Visual Question Answering (or VQA), a fascinating frontier of AI research, engages in addressing open-ended questions about images. This task places a computer in the role of providing a relevant, logical answer to a text-based question about a specific image. This requires a sophisticated understanding of not only visual and language processing, but also common sense knowledge to respond effectively.
BLIP is a Vision-Language Pre-training (VLP) framework, proposed by researchers at Salesforce, that learns from noisy image-text pairs. VLP frameworks allow the unification of Vision and Language, thus allowing a much more comprehensive range of downstream tasks than existing methods. Both BLIP and BLIP-2 are built on the foundation of the Transformer architecture, a popular choice for many natural language processing tasks due to its ability to handle long-range dependencies and its scalability.
The success of BLIP can be attributed to two major components: MED and CapFilt.
The MED model is jointly pre-trained with three vision-language objectives: image-text contrastive learning, image-text matching, and image-conditioned language modeling. The architecture is as follows:
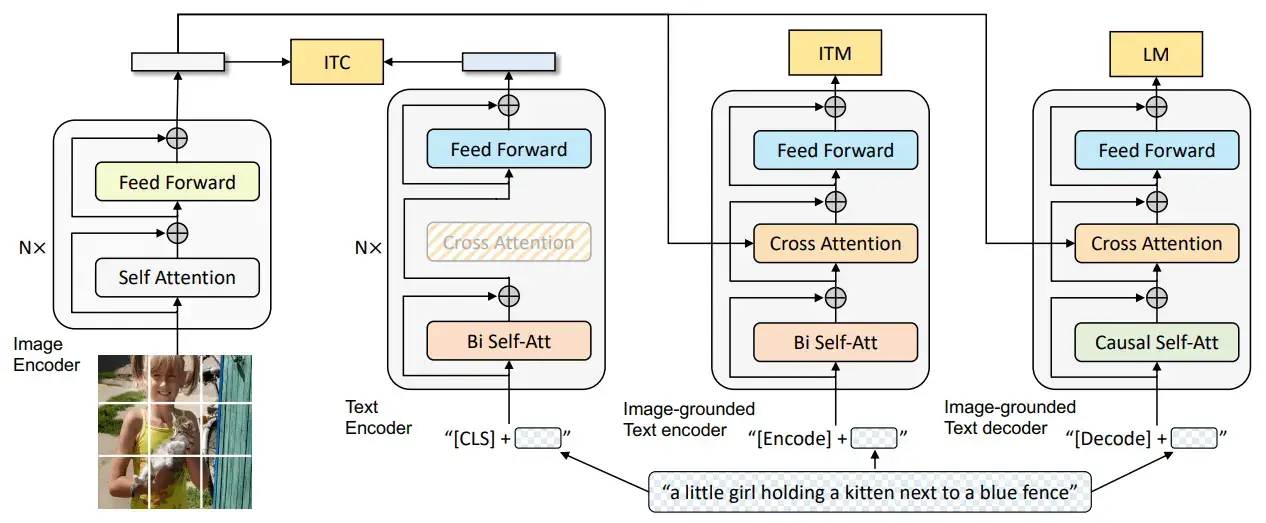
Note that the same color blocks share the parameters. We have an image encoder (the first model in the diagram) to encode the image into its latent space representation. It is then used to condition the text encoder (the third model in the diagram) and the text decoder (the fourth model in the diagram) on the input image using cross-attention layers. The cross-attention layer allows the models to capture the relationship between the two different sets of data (i.e., the input text and the input image) by attending to the most relevant parts of the context.
This proposed framework can operate in several ways, as follows:
The second model in the above diagram represents this. Its purpose is to encode the image and the text separately. This part of the framework is activated (and thus trained) using the image-text contrastive learning (ITC) loss. It allows us to encode only the text without looking at the image.
It's the third model in the above diagram. Its purpose is to encode the text with the injection of visual information via the cross-attention layers. This model is trained using the image-text matching (ITM) loss. This model allows us to encode the text depending on the image.
