Activating More Pixels in Image Super-Resolution Transformer [Paper Link]
Xiangyu Chen, Xintao Wang, Jiantao Zhou, Yu Qiao and Chao Dong
HAT: Hybrid Attention Transformer for Image Restoration [Paper Link]
Xiangyu Chen, Xintao Wang, Wenlong Zhang, Xiangtao Kong, Jiantao Zhou, Yu Qiao and Chao Dong
- ✅ 2022-05-09: Release the first version of the paper at Arxiv.
- ✅ 2022-05-20: Release the codes, models and results of HAT.
- ✅ 2022-08-29: Add a Replicate demo for SRx4.
- ✅ 2022-09-25: Add the tile mode for inference with limited GPU memory.
- ✅ 2022-11-24: Upload a GAN-based HAT model for Real-World SR (Real_HAT_GAN_SRx4.pth).
- ✅ 2023-03-19: Update paper to CVPR version. Small HAT models are added.
- ✅ 2023-04-05: Upload the HAT-S codes, models and results.
- ✅ 2023-08-01: Upload another GAN model for sharper results (Real_HAT_GAN_SRx4_sharper.pth).
- ✅ 2023-08-01: Upload the training configs for the Real-World GAN-based model.
- ✅ 2023-09-11: Release the extended version of the paper at Arxiv.
- (To do) Add the tile mode for Replicate demo.
- (To do) Update the Replicate demo for Real-World SR.
- (To do) Add HAT models for Multiple Image Restoration tasks.
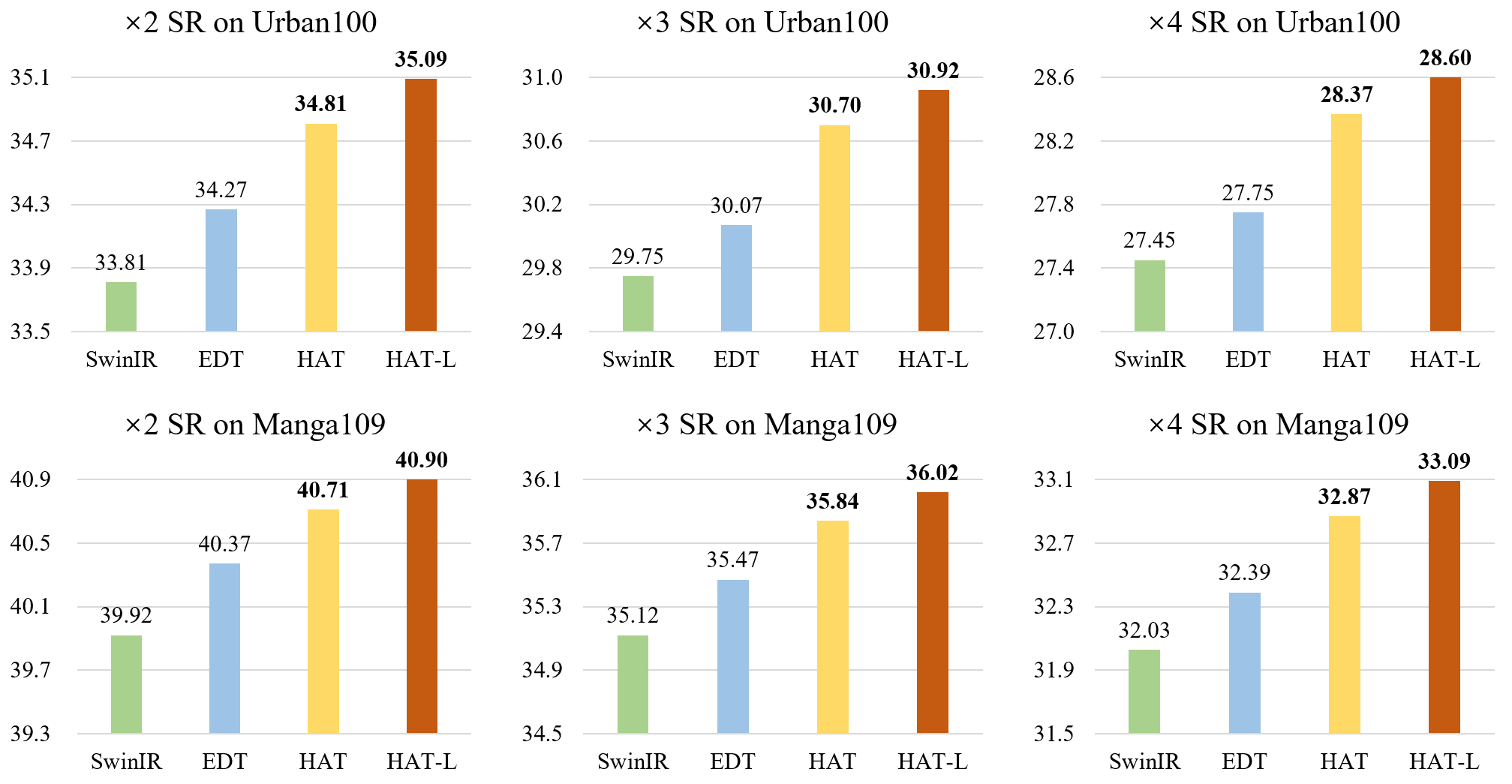
Benchmark results on SRx4 without ImageNet pretraining. Mulit-Adds are calculated for a 64x64 input.
