![]()
![]()
bpftime is a High-Performance userspace eBPF runtime and General Extension Framework designed for userspace. It enables faster Uprobe, USDT, Syscall hooks, XDP, and more event sources by bypassing the kernel and utilizing an optimized compiler like LLVM.
📦 Key Features
🔨 Quick Start
🔌 Examples & Use Cases
⌨️ Linux Plumbers 23 talk
📖 Slides
📚 Arxiv preprint
Checkout our documents in eunomia.dev!
bpftime is not userspace eBPF VM, it's a userspace runtime framework includes everything to run eBPF in userspace: loader, verifier, helpers, maps, ufunc and multiple events such as Observability, Network, Policy or Access Control. It has multiple VM backend options support. For eBPF VM only, please see llvmbpf.
⚠️ Note:bpftimeis currently under active development and refactoring towards v2. It may contain bugs or unstable API. Please use it with caution. For more details, check our roadmap. We'd love to hear your feedback and suggestions! Feel free to open an issue or Contact us.
- Performance Gains: Achieve better performance by
bypassing the kernel(e.g., viaUserspace DBIorNetwork Drivers), with more configurable, optimized and more arch supported JIT/AOT options likeLLVM, while maintaining compatibility with Linux kernel eBPF. - Cross-Platform Compatibility: Enables
eBPF functionality and large ecosystemwhere kernel eBPF is unavailable, such as on older or alternative operating systems, or where kernel-level permissions are restricted, without changing your tool. - Flexible and General Extension Language & Runtime for Innovation: eBPF is designed for innovation, evolving into a General Extension Language & Runtime in production that supports very diverse use cases.
bpftime's modular design allows easy integration as a library for adding new events and program types without touching kernel. Wishing it could enable rapid prototyping and exploration of new features!
- Dynamic Binary rewriting: Run eBPF programs in userspace, attaching them to
UprobesandSyscall tracepoints: No manual instrumentation or restart required!. It cantraceorchangethe execution of a function,hookorfilterall syscalls of a process safely, and efficiently with an eBPF userspace runtime. Can inject eBPF runtime into any running process without the need for a restart or manual recompilation. - Performance: Experience up to a
10xspeedup in Uprobe overhead compared to kernel uprobe and uretprobe. Read/Write userspace memory is also faster than kernel eBPF. - Interprocess eBPF Maps: Implement userspace
eBPF mapsin shared userspace memory for summary aggregation or control plane communication. - Compatibility: use
existing eBPF toolchainslike clang, libbpf and bpftrace to develop userspace eBPF application without any modifications. Supporting CO-RE via BTF, and offering userspaceufuncaccess. - Multi JIT Support: Support llvmbpf, a high-speed
JIT/AOTcompiler powered by LLVM, or usingubpf JITand INTERPRETER. The vm can be built asa standalone librarylike ubpf. - Run with kernel eBPF: Can load userspace eBPF from kernel, and using kernel eBPF maps to cooperate with kernel eBPF programs like kprobes and network filters.
- Integrate with AF_XDP or DPDK: Run your
XDPnetwork applications with better performance in userspace just like in kernel!(experimental)
vm: The eBPF VM and JIT compiler for bpftime, you can choose from bpftime LLVM JIT/AOT compiler and ubpf. The llvm-based vm in bpftime can also be built as a standalone library and integrated into other projects, similar to ubpf.runtime: The userspace runtime for eBPF, including the maps, helpers, ufuncs and other runtime safety features.Attach events: support attaching eBPF programs toUprobes,Syscall tracepoints,XDPand other events with bpf_link, and also the driver event sources.verifier: Support using PREVAIL as userspace verifier, or usingLinux kernel verifierfor better results.Loader: Includes aLD_PRELOADloader library in userspace can work with current eBPF toolchain and library without involving any kernel, Another option is daemon when Linux eBPF is available.
With bpftime, you can build eBPF applications using familiar tools like clang and libbpf, and execute them in userspace. For instance, the malloc eBPF program traces malloc calls using uprobe and aggregates the counts using a hash map.
You can refer to eunomia.dev/bpftime/documents/build-and-test for how to build the project, or using the container images from GitHub packages.
