql.com/doc/refman/8.0/en/show-databases.html) in which the table resides. | string | Required |
+| **`/stream`** | Stream | Name of the table to be captured from the database. | string | Required |
+| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental`. | string | Required |
:::info
When you configure this connector in the web application, the automatic **discovery** process sets up a binding for _most_ tables it finds in your database, but there are exceptions.
@@ -256,6 +272,7 @@ You can add bindings for such tables manually.
:::
### Sample
+
A minimal capture definition will look like the following:
```yaml
@@ -280,7 +297,6 @@ Your capture definition will likely be more complex, with additional bindings fo
[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
-
## Troubleshooting Capture Errors
The `source-mysql` connector is designed to halt immediately if something wrong or unexpected happens, instead of continuing on and potentially outputting incorrect data. What follows is a non-exhaustive list of some potential failure modes, and what action should be taken to fix these situations:
@@ -322,4 +338,3 @@ The `"binlog retention period is too short"` error should normally be fixed by s
### Empty Collection Key
Every Flow collection must declare a [key](/concepts/collections.md#keys) which is used to group its documents. When testing your capture, if you encounter an error indicating collection key cannot be empty, you will need to either add a key to the table in your source, or manually edit the generated specification and specify keys for the collection before publishing to the catalog as documented [here](/concepts/collections.md#empty-keys).
-
diff --git a/site/docs/reference/Connectors/capture-connectors/MySQL/amazon-rds-mysql.md b/site/docs/reference/Connectors/capture-connectors/MySQL/amazon-rds-mysql.md
index 56d74d2dc0..89866d93fa 100644
--- a/site/docs/reference/Connectors/capture-connectors/MySQL/amazon-rds-mysql.md
+++ b/site/docs/reference/Connectors/capture-connectors/MySQL/amazon-rds-mysql.md
@@ -1,6 +1,7 @@
---
sidebar_position: 5
---
+
# Amazon RDS for MySQL
This is a change data capture (CDC) connector that captures change events from a MySQL database via the [Binary Log](https://dev.mysql.com/doc/refman/8.0/en/binary-log.html).
@@ -8,21 +9,23 @@ This is a change data capture (CDC) connector that captures change events from a
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-mysql:dev`](https://github.com/estuary/connectors/pkgs/container/source-mysql) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
## Prerequisites
+
To use this connector, you'll need a MySQL database setup with the following.
-* [`binlog_format`](https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html#sysvar_binlog_format)
+
+- [`binlog_format`](https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html#sysvar_binlog_format)
system variable set to `ROW` (the default value).
-* [Binary log expiration period](https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html#sysvar_binlog_expire_logs_seconds) set to MySQL's default value of 30 days (2592000 seconds) if at all possible.
+- [Binary log expiration period](https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html#sysvar_binlog_expire_logs_seconds) set to MySQL's default value of 30 days (2592000 seconds) if at all possible.
- This value may be set lower if necessary, but we [strongly discourage](#insufficient-binlog-retention) going below 7 days as this may increase the likelihood of unrecoverable failures.
-* A watermarks table. The watermarks table is a small "scratch space"
+- A watermarks table. The watermarks table is a small "scratch space"
to which the connector occasionally writes a small amount of data (a UUID,
specifically) to ensure accuracy when backfilling preexisting table contents.
- The default name is `"flow.watermarks"`, but this can be overridden in `config.json`.
-* A database user with appropriate permissions:
+- A database user with appropriate permissions:
- `REPLICATION CLIENT` and `REPLICATION SLAVE` privileges.
- Permission to insert, update, and delete on the watermarks table.
- Permission to read the tables being captured.
- Permission to read from `information_schema` tables, if automatic discovery is used.
-* If the table(s) to be captured include columns of type `DATETIME`, the `time_zone` system variable
+- If the table(s) to be captured include columns of type `DATETIME`, the `time_zone` system variable
must be set to an IANA zone name or numerical offset or the capture configured with a `timezone` to use by default.
## Setup
@@ -30,44 +33,48 @@ To use this connector, you'll need a MySQL database setup with the following.
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * [Modify the database](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), setting **Public accessibility** to **Yes**.
- * Edit the VPC security group associated with your database, or create a new VPC security group and associate it with the database as described in [the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create). Create a new inbound rule and a new outbound rule that allow all traffic from the IP address `34.121.207.128`.
+
+ - [Modify the database](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), setting **Public accessibility** to **Yes**.
+ - Edit the VPC security group associated with your database, or create a new VPC security group and associate it with the database as described in [the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create). Create a new inbound rule and a new outbound rule that allow all traffic from the IP addresses: `34.121.207.128, 35.226.75.135, 34.68.62.148`.
2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
2. Create a RDS parameter group to enable replication in MySQL.
1. [Create a parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithDBInstanceParamGroups.html#USER_WorkingWithParamGroups.Creating).
- Create a unique name and description and set the following properties:
- * **Family**: mysql8.0
- * **Type**: DB Parameter group
+ Create a unique name and description and set the following properties:
+
+ - **Family**: mysql8.0
+ - **Type**: DB Parameter group
2. [Modify the new parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithDBInstanceParamGroups.html#USER_WorkingWithParamGroups.Modifying) and update the following parameters:
- * binlog_format: ROW
- * binlog_row_metadata: FULL
- * read_only: 0
- 3. If using the primary instance (not recommended), [associate the parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithDBInstanceParamGroups.html#USER_WorkingWithParamGroups.Associating)
- with the database and set [Backup Retention Period](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithAutomatedBackups.html#USER_WorkingWithAutomatedBackups.Enabling) to 7 days.
- Reboot the database to allow the changes to take effect.
+ - binlog_format: ROW
+ - binlog_row_metadata: FULL
+ - read_only: 0
+
+ 3. If using the primary instance (not recommended), [associate the parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithDBInstanceParamGroups.html#USER_WorkingWithParamGroups.Associating)
+ with the database and set [Backup Retention Period](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithAutomatedBackups.html#USER_WorkingWithAutomatedBackups.Enabling) to 7 days.
+ Reboot the database to allow the changes to take effect.
3. Create a read replica with the new parameter group applied (recommended).
1. [Create a read replica](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_ReadRepl.html#USER_ReadRepl.Create)
- of your MySQL database.
+ of your MySQL database.
2. [Modify the replica](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html)
- and set the following:
- * **DB parameter group**: choose the parameter group you created previously
- * **Backup retention period**: 7 days
- * **Public access**: Publicly accessible
+ and set the following:
+
+ - **DB parameter group**: choose the parameter group you created previously
+ - **Backup retention period**: 7 days
+ - **Public access**: Publicly accessible
3. Reboot the replica to allow the changes to take effect.
4. Switch to your MySQL client. Run the following commands to create a new user for the capture with appropriate permissions,
-and set up the watermarks table:
+ and set up the watermarks table:
```sql
CREATE DATABASE IF NOT EXISTS flow;
@@ -81,13 +88,13 @@ GRANT INSERT, UPDATE, DELETE ON flow.watermarks TO 'flow_capture';
```
5. Run the following command to set the binary log retention to 7 days, the maximum value which RDS MySQL permits:
+
```sql
CALL mysql.rds_set_configuration('binlog retention hours', 168);
```
6. In the [RDS console](https://console.aws.amazon.com/rds/), note the instance's Endpoint and Port. You'll need these for the `address` property when you configure the connector.
-
### Setting the MySQL time zone
MySQL's [`time_zone` server system variable](https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_time_zone) is set to `SYSTEM` by default.
@@ -99,12 +106,12 @@ To avoid this, you must explicitly set the time zone for your database.
You can:
-* Specify a numerical offset from UTC.
- - For MySQL version 8.0.19 or higher, values from `-13:59` to `+14:00`, inclusive, are permitted.
- - Prior to MySQL 8.0.19, values from `-12:59` to `+13:00`, inclusive, are permitted
+- Specify a numerical offset from UTC.
-* Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
+ - For MySQL version 8.0.19 or higher, values from `-13:59` to `+14:00`, inclusive, are permitted.
+ - Prior to MySQL 8.0.19, values from `-12:59` to `+13:00`, inclusive, are permitted
+- Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
For example, if you're located in New Jersey, USA, you could set `time_zone` to `-05:00` or `-04:00`, depending on the time of year.
Because this region observes daylight savings time, you'd be responsible for changing the offset.
@@ -118,7 +125,7 @@ If you are unable to set the `time_zone` in the database and need to capture tab
## Backfills and performance considerations
-When the a MySQL capture is initiated, by default, the connector first *backfills*, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
+When the a MySQL capture is initiated, by default, the connector first _backfills_, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
This is desirable in most cases, as in ensures that a complete view of your tables is captured into Flow.
However, you may find it appropriate to skip the backfill, especially for extremely large tables.
@@ -126,6 +133,7 @@ However, you may find it appropriate to skip the backfill, especially for extrem
In this case, you may turn of backfilling on a per-table basis. See [properties](#properties) for details.
## Configuration
+
You configure connectors either in the Flow web app, or by directly editing the catalog specification file.
See [connectors](/concepts/connectors.md#using-connectors) to learn more about using connectors. The values and specification sample below provide configuration details specific to the MySQL source connector.
@@ -133,26 +141,26 @@ See [connectors](/concepts/connectors.md#using-connectors) to learn more about u
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
-| **`/user`** | Login User | The database user to authenticate as. | string | Required, `"flow_capture"` |
-| **`/password`** | Login Password | Password for the specified database user. | string | Required |
-| `/timezone` | Timezone | Timezone to use when capturing datetime columns. Should normally be left blank to use the database's `'time_zone'` system variable. Only required if the `'time_zone'` system variable cannot be read and columns with type datetime are being captured. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the `'time_zone'` system variable if both are set. | string | |
-| `/advanced/watermarks_table` | Watermarks Table Name | The name of the table used for watermark writes. Must be fully-qualified in '<schema>.<table>' form. | string | `"flow.watermarks"` |
-| `/advanced/dbname` | Database Name | The name of database to connect to. In general this shouldn't matter. The connector can discover and capture from all databases it's authorized to access. | string | `"mysql"` |
-| `/advanced/node_id` | Node ID | Node ID for the capture. Each node in a replication cluster must have a unique 32-bit ID. The specific value doesn't matter so long as it is unique. If unset or zero the connector will pick a value. | integer | |
-| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
-| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `131072` |
-| `/advanced/skip_binlog_retention_check` | Skip Binlog Retention Sanity Check | Bypasses the 'dangerously short binlog retention' sanity check at startup. Only do this if you understand the danger and have a specific need. | boolean | |
+| Property | Title | Description | Type | Required/Default |
+| --------------------------------------- | ---------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------- | -------------------------- |
+| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
+| **`/user`** | Login User | The database user to authenticate as. | string | Required, `"flow_capture"` |
+| **`/password`** | Login Password | Password for the specified database user. | string | Required |
+| `/timezone` | Timezone | Timezone to use when capturing datetime columns. Should normally be left blank to use the database's `'time_zone'` system variable. Only required if the `'time_zone'` system variable cannot be read and columns with type datetime are being captured. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the `'time_zone'` system variable if both are set. | string | |
+| `/advanced/watermarks_table` | Watermarks Table Name | The name of the table used for watermark writes. Must be fully-qualified in '<schema>.<table>' form. | string | `"flow.watermarks"` |
+| `/advanced/dbname` | Database Name | The name of database to connect to. In general this shouldn't matter. The connector can discover and capture from all databases it's authorized to access. | string | `"mysql"` |
+| `/advanced/node_id` | Node ID | Node ID for the capture. Each node in a replication cluster must have a unique 32-bit ID. The specific value doesn't matter so long as it is unique. If unset or zero the connector will pick a value. | integer | |
+| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
+| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `131072` |
+| `/advanced/skip_binlog_retention_check` | Skip Binlog Retention Sanity Check | Bypasses the 'dangerously short binlog retention' sanity check at startup. Only do this if you understand the danger and have a specific need. | boolean | |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|-------|------|------|---------| --------|
-| **`/namespace`** | Namespace | The [database/schema](https://dev.mysql.com/doc/refman/8.0/en/show-databases.html) in which the table resides. | string | Required |
-| **`/stream`** | Stream | Name of the table to be captured from the database. | string | Required |
-| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental`. | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | --------- | -------------------------------------------------------------------------------------------------------------- | ------ | ---------------- |
+| **`/namespace`** | Namespace | The [database/schema](https://dev.mysql.com/doc/refman/8.0/en/show-databases.html) in which the table resides. | string | Required |
+| **`/stream`** | Stream | Name of the table to be captured from the database. | string | Required |
+| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental`. | string | Required |
:::info
When you configure this connector in the web application, the automatic **discovery** process sets up a binding for _most_ tables it finds in your database, but there are exceptions.
@@ -162,6 +170,7 @@ You can add bindings for such tables manually.
:::
### Sample
+
A minimal capture definition will look like the following:
```yaml
@@ -227,4 +236,3 @@ The `"binlog retention period is too short"` error should normally be fixed by s
### Empty Collection Key
Every Flow collection must declare a [key](/concepts/collections.md#keys) which is used to group its documents. When testing your capture, if you encounter an error indicating collection key cannot be empty, you will need to either add a key to the table in your source, or manually edit the generated specification and specify keys for the collection before publishing to the catalog as documented [here](/concepts/collections.md#empty-keys).
-
diff --git a/site/docs/reference/Connectors/capture-connectors/MySQL/google-cloud-sql-mysql.md b/site/docs/reference/Connectors/capture-connectors/MySQL/google-cloud-sql-mysql.md
index b49d36a237..f1c20e95a8 100644
--- a/site/docs/reference/Connectors/capture-connectors/MySQL/google-cloud-sql-mysql.md
+++ b/site/docs/reference/Connectors/capture-connectors/MySQL/google-cloud-sql-mysql.md
@@ -1,6 +1,7 @@
---
sidebar_position: 5
---
+
# Google Cloud SQL for MySQL
This is a change data capture (CDC) connector that captures change events from a MySQL database via the [Binary Log](https://dev.mysql.com/doc/refman/8.0/en/binary-log.html).
@@ -8,21 +9,23 @@ This is a change data capture (CDC) connector that captures change events from a
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-mysql:dev`](https://github.com/estuary/connectors/pkgs/container/source-mysql) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
## Prerequisites
+
To use this connector, you'll need a MySQL database setup with the following.
-* [`binlog_format`](https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html#sysvar_binlog_format)
+
+- [`binlog_format`](https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html#sysvar_binlog_format)
system variable set to `ROW` (the default value).
-* [Binary log expiration period](https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html#sysvar_binlog_expire_logs_seconds) set to MySQL's default value of 30 days (2592000 seconds) if at all possible.
+- [Binary log expiration period](https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html#sysvar_binlog_expire_logs_seconds) set to MySQL's default value of 30 days (2592000 seconds) if at all possible.
- This value may be set lower if necessary, but we [strongly discourage](#insufficient-binlog-retention) going below 7 days as this may increase the likelihood of unrecoverable failures.
-* A watermarks table. The watermarks table is a small "scratch space"
+- A watermarks table. The watermarks table is a small "scratch space"
to which the connector occasionally writes a small amount of data (a UUID,
specifically) to ensure accuracy when backfilling preexisting table contents.
- The default name is `"flow.watermarks"`, but this can be overridden in `config.json`.
-* A database user with appropriate permissions:
+- A database user with appropriate permissions:
- `REPLICATION CLIENT` and `REPLICATION SLAVE` privileges.
- Permission to insert, update, and delete on the watermarks table.
- Permission to read the tables being captured.
- Permission to read from `information_schema` tables, if automatic discovery is used.
-* If the table(s) to be captured include columns of type `DATETIME`, the `time_zone` system variable
+- If the table(s) to be captured include columns of type `DATETIME`, the `time_zone` system variable
must be set to an IANA zone name or numerical offset or the capture configured with a `timezone` to use by default.
## Setup
@@ -30,16 +33,18 @@ To use this connector, you'll need a MySQL database setup with the following.
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * [Enable public IP on your database](https://cloud.google.com/sql/docs/mysql/configure-ip#add) and add `34.121.207.128` as an authorized IP address.
+
+ - [Enable public IP on your database](https://cloud.google.com/sql/docs/mysql/configure-ip#add) and add `34.121.207.128, 35.226.75.135, 34.68.62.148` as authorized IP addresses.
2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
2. Set the instance's `binlog_expire_logs_seconds` [flag](https://cloud.google.com/sql/docs/mysql/flags?_ga=2.8077298.-1359189752.1655241239&_gac=1.226418280.1655849730.Cj0KCQjw2MWVBhCQARIsAIjbwoOczKklaVaykkUiCMZ4n3_jVtsInpmlugWN92zx6rL5i7zTxm3AALIaAv6nEALw_wcB)
-to `2592000`.
+ to `2592000`.
3. Using [Google Cloud Shell](https://cloud.google.com/sql/docs/mysql/connect-instance-cloud-shell) or your preferred client, create the watermarks table.
+
```sql
CREATE DATABASE IF NOT EXISTS flow;
CREATE TABLE IF NOT EXISTS flow.watermarks (slot INTEGER PRIMARY KEY, watermark TEXT);
@@ -47,8 +52,9 @@ CREATE TABLE IF NOT EXISTS flow.watermarks (slot INTEGER PRIMARY KEY, watermark
4. Create the `flow_capture` user with replication permission, the ability to read all tables, and the ability to read and write the watermarks table.
- The `SELECT` permission can be restricted to just the tables that need to be
- captured, but automatic discovery requires `information_schema` access as well.
+The `SELECT` permission can be restricted to just the tables that need to be
+captured, but automatic discovery requires `information_schema` access as well.
+
```sql
CREATE USER IF NOT EXISTS flow_capture
IDENTIFIED BY 'secret'
@@ -57,8 +63,9 @@ GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'flow_capture';
GRANT SELECT ON *.* TO 'flow_capture';
GRANT INSERT, UPDATE, DELETE ON flow.watermarks TO 'flow_capture';
```
+
5. In the Cloud Console, note the instance's host under Public IP Address. Its port will always be `3306`.
-Together, you'll use the host:port as the `address` property when you configure the connector.
+ Together, you'll use the host:port as the `address` property when you configure the connector.
### Setting the MySQL time zone
@@ -71,15 +78,16 @@ To avoid this, you must explicitly set the time zone for your database.
You can:
-* Specify a numerical offset from UTC.
- - For MySQL version 8.0.19 or higher, values from `-13:59` to `+14:00`, inclusive, are permitted.
- - Prior to MySQL 8.0.19, values from `-12:59` to `+13:00`, inclusive, are permitted
+- Specify a numerical offset from UTC.
+
+ - For MySQL version 8.0.19 or higher, values from `-13:59` to `+14:00`, inclusive, are permitted.
+ - Prior to MySQL 8.0.19, values from `-12:59` to `+13:00`, inclusive, are permitted
-* Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
+- Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
-* If you're using Amazon Aurora, create or modify the [DB cluster parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html)
-associated with your MySQL database.
-[Set](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.ModifyingCluster) the `time_zone` parameter to the correct value.
+- If you're using Amazon Aurora, create or modify the [DB cluster parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html)
+ associated with your MySQL database.
+ [Set](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.ModifyingCluster) the `time_zone` parameter to the correct value.
For example, if you're located in New Jersey, USA, you could set `time_zone` to `-05:00` or `-04:00`, depending on the time of year.
Because this region observes daylight savings time, you'd be responsible for changing the offset.
@@ -93,7 +101,7 @@ If you are unable to set the `time_zone` in the database and need to capture tab
## Backfills and performance considerations
-When the a MySQL capture is initiated, by default, the connector first *backfills*, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
+When the a MySQL capture is initiated, by default, the connector first _backfills_, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
This is desirable in most cases, as in ensures that a complete view of your tables is captured into Flow.
However, you may find it appropriate to skip the backfill, especially for extremely large tables.
@@ -101,6 +109,7 @@ However, you may find it appropriate to skip the backfill, especially for extrem
In this case, you may turn of backfilling on a per-table basis. See [properties](#properties) for details.
## Configuration
+
You configure connectors either in the Flow web app, or by directly editing the catalog specification file.
See [connectors](/concepts/connectors.md#using-connectors) to learn more about using connectors. The values and specification sample below provide configuration details specific to the MySQL source connector.
@@ -108,26 +117,26 @@ See [connectors](/concepts/connectors.md#using-connectors) to learn more about u
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
-| **`/user`** | Login User | The database user to authenticate as. | string | Required, `"flow_capture"` |
-| **`/password`** | Login Password | Password for the specified database user. | string | Required |
-| `/timezone` | Timezone | Timezone to use when capturing datetime columns. Should normally be left blank to use the database's `'time_zone'` system variable. Only required if the `'time_zone'` system variable cannot be read and columns with type datetime are being captured. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the `'time_zone'` system variable if both are set. | string | |
-| `/advanced/watermarks_table` | Watermarks Table Name | The name of the table used for watermark writes. Must be fully-qualified in '<schema>.<table>' form. | string | `"flow.watermarks"` |
-| `/advanced/dbname` | Database Name | The name of database to connect to. In general this shouldn't matter. The connector can discover and capture from all databases it's authorized to access. | string | `"mysql"` |
-| `/advanced/node_id` | Node ID | Node ID for the capture. Each node in a replication cluster must have a unique 32-bit ID. The specific value doesn't matter so long as it is unique. If unset or zero the connector will pick a value. | integer | |
-| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
-| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `131072` |
-| `/advanced/skip_binlog_retention_check` | Skip Binlog Retention Sanity Check | Bypasses the 'dangerously short binlog retention' sanity check at startup. Only do this if you understand the danger and have a specific need. | boolean | |
+| Property | Title | Description | Type | Required/Default |
+| --------------------------------------- | ---------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------- | -------------------------- |
+| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
+| **`/user`** | Login User | The database user to authenticate as. | string | Required, `"flow_capture"` |
+| **`/password`** | Login Password | Password for the specified database user. | string | Required |
+| `/timezone` | Timezone | Timezone to use when capturing datetime columns. Should normally be left blank to use the database's `'time_zone'` system variable. Only required if the `'time_zone'` system variable cannot be read and columns with type datetime are being captured. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the `'time_zone'` system variable if both are set. | string | |
+| `/advanced/watermarks_table` | Watermarks Table Name | The name of the table used for watermark writes. Must be fully-qualified in '<schema>.<table>' form. | string | `"flow.watermarks"` |
+| `/advanced/dbname` | Database Name | The name of database to connect to. In general this shouldn't matter. The connector can discover and capture from all databases it's authorized to access. | string | `"mysql"` |
+| `/advanced/node_id` | Node ID | Node ID for the capture. Each node in a replication cluster must have a unique 32-bit ID. The specific value doesn't matter so long as it is unique. If unset or zero the connector will pick a value. | integer | |
+| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
+| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `131072` |
+| `/advanced/skip_binlog_retention_check` | Skip Binlog Retention Sanity Check | Bypasses the 'dangerously short binlog retention' sanity check at startup. Only do this if you understand the danger and have a specific need. | boolean | |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|-------|------|------|---------| --------|
-| **`/namespace`** | Namespace | The [database/schema](https://dev.mysql.com/doc/refman/8.0/en/show-databases.html) in which the table resides. | string | Required |
-| **`/stream`** | Stream | Name of the table to be captured from the database. | string | Required |
-| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental`. | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | --------- | -------------------------------------------------------------------------------------------------------------- | ------ | ---------------- |
+| **`/namespace`** | Namespace | The [database/schema](https://dev.mysql.com/doc/refman/8.0/en/show-databases.html) in which the table resides. | string | Required |
+| **`/stream`** | Stream | Name of the table to be captured from the database. | string | Required |
+| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental`. | string | Required |
:::info
When you configure this connector in the web application, the automatic **discovery** process sets up a binding for _most_ tables it finds in your database, but there are exceptions.
@@ -137,6 +146,7 @@ You can add bindings for such tables manually.
:::
### Sample
+
A minimal capture definition will look like the following:
```yaml
@@ -202,4 +212,3 @@ The `"binlog retention period is too short"` error should normally be fixed by s
### Empty Collection Key
Every Flow collection must declare a [key](/concepts/collections.md#keys) which is used to group its documents. When testing your capture, if you encounter an error indicating collection key cannot be empty, you will need to either add a key to the table in your source, or manually edit the generated specification and specify keys for the collection before publishing to the catalog as documented [here](/concepts/collections.md#empty-keys).
-
diff --git a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/PostgreSQL.md b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/PostgreSQL.md
index f8a7925814..cf2fbc5fca 100644
--- a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/PostgreSQL.md
+++ b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/PostgreSQL.md
@@ -1,6 +1,7 @@
---
sidebar_position: 6
---
+
# PostgreSQL
This connector uses change data capture (CDC) to continuously capture updates in a PostgreSQL database into one or more Flow collections.
@@ -15,25 +16,26 @@ This connector supports PostgreSQL versions 10.0 and later on major cloud platfo
Setup instructions are provided for the following platforms:
-* [Self-hosted PostgreSQL](#self-hosted-postgresql)
-* [Amazon RDS](./amazon-rds-postgres/)
-* [Amazon Aurora](#amazon-aurora)
-* [Google Cloud SQL](./google-cloud-sql-postgres/)
-* [Azure Database for PostgreSQL](#azure-database-for-postgresql)
+- [Self-hosted PostgreSQL](#self-hosted-postgresql)
+- [Amazon RDS](./amazon-rds-postgres/)
+- [Amazon Aurora](#amazon-aurora)
+- [Google Cloud SQL](./google-cloud-sql-postgres/)
+- [Azure Database for PostgreSQL](#azure-database-for-postgresql)
## Prerequisites
You'll need a PostgreSQL database setup with the following:
-* [Logical replication enabled](https://www.postgresql.org/docs/current/runtime-config-wal.html) — `wal_level=logical`
-* [User role](https://www.postgresql.org/docs/current/sql-createrole.html) with `REPLICATION` attribute
-* A [replication slot](https://www.postgresql.org/docs/current/warm-standby.html#STREAMING-REPLICATION-SLOTS). This represents a “cursor” into the PostgreSQL write-ahead log from which change events can be read.
- * Optional; if none exist, one will be created by the connector.
- * If you wish to run multiple captures from the same database, each must have its own slot.
+
+- [Logical replication enabled](https://www.postgresql.org/docs/current/runtime-config-wal.html) — `wal_level=logical`
+- [User role](https://www.postgresql.org/docs/current/sql-createrole.html) with `REPLICATION` attribute
+- A [replication slot](https://www.postgresql.org/docs/current/warm-standby.html#STREAMING-REPLICATION-SLOTS). This represents a “cursor” into the PostgreSQL write-ahead log from which change events can be read.
+ - Optional; if none exist, one will be created by the connector.
+ - If you wish to run multiple captures from the same database, each must have its own slot.
You can create these slots yourself, or by specifying a name other than the default in the advanced [configuration](#configuration).
-* A [publication](https://www.postgresql.org/docs/current/sql-createpublication.html). This represents the set of tables for which change events will be reported.
- * In more restricted setups, this must be created manually, but can be created automatically if the connector has suitable permissions.
-* A watermarks table. The watermarks table is a small “scratch space” to which the connector occasionally writes a small amount of data to ensure accuracy when backfilling preexisting table contents.
- * In more restricted setups, this must be created manually, but can be created automatically if the connector has suitable permissions.
+- A [publication](https://www.postgresql.org/docs/current/sql-createpublication.html). This represents the set of tables for which change events will be reported.
+ - In more restricted setups, this must be created manually, but can be created automatically if the connector has suitable permissions.
+- A watermarks table. The watermarks table is a small “scratch space” to which the connector occasionally writes a small amount of data to ensure accuracy when backfilling preexisting table contents.
+ - In more restricted setups, this must be created manually, but can be created automatically if the connector has suitable permissions.
:::tip Configuration Tip
To configure this connector to capture data from databases hosted on your internal network, you must set up SSH tunneling. For more specific instructions on setup, see [configure connections with SSH tunneling](/guides/connect-network/).
@@ -43,12 +45,12 @@ To configure this connector to capture data from databases hosted on your intern
To meet these requirements, follow the steps for your hosting type.
-* [Self-hosted PostgreSQL](#self-hosted-postgresql)
-* [Amazon RDS](./amazon-rds-postgres/)
-* [Amazon Aurora](#amazon-aurora)
-* [Google Cloud SQL](./google-cloud-sql-postgres/)
-* [Azure Database for PostgreSQL](#azure-database-for-postgresql)
-* [Supabase](Supabase)
+- [Self-hosted PostgreSQL](#self-hosted-postgresql)
+- [Amazon RDS](./amazon-rds-postgres/)
+- [Amazon Aurora](#amazon-aurora)
+- [Google Cloud SQL](./google-cloud-sql-postgres/)
+- [Azure Database for PostgreSQL](#azure-database-for-postgresql)
+- [Supabase](Supabase)
### Self-hosted PostgreSQL
@@ -57,31 +59,35 @@ The simplest way to meet the above prerequisites is to change the WAL level and
For a more restricted setup, create a new user with just the required permissions as detailed in the following steps:
1. Connect to your instance and create a new user and password:
+
```sql
CREATE USER flow_capture WITH PASSWORD 'secret' REPLICATION;
```
+
2. Assign the appropriate role.
- 1. If using PostgreSQL v14 or later:
-
- ```sql
- GRANT pg_read_all_data TO flow_capture;
- ```
-
- 2. If using an earlier version:
-
- ```sql
- ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES to flow_capture;
- GRANT SELECT ON ALL TABLES IN SCHEMA public, TO flow_capture;
- GRANT SELECT ON ALL TABLES IN SCHEMA information_schema, pg_catalog TO flow_capture;
- ```
-
- where `` lists all schemas that will be captured from.
- :::info
- If an even more restricted set of permissions is desired, you can also grant SELECT on
- just the specific table(s) which should be captured from. The ‘information_schema’ and
- ‘pg_catalog’ access is required for stream auto-discovery, but not for capturing already
- configured streams.
- :::
+
+ 1. If using PostgreSQL v14 or later:
+
+ ```sql
+ GRANT pg_read_all_data TO flow_capture;
+ ```
+
+ 2. If using an earlier version:
+
+ ```sql
+ ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES to flow_capture;
+ GRANT SELECT ON ALL TABLES IN SCHEMA public, TO flow_capture;
+ GRANT SELECT ON ALL TABLES IN SCHEMA information_schema, pg_catalog TO flow_capture;
+ ```
+
+ where `` lists all schemas that will be captured from.
+ :::info
+ If an even more restricted set of permissions is desired, you can also grant SELECT on
+ just the specific table(s) which should be captured from. The ‘information_schema’ and
+ ‘pg_catalog’ access is required for stream auto-discovery, but not for capturing already
+ configured streams.
+ :::
+
3. Create the watermarks table, grant privileges, and create publication:
```sql
@@ -97,35 +103,36 @@ setting is recommended (because most users will want changes to a partitioned ta
under the name of the root table) but is not required.
4. Set WAL level to logical:
+
```sql
ALTER SYSTEM SET wal_level = logical;
```
-5. Restart PostgreSQL to allow the WAL level change to take effect.
+5. Restart PostgreSQL to allow the WAL level change to take effect.
### Amazon Aurora
You must apply some of the settings to the entire Aurora DB cluster, and others to a database instance within the cluster.
For each step, take note of which entity you're working with.
-
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * [Modify the instance](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Modifying.html#Aurora.Modifying.Instance), choosing **Publicly accessible** in the **Connectivity** settings.
- * Edit the VPC security group associated with your instance, or create a new VPC security group and associate it with the instance as described in [the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create). Create a new inbound rule and a new outbound rule that allow all traffic from the IP address `34.121.207.128`.
- 2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - [Modify the instance](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Modifying.html#Aurora.Modifying.Instance), choosing **Publicly accessible** in the **Connectivity** settings.
+ - Edit the VPC security group associated with your instance, or create a new VPC security group and associate it with the instance as described in [the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create). Create a new inbound rule and a new outbound rule that allow all traffic from the IP addresses `34.121.207.128, 35.226.75.135, 34.68.62.148`.
+ 2. To allow secure connections via SSH tunneling:
+ - Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
2. Enable logical replication on your Aurora DB cluster.
1. Create a [parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.CreatingCluster).
- Create a unique name and description and set the following properties:
- * **Family**: aurora-postgresql13, or substitute the version of Aurora PostgreSQL used for your cluster.
- * **Type**: DB Cluster Parameter group
+ Create a unique name and description and set the following properties:
+
+ - **Family**: aurora-postgresql13, or substitute the version of Aurora PostgreSQL used for your cluster.
+ - **Type**: DB Cluster Parameter group
2. [Modify the new parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.ModifyingCluster) and set `rds.logical_replication=1`.
@@ -134,36 +141,37 @@ For each step, take note of which entity you're working with.
4. Reboot the cluster to allow the new parameter group to take effect.
3. In the PostgreSQL client, connect to your instance and run the following commands to create a new user for the capture with appropriate permissions,
-and set up the watermarks table and publication.
- ```sql
- CREATE USER flow_capture WITH PASSWORD 'secret';
- GRANT rds_replication TO flow_capture;
- GRANT SELECT ON ALL TABLES IN SCHEMA public TO flow_capture;
- ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO flow_capture;
- CREATE TABLE IF NOT EXISTS public.flow_watermarks (slot TEXT PRIMARY KEY, watermark TEXT);
- GRANT ALL PRIVILEGES ON TABLE public.flow_watermarks TO flow_capture;
- CREATE PUBLICATION flow_publication;
- ALTER PUBLICATION flow_publication SET (publish_via_partition_root = true);
- ALTER PUBLICATION flow_publication ADD TABLE public.flow_watermarks, ;
- ```
+ and set up the watermarks table and publication.
- where `` lists all tables that will be captured from. The `publish_via_partition_root`
- setting is recommended (because most users will want changes to a partitioned table to be captured
- under the name of the root table) but is not required.
+```sql
+CREATE USER flow_capture WITH PASSWORD 'secret';
+GRANT rds_replication TO flow_capture;
+GRANT SELECT ON ALL TABLES IN SCHEMA public TO flow_capture;
+ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO flow_capture;
+CREATE TABLE IF NOT EXISTS public.flow_watermarks (slot TEXT PRIMARY KEY, watermark TEXT);
+GRANT ALL PRIVILEGES ON TABLE public.flow_watermarks TO flow_capture;
+CREATE PUBLICATION flow_publication;
+ALTER PUBLICATION flow_publication SET (publish_via_partition_root = true);
+ALTER PUBLICATION flow_publication ADD TABLE public.flow_watermarks, ;
+```
-6. In the [RDS console](https://console.aws.amazon.com/rds/), note the instance's Endpoint and Port. You'll need these for the `address` property when you configure the connector.
+where `` lists all tables that will be captured from. The `publish_via_partition_root`
+setting is recommended (because most users will want changes to a partitioned table to be captured
+under the name of the root table) but is not required.
+6. In the [RDS console](https://console.aws.amazon.com/rds/), note the instance's Endpoint and Port. You'll need these for the `address` property when you configure the connector.
