Reference : https://www.coursera.org/learn/competitive-data-science/home/welcome
Starting Approx. on 1st week of August 2020
- Prerequisites
- Lecture 1 : Feature Processing
- Lecture 2 : Exploratory Data Analysis (EDA)
- Lecture 3 : Validation and Overfitting revisited
- ~~Lecture 4 : Data Leakages -~~Cancellata Completamente
- Lecture 4 : Metrics Optimization
- Lecture 5 : Mean Encodings
- Lecture 6: Hyperparameters Tuning
- Lecture 7: Advanced Features
- Lecture 8: Ensembling
- Code Samples (QUI CI SONO I NOTEBOOK)
- Some more links
- Some more libs
(Se non vi dovesse aprire qualcuno di questi articoli, accedete con la modalità "in incognito" del vostro browser e dovrebbe andare)
- Random Forest (& Decision Trees) : https://towardsdatascience.com/an-implementation-and-explanation-of-the-random-forest-in-python-77bf308a9b76
- K Nearest Neighbors : https://towardsdatascience.com/machine-learning-basics-with-the-k-nearest-neighbors-algorithm-6a6e71d01761
- XGBoost : https://towardsdatascience.com/a-beginners-guide-to-xgboost-87f5d4c30ed7
Videos : https://drive.google.com/folderview?id=1__WFpqBAQWJ-YS80cRKv_qOYQ_8y1E1u (con la mail di Unito avete accesso immediato)
Intro : feature, physics, and scaling —> In physics we usually have some hints on how to "preprocess" features, i.e. we have some law...
- Linear Models
- Tree-Based Models
- k Nearest Neighbors (kNN)
- Neural Networks
- No Free Lunch Theorem
Lecture: Numeric Features, Categorical and Ordinal Features, Datetime and Coordinates, Handling Missing Values
Additional Material and Links:
- Preprocessing in Scikit-Learn
- About Feature Scaling and Normalization - Sebastian Raschka
- Gradient Descent and Feature Scaling - Andrew NG
- How to Engineer Features, Feature Engineering
- Best Practices in Feature Engineering
Text:
- Text Preprocessing: lowercase, lemmatization, stemming, stopwords
- Bag of Words (sklearn CountVectorizer), PostProcessing: TfIdf (Term frequencies Inverse document frequencies) , N-Grams
- Embeddings (Word2Vec, Glove, FastText, Doc2Vec) : vectorizing text King-Queen Man-Woman —> Pretrained Models
Images:
- CNNs for feature extraction, Images —> Vectors; Descriptors (output from different layers)
- Finetuning & Training from Scratch
- Augmentation (Cropping, Rotating etc..)
Additional Material & Links:
Bag of words (Text)
Word2vec (Text)
- Tutorial to Word2vec
- Tutorial to word2vec usage
- Text Classification With Word2Vec
- Introduction to Word Embedding Models with Word2Vec
NLP Libraries
Pretrained models (Images)
Finetuning (Images)
- How to Retrain Inception's Final Layer for New Categories in Tensorflow
- Fine-tuning Deep Learning Models in Keras
It allows you to better understand the data: Do EDA first, don't immediately dig into modeling.
Main tools:
- Visualizations: Patterns lead to questions
- Exploiting Leaks
A few steps in EDA:
- Get domain knowledge
- Check if data is intuitive, possible misinterpretations
- Understand how the data was generated (class imbalance, crucial for proper validation scheme)
Sensitive data are usually hashed to avoid privacy related issues (setting up a notebook)
-
We can try to decode (de-anonymize) the data, in a legal way (of course 🙂) by guessing the true meaning of the features or at least guess the true type (categorical etc..) —> individual features
-
Or else, we can try to figure out feature relations
-
Helpful Function: df.dtypes(), df.info(), x.value_counts(), x.isnull()
- Histograms (plt.hist(x)), they aggregate data tho —> can be confusing
- Index vs Values Plot
- Feature statistics with pandas —> df.describe()
- Features Mean vs Feature (by sorting this plot you can find relations —> in a data augmentation framework it might be useful)
- Plots in order to explore feature relations → Visualizations are our art tools in the art of EDA
- plt.scatter(x1, x2)
- pd.scatter_matrix(df)
- df.corr(), plt.matshow()
The organizers could give us a fraction of objects they have or a fraction of features. And that is why we can have some issues with the data
- E.g. a feature that takes the same value in both training and test set (maybe it's a fraction of the whole amount of data that organizers have) —> since it is constant it's not useful for our purposes —> remove it
- Duplicated features , sometimes two columns are completely identical —> remove one (traintest.T.drop_duplicates())
- Duplicated categorical features, features are identical but rows have different names (let's rename levels of features and find duplicated)
for f in categorical_features:
traintest[f] = traintest[f].factorize()
traintest.T.drop_duplicates()! We need to do label encoding correctly !
- Same with rows —> but one more question: why do have duplicated rows? A bug in the generation process?!
- Check if dataset is shuffled ! (very useful) if not there might be data leakage. We can plot a feature vs row index and additionally smooth values with rolling average techniques
- One more time —> Visualize every possible thing —> Cool viz lead to cool features 😉
Additional Material & Links:
Visualization tools
Others (Advanced)
