Notes for Introduction to Algorithms
-
The notes are sorted according to the teaching order of NEU CS 5800 Prof. Virgil Pavlu, some chapters of the original book are skimmed.
-
笔记按照NEU CS 5800 Prof. Virgil Pavlu 的教授顺序来排序,有掠过原书的一些章节。
-
如果不支持markdown可以下载pdf。
-
持续更新中,有一些图片还未上传到图床。
-
notes by
Yiqiu Huang
根据算法导论的原文:
T(n) = number of computational steps required to run the algorithm/program for input of size n
也就是,
-
但是我们在意的是,算法伴随
$n$ 的增长以后的倍数规模,而不是具体的步骤数量;下面这些是常见的表示方法
- 比如
$T(n) = Θ(n^2)$ 代表了quadratic running time -
$T(n) = O(n logn)$ 说明$T(n)$ 至多是$n$的$nlog(n)$ 倍数;
- 比如
渐进分析 Asymptotic notation:
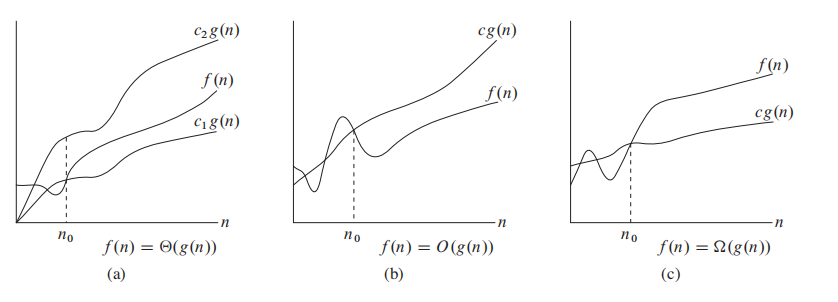
图:$\Theta 、O、\Omega $ 的含义
最简单的理解他们的方法就是,:
以$O$ 为例,看图$(b)$ ,当 input size
现在有一个问题:
遍历一遍size为
正常人都会说是$O(n)$。
但是严格来说 ,你要说
但是平时我们希望找到tight bound, 也就是更紧密的边界。
因此遍历数组用$\Theta(n)$ 来表示,我认为是最合适的;
原文定义如下:
For a given function g(n), we denote by
$\Theta(g(n))$ the set of functions:
$\Theta(g(n))$ = {$f(n)$: there exist positive constants$c_1$ ,$c_2$ , and$n_0$ such that$0\leq c_1g(n) \leq f(n) \leq c_2g(n)$ for all n$\geq$ n0 }如果满足如上条件,我们说 g(n) is an asymptotically tight bound for f(n)
简单来说就是
注意,$\Theta(g(n))$ 本身描述的是一个集合,用来表示所有$\Theta(n)$运行时间的函数集合,所以你可以这么写: $$ f(n) \in \Theta(n) $$
不过习惯上这么写: $$ f(n) = \Theta(n) $$ 这样写有自己独特的优势。
原文定义如下:
For a given function g(n), we denote by
$O$ (g(n)) the set of functions:
$O(g(n))$ = {$f(n)$: there exist positive constants$c$ and$n_0$ such that$0\leq f(n) \leq c g(n)$ for all n$\geq$ n0 }如果满足如上条件,我们说 g(n) is an asymptotically upper bound for f(n)
简单来说就是n到一定大小以后(
最简单的说,$O$ notation 就像是小于号,它描述的是上界。
平时我们习惯用大O表示法来表示runtime,比如寻找一个数组的最大值,我们说runtime 是 O(n);
这么说不完全严谨,因此O(n)描述的是上界(upper bound),无法说明how tight that bound is, 你说寻找最大值的算法是$O(n^2)$,$O(n^3)$也没问题。
原文定义如下:
For a given function g(n), we denote by
$\Omega$ (g(n)) the set of functions:
$\Omega(g(n))$ = {$f(n)$: there exist positive constants$c$ and$n_0$ such that$0 \leq c g(n) \leq f(n)$ for all$n \geq n_0$ }如果满足如上条件,我们说 g(n) is an asymptotically lower bound for f(n)
简单来说就是n到一定大小以后(
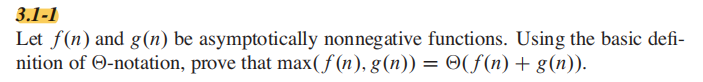
答案:
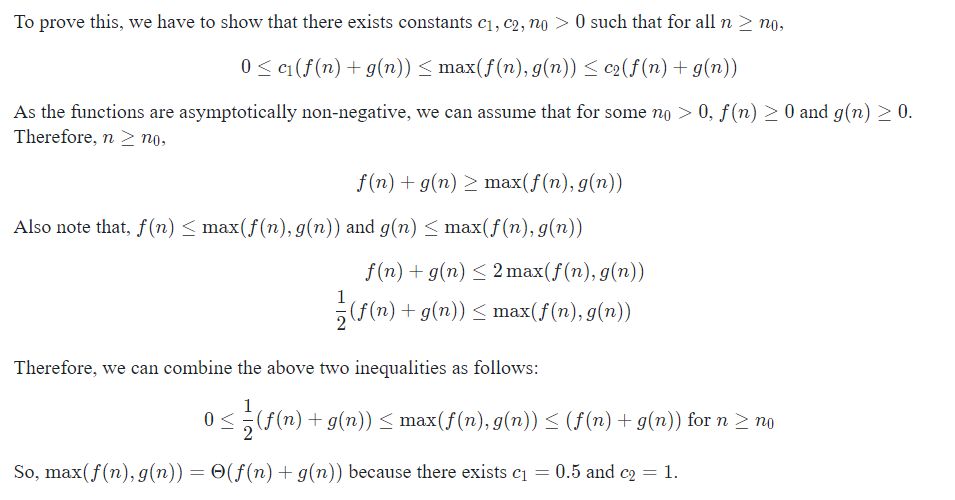
本质上,你要证明常数存在,来证明公式正确。
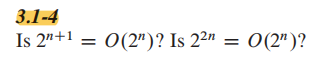
类似的技巧:
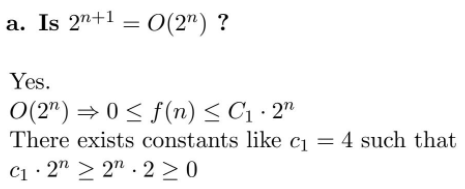

分治法:
Divide the problem into a number of subproblems that are smaller instances of the
same problem.
Conquer the subproblems by solving them recursively.
Combine the solutions to the subproblems into the solution for the original problem.
与我们熟悉的 Mergesort 一一对应:
Divide: 把长度为 n 的序列切分为两个长度为
$\frac{n}{2}$ 的序列Conquer: 递归的调用mergesort来sort sequence。(原文:Sort the two subsequences recursively using merge sort)
Combine: 合并两个sorted sequence
Suppose that our division of the problem yields a subproblems, each of which is 1/b the size of the original.
- 注意,Mergesort的a = b = 2, 很多分治法a 并不等于 b,a 更不等于 2
- 注意后面这句话: each of which is 1/b the size of the original 他的意思是每个子问题的size都是原来的1/b,那么随着递归的进行,子问题的size就是:
用白话来说就是,mergesort产生了2个size是(n/2)的subproblem。
假设mergesort的runtime 是T(n),我们有 a 个size 为b/n 的子问题,因此我们需要 aT(n/b) 来解决他们。
除此之外,我们需要 D(n) 来divide the problem into subproblem, 以及 C(n) 来combine我们的solution from all subproblem, 我们的总时间为:
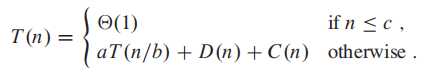
这段比较重要,还是原汁原味吧:
Divide: The divide step just computes the middle of the subarray, which takes
constant time. Thus, D.n/ D ‚.1/.
Conquer: We recursively solve two subproblems, each of size n=2, which contributes 2T(n/2) to the running time.
Combine: We have already noted that the MERGE procedure on an n-element
subarray takes time ‚.n/, and so C.n/ D ‚.n/.
Divide: mergesort 在 diide 时只计算出中位数,所以是contant time, D(n) = 1
Conquer: 我们递归的解决两个子问题,每一个子问题的size是 n/2, 因此是 2T(n/2)
Combine: combine的本质就是遍历,谁小谁先进sorted array, 因此
$C(n) = \Theta(n)$
因此:
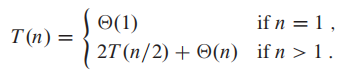
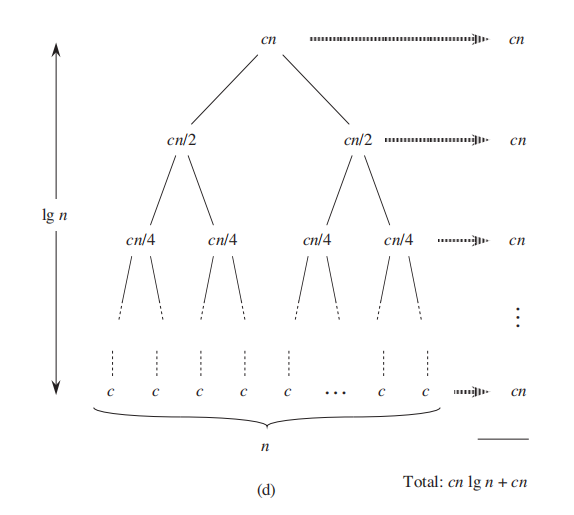
递归法往往能写成以下的格式:

主要有三种方法求解分治法的时间复杂度
In the substitution method, we guess a bound and then use mathematical in�
duction to prove our guess correct.
The recursion-tree method converts the recurrence into a tree whose nodes
represent the costs incurred at various levels of the recursion. We use techniques
for bounding summations to solve the recurrence.
The master method provides bounds for recurrences of the form
$T(n) = aT(\frac{n}{b}) + f(n)$






使用Master Theorum可以快速求出常见递归的时间复杂度。
比较重要,比较实用,比较递归参数的大小得到时间复杂度:

Binary search, Mergesort 的runtime 可以轻松的求出。
首先求出递归的数学表达:
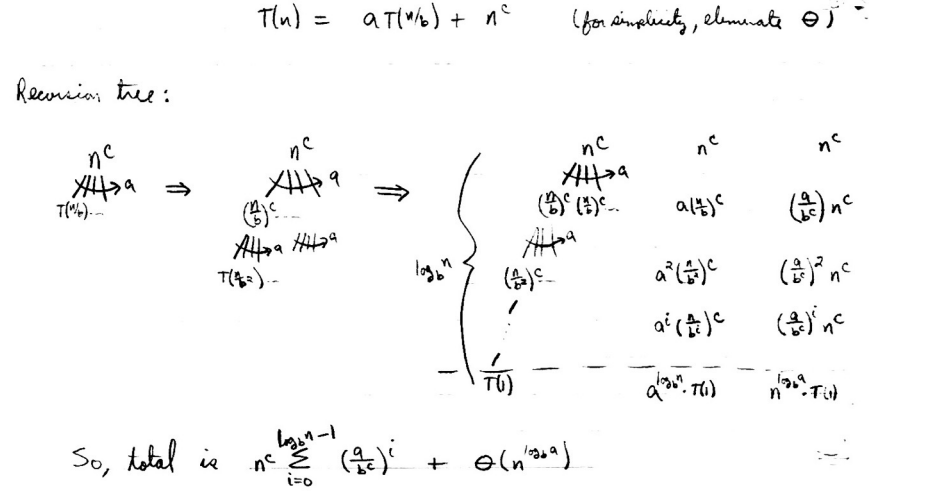
对于关键项
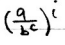
来说,有三种表达 <1,=1,>1,so three

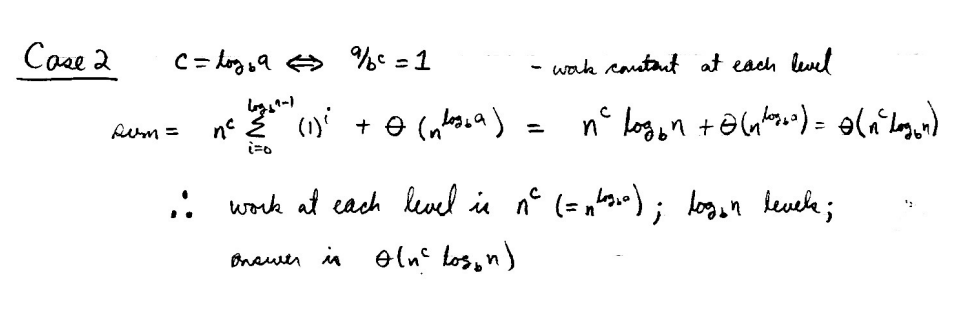

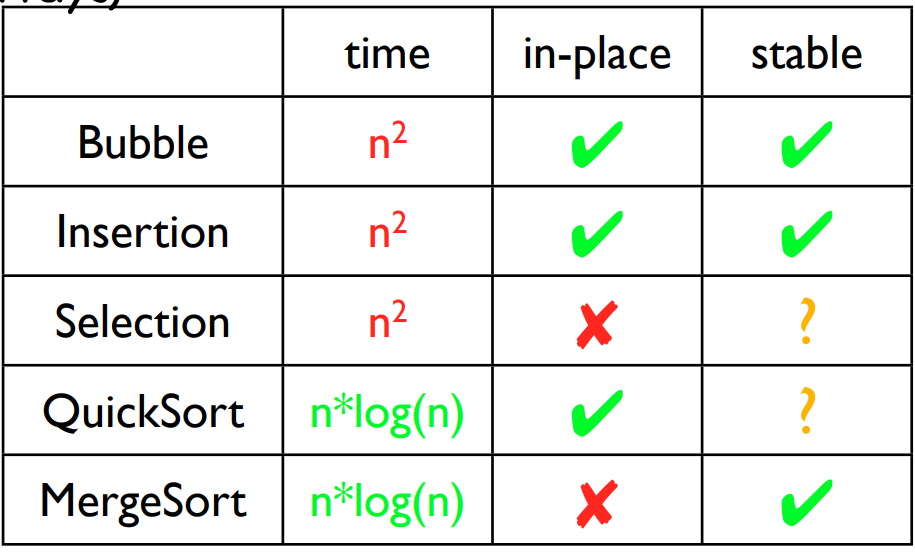
算法本身不做介绍。
worst running time is O(log n)
二叉树的本质是一种比较算法, 在这里先引入这个概念:
Insertion sort
最大堆性质:
In a max-heap, the max-heap property is that for every node i other than the root:
最小堆性质与之相反;
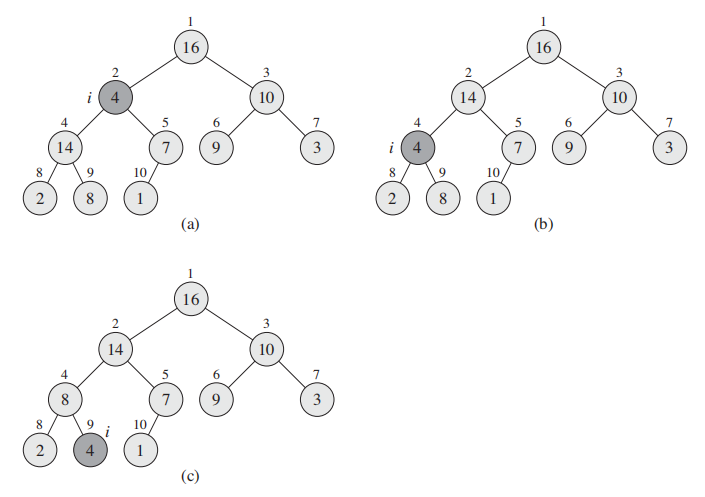
为了满足最大堆性质,你需要调用:

