Occlusion
This document describes examples of simple implementations of bottom occlusion due to silt and object occlusion due to marine growth. Both examples are implemented by manipulating visual elements of the the model's SDF (or URDF) links.
Both bottom and object occlusion can be observed by using the following command:
roslaunch dave_demo_launch dave_simple_occlusion_demo.launch
The command will launch a Gazebo simulation similar to the one associated with the Bar Retrieval demo (in fact, this simulation's RexRov vehicle can be controlled in exactly the same manner as the demo version). The differences are that the "grabbable bar" will be partially occluded by "silt", and the scene includes a large "moss covered" cinderblock.
Because the occlusion effect is achieved by manipulating visual SDF elements, only those sensors and plugins that rely on the rendering pipeline will be affected. In particular, the Gazebo GPURaySensor and CameraSensor and DepthCameraSensor will experience occlusion. Senors and plugins that rely on simulation's physics engine such as the Gazebo RaySensor and SonarSensor, interact with the collision SDV elements and are not affected. Other models, including vehicles and physical manipulators, will "penetrate" the visual occlusion and interact with the collision model.
Upon launching the simulation, the "grabbable bar" and RexRov vehicle will be situation as depicted in the following image:
The bar in this image is partially submerged in the bottom "silt". The effect is achieved by shifting the visual element of the model's link in the positive Z direction by 0.1 meters (approximately 4 inches). The model itself is provided in the dave_object_models ROS package as the occluded_sand_heightmap model.
<link name="link">
<collision name="ground">
<pose>0 0 0 0 0 0</pose>
<geometry>
<mesh><uri>model://occluded_sand_heightmap/meshes/heightmap.dae</uri></mesh>
</geometry>
</collision>
<visual name="ground_sand">
<cast_shadows>true</cast_shadows>
<pose>0 0 0.1 0 0 0</pose>
<geometry>
<mesh><uri>model://occluded_sand_heightmap/meshes/heightmap.dae</uri></mesh>
</geometry>
...
</visual>
</link>In this case, the "sand" is implemented as a mesh rather than as a heightmap, but the linear shift provides the desired effect because no models with which we are concerned are expected to be on the "other side" of the "bottom (i.e., the vehicle will never be on the side of the model in which the visual component is inside the collision component). This approach will also work for terrain specified using a heightmap.
Upon launch of the simulation, a large cinderblock is located to the left of the RexRov vehicle. The cinderblock is occluded by a thin layer of visual "moss". The following image shows the RexRov's manipulator interacting with the cinderblock. Of note, the end of the manipulator is partially obscured by the occlusion, and it is pushing the cinderblock by interacting with the model's collision element.
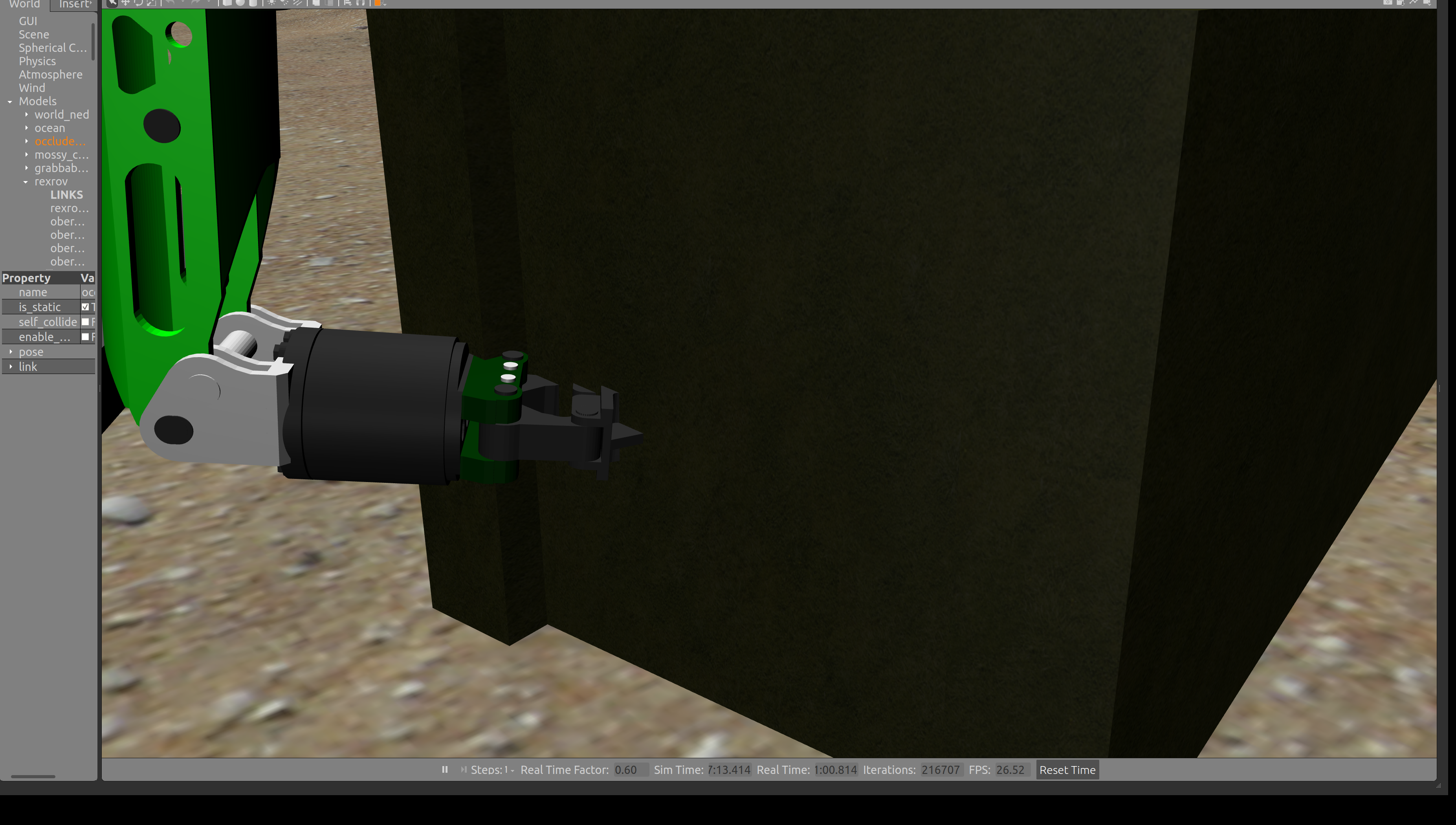
Unlike terrain, occlusion cannot be implemented on models such as this one with a linear shift of the visual element. Rather, visual occlusion on all sides is achieved by increasing the scale of the visual model as indicated in the following snippet from the dave_object_models/mossy_cinder_block model.
<link>
<visual name="visual">
<geometry>
<mesh>
<scale>1.1 1.1 1.1</scale>
<uri>model://mossy_cinder_block/meshes/mossy_cinder_block.dae</uri>
</mesh>
</geometry>
</visual>
<collision name="left">
<pose>0 -0.25395 0.3048 0 0 0</pose>
<geometry>
<box>
<size>1.30485 0.1017 0.6096</size>
</box>
...
</geometry>
</collision>
...
</link>The scale for this particular model is 1.1 in all three axes. The collision model is approximately 1.3 meters in length, 0.75 meters in width, and 0.3 meters high, so the depth of the occlusion varies (uniform occlusion requires varying the scale of the visual model with each axis). In general, the amount of scaling required to achieve a specific depth of occlusion using this technique will vary with the size of the model (i.e., larger models will achieve the same depth of occlusion with smaller visual scale increases than smaller models).