SO 5.8 Tutorials TrickyThreadPool TrickyThreadPoolSimulation
The problem with adv_thread_pool is the same weight for all waiting messages. Once a worker thread finishes processing of the previous message the dispatcher assigns the first waiting message to the thread regardless of the type of that message. It leads to cases when all worker threads are busy by processing init_device_t or reinit_device_t messages and a lot of perform_io_t are waiting in the queue.
To solve this problem let's create a tricky thread_pool dispatcher that will have two sub-pools of worker threads of two types.
A worker thread of the first type will handle messages of all types. Messages init_device_t and reinit_device_t will have priority handling, but if there are no messages of those types then a message of any other type will be handled.
A worker thread of the second type can't handle messages of init_device_t and reinit_device_t type. It means that a thread of the second type can handle perform_io_t, but not init_device_t, nor reinit_device_t.
So if we have 50 messages of type reinit_device_t and 150 messages of type perform_io_t then the first sub-pool will process reinit_device_t messages, but the second sub-pool will process only perform_io_t at the same time. When all reinit_device_t message will be handled the first sub-pool will start the processing of perform_io_t messages.
It means that our tricky_thread_pool dispatcher has a separate sub-pool of thread for handling "fast" events. And that allows us not to "freeze" when there is a big amount of "slow" events (like a bunch of init_device_t messages at the start of the work).
To run a simulation with a tricky_thread_pool dispatcher we have to slightly modify the already shown run_example function:
void run_example(const args_t & args ) {
print_args(args);
so_5::launch([&](so_5::environment_t & env) {
env.introduce_coop([&](so_5::coop_t & coop) {
const auto dashboard_mbox =
coop.make_agent<a_dashboard_t>()->so_direct_mbox();
// Run the device manager of an instance of our tricky dispatcher.
coop.make_agent_with_binder<a_device_manager_t>(
tricky_dispatcher_t::make(env, args.thread_pool_size_),
args,
dashboard_mbox);
});
});
}It means that we create the same agents but bind a_device_manager_t to a different dispatcher.
As a result of a simulation with the same params we will see a different picture:
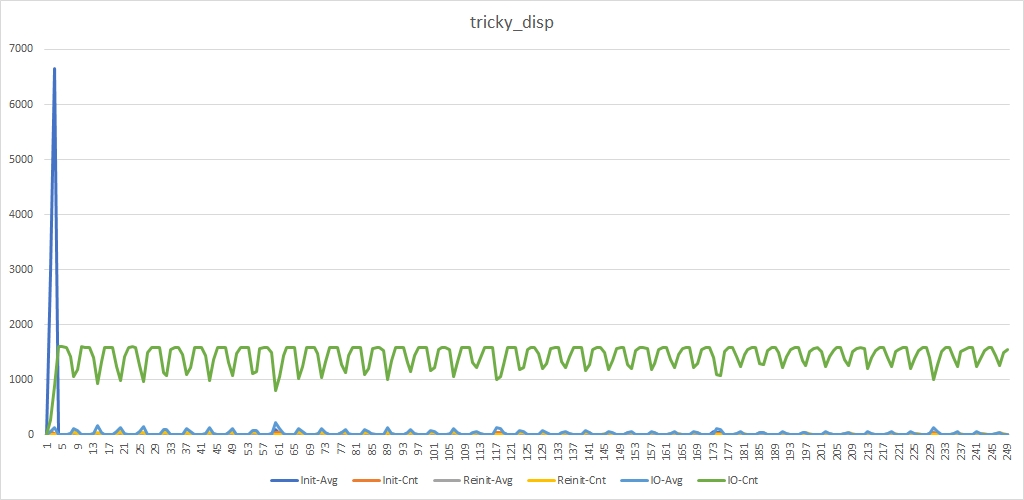
We still have the blue peak. It even higher now. It isn't a surprise because the lesser count of worker threads handle init_device_t messages. But we don't see gray peaks and green flops are shallower now.
It means that we have got the desired result. And now we can discuss the implementation of the tricky_thread_pool dispatcher.
The whole source code of tricky_thread_pool dispatcher implementation can be found here. Below we'll discuss the main points of that implementation.
