Decoupling in Cloud Era: Building Cloud native microservices with Spring Cloud Azure
For the past decade, Spring is famous for its dependency injection feature which helps Java developers to build loosely coupled system. Put it simply, users just need to focus on abstraction provided by interface, then instance of concrete implementation will be ready for use. As cloud become increasingly popular in recent years, how to exploit the auto-scaling and auto-provisioning features provided by cloud environment and loosely couple with specific cloud vendor become an interesting challenge. That's where cloud native come into play. Let's move forward to see what's cloud native and microservice first.
Even I have seen this term many times, it's still not an easy question. Cloud native is a lot more than just signing up with a cloud provider and using it to run your existing applications. It pushes you to rethink the design, implementation, deployment, and operation of your application. Let's look at two popular definitions first:
Pivotal, the software company that offers the popular Spring framework and a cloud platform, describes cloud native as:
Cloud native is an approach to building and running applications that fully exploit the advantages of the cloud computing model.
The Cloud Native Computing Foundation, an organization that aims to create and drive the adoption of the cloud-native programming paradigm, defines cloud-native as:
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
To summarize, cloud native application should utilize the advantages of the cloud computing model. And microsevice is one way to implement it. Maybe below explanation will make this more clear:
A cloud native application is specifically designed for a cloud computing environment as opposed to simply being migrated to the cloud.
Let's check Martin Fowler's definition of microservice first:
Microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies.
But I love another simple one:
Microservices are small, focused and autonomous services that work together.
Small and focused means Single Responsibility. One service just needs to do one thing well. Autonomous means fault tolerance and each service evolves and deploys independently from each other.
The concept of microservices is nothing new. But it hasn't been so popular due to hard implementation in traditional on-premise organization. Now cloud-based microservice taking full advantages of scalability, reliability and low maintenance costs provided by cloud become more popular.
Key benefits as below:
- Resilience. One component's failure shouldn't take down the whole system. This is usually achieved by defining clear service boundary.
- Scaling. You don't need to scale everything together when only one part is constrained in performance.
- Ease of deployment. Making a change to a single service can speed the release cycle and smooth the troubleshooting process.
- Composablility. Since each service focuses on one thing, it's easy to reuse them like unix pipeline.
- Optimizing for replaceablity. One small individual service is easier to be replaced with a better implementation or technology.
In order to implement microservice architecture easily, industry has identified some common patterns to help this. Some well-known patterns are centralized configuration management, service discover, asynchronous message-driven and distributed tracing. Spring Cloud provides these patterns as usable building blocks and helps us follow the cloud native best practices. Besides this, Spring Cloud's unique value could be represented in several aspects:
- Define a common abstraction for frequently used patterns. This is another beautiful application of Spring's decoupling philosophy. Each pattern is not tightly coupled with concrete implementation. Take configuration server as example, you have the freedom to change backend storage without affecting other services. Spring Cloud Discovery and Spring Cloud Stream also followed this philosophy.
- Modular component. Many people think Spring Cloud as a fully-packaged solution at their first impression. Actually, it's not a all-or-nothing solution. You can only choose one module, then use it as one microservice, other services can use any other framework. It's like Lego-brick, you can pick the pieces you like, and the only thing you need to make sure is that this piece is compatible with others.
Now let's look at how Spring Cloud modules fit into microservice pattern.

To meet the requirement of Store config in environment and microservice architecture, we need to put all services' config in one centralized place. To achieve this, the following features are needed:
- Support multiple environments such as dev, test and prod. Then we can have one package built for all environments.
- Transparent config fetching. These centralized config should be fetched automatically without any user coding.
- Automatic property refresh when property changes. Service should be notified by such change and reload new property.
- Maintain change history and easily revert to older version. This is a really useful feature to revert mistaken changes in production environment.
Spring Cloud Config supports all these features by using one simple annotations. What you need is annotating @EnableConfigServer in config service and including starter in other services to enable client. For more details, please refer Spring Cloud Config doc.
Service discovery plays an important role in most distributed systems and service oriented architectures. The problem seems simple at first: How do clients know the IP and port for a service that cloud exist on multiple hosts? Things get more complicated as you start deploying more services in versatile cloud environment.
In reality, this is usually done in two steps:
- Service Registration - The process of a service registering its location in a central registry. It usually registers its host and port and sometimes authentication credentials, protocols, versions and environment details.
- Service Discovery - The process of a client application querying the central registry to learn the location of services.