It is the fourth model in the above diagram and is used for decoding the text with the visual information injected via the cross-attention layers. It is learned using language modeling (LM) loss. This lets us decode the text depending on the image.
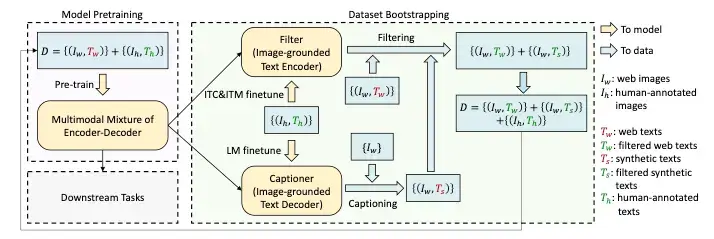
Image from Original BLIP paper
Since current models require massive amounts of data, it isn't easy to get high-quality data due to high annotation costs. CapFilt is a new method to improve the quality of the text corpus. It introduces two modules both of which are initialized from the same pre-trained objective and fine-tuned individually on the COCO dataset:
It is used to generate captions given the web images. It is an image-grounded text decoder and is fine-tuned with the LM objective to decode texts from given images.
It is used to remove noisy image-text pairs. The filter is an image-grounded text encoder and is finetuned with the ITC and ITM objectives to learn whether a text matches an image.
The image captioner generates synthetic captions for the web images and the filter removes noisy texts from both the original web texts and the synthetic texts. A key thing to notice is that the human-labeled captions remain as they are (not filtered) and are assumed to be the ground truth. These filtered image-text pairs along with the human-labeled captions form the new dataset which is then used to pre-train a new model. Related: Image Captioning using PyTorch and Transformers in Python
BLIP-2 is an advanced model proposed for Visual Question Answering designed to improve upon its predecessor, the BLIP model, by incorporating several enhancements.
The BLIP-2 model uses a two-stream architecture where one stream processes the image (like an image encoder) and the other processes the question (like a Large Language Model or an LLM). These two fixed streams of models are then fused to combine the features from the visual and textual inputs using a novel proposed fusion mechanism, named Q-former.
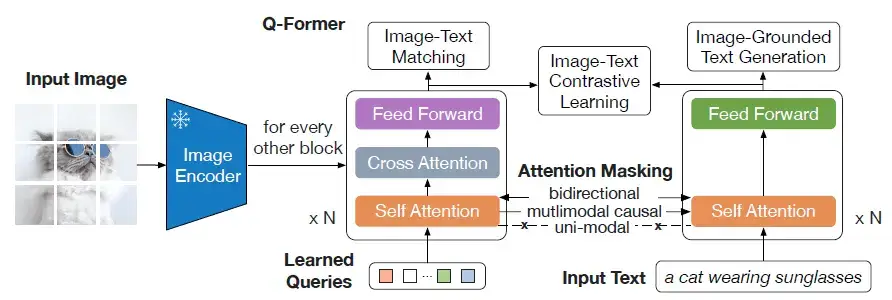
The Q-former consists of two submodules:
It is the model in the center of the above diagram. It interacts with the frozen image encoder for visual feature extraction. A fixed number of "learnable" queries are given as input to this transformer. These queries interact with each other through the self-attention layers and interact with the image features through the cross-attention layer as shown in the diagram. These queries can also interact with the text simply by sending a concatenation of the learnable queries and text tokens to the self-attention layer.
It is the model on the right in the above diagram. It acts as both the text decoder and text encoder. The text input to this model can also interact with the learnable queries in the same way mentioned above. Hence both the submodules share the self-attention layers.
The Q-former is trained on a range of objectives:
It helps in maximizing the mutual information we gain from the image and the text features by contrasting the image-text similarity of the positive pairs against the negative pairs.
Only the self-attention layer allows the interaction between the learnable image queries and the encoded text. Hence to perform this task, the learnable queries are forced to extract the visual features from the image features given to us by the frozen image encoder. These visual features also capture the information about the text.
In this task, the model is required to do a binary classification and tell us if an image-text pair is a positive pair or a negative pair.