### Azure Database for PostgreSQL
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * Create a new [firewall rule](https://docs.microsoft.com/en-us/azure/postgresql/flexible-server/how-to-manage-firewall-portal#create-a-firewall-rule-after-server-is-created) that grants access to the IP address `34.121.207.128`.
+
+ - Create a new [firewall rule](https://docs.microsoft.com/en-us/azure/postgresql/flexible-server/how-to-manage-firewall-portal#create-a-firewall-rule-after-server-is-created) that grants access to the IP addresses `34.121.207.128, 35.226.75.135, 34.68.62.148`.
2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
2. In your Azure PostgreSQL instance's support parameters, [set replication to logical](https://docs.microsoft.com/en-us/azure/postgresql/single-server/concepts-logical#set-up-your-server) to enable logical replication.
@@ -173,26 +181,27 @@ and set up the watermarks table and publication.
CREATE USER flow_capture WITH PASSWORD 'secret' REPLICATION;
```
- * If using PostgreSQL v14 or later:
+- If using PostgreSQL v14 or later:
```sql
GRANT pg_read_all_data TO flow_capture;
```
- * If using an earlier version:
+- If using an earlier version:
- ```sql
- ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES to flow_capture;
- GRANT SELECT ON ALL TABLES IN SCHEMA public, TO flow_capture;
- GRANT SELECT ON ALL TABLES IN SCHEMA information_schema, pg_catalog TO flow_capture;
- ```
- where `` lists all schemas that will be captured from.
+ ```sql
+ ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES to flow_capture;
+ GRANT SELECT ON ALL TABLES IN SCHEMA public, TO flow_capture;
+ GRANT SELECT ON ALL TABLES IN SCHEMA information_schema, pg_catalog TO flow_capture;
+ ```
+
+ where `` lists all schemas that will be captured from.
- :::info
- If an even more restricted set of permissions is desired, you can also grant SELECT on
- just the specific table(s) which should be captured from. The ‘information_schema’ and ‘pg_catalog’ access is required for stream auto-discovery, but not for capturing already
- configured streams.
- :::
+ :::info
+ If an even more restricted set of permissions is desired, you can also grant SELECT on
+ just the specific table(s) which should be captured from. The ‘information_schema’ and ‘pg_catalog’ access is required for stream auto-discovery, but not for capturing already
+ configured streams.
+ :::
4. Set up the watermarks table and publication.
@@ -209,12 +218,12 @@ ALTER PUBLICATION flow_publication ADD TABLE public.flow_watermarks, ;
- ```
-
- where `` lists all tables that will be captured from. The `publish_via_partition_root`
- setting is recommended (because most users will want changes to a partitioned table to be captured
- under the name of the root table) but is not required.
+ and set up the watermarks table and publication.
-6. In the [RDS console](https://console.aws.amazon.com/rds/), note the instance's Endpoint and Port. You'll need these for the `address` property when you configure the connector.
+```sql
+CREATE USER flow_capture WITH PASSWORD 'secret';
+GRANT rds_replication TO flow_capture;
+GRANT SELECT ON ALL TABLES IN SCHEMA public TO flow_capture;
+ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO flow_capture;
+CREATE TABLE IF NOT EXISTS public.flow_watermarks (slot TEXT PRIMARY KEY, watermark TEXT);
+GRANT ALL PRIVILEGES ON TABLE public.flow_watermarks TO flow_capture;
+CREATE PUBLICATION flow_publication;
+ALTER PUBLICATION flow_publication SET (publish_via_partition_root = true);
+ALTER PUBLICATION flow_publication ADD TABLE public.flow_watermarks, ;
+```
+where `` lists all tables that will be captured from. The `publish_via_partition_root`
+setting is recommended (because most users will want changes to a partitioned table to be captured
+under the name of the root table) but is not required.
+
+6. In the [RDS console](https://console.aws.amazon.com/rds/), note the instance's Endpoint and Port. You'll need these for the `address` property when you configure the connector.
## Backfills and performance considerations
-When the a PostgreSQL capture is initiated, by default, the connector first *backfills*, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
+When the a PostgreSQL capture is initiated, by default, the connector first _backfills_, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
This is desirable in most cases, as in ensures that a complete view of your tables is captured into Flow.
However, you may find it appropriate to skip the backfill, especially for extremely large tables.
@@ -94,7 +94,7 @@ See [connectors](/concepts/connectors.md#using-connectors) to learn more about u
#### Endpoint
| Property | Title | Description | Type | Required/Default |
-|---------------------------------|---------------------|---------------------------------------------------------------------------------------------------------------------------------------------|---------|----------------------------|
+| ------------------------------- | ------------------- | ------------------------------------------------------------------------------------------------------------------------------------------- | ------- | -------------------------- |
| **`/address`** | Address | The host or host:port at which the database can be reached. | string | Required |
| **`/database`** | Database | Logical database name to capture from. | string | Required, `"postgres"` |
| **`/user`** | User | The database user to authenticate as. | string | Required, `"flow_capture"` |
@@ -105,12 +105,12 @@ See [connectors](/concepts/connectors.md#using-connectors) to learn more about u
| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
| `/advanced/slotName` | Slot Name | The name of the PostgreSQL replication slot to replicate from. | string | `"flow_slot"` |
| `/advanced/watermarksTable` | Watermarks Table | The name of the table used for watermark writes during backfills. Must be fully-qualified in '<schema>.<table>' form. | string | `"public.flow_watermarks"` |
-| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
+| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
#### Bindings
| Property | Title | Description | Type | Required/Default |
-|------------------|-----------|--------------------------------------------------------------------------------------------|--------|------------------|
+| ---------------- | --------- | ------------------------------------------------------------------------------------------ | ------ | ---------------- |
| **`/namespace`** | Namespace | The [namespace/schema](https://www.postgresql.org/docs/9.1/ddl-schemas.html) of the table. | string | Required |
| **`/stream`** | Stream | Table name. | string | Required |
| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental`. | string | Required |
@@ -141,6 +141,7 @@ captures:
syncMode: incremental
target: ${PREFIX}/${COLLECTION_NAME}
```
+
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
@@ -173,7 +174,7 @@ If you encounter an issue that you suspect is due to TOASTed values, try the fol
- Ensure your collection's schema is using the merge [reduction strategy](/concepts/schemas.md#reduce-annotations).
- [Set REPLICA IDENTITY to FULL](https://www.postgresql.org/docs/9.4/sql-altertable.html) for the table. This circumvents the problem by forcing the
-WAL to record all values regardless of size. However, this can have performance impacts on your database and must be carefully evaluated.
+ WAL to record all values regardless of size. However, this can have performance impacts on your database and must be carefully evaluated.
- [Contact Estuary support](mailto:support@estuary.dev) for assistance.
## Publications
diff --git a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/google-cloud-sql-postgres.md b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/google-cloud-sql-postgres.md
index e57529830c..6d3af37242 100644
--- a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/google-cloud-sql-postgres.md
+++ b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/google-cloud-sql-postgres.md
@@ -1,6 +1,7 @@
---
sidebar_position: 6
---
+
# Google Cloud SQL for PostgreSQL
This connector uses change data capture (CDC) to continuously capture updates in a PostgreSQL database into one or more Flow collections.
@@ -14,55 +15,57 @@ This connector supports PostgreSQL versions 10.0 and later.
## Prerequisites
You'll need a PostgreSQL database setup with the following:
-* [Logical replication enabled](https://www.postgresql.org/docs/current/runtime-config-wal.html) — `wal_level=logical`
-* [User role](https://www.postgresql.org/docs/current/sql-createrole.html) with `REPLICATION` attribute
-* A [replication slot](https://www.postgresql.org/docs/current/warm-standby.html#STREAMING-REPLICATION-SLOTS). This represents a “cursor” into the PostgreSQL write-ahead log from which change events can be read.
- * Optional; if none exist, one will be created by the connector.
- * If you wish to run multiple captures from the same database, each must have its own slot.
+
+- [Logical replication enabled](https://www.postgresql.org/docs/current/runtime-config-wal.html) — `wal_level=logical`
+- [User role](https://www.postgresql.org/docs/current/sql-createrole.html) with `REPLICATION` attribute
+- A [replication slot](https://www.postgresql.org/docs/current/warm-standby.html#STREAMING-REPLICATION-SLOTS). This represents a “cursor” into the PostgreSQL write-ahead log from which change events can be read.
+ - Optional; if none exist, one will be created by the connector.
+ - If you wish to run multiple captures from the same database, each must have its own slot.
You can create these slots yourself, or by specifying a name other than the default in the advanced [configuration](#configuration).
-* A [publication](https://www.postgresql.org/docs/current/sql-createpublication.html). This represents the set of tables for which change events will be reported.
- * In more restricted setups, this must be created manually, but can be created automatically if the connector has suitable permissions.
-* A watermarks table. The watermarks table is a small “scratch space” to which the connector occasionally writes a small amount of data to ensure accuracy when backfilling preexisting table contents.
- * In more restricted setups, this must be created manually, but can be created automatically if the connector has suitable permissions.
+- A [publication](https://www.postgresql.org/docs/current/sql-createpublication.html). This represents the set of tables for which change events will be reported.
+ - In more restricted setups, this must be created manually, but can be created automatically if the connector has suitable permissions.
+- A watermarks table. The watermarks table is a small “scratch space” to which the connector occasionally writes a small amount of data to ensure accuracy when backfilling preexisting table contents.
+ - In more restricted setups, this must be created manually, but can be created automatically if the connector has suitable permissions.
## Setup
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * [Enable public IP on your database](https://cloud.google.com/sql/docs/mysql/configure-ip#add) and add `34.121.207.128` as an authorized IP address.
+
+ - [Enable public IP on your database](https://cloud.google.com/sql/docs/mysql/configure-ip#add) and add `34.121.207.128, 35.226.75.135, 34.68.62.148` as authorized IP addresses.
2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](../../../../../guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](../../../../concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - Follow the guide to [configure an SSH server for tunneling](../../../../../guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](../../../../concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
2. On Google Cloud, navigate to your instance's Overview page. Click "Edit configuration". Scroll down to the Flags section. Click "ADD FLAG". Set [the `cloudsql.logical_decoding` flag to `on`](https://cloud.google.com/sql/docs/postgres/flags) to enable logical replication on your Cloud SQL PostgreSQL instance.
3. In your PostgreSQL client, connect to your instance and issue the following commands to create a new user for the capture with appropriate permissions,
-and set up the watermarks table and publication.
-
- ```sql
- CREATE USER flow_capture WITH REPLICATION
- IN ROLE cloudsqlsuperuser LOGIN PASSWORD 'secret';
- GRANT SELECT ON ALL TABLES IN SCHEMA public TO flow_capture;
- ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO flow_capture;
- CREATE TABLE IF NOT EXISTS public.flow_watermarks (slot TEXT PRIMARY KEY, watermark TEXT);
- GRANT ALL PRIVILEGES ON TABLE public.flow_watermarks TO flow_capture;
- CREATE PUBLICATION flow_publication;
- ALTER PUBLICATION flow_publication SET (publish_via_partition_root = true);
- ALTER PUBLICATION flow_publication ADD TABLE public.flow_watermarks, ;
- ```
-
- where `` lists all tables that will be captured from. The `publish_via_partition_root`
- setting is recommended (because most users will want changes to a partitioned table to be captured
- under the name of the root table) but is not required.
+ and set up the watermarks table and publication.
+
+```sql
+CREATE USER flow_capture WITH REPLICATION
+IN ROLE cloudsqlsuperuser LOGIN PASSWORD 'secret';
+GRANT SELECT ON ALL TABLES IN SCHEMA public TO flow_capture;
+ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO flow_capture;
+CREATE TABLE IF NOT EXISTS public.flow_watermarks (slot TEXT PRIMARY KEY, watermark TEXT);
+GRANT ALL PRIVILEGES ON TABLE public.flow_watermarks TO flow_capture;
+CREATE PUBLICATION flow_publication;
+ALTER PUBLICATION flow_publication SET (publish_via_partition_root = true);
+ALTER PUBLICATION flow_publication ADD TABLE public.flow_watermarks, ;
+```
+
+where `` lists all tables that will be captured from. The `publish_via_partition_root`
+setting is recommended (because most users will want changes to a partitioned table to be captured
+under the name of the root table) but is not required.
4. In the Cloud Console, note the instance's host under Public IP Address. Its port will always be `5432`.
-Together, you'll use the host:port as the `address` property when you configure the connector.
+ Together, you'll use the host:port as the `address` property when you configure the connector.
## Backfills and performance considerations
-When the a PostgreSQL capture is initiated, by default, the connector first *backfills*, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
+When the a PostgreSQL capture is initiated, by default, the connector first _backfills_, or captures the targeted tables in their current state. It then transitions to capturing change events on an ongoing basis.
This is desirable in most cases, as in ensures that a complete view of your tables is captured into Flow.
However, you may find it appropriate to skip the backfill, especially for extremely large tables.
@@ -79,7 +82,7 @@ See [connectors](../../../../concepts/connectors.md#using-connectors) to learn m
#### Endpoint
| Property | Title | Description | Type | Required/Default |
-|---------------------------------|---------------------|---------------------------------------------------------------------------------------------------------------------------------------------|---------|----------------------------|
+| ------------------------------- | ------------------- | ------------------------------------------------------------------------------------------------------------------------------------------- | ------- | -------------------------- |
| **`/address`** | Address | The host or host:port at which the database can be reached. | string | Required |
| **`/database`** | Database | Logical database name to capture from. | string | Required, `"postgres"` |
| **`/user`** | User | The database user to authenticate as. | string | Required, `"flow_capture"` |
@@ -90,12 +93,12 @@ See [connectors](../../../../concepts/connectors.md#using-connectors) to learn m
| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
| `/advanced/slotName` | Slot Name | The name of the PostgreSQL replication slot to replicate from. | string | `"flow_slot"` |
| `/advanced/watermarksTable` | Watermarks Table | The name of the table used for watermark writes during backfills. Must be fully-qualified in '<schema>.<table>' form. | string | `"public.flow_watermarks"` |
-| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
+| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
#### Bindings
| Property | Title | Description | Type | Required/Default |
-|------------------|-----------|--------------------------------------------------------------------------------------------|--------|------------------|
+| ---------------- | --------- | ------------------------------------------------------------------------------------------ | ------ | ---------------- |
| **`/namespace`** | Namespace | The [namespace/schema](https://www.postgresql.org/docs/9.1/ddl-schemas.html) of the table. | string | Required |
| **`/stream`** | Stream | Table name. | string | Required |
| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental`. | string | Required |
@@ -122,6 +125,7 @@ captures:
syncMode: incremental
target: ${PREFIX}/${COLLECTION_NAME}
```
+
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
[Learn more about capture definitions.](../../../../concepts/captures.md#pull-captures)
@@ -154,7 +158,7 @@ If you encounter an issue that you suspect is due to TOASTed values, try the fol
- Ensure your collection's schema is using the merge [reduction strategy](../../../../concepts/schemas.md#reduce-annotations).
- [Set REPLICA IDENTITY to FULL](https://www.postgresql.org/docs/9.4/sql-altertable.html) for the table. This circumvents the problem by forcing the
-WAL to record all values regardless of size. However, this can have performance impacts on your database and must be carefully evaluated.
+ WAL to record all values regardless of size. However, this can have performance impacts on your database and must be carefully evaluated.
- [Contact Estuary support](mailto:support@estuary.dev) for assistance.
## Publications
diff --git a/site/docs/reference/Connectors/capture-connectors/SQLServer/amazon-rds-sqlserver.md b/site/docs/reference/Connectors/capture-connectors/SQLServer/amazon-rds-sqlserver.md
index 42c18ed5ce..ce4d89f246 100644
--- a/site/docs/reference/Connectors/capture-connectors/SQLServer/amazon-rds-sqlserver.md
+++ b/site/docs/reference/Connectors/capture-connectors/SQLServer/amazon-rds-sqlserver.md
@@ -4,7 +4,6 @@ sidebar_position: 3
# Amazon RDS for SQL Server
-
This connector uses change data capture (CDC) to continuously capture updates in a Microsoft SQL Server database into one or more Flow collections.
It’s available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/source-sqlserver:dev`](https://ghcr.io/estuary/source-sqlserver:dev) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
@@ -17,41 +16,42 @@ This connector designed for databases using any version of SQL Server which has
To capture change events from SQL Server tables using this connector, you need:
-* For each table to be captured, a primary key should be specified in the database.
-If a table doesn't have a primary key, you must manually specify a key in the associated Flow collection definition while creating the capture.
-[See detailed steps](#specifying-flow-collection-keys).
+- For each table to be captured, a primary key should be specified in the database.
+ If a table doesn't have a primary key, you must manually specify a key in the associated Flow collection definition while creating the capture.
+ [See detailed steps](#specifying-flow-collection-keys).
-* [CDC enabled](https://learn.microsoft.com/en-us/sql/relational-databases/track-changes/enable-and-disable-change-data-capture-sql-server?view=sql-server-ver16)
-on the database and the individual tables to be captured.
-(This creates *change tables* in the database, from which the connector reads.)
+- [CDC enabled](https://learn.microsoft.com/en-us/sql/relational-databases/track-changes/enable-and-disable-change-data-capture-sql-server?view=sql-server-ver16)
+ on the database and the individual tables to be captured.
+ (This creates _change tables_ in the database, from which the connector reads.)
-* A **watermarks table**. The watermarks table is a small “scratch space” to which the connector occasionally writes a small amount of data to ensure accuracy when backfilling preexisting table contents.
+- A **watermarks table**. The watermarks table is a small “scratch space” to which the connector occasionally writes a small amount of data to ensure accuracy when backfilling preexisting table contents.
-* A user role with:
- * `SELECT` permissions on the CDC schema and the schemas that contain tables to be captured.
- * Access to the change tables created as part of the SQL Server CDC process.
- * `SELECT`, `INSERT`, and `UPDATE` permissions on the watermarks table
+- A user role with:
+ - `SELECT` permissions on the CDC schema and the schemas that contain tables to be captured.
+ - Access to the change tables created as part of the SQL Server CDC process.
+ - `SELECT`, `INSERT`, and `UPDATE` permissions on the watermarks table
To meet these requirements, follow the steps for your hosting type.
-* [Self-hosted SQL Server](#setup-self-hosted-sql-server)
-* [Azure SQL Database](#setup-azure-sql-database)
-* [Amazon RDS for SQL Server](#setup-amazon-rds-for-sql-server)
-* [Google Cloud SQL for SQL Server](#setup-google-cloud-sql-for-sql-server)
+- [Self-hosted SQL Server](#setup-self-hosted-sql-server)
+- [Azure SQL Database](#setup-azure-sql-database)
+- [Amazon RDS for SQL Server](#setup-amazon-rds-for-sql-server)
+- [Google Cloud SQL for SQL Server](#setup-google-cloud-sql-for-sql-server)
## Setup
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * [Modify the database](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), setting **Public accessibility** to **Yes**.
- * Edit the VPC security group associated with your database, or create a new VPC security group and associate it with the database as described in [the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create).Create a new inbound rule and a new outbound rule that allow all traffic from the IP address `34.121.207.128`.
+
+ - [Modify the database](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), setting **Public accessibility** to **Yes**.
+ - Edit the VPC security group associated with your database, or create a new VPC security group and associate it with the database as described in [the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create).Create a new inbound rule and a new outbound rule that allow all traffic from the IP addresses `34.121.207.128, 35.226.75.135, 34.68.62.148`.
2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
-2. In your SQL client, connect to your instance as the default `sqlserver` user and issue the following commands.
+2. In your SQL client, connect to your instance as the default `sqlserver` user and issue the following commands.
```sql
USE ;
@@ -72,6 +72,7 @@ GRANT SELECT, INSERT, UPDATE ON dbo.flow_watermarks TO flow_capture;
-- You should add similar query for all other tables you intend to capture.
EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'flow_watermarks', @role_name = 'flow_capture';
```
+
6. In the [RDS console](https://console.aws.amazon.com/rds/), note the instance's Endpoint and Port. You'll need these for the `address` property when you configure the connector.
## Configuration
@@ -83,24 +84,24 @@ See [connectors](/concepts/connectors.md#using-connectors) to learn more about u
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
-| **`/database`** | Database | Logical database name to capture from. | string | Required |
-| **`/user`** | User | The database user to authenticate as. | string | Required, `"flow_capture"` |
-| **`/password`** | Password | Password for the specified database user. | string | Required |
-| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
-| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `4096` |
-| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
-| `/advanced/watermarksTable` | Watermarks Table | The name of the table used for watermark writes during backfills. Must be fully-qualified in '<schema>.<table>' form. | string | `"dbo.flow_watermarks"` |
+| Property | Title | Description | Type | Required/Default |
+| ------------------------------- | ------------------- | ------------------------------------------------------------------------------------------------------------------------------------------- | ------- | -------------------------- |
+| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
+| **`/database`** | Database | Logical database name to capture from. | string | Required |
+| **`/user`** | User | The database user to authenticate as. | string | Required, `"flow_capture"` |
+| **`/password`** | Password | Password for the specified database user. | string | Required |
+| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
+| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `4096` |
+| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
+| `/advanced/watermarksTable` | Watermarks Table | The name of the table used for watermark writes during backfills. Must be fully-qualified in '<schema>.<table>' form. | string | `"dbo.flow_watermarks"` |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|-------|------|------|---------| --------|
-| **`/namespace`** | Namespace | The [namespace/schema](https://learn.microsoft.com/en-us/sql/relational-databases/databases/databases?view=sql-server-ver16#basic-information-about-databases) of the table. | string | Required |
-| **`/stream`** | Stream | Table name. | string | Required |
-| `/primary_key` | Primary Key Columns | array | The columns which together form the primary key of the table. | |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | ------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------- | ---------------- |
+| **`/namespace`** | Namespace | The [namespace/schema](https://learn.microsoft.com/en-us/sql/relational-databases/databases/databases?view=sql-server-ver16#basic-information-about-databases) of the table. | string | Required |
+| **`/stream`** | Stream | Table name. | string | Required |
+| `/primary_key` | Primary Key Columns | array | The columns which together form the primary key of the table. | |
### Sample
@@ -122,6 +123,7 @@ captures:
primary_key: ["id"]
target: ${PREFIX}/${COLLECTION_NAME}
```
+
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
@@ -136,8 +138,8 @@ In cases where a SQL Server table you want to capture doesn't have a primary key
you can manually add it to the collection definition during the [capture creation workflow](/guides/create-dataflow.md#create-a-capture).
1. After you input the endpoint configuration and click **Next**,
-the tables in your database have been mapped to Flow collections.
-Click each collection's **Specification** tab and identify a collection where `"key": [ ],` is empty.
+ the tables in your database have been mapped to Flow collections.
+ Click each collection's **Specification** tab and identify a collection where `"key": [ ],` is empty.
2. Click inside the empty key value in the editor and input the name of column in the table to use as the key, formatted as a JSON pointer. For example `"key": ["/foo"],`
diff --git a/site/docs/reference/Connectors/capture-connectors/SQLServer/google-cloud-sql-sqlserver.md b/site/docs/reference/Connectors/capture-connectors/SQLServer/google-cloud-sql-sqlserver.md
index d033e546e8..981c800bb2 100644
--- a/site/docs/reference/Connectors/capture-connectors/SQLServer/google-cloud-sql-sqlserver.md
+++ b/site/docs/reference/Connectors/capture-connectors/SQLServer/google-cloud-sql-sqlserver.md
@@ -1,6 +1,7 @@
---
sidebar_position: 6
---
+
# Google Cloud SQL for SQL Server
This connector uses change data capture (CDC) to continuously capture updates in a Microsoft SQL Server database into one or more Flow collections.
@@ -15,31 +16,32 @@ This connector is designed for databases using any version of SQL Server which h
To capture change events from SQL Server tables using this connector, you need:
-* For each table to be captured, a primary key should be specified in the database.
-If a table doesn't have a primary key, you must manually specify a key in the associated Flow collection definition while creating the capture.
-[See detailed steps](#specifying-flow-collection-keys).
+- For each table to be captured, a primary key should be specified in the database.
+ If a table doesn't have a primary key, you must manually specify a key in the associated Flow collection definition while creating the capture.
+ [See detailed steps](#specifying-flow-collection-keys).
-* [CDC enabled](https://learn.microsoft.com/en-us/sql/relational-databases/track-changes/enable-and-disable-change-data-capture-sql-server?view=sql-server-ver16)
-on the database and the individual tables to be captured.
-(This creates *change tables* in the database, from which the connector reads.)
+- [CDC enabled](https://learn.microsoft.com/en-us/sql/relational-databases/track-changes/enable-and-disable-change-data-capture-sql-server?view=sql-server-ver16)
+ on the database and the individual tables to be captured.
+ (This creates _change tables_ in the database, from which the connector reads.)
-* A **watermarks table**. The watermarks table is a small “scratch space” to which the connector occasionally writes a small amount of data to ensure accuracy when backfilling preexisting table contents.
+- A **watermarks table**. The watermarks table is a small “scratch space” to which the connector occasionally writes a small amount of data to ensure accuracy when backfilling preexisting table contents.
-* A user role with:
- * `SELECT` permissions on the CDC schema and the schemas that contain tables to be captured.
- * Access to the change tables created as part of the SQL Server CDC process.
- * `SELECT`, `INSERT`, and `UPDATE` permissions on the watermarks table
+- A user role with:
+ - `SELECT` permissions on the CDC schema and the schemas that contain tables to be captured.
+ - Access to the change tables created as part of the SQL Server CDC process.
+ - `SELECT`, `INSERT`, and `UPDATE` permissions on the watermarks table
### Setup
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * [Enable public IP on your database](https://cloud.google.com/sql/docs/sqlserver/configure-ip#add) and add `34.121.207.128` as an authorized IP address.
+
+ - [Enable public IP on your database](https://cloud.google.com/sql/docs/sqlserver/configure-ip#add) and add `34.121.207.128, 35.226.75.135, 34.68.62.148` as authorized IP addresses.
2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
2. In your SQL client, connect to your instance as the default `sqlserver` user and issue the following commands.
@@ -64,7 +66,7 @@ EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'flow_waterm
```
3. In the Cloud Console, note the instance's host under Public IP Address. Its port will always be `1433`.
-Together, you'll use the host:port as the `address` property when you configure the connector.
+ Together, you'll use the host:port as the `address` property when you configure the connector.
## Configuration
@@ -75,24 +77,24 @@ See [connectors](/concepts/connectors.md#using-connectors) to learn more about u
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
-| **`/database`** | Database | Logical database name to capture from. | string | Required |
-| **`/user`** | User | The database user to authenticate as. | string | Required, `"flow_capture"` |
-| **`/password`** | Password | Password for the specified database user. | string | Required |
-| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
-| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `4096` |
-| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
-| `/advanced/watermarksTable` | Watermarks Table | The name of the table used for watermark writes during backfills. Must be fully-qualified in '<schema>.<table>' form. | string | `"dbo.flow_watermarks"` |
+| Property | Title | Description | Type | Required/Default |
+| ------------------------------- | ------------------- | ------------------------------------------------------------------------------------------------------------------------------------------- | ------- | -------------------------- |
+| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
+| **`/database`** | Database | Logical database name to capture from. | string | Required |
+| **`/user`** | User | The database user to authenticate as. | string | Required, `"flow_capture"` |
+| **`/password`** | Password | Password for the specified database user. | string | Required |
+| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
+| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `4096` |
+| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
+| `/advanced/watermarksTable` | Watermarks Table | The name of the table used for watermark writes during backfills. Must be fully-qualified in '<schema>.<table>' form. | string | `"dbo.flow_watermarks"` |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|-------|------|------|---------| --------|
-| **`/namespace`** | Namespace | The [namespace/schema](https://learn.microsoft.com/en-us/sql/relational-databases/databases/databases?view=sql-server-ver16#basic-information-about-databases) of the table. | string | Required |
-| **`/stream`** | Stream | Table name. | string | Required |
-| `/primary_key` | Primary Key Columns | array | The columns which together form the primary key of the table. | |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | ------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------- | ---------------- |
+| **`/namespace`** | Namespace | The [namespace/schema](https://learn.microsoft.com/en-us/sql/relational-databases/databases/databases?view=sql-server-ver16#basic-information-about-databases) of the table. | string | Required |
+| **`/stream`** | Stream | Table name. | string | Required |
+| `/primary_key` | Primary Key Columns | array | The columns which together form the primary key of the table. | |
### Sample
@@ -114,6 +116,7 @@ captures:
primary_key: ["id"]
target: ${PREFIX}/${COLLECTION_NAME}
```
+
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
@@ -128,8 +131,8 @@ In cases where a SQL Server table you want to capture doesn't have a primary key
you can manually add it to the collection definition during the [capture creation workflow](/guides/create-dataflow.md#create-a-capture).
1. After you input the endpoint configuration and click **Next**,
-the tables in your database have been mapped to Flow collections.
-Click each collection's **Specification** tab and identify a collection where `"key": [ ],` is empty.
+ the tables in your database have been mapped to Flow collections.
+ Click each collection's **Specification** tab and identify a collection where `"key": [ ],` is empty.
2. Click inside the empty key value in the editor and input the name of column in the table to use as the key, formatted as a JSON pointer. For example `"key": ["/foo"],`
diff --git a/site/docs/reference/Connectors/capture-connectors/SQLServer/sqlserver.md b/site/docs/reference/Connectors/capture-connectors/SQLServer/sqlserver.md
index 70a1375ea8..98f1cf9ecc 100644
--- a/site/docs/reference/Connectors/capture-connectors/SQLServer/sqlserver.md
+++ b/site/docs/reference/Connectors/capture-connectors/SQLServer/sqlserver.md
@@ -1,6 +1,7 @@
---
sidebar_position: 3
---
+
# Microsoft SQL Server
This connector uses change data capture (CDC) to continuously capture updates in a Microsoft SQL Server database into one or more Flow collections.
@@ -9,42 +10,42 @@ It’s available for use in the Flow web application. For local development or o
## Supported versions and platforms
-This connector will work on both hosted deployments and all major cloud providers. It is designed for databases using any version of SQL Server which has CDC support, and is regularly tested against SQL Server 2017 and up.
+This connector will work on both hosted deployments and all major cloud providers. It is designed for databases using any version of SQL Server which has CDC support, and is regularly tested against SQL Server 2017 and up.
Setup instructions are provided for the following platforms:
-* [Self-hosted SQL Server](#self-hosted-sql-server)
-* [Azure SQL Database](#azure-sql-database)
-* [Amazon RDS for SQL Server](./amazon-rds-sqlserver/)
-* [Google Cloud SQL for SQL Server](./google-cloud-sql-sqlserver/)
+- [Self-hosted SQL Server](#self-hosted-sql-server)
+- [Azure SQL Database](#azure-sql-database)
+- [Amazon RDS for SQL Server](./amazon-rds-sqlserver/)
+- [Google Cloud SQL for SQL Server](./google-cloud-sql-sqlserver/)
## Prerequisites
To capture change events from SQL Server tables using this connector, you need:
-* For each table to be captured, a primary key should be specified in the database.
-If a table doesn't have a primary key, you must manually specify a key in the associated Flow collection definition while creating the capture.
-[See detailed steps](#specifying-flow-collection-keys).
+- For each table to be captured, a primary key should be specified in the database.
+ If a table doesn't have a primary key, you must manually specify a key in the associated Flow collection definition while creating the capture.
+ [See detailed steps](#specifying-flow-collection-keys).
-* [CDC enabled](https://learn.microsoft.com/en-us/sql/relational-databases/track-changes/enable-and-disable-change-data-capture-sql-server?view=sql-server-ver16)
-on the database and the individual tables to be captured.
-(This creates *change tables* in the database, from which the connector reads.)
+- [CDC enabled](https://learn.microsoft.com/en-us/sql/relational-databases/track-changes/enable-and-disable-change-data-capture-sql-server?view=sql-server-ver16)
+ on the database and the individual tables to be captured.
+ (This creates _change tables_ in the database, from which the connector reads.)
-* A **watermarks table**. The watermarks table is a small “scratch space” to which the connector occasionally writes a small amount of data to ensure accuracy when backfilling preexisting table contents.
+- A **watermarks table**. The watermarks table is a small “scratch space” to which the connector occasionally writes a small amount of data to ensure accuracy when backfilling preexisting table contents.
-* A user role with:
- * `SELECT` permissions on the CDC schema and the schemas that contain tables to be captured.
- * Access to the change tables created as part of the SQL Server CDC process.
- * `SELECT`, `INSERT`, and `UPDATE` permissions on the watermarks table
+- A user role with:
+ - `SELECT` permissions on the CDC schema and the schemas that contain tables to be captured.
+ - Access to the change tables created as part of the SQL Server CDC process.
+ - `SELECT`, `INSERT`, and `UPDATE` permissions on the watermarks table
## Setup
To meet these requirements, follow the steps for your hosting type.
-* [Self-hosted SQL Server](#self-hosted-sql-server)
-* [Azure SQL Database](#azure-sql-database)
-* [Amazon RDS for SQL Server](./amazon-rds-sqlserver/))
-* [Google Cloud SQL for SQL Server](./google-cloud-sql-sqlserver/)
+- [Self-hosted SQL Server](#self-hosted-sql-server)
+- [Azure SQL Database](#azure-sql-database)
+- [Amazon RDS for SQL Server](./amazon-rds-sqlserver/))
+- [Google Cloud SQL for SQL Server](./google-cloud-sql-sqlserver/)
### Self-hosted SQL Server
@@ -71,25 +72,27 @@ EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'flow_waterm
```
2. Allow secure connection to Estuary Flow from your hosting environment. Either:
- * Set up an [SSH server for tunneling](/guides/connect-network/).
+
+ - Set up an [SSH server for tunneling](/guides/connect-network/).
When you fill out the [endpoint configuration](#endpoint),
include the additional `networkTunnel` configuration to enable the SSH tunnel.
See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks)
for additional details and a sample.
- * Whitelist the Estuary IP address, `34.121.207.128` in your firewall rules.
+ - Whitelist the Estuary IP addresses: `34.121.207.128, 35.226.75.135, 34.68.62.148` in your firewall rules.
### Azure SQL Database
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * Create a new [firewall rule](https://learn.microsoft.com/en-us/azure/azure-sql/database/firewall-configure?view=azuresql#use-the-azure-portal-to-manage-server-level-ip-firewall-rules) that grants access to the IP address `34.121.207.128`.
+
+ - Create a new [firewall rule](https://learn.microsoft.com/en-us/azure/azure-sql/database/firewall-configure?view=azuresql#use-the-azure-portal-to-manage-server-level-ip-firewall-rules) that grants access to the IP addresses: `34.121.207.128, 35.226.75.135, 34.68.62.148`.
2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
2. In your SQL client, connect to your instance as the default `sqlserver` user and issue the following commands.
@@ -115,8 +118,7 @@ EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'flow_waterm
3. Note the following important items for configuration:
- * Find the instance's host under Server Name. The port is always `1433`. Together, you'll use the host:port as the `address` property when you configure the connector.
