-
Notifications
You must be signed in to change notification settings - Fork 291
/
cordinate-angle.md
164 lines (82 loc) · 12.6 KB
/
cordinate-angle.md
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
# 1. 回顾线性回归
首先我们简要回归下线性回归的一般形式:
$$h_\mathbf{\theta}(\mathbf{X}) = \mathbf{X\theta}$$
需要极小化的损失函数是:
$$J(\mathbf\theta) = \frac{1}{2}(\mathbf{X\theta} - \mathbf{Y})^T(\mathbf{X\theta} - \mathbf{Y})$$
如果用梯度下降法求解,则每一轮θ迭代的表达式是:
$$\mathbf\theta= \mathbf\theta - \alpha\mathbf{X}^T(\mathbf{X\theta} - \mathbf{Y})$$
其中α为步长。
如果用最小二乘法,则θ的结果是:
$$\mathbf{\theta} = (\mathbf{X^{T}X})^{-1}\mathbf{X^{T}Y}$$
# 2. 回顾Ridge回归
由于直接套用线性回归可能产生过拟合,我们需要加入正则化项,如果加入的是L2正则化项,就是Ridge回归,有时也翻译为脊回归。它和一般线性回归的区别是在损失函数上增加了一个L2正则化的项,和一个调节线性回归项和正则化项权重的系数α。损失函数表达式如下:
$$J(\mathbf\theta) = \frac{1}{2}(\mathbf{X\theta} - \mathbf{Y})^T(\mathbf{X\theta} - \mathbf{Y}) + \frac{1}{2}\alpha||\theta||_2^2$$
其中α为常数系数,需要进行调优。$$||\theta||_2$$为L2范数。
Ridge回归的解法和一般线性回归大同小异。如果采用梯度下降法,则每一轮θ迭代的表达式是:
$$\mathbf\theta= \mathbf\theta - (\beta\mathbf{X}^T(\mathbf{X\theta} - \mathbf{Y}) + \alpha\theta)$$
其中β为步长。
如果用最小二乘法,则θ的结果是:
$$\mathbf{\theta = (X^TX + \alpha E)^{-1}X^TY}$$
其中E为单位矩阵。
Ridge回归在不抛弃任何一个变量的情况下,缩小了回归系数,使得模型相对而言比较的稳定,但这会使得模型的变量特别多,模型解释性差。有没有折中一点的办法呢?即又可以防止过拟合,同时克服Ridge回归
模型变量多的缺点呢?有,这就是下面说的Lasso回归。
# 3. 初识Lasso回归
Lasso回归有时也叫做线性回归的L1正则化,和Ridge回归的主要区别就是在正则化项,Ridge回归用的是L2正则化,而Lasso回归用的是L1正则化。Lasso回归的损失函数表达式如下:
$$J(\mathbf\theta) = \frac{1}{2n}(\mathbf{X\theta} - \mathbf{Y})^T(\mathbf{X\theta} - \mathbf{Y}) + \alpha||\theta||_1$$
其中n为样本个数,α为常数系数,需要进行调优。$$||\theta||_1$$为L1范数。
Lasso回归使得一些系数变小,甚至还是一些绝对值较小的系数直接变为0,因此特别适用于参数数目缩减与参数的选择,因而用来估计稀疏参数的线性模型。
但是Lasso回归有一个很大的问题,导致我们需要把它单独拎出来讲,就是它的损失函数不是连续可导的,由于L1范数用的是绝对值之和,导致损失函数有不可导的点。也就是说,我们的最小二乘法,梯度下降法,牛顿法与拟牛顿法对它统统失效了。那我们怎么才能求有这个L1范数的损失函数极小值呢?