There are different attention masks used in the self-attention layer as follows:
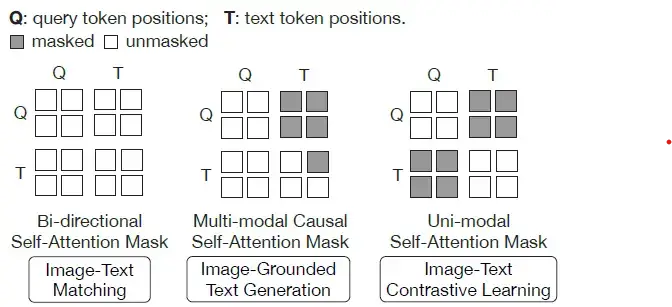
Image from Original BLIP-2 Paper
It allows both the learnable query tokens and the text tokens to interact with each other.
It allows the query tokens to interact with one another and allows the text tokens to interact only with the previously predicted text tokens and the query tokens.
It allows both the query and text tokens to interact amongst themselves but not with each other.
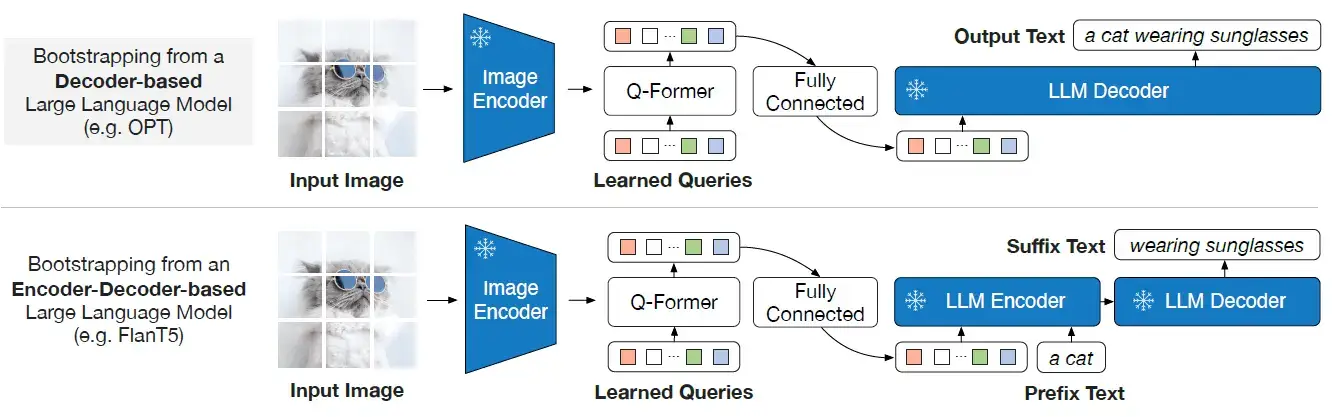
Image from Original BLIP-2 Paper
As shown above, in the generative pre-training stage, the Q-Former connects the Image encoder to the LLM. The output query embeddings are prepended to the input text embeddings, functioning as soft visual prompts that condition the LLM on visual representation extracted by the Q-Former. Since output embeddings are limited, this also serves as an information bottleneck that feeds only the most useful information to the LLM while removing any irrelevant information. This reduces the burden of the LLM to learn vision-language alignment, thus mitigating the catastrophic forgetting problem.
Notice in the diagram that to bring the output query embeddings Z into the same text embedding dimension, a linear fully connected layer is used.
The LLM being used here can be of two types:
It is pre-trained with language modeling loss where the frozen LLM is tasked to generate the text conditioned on visual representation from Q-Former.
It is pre-trained with prefix language modeling loss where the text is split into two parts and the first part along with the visual representation is sent as input to the LLM's encoder. The suffix text is used as a generation target for the LLM's decoder.
The Generative Image-to-text Transformer (GIT) is another model designed to unify vision-language tasks such as image/video captioning and question answering. It was proposed by a team of researchers at Microsoft. The GIT model is unique in its simplicity, consisting of just one image encoder and one text decoder under a single language modeling task.