-
+ - Find the instance's host under Server Name. The port is always `1433`. Together, you'll use the host:port as the `address` property when you configure the connector.
## Configuration
@@ -127,24 +129,24 @@ See [connectors](/concepts/connectors.md#using-connectors) to learn more about u
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
-| **`/database`** | Database | Logical database name to capture from. | string | Required |
-| **`/user`** | User | The database user to authenticate as. | string | Required, `"flow_capture"` |
-| **`/password`** | Password | Password for the specified database user. | string | Required |
-| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
-| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `4096` |
-| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
-| `/advanced/watermarksTable` | Watermarks Table | The name of the table used for watermark writes during backfills. Must be fully-qualified in '<schema>.<table>' form. | string | `"dbo.flow_watermarks"` |
+| Property | Title | Description | Type | Required/Default |
+| ------------------------------- | ------------------- | ------------------------------------------------------------------------------------------------------------------------------------------- | ------- | -------------------------- |
+| **`/address`** | Server Address | The host or host:port at which the database can be reached. | string | Required |
+| **`/database`** | Database | Logical database name to capture from. | string | Required |
+| **`/user`** | User | The database user to authenticate as. | string | Required, `"flow_capture"` |
+| **`/password`** | Password | Password for the specified database user. | string | Required |
+| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
+| `/advanced/backfill_chunk_size` | Backfill Chunk Size | The number of rows which should be fetched from the database in a single backfill query. | integer | `4096` |
+| `/advanced/skip_backfills` | Skip Backfills | A comma-separated list of fully-qualified table names which should not be backfilled. | string | |
+| `/advanced/watermarksTable` | Watermarks Table | The name of the table used for watermark writes during backfills. Must be fully-qualified in '<schema>.<table>' form. | string | `"dbo.flow_watermarks"` |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|-------|------|------|---------| --------|
-| **`/namespace`** | Namespace | The [namespace/schema](https://learn.microsoft.com/en-us/sql/relational-databases/databases/databases?view=sql-server-ver16#basic-information-about-databases) of the table. | string | Required |
-| **`/stream`** | Stream | Table name. | string | Required |
-| `/primary_key` | Primary Key Columns | array | The columns which together form the primary key of the table. | |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | ------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------- | ---------------- |
+| **`/namespace`** | Namespace | The [namespace/schema](https://learn.microsoft.com/en-us/sql/relational-databases/databases/databases?view=sql-server-ver16#basic-information-about-databases) of the table. | string | Required |
+| **`/stream`** | Stream | Table name. | string | Required |
+| `/primary_key` | Primary Key Columns | array | The columns which together form the primary key of the table. | |
### Sample
@@ -166,6 +168,7 @@ captures:
primary_key: ["id"]
target: ${PREFIX}/${COLLECTION_NAME}
```
+
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
@@ -180,8 +183,8 @@ In cases where a SQL Server table you want to capture doesn't have a primary key
you can manually add it to the collection definition during the [capture creation workflow](/guides/create-dataflow.md#create-a-capture).
1. After you input the endpoint configuration and click **Next**,
-the tables in your database have been mapped to Flow collections.
-Click each collection's **Specification** tab and identify a collection where `"key": [ ],` is empty.
+ the tables in your database have been mapped to Flow collections.
+ Click each collection's **Specification** tab and identify a collection where `"key": [ ],` is empty.
2. Click inside the empty key value in the editor and input the name of column in the table to use as the key, formatted as a JSON pointer. For example `"key": ["/foo"],`
diff --git a/site/docs/reference/Connectors/capture-connectors/apache-kafka.md b/site/docs/reference/Connectors/capture-connectors/apache-kafka.md
index b444153e98..eeff448818 100644
--- a/site/docs/reference/Connectors/capture-connectors/apache-kafka.md
+++ b/site/docs/reference/Connectors/capture-connectors/apache-kafka.md
@@ -1,4 +1,3 @@
-
# Apache Kafka
This connector captures streaming data from Apache Kafka topics.
@@ -20,10 +19,10 @@ Support for Avro Kafka messages will be added soon. For more information, [conta
## Prerequisites
-* A Kafka cluster with:
- * [bootstrap.servers](https://kafka.apache.org/documentation/#producerconfigs_bootstrap.servers) configured so that clients may connect via the desired host and port
- * An authentication mechanism of choice set up (highly recommended for production environments)
- * Connection security enabled with TLS (highly recommended for production environments)
+- A Kafka cluster with:
+ - [bootstrap.servers](https://kafka.apache.org/documentation/#producerconfigs_bootstrap.servers) configured so that clients may connect via the desired host and port
+ - An authentication mechanism of choice set up (highly recommended for production environments)
+ - Connection security enabled with TLS (highly recommended for production environments)
### Authentication and connection security
@@ -53,7 +52,7 @@ Other connection security methods may be enabled in the future.
If using AWS Managed Streaming for Apache Kafka (MSK), you can use IAM authentication with our connector. Read more about IAM authentication with MSK in AWS docs: [IAM access control](https://docs.aws.amazon.com/msk/latest/developerguide/iam-access-control.html).
-Additionally, you want to make sure that your VPC configuration allows inbound and outbound requests to Estuary's IP address: `34.121.207.128`
+Additionally, you want to make sure that your VPC configuration allows inbound and outbound requests to Estuary's IP addresses: `34.121.207.128, 35.226.75.135, 34.68.62.148`
## Configuration
@@ -64,29 +63,30 @@ See [connectors](../../../concepts/connectors.md#using-connectors) to learn more
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|-----------------------------------------|-----------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------|-------------------------|
-| **`/bootstrap_servers`** | Bootstrap servers | The initial servers in the Kafka cluster to connect to, separated by commas. The Kafka client will be informed of the rest of the cluster nodes by connecting to one of these nodes. | string | Required |
-| **`/tls`** | TLS | TLS connection settings. | string | `"system_certificates"` |
-| `/credentials` | Credentials | Connection details used to authenticate a client connection to Kafka via SASL. | null, object | |
-| `/credentials/auth_type` | Authentication type | One of `UserPassword` for SASL or `AWS` for IAM authentication | string | |
-| `/credentials/mechanism` | SASL Mechanism | SASL mechanism describing how to exchange and authenticate client servers. | string | |
-| `/credentials/password` | Password | Password, if applicable for the authentication mechanism chosen. | string | |
-| `/credentials/username` | Username | Username, if applicable for the authentication mechanism chosen. | string | |
-| `/credentials/aws_access_key_id` | AWS Access Key ID | Supply if using auth_type: AWS | string | |
-| `/credentials/aws_secret_access_key` | AWS Secret Access Key | Supply if using auth_type: AWS | string | |
-| `/credentials/region` | AWS Region | Supply if using auth_type: AWS | string | |
+| Property | Title | Description | Type | Required/Default |
+| ------------------------------------ | --------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------ | ----------------------- |
+| **`/bootstrap_servers`** | Bootstrap servers | The initial servers in the Kafka cluster to connect to, separated by commas. The Kafka client will be informed of the rest of the cluster nodes by connecting to one of these nodes. | string | Required |
+| **`/tls`** | TLS | TLS connection settings. | string | `"system_certificates"` |
+| `/credentials` | Credentials | Connection details used to authenticate a client connection to Kafka via SASL. | null, object | |
+| `/credentials/auth_type` | Authentication type | One of `UserPassword` for SASL or `AWS` for IAM authentication | string | |
+| `/credentials/mechanism` | SASL Mechanism | SASL mechanism describing how to exchange and authenticate client servers. | string | |
+| `/credentials/password` | Password | Password, if applicable for the authentication mechanism chosen. | string | |
+| `/credentials/username` | Username | Username, if applicable for the authentication mechanism chosen. | string | |
+| `/credentials/aws_access_key_id` | AWS Access Key ID | Supply if using auth_type: AWS | string | |
+| `/credentials/aws_secret_access_key` | AWS Secret Access Key | Supply if using auth_type: AWS | string | |
+| `/credentials/region` | AWS Region | Supply if using auth_type: AWS | string | |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|-------|------|------|---------| --------|
-| **`/stream`** | Stream | Kafka topic name. | string | Required |
-| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental` | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| --------------- | --------- | ---------------------------------------------- | ------ | ---------------- |
+| **`/stream`** | Stream | Kafka topic name. | string | Required |
+| **`/syncMode`** | Sync mode | Connection method. Always set to `incremental` | string | Required |
### Sample
User and password authentication (SASL):
+
```yaml
captures:
${PREFIX}/${CAPTURE_NAME}:
@@ -94,17 +94,17 @@ captures:
connector:
image: ghcr.io/estuary/source-kafka:dev
config:
- bootstrap_servers: localhost:9093
- tls: system_certificates
- credentials:
- auth_type: UserPassword
- mechanism: SCRAM-SHA-512
- username: bruce.wayne
- password: definitely-not-batman
+ bootstrap_servers: localhost:9093
+ tls: system_certificates
+ credentials:
+ auth_type: UserPassword
+ mechanism: SCRAM-SHA-512
+ username: bruce.wayne
+ password: definitely-not-batman
bindings:
- resource:
- stream: ${TOPIC_NAME}
- syncMode: incremental
+ stream: ${TOPIC_NAME}
+ syncMode: incremental
target: ${PREFIX}/${COLLECTION_NAME}
```
@@ -117,17 +117,17 @@ captures:
connector:
image: ghcr.io/estuary/source-kafka:dev
config:
- bootstrap_servers: localhost:9093
- tls: system_certificates
- credentials:
- auth_type: AWS
- aws_access_key_id: AK...
- aws_secret_access_key: secret
- region: us-east-1
+ bootstrap_servers: localhost:9093
+ tls: system_certificates
+ credentials:
+ auth_type: AWS
+ aws_access_key_id: AK...
+ aws_secret_access_key: secret
+ region: us-east-1
bindings:
- resource:
- stream: ${TOPIC_NAME}
- syncMode: incremental
+ stream: ${TOPIC_NAME}
+ syncMode: incremental
target: ${PREFIX}/${COLLECTION_NAME}
```
diff --git a/site/docs/reference/Connectors/capture-connectors/mongodb.md b/site/docs/reference/Connectors/capture-connectors/mongodb.md
index adfa888431..3429250818 100644
--- a/site/docs/reference/Connectors/capture-connectors/mongodb.md
+++ b/site/docs/reference/Connectors/capture-connectors/mongodb.md
@@ -1,4 +1,3 @@
-
# MongoDB
This connector captures data from your MongoDB collections into Flow collections.
@@ -18,9 +17,9 @@ collection.
You'll need:
-* Credentials for connecting to your MongoDB instance and database
+- Credentials for connecting to your MongoDB instance and database
-* Read access to your MongoDB database(s), see [Role-Based Access
+- Read access to your MongoDB database(s), see [Role-Based Access
Control](https://www.mongodb.com/docs/manual/core/authorization/) for more information.
:::tip Configuration Tip
@@ -28,11 +27,11 @@ If you are using a user with access to all databases, then in your mongodb addre
`?authSource=admin` parameter so that authentication is done through your admin database.
:::
-* ReplicaSet enabled on your database, see [Deploy a Replica
+- ReplicaSet enabled on your database, see [Deploy a Replica
Set](https://www.mongodb.com/docs/manual/tutorial/deploy-replica-set/).
-* If you are using MongoDB Atlas, or your MongoDB provider requires whitelisting of IPs, you need to
- whitelist Estuary's IP `34.121.207.128`.
+- If you are using MongoDB Atlas, or your MongoDB provider requires whitelisting of IPs, you need to
+ whitelist Estuary's IPs: `34.121.207.128, 35.226.75.135, 34.68.62.148`.
## Configuration
@@ -46,19 +45,18 @@ MongoDB source connector.
#### Endpoint
| Property | Title | Description | Type | Required/Default |
-|-----------------|----------|------------------------------------------------------------------------------------------------------------------------------------|--------|------------------|
+| --------------- | -------- | ---------------------------------------------------------------------------------------------------------------------------------- | ------ | ---------------- |
| **`/address`** | Address | Host and port of the database. Optionally can specify scheme for the URL such as mongodb+srv://host. | string | Required |
| **`/user`** | User | Database user to connect as. | string | Required |
| **`/password`** | Password | Password for the specified database user. | string | Required |
| `/database` | Database | Optional comma-separated list of the databases to discover. If not provided will discover all available databases in the instance. | string | |
-
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-| ------- | ------ | ------ | --------- | -------- |
-| **`/database`** | Database | Database name | string | Required |
-| **`/collection`** | Stream | Collection name | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| ----------------- | -------- | --------------- | ------ | ---------------- |
+| **`/database`** | Database | Database name | string | Required |
+| **`/collection`** | Stream | Collection name | string | Required |
### Sample
@@ -87,7 +85,6 @@ As an alternative to connecting to your MongoDB instance directly, you can allow
2. Configure your connector as described in the [configuration](#configuration) section above, with the addition of the `networkTunnel` stanza to enable the SSH tunnel, if using. See [Connecting to endpoints on secure networks](../../../concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
-
## Backfill and real-time updates
When performing the initial database snapshot, the connector continuously reads from [**change
diff --git a/site/docs/reference/Connectors/capture-connectors/sftp.md b/site/docs/reference/Connectors/capture-connectors/sftp.md
index 18b0c587b5..599aeefb8d 100644
--- a/site/docs/reference/Connectors/capture-connectors/sftp.md
+++ b/site/docs/reference/Connectors/capture-connectors/sftp.md
@@ -6,7 +6,7 @@ It is available for use in the Flow web application. For local development or op
## Prerequisites
-You'll need an SFTP server that can accept connections from the Estuary Flow IP address `34.121.207.128` using password authentication.
+You'll need an SFTP server that can accept connections from the Estuary Flow IP addresses `34.121.207.128, 35.226.75.135, 34.68.62.148` using password authentication.
## Subdirectories and Symbolic Links
@@ -38,62 +38,60 @@ As an example, consider a directory structure like the following with a data fil
Setting `Ascending Keys` is only recommended if you have strict control over the naming of files and can ensure they are added in increasing lexical ordering.
-
-
## Configuration
You configure connectors either in the Flow web app, or by directly editing the catalog specification file. See [connectors](../../../concepts/connectors.md#using-connectors) to learn more about using connectors. The values and specification sample below provide configuration details specific to the SFTP source connector.
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/address`** | Address | Host and port of the SFTP server. Example: `myserver.com:22` | string | Required |
-| **`/username`** | Username | Username for authentication. | string | Required |
-| `/password` | Password | Password for authentication. Only one of Password or SSHKey must be provided. | string | |
-| `/sshKey` | SSH Key | SSH Key for authentication. Only one of Password or SSHKey must be provided. | string | |
-| **`/directory`** | Directory | Directory to capture files from. All files in this directory and any subdirectories will be included. | string | Required |
-| `/matchFiles` | Match Files Regex | Filter applied to all file names in the directory. If provided, only files whose path (relative to the directory) matches this regex will be captured. For example, you can use `.*\.json` to only capture json files. | string | |
-| `/advanced` | | Options for advanced users. You should not typically need to modify these. | object | |
-| `/advanced/ascendingKeys` | Ascending Keys | May improve sync speeds by listing files from the end of the last sync, rather than listing all files in the configured directory. This requires that you write files in ascending lexicographic order, such as an RFC-3339 timestamp, so that lexical path ordering matches modification time ordering. | boolean | `false` |
-| `/parser` | Parser Configuration | Configures how files are parsed (optional, see below) | object | |
-| `/parser/compression` | Compression | Determines how to decompress the contents. The default, 'Auto', will try to determine the compression automatically. | null, string | `null` |
-| `/parser/format` | Format | Determines how to parse the contents. The default, 'Auto', will try to determine the format automatically based on the file extension or MIME type, if available. | object | `{"type":"auto"}` |
+| Property | Title | Description | Type | Required/Default |
+| ------------------------- | -------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------ | ----------------- |
+| **`/address`** | Address | Host and port of the SFTP server. Example: `myserver.com:22` | string | Required |
+| **`/username`** | Username | Username for authentication. | string | Required |
+| `/password` | Password | Password for authentication. Only one of Password or SSHKey must be provided. | string | |
+| `/sshKey` | SSH Key | SSH Key for authentication. Only one of Password or SSHKey must be provided. | string | |
+| **`/directory`** | Directory | Directory to capture files from. All files in this directory and any subdirectories will be included. | string | Required |
+| `/matchFiles` | Match Files Regex | Filter applied to all file names in the directory. If provided, only files whose path (relative to the directory) matches this regex will be captured. For example, you can use `.*\.json` to only capture json files. | string | |
+| `/advanced` | | Options for advanced users. You should not typically need to modify these. | object | |
+| `/advanced/ascendingKeys` | Ascending Keys | May improve sync speeds by listing files from the end of the last sync, rather than listing all files in the configured directory. This requires that you write files in ascending lexicographic order, such as an RFC-3339 timestamp, so that lexical path ordering matches modification time ordering. | boolean | `false` |
+| `/parser` | Parser Configuration | Configures how files are parsed (optional, see below) | object | |
+| `/parser/compression` | Compression | Determines how to decompress the contents. The default, 'Auto', will try to determine the compression automatically. | null, string | `null` |
+| `/parser/format` | Format | Determines how to parse the contents. The default, 'Auto', will try to determine the format automatically based on the file extension or MIME type, if available. | object | `{"type":"auto"}` |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/stream`** | Prefix | Path to the captured directory. | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| ------------- | ------ | ------------------------------- | ------ | ---------------- |
+| **`/stream`** | Prefix | Path to the captured directory. | string | Required |
### Sample
```yaml
captures:
${CAPTURE_NAME}:
- endpoint:
- connector:
- image: "ghcr.io/estuary/source-sftp:dev"
- config:
- address: myserver.com:22
- username:
- password:
- directory: /data
- parser:
- compression: zip
- format:
- type: csv
- config:
- delimiter: ","
- encoding: UTF-8
- errorThreshold: 5
- headers: [ID, username, first_name, last_name]
- lineEnding: "\\r"
- quote: "\""
- bindings:
- - resource:
- stream: /data
- target: ${COLLECTION_NAME}
+ endpoint:
+ connector:
+ image: "ghcr.io/estuary/source-sftp:dev"
+ config:
+ address: myserver.com:22
+ username:
+ password:
+ directory: /data
+ parser:
+ compression: zip
+ format:
+ type: csv
+ config:
+ delimiter: ","
+ encoding: UTF-8
+ errorThreshold: 5
+ headers: [ID, username, first_name, last_name]
+ lineEnding: "\\r"
+ quote: '"'
+ bindings:
+ - resource:
+ stream: /data
+ target: ${COLLECTION_NAME}
```
### Advanced: Parsing SFTP Files
@@ -111,32 +109,32 @@ which is part of the [endpoint configuration](#endpoint) for this connector.
The parser configuration includes:
-* **Compression**: Specify how the bucket contents are compressed.
-If no compression type is specified, the connector will try to determine the compression type automatically.
-Options are:
+- **Compression**: Specify how the bucket contents are compressed.
+ If no compression type is specified, the connector will try to determine the compression type automatically.
+ Options are:
- * **zip**
- * **gzip**
- * **zstd**
- * **none**
+ - **zip**
+ - **gzip**
+ - **zstd**
+ - **none**
-* **Format**: Specify the data format, which determines how it will be parsed.
-Options are:
+- **Format**: Specify the data format, which determines how it will be parsed.
+ Options are:
- * **Auto**: If no format is specified, the connector will try to determine it automatically.
- * **Avro**
- * **CSV**
- * **JSON**
- * **Protobuf**
- * **W3C Extended Log**
+ - **Auto**: If no format is specified, the connector will try to determine it automatically.
+ - **Avro**
+ - **CSV**
+ - **JSON**
+ - **Protobuf**
+ - **W3C Extended Log**
- :::info
- At this time, Flow only supports SFTP captures with data of a single file type.
- Support for multiple file types, which can be configured on a per-binding basis,
- will be added in the future.
+ :::info
+ At this time, Flow only supports SFTP captures with data of a single file type.
+ Support for multiple file types, which can be configured on a per-binding basis,
+ will be added in the future.
- For now, use a prefix in the endpoint configuration to limit the scope of each capture to data of a single file type.
- :::
+ For now, use a prefix in the endpoint configuration to limit the scope of each capture to data of a single file type.
+ :::
#### CSV configuration
@@ -144,42 +142,45 @@ CSV files include several additional properties that are important to the parser
In most cases, Flow is able to automatically determine the correct values,
but you may need to specify for unusual datasets. These properties are:
-* **Delimiter**. Options are:
- * Comma (`","`)
- * Pipe (`"|"`)
- * Space (`"0x20"`)
- * Semicolon (`";"`)
- * Tab (`"0x09"`)
- * Vertical tab (`"0x0B"`)
- * Unit separator (`"0x1F"`)
- * SOH (`"0x01"`)
- * Auto
+- **Delimiter**. Options are:
+
+ - Comma (`","`)
+ - Pipe (`"|"`)
+ - Space (`"0x20"`)
+ - Semicolon (`";"`)
+ - Tab (`"0x09"`)
+ - Vertical tab (`"0x0B"`)
+ - Unit separator (`"0x1F"`)
+ - SOH (`"0x01"`)
+ - Auto
-* **Encoding** type, specified by its [WHATWG label](https://encoding.spec.whatwg.org/#names-and-labels).
+- **Encoding** type, specified by its [WHATWG label](https://encoding.spec.whatwg.org/#names-and-labels).
-* Optionally, an **Error threshold**, as an acceptable percentage of errors. If set to a number greater than zero, malformed rows that fall within the threshold will be excluded from the capture.
+- Optionally, an **Error threshold**, as an acceptable percentage of errors. If set to a number greater than zero, malformed rows that fall within the threshold will be excluded from the capture.
-* **Escape characters**. Options are:
- * Backslash (`"\\"`)
- * Disable escapes (`""`)
- * Auto
+- **Escape characters**. Options are:
-* Optionally, a list of column **Headers**, if not already included in the first row of the CSV file.
+ - Backslash (`"\\"`)
+ - Disable escapes (`""`)
+ - Auto
+
+- Optionally, a list of column **Headers**, if not already included in the first row of the CSV file.
If any headers are provided, it is assumed that the provided list of headers is complete and authoritative.
The first row of your CSV file will be assumed to be data (not headers), and you must provide a header value for every column in the file.
-* **Line ending** values
- * CRLF (`"\\r\\n"`) (Windows)
- * CR (`"\\r"`)
- * LF (`"\\n"`)
- * Record Separator (`"0x1E"`)
- * Auto
-
-* **Quote character**
- * Double Quote (`"\""`)
- * Single Quote (`"`)
- * Disable Quoting (`""`)
- * Auto
+- **Line ending** values
+
+ - CRLF (`"\\r\\n"`) (Windows)
+ - CR (`"\\r"`)
+ - LF (`"\\n"`)
+ - Record Separator (`"0x1E"`)
+ - Auto
+
+- **Quote character**
+ - Double Quote (`"\""`)
+ - Single Quote (`"`)
+ - Disable Quoting (`""`)
+ - Auto
The sample specification [above](#sample) includes these fields.
diff --git a/site/docs/reference/Connectors/materialization-connectors/Elasticsearch.md b/site/docs/reference/Connectors/materialization-connectors/Elasticsearch.md
index 85266318a5..a546aedbaf 100644
--- a/site/docs/reference/Connectors/materialization-connectors/Elasticsearch.md
+++ b/site/docs/reference/Connectors/materialization-connectors/Elasticsearch.md
@@ -1,5 +1,3 @@
-
-
# Elasticsearch
This connector materializes Flow collections into indices in an Elasticsearch cluster.
@@ -10,11 +8,11 @@ It is available for use in the Flow web application. For local development or op
To use this connector, you'll need:
-* An Elastic cluster with a known [endpoint](https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started.html#send-requests-to-elasticsearch)
-* The role used to connect to Elasticsearch must have at least the following privileges (see Elastic's documentation on [defining roles](https://www.elastic.co/guide/en/elasticsearch/reference/current/defining-roles.html#roles-indices-priv) and [security privileges](https://www.elastic.co/guide/en/elasticsearch/reference/current/security-privileges.html#privileges-list-indices)):
- * **Cluster privilege** of `monitor`
- * For each index to be created: `read`, `write`, `view_index_metadata`, and `create_index`. When creating **Index privileges**, you can use a wildcard `"*"` to grant the privileges to all indices.
-* At least one Flow collection
+- An Elastic cluster with a known [endpoint](https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started.html#send-requests-to-elasticsearch)
+- The role used to connect to Elasticsearch must have at least the following privileges (see Elastic's documentation on [defining roles](https://www.elastic.co/guide/en/elasticsearch/reference/current/defining-roles.html#roles-indices-priv) and [security privileges](https://www.elastic.co/guide/en/elasticsearch/reference/current/security-privileges.html#privileges-list-indices)):
+ - **Cluster privilege** of `monitor`
+ - For each index to be created: `read`, `write`, `view_index_metadata`, and `create_index`. When creating **Index privileges**, you can use a wildcard `"*"` to grant the privileges to all indices.
+- At least one Flow collection
:::tip
If you haven't yet captured your data from its external source, start at the beginning of the [guide to create a dataflow](../../../guides/create-dataflow.md). You'll be referred back to this connector-specific documentation at the appropriate steps.
@@ -35,24 +33,23 @@ The connector will automatically create an Elasticsearch index for each binding
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|-------------------------------|--------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------|------------------|
-| **`/endpoint`** | Endpoint | Endpoint host or URL. Must start with http:// or https://. If using Elastic Cloud this follows the format https://CLUSTER_ID.REGION.CLOUD_PLATFORM.DOMAIN:PORT | string | Required |
-| **`/credentials`** | | | object | Required |
-| `/credentials/username` | Username | Username to use for authenticating with Elasticsearch. | string | |
-| `/credentials/password` | Password | Password to use for authenticating with Elasticsearch. | string | |
-| `/credentials/apiKey` | API Key | API key for authenticating with the Elasticsearch API. Must be the 'encoded' API key credentials, which is the Base64-encoding of the UTF-8 representation of the id and api_key joined by a colon (:). | string | |
-| `advanced/number_of_replicas` | Index Replicas | The number of replicas to create new indices with. Leave blank to use the cluster default. | integer | |
+| Property | Title | Description | Type | Required/Default |
+| ----------------------------- | -------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------- | ---------------- |
+| **`/endpoint`** | Endpoint | Endpoint host or URL. Must start with http:// or https://. If using Elastic Cloud this follows the format https://CLUSTER_ID.REGION.CLOUD_PLATFORM.DOMAIN:PORT | string | Required |
+| **`/credentials`** | | | object | Required |
+| `/credentials/username` | Username | Username to use for authenticating with Elasticsearch. | string | |
+| `/credentials/password` | Password | Password to use for authenticating with Elasticsearch. | string | |
+| `/credentials/apiKey` | API Key | API key for authenticating with the Elasticsearch API. Must be the 'encoded' API key credentials, which is the Base64-encoding of the UTF-8 representation of the id and api_key joined by a colon (:). | string | |
+| `advanced/number_of_replicas` | Index Replicas | The number of replicas to create new indices with. Leave blank to use the cluster default. | integer | |
#### Bindings
| Property | Title | Description | Type | Required/Default |
-|----------------------|------------------|----------------------------------------------------------------------------------------|---------|------------------|
+| -------------------- | ---------------- | -------------------------------------------------------------------------------------- | ------- | ---------------- |
| **`/index`** | index | Name of the Elasticsearch index to store the materialization results. | string | Required |
| **`/delta_updates`** | Delta updates | Whether to use standard or [delta updates](#delta-updates). | boolean | `false` |
| `/number_of_shards` | Number of shards | The number of shards to create the index with. Leave blank to use the cluster default. | integer | `1` |
-
### Sample
```yaml
@@ -60,15 +57,15 @@ materializations:
PREFIX/mat_name:
endpoint:
connector:
- # Path to the latest version of the connector, provided as a Docker image
+ # Path to the latest version of the connector, provided as a Docker image
image: ghcr.io/estuary/materialize-elasticsearch:dev
config:
endpoint: https://ec47fc4d2c53414e1307e85726d4b9bb.us-east-1.aws.found.io:9243
credentials:
username: flow_user
password: secret
- # If you have multiple collections you need to materialize, add a binding for each one
- # to ensure complete data flow-through
+ # If you have multiple collections you need to materialize, add a binding for each one
+ # to ensure complete data flow-through
bindings:
- resource:
index: my-elasticsearch-index
@@ -77,7 +74,7 @@ materializations:
## Setup
-You must configure your Elasticsearch cluster to allow connections from Estuary. It may be necessary to whitelist Estuary Flow's IP address `34.121.207.128`.
+You must configure your Elasticsearch cluster to allow connections from Estuary. It may be necessary to whitelist Estuary Flow's IP addresses `34.121.207.128, 35.226.75.135, 34.68.62.148`.
Alternatively, you can allow secure connections via SSH tunneling. To do so:
@@ -112,7 +109,7 @@ is shown below:
"bindings": [
{
"resource": {
- "index": "my-elasticsearch-index",
+ "index": "my-elasticsearch-index"
},
"source": "PREFIX/source_collection",
"fields": {
@@ -136,8 +133,8 @@ The changelog includes a list of breaking changes made to this connector. Backwa
#### V3: 2023-08-21
-* Index mappings will now be created based on the selected fields of the materialization. Previously only dynamic runtime mappings were created, and the entire root document was always materialized.
+- Index mappings will now be created based on the selected fields of the materialization. Previously only dynamic runtime mappings were created, and the entire root document was always materialized.
-* Moved "number of replicas" configuration for new indices to an advanced, optional, endpoint-level configuration.
+- Moved "number of replicas" configuration for new indices to an advanced, optional, endpoint-level configuration.
-* The "number of shards" resource configuration is now optional.
+- The "number of shards" resource configuration is now optional.
diff --git a/site/docs/reference/Connectors/materialization-connectors/MySQL/amazon-rds-mysql.md b/site/docs/reference/Connectors/materialization-connectors/MySQL/amazon-rds-mysql.md
index 9a643d0e38..d410bc6945 100644
--- a/site/docs/reference/Connectors/materialization-connectors/MySQL/amazon-rds-mysql.md
+++ b/site/docs/reference/Connectors/materialization-connectors/MySQL/amazon-rds-mysql.md
@@ -10,13 +10,13 @@ open-source workflows,
To use this connector, you'll need:
-* A MySQL database to which to materialize, and user credentials.
- * MySQL versions 5.7 and later are supported
- * The connector will create new tables in the database per your specification,
+- A MySQL database to which to materialize, and user credentials.
+ - MySQL versions 5.7 and later are supported
+ - The connector will create new tables in the database per your specification,
so user credentials must have access to create new tables.
- * The `local_infile` global variable must be enabled. You can enable this
+ - The `local_infile` global variable must be enabled. You can enable this
setting by running `SET GLOBAL local_infile = true` in your database.
-* At least one Flow collection
+- At least one Flow collection
## Setup
@@ -27,54 +27,60 @@ There are two ways to do this: by granting direct access to Flow's IP or by crea
1. Edit the VPC security group associated with your database instance, or create a new VPC security group and associate it with the database instance.
- 1. [Modify the instance](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), choosing **Publicly accessible** in the **Connectivity** settings.
+ 1. [Modify the instance](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), choosing **Publicly accessible** in the **Connectivity** settings.
- 2. Per the [steps in the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create),
- create a new inbound rule and a new outbound rule that allow all traffic from the IP address `34.121.207.128`.
+ 2. Per the [steps in the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create),
+ create a new inbound rule and a new outbound rule that allow all traffic from the IP addresses `34.121.207.128, 35.226.75.135, 34.68.62.148`.
### Connect With SSH Tunneling
-To allow SSH tunneling to a database instance hosted on AWS, you'll need to create a virtual computing environment, or *instance*, in Amazon EC2.
+To allow SSH tunneling to a database instance hosted on AWS, you'll need to create a virtual computing environment, or _instance_, in Amazon EC2.
1. Begin by finding your public SSH key on your local machine.
In the `.ssh` subdirectory of your user home directory,
look for the PEM file that contains the private SSH key. Check that it starts with `-----BEGIN RSA PRIVATE KEY-----`,
which indicates it is an RSA-based file.
- * If no such file exists, generate one using the command:
+
+ - If no such file exists, generate one using the command:
+
```console
ssh-keygen -m PEM -t rsa
- ```
- * If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+ ```
+
+ - If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+
```console
ssh-keygen -p -N "" -m pem -f /path/to/key
- ```
+ ```
2. [Import your SSH key into AWS](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-key-pairs.html#how-to-generate-your-own-key-and-import-it-to-aws).
3. [Launch a new instance in EC2](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/LaunchingAndUsingInstances.html). During setup:
- * Configure the security group to allow SSH connection from anywhere.
- * When selecting a key pair, choose the key you just imported.
+
+ - Configure the security group to allow SSH connection from anywhere.
+ - When selecting a key pair, choose the key you just imported.
4. [Connect to the instance](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AccessingInstances.html),
-setting the user name to `ec2-user`.
+ setting the user name to `ec2-user`.
5. Find and note the [instance's public DNS](https://docs.aws.amazon.com/vpc/latest/userguide/vpc-dns.html#vpc-dns-viewing). This will be formatted like: `ec2-198-21-98-1.compute-1.amazonaws.com`.
-* **Connect with SSH tunneling**
- 1. Refer to the [guide](/guides/connect-network/) to configure an SSH server on the cloud platform of your choice.
+- **Connect with SSH tunneling**
- 2. Configure your connector as described in the [configuration](#configuration) section above,
- with the additional of the `networkTunnel` stanza to enable the SSH tunnel, if using.
- See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks)
- for additional details and a sample.
+ 1. Refer to the [guide](/guides/connect-network/) to configure an SSH server on the cloud platform of your choice.
+
+ 2. Configure your connector as described in the [configuration](#configuration) section above,
+ with the additional of the `networkTunnel` stanza to enable the SSH tunnel, if using.
+ See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks)
+ for additional details and a sample.
:::tip Configuration Tip
To configure the connector, you must specify the database address in the format
`host:port`. (You can also supply `host` only; the connector will use the port `3306` by default, which is correct in many cases.)
You can find the host and port in the following locations in each platform's console:
-* Amazon RDS: host as Endpoint; port as Port.
-:::
+- Amazon RDS: host as Endpoint; port as Port.