| Model | Params(M) | Multi-Adds(G) | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|---|
| SwinIR | 11.9 | 53.6 | 32.92 | 29.09 | 27.92 | 27.45 | 32.03 |
| HAT-S | 9.6 | 54.9 | 32.92 | 29.15 | 27.97 | 27.87 | 32.35 |
| HAT | 20.8 | 102.4 | 33.04 | 29.23 | 28.00 | 27.97 | 32.48 |
Note that:
- The default settings in the training configs (almost the same as Real-ESRGAN) are for training Real_HAT_GAN_SRx4_sharper.
- Real_HAT_GAN_SRx4 is trained using similar settings without USM the ground truth.
- Real_HAT_GAN_SRx4 would have better fidelity.
- Real_HAT_GAN_SRx4_sharper would have better perceptual quality.
Results produced by Real_HAT_GAN_SRx4_sharper.pth.

Comparison with the state-of-the-art Real-SR methods.

@InProceedings{chen2023activating,
author = {Chen, Xiangyu and Wang, Xintao and Zhou, Jiantao and Qiao, Yu and Dong, Chao},
title = {Activating More Pixels in Image Super-Resolution Transformer},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
pages = {22367-22377}
}
@article{chen2023hat,
title={HAT: Hybrid Attention Transformer for Image Restoration},
author={Chen, Xiangyu and Wang, Xintao and Zhang, Wenlong and Kong, Xiangtao and Qiao, Yu and Zhou, Jiantao and Dong, Chao},
journal={arXiv preprint arXiv:2309.05239},
year={2023}
}
- PyTorch >= 1.7 (Recommend NOT using torch 1.8!!! It would cause abnormal performance.)
- BasicSR == 1.3.4.9
Install Pytorch first. Then,
pip install -r requirements.txt
python setup.py develop
Without implementing the codes, chaiNNer is a nice tool to run our models.
Otherwise,
- Refer to
./options/testfor the configuration file of the model to be tested, and prepare the testing data and pretrained model. - The pretrained models are available at Google Drive or Baidu Netdisk (access code: qyrl).
- Then run the following codes (taking
HAT_SRx4_ImageNet-pretrain.pthas an example):
python hat/test.py -opt options/test/HAT_SRx4_ImageNet-pretrain.yml
The testing results will be saved in the ./results folder.
- Refer to
./options/test/HAT_SRx4_ImageNet-LR.ymlfor inference without the ground truth image.
Note that the tile mode is also provided for limited GPU memory when testing. You can modify the specific settings of the tile mode in your custom testing option by referring to ./options/test/HAT_tile_example.yml.
- Refer to
./options/trainfor the configuration file of the model to train. - Preparation of training data can refer to this page. ImageNet dataset can be downloaded at the official website.
- The training command is like
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=8 --master_port=4321 hat/train.py -opt options/train/train_HAT_SRx2_from_scratch.yml --launcher pytorch
- Note that the default batch size per gpu is 4, which will cost about 20G memory for each GPU.
The training logs and weights will be saved in the ./experiments folder.
The inference results on benchmark datasets are available at Google Drive or Baidu Netdisk (access code: 63p5).
If you have any question, please email [email protected] or join in the Wechat group of BasicSR to discuss with the authors.