Notebookssss
Notebooksss too
- Hardcore EDA —> sorted correlation matrix
You've probably noticed that it's much about Reverse Engineering & Creativity
(Notebook: )
(Videos: https://drive.google.com/drive/folders/18jgjbsvMGBLWpuCmFCR6f2CaZK-900QQ?usp=sharing)
- Train, Validation & Test (Public + Private) Sets
- Underfitting vs Overfitting Recap
- Overfitting in general ≠ Overfitting in Competitions
- Holdout: ngroups = 1 (sklearn.model_selection.ShuffleSplit)
- K-Fold: ngroups = k (sklearn.model_selection.KFold) and difference between K-Fold and K times Holdout
- Leave-one-out: ngroups = len(train) (sklearn.model_selection.LeaveOneOut), useful if we have too little data
- Stratification : a random split can sometimes fail, we need a way to ensure similar target distribution over different folds
The main rule you should know — never use data you train on to measure the quality of your model. The trick is to split all your data into training and validation parts.
Below you will find several ways to validate a model.
- **Holdout scheme:
- Split train data into two parts: partA and partB
- Fit the model on partA, predict for partB
- Use predictions for partB for estimating model quality. Find such hyper-parameters that quality on partB is maximized.
- **K-Fold scheme:
- Split train data into K folds.
- Use the predictions to calculate quality on each fold. Find such hyper-parameters, that quality on each fold is maximized. You can also estimate mean and variance of the loss. This is very helpful in order to understand significance of improvement.
- **LOO (Leave-One-Out) scheme:
- Iterate over samples: retrain the model on all samples except current sample, predict for the current sample. You will need to retrain the model N times (if N is the number of samples in the dataset).
- In the end you will get LOO predictions for every sample in the trainset and can calculate loss.
Notice, that these validation schemes are supposed to be used to estimate the quality of the model. When you've found the right hyper-parameters and want to get test predictions don't forget to retrain your model using all training data.
Setup validation to mimic train / test split. E.g. time series, we need to rely on the time trend instead of randomly picking up values —> Time Based Splits
Different splitting strategies can differ significantly
- In generated features
- In a way the model will rely on that features
- In some kind of target leak
Splitting Data into Train and Validation
- Random, Rowwise ; Most common, we assume that rows are independent from each other
- Timewise, we generally have everything before some date in the train-set and everything after in the test-set (e.g. Moving window validation)
- By ID, id can be a unique identifier of something
- Combined, combining some of the above mentioned
Logic of feature generation depends on the data splitting strategy.
Validation problems (usually caused by inconsistency of data):
-
Validation Stage (e.g. if we are predicting sales we should take a look at holidays, so there's a reason to expect some particular behavior)
-
Submission Stage (e.g. LeaderBoard (LB) score is consistently higher/lower that validation score, LB score is not correlated with validation score at all) —> Leaderboard Probing (calculate mean for train data and try to probe the test data distribution by submitting .. 🤯)
What if we have imbalanced distributions? We should ensure the same distribution in test and validation (again, by LB probing)
LB Shuffle: it happens when positions on Public and Private LB are drastically different, main reasons:
- Randomness (main main reason)
- Little amount of data
- Different Public & Private distributions
Additional Material & Links:
(Not sure to do it, it really depends on the competition, if it is Kaggle-like we should take a look at leaks)
- Leaks in time series: Split should be done on time
- In real life we don't have information from the future
- Check train, public and private splits. If one of them is not on time you've found a data leak
- Even when split by time, features may contain information about future: User history in CTR tasks; Weather
- Unexpected information:
- Metadata
- Information on IDs
- Row Order
- Categories tightly connected with "id" are vulnerable to LB probing
- Adapting global mean via LB probing
- Some competition with data leakages: Truly Native; Expedia; Flavours of Physics
- Pairwise tasks, data leakage in item frequencies
Additional Material & Links:
- Why there are so many
- Why should we care about them in competitions
- Loss vs Metric
- Review the most important metrics
- Optimization techniques for the metrics
Metrics are an essential part of any competition, they are used to evaluate our submissions. Why do we have different metrics for each competition? There are different ways to measure the quality of an algorithm
- E.g. How to formalize effectiveness for an online shop ? It can be the number of times the website was visited or the number of times something was ordered using this website
Chosen metric determines optimal decision boundary

