-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
4 changed files
with
619 additions
and
0 deletions.
There are no files selected for viewing
File renamed without changes.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,202 @@ | ||
| --- | ||
|
|
||
| title: Easel(트위터 클론 프로젝트)의 기술 회고 | ||
| date: 2024-02-01 | ||
| categories: [Easel] | ||
| tags: [Easel, gRPC, SpringCloudGateway, Lock, Mock, MockBean, Cypher, CI/CD, Async, Kafka, Redis, Passport] | ||
| layout: post | ||
| toc: true | ||
| math: true | ||
| mermaid: true | ||
|
|
||
| --- | ||
|
|
||
| # 새롭게 접한 기술 스택 | ||
|
|
||
| - **gRPC 동작원리** | ||
| - gRPC는 왜 빠르게 동작하는가? | ||
| - gRPC Gateway가 필요한 상황 | ||
| - **Spring Cloud Gateway 동작원리** | ||
| - Spring Cloud Gateway Filter vs Spring Security Filter vs Spring Reactive Security Filter | ||
| - **비관적 락 vs 낙관적 락** | ||
| - 낙관적 락을 애플리케이션 단위에서 구현해보기 | ||
| - **Mock vs MockBean** | ||
| - 모킹 의존성에 관한 두 애노테이션의 차이점 | ||
| - **Cypher 문법** | ||
| - **우리 프로젝트의 CI/CD 배포 플로우** | ||
| - **비동기 쓰레드 및 큐가 꽉차면 어떻게되는지?** | ||
| - **Kafka** | ||
| - 카프카의 구성요소 및 구조 | ||
| - 컨슈머의 내부 동작 원리 | ||
| - 프로듀서의 내부 동작 원리 | ||
| - 이벤트 전송 간 오류가 발생했을 때 어떻게 처리할 것인지? | ||
| - 프로듀싱 실패 | ||
| - 컨슈밍 실패 | ||
| - 컨슘 후 컨슈머에서 로직 처리 실패 | ||
| - 카프카의 전송 보장 옵션 | ||
| - DLT | ||
| - **Redis** | ||
| - Redis의 캐싱 전략 | ||
| - Caffeine Cache와 비교 | ||
| - **Passport** | ||
| - Passport란 무엇이고 왜 쓰는 것인가? | ||
|
|
||
| - ElasticSearch | ||
| - ES의 구조 | ||
| - 다른 DBMS에 비해 검색을 빠르게 지원하는 원리 | ||
|
|
||
| --- | ||
|
|
||
| # 트러블 슈팅 | ||
|
|
||
| --- | ||
|
|
||
| # gRPC | ||
|
|
||
| - [참고자료](https://medium.com/naver-cloud-platform/nbp-%EA%B8%B0%EC%88%A0-%EA%B2%BD%ED%97%98-%EC%8B%9C%EB%8C%80%EC%9D%98-%ED%9D%90%EB%A6%84-grpc-%EA%B9%8A%EA%B2%8C-%ED%8C%8C%EA%B3%A0%EB%93%A4%EA%B8%B0-1-39e97cb3460) | ||