To get started, you can build and run a libbpf based eBPF program starts with bpftime cli:
make -C example/malloc # Build the eBPF program example
export PATH=$PATH:~/.bpftime/
bpftime load ./example/malloc/mallocIn another shell, Run the target program with eBPF inside:
$ bpftime start ./example/malloc/victim
Hello malloc!
malloc called from pid 250215
continue malloc...
malloc called from pid 250215You can also dynamically attach the eBPF program with a running process:
$ ./example/malloc/victim & echo $! # The pid is 101771
[1] 101771
101771
continue malloc...
continue malloc...And attach to it:
$ sudo bpftime attach 101771 # You may need to run make install in root
Inject: "/root/.bpftime/libbpftime-agent.so"
Successfully injected. ID: 1You can see the output from original program:
$ bpftime load ./example/malloc/malloc
...
12:44:35
pid=247299 malloc calls: 10
pid=247322 malloc calls: 10Alternatively, you can also run our sample eBPF program directly in the kernel eBPF, to see the similar output. This can be an example of how bpftime can work compatibly with kernel eBPF.
$ sudo example/malloc/malloc
15:38:05
pid=30415 malloc calls: 1079
pid=30393 malloc calls: 203
pid=29882 malloc calls: 1076
pid=34809 malloc calls: 8See eunomia.dev/bpftime/documents/usage for more details.
For more examples and details, please refer to eunomia.dev/bpftime/documents/examples/ webpage.
Examples including:
- Minimal examples of eBPF programs.
- eBPF
Uprobe/USDTtracing andsyscall tracing:- sslsniff for trace SSL/TLS unencrypted data.
- opensnoop for trace file open syscalls.
- More bcc/libbpf-tools.
- Run with bpftrace commands or scripts.
- error injection: change function behavior with
bpf_override_return. - Use the eBPF LLVM JIT/AOT vm as a standalone library.
- Userspace XDP with DPDK and AF_XDP
bpftime supports two modes:
Left: original kernel eBPF | Right: bpftime
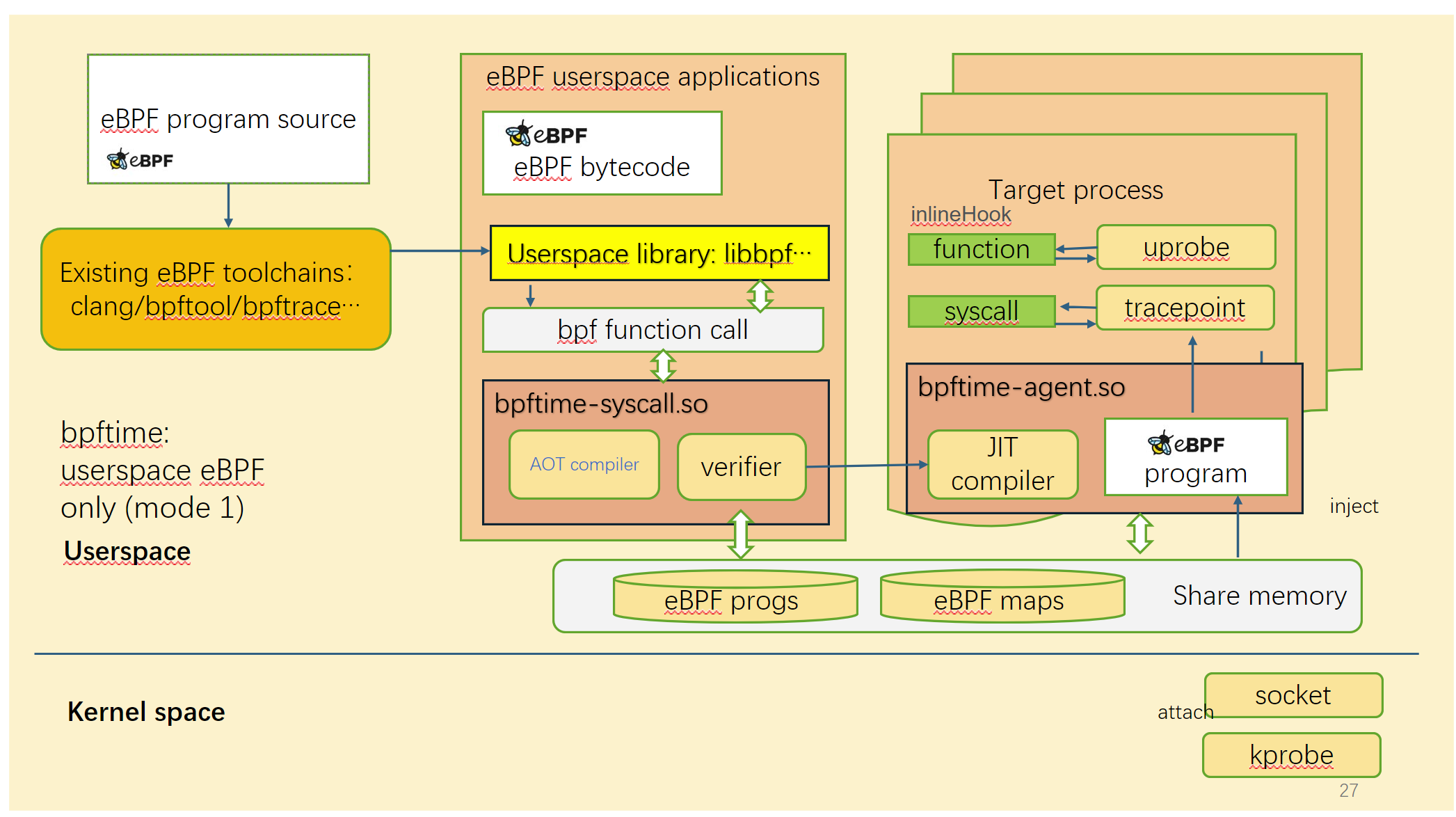
In this mode, bpftime can run eBPF programs in userspace without kernel, so it can be ported into low version of Linux or event other systems, and running without root permissions. It relies on a userspace verifier to ensure the safety of eBPF programs.