If your model is scored with some metric, you get best results by optimizing exactly that metric
With LB probing we can check if the train and test sets have some incongruences with respect distributions, we gotta be careful wrt metrics optimization if there's some imbalance
(Add Notebook)
- MSE, RMSE, R-Squared
- MAE
- MSPE, MAPE
- MSLE
MSE: Mean Square Error

RMSE: Root Mean Square Error

R-Squared:

MAE: Mean Absolute Error

MSPE : Mean Square Percentage Error

MAPE: Mean Absolute Percentage Error

(R)MSLE: Root Mean Square Logarithmic Error

Accuracy : How frequently our class prediction is correct

- Best constant : predict the most frequent class —> dummy example : Dataset of 10 cats and 90 dogs —> Always predicts dog and we get 90% accuracy, the baseline accuracy could be very high even if the result is not correct
Log Loss : Logarithmic Loss

AUC ROC : Area Under Curve
Cohen's Kappa (& Weighted Kappa)


Loss and Metric
- Target Metric : is what we want to optimize (e.g Accuracy)
- Optimization loss : is what our model optimizes

Approaches for target metric optimization
- Just run the right model (lol!) : MSE, Logloss
- Preprocess train and optimize another metric : MSPE, MAPE, RMSLE
- Optimize another metric, postprocess predictions: Accuracy, Kappa
- Write Custom Loss Function (if you can)
- Optimize another metric, use early stopping
Probability Calibration
- Platt Scaling : Just fit Logistic Regression to your prediction
- Isotonic Regression
- Stacking : Just fit XGBoost or neural net to your predictions
Additional Material & Links :
DAIgnosis: Exploring the Space of Metrics
Classification
- Evaluation Metrics for Classification Problems: Quick Examples + References
- Decision Trees: “Gini” vs. “Entropy” criteria
- Understanding ROC curves
Ranking
- Learning to Rank using Gradient Descent -- original paper about pairwise method for AUC optimization
- Overview of further developments of RankNet
- RankLib (implemtations for the 2 papers from above)
- Learning to Rank Overview
Clustering
(We can follow this one —> https://www.kaggle.com/vprokopev/mean-likelihood-encodings-a-comprehensive-study)
The general idea of this technique is to add new variables based on some feature. In simplest cases, we encode each level of a categorical variable with the corresponding target mean
Why does it work ?
- Label encoding gives random order.. No correlation with target
- Mean encoding helps to separate zeros from ones
It turns out that this sorting quality of mean encoding is quite helpful. Remember, what is the most popular and effective way to solve machine learning problem? Is grading using trees (XGBoost). One of the few downsides is an inability to handle high cardinality categorical variables. Trees have limited depth, with mean encoding, we can compensate it!
(Notebook)
-
Cross Validation inside training data (CV loop)
Usually decent results with 4-5 folds
-
Smoothing
-
Adding random noise
-
Sorting and calculating expanding mean
- Regression and multiclass
- Many-to-many relations
- Time Series
- Interactions and numerical features
-
Select the most influential parameters
There are tons of params and we can't tune all of them
-
Understand, how exactly they influence the training
-
Tune them
Manually (change and examine)
Automatically (hyperopt, grid search etc..) —> some libraries : Hyperopt; Scikit-optimize; Spearmint; GPyOpt; RoBo; SMAC3
We need to define a function that specifies all the params and a search space, the range for the paramas where we want to look for the solution.
-
Different values for params can lead to 3 behaviors:
- Underfitting (bad)
- Good Fit and Generalization (good)
- Overfitting (bad)
Color-Coding Legend
Red Parameter :
- Increasing it impedes fitting, it reduces overfitting
Green parameter:
- Increasing it leads to a better fit on train set, increase it if model underfits, decrease it if it overfits
-
GBDT (XGBoost & LightGBM)
Parameters

