-
Notifications
You must be signed in to change notification settings - Fork 1.8k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
* minor updates to langchain demo * update langchain example
- Loading branch information
Showing
8 changed files
with
157 additions
and
197 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,7 +1,4 @@ | ||
| OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX | ||
| CUBE_API_URL=https://anonymous-colstrip.gcp-us-central1.cubecloudapp.dev/cubejs-api/v1 | ||
| CUBE_API_SECRET=SECRET | ||
| DATABASE_URL=postgresql://cube:[email protected]:5432/anonymous-colstrip | ||
| LANGCHAIN_TRACING_V2=true | ||
| LANGCHAIN_ENDPOINT=https://api.smith.langchain.com | ||
| LANGCHAIN_API_KEY=ls__XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX | ||
| OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXXXXXX | ||
| CUBE_API_URL=https://example-url.gcp-us-central1.cubecloudapp.dev/cubejs-api/v1 | ||
| CUBE_API_SECRET=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX | ||
| DATABASE_URL=postgresql://cube:[email protected]:5432/example |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,3 @@ | ||
| .env | ||
| __pycache__ | ||
| vectorstore.pkl |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,18 +1,30 @@ | ||
| # Cube and Langchain demo app | ||
| # Tabular Data Retrieval | ||
|
|
||
| This is an example of a chatbot built with Cube, Langchain, and Streamlit. | ||
| This is an example of a chatbot built with Cube, Langchain, Snowflake and Streamlit. | ||
|
|
||
| [Why use a semantic layer with LLM for chatbots?](https://cube.dev/blog/semantic-layer-the-backbone-of-ai-powered-data-experiences) | ||
| [Check this app deployed on Streamlit Cloud.](https://cube-langchain.streamlit.app/) | ||
|
|
||
| ## Pre-requisites | ||
| ## Why Semantic Layer for LLM-powered apps? | ||
|
|
||
| - Valid Cube Cloud deployment. Your data model should have at least one view. | ||
| - This example uses OpenAI API, so you'll need an OpenAI API key. | ||
| - Python version `>=` 3.8 | ||
