Logger
This page will attempt to explain the motivation behind the logger, the expected behavior of the logger, and how it works.
There are several reasons why having a logger is important.
- In general, in any system, it's a good idea to have some sort of record of the events that happened. Logs allow us to do this.
- Not all status messages are created equal. Some messages are useful only when debugging; others are critical, and notify the user of something terrible that has happened. A logger allows us to choose which "class" of messages we see.
- When Runtime is running, there is literally no way for us to tell what's going on if we don't have a logger and are just connected to Runtime through Dawn. The Raspberry Pi does not have a screen attached and runs as a background service, so under normal operation we can't see any output from the program. Having a logger that emits logs over the network to Dawn for us view in the Dawn console is an absolutely critical feature for us to debug efficiently.
The logger is a tool that allows any process within Runtime to submit log messages which are then emitted on standard out (the terminal), to a file, over the network to Dawn, or some combination of the three.
The logger supports five different log levels, which are, in order of least critical to most critical: DEBUG, INFO, WARN, ERROR, and FATAL. The logger needs to be able to let only logs submitted at or above the level specified for the given output location to be emitted to that output location. To choose which log level to assign a given log statement, follow these general guidelines:
-
DEBUG: these messages are not useful to the student (or are already displayed to the student in Dawn), but are useful for, well, debugging. -
INFO: these message are useful to the student. When the student calls "print" in their student code, they show up in the Dawn console at this level, which should give you an idea of what class of message belong at this level. -
WARN: these messages are used to indicate that something bad probably happened (or is about to happen) -
ERROR: these message are used to indicate that something bad definitely happened (subscribing to or connecting an unidentifiable device, for example) -
FATAL: these messages are used to indicate that something happened that was so bad that Runtime will crash (not being to allocate shared memory, for example)
Finally, changing the settings for the logger should be fast. You shouldn't have to recompile all of Runtime just to get the logger to run with different output settings. So, there is a configuration file that is parsed by the logger when a process starts that configures the settings dynamically. This means that all you need to do in order to change the output settings is to edit logger.config, save it, and restart Runtime.
For an explanation of the different settings in logger.config, see the comments in that file itself.
-
logger.h: the (very simple) interface presented to the other Runtime processes for using the logger -
logger.c: the implementation of the logger interface -
logger.config: the configuration file for configuring the output settings in the
This section will attempt to explain some of the design decisions that were made for the logger, and pick apart some of the more obtuse or unclear code in the logger.
This level is not one of the standard log levels because it is used for one very specific purpose: printing Python tracebacks if and when student code errors. All the other logs contain a header that shows the log level, the process that generated that log, and the timestamp of the log. We don't want this header when printing Python tracebacks; we want the traceback to appear exactly as it would appear in the Python interpreter. That's why we needed a sixth "secret" level in the logger. This level has an internal representation that is between WARN and ERROR. The reason is this:
- The
PYTHONlevel must be higher thanINFO, so that students an see the tracebacks on their console - The
PYTHONlevel should be lower thanERROR, sinceERRORis used to indicate that something very bad is about to happen to Runtime. Student code erroring should not cause Runtime to break in any way, soPYTHON<ERROR.
All of the logic described below is contained in the function log_printf used to generate the log message emitted to the desired outputs.
First, the input format string is parsed to generate the fully formatted message string. Then, if the log level is PYTHON, that string is copied verbatim into the final_msg string with no additional modifications. Otherwise, the log message header is generated. We get the current system time formatted as a string, then construct the header and append them all together into the final_msg string one after the other. We now have the string that needs to be sent to the desired output locations contained in the string final_msg. The rest of the function is relatively straightforward:
- If the user has specified logs are to be emitted to standard output and the level of this log is higher than the level specified for standard output, then print
final_msgto standard output usingprintf. - If the user has specified logs are to be emitted to a file and the level of this log is higher than the level specified for the log file, then print
final_msgto the file usingfprintf. - If the user has specified logs are to be emitted to the network and the level of this log is higher than the level specified for the network, then write
final_msgto the FIFO pipe connected tonet_handlerusingwriten(defined inruntime_util), to be read and processed when a connection with Dawn is made.
