Releases: wanghenshui/cppweeklynews
C++ 中文周刊 第108期
弄了个qq频道,手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
本周内容不多,但是比较难理解
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 上周更新 2023-03-29 第195期
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2023-04-05 第196期
Xmake v2.7.8 发布,改进包虚拟环境和构建速度 https://tboox.org/cn/2023/04/04/xmake-update-v2.7.8/
文章
虚基类
struct A {
int a{};
};
struct B : virtual A {};
struct C : virtual A {};
struct D : B, C {};
int main() {
D d{};
d.a = {}; // without virtual -> request for member 'a' is ambiguous
}介绍协程应用以及如何更好的封装成Lazy类
LTO/PGO 涨涨见识
了解一波fuzzer。据我了解应用的很少
感觉就是分层
gcc优化技术债,把iostream的依赖减小了
和Folly的Sync<T>一个东西, 帮你把mutex和你的值装在一起,免得你自己调用lock unlock
使用
struct Thing {
MutexProtected<Field> field;
};
thing->field.with([&](Field& field) {
use(field);
});
代码 https://github.com/SerenityOS/serenity/blob/master/Kernel/Locking/MutexProtected.h
[uuid(a6107c25-4c22-4a12-8440-7eb8f5972e50)]
class Widget : public IWidget
{
/* ... */
};
这代码啥意思? MSVC方言
有异常不处理,遇到了会给你一种代码挂住了没执行的感觉,尤其是在协程内
winrt::IAsyncAction DoAwesomeThings()
{
co_await promise.initial_suspend();
try {
Step1();
printf("About to call Step2!\n");
Step2();
printf("Step2 returned!\n"); // never executes!
Step3();
} catch (...) {
promise.unhandled_exception();
}
co_await promise.final_suspend();
}push_back 当你想把已有的临时对象放到你的vector或者想把已有的对象move到你的vector
emplace_back 当你想创建临时对象,放到你的vector,没必要创建个临时对象再push_back
开源项目需要人手
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群384042845和作者对线
- pika 一个nosql 存储, redis over rocksdb,非常需要人贡献代码胖友们, 感兴趣的欢迎加群294254078前来对线
- Unilang deepin的一个通用编程语言,点子有点意思,也缺人,感兴趣的可以github讨论区或者deepin论坛看一看。这里也挂着长期推荐了
- paozhu 国人开发的web库,和drogon联系过没共建而考虑自己的需求基于asio开发。感兴趣的可以体验一下,挂在这里长期推荐了
工作招聘
感觉有点干够了这个活。有没有啥岗位推荐的
如果有疑问评论最好在上面链接到评论区里评论,这样方便搜索,微信公众号有点封闭/知乎吞评论
C++ 中文周刊 第106期
公众号

弄了个qq频道,手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
难得线上稳定 T_T 不过本周内容依旧不多
之前给大家推荐的llvm中文邮件列表不知道大家关注没,发送一个标题为「subscribe」的邮件(正文可以为空)到 [email protected]
有人发LLVM的一些使用,还是挺有意思的
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2023-03-22 第194期
AMD EPYC Genoa-X CPU 曝光:配备 1.25GB 缓存,预计将于年内推出
3D Vcache服务器,1G多cache,离谱,zen3就很省钱,zen4这波又得扩大一波市场占用率,英特尔慌不慌
文章
class parse {
public:
parse(std::string str) : str_(str) {}
template<typename T>
operator T() && {
if constexpr (std::is_integral_v<T>) {
T t = atoi(str_.data());
return t;
}
else {
return str_;
}
}
private:
std::string str_;
};
std::string str = "42";
int i = parse(str);
assert(i == 42);
std::string s = parse(str);
assert(s == "42");有趣
enum class error { runtime_error };
[[nodiscard]] auto foo() -> std::expected<int, error> {
return std::unexpected(error::runtime_error);
}
int main() {
const auto e = foo();
e.and_then([](const auto& e) -> std::expected<int, error> {
std::cout << int(e); // not printed
return {};
}).or_else([](const auto& e) -> std::expected<int, error> {
std::cout << int(e); // prints 0
return {};
});
}真不容易,之前就该有的东西
省流,替换unordered_map为tsl/robin_map.h,性能提升明显(2023了大家应该都知道标准库这个map垃圾了)
省流: 空基类优化
苹果M1平台下的perf counter https://gist.github.com/ibireme/173517c208c7dc333ba962c1f0d67d12
例子
#include "performancecounters/event_counter.h"
event_collector collector;
void f() {
event_aggregate aggregate{};
for (size_t i = 0; i < repeat; i++) {
collector.start();
function(); // benchmark this function
event_count allocate_count = collector.end();
aggregate << allocate_count;
}
}
快一点,但不多,一般来说热点也不在这
监控服务,发现性能瓶颈,但发现监控服务本身成了瓶颈,修复监控服务的bug,有意思
看不懂,但感觉有点意思
实现了个限流桶算法。看个乐,直接贴了
https://github.com/mvorbrodt/blog/blob/master/src/token_bucket.hpp
视频
看代码
#include <list>
#include <vector>
template <template <typename T, typename Alloc = std::allocator<T>>
class Container>
[[nodiscard]] constexpr auto transform_into(auto f, const auto &input) noexcept(
noexcept(f(input.front())))
requires requires { f(input.front()); }
{
Container<decltype(f(input.front()))> retval;
retval.reserve(input.size());
for (auto &&value : input) {
retval.push_back(f(value));
}
return retval;
}
int main() {
std::list<int> data{1, 2, 3, 4};
const auto result =
transform_into<std::vector>([](const auto i) { return i * 1.1; }, data);
static_assert(std::is_same_v<decltype(result)::value_type, double>);
}只能说,这个例子不配这种级别的抽象
开源项目需要人手
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群384042845和作者对线
- pika 一个nosql 存储, redis over rocksdb,非常需要人贡献代码胖友们, 感兴趣的欢迎加群294254078前来对线
- Unilang deepin的一个通用编程语言,点子有点意思,也缺人,感兴趣的可以github讨论区或者deepin论坛看一看。这里也挂着长期推荐了
- paozhu 国人开发的web库,和drogon联系过没共建而考虑自己的需求基于asio开发。感兴趣的可以体验一下,挂在这里长期推荐了
新项目介绍/版本更新
- StaticAnalysis 一个静态分析的action模版
工作招聘
看到这里或许你有建议或者疑问或者指出错误,请留言评论! 多谢! 你的评论非常重要!也可以帮忙点赞收藏转发!多谢支持!
如果有疑问评论最好在上面链接到评论区里评论,这样方便搜索,微信公众号有点封闭/知乎吞评论
C++ 中文周刊 第105期
公众号
弄了个qq频道,手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
值班心累,本周内容非常少
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2023-03-15 第193期
线下聚会了说是
文章
TLDR 尽可能使用string_view替代std::string,速度提升显著
扩展思路
字节跳动一个json库,兼顾速度和好用,可以关注一波
介绍用户自定义字符操作符的
比如 ms,再比如
long double operator""_deg_to_rad(long double deg)
{
long double radians = deg * std::numbers::pi_v<long double> / 180;
return radians;
}
// ...
// value is now 90 degree in radiants -> 1.5707...
double value = 90.0_deg_to_rad;#include <format>
#include <iostream>
#include <ranges>
#include <vector>
int main() {
std::vector a { 10, 20, 30, 40, 50 };
std::vector<std::string> b { "one", "two", "three", "four" };
for (const auto& [num, name] : std::views::zip(a, b))
std::cout << std::format("{} -> {}\n", num, name);
}
zip介绍的文章,c++23可用
constexpr auto isPrint = [](auto c) { return std::isprint(c); };
constexpr auto isXDigit = [](auto c) { return std::isxdigit(c); };
constexpr auto hexdigital = std::views::filter(isXDigit);
constexpr auto printable = std::views::filter(isPrint);
constexpr auto digits = std::views::iota('\0')
| std::views::take(256)
| hexdigital;
for (char c : digits) ~~~ // Error
for (char c : digits | printable) ~~~ // Error报错真么办,本质上,digits这里的遍历不是const,只能decay,c++23用auto解决
for (char c : auto(digits)) ~~~ // OK
for (char c : auto(digits) | printable) ~~~ // OK另外,反转,直接贴代码
constexpr auto rest = [](auto fv) {
return fv.base() | std::views::filter(std::not_fn(fv.pred()));
};
for (char c : rest(digits)) ~~~ // OK
for (char c : rest(digits) | printable) ~~~ // OK大概慢几倍。当然发现bug最重要
写了个针对arm sve指令的trim优化
原版
size_t trimspaces(const char *s, size_t len, char *out) {
char * init_out{out};
for(size_t i = 0; i < len; i++) {
*out = s[i];
out += (s[i] != ' ');
}
return out - init_out;
}改进
size_t sve_trimspaces(const char *s, size_t len, char *out) {
uint8_t *out8 = reinterpret_cast<uint8_t *>(out);
size_t i = 0;
for (; i + svcntw() <= len; i += svcntw()) {
svuint32_t input = svld1sb_u32(svptrue_b32(), (const int8_t *)s + i);
svbool_t matches = svcmpne_n_u32(svptrue_b32(), input, 32);
svuint32_t compressed = svcompact_u32(matches, input);
svst1b_u32(svptrue_b32(), out8, compressed);
out8 += svcntp_b32(svptrue_b32(), matches);
}
if (i < len) {
svbool_t read_mask = svwhilelt_b32(i, len);
svuint32_t input = svld1sb_u32(read_mask, (const int8_t *)s + i);
svbool_t matches = svcmpne_n_u32(read_mask, input, 32);
svuint32_t compressed = svcompact_u32(matches, input);
svst1b_u32(read_mask, out8, compressed);
out8 += svcntp_b32(read_mask, matches);
}
return out8 - reinterpret_cast<uint8_t *>(out);
}快个几倍大概
int main() {
std::cout << std::format("{}", std::vector{1, 2, 3}); // [1, 2, 3]
std::cout << std::format("{:n}", std::vector{1, 2, 3}); // 1, 2, 3
std::cout << std::format("{}", std::tuple{'1', 2., 3}); // ('1', 2, 3)
std::cout << std::format("{}", std::vector{std::pair{'a',1}, std::pair{'b',2}}); // [(a, 1), (b, 2)]
std::cout << std::format("{:m}", std::vector{std::pair{'a',1}, std::pair{'b',2}}); // {(a, 1), (b, 2)}
}不多说
视频
确实没啥人用
开源项目需要人手
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群384042845和作者对线
- pika 一个nosql 存储, redis over rocksdb,非常需要人贡献代码胖友们, 感兴趣的欢迎加群294254078前来对线
- Unilang deepin的一个通用编程语言,点子有点意思,也缺人,感兴趣的可以github讨论区或者deepin论坛看一看。这里也挂着长期推荐了
- paozhu 国人开发的web库,和drogon联系过没共建而考虑自己的需求基于asio开发。感兴趣的可以体验一下,挂在这里长期推荐了
工作招聘
值班快要折磨死我了,有没有工作介绍给我
看到这里或许你有建议或者疑问或者指出错误,请留言评论! 多谢! 你的评论非常重要!也可以帮忙点赞收藏转发!多谢支持!