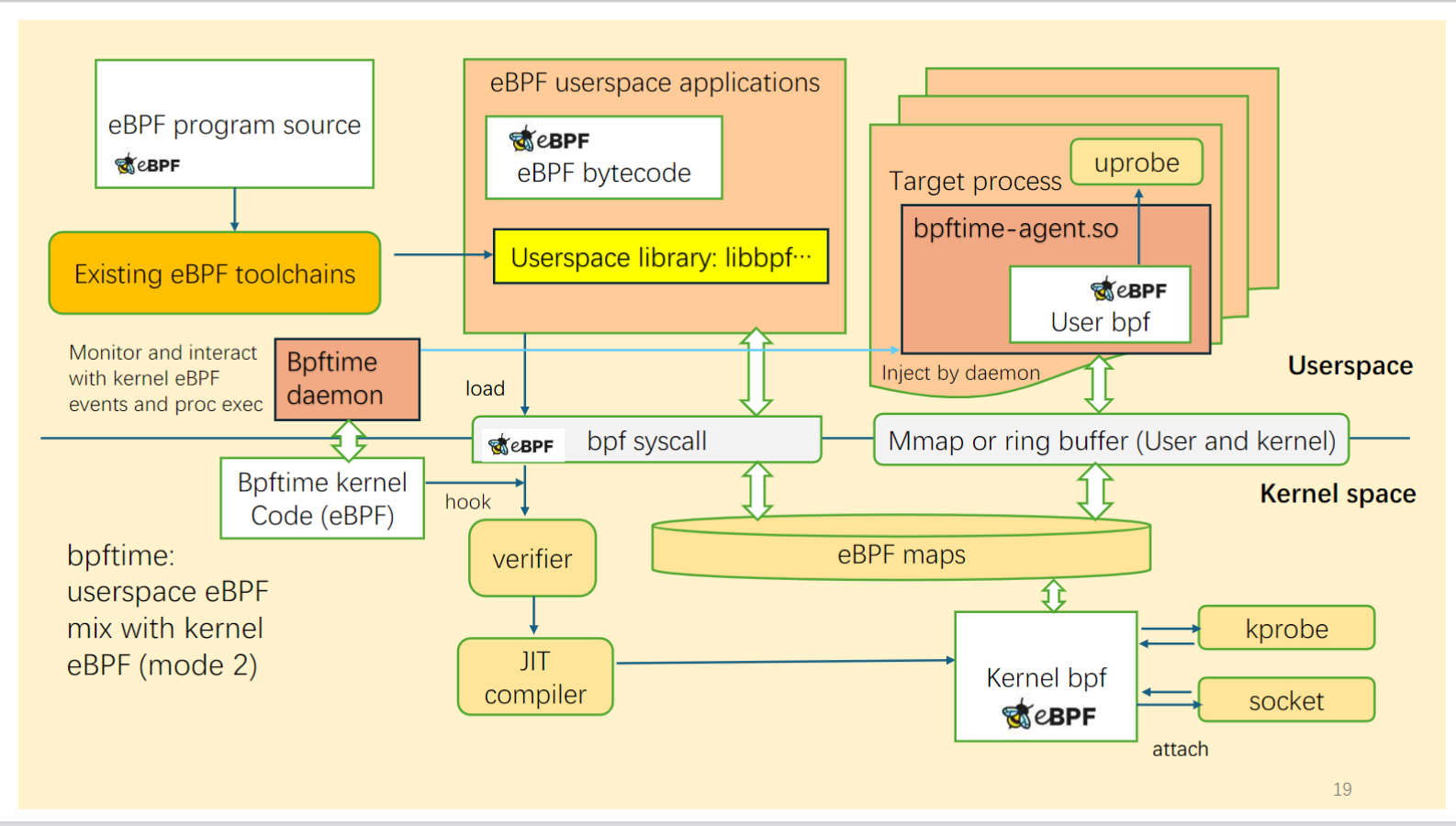
In this mode, bpftime can run together with kernel eBPF. It can load eBPF programs from kernel, and using kernel eBPF maps to cooperate with kernel eBPF programs like kprobes and network filters.