-
Random Forest / Extra Trees
(Notebook on how to find sufficient n_estimators)
N_estimators (the higher the better)
max_depth (it can be unlimited)
max_features
min_samples_leaf
Others: criterion (gini etc) , random_state, n_jobs
-
Number of neurons per layer
-
Number of layers
-
Optimizers
SGD + Momentum
- Better generalization
Adam/Adagrad ...
- Adaptive methods lead to more overfitting
-
Batch Size
-
Learning Rate, there's a connection between batch size and learning rate (proporzionalità diretta nelle dimensioni delle due)
-
Regularization
- L2 / L1 for weights
- Dropout /Dropconnect
- Static Dropconnect
- SVC/SVR (sklearn)
- Logistic Regression + regularizers (sklearn)
- SGDClassifier /Regressor (sklearn)
- FTRL, Follow The Regularized Leader (Vowpal Wabbit) —> For the data sets that do not fit in the memory, we can use Vowpal Wabbit. It implements learning of linear models in online fashion. It only reads data row by row directly from the hard drive and never loads the whole data set in the memory. Thus, allowing to learn on a very huge data sets.
Regularization Parameter (C, alpha, lambda ...)
-
Data Loading
Do basic preprocessing and convert csv/txt files into hdf5/npy for much faster loading
Don't forget that by default data is stored in 64-bit arrays, most of the times you can safely downcast it to 32-bits
Large datasets can be processed in chunks
-
Performance Evaluation
Extensive validation is not always needed
Start with fastest models LightGBM

-
Fast & Dirty always Better
Don't pay too much attention to code quality
Keep things simple: save only important things
-
Initial Pipeline
Start with simple solution
Debug full pipeline (from reading data to writing submission file)
-
Best Practices from Software Development
Use good variable names
Keep your research reproducible (fix random seeds, use Version Control Systems)
Reuse Code
-
Read Papers !!
-
My Pipeline
Read Forums and Examine kernel first (you'll find some discussions going on)
Start with EDA and a baseline
Add features in bulks
Hyperparameters optimization
Use macros for frequent code and custom libraries as well
Additional Material & Links:
- Tuning the hyper-parameters of an estimator (sklearn)
- Optimizing hyperparameters with hyperopt
- Complete Guide to Parameter Tuning in Gradient Boosting (GBM) in Python
- Far0n's framework for Kaggle competitions "kaggletils"
- 28 Jupyter Notebook tips, tricks and shortcuts

-
Statistics on initial features
-
Neighbors (kNN, Bray - Curtis metric etc)
-
Matrix Factorizations for Feature Extraction (NMF, SVD, PCA)
Pay attention to apply the same transformation to all your data (concatenate train & test and apply PCA or whatever)
-
Feature Interactions
Sums, Diffs, Multiplications, Divisions

-
t-SNE , UMAP (Manifold Learning Methods)
Interpretation of hyperparameters (e.g. Perplexity)

Additional Material & Links:
Matrix Factorization:
t-SNE:
- Multicore t-SNE implementation
- Comparison of Manifold Learning methods (sklearn)
- How to Use t-SNE Effectively (distill.pub blog)
- tSNE homepage (Laurens van der Maaten)
- Example: tSNE with different perplexities (sklearn)
Interactions:
- Facebook Research's paper about extracting categorical features from trees
- Example: Feature transformations with ensembles of trees (sklearn)
Prendiamo da qui —> (https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205#)
An ensemble method combines the predictions of many individual classifiers by majority voting.
Ensemble of low-correlating classifiers with slightly greater than 50% accuracy will outperform each of the classifiers individually.

