HugeGraphServer为HugeGraph图数据库提供了RESTful API接口。除了顶点和边的CRUD基本操作以外,还提供了一些遍历(traverser)方法,我们称为traverser API。这些遍历方法实现了一些复杂的图算法,方便用户对图进行分析和挖掘。
HugeGraph支持的Traverser API包括:
- K-out API,根据起始顶点,查找恰好N步可达的邻居,分为基础版和高级版:
- 基础版使用GET方法,根据起始顶点,查找恰好N步可达的邻居
- 高级版使用POST方法,根据起始顶点,查找恰好N步可达的邻居,与基础版的不同在于:
- 支持只统计邻居数量
- 支持边属性过滤
- 支持返回到达邻居的最短路径
- K-neighbor API,根据起始顶点,查找N步以内可达的所有邻居,分为基础版和高级版:
- 基础版使用GET方法,根据起始顶点,查找N步以内可达的所有邻居
- 高级版使用POST方法,根据起始顶点,查找N步以内可达的所有邻居,与基础版的不同在于:
- 支持只统计邻居数量
- 支持边属性过滤
- 支持返回到达邻居的最短路径
- Same Neighbors, 查询两个顶点的共同邻居
- Jaccard Similarity API,计算jaccard相似度,包括两种:
- 一种是使用GET方法,计算两个顶点的邻居的相似度(交并比)
- 一种是使用POST方法,在全图中查找与起点的jaccard similarity最高的N个点
- Shortest Path API,查找两个顶点之间的最短路径
- All Shortest Paths,查找两个顶点间的全部最短路径
- Weighted Shortest Path,查找起点到目标点的带权最短路径
- Single Source Shortest Path,查找一个点到其他各个点的加权最短路径
- Multi Node Shortest Path,查找指定顶点集之间两两最短路径
- Paths API,查找两个顶点间的全部路径,分为基础版和高级版:
- 基础版使用GET方法,根据起点和终点,查找两个顶点间的全部路径
- 高级版使用POST方法,根据一组起点和一组终点,查找两个集合间符合条件的全部路径
- Customized Paths API,从一批顶点出发,按(一种)模式遍历经过的全部路径
- Template Path API,指定起点和终点以及起点和终点间路径信息,查找符合的路径
- Crosspoints API,查找两个顶点的交点(共同祖先或者共同子孙)
- Customized Crosspoints API,从一批顶点出发,按多种模式遍历,最后一步到达的顶点的交点
- Rings API,从起始顶点出发,可到达的环路路径
- Rays API,从起始顶点出发,可到达边界的路径(即无环路径)
- Fusiform Similarity API,查找一个顶点的梭形相似点
- Vertices API
- 按ID批量查询顶点;
- 获取顶点的分区;
- 按分区查询顶点;
- Edges API
- 按ID批量查询边;
- 获取边的分区;
- 按分区查询边;
使用方法中的例子,都是基于TinkerPop官网给出的图:
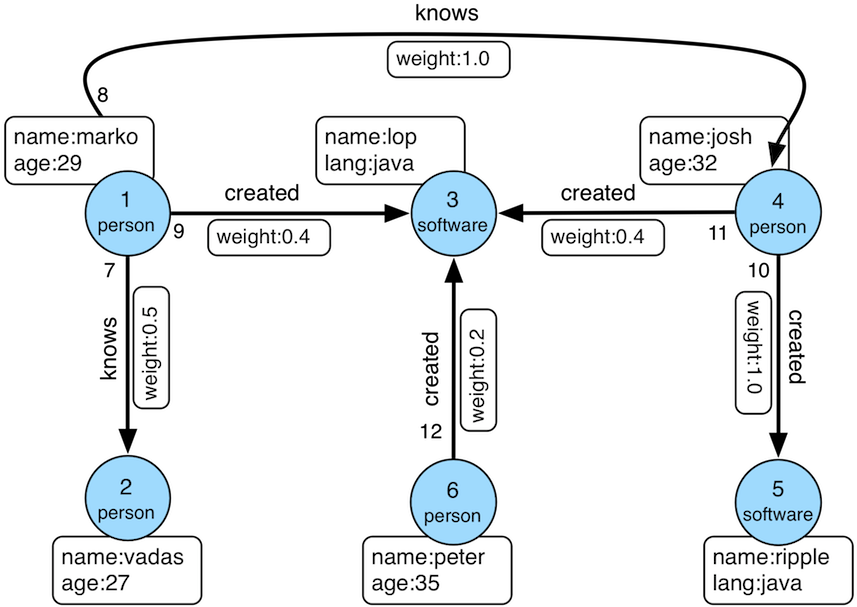
数据导入程序如下:
public class Loader {
public static void main(String[] args) {
HugeClient client = new HugeClient("http://127.0.0.1:8080", "hugegraph");
SchemaManager schema = client.schema();
schema.propertyKey("name").asText().ifNotExist().create();
schema.propertyKey("age").asInt().ifNotExist().create();
schema.propertyKey("city").asText().ifNotExist().create();
schema.propertyKey("weight").asDouble().ifNotExist().create();
schema.propertyKey("lang").asText().ifNotExist().create();
schema.propertyKey("date").asText().ifNotExist().create();
schema.propertyKey("price").asInt().ifNotExist().create();
schema.vertexLabel("person")
.properties("name", "age", "city")
.primaryKeys("name")
.nullableKeys("age")
.ifNotExist()
.create();
schema.vertexLabel("software")
.properties("name", "lang", "price")
.primaryKeys("name")
.nullableKeys("price")
.ifNotExist()
.create();
schema.indexLabel("personByCity")
.onV("person")
.by("city")
.secondary()
.ifNotExist()
.create();
schema.indexLabel("personByAgeAndCity")
.onV("person")
.by("age", "city")
.secondary()
.ifNotExist()
.create();
schema.indexLabel("softwareByPrice")
.onV("software")
.by("price")
.range()
.ifNotExist()
.create();
schema.edgeLabel("knows")
.multiTimes()
.sourceLabel("person")
.targetLabel("person")
.properties("date", "weight")
.sortKeys("date")
.nullableKeys("weight")
.ifNotExist()
.create();
schema.edgeLabel("created")
.sourceLabel("person").targetLabel("software")
.properties("date", "weight")
.nullableKeys("weight")
.ifNotExist()
.create();
schema.indexLabel("createdByDate")
.onE("created")
.by("date")
.secondary()
.ifNotExist()
.create();
schema.indexLabel("createdByWeight")
.onE("created")
.by("weight")
.range()
.ifNotExist()
.create();
schema.indexLabel("knowsByWeight")
.onE("knows")
.by("weight")
.range()
.ifNotExist()
.create();
GraphManager graph = client.graph();
Vertex marko = graph.addVertex(T.label, "person", "name", "marko",
"age", 29, "city", "Beijing");
Vertex vadas = graph.addVertex(T.label, "person", "name", "vadas",
"age", 27, "city", "Hongkong");
Vertex lop = graph.addVertex(T.label, "software", "name", "lop",
"lang", "java", "price", 328);
Vertex josh = graph.addVertex(T.label, "person", "name", "josh",
"age", 32, "city", "Beijing");
Vertex ripple = graph.addVertex(T.label, "software", "name", "ripple",
"lang", "java", "price", 199);
Vertex peter = graph.addVertex(T.label, "person", "name", "peter",
"age", 35, "city", "Shanghai");
marko.addEdge("knows", vadas, "date", "20160110", "weight", 0.5);
marko.addEdge("knows", josh, "date", "20130220", "weight", 1.0);
marko.addEdge("created", lop, "date", "20171210", "weight", 0.4);
josh.addEdge("created", lop, "date", "20091111", "weight", 0.4);
josh.addEdge("created", ripple, "date", "20171210", "weight", 1.0);
peter.addEdge("created", lop, "date", "20170324", "weight", 0.2);
}
}顶点ID为:
"2:ripple",
"1:vadas",
"1:peter",
"1:josh",
"1:marko",
"2:lop"
边ID为:
"S1:peter>2>>S2:lop",
"S1:josh>2>>S2:lop",
"S1:josh>2>>S2:ripple",
"S1:marko>1>20130220>S1:josh",
"S1:marko>1>20160110>S1:vadas",
"S1:marko>2>>S2:lop"
根据起始顶点、方向、边的类型(可选)和深度depth,查找从起始顶点出发恰好depth步可达的顶点
- source:起始顶点id,必填项
- direction:起始顶点向外发散的方向(OUT,IN,BOTH),选填项,默认是BOTH
- max_depth:步数,必填项
- label:边的类型,选填项,默认代表所有edge label
- nearest:nearest为true时,代表起始顶点到达结果顶点的最短路径长度为depth,不存在更短的路径;nearest为false时,代表起始顶点到结果顶点有一条长度为depth的路径(未必最短且可以有环),选填项,默认为true
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,选填项,默认为10000
- capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
- limit:返回的顶点的最大数目,选填项,默认为10000000
GET http://localhost:8080/graphs/{graph}/traversers/kout?source="1:marko"&max_depth=2
200{
"vertices":[
"2:ripple",
"1:peter"
]
}查找恰好N步关系可达的顶点。两个例子:
- 家族关系中,查找一个人的所有孙子,person A通过连续的两条“儿子”边到达的顶点集合。
- 社交关系中发现潜在好友,例如:与目标用户相隔两层朋友关系的用户,可以通过连续两条“朋友”边到达的顶点。
根据起始顶点、步骤(包括方向、边类型和过滤属性)和深度depth,查找从起始顶点出发恰好depth步可达的顶点。
与K-out基础版的不同在于:
- 支持只统计邻居数量
- 支持边属性过滤
- 支持返回到达邻居的最短路径
- source:起始顶点id,必填项
- 从起始点出发的Step,必填项,结构如下:
- direction:表示边的方向(OUT,IN,BOTH),默认是BOTH
- labels:边的类型列表
- properties:通过属性的值过滤边
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,默认为 10000 (注: 0.12版之前 step 内仅支持 degree 作为参数名, 0.12开始统一使用 max_degree, 并向下兼容 degree 写法)
- skip_degree:用于设置查询过程中舍弃超级顶点的最小边数,即当某个顶点的邻接边数目大于 skip_degree 时,完全舍弃该顶点。选填项,如果开启时,需满足
skip_degree >= max_degree约束,默认为0 (不启用),表示不跳过任何点 (注意: 开启此配置后,遍历时会尝试访问一个顶点的 skip_degree 条边,而不仅仅是 max_degree 条边,这样有额外的遍历开销,对查询性能影响可能有较大影响,请确认理解后再开启)
- max_depth:步数,必填项
- nearest:nearest为true时,代表起始顶点到达结果顶点的最短路径长度为depth,不存在更短的路径;nearest为false时,代表起始顶点到结果顶点有一条长度为depth的路径(未必最短且可以有环),选填项,默认为true
- count_only:Boolean值,true表示只统计结果的数目,不返回具体结果;false表示返回具体的结果,默认为false
- with_path:true表示返回起始点到每个邻居的最短路径,false表示不返回起始点到每个邻居的最短路径,选填项,默认为false
- with_vertex,选填项,默认为false:
- true表示返回结果包含完整的顶点信息(路径中的全部顶点)
- with_path为true时,返回所有路径中的顶点的完整信息
- with_path为false时,返回所有邻居的完整信息
- false时表示只返回顶点id
- true表示返回结果包含完整的顶点信息(路径中的全部顶点)
- capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
- limit:返回的顶点的最大数目,选填项,默认为10000000
POST http://localhost:8080/graphs/{graph}/traversers/kout
{
"source": "1:marko",
"step": {
"direction": "BOTH",
"labels": ["knows", "created"],
"properties": {
"weight": "P.gt(0.1)"
},
"max_degree": 10000,
"skip_degree": 100000
},
"max_depth": 1,
"nearest": true,
"limit": 10000,
"with_vertex": true,
"with_path": true
}200{
"size": 3,
"kout": [
"1:josh",
"1:vadas",
"2:lop"
],
"paths": [
{
"objects": [
"1:marko",
"1:josh"
]
},
{
"objects": [
"1:marko",
"1:vadas"
]
},
{
"objects": [
"1:marko",
"2:lop"
]
}
],
"vertices": [
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 29,
"city": "Beijing"
}
},
{
"id": "1:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Beijing"
}
},
{
"id": "1:vadas",
"label": "person",
"type": "vertex",
"properties": {
"name": "vadas",
"age": 27,
"city": "Hongkong"
}
},
{
"id": "2:lop",
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "java",
"price": 328
}
}
]
}
参见3.2.1.3
根据起始顶点、方向、边的类型(可选)和深度depth,查找包括起始顶点在内、depth步之内可达的所有顶点
相当于:起始顶点、K-out(1)、K-out(2)、... 、K-out(max_depth)的并集
- source: 起始顶点id,必填项
- direction:起始顶点向外发散的方向(OUT,IN,BOTH),选填项,默认是BOTH
- max_depth:步数,必填项
- label:边的类型,选填项,默认代表所有edge label
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,选填项,默认为10000
- limit:返回的顶点的最大数目,也即遍历过程中最大的访问的顶点数目,选填项,默认为10000000
GET http://localhost:8080/graphs/{graph}/traversers/kneighbor?source=“1:marko”&max_depth=2
200{
"vertices":[
"2:ripple",
"1:marko",
"1:josh",
"1:vadas",
"1:peter",
"2:lop"
]
}查找N步以内可达的所有顶点,例如:
- 家族关系中,查找一个人五服以内所有子孙,person A通过连续的5条“亲子”边到达的顶点集合。
- 社交关系中发现好友圈子,例如目标用户通过1条、2条、3条“朋友”边可到达的用户可以组成目标用户的朋友圈子
根据起始顶点、步骤(包括方向、边类型和过滤属性)和深度depth,查找从起始顶点出发depth步内可达的所有顶点。
与K-neighbor基础版的不同在于:
- 支持只统计邻居数量
- 支持边属性过滤
- 支持返回到达邻居的最短路径
- source:起始顶点id,必填项
- 从起始点出发的Step,必填项,结构如下:
- direction:表示边的方向(OUT,IN,BOTH),默认是BOTH
- labels:边的类型列表
- properties:通过属性的值过滤边
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,默认为 10000 (注: 0.12版之前 step 内仅支持 degree 作为参数名, 0.12开始统一使用 max_degree, 并向下兼容 degree 写法)
- skip_degree:用于设置查询过程中舍弃超级顶点的最小边数,即当某个顶点的邻接边数目大于 skip_degree 时,完全舍弃该顶点。选填项,如果开启时,需满足
skip_degree >= max_degree约束,默认为0 (不启用),表示不跳过任何点 (注意: 开启此配置后,遍历时会尝试访问一个顶点的 skip_degree 条边,而不仅仅是 max_degree 条边,这样有额外的遍历开销,对查询性能影响可能有较大影响,请确认理解后再开启)
- max_depth:步数,必填项
- count_only:Boolean值,true表示只统计结果的数目,不返回具体结果;false表示返回具体的结果,默认为false
- with_path:true表示返回起始点到每个邻居的最短路径,false表示不返回起始点到每个邻居的最短路径,选填项,默认为false
- with_vertex,选填项,默认为false:
- true表示返回结果包含完整的顶点信息(路径中的全部顶点)
- with_path为true时,返回所有路径中的顶点的完整信息
- with_path为false时,返回所有邻居的完整信息
- false时表示只返回顶点id
- true表示返回结果包含完整的顶点信息(路径中的全部顶点)
- limit:返回的顶点的最大数目,选填项,默认为10000000
POST http://localhost:8080/graphs/{graph}/traversers/kneighbor
{
"source": "1:marko",
"step": {
"direction": "BOTH",
"labels": ["knows", "created"],
"properties": {
"weight": "P.gt(0.1)"
},
"max_degree": 10000,
"skip_degree": 100000
},
"max_depth": 3,
"limit": 10000,
"with_vertex": true,
"with_path": true
}200{
"size": 6,
"kneighbor": [
"2:ripple",
"1:marko",
"1:josh",
"1:vadas",
"1:peter",
"2:lop"
],
"paths": [
{
"objects": [
"1:marko",
"1:josh",
"2:ripple"
]
},
{
"objects": [
"1:marko"
]
},
{
"objects": [
"1:marko",
"1:josh"
]
},
{
"objects": [
"1:marko",
"1:vadas"
]
},
{
"objects": [
"1:marko",
"2:lop",
"1:peter"
]
},
{
"objects": [
"1:marko",
"2:lop"
]
}
],
"vertices": [
{
"id": "2:ripple",
"label": "software",
"type": "vertex",
"properties": {
"name": "ripple",
"lang": "java",
"price": 199
}
},
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 29,
