This project implements a Lambda function using a container image to enhance audio files using the DeepFilter model.
Our Dockerfile is structured to create an efficient and functional container for running the DeepFilter model in an AWS Lambda environment. Here's a breakdown of the key components:
-
Base Image:
FROM public.ecr.aws/lambda/python:3.10
Use the official AWS Lambda Python 3.10 image as our base, ensuring compatibility with the Lambda environment.
Why Python 3.10? You can only install numpy >= 2 with Python 3.12, and since DeepFilter relies on an older version of numpy, we need to use Python 3.10.
-
System Dependencies:
RUN yum update -y && yum install -y git wget tar xz gcc gcc-c++ make ...Update the system and install essential build tools and libraries needed for compiling certain Python packages and dependencies.
-
HDF5 Installation:
ENV HDF5_VERSION=1.12.2 RUN wget https://support.hdfgroup.org/ftp/HDF5/releases/hdf5-1.12/hdf5-${HDF5_VERSION}/src/hdf5-${HDF5_VERSION}.tar.gz ...
Install HDF5 from source, which is a system dependency for DeepFilter.
-
Rust and Cargo Installation:
RUN curl https://sh.rustup.rs -sSf | sh -s -- -yInstall Rust and Cargo, which are required for building some Python packages with Rust extensions.
-
FFmpeg Installation:
RUN wget https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-arm64-static.tar.xz ...
Download and install a static build of FFmpeg.
Why a static build? Yum, the package manager for Amazon Linux 2, doesn't have FFmpeg.
-
PyTorch and torchaudio Installation:
RUN pip install torch==2.0.0 torchaudio==2.0.1 -f https://download.pytorch.org/whl/cpu/torch_stable.html
Install specific versions of PyTorch and torchaudio optimized for CPU usage. Install these specific versions to run DeepFilter on CPU.
-
Python Dependencies:
RUN pip install numpy pydub boto3 deepfilternet
Install various Python packages required for our application, including the DeepFilterNet library.
-
Environment Variables:
ENV RUSTFLAGS="-L ${HDF5_LIBDIR}" \ LIBHDF5_LIBDIR=${HDF5_LIBDIR} \ LIBHDF5_INCLUDEDIR=${HDF5_INCLUDEDIR}
Set environment variables necessary for building packages that depend on HDF5.
-
Code and Model Copying:
COPY main.py ${LAMBDA_TASK_ROOT}/ COPY modules/ ${LAMBDA_TASK_ROOT}/modules/ COPY models/ /opt/deepfilter_models/
Copy application code and the DeepFilter models into the container.
-
CMD Specification:
CMD [ "main.lambda_handler" ]We specify the Lambda handler function as the container's entry point.
This Dockerfile creates a comprehensive environment with all necessary dependencies and configurations to run our DeepFilter Lambda function efficiently.
The Lambda function is designed to work within the constraints of the AWS Lambda environment, particularly the read-only filesystem outside of /tmp.
The model initialization process is handled in two steps to work around the read-only nature of the Lambda environment:
-
Copying Model Files: When the Lambda function starts, it first copies the model files from
/opt/deepfilter_models/(read-only) to/tmp/deepfilter_models/(writable).def copy_model_files(): if not os.path.exists(TMP_MODEL_DIR): shutil.copytree('/opt/deepfilter_models/', TMP_MODEL_DIR)
Lambda environments are read-only, so we need to copy the model files to a writable directory.
-
Loading the Model: After copying, the function loads the model from the
/tmpdirectory.def load_deepfilter_model(model, df_state): if model is None or df_state is None: copy_model_files() model, df_state, _ = init_df(model_base_dir=TMP_MODEL_DIR)
Notice the function declaration in the serverless.yml file. First add the appropriate definitions to your serverless stack.
functions:
cleanAudio:
image: {accountID}.dkr.ecr.{region}.amazonaws.com/deepfilter-lambda-container:latest
timeout: 600
memorySize: 2048
ephemeralStorageSize: 4096
environment:
TABLE_NAME: Audio-${self:provider.stage}
STAGE: ${self:provider.stage}
provisionedConcurrency: 1To deploy the Lambda function, you need to have the AWS CLI installed and configured with the appropriate permissions.
-
Build the Docker Image:
docker build -t deepfilter-lambda-container . -
Push the Docker Image to ECR:
aws ecr get-login-password --region {region} | docker login --username AWS --password-stdin {accountID}.dkr.ecr.{region}.amazonaws.com docker tag deepfilter-lambda-container:latest {accountID}.dkr.ecr.{region}.amazonaws.com/deepfilter-lambda-container:latest docker push {accountID}.dkr.ecr.{region}.amazonaws.com/deepfilter-lambda-container:latest -
Deploy the Lambda Function:
serverless deploy
This will deploy the Lambda function to your AWS account.
With container lambdas, cold starts can be a problem. You can pre-warm the Lambda with pings, but it does not solve the problem.
Provisioned concurrency is a feature of AWS Lambda that allows you to reserve a specified number of concurrent executions for your function. This can help achieve consistent performance by ensuring that the function has the resources it needs to handle requests quickly and efficiently.
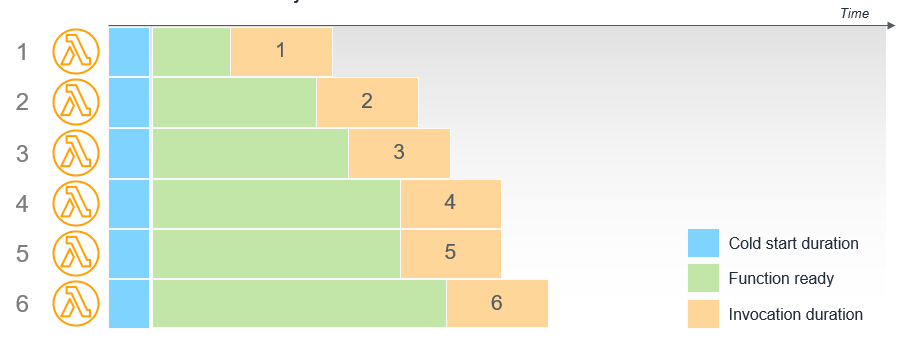
There are many ways to work with the fact that AppSync and API Gateway time out after 30 and 29 seconds respectively, as well as Lambda rate limits. Some methods are listed below.
- Use Step Functions to run the lambda function.
- Start the Lambda asynchonously from another Lambda with a 'Job' definition and have the audio clean Lambda update the job definition to a status of 'complete' when it is finished. The frontend polls the job status while a user is active on the page and the job status is not complete, and if the job status is complete when a user loads the page, no ping is needed. Only works for a few samples due rate limits.
- Call a Lambda from this Lambda which creates a subscription that the client can read when the job is complete.
- To start cleaning samples, call a Lambda which populates an SQS queue with your samples - one message per sample, batched by 10. Create a Processing table to store the batchID and progress. Have this Lambda update the processing table with an incremental update. Poll the Processing table for completed / total.
The file tree is as follows:
.
├── Dockerfile
├── main.py
├── models
│ ├── checkpoints
│ │ └── model_120.ckpt.best
│ └── config.ini
├── modules
│ ├── __init__.py
│ └── init.py
├── poetry.lock
├── push.sh
└── pyproject.toml