-
-
Notifications
You must be signed in to change notification settings - Fork 8
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
* added logs directory for storing logs (by date) * added VERSION file to keep track of code version * updated .gitignore to untrack log files
- Loading branch information
1 parent
0d333dc
commit 32d9924
Showing
4 changed files
with
389 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1 @@ | ||
| v0.1.0-beta |
File renamed without changes.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,384 @@ | ||
| { | ||
| "cells": [ | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 4, | ||
| "metadata": { | ||
| "ExecuteTime": { | ||
| "end_time": "2022-05-07T11:36:11.912483Z", | ||
| "start_time": "2022-05-07T11:36:11.893439Z" | ||
| }, | ||
| "deletable": false, | ||
| "editable": false | ||
| }, | ||
| "outputs": [ | ||
| { | ||
| "data": { | ||
| "text/plain": [ | ||
| "'v0.1.0-beta'" | ||
| ] | ||
| }, | ||
| "execution_count": 4, | ||
| "metadata": {}, | ||
| "output_type": "execute_result" | ||
| } | ||
| ], | ||
| "source": [ | ||
| "# code versioning is important, and useful to keep track of all necessary\n", | ||
| "# changes. individual release information is available in CHANGELOG.md file,\n", | ||
| "# and the current version of the code is tracked with VERSION file.\n", | ||
| "# this cell prints the current version information in output using `read()`\n", | ||
| "open(\"../VERSION\", 'rt').read() # bump codecov" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "<h1 align = \"center\">Boilerplate/Template Design</h1>\n", | ||
| "\n", | ||
| "---\n", | ||
| "\n", | ||
| "\n", | ||
| "**Objective:** The file provides a simple *boilerplate* to concentrate on what is necessary, and stop doing same tasks! The boilerplate is also configured with certain [**nbextensions**](https://gitlab.com/ZenithClown/computer-configurations-and-setups) that I personally use. Install them, if required, else ignore them as they do not participate in any type of code-optimizations. For any new project *edit* this file or `File > Make a Copy` to get started with the project. Some settings and configurations are already provided, as mentioned below." | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "## Code Imports\n", | ||
| "\n", | ||
| "**PEP8 Style Guide** lists out the following [*guidelines*](https://peps.python.org/pep-0008/#imports) for imports:\n", | ||
| " 1. Imports should be on separate lines,\n", | ||
| " 2. Import order should be:\n", | ||
| " * standard library/modules,\n", | ||
| " * related third party imports,\n", | ||
| " * local application/user defined imports\n", | ||
| " 3. Wildcard import (`*`) should be avoided, else specifically tagged with **`# noqa: F403`** as per `flake8` [(ignoring errors)](https://flake8.pycqa.org/en/3.1.1/user/ignoring-errors.html).\n", | ||
| " 4. Avoid using relative imports; use explicit imports instead." | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 21, | ||
| "metadata": { | ||
| "ExecuteTime": { | ||
| "end_time": "2022-05-07T12:11:12.075763Z", | ||
| "start_time": "2022-05-07T12:11:12.070760Z" | ||
| } | ||
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "import sys # append additional directories to list" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 19, | ||
| "metadata": { | ||