+ :::
## Configuration
@@ -85,18 +91,18 @@ Use the below properties to configure a MySQL materialization, which will direct
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|-----------------------------|------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------|------------------|
-| **`/database`** | Database | Name of the logical database to materialize to. | string | Required |
-| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `3306`. | string | Required |
-| **`/password`** | Password | Password for the specified database user. | string | Required |
-| **`/user`** | User | Database user to connect as. | string | Required |
-| `/timezone` | Timezone | Timezone to use when materializing datetime columns. Should normally be left blank to use the database's 'time_zone' system variable. Only required if the 'time_zone' system variable cannot be read. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the 'time_zone' system variable if both are set. | string | |
-| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
-| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
-| `/advanced/ssl_server_ca` | SSL Server CA | Optional server certificate authority to use when connecting with custom SSL mode | string | |
-| `/advanced/ssl_client_cert` | SSL Client Certificate | Optional client certificate to use when connecting with custom SSL mode. | string | |
-| `/advanced/ssl_client_key` | SSL Client Key | Optional client key to use when connecting with custom SSL mode. | string | |
+| Property | Title | Description | Type | Required/Default |
+| --------------------------- | ---------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------ | ---------------- |
+| **`/database`** | Database | Name of the logical database to materialize to. | string | Required |
+| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `3306`. | string | Required |
+| **`/password`** | Password | Password for the specified database user. | string | Required |
+| **`/user`** | User | Database user to connect as. | string | Required |
+| `/timezone` | Timezone | Timezone to use when materializing datetime columns. Should normally be left blank to use the database's 'time_zone' system variable. Only required if the 'time_zone' system variable cannot be read. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the 'time_zone' system variable if both are set. | string | |
+| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
+| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
+| `/advanced/ssl_server_ca` | SSL Server CA | Optional server certificate authority to use when connecting with custom SSL mode | string | |
+| `/advanced/ssl_client_cert` | SSL Client Certificate | Optional client certificate to use when connecting with custom SSL mode. | string | |
+| `/advanced/ssl_client_key` | SSL Client Key | Optional client key to use when connecting with custom SSL mode. | string | |
### Setting the MySQL time zone
@@ -110,15 +116,16 @@ To avoid this, you must explicitly set the time zone for your database.
You can:
-* Specify a numerical offset from UTC.
- - For MySQL version 8.0.19 or higher, values from `-13:59` to `+14:00`, inclusive, are permitted.
- - Prior to MySQL 8.0.19, values from `-12:59` to `+13:00`, inclusive, are permitted
+- Specify a numerical offset from UTC.
-* Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
+ - For MySQL version 8.0.19 or higher, values from `-13:59` to `+14:00`, inclusive, are permitted.
+ - Prior to MySQL 8.0.19, values from `-12:59` to `+13:00`, inclusive, are permitted
-* If you're using Amazon Aurora, create or modify the [DB cluster parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html)
-associated with your MySQL database.
-[Set](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.ModifyingCluster) the `time_zone` parameter to the correct value.
+- Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
+
+- If you're using Amazon Aurora, create or modify the [DB cluster parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html)
+ associated with your MySQL database.
+ [Set](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.ModifyingCluster) the `time_zone` parameter to the correct value.
For example, if you're located in New Jersey, USA, you could set `time_zone` to `-05:00` or `-04:00`, depending on the time of year.
Because this region observes daylight savings time, you'd be responsible for changing the offset.
@@ -135,6 +142,7 @@ to assume a time zone using the `timezone` configuration property (see above). T
#### SSL Mode
Possible values:
+
- `disabled`: A plain unencrypted connection is established with the server
- `preferred`: Only use SSL connection if the server asks for it
- `required`: Connect using an SSL connection, but do not verify the server's
@@ -153,10 +161,10 @@ authorize the client.
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
-| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | ------------ | ------------------------------------------------------------------------------------------------------------------ | ------- | ---------------- |
+| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
+| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
### Sample
@@ -195,159 +203,159 @@ Flow considers all the reserved words in the official [MySQL documentation](http
These reserved words are listed in the table below. Flow automatically quotes fields that are in this list.
-|Reserved words| | | | |
-|---|---|---|---|---|
-|accessible|clone|describe|float|int|
-|account|close|description|float4|int1|
-|action|coalesce|des_key_file|float8|int2|
-|active|code|deterministic|flush|int3|
-|add|collate|diagnostics|following|int4|
-|admin|collation|directory|follows|int8|
-|after|column|disable|for|integer|
-|against|columns|discard|force|intersect|
-|aggregate|column_format|disk|foreign|interval|
-|algorithm|column_name|distinct|format|into|
-|all|comment|distinctrow|found|invisible|
-|alter|commit|div|from|invoker|
-|always|committed|do|full|io|
-|analyse|compact|double|fulltext|io_after_gtid|
-|analyze|completion|drop|function|io_before_gti|
-|and|component|dual|general|io_thread|
-|any|compressed|dumpfile|generate|ipc|
-|array|compression|duplicate|generated|is|
-|as|concurrent|dynamic|geomcollectio|isolation|
-|asc|condition|each|geometry|issuer|
-|ascii|connection|else|geometrycolle|iterate|
-|asensitive|consistent|elseif|get|join|
-|at|constraint|empty|get_format|json|
-|attribute|constraint_ca|enable|get_master_pu|json_table|
-|authenticatio|constraint_na|enclosed|get_source_pu|json_value|
-|autoextend_si|constraint_sc|encryption|global|key|
-|auto_incremen|contains|end|grant|keyring|
-|avg|context|ends|grants|keys|
-|avg_row_lengt|continue|enforced|group|key_block_siz|
-|backup|convert|engine|grouping|kill|
-|before|cpu|engines|groups|lag|
-|begin|create|engine_attrib|group_replica|language|
-|between|cross|enum|gtid_only|last|
-|bigint|cube|error|handler|last_value|
-|binary|cume_dist|errors|hash|lateral|
-|binlog|current|escape|having|lead|
-|bit|current_date|escaped|help|leading|
-|blob|current_time|event|high_priority|leave|
-|block|current_times|events|histogram|leaves|
-|bool|current_user|every|history|left|
-|boolean|cursor|except|host|less|
-|both|cursor_name|exchange|hosts|level|
-|btree|data|exclude|hour|like|
-|buckets|database|execute|hour_microsec|limit|
-|bulk|databases|exists|hour_minute|linear|
-|by|datafile|exit|hour_second|lines|
-|byte|date|expansion|identified|linestring|
-|cache|datetime|expire|if|list|
-|call|day|explain|ignore|load|
-|cascade|day_hour|export|ignore_server|local|
-|cascaded|day_microseco|extended|import|localtime|
-|case|day_minute|extent_size|in|localtimestam|
-|catalog_name|day_second|factor|inactive|lock|
-|chain|deallocate|failed_login_|index|locked|
-|challenge_res|dec|false|indexes|locks|
-|change|decimal|fast|infile|logfile|
-|changed|declare|faults|initial|logs|
-|channel|default|fetch|initial_size|long|
-|char|default_auth|fields|initiate|longblob|
-|character|definer|file|inner|longtext|
-|charset|definition|file_block_si|inout|loop|
-|check|delayed|filter|insensitive|low_priority|
-|checksum|delay_key_wri|finish|insert|master|
-|cipher|delete|first|insert_method|master_auto_p|
-|class_origin|dense_rank|first_value|install|master_bind|
-|client|desc|fixed|instance|master_compre|
-|master_connec|never|preserve|restrict|source_host|
-|master_delay|new|prev|resume|source_log_fi|
-|master_heartb|next|primary|retain|source_log_po|
-|master_host|no|privileges|return|source_passwo|
-|master_log_fi|nodegroup|privilege_che|returned_sqls|source_port|
-|master_log_po|none|procedure|returning|source_public|
-|master_passwo|not|process|returns|source_retry_|
-|master_port|nowait|processlist|reuse|source_ssl|
-|master_public|no_wait|profile|reverse|source_ssl_ca|
-|master_retry_|no_write_to_b|profiles|revoke|source_ssl_ca|
-|master_server|nth_value|proxy|right|source_ssl_ce|
-|master_ssl|ntile|purge|rlike|source_ssl_ci|
-|master_ssl_ca|null|quarter|role|source_ssl_cr|
-|master_ssl_ca|nulls|query|rollback|source_ssl_cr|
-|master_ssl_ce|number|quick|rollup|source_ssl_ke|
-|master_ssl_ci|numeric|random|rotate|source_ssl_ve|
-|master_ssl_cr|nvarchar|range|routine|source_tls_ci|
-|master_ssl_cr|of|rank|row|source_tls_ve|
-|master_ssl_ke|off|read|rows|source_user|
-|master_ssl_ve|offset|reads|row_count|source_zstd_c|
-|master_tls_ci|oj|read_only|row_format|spatial|
-|master_tls_ve|old|read_write|row_number|specific|
-|master_user|on|real|rtree|sql|
-|master_zstd_c|one|rebuild|savepoint|sqlexception|
-|match|only|recover|schedule|sqlstate|
-|maxvalue|open|recursive|schema|sqlwarning|
-|max_connectio|optimize|redofile|schemas|sql_after_gti|
-|max_queries_p|optimizer_cos|redo_buffer_s|schema_name|sql_after_mts|
-|max_rows|option|redundant|second|sql_before_gt|
-|max_size|optional|reference|secondary|sql_big_resul|
-|max_updates_p|optionally|references|secondary_eng|sql_buffer_re|
-|max_user_conn|options|regexp|secondary_eng|sql_cache|
-|medium|or|registration|secondary_loa|sql_calc_foun|
-|mediumblob|order|relay|secondary_unl|sql_no_cache|
-|mediumint|ordinality|relaylog|second_micros|sql_small_res|
-|mediumtext|organization|relay_log_fil|security|sql_thread|
-|member|others|relay_log_pos|select|sql_tsi_day|
-|memory|out|relay_thread|sensitive|sql_tsi_hour|
-|merge|outer|release|separator|sql_tsi_minut|
-|message_text|outfile|reload|serial|sql_tsi_month|
-|microsecond|over|remote|serializable|sql_tsi_quart|
-|middleint|owner|remove|server|sql_tsi_secon|
-|migrate|pack_keys|rename|session|sql_tsi_week|
-|minute|page|reorganize|set|sql_tsi_year|
-|minute_micros|parser|repair|share|srid|
-|minute_second|partial|repeat|show|ssl|
-|min_rows|partition|repeatable|shutdown|stacked|
-|mod|partitioning|replace|signal|start|
-|mode|partitions|replica|signed|starting|
-|modifies|password|replicas|simple|starts|
-|modify|password_lock|replicate_do_|skip|stats_auto_re|
-|month|path|replicate_do_|slave|stats_persist|
-|multilinestri|percent_rank|replicate_ign|slow|stats_sample_|
-|multipoint|persist|replicate_ign|smallint|status|
-|multipolygon|persist_only|replicate_rew|snapshot|stop|
-|mutex|phase|replicate_wil|socket|storage|
-|mysql_errno|plugin|replicate_wil|some|stored|
-|name|plugins|replication|soname|straight_join|
-|names|plugin_dir|require|sounds|stream|
-|national|point|require_row_f|source|string|
-|natural|polygon|reset|source_auto_p|subclass_orig|
-|nchar|port|resignal|source_bind|subject|
-|ndb|precedes|resource|source_compre|subpartition|
-|ndbcluster|preceding|respect|source_connec|subpartitions|
-|nested|precision|restart|source_delay|super|
-|network_names|prepare|restore|source_heartb|suspend|
-|swaps|timestampdiff|undo_buffer_s|utc_date|when|
-|switches|tinyblob|unicode|utc_time|where|
-|system|tinyint|uninstall|utc_timestamp|while|
-|table|tinytext|union|validation|window|
-|tables|tls|unique|value|with|
-|tablespace|to|unknown|values|without|
-|table_checksu|trailing|unlock|varbinary|work|
-|table_name|transaction|unregister|varchar|wrapper|
-|temporary|trigger|unsigned|varcharacter|write|
-|temptable|triggers|until|variables|x509|
-|terminated|true|update|varying|xa|
-|text|truncate|upgrade|vcpu|xid|
-|than|type|url|view|xml|
-|then|types|usage|virtual|xor|
-|thread_priori|unbounded|use|visible|year|
-|ties|uncommitted|user|wait|year_month|
-|time|undefined|user_resource|warnings|zerofill|
-|timestamp|undo|use_frm|week|zone|
-|timestampadd|undofile|using|weight_string|
+| Reserved words | | | | |
+| -------------- | ------------- | ------------- | ------------- | ------------- |
+| accessible | clone | describe | float | int |
+| account | close | description | float4 | int1 |
+| action | coalesce | des_key_file | float8 | int2 |
+| active | code | deterministic | flush | int3 |
+| add | collate | diagnostics | following | int4 |
+| admin | collation | directory | follows | int8 |
+| after | column | disable | for | integer |
+| against | columns | discard | force | intersect |
+| aggregate | column_format | disk | foreign | interval |
+| algorithm | column_name | distinct | format | into |
+| all | comment | distinctrow | found | invisible |
+| alter | commit | div | from | invoker |
+| always | committed | do | full | io |
+| analyse | compact | double | fulltext | io_after_gtid |
+| analyze | completion | drop | function | io_before_gti |
+| and | component | dual | general | io_thread |
+| any | compressed | dumpfile | generate | ipc |
+| array | compression | duplicate | generated | is |
+| as | concurrent | dynamic | geomcollectio | isolation |
+| asc | condition | each | geometry | issuer |
+| ascii | connection | else | geometrycolle | iterate |
+| asensitive | consistent | elseif | get | join |
+| at | constraint | empty | get_format | json |
+| attribute | constraint_ca | enable | get_master_pu | json_table |
+| authenticatio | constraint_na | enclosed | get_source_pu | json_value |
+| autoextend_si | constraint_sc | encryption | global | key |
+| auto_incremen | contains | end | grant | keyring |
+| avg | context | ends | grants | keys |
+| avg_row_lengt | continue | enforced | group | key_block_siz |
+| backup | convert | engine | grouping | kill |
+| before | cpu | engines | groups | lag |
+| begin | create | engine_attrib | group_replica | language |
+| between | cross | enum | gtid_only | last |
+| bigint | cube | error | handler | last_value |
+| binary | cume_dist | errors | hash | lateral |
+| binlog | current | escape | having | lead |
+| bit | current_date | escaped | help | leading |
+| blob | current_time | event | high_priority | leave |
+| block | current_times | events | histogram | leaves |
+| bool | current_user | every | history | left |
+| boolean | cursor | except | host | less |
+| both | cursor_name | exchange | hosts | level |
+| btree | data | exclude | hour | like |
+| buckets | database | execute | hour_microsec | limit |
+| bulk | databases | exists | hour_minute | linear |
+| by | datafile | exit | hour_second | lines |
+| byte | date | expansion | identified | linestring |
+| cache | datetime | expire | if | list |
+| call | day | explain | ignore | load |
+| cascade | day_hour | export | ignore_server | local |
+| cascaded | day_microseco | extended | import | localtime |
+| case | day_minute | extent_size | in | localtimestam |
+| catalog_name | day_second | factor | inactive | lock |
+| chain | deallocate | failed*login* | index | locked |
+| challenge_res | dec | false | indexes | locks |
+| change | decimal | fast | infile | logfile |
+| changed | declare | faults | initial | logs |
+| channel | default | fetch | initial_size | long |
+| char | default_auth | fields | initiate | longblob |
+| character | definer | file | inner | longtext |
+| charset | definition | file_block_si | inout | loop |
+| check | delayed | filter | insensitive | low_priority |
+| checksum | delay_key_wri | finish | insert | master |
+| cipher | delete | first | insert_method | master_auto_p |
+| class_origin | dense_rank | first_value | install | master_bind |
+| client | desc | fixed | instance | master_compre |
+| master_connec | never | preserve | restrict | source_host |
+| master_delay | new | prev | resume | source_log_fi |
+| master_heartb | next | primary | retain | source_log_po |
+| master_host | no | privileges | return | source_passwo |
+| master_log_fi | nodegroup | privilege_che | returned_sqls | source_port |
+| master_log_po | none | procedure | returning | source_public |
+| master_passwo | not | process | returns | source*retry* |
+| master_port | nowait | processlist | reuse | source_ssl |
+| master_public | no_wait | profile | reverse | source_ssl_ca |
+| master*retry* | no_write_to_b | profiles | revoke | source_ssl_ca |
+| master_server | nth_value | proxy | right | source_ssl_ce |
+| master_ssl | ntile | purge | rlike | source_ssl_ci |
+| master_ssl_ca | null | quarter | role | source_ssl_cr |
+| master_ssl_ca | nulls | query | rollback | source_ssl_cr |
+| master_ssl_ce | number | quick | rollup | source_ssl_ke |
+| master_ssl_ci | numeric | random | rotate | source_ssl_ve |
+| master_ssl_cr | nvarchar | range | routine | source_tls_ci |
+| master_ssl_cr | of | rank | row | source_tls_ve |
+| master_ssl_ke | off | read | rows | source_user |
+| master_ssl_ve | offset | reads | row_count | source_zstd_c |
+| master_tls_ci | oj | read_only | row_format | spatial |
+| master_tls_ve | old | read_write | row_number | specific |
+| master_user | on | real | rtree | sql |
+| master_zstd_c | one | rebuild | savepoint | sqlexception |
+| match | only | recover | schedule | sqlstate |
+| maxvalue | open | recursive | schema | sqlwarning |
+| max_connectio | optimize | redofile | schemas | sql_after_gti |
+| max_queries_p | optimizer_cos | redo_buffer_s | schema_name | sql_after_mts |
+| max_rows | option | redundant | second | sql_before_gt |
+| max_size | optional | reference | secondary | sql_big_resul |
+| max_updates_p | optionally | references | secondary_eng | sql_buffer_re |
+| max_user_conn | options | regexp | secondary_eng | sql_cache |
+| medium | or | registration | secondary_loa | sql_calc_foun |
+| mediumblob | order | relay | secondary_unl | sql_no_cache |
+| mediumint | ordinality | relaylog | second_micros | sql_small_res |
+| mediumtext | organization | relay_log_fil | security | sql_thread |
+| member | others | relay_log_pos | select | sql_tsi_day |
+| memory | out | relay_thread | sensitive | sql_tsi_hour |
+| merge | outer | release | separator | sql_tsi_minut |
+| message_text | outfile | reload | serial | sql_tsi_month |
+| microsecond | over | remote | serializable | sql_tsi_quart |
+| middleint | owner | remove | server | sql_tsi_secon |
+| migrate | pack_keys | rename | session | sql_tsi_week |
+| minute | page | reorganize | set | sql_tsi_year |
+| minute_micros | parser | repair | share | srid |
+| minute_second | partial | repeat | show | ssl |
+| min_rows | partition | repeatable | shutdown | stacked |
+| mod | partitioning | replace | signal | start |
+| mode | partitions | replica | signed | starting |
+| modifies | password | replicas | simple | starts |
+| modify | password_lock | replicate*do* | skip | stats_auto_re |
+| month | path | replicate*do* | slave | stats_persist |
+| multilinestri | percent_rank | replicate_ign | slow | stats*sample* |
+| multipoint | persist | replicate_ign | smallint | status |
+| multipolygon | persist_only | replicate_rew | snapshot | stop |
+| mutex | phase | replicate_wil | socket | storage |
+| mysql_errno | plugin | replicate_wil | some | stored |
+| name | plugins | replication | soname | straight_join |
+| names | plugin_dir | require | sounds | stream |
+| national | point | require_row_f | source | string |
+| natural | polygon | reset | source_auto_p | subclass_orig |
+| nchar | port | resignal | source_bind | subject |
+| ndb | precedes | resource | source_compre | subpartition |
+| ndbcluster | preceding | respect | source_connec | subpartitions |
+| nested | precision | restart | source_delay | super |
+| network_names | prepare | restore | source_heartb | suspend |
+| swaps | timestampdiff | undo_buffer_s | utc_date | when |
+| switches | tinyblob | unicode | utc_time | where |
+| system | tinyint | uninstall | utc_timestamp | while |
+| table | tinytext | union | validation | window |
+| tables | tls | unique | value | with |
+| tablespace | to | unknown | values | without |
+| table_checksu | trailing | unlock | varbinary | work |
+| table_name | transaction | unregister | varchar | wrapper |
+| temporary | trigger | unsigned | varcharacter | write |
+| temptable | triggers | until | variables | x509 |
+| terminated | true | update | varying | xa |
+| text | truncate | upgrade | vcpu | xid |
+| than | type | url | view | xml |
+| then | types | usage | virtual | xor |
+| thread_priori | unbounded | use | visible | year |
+| ties | uncommitted | user | wait | year_month |
+| time | undefined | user_resource | warnings | zerofill |
+| timestamp | undo | use_frm | week | zone |
+| timestampadd | undofile | using | weight_string |
## Changelog
diff --git a/site/docs/reference/Connectors/materialization-connectors/MySQL/google-cloud-sql-mysql.md b/site/docs/reference/Connectors/materialization-connectors/MySQL/google-cloud-sql-mysql.md
index 775a01ba30..9e34155757 100644
--- a/site/docs/reference/Connectors/materialization-connectors/MySQL/google-cloud-sql-mysql.md
+++ b/site/docs/reference/Connectors/materialization-connectors/MySQL/google-cloud-sql-mysql.md
@@ -10,19 +10,19 @@ open-source workflows,
To use this connector, you'll need:
-* A MySQL database to which to materialize, and user credentials.
- * MySQL versions 5.7 and later are supported
- * The connector will create new tables in the database per your specification,
+- A MySQL database to which to materialize, and user credentials.
+ - MySQL versions 5.7 and later are supported
+ - The connector will create new tables in the database per your specification,
so user credentials must have access to create new tables.
- * The `local_infile` global variable must be enabled. You can enable this
+ - The `local_infile` global variable must be enabled. You can enable this
setting by running `SET GLOBAL local_infile = true` in your database.
-* At least one Flow collection
+- At least one Flow collection
## Setup
-### Conenecting Directly to Google Cloud SQL
+### Conenecting Directly to Google Cloud SQL
-1. [Enable public IP on your database](https://cloud.google.com/sql/docs/mysql/configure-ip#add) and add `34.121.207.128` as an authorized IP address.
+1. [Enable public IP on your database](https://cloud.google.com/sql/docs/mysql/configure-ip#add) and add `34.121.207.128, 35.226.75.135, 34.68.62.148` as authorized IP addresses.
### Connect With SSH Tunneling
@@ -32,25 +32,31 @@ To allow SSH tunneling to a database instance hosted on Google Cloud, you must s
In the `.ssh` subdirectory of your user home directory,
look for the PEM file that contains the private SSH key. Check that it starts with `-----BEGIN RSA PRIVATE KEY-----`,
which indicates it is an RSA-based file.
- * If no such file exists, generate one using the command:
+
+ - If no such file exists, generate one using the command:
+
```console
ssh-keygen -m PEM -t rsa
- ```
- * If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+ ```
+
+ - If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+
```console
ssh-keygen -p -N "" -m pem -f /path/to/key
- ```
- * If your Google login differs from your local username, generate a key that includes your Google email address as a comment:
+ ```
+
+ - If your Google login differs from your local username, generate a key that includes your Google email address as a comment:
+
```console
ssh-keygen -m PEM -t rsa -C user@domain.com
- ```
+ ```
2. [Create and start a new VM in GCP](https://cloud.google.com/compute/docs/instances/create-start-instance), [choosing an image that supports OS Login](https://cloud.google.com/compute/docs/images/os-details#user-space-features).
3. [Add your public key to the VM](https://cloud.google.com/compute/docs/connect/add-ssh-keys).
-5. [Reserve an external IP address](https://cloud.google.com/compute/docs/ip-addresses/reserve-static-external-ip-address) and connect it to the VM during setup.
-Note the generated address.
+4. [Reserve an external IP address](https://cloud.google.com/compute/docs/ip-addresses/reserve-static-external-ip-address) and connect it to the VM during setup.
+ Note the generated address.
:::tip Configuration Tip
To configure the connector, you must specify the database address in the format
@@ -58,7 +64,6 @@ To configure the connector, you must specify the database address in the format
You can find the host and port in the following locations in each platform's console:
:::
-
## Configuration
To use this connector, begin with data in one or more Flow collections.
@@ -68,18 +73,18 @@ Use the below properties to configure a MySQL materialization, which will direct
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|-----------------------------|------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------|------------------|
-| **`/database`** | Database | Name of the logical database to materialize to. | string | Required |
-| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `3306`. | string | Required |
-| **`/password`** | Password | Password for the specified database user. | string | Required |
-| **`/user`** | User | Database user to connect as. | string | Required |
-| `/timezone` | Timezone | Timezone to use when materializing datetime columns. Should normally be left blank to use the database's 'time_zone' system variable. Only required if the 'time_zone' system variable cannot be read. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the 'time_zone' system variable if both are set. | string | |
-| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
-| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
-| `/advanced/ssl_server_ca` | SSL Server CA | Optional server certificate authority to use when connecting with custom SSL mode | string | |
-| `/advanced/ssl_client_cert` | SSL Client Certificate | Optional client certificate to use when connecting with custom SSL mode. | string | |
-| `/advanced/ssl_client_key` | SSL Client Key | Optional client key to use when connecting with custom SSL mode. | string | |
+| Property | Title | Description | Type | Required/Default |
+| --------------------------- | ---------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------ | ---------------- |
+| **`/database`** | Database | Name of the logical database to materialize to. | string | Required |
+| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `3306`. | string | Required |
+| **`/password`** | Password | Password for the specified database user. | string | Required |
+| **`/user`** | User | Database user to connect as. | string | Required |
+| `/timezone` | Timezone | Timezone to use when materializing datetime columns. Should normally be left blank to use the database's 'time_zone' system variable. Only required if the 'time_zone' system variable cannot be read. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the 'time_zone' system variable if both are set. | string | |
+| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
+| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
+| `/advanced/ssl_server_ca` | SSL Server CA | Optional server certificate authority to use when connecting with custom SSL mode | string | |
+| `/advanced/ssl_client_cert` | SSL Client Certificate | Optional client certificate to use when connecting with custom SSL mode. | string | |
+| `/advanced/ssl_client_key` | SSL Client Key | Optional client key to use when connecting with custom SSL mode. | string | |
### Setting the MySQL time zone
@@ -93,11 +98,12 @@ To avoid this, you must explicitly set the time zone for your database.
You can:
-* Specify a numerical offset from UTC.
- - For MySQL version 8.0.19 or higher, values from `-13:59` to `+14:00`, inclusive, are permitted.
- - Prior to MySQL 8.0.19, values from `-12:59` to `+13:00`, inclusive, are permitted
+- Specify a numerical offset from UTC.
+
+ - For MySQL version 8.0.19 or higher, values from `-13:59` to `+14:00`, inclusive, are permitted.
+ - Prior to MySQL 8.0.19, values from `-12:59` to `+13:00`, inclusive, are permitted
-* Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
+- Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
For example, if you're located in New Jersey, USA, you could set `time_zone` to `-05:00` or `-04:00`, depending on the time of year.
Because this region observes daylight savings time, you'd be responsible for changing the offset.
@@ -114,6 +120,7 @@ to assume a time zone using the `timezone` configuration property (see above). T
#### SSL Mode
Possible values:
+
- `disabled`: A plain unencrypted connection is established with the server
- `preferred`: Only use SSL connection if the server asks for it
- `required`: Connect using an SSL connection, but do not verify the server's
@@ -132,10 +139,10 @@ authorize the client.
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
-| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | ------------ | ------------------------------------------------------------------------------------------------------------------ | ------- | ---------------- |
+| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
+| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
### Sample
@@ -161,25 +168,26 @@ materializations:
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * [Enable public IP on your database](https://cloud.google.com/sql/docs/mysql/configure-ip#add) and add `34.121.207.128` as an authorized IP address.
- 2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - [Enable public IP on your database](https://cloud.google.com/sql/docs/mysql/configure-ip#add) and add `34.121.207.128, 35.226.75.135, 34.68.62.148` as authorized IP addresses.
+ 2. To allow secure connections via SSH tunneling:
+ - Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
2. Configure your connector as described in the [configuration](#configuration) section above,
-with the additional of the `networkTunnel` stanza to enable the SSH tunnel, if using.
-See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks)
-for additional details and a sample.
+ with the additional of the `networkTunnel` stanza to enable the SSH tunnel, if using.
+ See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks)
+ for additional details and a sample.
:::tip Configuration Tip
To configure the connector, you must specify the database address in the format
`host:port`. (You can also supply `host` only; the connector will use the port `3306` by default, which is correct in many cases.)
-You can find the host host in the GCP console as "Private IP Address". The pport is always `3306`. You may need to [configure private IP](https://cloud.google.com/sql/docs/mysql/configure-private-ip) on your database.
+You can find the host host in the GCP console as "Private IP Address". The pport is always `3306`. You may need to [configure private IP](https://cloud.google.com/sql/docs/mysql/configure-private-ip) on your database.
:::
3. Create the `flow_materialize` user with `All` privileges on your database. This user will need the ability to create and update the `flow_materializations` table.
+
```sql
CREATE USER IF NOT EXISTS flow_materialize
IDENTIFIED BY 'secret'
@@ -188,7 +196,7 @@ GRANT ALL PRIVELEGES ON .* TO 'flow_materialize';
```
4. In the Cloud Console, note the instance's host under Public IP Address. Its port will always be `3306`.
-Together, you'll use the host:port as the `address` property when you configure the connector.
+ Together, you'll use the host:port as the `address` property when you configure the connector.
## Delta updates
@@ -208,159 +216,159 @@ Flow considers all the reserved words in the official [MySQL documentation](http
These reserved words are listed in the table below. Flow automatically quotes fields that are in this list.
