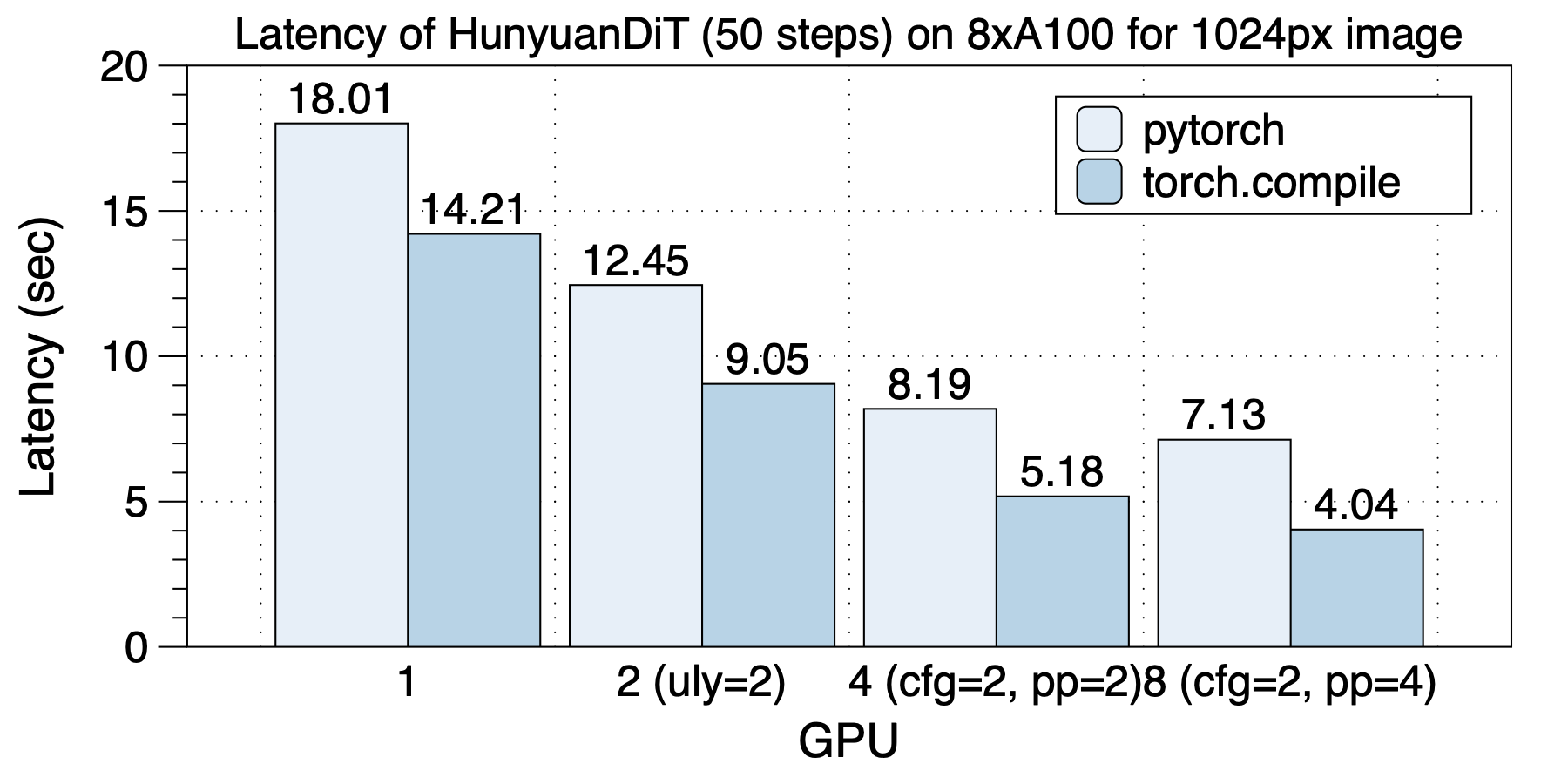
在8xA100(NVLink)机器上,在使用不同GPU数目时,最佳的并行方案都是不同的。这说明了多种并行和混合并行的重要性。
最佳的并行策略在不同GPU规模时分别是:在2个GPU上,使用ulysses_degree=2;在4个GPU上,使用cfg_parallel=2, ulysses_degree=2;在8个GPU上,使用cfg_parallel=2, pipefusion_parallel=4。
torch.compile带来的加速效果也很可观,同样并行方案有1.26x到1.76x加速效果,对于8 GPU的场景是最明显的,有1.76x加速。
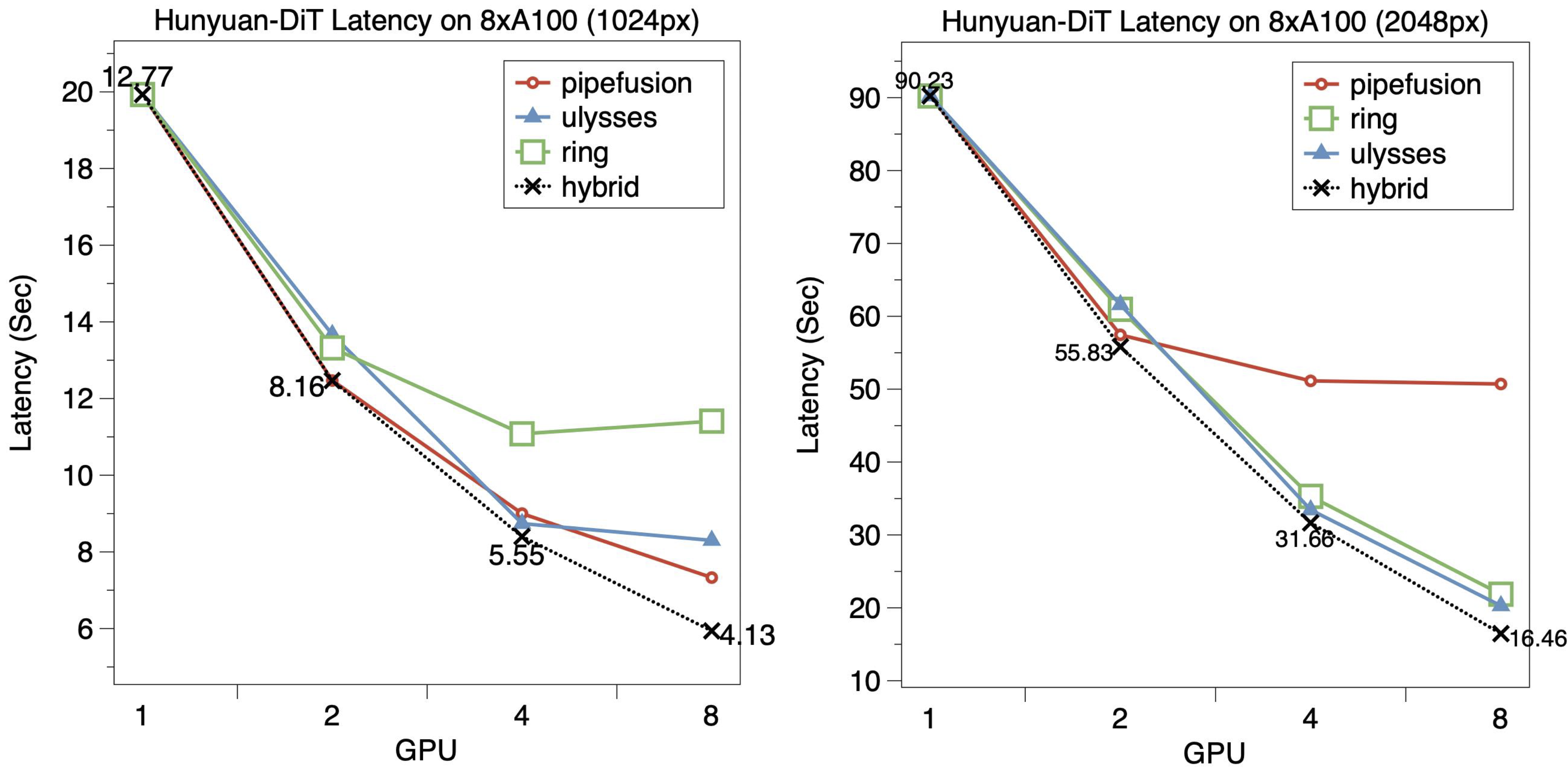
下图展示了HunyuanDiT在8xA100 GPU上的可扩展性。我们额外测试了2048px图像生成任务,尽管HunyuanDiT并不具备生成2048px图像的能力。 HunyuanDiT采用DiT块通过Skip Connection相互连接的结构,每个DiT块既与相邻块相连,也与非相邻块相连。
对于1024px图像生成任务,最佳的混合并行配置如下:2个GPU时使用pipefusion=2;4个GPU时使用cfg=2, pipefusion=2;8个GPU时使用cfg=2, pipefusion=4。PipeFusion的预热步数设为1。 在4个和8个GPU上,混合并行分别比单一并行方法获得了1.04x和1.23x的加速。在8个GPU上,PipeFusion的延迟低于SP-Ulysses,但在4个GPU上两者延迟相近。 在所有并行方法中,SP-Ring展现出最差的可扩展性。
对于2048px图像生成任务,8个GPU时的最佳混合并行配置变为cfg=2, pipefusion=2, ring=2。 同样,在4个和8个GPU上,混合并行相比单一并行方法获得了小幅提升。然而,在使用4个或8个GPU时,由于GPU之间Skip Connection需要额外的点对点通信,PipeFusion表现出比SP-Ulysses和SP-Ring更高的延迟。 当PipeFusion的并行度为2时,这个问题得到缓解,这突显了在混合配置中使用合适并行度的重要性。 随着图像尺寸从1024px增加到2048px,SP-Ring和SP-Ulysses之间的性能差距减小,这是因为模型的计算通信比降低,使得SP-Ring能够隐藏更多的通信开销。
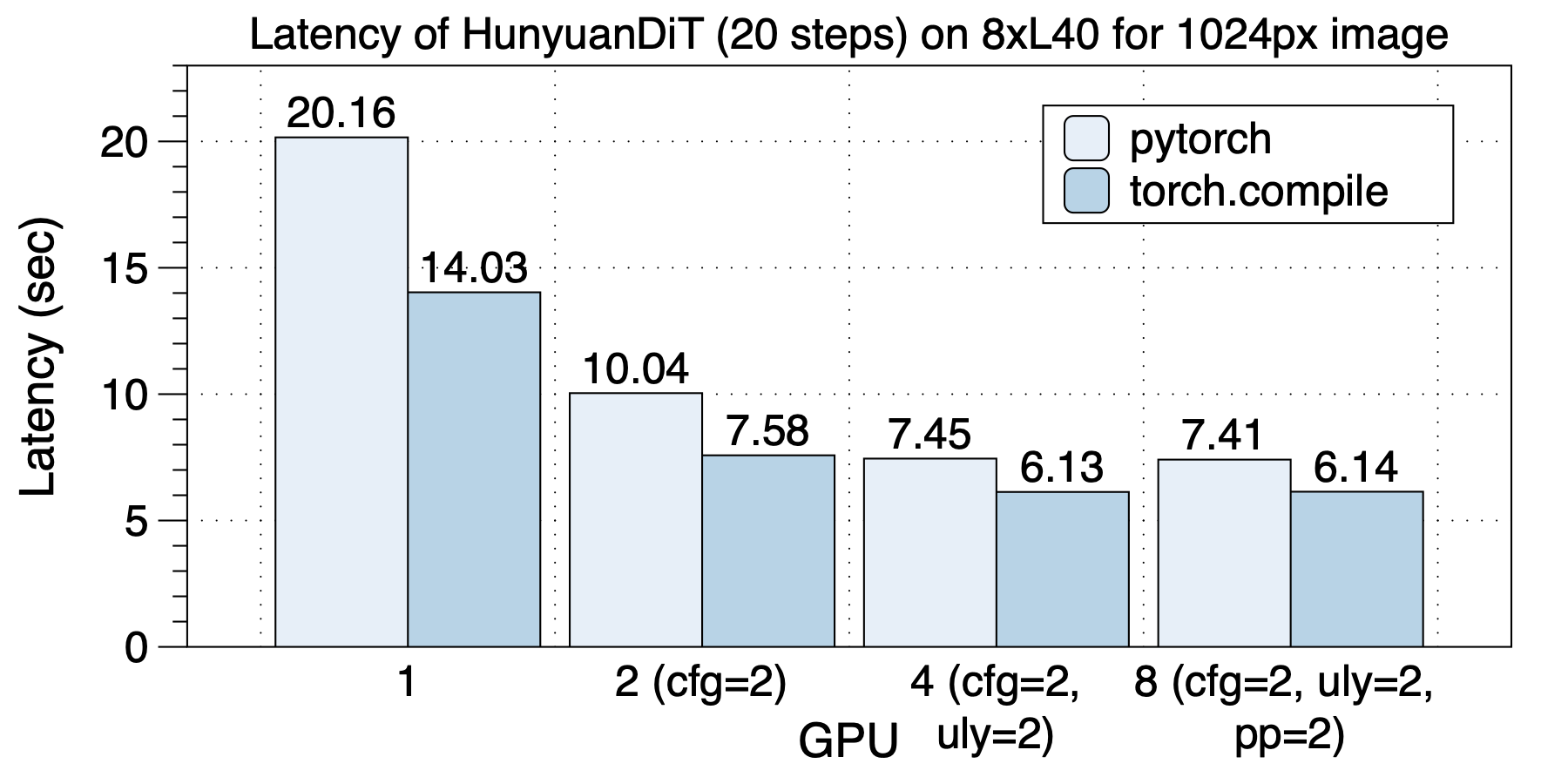
在8xL40 (PCIe)上的延迟情况如下图所示。同样,不同GPU规模,最佳并行策略都是不同的。 和A100上不同,在L40上,8 GPU和4 GPU的延迟没有明显变化。我们认为是PCIe导致跨socket之间通信带宽过低导致的。
torch.compile带来1.2x到1.43x加速。
在8xL20 (PCIe)上的延迟情况如下图所示。L20的FP16 FLOPS是119.5 TFLOPS,相比L40是181.05 TFLOPS。但是在8 GPU上,L20的延迟反而相比L40更低。
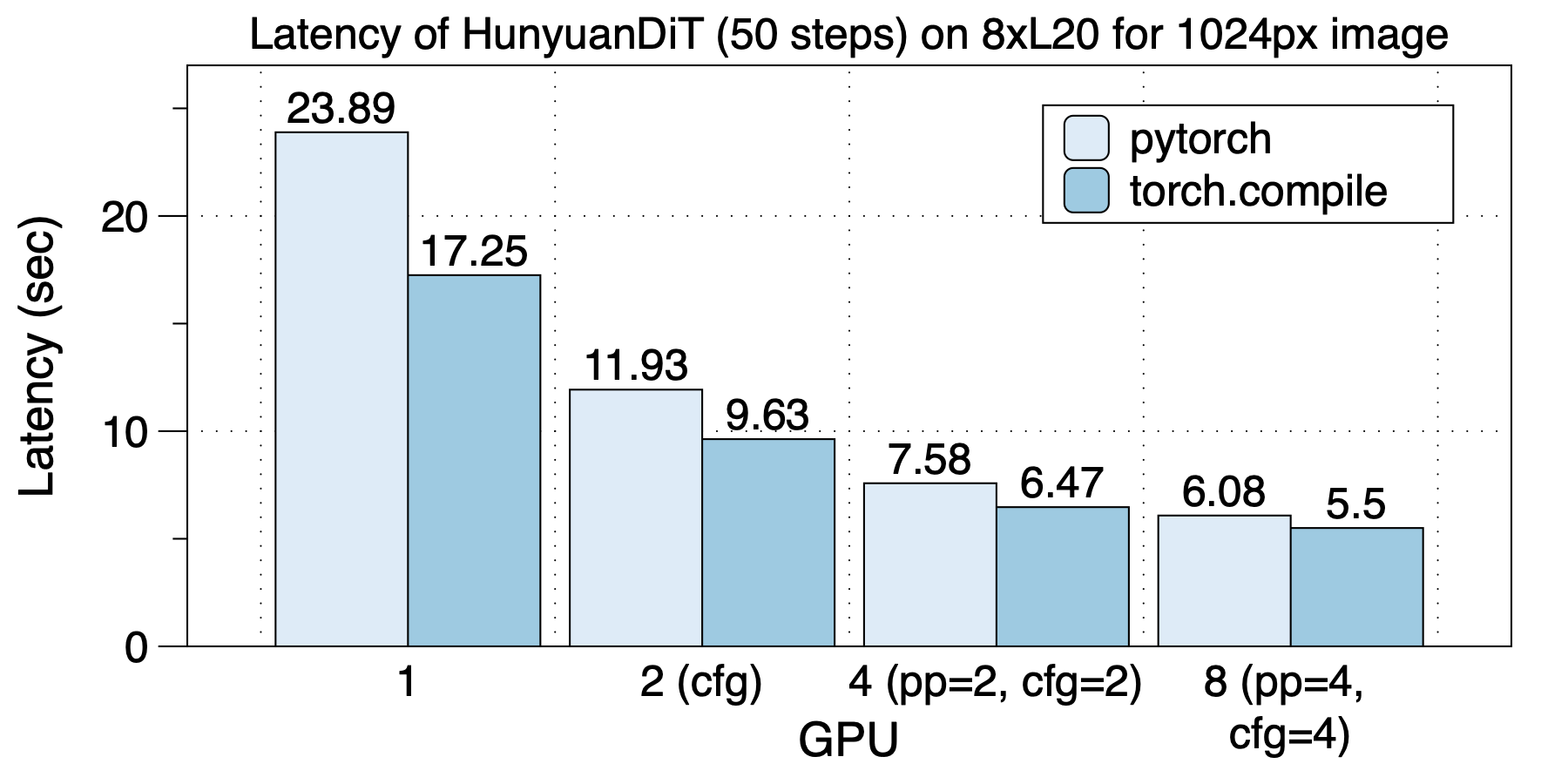
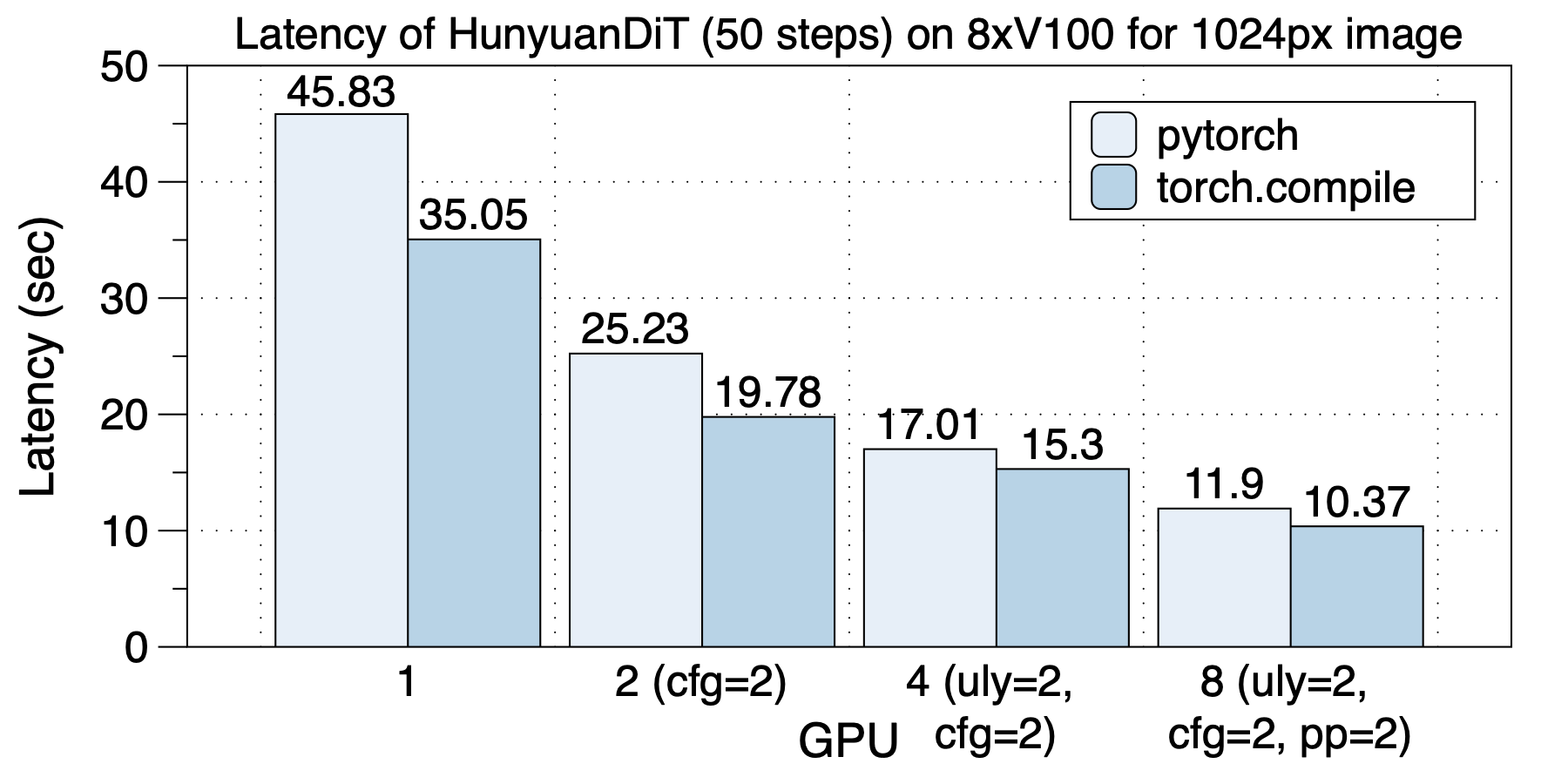
在8xV100上的加速下如下图所示。torch.compile带来1.10x到1.30x加速。
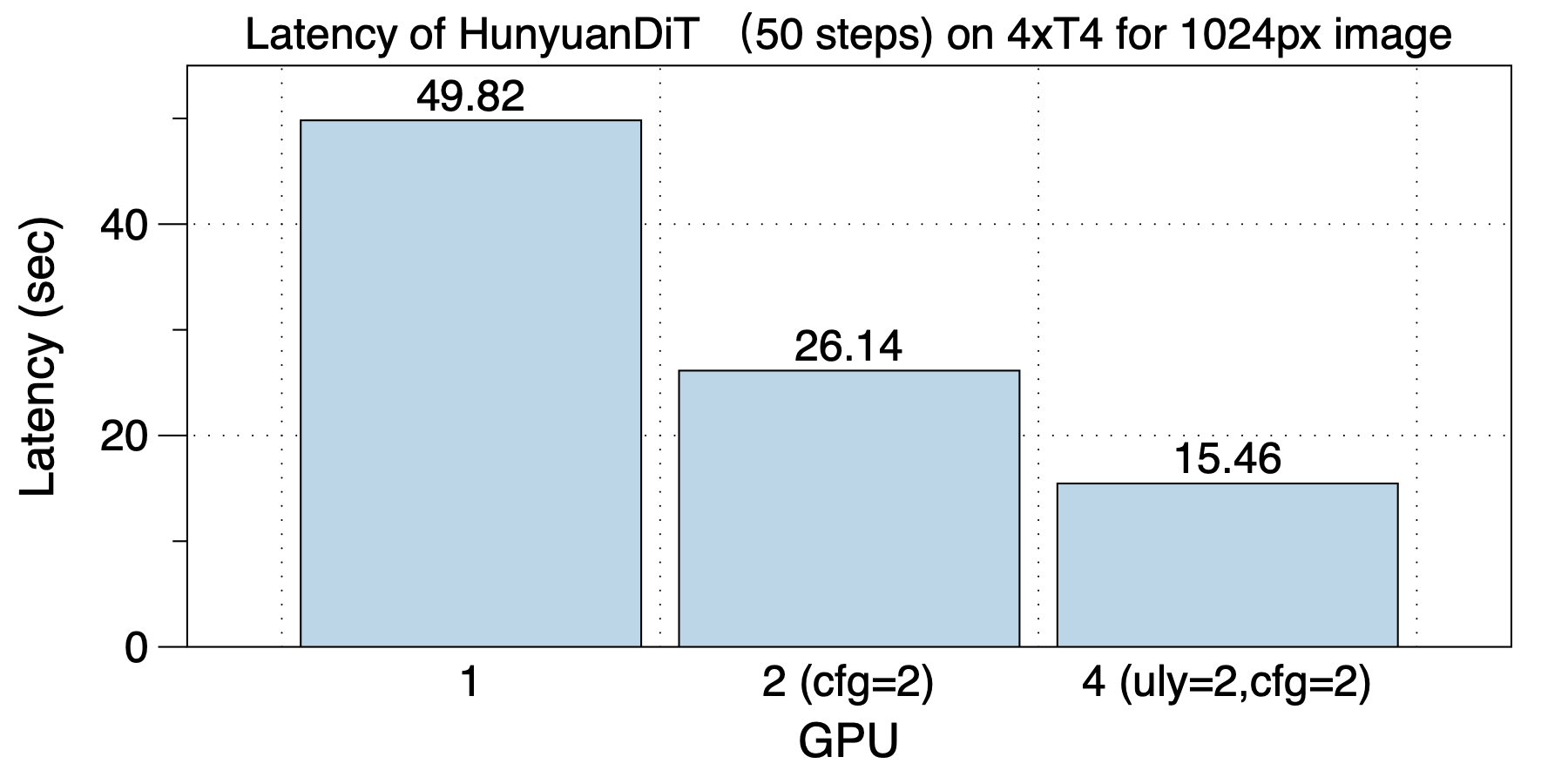
在4xT4上的加速下如下图所示。