{kind=link}
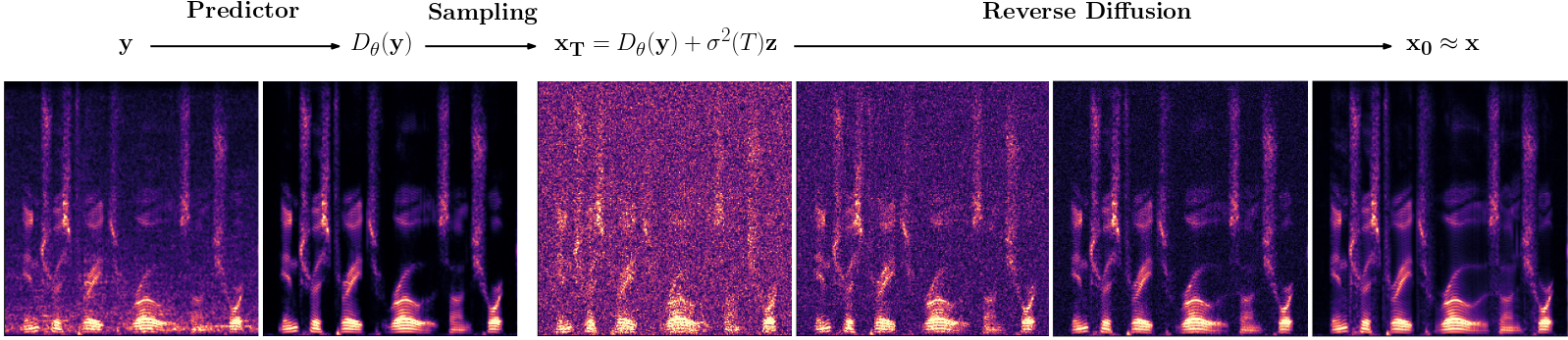
This repository contains the official PyTorch implementation for the paper:
Audio examples and supplementary materials are available on our project page.
- Create a new virtual environment with Python 3.8 (we have not tested other Python versions, but they may work).
- Install the package dependencies via
pip install -r requirements.txt. - Your logs will be stored as local TensorBoard logs. Run
tensorboard --logdir logs/to see them.
- We provide pretrained checkpoints for the models trained on TIMIT+Chime3 (enhancement), WSJ0+Chime3 (enhancement), Voicebank/DEMAND (enhancement) and WSJ0+Reverb (dereverberation), as in the original paper [1]. We also included the checkpoints for WSJ0+Wind as in [3]. All checkpoints can be downloaded here.
Usage:
- For resuming training, you can use the
--resume_from_checkpointoption oftrain.py. - For evaluating these checkpoints, use the
--ckptoption ofenhancement.py(see section Evaluation below).
Training is done by executing train.py. A minimal running example with default settings (as in our paper [2]) can be run with
python train.py --format <your_format>--base_dir <your_base_dir> --gpus 0,where
your_base_dirshould be a path to a folder containing subdirectoriestrain/andvalid/(optionallytest/as well). The subdirectory structure depends onyour_format:your_format=wsj0: Each subdirectory must itself have two subdirectoriesclean/andnoisy/, with the same filenames present in both.- Add formats on your own, correpsonding to your data structure
To see all available training options, run python train.py --help.
These include options for the backbone DNN, the SDE parameters, the PytorchLightning Trainer usual parameters such as max_epochs, limit_train_batches and so on.
Note:
- This paper [1] uses a lighter configuration of the NCSN++ backbone with 27.8M parameters, which is passed with
--backbone ncsnppby default. By contrast, the architecture used in the paper [2] uses--backbone ncsnpp-largewhich is the baseline 65M parameters NCSN++.
To evaluate on a test set, run
python enhancement.py --test_dir <your_test_dir> --enhanced_dir <your_enhanced_dir> --ckpt <path_to_model_checkpoint>to generate the enhanced .wav files. The --cpkt parameter of enhancement.py should be the path to a trained model checkpoint, as stored by the logger in logs/.
- In
preprocessing/, you will find the data generation script used to create all the datasets used in the paper. Minimal example is:
cd preprocessing;
python3 create_data.py --task <your_task> --speech <your_speech_format> --noise <your_noise_data>
Please check the script for other options
- For the wind noise generation scripts and non-linear mixing technique presented in [3], we refer the reader to [4] and suggest asking the authors about their wind noise generator code. We only provide here the script for parsing the commands to that generator + the non-linar mixing method. We are not responsible for distribution of the code by [4].
We kindly ask you to cite our papers in your publication when using any of our research or code:
@article{lemercier2023storm,
author={Lemercier, Jean-Marie and Richter, Julius and Welker, Simon and Gerkmann, Timo},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
title={StoRM: A Diffusion-Based Stochastic Regeneration Model for Speech Enhancement and Dereverberation},
year={2023},
volume={31},
number={},
pages={2724-2737},
doi={10.1109/TASLP.2023.3294692}}
@inproceedings{lemercier2023wind,
author={Lemercier, Jean-Marie and Thiemannm, Joachim and Konig, Raphael and Gerkmann, Timo},
booktitle={VDE 15th ITG conference on Speech Communication},
title={Wind Noise Reduction with a Diffusion-based Stochastic Regeneration Model},
year={2023}}
[1] Jean-Marie Lemercier, Julius Richter, Simon Welker, and Timo Gerkmann. "StoRM: A Stochastic Regeneration Model for Speech Enhancement And Dereverberation", IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2724-2737, 2023.
[2] Julius Richter, Simon Welker, Jean-Marie Lemercier, Bunlong Lay and Timo Gerkmann. "Speech Enhancement and Dereverberation with Diffusion-Based Generative Models", IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2351-2364, 2023.
[3] Jean-Marie Lemercier, Joachim Thiemann, Raphael Konig and Timo Gerkmann. "Wind Noise Reduction with a Diffusion-based Stochastic Regeneration Model", ITG Speech Communication, Aachen, Germany, 2023
[4] D. Mirabilii et al. "Simulating wind noise with airflow speed-dependent characteristics,” Int. Workshop on Acoustic Signal Enhancement, Aachen, Germany, 2022