"city": "Beijing"
}
},
{
"id": "1:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Beijing"
}
},
{
"id": "1:vadas",
"label": "person",
"type": "vertex",
"properties": {
"name": "vadas",
"age": 27,
"city": "Hongkong"
}
},
{
"id": "1:peter",
"label": "person",
"type": "vertex",
"properties": {
"name": "peter",
"age": 35,
"city": "Shanghai"
}
},
{
"id": "2:lop",
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "java",
"price": 328
}
}
]
}参见3.2.3.3
查询两个点的共同邻居
- vertex:一个顶点id,必填项
- other:另一个顶点id,必填项
- direction:顶点向外发散的方向(OUT,IN,BOTH),选填项,默认是BOTH
- label:边的类型,选填项,默认代表所有edge label
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,选填项,默认为10000
- limit:返回的共同邻居的最大数目,选填项,默认为10000000
GET http://localhost:8080/graphs/{graph}/traversers/sameneighbors?vertex=“1:marko”&other="1:josh"
200{
"same_neighbors":[
"2:lop"
]
}查找两个顶点的共同邻居:
- 社交关系中发现两个用户的共同粉丝或者共同关注用户
计算两个顶点的jaccard similarity(两个顶点邻居的交集比上两个顶点邻居的并集)
- vertex:一个顶点id,必填项
- other:另一个顶点id,必填项
- direction:顶点向外发散的方向(OUT,IN,BOTH),选填项,默认是BOTH
- label:边的类型,选填项,默认代表所有edge label
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,选填项,默认为10000
GET http://localhost:8080/graphs/{graph}/traversers/jaccardsimilarity?vertex="1:marko"&other="1:josh"
200{
"jaccard_similarity": 0.2
}用于评估两个点的相似性或者紧密度
计算与指定顶点的jaccard similarity最大的N个点
jaccard similarity的计算方式为:两个顶点邻居的交集比上两个顶点邻居的并集
- vertex:一个顶点id,必填项
- 从起始点出发的Step,必填项,结构如下:
- direction:表示边的方向(OUT,IN,BOTH),默认是BOTH
- labels:边的类型列表
- properties:通过属性的值过滤边
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,默认为 10000 (注: 0.12版之前 step 内仅支持 degree 作为参数名, 0.12开始统一使用 max_degree, 并向下兼容 degree 写法)
- skip_degree:用于设置查询过程中舍弃超级顶点的最小边数,即当某个顶点的邻接边数目大于 skip_degree 时,完全舍弃该顶点。选填项,如果开启时,需满足
skip_degree >= max_degree约束,默认为0 (不启用),表示不跳过任何点 (注意: 开启此配置后,遍历时会尝试访问一个顶点的 skip_degree 条边,而不仅仅是 max_degree 条边,这样有额外的遍历开销,对查询性能影响可能有较大影响,请确认理解后再开启)
- top:返回一个起点的jaccard similarity中最大的top个,选填项,默认为100
- capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
POST http://localhost:8080/graphs/{graph}/traversers/jaccardsimilarity
{
"vertex": "1:marko",
"step": {
"direction": "BOTH",
"labels": [],
"max_degree": 10000,
"skip_degree": 100000
},
"top": 3
}200{
"2:ripple": 0.3333333333333333,
"1:peter": 0.3333333333333333,
"1:josh": 0.2
}用于在图中找出与指定顶点相似性最高的顶点
根据起始顶点、目的顶点、方向、边的类型(可选)和最大深度,查找一条最短路径
- source:起始顶点id,必填项
- target:目的顶点id,必填项
- direction:起始顶点向外发散的方向(OUT,IN,BOTH),选填项,默认是BOTH
- max_depth:最大步数,必填项
- label:边的类型,选填项,默认代表所有edge label
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,选填项,默认为10000
- skip_degree:用于设置查询过程中舍弃超级顶点的最小边数,即当某个顶点的邻接边数目大于 skip_degree 时,完全舍弃该顶点。选填项,如果开启时,需满足
skip_degree >= max_degree约束,默认为0 (不启用),表示不跳过任何点 (注意: 开启此配置后,遍历时会尝试访问一个顶点的 skip_degree 条边,而不仅仅是 max_degree 条边,这样有额外的遍历开销,对查询性能影响可能有较大影响,请确认理解后再开启) - capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
GET http://localhost:8080/graphs/{graph}/traversers/shortestpath?source="1:marko"&target="2:ripple"&max_depth=3
200{
"path":[
"1:marko",
"1:josh",
"2:ripple"
]
}查找两个顶点间的最短路径,例如:
- 社交关系网中,查找两个用户有关系的最短路径,即最近的朋友关系链
- 设备关联网络中,查找两个设备最短的关联关系
根据起始顶点、目的顶点、方向、边的类型(可选)和最大深度,查找两点间所有的最短路径
- source:起始顶点id,必填项
- target:目的顶点id,必填项
- direction:起始顶点向外发散的方向(OUT,IN,BOTH),选填项,默认是BOTH
- max_depth:最大步数,必填项
- label:边的类型,选填项,默认代表所有edge label
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,选填项,默认为10000
- skip_degree:用于设置查询过程中舍弃超级顶点的最小边数,即当某个顶点的邻接边数目大于 skip_degree 时,完全舍弃该顶点。选填项,如果开启时,需满足
skip_degree >= max_degree约束,默认为0 (不启用),表示不跳过任何点 (注意: 开启此配置后,遍历时会尝试访问一个顶点的 skip_degree 条边,而不仅仅是 max_degree 条边,这样有额外的遍历开销,对查询性能影响可能有较大影响,请确认理解后再开启) - capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
GET http://localhost:8080/graphs/{graph}/traversers/allshortestpaths?source="A"&target="Z"&max_depth=10
200{
"paths":[
{
"objects": [
"A",
"B",
"C",
"Z"
]
},
{
"objects": [
"A",
"M",
"N",
"Z"
]
}
]
}查找两个顶点间的所有最短路径,例如:
- 社交关系网中,查找两个用户有关系的全部最短路径,即最近的朋友关系链
- 设备关联网络中,查找两个设备全部的最短关联关系
根据起始顶点、目的顶点、方向、边的类型(可选)和最大深度,查找一条带权最短路径
- source:起始顶点id,必填项
- target:目的顶点id,必填项
- direction:起始顶点向外发散的方向(OUT,IN,BOTH),选填项,默认是BOTH
- label:边的类型,选填项,默认代表所有edge label
- weight:边的权重属性,必填项,必须是数字类型的属性
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,选填项,默认为10000
- skip_degree:用于设置查询过程中舍弃超级顶点的最小边数,即当某个顶点的邻接边数目大于 skip_degree 时,完全舍弃该顶点。选填项,如果开启时,需满足
skip_degree >= max_degree约束,默认为0 (不启用),表示不跳过任何点 (注意: 开启此配置后,遍历时会尝试访问一个顶点的 skip_degree 条边,而不仅仅是 max_degree 条边,这样有额外的遍历开销,对查询性能影响可能有较大影响,请确认理解后再开启) - capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
- with_vertex:true表示返回结果包含完整的顶点信息(路径中的全部顶点),false时表示只返回顶点id,选填项,默认为false
GET http://localhost:8080/graphs/{graph}/traversers/weightedshortestpath?source="1:marko"&target="2:ripple"&weight="weight"&with_vertex=true
200{
"path": {
"weight": 2.0,
"vertices": [
"1:marko",
"1:josh",
"2:ripple"
]
},
"vertices": [
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 29,
"city": "Beijing"
}
},
{
"id": "1:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Beijing"
}
},
{
"id": "2:ripple",