| When building text-to-SQL applications, it is crucial to provide LLM with rich context about underlying data model. Without enough context it’s hard for humans to comprehend data, LLM will simply compound on that confusion to produce wrong answers. | ||
|
|
||
| ## How to run | ||
| In many cases it is not enough to feed LLM with database schema and expect it to generate the correct SQL. To operate correctly and execute trustworthy actions, it needs to have enough context and semantics about the data it consumes; it must understand the metrics, dimensions, entities, and relational aspects of the data by which it's powered. Basically—LLM needs a semantic layer. | ||
|
|
||
| 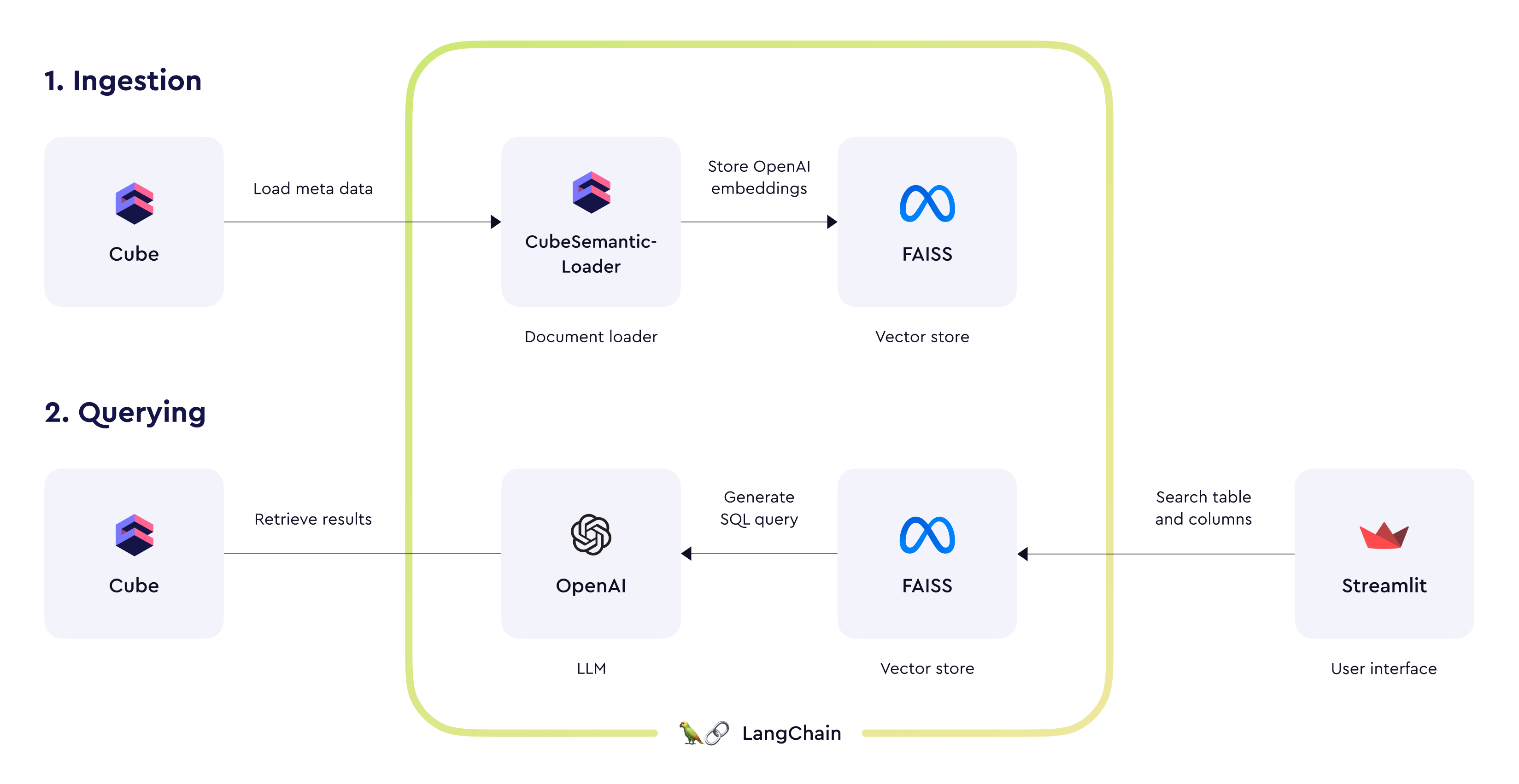 | ||
|
|
||
| [Read more on why to use a semantic layer with LLM-power apps.](https://cube.dev/blog/semantic-layer-the-backbone-of-ai-powered-data-experiences) | ||
|
|
||
|
|
||
|
|
||
|
|
||
| ## Getting Started | ||
|
|
||
| - **Cube project**. If you don't have a Cube project already, you follow [this tutorial](https://cube.dev/docs/product/getting-started/cloud) to get started with with sample e-commerce data model. | ||
| - **OpenAI API**. This example uses OpenAI API, so you'll need an OpenAI API key. | ||
| - Make sure you have Python version >= 3.8 | ||
| - Install dependencies: `pip install -r requirements.txt` | ||
| - Copy `.env.example` as `.env` and fill it in with your credentials | ||
| - Run `python ingest.py`. It will use `CubeSemanticLoader` Langchain library to load metadata and save it in vectorstore | ||
| - Run `streamlit run main.py` | ||
| - Copy `.env.example` as `.env` and fill it in with your credentials. You need OpenAI API Key and credentials to access your Cube deployment. | ||
| - Run `streamlit run streamlit_app.py` | ||
|
|
||
| ## Community | ||
| If you have any questions or need help - please [join our Slack community](https://slack.cube.dev/?ref=langchain-example-readme) of amazing developers and data engineers. |
This file was deleted.
Oops, something went wrong.
