sharding-jdbc分库分表配置说明:
Spring官方推荐约定大于配置
- 数据源名称命名约定:
数据库逻辑名称+中划线+编号 = ds-xx。eg. ds-0,ds-1,ds-2- springboot 2.x后,不支持参数以下划线方式实现驼峰命名,也不支持直接驼峰命名参数
- 表名称命名约定
表逻辑名称+下划线+编号 = table_name_xx。 比如 account_1,account_2- 表名称必须全小写。 比如 account_1,不能写成 ACCOUNT_1
- 以前的单表扩容为分库分表形式,原表名称无需变更表名称带上编号
使用前说明:
- 自定义配置注意必填字段
- 提供的分库分表策略见第5点,
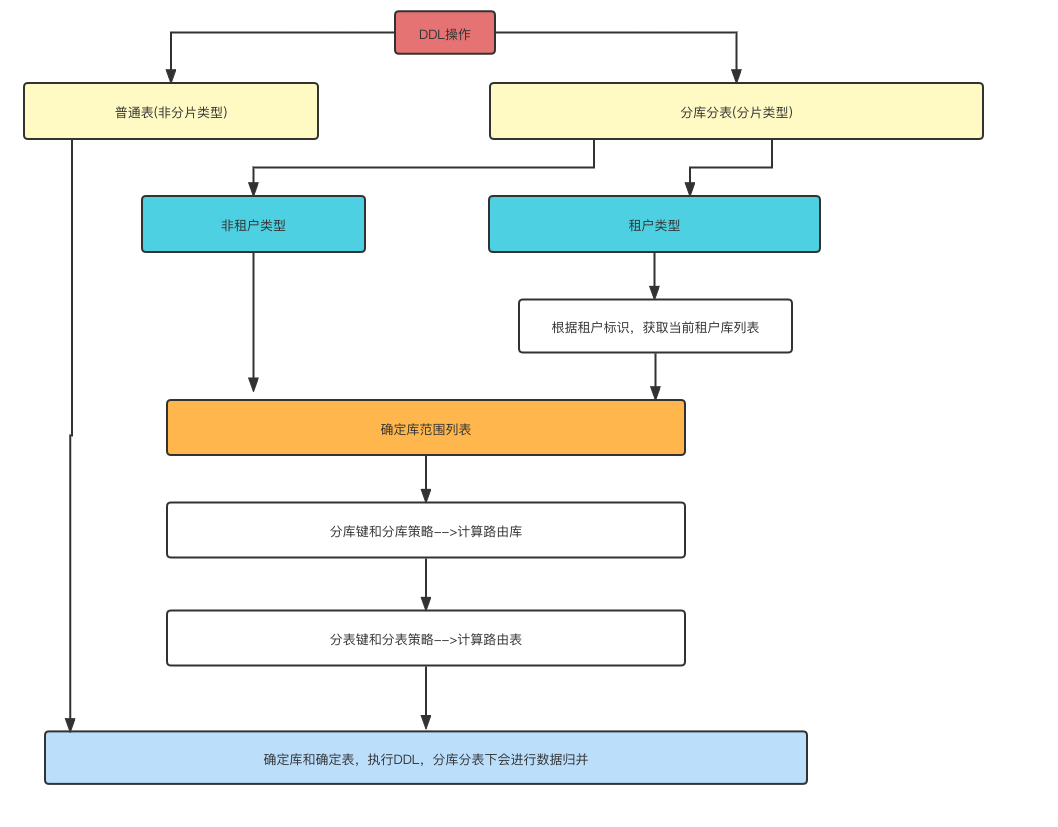
允许一个实体类对应多个表:该参数和Springboot版本有关,非必配
spring.main.allow-bean-definition-overriding=truespring.shardingsphere.datasource.names= # 数据源名称,多数据源以逗号分隔
spring.shardingsphere.datasource.<data-source-name>.type= # 数据库连接池类名称
spring.shardingsphere.datasource.<data-source-name>.driver-class-name= # 数据库驱动类名
spring.shardingsphere.datasource.<data-source-name>.url= # 数据库 url 连接
spring.shardingsphere.datasource.<data-source-name>.username= # 数据库用户名
spring.shardingsphere.datasource.<data-source-name>.password= # 数据库密码
spring.shardingsphere.datasource.<data-source-name>.xxx= # 数据库连接池的其它属性
spring.shardingsphere.sharding.tables.<logic-table-name>.actual-data-nodes= # 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
# 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
# 用于单分片键的标准分片场景
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.sharding-column= # 分片列名称
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.precise-algorithm-class-name= # 精确分片算法类名称,用于 = 和 IN。该类需实现 PreciseShardingAlgorithm 接口并提供无参数的构造器
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.range-algorithm-class-name= # 范围分片算法类名称,用于 BETWEEN,可选。该类需实现 RangeShardingAlgorithm 接口并提供无参数的构造器
# 用于多分片键的复合分片场景
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.complex.sharding-columns= # 分片列名称,多个列以逗号分隔
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.complex.algorithm-class-name= # 复合分片算法类名称。该类需实现 ComplexKeysShardingAlgorithm 接口并提供无参数的构造器
# 行表达式分片策略
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.inline.sharding-column= # 分片列名称
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.inline.algorithm-expression= # 分片算法行表达式,需符合 groovy 语法
# Hint 分片策略
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.hint.algorithm-class-name= # Hint 分片算法类名称。该类需实现 HintShardingAlgorithm 接口并提供无参数的构造器
# 分表策略,同分库策略
spring.shardingsphere.sharding.tables.<logic-table-name>.table-strategy.xxx= # 省略
spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.column= # 自增列名称,缺省表示不使用自增主键生成器
spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.type= # 自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID
spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.props.<property-name>= # 属性配置, 注意:使用 SNOWFLAKE 算法,需要配置 worker.id 与 max.tolerate.time.difference.milliseconds 属性。若使用此算法生成值作分片值,建议配置 max.vibration.offset 属性