There is no specific interface for a dispatcher in SObjectizer-5.8. Literally, any object can play the role of the dispatcher. But there are two interfaces tightly related to a dispatcher and those should be implemented for a custom dispatcher.
The first interface is disp_binder_t. An object of that type is responsible for binding an agent to the dispatcher instance. Every dispatcher has its own implementation of disp_binder_t interface.
The second interface is event_queue_t. Its goal is providing a way to push the demand for message handling to the dispatcher. Again, every dispatcher has its own implementation of event_queue_t interface.
The standard dispatchers in SObjectizer-5.8 also provide a dispatcher_handle_t type. This type is like shared_ptr and is used for holding a smart reference to an instance of the dispatcher. So if we look at the signature of make_dispatcher function for example for adv_thread_pool dispatcher we can see the following prototype:
inline dispatcher_handle_t
make_dispatcher(
//! SObjectizer Environment to work in.
environment_t & env,
//! Count of working threads.
std::size_t thread_count )
{
... // Some implementation.
}The implementation of standard dispatchers in SObjectizer vary significantly. Some dispatchers have different types for all entities: a separate type for the dispatcher itself, a separate type for implementation of disp_binder_t, a separate type for event_queue_t, and a separate dispatcher_handle_t. Some dispatchers use the one type for the dispatcher and for disp_binder_t, and a separate type for event_queue_t, and yet another for dispatcher_handle_t.
In our case, we don't need a dispatcher_handle_t type. Such type is useful if a dispatcher created long before the creation of agents to be bound to it. In such cases dispatcher_handle_t works just as shared_ptr. In the example discussed, we have to create just one agent and can bind it to our dispatcher immediately. So we can use such a helper method for the creation of tricky_thread_pool dispatcher:
so_5::disp_binder_shptr_t make(
so_5::environment_t & env, unsigned pool_size) {...}With that make method we can write the creation of an agent that way:
// Run the device manager of an instance of our tricky dispatcher.
coop.make_agent_with_binder<a_device_manager_t>(
tricky_dispatcher_t::make(env, args.thread_pool_size_),
args,
dashboard_mbox);But what's about disp_binder_t and event_queue_t interfaces?
Our tricky_thread_pool dispatcher has very simple implementation so there is no need to create a lot of separate classes. We'll have just one class that implements disp_binder_t, event_queue_t interfaces and the main logic of our tricky dispatcher. Because of that our dispatcher class will look like:
class tricky_dispatcher_t
: public so_5::disp_binder_t
, public so_5::event_queue_t {
...
};Let's look at the content of tricky_dispatcher_t class:
class tricky_dispatcher_t
: public so_5::disp_binder_t
, public so_5::event_queue_t {
class rundown_latch_t {...};
// A kind of std::lock_guard, but for rundown_latch_t.
class auto_acquire_release_rundown_latch_t {...};
// Type of container for worker threads.
using thread_pool_t = std::vector<std::thread>;
// Channels to be used as event-queues.
so_5::mchain_t start_finish_ch_;
so_5::mchain_t init_reinit_ch_;
so_5::mchain_t other_demands_ch_;
// The pool of worker threads for that dispatcher.
thread_pool_t work_threads_;
// Synchronization objects required for thread management.
//
// This one is for starting worker threads.
// The leader thread should wait while all workers are created.
rundown_latch_t launch_room_;
// This one is for handling evt_start,
// All workers (except the leader) have to wait while evt_start completed.
rundown_latch_t start_room_;
// This on is for handling evt_finish.
// The leader thread has to wait while all workers complete their work.
rundown_latch_t finish_room_;
static const std::type_index init_device_type;
static const std::type_index reinit_device_type;
...
};
const std::type_index tricky_dispatcher_t::init_device_type =
typeid(a_device_manager_t::init_device_t);
const std::type_index tricky_dispatcher_t::reinit_device_type =
typeid(so_5::mutable_msg<a_device_manager_t::reinit_device_t>);Here we can see three mchain that will be used as message queues and a container for worker threads. That is almost all that is necessary for our dispatcher.