| "ExecuteTime": { | ||
| "end_time": "2022-05-07T12:10:02.733632Z", | ||
| "start_time": "2022-05-07T12:10:02.710632Z" | ||
| } | ||
| }, | ||
| "outputs": [ | ||
| { | ||
| "ename": "ImportError", | ||
| "evalue": "cannot import name 'append' from 'sys' (unknown location)", | ||
| "output_type": "error", | ||
| "traceback": [ | ||
| "\u001b[1;31m---------------------------------------------------------------------------\u001b[0m", | ||
| "\u001b[1;31mImportError\u001b[0m Traceback (most recent call last)", | ||
| "\u001b[1;32mC:\\Users\\DEBMAL~1\\AppData\\Local\\Temp/ipykernel_14544/2634436275.py\u001b[0m in \u001b[0;36m<module>\u001b[1;34m\u001b[0m\n\u001b[0;32m 3\u001b[0m \u001b[1;32mfrom\u001b[0m \u001b[0mos\u001b[0m\u001b[1;33m.\u001b[0m\u001b[0mpath\u001b[0m \u001b[1;32mimport\u001b[0m \u001b[0mjoin\u001b[0m \u001b[1;31m# joins mutiple path without os dependency\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0;32m 4\u001b[0m \u001b[1;31m# from copy import deepcopy # make an actual copy of immutable objects like `str`\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[1;32m----> 5\u001b[1;33m \u001b[1;32mfrom\u001b[0m \u001b[0msys\u001b[0m \u001b[1;32mimport\u001b[0m \u001b[0mappend\u001b[0m \u001b[1;31m# append additional directories to import codes\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0m\u001b[0;32m 6\u001b[0m \u001b[1;31m# from tqdm import tqdm as TQ # for displaying a nice progress bar while running\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0;32m 7\u001b[0m \u001b[1;31m# from uuid import uuid1 as UUID # for generating unique identifier\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n", | ||
| "\u001b[1;31mImportError\u001b[0m: cannot import name 'append' from 'sys' (unknown location)" | ||
| ] | ||
| } | ||
| ], | ||
| "source": [ | ||
| "from time import ctime # print computer time in human redable format\n", | ||
| "from os import makedirs # create directories dynamically\n", | ||
| "from os.path import join # joins mutiple path without os dependency\n", | ||
| "# from copy import deepcopy # make an actual copy of immutable objects like `str`\n", | ||
| "# from tqdm import tqdm as TQ # for displaying a nice progress bar while running\n", | ||
| "# from uuid import uuid1 as UUID # for generating unique identifier\n", | ||
| "# from datetime import datetime as dt # formatting/defining datetime objects" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "[**`logging`**](https://docs.python.org/3/howto/logging.html) is a standard python module that is meant for tracking any events that happen during any software/code operations. This module is super powerful and helpful for code debugging and other purposes. The next section defines a `logging` configuration in **`../logs/`** directory. Modify the **`LOGS_DIR`** variable under *Global Arguments* to change the default directory. The module is configured with a simplistic approach, such that any `print())` statement can be update to `logging.LEVEL_NAME()` and the code will work. Use logging operations like:\n", | ||
| "\n", | ||
| "```python\n", | ||
| " >> logging.debug(\"This is a Debug Message.\")\n", | ||
| " >> logging.info(\"This is a Information Message.\")\n", | ||
| " >> logging.warning(\"This is a Warning Message.\")\n", | ||
| " >> logging.error(\"This is a ERROR Message.\")\n", | ||