"label": "software",
"type": "vertex",
"properties": {
"name": "ripple",
"lang": "java",
"price": 199
}
}
]
}查找两个顶点间的带权最短路径,例如:
- 交通线路中查找从A城市到B城市花钱最少的交通方式
从一个顶点出发,查找该点到图中其他顶点的最短路径(可选是否带权重)
- source:起始顶点id,必填项
- direction:起始顶点向外发散的方向(OUT,IN,BOTH),选填项,默认是BOTH
- label:边的类型,选填项,默认代表所有edge label
- weight:边的权重属性,选填项,必须是数字类型的属性,如果不填或者虽然填了但是边没有该属性,则权重为1.0
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,选填项,默认为10000
- skip_degree:用于设置查询过程中舍弃超级顶点的最小边数,即当某个顶点的邻接边数目大于 skip_degree 时,完全舍弃该顶点。选填项,如果开启时,需满足
skip_degree >= max_degree约束,默认为0 (不启用),表示不跳过任何点 (注意: 开启此配置后,遍历时会尝试访问一个顶点的 skip_degree 条边,而不仅仅是 max_degree 条边,这样有额外的遍历开销,对查询性能影响可能有较大影响,请确认理解后再开启) - capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
- limit:查询到的目标顶点个数,也是返回的最短路径的条数,选填项,默认为10
- with_vertex:true表示返回结果包含完整的顶点信息(路径中的全部顶点),false时表示只返回顶点id,选填项,默认为false
GET http://localhost:8080/graphs/{graph}/traversers/singlesourceshortestpath?source="1:marko"&with_vertex=true
200{
"paths": {
"2:ripple": {
"weight": 2.0,
"vertices": [
"1:marko",
"1:josh",
"2:ripple"
]
},
"1:josh": {
"weight": 1.0,
"vertices": [
"1:marko",
"1:josh"
]
},
"1:vadas": {
"weight": 1.0,
"vertices": [
"1:marko",
"1:vadas"
]
},
"1:peter": {
"weight": 2.0,
"vertices": [
"1:marko",
"2:lop",
"1:peter"
]
},
"2:lop": {
"weight": 1.0,
"vertices": [
"1:marko",
"2:lop"
]
}
},
"vertices": [
{
"id": "2:ripple",
"label": "software",
"type": "vertex",
"properties": {
"name": "ripple",
"lang": "java",
"price": 199
}
},
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 29,
"city": "Beijing"
}
},
{
"id": "1:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Beijing"
}
},
{
"id": "1:vadas",
"label": "person",
"type": "vertex",
"properties": {
"name": "vadas",
"age": 27,
"city": "Hongkong"
}
},
{
"id": "1:peter",
"label": "person",
"type": "vertex",
"properties": {
"name": "peter",
"age": 35,
"city": "Shanghai"
}
},
{
"id": "2:lop",
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "java",
"price": 328
}
}
]
}查找从一个点出发到其他顶点的带权最短路径,比如:
- 查找从北京出发到全国其他所有城市的耗时最短的乘车方案
查找指定顶点集两两之间的最短路径
- vertices:定义起始顶点,必填项,指定方式包括:
- ids:通过顶点id列表提供起始顶点
- label和properties:如果没有指定ids,则使用label和properties的联合条件查询起始顶点
- label:顶点的类型
- properties:通过属性的值查询起始顶点
注意:properties中的属性值可以是列表,表示只要key对应的value在列表中就可以
- step:表示从起始顶点到终止顶点走过的路径,必填项,Step的结构如下:
- direction:表示边的方向(OUT,IN,BOTH),默认是BOTH
- labels:边的类型列表
- properties:通过属性的值过滤边
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,默认为 10000 (注: 0.12版之前 step 内仅支持 degree 作为参数名, 0.12开始统一使用 max_degree, 并向下兼容 degree 写法)
- skip_degree:用于设置查询过程中舍弃超级顶点的最小边数,即当某个顶点的邻接边数目大于 skip_degree 时,完全舍弃该顶点。选填项,如果开启时,需满足
skip_degree >= max_degree约束,默认为0 (不启用),表示不跳过任何点 (注意: 开启此配置后,遍历时会尝试访问一个顶点的 skip_degree 条边,而不仅仅是 max_degree 条边,这样有额外的遍历开销,对查询性能影响可能有较大影响,请确认理解后再开启)
- max_depth:步数,必填项
- capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
- with_vertex:true表示返回结果包含完整的顶点信息(路径中的全部顶点),false时表示只返回顶点id,选填项,默认为false
POST http://localhost:8080/graphs/{graph}/traversers/multinodeshortestpath
{
"vertices": {
"ids": ["382:marko", "382:josh", "382:vadas", "382:peter", "383:lop", "383:ripple"]
},
"step": {
"direction": "BOTH",
"properties": {
}
},
"max_depth": 10,
"capacity": 100000000,
"with_vertex": true
}200{
"paths": [
{
"objects": [
"382:peter",
"383:lop"
]
},
{
"objects": [
"382:peter",
"383:lop",
"382:marko"
]
},
{
"objects": [
"382:peter",
"383:lop",
"382:josh"
]
},
{
"objects": [
"382:peter",
"383:lop",
"382:marko",
"382:vadas"
]
},
{
"objects": [
"383:lop",
"382:marko"
]
},
{
"objects": [
"383:lop",
"382:josh"
]
},
{
"objects": [
"383:lop",
"382:marko",
"382:vadas"
]
},
{
"objects": [
"382:peter",
"383:lop",
"382:josh",
"383:ripple"
]
},
{
"objects": [
"382:marko",
"382:josh"
]
},
{
"objects": [
"383:lop",
"382:josh",
"383:ripple"
]
},
{
"objects": [
"382:marko",
"382:vadas"
]
},
{
"objects": [
"382:marko",
"382:josh",
"383:ripple"
]
},
{
"objects": [
"382:josh",
"383:ripple"
]
},
{
"objects": [
"382:josh",
"382:marko",
"382:vadas"
]
},
{
"objects": [
"382:vadas",
"382:marko",
"382:josh",
"383:ripple"
]
}
],
"vertices": [
{
"id": "382:peter",
"label": "person",
"type": "vertex",
"properties": {
"name": "peter",
"age": 29,
"city": "Shanghai"
}
},
{
"id": "383:lop",
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "java",
"price": 328
}
},
{
"id": "382:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 29,
"city": "Beijing"
}
},
{
"id": "382:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Beijing"
}
},
{
"id": "382:vadas",
"label": "person",
"type": "vertex",
"properties": {
"name": "vadas",
"age": 27,
"city": "Hongkong"
}
},
{
"id": "383:ripple",
"label": "software",
"type": "vertex",
"properties": {
"name": "ripple",
"lang": "java",
"price": 199
}
}
]
}查找多个点之间的最短路径,比如:
- 查找多个公司和法人之间的最短路径
根据起始顶点、目的顶点、方向、边的类型(可选)和最大深度等条件查找所有路径
- source:起始顶点id,必填项
- target:目的顶点id,必填项
- direction:起始顶点向外发散的方向(OUT,IN,BOTH),选填项,默认是BOTH
- label:边的类型,选填项,默认代表所有edge label
- max_depth:步数,必填项