|
|
||
| - [참고자료](https://medium.com/naver-cloud-platform/nbp-%EA%B8%B0%EC%88%A0-%EA%B2%BD%ED%97%98-%EC%8B%9C%EB%8C%80%EC%9D%98-%ED%9D%90%EB%A6%84-grpc-%EA%B9%8A%EA%B2%8C-%ED%8C%8C%EA%B3%A0%EB%93%A4%EA%B8%B0-2-b01d390a7190) | ||
|
|
||
| - [참고자료](https://medium.com/@lchang1994/deep-dive-grpc-protobuf-http-2-0-74e6295f1d38) | ||
|
|
||
| ## gRPC 등장 배경 | ||
|
|
||
| ### IPC (Inter Process Communication 프로세스 간 통신) | ||
|
|
||
| 운영체제에는 IPC기법이 있다. 이 방식으로 서로 다른 서버간의 프로세스끼리 통신을 하며 정보를 교환할 수 있다. | ||
|
|
||
| IPC 기법에는 소켓, 공유 메모리, PIPE, 메시지 큐 등 여러가지 기법이있다. | ||
|
|
||
| 그 중 소켓 통신은 E2E를 직접 연결하여 데이터를 스트리밍하며 받는 형태로 통신하기 때문에 통신간에 발생하는 예외처리, 주고받아야할 데이터가 방대해질 때의 후처리가 매우 어렵기 때문에 확장성 측면의 불편함이 있다. | ||
|
|
||
| ### RPC (Remote Procedure Call 원격 프로시저 호출) | ||
|
|
||
| 이러한 IPC의 단점을 조금 더 완화하고자 RPC기법이 등장했다. | ||
|
|
||
| RPC는 네트워크 상으로 연결된 원격 서버의 함수를 호출 할 수 있도록 해서 네트워크 통신을 위한 작업을 고려하지 않도록할 수 있고 통신이나 call 방식에 신경쓰지 않고 원격지의 자원을 사용할 수 있다. | ||
|
|
||
| RPC에는 `Stub`이라는 주요 개념이 등장한다. `Stub`이란 Client와 Server간의 데이터를 각 환경에 맞게 변환해주는 것이다. | ||
|
|
||
| 만약 `Stub`이 없다면 | ||
|
|
||
| - Client와 Server는 전혀 다른 메모리 공간을 사용하고 있기 때문에 Client측 에서 가리키던 포인터가 Server측으로 넘어가게 되면서 전혀 다른 곳을 가리키게된다. | ||
| - Client는 리틀 엔디안 형식을 사용하지만 Server측은 빅 엔디안 형식을 사용한다는 경우 의도와 다르게 동작할 것이다. | ||
|
|
||
| 이러한 이유들로 각 데이터들은 `Stub`을 거쳐 Packet의 형태로 전달된다. | ||
|
|
||
| ## gRPC | ||
|
|
||
| 구글에서 개발한 프레임워크이다. PB(Protocol Buffer, 프로토콜 버퍼)기반 Serizlaizer에 HTTP/2를 결합한 RPC 프레임워크이다. | ||
|
|
||
| 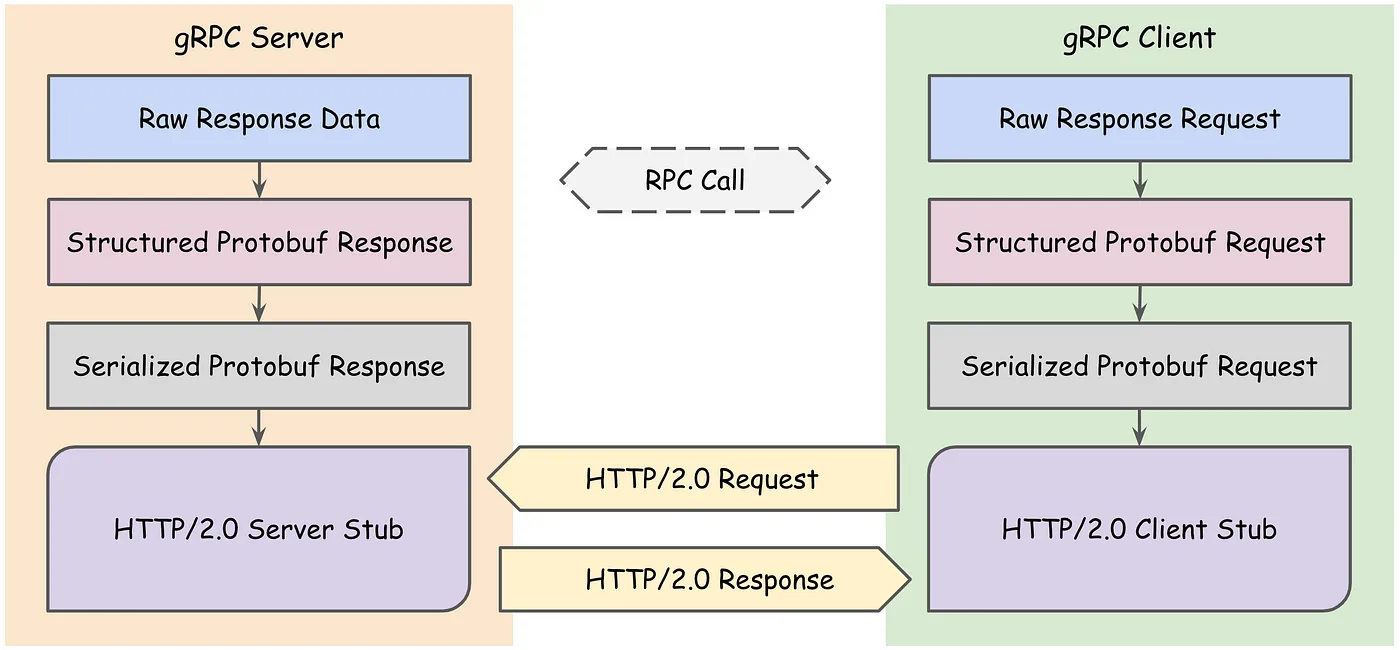 | ||
|
|
||
| ### HTTP/2 | ||
|
|
||
| 우리가 일반적으로 사용하는 HTTP/1.1은 기본적으로 클라이언트의 요청이 올때만 서버가 응답을 하는 구조로 매 요청마다 Connection을 생성한다. Cookie등 메타 데이터들을 저장하는 무거운 Header가 요청마다 중복 전달되어 비효율적이고 느린 속도를 가진다. | ||
