-
Notifications
You must be signed in to change notification settings - Fork 24
/
Copy pathtf_sc.Rmd
238 lines (196 loc) · 8.15 KB
/
tf_sc.Rmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
---
title: "Transcription factor activity inference from scRNA-seq"
author:
- name: Pau Badia-i-Mompel
affiliation:
- Heidelberg Universiy
output:
BiocStyle::html_document:
self_contained: true
toc: true
toc_float: true
toc_depth: 3
code_folding: show
package: "`r pkg_ver('decoupleR')`"
vignette: >
%\VignetteIndexEntry{Transcription factor activity inference from scRNA-seq}
%\VignetteEngine{knitr::rmarkdown}
%\VignetteEncoding{UTF-8}
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(
collapse = TRUE,
comment = "#>"
)
```
scRNA-seq yield many molecular readouts that are hard to interpret by
themselves. One way of summarizing this information is by inferring
transcription factor (TF) activities from prior knowledge.
In this notebook we showcase how to use `decoupleR` for transcription factor activity
inference with a down-sampled PBMCs 10X data-set. The data consists of 160
PBMCs from a Healthy Donor. The original data is freely available from 10x Genomics
[here](https://cf.10xgenomics.com/samples/cell/pbmc3k/pbmc3k_filtered_gene_bc_matrices.tar.gz)
from this [webpage](https://support.10xgenomics.com/single-cell-gene-expression/datasets/1.1.0/pbmc3k).
# Loading packages
First, we need to load the relevant packages, `Seurat` to handle scRNA-seq data
and `decoupleR` to use statistical methods.
```{r "load packages", message = FALSE}
## We load the required packages
library(Seurat)
library(decoupleR)
# Only needed for data handling and plotting
library(dplyr)
library(tibble)
library(tidyr)
library(patchwork)
library(ggplot2)
library(pheatmap)
```
# Loading the data-set
Here we used a down-sampled version of the data used in the `Seurat`
[vignette](https://satijalab.org/seurat/articles/pbmc3k_tutorial.html).
We can open the data like this:
```{r "load data"}
inputs_dir <- system.file("extdata", package = "decoupleR")
data <- readRDS(file.path(inputs_dir, "sc_data.rds"))
```
We can observe that we have different cell types:
```{r "umap", message = FALSE, warning = FALSE}
p <- Seurat::DimPlot(data,
reduction = "umap",
label = TRUE,
pt.size = 0.5) +
Seurat::NoLegend()
p
```
# CollecTRI network
[CollecTRI](https://github.com/saezlab/CollecTRI) is a comprehensive resource
containing a curated collection of TFs and their transcriptional targets
compiled from 12 different resources. This collection provides an increased
coverage of transcription factors and a superior performance in identifying
perturbed TFs compared to our previous
[DoRothEA](https://saezlab.github.io/dorothea/) network and other literature
based GRNs. Similar to DoRothEA, interactions are weighted by their mode of
regulation (activation or inhibition).
For this example we will use the human version (mouse and rat are also
available). We can use `decoupleR` to retrieve it from `OmniPath`. The argument
`split_complexes` keeps complexes or splits them into subunits, by default we
recommend to keep complexes together.
```{r "collectri"}
net <- decoupleR::get_collectri(organism = 'human',
split_complexes = FALSE)
net
```
# Activity inference with Univariate Linear Model (ULM)
To infer TF enrichment scores we will run the Univariate Linear Model (`ulm`) method. For each sample in our dataset (`mat`) and each TF in our network (`net`), it fits a linear model that predicts the observed gene expression
based solely on the TF's TF-Gene interaction weights. Once fitted, the obtained t-value of the slope is the score. If it is positive, we interpret that the TF is active and if it is negative we interpret that it is inactive.
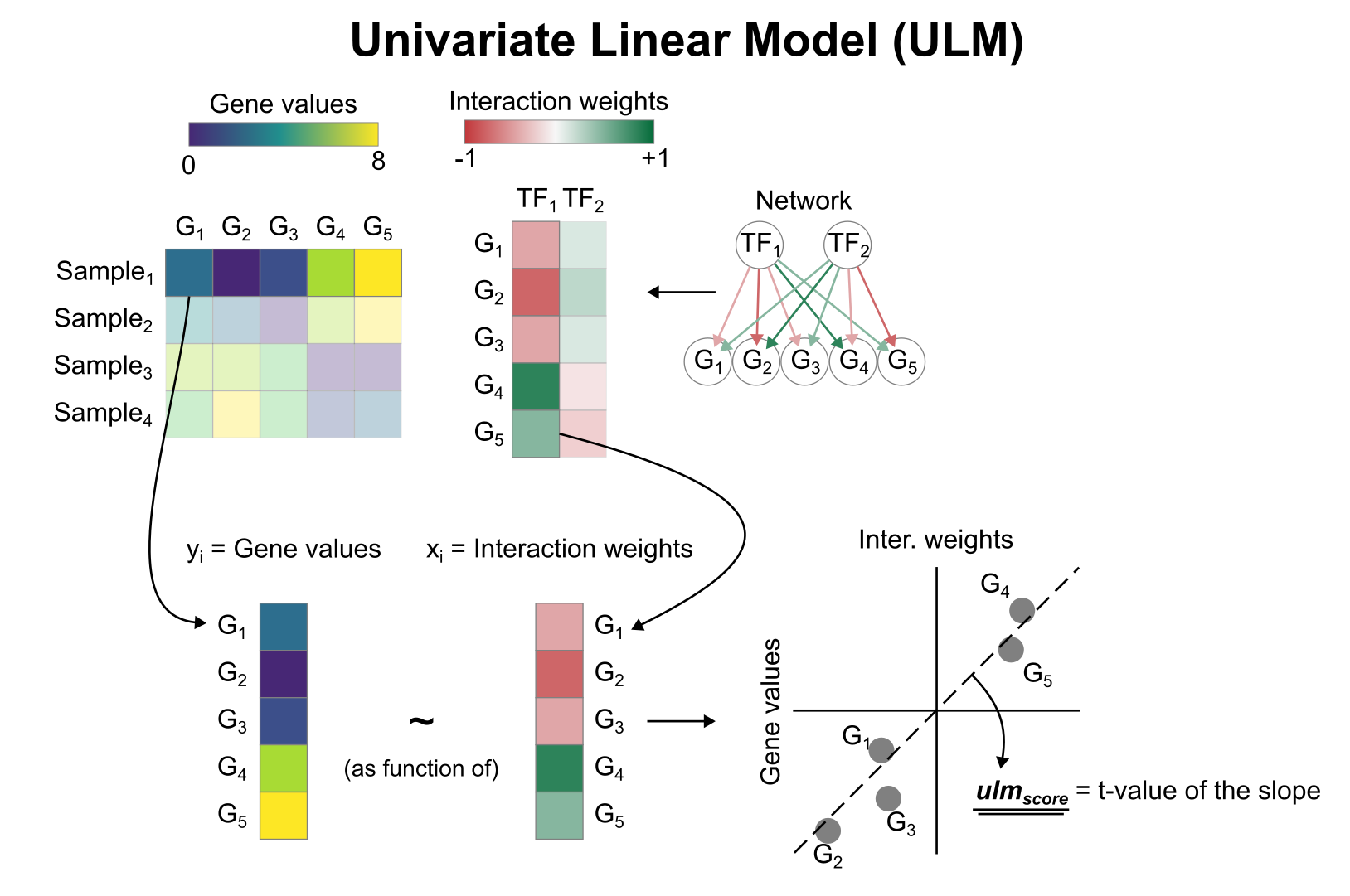
To run `decoupleR` methods, we need an input matrix (`mat`), an input prior
knowledge network/resource (`net`), and the name of the columns of net that we
want to use.
```{r "ulm", message=FALSE}
# Extract the normalized log-transformed counts
mat <- as.matrix(data@assays$RNA@data)
# Run ulm
acts <- decoupleR::run_ulm(mat = mat,
net = net,
.source = 'source',
.target = 'target',
.mor='mor',
minsize = 5)
acts
```
# Visualization
From the obtained results, we store
them in our object as a new assay called `tfsulm`:
```{r "new_assay", message=FALSE}
# Extract ulm and store it in tfsulm in pbmc
data[['tfsulm']] <- acts %>%
tidyr::pivot_wider(id_cols = 'source',
names_from = 'condition',
values_from = 'score') %>%
tibble::column_to_rownames('source') %>%
Seurat::CreateAssayObject(.)
# Change assay
DefaultAssay(object = data) <- "tfsulm"
# Scale the data
data <- Seurat::ScaleData(data)
data@assays$tfsulm@data <- data@[email protected]
```
This new assay can be used to plot activities. Here we observe the activity
inferred for PAX5 across cells, which it is particulary active in B cells.
Interestingly, PAX5 is a known TF crucial for B cell identity and function.
The inference of activities from “foot-prints” of target genes is more
informative than just looking at the molecular readouts of a given TF, as an
example here is the gene expression of PAX5, which is not very informative by
itself:
```{r "projected_acts", message = FALSE, warning = FALSE, fig.width = 12, fig.height = 4}
p1 <- Seurat::DimPlot(data,
reduction = "umap",
label = TRUE,
pt.size = 0.5) +
Seurat::NoLegend() +
ggplot2::ggtitle('Cell types')
colors <- rev(RColorBrewer::brewer.pal(n = 11, name = "RdBu")[c(2, 10)])
p2 <- Seurat::FeaturePlot(data, features = c("PAX5")) +
ggplot2::scale_colour_gradient2(low = colors[1], mid = 'white', high = colors[2]) +
ggplot2::ggtitle('PAX5 activity')
DefaultAssay(object = data) <- "RNA"
p3 <- Seurat::FeaturePlot(data,
features = c("PAX5")) +
ggplot2::ggtitle('PAX5 expression')
Seurat::DefaultAssay(data) <- "tfsulm"
p <- p1 | p2 | p3
p
```
# Exploration
We can also see what is the mean activity per group of the top 20 more variable
TFs:
```{r "mean_acts", message = FALSE, warning = FALSE}
n_tfs <- 25
# Extract activities from object as a long dataframe
df <- t(as.matrix(data@assays$tfsulm@data)) %>%
as.data.frame() %>%
dplyr::mutate(cluster = Seurat::Idents(data)) %>%
tidyr::pivot_longer(cols = -cluster,
names_to = "source",
values_to = "score") %>%
dplyr::group_by(cluster, source) %>%
dplyr::summarise(mean = mean(score))
# Get top tfs with more variable means across clusters
tfs <- df %>%
dplyr::group_by(source) %>%
dplyr::summarise(std = stats::sd(mean)) %>%
dplyr::arrange(-abs(std)) %>%
head(n_tfs) %>%
dplyr::pull(source)
# Subset long data frame to top tfs and transform to wide matrix
top_acts_mat <- df %>%
dplyr::filter(source %in% tfs) %>%
tidyr::pivot_wider(id_cols = 'cluster',
names_from = 'source',
values_from = 'mean') %>%
tibble::column_to_rownames('cluster') %>%
as.matrix()
# Choose color palette
colors <- rev(RColorBrewer::brewer.pal(n = 11, name = "RdBu"))
colors.use <- grDevices::colorRampPalette(colors = colors)(100)
my_breaks <- c(seq(-2, 0, length.out = ceiling(100 / 2) + 1),
seq(0.05, 2, length.out = floor(100 / 2)))
# Plot
pheatmap::pheatmap(mat = top_acts_mat,
color = colors.use,
border_color = "white",
breaks = my_breaks,
cellwidth = 15,
cellheight = 15,
treeheight_row = 20,
treeheight_col = 20)
```
Here we can observe other known marker TFs appearing, EBF1 for B cells
RFX5 for the myeloid lineage and EOMES for the lymphoid.
# Session information
```{r session_info, echo=FALSE}
options(width = 120)
sessioninfo::session_info()
```