Full body Generation of anime girls Development & Research logs
-
Satisfy my desire there's Anime Face Gans but I want more waifu!
-
Can be used as a placeholder sprite in game development I also develop some noob games as a hobby and I wanted to use some good sprite as a placeholder or as the real sprite for my game
Gans or Generative Advisoral Networks to be exact it's a class of machine learning frameworks by Ian Goodfellow - Wikipedia since its publication, there's tons of research and Implementation after it Gans Mainly Involved two main components and I'll conceptually introduce them with an example from A fake money maker and Police
first, we have a Generator by the name you can already what's his job Generator or Moneymaker will be trying to generate data in this case, an image of Fake bills to fool the police
police or discriminator on the other hand will be given an information that there's a fake bill and it need to detect them (work like a classification model)
as the Moneymaker trying to fool and got caught by police it'll learn what style and shape, color, and tone to use to fool the police and as the police saw more bill experience fakes and reals data it'll learn to get better at detecting these result in a training loop where the two of them get good together to the point that the money maker or Generator to be exact can completely fool even good police/discriminator
Note: Though there's a variety of Gans models but they're all based on Generator and Discriminator improvement in this project, we'll work on dcgans, wgan-gp, progans, stylegans
before getting our hands dirty with coding and model structure Like other ML models, we need good data Gans was no exception The conditions that we need to pay attention to are
-
Clear Background
-
Same or Similar Art Style
-
A considerably large amount of data - 10k or above
But from the available datasets, I've found on the internet There's NONE that satisfies these conditions Especially Full Body Image & Clear Background
So there's no other way except to scrape it myself
Firstly I've thought about the required condition for the site that I'll scrape from
-
Easy to filter image (image filtering exist & or image tags Exist)
-
A considerably large amount of data - 10k or above
-
Satisfy Datasets requirements
I've begun to search for a site that satisfies my requirement and I've found
| Site / Req | Filter | Data | Datasets - Req |
|---|---|---|---|
| Gelbooru | very easy | large | satisfy |
| Getchu | very hard | large | satisfy |
| Fandom | very hard | large | not - satisfy |
| anime-char-database | easy | small | not - satisfy |
Based on this table we Have
-
Gelbooru
-
Getchu
Which requires more inspection, They have their pain in the ass
Gelbooru is a hentai image (porn) site which results in their
-
detailed and & precise tags
-
easy to scrape
-
it's NSFW (nude / porn / etc...)
-
not ensure similar art style
-
contain some datasets that are out of the domain
Getchu is a Visual Novel game seller that shows the character info which results in their
- Safe Image
- ensure considerably similar art style
- reliable quality of data
- Also, Contain Half-Body images
- All Japanese with no option for English so it's harder to figure out
- Website hosted in jp server and it's slow so it's hard to scrape from my place
I've Come to the conclusion that'll scrape Getchu because it's
- similar art style
- reliable quality of data
But at that time Getchu server is too slow if I access it from my places so I need to go with Gelbooru instead
But the Problem is Gelbooru is NSFW which is unacceptable
But I managed to find a Gelbooru alternative by simply searching "Gelbooru Safeforworks"
Alternative site for Gelbooru with the safe structure images and tags but it excludes all NSFW contents
After figuring out how their website filter works I know it'll take some time to write my web-scraper
But why would I write it myself LOL
I began to search on GitHub if there's an image crawler existed for these sites
I've found a simple Unknow-project But EXACTLY matched my need It's an image crawler for booru site which allows you to use tags for filtering GitHub - LittleJake/animate-image-crawler: A crawler for booru site. (gelbooru and safebooru, etc.)
So I've skipped the whole process of writing a web scraper
thank our code☭ this random project
I've manually tried many tags combination for Safebooru and I've found with --tags='full_body solo standing 1girl white_background'
For filtering, We can get 1girl standing with clear-background So I used it with this image crawler and got my hand on 20k images
Well on 20k datasets with an efficiency of 70% it worth cleaning but at this rate, we would need to clean out 6k of data which is a terrible job, But I've already filtered 3k of data out manually before I find the efficiency of data so we need to figure our way out from there
based on the 2k of data I've filtered out we can categorize filtered the data to
-
Chibi
-
More than 1 character
-
Too flashy background
-
Weird viewpoint
From 3k of data, the Majority of them(1:4) fall into "Chibi" category
Chibi

