forked from run-llama/llama_index
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge branch 'jerryjliu:main' into falkor-visual
- Loading branch information
Showing
95 changed files
with
5,986 additions
and
93 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,8 @@ | ||
| .. _Ref-Finetuning: | ||
|
|
||
| Finetuning | ||
| ============= | ||
|
|
||
| .. automodule:: llama_index.finetuning | ||
| :members: | ||
| :inherited-members: |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,146 @@ | ||
| # Unit Testing LLMs With DeepEval | ||
|
|
||
| [DeepEval](https://github.com/confident-ai/deepeval) provides unit testing for AI agents and LLM-powered applications. It provides a really simple interface for LlamaIndex developers to write tests and helps developers ensure AI applications run as expected. | ||
|
|
||
| DeepEval provides an opinionated framework to measure responses and is completely open-source. | ||
|
|
||
| ### Installation and Setup | ||
|
|
||
| Adding [DeepEval](https://github.com/confident-ai/deepeval) is simple, just install and configure it: | ||
|
|
||
| ```sh | ||
| pip install -q -q llama-index | ||
| pip install -U deepeval | ||
| ``` | ||
|
|
||
| Once installed , you can get set up and start writing tests. | ||
|
|
||
| ```sh | ||
| # Optional step: Login to get a nice dashboard for your tests later! | ||
| # During this step - make sure to save your project as llama | ||
| deepeval login | ||
| deepeval test generate test_sample.py | ||
| ``` | ||
|
|
||
| You can then run tests as such: | ||
|
|
||
| ```bash | ||
| deepeval test run test_sample.py | ||
| ``` | ||
|
|
||
| After running this, you will get a beautiful dashboard like so: | ||
|
|
||
| 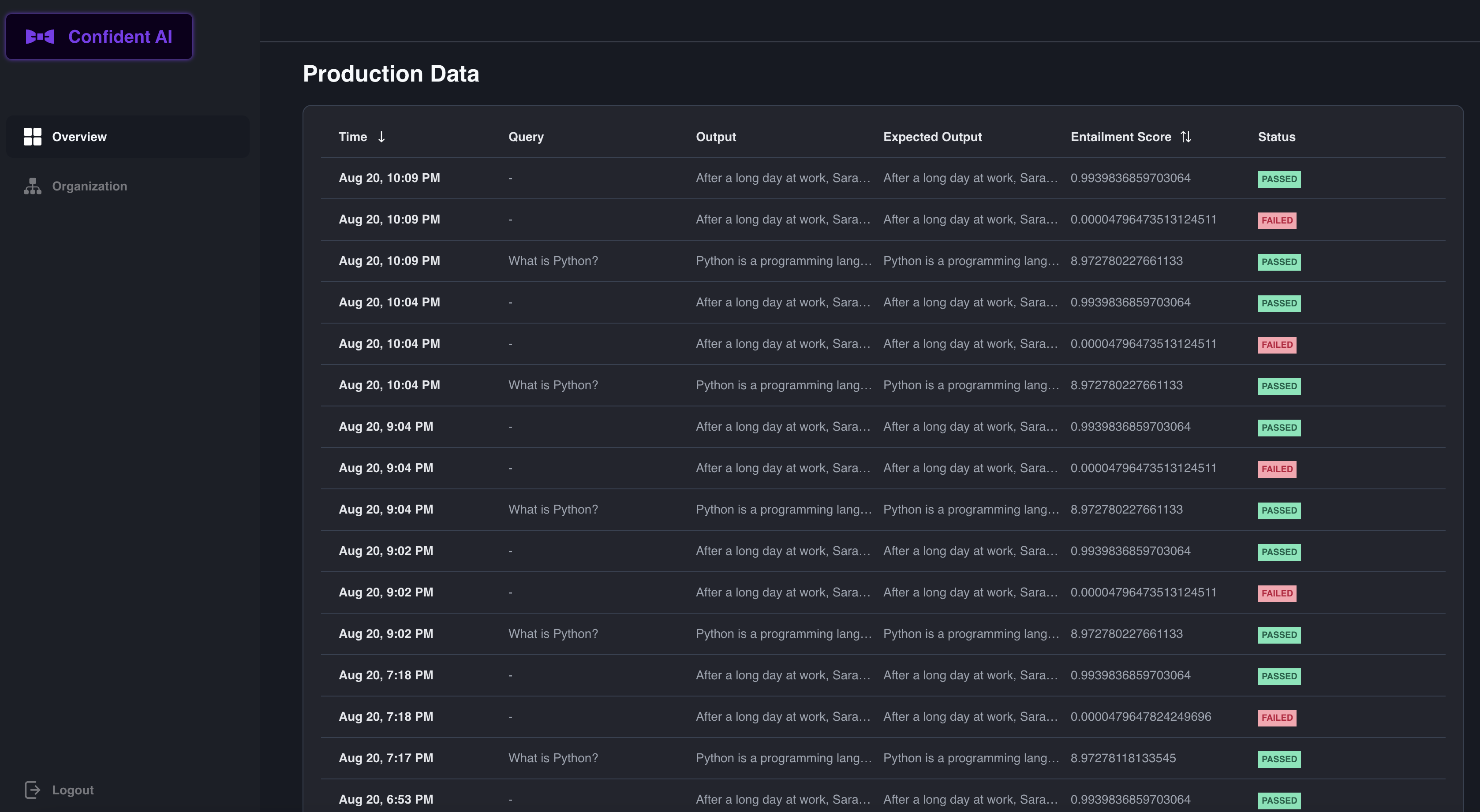 | ||
|
|
||
| ## Types of Tests | ||
|
|
||
| DeepEval presents an opinionated framework for the types of tests that are being run. It breaks down LLM outputs into: | ||
| - Answer Relevancy - [Read more here](https://docs.confident-ai.com/docs/measuring_llm_performance/answer_relevancy) | ||
| - Factual Consistency (to measure the extent of hallucinations) - [Read more here](https://docs.confident-ai.com/docs/measuring_llm_performance/factual_consistency) | ||
| - Conceptual Similarity (to know if answers are in line with expectations) - [Read more here](https://docs.confident-ai.com/docs/measuring_llm_performance/conceptual_similarity) | ||
| - Toxicness - [Read more here](https://docs.confident-ai.com/docs/measuring_llm_performance/non_toxic) | ||
| - Bias (can come up from finetuning) - [Read more here](https://docs.confident-ai.com/docs/measuring_llm_performance/debias) | ||
|
|
||
| You can more about the [DeepEval Framework](https://docs.confident-ai.com/docs/framework) here. | ||
|
|
||
| ## Use With Your LlamaIndex | ||
|
|
||
| DeepEval integrates nicely with LlamaIndex's `ResponseEvaluator` class. Below is an example of the factual consistency documentation. | ||
|
|
||
| ```python | ||
|
|
||
| from llama_index.response.schema import Response | ||
| from typing import List | ||
| from llama_index.schema import Document | ||