Please read the wiki page on pipes and FIFOs before proceeding.
The logger uses a FIFO pipe to facilitate logging to the network. Every process that initializes the logger becomes a writer to the log FIFO (whose file path is defined is logger.h). The only reader of the FIFO is the network handler thread that is taking care of the connection between Runtime and Dawn, since all logs output over the network are sent to Dawn by that thread.
One property of FIFOs is that by default, attempting to open a FIFO for writing without a read end will cause the call to open to block until a read end is opened. This is a problem for us though, since the only reader of the FIFO pipe is the thread in the network handler managing the connection between Runtime and Dawn. That thread is only spawned when Dawn connects to Runtime, and that requires Runtime to be up and running for that connection to occur. Therefore, when each process initializes the logger, we have to open the log FIFO in write-only and non-blocking mode with the flags O_WRONLY | O_NONBLOCK in order for the call to open to return immediately and the setup routines for all the processes can continue to boot up Runtime.
Below is a state machine diagram detailing how the log FIFO moves from one state to the next. The image can be found at runtime-docs/Log-FIFO-State-Machine.
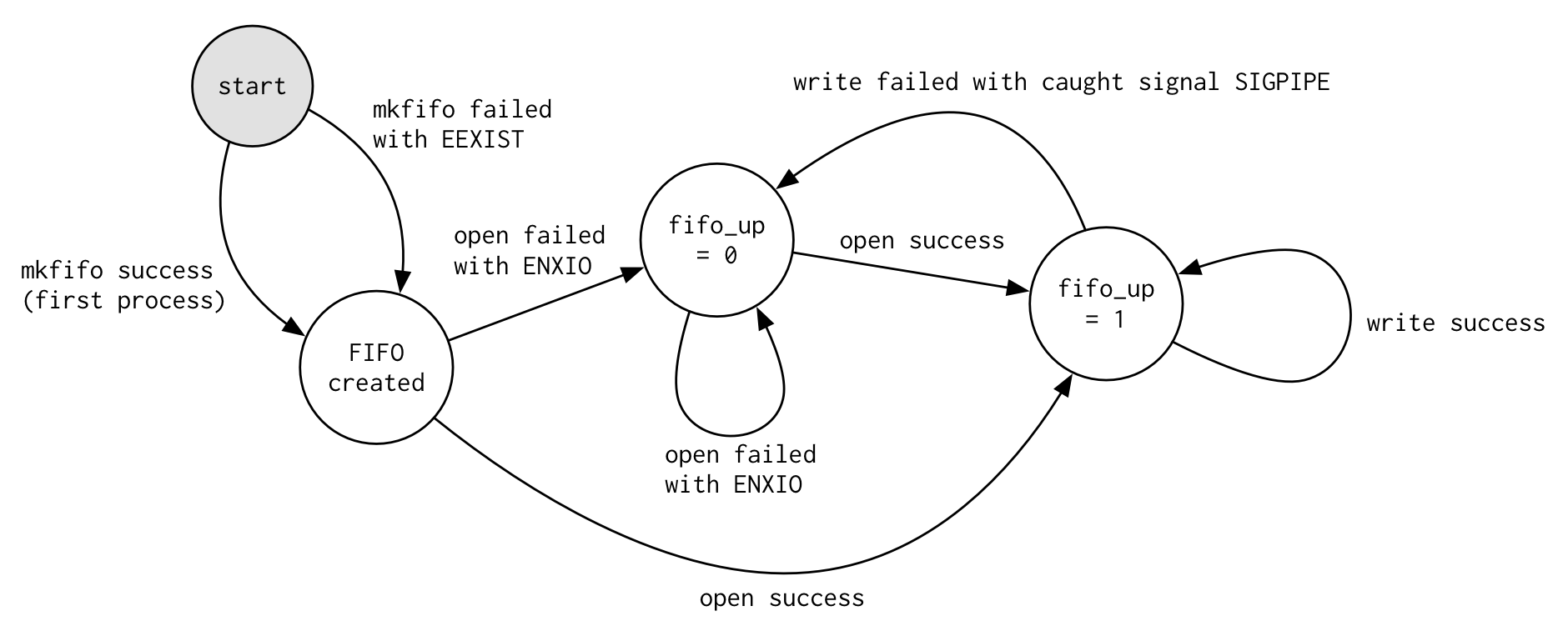
fifo_up is a global variable that represents whether the pipe is ready to be written to (fifo_up = 1) or not (fifo_up = 0). When the logger is initialized with logger_init, fifo_up = 0 to start with, and logger_init tries to make and open the FIFO pipe for a first time. The first process to call mkfifo will succeed, because the FIFO pipe will not exist on the system and the pipe will be created successfully. Afterwards, every call to mkfifo from any process will fail, because you cannot create two FIFO pipes with the same name. We ignore this error (EEXIST).