How to choose service discovery solution should be considered in several aspects:
- Fault Tolerance - What happens when a registered service fails? Sometimes it is unregistered immediately in graceful shutdown, but most time we need a timeout mechanism. Services are continuously sending heartbeats to ensure liveness. Besides this, clients also need to be able to handle failed services by retrying another one automatically.
- Load Balancing - If multiple hosts are registered under a service, how do all we balance the load across the hosts? Will load balancing happen on registry side or client side? Can we provide our custom load balancing policy?
- Integration Effort - How complicated is integrating process? Only some new dependency and/or configuration change? Or invasive discovery code? Sometimes a separate sidekick process is a good option when your language is unsupported.
- Availability Concerns - Is registry itself highly available? Can it be upgraded without any downtime? The registry should not be a single point of failure.
Spring Cloud provides a common abstraction for both registration and discovery, which means you just need to use @EnableDiscoveryClient to make it work. Examples of discovery implementations include Spring Cloud Discovery Eureka and Spring Cloud Discovery Zookeeper. You should choose concrete implementation based on your user case. For more details, please refer Spring cloud Discovery doc.
Suppose we have some microserivces, then they must communicate with each other. Obviously, traditional synchronous way is blocking and hard to scale, which can't survive in sophisticated distributed environment, so asynchronous message-driven is right way to go. In modern world, every request cloud be considered as a message. So various messaging middle-wares get birth with their own message formats and APIs. It's a disaster to make all these middle-wares communicate with each other. Actually, solving this problem is easy, just defining a unified message interface, then each middle-ware provides adapter which knows how to convert between their message format and standard one. Now you have grasped the core design principle of Spring Integration. Spring Integration is motivated by the following goals:
- Provide a simple model for implementing complex enterprise integration solutions.
- Facilitate asynchronous, message-driven behavior within a Spring-based application.
- Promote intuitive, incremental adoption for existing Spring users.
And guided by the following principles:
- Components should be loosely coupled for modularity and testability.
- The framework should enforce separation of concerns between business logic and integration logic.
- Extension points should be abstract in nature but within well-defined boundaries to promote reuse and portability.
For more details, please refer Spring Integration doc.
However, Spring Integration is still at lower level and contains non-intuitive confusing terminologies. The programming model isn't as easy to use as other Spring technologies. So Spring Cloud Stream was invented. It is based on standard message format and various adapters provided by Spring integration, working at a high level binder abstraction to produce, process and consume message in a much easier way. It looks like unix pipeline, you just need to worry about how to process message. Message will come and go as you expected. Spring Cloud Stream offers high level features as below:
- Consumer Group. This is first introduced and popularized by Apache Kafka. It can support publish-subscribe and competing queue in one programming model.
- Partition. Based on partition key provided by user, produced message with same partition key will be guaranteed in one physical segment. This is critical in stateful processing, since related data need to be processed together for either performance or consistency reasons.
- Automatic content negotiation. Automatic message type conversion based on which type of message users accept.
For more details, please refer Spring Cloud Stream doc.
Under microservice architecture, one external request might involve several internal service calls, and these services might spread over many machines. Although most solutions have implemented centralized logging storage and search, but it is still hard to trace end-to-end transactions spanning across multiple services. Figuring out how a request travels through the application also means manually searching log keyword many times to find clues. This is really time-consuming and error-prone especially when you may not have enough understanding of microservice topology. Actually, what we need is correlating and aggregating these logs in one place.
Spring Cloud Sleuth implements such correlation by introducing concepts of Span and Trace. The Span represents a basic unit of work, such as calling a service, identified by span ID. A set of spans form a tree-like structure called Trace. The trace ID will remain the same as one microservice calls the next. Both will be included in each log entry. Furthermore, it automatically instruments common communication channels:
- Requests over Spring Cloud Stream Binder we discussed before
- HTTP headers received at Spring MVC controllers
- Requests made with
RestTemplate - ...and most other types of requests and replies inside Spring-ecosystem
With such raw data at hand, it's still hard to understand things such as which microservice call consumes most time. Zipkin provides and beautiful UI to help us visualize and understand. You can have a Zipkin server ready for use with a simple annotation @EnableZipkinServer. For more details, please refer Spring Cloud Sleuth doc
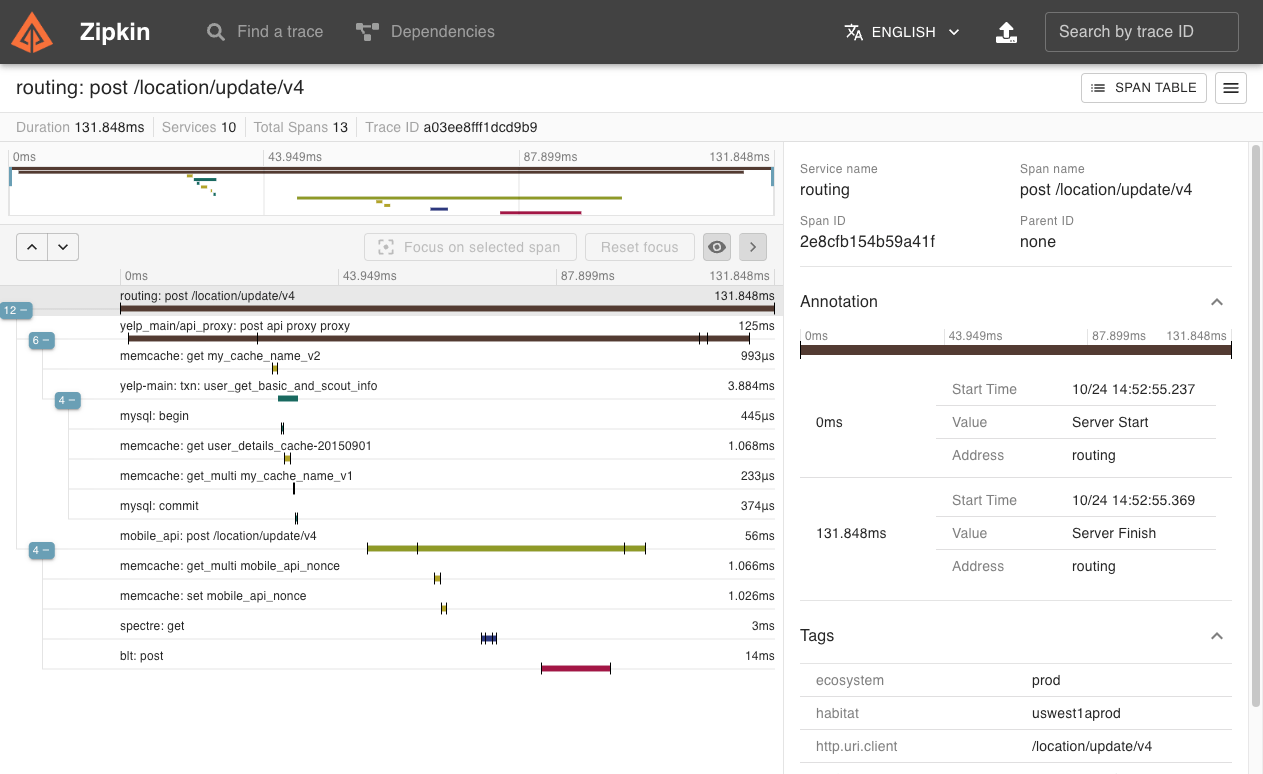
Spring Cloud provides great support for common patterns, but there is still gap for implementing microservices on specific cloud environment. So Spring Cloud Azure follows common abstractions provided by Spring Cloud, then take one step further to provide automatic resource provision and auto config Azure service specific properties. With this, users just need to understand logical concepts of Azure services without touching and suffering from low level details about config and SDK API. Take Azure Event Hub as a example, you only need to know this is message service with similar design as Kafka, then you can use Spring Cloud Stream Binder for Event hub to produce and consume from it.
The design motivations are as below:
- Seamless Spring Cloud integration with Azure. Users can easily adopt Azure services without having to modify existing code. Only dependencies and a few configuration settings are needed.
- Least configuration. This is done by taking advantage of Spring boot auto config to preconfigure default properties values based on Azure Resource Management API. Users can override these properties with their own.
- Provision resource automatically. If resources are not existed, our modules will create them under user specified subscription and resource group.
- No cloud vendor lock in. With our modules, users can easily consume Azure services as well as benefit from conveniences provided by Spring Cloud, without getting locked in with one specific cloud vendor.
One of things developers hate doing is configuration. Before configuring each property, developers need to go through the documentation and fully understand each property's meaning, then carefully copy each property from some place and paste into application's property file. However, it's not done yet, they also need to properly comment each property to make other developers to know which one to change in which scenario and avoid mistaken changes. That's the pain point we want to solve, so we have auto config based on Spring boot. If you want to use event hub, you don't need to understand what's connection string, you just fill event hub namespace(like Kafka cluster name) and event hub name(like Kafka topic name), other things will be auto configured. Of course, you have the ability to provide your customized config to override default ones.