-|Reserved words| | | | |
-|---|---|---|---|---|
-|accessible|clone|describe|float|int|
-|account|close|description|float4|int1|
-|action|coalesce|des_key_file|float8|int2|
-|active|code|deterministic|flush|int3|
-|add|collate|diagnostics|following|int4|
-|admin|collation|directory|follows|int8|
-|after|column|disable|for|integer|
-|against|columns|discard|force|intersect|
-|aggregate|column_format|disk|foreign|interval|
-|algorithm|column_name|distinct|format|into|
-|all|comment|distinctrow|found|invisible|
-|alter|commit|div|from|invoker|
-|always|committed|do|full|io|
-|analyse|compact|double|fulltext|io_after_gtid|
-|analyze|completion|drop|function|io_before_gti|
-|and|component|dual|general|io_thread|
-|any|compressed|dumpfile|generate|ipc|
-|array|compression|duplicate|generated|is|
-|as|concurrent|dynamic|geomcollectio|isolation|
-|asc|condition|each|geometry|issuer|
-|ascii|connection|else|geometrycolle|iterate|
-|asensitive|consistent|elseif|get|join|
-|at|constraint|empty|get_format|json|
-|attribute|constraint_ca|enable|get_master_pu|json_table|
-|authenticatio|constraint_na|enclosed|get_source_pu|json_value|
-|autoextend_si|constraint_sc|encryption|global|key|
-|auto_incremen|contains|end|grant|keyring|
-|avg|context|ends|grants|keys|
-|avg_row_lengt|continue|enforced|group|key_block_siz|
-|backup|convert|engine|grouping|kill|
-|before|cpu|engines|groups|lag|
-|begin|create|engine_attrib|group_replica|language|
-|between|cross|enum|gtid_only|last|
-|bigint|cube|error|handler|last_value|
-|binary|cume_dist|errors|hash|lateral|
-|binlog|current|escape|having|lead|
-|bit|current_date|escaped|help|leading|
-|blob|current_time|event|high_priority|leave|
-|block|current_times|events|histogram|leaves|
-|bool|current_user|every|history|left|
-|boolean|cursor|except|host|less|
-|both|cursor_name|exchange|hosts|level|
-|btree|data|exclude|hour|like|
-|buckets|database|execute|hour_microsec|limit|
-|bulk|databases|exists|hour_minute|linear|
-|by|datafile|exit|hour_second|lines|
-|byte|date|expansion|identified|linestring|
-|cache|datetime|expire|if|list|
-|call|day|explain|ignore|load|
-|cascade|day_hour|export|ignore_server|local|
-|cascaded|day_microseco|extended|import|localtime|
-|case|day_minute|extent_size|in|localtimestam|
-|catalog_name|day_second|factor|inactive|lock|
-|chain|deallocate|failed_login_|index|locked|
-|challenge_res|dec|false|indexes|locks|
-|change|decimal|fast|infile|logfile|
-|changed|declare|faults|initial|logs|
-|channel|default|fetch|initial_size|long|
-|char|default_auth|fields|initiate|longblob|
-|character|definer|file|inner|longtext|
-|charset|definition|file_block_si|inout|loop|
-|check|delayed|filter|insensitive|low_priority|
-|checksum|delay_key_wri|finish|insert|master|
-|cipher|delete|first|insert_method|master_auto_p|
-|class_origin|dense_rank|first_value|install|master_bind|
-|client|desc|fixed|instance|master_compre|
-|master_connec|never|preserve|restrict|source_host|
-|master_delay|new|prev|resume|source_log_fi|
-|master_heartb|next|primary|retain|source_log_po|
-|master_host|no|privileges|return|source_passwo|
-|master_log_fi|nodegroup|privilege_che|returned_sqls|source_port|
-|master_log_po|none|procedure|returning|source_public|
-|master_passwo|not|process|returns|source_retry_|
-|master_port|nowait|processlist|reuse|source_ssl|
-|master_public|no_wait|profile|reverse|source_ssl_ca|
-|master_retry_|no_write_to_b|profiles|revoke|source_ssl_ca|
-|master_server|nth_value|proxy|right|source_ssl_ce|
-|master_ssl|ntile|purge|rlike|source_ssl_ci|
-|master_ssl_ca|null|quarter|role|source_ssl_cr|
-|master_ssl_ca|nulls|query|rollback|source_ssl_cr|
-|master_ssl_ce|number|quick|rollup|source_ssl_ke|
-|master_ssl_ci|numeric|random|rotate|source_ssl_ve|
-|master_ssl_cr|nvarchar|range|routine|source_tls_ci|
-|master_ssl_cr|of|rank|row|source_tls_ve|
-|master_ssl_ke|off|read|rows|source_user|
-|master_ssl_ve|offset|reads|row_count|source_zstd_c|
-|master_tls_ci|oj|read_only|row_format|spatial|
-|master_tls_ve|old|read_write|row_number|specific|
-|master_user|on|real|rtree|sql|
-|master_zstd_c|one|rebuild|savepoint|sqlexception|
-|match|only|recover|schedule|sqlstate|
-|maxvalue|open|recursive|schema|sqlwarning|
-|max_connectio|optimize|redofile|schemas|sql_after_gti|
-|max_queries_p|optimizer_cos|redo_buffer_s|schema_name|sql_after_mts|
-|max_rows|option|redundant|second|sql_before_gt|
-|max_size|optional|reference|secondary|sql_big_resul|
-|max_updates_p|optionally|references|secondary_eng|sql_buffer_re|
-|max_user_conn|options|regexp|secondary_eng|sql_cache|
-|medium|or|registration|secondary_loa|sql_calc_foun|
-|mediumblob|order|relay|secondary_unl|sql_no_cache|
-|mediumint|ordinality|relaylog|second_micros|sql_small_res|
-|mediumtext|organization|relay_log_fil|security|sql_thread|
-|member|others|relay_log_pos|select|sql_tsi_day|
-|memory|out|relay_thread|sensitive|sql_tsi_hour|
-|merge|outer|release|separator|sql_tsi_minut|
-|message_text|outfile|reload|serial|sql_tsi_month|
-|microsecond|over|remote|serializable|sql_tsi_quart|
-|middleint|owner|remove|server|sql_tsi_secon|
-|migrate|pack_keys|rename|session|sql_tsi_week|
-|minute|page|reorganize|set|sql_tsi_year|
-|minute_micros|parser|repair|share|srid|
-|minute_second|partial|repeat|show|ssl|
-|min_rows|partition|repeatable|shutdown|stacked|
-|mod|partitioning|replace|signal|start|
-|mode|partitions|replica|signed|starting|
-|modifies|password|replicas|simple|starts|
-|modify|password_lock|replicate_do_|skip|stats_auto_re|
-|month|path|replicate_do_|slave|stats_persist|
-|multilinestri|percent_rank|replicate_ign|slow|stats_sample_|
-|multipoint|persist|replicate_ign|smallint|status|
-|multipolygon|persist_only|replicate_rew|snapshot|stop|
-|mutex|phase|replicate_wil|socket|storage|
-|mysql_errno|plugin|replicate_wil|some|stored|
-|name|plugins|replication|soname|straight_join|
-|names|plugin_dir|require|sounds|stream|
-|national|point|require_row_f|source|string|
-|natural|polygon|reset|source_auto_p|subclass_orig|
-|nchar|port|resignal|source_bind|subject|
-|ndb|precedes|resource|source_compre|subpartition|
-|ndbcluster|preceding|respect|source_connec|subpartitions|
-|nested|precision|restart|source_delay|super|
-|network_names|prepare|restore|source_heartb|suspend|
-|swaps|timestampdiff|undo_buffer_s|utc_date|when|
-|switches|tinyblob|unicode|utc_time|where|
-|system|tinyint|uninstall|utc_timestamp|while|
-|table|tinytext|union|validation|window|
-|tables|tls|unique|value|with|
-|tablespace|to|unknown|values|without|
-|table_checksu|trailing|unlock|varbinary|work|
-|table_name|transaction|unregister|varchar|wrapper|
-|temporary|trigger|unsigned|varcharacter|write|
-|temptable|triggers|until|variables|x509|
-|terminated|true|update|varying|xa|
-|text|truncate|upgrade|vcpu|xid|
-|than|type|url|view|xml|
-|then|types|usage|virtual|xor|
-|thread_priori|unbounded|use|visible|year|
-|ties|uncommitted|user|wait|year_month|
-|time|undefined|user_resource|warnings|zerofill|
-|timestamp|undo|use_frm|week|zone|
-|timestampadd|undofile|using|weight_string|
+| Reserved words | | | | |
+| -------------- | ------------- | ------------- | ------------- | ------------- |
+| accessible | clone | describe | float | int |
+| account | close | description | float4 | int1 |
+| action | coalesce | des_key_file | float8 | int2 |
+| active | code | deterministic | flush | int3 |
+| add | collate | diagnostics | following | int4 |
+| admin | collation | directory | follows | int8 |
+| after | column | disable | for | integer |
+| against | columns | discard | force | intersect |
+| aggregate | column_format | disk | foreign | interval |
+| algorithm | column_name | distinct | format | into |
+| all | comment | distinctrow | found | invisible |
+| alter | commit | div | from | invoker |
+| always | committed | do | full | io |
+| analyse | compact | double | fulltext | io_after_gtid |
+| analyze | completion | drop | function | io_before_gti |
+| and | component | dual | general | io_thread |
+| any | compressed | dumpfile | generate | ipc |
+| array | compression | duplicate | generated | is |
+| as | concurrent | dynamic | geomcollectio | isolation |
+| asc | condition | each | geometry | issuer |
+| ascii | connection | else | geometrycolle | iterate |
+| asensitive | consistent | elseif | get | join |
+| at | constraint | empty | get_format | json |
+| attribute | constraint_ca | enable | get_master_pu | json_table |
+| authenticatio | constraint_na | enclosed | get_source_pu | json_value |
+| autoextend_si | constraint_sc | encryption | global | key |
+| auto_incremen | contains | end | grant | keyring |
+| avg | context | ends | grants | keys |
+| avg_row_lengt | continue | enforced | group | key_block_siz |
+| backup | convert | engine | grouping | kill |
+| before | cpu | engines | groups | lag |
+| begin | create | engine_attrib | group_replica | language |
+| between | cross | enum | gtid_only | last |
+| bigint | cube | error | handler | last_value |
+| binary | cume_dist | errors | hash | lateral |
+| binlog | current | escape | having | lead |
+| bit | current_date | escaped | help | leading |
+| blob | current_time | event | high_priority | leave |
+| block | current_times | events | histogram | leaves |
+| bool | current_user | every | history | left |
+| boolean | cursor | except | host | less |
+| both | cursor_name | exchange | hosts | level |
+| btree | data | exclude | hour | like |
+| buckets | database | execute | hour_microsec | limit |
+| bulk | databases | exists | hour_minute | linear |
+| by | datafile | exit | hour_second | lines |
+| byte | date | expansion | identified | linestring |
+| cache | datetime | expire | if | list |
+| call | day | explain | ignore | load |
+| cascade | day_hour | export | ignore_server | local |
+| cascaded | day_microseco | extended | import | localtime |
+| case | day_minute | extent_size | in | localtimestam |
+| catalog_name | day_second | factor | inactive | lock |
+| chain | deallocate | failed*login* | index | locked |
+| challenge_res | dec | false | indexes | locks |
+| change | decimal | fast | infile | logfile |
+| changed | declare | faults | initial | logs |
+| channel | default | fetch | initial_size | long |
+| char | default_auth | fields | initiate | longblob |
+| character | definer | file | inner | longtext |
+| charset | definition | file_block_si | inout | loop |
+| check | delayed | filter | insensitive | low_priority |
+| checksum | delay_key_wri | finish | insert | master |
+| cipher | delete | first | insert_method | master_auto_p |
+| class_origin | dense_rank | first_value | install | master_bind |
+| client | desc | fixed | instance | master_compre |
+| master_connec | never | preserve | restrict | source_host |
+| master_delay | new | prev | resume | source_log_fi |
+| master_heartb | next | primary | retain | source_log_po |
+| master_host | no | privileges | return | source_passwo |
+| master_log_fi | nodegroup | privilege_che | returned_sqls | source_port |
+| master_log_po | none | procedure | returning | source_public |
+| master_passwo | not | process | returns | source*retry* |
+| master_port | nowait | processlist | reuse | source_ssl |
+| master_public | no_wait | profile | reverse | source_ssl_ca |
+| master*retry* | no_write_to_b | profiles | revoke | source_ssl_ca |
+| master_server | nth_value | proxy | right | source_ssl_ce |
+| master_ssl | ntile | purge | rlike | source_ssl_ci |
+| master_ssl_ca | null | quarter | role | source_ssl_cr |
+| master_ssl_ca | nulls | query | rollback | source_ssl_cr |
+| master_ssl_ce | number | quick | rollup | source_ssl_ke |
+| master_ssl_ci | numeric | random | rotate | source_ssl_ve |
+| master_ssl_cr | nvarchar | range | routine | source_tls_ci |
+| master_ssl_cr | of | rank | row | source_tls_ve |
+| master_ssl_ke | off | read | rows | source_user |
+| master_ssl_ve | offset | reads | row_count | source_zstd_c |
+| master_tls_ci | oj | read_only | row_format | spatial |
+| master_tls_ve | old | read_write | row_number | specific |
+| master_user | on | real | rtree | sql |
+| master_zstd_c | one | rebuild | savepoint | sqlexception |
+| match | only | recover | schedule | sqlstate |
+| maxvalue | open | recursive | schema | sqlwarning |
+| max_connectio | optimize | redofile | schemas | sql_after_gti |
+| max_queries_p | optimizer_cos | redo_buffer_s | schema_name | sql_after_mts |
+| max_rows | option | redundant | second | sql_before_gt |
+| max_size | optional | reference | secondary | sql_big_resul |
+| max_updates_p | optionally | references | secondary_eng | sql_buffer_re |
+| max_user_conn | options | regexp | secondary_eng | sql_cache |
+| medium | or | registration | secondary_loa | sql_calc_foun |
+| mediumblob | order | relay | secondary_unl | sql_no_cache |
+| mediumint | ordinality | relaylog | second_micros | sql_small_res |
+| mediumtext | organization | relay_log_fil | security | sql_thread |
+| member | others | relay_log_pos | select | sql_tsi_day |
+| memory | out | relay_thread | sensitive | sql_tsi_hour |
+| merge | outer | release | separator | sql_tsi_minut |
+| message_text | outfile | reload | serial | sql_tsi_month |
+| microsecond | over | remote | serializable | sql_tsi_quart |
+| middleint | owner | remove | server | sql_tsi_secon |
+| migrate | pack_keys | rename | session | sql_tsi_week |
+| minute | page | reorganize | set | sql_tsi_year |
+| minute_micros | parser | repair | share | srid |
+| minute_second | partial | repeat | show | ssl |
+| min_rows | partition | repeatable | shutdown | stacked |
+| mod | partitioning | replace | signal | start |
+| mode | partitions | replica | signed | starting |
+| modifies | password | replicas | simple | starts |
+| modify | password_lock | replicate*do* | skip | stats_auto_re |
+| month | path | replicate*do* | slave | stats_persist |
+| multilinestri | percent_rank | replicate_ign | slow | stats*sample* |
+| multipoint | persist | replicate_ign | smallint | status |
+| multipolygon | persist_only | replicate_rew | snapshot | stop |
+| mutex | phase | replicate_wil | socket | storage |
+| mysql_errno | plugin | replicate_wil | some | stored |
+| name | plugins | replication | soname | straight_join |
+| names | plugin_dir | require | sounds | stream |
+| national | point | require_row_f | source | string |
+| natural | polygon | reset | source_auto_p | subclass_orig |
+| nchar | port | resignal | source_bind | subject |
+| ndb | precedes | resource | source_compre | subpartition |
+| ndbcluster | preceding | respect | source_connec | subpartitions |
+| nested | precision | restart | source_delay | super |
+| network_names | prepare | restore | source_heartb | suspend |
+| swaps | timestampdiff | undo_buffer_s | utc_date | when |
+| switches | tinyblob | unicode | utc_time | where |
+| system | tinyint | uninstall | utc_timestamp | while |
+| table | tinytext | union | validation | window |
+| tables | tls | unique | value | with |
+| tablespace | to | unknown | values | without |
+| table_checksu | trailing | unlock | varbinary | work |
+| table_name | transaction | unregister | varchar | wrapper |
+| temporary | trigger | unsigned | varcharacter | write |
+| temptable | triggers | until | variables | x509 |
+| terminated | true | update | varying | xa |
+| text | truncate | upgrade | vcpu | xid |
+| than | type | url | view | xml |
+| then | types | usage | virtual | xor |
+| thread_priori | unbounded | use | visible | year |
+| ties | uncommitted | user | wait | year_month |
+| time | undefined | user_resource | warnings | zerofill |
+| timestamp | undo | use_frm | week | zone |
+| timestampadd | undofile | using | weight_string |
## Changelog
diff --git a/site/docs/reference/Connectors/materialization-connectors/MySQL/mysql.md b/site/docs/reference/Connectors/materialization-connectors/MySQL/mysql.md
index 84308b5956..f84a429281 100644
--- a/site/docs/reference/Connectors/materialization-connectors/MySQL/mysql.md
+++ b/site/docs/reference/Connectors/materialization-connectors/MySQL/mysql.md
@@ -10,21 +10,21 @@ open-source workflows,
To use this connector, you'll need:
-* A MySQL database to which to materialize, and user credentials.
- * MySQL versions 5.7 and later are supported
- * The connector will create new tables in the database per your specification,
+- A MySQL database to which to materialize, and user credentials.
+ - MySQL versions 5.7 and later are supported
+ - The connector will create new tables in the database per your specification,
so user credentials must have access to create new tables.
- * The `local_infile` global variable must be enabled. You can enable this
+ - The `local_infile` global variable must be enabled. You can enable this
setting by running `SET GLOBAL local_infile = true` in your database.
-* At least one Flow collection
+- At least one Flow collection
## Setup
To meet these requirements, follow the steps for your hosting type.
-* [Amazon RDS](./amazon-rds-mysql/)
-* [Google Cloud SQL](./google-cloud-sql-mysql/)
-* [Azure Database for MySQL](#azure-database-for-mysql)
+- [Amazon RDS](./amazon-rds-mysql/)
+- [Google Cloud SQL](./google-cloud-sql-mysql/)
+- [Azure Database for MySQL](#azure-database-for-mysql)
In addition to standard MySQL, this connector supports cloud-based MySQL instances. Google Cloud Platform, Amazon Web Service, and Microsoft Azure are currently supported. You may use other cloud platforms, but Estuary doesn't guarantee performance.
@@ -35,9 +35,9 @@ To connect securely, you can either enable direct access for Flows's IP or use a
You must configure your database to allow connections from Estuary.
There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
-* **Connect Directly With Azure Database For MySQL**: Create a new [firewall rule](https://learn.microsoft.com/en-us/azure/mysql/single-server/how-to-manage-firewall-using-portal) that grants access to the IP address `34.121.207.128`
+- **Connect Directly With Azure Database For MySQL**: Create a new [firewall rule](https://learn.microsoft.com/en-us/azure/mysql/single-server/how-to-manage-firewall-using-portal) that grants access to the IP addresses: `34.121.207.128, 35.226.75.135, 34.68.62.148`
-* **Connect With SSH Tunneling**: Follow the instructions for setting up an SSH connection to [Azure Database](/guides/connect-network/#setup-for-azure).
+- **Connect With SSH Tunneling**: Follow the instructions for setting up an SSH connection to [Azure Database](/guides/connect-network/#setup-for-azure).
## Configuration
@@ -48,18 +48,18 @@ Use the below properties to configure a MySQL materialization, which will direct
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|-----------------------------|------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------|------------------|
-| **`/database`** | Database | Name of the logical database to materialize to. | string | Required |
-| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `3306`. | string | Required |
-| **`/password`** | Password | Password for the specified database user. | string | Required |
-| **`/user`** | User | Database user to connect as. | string | Required |
-| `/timezone` | Timezone | Timezone to use when materializing datetime columns. Should normally be left blank to use the database's 'time_zone' system variable. Only required if the 'time_zone' system variable cannot be read. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the 'time_zone' system variable if both are set. | string | |
-| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
-| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
-| `/advanced/ssl_server_ca` | SSL Server CA | Optional server certificate authority to use when connecting with custom SSL mode | string | |
-| `/advanced/ssl_client_cert` | SSL Client Certificate | Optional client certificate to use when connecting with custom SSL mode. | string | |
-| `/advanced/ssl_client_key` | SSL Client Key | Optional client key to use when connecting with custom SSL mode. | string | |
+| Property | Title | Description | Type | Required/Default |
+| --------------------------- | ---------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------ | ---------------- |
+| **`/database`** | Database | Name of the logical database to materialize to. | string | Required |
+| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `3306`. | string | Required |
+| **`/password`** | Password | Password for the specified database user. | string | Required |
+| **`/user`** | User | Database user to connect as. | string | Required |
+| `/timezone` | Timezone | Timezone to use when materializing datetime columns. Should normally be left blank to use the database's 'time_zone' system variable. Only required if the 'time_zone' system variable cannot be read. Must be a valid IANA time zone name or +HH:MM offset. Takes precedence over the 'time_zone' system variable if both are set. | string | |
+| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
+| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
+| `/advanced/ssl_server_ca` | SSL Server CA | Optional server certificate authority to use when connecting with custom SSL mode | string | |
+| `/advanced/ssl_client_cert` | SSL Client Certificate | Optional client certificate to use when connecting with custom SSL mode. | string | |
+| `/advanced/ssl_client_key` | SSL Client Key | Optional client key to use when connecting with custom SSL mode. | string | |
### Setting the MySQL time zone
@@ -73,15 +73,16 @@ To avoid this, you must explicitly set the time zone for your database.
You can:
-* Specify a numerical offset from UTC.
- - For MySQL version 8.0.19 or higher, values from `-13:59` to `+14:00`, inclusive, are permitted.
- - Prior to MySQL 8.0.19, values from `-12:59` to `+13:00`, inclusive, are permitted
+- Specify a numerical offset from UTC.
-* Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
+ - For MySQL version 8.0.19 or higher, values from `-13:59` to `+14:00`, inclusive, are permitted.
+ - Prior to MySQL 8.0.19, values from `-12:59` to `+13:00`, inclusive, are permitted
-* If you're using Amazon Aurora, create or modify the [DB cluster parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html)
-associated with your MySQL database.
-[Set](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.ModifyingCluster) the `time_zone` parameter to the correct value.
+- Specify a named timezone in [IANA timezone format](https://www.iana.org/time-zones).
+
+- If you're using Amazon Aurora, create or modify the [DB cluster parameter group](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html)
+ associated with your MySQL database.
+ [Set](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithDBClusterParamGroups.html#USER_WorkingWithParamGroups.ModifyingCluster) the `time_zone` parameter to the correct value.
For example, if you're located in New Jersey, USA, you could set `time_zone` to `-05:00` or `-04:00`, depending on the time of year.
Because this region observes daylight savings time, you'd be responsible for changing the offset.
@@ -98,6 +99,7 @@ to assume a time zone using the `timezone` configuration property (see above). T
#### SSL Mode
Possible values:
+
- `disabled`: A plain unencrypted connection is established with the server
- `preferred`: Only use SSL connection if the server asks for it
- `required`: Connect using an SSL connection, but do not verify the server's
@@ -116,10 +118,10 @@ authorize the client.
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
-| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | ------------ | ------------------------------------------------------------------------------------------------------------------ | ------- | ---------------- |
+| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
+| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
### Sample
@@ -148,38 +150,38 @@ To connect securely, you can either enable direct access for Flows's IP or use a
Google Cloud Platform, Amazon Web Service, and Microsoft Azure are currently supported.
You may use other cloud platforms, but Estuary doesn't guarantee performance.
-
### Setup
You must configure your database to allow connections from Estuary.
There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
-* **Connect directly with Amazon RDS or Amazon Aurora**: Edit the VPC security group associated with your database instance, or create a new VPC security group and associate it with the database instance.
- 1. [Modify the instance](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), choosing **Publicly accessible** in the **Connectivity** settings.
+- **Connect directly with Amazon RDS or Amazon Aurora**: Edit the VPC security group associated with your database instance, or create a new VPC security group and associate it with the database instance.
- 2. Per the [steps in the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create),
- create a new inbound rule and a new outbound rule that allow all traffic from the IP address `34.121.207.128`.
+ 1. [Modify the instance](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), choosing **Publicly accessible** in the **Connectivity** settings.
-* **Connect directly with Google Cloud SQL**: [Enable public IP on your database](https://cloud.google.com/sql/docs/mysql/configure-ip#add) and add `34.121.207.128` as an authorized IP address. See the instructions below to use SSH Tunneling instead of enabling public access.
+ 2. Per the [steps in the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create),
+ create a new inbound rule and a new outbound rule that allow all traffic from the IP addresses ``.
+- **Connect directly with Google Cloud SQL**: [Enable public IP on your database](https://cloud.google.com/sql/docs/mysql/configure-ip#add) and add `34.121.207.128, 35.226.75.135, 34.68.62.148` as authorized IP addresses. See the instructions below to use SSH Tunneling instead of enabling public access.
+- **Connect with SSH tunneling**
-* **Connect with SSH tunneling**
- 1. Refer to the [guide](/guides/connect-network/) to configure an SSH server on the cloud platform of your choice.
+ 1. Refer to the [guide](/guides/connect-network/) to configure an SSH server on the cloud platform of your choice.
- 2. Configure your connector as described in the [configuration](#configuration) section above,
- with the additional of the `networkTunnel` stanza to enable the SSH tunnel, if using.
- See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks)
- for additional details and a sample.
+ 2. Configure your connector as described in the [configuration](#configuration) section above,
+ with the additional of the `networkTunnel` stanza to enable the SSH tunnel, if using.
+ See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks)
+ for additional details and a sample.
:::tip Configuration Tip
To configure the connector, you must specify the database address in the format
`host:port`. (You can also supply `host` only; the connector will use the port `3306` by default, which is correct in many cases.)
You can find the host and port in the following locations in each platform's console:
-* Amazon RDS and Amazon Aurora: host as Endpoint; port as Port.
-* Google Cloud SQL: host as Private IP Address; port is always `3306`. You may need to [configure private IP](https://cloud.google.com/sql/docs/mysql/configure-private-ip) on your database.
-* Azure Database: host as Server Name; port under Connection Strings (usually `3306`).
-:::
+
+- Amazon RDS and Amazon Aurora: host as Endpoint; port as Port.
+- Google Cloud SQL: host as Private IP Address; port is always `3306`. You may need to [configure private IP](https://cloud.google.com/sql/docs/mysql/configure-private-ip) on your database.
+- Azure Database: host as Server Name; port under Connection Strings (usually `3306`).
+ :::
## Delta updates
@@ -199,159 +201,159 @@ Flow considers all the reserved words in the official [MySQL documentation](http
These reserved words are listed in the table below. Flow automatically quotes fields that are in this list.
-|Reserved words| | | | |
-|---|---|---|---|---|
-|accessible|clone|describe|float|int|
-|account|close|description|float4|int1|
-|action|coalesce|des_key_file|float8|int2|
-|active|code|deterministic|flush|int3|
-|add|collate|diagnostics|following|int4|
-|admin|collation|directory|follows|int8|
-|after|column|disable|for|integer|
-|against|columns|discard|force|intersect|
-|aggregate|column_format|disk|foreign|interval|
-|algorithm|column_name|distinct|format|into|
-|all|comment|distinctrow|found|invisible|
-|alter|commit|div|from|invoker|
-|always|committed|do|full|io|
-|analyse|compact|double|fulltext|io_after_gtid|
-|analyze|completion|drop|function|io_before_gti|
-|and|component|dual|general|io_thread|
-|any|compressed|dumpfile|generate|ipc|
-|array|compression|duplicate|generated|is|
-|as|concurrent|dynamic|geomcollectio|isolation|
-|asc|condition|each|geometry|issuer|
-|ascii|connection|else|geometrycolle|iterate|
-|asensitive|consistent|elseif|get|join|
-|at|constraint|empty|get_format|json|
-|attribute|constraint_ca|enable|get_master_pu|json_table|
-|authenticatio|constraint_na|enclosed|get_source_pu|json_value|
-|autoextend_si|constraint_sc|encryption|global|key|
-|auto_incremen|contains|end|grant|keyring|
-|avg|context|ends|grants|keys|
-|avg_row_lengt|continue|enforced|group|key_block_siz|
-|backup|convert|engine|grouping|kill|
-|before|cpu|engines|groups|lag|
-|begin|create|engine_attrib|group_replica|language|
-|between|cross|enum|gtid_only|last|
-|bigint|cube|error|handler|last_value|
-|binary|cume_dist|errors|hash|lateral|
-|binlog|current|escape|having|lead|
-|bit|current_date|escaped|help|leading|
-|blob|current_time|event|high_priority|leave|
-|block|current_times|events|histogram|leaves|
-|bool|current_user|every|history|left|
-|boolean|cursor|except|host|less|
-|both|cursor_name|exchange|hosts|level|
-|btree|data|exclude|hour|like|
-|buckets|database|execute|hour_microsec|limit|
-|bulk|databases|exists|hour_minute|linear|
-|by|datafile|exit|hour_second|lines|
-|byte|date|expansion|identified|linestring|
-|cache|datetime|expire|if|list|
-|call|day|explain|ignore|load|
-|cascade|day_hour|export|ignore_server|local|
-|cascaded|day_microseco|extended|import|localtime|
-|case|day_minute|extent_size|in|localtimestam|
-|catalog_name|day_second|factor|inactive|lock|
-|chain|deallocate|failed_login_|index|locked|
-|challenge_res|dec|false|indexes|locks|
-|change|decimal|fast|infile|logfile|
-|changed|declare|faults|initial|logs|
-|channel|default|fetch|initial_size|long|
-|char|default_auth|fields|initiate|longblob|
-|character|definer|file|inner|longtext|
-|charset|definition|file_block_si|inout|loop|
-|check|delayed|filter|insensitive|low_priority|
-|checksum|delay_key_wri|finish|insert|master|
-|cipher|delete|first|insert_method|master_auto_p|
-|class_origin|dense_rank|first_value|install|master_bind|
-|client|desc|fixed|instance|master_compre|
-|master_connec|never|preserve|restrict|source_host|
-|master_delay|new|prev|resume|source_log_fi|
-|master_heartb|next|primary|retain|source_log_po|
-|master_host|no|privileges|return|source_passwo|
-|master_log_fi|nodegroup|privilege_che|returned_sqls|source_port|
-|master_log_po|none|procedure|returning|source_public|
-|master_passwo|not|process|returns|source_retry_|
-|master_port|nowait|processlist|reuse|source_ssl|
-|master_public|no_wait|profile|reverse|source_ssl_ca|
-|master_retry_|no_write_to_b|profiles|revoke|source_ssl_ca|
-|master_server|nth_value|proxy|right|source_ssl_ce|
-|master_ssl|ntile|purge|rlike|source_ssl_ci|
-|master_ssl_ca|null|quarter|role|source_ssl_cr|
-|master_ssl_ca|nulls|query|rollback|source_ssl_cr|
-|master_ssl_ce|number|quick|rollup|source_ssl_ke|
-|master_ssl_ci|numeric|random|rotate|source_ssl_ve|
-|master_ssl_cr|nvarchar|range|routine|source_tls_ci|
-|master_ssl_cr|of|rank|row|source_tls_ve|
-|master_ssl_ke|off|read|rows|source_user|
-|master_ssl_ve|offset|reads|row_count|source_zstd_c|
-|master_tls_ci|oj|read_only|row_format|spatial|
-|master_tls_ve|old|read_write|row_number|specific|
-|master_user|on|real|rtree|sql|
-|master_zstd_c|one|rebuild|savepoint|sqlexception|
-|match|only|recover|schedule|sqlstate|
-|maxvalue|open|recursive|schema|sqlwarning|
-|max_connectio|optimize|redofile|schemas|sql_after_gti|
-|max_queries_p|optimizer_cos|redo_buffer_s|schema_name|sql_after_mts|
-|max_rows|option|redundant|second|sql_before_gt|
-|max_size|optional|reference|secondary|sql_big_resul|
-|max_updates_p|optionally|references|secondary_eng|sql_buffer_re|
-|max_user_conn|options|regexp|secondary_eng|sql_cache|
-|medium|or|registration|secondary_loa|sql_calc_foun|
-|mediumblob|order|relay|secondary_unl|sql_no_cache|
-|mediumint|ordinality|relaylog|second_micros|sql_small_res|
-|mediumtext|organization|relay_log_fil|security|sql_thread|
-|member|others|relay_log_pos|select|sql_tsi_day|
-|memory|out|relay_thread|sensitive|sql_tsi_hour|
-|merge|outer|release|separator|sql_tsi_minut|
-|message_text|outfile|reload|serial|sql_tsi_month|
-|microsecond|over|remote|serializable|sql_tsi_quart|
-|middleint|owner|remove|server|sql_tsi_secon|
-|migrate|pack_keys|rename|session|sql_tsi_week|
-|minute|page|reorganize|set|sql_tsi_year|
-|minute_micros|parser|repair|share|srid|
-|minute_second|partial|repeat|show|ssl|
-|min_rows|partition|repeatable|shutdown|stacked|
-|mod|partitioning|replace|signal|start|
-|mode|partitions|replica|signed|starting|
-|modifies|password|replicas|simple|starts|
-|modify|password_lock|replicate_do_|skip|stats_auto_re|
-|month|path|replicate_do_|slave|stats_persist|
-|multilinestri|percent_rank|replicate_ign|slow|stats_sample_|
-|multipoint|persist|replicate_ign|smallint|status|
-|multipolygon|persist_only|replicate_rew|snapshot|stop|
-|mutex|phase|replicate_wil|socket|storage|
-|mysql_errno|plugin|replicate_wil|some|stored|
-|name|plugins|replication|soname|straight_join|
-|names|plugin_dir|require|sounds|stream|
-|national|point|require_row_f|source|string|
-|natural|polygon|reset|source_auto_p|subclass_orig|
-|nchar|port|resignal|source_bind|subject|
-|ndb|precedes|resource|source_compre|subpartition|
-|ndbcluster|preceding|respect|source_connec|subpartitions|
-|nested|precision|restart|source_delay|super|
-|network_names|prepare|restore|source_heartb|suspend|
-|swaps|timestampdiff|undo_buffer_s|utc_date|when|
-|switches|tinyblob|unicode|utc_time|where|
-|system|tinyint|uninstall|utc_timestamp|while|
-|table|tinytext|union|validation|window|
-|tables|tls|unique|value|with|
-|tablespace|to|unknown|values|without|
-|table_checksu|trailing|unlock|varbinary|work|
-|table_name|transaction|unregister|varchar|wrapper|
-|temporary|trigger|unsigned|varcharacter|write|
-|temptable|triggers|until|variables|x509|
-|terminated|true|update|varying|xa|
-|text|truncate|upgrade|vcpu|xid|
-|than|type|url|view|xml|
-|then|types|usage|virtual|xor|
-|thread_priori|unbounded|use|visible|year|
-|ties|uncommitted|user|wait|year_month|
-|time|undefined|user_resource|warnings|zerofill|
-|timestamp|undo|use_frm|week|zone|
-|timestampadd|undofile|using|weight_string|
+| Reserved words | | | | |
+| -------------- | ------------- | ------------- | ------------- | ------------- |
+| accessible | clone | describe | float | int |
+| account | close | description | float4 | int1 |
+| action | coalesce | des_key_file | float8 | int2 |
+| active | code | deterministic | flush | int3 |
+| add | collate | diagnostics | following | int4 |
+| admin | collation | directory | follows | int8 |
+| after | column | disable | for | integer |
+| against | columns | discard | force | intersect |
+| aggregate | column_format | disk | foreign | interval |
+| algorithm | column_name | distinct | format | into |
+| all | comment | distinctrow | found | invisible |
+| alter | commit | div | from | invoker |
+| always | committed | do | full | io |
+| analyse | compact | double | fulltext | io_after_gtid |
+| analyze | completion | drop | function | io_before_gti |
+| and | component | dual | general | io_thread |
+| any | compressed | dumpfile | generate | ipc |
+| array | compression | duplicate | generated | is |
+| as | concurrent | dynamic | geomcollectio | isolation |
+| asc | condition | each | geometry | issuer |
+| ascii | connection | else | geometrycolle | iterate |
+| asensitive | consistent | elseif | get | join |
+| at | constraint | empty | get_format | json |
+| attribute | constraint_ca | enable | get_master_pu | json_table |
+| authenticatio | constraint_na | enclosed | get_source_pu | json_value |
+| autoextend_si | constraint_sc | encryption | global | key |
+| auto_incremen | contains | end | grant | keyring |
+| avg | context | ends | grants | keys |
+| avg_row_lengt | continue | enforced | group | key_block_siz |
+| backup | convert | engine | grouping | kill |
+| before | cpu | engines | groups | lag |
+| begin | create | engine_attrib | group_replica | language |
+| between | cross | enum | gtid_only | last |
+| bigint | cube | error | handler | last_value |
+| binary | cume_dist | errors | hash | lateral |
+| binlog | current | escape | having | lead |
+| bit | current_date | escaped | help | leading |
+| blob | current_time | event | high_priority | leave |
+| block | current_times | events | histogram | leaves |
+| bool | current_user | every | history | left |
+| boolean | cursor | except | host | less |
+| both | cursor_name | exchange | hosts | level |
+| btree | data | exclude | hour | like |
+| buckets | database | execute | hour_microsec | limit |
+| bulk | databases | exists | hour_minute | linear |
+| by | datafile | exit | hour_second | lines |
+| byte | date | expansion | identified | linestring |
+| cache | datetime | expire | if | list |
+| call | day | explain | ignore | load |
+| cascade | day_hour | export | ignore_server | local |
+| cascaded | day_microseco | extended | import | localtime |
+| case | day_minute | extent_size | in | localtimestam |
+| catalog_name | day_second | factor | inactive | lock |
+| chain | deallocate | failed*login* | index | locked |
+| challenge_res | dec | false | indexes | locks |
+| change | decimal | fast | infile | logfile |
+| changed | declare | faults | initial | logs |
+| channel | default | fetch | initial_size | long |
+| char | default_auth | fields | initiate | longblob |
+| character | definer | file | inner | longtext |
+| charset | definition | file_block_si | inout | loop |
+| check | delayed | filter | insensitive | low_priority |
+| checksum | delay_key_wri | finish | insert | master |
+| cipher | delete | first | insert_method | master_auto_p |
+| class_origin | dense_rank | first_value | install | master_bind |
+| client | desc | fixed | instance | master_compre |
+| master_connec | never | preserve | restrict | source_host |
+| master_delay | new | prev | resume | source_log_fi |
+| master_heartb | next | primary | retain | source_log_po |
+| master_host | no | privileges | return | source_passwo |
+| master_log_fi | nodegroup | privilege_che | returned_sqls | source_port |
+| master_log_po | none | procedure | returning | source_public |
+| master_passwo | not | process | returns | source*retry* |
+| master_port | nowait | processlist | reuse | source_ssl |
+| master_public | no_wait | profile | reverse | source_ssl_ca |
+| master*retry* | no_write_to_b | profiles | revoke | source_ssl_ca |
+| master_server | nth_value | proxy | right | source_ssl_ce |
+| master_ssl | ntile | purge | rlike | source_ssl_ci |
+| master_ssl_ca | null | quarter | role | source_ssl_cr |
+| master_ssl_ca | nulls | query | rollback | source_ssl_cr |
+| master_ssl_ce | number | quick | rollup | source_ssl_ke |
+| master_ssl_ci | numeric | random | rotate | source_ssl_ve |
+| master_ssl_cr | nvarchar | range | routine | source_tls_ci |
+| master_ssl_cr | of | rank | row | source_tls_ve |
+| master_ssl_ke | off | read | rows | source_user |
+| master_ssl_ve | offset | reads | row_count | source_zstd_c |
+| master_tls_ci | oj | read_only | row_format | spatial |
+| master_tls_ve | old | read_write | row_number | specific |
+| master_user | on | real | rtree | sql |
+| master_zstd_c | one | rebuild | savepoint | sqlexception |
+| match | only | recover | schedule | sqlstate |
+| maxvalue | open | recursive | schema | sqlwarning |
+| max_connectio | optimize | redofile | schemas | sql_after_gti |
+| max_queries_p | optimizer_cos | redo_buffer_s | schema_name | sql_after_mts |
+| max_rows | option | redundant | second | sql_before_gt |
+| max_size | optional | reference | secondary | sql_big_resul |
+| max_updates_p | optionally | references | secondary_eng | sql_buffer_re |
+| max_user_conn | options | regexp | secondary_eng | sql_cache |
+| medium | or | registration | secondary_loa | sql_calc_foun |
+| mediumblob | order | relay | secondary_unl | sql_no_cache |
+| mediumint | ordinality | relaylog | second_micros | sql_small_res |
+| mediumtext | organization | relay_log_fil | security | sql_thread |
+| member | others | relay_log_pos | select | sql_tsi_day |
+| memory | out | relay_thread | sensitive | sql_tsi_hour |
+| merge | outer | release | separator | sql_tsi_minut |
+| message_text | outfile | reload | serial | sql_tsi_month |
+| microsecond | over | remote | serializable | sql_tsi_quart |
+| middleint | owner | remove | server | sql_tsi_secon |
+| migrate | pack_keys | rename | session | sql_tsi_week |
+| minute | page | reorganize | set | sql_tsi_year |
+| minute_micros | parser | repair | share | srid |
+| minute_second | partial | repeat | show | ssl |
+| min_rows | partition | repeatable | shutdown | stacked |
+| mod | partitioning | replace | signal | start |
+| mode | partitions | replica | signed | starting |
+| modifies | password | replicas | simple | starts |
+| modify | password_lock | replicate*do* | skip | stats_auto_re |
+| month | path | replicate*do* | slave | stats_persist |
+| multilinestri | percent_rank | replicate_ign | slow | stats*sample* |
+| multipoint | persist | replicate_ign | smallint | status |
+| multipolygon | persist_only | replicate_rew | snapshot | stop |
+| mutex | phase | replicate_wil | socket | storage |
+| mysql_errno | plugin | replicate_wil | some | stored |
+| name | plugins | replication | soname | straight_join |
+| names | plugin_dir | require | sounds | stream |
+| national | point | require_row_f | source | string |
+| natural | polygon | reset | source_auto_p | subclass_orig |
+| nchar | port | resignal | source_bind | subject |
+| ndb | precedes | resource | source_compre | subpartition |
+| ndbcluster | preceding | respect | source_connec | subpartitions |
+| nested | precision | restart | source_delay | super |
+| network_names | prepare | restore | source_heartb | suspend |
+| swaps | timestampdiff | undo_buffer_s | utc_date | when |
+| switches | tinyblob | unicode | utc_time | where |
+| system | tinyint | uninstall | utc_timestamp | while |
+| table | tinytext | union | validation | window |
+| tables | tls | unique | value | with |
+| tablespace | to | unknown | values | without |
+| table_checksu | trailing | unlock | varbinary | work |
+| table_name | transaction | unregister | varchar | wrapper |
+| temporary | trigger | unsigned | varcharacter | write |
+| temptable | triggers | until | variables | x509 |
+| terminated | true | update | varying | xa |
+| text | truncate | upgrade | vcpu | xid |
+| than | type | url | view | xml |
+| then | types | usage | virtual | xor |
+| thread_priori | unbounded | use | visible | year |
+| ties | uncommitted | user | wait | year_month |
+| time | undefined | user_resource | warnings | zerofill |
+| timestamp | undo | use_frm | week | zone |
+| timestampadd | undofile | using | weight_string |
## Changelog
diff --git a/site/docs/reference/Connectors/materialization-connectors/PostgreSQL/PostgreSQL.md b/site/docs/reference/Connectors/materialization-connectors/PostgreSQL/PostgreSQL.md
index c6e5c4f4ca..74bbcffaf3 100644
--- a/site/docs/reference/Connectors/materialization-connectors/PostgreSQL/PostgreSQL.md
+++ b/site/docs/reference/Connectors/materialization-connectors/PostgreSQL/PostgreSQL.md
@@ -1,4 +1,3 @@
-
This connector materializes Flow collections into tables in a PostgreSQL database.
