Notation
KoDEx uses special notations in KDocs to indicate that a certain (tag) processor should be applied
in that place.
These notations follow the Javadoc/KDoc @tag content/{@tag content} tag conventions.
Tags without {} are allowed, but only at the beginning of a line, like you're used to with
@param, @return, @throws, etc. If you want to use them in the middle of a line, or inside ``` blocks,
you should use {}.
Tag processors have access to any number of arguments they need, which are separated by spaces, like:
/**
* @tag arg1 arg2 arg3 extra text
* or {@tag arg1 arg2 arg3}
*/though, most only need one or two arguments. It's up to the tag processor what to do with excessive arguments, but most tag processors will leave them in place.
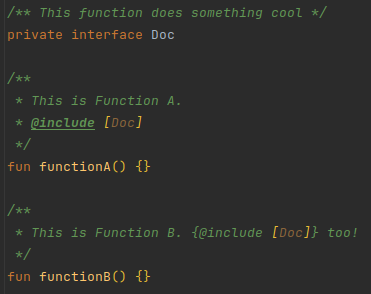
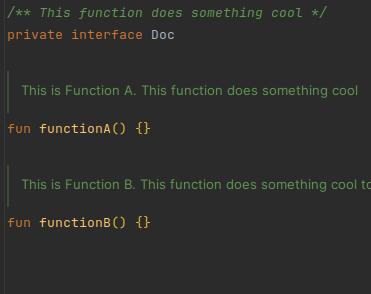
The most used tag across the library is @include [Reference].
This tag includes all the content of the supplied reference's KDoc in the current KDoc.
The reference can be a class, function, property, or any other documented referable entity
(type aliases are an exception, as Dokka does not support them).
The reference can be a fully qualified name or a relative name; imports and aliases are taken into account.
You cannot include something from another library at the moment.
Writing something after the include tag, like
/**
* @include [Reference] some text
*/is allowed and will remain in place. Like:
/**
* This is from the reference. some text
*/Referring to a function with the same name as the current element is allowed and will be resolved correctly (although, the IntelliJ plugin will not resolve it correctly). KoDEx assumes you don't want a circular reference, as that does not work for obvious reasons.
Finally, if you include some KDoc that contains a [reference], KoDEx will replace that reference
with its fully qualified path. This is important because we cannot assume that the target file has access to
the same imports as the source file. The original name will be left in place as alias, like
[reference][path.to.reference].
This is also done for references used as key in @set and @get / $ tags.
This tag is not used in the DataFrame project at the moment. It's used like:
/**
* @includeFile (path/to/file.kt)
*/and, as expected, it pastes the content of the file at the location of the tag.
Both the relative- and absolute paths are supported.
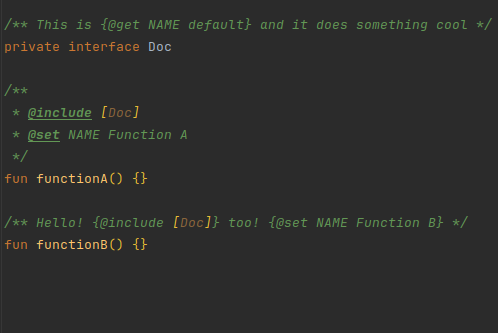
Combined with @include, these tags are the most powerful ones available.
They allow you to create templates and fill them in with different values at the location they're included.
@set is used to set a variable, and @get / $ is used to get the value of a variable
(with an optional default value).
What's important to note is that this processor is run after the @include processor and the variables
that are created with @set are only available in the current KDoc.
To form an idea of how they are processed, it's best to think of waves of processing again.
All @set tags are processed before any @get / $ tags.
So there's no {@set A {@get B}} cycle, as that would not work.
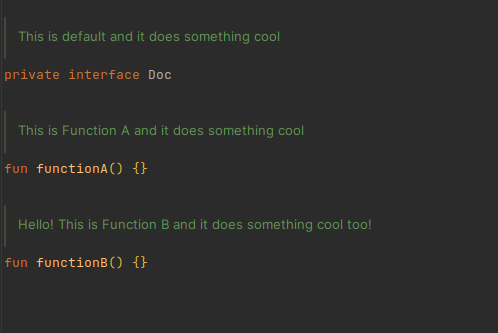
For example, given the KDoc from the picture above:
/**
* @include [Doc]
* @set NAME Function A
*/After running the @include processor, the intermediate state of the KDoc will be:
/**
* This is {@get NAME default} and it does something cool
* @set NAME Function A
*/Then, all @set statements are processed:
/**
* This is {@get NAME default} and it does something cool
*/NAME is "Function A" now.
Then all @get statements are processed:
/**
* This is Function A and it does something cool
*/You can put as many @set and @get / $ tags in a KDoc as you want, just make sure to pick unique
key names :).
I'd always recommend using a [Reference] as key name.
It's a good practice to keep the key names unique and refactor-safe.
