这是我 2012 年的毕业设计,当时我非常震惊于 Everything 的搜索速度,所以决定自己实现一个。
如果你不知道什么是 Everything,请看这里
Everything 是一款专有的免费 Windows 桌面搜索引擎,可以在 NTFS 卷上通过名称快速查找文件和文件夹。
在这里对当时的我几乎为零的 MFC 和 C++ 经验表示抱歉。
如果想知道如何获取 NTFS 卷上的所有文件并将它们进行哈希,请阅读 QSearch/Volume.h
哦,图片里的语言还是中文呢 ^_^

- 将上面的图片保存为 -> *.jpg
- 将 .jpg 改名为 .7z
- 解压缩 *.7z -> (QSearch.exe config.ini)
我希望有一天能够对它进行重构,但是现在我已经不再使用 Windows 了。
- 读取 NTFS 的 MFT
- 哈希表的构建
- 文件的系统路径
- GUI 与 worker 线程
- 多种查找方式
- MFC 界面
- 4 月初 - 4 月中 确定研究方向
- 4 月下 - 4 月底 各知识点的准备,简单的 test
- 5 月初 程序的设计与开发的调试与运行
- 5 月中 - 5 月底 撰写毕业设计论文
- CPU 与内存占用在合理的范围内
- 软件稳定,提供不同的搜索选项
- 相对于 Windows 的查找功能,定位文件速度超快
摘要
本文介绍了在 Windows NTFS 磁盘格式下,枚举硬盘上所有文件以及文件夹的名称,以及利用 C++ 的 STL 构建哈希表,还有 MFC 的 GUI 与 worker 线程,最终根据用户输入的关键字,实现像 Google 关键字查找那样简单的搜索,然后瞬间返回所有匹配的文件/文件夹以及递归得到该文件/文件夹的系统路径。
关键词:NTFS, 快速,关键词,查找,文件路径
Windows 的目录结构,在 NTFS 卷中,文件在目录中以 B+树的形式排列,在目录中查找文件时按 B+树的搜索方法先搜索根节点(从根目录开始),然后按要找的文件名与根节点中的子节点对应的文件名相比较以确定在哪个子节点对应的存储区中搜索,然后以子节点为当前的根节点再搜索,直到找到文件为止。[1]
微软系统提供的搜索虽然可以搜索文本内容,但速度十分不理想。
大多数情况下,我们只想知道文件存放在电脑的哪个文件夹下,而本程序很好的解决了这一点。
NTFS(New Technology File System)是 Windows NT 以及之后的 Windows 的标准文件系统。
NTFS 取代了文件分配表(FAT)文件系统,为 Microsoft 的 Windows 系列操作系统提供文件系统。
NTFS 对 FAT 和 HPFS(高性能文件系统)作了若干改进,例如,支持元数据,并且使用了高级数据结构,以便于改善性能、可靠性和磁盘空间利用率。[2]
随着以 NT 为内核的 Windows 2000/XP 的普及,很多个人用户开始用到了 NTFS。
NTFS 也是以簇为单位来存储数据文件,但 NTFS 中簇的大小并不依赖于磁盘或分区大小。
簇尺寸缩小不但降低了磁盘空间的浪费,还减少了产生磁盘碎片的可能。
NTFS 支持文件加密管理功能,可为用户提供更高层次的安全保证。[3]
读取磁盘全部文件名称作为数据,根据用户输入关键字,在数据中匹配。
正确的连同路径一起返回给用户,以方便的打开文件。
具体设计思路如图 3-1 所示。
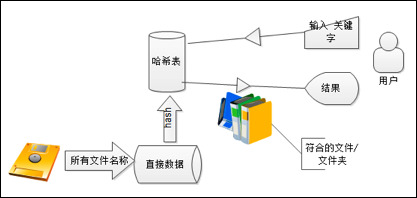
哈希表最大的优点,就是把数据的存储和查找消耗的时间大大降低,几乎可以看成是常数时间;而代价仅仅是消耗比较多的内存。
然而在当前可利用内存越来越多的情况下,用空间换时间的做法是值得的。
另外,编码比较容易也是它的特点之一。
程序的重中之重是读取 USN。
USN 是 Update Service Number Journal or Change Journal 的缩写,对 NTFS 卷里所修改过的信息进行相关记录的功能,可以在分区中设置监视更改的文件和目录的数量,记录下监视对象修改时间和修改内容。
当启用 USN 日志时,对于每一个 NTFS 卷,当有添加、删除和修改文件的信息时,NTFS 都使用 USN 日志记录下来,并储存为 USN_RECORD 的格式。
USN 日志相当于 WORD 目录,提供了索引,当然文章内容发生变化的时候,USN 日志会记录下来何时做了修改,但它并不记录里面具体修改了什么东西,所以索引文件很小。