Each time we call log_printf after the initial logger_init and fifo_up is still 0, we attempt to open the FIFO again. If the read end of the pipe is not yet ready (Dawn has not connected), open will fail with error code ENXIO and we stay at fifo_up = 0. Otherwise, if we successfully opened the FIFO pipe, fifo_up = 1 and we now can write logs to the FIFO to be processed by the network handler thread.
If Dawn suddenly disconnects, the network handler thread will be terminated and the read end of the pipe will be closed. The next time a process tries to write to the pipe, it will result in the signal SIGPIPE being generated (due to attempting to write to a pipe with no read end). We catch that signal, set fifo_up = 0 again, and go back to trying to open the pipe each time log_printf is called.
This discussion focuses on the contents of the read_config_file() function in logger.c, and the purpose of the logger.config file.
Recall that we decided to use a logger configuration file so that changing the output configuration of the logger would not require recompiling all of Runtime.
We wanted to be able to output logs to more than one location, since in production it would be obviously be useful for students to see logs on their consoles (logging to network), but it would also be useful to simultaneously have Runtime output those same logs to a file on the Raspberry Pi, so that if Runtime breaks and students come to staff to help debug their robot, we can ssh into the robot, open up the log file, and use the logs as a starting point to figure out what went wrong.
We also need the ability to independently control the levels of logs that are outputted to each location. Continuing the previous discussion, we definitely want the students to be able to see their own print statements on the Dawn consoles, which are logged at INFO. But we don't want all of those student print statements to also be logged onto the log file on the Raspberry Pi! That file would grow to be huge and impossible to search for warnings and errors that will probably be the source of Runtime crashes when they occur. Therefore, we need the ability to set the ability to log at INFO to the network, and to log at WARN to the file. This is why the configuration file has so many options and we need so much flexibility in the logger.
Finally, the reason why we don't specify the full, absolute path of logger.config is purely for convenience. On different systems, the location of the logger.config file is going to be different (on my computer, it's /Users/ben/Desktop/....../runtime/logger/logger.config, whereas on the Raspberry Pi it's /home/pi/runtime/logger/logger.config). If we hardcoded the entire absolute path into the program, you'd have to change that path and recompile all of Runtime each time you ran it, which is annoying. So, we use the special macro __FILE__, which is defined to be the path of the file
when it was included in the compilation command of an executable that uses logger.c. This is better illustrated with an example.
Suppose you're compiling shm.c. The compilation command ends up being:
gcc shm.c shm_wrapper.c ../logger/logger.c ../runtime_util/runtime_util.c -o shm
Due to this command, the __FILE__ macro will evaluate to ../logger/logger.c within logger.c, and that information is saved in the final executable.
We use the value of __FILE__ to construct the path to logger.config, because all we need to do is find the location of the last / character, and then append logger.config to the path starting at that location. In our example above, we start with __FILE__ = "../logger/logger.c". Finding the location of the last / and then appending logger.config to it gives the path ../logger/logger.config, which is a valid relative path to the configuration file from the directory that the shm executable was created. This means that, if you were to run this executable from some other directory (for example, by doing ./shm_wrapper/shm from the top-level directory runtime), it won't work (since ../logger/logger.config is not a valid path to the configuration file from the runtime directory).