|
|
||
| HTTP/2에서는 한 Connection으로 동시에 여러 개 메시지를 주고 받으며, Header를 압축하여 중복 제거 후 전달하기에 HTTP/1.1에 비해 효율적이다. 클라이언트 요청 없이도 서버가 리소스를 전달할 수도 있기 때문에 클라이언트 요청을 최소화 할 수 있다. | ||
|
|
||
| - HTTP 1.1과 HTTP 2.0의 주요한 차이점은 HTTP 메세지가 1.1에서는 TEXT로 전송되었던 것과 달리, 2.0에서는 Binary Frame으로 인코딩되어 전송된다는 점이다. | ||
|
|
||
| ### ProtoBuf (Protocol Buffer, 프로토콜 버퍼) | ||
|
|
||
| Google에서 개발한 구조화된 데이터를 직렬화(Serialization)하는 기법이다. 직렬화란, 데이터 표현을 바이트 단위로 변환하는 작업으로 아래 그림처럼 같은 정보를 저장해도 | ||
|
|
||
| **TEXT기반인 JSON**의 경우 `82Byte`가 소요되는데 **직렬화 된 Protocol Buffer**는 필드 번호, 필드 유형 등을 1Byte로 받아서 식별하고, 주어진 length 만큼만 읽도록 하여 `33Byte`만 필요하게 된다. | ||
|
|
||
| 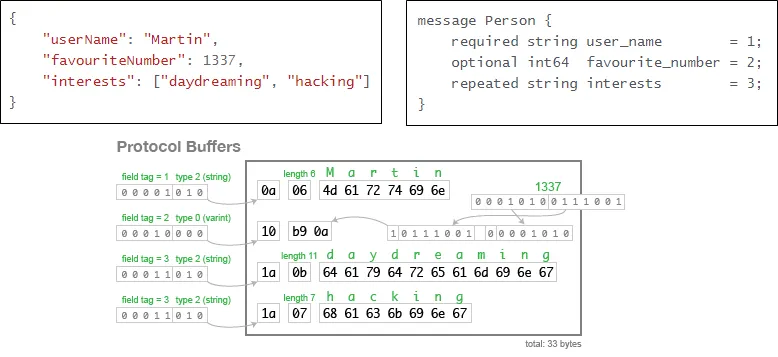 | ||
|
|
||
| ### Base 128 Varint | ||
|
|
||
| [Protobuf-guide](https://protobuf.dev/programming-guides/encoding/)에 따르면 프로토버퍼는 기본 인코딩 기법으로 Base 128 Varints라는 인코딩 형식을 사용하여 데이터를 압축적으로 표현할 수 있다. | ||
|
|
||
| Varint는 가변 길이의 정수를 인코딩하는 방식으로 1~10Byte의 길이를 가지고 그 크기는 인코딩하려는 값에 따라 달라진다. | ||
|
|
||
| Varint 인코딩 방식은 다음과 같다. | ||
|
|
||
| - 각 바이트의 최하위 7비트는 정수의 일부를 나타낸다. | ||
| - 각 바이트의 최상위 비트는 다음 바이트가 더 있음을 나타낸다. | ||
| - 숫자는 7비트 단위로 나누어져 있으며, 최하위 그룹부터 시작하여 최상위 그룹까지 인코딩된다. | ||
|
|
||
| - 예를 들어, 숫자 300을 varint로 인코딩하면 | ||
| - 300 = 2^8 + 44 | ||
| - 300은 두 바이트로 인코딩된다 : [1000 1100, 0000 0010] | ||
|
|
||
| 이러한 방식은 작은 숫자를 효율적으로 인코딩하며, 네트워크를 통한 데이터 전송을 최적화하는 데 도움이 됩니다. | ||
|
|
||
| --- | ||
|
|
||
| # Kafka | ||
|
|
||
| ## Kafka Topic | ||
|
|
||
| Kafka는 서버 간 통신을 위해 사용하는 메세지를 Topic이라는 곳을 통해서 통신한다. | ||
|
|
||
| 이 Topic은 여러개의 파티션으로 구성될 수 있다. 그리고 메세지는 이 파티션에 추가되는 방식이다. | ||
|
|
||
| 파티션별로 메세지의 순서(오프셋)이 존재하여 순서를 보장하도록 구성되어있다. | ||
|
|
||
| --- | ||
|
|
||
| ## Kafka Producer | ||