而当你想查找文章具体的段落时,你就不用狂转鼠标滚轮,直接看目录即可,定位也只需要按住 ctrl+鼠标单击。
同理,当你想查找某一篇文件时,可以直接通过查找 USN 日志(也就是建立的索引)就知道这个文件是否存在。
PS:Windows 虽然不是“一切皆是文件”(Unix/Linux 的基本哲学之一),但文件夹也是以文件的形式存在,所以也可以通过 USN 来查找位置。
由于 NTFS 格式本来就是微软的专利,所以提供了一系列的 API 函数,供我们方便的访问。
作为古老但是经典的 Visual C++ 6.0 编程工具,但那时尚未有 NTFS 格式,所以选择了 VC2005 作为集成开发环境,而且只能运行在 2000 以后的 Windows 系统。
下面的均为微软提供的 API 函数,包含在 <Winioctl.h> 头文件中。
调用以下函数,找出为 NTFS 格式的磁盘
GetVolumeInformation(
lpRootPathName: PChar; // 磁盘驱动器代码字符串
lpVolumeNameBuffer: PChar; // 磁盘驱动器卷标名称
nVolumeNameSize: DWORD; // 磁盘驱动器卷标名称长度
lpVolumeSerialNumber: PDWORD; // 磁盘驱动器卷标序列号
var lpMaximumComponentLength: DWORD; // 系统允许的最大文件名长度
var lpFileSystemFlags: DWORD; // 文件系统标识
lpFileSystemNameBuffer: PChar; // 格式类型
nFileSystemNameSize: DWORD // 文件操作系统名称长度
);其中的 lpFileSystemNameBuffer,即为我们所要的,会返回"FAT32","NTFS"等字符串。
然后用一个循环,统计 A-Z 为 NTFS 格式的盘符,然后初始化。
HANDLE hVol = CreateFile(
"盘符字符串", // 必须如\.\C: (A-Z)的形式
GENERIC_READ | GENERIC_WRITE, // 可以为
FILE_SHARE_READ | FILE_SHARE_WRITE, // 必须包含有FILE_SHARE_WRITE
NULL, // 这里不需要
OPEN_EXISTING, // 必须包含OPEN_EXISTING, CREATE_ALWAYS可能会导致错误
FILE_ATTRIBUTE_READONLY, // FILE_ATTRIBUTE_NORMAL可能会导致错误
NULL); // 这里不需要需要注意的几点:
- CreateFile 返回一个句柄,下面需要用到;
- 由于盘符必须为
\\.\C:的形式,在C++语言中反斜杠"//"才代表 "/"; - 需要管理员权限(vista,win7 中会弹出 UAC)。
如果 hVol != INVALID_HANDLE_VALUE,就代表获取句柄成功,可以继续下一步了。
用 FSCTL_CREATE_USN_JOURNAL 作为 DeviceIoControl 的控制代码。
Cujd 是一个指向输入缓冲区的指针,指向 CREATE_USN_JOURNAL_DATA 结构体。
用 FSCTL_QUERY_USN_JOURNAL 作为 DeviceIoControl 的控制代码。
lpOutBuffer 返回一个 USN_JOURNAL_DATA,是一个结构体。
typedef struct {
DWORDLONG UsnJournalID;
USN FirstUsn;
USN NextUsn;
USN LowestValidUsn;
USN MaxUsn;
DWORDLONG MaximumSize;
DWORDLONG AllocationDelta;
} USN_JOURNAL_DATA, *PUSN_JOURNAL_DATA;UsnJournalID, FirstUsn, NextUsn 下一步会用到。
由于 USN 是以 USN_RECORD 形式储存的,其结构为:
typedef struct {
DWORD RecordLength; // 记录长度
WORD MajorVersion; // 主版本
WORD MinorVersion; // 次版本
DWORDLONG FileReferenceNumber; // 文件引用数
