Welcome to the Smart-Traffic-Signals-in-India-using-Deep-Reinforcement-Learning-and-Advanced-Computer-Vision wiki!

With a growth in the economic sector since the early 1990s, India has been undergoing a paradigm shift in the domain of transportation as well. With the explosion in the number of road-vehicles, the surge in traffic density (especially in metropolitan cities like Bangalore and Delhi) has become a major cause of concern. It has, therefore, become really important to develop Intelligent traffic signals and systems in order to optimize the escalating traffic flow. For a developing country like India where the majority of motorists are still negligent of traffic laws and are often seen breaking them, for e.g, driving in opposite lanes, violating an indicator near turns and turning in a wrong direction, and many more such instances which eventually lead to traffic jams.
In such Indian scenarios, the power of reinforcement learning applied on traffic behavior can be leveraged to greatly reduce these traffic jams. We have designed a script for applying Deep Reinforcement Learning using SUMO simulator in the repository. We have used DQN+Target Network+Experience Replay in our project and processed frames from simulator using computer vision
We have used SUMO as our running environment and have experimented with number of sceneraios and agents. Following image shall better help understand the scenarios used-

In (a), equal traffic is supplied to all the carriageways. In (b), equal traffic is supplied to two of the carriageways, the other two carriageways are kept empty. In (c), the traffic in the two non-empty carriageways is made unequal. In (d), an obstacle (labeled in red) is introduced in one of the carriageways.
We also worked with Two junctions for multi agent RL setup-

We have used background subtraction for calculation of queue length of vehciles in a lane or section and four of these make a junction which acts as our state space. For a realistic scenario the figure below shall represent an accurate representation of the process-

The same we have done by taking in the frames from the simulator by recording the screen and then extracting each lane frame from the four lanes and then processing it to get the queue lenghts.

Here after getting a simulator frame, we convert it bird eye view so it looks like an image taken from a traffic camera and then perform background subtraction to get the queue length.
The Queue length obtained from the CV module goes into the RL model. We have used Queue length as our state space and the decision to switch green signal to the next lane or not is decided by the RL model.
State space - Queue lengths+ Phases
Action Space - Switch || Not Switch
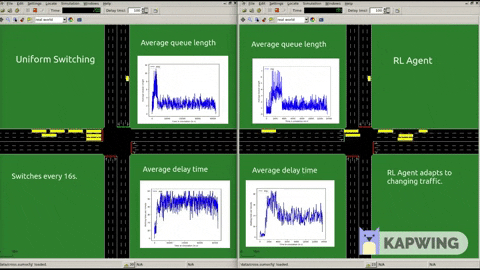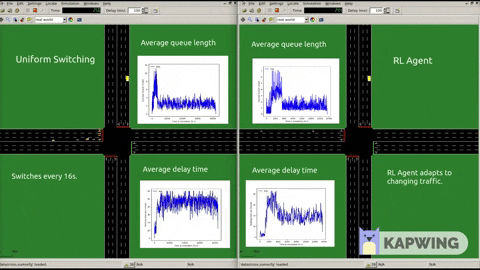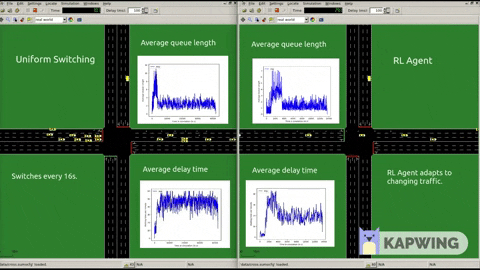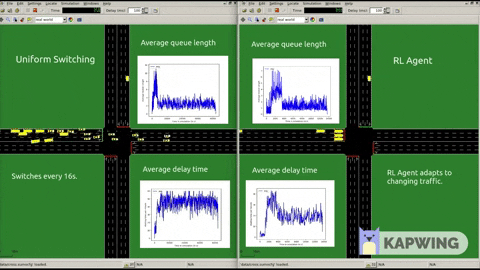
Following graphs show our results when put against Round Robin 40 seconds. We also experimented with various reward functions also.