|
|
||
| 프로듀서는 토픽에 대한 메세지를 보내는 애플리케이션을 가리킨다. | ||
|
|
||
| --- | ||
|
|
||
| ## Kafka Consumer | ||
|
|
||
| 컨슈머는 토픽에 대한 메세지를 소비하는 애플리케이션을 가리킨다. | ||
|
|
||
| — | ||
|
|
||
| ## Kafka Broker | ||
|
|
||
| 하나의 Kafka 서버를 브로커라고 한다. Spring Boot 환경에서 Kafka를 사용하고자 할 때 아래와 같은 설정정보를 등록하곤 한다. | ||
|
|
||
| ```yml | ||
| spring: | ||
| kafka: | ||
| bootstrap-servers: localhost:9092 | ||
| ``` | ||
|
|
||
| 위 bootstrap-servers 구문으로 Kafka의 Broker 주소를 명시하는 것이다. | ||
|
|
||
| Broker는 Producer에게 메세지를 수신하고, 오프셋을 지정한 후 해당 메세지를 디스크에 저장한다. | ||
|
|
||
| 또한 Consumer의 파티션 읽기 요청에 응답하여 디스크에 저장된 메세지를 전송한다. | ||
|
|
||
| 이 과정에서 브로커 서버 내 사용하지 않는 메모리를 페이지 캐싱으로 캐싱하여 조금 더 빠르게 I/O작업을 할 수 있도록 구성되어있다. | ||
|
|
||
| Producer -> Topic -> Consumer | ||
|
|
||
| 이렇게 Producer나 Consumer가 바로 토픽에 접근하는 흐름이 아니라 | ||
|
|
||
| Producer -> Broker -> Topic(Broker's Disk) | ||
|
|
||
| 와 같은 흐름으로 동작하는 것이였다. | ||
|
|
||
| 각 파티션은 하나의 브로커가 소유하고 그 브로커를 파티션 리더라고 칭한다. | ||
|
|
||
| 같은 파티션이 여러 브로커에게 지정될 수 있는데 이런 상황에서는 파티션 리더가 복제된다. | ||
|
|
||
| 복제된 파티션에는 메세지가 중복으로 저장되지만 장애 발생 시 장애 발생 한 지점의 브로커가 파티션의 소유권을 인계받아 그 파티션을 처리할 수 있는 가용성 측면의 장점이 있다. | ||
|
|
||
| --- | ||
|
|
||
| ## Kafka Controller | ||
|
|
||
| Kafka 생태계에서는 여러개의 Broker가 있을 때 그 중 하나가 Controller의 역할을 수행한다. | ||
|
|
||
| Controller는 각 Broker들에게 담당할 파티션을 할당하고 다른 Broker들이 정상적으로 동작하는지 모니터링하는 관리적인 역할이 부여되고 파티션의 리더를 선출하는 역할을 한다. | ||
|
|
||
| 모든 Broker는 Controller Node를 생성하도록 시도하는데, 가장 먼저 생성한 Broker가 Controller Broker가 되는 것이다. | ||
|
|
||
| --- | ||
|
|
||
| # Zookeeper | ||
|
|
||
| 분산 처리 시스템을 총괄하는 코디네이터라고 알려져있다. | ||
|
|
||
| 이러한 중앙 관리 시스템이 없다면 분산 시스템 환경은 각각의 애플리케이션이 돌아가는 환경이 다르고 네트워크에서 발생하는 문제로 관리적인 측면에서 매우 어려움을 겪을 수 있다. | ||
|
|
Oops, something went wrong.