| from deepeval.metrics.factual_consistency import FactualConsistencyMetric | ||
|
|
||
| from llama_index import ( | ||
| TreeIndex, | ||
| VectorStoreIndex, | ||
| SimpleDirectoryReader, | ||
| LLMPredictor, | ||
| ServiceContext, | ||
| Response, | ||
| ) | ||
| from llama_index.llms import OpenAI | ||
| from llama_index.evaluation import ResponseEvaluator | ||
|
|
||
| import os | ||
| import openai | ||
|
|
||
| api_key = "sk-XXX" | ||
| openai.api_key = api_key | ||
|
|
||
| gpt4 = OpenAI(temperature=0, model="gpt-4", api_key=api_key) | ||
| service_context_gpt4 = ServiceContext.from_defaults(llm=gpt4) | ||
| evaluator_gpt4 = ResponseEvaluator(service_context=service_context_gpt4) | ||
|
|
||
| ``` | ||
|
|
||
| #### Getting a lLamaHub Loader | ||
|
|
||
| ```python | ||
| from llama_index import download_loader | ||
|
|
||
| WikipediaReader = download_loader("WikipediaReader") | ||
|
|
||
| loader = WikipediaReader() | ||
| documents = loader.load_data(pages=['Tokyo']) | ||
| tree_index = TreeIndex.from_documents(documents=documents) | ||
| vector_index = VectorStoreIndex.from_documents( | ||
| documents, service_context=service_context_gpt4 | ||
| ) | ||
| ``` | ||
|
|
||
| We then build an evaluator based on the `BaseEvaluator` class that requires an `evaluate` method. | ||
|
|
||
| In this example, we show you how to write a factual consistency check. | ||
|
|
||
| ```python | ||
| class FactualConsistencyResponseEvaluator: | ||
| def get_context(self, response: Response) -> List[Document]: | ||
| """Get context information from given Response object using source nodes. | ||
| Args: | ||
| response (Response): Response object from an index based on the query. | ||
| Returns: | ||
| List of Documents of source nodes information as context information. | ||
| """ | ||
| context = [] | ||
|
|
||
| for context_info in response.source_nodes: | ||
| context.append(Document(text=context_info.node.get_content())) | ||
|
|
||
| return context | ||
|
|
||
| def evaluate(self, response: Response) -> str: | ||
| """Evaluate factual consistency metrics | ||
| """ | ||
| answer = str(response) | ||
| context = self.get_context(response) | ||
| metric = FactualConsistencyMetric() | ||
| context = " ".join([d.text for d in context]) | ||
| score = metric.measure(output=answer, context=context) | ||
| if metric.is_successful(): | ||
| return "YES" | ||
| else: | ||
| return "NO" | ||
|
|
||
| evaluator = FactualConsistencyResponseEvaluator() | ||
| ``` | ||
|
|
||
| You can then evaluate as such: | ||
|
|
||
| ```python | ||
| query_engine = tree_index.as_query_engine() | ||
| response = query_engine.query("How did Tokyo get its name?") | ||
| eval_result = evaluator.evaluate(response) | ||
| ``` | ||
|
|
||
| ### Useful Links | ||
|
|
||
| * [Read About The DeepEval Framework](https://docs.confident-ai.com/docs/framework) | ||
| * [Answer Relevancy](https://docs.confident-ai.com/docs/measuring_llm_performance/answer_relevancy) | ||
| * [Conceptual Similarity](https://docs.confident-ai.com/docs/measuring_llm_performance/conceptual_similarity) . | ||
| * [Bias](https://docs.confident-ai.com/docs/measuring_llm_performance/debias) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,62 @@ | ||
| # Using Managed Indices | ||
|
|
||
| LlamaIndex offers multiple integration points with Managed Indices. A managed index is a special type of index that is not managed locally as part of LlamaIndex but instead is managed via an API, such as [Vectara](https://vectara.com). | ||
|
|
||
| ## Using a Managed Index | ||
|
|
||
| Similar to any other index within LlamaIndex (tree, keyword table, list), any `ManagedIndex` can be constructed with a collection | ||
| of documents. Once constructed, the index can be used for querying. | ||
|
|
||
| If the Index has been previously populated with documents - it can also be used directly for querying. | ||
|
|
||
| `VectaraIndex` is currently the only supported managed index, although we expect more to be available soon. | ||
| Below we show how to use it. | ||
|
|
||
| **Vectara Index Construction/Querying** | ||
|
|
||
| Use the [Vectara Console](https://console.vectara.com/login) to create a corpus (aka Index), and add an API key for access. | ||
| Then put the customer id, corpus id, and API key in your environment as shown below. | ||
|
|
||
| Then construct the Vectara Index and query it as follows: | ||
|
|
||
| ```python | ||
| from llama_index import ManagedIndex, SimpleDirectoryReade | ||
| from llama_index.managed import VectaraIndex | ||
|
|
||
| # Load documents and build index | ||
| vectara_customer_id = os.environ.get("VECTARA_CUSTOMER_ID") | ||
| vectara_corpus_id = os.environ.get("VECTARA_CORPUS_ID") | ||
| vectara_api_key = os.environ.get("VECTARA_API_KEY") | ||
| documents = SimpleDirectoryReader('../paul_graham_essay/data').load_data() | ||
| index = VectaraIndex.from_documents(documents, vectara_customer_id=vectara_customer_id, vectara_corpus_id=vectara_corpus_id, vectara_api_key=vectara_api_key) | ||
|
|
||
| # Query index | ||
| query_engine = index.as_query_engine() | ||
| response = query_engine.query("What did the author do growing up?") | ||
| ``` | ||
|
|
||
| Note that if the environment variables `VECTARA_CUSTOMER_ID`, `VECTARA_CORPUS_ID` and `VECTARA_API_KEY` are in the environment already, you do not have to explicitly specifying them in your call and the VectaraIndex class will read them from the enviornment. For example this should be equivalent to the above, if these variables are in the environment already: | ||
|
|
||
| ```python | ||
| from llama_index import ManagedIndex, SimpleDirectoryReade | ||
| from llama_index.managed import VectaraIndex | ||
|
|
||
| # Load documents and build index | ||
| documents = SimpleDirectoryReader('../paul_graham_essay/data').load_data() | ||
| index = VectaraIndex.from_documents(documents) | ||
|
|
||
| # Query index | ||
| query_engine = index.as_query_engine() | ||
| response = query_engine.query("What did the author do growing up?") | ||
| ``` | ||
|
|
||
|
|
||
|
|
||
|
|
||
| ```{toctree} | ||
| --- | ||
| caption: Examples | ||
| maxdepth: 1 | ||
| --- | ||
| ../../examples/vector_stores/VectaraDemo.ipynb | ||
| ``` |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.