Condorcet's jury theorem:
-
If each member of the jury (of size N) makes an independent judgement and the probability p of the correct decision by each juror is more than 0.5, then the probability of the correct decision PN by the majority m tends to one. On the other hand, if p<0.5 for each juror, then the probability tends to zero.

-
where m as a minimal number of jurors that would make a majority.
-
But real votes are not independent, and do not have uniform probabilities.

Uncorrelated submissions clearly do better when ensembled than correlated submissions.
Majority votes make most sense when the evaluation metric requires hard predictions.
Choose bagging for base models with high variance.
Choose boosting for base models with high bias.
Use averaging, voting or rank averaging on manually-selected well-performing ensembles.
- Averaging is taking the mean of individual model predictions.
- Averaging predictions often reduces variance (as bagging does).
- It’s a fairly trivial technique that results in easy, sizeable performance improvements.
- Averaging exactly the same linear regressions won't give any penalty.
- An often heard shorthand for this on Kaggle is "bagging submissions".
Weighted averaging
-
Use weighted averaging to give a better model more weight in a vote.
-
A very small number of parameters rarely lead to overfitting.
-
It is faster to implement and to run.
-
It does not make sense to explore weights individually (α+β≠1) for:
α+β≠1)
- AUC: For any α, β, dividing the predictions by α+β will not change AUC.
- Accuracy (implemented with argmax): Similarly to AUC, argmax position will not change.
Conditional averaging
- Use conditional averaging to cancel out erroneous ranges of individual estimators.
- Can be automatically learned by boosting trees and stacking.
- Bagging (bootstrap aggregating) considers homogeneous models, learns them independently from each other in parallel, and combines them following some kind of deterministic averaging process.
- Bagging combines strong learners together in order to "smooth out" their predictions and reduce variance.
- Bootstrapping allows to fit models that are roughly independent.
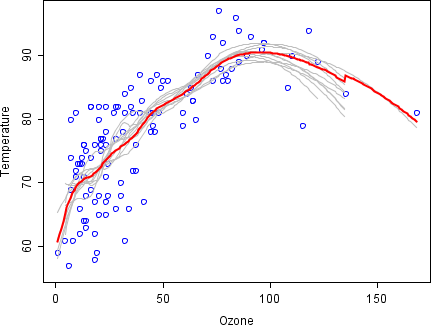
- The procedure is as follows:
- Create N random sub-samples (with replacement) for the dataset of size N.
- Fit a base model on each sample.
- Average predictions from all models.
- Can be used with any type of method as a base model.
- Bagging is effective on small datasets.
- Out-of-bag estimate is the mean estimate of the base algorithms on 37% of inputs that are left out of a particular bootstrap sample.
- Helps avoid the need for an independent validation dataset.
- Parameters to consider:
- Random seed
- Row sampling or bootstrapping
- Column sampling or bootstrapping
- Size of sample (use a much smaller sample size on a larger dataset)
- Shuffling
- Number of bags
- Parallelism
- See Tree-Based Models
Bootstrapping
- Bootstrapping is random sampling with replacement.
- With sampling with replacement, each sample unit has an equal probability of being selected.
- Samples become approximatively independent and identically distributed (i.i.d).
- It is a convenient way to treat a sample like a population.
- This technique allows estimation of the sampling distribution of almost any statistic using random sampling methods.
- It is a straightforward way to derive estimates of standard errors and confidence intervals for complex estimators.
- For example:
- Select a random element from the original sample of size N and do this B times.
- Calculate the mean of each sub-sample.
- Obtain a 95% confidence interval around the mean estimate for the original sample.
- Two important assumptions:
- N should be large enough to capture most of the complexity of the underlying distribution (representativity).
- N should be large enough compared to B so that samples are not too much correlated (independence).
- An average bootstrap sample contains 63.2% of the original observations and omits 36.8%.
- Boosting considers homogeneous models, learns them sequentially in a very adaptative way (a base model depends on the previous ones) and combines them following a deterministic strategy.
- This technique is called boosting because we expect an ensemble to work much better than a single estimator.
- Sequential methods are no longer fitted independently from each others and can't be performed in parallel.
- Each new model in the ensemble focuses its efforts on the most difficult observations to fit up to now.
- Boosting combines weak learners together in order to create a strong learner with lower bias.
- A weak learner is defined as one whose performance is at least slightly better than random chance.
- These learners are also in general less computationally expensive to fit.
Adaptive boosting
-
At each iteration, adaptive boosting changes the sample distribution by modifying the weights of instances.
- It increases the weights of the wrongly predicted instances.
- The weak learner thus focuses more on the difficult instances.
-
The procedure is as follows:
-
Fit a weak learner ht with the current observations weights.
ht
-
Estimate the learner's performance and compute its weight αt (contribution to the ensemble).
αt
-
Update the strong learner by adding the new weak learner multiplied by its weight.
-
Compute new observations weights that expresse which observations to focus on.