两种的求极值解法坐标轴下降法(coordinate descent)和最小角回归法( Least Angle Regression, LARS)该隆重出场了。
# 4. 用坐标轴下降法求解Lasso回归
坐标轴下降法顾名思义,是沿着坐标轴的方向去下降,这和梯度下降不同。梯度下降是沿着梯度的负方向下降。不过梯度下降和坐标轴下降的共性就都是迭代法,通过启发式的方式一步步迭代求解函数的最小值。
坐标轴下降法的数学依据主要是这个结论(此处不做证明):一个可微的凸函数J\(θ\), 其中θ是nx1的向量,即有n个维度。如果在某一点$$\overline\theta$$,使得J\(θ\)在每一个坐标轴$$\overline\theta_i$$\(i = 1,2,...n\)上都是最小值,那么$$J(\overline\theta_i)$$就是一个全局的最小值。
于是我们的优化目标就是在θ的n个坐标轴上\(或者说向量的方向上\)对损失函数做迭代的下降,当所有的坐标轴上的$$\theta_i$$\(i = 1,2,...n\)都达到收敛时,我们的损失函数最小,此时的θ即为我们要求的结果。
下面我们看看具体的算法过程:
1. 首先,我们把θ向量随机取一个初值。记为$$\theta^{(0)}$$,上面的括号里面的数字代表我们迭代的轮数,当前初始轮数为0.
2. 对于第k轮的迭代。我们从$$\theta_1^{(k)}$$开始,到$$x = y$$为止,依次求$$\theta_i^{(k)}$$。$$\theta_i^{(k)}$$的表达式如下:
$$\theta_i^{(k)} \in argmin J(\theta_1^{(k)}, \theta_2^{(k)}, ... \theta_{i-1}^{(k)}, \theta_i, \theta_{i+1}^{(k-1)}, ..., \theta_n^{(k-1)})$$
也就是说$$\theta_i^{(k)}$$是使$$J(\theta_1^{(k)},\theta_2^{(k)},...\theta_{i-1}^{(k)},\theta_i^{(k)},\theta_{i+1}^{(k)},....,\theta_n^{(k)})$$最小化时候的θi的值。此时J\(θ\)只有$$\theta_i^{(k)}$$是变量,其余均为常量,因此最小值容易通过求导求得。
如果上面这个式子不好理解,我们具体一点,在第k轮,θ向量的n个维度的迭代式如下:
$$\theta_1^{(k)} \in argmin J(\theta_1, \theta_2^{(k-1)}, ... , \theta_n^{(k-1)})$$
$$\theta_2^{(k)} \in argmin J(\theta_1^{(k)}, \theta_2, \theta_3^{(k-1)}... , \theta_n^{(k-1)})$$
...
$$\theta_n^{(k)} \in argmin J(\theta_1^{(k)}, \theta_2^{(k)}, ... , \theta_{n-1}^{(k)}, \theta_n)$$
1. 检查$$\theta_i^{(k)}$$向量和$$\theta_i^{(k-1)}$$向量在各个维度上的变化情况,如果在所有维度上变化都足够小,那么$$\theta_i^{(k)}$$即为最终结果,否则转入2,继续第k+1轮的迭代。
以上就是坐标轴下降法的求极值过程,可以和梯度下降做一个比较:
a\) 坐标轴下降法在每次迭代中在当前点处沿一个坐标方向进行一维搜索 ,固定其他的坐标方向,找到一个函数的局部极小值。而梯度下降总是沿着梯度的负方向求函数的局部最小值。
b\) 坐标轴下降优化方法是一种非梯度优化算法。在整个过程中依次循环使用不同的坐标方向进行迭代,一个周期的一维搜索迭代过程相当于一个梯度下降的迭代。
c\) 梯度下降是利用目标函数的导数来确定搜索方向的,该梯度方向可能不与任何坐标轴平行。而坐标轴下降法法是利用当前坐标方向进行搜索,不需要求目标函数的导数,只按照某一坐标方向进行搜索最小值。
d\) 两者都是迭代方法,且每一轮迭代,都需要O\(mn\)的计算量\(m为样本数,n为系数向量的维度\)
# 5. 用最小角回归法求解Lasso回归
第四节介绍了坐标轴下降法求解Lasso回归的方法,此处再介绍另一种常用方法, 最小角回归法\(Least Angle Regression, LARS\)。
在介绍最小角回归前,我们先看看两个预备算法,好吧,这个算法真没有那么好讲。
## 5.1 前向选择(Forward Selection)算法
第一个预备算法是前向选择(Forward Selection)算法。
前向选择算法的原理是是一种典型的贪心算法。要解决的问题是对于:
Y=Xθ这样的线性关系,如何求解系数向量θ的问题。其中Y为 mx1的向量,X为mxn的矩阵,θ为nx1的向量。m为样本数量,n为特征维度。
把 矩阵X看做n个mx1的向量$$X_i$$\(i=1,2,...n\),在Y的X变量$$X_i$$\(i =1,2,...m\)中,选择和目标Y最为接近\(余弦距离最小\)的一个变量$$X_k$$,用$$X_k$$来逼近Y,得到下式:
$$\bar{Y} =X_k\theta_k$$
其中:$$\theta_k=\frac{<X_k, \bar Y>}{||X_k||_2}$$
即:$$\bar Y$$是Y在$$X_k$$上的投影。那么,可以定义残差\(residual\): $$Y_{yes}=Y-\bar Y$$。由于是投影,所以很容易知道$$Y_{yes}$$和$$X_k$$是正交的。再以$$Y_{yes}$$为新的因变量,去掉$$X_k$$后,剩下的自变量的集合$$X_i$$,i=1,2,3...k−1,k+1,...n}为新的自变量集合,重复刚才投影和残差的操作,直到残差为0,或者所有的自变量都用完了,才停止算法。
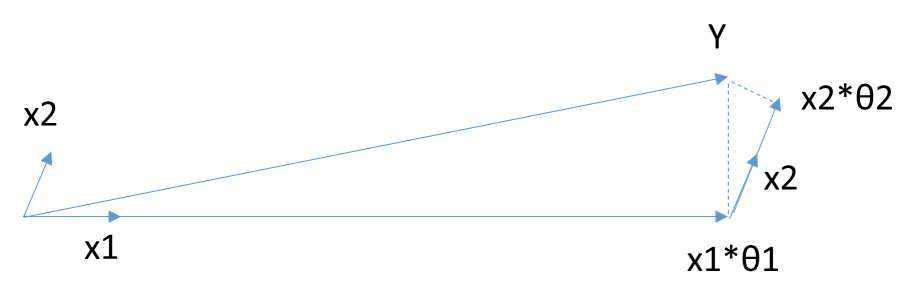
当X只有2维时,例子如上图,和Y最接近的是$$X_1$$、,首先在$$X_1$$上面投影,残差如上图长虚线。此时$$X_1\theta_1$$
模拟了Y, $$\theta_1$$模拟了θ\(仅仅模拟了一个维度\)。接着发现最接近的是$$X_2$$,此时用残差接着在$$X_2$$投影,残差如图中短虚线。由于没有其他自变量了,此时$$X_1\theta_1+X_2\theta_2$$模拟了Y, 对应的模拟了两个维度的θ即为最终结果,此处θ计算涉及较多矩阵运算,这里不讨论。
此算法对每个变量只需要执行一次操作,效率高,速度快。但也容易看出,当自变量不是正交的时候,由于每次都是在做投影,所有算法只能给出一个局部近似解。因此,这个简单的算法太粗糙,还不能直接用于我们的Lasso回归。
## 5.2 前向梯度(Forward Stagewise)算法
第二个预备算法是前向梯度(Forward Stagewise)算法。