如果有疑问评论最好在上面链接到评论区里评论,这样方便搜索,微信公众号有点封闭/知乎吞评论
C++ 中文周刊 第103期
公众号
弄了个qq频道,手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
本周内容不多,线上一堆问题,没空看
资讯
标准委员会动态/ide/编译器信息放在这里
hellogcc本周没更新
文章
之前咱们也发过。这回是中文版本
一些代码技巧,比如全局RE实例,googlebenchmark教学,Popcount使用等等。值得一看
手把手教你糊一个类型擦除,直接贴代码
#include <iostream>
#include <algorithm>
#include <memory>
namespace cwt {
class knight {
public:
explicit knight(std::size_t strength)
: m_strength(strength) {}
std::size_t get_strength() const {
return m_strength;
}
void who_am_i() const {
std::cout << "i'm a knight\n";
}
private:
std::size_t m_strength;
};
class skeleton {
public:
explicit skeleton(std::size_t strength)
: m_strength(strength) {}
std::size_t get_strength() const {
return m_strength;
}
void who_am_i() const {
std::cout << "i'm a skeleton\n";
}
private:
std::size_t m_strength;
};
class character {
public:
template<typename T, typename Renderer>
character(T&& character, Renderer&& renderer) {
m_character = std::make_unique<c_model<T, Renderer>>(std::move(character), std::move(renderer));
}
void who_am_i() const {
m_character->who_am_i();
}
std::size_t get_strength() const {
return m_character->get_strength();
}
void render() {
m_character->render();
}
private:
struct c_concept {
virtual ~c_concept() {}
virtual std::size_t get_strength() const = 0;
virtual void who_am_i() const = 0;
virtual void render() const = 0;
};
template<typename T, typename Renderer>
struct c_model : public c_concept {
c_model(T const& value, Renderer const& renderer)
: m_character(value), m_renderer(renderer) {};
std::size_t get_strength() const override {
return m_character.get_strength();
}
void who_am_i() const override {
m_character.who_am_i();
}
void render() const override{
m_renderer(m_character);
}
T m_character;
Renderer m_renderer;
};
private:
std::unique_ptr<c_concept> m_character;
};
} // namespace cwt
struct knight_renderer{
void operator()(const cwt::knight& k) const {
std::cout << "I'll take care of rendering" << std::endl;
}
};
void knight_render_function(const cwt::knight& knight){
std::cout << "I could also render a knight" << std::endl;
}
int main(){
cwt::character character{cwt::knight(10), knight_renderer{}};
character.render();
character = cwt::character{cwt::knight(10), [](const cwt::knight& k){
knight_render_function(k);
}};
character.render();
character = cwt::character{cwt::skeleton(2), [](const cwt::skeleton& s){
std::cout << "This might be another rendering technique" << std::endl;
}};
character.render();
}直接列代码了
sort
#include <algorithm>
#include <ranges>
#include <iostream>
int main() {
std::pair<int, std::string_view> pairs[] = {
{2, "foo"}, {1, "bar"}, {0, "baz"}
};
// member access:
std::ranges::sort(pairs, std::ranges::less{},
&std::pair<int, std::string_view>::first);
// a lambda:
std::ranges::sort(pairs, std::ranges::less{},
[](auto const& p) { return p.first; });
}
tranform
#include <algorithm>
#include <vector>
#include <iostream>
#include <ranges>
struct Product {
std::string name_;
double value_ { 0.0 };
};
int main() {
std::vector<Product> prods{7, {"Box ", 1.0}};
// standard version:
std::transform(begin(prods), end(prods), begin(prods),
[v = 0](const Product &p) mutable {
return Product { p.name_ + std::to_string(v++), 1.0};
}
);
for (auto &p : prods) std::cout << p.name_ << ", ";
std::cout << '\n';
// ranges version:
std::ranges::transform(prods, begin(prods),
[v = 0](const std::string &n) mutable {
return Product { n + std::to_string(v++), 1.0};
},
&Product::name_);
for (auto &p : prods) std::cout << p.name_ << ", ";
}
这书好像有中文翻译版本?
consteval auto foo(const auto (&value)[1]) { return value[0]; }
static_assert(42 == foo({42}));这也是初始化列表的坑爹的地方
降低内存使用
聚合循环
double min = a[0];
for (int i = 1; i < n; i++) {
if (a[i] < min) { min = a[i] };
}
double max = a[0];
for (int i = 1; i < n; i++) {
if (a[i] > max) { max = a[i] };
}了解一波
老生常谈了
- The unintentionally-expanding scope of the SEM_NOGPFAULTERRORBOX flag
- Enumerating Windows clipboard history in C++/WinRT and C#
- If you want to sort a Windows Runtime collection, you may first want to capture it into something a bit easier to manipulate
讲windows api的,不多逼逼
视频
涉及到符号,取余数就有点让人看不懂了,比如
-1 % 10 c的表现是-1,而不是9,所以算法得是(-1 % 10) + 10) % 10
小伙很年轻啊,他列了一些常规优化点。这里直接列了,大家自己检查一下
O2, -ffast-math(这个有坑,要注意你的程序是否涉及浮点精度问题,之前讲过)
LTO,
静态编译
PGO,这个大部分都没用 -fprofile-generate -fprofile-use
二进制patch,LLVM BOLT,根据PGO文件修正
no-rtti, no-exception,likely,inline,assume,__restrict__,__attribute__((pure))
编写cache友好型代码
避免分支切换
SIMD
这个talk还是很值得一看的,光看PPT也能有收获
开源项目需要人手
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群384042845和作者对线
- pika 一个nosql 存储, redis over rocksdb,非常需要人贡献代码胖友们, 感兴趣的欢迎加群294254078前来对线
- Unilang deepin的一个通用编程语言,点子有点意思,也缺人,感兴趣的可以github讨论区或者deepin论坛看一看。这里也挂着长期推荐了
- paozhu 国人开发的web库,和drogon联系过没共建而考虑自己的需求基于asio开发。感兴趣的可以体验一下,挂在这里长期推荐了
新项目介绍/版本更新
- libfork 协程调度库,用了很多最近的论文算法
- mperf:移动/嵌入式平台算子性能调优利器 移动平台用的
工作招聘
有没有招聘需要广告的,发我,贴这里
看到这里或许你有建议或者疑问或者指出错误,请留言评论! 多谢! 你的评论非常重要!也可以帮忙点赞收藏转发!多谢支持!
如果有疑问评论最好在上面链接到评论区里评论,这样方便搜索,微信公众号有点封闭/知乎吞评论
C++ 中文周刊 第102期
公众号
弄了个qq频道,手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
本周内容我没有细看。有些值得展开说说
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2023-01-04 第183期
本月邮件列表 https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2023/#mailing2023-02
文章
constexpr size_t Rows = 5;
const std::map<std::string, std::array<double, Rows>> productToOrders{
{ "apples", {100, 200, 50.5, 30, 10}},
{ "bananas", {80, 10, 100, 120, 70}},
{ "carrots", {130, 75, 25, 64.5, 128}},
{ "tomatoes", {70, 100, 170, 80, 90}}
};
// print headers:
for (const auto& [key, val] : productsToOrders)
std::cout << std::setw(10) << key;
std::cout << '\n';
// print values:
for (size_t i = 0; i < NumRows; ++i) {
for (const auto& [key, val] : productsToOrders) {
std::cout << std::setw(10) << std::fixed
<< std::setprecision(2) << val[i];
}
std::cout << '\n';
}
template <typename T>
size_t MaxKeyLength(const std::map<std::string, T>& m) {
size_t maxLen = 0;
for (const auto& [key, val] : m)
if (key.length() > maxLen)
maxLen = key.length();
return maxLen;
}
const auto ColLength = MaxKeyLength(productsToOrders) + 2;
// print values:
for (size_t i = 0; i < NumRows; ++i) {
for (const auto& values : std::views::values(productsToOrders)) {
std::cout << std::format("{:>{}.2f}", values[i], ColLength);
}
std::cout << '\n';
}
/*
****apples***bananas***carrots**tomatoes
100.00 80.00 130.00 70.00
200.00 10.00 75.00 100.00
50.50 100.00 25.00 170.00
30.00 120.00 64.50 80.00
10.00 70.00 128.00 90.00
*/没啥说的
if里面的条件判断,最好外面算好再放进if里
if ((_someLongNamedVar != FooLongNameEnum::Unknown && _someLongNamedMap.count (_someLongNamedVar) == 0))改成
bool someLongNamedVarIsNotUnknown = _parameterCommand != FooLongNameEnum::Unknown;
bool someLongNamedMapCountIsZero = _someLongNamedMap.count(_someLongNamedVar) == 0提高可读性,关爱同事
一些c的边角邪门歪道。只有特殊场景能用到,比如位域
struct cat {
unsigned int legs : 3; // 3 bits for legs (0-4 fit in 3 bits)
unsigned int lives : 4; // 4 bits for lives (0-9 fit in 4 bits)
};
struct bar {
unsigned char x : 5;
unsigned short : 0; // 帮你padding
unsigned char y : 7;
}就不逐一介绍了
-
C++ Coroutines Part 1: co_yield, co_return and a Prime Sieve
-
Did you know that std::unique_ptr can be constexpr in C++23?