There is no need to have two containers for two types of worker threads: we can store all threads in just one container for simplicity. The first part of that container will be occupied by threads of the first type, and the second part -- by threads of the second type. The presence of just one container simplified the procedure of dispatcher's shutdown:
// Helper method for shutdown and join all threads.
void shutdown_work_threads() noexcept {
// All channels should be closed first.
so_5::close_drop_content(so_5::terminate_if_throws, start_finish_ch_);
so_5::close_drop_content(so_5::terminate_if_throws, init_reinit_ch_);
so_5::close_drop_content(so_5::terminate_if_throws, other_demands_ch_);
// Now all threads can be joined.
for(auto & t : work_threads_)
t.join();
// The pool should be dropped.
work_threads_.clear();
}There are three mchains in tricky_dispatcher_t class. Two of them are used as message queues. But the first one, init_reinit_ch_ will hold only messages of types init_device_t or reinit_device_t. The second, other_demands_ch_ will hold messages of any other types.
Yet another mchain, start_finish_ch_, is necessary to handle evt_start and evt_finish demands. We'll talk about such demands below.
We'll see the usage of those mchains bellow when the implementation of worker threads will be discussed.
An instance of our tricky dispatcher is automatically started in the constructor and stopped in the destructor:
// The constructor that starts all worker threads.
tricky_dispatcher_t(
// SObjectizer Environment to work in.
so_5::environment_t & env,
// The size of the thread pool.
unsigned pool_size)
: start_finish_ch_{
so_5::create_mchain(env,
2u, // Just evt_start and evt_finish.
so_5::mchain_props::memory_usage_t::preallocated,
so_5::mchain_props::overflow_reaction_t::abort_app)
}
, init_reinit_ch_{so_5::create_mchain(env)}
, other_demands_ch_{so_5::create_mchain(env)}
{
const auto [first_type_count, second_type_count] =
calculate_pools_sizes(pool_size);
launch_work_threads(first_type_count, second_type_count);
}
~tricky_dispatcher_t() noexcept override {
// All worker threads should be stopped.
shutdown_work_threads();
}It means that a tricky dispatcher starts as soon as we created it. And will be stopped automatically when all agents bound to it will be destroyed (aka deregistered from SObjectizer). All the standard dispatchers in SObjectizer-5.8 work that way.
Now we can take a look at the implementation of worker threads. That's all:
// A handler for so_5::execution_demand_t.
static void exec_demand_handler(so_5::execution_demand_t d) {
d.call_handler(so_5::null_current_thread_id());
}
// The body for a thread of the first type.
void first_type_thread_body() {
// Run until all channels will be closed.
so_5::select(so_5::from_all().handle_all(),
receive_case(init_reinit_ch_, exec_demand_handler),
receive_case(other_demands_ch_, exec_demand_handler));
}
// The body for a thread of the second type.
void second_type_thread_body() {
// Run until all channels will be closed.
so_5::select(so_5::from_all().handle_all(),
receive_case(other_demands_ch_, exec_demand_handler));
}A thread of the first type reads messages from two mchains until they will be closed. It means that if there are init_device_t or reinit_device_t messages they will be handled. But if init_reinit_ch_ is empty then messages from the second mchain will be handled.
A thread of the second type even simpler: it reads only one mchain.
To make the picture full it is necessary to show launch_work_threads method. There is nothing magical:
// Launch all threads.
// If there is an error then all previously started threads
// should be stopped.
void launch_work_threads(
unsigned first_type_threads_count,
unsigned second_type_threads_count) {
work_threads_.reserve(first_type_threads_count + second_type_threads_count);
try {
// The leader has to be suspended until all workers will be created.
auto_acquire_release_rundown_latch_t launch_room_changer{launch_room_};
// Start the leader thread first.
work_threads_.emplace_back([this]{ leader_thread_body(); });
// Now we can launch all remaining workers.
for(auto i = 1u; i < first_type_threads_count; ++i)
work_threads_.emplace_back([this]{ first_type_thread_body(); });
for(auto i = 0u; i < second_type_threads_count; ++i)
work_threads_.emplace_back([this]{ second_type_thread_body(); });
}
catch(...) {
shutdown_work_threads();
throw; // Rethrow an exception to be handled somewhere upper.
