Releases: wanghenshui/cppweeklynews
C++ 中文周刊 第141期
qq群 手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
最近在找工作准备面试题,更新可能有些拖沓,见谅
本周内容比较少
本期文章由 黄亮Anthony HNY 赞助
资讯
标准委员会动态/ide/编译器信息放在这里
clion新增AI助手 https://www.jetbrains.com/clion/whatsnew/
编译器信息最新动态推荐关注hellogcc公众号 OSDT Weekly 2023-12-06 第231期
文章
感兴趣的可以看一下。很短
抽出相同的二进制,节省二进制大小。和inline逻辑相反
可能会有性能衰退
原理?如何找出重复的二进制序列?后缀树爆搜
也可以从不同角度来做,比如IR层
具体很细节。感兴趣的可以看看
借助outline做冷热分离,有性能提升,还挺有意思的,算是PGO一部分吧,拿到profile来分析
stream就是垃圾 strstream没人用。有spanstream代替
lemire博士新活
常规
int parse_uint8_naive(const char *str, size_t len, uint8_t *num) {
uint32_t n = 0;
for (size_t i = 0, r = len & 0x3; i < r; i++) {
uint8_t d = (uint8_t)(str[i] - '0');
if (d > 9)
return 0;
n = n * 10 + d;
}
*num = (uint8_t)n;
return n < 256 && len && len < 4;
}
当然c++可以用from chars加速
int parse_uint8_fromchars(const char *str, size_t len, uint8_t *num) {
auto [p, ec] = std::from_chars(str, str + len, *num);
return (ec == std::errc());
}能不能更快?这是u8场景,考虑SWAR,组成一个int来处理
int parse_uint8_fastswar(const char *str, size_t len,
uint8_t *num) {
if(len == 0 || len > 3) { return 0; }
union { uint8_t as_str[4]; uint32_t as_int; } digits;
memcpy(&digits.as_int, str, sizeof(digits));
digits.as_int ^= 0x30303030lu;
digits.as_int <<= ((4 - len) * 8);
uint32_t all_digits =
((digits.as_int | (0x06060606 + digits.as_int)) & 0xF0F0F0F0)
== 0;
*num = (uint8_t)((0x640a01 * digits.as_int) >> 24);
return all_digits
& ((__builtin_bswap32(digits.as_int) <= 0x020505));
}评论区bob给了个更快的
int parse_uint8_fastswar_bob(const char *str, size_t len, uint8_t *num) {
union { uint8_t as_str[4]; uint32_t as_int; } digits;
memcpy(&digits.as_int, str, sizeof(digits));
digits.as_int ^= 0x303030lu;
digits.as_int <<= (len ^ 3) * 8;
*num = (uint8_t)((0x640a01 * digits.as_int) >> 16);
return ((((digits.as_int + 0x767676) | digits.as_int) & 0x808080) == 0)
&& ((len ^ 3) < 3)
&& __builtin_bswap32(digits.as_int) <= 0x020505ff;
}感兴趣可以玩一玩
场景 完美hash,4bytes字符串做key,如何快速算hash?
直接把字符串当成int来算
#define SIZE 512
uint8_t lut[SIZE] = {};
// multiply, shift, mask
uint32_t simple_hash(uint32_t u) {
uint64_t h = (uint64_t) u * 0x43ff9fb13510940a;
h = (h >> 32) % SIZE;
return (uint32_t) h;
}
// generate, cast and hash
void build_lut() {
char strings[256*4];
memset(strings, 0, sizeof(strings));
char *iter = strings;
for (int i = 0; i < 256; ++i) {
sprintf(iter, "%d", i);
iter += 4;
}
iter = strings;
for (int i = 0; i < 256; ++i) {
unsigned c = *(unsigned*) iter;
iter += 4;
unsigned idx = simple_hash(c);
lut[idx] = i;
}
}视频
cppcon2023 工作日开始更新视频了,这周好玩的列一下
- A Long Journey of Changing std::sort Implementation at Scale - Danila Kutenin - CppCon 2023 https://www.youtube.com/watch?v=cMRyQkrjEeI
这个作者danlark在llvm比较活跃
这个视频非常值得一看,列举了sort的改进优化,各个系统的差异,以及nth_element的副作用问题
很多库写的median算法实际是错的!
https://godbolt.org/z/9xWoYTfMP
int median(std::vector<int>& v) {
int mid = v.size() / 2;
std::nth_element(v.begin(), v.begin() + mid, v.end());
int result = v[mid];
if (v.size() % 2 == 0) {
std::nth_element(v.begin(), v.begin() + mid - 1, v.end());
result = (v[mid] + v[mid-1])/2;
// result = (result + v[mid-1]) /2;
}
return result;
}
由于nth_element不保证整体有序,只保证n的位置是对的,所以第二次的计算可能改变第一次的结果
然而社区很多median实现都是错的
- Customization Methods: Connecting User and C++ Library Code - Inbal Levi - CppCon 2023 https://www.youtube.com/watch?v=mdh9GLWXWyY
介绍了一些查找逻辑的设计,从swap到ADL,到CPO tag_invoke 再到最近的讨论,有Custom function设计
还算有意思 。但有句讲句tag_invoke很扭曲,cpo也是
- Variable Monitoring with Declarative Interfaces - Nikolaj Fogh - Meeting C++ 2023 https://www.youtube.com/watch?v=AJDbu1kaj5g
auto myMonitor = Monitor([](int i){ return i > 0; }, [](bool valid){ std::cout << "Valid: " << valid << std::endl; }]);
int variable = 0;
myMonitor(variable); // Prints Valid: 0
variable = 1;
myMonitor(variable); // Prints Valid: 1不过不知道有啥用途。signal handler类似的玩意
比如监控内存,真到了瓶颈,直接在发现的位置条件判断也不是不行
或者类似bvar之类的玩意,把数据导出 回调交给别的组件
不知道什么场景能用上
招聘
字节的音视频团队,主要负责剪映上的音视频/非线性编辑相关工作,业务前景也比较好,目前有三个方向的岗位
- 桌面端音视频研发 https://job.toutiao.com/s/i8enPrw5
- 多端音视频引擎研发 https://job.toutiao.com/s/i8enr7Es
- C++工程基础架构研发 https://job.toutiao.com/s/i8enjTHT
base北上广深杭都可以,薪资open,有兴趣的同学可以通过链接投递
英伟达招llvm实习生
联系方式 [email protected]
或微信 aoewqf1997 (请备注“LLVM实习生”
C++ 中文周刊 2024 01 19 第146期
qq群 点击进入
欢迎投稿,推荐或自荐文章/软件/资源等
本期文章由 黄亮Anthony Amnisia HNY CHENL 赞助
上周和朋友们吃饭耽误了,一直没空写
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-01-17 第237期
最近的最大热门就是Linux社区又有人讨论引入c++了,很多c宏实际上做的就是一部份concept工作,引入concept还是很爽的,不过linus有生之年应该不会引入,不过是又一次炒冷饭
祝linus健康
文章
The C++20 Naughty and Nice List for Game Devs
介绍一些对游戏开发比较好的c++20特性
- <=> 不错
coroutine不错std::bit_cast不错 复制转换,避免UB<numbers>不错,有PI可以用了- 新的同步原语
<barrier>,<latch>, and<semaphore> <span>可以- Designated initializers 非常好用,c一直都有,居然没兼容
struct Point {
float x;
float y;
float z;
};
Point origin{.x = 0.f, .y = 0.f, .z = 0.f};char8_t比较脑瘫,众所周知,char8_t是unsigned char,但u8 udl以前是修饰char的,c++20改成修饰char8_t了
破坏u8语义了,msvc可以/Zc:char8_t关掉,gcc也可以关 -fno-char8_t
https://en.cppreference.com/w/cpp/language/string_literal 第五条 六条
(5,6) UTF-8 string literal
const char[N](until C++20)
const char8_t[N](since C++20)
no_unique_address msvc有ABI问题,慎用
Modules没法用
ranges没屌用
format 二进制太大了
source_location 没易用性提升不说,std::source_location::file_name居然返回 const char*
怎么想的我真他妈服了
Why My Print Didn't Output Before a Segmentation Fault
#include <stdio.h>
int main(void)
{
printf("%s", "Hello!");
int *p = NULL;
*p = 5;
// Will not be reached due to crash above
printf("%s", "Another Hello!");
}
//$ gcc -Wall -Wextra -o hello hello.c && ./hello
//Segmentation fault (core dumped)经典buffer IO没刷buffer。怎么改成正常的?加\n 用stderr用fflush
C++ time_point wackiness across platforms
timepoint在mac上有精度损失,代码
#include <stdio.h>
#include <chrono>
int main() {
std::chrono::system_clock::time_point tp =
std::chrono::system_clock::from_time_t(1234567890);
// Okay.
tp += std::chrono::milliseconds(1);
// No problem here so far.
tp += std::chrono::microseconds(1);
// But... this fails on Macs:
// tp += std::chrono::nanoseconds(123);
// So you adapt, and this works everywhere. It slices off some of that
// precision without any hint as to why or when, and it's ugly too!
tp += std::chrono::duration_cast<std::chrono::system_clock::duration>(
std::chrono::nanoseconds(123));
// Something like this swaps the horizontal verbosity for vertical
// stretchiness (and still slices off that precision).
using std::chrono::duration_cast;
using std::chrono::system_clock;
using std::chrono::nanoseconds;
tp += duration_cast<system_clock::duration>(nanoseconds(123));
// This is what you ended up with:
auto tse = tp.time_since_epoch();
printf("%lld\n", (long long) duration_cast<nanoseconds>(tse).count());
// Output meaning when split up:
//
// sec ms us ns
//
// macOS: 1234567890 001 001 000 <-- 000 = loss of precision (246 ns)
//
// Linux: 1234567890 001 001 246 <-- 246 = 123 + 123 (expected)
//
return 0;
}Implementing the missing sign instruction in AVX-512
sign函数很常用, 大概长这样
function sign(a, b): # a and b are integers
if b == 0 : return 0
if b < 0 : return -a
if b > 0 : return a
很容易用sign实现abs
abs(a) = sign(a,a)
进入正题,写一个avx512 sign
#include <x86intrin.h>
__m512i _mm512_sign_epi8(__m512i a, __m512i b) {
__m512i zero = _mm512_setzero_si512();
__mmask64 blt0 = _mm512_movepi8_mask(b);
__mmask64 ble0 = _mm512_cmple_epi8_mask(b, zero);
__m512i a_blt0 = _mm512_mask_mov_epi8(zero, blt0, a);
return _mm512_mask_sub_epi8(a, ble0, zero, a_blt0);;
}如果单独处理0场景,可以这样
#include <x86intrin.h>
__m512i _mm512_sign_epi8_cheated(__m512i a, __m512i b) {
__m512i zero = _mm512_setzero_si512();
__mmask64 blt0 = _mm512_movepi8_mask(b);
return _mm512_mask_sub_epi8(a, blt0, zero, a);;
}
/*
function sign_cheated(a, b): # a and b are integers
if b < 0 : return -a
if b ≥ 0 : return a
*/What the func is that?
c++26咱们有四个function了 std::function std::move_only_function
std::copyable_function std::function_ref
都什么玩意?
std::function_ref好理解,就std::function的引用view版本,那他为啥不叫std::function_view?
