Pytorch implementation of a novel multi-view 3D shape recognition paper [1] is mainly adopted and widely used in this project.
This study is a 3D object recognition by 2D images project for manufacturing parts along an assembly line. We adopt the "Multi-View Convolutional Neural Networks for 3D Shape Recognition" (MVCNN) [1] study for the model to recognize 101 parts (classes). The paper uses 12 (and more) rendered views whereas, for us, it is not practical to get several views, i.e., 15-20, for inference in a real-world setting. Thus, we use 3 rendered views of the 3D parts. Initially, we provide fewer classes (first 10, then 20, then 50) for the model to learn. However, the model performance has dropped as the number of classes increases. Then, we apply two-stage architecture, where we group classes randomly (let's say classes 1, 6, 59, 95, 30 are labeled as group 1; classes 12, 77, 64, 3, 88 are labeled as group 2, and so on). The goal of the first stage is to label the groups of classes correctly and, the second stage makes the final prediction, which is the correct class label, among each cluster. The first stage is initialized with pre-trained ResNet18 on ImageNet (classification layer excluded) and the second stage is trained ResNet18 with the weights learnt during the first stage. Both stages are trained for 40 epochs that use the Adam optimizer and weight decay factor of 0.001 with cross-entropy as the loss function.

The purpose of the recognition task is to make the finalized model recognize 3D objects in the real world (the assembly line) whereas it has been trained with the synthetic 2D images rendered by Unity. For that purpose, we've constructed a physical cabin with 3 cameras in front of a white background to use as an assembly-line scenario. Such a real-world setting enables us to capture views of 3D manufacturing parts for testing. Our main goal is to increase the model performance for the inference task of the object views captured in that cabin while the model has been trained with renderings generated in the Unity environment.

Unity game engine is used to generate the train set, we obtain renderings of 3D models from 3 views (cameras). 3D models are .stl format, initially, we convert them to .obj so that unity can import the models. We add random scaling to the original size between [0.9, 1.1], and apply axis-independent random translation with a range of [-1/6w, 1/6w], where w is the width of the simulation environment and arbitrary rotation to give the objects tilt movement. This randomization enhances the number of samples in the dataset. After we generate the renderings, we apply motion blur to 1/3 of the samples.
data.generation.mp4
After some training and applying regularization, we realized that the dataset needs to be augmented to tackle overfitting. Our data augmentation approach is based on Domain Randomization [2]. It suggests extending the variety of the simulated samples so that the chances for the simulation environment to reach the real world increase.
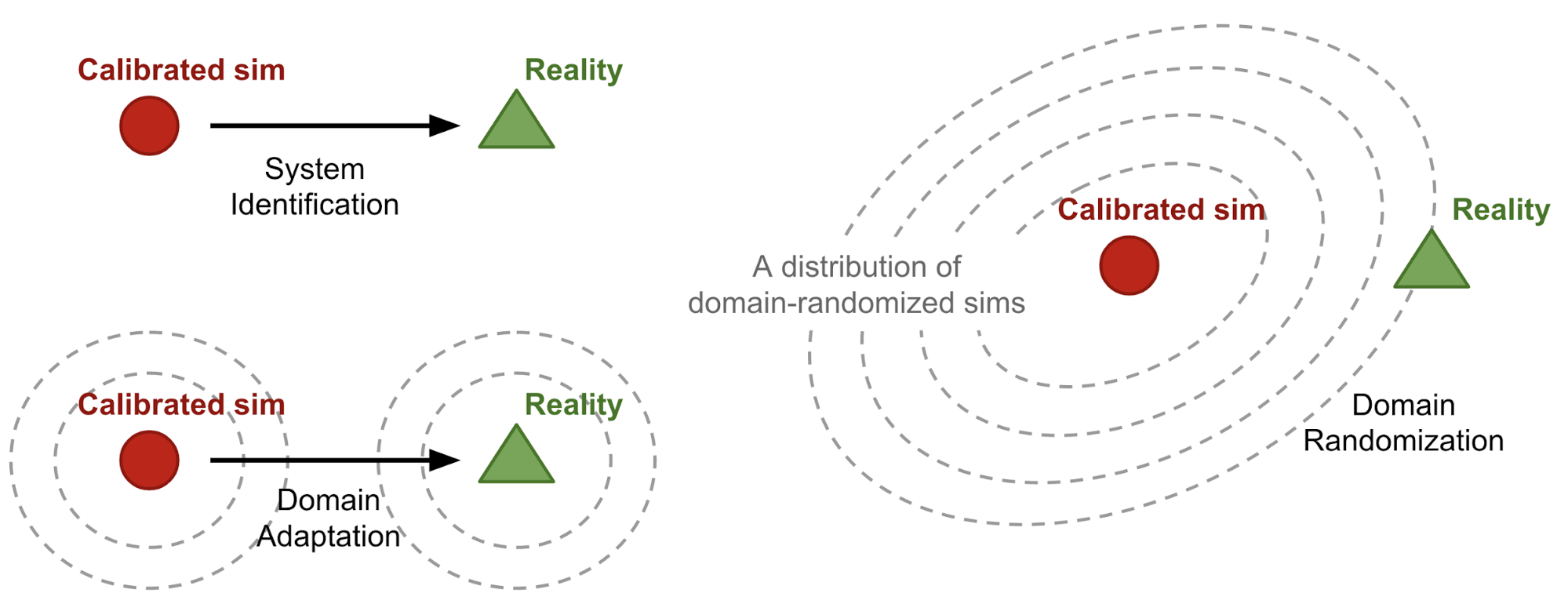
With this in mind, we added artifacts and noise to the Unity simulation environment generated, such that:
-
Background texture: 20 different textures are applied randomly to the background. These textures can be plain and/or have noise or patterns.
-
Illumination: There are 4 lights in the simulation setting. They can be enabled or disabled, and their intensities are randomly changed.

There are n = 102 class labels in the dataset (0 to 101), label 101 stands for the plain background where no object view is captured. Therefore, there are 101 labels to recognize. After data augmentation, the dataset contains 21000 samples/class for the train set and 2100 samples/class for the validation set, 25% of these samples are blur applied versions to Unity-generated renderings. We have two separate test sets. The first set consists of 2100 samples/class of unity-generated renderings whereas the second set includes 300 samples/class which are obtained in the cabin for 36 classes (as we solely have 36 of 101 3D parts physically). All the samples are in a resolution of 224x224.

Even though few manufacturing parts are almost indistinguishable in the dataset, the model performs high accuracy scores for inference tasks of the unity-generated test set. On the other hand, what matters for that project is for the model to make accurate inferences from the real-world scenario. This is why we've built the cabin for our real-world scenario and captured views of 3D parts in hand as the real-world test set. Since fewer parts are physically available for us, the real-world test set remained limited to 36 classes, still, the results give us an interpretation. Below scores clearly show that training the same model with augmented data increases the accuracy. It's more obvious for the real-world test set, which suggests that data augmentation inspired by the domain randomization [2] approach successfully closes the gap between the real world and simulation environment.

[1] Su, Hang, et al. "Multi-view convolutional neural networks for 3d shape recognition." Proceedings of the IEEE international conference on computer vision. 2015.
[2] Tobin, Josh, et al. "Domain randomization for transferring deep neural networks from simulation to the real world." 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2017.
[3] Weng, L. Domain Randomization for Sim2Real Transfer. Retrieved from https://lilianweng.github.io/posts/2019-05-05-domain-randomization/.