Onnxrt 11 7 sync merge #22
Closed
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
### Description this is for ORT 1.17.0 - make ORT to use ONNX release 1.15.0 branch. Eventually will update to the release tag once ONNX 1.15.0 is released ### Motivation and Context Prepare for ORT 1.17.0 release. People can start work on new and updated ONNX ops in ORT. --------- Signed-off-by: Liqun Fu <[email protected]>
### Description <!-- Describe your changes. --> Fix for this issue which raise the error of FileNotAccessd in windows when the context of TemporaryDirectory finished. microsoft#17627 ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> microsoft#17627
### Description <!-- Describe your changes. --> * Allow either an allocator or a MemBuffer to be used when creating an OrtValue from an TensorProto * `Tensor<std::string>` requires an allocator to allocate/free the string values * Forcing the buffer to be allocated outside of the Tensor doesn't seem to provide any benefit in this usage as the Tensor class disables copy and assignment (so we wouldn't create 2 copies of the buffer via the Tensor class that externally managing the would buffer avoid) * New approach means we don't need to manage the buffers in the optimizer Info class as the Tensor dtor will do that * Update naming - MLValue was replaced by OrtValue a long time ago ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> microsoft#17392
…zer (microsoft#17618) ### Description <!-- Describe your changes. --> Add ability for transpose optimizer to look past a DQ node if it has a constant initializer as input. This allows UnsqueezeInput/TransposeInput to modify the initializer in-place in the same way it would for a non-QDQ format model. Shared initializers are also handled, and any additional Squeeze/Transpose added to the other usages of the initializer should cancel out when we push the same Transpose though them. The in-place modification means we don't need to run QDQ fixup and constant folding after layout transformation. This means we do not need to enable those optimizers in a minimal build to get an optimal model post-layout transformation. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> Ensure layout transformation produces optimal model in full and minimal builds. --------- Co-authored-by: Edward Chen <[email protected]>
Add Gelu/QuickGelu/GeluGrad/QuickGeluGrad support to Triton Codegen so that it can be fused with some other connected supported Ops. For example, in llama2, it can be fused with Mul so we will have extra 1-2% perf gain.
### Description A follow-up for microsoft#17125
This caused a cmake configuration error.
### Description Move appending source name behind the ModifyNameIfDisabledTest ### Motivation and Context In winml, disabled test name doesn't include the model source name. WinML job will be broken in the new image. https://dev.azure.com/onnxruntime/onnxruntime/_build/results?buildId=1151451&view=logs&s=4eef7ad1-5202-529d-b414-e2b14d056c05 ### Verified https://dev.azure.com/onnxruntime/onnxruntime/_build/results?buildId=1151691&view=logs&s=4eef7ad1-5202-529d-b414-e2b14d056c05
…ault constructor (microsoft#17705) ### Description <!-- Describe your changes. --> ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
### Description
The condition check is not correct
```
if (is_unidirectional_ && enable_fused_causal_attention_) { // GPT
}
else { // BERT
}
```
Change it to
```
if (is_unidirectional_) { // GPT
}
else { // BERT
}
```
Another walkaround is to enable fused causal attention by adding an
environment variable `ORT_ENABLE_FUSED_CAUSAL_ATTENTION=1` before
running stable diffusion.
### Motivation and Context
Without the fix, optimized CLIP model of stable diffusion will encounter
error in running Attention node:
2023-09-24 16:15:31.206037898 [E:onnxruntime:,
sequential_executor.cc:514 ExecuteKernel] Non-zero status code returned
while running Attention node. Name:'Attention_0' Status Message:
/onnxruntime_src/onnxruntime/contrib_ops/cuda/bert/tensorrt_fused_multihead_attention/mha_runner.cu:207
bool
onnxruntime::contrib::cuda::FusedMHARunnerFP16v2::mhaImpl::is_flash_attention(int)
const interface->mHasCausalMask == false was false.
Note that the bug has been there for a long time. It is just surfaced
since we recently added a fusion for CLIP, which will trigger the error.
We will add a comprehensive test for causal attention later to avoid
such corner cases.
### Description <!-- Describe your changes. --> - Treat Resize as layout sensitive by default - whilst the ONNX spec does not specify a layout, EPs tend to implement only one - add second usage in L2 of TransposeOptimizer to plugin the ability to push a Transpose through a Resize assigned to the CPU EP - Allow EP specific logic for changes the ops considered to be layout sensitive to be plugged in - expected usage is for microsoft#17200 ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> Finish simplifying/clarifying transpose optimization and layout transformation that was proposed in microsoft#15552. This PR along with microsoft#17618 should complete the changes. --------- Co-authored-by: Edward Chen <[email protected]>
### Description /usr/local/bin can only be modified by root. This command seems unnecessary
### Description Add ConvTranspose implementation using MatMul to increase perf. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
<del> **This PR is based on a few prerequisites PRs. They are listed as below:** - microsoft#17465 - microsoft#17469 - microsoft#17470 - microsoft#17472 - microsoft#17473 - microsoft#17484 Please review the current change by only looking at commit e2e6623 and later. </del> ### Description This PR introduces WebGPU IO binding. This new feature allows onnxruntime-web users to use tensors created from GPU as model input/output so that a model inferencing can be done without unnecessary data copy between CPU and GPU for model input/output. ### Examples An E2E demo/example is being worked on. Following is some simple demo with code snippet. Let's first check today how we do: ```js // STEP.1 - create an inference session: const mySession = await ort.InferenceSession.create('./my_model.onnx', { executionProviders: ['webgpu'] }); // STEP.2 - create model input: (supposing myImageCpuData is a Float32Array) const feeds = { 'input_image:0': new ort.Tensor('float32', myImageCpuData, [1, 224, 224, 3]) }; // STEP.3 - run model const myResults = await mySession.run(feeds); // STEP.4 - get output data const myData = myResults['output_image:0'].data; // Float32Array ``` #### for inputs (GPU tensor): Now, with IO binding, you can create a tensor from a GPU buffer, and feed it to the model: ```js // new STEP.2.A - create model input from a GPU buffer: (supposing myInputGpuBuffer is a `GPUBuffer` object with input data) const feeds = { 'input_image:0': ort.Tensor.fromGpuBuffer(myInputGpuBuffer, { dataType: 'float32', dims: [1, 224, 224, 3] }) }; ``` ### for outputs (pre-allocated GPU tensor) you can also do that for output, **if you know the output shape**: ```js // new STEP.2.B - create model output from a GPU buffer: (supposing myOutputGpuBuffer is a pre-allocated `GPUBuffer` object) const fetches = { 'output_image:0': ort.Tensor.fromGpuBuffer(myOutputGpuBuffer, { dataType: 'float32', dims: [1, 512, 512, 3] }) }; // new STEP.3 - run model with pre-allocated output (fetches) const myResults = await mySession.run(feeds, fetches); ``` ### for outputs (specify location) if you do not know the output shape, you can specify the output location when creating the session: ```js // new STEP.1 - create an inference session with an option "preferredOutputLocation": const mySession = await ort.InferenceSession.create('./my_model.onnx', { executionProviders: ['webgpu'], preferredOutputLocation: "gpu-buffer" }); ``` if the model has multiple outputs, you can specify them seperately: ```js // new STEP.1 - create an inference session with an option "preferredOutputLocation": const mySession = await ort.InferenceSession.create('./my_model.onnx', { executionProviders: ['webgpu'], preferredOutputLocation: { "output_image:0": "gpu-buffer" } }); ``` now you don't need to prepare the `fetches` object and onnxruntime-web will prepare output data on the location that specified. #### read data when you get the output tensor, you can: ```js // get the gpu buffer object: const gpuBuffer = myOutputTensor.gpuBuffer; // GPUBuffer // get the CPU data asynchronizely const cpuData = await myOutputTensor.getData(); // get the CPU data asynchronizely and release the underlying GPU resources const cpuData = await myOutputTensor.getData(true); // dispose the tensor (release the underlying GPU resources). This tensor object will be invalid after dispose() is called. myOutputTensor.dispose(); ``` #### resource management JavaScript has GC so you don't need to worry about managing JavaScript objects. But there are 2 types of resources that are not managed by GC: - GPU buffer that used in tensors - Underlying ORT native resources To simplify, most of the unmanaged resources and handled inside ORT web. But there are a few resources that need users to manage: - All external GPU resources, including GPU buffers inside all tensors created by `Tensor.fromGpuBuffer()`, will not be managed by ORT. User should manage those GPU buffers themselves. - When a session is created with `preferredOutputLocation` == "gpu-buffer" specified in session options, and the corresponding output is not pre-allocated, user need to call the output tensor's `dispose()` or `getData(true)` to manually release the underlying GPU buffers. - ORT internal errors (including providing a pre-allocated output tensor with wrong type/dims) will invalidate the whole wasm memory and is not recoverable. An exception is thrown in this situation.
### Description Google test can be built either with absl/re2 or not. This PR enables the build option so that google test framework can print out a nice stacktrace when something went wrong. It helps locate test errors in CI build pipelines. Also, Google test will remove the build option and make it always ON. So sooner or later we must make this change.
…osoft#17730) Python API to check whether collective ops are available or not ### Description <!-- Describe your changes. --> Adding an API to check whether collective ops are available or not. Since there is no independent MPI enabled build, this flag can be used on Python front for branching. Specifically, to conditionally enable tests. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> Flag to be used in Python to check whether onnxruntime supports collective ops or not. Handy for conditionally enabling/disabling tests and for other branching decisions.
### Description <!-- Describe your changes. --> Use `.buffer` of Uint8Array to get ArrayBuffer. TODO: Add E2E React Native test case to cover JS level testing to avoid future breakage. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> microsoft#17732 Co-authored-by: rachguo <[email protected]>
### Description Following the design document: * Added CreateTrainingSessionHandler to the Backend interface * All existing Backend implementations throw an error for the new method createTrainingSessionHandler * Created TrainingSession namespace, interface, and TrainingSessionFactory interface * Created TrainingSessionImpl class implementation As methods are implemented, the TrainingSession interface will be added to or modified. ### Motivation and Context Adding the public-facing interfaces to the onnxruntime-common package is one of the first steps to support ORT training for web bindings. --------- Co-authored-by: Caroline Zhu <[email protected]>
…crosoft#17727) ### Description Add support for specifying a custom logging function per session. Bindings for other languages will be added after this PR is merged. ### Motivation and Context Users want a way to override the logging provided by the environment.
### Description Another three ops for fp16 --------- Co-authored-by: Guenther Schmuelling <[email protected]> Co-authored-by: Yulong Wang <[email protected]>
The patch also introduces the method which copies data from GPU to CPU synchronously. ### Description <!-- Describe your changes. --> ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
) In [`quantize_subgraph`](https://github.com/microsoft/onnxruntime/blob/v1.16.0/onnxruntime/python/tools/quantization/onnx_quantizer.py#L188-L189) `self.weight_qType` and `self.activation_qType` are [integers](https://github.com/microsoft/onnxruntime/blob/v1.16.0/onnxruntime/python/tools/quantization/onnx_quantizer.py#L115-L116) while `ONNXQuantizer` expects `QuantType`
### Description <!-- Describe your changes. --> Update E2E test to also check InferenceSession.create with bytes. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> Add tests to validate microsoft#17739
### Description <!-- Describe your changes. --> WebNN only supports 2-D input tensor along axis 1. For now, we use Reshape and Transpose wraparound to get the compatible input. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> Enable more models to run on WebNN.
### Description
Allow WebGPU backend to specify `preferredLayout`. Default is NHWC.
```js
const options = {executionProviders: [{name:'webgpu', preferredLayout: 'NCHW'}]};
sess1 = await ort.InferenceSession.create('./mobilenetv2-12.onnx', options);
```
### Motivation and Context
- implement @qjia7's requirement for an easier way to do performance
comparison between NCHW vs NHWC.
- It's possible that NCHW does better on some models and NHWC on others.
So offer user the capability to switch.
…soft#18127) ### Description Update the C# nuget build infrastructure to make building a test nuget package more user friendly and to simplify - Remove usage of dotnet and msbuild in CIs - was temporary requirement until .net 6 MAUI was added to the released Visual Studio - remove SelectedTargets property and its usage - Add property for excluding mobile targets - generally we exclude based on the nuget package name - can now specify `/p:IncludeMobileTargets=false` on the command line to force exclusion - support building test package using build.py `--build_nuget` better - limit inclusion of xamarin targets as building with them requires a lot more infrastructure - use msbuild directly if xamarin targets are included. use dotnet otherwise. - remove quoting of property values as it doesn't appear to be necessary and breaks when msbuild is being used - add infrastructure to be able to pack the nuget package on linux with `dotnet pack` - `nuget pack` is not user friendly as-per comments in changes - requires stub csproj to provide the nuspec path - Remove netstandard1.0 targets from nuspec - we removed support from the actual bindings previously - Remove usage of nuget-staging directory when creating nuget package on linux - the nuspec file element has a fully qualified path for a source file so there is no obvious benefit to copying to a staging directory prior to packing ### Motivation and Context Address issues with 1P users trying to create test nuget packages locally. Long overdue cleanup of CI complexity.
### Description
QNN EP has 2 unit tests failing:
TEST_F(QnnHTPBackendTests, DISABLED_PadReflectMode)
TEST_F(QnnHTPBackendTests, DISABLED_Pad4dOutOfRangePadConstantValue)
For the first unit test, in QNN's master definition, it is stated that
when using MIRROR_REFLECT, the before and after pad amounts must not be
greater than shape(in[0])[i] - 1. Therefore, we need to change the pad
amount from {0,2,0,0} to {0,1,0,0}.
For second unit test, QNN does not have limitations stating that pad
constant should be smaller than input[0]. The reason that the test is
failing is because the unit test did not take the pad constant into
consideration when doing quantization.
### Motivation and Context
Fix the 2 unit tests mentioned in description.
### Description Added uniforms support to unary ops. ### Motivation and Context Improve performance
This PR fixes the the signed mismatch warning in DmlRuntimeFusedGraphKernel. This warning is treated as an error on the x86 versions of our internal builds preventing us from updating to latest ORT.
### Description Change a bitwise logical xor to logical-wise ### Motivation and Context For Boolean values we should not use bitwise operations.
Make MlasTestFixture::mlas_tester an inline variable. With this change we no longer need to define `MlasTestFixture<T>::mlas_tester` outside of the class definition.
### Description Replace block-wise 4b quantization implementation ### Motivation and Context In microsoft#18101 we have an augmented block-wise 4b quantization interface and implementation. Here we use this new implementation in onnxruntime contrib ops --------- Co-authored-by: Edward Chen <[email protected]>
When the model has "shape tensor" as one of the inputs and user provides explicit profile shapes for it, TRT EP doesn't correctly set the "shape tensor" input. Also, there is a bug for applying explicit profile shapes for the shape tensor input. Note: It seems the model has shape tensor input is a rare case. Most of the cases, the inputs are all execution tensor.
### Description This PR removes an internal `ORT_ENFORCE` when binding `torch.tensor` inputs using IO binding for end-to-end scripts. ### Motivation and Context In merged exports of PyTorch models to ONNX, each past key and past value in the past KV cache has an input shape of `(batch_size, num_heads, past_sequence_length, head_size)`. In the first pass through the model to process the prompt, `past_sequence_length = 0`. Therefore, each of these inputs is of shape `(batch_size, num_heads, 0, head_size)`. In subsequent passes, `past_sequence_length > 0`. When binding a `torch.tensor` of shape `(batch_size, num_heads, 0, head_size)` with `io_binding.bind_input`, the tensor's `data_ptr()` must be passed. For a `torch.tensor` of this shape, its `data_ptr()` returns 0. Because it returns 0, the existing `ORT_ENFORCE` is therefore false and an error is raised. By removing the internal `ORT_ENFORCE`, no error is raised and the model runs successfully. LLaMA-2 Example: Input Name | Input Size | Device | Device ID | Torch Dtype | data_ptr() ------------- | ----------- | ------- | ----------- | ------------- | ----------- input_ids | torch.Size([1, 11]) | cuda | 7 | torch.int64 | 140639561842688 attention_mask | torch.Size([1, 11]) | cuda | 7 | torch.int64 | 140639561843200 position_ids | torch.Size([1, 11]) | cuda | 7 | torch.int64 | 140639561844224 past_key_values.0.key | torch.Size([1, 32, 0, 128]) | cuda | 7 | torch.float32 | 0 past_key_values.0.value | torch.Size([1, 32, 0, 128]) | cuda | 7 | torch.float32 | 0 ... | ... | ... | ... | ... | ...
…oft#18274) microsoft#17468 The above PR didn't fully fix the issue for some environments. This PR fixes this.
### Description <!-- Describe your changes. --> When take a tensor's data as raw, clear data with other types within the tensor. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? --> One model's graph transformation caused a node with multiple data types. This would make the model valid.
### Description Add CI changes for microsoft#18287 Install onnx explicitly to pass windows GPU+dml stage. ### Motivation and Context 'eigen-3.4' was refering to a branch, not to a tag. There is now an Eigen 3.4.1 on that branch, and thus the hash has changed. See microsoft#18286 (comment)
1. Now we use a released version of ONNX, so we can directly download a prebuilt package from pypi.org. We do not need to build one from source. 2. Update protobuf python package's version to match the C/C++ version we are using. 3. Update tensorboard python python because the current one is incompatible with the newer protobuf version.
### Description TestInlinedLocalFunctionNotRemoved checks that local functions are not removed but TVM EP optimizes the whole graph after it is inlined.
### Description Enable Expand Op. There no directly mapping from Onnx Expand op to QNN. Need to use ElementWiseMultiply to do the data broadcast. Basically create the 2nd input with value 1.0 and use the shape data from Expand op.
Implementat DistributedSqueeze & DistributedUnsqueeze for llama 2.
…ft#18288) Although SimplifiedLayerNorm is faster than LayerNorm, DML doesn't have an optimized implementation for the former yet and LayerNorm ends up being faster.
Update a few optimizations for Stable Diffusion XL: (1) Add SkipGroupNorm fusion (2) Remvoe GroupNorm fusion limits. Previously, we only fuse GroupNorm when channels is one of `320, 640, 960, 1280, 1920, 2560, 128, 256, 512` so some GroupNorm in refiner was not fused. (3) Tune SkipLayerNormalization to use vectorized kernel for hidden size 320, 640 and 1280. Pipeline Improvements: (4) Enable cuda graph for unetxl. (5) Change optimization to generate optimized fp32 model with ORT, then convert to fp16. Otherwise, fp16 model might be invalid. (6) Add option to enable-vae-slicing. Bug fixes: (a) Fix vae decode in SD demo. (b) Fix UnipPC add_noise missing a parameter. (c) EulerA exception in SDXL demo. Disable it for now. (d) Batch size > 4 has error in VAE without slicing. Force to enable vae slicing when batch size > 4. #### Performance Test on A100-SXM4-80GB Description about the experiment in results: *Baseline*: removed GroupNorm fusion limits; CUDA graph is enabled in Clip and VAE, but not in Clip2 and UNet. *UNetCG*: Enable Cuda Graph on UNet *SLN*: Tune SkipLayerNormalization *SGN*: Add SkipGroupNorm fusion The latency (ms) of generating an image of size 1024x1024 with 30 steps base model and 9 steps of refiner model: | Baseline | UNetCG| UNetCG+SLN | UNetCG+SLN+SGN -- | -- | -- | -- | -- Base Clip | 3.74 | 3.70 | 3.88 | 3.81 Base Unet x30 | 2567.73 | 2510.69 | 2505.09 | 2499.99 Refiner Clip | 7.59 | 7.42 | 7.41 | 7.58 Refiner Unet x 9 | 814.43 | 803.03 | 802.20 | 799.06 Refiner VAE Decoder | 84.62 | 85.18 | 85.24 | 87.43 E2E | 3480.56 | 3412.05 | 3405.77 | 3400.23 We can see that enable cuda graph brought major gain (around 68ms). SLN Tuning has about 7ms gain. SkipGroupNorm fusion has 5ms gain. SkipGroupNorm fusion won't reduce latency much, while it also has benefit of reducing memory usage, so it is recommended to enable it. ### Motivation and Context Additional optimizations upon previous work in microsoft#17536.
improve 2 python functions a little bit. according to a profiling result from a real user case, we find that 2 python function can be improved. the first is the result before improvement, the second is after improvement, we can see 8ms saved from the improvement. 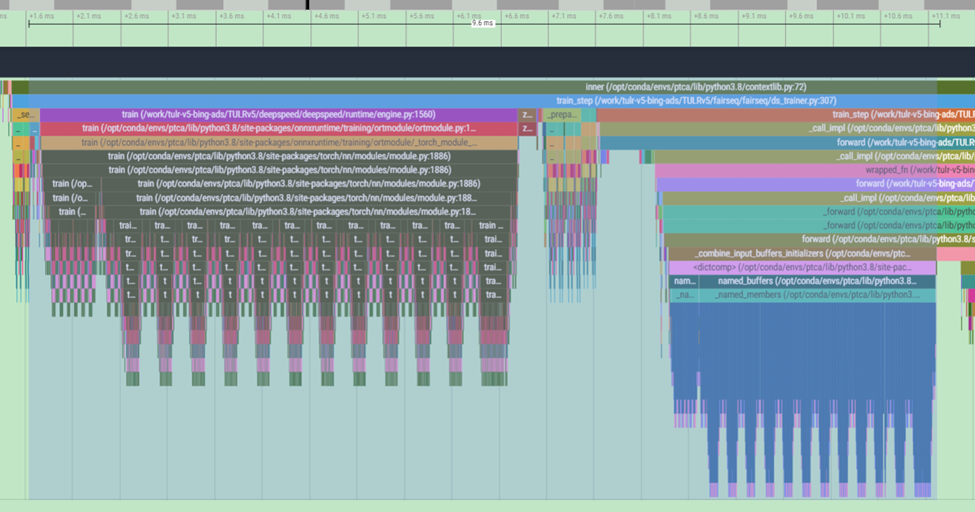 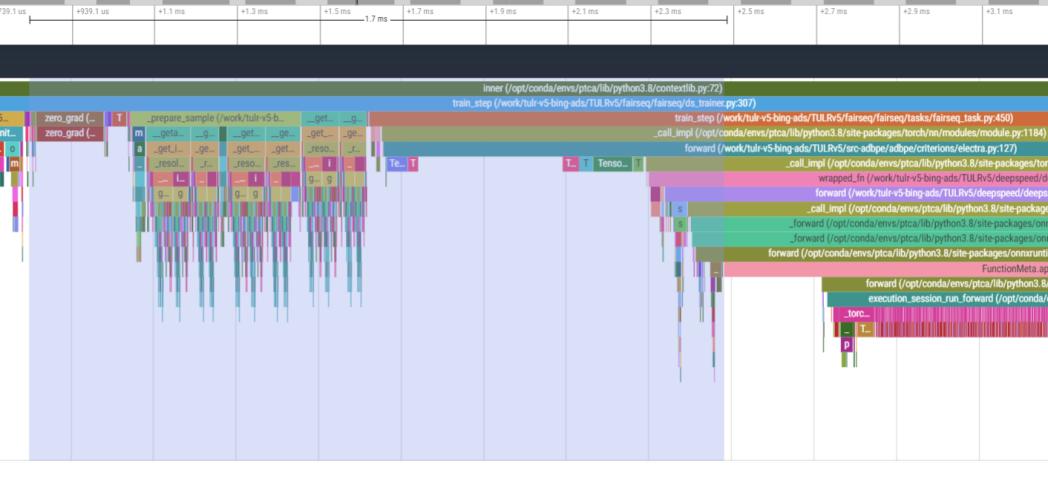
{kind=link}
{kind=link}
### Customize _get_tensor_rank for model export in stage3 Weight/Params sizes are all (0), so exporter logic depending on input shape will fail. This PR override `_get_tensor_rank` function by retrieving the shape for weight differently. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
### Description Add the pool definition in 2 stages even the pool is Microsoft-Hosted Pool. ### Motivation and Context Recently, in Nuget pipeline, when we click the Stages to Run  It always pops up ``` Encountered error(s) while parsing pipeline YAML: Could not find a pool with ID 5206. The pool does not exist or has not been authorized for use. For authorization details, refer to https://aka.ms/yamlauthz. Could not find a pool with ID 5206. The pool does not exist or has not been authorized for use. For authorization details, refer to https://aka.ms/yamlauthz. ```
This is a graph implementation of RotaryEmbedding since there's no time to add it to DML before 1.16.2, but it eventually should move into DirectML since we're bandwidth-bound.
### Description Added Uniform support to binary ops ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> To improve performance
…oft#18280) ### Description <!-- Describe your changes. --> Updates input/output type constraints on training operators ConcatTraining and SplitTraining to include bfloat16 which was introduced in IR version 4. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> Enabling `meta-llama/Llama-2-70b` to be finetuned with ONNX Runtime training. Co-authored-by: Prathik Rao <[email protected]@orttrainingdev8.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
|
Closing this out. needed changes found in #23 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Description
Sync merge of upstream changes for 6.0 internal testing, fixes build issues seen with eigen 3.4 which are fixed upstream.
Motivation and Context
Fixes builds for ROCm 6.0
TODO: MIgraphX EP changes still in review: microsoft#17931
Will need to be pulled in once put into mainline.