前向梯度算法和前向选择算法有类似的地方,也是在Y的X变量$$X_i$$\(i =1,2,...n\)中,选择和目标Y最为接近\(余弦距离最小\)的一个变量$$X_k$$,用$$X_k$$来逼近Y,但是前向梯度算法不是粗暴的用投影,而是每次在最为接近的自变量$$X_t$$的方向移动一小步,然后再看残差$$Y_{yes}$$和哪个$$X_i$$\(i =1,2,...n\)最为接近。此时我们也不会把$$X_t$$去除,因为我们只是前进了一小步,有可能下面最接近的自变量还是$$X_t$$。如此进行下去,直到残差$$Y_{yes}$$减小到足够小,算法停止。
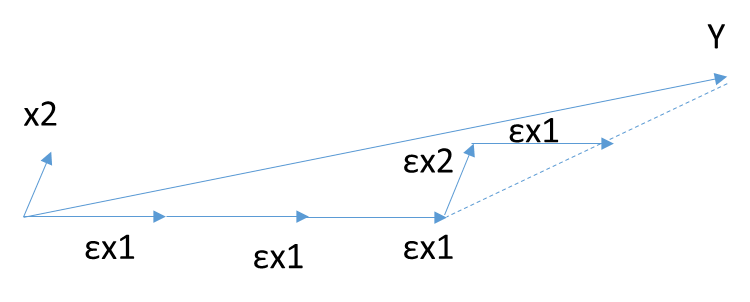
当X只有2维时,例子如上图,和Y最接近的是$$X_1$$,首先在$$X_1$$上面走一小段距离,此处ε为一个较小的常量,发现此时的残差还是和$$X_1$$最接近。那么接着沿$$X_1$$走,一直走到发现残差不是和$$X_1$$最接近,而是和$$X_2$$最接近,此时残差如上图长虚线。接着沿着$$X_2$$走一小步,发现残差此时又和$$X_1$$最接近,那么开始沿着$$X_1$$走,走完一步后发现残差为0,那么算法停止。此时Y由刚才所有的所有步相加而模拟,对应的算出的系数θ即为最终结果。此处θ计算涉及较多矩阵运算,这里不讨论。
当算法在ε很小的时候,可以很精确的给出最优解,当然,其计算的迭代次数也是大大的增加。和前向选择算法相比,前向梯度算法更加精确,但是更加复杂。
有没有折中的办法可以综合前向梯度算法和前向选择算法的优点,做一个折中呢?有!这就是终于要出场的最小角回归法。
## 5.3 最小角回归\(Least Angle Regression, LARS\)算法
好吧,最小角回归\(Least Angle Regression, LARS\)算法终于出场了。最小角回归法对前向梯度算法和前向选择算法做了折中,保留了前向梯度算法一定程度的精确性,同时简化了前向梯度算法一步步迭代的过程。具体算法是这样的:
首先,还是找到与因变量Y最接近或者相关度最高的自变量$$X_k$$,使用类似于前向梯度算法中的残差计算方法,得到新的目标$$Y_{yes}$$,此时不用和前向梯度算法一样小步小步的走。而是直接向前走直到出现一个$$X_t$$,使得$$X_t$$和$$Y_{yes}$$的相关度和$$X_k$$与$$Y_{yes}$$的相关度是一样的,此时残差$$Y_{yes}$$就在$$X_t$$和$$X_k$$的角平分线方向上,此时我们开始沿着这个残差角平分线走,直到出现第三个特征$$X_p$$和$$Y_{yes}$$的相关度足够大的时候,即$$X_p$$到当前残差$$Y_{yes}$$的相关度和θt,θk与$$Y_{yes}$$的一样。将其也带入到Y的逼近特征集合中,并用Y的逼近特征集合的共同角分线,作为新的逼近方向。以此循环,直到$$Y_{yes}$$足够的小,或者说所有的变量都已经取完了,算法停止。此时对应的系数θ即为最终结果。
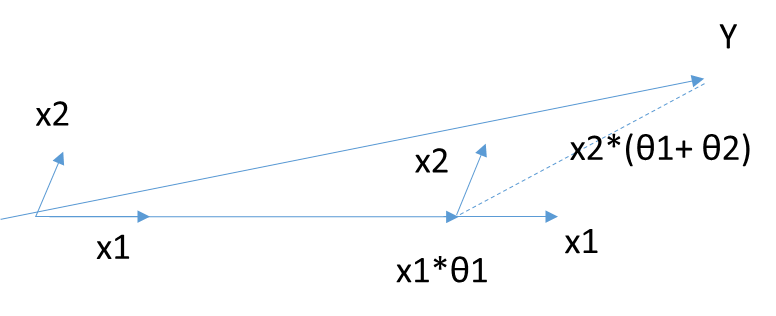
当θ只有2维时,例子如上图,和Y最接近的是$$X_1$$,首先在$$X_1$$上面走一段距离,一直到残差在$$X_1$$和$$X_2$$的角平分线上,此时沿着角平分线走,直到残差最够小时停止,此时对应的系数β即为最终结果。此处θ计算涉及较多矩阵运算,这里不讨论。
最小角回归法是一个适用于高维数据的回归算法,其主要的优点有:
1)特别适合于特征维度n远高于样本数m的情况。
2)算法的最坏计算复杂度和最小二乘法类似,但是其计算速度几乎和前向选择算法一样
3)可以产生分段线性结果的完整路径,这在模型的交叉验证中极为有用
主要的缺点是:
由于LARS的迭代方向是根据目标的残差而定,所以该算法对样本的噪声极为敏感。