It is available for use in the Flow web application. For local development or open-source workflows, [`ghcr.io/estuary/materialize-postgres:dev`](https://ghcr.io/estuary/materialize-postgres:dev) provides the latest version of the connector as a Docker image. You can also follow the link in your browser to see past image versions.
@@ -7,17 +6,17 @@ It is available for use in the Flow web application. For local development or op
To use this connector, you'll need:
-* A Postgres database to which to materialize, and user credentials.
+- A Postgres database to which to materialize, and user credentials.
The connector will create new tables in the database per your specification. Tables created manually in advance are not supported.
-* At least one Flow collection
+- At least one Flow collection
## Setup
To meet these requirements, follow the steps for your hosting type.
-* [Amazon RDS](./amazon-rds-postgres/)
-* [Google Cloud SQL](./google-cloud-sql-postgres/)
-* [Azure Database for PostgreSQL](#azure-database-for-postgresql)
+- [Amazon RDS](./amazon-rds-postgres/)
+- [Google Cloud SQL](./google-cloud-sql-postgres/)
+- [Azure Database for PostgreSQL](#azure-database-for-postgresql)
In addition to standard PostgreSQL, this connector supports cloud-based PostgreSQL instances. Google Cloud Platform, Amazon Web Service, and Microsoft Azure are currently supported. You may use other cloud platforms, but Estuary doesn't guarantee performance.
@@ -26,17 +25,18 @@ To connect securely, you can either enable direct access for Flows's IP or use a
:::tip Configuration Tip
To configure the connector, you must specify the database address in the format `host:port`. (You can also supply `host` only; the connector will use the port `5432` by default, which is correct in many cases.)
You can find the host and port in the following locations in each platform's console:
-* Amazon RDS and Amazon Aurora: host as Endpoint; port as Port.
-* Google Cloud SQL: host as Private IP Address; port is always `5432`. You may need to [configure private IP](https://cloud.google.com/sql/docs/postgres/configure-private-ip) on your database.
-* Azure Database: host as Server Name; port under Connection Strings (usually `5432`).
-* TimescaleDB: host as Host; port as Port.
-:::
+
+- Amazon RDS and Amazon Aurora: host as Endpoint; port as Port.
+- Google Cloud SQL: host as Private IP Address; port is always `5432`. You may need to [configure private IP](https://cloud.google.com/sql/docs/postgres/configure-private-ip) on your database.
+- Azure Database: host as Server Name; port under Connection Strings (usually `5432`).
+- TimescaleDB: host as Host; port as Port.
+ :::
### Azure Database for PostgreSQL
-* **Connect Directly With Azure Database For PostgreSQL**: Create a new [firewall rule](https://docs.microsoft.com/en-us/azure/postgresql/flexible-server/how-to-manage-firewall-portal#create-a-firewall-rule-after-server-is-created) that grants access to the IP address `34.121.207.128`.
+- **Connect Directly With Azure Database For PostgreSQL**: Create a new [firewall rule](https://docs.microsoft.com/en-us/azure/postgresql/flexible-server/how-to-manage-firewall-portal#create-a-firewall-rule-after-server-is-created) that grants access to the IP addresses `34.121.207.128, 35.226.75.135, 34.68.62.148`.
-* **Connect With SSH Tunneling**: Follow the instructions for setting up an SSH connection to [Azure Database](/guides/connect-network/#setup-for-azure).
+- **Connect With SSH Tunneling**: Follow the instructions for setting up an SSH connection to [Azure Database](/guides/connect-network/#setup-for-azure).
## Configuration
@@ -47,24 +47,24 @@ Use the below properties to configure a Postgres materialization, which will dir
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|-----------------|----------|-------------------------------------------------|---------|------------------|
-| `/database` | Database | Name of the logical database to materialize to. | string | |
-| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `5432`. | string | Required |
-| **`/password`** | Password | Password for the specified database user. | string | Required |
-| `/schema` | Database Schema | Database [schema](https://www.postgresql.org/docs/current/ddl-schemas.html) to use for materialized tables (unless overridden within the binding resource configuration) as well as associated materialization metadata tables | string | `"public"` |
-| **`/user`** | User | Database user to connect as. | string | Required |
-| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
-| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
+| Property | Title | Description | Type | Required/Default |
+| ------------------- | ---------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------ | ---------------- |
+| `/database` | Database | Name of the logical database to materialize to. | string | |
+| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `5432`. | string | Required |
+| **`/password`** | Password | Password for the specified database user. | string | Required |
+| `/schema` | Database Schema | Database [schema](https://www.postgresql.org/docs/current/ddl-schemas.html) to use for materialized tables (unless overridden within the binding resource configuration) as well as associated materialization metadata tables | string | `"public"` |
+| **`/user`** | User | Database user to connect as. | string | Required |
+| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
+| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| `/additional_table_create_sql` | Additional Table Create SQL | Additional SQL statement(s) to be run in the same transaction that creates the table. | string | |
-| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
-| `/schema` | Alternative Schema | Alternative schema for this table (optional). Overrides schema set in endpoint configuration. | string | |
-| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| ------------------------------ | --------------------------- | ------------------------------------------------------------------------------------------------------------------ | ------- | ---------------- |
+| `/additional_table_create_sql` | Additional Table Create SQL | Additional SQL statement(s) to be run in the same transaction that creates the table. | string | |
+| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
+| `/schema` | Alternative Schema | Alternative schema for this table (optional). Overrides schema set in endpoint configuration. | string | |
+| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
#### SSL Mode
@@ -102,102 +102,102 @@ Flow considers all the reserved words that are marked as "reserved" in any of th
These reserve words are listed in the table below. Flow automatically quotes fields that are in this list.
-|Reserved words| | | | |
-|---|---|---|---|---|
-| abs| current_transform_group_for_type| indicator| order| sqlexception|
-| absolute| current_user| initial| out| sqlstate|
-| acos| cursor| initially| outer| sqlwarning|
-|action| cycle| inner| output| sqrt|
-|add| datalink| inout| over| start|
-|all| date| input| overlaps| static|
-|allocate| day| insensitive| overlay| stddev_pop|
-|alter| deallocate| insert| pad| stddev_samp|
-|analyse| dec| int| parameter| submultiset|
-|analyze| decfloat| integer| partial| subset|
-|and| decimal| intersect| partition| substring|
-|any| declare| intersection| pattern| substring_regex|
-|are| default| interval| per| succeeds|
-|array| deferrable| into| percent| sum|
-|array_agg| deferred| is| percentile_cont| symmetric|
-|array_max_cardinality| define| isnull| percentile_disc| system|
-|as| delete| isolation| percent_rank| system_time|
-|asc| dense_rank| join| period| system_user|
-|asensitive| deref| json_array| permute| table|
-|asin| desc| json_arrayagg| placing| tablesample|
-|assertion| describe| json_exists| portion| tan|
-|asymmetric| descriptor| json_object| position| tanh|
-|at| deterministic| json_objectagg| position_regex| temporary|
-|atan| diagnostics| json_query| power| then|
-|atomic| disconnect| json_table| precedes| time|
-|authorization| distinct| json_table_primitive| precision| timestamp|
-|avg| dlnewcopy| json_value| prepare| timezone_hour|
-|begin| dlpreviouscopy| key| preserve| timezone_minute|
-|begin_frame| dlurlcomplete| lag| primary| to|
-|begin_partition| dlurlcompleteonly| language| prior| trailing|
-|between| dlurlcompletewrite| large| privileges| transaction|
-|bigint| dlurlpath| last| procedure| translate|
-|binary| dlurlpathonly| last_value| ptf| translate_regex|
-|bit| dlurlpathwrite| lateral| public| translation|
-|bit_length| dlurlscheme| lead| range| treat|
-|blob| dlurlserver| leading| rank| trigger|
-|boolean| dlvalue| left| read| trim|
-|both| do| level| reads| trim_array|
-|by| domain| like| real| true|
-|call| double| like_regex| recursive| truncate|
-|called| drop| limit| ref| uescape|
-|cardinality| dynamic| listagg| references| union|
-|cascade| each| ln| referencing| unique|
-|cascaded| element| local| regr_avgx| unknown|
-|case| else| localtime| regr_avgy| unmatched|
-|cast| empty| localtimestamp| regr_count| unnest|
-|catalog| end| log| regr_intercept| update|
-|ceil| end-exec| log10| regr_r2| upper|
-|ceiling| end_frame| lower| regr_slope| usage|
-|char| end_partition| match| regr_sxx| user|
-|character| equals| matches| regr_sxy| using|
-|character_length| escape| match_number| regr_syy| value|
-|char_length| every| match_recognize| relative| values|
-|check| except| max| release| value_of|
-|classifier| exception| measures| restrict| varbinary|
-|clob| exec| member| result| varchar|
-|close| execute| merge| return| variadic|
-|coalesce| exists| method| returning| varying|
-|collate| exp| min| returns| var_pop|
-|collation| external| minute| revoke| var_samp|
-|collect| extract| mod| right| verbose|
-|column| false| modifies| rollback| versioning|
-|commit| fetch| module| rollup| view|
-|concurrently| filter| month| row| when|
-|condition| first| multiset| rows| whenever|
-|connect| first_value| names| row_number| where|
-|connection| float| national| running| width_bucket|
-|constraint| floor| natural| savepoint| window|
-|constraints| for| nchar| schema| with|
-|contains| foreign| nclob| scope| within|
-|continue| found| new| scroll| without|
-|convert| frame_row| next| search| work|
-|copy| free| no| second| write|
-|corr| freeze| none| section| xml|
-|corresponding| from| normalize| seek| xmlagg|
-|cos| full| not| select| xmlattributes|
-|cosh| function| notnull| sensitive| xmlbinary|
-|count| fusion| nth_value| session| xmlcast|
-|covar_pop| get| ntile| session_user| xmlcomment|
-|covar_samp| global| null| set| xmlconcat|
-|create| go| nullif| show| xmldocument|
-|cross| goto| numeric| similar| xmlelement|
-|cube| grant| occurrences_regex| sin| xmlexists|
-|cume_dist| group| octet_length| sinh| xmlforest|
-|current| grouping| of| size| xmliterate|
-|current_catalog| groups| offset| skip| xmlnamespaces|
-|current_date| having| old| smallint| xmlparse|
-|current_default_transform_group| hold| omit| some| xmlpi|
-|current_path| hour| on| space| xmlquery|
-|current_role| identity| one| specific| xmlserialize|
-|current_row| ilike| only| specifictype| xmltable|
-|current_schema| immediate| open| sql| xmltext|
-|current_time| import| option| sqlcode| xmlvalidate|
-|current_timestamp| in| or| sqlerror| year|
+| Reserved words | | | | |
+| ------------------------------- | -------------------------------- | -------------------- | --------------- | --------------- |
+| abs | current_transform_group_for_type | indicator | order | sqlexception |
+| absolute | current_user | initial | out | sqlstate |
+| acos | cursor | initially | outer | sqlwarning |
+| action | cycle | inner | output | sqrt |
+| add | datalink | inout | over | start |
+| all | date | input | overlaps | static |
+| allocate | day | insensitive | overlay | stddev_pop |
+| alter | deallocate | insert | pad | stddev_samp |
+| analyse | dec | int | parameter | submultiset |
+| analyze | decfloat | integer | partial | subset |
+| and | decimal | intersect | partition | substring |
+| any | declare | intersection | pattern | substring_regex |
+| are | default | interval | per | succeeds |
+| array | deferrable | into | percent | sum |
+| array_agg | deferred | is | percentile_cont | symmetric |
+| array_max_cardinality | define | isnull | percentile_disc | system |
+| as | delete | isolation | percent_rank | system_time |
+| asc | dense_rank | join | period | system_user |
+| asensitive | deref | json_array | permute | table |
+| asin | desc | json_arrayagg | placing | tablesample |
+| assertion | describe | json_exists | portion | tan |
+| asymmetric | descriptor | json_object | position | tanh |
+| at | deterministic | json_objectagg | position_regex | temporary |
+| atan | diagnostics | json_query | power | then |
+| atomic | disconnect | json_table | precedes | time |
+| authorization | distinct | json_table_primitive | precision | timestamp |
+| avg | dlnewcopy | json_value | prepare | timezone_hour |
+| begin | dlpreviouscopy | key | preserve | timezone_minute |
+| begin_frame | dlurlcomplete | lag | primary | to |
+| begin_partition | dlurlcompleteonly | language | prior | trailing |
+| between | dlurlcompletewrite | large | privileges | transaction |
+| bigint | dlurlpath | last | procedure | translate |
+| binary | dlurlpathonly | last_value | ptf | translate_regex |
+| bit | dlurlpathwrite | lateral | public | translation |
+| bit_length | dlurlscheme | lead | range | treat |
+| blob | dlurlserver | leading | rank | trigger |
+| boolean | dlvalue | left | read | trim |
+| both | do | level | reads | trim_array |
+| by | domain | like | real | true |
+| call | double | like_regex | recursive | truncate |
+| called | drop | limit | ref | uescape |
+| cardinality | dynamic | listagg | references | union |
+| cascade | each | ln | referencing | unique |
+| cascaded | element | local | regr_avgx | unknown |
+| case | else | localtime | regr_avgy | unmatched |
+| cast | empty | localtimestamp | regr_count | unnest |
+| catalog | end | log | regr_intercept | update |
+| ceil | end-exec | log10 | regr_r2 | upper |
+| ceiling | end_frame | lower | regr_slope | usage |
+| char | end_partition | match | regr_sxx | user |
+| character | equals | matches | regr_sxy | using |
+| character_length | escape | match_number | regr_syy | value |
+| char_length | every | match_recognize | relative | values |
+| check | except | max | release | value_of |
+| classifier | exception | measures | restrict | varbinary |
+| clob | exec | member | result | varchar |
+| close | execute | merge | return | variadic |
+| coalesce | exists | method | returning | varying |
+| collate | exp | min | returns | var_pop |
+| collation | external | minute | revoke | var_samp |
+| collect | extract | mod | right | verbose |
+| column | false | modifies | rollback | versioning |
+| commit | fetch | module | rollup | view |
+| concurrently | filter | month | row | when |
+| condition | first | multiset | rows | whenever |
+| connect | first_value | names | row_number | where |
+| connection | float | national | running | width_bucket |
+| constraint | floor | natural | savepoint | window |
+| constraints | for | nchar | schema | with |
+| contains | foreign | nclob | scope | within |
+| continue | found | new | scroll | without |
+| convert | frame_row | next | search | work |
+| copy | free | no | second | write |
+| corr | freeze | none | section | xml |
+| corresponding | from | normalize | seek | xmlagg |
+| cos | full | not | select | xmlattributes |
+| cosh | function | notnull | sensitive | xmlbinary |
+| count | fusion | nth_value | session | xmlcast |
+| covar_pop | get | ntile | session_user | xmlcomment |
+| covar_samp | global | null | set | xmlconcat |
+| create | go | nullif | show | xmldocument |
+| cross | goto | numeric | similar | xmlelement |
+| cube | grant | occurrences_regex | sin | xmlexists |
+| cume_dist | group | octet_length | sinh | xmlforest |
+| current | grouping | of | size | xmliterate |
+| current_catalog | groups | offset | skip | xmlnamespaces |
+| current_date | having | old | smallint | xmlparse |
+| current_default_transform_group | hold | omit | some | xmlpi |
+| current_path | hour | on | space | xmlquery |
+| current_role | identity | one | specific | xmlserialize |
+| current_row | ilike | only | specifictype | xmltable |
+| current_schema | immediate | open | sql | xmltext |
+| current_time | import | option | sqlcode | xmlvalidate |
+| current_timestamp | in | or | sqlerror | year |
## Changelog
@@ -209,12 +209,12 @@ editing always upgrades your materialization to the latest connector version.**
#### V4: 2022-11-30
This version includes breaking changes to materialized table columns.
-These provide more consistent column names and types, but tables created from previous versions of the connector may
+These provide more consistent column names and types, but tables created from previous versions of the connector may
not be compatible with this version.
-* Capitalization is now preserved when fields in Flow are converted to Postgres column names.
+- Capitalization is now preserved when fields in Flow are converted to Postgres column names.
Previously, fields containing uppercase letters were converted to lowercase.
-* Field names and values of types `date`, `duration`, `ipv4`, `ipv6`, `macaddr`, `macaddr8`, and `time` are now converted into
+- Field names and values of types `date`, `duration`, `ipv4`, `ipv6`, `macaddr`, `macaddr8`, and `time` are now converted into
their corresponding Postgres types.
Previously, only `date-time` was converted, and all others were materialized as strings.
diff --git a/site/docs/reference/Connectors/materialization-connectors/PostgreSQL/amazon-rds-postgres.md b/site/docs/reference/Connectors/materialization-connectors/PostgreSQL/amazon-rds-postgres.md
index e23be65587..9df58f89fd 100644
--- a/site/docs/reference/Connectors/materialization-connectors/PostgreSQL/amazon-rds-postgres.md
+++ b/site/docs/reference/Connectors/materialization-connectors/PostgreSQL/amazon-rds-postgres.md
@@ -8,9 +8,9 @@ It is available for use in the Flow web application. For local development or op
To use this connector, you'll need:
-* A Postgres database to which to materialize, and user credentials.
+- A Postgres database to which to materialize, and user credentials.
The connector will create new tables in the database per your specification. Tables created manually in advance are not supported.
-* At least one Flow collection
+- At least one Flow collection
## Setup
@@ -20,44 +20,51 @@ There are two ways to do this: by granting direct access to Flow's IP or by crea
### Connect Directly With Amazon RDS or Amazon Aurora
1. Edit the VPC security group associated with your database instance, or create a new VPC security group and associate it with the database instance.
- 1. [Modify the instance](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), choosing **Publicly accessible** in the **Connectivity** settings. See the instructions below to use SSH Tunneling instead of enabling public access.
- 2. Refer to the [steps in the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create).
- Create a new inbound rule and a new outbound rule that allow all traffic from the IP address `34.121.207.128`.
+ 1. [Modify the instance](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), choosing **Publicly accessible** in the **Connectivity** settings. See the instructions below to use SSH Tunneling instead of enabling public access.
+
+ 2. Refer to the [steps in the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create).
+ Create a new inbound rule and a new outbound rule that allow all traffic from the IP addresses: `34.121.207.128, 35.226.75.135, 34.68.62.148`.
### Connect With SSH Tunneling
-To allow SSH tunneling to a database instance hosted on AWS, you'll need to create a virtual computing environment, or *instance*, in Amazon EC2.
+To allow SSH tunneling to a database instance hosted on AWS, you'll need to create a virtual computing environment, or _instance_, in Amazon EC2.
1. Begin by finding your public SSH key on your local machine.
In the `.ssh` subdirectory of your user home directory,
look for the PEM file that contains the private SSH key. Check that it starts with `-----BEGIN RSA PRIVATE KEY-----`,
which indicates it is an RSA-based file.
- * If no such file exists, generate one using the command:
+
+ - If no such file exists, generate one using the command:
+
```console
ssh-keygen -m PEM -t rsa
- ```
- * If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+ ```
+
+ - If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+
```console
ssh-keygen -p -N "" -m pem -f /path/to/key
- ```
+ ```
2. [Import your SSH key into AWS](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-key-pairs.html#how-to-generate-your-own-key-and-import-it-to-aws).
3. [Launch a new instance in EC2](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/LaunchingAndUsingInstances.html). During setup:
- * Configure the security group to allow SSH connection from anywhere.
- * When selecting a key pair, choose the key you just imported.
+
+ - Configure the security group to allow SSH connection from anywhere.
+ - When selecting a key pair, choose the key you just imported.
4. [Connect to the instance](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AccessingInstances.html),
-setting the user name to `ec2-user`.
+ setting the user name to `ec2-user`.
5. Find and note the [instance's public DNS](https://docs.aws.amazon.com/vpc/latest/userguide/vpc-dns.html#vpc-dns-viewing). This will be formatted like: `ec2-198-21-98-1.compute-1.amazonaws.com`.
:::tip Configuration Tip
To configure the connector, you must specify the database address in the format `host:port`. (You can also supply `host` only; the connector will use the port `5432` by default, which is correct in many cases.)
You can find the host and port in the following locations in each platform's console:
-* Amazon RDS: host as Endpoint; port as Port.
-:::
+
+- Amazon RDS: host as Endpoint; port as Port.
+ :::
## Configuration
@@ -68,24 +75,24 @@ Use the below properties to configure a Postgres materialization, which will dir
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|-----------------|----------|-------------------------------------------------|---------|------------------|
-| `/database` | Database | Name of the logical database to materialize to. | string | |
-| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `5432`. | string | Required |
-| **`/password`** | Password | Password for the specified database user. | string | Required |
-| `/schema` | Database Schema | Database [schema](https://www.postgresql.org/docs/current/ddl-schemas.html) to use for materialized tables (unless overridden within the binding resource configuration) as well as associated materialization metadata tables | string | `"public"` |
-| **`/user`** | User | Database user to connect as. | string | Required |
-| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
-| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
+| Property | Title | Description | Type | Required/Default |
+| ------------------- | ---------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------ | ---------------- |
+| `/database` | Database | Name of the logical database to materialize to. | string | |
+| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `5432`. | string | Required |
+| **`/password`** | Password | Password for the specified database user. | string | Required |
+| `/schema` | Database Schema | Database [schema](https://www.postgresql.org/docs/current/ddl-schemas.html) to use for materialized tables (unless overridden within the binding resource configuration) as well as associated materialization metadata tables | string | `"public"` |
+| **`/user`** | User | Database user to connect as. | string | Required |
+| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
+| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| `/additional_table_create_sql` | Additional Table Create SQL | Additional SQL statement(s) to be run in the same transaction that creates the table. | string | |
-| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
-| `/schema` | Alternative Schema | Alternative schema for this table (optional). Overrides schema set in endpoint configuration. | string | |
-| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| ------------------------------ | --------------------------- | ------------------------------------------------------------------------------------------------------------------ | ------- | ---------------- |
+| `/additional_table_create_sql` | Additional Table Create SQL | Additional SQL statement(s) to be run in the same transaction that creates the table. | string | |
+| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
+| `/schema` | Alternative Schema | Alternative schema for this table (optional). Overrides schema set in endpoint configuration. | string | |
+| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
#### SSL Mode
@@ -122,102 +129,102 @@ Flow considers all the reserved words that are marked as "reserved" in any of th
These reserve words are listed in the table below. Flow automatically quotes fields that are in this list.
-|Reserved words| | | | |
-|---|---|---|---|---|
-| abs| current_transform_group_for_type| indicator| order| sqlexception|
-| absolute| current_user| initial| out| sqlstate|
-| acos| cursor| initially| outer| sqlwarning|
-|action| cycle| inner| output| sqrt|
-|add| datalink| inout| over| start|
-|all| date| input| overlaps| static|
-|allocate| day| insensitive| overlay| stddev_pop|
-|alter| deallocate| insert| pad| stddev_samp|
-|analyse| dec| int| parameter| submultiset|
-|analyze| decfloat| integer| partial| subset|
-|and| decimal| intersect| partition| substring|
-|any| declare| intersection| pattern| substring_regex|
-|are| default| interval| per| succeeds|
-|array| deferrable| into| percent| sum|
-|array_agg| deferred| is| percentile_cont| symmetric|
-|array_max_cardinality| define| isnull| percentile_disc| system|
-|as| delete| isolation| percent_rank| system_time|
-|asc| dense_rank| join| period| system_user|
-|asensitive| deref| json_array| permute| table|
-|asin| desc| json_arrayagg| placing| tablesample|
-|assertion| describe| json_exists| portion| tan|
-|asymmetric| descriptor| json_object| position| tanh|
-|at| deterministic| json_objectagg| position_regex| temporary|
-|atan| diagnostics| json_query| power| then|
-|atomic| disconnect| json_table| precedes| time|
-|authorization| distinct| json_table_primitive| precision| timestamp|
-|avg| dlnewcopy| json_value| prepare| timezone_hour|
-|begin| dlpreviouscopy| key| preserve| timezone_minute|
-|begin_frame| dlurlcomplete| lag| primary| to|
-|begin_partition| dlurlcompleteonly| language| prior| trailing|
-|between| dlurlcompletewrite| large| privileges| transaction|
-|bigint| dlurlpath| last| procedure| translate|
-|binary| dlurlpathonly| last_value| ptf| translate_regex|
-|bit| dlurlpathwrite| lateral| public| translation|
-|bit_length| dlurlscheme| lead| range| treat|
-|blob| dlurlserver| leading| rank| trigger|
-|boolean| dlvalue| left| read| trim|
-|both| do| level| reads| trim_array|
-|by| domain| like| real| true|
-|call| double| like_regex| recursive| truncate|
-|called| drop| limit| ref| uescape|
-|cardinality| dynamic| listagg| references| union|
-|cascade| each| ln| referencing| unique|
-|cascaded| element| local| regr_avgx| unknown|
-|case| else| localtime| regr_avgy| unmatched|
-|cast| empty| localtimestamp| regr_count| unnest|
-|catalog| end| log| regr_intercept| update|
-|ceil| end-exec| log10| regr_r2| upper|
-|ceiling| end_frame| lower| regr_slope| usage|
-|char| end_partition| match| regr_sxx| user|
-|character| equals| matches| regr_sxy| using|
-|character_length| escape| match_number| regr_syy| value|
-|char_length| every| match_recognize| relative| values|
-|check| except| max| release| value_of|
-|classifier| exception| measures| restrict| varbinary|
-|clob| exec| member| result| varchar|
-|close| execute| merge| return| variadic|
-|coalesce| exists| method| returning| varying|
-|collate| exp| min| returns| var_pop|
-|collation| external| minute| revoke| var_samp|
-|collect| extract| mod| right| verbose|
-|column| false| modifies| rollback| versioning|
-|commit| fetch| module| rollup| view|
-|concurrently| filter| month| row| when|
-|condition| first| multiset| rows| whenever|
-|connect| first_value| names| row_number| where|
-|connection| float| national| running| width_bucket|
-|constraint| floor| natural| savepoint| window|
-|constraints| for| nchar| schema| with|
-|contains| foreign| nclob| scope| within|
-|continue| found| new| scroll| without|
-|convert| frame_row| next| search| work|
-|copy| free| no| second| write|
-|corr| freeze| none| section| xml|
-|corresponding| from| normalize| seek| xmlagg|
-|cos| full| not| select| xmlattributes|
-|cosh| function| notnull| sensitive| xmlbinary|
-|count| fusion| nth_value| session| xmlcast|
-|covar_pop| get| ntile| session_user| xmlcomment|
-|covar_samp| global| null| set| xmlconcat|
-|create| go| nullif| show| xmldocument|
-|cross| goto| numeric| similar| xmlelement|
-|cube| grant| occurrences_regex| sin| xmlexists|
-|cume_dist| group| octet_length| sinh| xmlforest|
-|current| grouping| of| size| xmliterate|
-|current_catalog| groups| offset| skip| xmlnamespaces|
-|current_date| having| old| smallint| xmlparse|
-|current_default_transform_group| hold| omit| some| xmlpi|
-|current_path| hour| on| space| xmlquery|
-|current_role| identity| one| specific| xmlserialize|
-|current_row| ilike| only| specifictype| xmltable|
-|current_schema| immediate| open| sql| xmltext|
-|current_time| import| option| sqlcode| xmlvalidate|
-|current_timestamp| in| or| sqlerror| year|
+| Reserved words | | | | |
+| ------------------------------- | -------------------------------- | -------------------- | --------------- | --------------- |
+| abs | current_transform_group_for_type | indicator | order | sqlexception |
+| absolute | current_user | initial | out | sqlstate |
+| acos | cursor | initially | outer | sqlwarning |
+| action | cycle | inner | output | sqrt |
+| add | datalink | inout | over | start |
+| all | date | input | overlaps | static |
+| allocate | day | insensitive | overlay | stddev_pop |
+| alter | deallocate | insert | pad | stddev_samp |
+| analyse | dec | int | parameter | submultiset |
+| analyze | decfloat | integer | partial | subset |
+| and | decimal | intersect | partition | substring |
+| any | declare | intersection | pattern | substring_regex |
+| are | default | interval | per | succeeds |
+| array | deferrable | into | percent | sum |
+| array_agg | deferred | is | percentile_cont | symmetric |
+| array_max_cardinality | define | isnull | percentile_disc | system |
+| as | delete | isolation | percent_rank | system_time |
+| asc | dense_rank | join | period | system_user |
+| asensitive | deref | json_array | permute | table |
+| asin | desc | json_arrayagg | placing | tablesample |
+| assertion | describe | json_exists | portion | tan |
+| asymmetric | descriptor | json_object | position | tanh |
+| at | deterministic | json_objectagg | position_regex | temporary |
+| atan | diagnostics | json_query | power | then |
+| atomic | disconnect | json_table | precedes | time |
+| authorization | distinct | json_table_primitive | precision | timestamp |
+| avg | dlnewcopy | json_value | prepare | timezone_hour |
+| begin | dlpreviouscopy | key | preserve | timezone_minute |
+| begin_frame | dlurlcomplete | lag | primary | to |
+| begin_partition | dlurlcompleteonly | language | prior | trailing |
+| between | dlurlcompletewrite | large | privileges | transaction |
+| bigint | dlurlpath | last | procedure | translate |
+| binary | dlurlpathonly | last_value | ptf | translate_regex |
+| bit | dlurlpathwrite | lateral | public | translation |
+| bit_length | dlurlscheme | lead | range | treat |
+| blob | dlurlserver | leading | rank | trigger |
+| boolean | dlvalue | left | read | trim |
+| both | do | level | reads | trim_array |
+| by | domain | like | real | true |
+| call | double | like_regex | recursive | truncate |
+| called | drop | limit | ref | uescape |
+| cardinality | dynamic | listagg | references | union |
+| cascade | each | ln | referencing | unique |
+| cascaded | element | local | regr_avgx | unknown |
+| case | else | localtime | regr_avgy | unmatched |
+| cast | empty | localtimestamp | regr_count | unnest |
+| catalog | end | log | regr_intercept | update |
+| ceil | end-exec | log10 | regr_r2 | upper |
+| ceiling | end_frame | lower | regr_slope | usage |
+| char | end_partition | match | regr_sxx | user |
+| character | equals | matches | regr_sxy | using |
+| character_length | escape | match_number | regr_syy | value |
+| char_length | every | match_recognize | relative | values |
+| check | except | max | release | value_of |
+| classifier | exception | measures | restrict | varbinary |
+| clob | exec | member | result | varchar |
+| close | execute | merge | return | variadic |
+| coalesce | exists | method | returning | varying |
+| collate | exp | min | returns | var_pop |
+| collation | external | minute | revoke | var_samp |
+| collect | extract | mod | right | verbose |
+| column | false | modifies | rollback | versioning |
+| commit | fetch | module | rollup | view |
+| concurrently | filter | month | row | when |
+| condition | first | multiset | rows | whenever |
+| connect | first_value | names | row_number | where |
+| connection | float | national | running | width_bucket |
+| constraint | floor | natural | savepoint | window |
+| constraints | for | nchar | schema | with |
+| contains | foreign | nclob | scope | within |
+| continue | found | new | scroll | without |
+| convert | frame_row | next | search | work |
+| copy | free | no | second | write |
+| corr | freeze | none | section | xml |
+| corresponding | from | normalize | seek | xmlagg |
+| cos | full | not | select | xmlattributes |
+| cosh | function | notnull | sensitive | xmlbinary |
+| count | fusion | nth_value | session | xmlcast |
+| covar_pop | get | ntile | session_user | xmlcomment |
+| covar_samp | global | null | set | xmlconcat |
+| create | go | nullif | show | xmldocument |
+| cross | goto | numeric | similar | xmlelement |
+| cube | grant | occurrences_regex | sin | xmlexists |
+| cume_dist | group | octet_length | sinh | xmlforest |
+| current | grouping | of | size | xmliterate |
+| current_catalog | groups | offset | skip | xmlnamespaces |
+| current_date | having | old | smallint | xmlparse |
+| current_default_transform_group | hold | omit | some | xmlpi |
+| current_path | hour | on | space | xmlquery |
+| current_role | identity | one | specific | xmlserialize |
+| current_row | ilike | only | specifictype | xmltable |
+| current_schema | immediate | open | sql | xmltext |
+| current_time | import | option | sqlcode | xmlvalidate |
+| current_timestamp | in | or | sqlerror | year |
## Changelog
@@ -229,12 +236,12 @@ editing always upgrades your materialization to the latest connector version.**
#### V4: 2022-11-30
This version includes breaking changes to materialized table columns.