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,选填项,默认为10000
- capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
- limit:返回的路径的最大数目,选填项,默认为10
GET http://localhost:8080/graphs/{graph}/traversers/paths?source="1:marko"&target="1:josh"&max_depth=5
200{
"paths":[
{
"objects":[
"1:marko",
"1:josh"
]
},
{
"objects":[
"1:marko",
"2:lop",
"1:josh"
]
}
]
}查找两个顶点间的所有路径,例如:
- 社交网络中,查找两个用户所有可能的关系路径
- 设备关联网络中,查找两个设备之间所有的关联路径
根据起始顶点、目的顶点、步骤(step)和最大深度等条件查找所有路径
- sources:定义起始顶点,必填项,指定方式包括:
- ids:通过顶点id列表提供起始顶点
- label和properties:如果没有指定ids,则使用label和properties的联合条件查询起始顶点
- label:顶点的类型
- properties:通过属性的值查询起始顶点
注意:properties中的属性值可以是列表,表示只要key对应的value在列表中就可以
- targets:定义终止顶点,必填项,指定方式包括:
- ids:通过顶点id列表提供终止顶点
- label和properties:如果没有指定ids,则使用label和properties的联合条件查询终止顶点
- label:顶点的类型
- properties:通过属性的值查询终止顶点
注意:properties中的属性值可以是列表,表示只要key对应的value在列表中就可以
- step:表示从起始顶点到终止顶点走过的路径,必填项,Step的结构如下:
- direction:表示边的方向(OUT,IN,BOTH),默认是BOTH
- labels:边的类型列表
- properties:通过属性的值过滤边
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,默认为 10000 (注: 0.12版之前 step 内仅支持 degree 作为参数名, 0.12开始统一使用 max_degree, 并向下兼容 degree 写法)
- skip_degree:用于设置查询过程中舍弃超级顶点的最小边数,即当某个顶点的邻接边数目大于 skip_degree 时,完全舍弃该顶点。选填项,如果开启时,需满足
skip_degree >= max_degree约束,默认为0 (不启用),表示不跳过任何点 (注意: 开启此配置后,遍历时会尝试访问一个顶点的 skip_degree 条边,而不仅仅是 max_degree 条边,这样有额外的遍历开销,对查询性能影响可能有较大影响,请确认理解后再开启)
- max_depth:步数,必填项
- nearest:nearest为true时,代表起始顶点到达结果顶点的最短路径长度为depth,不存在更短的路径;nearest为false时,代表起始顶点到结果顶点有一条长度为depth的路径(未必最短且可以有环),选填项,默认为true
- capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
- limit:返回的路径的最大数目,选填项,默认为10
- with_vertex:true表示返回结果包含完整的顶点信息(路径中的全部顶点),false时表示只返回顶点id,选填项,默认为false
POST http://localhost:8080/graphs/{graph}/traversers/paths
{
"sources": {
"ids": ["1:marko"]
},
"targets": {
"ids": ["1:peter"]
},
"step": {
"direction": "BOTH",
"properties": {
"weight": "P.gt(0.01)"
}
},
"max_depth": 10,
"capacity": 100000000,
"limit": 10000000,
"with_vertex": false
}200{
"paths": [
{
"objects": [
"1:marko",
"1:josh",
"2:lop",
"1:peter"
]
},
{
"objects": [
"1:marko",
"2:lop",
"1:peter"
]
}
]
}
查找两个顶点间的所有路径,例如:
- 社交网络中,查找两个用户所有可能的关系路径
- 设备关联网络中,查找两个设备之间所有的关联路径
根据一批起始顶点、边规则(包括方向、边的类型和属性过滤)和最大深度等条件查找符合条件的所有的路径
- sources:定义起始顶点,必填项,指定方式包括:
- ids:通过顶点id列表提供起始顶点
- label和properties:如果没有指定ids,则使用label和properties的联合条件查询起始顶点
- label:顶点的类型
- properties:通过属性的值查询起始顶点
注意:properties中的属性值可以是列表,表示只要key对应的value在列表中就可以
- steps:表示从起始顶点走过的路径规则,是一组Step的列表。必填项。每个Step的结构如下:
- direction:表示边的方向(OUT,IN,BOTH),默认是BOTH
- labels:边的类型列表
- properties:通过属性的值过滤边
- weight_by:根据指定的属性计算边的权重,sort_by不为NONE时有效,与default_weight互斥
- default_weight:当边没有属性作为权重计算值时,采取的默认权重,sort_by不为NONE时有效,与weight_by互斥
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,默认为 10000 (注: 0.12版之前 step 内仅支持 degree 作为参数名, 0.12开始统一使用 max_degree, 并向下兼容 degree 写法)
- sample:当需要对某个step的符合条件的边进行采样时设置,-1表示不采样,默认为采样100
- sort_by:根据路径的权重排序,选填项,默认为NONE:
- NONE表示不排序,默认值
- INCR表示按照路径权重的升序排序
- DECR表示按照路径权重的降序排序
- capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
- limit:返回的路径的最大数目,选填项,默认为10
- with_vertex:true表示返回结果包含完整的顶点信息(路径中的全部顶点),false时表示只返回顶点id,选填项,默认为false
POST http://localhost:8080/graphs/{graph}/traversers/customizedpaths
{
"sources":{
"ids":[
],
"label":"person",
"properties":{
"name":"marko"
}
},
"steps":[
{
"direction":"OUT",
"labels":[
"knows"
],
"weight_by":"weight",
"max_degree":-1
},
{
"direction":"OUT",
"labels":[
"created"
],
"default_weight":8,
"max_degree":-1,
"sample":1
}
],
"sort_by":"INCR",
"with_vertex":true,
"capacity":-1,
"limit":-1
}200{
"paths":[
{
"objects":[
"1:marko",
"1:josh",
"2:lop"
],
"weights":[
1,
8
]
}
],
"vertices":[
{
"id":"1:marko",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:marko>city",
"value":"Beijing"
}
],
"name":[
{
"id":"1:marko>name",
"value":"marko"
}
],
"age":[
{
"id":"1:marko>age",
"value":29
}
]
}
},
{
"id":"1:josh",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:josh>city",
"value":"Beijing"
}
],
"name":[
{
"id":"1:josh>name",
"value":"josh"
}
],
"age":[
{
"id":"1:josh>age",
"value":32
}
]
}
},
{
"id":"2:lop",
"label":"software",
"type":"vertex",
"properties":{
"price":[
{
"id":"2:lop>price",
"value":328
}
],
"name":[
{
"id":"2:lop>name",
"value":"lop"
}
],
"lang":[
{
"id":"2:lop>lang",
"value":"java"
}
]
}
}
]
}适合查找各种复杂的路径集合,例如:
- 社交网络中,查找看过张艺谋所导演的电影的用户关注的大V的路径(张艺谋--->电影---->用户--->大V)
- 风控网络中,查找多个高风险用户的直系亲属的朋友的路径(高风险用户--->直系亲属--->朋友)
根据一批起始顶点、边规则(包括方向、边的类型和属性过滤)和最大深度等条件查找符合条件的所有的路径
- sources:定义起始顶点,必填项,指定方式包括:
- ids:通过顶点id列表提供起始顶点
- label和properties:如果没有指定ids,则使用label和properties的联合条件查询起始顶点
- label:顶点的类型
- properties:通过属性的值查询起始顶点
注意:properties中的属性值可以是列表,表示只要key对应的value在列表中就可以
- targets:定义终止顶点,必填项,指定方式包括:
- ids:通过顶点id列表提供终止顶点
- label和properties:如果没有指定ids,则使用label和properties的联合条件查询终止顶点
- label:顶点的类型
- properties:通过属性的值查询终止顶点
注意:properties中的属性值可以是列表,表示只要key对应的value在列表中就可以
- steps:表示从起始顶点走过的路径规则,是一组Step的列表。必填项。每个Step的结构如下:
- direction:表示边的方向(OUT,IN,BOTH),默认是BOTH