"More than 1 character" and so on by order More Than 1

From my Point of view I've found that Chibi Images is quite repetitive in other words, it's easy to spot on
so why don't I train the classification model to filter them out since it'll be easier to just train classification model than classified the images myself
I began with the Sequential model but well it's too long so I'll skip my effort on this part just to let you know it didn't work out well enough
so transfer learning is the solution since I just need a good classifier with low effort :P I decided to go with VGG16 and fine-tune the last fourth layer
base_model = VGG16(weights="imagenet", include_top=False, input_shape=train_images[0].shape)I split data into two category [''chibi,'not_chibi']
Chibi -> Chibi images
not_chibi -> Cleaned images
Crop image before resize to maintain aspect-ratio

def square_pad(image):
w,h,c = image.shape
if w>=h:
out = np.zeros([w,w,c])
out[:,int((w-h)/2):int((w-h)/2)+h,:] = image
else:
out = np.zeros([h,h,c])
out[int((h-w)/2):int((h-w)/2)+w,:,:] = image
return outturn out# Freeze convolution blocks
for layer in base_model.layers[:15]:
layer.trainable = FalseRESULT:
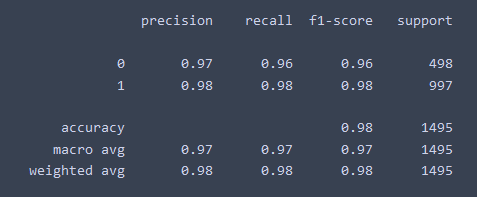
98% Accuracy which is pretty good for just 12 epoch (well it's transfer learning ofc it would be good :p)
then I use it to filter the datasets and split them into chibi and not_chibi folder It's not that fast with 5. X images/sec but it's still better than doing it manually On 16k images
Chibi
Not Chibi
The Result is Pretty Satisfying with 2.4k Chibi was Filtered out with just 5X bad picking!!! Imagine doing that manually Lol NOTE: This model also performed well with out-of-domain data Ex. Random internet chibi/not chibi character images
After that, we've got our hands on 13.5 k images but we still have something like this in it "not_single" images
Which is Unacceptable