}
}Here we can see start of another thread type:
// Start the leader thread first.
work_threads_.emplace_back([this]{ leader_thread_body(); });It's time to speak about evt_start and evt_finish demands and guarantees that have to be provided by a dispatcher.
There are two special demands that are sent to an agent by SObjectizer: evt_start (for calling agent_t::so_evt_start) and evt_finish (for calling agent_t::so_evt_finish). And a dispatcher has to provide the following guarantees related to evt_start/finish demands:
- processing of
evt_startmust to started and completed before processing of all other demands (it especially important for dispatches that can run agent's event handlers in parallel, like adv_thread_pool-dispatcher); - processing of the
evt_finishmust be started after the completion of all the previous requests for an agent; - the
evt_finishmust be the last demand processed for an agent.
To fulfil such requirements the tricky_dispatcher_t uses a separate mchain for holding evt_start and evt_finish demands only. It also uses a special thread named the leader thread. It starts first and completes after all other worker thread. This thread receives and handles evt_start and evt_finish demands:
// The body of the leader thread.
void leader_thread_body() {
// We have to wait while all workers are created.
// NOTE: not all of them can start their work actually, but all
// std::thread objects should be created.
launch_room_.wait_then_close();
{
// We have to block all other threads until evt_start will be processed.
auto_acquire_release_rundown_latch_t start_room_changer{start_room_};
// Process evt_start.
so_5::receive(so_5::from(start_finish_ch_).handle_n(1),
exec_demand_handler);
}
// Now the leader can play the role of the first thread type.
first_type_thread_body();
// All worker should finish their work before processing of evt_finish.
finish_room_.wait_then_close();
// Process evt_finish.
so_5::receive(so_5::from(start_finish_ch_).handle_n(1),
exec_demand_handler);
}After handling of evt_start and before receiving evt_finish it plays the role of the first thread type.
To implement event_queue_t interface we have to define three methods (since v.5.8.0, previous versions require just one): push(), push_evt_start, and push_evt_finish. In our tricky dispatcher these methods look the following way:
// Implementation of the methods inherited from event_queue.
void push(so_5::execution_demand_t demand) override {
if(init_device_type == demand.m_msg_type ||
reinit_device_type == demand.m_msg_type) {
// That demand should go to a separate queue.
so_5::send<so_5::execution_demand_t>(init_reinit_ch_, std::move(demand));
}
else {
// That demand should go to the common queue.
so_5::send<so_5::execution_demand_t>(other_demands_ch_, std::move(demand));
}
}
void push_evt_start(so_5::execution_demand_t demand) override {
so_5::send<so_5::execution_demand_t>(start_finish_ch_, std::move(demand));
}
// NOTE: don't care about exception, if the demand can't be stored
// into the queue the application has to be aborted anyway.
void push_evt_finish(so_5::execution_demand_t demand) noexcept override {
// Chains for "ordinary" messages has to be closed.
so_5::close_retain_content(so_5::terminate_if_throws, init_reinit_ch_);
so_5::close_retain_content(so_5::terminate_if_throws, other_demands_ch_);
// Now we can store the evt_finish demand in the special chain.
so_5::send<so_5::execution_demand_t>(start_finish_ch_, std::move(demand));
}The logic of the push method is very simple: if the message to be stored has type init_device_t or reinit_device_t then it's going to init_reinit_ch_ channel. Otherwise, it's going to other_demands_ch_.
There are two things related to SObjectizer's specifics. The first one is the usage of execution_demand_t as the argument of push() methods. Dispatchers in SObjectizer hold not raw messages in their queues, but instances of execution_demand_t. Every execution demand contains a reference to the source message and some additional information like the type of the source message. The type of message is checked in our implementation of push() method.
The second thing is the representation of the type of message as std::type_index. SObjectizer uses RTTI for type dectection of message type and the corresponding value of std::type_index is stored in execution_demand_t. This is why there are static members init_device_type and reinit_device_type in the tricky_dispatcher_t class: they allow to check the type of message to be stored.