The GIT model was trained on a massive dataset of 0.8 billion image-text pairs. This large-scale pre-training data and the model size significantly boost the model's performance. The GIT model has achieved impressive performance on numerous challenging benchmarks, even surpassing human performance on the TextCaps benchmark.
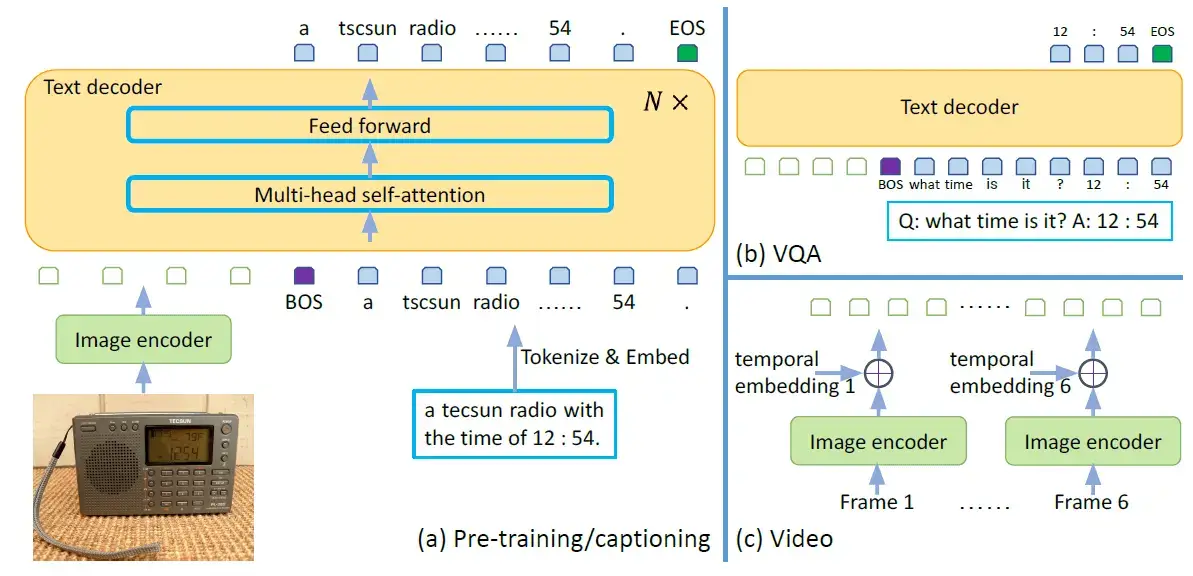
Image from the original GIT paper
The GIT model consists of an image encoder and a text decoder.
It is initialized as a contrastive pre-trained model, which takes a raw image as input and outputs a compact 2D feature map. This feature map is then flattened into a list of features, which are projected into a certain dimension (D) and fed into the text decoder.
It is a randomly initialized transformer module tasked with predicting the text description. It consists of multiple transformer blocks, each of which is composed of a self-attention layer and a feed-forward layer. The text is tokenized and embedded into D dimensions, followed by the addition of positional encoding and a layer normalization layer. The image features are concatenated with the text embeddings as input to the transformer module. The text begins with a [BOS] token and is decoded in an auto-regressive way until the [EOS] token or the maximum steps are reached. The entire model is trained using a language modeling task, where the goal is to predict the next word in a sentence given the previous words.
An important thing to note is that the attention mask is applied such that the text token only depends on the preceding tokens and all image tokens, and image tokens can attend to each other. This is different from a unidirectional attention mask, where not every image token can rely on all other image tokens.
The above figure also illustrates how the GIT model can be used for VQA from videos as well. To do this, we can first pass the different frames of the video through the image encoder to get the different frame embeddings. Then, we can add the temporal embeddings to the frame embeddings to avoid loss of temporal information and pass the final result to the text decoder.
For Visual Question Answering we Propose a Gemini Model(gemini-1.5-flash)
Google doesnot provide the clear architecture for the gemini model they released architecture as follows:

code for Our Visual Question Answering is as
#VQA from User input Questions
from PIL import Image
import requests
from io import BytesIO
from IPython.display import display
import google.generativeai as genai
# Bold formatting for output
BOLD_BEGIN = "\033[1m"
BOLD_END = "\033[0m"
# Set the API key directly in the code
api_key = "Your API key" # your api key
# Ensure the API key is set
if not api_key:
raise ValueError("API_KEY must be set.")
# Configure the generative AI client
genai.configure(api_key=api_key)
# Instantiate the Gemini model specifically for vision
model = genai.GenerativeModel(model_name="gemini-1.5-flash")
# Function to load and display the image from a URL
def display_image(url):
response = requests.get(url)
img = Image.open(BytesIO(response.content))
display(img)
return img
# Function to load and display a local image
def display_local_image(img_path):
img = Image.open(img_path)
display(img)
return img
# Function to process image and ask VQA questions
def process_image(img, questions):
# Iterate over questions and perform VQA
for question in questions:
response = model.generate_content([question, img])
response.resolve()
# Output the VQA response
print(f"{BOLD_BEGIN}Q:{BOLD_END} {question}")
print(f"{BOLD_BEGIN}A:{BOLD_END} {response.text}\n")
# User input for image source
image_source = input("Enter 'url' for a web image or 'local' for a local image: ").strip().lower()
if image_source == 'url':
image_url = input("Enter the URL of the image: ").strip()
img = display_image(image_url)
elif image_source == 'local':
local_image_path = input("Enter the path to the local image: ").strip()
img = display_local_image(local_image_path)
else:
print("Invalid input. Please enter 'url' or 'local'.")
img = None
if img:
# User input for questions
print("Enter your questions one by one. Type 'done' when finished.")
questions = []
while True:
question = input("Question: ").strip()
if question.lower() == 'done':
break
if question:
questions.append(question)
if questions:
process_image(img, questions)
else:
print("No questions were provided.")and Streamlit app for this repo is
import streamlit as st
from PIL import Image
import requests
from io import BytesIO
import google.generativeai as genai
# Function to load image from URL
def load_image_from_url(url):
try:
response = requests.get(url)
response.raise_for_status() # Raise an error for bad HTTP responses
img = Image.open(BytesIO(response.content))
return img
except requests.exceptions.RequestException as e:
st.error(f"Error fetching the image from URL: {e}")
return None
except IOError as e:
st.error(f"Error opening the image file: {e}")
return None
# Function to process image and ask VQA questions
def process_image(image, questions, api_key):
# Configure the generative AI client
genai.configure(api_key=api_key)
# Instantiate the Gemini model
model = genai.GenerativeModel(model_name="gemini-1.5-flash")
responses = []
for question in questions:
response = model.generate_content([question, image])
responses.append((question, response.text))
return responses
# Streamlit app
def main():
st.title("Visual Question Answering with Gemini")
# API Key Input
api_key = st.text_input("Enter your API key:", type="password")
if not api_key:
st.warning("Please enter your API key.")
return
# Image upload section
image_source = st.radio("Select image source", ('URL', 'Local Upload'))
img = None # Initialize img variable
if image_source == 'URL':
image_url = st.text_input("Enter the URL of the image:")
if image_url:
img = load_image_from_url(image_url)
if img:
st.image(img, caption='Uploaded Image', use_column_width=True)
elif image_source == 'Local Upload':
uploaded_file = st.file_uploader("Choose an image file", type=["jpg", "jpeg", "png"])
if uploaded_file is not None:
try:
img = Image.open(uploaded_file)
st.image(img, caption='Uploaded Image', use_column_width=True)
except IOError as e:
st.error(f"Error opening the uploaded file: {e}")
# Questions input section
questions = st.text_area("Enter your questions (one per line):", height=200)
questions_list = questions.splitlines()
if st.button("Submit Questions"):
if img and questions_list:
responses = process_image(img, questions_list, api_key)
for question, answer in responses:
st.write(f"**Q:** {question}")
st.write(f"**A:** {answer}")
else:
if not img:
st.error("Please upload a valid image or provide a valid URL.")
if not questions_list:
st.error("Please enter your questions.")
if __name__ == "__main__":
main()