-These provide more consistent column names and types, but tables created from previous versions of the connector may
+These provide more consistent column names and types, but tables created from previous versions of the connector may
not be compatible with this version.
-* Capitalization is now preserved when fields in Flow are converted to Postgres column names.
+- Capitalization is now preserved when fields in Flow are converted to Postgres column names.
Previously, fields containing uppercase letters were converted to lowercase.
-* Field names and values of types `date`, `duration`, `ipv4`, `ipv6`, `macaddr`, `macaddr8`, and `time` are now converted into
+- Field names and values of types `date`, `duration`, `ipv4`, `ipv6`, `macaddr`, `macaddr8`, and `time` are now converted into
their corresponding Postgres types.
Previously, only `date-time` was converted, and all others were materialized as strings.
diff --git a/site/docs/reference/Connectors/materialization-connectors/PostgreSQL/google-cloud-sql-postgres.md b/site/docs/reference/Connectors/materialization-connectors/PostgreSQL/google-cloud-sql-postgres.md
index d5ba6be8b1..e64a5020b4 100644
--- a/site/docs/reference/Connectors/materialization-connectors/PostgreSQL/google-cloud-sql-postgres.md
+++ b/site/docs/reference/Connectors/materialization-connectors/PostgreSQL/google-cloud-sql-postgres.md
@@ -8,18 +8,18 @@ It is available for use in the Flow web application. For local development or op
To use this connector, you'll need:
-* A Postgres database to which to materialize, and user credentials.
+- A Postgres database to which to materialize, and user credentials.
The connector will create new tables in the database per your specification. Tables created manually in advance are not supported.
-* At least one Flow collection
+- At least one Flow collection
## Setup
You must configure your database to allow connections from Estuary.
There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
-### Conenecting Directly to Google Cloud SQL
+### Conenecting Directly to Google Cloud SQL
-1. [Enable public IP on your database](https://cloud.google.com/sql/docs/mysql/configure-ip#add) and add `34.121.207.128` as an authorized IP address.
+1. [Enable public IP on your database](https://cloud.google.com/sql/docs/mysql/configure-ip#add) and add `34.121.207.128, 35.226.75.135, 34.68.62.148` as authorized IP addresses.
### Connect With SSH Tunneling
@@ -29,32 +29,38 @@ To allow SSH tunneling to a database instance hosted on Google Cloud, you must s
In the `.ssh` subdirectory of your user home directory,
look for the PEM file that contains the private SSH key. Check that it starts with `-----BEGIN RSA PRIVATE KEY-----`,
which indicates it is an RSA-based file.
- * If no such file exists, generate one using the command:
+
+ - If no such file exists, generate one using the command:
+
```console
ssh-keygen -m PEM -t rsa
- ```
- * If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+ ```
+
+ - If a PEM file exists, but starts with `-----BEGIN OPENSSH PRIVATE KEY-----`, convert it with the command:
+
```console
ssh-keygen -p -N "" -m pem -f /path/to/key
- ```
- * If your Google login differs from your local username, generate a key that includes your Google email address as a comment:
+ ```
+
+ - If your Google login differs from your local username, generate a key that includes your Google email address as a comment:
+
```console
ssh-keygen -m PEM -t rsa -C user@domain.com
- ```
+ ```
2. [Create and start a new VM in GCP](https://cloud.google.com/compute/docs/instances/create-start-instance), [choosing an image that supports OS Login](https://cloud.google.com/compute/docs/images/os-details#user-space-features).
3. [Add your public key to the VM](https://cloud.google.com/compute/docs/connect/add-ssh-keys).
-5. [Reserve an external IP address](https://cloud.google.com/compute/docs/ip-addresses/reserve-static-external-ip-address) and connect it to the VM during setup.
-Note the generated address.
+4. [Reserve an external IP address](https://cloud.google.com/compute/docs/ip-addresses/reserve-static-external-ip-address) and connect it to the VM during setup.
+ Note the generated address.
:::tip Configuration Tip
To configure the connector, you must specify the database address in the format `host:port`. (You can also supply `host` only; the connector will use the port `5432` by default, which is correct in many cases.)
You can find the host and port in the following location:
-* Host as Private IP Address; port is always `5432`. You may need to [configure private IP](https://cloud.google.com/sql/docs/postgres/configure-private-ip) on your database.
-:::
+- Host as Private IP Address; port is always `5432`. You may need to [configure private IP](https://cloud.google.com/sql/docs/postgres/configure-private-ip) on your database.
+ :::
## Configuration
@@ -65,24 +71,24 @@ Use the below properties to configure a Postgres materialization, which will dir
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|-----------------|----------|-------------------------------------------------|---------|------------------|
-| `/database` | Database | Name of the logical database to materialize to. | string | |
-| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `5432`. | string | Required |
-| **`/password`** | Password | Password for the specified database user. | string | Required |
-| `/schema` | Database Schema | Database [schema](https://www.postgresql.org/docs/current/ddl-schemas.html) to use for materialized tables (unless overridden within the binding resource configuration) as well as associated materialization metadata tables | string | `"public"` |
-| **`/user`** | User | Database user to connect as. | string | Required |
-| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
-| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
+| Property | Title | Description | Type | Required/Default |
+| ------------------- | ---------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------ | ---------------- |
+| `/database` | Database | Name of the logical database to materialize to. | string | |
+| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `5432`. | string | Required |
+| **`/password`** | Password | Password for the specified database user. | string | Required |
+| `/schema` | Database Schema | Database [schema](https://www.postgresql.org/docs/current/ddl-schemas.html) to use for materialized tables (unless overridden within the binding resource configuration) as well as associated materialization metadata tables | string | `"public"` |
+| **`/user`** | User | Database user to connect as. | string | Required |
+| `/advanced` | Advanced Options | Options for advanced users. You should not typically need to modify these. | object | |
+| `/advanced/sslmode` | SSL Mode | Overrides SSL connection behavior by setting the 'sslmode' parameter. | string | |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| `/additional_table_create_sql` | Additional Table Create SQL | Additional SQL statement(s) to be run in the same transaction that creates the table. | string | |
-| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
-| `/schema` | Alternative Schema | Alternative schema for this table (optional). Overrides schema set in endpoint configuration. | string | |
-| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| ------------------------------ | --------------------------- | ------------------------------------------------------------------------------------------------------------------ | ------- | ---------------- |
+| `/additional_table_create_sql` | Additional Table Create SQL | Additional SQL statement(s) to be run in the same transaction that creates the table. | string | |
+| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
+| `/schema` | Alternative Schema | Alternative schema for this table (optional). Overrides schema set in endpoint configuration. | string | |
+| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
### Sample
@@ -115,102 +121,102 @@ Flow considers all the reserved words that are marked as "reserved" in any of th
These reserve words are listed in the table below. Flow automatically quotes fields that are in this list.
-|Reserved words| | | | |
-|---|---|---|---|---|
-| abs| current_transform_group_for_type| indicator| order| sqlexception|
-| absolute| current_user| initial| out| sqlstate|
-| acos| cursor| initially| outer| sqlwarning|
-|action| cycle| inner| output| sqrt|
-|add| datalink| inout| over| start|
-|all| date| input| overlaps| static|
-|allocate| day| insensitive| overlay| stddev_pop|
-|alter| deallocate| insert| pad| stddev_samp|
-|analyse| dec| int| parameter| submultiset|
-|analyze| decfloat| integer| partial| subset|
-|and| decimal| intersect| partition| substring|
-|any| declare| intersection| pattern| substring_regex|
-|are| default| interval| per| succeeds|
-|array| deferrable| into| percent| sum|
-|array_agg| deferred| is| percentile_cont| symmetric|
-|array_max_cardinality| define| isnull| percentile_disc| system|
-|as| delete| isolation| percent_rank| system_time|
-|asc| dense_rank| join| period| system_user|
-|asensitive| deref| json_array| permute| table|
-|asin| desc| json_arrayagg| placing| tablesample|
-|assertion| describe| json_exists| portion| tan|
-|asymmetric| descriptor| json_object| position| tanh|
-|at| deterministic| json_objectagg| position_regex| temporary|
-|atan| diagnostics| json_query| power| then|
-|atomic| disconnect| json_table| precedes| time|
-|authorization| distinct| json_table_primitive| precision| timestamp|
-|avg| dlnewcopy| json_value| prepare| timezone_hour|
-|begin| dlpreviouscopy| key| preserve| timezone_minute|
-|begin_frame| dlurlcomplete| lag| primary| to|
-|begin_partition| dlurlcompleteonly| language| prior| trailing|
-|between| dlurlcompletewrite| large| privileges| transaction|
-|bigint| dlurlpath| last| procedure| translate|
-|binary| dlurlpathonly| last_value| ptf| translate_regex|
-|bit| dlurlpathwrite| lateral| public| translation|
-|bit_length| dlurlscheme| lead| range| treat|
-|blob| dlurlserver| leading| rank| trigger|
-|boolean| dlvalue| left| read| trim|
-|both| do| level| reads| trim_array|
-|by| domain| like| real| true|
-|call| double| like_regex| recursive| truncate|
-|called| drop| limit| ref| uescape|
-|cardinality| dynamic| listagg| references| union|
-|cascade| each| ln| referencing| unique|
-|cascaded| element| local| regr_avgx| unknown|
-|case| else| localtime| regr_avgy| unmatched|
-|cast| empty| localtimestamp| regr_count| unnest|
-|catalog| end| log| regr_intercept| update|
-|ceil| end-exec| log10| regr_r2| upper|
-|ceiling| end_frame| lower| regr_slope| usage|
-|char| end_partition| match| regr_sxx| user|
-|character| equals| matches| regr_sxy| using|
-|character_length| escape| match_number| regr_syy| value|
-|char_length| every| match_recognize| relative| values|
-|check| except| max| release| value_of|
-|classifier| exception| measures| restrict| varbinary|
-|clob| exec| member| result| varchar|
-|close| execute| merge| return| variadic|
-|coalesce| exists| method| returning| varying|
-|collate| exp| min| returns| var_pop|
-|collation| external| minute| revoke| var_samp|
-|collect| extract| mod| right| verbose|
-|column| false| modifies| rollback| versioning|
-|commit| fetch| module| rollup| view|
-|concurrently| filter| month| row| when|
-|condition| first| multiset| rows| whenever|
-|connect| first_value| names| row_number| where|
-|connection| float| national| running| width_bucket|
-|constraint| floor| natural| savepoint| window|
-|constraints| for| nchar| schema| with|
-|contains| foreign| nclob| scope| within|
-|continue| found| new| scroll| without|
-|convert| frame_row| next| search| work|
-|copy| free| no| second| write|
-|corr| freeze| none| section| xml|
-|corresponding| from| normalize| seek| xmlagg|
-|cos| full| not| select| xmlattributes|
-|cosh| function| notnull| sensitive| xmlbinary|
-|count| fusion| nth_value| session| xmlcast|
-|covar_pop| get| ntile| session_user| xmlcomment|
-|covar_samp| global| null| set| xmlconcat|
-|create| go| nullif| show| xmldocument|
-|cross| goto| numeric| similar| xmlelement|
-|cube| grant| occurrences_regex| sin| xmlexists|
-|cume_dist| group| octet_length| sinh| xmlforest|
-|current| grouping| of| size| xmliterate|
-|current_catalog| groups| offset| skip| xmlnamespaces|
-|current_date| having| old| smallint| xmlparse|
-|current_default_transform_group| hold| omit| some| xmlpi|
-|current_path| hour| on| space| xmlquery|
-|current_role| identity| one| specific| xmlserialize|
-|current_row| ilike| only| specifictype| xmltable|
-|current_schema| immediate| open| sql| xmltext|
-|current_time| import| option| sqlcode| xmlvalidate|
-|current_timestamp| in| or| sqlerror| year|
+| Reserved words | | | | |
+| ------------------------------- | -------------------------------- | -------------------- | --------------- | --------------- |
+| abs | current_transform_group_for_type | indicator | order | sqlexception |
+| absolute | current_user | initial | out | sqlstate |
+| acos | cursor | initially | outer | sqlwarning |
+| action | cycle | inner | output | sqrt |
+| add | datalink | inout | over | start |
+| all | date | input | overlaps | static |
+| allocate | day | insensitive | overlay | stddev_pop |
+| alter | deallocate | insert | pad | stddev_samp |
+| analyse | dec | int | parameter | submultiset |
+| analyze | decfloat | integer | partial | subset |
+| and | decimal | intersect | partition | substring |
+| any | declare | intersection | pattern | substring_regex |
+| are | default | interval | per | succeeds |
+| array | deferrable | into | percent | sum |
+| array_agg | deferred | is | percentile_cont | symmetric |
+| array_max_cardinality | define | isnull | percentile_disc | system |
+| as | delete | isolation | percent_rank | system_time |
+| asc | dense_rank | join | period | system_user |
+| asensitive | deref | json_array | permute | table |
+| asin | desc | json_arrayagg | placing | tablesample |
+| assertion | describe | json_exists | portion | tan |
+| asymmetric | descriptor | json_object | position | tanh |
+| at | deterministic | json_objectagg | position_regex | temporary |
+| atan | diagnostics | json_query | power | then |
+| atomic | disconnect | json_table | precedes | time |
+| authorization | distinct | json_table_primitive | precision | timestamp |
+| avg | dlnewcopy | json_value | prepare | timezone_hour |
+| begin | dlpreviouscopy | key | preserve | timezone_minute |
+| begin_frame | dlurlcomplete | lag | primary | to |
+| begin_partition | dlurlcompleteonly | language | prior | trailing |
+| between | dlurlcompletewrite | large | privileges | transaction |
+| bigint | dlurlpath | last | procedure | translate |
+| binary | dlurlpathonly | last_value | ptf | translate_regex |
+| bit | dlurlpathwrite | lateral | public | translation |
+| bit_length | dlurlscheme | lead | range | treat |
+| blob | dlurlserver | leading | rank | trigger |
+| boolean | dlvalue | left | read | trim |
+| both | do | level | reads | trim_array |
+| by | domain | like | real | true |
+| call | double | like_regex | recursive | truncate |
+| called | drop | limit | ref | uescape |
+| cardinality | dynamic | listagg | references | union |
+| cascade | each | ln | referencing | unique |
+| cascaded | element | local | regr_avgx | unknown |
+| case | else | localtime | regr_avgy | unmatched |
+| cast | empty | localtimestamp | regr_count | unnest |
+| catalog | end | log | regr_intercept | update |
+| ceil | end-exec | log10 | regr_r2 | upper |
+| ceiling | end_frame | lower | regr_slope | usage |
+| char | end_partition | match | regr_sxx | user |
+| character | equals | matches | regr_sxy | using |
+| character_length | escape | match_number | regr_syy | value |
+| char_length | every | match_recognize | relative | values |
+| check | except | max | release | value_of |
+| classifier | exception | measures | restrict | varbinary |
+| clob | exec | member | result | varchar |
+| close | execute | merge | return | variadic |
+| coalesce | exists | method | returning | varying |
+| collate | exp | min | returns | var_pop |
+| collation | external | minute | revoke | var_samp |
+| collect | extract | mod | right | verbose |
+| column | false | modifies | rollback | versioning |
+| commit | fetch | module | rollup | view |
+| concurrently | filter | month | row | when |
+| condition | first | multiset | rows | whenever |
+| connect | first_value | names | row_number | where |
+| connection | float | national | running | width_bucket |
+| constraint | floor | natural | savepoint | window |
+| constraints | for | nchar | schema | with |
+| contains | foreign | nclob | scope | within |
+| continue | found | new | scroll | without |
+| convert | frame_row | next | search | work |
+| copy | free | no | second | write |
+| corr | freeze | none | section | xml |
+| corresponding | from | normalize | seek | xmlagg |
+| cos | full | not | select | xmlattributes |
+| cosh | function | notnull | sensitive | xmlbinary |
+| count | fusion | nth_value | session | xmlcast |
+| covar_pop | get | ntile | session_user | xmlcomment |
+| covar_samp | global | null | set | xmlconcat |
+| create | go | nullif | show | xmldocument |
+| cross | goto | numeric | similar | xmlelement |
+| cube | grant | occurrences_regex | sin | xmlexists |
+| cume_dist | group | octet_length | sinh | xmlforest |
+| current | grouping | of | size | xmliterate |
+| current_catalog | groups | offset | skip | xmlnamespaces |
+| current_date | having | old | smallint | xmlparse |
+| current_default_transform_group | hold | omit | some | xmlpi |
+| current_path | hour | on | space | xmlquery |
+| current_role | identity | one | specific | xmlserialize |
+| current_row | ilike | only | specifictype | xmltable |
+| current_schema | immediate | open | sql | xmltext |
+| current_time | import | option | sqlcode | xmlvalidate |
+| current_timestamp | in | or | sqlerror | year |
## Changelog
@@ -222,12 +228,12 @@ editing always upgrades your materialization to the latest connector version.**
#### V4: 2022-11-30
This version includes breaking changes to materialized table columns.
-These provide more consistent column names and types, but tables created from previous versions of the connector may
+These provide more consistent column names and types, but tables created from previous versions of the connector may
not be compatible with this version.
-* Capitalization is now preserved when fields in Flow are converted to Postgres column names.
+- Capitalization is now preserved when fields in Flow are converted to Postgres column names.
Previously, fields containing uppercase letters were converted to lowercase.
-* Field names and values of types `date`, `duration`, `ipv4`, `ipv6`, `macaddr`, `macaddr8`, and `time` are now converted into
+- Field names and values of types `date`, `duration`, `ipv4`, `ipv6`, `macaddr`, `macaddr8`, and `time` are now converted into
their corresponding Postgres types.
Previously, only `date-time` was converted, and all others were materialized as strings.
diff --git a/site/docs/reference/Connectors/materialization-connectors/SQLServer/amazon-rds-sqlserver.md b/site/docs/reference/Connectors/materialization-connectors/SQLServer/amazon-rds-sqlserver.md
index 8c6e1d4453..4eda345fbd 100644
--- a/site/docs/reference/Connectors/materialization-connectors/SQLServer/amazon-rds-sqlserver.md
+++ b/site/docs/reference/Connectors/materialization-connectors/SQLServer/amazon-rds-sqlserver.md
@@ -10,25 +10,26 @@ open-source workflows,
To use this connector, you'll need:
-* A SQLServer database to which to materialize, and user credentials.
- * SQLServer 2017 and later are supported
- * The connector will create new tables in the database per your specification,
+- A SQLServer database to which to materialize, and user credentials.
+ - SQLServer 2017 and later are supported
+ - The connector will create new tables in the database per your specification,
so user credentials must have access to create new tables.
-* At least one Flow collection
+- At least one Flow collection
## Setup Amazon RDS for SQL Server
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * [Modify the database](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), setting **Public accessibility** to **Yes**.
- * Edit the VPC security group associated with your database, or create a new VPC security group and associate it as described in [the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create).Create a new inbound rule and a new outbound rule that allow all traffic from the IP address `34.121.207.128`.
+
+ - [Modify the database](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), setting **Public accessibility** to **Yes**.
+ - Edit the VPC security group associated with your database, or create a new VPC security group and associate it as described in [the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create).Create a new inbound rule and a new outbound rule that allow all traffic from the IP addresses `34.121.207.128, 35.226.75.135, 34.68.62.148`.
2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](../../../../../guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](../../../../concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - Follow the guide to [configure an SSH server for tunneling](../../../../../guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](../../../../concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
-2. In your SQL client, connect to your instance as the default `sqlserver` user and issue the following commands.
+2. In your SQL client, connect to your instance as the default `sqlserver` user and issue the following commands.
```sql
USE ;
@@ -38,6 +39,7 @@ CREATE USER flow_materialize FOR LOGIN flow_materialize;
-- Grant control on the database to flow_materialize
GRANT CONTROL ON DATABASE:: TO flow_materialize;
```
+
3. In the [RDS console](https://console.aws.amazon.com/rds/), note the instance's Endpoint and Port. You'll need these for the `address` property when you configure the connector.
## Connecting to SQLServer
@@ -45,14 +47,15 @@ GRANT CONTROL ON DATABASE:: TO flow_materialize;
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * [Modify the database](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), setting **Public accessibility** to **Yes**.
- * Edit the VPC security group associated with your database, or create a new VPC security group and associate it as described in [the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create).Create a new inbound rule and a new outbound rule that allow all traffic from the IP address `34.121.207.128`.
+
+ - [Modify the database](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html), setting **Public accessibility** to **Yes**.
+ - Edit the VPC security group associated with your database, or create a new VPC security group and associate it as described in [the Amazon documentation](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.RDSSecurityGroups.html#Overview.RDSSecurityGroups.Create).Create a new inbound rule and a new outbound rule that allow all traffic from the IP addresses `34.121.207.128, 35.226.75.135, 34.68.62.148`.
2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](../../../../../guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](../../../../concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - Follow the guide to [configure an SSH server for tunneling](../../../../../guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](../../../../concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
-2. In your SQL client, connect to your instance as the default `sqlserver` user and issue the following commands.
+2. In your SQL client, connect to your instance as the default `sqlserver` user and issue the following commands.
```sql
USE ;
@@ -62,8 +65,8 @@ CREATE USER flow_materialize FOR LOGIN flow_materialize;
-- Grant control on the database to flow_materialize
GRANT CONTROL ON DATABASE:: TO flow_materialize;
```
-3. In the [RDS console](https://console.aws.amazon.com/rds/), note the instance's Endpoint and Port. You'll need these for the `address` property when you configure the connector.
+3. In the [RDS console](https://console.aws.amazon.com/rds/), note the instance's Endpoint and Port. You'll need these for the `address` property when you configure the connector.
## Configuration
@@ -74,19 +77,19 @@ Use the below properties to configure a SQLServer materialization, which will di
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|-----------------------------|------------------------|--------------------------------------------------------------------------------------------|--------|------------------|
-| **`/database`** | Database | Name of the logical database to materialize to. | string | Required |
-| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `3306`. | string | Required |
-| **`/password`** | Password | Password for the specified database user. | string | Required |
-| **`/user`** | User | Database user to connect as. | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| --------------- | -------- | ------------------------------------------------------------------------------------------ | ------ | ---------------- |
+| **`/database`** | Database | Name of the logical database to materialize to. | string | Required |
+| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `3306`. | string | Required |
+| **`/password`** | Password | Password for the specified database user. | string | Required |
+| **`/user`** | User | Database user to connect as. | string | Required |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
-| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | ------------ | ------------------------------------------------------------------------------------------------------------------ | ------- | ---------------- |
+| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
+| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
### Sample
@@ -119,105 +122,105 @@ Flow considers all the reserved words in the official [SQLServer documentation](
These reserved words are listed in the table below. Flow automatically quotes fields that are in this list.
-|Reserved words| | | | |
-|---|---|---|---|---|
-|absolute|connect|else|intersect|on|
-|action|connection|end|intersection|only|
-|ada|constraint|end-exec|interval|open|
-|add|constraints|equals|into|opendatasourc|
-|admin|constructor|errlvl|is|openquery|
-|after|contains|escape|isolation|openrowset|
-|aggregate|containstable|every|iterate|openxml|
-|alias|continue|except|join|operation|
-|all|convert|exception|key|option|
-|allocate|corr|exec|kill|or|
-|alter|corresponding|execute|language|order|
-|and|count|exists|large|ordinality|
-|any|covar_pop|exit|last|out|
-|are|covar_samp|external|lateral|outer|
-|array|create|extract|leading|output|
-|as|cross|false|left|over|
-|asc|cube|fetch|less|overlaps|
-|asensitive|cume_dist|file|level|overlay|
-|assertion|current|fillfactor|like|pad|
-|asymmetric|current_catal|filter|like_regex|parameter|
-|at|current_date|first|limit|parameters|
-|atomic|current_defau|float|lineno|partial|
-|authorization|current_path|for|ln|partition|
-|avg|current_role|foreign|load|pascal|
-|backup|current_schem|fortran|local|path|
-|before|current_time|found|localtime|percent|
-|begin|current_times|free|localtimestam|percent_rank|
-|between|current_trans|freetext|locator|percentile_co|
-|binary|current_user|freetexttable|lower|percentile_di|
-|bit|cursor|from|map|pivot|
-|bit_length|cycle|full|match|plan|
-|blob|data|fulltexttable|max|position|
-|boolean|database|function|member|position_rege|
-|both|date|fusion|merge|postfix|
-|breadth|day|general|method|precision|
-|break|dbcc|get|min|prefix|
-|browse|deallocate|global|minute|preorder|
-|bulk|dec|go|mod|prepare|
-|by|decimal|goto|modifies|preserve|
-|call|declare|grant|modify|primary|
-|called|default|group|module|print|
-|cardinality|deferrable|grouping|month|prior|
-|cascade|deferred|having|multiset|privileges|
-|cascaded|delete|hold|names|proc|
-|case|deny|holdlock|national|procedure|
-|cast|depth|host|natural|public|
-|catalog|deref|hour|nchar|raiserror|
-|char|desc|identity|nclob|range|
-|char_length|describe|identity_inse|new|read|
-|character|descriptor|identitycol|next|reads|
-|character_len|destroy|if|no|readtext|
-|check|destructor|ignore|nocheck|real|
-|checkpoint|deterministic|immediate|nonclustered|reconfigure|
-|class|diagnostics|in|none|recursive|
-|clob|dictionary|include|normalize|ref|
-|close|disconnect|index|not|references|
-|clustered|disk|indicator|null|referencing|
-|coalesce|distinct|initialize|nullif|regr_avgx|
-|collate|distributed|initially|numeric|regr_avgy|
-|collation|domain|inner|object|regr_count|
-|collect|double|inout|occurrences_r|regr_intercep|
-|column|drop|input|octet_length|regr_r2|
-|commit|dump|insensitive|of|regr_slope|
-|completion|dynamic|insert|off|regr_sxx|
-|compute|each|int|offsets|regr_sxy|
-|condition|element|integer|old|regr_syy|
-|relative|semanticsimil|structure|truncate|window|
-|release|semanticsimil|submultiset|try_convert|with|
-|replication|sensitive|substring|tsequal|within|group|
-|restore|sequence|substring_reg|uescape|within|
-|restrict|session|sum|under|without|
-|result|session_user|symmetric|union|work|
-|return|set|system|unique|write|
-|returns|sets|system_user|unknown|writetext|
-|revert|setuser|table|unnest|xmlagg|
-|revoke|shutdown|tablesample|unpivot|xmlattributes|
-|right|similar|temporary|update|xmlbinary|
-|role|size|terminate|updatetext|xmlcast|
-|rollback|smallint|textsize|upper|xmlcomment|
-|rollup|some|than|usage|xmlconcat|
-|routine|space|then|use|xmldocument|
-|row|specific|time|user|xmlelement|
-|rowcount|specifictype|timestamp|using|xmlexists|
-|rowguidcol|sql|timezone_hour|value|xmlforest|
-|rows|sqlca|timezone_minu|values|xmliterate|
-|rule|sqlcode|to|var_pop|xmlnamespaces|
-|save|sqlerror|top|var_samp|xmlparse|
-|savepoint|sqlexception|trailing|varchar|xmlpi|
-|schema|sqlstate|tran|variable|xmlquery|
-|scope|sqlwarning|transaction|varying|xmlserialize|
-|scroll|start|translate|view|xmltable|
-|search|state|translate_reg|waitfor|xmltext|
-|second|statement|translation|when|xmlvalidate|
-|section|static|treat|whenever|year|
-|securityaudit|statistics|trigger|where|zone|
-|select|stddev_pop|trim|while|
-|semantickeyph|stddev_samp|true|width_bucket|
+| Reserved words | | | | |
+| -------------- | ------------- | ------------- | ------------- | ------------- | ----- |
+| absolute | connect | else | intersect | on |
+| action | connection | end | intersection | only |
+| ada | constraint | end-exec | interval | open |
+| add | constraints | equals | into | opendatasourc |
+| admin | constructor | errlvl | is | openquery |
+| after | contains | escape | isolation | openrowset |
+| aggregate | containstable | every | iterate | openxml |
+| alias | continue | except | join | operation |
+| all | convert | exception | key | option |
+| allocate | corr | exec | kill | or |
+| alter | corresponding | execute | language | order |
+| and | count | exists | large | ordinality |
+| any | covar_pop | exit | last | out |
+| are | covar_samp | external | lateral | outer |
+| array | create | extract | leading | output |
+| as | cross | false | left | over |
+| asc | cube | fetch | less | overlaps |
+| asensitive | cume_dist | file | level | overlay |
+| assertion | current | fillfactor | like | pad |
+| asymmetric | current_catal | filter | like_regex | parameter |
+| at | current_date | first | limit | parameters |
+| atomic | current_defau | float | lineno | partial |
+| authorization | current_path | for | ln | partition |
+| avg | current_role | foreign | load | pascal |
+| backup | current_schem | fortran | local | path |
+| before | current_time | found | localtime | percent |
+| begin | current_times | free | localtimestam | percent_rank |
+| between | current_trans | freetext | locator | percentile_co |
+| binary | current_user | freetexttable | lower | percentile_di |
+| bit | cursor | from | map | pivot |
+| bit_length | cycle | full | match | plan |
+| blob | data | fulltexttable | max | position |
+| boolean | database | function | member | position_rege |
+| both | date | fusion | merge | postfix |
+| breadth | day | general | method | precision |
+| break | dbcc | get | min | prefix |
+| browse | deallocate | global | minute | preorder |
+| bulk | dec | go | mod | prepare |
+| by | decimal | goto | modifies | preserve |
+| call | declare | grant | modify | primary |
+| called | default | group | module | print |
+| cardinality | deferrable | grouping | month | prior |
+| cascade | deferred | having | multiset | privileges |
+| cascaded | delete | hold | names | proc |
+| case | deny | holdlock | national | procedure |
+| cast | depth | host | natural | public |
+| catalog | deref | hour | nchar | raiserror |
+| char | desc | identity | nclob | range |
+| char_length | describe | identity_inse | new | read |
+| character | descriptor | identitycol | next | reads |
+| character_len | destroy | if | no | readtext |
+| check | destructor | ignore | nocheck | real |
+| checkpoint | deterministic | immediate | nonclustered | reconfigure |
+| class | diagnostics | in | none | recursive |
+| clob | dictionary | include | normalize | ref |
+| close | disconnect | index | not | references |
+| clustered | disk | indicator | null | referencing |
+| coalesce | distinct | initialize | nullif | regr_avgx |
+| collate | distributed | initially | numeric | regr_avgy |
+| collation | domain | inner | object | regr_count |
+| collect | double | inout | occurrences_r | regr_intercep |
+| column | drop | input | octet_length | regr_r2 |
+| commit | dump | insensitive | of | regr_slope |
+| completion | dynamic | insert | off | regr_sxx |
+| compute | each | int | offsets | regr_sxy |
+| condition | element | integer | old | regr_syy |
+| relative | semanticsimil | structure | truncate | window |
+| release | semanticsimil | submultiset | try_convert | with |
+| replication | sensitive | substring | tsequal | within | group |
+| restore | sequence | substring_reg | uescape | within |
+| restrict | session | sum | under | without |
+| result | session_user | symmetric | union | work |
+| return | set | system | unique | write |
+| returns | sets | system_user | unknown | writetext |
+| revert | setuser | table | unnest | xmlagg |
+| revoke | shutdown | tablesample | unpivot | xmlattributes |
+| right | similar | temporary | update | xmlbinary |
+| role | size | terminate | updatetext | xmlcast |
+| rollback | smallint | textsize | upper | xmlcomment |
+| rollup | some | than | usage | xmlconcat |
+| routine | space | then | use | xmldocument |
+| row | specific | time | user | xmlelement |
+| rowcount | specifictype | timestamp | using | xmlexists |
+| rowguidcol | sql | timezone_hour | value | xmlforest |
+| rows | sqlca | timezone_minu | values | xmliterate |
+| rule | sqlcode | to | var_pop | xmlnamespaces |
+| save | sqlerror | top | var_samp | xmlparse |
+| savepoint | sqlexception | trailing | varchar | xmlpi |
+| schema | sqlstate | tran | variable | xmlquery |
+| scope | sqlwarning | transaction | varying | xmlserialize |
+| scroll | start | translate | view | xmltable |
+| search | state | translate_reg | waitfor | xmltext |
+| second | statement | translation | when | xmlvalidate |
+| section | static | treat | whenever | year |
+| securityaudit | statistics | trigger | where | zone |
+| select | stddev_pop | trim | while |
+| semantickeyph | stddev_samp | true | width_bucket |
## Changelog
diff --git a/site/docs/reference/Connectors/materialization-connectors/SQLServer/google-cloud-sql-sqlserver.md b/site/docs/reference/Connectors/materialization-connectors/SQLServer/google-cloud-sql-sqlserver.md
index b4940f6fa2..dca747f66e 100644
--- a/site/docs/reference/Connectors/materialization-connectors/SQLServer/google-cloud-sql-sqlserver.md
+++ b/site/docs/reference/Connectors/materialization-connectors/SQLServer/google-cloud-sql-sqlserver.md
@@ -10,24 +10,26 @@ open-source workflows,
To use this connector, you'll need:
-* A SQLServer database to which to materialize, and user credentials.
- * SQLServer 2017 and later are supported
- * The connector will create new tables in the database per your specification,
+- A SQLServer database to which to materialize, and user credentials.
+ - SQLServer 2017 and later are supported
+ - The connector will create new tables in the database per your specification,
so user credentials must have access to create new tables.
-* At least one Flow collection
+- At least one Flow collection
## Setup Google Cloud SQL for SQL Server
Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
- 1. To allow direct access:
- * [Enable public IP on your database](https://cloud.google.com/sql/docs/sqlserver/configure-ip#add) and add `34.121.207.128` as an authorized IP address.
+1. To allow direct access:
- 2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](../../../../../guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](../../../../concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - [Enable public IP on your database](https://cloud.google.com/sql/docs/sqlserver/configure-ip#add) and add `34.121.207.128, 35.226.75.135, 34.68.62.148` as authorized IP addresses.
-2. In your SQL client, connect to your instance as the default `sqlserver` user and issue the following commands.
+2. To allow secure connections via SSH tunneling:
+
+ - Follow the guide to [configure an SSH server for tunneling](../../../../../guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](../../../../concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+
+3. In your SQL client, connect to your instance as the default `sqlserver` user and issue the following commands.
