Examples to show how to execute the different subcommands from the ebooktools.py script.
Check also some important tips about using the ebooktools.py script.
Contents
In order to avoid data loss, use the --dry-run or --symlink-only option to test that a given subcommand would do what you expect it to do, as explained in the Security and safety section.
When --dry-run is enabled, no file rename/move/symlink/etc. operations will actually be executed.
When --symlink-only is enabled, symbolic links to ebook files are created instead of moving them.
Thus, these flags are convenient with the subcommands organize, rename,
and split which will modify the input files. Though only --dry-run
applies to split.
⭐
When using these two flags, you will be able to know what theebooktools.pyscript would have done by looking at the messages printed out in the terminal. Use the --log-level debug flag to get more information about what is theebooktools.pyperforming as operation (e.g. rename/move/symlink/ect.).
Sometimes, it might be more convenient to edit the main configuration file
config.py instead of building a long command in the terminal with all the
options for a given subcommand (e.g. organize).
For example, you might have the following long command in the terminal:
$ ebooktools organize ~/folder_to_organize/ -o ~/output_folder/ --ofp ~/output_folder_pamphlets/ --owi
Instead of providing command-line arguments, we will edit the configuration
file config.py by running the following edit subcommand:
$ ebooktools edit main
The config.py file will be opened by the default source code editor
associated with this type of file and then you can modify the right
configuration variables for the given subcommand.
You can then run the given subcommand with the -u flag (short name
for the --use-config option) and all the updated options in the
configuration file will be used:
$ ebooktools organize -u
where organize can also be any of the other supported subcommands.
The -u, --use-config flag tells the ebooktools.py script to only use the
parameters defined in the config file config.py.
⭐
See edit for more info about this subcommand.
$ ebooktools convert --ocr always pdf_to_convert.pdf -o converted.txt
By setting --ocr to always, the pdf file will be first OCRed before
trying the simple conversion tools (pdftotext or calibre's
ebook-convert if the former command is not found).
Output:
Running pyebooktools v0.1.0a3
Verbose option disabled
OCR=always, first try OCR then conversion
Will run OCR on file 'pdf_to_convert.pdf' with 1 page...
OCR successful!
$ ebooktools convert pdf_to_convert.pdf -o converted.txt
If pdftotext is present, it is used to convert the pdf file to text.
Otherwise, calibre's ebook-convert is used for the conversion.
Output:
Running pyebooktools v0.1.0a3
Verbose option disabled
OCR=false, try only conversion...
Conversion successful!
The two config files that can be edited are the main and logging
config files, named config.py and logging.py respectively. We will only focus
in the main config file because it is the most important one since it contains
all the options for the ebooktools.py script.
To edit the main config file with PyCharm:
$ ebooktools edit -a charm main
A tab with the main config file will be opened in PyCharm's Editor window:
To reset the main config file with factory settings as defined in default_config.py:
$ ebooktools edit -r main
Find ISBNs in the string '978-159420172-1 978-1892391810 0000000000
0123456789 1111111111':
$ ebooktools find '978-159420172-1 978-1892391810 0000000000 0123456789 1111111111'
The input string can be enclosed within single or double quotes.
Output:
Running pyebooktools v0.1.0a3
Verbose option disabled
Extracted ISBNs:
9781594201721
9781892391810
The other sequences '0000000000 0123456789 1111111111' are rejected because
they are matched with the regular expression isbn_blacklist_regex.
By default, the extracted
ISBNs are separated by newlines, \n.
ℹ️
If you want to search ISBNs in a multiple-lines string, e.g. you copied many pages from a document, you must follow the
findsubcommand with a backslash\and enclose the string within double quotes, like so:$ ebooktools find \ " 978-159420172-1 blablabla blablabla blablabla 978-1892391810 0000000000 0123456789 blablabla blablabla blablabla 1111111111 blablabla blablabla "
$ ebooktools find pdf_file.pdf
Output:
Running pyebooktools v0.1.0a3
Verbose option disabled
Searching file 'pdf_file.pdf' for ISBN numbers...
Extracted ISBNs:
9789580158448
1000100111
The search for ISBNs starts in the first pages of the document to increase the likelihood that the first extracted ISBN is the correct one. Then the last pages are analyzed in reverse. Finally, the rest of the pages are searched.
Thus, in this example, the first extracted ISBN is the correct one associated with the book since it was found in the first page.
The last sequence 1000100111 was found in the middle of the document and is
not an ISBN even though it is a technically valid but wrong ISBN that the
regular expression isbn_blacklist_regex didn't catch. Maybe it is a binary
sequence that is part of a problem in a book about digital system.
The following examples show how to organize ebooks depending on different cases:
- Organize ebooks with only output_folder: ignore ebooks without ISBNs
- Organize ebooks with output_folder_corrupt: organize ebooks and check
for corruption (e.g. zero-filled files or broken
.pdffiles) - Organize ebooks with output_folder_pamphlets: e.g. small pdfs or saved webpages
- Organize ebooks with output_folder_uncertain: organize ebooks that don't have any ISBN in them.
⭐
You can use organize to check ebooks for corruption without organizing them by using the --corruption-check-only flag. See the Check ebooks for corruption only example for more details.
ℹ️
You can also combine all these cases by using all of the output folders along with the --owi flag in the command-line when calling the organize subcommand.
Or better you can also do it through the config file
config.pyby running the following edit subcommand:$ ebooktools edit mainThe
config.pyfile will be opened by the default source code editor associated with this type of file and then you can modify the right configuration variables.Then run the
organizesubcommand with the-uflag and the updated options in the configuration file will be used:$ ebooktools organize -uSee edit for more info about this subcommand.
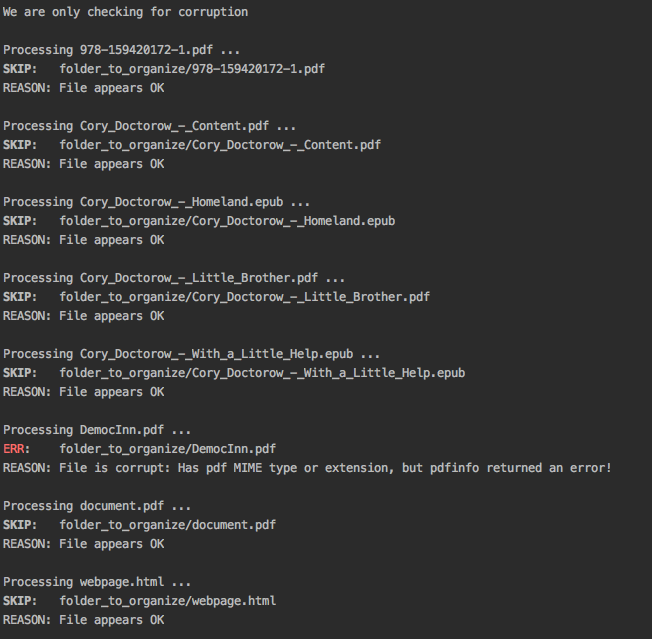
We only want to check the following ebook files for corruption (e.g. zero-filled files, broken pdfs, corrupt archive, etc.):