spring.shardingsphere.sharding.binding-tables[0]= # 绑定表规则列表
spring.shardingsphere.sharding.binding-tables[1]= # 绑定表规则列表
spring.shardingsphere.sharding.binding-tables[x]= # 绑定表规则列表
spring.shardingsphere.sharding.broadcast-tables[0]= # 广播表规则列表
spring.shardingsphere.sharding.broadcast-tables[1]= # 广播表规则列表
spring.shardingsphere.sharding.broadcast-tables[x]= # 广播表规则列表
spring.shardingsphere.sharding.default-data-source-name= # 未配置分片规则的表将通过默认数据源定位
spring.shardingsphere.sharding.default-database-strategy.xxx= # 默认数据库分片策略,同分库策略
spring.shardingsphere.sharding.default-table-strategy.xxx= # 默认表分片策略,同分表策略
spring.shardingsphere.sharding.default-key-generator.type= # 默认自增列值生成器类型,缺省将使用 org.apache.shardingsphere.core.keygen.generator.impl.SnowflakeKeyGenerator。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID
spring.shardingsphere.sharding.default-key-generator.props.<property-name>= # 自增列值生成器属性配置, 比如 SNOWFLAKE 算法的 worker.id 与 max.tolerate.time.difference.milliseconds
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.master-data-source-name= # 详见读写分离部分
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[0]= # 详见读写分离部分
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[1]= # 详见读写分离部分
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[x]= # 详见读写分离部分
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-class-name= # 详见读写分离部分
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-type= # 详见读写分离部分
# org.apache.shardingsphere.core.constant.properties.ShardingPropertiesConstant
# org.apache.shardingsphere.core.BaseShardingEngine.shard
spring.shardingsphere.props.sql.show= # 是否开启 SQL 显示,默认值: false
spring.shardingsphere.props.executor.size= # 工作线程数量,默认值: CPU 核数# 省略数据源配置,与数据分片一致
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.master-data-source-name= # 主库数据源名称
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[0]= # 从库数据源名称列表
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[1]= # 从库数据源名称列表
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[x]= # 从库数据源名称列表
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-class-name= # 从库负载均衡算法类名称。该类需实现 MasterSlaveLoadBalanceAlgorithm 接口且提供无参数构造器
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-type= # 从库负载均衡算法类型,可选值:ROUND_ROBIN,RANDOM。若 `load-balance-algorithm-class-name` 存在则忽略该配置
spring.shardingsphere.props.sql.show= # 是否开启 SQL 显示,默认值: false
spring.shardingsphere.props.executor.size= # 工作线程数量,默认值: CPU 核数
spring.shardingsphere.props.check.table.metadata.enabled= # 是否在启动时检查分表元数据一致性,默认值: false# 省略数据源配置,与数据分片一致
spring.shardingsphere.encrypt.encryptors.<encryptor-name>.type= # 加解密器类型,可自定义或选择内置类型:MD5/AES
spring.shardingsphere.encrypt.encryptors.<encryptor-name>.props.<property-name>= # 属性配置, 注意:使用 AES 加密器,需要配置 AES 加密器的 KEY 属性:aes.key.value
spring.shardingsphere.encrypt.tables.<table-name>.columns.<logic-column-name>.plainColumn= # 存储明文的字段
spring.shardingsphere.encrypt.tables.<table-name>.columns.<logic-column-name>.cipherColumn= # 存储密文的字段
spring.shardingsphere.encrypt.tables.<table-name>.columns.<logic-column-name>.assistedQueryColumn= # 辅助查询字段,针对 ShardingQueryAssistedEncryptor 类型的加解密器进行辅助查询
spring.shardingsphere.encrypt.tables.<table-name>.columns.<logic-column-name>.encryptor= # 加密器名字# 省略数据源、数据分片、读写分离和数据脱敏配置
spring.shardingsphere.orchestration.name= # 治理实例名称
spring.shardingsphere.orchestration.overwrite= # 本地配置是否覆盖注册中心配置。如果可覆盖,每次启动都以本地配置为准
spring.shardingsphere.orchestration.registry.type= # 配置中心类型。如:zookeeper
spring.shardingsphere.orchestration.registry.server-lists= # 连接注册中心服务器的列表。包括 IP 地址和端口号。多个地址用逗号分隔。如: host1:2181,host2:2181
spring.shardingsphere.orchestration.registry.namespace= # 注册中心的命名空间
spring.shardingsphere.orchestration.registry.digest= # 连接注册中心的权限令牌。缺省为不需要权限验证
spring.shardingsphere.orchestration.registry.operation-timeout-milliseconds= # 操作超时的毫秒数,默认 500 毫秒
spring.shardingsphere.orchestration.registry.max-retries= # 连接失败后的最大重试次数,默认 3 次
spring.shardingsphere.orchestration.registry.retry-interval-milliseconds= # 重试间隔毫秒数,默认 500 毫秒
spring.shardingsphere.orchestration.registry.time-to-live-seconds= # 临时节点存活秒数,默认 60 秒
spring.shardingsphere.orchestration.registry.props= # 配置中心其它属性druid.enabled=false数据源配置
# 数据源名称(必选)
# 多个逗号隔开,改配置名称和下面数据源配置对应
spring.shardingsphere.datasource.names=ds-1,ds-2
# 默认数据源(有单表的情况时,必须配置;若所有表都是分库分表的情景,则可以不配置)
spring.shardingsphere.sharding.default-data-source-name=ds-1
# 数据源配置(必选)
# 此处ds-1,ds-2与上面数据源名称对应
spring.shardingsphere.datasource.ds-1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds-1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds-1.url=jdbc:mysql://xxxx:10032/sanwu_sharding-1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds-1.username=username
spring.shardingsphere.datasource.ds-1.password=password
spring.shardingsphere.datasource.ds-2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds-2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds-2.url=jdbc:mysql://xxxx:10032/sanwu_sharding_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds-2.username=username
spring.shardingsphere.datasource.ds-2.password=password默认策略配置,当没有配置对应策略是,走下面默认配置
spring.shardingsphere.sharding.default-data-source-name= # 未配置分片规则的表将通过默认数据源定位
spring.shardingsphere.sharding.default-database-strategy.xxx= # 默认数据库分片策略,同分库策略
spring.shardingsphere.sharding.default-table-strategy.xxx= # 默认表分片策略,同分表策略
spring.shardingsphere.sharding.default-key-generator.type= # 默认自增列值生成器类型,缺省将使用打印SQL以及工作线程数
spring.shardingsphere.props.sql.show=true # 是否开启 SQL 显示,默认值: false
spring.shardingsphere.props.executor.size=2 # 工作线程数量,默认值: CPU 核数sharding-jdbc支持4种分库分表策略
- inline行表达式策略:仅支持单分片键
- standard标准策略:仅支持单分片键
- complex混合策略:主要处理多分片键
- hint强制分片策略:自定义分片键,该分片键不一定是table中的字段
支持两种表id生成策略: 官方说明文档
- UUID
- SNOWFLAKE
course表有两个分表:course_1,couser_2
# 实际逻辑表(必选)
spring.shardingsphere.sharding.tables.course.actual-data-nodes=ds-1.course_$->{1..2}
# 分表策略(必选):四种策略只能选一种
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# 主键生成策略,支持:UUID和SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 主键生产策略的属性配置:UUID时不需要配置
# 使用 SNOWFLAKE 算法,需要配置 worker.id 与 max.tolerate.time.difference.milliseconds 属性。
# 若使用此算法生成值作分片值,建议配置 max.vibration.offset 属性
# spring.shardingsphere.sharding.tables.course.key-generator.props.<property-name>= 1和单库多表配置相比,只是多了一个数据库路由策略配置
# ----- 实际逻辑表1 user_course_xx
spring.shardingsphere.sharding.tables.user_course.actual-data-nodes=ds-$->{1..2}.user_course_$->{1..2}
# 分库策略
spring.shardingsphere.sharding.tables.user_course.database-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.user_course.database-strategy.inline.algorithm-expression=ds-$->{cid % 2 + 1}
# 分表策略
spring.shardingsphere.sharding.tables.user_course.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.user_course.table-strategy.inline.algorithm-expression=user_course_$->{user_id % 2 + 1}
# 主键生成策略,支持:UUID和SNOWFLAKE
spring.shardingsphere.sharding.tables.user_course.key-generator.column=cid
spring.shardingsphere.sharding.tables.user_course.key-generator.type=UUID
# ----- 实际逻辑表2 user_standard_xx
spring.shardingsphere.sharding.tables.user_standard.actual-data-nodes=ds-$->{1..2}.user_standard_$->{1..2}
# 分库策略
spring.shardingsphere.sharding.tables.user_standard.database-strategy.standard.sharding-column=cid
spring.shardingsphere.sharding.tables.user_standard.database-strategy.standard.precise-algorithm-class-name=com.sanwu.infra.sharding.DBCidShardingAlgorithm
#spring.shardingsphere.sharding.tables.user_standard.database-strategy.standard.range-algorithm-class-name=ds-$->{cid % 2 + 1}
# 分表策略
spring.shardingsphere.sharding.tables.user_standard.table-strategy.standard.sharding-column=user_id
#spring.shardingsphere.sharding.tables.user_standard.table-strategy.inline.algorithm-expression=user_course_$->{user_id % 2 + 1}
spring.shardingsphere.sharding.tables.user_standard.table-strategy.standard.precise-algorithm-class-name=com.sanwu.infra.sharding.TableCidShardingAlgorithm
#spring.shardingsphere.sharding.tables.user_standard.table-strategy.standard.range-algorithm-class-name=user_id绑定表:指分片规则一致的主表和子表,主要解决主表和字表的笛卡尔积问题.
spring.shardingsphere.sharding.binding-tables[0]= # 绑定表规则列表
spring.shardingsphere.sharding.binding-tables[1]= # 绑定表规则列表
spring.shardingsphere.sharding.binding-tables[x]= # 绑定表规则列表例如:t_order 表和 t_order_item 表,均按照 order_id 分片,则此两张表互为绑定表关系。 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。 举例说明,如果 SQL 为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4 条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);在配置绑定表关系后,路由的 SQL 应该为 2 条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);其中 t_order 在 FROM 的最左侧,ShardingSphere 将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么 t_order_item 表的分片计算将会使用 t_order 的条件。 因此,绑定表间的分区键需要完全相同。
广播表:指所有的分片数据源中都存在的表,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
spring.shardingsphere.sharding.broadcast-tables[0]= # 广播表规则列表
spring.shardingsphere.sharding.broadcast-tables[1]= # 广播表规则列表
spring.shardingsphere.sharding.broadcast-tables[x]= # 广播表规则列表用于主从模式中,进行数据读写分离:主库写,从库读
# 省略数据源配置,与数据分片一致
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.master-data-source-name= # 主库数据源名称
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[0]= # 从库数据源名称列表
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[1]= # 从库数据源名称列表
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[x]= # 从库数据源名称列表
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-class-name= # 从库负载均衡算法类名称。该类需实现 MasterSlaveLoadBalanceAlgorithm 接口且提供无参数构造器
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-type= # 从库负载均衡算法类型,可选值:ROUND_ROBIN,RANDOM。若 `load-balance-algorithm-class-name` 存在则忽略该配置# 省略数据源配置,与数据分片一致
spring.shardingsphere.encrypt.encryptors.<encryptor-name>.type= # 加解密器类型,可自定义或选择内置类型:MD5/AES
spring.shardingsphere.encrypt.encryptors.<encryptor-name>.props.<property-name>= # 属性配置, 注意:使用 AES 加密器,需要配置 AES 加密器的 KEY 属性:aes.key.value
spring.shardingsphere.encrypt.tables.<table-name>.columns.<logic-column-name>.plainColumn= # 存储明文的字段
spring.shardingsphere.encrypt.tables.<table-name>.columns.<logic-column-name>.cipherColumn= # 存储密文的字段
spring.shardingsphere.encrypt.tables.<table-name>.columns.<logic-column-name>.assistedQueryColumn= # 辅助查询字段,针对 ShardingQueryAssistedEncryptor 类型的加解密器进行辅助查询
spring.shardingsphere.encrypt.tables.<table-name>.columns.<logic-column-name>.encryptor= # 加密器名字sharding-jdbc支持4种分库分表策略:inline、standard、complex、hint。
实际应用中,经常会需要使用hint或complex方式去自定义自己的分库分表的策略实现类继承对应的实现类接口,以支持业务。
- 根据自ID分库
- 根据租户字段和主键类型字段分库
- 根据租户字段分库(限每个租户只有一个库)
- 根据租户字段和sharding_mapping业务字段分库):
- 根据主键分表
- 混合策略分表:依赖sharding_mapping分库分表
- 根据日期月份和年份分表
增加配置字段insert-table-nodes:该字段用于配置允许插入数据的表节点,非全量表节点,必填字段。
目的:
- 平滑扩容时,只向新表插入数据,旧表仅提供查询,不允许插入
- 向指定表插入数据,其他表不在新增
- 数据库中分表分布不均衡,生成库和表编号。比如ds_1有表user_1,user_2,ds_2库有user_3。
应对场景:原先有10个分表,均匀向这10个表插入数据。但是随着业务发展,10个爆满了。 需要扩展新表,同时旧表不允许在插入数据(因为已经很多了)。那么此时该参数配置可以插入数据的表。
引入映射表sharding_mapping,并指定用于映射分表键的业务键:mappingBizIdColumn
1)设计目的
- 处理有层级关系业务表路由以及主键的创建
- 该方式依赖与sharding-jdbc的混合策略
2)业务场景
一个公司firm,有多个账号account。现有账户表account,表中有字段:账号account_no、公司唯一编码firm_id
现在对账号表按account_no分表,并有如下要求:
同一个公司firm_id的账号必须分到同一个表
根据公司firm_id查询时,不进行全表扫描
解决方案: 维护公司firm_id和分库分表映射关系表:sharding_mapping
依赖sharding_mapping的路由规则:
- 有路由键account_no,根据路由键计算到指定的表
- 无路由键account_no,但有公司firm_id,则根据firm_id查询sharding_mapping表获取路由库和表信息
- 自定义路由实现类,实现
ComplexKeysShardingAlgorithm
- 字段配置:mappingBizIdColumn:用于查询sharding_mapping映射关系的键
sanwu.sharding.config.tables.sw_account.mapping-biz-id-column=firm_id
# 必须搭配sharding-jdbc的混合策略配置
sharding.jdbc.config.sharding.tables.sw_account.actual-data-nodes=ds-$->{0..1}.sw_account$->{0..1}
sharding.jdbc.config.sharding.tables.sw_account.table-strategy.complex.sharding-columns=account_no,firm_id
sharding.jdbc.config.sharding.tables.sw_account.table-strategy.complex.algorithm-class-name=com.sanwu.sharding.algorithm.TableByMappingComplexShardingAlgorithm建表SQL(建在当前服务所连接数据库,同sequence表所在库)
DROP table if exists sharding_mapping;
create table `sharding_mapping`
(
`id` bigint(20) unsigned auto_increment not null,
`rent_name` varchar(128) default null comment '租户信息',
`prod_code` varchar(32) not null comment 'prod code',
`biz_id` varchar(128) not null comment '业务id',
`database` varchar(64) default "99" comment '分库编号',
`table` varchar(64) not null comment '分表编号',
`created_time` datetime default now(),
primary key (`id`),
unique key `biz_id_prod_code_uqx` (`biz_id`,`prod_code`)
) engine=innodb default charset=utf8 COMMENT '分片映射表';租户架构情况
- 共享硬件和服务,数据库隔离,不共享
- 如果是隔离级别最高的租户架构,服务硬件独立,数据库独立,不需要使用该配置,普通配置即可
举例现有表t_user进行分库分表:
- 分表有字段:rent(租户),user_id
- user-db-1库有分表:t_user_1,t_user_2
- user-db-2库有分表:t_user_1,t_user_2
- boss-db-1库有分表:t_user_3,t_user_4
- boss-db-2库有分表:t_user_3,t_user_4
- 根据user_id进行分表,期望user路由到user_db分库,boss用户路由到boss_db分库
分库分表首先是基于现有的业务量和未来的增量做出判断。
举个例子,现在我们日单量是10万单,预估一年后可以达到日100万单,根据业务属性,一般我们就支持查询半年内的订单,超过半年的订单需要做归档处理。
那么以日订单100万半年的数量级来看,不分表的话我们订单量将达到100万X180=1.8亿
以这个数据量级不分表的话,RT(响应时间)系统根本无法接受吧。
根据经验单表几百万的数量对于数据库是没什么压力的,那么只要分256张表就足够了,1.8亿/256≈70万,如果为了保险起见,也可以分到512张表。那么考虑一下,如果业务量再增长10倍达到1000万单每天,分表1024就是比较合适的选择。
分表参考公式:
(用户数量 * 用户每年产生数据量) / 每个表200-500万数据 = 分表数量
参考资料:百亿级数据分表后怎么分页查询?