-

Gradient boosting
Gradient boosting doesn’t modify the sample distribution:
- At each iteration, the weak learner trains on the remaining errors (so-called pseudo-residuals) of the strong learner.
Gradient boosting doesn’t weight weak learnes according to their performance:
- The contribution of the weak learner (so-called multiplier) to the strong one is computed using gradient descent.
- The computed contribution is the one minimizing the overall error of the strong learner.
Allows optimization of an arbitrary differentiable loss function.
The procedure is as follows:
-
Compute pseudo-residuals that indicate, for each observation, in which direction we would like to move.
-
Fit a weak learner ht to the pseudo-residuals (negative gradient of the loss)
-
Add the predictions of ht multiplied by the step size α (learning rate) to the predictions of ensemble


- Stacking considers heterogeneous models, learns them in parallel and combines them by training a meta-model to output a prediction based on the different weak models predictions.
- Stacking on a small holdout set is blending.
- Stacking with linear regression is sometimes the most effective way of stacking.
- Non-linear stacking gives surprising gains as it finds useful interactions between the original and the meta-model features.
- Feature-weighted linear stacking stacks engineered meta-features together with model predictions.
- At the end of the day you don’t know which base models will be helpful.
- Stacking allows you to use classifiers for regression problems and vice versa.
- Base models should be as diverse as possible:
- 2-3 GBMs (one with low depth, one with medium and one with high)
- 2-3 NNs (one deeper, one shallower)
- 1-2 ExtraTrees/RFs (again as diverse as possible)
- 1-2 linear models such as logistic/ridge regression
- 1 kNN model
- 1 factorization machine
- Use different features for different models.
- Use feature engineering:
- Pairwise distances between meta features
- Row-wise statistics (like mean)
- Standard feature selection techniques
- Meta models can be shallow:
- GBMs with small depth (2-3)
- Linear models with high regularization
- ExtraTrees
- Shallow NNs (1 hidden layer)
- kNN with BrayCurtis distance
- A simple weighted average (find weights with bruteforce)
- Use automated stacking for complex cases to optimize:
- CV-scores
- Standard deviation of the CV-scores (a smaller deviation is a safer choice)
- Complexity/memory usage and running times
- Correlation (uncorrelated model predictions are preferred).
- Greedy forward model selection:
- Start with a base ensemble of 3 or so good models.
- Add a model when it increases the train set score the most.
Multi-level stacking
-
Always do OOF predictions: you never know when you need to train a 2nd or 3rd level meta-classifier.
-
Try skip connections to deeper layers.
-
For 7.5 models in previous layer add 1 meta model in next layer.
-
Try StackNet which resembles a feedforward neural network and uses Wolpert's stacked generalization (built iteratively one layer at a time) in multiple levels to improve accuracy in machine learning problems.
-
Try Heamy - a set of useful tools for competitive data science (including ensembling).
https://drive.google.com/drive/folders/1CkGuP3wn9AAhEXIVEcHFKOVK9OCn3B2I?usp=sharing (è anche qua sul drive del MLJC)
http://ndres.me/kaggle-past-solutions/
https://www.kaggle.com/python10pm/plotting-with-python-learn-80-plots-step-by-step