Finally, you need to make sure you take the order of tags processing into account. As stated by the README, tags are processed in the following order:
- Inline tags
- depth-first
- top-to-bottom
- left-to-right
- Block tags
- top-to-bottom
This means that you can overwrite a variable by a block tag that was set by an inline tag even if the inline tag is written below the block tag!
For example:
/**
* $NAME
* @set NAME a
* {@set NAME b}
*/Here, NAME is first set to "b" and the {@set NAME b} part is erased from the doc.
Then NAME is set to "a" and that line disappears too.
$NAME is rewritten to {@get NAME} and then it's replaced by retrieving the value of NAME,
which makes the final doc look like:
/**
* a
*
*/
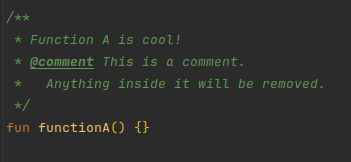
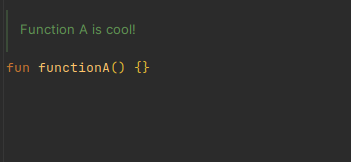
Just like being able to use // in code to comment out lines, you can use @comment to comment out KDoc content.
This is useful for documenting something about the preprocessing processes that should not be visible in the
published sources.jar.
Anything inside a @comment tag block or inline tag {} will be removed from the KDoc when the processor is run.
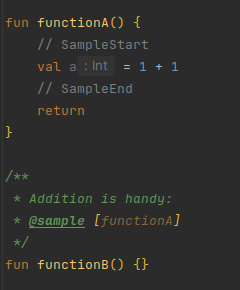
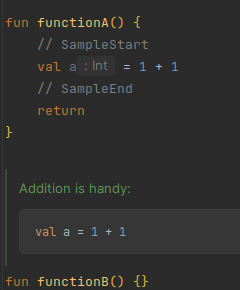
While this processor is not used in the DataFrame project at the moment, it can be seen as an extension
to the normal @sample tag. While the 'normal' @sample [Reference] tag shows the code from the target reference as
is,
@sample and @sampleNoComments actually copy over the code to inside a ```kt ``` (or java) code block in the
KDoc.
Just like korro, if // SampleStart or // SampleEnd are present in the code,
only the code between these markers will be included in the KDoc.
@sampleNoComments is the same as @sample, but it will remove all KDocs from the code before pasting it here.
There's a special annotation, @ExportAsHtml, that allows you to export the content of the KDoc of the annotated
function, interface, or class as HTML.
The Markdown of the KDoc is rendered to HTML using JetBrains/markdown and exported to a folder of your choice.
The annotation supports two parameters: theme, and stripReferences, which both are true by default.
When the theme argument is true, some CSS is added to the HTML output to make it look good in combination with
WriterSide. If the stripReferences is true, all [] references are stripped,
like [name][fully.qualified.name] -> <code>name</code>. This makes the output a lot more readable since
the references won't be clickable in the HTML output anyway.
Optionally, the tags @exportAsHtmlStart and @exportAsHtmlEnd can be used to mark the start and end of the content
to be exported as HTML.
This is useful when you only want to export a part of the KDoc.
@ExportAsHtml can also safely be used in combination with @ExcludeFromSources.
The final wave of processing is the removal of escape characters.
This is done by the REMOVE_ESCAPE_CHARS_PROCESSOR.
The escape character \ is used to escape the special characters @, {, }, [, ], $, and \ itself.
Escaped characters are ignored by processors and are left in place.
This means that /** {\@get TEST} */ will become /** {@get TEST} */ after preprocessing instead of actually
fetching the value of TEST.
Similarly, /** [Reference\] */ will not be replaced by the fully qualified path of Reference after it is
@include'd somewhere else.
This can come in handy when building difficult templates containing a lot of [] characters that should not be
treated as references.
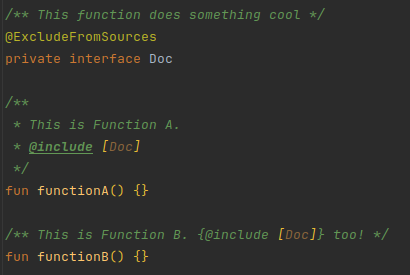
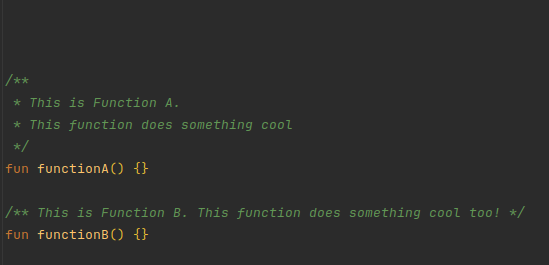
The @ExcludeFromSources annotation is used to exclude a class, function, or property from the sources.jar file.
This is useful to clean up the sources and delete interfaces or classes that are only used as KDoc 'source'.
The annotation is not a KDoc tag but a normal Kotlin annotation detected by KoDEx.
Since v0.3.9 it's also possible to
exclude a whole file from the sources.jar by adding the annotation to the top of the file,
like @file:ExcludeFromSources.