- labels:边的类型列表
- properties:通过属性的值过滤边
- max_times:当前step可以重复的次数,当为N时,表示从起始顶点可以经过当前step 1-N 次
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,默认为 10000 (注: 0.12版之前 step 内仅支持 degree 作为参数名, 0.12开始统一使用 max_degree, 并向下兼容 degree 写法)
- skip_degree:用于设置查询过程中舍弃超级顶点的最小边数,即当某个顶点的邻接边数目大于 skip_degree 时,完全舍弃该顶点。选填项,如果开启时,需满足
skip_degree >= max_degree约束,默认为0 (不启用),表示不跳过任何点 (注意: 开启此配置后,遍历时会尝试访问一个顶点的 skip_degree 条边,而不仅仅是 max_degree 条边,这样有额外的遍历开销,对查询性能影响可能有较大影响,请确认理解后再开启)
- with_ring:Boolean值,true表示包含环路;false表示不包含环路,默认为false
- capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
- limit:返回的路径的最大数目,选填项,默认为10
- with_vertex:true表示返回结果包含完整的顶点信息(路径中的全部顶点),false时表示只返回顶点id,选填项,默认为false
POST http://localhost:8080/graphs/{graph}/traversers/templatepaths
{
"sources": {
"ids": [],
"label": "person",
"properties": {
"name": "vadas"
}
},
"targets": {
"ids": [],
"label": "software",
"properties": {
"name": "ripple"
}
},
"steps": [
{
"direction": "IN",
"labels": ["knows"],
"properties": {
},
"max_degree": 10000,
"skip_degree": 100000
},
{
"direction": "OUT",
"labels": ["created"],
"properties": {
},
"max_degree": 10000,
"skip_degree": 100000
},
{
"direction": "IN",
"labels": ["created"],
"properties": {
},
"max_degree": 10000,
"skip_degree": 100000
},
{
"direction": "OUT",
"labels": ["created"],
"properties": {
},
"max_degree": 10000,
"skip_degree": 100000
}
],
"capacity": 10000,
"limit": 10,
"with_vertex": true
}200{
"paths": [
{
"objects": [
"1:vadas",
"1:marko",
"2:lop",
"1:josh",
"2:ripple"
]
}
],
"vertices": [
{
"id": "2:ripple",
"label": "software",
"type": "vertex",
"properties": {
"name": "ripple",
"lang": "java",
"price": 199
}
},
{
"id": "1:marko",
"label": "person",
"type": "vertex",
"properties": {
"name": "marko",
"age": 29,
"city": "Beijing"
}
},
{
"id": "1:josh",
"label": "person",
"type": "vertex",
"properties": {
"name": "josh",
"age": 32,
"city": "Beijing"
}
},
{
"id": "1:vadas",
"label": "person",
"type": "vertex",
"properties": {
"name": "vadas",
"age": 27,
"city": "Hongkong"
}
},
{
"id": "2:lop",
"label": "software",
"type": "vertex",
"properties": {
"name": "lop",
"lang": "java",
"price": 328
}
}
]
}
适合查找各种复杂的模板路径,比如personA -(朋友)-> personB -(同学)-> personC,其中"朋友"和"同学"边可以分别是最多3层和4层的情况
根据起始顶点、目的顶点、方向、边的类型(可选)和最大深度等条件查找相交点
- source:起始顶点id,必填项
- target:目的顶点id,必填项
- direction:起始顶点到目的顶点的方向, 目的点到起始点是反方向,BOTH时不考虑方向(OUT,IN,BOTH),选填项,默认是BOTH
- label:边的类型,选填项,默认代表所有edge label
- max_depth:步数,必填项
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,选填项,默认为10000
- capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
- limit:返回的交点的最大数目,选填项,默认为10
GET http://localhost:8080/graphs/{graph}/traversers/crosspoints?source="2:lop"&target="2:ripple"&max_depth=5&direction=IN
200{
"crosspoints":[
{
"crosspoint":"1:josh",
"objects":[
"2:lop",
"1:josh",
"2:ripple"
]
}
]
}查找两个顶点的交点及其路径,例如:
- 社交网络中,查找两个用户共同关注的话题或者大V
- 家族关系中,查找共同的祖先
根据一批起始顶点、多种边规则(包括方向、边的类型和属性过滤)和最大深度等条件查找符合条件的所有的路径终点的交集
-
sources:定义起始顶点,必填项,指定方式包括:
- ids:通过顶点id列表提供起始顶点
- label和properties:如果没有指定ids,则使用label和properties的联合条件查询起始顶点
- label:顶点的类型
- properties:通过属性的值查询起始顶点
注意:properties中的属性值可以是列表,表示只要key对应的value在列表中就可以
-
path_patterns:表示从起始顶点走过的路径规则,是一组规则的列表。必填项。每个规则是一个PathPattern
- 每个PathPattern是一组Step列表,每个Step结构如下:
- direction:表示边的方向(OUT,IN,BOTH),默认是BOTH
- labels:边的类型列表
- properties:通过属性的值过滤边
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,默认为 10000 (注: 0.12版之前 step 内仅支持 degree 作为参数名, 0.12开始统一使用 max_degree, 并向下兼容 degree 写法)
- skip_degree:用于设置查询过程中舍弃超级顶点的最小边数,即当某个顶点的邻接边数目大于 skip_degree 时,完全舍弃该顶点。选填项,如果开启时,需满足
skip_degree >= max_degree约束,默认为0 (不启用),表示不跳过任何点 (注意: 开启此配置后,遍历时会尝试访问一个顶点的 skip_degree 条边,而不仅仅是 max_degree 条边,这样有额外的遍历开销,对查询性能影响可能有较大影响,请确认理解后再开启)
- 每个PathPattern是一组Step列表,每个Step结构如下:
-
capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
-
limit:返回的路径的最大数目,选填项,默认为10
-
with_path:true表示返回交点所在的路径,false表示不返回交点所在的路径,选填项,默认为false
-
with_vertex,选填项,默认为false:
- true表示返回结果包含完整的顶点信息(路径中的全部顶点)
- with_path为true时,返回所有路径中的顶点的完整信息
- with_path为false时,返回所有交点的完整信息
- false时表示只返回顶点id
- true表示返回结果包含完整的顶点信息(路径中的全部顶点)
POST http://localhost:8080/graphs/{graph}/traversers/customizedcrosspoints
{
"sources":{
"ids":[
"2:lop",
"2:ripple"
]
},
"path_patterns":[
{
"steps":[
{
"direction":"IN",
"labels":[
"created"
],
"max_degree":-1
}
]
}
],
"with_path":true,
"with_vertex":true,
"capacity":-1,
"limit":-1
}200{
"crosspoints":[
"1:josh"
],
"paths":[
{
"objects":[
"2:ripple",
"1:josh"
]
},
{
"objects":[
"2:lop",
"1:josh"
]
}
],
"vertices":[
{
"id":"2:ripple",
"label":"software",
"type":"vertex",
"properties":{
"price":[
{
"id":"2:ripple>price",
"value":199
}
],
"name":[
{
"id":"2:ripple>name",
"value":"ripple"
}
],
"lang":[
{
"id":"2:ripple>lang",
"value":"java"
}
]
}
},
{
"id":"1:josh",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:josh>city",
"value":"Beijing"
}
],
"name":[
{
"id":"1:josh>name",
"value":"josh"
}
],
"age":[
{
"id":"1:josh>age",
"value":32
}
]
}
},
{