So I'll just use the same code to train classification on it
Square Pad them

Train
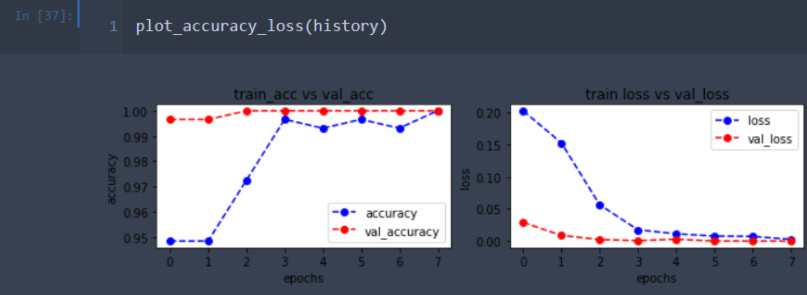
Evaluate
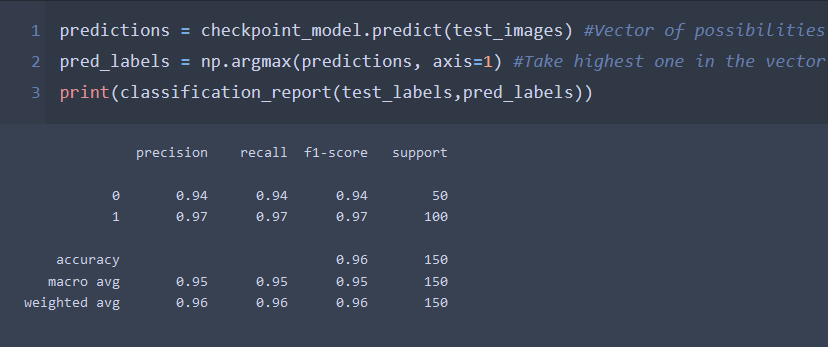
The result is satisfying so we can use it to filter the images
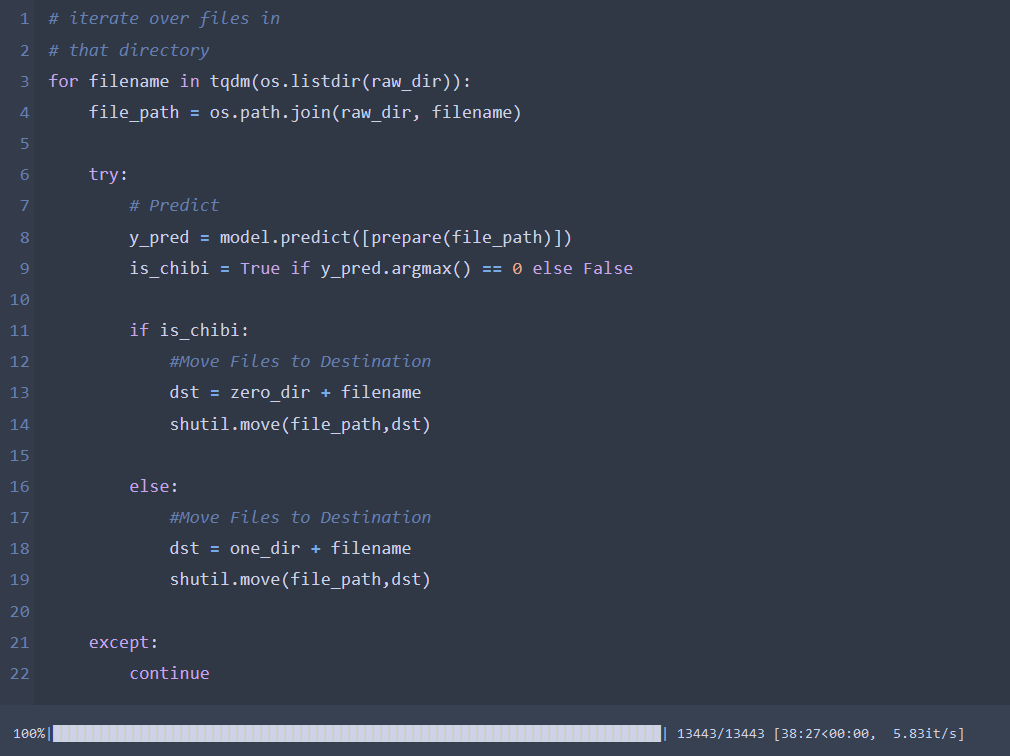
The result is "OKAY" But not on par with Chibi - Classifier model I Assume that the cause comes from lower datasets (APX 100 ~ images) to train with
So it predicted some single images as not_single
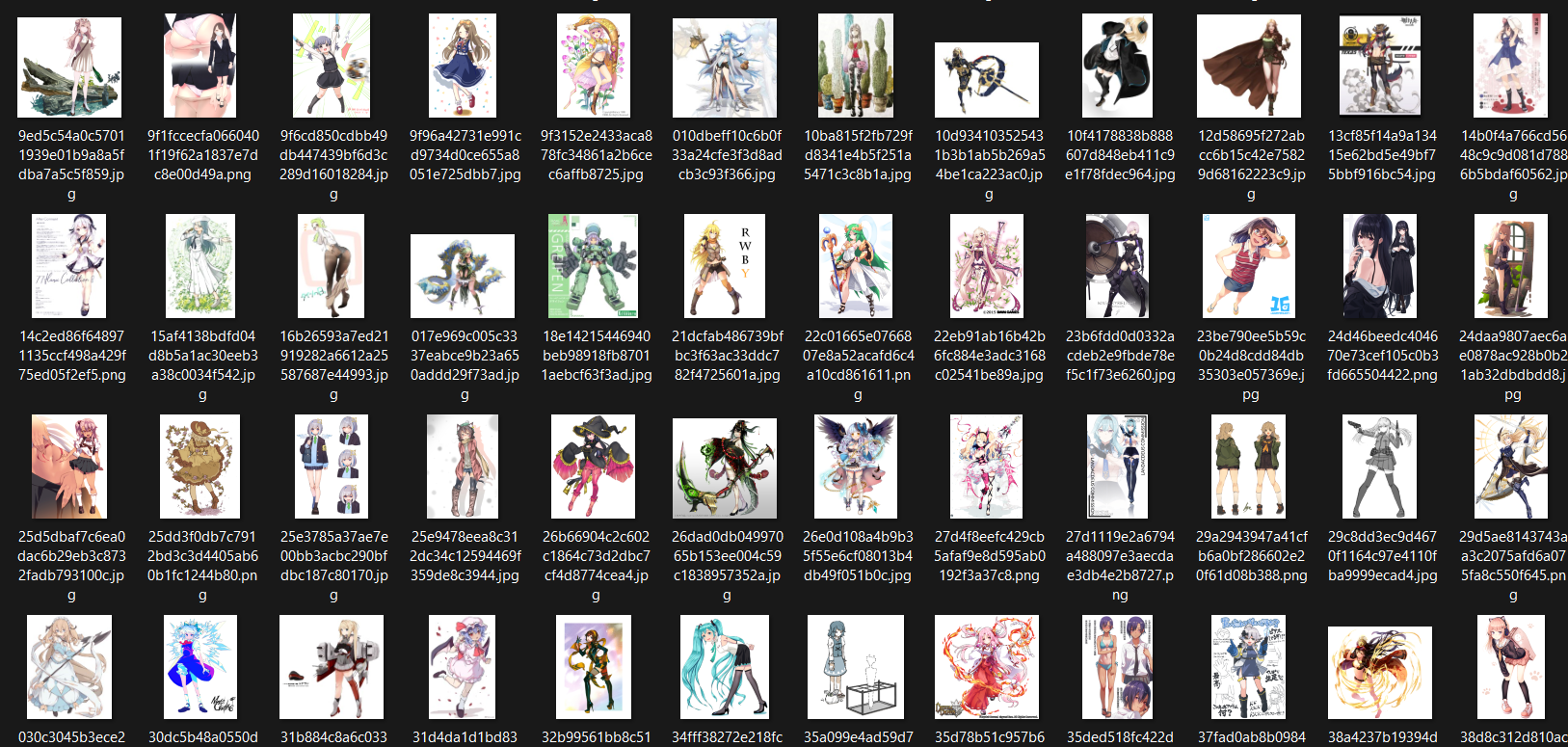
But it isn't too bad since I've filtered almost all "Not_single" images automatically 900~ Images were filtered out
I've left with 12k images
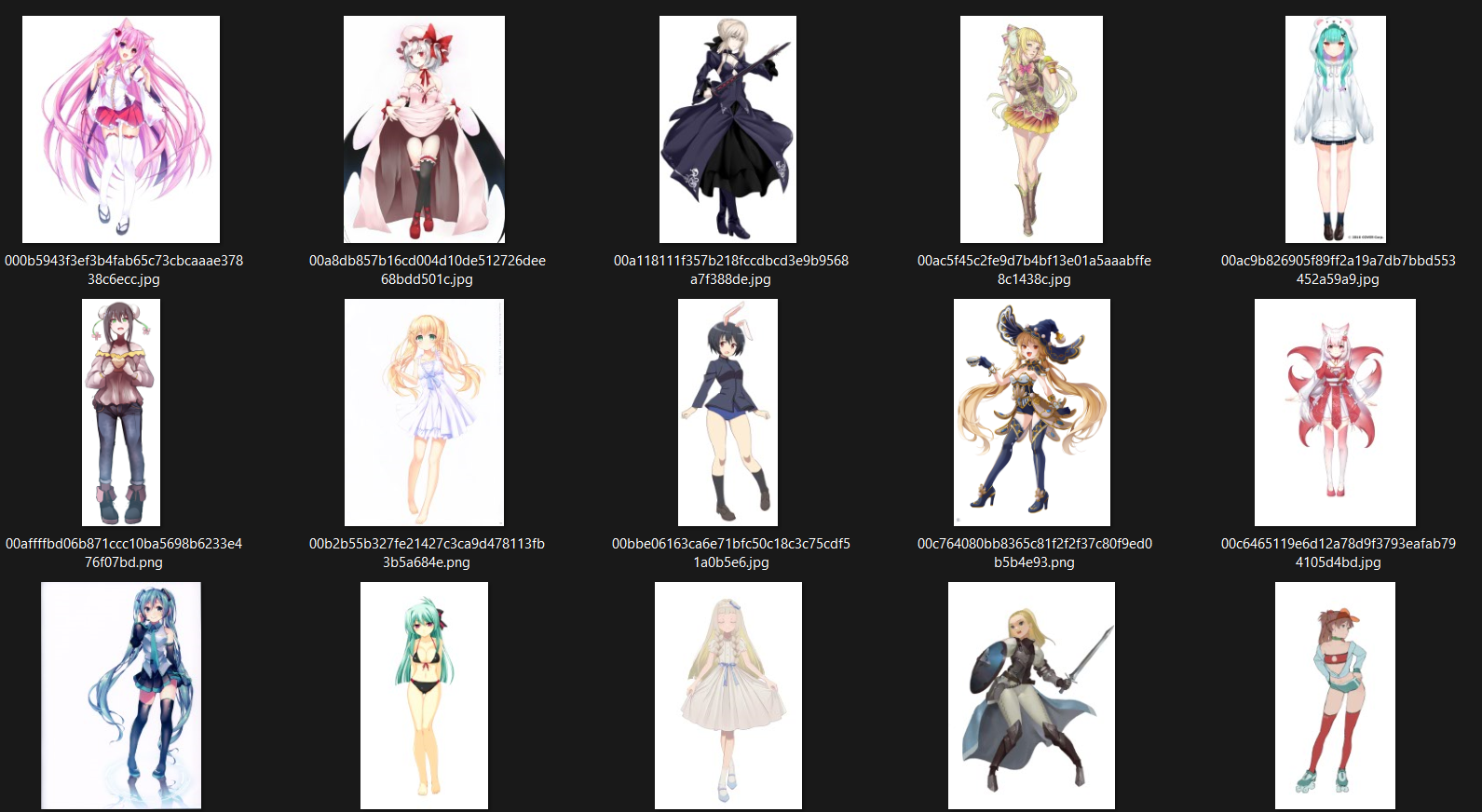
But still, There would've surely had something that I should cleanout
So I get back to reality and started cleaning the datasets
The main concern that I'll filter them out is