struct interface {
constexpr virtual ~interface() = default;
constexpr virtual auto get() const -> int = 0;
};
struct implementation final : interface {
constexpr explicit(true) implementation(int value) : value{value} {}
constexpr auto get() const -> int { return value; }
private:
int value{};
};
constexpr auto foo(auto value) {
std::unique_ptr<interface> i = std::make_unique<implementation>(value);
return i->get();
}
static_assert(42 == foo(42));逆天
void MyClass::DoSomething() {
try {
auto name = m_user.GetName();
m_label.Text(name);
} catch (...) {
m_label.Text(L"unknown");
}
}如果m_label.Text(L"unknown");异常,怎么办?
一种猥琐的角度
winrt::fire_and_forget MyClass::DoSomethingAsync()
{
auto lifetime = get_strong();
try {
auto name = co_await m_user.GetNameAsync();
m_label.Text(name);
} catch (...) {
try {
m_label.Text(L"unknown");
} catch (...) {
LOG_CAUGHT_EXCEPTION();
}
}
}你就说catch没catch住吧,别管几个if
或者,不太常见的写法
winrt::fire_and_forget MyClass::DoSomethingAsync() try
{
auto lifetime = get_strong();
try {
auto name = co_await m_user.GetNameAsync();
m_label.Text(name);
} catch (...) {
m_label.Text(L"unknown");
}
} catch (...) {
// The function is best-effort. Ignore failures.
}
你学废了吗
说实话,我不是很懂。值得研究一波
教你使用opentelemetry
介绍文档工具和github action集成
还是实验性质。感觉没人用
图形生成?高游戏的?我不是很懂
讲解magic_enum原理
看不懂
视频
还是__buildin_dump_struct实现。循序渐进。可以看看。我周末传b站一份
这个也很有意思,值得研究研究。我周末传b站一份
开源项目需要人手
-
asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群384042845和作者对线
最近写了很多高科技,比如https://github.com/lhmouse/asteria/blob/master/rocket/ascii_numget.hpp 很多细节考量 -
pika 一个nosql 存储, redis over rocksdb,非常需要人贡献代码胖友们, 感兴趣的欢迎加群294254078前来对线
有很多的issue task没人做,想参与开源项目开发的,来练练手
新项目介绍/版本更新
- concurrencpp 又一个协程库
工作招聘
有想打广告的可以发给我。五毛一条
看到这里或许你有建议或者疑问或者指出错误,请留言评论! 多谢! 你的评论非常重要!也可以帮忙点赞收藏转发!多谢支持!
如果有疑问评论最好在上面链接到评论区里评论,这样方便搜索,微信公众号有点封闭/知乎吞评论
C++ 中文周刊 第101期
公众号
弄了个qq频道,手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
最近有点忙,看的不是很细
资讯
之前聊过很多次的perf book,有中文版本了,中文名 现代CPU性能分析与优化
https://item.m.jd.com/product/10068178465763.html
这里没有带货的意思嗷,英语比较熟的,可以在这里免费获取这本书
https://book.easyperf.net/perf_book 填一下邮箱就会发给你邮件
如果不熟,支持中文书也可以买一下。不过我感觉新书刚上有点贵了,一般来说三月末有个读书节之类的活动,有打折,可以到时候再买。
另外就是有没有出版社大哥能不能赞助两本我抽了,没有我就三月底自己买来抽了
A call to action:Think seriously about “safety”; then do something sensible about it
针对NSA的c++不安全的说法,BS慌了。和大家讨论一下改进措施
另外这里也吵翻天了 C++ 之父为什么说 Rust 等内存安全语言的安全性并不优于 C++? https://www.zhihu.com/question/584122632
草药老师发了开会总结
AMD RDNA™ 3 指令集架构 (ISA) 参考指南现已推出
用了新显卡的关注下
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2023-02-15 第189期
文章
enum的周边设施,std::is_enum std::underlying_type std::is_scoped_enum std::to_underlying
UE教程
std::initializer_list<int> wrong() { // for illustration only!
return { 1, 2, 3, 4};
}
int main() {
std::initializer_list<int> x = wrong();
}
初始化列表的坑爹之处,生命周期有问题,别这么写。没关系,编译器会告警的。你说你不看告警?
算字符串占多少
size_t scalar_utf8_length(const char * c, size_t len) {
size_t answer = 0;
for(size_t i = 0; i<len; i++) {
if((c[i]>>7)) { answer++;}
}
return answer + len;
}显然,可以SIMD
size_t avx2_utf8_length_basic(const uint8_t *str, size_t len) {
size_t answer = len / sizeof(__m256i) * sizeof(__m256i);
size_t i;
for (i = 0; i + sizeof(__m256i) <= len; i += 32) {
__m256i input = _mm256_loadu_si256((const __m256i *)(str + i));
answer += __builtin_popcount(_mm256_movemask_epi8(input));
}
return answer + scalar_utf8_length(str + i, len - i);
}优化一下
ize_t avx2_utf8_length_mkl(const uint8_t *str, size_t len) {
size_t answer = len / sizeof(__m256i) * sizeof(__m256i);
size_t i = 0;
__m256i four_64bits = _mm256_setzero_si256();
while (i + sizeof(__m256i) <= len) {
__m256i runner = _mm256_setzero_si256();
size_t iterations = (len - i) / sizeof(__m256i);
if (iterations > 255) { iterations = 255; }
size_t max_i = i + iterations * sizeof(__m256i) - sizeof(__m256i);
for (; i <= max_i; i += sizeof(__m256i)) {
__m256i input = _mm256_loadu_si256((const __m256i *)(str + i));
runner = _mm256_sub_epi8(
runner, _mm256_cmpgt_epi8(_mm256_setzero_si256(), input));
}
four_64bits = _mm256_add_epi64(four_64bits,
_mm256_sad_epu8(runner, _mm256_setzero_si256()));
}
answer += _mm256_extract_epi64(four_64bits, 0) +
_mm256_extract_epi64(four_64bits, 1) +
_mm256_extract_epi64(four_64bits, 2) +
_mm256_extract_epi64(four_64bits, 3);
return answer + scalar_utf8_length(str + i, len - i);
}代码在这 https://github.com/lemire/Code-used-on-Daniel-Lemire-s-blog/tree/master/2023/02/16 我已经看不懂了
帮你抓安全问题
LLVM变动,不懂不评价
llvm变动,没细看,不过使用libc++可以白捡这个llvm优化,人家clickhouse都用上了
module体验
这个概念是需要掌握的。虚拟地址,页表等等
手把手教你渲染个飞机
MaskRay写完UBsan介绍又写这个了。笔耕不辍这是
聪明的你肯定想到了还原堆栈要怎么做。汇编我看不懂,你比我聪明
论文。实现个checker
聪明的你肯定想到了pthread_cancel以及SIG_CANCEL,然后怎么实现??
评审c代码的一些经验
比如 assert
#define ASSERT(c) if (!(c)) __builtin_trap()再比如
char *s = ...;
if (isdigit(s[0] & 255)) {
...
}为什么不能直接用?
或者直接用这玩意
_Bool xisdigit(char c)
{
return c>='0' && c<='9';
}还有setjmp and longjmp 信号atomic之类的。都没细说。总之谨慎
讲了几个其他语言优化更好的点,替换c++。没啥说的。都能替
@wu-hanqing 投稿。咱们之前在94期也提到过,就是shared_ptr有个别名构造。别用。很坑。鼓励大家投稿。不然显得我玩单机互联网
template<class T>
concept foo_like = requires(T t) { t.foo; };
template<auto Concept>
struct foo {
auto fn(auto f) {
static_assert(requires { Concept(f); });
}
};
int main() {
foo<[](foo_like auto){}> f{};
struct { int foo{}; } foo;
struct { } bar;
f.fn(foo); // ok
f.fn(bar); // error: contrain not satisfied
}注意这个concept套娃用法,通过lambda绕进去
我觉得还是看个乐。这玩意以后肯定不能这么写,过于邪门歪道
还不懂?再看一遍
这个定位非常非常非常精彩
首先,perf
sudo perf stat -C8 --timeout 10000火焰图
git clone https://github.com/brendangregg/FlameGraph
git -C FlameGraph remote add adamnovak https://github.com/adamnovak/FlameGraph
git -C FlameGraph fetch adamnovak
git -C FlameGraph cherry-pick 7ff8d4c6b1f7c4165254ad8ae262f82668c0c13b # C++ template display fix
x=remote
sudo timeout 10 perf record --call-graph=fp -C8 -o $x.data
sudo perf script -i $x.data > $x.perf
FlameGraph/stackcollapse-perf.pl $x.perf > $x.folded
FlameGraph/flamegraph.pl $x.folded > $x.svg
查到 compact_radix_tree::tree::get_at() and database::apply(). 有问题
sudo perf annotate -i $x.data
代码已经找到,但是为啥??