| " >> logging.critical(\"This is a CRITICAL Message.\")\n", | ||
| "```\n", | ||
| "\n", | ||
| "Note: some directories related to logging is created by default. This can be updated/changed in the following configuration section." | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 9, | ||
| "metadata": { | ||
| "ExecuteTime": { | ||
| "end_time": "2022-05-07T11:55:57.663629Z", | ||
| "start_time": "2022-05-07T11:55:57.657630Z" | ||
| } | ||
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "import logging # configure logging on `global arguments` section, as file path is required" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 4, | ||
| "metadata": {}, | ||
| "outputs": [], | ||
| "source": [ | ||
| "# import numpy as np\n", | ||
| "import pandas as pd" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "## Global Argument(s)\n", | ||
| "\n", | ||
| "The global arguments are *notebook* specific, however they may also be extended to external libraries and functions on import. The *boilerplate* provides a basic ML directory structure which contains a directory for `data` and a separate directory for `output`. In addition, a separate directory (`data/processed`) is created to save processed dataset such that preprocessing can be avoided." | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 11, | ||
| "metadata": { | ||
| "ExecuteTime": { | ||
| "end_time": "2022-05-07T12:02:30.668471Z", | ||
| "start_time": "2022-05-07T12:02:30.661377Z" | ||
| } | ||
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "ROOT = \"..\" # the document root is one level up, that contains all code structure\n", | ||
| "DATA = join(ROOT, \"data\") # the directory contains all data files, subdirectory (if any) can also be used/defined\n", | ||
| "\n", | ||
| "# processed data directory can be used, such that preprocessing steps is not\n", | ||
| "# required to run again-and-again each time on kernel restart\n", | ||
| "PROCESSED_DATA = join(DATA, \"processed\")" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 14, | ||
| "metadata": { | ||
| "ExecuteTime": { | ||
| "end_time": "2022-05-07T12:02:38.898998Z", | ||
| "start_time": "2022-05-07T12:02:38.888970Z" | ||
| } | ||
| }, | ||
| "outputs": [ | ||
| { | ||
| "name": "stdout", | ||
| "output_type": "stream", | ||
| "text": [ | ||
| "Code Execution Started on: Sat, May 07 2022\n" | ||
| ] | ||
| } | ||
| ], | ||
| "source": [ | ||
| "# long projects can be overwhelming, and keeping track of files, outputs and\n", | ||
| "# saved models can be intriguing! to help this out, `today` can be used. for\n", | ||
| "# instance output can be stored at `output/<today>/` etc.\n", | ||
| "# `today` is so configured that it permits windows/*.nix file/directory names\n", | ||
| "today = dt.strftime(dt.strptime(ctime(), \"%a %b %d %H:%M:%S %Y\"), \"%a, %b %d %Y\")\n", | ||
| "print(f\"Code Execution Started on: {today}\") # only date, name of the sub-directory" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 15, | ||
| "metadata": { | ||
| "ExecuteTime": { | ||
| "end_time": "2022-05-07T12:07:25.311475Z", | ||
| "start_time": "2022-05-07T12:07:25.297545Z" | ||
| } | ||
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "OUTPUT_DIR = join(ROOT, \"output\", today)\n", | ||
| "makedirs(OUTPUT_DIR, exist_ok = True) # create dir if not exist\n", | ||
