Capacity Test Results
January 5, 2015
The sensorimotor inference and temporal pooling algorithm will be at the heart of any HTM that learns while behaving and pursuing goals. Therefore it is important to test the algorithm's functionality and capacity, understand how well it works and when it starts breaking, and find a good set of parameters to work with. We would like to see that it can learn to model reasonably-sized scenarios within a single region, which we can then expand with a hierarchy. Once this is established, we can build on this fundamental mechanism towards goal-oriented behavior.
Towards these goals, we have implemented an experiment that tests the capacity of the sensorimotor inference and temporal pooling algorithms. It is a generalized sensorimotor learning problem that is not specific to any particular modality, but can be applied to any such modality. We wanted to measure the raw memorization capacity of the algorithm without taking advantage of generalization between patterns, so every pattern is represented in this experiment by a random SDR. This is the hardest scenario to learn in, requiring the most memory, so it should give us a good understanding of the boundary limits of the algorithm in a single region.
The setup for the experiment is as follows:
-
Create N worlds, each made up of M elements. Each element is a random (and unique) SDR. For example, if N=3 and M=4, the worlds would look like: ABCD, EFGH, IJKL.
-
An agent can move around a world and perceive elements.
-
Set up two HTM layers, one sensorimotor layer 4, and one temporal pooling layer 3 (which pools over layer 4). When the agent perceives an element, its SDR activates columns in layer 4.
-
As the agent moves around the different worlds, record the activations of layer 4 and layer 3.
-
Train the layers by having the agent do exhaustive sweeps for each world, moving from every element to every other element in the world, with resets in between worlds.
a. With learning enabled in layer 4 and disabled in layer 3, do two exhaustive sweeps through each world.
b. With learning disabled in layer 4 and enabled in layer 3, do one exhaustive sweep through each world.
Note: Ideally, we would want to be able to keep learning enabled in both layers simultaneously while training, but for now this was the easiest way to have controlled learning and get good results.
-
Test by having the agent move for some number of iterations randomly within each world, with resets in between worlds.
-
Characterize the representations formed in the temporal pooling layer of each world as the agent moves around. We are interested in two metrics: stability and distinctness (see section "Metrics" below).
-
Fix M, and increase N. Record the effect on stability and distinctness.
-
Fix N, and increase M. Record the effect on stability and distinctness.
The metrics we choose should reflect how well the region has learned to recognize worlds it has seen, and distinguish between them. Therefore we chose two metrics to measure: stability and distinctness. Stability indicates whether the same cells are active each time the same world is seen. Distinctness indicates whether the cells that are active in a world are different from the cells that are active in other worlds. It is easy to get stability without distinctness; just pick the same cells for all worlds. It is also easy to get distinctness without stability; just pick a random set of cells every time. To get both stability and distinctness requires actually learning the different worlds and making good predictions.
Stability is measured by looking at the temporal pooler representation at each iteration as the agent moves around a particular world, and comparing against every other iteration in that same world. Stability confusion is represented as the number of cells active minus the number of cells overlapping between the representations. Perfect stability is a confusion value of 0.
Distinctness is measured by looking at the temporal pooler representation at each iteration as the agent moves around a particular world, and comparing against every other iteration in every other world. Distinctness confusion is represented as the number of cells overlapping between the representations. Perfect distinctness is a confusion value of 0.
Note: Some of the columns in the spreadsheets below are hidden (the ones between R and AR). Expand them if you want to see more information.
tmParams:
cellsPerColumn: 8
initialPermanence: 0.5
connectedPermanence: 0.6
permanenceIncrement: 0.1
permanenceDecrement: 0.02
maxSegmentsPerCell: 255
maxSynapsesPerSegment: 255
tpParams:
synPermInactiveDec: 0
synPermActiveInc: 0.001
synPredictedInc: 0.5
These parameters are called strict because they place stringent requirements on the Temporal Memory's performance. Specifically, maxNewSynapseCount is equal to the number of active cells, which means there is no subsampling. The activationThreshold and minThreshold is also equal to the number of active cells. These two facts imply that a cell will only be predicted if one of its distal dendrite segments has all of its synapses active. In the Temporal Pooler, the poolingThreshUnpredicted is 0, which resets pooling cells at the first sign of failing predictions in the Temporal Memory.
n: 1024
w: 20
tmParams:
columnDimensions: [1024]
minThreshold: 40
activationThreshold: 40
maxNewSynapseCount: 40
tpParams:
columnDimensions: [1024]
numActiveColumnsPerInhArea: 20
potentialPct: 0.9
initConnectedPct: 0.5
poolingThreshUnpredicted: 0.0
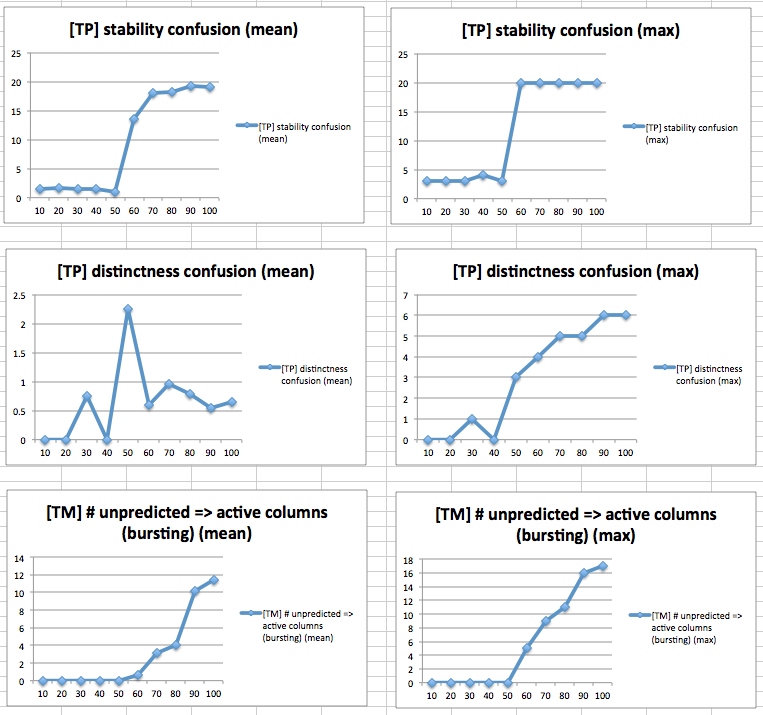

This parameter set is called reasonable since it relaxes the strict requirements of the strict set and uses "typical" parameter values. The temporal memory parameters allow for subsampling and prediction from incomplete sets of active cells. The Temporal Pooler will maintain its current pooling representation in the face of some resonable temporal prediction error in the Temporal Memory.
n: 1024
w: 20
tmParams:
columnDimensions: [1024]
minThreshold: 9
activationThreshold: 12
maxNewSynapseCount: 20
tpParams:
columnDimensions: [1024]
numActiveColumnsPerInhArea: 20
potentialPct: 0.9
initConnectedPct: 0.5
poolingThreshUnpredicted: 0.4

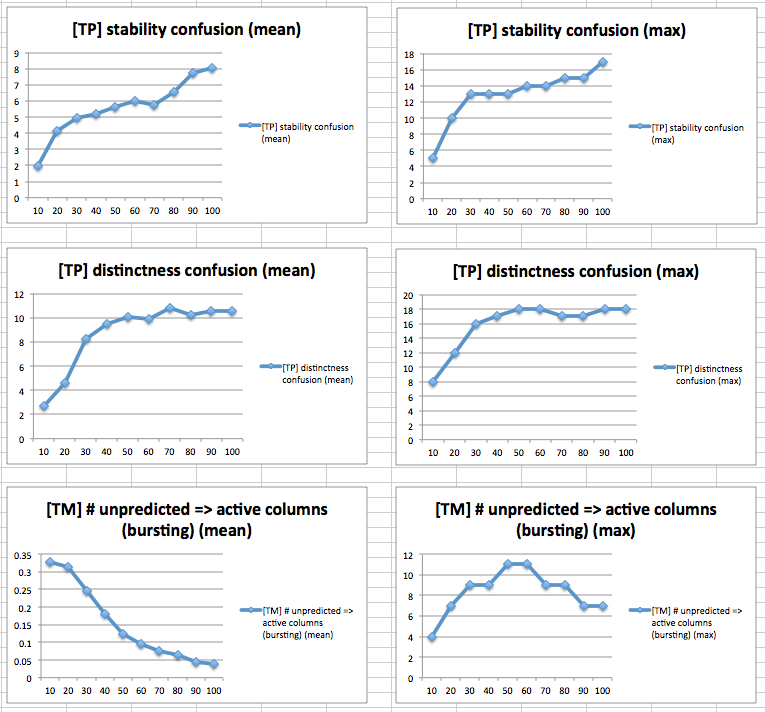
n: 1024
w: 20
tmParams:
columnDimensions: [1024]
minThreshold: 15
activationThreshold: 20
maxNewSynapseCount: 30
tpParams:
columnDimensions: [1024]
numActiveColumnsPerInhArea: 20
potentialPct: 0.9
initConnectedPct: 0.5
poolingThreshUnpredicted: 0.4
Note: Only ran up to 80 elements, because any higher than that hit the synapse limit. Just be aware that the scale for this chart is different from the others.

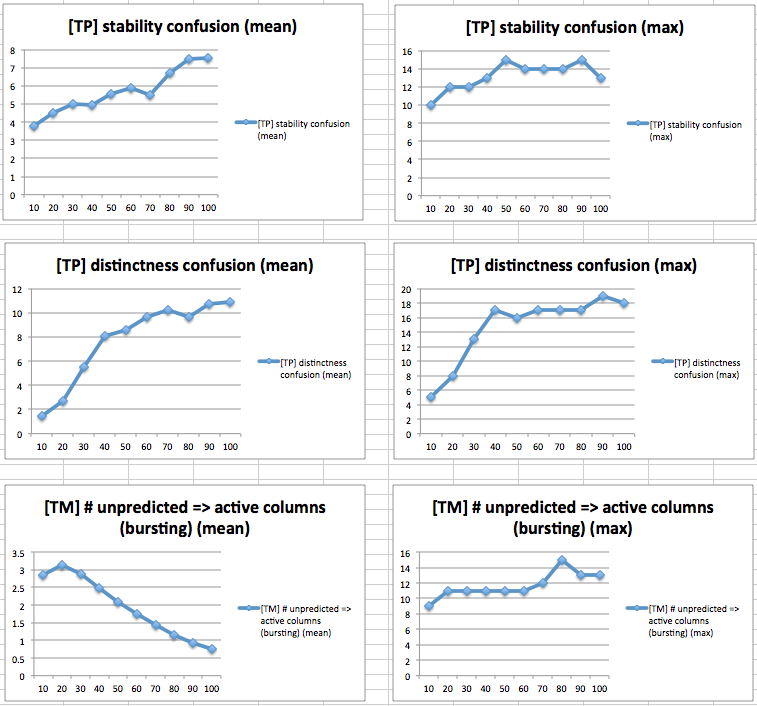
n: 1024
w: 20
tmParams:
columnDimensions: [1024]
minThreshold: 20
activationThreshold: 20
maxNewSynapseCount: 30
tpParams:
columnDimensions: [1024]