DWORDLONG ParentFileReferenceNumber; // 父目录引用数
USN Usn; // USN
LARGE_INTEGER TimeStamp; // 时间戳
DWORD Reason; // 原因
DWORD SourceInfo; // 源信息
DWORD SecurityId; // 安全
ID DWORD FileAttributes; // 文件属性
WORD FileNameLength; // 文件长度
WORD FileNameOffset; // 文件名偏移
DWORD ExtraInfo1;
DWORD ExtraInfo2; DWORD ExtraInfo3; // Hypothetically added in version 2.3
WCHAR FileName[1]; // 文件名第一位的指针
} USN_RECORD, *PUSN_RECORD;注意里面的 FileReferenceNumber, ParentFileReferenceNumber, FileNameLength, FileName,这几个变量至关重要。
DeviceIoControl() 与 FSCTL_ENUM_USN_DATA 配合。
while (0 != DeviceIoControl(hVol,
FSCTL_ENUM_USN_DATA,
&med,
sizeof (med),
Buffer,
BUF_LEN,
&usnDataSize,
NULL)) {
DWORD dwRetBytes = usnDataSize - sizeof (USN);
// 找到第一个 USN 记录
UsnRecord = (PUSN_RECORD)(((PCHAR)Buffer)+sizeof (USN));
while (dwRetBytes > 0) {
// 获取到的信息
CString CfileName(UsnRecord->FileName, UsnRecord->FileNameLength/2);
pfrnName.filename = nameCur.filename = CfileName;
pfrnName.pfrn = nameCur.pfrn = UsnRecord->ParentFileReferenceNumber;
// Vector
VecNameCur.push_back(nameCur);
// 构建 hash...
frnPfrnNameMap[UsnRecord->FileReferenceNumber] = pfrnName;
// 获取下一个记录
DWORD recordLen = UsnRecord->RecordLength;
dwRetBytes -= recordLen;
UsnRecord = (PUSN_RECORD)(((PCHAR)UsnRecord)+recordLen);
}
// 获取下一页数据
med.StartFileReferenceNumber = *(USN *)&Buffer;
}其中,Med 为:
MFT_ENUM_DATA med;
med.StartFileReferenceNumber = 0;
med.LowUsn = 0; // UsnInfo.FirstUsn;这里经测试发现,如果用 FirstUsn 有时候不正确,导致获取到不完整的数据,还是直接写 0 好。
med.HighUsn = UsnInfo.NextUsn;
在这个循环中,把每次获取到的文件名,分别插入 vector 与哈希表中(下文有介绍)。
DeviceIoControl(hVol,
FSCTL_DELETE_USN_JOURNAL,
&dujd,
sizeof (dujd),
NULL,
0,
&br,
NULL)将数据先保存为 Allfile.txt 文本,以便用来分析,如图 4-1。
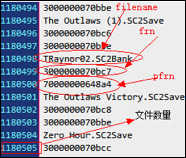

用了自己电脑上的 D 盘作为测试,枚举出了全部的文件。
如图,大约有 40W 文件,一共有 100 多 W 条数据,文件大小约 20MB。
这对于之后的程序占用内存的数量,有了个模糊的估计,大约在 50M 左右。
对于即使只有 1G 的内存,也在合理范围内。
有了原始数据,分析如下:
比如 Linux 编程实践.isz 这个文件,其系统路径为:D:\Ghost\Linux\Linux 编程实践.isz,在看文件中的结果:
D:\
Frn: 5000000000005
Pfrn: NULL
……
……
Ghost
Frn: 20000000000fd
Pfrn: 5000000000005
……
……
Linux
Frn: e0000000010d2
Pfrn: 20000000000fd
……
……
Linux编程实践.isz
Frn: 190000000003b2
Pfrn: e0000000010d2
可以得出:
Linux编程实践.isz->Pfrn == Linux->Frn
Linux->Pfrn == Ghost->Frn
Ghost->Pfrn == D:\ -> Frn
D:\ -> Pfrn 停止
所以用一个递归函数(直接或间接地调用自身的函数),便可得到完整的路径。
typedef struct _name_cur {
CString filename;
DWORDLONG pfrn;
} Name_Cur;Vector:
一种顺序容器。
vector 中的元素通过其位置下标访问。
可通过调用 push_back 或 insert 函数在 vector 中添加元素。
在 vector 中添加元素可能会导致重新为容器分配内存空间,也可能会使所有的迭代器失效。
在 vector 容器中间添加(或删除)元素将使所有指向插入(或删除)点后面的元素的迭代器失效。
用 Vector 来存放<文件名,当前目录>,由于模糊查找的要求,二分查找之类的快速查找方式,在这里反而不适用,而 Vector 从 begin 到 end 的线性遍历方式,反而比较符合这一要求。
typedef struct pfrn_name {
DWORDLONG pfrn;
CString filename;
} Pfrn_Name;
typedef map<DWORDLONG, Pfrn_Name> Frn_Pfrn_Name_Map;这里利用 STL 提供的 map 库函数,map 是键-值对的集合。
map 类型通常可理解为关联数组(associative array):可使用键作为下标来获取一个值,正如内置数组类型一样。
而关联的本质在于元素的值与某个特定的键相关联,而并非通过元素在数组中的位置来获取。
- 考虑到若是自己实现哈希函数,可能有若干 bug,影响进度,不如使用 STL 提供的稳定的 map 来实现。
- “Don't Reinvent the Wheel”不要重复发明轮子。
- 如 Google 的 Android,是 Google 没有能力单独开发一个系统内核,才用了很成熟的 Linux 内核?我想也以 Google 这样的世界巨头公司,是不可能没有这个能力的,而是尊崇了不要重复发明轮子的原则。
这里就用到了在 4.1.5 节,获取 USN Journal 文件的信息那个循环中,把每次获取到的 USN_RECORD 信息,里面的 filename, pfrn, frn 分别插入到 vector 与哈希表中。
pfrnName.filename = nameCur.filename = CfileName;
pfrnName.pfrn = nameCur.pfrn = UsnRecord->ParentFileReferenceNumber;
VecNameCur.push_back(nameCur);
frnPfrnNameMap[UsnRecord->FileReferenceNumber] = pfrnName;
开始一个项目时,VC2005 提供了命令行(控制台)项目,以及 GUI 项目。
命令行编程非常的方便、快捷、实用,而且相对的简单。
在控制台能满足的情况下,用界面是没有必要的。
或者有时目标平台不能够显示图形用户界面。
不过,GUI 有着更明显的优势,比如菜单系统以及更好的交互性。
另外,在菜单选择,字段之间移动数据录入过程中,鼠标是非常有用的,GUI 是必经之路。
所以,写程序时,先在 console 下试验了些中间数据,没问题结束后,在转向 GUI 界面。
MFC:Microsoft Foundation Classes,也就是一般人简称的 MFC,是微软公司对于“降低 Windows 程序设计之厌烦无聊及困难度”而做出的最大贡献。
MFC 使得对话框的产生极为简单。
它也实现出了消息派送系统(message dispatching),处理 WPARAM 和 LPARAM 的易犯错误。
