❤️💕💕Go语言高级篇章,在此之前建议您先了解基础和进阶篇。Myblog:http://nsddd.top
[TOC]
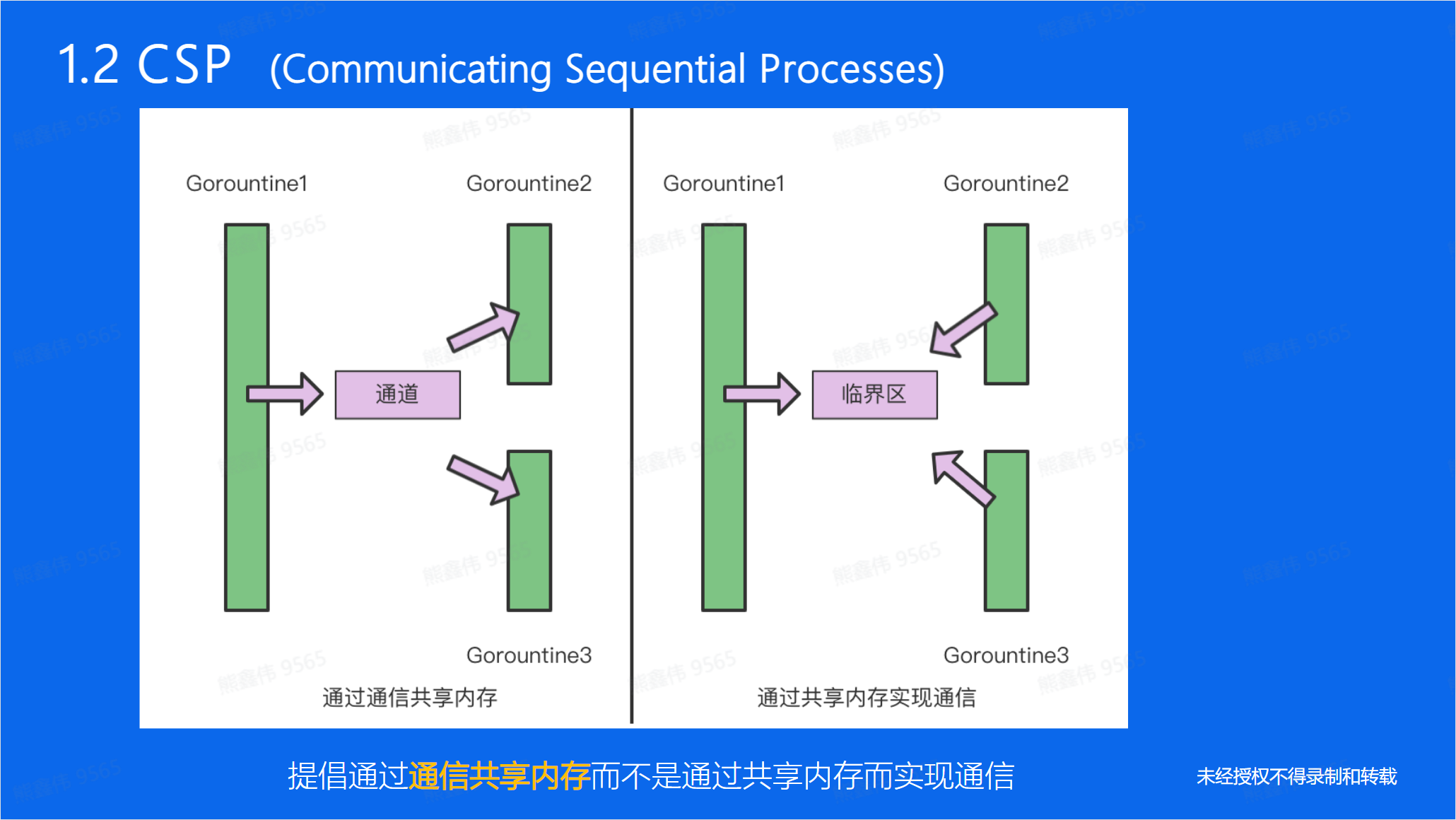
通信共享内存(Communicating Sequential Processes, CSP)是一种并发编程模型,它将并发程序视为若干独立的进程,这些进程之间通过通信来协调工作。
其中一种常用的通信方式是共享内存,即多个进程共用一块内存区域,并通过读写操作来实现通信。这种方式的优点是通信速度快,因为数据不需要经过网络传输,但缺点是需要额外的同步机制来保证数据的一致性。
通信共享内存是一种比较流行的并发编程模型,并且在一些多处理器系统中得到了广泛应用。
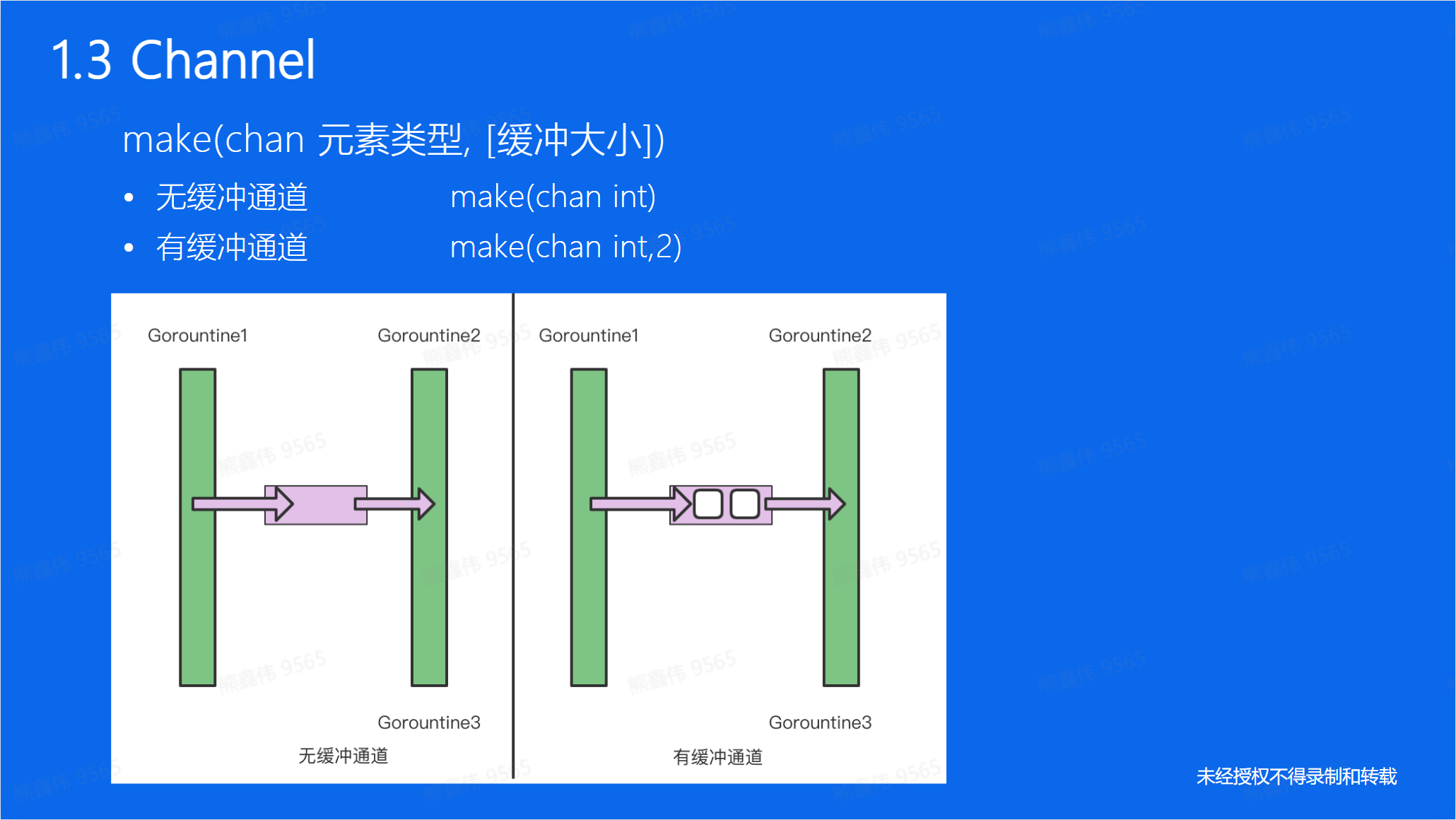
在 Go 语言中,通道是用于在 goroutines 之间传递数据的类型。通道可以是无缓冲的或有缓冲的。
- 无缓冲通道:在没有接收方接收之前,发送方会被阻塞。这意味着如果发送方试图发送数据,而接收方并没有准备好接收,那么发送方将会一直等待。
- 有缓冲通道:具有固定大小的缓冲区。在接收方没有准备好接收之前,发送方可以继续发送数据,直到缓冲区满为止。这意味着发送方不会被阻塞,直到缓冲区满。
使用无缓冲通道时,消息传递会更加同步,因为发送方和接收方必须同时准备好。
而使用有缓冲通道时,消息传递会更加异步,因为发送方和接收方不必同时准备好。
💡简单的一个案例如下:

📜 对上面的解释:
我们在前面解释过了,有缓冲的适合异步,无缓冲的适合同步,我们代入生产者和消费者的角色。
通过 src channel 实现 A 协程和 B 协程的通信。
生产者同步的去生产,消费者异步的去取出数据,这样可以通过通信实现共享内存。
同样的看输出的顺序性,这个程序是 并发安全 的
[[并发安全]] :并发安全是指在多个线程或进程并发执行时,程序的正确性不会受到影响。并发安全的程序可以在多个线程或进程中并发执行,而不会出现数据不一致的问题。
并发安全的程序通常需要使用一些机制来确保在多个线程或进程并发执行时不会出现竞争条件。这些机制包括互斥锁、读写锁、信号量等。
共享内存通信是指多个进程之间通过共享同一块物理内存来进行通信的方式。在这种方式中,多个进程可以同时读写共享内存中的数据,从而实现进程间的通信。
共享内存通信的优点在于通信速度快,因为数据不需要经过网络传输。但是,由于多个进程可以同时对共享内存进行操作,因此需要额外的同步机制来保证数据的一致性,以避免数据竞争等问题。
共享内存通信是一种常用的进程间通信方式,在多处理器系统中得到了广泛应用。
这样的我们采用 加锁和解锁 来解决:
使用全局变量和互斥锁实现共享内存通信:
package main
import (
"fmt"
"sync"
)
var data int
var lock sync.Mutex
func main() {
go func() {
lock.Lock() //加锁
data += 1
lock.Unlock() //解锁
}()
lock.Lock()
fmt.Println(data)
lock.Unlock()
}📜 对上面的解释:
对临界区权限控制保证并发安全。
使用 Channel 实现共享内存通信:
package main
import "fmt"
func main() {
ch := make(chan int)
go func() {
ch <- 1
}()
fmt.Println(<-ch)
}使用 sync.Map 实现共享内存通信:
package main
import (
"fmt"
"sync"
)
func main() {
var data sync.Map
data.Store("key", 1)
value, _ := data.Load("key")
fmt.Println(value)
}这三种方法都可以实现共享内存通信
package main
import (
"fmt"
"sync"
)
func worker(id int, wg *sync.WaitGroup) {
fmt.Printf("Worker %d starting\n", id)
// Do some work here
fmt.Printf("Worker %d done\n", id)
// Notify the WaitGroup that this worker is done
wg.Done()
}
func main() {
var wg sync.WaitGroup
for i := 1; i <= 5; i++ {
// Increment the WaitGroup counter
wg.Add(1)
// Create a new goroutine for each worker
go worker(i, &wg)
}
// Wait for all the workers to finish
wg.Wait()
fmt.Println("All workers done")
}📜 对上面的解释:
- 在上面的代码中,我们在
main函数中定义了一个sync.WaitGroup类型的变量wg。 - 我们在循环中创建了五个工作 goroutine,并且在每次循环中调用
wg.Add(1)来增加 WaitGroup 计数器。 - 每个 worker goroutine 在完成工作后,会调用
wg.Done()来减少 WaitGroup 计数器。 - 在
main函数的最后,我们调用wg.Wait()来等待所有 worker goroutine 完成工作。 - 当 WaitGroup 计数器归零时,
wg.Wait()函数才会返回,这样我们就可以确保所有 worker goroutine 都完成工作之后再继续执行后面的代码。
简单来说,waitGroup 是一种用来等待一组 goroutine 结束的工具。每个goroutine完成时会调用Done函数,在main函数中调用wait函数等待所有goroutine结束。
Go语言提供了一种简单而高效的依赖管理方式,叫做"go mod"。它是Go语言1.11版本中引入的,可以解决项目依赖管理和版本控制问题。
使用"go mod"来管理依赖非常简单,只需要在命令行中输入"go mod init"来初始化项目,然后在代码中import需要的包,"go mod"会自动下载并管理这些依赖。
在项目中可以使用"go.mod"文件和"go.sum"文件来管理项目的依赖关系和版本信息,这使得团队协作和部署变得更加方便。
在了解 Kubernetes 的源码的时候,观察到一个 vendor 目录,这个目录对我们来说很重要!
方法:
项目目录下添加 vendor 文件,所有依赖包副本形式放在 $ProjectRoot/vendor
依赖寻址方式:vendor –> GOPATH
[[vendor]]⭕ :
目录结构:
root@cubmaster01:~/go/src/k8s.io/kubernetes# cd vendor/;ls
bitbucket.org go.etcd.io go.opencensus.io go.starlark.net modules.txt
cloud.google.com golang.org go.opentelemetry.io go.uber.org OWNERS
github.com google.golang.org gopkg.in k8s.io sigs.k8s.ioGo Vendor是Go语言中一种依赖管理方式,它提供了一种将项目依赖的第三方库打包到项目中的方式。它通过在项目目录下创建一个"vendor"目录来管理依赖,将第三方库拷贝到该目录中。
在使用Go Vendor时,需要使用工具(如"govendor")来管理依赖,包括添加、更新和删除依赖。这种方式的优点是可以更好地控制项目依赖的版本,并且不会因为网络问题或者其他原因导致依赖下载失败。
Kubernetes中的vendor是指将第三方库依赖打包进Kubernetes项目中,这样就不需要在运行Kubernetes时再去下载依赖。这样做的好处是可以确保项目在不同环境中的稳定性和可靠性,并且可以更好地控制项目依赖的版本。
命令:
go mod download: 下载项目所有依赖。go mod edit: 打开编辑器来编辑 go.mod 文件。go mod graph: 打印项目依赖图。go mod init: 初始化一个新的 go.mod 文件,并在其中添加当前模块。go mod tidy: 删除无用的依赖。go mod vendor: 将项目依赖复制到 vendor 目录中。go mod verify: 检查依赖的签名。go mod why: 显示为什么需要依赖。

在 Go 语言中,依赖的分发通常通过包管理器进行。Go 语言支持多种包管理工具,如 go mod、govendor、glide 等,它们都可以用来管理项目依赖。
- go mod是 Go 官方推荐的依赖管理工具,它采用了模块化管理方式,可以很好地解决依赖版本冲突和网络问题。
- govendor是一个第三方包管理工具,它支持将依赖打包到项目中,可以确保项目在不同环境中的稳定性和可靠性。
- glide是一个基于 glide.yaml 的 Go 包管理工具,支持多种版本管理策略。
除了这些包管理工具之外,还可以通过其他方式来管理和分发 Go 语言的依赖。比如将项目打包成二进制文件,或者将项目发布到代码仓库,其他人可以通过 git clone 来获取项目代码和依赖。
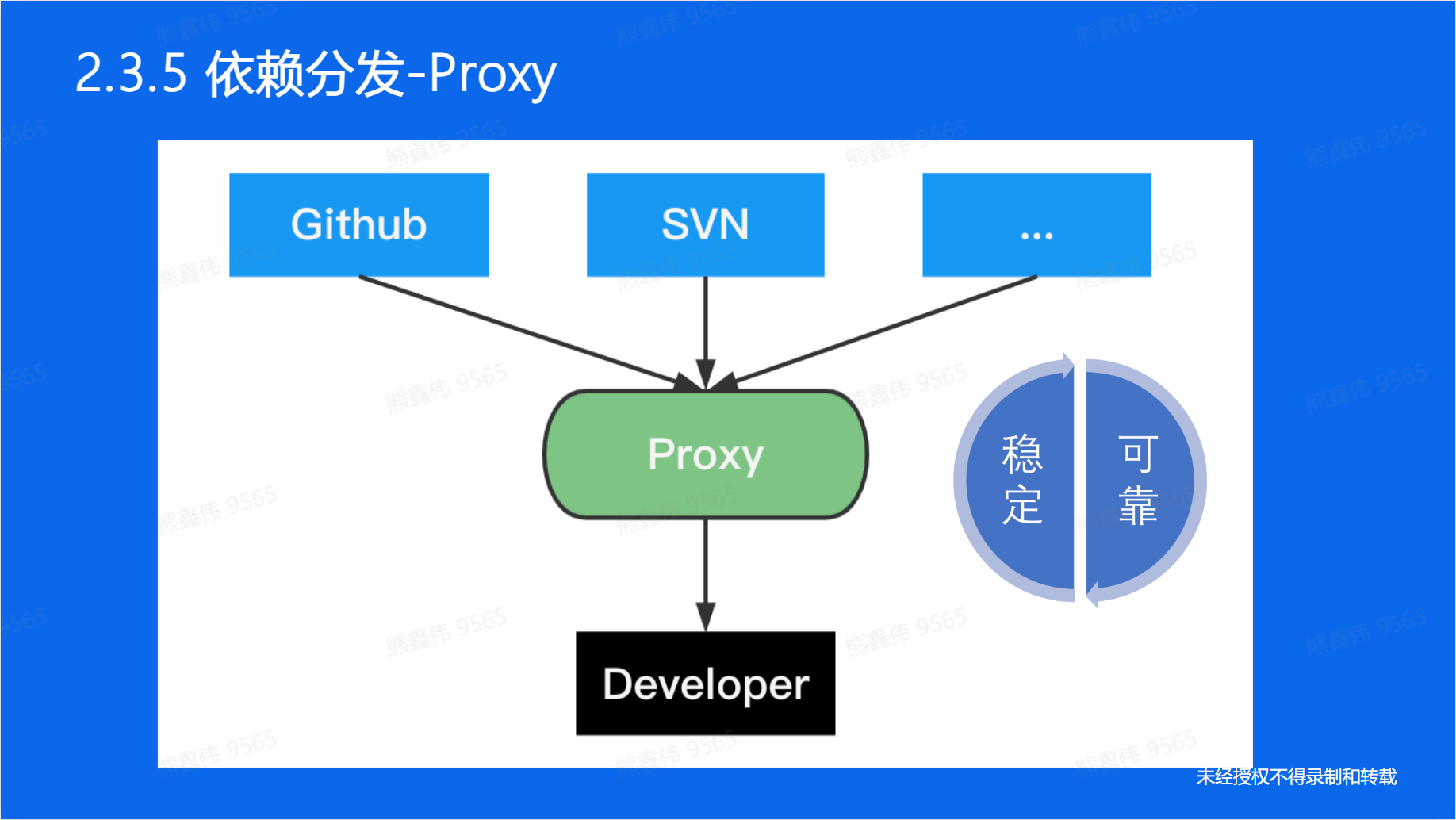
Go proxy是Go语言中用来设置代理服务器的一种方式。当使用Go语言进行网络请求时,如果网络环境需要使用代理服务器,可以使用Go proxy来设置代理。

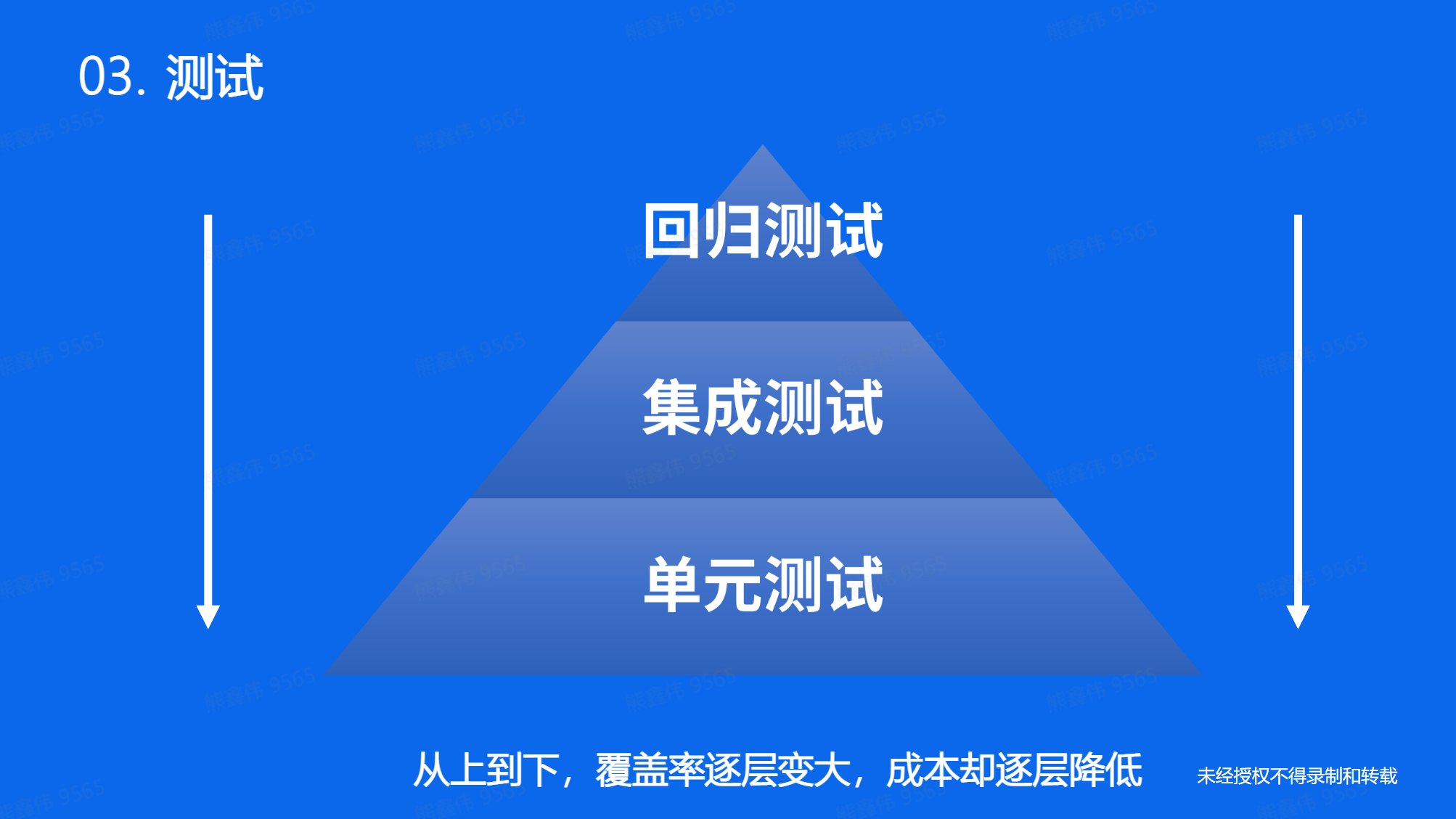
学习Go语言的测试是很有用的。 Go语言提供了自带的测试框架,可以很容易地编写单元测试和性能测试。
在Go语言中,测试文件的命名应该以 _test.go 为后缀。 测试函数的命名应该以 Test 开头。
💡简单的一个案例如下:
package main
import "testing"
func TestAdd(t *testing.T) {
result := add(1, 2)
expected := 3
if result != expected {
t.Errorf("add(1, 2) = %d; expected %d", result, expected)
}
}单元测试覆盖率是一种测量代码中有多少行/函数/分支被测试过的指标。它可以帮助你确定你的代码中是否有未被测试过的部分。
Go语言有一个内置的命令 go test -cover 可以帮助你计算代码的测试覆盖率。 例如,你可以运行 go test -cover 来计算main_test.go文件中的测试覆盖率。
你也可以使用第三方工具来查看更详细的报告,例如 go-carpet, gocov, 和 goveralls。
需要结合测试设计原则,和业务场景来决定测试覆盖率的阈值。
覆盖率–tips:
- 一般覆盖率 50% ~ 60%,较高覆盖率 80% +
- 测试分支相互独立、全面覆盖
- 测试单元粒度足够小、函数单一职责
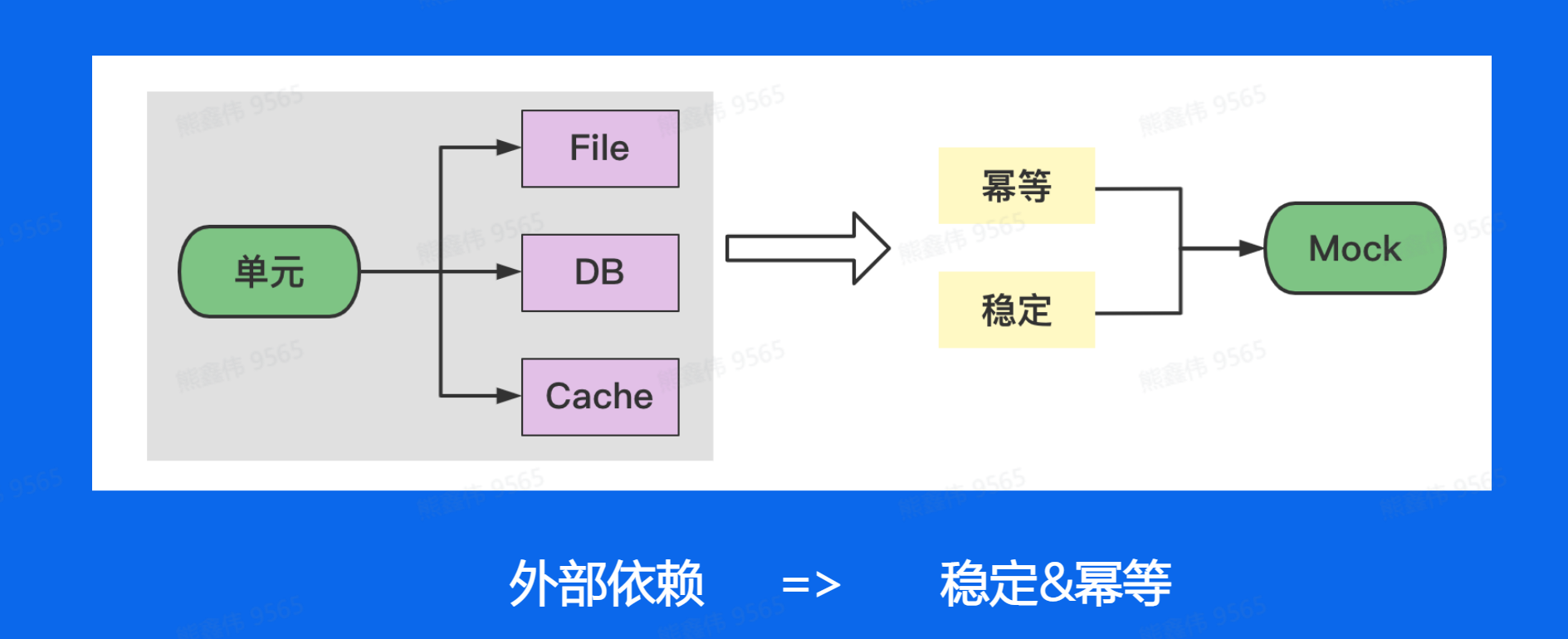
测试依赖是指在执行测试之前需要先创建或配置的对象或资源。 例如,如果你的测试需要连接到数据库,那么连接数据库就是一个测试依赖(还有Cache、file…)。
在 Go 语言中,您可以使用一些技巧来管理测试依赖,例如:
- 使用 setup 函数来创建和配置测试依赖。
- 使用 defer 语句来在测试结束后清理测试依赖。
- 使用 mock 库来替换真实依赖。
💡简单的一个案例如下:
package main
import (
"io/ioutil"
"os"
"testing"
)
// TestReadFile 是一个读取文件的测试函数
func TestReadFile(t *testing.T) {
// 测试依赖:创建一个临时文件,并写入内容
file, err := ioutil.TempFile("", "test")
if err != nil {
t.Fatalf("Failed to create temp file: %v", err)
}
defer os.Remove(file.Name()) // 清理测试依赖
if _, err := file.Write([]byte("Hello World!")); err != nil {
t.Fatalf("Failed to write to temp file: %v", err)
}
// 测试案例:调用 readFile 函数读取文件内容
content, err := readFile(file.Name())
if err != nil {
t.Fatalf("Failed to read file: %v", err)
}
if content != "Hello World!" {
t.Errorf("Unexpected content: %s", content)
}
}Mock 函数打桩是一种将真实依赖替换为模拟实现的技术。它可以帮助你在测试中更好地控制依赖,从而使测试更加稳定和可靠。
- 为函数打桩
- 为方法打桩
在 Go 语言中,你可以使用第三方库来帮助你编写 mock 函数,例如 mockgen 和 testify/mock 。
package main
import (
"testing"
"github.com/stretchr/testify/mock"
)
// MyDependency 是一个接口,定义了需要 mock 的函数
type MyDependency interface {
DoSomething(input string) (output string, err error)
}
// MyDependencyFunc 是一个函数,实现了 MyDependency 接口
func MyDependencyFunc(input string) (output string, err error) {
// 真实的实现
return "real output", nil
}
func TestMyFunc(t *testing.T) {
// 创建 mock 实现
mockDependency := new(MyDependencyMock)
mockDependency.On("DoSomething", "input").Return("mock output", nil)
// 将 mock 实现传入需要测试的函数
output, err := myFunc(mockDependency)
if err != nil {
t.Errorf("Unexpected error: %v", err)
}
if output != "mock output" {
t.Errorf("Unexpected output: %s", output)
}
}基准测试(benchmark test)是一种测量代码性能的测试方法。它可以帮助你了解代码在不同输入条件下的性能表现。
Go语言有一个内置的命令go test -bench,可以帮助你编写和运行基准测试。
💡简单的一个案例如下:
package main
import (
"testing"
)
func BenchmarkAdd(b *testing.B) {
for i := 0; i < b.N; i++ {
add(i, i)
}
}📜 对上面的解释:
- BenchmarkAdd是一个基准测试函数,它测试了一个名为 add 的函数。
- b.N 表示基准测试要运行的次数。
- add(i, i) 函数调用了需要测试的函数,它是测试案例。
运行基准测试可以使用命令 go test -bench=. 其中 . 代表当前目录下所有的基准测试。
基准测试的结果会显示每次运行的时间,这样你就可以比较不同实现之间的性能差异。
并行基准测试:
并行基准测试是指同时运行多个基准测试来提高测试效率。在 Go 语言中,可以使用 testing.B.RunParallel 函数来实现并行基准测试。
package main
import (
"testing"
)
func BenchmarkAdd(b *testing.B) {
b.RunParallel(
func(pb *testing.PB) {
for pb.Next() {
add(1, 2)
}
})
}b.RunParallel函数会并行运行多个基准测试。pb.Next()表示运行下一次基准测试。add(1, 2)函数调用了需要测试的函数,它是测试案例。
请注意,在并行基准测试中,整体运行次数是由 testing.B.N 来控制的,而不是单个 goroutine。因此,并行基准测试可能需要更多的内存和 CPU 资源,因此在实际使用中需要根据需求权衡是否使用并行基准测试。
另外,在并行基准测试中,如果你的函数有共享的变量和状态,需要注意使用互斥锁或其他同步机制来保证线程安全。
需求
- 实现一个展示话题(标题,文字描述)和回帖列表的后端http接口;
- 本地文件存储数据
组件及技术点
- web框架:Gin - github.com/gin-gonic/g…
- 了解go web框架的简单使用
- 分层结构设计:github.com/bxcodec/go-…
- 了解分层设计的概念
- 文件操作:读文件pkg.go.dev/io
- 数据查询:索引www.baike.com/wikiid/5527…

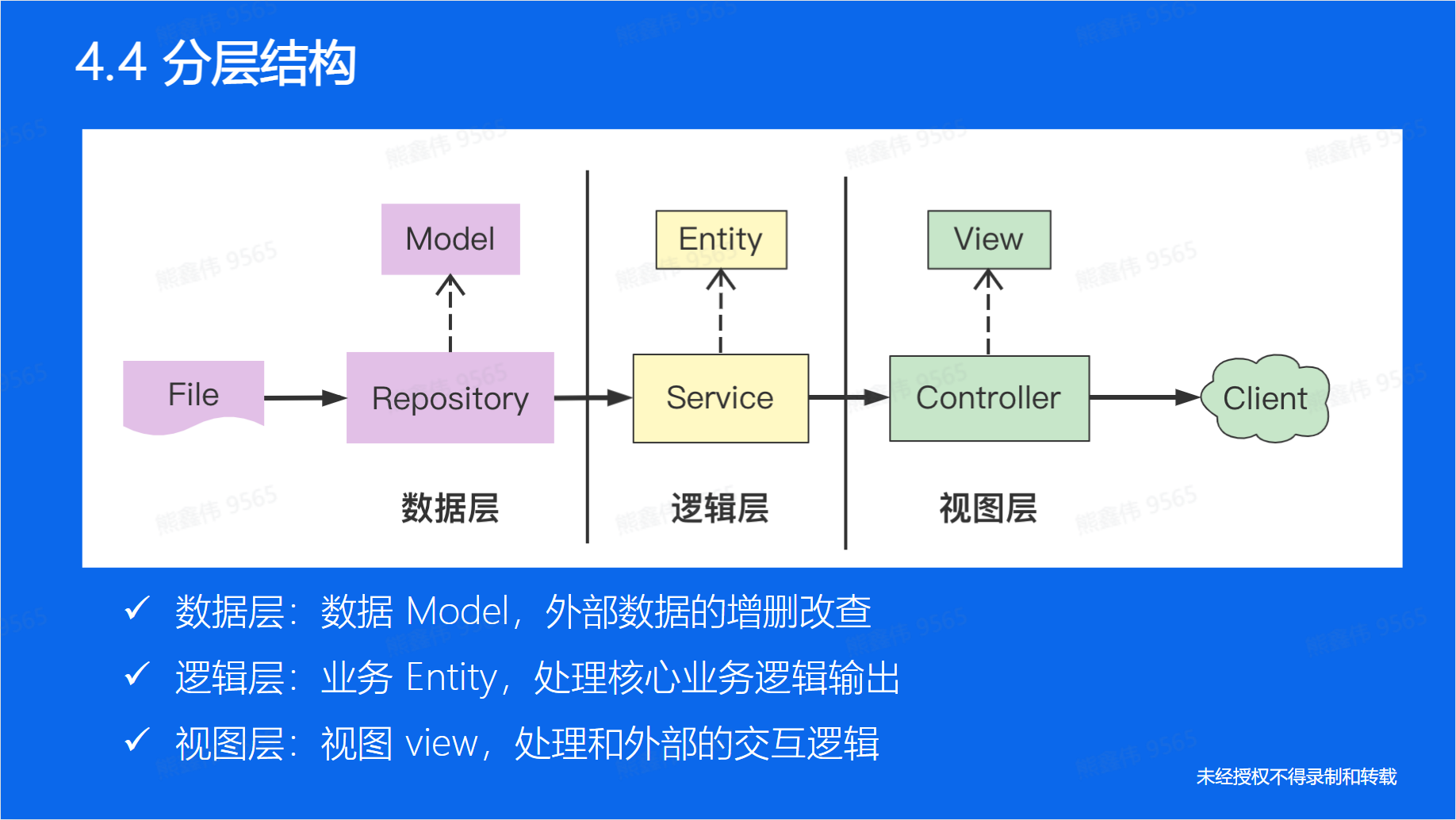
Go语言项目的分层结构通常包括三个部分:模型层、服务层和控制器层。
- 模型层 (Model layer): 负责存储和维护数据。这一层通常与数据库相关,负责定义数据结构和数据库操作。
- 服务层 (Service layer): 负责处理业务逻辑。这一层通常与模型层和其他服务层相关,负责实现业务逻辑并调用模型层和其他服务层的函数。
- 控制器层 (Controller layer): 负责处理 Web 请求和响应。这一层通常与服务层相关,负责解析 Web 请求并调用服务层的函数来响应请求。这一层通常使用路由和控制器函数来处理请求和响应。
以上三层之间应该保持松耦合关系,避免相互依赖。这样可以使得代码更易于维护和测试。
另外,还有一个会用到的是数据传输层(DTO),用来在不同层之间传递数据,以避免相互依赖。
最后,关于项目文件结构,可以按照不同层放置在不同的文件夹中,这样可以更容易地维护和组织代码.
组件工具
目录结构:
$ tree.com
卷 Data 的文件夹 PATH 列表
卷序列号为 3EA4-3AC8
D:.
├─attention
├─concurrence
├─handler
├─repository # 数据层
├─service # 逻辑层
└─util
$ ls -al
total 154
drwxr-xr-x 1 smile 197121 0 Jan 15 15:16 .
drwxr-xr-x 1 smile 197121 0 Jan 15 15:15 ..
drwxr-xr-x 1 smile 197121 0 Jan 15 15:16 .git
-rw-r--r-- 1 smile 197121 289 Jan 15 15:16 .gitignore
-rw-r--r-- 1 smile 197121 11558 Jan 15 15:16 LICENSE
-rw-r--r-- 1 smile 197121 20 Jan 15 15:16 README.md
drwxr-xr-x 1 smile 197121 0 Jan 15 15:16 attention
-rw-r--r-- 1 smile 197121 49210 Jan 15 15:16 avatar.jpg
drwxr-xr-x 1 smile 197121 0 Jan 15 15:16 concurrence
-rw-r--r-- 1 smile 197121 2464 Jan 15 15:16 example.sql
-rw-r--r-- 1 smile 197121 1435 Jan 15 15:16 go.mod
-rw-r--r-- 1 smile 197121 13570 Jan 15 15:16 go.sum
drwxr-xr-x 1 smile 197121 0 Jan 15 15:16 handler
drwxr-xr-x 1 smile 197121 0 Jan 15 15:16 repository
drwxr-xr-x 1 smile 197121 0 Jan 15 15:16 service
-rw-r--r-- 1 smile 197121 1075 Jan 15 15:16 sever.go
drwxr-xr-x 1 smile 197121 0 Jan 15 15:16 util主要包括 Topic、Post、user

type Post struct {
Id int64 `gorm:"column:id"`
ParentId int64 `gorm:"parent_id"`
UserId int64 `gorm:"column:user_id"`
Content string `gorm:"column:content"`
DiggCount int32 `gorm:"column:digg_count"`
CreateTime time.Time `gorm:"column:create_time"`
}
type Topic struct {
Id int64 `gorm:"column:id"`
UserId int64 `gorm:"column:user_id"`
Title string `gorm:"column:title"`
Content string `gorm:"column:content"`
CreateTime time.Time `gorm:"column:create_time"`
}
type User struct {
Id int64 `gorm:"column:id"`
Name string `gorm:"column:name"`
Avatar string `gorm:"column:avatar"`
Level int `gorm:"column:level"`
CreateTime time.Time `gorm:"column:create_time"`
ModifyTime time.Time `gorm:"column:modify_time"`
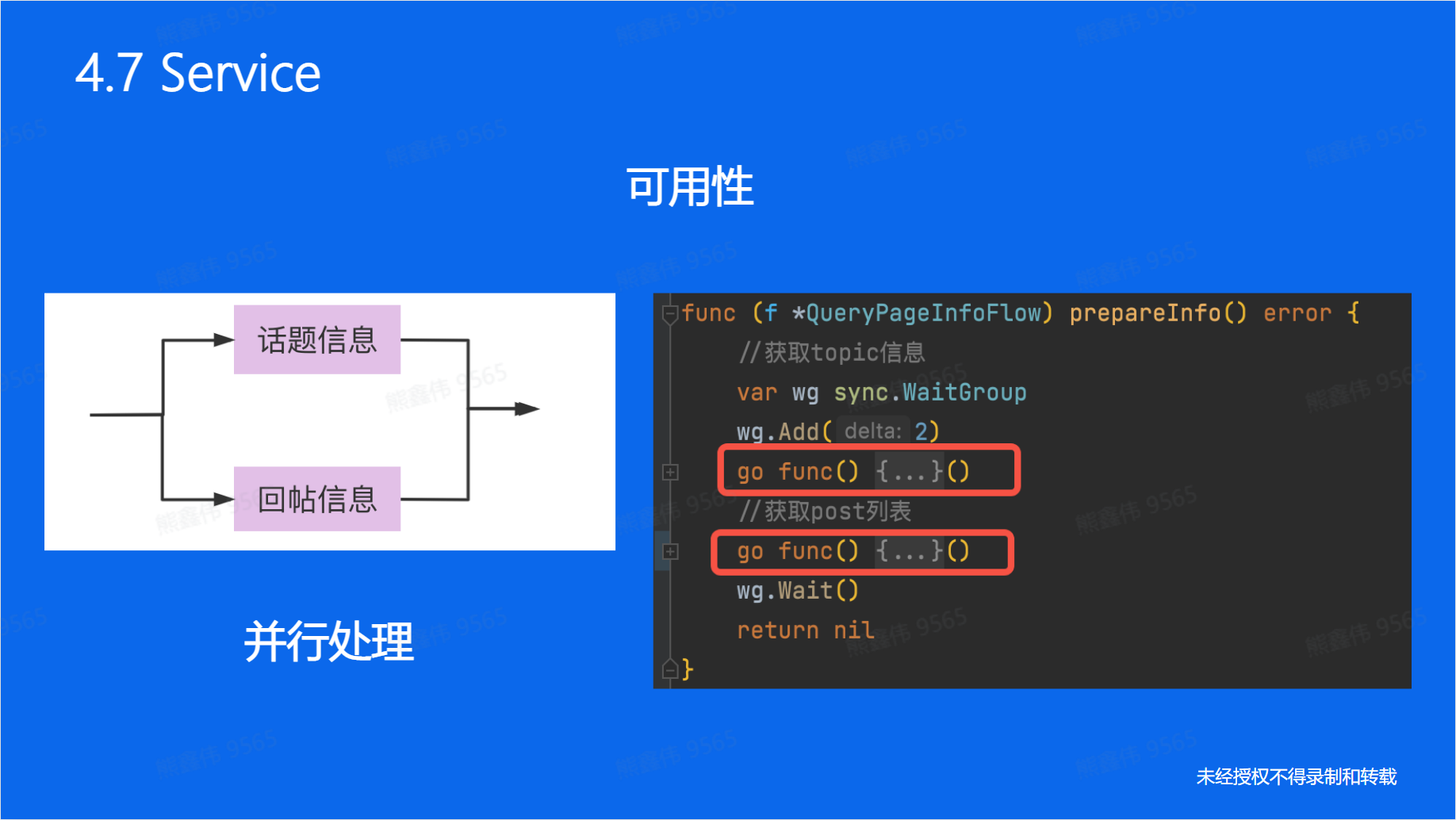
}如何实现查询操作?可以通过全扫描对应,MySQL全表扫描,这样能实现,但是并不高效。
⭕ 或许我们可以用索引,我们通过目录定位结果。
Map 时间复杂度是 O1

实例:


有了这两个函数,我们就可以上传到逻辑层,对其进行封装.
对传入的进行校验,然后组装实体


控制层:
通过 gin 搭建web框架:
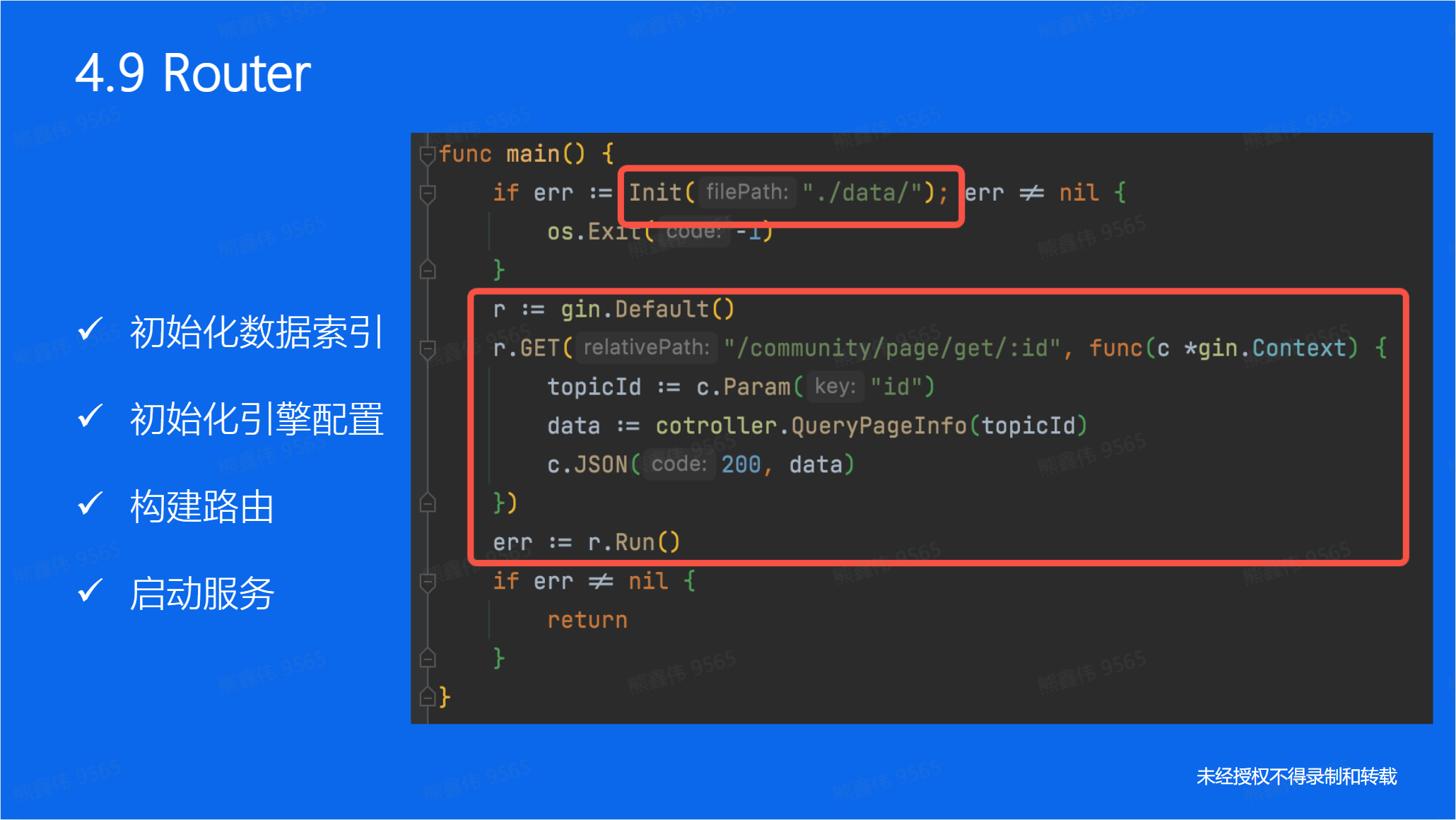
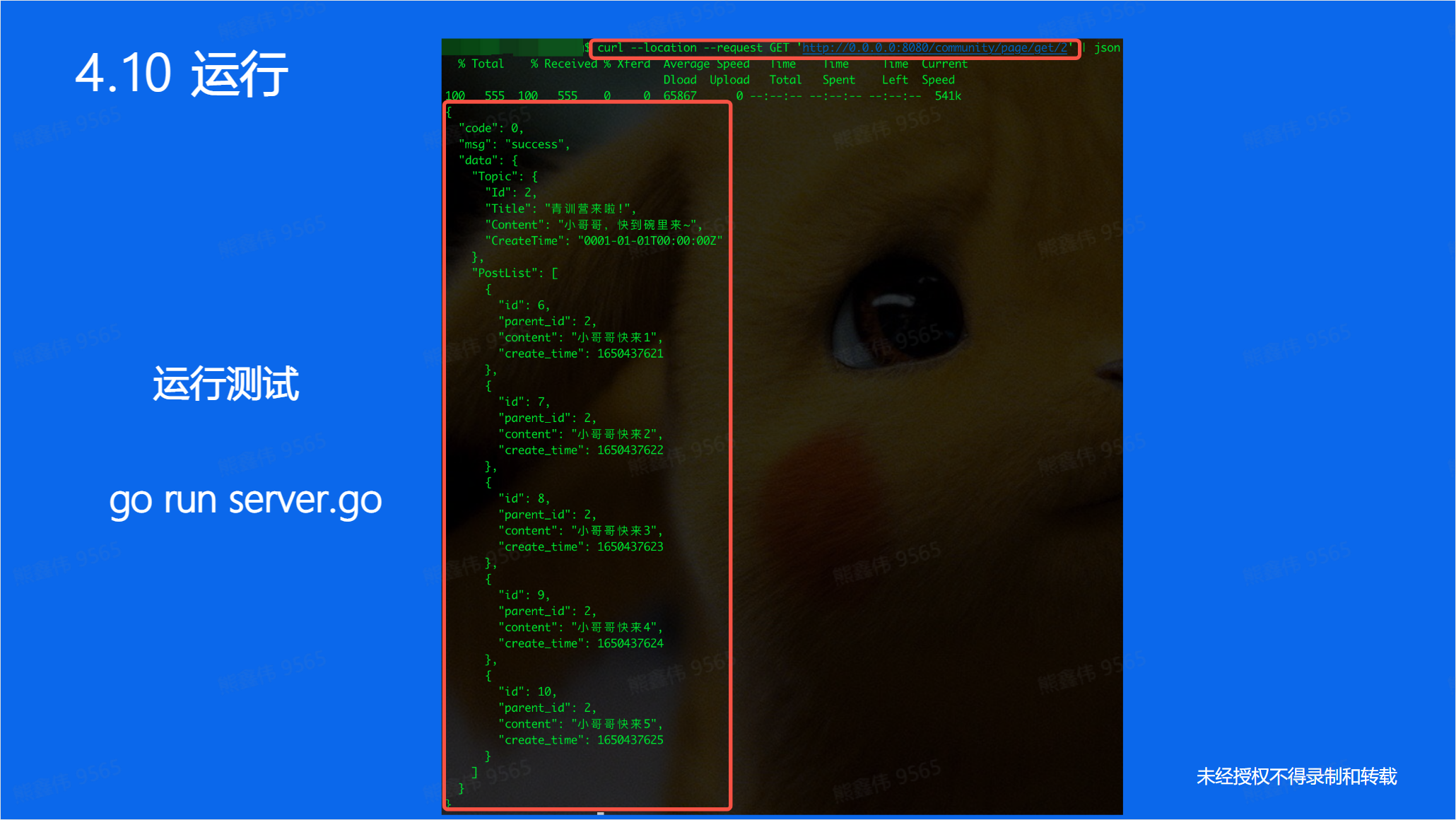
对于学习Go语言来说,一定要学习它的设计思维和编程思维,而不是带入别的语言来批判新的语言,这样你总归无路可循。
在掌握Go基础之后,可以 通过“三刷”的方式掌握SQL、Redis、Linux、Nginx的基础知识点,这样就有能力开发Web项目了。
要进阶就要学 “微服务” 和 “DDD”!
软件的架构模式总的说经历了三个阶段的演进:从单机、集中式到分布式微服务架构。
分布式微服务架构是主流趋势,越来越多的企业采用分布式微服务架构进行业务转型。
那么如何才能更好的从单体架构和集中式架构转型到分布式微服务架构呢?答案就是:DDD。 这也是我们的进阶之道。
DDD (Domain Driven Design):领域驱动设计。