numActiveColumnsPerInhArea: 20
potentialPct: 0.9
initConnectedPct: 0.5
poolingThreshUnpredicted: 0.4
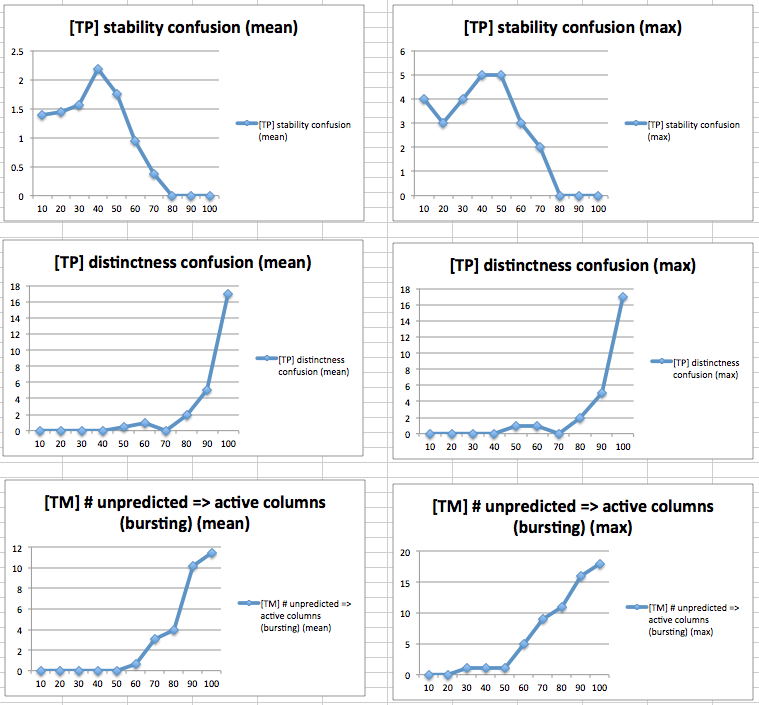

n: 2048
w: 40
tmParams:
columnDimensions: [2048]
minThreshold: 40
activationThreshold: 40
maxNewSynapseCount: 60
tpParams:
columnDimensions: [2048]
numActiveColumnsPerInhArea: 40
potentialPct: 0.9
initConnectedPct: 0.5
poolingThreshUnpredicted: 0.4
Note: Notice that the scale for these charts is different from the others, since it skips by 20 instead of by 10. This was to speed up the tests.


n: 2048
w: 40
tmParams:
columnDimensions: [2048]
minThreshold: 20
activationThreshold: 20
maxNewSynapseCount: 30
tpParams:
columnDimensions: [2048]
numActiveColumnsPerInhArea: 40
potentialPct: 0.9
initConnectedPct: 0.5
poolingThreshUnpredicted: 0.4
Note: Notice that the scale for these charts is different from the others, since it skips by 20 instead of by 10. This was to speed up the tests.


It took several iterations of parameter tuning to find a good set of parameters, and there may be a better set yet. But the best results so far came from 1024 columns, reasonable parameters (v3). With this parameter set, we can handle up to 2 worlds, 90 elements and up to 70 worlds, 10 elements with max stability confusion and max distinctness confusion less than or equal to 6 (out of 20 cells).
These results are good because it means we can learn a fairly large number of transitions (2 worlds, 90 elements is a lot of transitions per world) in a single region. We expected that we could learn around 50 worlds in layer 3, considering that we are operating with 2% sparsity while leads to 100/2 perfectly unique sets of pooling cells (see section Pooling capacity below). These results show that we can learn 70 worlds (with 10 elements each) before we start getting confused.
With the strict parameter set, max stability confusion would spike to 20 at a discrete point. In the experiment increasing the number of elements per world, this point was the same point at which there was any bursting columns in layer 4. This makes sense because the strict parameter set causes the temporal pooler to stop pooling the moment there is any bursting at all. And bursting happens when layer 4 runs out of segments on its cells, and has to start deleting old segments to make room for new ones. In the experiment increasing the number of worlds, there was no bursting, since there aren't as many transitions per worlds for layer 4 to represent and therefore doesn't run out of segments. In fact, layer 4 was predicting perfectly the whole time. Therefore stability confusion spiked purely because of layer 3 running out of capacity; however it is not yet clear exactly why.
Between the strict parameters and reasonable parameters, we can compare at the number of segments and synapses formed. The number of temporal memory segments was the same in both. However, the number of temporal memory synapses was smaller with the reasonable parameters. The number of temporal pooling connections per column was the same in both. At least in terms of synapses, the reasonable parameters use less memory than the strict ones.