One great benefit of cloud is programmable API to create and query resource you own. This is the key to automation. Based on Azure resource manager, Spring Cloud Azure provides automatic resource provision. The resource has a broader range than you expect, one example is consumer group of event hub. When you have a new service acting as another new consumer group, you really don't want to create this consumer group manually.
We have talked the benefits of Spring Cloud Stream. Let's suppose you have used this project, but you want to migrate into Azure. You might have already used Kafka or RabbitMQ binder, but it seems that Azure doesn't provide such managed Kafka or RabbitMQ offering. Then how could you migrate with little change effort? Actually, you don't care which message middle-ware you're using, you just want to have one thing providing similar function and performance requirement. So you can just change the dependency from kafka binder into event hub binder without any code change to smooth cloud migration. If you want to take full advantage of event hub binder in the future, you need to know the following features:
Event Hub provides similar support of lightweight consumer group as Apache Kafka, but with slight different logic. While Kafka stores all committed offsets in the broker, you have to store offsets of event hub messages being processed manually. Event Hub SDK provide the function to store such offsets inside Azure Storage Account.
Event Hub provides similar concept of physical partition as Kafka. But unlike Kafka's auto rebalancing between consumers and partitions, Event Hub provides a kind of preemptive mode. Storage account acts as lease to determine which partition is owned by which consumer. When a new consumer starts, it will try to steal some partitions from most heavy-loaded consumer to achieve workload balancing.
In a distributed publish-subscribe messaging system, there're three messaging semantics: at-least-once, at-most-once and exactly-once. For now, we only consider consumer side:
-
At least once: The consumer receives and processes the message. It doesn't send acknowledge to the broker until having finished message processing successfully. If for some reason the processing isn't finished e.g. the consumer node is down, the same message will be reprocessed (as the next available event in the partition) so this ensures
at least onceconsumption. In this case, consumer may process the same message more than once (until it is successfully processed).manualcheckpoint mode provides the capability to do manual checkpoint after processing the message. -
At most once: In this mode, the consumer receives the message and sends acknowledgement to message broker immediately. Then it starts processing. But if the consumer is down during processing, the message will not be reprocessed again since broker thinks the consumer has already received the message. In this case, consumer processes one message at most once, but it may miss some messages due to processing failure. The is default
batchcheckpoint mode supported by event hub binder. - Exactly once: With at least once semantics, we can have a unique message id to deduplicate already processed message. Or we can have idempotent message processing. Learn more about Exactly once.
By exposing Checkpointer through custom message header, event hub binder could support different message consuming semantics.
For more details, please refer Spring Cloud Stream Event Hub binder doc. Also you can follow Sample to try it.
Spring resource provide a common interface to manipulate stream based resource, such as UrlResource, ClassPathResource and FileSystemResource. It's obvious that Azure storage blob is a good fit for this as BlobResource. In this Resource, all implementation details are hidden and missing file will be automatically created.
public interface Resource extends InputStreamSource {
boolean exists();
boolean isOpen();
URL getURL() throws IOException;
File getFile() throws IOException;
Resource createRelative(String relativePath) throws IOException;
String getFilename();
String getDescription();
}For more details, please refer Spring Resource with Azure Storage doc. Also you can follow Sample to try it.
Although Spring Cloud have provided complete support for building microservices, but for new users who want to build a runnable microservices, it's still a challenging task. Steps including:
- Setup module and dependencies for each microservice. Although Spring Initializr could help this, it's still huge effort since the number of microservice might be big.
- Ensure the dependency and version among all services are compatible.
- Configure properties for each service and some properties are related. This is error-prone when doing manually.
- Common infrastructure services provided by Spring Cloud have their own annotation and config to make service run. You need to follow offical samples to make all these correct.
- Many users want to run these services locally by docker. Manually writing dockerFile is time-consuming and need deep understanding of relationship of microservices.
To solve the issues above, we built Spring Cloud Azure Playgroup to help users do this easily. The features supported as below:
- Based on Spring Initializr, generate all services in one time.
- Each microservice contains dependency, annotation, config and sample code. One command to run based on dockerFile.
- User can customize service's name and port to avoid confliction with other services running locally.
- Options to push to GitHub or download. GitHub is easy to share with team members.
You can try this on https://aka.ms/springcloud
This project is open source. You can contribute and submit issue here. Please star if you like it.