Document Chat Bot
Imagine an application that enables you to engage in a conversational interaction with your documents.
Often, documents are lengthy and contain multiple pages, making it challenging to locate specific information quickly. The conventional method of skimming through pages can be time-consuming and tedious.
However, advancements in Natural Language Processing (NLP) through deep learning have significantly simplified such tasks.
In this blog, I will demonstrate how we can leverage LangChain to build an application that enables users to engage in conversations with their documents.
Primarily, LangChain can serve as a Personal AI Assistant or a mini-study buddy, enhancing your productivity and making your time more effective.
For those new to the realm of LangChain, here’s a brief introduction.
LangChain is an open-source framework designed to simplify the development of applications using large language models, such as GPT-4. It is available in Python and Javascript (TypeScript) packages.
The framework is highly approachable, leveraging a structure that organizes vast amounts of data into manageable “chunks” subsequently embedded into a vector store.
Let’s begin with the environment setup.
In this guide, Python version 3.9 is utilized. To ensure a clean working environment, create a separate environment with the specified dependencies listed in “requirements.txt”:
pip install -r requirements.txt
Next, create three new Python files within your project directory:
Chat_PDFs_LangChain_App
|
|-- app.py
|
|-- htmlTemplates.py
|
|-- utils.py
To protect your API keys, create a .env file in your project’s root directory. This precaution prevents accidental exposure in public repositories and safeguards your keys from unauthorized access.
Load Required Libraries Ensure all necessary libraries are installed to verify that the environment is ready for work.
utils.py
from PyPDF2 import PdfReader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings, HuggingFaceInstructEmbeddings
from langchain.vectorstores.faiss import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain, StuffDocumentsChain, LLMChain
from langchain.llms import HuggingFaceHubpy
app.py
import streamlit as st
from dotenv import load_dotenv
from htmlTemplates import css, bot_template, user_template
from utils_new import ChatPDFs
Setting up the application layout is simplified using Streamlit, an open-source framework for rapidly building and sharing web apps.
# Set page configuration like title, favicon, layout, initial sidebar state, and menu items
st.set_page_config(page_title="Chat_PDFs_LangChain_App", page_icon="🐱💻")
# handle different types of inputs and display them in the app
st.write(css, unsafe_allow_html=True)
# Display a header with a colored divider, anchor, and tooltip
st.header("Chat with your PDFs 💻")
# Get user input in the form of a string
user_question = st.text_input("Pose a question regarding your documents:")
# Upload files to the app, allowing users to upload multiple files at once
pdf_docs = st.file_uploader("Upload your PDFs here and click on 'Process'", accept_multiple_files=True)
# Create a button widget
st.button("Process"):
# Perform processing when the button is clicked
This configuration sets up a user-friendly interface for chatting with PDFs using Streamlit. Feel free to customize the layout and styling according to your preferences.

utils.py
Here, the “get_pdf_text” function takes a list of PDF file paths as input and returns the concatenated text from all the pages of your PDF files.
def get_pdf_text(pdf_docs):
txt = ""
for pdf in pdf_docs:
pdf_reader = PdfReader(pdf)
for page in pdf_reader.pages:
txt += page.extract_text()
return txt
Splitting text into smaller chunks is crucial because language models are often constrained by the amount of text they can process effectively.
LangChain employs a simple method called “Split by Character” using the “CharacterTextSplitter”. By default, it splits the text based on a specific character (usually “\n\n”) and measures the chunk length by the number of characters.
-
Method Used: Splitting by a single character.
-
Measurement of Chunk Size: Based on the number of characters.
This approach ensures that the text is divided into manageable chunks, optimizing the language model’s efficiency.
def get_txt_chunks(text):
txt_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=205,
length_function=len
)
chunks = txt_splitter.split_text(text)
return chunks
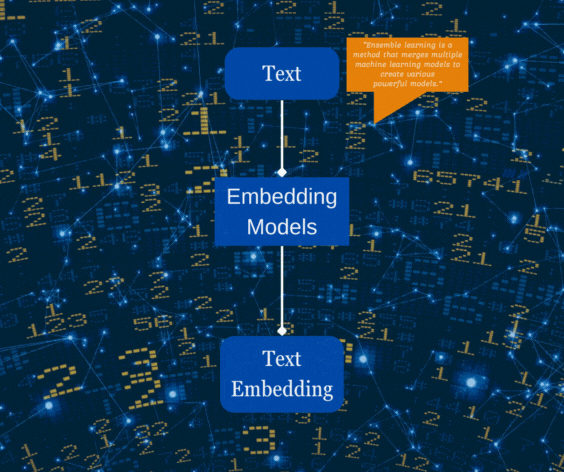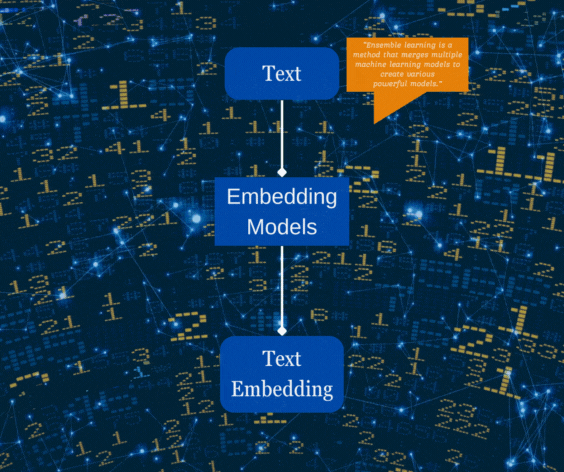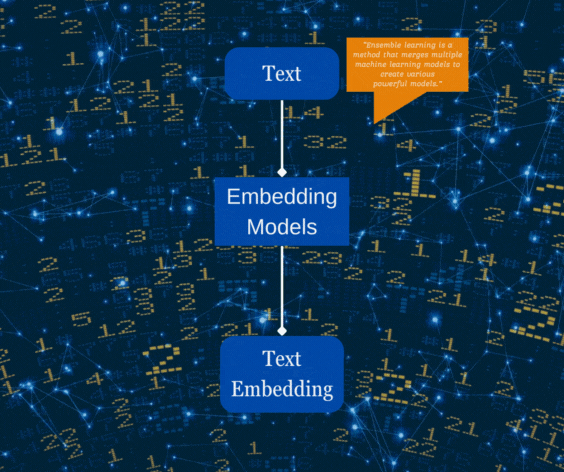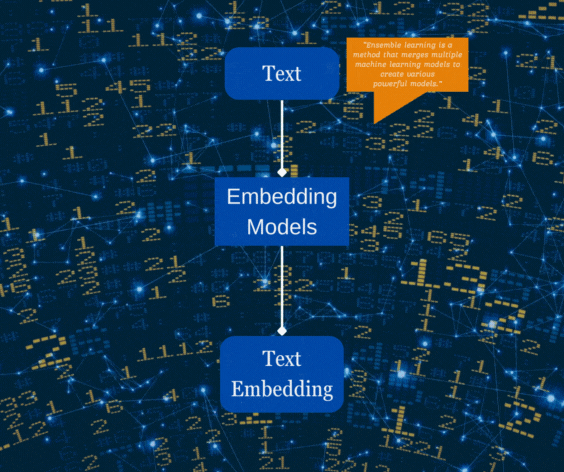
Utilizing Embeddings for Data Chunks and Conversion to Vectors with OpenAIEmbeddings / HuggingFaceInstructEmbeddings
In the realm of large language operations, Text Embeddings serve as the cornerstone. The transformation of text into vector forms stands out as one of the most efficient approaches when working with language models in Natural Language Processing (NLP).
Both OpenAIEmbeddings and HuggingFaceInstructEmbeddings demonstrate efficiency in their ways.
Notably, examining the Massive Text Embedding Benchmark (MTEB) Leaderboard as of December 2023, according to the HuggingFace chart:
+------------------------------------------------+----------------------------+
| Model | Embedding Output Dimensions|
+------------------------------------------------+----------------------------+
| HuggingFaceInstructEmbeddings(instructor-large)| 768 |
| | |
| | |
| OpenAIEmbeddings (text-embedding-ada-002) | 1536 |
+------------------------------------------------+----------------------------+
In our case, we opt to use the embeddings provided by HuggingFaceInstructEmbeddings with the model name “*hkunlp/instructor-large*”.
Once text is embedded, various operations such as grouping, sorting, searching, etc., become feasible. These embeddings take text as input and return a list of floats, forming a vector representation (embeddings). These vectors can be interpreted as numerical representations of the input text.
# Generate embeddings for the given text chunks
def get_vector_db(text_chunks):
embeddings = HuggingFaceInstructEmbeddings(model_name="hkunlp/instructor-large")
vector_db = FAISS.from_texts(texts=text_chunks, embedding=embeddings)
return vector_db
Initialize the conversation chain in the LLM:
from langchain.llms import HuggingFaceHub, OpenAI
For this instance, we have opted for the HuggingFaceHub, and the chosen model is identified by the repository ID “google/flan-t5-xxl.”
“ Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints,1 which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models. ”
ConversationBufferMemory: The ConversationBufferMemory facilitates the storage of messages and subsequently extracts them into a variable.
ConversationalRetrievalChain: The ConversationalRetrievalChain empowers the chain to engage in a conversation based on retrieved documents. This chain takes in chat history (a list of messages) and new questions, returning an answer to the posed question.
Conversational memory is instrumental for a chatbot to respond in a chat-like manner to multiple queries. It ensures a coherent conversation, preventing each query from being treated as an independent input devoid of past interactions.
memory = ConversationBufferMemory(memory_key='chat_history', return_messages=True)
In the illustration, the blue boxes represent user prompts, and the grey boxes denote the LLM’s responses. Without conversational memory (on the right), the LLM cannot respond using knowledge from previous interactions.
The conversational memory allows a Large Language Model (LLM) to remember prior interactions with the user. By default, LLMs are stateless, meaning each incoming query is processed independently of other interactions. For a stateless agent, only the current input holds significance.
conversation_chain = ConversationalRetrievalChain.from_llm(llm=HuggingFaceHub(repo_id=repo_id,
model_kwargs={"temperature": 0.5, "max_length": 64},
retriever=vector_db.as_retriever(), memory=vector_db.as_retriever())
The ConversationalRetrievalChain is a conversational AI model designed to retrieve relevant responses based on user queries. Developed by the Langchain team, this model employs a retrieval-based approach, searching through a database of pre-existing responses to provide the most suitable answer for a given query. Trained on a large dataset of conversations, the model learns patterns and context to deliver accurate and helpful responses.
Implementing as a Class in app.py
def handle_userinput(user_question):
response = st.session_state.conversation({'question': user_question})
st.session_state.chat_history = response['chat_history']
for i, message in enumerate(st.session_state.chat_history):
if i % 2 == 0:
st.write(user_template.replace(
"{{MSG}}", message.content), unsafe_allow_html=True)
else:
st.write(bot_template.replace(
"{{MSG}}", message.content), unsafe_allow_html=True)
This function receives “user_question” as input and produces a response utilizing “*st.session_state.conversation*”, which serves as a repository for the entire conversation history between the user and the bot.
Within the function, “*st.session_state.chat_history” iterates through the chat history, displaying each message in the appropriate format. The formatting is achieved using the “user_template” extracted from “htmlTemplates.py”*.
To launch the application using Streamlit, execute the following command line:
streamlit run app.py
Follow these steps:
-
Upload multiple documents.
-
Click on “Process”.
-
Wait for the documents to load.
-
Pose your questions in the provided area.
-
Retrieve your answers from the documents.
Now, everything is perfectly set.
After users upload multiple files (PDFs), the subsequent process involves triggering processing, encompassing the following steps:
-
Extract Text from Uploaded Files: Utilize the uploaded PDFs to extract the text content.
-
Split Text into Chunks: Divide the extracted text into manageable chunks, facilitating efficient processing.
-
Create a Vector Store: Generate a vector store from the text chunks, providing a structured representation.
-
Create a Conversational Chain Using Vector Store: Establish a conversational chain, leveraging the vector store to enable interactive conversations.
Additionally, it’s crucial to handle various aspects, including:
-
User Input Cases: Address different scenarios related to user input, ensuring a smooth user experience.
-
Processing Time of Files: Manage the time taken for processing files, optimizing efficiency.
-
Conversational State Management: Effectively handle the conversational state within the Streamlit web app, ensuring seamless interactions.
By encapsulating these functionalities within a class structure and executing the main function in steps, the implementation becomes organized and modular, promoting maintainability and extensibility.

Thank you for taking the time to read! Your feedback is most welcome!
Hope this helps! Feel free to let me know if this post was useful. 😃
Hungry for AI? Follow, bite-sized brilliance awaits! ⚡
🔔 Follow Me: LinkedIn | GitHub | Twitter

{kind=link}