NOTE. SObjectizer can't recover if push_evt_finish method throws, that is why it's declared as noexcept. But noexcept guarantee can't be provided in such an implementation, because so_5::send can throw. We don't care about the consequences, it's better to terminate the whole application if so_5::send throws in push_evt_finish.
The disp_binder_t in SObjectizer-5.8 contains four pure virtual methods that should be defined in the dispatcher implementation. They reflect the multi-stage procedure of the binding of an agent to a dispatcher. This procedure includes the following steps:
- preallocation of all necessary resources for all agents for the coop being registered. If a resource for some agent can't be allocated then all previously allocated resources should be deallocated and the registration procedure will be canceled. The failures on this stage are allowed and regarded as recoverable;
- binding of all agents from the registering coop to the corresponding dispatchers. It's assumed that all necessary resources are preallocated on the previous step. So a failure on that stage is regarded as unrecoverable.
Because of that, the first three virtual methods of disp_binder_t interface are:
// Preallocation of resources for a particular agent.
// Called on preallocation stage.
// Can throw exceptions.
void preallocate_resources(so_5::agent_t & agent) = 0;
// Deallocation of the resources allocated by the previous
// call to preallocate_resources() method.
// Called on preallocation stage in the case of an error in
// some call to preallocate_resources().
// Can't throw exceptions.
void undo_preallocation(so_5::agent_t & agent) noexcept = 0;
// Binding an agent to the dispatcher by using resources
// preallocated in the previous call to preallocate_resources() method.
void bind(so_5::agent_t & agent) noexcept = 0;The preallocate_resources method is called on the first stage of the registration procedure for all agents from the registering coop. If some call throws an exception then undo_preallocation will be called for all agents processed up to that moment.
If the first stage is completed successfully then bind method is called for all agents from the registering coop.
It's important to note that undo_preallocation is called only in the case of a failure on the first stage of the registration procedure. If that stage is passed successfully that method is never called.
The fourth virtual method from disp_binder_t interface is:
// Unbinding an agent from the dispatcher.
// Called during the deregistration procedure.
// Cleans up all resources related to that agent (if any).
// Can't throw exceptions.
void unbind(so_5::agent_t & agent) noexcept = 0;The unbind method is called during the coop's deregistration procedure. At that moment all agents from the coop are completely stopped. In the unbind method the dispatcher should deallocate all resources associated with the agent (if such resources exist).
There is a principal difference between undo_preallocation and unbind methods: undo_preallocation is called only in the case of an error on the first stage of the coop's registration procedure. In that case unbind is not called at all. But if a coop is successfully registered then undo_preallocation won't be called, but unbind will be called for every agent from that coop on the deregistration.
Our tricky dispatcher doesn't require complex binding/unbinding actions because all necessary resources are already created and initialized. Because of that, almost all methods from disp_binder_t interface are empty:
void preallocate_resources(so_5::agent_t & /*agent*/) override {
// There is no need to do something.
}
void undo_preallocation(so_5::agent_t & /*agent*/) noexcept override {
// There is no need to do something.
}
void bind(so_5::agent_t & agent) noexcept override {
agent.so_bind_to_dispatcher(*this);
}
void unbind(so_5::agent_t & /*agent*/) noexcept override {
// There is no need to do something.
}The only action we have to perform is a call to agent_t::so_bind_to_dispatcher() in bind() method to pass a reference to event_queue_t implementation to an agent. Because tricky_dispatcher_t implements event_queue_t interface we just pass a reference to itself.
The standard dispatchers in SObjectizer-5.8 much more complex than the implementation discussed above. So the good implementation of a universal dispatcher is not so easy task. But in some cases, where the standard SObjectizer's dispatchers are not appropriate, a user can implement own dispatcher and this could be a quite doable thing.
It's worth to say that our tricky_dispatcher_t is so simple because of the fact that all events of a_device_manager_t are thread-safe. So we can run them on any worker thread regardless of any other events are already in the processing. But if there would be at least one non-thread-safe event handler in a_device_manager_t our simple implementation will be incorrect.
If you have any question about writing your own dispatcher for SObjectizer or you have any other SObjectizer-related question you can ask us in SObjectizer's Google Group. We'll glad to answer you.