这段代码的逻辑就是找出
- 如果最大值是$i$,那么左右子树小于$i$, 满足max-heap property,无事发生。
- 如果不是,将$i$与largest 交换;交换后当前node满足max-heap, 但是子树不一定满足;因此对子树继续进行max-heapify
MAX-HEAPIFY 复杂度分析:


根据heap(二叉树)的性质,$A[(\frac{n}{2} + 1) ... n]$都是叶节点;因此从$ \frac{n}{2}$ downto 1进行heapify
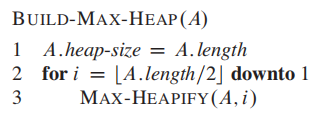
这样就完成了BUILD-MAX-HEAP。
下面来自例题:

答案:

Heapify -> 得到最大值 ->换到最后一位,不再管他,size - 1 -> 循环
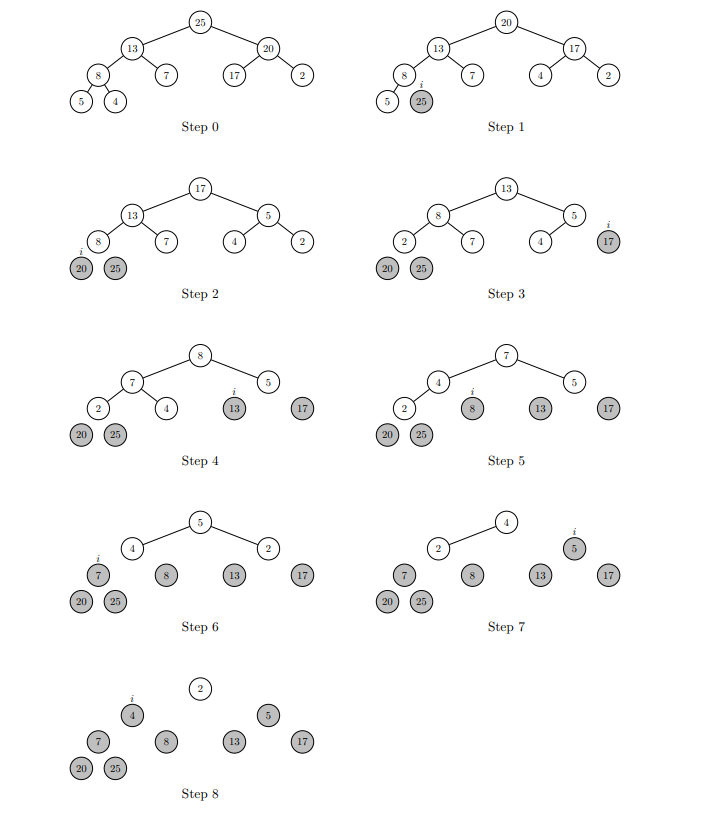
A divide-and-conquer algorithm with worst-case running time of



Partition 是 quicksort 最重要的机制。

Partition 会选择 x = A[r] 作为 pivot element。你要理解的是在Partition的过程中,有四个区域,先理解这个思路,伪码就能看懂了:
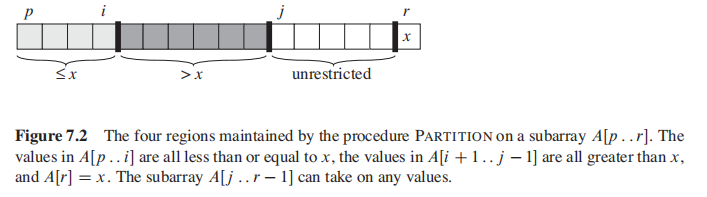
[j,r-1] 还没看到的区域
[p, i] 小于pivot 的区域
[i,j] 大于pivot的区域
[r] pivot element
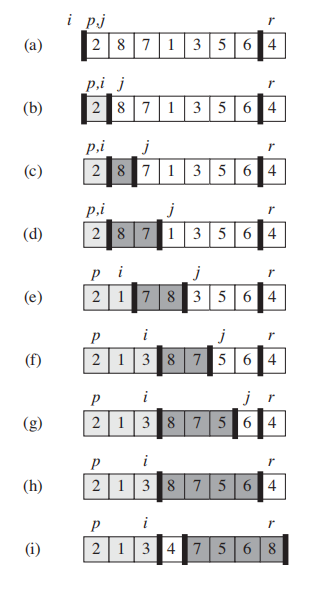
注意,partition返回的是i + 1.
Worst-case partitioning
The worst-case behavior for quicksort occurs when the partitioning routine produces one subproblem with

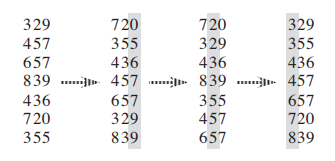

老师讲的很少,这块不复习了。

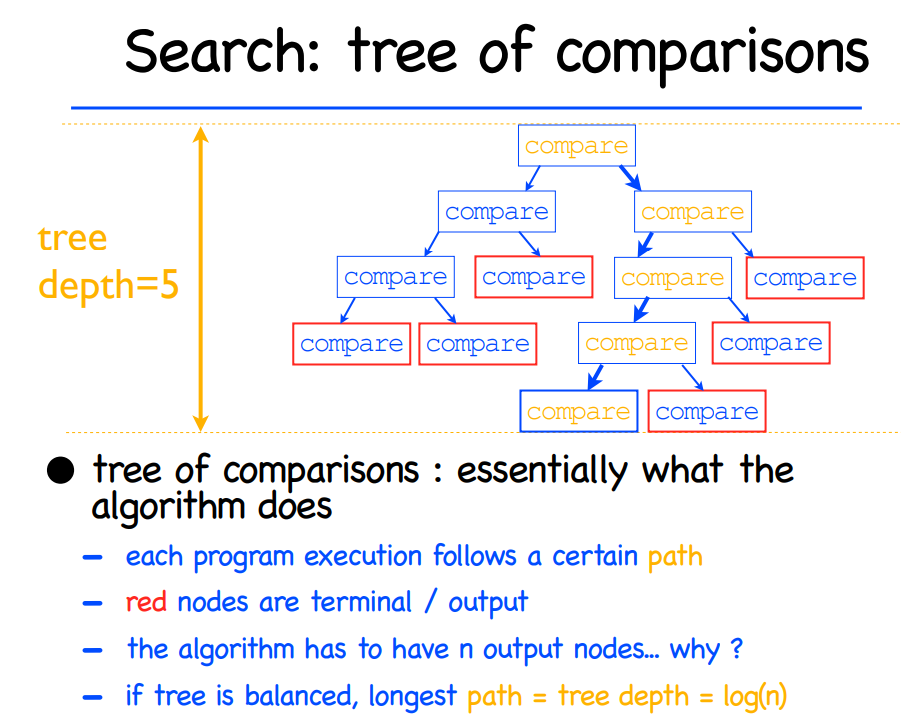
常见的算法主要是比较算法(comparison sort),比如mergesort在merge的部分需要比较两个数字的大小来排序。comparison sort 可以用下图的例子来类比:
求出树的高度h**(i.e., 抵达leaf的worst case时间)**,就是排序的worst case时间。
输入n的permutation 为n!, 参考下图的决策树,运行时间即为h,可以得出 $$ h = \Omega(n lgn) $$ 摘一段原文:
为什么
Some intuition about why: $$ lg(n!) = \Theta(n\cdot lgn) $$ 你需要记住
and
在选择最小值的算法上,我们都知道:
遍历数组,经过n-1次的比较我们可以找到最小值。This is the best we could do.
The general selection problem appears more diffificult than the simple problem of finding a minimum. Yet, surprisingly, the asymptotic running time for both problems is the same: $$ \Theta(n) $$
RANDOMIZED-SELECT类似quickSort,也是一种divide-and-conquer alg.
The following code for RANDOMIZED-SELECT returns the i smallest element of array A[p...r]
-
Line 1 & Line 2: 如果array长度为1,那直接返回array中的值
-
Line3: 类似quickSort的partition, 选择pivot,让A[p...q-1]的小于pivot, 让A[q+1,r]的值大于pivot, **A[q]**就是pivot number
-
Line4: 计算k(即A[p...q-1]的长度 + 1)
-
Line5: 如果 i == k,即你要的i th 等于 k,找到了答案,返回A[q]
-
Line7, 8,9: 否则,根据 i与k的关系继续调用RANDOMIZED-SELECT(if i>k, the desired element will lies in high partition part)
The worst-case running time for RANDOMIZED-SELECT is $$ \Theta(n^2) $$
select algorithm 应该就是median-of-medians,但是没有在wiki上得证。
大致思路:
- Divide the n elements of the input array into n/5 groups of 5 elements each gourp
- Find the median of each of the n/5 groups by insertion sorting
通常找第
Use a divide and conquer strategy to efficiently compute the
$i^th$ smallest number in an unsorted list of size n.
好文:https://brilliant.org/wiki/median-finding-algorithm/
给定A的,找到4th smallest element:
把A分成n/5份,保证每个subgroup有5个元素
分别求中位数:
Sort M:
求出M 中的中位数 len(M)/2 = 1, which is 76 (这一步就是所谓median-of-medians)
使用76作为pivot, partition(A),左边元素小于pivot index(76的idx是5),右边大于pivot index;
76的index是5, 5 > 3, 所以继续,在左半边(p, q-1)继续partition,也就是
最后只剩5个元素的时候会直接排序,书中说小于5个的元素排序时间复杂度是n,idk y。
注:sort小于5的array时间为O(n)? WTF? 这点我也没搞懂
详细分析参考上方的原文链接。以下为intuition:
-
T(n/5) + O(n):
我们把n分成了n/5的subproblem, partition需要上述的时间,参考quickSort。
-
T(7n/10)
在M(median list, 参考example M)中,M的长度为n/5 ,因此M中有一半的元素小于p(M的中位数,也就是中位数的中位数),也就是n/10,这一半的元素本身又有2个元素小于自己,因为这些元素本身是median of 5 element,因此有n/10 + 2* n/10 = 3n/10 的元素小于p。
因此在worst case情况下,算法每次都会recurse on the remaining 7n/10的元素。
根据master thoerum, 得出time complexity O(n)
Intro: 贪心算法(greedy algorithm) 的好处是什么?解读一下原文:
For many optimization problems, using dynamic programming to determine the best choices is overkill;
用简单的话来概括原文,就是使用动态规划解决优化问题有点杀鸡用牛刀的意思(overkill)。
A greedy algorithm always makes the choice that looks best at the moment. That is, it makes a locally optimal choice in the hope that this choice will lead to a globally optimal solution.
贪心算法做当前步骤的最好选择,每一步都这么做,最后得到全局最优解。
这句话听着怪怪的,为什么每次只选当前的最好能得到全局最优解呢?原文也说了:
Greedy algorithms do not always yield optimal solutions, but for many problems they do
即,贪心算法并不总是对的。有一些问题贪心算法能始终保持正确,有些问题贪心算法并不适用;我们只关心那些能100%正确的贪心算法;
因此,贪心算法难以设计,只适用于部分优化问题,但是他的computitional step比dp更少;
学习贪心算法最经典就是三个例子:Knapsack问题 , Activity-selection 问题 ,和找零钱 (coin change)问题。你在知乎等网站上搜贪心算法,也基本是这三个例子,属于典中典。
目标:给定一堆任务的开始和结束时间,在activities时间不能重合的情况下,选择最大activities数量的集合。
我们有n个activities,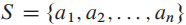 每个activity a i 有 start time f i 和 finish time s i
每个activity a i 有 start time f i 和 finish time s i
你选择的集合中,a i 和a j ,时间区间 [si,fi] 不能有重合的部分。
比如 set :{a 1, a 2} 是一个不合格的set, 因为 a 1 的区间[1,4] 和 a 2 的区间[3,5] 在[3,4]区间上有重合,我们要避免这样的overlap,选出最大的子集。
想法1:
根据直觉,在当前每一步都找 可行的$s_i$最小的任务行吗?
#假设活动根据开始时间si进行排序
#创建答案集合
answer = {}
#遍历每个活动
for each activity:
if 当前活动ai的开始时间si < answer最后一项的fi:
answer.union(ai)
这里省略了的第一次选择时 answer是空集的边界问题。
如果给定的集合是
| 1 | 4 | 6 | |
| 3 | 5 | 7 |
这个想法是正确的;
但是如果给定的集合是
| 1 | 4 | 6 | |
| 10 | 5 | 7 |
这个想法的答案就是
因此,这就是一个不是100%准确的贪心算法,是错误的。
贪心算法的核心在于,我们要找出最好的greedy choice。在这个问题中,我们每一步都需要:
we should choose an activity that leaves the resource available
for as many other activities as possible.
即,每一次选择都给后续的选择尽可能的留下更多空间;
正确的做法
根据活动的结束时间来选择活动。
即,在当前可行的actibity中,选择$f_i$最小的actibity加入集合。
继续刚才的例子:
| 1 | 4 | 6 | |
| 10 | 5 | 7 |
这样的算法会先挑选出$a_2$(因为5是当前最小的$f_i$), 再挑出$a_3$,因此是正确的;
建议自己画几个例子,就能理解了;
Greedy Algorithm的核心就是如下两点:
- 贪心选择Greedy choice: 每次都寻找最早结束的activity, Let's call it a earliest
- 子问题Subproblem: a earliest have finished. (排除有overlap的activity)
剩下的,交给递归recursive
![image-20211008004254723]()
(#注意,书中假设activity list: n已经按照finish time list: f 进行升序的排序),因此time complexity O(n)):
It also assumes that the input activities are ordered by monotonically increasing finish time.
OPTIONAL的内容:
经过经典的递归greedy algorithm解法,经典的下一步就是把rucursive变成iterative的解法。
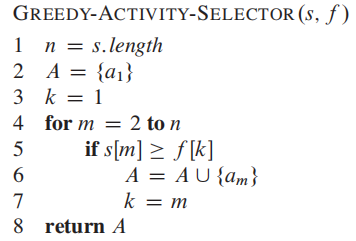
贪心算法的核心性质:
Greedy-choice property
The first key ingredient is the greedy-choice property: we can assemble a globally
optimal solution by making locally optimal (greedy) choices.
这个性质比较好理解,这也是greedy和DP的主要区别。
Optimal substructure
A problem exhibits optimal substructure if an optimal solution to the problem
contains within it optimal solutions to subproblems.
这个性质可能需要时间消化,以activity-selection问题为例:
if an optimal solution to subproblem
$S_{ij}$ includes an activity$a_k$ , then it must also contain optimal solutions to the subproblems$S_{ik}$ and$S_{kj}$
下方是书中给出的步骤:

总结
- 贪心算法only make locally optimal choiceœ, 部分的贪心算法不能保证走向 global-optimal solution, 但我们只关心那些能保证走向global-optimal solution的算法。
- 贪心算法的核心在于寻找strategy, 你需要证明你的贪心策略是正确的。
证明贪心算法需要证明以下两个性质
Greedy-choice property
The first key ingredient is the greedy-choice property: we can assemble a globally optimal solution by making locally optimal (greedy) choices.
Optimal substructure
A problem exhibits optimal substructure if an optimal solution to the problem contains within it optimal solutions to subproblems.