Current hook implementation is based on binary rewriting and the underly technique is inspired by:
- Userspace function hook: frida-gum
- Syscall hooks: zpoline and pmem/syscall_intercept.
The hook can be easily replaced with other DBI methods or frameworks, or add more hook mechanisms in the future.
See our draft arxiv paper bpftime: userspace eBPF Runtime for Uprobe, Syscall and Kernel-User Interactions for details.
How is the performance of userspace uprobe compared to kernel uprobes?
| Probe/Tracepoint Types | Kernel (ns) | Userspace (ns) |
|---|---|---|
| Uprobe | 3224.172760 | 314.569110 |
| Uretprobe | 3996.799580 | 381.270270 |
| Syscall Tracepoint | 151.82801 | 232.57691 |
| Manually Instrument | Not avaliable | 110.008430 |
It can be attached to functions in running process just like the kernel uprobe does.
How is the performance of LLVM JIT/AOT compared to other eBPF userspace runtimes, native code or wasm runtimes?

Across all tests, the LLVM JIT for bpftime consistently showcased superior performance. Both demonstrated high efficiency in integer computations (as seen in log2_int), complex mathematical operations (as observed in prime), and memory operations (evident in memcpy and strcmp). While they lead in performance across the board, each runtime exhibits unique strengths and weaknesses. These insights can be invaluable for users when choosing the most appropriate runtime for their specific use-cases.
see github.com/eunomia-bpf/bpf-benchmark for how we evaluate and details.
Hash map or ring buffer compared to kernel(TODO)
See benchmark dir for detail performance benchmarks.
bpftimeallows you to useclangandlibbpfto build eBPF programs, and run them directly in this runtime, just like normal kernel eBPF. We have tested it with a libbpf version in third_party/libbpf. No specify libbpf or clang version needed.- Some kernel helpers and kfuncs may not be available in userspace.
- It does not support direct access to kernel data structures or functions like
task_struct.
Refer to eunomia.dev/bpftime/documents/available-features for more details.
See eunomia.dev/bpftime/documents/build-and-test for details.
bpftime is continuously evolving with more features in the pipeline:
- Keep compatibility with the evolving kernel
- Refactor for General Extension Framework
- Trying to refactor, bug fixing for
Production. - More examples and usecases:
- Userspace Network Driver on userspace eBPF
- Hotpatch userspace application
- Error injection and filter syscall
- Syscall bypassing, batching
- Userspace Storage Driver on userspace eBPF
- etc...
Stay tuned for more developments from this promising project! You can find bpftime on GitHub.
This project is licensed under the MIT License.
Have any questions or suggestions on future development? Free free to open an issue or contact [email protected] !
Our arxiv preprint: https://arxiv.org/abs/2311.07923
@misc{zheng2023bpftime,
title={bpftime: userspace eBPF Runtime for Uprobe, Syscall and Kernel-User Interactions},
author={Yusheng Zheng and Tong Yu and Yiwei Yang and Yanpeng Hu and XiaoZheng Lai and Andrew Quinn},
year={2023},
eprint={2311.07923},
archivePrefix={arXiv},
primaryClass={cs.OS}
}eunomia-bpf community is sponsored by PLCT Lab from ISCAS.
Thanks for other sponsors and discussions help building this project: Prof. Marios Kogias from Imperial College London, Prof. Xiaozheng lai from SCUT, Prof lijun chen from XUPT, Prof. Qi Li from THU NISL Lab, and Linux eBPF maintainers in the LPC 23 eBPF track.