| "\n", | ||
| "# also create directory for `logs`\n", | ||
| "LOGS_DIR = join(ROOT, \"logs\", open(\"../VERSION\", 'rt').read())\n", | ||
| "makedirs(LOGS_DIR, exist_ok = True)" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 16, | ||
| "metadata": { | ||
| "ExecuteTime": { | ||
| "end_time": "2022-05-07T12:07:35.345557Z", | ||
| "start_time": "2022-05-07T12:07:35.334528Z" | ||
| } | ||
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "logging.basicConfig(\n", | ||
| " filename = join(LOGS_DIR, f\"{today}.log\"), # change `reports` file name\n", | ||
| " filemode = \"a\", # append logs to existing file, if file exists\n", | ||
| " format = \"%(asctime)s - %(name)s - CLASS:%(levelname)s:%(levelno)s:L#%(lineno)d - %(message)s\",\n", | ||
| " level = logging.DEBUG\n", | ||
| ")" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "## User Defined Function(s)\n", | ||
| "\n", | ||
| "It is recommended that any UDFs are defined outside the scope of the *jupyter notebook* such that development/editing of function can be done more practically. As per *programming guidelines* as [`src`](https://fileinfo.com/extension/src) file/directory is beneficial in code development and/or production release. However, *jupyter notebook* requires *kernel restart* if any imported code file is changed in disc, for this frequently changing functions can be defined in this section.\n", | ||
| "\n", | ||
| "**Getting Started** with **`PYTHONPATH`**\n", | ||
| "\n", | ||
| "One must know what are [Environment Variable](https://medium.com/chingu/an-introduction-to-environment-variables-and-how-to-use-them-f602f66d15fa) and how to call/use them in your choice of programming language. Note that an environment variable is *case sensitive* in all operating systems (except windows, since DOS is not case sensitive). Generally, we can access environment variables from terminal/shell/command prompt as:\n", | ||
| "\n", | ||
| "```shell\n", | ||
| "# macOS/*nix\n", | ||
| "echo $VARNAME\n", | ||
| "\n", | ||
| "# windows\n", | ||
| "echo %VARNAME%\n", | ||
| "```\n", | ||
| "\n", | ||
| "Once you've setup your system with [`PYTHONPATH`](https://bic-berkeley.github.io/psych-214-fall-2016/using_pythonpath.html) as per [*python documentation*](https://docs.python.org/3/using/cmdline.html#envvar-PYTHONPATH) is an important directory where any `import` statements looks for based on their order of importance. If a source code/module is not available check necessary environment variables and/or ask the administrator for the source files.\n", | ||
| "\n", | ||
| "For testing purpose, the module boasts the use of `src`, `utils` and `config` directories. However, these directories are available at `ROOT` level, and thus using `sys.path.append()` to add directories while importing." | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": 22, | ||
| "metadata": { | ||
| "ExecuteTime": { | ||
| "end_time": "2022-05-07T12:16:49.796170Z", | ||
| "start_time": "2022-05-07T12:16:49.787123Z" | ||
| }, | ||
| "deletable": false, | ||
| "editable": false | ||
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "sys.path.append(join(ROOT, \"src\")) # source files\n", | ||
| "sys.path.append(join(ROOT, \"src\", \"agents\")) # agents for an efficient rl model\n", | ||
