❤️💕💕Go语言高级篇章,在此之前建议您先了解基础和进阶篇。Myblog:http://nsddd.top
[TOC]
Go语言中 sync 包里提供了互斥锁 Mutex 和读写锁 RWMutex 用于处理并发过程中可能出现同时两个或多个协程(或线程)读或写同一个变量的情况。
锁是 sync 包中的核心,它主要有两个方法,分别是加锁(Lock)和解锁(Unlock)。
在并发的情况下,多个线程或协程同时其修改一个变量,使用锁能保证在某一时间内,只有一个协程或线程修改这一变量。
package main
import (
"fmt"
"time"
)
func main() {
var a = 0
for i := 0; i < 1000; i++ {
go func(idx int) {
a += 1
fmt.Println(a)
}(i)
}
time.Sleep(time.Second)
}从理论上来说,上面的程序会将 a 的值依次递增输出,然而实际结果却是下面这样子的。
537
995
996
997
538
999
1000通过运行结果可以看出 a 的值并不是按顺序递增输出的,这是为什么呢?
协程的执行顺序大致如下所示:
- 从寄存器读取 a 的值;
- 然后做加法运算;
- 最后写到寄存器。
按照上面的顺序,假如有一个协程取得 a 的值为 3,然后执行加法运算,此时又有一个协程对 a 进行取值,得到的值同样是 3,最终两个协程的返回结果是相同的。
而锁的概念就是,当一个协程正在处理 a 时将 a 锁定,其它协程需要等待该协程处理完成并将 a 解锁后才能再进行操作,也就是说同时处理 a 的协程只能有一个,从而避免上面示例中的情况出现。
上面的示例中出现的问题怎么解决呢?加一个互斥锁 Mutex 就可以了。那什么是互斥锁呢 ?互斥锁中其有两个方法可以调用,如下所示:
func (m *Mutex) Lock()
func (m *Mutex) Unlock()结果:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var a = 0
var lock sync.Mutex
for i := 0; i < 1000; i++ {
go func(idx int) {
lock.Lock()
defer lock.Unlock()
a += 1
fmt.Printf("goroutine %d, a=%d\n", idx, a)
}(i)
}
// 等待 1s 结束主程序
// 确保所有协程执行完
time.Sleep(time.Second)
}🚀 编译结果如下:
goroutine 995, a=996
goroutine 996, a=997
goroutine 997, a=998
goroutine 998, a=999
goroutine 999, a=1000sync包中比较常用的几个方法及其功能的介绍:
sync.Mutex:互斥锁,它是一种最基本的锁,也是最常用的一种锁。互斥锁只有两种状态:锁定和未锁定,每次只能有一个线程获取锁,其他线程需要等待锁被释放后才能再次尝试获取锁。sync.RWMutex:读写锁,它是一种高级锁,适用于读多写少的场景。读写锁与互斥锁不同的是,读写锁支持多个读操作同时进行,但写操作只能有一个进行。当读操作和写操作同时存在时,写操作优先级更高。sync.WaitGroup:等待组,它用于等待一组goroutine执行完成。等待组有两个主要方法:Add方法用于添加 goroutine 87数量,Done方法用于减少goroutine数量。当等待组内所有goroutine执行完成后,调用Wait方法可以阻塞等待直到所有goroutine完成。sync.Cond:条件变量,它可以让一个goroutine等待另一个goroutine的信号,从而实现线程间的同步。条件变量通常与互斥锁一起使用,可以让等待某个条件的goroutine在条件满足时被唤醒。sync.Once:一次性初始化,它用于保证一个函数只被执行一次。Once的主要方法是Do,它接收一个函数作为参数,只有在第一次调用Do方法时,才会执行该函数。后续对Do方法的调用都将被忽略。
package main
import (
"fmt"
"sync"
)
var (
count int
lock sync.Mutex
)
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
lock.Lock()
defer lock.Unlock()
count++
}()
}
wg.Wait()
fmt.Println("count:", count)
}在这个示例中,我们定义了一个全局变量count和一个sync.Mutex类型的锁lock。然后我们开启了10个goroutine,每个goroutine都会对count进行加一的操作,这个加一的操作需要先获取锁,然后在操作完成后再释放锁。在这个过程中,如果没有使用锁,那么多个goroutine同时对count进行修改,就会导致数据不一致(是指的是其他函数如果也对count进行修改)。使用sync.Mutex能够保证每次只有一个goroutine能够修改count,从而保证数据的一致性。
🚀 编译结果如下:
[Running] go run "c:\Users\smile\Desktop\test\sync.go"
count: 10package main
import (
"fmt"
"sync"
)
var (
count int
rwlock sync.RWMutex
)
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
rwlock.Lock()
defer rwlock.Unlock()
count++
}()
}
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
rwlock.RLock()
defer rwlock.RUnlock()
fmt.Println("count:", count)
}()
}
wg.Wait()
}在这个示例中,我们使用了sync.RWMutex类型的锁rwlock。前面的10个goroutine都对count进行了加一的操作,这个操作需要获取写锁。后面的10个goroutine都只是读取count的值,这个操作只需要获取读锁。使用读写锁能够提高并发性能,因为读操作可以同时进行,而写操作只能有一个进行。
🚀 编译结果如下:
[Running] go run "c:\Users\smile\Desktop\test\sync.go"
count: 0
count: 10
count: 10
count: 10
count: 10
count: 10
count: 10
count: 10
count: 10
count: 10
sync.WaitGroup:等待组,它用于等待一组goroutine执行完成。等待组有两个主要方法:Add方法用于添加goroutine数量,Done方法用于减少goroutine数量。当等待组内所有goroutine执行完成后,调用Wait方法可以阻塞等待直到所有goroutine完成。

sync.Cond:条件变量,它可以让一个goroutine等待另一个goroutine的信号,从而实现线程间的同步。条件变量通常与互斥锁一起使用,可以让等待某个条件的goroutine在条件满足时被唤醒。
sync.Once:一次性初始化,它用于保证一个函数只被执行一次。Once的主要方法是Do,它接收一个函数作为参数,只有在第一次调用Do方法时,才会执行该函数。后续对Do方法的调用都将被忽略。
Go语言的线程调度还是蛮重要的,细节讲一下:
- 进程:资源分配的基本单位
- 线程:这是调度分配的基本单位(用户态线程不分配资源——)
无论是线程还是进程,其实我的理解是,线程也是属于进程,在 Linux 中都是以 task_struct 描述,从内核的本质上看,与进程无本质区别。
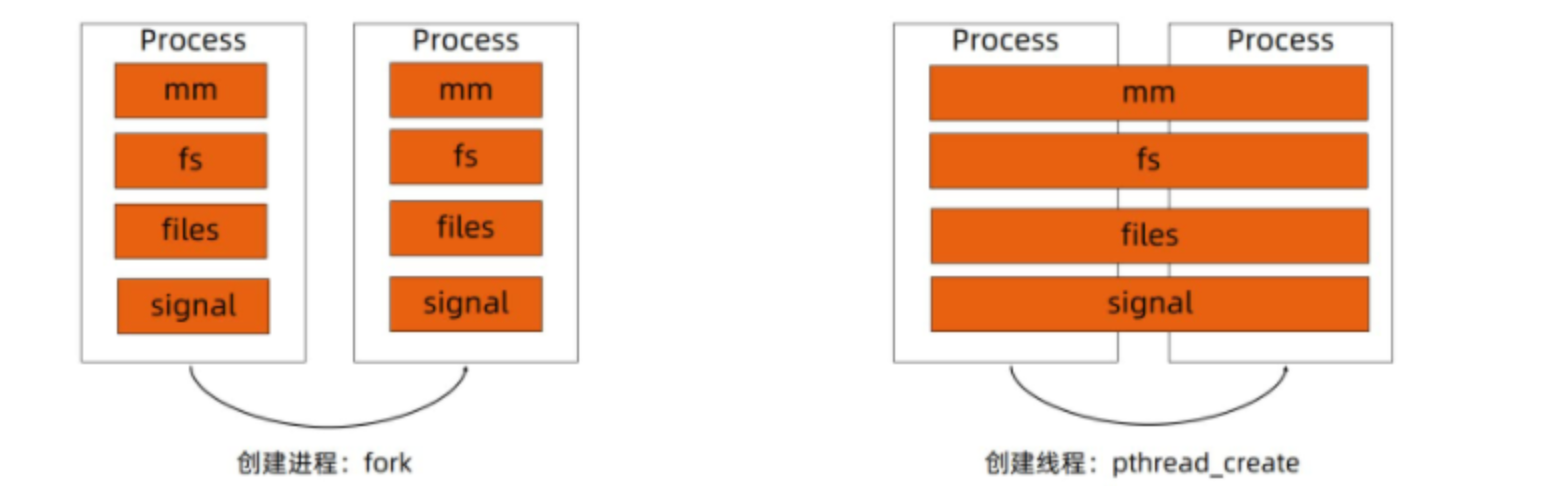
上面的图 告诉我们,线程也可以是一种特殊的进程,进程也是从 init system 根进程 中 不断地 fork 出来的二叉树。那么线程也是一直 copy 进程。
不同的操作系统,大型的系统,比如说 Linux、Kubernetes 都有自己的调度策略。
对于 Go语言 来说,轻量级协程可算是终结者级别的武器,更是有深厚的调度策略值得我们去研究:
这些如何去调度这些协程何时去执行、如何更合理的分配操作系统资源,需要一个设计良好的调度器来支持。
为了引出一个调度策略的话题,我们从一个简单的 go func() 开始:
💡简单的一个案例如下:
func main() {
for i := 0; i < 10; i++ {
go func() {
fmt.Println(i)
}()
}
time.Sleep(1 * time.Second)
}这段代码中,我们开启了10个协程,每个协程打印去打印i这个变量。由于这10个协程的调度时机并不固定,所以等到协程被调度执行的时候才会去取循环中变量i的值。
我们写的这段代码,每个我们开启的协程都是一个计算任务,这些任务会被提交给go的runtime。如果计算任务非常多,有成千上万个,那么这些任务是不可能同时被立刻执行的,所以这个计算任务一定会被先暂存起来,一般的做法是放到内存的队列中等待被执行。
而消费端则是一个go runtime维护的一个调度循环。调度循环简单来说,就是不断从队列中消费计算任务并执行。这里本质上就是一个生产者-消费者模型,实现了用户任务与调度器的解耦。
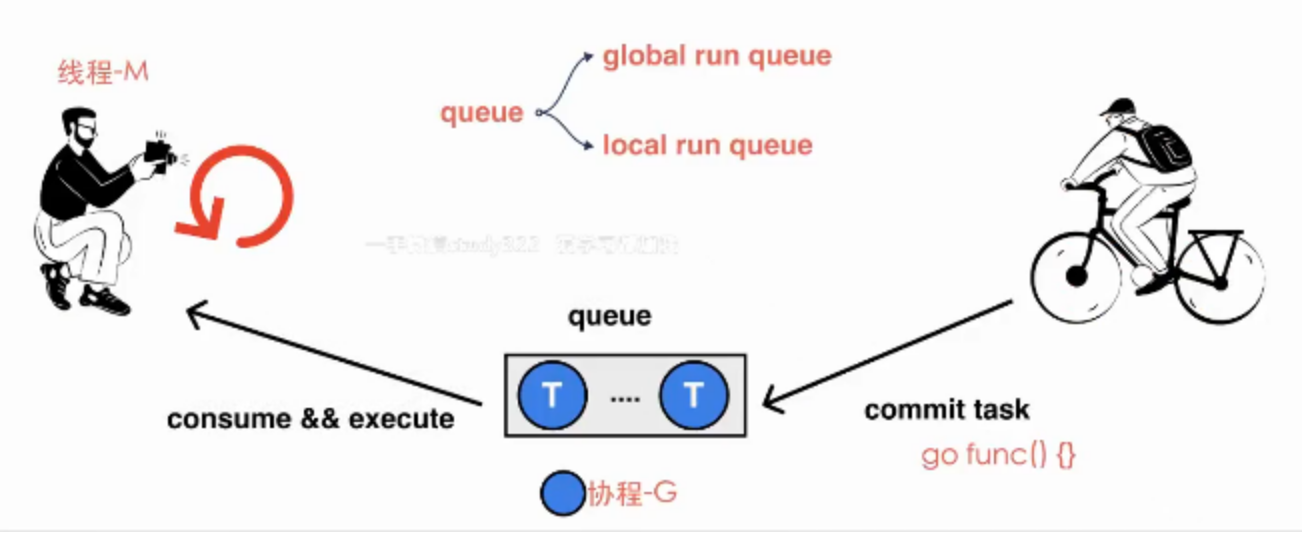
这里图中的G就代表我们的一个goroutine计算任务,M就代表操作系统线程
Linux 进程的内存使用:
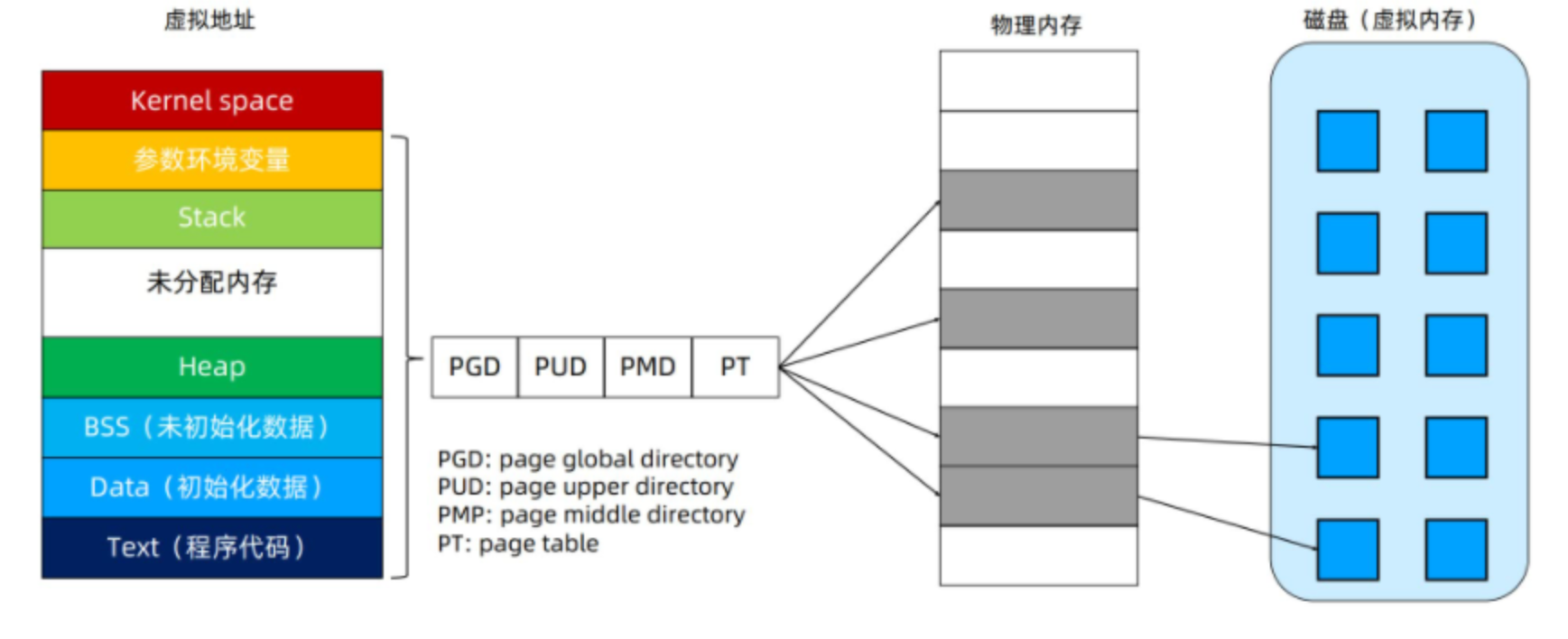
上面是高地址:栈,先进先出,栈是向下生长的,线程中就是栈内存管理
后面是堆,堆是向上生长的
在早期内存管理中,如果程序太大,超过了空闲内存容量,就没有办法把全部程序装入到内存,这时怎么办? 在许多年前,人们采用了一种叫做覆盖技术,这样一种解决方案。
这个方案就是 虚拟内存技术,它的基本思路: 程序运行进程的总大小可以超过实际可用的物理内存的大小。每个进程都可以有自己独立的虚拟地址空间。然后通过CPU和MMU把虚拟内存地址转换为实际物理地址。
这个就相当于在物理内存和程序之间增加了一个中间层,虚拟内存。 虚拟存储也可以看作是对内存的一种抽象。而且这种抽象带来诸多好处:
- 它将内存看成是一个存储在磁盘上的地址空间的高速缓存,在内存中只保留了活动区域,可以根据需要在磁盘和内存间来回传送数据,高效使用内存。
- 它为每个进程提供了一致的地址空间,简化了存储的管理。
- 对进程起到保护作用,不被其他进程地址空间破坏,因为每个进程的地址空间都是相互独立。
Linux发展到现在支持多级页表。
我们对上面图的📜 对上面的解释:
Kernel space:linux内核空间内存Stack:进程栈空间,程序运行时使用。它向下增长,系统自动管理Memory Mapping Segment:内存映射区,通过mmap系统调用,将文件映射到进程的地址空间,或者匿名映射。Heap:堆空间。这个就是程序里动态分配的空间。linux下使用malloc调用扩展(用brk/sbrk扩展内存空间),free函数释放(也就是缩减内存空间)BSS段:包含未初始化的静态变量和全局变量Data段:代码里已初始化的静态变量、全局变量Text段:代码段,进程的可执行文件
我们运行 Go语言 的一个二进制文件,或者编译成二进制的时候,查看:
❯ size sealer
text data bss dec hex filename
70667900 1079425 413880 72161205 44d17b5 sealer我们可以逐渐📜 对上面的解释:
text:这是程序的代码段大小,它包含了可执行的机器指令。在这个示例中,text大小为70667900字节,也就是约67.4 MB。这个值通常会占用可执行文件大小的很大一部分。data:这是程序的已初始化数据大小,包括全局变量和静态变量等。在这个示例中,data大小为1079425字节,也就是约1 MB。bss:这是程序的未初始化数据大小,包括未初始化的全局变量和静态变量等。在这个示例中,bss大小为413880字节,也就是约0.4 MB。dec:这是程序的总大小,包括text、data和bss等。在这个示例中,dec大小为72161205字节,也就是约68.8 MB。hex:这是dec的十六进制表示。
⚠️ 注意: Go语言是不支持 静态变量的~所以说:Go语言是不能写入 data、bss、dec的,是通过 runtime 自带的变量。
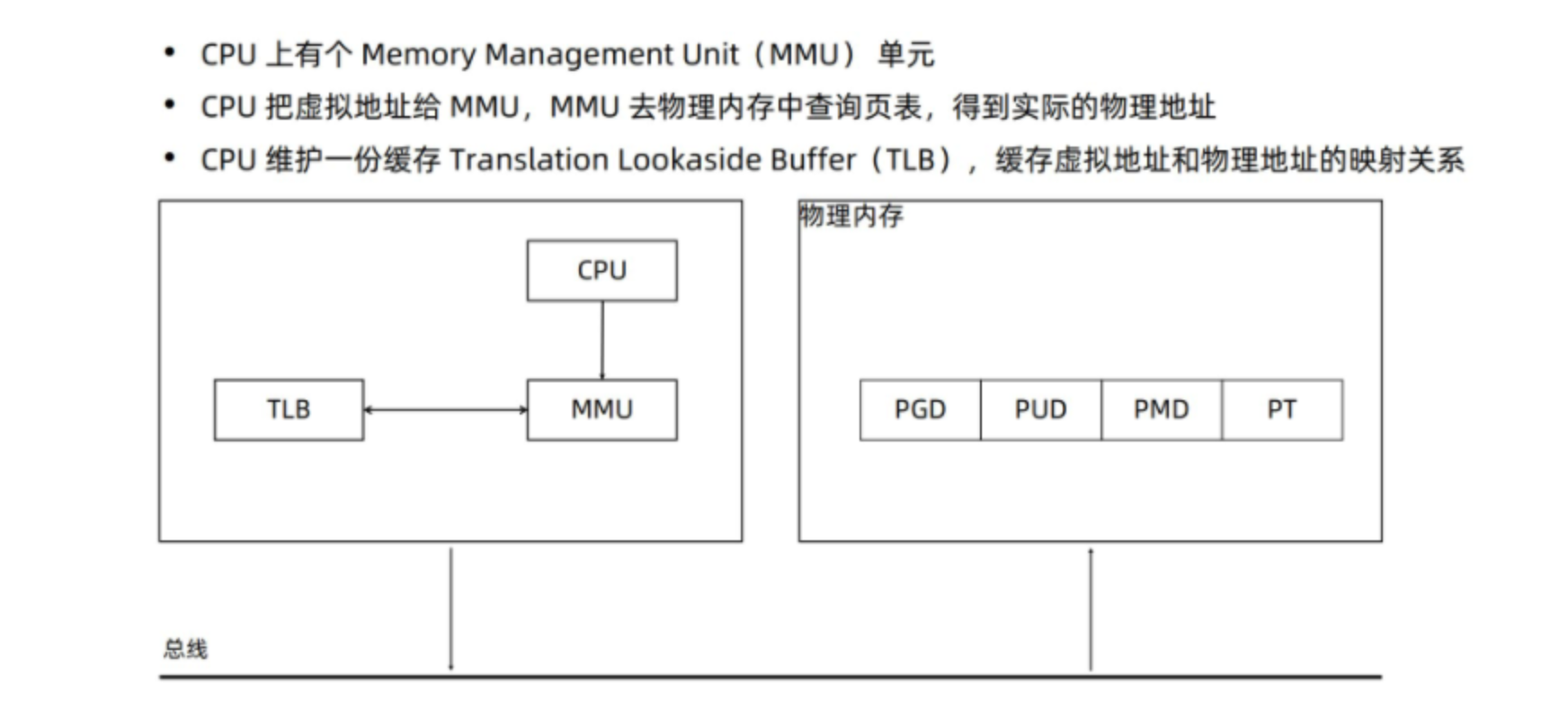
我们最终的目的是了解 进程切换的开销,所以回到主题:
进程的切换,整个进程的虚拟地址都将会切换掉。
进程切换是指从一个进程切换到另一个进程。在操作系统中,进程切换通常需要执行一些额外的操作,以便将控制权从当前进程转移到另一个进程。这些操作涉及到操作系统内核的一些特定的处理和资源调度,因此会带来一定的开销。

直接开销是指直接与进程切换相关的开销,包括:
- 保存和恢复寄存器状态:进程切换时,操作系统需要保存当前进程的寄存器状态,并恢复新进程的寄存器状态。
- 更新内核数据结构:操作系统需要更新进程控制块(Process Control Block,PCB)等内核数据结构,以便管理进程的状态和资源。
- 刷新内存和硬件缓存:当一个进程被挂起时,操作系统需要将其在内存和硬件缓存中的数据刷新到磁盘或其他介质中。
- 上下文切换:操作系统需要切换到新进程的上下文,以便在正确的环境下运行新进程。
间接开销是指与进程切换相关的其他开销,包括:
- 内存分配和释放:进程切换可能需要分配和释放内存,这些操作需要消耗时间和资源。
- 调度决策:进程切换可能会导致操作系统重新评估进程的优先级和调度策略,这需要一些开销。
- 虚拟内存管理:进程切换可能会导致虚拟内存管理机制重新映射物理内存和虚拟内存,这需要一些开销。
线程我们知道,可以不需要资源的分配哈,是不是更容易切换? 是的
线程从内核的角度看:线程依旧是一个进程。依然需要系统调用。
- 线程本质上只是一批共享资源的进程,线程本质上仍然需要内核进行线程切换。
- 一组线程因为共享内存资源,因此一个进程的所有线程共享虚拟地址资源,线程相比较进程:主要是节省了虚拟地址空间的切换。
🆗,我们也知道对吧,还有个用户线程,用户线程在用户空间创建的可执行单元,创建和销毁完全在用户态完成。
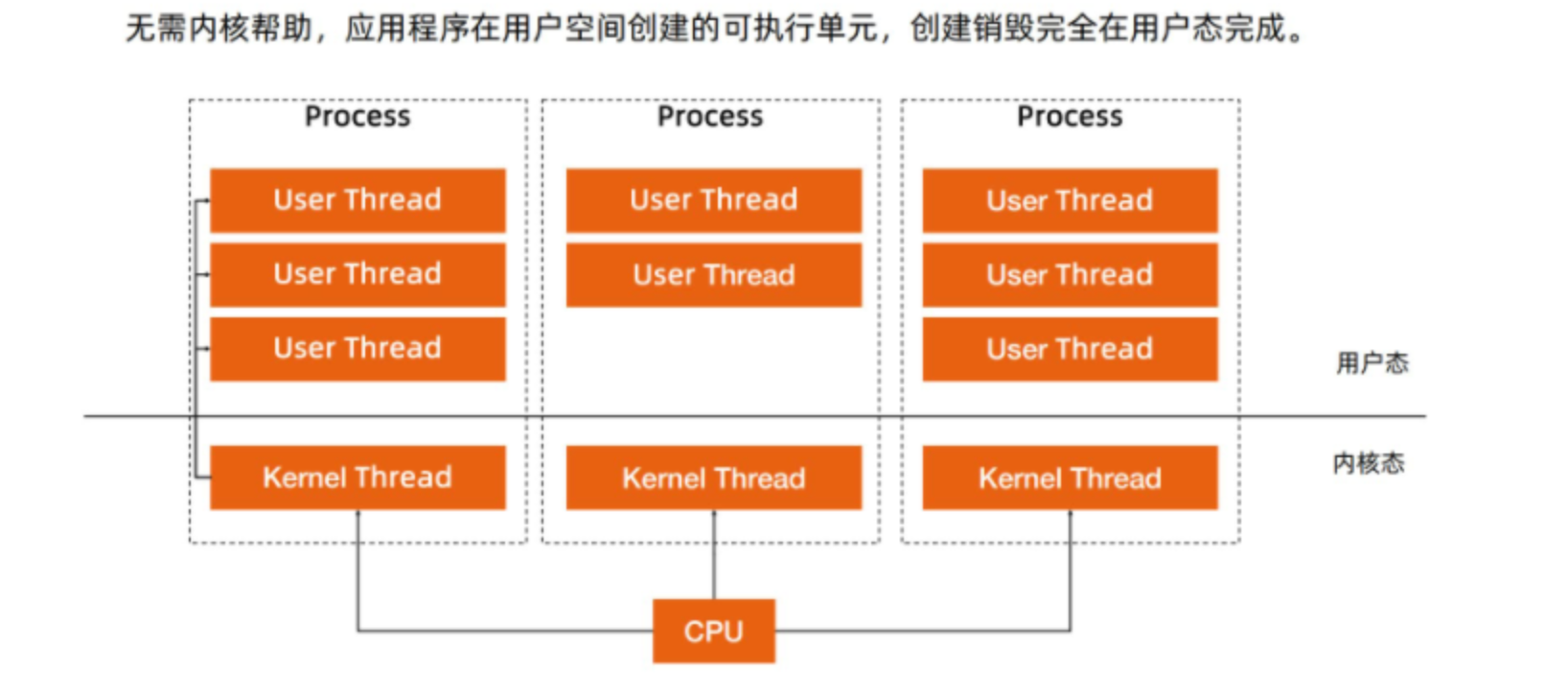
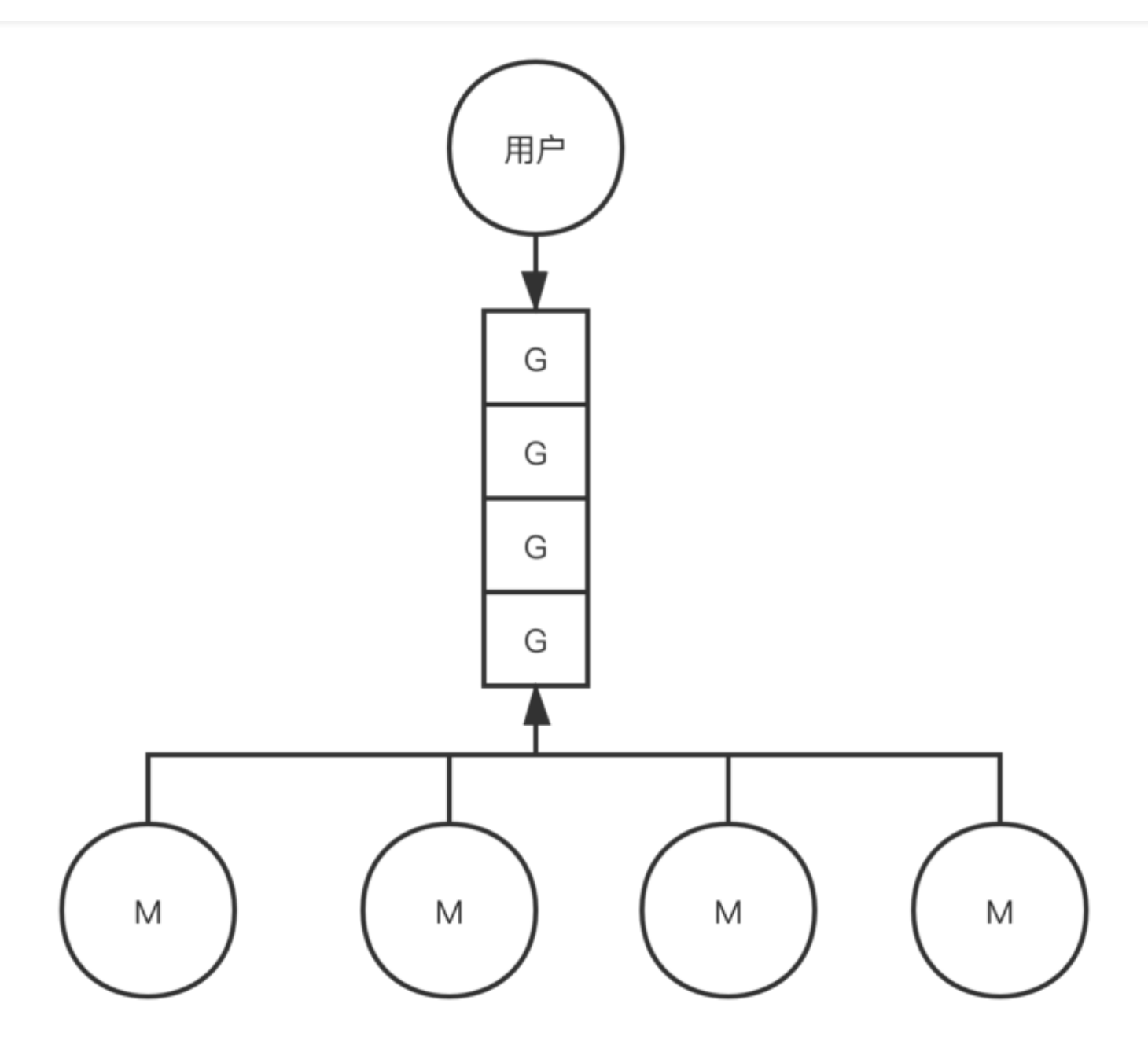
那么 Goruntime 就是基于 GMP 模型实现用户态线程的。

在 Go 中,线程是运行 goroutine 的实体,调度器的功能是把可运行的 goroutine 分配到工作线程上。
Processor,它包含了运行 goroutine 的资源,如果线程想运行 goroutine,必须先获取 P,P 中还包含了可运行的 G 队列。
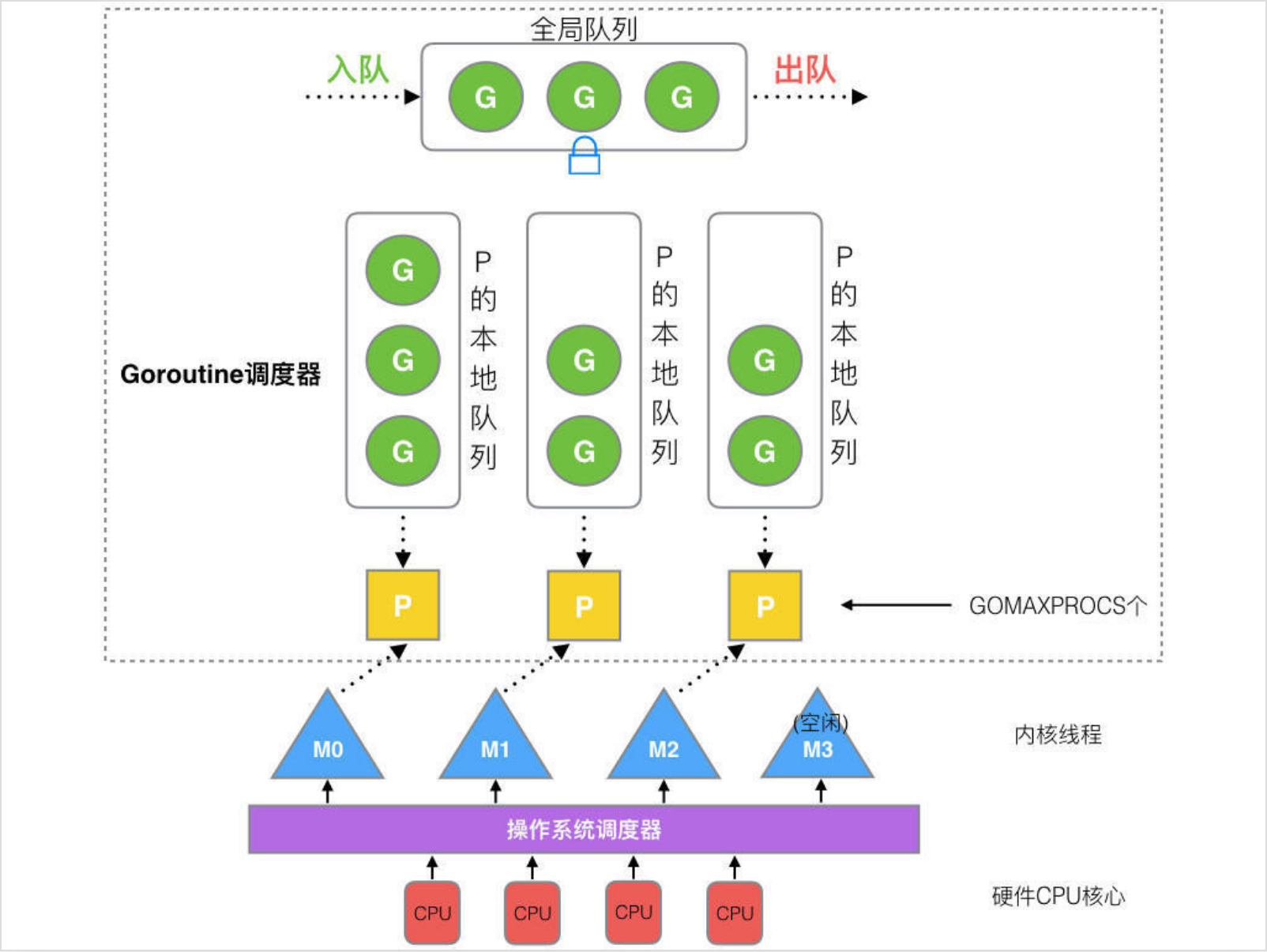
- 全局队列(Global Queue):存放等待运行的 G。
- P 的本地队列:同全局队列类似,存放的也是等待运行的 G,存的数量有限,不超过 256 个。新建 G’时,G’优先加入到 P 的本地队列,如果队列满了,则会把本地队列中一半的 G 移动到全局队列。
- P 列表:所有的 P 都在程序启动时创建,并保存在数组中,最多有 GOMAXPROCS(可配置) 个。
- M:线程想运行任务就得获取 P,从 P 的本地队列获取 G,P 队列为空时,M 也会尝试从全局队列拿一批 G 放到 P 的本地队列,或从其他 P 的本地队列偷一半放到自己 P 的本地队列。M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。
模型细节:
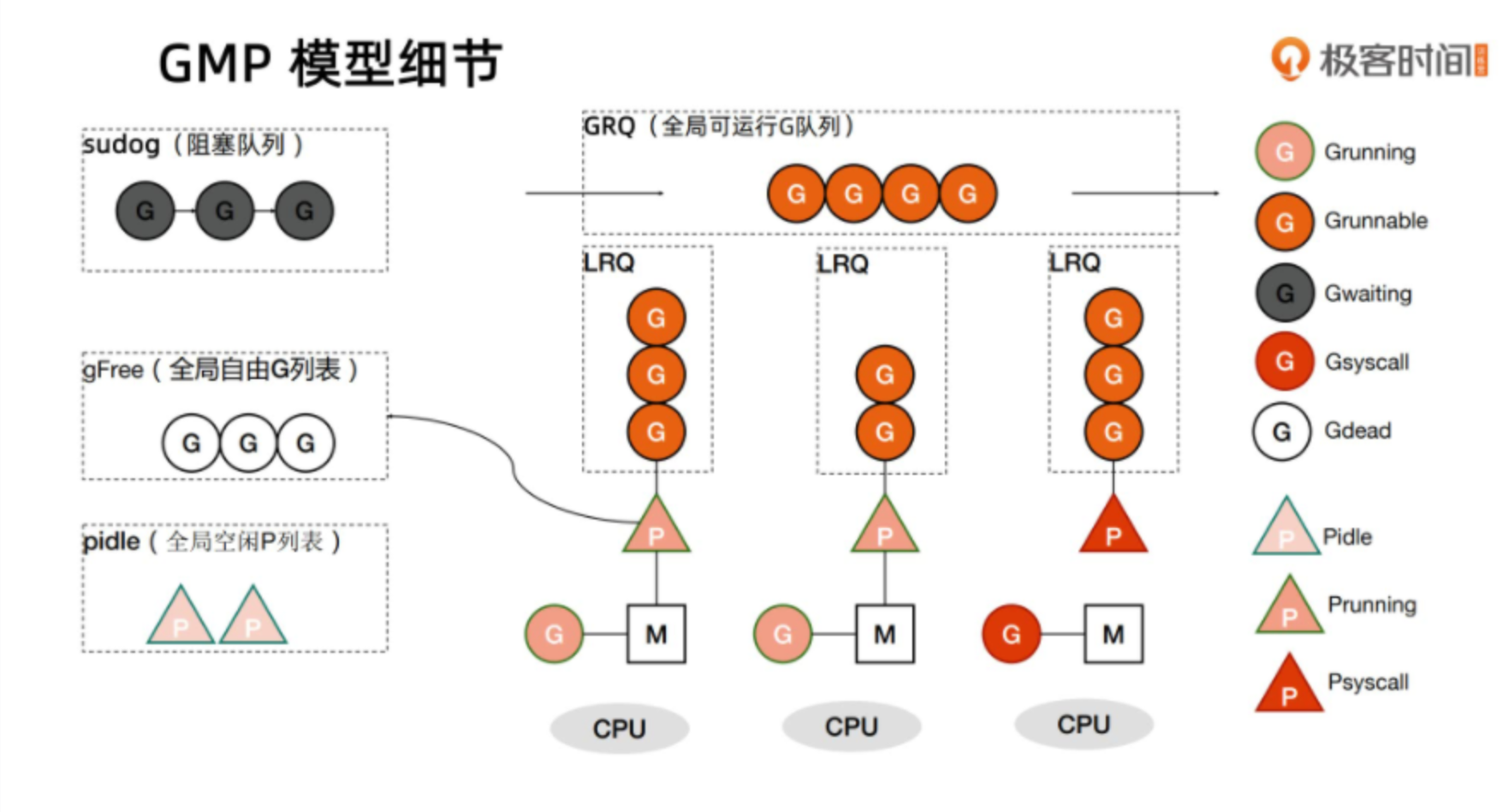
接上面的例子,我们生产了10个计算任务,我们一定是要在内存中先把它存起来等待调度器去消费的。那么很显然,最合适的数据结构就是队列,先来先服务。但是这样做是有问题的。现在我们都是多核多线程模型,消费者肯定不止有一个,所以如果多个消费者去消费同一个队列,会出现线程安全的问题,必须加锁。所有计算任务G都必须在M上来执行。