-
Not to my liking, out of overall style - Kemo, Pokemon, Weird things
-
Weird Pose - yoga pose or something like that
-
Too Much Effect - An Explosion Effect / Sparkle / or some sort
From 12k datasets | 2k~ was filtered out - > And I've Left with 10k Cleaned Datasets
I Then uploaded it to Google-Drive which You can found it here
https://drive.google.com/drive/folders/1szQAsdtu9U9Dum0FPflC93R3D-w8qFCC?usp=sharing
And that's the End of my datasets, For now
Because I'm new to Gans, and also new to machine learning I'll start from the well know Gans which I know didn't suitable for full body gans but who cares :P
I've trained DC Gans on anime face datasets before and it worked quite well
So I'm interested in trying it with my real datasets But since it has too much detail to capture I Assumed that it'll be a mess, by far the result's a mess I've Faced vanishing gradient and mode collapse on my model and the result is the same noise over and over
So I decided to change the loss function to Wasserstein loss which improves the stability of Gans model basically (Wgans) but in my senpai(senior) code he uses WGAN-GP which also changed the weight clipping method used on discriminator to Gradient Penalty L03 - Wasserstein GANs with Gradient Penalty - YouTube
The weight clipping is limit the range of weight and if it's over the length we'll just use the max value
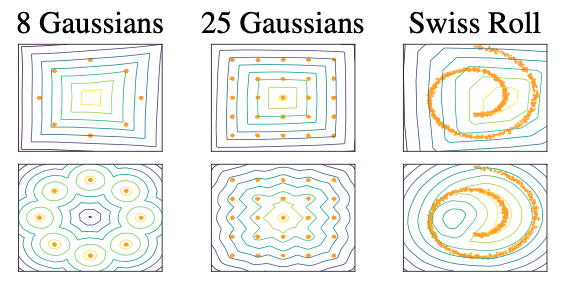
Result in simpler distribution (row 1 images) Compare to (row 2 images) using Wgans-GP
I don't know much in-depth about them but by far, This is what I understand The result improves quite a lot but by far it's not that good with 100~ epochs on 128x128 - > 10k datasets (i resized it from my original 258x258 datasets)