| "sys.path.append(join(ROOT, \"src\", \"engine\")) # ai/ml code engines for modelling\n", | ||
| "sys.path.append(join(ROOT, \"src\", \"models\")) # defination of actual ai/ml model\n", | ||
| "sys.path.append(join(ROOT, \"utilities\")) # provide a list of utility functions" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "## Read Input File(s)\n", | ||
| "\n", | ||
| "A typical machine learning project revolves around six important stages (as available in [Amazon ML Life Cycle Documentation](https://docs.aws.amazon.com/wellarchitected/latest/machine-learning-lens/well-architected-machine-learning-lifecycle.html)). The notebook boilerplate is provided to address two pillars:\n", | ||
| "\n", | ||
| " 1. **Data Processing:** An integral part of any machine learning project, which is the most time consuming step! A brief introduction and best practices is available [here](https://towardsdatascience.com/introduction-to-data-preprocessing-in-machine-learning-a9fa83a5dc9d).\n", | ||
| " 2. **Model Development:** From understanding to deployment, this section address development (training, validating and testing) of an machine learning model.\n", | ||
| "\n", | ||
| "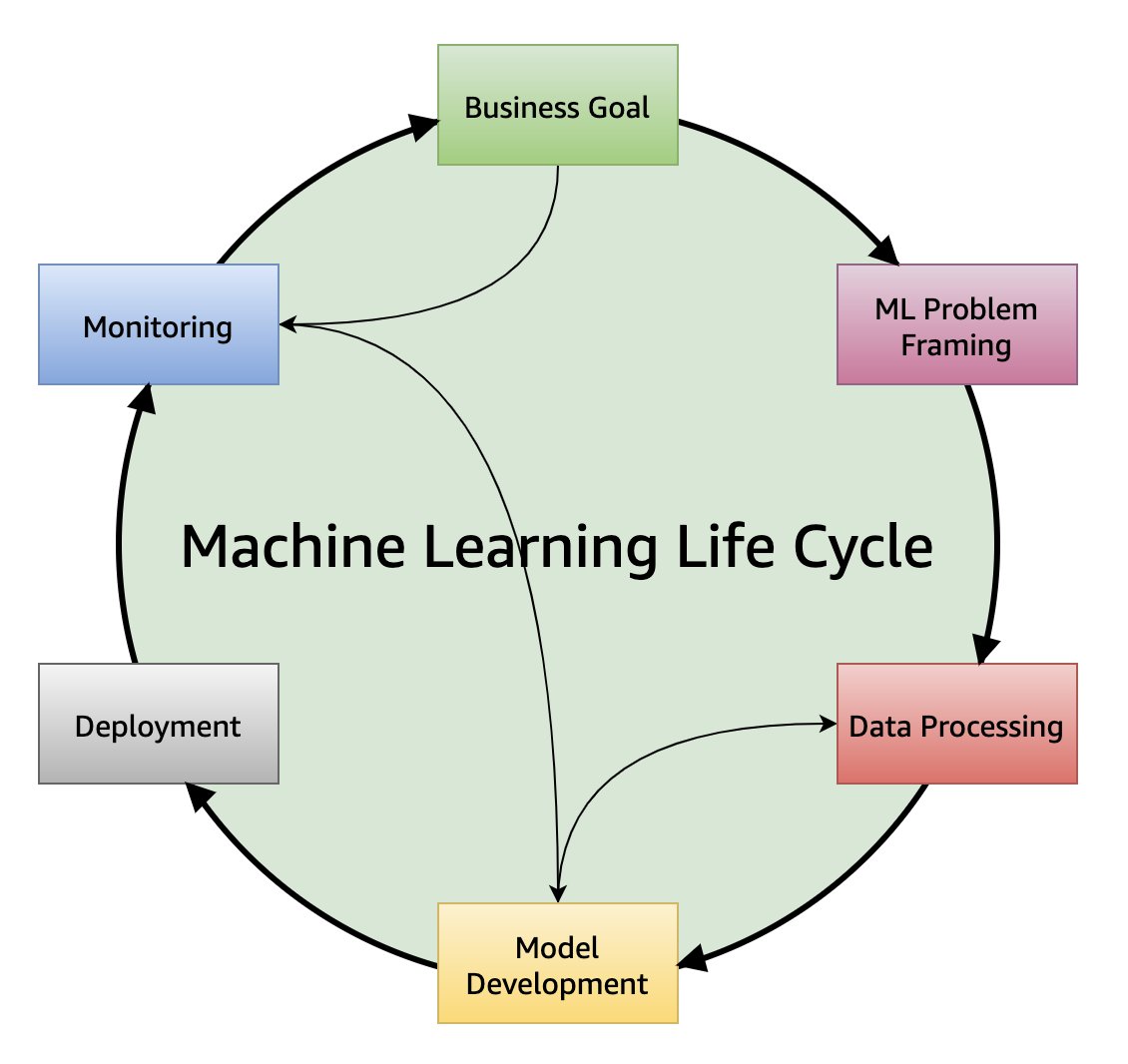" | ||
| ] | ||
| } | ||
| ], | ||
| "metadata": { | ||
| "hide_input": false, | ||
| "kernelspec": { | ||
| "display_name": "Python 3 (ipykernel)", | ||
| "language": "python", | ||
| "name": "python3" | ||
| }, | ||
| "language_info": { | ||
| "codemirror_mode": { | ||
| "name": "ipython", | ||
| "version": 3 | ||
| }, | ||
| "file_extension": ".py", | ||
| "mimetype": "text/x-python", | ||
| "name": "python", | ||
| "nbconvert_exporter": "python", | ||
| "pygments_lexer": "ipython3", | ||
| "version": "3.9.7" | ||
| }, | ||
| "latex_envs": { | ||
| "LaTeX_envs_menu_present": true, | ||
| "autoclose": true, | ||
| "autocomplete": true, | ||
| "bibliofile": "biblio.bib", | ||
| "cite_by": "apalike", | ||
| "current_citInitial": 1, | ||
| "eqLabelWithNumbers": true, | ||
| "eqNumInitial": 1, | ||
| "hotkeys": { | ||
| "equation": "Ctrl-E", | ||
| "itemize": "Ctrl-I" | ||
| }, | ||
| "labels_anchors": false, | ||
| "latex_user_defs": false, | ||
| "report_style_numbering": false, | ||
| "user_envs_cfg": false | ||
| }, | ||
| "toc": { | ||
| "base_numbering": 1, | ||
| "nav_menu": {}, | ||
| "number_sections": false, | ||
| "sideBar": true, | ||
| "skip_h1_title": true, | ||
| "title_cell": "Table of Contents", | ||
| "title_sidebar": "Contents", | ||
| "toc_cell": false, | ||
| "toc_position": {}, | ||
| "toc_section_display": true, | ||
| "toc_window_display": false | ||
| }, | ||
| "varInspector": { | ||
| "cols": { | ||
| "lenName": 16, | ||
| "lenType": 16, | ||
| "lenVar": 40 | ||
| }, | ||
| "kernels_config": { | ||
| "python": { | ||
| "delete_cmd_postfix": "", | ||
| "delete_cmd_prefix": "del ", | ||
| "library": "var_list.py", | ||
| "varRefreshCmd": "print(var_dic_list())" | ||
| }, | ||
| "r": { | ||
| "delete_cmd_postfix": ") ", | ||
| "delete_cmd_prefix": "rm(", | ||
| "library": "var_list.r", | ||
| "varRefreshCmd": "cat(var_dic_list()) " | ||
| } | ||
| }, | ||
| "types_to_exclude": [ | ||
| "module", | ||
| "function", | ||
| "builtin_function_or_method", | ||
| "instance", | ||
| "_Feature" | ||
| ], | ||
| "window_display": false | ||
| } | ||
| }, | ||
| "nbformat": 4, | ||
| "nbformat_minor": 2 | ||
| } |