This file was deleted.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,123 @@ | ||
| import streamlit as st | ||
| import pandas as pd | ||
| import os | ||
| import re | ||
| import pickle | ||
| import jwt | ||
|
|
||
| from dotenv import load_dotenv | ||
| from langchain import OpenAI | ||
| from langchain.embeddings import OpenAIEmbeddings | ||
| from langchain.vectorstores.faiss import FAISS | ||
| from langchain.document_loaders import CubeSemanticLoader | ||
| from pathlib import Path | ||
|
|
||
| from utils import ( | ||
| create_docs_from_values, | ||
| create_vectorstore, | ||
| init_vectorstore, | ||
| check_input, | ||
| log, | ||
| call_sql_api, | ||
| CUBE_SQL_API_PROMPT, | ||
| _NO_ANSWER_TEXT, | ||
| PROMPT_POSTFIX, | ||
| ) | ||
|
|
||
| load_dotenv() | ||
|
|
||
| def ingest_cube_meta(): | ||
| security_context = {} | ||
| token = jwt.encode(security_context, os.environ["CUBE_API_SECRET"], algorithm="HS256") | ||
|
|
||
| loader = CubeSemanticLoader(os.environ["CUBE_API_URL"], token) | ||
| documents = loader.load() | ||
|
|
||
| embeddings = OpenAIEmbeddings() | ||
| vectorstore = FAISS.from_documents(documents, embeddings) | ||
|
|
||
| # Save vectorstore | ||
| with open("vectorstore.pkl", "wb") as f: | ||
| pickle.dump(vectorstore, f) | ||
|
|
||
| if not Path("vectorstore.pkl").exists(): | ||
| with st.spinner('Loading context from Cube API...'): | ||
| ingest_cube_meta(); | ||
|
|
||
| llm = OpenAI( | ||
| temperature=0, openai_api_key=os.environ.get("OPENAI_API_KEY"), verbose=True | ||
| ) | ||
|
|
||
| st.title("Cube and LangChain demo 🤖🚀") | ||
|
|
||
| multi = ''' | ||
| Follow [this tutorial on Github](https://github.com/cube-js/cube/tree/master/examples/langchain) to clone this project and run it locally. | ||
| You can use these sample questions to quickly test the demo -- | ||
| * How many orders? | ||
| * How many completed orders? | ||
| * What are top selling product categories? | ||
| * What product category drives the highest average order value? | ||
| ''' | ||
| st.markdown(multi) | ||
|
|
||
| question = st.text_input( | ||
| "Your question: ", placeholder="Ask me anything ...", key="input" | ||
| ) | ||
|
|
||
| if st.button("Submit", type="primary"): | ||
| check_input(question) | ||
| vectorstore = init_vectorstore() | ||
|
|
||
| # log("Quering vectorstore and building the prompt...") | ||
|
|
||
| docs = vectorstore.similarity_search(question) | ||
| # take the first document as the best guess | ||
| table_name = docs[0].metadata["table_name"] | ||
|
|
||
| # Columns | ||
| columns_question = "All available columns" | ||
| column_docs = vectorstore.similarity_search( | ||
| columns_question, filter=dict(table_name=table_name), k=15 | ||
| ) | ||
|
|
||
| lines = [] | ||
| for column_doc in column_docs: | ||
| column_title = column_doc.metadata["column_title"] | ||
| column_name = column_doc.metadata["column_name"] | ||
| column_data_type = column_doc.metadata["column_data_type"] | ||
| print(column_name) | ||
| lines.append( | ||
| f"title: {column_title}, column name: {column_name}, datatype: {column_data_type}, member type: {column_doc.metadata['column_member_type']}" | ||
| ) | ||
| columns = "\n\n".join(lines) | ||
|
|
||
| # Construct the prompt | ||
| prompt = CUBE_SQL_API_PROMPT.format( | ||
| input_question=question, | ||
| table_info=table_name, | ||
| columns_info=columns, | ||
| top_k=1000, | ||
| no_answer_text=_NO_ANSWER_TEXT, | ||
| ) | ||
|
|
||
| # Call LLM API to get the SQL query | ||
| log("Calling LLM API to generate SQL query...") | ||
| llm_answer = llm(prompt) | ||
| bare_llm_answer = re.sub(r"(?i)Answer:\s*", "", llm_answer) | ||
|
|
||
| if llm_answer.strip() == _NO_ANSWER_TEXT: | ||
| st.stop() | ||
|
|
||
| sql_query = llm_answer | ||
|
|
||
| log("Query generated by LLM:") | ||
| st.info(sql_query) | ||
|
|
||
| # Call Cube SQL API | ||
| log("Sending the above query to Cube...") | ||
| columns, rows = call_sql_api(sql_query) | ||
|
|
||
| # Display the result | ||
| df = pd.DataFrame(rows, columns=columns) | ||
| st.table(df) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters