原文:https://os.phil-opp.com/double-fault-exceptions/
原作者:@phil-opp
译者:倪广野
这篇文章将深入探究双重异常(double fault),这是一个在CPU调用异常处理函数失败的时候触发的异常。通过处理双重异常,可以避免会引起系统复位的三重异常。为了彻底防止各种情况下的三重异常,需要建立中断栈表( Interrupt Stack Table )去捕获所有不同内核栈的双重异常。
这个博客在 GitHub 上开源。如果你遇到问题或困难,请到那里提 issue 。或者你也可以在博客的最下方留言。你可以在 post-06 分支找到这篇文章的完整源码。
译注:中文版请移步《编写 Rust 语言的操作系统》
简单点说,双重异常就是一个在CPU调用异常处理函数失败的时候触发的特定异常。例如,CPU触发缺页异常(page fault),但是中断描述符表( Interrupt Descriptor Table ,IDT)中却没有对应处理函数的情况。所以,这和编程语言中捕获所有异常的代码块(catch-all blocks)有些相似,例如 C++ 中的 catch(...) 或 Java和 C# 中的 catch(Exception e) 。
双重异常的表现和普通异常区别不大。它拥有一个特定的向量号(Interrupt Vector Number) 8 ,我们可以在 IDT 中定义一个对应的处理函数。定义双重异常的处理函数十分重要,因为双重异常在不被处理的情况下会引发致命的三重异常。三重异常不能被捕获,而且会引起大多数硬件的系统复位。
让我们通过触发一个没有处理函数的普通异常来引发双重异常:
// in src/main.rs
#[no_mangle]
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
// trigger a page fault
unsafe {
*(0xdeadbeef as *mut u64) = 42;
};
// as before
#[cfg(test)]
test_main();
println!("It did not crash!");
loop {}
}我们使用 unsafe 去写入非法的内存地址 0xdeadbeef 。这个虚拟地址没有在页表中被映射到物理地址,这会触发一个缺页异常。而缺页异常的处理函数还没有被定义到 IDT ,因此双重异常被触发了。
现在启动内核,它会进入到无穷尽的启动循环。原因如下:
- CPU 试图写入非法的内存地址
0xdeadbeef,这会触发缺页异常。 - CPU 查找到 IDT 中缺页异常对应的条目,并且没有发现对应的处理函数。因为它不能正常调用缺页异常的处理函数,所以触发了双重异常。
- CPU 查找到 IDT 中双重异常对应的条目,并且也没有发现对应的处理函数。因此,三重异常被触发。
- 三重异常是致命的。QEMU 像大多数的硬件一样选择系统复位。
所以为了阻止三重异常,我们需要提供缺页异常或双重异常的处理函数。我们希望阻止所有情况下的三重异常,因此我们选择建立所有异常未被处理时都会调用的双重异常处理函数。
双重异常由普通异常和错误码组成,所以我们可以像断点异常处理函数那样定义一个双重异常处理函数。
// in src/interrupts.rs
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
idt.double_fault.set_handler_fn(double_fault_handler); // new
idt
};
}
// new
extern "x86-interrupt" fn double_fault_handler(
stack_frame: &mut InterruptStackFrame, _error_code: u64) -> !
{
panic!("EXCEPTION: DOUBLE FAULT\n{:#?}", stack_frame);
}双重异常处理函数打印了一个简短的错误消息和异常栈帧信息。双重异常的错误码通常会是0,所以没有必要打印出来。双重异常处理函数和断点异常处理函数的区别在于,它是一个发散函数( diverging)。因为 x86_64 体系架构不允许从双重异常中返回。
现在启动内核,我们可以看见双重异常处理函数被调用了:
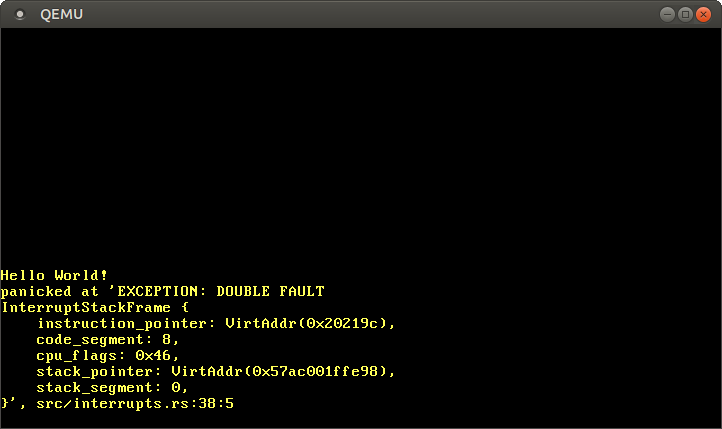
工作正常!这次发生了什么:
- CPU 试图写入非法的内存地址
0xdeadbeef,这会触发缺页异常。 - 像上次一样,CPU 查找到 IDT 中缺页异常对应的条目,并且没有发现对应的处理函数。因为它不能正常调用缺页异常的处理函数,所以触发了双重异常。
- CPU 跳转到双重异常处理函数——它现在是就绪的了。
因为 CPU 现在可以正常调用双重异常处理函数,所以三重异常(和启动循环)不会再次出现。
这非常容易理解!那么我们为什么需要用整篇文章讨论这个话题? 我们现在可以捕获大多数双重异常,但是在某些情况下,现在的方式并不足够有效。
在探究某个特定的原因之前,我们需要理解双重异常的确切定义。上文中,我们给出了相当粗略的定义:
双重异常就是一个在CPU调用异常处理函数失败的时候触发的特定异常。
“调用异常处理函数失败”的准确含义是什么? 处理函数不可用? 处理函数被换出( swapped out)? 并且如果处理函数自身触发了异常会发生什么?
例如,下列情况会发生什么:
- 断点异常触发,但是对应的处理函数被换出?
- 缺页异常触发,但是缺页异常处理函数被换出?
- 除0异常引发了断点异常,但是断点异常处理函数被换出?
- 内核栈溢出,同时保护页( guard page)被命中(hit)?
幸运的是,AMD64手册((PDF)给出了明确定义(8.2.9章节)。根据手册的定义,“当第二个异常出现在先前的(第一个)异常处理函数执行期间,双重异常可能会被触发”。“可能”二字说明:只有特定的异常组合才会导致双重异常。这些组合是:
所以缺页异常紧跟除0异常不会触发双重异常(缺页异常处理函数被调用),但是一般保护错误紧跟除0异常一定会触发双重异常。
参考这张表格,可以得到上述前三个问题的答案:
- 断点异常触发,但是对应的处理函数被换出,缺页异常会被触发,然后调用缺页异常处理函数。
- 缺页异常触发,但是缺页异常处理函数被换出,双重异常会被触发,然后调用双重异常处理函数。
- 除0异常引发了断点异常,CPU试图调用断点异常处理函数。如果断点异常处理函数被换出,缺页异常会被触发,然后调用缺页异常处理函数。
实际上,异常在 IDT 中没有对应的处理函数时会遵顼以下方案:
当异常发生时,CPU 试图读取对应的 IDT 条目。如果条目是0,说明这不是一个合法的 IDT 条目,一般保护错误会被触发。我们没有定义一般保护错误的处理函数,所以另一个一般保护错误被触发。根据上表,这会导致双重异常。
让我们开始探究第四个问题:
内核栈溢出,同时保护页( guard page)被命中(hit)?