It captured the shape of a human at this point, it proved that the quality of my datasets Is decent enough for the model to form the right shape
The data problem is resolved, though the Model didn't capture the important detail of the data Such as Face & Accessory, So I need to figure my way out of this
My Approach Is progans since I hope scaling model as we scale images
As progans paper claims, it should capture resolution as
Generator and Discriminator(critic) scaled together
The Results show quite an improvement

But as you can see it still didn't capture a detailed feature of a body so we need a better way to improve the performance
I've Found StyleGans, one of the famous architecture for Gans The Brief introduction is instead of using random noise we map those noise to style and style transfer it with ADaIN to the generated image but Gans Model takes a long time to train so I'll go with 64x64 because it takes less time if I managed to improve it I'll Scale it up
Result on 64x64 resolution - latent size 256
 with the latent size of 256 results is pretty shitty lol
with the latent size of 256 results is pretty shitty lol
Result on 64x64 resolution - latent size 512

latent size of 512 makes it work (it should've worked if I use 512 latent sizes lol) Tips: Big latent Size can make the model take much time to adapt but it's better than NOT ENOUGH latent size
As you can see I think the model did quite a good job on my data but there's something that I would like to call "Dark Matter" in the result


I assume that the cause comes from something like THIS


since the output of the model, I saw so far none of them that's considerably GOOD have an "effect" or "Accessory" like samples of datasets shown above
the different posing and facing that I thought would be a problem did not happen since there's a variety of posing that I've found while generating data using random noise
so from this reason what I'll do is CLEAN the datasets again, This time we targeted on
-
Have An Effect
-
Have weird accessory

This time I use resnet 50 instead of VGG16
firstly I clean 500 images manually Then use the same process - Square Pad -> Resize -> Train I'm too lazy so I put all the images I don't want into the BAD(1) folder And Keep what I want in the GOOD(0) folder
Split Train, Test
TRAIN ---> BOOM!
If I use this model to classify I prob cleaned most of the BAD data but'll lose some of the GOOD data but since I don't care if I lose some I'll use this to clean my data anyway

CLEAN - Data
 Simply just predict then move files
Simply just predict then move files
we've left with a good & bad folder