- Dynamic programming, like the divide-and-conquer method, solves problems by
combining the solutions to subproblems.
- In contrast, dynamic programming applies when the subproblems overlap—that is, when subproblems share subsubproblems.:
- divide-and-conquer algorithm does more work than necessary, repeatedly solving the common subsubproblems.
- dynamic-programming algorithm solves each subsubproblem just once and then saves its answer in a table, thereby avoiding the work of recomputing the answer every time it solves each subsubproblem.

切绳子问题定义如下:
给定一个总长度为n的绳子,给定价格
Task: 如何切分绳子,使得总价值
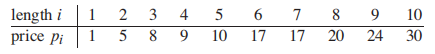
比如给定长度为4的绳子,绳子可以切分的长度和根据上图计算得出的总价值分别如下:
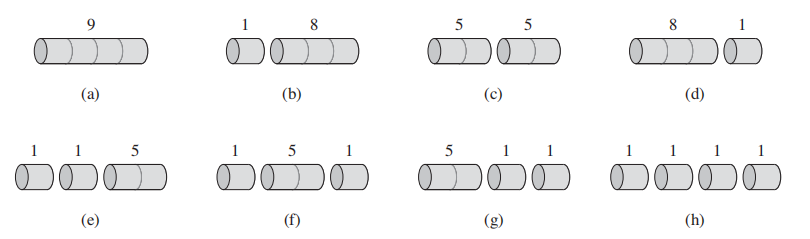
可以看出 (c)的总价值为10,是最大的。
切绳子问题展现出了optimal substructure:
原始问题是 problem of size(n), 当我们第一次cut之后,我们就在解决两个独立的子问题。
optimal solutions to a problem incorporate optimal solutions to related subproblems, which we may solve independently.
i.e. 子问题的最优解被包含在了全局问题的最优解中。
Method 1: Brute force
长度为n的绳子共有
Method 2: Recursive top-down implementation
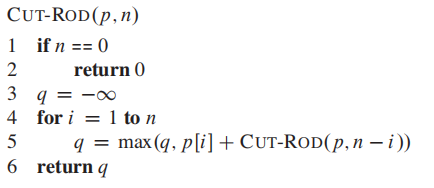
@param:
**p** : array p[1..n] of price
n: 长度n
#comment
3:init max value to -infinity
4-5: compute max value q
CUT-ROD is very inefficient. it solves the same subproblems repeatedly.
下图展示了 CUT-ROD(p, 4)的递归,可以看到相同的子问题被反复的计算。
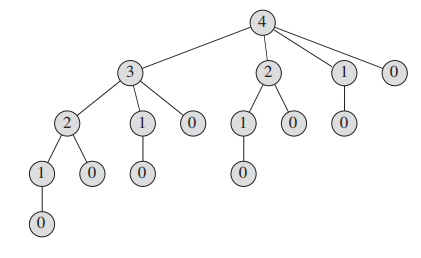
时间复杂度T(n) =
Method 3 dynamic programming for optimal rod cutting
动态规划出现了!
核心思想:每个子问题只解决一次,使用额外的空间来保存子问题的solution。
We just look it up, rather than re-compute it.
It is a time-memory trade-off.
There are usually two equivalent ways to implement a dynamic-programming
approach.
The fifirst approach is top-down with memoization.
The first approach is top-down with memoization. In this approach, we write the procedure recursively in a natural manner, but modifified to save the result of each subproblem (usually in an array or hash table). The procedure now first checks to see whether it has previously solved this subproblem. If so, it returns the saved value, saving further computation at this level; if not, the procedure computes the value in the usual manner. We say that the recursive procedure has been memoized;it “remembers” what results it has computed previously.The second approach is the bottom-up method.
This approach typically depends on some natural notion of the “size” of a subproblem, such that solving any particular subproblem depends only on solving “smaller” subproblems. We sort the subproblems by size and solve them in size order, smallest first. When solving a particular subproblem, we have already solved all of the smaller subproblems its solution depends upon, and we have saved their solutions. We solve each subproblem only once, and when we first see it, we have already solved all of its prerequisite subproblems.
简单来说,二者差别如下:
top-down方法先检索是否有该subproblem的答案;
如果有,使用该答案。
否则, 计算该答案,进入递归。
而bottom-up方法使用问题大小的自然顺序(natural notion of the size of problem),**从最小的问题开始, 自底向上 的逐一解决,**因此解决到大问题时,之前的小问题已经解决完了。
原文的详细定义点开上方折叠。
**Pseudocode for the top-down CUT-ROD procedure: **
top-down:

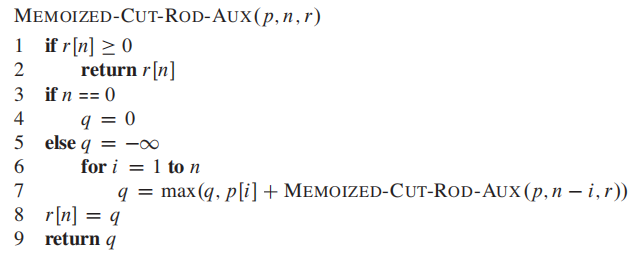
bottom-up:
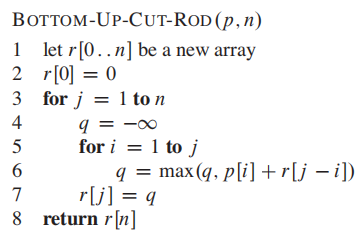
下图为bottom-up 方法我个人的部分演算:
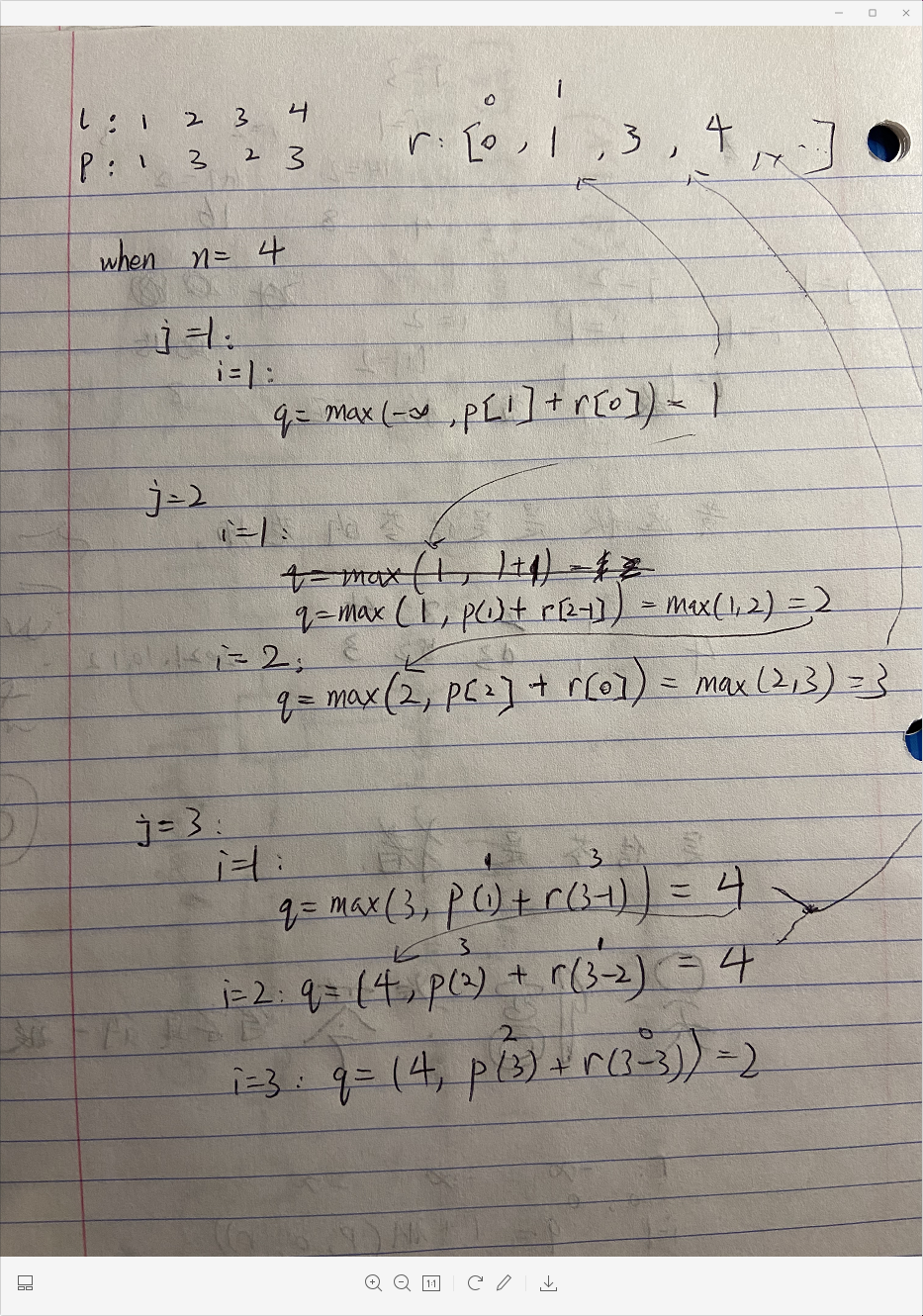
我们熟知的矩阵乘法的伪码如下:

假设我们要连乘矩阵 <$A_1,A_2,A_3,A_4$>, 我们有以下5种方法, i,e, we can fuuly parenthesize the product in 5 distinct ways:
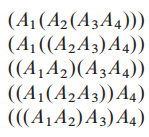
现在我们来分析假设我们要连乘矩阵 <$A_1,A_2,A_3$> ,他们的维度分别为**<10 x 100, 100 x 5, 5 x 50>**。
parenthesization ** <$((A_1,A_2),A_3$)> 中,第一次括号内运算会有10 * 100 * 5 = 5000 次运算,然后再有 10 * 5 * 50 = 2500 次运算,总共有7500**次的运算。
而<$(A_1,(A_2,A_3)$)>,第一个括号 100 * 5 * 50 = 25000次运算,之后有10 * 100 * 50 = 50000 的运算,总共有75000次运算,比第一个快十倍。
如下,我们引出矩阵连乘问题:
Our goal is to determine an order for multiplying matrices that has the lowest cost.
即,找出最快矩阵连乘的顺序。
假设我们有下方的矩阵:
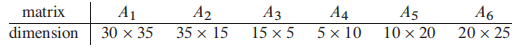
注意,其中,矩阵$A_i$的维度是
Method 1 brute-force 穷举法
根据矩阵数量,这是inefficient的递归公式:
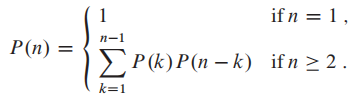
**
Method 1 Applying dynamic programming
记得之前的四个步骤:


现在大概跟一遍:
Step 1: The structure of an optimal parenthesization
假设我们有如下optimal 的待乘矩阵
因为如果$A_i,A_{i+1},...,A_{k}$ 有更好的方法,那么
上面的方法是反证法(contradiction)。
Step 2: A recursive solution
如果我们在$A_k$ (i < k < j) 将待乘矩阵分开,那么我们会得到两个子问题$A_i,A_{i+1},...,A_{k}$ 和
我们让 m[i, j] 来表示全局问题的最优解(即最小的multiplication 次数),两个子问题即为 m[i,k], m[k+1,j];
合并两个子问题的product
这样,我们的问题变成了
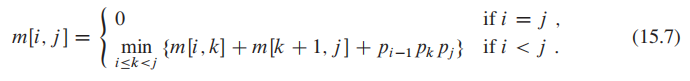
Step 3: Computing the optimal costs
回顾一下斐波那契数列,斐波那契数列也可以用动态规划来表示;
如果只用递归的方法调用斐波那契数列,递归的过程中,F(5)和F(8)都会重新计算F(4),F(3)....
动态规划的标志就是他储存了已经计算过的答案来防止re-compute。
假设我们有下方的矩阵:
注意,其中,矩阵$A_i$的维度是
bottom-up approach:
- set
$m[i,i]$ = 0 ($m[i,i]$ 代表矩阵乘以矩阵本身,连子问题都不算,只是trivial), 这也是为什么源码的n-1,n=6的问题我们只需要计算五个就好了 - compute
$m[i,i+1]$ for$i = 1,2,...,n-1$ - then compute
$m[i,i+2]$ for$i = 1,2,...,n-1$ , and so forth

作为一个bottom-up的DP, 我们每次都在尝试想上计算;比如当算到$m[2,5]$时, 我们其实在做以下事情
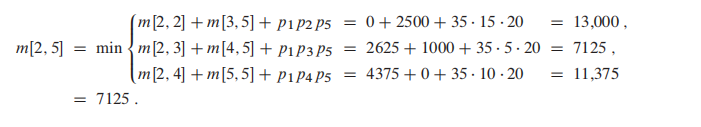
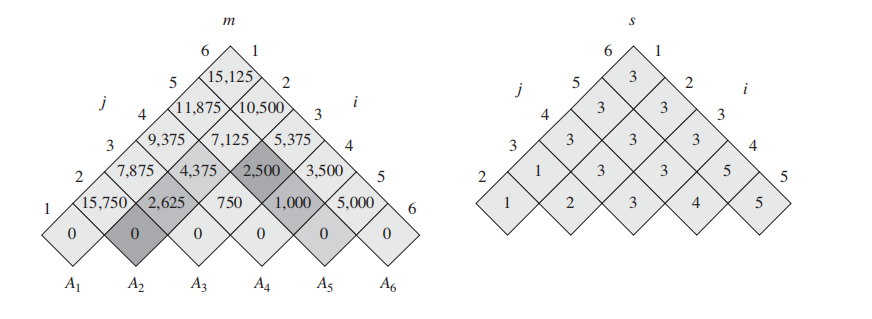
上图左侧的table即为伪码中的 m table, 右边的是 s table。
m表只给出了m[i,...,j] 的对应最优计算次数,并没有告诉我们 m[1,6] 的过程应该怎么进行切分;因此我们需要右边的 s table 来告诉我们。
**$s[i,j]$ 记录了每一次的最优切分k。**通过s表递归的寻找k,我们就能知道最优切分。
如果上面你看懂了,下面这三张图你可以跳过。
这代码
好一个bottom-up:



Optimal substructure
A problem exhibits optimal substructure if an optimal solution to the problem contains within it optimal solutions to subproblems.
有些问题没有Optimal substructure性质,比如给定一个没有权值的有向图(directed graph):
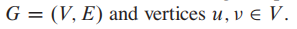
现在有两个问题,定义如下:
-
无权值的最短路径问题(Unweighted shortest path):找到某顶点u到某顶点v的 最少边的数量。
(英文比较好看懂:Find a path from u to v consisting of the fewest edges.)
- 无权值的最长路径问题(Unweighted longest simple path:): 找到某顶点u到某顶点v的 最多边的数量。
哪个问题有optimal structure呢?
问题1有。
查缺补漏:图的定义如下:
A directed graph (or digraph) is a set of vertices and a collection of directed edges**(边)** that each connects an ordered pair of vertices**(顶点)**.
一句话说,由顶点 set:V 和 边 set :E组成
**Unweighted shortest path:**3
Find a path from u to consisting of the fewest
edges. Such a path must be simple, since removing a cycle from a path pro�
duces a path with fewer edges.
作者很懒还没写完
作业以及课本包含一些经典DP的leetcode题目,如下:
516. Longest Palindromic Subsequence
887. Super Egg Drop (took me a long while...for real...)
得从brute force开始:
https://leetcode.com/problems/super-egg-drop/discuss/159079/Python-DP-from-kn2-to-knlogn-to-kn
到这位大神的:
https://leetcode.com/problems/super-egg-drop/discuss/158974/C%2B%2BJavaPython-2D-and-1D-DP-O(KlogN)
- stack:
last-in,first-out
Methods: push , pop

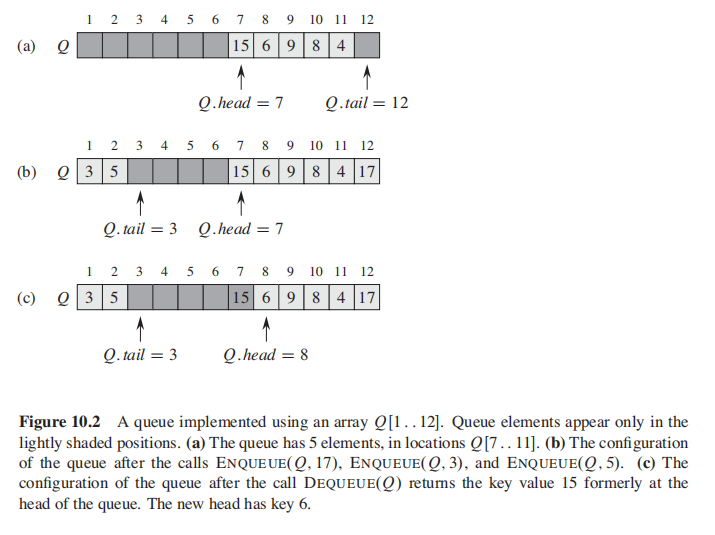
- queue
queue: first-in, first-out
Methods: deque, enque
The order in alinked list is determined by a pointer.
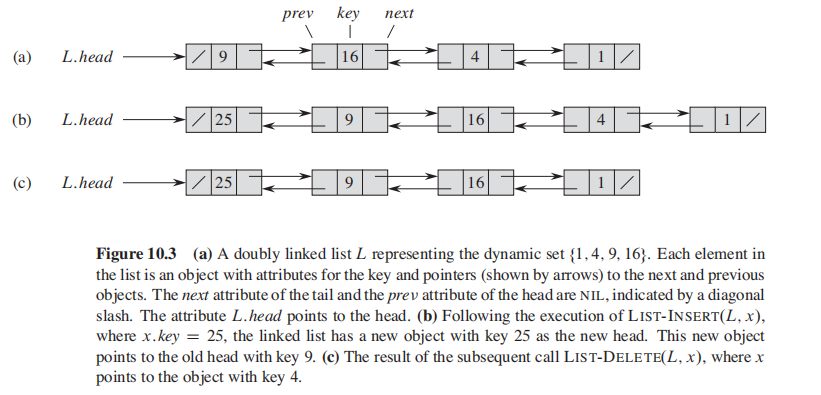
Methods: search, insert, delete
搜索:
时间复杂度:$O(n)$
插入:
注意,这个是从前面插入;
不用遍历,因此时间复杂度是
删除:
需要先使用Search功能,因此worst case时间复杂度是$O(n)$

好像没啥说的
- Binary Search Tree


inorder tree walk. This algorithm is so named because it prints the key of the root of a subtree
between printing the values in its left subtree and printing those in its right subtree.
Min
最小值就是找到最左的节点
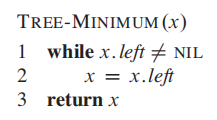
Max
最大值就是找到最右的节点

Successor and Predecessor是个啥?
**Successor **
If all keys are distinct, the successor of a node x is the node with the smallest key greater than x.key.
即,x的successor是刚好大于x的那个节点;
为了找到这个节点:

我们的目标是找到刚好比x大的元素,所以:
-
如果x的右子树不为空,那么找到右子树中的最小元素即可;
要找到右子树中的最小元素,对着x.right调用
min方法即可; -
如果x的右子树是空的,那么sucessor只能在x的头上;此时又有两种情况:
- 假设y是x的parent, 若x是y的左子树,说明x<y,那么直接返回y;
- 否则, x是y的右子树,x>y, 再往上走;(如果走到根节点,就会返回NIL)
Predecessor
与Successor 相反,Predecessor是刚好小于 x 的节点;
假设我们要找的节点x是存在于树中的。
因此:
- 如果x.left
$\neq$ NIL, 那么Predecessor就是x.left中的最大值; - 否则,Predecessor不存在;
书中BST涉及的一些leetcode:
110.Balanced Binary Tree:https://leetcode.com/problems/balanced-binary-tree/
比较tricky地方在于,检查BST是否平衡,不只是统计根节点的左右子树最大高度差,因为可能发生这种情况:
对于根节点来说,height(左子树) - height(右子树)的高度差小于2;
但是对于节点10来说,高度差是2,破坏了平衡;
因此,你需要对每一个节点都check balance。
- Insert into a Binary Search Tree: https://leetcode.com/problems/insert-into-a-binary-search-tree/
找到位置插入即可,优雅的代码来自:
这哥们老想写成一行,为了可读性我给他展开了:
class Solution(object):
def insertIntoBST(self, root, val):
if root == None:
return TreeNode(val)
if root.val > val:
root.left = self.insertIntoBST(root.left,val)
else:
root.right = self.insertIntoBST(root.right,val)
return root
- Delete Node in a BST: https://leetcode.com/problems/delete-node-in-a-bst/
原文写的太复杂了,用到了transplant; 因此使用leetcode大哥的;
删除操作有3个case;
-
如果节点没有children, 那么直接删除;
-
如果节点没有左children, 那么右children直接顶上来;
-
否则,找到左children中的最大值,并且顶上去;
代码来自:
class Solution:
def deleteNode(self, root, key):
"""
:type root: TreeNode
:type key: int
:rtype: TreeNode
"""
if not root:
return
# we always want to delete the node when it is the root of a subtree,
# so we handle left or right according to the val.
# if the node does not exist, we will hit the very first if statement and return None.
if key > root.val:
root.right = self.deleteNode(root.right, key)
elif key < root.val:
root.left = self.deleteNode(root.left, key)
# now the key is the root of a subtree
else:
# if the subtree does not have a left child, we just return its right child
# to its father, and they will be connected on the higher level recursion.
if not root.left:
return root.right
# if it has a left child, we want to find the max val on the left subtree to
# replace the node we want to delete.
else:
# try to find the max value on the left subtree
tmp = root.left
while tmp.right:
tmp = tmp.right
# replace
root.val = tmp.val
# since we have replaced the node we want to delete with the tmp, now we don't
# want to keep the tmp on this tree, so we just use our function to delete it.
# pass the val of tmp to the left subtree and repeat the whole approach.
root.left = self.deleteNode(root.left, tmp.val)
return rootso f**king clean!
见过的最优雅代码之一了!
https://docs.python.org/2/library/functions.html#hash
Python 官方文档:

用来for loop 比较 key 值是否相等的
使用pyhon试试 $hash $ 函数:
Direct addressing is a simple technique that works well when the universe U of keys is reasonably small.
直接寻址法 适用于key比较少的时候。
这样的方法同时记住了 key 和 data(而不是data的address) ,非常占用空间;
Python用久了让人有 dict 很简单的错觉,所以这个内容让我思考了很久。
建议先看一下下文:
https://zhuanlan.zhihu.com/p/74003719
With direct addressing, an element with key k is stored in slot k.
With hashing, this element is stored in slot h(k); that is, we use a hash function h to compute the
slot from the key k.
Here, h maps the universe U of keys into the slots of a hash
table T[0 .. m-1]:
h: U ---> {0,1, ... , m-1}
简而言之:
An element with key k hashes to slot h(k);
hash function减少了indices的范围;
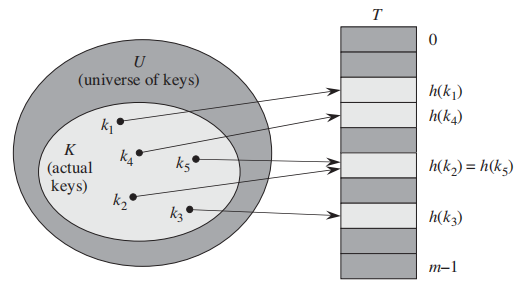
但是有时候两个key会被match到一个slot里面;这就是一个 collision; 参考上图。
比如我们的 hash(x) = x%10, 这样的话25 和 35就会被match到同一个slot上,这就是一个冲突;
发生冲突并不可怕,有一些有效的方法能化解冲突带来的结果;(冲突本身是不可能解决的)
哈希算法最重要的特点就是:
- 相同的输入一定得到相同的输出;
- 不同的输入大概率得到不同的输出。
下面介绍原书中提供的最简单的冲突解决方法;
1. Chaining:
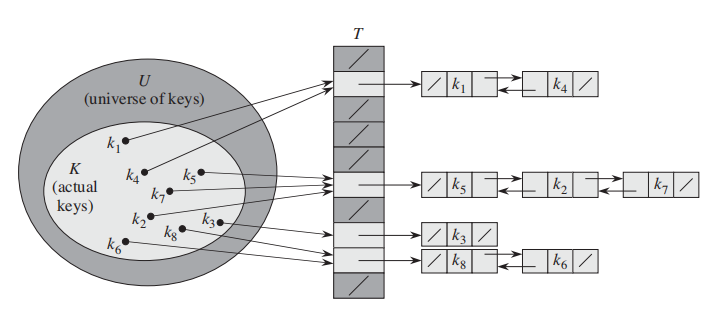
让每一个key都对应一个linked list;
一个例子:
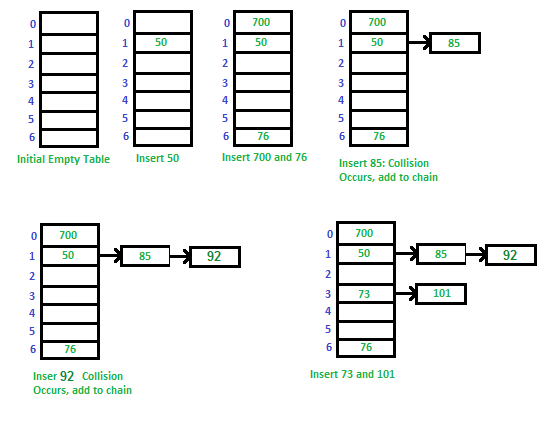
2. 开放寻址法(open addressing):
什么是好的 hash function?
- simple uniform hashing: each key is equally likely to hash to any of the m slots
如果完全随机的插入slot, 就可以满足这个条件;
Most hash functions assume that the universe of keys is the set N= {0,1,2, ......}
of natural numbers. Thus, if the keys are not natural numbers, we find a way to
interpret them as natural numbers.
比如最简单的division method: $$ h(k) = k \mod m $$
A hashing technique perfect hashing if $O(1)$memory accesses are required to perform a search in the worst case.
为了做到完美哈希,第一个因素和之前的方法是一样的:选择一个好的 hash function $ h $ 把
之后,除了使用chaining 搭建新 linked list的方法之外,转而使用一个小的第二哈希表 secondary hash table
**Theorem: **
Suppose that we store n keys in a hash table of size
$m = n^2$ using a hash function$h$ randomly chosen from a universal class of hash functions.Then, the probability is less than
$1/2$ that there are any collisions.翻译:
使用随意一个哈希函数
$h$ ,把 n 个keys存到$m = n^2$ 个slot里,有冲突的概率小于$1/2$