另外两个是啥玩意?
回到function上,function的缺点是什么?看代码
struct Functor {
void operator()() { std::cout << "Non-const\n"; }
void operator()() const { std::cout << "Const\n"; }
};
const Functor ftor; // I'm const!
const std::function<void()> f = ftor; // So am I! Const all the way
f(); // Prints "Non-const"
问题就在于function的表现,复制的时候,用的是值,自然用的是non const版本
这是缺陷!如何变成正常的样子?也就是这样
std::function<void()> f = ftor; f(); // prints "Non-const"
const std::function<void()> f = ftor; f(); // prints "Const"为了修复这个const 问题,引入move_only_function 显然只能初始化一次
另外引入copyable_function 告诉大伙,function应该是copyable_function,大家注意语义
raymond chen环节,看不太懂
How do I prevent my C++/WinRT implementation class from participating in COM aggregation?
In C++/WinRT, how can I await multiple coroutines and capture the results?, part 1
In C++/WinRT, how can I await multiple coroutines and capture the results?, part 2
In C++/WinRT, how can I await multiple coroutines and capture the results?, part 3
视频
Taro: Task Graph-Based Asynchronous Programming Using C++ Coroutine – Dian-Lun Lin - CppCon 2023
他这个设计就是taskflow的coroutine版本!说实话我之前想到过这个点子,但人家费心思实现了,我就想想
热门库最近更新了什么
这个环节我会偶尔更新一下某些库最近的动态更新/代码讲解之类的
之前说想要搞但一直偷懒,这里更新一期seastar,下期folly/brpc之类的,也希望大家给点建议
seastar一直是非常积极跟进标准演进的库,代码新特性用的多,也和周边库配合的很好
比如配置fmt支持compile time string
最近的改动,他们给内置的内存池加了PROFILE配置
另外,有几个优化其实很小,比如判断内部peer已经用不到了,只clear但还占用内存,可以主动清掉
diff --git a/include/seastar/core/shared_future.hh b/include/seastar/core/shared_future.hh
index 0e1e31e6..4a2ea71f 100644
--- a/include/seastar/core/shared_future.hh
+++ b/include/seastar/core/shared_future.hh
@@ -168,6 +168,9 @@ class shared_future {
_peers.pop_front();
}
}
+ // _peer is now empty, but let's also make sure it releases any
+ // memory it might hold in reserve.
+ _peers = {};
_keepaliver.release();
}另外就是修复bug 同一个端口,同时listen同时accept场景应该抛异常
互动环节
最近甲流非常严重,周围很多得的进医院的,但一开始按照普通感冒治疗没用,得抗病毒多喝水
希望大家别得
啥也不是,散会!
C++ 中文周刊 第145期
qq群 点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等评论区留言
本期文章由 黄亮Anthony HNY 赞助
2024 01 07
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-01-03 第235期
文章
现代分支预测:从学术界到工业界
看个乐呵, 了解概念对于CPU运行还是有点理解的
LLVM中指令选择的流程是啥样的?
LLVM知识,学吧,都是知识,早晚碰到
【数据结构】Jemalloc中的Radix Tree
解析Jemalloc的关键数据结构
jemalloc最新知识,学吧
Optimizing the unoptimizable: a journey to faster C++ compile times
编译很慢,怎么抓?
#include <fmt/core.h>
int main() {
fmt::print("Hello, {}!\n", "world");
}
// c++ -ftime-trace -c hello.cc -I include -std=c++20ftime-trace的数据可以放到浏览器的tracing里,比如 chrome://tracing/
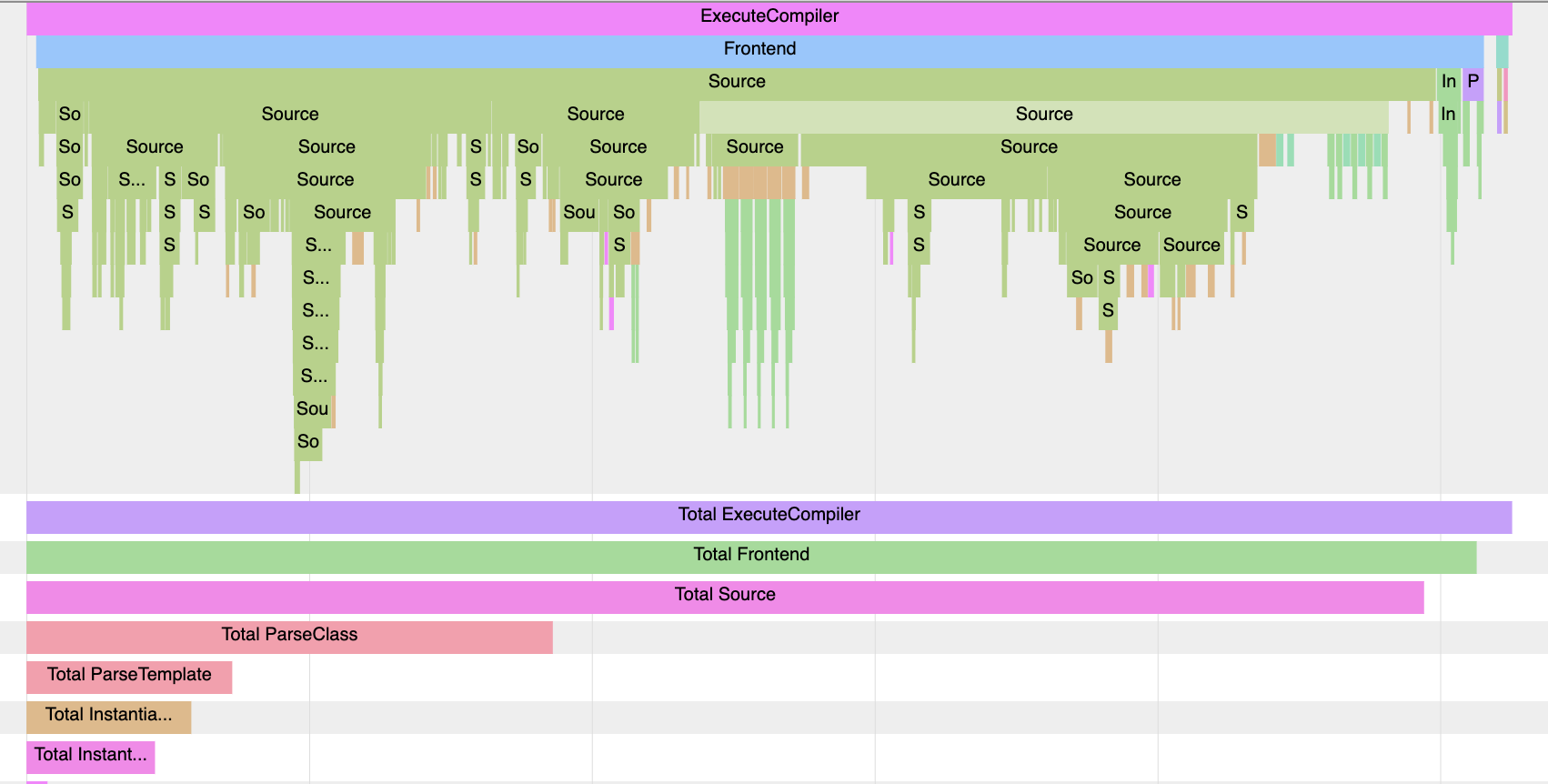
我没看懂他是怎么分析出头文件的耗时的,总之,把string前向声明一下
#ifdef FMT_BEGIN_NAMESPACE_STD
FMT_BEGIN_NAMESPACE_STD
template <typename Char>
struct char_traits;
template <typename T>
class allocator;
template <typename Char, typename Traits, typename Allocator>
class basic_string;
FMT_END_NAMESPACE_STD
#else
# include <string>
#endif但是这种接口编译不过
template <typename... T>
FMT_NODISCARD FMT_INLINE auto format(format_string<T...> fmt, T&&... args)
-> basic_string<char> {
return vformat(fmt, fmt::make_format_args(args...));
}因为basic_string<char>找不到实现,怎么破?
template <typename... T, typename Char = char>
FMT_NODISCARD FMT_INLINE auto format(format_string<T...> fmt, T&&... args)
-> basic_string<Char> {
return vformat(fmt, fmt::make_format_args(args...));
}
然后这个操作就省掉了大量编译时间
Why doesn’t my code compile when I change a shared_ptr(p) to an equivalent make_shared(p)?
结构是这样的
class WidgetContainer : IWidgetCallback
{
//
};
auto widget = std::shared_ptr<Widget>(new Widget(this));能不能换成make_shared?不能,因为是private继承
怎么破?
auto widget = std::make_shared<Widget>(
static_cast<IWidgetCallback*>(this));Did you know about C++26 static reflection proposal (2/N)?
struct foo {
int a{};
int b{};
int c{};
};
static_assert(3 == std::size(std::meta::nonstatic_data_members_of(^foo)));Inside STL: The deque, implementation
deque msvc实现有坑爹的地方
| gcc | clang | msvc | |
|---|---|---|---|
| Block size | as many as fit in 512 bytes but at least 1 element | as many as fit in 4096 bytes but at least 16 elements | power of 2 that fits in 16 bytes but at least 1 element |
| Initial map size | 8 | 2 | 8 |
| Map growth | 2× | 2× | 2× |
| Map shrinkage | On request | On request | On request |
| Initial first/last | Center | Start | Start |
| Members | block** map; size_t map_size; iterator first; iterator last; |
block** map; block** first_block; block** last_block; block** end_block; size_t first; size_t size; |
block** map; size_t map_size; size_t first; size_t size; |
| Map layout | counted array | simple_deque | counted array |
| Valid range | Pair of iterators | Start and count | Start and count |
| Iterator | T* current; T* current_block_begin; T* current_block_end; block** current_block; |
T* current; block** current_block; | deque* parent; size_t index; |
| begin()/end() | Copy first and last. | Break first and first + size into block index and offset. | Break first and first + size into block index and offset. |
| Spare blocks | Aggressively pruned | Keep one on each end | Keep all |
block size太小了
windows相关
- How to allocate address space with a custom alignment or in a custom address region
- How do I prevent my ATL class from participating in COM aggregation? DECLARE_NOT_AGGREGATABLE didn’t work
- The case of the vector with an impossibly large size
视频
What we've been (a)waiting for? - Hana Dusíková - Meeting C++ 2023
介绍协程并写了个co curl 有点意思,视频我也传B站了 https://www.bilibili.com/video/BV1NG411B7Fy/
代码在这里 https://github.sheincorp.cn/hanickadot/co_curl
开源项目更新/新项目介绍
- fmt 10.2更新,支持duration打印 %j 还支持这么玩
#include <fmt/chrono.h>
int main() {
fmt::print("{}\n", std::chrono::days(42)); // prints "42d"
}编译期物理计算的
- nanobind 一个python binding,速度性能都不错,群友kenshin推荐
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群753302367和作者对线
- Unilang deepin的一个通用编程语言,点子有点意思,也缺人,感兴趣的可以github讨论区或者deepin论坛看一看。这里也挂着长期推荐了
- gcc-mcf 懂的都懂
工作招聘
https://job.toutiao.com/s/i8Tv36Jf
字节杭州虚拟机v8研发
字节的音视频团队,主要负责剪映上的音视频/非线性编辑相关工作,业务前景也比较好,目前有三个方向的岗位
- 桌面端音视频研发 https://job.toutiao.com/s/i8enPrw5
- 多端音视频引擎研发 https://job.toutiao.com/s/i8enr7Es
- C++工程基础架构研发 https://job.toutiao.com/s/i8enjTHT
base北上广深杭都可以,薪资open,有兴趣的同学可以通过链接投递
互动环节
新的一年开始了,本周刊也走过了三个年头,希望大家都健康我也继续保持更新下去
如果有疑问评论最好在上面链接到评论区里评论,这样方便搜索,微信公众号有点封闭/知乎吞评论
C++ 中文周刊 第144期
qq群 点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
请提交 issue 或评论区留言
大家新年快乐
群友讨论了一个场景
#include <vector>
#include <memory_resource>
#include <iostream>
int main() {
std::pmr::monotonic_buffer_resource pool{10000};
std::pmr::synchronized_pool_resource pool2;
std::pmr::vector<int> vec(5, &pool);
static_assert(!std::allocator_traits<std::pmr::vector<int>::allocator_type>::propagate_on_container_swap::value, "is true");
std::pmr::vector<int> vec2(4, &pool2);
std::cout << vec.data() << " " << vec2.data() << std::endl;
vec2.swap(vec);
std::cout << vec.data() << " " << vec2.data() << std::endl;
return 0;
}
// 0x557469f1c500 0x557469f1eea0
// 0x557469f1eea0 0x557469f1c500地址居然是可交换的,显然这是UB
std::allocator_traits<allocator_type>::propagate_on_container_swap::value
If std::allocator_traits<allocator_type>::propagate_on_container_swap::value is true, then the allocators are exchanged using an unqualified call to non-member swap. Otherwise, they are not swapped (and if get_allocator() != other.get_allocator(), the behavior is undefined).
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2023-12-27 第234期
文章
- 1. 基于 c++ executions的异步实现 - 从理论到实践
- 基于 c++ executions的异步实现 - libunifex的使用与实现概述
- 3. exectuions 依赖的管道实现 - 在C++中实现LINQ
- 4. executions 依赖的定制机制 - 揭秘 cpo与tag_invoke!
- 5. 基于 c++ executions的异步实现 - libunifex中的concepts详解
- 6. 基于 c++ executions的异步实现 - strutured concurrency实现解析
- 7. 基于 c++ executions的异步实现 - libunifex的scheduler实现
沈芳的一波execution文章,写得不错,学吧,都是知识
还是协程,再看一遍
tag_invoke疑似有点太泛型了,作者觉得还是rust traits直观,提出了个traits object的概念
看代码 https://godbolt.org/z/Ge43cWfn8
#include <type_traits>
constexpr inline struct {
constexpr auto eq(auto rhs, auto lhs) const {return rhs == lhs;}
constexpr auto ne(auto rhs, auto lhs) const {return !eq(lhs, rhs);}
} partial_eq_default;
template<class T>
constexpr inline auto partial_eq = partial_eq_default;
template<>
constexpr inline auto partial_eq<double> = std::false_type{};
constexpr bool f(auto lhs, auto rhs) {
return partial_eq<decltype(lhs)>.eq(lhs, rhs);
}
// bool g(double lhs, double rhs) {
// auto& op = partial_eq<decltype(lhs)>;
// return op.ne(lhs, rhs);
// }
constexpr bool g(int lhs, int rhs) {
auto& op = partial_eq<int>;
return op.ne(lhs, rhs);
}
static_assert(f('a', 'a'));
static_assert(!f('a', 'b'));
static_assert(g('a', 'b'));
int main() {
bool b1 = f(1,2);
bool b2 = g(1,2);
return 0;
}挺好的。之前132期提到定制log就是类似的技术
namespace logging {
namespace null {
struct config {
struct {
template <level L, typename... Ts>
// NOLINTNEXTLINE(cppcoreguidelines-missing-std-forward)
constexpr auto log(Ts &&...) const noexcept -> void {}
} logger;
};
} // namespace null
template <typename...> inline auto config = null::config{};
template <level L, typename... Ts, typename... TArgs>
static auto log(TArgs &&...args) -> void {
auto &cfg = config<Ts...>;
cfg.logger.template log<L>(std::forward<TArgs>(args)...);
}
}
#include <meta>
int main() {
struct foo {};
std::cout << std::meta::name_of(^foo); // prints foo
}没啥说的
众所周知,static局部对象只初始化一次
struct ExpensiveInitialization {
ExpensiveInitialization() noexcept;
void DoWork() noexcept;
};
void DoWork() noexcept {
static ExpensiveInitialization expensive;
expensive.DoWork();
}但如果DoWork或者ExpensiveInitialization变成模版函数,是不是意味着 static每个函数都构建一次?破坏了语义?
作者提出了一种模版特化校验的方法
#include <type_traits>
template<bool const* p, typename SLOC>
struct assert_single_instantiation final {
friend consteval std::integral_constant<bool const*, p> detect_multiple_instances(SLOC) {
return {};
}
};
#define ASSERT_SINGLE_INSTANTIATION \
{ \
static constexpr bool _b = false; \
[](auto sloc) noexcept { \
[[maybe_unused]] assert_single_instantiation<&_b, decltype(sloc)> _; \
}(std::integral_constant<int, __COUNTER__>()); \
}
#define singleton_static ASSERT_SINGLE_INSTANTIATION; static
struct ExpensiveInitialization {
ExpensiveInitialization() noexcept;
void DoWork() noexcept;
};
void DoWork() noexcept {
singleton_static ExpensiveInitialization expensive;
expensive.DoWork();
}
没有任何额外开销 https://godbolt.org/z/hcEWeqf6P
就是我没看明白怎么用的
raymond chen windows环节
- How to allocate address space with a custom alignment or in a custom address region
- What does it mean when the compiler says that it can’t convert something to itself?
视频
My favourite memory leak - Björn Fahller - Lightning Talks @ Meeting C++ 2023
一段会泄漏内存的抽象代码
#include <vector>
struct V : std::vector<V> {}
int main() {
V v;
v.emplack_back();
v.swap(v.front());
}非常幽默
众所周知,vector是三个指针,begin end storend三部分,swap交换自己的时候,这三个指针怎么赋值?
当然,写成c就更容易懂了 (感谢群友@只看封面)
V相当于 class V { V* data;}
Implementing coroutines using C++17 - Alon Wolf - Lightning Talks @ Meeting C++ 2023
看不太懂,也没放源代码。感觉是用intel的jmp汇编和goto搞跳转
开源项目
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群753302367和作者对线
- Unilang deepin的一个通用编程语言,点子有点意思,也缺人,感兴趣的可以github讨论区或者deepin论坛看一看。这里也挂着长期推荐了
- gcc-mcf 懂的都懂
- https://github.com/PickNikRobotics/data_tamer 一个时间采集数据结构,类似bvar
- https://github.com/Futureblur/magnet 又一个包管理器
- https://github.com/proh14/ptext 一个类似nano的编辑器
- https://github.com/germandiagogomez/words-counter-benchmarks-game 一个word count各种实现压测比较
- https://github.com/tdanyluk/bgi2 BGI2 (Beginners' Graphic Interface 2) library 看不懂是啥
- https://github.com/spacewalk01/nanosam-cpp C++ TensorRT Implementation of NanoSAM 不知道是啥
- https://github.com/ChristianPanov/lwlog 又一个日志库
工作招聘
字节的音视频团队,主要负责剪映上的音视频/非线性编辑相关工作,业务前景也比较好,目前有三个方向的岗位
- 桌面端音视频研发 https://job.toutiao.com/s/i8enPrw5
- 多端音视频引擎研发 https://job.toutiao.com/s/i8enr7Es
- C++工程基础架构研发 https://job.toutiao.com/s/i8enjTHT
base北上广深杭都可以,薪资open,有兴趣的同学可以通过链接投递
互动环节
大家新年快乐,祝大家健康!散会!
如果有疑问评论最好在上面链接到评论区里评论,这样方便搜索,微信公众号有点封闭/知乎吞评论
C++ 中文周刊 第143期
qq群 点击进入
另外公众号挂了c++templates 第二版优惠
从上面的链接里下单的兄弟买书到货后可以找我退佣金,加我微信,公众号后台回复即可
本期文章由 黄亮 不语 赞助
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2023-12-20 第233期
委员会邮件 https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2023/#mailing2023-12
本月委员会邮件没有什么新鲜的,顶多fiber_context。这里不展开了
文章
Did you know that C++26 added Pack Indexing?
template<auto N> consteval auto nth(auto... ts) { return ts...[N]; }
static_assert(1 == nth<0>(1, 2, 3));
static_assert(2 == nth<1>(1, 2, 3));
static_assert(3 == nth<2>(1, 2, 3));
还不确定有什么作用
The double life of objects
const的副作用
经典例子
#include <iostream>
int main() {
const int i = 9;
int& j = const_cast<int&>(i);
j = 4;
std::cout << i << std::endl; // prints 9
std::cout << j << std::endl; // prints 4
}
https://godbolt.org/z/vGG3cdavE
但是这个例子,返回优化了,即使没有实现move
#include <iostream>
#include <cassert>
class Rng {
int _min;
int _max;
// invariant: _min <= _max
public:
Rng(int lo, int hi)
// precond: lo <= hi
: _min(lo), _max(hi)
{ assert(_min <= _max); }
int const& min() const { return _min; }
int const& max() const { return _max; }
void set(int lo, int hi)
// precond: lo <= hi
{
_min = lo;
_max = hi;
assert(_min <= _max);
}
Rng(Rng&&) { assert(false); } // this is never called
Rng(Rng const&) { assert(false); } // this is never called
};
const Rng foo() {
const Rng r {1, 2};
std::cout << &r << std::endl;
return r;
}
Rng bar() {
Rng r = foo();
r.set(3, 4);
std::cout << &r << std::endl;
return r;
}
int main() {
const Rng z = bar();
std::cout << &z << std::endl;
}https://godbolt.org/z/n9nn5GjMM
注意这两个例子的区别,统一作用域上的修改
上面的这个xyz 本质上就是一个对象,和第一个例子同一个域里const_cast导致变化不同
About time - how to unit test code that depends on time
怎么mock时间?比如特化?
template <typename ...>
constexpr auto clock_impl = std::chrono::some_clock{};
template <typename ... Ts>
struct app_clock {
static
std::chrono::some_clock::time_point now()
{
return clock_impl<Ts...>.now();
}
};
struct test_clock {
using time_point = std::chrono::some_clock::time_point;
static time_point now() { return {};}
};
template <>
constexpr auto clock_impl<> = test_clock{};https://godbolt.org/z/GbWYaGc7q
浮点数误差入门
讲的不错
linux kernel list 为什么用WRITE_ONCE?
写的很有深度,值得一看
从一个crash问题展开,探索gcc编译优化细节
省流 arm O3 优化bug
Trivial Auto Var Init Experiments
-ftrivial-auto-var-init=[pattern|zero|uninitialized]
帮助自动初始化栈上的局部变量
开销很大,研究了一圈放弃了
Two kinds of function template parameters
一种是make_unique这种需要指定T的,一种是swap sort这种不指定T的
如何跨过这种边界,有设计,比如CTAD,但这并不建议使用
那就只能多提供重载了,比如optional
template<class T, class A>
optional<T> make_optional(A);
template<class A>
optional<A> make_optional(A);然后她举了个例子,怎么设计强制制定T和忽略T
https://godbolt.org/z/h38PhG3Y6
#include <type_traits>
#include <iostream>
//template<class T, class A>
//T implicitly_convert_to(std::type_identity_t<A>) = delete;
template<class T, class A,
std::enable_if_t<std::is_convertible_v<A, T>, int> E = 0>
T implicitly_convert_to(A arg) { return T(arg); }
int main() {
//auto i0 = implicitly_convert_to(9.9999999);
//std::cout << i0 << "\n";
auto i1 = implicitly_convert_to<int>(9.9999999);
std::cout << i1 << "\n";
//auto j2 = implicitly_convert_to<int, float>(9.9999999);
//std::cout << j2 <<"\n";
return 0;
}看一乐
A Coroutines-Based Single Consumer – Single Producer Workflow by Ljubic Damir
直接贴代码了
https://godbolt.org/z/MvYfbEP8r
https://godbolt.org/z/57zsK9rEn
设计的挺有意思的,鉴于篇幅,放在后面
手动优化C++代码来加快编译速度?!
constexpr的代码 编译器没有做充分的优化。这可能加剧编译时长
算是个坑爹细节。运行时能充分优化的代码到了constexpr期反而没优化了
Raymond windows环节,看不懂
- How do I specify an optional string parameter to a Windows Runtime method?
- If the RegisterClass function takes ownership of the custom background brush, why is it leaking?
- How do I get access to the wParam and lParam of the WM_QUERYENDSESSION method from my MFC message handler?
视频
Cache-friendly Design in Robot Path Planning with C++ - Brian Cairl - CppCon 2023
寻路算法,A*之类的,如何缓存友好。STL不太行
valgrind 也可以测试cache性能,判断miss
valgrind --tool=cachegrind --cache-sim=yesperf也可以,就不说了
结论就是 顺序访问 不要跳转 只访问用到的数据 s执行路径里没有malloc
比如std::unordered_multimap::equal_range 内存不连续,miss就很多
"Distributed Ranges": Model for Building Distributed Data Structures, Algorithms & Views - Ben Brock
概念很帅,把range推广到分布式,做的一些工作
代码在这里 https://github.com/oneapi-src/distributed-ranges/tree/main
代码段
#include <iostream>
#include <vector>
#include <coroutine>
#include <chrono>
#include <thread>
#include <utility>
#include <functional>
#include <memory>
#include <algorithm>
#include <iterator>
#include <atomic>
#define FUNC() std::cout << __func__ << '\n'
namespace details {
template <typename InputIterator>
void printIterable(InputIterator first, InputIterator last) {
using value_type = std::decay_t<decltype(*first)>;
std::cout << '[';
if constexpr (std::is_same_v<std::uint8_t, value_type>) {
std::copy(first, std::prev(last), std::ostream_iterator<std::uint16_t>(std::cout, ", "));
std::cout << static_cast<std::uint16_t>(*std::prev(last)) << "]\n";
} else {
std::copy(first, std::prev(last), std::ostream_iterator<value_type>(std::cout, ", "));
std::cout << *std::prev(last) << "]\n";
}
}
template <typename Container>
void printContainer(const Container& container) {
printIterable(std::cbegin(container), std::cend(container));
}
}
class [[nodiscard]] AudioDataResult final {
public:
class promise_type;
using handle_type = std::coroutine_handle<promise_type>;
// Predefined interface that has to be specify in order to implement
// coroutine's state-machine transitions
class promise_type {
public:
using value_type = std::vector<int>;
AudioDataResult get_return_object() {
return AudioDataResult{handle_type::from_promise(*this)};
}
std::suspend_never initial_suspend() noexcept { return {}; }
std::suspend_always final_suspend() noexcept { return {}; }
void return_void() {}
void unhandled_exception() {
std::rethrow_exception(std::current_exception());
}
// Generates the value and suspend the "producer"
template <typename Data>
requires std::convertible_to<std::decay_t<Data>, value_type>
std::suspend_always yield_value(Data&& value) {
data_ = std::forward<Data>(value);
data_ready_.store(true, std::memory_order_relaxed);
return {};
}
auto await_transform(handle_type other) {
// Awaiter interface: for consumer waiting on data being ready
struct AudioDataAwaiter {
explicit AudioDataAwaiter(promise_type& promise) noexcept: promise_(promise) {}
bool await_ready() const { return promise_.data_ready_.load(std::memory_order_relaxed);}
void await_suspend(handle_type) const {
while(not promise_.data_ready_.exchange(false)) {
std::this_thread::yield();
}
}
value_type&& await_resume() const {
return std::move(promise_.data_);
}
private:
promise_type& promise_;
};//Awaiter interface
return AudioDataAwaiter{other.promise()};
}
private:
value_type data_;
std::atomic<bool> data_ready_;
}; //promise_type interface
explicit operator handle_type() const { retur...C++ 中文周刊 第142期
公众号

qq群 手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
文章大部分来自
https://discu.eu/weekly/candcpp/2023/49/
https://www.meetingcpp.com/blog/blogroll/items/Meeting-Cpp-weekly-Blogroll-408.html
本期文章由 黄亮Anthony 赞助
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 OSDT Weekly 2023-12-13 第232期
另外PLCT有rsicv竞赛,感兴趣的可以参加一下 rvspoc.org
boost发布1.84版本,c++03全部抛弃,windows只支持win10及以上
新增redis cobalt库之前讲过
另外asio移除了execution相关设计。。
PFR支持fieldname 反射,要求c++20 https://github.com/boostorg/pfr/pull/129/files
效果 https://godbolt.org/z/xbo7bos86
#include <https://raw.githubusercontent.com/denzor200/pfr/amalgamate_get_name/include/boost/pfr/gen/pfr.hpp>
#include <functional>
#include <cstdio>
#include <cstring>
struct Any {
Any() {};
};
struct XClass {
int member1;
Any this_is_a_name; // not constexpr constructible
std::reference_wrapper<char> c; // not default constructible
};
int main() {
char buf[32] {0};
constexpr auto first = boost::pfr::get_name<0, XClass>();
memcpy(buf, first.data(), first.size());
puts(buf);
static_assert("member1" == boost::pfr::get_name<0, XClass>());
static_assert("this_is_a_name" == boost::pfr::get_name<1, XClass>());
static_assert("c" == boost::pfr::get_name<2, XClass>());
}Unordered支持concurrent_flat_set以及并发visit
其他的没啥说的。自己看吧