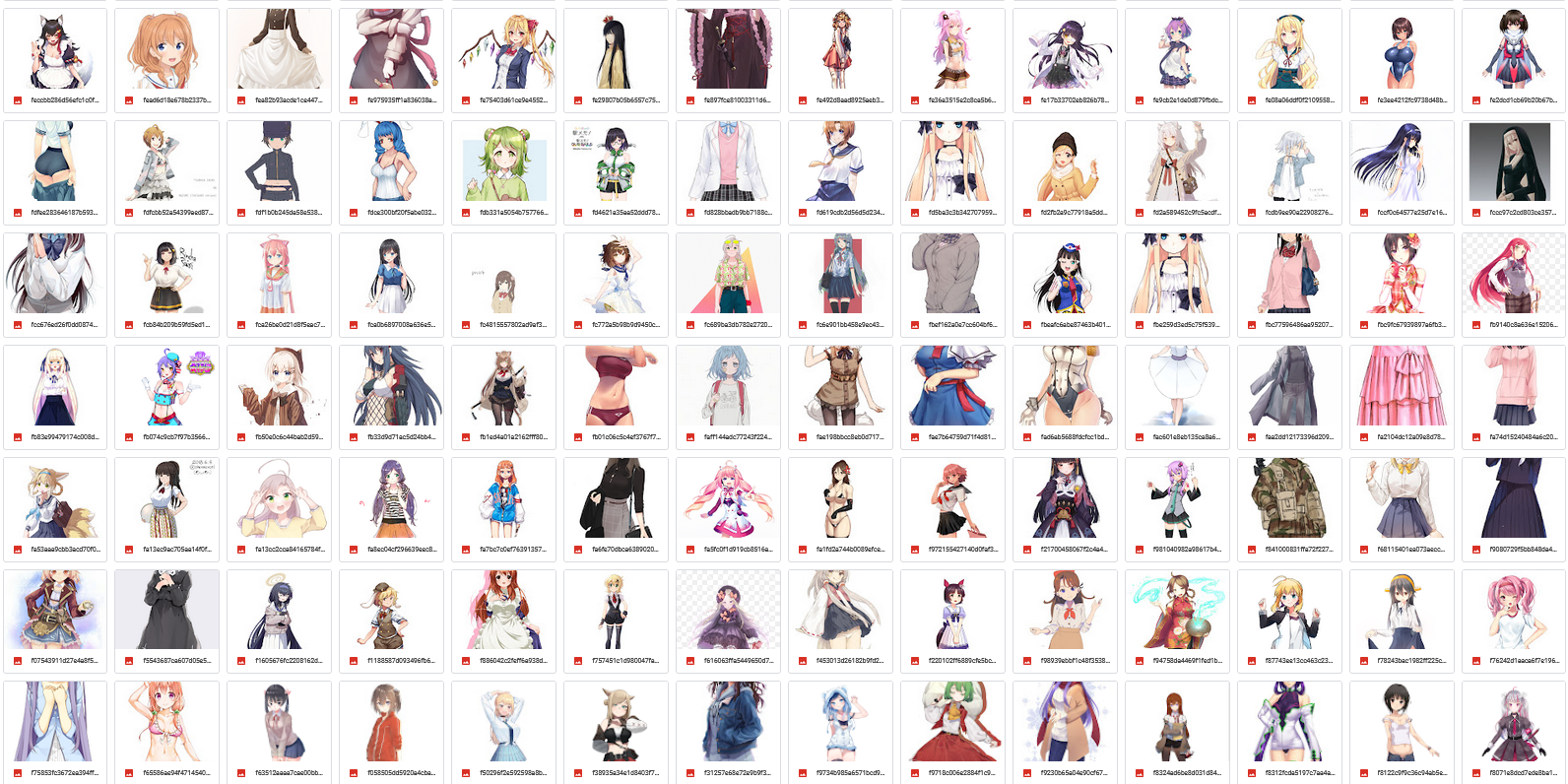
As you can see, The Good Folder contains a lot simpler images and we've left with 4.2k APX~ of images to train with which is insufficient but I think we should try it out first!
I trained model 2 with everything the same as model 1 except datasets of 1 is Cleaned and 2 is ULTRA_Cleaned
Result on 64x64 resolution - latent size 512


The left side is Model 1 And the Right Side is Model 2
From my point of view, Model 2 is better in every bit of detail especially legs & face so I would like to scale up Model 2 to 128 but before that, I think I need better matrices for evaluation to know so let's do it
FID or [Fréchet inception distance](Fréchet inception distance - Wikipedia) is one of the ways to compare two distributions of images if they contain the same feature, stylin ,& etc...
so we can use it without generated output if it contains the same feature as it should contain if it's Real Images
Implement it yourself would be a pain, But luckily there's a library for it GitHub - mseitzer/pytorch-fid: Compute FID scores with PyTorch.
To compare two distributions of images. First, we need images to be compared with (which I already have) and images to be compared.
I need to generate tons of images using both models. Then I can compare their FID score
First I generate 10k of model 1 images Then also models 2 images

I compare model 1 datasets (cleaned raw (A)) with model 2 (ultimately cleaned (b))
Model 1 (A)

Model 2 (B)

You can see that model 2 perform better (ultimately)
| Model | Datasets | Fid |
|---|---|---|
| style_gans (A) | cleaned raw (A) | 136.05 |
| style_gans (B) | ultimate cleaned (B) | 73.46 |
so my conclusion is Model (B) datasets to scaling up! so let's do it
with the power of one of our sponsors AWS - Amazon Web Services
I used their instance (p3.xlarge) which is basically Nvidia v100 with 16 GB Vram