题目来自Homework 8
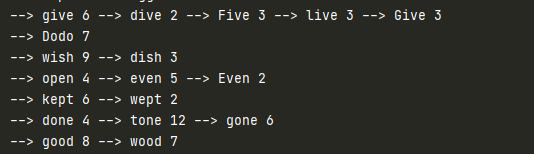
Implement a hash for text.
Given a string as input, construct a hash with words as keys, and wordcounts as values. Your implementation should include:
• a hash function that has good properties for text
• storage and collision management using linked lists
• operations: insert(key,value), delete(key), increase(key), find(key), list-all-keys
先来找一个适合string的hash func,google了以后:
http://www.cse.yorku.ca/~oz/hash.html
实施
复习一下:
Python
ord:输入一个字符,返回ASCII数值
hex:输入整数,返回16进制
实施hash_djb2:
忘记位运算的先复习一下;
def hash_djb2(s):
hash = 5381
for x in s:
hash = (( hash << 5) + hash) + ord(x)
return hash & 0xFFFFFFFF这个函数的magic在于他的两个魔法数字:33和5381,这里用的是5381;这是一个经验主义得到的magic number,不用纠结太多;
贴一点test case:
print(hash_djb2(u'hello world')) # '0xa6bd702fL'
print(hash_djb2('a'))
print(hash_djb2('b'))
#输出:
894552257
177670
177671python自己实现哈希表
目标如下:
-
给定一段长文本txt文件,我的hashmap读入文件,以word作为key,word count作为value;
-
使用chaining 方法来handle collision
结果是这样的:
跳表在工业中也会被经常用到,墙裂建议阅读下文:
https://www.jianshu.com/p/9d8296562806
简单概括重点:
跳表的索引高度
假如原始链表包含 n 个元素,则一级索引元素个数为 n/2、二级索引元素个数为 n/4、三级索引元素个数为 n/8 以此类推。所以,索引节点的总和是:n/2 + n/4 + n/8 + … + 8 + 4 + 2 = n-2,空间复杂度是 O(n)。
为什么Redis选择使用跳表而不是红黑树来实现有序集合?
Redis 中的有序集合(zset) 支持的操作:
- 插入一个元素
- 删除一个元素
- 查找一个元素
- 有序输出所有元素
- 按照范围区间查找元素(比如查找值在 [100, 356] 之间的数据)
其中,前四个操作红黑树也可以完成,且时间复杂度跟跳表是一样的。但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高。按照区间查找数据时,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了,非常高效。
跳表Skiplist的Python实现。
https://leetcode.com/problems/design-skiplist/discuss/?currentPage=1&orderBy=most_votes&query=
Python:
这个实现是我从leetcode某个大哥那抄过来的,有做改动;
It really took me one day to understand....
class Node:
def __init__(self, val):
self.val = val
self.next = None
self.down = None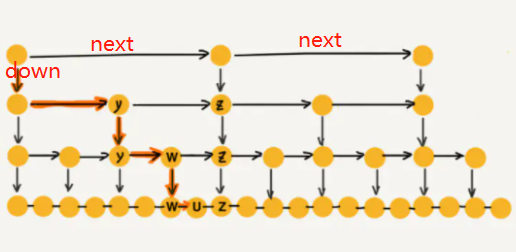
next 指的是相同级别的下一个元素,就是往右走;
down 指的是下一个级别的相同元素,就是往下走;
初始化:
class Skiplist:
def __init__(self):
self.levels = []
self.max_level = 4
prev = None
for i in range(self.max_level):
node = Node(-math.inf)
self.levels.append(node)
if prev:
prev.down = node
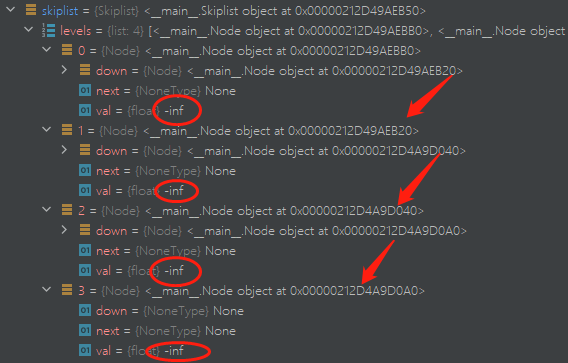
prev = node在这次的实现中,levels储存的是每个级别的单链表。
index = 0 的位置存的是最高级的链表,我们在这一级别实现skip 操作;
index = 3 存的是最基础的链表,也就是长度为
后面统一一下口径,最高级的链表指 index = 0, 元素最少的那一条链表;
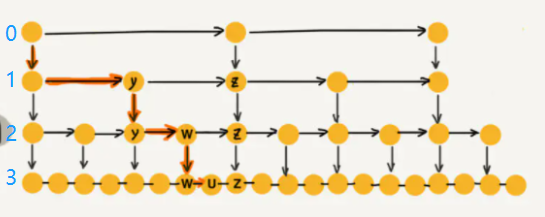
通过上述代码,你实现了如下的操作:
self.level中储存了每个级别的对应的链表, 每个级别链表的初始化都为负无穷:-math.inf- 让每个更高级的链表对象指向更基础的级别;
如图:
实现iter
def _iter(self, val):
res = []
l = self.levels[0]
while l:
while l.next and l.next.val < val:
l = l.next
res.append(l)
l = l.down
return res这个函数是很核心的函数,后面的操作都会用到它;
这个函数实现了skip的作用:
-
输入一个
val, 只要下一个元素比val小,就往右走(next); -
否则,就往下走(
down);
为什么是while l,因为他只能往右或者往下走,就一定有走到None的时候;
所以,这个函数中返回的结果res是每个级别中刚好小于val的那个node节点对象;
即使下一个元素能等于val, 也停留在之前一个,方便后续delete操作;
这个函数实现了,理解了返回的res是什么,后续就简单了;
search 搜索操作:
def search(self, target: int) -> bool: last = self._iter(target)[-1] return last.next and last.next.val == target上一个_iter函数停留在输入值的前一个数,所以直接检查下一个元素就好了;
add/insert操作
def add(self, num: int) -> None: res = self._iter(num) prev = None for i in range(len(res) - 1, -1, -1): node = Node(num) #res[i]是刚好比val小的元素,那么next就比val大咯 node.next = res[i].next #指向低级链表 node.down = prev #res[i]是刚好比val小的元素 res[i].next = node prev = node rand = random.random() if rand > 0.5: break- 这个
for是从低级走到高级的 - 在保证了基础级别存在插入的数值以后,每个更高级的节点都
random一次,大于0.5就在更高级的节点添加该节点;
erase/delete删除操作
有了_iter操作后很简单,不用说了
先仔细阅读下原文:
A red-black tree is a binary search tree with one extra bit of storage per node: its
color, which can be either RED or BLACK. By constraining the node colors on any
simple path from the root to a leaf, red-black trees ensure that no such path is more
than twice as long as any other, so that the tree is approximately balanced.
Each node of the tree now contains the attributes
color,key,left,right, andp.

所以红黑树本质就是自平衡的BST,但是他多了颜色属性,并且服从红黑树性质:
1)每个结点要么是红的,要么是黑的。 2)根结点是黑的。 3)每个叶结点(叶结点即指树尾端NIL指针或NULL结点)是黑的。 4)如果一个结点是红的,那么它的俩个儿子都是黑的。 5)对于任一结点而言,其到叶结点树尾端NIL指针的每一条路径都包含相同数目的黑结点。
红黑树的查找、插入、删除的时间复杂度最坏为O(log n)。
如果忘记了BST的性质,先去上面复习一下 Insertion 和 Deletion 的操作。
When we do a left rotation on a node x, we assume that its right child y is not T:nil; x may be any node
in the tree whose right child is not T:nil. The left rotation “pivots” around the link
from x to y. It makes y the new root of the subtree, with x as y’s left child and y’s
left child as x’s right child.
我们要左旋节点某子树的根节点: x;
假设x 的右child y的 不为空:
旋转围绕着 x和y的连接,我们让:
- ``y``成为该子树的root, - ``x``成为 ``y`` 的左child, ``y`` 原来的左child成为 ``x``的右child。
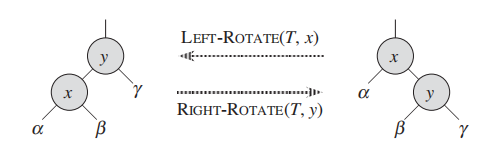
figure 来自原文13.2 p313
伪码:

左旋、右旋的时间复杂度为**$O(1)$**。
插入的时间复杂度为

为了保证红黑树性质,需要一个额外的fix函数来 recolor 以及 rotate

今天被旋晕了,下次再来吧
Case 1: z's uncle y is red
Case 2: z’s uncle y is black and z is a right child
Case 3: z’s uncle y is black and z is a left child
总共有6个cases;
因为3个3个cases之间是对称的,因此
我们关注三个case:
Case 1:
z'suncleyis redCase 2: z’s uncle y is black and z is a right child
Case 3: z’s uncle y is black and z is a left child
Case 1: z's uncle y is red
z的舅舅是红色的,此时违反了性质4: 即一个red的儿子必须是两个black;
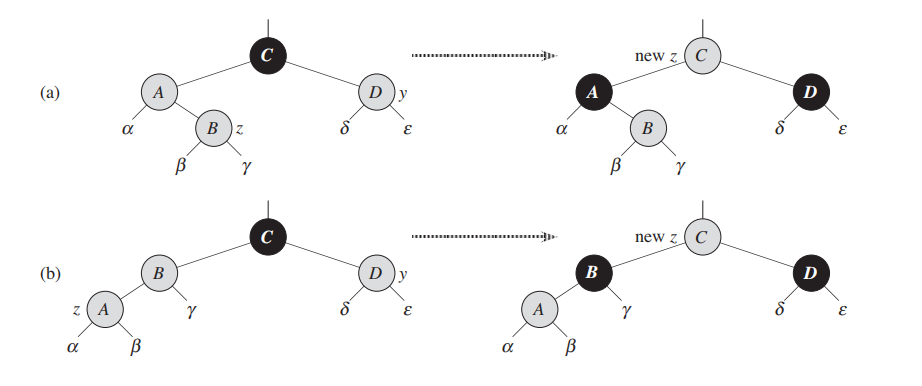
此时的操作:
1. 把uncle由红变黑;2. 把parent(A)变黑3. 把爷爷(c)变红;4. 把指针从z移到爷爷
Case 2: z’s uncle y is black and z is a right child
case 2和 case 3是相互交织的;
case 2还是违反了性质4;此时用一个左旋/右旋直接进入case 3;
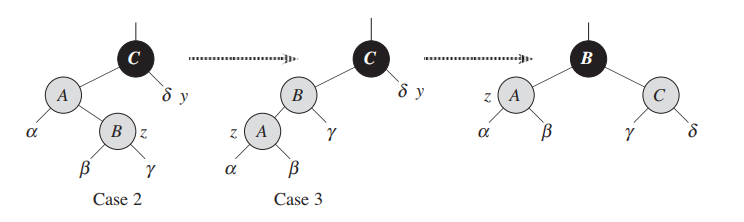
1.移动指针到parent2.旋转,进入case3
Case 3: z’s uncle y is black and z is a left child
1.翻转parent和爷爷的color;2.对爷爷调用旋转;
插入以后会导致RBT的那些性质会被violated?
- Property 2: 根节点是黑
当树为空时,插入的节点是红色的,这时违反;
- Property 4: 红色节点不能有红色节点,只能有两个黑色节点;(NIL也算黑色)
https://www.quora.com/Difference-between-binary-search-tree-and-red-black-tree
一开始没理解R-B-Tree 比 BST强的地方,谷歌了一下总结如下:
常规的BST不是self-balancing的,因此你的插入顺序会导致其他操作的时间复杂度发生变化;
比如:
- if you inserted in order {2, 3, 1}, the BST will be O( log(N) )
- however if you inserted {1,2,3}, the BST will be O( N ), like a linked list.
而RB-Tree总能自平衡,来确保你的操作总会是$O(lgn)$。
Red Black Tree : best case O(logN), worst case O(logN) Binary Search Tree: best case O(logN), worst case O(N)
在平摊分析中,执行一系列数据结构操作所需要的时间是通过执行的所有操作求平均而得出的。
如果堆栈添加一个新的操作MULTIPOP 来一次性弹出栈顶的
PUSH(S, x):将x压入S
POP(S):弹出栈顶
MULTIPOP(S, k):弹出栈顶k个对象
在最坏情况下,MULTIPOP操作的时间复杂度为O(n)。
现在开始分析由n个PUSH, POP和MULTIPOP操作序列,其作用于一个初始为空的栈:
每个操作的最坏情况是$O(n)$, 因此n个操作序列的代价是$O(n^2)$;
这一分析虽然正确,但是这个bound不够紧凑;
一个对象在每次被压入栈后,至多被弹出一次。所以,调用POP(包括MULTIPOP)的次数至多等于PUSH的次数,即至多为n.。对任意的n,包含n个PUSH, POP, MULTIPOP操作的序列的总时间为O(n). 每个操作的平均代价为O(n) / n = O(1).。
聚集分析中,将每个操作的平摊代价指派为平均代价。所以三个栈操作的平摊代价都是O(1)。
直觉是这样的:Accounting Method,要求你先计算出每个操作要“存”多少钱,然后给别的操作消费。
在平摊分析的记帐方法中,对不同的操作赋予不同的费用,某些操作的费用比它们的实际代价或多或少。
我们对一个操作的收费的数量称为平摊代价。当一个操作的平摊代价超过了它的实际代价时,两者的差值就被当作存款(credit),并赋予数据结构中的一些特定对象,可以用来补偿那些平摊代价低于其实际代价的操作。
数据结构中存储的总存款等于总的平摊代价和总的实际代价之差。注意:总存款不能是负的。
核心思想是PAY IN ADVANCE:提前支付费用
Stack Operations
| 操作 | 真实花费 | 平摊花费 |
|---|---|---|
| Push | 1 | 2 |
| Pop | 1 | 0 |
| MultiPop | min(k,s) | 0 |
可以看到对于Push操作,平摊花费比真实花费要多1,这个1即使credit。即栈中的每个元素都有一个值为1的credit,之后的Pop操作和Multipop操作平摊花费都为0,相当于是使用一个credit。因为在Pop前都必须调用了相应数量的Push,所以总和的credit永远不会小于0
因此对于一系列n个操作而言,其总共的平摊花费也是O(n)。
原文:

我们假设数据结构$Di−1$在进行了第$i$个操作后,变为了数据结构$Di$,其中第i个操作的真实花费为$ci$,数据$Di$的势能为$Φ(Di)$,数据$Di−1$的势能为$Φ(Di−1)$。在使用势能法时,平摊开销(amortized cost)就是:
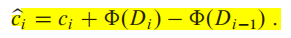
平摊开销 = 真实开销 + 势能差 (核心思想和上一节的acounting 方法一样,把“提前支付”变成了储存势能 -> 释放势能)
经过
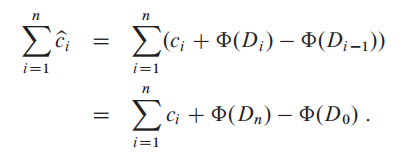
继续使用stack作为例子:
我们定义potential function
那么对于空栈$D_0$来,他的$Φ(D_0)$就是0;
如果第$i$次的操作是对一个 长度为 $s$的堆栈 $D_0$ 进行PUSH操作,那么势能差:
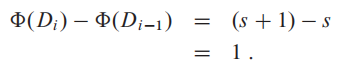
求出平摊开销:
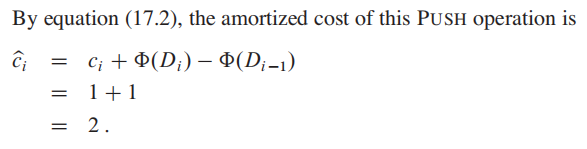
如果第 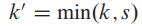 个数据对象全部pop出去,那么势能差为:
个数据对象全部pop出去,那么势能差为:
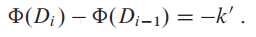
平摊开销:
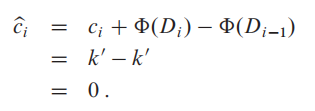
好文:帮助理解
https://www.zhihu.com/question/40156083
这算法看的比红黑树还眩晕,细节参考原文吧,网上教程也很少;
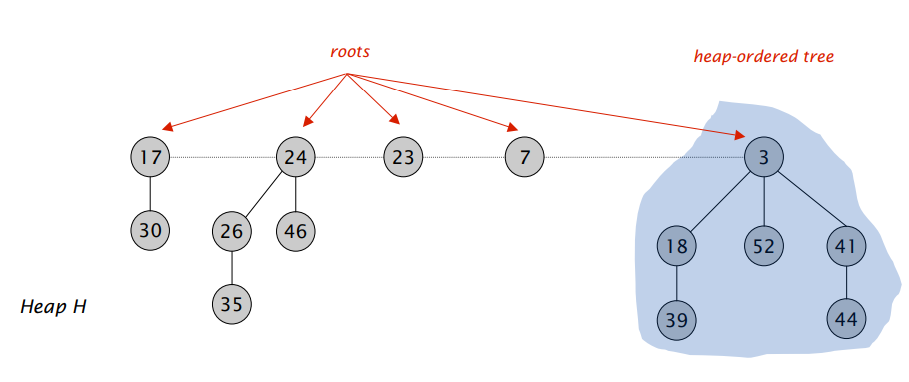
- 一组满足堆性质(一般是最小堆性质)的树的集合
- 始终保持一个指针指向最小的元素的对象
- 使用
markednode属性,来保持heaps的扁平
Mergeable Heaps: 可和并堆:
定义:
可合并堆支持以下五个操作,并且每一个元素都有一个
key:
Fibonacci 堆额外支持以下两个操作:
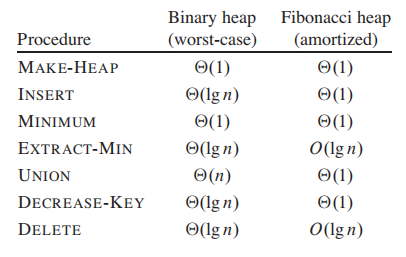
操作的时间复杂度如下:



最重要的第一句话就是:
A Fibonacci heap is a collection of rooted trees that are min-heap ordered. That
is, each tree obeys the min-heap property:
即:
- 斐波那契堆是树的集合,每一棵树都满足最小堆性质;
就像是$[root1,root2, ..., rootN]$, 每个root都是一个树;他们彼此之间用Double Linked List串起来;
-
Fib Heap的特点是始终维护一个指针指向最小值的节点;
-
root的每一个node
$x$ 都有x.p指向parent,x.child指向一个children;
x的children用双向链表 像环一样的连在一起,我们叫他child list of x
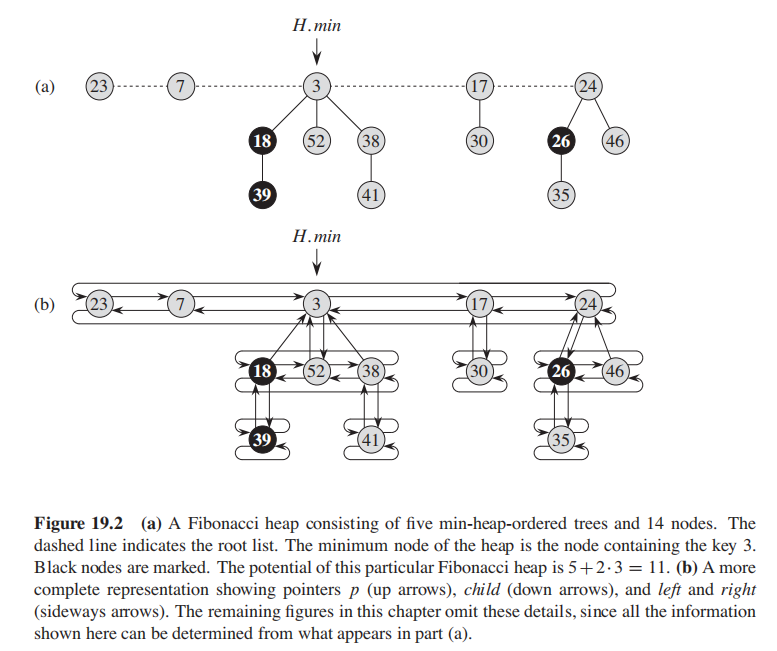
看伪码会看傻逼的,我总结一下几个操作:

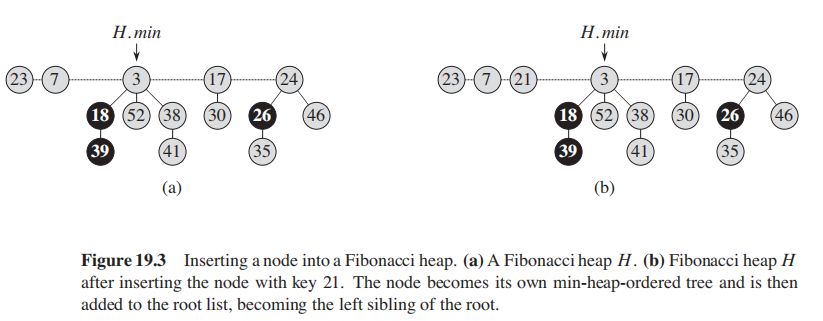
注意:
- 我们直接插入root list而不是某个节点的child list

合并两个堆,这个操作比较简单,核心就是直接concatenate两个堆的root list, 更新min指针;
这个操作会像pop出当前最小的节点,然后调用consolidate来确保自己的结构不被破坏;
这是最核心的操作,也是最眩晕的操作:

-
根据
min指针取出最小对象,sayz; -
如果
z有child, 把所有child先升级到root list当中,然后将parent设置为None; -
设置好各种left 和 right指针,把
z移除; -
判断:
- 如果
z是唯一节点,那么成了空堆,把min指针和root list都设置为None - 很可惜他往往不是唯一节点,那么就要调用
consolidate方法
- 如果
-
最后将树的节点数-1
consolidate:
degree的作用在这个函数体现,我们要确定每个node的degree都是不同的;
- 遍历root list的节点:
- 如果degree相同,把值小的节点从从root list中拿掉,连接到值大的节点的child方法上;这个操作是用
heap-link函数来实现的;之后,把值更大的节点的degree + 1
- 如果degree相同,把值小的节点从从root list中拿掉,连接到值大的节点的child方法上;这个操作是用
经过这个操作以后,堆结构会变得更加扁平;
关于decrease key操作,降低某个节点的值,所以可能破坏最小堆性质;
因此又是一堆伪码;上张图理解一下intuition吧:

BFS/DFS:
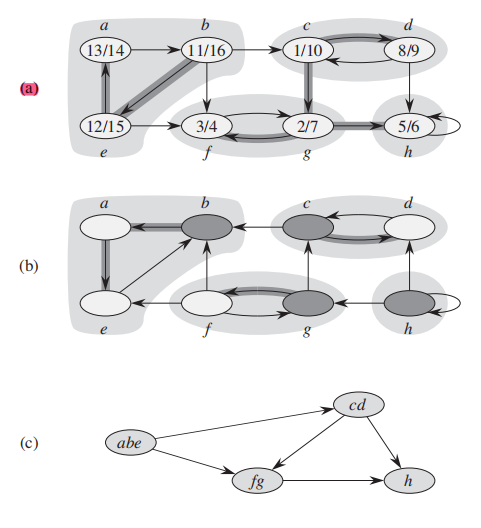
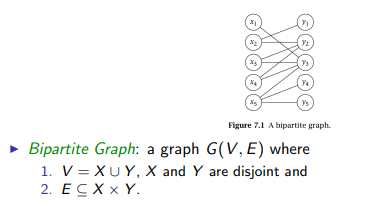
Topological sort:
表示图的标准方法: $$ G = (V,E) $$ Graph是由Vertices定点和Edges边组成的;
无向图有两种表示法:
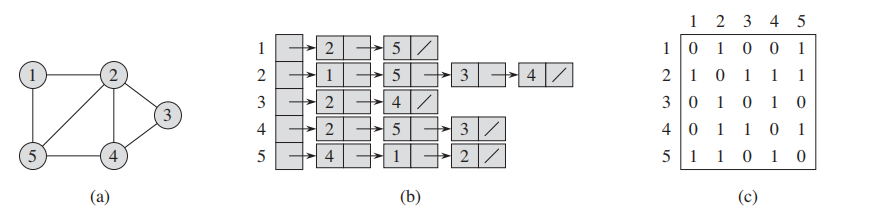
(a): 由5个顶点,7个边组成的无向图
(b): list表示法(adjaceny-list representation) of G
(c): matrix表示法(The adjacency-matrix representation) of G
再无向图中,(c)是对称的;
**有向图(directed graph)**表示法类似:
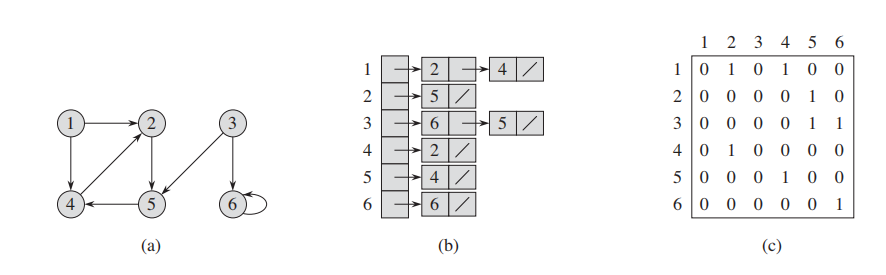
(a):由6个顶点,8个边组成的无向图
(b): list表示法(adjaceny-list representation) of G
(c): matrix表示法(The adjacency-matrix representation) of G
广度优先搜索,没啥说的了;

这里color = white代表没遇到过的节点;
d表示距离;
这里使用堆栈的方法来储存接下来要开始BFS的节点;
RUNTIME:

请注意开始和结束的时间,使用DFS来计算终止时间的方法会在后续算法被用到。
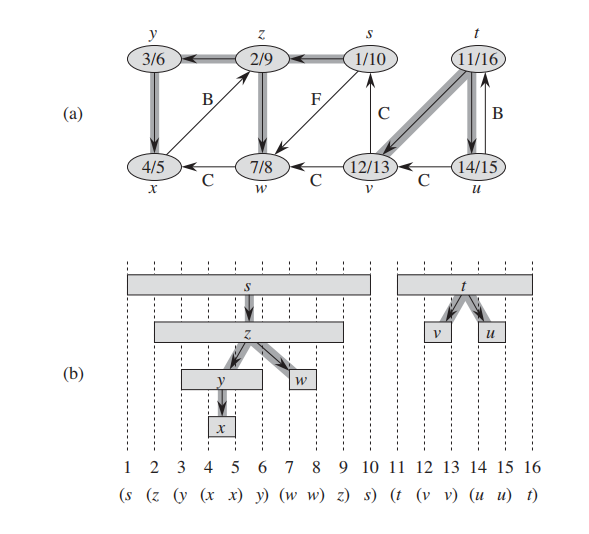
DAG(Directed acyclic graph)有向无环图:
无法形成cycle就是DAG,最后一定会终止在某个点;
严格的定义如下:
因为这样的特性,才能被拓扑排序;
拓扑排序 (Topological Sort):

RUNTIME:
啥是紧密连接组件?看图就懂了:
严格定义如下:
Strongly connected component of a directed graph
v are reachable from each other.
使用DFS来发现紧密组件:

Spanning Trees:
A set of edges A that “span” or “touch” all vertices, and forms no cycles
最小生成树往往是在无向有权图上来讨论。
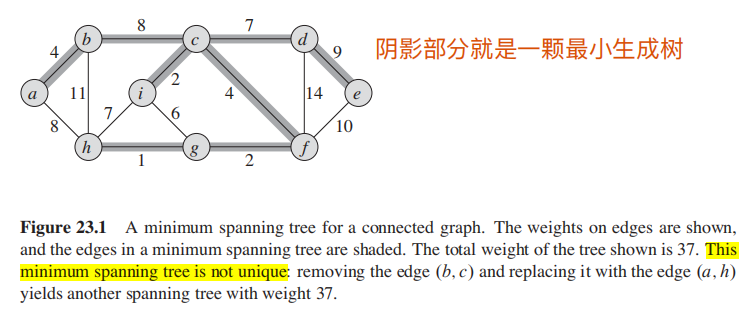
最小生成树不一定是唯一的;
简单的定义:你希望找到一组边:
-
**1.连接了所有点 **
-
2. 总权重最小
严格定义如下:

找到最小生成树的算法的大致模糊思路如下,详细的会在下一节展,这里看看就好:

A是一组边的集合,一开始设为空集,最终会成为一颗MST(最小生成树);
如图,在A成为完整MST前,每一步我们都:
- 找到一条 "safe edge", 并加入A
知道A成为完整MST。
因此,核心就是如何判断edge是不是safe的。
有以下的算法能实现上述的思路:
- Prim algorithm
- Kruskal algorithm
在展开算法前,对一些术语下定义:
先给原文,再给我的简单理解:

- 图的切分:cut(S, V - S)
cut(S, V - S);
很直观,切分后S代表黑点;V-S是白点,下方;
-
如果一条边在S和V-S各有一个顶点,那我们说这条边cross cut(S, V - S)
-
在cross的边中,weight最小的边叫做light edge.
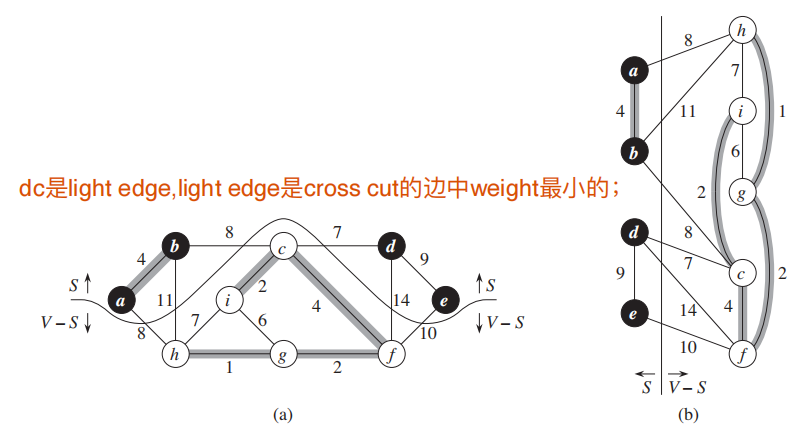
两个算法都是贪心算法。

1. Sort all the edges in non-decreasing order of their weight. 2. Pick the smallest edge. Check if it forms a cycle with the spanning tree formed so far. If cycle is not formed, include this edge. Else, discard it. 3. Repeat step#2 until there are (V-1) edges in the spanning tree.
第六行的find-set操作其实就是检查图是否有形成cycle。
所以,核心就是将边先按照升序排序,然后进行遍历;
因此每次都是当前最小权重的edge。
对当前遍历到的边:
- 如果加入这条边后,形成了cycle, 那么跳过这条边;
- 反之,没有形成cycle,那么将当前的边加入A
最后返回。
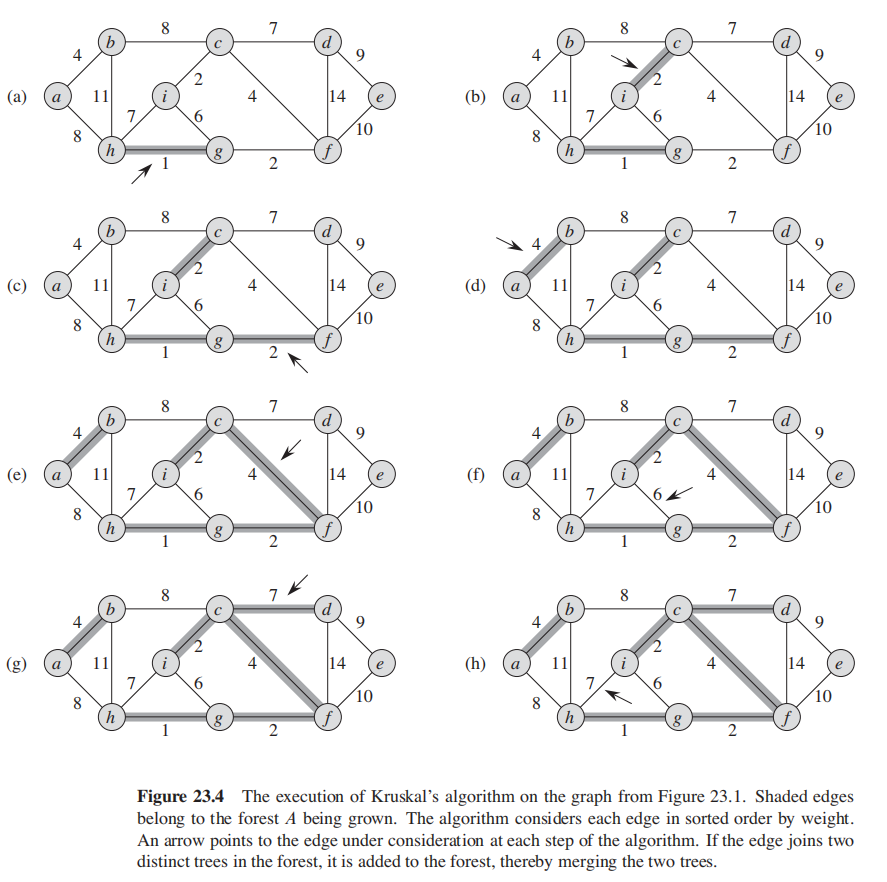
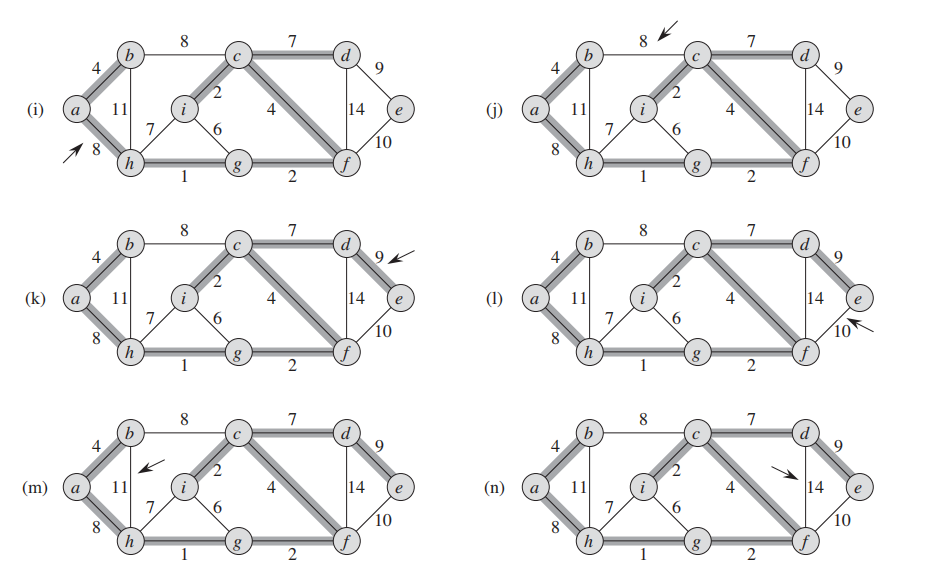
一个简单的并查集算法:
# Python Program for union-find algorithm to detect cycle in a undirected graph
# we have one egde for any two vertex i.e 1-2 is either 1-2 or 2-1 but not both
from collections import defaultdict
# This class represents a undirected graph using adjacency list representation
class Graph:
def __init__(self, num_of_vertices):
self.V = num_of_vertices
self.graph = defaultdict(list)
# function to add an edge to graph
def addEdge(self, u, v):
self.graph[u].append(v)
# A utility function to find the subset of an element i
def find_parent(self, parent, i):
if parent[i] == -1:
return i
if parent[i] != -1:
return self.find_parent(parent, parent[i])
# A utility function to do union of two subsets
def union(self, parent, x, y):
parent[x] = y
# The main function to check whether a given graph
# contains cycle or not
def isCyclic(self):
parent = [-1] * (self.V)
# Iterate through all edges of graph, find subset of both
# vertices of every edge, if both subsets are same, then
# there is cycle in graph.
for i in self.graph:
for j in self.graph[i]:
x = self.find_parent(parent, i)
y = self.find_parent(parent, j)
if x == y:
return True
self.union(parent, x, y)
# Create a graph given in the above diagram
g = Graph(3)
g.addEdge(0, 1)
g.addEdge(1, 2)
g.addEdge(2, 0)
if g.isCyclic():
print("Graph contains cycle")
else:
print("Graph does not contain cycle ")
# This code is contributed by Neelam Yadav
Big name Algorithm:
-
Dijkstra algorithm
-
Floyd Warshall algorithm
本章节关注单源头(single source)最短路径问题:给定图
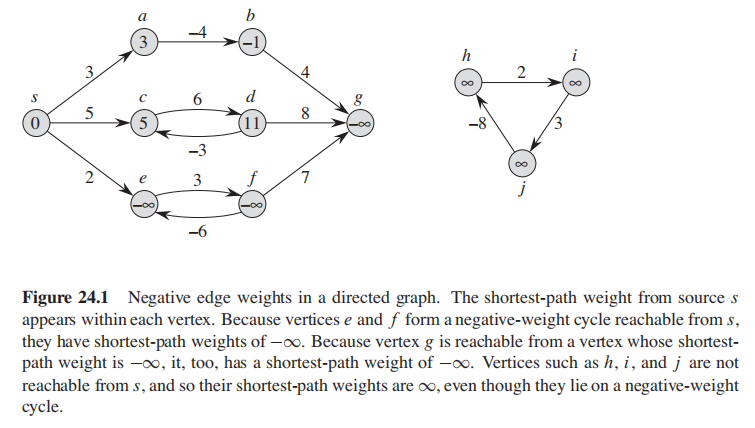
-
$s - b$ 只有一条路径,此时负权重边无影响; -
$s - d$ 有无限条路径:$<s,c>, <s,c,d,c>,<s,c,d,c,d,c>$, 但是最小权值路径还是$<s,c>$,因此也不受影响; - 关于
$s-e$ , 同样有无限路径:$<s,e>, <s,e,f,e>,<s,e,f,e,f,e>$, 但是$<e,f,e>$ 的权重是$3 + (-6) = -3 < 0$, 因此$<s,e>$ **没有最短路径;**因此我们表示$<s,e> = -\infty$ ; -
$<s,g>$ ,因为$g$和$f$是相连的,因此$<s,g>$也没有最短路径;$<s,e> = -\infty$ ; -
$s$ 永远无法抵达$h, i, j$ ,所以$<s,h> = <s,i> = <s,j> = \infty$
Dijkstra算法 假设所有边都是非负数;
Bellman-Fordrm 算法 没有这种假设;
good explanation from :
https://stackoverflow.com/questions/2592769/what-is-the-relaxation-condition-in-graph-theory
- You have two nodes,
uandv - For every node, you have a tentative distance from the source node (for all nodes except for the source, it starts at positive infinity and it only decreases up to reaching its minimum).
你使用relaxation来检测是否能improve到达某个节点的shortest path。(每个节点初始值默认为无穷大)
举个例子:
s ~~~~~~~> v
\ ^
\ |
\~~~~~> u
比如上图,s是源点,那么:
- 目前已知从s出发能到达v, 我们表示为distance(s,v)
- 你也知道s能到u, 表示为distance(s,u)
在使用Relaxation的某个算法的某个时刻遍历到$<u,v>$ 这条边,就会判断:If dist[u] + weight(u, v) < dist[v], 那么 s~>u->v is shorter than s~>v, 所以我们应该更新s - v的最短路径!
理解这个很重要,后面直接用Relax来表示这个机制;
初始化一个长度是
之后就是Relaxation: 像DP 一样不断更新$s$ 到其他点的最短路径;


2
V0-----------V1
\ \
4 \ \ 5
\ \
V2------------V3
2
书上例子不太好,用这个走一遍:
-
- 初始化$dist = [0, inf, inf, inf]$
-
- 走到边$<v0 - v1>$ ,
$dist[0] + 2 < dist[1]$ 成立, 更新$dist = [0, 2, inf, inf]$
- 走到边$<v0 - v1>$ ,
-
- 走到边$<v0 - v2>$ ,
$dist[0] + 4 < dist[2]$ 成立, 更新$dist = [0, 2, 4, inf]$
- 走到边$<v0 - v2>$ ,
-
- 走到边$<v1 - v3>$ ,
$dist[1] + 5 < dist[3]$ 成立, 更新$dist = [0, 2, 4, 7]$
- 走到边$<v1 - v3>$ ,
-
- 走到边$<v2 - v3>$ ,
$dist[2] + 2 < dist[3] = 7$ 成立, 更新$dist = [0, 2, 4, 6]$
- 走到边$<v2 - v3>$ ,
这是第一遍,我们总共要走
为啥要走$V-1$遍呢?目前我发现和储存顺序有关;
再来一个例子:
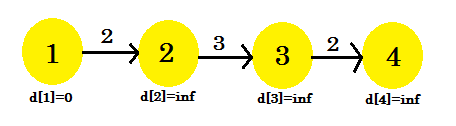
如果你按照顺序 1-2, 2-3, 3-4来储存,可以一遍过;
但是如果是3-4, 2-3, 1-2,你需要$V-1$ 也就是三次才能走对;
因为如果当前节点之前没遇到过,$dist[当前节点]$就是$\infty$, 无法被更新;
在程序里会判断每一步的出发点是否是NIL; 可以去代码试一下;
657
对拓扑排序好的DAG,按照顺序用一遍RELAX即可:

RUNTIME: $ O(V+E) $
Dijkstra算法比Bellman-ford更快,但是需要图中不存在负循环;

- 2,3行的
$S$ 代表最短路径集合,而$Q$ 是没探索的点,也就是$V-S$ ,一开始就是所有点$G.V$; Q是用最小优先队列(堆算法)实现的,有EXTRACT-MEAN方法;还需要MIN-HEAPIFY方法;
只要
- 从Q
In this chapter, we consider the problem of fifinding shortest paths between all pairs
of vertices in a graph.
上一张是sinle source shortest path (SSSP),求出源点到其他所有点的最短距离;
本章节关注All-Pairs Shortest Paths (APSP), 求出所有点之间的最短距离。
使用DP的方法不断更新最小路径;
回顾一下矩阵A 乘以 矩阵B的是matrix multiplycation算法:
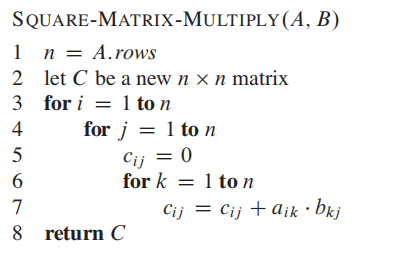
APSP图算法和这个极为相似:
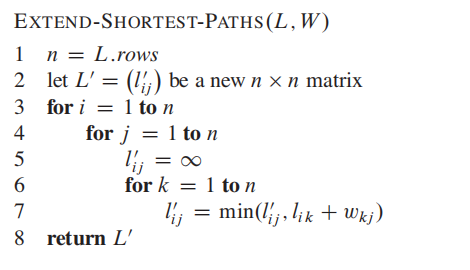
时间复杂度是$O(n^3)$
解释一下
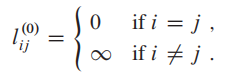
如果m大于1:
 :
:
这里是DP的思想,遍历所有中介点k来尝试更新
总体的APSP算法如下:

总耗时$O(n^4)$.
总体思想如下:
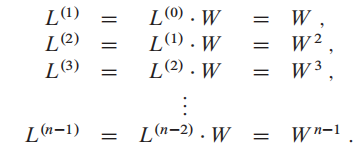
这是一个Bottom up的算法,随着m的增加,我们不断更新L矩阵;到最后m = n-1,就得到了全局的最小权重路径;
这个算法又绕又慢,不看也罢;
时间复杂度:$O(V^3)$
简单粗暴多了(可以直接看下面的改进版,忽略这个)
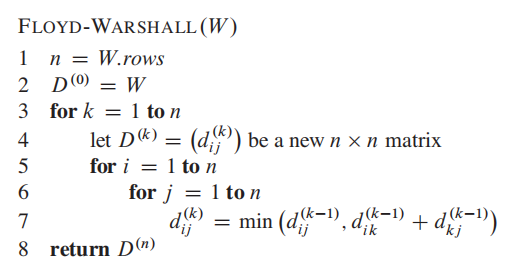
改进版:
W是矩阵表示法的图,输入进去:
这个算法我们只需要维护一个矩阵,减少了空间占用;
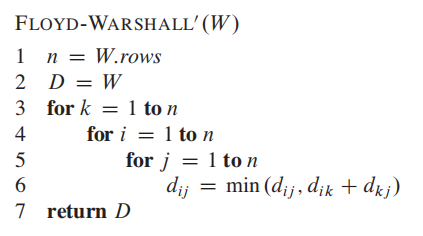
一句话概括就是在所有$i$ 到
顺便贴一下leetcode:[https://leetcode.com/problems/find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance/]
Flow networks
A flow network
$G = (V,E)$ is a directed graph in which each edge$(u,v) \in E$ has a nonnegative capacity$c(u,v) \geq 0$ .
Flow networks是有向图,每一条边多了一个运载能力(capacity),代表通过这条边的上线;(想象网络负载的场景)
在这一章我们主要关注 Maximum flow problem:
In maximum flow problem, we are given a flow network G with source s and sink t, and we wish to find a flflow of maximum value.
这里又引入了两个概念:source 和 Sink
注意,这里叫Method的原因是这个算法没有准确的runtime,会根据你的实现方式/数据输入发生很大的变化;

第2,3句包含的信息量太大了,第一次看容易懵逼。
为了理解这个算法,引入残差网络的概念:
这个ResNet不是CV里的那个resnet。
注意,普通的network flow只允许单向边,单向边代表了flow的大小;
Residual network只是在原有基础上,借助原有的capacity属性浓缩了更多信息,并且变成了双向的(也可能是单向)。
统一一下数学说法:
-
$c(u,v)$ 来表示节点的capacity; -
$f(u,v)$ 表示当前的flow的大小;
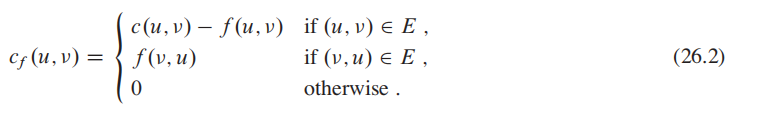
augmentation
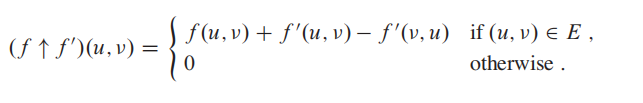


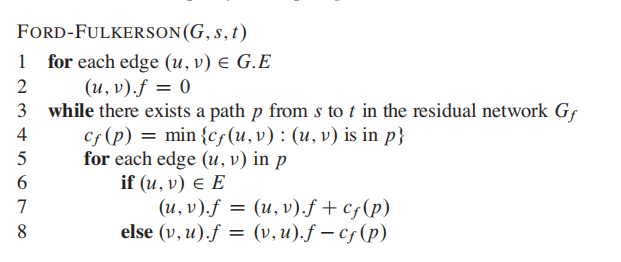
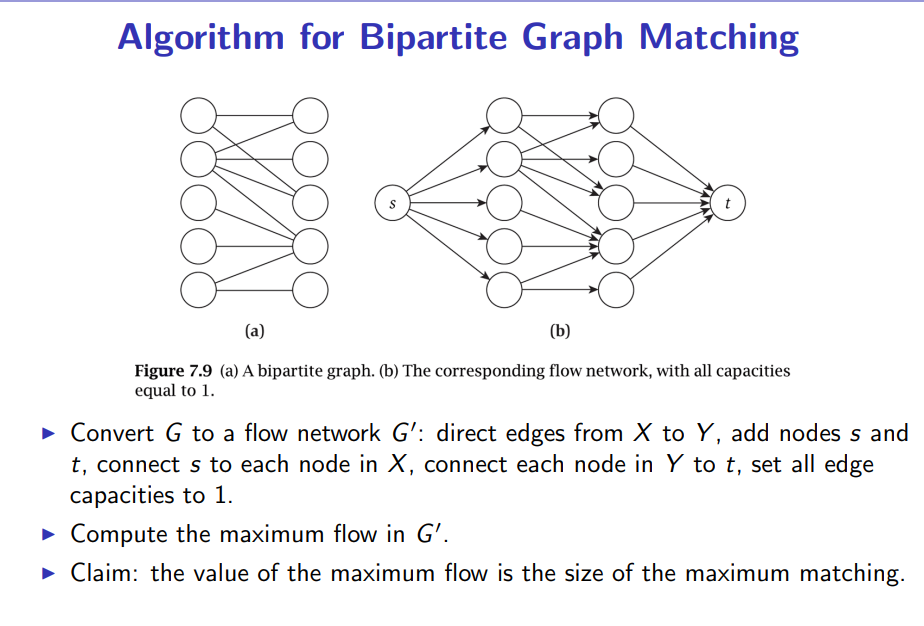
Push-Relabel Algorithm 比 Ford-Fulkerson algorithm 更快;
push-relabel approach based algorithm that works in
和Ford-Fulkerson algorithm 一样,Push-Relabel Algorithm也是使用残差网络;
Push-Relabel的机制更加注重当前的点位而不是全局;
Preflow()
1) Initialize height and flow of every vertex as 0.
2) Initialize height of source vertex equal to total
number of vertices in graph.
3) Initialize flow of every edge as 0.
4) 对于源点的临近点, flow and excess flow is equal to capacity initially.
-
Push() is used to make the flow from a node which has excess flow. If a vertex has excess flow and there is an adjacent with smaller height (in residual graph), we push the flow from the vertex to the adjacent with lower height. The amount of pushed flow through the pipe (edge) is equal to the minimum of excess flow and capacity of edge.
-
Relabel() operation is used when a vertex has excess flow and none of its adjacent is at lower height. We basically increase height of the vertex so that we can perform push(). To increase height, we pick the minimum height adjacent (in residual graph, i.e., an adjacent to whom we can add flow) and add 1 to it.
这个算法的代码几乎搜不到,花了几天看懂以后真觉得是个蛮神奇的算法,第一次有算法能给我"立体"的感觉。
算法的Intuition:
先看一下算法导论原文的伪码:

1. 初始化
2. while 有任何一条边能进行push或者relabel操作:
执行 push 或者 relabel
一开始看的一头雾水。
-
首先,之前说了,算法允许一个点的inflow大于outflow; 因此,有一个蓄水池的机制,用来储存这个多出来的excess flow;
-
同时, 我们赋予了每个点新属性:
height(代表高度)
现在,把图想象成水管(edge)和连接点(vertex)。
-
起初,source高度是最高的,其他点的高度都是
$0$ ;水往低处流,因此source向邻近点注射水流 (flow),根据source的邻边的capacity总和,直接有多少capacity就发射多少的flow;(因此通常会"超发",多出来的水就是excess flow,就会触发蓄水池) -
接着就进入了while:
- 只要周围有高度更低的边,我们就让水往低处流,使用
push - 否则,使用
relabel来增加$height$, 确保自己比周围一个点高 - 如果蓄水池中所有点 (除了source) 的
$excess flow == 0$ ,跳出while
- 只要周围有高度更低的边,我们就让水往低处流,使用
这个算法精髓的地方在于,一开始我们"超发"水流,就会导致有$excess flow$;
但是到最后,relabel会把点的
这句话理解了,你就get到了核心的思想!
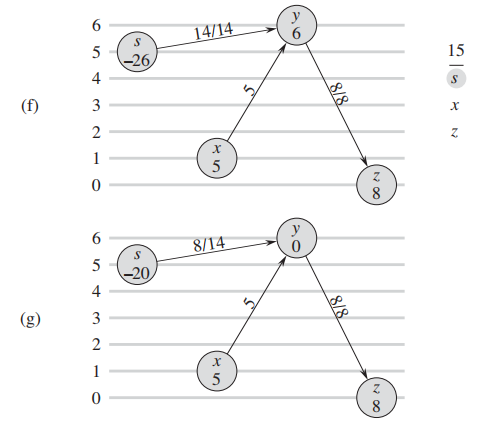
下图来自算法导论原文p752, 纵轴代表了点的height属性
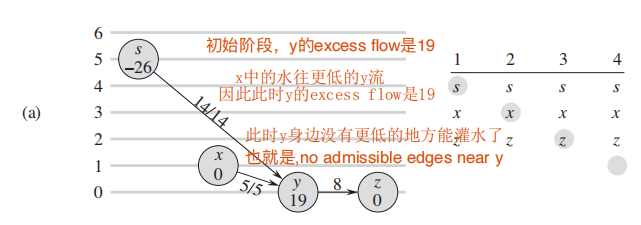
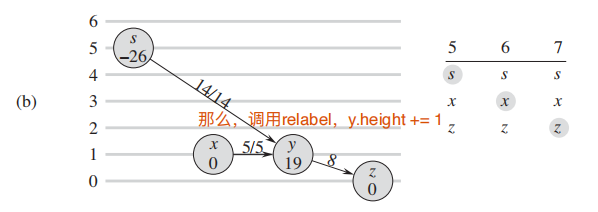
d. 由于周围没有admissive edge, 继续调用 relabel 升高高度:
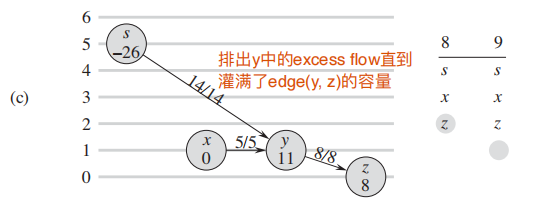
e: 调用 relabel 以后,$y$ 中的excess flow灌回了
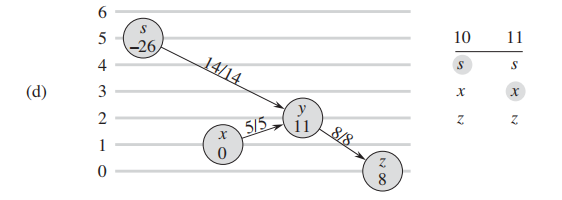
f: 没有admissive edge继续升高 y:
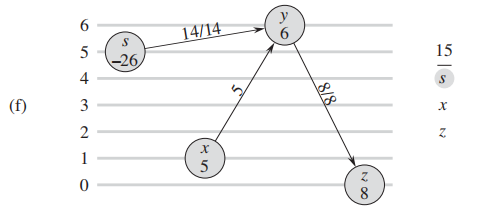
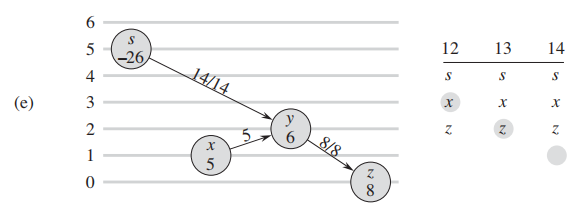
f,g: y的flow灌回了source以后,没有了excess flow,算法终止。
具体实现稍微和原文有些出入,但是思想是一样的;


唯一要注意的是初始化操作preflow的7-10行将source周围的点根据capacity属性直接灌满了;
这个算法和ford-fulkerson注重全局的思路不一样,Push-Relabel Algorithm更加localized, 也就会不停的更新当前的点,直到这个点没有 Discharge完成的。

Python Implementation:
# push-relabel algorithm
def MaxFlow(C, s, t):
n = len(C) # C is the capacity matrix
F = [[0] * n for i in range(n)]
# the residual capacity from u to v is C[u][v] - F[u][v]
height = [0] * n # height of node
excess = [0] * n # flow into node minus flow from node
seen = [0] * n # neighbours seen since last relabel
# node list other than s and t
nodelist = [i for i in range(n) if i != s and i != t]
def push(u, v):
send = min(excess[u], C[u][v] - F[u][v])
F[u][v] += send
F[v][u] -= send
excess[u] -= send
excess[v] += send
def relabel(u):
'''
find smallest new height from neighbor for making a push possible
'''
min_height = float('inf')
for v in range(n):
if C[u][v] - F[u][v] > 0 and v != u:
min_height = min(min_height, height[v])
height[u] = min_height + 1
def discharge(u):
'''
An overflowing vertex u is discharged by pushing all of its excess flow through
admissible edges to neighboring vertices. Perform relabel if neccesary.
'''
while excess[u] > 0:
if seen[u] < n: # check next neighbour
v = seen[u]
#if admissive and height greater than nerghbor
if C[u][v] - F[u][v] > 0 and height[u] > height[v]:
push(u, v)
else:
seen[u] += 1
else: # we have checked all neighbours. must relabel
relabel(u)
seen[u] = 0
height[s] = n # longest path from source to sink is less than n long
excess[s] = float("inf")
# initialize: send as much flow as possible to neighbours of source
for v in range(1,n):
push(s, v)
p = 0
while p < len(nodelist):
u = nodelist[p]
old_height = height[u]
discharge(u)
if height[u] > old_height:
nodelist.insert(0, nodelist.pop(p)) # move to front of list
p = 0 # start from front of list
else:
p += 1
return sum(F[s])
# C = [[0, 3, 3, 0, 0, 0],
# [0, 0, 2, 3, 0, 0],
# [0, 0, 0, 0, 2, 0],
# [0, 0, 0, 0, 4, 2],
# [0, 0, 0, 0, 0, 2],
# [0, 0, 0, 0, 0, 3]]
#Example given in CLRS p752
C = [[0,0,14,0],
[0,0,5,0],
[0,0,0,8],
[0,0,0,0]]
source = 0 # source
sink = 3 # sink
max_flow_value = MaxFlow(C, source, sink)
print("Push-Relabeled(Preflow-push) algorithm")
print("max_flow_value is: ", max_flow_value)原码
是一种计算机中对数字的二进制定点表示方法。原码表示法在数值前面增加了一位符号位(即最高位为符号位):正数该位为0,负数该位为1(0有两种表示:+0和-0),其余位表示数值的大小。
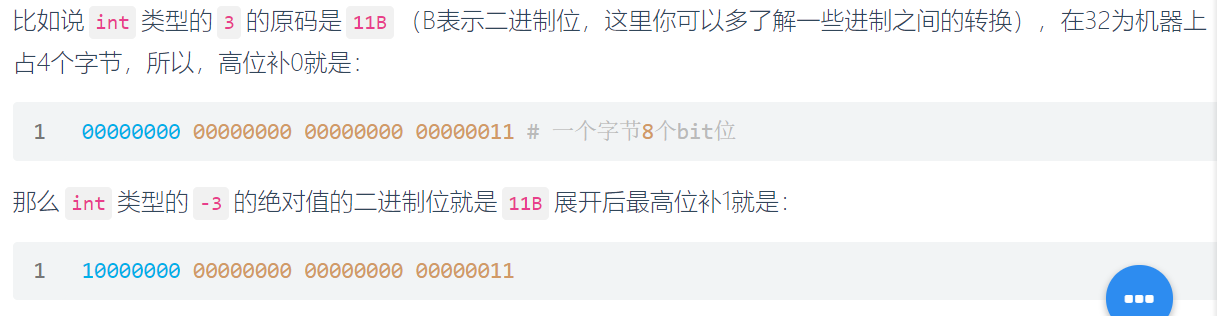
缺点:
-
原码中的0分为
+0和-0 -
在进行不同符号的加法运算或者同符号的减法运算时,不能直接判断出结果的正负,我们必须要将两个值的绝对值进行比较。然后再进行加减操作。
反码
正数的反码就是原码:

补码
在计算机系统中,数值一律用补码来表示和存储。
原因在于,使用补码,可以将符号位和数值域统一处理;同时,加法和减法也可以统一处理。此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路支持。
记住口诀:正数的补码与原码相同,负数的补码为其原码除符号位外所有位取反(这就是反码了),然后最低位加1。
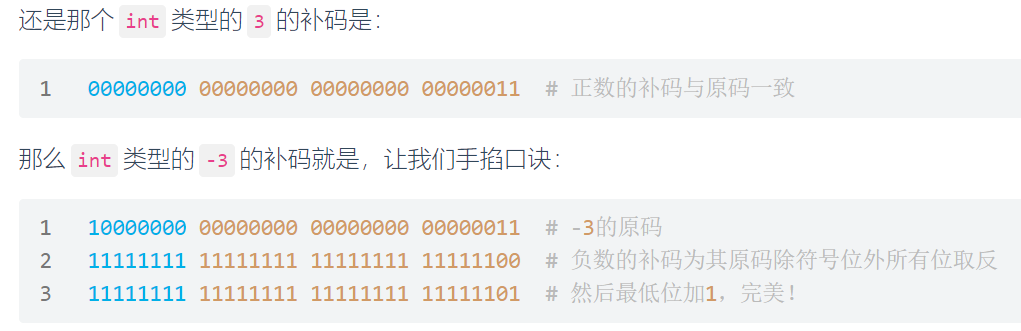
方法1:
如果数字能不停被2整除,并且最终等于1,那么是2的次方;
否则不是。
这个方法的时间复杂度是$O(lgn)$
def isPowerOfTwo(n): if (n == 0): return False while (n != 1): if (n % 2 != 0): return False n = n // 2 return True方法2:
使用位运算。
如果一个数是2的次方,那么位运算:n & (n - 1)结果必定是0。(只要n > 0)
为啥呢?
2, 4, 8, 16 .... 这样的2的次方的数字的二进制数都只有第一位是1;
只要把他们减一,比如:
把4 - 1 = 3 –> 011 16 - 1 = 15 –> 01111
而4 = 100
16 = 10000,
这样如果进行&运算,就不会有任何一位相等;4&3 == 0, 16&15 == 0;
所以我们的函数:
def isPowerOfTwo(x): return (x and (not(x & (x - 1))))首先, python中有内置函数,来count1:
>>> bin(5)'0b101'>>> bin(5).count('1')2但是这不是我们想要的。
玩的就是old school:
继续上一个算法 ,每次一个数字n被减去 1, 最右边的1 和 再往右的数字就会被翻转;
因此这个神奇的操作:
n & (n - 1)每次会让原来的数字中少一个1;(每次转掉一个1)
就这样用循环来count 1的数量即可;
以23 和 22 为例子:
23 : 10111
22: 10110
23 & 22 = 10110 = 22
21: 10101
22 & 21 = 10100 = 20
19: 10011
20 & 19 = 10000 = 16
16 & 15 = 0
来一题LC:汉明距离:
https://leetcode.com/problems/hamming-distance/
class Solution:
def hammingDistance(self, x: int, y: int) -> int:
x = x^y
res = 0
while x:
x = x & (x - 1)
res += 1
return res先进性异位运算,在count("1")即可。
另外,leetcode大神常使用
if num & 1:
then num is odd
else:
num is even来判断一个输入num是奇数还是偶数;

egg_drop
cd /d