https://www.boost.org/users/history/version_1_84_0.html
文章
代码在这里 https://github.com/cdacamar/fredbuf
手把手教你实现编辑器
在130期咱们就聊过,如果cacheline 64,设置align 128能降低影响。lemire给了一种简单的测试方法,拷贝数组
https://github.com/lemire/Code-used-on-Daniel-Lemire-s-blog/blob/master/2023/12/12/cacheline.c
小于cacheline,带宽没啥区别,受cacheline影响了,大于cacheline,越大越快,理论上加入cacheline 64 拷贝128,应该获得翻倍的速度,但是实际上并不是
建议大家自己玩玩,测一下效果。在m1表现也不太一样,但是小于cacheline拷贝速度不变这个现象是不变的
140期的调度器实现有bug,问题代码
class Scheduler {
std::priority_queue<job, std::vector<job>, Comperator> _prioTasks;
public:
void emplace(int prio, std::coroutine_handle<> task) {
_prioTasks.push(std::make_pair(prio, task));
}
};
Task createTask(const std::string& name) {
std::cout << name << " start\n";
co_await std::suspend_always();
for (int i = 0; i <= 3; ++i ) {
std::cout << name << " execute " << i << "\n"; // (5)
co_await std::suspend_always();
}
co_await std::suspend_always();
std::cout << name << " finish\n";
}
scheduler1.emplace(0, createTask("TaskA").get_handle());看出来哪里有问题没有?createtask 的name的生命周期问题
成员函数参数不能直接用this
struct Sample
{
int increment;
void add(int v = increment); // not allowed
void notify_all(Sample* source = this); // not allowed
};猥琐绕过
struct Sample
{
int increment;
void add(int v);
void add() { add(increment); }
void notify_all(Sample* source);
void notify_all() { notify_all(this); }
};
Sample s;
s.add(2); // adds 2
s.add(); // adds s.increment
s.notify_all(); // uses source = s
s.notify_all(other); // uses source = other随机浮点数
比如 这个实现 https://dotat.at/@/2023-06-23-random-double.html
double pcg64_random_double(pcg64_t *rng) {
return (double)(pcg64_random(rng) >> 11) * 0x1.0p-53;
}luajit是这样的
uint64_t lj_prng_u64d(PRNGState *rs) {
uint64_t z, r = 0;
TW223_STEP(rs, z, r)
/* Returns a double bit pattern in the range 1.0 <= d < 2.0. */
return (r & 0x000fffffffffffffull) | 0x3ff0000000000000ull;
}
/* Then to give d in [0, 1) range: */
U64double u;
double d;
u.u64 = lj_prng_u64d(rs);
d = u.d - 1.0;lemire博士的golang版本
// toFloat64 -> [0,1)
func toFloat64(seed *uint64) float64 {
x := splitmix64(seed)
x &= 0x1fffffffffffff // %2**53
return float64(x) / float64(0x1fffffffffffff)
}原理是这个 https://www.zhihu.com/question/25037345/answer/29879012
01之间
double rand_between_zero_and_one() {
double d;
uint64_t x = rand_u64() >> 11; /* 53-bit uniform integer */
uint64_t e = 1022;
do {
if (rand_u64() & 1) break; /* 1-bit uniform integer */
e -= 1;
} while (e > 1022-75);
x = ((x + 1) >> 1) + (e << 52);
memcpy(&d, &x, sizeof(d));
return d;
}优化
double rand_between_zero_and_one() {
double d;
uint64_t x = rand_u64();
uint64_t e = __builtin_ctzll(x) - 11ull;
if ((int64_t)e >= 0) e = __builtin_ctzll(rand_u64());
x = (((x >> 11) + 1) >> 1) - ((e - 1011ull) << 52);
memcpy(&d, &x, sizeof(d));
return d;
}主要是要懂浮点数格式以及如何恰当的均匀分布
contains
#include <string>
#include <iostream>
int main(){
const std::string url = "https://isocpp.org";
if (url.contains("https") &&
url.contains(".org") &&
url.contains("isocpp"))
std::cout << "you're using the correct site!\n";
}
starts_with(), ends_with()
insert range
#include <iostream>
#include <iterator>
#include <string>
int main() {
const auto source = {'l', 'i', 'b', '_'};
std::string target{"__cpp_containers_ranges"};
const auto pos = target.find("container");
auto iter = std::next(target.begin(), pos);
#ifdef __cpp_lib_containers_ranges
target.insert_range(iter, source);
#else
target.insert(iter, source.begin(), source.end());
#endif
std::cout << target;
}
spanstream
#include <iostream>
#include <sstream>
#include <spanstream> // << new headeer!
void* operator new(std::size_t sz){
std::cout << "Allocating: " << sz << '\n';
return std::malloc(sz);
}
int main() {
std::cout << "start...\n";
std::stringstream ss;
ss << "one string that doesn't fit into SSO";
ss << "another string that hopefully won't fit";
std::cout << "spanstream:\n";
char buffer[128] { 0 };
std::span<char> spanBuffer(buffer);
std::basic_spanstream<char> ss2(spanBuffer);
ss2 << "one string that doesn't fit into SSO";
ss2 << "another string that hopefully won't fit";
std::cout << buffer;
}
想了解cpython的可以看看
介绍spanstream的, 直接贴代码了
#include <iostream>
#include <span>
#include <spanstream>
#include <cassert>
void printSpan(auto spanToPrint) {
for (size_t i = 0; i < spanToPrint.size(); ++i) {
std::cout << spanToPrint[i];
}
}
void useSpanbuf() {
std::array<char, 16> charArray;
std::span<char, 16> charArraySpan(charArray);
std::spanbuf buf;
char c = 'a';
for (size_t i = 0; i < 16; ++i) {
charArraySpan[i] = c;
++c;
}
buf.span(charArraySpan);
// we can easily print a span got from the buffer
std::span bufview = buf.span();
std::cout << "bufview: ";
for (size_t i = 0; i < 16; ++i) {
std::cout << bufview[i];
}
std::cout << '\n';
}
void useSpanstream() {
std::array<char, 16> charArray;
std::ospanstream oss(charArray);
oss << "Fortytwo is " << 42;
// copying the contents to a span
std::string s{oss.span().data(),size_t(oss.span().size())};
assert(s == "Fortytwo is 42");
}
int main() {
useSpanbuf();
useSpanstream();
return 0;
}Raymond chen环节。我直接贴连接了。window是我不懂
- How can I work around the absence of default parameters in the Windows Runtime?
- How do I specify an optional parameter to a Windows Runtime method?
linux环节
shmem tmpfs 比较经典
linux 5.6引入的,有意思
视频
姚奕正qds推荐
把 reflection/injection, pattern matching, senders都说了一遍,可以算是一个完全的新c++
在指针上做计算风险高,这也是为啥要引入span stringview,不用char * 信息丢失太多
cppcon2023
cpponsea 2023
...
C++ 中文周刊 第140期
公众号
qq群 手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
最近在找工作准备面试题,更新可能有些拖沓,见谅
本周内容比较少
本期文章由 YellowHornby HNY 不语 黄亮Anthony 赞助
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 OSDT Weekly 2023-11-29 第230期
文章/视频
能返回值优化,不move
定位到 mmap_sem 互斥锁冲突,查找来源
哪里会有mmap?
- 内存分配器 ptmalloc / tcmalloc 大页
- fopen/fseek?
逐个排除定位到是fseek内部有mmap,新版本glibc已经去掉了mmap改了回来,打patch
那么为什么fseek会调用mmap呢?就不能malloc吗 buffer能多大?
本台记者Anein分析是历史原因,为了初始化不清空0,用mmap偷懒了一下。原来大家都偷懒
densemap就是flatmap-
看个乐,别学。还是friend注入那套玩意儿
整型溢出似乎没有好的解决办法,除了多注意/自定义类型加边界检查
介绍了其他语言的解决方法,比如rust 的 overflowing_mul overflowing_add
google内部也有类似的库设计 https://github.com/chromium/subspace/pull/410/files
似乎除了这些,没有更好的办法?
一个幽默的typemap
说到typemap映射,第一反应是字符串/typeindex?是的他就这么实现的,不过用了匿名的类
typeindex计算是很慢的。数量大不建议这么玩,这里展示这种可能性
#include <map>
#include <string>
#include <iostream>
#include <typeindex>
#include <any>
#include <optional>
using dict = std::map<std::type_index, std::any>;
template <class Name, class T>
struct key final { explicit key() = default;};
template <class Name, class T>
auto get(const dict& d, key<Name, T> k) ->std::optional<T> {
if (auto pos = d.find(typeid(k)); pos!=d.end()) {
return std::any_cast<T>(pos->second);
}
return std::nullopt;
}
template <class Name, class T, class V>
void set(dict& d, key<Name, T> k, V&& v) {
constexpr bool convertible = std::is_convertible_v<V, T>;
static_assert(convertible);
if constexpr (convertible) {
d.insert_or_assign(typeid(k), T{std::forward<V>(v)});
}
}
// key里面的类可以只声明不实现,当tag用,只要唯一就行
using age_k = key<struct _age_, int>;
using gender_k = key<struct _gender_, std::pair<float,float>>;
using name_k = key<struct _name_, std::string>;
constexpr inline auto age = age_k{};
constexpr inline auto gender = gender_k{};
constexpr inline auto name = name_k{};
int main() {
auto person = dict();
set(person, age, 14);
set(person, gender,std::pair{0.5,0.5});
set(person, name,"ted");
const auto a = get(person, age);
const auto g = get(person, gender);
const auto n = get(person, name);
std::cout <<*a <<g->first << g->second << *n<<"\n";
}
https://godbolt.org/z/z1hvxzf1e 可以自己玩一下
如果真要考虑用,首先不能用typeindex,得实现一个类转字符串,还得保证唯一性,然后用hashmap存就行
另外不用std::any,用create函数之类的代替
这种需求感觉游戏行业有这种场景
对于array,编译期检查越界应该是可能的
int get_last_elem(const std::array<int, 5>& arr) {
return arr.at(5); // oops, off-by-one
}
这种明显越界,编译期能不能抓到?能,但不报错,会直接抛异常,编译器比较信任你,觉得你喜欢异常
get_last_elem(std::array<int, 5ul> const&): # @get_last_elem(std::array<int, 5ul> const&)
push rax
lea rdi, [rip + .L.str]
mov esi, 5
mov edx, 5
xor eax, eax
call std::__throw_out_of_range_fmt(char const*, ...)@PLTflux库写了个编译期检查的设计
int get_last_elem(const std::array<int, 5>& arr) {
return flux::read_at(arr, 5); // oops, off-by-one
}
编译期就抓到直接报错,如何实现?