"id":"2:lop",
"label":"software",
"type":"vertex",
"properties":{
"price":[
{
"id":"2:lop>price",
"value":328
}
],
"name":[
{
"id":"2:lop>name",
"value":"lop"
}
],
"lang":[
{
"id":"2:lop>lang",
"value":"java"
}
]
}
}
]
}查询一组顶点通过多种路径在终点有交集的情况。例如:
- 在商品图谱中,多款手机、学习机、游戏机通过不同的低级别的类目路径,最终都属于一级类目的电子设备
根据起始顶点、方向、边的类型(可选)和最大深度等条件查找可达的环路
例如:1 -> 25 -> 775 -> 14690 -> 25, 其中环路为 25 -> 775 -> 14690 -> 25
- source:起始顶点id,必填项
- direction:起始顶点发出的边的方向(OUT,IN,BOTH),选填项,默认是BOTH
- label:边的类型,选填项,默认代表所有edge label
- max_depth:步数,必填项
- source_in_ring:环路是否包含起点,选填项,默认为true
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,选填项,默认为10000
- capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
- limit:返回的可达环路的最大数目,选填项,默认为10
GET http://localhost:8080/graphs/{graph}/traversers/rings?source="1:marko"&max_depth=2
200{
"rings":[
{
"objects":[
"1:marko",
"1:josh",
"1:marko"
]
},
{
"objects":[
"1:marko",
"1:vadas",
"1:marko"
]
},
{
"objects":[
"1:marko",
"2:lop",
"1:marko"
]
}
]
}查询起始顶点可达的环路,例如:
- 风控项目中,查询一个用户可达的循环担保的人或者设备
- 设备关联网络中,发现一个设备周围的循环引用的设备
根据起始顶点、方向、边的类型(可选)和最大深度等条件查找发散到边界顶点的路径
例如:1 -> 25 -> 775 -> 14690 -> 2289 -> 18379, 其中 18379 为边界顶点,即没有从 18379 发出的边
- source:起始顶点id,必填项
- direction:起始顶点发出的边的方向(OUT,IN,BOTH),选填项,默认是BOTH
- label:边的类型,选填项,默认代表所有edge label
- max_depth:步数,必填项
- max_degree:查询过程中,单个顶点遍历的最大邻接边数目,选填项,默认为10000
- capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
- limit:返回的非环路的最大数目,选填项,默认为10
GET http://localhost:8080/graphs/{graph}/traversers/rays?source="1:marko"&max_depth=2&direction=OUT
200{
"rays":[
{
"objects":[
"1:marko",
"1:vadas"
]
},
{
"objects":[
"1:marko",
"2:lop"
]
},
{
"objects":[
"1:marko",
"1:josh",
"2:ripple"
]
},
{
"objects":[
"1:marko",
"1:josh",
"2:lop"
]
}
]
}查找起始顶点到某种关系的边界顶点的路径,例如:
- 家族关系中,查找一个人到所有还没有孩子的子孙的路径
- 设备关联网络中,找到某个设备到终端设备的路径
按照条件查询一批顶点对应的"梭形相似点"。当两个顶点跟很多共同的顶点之间有某种关系的时候,我们认为这两个点为"梭形相似点"。举个例子说明"梭形相似点":"读者A"读了100本书,可以定义读过这100本书中的80本以上的读者,是"读者A"的"梭形相似点"
-
sources:定义起始顶点,必填项,指定方式包括:
- ids:通过顶点id列表提供起始顶点
- label和properties:如果没有指定ids,则使用label和properties的联合条件查询起始顶点
- label:顶点的类型
- properties:通过属性的值查询起始顶点
注意:properties中的属性值可以是列表,表示只要key对应的value在列表中就可以
-
label:边的类型,选填项,默认代表所有edge label
-
direction:起始顶点向外发散的方向(OUT,IN,BOTH),选填项,默认是BOTH
-
min_neighbors:最少邻居数目,邻居数目少于这个阈值时,认为起点不具备"梭形相似点"。比如想要找一个"读者A"读过的书的"梭形相似点",那么
min_neighbors为100时,表示"读者A"至少要读过100本书才可以有"梭形相似点",必填项 -
alpha:相似度,代表:起点与"梭形相似点"的共同邻居数目占起点的全部邻居数目的比例,必填项
-
min_similars:"梭形相似点"的最少个数,只有当起点的"梭形相似点"数目大于或等于该值时,才会返回起点及其"梭形相似点",选填项,默认值为1
-
top:返回一个起点的"梭形相似点"中相似度最高的top个,必填项,0表示全部
-
group_property:与
min_groups一起使用,当起点跟其所有的"梭形相似点"某个属性的值有至少min_groups个不同值时,才会返回该起点及其"梭形相似点"。比如为"读者A"推荐"异地"书友时,需要设置group_property为读者的"城市"属性,min_group至少为2,选填项,不填代表不需要根据属性过滤 -
min_groups:与
group_property一起使用,只有group_property设置时才有意义 -
max_degree:查询过程中,单个顶点遍历的最大邻接边数目,选填项,默认为10000
-
capacity:遍历过程中最大的访问的顶点数目,选填项,默认为10000000
-
limit:返回的结果数目上限(一个起点及其"梭形相似点"算一个结果),选填项,默认为10
-
with_intermediary:是否返回起点及其"梭形相似点"共同关联的中间点,默认为false
-
with_vertex,选填项,默认为false:
- true表示返回结果包含完整的顶点信息
- false时表示只返回顶点id
POST http://localhost:8080/graphs/hugegraph/traversers/fusiformsimilarity
{
"sources":{
"ids":[],
"label": "person",
"properties": {
"name":"p1"
}
},
"label":"read",
"direction":"OUT",
"min_neighbors":8,
"alpha":0.75,
"min_similars":1,
"top":0,
"group_property":"city",
"min_group":2,
"max_degree": 10000,
"capacity": -1,
"limit": -1,
"with_intermediary": false,
"with_vertex":true
}
200{
"similars": {
"3:p1": [
{
"id": "3:p2",
"score": 0.8888888888888888,
"intermediaries": [
]
},
{
"id": "3:p3",
"score": 0.7777777777777778,
"intermediaries": [
]
}
]
},
"vertices": [
{
"id": "3:p1",
"label": "person",
"type": "vertex",
"properties": {
"name": "p1",
"city": "Beijing"
}
},
{
"id": "3:p2",
"label": "person",
"type": "vertex",
"properties": {
"name": "p2",
"city": "Shanghai"
}
},
{
"id": "3:p3",
"label": "person",
"type": "vertex",
"properties": {
"name": "p3",
"city": "Beijing"
}
}
]
}查询一组顶点相似度很高的顶点。例如:
- 跟一个读者有类似书单的读者
- 跟一个玩家玩类似游戏的玩家
- ids:要查询的顶点id列表
GET http://localhost:8080/graphs/hugegraph/traversers/vertices?ids="1:marko"&ids="2:lop"
200{
"vertices":[
{
"id":"1:marko",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:marko>city",
"value":"Beijing"
}
],
"name":[
{
"id":"1:marko>name",
"value":"marko"
}
],
"age":[
{
"id":"1:marko>age",
"value":29
}
]
}
},
{
"id":"2:lop",
"label":"software",
"type":"vertex",
"properties":{
"price":[
{
"id":"2:lop>price",
"value":328
}
],
"name":[
{
"id":"2:lop>name",
"value":"lop"
}
],
"lang":[
{
"id":"2:lop>lang",
"value":"java"
}
]
}
}
]
}通过指定的分片大小split_size,获取顶点分片信息(可以与 3.2.21.3 中的 Scan 配合使用来获取顶点)。
- split_size:分片大小,必填项
GET http://localhost:8080/graphs/hugegraph/traversers/vertices/shards?split_size=67108864
200{
"shards":[
{
"start": "0",
"end": "2165893",
"length": 0
},
{
"start": "2165893",
"end": "4331786",
"length": 0
},
{
"start": "4331786",
"end": "6497679",
"length": 0
},
{
"start": "6497679",
"end": "8663572",
"length": 0
},
......