MFC 甚至是引诱某些人进入 C++ 的原动力。
本程序用微软提供的 MFC 实现,如图 4-2:
KISS 原则就是"Keep It Sample And Stupid"的缩写,简洁和易于操作是设计的最重要的原则。
KISS 原则在设计上可能最被推崇的,在家装设计,界面设计,操作设计上,复杂的东西越来越被众人所 BS 了,而简单的东西越来越被人所认可,比如这些 UI 的设计和我们中国网页是负面的例子。
“宜家”(IKEA)简约、效率的家居设计、生产思路;“微软”(Microsoft)“所见即所得”的理念;“谷歌”(Google)简约、直接的商业风格,无一例外的遵循了“kiss”原则。[7]
在 kiss 原则下,尽可能做到简洁。
添加 Editbox button listbox menu[8] 这几个控件,分别实现功能为:
- Editbox
- 得到用户输入的需要查找的字符串
- Button
- 得到 EditBox 中的字符串
- 字符太短弹出提示
- 加上放大镜图片,功能一目了然
- Listbox
- 显示匹配的文件名与路径,双击可打开文件
- 由于路径可能比较长,加入水平滚动条
- 双击 Listbox 中的结果文件路径,打开被双击选中的文件
- Menu
- 菜单,可以选择大小写、查找顺序
线程的好处:线程价廉。
线程启动比较快,退出比较快,对系统资源的冲击也比较小。
另外考虑到:
- 由于 io 的限制,对同一块硬盘,用多线程同时读取 MFT,意义不是很大
- 磁盘访问位于同一硬盘不同分区的 MFT,有可能反而会影响速度。而对于多块硬盘的电脑,应该可大大提高效率。但是多块硬盘的用户,可能组成了 RAID 磁盘列阵。最好的解决方案应该就是 A-Z 盘顺序读取。
- 最初创建 MFC 时,顺序执行,结果导致界面在全部数据统计结束后才能显示,在此过程中,用户很容易失去耐心。
- 最终决定一个 UI 线程,一个 worker 线程后台统计数据。
MFC 早加入了对多线程的支持。
在一个典型的 MFC 程序中,多线程的支持隐藏在一大段非常惊人的工作之后。
MFC 甚至企图强化某些与多线程有关的 Win32 观念。
GUI 与 worker 线程都是以 AfxBeginThread() 启动,但是 MFC 利用 C++ 函数的 overloading 性质,对该函数提供了两种不同的声明。编译器会根据你所提供的参数,自动选择正确的一个来用。[9]
用 AfxBeginThread 来启动线程。
pParam 任意 4 字节数值,用来传给新线程。
它可以是个整数,或指针,或单纯只是个 0。
这里只用到前面两个参数即可,对象中的线程函数,以及该对象指针。
在任务管理器中可以看到两个线程,如图 4-3 所示:

当 worker 线程完成任务后,便会自动结束,回复为一个线程。
现在越来越多的程序点击右上角的关闭,实际为最小化到托盘图标。真正退出程序需要从托盘图标上右键退出。
实现最小化而不退出程序,可以方便的查找文件。
- 最小化在任务栏显示。
- 点击关闭,退出到托盘图标,而不在任务栏显示;双击回复显示窗口。
- 托盘图标添加菜单。
实际应用中,文件名不可能清楚的记得,比如 test.2012-5-14.txt,经常是输入“test.txt”,所以需要模糊查找。
由于在 console 下,以<filename, pfrn>创建哈希表,如果要实现模糊查找,哈希表变没有必要,可以直接利用容器 vector。
根据实际情况,不需要很严格的通配符,* ? 即可解决大部分查找问题,加上用户一般可能不知道通配符的使用,更不用说正则表达式。
所以以 “空格” 代替 * ?,实现百度 Google 那样以空格隔开关键字的查找方式,是个很好的解决办法。
一般会有以下三种情况:
- 用户可能记不清文件名称或者路径的大小写
- 有时文件过多,可能需要严格的大小写,以过滤正确文件
- 记不清关键字的顺序
所以提供下面两个选项:
- 严格大小写
- 无顺序
根据普遍情况,默认为:大小写不敏感,有顺序的查找方式。
- 考虑到有些文件夹被用来存放用户私密文件。
- 系统文件夹,例如:
c:\windows\*一般用户是用不到的,同等搜索只会增加不必要的文件,拖重系统负担。
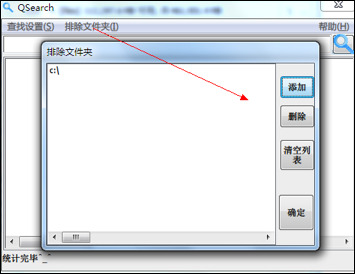
所以有必要添加一个排除文件夹选项,如图 4-4
相应的函数为:
bool isIgnore(vector<string>* pignorelist) {
string tmp = CW2A(path);
for (vector<string>::iterator it = pignorelist->begin(); it != pignorelist->end(); ++it) {
size_t i = it->length();
if (!tmp.compare(0, i, *it, 0, i)) {
return true;
}
}
return false;
}新建匹配字符串类
class cmpStrStr {
public:
cmpStrStr(bool uplow, bool inorder) {
this->uplow = uplow;
this->isOrder = inorder;
}
~cmpStrStr() {}
bool cmpStrFilename(CString str, CString filename);
bool infilename(CString& strtmp, CString& filenametmp);
private:
bool uplow;
bool isOrder;
};遍历4.2.1中的 VecNameCur,通过 cmpStrFilename 匹配函数,得到符合的 filename
for (vector<Name_Cur>::const_iterator cit = VecNameCur.begin(); cit != VecNameCur.end(); ++cit) {
if (cmpstrstr.cmpStrFilename(str, cit->filename)) {
path.Empty();
// 还原 路径
// vol:\ path \ cit->filename
getPath(cit->pfrn, path);
path += cit->filename;
// path已是全路径
if (isIgnore(pignorelist)) {
continue;
}
rightFile.push_back(path);
//path.Empty();
}
}cmpStrFilename 函数:
int pos = 0;
int end = str.GetLength();
while (pos < end) {
// 对于str,取得 每个空格分开为的关键词
pos = str.Find(_T(' '));
CString strtmp;
if (pos == -1) {
// 无空格
strtmp = str;
pos = end;
} else {
strtmp = str.Mid(0, pos - 0);
}
if (!infilename(strtmp, filename)) {
return false;
}
str.Delete(0, pos);
str.TrimLeft(' ');
}可以在 infilename 函数中,很方便改写字符串匹配的算法,实现某些拓展
CString filenametmp(filename);
int pos;
if (!uplow) {
// 大小写敏感
filenametmp.MakeLower();
pos = filenametmp.Find(strtmp.MakeLower());
} else {
pos = filenametmp.Find(strtmp);
}
if (-1 == pos) {
return false;
}
if (!isOrder) {
// 无顺序
filename.Delete(0, pos + 1);
}得到匹配的文件名后,下一步就是得到文件的系统路径。
把上面得到的匹配文件名称的全名,传入4.2.2中构建的 frnPfrnNameMap 哈希表,递归得到路径。
CString Volume::getPath(DWORDLONG frn, CString& path) {
// 查找2
Frn_Pfrn_Name_Map::iterator it = frnPfrnNameMap.find(frn);
if (it != frnPfrnNameMap.end()) {
if (0 != it->second.pfrn) {
getPath(it->second.pfrn, path);
}
path += it->second.filename;
path += (_T("\"));