[[gnu::error("out-of-bounds sequence access detected")]]
void static_bounds_check_failed();
template <typename Index>
void bounds_check(Index idx, Index limit)
{
if (__builtin_constant_p(idx) && __builtin_constant_p(limit)) {
if (idx < Index{0} || idx >= limit) {
/* ...report error at compile time... */
}
} else {
/* ...perform normal run-time bounds check... */
}
但存在问题,__builtin_constant_p并不是那么可信
https://gcc.gnu.org/bugzilla/show_bug.cgi?id=112296
https://gcc.gnu.org/bugzilla/show_bug.cgi?id=89029
只能说,缘分相信编译器,可能帮你一下
安全加固的编译配置
-O2 -Wall -Wformat=2 -Wconversion -Wtrampolines -Wimplicit-fallthrough \
-U_FORTIFY_SOURCE -D_FORTIFY_SOURCE=3 \
-D_GLIBCXX_ASSERTIONS \
-fstrict-flex-arrays=3 \
-fstack-clash-protection -fstack-protector-strong \
-Wl,-z,nodlopen -Wl,-z,noexecstack \
-Wl,-z,relro -Wl,-z,nowFORTIFY有性能影响
这些还是要关注一下性能影响,中间三行有影响。如果某些行业必须加固那也没办法
tag pointer
指针一般8字节64bits,只用48bits表示内存空间,剩下的16bits有很多可以倒腾的空间,嵌入一些信息
提问: 48bit能表示多大内存?
剩下的这16bit能做什么文章?
- x86_64 加标志位区分内核内存还是用户态内存
- rsicv也有类似设计
- arm是49位内存,其他设计也是类似的
各种硬件系统还有自己的其他设计,利用bit,这里就不展开了
- Intel 有 Linear Address Masking (LAM)
- AMD有 Upper Address Ignore
- rsicv有 pointer masking extension
- arm有 Top Byte Ignore (TBI)
这波报菜名大部分都没什么接触的机会。
考虑自定义的场景
-
fixie trie 用不到的16位用来做bitmap
-
llvm pointpairpointer 其实有点union双关用法了 https://github.com/llvm/llvm-project/blob/dc8b055c71d2ff2f43c0f4cac66e15a210b91e3b/llvm/include/llvm/ADT/PointerIntPair.h#L64
- 暴论 tag pointer 就是union
-
显然 ZGC的pointer设计也是tag pointer https://dinfuehr.github.io/blog/a-first-look-into-zgc/
-
显然 objc和go的tag pointer自然都是,这俩比较有名,就不列了
-
当然 v8 中的pointer compression 自然也是 tag pointer https://v8.dev/blog/pointer-compression
-
那么异或链表自然也是tag pointer
-
当然酒店传单也是tag pointer,不仅可以订餐还可以点按摩是不是
-
Lightning Talk: When C++ Managers Fail... Richard Shepherd - C++ on Sea 2023
重新考虑单例实现
static 单例 static保证 成功 创建 一次
那么存在构造函数抛异常的可能性。注意你的单例的T是不是可能构造抛异常
可能挽救一下就成了这个德行
class Manager {
Resouce* resource_;
Manager() : resource_{CreateResource()} {
if (!resource_) {
throw std::exception("Not ready")
}
}
public:
static Manager* Instance() {
try {
static Manager s;
return &s;
} catch (...) {
return nullptr;
}
}
};只展示代码段,没啥别的说的
简单加个优先级,是的,没错,用priority_queue
#include <coroutine>
#include <iostream>
#include <queue>
#include <utility>
struct Task {
struct promise_type {
std::suspend_always initial_suspend() noexcept { return {}; }
std::suspend_always final_suspend() noexcept { return {}; }
Task get_return_object() {
return std::coroutine_handle<promise_type>::from_promise(*this);
}
void return_void() {}
void unhandled_exception() {}
};
Task(std::coroutine_handle<promise_type> handle): handle{handle}{}
auto get_handle() { return handle; }
std::coroutine_handle<promise_type> handle;
};
class Scheduler {
std::priority_queue<std::pair<int, std::coroutine_handle<>>> _prioTasks;
public:
void emplace(int prio, std::coroutine_handle<> task) {
_prioTasks.push(std::make_pair(prio, task));
}
void schedule() {
while(!_prioTasks.empty()) {
auto [prio, task] = _prioTasks.top();
_prioTasks.pop();
task.resume();
if(!task.done()) {
_prioTasks.push(std::make_pair(prio, task));
}
else {
task.destroy();
}
}
}
};
Task createTask(const std::string& name) {
std::cout << name << " start\n";
co_await std::suspend_always();
std::cout << name << " execute\n";
co_await std::suspend_always();
std::cout << name << " finish\n";
}
int main() {
Scheduler scheduler1;
scheduler1.emplace(0, createTask("TaskA").get_handle());
scheduler1.emplace(1, createTask(" TaskB").get_handle());
scheduler1.schedule();
Scheduler scheduler2;
scheduler2.emplace(1, createTask("TaskA").get_handle());
scheduler2.emplace(0, createTask(" TaskB").get_handle());
scheduler2.schedule();
}开源项目介绍
-
asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群384042845和作者对线
-
Unilang deepin的一个通用编程语言,点子有点意思,也缺人,感兴趣的可以github讨论区或者deepin论坛看一看。这里也挂着长期推荐了
-
https://gitee.com/okstar-org/ok-edu-desktop 一个IM通信软件,做IM的可以关注,现在正在做全面整合阶段,开始组建商业团队阶段,年底开始融资,你参加了就快发财了,会的快来
-
https://github.com/hanickadot/cthash 编译期sha算法
互动环节
github上闲逛看到个44个commit 1800 star的项目,震惊,asteria我看就写的不错,上千次提交了才几百星
可能star主要和曝光度有关了,说明吹牛逼还是有用的朋友们
另外突击检查!手写upper bound,写不出的深蹲十个
C++ 中文周刊 第138期
公众号
qq群 手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
最近在找工作准备面试题,更新可能有些拖沓,见谅
本期文章由 不语 黄亮 赞助
资讯
标准委员会动态/ide/编译器信息放在这里
c++26进展如火如荼 反射又又又又又一次被端了出来,给了一堆符号语法,我说婷婷吧,感觉够呛
感兴趣的可以看看这个 C++26静态反射提案解析
我觉得我不是第一个讨厌这个语法的人
boost 1.84预览版出炉 https://www.boost.org/users/history/version_1_84_0.html
新加入cobalt协程组件和redis客户端两个库,都是堆在asio上面的。可以偷学一下,卷死同行
什么!你说asio你都没研究过,算了还是别研究了,周末应该休息,看一乐就行了
编译器信息最新动态推荐关注hellogcc公众号 OSDT Weekly 2023-11-15 第228期
文章
这个是我第一次见到计算层引入协程的实践,之前有个corobase论文,另外像scylladdb redpanda更多是把协程放在简单任务逻辑以及文件处理上
这个还是挺精彩的
为啥coroutine需要额外的栈空间?协程栈不应该在heap上吗?
比如这坨代码
#include <coroutine>
#include <exception>
// Define a coroutine type called "task"
// (not relevant to scenario but we need *something*.)
struct task { void* p; };
namespace std
{
template<typename...Args>
struct coroutine_traits<task, Args...>
{
struct promise_type
{
task get_return_object() { return { this }; }
void unhandled_exception() { std::terminate(); }
void return_void() {}
suspend_never initial_suspend() { return {}; }
suspend_never final_suspend() noexcept { return {}; }
};
};
}
// End of "task" boilerplate.
void consume(void*);
task sample()
{
char large[65536];
consume(large);
co_return;
}因为这个coroutine并不会suspend,能走heap allocation elision优化HALO
可能这种场景你可能得关注栈溢出问题,如果你是msvc用户,恭喜你,msvc有bug,没做优化,还是在堆heap上
为什么没做优化?做了,但是没完全生效,代码里写了生成 __coro_elision_buffer
但没判断出__coro_elision_buffer 完全没用没彻底优化掉。已经在修了
当然这种优化是好的,只是提醒你注意你的协程局部对象生命周期而已,你要是害怕,这么玩也不是不行
task sample()
{
auto large = std::make_unique_for_overwrite<char[]>(65536);
consume(large.get());
co_return;
}很精彩的bit反转,客户端确实少见
了解llvm的,看一乐, 作者还是学生,挺厉害的
shared_future::get有复制,注意T的复制是否过重
作者建议干脆别用
其实就是memcheck
std::source_location本应该是编译期字符串,但是却只提供一个const char *
脑瘫接口
QString getSheep() {
return QStringLiteral("🐑");
}这个🐏怎么打呢
QString getSheep() {
return QStringLiteral("\N{SHEEP}");
}目前这种用法也就clang15支持
首先要知道peephole优化是啥,
简单说就是小汇编代码段重写,删除,代数优化,降低寄存器复用提高吞吐 简化控制流 指令合一
考虑一个打表
constexpr static bool is_forbidden_host_code_point_table[] = {
1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
bool is_forbidden_host_code_point(char c) {
return is_forbidden_host_code_point_table[uint8_t(c)];
}一个一个敲,眼睛都花了。怎么生成?感谢constexpr
constexpr static std::array<uint8_t, 256> is_forbidden_array = []() {
std::array<uint8_t, 256> result{};
for (uint8_t c : {'\0', '\x09', '\x0a','\x0d', ' ', '#', '/', ':',
'<', '>', '?', '@', '[', '\\', ']', '^', '|'}) {
result[c] = true;
}
return result;
}();
bool is_forbidden_host_code_point_array(char c) {
return is_forbidden_array[uint8_t(c)];
}编译器帮我打表。快说谢谢constexpr
加个flag标记初始化过了
好好好你这么整是吧
开源项目介绍
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群384042845和作者对线
最近进展,优化JIT/基础组件调优,对于做语言的还是能见识到一点东西的
- Unilang deepin的一个通用编程语言,点子有点意思,也缺人,感兴趣的可以github讨论区或者deepin论坛看一看。这里也挂着长期推荐了
- gcc-mcf 懂的都懂
- https://github.com/hggq/paozhu 一个网络框架
- https://gitee.com/okstar-org/ok-edu-desktop 一个IM通信软件,做IM的可以关注,现在正在做全面整合阶段,开始组建商业团队阶段,年底开始融资,你参加了就快发财了,会的快来
- https://github.com/volt-software/Ichor/tree/v0.3.0 一个c++20 服务框架
有个哥们给gcc加上了特殊的翻译 https://github.com/Mosklia/gcc-hentai
预览效果 喜剧效果比较强

视频
*(char*)0 = 0;- What Does the C++ Programmer Intend With This Code? - JF Bastien - C++ on Sea 2023 https://www.youtube.com/watch?v=dFIqNZ8VbRY
这哥们非常夸张
其实这个在嵌入式比较常见,就是给内存0的地方清零
由于众所周知的问题,nullptr的值是0,linux windows访问0地址直接崩溃,毕竟UB
你为啥这么写?作者讲这个为什么讲了一个小时我靠
精彩是精彩,有点长了,喜欢脱口秀的可以看看
互动环节
最近看到俩bug
一个是存储引擎 字符串比较用strcmp
一个是编解码 string.substr(0,0)
另外在知乎看到的 https://www.zhihu.com/question/630025869
std::vector<int> vec{10,2,2,10};
auto max_iter = std::max_element(vec.begin(), vec.end());
vec.erase(std::remove(vec.begin(), vec.end(), *max_iter), vec.end());
// vec中的元素变成了{2,10}这个是经典alias语义问题,也是为啥大家实现decay_copy的源头,还是有人能遇到
读者们有没有好玩的bug,欢迎评论区反馈
话说我也写过不同基类虚函数同名字导致查找莫名其妙匹配的bug,哈哈。互坑
C++ 中文周刊 第136期
qq群 手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
感谢 不语 赞助
最近在找工作准备面试题,更新可能有些拖沓,见谅
以后可能要改变一下内容
一周发文章总结,一周发视频总结,这样两种内容交叉一下
本期发视频总结
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 OSDT Weekly 2023-10-25 第225期
视频
CPPNorth去年的讲一下。今年的PPT没全放出来
Amir Kirsh - Are your Structures Bindable
怎么检测一个类型是否能结构化展开?structure_bindale?
代码在 https://godbolt.org/z/ocox9sqed
不知道什么场景能用上。看一乐
Amir Kirsh - The fine details behind C++ containers and algorithms
一些容器使用上的经验/坑
vector push_back的T有三种场景
- trivially copyable 直接memcopy
- nothrow_move_constructible 直接move 这就要求T的move构造要noexcept
- 拷贝构造
std::copy 可能mommove 可能for循环无优化,注意使用
list原地sort通常不如拷贝到vector再sort 数据局部性问题
开头插入,list还是vector都不如 reserve预留空间 + push_back + 反转 reverse 快
尽可能降低挪动
https://quick-bench.com/q/Cx35L5th0bsvDMVHCdK61g08_z4 这个思路还是挺有意思的
按照index下标erase vector的优化,可以通过move来代替erase,最后只erase一次
这里index是降序的
size_t removed = 0;
for(auto index: indices_to_erase) { // indices_to_erase are sorted in descending order
std::move(vec.begin() + index + 1, vec.end() - removed, vec.begin() + index);
++removed;
}
vec.erase(vec.end() - removed, vec.end());降低交换次数,move相当于交换+移动,减少拷贝,删除的越多,收益越大
如果index数组是升序的,怎么写?
unordered_map的优化
尽可能用insert_or_assign,比赋值快
https://stackoverflow.com/questions/63041408/unordered-map-excess-calls-to-hash-function
计算hash过于频繁
我觉得还是别用这破玩意了
try_emplace提高性能,这个之前咱们也提过,但一定要用对,不然可能性能下降。或者装作不知道这个函数吧
另外删改写回场景c++17可以通过extract node insert node实现,性能更好一些
https://quick-bench.com/q/QtFK3ZJSXuf53l82e_z96Mq8fyk
range尽可能使用
constexpr std::string_view words{"Hello-_-C++-_-20-_-!"};
constexpr std::string_view delim{"-_-"};
for (const auto word : std::views::split(words, delim)) {
std::cout << std::quoted(std::string_view(word.begin(), word.end())) << ' ';
}
或者用 https://zh.cppreference.com/w/cpp/ranges/lazy_split_view
为啥还有lazy版本?难道split_view不是lazy的?
并不是,主要原因是split_view比较难用 https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2021/p2210r2.html
不展开了跑题了朋友们
Dean Moldovan - A std-fs-path from bug to patch
std::fs::path 不是unicode-safe的
特殊字母会有问题,想要用utf-8,可以用std::fs::u8path
他们不会搞定制clang-tidy规则,改系统源代码,给std::fs::path加deprecate信息。。。
Timur Doumler - C++ Lambda Idioms
lambda转函数指针
int main() {
auto f = +[](int i){ return i * i; };
static_assert(std::is_same_v<decltype(f), int(*)(int)>);
}怎么立即执行lambda?加括号?有没有更好的写法?invoke
捕获初始化优化代码
比如这种
const std::vector<std::string> vs = {"apple", "orange", "foobar", "lemon"};
const std::string prefix = "foo";
auto result = std::find_if(
vs.begin(), vs.end(),
[&prefix](const std::string& s) {
return s == prefix + "bar";
});
if (result != vs.end())
std::cout << prefix << "-something found!\n";
这个prefix的构造就很脑瘫,怎么写更合理?把"bar"放外面?如果"bar"没法放外面只能这么构造怎么办?
const std::vector<std::string> vs = {"apple", "orange", "foobar", "lemon"};
const std::string prefix = "foo";
auto result = std::find_if(
vs.begin(), vs.end(),
[str = prefix + "bar" ](const std::string& s) {
return s == str;
});
if (result != vs.end())
std::cout << prefix << "-something found!\n";
通过捕获的构造来替换内部的构造
lambda递归调用
常规
int main() {
std::function<int(int)> f = [&](int i) {
if (i == 0) return 1;
return i * f(i - 1);
};
std::cout << f(5); // prints 120
}function有类型擦除开销,有没有其他方案?Y组合子?
int main() {
auto f = [&](auto&& self, int i) {
if (i == 0) return 1;
return i * self(self, i - 1);
};
auto recursive = [](auto&& f, auto&&... args) {
return f(f, std::forward<decltype(args)>(args)...);
};
std::cout << recursive(f, 5); // prints 120
}
c++23的deducing this可以很好的写出来
int main() {
auto f = [&](this auto&& self, int i){
if (i == 0) return 1;
return i * self(i - 1);
};
std::cout << f(5); // prints 120
}这玩意结合overload惯用法可以有更花的玩法
struct Leaf {};
struct Node;
using Tree = std::variant<Leaf, Node*>;
struct Node {
Tree left, right;
};
template <typename... Ts>
struct overload : Ts... { using Ts::operator()...; }
int countLeaves(const Tree& tree) {
return std::visit(overload{
[] (const Leaf&) { return 1; },
[] (this const auto& self, const Node* node) -> int {
return visit(self, node->left) + visit(self, node->right);
}
},
tree);
}- Tristan Brindle - Cpp20 Ranges in Practice
其他
P99 CONF 2023 | Adventures in Thread-per-Core Async with Redpanda and Seastar by Travis Downs
https://www.bilibili.com/video/BV1gg4y1d7jB/
redpanda有一些coroutine实践,有点意思
seastar是thread per core 消息传递 share nothing,异步的处理阻塞非常重要
原来的seaster是传递future continuation的,引入couroutine就可以把then链切成co_await
但引入coroutine也是有代价的
- 只要suspend就有栈开销,除非
- suspend不发生,不可达 不co_await co_yeild
小的任务,不建议coroutine,能同步就同步,不能同步再then链,不能then链再coroutine
开源项目需要人手
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群384042845和作者对线
- Unilang deepin的一个通用编程语言,点子有点意思,也缺人,感兴趣的可以github讨论区或者deepin论坛看一看。这里也挂着长期推荐了
- gcc-mcf 懂的都懂
- https://gitee.com/okstar-org/ok-edu-desktop 一个IM通信软件,做IM的可以关注,现在正在做全面整合阶段,开始组建商业团队阶段,年底开始融资,你参加了就快发财了,会的快来
C++ 中文周刊 第134期
qq群 手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
感谢 不语 赞助
和群友讨论的指针乱分类
| 指针定义 九宫格 |
定义纯粹派 必须是指针 |
定义中立派 有指针的能力 |
定义自由派 没有能力也行 |
|---|---|---|---|
| 形式纯粹派 必须有* |
void * | operator*() | "" 是char当然是指针 |
| 形式中立派 得有指向含义 |
智能指针 | 引用也是指针 | fd/handle也是指针 当然数组也是指针 |
| 形式自由派 有指针就行 |
表针也是指针 指南针更是指针 鼠标也是指针 |
针灸也是指针 东方不败自然也是指针 手指也是指针 |
广告也是指针 地址通讯录也是指针 酒店小卡片也是指针 |
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 OSDT Weekly 2023-10-11 第223期
brpc rpcz功能 存在xss跨站漏洞,建议尽快升级 1.6.1
如果无法升级,可以打补丁 https://github.com/apache/brpc/pull/2411/files
文章
GCC Preparing To Introduce "-fhardened" Security Hardening Option
Mick235711 投稿
gcc 14.1的新选项-fhardened会自动开启大部分相对轻量级的安全检查,包括3级保护(常见C库函数,比如strcpy等等的内存溢出诊断),标准库断言(这里面包括std::span和其他容器的operator[]边界检查),栈溢出检查等等
How to compare signed and unsigned integers in C++20?
介绍 std::cmp_xx的 之前也介绍过
使用 jegdb 来调试内存相关 crash
通过jemalloc meta信息反查bug,有点东西
flat_map性能调研
了解个大概
C++26静态反射提案解析
看一乐
视频
接着上期的内容
cppcon 2022
- A-Faster-Serialization-Library-Based-on-Compile-time-Reflection-and-C-20-Yu-Qi-CppCon-2022
介绍qimosmos的strucpack的。挺有意思。资料也很多,这里就不罗列了,感兴趣的可以搜一下,标记个TODO,咱们以后有时间单独讲一下
- binary-search-cppcon
优化二分
二分谁都知道吧
int lower_bound(int x) {
int l = 0, r = n - 1;
while (l < r) {
int m = (l + r) / 2;
if (t[m] >= x)
r = m;
else
l = m + 1;
}
return t[l];
}不会写的深蹲十个
CPU执行基本流程还记得吧 fetch decode execute write。 然后CPU有流水线pipeline优化,整个流程15-20cycle
流水线优化能并发上面的步骤,什么能阻碍流水线优化?
- structural hazard 太多指令用相同的CPU地址,这个是fetch decode机器码环节,无解
- data hazard 需要等待前面的数据,这个其实是软件问题,也没啥好办法
- control hazard CPU不知道下一次该执行什么指令,存在依赖 分支miss的场景,这个是可以挽救修正的
我们回头再看二分的代码
while循环还好说,里面的if是非常重的
怎么改成无分支版本?换一种思路,我们不挪动index,我们挪动数组地址
int lower_bound(int x) {
int* base = t ,len = n;
while(len> 1) {
int half = len / 2;
if (base[half - 1] < x) {
base += half;
len = len - half; // = ceil(len / 2)
} else {
len = half; // = floor(len / 2)
}
}
return *base;
}注意到重复代码,这样能把else去掉
int lower_bound(int x) {
int* base = t ,len = n;
while(len> 1) {
int half = len / 2;
if (base[half - 1] < x) {
base += half;
}
len -= half; // = ceil(len / 2)
}
return *base;
}显然,这个if也能优化掉
while(len> 1) {
int half = len / 2;
base += (base[half - 1] < x) * half; // will be replaced with a "cmov"
len -= half; // = ceil(len / 2)
}改成无分支版本,性能直接提升一大截,但是,对于大数组,性能是下降的,怎么办?prefetch
while(len > 1) {
int half = len / 2;
len -= half;
__builtin_prefetch(&base[len / 2 - 1]);
// middle of the left half
__builtin_prefetch(&base[half + len / 2 - 1]); // middle of the right half
base += (base[half - 1] < x) * half;
}接下来要上强度了朋友们
prefetch实际上也解决不了特大数组的问题,因为二分,一开始的块必然很大,你怎么prefetch也白搭
我们需要从另一种角度解决问题,比如二叉树 堆 线段树的特性
利用树的特点,以及树的局部性友好,对于二分开头有明显的加速效果
二叉树的的特点就决定了,肯定不需要手写分支
那怎么构造堆呢
int a[n];
alignas(64) int t[n + 1]; //the original sorted array and the eytzinger array we build
//^ we need one element more because of one-based indexing
void eytzinger(int k = 1) {
static int i = 0;
if (k <= n) {
eytzinger(2 * k);
t[k] = a[i++];
eytzinger(2 * k + 1);
}
}
int lower_bound(int x) {
int k = 1;
while (k <= n) {
__builtin_prefetch(&t[k * 16]);
k = 2 * k + (t[k]< x);
}
k >>= __builtin_ffs(~k);
return t[k];
}性能好起来了,但感觉有优化空间
- prefetch感觉有点多
- 带宽bandwidth换延迟,如果内存带宽没这么富裕怎么办
考虑b树,深度更低,局部性更好,跳转更少, 降低带宽
如何构造
const int B = 16, nblocks = (n + B - 1) / B;
int btree[nblocks][B];
int go(int k, int i) { return k * (B + 1) + i + 1; }
void build(int k = 0) {
static int t = 0;
while (k < nblocks) {
for (int i = 0; i < B; i++) {
build(go(k, i));
btree[k][i] = (t < n ? a[t++] : INT_MAX);
}
build(go(k, B));
}
}如何找节点的二分?
// compute the "local" lower bound in a node
int rank(int x, int *node) {
for (int i = 0; i < B; i++)
if (node[i] >= x)
return i;
return B;
}优化if
int rank(int x, int *node) {
int mask = (1 << B);
for (int i = 0; i < B; i++)
mask |= (btree[k][i] >= x) << i;
return __builtin_ffs(mask) - 1;
}优化for循环,SIMD
typedef __m256i reg;
// compute a 8-bit mask corresponding to "<" elements
int cmp(reg x_vec, int* y_ptr) {
reg y_vec = _mm256_load_si256((reg*) y_ptr); // load 8 sorted elements
reg mask = _mm256_cmpgt_epi32(x_vec, y_vec); // compare against the key
return _mm256_movemask_ps((__m256)mask); // extract the 8-bit mask
}
int rank(reg x_vec, int *node) {
int mask = ~(
cmp(x, node) +
(cmp(x, node + 8) << 8)
);
return __builtin_ffs(mask) - 1; // alternative: popcount
}最终代码
int lower_bound(int _x) {
int k = 0, res = INT_MAX;
reg x = _mm256_set1_epi32(_x);
while (k < nblocks) {
int i = rank(x,btree[k]);
if (i < B)// a local lower bound may not exist in the leaf node
res = btree[k][i];
k = go(k, i) ;
}
return res;
}这个if很难受,怎么优化?
考虑b+树,说实话我已经汗流浃背了。就不考虑了
作者还探索了其他树,优化更彻底
代码在这 https://github.com/sslotin/amh-code/blob/main/binsearch
文章在这里 https://en.algorithmica.org/hpc/data-structures/binary-search/
他的博客咱们推荐过很多次。写的很好,就是太深了得研究半天,这里标记个TODO,后面再看
见识到思路其实是很巧妙的,换种角度考虑问题
- Fast-High-Quality-Pseudo-Random-Numbers-CPPCon2022-Roth-Michaels
简单来说,PCG32 Xoshiro128比标准库的rand以及mt19937快得多
- HPX-A-C-Standard-Library-for-Parallelism-and-Concurrency-CppCon-2022-1
介绍HPX的,基本每年都介绍
介绍c++20线程相关的组件,jthread就不说了
stop resource
void stoppable_func(std::stop_token st){
while(!st.stop_requested()){
do_stuff();
}
}
void stopper(std::stop_source source){
while(!done()){
do_something();
}
source.request_stop();
}也可以定制
Data read_file(std::stop_token st, std::filesystem::path filename ){
auto handle=open_file(filename);
std::stop_callback cb(st,[&]{ cancel_io(handle);});
return read_data(handle); // blocking
}latch
void foo(){
unsigned const thread_count=...;
std::latch done(thread_count);
std::vector<std::optional<my_data>> data(thread_count);
std::vector<std::jthread> threads;
for(unsigned i=0;i<thread_count;++i)
threads.push_back(std::jthread([&,i]{
data[i]=make_data(i);
done.count_down();
do_more_stuff();
}));
done.wait();
process_data(data);
}barrier,感觉就是latch加上callback了
unsigned const num_threads=...;
void finish_task();
std::barrier<std::function<void()>> b(num_threads,finish_task);
void worker_thread(std::stop_token st,unsigned i){
while(!st.stop_requested()){
do_stuff(i);
b.arrive_and_wait();
}
}mutex 一种死锁场景
class account {
std::mutex m;
currency_value balance;
public:
friend void transfer(account& from,account& to, currency_value amount) {
std::scoped_lock lock_from(from.m);
std::scoped_lock lock_to(to.m);
from.balance -= amount;
to.balance += amount;
}
};相信各位也看出来什么场景会死锁 (同时发生互相转账)
c++20之后 scoped_lock可以同时锁多个锁
friend void transfer(account& from,account& to, currency_value amount)
{
std::scoped_lock locks(from.m,to.m);
from.balance -= amount;
to.balance += amount;
}间接规避了死锁的问题 其实相当于两把锁合成一个来锁。
相当于要么同时锁上,要么等待。避免了两个上锁之间的间隔,也就避免了循环死锁问题。增加点耗时就是了,反正不出错
还有一些别的。没啥新鲜的东西,就不说了
- Managing APIs in Enterprise Systems
这个是通过visit来合并不同API的
场景是两个不同的Response,通过一个接口处理
- Optimization-Remarks
Rpass llvm-opt-report opt-viewer 三板斧
opt viewer godbolt上也集成了 https://godbolt.org/z/jG5jq7c9a
作者写了个optview2
如何看懂optview告警
| Symptom | Probable cause | Action |
|---|---|---|
| Inlining Failure | Add header / forceinline /increase threshold | |
| Clobbered by store | Aliasing | restrict / force type diff |
| Clobbered by load | Escape | Attributes pure / const /noescape (typically before the remark site) |
| Failed to move load loop invariant | Escape | All the above + copy to local |
| 其他场景 | 看不懂 | 最小代码段扔进godbolt再看 |
- The-Surprising-Complexity-of-Formatting-Ranges
介绍 fmt 占位符解析实现的。很长
- Type-Erasure-The-Implementation-Details-Klaus-Iglberger-CppCon-2022
介绍type erasure技术(function,any),这个技术大家都知道,还介绍了一些优化,比如SBO
所谓SBO就是给对象加一个数组buffer,当对象足够小,就用buffer placement new,避免系统new
代码大概这样
static constexpr size_t buffersize = 128UL;
static constexpr size_t alignment = 16UL;
alignas(alignment) std::array<std::byte,buffersize> buffer;
template< typename ShapeT >
Shape( ShapeT const& x ) {
using M = Model<ShapeT>;
static_assert( sizeof(M) <= buffersize, "Given type is too large" );
static_assert( alignof(M) <= alignment, "Given type is overaligned" );
::new (pimpl()) M( shape );
}还有就是手工绑定 manual virtual dispatch MVD
去掉虚函数,...