```sql
USE ;
@@ -39,18 +41,19 @@ GRANT CONTROL ON DATABASE:: TO flow_materialize;
```
3. In the Cloud Console, note the instance's host under Public IP Address. Its port will always be `1433`.
-Together, you'll use the host:port as the `address` property when you configure the connector.
+ Together, you'll use the host:port as the `address` property when you configure the connector.
## Connecting to SQLServer
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * [Enable public IP on your database](https://cloud.google.com/sql/docs/sqlserver/configure-ip#add) and add `34.121.207.128` as an authorized IP address.
+
+ - [Enable public IP on your database](https://cloud.google.com/sql/docs/sqlserver/configure-ip#add) and add `34.121.207.128, 35.226.75.135, 34.68.62.148` as authorized IP addresses.
2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](../../../../../guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](../../../../concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - Follow the guide to [configure an SSH server for tunneling](../../../../../guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](../../../../concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
2. In your SQL client, connect to your instance as the default `sqlserver` user and issue the following commands.
@@ -64,7 +67,7 @@ GRANT CONTROL ON DATABASE:: TO flow_materialize;
```
3. In the Cloud Console, note the instance's host under Public IP Address. Its port will always be `1433`.
-Together, you'll use the host:port as the `address` property when you configure the connector.
+ Together, you'll use the host:port as the `address` property when you configure the connector.
## Configuration
@@ -75,19 +78,19 @@ Use the below properties to configure a SQLServer materialization, which will di
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|-----------------------------|------------------------|--------------------------------------------------------------------------------------------|--------|------------------|
-| **`/database`** | Database | Name of the logical database to materialize to. | string | Required |
-| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `1433`. | string | Required |
-| **`/password`** | Password | Password for the specified database user. | string | Required |
-| **`/user`** | User | Database user to connect as. | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| --------------- | -------- | ------------------------------------------------------------------------------------------ | ------ | ---------------- |
+| **`/database`** | Database | Name of the logical database to materialize to. | string | Required |
+| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `1433`. | string | Required |
+| **`/password`** | Password | Password for the specified database user. | string | Required |
+| **`/user`** | User | Database user to connect as. | string | Required |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
-| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | ------------ | ------------------------------------------------------------------------------------------------------------------ | ------- | ---------------- |
+| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
+| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
### Sample
@@ -108,7 +111,6 @@ materializations:
source: ${PREFIX}/${COLLECTION_NAME}
```
-
## Delta updates
This connector supports both standard (merge) and [delta updates](../../../../concepts/materialization.md#delta-updates).
@@ -121,105 +123,105 @@ Flow considers all the reserved words in the official [SQLServer documentation](
These reserved words are listed in the table below. Flow automatically quotes fields that are in this list.
-|Reserved words| | | | |
-|---|---|---|---|---|
-|absolute|connect|else|intersect|on|
-|action|connection|end|intersection|only|
-|ada|constraint|end-exec|interval|open|
-|add|constraints|equals|into|opendatasourc|
-|admin|constructor|errlvl|is|openquery|
-|after|contains|escape|isolation|openrowset|
-|aggregate|containstable|every|iterate|openxml|
-|alias|continue|except|join|operation|
-|all|convert|exception|key|option|
-|allocate|corr|exec|kill|or|
-|alter|corresponding|execute|language|order|
-|and|count|exists|large|ordinality|
-|any|covar_pop|exit|last|out|
-|are|covar_samp|external|lateral|outer|
-|array|create|extract|leading|output|
-|as|cross|false|left|over|
-|asc|cube|fetch|less|overlaps|
-|asensitive|cume_dist|file|level|overlay|
-|assertion|current|fillfactor|like|pad|
-|asymmetric|current_catal|filter|like_regex|parameter|
-|at|current_date|first|limit|parameters|
-|atomic|current_defau|float|lineno|partial|
-|authorization|current_path|for|ln|partition|
-|avg|current_role|foreign|load|pascal|
-|backup|current_schem|fortran|local|path|
-|before|current_time|found|localtime|percent|
-|begin|current_times|free|localtimestam|percent_rank|
-|between|current_trans|freetext|locator|percentile_co|
-|binary|current_user|freetexttable|lower|percentile_di|
-|bit|cursor|from|map|pivot|
-|bit_length|cycle|full|match|plan|
-|blob|data|fulltexttable|max|position|
-|boolean|database|function|member|position_rege|
-|both|date|fusion|merge|postfix|
-|breadth|day|general|method|precision|
-|break|dbcc|get|min|prefix|
-|browse|deallocate|global|minute|preorder|
-|bulk|dec|go|mod|prepare|
-|by|decimal|goto|modifies|preserve|
-|call|declare|grant|modify|primary|
-|called|default|group|module|print|
-|cardinality|deferrable|grouping|month|prior|
-|cascade|deferred|having|multiset|privileges|
-|cascaded|delete|hold|names|proc|
-|case|deny|holdlock|national|procedure|
-|cast|depth|host|natural|public|
-|catalog|deref|hour|nchar|raiserror|
-|char|desc|identity|nclob|range|
-|char_length|describe|identity_inse|new|read|
-|character|descriptor|identitycol|next|reads|
-|character_len|destroy|if|no|readtext|
-|check|destructor|ignore|nocheck|real|
-|checkpoint|deterministic|immediate|nonclustered|reconfigure|
-|class|diagnostics|in|none|recursive|
-|clob|dictionary|include|normalize|ref|
-|close|disconnect|index|not|references|
-|clustered|disk|indicator|null|referencing|
-|coalesce|distinct|initialize|nullif|regr_avgx|
-|collate|distributed|initially|numeric|regr_avgy|
-|collation|domain|inner|object|regr_count|
-|collect|double|inout|occurrences_r|regr_intercep|
-|column|drop|input|octet_length|regr_r2|
-|commit|dump|insensitive|of|regr_slope|
-|completion|dynamic|insert|off|regr_sxx|
-|compute|each|int|offsets|regr_sxy|
-|condition|element|integer|old|regr_syy|
-|relative|semanticsimil|structure|truncate|window|
-|release|semanticsimil|submultiset|try_convert|with|
-|replication|sensitive|substring|tsequal|within|group|
-|restore|sequence|substring_reg|uescape|within|
-|restrict|session|sum|under|without|
-|result|session_user|symmetric|union|work|
-|return|set|system|unique|write|
-|returns|sets|system_user|unknown|writetext|
-|revert|setuser|table|unnest|xmlagg|
-|revoke|shutdown|tablesample|unpivot|xmlattributes|
-|right|similar|temporary|update|xmlbinary|
-|role|size|terminate|updatetext|xmlcast|
-|rollback|smallint|textsize|upper|xmlcomment|
-|rollup|some|than|usage|xmlconcat|
-|routine|space|then|use|xmldocument|
-|row|specific|time|user|xmlelement|
-|rowcount|specifictype|timestamp|using|xmlexists|
-|rowguidcol|sql|timezone_hour|value|xmlforest|
-|rows|sqlca|timezone_minu|values|xmliterate|
-|rule|sqlcode|to|var_pop|xmlnamespaces|
-|save|sqlerror|top|var_samp|xmlparse|
-|savepoint|sqlexception|trailing|varchar|xmlpi|
-|schema|sqlstate|tran|variable|xmlquery|
-|scope|sqlwarning|transaction|varying|xmlserialize|
-|scroll|start|translate|view|xmltable|
-|search|state|translate_reg|waitfor|xmltext|
-|second|statement|translation|when|xmlvalidate|
-|section|static|treat|whenever|year|
-|securityaudit|statistics|trigger|where|zone|
-|select|stddev_pop|trim|while|
-|semantickeyph|stddev_samp|true|width_bucket|
+| Reserved words | | | | |
+| -------------- | ------------- | ------------- | ------------- | ------------- | ----- |
+| absolute | connect | else | intersect | on |
+| action | connection | end | intersection | only |
+| ada | constraint | end-exec | interval | open |
+| add | constraints | equals | into | opendatasourc |
+| admin | constructor | errlvl | is | openquery |
+| after | contains | escape | isolation | openrowset |
+| aggregate | containstable | every | iterate | openxml |
+| alias | continue | except | join | operation |
+| all | convert | exception | key | option |
+| allocate | corr | exec | kill | or |
+| alter | corresponding | execute | language | order |
+| and | count | exists | large | ordinality |
+| any | covar_pop | exit | last | out |
+| are | covar_samp | external | lateral | outer |
+| array | create | extract | leading | output |
+| as | cross | false | left | over |
+| asc | cube | fetch | less | overlaps |
+| asensitive | cume_dist | file | level | overlay |
+| assertion | current | fillfactor | like | pad |
+| asymmetric | current_catal | filter | like_regex | parameter |
+| at | current_date | first | limit | parameters |
+| atomic | current_defau | float | lineno | partial |
+| authorization | current_path | for | ln | partition |
+| avg | current_role | foreign | load | pascal |
+| backup | current_schem | fortran | local | path |
+| before | current_time | found | localtime | percent |
+| begin | current_times | free | localtimestam | percent_rank |
+| between | current_trans | freetext | locator | percentile_co |
+| binary | current_user | freetexttable | lower | percentile_di |
+| bit | cursor | from | map | pivot |
+| bit_length | cycle | full | match | plan |
+| blob | data | fulltexttable | max | position |
+| boolean | database | function | member | position_rege |
+| both | date | fusion | merge | postfix |
+| breadth | day | general | method | precision |
+| break | dbcc | get | min | prefix |
+| browse | deallocate | global | minute | preorder |
+| bulk | dec | go | mod | prepare |
+| by | decimal | goto | modifies | preserve |
+| call | declare | grant | modify | primary |
+| called | default | group | module | print |
+| cardinality | deferrable | grouping | month | prior |
+| cascade | deferred | having | multiset | privileges |
+| cascaded | delete | hold | names | proc |
+| case | deny | holdlock | national | procedure |
+| cast | depth | host | natural | public |
+| catalog | deref | hour | nchar | raiserror |
+| char | desc | identity | nclob | range |
+| char_length | describe | identity_inse | new | read |
+| character | descriptor | identitycol | next | reads |
+| character_len | destroy | if | no | readtext |
+| check | destructor | ignore | nocheck | real |
+| checkpoint | deterministic | immediate | nonclustered | reconfigure |
+| class | diagnostics | in | none | recursive |
+| clob | dictionary | include | normalize | ref |
+| close | disconnect | index | not | references |
+| clustered | disk | indicator | null | referencing |
+| coalesce | distinct | initialize | nullif | regr_avgx |
+| collate | distributed | initially | numeric | regr_avgy |
+| collation | domain | inner | object | regr_count |
+| collect | double | inout | occurrences_r | regr_intercep |
+| column | drop | input | octet_length | regr_r2 |
+| commit | dump | insensitive | of | regr_slope |
+| completion | dynamic | insert | off | regr_sxx |
+| compute | each | int | offsets | regr_sxy |
+| condition | element | integer | old | regr_syy |
+| relative | semanticsimil | structure | truncate | window |
+| release | semanticsimil | submultiset | try_convert | with |
+| replication | sensitive | substring | tsequal | within | group |
+| restore | sequence | substring_reg | uescape | within |
+| restrict | session | sum | under | without |
+| result | session_user | symmetric | union | work |
+| return | set | system | unique | write |
+| returns | sets | system_user | unknown | writetext |
+| revert | setuser | table | unnest | xmlagg |
+| revoke | shutdown | tablesample | unpivot | xmlattributes |
+| right | similar | temporary | update | xmlbinary |
+| role | size | terminate | updatetext | xmlcast |
+| rollback | smallint | textsize | upper | xmlcomment |
+| rollup | some | than | usage | xmlconcat |
+| routine | space | then | use | xmldocument |
+| row | specific | time | user | xmlelement |
+| rowcount | specifictype | timestamp | using | xmlexists |
+| rowguidcol | sql | timezone_hour | value | xmlforest |
+| rows | sqlca | timezone_minu | values | xmliterate |
+| rule | sqlcode | to | var_pop | xmlnamespaces |
+| save | sqlerror | top | var_samp | xmlparse |
+| savepoint | sqlexception | trailing | varchar | xmlpi |
+| schema | sqlstate | tran | variable | xmlquery |
+| scope | sqlwarning | transaction | varying | xmlserialize |
+| scroll | start | translate | view | xmltable |
+| search | state | translate_reg | waitfor | xmltext |
+| second | statement | translation | when | xmlvalidate |
+| section | static | treat | whenever | year |
+| securityaudit | statistics | trigger | where | zone |
+| select | stddev_pop | trim | while |
+| semantickeyph | stddev_samp | true | width_bucket |
## Changelog
diff --git a/site/docs/reference/Connectors/materialization-connectors/SQLServer/sqlserver.md b/site/docs/reference/Connectors/materialization-connectors/SQLServer/sqlserver.md
index 19b0cf2bb5..766c4603cb 100644
--- a/site/docs/reference/Connectors/materialization-connectors/SQLServer/sqlserver.md
+++ b/site/docs/reference/Connectors/materialization-connectors/SQLServer/sqlserver.md
@@ -10,20 +10,20 @@ open-source workflows,
To use this connector, you'll need:
-* A SQLServer database to which to materialize, and user credentials.
- * SQLServer 2017 and later are supported
- * The connector will create new tables in the database per your specification,
+- A SQLServer database to which to materialize, and user credentials.
+ - SQLServer 2017 and later are supported
+ - The connector will create new tables in the database per your specification,
so user credentials must have access to create new tables.
-* At least one Flow collection
+- At least one Flow collection
## Setup
To meet these requirements, follow the steps for your hosting type.
-* [Self-hosted SQL Server](#self-hosted-sql-server)
-* [Azure SQL Database](#azure-sql-database)
-* [Amazon RDS for SQL Server](./amazon-rds-sqlserver/)
-* [Google Cloud SQL for SQL Server](./google-cloud-sql-sqlserver/)
+- [Self-hosted SQL Server](#self-hosted-sql-server)
+- [Azure SQL Database](#azure-sql-database)
+- [Amazon RDS for SQL Server](./amazon-rds-sqlserver/)
+- [Google Cloud SQL for SQL Server](./google-cloud-sql-sqlserver/)
### Self-hosted SQL Server
@@ -39,25 +39,27 @@ GRANT CONTROL ON DATABASE:: TO flow_materialize;
```
2. Allow secure connection to Estuary Flow from your hosting environment. Either:
- * Set up an [SSH server for tunneling](/guides/connect-network/).
+
+ - Set up an [SSH server for tunneling](/guides/connect-network/).
When you fill out the [endpoint configuration](#endpoint),
include the additional `networkTunnel` configuration to enable the SSH tunnel.
See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks)
for additional details and a sample.
- * Whitelist the Estuary IP address, `34.121.207.128` in your firewall rules.
+ - Whitelist the Estuary IP addresses, `34.121.207.128, 35.226.75.135, 34.68.62.148` in your firewall rules.
### Azure SQL Database
1. Allow connections between the database and Estuary Flow. There are two ways to do this: by granting direct access to Flow's IP or by creating an SSH tunnel.
1. To allow direct access:
- * Create a new [firewall rule](https://learn.microsoft.com/en-us/azure/azure-sql/database/firewall-configure?view=azuresql#use-the-azure-portal-to-manage-server-level-ip-firewall-rules) that grants access to the IP address `34.121.207.128`.
+
+ - Create a new [firewall rule](https://learn.microsoft.com/en-us/azure/azure-sql/database/firewall-configure?view=azuresql#use-the-azure-portal-to-manage-server-level-ip-firewall-rules) that grants access to the IP addresses `34.121.207.128, 35.226.75.135, 34.68.62.148`.
2. To allow secure connections via SSH tunneling:
- * Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
- * When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
+ - Follow the guide to [configure an SSH server for tunneling](/guides/connect-network/)
+ - When you configure your connector as described in the [configuration](#configuration) section above, including the additional `networkTunnel` configuration to enable the SSH tunnel. See [Connecting to endpoints on secure networks](/concepts/connectors.md#connecting-to-endpoints-on-secure-networks) for additional details and a sample.
2. In your SQL client, connect to your instance as the default `sqlserver` user and issue the following commands.
@@ -72,9 +74,7 @@ GRANT CONTROL ON DATABASE:: TO flow_materialize;
3. Note the following important items for configuration:
- * Find the instance's host under Server Name. The port is always `1433`. Together, you'll use the host:port as the `address` property when you configure the connector.
-
-
+ - Find the instance's host under Server Name. The port is always `1433`. Together, you'll use the host:port as the `address` property when you configure the connector.
## Configuration
@@ -85,19 +85,19 @@ Use the below properties to configure a SQLServer materialization, which will di
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|-----------------------------|------------------------|--------------------------------------------------------------------------------------------|--------|------------------|
-| **`/database`** | Database | Name of the logical database to materialize to. | string | Required |
-| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `3306`. | string | Required |
-| **`/password`** | Password | Password for the specified database user. | string | Required |
-| **`/user`** | User | Database user to connect as. | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| --------------- | -------- | ------------------------------------------------------------------------------------------ | ------ | ---------------- |
+| **`/database`** | Database | Name of the logical database to materialize to. | string | Required |
+| **`/address`** | Address | Host and port of the database. If only the host is specified, port will default to `3306`. | string | Required |
+| **`/password`** | Password | Password for the specified database user. | string | Required |
+| **`/user`** | User | Database user to connect as. | string | Required |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|---|---|---|---|---|
-| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
-| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | ------------ | ------------------------------------------------------------------------------------------------------------------ | ------- | ---------------- |
+| **`/table`** | Table | Table name to materialize to. It will be created by the connector, unless the connector has previously created it. | string | Required |
+| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
### Sample
@@ -118,7 +118,6 @@ materializations:
source: ${PREFIX}/${COLLECTION_NAME}
```
-
## Delta updates
This connector supports both standard (merge) and [delta updates](/concepts/materialization.md#delta-updates).
@@ -131,105 +130,105 @@ Flow considers all the reserved words in the official [SQLServer documentation](
These reserved words are listed in the table below. Flow automatically quotes fields that are in this list.
-|Reserved words| | | | |
-|---|---|---|---|---|
-|absolute|connect|else|intersect|on|
-|action|connection|end|intersection|only|
-|ada|constraint|end-exec|interval|open|
-|add|constraints|equals|into|opendatasourc|
-|admin|constructor|errlvl|is|openquery|
-|after|contains|escape|isolation|openrowset|
-|aggregate|containstable|every|iterate|openxml|
-|alias|continue|except|join|operation|
-|all|convert|exception|key|option|
-|allocate|corr|exec|kill|or|
-|alter|corresponding|execute|language|order|
-|and|count|exists|large|ordinality|
-|any|covar_pop|exit|last|out|
-|are|covar_samp|external|lateral|outer|
-|array|create|extract|leading|output|
-|as|cross|false|left|over|
-|asc|cube|fetch|less|overlaps|
-|asensitive|cume_dist|file|level|overlay|
-|assertion|current|fillfactor|like|pad|
-|asymmetric|current_catal|filter|like_regex|parameter|
-|at|current_date|first|limit|parameters|
-|atomic|current_defau|float|lineno|partial|
-|authorization|current_path|for|ln|partition|
-|avg|current_role|foreign|load|pascal|
-|backup|current_schem|fortran|local|path|
-|before|current_time|found|localtime|percent|
-|begin|current_times|free|localtimestam|percent_rank|
-|between|current_trans|freetext|locator|percentile_co|
-|binary|current_user|freetexttable|lower|percentile_di|
-|bit|cursor|from|map|pivot|
-|bit_length|cycle|full|match|plan|
-|blob|data|fulltexttable|max|position|
-|boolean|database|function|member|position_rege|
-|both|date|fusion|merge|postfix|
-|breadth|day|general|method|precision|
-|break|dbcc|get|min|prefix|
-|browse|deallocate|global|minute|preorder|
-|bulk|dec|go|mod|prepare|
-|by|decimal|goto|modifies|preserve|
-|call|declare|grant|modify|primary|
-|called|default|group|module|print|
-|cardinality|deferrable|grouping|month|prior|
-|cascade|deferred|having|multiset|privileges|
-|cascaded|delete|hold|names|proc|
-|case|deny|holdlock|national|procedure|
-|cast|depth|host|natural|public|
-|catalog|deref|hour|nchar|raiserror|
-|char|desc|identity|nclob|range|
-|char_length|describe|identity_inse|new|read|
-|character|descriptor|identitycol|next|reads|
-|character_len|destroy|if|no|readtext|
-|check|destructor|ignore|nocheck|real|
-|checkpoint|deterministic|immediate|nonclustered|reconfigure|
-|class|diagnostics|in|none|recursive|
-|clob|dictionary|include|normalize|ref|
-|close|disconnect|index|not|references|
-|clustered|disk|indicator|null|referencing|
-|coalesce|distinct|initialize|nullif|regr_avgx|
-|collate|distributed|initially|numeric|regr_avgy|
-|collation|domain|inner|object|regr_count|
-|collect|double|inout|occurrences_r|regr_intercep|
-|column|drop|input|octet_length|regr_r2|
-|commit|dump|insensitive|of|regr_slope|
-|completion|dynamic|insert|off|regr_sxx|
-|compute|each|int|offsets|regr_sxy|
-|condition|element|integer|old|regr_syy|
-|relative|semanticsimil|structure|truncate|window|
-|release|semanticsimil|submultiset|try_convert|with|
-|replication|sensitive|substring|tsequal|within|group|
-|restore|sequence|substring_reg|uescape|within|
-|restrict|session|sum|under|without|
-|result|session_user|symmetric|union|work|
-|return|set|system|unique|write|
-|returns|sets|system_user|unknown|writetext|
-|revert|setuser|table|unnest|xmlagg|
-|revoke|shutdown|tablesample|unpivot|xmlattributes|
-|right|similar|temporary|update|xmlbinary|
-|role|size|terminate|updatetext|xmlcast|
-|rollback|smallint|textsize|upper|xmlcomment|
-|rollup|some|than|usage|xmlconcat|
-|routine|space|then|use|xmldocument|
-|row|specific|time|user|xmlelement|
-|rowcount|specifictype|timestamp|using|xmlexists|
-|rowguidcol|sql|timezone_hour|value|xmlforest|
-|rows|sqlca|timezone_minu|values|xmliterate|
-|rule|sqlcode|to|var_pop|xmlnamespaces|
-|save|sqlerror|top|var_samp|xmlparse|
-|savepoint|sqlexception|trailing|varchar|xmlpi|
-|schema|sqlstate|tran|variable|xmlquery|
-|scope|sqlwarning|transaction|varying|xmlserialize|
-|scroll|start|translate|view|xmltable|
-|search|state|translate_reg|waitfor|xmltext|
-|second|statement|translation|when|xmlvalidate|
-|section|static|treat|whenever|year|
-|securityaudit|statistics|trigger|where|zone|
-|select|stddev_pop|trim|while|
-|semantickeyph|stddev_samp|true|width_bucket|
+| Reserved words | | | | |
+| -------------- | ------------- | ------------- | ------------- | ------------- | ----- |
+| absolute | connect | else | intersect | on |
+| action | connection | end | intersection | only |
+| ada | constraint | end-exec | interval | open |
+| add | constraints | equals | into | opendatasourc |
+| admin | constructor | errlvl | is | openquery |
+| after | contains | escape | isolation | openrowset |
+| aggregate | containstable | every | iterate | openxml |
+| alias | continue | except | join | operation |
+| all | convert | exception | key | option |
+| allocate | corr | exec | kill | or |
+| alter | corresponding | execute | language | order |
+| and | count | exists | large | ordinality |
+| any | covar_pop | exit | last | out |
+| are | covar_samp | external | lateral | outer |
+| array | create | extract | leading | output |
+| as | cross | false | left | over |
+| asc | cube | fetch | less | overlaps |
+| asensitive | cume_dist | file | level | overlay |
+| assertion | current | fillfactor | like | pad |
+| asymmetric | current_catal | filter | like_regex | parameter |
+| at | current_date | first | limit | parameters |
+| atomic | current_defau | float | lineno | partial |
+| authorization | current_path | for | ln | partition |
+| avg | current_role | foreign | load | pascal |
+| backup | current_schem | fortran | local | path |
+| before | current_time | found | localtime | percent |
+| begin | current_times | free | localtimestam | percent_rank |
+| between | current_trans | freetext | locator | percentile_co |
+| binary | current_user | freetexttable | lower | percentile_di |
+| bit | cursor | from | map | pivot |
+| bit_length | cycle | full | match | plan |
+| blob | data | fulltexttable | max | position |
+| boolean | database | function | member | position_rege |
+| both | date | fusion | merge | postfix |
+| breadth | day | general | method | precision |
+| break | dbcc | get | min | prefix |
+| browse | deallocate | global | minute | preorder |
+| bulk | dec | go | mod | prepare |
+| by | decimal | goto | modifies | preserve |
+| call | declare | grant | modify | primary |
+| called | default | group | module | print |
+| cardinality | deferrable | grouping | month | prior |
+| cascade | deferred | having | multiset | privileges |
+| cascaded | delete | hold | names | proc |
+| case | deny | holdlock | national | procedure |
+| cast | depth | host | natural | public |
+| catalog | deref | hour | nchar | raiserror |
+| char | desc | identity | nclob | range |
+| char_length | describe | identity_inse | new | read |
+| character | descriptor | identitycol | next | reads |
+| character_len | destroy | if | no | readtext |
+| check | destructor | ignore | nocheck | real |
+| checkpoint | deterministic | immediate | nonclustered | reconfigure |
+| class | diagnostics | in | none | recursive |
+| clob | dictionary | include | normalize | ref |
+| close | disconnect | index | not | references |
+| clustered | disk | indicator | null | referencing |
+| coalesce | distinct | initialize | nullif | regr_avgx |
+| collate | distributed | initially | numeric | regr_avgy |
+| collation | domain | inner | object | regr_count |
+| collect | double | inout | occurrences_r | regr_intercep |
+| column | drop | input | octet_length | regr_r2 |
+| commit | dump | insensitive | of | regr_slope |
+| completion | dynamic | insert | off | regr_sxx |
+| compute | each | int | offsets | regr_sxy |
+| condition | element | integer | old | regr_syy |
+| relative | semanticsimil | structure | truncate | window |
+| release | semanticsimil | submultiset | try_convert | with |
+| replication | sensitive | substring | tsequal | within | group |
+| restore | sequence | substring_reg | uescape | within |
+| restrict | session | sum | under | without |
+| result | session_user | symmetric | union | work |
+| return | set | system | unique | write |
+| returns | sets | system_user | unknown | writetext |
+| revert | setuser | table | unnest | xmlagg |
+| revoke | shutdown | tablesample | unpivot | xmlattributes |
+| right | similar | temporary | update | xmlbinary |
+| role | size | terminate | updatetext | xmlcast |
+| rollback | smallint | textsize | upper | xmlcomment |
+| rollup | some | than | usage | xmlconcat |
+| routine | space | then | use | xmldocument |
+| row | specific | time | user | xmlelement |
+| rowcount | specifictype | timestamp | using | xmlexists |
+| rowguidcol | sql | timezone_hour | value | xmlforest |
+| rows | sqlca | timezone_minu | values | xmliterate |
+| rule | sqlcode | to | var_pop | xmlnamespaces |
+| save | sqlerror | top | var_samp | xmlparse |
+| savepoint | sqlexception | trailing | varchar | xmlpi |
+| schema | sqlstate | tran | variable | xmlquery |
+| scope | sqlwarning | transaction | varying | xmlserialize |
+| scroll | start | translate | view | xmltable |
+| search | state | translate_reg | waitfor | xmltext |
+| second | statement | translation | when | xmlvalidate |
+| section | static | treat | whenever | year |
+| securityaudit | statistics | trigger | where | zone |
+| select | stddev_pop | trim | while |
+| semantickeyph | stddev_samp | true | width_bucket |
## Changelog
diff --git a/site/docs/reference/Connectors/materialization-connectors/amazon-redshift.md b/site/docs/reference/Connectors/materialization-connectors/amazon-redshift.md
index 9911fb2612..c75d69a65b 100644
--- a/site/docs/reference/Connectors/materialization-connectors/amazon-redshift.md
+++ b/site/docs/reference/Connectors/materialization-connectors/amazon-redshift.md
@@ -1,4 +1,3 @@
-
# Amazon Redshift
This connector materializes Flow collections into tables in an Amazon Redshift database.
@@ -14,15 +13,15 @@ versions.
To use this connector, you'll need:
-* A Redshift cluster accessible either directly or using an SSH tunnel. The user configured to
+- A Redshift cluster accessible either directly or using an SSH tunnel. The user configured to
connect to Redshift must have at least "create table" permissions for the configured schema. The
connector will create new tables in the database per your specification. Tables created manually
in advance are not supported. See [setup](#setup) for more information.
-* An S3 bucket for staging temporary files. For best performance the bucket should be in the same
+- An S3 bucket for staging temporary files. For best performance the bucket should be in the same
region as your Redshift cluster. See [this
guide](https://docs.aws.amazon.com/AmazonS3/latest/userguide/create-bucket-overview.html) for
instructions on setting up a new S3 bucket.
-* An AWS root or IAM user with [read and write
+- An AWS root or IAM user with [read and write
access](https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_examples_s3_rw-bucket.html)
to the S3 bucket. For this user, you'll need the **access key** and **secret access key**. See the
[AWS blog](https://aws.amazon.com/blogs/security/wheres-my-secret-access-key/) for help finding
@@ -38,7 +37,7 @@ more of your Flow collections to your desired tables in the database.
#### Endpoint
| Property | Title | Description | Type | Required/Default |
-|---------------------------|-------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------|------------------|
+| ------------------------- | ----------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------ | ---------------- |
| **`/address`** | Address | Host and port of the database. Example: red-shift-cluster-name.account.us-east-2.redshift.amazonaws.com:5439 | string | Required |
| **`/user`** | User | Database user to connect as. | string | Required |
| **`/password`** | Password | Password for the specified database user. | string | Required |
@@ -52,11 +51,11 @@ more of your Flow collections to your desired tables in the database.
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-|--------------------------------|-----------------------------|---------------------------------------------------------------------------------------|---------|------------------|
-| **`/table`** | Table | Name of the database table. | string | Required |
-| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. Default is false. | boolean | `false` |
-| `/schema` | Alternative Schema | Alternative schema for this table (optional). | string | |
+| Property | Title | Description | Type | Required/Default |
+| ---------------- | ------------------ | ------------------------------------------------------------------------- | ------- | ---------------- |
+| **`/table`** | Table | Name of the database table. | string | Required |
+| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. Default is false. | boolean | `false` |
+| `/schema` | Alternative Schema | Alternative schema for this table (optional). | string | |
### Sample
@@ -89,9 +88,9 @@ about how to configure this [here](../../materialization-sync-schedule.md).
## Setup
You must configure your cluster to allow connections from Estuary. This can be accomplished by
-making your cluster accessible over the internet for Estuary Flow's IP address `34.121.207.128`, or
-using an SSH tunnel. Connecting to the S3 staging bucket does not use the network tunnel and
-connects over HTTPS only.
+making your cluster accessible over the internet for Estuary Flow's IP addresses
+`34.121.207.128, 35.226.75.135, 34.68.62.148`, or using an SSH tunnel. Connecting to the S3
+staging bucket does not use the network tunnel and connects over HTTPS only.
Instructions for making a cluster accessible over the internet can be found
[here](https://aws.amazon.com/premiumsupport/knowledge-center/redshift-cluster-private-public/).
@@ -103,10 +102,10 @@ For allowing secure connections via SSH tunneling:
AWS EC2 instance.
2. Configure your connector as described in the [configuration](#configuration) section above, with
-the additional of the `networkTunnel` stanza to enable the SSH tunnel, if using. See [Connecting to
-endpoints on secure
-networks](../../../../concepts/connectors/#connecting-to-endpoints-on-secure-networks) for additional
-details and a sample.
+ the additional of the `networkTunnel` stanza to enable the SSH tunnel, if using. See [Connecting to
+ endpoints on secure
+ networks](../../../../concepts/connectors/#connecting-to-endpoints-on-secure-networks) for additional
+ details and a sample.
## Naming Conventions
diff --git a/site/docs/reference/Connectors/materialization-connectors/mongodb.md b/site/docs/reference/Connectors/materialization-connectors/mongodb.md
index 14b8c36a1e..d56940900f 100644
--- a/site/docs/reference/Connectors/materialization-connectors/mongodb.md
+++ b/site/docs/reference/Connectors/materialization-connectors/mongodb.md
@@ -1,5 +1,3 @@
-
-
# MongoDB
This connector materializes data from your Flow collections to your MongoDB collections.
@@ -18,13 +16,13 @@ and values) organized in **collections**. MongoDB documents have a mandatory
You'll need:
-* Credentials for connecting to your MongoDB instance and database.
+- Credentials for connecting to your MongoDB instance and database.
-* Read and write access to your MongoDB database and desired collections. See [Role-Based Access
+- Read and write access to your MongoDB database and desired collections. See [Role-Based Access
Control](https://www.mongodb.com/docs/manual/core/authorization/) for more information.
-* If you are using MongoDB Atlas, or your MongoDB provider requires whitelisting
- of IPs, you need to whitelist Estuary's IP: `34.121.207.128`.
+- If you are using MongoDB Atlas, or your MongoDB provider requires whitelisting
+ of IPs, you need to whitelist Estuary's IPs: `34.121.207.128, 35.226.75.135, 34.68.62.148`.
## Configuration
@@ -35,19 +33,19 @@ See [connectors](../../../concepts/connectors.md#using-connectors) to learn more
#### Endpoint
-| Property | Title | Description | Type | Required/Default |
-|---------------------------------|---------------------|---------------------------------------------------------------------------------------------------------------------------------------------|---------|----------------------------|
-| **`/address`** | Address | Host and port of the database. Optionally can specify scheme for the URL such as mongodb+srv://host. | string | Required |
-| **`/database`** | Database | Name of the database to capture from. | string | Required |
-| **`/user`** | User | Database user to connect as. | string | Required |
-| **`/password`** | Password | Password for the specified database user. | string | Required |
+| Property | Title | Description | Type | Required/Default |
+| --------------- | -------- | ---------------------------------------------------------------------------------------------------- | ------ | ---------------- |
+| **`/address`** | Address | Host and port of the database. Optionally can specify scheme for the URL such as mongodb+srv://host. | string | Required |
+| **`/database`** | Database | Name of the database to capture from. | string | Required |
+| **`/user`** | User | Database user to connect as. | string | Required |
+| **`/password`** | Password | Password for the specified database user. | string | Required |
#### Bindings
-| Property | Title | Description | Type | Required/Default |
-| ------- | ------ | ------ | --------- | -------- |
-| **`/collection`** | Stream | Collection name | string | Required |
-| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
+| Property | Title | Description | Type | Required/Default |
+| ----------------- | ------------ | ------------------------------------------------------- | ------- | ---------------- |
+| **`/collection`** | Stream | Collection name | string | Required |
+| `/delta_updates` | Delta Update | Should updates to this table be done via delta updates. | boolean | `false` |
### Sample