查事件
sudo perf stat --timeout 1000000 -C8 ...events... -x\t 2>&1 | sed 's/<not counted>/0/g'

需要关注的事件
CPU_CYCLES, obviously, because we were doing the measurement for the same amount of time in both cases.
LDREX_SPEC “exclusive operation speculatively executed” — but since it happens only 1,000 times per second, it can’t possibly be the cause.
EXC_UNDEF “number of undefined exceptions taken locally” — I don’t even know what this means, but it doesn’t seem like a reasonable bottleneck.
STALL_BACKEND only supports our suspicion that the CPU is bottlenecked on memory somehow.
REMOTE_ACCESS
REMOTE_ACCESS明显离谱了,seastar已经绑核,哪里来的跨核访问???
程序本身的静态数据跨核了????
sudo cat /proc/$(pgrep -x scylla)/numa_mapsN0=x N1=y means that x pages in the address range are allocated on node 0 and y pages are allocated on node 1. By cross-referencing readelf --headers /opt/scylladb/libexec/scylla we can determine that .text, .rodata and other read-only sections are on node 0, while .data, .bss and other writable sections are on node 1.

发现这几个段不在一个核??不应该啊
强制绑核,发现问题确实如此 /usr/bin/numactl --membind 1 to /usr/bin/scylla scylla_args…:
用mbind分析为什么,发现了一个page有共享问题,那就是cacheline颠簸了
Using this ability, we discover that only one page matters: 0x28c0000, which contains .data, .got.plt and the beginning of .bss. When this page is on node 1, the run is slow, even if all other pages are on node 0. When it’s on node 0, the run is fast, even if all other pages are on node 1.尝试改二进制,加padding,解决了??根因是什么?怎么加padding?
We can move the suspicious area by stuffing some padding before it. .tm_clone_table seems like a good enough place to do that. We can add an array in .tm_cl...Contributors
Assets 2
C++ 中文周刊 第100期
公众号
弄了个qq频道,手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
本周内容不多
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2023-02-08 第188期
关于标准委员会的吵架动态,可以看 https://www.zhihu.com/people/mick235711 的动态。这里就不转发了
文章
360发布了他们的代码安全规范,还是值得一看的,UB描述了很多
一段到处都在传播的代码
#include <iostream>
int main() {
while(1)
;
}
void unreachable() {
std::cout << "hello world\n";
}clang会打印hello world而gcc/msvc不会,为啥??
简单来说是没用到的死循环直接给删了,然后没有ret,直接跳到下一个函数了
这也是UB的一种。感兴趣的可以点进去看看
-O3 -flto 性能起码提升5%,后续引入PGO继续探索。PGO还是很值得研究的,针对业务来优化效率更高
static_assert(0 == std::rank_v<void>);
static_assert(0 == std::rank_v<int>);
static_assert(1 == std::rank_v<int[]>);
static_assert(0 == std::rank_v<int[0]>);
static_assert(1 == std::rank_v<int[1]>);
static_assert(1 == std::rank_v<int[42]>);
static_assert(2 == std::rank_v<int[][2]>);
static_assert(2 == std::rank_v<int[1][2]>);
static_assert(3 == std::rank_v<int[1][2][3]>);
数组的维度,这玩意和向量的秩英文名一样啊。。
如何实现?
#include <type_traits>
template<class T>
struct prev;
template<class T, int N>
struct prev<T[N]> : std::type_identity<T> {};
template<class T>
struct prev<T[]> : std::type_identity<T> {};
template<class T>
constexpr auto return_rank()
{
if constexpr (::std::is_array_v<T>) {
return return_rank<typename prev<T>::type>() + 1;
}
return 0;
}
template<class T>
constexpr auto rank_v = return_rank<T>();QML_DISABLE_DISK_CACHE=1 加速 QML编译
省流:可以
又是WinAPI,我看不懂不多逼逼
浮点数比较,很烦
bool cmpEq(double a, double b,
double epsilon = 1e-7, double abstol = 1e-12)
{
if (a == b) { // 判断inf用的,傻逼inf
return true;
}
double diff = std::fabs(a - b);
double reltol = std::max(std::fabs(a),
std::fabs(b)) * epsilon;
return diff < reltol || diff < abstol;
}家人们还是看看远处的boost实现吧 https://www.boost.org/doc/libs/1_81_0/boost/test/tools/floating_point_comparison.hpp
寄存器,用eax, ebx, ecx, edx, ebp, esp, esi, edi, r8, r9, r10, r11, r12, r13, r14, r15 ,rax eax宽度区别
传参数,用 rdi, rsi, rdx, rcx, r8 r9, 放不下放栈上
来个例子
long myfunc(long a, long b, long c, long d,
long e, long f, long g, long h)
{
long xx = a * b * c * d * e * f * g * h;
long yy = a + b + c + d + e + f + g + h;
long zz = utilfunc(xx, yy, xx % yy);
return zz + 20;
}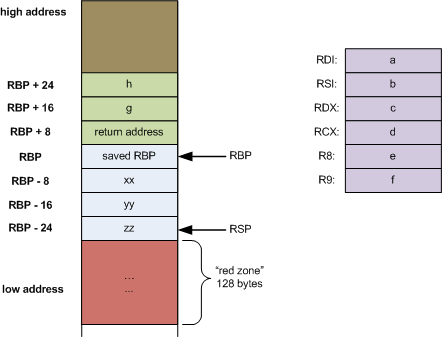
rbp 大家也都懂,也会优化掉,因为可以根据rsp算出来。-fno-omit-frame-pointer可以保留
看不懂
书评。没看到书没啥说的
测了一些软件用O3编译二进制大了点,但性能都有提升
视频
最近没啥看的
开源项目需要人手
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群384042845和作者对线
- pika 一个nosql 存储, redis over rocksdb,非常需要人贡献代码胖友们, 感兴趣的欢迎加群294254078前来对线
新项目介绍/版本更新
- PocketPy 嵌入式python实现,有点意思
- Boost.Mustache 说不定能进 mustache模版
- quill v2.7.0 released - Asynchronous Low Latency C++ Logging Library 之前也聊过,版本更新
- CTHASH (Compile Time Hash) 编译期 sha实现
- CoFSM 基于协程的状态机
- kelcoro 协程库
- Cryptography library for modern C++.
看到这里或许你有建议或者疑问或者指出错误,请留言评论! 多谢! 你的评论非常重要!也可以帮忙点赞收藏转发!多谢支持!
如果有疑问评论最好在上面链接到评论区里评论,这样方便搜索,微信公众号有点封闭/知乎吞评论
C++ 中文周刊 第99期
公众号
弄了个qq频道,手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
20230203
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 2023-02-01 第187期
有武汉线下活动,可以关注
fishshell这个项目宣布用rust重写了。理由是c++太差了周边编译设施等等太难用了之类的
对此笔者锐评:确实
reddit社区对此锐评: Stop Comparing Rust to Old C++
我觉得有点露怯了,实话实说,构建确实不好用,演进也慢,你说meson conan能用我只能说还差点意思
而且c++开源社区开发人员也差点意思,没那个功夫,但rust就很不一样,很多人愿意拿rust练手。
只能说c++周边的演进还需要加快一些。周边文章咨询写的多一些,更通俗易懂一些,知道的人越多越好。大家多写文章多分享啊
本周还有一个事情是yandex的代码泄露,磁力链接在这个答案可以看到,https://www.zhihu.com/question/580980335/answer/2867507106
这两天看了下,cpp的项目挺有意思,但两个组件库util和mapreduce是没泄露的,比较可惜,要是都泄露了我就要创业了
不过一个成熟的引擎,数据是最重要的,没有数据,工具没啥意义。
他们的代码接口风格还是98那套Interface形式,但是都用的pragram once,没用Macro Guard,给人一种老太太用神仙水的反差感
另外有人问为啥他们数据库代码没泄露。。他们用的ydb本身就是开源的。
文章
jetbrains出的报告,关于c++20使用,编译工具cmake使用率,代码分析使用率做了个列举,这里直接贴一下
构建工具,cmake越来越普及,虽然难用
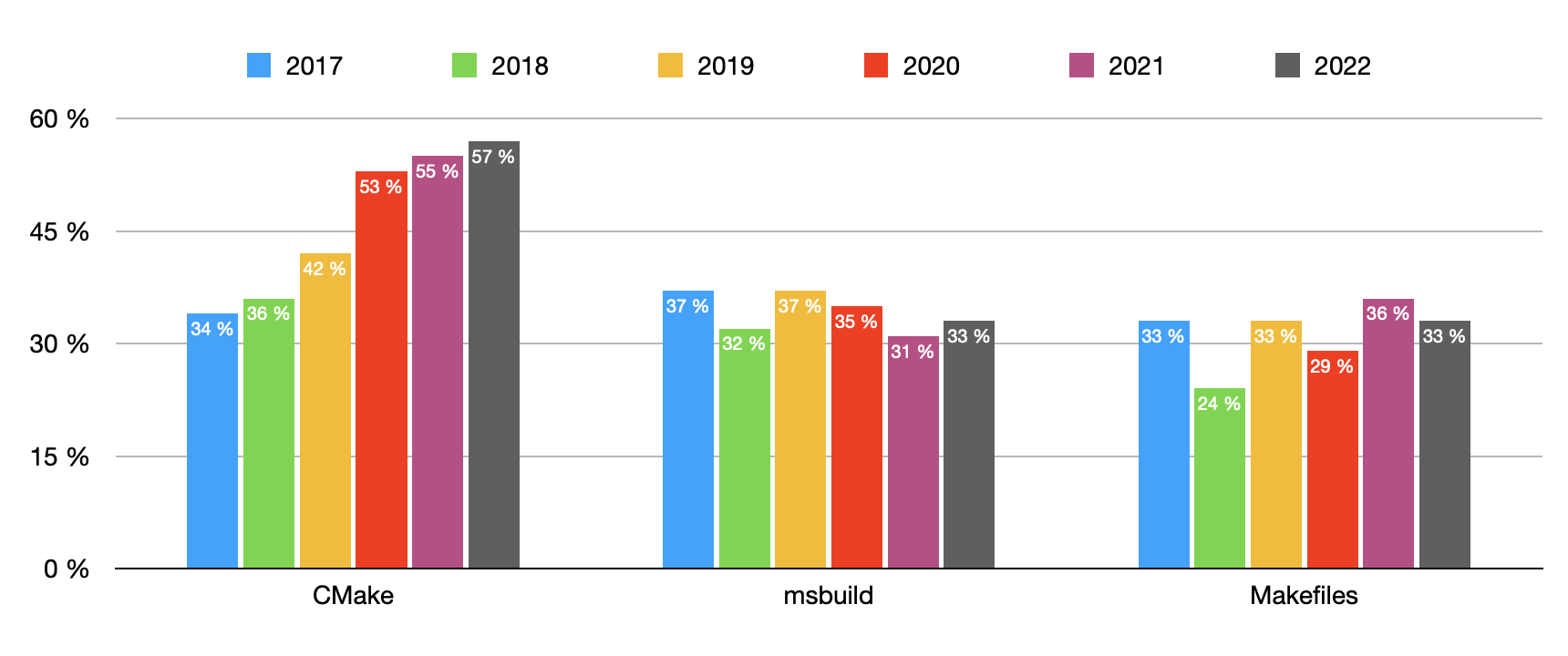
什么?你想问包管理工具?