保护页是存在栈底的特定内存页,它被用来发现栈溢出。保护页没有映射到任何物理内存页,所以访问它会导致缺页异常而不是无声无息地损坏其它内存。引导程序(bootloader)为内核栈建立了保护页,所以内核栈溢出会触发缺页异常。
当缺页异常发生,CPU 查找 IDT 中地缺页异常处理函数并将中断栈帧( interrupt stack frame)压入内核栈。然而,当前栈指针依然指向不可用地保护页。因此,第二个缺页异常被触发了,这会引发双重异常(根据上表)。
CPU 试图调用双重异常处理函数,它当然会试图压入异常栈帧。此时栈指针依然会指向保护页(因为栈溢出了),所以第三个缺页异常被触发了,紧接着三重异常和系统复位也发生了。当前的双重异常处理函数无法阻止这种情形下的三重异常。
让我们复现这个情形吧!通过调用无穷的递归函数可以轻易引发内核栈溢出:
// in src/main.rs
#[no_mangle] // don't mangle the name of this function
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
fn stack_overflow() {
stack_overflow(); // for each recursion, the return address is pushed
}
// trigger a stack overflow
stack_overflow();
[…] // test_main(), println(…), and loop {}
}在QEMU中执行程序的时候,操作系统再次进入无限重启的情况:
如何阻止这个问题? 由于压入异常栈帧是CPU硬件的操作,所以我们不能干扰这一步。我们只能以某种方式让内核栈在双重异常触发的时候保持可用(不会溢出)。幸运的是,x86_64 架构提供了这个问题的解决方式。
x86_64 架构可以在异常发生时切换到预定义且已知良好的栈中。这个切换发生在硬件级别,所以它可以在CPU压入异常栈帧之前完成。
切换机制基于中断栈表( Interrupt Stack Table ,IST)。IST由7个指向已知良好的栈的指针组成。Rust风格的伪代码:
struct InterruptStackTable {
stack_pointers: [Option<StackPointer>; 7],
}对于每一个异常处理器,我们可以通过对应 IDT entry 中的 stack_pointers字段在 IST 中找到一个栈。例如,双重异常处理器可以使用 IST 中的第一个栈。此后,CPU会主动在双重异常发生时切换到这个栈。切换之前不会由任何东西被压入栈中,所以它可以阻止三重异常的发生。
中断栈表是早期遗留下来的结构体——任务状态段( Task State Segment,TSS)的一部分。在32位模式下,TSS 被用来保存任务(task)相关的各种信息(例如寄存器的状态),包括硬件上下文切换(hardware context switching)等。然而,在64位模式下,硬件上下文切换不再被支持,同时 TSS 的格式也已经面目全非。
在 x86_64 架构下,TSS 不再保存任何关于任务(task)的信息。取而代之的是两个栈表( IST 是其中之一)。TSS 在32位和64位模式下唯一相同的字段是指向 I/O port permissions bitmap 的指针。
在64位模式下, TSS 的格式如下:
| Field | Type |
|---|---|
| (保留位) | u32 |
| 特权栈表(Privilege Stack Table) | [u64; 3] |
| (保留位) | u64 |
| 中断栈表(Interrupt Stack Table) | [u64; 7] |
| (保留位) | u64 |
| (保留位) | u16 |
| I/O Map Base Address | u16 |
特权栈表会在 CPU 改变特权级别的时候被使用。例如,CPU 处在用户模式(user mode,特权级别 3 )时触发了异常,它通常会在调用异常处理函数之前切换到内核模式(kernel mode,特权级别 0 )。在这种情况下,CPU 会切换到特权栈表的第0个栈中(因为目标特权级别是0)。我们当前的内核没有运行在用户模式下的程序,所以可以暂时忽略特权栈表。
为了创建一个在自身的中断栈表中包含不同双重异常栈的 TSS ,我们需要一个 TSS 结构体。幸运的是, x86_64 模块已经提供了 TaskStateSegment 结构体 供我们使用。
我们在新的 gdt 模块(下文中解释)中创建 TSS 。
// in src/lib.rs
pub mod gdt;
// in src/gdt.rs
use x86_64::VirtAddr;
use x86_64::structures::tss::TaskStateSegment;
use lazy_static::lazy_static;
pub const DOUBLE_FAULT_IST_INDEX: u16 = 0;
lazy_static! {
static ref TSS: TaskStateSegment = {
let mut tss = TaskStateSegment::new();
tss.interrupt_stack_table[DOUBLE_FAULT_IST_INDEX as usize] = {
const STACK_SIZE: usize = 4096 * 5;
static mut STACK: [u8; STACK_SIZE] = [0; STACK_SIZE];
let stack_start = VirtAddr::from_ptr(unsafe { &STACK });
let stack_end = stack_start + STACK_SIZE;
stack_end
};
tss
};
}由于Rust的常量求值器( Rust's const evaluator )并不支持在编译期内完成初始化,所以我们使用了 lazy_static 。我们定义了 IST 的第0个条目指向双重异常栈( IST 的其它条目也可以正常运行),然后向第0个条目写入了双重异常栈的顶部地址(因为 x86 机器的栈地址向下扩展,也就是从高地址到低地址)。
因为我们的内核还没有实现内存管理机制,所以我们还没有一个像样的方式去分配新的栈。作为替代,我们当前使用 static mut 数组作为栈的存储。 unsafe 是必要的,因为编译器不能确保可变静态变量被访问时的竞争自由。使用 static mut 而不是 static 是因为 bootloader 会把它映射到只读内存页上。下篇文章中,我们会使用一个像样的栈内存分配方式去取代这个方式,那时就不再需要 unsafe 了。
不得不提的是,这个双重异常栈没有保护页去避免栈溢出。这意味着我们不能在双重异常处理函数中做任何过度使用函数栈的的事情,以避免栈溢出破坏栈地址以下的内存。
我们需要一种方式让 CPU 明白新的 TSS 已经可用了。不幸的是,这个过程很复杂,因为 TSS 使用了分段系统(历史遗留问题)。既然不能直接加载 TSS ,我们需要在全局描述符表( Global Descriptor Table ,GDT)中增加一个段描述符。然后就可以通过各自的 GDT 指针调用 ltr 指令 去加载 TSS 。
全局描述符表是分页机制成为事实上的标准之前的一个古老概念,它被用于内存分段( memory segmentation )。全局描述符表在64位模式下依然发挥着作用,例如内核/用户模式的配置和 TSS 的加载。GDT 包含了一个程序的所有分段。在分页机制还没有成为标准的古老体系架构中,GDT 被用来隔离所有的程序。你可以检阅开源手册 “Three Easy Pieces” 的同名章节获取更多关于分段机制的信息。虽然64位模式下不再支持分段机制,但是GDT 仍然保留了下来。它被用于两件事情:在内核空间和用户空间之间切换,加载 TSS 结构体。
创建一个包含用于 TSS 静态变量的段的 GDT :
// in src/gdt.rs
use x86_64::structures::gdt::{GlobalDescriptorTable, Descriptor};
lazy_static! {
static ref GDT: GlobalDescriptorTable = {
let mut gdt = GlobalDescriptorTable::new();
gdt.add_entry(Descriptor::kernel_code_segment());
gdt.add_entry(Descriptor::tss_segment(&TSS));
gdt
};
}由于Rust的常量求值器( Rust's const evaluator )并不支持在编译期内完成初始化,所以我们再次使用了 lazy_static 。我们创建了一个包含代码段(code segment)和 TSS 段( TSS segment)的 GDT 。
通过在 init 函数调用新建立的 gdt::init 函数加载 GDT :
// in src/gdt.rs
pub fn init() {
GDT.load();
}
// in src/lib.rs
pub fn init() {
gdt::init();
interrupts::init_idt();
}现在 GDT 已经加载完毕(因为 _start 函数调用了 init 函数),但是仍然出现了栈溢出引发的启动循环。
由于段寄存器和 TSS 寄存器仍然保存着来自于旧的 GDT 的内容,我们新 GDT 的分段并没有起作用。所以我们还需要修改双重异常对应的 IDT 条目去让它使用新的栈。
总的来说,我们需要完成以下步骤:
- 重新装载代码段寄存器:我们修改了 GDT ,所以应当重新装载代码段寄存器——
cs。这是必要的,既然现在旧的段选择子可以指向不同的 GDT 描述符(例如 TSS 描述符)。 - 加载 TSS :我们已经加载了包含 TSS 段选择子的 GDT ,但是仍然需要告知 CPU 使用新的 TSS 。
- 更新 IDT 条目:一旦 TSS 加载完毕,CPU便访问到了合法的中断栈表( IST )。然后通过更新双重异常条目告知 CPU 使用新的双重异常栈。
第一、二步需要我们在 gdt::init 函数中访问 code_selector 和 tss_selector 变量。为了实现这个操作,我们可以通过一个新的 Selectors 结构体将它们包含在 static 块中。
// in src/gdt.rs
use x86_64::structures::gdt::SegmentSelector;
lazy_static! {
static ref GDT: (GlobalDescriptorTable, Selectors) = {
let mut gdt = GlobalDescriptorTable::new();
let code_selector = gdt.add_entry(Descriptor::kernel_code_segment());
let tss_selector = gdt.add_entry(Descriptor::tss_segment(&TSS));
(gdt, Selectors { code_selector, tss_selector })
};
}
struct Selectors {
code_selector: SegmentSelector,
tss_selector: SegmentSelector,
}现在可以使用选择子(selectors)重新加载 cs 段寄存器并加载新的 TSS :
// in src/gdt.rs
pub fn init() {
use x86_64::instructions::segmentation::set_cs;
use x86_64::instructions::tables::load_tss;
GDT.0.load();
unsafe {
set_cs(GDT.1.code_selector);
load_tss(GDT.1.tss_selector);
}
}我们使用 set_cs 和 load_tss 函数分别重新加载代码段寄存器和 TSS 。我们需要在 unsafe 代码块中调用这两个函数,因为它们均被声明为 unsafe —— 它们可能由于加载了非法的选择子而破坏内存安全。
现在,合法的 TSS 和 中断栈表已经加载完毕,我们可以在 IDT 中设置用于双重异常的栈指针:
// in src/interrupts.rs
use crate::gdt;
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
unsafe {
idt.double_fault.set_handler_fn(double_fault_handler)
.set_stack_index(gdt::DOUBLE_FAULT_IST_INDEX); // new
}
idt
};
}set_stack_index 方法是不安全的,因为调用者必须保证使用的指针是合法的并且没有被用于其它异常。
That's it! CPU 会在所有双重异常发生的时候切换到双重异常栈。因此,我们可以捕获所有双重异常——包括在内核栈溢出的情况中。
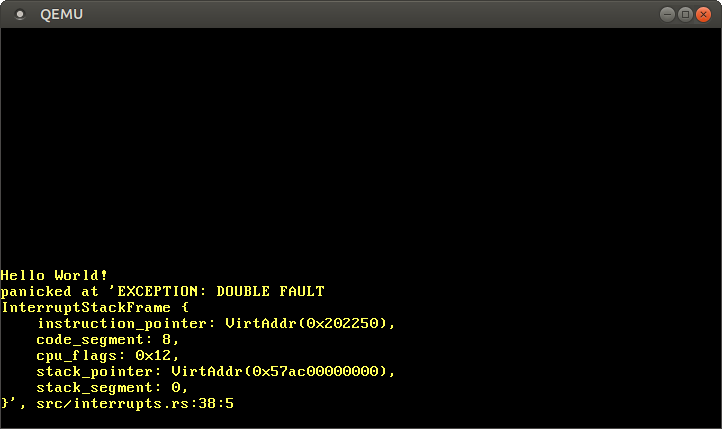
从现在起,三重异常永远不会再次出现了!为了确保不会意外地弄坏上面的程序,我们应该加上测试。
为了测试新的 gdt 模块并且确保在栈溢出的情况下,双重异常处理函数被正确的调用,我们可以增加一个集成测试。思路是在测试函数中触发一个双重异常并验证双重异常处理函数被调用。
从最小可用版本开始:
// in tests/stack_overflow.rs
#![no_std]
#![no_main]
use core::panic::PanicInfo;
#[no_mangle]
pub extern "C" fn _start() -> ! {
unimplemented!();
}
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
blog_os::test_panic_handler(info)
}类似于 panic_handler 测试,新的测试不会运行在测试环境下( without a test harness)。原因在于我们不能在双重异常之后继续执行,所以连续进行多个测试是行不通的。为了禁用测试环境,需要在 Cargo.toml 中增加以下配置:
# in Cargo.toml
[[test]]
name = "stack_overflow"
harness = false现在,执行 cargo test --test stack_overflow 会编译成功。测试当然会由于 unimplemented 宏的崩溃(panics)而失败。
_start 函数的实现如下所示:
// in tests/stack_overflow.rs
use blog_os::serial_print;
#[no_mangle]
pub extern "C" fn _start() -> ! {
serial_print!("stack_overflow::stack_overflow...\t");
blog_os::gdt::init();
init_test_idt();
// trigger a stack overflow
stack_overflow();
panic!("Execution continued after stack overflow");
}
#[allow(unconditional_recursion)]
fn stack_overflow() {
stack_overflow(); // for each recursion, the return address is pushed
volatile::Volatile::new(0).read(); // prevent tail recursion optimizations
}调用 gdt::init 函数初始化新的 GDT 。我们调用了 init_test_idt 函数(稍后会解释它)而不是 interrupts::init_idt 函数。原因在于我们希望注册一个自定义的双重异常处理函数执行exit_qemu(QemuExitCode::Success) 而不是直接崩溃( panicking)。
stack_overflow 函数和 main.rs 中的函数几乎一致。唯一的不同是我们在函数末尾增加了额外的 volatile 读,这是使用 Volatile 类型阻止编译器的尾调用优化( tail call elimination)。此外,这个优化允许编译器将递归函数转化为循环。因此,函数调用的时候不会有额外的栈帧产生,栈的使用是固定不变的(译注:上文中提到这个双重异常栈没有保护页去避免栈溢出。如果在双重异常处理函数中做任何过度使用函数栈的的事情,会导致栈溢出破坏栈地址以下的内存)。
在测试场景中,我们希望栈溢出的发生,所以在函数的末尾增加了一个模拟的 volatile 读语句,这个语句不会被编译器优化掉。因此,这个函数不再是尾递归,也不会被转化为循环。我们同时使用 allow(unconditional_recursion) 属性禁止了编译器的警告——这个函数会无休止地重复。
如上所述,这个测试需要独立持有双重异常处理函数的 IDT 。实现如下:
// in tests/stack_overflow.rs
use lazy_static::lazy_static;
use x86_64::structures::idt::InterruptDescriptorTable;
lazy_static! {
static ref TEST_IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
unsafe {
idt.double_fault
.set_handler_fn(test_double_fault_handler)
.set_stack_index(blog_os::gdt::DOUBLE_FAULT_IST_INDEX);
}
idt
};
}
pub fn init_test_idt() {
TEST_IDT.load();
}这个实现和 interrupts.rs 中普通的 IDT 非常相似。和在普通的 IDT 中一样,我们在 IST 中将双重异常处理函数设置为独立的栈。 init_test_idt 函数通过 load 方法加载 IDT 到CPU中。
现在唯一缺少的便是双重异常处理函数了。实现如下:
// in tests/stack_overflow.rs
use blog_os::{exit_qemu, QemuExitCode, serial_println};
use x86_64::structures::idt::InterruptStackFrame;
extern "x86-interrupt" fn test_double_fault_handler(
_stack_frame: &mut InterruptStackFrame,
_error_code: u64,
) -> ! {
serial_println!("[ok]");
exit_qemu(QemuExitCode::Success);
loop {}
}当双重异常处理函数被调用,我们退出QEMU,并且退出码是代表着测试通过的成功退出码。随着集成测试各自独立地执行完毕,我们需要在测试文件的顶部再次设置 #![feature(abi_x86_interrupt)] 属性。
现在可以使用 cargo test --test stack_overflow命令运行双重异常测试了(或者使用 cargo test 直接运行所有测试)。不出所料,控制台输出了 stack_overflow... [ok] 消息。如果注释掉 set_stack_index 行:测试应当失败。
在这篇文章中,我们学到了双重异常及其触发条件,添加了基本的双重异常处理函数打印错误消息,同时补充了相应的集成测试。
我们也让硬件支持了双重异常发生时的栈切换,这让它可以在栈溢出的情况下正常工作。在实现的同时,我们学到了任务状态段(TSS),包含其中的中断栈表(IST),以及旧体系架构中用于分段机制的全局描述符(GDT)。
下一篇文章,我们将阐明如何处理来自外部设备的中断,例如时钟、键盘或网卡等。这些硬件中断和异常十分相似,它们也会通过 IDT 分发到相应的处理函数。然而与异常不同的是,它们并不直接由 CPU 内部产生。中断控制器(interrupt controller)会汇总这些中断,然后根据它们的优先级高低发送到 CPU 。在下篇文章中,我们会介绍 Intel 8259 (“PIC”) 中断控制器,并学习如何实现键盘支持(keyboard support)。
创建并维护这个博客 和相关的库是一个繁重的工作,但是我非常喜欢这个它。你的支持可以鼓励我投入更多的时间在新的内容,新的功能以及持续维护工作上。
支持我的最好方式是 sponsor me on GitHub 。GitHub 会匹配赞助(译注:见GitHub Sponsors Matching Fund)直到2020年10月!我同时拥有 Patreon 和 Donorbox 账户。最后一种是最灵活的,它支持多国货币和一次性捐赠。
谢谢!
译注:《支持我》章节中的“我”均指原作者 @Philipp Oppermann 。