This is the command to check these ebooks for corruption only:
$ ebooktools organize --cco ~/folder_to_organize/
where
- --cco is the short name for the
corruption-check-onlyflag and checks ebooks for corruption only without organizing them - folder_to_organize contains the ebooks that need to be organized or checked (as in our case)
Output:
ℹ️
- Since output_folder_corrupt was no provided in the previous command-line, the corrupted file was just flagged as corrupt without moving it to another folder.
- The Organize ebooks with output_folder_corrupt example shows you how to organize your ebooks by separating the corrupted ebooks from the good ones.
We want to organize the following ebook files:
This is the command to organize these ebooks:
$ ebooktools organize ~/folder_to_organize/ -o ~/output_folder/
where
- folder_to_organize contains the ebooks that need to be organized
- output_folder will contain all the renamed ebooks for which an ISBN was found in it
Output:
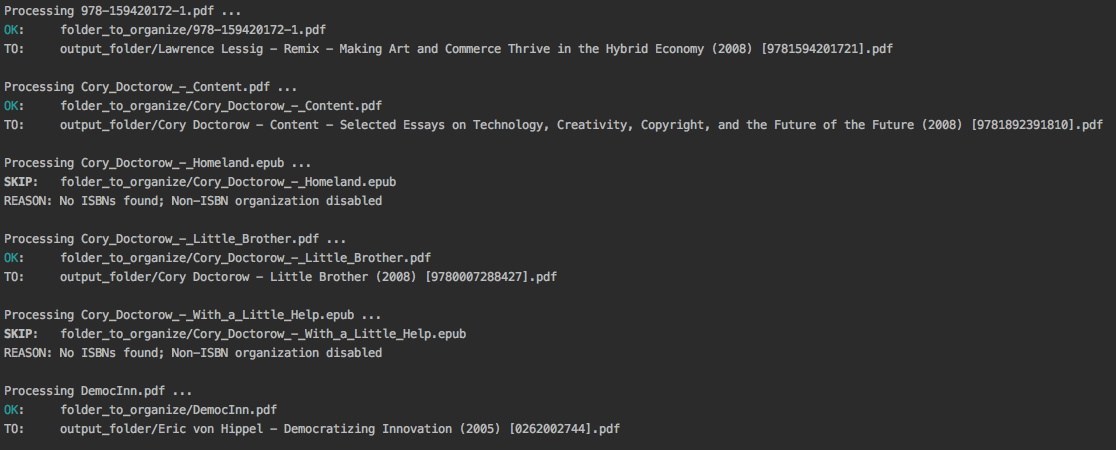
Content of output_folder:

ℹ️
Since the --owi flag was not used, two ebook files that didn't contain
ISBNs could not be further processed and thus were left as they are in the
original directory folder_to_organize. See Organize ebooks with
output_folder_uncertain where this flag is enabled to organize
ebooks without ISBNs by getting these book identifiers through other
means (e.g. calibre's ebook-meta).
We want to organize the following ebook files, one of which is corrupted:

This is the command to organize these ebooks as wanted:
$ ebooktools organize ~/folder_to_organize/ -o ~/output_folder/ --ofc ~/output_folder_corrupt/
where
- output_folder will contain all the renamed ebooks for which an ISBN was found in it
- output_folder_corrupt will contain any corrupted ebook (e.g. zero-filled
files, corrupt archives or broken
.pdffiles)
Output:

Content of output_folder:

Content of output_folder_corrupt:

ℹ️
Along each corrupted file, a metadata file is saved containing information about the corruption reason and the ebook's old file path.
We want to organize the following ebook files, some of which are pamphlets:

ℹ️
If no ISBN was found for a non-pdf file and the file size is less than pamphlet_max_filesize_kib, then it is considered as a pamphlet.
This is the command to organize these ebooks as wanted:
$ ebooktools organize ~/folder_to_organize/ -o ~/output_folder/ --ofp ~/output_folder_pamphlets/ --owi
where
- output_folder will contain all the renamed ebooks for which an ISBN was found in it
- output_folder_pamphlets will contain all the pamphlets-like documents
- --owi is a flag to enable the organization of documents without ISBNs such as pamphlets
Output:
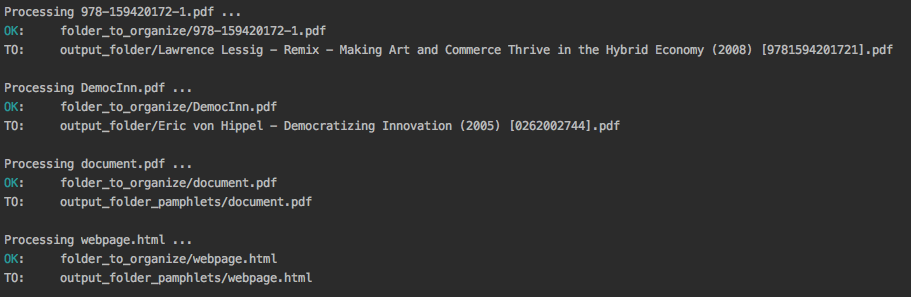
Content of output_folder:

Content of output_folder_pamphlets:
We want to organize the following ebook files, some of which do not contain any ISBNs:

This is the command to organize these ebooks as wanted:
$ ebooktools organize ~/folder_to_organize/ -o ~/output_folder/ --ofu ~/output_folder_uncertain/ --owi
where
- output_folder will contain all the renamed ebooks for which an ISBN was found in it
- output_folder_uncertain will contain all the renamed ebooks for which no ISBNs could be found in them
- --owi is a flag to enable the organization of ebooks without ISBNs
Output:
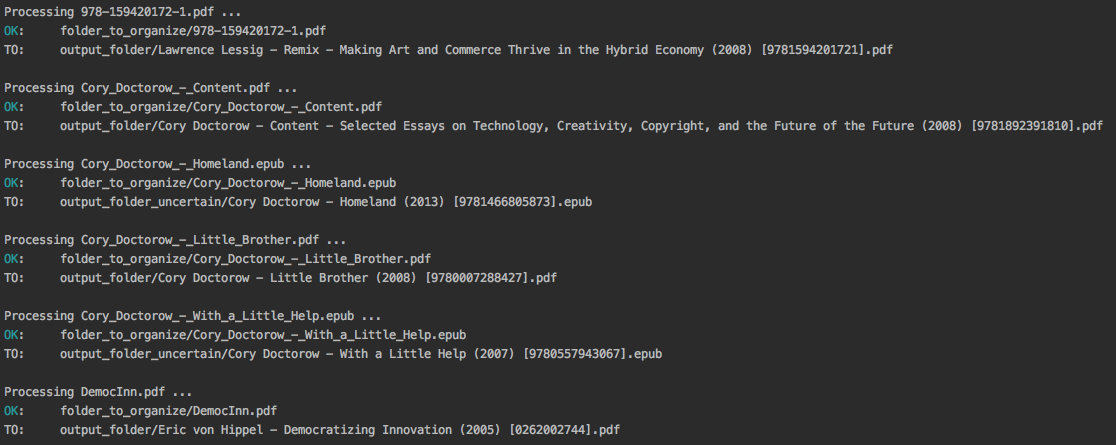
Content of output_folder:

Content of output_folder_uncertain:

ℹ️
For those ebooks for which no ISBNs could be found in them, the
ebooktools.pyscript takes the following steps to organize them:
- Use calibre's ebook-meta to extract the author and title metadata from the ebook file
- Search the online metadata sources (
Goodreads,Amazon.com,Google) by the extracted author & title and just by title- If there is no useful metadata or nothing is found online, the script will try to use the filename for searching
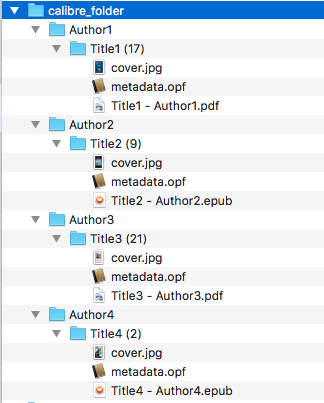
We want to rename ebook files from a calibre library folder and save their
symlinks along with their copied metadata.opf files in a separate folder.
Content of calibre_folder:
This is the command to rename these ebooks as wanted:
$ ebooktools rename ~/calibre_folder/ -o ~/output_folder/ --sm opfcopy --sl
where
- output_folder is where the renamed books (or their symbolic links) will be moved to along with their metadata files
- --sm opfcopy copies calibre's
metadata.opfnext to each renamed file with a output_metadata_extension extension - --sl is a flag for creating symbolic links to ebooks, instead of moving them
to the
output_folder
Output:
Running pyebooktools v0.1.0a3
Verbose option disabled
Files sorted in asc
Parsing metadata for 'Title1 - Author1.pdf'...
Saving book file and metadata...
Parsing metadata for 'Title2 - Author2.epub'...
Saving book file and metadata...
Parsing metadata for 'Title3 - Author3.pdf'...
Saving book file and metadata...
Parsing metadata for 'Title4 - Author4.epub'...
Saving book file and metadata...
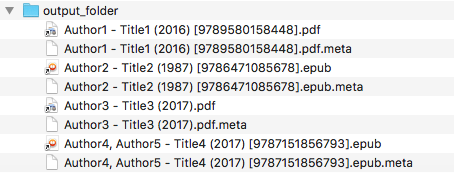
Content of output_folder:
ℹ️
- The ebook files are renamed based on the content of their associated
metadata.opffiles and the new filenames follow the output_filename_template format.- The
metadata.opffiles are copied with themetaextension (default) beside the symlinks to the ebook files.
We have a folder containing four ebooks and the metadata file for two of them:
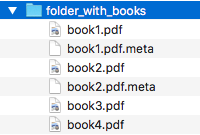
We want to split these ebook files into folders containing two files each and their numbering should start at 1:
$ ebooktools split ~/folder_with_books/ -o ~/output_folder/ -s 1 --fpf 2
where
- output_folder in which all the new consecutively named folders will be created
- -s is the number of the first folder
- --fpf is the number of files per folder
Content of output_folder
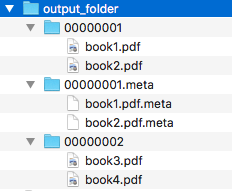
ℹ️
Note that the metadata folders contain only one file each as expected.
| [OWI] | https://github.com/raul23/pyebooktools#organize-without-isbn-label |