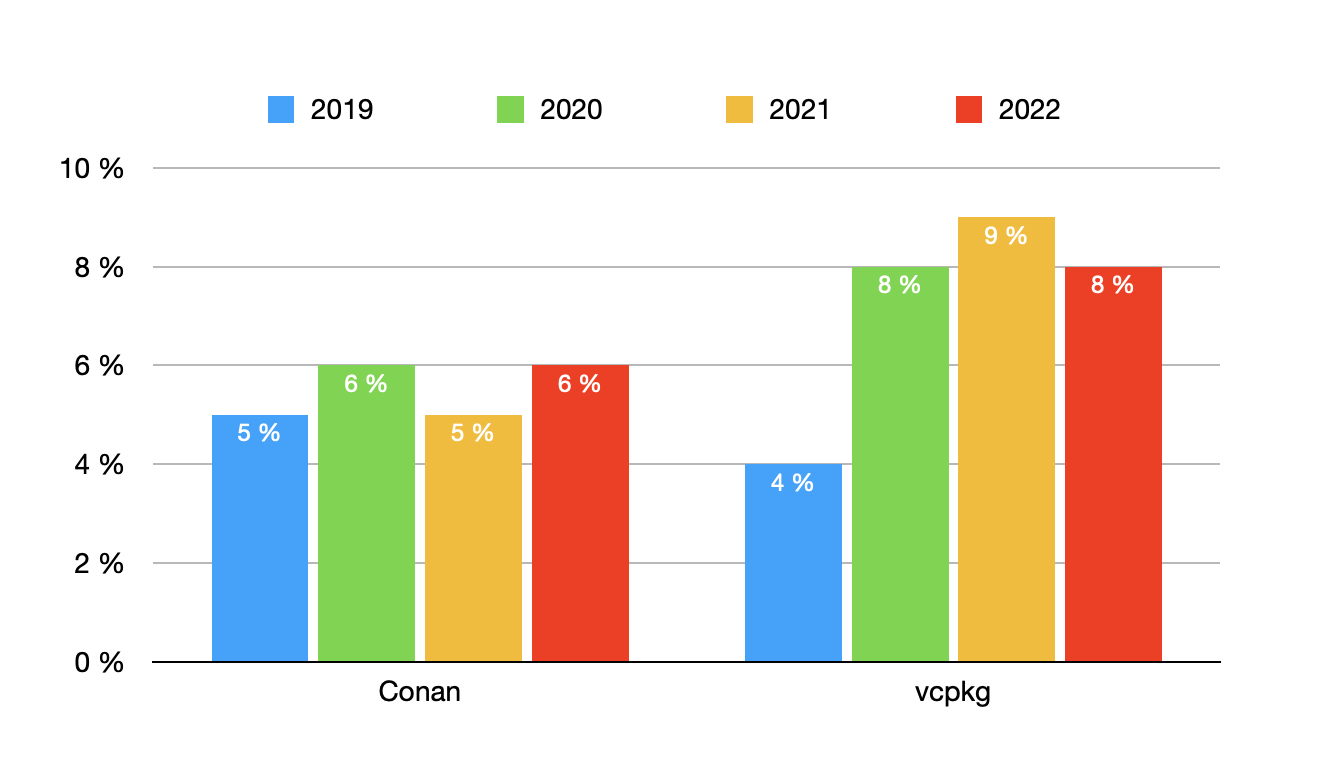
嘻嘻,没人用
用什么测试框架?
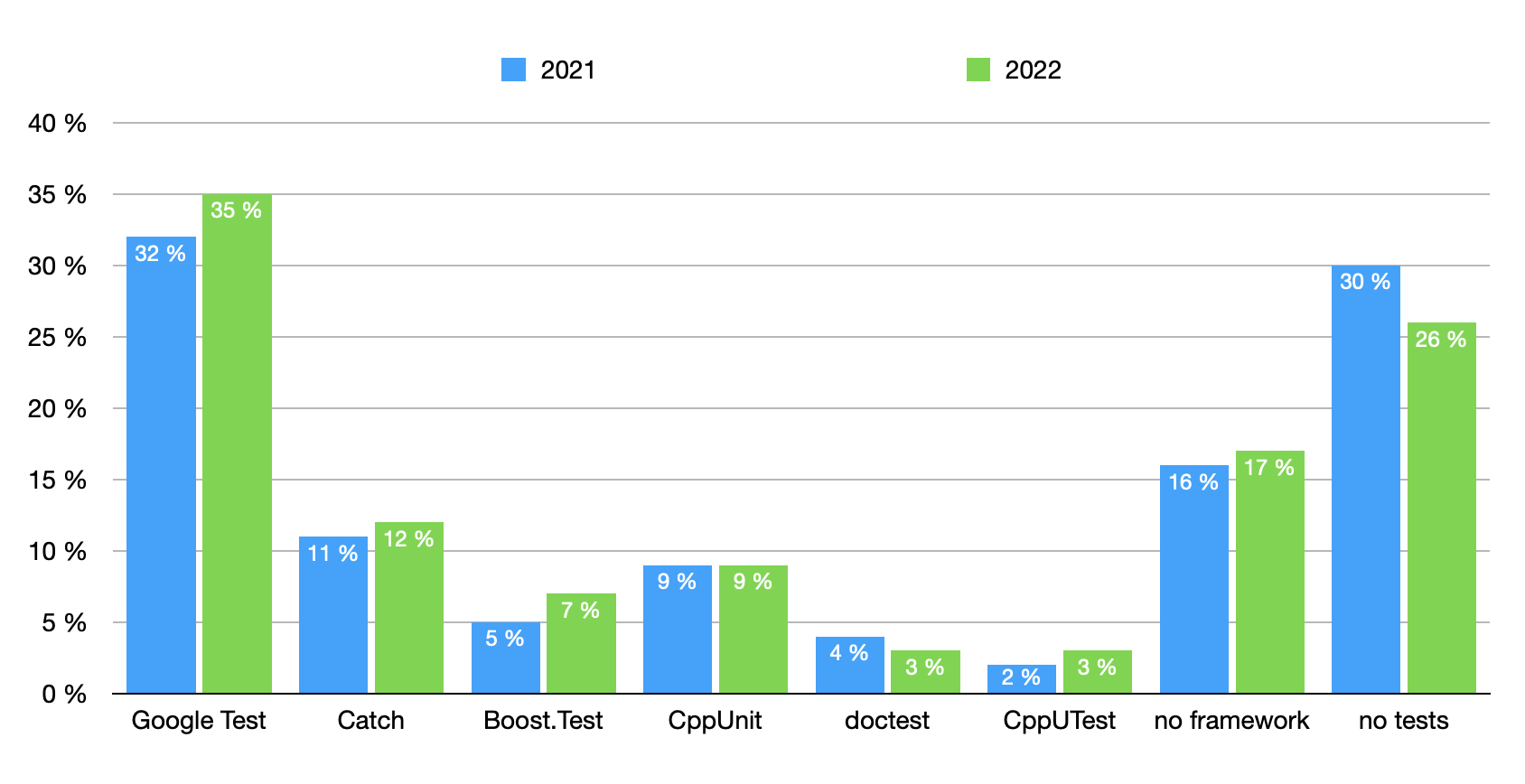
甚至不写测试
使用什么代码分析工具?