Going to 2048 columns (and scaling all the parameters up appropriately) didn't seem to make a huge difference in capacity. It still broke around the same places, whether using the same activation thresholds as in the 1024 column experiments, or using double the thresholds. This is somewhat surprising, especially for the experiment increasing the number of worlds, since it begs the question: what exactly is happening in layer 3 when capacity runs out as the number of worlds increases?
In the experiment 1024 columns, reasonable parameters (v3), we start seeing the stability confusion go up at 80 worlds, 10 elements. This indicates that each world no longer has a single stable representation. However, it doesn't preclude the possibility of each world having a couple stable representations that it keeps toggling between. This wouldn't be so bad, because it could still be pooled into a single representation for the world at a higher level, or grouped together by a classifier. As long as distinctness confusion is low, it would be okay to see multiple stable clusters per world.
Somehow, we should measure the representations of the worlds more finely, and determine how many clusters there are per world, to get a better sense of what the real breaking point is.
Define a pool as a set of inputs that can be grouped or "pooled together" by a column. In the temporal pooler, imagine there is one proximal dendrite with one segment per column and 100 columns with 2% sparsity. Then the temporal pooler can form 50 unique pools because each SDR must involve 2 unique columns and 100/50 = 2.
To try and increase this capacity, what if we were to have multiple segments on the proximal dendrites, like we do with the distal dendrites?
If there are two segments per proximal dendrite, the temporal pooler can form 100 unique pools. This is because each proximal dendrite can now participate in two pools. So the number of pools scales linearly with the number of segments per proximal dendrite. But we cannot keep adding segments and therefore synapses indefinitely.
Another option is to have each cell in the column pool separately. This involves each cell having its own proximal dendrite, predicted inputs being pooled into these dendrites. The advantage of this is that it would increase the pooling capacity by a factor of the number of cells per column.
The disadvantage with this modification is that during flash inference, individual pooling cells in columns will be activated, rather than bursting the column, as if to say "I do know which context I'm seeing this input in!" (even though there was in fact no prediction, and therefore no way to know the context).
Here is an example of where this breaks:
Let's say a sensory-motor pooling layer has learned all transitions in the world ABC. We want it to also learn the world XBY.
Specifically, we want B in ABC (call it B') and B in XBY (call it B'') to be represented with different cells in the same columns. This will allow higher layers to pool separately over the different Bs, and not get confused.
So we start by showing Y from the lower layer. Then, we move left to see B. However, this will activate the B' cells (rather than bursting the B columns), and it is the B' cells that will learn the sensory-motor transition Y => B.
We had to make a number of optimizations to get the experiments running in reasonable time. Here are some of the optimizations we made:
- Implemented a
Connectionsdata structure in C++, that implements the most time-intensive operations for a collection of cells, including computing the activity of the cells due to dendritic input. - Implemented a version of sensorimotor temporal memory that uses the
Connectionsdata structure. - Optimized the
Connectionsdata structure. - Optimized the python temporal pooling code.
- Created a harness that runs experiments in parallel.
- Ran experiments on a compute optimized EC2 instance.
Experiments took anywhere between 5 minutes to 12 hours to run for 1024 columns, and up to 32 hours for 2048 columns. The runtime of each experiment is in the data files above.
Here are some of the things we can do moving forward, in no particular order:
- As mentioned above, we currently train layer 3 separate from layer 4 (by keeping learning enabled for only one at a time). We would like to either find good parameters or modify the algorithm such that we can keep learning enabled in both and train them simultaneously.
- As mentioned above, we want to measure the stability of the representations more finely, and see if there are clusters of stability in the worlds.
- There is always optimization; we want to run the experiments faster. The current bottlenecks are: temporal pooling in python (which should use the
Connectionsdata structure), and thecomputeActivityfunction in theConnectionsdata structure (which is the slowest part of the data structure). - Determine the capacity with varying both # of worlds and # of elements.