In der Bubble-Phase wird die Eingabe-Liste von links nach rechts durchlaufen. Dabei wird in jedem Schritt das aktuelle Element mit dem rechten Nachbarn verglichen. Falls die beiden Elemente das Sortierkriterium verletzen, werden sie getauscht. Am Ende der Phase steht bei auf- bzw. absteigender Sortierung das größte bzw. kleinste Element der Eingabe am Ende der Liste.
Die Bubble-Phase wird solange wiederholt, bis die Eingabeliste vollständig sortiert ist. Dabei muss das letzte Element des vorherigen Durchlaufs nicht mehr betrachtet werden, da die restliche zu sortierende Eingabe keine größeren bzw. kleineren Elemente mehr enthält.
Je nachdem, ob auf- oder absteigend sortiert wird, steigen die größeren oder kleineren Elemente wie Blasen im Wasser (daher der Name) immer weiter nach oben, das heißt, an das Ende der Liste. Es werden stets zwei Zahlen miteinander in „Bubbles“ vertauscht.
Um die Darstellung des Algorithmus nicht künstlich zu verkomplizieren, wird im Folgenden als Vergleichsrelation > {\displaystyle >} > (größer als) verwendet. Wie bei jedem auf Vergleichen basierenden Sortierverfahren kann diese auch durch eine andere Relation ersetzt werden, die eine totale Ordnung definiert.
Der Algorithmus in seiner einfachsten Form als Pseudocode:
bubbleSort(Array A)
for (n=A.size; n>1; --n){
for (i=0; i<n-1; ++i){
if (A[i] > A[i+1]){
A.swap(i, i+1)
} // Ende if
} // Ende innere for-Schleife
} // Ende äußere for-SchleifeDie Eingabe ist in einem Array gespeichert. Die äußere Schleife verringert schrittweise die rechte Grenze für die Bubble-Phase, da nach jedem Bubblen an der rechtesten Position das größte Element der jeweils unsortierten Rest-Eingabe steht. In der inneren Schleife wird der noch nicht sortierte Teil des Feldes durchlaufen. Dabei werden zwei benachbarte Daten vertauscht, wenn sie in falscher Reihenfolge sind (also das Sortierkriterium verletzen).
Allerdings nutzt diese einfachste Variante nicht die Eigenschaft aus, dass nach einer Iteration, in der keine Vertauschungen stattfanden, auch in den restlichen Iterationen keine Vertauschungen mehr stattfinden. Der folgende Pseudocode berücksichtigt dies:
bubbleSort2(Array A)
n = A.size
do{
swapped = false
for (i=0; i<n-1; ++i){
if (A[i] > A[i+1]){
A.swap(i, i+1)
swapped = true
} // Ende if
} // Ende for
n = n-1
} while (swapped)Die äußere Schleife durchläuft die zu sortierenden Daten, bis keine Vertauschungen mehr notwendig sind.
Eine weitere Optimierung besteht in der Ausnutzung der Eigenschaft, dass am Ende einer äußeren Iteration alle Elemente rechts von der letzten Tauschposition schon an ihrer endgültigen Position stehen:
bubbleSort3(Array A)
n = A.size
do{
newn = 1
for (i=0; i<n-1; ++i){
if (A[i] > A[i+1]){
A.swap(i, i+1)
newn = i+1
} // ende if
} // ende for
n = newn
} while (n > 1)Eine Reihe von fünf Zahlen soll aufsteigend sortiert werden.
Die fett gedruckten Zahlen werden jeweils verglichen. Ist die linke größer als die rechte, so werden beide vertauscht; das Zahlenpaar ist dann blau markiert. Im ersten Durchlauf wandert somit die größte Zahl ganz nach rechts. Der zweite Durchlauf braucht somit die letzte und vorletzte Position nicht mehr zu vergleichen. → Dritter Durchlauf: kein Vergleich letzte/vorletzte/vorvorletzte…
55 07 78 12 42 1. Durchlauf
07 55 78 12 42
07 55 78 12 42
07 55 12 78 42 Letzter Vergleich
07 55 12 42 78 2. Durchlauf
07 55 12 42 78
07 12 55 42 78 Letzter Vergleich
07 12 42 55 78 3. Durchlauf
07 12 42 55 78 Letzter Vergleich
07 12 42 55 78 4. Durchlauf + Letzter Vergleich
07 12 42 55 78 Fertig sortiert.
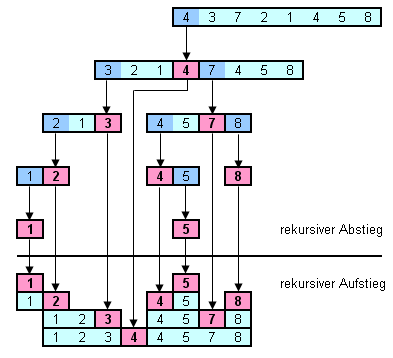
Zunächst wird die zu sortierende Liste in zwei Teillisten („linke“ und „rechte“ Teilliste) getrennt. Dazu wählt Quicksort ein sogenanntes Pivotelement aus der Liste aus. Alle Elemente, die kleiner als das Pivotelement sind, kommen in die linke Teilliste, und alle, die größer sind, in die rechte Teilliste. Die Elemente, die gleich dem Pivotelement sind, können sich beliebig auf die Teillisten verteilen. Nach der Aufteilung sind die Elemente der linken Liste kleiner oder gleich den Elementen der rechten Liste.
Anschließend muss man also nur noch jede Teilliste in sich sortieren, um die Sortierung zu vollenden. Dazu wird der Quicksort-Algorithmus jeweils auf der linken und auf der rechten Teilliste ausgeführt. Jede Teilliste wird dann wieder in zwei Teillisten aufgeteilt und auf diese jeweils wieder der Quicksort-Algorithmus angewandt, und so fort. Diese Selbstaufrufe werden als Rekursion bezeichnet. Wenn eine Teilliste der Länge eins oder null auftritt, so ist diese bereits sortiert und es erfolgt der Abbruch der Rekursion.
Die Positionen der Elemente, die gleich dem Pivotelement sind, hängen vom verwendeten Teilungsalgorithmus ab. Sie können sich beliebig auf die Teillisten verteilen. Da sich die Reihenfolge von gleichwertigen Elementen zueinander ändern kann, ist Quicksort im Allgemeinen nicht stabil (stabile in-place Varianten existieren jedoch[3]).
Das Verfahren muss sicherstellen, dass jede der Teillisten mindestens um eins kürzer ist als die Gesamtliste. Dann endet die Rekursion garantiert nach endlich vielen Schritten. Das kann z. B. dadurch erreicht werden, dass das ursprünglich als Pivot gewählte Element auf einen Platz zwischen den Teillisten gesetzt wird und somit zu keiner Teilliste gehört.
Die Implementierung der Teilung erfolgt als In-place-Algorithmus: Die Elemente werden nicht in zusätzlichen Speicher kopiert, sondern nur innerhalb der Liste vertauscht. Dafür wird ein Verfahren verwendet, das als Teilen oder auch Partitionieren bezeichnet wird. Danach sind die beiden Teillisten gleich in der richtigen Position. Sobald die Teillisten in sich sortiert wurden, ist die Sortierung der Gesamtliste beendet.
Der folgende Pseudocode illustriert die Arbeitsweise des Algorithmus, wobei daten die zu sortierende Liste mit n Elementen ist. Bei jedem Aufruf von quicksort() gibt links den Index des ersten Elements in der Teilliste an und rechts den des letzten. Beim ersten Aufruf (oberste Rekursionsebene) ist links = 0 und rechts = n-1. Die übergebene Liste wird dabei rekursiv immer weiter geteilt, bis sie nur noch einen Wert enthält.
funktion quicksort(links, rechts)
falls links < rechts dann
teiler:= teile(links, rechts)
quicksort(links, teiler-1)
quicksort(teiler+1, rechts)
ende
endeDie folgende Implementierung der Funktion teile teilt das Feld so, dass sich das Pivotelement an seiner endgültigen Position befindet und alle kleineren Elemente davor stehen, während alle größeren danach kommen:
funktion teile(links, rechts)
i:= links
// Starte mit j links vom Pivotelement
j:= rechts - 1
pivot:= daten[rechts]
wiederhole
// Suche von links ein Element, welches größer oder gleich dem Pivotelement ist
wiederhole solange i < rechts und daten[i] < pivot
i:= i + 1
ende
// Suche von rechts ein Element, welches kleiner als das Pivotelement ist
wiederhole solange j > links und daten[j] ≥ pivot
j:= j - 1
ende
falls i < j dann
tausche daten[i] mit daten[j]
ende
solange i < j // solange i an j nicht vorbeigelaufen ist
// Tausche Pivotelement (daten[rechts]) mit neuer endgültiger Position (daten[i])
// und gib die neue Position des Pivotelements zurück, beende Durchlauf
tausche daten[i] mit daten[rechts]
antworte i
endeNach der Wahl des Pivotelementes wird zunächst ein Element vom Anfang der Liste beginnend gesucht (Index i), welches größer als das Pivotelement ist. Entsprechend wird vom Ende der Liste beginnend ein Element kleiner als das Pivotelement gesucht (Index j). Die beiden Elemente werden dann vertauscht und landen damit in der jeweils richtigen Teilliste. Dann werden die beiden Suchvorgänge von den erreichten Positionen fortgesetzt, bis sich die untere und obere Suche treffen; dort ist die Grenze zwischen den beiden Teillisten.