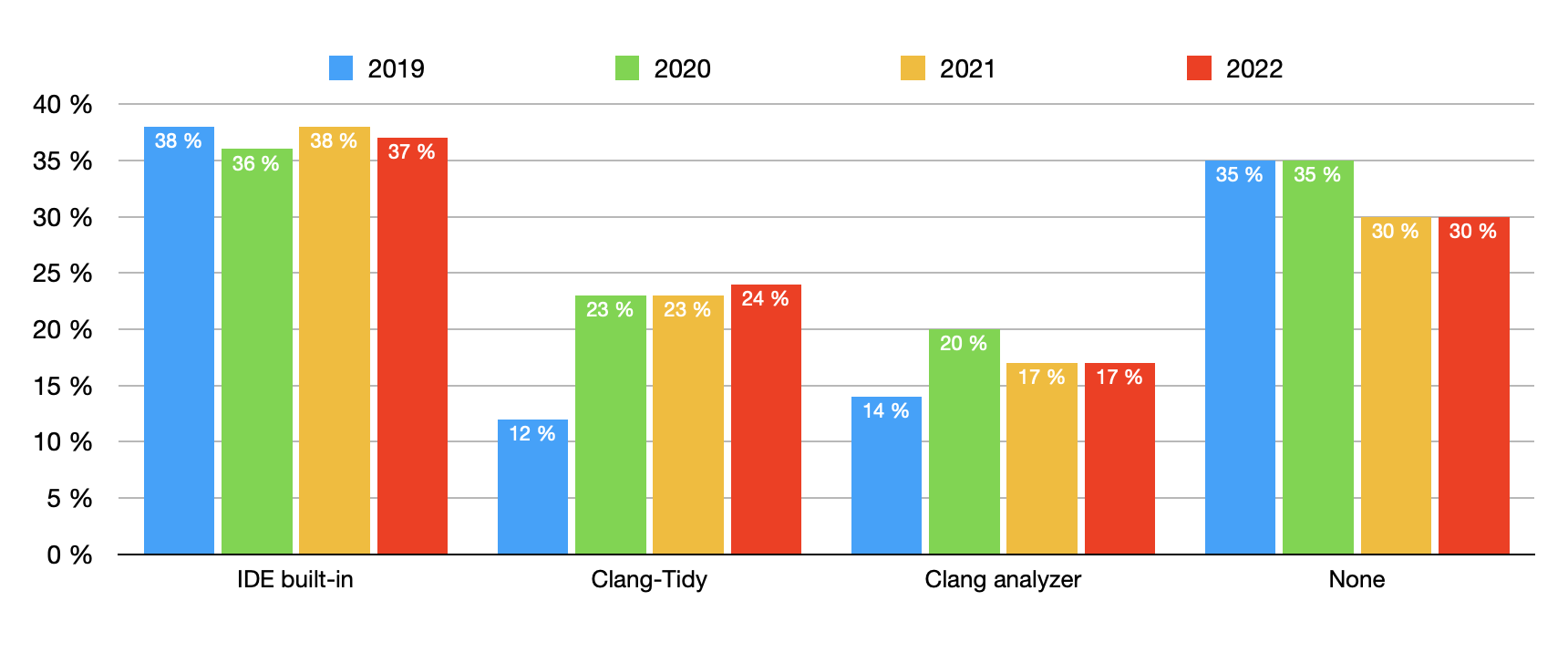
嘻嘻,甚至不用分析工具
完整报告可以去他们官网看。这里不列举了
其实就是链式构造啦
template<typename This>
struct ToggleBuilder {
template<typename... T>
auto& When(bool flag, auto f, T&&... params)
{
auto& actualThis = static_cast<This&>(*this);
if (flag)
{
std::invoke(f, actualThis, std::forward<T>(params)...);
}
return actualThis;
}
};
class MessageBuilder : public ToggleBuilder<MessageBuilder> {
MessageBuilder& WithPayload(std::string payload)
{
m_payload = std::move(payload);
return *this;
}
//...
};
Message CreateMessage(std::string payload, const Config& config)
{
return MessageBuilder{}
WithPayload(std::move(payload)).
When(config.someSpecialRecipeEnabled, [](MessageBuilder& builder){
return builder.WithAppender(GetSpecialAppenderParams()).
WithAppender(GetAnotherSpecialAppenderParams());
}).
// ...
.Build();
}来个现实生活中的例子,OnnxRuntime
auto session = SessionBuilder{}.
WithLogger(MakeLoggerFrom(config)).
WithModel(config.modelPath).
WithCUDAExecutionProvider(config.cudaOptions).
WithOpenVINOExecutionProvider(config.openVinoOptions).
WithOptimizationLevel(config.optimizationLevel).
WithNumberOfIntraThreads(config.intraThreads).
//...
Build();用上面那个设计,相当于
auto session = SessionBuilder{}.
WithLogger(MakeLoggerFrom(config)).
WithModel(config.modelPath).
When(config.useCuda, &SessionBuilder::WithCUDAExecutionProvider, config.cudaOptions).
When(config.useOpenVino, &SessionBuilder::WithOpenVINOExecutionProvider, config.openVinoOptions).
WithOptimizationLevel(config.optimizationLevel).
WithNumberOfIntraThreads(config.intraThreads).
//...
Build();当然 rust这种代码也有很多
显然能想到
std::string output = std::to_string(address >> 24);
for (int i = 2; i >= 0; i--) {
output.append(std::to_string((address >> (i * 8)) % 256) + ".");
}
使用to_chars
std::string output(4 * 3 + 3, '\0'); // allocate just one big string
char *point = output.data();
char *point_end = output.data() + output.size();
point = std::to_chars(point, point_end, uint8_t(address >> 24)).ptr;
for (int i = 2; i >= 0; i--) {
*point++ = '.';
point = std::to_chars(point, point_end, uint8_t(address >> (i * 8))).ptr;
}
output.resize(point - output.data());
干脆查表
char *to_chars_52(char *p, unsigned char x) {
constexpr std::string_view table[256] = {
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
"10", "11", "12", "13", "14", "15", "16", "17", "18", "19",
"20", "21", "22", "23", "24", "25", "26", "27", "28", "29",
"30", "31", "32", "33", "34", "35", "36", "37", "38", "39",
"40", "41", "42", "43", "44", "45", "46", "47", "48", "49",
"50", "51", "52", "53", "54", "55", "56", "57", "58", "59",
"60", "61", "62", "63", "64", "65", "66", "67", "68", "69",
"70", "71", "72", "73", "74", "75", "76", "77", "78", "79",
"80", "81", "82", "83", "84", "85", "86", "87", "88", "89",
"90", "91", "92", "93", "94", "95", "96", "97", "98", "99",
"100", "101", "102", "103", "104", "105", "106", "107", "108", "109",
"110", "111", "112", "113", "114", "115", "116", "117", "118", "119",
"120", "121", "122", "123", "124", "125", "126", "127", "128", "129",
"130", "131", "132", "133", "134", "135", "136", "137", "138", "139",
"140", "141", "142", "143", "144", "145", "146", "147", "148", "149",
"150", "151", "152", "153", "154", "155", "156", "157", "158", "159",
"160", "161", "162", "163", "164", "165", "166", "167", "168", "169",
"170", "171", "172", "173", "174", "175", "176", "177", "178", "179",
"180", "181", "182", "183", "184", "185", "186", "187", "188", "189",
"190", "191", "192", "193", "194", "195", "196", "197", "198", "199",
"200", "201", "202", "203", "204", "205", "206", "207", "208", "209",
"210", "211", "212", "213", "214", "215", "216", "217", "218", "219",
"220", "221", "222", "223", "224", "225", "226", "227", "228", "229",
"230", "231", "232", "233", "234", "235", "236", "237", "238", "239",
"240", "241", "242", "243", "244", "245", "246", "247", "248", "249",
"250", "251", "252", "253", "254", "255",
};
std::string_view sv = table[x];
std::memcpy(p, sv.data(), sv.size());
return p + sv.size();
}
// credit: Peter Dimov
std::string ipv52(const uint64_t address) noexcept {
std::string output(4 * 3 + 3, '\0');
char *p = output.data();
p = to_chars_52(p, uint8_t(address >> 24));
*p++ = '.';
p = to_chars_52(p, uint8_t(address >> 16));
*p++ = '.';
p = to_chars_52(p, uint8_t(address >> 8));
*p++ = '.';
p = to_chars_52(p, uint8_t(address >> 0));
output.resize(p - output.data());
return output;
}代码在这里
https://github.com/lemire/Code-used-on-Daniel-Lemire-s-blog/blob/master/2023/02/01/str.cpp
CPU角度省内存技巧,使用上这些技巧,你的代码搞不好变慢,各种加fence。说实话,没看懂意图
介绍UBSan的方方面面使用
老文,但挺有意思。直接贴代码了。原理去原文看吧
// should be much more precise with large b
inline double fastPrecisePow(double a, double b) {
// calculate approximation with fraction of the exponent
int e = (int) b;
union {
double d;
int x[2];
} u = { a };
u.x[1] = (int)((b - e) * (u.x[1] - 1072632447) + 1072632447);
u.x[0] = 0;
// exponentiation by squaring with the exponent's integer part
// double r = u.d makes everything much slower, not sure why
double r = 1.0;
while (e) {
if (e & 1) {
r *= a;
}
a *= a;
e >>= 1;
}
return r * u.d;
}
#include <iostream>
int main() {
for (auto x : {"hello", "coding", "world"})
std::cout << x << ", ";
}
等价于
#include <iostream>
int main()
{
{
const char *const __list21[3]{"hello", "coding", "world"};
std::initializer_list<const char *> && __range1
= std::initializer_list<const char *>{__list21, 3};
const char *const * __begin1 = __range1.begin();
const char *const * __end1 = __range1.end();
for(; __begin1 != __end1; ++__begin1) {
const char * x = *__begin1;
std::operator<<(std::operator<<(std::cout, x), ", ");
}
}
return 0;
}
std::initializer_list不能细想,越想越复杂
演示代码。说实话没怎么看懂
介绍 std::regular 的
看代码就懂了
template<class T>
concept movable = is_object_v<T> && move_constructible<T> &&
assignable_from<T&, T> && swappable<T>;
template<class T>
concept copyable = copy_constructible<T> && movable<T> && assignable_from<T&, const T&>;
template<class T>
concept semiregular = copyable<T> && default_constructible<T>;
template<class T>
concept regular = semiregular<T> &&...C++ 中文周刊 第98期
公众号
弄了个qq频道,手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
20230128 唉,不想上班
文章
还是介绍c++23特性,鉴于中文资料还是比较少的,这里推荐一下
之前咱们也讲过很多次别名引入导致的性能低下,编译期不能充分优化的问题。这里又科普一遍,还有谁不知道?