]
}通过指定的分片信息批量查询顶点(Shard信息的获取参见 3.2.21.2 Shard)。
- start:分片起始位置,必填项
- end:分片结束位置,必填项
- page:分页位置,选填项,默认为null,不分页;当page为“”时表示分页的第一页,从start指示的位置开始
- page_limit:分页获取顶点时,一页中顶点数目的上限,选填项,默认为100000
GET http://localhost:8080/graphs/hugegraph/traversers/vertices/scan?start=0&end=4294967295
200{
"vertices":[
{
"id":"2:ripple",
"label":"software",
"type":"vertex",
"properties":{
"price":[
{
"id":"2:ripple>price",
"value":199
}
],
"name":[
{
"id":"2:ripple>name",
"value":"ripple"
}
],
"lang":[
{
"id":"2:ripple>lang",
"value":"java"
}
]
}
},
{
"id":"1:vadas",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:vadas>city",
"value":"Hongkong"
}
],
"name":[
{
"id":"1:vadas>name",
"value":"vadas"
}
],
"age":[
{
"id":"1:vadas>age",
"value":27
}
]
}
},
{
"id":"1:peter",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:peter>city",
"value":"Shanghai"
}
],
"name":[
{
"id":"1:peter>name",
"value":"peter"
}
],
"age":[
{
"id":"1:peter>age",
"value":35
}
]
}
},
{
"id":"1:josh",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:josh>city",
"value":"Beijing"
}
],
"name":[
{
"id":"1:josh>name",
"value":"josh"
}
],
"age":[
{
"id":"1:josh>age",
"value":32
}
]
}
},
{
"id":"1:marko",
"label":"person",
"type":"vertex",
"properties":{
"city":[
{
"id":"1:marko>city",
"value":"Beijing"
}
],
"name":[
{
"id":"1:marko>name",
"value":"marko"
}
],
"age":[
{
"id":"1:marko>age",
"value":29
}
]
}
},
{
"id":"2:lop",
"label":"software",
"type":"vertex",
"properties":{
"price":[
{
"id":"2:lop>price",
"value":328
}
],
"name":[
{
"id":"2:lop>name",
"value":"lop"
}
],
"lang":[
{
"id":"2:lop>lang",
"value":"java"
}
]
}
}
]
}- 按id列表查询顶点,可用于批量查询顶点,比如在path查询到多条路径之后,可以进一步查询某条路径的所有顶点属性。
- 获取分片和按分片查询顶点,可以用来遍历全部顶点
- ids:要查询的边id列表
GET http://localhost:8080/graphs/hugegraph/traversers/edges?ids="S1:josh>1>>S2:lop"&ids="S1:josh>1>>S2:ripple"
200{
"edges": [
{
"id": "S1:josh>1>>S2:lop",
"label": "created",
"type": "edge",
"inVLabel": "software",
"outVLabel": "person",
"inV": "2:lop",
"outV": "1:josh",
"properties": {
"date": "20091111",
"weight": 0.4
}
},
{
"id": "S1:josh>1>>S2:ripple",
"label": "created",
"type": "edge",
"inVLabel": "software",
"outVLabel": "person",
"inV": "2:ripple",
"outV": "1:josh",
"properties": {
"date": "20171210",
"weight": 1
}
}
]
}通过指定的分片大小split_size,获取边分片信息(可以与 3.2.22.3 中的 Scan 配合使用来获取边)。
- split_size:分片大小,必填项
GET http://localhost:8080/graphs/hugegraph/traversers/edges/shards?split_size=4294967295
200{
"shards":[
{
"start": "0",
"end": "1073741823",
"length": 0
},
{
"start": "1073741823",
"end": "2147483646",
"length": 0
},
{
"start": "2147483646",
"end": "3221225469",
"length": 0
},
{
"start": "3221225469",
"end": "4294967292",
"length": 0
},
{
"start": "4294967292",
"end": "4294967295",
"length": 0
}
]
}通过指定的分片信息批量查询边(Shard信息的获取参见 3.2.22.2)。
- start:分片起始位置,必填项
- end:分片结束位置,必填项
- page:分页位置,选填项,默认为null,不分页;当page为“”时表示分页的第一页,从start指示的位置开始
- page_limit:分页获取边时,一页中边数目的上限,选填项,默认为100000
GET http://localhost:8080/graphs/hugegraph/traversers/edges/scan?start=0&end=3221225469
200{
"edges":[
{
"id":"S1:peter>2>>S2:lop",
"label":"created",
"type":"edge",
"inVLabel":"software",
"outVLabel":"person",
"inV":"2:lop",
"outV":"1:peter",
"properties":{
"weight":0.2,
"date":"20170324"
}
},
{
"id":"S1:josh>2>>S2:lop",
"label":"created",
"type":"edge",
"inVLabel":"software",
"outVLabel":"person",
"inV":"2:lop",
"outV":"1:josh",
"properties":{
"weight":0.4,
"date":"20091111"
}
},
{
"id":"S1:josh>2>>S2:ripple",
"label":"created",
"type":"edge",
"inVLabel":"software",
"outVLabel":"person",
"inV":"2:ripple",
"outV":"1:josh",
"properties":{
"weight":1,
"date":"20171210"
}
},
{
"id":"S1:marko>1>20130220>S1:josh",
"label":"knows",
"type":"edge",
"inVLabel":"person",
"outVLabel":"person",
"inV":"1:josh",
"outV":"1:marko",
"properties":{
"weight":1,
"date":"20130220"
}
},
{
"id":"S1:marko>1>20160110>S1:vadas",
"label":"knows",
"type":"edge",
"inVLabel":"person",
"outVLabel":"person",
"inV":"1:vadas",
"outV":"1:marko",
"properties":{
"weight":0.5,
"date":"20160110"
}
},
{
"id":"S1:marko>2>>S2:lop",
"label":"created",
"type":"edge",
"inVLabel":"software",
"outVLabel":"person",
"inV":"2:lop",
"outV":"1:marko",
"properties":{
"weight":0.4,
"date":"20171210"
}
}
]
}- 按id列表查询边,可用于批量查询边
- 获取分片和按分片查询边,可以用来遍历全部边