Brought to you by Dr. Mahsa Mirzargar's independent study trio (In no particular order): Nathan Michaels, Devin Grossman, and David Michaels.
- To download our code, do a
git cloneon this bad boy. To download our data, first get access to Yelp's dataset: https://www.yelp.com/dataset/. Then, please reach out to the maintainers of this repository to receive access to our engineered features. - At the moment, the plan is to have a
sqlite3database on each machine locally. When we want to add to that database, we will share ajsonfile amongst the collaborators who will be able to run a simple script to load that data into their database.
- We have access to data from 12 "metropolitan areas", 4.7 million reviews of 156,000 businesses. We also have data on 1.1 million users and 1 million "tips" from these users.
- Business Features: For each business, we have its location, average rating, information on its food category, its business hours, and data on when people went to the restaurant.
- Users Features: We have data on a User's friends, a User's reviews, and a User's review count.
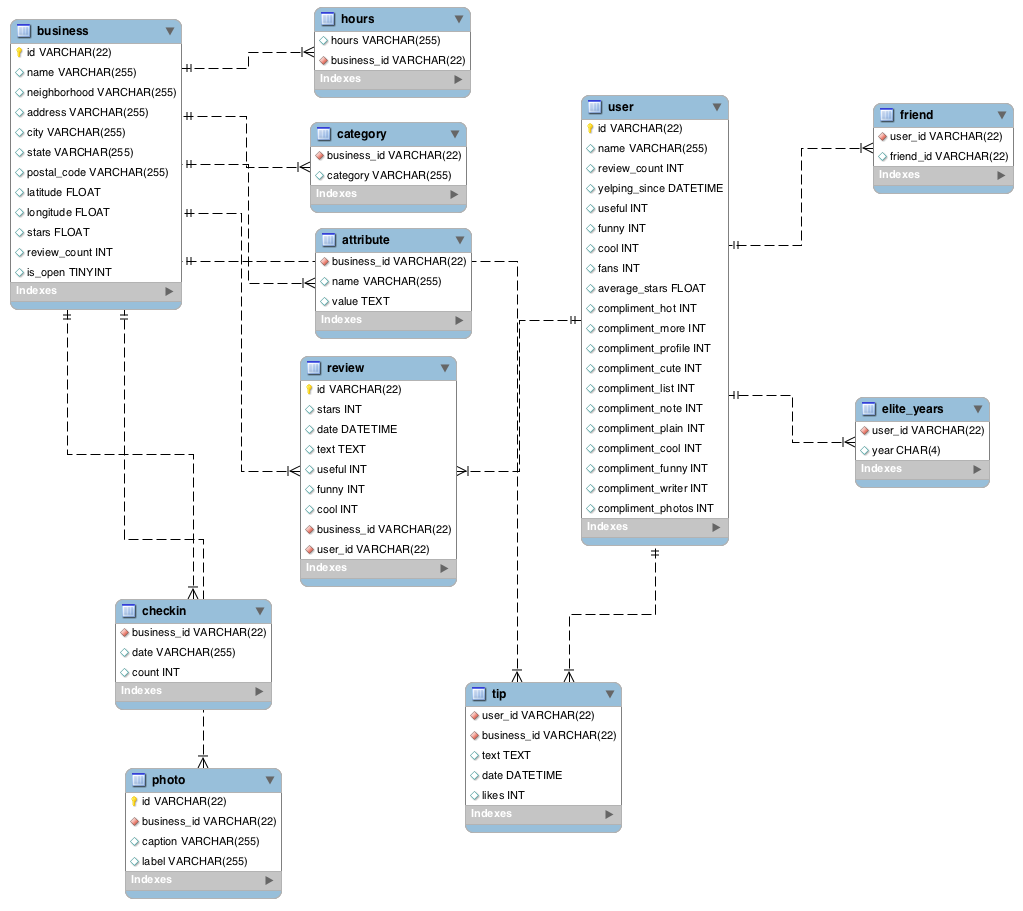
In order to gain a good understanding of our dataset, we are exploring simple correlations between variables. Here are some correlations we're looking to explore:
- Business rating vs. (# Reviews or # tips)
- photos vs. Average Rating
- location (city/state) vs # reviews
- Business number of reviews vs. Business check-ins
- Number of businesses by city
- Rating distribution by city
- explore “business competition” (normalize by average of zip/city/state)
- Clustering of similarly rated businesses
- By radius
- By avg rating with circle vs. business merge
- patterns of clustered businesses (good competition? bad competition?)
- displayed in reviews
- consolidation between competing restaurants ratings
- geographically close or not close?
- Clustering of similarly rated businesses
- reviews vs avg length vs rating of that review vs user rating
- Business Rating vs. Business Review Count
- Business Rating vs. Total Check-ins (need to engineer this feature)
- User’s number of friends vs. User review count
- Business rating vs. Total review count of all users that reviewed that Business
- Business rating vs. user’s average rating weighted by number of friend
- Business rating vs. User’s reviewed were elite
- Number of reviews that are on a business we have
- Number of reviews that are on Users we have
- Number of friends that we don’t have data on
- user number of ratings vs. User number of friends
- General patterns of users
- How many users are there?
- How many review more than 5 times
- Geographic data: Businesses by city
- Number of
- Which cities
- Distribution of ratings
- Time data of tips and reviews
- Check in data
- Usefulness of compliments, fans, cool, funny, etc for users
- Yelping since (for Users)
- Look into some individual users
- Define a User Rating
- What makes a user valuable? In what context?
- How do you find "valuable users"
- Variance of User's Reviews
- User Influentiality
- Graphs/Interconnectedness
- How to __ "Influential Users"
- ID
- Use
- What makes a user valuable? In what context?
- It's difficult. We are in this mid-range data size that we will use for read-heavy operations and will only write new data once in a while (when we add features). We can't and shouldn't share this data via GitHub since it screws with the file size. We tried creating a module,
juicy, that would partition any JSON file into many <100MB files that we could share via GitHub. But that turned out poorly as it took forever to upload and download and Git isn't meant for data. Also, the loading of JSON into Python objects is pretty honking memory intensive. After a handful of optimizations, it still takes up at least double the memory size (for a 4GB file, that's at least 8GB and we can't assume RAM sizes of over 8GB). - A path that hasn't been explored for the
jsonroute is theijsonmodule. - The plan as of November 9th, 2017 is to give everyone a copy of a
sqlite3version of the Yelp SQL database (the conversion process relied on themysql2sqlite.shthat you can find on GitHub). When someone wants to add a feature, we can share that feature via ajsonfile (which should usually be relatively small) and each person can run a script to add thatjsonfile to theirsqlite3database.