simd指令教学,感兴趣的可以看看
https://godbolt.org/z/PPsn4KM7Y
简单来说还是embed,借助embed实现concept reflexpr
讨论optional各种构造转换
- c++20 编译期解析(compile-time parsing)以及实现类似rust macro rule
https://godbolt.org/z/zKbWc7MhE
https://godbolt.org/z/5ajjYs754
直接贴代码了。很复杂,值得研究一波
老文,讲了一些c++20的改进,比如constexpr
#include <iostream>
#include <variant>
constexpr std::variant<int, double> foo(int x) {
std::variant<int, double> oi { x * 0.1 };
if (x > 10)
oi = x;
return oi;
}
int main() {
constexpr auto dv = foo(1);
static_assert(std::holds_alternative<double>(dv));
constexpr auto iv = foo(100);
static_assert(std::holds_alternative<int>(iv));
}再比如经典坑
std::variant<string, bool> x = "abc"; // 此时的x是bool,惊不惊喜修订在这 https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p0608r3.html
一些维护大项目的经验,比如ccache加速CICD,项目组织以及重用代码,甚至给了一个cmake模板 https://github.com/tfc/cmake_cpp_example
看着还不错
Raymond chen又发了一堆winrt的文章,我不了解,没细读,这里直接贴出来
- Inside C++/WinRT: Apartment switching: Bypassing the context callback
- Inside C++/WinRT: Apartment switching: Unblocking the outgoing thread
- Inside C++/WinRT: Apartment switching: The basic idea
- Inside C++/WinRT: Coroutine completions: The oversimplified version
- How can I call a method on a derived class from a base class, say, to get a strong reference to the containing object?
对OI感兴趣的可以看看,有几个模板库 比如这个https://github.com/emthrm/cp-library
看个乐
感兴趣可以看看
温故知新
树的几种遍历,针对递归型,什么遍历,就在什么位置调用
如果是非递归用堆栈,前序遍历,那就堆栈里放left/right,后序遍历,那堆栈就放当前节点,中序遍历,那就先放left,放完了也就定好顺序了,访问节点和right就行了
我这里描述的非常模糊,边界条件也没说,不懂的话找个代码看看,我说个大概意思
在执行main之前还会执行别的动作。就是利用这个性质来打印。说实话一般
视频
就是基于cling的一个python内调用c++的工具。cling有句讲句活跃程度堪忧
>>> import cppyy
>>> cppyy.cppdef("""
... class MyClass {
... public:
... MyClass(int i) : m_data(i) {}
... virtual ~MyClass() {}
... virtual int add_int(int i) { return m_data + i; }
... int m_data;
... };""")
True
>>> from cppyy.gbl import MyClass
>>> m = MyClass(42)
>>> cppyy.cppdef("""
... void say_hello(MyClass* m) {
... std::cout << "Hello, the number is: " << m->m_data << std::endl;
... }""")
True
>>> MyClass.say_hello = cppyy.gbl.say_hello
>>> m.say_hello()
Hello, the number is: 42
>>> m.m_data = 13
>>> m.say_hello()
Hello, the number is: 13
>>> class PyMyClass(MyClass):
... def add_int(self, i): # python side override (CPython only)
... return self.m_data + 2*i
...
>>> cppyy.cppdef("int callback(MyClass* m, int i) { return m->add_int(i); }")
True
>>> cppyy.gbl.callback(m, 2) # calls C++ add_int
15
>>> cppyy.gbl.callback(PyMyClass(1), 2) # calls Python-side override
5鉴于我们是c++周刊,python代码就不多列举了。大家感兴趣的自己玩玩

我没懂,这种和经典singleton有啥不一样吗,哦singleton全局的
gdb结合tui,结合python等等,没总结,感兴趣的可以看看
ppt在这里 https://www.jonathanmueller.dev/talk/meetingcpp2022/
作者在搞一个脚本语言虚拟机,对比switch,改成jumptable带来很大受益,讲的就是这个调优过程
话说回来,不看视频只看ppt的话 https://meetingcpp.com/mcpp/slides/?year=2022 这里有挺有有意思的
我觉得非常值得一看
我觉得还是直接看ppt吧,非常容易懂,我记得以前godbolt也讲过类似的主题
我贴一下代码
;--- 经典寄存器使用
mov rdi, 2
mov rsi, 4
add rdi, rsi
;结果 rdi 6, rsi 4
;--- 堆栈push/pop
mov rdi, 0xfedcba9876543210
push rdi
pop rsi
;结果 rsi=rdi=0xfedcba9876543210,经典赋值,两条指令,mov要多用一个寄存器/地址中转
;--- 访问地址
mov rsi, 0x3333333333333333
mov rdi, 0x2222222222222222
mov qword ptr [rsp - 8], rsi
add rdi, qword ptr [rsp - 8]
;这里数组括号就是访问地址,把rsi弄到rsp-8的位置存一下,然后 add访问哪个地址的值,也就是rsi的值,加到rdi
; rdi 0x5555555555555555, rsi不变
; 为什么-8 因为rsi都是64位的寄存器
; byte: rax 8 eax 4 ax 2 al/ah 1
;来一个32位的例子
mov esi, 0x3333333333333333
mov edi, 0x2222222222222222
mov dword ptr [rsp - 8], esi
add edi, dword ptr [rsp - 8]
;结果就不说了
;再来一个word例子
mov word ptr [rsp-8], 0x1111
mov word ptr [rsp-6], 0x2222
mov word ptr [rsp-4], 0x3333
mov word ptr [rsp-2], 0x4444
lea rdi, [rsp-8] ; rdi指向rsp-8这个位置了
mov ax, word ptr [rdi+6] ; ax 0x4444懂吧
mov rsi, 0
mov ax, word ptr [rdi+rsi*2] ; 0x1111
inc rsi
mov ax, word ptr [rdi+rsi*2] ; 0x2222
;---- 条件
mov rsi, 2
mov rdi, 3
cmp rdi, rsi ;和j命令配合不满足继续走到jmp
jg .greater
mov rax, 0
jmp .endif
.greater:
mov rax, 1
.endif:
;---- 循环
; c代码这样
; int rax=0;
; for (int rcx=1;rcx!=3;++rcx) {rax += rcx;}
mov rax, 0
mov rcx, 1
.for
cmp rcx, 3
je .endfor
add rax, rcx
inc rcx
jmp .for
.endfor
;---- 来个函数
;int sum(int a, int b){ return a + b;}
sum(int, int):
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], edi
mov DWORD PTR [rbp-8], esi
mov edx, DWORD PTR [rbp-4]
mov eax, DWORD PTR [rbp-8]
add eax, edx
pop rbp
ret
;能看懂吧,另外优化后肯定能看懂,省掉把入参传到栈上来回折腾的流程了
sum(int, int):
lea eax, [rdi+rsi]
ret
再来个例子,调用函数
;int times_two(int i);
;int sum_times_two(int a, int b){ return times_two(a + b);}
;int times_two(int i){ return i*2;}
sum_times_two(int, int):
push rbp
mov rbp, rsp
sub rsp, 16
mov DWORD PTR [rbp-4], edi
mov DWORD PTR [rbp-8], esi
mov edx, DWORD PTR [rbp-4]
mov eax, DWORD PTR [rbp-8]
add eax, edx
mov edi, eax
call times_two(int) ;看edi的用法
leave
ret
times_two(int):
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], edi
mov eax, DWORD PTR [rbp-4]
add eax, eax
pop rbp
ret开源项目需要人手
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群384042845和作者对线
- pika 一个nosql 存储, redis over rocksdb,非常需要人贡献代码胖友们, 感兴趣的欢迎加群294254078前来对线
新项目介绍/版本更新
- Announcing Dear ImGui Bundle 一个imgui周边整理工具包
- Xmake v2.7.6 Released, Add Verilog and Cplusplus Module Distribution Support 强啊
- gcl 有点像graphviz接口
- catch2 3.3 支持测试用例跳过了,类似gtest的disable。
工作招聘
目前没看着有啥好工作,尽量别被开吧
看到这里或许你有建议或者疑问或者指出错误,请留言评论! 多谢! 你的评论非常重要!也可以帮忙点赞收藏转发!多谢支持!
