Update train_agent.md #1237
Update train_agent.md #1237
Conversation
Fixed some one bug (agent initialized without `env`) and add the average value calculation (for later visualization).
|
@TangLongbin Could you summarise what you are fixing or solving in this PR? |
Sure! I remembered that i added description when pulling the request, but it's gone for some reasons. Sorry for that! I'll explain the modification here:
|
{kind=link}
Description
In train_agent.md, the class BlackjackAgent needs env for initialization, but the demo code is initialized without env which results in errors. I added the parameters and use 'agent.env' instead of 'env' in the training.
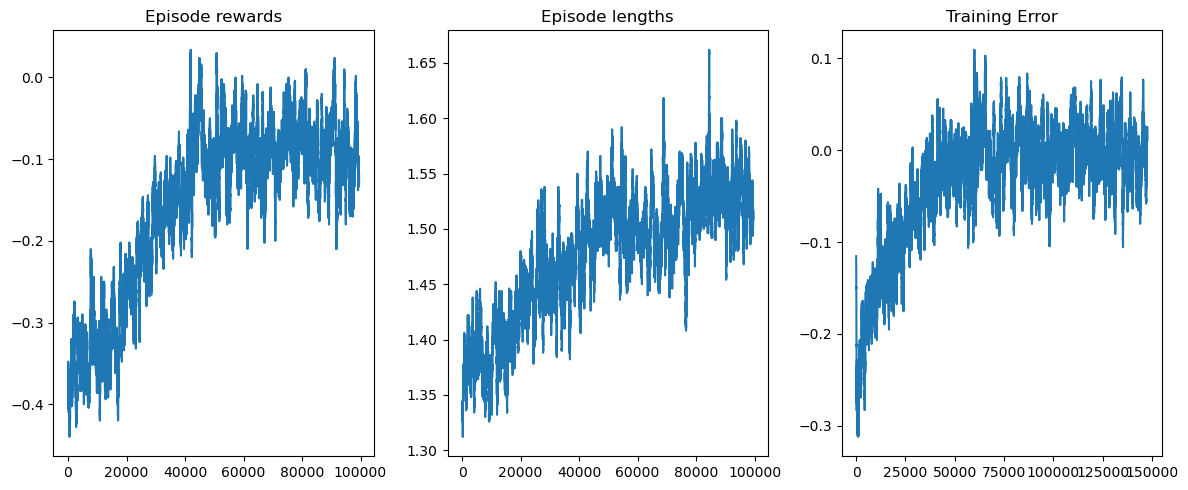
No code for post-processing the training log (such as reward, episode length and training error) visualization. It should be average value rather value of each episode (gym.wrappers.RecordEpisodeStatistics only records this) which is not the same as figure provided in the doc. So I add the average value calculation (for later visualization) and the visualization code using matplotlib to help people get the result the expected.
Type of change
Please delete options that are not relevant.
Screenshots
Please attach before and after screenshots of the change if applicable.
Checklist:
pre-commitchecks withpre-commit run --all-files(seeCONTRIBUTING.mdinstructions to set it up)