}
return path;
}理论上,时间复杂度分别为:

在 AMD Athlon(tm) II X2 245 2.9GHz 处理器上,结果几乎瞬间完成。
由于电脑文件数量巨大——通常为 10W-100W 级别,所以程序本身内存占用可以忽略不计。
234,708 个文件 约 43M。
对于如今至少 2G 的内存的系统来说,算不上负担。
电脑上的 O 盘无法初始化 USN 日志文件,通过调试发现:
DeviceIoControl 返回 0,GetLastError 0x70
查阅 msdn,原因是 ERROR_SHARING_PAUSED
原来是忘记初始化添加以下代码,程序即可正常访问 O 盘
CREATE_USN_JOURNAL_DATA cujd;
cujd.MaximumSize = 0; // 0表示使用默认值
cujd.AllocationDelta = 0; // 0表示使用默认值最初在字符串处理方面,用标准库函数的 string 作为处理方法,但在 unicode 下为双字节的 wchar,在字符串转换方面陷入不少麻烦,最后全部以 CString 作为默认字符串,并以_T(""),初始化字符串得以解决。
#ifdef,里面不能设断点,后来才注意到#define 写在了 include 前面。
开始以面向过程的思想设计,陷入了不断的以传参的方式,传递相同的句柄的麻烦之中,后来改为用类的方法,改善许多。
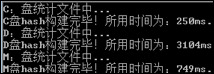
在构建哈希函数时,想到了三种方法,分别作了实验,用 time 函数统计所用时间,结果如下:
- 修改代码后,一次性读取 usn,存入临时文件,读取、构建哈希表
- 每次运行,时间平均 27s 左右
- 使用 vector,将数据保存在内存中,release 后,
- 结果喜人,时间提高近 10 倍!!!如图 7-1 所示:
完全在可接受的范围之内。
第一次运行明显耗时较长,之后从磁盘缓存中预读文件,速度飙升。
分析热点应该在于磁盘寻道时间、以及文件读取。
在4.3.2中,双击 ListBox 中的文件路径,打开响应文件时,刚开始用了 system()系统函数,但是会弹出一个黑色的控制台窗口,并且主窗口处于锁定状态,等文件关闭后,才能继续执行,非常不利于用户体验。
改为调用 ShellExecute 函数,从而开辟一个新的进程,主窗口也可以继续执行。
V1.0 版本放出后,有同学反映后台统计文件时,没有提示,所以不知道什么时候完成。
于是在主界面底部加了个进度条,增强交互性,如图 7-2:
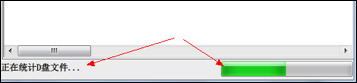
当然,线程函数也作出了必要的修改:
至此,程序基本功能完成,在多台电脑,以及不同的系统上(XP 以及之后的 windows 系列)测试,基本没有假死以及程序挂掉的情况。
由于时间等原因还有许多的功能没有实现,比如界面无法伸展,不能动态的统计文件数据等等。
- [1] 硬件白皮书. NTFS 文件系统规范[OL]. 百度文库,2011: 30.
- [2] Beiyu. NTFS 文件系统若干技术研究[OL]. 2007: 7.
- [3] 婴儿. 互动百科[OL]. http://www.hudong.com/wiki/ntfs
- [4] Microsoft. MSDN Library[OL]. 2012 :
- [5] Stanley B.Lippman / Josée LaJoie / Barbara E.Moo. C++ Primer[M]. - Addison-Wesley Professional , 2006 : 10.3
- [6] Eric S. Raymond. 译者: 姜宏、何源、蔡晓骏. UNIX 编程艺术[m]. 电子工业出版- 社, 2006:
- [7] 陈皓. 一些软件设计的原则[OL]. http://coolshell.cn/articles/4535.html
- [8] 孙鑫. VC++深入详解[m]. 电子工业, 2006
- [9] Jim Beveridge / Robert Wiener. Multithreading Applications in Win32: The Complete Guide to Threads
- [10] Addison-Wesley Professional, 1996: 223-243