如果有疑问评论最好在上面链接到评论区里评论,这样方便搜索,微信公众号有点封闭/知乎吞评论
C++ 中文周刊 第97期
弄了个qq频道,手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等
祝大家新年快乐。
资讯
标准委员会动态/ide/编译器信息放在这里
一月邮件列表
https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2023/#mailing2023-01
编译器信息最新动态推荐关注hellogcc公众号 OSDT Weekly 2023-01-18 第185期
文章
笑死 #embed 早晚玩出花来
https://godbolt.org/z/Tj6c7jz1o
#include <string_view>
#include <array>
template <std::size_t N>
struct fixed_string final {
constexpr explicit(true) fixed_string(const auto... cs) : data{cs...} {}
constexpr explicit(false) fixed_string(const char (&str)[N + 1]) {
std::copy_n(str, N + 1, std::data(data));
}
[[nodiscard]] constexpr auto operator<=>(const fixed_string&) const =
default;
[[nodiscard]] constexpr explicit(false) operator std::string_view() const {
return {std::data(data), N};
}
[[nodiscard]] constexpr auto size() const -> std::size_t { return N; }
std::array<char, N + 1> data{};
};
template <std::size_t N>
fixed_string(const char (&str)[N]) -> fixed_string<N - 1>;
fixed_string(const auto... Cs) -> fixed_string<sizeof...(Cs)>;
template<fixed_string Name>
constexpr auto meta_contains = [] {
static constexpr char self[] = {
#embed __FILE__
};
const auto code = std::string_view(std::data(self), std::size(self));
const auto find = code.find(Name);
return find != std::string_view::npos and code[find-1] != '\"';
}();
struct foo {};
struct bar {};
auto fn() -> void;
static_assert(not meta_contains<"struct x">);
static_assert(not meta_contains<"STD::string_view">);
static_assert(meta_contains<"std::string_view">);
static_assert(meta_contains<"struct foo">);
static_assert(meta_contains<"struct bar">);
static_assert(meta_contains<"auto fn()">);再学点range
adjacent
std::vector v = { 1, 2, 3, 4, 5, 6, 7, 8 };
for (auto const& t : v | std::views::adjacent<3>) {
std::cout << '[' << std::get<0>(t) << ','
<< std::get<1>(t) << ','
<< std::get<2>(t)
<< ']' << '\n';
}
/*
[1,2,3]
[2,3,4]
[3,4,5]
[4,5,6]
[5,6,7]
[6,7,8]
*/
//也可以这样
for (auto const& [a,b,c] : v | std::views::adjacent<3>) {
std::cout << '[' << a << ',' << b << ',' << c << ']' << '\n';
}slide和adjacent差不多,代码贴一下
auto print(R&& r) {
std::cout << '[';
bool first = true;
for (auto const e : r) {
if(first) first = false;
else std::cout << ',';
std::cout << e;
}
std::cout << ']' << '\n';
}
std::vector v = { 1, 2, 3, 4, 5, 6, 7, 8 };
for (auto const& c : v | std::views::slide(3)) {
print(c);
}
/*
[1,2,3]
[2,3,4]
[3,4,5]
[4,5,6]
[5,6,7]
[6,7,8]
*/chunk,分段
for (auto const& c : v | std::views::chunk(3)) {
print(c);
}
/*
[1,2,3]
[4,5,6]
[7,8]
*/chunk_by类似chunk,能提供一个谓词判断
bool differ_by_one(int const a, int const b)
{
return std::abs(a - b) <= 1;
}
std::vector v = {1,1,2,3,2,2,1,3,4,8,7,6,7};
for (auto const& c : v | std::views::chunk_by(differ_by_one))
{
print(c);
}
/* 按照相邻差1来分段
[1,1,2,3,2,2,1]
[3,4]
[8,7,6,7]
*/再来个例子
bool same_kind(char const a, char const b)
{
bool b1 = std::isdigit(a);
bool b2 = std::isdigit(b);
return (b1 && b2) || (!b1 && !b2);
}
std::string s {"1234abc56e789fghi"};
for (auto const& c : s | std::views::chunk_by(same_kind))
{
print(c);
}
/*
按照字母类型来分段
[1,2,3,4]
[a,b,c]
[5,6]
[e]
[7,8,9]
[f,g,h,i]
*/#include <iostream>
class MyDistance{
public:
explicit MyDistance(double i):m(i){}
friend MyDistance operator +(const MyDistance& a, const MyDistance& b){ // (1)
return MyDistance(a.m + b.m);
}
friend MyDistance operator -(const MyDistance& a, const MyDistance& b){ // (2)
return MyDistance(a.m - b.m);
}
friend std::ostream& operator<< (std::ostream &out, const MyDistance& myDist){ // (3)
out << myDist.m << " m";
return out;
}
private:
double m;
};
int main() {
std::cout << "MyDistance(5.5) + MyDistance(5.5): " << MyDistance(5.5) + MyDistance(5.5) << '\n'; // (4)
std::cout << "MyDistance(5.5) - MyDistance(5.5): " << MyDistance(5.5) - MyDistance(5.5) << '\n'; // (5)
}没啥说的,没有friend就找不到这几个operator函数,而且这么写也不用非得是成员函数
好像之前说过这个?反复强调,undefined behavior未定义行为不等于实现定义,有可能是历史遗留问题,也有可能就毁灭地球
逆天用法
std::vector<unsigned char> getFavicon() {
return {
#embed "favicon.ico"
};
}
这种场景embed可能退化成initializer_list,复制到栈上,然后再复制到vector,堆上,白白浪费
`#embed`就老老实实当属性二进制用,这种写法也不是不行,字符串不大也可以
作者写了个提案,方便解决这种情况。具体没看,大概就是识别优化掉这玩意看段代码
#include <array>
struct Node {
int a = 1, b = 1;
};
std::array <Node, 10'000> a;
int main() {}
问题在于array占用80k额外空间,加上Node初始化占用多余的空间,怎么样能省?初始化可以用0,省掉,本身全局变量并没有很好的办法优化掉
视频
- The Magic Behind Optimizing Compilers: Static Program Analysis - Philipp Schubert - Meeting C++ 2022
介绍静态分析工具 https://github.com/secure-software-engineering/phasar
看不懂

代码在这里 https://github.com/sslotin/amh-code
他也是咱们之前提到过很多次的这个博客 https://en.algorithmica.org/hpc/ 的作者。
这个讲的就是这个博客的内容,如何优化binary search,简单来说是SIMD,说实话SIMD我不太懂。没怎么看,不过我觉得是值得一看的

这里的aliasing表述的是多个指针使用指向同一个对象的情况,比如滥用引用,比如自己给自己赋值,之前也提到过误用引用导致错误而引入decay_copy以及c++23的auto,本质上这种问题还是指针的歧义,导致编译器保守了,没有彻底优化
来个代码
void byRef(std::vector<double>& v, const double& coeff) {
for (auto& i : v) i *= std::sin(coeff);
}
void byVal(std::vector<double>& v, double coeff) {
for (auto& i : v) i *= std::sin(coeff);
}
注意coeff这种没有必要的const&
再比如
using namespace std;
using namespace std::literals;
template <typename Fun>
void test(string_view name, Fun F) {
char buffer[50] = "hello ";
F(buffer + 1, buffer, 6);
buffer[0] = ' ';
cout << name << " [" << buffer << "] "
<< (" hello "sv == buffer ? "Good\n" : "Bad\n");
}
void loopcpy(char* dst, const char* src, int size) {
while (size--) *dst++ = *src++;
}
int main() {
test("NOP ", [](auto...) {});
test("loopcpy", loopcpy);
test("strcpy ", [](auto dst, auto src, auto...) { strcpy(dst, src); });
test("strncpy ", strncpy);
test("memcpy ", memcpy);
test("memmove", memmove);
test("copy_n ",
[](auto dst, auto src, auto size) { copy_n(src, size, dst); });
return 0;
}loopcpy这种明显无法区分src dst相同的副作用
在比如
using namespace std;
using namespace std::literals;
int main() {
// members();
complex<int> x{2, 2};
x *= reinterpret_cast<int*>(&x)[0]; // multiply by real part
cout << "expect (4,4) and get " << x << "\n";
// lambdas();
auto add_to_all = [](auto& v, const auto& suffix) {
for_each(begin(v), end(v), [&](auto& x) { x += suffix; });
};
vector<int> v{1, 2, 3};
add_to_all(v, v[0]);
cout << "expected [2,3,4] and got [" << v[0] << "," << v[1] << "," << v[2]
<< "]\n";
return 0;
}自己改自己以及滥用引用
再比如
int main() {
auto minmax = [](const string& i, const string& j, string* out_min,
string* out_max) {
*out_min = min(i, j);
*out_max = max(i, j);
};
array<string, 2> arr{"22222", "11111"};
// try to sort
minmax(arr[0], arr[1], &arr[0], &arr[1]);
cout << "expect 22222 and get " << arr[1] << "\n";
auto concat = [](string& result, const auto&... args) {
((result += args), ...);
};
string x{"hello "}, y{"world "};
concat(x, y, x);
cout << "expect [hello world hello ] and get [" << x << "]\n";
return 0;
}这种问题c就有,union都有,但c有__restrict__ c++没有。那么怎么从代码角度避免这种问题?
传值,引用用std::ref,强类型区分
开源项目需要人手
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群384042845和作者对线
- pika 一个nosql 存储, redis over rocksdb,非常需要人贡献代码胖友们, 感兴趣的欢迎加群294254078前来对线